この記事のポイント
 データサイロ解消の第一歩としてOneLakeへの集約が最適。全Fabricワークロードが同一ストレージを共有するためETLパイプラインを大幅に削減できる
データサイロ解消の第一歩としてOneLakeへの集約が最適。全Fabricワークロードが同一ストレージを共有するためETLパイプラインを大幅に削減できる- 外部ストレージ(S3・GCS・ADLS Gen2)のデータはショートカット機能でコピーなしで統合すべき。データ移動コストとストレージ二重課金を回避できる
- PostgreSQL・Cosmos DB・Snowflakeとの連携にはミラーリングが有効。ニアリアルタイム同期が必要なケースで第一候補になる
- 既存ADLS Gen2資産はOneLakeへの移行が容易、API/SDK互換でDatabricks等の既存ツールからもそのままアクセス可能
- ストレージ単価は約$0.023/GB/月と安価だが、トランザクションはCUから消費される。大量クエリ環境ではCU容量の事前見積りが不可欠

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
OneLakeは、Microsoft Fabricに標準搭載された統合データレイクです。テナントに1つだけ存在し、すべてのFabricワークロードが同じストレージ基盤を共有します。
「データ用のOneDrive」と表現されるように、追加のプロビジョニングなしで利用でき、ショートカットやミラーリングによって外部データソースをデータコピーなしで統合できる仕組みを備えています。
本記事では、OneLakeの概要からアーキテクチャ、主要機能、ADLS Gen2との違い、使い方、活用事例、料金体系までを、2026年3月時点の最新情報をもとに解説します。
➡️【AI総合研究所】お問い合わせページ
✅Microsoft 365 Copilotの最新エージェント機能「Copilot Cowork」については、以下の記事をご覧ください。
Copilot Coworkとは?機能や料金、Claude Coworkとの違いを解説
OneLakeとは
OneLakeは、Microsoft Fabricに標準搭載された統合データレイクです。Microsoftはこれを「データ用のOneDrive」と表現しており、組織全体のデータを1か所に集約する基盤として設計されています。

従来のデータレイク環境では、部門やプロジェクトごとにストレージアカウントを個別に作成し、それぞれの接続設定・アクセス権限・課金を管理する必要がありました。データが分散するほど管理コストが膨らみ、組織横断の分析が困難になるという課題は多くの企業で発生しています。
OneLakeは、テナントに1つだけ存在し、すべてのFabricワークロードが自動的にこの単一のストレージ基盤を共有するというアプローチでこの課題を解決します。追加のプロビジョニングやストレージアカウントの作成は不要で、Fabricのワークスペースを作成するだけでOneLake上にデータ領域が確保されます。

なぜOneLakeが必要なのか
OneLakeが登場した背景には、従来のデータレイク運用における3つの構造的な課題があります。

-
データサイロの乱立
部門ごとにAzure Data Lake Storage(ADLS)アカウントやAWS S3バケットを作成し、データが分散する。部門横断の分析を行うたびにETLパイプラインを構築する必要がある。
-
ガバナンスの複雑化
ストレージが増えるほど、アクセス権限・暗号化・監査ログの管理が煩雑になる。セキュリティポリシーの一貫性を保つことが難しくなる。
-
データの重複とコスト増
同じデータを複数の場所にコピーして保持するため、ストレージコストが膨らみ、データの鮮度や整合性の問題も発生する。
OneLakeは、こうした課題に対して「全社で1つのデータレイクを共有し、外部データはショートカットで仮想的に参照する」というアプローチで応えています。
Fabricエコシステムでの位置づけ
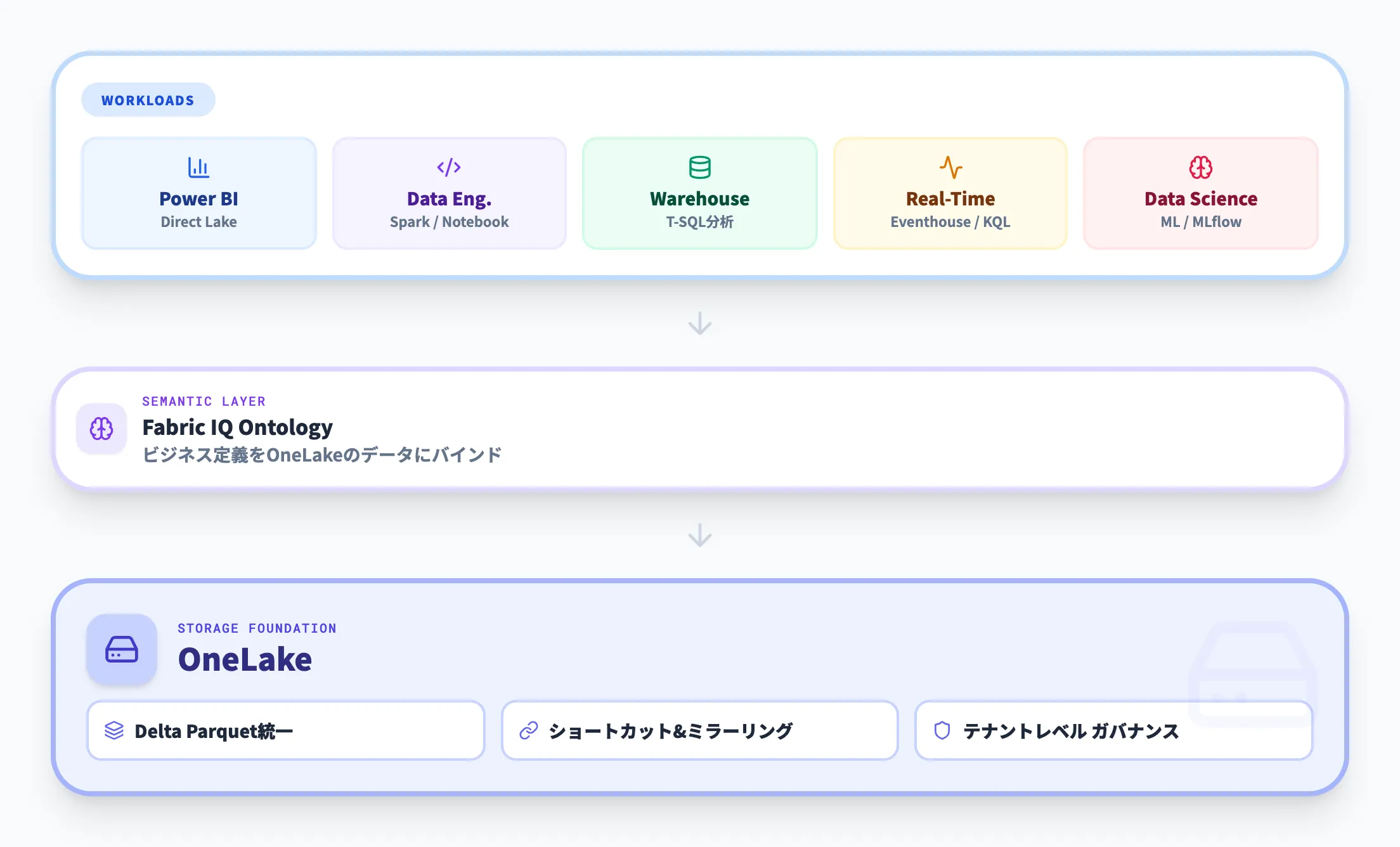
OneLakeは、Microsoft Fabricのストレージ基盤レイヤーとして、すべてのワークロードの下に位置しています。
-
Data Engineering(Spark/Notebook)、Data Warehouse、Lakehouse、Real-Time Intelligence、Data Scienceなどのワークロードは、すべてOneLake上のデータを読み書きする
-
Power BIのDirect Lakeモードは、OneLakeからデータを直接読み取ってレポートを表示する(FabricとPower BIの連携も参照)
-
Fabric IQのOntologyは、OneLake上のデータにビジネス定義をバインドする
つまり、OneLakeはFabricのすべてのワークロードが「同じデータを同じ場所で共有する」ための土台です。
OneLakeのアーキテクチャ
OneLakeのアーキテクチャは、3階層の論理構造と、ADLS Gen2互換のストレージ基盤で構成されています。
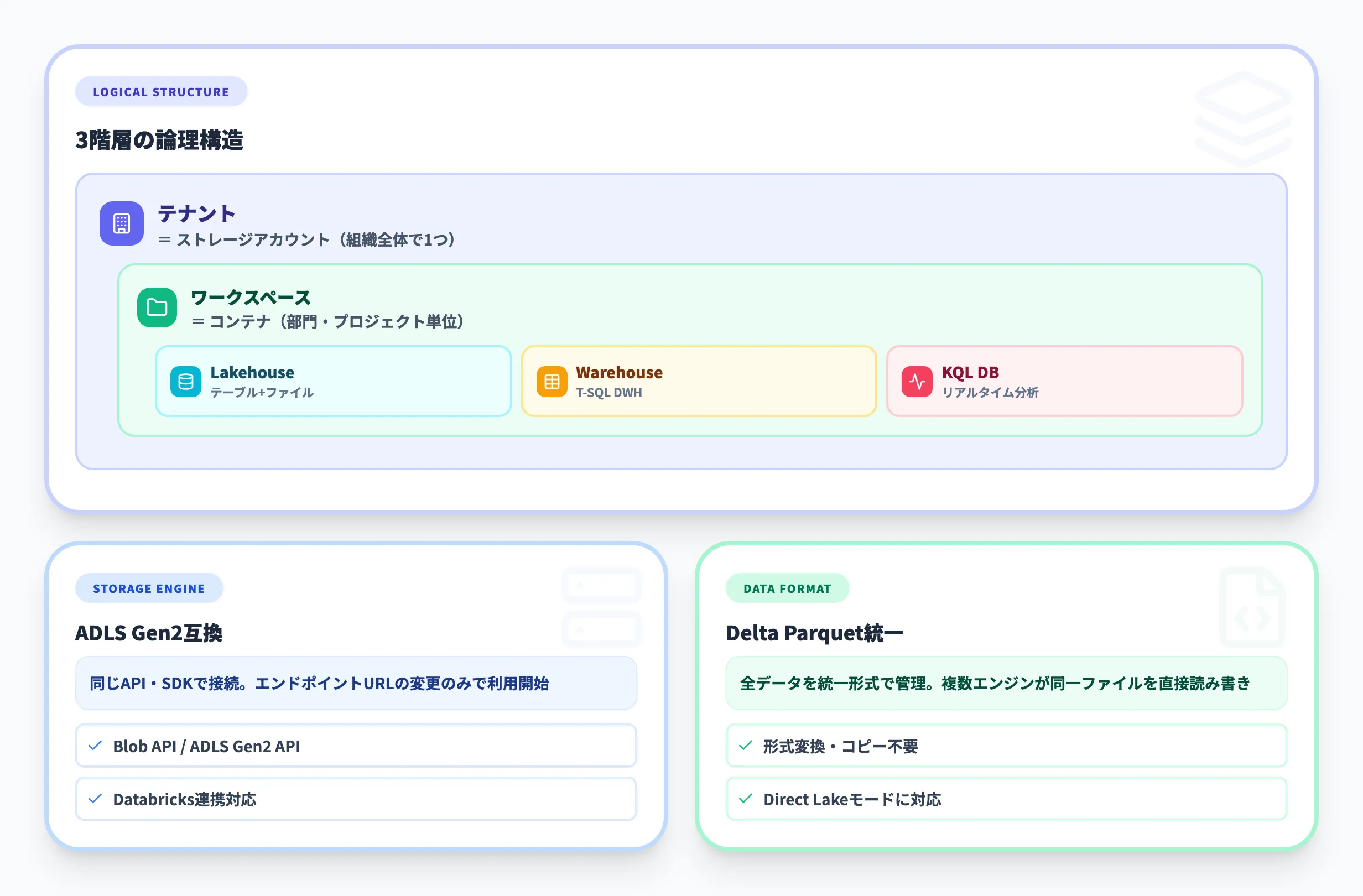
テナント・ワークスペース・アイテムの階層
OneLakeの論理構造は、以下の3階層で整理できます。
| 階層 | 対応するADLS Gen2の概念 | 役割 |
|---|---|---|
| テナント | ストレージアカウント | 組織全体で1つ。OneLake自体に相当 |
| ワークスペース | コンテナ | プロジェクトや部門ごとに作成。アクセス権限の管理単位 |
| データアイテム | フォルダ | Lakehouse、Warehouse、KQLデータベースなどの実体 |
ここで重要なのは、テナントごとにOneLakeは1つだけという点です。ADLS Gen2では必要に応じて複数のストレージアカウントを作成できましたが、OneLakeでは組織全体が1つの論理データレイクを共有します。ワークスペースによるアクセス制御で部門間の分離を実現しつつ、データの発見や横断利用はテナント全体で可能になります。
ADLS Gen2互換のストレージ基盤
OneLakeは、ADLS Gen2の上に構築されており、同じAPI・SDKをそのまま利用できます。
-
ADLS Gen2 APIおよびAzure Blob Storage APIに対応しているため、既存のアプリケーションからの接続先をOneLakeのエンドポイントに変更するだけで利用を開始できる
-
Azure DatabricksからもOneLakeのデータに直接アクセス可能。2025年以降はUnity Catalogからのフェデレーテッドクエリ(プレビュー)もサポートされている
-
OneLakeのエンドポイントURLは onelake.dfs.fabric.microsoft.com の形式で、組織全体が1つのストレージアカウントとして扱える
ADLS Gen2との互換性があるため、既存のデータパイプラインやツールをOneLakeに接続する際の移行コストを抑えられます。ただし、一部のAPI(ACL関連など)には制限があり、完全互換ではない点には注意が必要です。公式のAPI互換性ドキュメントで詳細を確認できます。
Delta Parquet形式とマルチエンジン対応
OneLakeに保存されるすべてのデータは、Delta Parquet形式で管理されます。
-
T-SQL(Data Warehouse)、Apache Spark(Data Engineering/Data Science)、Analysis Services(Power BI)など、複数の分析エンジンが同一のデータファイルを直接読み書きできる
-
「ワークロードごとにデータをコピーして別形式に変換する」という従来の手間が不要になる
-
Power BIのDirect Lakeモードは、OneLakeのDelta ParquetファイルをImportせずに直接読み取るため、Importモードのパフォーマンスとirect Queryモードのリアルタイム性を兼ね備える
Delta Parquet形式による標準化は、OneLakeの「1つのデータを複数のエンジンで共有する」というコンセプトを実現する中核的な仕組みです。
OneLakeの主要機能
OneLakeには、データ統合とアクセスを効率化するいくつかの重要な機能があります。ここでは、ショートカット、ミラーリング、File Explorer、そして2026年の新機能を整理します。

ショートカット(Shortcuts)
ショートカットは、外部ストレージの特定フォルダをデータコピーなしでOneLake内に仮想的にマウントする機能です。Windowsのシンボリックリンクに近い仕組みで、参照先のデータをそのまま読み取れます。
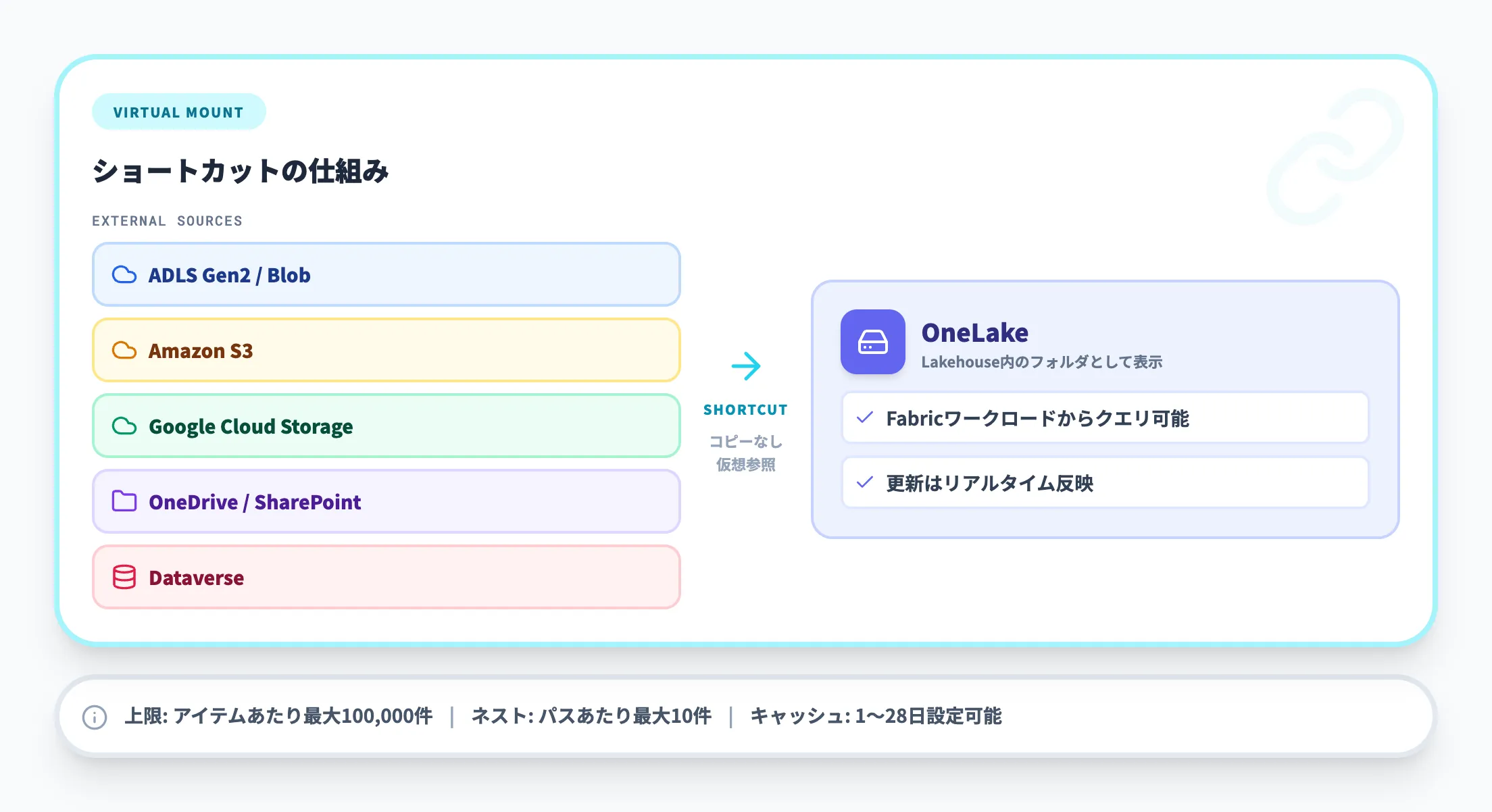
2026年3月時点で対応しているショートカットソースは以下のとおりです。
| カテゴリ | 対応ソース |
|---|---|
| OneLake内部 | 同一テナント内の他のLakehouse・Warehouse |
| Azure | ADLS Gen2、Azure Blob Storage |
| AWS | Amazon S3、S3互換ストレージ |
| Google Cloud | Google Cloud Storage |
| Microsoft 365 | OneDrive、SharePoint |
| その他 | Dataverse、オンプレミスデータゲートウェイ経由 |
ショートカットの利点は、データをコピーせずに一元的なビューを構築できることです。たとえば、AWSのS3バケットに蓄積されたログデータをOneLakeにショートカットすれば、Fabricのワークロードからそのままクエリできます。データの移動が不要なため、ストレージコストの重複も発生しません。
ただし、いくつかの制限があります。
-
アイテムあたりの上限は最大100,000ショートカット
-
パスあたりの上限は最大10ショートカット(ネスト)
-
ショートカット先のデータ更新は参照時にリアルタイムで反映されるが、メタデータキャッシュの更新にはタイムラグが生じる場合がある
2025年以降に追加された機能として、ショートカットキャッシュ(GCS/S3/S3互換/オンプレミスゲートウェイ対応)とショートカット変換(JSON/ParquetをDeltaテーブルに自動変換、プレビュー)があります。ショートカットキャッシュは、1〜28日のリテンション期間を設定でき、外部ストレージへのアクセス回数を削減してパフォーマンスとコストを最適化します。
ミラーリング(Mirroring)
ミラーリングは、外部データベースからOneLakeへニアリアルタイムでデータをレプリケーションする機能です。ショートカットが「参照」であるのに対し、ミラーリングは「複製」です。

2026年3月時点のミラーリング対応状況は以下のとおりです。
| ステータス | 対応ソース |
|---|---|
| GA(一般提供) | PostgreSQL、Cosmos DB、SQL Server(2016〜2025)、Snowflake(Iceberg) |
| プレビュー | SAP(Datasphere経由)、Oracle、Google BigQuery |
ミラーリングが特に有効なのは、トランザクションデータベースの分析コピーが必要なシナリオです。たとえば、本番のPostgreSQLデータベースに直接分析クエリを実行すると負荷がかかりますが、ミラーリングでOneLakeにレプリケーションすれば、本番への影響なく分析できます。
注目すべきは、2026年2月にSnowflake相互運用がGAになった点です。IcebergテーブルのOneLakeへのネイティブ保存と双方向読み取りが可能になり、SnowflakeとFabricのマルチクラウド連携が大幅に容易になりました。
なお、ミラーリングで使用するストレージには、購入したCapacity SKUに応じた無料枠が設定されています。たとえばF64 SKUの場合は64TBまで無料です。詳細は料金セクションで後述します。
OneLake File Explorer
OneLake File Explorerは、WindowsエクスプローラーからOneLakeのデータをブラウズ・アップロード・ダウンロードできるデスクトップアプリケーションです。
-
ローカルファイルシステムのようにOneLakeのフォルダを操作できる
-
ドラッグ&ドロップでファイルをアップロード可能
-
技術者でなくてもデータの確認やファイルの追加を行える
データエンジニアがAPIやSDKを使ってプログラム的にアクセスするだけでなく、ビジネスユーザーがExcelファイルを直接OneLakeにアップロードするといった使い方も想定されています。
2026年の主要アップデート
2025年後半から2026年にかけて、OneLakeには複数の新機能が追加されています。
-
Snowflake相互運用のGA(2026年2月)
IcebergテーブルのOneLakeへのネイティブ保存と、双方向の読み取りが一般提供開始
-
SharePoint/OneDriveショートカットのID認証(2026年2月)
ワークスペースID・サービスプリンシパル認証に対応し、セキュリティと自動化が強化
-
OneLake Table APIs(プレビュー)
Apache Iceberg REST Catalogプロトコルに対応し、DeltaテーブルをIceberg互換リーダーからアクセス可能にする仮想化機能
-
OneLake Security(プレビュー)
フォルダ・行・列レベルの細粒度アクセス制御。詳細はセキュリティセクションで後述
-
Excel OneLake統合(プレビュー)
ExcelからOneLakeデータの直接読み込み
これらのアップデートにより、OneLakeは「Fabric内部のストレージ」から「マルチクラウド・マルチツールのハブ」へと役割を広げています。
OneLakeとADLS Gen2の違い
Azure Data Lake Storage Gen2(ADLS Gen2)はOneLakeのベースとなっている技術ですが、利用モデルは大きく異なります。
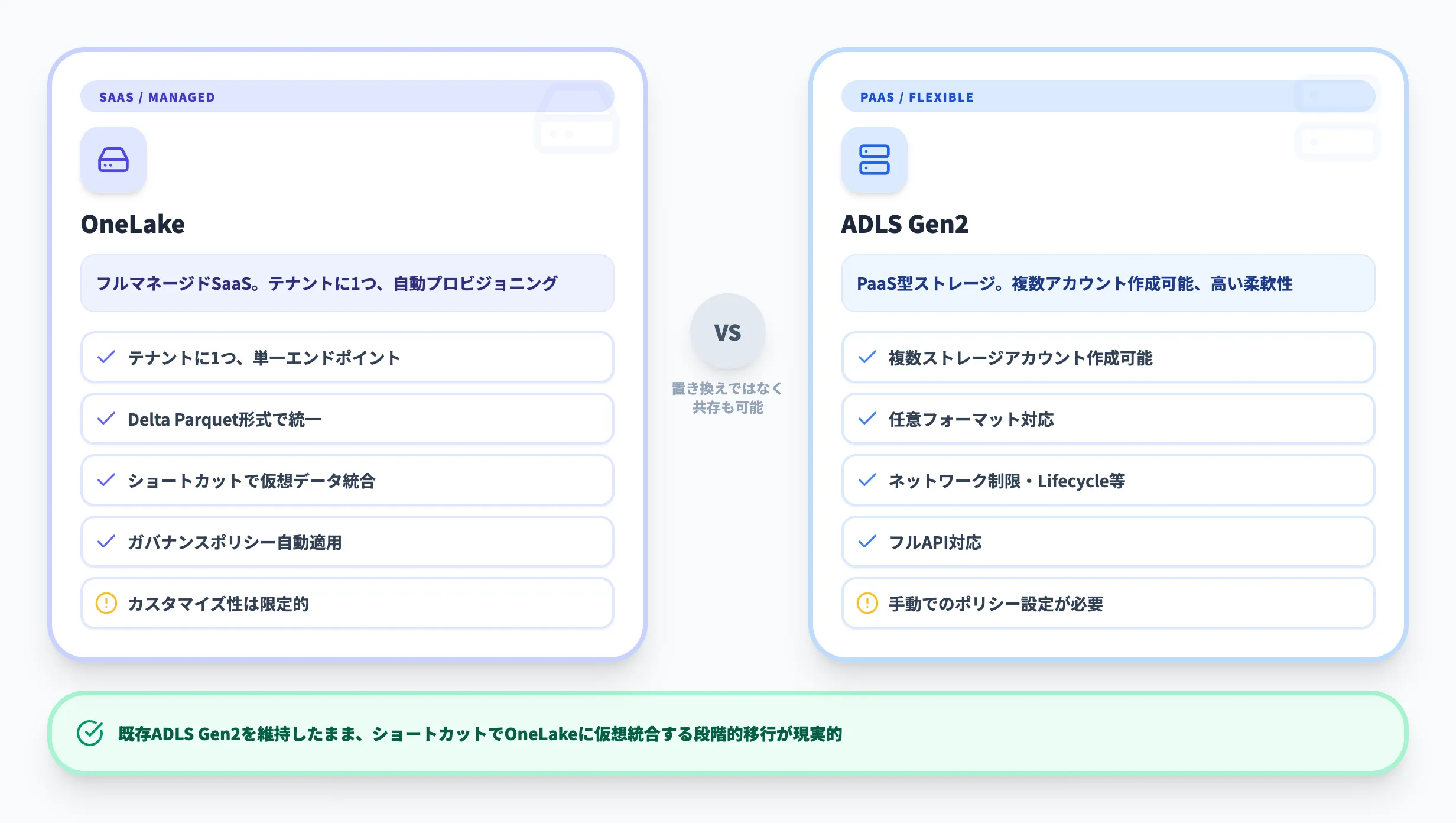
以下の表で主な違いを整理します。
| 比較項目 | OneLake | ADLS Gen2 |
|---|---|---|
| サービスモデル | SaaS(フルマネージド) | PaaS |
| テナント構造 | テナントに1つだけ、単一エンドポイント | 複数ストレージアカウント作成可能 |
| データ形式 | Delta Parquet(統一) | 任意(Parquet/CSV/JSON等) |
| API互換性 | ADLS Gen2/Blob API対応(一部制限あり) | フルAPI |
| ガバナンス | テナントレベルのポリシー自動適用 | 手動でのポリシー設定が必要 |
| 仮想データ統合 | ショートカットでコピーなし参照 | コピーまたは外部テーブルが必要 |
| 分析エンジン統合 | Fabricワークロード(Spark/T-SQL/Power BI)がネイティブ統合 | Azure Databricks/Synapse等から接続設定が必要 |
| 課金モデル | ストレージ: GB従量課金、トランザクション: CU消費 | ストレージ: GB従量課金、トランザクション: 操作単位課金 |
| カスタマイズ性 | 限定的(マネージド) | 高い柔軟性 |
ここで注目すべきは、OneLakeとADLS Gen2は「置き換え」ではなく「共存」も可能という点です。OneLakeのショートカット機能を使えば、既存のADLS Gen2ストレージアカウントのデータをOneLake内に仮想的に統合できます。つまり、既存のデータレイクを維持したまま、段階的にFabricのエコシステムに統合するアプローチが可能です。
一方で、OneLakeはフルマネージドのSaaS型であるため、ADLS Gen2のようなストレージアカウント単位の細かいカスタマイズ(ネットワーク制限、Lifecycleポリシーなど)には一部制限があります。高度な制御が必要なシナリオでは、ADLS Gen2を直接利用し、OneLakeにはショートカットで参照する構成が推奨されます。
OneLakeの使い方
ここでは、OneLakeを利用するための前提条件と、基本的な操作手順の概要を解説します。
前提条件
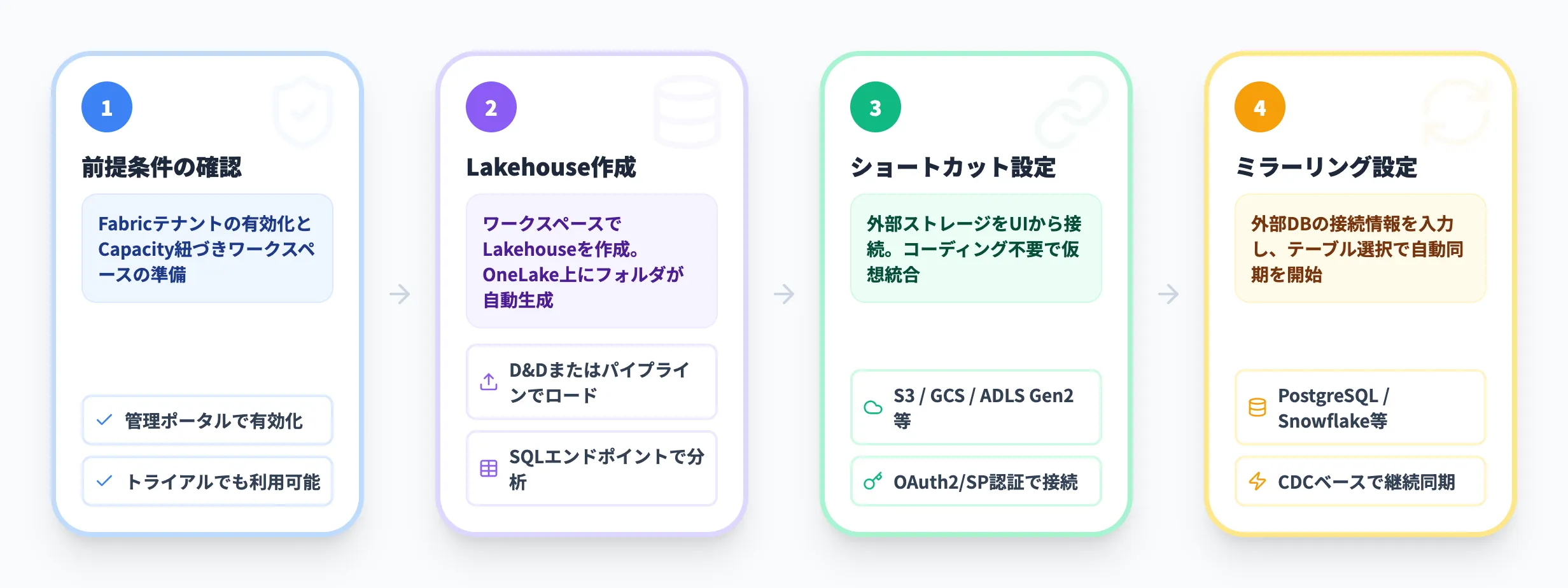
OneLakeを利用するには、以下の前提条件を満たす必要があります。
-
Microsoft Fabricが有効化されたテナントが必要。テナント管理者がFabric管理ポータルで有効化する
-
Fabricキャパシティに紐づくワークスペースが必要。無料トライアルキャパシティでも利用可能(Fabric IQとは異なり、OneLake自体はトライアルでも使える)
-
OneLake自体には追加のプロビジョニングは不要。Fabricテナントに自動的に付属する
OneLakeは「作成する」ものではなく、Fabricテナントに「最初から存在する」ものです。利用者がやることは、ワークスペースを作成し、その中にLakehouseやWarehouseなどのデータアイテムを作成することです。
Lakehouseの作成
OneLakeにデータを格納する最も一般的な方法は、Lakehouseを作成することです。
-
Fabricポータルにアクセスし、ワークスペースを選択する
-
「+ 新規」→「Lakehouse」を選択する
名前を入力してLakehouseを作成する。作成と同時にOneLake上にフォルダが自動生成される。
-
データを格納する
ドラッグ&ドロップでファイルをアップロードするか、パイプラインやSparkノートブックでデータをロードする。
-
SQLエンドポイントで分析する
Lakehouseに格納されたデータは、自動生成されるSQLエンドポイントからT-SQLでクエリできる。
Lakehouseは、OneLake上に作成されるデータアイテムの一種であり、ファイル領域(非構造化データ)とテーブル領域(Delta形式の構造化データ)の両方を持ちます。
【関連記事】
【Microsoft Fabric】Lakehouseとは?機能や料金、Data Warehouseとの違いを徹底解説
ショートカットの設定
外部データソースをOneLakeに仮想統合するには、ショートカットを設定します。
-
Lakehouseの画面で「...」メニューから「新しいショートカット」を選択する
-
ショートカットの種類を選択する
OneLake内部、ADLS Gen2、Amazon S3、Google Cloud Storage、Dataverseなどから選択する。
-
接続情報を入力する
たとえばADLS Gen2の場合は、ストレージアカウントURL・コンテナ名・フォルダパスを指定する。認証にはOAuth2やサービスプリンシパルを使用する。
-
ショートカットの名前とパスを確定する
作成後、Lakehouse内のフォルダとして外部データが表示され、Fabricのワークロードからそのままアクセスできるようになる。
ショートカットの設定はUIベースで完結するため、コーディングは不要です。ただし、外部ストレージへのアクセス権限(IAMロールやサービスプリンシパル)の設定は別途必要です。
ミラーリングの設定
外部データベースのデータをOneLakeにレプリケーションするには、ミラーリングを設定します。
-
Fabricポータルでミラーリングアイテムを作成し、接続先データベース(PostgreSQL、Cosmos DB、SQL Server等)の接続情報を入力する
-
対象テーブルを選択すると、初回の全量レプリケーションが実行され、以降は変更分がニアリアルタイムで同期される
-
レプリケーションされたデータはDelta Parquet形式でOneLakeに保存されるため、Fabricの全ワークロードからクエリ可能
ミラーリングはData Factoryのパイプラインとは異なり、継続的な自動同期が特徴です。パイプラインがバッチ実行(スケジュールや手動トリガー)であるのに対し、ミラーリングはChange Data Capture(CDC)ベースでニアリアルタイムに動作します。

OneLakeの活用事例
OneLakeは、Microsoft Fabricの導入企業で広く利用されています。Fabricは2025年時点で31,000以上の顧客に採用されており、年間経常収益は$2Bを超えています。ここでは、OneLakeの活用が具体的に報告されている事例を紹介します。
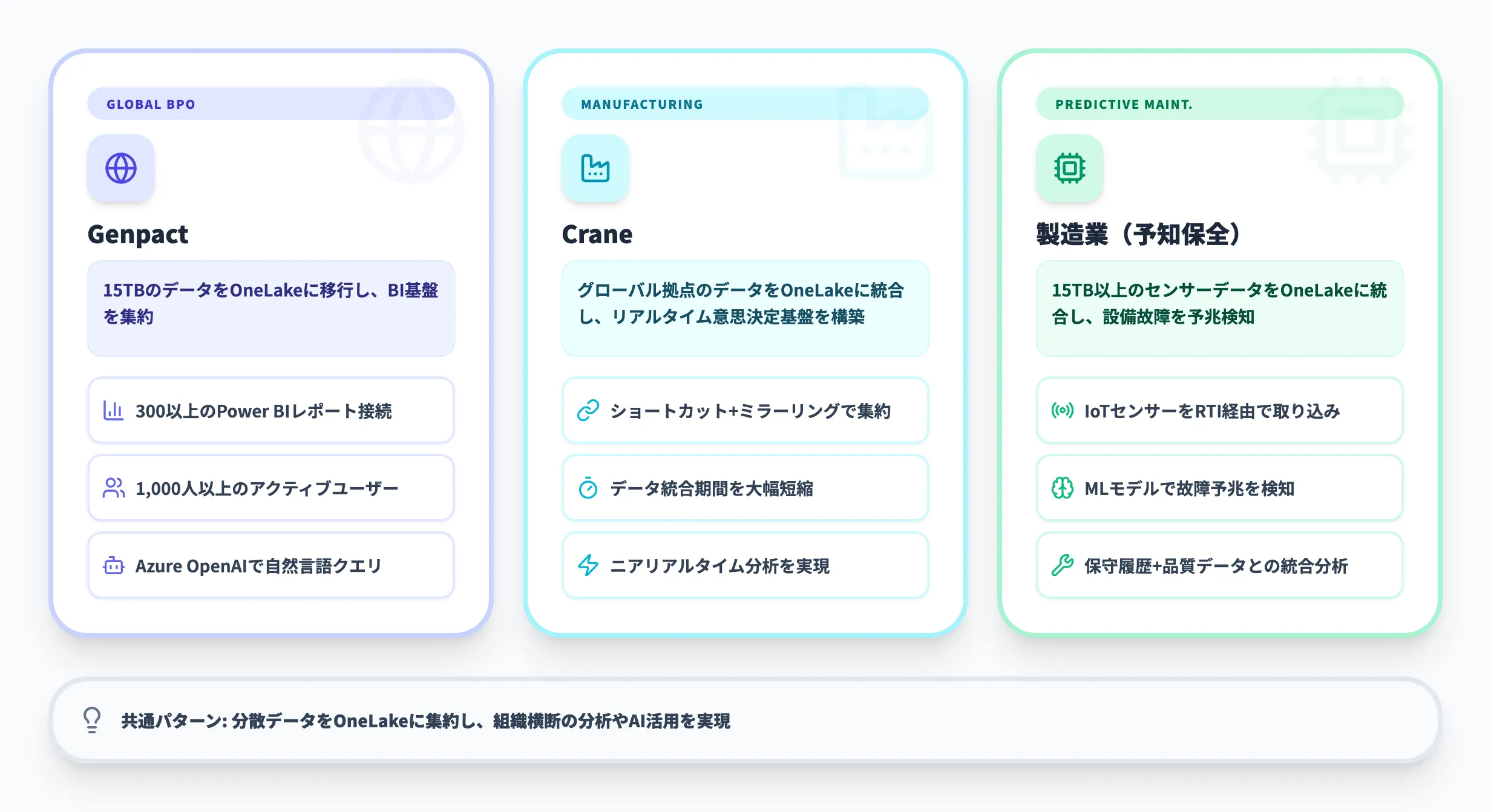
Genpact(グローバルBPO・データ統合)
グローバルBPO企業のGenpactは、Microsoft Fabric導入事例として以下の成果を報告しています。
-
15TBのデータをOneLakeに移行し、300以上のPower BIレポートを接続
-
1,000人以上のアクティブユーザーがOneLake上のデータを利用
-
Azure OpenAIと連携し、HR・財務向けの自然言語クエリ機能を構築
Genpactのケースは、大規模なデータ統合とBI基盤の集約にOneLakeが活用された典型的な事例です。複数のデータソースをOneLakeに集約することで、レポートの整合性とアクセスの効率化を実現しています。
Crane(製造業・グローバル分析基盤)
製造業のCraneは、iLink Digitalのパートナー支援のもと、グローバル拠点に分散していたデータをOneLakeに統合しています。
-
各拠点のデータをショートカットとミラーリングでOneLakeに集約し、ニアリアルタイムの意思決定エンジンを構築
-
従来はETLパイプラインの構築に数週間かかっていたデータ統合が、ショートカットにより大幅に短縮
製造業(予知保全・センサーデータ統合)
匿名事例ですが、製造業での予知保全ケーススタディとして、15TB以上のセンサーデータ・保守ログ・品質メトリクスをOneLakeに統合し、機械学習による予知保全を実現した事例が報告されています。
-
IoTセンサーデータをReal-Time Intelligence経由でOneLakeにストリーミング
-
保守履歴や品質検査データとの統合分析により、設備故障の予兆を検知
これらの事例に共通するのは、「分散していたデータをOneLakeに集約し、組織横断の分析やAI活用を実現する」というパターンです。
【関連記事】
Microsoft Fabric導入事例6選!国内企業の成果と導入パターンを解説
OneLakeのセキュリティとデータ保護
OneLakeは組織全体のデータを集約する基盤であるため、セキュリティとデータ保護は特に重要な要素です。

アクセス制御
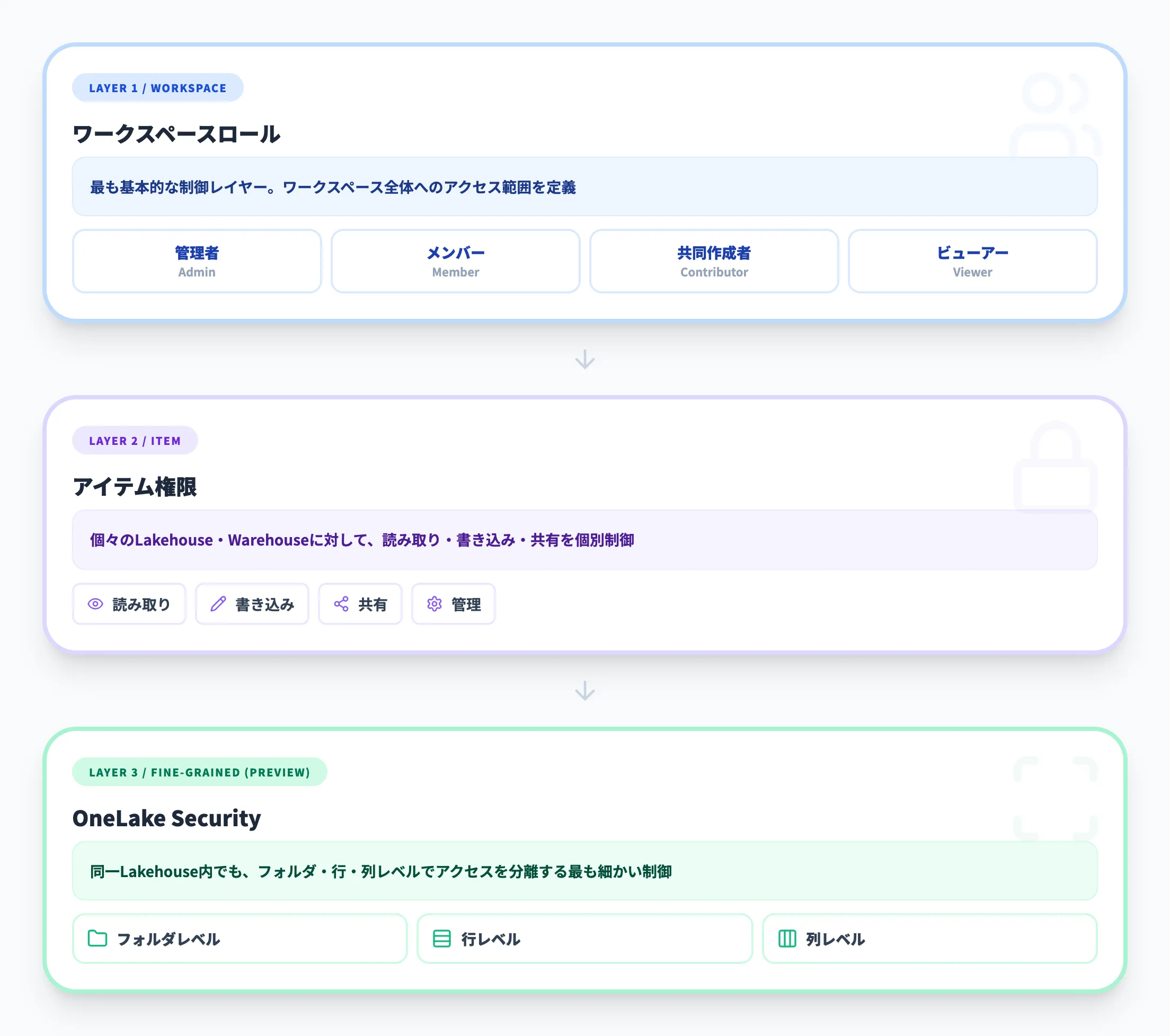
OneLakeのアクセス制御は、以下の3階層で構成されています。
-
ワークスペースロール
管理者・メンバー・共同作成者・ビューアーの4ロールで、ワークスペース単位のアクセスを制御する。これが最も基本的な制御レイヤー。
-
アイテム権限
個々のLakehouseやWarehouseに対して、読み取り・書き込み・共有などの権限を設定する。
-
OneLake Security(プレビュー)
2025年以降に追加された新機能で、フォルダレベル・行レベル・列レベルの細粒度アクセス制御を提供する。OneLakeデータアクセスロールをカスタム定義し、特定のユーザーやグループに対してフォルダ単位でのアクセスを制御できる。
OneLake Securityはプレビュー段階ですが、「同じLakehouse内でも部門ごとにアクセスできるフォルダを分ける」といったユースケースが可能になり、マルチテナント的な運用のニーズに応えます。
データ保護
OneLakeには、データ損失を防ぐための複数の保護機能があります。
-
ソフトデリート
データを削除しても7日間は復旧可能。誤削除や意図しない操作からの回復に対応する。ただし、ソフトデリート期間中もアクティブデータと同じレートでストレージ課金が発生する。
-
ゾーン冗長ストレージ(ZRS)
同一リージョン内の複数データセンターにデータを複製し、単一データセンターの障害からデータを保護する。
-
BCDR(Business Continuity and Disaster Recovery)
セカンダリリージョンへの地理的レプリケーションをオプションで有効化できる。リージョン全体の障害時にもデータを保護するが、ストレージコストは増加する。
-
カスタマーマネージドキー(CMK)
暗号化キーを組織が自主管理できる機能。2025年にGA。コンプライアンス要件が厳しい業界(金融・医療等)での利用に対応する。
データ保護の選択はコストとのトレードオフになるため、ビジネスの重要度に応じて適切なレベルを選択することが重要です。特にBCDRはストレージコストが約1.8倍($0.0414/GB/月)になるため、すべてのデータに一律適用するのではなく、クリティカルなデータのみに適用する構成が一般的です。
OneLakeの料金体系
OneLakeの料金は、ストレージ料金とトランザクション料金の2つの要素で構成されています。ストレージはGB単位の従量課金、トランザクションはFabric Capacity Units(CU)から消費されるという二重構造になっています。
ストレージ料金
OneLakeのストレージは、保存データ量に応じたGB単位の従量課金です。
以下の表は2026年3月時点の料金です。
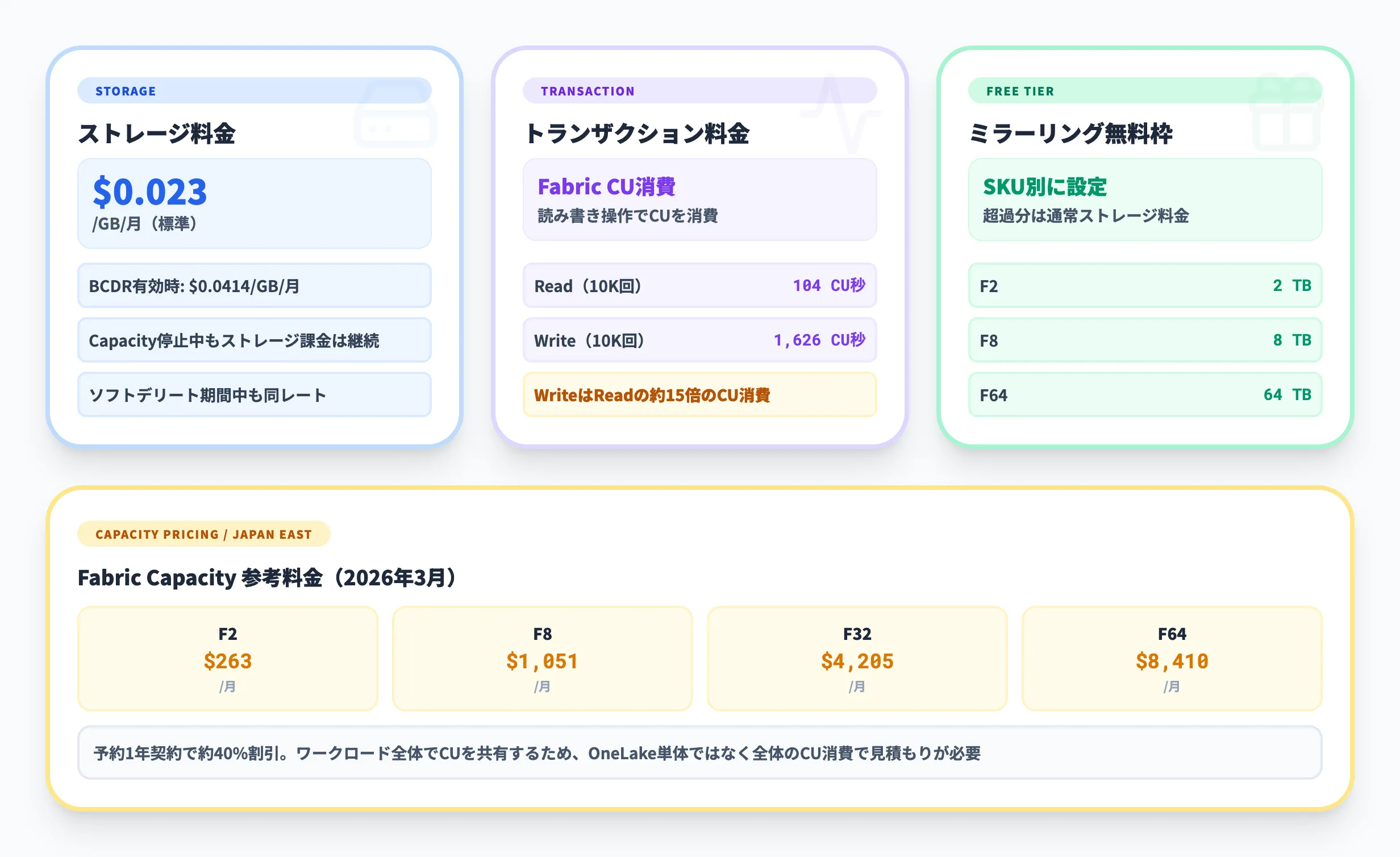
| 項目 | 料金 | 備考 |
|---|---|---|
| OneLake標準ストレージ | 約$0.023/GB/月(約$23/TB/月) | 基本のストレージ料金 |
| OneLake BCDRストレージ | 約$0.0414/GB/月 | 地理的レプリケーション有効時 |
| KQLキャッシュ | 約$0.246/GB/月 | Real-Time Intelligence向け |
ストレージ料金はFabric Capacity Units(CU)からは消費されず、別枠の従量課金です。つまり、Fabricキャパシティを一時停止しても、OneLake上に保存されているデータのストレージ料金は引き続き発生します。
ソフトデリートされたデータ(削除後7日間の復旧期間中のデータ)も、アクティブデータと同じレートで課金される点に注意が必要です。
トランザクション料金
OneLakeへのデータの読み書きは、Fabric Capacity Units(CU)を消費します。
以下は主なトランザクション操作とCU消費量です。
| 操作 | 単位 | CU消費量 |
|---|---|---|
| Read | 4MBごと、10,000回あたり | 104 CU秒 |
| Write | 4MBごと、10,000回あたり | 1,626 CU秒 |
| Other Operations | 10,000回あたり | 104 CU秒 |
| Iterative Read | 10,000回あたり | 1,626 CU秒 |
| Iterative Write | 100回あたり | 1,300 CU秒 |
WriteはReadの約15倍のCUを消費するため、書き込み頻度の高いワークロード(ストリーミングデータの取り込み、ETLパイプラインの出力など)では、CU消費量を事前に見積もっておくことが重要です。BCDRが有効な場合はWrite系のCU消費量がさらに増加します。
ミラーリングのストレージ無料枠
ミラーリングで使用するストレージには、購入したCapacity SKUに応じた無料枠が設定されています。
| SKU | ミラーリング無料枠 |
|---|---|
| F2 | 2TB |
| F4 | 4TB |
| F8 | 8TB |
| F16 | 16TB |
| F32 | 32TB |
| F64 | 64TB |
無料枠を超過した分は、通常のOneLakeストレージ料金($0.023/GB/月)で課金されます。ミラーリングの対象データ量が大きい場合は、SKUサイズと無料枠のバランスを確認してから導入することをおすすめします。
Fabric Capacityの参考料金
OneLakeのトランザクション処理に使用するFabric Capacityの参考料金は以下のとおりです。2026年3月時点、Japan East(東日本)リージョンの従量課金です。
| SKU | 月額料金(従量課金) | 予約1年割引 |
|---|---|---|
| F2 | 約$263 | 約40%割引 |
| F4 | 約$526 | 約40%割引 |
| F8 | 約$1,051 | 約40%割引 |
| F16 | 約$2,102 | 約40%割引 |
| F32 | 約$4,205 | 約$2,501 |
| F64 | 約$8,410 | 約40%割引 |
Fabric Capacityは「ワークロード全体で共有するコンピューティングリソース」であり、OneLakeのトランザクション以外にもData Warehouse、Spark、Power BIなどの処理でCUが消費されます。OneLakeのトランザクション単体ではコストが小さくても、ワークロード全体でのCU消費を見積もることが重要です。

OneLakeの「データ統合」をAIエージェントの「業務判断基盤」にするなら
OneLakeでデータサイロを解消した先にあるのは、統合されたデータを実際の業務アクションにつなげる仕組みの構築です。
AI Agent Hubは、OneLakeにZero ETLで仮想統合されたデータにAIエージェントが直接アクセスし、業務を自動実行するエンタープライズAI基盤です。
- OneLakeの仮想統合データにAgentが直接アクセス
ショートカットやミラーリングでOneLakeに集約したデータを、AIエージェントがTeamsから自然言語で問い合わせ。取得した結果をそのまま報告・申請・承認に変換します。
- Agentが動くほどデータが蓄積される好循環
AIエージェントの実行ログ・承認履歴・ROIデータがすべてOneLakeに集約。データ活用と改善のサイクルを構造的に回せます。
- 使い慣れたMicrosoft環境をそのまま活用
Teamsなど既存のMicrosoftツールの延長でAIエージェントが動作。新しいツールの学習コストはゼロです。
- データは100%自社テナント内に保持
AIの学習対象から完全除外。Azure Managed Applicationsとして自社テナント内で動作が完了する設計です。
AI総合研究所の専任チームが、設計から運用まで伴走支援します。まずは無料の資料で、自社の業務にどう活用できるかご確認ください。
OneLakeの統合データをAgent活用に直結

データ仮想統合からAI業務自動化へ
OneLakeのショートカット・ミラーリングで仮想統合したデータを、AIエージェントが直接参照。データサイロ解消と業務自動化を同時に実現します。
まとめ
本記事では、Microsoft FabricのOneLakeについて、定義からアーキテクチャ、主要機能、ADLS Gen2との違い、使い方、活用事例、セキュリティ、料金体系までを整理しました。
-
OneLakeは、Fabricテナントに1つだけ存在する統合データレイクで、すべてのワークロードが同じストレージ基盤を共有する。「データ用のOneDrive」として、データサイロの解消とガバナンスの統一を目指す設計
-
ショートカットでADLS Gen2・S3・GCSなどの外部ストレージをコピーなしで仮想統合し、ミラーリングでPostgreSQL・Cosmos DB・Snowflakeなどの外部DBをニアリアルタイムでレプリケーション
-
ADLS Gen2の上に構築されており、既存のAPI・SDK・ツールをそのまま利用可能。段階的な移行や共存が可能
-
ストレージはGB従量課金(約$0.023/GB/月)、トランザクションはFabric CUから消費される二重構造。ミラーリングにはSKUに応じた無料枠あり
-
2026年にはSnowflake相互運用のGA、OneLake Security(細粒度アクセス制御)のプレビュー、Iceberg REST Catalog対応など、マルチクラウド・マルチツール対応が加速
OneLakeは、Microsoft Fabricの「すべてのデータを1か所に」というビジョンを支える土台です。既存のデータレイクからの移行を検討している企業にとっては、ショートカットによる段階的な統合から始められる点が現実的なアプローチとなります。
AI総合研究所では、Microsoft Fabricを活用したデータ基盤設計+AI活用の導入支援を行っています。OneLakeの設計やデータ統合にご興味があれば、お気軽にお問い合わせください。










