この記事のポイント
 GPT-5.6は数字=世代/Sol・Terra・Luna=機能ティアの新命名体系を導入、3ティアが独自の更新サイクルで進化する設計
GPT-5.6は数字=世代/Sol・Terra・Luna=機能ティアの新命名体系を導入、3ティアが独自の更新サイクルで進化する設計- Sol $5/$30、Terra $2.50/$15、Luna $1/$6(100万トークン)の3ティア単価で、TerraはGPT-5.5と同等性能で2倍安価に提供される
- プレビュー期間中はAPI/Codex経由で少数のtrusted partners and organizationsのみ、ChatGPT提供はなく一般提供は今後数週間以内の予定
- SolはTerminal-Bench 2.1で新SOTA、ExploitBenchではClaude Mythos Previewと互角を出力トークン約1/3で達成
- GPT-5.5・Claude Opus 4.8を併用しながら、GAまでにCodex統合・セキュリティ業務適用・移行判断軸を整えるのが現実的な備え

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
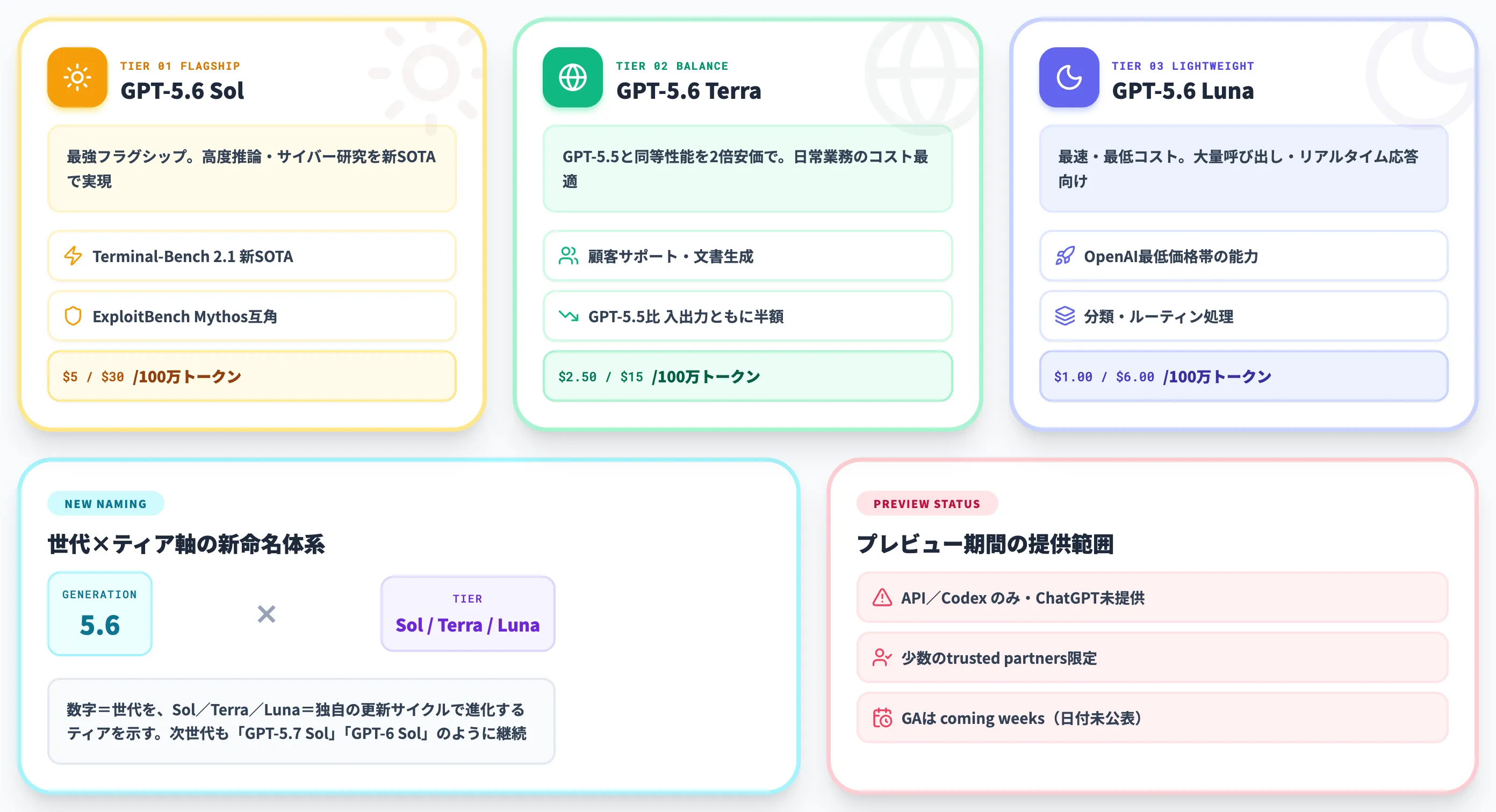
GPT-5.6 Sol/Terra/Luna(ジーピーティー・ファイブポイントシックス、ソル/テラ/ルナ)は、OpenAIが2026年6月26日に発表した次世代モデルファミリーです。
数字(5.6)が世代を、Sol/Terra/Lunaが性能・速度・コストの3ティアを表す新しい命名体系を導入し、各ティアが独自の更新サイクルで進化していく設計になっています。
一方で初期はTrump政権の要請に基づきAPI/Codex経由で少数のtrusted partners and organizationsのみに限定提供され、ChatGPTからは現時点で利用できません。
本記事では、Sol/Terra/Lunaそれぞれの性能と料金、新導入のmax/ultra推論モード、段階リリースの背景にある大統領令、現行GPT-5.5・Claude Opus 4.8との比較、企業が一般提供(GA)までに備える実務指針までを、2026年6月時点の公式情報で体系的に解説します。
目次
GPT-5.6とは?OpenAIがSol/Terra/Lunaで打ち出した次世代モデル階層
ExploitBenchでMythos Previewと互角
GPT-5.6のアクセス制限とTrump大統領令による段階リリース
GPT-5.6と他フロンティアモデル(Claude Opus 4.8・Gemini 3.1 Pro・GPT-5.5)の比較
GPT-5.6とは?OpenAIがSol/Terra/Lunaで打ち出した次世代モデル階層
GPT-5.6は、OpenAIが2026年6月26日にプレビュー公開した次世代フロンティアモデルのファミリーです。
GPT-5.6 Sol(フラグシップ)、GPT-5.6 Terra(バランス型)、GPT-5.6 Luna(低コスト型)の3モデルで構成され、世代を示す数字(5.6)とは別に「Sol/Terra/Luna」の機能ティア軸を新設した点が従来のGPT-5.5系統との最大の違いです。
GPTシリーズの中での位置づけ
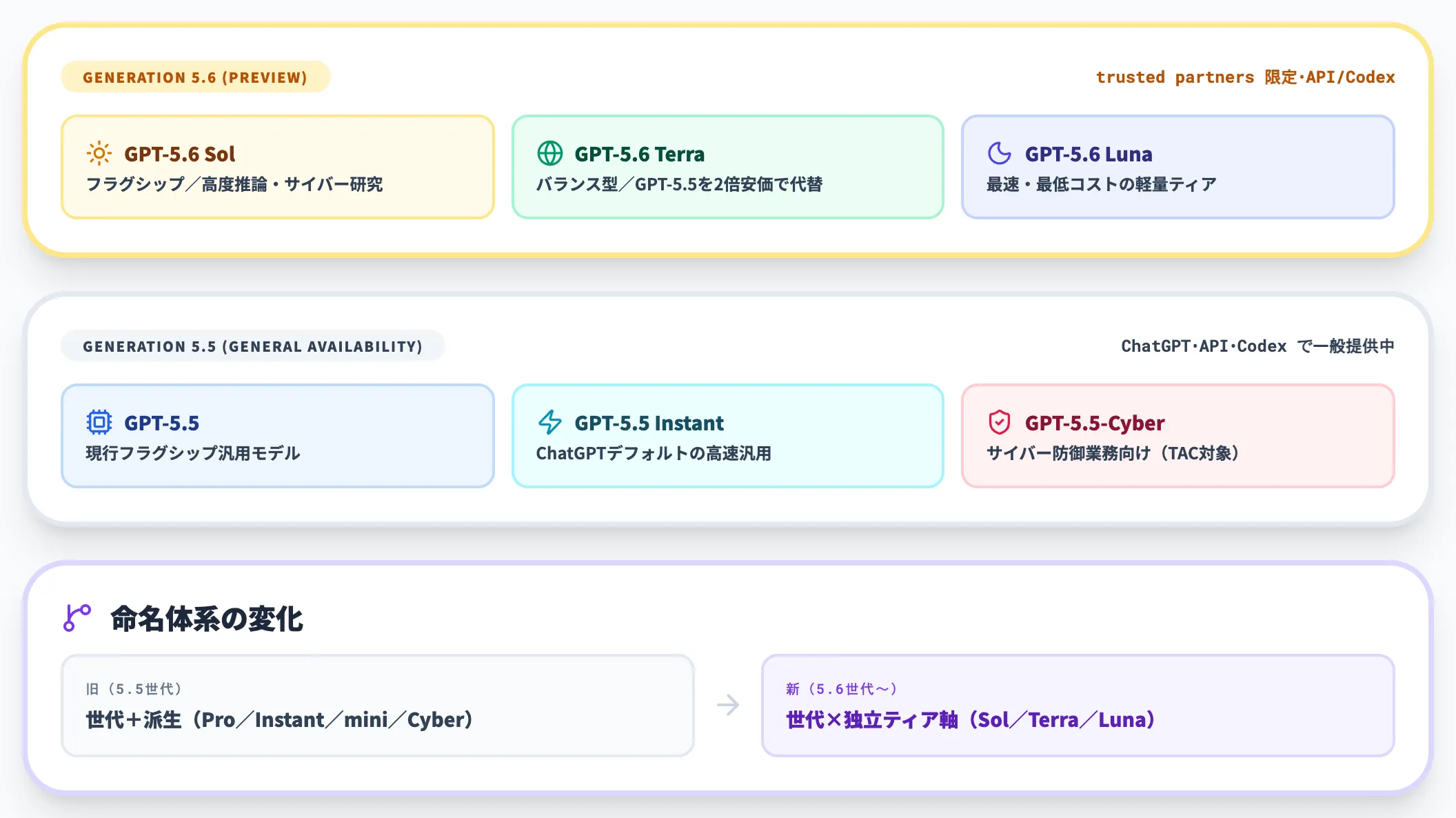
GPT-5シリーズはこれまで、数字の小数点以下が世代を示し、その世代内で「Pro/Instant/mini/Cyber」などの派生が並列する構造でした。
GPT-5.6では数字(世代)と機能ティア(Sol/Terra/Luna)を切り離した新方式に移行しています。
以下の表で、GPT-5.6と直前世代の位置づけを整理しました。
| モデル | 主用途 | 提供形態 |
|---|---|---|
| GPT-5.6 Sol | 最強フラグシップ(高度推論・サイバー研究) | API/Codexのtrusted partners限定(プレビュー) |
| GPT-5.6 Terra | 日常業務向けバランス型(GPT-5.5と同等性能で2倍安価) | API/Codexのtrusted partners限定(プレビュー) |
| GPT-5.6 Luna | 最も高速・低コストな軽量モデル | API/Codexのtrusted partners限定(プレビュー) |
| GPT-5.5 | 現行フラグシップ汎用モデル | API/ChatGPT/Codexで一般提供 |
| GPT-5.5 Instant | ChatGPTデフォルトの高速汎用モデル | ChatGPTで一般提供 |
| GPT-5.5-Cyber | サイバー防御業務向け(Trusted Access for Cyber) | 検証済み防御者向け |
表のとおり、GPT-5.6世代は3ティアすべてがプレビュー段階で、一般公開されている主力は依然としてGPT-5.5系統です。
ティア名(Sol/Terra/Luna)は今後の世代でも継続し、たとえば次世代のフラグシップは「GPT-5.7 Sol」「GPT-6 Sol」のように世代数字と組み合わせて呼ばれる可能性があります。
「Sol」「Terra」「Luna」という命名の意味

「Sol」「Terra」「Luna」はそれぞれラテン語で太陽・地球・月を意味し、3ティアの関係性が太陽系の階層構造になぞらえられています。
OpenAIは公式ブログで「数字はモデルの世代を表し、Sol/Terra/Lunaは独自のcadence(更新ペース)で進化する持続的な機能ティアを表す」と説明しています。
この命名変更で重要なのは、従来のGPT-5.4/5.5/5.5 Instantのような派生名から、ティアが独立した軸として明示された点です。
利用者は「Sol(最強)」「Terra(バランス)」「Luna(高速・低コスト)」の3軸で用途に合わせてティアを選び、世代更新があってもティア選定の判断軸を引き継げる設計になっています。

GPT-5.6 Solの能力——Mythos並びの実証
ここからは、フラグシップであるGPT-5.6 Solの能力をベンチマークと公式評価の両面から整理します。
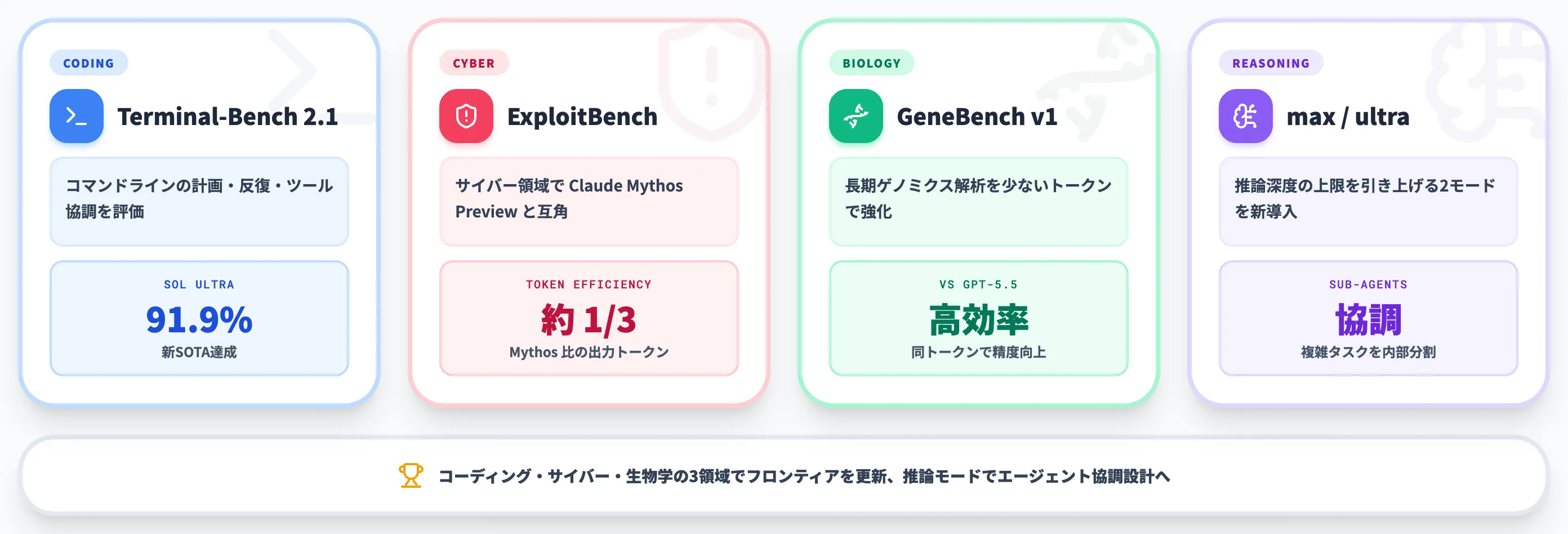
OpenAIは公式ブログ「Previewing GPT‑5.6 Sol: a next-generation model」で、コーディング・生物学・サイバーセキュリティの3領域でフロンティアを更新したと説明しており、システムカードも公開されています。
Terminal-Bench 2.1で新SOTAを記録
GPT-5.6 Solの代表的なベンチマーク結果は、コマンドラインワークフローの計画・反復・ツール協調を測るTerminal-Bench 2.1における新SOTAです。
OpenAIは公式ブログで、Solがこのベンチマークでstate of the art(最先端)を更新したと明示しています。
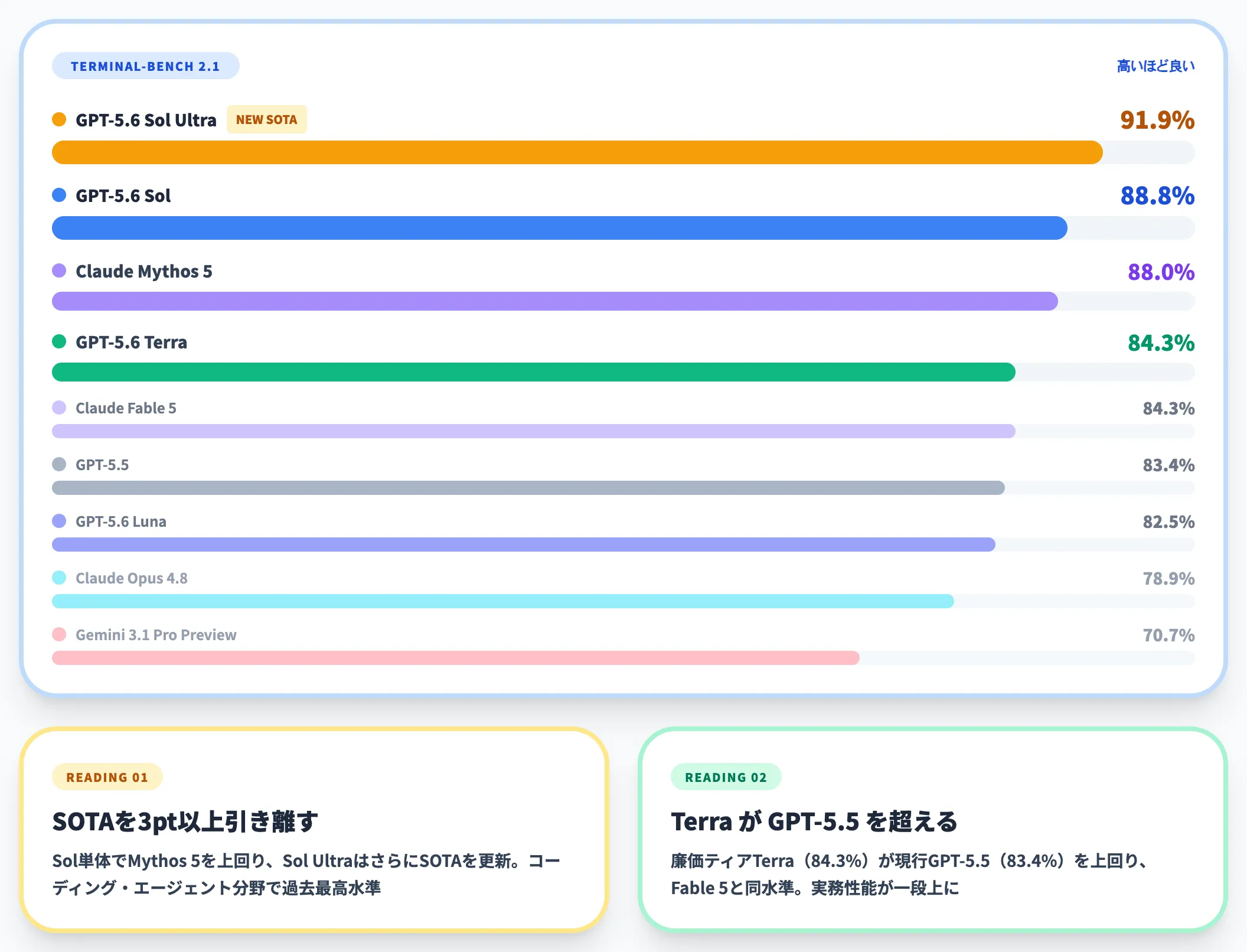
公式チャートに掲載された数値では**Sol単体で88.8%、後述するultraモードのSol Ultraで91.9%**に達しており、コーディング・エージェント分野で過去最高水準のスコアです。
公式チャートに掲載されたスコアは**Sol Ultra 91.9%・Sol 88.8%・Claude Mythos 5 88.0%・GPT-5.6 Terra 84.3%・Claude Fable 5 84.3%・GPT-5.5 83.4%・GPT-5.6 Luna 82.5%・Claude Opus 4.8 78.9%・Gemini 3.1 Pro Preview 70.7%**の順で、Sol単体でClaude Mythos 5を上回り、Sol Ultraがさらに3ポイント以上引き離してSOTAを更新しています。
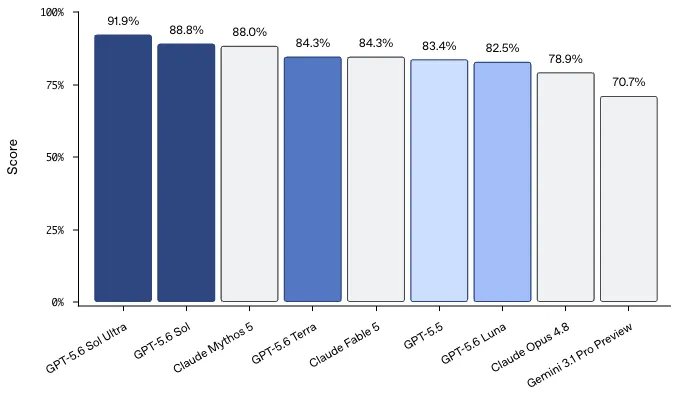
Terminal-Bench 2.1におけるGPT-5.6 Sol/Terra/Lunaと競合モデルのスコア(出典:OpenAI)
注目すべきは、廉価ティアのTerra(84.3%)が現行GPT-5.5(83.4%)を上回り、Claude Fable 5(84.3%)と同水準に並んでいる点です。
Terminal-Benchはコマンドの順序計画・エラー時の自律修正・複数ツールの協調を一度に求めるため、単純なコード補完よりも実務に近い性能評価軸です。Codex統合や開発エージェントとしての実用性が一段引き上がっていることを意味します。
ExploitBenchでMythos Previewと互角
サイバーセキュリティ領域では、Anthropicが業界に衝撃を与えたClaude Mythos Previewとの比較が注目ポイントです。
OpenAIは公式ブログで、SolがサイバーセキュリティベンチマークExploitBenchにおいてMythos Previewと competitive(互角)であり、しかも出力トークンを約1/3に抑えて同等性能を達成したと公表しています。
以下の表で、Sol/Mythos Previewのサイバー領域での位置づけを整理しました。
| モデル | ExploitBench位置づけ | 出力トークン効率 |
|---|---|---|
| GPT-5.6 Sol | Mythos Previewと competitive | Mythosの約1/3 |
| Claude Mythos Preview | サイバー特化未公開モデル(基準) | 基準 |
Mythosは「サイバー能力に特化的に強い未公開モデル」として登場し、Project Glasswing経由の極めて限定的なアクセスで運用されてきた経緯があります。
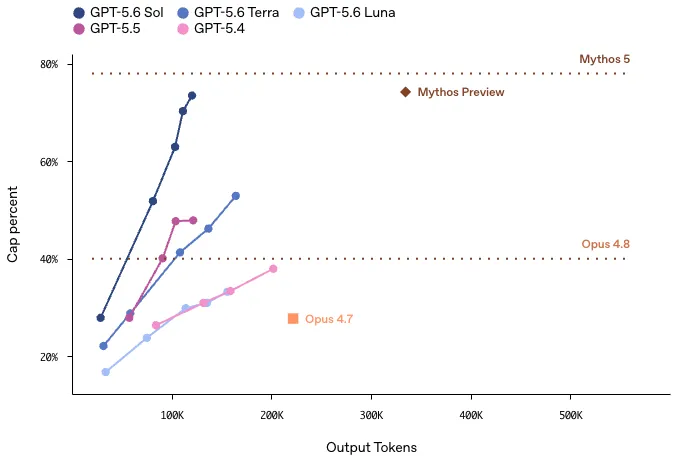
ExploitBenchにおけるGPT-5.6 SolとClaude Mythos Preview/Mythos 5の性能・出力トークン比較(出典:OpenAI)
公式チャートの上端付近にあるMythos Previewの◆マーカーは、横軸の出力トークン約350k付近に位置しています。
一方でSol(紺色の折れ線)は、出力トークン約120k付近で同等のスコア帯(73%前後)に到達しており、Mythosと同水準の性能を約3分の1のトークンで実現していることが視覚的にも確認できます。
Mythos 5(上端の点線・77%)にはまだ届かないものの、コスト効率を伴ってフロンティアサイバー性能に肩を並べたことを意味します。
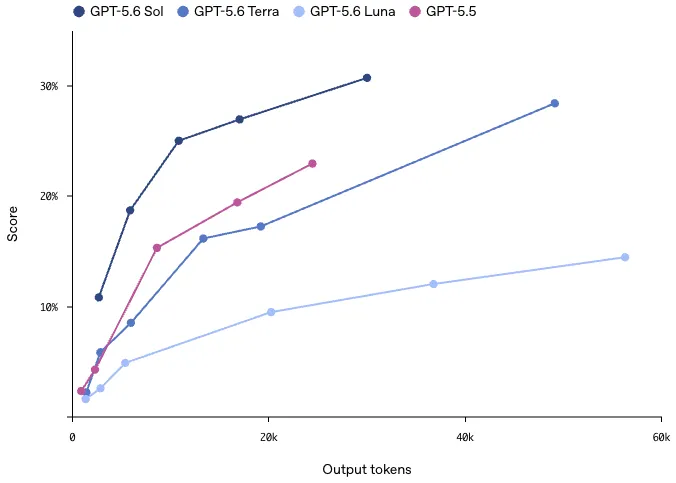
加えて、UC Berkeley研究者とOpenAIなど複数フロンティアラボが共同設計したExploitGymでは、Sol/Terra/Lunaの3モデルすべてが推論強度を上げるとサイバー能力を強く改善することが示されています。
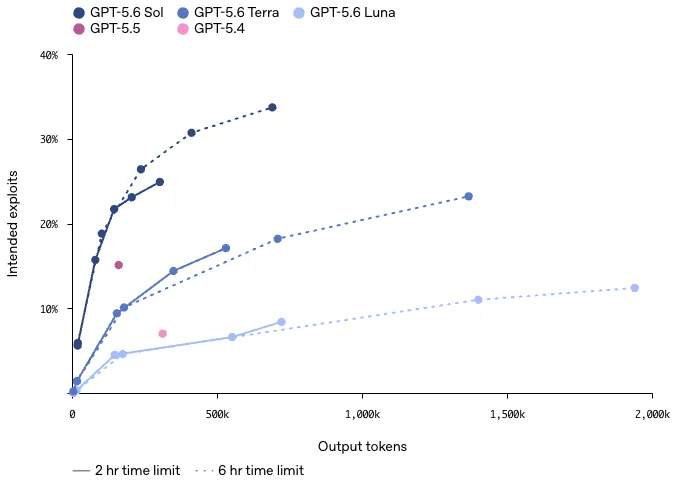
ExploitGymにおけるGPT-5.6 Sol/Terra/Lunaの推論強度別性能(実線=2時間制限、点線=6時間制限)(出典:OpenAI)
3ティア共通で推論時間(横軸の出力トークン数)を伸ばすほど Intended exploits(縦軸)が単調に改善しており、特にSolは33%超まで到達してGPT-5.5(マゼンタ点・約15%)の倍以上のスコア帯に入っています。推論強度を増やすほど効率改善が効くという性質は、防御業務で時間制約をある程度許容できるユースケース(夜間バッチ・週次監査)と相性がよい構造です。
GeneBench v1で生物学ワークフローを強化
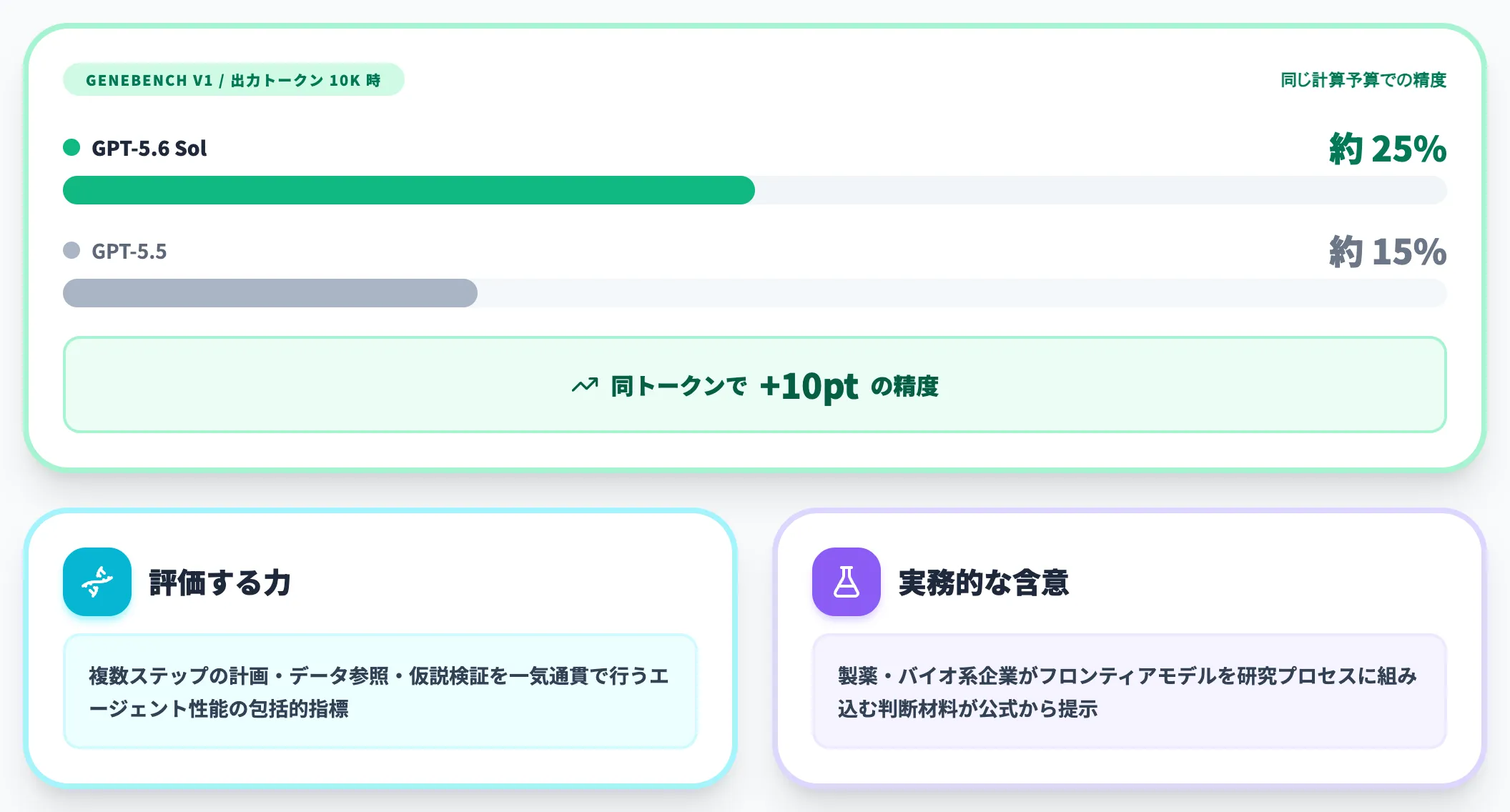
生物学分野では、長期的なゲノミクス・定量生物学の解析を評価するGeneBench v1でGPT-5.5を上回る結果が出ています。
OpenAIは公式ブログで「より少ないトークンでGPT-5.5より強い結果」と説明しており、これは推論効率の改善が生物学領域にも波及していることを示しています。
GeneBench v1におけるGPT-5.6 Sol/Terra/LunaとGPT-5.5の性能・トークン効率比較(出典:OpenAI)
公式チャートを見ると、横軸の出力トークン数が同じ水準でもSol(紺色)の到達スコアがGPT-5.5(マゼンタ)を明確に上回っています。たとえば出力トークン10kあたりでGPT-5.5が約15%なのに対し、Solは約25%まで到達しており、同じ計算予算でより高い精度を出せる構造になっています。
GeneBench v1のような長期ホライズン評価では、複数ステップの計画・データ参照・仮説検証を一気通貫で行う能力が問われるため、エージェント性能の包括的な指標として参照されます。製薬・バイオ系企業がフロンティアモデルを研究プロセスに組み込む際の現実的な判断材料が、ようやく公式から提示された格好です。
max・ultra推論モードの追加
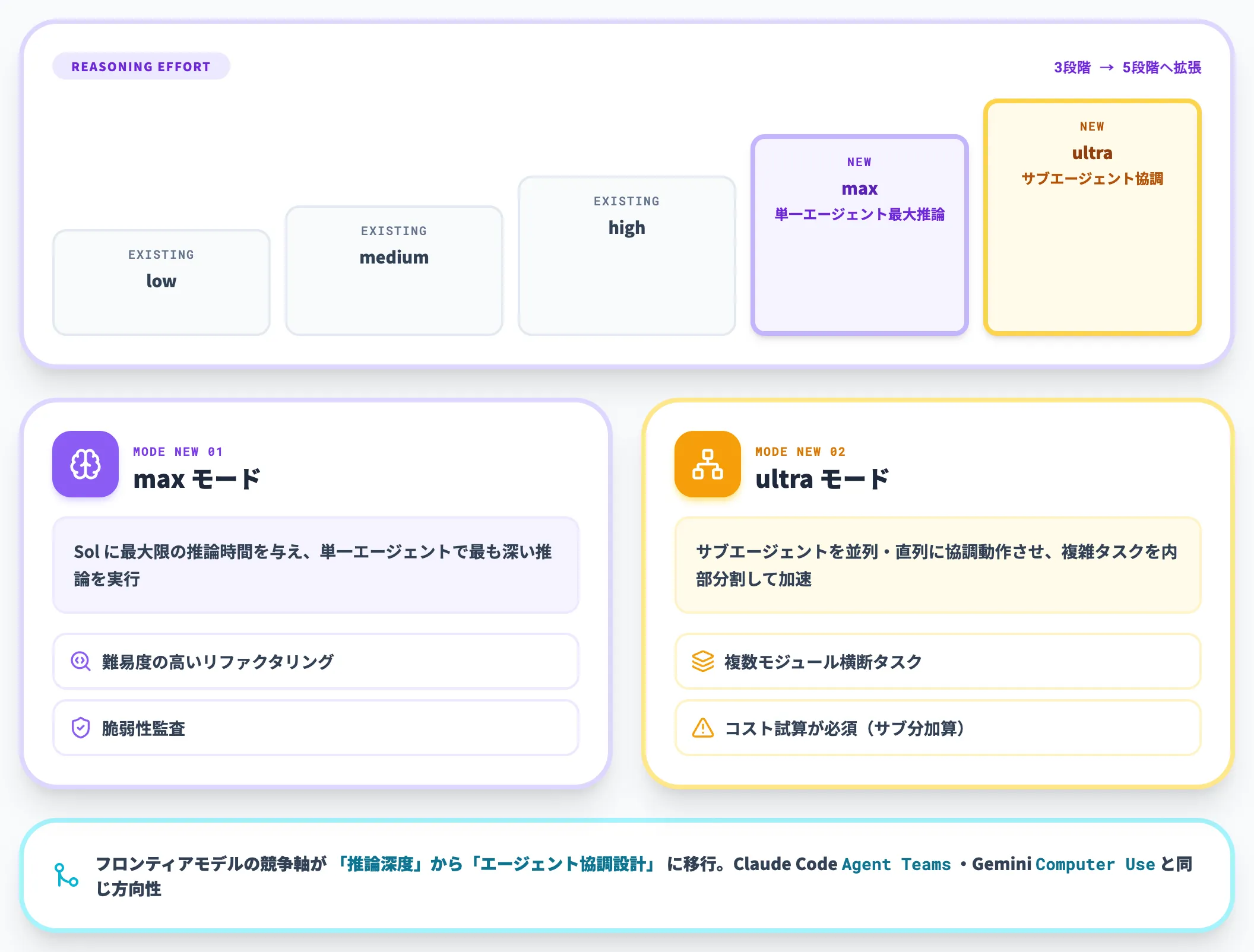
GPT-5.6で最も実装インパクトが大きいのが、新しい推論強度オプションの追加です。
以下の表で、新導入の2モードを整理しました。
| モード | 動作 | 対象モデル |
|---|---|---|
| max | Solに最大限の推論時間を与え、最も深い推論を実行 | GPT-5.6 Sol |
| ultra | 単一エージェントの能力を超え、サブエージェントを協調動作させて複雑タスクを加速 | GPT-5.6 Sol |
このうちultraモードは、複数のサブエージェントを並列・直列に協調動作させる仕組みで、単一エージェントでは扱いきれない複雑なワークフローを内部分割して処理します。
前述したSol Ultraのスコア91.9%(Terminal-Bench 2.1)は、このultraモードを使った結果です。
実装上の意味は2点に整理できます。
-
コーディングエージェント側の選択肢が一段増える
従来は「reasoning effort: low / medium / high」の3段階だったところに「max」「ultra」が追加された。難易度の高いリファクタリングや脆弱性監査ではmax、複数モジュールにまたがる長期タスクではultra、と使い分けることでコストと精度のバランスを細かく取れる。
-
APIコスト設計が複雑になる
ultraモードはサブエージェント数だけトークン消費が増えるため、料金単価の「Sol $5/$30」だけを見ると過小見積もりになりやすい。本番運用前に想定タスクで実コストを計測する工程が必須になる。
このモード追加は、Anthropic Claude CodeのAgent TeamsやGoogle GeminiのComputer Useと同じ方向性(エージェントが内部でエージェントを動かす多層構造)の流れに沿っており、フロンティアモデルの競争軸が「推論深度」から「エージェント協調設計」に移ってきたことを示しています。
GPT-5.6 Terra・Lunaの位置づけと使い分け

GPT-5.6世代の特徴は、フラグシップであるSolだけでなく、TerraとLunaという2つの廉価ティアも同時にプレビュー公開された点にあります。
ここでは2つの廉価ティアの位置づけと、3ティアの使い分け判断を整理します。
Terra——GPT-5.5を2倍安価で代替
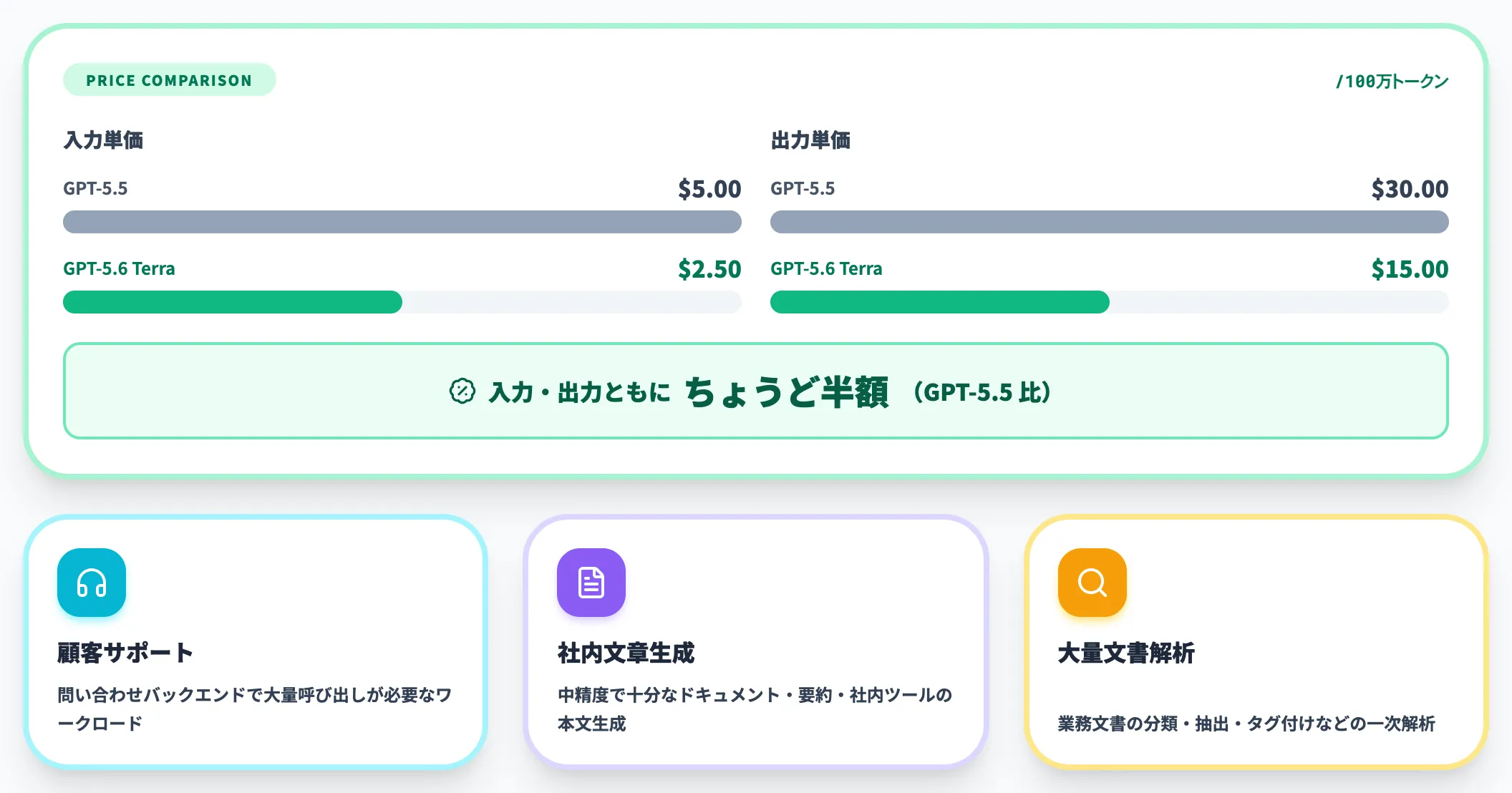
GPT-5.6 Terraは、日常業務向けのバランス型モデルとして設計されています。
OpenAIは公式ブログで、Terraについて「GPT-5.5に対して competitive な性能を、2倍安いコストで提供する」と説明しています。
つまりTerraは「Solほどの推論深度は不要だが、GPT-5.5レベルの汎用性能をコスト最適に使いたい」というユースケースを直撃するティアです。
具体的な想定用途は、顧客サポートのバックエンド・社内ツールの文章生成・大量文書のドキュメント解析など、高ボリューム×中精度のビジネスワークになります。
Luna——最も高速・最低コストの軽量ティア
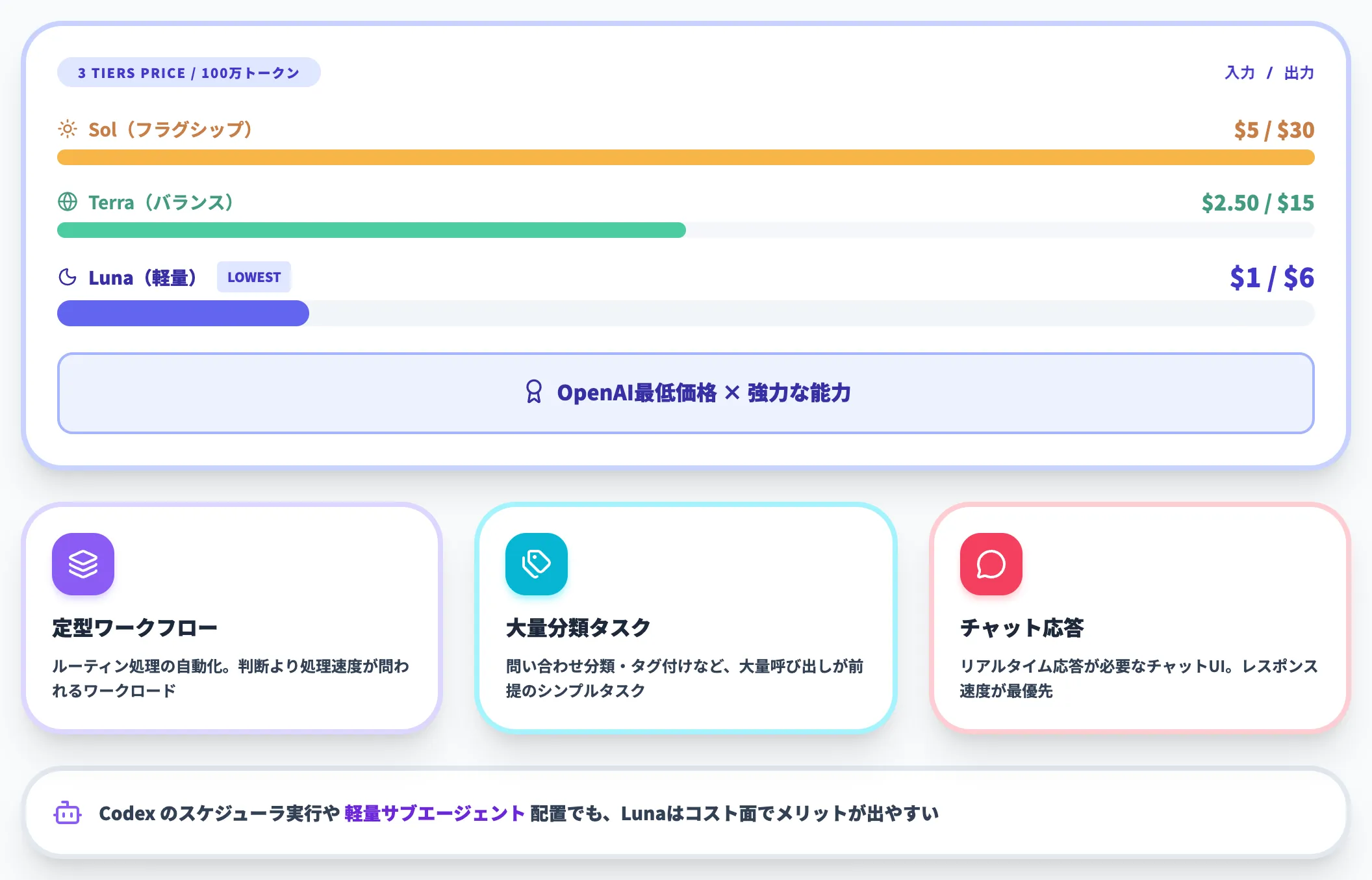
GPT-5.6 Lunaは、ファミリー内で最も高速・最低コストなティアで、応答速度とスケーラビリティが重視されるユースケース向けに設計されています。
OpenAIは公式ブログで「OpenAIの最低価格で強力な能力を提供する」と説明しており、推論深度よりもレスポンスタイムとコスト効率を優先する場面で第一候補になります。
想定される用途は、定型的なルーティンワークフロー・大量呼び出しが必要な分類タスク・チャットインターフェースのリアルタイム応答などです。
Codexのスケジューラ実行や軽量サブエージェントとしての配置でも、コスト面でメリットが出やすいティアです。
3ティアの使い分け判断
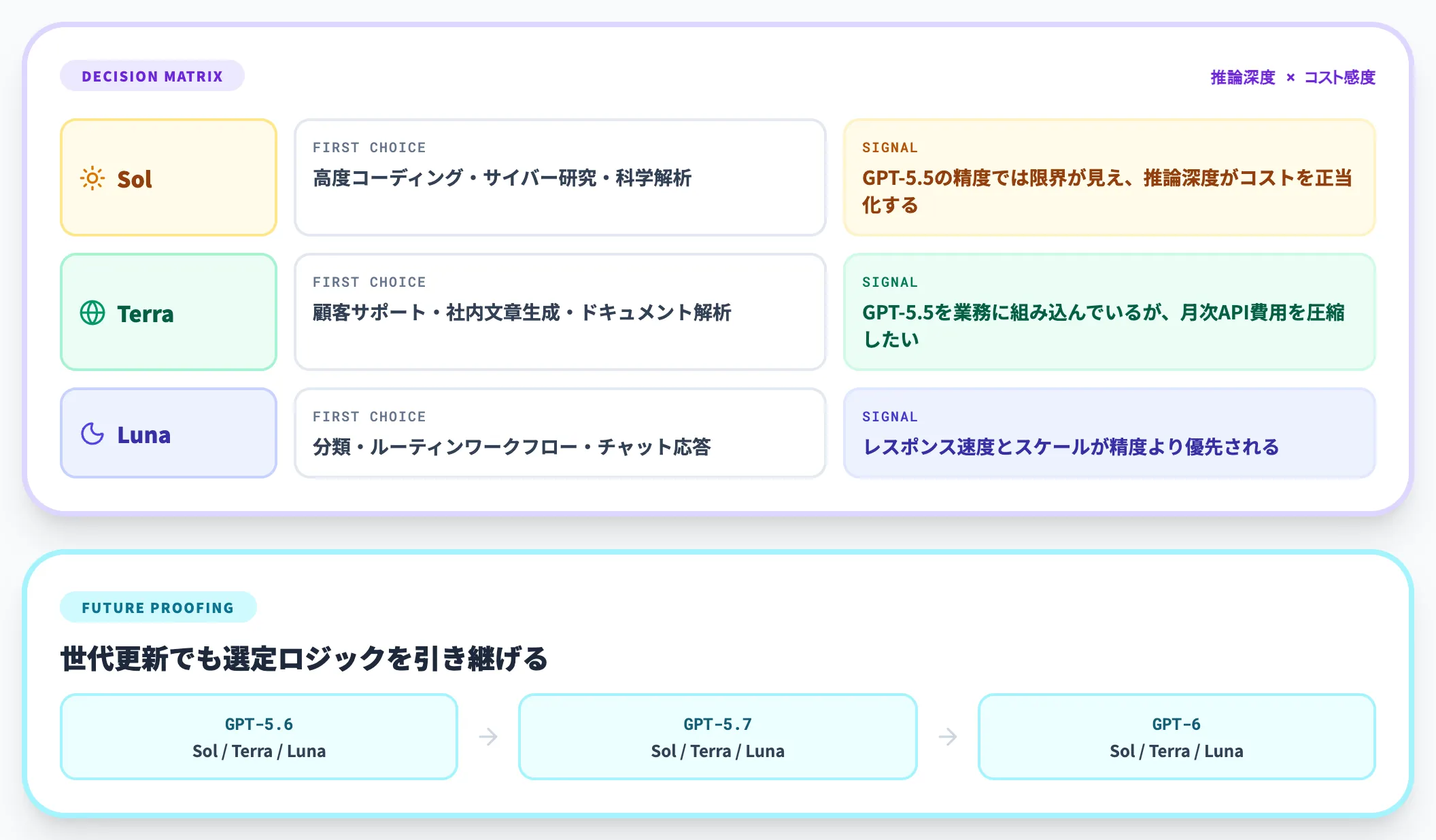
3ティアを実務でどう使い分けるかは、タスクの推論深度要件とコスト感度の組み合わせで決まります。
以下の表で、3ティアの典型ユースケースを整理しました。
| ティア | 第一候補ユースケース | 採用シグナル |
|---|---|---|
| Sol | 高度コーディング・サイバー研究・科学解析 | GPT-5.5の精度では限界が見え始めている/推論深度がコストを正当化する |
| Terra | 顧客サポート・社内文章生成・ドキュメント解析 | GPT-5.5を業務に組み込んでいるが、月次API費用を圧縮したい |
| Luna | 分類・ルーティンワークフロー・チャット応答 | レスポンス速度とスケールが精度より優先される/大量呼び出しが前提 |
従来は「GPT-5.5 Pro/GPT-5.5/GPT-5.5 Instant」のように同世代内でPro/Standard/Instantを選ぶ構造だったところに、GPT-5.6ではティア軸そのものが命名に組み込まれたわけです。
これにより、世代更新(5.6→5.7→6.0)があってもティア選定ロジック(Sol/Terra/Luna)を引き継げる利点があります。
実務的な使い分けとしては、まず社内タスクのワークロード分析を行い、推論深度要件で3ティアに振り分け、運用後にコスト・精度の実測値で再配置するのがオーソドックスな進め方です。
GPT-5.6の料金体系

GPT-5.6の料金は、3ティアそれぞれの単価とプロンプトキャッシュの新仕様の2軸で構成されます。
本セクションでは料金構造を整理し、現行GPT-5.5・Claude Opus 4.8との比較で実務的な意味を読み解きます。
Sol・Terra・Lunaの単価表
OpenAI Help Center公式ページに掲載された3ティアの単価は以下のとおりです。
| モデル | モデルID | 入力(100万トークンあたり) | 出力(100万トークンあたり) |
|---|---|---|---|
| GPT-5.6 Sol | gpt-5.6-sol | $5.00 | $30.00 |
| GPT-5.6 Terra | gpt-5.6-terra | $2.50 | $15.00 |
| GPT-5.6 Luna | gpt-5.6-luna | $1.00 | $6.00 |
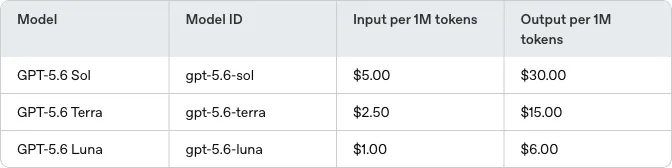
OpenAI Help Centerに掲載されたGPT-5.6 Sol/Terra/Lunaの公式料金(出典:OpenAI Help Center)

注目すべきはSolの単価が現行GPT-5.5と同じ$5/$30である点です。
つまりOpenAIは、性能が一段上のSolを「GPT-5.5と同じ価格で提供」しています。
Terraは$2.50/$15で、GPT-5.5に対して入力・出力ともにちょうど半額。Lunaはさらに$1/$6まで下がり、低コスト帯のフロンティアモデルとしてはトップクラスの単価です。
この単価設計は、AnthropicのClaude Opus 4.8(通常$5/$25・Fast modeは$10/$50)と並べると、Sol($5/$30)は通常モードでほぼ同水準、出力単価ではOpus 4.8通常モードがわずかに安い構成です。
Anthropic側のMythos世代モデルClaude Fable 5($10/$50)は2026年6月12日以降アクセス停止中のため、Sol/Terra/Lunaが対峙する「使えるフロンティアモデル」の選択肢は事実上Opus 4.8・現行GPT-5.5・Gemini 3.1 Pro系統に絞られています。
プロンプトキャッシュの新仕様
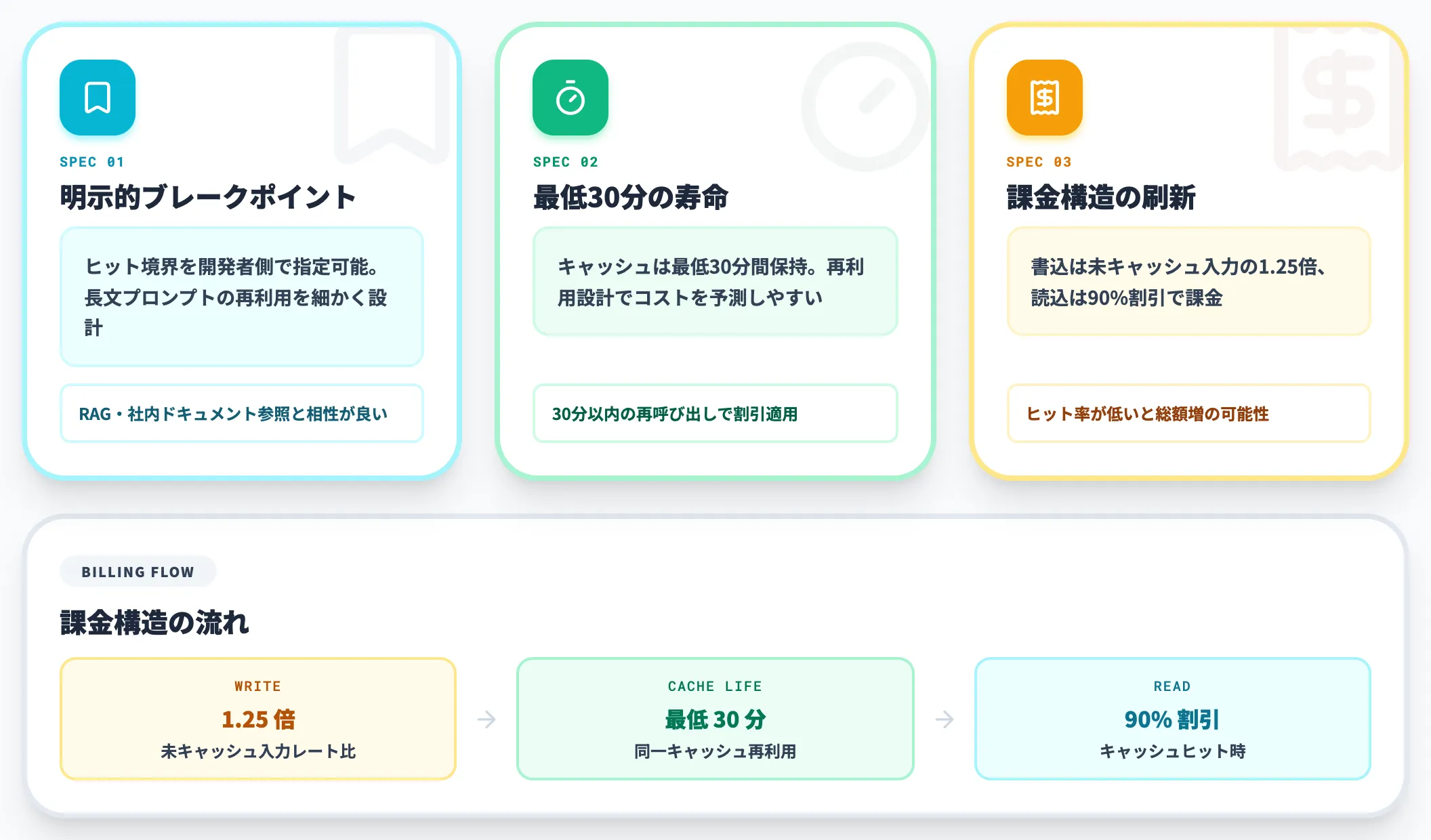
GPT-5.6で同時に導入されたのが、より予測しやすいプロンプトキャッシュです。
OpenAI公式の説明では、新仕様の要点は以下の3点です。
-
明示的なキャッシュブレークポイントのサポート
従来は自動キャッシュに委ねられていたヒット境界を、開発者側で明示できるようになった。長文プロンプトのキャッシュ再利用を細かく設計可能。
-
30分の最低キャッシュ寿命
キャッシュは最低30分間保持される。同一キャッシュ対象を再利用できる設計であれば、30分以内の再利用でコストを予測しやすくなる。
-
新しい課金構造
GPT-5.6以降のモデルでは、キャッシュ書き込みは未キャッシュ入力レートの1.25倍で課金され、キャッシュ読み込みは引き続き90%割引を受けられる。
この変更で実務的に意味があるのは、長文コンテキストを繰り返し参照する用途のコスト予測精度が上がることです。
たとえば社内ドキュメント数十万トークンを毎回プロンプトに含めるRAGアプリケーションでは、明示キャッシュブレークポイントを設計することで「初回フル課金+以降90%引き」の構造を見積もりに取り込みやすくなります。
ただしキャッシュ書き込みの1.25倍課金は、これまで隠れていたコストが顕在化した形でもあります。ヒット率が低いワークロードでは、従来の単純な$5/$30積算より総額が増える可能性がある点に注意が必要です。
Cerebras上で750 tps提供(7月開始予定)
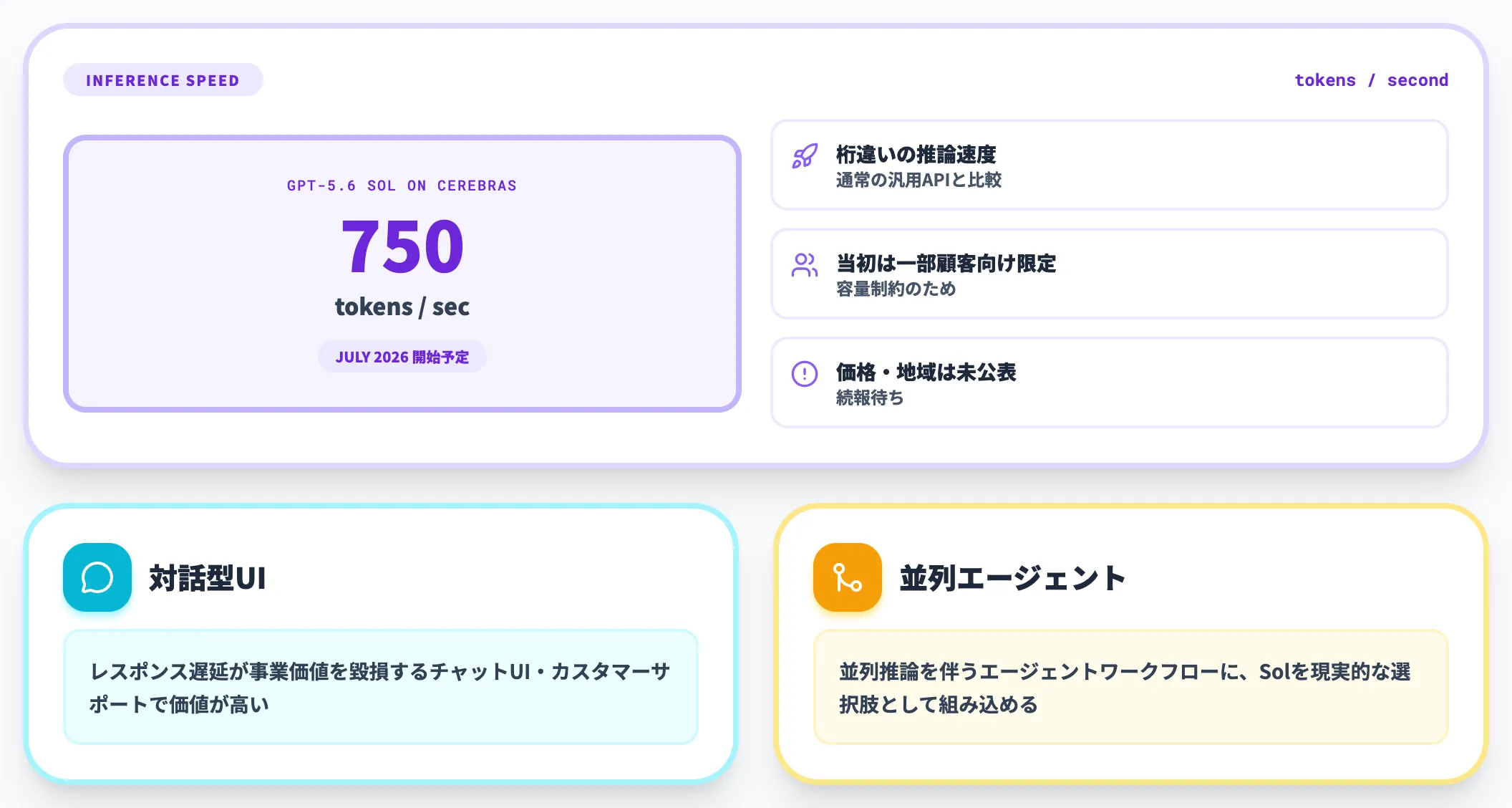
OpenAIは公式ブログ末尾で、Cerebras上でGPT-5.6 Solを最大750トークン/秒で提供する計画を明らかにしました。
開始時期は2026年7月で、当初は容量制約のため一部顧客向け限定となります。
750 tpsは、現行の汎用APIと比べて桁違いに高速な推論速度で、リアルタイムエージェントやインタラクティブなコーディング支援に特化した用途で価値が出やすい数字です。
実務的な意味としては、レスポンス速度が決定的に重要なエージェントワークフロー(対話型UIや並列推論)で、GPT-5.6 Solを現実的な選択肢として組み込めるようになる点が挙げられます。
ただし価格・対象顧客・地域は2026年6月時点で公表されていないため、続報を待つ必要があります。
GPT-5.6のアクセス制限とTrump大統領令による段階リリース

GPT-5.6の最大の特徴は、性能ではなくアクセス制限の異例さにあります。
ここでは、API/Codex限定での提供範囲、Trump政権の関与経緯、Trusted Access for Cyberとの関係、一般提供(GA)見通しまでを整理します。
API/Codex限定でChatGPT未提供

GPT-5.6 Sol/Terra/Lunaは、プレビュー期間中APIとCodexのみで提供され、ChatGPT(消費者向け/企業向けともに)からは利用できません。
OpenAIは公式Help Centerで「ChatGPTはプレビューに含まれず、今後数週間以内にChatGPT・Codex・APIでの一般提供を計画している」と明示しています。
提供範囲を整理すると以下のとおりです。
- 対象は少数のtrusted partners and organizations(OpenAI account representative経由でのみ案内)
- 個人ユーザーは対象外、申請窓口・waitlistなし
- APIアクセスとCodexアクセスは個別承認(一方の承認で他方が自動的に有効にはならない)
- 既存のAlphaアクセスがあったからといってGPT-5.6プレビューへの自動アクセスは保証されない
この提供方式は、Anthropic Claude Mythosの「Project Glasswing経由12組織+40超」と比較してもさらに密な限定提供です。
trusted partnersの具体的な企業名は公表されていませんが、米政府機関との調整プロセスを経て段階的に拡大される設計になっています。
Trump大統領令が背景にある段階リリース
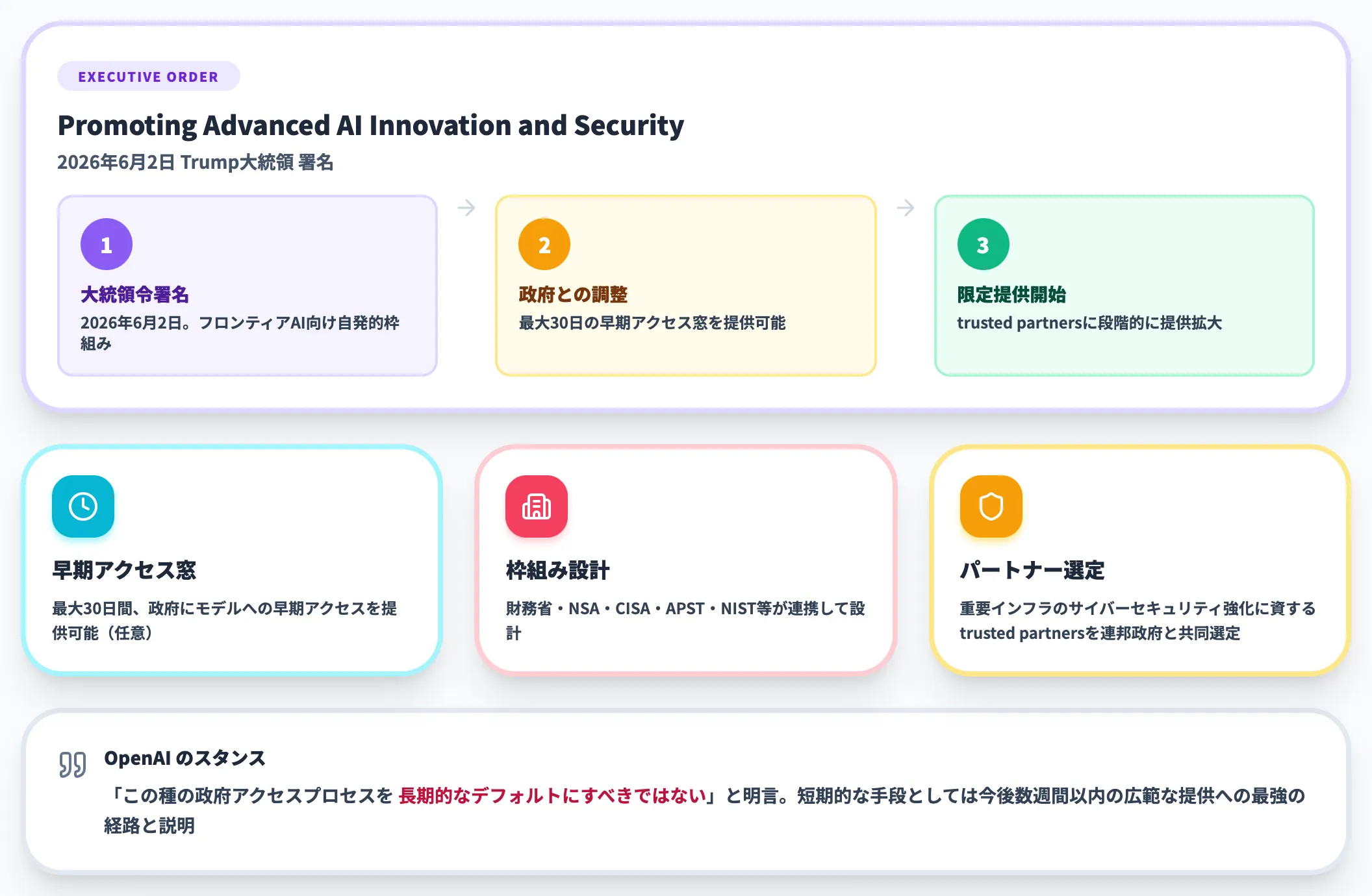
なぜここまで限定的な提供なのか。背景には、**2026年6月2日にTrump大統領が署名した大統領令「Promoting Advanced Artificial Intelligence Innovation and Security」**があります。
この大統領令は、フロンティアAIモデルのセキュアな展開のための自発的な枠組みを連邦政府機関に確立させるもので、要点は以下のとおりです。
- 開発者は、他のtrusted partnersへの提供前に最大30日間、政府にモデルへの早期アクセスを提供できる
- 財務省・国防省(NSA)・DHS(CISA)が、National Cyber DirectorやAPST、商務省(NIST)等と協議して枠組みを設計する
- 開発者は連邦政府と協力して「重要インフラのサイバーセキュリティを強化する trusted partners」を選定する
OpenAIは公式ブログで、「政府との継続的なエンゲージメントの一環として、ローンチ前にプランとモデル能力を共有し、政府と調整したうえで限定パートナーから提供を開始した」と説明しています。
ただし、OpenAIは同時に**「この種の政府アクセスプロセスを長期的なデフォルトにすべきではない」**とも明言しています。
その理由として、ユーザー・開発者・企業・サイバー防御者・グローバルパートナーへの提供が遅れることを挙げ、「短期的な手段としては今後数週間以内の広範な提供への最強の経路だと考える」と述べています。
つまりGPT-5.6の段階リリースは、OpenAI自身も推奨する運用形態ではなく、政府との調整プロセスの試行的な適用という位置づけです。
Trusted Access for Cyberとの違い

混同しやすいのが、OpenAIが既に運用しているGPT-5.5-Cyber向けの**Trusted Access for Cyber(TAC)**プログラムとの関係です。
OpenAI Help Centerは明確に「Trusted Access for Cyberへの参加は、それ自体ではGPT-5.6プレビューへのアクセスを提供しない」と説明しています。
両プログラムの違いを整理すると以下のとおりです。
| プログラム | 対象モデル | アクセス方式 | 目的 |
|---|---|---|---|
| Trusted Access for Cyber | GPT-5.5(高度サイバー能力解放版) | 検証済み防御担当者向け | サイバー防御業務での高度能力解放 |
| GPT-5.6プレビュー | Sol/Terra/Luna全モデル | 少数のtrusted partners and organizations限定 | 段階リリース運用の試行 |
つまり、既にTrusted Access for Cyberを利用している企業であっても、GPT-5.6プレビューへの参加は別途OpenAI account representativeからの個別案内が必要です。
一般提供(GA)の見通しはcoming weeks
OpenAIは公式ブログとHelp Centerの両方で、GPT-5.6 Sol/Terra/LunaのChatGPT・Codex・APIでの一般提供を「coming weeks(今後数週間以内)」に計画していると明示しています。
ただし具体的なGA日付は公表されていません。
一部の予測市場や報道では7〜8月ごろとの観測もありますが、いずれも公式コミットではない点に注意が必要です。
実務的なスタンスとしては、**「GAまで使えない期間を前提に、現行GPT-5.5でできる先行準備を進める」**のが現実的な対応になります。具体的な備えは後述するH2「企業がGPT-5.6世代に備える実務指針」で整理します。

GPT-5.6のセーフガード設計
GPT-5.6 Solは、OpenAIが過去最大規模のセーフガード設計を施したモデルでもあります。
ここでは、レイヤード構成・Cyber Critical閾値の評価結果・自動red-teamingの投入規模・dual-use領域での実運用挙動までを整理します。
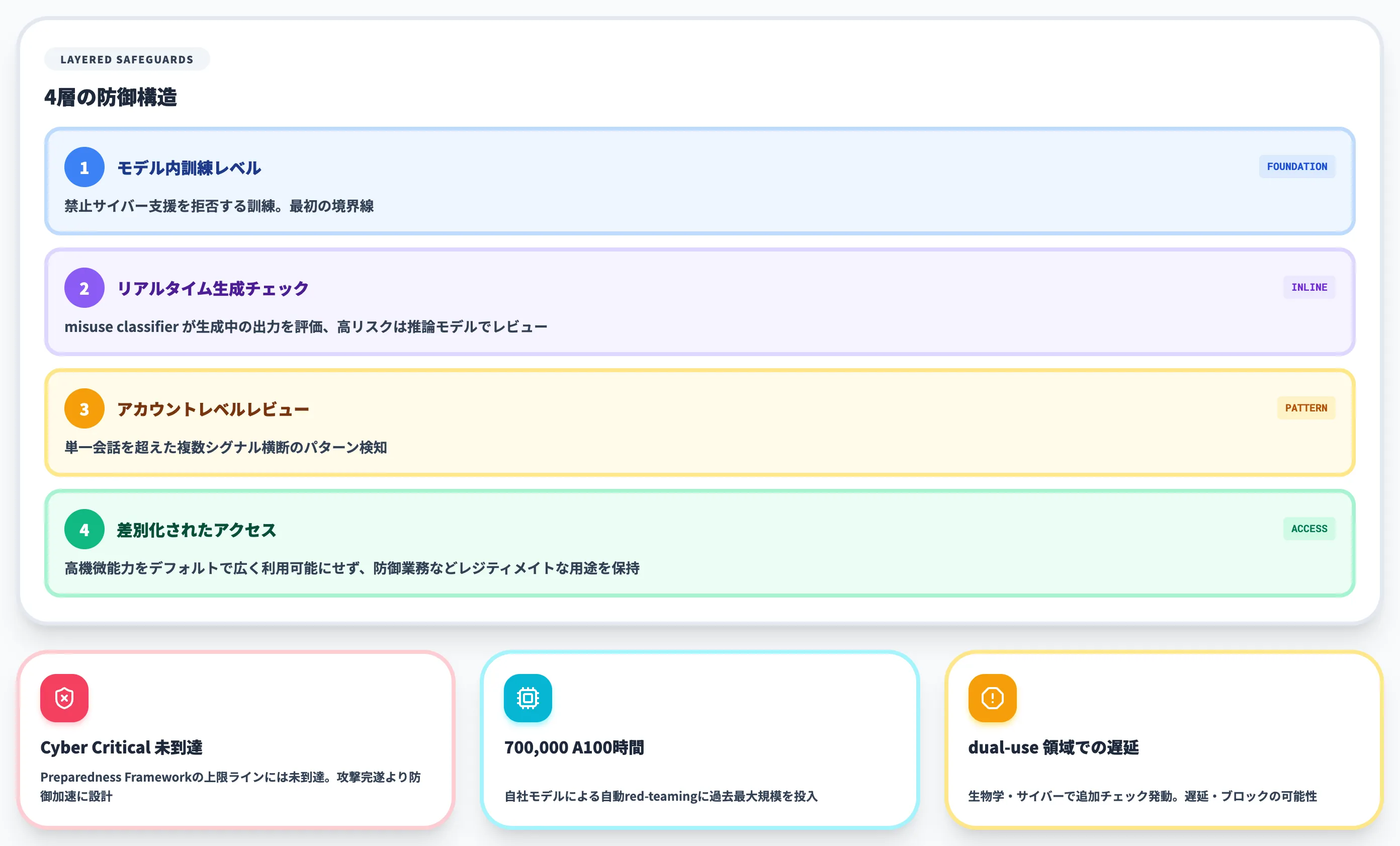
レイヤードセーフガードの多段構成

OpenAIは公式ブログで、GPT-5.6 Sol/Terra/Lunaにレイヤード(多層)セーフガードを実装したと説明しています。
各モデルの能力に応じて構成を変えつつ、共通する層は以下のとおりです。
-
モデル内訓練レベル
禁止サイバー支援(ユーザーが意図を偽装したり脱獄を試みたケースを含む)を拒否するよう訓練。最初の境界線として機能。
-
リアルタイム生成チェック
サイバー・生物学領域のmisuse classifierが生成中の出力を評価。高リスクケースでは、より大きな推論モデルが会話とコンテキストをレビューするまで生成を一時停止する。
-
アカウントレベルレビュー
フラグされた活動は、関連する会話や複数のリスクシグナルにわたるアカウントレベルレビューをトリガーできる。単一会話を超えてパターンを見ることで、悪意ある継続行動とレジティメイトなdual-use作業を区別する。
-
差別化されたアクセス
高度に機微な能力をデフォルトで広く利用可能にすることなく、防御業務などレジティメイトな用途を保持する。
このレイヤード構造の狙いは、単一のセーフガードでは防ぎきれない adaptive misuse(適応的悪用)への耐性です。
たとえばモデルが直接拒否しないケースでも、リアルタイムチェックで生成途中の出力をブロックでき、それも回避された場合はアカウントレベルで継続パターンを検知する設計になっています。
Cyber Criticalしきい値には未到達

OpenAIは公式ブログで、GPT-5.6 SolがPreparedness Frameworkの「Cyber Critical」しきい値を超えていないことを明示しています。
Cyber Criticalは、OpenAIが自社で設定したサイバー能力の上限ライン(重大なリスクをもたらすレベル)で、これを超えると追加の安全対策と段階配布が必要になる基準です。
具体的な評価対象として、SolはChromiumとFirefoxで評価が行われました。結果は以下のとおりです。
- バグとエクスプロイトprimitive(部品)の発見はできた
- ただしテスト条件下では自律的にfull-chain exploit(完全な攻撃チェーン)を生成しなかった
これは、Anthropic Claude Mythosが「Linuxカーネルで最大4つの脆弱性を組み合わせた自律エクスプロイトチェーン構築」を示した能力との明確な差です。
OpenAIは「benchmarkしきい値は、モデルが他のツールと組み合わせて使われるすべての方法を捉えることはできない」と注記しつつ、「Solは『人々が脆弱性を発見・修正する手助け』により優れており、『エンド・ツー・エンドの攻撃を信頼性高く実行する』方には設計されていない」と説明しています。
つまり、GPT-5.6 Solはサイバー防御業務(脆弱性発見・パッチ開発・コードレビュー・防御テスト)を強く加速する一方で、攻撃側の自律完遂能力は意図的に抑えられている設計です。
700,000 A100時間の自動red-teaming

セーフガードの堅牢化は、攻撃者の戦術が変化しても効果を維持する必要があります。OpenAIはこの課題に対し、自社モデルを使った自動red-teamingに700,000 A100換算時間を投入したと公表しています。
この自動red-teamingは、特定のプロンプト1つに効くだけでなく**多数のプロンプト・コンテキストに横断的に効く「universal jailbreaks」**を発見することを目的に設計されました。
人間によるテストだけでは到達できない攻撃パターンの探索範囲を広げ、失敗パターンを早期に特定し、発見から対策実装までのリードタイムを短縮する役割を果たしています。
加えて、第三者テスターによるhuman expert red teamingも並行で実施されており、プレビュー期間中も継続される予定です。
dual-use領域での実運用ブロック挙動
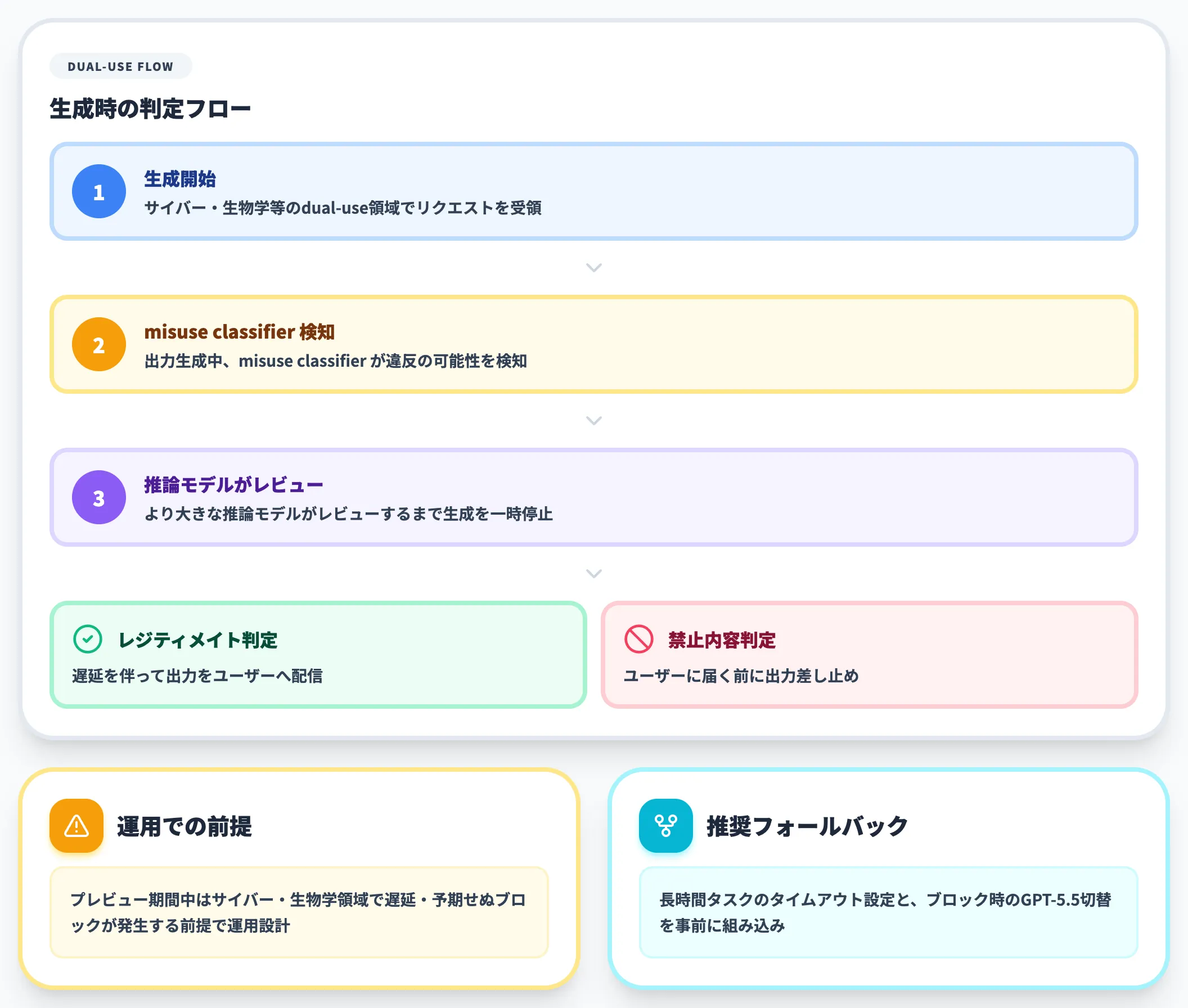
セーフガードの強化は、レジティメイトな業務に副作用を及ぼすこともあります。OpenAI Help Centerは、生物学・サイバーセキュリティのようなdual-use領域では、リクエストがブロックされたり、追加の安全チェックのために生成が遅延することがあると明示しています。
具体的には、出力生成中に misuse classifier が違反の可能性を検知すると、より大きな推論モデルがレビューするまで生成が一時停止します。
レビュー結果が「禁止内容」と判定されれば、出力はユーザーに届く前に差し止められる仕組みです。
OpenAIは「プレビューはまさにこの挙動をテストすることを目的としており、レジティメイトユーザーが通常の業務を信頼性・効率性をもって完了できるかを評価する」と説明しており、フィードバックを受けて広範提供前に不要なブロックを減らす方針です。
実務的な意味としては、プレビュー期間中はサイバー・生物学領域の業務でレスポンス遅延や予期せぬブロックが発生する前提で運用設計を組むことが必要になります。
長時間タスクのタイムアウト設定や、ブロック時のフォールバック(GPT-5.5への切り替え等)を事前に組み込んでおくと、ユーザー体験への影響を最小化できます。
GPT-5.6と他フロンティアモデル(Claude Opus 4.8・Gemini 3.1 Pro・GPT-5.5)の比較

GPT-5.6を実務でどう位置づけるかは、競合フロンティアモデルとの相対関係で決まります。
ここでは、Anthropic Claude Opus 4.8、Google Gemini 3.1 Pro Preview、現行GPT-5.5の3モデルとSol/Terra/Lunaを比較します。
性能・単価・提供形態の比較表

以下の表で、主要4モデルファミリーを横並びで整理しました。
| モデル | フラグシップ単価(入/出・100万トークン) | 主な強み | 2026年6月時点の提供状況 |
|---|---|---|---|
| GPT-5.6 Sol | $5 / $30 | Terminal-Bench 2.1新SOTA・ExploitBench Mythos互角 | プレビュー(API/Codex限定・少数のtrusted partners) |
| Claude Opus 4.8 | $5 / $25(Fast modeは$10 / $50) | 推論深度・長期エージェント運用の安定性 | 一般提供 |
| Gemini 3.1 Pro Preview | Standard $2/$12(200k tokens以下)、$4/$18(200k tokens超) | ARC-AGI-2 77.1%・マルチモーダル | プレビュー提供 |
| GPT-5.5 | $5 / $30 | 汎用バランス・Codex統合・広範な実績 | 一般提供(ChatGPT・API・Codex) |
| Claude Fable 5 | $10 / $50 | SWE-Bench Pro 80.3%・Mythos世代の一般公開モデル | 2026年6月12日以降アクセス停止(米政府の輸出規制要請) |
表から読み取れる重要なポイントは3点です。
- SolはGPT-5.5と同じ$5/$30で性能を一段引き上げ
同単価で性能が上がるため、GAの暁にはGPT-5.5ユーザーの自然な乗り換え先として機能します。
- Claude Opus 4.8($5/$25・Fast modeは$10/$50)とSol($5/$30)は近い価格帯
性能差・推論モードの選び方で使い分ける関係になります。
Claude Fable 5は2026年6月12日以降アクセス停止中のため現時点では実務の併用候補から外れ、Claude Mythos 5も limited availability のため通常の選定候補からは外す前提で、Anthropic併用候補は一般企業にとってはOpus 4.8系統が中心になります。
- Terra($2.50/$15)の単価はバランス型としてはトップクラス
GPT-5.5で動かしている業務を将来Terraに置き換えるだけで月次コストが半額になる試算が成り立ちます。
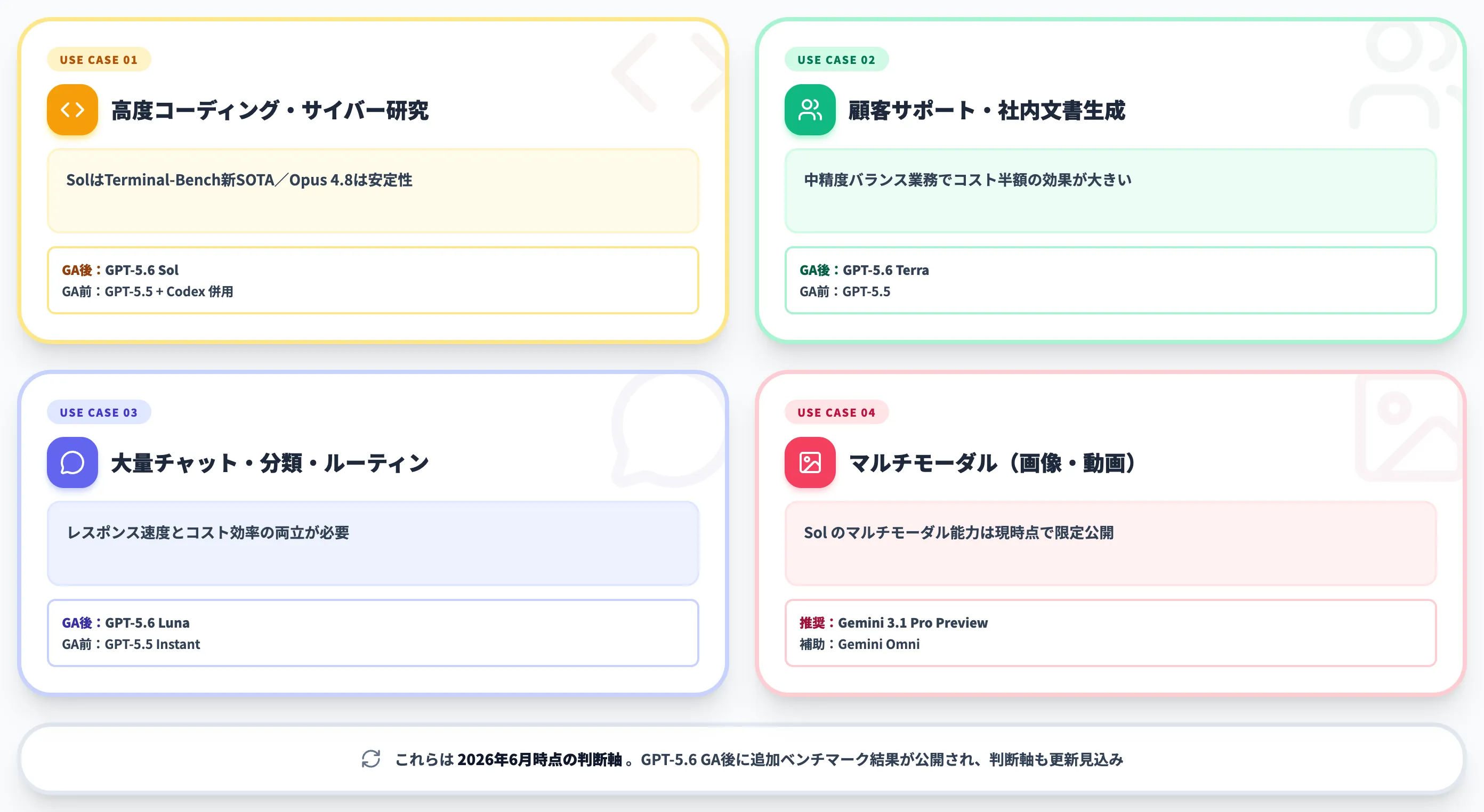
ケース別の第一候補
実務での使い分けは、用途別に整理すると以下のようになります。
-
高度コーディング・サイバー防御研究
GPT-5.6 Sol(GA後)またはClaude Opus 4.8。SolはTerminal-Bench新SOTAとExploitBench Mythos互角の実証あり。Opus 4.8は安定性で先行。GAまでは現行GPT-5.5+Codex併用が現実的
-
顧客サポート・社内文書生成
GPT-5.6 Terra(GA後)または現行GPT-5.5。GA前はGPT-5.5で運用し、Terra提供開始後に月次コスト半減を目指す移行ロードマップが組みやすい
-
大量チャット・分類・ルーティン処理
GPT-5.6 Luna(GA後)またはGPT-5.5 Instant。Lunaは$1/$6の最低価格帯で、レスポンス速度とコスト効率の両立が可能
-
マルチモーダル要件(画像・動画含む) →
Gemini 3.1 Pro Previewまたは**Gemini Omni**。GPT-5.6 Solはマルチモーダル能力の詳細が現時点で限定公開のため、画像・動画タスクではGemini系統が引き続き有力
これらはあくまで2026年6月時点の判断軸で、GPT-5.6のGAが進めばSWE-Bench Pro等の追加ベンチマーク結果が公開され、判断軸も更新される見込みです。
企業がGPT-5.6世代に備える実務指針
GPT-5.6プレビューに直接アクセスできる企業は限られていますが、今後数週間以内のGAを見据えた準備はすべての企業に意味があります。
ここでは、AI総合研究所が支援している企業の傾向も踏まえ、ケース別に「GAまでに何をすべきか」を整理します。

GA待ち期間で先行準備できる4つの打ち手

ほとんどの企業はGPT-5.6プレビューへの直接アクセスを得られません。
しかしGAまでの数週間〜数ヶ月で先行準備を進めておけば、GA当日から即座にGPT-5.6を業務に組み込めます。以下の表で、4タイプ別の優先度高アクションをまとめました。
| 対象企業 | GA待ちで先行すべきこと | GA後の判断基準 |
|---|---|---|
| Codex統合済みの開発企業 | GPT-5.5+Codexで業務フローを定着、ベンチマークタスクを内製化 | Terminal-Bench型タスクで実測してSol切替を判断 |
| 高ボリュームAPI利用企業 | GPT-5.5ベースのAPI呼び出しをコスト可視化、トークン削減施策を準備 | TerraでGPT-5.5を置き換えて月次コスト半減を実現 |
| サイバー防御業務担当企業 | GPT-5.5-Cyber等で防御業務へのAI統合を試行 | Sol GA後はExploitBench型タスクで効率検証 |
| マルチクラウド志向企業 | Claude Opus 4.8・Gemini 3.1 Pro Preview・GPT-5.5の3軸併用を整備 | Sol/Terra/Lunaが揃った後、用途別の最適配分を再設計 |
このあと、各ケースの背景を深掘りします。
Codex統合済みの開発企業の場合
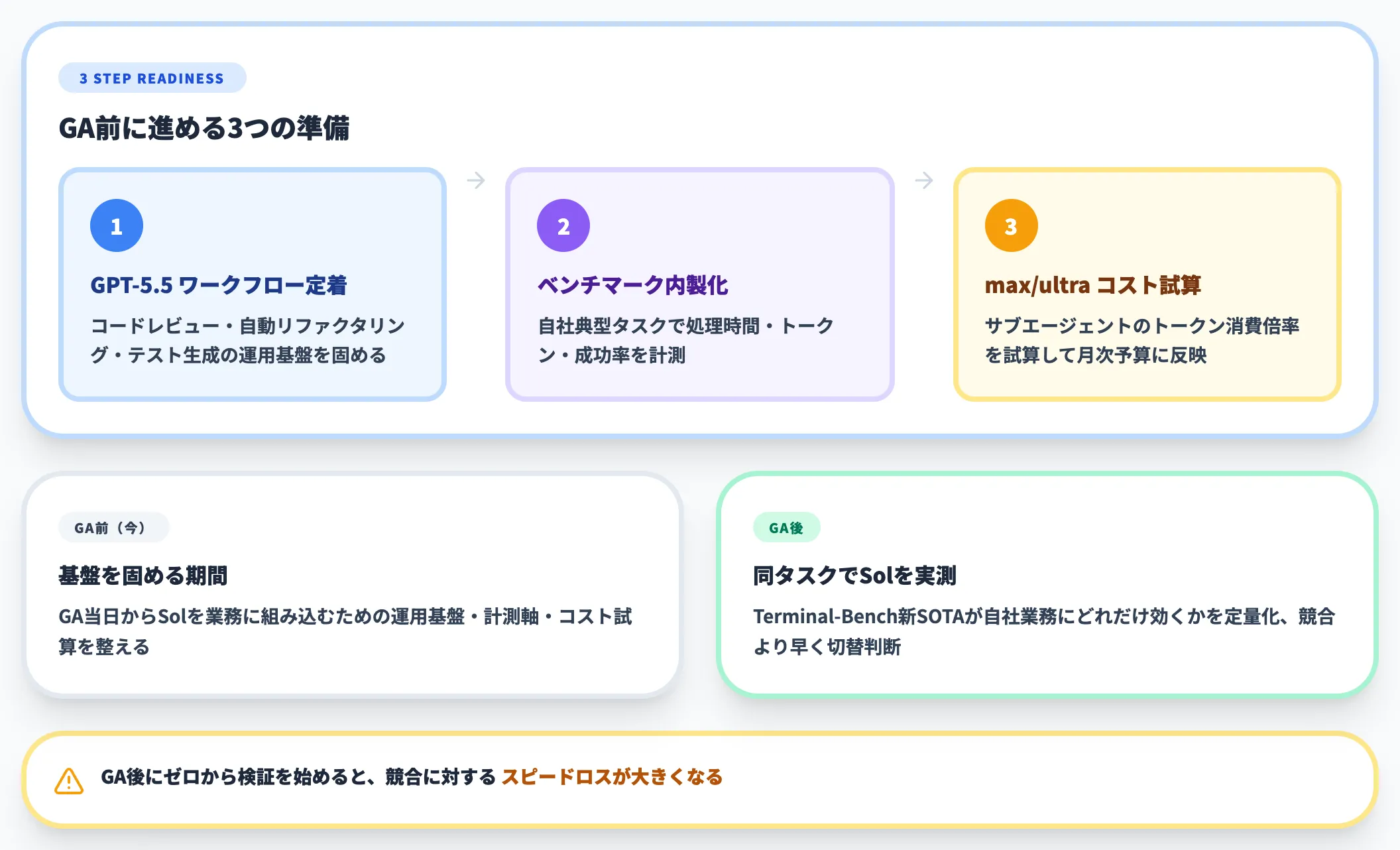
Codex CLIやCodex Computer Useを業務に組み込んでいる企業は、GPT-5.6 Sol GAから最も大きな恩恵を受ける層です。
優先すべき準備は以下の3つです。
GPT-5.5ベースのワークフロー定着
GPT-5.5+Codexでコードレビュー・自動リファクタリング・テスト生成の運用を確立する。
GAで急にSolに切り替えると、運用フロー側の混乱が大きくなる。先に運用基盤を固めておく。
ベンチマークタスクの内製化
社内の典型的なコーディングタスク(自社固有のリファクタリング・新機能実装)でGPT-5.5の処理時間・トークン消費・成功率を計測する。
GA後にSolで同じタスクを実測することで、「Terminal-Bench新SOTA」が自社の業務にどれだけ効くかを定量化できる。
max・ultraモードのコスト試算
公式単価$5/$30はあくまでベース単価で、ultraモードはサブエージェント分のトークン消費が加わる。
代表タスクで「ultraモードのトークン消費 ÷ 通常モードのトークン消費」の倍率を試算し、本番運用の月次予算に組み込む準備をしておく。
これらは、GA当日から運用判断ができる状態を作るための準備です。GA後にゼロから検証を始めると、競合に対するスピードロスが大きくなります。
高ボリュームAPI利用企業の場合
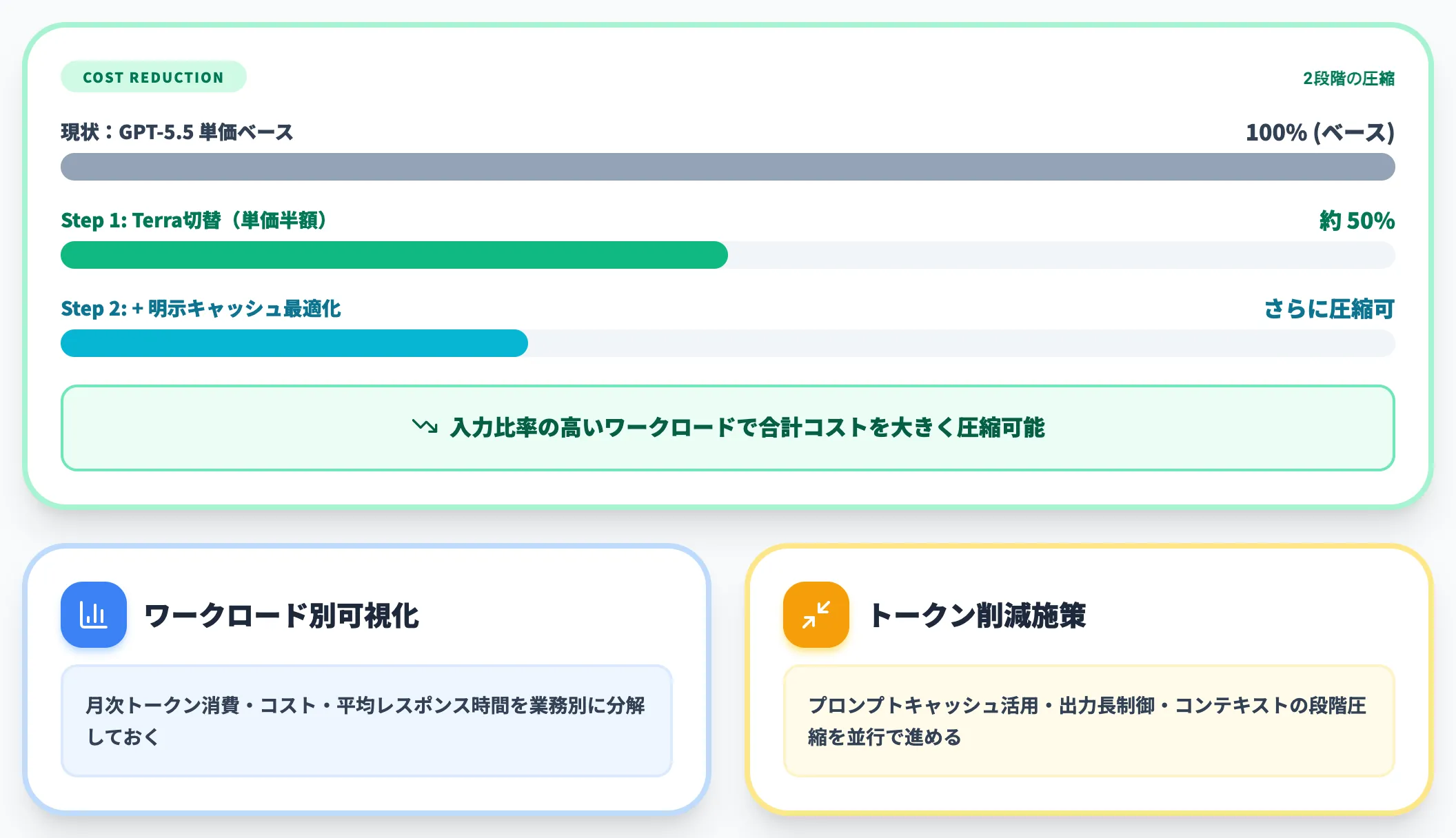
GPT-5.5を顧客サポート・社内ドキュメント生成・要約タスクなど大量呼び出しで使っている企業は、TerraへのスムーズなマイグレーションでコストROIを劇的に改善できる可能性があります。
具体的な準備は次の2点です。
- 現行GPT-5.5のAPI呼び出しをワークロード別に可視化する。月次トークン消費・コスト・平均レスポンス時間を業務別に分解しておく
- トークン削減施策を並行で進める。プロンプトキャッシュの活用・出力長制御・コンテキストの段階圧縮など、Terra切替前にコスト削減の最大化を進める
Terraに切り替えると入力・出力単価がちょうど半額になります。これに加えてプロンプトキャッシュの新仕様(30分最低・90%読み込み割引)を組み合わせれば、キャッシュヒット率や対象トークン比率次第ですが、入力側の比率が高いワークロードでは合計コストを大きく圧縮できる余地があります。
業務影響なしで月次API費用を大幅圧縮できるのは、GPT-5.6世代の最大の実務メリットの一つです。
サイバー防御業務担当企業の場合
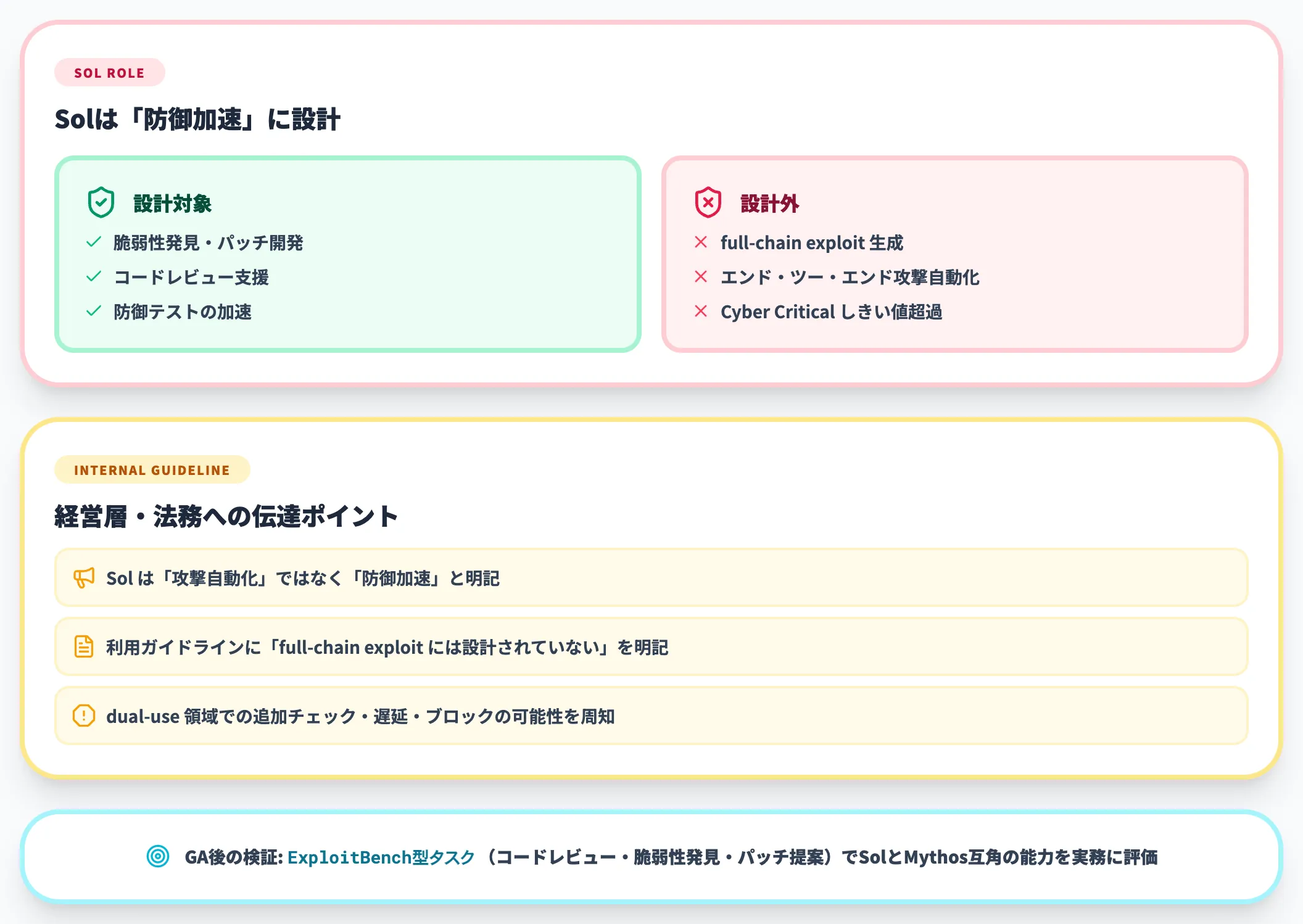
CISO配下のSOC・セキュリティ研究チーム・脆弱性管理担当を抱える企業は、Sol GAでサイバー防御業務にAIを組み込む現実的な選択肢が増えます。
GPT-5.5-CyberやGPT-5.4-CyberなどTrusted Access for Cyber対象モデルをすでに評価している場合、GA後にExploitBench型のタスク(コードレビュー・脆弱性発見・パッチ提案)でSolとMythos互角の能力を実務にどう活かすかを試す段階に進めます。
ただし重要なのは、Solは「攻撃自動化」ではなく「防御加速」に設計されている点を経営層・法務に正しく伝えることです。
Preparedness FrameworkのCyber Critical未到達という公式表明があるため、社内の利用ガイドラインに「Solはfull-chain exploit生成には設計されていない」「dual-use領域では追加チェックで遅延・ブロックが発生し得る」を明記しておくと、運用上のトラブルを減らせます。
マルチクラウド志向企業の場合
Anthropic Claude・Google Gemini・OpenAI GPTを併用するマルチクラウド戦略を取っている企業は、現時点の判断軸を整理しておく価値があります。
2026年6月時点のフロンティアモデル選択肢は以下のように整理できます。
- コーディング・サイバー研究 → Claude Opus 4.8(安定性)/GPT-5.5(Codex統合)/GPT-5.6 Sol GA後
- マルチモーダル → Gemini 3.1 Pro Preview/Gemini Interactions API
- 長文コンテキスト → Gemini 3.1 Pro Preview/Claude Opus 4.8
- コスト効率重視の大量処理 → GPT-5.5 Instant/GPT-5.6 Terra GA後/GPT-5.6 Luna GA後
GPT-5.6 Sol/Terra/Lunaが揃った後は、用途別の最適配分をモデル横断で再設計するタイミングになります。
特にTerra($2.50/$15)の登場で、これまでGPT-5.5でカバーしていた中精度バランス業務の単価が半分になる効果は大きく、マルチクラウド全体のコスト構造を見直す契機になります。
移行判断のチェックリスト
GPT-5.6 GA後に「採用するか」「どのティアか」「どの業務から」を判断する際の確認項目を、以下のチェックリストで整理しました。
- 自社の代表タスクでGPT-5.5の処理時間・トークン消費・成功率を計測済みか
- ultraモード採用時のサブエージェントトークン倍率を試算済みか
- プロンプトキャッシュの明示ブレークポイント設計を準備済みか
- dual-use領域(サイバー・生物学)でのブロック・遅延に対するフォールバック(GPT-5.5への切替等)を組み込み済みか
- 月次API費用のワークロード別可視化ができているか
- Trusted Access for CyberとGPT-5.6プレビューの違いを社内で正しく理解しているか
- GA後の最初の30日で実測するベンチマークタスクと評価指標が定まっているか
これらが揃っていれば、GA初日から実運用ベースの移行判断が可能になります。AI総合研究所の支援現場でも、GA前の準備が整っている企業ほど、新モデル登場後のコスト改善・業務改善のスピードに明確な差が出る傾向があります。

GPT-5.6世代の選択肢を業務に定着させるなら
GPT-5.6 Sol/Terra/Lunaのプレビュー登場で、フロンティアモデルの選択肢は広がりつつあります。しかし、最新モデルの能力を業務成果に変えるには、モデル選定の前に「自社の業務フローにAIエージェントをどう組み込むか」の基盤設計が鍵になります。
ここで効いてくるのが、自社のAzureテナント内で動くエンタープライズAIエージェント基盤 AI Agent Hub です。Microsoft Teamsを実行入口に、9種類の業務特化Agent(経費申請・請求書受領・設計製図・AI-OCR等)と組み合わせて、モデルの世代交代に関わらず業務側の運用基盤を継続的に活かせます。
- モデル世代交代に依存しない業務基盤
GPT-5.5 → GPT-5.6 → GPT-5.7とフロンティアが進化しても、業務側のエージェント定義・実行ログ・承認フローは継続的に蓄積。モデル差し替えで業務フローを作り直す手間が発生しません。
- データは100%自社テナント内に保持
GPT-5.6プレビューのような外部API依存と異なり、Azure Managed Applicationsとして自社テナント内で完結。サイバー業務・ガバナンス対象データを外に出さずに本番運用へ持ち込めます。
- 構築基盤が違っても管理は1つのダッシュボードに集約
Microsoft FoundryでもCopilot StudioでもN8nでも、どこで構築したAgentも実行ログ・アクセス権限・セキュリティスキャンを統合管理。シャドーAIの乱立を防ぎます。
AI総合研究所の専任チームが、フロンティアモデルの選定から業務実装・運用基盤の設計まで一貫してサポートします。AI Agent HubのLPで、自社の業務にどう組み込めるか具体例とあわせてご確認ください。
フロンティアモデル選定を業務実装まで繋ぐ

モデル選定から運用基盤の設計まで一元化
GPT-5.6世代のような新世代LLMの登場でも、業務に定着させるには自社テナント内のAIエージェント基盤が鍵になります。AI Agent HubのLPで、モデル選定から業務実装・運用設計までの全体像をご確認ください。
まとめ
本記事では、OpenAIが2026年6月26日にプレビュー公開したGPT-5.6シリーズについて、Sol/Terra/Lunaの命名思想・性能・料金・段階リリースの背景・セーフガード設計・競合比較・企業の備えまで、2026年6月時点の公式情報で解説しました。要点を改めて整理します。
-
GPT-5.6は数字(世代)とSol/Terra/Luna(機能ティア)を分離した新命名体系を導入し、3ティアがそれぞれ独自のリリースサイクルで進化する設計に移行した
-
GPT-5.6 SolはTerminal-Bench 2.1で新SOTA、ExploitBenchではClaude Mythos Previewと互角を出力トークン約1/3で達成。一方でPreparedness FrameworkのCyber Criticalしきい値には未到達で、防御加速に振った設計になっている
-
3ティアの単価はSol $5/$30、Terra $2.50/$15、Luna $1/$6で、Terraは現行GPT-5.5と同等性能で2倍安価。プロンプトキャッシュも30分最低・1.25x書き込み・90%読み込み割引の新仕様に刷新
-
プレビュー期間中はAPI/Codex経由で少数のtrusted partners and organizationsのみ。Trump政権の2026年6月2日大統領令「Promoting Advanced AI Innovation and Security」に基づく自発的な段階リリース運用で、OpenAI自身は「長期的なデフォルトにすべきでない」と表明
-
GA見通しは「coming weeks」で具体日付未公表。企業の現実的な備えは、GPT-5.5+Codexで業務フローを定着させつつ、Terra切替によるコスト半減・Sol採用によるサイバー防御業務加速の準備を並行で進めること
GPT-5.6世代はAI業界にとって、「能力の進化」と「アクセス制限の在り方」が同時に問われる節目です。企業にとっての本質的な問いは、「GPT-5.6を使えるか」ではなく、**「GPT-5.6世代のAIが市場に登場する前提で、自社の業務プロセスとAI活用基盤を整え直せるか」**にあります。
まずは現行のGPT-5.5やClaude Opus 4.8など利用可能なモデルで業務統合を進めつつ、GA後にスムーズに移行できる準備を整えることが、新世代AI時代を生き抜くための最も実用的な第一歩になります。









