この記事のポイント
 部門間でデータ定義が乱立している組織は、Fabric IQのOntologyでセマンティックレイヤーを統一すべき。AIエージェントの回答精度が大幅に向上する
部門間でデータ定義が乱立している組織は、Fabric IQのOntologyでセマンティックレイヤーを統一すべき。AIエージェントの回答精度が大幅に向上する- Operations AgentはLLM生成ルールでリアルタイム監視し条件合致時にAI推奨アクションを提示、在庫管理・異常検知など即時対応に最適
- Work IQ・Fabric IQ・Foundry IQの3層構造を活かすには、まずFabric IQのOntology定義から着手するのが効果的
- 追加SKU不要で既存Fabricサブスクリプションから利用開始できるため、導入障壁は低い。ただしCUメーター課金が発生するため事前の容量計画が必須
- プレビュー段階のため本番ワークロードへの全面適用は避け、特定ドメインでのパイロット検証から始めるべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Microsoft Fabric IQ(プレビュー)は、Fabric上のデータにビジネス用語で「意味」を与え、AIエージェントやアプリケーションから一貫した文脈で活用できるようにするセマンティックレイヤーです。
2025年11月のMicrosoft Ignite 2025で発表され、Ontology(オントロジー)・Plan・Graph(グラフ)・Data Agent・Operations Agentといったコンポーネントを備えています。
本記事では、Fabric IQの概要からIQエコシステムでの位置づけ、各コンポーネントの仕組み、使い方、活用事例、料金体系までを、2026年3月時点の最新情報をもとに解説します。
✅Microsoft 365 Copilotの最新エージェント機能「Copilot Cowork」については、以下の記事をご覧ください。
Copilot Coworkとは?機能や料金、Claude Coworkとの違いを解説
目次
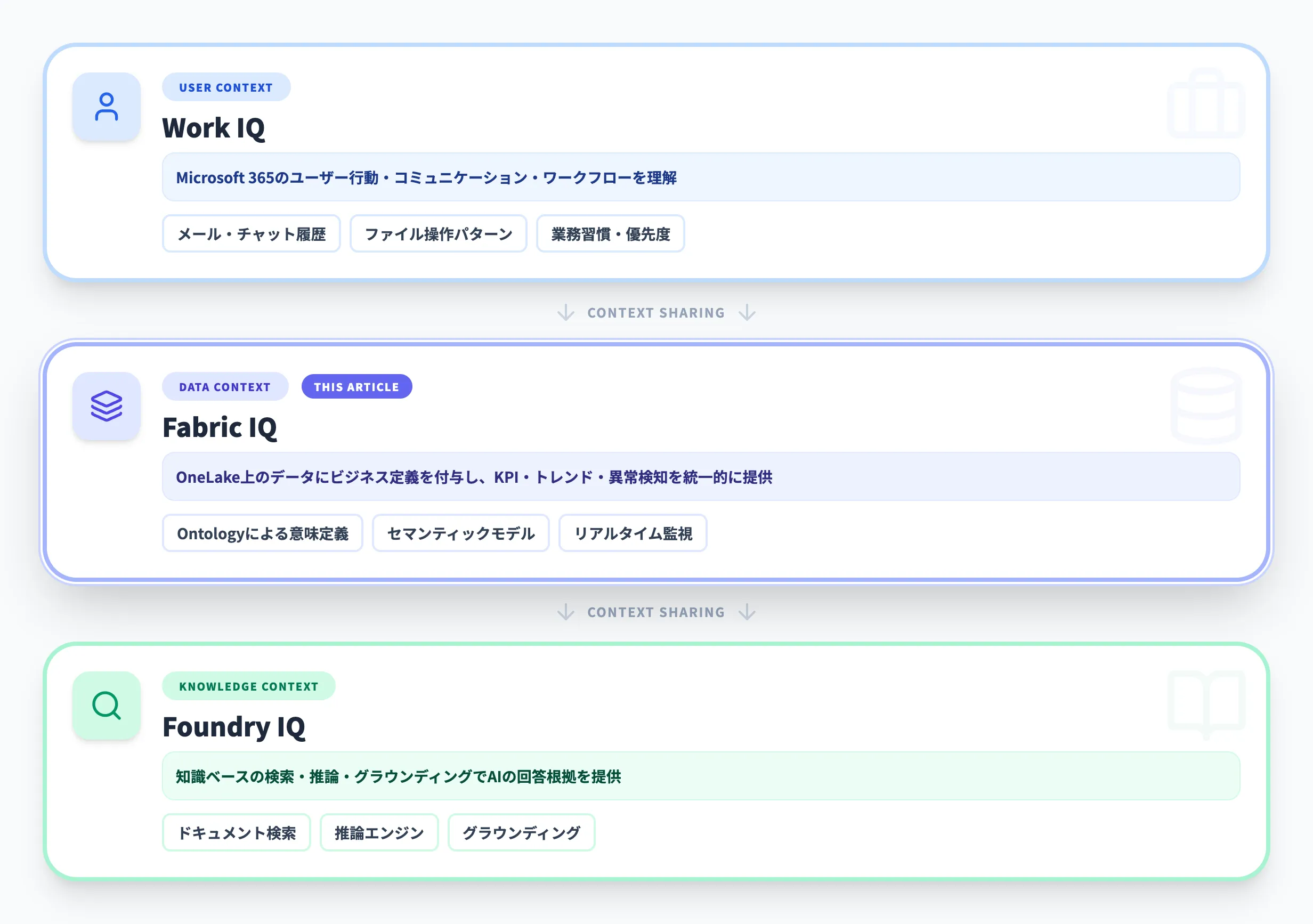
Microsoft IQエコシステムでのFabric IQの位置づけ
Work IQ・Fabric IQ・Foundry IQの3層構造
Fabric IQとは
Fabric IQ(プレビュー)は、Microsoft Fabricに新たに追加されたワークロードで、OneLake上のデータにビジネス用語で「意味」を定義し、AIエージェントやアプリケーションから統一的に活用できるセマンティックレイヤーを構築する機能です。
2025年11月のMicrosoft Ignite 2025で発表され、2026年3月時点ではパブリックプレビューとして提供されています。

従来のデータ基盤では、データの構造や形式は定義できても、「このテーブルの"顧客"はどの業務定義の顧客なのか」「"売上"は税込か税抜か」といったビジネス上の意味を一元的に管理する仕組みが不足していました。
部門ごとに異なる定義が乱立し、レポートの数字が食い違うといった課題は多くの企業で発生しています。
Fabric IQは、こうした課題を解決するために**Ontology(オントロジー)**という仕組みでビジネス用語・エンティティ型・関係性・ルールを定義し、OneLake上の実データにバインド(紐づけ)します。
これにより、どのワークロードやAIエージェントからアクセスしても、同じビジネス定義でデータを解釈できるようになります。
なぜFabric IQが必要なのか

Fabric IQが登場した背景には、データ基盤とAI活用の間にあるセマンティックギャップ(意味の断絶)の問題があります。
-
部門間のデータ定義のばらつき
営業部門と経理部門で「売上」の定義が異なる、製品コードの体系が事業部ごとに違うなど、データマートが乱立するとレポートの整合性が取れなくなる。
-
AIエージェントの精度向上
AIエージェントが正確な回答を返すためには、データの構造だけでなく「何を意味するか」を理解する必要がある。
Ontologyがないと、エージェントは列名やテーブル名の推測に頼ることになり、誤回答のリスクが高まる。
-
リアルタイム意思決定の需要
IoTセンサーやトランザクションデータをリアルタイムに監視し、異常を検知して即座にアクションを起こすシナリオでは、データの意味を事前に定義しておかないと自動化が成り立たない。
Fabric IQは、こうした課題に対して「データに意味を与える」というアプローチで応えるワークロードです。

Microsoft IQエコシステムでのFabric IQの位置づけ
Fabric IQは単独の機能ではなく、Microsoftが構築するIQエコシステムの中核を担うレイヤーの一つです。
ここでは、3つのIQレイヤーの役割とその連携を整理します。
Work IQ・Fabric IQ・Foundry IQの3層構造

Microsoftは2025年後半から、クラウド全体のインテリジェンスを3つのIQレイヤーで体系化する方針を打ち出しています。
以下の表で、各レイヤーの役割を整理します。
| レイヤー | 対象製品 | 提供するコンテキスト | 具体例 |
|---|---|---|---|
| Work IQ | Microsoft 365 | ユーザーコンテキスト | メール、チャット、ファイル操作、ワークフロー習慣 |
| Fabric IQ | Microsoft Fabric | データコンテキスト | KPI定義、トレンド、異常検知、セマンティックモデル |
| Foundry IQ | Microsoft Foundry | 知識コンテキスト | 知識検索、推論、グラウンディング |
ここで重要なのは、各レイヤーが「別々のAI」ではなく、共通のインテリジェンス基盤として連携する設計になっている点です。
たとえば、Copilotが業務に関する質問を受けたとき、Work IQがユーザーの文脈を提供し、Fabric IQがデータの意味を補完し、Foundry IQが知識ベースから根拠を検索するという協調動作が想定されています。
3つのIQレイヤーが連携するシナリオ

具体的なシナリオで連携イメージを見てみます。
たとえば、物流企業で「都市部の配送遅延が増加している」という状況が発生した場合、以下のような連携が考えられます。
-
Fabric IQ
OneLake上の配送データとOntologyを使い、遅延パターンを検知する。Operations Agentが「都市部ルートの平均遅延が閾値を超えた」とアラートを発火する。
-
Foundry IQ
契約書や業務マニュアルの知識ベースを検索し、「遅延が一定時間を超えた場合のペナルティ条項」を特定する。
-
Work IQ
運用チームの勤務状況やコミュニケーション履歴から、「対応可能なドライバーと管理者」を特定し、Teamsで通知を送る。
このように、3層のIQが協調することで、「異常検知 → 根拠確認 → 対応者への通知」までを自動化・半自動化できる構想です。
ただし、2026年3月時点ではこの3層統合はまだ発展途上であり、すべてが自動で連携するわけではありません。
Fabric IQの主要コンポーネント
Fabric IQは、以下の6つのコンポーネントで構成されています。それぞれの役割と関係性を整理します。
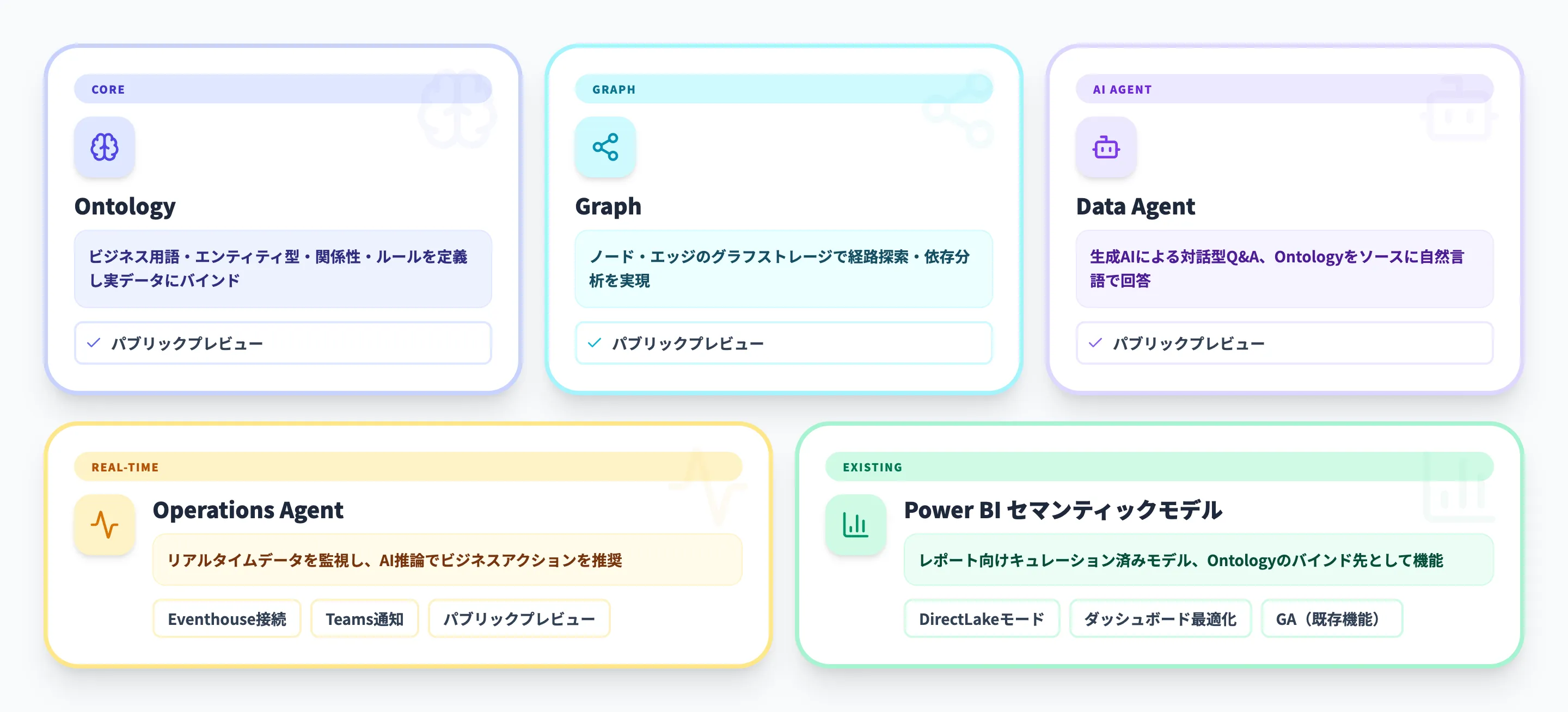
| コンポーネント | ステータス | 役割 |
|---|---|---|
| Ontology | パブリックプレビュー | ビジネス用語・エンティティ型・関係性・ルールを定義し、実データにバインド |
| Plan | パブリックプレビュー | 予算・予測・シナリオモデリングをFabric上で実行。Ontologyのエンティティに対して計画データを作成 |
| Graph | パブリックプレビュー | ノード・エッジのグラフストレージとコンピュート。経路探索・依存分析 |
| Data Agent | パブリックプレビュー | 生成AIを使った対話型Q&A。Ontologyをソースとして接続可能 |
| Operations Agent | パブリックプレビュー | LLM生成のルールでリアルタイムデータを監視し、条件合致時にAIが推奨アクションを提示 |
| Power BIセマンティックモデル | GA(既存機能) | レポート・インタラクティブ分析に最適化されたキュレーション済みモデル |
この中でFabric IQとして新たに加わったのはOntology・Plan・Graph・Operations Agentの4つです。
Data AgentはFabricデータエージェントとして先行提供されていた機能がFabric IQの傘下に統合された形で、Power BIセマンティックモデルは既存のGA機能がIQの文脈で再定義されています。
Ontology(オントロジー)

Ontologyは、Fabric IQの中核をなすコンポーネントです。
エンティティ型(顧客、製品、注文など)、プロパティ(名前、価格、日付など)、リレーションシップ(顧客が製品を購入する、など)、ルール(ビジネスロジック)を定義し、OneLake上の実データにバインド(紐づけ)します。
-
エンティティ型
従来のテーブル定義に「ビジネス上の意味」を加えたもの。たとえば「顧客」エンティティにはテーブルのどの列が名前で、どの列がIDかといったバインディングに加え、「この顧客はB2B取引先を指す」といった業務定義も記述できる
-
リレーションシップ
外部キー結合だけでなく、ビジネス上の関係性(「この製品はこのカテゴリに属する」「この顧客はこの地域を担当する」など)を明示的に定義する
-
ルールは、計算式やビジネスロジック(「売上 = 単価 × 数量 − 割引」など)をOntology上で定義し、どのワークロードからでも同じ計算結果を得られるようにする
Ontologyで定義したセマンティクスは、Data AgentやOperations Agent、Power BIなど複数のコンシューマーから参照できます。
つまり、ビジネス定義を一か所で管理し、全社的に統一する「Single Source of Truth(信頼できる唯一の情報源)」を目指す仕組みです。
Plan(プラン)

Plan(プレビュー)は、FabCon 2026(2026年3月)で発表された新しいコンポーネントです。
Ontologyで定義したエンティティに対して、予算・予測・シナリオモデリングをFabric上で直接実行できる機能を提供します。
-
予算策定
Ontologyのエンティティ(製品、部門、地域など)に対して予算を割り当て、実績データとリアルタイムに比較できる
-
予測モデリング
過去データに基づくAI支援の予測を生成し、Ontologyの文脈(ビジネス定義)を反映した予測シナリオを作成できる
-
シナリオ分析
「価格を10%引き上げた場合」「新市場に参入した場合」など、What-if分析をOntologyのエンティティ単位で実行できる
従来、予算策定やシナリオモデリングは専用のEPM(Enterprise Performance Management)ツールやExcelスプレッドシートで管理されることが一般的でした。PlanはこれらのワークフローをFabric上に統合し、Ontologyの定義と直接連携させることで、計画データと実績データの一貫性を保つことを目指しています。
Graph(グラフ)
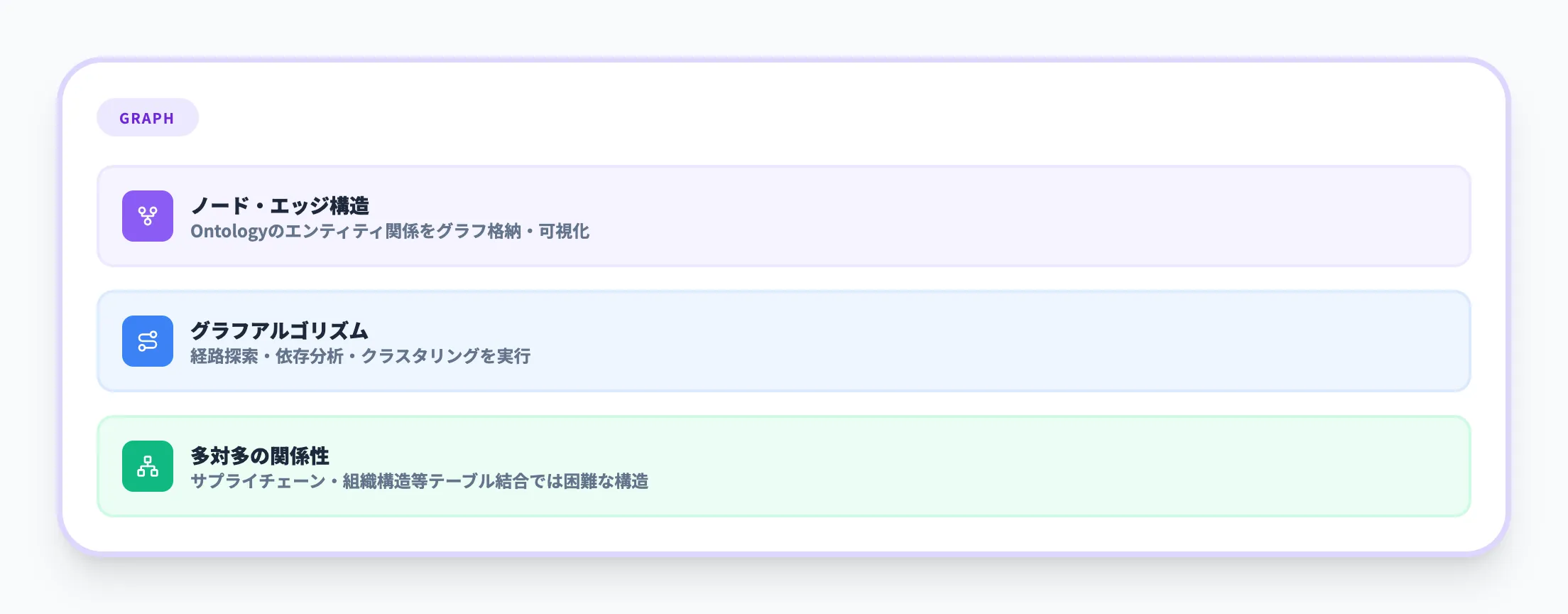
Graphは、**ノード(頂点)とエッジ(辺)**で構成されるグラフストレージとコンピューティングを提供するコンポーネントです。
-
Ontologyで定義したエンティティ同士の関係性を、グラフ構造として格納・可視化できる
-
パス検索(「AからBに至る最短経路は?」)、依存関係分析(「このサプライヤーに影響を受ける全製品は?」)、クラスタリングなどのグラフアルゴリズムを利用可能
-
Ontologyとの連携により、グラフのノードやエッジにビジネス上の意味が自動的に付与される
Graphが特に有効なのは、多対多の複雑な関係性を扱うシナリオです。
サプライチェーンの依存関係、組織の指揮命令系統、ネットワークトポロジーなど、テーブル結合だけでは表現しにくい構造をGraphで自然に扱えます。
Data Agent(データエージェント)
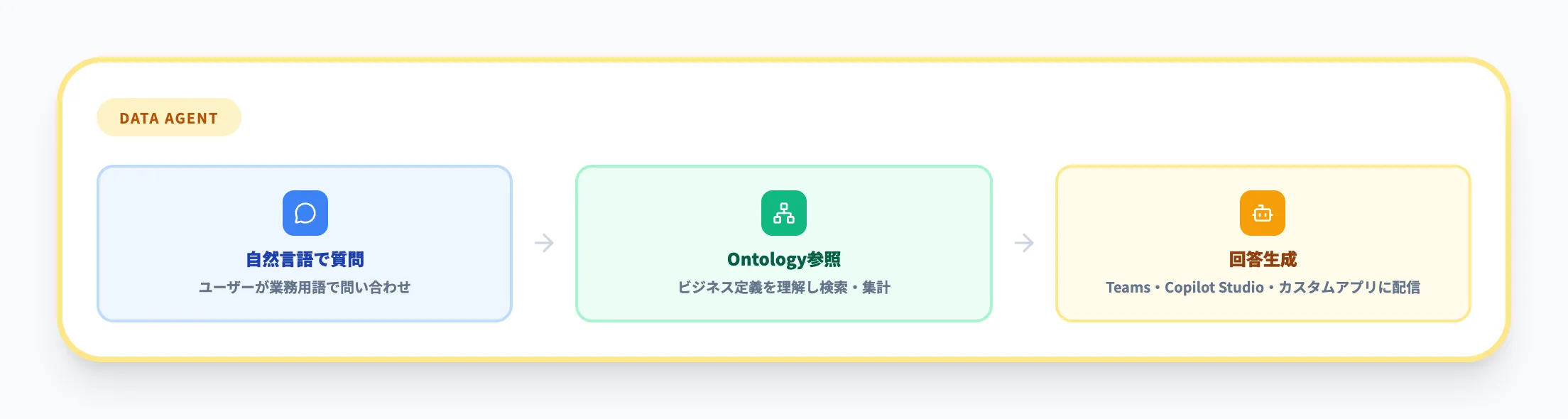
Data Agentは、生成AIを使った対話型のQ&Aシステムです。
ユーザーが自然言語で質問すると、Ontologyやセマンティックモデルをソースとしてデータを検索・集計し、回答を生成します。
-
Ontologyをソースとして接続することで、エージェントがビジネス定義を理解した状態で回答できる
-
Lakehouse、Warehouse、Power BIセマンティックモデルなど複数のデータソースを横断して検索可能
-
Microsoft Teams、Copilot Studio、カスタムアプリケーションに組み込んで利用できる
Data AgentはFabric IQが登場する前から提供されていた機能ですが、Ontologyとの統合により「データの意味を理解した上で回答する」精度の向上が期待されています。
従来はテーブル名や列名の推測に頼っていた部分が、Ontologyのエンティティ定義によって補完されるためです。
Operations Agent(オペレーションエージェント)

Operations Agentは、リアルタイムデータを監視し、定義されたルール・条件に基づいて異常を検知し、AIによる推奨アクションを提示するハイブリッド型のエージェントです。
-
Eventhouse(Real-Time Intelligence)のKQLデータベースに接続し、ストリーミングデータを5分間隔で監視する
-
ユーザーが自然言語でビジネス目標や指示を入力すると、LLMがプレイブック(エンティティ・ルール・KQLクエリの構造化定義)を自動生成する。このプレイブックに基づいてエージェントがデータを監視する
-
ルール・条件に合致するデータが検知されると、LLMがデータを分析し、推奨アクションと対応メッセージをMicrosoft Teams経由で通知する
-
推奨アクションに対してユーザーが承認・却下を行い、承認された場合はPower Automateフローなどで実行に移せる
Operations Agentが従来のFabric Activatorと異なるのは、ルール生成と推奨メッセージの両方にLLMを活用するハイブリッド型である点です。監視ループ自体はルール・条件ベースの決定論的な処理で動作しますが、そのルールの作成と、条件合致時の原因分析・対応策の提案にAIを使います。つまり「何を監視するか」の設計をAIが支援し、「条件に合致したか」の判定はルールベースで行い、「どう対応すべきか」の推奨にAIが関与する3段階の構造です。
Power BIセマンティックモデルとの関係
Power BIのセマンティックモデル(旧データセット)は、もともとFabricに存在していた分析用のキュレーション済みモデルです。
Fabric IQの文脈では、Ontologyの定義生成元やバインド先としての役割が加わります。
-
Ontologyのエンティティ定義はImport・DirectLake・DirectQueryいずれのセマンティックモデルからも生成できる。ただし、データバインディングの自動生成とクエリ実行はDirectLakeモードのみ対応
-
データバインディングは、OneLakeのマネージドレイクハウステーブル(静的データ)やEventhouse(時系列データ)に手動で設定することも可能
-
Power BIセマンティックモデルはレポート・ダッシュボード向けに最適化されたモデルであり、Ontologyはその上にビジネス定義を重ねる位置づけ
-
既存のPower BIセマンティックモデルがある場合、Ontologyを追加定義することでAIエージェント連携を段階的に強化できる
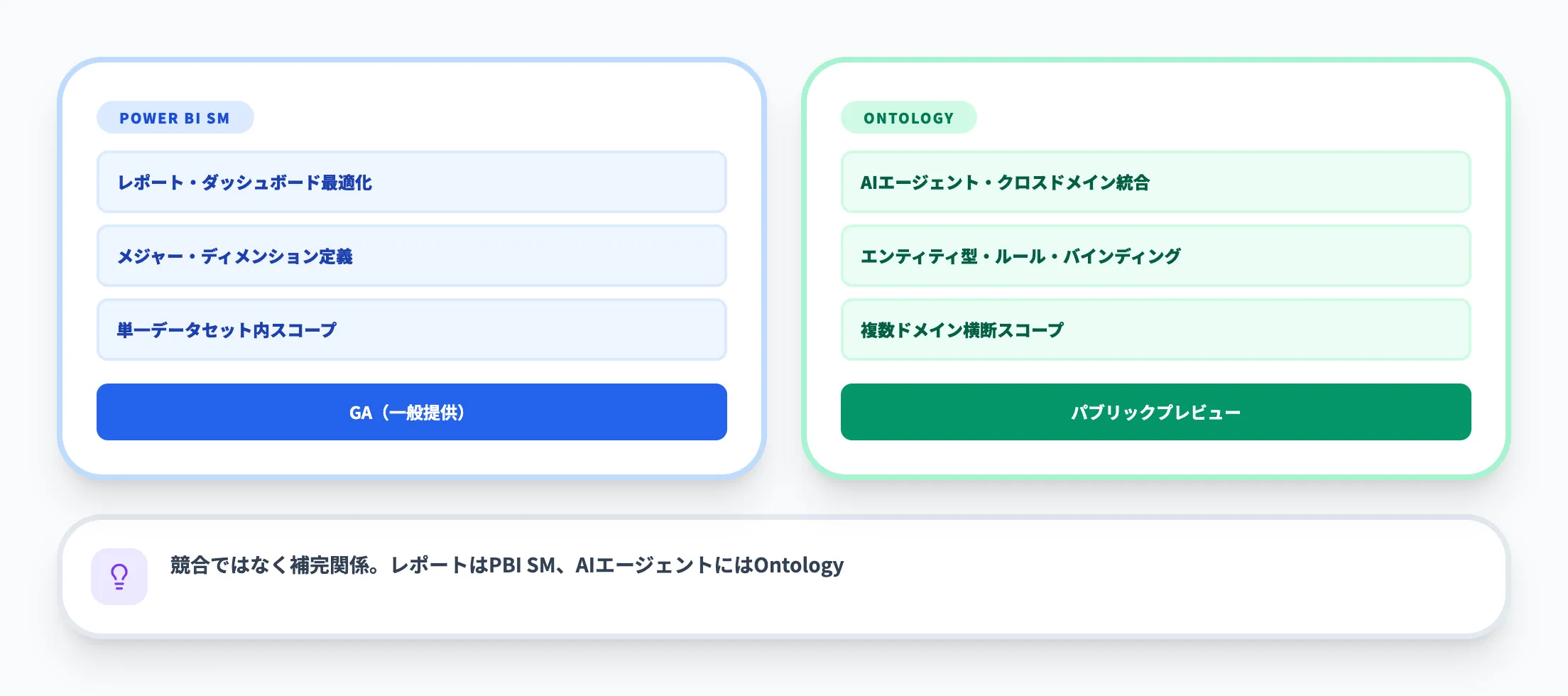
つまり、Power BIセマンティックモデルとOntologyは競合する関係ではなく、補完する関係です。
レポーティングにはPower BIセマンティックモデル、AIエージェントやクロスドメインのデータ統合にはOntologyという使い分けが基本になります。
Fabric IQの使い方
ここでは、Fabric IQを利用するための前提条件と、Ontologyの作成手順の概要を解説します。
前提条件と有効化手順
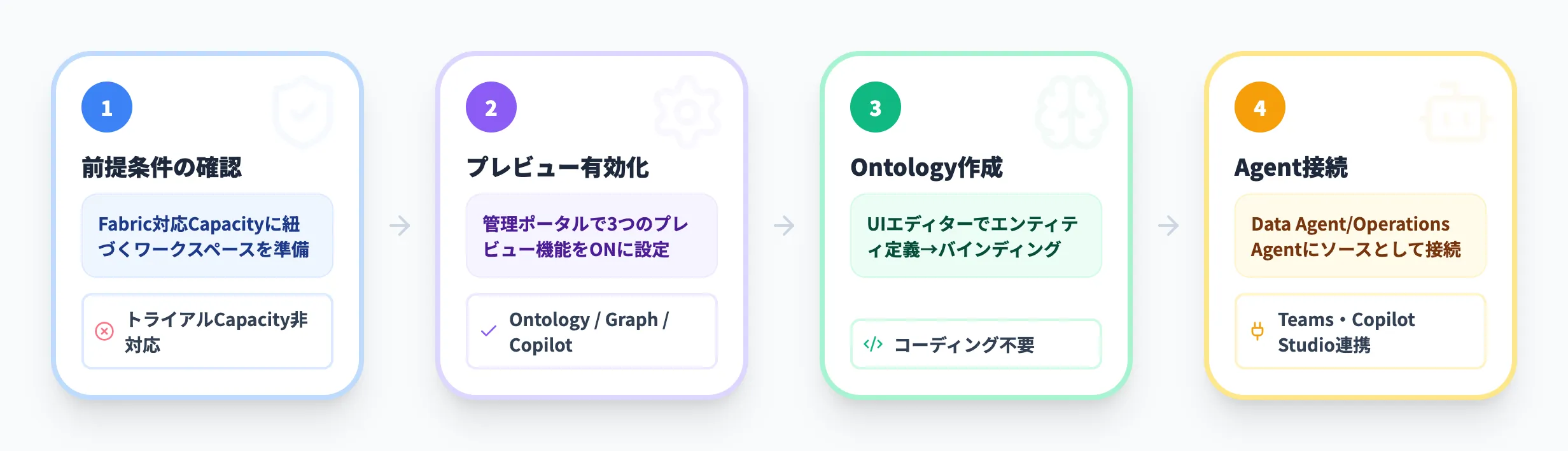
Fabric IQはコンポーネントごとに前提条件が異なります。Ontology・Graph・Plan、Data Agent、Operations Agentの3段階に分けて整理します。
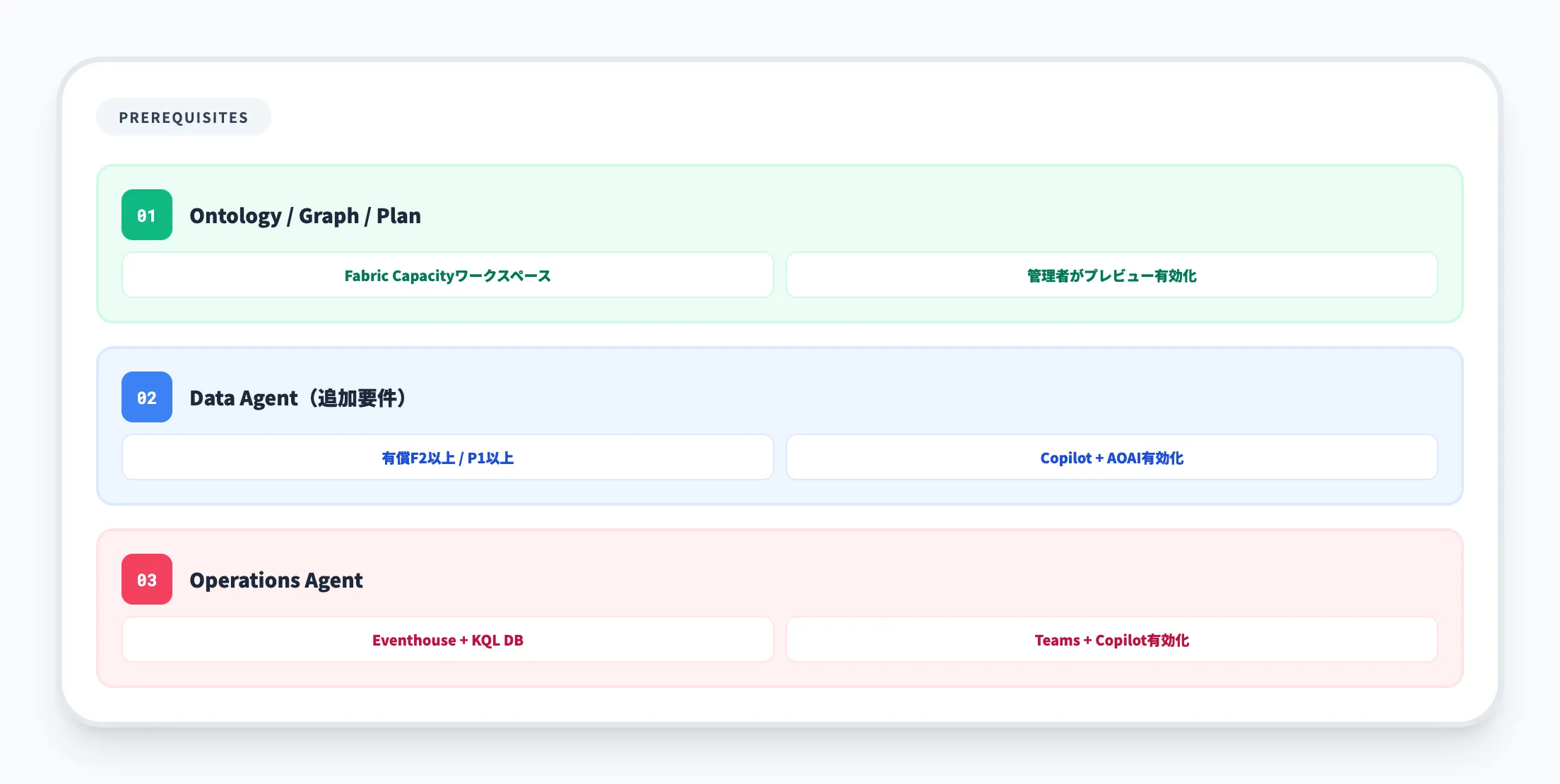
Ontology / Graph / Plan(基本機能)の前提条件
-
Microsoft Fabric対応のCapacityに紐づくワークスペースが必要
-
テナント管理者によるプレビュー機能の有効化が必要。Fabric管理ポータルで以下の2項目を有効にする
- Ontology(プレビュー)
- Graph(プレビュー)
Data Agent(対話型Q&A)の追加前提条件
Data Agentを利用する場合は、上記に加えて以下の設定と有償Capacityが必要です。
-
有償のF2以上またはP1以上のCapacityが必要(トライアルCapacityは非対応)
-
Data agent item types(プレビュー)の作成・共有を有効化
-
Copilot and Azure OpenAI Serviceを有効化
-
Azure OpenAIへのデータ送信(処理・保存)に関するリージョン外設定を有効化(Fabricキャパシティのリージョンによっては必須)
Operations Agent(リアルタイム監視)の前提条件
Operations Agentは独立した前提条件を持ちます。
-
**Fabric対応のCapacity(トライアルCapacityは非対応)**に紐づくワークスペースが必要
-
テナント管理者によるOperations Agent(プレビュー)の有効化が必要
-
Copilot and Azure OpenAI Serviceを有効化
-
Azure OpenAIへのデータ送信に関するリージョン外設定を有効化(Capacityが米国・EU以外のリージョンの場合は必須)
-
Eventhouse、KQLデータベース、Microsoft Teamsアカウントが必要
有効化後は、Fabricワークスペース内で「新しいアイテム」からOntologyやGraphを作成できるようになります。
Ontologyの作成手順(チュートリアル概要)
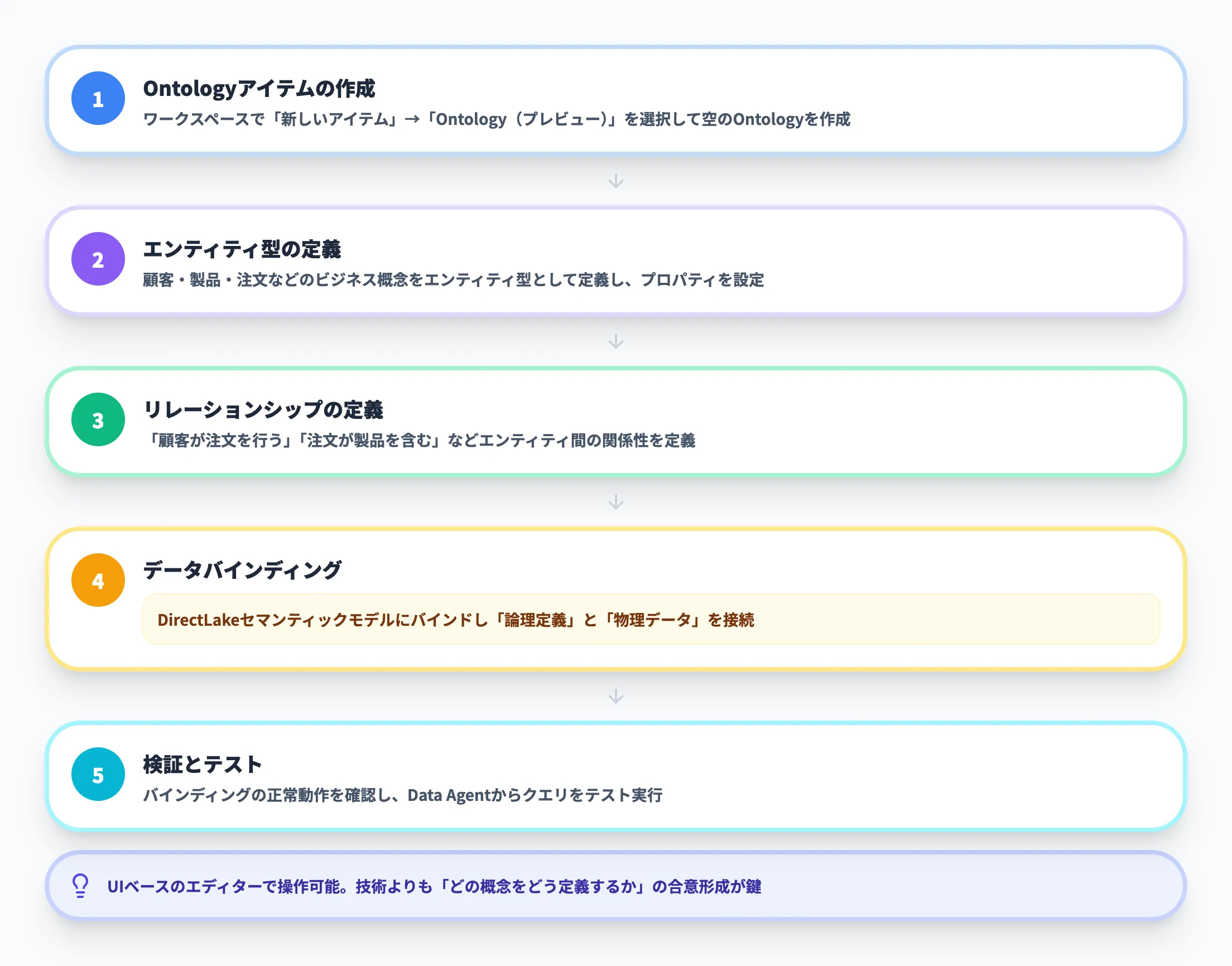
Microsoftは公式チュートリアル(全6パート)を公開しています。大まかな流れは以下のとおりです。
-
Ontologyアイテムの作成
Fabricワークスペースで「新しいアイテム」→「Ontology(プレビュー)」を選択し、空のOntologyを作成する。
-
エンティティ型の定義
ビジネス上の概念(顧客、製品、注文など)をエンティティ型として定義する。各エンティティ型にプロパティ(名前、価格、日付など)を設定する。
-
リレーションシップの定義
エンティティ型同士の関係性(「顧客が注文を行う」「注文が製品を含む」など)を定義する。
-
データバインディング
定義したエンティティ型やプロパティを、OneLake上の実データにバインドする。バインド先はOneLakeのマネージドレイクハウステーブル(静的データ)やEventhouse(時系列データ)を選択できる。セマンティックモデルから生成した場合はDirectLakeモードであればバインディングが自動生成される。ここで「論理的な定義」と「物理的なデータ」が接続される。
-
検証とテスト
バインディングが正しく機能しているかを確認し、Data Agentなどのコンシューマーからクエリをテストする。
Ontologyの作成はUIベースのエディターで行えるため、コーディングは不要です。
ただし、ビジネス用語の定義やリレーションシップの設計には、データエンジニアとビジネス担当者の協働が重要になります。技術的な作業よりも、「どの概念をどう定義するか」の合意形成が導入の鍵です。
Data Agentとの接続

Ontologyを作成したら、Data Agentのソースとして接続できます。
-
Data Agentの設定画面で、ソースとしてOntologyを選択する
-
エージェントは、Ontologyで定義されたエンティティ型・リレーションシップ・ルールを理解した状態で自然言語の質問に回答するようになる
-
Copilot Studioと連携すれば、Teamsやカスタムアプリにエージェントを組み込むことも可能
Data Agentの詳しい仕組みや作り方については、Microsoft Fabricデータエージェントとは?仕組みから作り方まで解説で詳しく紹介しています。
Fabric IQの活用事例
Fabric IQはプレビュー段階ですが、すでにいくつかの企業や業界での活用が報告されています。
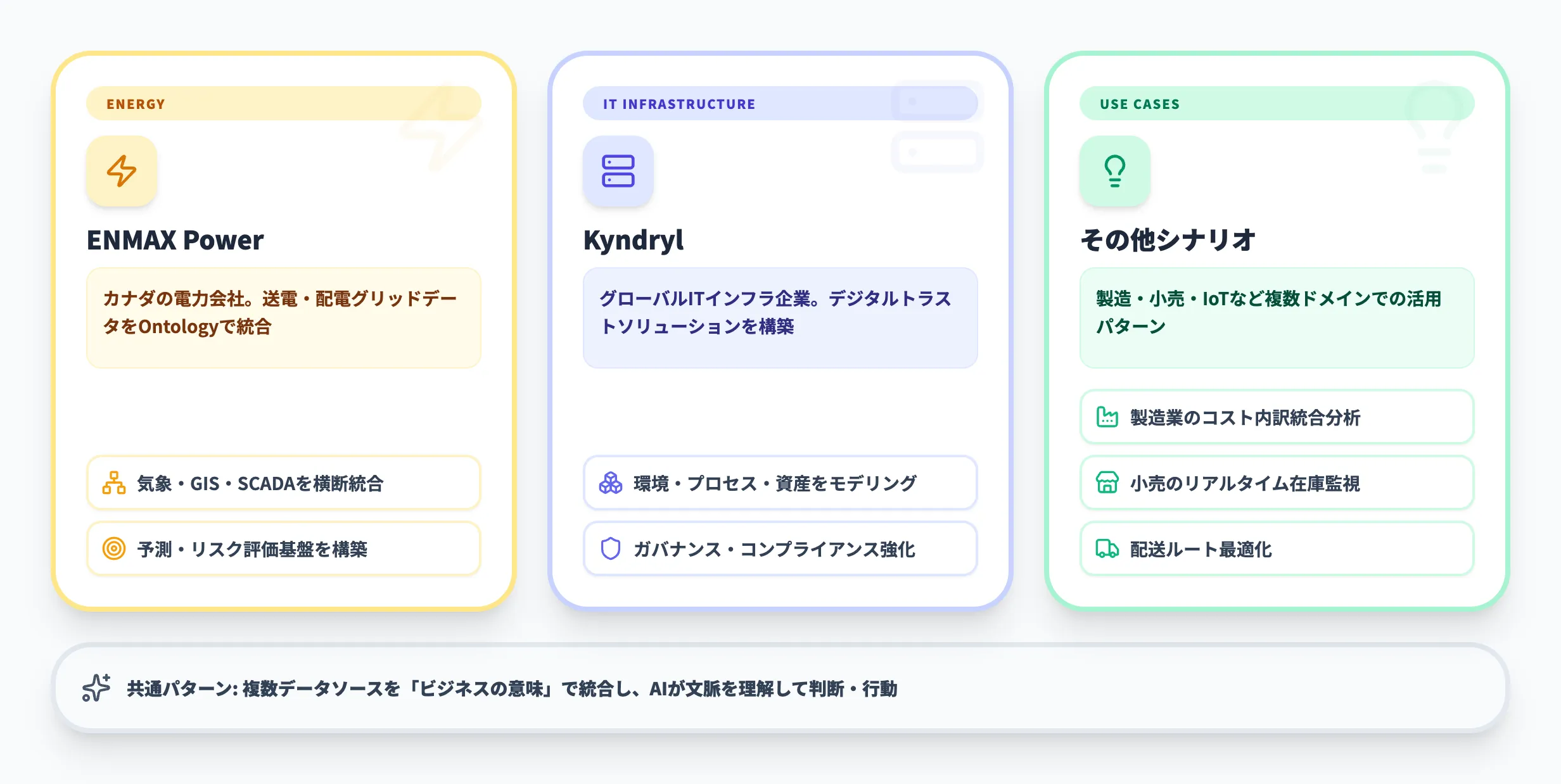
ENMAX Power(エネルギー・グリッドデータ統合)
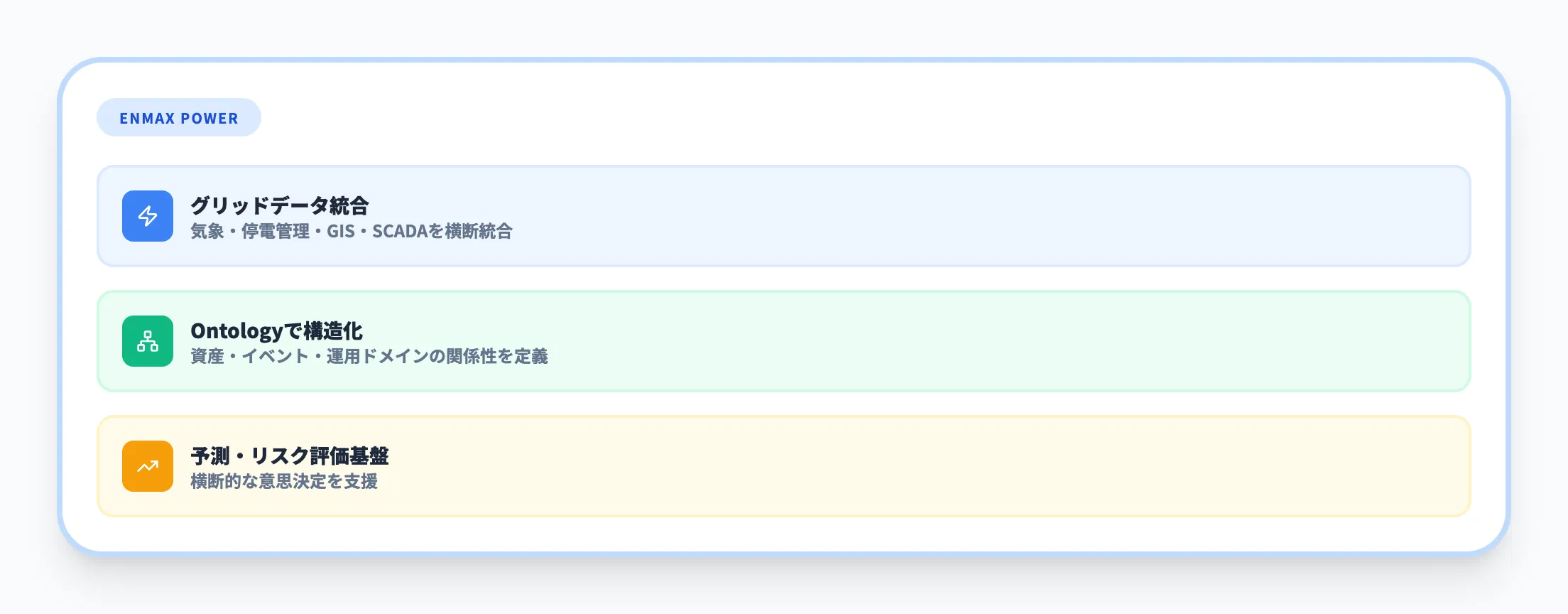
カナダの電力会社ENMAXは、Fabric IQのOntologyを活用して送電・配電グリッドデータの統合に取り組んでいます。
電力会社では、気象システム、停電管理、GIS(地理情報システム)、SCADA(監視制御システム)など複数の運用ドメインにデータが散在しています。
ENMAXはOntologyで資産・イベント・運用ドメインの関係性を構造化し、横断的な予測・リスク評価・意思決定の基盤を構築しています。
このケースは、複数の運用システムにまたがるデータを「ビジネス上の意味」で統合するというFabric IQの典型的な活用パターンです。
Kyndryl(ITサービス・デジタルツイン)
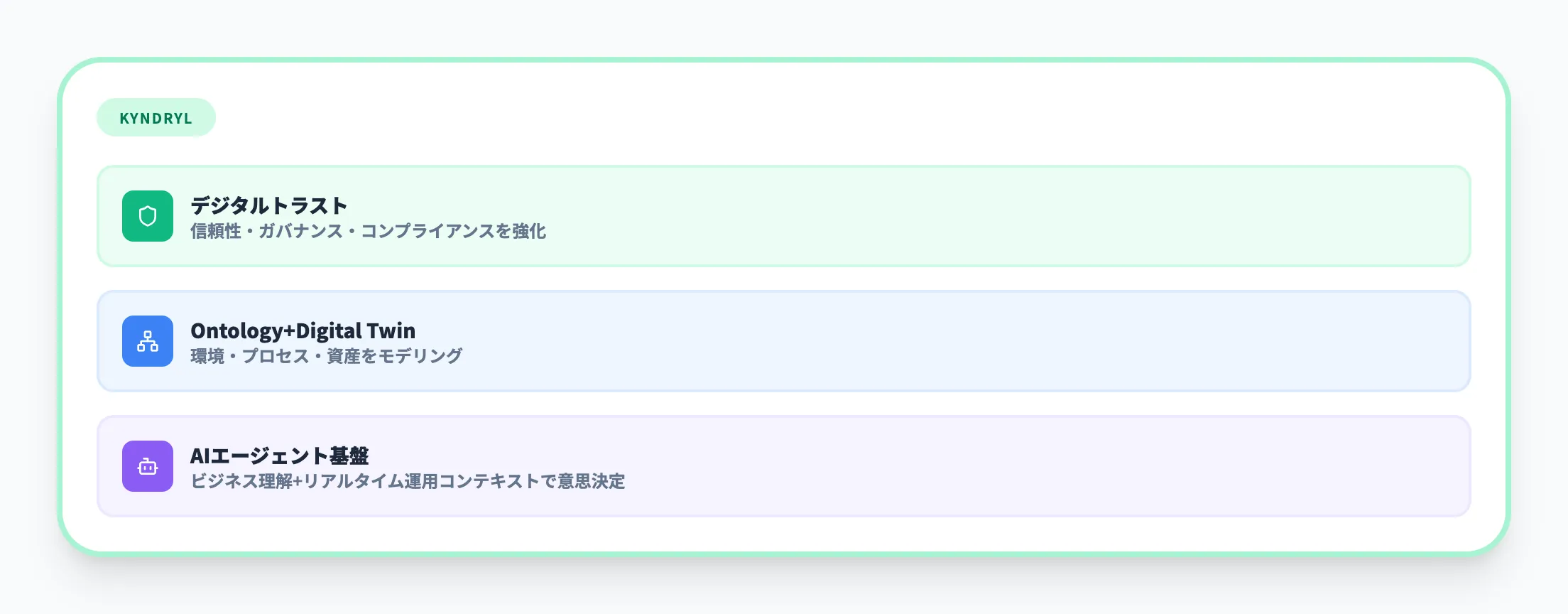
グローバルITインフラサービス企業のKyndrylは、Fabric IQ、Digital Twin Builder、Real-Time Intelligenceを組み合わせたデジタルトラストソリューションを構築しています。
-
環境・プロセス・資産のモデリングをOntologyで定義
-
AIエージェントがビジネス理解とリアルタイムの運用コンテキストに基づいて意思決定を行う基盤を整備
-
信頼性・ガバナンス・コンプライアンスをエージェントレベルで強化
Kyndrylのケースは、Fabric IQをAIエージェントのための「ビジネス理解の基盤」として位置づけている点が特徴です。データ基盤をAIエージェントが直接参照できる形に進化させるという、Fabric IQが目指す方向性を先行的に実践している事例といえます。
その他のユースケースシナリオ
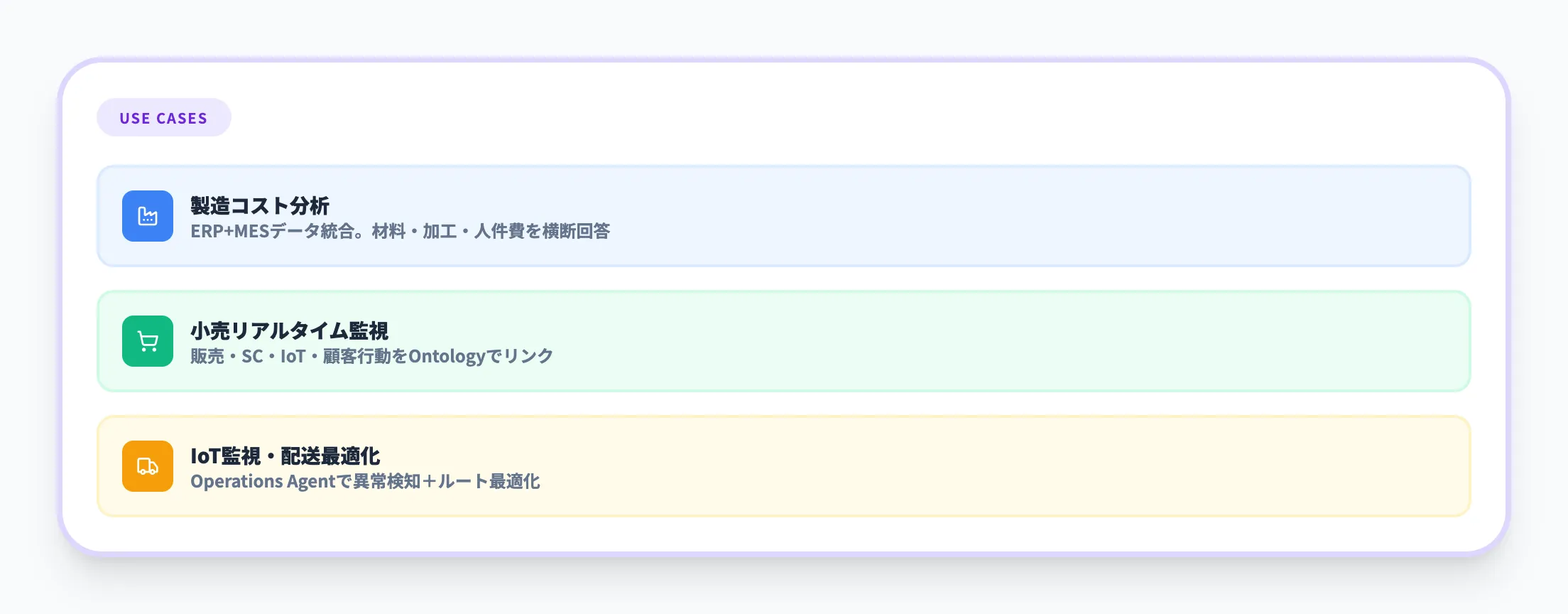
Microsoft公式やコミュニティでは、以下のようなユースケースシナリオも提示されています。
-
製造業のコスト分析
「製品」「コスト」「工程」の関係をOntologyで定義し、ERPとMESのデータを統合する。ユーザーが「主要製品の詳細なコスト内訳」を聞くと、Data Agentが材料費・加工費・人件費を統合的に回答する。
-
小売業のリアルタイム監視
販売トランザクション、サプライチェーンイベント、IoTセンサーデータ、顧客行動データをOntologyでリンクし、リアルタイムに監視する。
-
IoTデバイス監視・配送ルート最適化
Operations Agentを使い、IoTデバイスの異常検知や配送ルートの最適化をリアルタイムに実行する。
これらのシナリオに共通するのは、複数のデータソースを「ビジネスの意味」で統合し、AIエージェントが文脈を理解した上で判断・行動するという構図です。

従来のセマンティックモデルとFabric IQの違い

Fabric導入済みの企業にとって気になるのは、「既存のPower BIセマンティックモデルとFabric IQのOntologyはどう違うのか」という点です。
以下の表で主な違いを整理します。
| 観点 | Power BIセマンティックモデル | Fabric IQ Ontology |
|---|---|---|
| 主な用途 | レポート・ダッシュボード向けの分析モデル | AIエージェント・クロスドメイン統合向けのセマンティック定義 |
| 対象ユーザー | BIアナリスト・レポート作成者 | データエンジニア・ビジネスアーキテクト |
| 定義する内容 | メジャー・ディメンション・リレーションシップ | エンティティ型・プロパティ・リレーションシップ・ルール・バインディング |
| コンシューマー | Power BIレポート | Data Agent・Operations Agent・Graph・Power BI |
| スコープ | 単一のデータセット内 | 複数のドメイン・データソースを横断 |
| ステータス | GA(一般提供) | パブリックプレビュー |
注目すべきは、両者が競合ではなく補完関係にある点です。
Power BIセマンティックモデルはレポーティングに最適化されたモデルであり、Ontologyはその上に「ビジネス定義」のレイヤーを重ねます。
実際に、OntologyはDirectLakeセマンティックモデルにバインドして使う設計になっているため、既存のセマンティックモデルを活かしながらOntologyを追加するという段階的な導入が可能です。
「まずPower BIセマンティックモデルで分析基盤を整え、その上にOntologyを追加してAIエージェント連携を強化する」という順序が、現時点での現実的なアプローチです。
Fabric IQが向いている場面と向かない場面

Fabric IQはすべてのシナリオに必要なわけではありません。導入を検討すべき場面と、現時点では見送ってよい場面を整理します。
向いている場面

-
部門間でデータ定義が乱立しており、「どの数字が正しいか分からない」状態にある
Ontologyで統一的なビジネス定義を管理することで、部門横断のデータ整合性を確保できる。
-
AIエージェントの回答精度を高めたい
Data AgentがOntologyの定義を参照することで、テーブル名の推測に頼る回答からビジネス定義に基づく回答へ進化する。
-
リアルタイムデータの監視とルール+AIによるアクション推奨を自動化したい
Operations Agentの活用シナリオ。LLMがルールを生成し、条件合致時にAIが推奨アクションを提示する。IoT、運用監視、サプライチェーン管理など。
-
複数のデータドメインにまたがる複雑な関係性を可視化・分析したい
Graphによるネットワーク分析、依存関係追跡、経路探索。
向かない場面・注意点
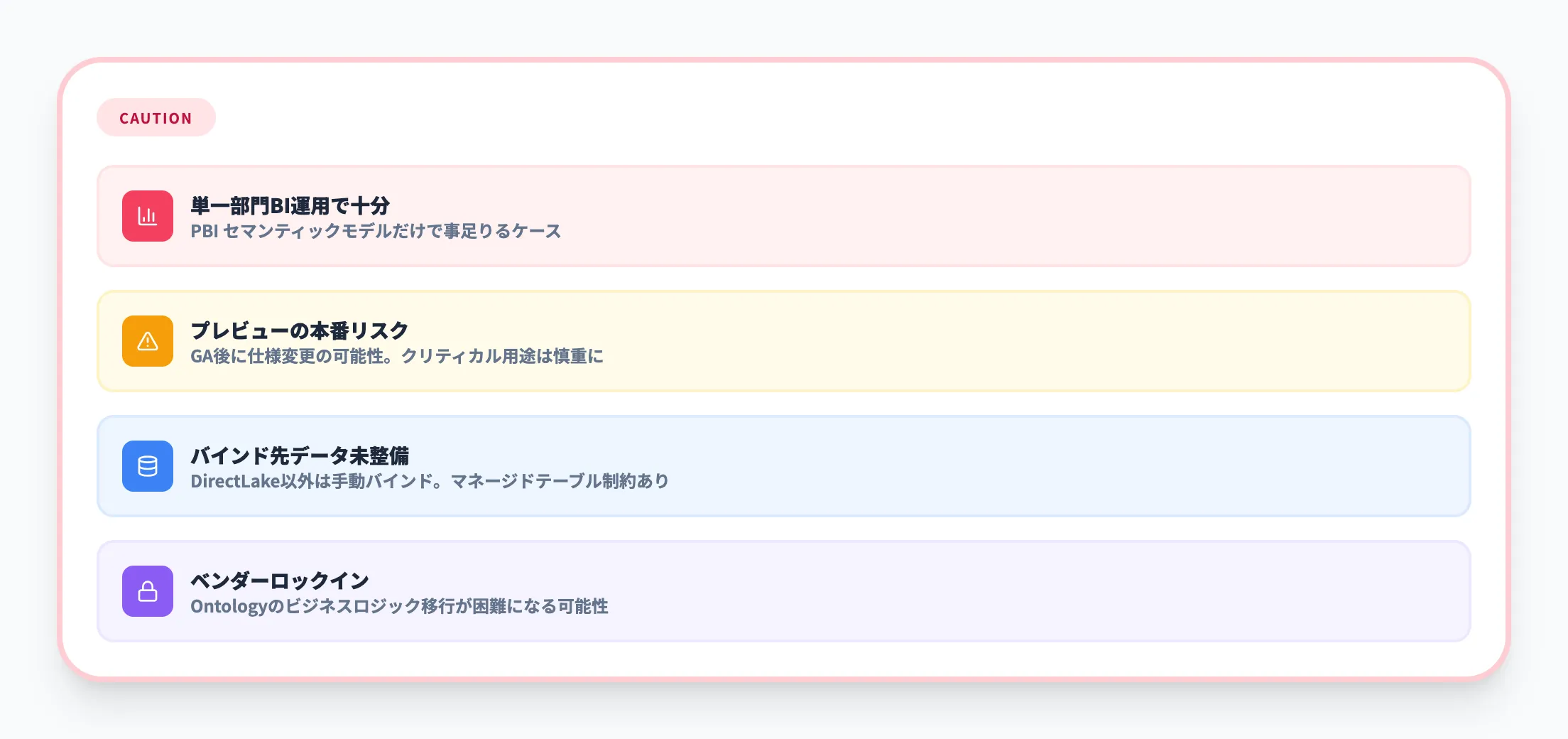
-
単一部門のBIレポーティングだけで十分な場合
Power BIセマンティックモデルで事足りるケースでは、Ontologyの追加は過剰な設計になりうる。
-
プレビュー機能を本番環境で使うリスクを許容できない場合
2026年3月時点ではパブリックプレビューであり、GA後に仕様が変更される可能性がある。本番クリティカルなワークロードへの適用は慎重に評価すべき。
-
データバインディング対象のデータソースが準備できていない場合
Ontologyの定義生成はどのセマンティックモデルモードでも可能だが、データバインディングとクエリ実行の自動生成はDirectLakeモードのみ対応。OneLakeのマネージドレイクハウステーブルやEventhouseへの手動バインドも可能だが、マネージドテーブルの制約(列マッピング無効、OneLakeセキュリティ無効など)を満たす必要がある。
-
ベンダーロックインを懸念する場合
アナリストの中には、「Ontologyに構築したビジネスロジックを他のプラットフォームに移行するのは難しくなる」という指摘もある。Microsoft以外のデータ基盤への移行を視野に入れている場合は、この点を事前に評価しておく必要がある。
Fabric IQの料金体系

Fabric IQは、既存のMicrosoft Fabricサブスクリプションに含まれる機能です。
追加のSKU購入やライセンス契約は不要ですが、各コンポーネントの利用に応じてCapacity Units(CU)が消費されます。
Ontologyの課金メーター
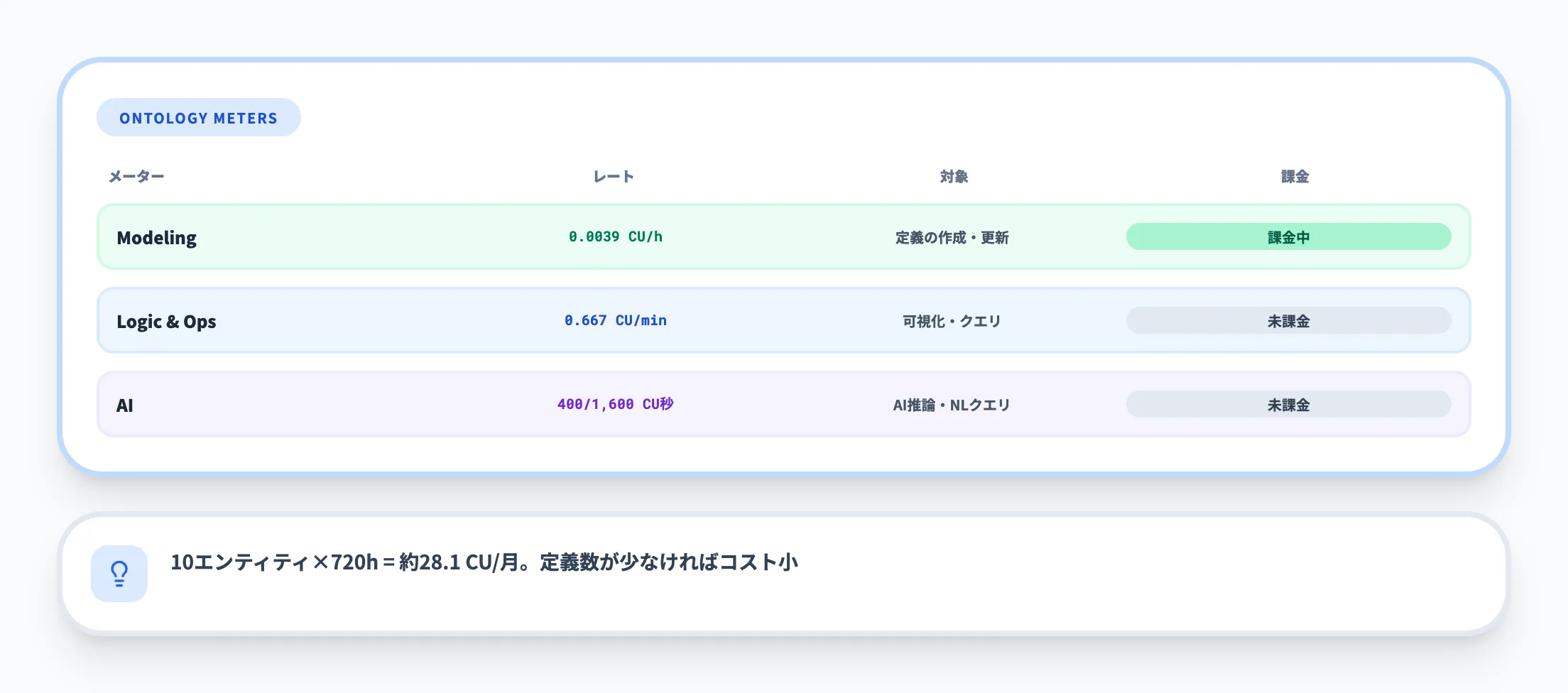
Ontologyには3つの課金メーターが定義されています。2026年3月時点の課金ステータスは以下のとおりです。
| メーター | 対象操作 | レート | 課金ステータス |
|---|---|---|---|
| Ontology Modeling | エンティティ型やリレーションシップの作成・更新・削除 | 0.0039 CU/時間(定義数 × 使用時間) | 課金中 |
| Ontology Logic and Operations | 可視化、クエリ、グラフ操作 | 0.666667 CU/分 | 未課金(Graph使用分のみ課金) |
| Ontology AI | AI推論・自然言語クエリ | 入力: 400 CU秒/1,000トークン、出力: 1,600 CU秒/1,000トークン | 未課金(Copilot in Fabric使用分のみ課金) |
Ontology Modelingの課金は「定義したエンティティ型の数 × 保持時間」で計算されます。たとえば、10個のエンティティ型を定義して1か月(720時間)保持した場合、10 × 720 × 0.0039 = 約28.1 CU/月が消費されます。
定義数が少なければコストは小さいですが、大規模なOntologyを構築する場合はCU消費を見積もっておく必要があります。
Operations Agentの課金メーター
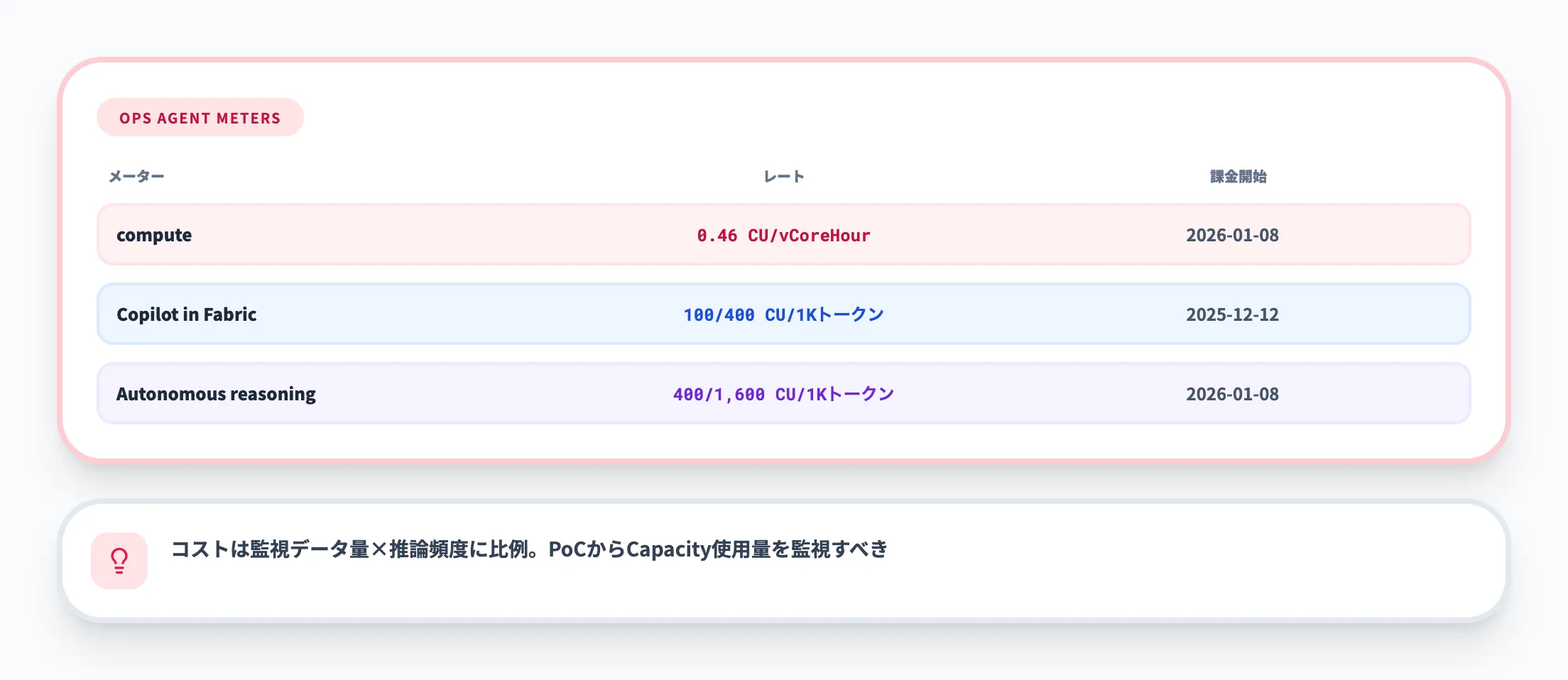
Operations Agentには独自の課金メーターがあり、2026年1月8日以降に課金が開始されています。
| メーター | レート | 課金開始日 |
|---|---|---|
| Operations Agent compute | 0.46 CU/vCoreHour | 2026年1月8日 |
| Copilot in Fabric | 入力: 100 CU/1,000トークン、出力: 400 CU/1,000トークン | 2025年12月12日 |
| Autonomous reasoning | 入力: 400 CU/1,000トークン、出力: 1,600 CU/1,000トークン | 2026年1月8日 |
Operations Agentのコストは、監視対象のデータ量と推論の頻度に比例します。
リアルタイムで大量のイベントを監視する場合はCU消費が大きくなるため、PoCの段階からCapacity使用量をモニタリングしておくことが重要です。
課金ステータスと今後の見通し

2026年3月時点では、一部のメーターが「未課金」(プレビュー期間中は無料)となっていますが、GA後にはすべてのメーターで課金が有効化される見込みです。
-
すでに課金中
Ontology Modeling、Operations Agent compute、Copilot in Fabric、Autonomous reasoning
-
未課金(今後有効化予定)
Ontology Logic and Operations(Graph使用分を除く)、Ontology AI(Copilot使用分を除く)
Fabric IQのコストは既存のCapacity(F SKU)から差し引かれる形で消費されるため、他のワークロード(Data Warehouse、Power BI、Notebookなど)とリソースを共有する点に注意が必要です。
Fabric IQの利用が増えると、他のワークロードのパフォーマンスに影響する可能性があります。
大規模なOntologyやOperations Agentの常時稼働を予定している場合は、Fabric IQ専用のCapacityを検討するか、少なくともCU消費のモニタリングを早い段階から始めることをおすすめします。

まとめ
本記事では、Microsoft Fabric IQ(プレビュー)の概要から、IQエコシステムでの位置づけ、6つの主要コンポーネント、使い方、活用事例、従来のセマンティックモデルとの違い、料金体系までを整理しました。
-
Fabric IQは、OneLake上のデータにビジネス用語でセマンティクス(意味)を定義し、AIエージェントやアプリケーションから統一的に活用できるセマンティックレイヤー
-
Ontologyがその中核を担い、エンティティ型・関係性・ルールを定義してOneLakeの実データにバインドする。Planが予算・予測・シナリオモデリングを、Graphが複雑な関係性の分析を、Operations Agentがリアルタイム監視と推奨アクションを提供する
-
Work IQ・Fabric IQ・Foundry IQの3層IQエコシステムにより、Microsoft Cloud全体でデータ・ユーザー・知識のコンテキストを横断的に連携する構想
-
既存のFabricサブスクリプションに含まれ追加SKU不要だが、CUメーターによる課金は発生する(Ontology Modeling、Operations Agent compute等)
-
2026年3月時点ではパブリックプレビュー。本番利用は慎重に評価しつつ、PoCでOntologyの定義と効果を検証するのが現実的なアプローチ
Fabric IQは、Microsoftが掲げる「データに意味を与え、AIが文脈を理解して行動する」というビジョンの具体的な実装です。プレビュー段階ではありますが、「部門横断のデータ定義統一」や「AIエージェントの精度向上」を目指す企業にとっては、早期のPoCで方向性を掴んでおく価値があります。
導入判断で押さえるべき論点
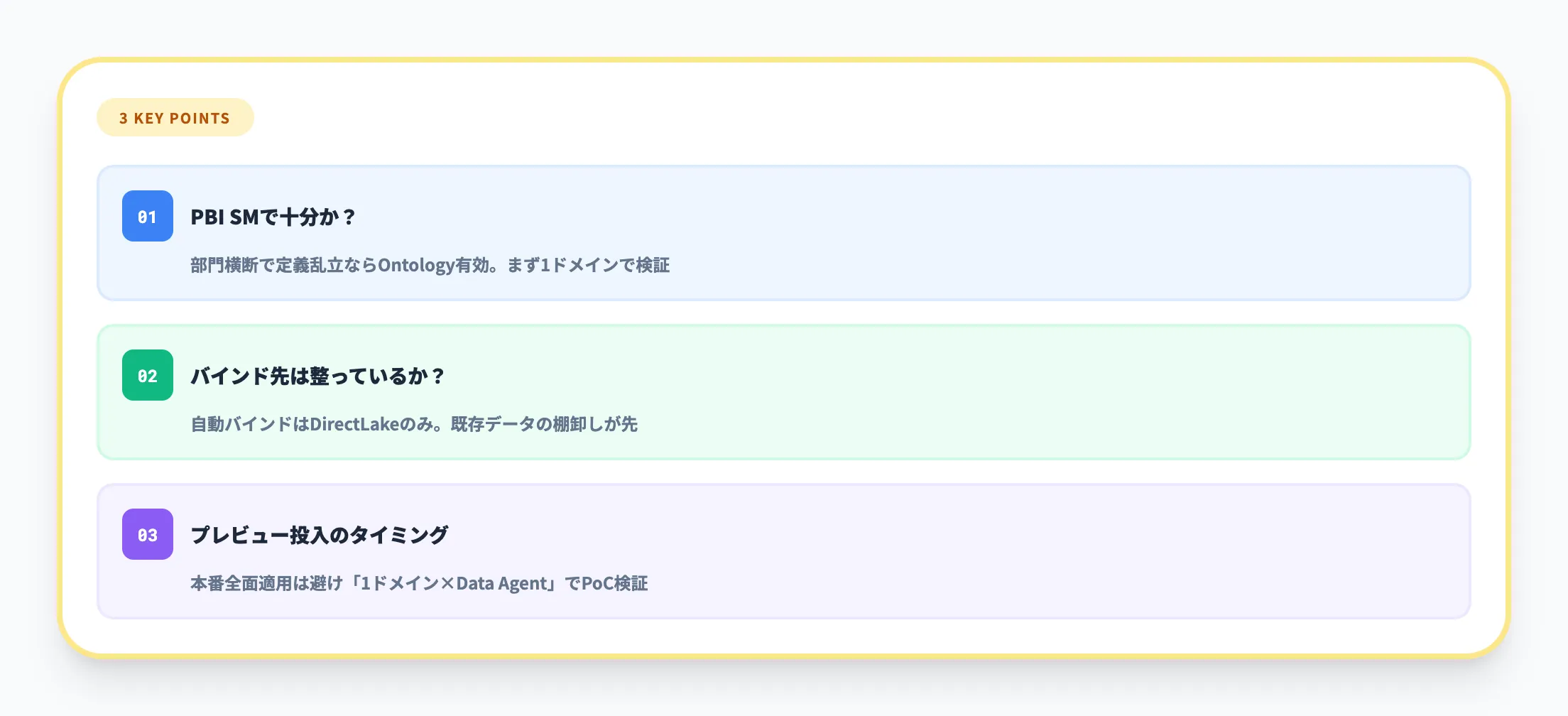
Fabric IQの導入を検討する際に、よく判断が分かれるポイントを3つ挙げます。
1. Power BIセマンティックモデルで十分か、Ontologyまで必要か
単一部門のレポーティングが中心であれば、既存のPower BIセマンティックモデルで対応できます。一方、部門横断でデータ定義が乱立し、レポートの数字が食い違っている状態なら、Ontologyによるセマンティックレイヤーの統一が有効です。まずは特定のドメイン(たとえば「顧客」の定義)でOntologyを構築し、Power BI単体との精度差を検証するのが現実的な判断材料になります。
2. データバインディング先の準備は整っているか
Ontologyの定義生成はImport・DirectLake・DirectQueryいずれのセマンティックモデルからも可能ですが、データバインディングの自動生成とクエリ実行はDirectLakeモードのみ対応です。OneLakeのマネージドレイクハウステーブルやEventhouseへの手動バインドも選択肢になりますが、マネージドテーブルの制約を満たす準備が必要です。既存データの状態を棚卸しし、どの方法でバインディングするかを先に整理しておくと、Ontology設計がスムーズに進みます。
3. プレビュー機能を使うタイミング
2026年3月時点ではパブリックプレビューであり、GA後に仕様変更が入る可能性があります。本番ワークロードへの全面適用は避け、PoCとして「1ドメイン×Data Agent」の組み合わせで効果を検証するのが安全です。FabCon 2026で発表されたPlanもプレビュー段階のため、これを前提にした設計は余裕を持ったスケジュールで進めるべきです。
Fabric上のデータはあるのにAIエージェントの回答がいまひとつ的確でない、部門ごとに「売上」「顧客」の定義が違ってレポートが噛み合わないといった状況があるなら、それはデータの意味が整理されていないことが原因かもしれません。Fabric IQのOntologyは、まさにこの課題を解決するための仕組みです。
まずはSharePoint上のデータ辞書を棚卸しし、定義がばらついているエンティティを特定するところから始めてみてください。その整理がOntology設計の第一歩になります。
セマンティクスでAgent回答精度を向上

データに意味を与えてAI活用を加速
Fabric IQのOntologyでデータに統一的なビジネス文脈を定義。AIエージェントがビジネス用語を正しく理解した回答を生成し、部門横断のデータ活用を加速させます。










