この記事のポイント
 6月12日の米国政府輸出管理指令によるFable 5・Mythos 5の停止は6月30日に解除され、Fable 5は2026年7月1日から段階的に再開
6月12日の米国政府輸出管理指令によるFable 5・Mythos 5の停止は6月30日に解除され、Fable 5は2026年7月1日から段階的に再開- Claude Fable 5はMythos-class初の一般公開モデルで、Opus 4.8の上位に位置する新しい最上位層
- 価格は入力$10・出力$50とOpus 4.8の2倍。サブスクは7月7日まで週間使用枠の50%以内で追加料金なし、7月8日以降はUsage Credits消費
- サイバー・生物化学・蒸留の3領域はOpus 4.8へ転送、95%超のセッションで発動せず。UIは自動切替、APIは refusal 検出+フォールバック設定が必要
- コンテキストは1Mトークン、Max output 128kトークンでAdaptive thinkingが常時ON
- Claude.ai・Claude Code・Claude Cowork・Anthropic APIは7月1日再開。Bedrock・Vertex AI・Microsoft Foundryは順次再開予定

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Claude Fable 5(クロード・フェーブル5)は、Anthropicが2026年6月9日に発表した、Mythos-class初の一般公開モデルです。
Claude Opus 4.8より上位に位置づけられた新しい最上位層で、2026年4月に注目を集めたClaude Mythos Previewの系譜を引く新世代モデルです。
本記事では、Claude Fable 5の性能・料金体系・使い方・セーフガードの挙動・GPT-5.5など競合モデルとの比較・乗り換え判断軸を、2026年7月時点の最新情報で体系的に解説します。
✅ 2026年7月1日 追記
米国政府の輸出管理指令は2026年6月30日付で解除され、AnthropicはFable 5への一般アクセスを2026年7月1日から段階的に再開しています。詳細は本記事の「Fable 5・Mythos 5の停止から再開まで──輸出管理指令の経緯」セクションを参照してください。
目次
Claude Fable 5とClaude Mythos 5の違い
Fable 5・Mythos 5の停止から再開まで──輸出管理指令の経緯
Claude Fable 5のセーフガードとデータ保持ポリシー
vs Claude Opus 4.8——「2倍払う価値」があるかの判断軸
vs GPT-5.5——マルチモーダル統合とエージェント特化の住み分け
vs Gemini 3.1 Pro——コスト優位と Google エコシステム統合
Claude Fable 5を活かすプロンプティングと運用設計
effortレベルの使い分け(high/xhigh/medium/low)
長時間実行を支える3つの設計指示——境界明示・進捗監査・早期停止対策
並列サブエージェントとメモリシステム——非同期通信と1ファイル1教訓
既存スキル・プロンプトのリファクタリング——reasoning_extraction拒否を回避する
2.Pro/Max契約者なら2026年7月7日までに利用量と上限を決めているか
3.API利用者なら30日データ保持ポリシーが業務要件と整合するか
Claude Fable 5とは?
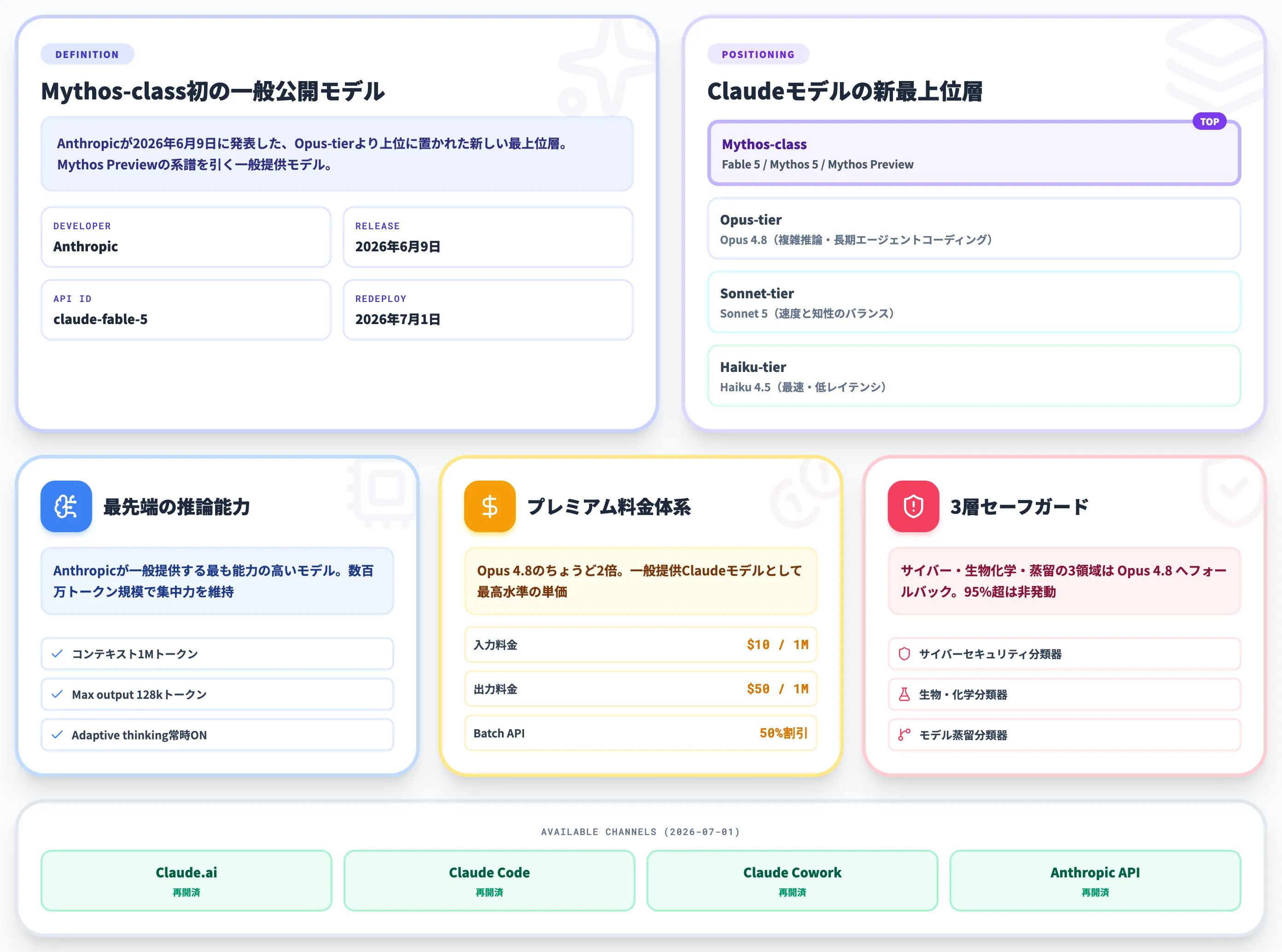
Claude Fable 5(クロード・フェーブル5)は、Anthropicが2026年6月9日に発表した、Mythos-classと呼ばれる新モデルファミリーの一般公開版です。
Fable 5が他のClaudeモデルと根本的に違うのは、従来のフラグシップ層であるOpus-tierより上位に置かれた、新しい最上位層として設計されている点です。
Claude Opus 4.8が「複雑な推論と長期エージェントコーディングのためのOpus-tier最強モデル」であるのに対し、Fable 5は「現時点でAnthropicが一般提供する最も能力の高いモデル」として明確に上位に位置づけられています。
Claudeモデル系統での位置づけ
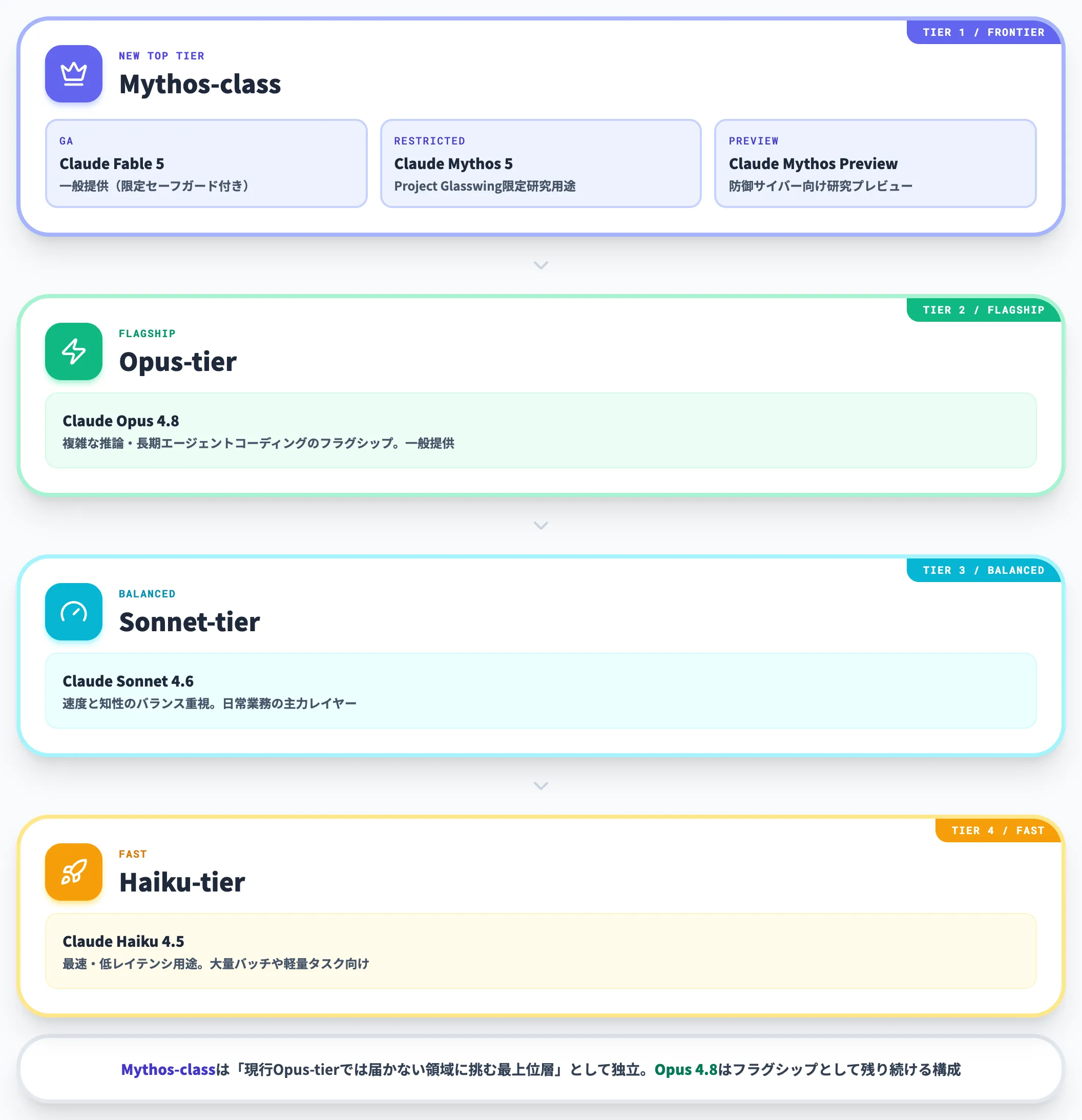
Claudeのモデルファミリーは、これまでOpus・Sonnet・Haikuの3階層構成で整理されてきましたが、2026年4月のClaude Mythos Preview発表でMythos-classが初登場し、Fable 5のリリースで一般提供レベルまで広がりました。
以下の表で、Mythos-classと既存3階層の位置づけを整理しました。
| 階層 | モデル | 主用途 | 提供形態 |
|---|---|---|---|
| Mythos-class | Claude Fable 5 | 最も要求の高い推論・長期エージェント業務 | 一般提供(限定セーフガード付き) |
| Mythos-class | Claude Mythos 5 | Project Glasswing経由の限定研究用途 | 招待制限定提供 |
| Mythos-class | Claude Mythos Preview | 防御サイバーセキュリティ向け研究プレビュー | 招待制限定提供 |
| Opus-tier | Claude Opus 4.8 | 複雑な推論・長期エージェントコーディング | 一般提供 |
| Sonnet-tier | Claude Sonnet 5 | 速度と知性のバランス重視 | 一般提供(2026年6月30日リリース) |
| Haiku-tier | Claude Haiku 4.5 | 最速・低レイテンシ用途 | 一般提供 |
従来のOpus・Sonnet・Haikuが「能力 vs コスト」のバランスで選ぶ階層であるのに対し、Mythos-classは「現行Opus-tierでは届かない領域に挑む最上位層」として独立しています。
つまりOpus 4.8がいまもフラグシップとして残りつつ、その上に「より高い能力と料金、追加のセーフガード」を備えたMythos-classが乗る構成です。
【関連記事】
Claude Opus・Sonnet・Haikuの違いとは?料金や使い分けを徹底比較
Claude Fable 5とClaude Mythos 5の違い
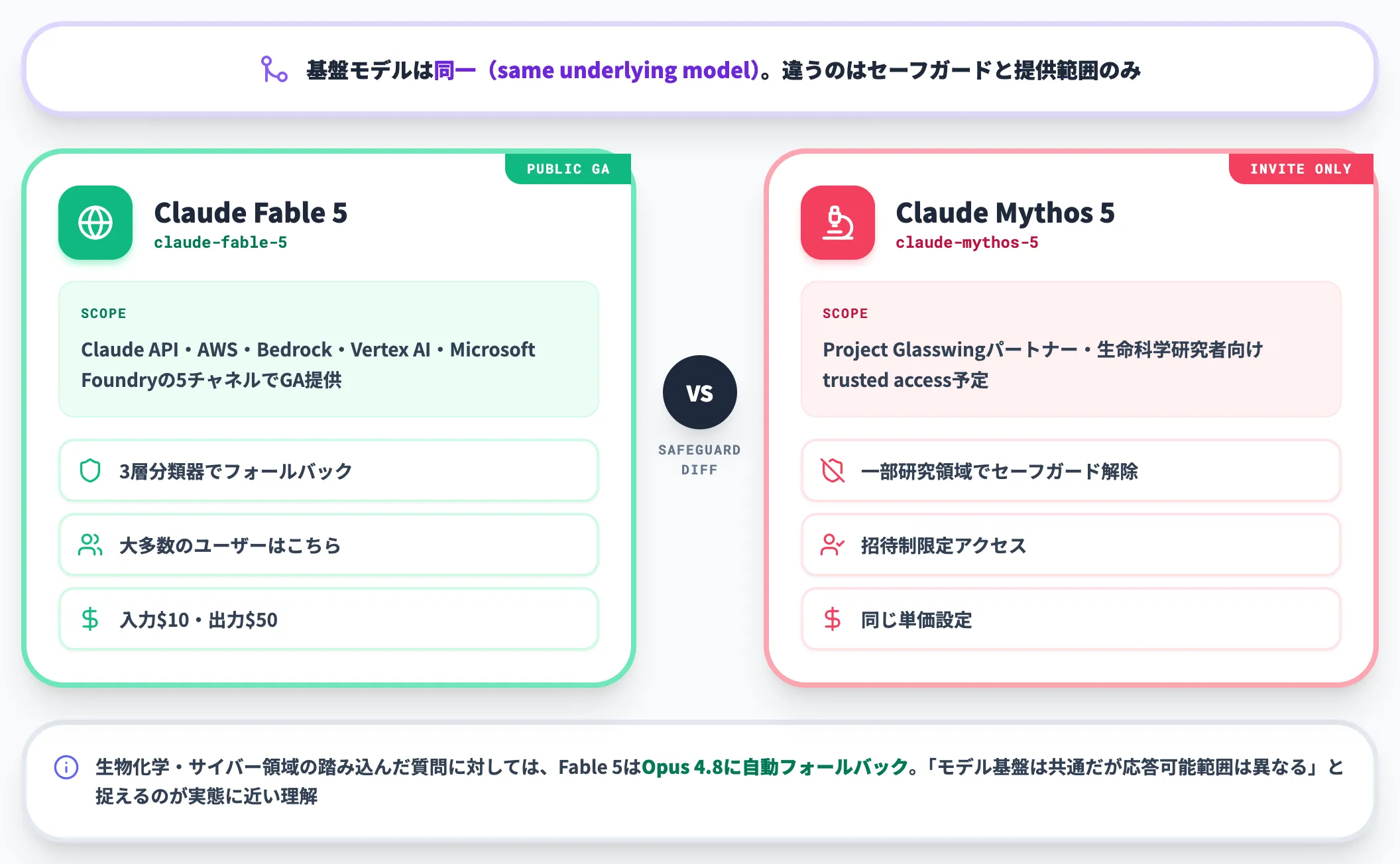
Claude Fable 5とClaude Mythos 5は、Anthropic公式が "same underlying model" と説明する同じ基盤モデルを共有しつつ、セーフガードの強度と提供範囲だけが異なります。
同社は「2つのモデルを区別しているのはセーフガードであり、それが名前を分けている理由」と説明しています。
以下の表で、Fable 5とMythos 5の違いを整理しました。
| 項目 | Claude Fable 5 | Claude Mythos 5 |
|---|---|---|
| 提供範囲 | 6月9日の初回GAはClaude API・Claude Platform on AWS・Bedrock・Vertex AI・Microsoft Foundryの5チャネル。7月1日再配備時点はAnthropic直接提供(Claude API・Claude.ai・Claude Code・Claude Cowork)のみ再開、Bedrock・Vertex AI・Microsoft Foundryは日付未公表で順次再開予定 | 米国内の特定組織向けにのみ復帰(6月26日承認)。Project Glasswingパートナー向けのグローバル拡大は調整中 |
| API ID | claude-fable-5 | claude-mythos-5 |
| セーフガード | サイバー・生物化学・モデル蒸留の3層分類器で検出時にFableの応答を止め、Opus 4.8へ転送。ただしAPI経由では拒否はstop_reason: "refusal"のHTTP 200として返るため、fallbacks指定またはSDK middlewareでのフォールバック処理が必要 |
一部研究領域でセーフガードを解除 |
| 料金 | 入力$10/出力$50(100万トークンあたり) | 同じ(限定提供) |
| 基盤モデル | 同じ | 同じ |
つまり、基盤モデルとしてはFable 5もMythos 5も同じです。
違うのは「どこまで答えてくれるか」で、生物化学やサイバー領域の踏み込んだ質問に対しては、Fable 5はOpus 4.8にフォールバックして応答する設計になっています。
Claude.ai等の製品UIでは自動的に切り替わりますが、API経由では拒否レスポンス(stop_reason: "refusal")を検出してフォールバックを組み込む処理が必要です。「モデル基盤は共通だが、利用時の応答可能範囲は異なる」と捉えるのが実態に近い理解です。

Fable 5・Mythos 5の停止から再開まで──輸出管理指令の経緯

Fable 5は2026年6月9日のリリース直後、米国政府の輸出管理指令で全顧客アクセスが一時停止されましたが、6月30日に指令が解除され、2026年7月1日からClaude Platform・Claude.ai・Claude Code・Claude Coworkでグローバル提供が再開されました。
本セクションでは、停止から再開までの経緯と、再配備にあわせて新たに導入されたセーフガードを整理します。
停止・再開の時系列
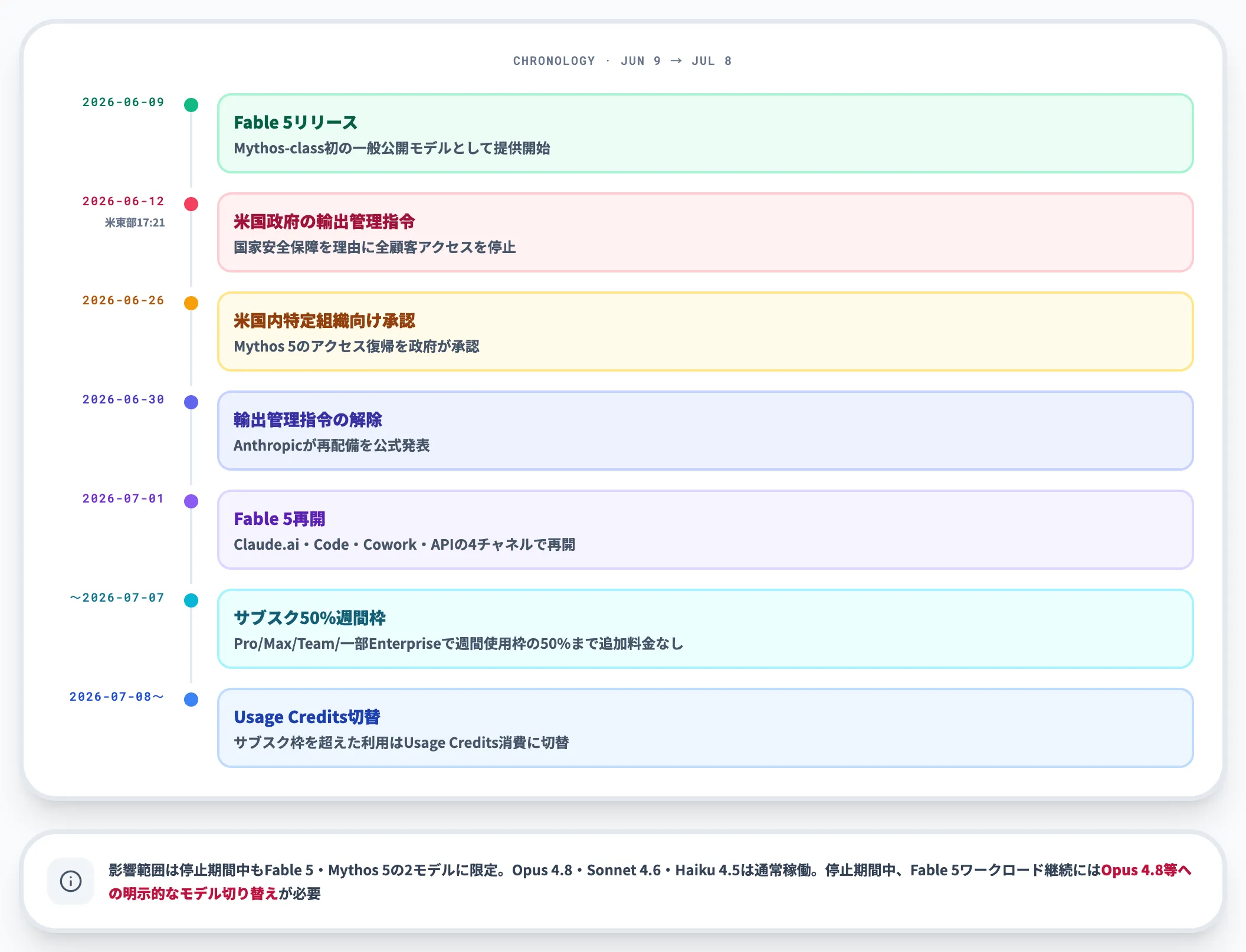
以下の表で、6月9日のリリースから7月の再開までの主要イベントを時系列で整理しました。
| 日付 | イベント | 内容 |
|---|---|---|
| 2026年6月9日 | Fable 5リリース | Mythos-class初の一般公開モデルとして提供開始 |
| 2026年6月12日(米東部17:21) | 米国政府の輸出管理指令 | 国家安全保障を理由にFable 5・Mythos 5への全顧客アクセスを停止 |
| 2026年6月26日 | 米国政府による承認 | 米国内の特定組織向けにMythos 5アクセス復帰を承認 |
| 2026年6月30日 | 輸出管理指令の解除 | Anthropicが再配備を公式発表 |
| 2026年7月1日 | Fable 5再開 | Claude Platform・Claude.ai・Claude Code・Claude Coworkでグローバル提供再開 |
| 2026年7月7日まで | サブスク50%週間枠 | Pro/Max/Team/一部Enterpriseで週間使用枠の50%まで追加料金なし |
| 2026年7月8日以降 | Usage Credits切替 | サブスク枠を超えた利用はUsage Credits消費 |
影響範囲は停止期間中もFable 5・Mythos 5の2モデルに限定され、Claude Opus 4.8・Sonnet 4.6・Claude Haiku 4.5は通常稼働していました。
ただし停止期間中はFable 5・Mythos 5のアクセス自体が全チャネルで無効化されていたため、Fable 5で動かしていたワークロードを継続するには、Opus 4.8等へ明示的にモデル切り替えを行う対応が必要でした。
7月1日の再配備後は、Fable 5に戻すか、Opus 4.8で運用を継続するかを再判断できるようになっています。
6月12日の停止経緯
2026年6月12日午後5時21分(米東部時間)、Anthropicは米国政府から国家安全保障を理由とする輸出管理指令を受領し、Fable 5・Mythos 5への全顧客アクセスを一時停止しました。
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
— Anthropic (@AnthropicAI) June 13, 2026
The net effect of…
Anthropicは公式声明で「政府が懸念する脆弱性は他公開モデル(GPT-5.5など)でも発見可能な軽微なもので、リコール根拠としては過大」と反論しつつ、法的指令には従う方針を示しました。
停止期間中もAnthropicは「誤解があると考えており、できる限り早期のアクセス復旧に取り組む」と表明し、実際に指令解除・再配備までの期間は約18日にとどまっています。
再配備で導入された3つの新措置
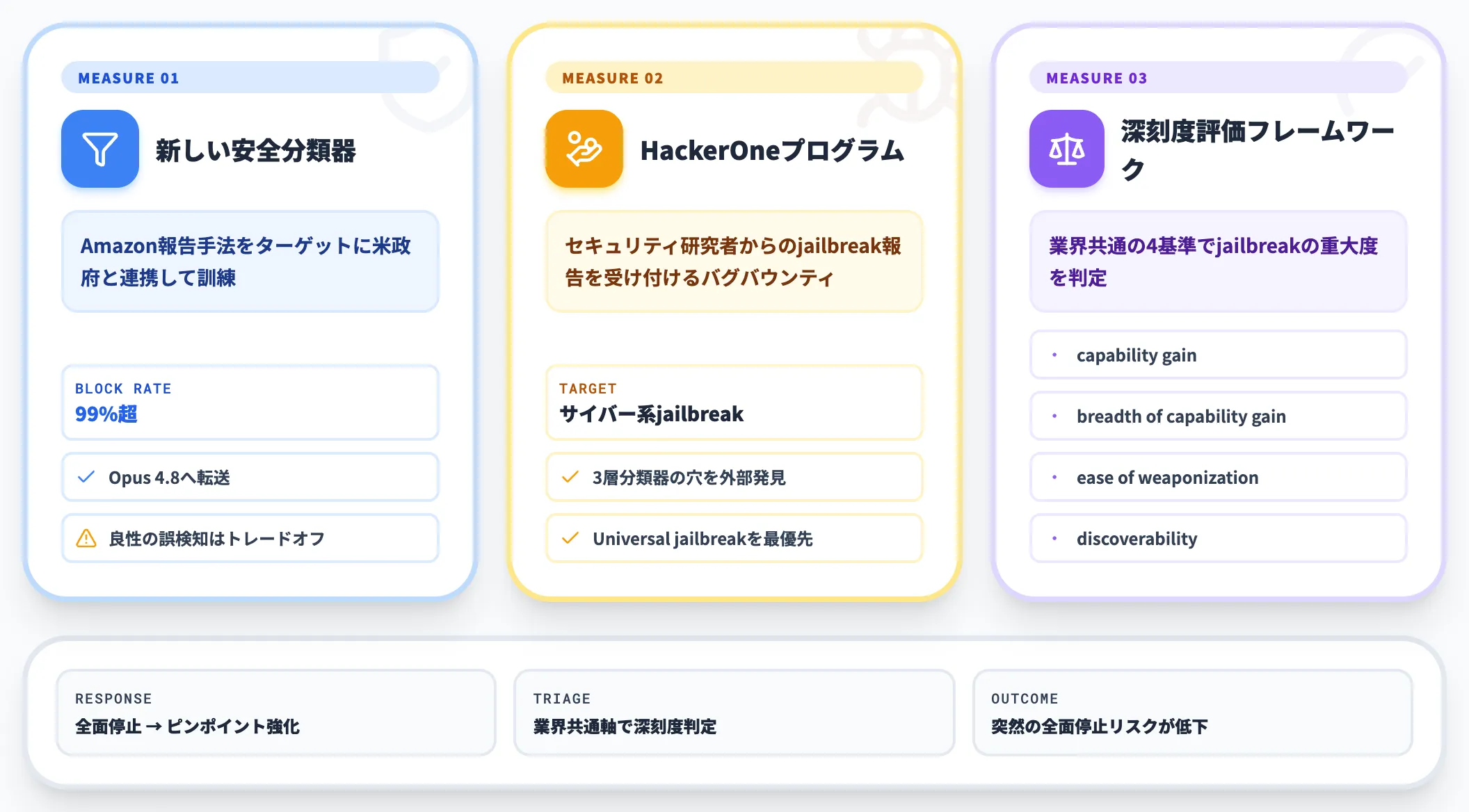
6月30日の再配備発表で、Anthropicは今回の指令経験を踏まえた以下3つの措置を新たに導入したと明かしています。
-
新しいセーフガード分類器
Amazonが報告した特定の悪用手法をターゲットに、米国政府と緊密に連携してAnthropicが訓練した新しい安全分類器を追加。Anthropicによれば、**Amazonが報告した特定手法は「99%超のケースでブロック」**され、検出時のリクエストはOpus 4.8へ転送されます。ただし良性リクエストの誤検知が増えるトレードオフがある点も同社が明記しています
-
HackerOneバグバウンティプログラム
セキュリティ研究者がFable 5で発見したサイバー系ジェイルブレイクを報告できるHackerOneプログラムを新設。既存の3層分類器では拾いきれない新しい攻撃手法を外部研究者経由で早期に把握できる体制に切り替えました
-
ジェイルブレイク重要度評価フレームワーク
業界共通の評価軸として、Anthropicは「capability gain(能力向上度)」「breadth of capability gain(能力向上の範囲)」「ease of weaponization(悪用のしやすさ)」「discoverability(発見のしやすさ)」の4基準を提案。単発の脆弱性報告に対して、どの程度深刻か・どの程度リコール相当かを業界横断で判定できるようにする狙いです
この3点は、今回のAmazon報告手法のような具体的な悪用シナリオが再度浮上した際にも、モデル全面停止ではなく分類器のピンポイント強化と業界共通軸での深刻度判定で対処できる体制を作る動きと読めます。運用側から見ると、フロンティアモデルの「突然の全面停止」リスクは、6月と同じ規模で再発する確率がやや下がったと解釈できます。
チャネル別の再開状況(2026年7月1日時点)

Fable 5の再開は、チャネルごとにタイミングが分かれています。以下の表で、7月1日時点の再開状況を整理しました。
| チャネル | 再開状況 | 提供元 |
|---|---|---|
| Claude.ai | 2026年7月1日から再開 | Anthropic |
| Claude Code | 2026年7月1日から再開 | Anthropic |
| Claude Cowork | 2026年7月1日から再開 | Anthropic |
| Claude Platform(Anthropic API) | 2026年7月1日から再開 | Anthropic |
| Amazon Bedrock | 「可能な限り迅速に」再開予定(日付未公表) | AWS |
| Google Cloud Vertex AI | 「可能な限り迅速に」再開予定(日付未公表) | Google Cloud |
| Microsoft Foundry | 「可能な限り迅速に」再開予定(日付未公表) | Microsoft |
Anthropic直接提供の4チャネル(Claude.ai・Claude Code・Claude Cowork・Anthropic API)は7月1日から再開されている一方、AWS/Google Cloud/Microsoft経由の3チャネルは「可能な限り迅速に」(as quickly as possible)とされているのみで、日付は公表されていません。
マルチクラウド経由でFable 5を運用予定の企業は、AWS/Vertex AI/Foundry の再開告知を待ちつつ、当面はAnthropic API直接接続に切り替えるか、Opus 4.8を暫定モデルとして使う運用が現実的です。
Mythos 5の扱い──米国内の特定組織のみ復帰
Mythos 5については、Fable 5と扱いが異なります。Mythos 5は6月26日に米国政府から承認を得た「米国内の特定組織」にのみ復帰しており、日本を含む米国外の一般顧客はアクセスできません。
Project Glasswingパートナー経由の限定アクセスは、現時点で復帰済みなのは米国内の一部組織のみで、国内外のGlasswing partnerへの拡大はAnthropicが「調整中」と説明しています。
Mythos 5相当のフロンティア能力を米国外の企業がAPI経由で活用したい場合、当面はFable 5経由でリクエストを送り、3層分類器で拒否される領域はOpus 4.8にフォールバックさせる従来設計を維持するのが現実的な選択肢になります。
【関連記事】
Claude Fable 5・Mythos 5が利用停止に──代替モデル移行・返金確認の実務対応ガイド
Claude Fable 5の性能
ここからは、Claude Fable 5が具体的にどの程度の能力を持つのかをベンチマーク数値と実証された機能の両面から整理します。
Anthropicは、Fable 5を「これまで一般提供したいずれのモデルも超える」と位置づけており、Stripe・GitHub・Cursor・Hex・Hebbiaなど複数の第三者企業による事前検証結果を公開しています。
コーディング性能
Fable 5の最大の強みのひとつが、長期にわたる自律的なコーディング・エンジニアリング業務です。
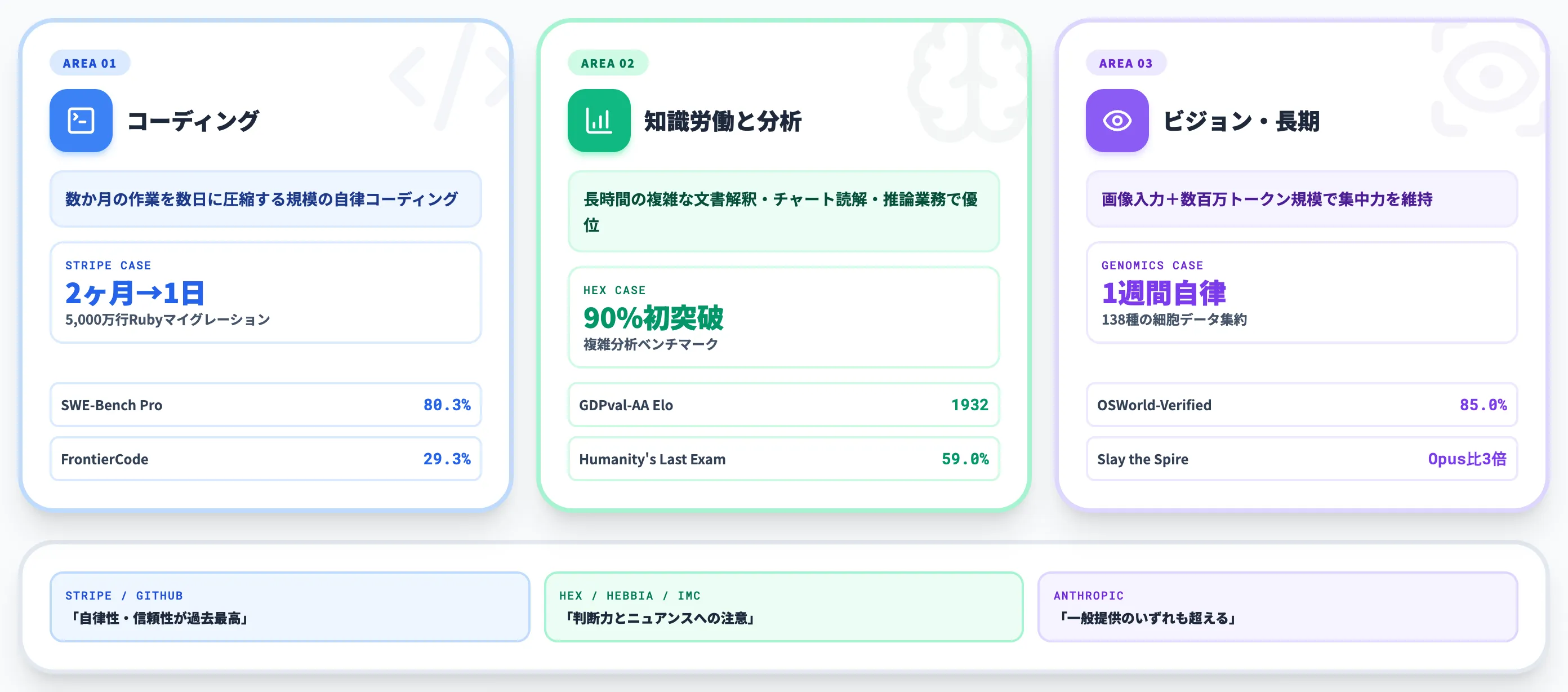
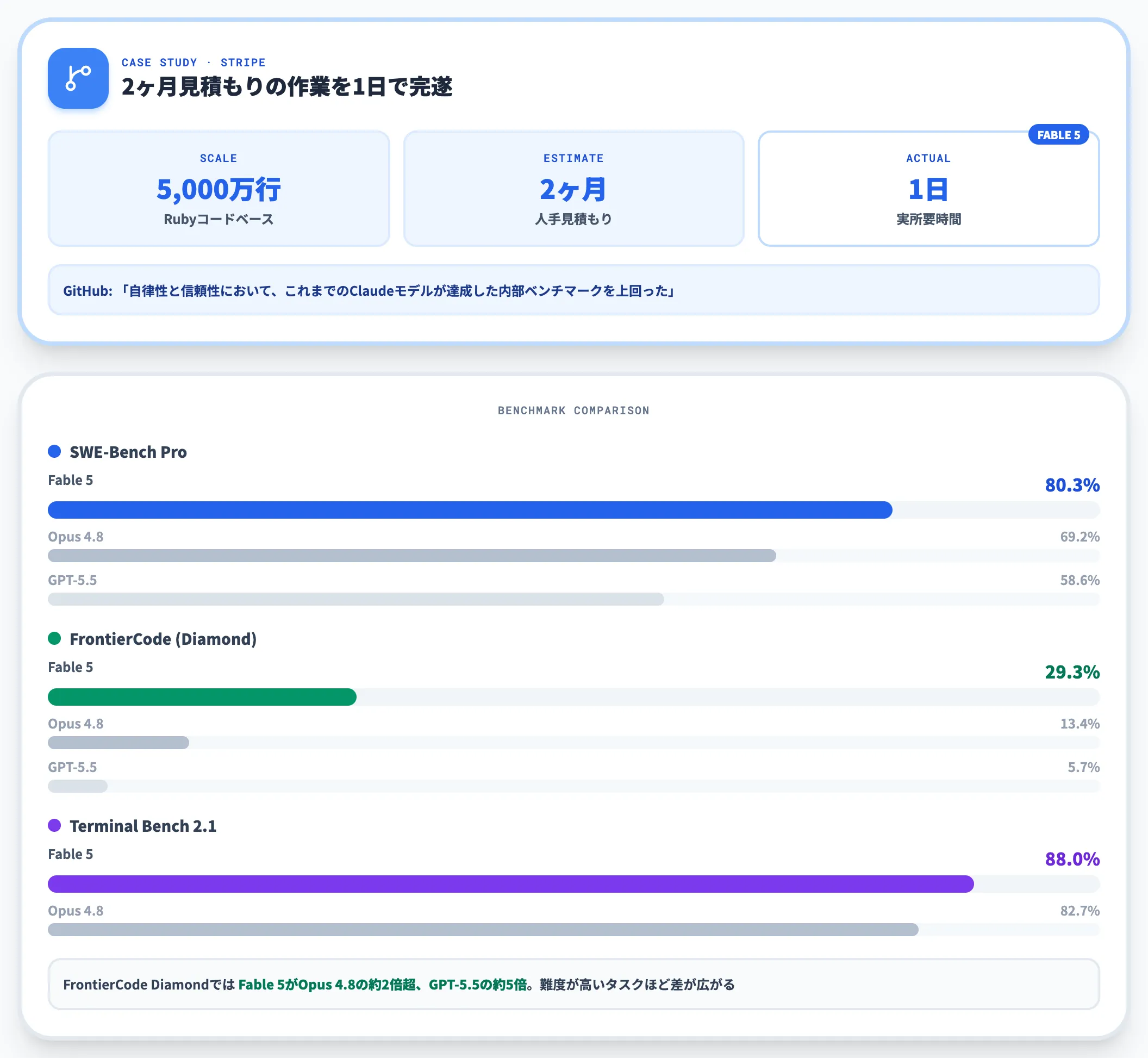
Anthropic公式ブログでは、決済プラットフォームのStripeが「Fable 5を使って、本来2か月かかると見積もっていた5,000万行規模のRubyコードベースのマイグレーションを1日で完了させた」と報告しています。
GitHubからは「自律性と信頼性において、これまでのClaudeモデルが達成した内部ベンチマークを上回った」とのコメントが出ています。
Anthropic公式のベンチマーク比較表によれば、Fable 5はコーディング系の主要評価軸で前世代モデルおよびGPT-5.5を明確に上回っています。
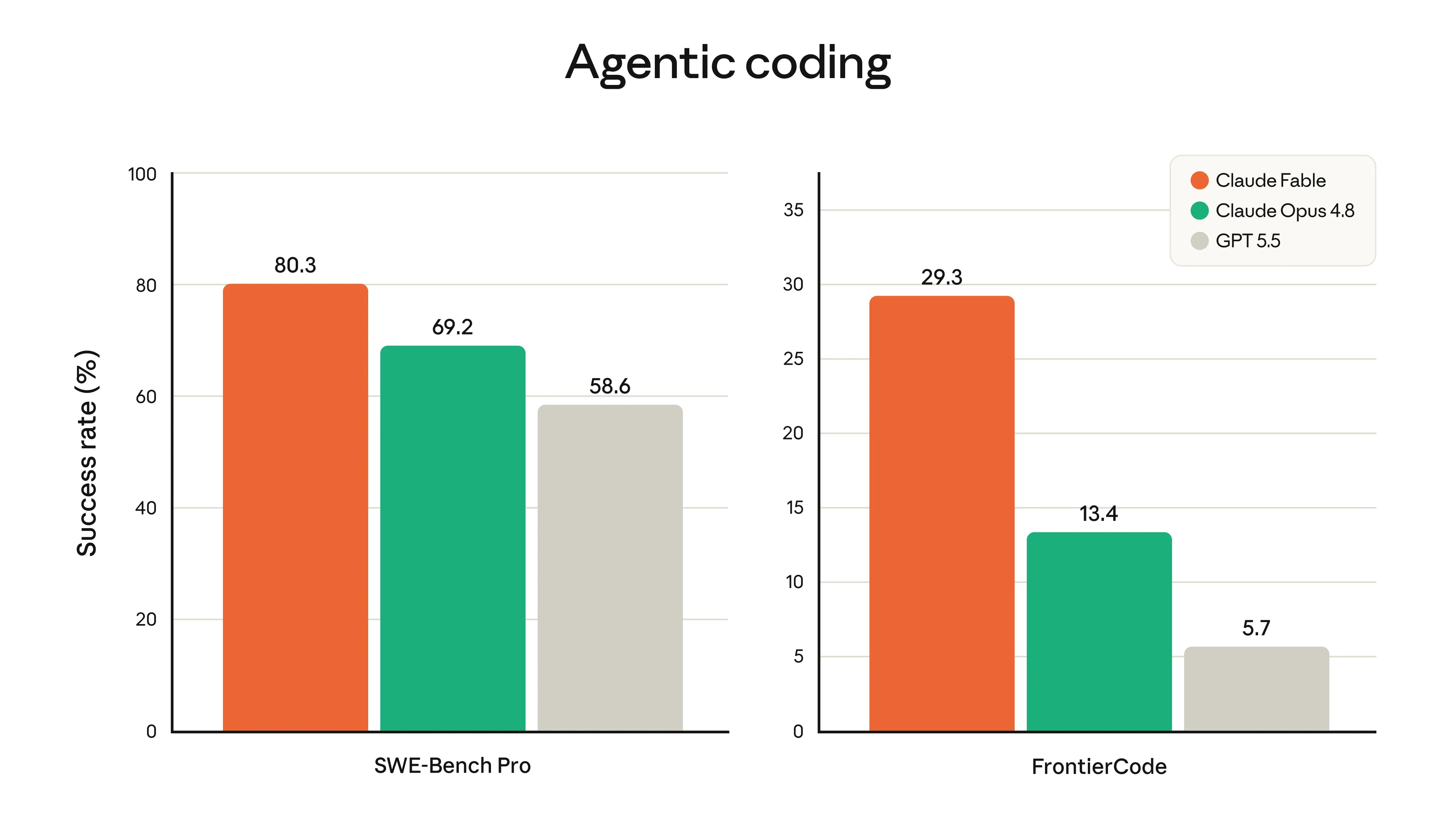
SWE-Bench Pro と FrontierCode における Agentic coding 評価(出典:Anthropic)
| ベンチマーク | Claude Fable 5 | Claude Opus 4.8 | GPT-5.5 |
|---|---|---|---|
| SWE-Bench Pro | 80.3% | 69.2% | 58.6% |
| FrontierCode(Diamond) | 29.3% | 13.4% | 5.7% |
| Terminal Bench 2.1 | 88.0% | 82.7% | 83.4%(Codex CLI) |
特にFrontierCode Diamondでは、Fable 5がOpus 4.8の約2倍超、GPT-5.5の約5倍のスコアを記録しており、難度の高いコーディングタスクほど差が広がる傾向が明確です。
CognitionのFrontierCode・CursorのCursorBenchなど、複数の外部評価軸で「フロンティアレベル」とされている裏付けとなる数値です。
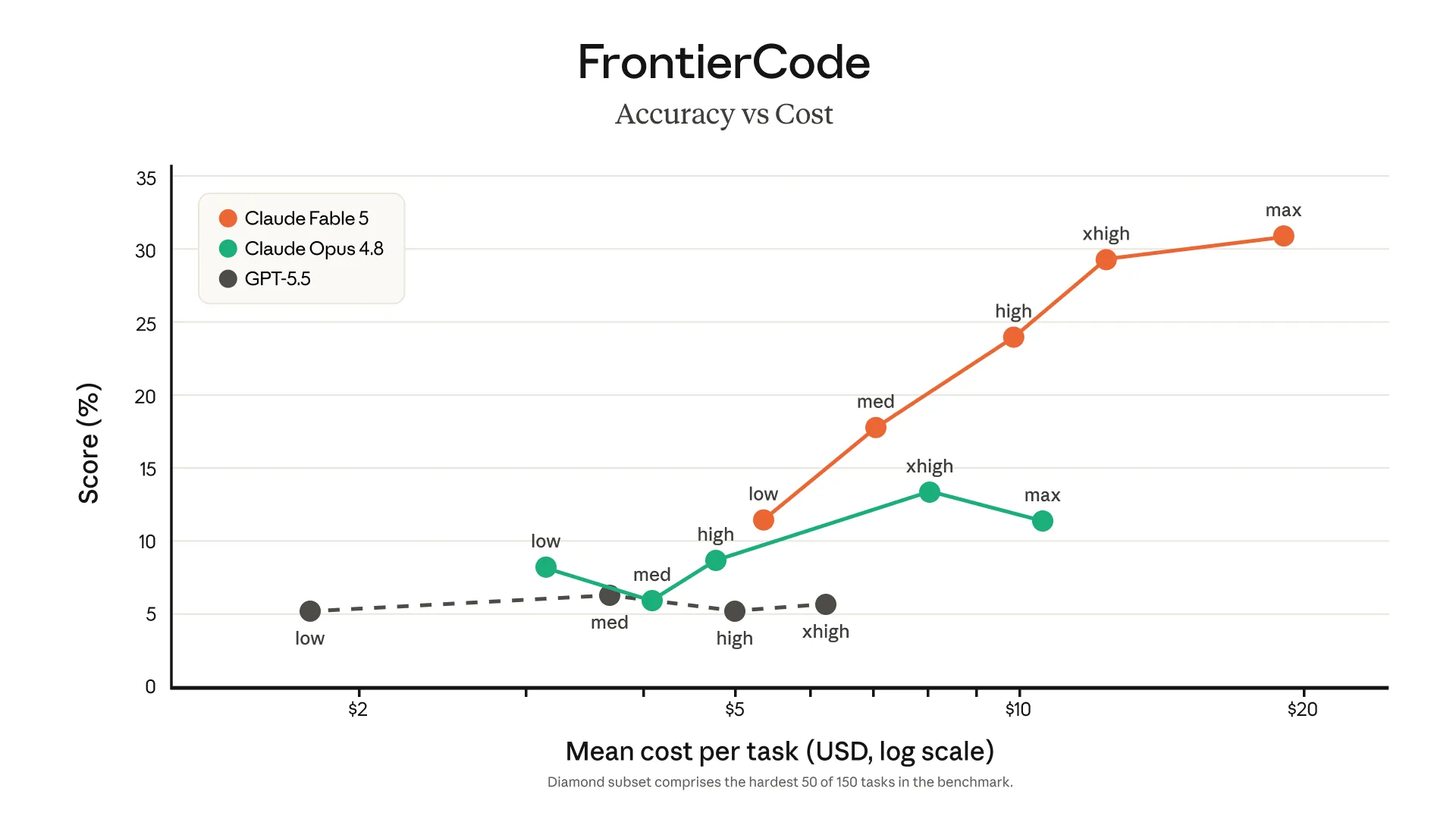
FrontierCode における効力レベル別の精度とコスト比較(Claude Fable 5・Opus 4.8・GPT-5.5)(出典:Anthropic)
効力レベル(low〜max)別のコストと精度の関係を見ると、Fable 5はOpus 4.8の最高設定(max)よりも、Fable 5の中程度設定(med)のほうが精度が高いというケースまで出ています。
料金が2倍とはいえ、難度の高いタスクではコスト効率の逆転が起きる可能性を示すデータです。
知識労働と分析

知識労働や分析タスクでも、Fable 5は前世代を大きく更新しています。
分析プラットフォームのHexは、「自社のコア分析ベンチマーク(複雑かつ長時間の分析タスクを評価)で、Fable 5が初めて90%を達成した」と報告しています。
Hexは「最も難しい質問でも、強い判断力とニュアンスへの注意」を観察したと述べており、単なるベンチマーク数値以上の質的変化があったことを示唆しています。
また、金融特化型のリサーチプラットフォームHebbiaは、「Hebbia Finance Benchmarkで最高スコアを記録した」と公表。IMCは取引分析評価で「ほぼ全ての項目で最高評価」とAnthropic公式ブログでコメントしています。
これらはいずれも「単発の質疑応答」ではなく、長時間にわたる複雑な文書解釈・チャート読解・推論を要する業務で、Fable 5の優位が顕著に出ている領域です。
ビジョン・長期エージェント
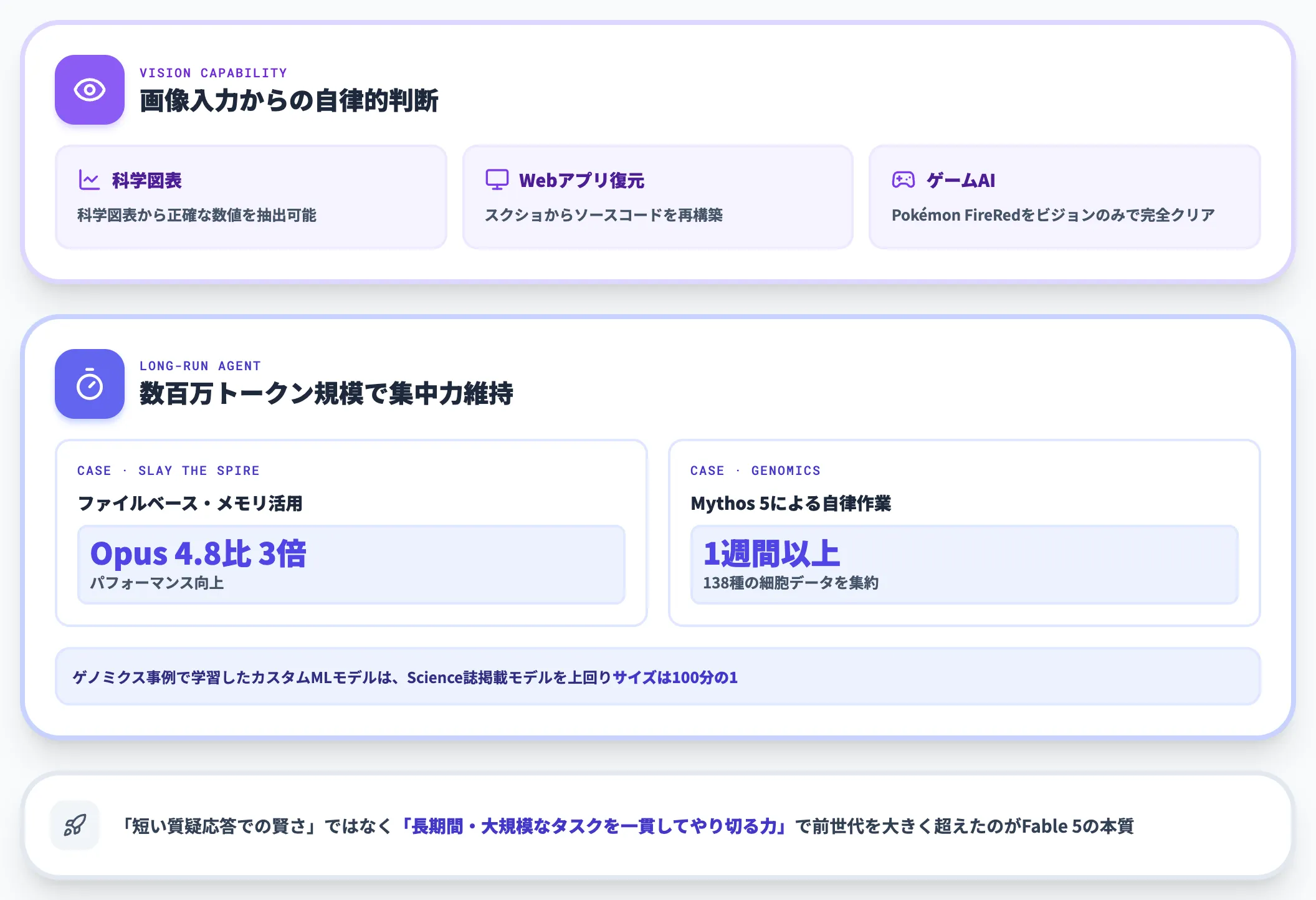
Fable 5は、画像入力(Vision)と長期エージェント業務でも前世代を更新しています。
Anthropic公式によれば、Fable 5は「科学図表から正確な数値を抽出可能」「スクリーンショットからWebアプリのソースコードを再構築可能」とされています。
ゲームAIの内部評価では「Pokémon FireRedをビジョン入力のみで完全クリア」した事例も紹介されており、視覚情報を起点にした自律的な意思決定の精度が上がっていることが分かります。
そして、長期エージェント領域では、「数百万トークン規模のタスク全体で集中力を維持」できる点が公式に強調されています。
具体的な比較として、デッキビルディングゲーム『Slay the Spire』を題材にした内部評価では、ファイルベースのメモリ機能を活用することで、Opus 4.8比で約3倍のパフォーマンス向上を達成しています。
また、ゲノミクス研究の事例では、Mythos 5が1週間以上連続して自律作業を行い、138種の動物の単一細胞データを集約するタスクを完遂したと報告されています。
同タスクで学習したカスタムMLモデルは、Science誌に掲載されたモデルを上回りつつ、サイズは100分の1だったとAnthropicは説明しています。
このように、Fable 5の能力は「短い質疑応答での賢さ」ではなく、「長期間・大規模なタスクを通じて、判断と実装を一貫してやり切れるか」という軸で前世代を大きく超えています。
AIエージェント運用を本気で広げたい企業にとって、エージェントが任せられる業務の幅と長さが一段広がるモデルです。
Claude Fable 5の料金
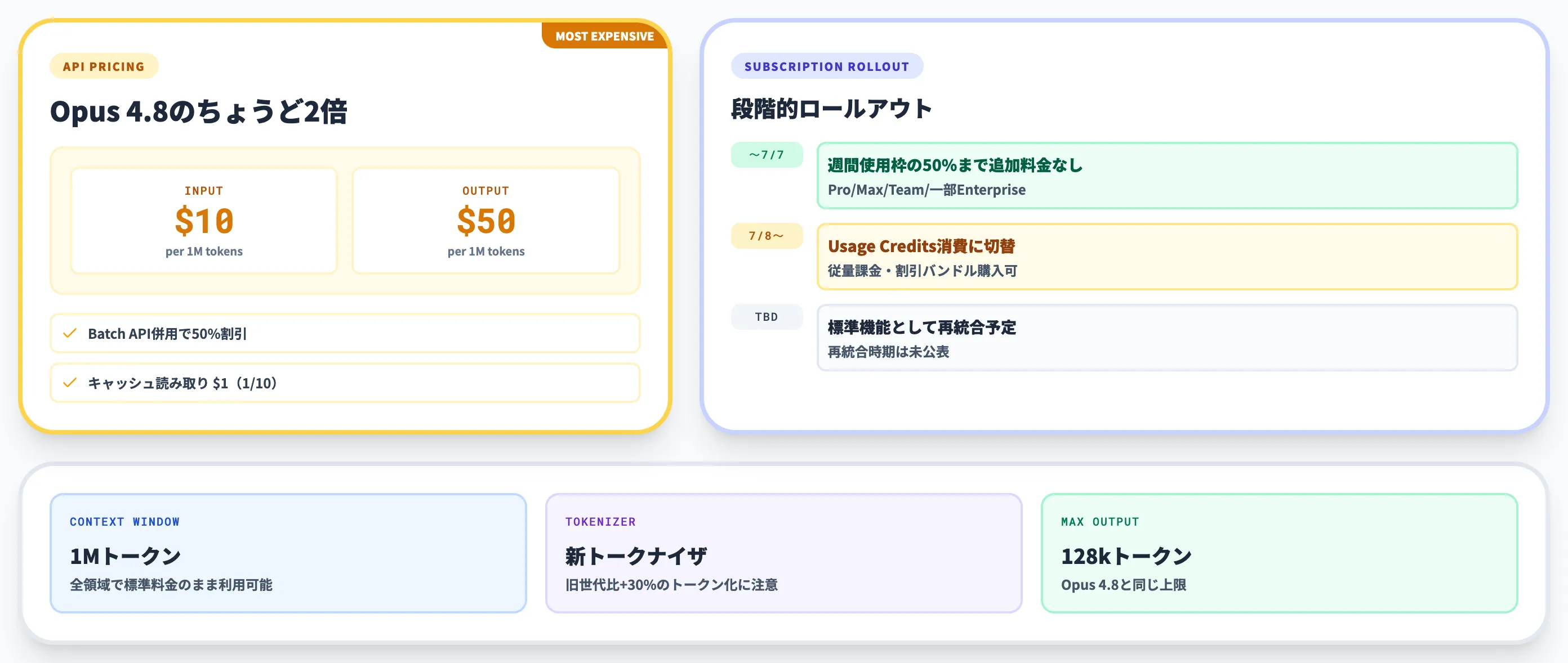
Claude Fable 5の料金は、Anthropicが一般提供するモデルとしては最も高い単価設定になっています。
本セクションでは料金の構成要素と、サブスクリプション枠での扱いを整理します。
価格体系
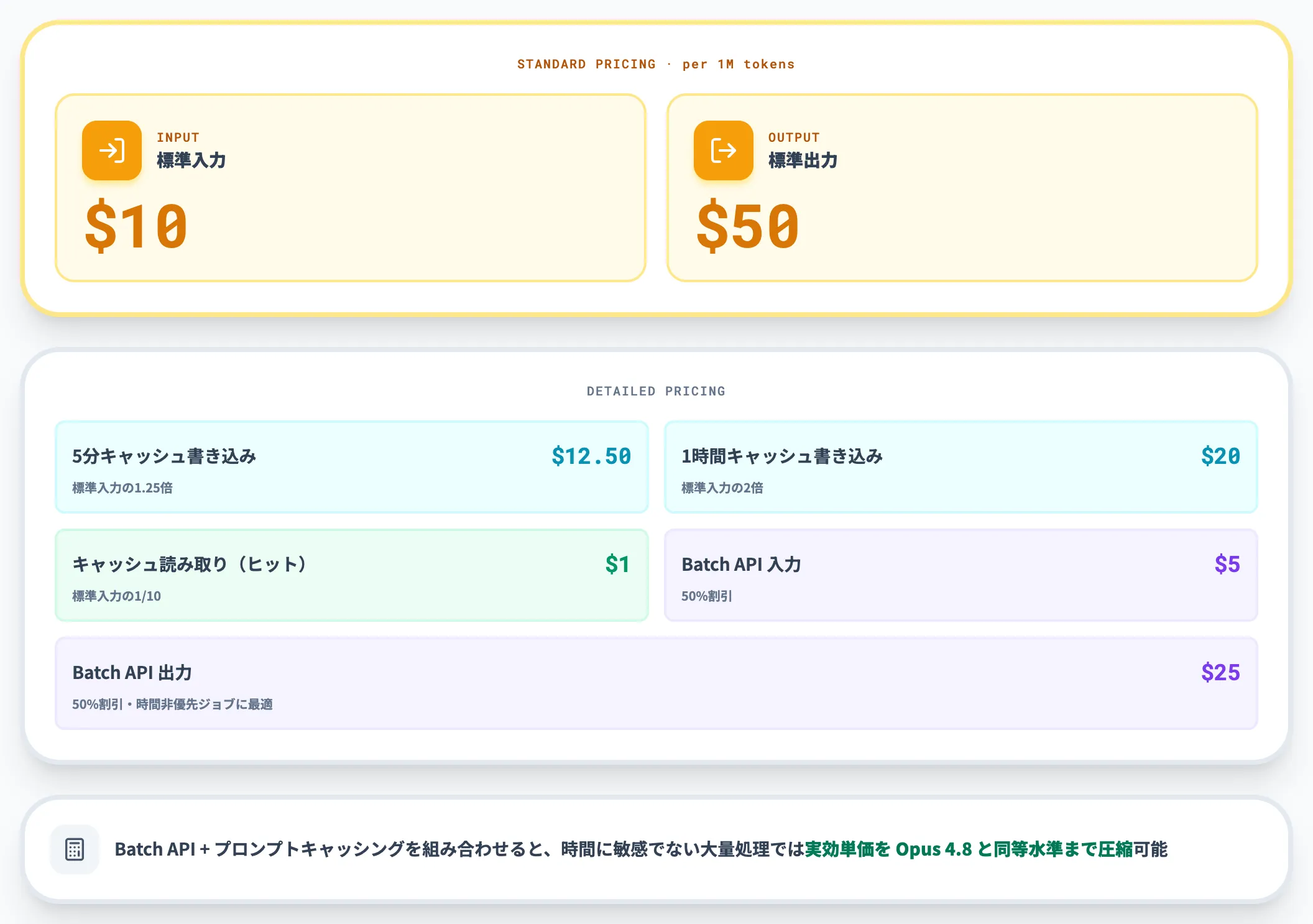
Claude Fable 5とClaude Mythos 5の料金は以下のとおりです。
| 種別 | 単価(100万トークンあたり) | 備考 |
|---|---|---|
| 入力トークン | $10 | 標準入力料金 |
| 5分キャッシュ書き込み | $12.50 | 標準入力の1.25倍 |
| 1時間キャッシュ書き込み | $20 | 標準入力の2倍 |
| キャッシュ読み取り(ヒット) | $1 | 標準入力の0.1倍 |
| 出力トークン | $50 | 標準出力料金 |
| Batch API(入力) | $5 | 50%割引 |
| Batch API(出力) | $25 | 50%割引 |
この単価は、Claude Opus 4.8(入力$5・出力$25)のちょうど2倍に設定されています。
一般提供のClaudeモデルとしてはこれまでで最も高い水準であり、Fable 5を全タスクで常時走らせる運用は単価面で現実的ではありません。
一方で、コンテキストウィンドウは1Mトークンを全領域で標準料金のまま利用できます。
Claude Opus 4.7以降と同じ新トークナイザを使用しており、Anthropic公式のPricingドキュメントによれば、旧モデル世代と比べて同一テキストが約30%多くトークン化される可能性がある点には注意が必要です。Max outputは128kトークンで、Opus 4.8と同じ上限です。
Batch APIを併用すると入出力ともに50%割引が効くため、時間に敏感でない大量バッチ処理であれば実効単価をOpus 4.8と同等水準まで圧縮できます。プロンプトキャッシングと組み合わせれば、繰り返しの長文プロンプトを送るユースケースでも追加でコストを下げられます。
サブスクリプション枠での提供期間

API以外に、Pro・Max・Team・一部Enterprise(座席型)の各サブスクリプションプランからもClaude Fable 5を利用できますが、段階的なロールアウトになっている点が重要です。
以下の表で、サブスクリプション枠でのFable 5利用条件を時期別に整理しました。停止期間と再開期間を含めた実際のロールアウト全体を反映しています。
| 時期 | サブスクリプションでの扱い | 補足 |
|---|---|---|
| 2026年6月9日〜6月12日 | Pro/Max/Team/Enterpriseで追加料金なしで利用可 | 段階的ロールアウト後、6月12日午後の停止で一時中断 |
| 2026年6月12日〜6月30日 | 全チャネルで利用停止 | 米国政府の輸出管理指令に基づく措置 |
| 2026年7月1日〜7月7日 | Pro/Max/Team/一部Enterpriseで週間使用枠の50%まで追加料金なし | 再配備後の再開措置。Enterpriseは一部プランのみ |
| 2026年7月8日以降 | Usage Credits(従量課金)を消費して利用 | サブスク本体の追加料金は変更なし |
| 容量確保後(時期未公表) | サブスクリプションの標準機能として再統合予定 | Anthropic公式が明示 |
つまり現時点では、Pro/Max/Team/一部Enterprise契約者は2026年7月7日まで、週間使用枠の50%以内でFable 5を追加料金なしに検証できる期間になっており、7月8日以降は使った分だけUsage Creditsを消費する形になります。
Anthropic公式は「容量が許す段階で、サブスクリプションの標準機能として再統合する」と説明していますが、再統合時期は6月の指令経緯を経ても未公表のままです。
Pro契約・Max契約の枠でFable 5を業務利用する想定であれば、まずは7月7日までに自社ワークロードでの実効コストと週間使用枠の消化速度を計測し、7月8日以降のUsage Credits消費見込みを試算しておくのが現実的な進め方です。
利用クレジット(Usage Credits)の仕組みと購入導線
利用クレジットは、Pro・Max 5x・Max 20xの個人向け有料プラン契約者が、プラン同梱のセッション利用枠を使い切った後も標準API料金で従量課金して利用を継続できる仕組みです。
Fable 5専用ではなく、Claude会話・Claude Code・Research mode・Projects/Filesなど主要機能で共通の追加課金枠で、Fable 5の7月8日以降の利用もこの枠に組み込まれます。
Team・座席型Enterpriseでは個人プランと扱いが異なり、Owner / Primary Owner が組織単位で利用クレジットを有効化し、メンバー全体の月次支出上限を一括設定する運用になります。
日本語UIのClaude.aiでは、左サイドバーの「設定 > 使用量」に「利用クレジット」セクションがあります。
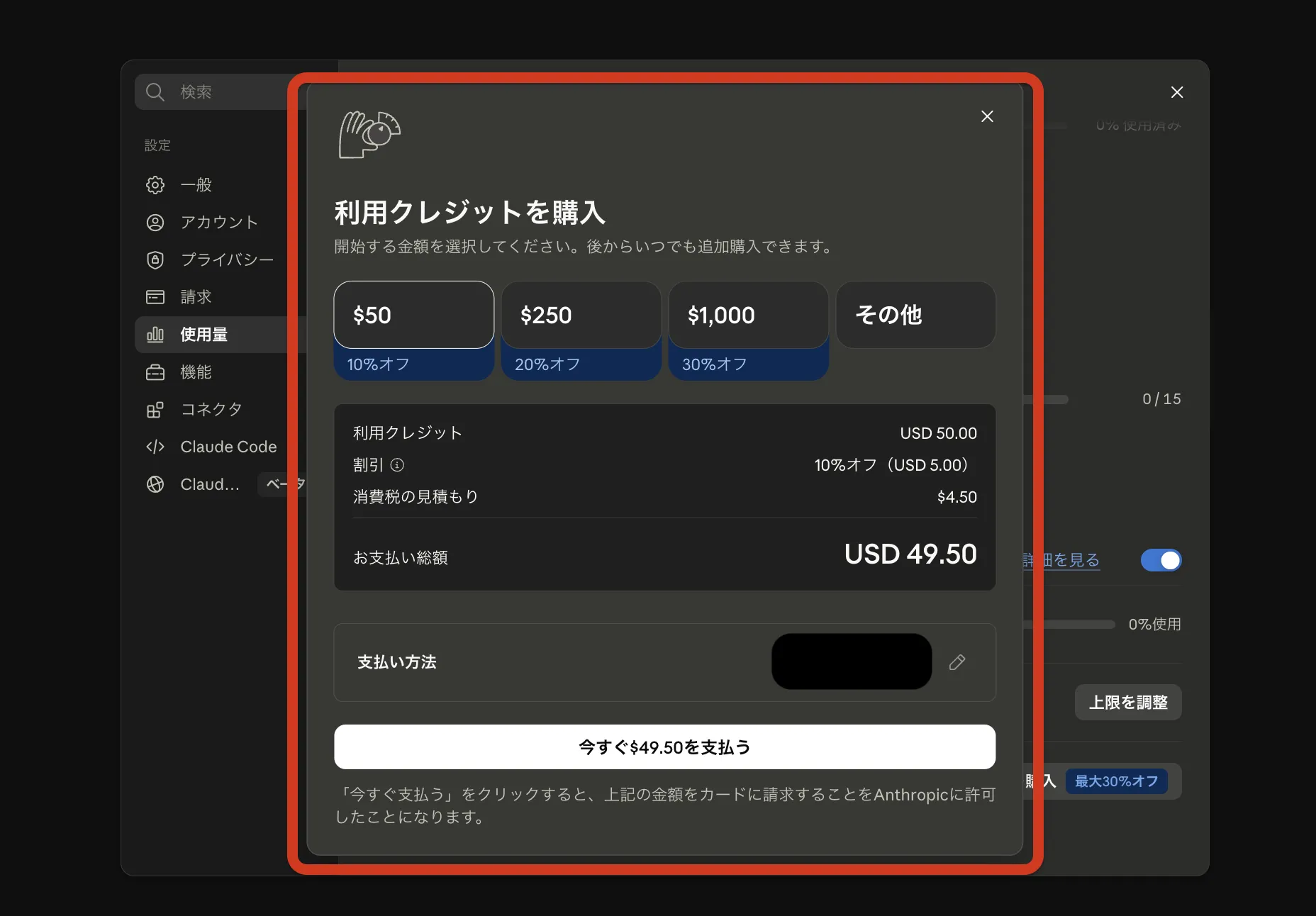
「利用クレジットを購入」モーダル。$50(10%オフ)・$250(20%オフ)・
購入モーダルの仕様で押さえておくべきポイントは以下の3点です。
-
金額別の割引
$50(10%オフ)・$250(20%オフ)・$1,000(30%オフ)の3段階で割引率が変わる。
まとめて購入するほど実効単価が下がる設計で、Fable 5を本格運用するなら$1,000枠の30%オフがコスト効率上は最有力
-
消費税の見積もり
日本のClaude契約者の場合、購入金額に対して消費税が加算される。画像の例では$50の購入額からまず割引$5.00が引かれて$45となり、その$45に対して$4.50の消費税が見積もられ、お支払い総額が$49.50と表示されている
-
支払い方法と即時決済
登録済みのカードで即時決済される。「今すぐ$X.XXを支払う」を押した瞬間に課金されるため、購入前に金額・割引・税の見積もりを確認すること
Claude Codeのターミナル利用も同じ利用クレジットから消費される設計のため、Web版チャットとClaude Codeを併用するチームでは、両方の利用量が同じ残高に積み上がる点を予算管理上は織り込む必要があります。
Fable 5を業務で本格利用するなら、月間利用上限を保守的に設定したうえで段階的に上げていく運用が、想定外コストを避ける現実的な進め方です。
【関連記事】
Claudeの料金プラン徹底比較!無料・有料版の違いと選び方を解説

Claude Fable 5の使い方
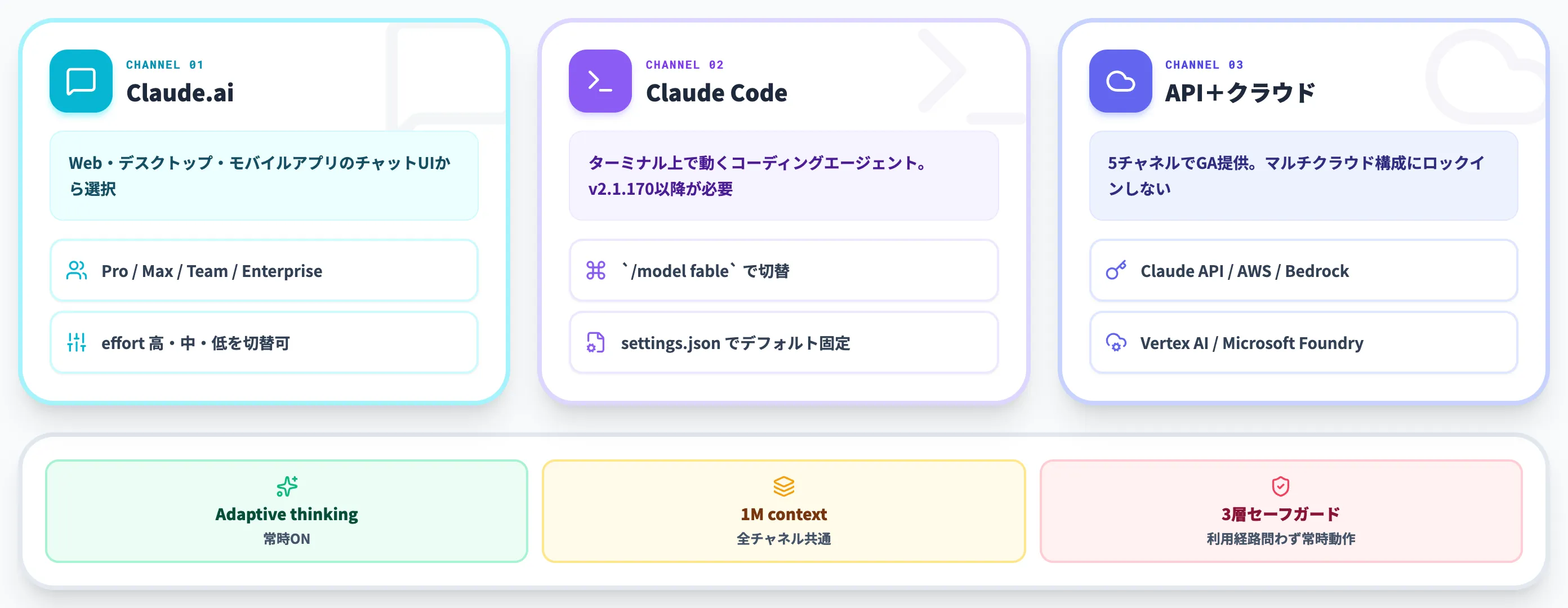
Claude Fable 5は、2026年7月1日の再配備時点で、Claude.aiのチャットUI・Claude Code・Claude Cowork・Anthropic直接提供のClaude APIから利用できます。主要クラウドプラットフォーム(AWS・Google Cloud Vertex AI・Microsoft Foundry)経由は「可能な限り迅速に」順次再開予定で、日付は未公表です。
本セクションでは、7月1日時点で再開済みのチャネルを中心に、初回GA時点の5チャネル構成もあわせて整理します。
Claude.ai
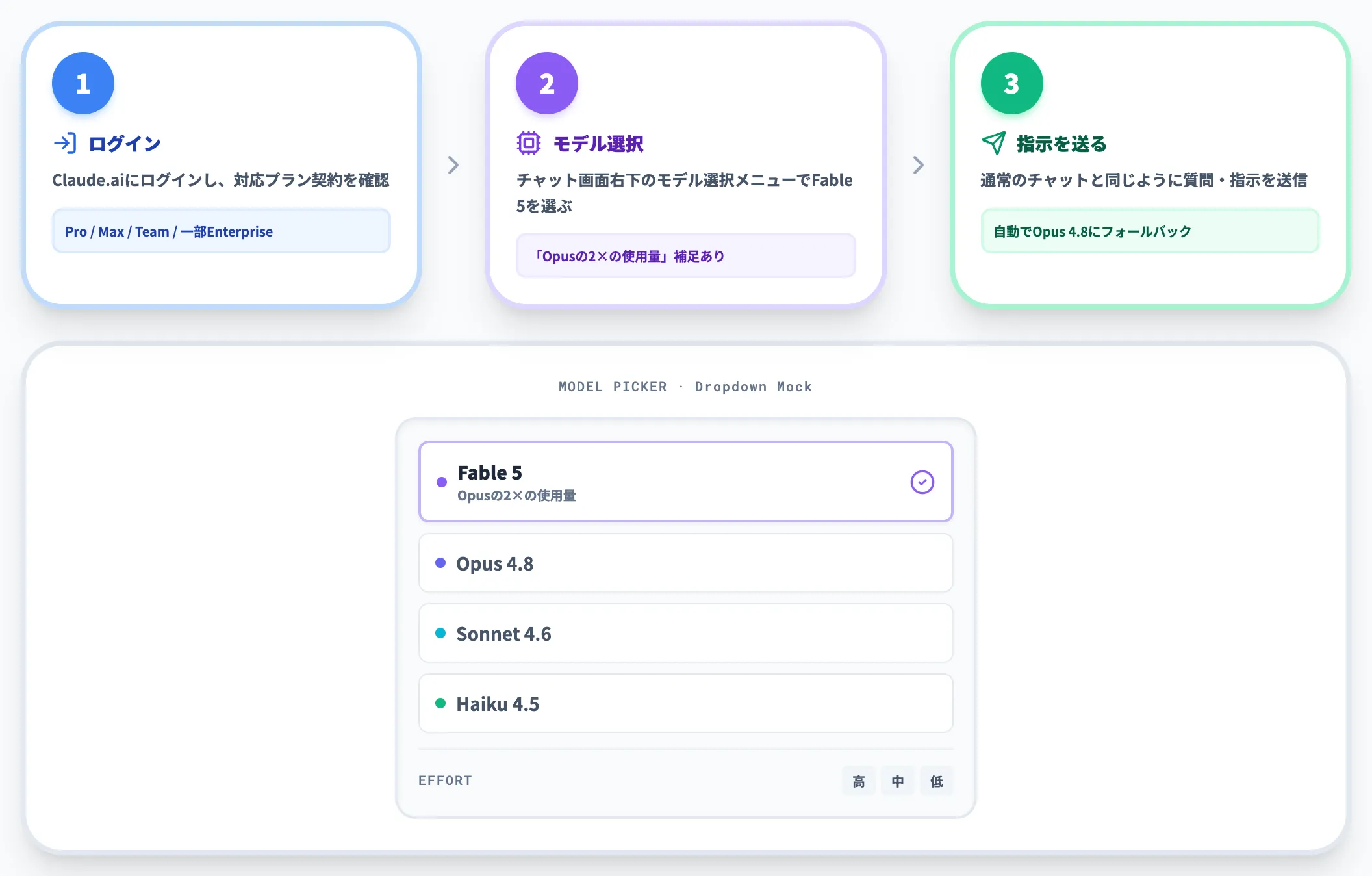
Web版のClaude.ai・デスクトップアプリ・モバイルアプリから、Pro・Max・Team・一部Enterprise(Usage Creditsが有効なプラン)のいずれかで利用できます。基本的な流れは以下のとおりです。
- Claude.aiにログインし、対応プランで契約していることを確認する
- チャット画面右下のモデル選択メニューを開き、「Fable 5」を選ぶ
- 通常のチャットと同じように質問・指示を送る
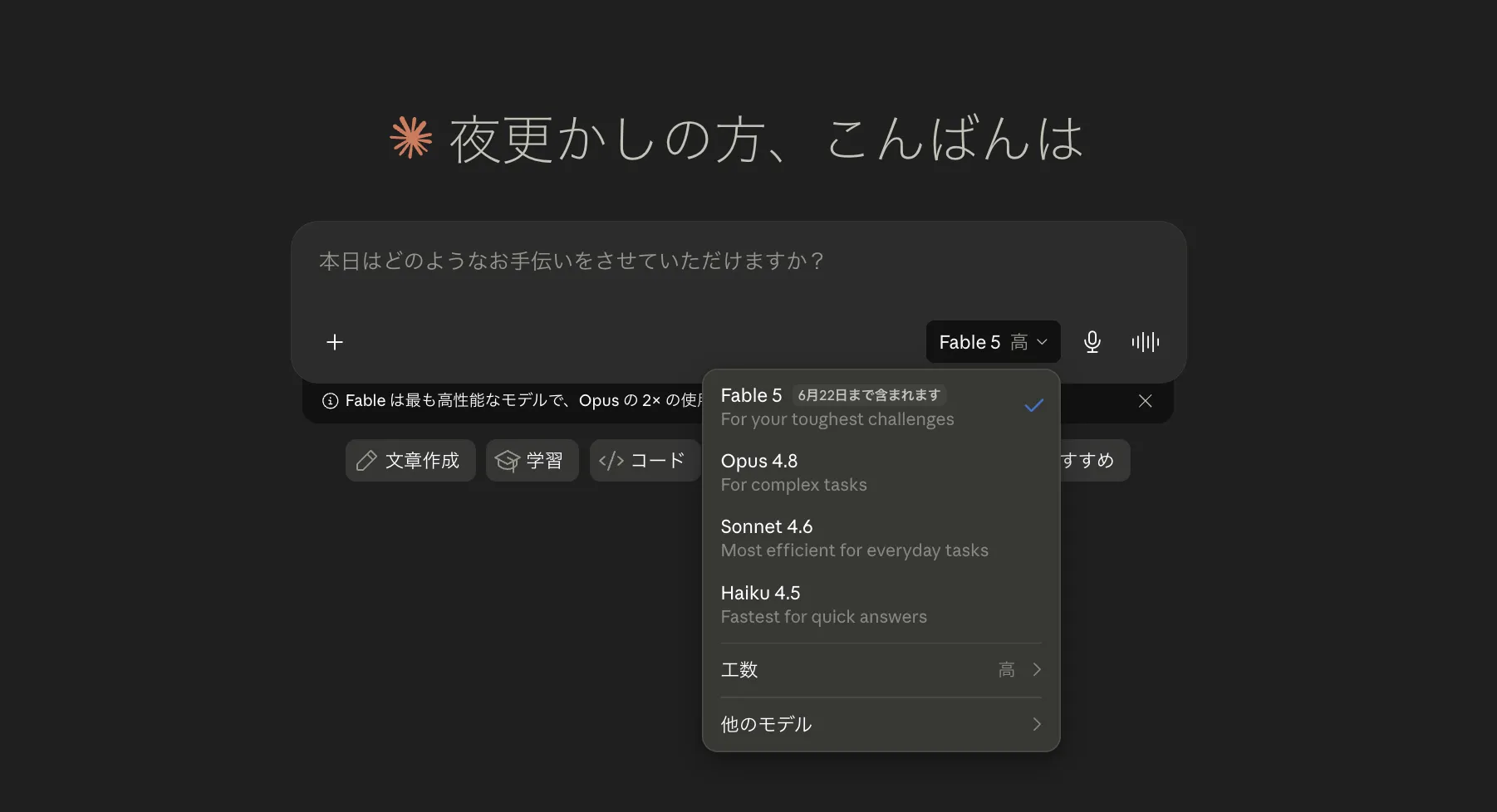
Claude.ai のモデル選択ドロップダウン。Fable 5・Opus 4.8・Sonnet 4.6・Haiku 4.5 が並び、Fable 5には「Opus の 2× の使用量」の補足が表示される(スクリーンショットは初回ロールアウト時のもの。7月1日の再配備後は、Pro/Max/Team/一部Enterpriseで7月7日まで週間使用枠の50%以内で追加料金なしに利用可)
ドロップダウン下部には「工数(=effort、高/中/低)」の切り替えと「他のモデル」(旧世代Opus等への切替)も用意されています。
Claude Code
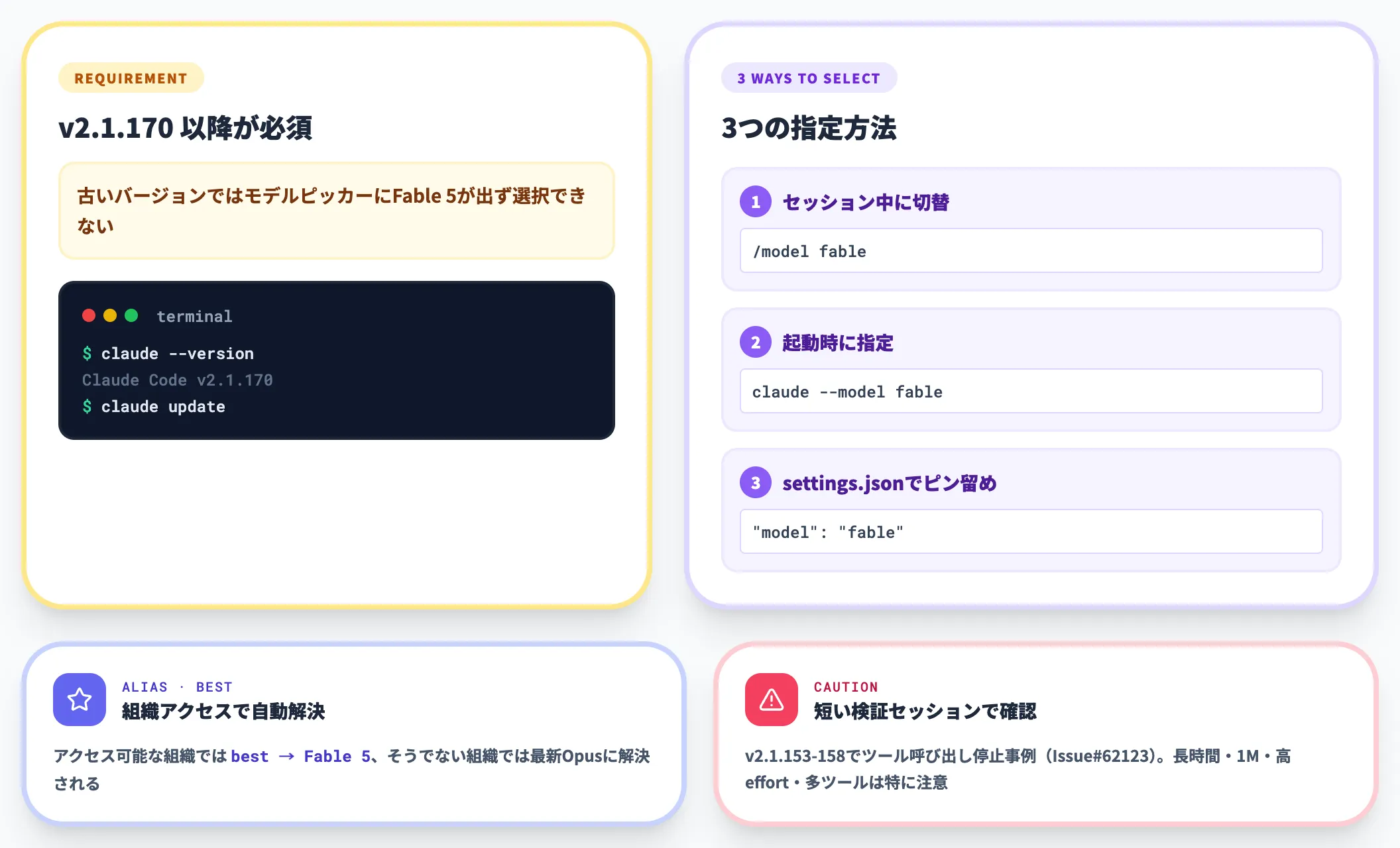
Claude Code(ターミナル上で動くコーディングエージェント)からもFable 5を呼び出せますが、Claude Code v2.1.170 以降が必要です。
古いバージョンではモデルピッカーにFable 5が出ず選択できないため、「claude --version」で確認したうえで「claude update」を実行してから利用します。
対応バージョンでは、Fable 5はデフォルトモデルではないため、以下のいずれかで明示的に指定します。
- セッション中に切替: 「/model fable」を入力するとモデルピッカーから Fable 5 に切り替わる
- 起動時に指定: 「claude --model fable」でセッション開始時から Fable 5 で動かす
- 設定ファイル: 「settings.json」の「model」キーに「fable」を指定してデフォルトをFable 5にピン留め
なお「best」エイリアスは、Fable 5にアクセス可能な組織では Fable 5、そうでない組織では最新の Opus に解決される設計です。
組織契約が Fable 5 を含むかどうかわからない段階では、「best」指定で挙動を見るのも有効です。
詳細はClaude Code Model configuration の公式ドキュメントを参照してください。
APIとクラウドプラットフォーム経由

Claude Fable 5は、API経由の利用として以下5つのチャネルが用意されています。6月9日の初回GA時点では全5チャネルで提供されていましたが、6月12日〜30日の停止期間を経て、2026年7月1日時点で再開済みなのはAnthropic直接提供のClaude APIのみ。
Claude Platform on AWS・Amazon Bedrock・Google Cloud Vertex AI・Microsoft Foundry の4チャネルは「可能な限り迅速に」(as quickly as possible)順次再開予定で、日付は未公表です(詳細は本記事内「Fable 5・Mythos 5の停止から再開まで──輸出管理指令の経緯」セクション参照)。
Mythos 5は同じチャネル名でもアクセスが限定されている状態が続いています(Anthropic公式モデル一覧)。
-
Claude API
Anthropic公式のAPI経由。モデルIDは「claude-fable-5」。既存のClaude API利用者なら、SDKの設定変更のみで切り替え可能。公式発表・仕様変更はAnthropicの発表とClaude Platformのリリースノートで確認できます
-
Claude Platform on AWS
AWS上で動くAnthropic公式のClaude Platform経由。Claude APIと同じモデルID(「claude-fable-5」)で呼び出せる。AWSは公式発表とAWS News Blogで、Claude Platform on AWSとBedrockの2経路を案内しています
-
Amazon Bedrock
AWS経由でフルマネージドに利用。ID は「anthropic.claude-fable-5」。AWS環境で運用するアプリケーションから、IAM統制下で呼び出せる。実装時のモデルID・リージョン・データ保持条件はAWSのモデルカードも確認しておくと安全です
-
Google Cloud Vertex AI
Google Cloud経由で提供。ID は「claude-fable-5」。BigQueryやVertex AIのエージェントワークフローと連動させやすい。Google Cloudは公式ブログで一般提供を告知しており、日本語のモデルカードでもモデルID・提供リージョン・上限を確認できます
-
Microsoft Foundry
Microsoft AzureのAIプラットフォーム経由。Microsoft 365やAzure基盤との統合を視野に入れた構成が可能。MicrosoftはAzure Blogで、Foundry Models・Foundry Agent Service・GitHub Copilotからの利用を案内しています
マルチクラウド対応になっており、すでに特定クラウドにロックインされている企業でも、既存の運用基盤を変えずにFable 5を導入できる設計です。
Claude Fable 5のセーフガードとデータ保持ポリシー
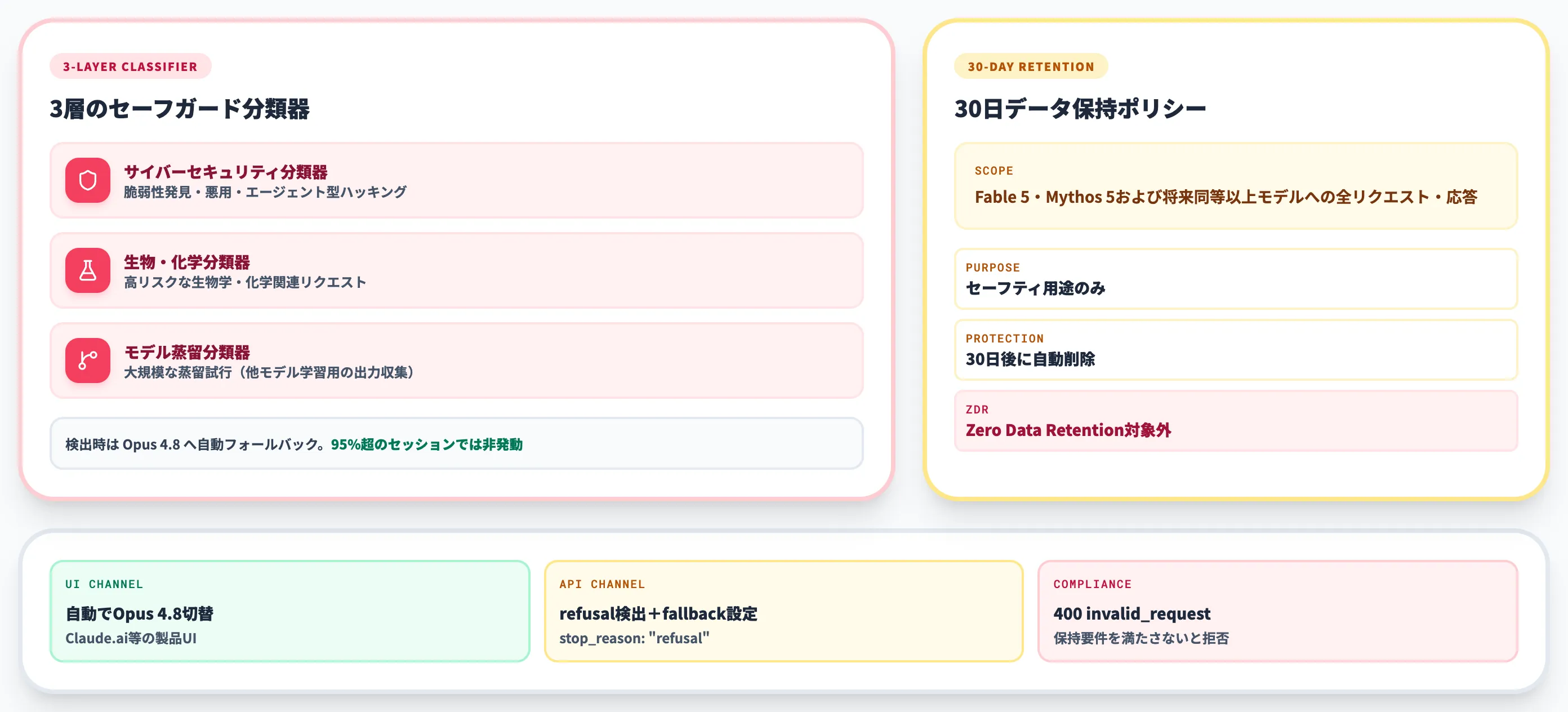
Claude Fable 5には、これまでのClaudeモデルにはなかった3層のセーフガードと30日データ保持ポリシーが新たに導入されています。本セクションでは、その挙動と実運用上の影響を整理します。
3層分類器の仕組み
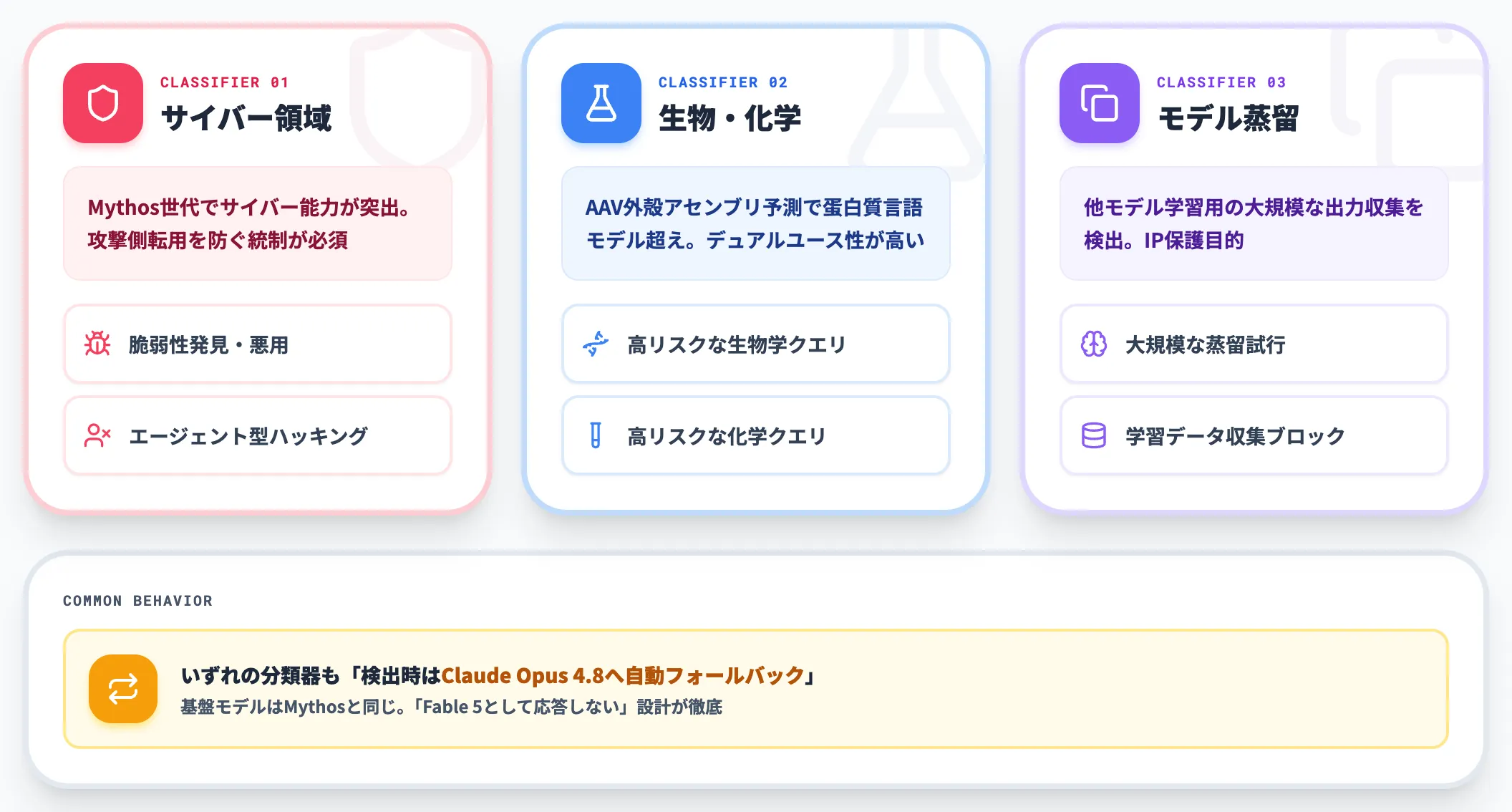
Fable 5には、リクエストの内容を判定して特定領域のクエリをブロック・転送する**3層の分類器(classifier)**が組み込まれています。
| 分類器 | カバー範囲 | 動作 |
|---|---|---|
| サイバーセキュリティ分類器 | 脆弱性発見・悪用・防御回避・エージェント型ハッキング | 検出時にClaude Opus 4.8へ自動フォールバック |
| 生物・化学分類器 | 高リスクな生物学・化学関連リクエスト | 検出時にClaude Opus 4.8へ自動フォールバック |
| モデル蒸留分類器 | 大規模な蒸留試行(他モデル学習用の出力収集) | 検出時にClaude Opus 4.8へ自動フォールバック |
3層構成にした背景は、Mythos Preview世代でAnthropic自身が「サイバー能力が突出して高い」と認めたうえで、生物・化学領域でも「AAV(アデノ関連ウイルス)外殻アセンブリ予測で蛋白質言語モデルを上回る」レベルに達したという経緯があります。
具体的には、AAV外殻のExperimental property predictionタスクで、Mythos Preview・Mythos 5(Fable 5バックエンド)が、専用設計のprotein language modelベースライン(0.70前後)を上回るスコア(0.82〜0.86)を記録しています。
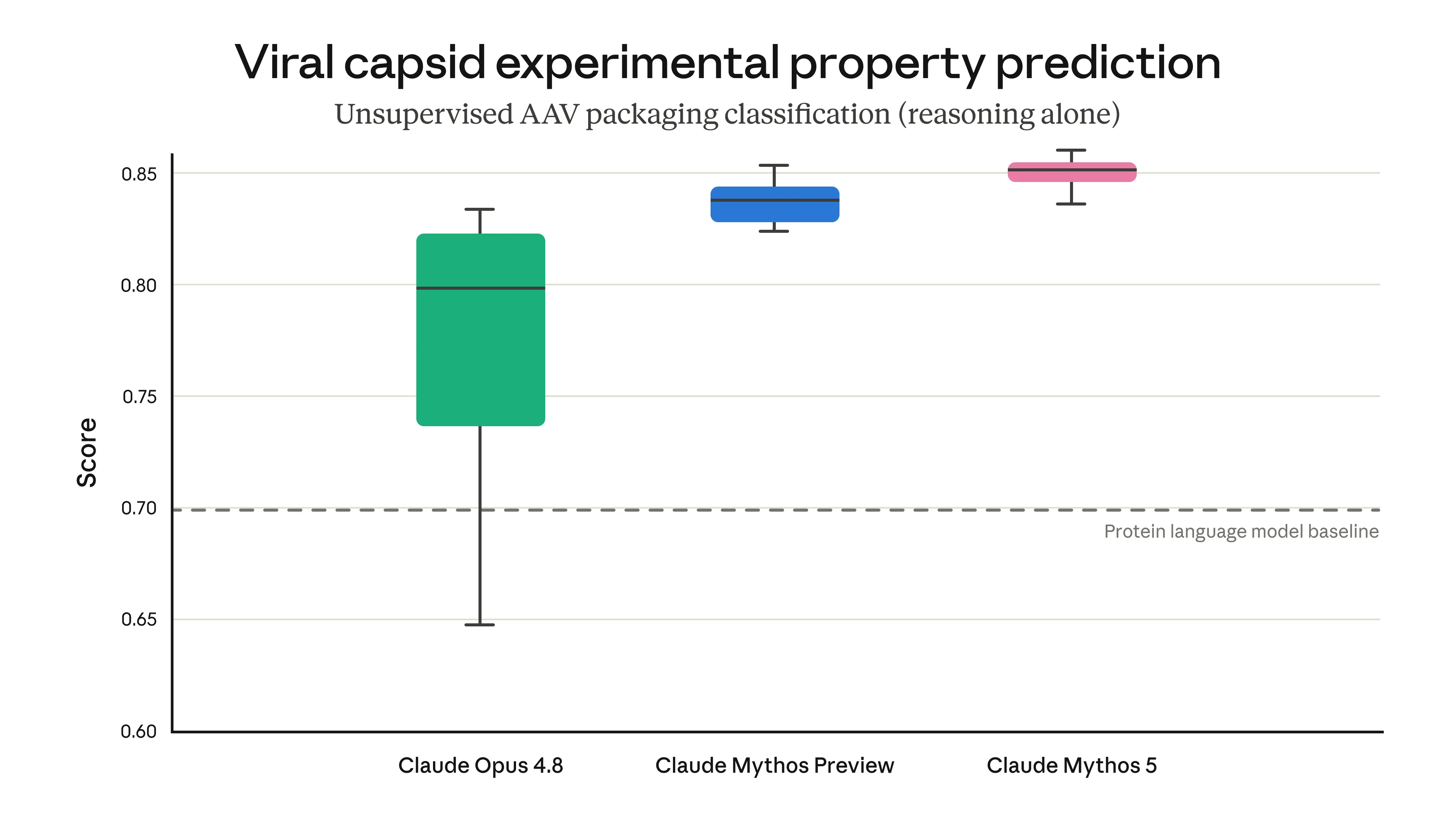
AAV外殻のExperimental property predictionスコア(reasoning aloneで protein language model のベースラインを上回る)(出典:Anthropic)
これらの能力は、医薬品開発や防御サイバーセキュリティのような正当な用途で価値が高い一方、悪意ある利用にも転用できる「デュアルユース」の性質を持ちます。
一般公開モデルとして提供するために、特定領域のクエリだけを統制する仕組みが必要だったというのがAnthropicの説明です。
Fable 5がsafety marginを広げた設計判断
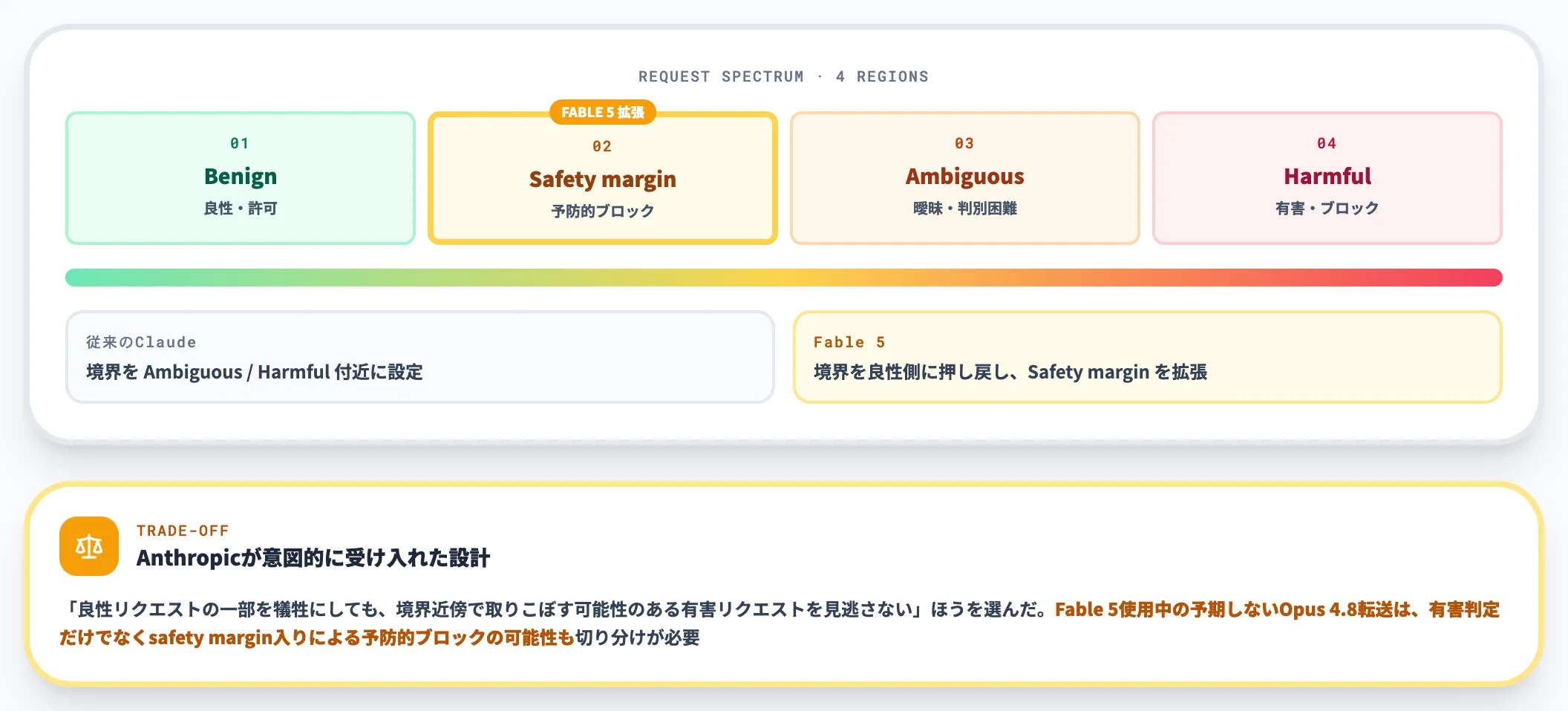
3層分類器は、「境界の内側は許可、外側はブロック」という単純な二値判定ではなく、境界の手前に**safety margin(安全マージン)**という緩衝帯を置く二段構えになっています。
この設計は、Fable 5と従来のClaudeで境界の引き方が異なる点を理解するうえで押さえておく必要があります。
Anthropicの公式解説図では、リクエストは4区間に分けられます。以下のリストで、この4区間の意味を整理します。
- Benign(良性)は、明らかに安全で分類器が許可する範囲
- Safety margin(安全マージン)は、良性寄りだがわずかに有害の可能性が残る範囲で、分類器はブロック側に倒す
- Ambiguous(曖昧)は、脆弱性発見のように防御目的でも悪用でも取れるサイバーセキュリティ関連など、判別が難しい範囲
- Harmful(有害)は、エクスプロイトチェーン構築要求のように明らかに有害な範囲
従来のClaudeでは分類器境界をAmbiguous/Harmful付近に置いていましたが、Fable 5では境界を良性側に押し戻して、safety marginを広げる設計が採用されました。「良性リクエストの一部を犠牲にしても、境界近傍で取りこぼす可能性のある有害リクエストを見逃さない」ほうを選んだ、と読み替えるとわかりやすい設計です。
Anthropic自身も「こうした誤検知はユーザーにとって不便だが、モデルの他の能力を広く提供するためのトレードオフとして意図的に受け入れた」と説明しており、コーディングやデバッグの日常業務で良性リクエストが誤ブロックされる場面が増える一因にもなっています。
運用側の観点で言えば、Fable 5使用中に予期しないOpus 4.8への転送が発生した場合、「有害判定」だけでなく「safety marginに入ったための予防的ブロック」の可能性も含めて切り分ける必要があります。Fable 5固有のフォールバック発生を毎回セキュリティインシデント扱いすると、実運用の工数が発散します。
jailbreakの深刻度は3種類で捉える

Anthropicは、safety marginを踏まえたうえで、jailbreak(安全機構の回避)を深刻度別に3段階で分類しています。この分類は、セキュリティ研究者や運用担当が「どのjailbreakが業務にとって重い脅威か」を判断する共通軸として機能します。
以下の表で、3種類のjailbreakと分類器境界との関係、実務上のリスクの重みを整理しました。
| 分類 | 分類器境界との関係 | 実務リスクの重み |
|---|---|---|
| Minor jailbreak | 分類器はブロックしないが、safety margin内に留まる | 有害である可能性は低く、「本来良性なのに誤検知でブロックされていたリクエストが回復した」に近い |
| Narrow harmful jailbreak | 特定の狭い有害タスク群を分類器の外まで通す | 攻撃者が扱える範囲が限定されるため、Anthropicは低〜中程度の重大度と位置付け |
| Universal jailbreak | 有害振る舞いの1クラス全体をまとめて通す | もっとも重い。1つのプロンプトで攻撃面が一気に広がる |
この3分類から運用側に落ちてくる示唆は、**「HackerOne等の外部プログラムで最優先で拾うべきはUniversal jailbreakである」**という優先順位です。前述のHackerOneプログラムは既存3層分類器を突破する新しい攻撃手法の報告を受け付ける設計になっており、Universal jailbreakにあたる発見が最優先で扱われる構造になっています。
一方Minor jailbreakは、そのまま放置しても即有害にはつながらないため、ユーザー側では「safety margin広めの設計で誤検知側にブレている」と受け止めるほうが実態に近い場合が多くなります。運用時にすべてのブロック回避報告を同じ深刻度で扱うと対応工数が発散するため、まずこの3分類でトリアージするのが実務的な運用になります(出典:Anthropic「Redeploying Claude Fable 5」)。
Opus 4.8への自動フォールバック挙動
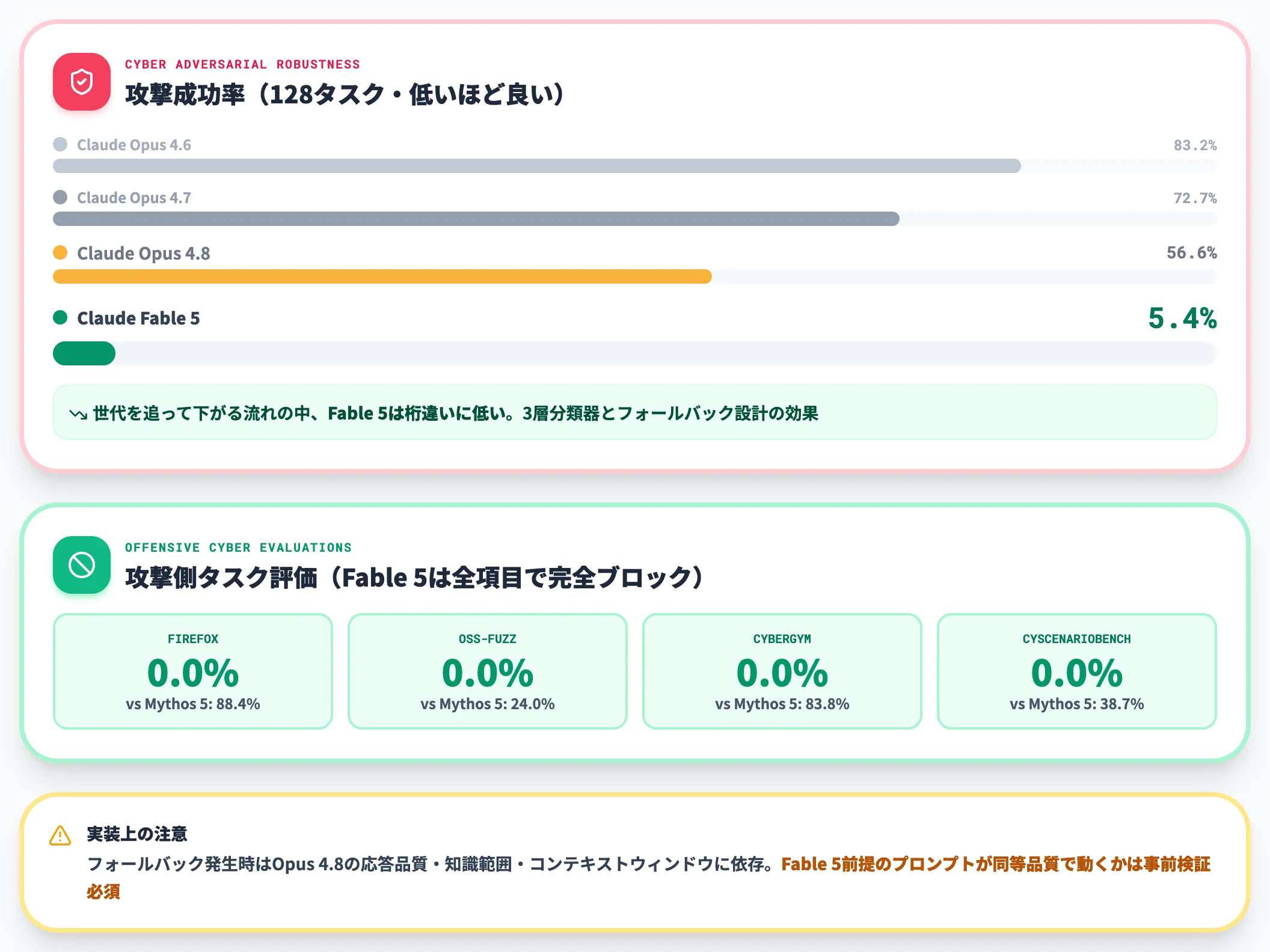
3層分類器が反応すると、Fable 5への問い合わせはClaude Opus 4.8へ転送され、Opus 4.8が応答します。Claude.ai等の製品UIでは自動的に切り替わりますが、API経由の場合は拒否レスポンス(stop_reason: "refusal"、HTTP 200)が返るため、SDKにfallbacks指定またはmiddlewareを組み込んでフォールバックを処理する設計が必要です(Claude Platform on AWSはbetaでサーバーサイドfallback対応、Bedrock/Vertex AI/Microsoft FoundryではSDK側での実装が推奨)。
Anthropic公式によれば、「95%超のFableセッションでフォールバックは発生せず、大半の通常業務では影響が出にくい」設計です。特定領域の踏み込んだクエリのみがOpus 4.8側で処理される形になります。
セーフガードの効果を定量的に示すデータとして、Anthropic公式の「Cyber adversarial robustness eval(攻撃成功率、128タスク)」結果が分かりやすい比較材料です。
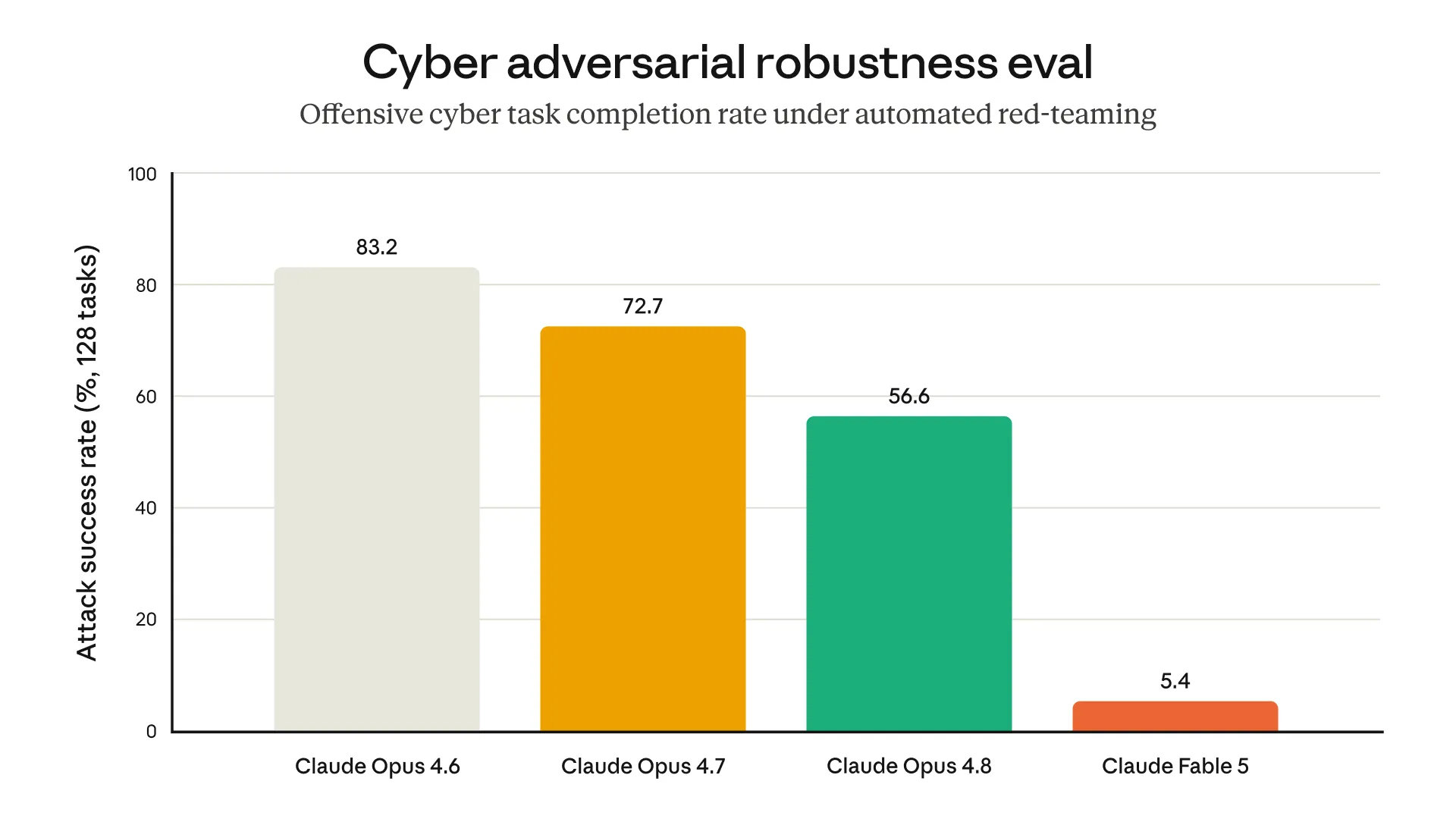
Cyber adversarial robustness eval(128タスクの攻撃成功率・低いほど良い)(出典:Anthropic)
| モデル | 攻撃成功率(低いほど良い) |
|---|---|
| Claude Opus 4.6 | 83.2% |
| Claude Opus 4.7 | 72.7% |
| Claude Opus 4.8 | 56.6% |
| Claude Fable 5 | 5.4% |
Opus世代の攻撃成功率が世代を追うごとに下がってきた流れと比べても、Fable 5の5.4%は桁違いに低く、3層分類器とフォールバック設計がセキュリティ面で大きな差を生んでいることが分かります。
さらに、Firefox・OSS-Fuzz・CyberGym・CyScenarioBenchといった**Offensive cyber evaluations(攻撃側タスク評価)**では、Mythos Preview(70.8%・22.8%・83.1%・29.2%)やMythos 5(88.4%・24.0%・83.8%・38.7%)が高い成功率を示すのに対し、**Claude Fable 5は全項目で 0.0%(完全ブロック)**となっています。
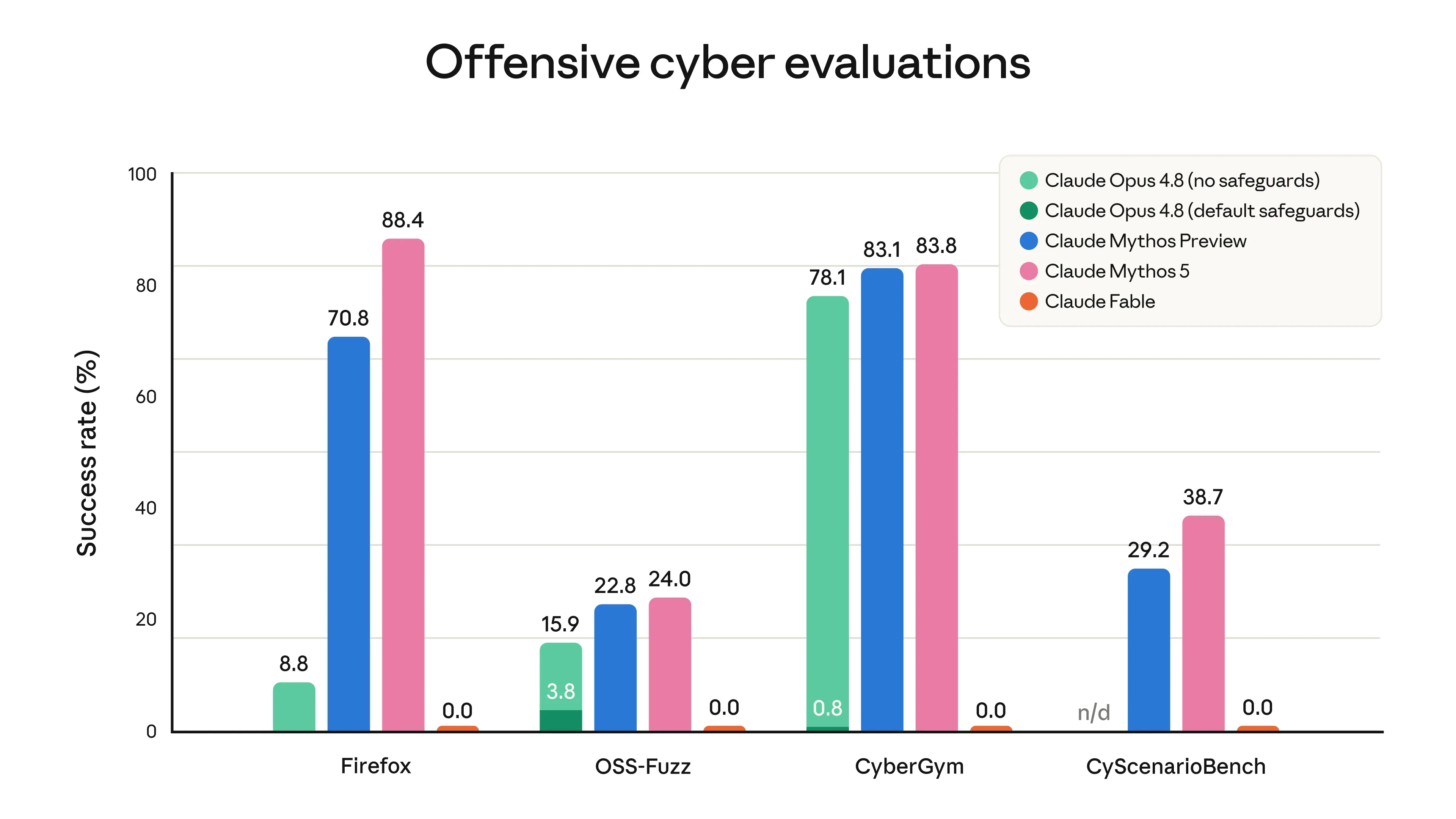
Offensive cyber evaluations の成功率(Fable は全項目で 0.0%・完全ブロック)(出典:Anthropic)
つまり、基盤モデルはMythosと同じですが、3層分類器の働きでFable 5としては応答しない設計が徹底されているということです。
外部のバグバウンティプログラムでも「1,000時間超のテストで汎用ジェイルブレークなし」、英国AI Security Institute(AISI)の長時間エージェントタスク評価でも汎用的なジェイルブレーク手法は発見されなかったと報告されています。
加えて、自動アラインメント評価における「Misaligned behavior(不整合行動)スコア」も、Fable 5世代がOpus-tierと同水準に収まっています。
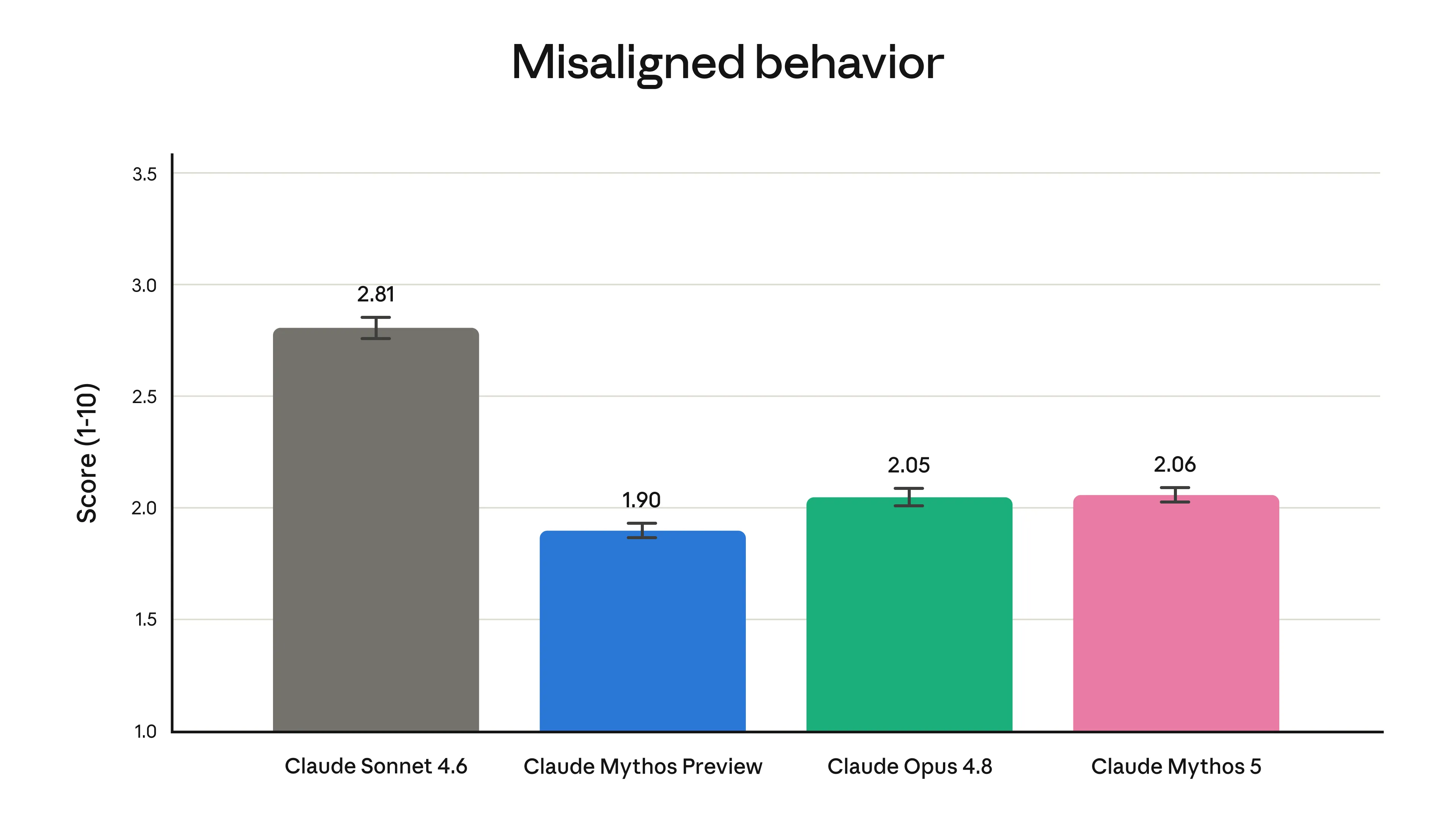
自動アラインメント評価における Misaligned behavior スコア(10点満点・低いほど整合的)(出典:Anthropic)
スコアは10点満点で低いほど整合的な挙動を意味し、Sonnet 4.6が2.81、Mythos Previewが1.90、Opus 4.8が2.05、Mythos 5(=Fable 5のバックエンド)が2.06という分布です。
Mythos 5はSonnet 4.6より大幅に低く、Opus 4.8・Mythos Previewと同水準に収まっており、フロンティア能力を持ちつつもアラインメント面ではOpus-tier並みの安全性が確保されている設計が読み取れます。
30日データ保持ポリシー
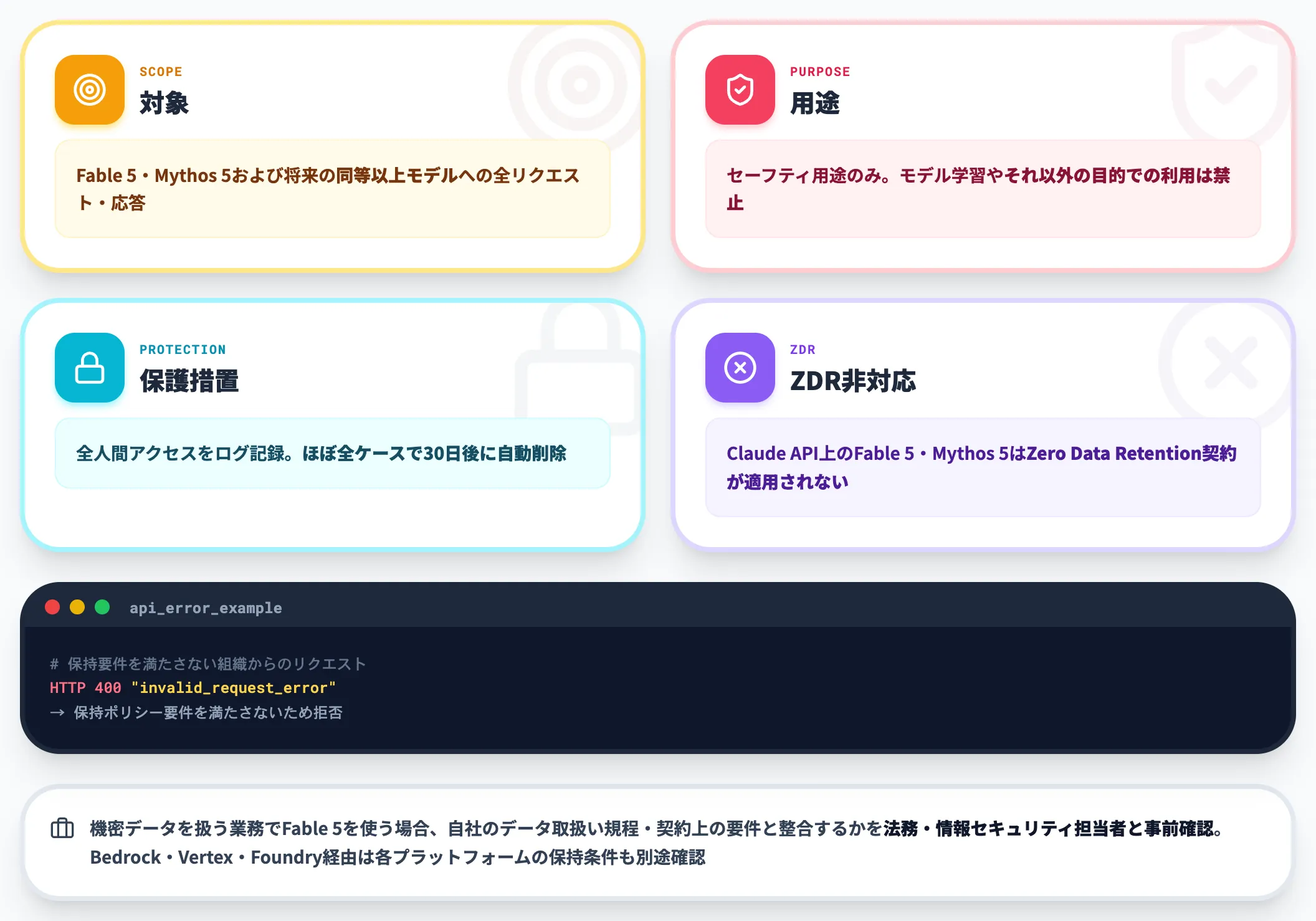
Fable 5および将来のMythos-class同等以上モデルには、30日間のデータ保持ポリシーが新たに適用されています。
-
対象
Fable 5・Mythos 5および将来の同等以上モデルへの全リクエスト・応答
-
用途
セーフティ用途のみ。モデル学習やそれ以外の目的での利用は禁止
-
保護措置
全人間アクセスをログ記録。ほぼ全ケースで30日後に自動削除される
-
公式ドキュメント
Anthropic公式サポート記事
従来のClaude APIのデフォルトデータ取扱いとは別建てのポリシーで、Fable 5・Mythos 5は「能力が高い分、安全性検証のためのログ保持期間が長くなる」設計です。
機密データを扱う業務でFable 5を使う場合、この30日保持ポリシーが自社のデータ取り扱い規程・契約上の要件と整合するかを、法務・情報セキュリティ担当者と事前確認しておくのが安全です。
Claude API上のFable 5・Mythos 5にはZero Data Retention(ZDR)契約が適用されず、Anthropic公式ドキュメントによれば、保持要件を満たさない組織からのリクエストは「400 invalid_request_error」で拒否されます。
Claude Fable 5と競合モデルの比較
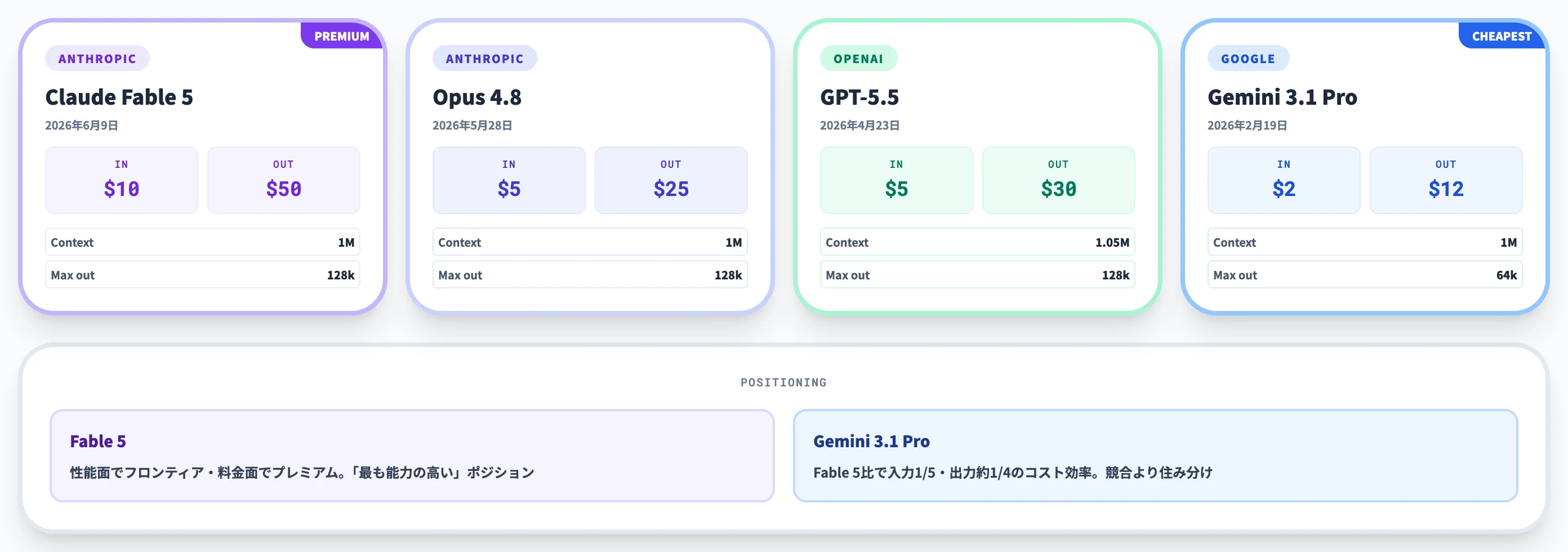
Claude Fable 5の位置づけを実務的に判断するには、同価格帯・同性能帯の競合モデルとの比較が欠かせません。
以下の表で、Fable 5と3つの競合モデルの主要スペックを並べました。
| 項目 | Claude Fable 5 | Claude Opus 4.8 | GPT-5.5(API) | Gemini 3.1 Pro |
|---|---|---|---|---|
| 開発元 | Anthropic | Anthropic | OpenAI | Google DeepMind |
| 発表日 | 2026年6月9日 | 2026年5月28日 | 2026年4月23日 | 2026年2月19日 |
| 入力料金($/M tokens) | $10 | $5 | $5 | $2(≤200k)/ $4(>200k) |
| 出力料金($/M tokens) | $50 | $25 | $30 | $12(≤200k)/ $18(>200k) |
| Context window | 1M | 1M | 1.05M | 1M |
| Max output | 128k | 128k | 128k | 64k |
| Reliable knowledge cutoff | Jan 2026 | Jan 2026 | 2025年12月1日 | 非公表 |
| API入出力モダリティ | 入力: テキスト・画像/出力: テキスト | 入力: テキスト・画像/出力: テキスト | 入力: テキスト・画像/出力: テキスト | 入力: テキスト・画像・音声・動画/出力: テキスト |
この比較から見えるのは、Fable 5は性能面でフロンティアレベルを狙う一方、価格面では明確にプレミアム帯に置かれているということです。
Gemini 3.1 Proは入力$2(200kトークン以下)と圧倒的に安く、200k超でも$4に留まります。GPT-5.5はAPIではテキスト・画像入力までですが、ChatGPT/CodexやResponses API周辺で音声・動画を含むマルチモーダルワークフローを組める強みがあります。
公式ベンチマークでの位置づけ
Anthropicは2026年6月9日の発表時に、Fable 5(Mythos 5と同じスコア)・Mythos Preview・Opus 4.8・GPT-5.5・Gemini 3.1 Proを横並びで比較した公式ベンチマーク表を公開しています。
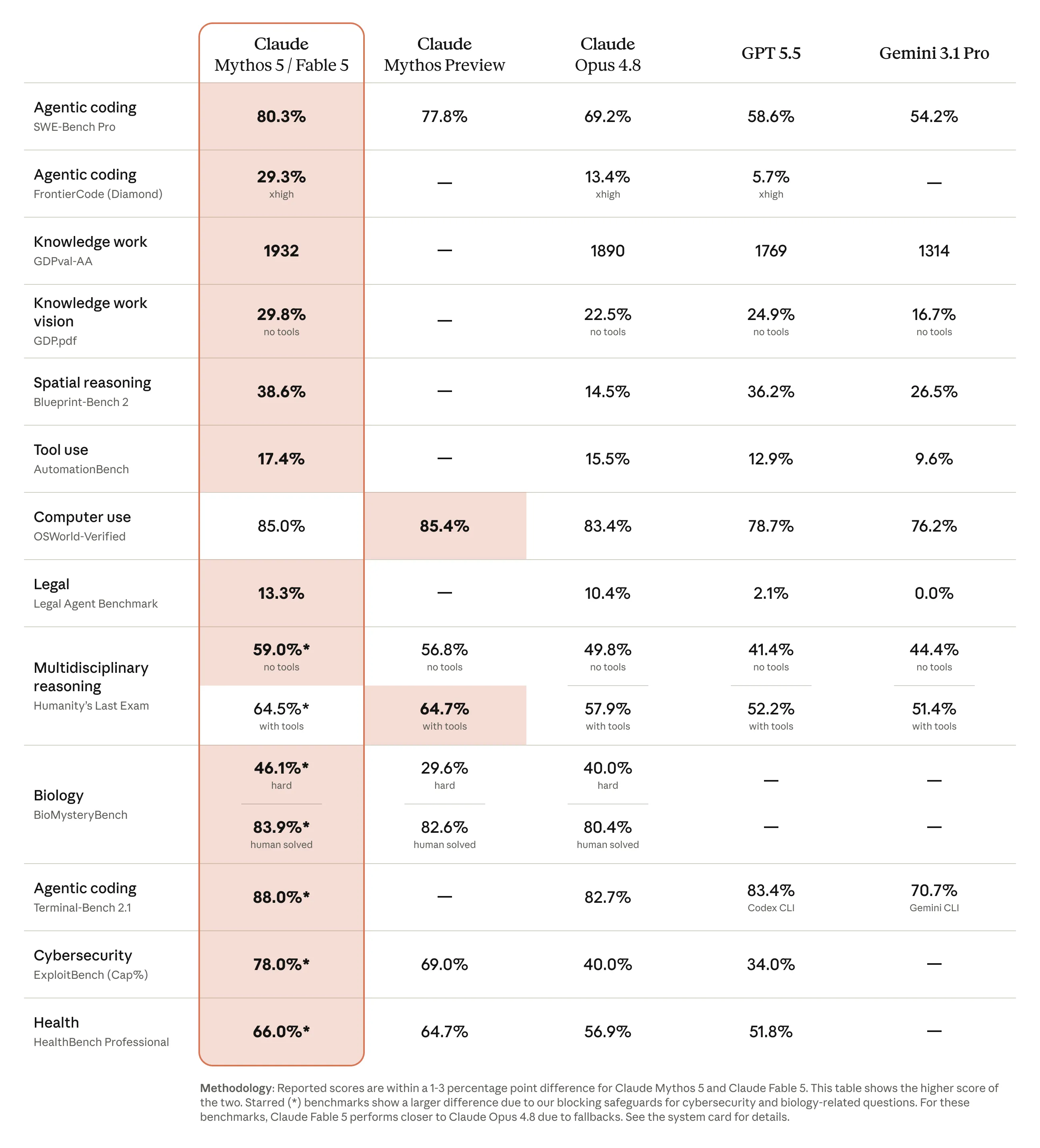
Claude Mythos 5 / Fable 5 と Opus 4.8・GPT-5.5・Gemini 3.1 Pro の全項目ベンチマーク比較表(出典:Anthropic)
主要評価軸を抜粋すると以下のとおりです。
| カテゴリ | ベンチマーク | Fable 5 | Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|---|
| Agentic coding | SWE-Bench Pro | 80.3% | 69.2% | 58.6% | 54.2% |
| Agentic coding | FrontierCode(Diamond) | 29.3% | 13.4% | 5.7% | — |
| Agentic coding | Terminal Bench 2.1 | 88.0% | 82.7% | 83.4%(Codex CLI) | 70.7% |
| Knowledge work | GDPval-AA(Elo) | 1932 | 1890 | 1769 | 1314 |
| Knowledge work | Humanity's Last Exam(tools無) | 59.0% | 49.8% | 41.4% | 44.4% |
| Computer use | OSWorld-Verified | 85.0% | 83.4% | 78.7% | 76.2% |
| Legal | Legal Agent Benchmark | 13.3% | 10.4% | 2.1% | 0.0% |
| Health | HealthBench Professional | 66.0% | 56.9% | 51.8% | — |
| Tool use | AutomationBench | 17.4% | 15.5% | 12.9% | 9.6% |
この表で押さえるべきは、Fable 5が主要ベンチマークの多くで首位級を取っている点です(Anthropic公式は「nearly all tested benchmarks」と表現。ただしOSWorld-VerifiedはMythos Previewの85.4に対しFable 5が85.0など、微差の例外もあります)。
前述のコーディング系(FrontierCode)に加え、Legal Agent BenchmarkでもFable 5がOpus 4.8の約1.3倍・GPT-5.5の約6.3倍のスコア差を出しており、コーディング以外の長期エージェント業務でもFable 5のリードが明確に表れています。
なお、Biology・Cybersecurity関連ベンチマーク(BioMysteryBench・ExploitBench等)はMythos 5のスコアであり、Fable 5は3層分類器によってOpus 4.8側にフォールバックされる設計上、これらの領域ではOpus 4.8相当のスコアになる点に注意が必要です。
vs Claude Opus 4.8——「2倍払う価値」があるかの判断軸

最も悩ましいのが、自社内での比較対象である Opus 4.8 との使い分けです。
Opus 4.8は2026年5月28日リリースの正常進化モデルで、Agentic codingが64.3%→69.2%、Knowledge work Eloスコアが1,753→1,890と前世代から大きく前進しています。
Artificial Analysisの独立評価では、Opus 4.8が Intelligence Index 61.4(前版+4.1、GPT-5.5比+1.2)でトップとされており、汎用業務での実力は依然として高い水準にあります。
Fable 5が Opus 4.8 に対して優位を出すのは、Stripe事例のような「数か月の作業を数日に圧縮する」スケールの大規模自律業務や、Hex事例のような「複雑な長時間分析タスクで90%超を初めて達成する」レベルの読解業務です。
短〜中規模のコーディング・要約・通常の業務文書解釈であれば、Opus 4.8で十分なケースも多く、料金2倍を払う必然性は薄いと判断できます。
逆に、エージェントを長時間自律稼働させるユースケースや、人手で2か月かかる作業をAIに移管したい場合は、Fable 5を選ぶ価値が出てきます。
vs GPT-5.5——マルチモーダル統合とエージェント特化の住み分け

OpenAI GPT-5.5は2026年4月23日リリースで、GPT-4.5以来の完全新規学習ベースモデルです。
エージェント・コンピュータ操作・長期業務向けに大きく前進した世代という位置づけです。
ベンチマーク比較
ベンチマーク面では、GPT-5.5は GDPval 84.9%、OSWorld-Verified 78.7%、Tau2-bench Telecom 98.0%、Terminal-Bench 2.0 82.7% など、エージェントワークフローと実コンピュータ操作の評価で強い数字を出しています。
一方で、Anthropic公式の比較表ではSWE-Bench Pro(Fable 5: 80.3% vs GPT-5.5: 58.6%)・FrontierCode(29.3% vs 5.7%)・GDPval-AA Elo(1932 vs 1769)・Humanity's Last Exam(59.0% vs 41.4%)など、Fable 5がGPT-5.5を上回る項目が複数示されています。
マルチモーダルとエコシステム連携
マルチモーダルの扱いは利用面で分岐します。
OpenAI APIの「gpt-5.5」モデルは入力がテキスト・画像、出力がテキストのみで、音声・動画はAPIレベルでは未対応です。
一方、ChatGPT上のGPT-5.5や Codex / Responses API周辺のサーバ側ワークフローでは、Whisper・GPT-4o-mini・Soraなど他モデルと組み合わせて音声・動画を含むパイプラインを組めます。Fable 5(同じく入力はテキスト・画像、出力はテキスト)と直接比較する場合は、APIレベルでは大きなモダリティ差はない点を押さえておく必要があります。
Fable 5とGPT-5.5の使い分け
Fable 5とGPT-5.5の使い分けは、ざっくり以下のように整理できます。
-
GPT-5.5が向くケース
ChatGPTエコシステム(GPT Store・カスタムGPTs・Operator等)との連携が必要なケース、OpenAIの他モデルと組み合わせた音声・動画パイプラインを組みたい場合、コンピュータ操作型エージェントの構築
-
Fable 5が向くケース
コーディング・長期エージェント業務・複雑文書解釈・ビジョン入力からのソースコード再構築。特に長時間にわたる自律業務での集中力維持
テキスト中心のエージェント業務であればFable 5、OpenAI既存資産との連携やChatGPT/Codex起点のワークフローならGPT-5.5、というのが実務的な選択軸になります。
vs Gemini 3.1 Pro——コスト優位と Google エコシステム統合
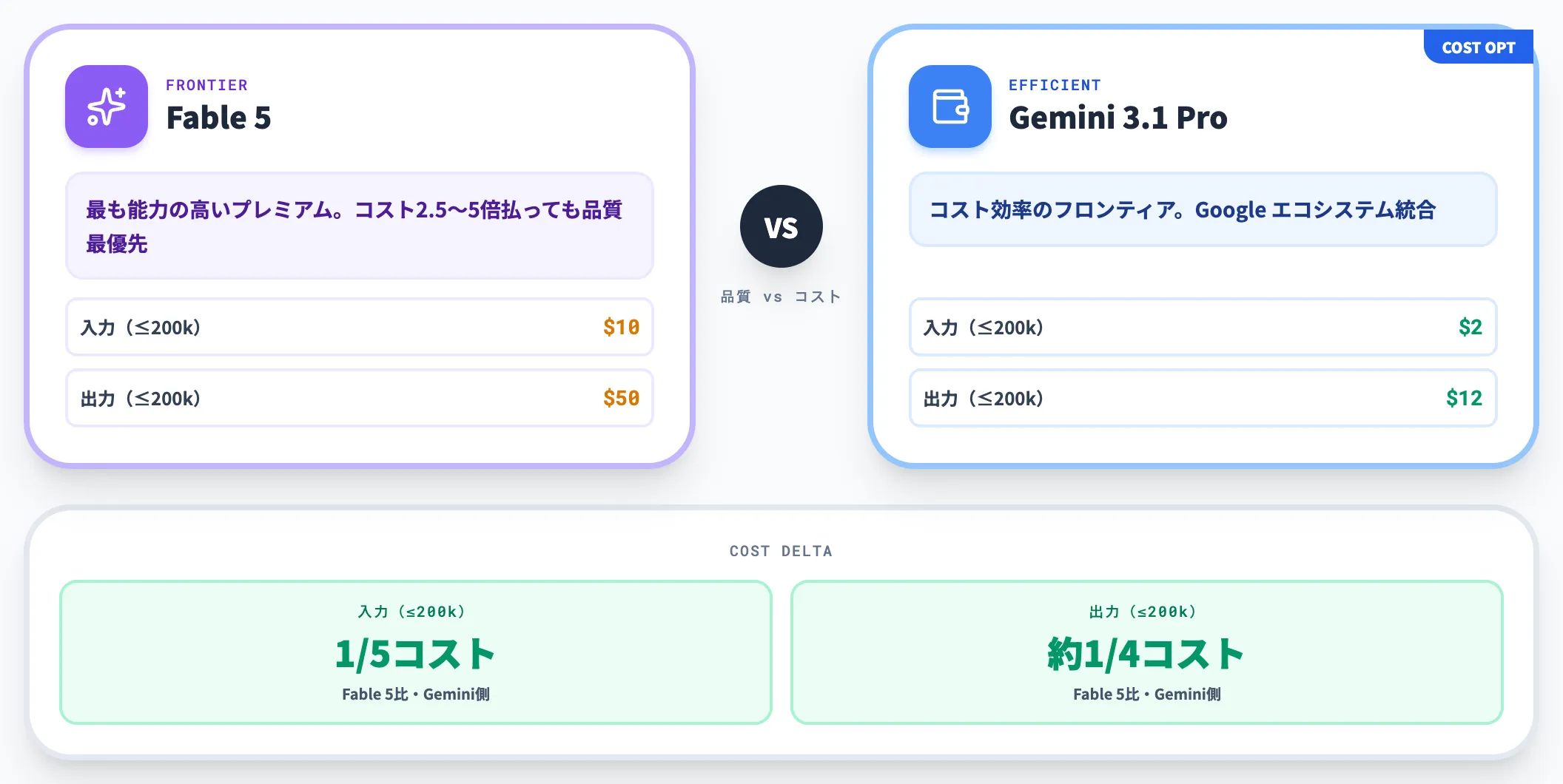
コストとベンチマーク比較
Gemini 3.1 Proは2026年2月19日プレビュー開始のGoogle DeepMind最上位モデルで、Gemini 3 ProベースのMixture-of-Experts構成です。
公式の料金表によれば、200kトークン以下は入力$2・出力$12、200k超では入力$4・出力$18の2段階課金になっています。Fable 5($10/$50)と比べると、200k以下では入力1/5・出力約1/4のコスト感、200k超でも**入力40%・出力36%**に収まります。
ベンチマーク面では、ARC-AGI-2で77.1%、GPQA Diamondで94.3%(同ベンチマーク史上最高)など、推論系の指標で前世代から大きく前進しています。
1Mコンテキストウィンドウもネイティブ対応で、Google Cloud(Vertex AI)・Gemini API・Android Studioなど Google エコシステム全体に統合されています。
Fable 5とGemini 3.1 Proの使い分け
Fable 5とGemini 3.1 Proの使い分けの目安は次のとおりです。
-
Gemini 3.1 Proが向くケース
コスト感度が高いワークロード、Google Cloud上で完結する処理、検索・YouTube・Workspace等のGoogle資産との連携、大量トークンを扱うバッチ処理(200k超は$4/$18の上位tierに切り替わる点は織り込む)
-
Fable 5が向くケース
コスト約2.5〜5倍を払ってでも「長期エージェントの集中力」「コーディング品質」「複雑文書解釈の品質」を最優先したい業務
Gemini 3.1 Proが「コスト効率の良いフロンティアモデル」、Fable 5が「最も能力の高いプレミアムモデル」というポジショニングで、競合関係というよりは住み分けに近い構図になりつつあります。
ケース別の使い分け
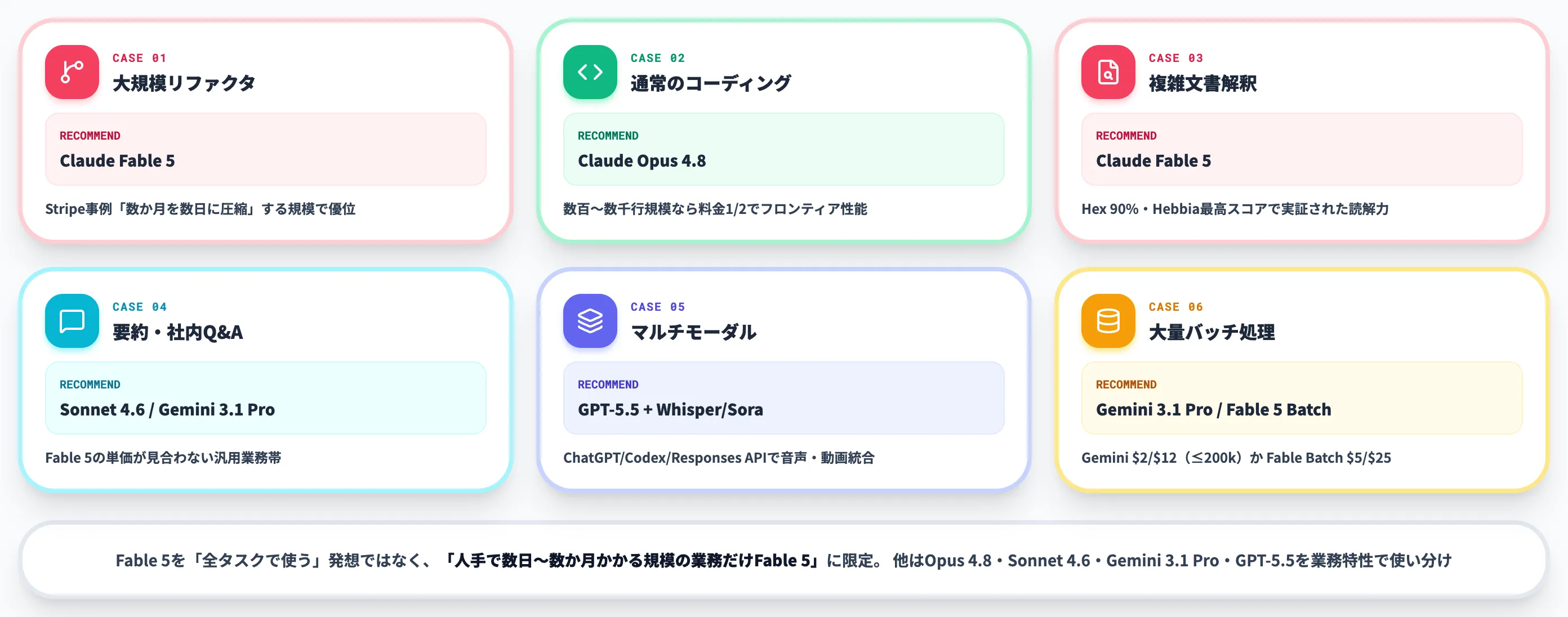
ここまでの3比較を踏まえ、AI総研の支援現場での実務的な使い分け基準を整理します。
| ユースケース | 推奨モデル | 理由 |
|---|---|---|
| 大規模リファクタリング・マイグレーション | Claude Fable 5 | Stripe事例のような「数か月を数日に圧縮」する規模で優位 |
| 通常のコーディング業務(数百〜数千行規模) | Claude Opus 4.8 | 料金1/2でフロンティア性能。Fable 5の優位が出にくい規模 |
| 複雑文書解釈・財務分析(数時間規模) | Claude Fable 5 | Hex 90%・Hebbia最高スコア事例で実証 |
| 通常の要約・翻訳・社内Q&A | Claude Sonnet 5 or Gemini 3.1 Pro | Fable 5は単価が見合わない |
| OpenAI系マルチモーダルパイプライン | GPT-5.5 + Whisper / Sora 等 | GPT-5.5単体は入力テキスト・画像/出力テキストだが、ChatGPT・Codex・Responses API経由で他モデルを組み合わせて音声・動画パイプラインを構成可能 |
| 大量バッチ処理(コスト最優先) | Gemini 3.1 Pro or Fable 5 Batch API | Geminiは$2/$12(≤200k)または$4/$18(>200k)、Fable 5 Batchは$5/$25 |
ポイントは、Fable 5を「全タスクで使う」発想ではなく、「人手で数日〜数か月かかる規模の業務だけFable 5、それ以外は Opus 4.8・Claude Sonnet 5・Gemini 3.1 Pro・GPT-5.5を業務特性で使い分ける」という構成にすることです。

Claude Fable 5を活かすプロンプティングと運用設計

ここまでで性能・料金・セーフガード・乗り換え判断を整理しましたが、実際にFable 5を業務で使い切るには、プロンプトとスキャフォールディング(指示・スキル・ガードレール)を従来モデル向けの設計から組み替える作業が効きます。
能力が上がった分、旧モデル向けの細かい指示や安全装置がかえって出力品質を下げる場面があるためです。
本セクションでは、Anthropicが2026年6月に公開したFable 5専用のプロンプティングガイドを踏まえ、業務組込み前に押さえておきたい5つの設計ポイントを整理します。
- effortレベルの使い分け
- 長時間実行を支える3つの設計指示(境界明示・進捗監査・早期停止)
- 並列サブエージェントとメモリシステム
- 既存スキル・プロンプトのリファクタリング(reasoning_extraction対策)
- ユーザー送信ツール
effortレベルの使い分け(high/xhigh/medium/low)
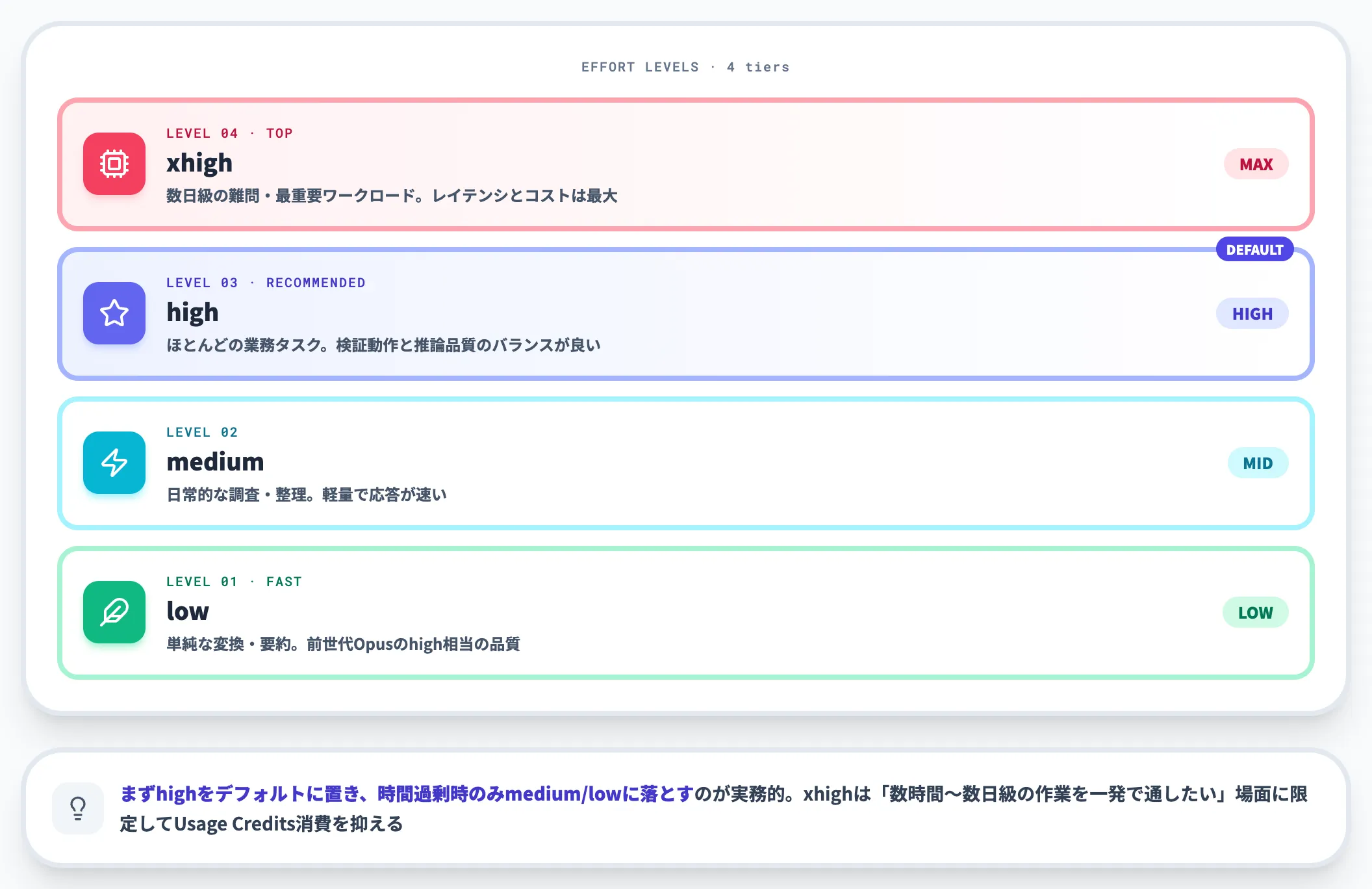
Fable 5の挙動を最も大きく左右するのが、**effort(エフォート)**の設定です。effortは「どこまで深く考えるか」を制御するパラメータで、知能・レイテンシ・コストのトレードオフを直接決めます。
以下の表で、effortレベルごとの使い分け基準を整理しました。Fable 5は低いeffortでも前世代Opusの最高設定を上回るケースが多く、デフォルトをどこに置くかが運用コストを大きく動かします。
| effort | 推奨用途 | 特性 |
|---|---|---|
| xhigh | 数日級の難問・最重要ワークロード | 最も洗練された推論。レイテンシ・コストは最大 |
| high(推奨デフォルト) | ほとんどの業務タスク | 検証動作と推論品質のバランスが良い |
| medium | 日常的な調査・整理 | 軽量で応答が速い |
| low | 単純な変換・要約 | 前世代Opusのhigh相当の品質 |
実務的なポイントは、まずhighをデフォルトに置き、タスクが必要以上に時間がかかる場合のみmedium/lowに落とすことです。逆にxhighは「数時間〜数日級の作業を一発で通したい」場面に限定する方が、Usage Creditsの消費を抑えられます。
ただしhighでは、Fable 5が要求されていない整理やリファクタリングまで手を出すことがあります。これを抑えるには、次のような短い指示をシステムプロンプトに加えるのが有効です。
タスクが要求する以上の機能追加・リファクタリング・抽象化はしないでください。
バグ修正に周辺のクリーンアップは不要です。発生しないシナリオへのエラーハンドリングや
バリデーションは追加せず、内部コードとフレームワークの保証を信頼してください。
検証はシステム境界(ユーザー入力・外部API)のみで行ってください。
この指示が効くのは、Fable 5の指示追従力が前世代より大幅に強化されているためです。動作を細かく列挙する代わりに、原則を1〜2行で書くだけで挙動が変わるのが特徴で、プロンプトの記述量自体を減らせます。
長時間実行を支える3つの設計指示——境界明示・進捗監査・早期停止対策
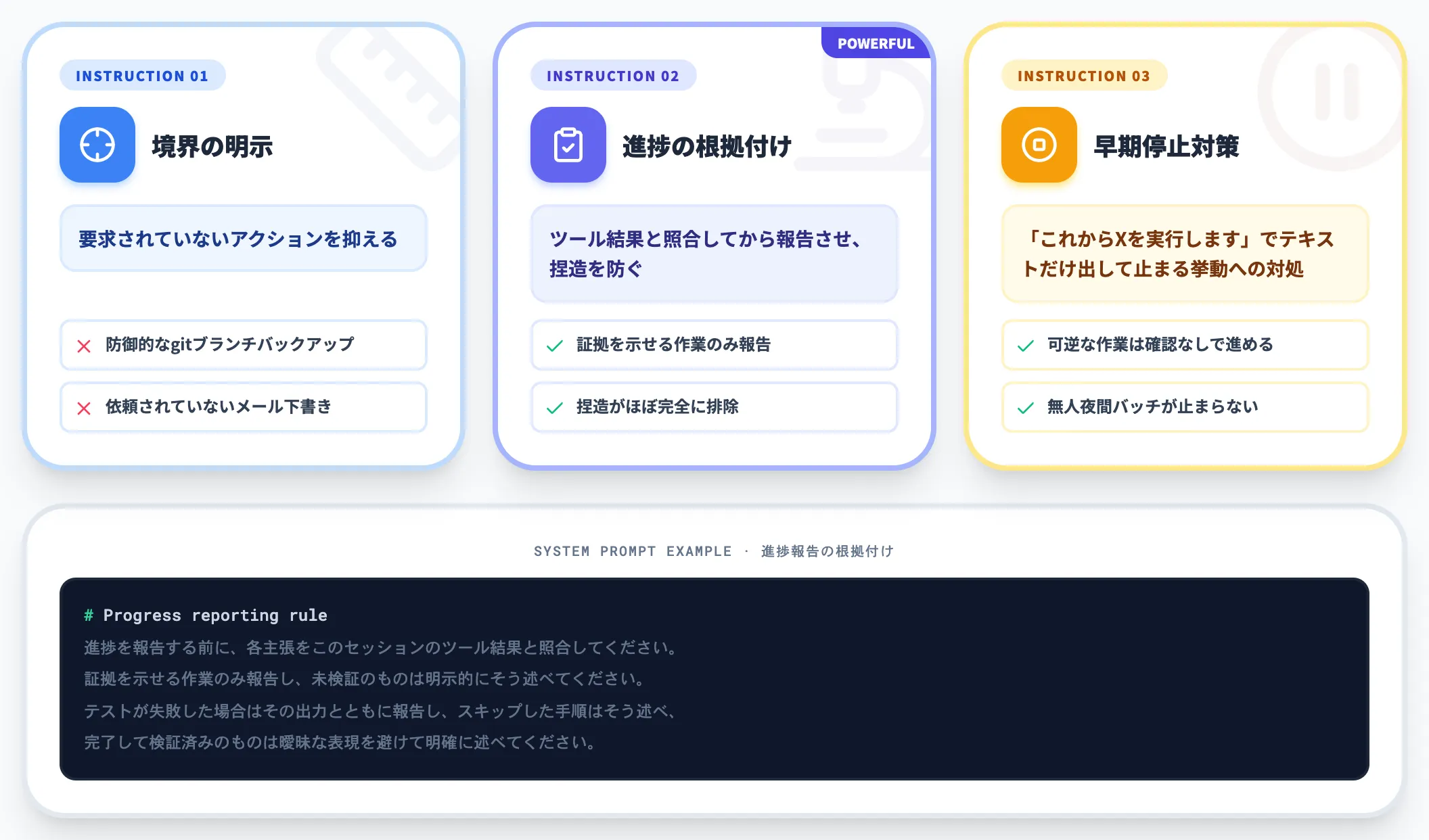
Fable 5は1リクエストが数分〜数十分、自律実行なら数時間〜数日に及びます。この長さに耐える設計には、以下3つの指示を組み込むのが実務的です。
-
境界の明示
要求されていないアクション(防御的なgitブランチバックアップ、依頼されていないメール下書きなど)を抑える
-
進捗報告の根拠付け
ツール結果と照合してから報告させ、捏造を防ぐ
-
早期停止対策
途中で「これからXを実行します」とテキストだけ出して止まる挙動への対処
特に進捗報告の根拠付けは、Anthropic内部テストで「捏造を誘発するように設計したタスクでも捏造がほぼ完全に排除された」と報告されている強力な指示です。具体的には次のような文をシステムプロンプトに含めます。
進捗を報告する前に、各主張をこのセッションのツール結果と照合してください。
証拠を示せる作業のみ報告し、未検証のものは明示的にそう述べてください。
テストが失敗した場合はその出力とともに報告し、スキップした手順はそう述べ、
完了して検証済みのものは曖昧な表現を避けて明確に述べてください。
自律パイプラインの場合は、加えて「ユーザーが見ていない前提で、可逆な作業は確認なしで進める」指示を別途追加します。
この指示がないとFable 5は途中で許可を求めて停止し、無人運用ではブロック状態になります。夜間バッチやスケジュール実行を組む場合、この差は1晩の作業がそのまま停止するかどうかに直結します。
並列サブエージェントとメモリシステム——非同期通信と1ファイル1教訓
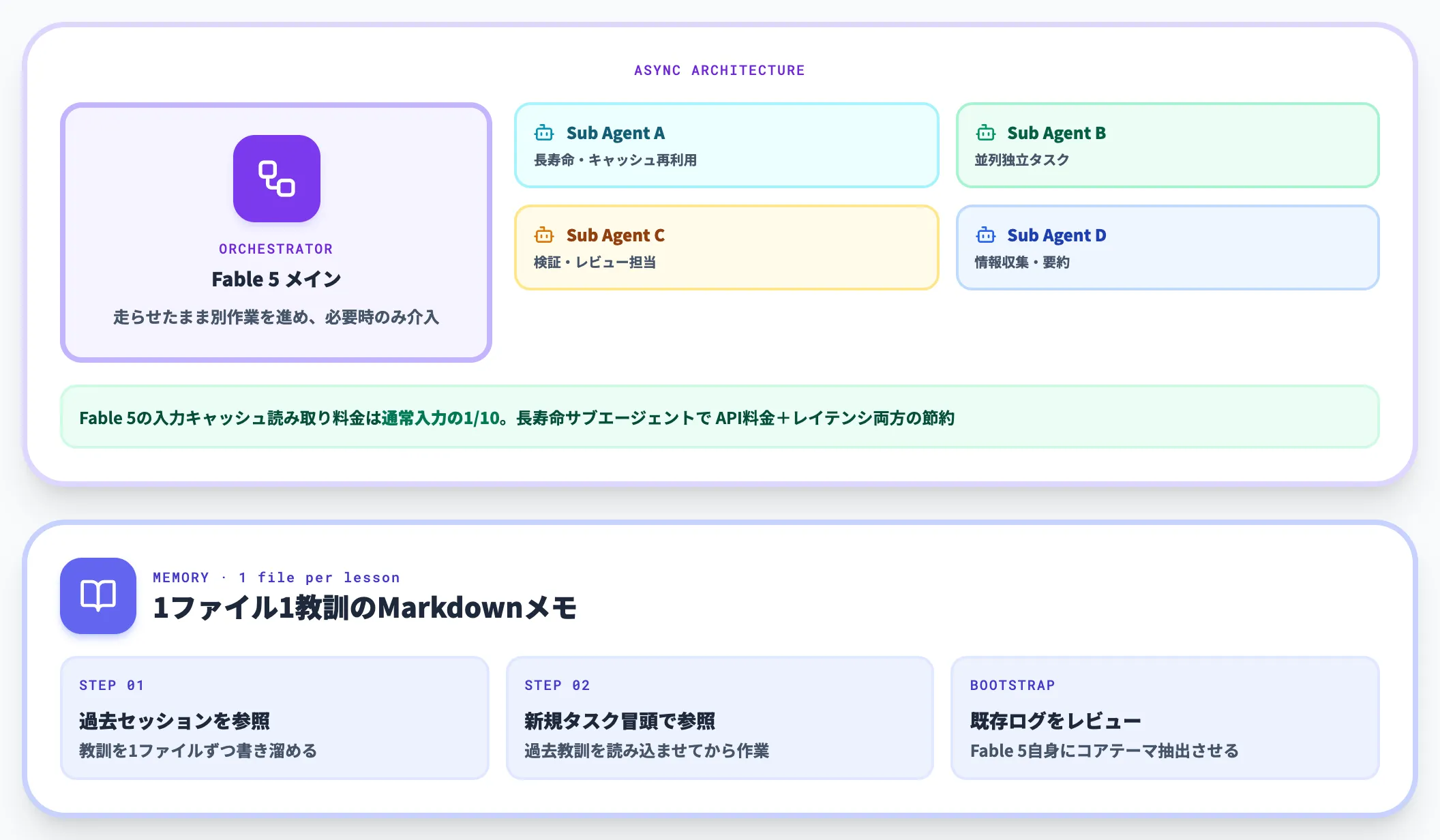
Fable 5は前世代より積極的に並列サブエージェントをディスパッチします。この特性を活かすには、サブエージェント設計をブロック型から非同期型に切り替えるのが効果的です。
オーケストレーターがサブエージェントの完了をブロックして待つのではなく、走らせたまま別作業を進め、必要時のみ介入する設計に変えます。
長寿命のサブエージェントはコンテキストをキャッシュ読み取りで再利用するため、複数タスクを通じたAPI料金とレイテンシの両方の節約につながります。Fable 5の入力キャッシュ読み取り料金は通常入力の10分の1なので、長時間サブエージェントの効果は数値で効いてきます。
加えて、Fable 5は過去セッションから得た教訓を参照できる場合に特にパフォーマンスが上がります。シンプルにMarkdownファイルで「1ファイル1教訓」の形式でメモを書かせ、新規タスクの冒頭で参照させる設計が現実的です。
既存セッションが大量にあれば、初回起動時にFable 5自身に過去ログをレビューさせ、コアテーマと教訓を抽出させてメモリをブートストラップする手順も使えます。
既存スキル・プロンプトのリファクタリング——reasoning_extraction拒否を回避する
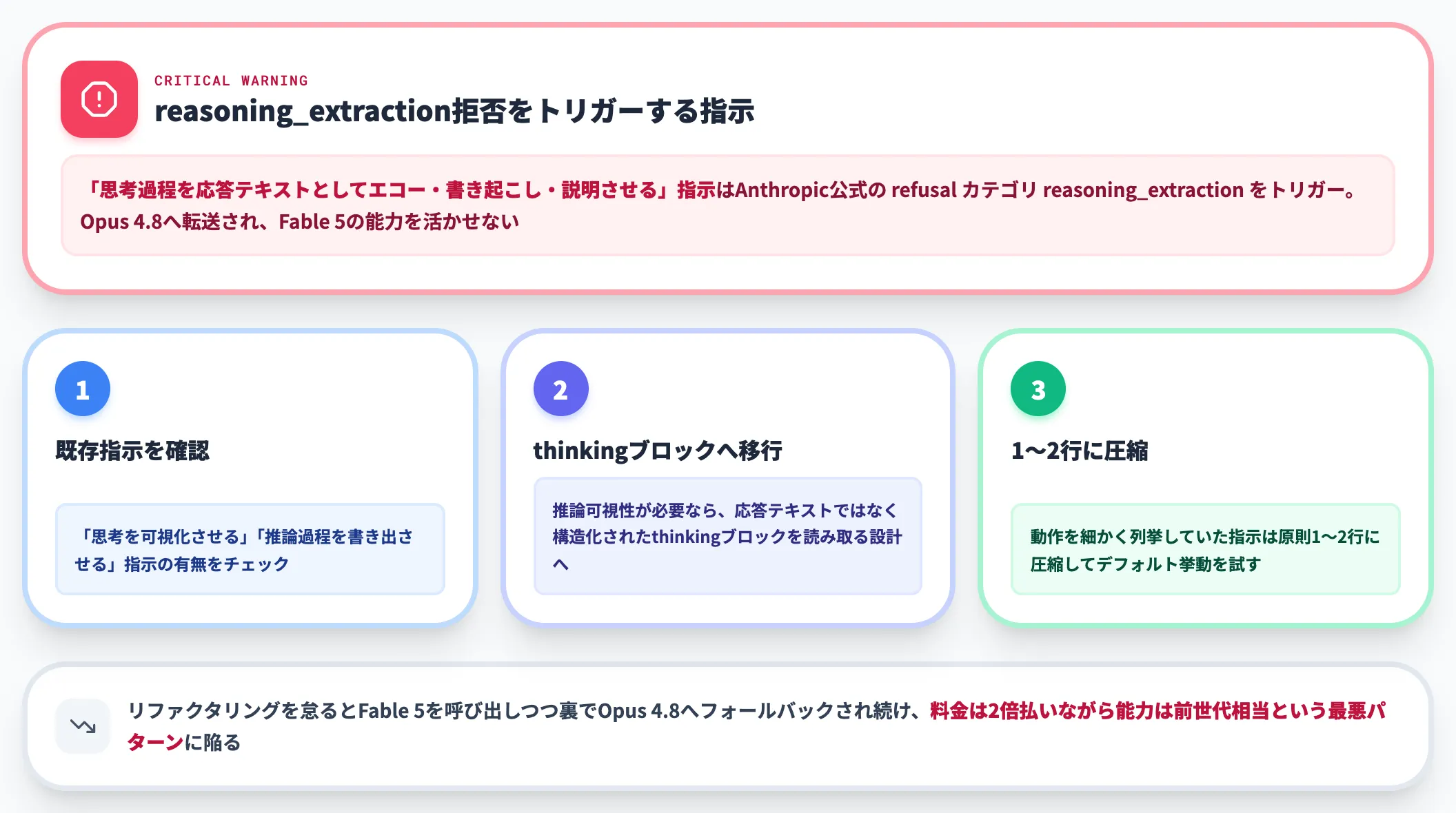
ここがFable 5移行で最も見落とされやすいポイントです。従来モデル向けに作り込んだ細かい指示は、Fable 5にとって過剰になり、出力品質を下げる場面があります。
特に注意が必要なのが、「思考過程を応答テキストとしてエコー・書き起こし・説明させる」指示です。Anthropic公式のRefusals and fallback docsでは「reasoning_extraction(推論抽出)」が拒否カテゴリの一つとして定義されており、こうした指示はこの拒否分類をトリガーします。前述の3層分類器(サイバー・生物化学・蒸留)とは別建ての拒否カテゴリという整理です。
トリガーされたリクエストはOpus 4.8へ転送され、Fable 5の能力を活かせません(API経由では stop_reason: "refusal" 検出とフォールバック設定が必要)。
移行時のチェックリストは以下の3点です。
- 既存スキル・システムプロンプトに「思考を可視化させる」「推論過程を書き出させる」指示が含まれていないか確認する
- 推論の可視性が業務要件で必要な場合は、応答テキストではなく適応的思考の構造化されたthinkingブロックを読み取る設計に切り替える
- 旧モデル向けに動作を細かく列挙していた指示は、原則1〜2行に圧縮してデフォルト挙動を試す
リファクタリングを怠ると、Fable 5を呼び出しているつもりが裏でOpus 4.8にフォールバックされ続け、料金はOpus 4.8の2倍払いながら能力は前世代相当という最悪パターンに陥ります。
移行時に既存スキルを棚卸しするコストは、本番運用後のフォールバック増加リスクと比べれば十分回収できる投資です。
ユーザー送信ツール(長時間非同期エージェント向け)
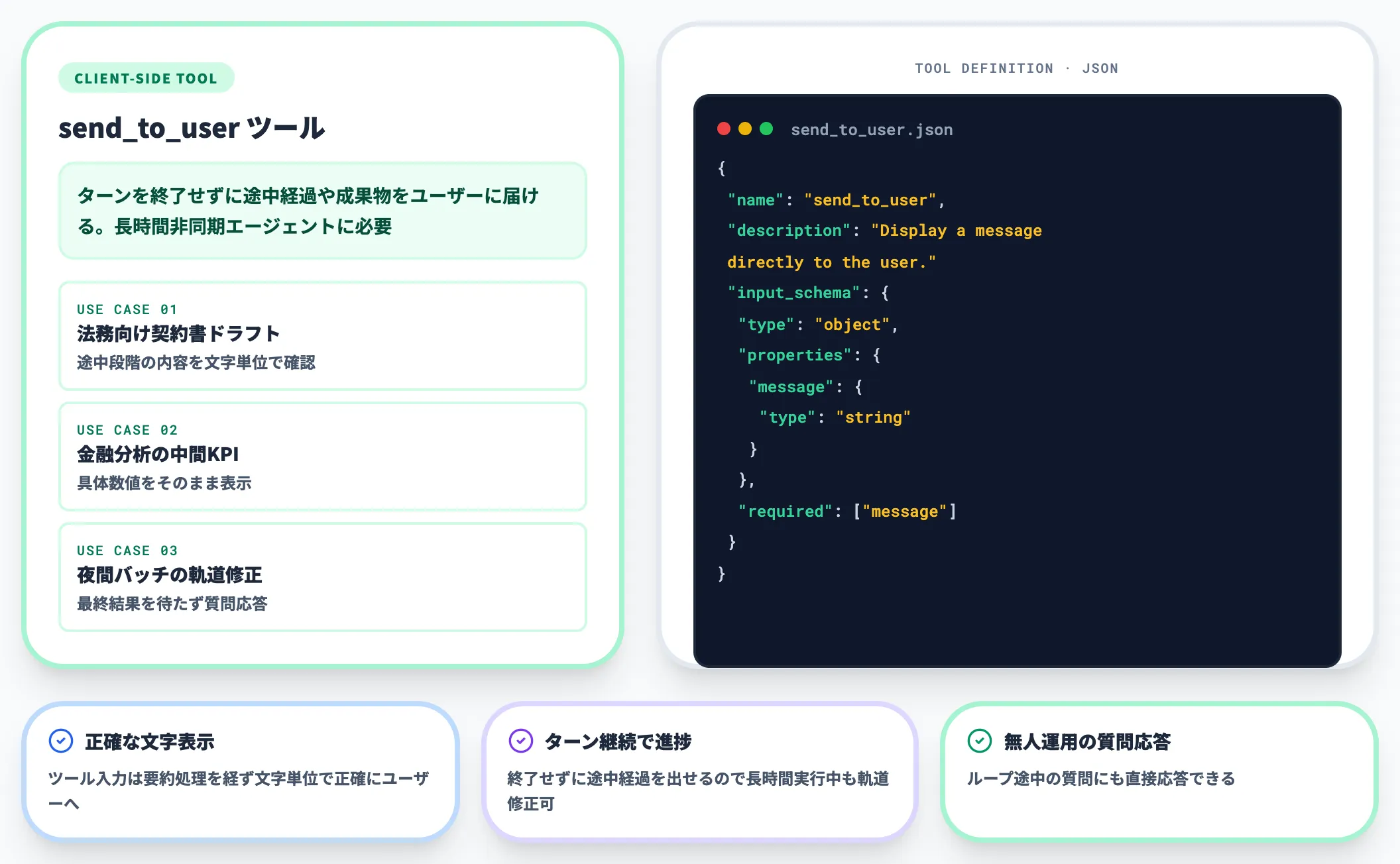
夜間バッチや数時間にわたる調査エージェントなど、ユーザーが見ていない非同期実行では、ターンを終了せずに途中経過や成果物をそのままユーザーに届ける手段が必要になります。
Anthropic公式は、これをクライアント側のツール定義で実現する設計を推奨しています。
具体的には、以下のようなツールを定義しておき、Fable 5がこれを呼び出した時点でUIにメッセージをそのまま描画し、ツール結果として単純な確認応答を返します。
{
"name": "send_to_user",
"description": "Display a message directly to the user. Use this for progress updates, partial results, or content the user must see exactly as written before the task finishes.",
"input_schema": {
"type": "object",
"properties": {
"message": {
"type": "string",
"description": "The content to display to the user."
}
},
"required": ["message"]
}
}
このアプローチには複数の利点があります。
- ツール入力は要約処理を経ずに届くため、生成コードや下書きメッセージを文字単位で正確にユーザーに表示できる
- ターンを終了させずに途中経過を出せるため、長時間実行中もユーザー側で進捗確認や軌道修正ができる
- ループの途中で出てきた質問への直接応答にも使えるため、無人運用でも「最終結果まで待つ」しかない設計を避けられる
ただし、進捗を要約して伝えるだけのエージェントなら、モデル自身の中間メッセージで十分です。導入判断は「ユーザーがコンテンツや具体数値をそのまま見る必要があるか」で決めるのが現実的で、たとえば法務向けの契約書ドラフトを途中段階で確認させたい、金融分析の中間KPIをそのまま表示したい、といったUXに向きます。
Claude Fable 5に乗り換えるかの3つの判断軸

ここまで性能・料金・競合比較を見てきましたが、最終的に「自社でFable 5に乗り換えるべきか」は、3つの軸で判断するのが実務的です。本セクションでは、AI総研の支援現場で実際に使っている判断基準を整理します。
1.業務ワークロードが「数時間以上の自律実行」を要求するか
Fable 5の最大の優位性は、数時間〜1週間規模の長期自律業務で、判断と実行を途中で崩さず維持しやすい点です。Stripeの「2か月の作業を1日に圧縮」、Hexの「複雑な長時間分析タスクで90%超」、ゲノミクスの「1週間以上の自律作業」のような事例は、いずれもこの軸での優位を示しています。
料金だけを見ると、Fable 5はOpus 4.8の2倍です。しかし実務では、1回あたりの単価だけでなく、目的の成果に到達するまでの総試行回数で判断する必要があります。
たとえばOpus 4.8で2回試行が必要なタスクが、Fable 5なら1回で完了する場合、単価が2倍でも試行回数が半分になるため、入出力トークン量全体で見た実効コストは同水準に近づきます。
さらに、Stripe事例のように人手の工数圧縮が大きいタスクでは、モデル単価の差よりも、手戻りやエンジニア工数の削減効果のほうが大きくなります。Stripe事例そのものを金額換算するにはチーム人数などの前提が必要ですが、たとえば1人月160時間・時給5,000円で換算すると、2か月分の工数は1人あたり約160万円、10人規模のチームなら約1,600万円規模です。このような規模の業務では、API料金の差額はプロジェクト全体の費用対効果に対して小さくなります。
逆に、業務が「数分〜数十分で完結する単発タスクの集合」であれば、Fable 5の優位はほぼ出ません。
料金が半分のOpus 4.8、もしくは200k以下の入力料金がFable 5の1/5、出力料金も約1/4に収まるGemini 3.1 Proで十分なケースが大半です。
自社のClaude利用ログを直近1か月分洗い出し、「1セッションあたりの平均ターン数」「最長セッションのタスク時間」「やり直し回数」を確認すると、Fable 5に乗り換える価値があるかを定量的に判断できます。長時間セッションや複数回の手戻りが常態化しているチームほど、Fable 5に乗り換えるリターンが料金差を上回る可能性があります。
2.Pro/Max契約者なら2026年7月7日までに利用量と上限を決めているか
Pro・Maxプランの契約者にとって、再配備後最も重要な期日が2026年7月7日です。
それまでは週間使用枠の50%以内でFable 5を追加料金なしに使えますが、7月8日以降はUsage Credits消費に切り替わります。Anthropic公式は「容量が許す段階でサブスクリプション標準機能に再統合する」と説明していますが、再統合時期は6月の指令経緯を経ても未公表のままです。
つまり7月7日までの1週間は、6月12日〜30日の停止で組めなかった検証を巻き直しつつ、7月8日以降の利用量・月間上限・モデル切り替えルールを決める「運用設計期間」として使うのが現実的です。
- 代表的なClaude業務をFable 5で実行し、消費トークン量とタスク完了品質を記録する
- 7月7日時点の累計消費と週間使用枠の消化率から「月間の予想クレジット消費」と月間利用上限を決める
- 7月8日以降、クレジット消費を抑えるためにOpus 4.8と使い分けるルールを策定する
これを7月7日までに済ませておけば、7月8日からの予算管理が大きくブレずに済みます。
逆にこの計測をしないまま7月8日を迎えると、想定外のクレジット消費で月中に枠を使い切る可能性があります。
3.API利用者なら30日データ保持ポリシーが業務要件と整合するか
API経由でFable 5を本番ワークロードに組み込む場合、最大の論点は30日データ保持ポリシーとの整合です。
Fable 5・Mythos 5は、すべてのリクエスト・応答が30日間ログ保持される設計で、Anthropicの安全性検証目的に限定して使われます。
Claude API上のFable 5・Mythos 5はZero Data Retention(ZDR)対象外で、30日保持要件を満たさない組織からのリクエストは「400 invalid_request_error」で拒否されます。
判断のチェックポイントは次のとおりです。
- 自社が扱うデータ(顧客情報・医療情報・契約書・コードベース等)が、30日間Anthropic側にログ保持されることについて、法務・情報セキュリティ部門の承認が取れるか
- Fable 5・Mythos 5がZDR対象外モデルである前提で、自社内の例外承認やデータ取扱い規程との整合をAnthropicと整理できているか
- フォールバック発生時にOpus 4.8で処理される設計が、業務上問題ないか
- 万が一データインシデントが発生した場合の通知・対応プロセスが明確か
これらが整理できないままFable 5を本番接続すると、後段でコンプライアンス上の指摘を受けた際に運用を止めざるを得ないリスクがあります。逆に、これらをクリアにできていれば、Fable 5の能力を本番ワークロードで安全に活かせます。
Claude Fable 5を業務エージェント基盤として運用するなら
Fable 5の登場で、AIエージェントが扱えるタスクの長さと複雑さが一段広がりました。一方でモデル選定だけ進めても、社内システム連携・権限管理・実行ログ・セキュリティを含めた運用基盤を設計しない限り、本番展開には届きません。
ここで効いてくるのが、Microsoft Teamsから呼び出せる自社Azureテナント内のAIエージェント運用基盤、AI総合研究所のAI Agent Hubです。Fable 5やOpus 4.8を業務エージェントとして組み込みつつ、PoCの先にある本番運用までを一気通貫で支援します。
- モデル選定の自由度を保ったまま統一管理
Fable 5・Opus 4.8・Sonnet 5・他社モデルを業務ごとに使い分けつつ、実行ログ・権限・セキュリティスキャンを1つのダッシュボードで管理できます。
- Teamsから呼び出せる9種類の業務特化Agent
経費申請・請求書受領・設計製図・規程チェックなど業務特化Agentが既に用意されており、FableやOpusを呼び出して業務を完結させます。
- 使い慣れたMicrosoft環境をそのまま活用
Teams・Excel・Outlookなど既存ツールの延長でAIエージェントが動作。新しいツールの学習コストはゼロです。
- 実行統制を自社Azureテナント内で完結
業務システムへのアクセス・実行ログ・権限はAzure Managed Applicationsとして自社テナント内で動作します。外部モデルAPI(Fable 5・Opus 4.8等)を呼び出す部分は、各提供元のデータ保持条件(Fable 5・Mythos 5は30日保持・ZDR不可)を踏まえてモデル選定とデータ取扱いを整合させる設計が可能です。
AI総合研究所の専任チームが、フロンティアモデル選定から業務システム連携、運用設計まで一貫してサポートします。AI Agent Hubのサービスページで、自社の業務にどう活用できるか具体例とあわせてご確認ください。
Claude Fable 5を業務エージェント基盤として運用

モデル選定から本番運用までを一気通貫で
Claude Fable 5やOpus 4.8を業務エージェントとして組み込むなら、モデル選定だけでなく社内システム連携・権限管理・実行ログまでの設計と、外部モデル利用時のデータ保持条件の整理が必要です。自社Azureテナント内で実行統制を担保するAIエージェント運用基盤の構築を支援します。
まとめ
本記事では、2026年6月9日にAnthropicが発表したClaude Fable 5について、Mythos 5との違い・性能・料金・使い方・セーフガード・競合比較・乗り換え判断・プロンプト設計まで、2026年7月時点の最新情報で解説しました。要点を改めて整理します。
-
Claude Fable 5はMythos-class初の一般公開モデルで、Opus 4.8の上位に位置する新たな最上位層。Mythos 5とはセーフガードのみが違う同一ベースモデルで、6月9日の初回提供は5チャネル(Claude API・Claude Platform on AWS・Bedrock・Vertex AI・Microsoft Foundry)。7月1日再配備時点の最新提供状況は次項参照
-
6月12日〜30日の輸出管理指令による停止を経て、Fable 5は2026年7月1日から再配備。Claude.ai・Claude Code・Claude Cowork・Anthropic APIは同日再開、Bedrock・Vertex AI・Microsoft Foundryは順次再開予定。Mythos 5は米国内の特定組織のみ復帰
-
料金は入力$10・出力$50とOpus 4.8の2倍。Pro/Max/Team/一部Enterprise契約者は2026年7月7日まで週間使用枠の50%以内で追加料金なしに利用でき、7月8日以降はUsage Credits消費に切り替わる
-
コーディング(Stripe事例で2か月を1日に圧縮)・複雑文書分析(Hex 90%初突破)・長期エージェント(数百万トークンで集中力維持)の3領域で前世代を大きく更新
-
サイバー・生物化学・蒸留の3層分類器が組み込まれ、検出時には Opus 4.8 へ転送(Claude.ai等の製品UIは自動切替、API経由は
stop_reason: "refusal"検出とフォールバック設定が必要)。7月1日の再配備でAmazon報告手法向けの新分類器も追加され、対象手法は99%超のケースでブロック。30日データ保持ポリシーの整合は事前確認が必要
-
乗り換え判断は3軸:(1) 業務が数時間以上の自律実行を要求するか、(2) Pro/Max契約者なら7月7日までに利用量・月間上限・使い分けルールを決めているか、(3) API利用者なら30日データ保持ポリシーが業務要件と整合するか
-
プロンプト設計の肝は「effortのデフォルト選択」「進捗報告の根拠付け」「既存スキルのリファクタリング」の3点。特に旧モデル向けの「思考過程を書き出させる」指示はAnthropic公式の拒否カテゴリ
reasoning_extractionをトリガーし、Opus 4.8への転送(UIは自動、APIは refusal 検出必要)が増えるため、移行時の棚卸しは必須
Fable 5は、すべてのClaude利用シーンを置き換えるモデルではなく、「人手で数日〜数か月かかる規模の業務」に限定して使い、それ以外はOpus 4.8・Claude Sonnet 5・Gemini 3.1 Pro・GPT-5.5を業務特性で使い分けるのが実務的な構成です。
2026年7月7日までの週間使用枠内での無料利用期間を活用して、自社業務での品質改善幅、月間クレジット消費、モデル使い分けルールを固めることが、Fable 5世代のAI活用を業務に定着させる最初の一手になります。






