この記事のポイント
 データ活用は「データ基盤×ユースケース×プラットフォーム」の3軸で設計するのが実務基準
データ活用は「データ基盤×ユースケース×プラットフォーム」の3軸で設計するのが実務基準- Microsoft Fabricは既存M365資産が厚い現場、DatabricksはMLOps重視、SnowflakeはSAP連携重視で選定が分かれる
- 予知保全・品質予測・需要予測の3ユースケースから着手するとPoCの成功確率が高い
- 隠れコスト4項目(接続構築・データ取り込み・教育・運用フィードバック)を見落とすとROIが崩れる
- 2026年はFabric IQ+NVIDIA OmniverseやSnowflake×SAP BDCなど、現場データとAI基盤の連携が一気に進む節目

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
製造業のデータ活用は、IoT・PLC・MES・PLM・ERPに散在するデータをAIで横断分析し、予知保全・品質予測・需要予測などの業務に直結させる段階に入りました。
2026年はMicrosoft FabricのReal-Time IntelligenceとNVIDIA Omniverse連携、SnowflakeのSAP Business Data Cloud(BDC)ゼロコピー連携など、製造業の現場データとクラウドAI基盤を結ぶアーキテクチャが一気に整備された節目の年です。
本記事では、製造業データのサイロ問題とAI分析基盤の4レイヤー、AIで実現する5つの主要ユースケース、Microsoft Fabric・Databricks・Snowflake 3プラットフォームの製造業フィット比較、PoCから現場展開までの進め方、導入で詰まる論点と回避策、主要基盤の料金体系までを2026年最新情報で体系的に整理します。
目次
Microsoft Fabricと物理AIの接続(Fabric IQ × NVIDIA Omniverse)
SAP × Snowflake Business Data Cloudのゼロコピー連携
設備稼働・エネルギー最適化:OEEとScopeを同時に管理する
Microsoft Fabric:M365資産が厚い現場に最適
日清製粉 × Microsoft Fabric Real-Time Intelligence
Snowflake × SAP Business Data Cloud(業界横断の標準化)
Lindt & Sprüngli × Snowflake(12か月で実装)
製造業のデータ活用の現在地と2026年の潮流
製造業のデータは、設計部門のPDM、購買のExcel台帳、製造現場のPLC/SCADA、品質部門のMES、経営層のBIダッシュボードと、部門ごとに別々の場所に蓄積されてきました。
問題は保管場所が多いことではなく、同じ製品・同じラインに関するデータが、部門ごとに違う前提で読まれていることです。設計が把握する不具合と、製造現場が見ている設備の挙動と、品質が報告する歩留まりが結びつかないまま、AI活用のテーマだけが先走るケースが目立ちます。
2026年に入って状況が変わったのは、現場データとクラウドAI基盤を結ぶアーキテクチャが一気に整備された点にあります。
Microsoft FabricのReal-Time IntelligenceとNVIDIA Omniverse連携、SnowflakeのSAP Business Data Cloudゼロコピー連携(2025年11月発表・2026年5月にAWS Commercial regionsでGA、Azure/GCPは2026年後半予定)など、これまでつなぎ込みが難しかった製造業の現場系・基幹系データが、AIワークロードからそのまま参照できるようになりつつあります。
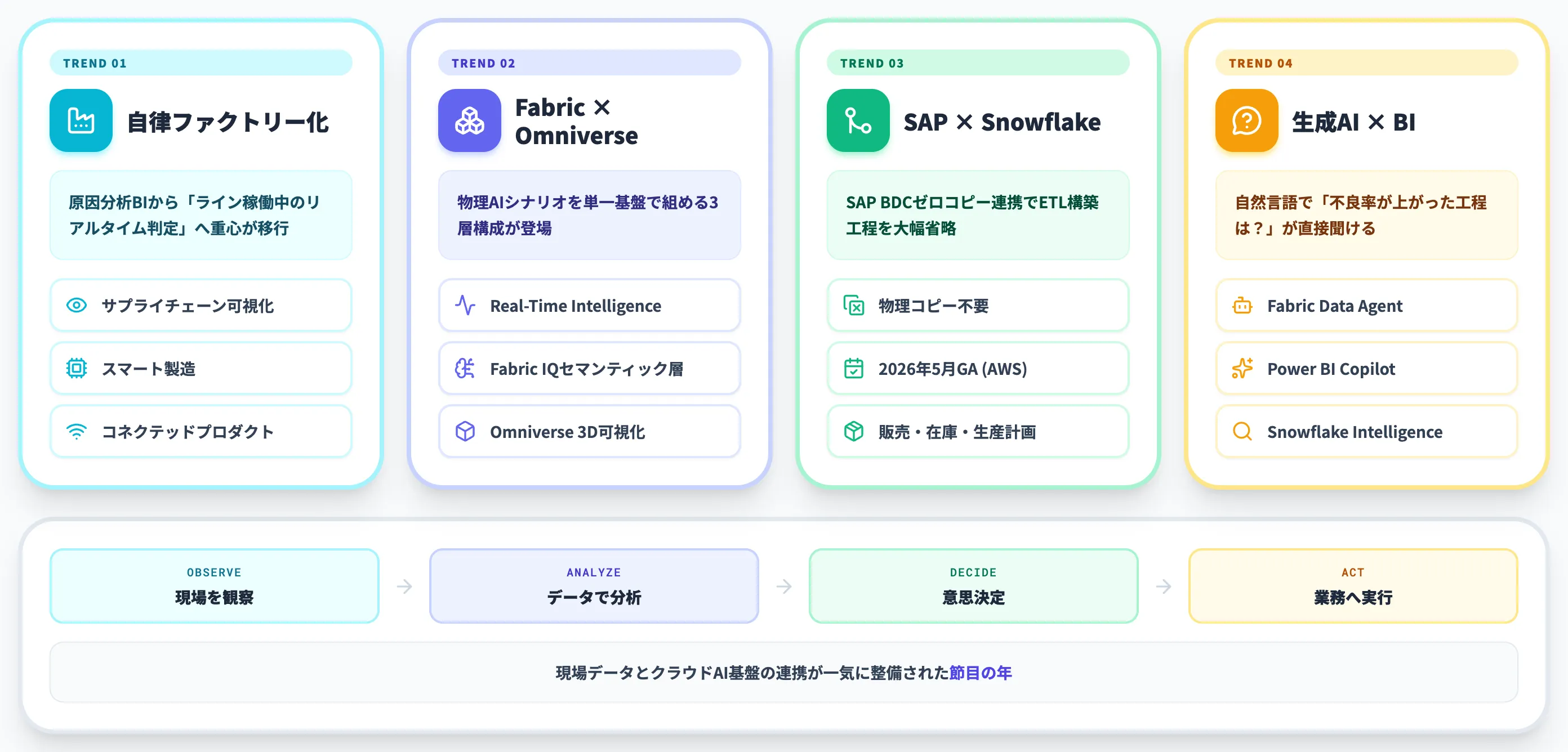
自律ファクトリーとAI主導の意思決定への流れ
Snowflakeの2026 Manufacturing Predictionsでは、2026年の製造業は「モダンデータエステート」へ移行する節目だと整理されています。
具体的には、サプライチェーンの可視化/スマート製造/コネクテッドプロダクトの3領域で、これまで断片的に扱われてきたデータをひとつの分析基盤に統合する動きが本格化します。

Observe → Analyze → Decide → Actの連続的な認知サイクル(出典:Microsoft Fabric Blog)
この連続サイクルが象徴するのは、現場で起きていることを観察し、データから分析し、意思決定を下し、アクションへつなげるという業務サイクル全体をデータ基盤がまかなうという考え方です。原因分析と可視化に閉じていた従来型BIから、ラインの状態を直接駆動する「実行起点のデータ活用」へ重心が移っています。
特に注目されているのが、ショップフロアのカメラ・センサーデータをリアルタイムで読み込み、品質判定・歩留まり予測・エネルギー最適化に直結させる用途です。
従来は「原因分析のためのデータ収集」が中心でしたが、2026年は「ライン稼働中のリアルタイム判定」が現実的な業務テーマに変わってきました。
Microsoft Fabricと物理AIの接続(Fabric IQ × NVIDIA Omniverse)
FabCon and SQLCon 2026の発表およびFabric Blogでは、Microsoft FabricのReal-Time IntelligenceとFabric IQが、NVIDIA Omniverseライブラリと統合され、デジタルツインや予知保全といった物理AIシナリオを支援する方針が示されました。
あわせてMicrosoft Build 2026では、Fabric IQ本体のGAと、Ontologiesの今後のGA、GPU-accelerated Fabric Data Warehouseの早期アクセス/プレビュー予定が公表されており、Fabric基盤の製造業適合性は2026年中にもう一段強化される見込みです。
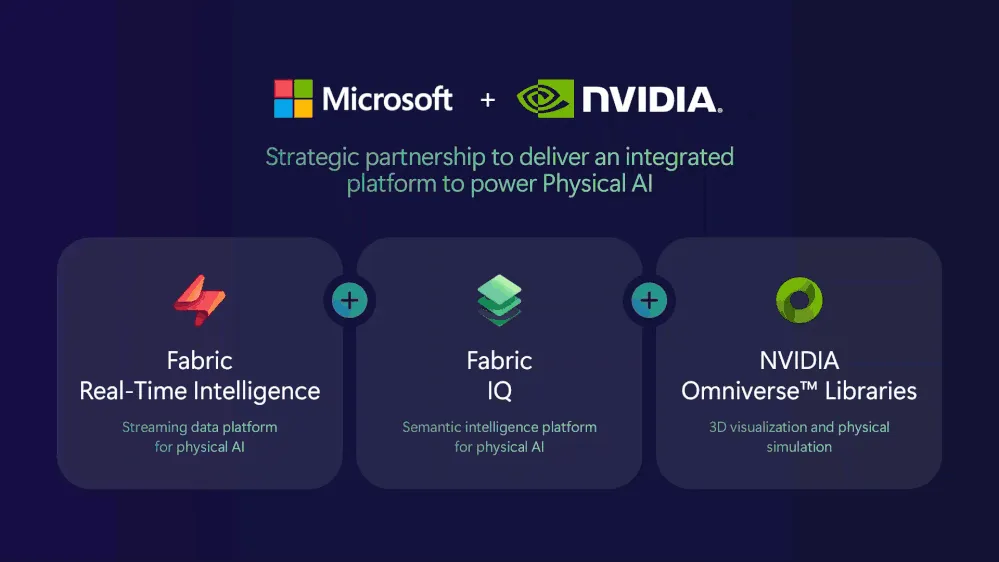
Microsoft FabricとNVIDIA Omniverseが連携する物理AI構成(出典:Microsoft Fabric Blog)
この連携の中核にあるのが、(1) Fabric Real-Time Intelligence によるストリーミング処理 (2) Fabric IQ による共通セマンティック層 (3) NVIDIA Omniverse ライブラリによる3D可視化・物理シミュレーション の3層が単一基盤に重なる構成です。
Vanderlandeのような企業が、これをベースに空港のデジタルツインを構築し始めています。
製造業の文脈で言えば、ラインの3Dモデル・センサー実測値・AI推論結果をひとつのワークスペースで扱える状態に近づいたという意味です。
これまでデジタルツインはCAD・シミュレーション・IoTのつなぎ込みが難しく、PoCどまりになりやすい領域でした。
Fabric IQが共通のセマンティック層を提供することで、製造現場のデータと推論結果を、業務側のダッシュボードやAIエージェントから同じ語彙で扱えるようになります。
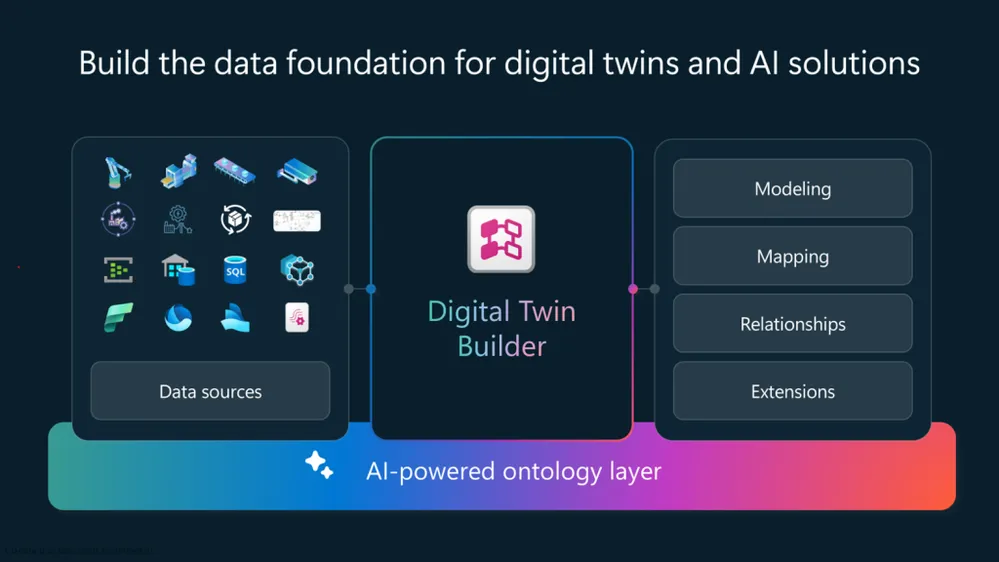
Fabric Real-Time Intelligence内のDigital Twin Builder(出典:Microsoft Fabric Blog)
実装面では、Fabric Real-Time IntelligenceにDigital Twin Builderがプレビュー提供され、KQLデータベース・Eventstream・Real-Time Dashboardと組み合わせて現実の設備をデジタル空間にモデリングする経路が公式に整理されています。
Hannover Messe 2026の現場では、この構成を活用したFactory of the Futureの提案が業界横断で共有されました。
Hannover Messe 2026におけるFactory of the Future構想(出典:Microsoft Cloud Blog)
SAP × Snowflake Business Data Cloudのゼロコピー連携

もう一つの大きな潮流が、SAP Business Data Cloud(BDC)とSnowflakeの双方向データ共有とゼロコピー統合です。連携は2025年11月に発表され、SAP BDC Zero-copy Connectorは2026年5月4日にGA。現時点ではAWS Commercial regionsでの提供で、Azure・GCPは2026年後半予定とされています(Snowflake SAP zero-copy blog)。
Snowflake公式では、SAPの基幹系データを物理コピーなしにSnowflakeから参照でき、製造業の販売・在庫・生産計画と、現場のIoTデータを横断分析できる構成が紹介されています。
SAP基盤を持つ製造業にとっては、「ERPデータを別途ETLで持ってくる」ステップを大幅に省略できる意味があり、データ活用の起点が変わるインパクトを持ちます。ただし採用検討時は提供リージョンの制約を必ず確認する必要があります。
生成AIとBIの融合(自然言語クエリ)
並行して進んでいるのが、BIに生成AIを組み込み、自然言語で分析できる潮流です。
SnowflakeはSnowflake Intelligence、MicrosoftはPower BIのCopilotやFabric Data Agentで、「先週と比べて不良率が上がった工程は?」のような業務質問に直接答えられる構成を整えています。

Microsoft IQによるAct-Decide-Analyze-Observeの4ステップ統合(出典:Microsoft Fabric Blog)
Microsoftの整理では、Act(行動)・Decide(決定)・Analyze(分析)・Observe(観察)の4ステップをMicrosoft IQが単一の知能層として統合する構成が示されています。
製造業では、現場の作業者・QC担当・保全担当それぞれが異なる切り口でデータを問いに行きます。自然言語クエリは、BIダッシュボードを毎回作り直さなくても、それぞれの業務文脈で必要な答えに到達できる手段として、2026年の中で実用域に入りつつあります。
製造業で扱うデータの種類とサイロ問題
製造業のデータ活用を設計する前に、自社にどんなデータが、どの場所に、どの粒度で残っているかを棚卸しすることが出発点になります。
ここを飛ばしてプラットフォームを決めると、「データはあるはずだが、AIから参照できる形になっていない」状態に陥ります。
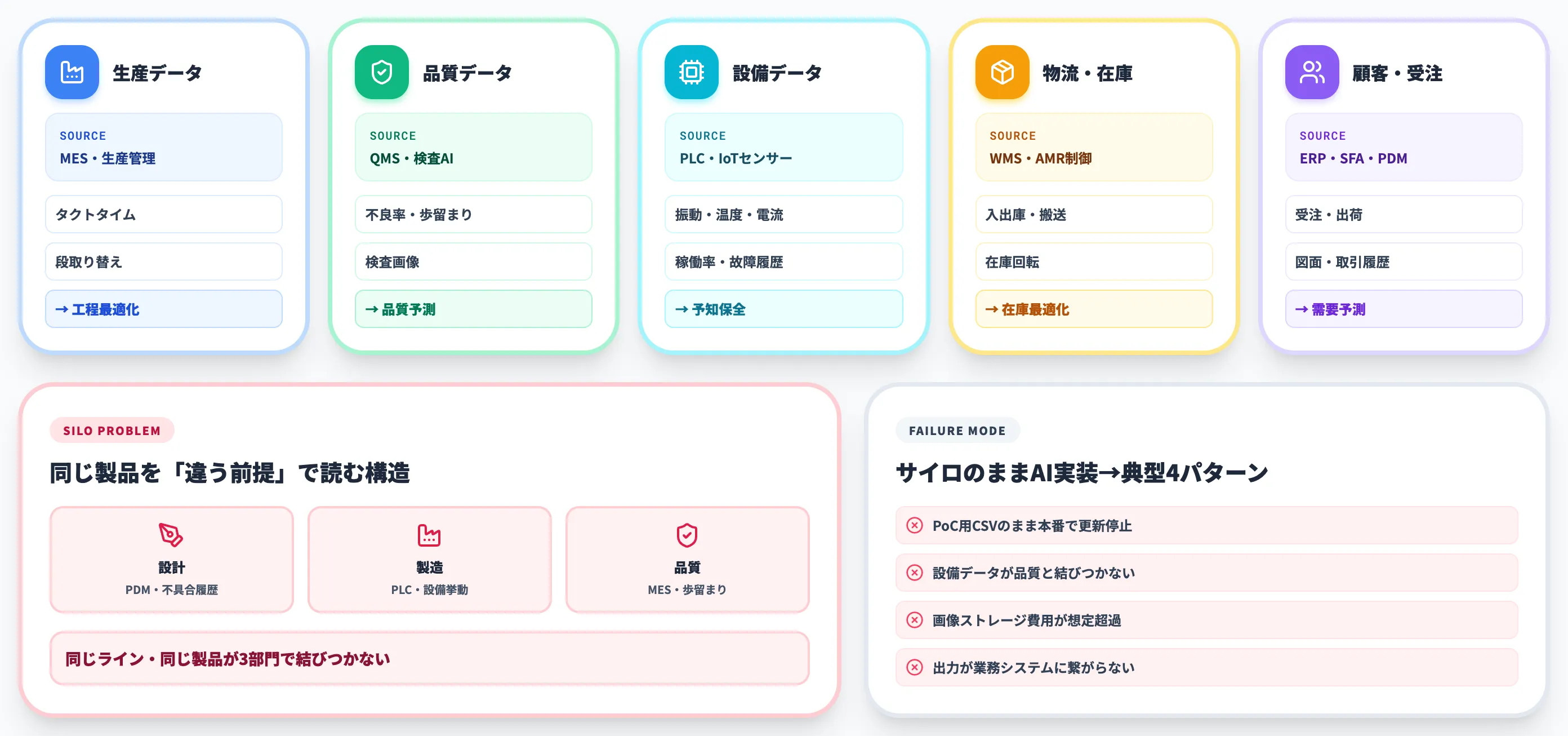
製造業データの5領域
製造業で扱うデータは、おおむね以下の5領域に整理できます。
| 領域 | 代表的なデータ | 主な発生源 | AI活用の典型用途 |
|---|---|---|---|
| 生産データ | 生産実績・タクトタイム・段取り替え時間 | MES・生産管理システム | 工程最適化・スループット改善 |
| 品質データ | 検査結果・不良率・歩留まり・画像 | QMS・検査装置・外観検査AI | 品質予測・歩留まり改善 |
| 設備データ | 稼働率・故障履歴・振動・温度・電流 | PLC・SCADA・IoTセンサー | 予知保全・OEE改善 |
| 物流・在庫データ | 入出庫・搬送・在庫回転 | WMS・AMR/AGV制御系 | 需要予測・在庫最適化 |
| 顧客・受注データ | 受注・出荷・図面・取引履歴 | ERP・SFA・PDM | 需要予測・原価分析 |
このうち、AI活用の効果が見えやすいのは設備データと品質データです。リアルタイム性が要求され、かつ過去ログから推論モデルを学習しやすい性質を持つためです。
一方で、顧客・受注データと生産データを組み合わせた需要予測・原価分析は、業務インパクトが大きい反面、データの粒度合わせ・マスター統合に手間がかかります。
データ活用の優先順位は、AI活用の難易度と業務インパクトの両方から決めることが実務基準です。
OT-IT分断の構造
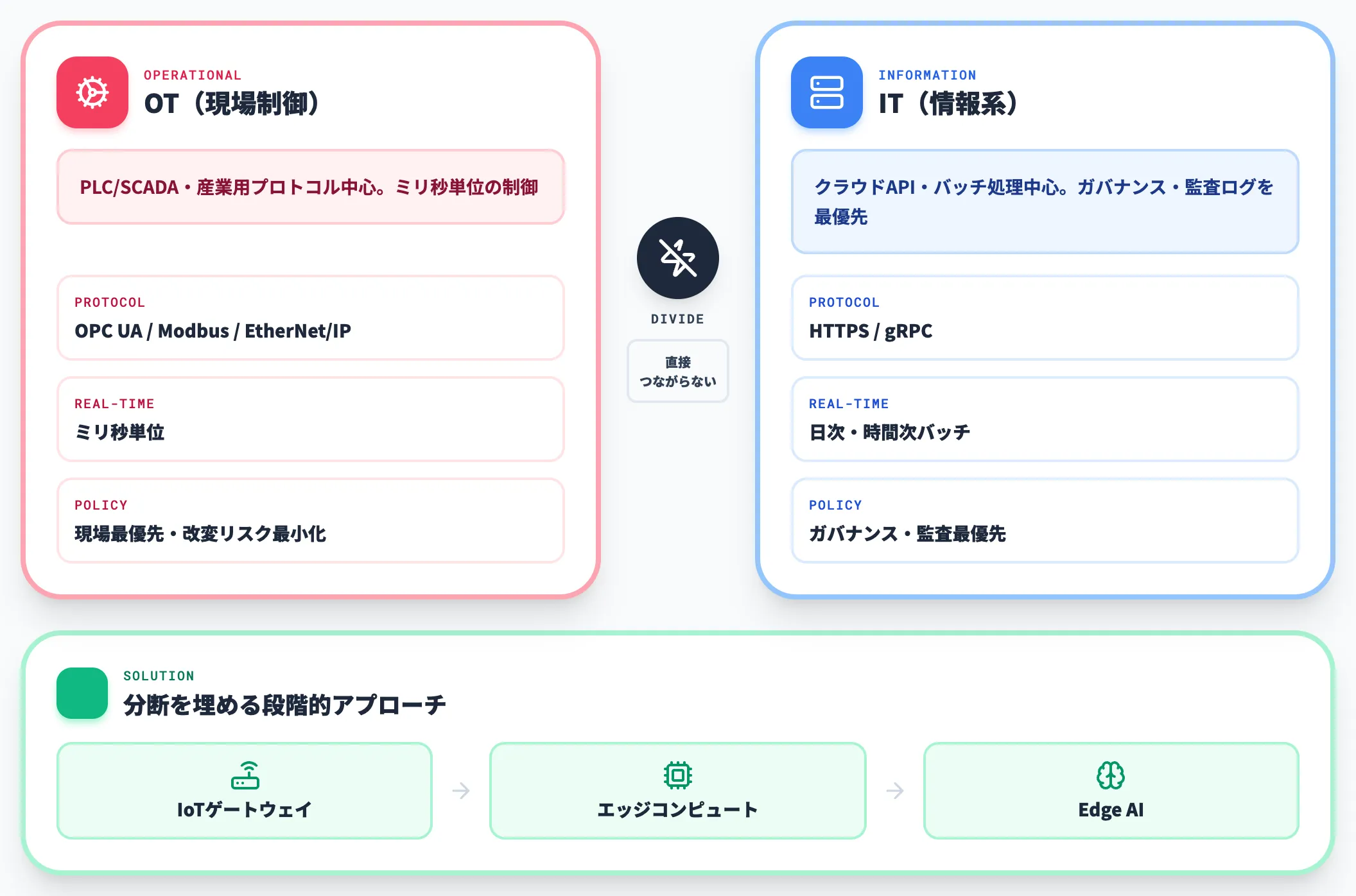
製造業のデータ活用が他業界より難しい根本要因は、OT(Operational Technology:現場制御)とIT(情報系)の分断にあります。
-
プロトコルの違い
PLC/SCADAは産業用プロトコル(OPC UA・Modbus・EtherNet/IPなど)で動き、IT側のクラウドAPI(HTTPS・gRPC)とは直接つながらない
-
リアルタイム性の要求差
製造現場はミリ秒単位の制御を前提とし、IT側のバッチ処理(日次・時間次)とサイクルが合わない
-
権限と運用ポリシーの違い
OTは「現場最優先・改変リスク最小化」、ITは「ガバナンス・監査ログ最優先」とポリシー設計が逆方向
この分断を埋めずにクラウド側だけでデータ基盤を整備すると、設備データだけがリアルタイムで届かず、ML推論の前提が崩れる事象が頻発します。
OT-IT統合は、IoTゲートウェイ・エッジコンピュート・Edge AIの組み合わせで段階的に解消するのが現実的なアプローチです。
サイロが残ったままAIを載せた時の失敗パターン

データサイロが残ったままAI活用を進めると、典型的に以下のパターンで止まります。
- PoCで使ったCSVをそのまま本番にも持ち込み、運用初日に更新が止まる
- 設備データだけ取れて品質データと結びつかず、原因分析がやり直しになる
- 画像データのストレージが急増し、想定を大きく超えるクラウド費用が発生する
- AIモデルは動いているが、出力先が現場の業務システムにつながらず、結果を誰も見ない
このどれかに当たった経験がある場合、プラットフォーム選定の前に、まずデータ基盤の4レイヤー設計を見直すことが、ROIを取り戻す近道です。
AI分析基盤を支える4レイヤー(収集→統合→分析→活用)
製造業のAI分析基盤は、収集・統合・分析・活用の4レイヤーで分けて設計するのが基本パターンです。それぞれのレイヤーで担う役割と、選定で押さえる観点を整理します。

収集レイヤー(OT〜SaaSまでをまとめて集める)
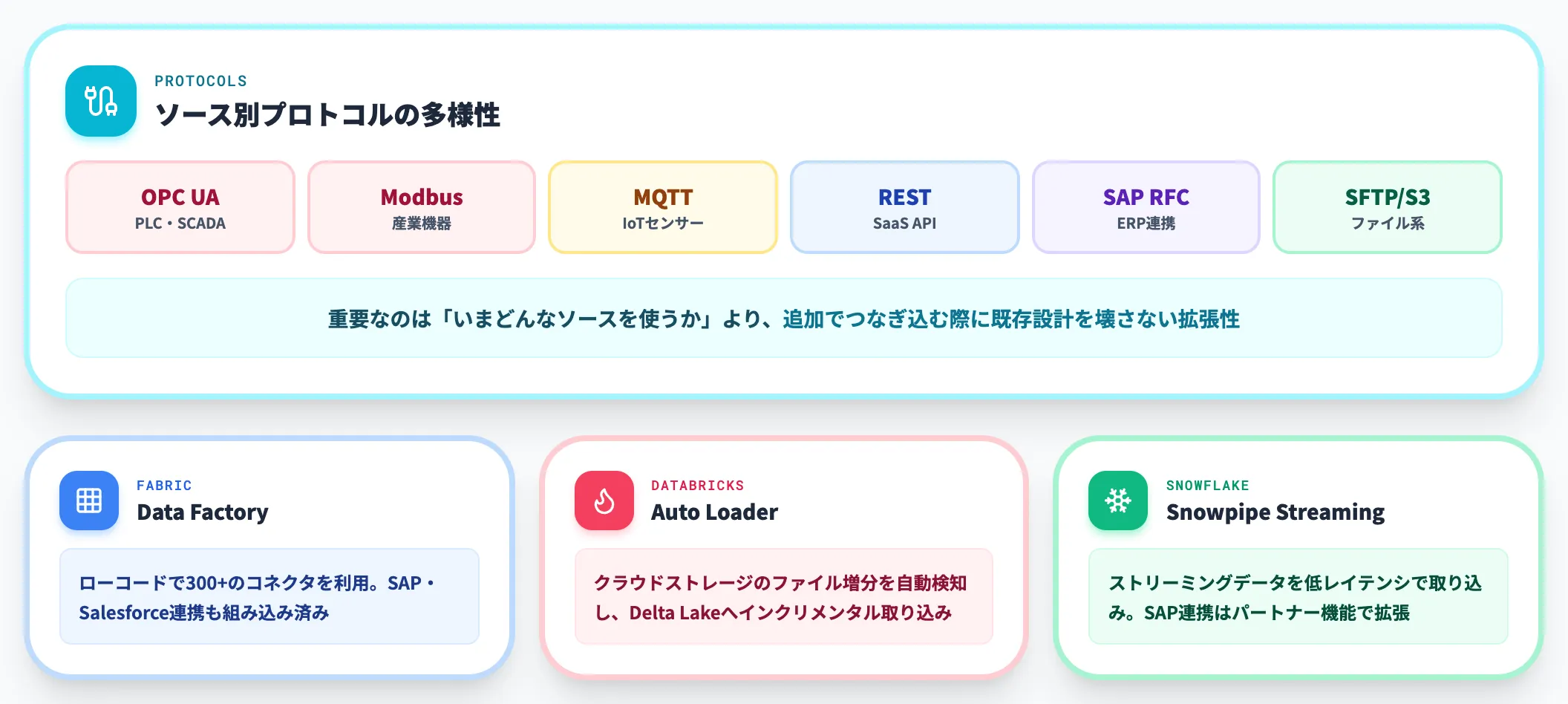
収集レイヤーは、PLC/SCADA・IoTセンサー・MES・PLM・ERP・SaaSなどから、データを基盤に運ぶ入口を担います。
製造業特有の難所は、プロトコルの種類が多すぎることです。OPC UA・Modbus・MQTT・REST・SFTP・SAP RFC・S3など、ソース側の事情で接続方式がバラバラになります。
このレイヤーで重要なのは、「いまどんなソースを使うか」ではなく、「追加でつなぎ込む際に既存設計を壊さないか」という拡張性です。Microsoft FabricのData Factory、DatabricksのAuto Loader、SnowflakeのSnowpipe Streamingが、それぞれ収集レイヤーの中核機能を担います。
統合レイヤー(メダリオン・AI-ready data)
統合レイヤーは、収集したデータを分析しやすい形に整える役割を持ちます。
代表的な設計パターンがメダリオンアーキテクチャです。
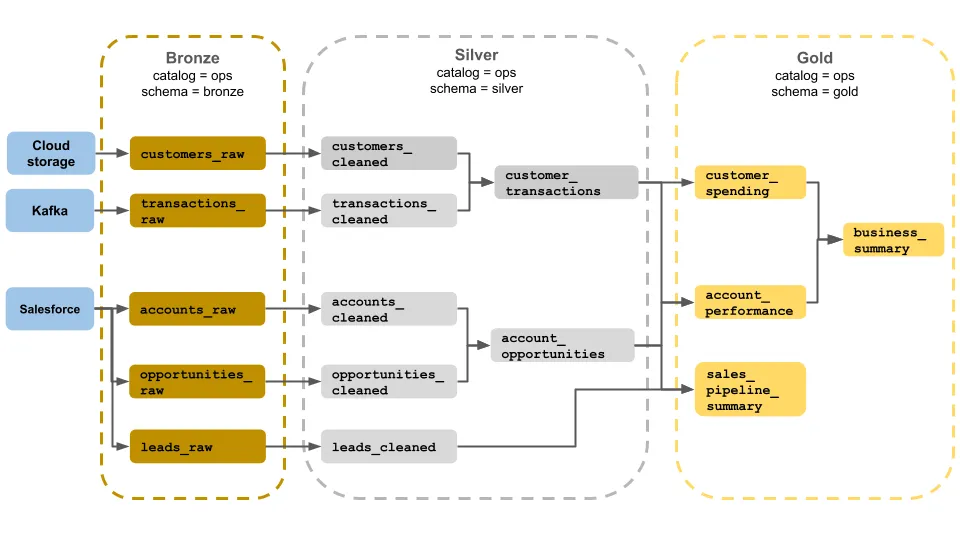
メダリオンアーキテクチャのBronze/Silver/Gold 3層(出典:Microsoft Learn)
図のとおり、Bronze(生データ)→ Silver(クレンジング済)→ Gold(業務指標・ML特徴量)の3層で段階的に品質を上げる構成で、Microsoft FabricのOneLake・DatabricksのLakehouse・SnowflakeのIcebergテーブルが、いずれもこの設計を前提にしています。
Bronzeはデータエンジニアと監査向け、SilverはアナリストとMLエンジニア向け、Goldはビジネスアナリストと経営層向けと、レイヤーごとに利用者の役割も分かれます。
製造業の場合、特に重要なのが**AI-ready dataの5要件**(正確性・完全性・一貫性・鮮度・アクセス性)に加えて、以下の2要件を満たすことです。
-
リアルタイム性
予知保全・品質判定は秒単位〜分単位の鮮度が前提。日次バッチでは間に合わない
-
トレーサビリティ
不良品が出たときに、どのロット・どのライン・どの設備から発生したかを遡れる構造であること
これらを支える共通の語彙がオントロジーです。
Microsoft FabricはFabric IQオントロジーで「製品・ライン・設備・ロット」のような業務概念をデータ層と紐付ける機能を提供しており、製造業のデータ統合と相性が良い設計になっています。
Fabric IQオントロジーが業務概念をグラフとして可視化する様子(出典:Microsoft Fabric Blog)
オントロジーグラフは、製品・ライン・設備・ロットといったノードと、それらをつなぐリレーションを可視的に管理します。
製造業では、設計部門が呼ぶ「部品コード」と購買部門が呼ぶ「仕入れ品目」が同一実体を指していることが頻繁にあり、こうしたグラフ管理は部門横断のデータ活用で意味的なズレを抑える基盤になります。
分析レイヤー(SQL・Spark・ML・RAG)
分析レイヤーは、整備されたデータから業務インサイトを引き出す役割です。
Real-Time Intelligenceを支える構成要素群(出典:Microsoft Fabric Blog)
Real-Time Intelligenceは、ストリーミング取り込み・KQLによる高速時系列分析・リアルタイムダッシュボードを基盤側で一体提供する設計で、製造業の秒〜分単位の分析要件に直接効きます。
製造業で使われる主要な分析手段は以下のとおりです。
-
SQL/Power BI/Tableau
集計・可視化・KPI管理。BI側で完結する分析
-
Spark/Notebook
時系列処理・大量画像処理・カスタム集計。データサイエンスチームが使う
-
機械学習(ML)
予知保全・需要予測・歩留まり予測などの予測モデル
-
RAG(検索拡張生成)
過去の不具合報告・設計仕様・保全マニュアルなど、文書データに対する質問応答
Microsoft FabricはData Science、DatabricksはMosaic AI、SnowflakeはCortexで、それぞれML/AIワークロードを基盤内で完結させる機能を提供しています。
活用レイヤー(BI・Copilot・AIエージェント)
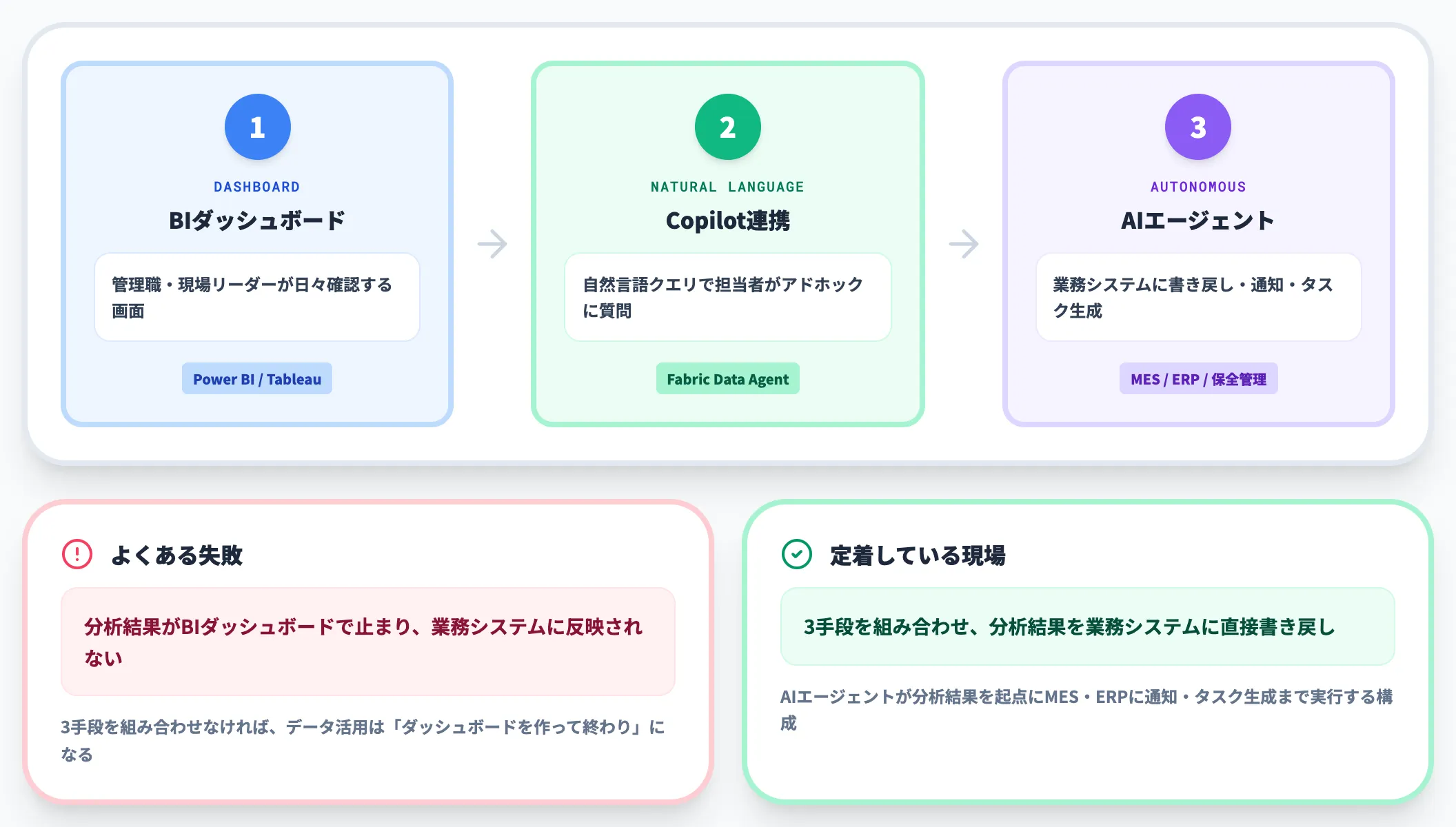
活用レイヤーは、分析結果を業務に届ける最後の関所です。
ここでよく失敗するのが、分析結果がBIダッシュボードで止まり、業務システムに反映されないパターンです。AI活用が定着している現場では、以下の3手段を組み合わせています。
-
BIダッシュボード
管理職・現場リーダーが日々確認する画面
-
Copilot/生成AI連携
自然言語クエリで担当者がアドホックに質問
-
AIエージェント
分析結果を起点に、業務システム(MES・ERP・保全管理)に書き戻し・通知・タスク生成
特にAIエージェント連携については、エージェント時代の設計原則を別記事で詳しく整理しています。
【関連記事】
AIエージェント時代のデータ基盤設計|主要プラットフォーム比較と構築を解説
AIで実現する主要ユースケース
データ基盤を整えた次の論点が、どのユースケースから着手するかです。
製造業のAIユースケースは多岐にわたりますが、データ活用の起点として効果が見えやすいのは以下の5つです。

予知保全:設備の故障を未然に防ぐ
予知保全は、振動・温度・電流・異音などのセンサーデータと故障履歴を機械学習で結びつけ、故障に至る前に異常パターンを検知する用途です。
設備停止のたびに数百万円〜数千万円の損失が出る製造ラインでは、ROIが見えやすい代表ユースケースになります。
Microsoft FabricのReal-Time Intelligence、Databricks Mosaic AI、Snowflakeいずれも時系列データのストリーム処理に対応しており、振動の周波数解析や異常検知モデルの実装は基盤の共通機能で組めます。
【関連記事】
予知保全とは?仕組みやメリット、AIの活用事例を解説
品質予測・歩留まり改善:検査結果を遡って原因をたどる
品質予測は、外観検査の結果・工程パラメータ・原材料ロット情報を統合し、不良品が出る前に工程条件を補正する用途です。
Hannover Messe 2026で示されたAI駆動製造業の最新動向(出典:NVIDIA Blog)
Snowflakeの2026 Predictionsでは、ショップフロアのカメラとセンサーを使ったインライン品質監視が、製造業の最優先テーマのひとつとして挙げられています。VLM(視覚言語モデル)の進化により、従来のCNNベース検査では検出しにくかった微細な傷・ロゴずれ・印字違いも判定可能になりつつあります。
【関連記事】
外観検査AIとは?仕組みや導入事例、おすすめツールを比較
需要予測・在庫最適化:生産計画と調達を連動させる
需要予測は、過去の受注・出荷データと外部要因(季節・為替・原材料価格)を統合し、生産計画と調達の精度を上げる用途です。
ERPデータと外部マクロデータ・サプライヤー情報を組み合わせる必要があるため、データ統合の力が試されるユースケースになります。
Snowflake×SAP BDCのゼロコピー連携や、Microsoft FabricのSAP統合が活きるテーマです。
【関連記事】
需要予測AIとは?仕組みやツール比較、製造業での活用法を解説
設備稼働・エネルギー最適化:OEEとScopeを同時に管理する
設備稼働率(OEE)の改善とエネルギー使用量の最適化は、近年カーボンニュートラル文脈とセットで扱われるユースケースです。
PLC/SCADAから稼働ログを集め、AIで停止要因を分類しながら、同時に電力・ガス・水使用量と紐付けることで、生産性とScope1・Scope2排出量(必要に応じてサプライチェーンに関わるScope3関連データも含めて)を同じダッシュボードで管理できる構成が作れます(参考:環境省 サプライチェーン排出量算定 / EPA Scope 1 and Scope 2 guidance)。
なお、購入電力はScope2、自社の燃料燃焼はScope1に分類されます。
【関連記事】
工場効率化とは?DXや自動化、AI活用の手段・事例・補助金まで徹底解説
ナレッジ承継:熟練工の判断を形式知化する
ナレッジ承継は、熟練工の作業ログ・判断履歴・口頭ノウハウをAIで形式知化し、若手・他部門でも再利用できる形にする用途です。
文書化されていない判断ロジックを扱うため、RAG型の検索拡張生成と、現場ヒアリング・動作データの組み合わせが鍵になります。日清製粉の事例(後述)では、熟練工のノウハウを機械学習でデジタル化する取り組みが、Fabric導入後の成果として報告されています。
【関連記事】
製造業のナレッジ承継をAIで実現する方法|流用設計や過去図面活用の事例、導入のコツを解説
5ユースケースのうち、自社で着手しやすいのは「設備データの可視化が進んでいるか」「品質データが構造化されているか」で見極めるのが実務的です。データ準備度が高い領域から始めると、PoCの成功率が大きく変わります。
主要プラットフォームの製造業フィット比較
データ基盤の主要プラットフォームとして、製造業で選択肢に挙がるのはMicrosoft Fabric・Databricks・Snowflakeの3つです。
それぞれの製造業フィットを整理します。
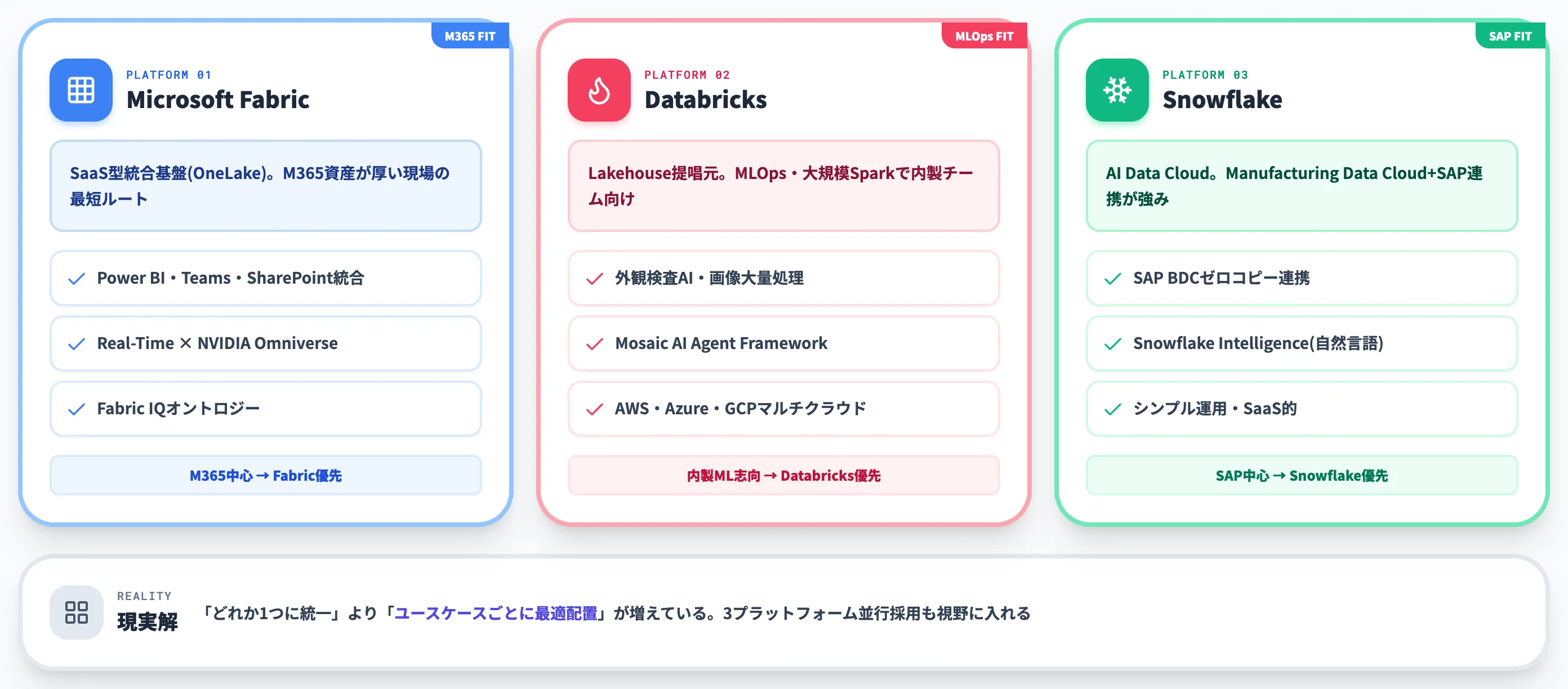
以下の表で、3プラットフォームの製造業適合性を比較しました。
| 観点 | Microsoft Fabric | Databricks | Snowflake |
|---|---|---|---|
| アーキテクチャ | SaaS型統合基盤(OneLake) | Lakehouse(クラウド3社対応) | AI Data Cloud(マルチクラウド) |
| 強み | M365・Power BI・Teams統合、Real-Time Intelligence | MLOps・大規模Spark処理、Mosaic AI Agent Framework | SAP連携、ゼロコピー、シンプル運用 |
| 製造業向け特化機能 | Fabric IQ × NVIDIA Omniverse(物理AI) | 大規模CV・予測モデル運用 | Manufacturing Data Cloud、SAP BDC連携 |
| 既存IT連携の前提 | M365・Power BI資産が前提 | データサイエンスチームが前提 | SAP/Oracle基幹系資産が前提 |
| 自然言語クエリ | Fabric Data Agent、Power BI Copilot | Genie・AI/BI Genie | Snowflake Intelligence |
| OT接続 | Azure IoT・Event Hub・Edge | Auto Loader・Delta Live Tables | Snowpipe Streaming・パートナー連携 |
3プラットフォームは「優劣」で並べるものではなく、既存のIT資産・データ人材の前提・OT接続要件に応じて第一候補が変わります。
Microsoft Fabric:M365資産が厚い現場に最適
Microsoft Fabricは、OneLakeを中心としたSaaS型統合基盤で、データレイクハウス・データウェアハウス・データサイエンス・リアルタイム分析・BIを単一ワークスペースで扱えるのが特徴です。

OneLakeを中核としたMicrosoft Fabricのデータ統合(出典:Microsoft Fabric Blog)
OneLakeは、Lakehouse・Data Warehouse・Real-Time Intelligence・Data Science・Data Factoryなど複数のワークロードが同じストレージレイヤーを共有する設計で、エンジン間のデータコピーを抑え、重複ETLを減らせます。
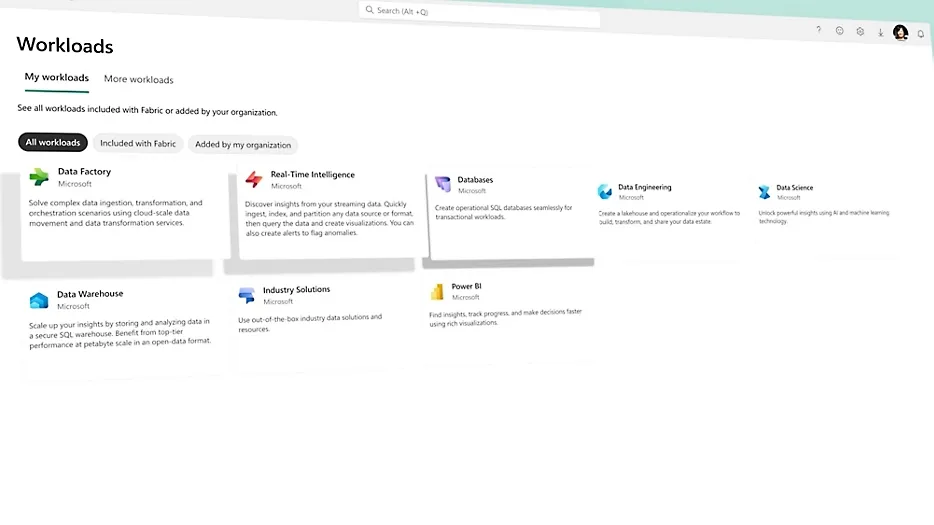
Microsoft Fabricで提供されるワークロード一覧(出典:Microsoft Fabric公式)
公式ページに表示される一覧のとおり、データエンジニアリング・データサイエンス・ウェアハウジング・リアルタイム分析・BI・データガバナンスが同じワークスペース内のメニューとして並びます。
製造業の文脈では、以下の点で他プラットフォームより優位に立ちます。
-
Power BI・Teams・SharePointとの統合
現場担当者が普段使っているMicrosoft 365環境に分析結果を直接届けられる
-
Real-Time Intelligence × NVIDIA Omniverse
ラインのデジタルツインと推論結果を同じワークスペースで扱う物理AI構成が組める
-
Fabric IQオントロジー
製品・ライン・設備・ロットなどの業務概念をデータ層に紐付け、自然言語クエリで意味的に正しい応答を得られる
「すでにM365が標準環境」「Power BIで現場向けダッシュボードを運用している」現場では、Fabricを起点にデータ活用を組むのが最短ルートです。
【関連記事】
Microsoft Fabricとは?使い方や価格体系、できることを徹底解説!
Databricks:MLOpsと大規模処理が必要なら
Databricksは、Lakehouseアーキテクチャの提唱元で、データサイエンス・MLOps・大規模Spark処理に強みがあります。
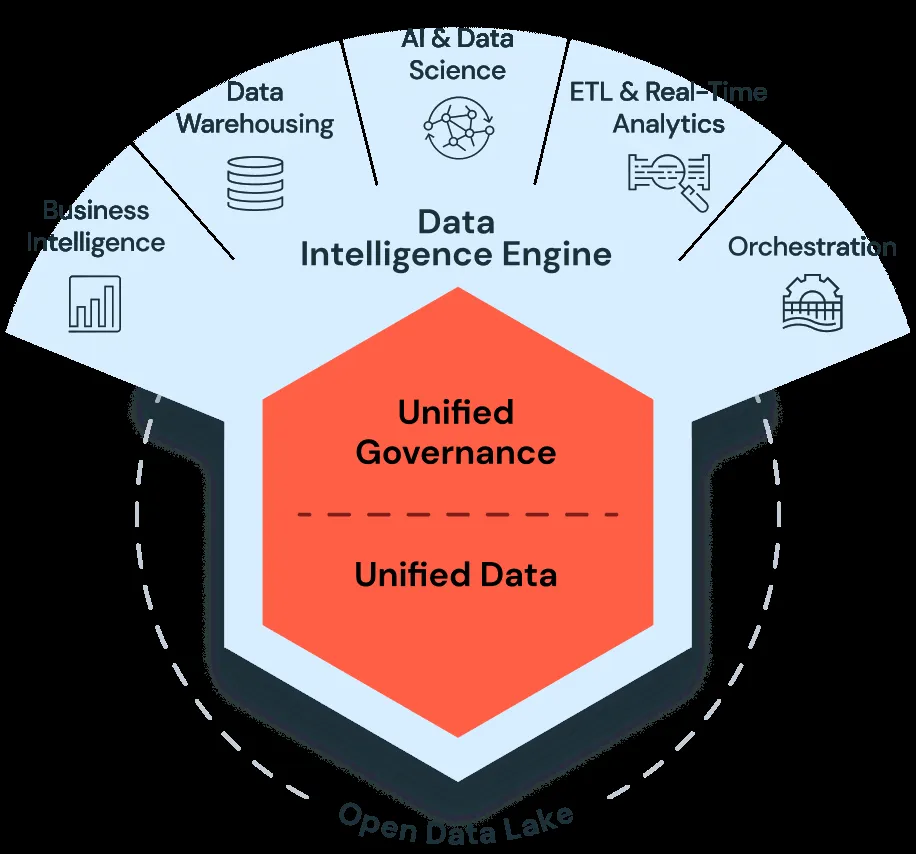
Databricks Data Intelligence Engineを中心としたプラットフォーム構成(出典:Databricks)
Databricksの中核にはData Intelligence Engineがあり、その上にAI/BI・データウェアハウス・ETL・データガバナンス・データサイエンス&AIが乗る統合構成になっています。
下層にはストレージ(Delta Lake / Iceberg)が共通化され、データの形式やクラウドを問わずワークロードが動きます。

Databricksの生成AI/エージェント開発プラットフォーム(出典:Databricks)
加えてDatabricksは、Mosaic AI Agent Framework・Vector Search・Model Servingを組み合わせた生成AIプラットフォームを基盤に内包しています。製造業文脈では、以下のユースケースでDatabricksが第一候補になります。
-
画像データ大量処理
外観検査AIの学習データ・推論ログをペタバイト級で扱う場合
-
Mosaic AI Agent Framework
複合AIシステム(複数モデル・複数ツール連携)を本番運用したい場合
-
マルチクラウド要件
AWS・Azure・GCPを併用しており、ベンダーロックインを避けたい場合
データサイエンスチームが社内にあり、本番MLパイプラインを内製化する現場には、Databricksの自由度が活きます。
Snowflake:SAP・基幹系統合を最優先するなら
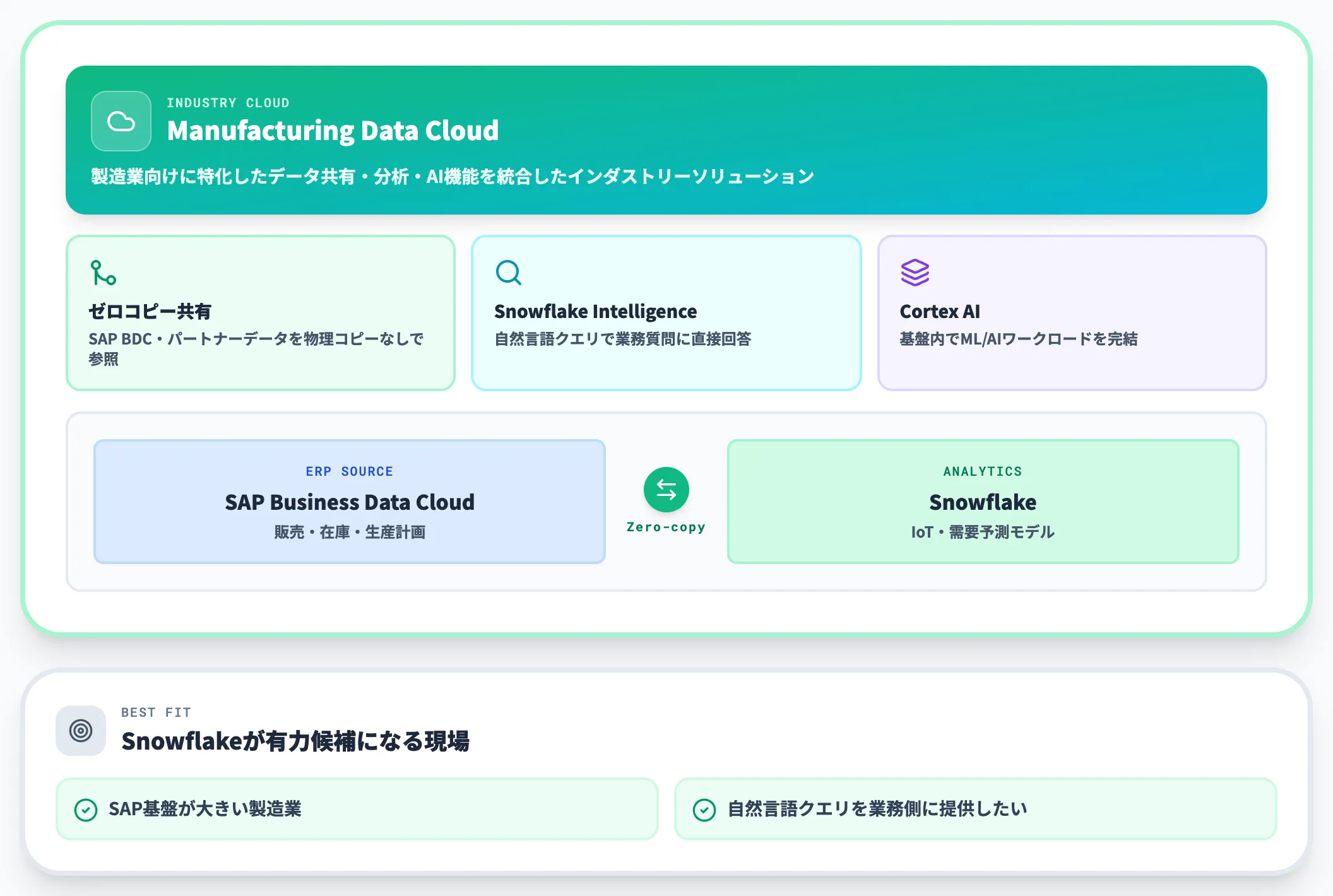
Snowflakeは、AI Data Cloudの構想のもとマルチクラウド対応のシンプルな運用が特徴です。製造業向けにManufacturing Data Cloudを提供しており、SAPやOracle EBSなど基幹系との統合に強みがあります。
特に2026年の動きとして注目されるのが、SAP Business Data Cloud(BDC)との双方向データ共有・ゼロコピー統合です。SAPデータを物理コピーなしにSnowflakeから参照でき、ERPと現場IoTを横断分析する構成が組めます。
SAP基盤が大きい製造業や、Snowflake Intelligenceで自然言語クエリを業務側に提供したい場面では、Snowflakeが有力候補になります。
選定軸の整理
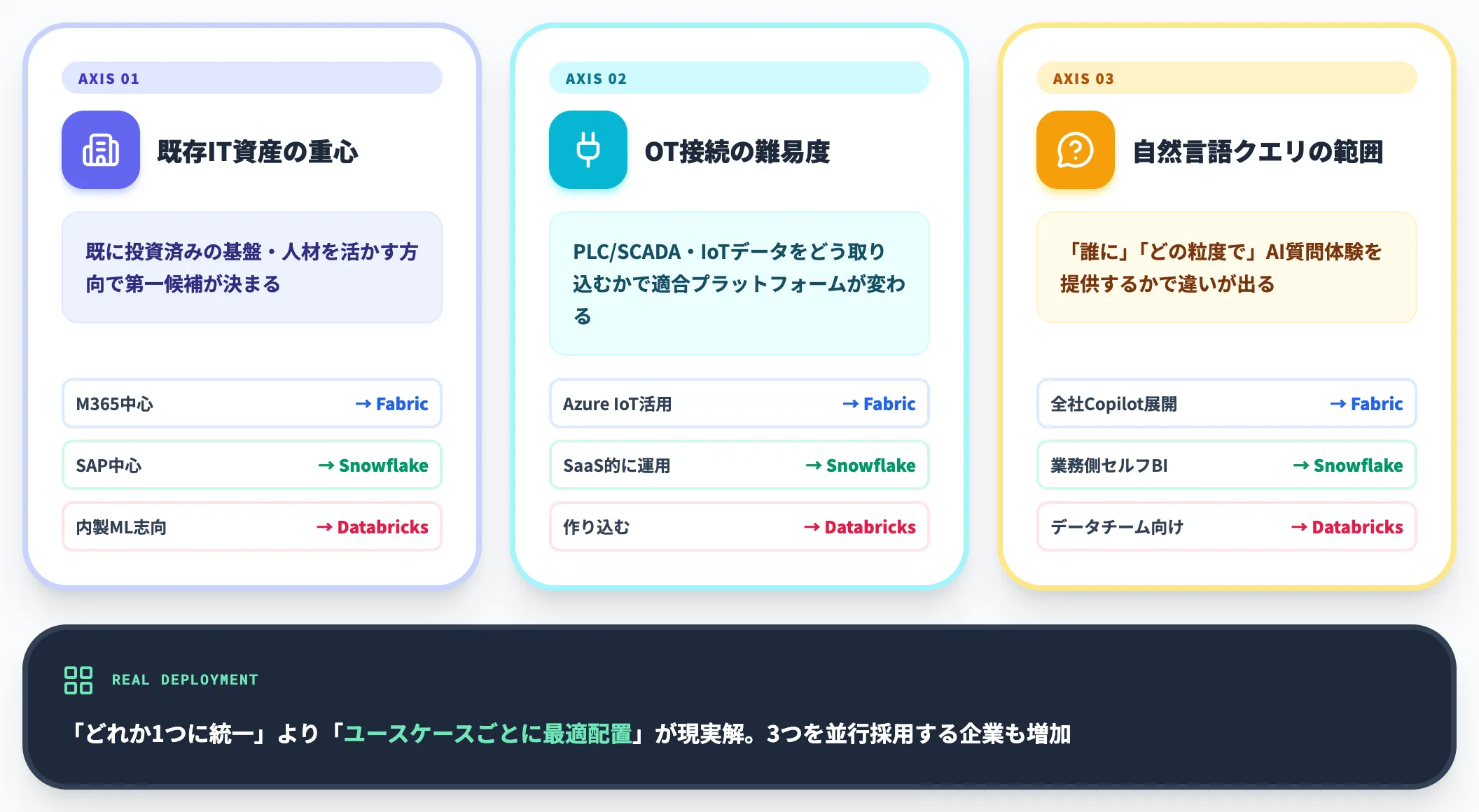
3プラットフォームの選定は、以下の3軸で考えると整理しやすくなります。
-
既存IT資産の重心
M365中心ならFabric、SAP中心ならSnowflake、内製ML志向ならDatabricks
-
OT接続の難易度
Azure IoT連携を活かせるならFabric、Snowpipe StreamingでSaaS的に運用するならSnowflake、ストリーミング処理を作り込むならDatabricks
-
自然言語クエリの提供範囲
全社的にCopilot/AI Agentを展開したいならFabric、業務側にセルフサービスBIを提供したいならSnowflake、データチーム向けにGenieを使うならDatabricks
3つすべてを並行採用する企業も増えており、「どれか1つに統一」より「ユースケースごとに最適配置」が現実解になりつつあります。FabricとDatabricksの比較は1003 Azureにおけるビッグデータ分析、Fabricの導入事例は10578 Microsoft Fabric導入事例6選で深掘りしています。

製造業におけるデータ基盤の導入ステップ
データ基盤の選定が決まったら、次は実装です。製造業のデータ活用は、PoC段階で止まる企業と、本番運用に乗せて現場定着まで届く企業に分かれます。違いを生むのは、ステップごとに何を確認してから次に進むかの運用設計です。
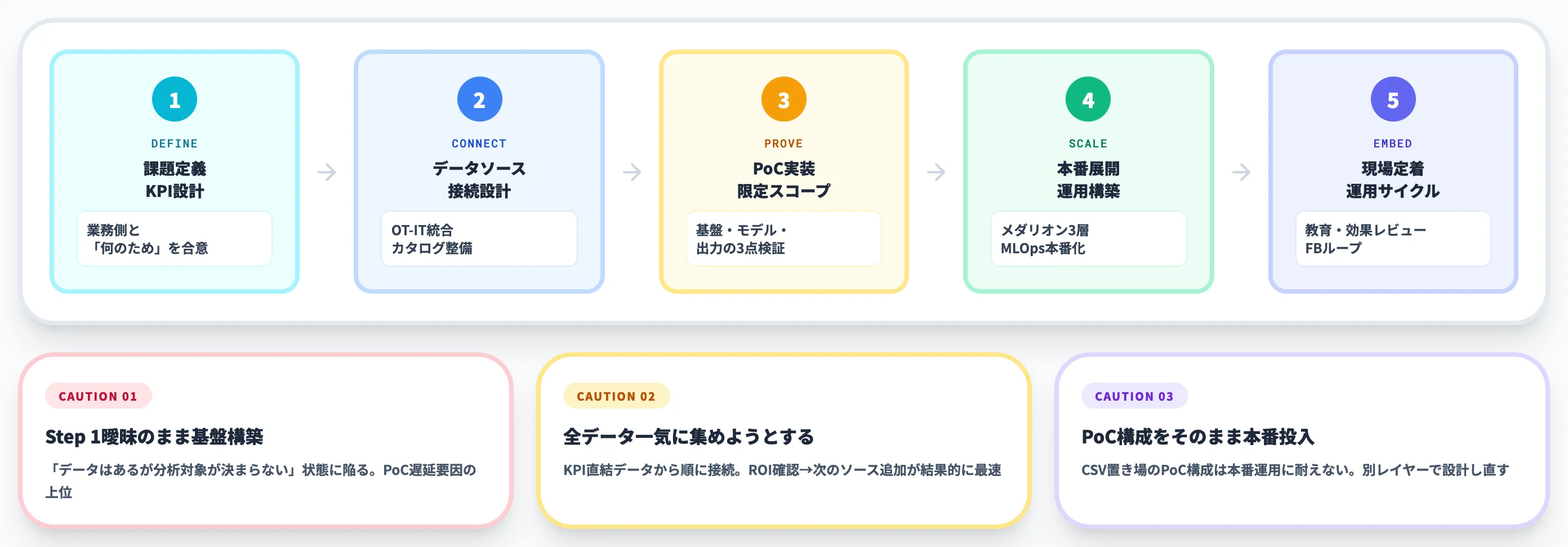
1.課題定義とKPI設計
最初のステップは、「何のためにデータを活用するか」を業務側と合意することです。
- 解きたい業務課題(例: 設備停止損失を3か月で30%削減)
- 成功判定のKPI(OEE・歩留まり・在庫回転率・MTBF など)
- KPIに直結するデータソースのリスト
- 想定する判断主体(現場・管理者・AI自動判定)
ここを曖昧にしたまま基盤構築から始めると、「データはあるが何を分析するか決まらない」状態が続きます。AI総研の支援経験でも、PoCの遅延要因の上位はほぼ「Step 1の曖昧さ」です。
2.データソース整理と接続設計
Step 2では、KPIに直結するデータソースを棚卸しし、収集レイヤーへの接続方式を設計します。
- ソース別の発生源・更新頻度・形式
- OT-IT統合の方式(IoTゲートウェイ・エッジAI・OPC UA→クラウド)
- データカタログの整備(オントロジー設計)
- ガバナンス(権限・監査・データマスキング)
ここで重要なのは、全データを一気に集めようとしないことです。Step 1で定義したKPIに必要なデータから順に接続し、ROIを確認してから次のソースを追加する段階的アプローチが結果的に早道です。
3.PoC実装
Step 3は、限定スコープで基盤・モデル・出力の3点が業務に効くかを検証します。
製造業のデータ活用PoCで必ず試すべきパターンは以下の5つです。
-
既存ETLからの段階移行
旧来のバッチETLと並行稼働させ、結果の一致率を比較する
-
リアルタイム×バッチ混在
ストリーミング処理(秒単位)と日次バッチを同じ基盤で扱えるか
-
データ品質ばらつき
欠損値・外れ値・単位ずれが混在する現場データで推論精度が崩れないか
-
メタデータ整備の難易度
オントロジー設計が部門間で合意できるか
-
ガバナンス検証
権限・監査ログ・データマスキングが要件を満たすか
PoCは「うまくいった/いかなかった」の結論だけでなく、**「本番でスケールさせる時に何が壁になるか」**まで洗い出すのがゴールです。
4.本番展開
PoCをクリアしたら本番展開に入ります。本番展開で押さえる観点は、PoCと別レイヤーで以下のものになります。
- メダリオン3層(Bronze/Silver/Gold)の正式運用
- データ品質モニタリング(Great Expectations・Fabric DQ など)
- ML/Agentの本番MLOps(モデルバージョン管理・再学習サイクル)
- インシデント対応プロセス(推論失敗時のフォールバック)
ここで「PoCの構成をそのまま本番に持ち込まない」ことが重要です。PoC用にCSV置き場で動かしていた構成が、本番運用に耐えないケースは頻発します。
5. 現場定着
最後のステップが、現場に使ってもらう仕組みを作ることです。
- 業務ダッシュボードの設計(管理職向け・現場向けの分離)
- 自然言語クエリ・Copilot活用の教育
- 推論結果に対するフィードバックループ(誤検知の運用ルール)
- 月次の効果レビューと改善
データ活用は「基盤を作って終わり」ではなく、運用フィードバックでチューニングし続けるサイクルです。Step 5を軽視するとPoCで見えていたROIが消えるため、運用担当の工数は最初から織り込む必要があります。
製造業におけるデータ基盤の実装事例
データ活用の実装は、具体的な事例から学ぶのが近道です。ここでは2026年時点で公開されている代表的な事例を紹介します。
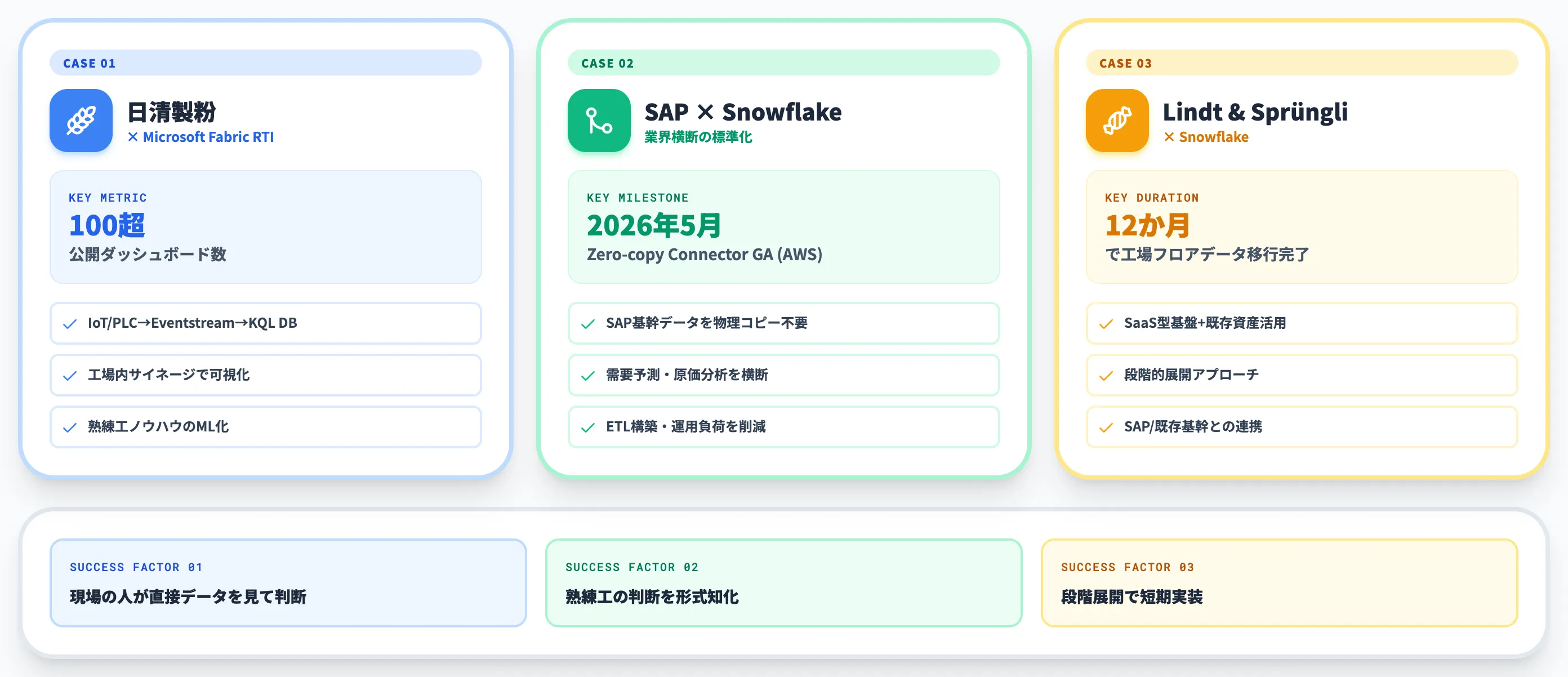
日清製粉 × Microsoft Fabric Real-Time Intelligence
日清製粉グループは、「日清製粉グループ中期経営計画2026」のもと、デジタル活用を成長の柱として位置づけ、Microsoft Fabric Real-Time Intelligenceを導入しています。
日清製粉が運用するFabric内ダッシュボードのインフォグラフィック(出典:Microsoft Customer Stories)
具体的な実装内容と効果は以下のとおりです。
- IoTセンサーおよびPLC(Programmable Logic Controller:現場制御装置)から生産・品質データをリアルタイムで収集
- Fabric Real-Time Intelligenceで即時処理し、Power BIダッシュボードや工場内サイネージで可視化
- すでに100を超えるダッシュボードが公開・共有
- Excelへの手動転記・集計作業を自動化し、機械学習への社内対応力を強化
- 熟練工のノウハウを機械学習でデジタル化する取り組みも進行中
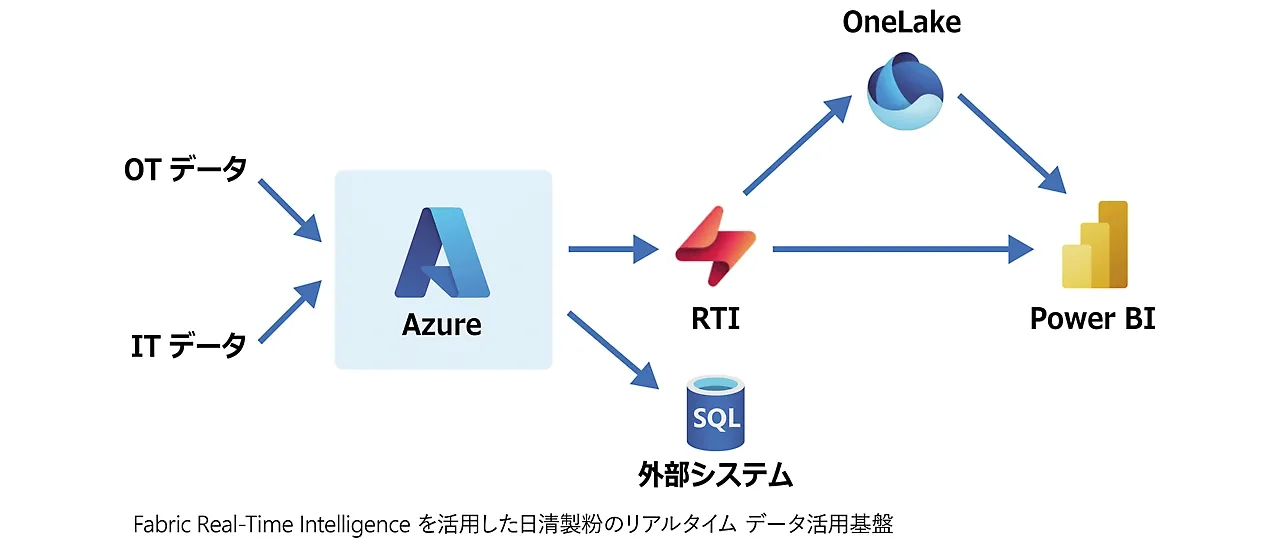
日清製粉のFabric Real-Time Intelligence活用基盤の全体像(出典:Microsoft Customer Stories)
基盤側ではIoT/PLCのデータがEventstreamを経由してKQLデータベース・Real-Time DashboardやPower BIに流れ込み、工場内サイネージへリアルタイム反映されます。
「現場の人が直接データを見て判断する」「熟練工の判断を形式知化する」という、製造業データ活用の理想形に近い構成が実装されています。
Snowflake × SAP Business Data Cloud(業界横断の標準化)
Snowflakeは2025年11月にSAPとの連携を発表し、SAP Business Data Cloud(BDC)とのZero-copy Connectorは2026年5月4日にGAしました。
現時点ではAWS Commercial regionsでの提供で、Azure・GCPは2026年後半予定です。
製造業文脈での意味は以下のとおりです。
- SAPの基幹データ(販売・在庫・生産計画)をSnowflake側から物理コピーなしで参照可能
- SnowflakeのIoT・センサーデータと組み合わせ、需要予測・原価分析を横断実行
- ETLパイプラインの構築・運用負荷を大幅に削減
SAP基盤が大きい製造業にとっては、「ERPデータを別途持ってくる」工程を省略できる意味で大きなインパクトを持ちます。導入検討時はリージョン制約を必ず確認してください。
Lindt & Sprüngli × Snowflake(12か月で実装)
スイスのチョコレート大手Lindt & Sprüngliは、12か月で工場フロアの設備データをSnowflakeへ移行したと紹介されています。
短期間で工場現場のデータをクラウド側に集約できた背景には、SaaS型基盤+既存資産活用+段階的展開のアプローチが効いたとされており、Snowflakeのシンプルな運用モデルと、SAP/既存基幹資産との連携可能性が、短期実装の鍵になりました。
その他の製造業ユースケース
ほかにも、外観検査AI・予知保全AI・需要予測AIなど領域別の事例は多数公開されています。製造業全般のAI活用事例は別記事で網羅しています。
【関連記事】
製造業におけるAIの活用事例30選|導入ポイントを徹底解説
導入で詰まる論点と回避策
データ活用の構想と実装の間には、いくつかの落とし穴があります。AI総研の支援経験から、特に頻発する詰まりポイントと回避策を整理します。
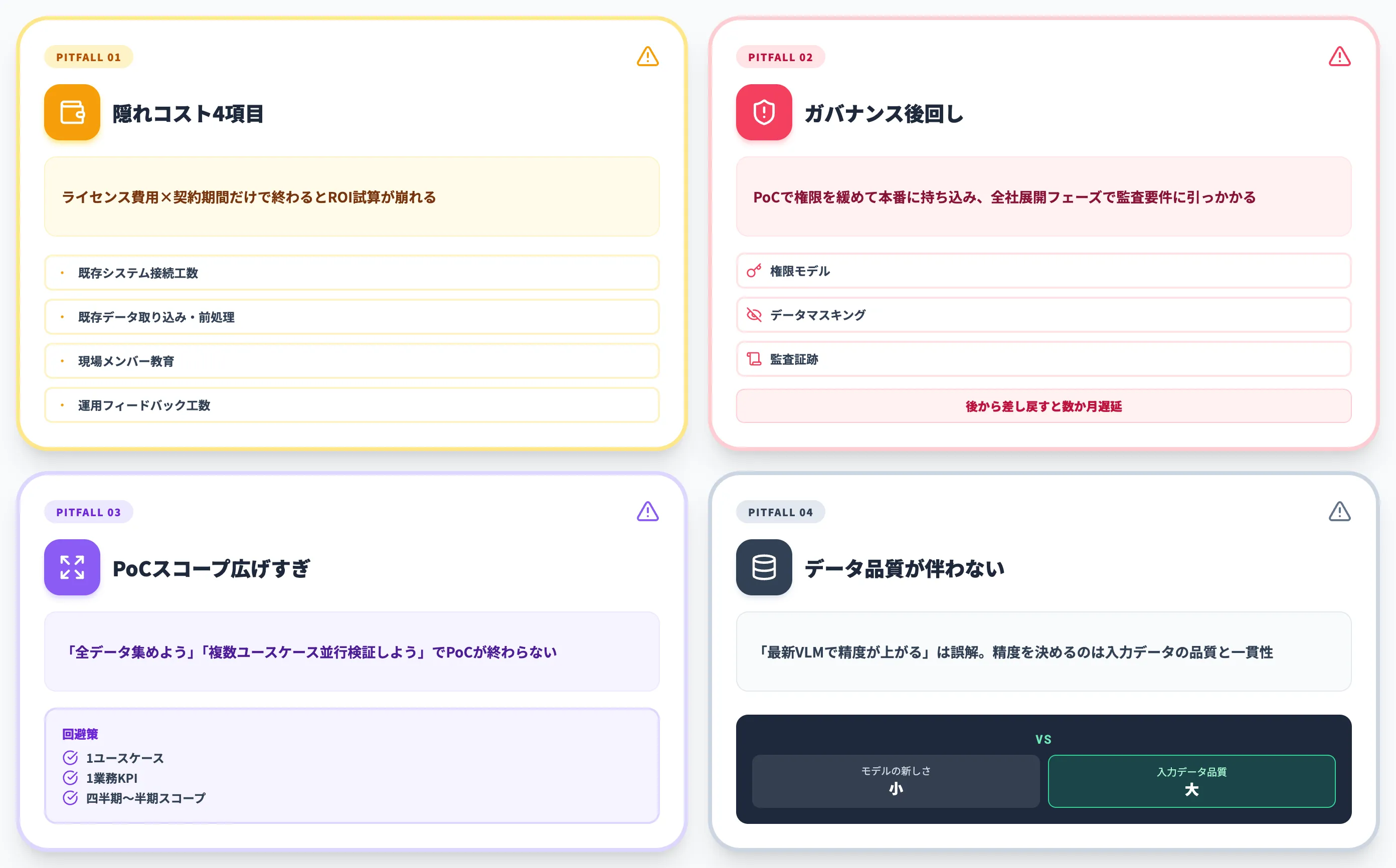
隠れコスト4項目を見落とすとROIが崩れる

データ基盤のROI試算は、ライセンス費用×契約期間で終わってはいけません。実装・運用の隠れコストとして、以下の4項目を必ず織り込みます。
-
初期セットアップ・既存システム接続の構築工数
OPC UA→クラウド接続、SAP/ERP連携、SSO設定、権限設計など
-
既存データの取り込み・前処理
古い設備ログのフォーマット統一、命名規則の標準化、メタデータ整備
-
現場メンバーへの教育・利用ガイド整備
Power BI・Copilot・AIエージェントの操作研修、部門別の利用ガイド
-
運用担当者の継続的なフィードバック工数
モデル精度のチューニング、誤検知対応、定期レビュー
AI総研の支援経験上、隠れコストはライセンス費用に匹敵する規模になることもあり、3年TCOで比較するとプラットフォーム選定の結論が変わるケースもあります。
ガバナンスを後回しにする落とし穴
PoCで動かすために権限・監査ログを緩めた状態で本番に持ち込み、全社展開フェーズで監査要件に引っかかるパターンが典型です。
データ基盤の権限モデル・データマスキング・監査証跡は、PoC段階から「本番で使う設計」を入れておくべきです。後から差し戻すと、本番リリースが数か月単位で遅れます。
PoCのスコープを広げすぎる罠
「せっかくだから全データを集めよう」「複数ユースケースを並行検証しよう」と広げると、PoCが終わらなくなります。
1ユースケース・1業務KPI・四半期〜半期程度の期間を目安にスコープを切ることが、結果的に最速で本番に到達するアプローチです(AI総研支援経験上の目安)。広げるのは2回目以降。
AIモデルだけ高度化してデータ品質が伴わない
最後の典型パターンが、「最新のVLMや大規模モデルを使えば精度が上がる」という誤解です。
製造業のAI活用で精度を決めるのは、モデルの新しさよりも入力データの品質と一貫性です。古い設備ログのまま大規模モデルに投入しても、推論はバラつきます。Step 2のデータソース整理に十分な時間を割くことが、結局は精度への近道です。
主要プラットフォームの料金体系
データ基盤のコストは、ライセンス費用・コンピュート単位・ストレージ・データ転送・サポートの組み合わせで決まります。3プラットフォームの料金体系を整理します。
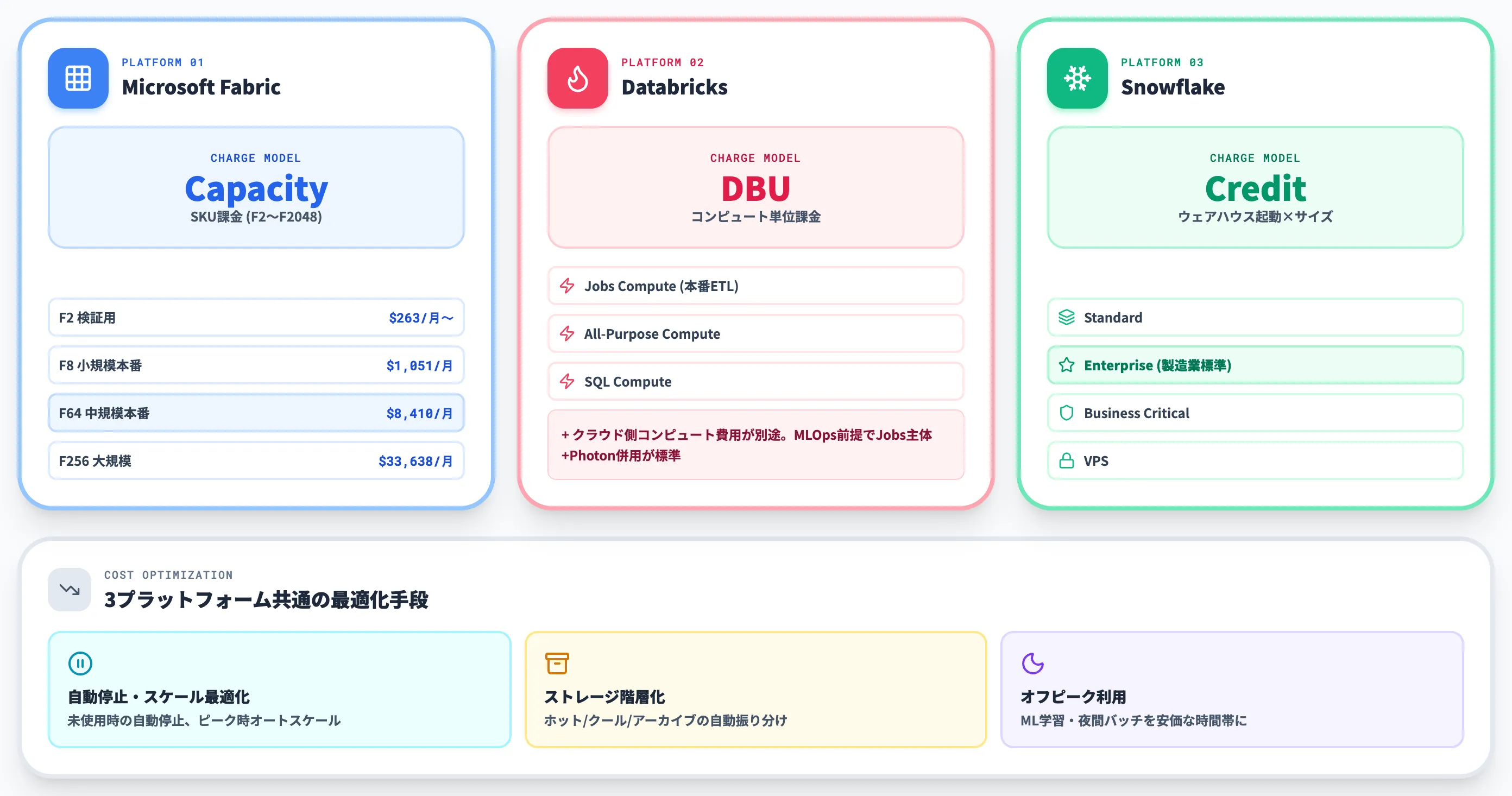
Microsoft Fabricの料金(Capacity単位)

Microsoft Fabricは、SKUベースのCapacity課金(F2〜F2048)が中心です。
以下の表で、Fabricの主要Capacity SKUの目安をまとめました(2026年6月時点・Microsoft Fabric Pricing / Fabricライセンス)。
| SKU | 月額目安(Pay-as-you-go) | 想定用途 |
|---|---|---|
| F2 | 約262.80 USD/月 | 個人検証・小規模ワークロード |
| F8 | 約1,051.20 USD/月 | 小規模本番 |
| F64 | 約8,409.60 USD/月 | 中規模本番 |
| F256 | 約33,638.40 USD/月 | 大規模・全社展開 |
F64以上のSKUでは、閲覧者がMicrosoft Fabric無料ライセンスのままでPower BIコンテンツを参照できる条件が緩和されます。ただしレポートの発行・共有には引き続きPower BI ProまたはPremium Per User(PPU)ライセンスが必要です(Power BI license types)。製造業の本番展開では、F64〜F256クラスが現実的な検討対象です。料金詳細は1035 Microsoft Fabricとはで深掘りしています。
Databricksの料金(DBU単位)
Databricksは、コンピュート単位のDBU(Databricks Unit)課金が中心です。
ワークロード種別(Jobs Compute / All-Purpose Compute / SQL Compute)とクラウド(AWS/Azure/GCP)でDBU単価が変わり、加えてクラウド側のコンピュート費用が別途発生します。
製造業の本番運用では、MLOps前提でJobs Compute主体・Photonエンジン併用の構成が一般的で、ワークロード規模に応じて個別見積もりで変動します。詳細はDatabricks料金記事で整理しています。
Snowflakeの料金(Credit単位)
Snowflakeは、Credit課金(仮想ウェアハウスの起動時間 × サイズ)が中心です。
Standard / Enterprise / Business Critical / VPS の4エディションで単価が異なり、Enterpriseエディションが製造業の本番運用では標準的な選択になります。自動停止機能・コンピュート分離(読み書き別ウェアハウス)でコストを最適化するのがSnowflake運用の基本です。詳細はSnowflake料金記事で深掘りしています。
コスト最適化の3つの考え方

3プラットフォームに共通するコスト最適化のポイントは以下の3つです。
-
自動停止・スケール最適化
未使用時の自動停止、ピーク時のオートスケール
-
ストレージ階層化
ホット/クール/アーカイブの自動振り分け(OneLake階層化・Snowflake Cold Storage 等)
-
オフピーク利用の活用
ML学習・夜間バッチを安価な時間帯に寄せる
特にOneLakeは2026年5月時点でストレージ階層化とライフサイクル管理がプレビュー提供されており、履歴データを自動で安価なTierへ移行する機能が公開されています(OneLake lifecycle management (preview))。コスト試算の段階で、こうした階層化機能を考慮するかどうかで3年TCOが大きく変わります。

AI Agent Hubで進める製造業データ活用
データ基盤の整備は、AIエージェントが業務に効くための土台でもあります。Fabric・Databricks・Snowflakeで整えたデータ資産を、PLM・MES・ERPと接続して業務プロセス全体を自動化する段階に進むと、AIエージェントの活用基盤が必要になります。
AI総合研究所のAI Agent Hubは、製造業向けに図面検索・図面見積・図面保存・ミーティング見積などのエージェントを提供しており、データ基盤と業務システムを結ぶ実装支援を行っています。
ライン稼働データを活かしてAI判断を業務側に届けるには、データ統合だけでなく、実行ログ・権限管理・セキュリティを含む基盤設計が不可欠です。製造業の現場で「AIで何ができるか」より「AIをどう運用に組み込むか」のフェーズに入った企業ほど、ここを早めに整える価値が高くなります。
製造業のデータ活用基盤を業務に定着させるために

データ統合からAIエージェント実装まで設計
Fabric・Databricks・Snowflakeで整備したデータ基盤を単体運用で終わらせず、PLM・MES・ERPと接続して業務プロセス全体を自動化。AI Agent Hubなら実行ログ・権限管理・セキュリティまで含めた基盤の設計・構築を支援します。
まとめ
製造業のデータ活用は、データ基盤×ユースケース×プラットフォームの3軸で設計するのが2026年の実務基準です。本記事の論点を1行ずつ振り返ります。
- 現在地と潮流: Fabric IQ × NVIDIA Omniverse、SAP × Snowflake BDC、生成AI連携BIで現場データとクラウドAI基盤の連携が一気に進んだ節目
- データの種類: 生産・品質・設備・物流・顧客の5領域。OT-IT分断を埋めずにAIだけ載せるとPoC止まりになる
- 4レイヤー設計: 収集→統合→分析→活用。メダリオンとAI-ready dataにリアルタイム性・トレーサビリティを加える
- 主要ユースケース: 予知保全・品質予測・需要予測・OEE/エネ・ナレッジ承継。データ準備度の高い領域から着手するのがPoC成功の近道
- プラットフォーム比較: M365資産はFabric、MLOps重視はDatabricks、SAP連携はSnowflakeが第一候補
- 導入ステップ: 課題定義→接続設計→PoC→本番→現場定着の5段階。各ステップで「次に進む判断基準」を明確にする
- 詰まる論点: 隠れコスト4項目・ガバナンス・PoCスコープ・データ品質。モデル高度化より入力品質
- 料金体系: Fabric Capacity・Databricks DBU・Snowflake Credit。階層化・自動停止・オフピーク活用で3年TCOを最適化
データ基盤の整備は単独で完結せず、AIエージェント・業務システム連携と一体で設計することで初めて業務インパクトに変わります。自社のM365/SAPの重心・データ準備度・OT統合の難易度を確認するところから、データ活用の現実的な次の一歩を整理することをおすすめします。










