この記事のポイント
 データレイクハウスを構築するなら、Bronze・Silver・Goldの3層メダリオンアーキテクチャを基本設計に採用すべき
データレイクハウスを構築するなら、Bronze・Silver・Goldの3層メダリオンアーキテクチャを基本設計に採用すべき- 監査証跡やデータ系譜の厳格な管理が必要ならData Vaultとの併用が有効。シンプルなBI基盤ならメダリオン単独で十分
- Microsoft Fabric環境ではLakehouse+Notebookでの実装が最適。マルチクラウド要件がある場合のみDatabricksを選ぶべき
- プラチナレイヤー(AIフィーチャーストア等)は要件が明確な場合のみ追加すべきで、初期導入時は3層構成に留めるのが堅実
- Fabric CU課金は予測可能なコスト管理、Databricks DBU課金はクラスター最適化に有利、組織の運用体制で選定する

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
メダリオンアーキテクチャとは、データをBronze(生データ)・Silver(クレンジング済み)・Gold(ビジネス活用)の3層で段階的に精製していく、データレイクハウスの設計パターンです。
Databricksが広めたこの手法は、現在ではMicrosoft Fabricが推奨設計として公式採用し、Google Cloud上でも多段設計として案内されるなど、主要プラットフォームで広く参照されています。
本記事では、メダリオンアーキテクチャの基本概念から各レイヤーの役割、従来のETL/ELTとの違い、Microsoft FabricとAzure Databricksでの実装パターン、導入事例、コミュニティで議論されるプラチナレイヤーなどの発展形、そして料金体系までを体系的に解説します。
メダリオンアーキテクチャとは?
メダリオンアーキテクチャ(Medallion Architecture)とは、データをBronze(生データ)・Silver(クレンジング済み)・Gold(ビジネス活用)の3つの層で段階的に精製していく、データレイクハウスの設計パターンです。
Databricksが広く普及させてきた代表的な設計パターンで、「マルチホップアーキテクチャ」とも呼ばれています。
2026年現在ではMicrosoft Fabricが公式の推奨設計として採用し、Google Cloud上でも多段設計として案内されるなど、主要プラットフォームで広く参照されています。

「データは溜めたが活用できていない」「部門ごとにデータが散在し、同じ指標でも数値が合わない」——多くの企業が抱えるこうした課題に対して、生データから分析用データまでの変換プロセスを明確な層で管理することで解決するのが、メダリオンアーキテクチャの基本的な考え方です。

データレイクハウスとの関係

メダリオンアーキテクチャを理解するうえで欠かせないのが、データレイクハウスという概念です。
以下の表で、データ基盤の主要な3つのアプローチを比較しました。
| アプローチ | 特徴 | 課題 |
|---|---|---|
| データレイク | あらゆるデータを生の形式で大量に蓄積できる | データ品質が保証されず「データの沼(Data Swamp)」になりやすい |
| データウェアハウス | 構造化されたデータを高速に分析できる | 非構造化データ(画像・ログなど)の取り扱いが困難 |
| データレイクハウス | レイクの柔軟性とウェアハウスの分析性能を統合 | 層の設計を誤ると複雑化しやすい |
ここで注目すべきは、データレイクハウスが「柔軟な保存」と「高品質な分析」を両立させようとしている点です。
メダリオンアーキテクチャは、このデータレイクハウス上でデータをどのように整理し、段階的に品質を高めていくかを定義した設計パターンにあたります。
なぜ今注目されるのか

メダリオンアーキテクチャが2026年の今、改めて注目を集めている背景には、いくつかの要因があります。
-
AI・機械学習の普及
RAG(検索拡張生成)やLLMを活用した社内AIを構築する際、学習データの品質がモデルの精度を大きく左右します。
Bronze→Silver→Goldの段階的な精製プロセスは、AIに投入するデータの品質管理と直結しています。
-
クラウドプラットフォームの公式採用
Microsoft Fabricが公式ドキュメントでメダリオンアーキテクチャを推奨設計として位置づけ、Databricksも引き続き中核的なアーキテクチャとして推進しています。
Google Cloud上でも多段設計として案内されるなど、主要プラットフォームで広く参照されるようになっています。
-
データガバナンスの要件強化
データの出所(リネージ)やアクセス権限の管理が法規制やコンプライアンスの観点から重要視されるなか、レイヤーごとにアクセス制御や品質ルールを設定できるメダリオンアーキテクチャは、ガバナンス要件にも合致します。
メダリオンアーキテクチャの3層構造
メダリオンアーキテクチャの中核は、データを3つの層(レイヤー)で段階的に精製していく仕組みです。
ここでは各レイヤーの役割、対象ユーザー、具体的な処理内容を解説します。
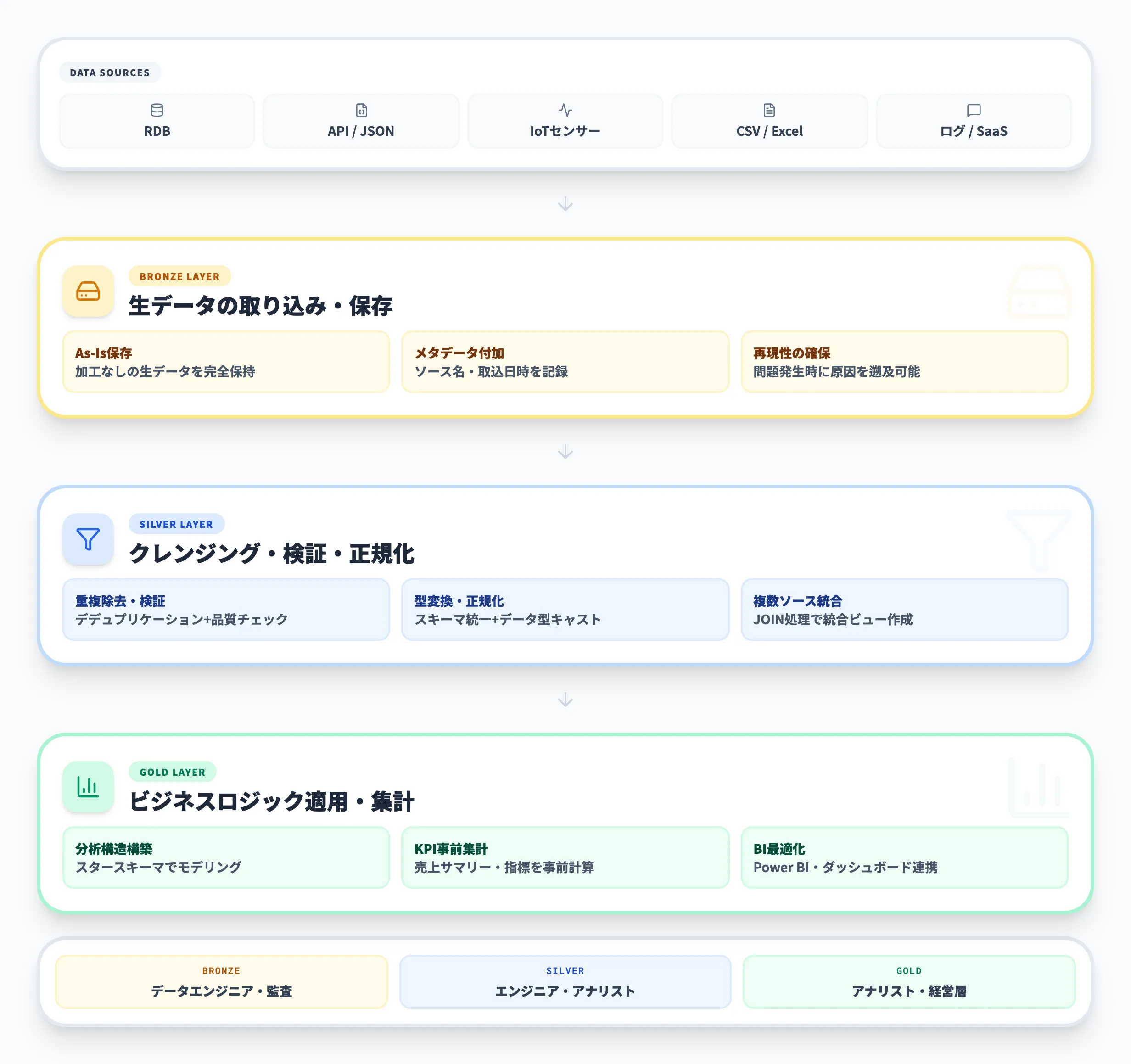
以下の表で、各レイヤーの基本的な特性を整理しました。
| レイヤー | 役割 | 対象ユーザー | データ品質 |
|---|---|---|---|
| Bronze | 生データの取り込み・保存 | データエンジニア、監査チーム | 未加工(As-Is) |
| Silver | クレンジング・検証・正規化 | データエンジニア、データアナリスト | 検証済み |
| Gold | ビジネスロジック適用・集計 | ビジネスアナリスト、経営層 | ビジネス対応済み |
ここで重要なのは、下位レイヤーから上位レイヤーに進むにつれて、データの品質と利用目的の特化度が高まっていくという設計思想です。各レイヤーの詳細を見ていきましょう。
Bronzeレイヤー(生データの取り込み)

Bronzeレイヤーは、メダリオンアーキテクチャの最下層にあたり、あらゆるデータソースから生データをそのまま取り込む「貯蔵庫」の役割を果たします。
Microsoft Learnの公式ドキュメントでは、取り込み時のポイントとして以下を推奨されています。
- データのスキーマ変更を防ぐため、STRING型やVARIANT型、BINARY型で格納する
- ソースシステム名や取り込み日時などのメタデータ列を追加する
- 生データは削除せず、不要になったものはコールドストレージにアーカイブする
Bronzeレイヤーの最大の目的はデータの完全な記録と再現性の確保です。加工前の生データを保持しておくことで、後工程で問題が見つかった際に原因を遡って調査できます。
監査やコンプライアンスの観点からも、この「生データの不変保存」は重要な要件です。
Silverレイヤー(クレンジング・検証)

Silverレイヤーでは、Bronzeレイヤーの生データに対してクレンジング(洗浄)や検証を施し、分析に耐えうる品質のデータセットを作り上げます。
主な処理内容は次のとおりです。
- 重複データの除去(デデュプリケーション)
- NULL値の処理、日付範囲の検証などのデータ品質チェック
- データ型の変換(文字列から日付型・数値型へのキャストなど)
- 複数のデータソースを結合(JOIN)して統合ビューを作成
- スキーマの標準化と正規化
Silverレイヤーは、データエンジニアだけでなくデータアナリストやデータサイエンティストも直接利用する層です。
ここで適切にクレンジングされたデータが、後段のGoldレイヤーやAI・機械学習の精度を左右するため、メダリオンアーキテクチャの中でも最も手間と注意が求められる工程と言えます。
Goldレイヤー(ビジネス活用)
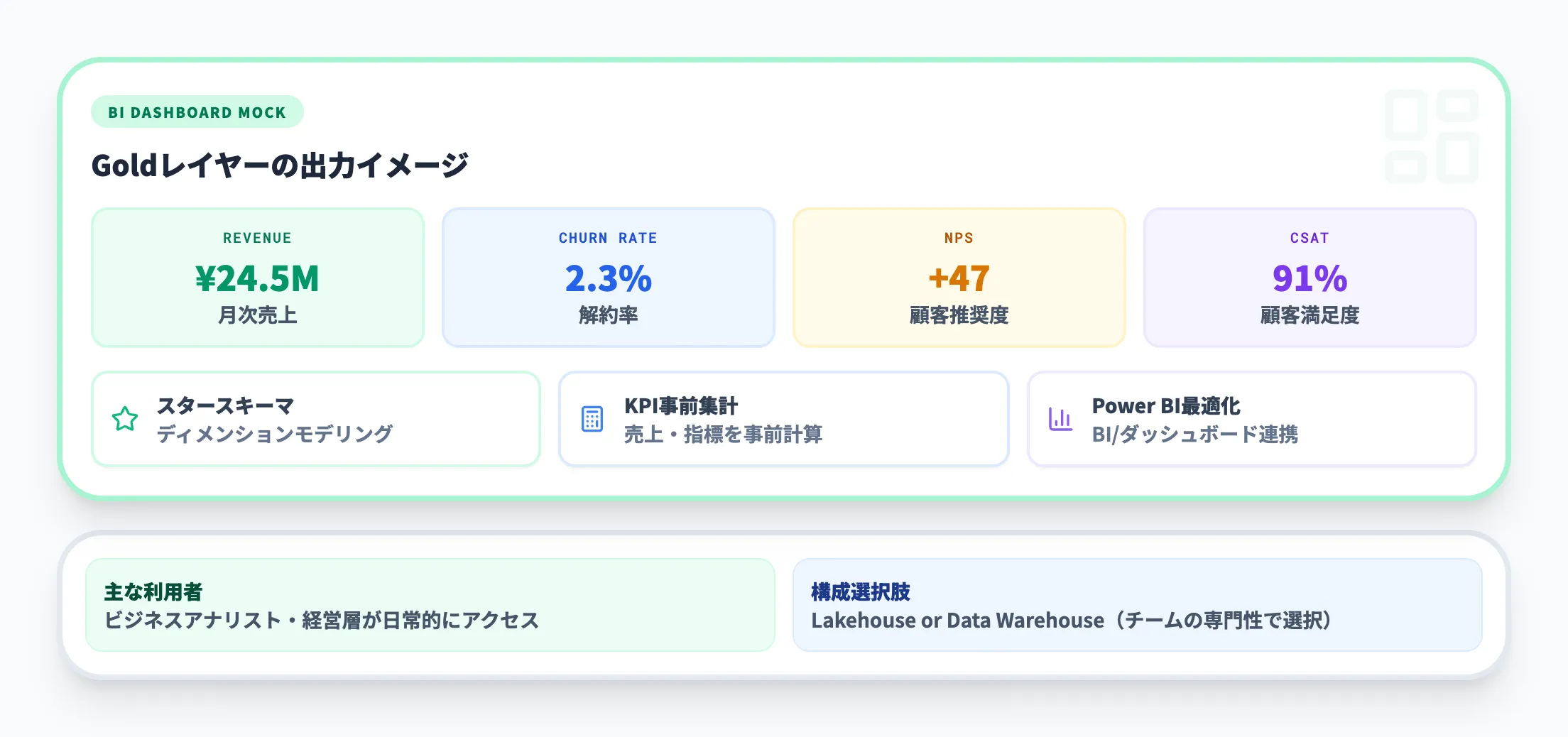
Goldレイヤーは、ビジネス上の意思決定に直接活用できる形にデータを仕上げる、メダリオンアーキテクチャの最上層です。
このレイヤーでは、以下のような処理を行います。
- ディメンションモデリング(スタースキーマ等)による分析構造の構築
- KPIや売上サマリーなどの事前集計
- Power BIなどのBIツールやダッシュボードへの最適化
- ビジネスドメインごとに複数のGoldテーブルを作成
Goldレイヤーのデータは、ビジネスアナリストや経営層が日常的にアクセスするものです。
Microsoftの公式ドキュメントでは、チームの好みや専門性に応じてレイクハウスまたはデータウェアハウスでGoldレイヤーを構築する選択肢が示されています。
SQL中心の消費パターンやwarehouse endpointを重視する場合はデータウェアハウスの採用も選択肢になります。
メダリオンアーキテクチャと従来手法の違い
メダリオンアーキテクチャは、データ処理の設計パターンとしてどのような特長があるのでしょうか。
ここでは、従来のETL/ELTパイプラインや他の設計パターンと比較し、それぞれの位置づけを明確にします。

ETL/ELTパイプラインとの比較
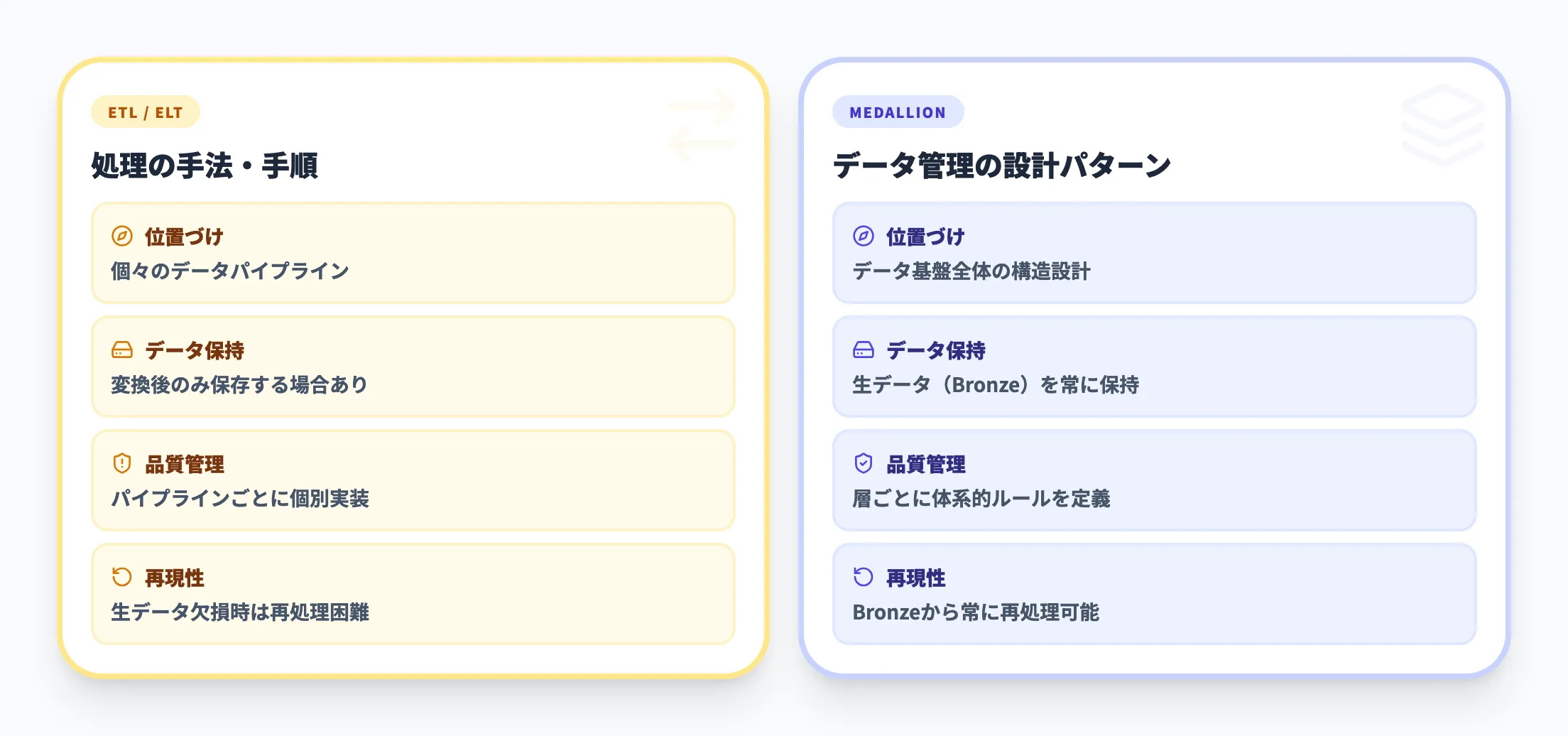
ETL(Extract-Transform-Load)やELT(Extract-Load-Transform)は、データを「抽出→変換→格納」する処理の流れを指す用語です。
メダリオンアーキテクチャとの関係を、以下の表で整理しました。
| 観点 | ETL/ELT | メダリオンアーキテクチャ |
|---|---|---|
| 位置づけ | データ処理の手法・手順 | データ管理の設計パターン |
| 対象範囲 | 個々のデータパイプライン | データ基盤全体の構造設計 |
| データ保持 | 変換後のデータのみ保存する場合もある | 少なくとも生データ(Bronze)を保持し、中間層のデータも保存しやすい設計(再処理が可能) |
| 品質管理 | パイプラインごとに個別に実装 | 層ごとに体系的な品質ルールを定義 |
| 再現性 | 生データが残らない場合は再処理困難 | Bronzeに生データが残るため常に再現可能 |
ここで押さえておきたいのは、メダリオンアーキテクチャとETL/ELTは対立する概念ではなく、補完関係にあるという点です。
メダリオンアーキテクチャは「データをどの順序で、どの層に配置するか」を決める設計図であり、各層間のデータ移動にはETLやELTの手法が実際に使われます。
つまり、メダリオンアーキテクチャを採用する場合でもETL/ELTは引き続き必要であり、両者は「設計」と「実行手段」の関係です。
Data Vaultなど他の設計パターンとの使い分け
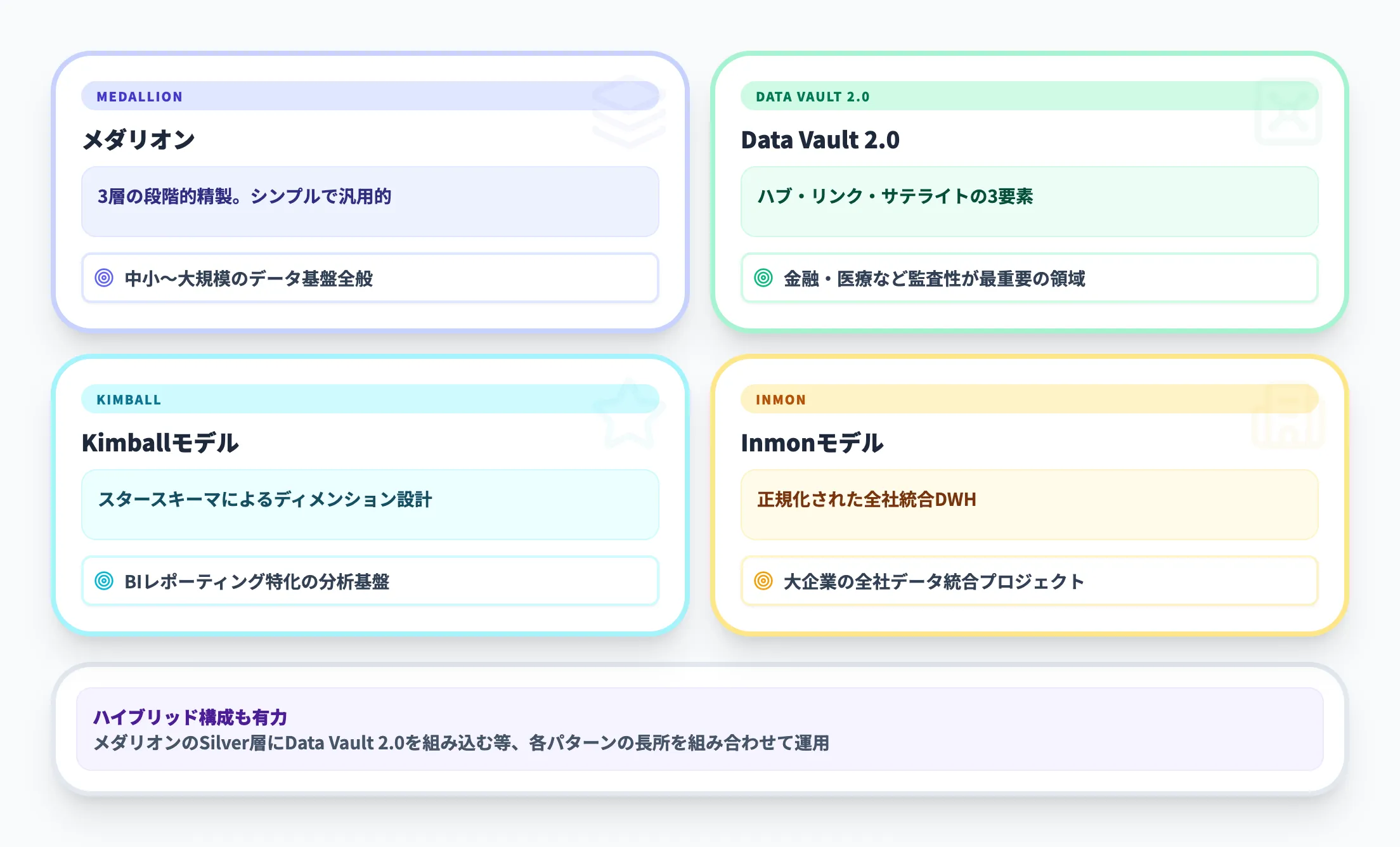
データ基盤の設計パターンにはメダリオンアーキテクチャ以外にもいくつかのアプローチがあります。
代表的なパターンとの比較を以下の表にまとめました。
| パターン | 特徴 | 向いている場面 |
|---|---|---|
| メダリオンアーキテクチャ | 3層の段階的精製。シンプルで理解しやすい | 中小〜大規模のデータ基盤全般 |
| Data Vault 2.0 | ハブ・リンク・サテライトの3要素でモデリング | 金融・医療など監査性が最重要の領域 |
| Kimballモデル | スタースキーマによるディメンションモデリング | BIレポーティング特化の分析基盤 |
| Inmonモデル | 正規化された全社統合データウェアハウス | 大企業の全社データ統合プロジェクト |
これらのパターンは、互いに排他的ではありません。
たとえば、メダリオンアーキテクチャのSilverレイヤーにData Vault 2.0のモデリングを組み込む「ハイブリッド構成」が、データエンジニアリングコミュニティで議論されています。
監査証跡の厳密な管理が求められる金融業界などでは、こうした組み合わせによって各パターンの長所を活かすアプローチが現実的な選択肢になっています。
メダリオンアーキテクチャの実装プラットフォーム
メダリオンアーキテクチャは設計パターンであるため、特定の製品に依存しません。
ただし、2026年時点で実装基盤として特に成熟しているのがMicrosoft FabricとAzure Databricksの2つです。
ここでは各プラットフォームでの実装パターンと選定基準を解説します。

Microsoft Fabricでの実装
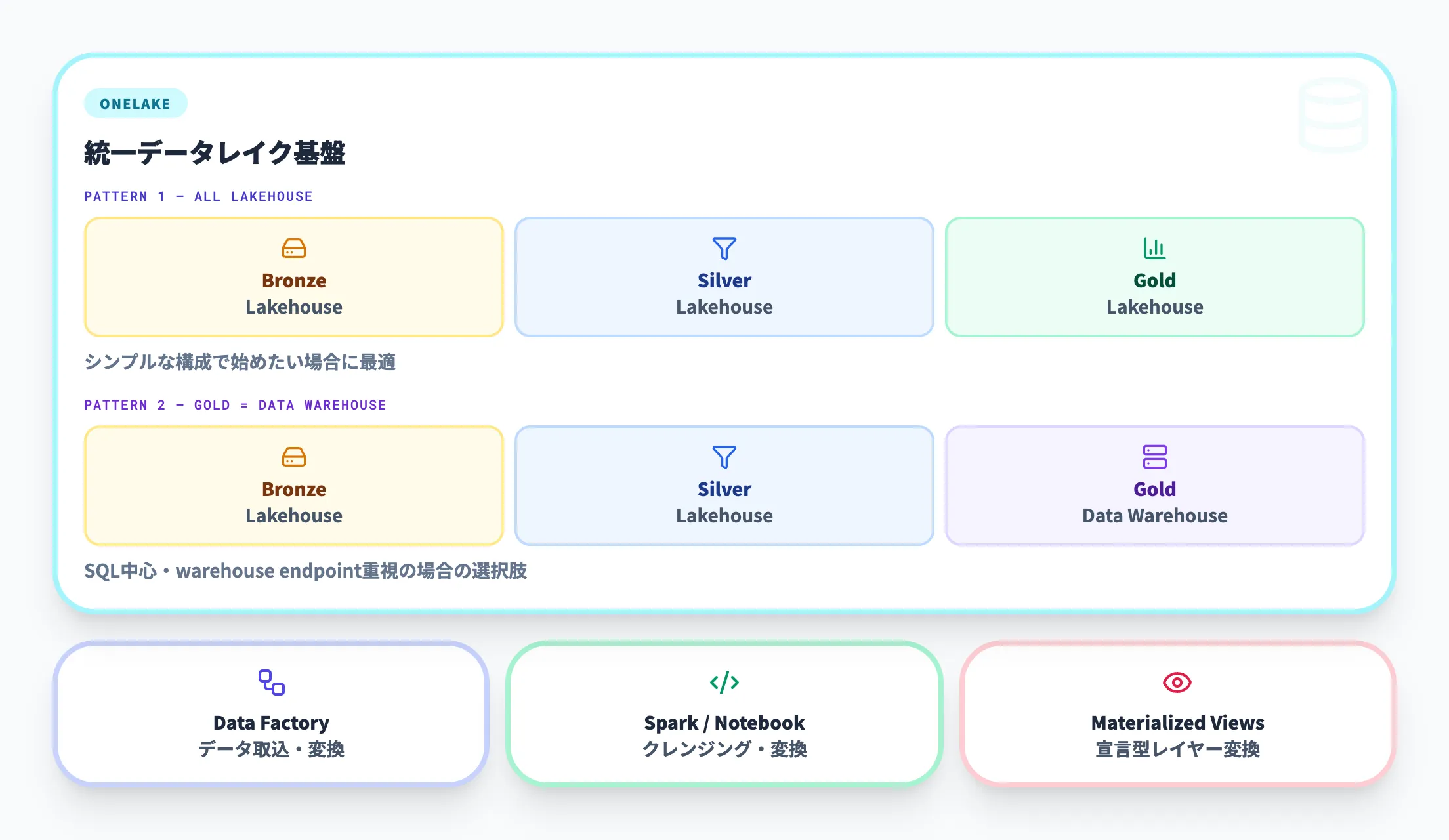
Microsoft Fabricは、メダリオンアーキテクチャを公式の推奨設計パターンとして位置づけています。
OneLakeを統一データレイクとし、その上にLakehouseを作成してBronze・Silver・Goldの各レイヤーを構築するのが基本的な実装パターンです。
公式ドキュメントでは、2つのデプロイメントモデルが紹介されています。
-
パターン1(全レイヤーをレイクハウスで構成)
Bronze・Silver・Goldすべてをレイクハウスとして作成し、SQLエンドポイント経由でアクセスします。シンプルな構成でメダリオンアーキテクチャを始めたい場合に適しています。
-
パターン2(GoldレイヤーをData Warehouseで構成)
BronzeとSilverはレイクハウス、Goldはデータウェアハウスとして構築します。SQL中心の消費パターンやwarehouse endpointを重視する場合の選択肢です。
2026年の注目機能として、具体化されたレイクビュー(Materialized Lake Views)があります。
これは宣言型のパイプラインでレイヤー間変換を定義し、依存関係の管理やデータ品質ルールの適用を自動化する機能です。
Data FactoryやData Engineering(Spark)と組み合わせて、Bronze→Silver→Goldのデータフローを構築します。
【関連記事】
OneLakeとは?Fabricの統合データレイクを徹底解説
Azure Databricksでの実装
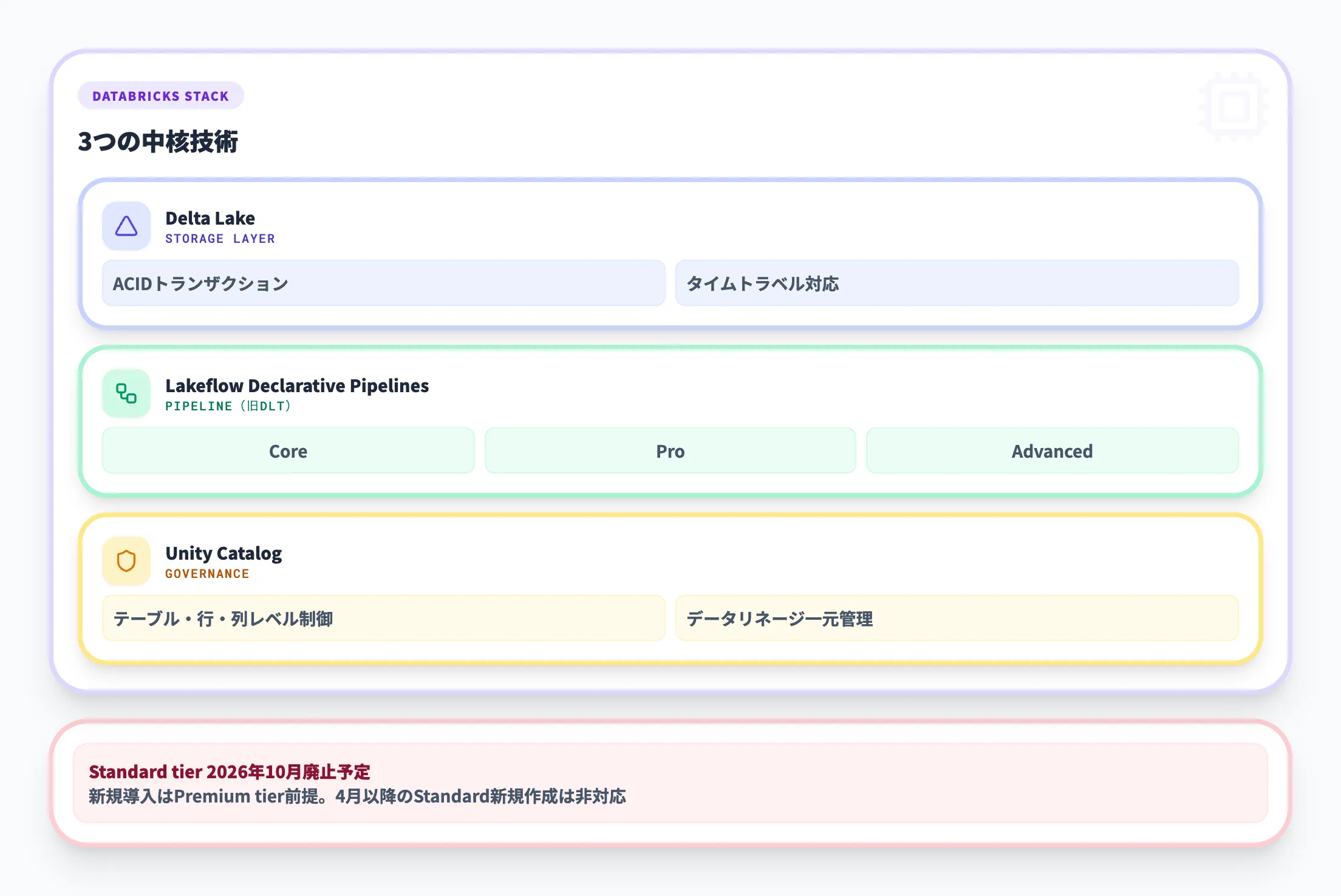
Azure Databricksは、Databricksが広く普及させてきたメダリオンアーキテクチャの代表的な実装基盤であり、Delta Lake・Lakeflow Spark Declarative Pipelines(旧称Delta Live Tables / DLT、2026年1月に改称)・Unity Catalogを中核技術として成熟した実装環境を提供しています。
Databricksでの標準的な構成要素は次のとおりです。
-
Delta Lake
ACIDトランザクション(データの整合性を保つ仕組み)をデータレイクに持ち込むオープンソース技術で、メダリオンアーキテクチャの各レイヤーのストレージ基盤として機能します。
タイムトラベル(過去のデータ状態への参照)にも対応しています。
-
Lakeflow Spark Declarative Pipelines(旧称Delta Live Tables / DLT)
Bronze→Silver→Goldのデータフローを宣言型で定義し、パイプラインの依存関係管理や品質チェックを自動化する機能です。
2026年1月にDelta Live TablesからLakeflow Spark Declarative Pipelinesに改称され、SQLまたはPythonで記述できます。
2 -
Unity Catalog
テーブル・行・列レベルのアクセス制御と、レイヤー間のデータリネージ(データの流れの追跡)を一元管理するガバナンス基盤です。
Fabric vs Databricksの選び方

どちらのプラットフォームを選ぶべきかは、組織の既存環境や利用目的によって異なります。
以下の表で、判断基準を整理しました。
| 判断基準 | Microsoft Fabric | Azure Databricks |
|---|---|---|
| 既存環境 | Microsoft 365やPower BIを利用中 | Sparkベースの分析基盤が稼働中 |
| 主な用途 | BI・レポーティング中心 | 大規模ETL・ML・AI処理中心 |
| 課金モデル | CU(容量ユニット)ベースの統一課金 | DBU(Databricks Unit)ベースのワークロード別課金 |
| ガバナンス | Microsoft Purviewとの統合 | Unity Catalogによる一元管理 |
| 学習コスト | Power BIユーザーなら移行しやすい | Sparkの知識が必要 |
ここでの選定ポイントは、既存のエコシステムとの親和性です。
Power BIやMicrosoft 365を中心に業務が回っている組織ではFabric、SparkやDelta Lakeベースの分析基盤をすでに運用している組織ではDatabricksが自然な選択になります。
両者を組み合わせてBronze・SilverはDatabricks、GoldはFabric(Power BI連携)という構成も実践されています。
Fabricのデータ基盤をAIアクションに接続

データ統合の先にあるAIエージェント活用
メダリオンアーキテクチャで整備したデータ基盤の真価は、そのデータをAIエージェントが業務に活かす段階で発揮されます。AI Agent HubはFabric OneLakeとZero ETLで接続し、分析から業務アクションまでを直結させます。
メダリオンアーキテクチャの企業事例
メダリオンアーキテクチャは概念としては理解しやすい一方、実際の導入ではどのような効果が出ているのでしょうか。ここでは、公開されている導入事例と業界別の活用パターンを紹介します。
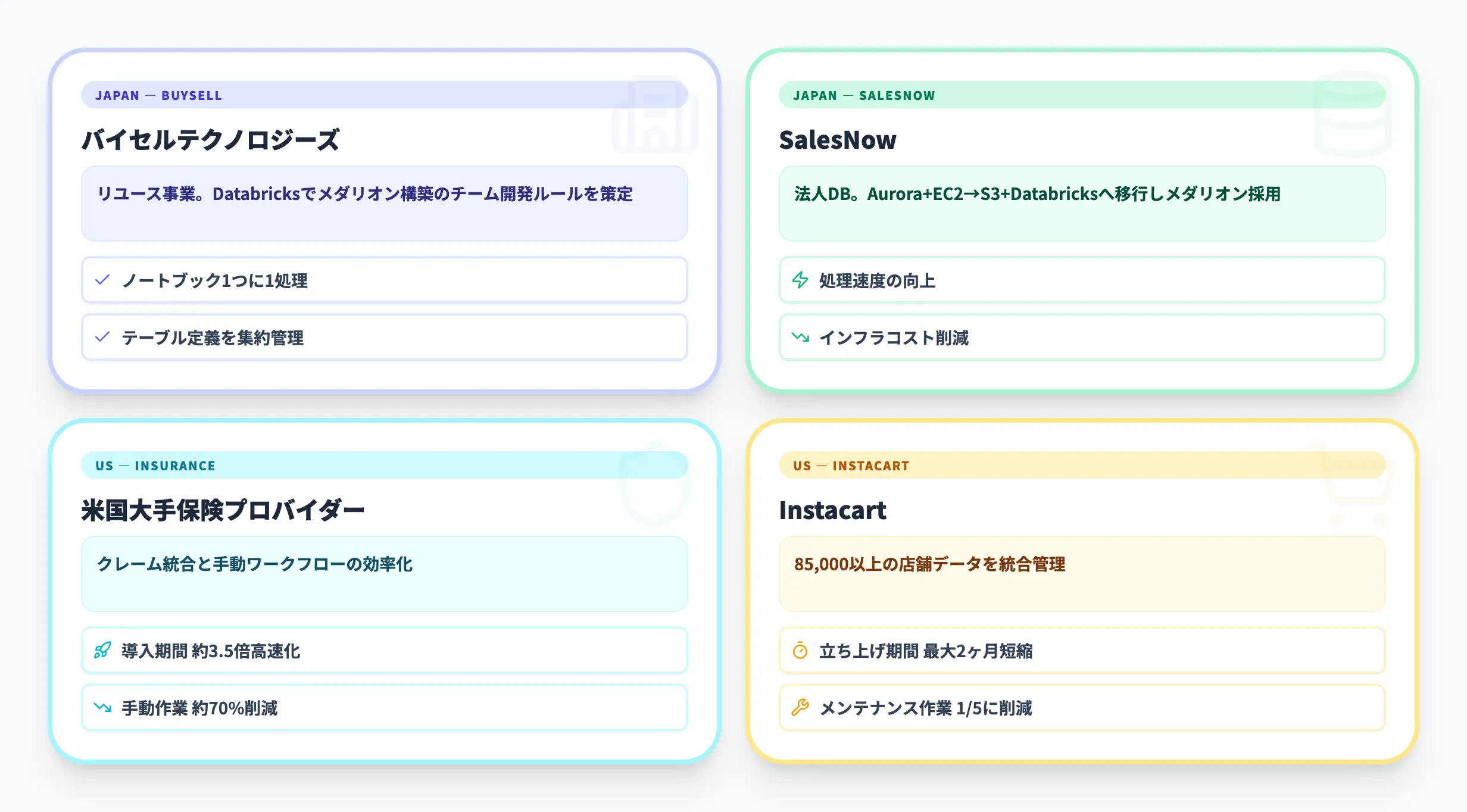
国内企業の導入事例

日本国内でもメダリオンアーキテクチャの導入が進んでいます。
-
バイセルテクノロジーズ
リユース事業を展開するバイセルテクノロジーズは、Databricksでメダリオンアーキテクチャを構築する際に、チーム開発のための実装ルールを策定した事例を自社テックブログで公開しています。
1つのノートブックに単一の処理のみを担当させる設計や、Delta Lakeのテーブル定義を集約管理する手法は、チーム開発での実践的な知見として参考になります。
-
SalesNow
法人データベースを提供するSalesNowは、Aurora PostgreSQLとEC2で構成されていた既存基盤をS3とDatabricksに移行し、メダリオンアーキテクチャを採用した事例をFindy Toolsに掲載しています。処理速度の向上とインフラコストの削減を実現したと報告されています。
【関連記事】
Microsoft Fabric導入事例6選!国内企業の成果と導入パターンを解説
海外での事例

海外ではより大規模な導入事例が報告されています。データ統合プラットフォームのNexlaが自社ブログで紹介している事例では、以下のような定量的な効果が示されています。
-
米国大手保険プロバイダー
クレーム統合と手動データワークフローの課題に対し、メダリオンアーキテクチャを導入。パートナー導入期間が約3.5倍高速化し、手動作業が約70%削減されたと報告されています。
-
Instacart(オンライン食料品配達)
85,000以上の店舗データを扱う環境で、メダリオンアーキテクチャベースのデータパイプラインを構築。新規小売パートナーの立ち上げ期間が最大2ヶ月短縮され、メンテナンス作業が5分の1に削減されたと報告されています。
いずれもNexla社のブログからの引用であり、同社のソリューションとの連携を前提とした事例です。
具体的な導入を検討する際は、自社の要件に照らして効果を精査することを推奨します。
業界別の活用パターン
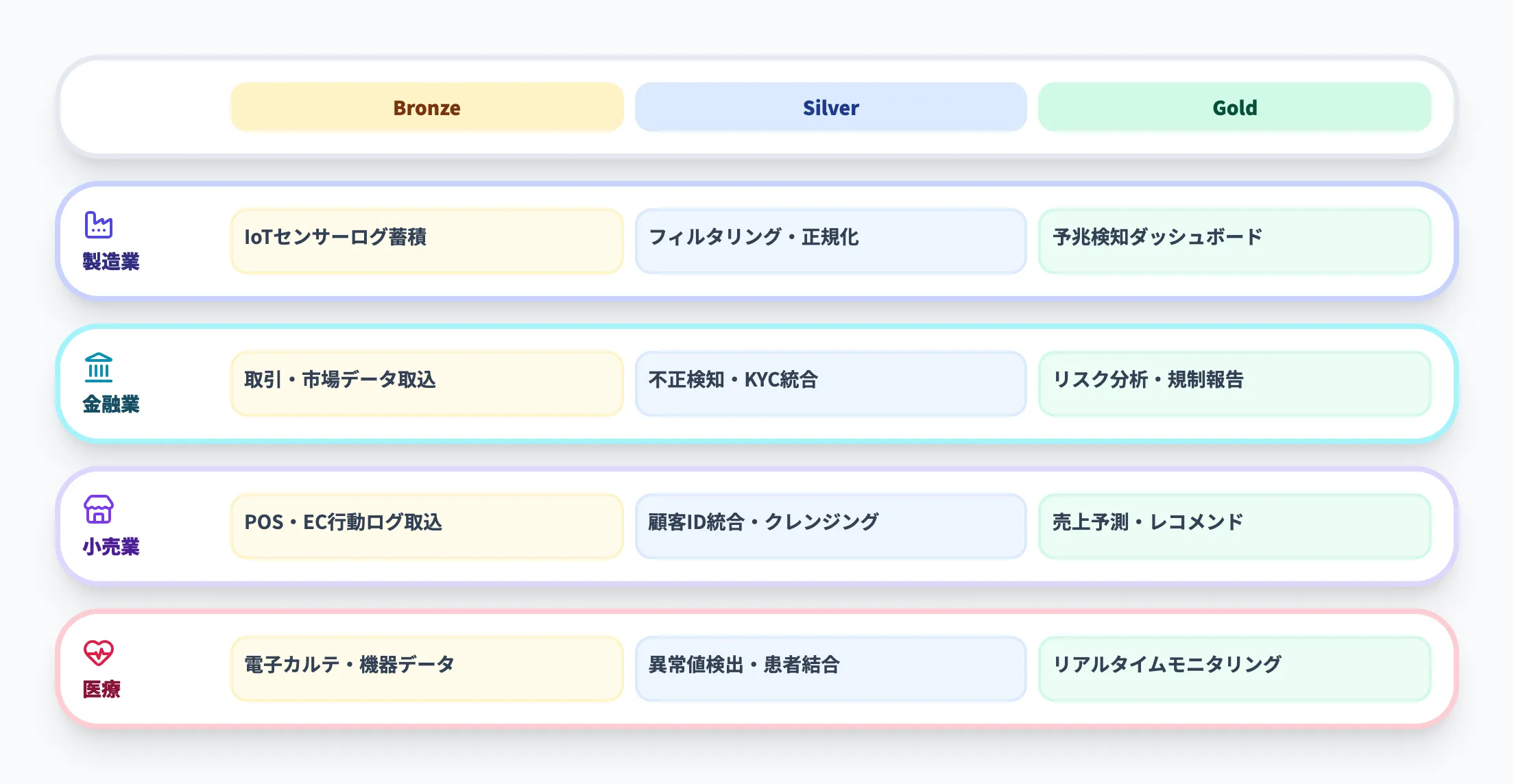
メダリオンアーキテクチャは、業界を問わず幅広いデータ基盤で活用されています。以下の表で、代表的な業界別のレイヤー活用パターンを整理しました。
| 業界 | Bronzeの活用 | Silverの活用 | Goldの活用 |
|---|---|---|---|
| 製造業 | IoTセンサーログの蓄積 | フィルタリング・型の正規化 | 予兆検知・保守自動化ダッシュボード |
| 金融業 | 取引データ・市場データの生取込 | 不正検知スコアリング・KYCデータ統合 | リスク分析レポート・規制当局向け報告 |
| 小売業 | POS・在庫・EC行動ログの取込 | データクレンジング・顧客ID統合 | 売上予測・レコメンドエンジン用データ |
| ヘルスケア | 電子カルテ・医療機器データの蓄積 | 異常値検出・患者記録との結合 | リアルタイム患者モニタリングダッシュボード |
どの業界でもBronzeで「完全な記録」を残し、Silverで「分析に使える品質」に高め、Goldで「意思決定に直結する形」に仕上げるという基本パターンは共通していることがわかります。
違いは各レイヤーで適用する具体的な処理内容にあります。

メダリオンアーキテクチャの発展形と最新動向
メダリオンアーキテクチャは、AIエージェントの台頭やデータメッシュの普及を背景に、コミュニティレベルで新たな拡張が議論されています。
ここでは、公式標準ではないものの注目を集めている発展形の動向を紹介します。

プラチナレイヤーとAI対応
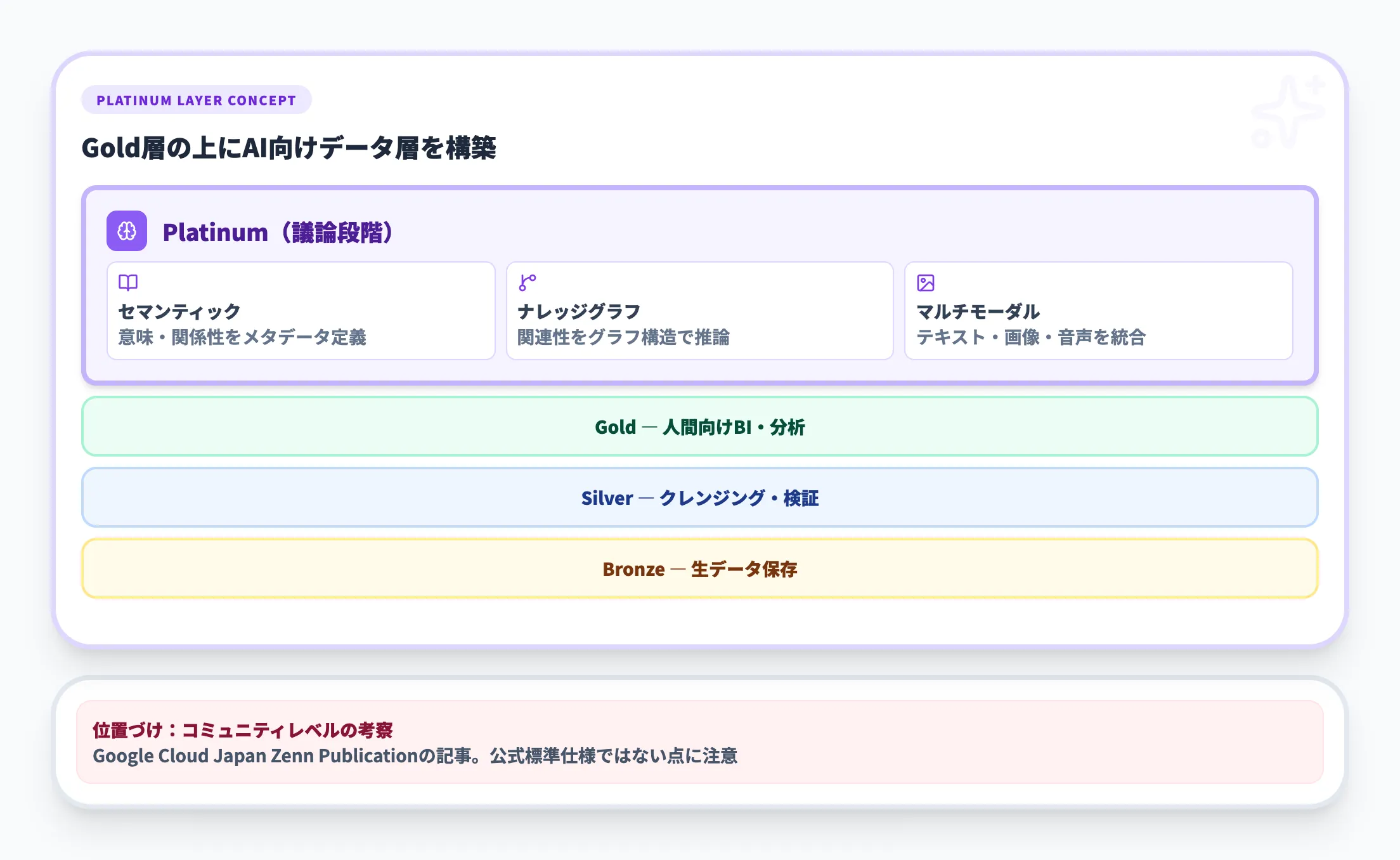
2025年7月、Google Cloud JapanのZenn Publicationにて、メダリオンアーキテクチャに4番目のレイヤー「プラチナレイヤー」を加える考え方について考察する記事が公開されました。これは公式の標準仕様ではなく、AIエージェント時代のデータ基盤をどう設計するかを議論するための提案です。
従来のGoldレイヤーは人間向けの分析やBIレポートに最適化されていますが、AIエージェントやLLMが直接データを活用するには、さらに別の準備が必要です。
プラチナレイヤーは、このAIが利用しやすい形にデータを整えるための層として提唱されています。
プラチナレイヤーの主な構成要素は次のとおりです。
セマンティックレイヤー
データの意味や関係性をメタデータとして定義し、AIがデータの「意味」を理解できるようにする層です。
ナレッジグラフ
データ間の関連性をグラフ構造で表現し、複雑な問いに対する推論を可能にします。
マルチモーダルデータ対応
テキスト・画像・音声など多様な形式のデータをベクトル埋め込みとして統合管理します。
この考え方はまだコミュニティレベルの議論段階ですが、AIエージェント向けのデータ基盤の設計を考えるうえで重要な方向性を示しています。
Microsoft Fabricでもデータエージェント機能が登場しており、メダリオンアーキテクチャ上のデータを自然言語で問い合わせるユースケースが現実のものになりつつあります。
メダリオンメッシュ(分散型データ管理)

もう1つの進化形が「メダリオンメッシュ」です。これは、各事業部門(ドメイン)が独自のBronze-Silver-Goldパイプラインを構築し、必要に応じてドメイン間でデータを共有するアプローチです。
従来のメダリオンアーキテクチャは、全社統合型の単一パイプラインを前提としていました。
しかし大規模組織では、すべてのデータを1つのパイプラインで処理しようとすると、ボトルネックや責任範囲の曖昧さが生じます。
メダリオンメッシュでは、以下のように分散と統治を両立させます。
- 各ドメインが自らの専門知識を活かしてパイプラインを構築・運用する
- Unity CatalogやDelta Sharingで「分散しつつも統治されたデータ共有」を実現する
- Microsoft Fabricでも公式ドキュメントでデータメッシュとの併用パターンが紹介されている
メダリオンメッシュは、組織のスケールに応じて従来のメダリオンアーキテクチャを発展させる有力な選択肢です。
ただし、導入にはドメイン間のデータ契約やメタデータ標準の整備が前提となるため、まずは部門単位でメダリオンアーキテクチャを確立し、段階的にメッシュ化を進めるアプローチが現実的です。
メダリオンアーキテクチャが向いている場面・向かない場面
メダリオンアーキテクチャは万能な設計パターンではありません。
ここでは、導入が効果的な場面とそうでない場面を整理し、判断の目安を示します。

以下の表で、メダリオンアーキテクチャの適性を対比しました。
| 向いている場面 | 向かない場面 |
|---|---|
| 複数のデータソースを統合する必要がある | 単一のRDBMSで完結するシンプルな業務アプリ |
| データの品質管理や監査証跡が重要 | リアルタイム性が最優先(ミリ秒単位の応答が必要) |
| BI・ML・AIなど多様な消費パターンがある | データ量が小規模で変換パイプラインの構築コストに見合わない |
| データ基盤を段階的に整備・拡張したい | 全社統合ではなく特定業務の一時的なデータ処理 |
| チーム開発でデータ品質の属人化を防ぎたい | データエンジニアリングの専門人材が確保できない |
| 再処理が必要になる可能性がある(スキーマ変更など) | ストレージコストの最小化が最優先 |
押さえておきたいのは、「向かない場面」は必ずしもメダリオンアーキテクチャが使えないという意味ではなく、投資対効果が見合わない可能性がある場面という位置づけです。
たとえばリアルタイム処理については、Microsoft FabricのReal-Time Intelligenceがメダリオンアーキテクチャ上でのストリーミング処理に対応しており、ユースケースによっては適用可能です。
また、ストレージコストについても、BronzeレイヤーをコールドストレージやLifecycle Policyで管理することで軽減できます。
導入を検討する際は、「データ基盤の将来的な拡張を見据えたとき、3層構造による整理がチーム全体の生産性を高めるか」を判断基準にすることを推奨します。
メダリオンアーキテクチャの実装にまつわるコスト
メダリオンアーキテクチャ自体は設計パターンであり、パターンそのものに料金はかかりません。コストが発生するのは、実装に使用するクラウドプラットフォームの利用料金です。
ここでは主要な2つのプラットフォームの料金体系を解説します。
Microsoft Fabricの料金イメージ

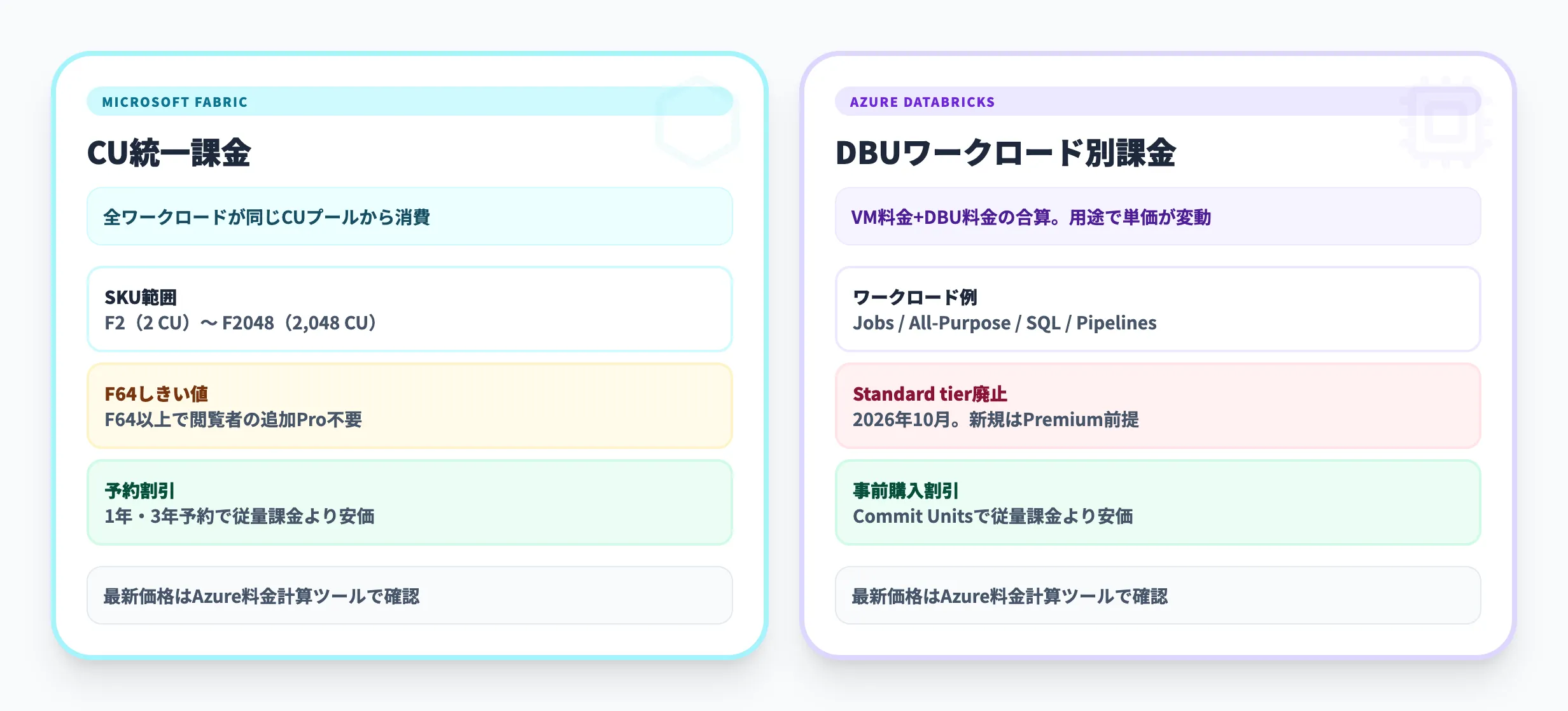
Microsoft Fabricは、CU(Capacity Unit:容量ユニット)を単位とした統一課金モデルを採用しています。
Power BI・Data Factory・Spark・Data Warehouse・Real-Time Intelligenceなど、すべてのワークロードが同じCUプールから消費される仕組みです。
SKUはF2(2 CU)からF2048(2,048 CU)まで用意されており、CU数に比例して月額料金が上がります。
従量課金のほか、予約購入(1年・3年)で割引が適用されます。
| SKU | CU数 | Power BIライセンス要件 |
|---|---|---|
| F2〜F32 | 2〜32 | Power BIコンテンツの閲覧者にPro License($14/ユーザー/月)が別途必要 |
| F64以上 | 64〜2,048 | 閲覧者の追加Proライセンス不要(コンテンツの発行・共有にはPro/PPUが引き続き必要) |
注目すべき判断ポイントはF64のしきい値です。F64はPremium P1相当のSKUで、F64以上では閲覧者の追加Proライセンスが不要になります。
利用ユーザー数が多い場合、F64以上のほうがトータルコストで有利になるケースがあります。なお、パイプライン・データウェアハウス・ノートブックなどPower BI以外のワークロードは、SKUに関係なくProライセンスは不要です。
Azure Databricksの料金イメージ
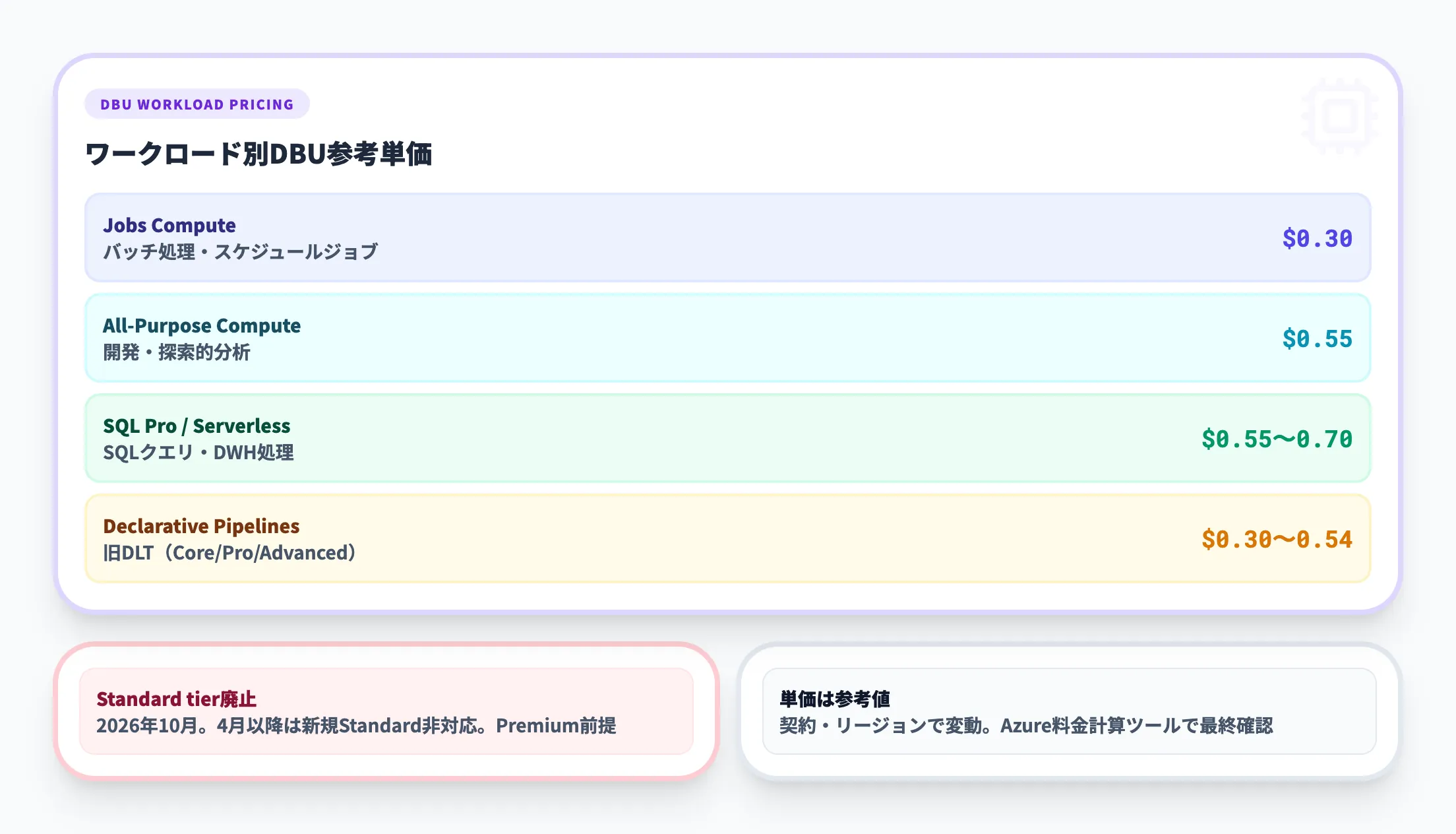
Azure Databricksは、DBU(Databricks Unit)を単位として課金され、VMインスタンス料金とDBU料金の合算でコストが決まります。
Premium tierのDBU単価はワークロードタイプごとに異なります。
以下は主なワークロードの参考価格です(契約条件・リージョンにより変動するため、正式な見積もりはAzure料金計算ツールで確認してください)。
| ワークロード | 参考DBU単価の例(USD/時間) | 用途 |
|---|---|---|
| Jobs Compute | $0.30 | バッチ処理・スケジュールジョブ |
| All-Purpose Compute | $0.55 | 開発・探索的分析 |
| SQL Pro | $0.55 | SQLによるデータウェアハウス処理 |
| SQL Serverless | $0.70 | オンデマンドSQLクエリ(VM費用込み) |
| Declarative Pipelines Core(旧DLT Core) | $0.30 | 基本的なパイプライン処理 |
| Declarative Pipelines Pro(旧DLT Pro) | $0.38 | 品質チェック付きパイプライン |
| Declarative Pipelines Advanced(旧DLT Advanced) | $0.54 | 高度な品質・リネージ管理 |
参考:Azure公式 - Azure Databricks の価格(2026年3月参照、米国リージョン基準)
メダリオンアーキテクチャの各レイヤー間のデータ処理にはLakeflow Spark Declarative Pipelines(旧称Delta Live Tables / DLT)がよく使われます。
Core・Pro・Advancedの3ティアに分かれており、品質管理やリネージ追跡の要件に応じて選択します。
前述のとおり、Standard tierは2026年10月に廃止予定です。新規導入ではPremium tierが前提となり、Standard tierと比較してDBU単価は約37%高くなりますが、Unity Catalog・監査ログ・RBAC・SQL Serverlessを含む包括的なガバナンス機能が利用できます。事前購入(Databricks Commit Units)で従量課金より安くなる場合があります。

メダリオンアーキテクチャで整備したデータをAIエージェントの業務判断に活用する
Bronze→Silver→Goldと段階的に品質を高めたデータは、ダッシュボードに表示するだけでは真価を発揮しません。Goldレイヤーのデータをもとに、AIエージェントが報告・申請・承認といった業務アクションまで自動実行する仕組みが、データ基盤投資のROIを大きく左右します。
AI Agent Hubは、Microsoft Fabric(OneLake)をデータ基盤として活用し、メダリオンアーキテクチャで精製されたGoldレイヤーのデータにAIエージェントが直接アクセスして業務を自動実行するエンタープライズAI基盤です。
- Goldレイヤーのデータから業務アクションへ直結
メダリオンアーキテクチャで品質保証されたGoldレイヤーのデータを、Zero ETLで仮想統合。Teamsチャットから自然言語で問い合わせた結果を、そのまま報告・申請・承認フローに変換します。
- Agentの実行データがBronzeに還流する好循環
AIエージェントの実行ログ・承認履歴・ROIデータがFabricに集約され、新たなBronzeデータとして蓄積。データ基盤とAgent基盤が相互に強化し合うサイクルが生まれます。
- 構築基盤が違っても管理は1つのダッシュボード
Microsoft FoundryでもCopilot Studioでもn8nでも、どこで構築したAgentも実行ログ・権限・セキュリティチェックを一元管理。シャドーAIの乱立を防ぎます。
AI総合研究所の専任チームが、メダリオンアーキテクチャを活用したデータ基盤設計からAIエージェントの業務実装まで一貫して支援します。無料の資料で、データ基盤とAIエージェントを接続する全体像をご確認ください。
Fabricのデータ基盤をAIアクションに接続
データ統合の先にあるAIエージェント活用
メダリオンアーキテクチャで整備したデータ基盤の真価は、そのデータをAIエージェントが業務に活かす段階で発揮されます。AI Agent HubはFabric OneLakeとZero ETLで接続し、分析から業務アクションまでを直結させます。
まとめ
本記事では、メダリオンアーキテクチャの基本概念から実装方法、最新動向、料金体系までを解説しました。
メダリオンアーキテクチャは、Bronze・Silver・Goldの3層構造でデータの品質を段階的に高めながら管理する設計パターンです。2026年現在、Microsoft FabricとAzure Databricksの両プラットフォームが公式に採用しており、データレイクハウス設計の事実上の標準になりつつあります。
導入を検討する際のポイントを3つにまとめます。
-
まずは小さく始める
全社統合を最初から目指すのではなく、特定の業務ドメイン(人事・経理・営業など)を対象にBronze→Silver→Goldのパイプラインを1本構築し、効果を検証するアプローチが現実的です。
-
既存環境に合わせてプラットフォームを選ぶ
Power BI中心の組織はMicrosoft Fabric、Spark中心の組織はAzure Databricksが自然な選択です。両者を組み合わせることも可能です。
-
将来のAI活用を見据える
コミュニティで議論されているプラチナレイヤーの考え方やデータメッシュとの併用など、Goldレイヤーの先にAIが活用しやすいデータ層を拡張する余地を残しておくことが、長期的なデータ戦略として有効です。










