この記事のポイント
 新規データ統合基盤を構築するなら、170種以上のコネクタとCopilot支援を備えたFabric Data Factoryが第一候補
新規データ統合基盤を構築するなら、170種以上のコネクタとCopilot支援を備えたFabric Data Factoryが第一候補- データ変換の複雑さに応じてパイプライン(コードベースETL/ELT)とDataflow Gen2(ローコード)を使い分けるべき
- ADF既存環境からの移行は、まずADF Items in Fabric(マウント方式)で検証し、段階的にネイティブ移行へ進めるのが最適
- OneLakeネイティブ連携とCU課金モデルにより、Fabric全体でコストを一元管理できる点がADFとの決定的な差
- パイプラインのオーケストレーションとデータ移動で課金が分かれるため、大量データ移動が多い場合はCU容量の事前試算が不可欠

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Microsoft Fabric Data Factoryは、Microsoft Fabricに組み込まれた次世代のデータ統合エクスペリエンスです。
170種以上のデータソースに対応し、パイプラインによるETL/ELTオーケストレーションとDataflow Gen2によるローコード変換の2軸で、OneLake上のLakehouseやData Warehouseへのデータ投入を一元管理できます。
本記事では、Fabric Data Factoryの基本概念から主要機能、Azure Data Factoryとの違い、ADFからの移行方法、日本企業の導入事例、料金体系までを体系的に解説します。
✅Microsoft 365 Copilotの最新エージェント機能「Copilot Cowork」については、以下の記事をご覧ください。
Copilot Coworkとは?機能や料金、Claude Coworkとの違いを解説
目次
Fabric Data Factoryにおけるパイプラインとデータフローの使い分け
Fabric Data FactoryとAzure Data Factoryの違い
Fabric Data Factoryとは?
Fabric Data Factoryは、Microsoft Fabricに組み込まれたクラウドネイティブのデータ統合サービスです。
社内外に散在するデータを収集・変換し、OneLake上のLakehouseやData Warehouseに統合するための一連の機能を提供します。

もともとAzure単体のサービスとして提供されていたAzure Data Factory(ADF)の設計思想を受け継ぎつつ、Fabricのエコシステムに最適化されたのがこのFabric Data Factoryです。
ADFと比較したときの主な進化ポイントは、OneLakeとのネイティブ統合、Copilotによる自然言語でのパイプライン生成、そしてFabric容量(CU)ベースの統一課金モデルです。

次世代データ統合基盤としての位置づけ

Fabric Data Factoryは、Fabricの各ワークロード(Data Engineering、Data Science、Real-Time Intelligence、Power BIなど)へデータを供給する「入口」としての役割を担います。
従来のADFでは、データの取り込みからストレージへの格納、分析ツールとの接続をそれぞれ個別に設定する必要がありました。
Fabric Data Factoryでは、OneLakeを共通のデータレイヤーとして活用することで、取り込んだデータをLakehouseやData Warehouseにそのまま格納し、追加の接続設定なしにPower BIやSparkノートブックから参照できます。
3つのコア機能

Fabric Data Factoryが提供するデータ統合の手段は、大きく3つに分かれます。
以下の表で、3つの機能の役割を整理しました。
| 機能 | 概要 | 主な用途 |
|---|---|---|
| パイプライン | コードベースのETL/ELTオーケストレーション | 複雑なデータフローの制御・スケジュール実行 |
| Dataflow Gen2 | Power Query Onlineベースのローコード変換 | GUIでのデータ変換・クレンジング |
| コピージョブ | 大量データの一括コピーに特化 | テーブル単位の高速データ移動 |
ここで注目すべきは、パイプラインとDataflow Gen2が「オーケストレーション」と「変換」という異なるレイヤーを担っている点です。
パイプラインが全体の処理順序やスケジュールを制御し、その中にDataflow Gen2を組み込むことで変換処理を実行する、という組み合わせが基本的な設計パターンになります。
Fabric Data Factoryの主要機能
Fabric Data Factoryの各機能を詳しく見ていきます。パイプライン、Dataflow Gen2、コピージョブに加え、170種以上のコネクタとCopilot統合がデータ統合の基盤を支えています。

パイプライン
パイプラインは、Fabric Data Factoryの中核となるオーケストレーション機能です。複数のデータ処理ステップを定義し、指定した順序で自動実行します。
ビジュアルデザイナー上でアクティビティ(処理単位)をドラッグ&ドロップで配置し、ノーコードでワークフローを構築できます。
実行方法は手動トリガー、スケジュール実行、イベントドリブン(データ到着時に自動起動)の3種類です。
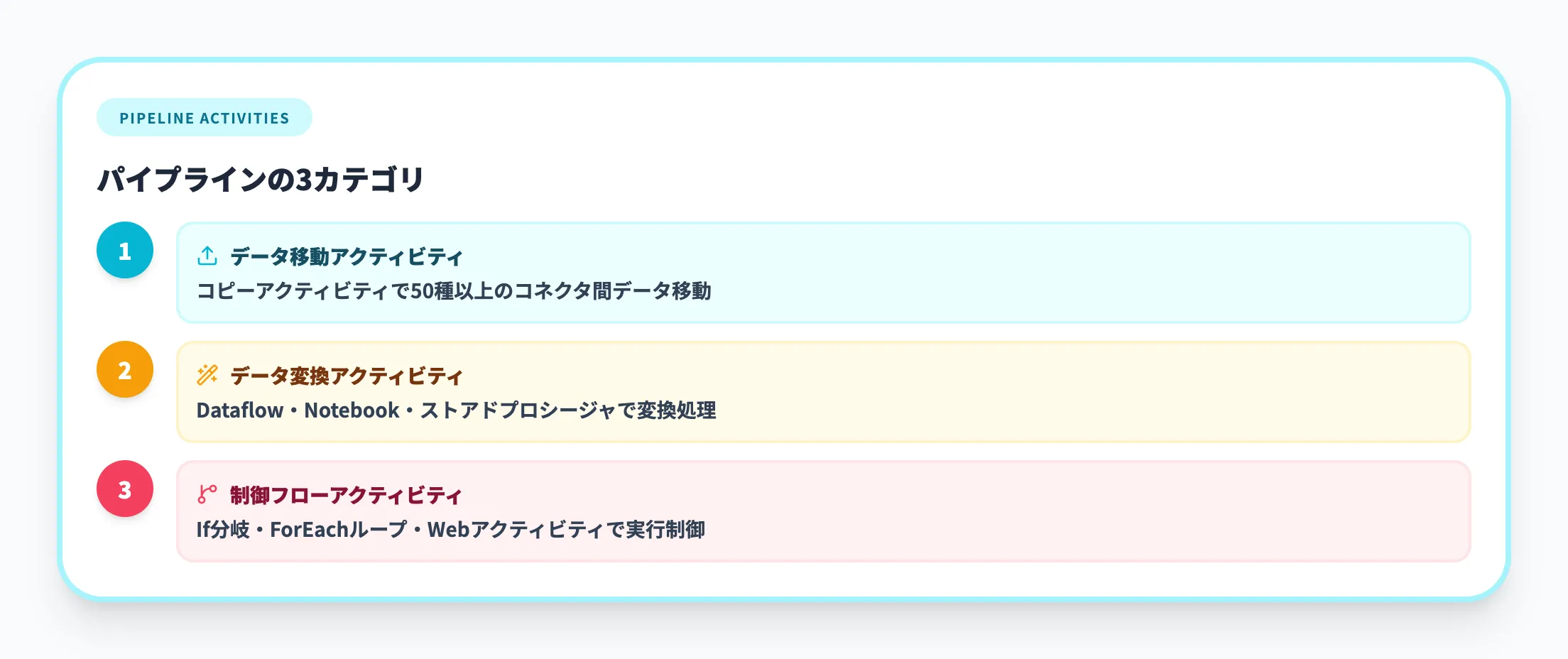
パイプラインのアクティビティは以下の3カテゴリに分類されます。
-
データ移動アクティビティ
ソースからデスティネーションへデータをコピーする処理です。コピーアクティビティが代表的で、50種以上のコネクタに対応し異なるデータストア間のデータ移動を実行します。
なお、Dataflow Gen2では170種以上の組み込みコネクタに対応しています。
-
データ変換アクティビティ
データフローアクティビティ、ノートブックアクティビティ、ストアドプロシージャアクティビティなどが含まれます。取り込んだデータに対してクレンジングや集計、形式変換を適用します。
-
制御フローアクティビティ
If条件分岐、ForEachループ、Webアクティビティ、変数の設定などがあります。パイプライン全体の実行フローを制御するための処理です。
2025年9月にGAしたInvoke Pipeline Activityも活用できます。これは既存のパイプラインを部品として呼び出す機能で、共通処理を再利用するモジュラー設計が可能になりました。
Dataflow Gen2
Dataflow Gen2は、Power Query Onlineをベースにしたローコードのデータ変換機能です。
GUIの操作だけで300種以上のデータ変換を適用でき、SQLやプログラミングの知識がなくてもデータのクレンジング・整形・結合が行えます。
従来のPower BIデータフロー(Gen1)との主な違いは以下の通りです。
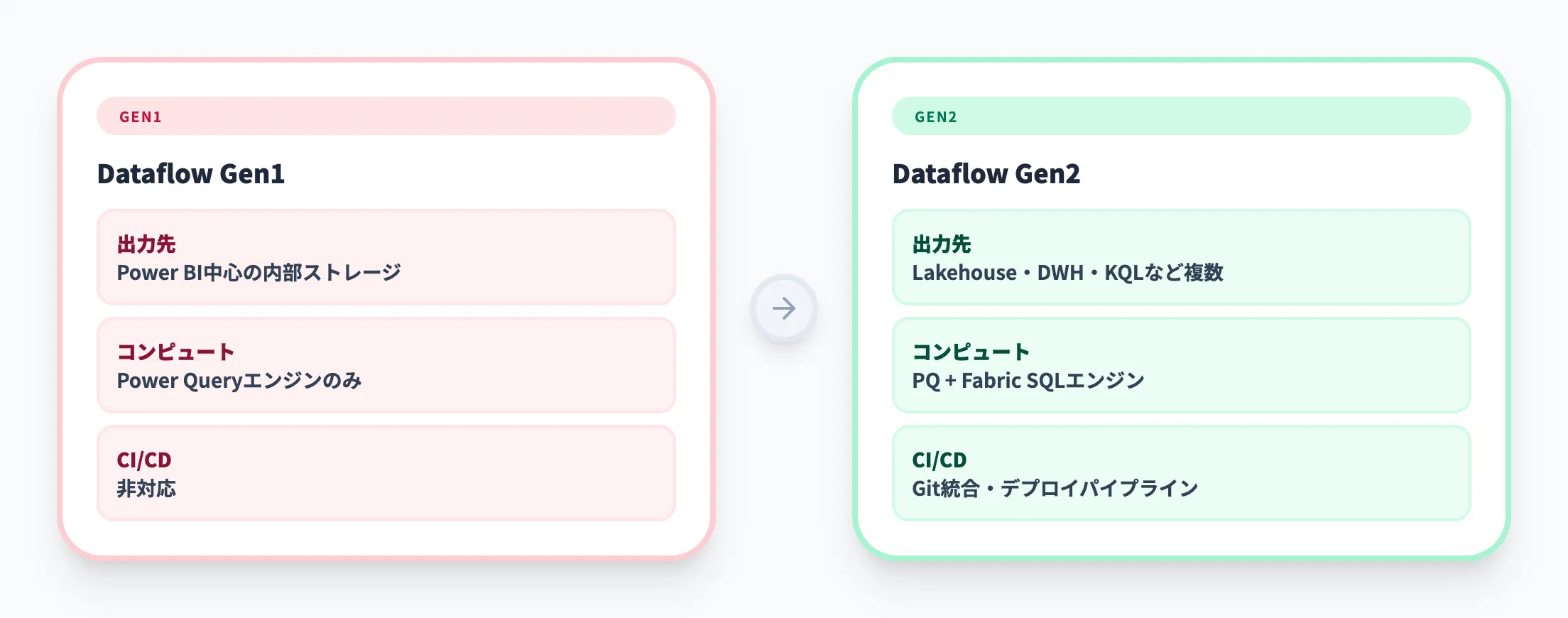
| 項目 | Dataflow Gen1 | Dataflow Gen2 |
|---|---|---|
| 出力先 | Power BI中心の内部ストレージ | Lakehouse・Data Warehouse・KQLデータベースなど複数 |
| コンピューティング | Power Query エンジンのみ | Fabric SQLコンピューティングエンジンも利用可 |
| CI/CD | 非対応 | Git統合・デプロイメントパイプライン対応 |
| 自動保存 | 手動保存 | 自動保存対応 |
特に重要なのは出力先の柔軟性です。Gen1ではPower BI中心の内部ストレージが前提でしたが、Gen2ではLakehouseのDeltaテーブルやData Warehouseのテーブルなど複数の保存先に直接出力できます。
つまり、Power BIに限定されない汎用的なデータパイプラインの一部としてDataflow Gen2を活用できるようになりました。
コピージョブ

コピージョブは、テーブル単位でデータを一括コピーするための機能です。パイプラインのコピーアクティビティと似ていますが、大量のテーブルを一度に選択してコピーする操作に最適化されています。
コピージョブの特徴は以下の通りです。
-
テーブル一括選択
ソースデータベースのテーブル一覧から必要なテーブルをまとめて選択し、一度にコピーを実行できます。
-
スキーマの自動マッピング
ソースとデスティネーションのスキーマを自動的に照合し、手動でのカラムマッピング作業を削減します。
-
増分コピー対応
初回のフルコピーの後、変更されたデータだけを差分コピーする設定が可能です。
コピージョブはパイプラインのような複雑な制御フローは持ちませんが、「まずは既存のデータベースからOneLakeにデータを持ってくる」という初期のデータ移行フェーズで特に有効です。
170種以上のコネクタ

Fabric Data Factoryは170種以上のデータソースに接続できます。主要なカテゴリは以下の通りです。
-
クラウドデータベース
Azure SQL Database、Azure Cosmos DB、Amazon RDS、Google BigQueryなど、主要なクラウドデータベースに対応しています。
-
オンプレミスデータベース
SQL Server、Oracle、MySQL、PostgreSQLなどのオンプレミスデータベースには、オンプレミスデータゲートウェイを経由して接続します。
-
SaaSアプリケーション
Salesforce、Dynamics 365、SAP、ServiceNowなどの業務アプリケーションからデータを取り込めます。
-
ファイル・ストレージ
Azure Blob Storage、Amazon S3、Google Cloud Storage、SFTP、SharePointなどのファイルストレージに対応しています。
ADFとの互換性は高く、公式の比較ドキュメントではアクティビティの約90%がFabric Data Factoryでサポートされているとされています。
コネクタについてもMicrosoftが継続的に追加しており、最新の対応状況は公式のコネクタ一覧で確認できます。
Copilot統合

Fabric Data FactoryにはCopilot(AI支援機能)が統合されており、自然言語による操作が可能です。
パイプラインでは、実行したい処理を日本語や英語で入力するとアクティビティの構成を自動生成します。
例えば「Azure SQL DatabaseからLakehouseにデータをコピーして、NULL値を除外する」といった指示から、コピーアクティビティとデータフローアクティビティを含むパイプラインを生成できます。
Dataflow Gen2でも同様に、Copilotに変換ロジックを自然言語で指示できます。列の追加、フィルタリング、データ型の変換といった操作を対話形式で進められるため、Power Queryの関数を暗記していなくてもデータ変換が行えます。
【関連記事】
Microsoft FabricとPower BIの違い、連携手順をわかりやすく解説
【Microsoft Fabric】Data Engineeringとは?Sparkの機能や料金体系を徹底解説
【Microsoft Fabric】Real-Time Intelligenceとは?機能や料金体系を徹底解説
【Microsoft Fabric】Data Scienceとは?MLflowやAutoML、料金体系を徹底解説
Microsoft Fabric導入事例6選!国内企業の成果と導入パターンを解説
Fabric Data Factoryにおけるパイプラインとデータフローの使い分け
Fabric Data Factoryを使い始めるとき、最初に直面するのが「パイプラインとDataflow Gen2のどちらを使うか」という選択です。
ここでは実践的な判断基準を整理します。

パイプラインが適しているケース
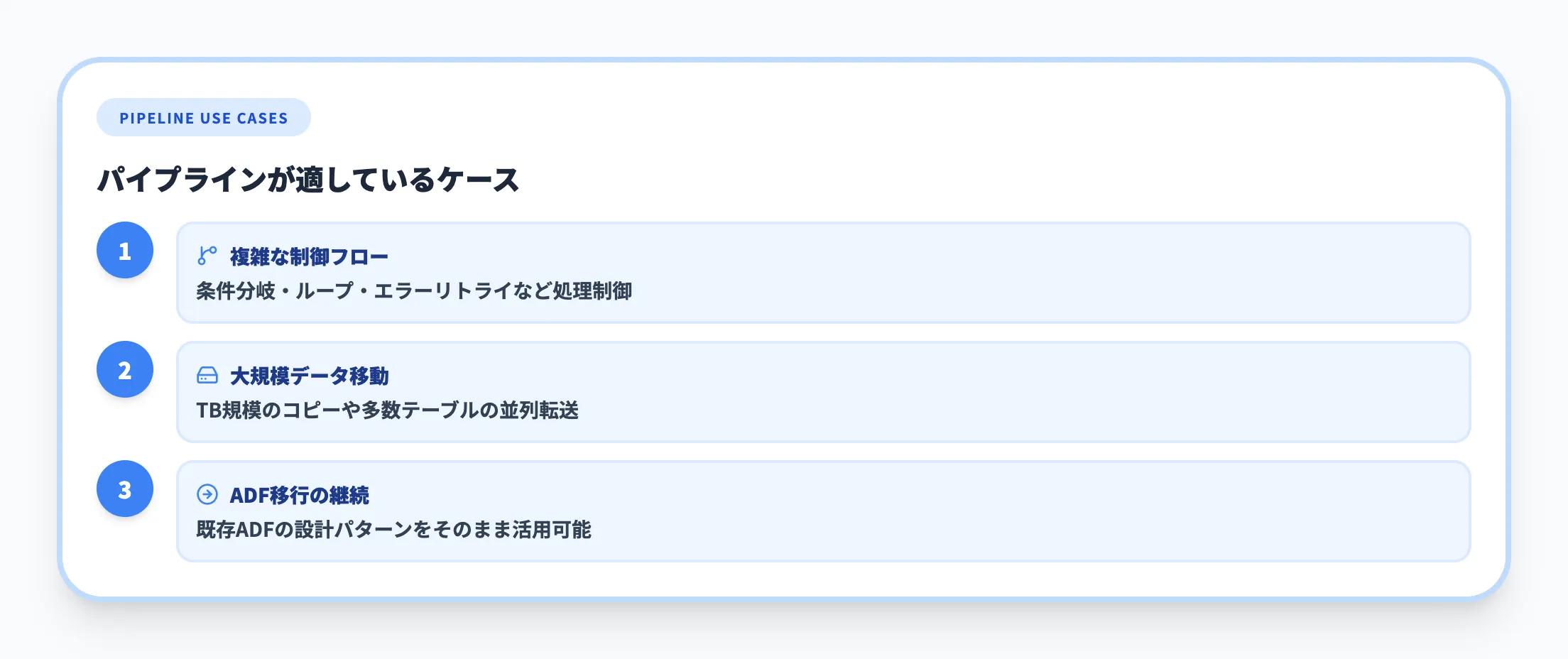
パイプラインは、以下のような要件がある場合に適しています。
-
複雑な制御フローが必要
条件分岐やループ、エラー時のリトライ、依存関係のあるタスクの直列実行など、処理フロー全体の制御が必要なケースです。
-
大規模なデータ移動
テラバイト規模のデータコピーや、多数のテーブルを並列にコピーする処理では、パイプラインのコピーアクティビティが最も効率的です。
-
既存のADFパイプラインの移行
ADFですでにパイプラインを運用している場合、Fabricのパイプラインに移行すれば既存の設計パターンをそのまま活かせます。
Dataflow Gen2が適しているケース

一方、Dataflow Gen2は以下のケースで力を発揮します。
-
GUIベースの変換操作
ビジネスアナリストやデータスチュワードなど、SQLやPythonに馴染みのないユーザーが変換ロジックを構築する場合に適しています。
-
Power Queryの既存スキルを活用
ExcelやPower BIでPower Queryを使い慣れているチームであれば、同じ操作感でデータ変換を構築できます。
-
中小規模のデータ変換
数十万〜数百万行程度のデータに対するクレンジングや集計であれば、Dataflow Gen2の方がセットアップが簡単です。
組み合わせパターン
実務では、パイプラインとDataflow Gen2を組み合わせて使うケースが最も一般的です。
以下の表は、典型的な組み合わせパターンを示しています。
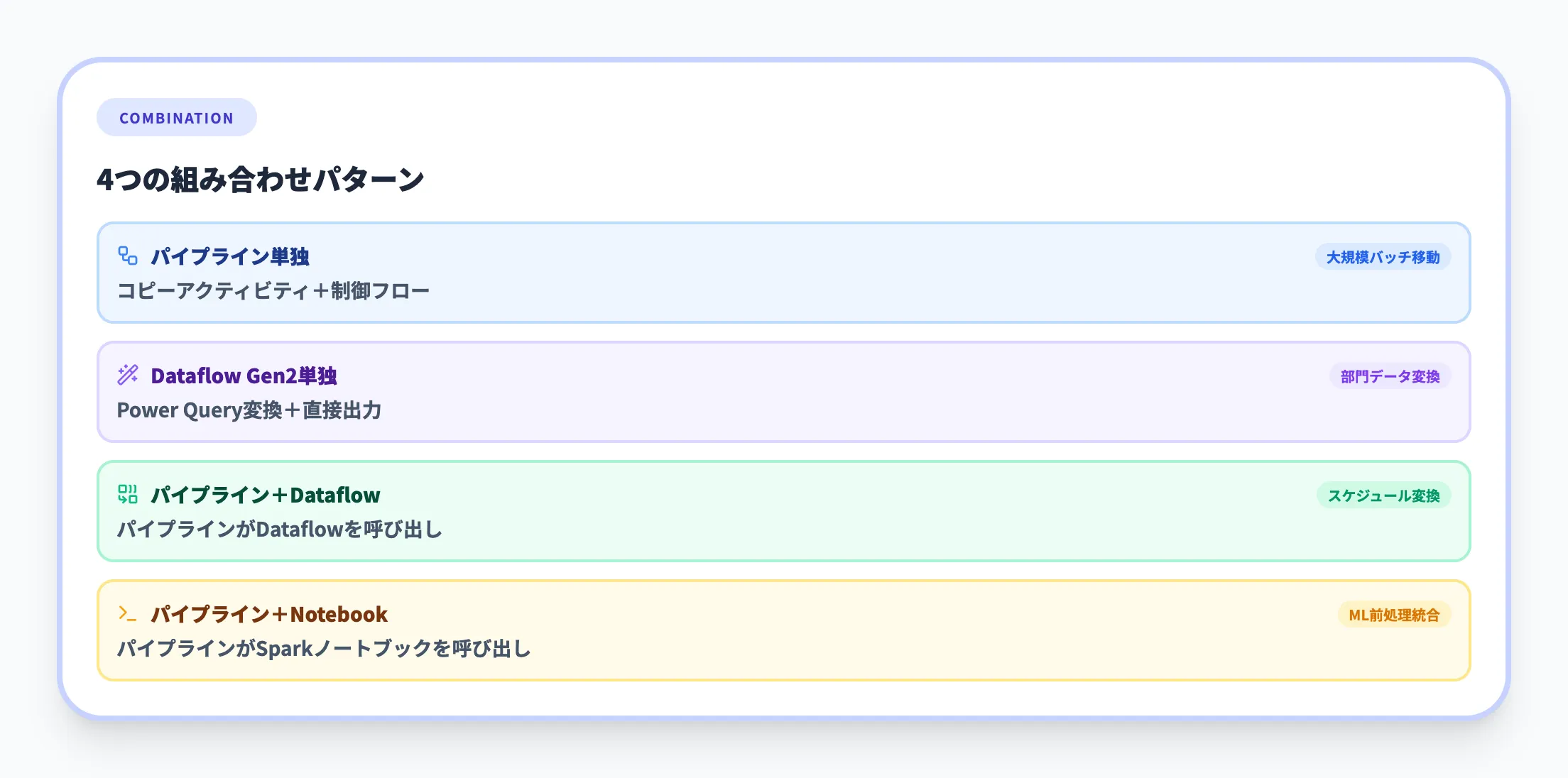
| パターン | 構成 | ユースケース |
|---|---|---|
| パイプライン単独 | コピーアクティビティ+制御フロー | 大規模データの定期バッチ移動 |
| Dataflow Gen2単独 | Power Query変換+直接出力 | 部門単位のデータクレンジング |
| パイプライン+Dataflow Gen2 | パイプラインがDataflowアクティビティを呼び出し | スケジュール実行付きのデータ変換 |
| パイプライン+ノートブック | パイプラインがSparkノートブックを呼び出し | 機械学習前処理との統合 |
最初はDataflow Gen2で変換ロジックを試作し、定期実行やエラーハンドリングが必要になった段階でパイプラインに組み込む、という段階的なアプローチが推奨されます。
Fabric Data FactoryとAzure Data Factoryの違い

Fabric Data Factoryの導入を検討する際、多くの企業がすでに運用中のAzure Data Factory(ADF)との関係を確認したいと考えるかと思います。
ここでは両者の機能差と選択基準を整理します。
機能比較

以下の表で、Fabric Data FactoryとAzure Data Factoryの主要な違いを比較しました。
| 比較項目 | Fabric Data Factory | Azure Data Factory |
|---|---|---|
| 設計思想 | モジュラー型・使いやすさ重視 | 堅牢性重視・複雑なワークフロー対応 |
| データストア | OneLake(Lakehouse/DWH)にネイティブ統合 | Azure Blob/ADLS Gen2等に個別接続 |
| AI/Copilot | ネイティブ統合済み | 限定的 |
| CI/CD | Git統合・デプロイメントパイプラインが標準装備 | ARMテンプレート+Azure DevOps/GitHub連携 |
| コネクタ/アクティビティ | アクティビティの約90%をカバー。コネクタも継続追加中 | フルセット(ベースライン) |
| 課金モデル | Fabric CU(容量ベース) | アクティビティ単位の従量課金 |
| セルフホスト統合ランタイム | オンプレミスデータゲートウェイで対応 | セルフホスト統合ランタイム |
| ネットワーク制御 | Virtual Network Data Gateway、Workspace Outbound Access Protection(プレビュー) | Managed VNet対応 |
大きな違いは課金モデルです。ADFではパイプラインの実行回数やアクティビティの種類ごとに個別に課金されますが、Fabric Data FactoryではFabric容量(CU)の消費として統合されます。
他のFabricワークロード(Lakehouse、Data Warehouse、Power BI)と共通の容量を使うため、組織全体のコスト管理がシンプルになります。
どちらを選ぶべきか

以下のガイドラインを参考に、自社の状況に合った選択を検討してください。
-
Fabric Data Factoryが向いている場合
OneLake上のLakehouseやData Warehouseへのデータ統合が主な用途で、Fabricの他ワークロードと一体的に利用する場合です。
Copilotの活用やシンプルなCI/CDを重視するチームにも適しています。
-
Azure Data Factoryが向いている場合
Fabricエコシステムの外にあるAzureサービスとの連携が中心で、セルフホスト統合ランタイムやManaged VNetなどの高度なネットワーク制御が必要な場合です。
また、Fabric未対応のコネクタを利用しているケースでは引き続きADFが必要です。
-
併用する場合
既存のADFパイプラインを維持しながら、新規のデータ統合要件はFabric Data Factoryで構築する、というハイブリッド運用も可能です。
ADF Items in Fabric機能を使えば、Fabric内から既存のADFパイプラインを直接実行・監視できるため、段階的な移行がしやすくなっています。
ADFからFabric Data Factoryへの移行

すでにAzure Data Factoryでパイプラインを運用している組織向けに、Fabric Data Factoryへの移行方法を解説します。Microsoftは3つの移行パスとアセスメントツールを提供しています。
移行アセスメントツール

移行を始める前に、まずADFの管理画面に組み込まれた移行アセスメント機能を使って現状を分析します。
アセスメントでは、既存のパイプラインやアクティビティごとに「Fabricへの移行可否」を自動判定します。
具体的には、各パイプラインがFabric Data Factoryでサポートされているアクティビティのみで構成されているかを検証し、結果をレポートとして出力します。
レポートには以下の情報が含まれます。
-
移行可能なパイプライン
すべてのアクティビティがFabricでサポートされており、そのまま移行できるパイプラインの一覧です。
-
部分的に移行可能なパイプライン
一部のアクティビティが未対応のため、修正が必要なパイプラインです。未対応のアクティビティと代替手段が提示されます。
-
移行非推奨のパイプライン
Fabric未対応の機能に依存しているパイプラインです。当面はADFでの運用を継続し、Fabricの機能追加を待つことが推奨されます。
3つの移行パス

アセスメントの結果をもとに、以下の3つの移行パスから最適な方法を選択します。
以下の表は、3つの移行パスの特徴をまとめたものです。
| 移行パス | 概要 | 適しているケース |
|---|---|---|
| ADF Items in Fabric(マウント) | 既存ADFインスタンスをFabric内にライブビューとして表示 | 段階移行・テスト期間 |
| PowerShell変換ツール | パイプライン・アクティビティを自動変換 | 標準パターンの大量一括移行 |
| 手動移行 | Fabricの新機能を活かしてゼロから再構築 | 複雑なカスタムロジックの最適化 |
ここで押さえておきたいのは、3つのパスは排他的ではないという点です。まずADF Items in Fabricで既存パイプラインをFabric上から監視し、標準的なパイプラインはPowerShellツールで一括変換し、複雑なパイプラインは手動で再設計する、という組み合わせが推奨されています。
移行の具体的な手順については、Microsoft公式の移行ガイドが詳しいドキュメントを提供しています。

Fabric Data Factoryの導入事例

Fabric Data Factoryを含むMicrosoft Fabricのデータ統合機能は、さまざまな業種で導入が進んでいます。ここでは日本企業の事例を中心に紹介します。
ヤマシタ(福祉用具レンタル・販売)

全国70拠点以上を展開する福祉用具のレンタル・販売企業であるヤマシタでは、各拠点の営業部門が個別にデータレポートを手作業で作成しており、本来の顧客対応に割ける時間が圧迫されていました。
Microsoft Fabricをデータ基盤として採用し、各拠点のデータをOneLakeに統合するパイプラインを構築したことで、営業部門のデータ作成業務を大幅に削減しました。
70拠点超のデータが一元管理されたことで全社横断のデータ活用基盤が整い、全国70以上の拠点すべてにDX人財を配置することを目指しています。
出典:Microsoft Customer Stories - ヤマシタ
Sky(メディア・データテック)

メディア・データテック企業のSkyでは、複数のクラウドサービスに分散したデータをAIエージェントの基盤として統合する必要がありました。
オンプレミスデータゲートウェイを活用して複数のクラウドサービスをFabricに接続し、OneLakeのショートカット機能でゼロコピーのデータ共有を実現しました。
これにより、データの物理的な複製を行わずにAI Foundryの各コンポーネントからデータにアクセスできる統合基盤を構築し、データエージェントによる「デジタルワーカー」の実装にもつなげています。
出典:Microsoft Customer Stories - Sky
INPEX(エネルギー)

国内最大手のエネルギー企業であるINPEXでは、ESG(環境・社会・ガバナンス)レポートの作成に際して、電子マニフェストや請求書からの廃棄物分類・集計・統合作業に約50時間の手作業が発生していました。
Microsoft Fabricを活用して「INPEX ESGデータハブ」を構築し、データの自動抽出・分類・統合パイプラインを整備したことで、手作業による処理時間を大幅に削減しました。
出典:Microsoft Customer Stories - INPEX
Fabric Data Factoryの注意点と制限事項

Fabric Data Factoryを導入する際に把握しておくべき制限事項と注意点を整理します。
-
ADFとのコネクタ互換性
公式の比較ドキュメントではADFのアクティビティの約90%がサポートされていますが、一部のコネクタやアクティビティは未対応です。
移行前にアセスメントツールで互換性を確認することが重要です。
-
セルフホスト統合ランタイムの非対応
ADFではセルフホスト統合ランタイムを使ってオンプレミスのデータソースに接続していましたが、Fabric Data Factoryではオンプレミスデータゲートウェイに置き換わります。機能的にはほぼ同等ですが、設定手順や管理方法が異なるため、移行時に再構成が必要です。
-
Dataflow Gen2の処理制約
Dataflow Gen2は処理内容や出力先、コンピューティング設定によって制約や性能差があります。大規模なデータセットを扱う場合は、パイプラインのコピーアクティビティやSparkノートブックとの併用を検討してください。
-
Fabric容量の共有制約
Data Factoryのパイプラインやデータフローは、Lakehouse、Data Warehouse、Power BIなど他のFabricワークロードとCU(容量ユニット)を共有します。
大量のパイプラインを同時実行するとCUが逼迫し、他のワークロードの処理速度に影響を与える可能性があります。Fabric Capacity Metricsアプリで使用状況を定期的に監視することを推奨します。
-
ネットワーク制御
ワークスペースレベルの送信アクセス保護(Outbound Access Protection)は2026年3月時点でプレビュー段階です。パイプラインやデータフローからの外部接続を細かく制御したい場合は、プレビュー機能の制約を確認したうえで利用してください。
-
Copilotの生成精度
Copilotは自然言語でパイプラインやDataflow Gen2を生成できますが、複雑な変換ロジックでは生成結果のレビューと手動調整が必要になる場合があります。
Fabric Data Factoryの料金体系

Fabric Data Factoryの料金は、他のFabricワークロードと同様にFabric容量(CU:Capacity Units)の消費ベースで計算されます。個別のアクティビティ単位で課金されるADFとは異なり、すべての処理がCU消費として統合されるのが特徴です。
パイプラインの課金モデル

パイプラインのCU消費は、以下の2つの要素に分かれます。
-
オーケストレーション
アクティビティの実行回数と実行時間に応じたCU消費です。制御フローアクティビティ(If条件分岐、ForEachループなど)や、Webアクティビティの呼び出しがここに含まれます。
-
データ移動
コピーアクティビティによるデータ転送量に応じたCU消費です。データ統合ユニット(DIU)の数と転送時間に基づいて計量されます。転送するデータ量が大きいほど、またDIU数が多いほどCU消費が増加します。
Dataflow Gen2の課金モデル

Dataflow Gen2のCU消費は、使用するコンピューティングエンジンによって異なります。
-
標準コンピューティング
Power Queryエンジンでの変換処理に対するCU消費です。通常のデータ変換・クレンジング処理がここに該当します。
-
高スケールコンピューティング
Fabric SQLコンピューティングエンジンを使用する場合のCU消費です。大規模なデータセットの処理や、SQLベースの変換が必要な場合に自動的に切り替わります。
F SKUと料金の目安

Fabric容量はF SKU(F2〜F2048)単位で購入します。主なSKUの位置づけは以下の通りです。
| SKU | CU数 | 位置づけ |
|---|---|---|
| F2 | 2 | 個人検証・PoC向け |
| F4〜F8 | 4〜8 | 小規模チーム |
| F16〜F32 | 16〜32 | 中規模チーム |
| F64〜F128 | 64〜128 | 部門・エンタープライズ |
| F256〜F2048 | 256〜2,048 | 大規模エンタープライズ |
この容量はData Factory専用ではなく、Lakehouse、Data Warehouse、Power BIなどすべてのFabricワークロードで共有します。Data Factoryのパイプライン実行がCUを消費している間、同じ容量で動作する他のワークロードの処理に影響する可能性がある点に注意が必要です。
正確なCU消費量はワークロードの種類やデータ量によって変動するため、Fabric Capacity Metricsアプリを使って実際の消費パターンを監視し、適切なSKUを選定することが推奨されます。
最新の料金情報はAzure公式の料金ページで確認してください。

Data Factoryで統合したデータをAIエージェントの業務判断に活かすなら
Data FactoryでETL/ELTパイプラインを整備した先にあるのは、OneLakeに統合されたデータをAIエージェントが業務アクションに変換する仕組みの構築です。
AI Agent Hubは、Data Factoryのパイプライン出力をAIエージェントのナレッジとして直結させるエンタープライズAI基盤です。
- 170種以上のデータソースをAgentが横断参照
Dataflow Gen2やパイプラインで統合した多様なデータソースを、AIエージェントがTeamsから自然言語で問い合わせ。データ加工からAI活用まで一貫した基盤を構築します。
- ADF移行のタイミングでAgent基盤を同時整備
Azure Data FactoryからFabric Data Factoryへの移行を機に、AIエージェント活用基盤も一括で設計。Fabricエコシステム内のシームレスな連携で投資効果を最大化できます。
- 使い慣れたMicrosoft環境をそのまま活用
Teamsなど既存のMicrosoftツールの延長でAIエージェントが動作。新しいツールの学習コストはゼロです。
- データは100%自社テナント内に保持
AIの学習対象から完全除外。Azure Managed Applicationsとして自社テナント内で動作が完了する設計です。
AI総合研究所の専任チームが、設計から運用まで伴走支援します。まずは無料の資料で、自社の業務にどう活用できるかご確認ください。
ETLパイプラインの先にAI業務自動化

データ統合からAgent実行まで直結
Data Factoryで統合したデータはOneLakeに蓄積され、AIエージェントの業務判断基盤として直接活用できます。ETLパイプラインからAgent実行まで、Fabric内で一気通貫のAI業務自動化を実現します。
まとめ
Fabric Data Factoryは、Microsoft Fabricに統合されたクラウドネイティブのデータ統合サービスです。
パイプラインによるオーケストレーションとDataflow Gen2によるローコード変換の2軸を中心に、170種以上のデータソースからOneLake上のLakehouseやData Warehouseへのデータ統合を一元管理できます。Azure Data Factoryの設計思想を受け継ぎつつ、OneLakeネイティブ統合、Copilot支援、CUベースの統一課金モデルによって、Fabricエコシステム内でのデータ統合がよりシンプルになっています。
すでにADFを運用している組織では、ADF Items in Fabric(マウント)、PowerShell変換ツール、手動再構築の3つの移行パスを状況に応じて組み合わせることで、段階的な移行が可能です。
導入を検討する際は、まずF2やF4の小規模SKUから始め、Fabric Capacity Metricsアプリで実際のCU消費パターンを確認しながら段階的にスケールアップしていくアプローチが推奨されます。










