この記事のポイント
 M365統合はFabric Data Agent、マルチクラウド/MLOpsはDatabricks、SQL中心はSnowflake Cortexが選定基準
M365統合はFabric Data Agent、マルチクラウド/MLOpsはDatabricks、SQL中心はSnowflake Cortexが選定基準- MCP(エージェント↔データソース)とA2A(エージェント↔エージェント)の2プロトコルが2026年のデータ接続標準
- 設計パターンはRAG型・NL2SQL型・パイプライン型の3つで、実務では複数を組み合わせた構成が主流
- Walmart・メルカリの事例が示すように、メタデータ整備とAgent-Ready要件の充足がエージェント活用の前提条件
- ガバナンス整備済み企業は本番運用数が12倍(Databricks調査)で、未整備のまま展開するとリスクが拡大

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
AIエージェントが業務を自律的に遂行する時代、その判断と行動の土台となるのがデータ基盤です。
エージェントが正確に情報を取得し、複数のデータソースを横断して推論を行うには、従来のBI向けデータ管理とは異なるアーキテクチャが求められます。
本記事では、MCP(Model Context Protocol)やA2Aプロトコルといったデータ接続技術から、Microsoft Fabric Data Agent・Databricks Mosaic AI・Snowflake Cortex Agentsの比較、RAG型・NL2SQL型・パイプライン型の設計パターン、マルチエージェントオーケストレーションまでを2026年最新情報で体系的に解説します。
✅2026年6月9日、AnthropicがMythos-class初の一般公開モデル「Claude Fable 5」を発表しました。Opus 4.8の上位に位置する新最上位モデルの詳細はこちら。
▶︎Claude Fable 5とは?Mythos 5との違いや料金、使い方を解説
目次
Databricks Mosaic AI / Agent Bricks
Walmart:AIエージェントによるサプライチェーン最適化
AIエージェントとデータ基盤の関係とは?

AIエージェントの判断と行動の土台となるのがデータ基盤です。
エージェントがどれだけ高性能なLLM(大規模言語モデル)を搭載していても、アクセスするデータの品質と範囲が不十分であれば、正確な判断は下せません。
ここでは、AIエージェントとデータ基盤がどのように関係するかを整理し、従来のAI活用との違いを明確にします。

データ基盤整備が追いつかない現状
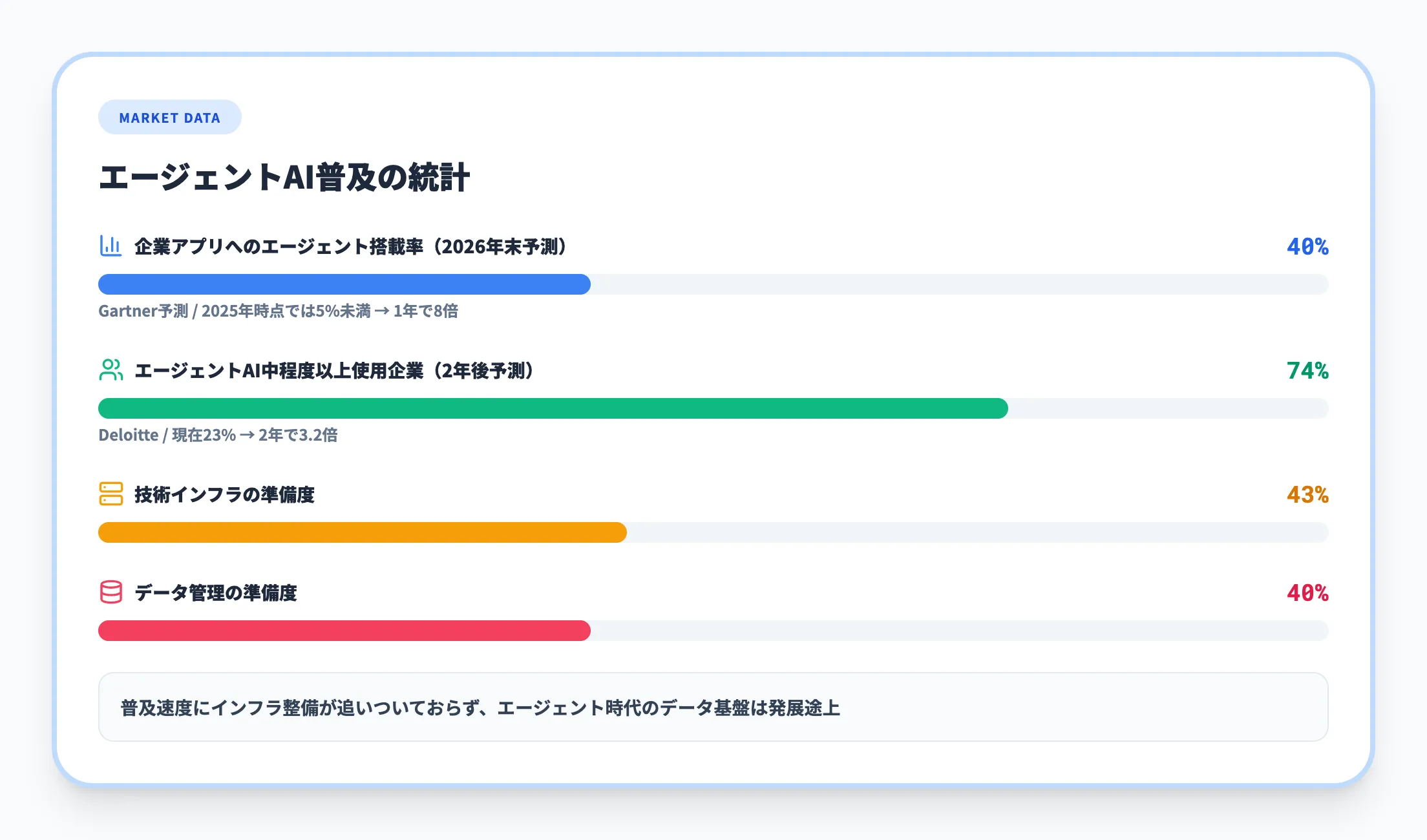
Gartnerは2025年8月の予測で、2026年末までに企業アプリケーションの40%にタスク特化型AIエージェントが搭載されると発表しました。
2025年時点では5%未満だったことを考えると、わずか1年で8倍の普及速度です。
Deloitteの「State of AI in the Enterprise 2026」でも、現在23%の企業がエージェントAIを中程度以上使用しており、2年以内に74%に拡大する見込みとされています。
この急速な普及の中で課題となっているのが、エージェントが活用するデータの整備です。
Deloitteの同調査では、技術インフラの準備度が43%、データ管理の準備度が40%にとどまっており、エージェント時代のデータ基盤はまだ発展途上であることがわかります。
なぜAIエージェントに専用のデータ基盤が必要なのか
従来のAI活用(チャットボットやBI分析)とエージェントAIでは、データ基盤に対する要件が根本的に異なります。以下の表で両者の違いを整理しました。
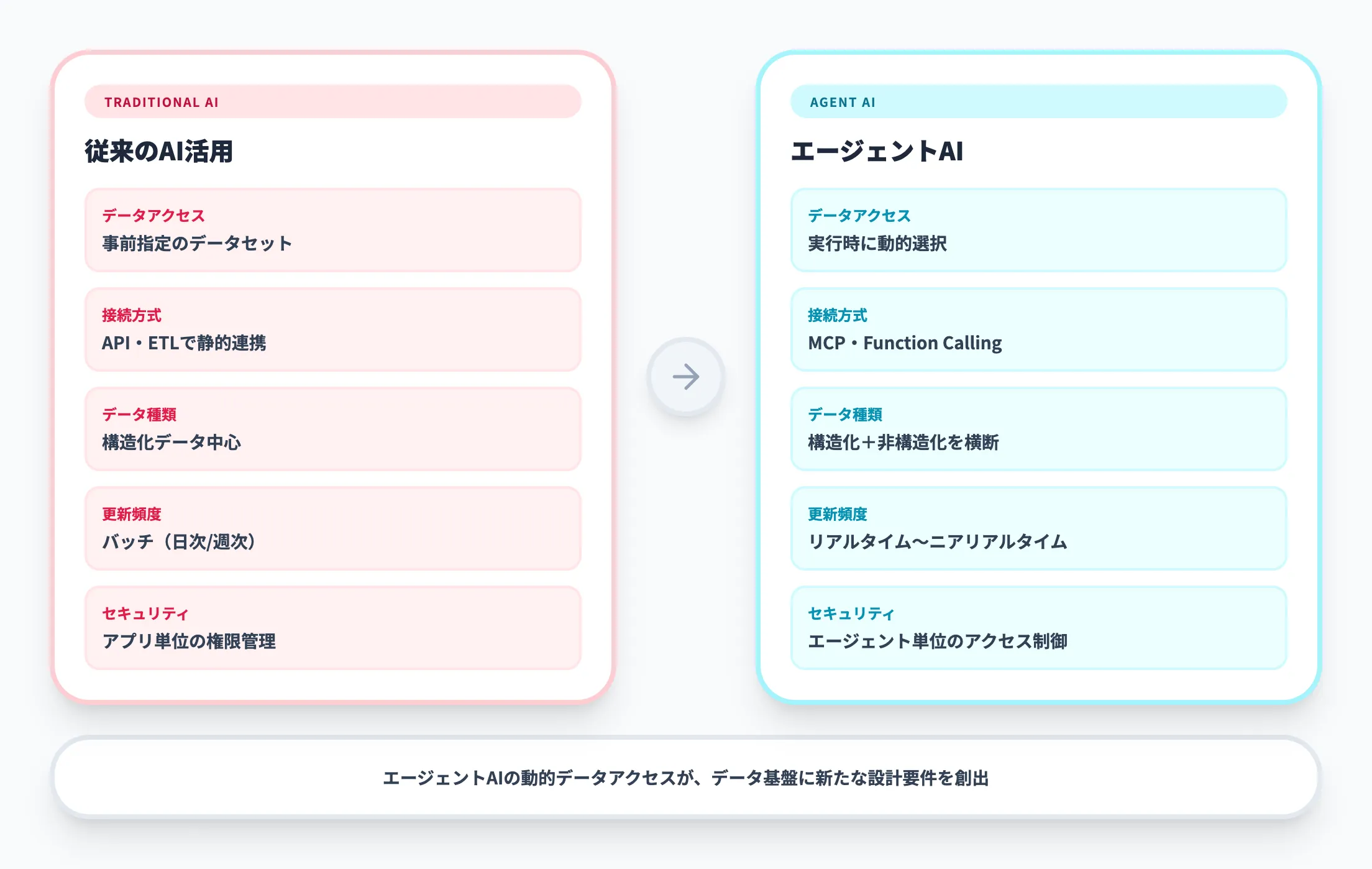
| 観点 | 従来のAI活用 | エージェントAI |
|---|---|---|
| データアクセス | 事前に指定されたデータセット | 実行時に動的にデータソースを選択 |
| 接続方式 | APIやETLで静的に連携 | MCP・Function Callingで動的に接続 |
| データの種類 | 構造化データ中心 | 構造化+非構造化を横断 |
| 更新頻度 | バッチ(日次/週次) | リアルタイム〜ニアリアルタイム |
| セキュリティ | アプリケーション単位の権限管理 | エージェント単位のきめ細かいアクセス制御 |
| ガバナンス | データ利用ポリシーの適用 | 自律行動の監査証跡・承認フローが必要 |
この違いを踏まえると、エージェントが企業で実用化されるためには、従来のデータ管理では対応しきれない3つの要件を満たす必要があります。
エージェントが求めるデータアクセスの3要件
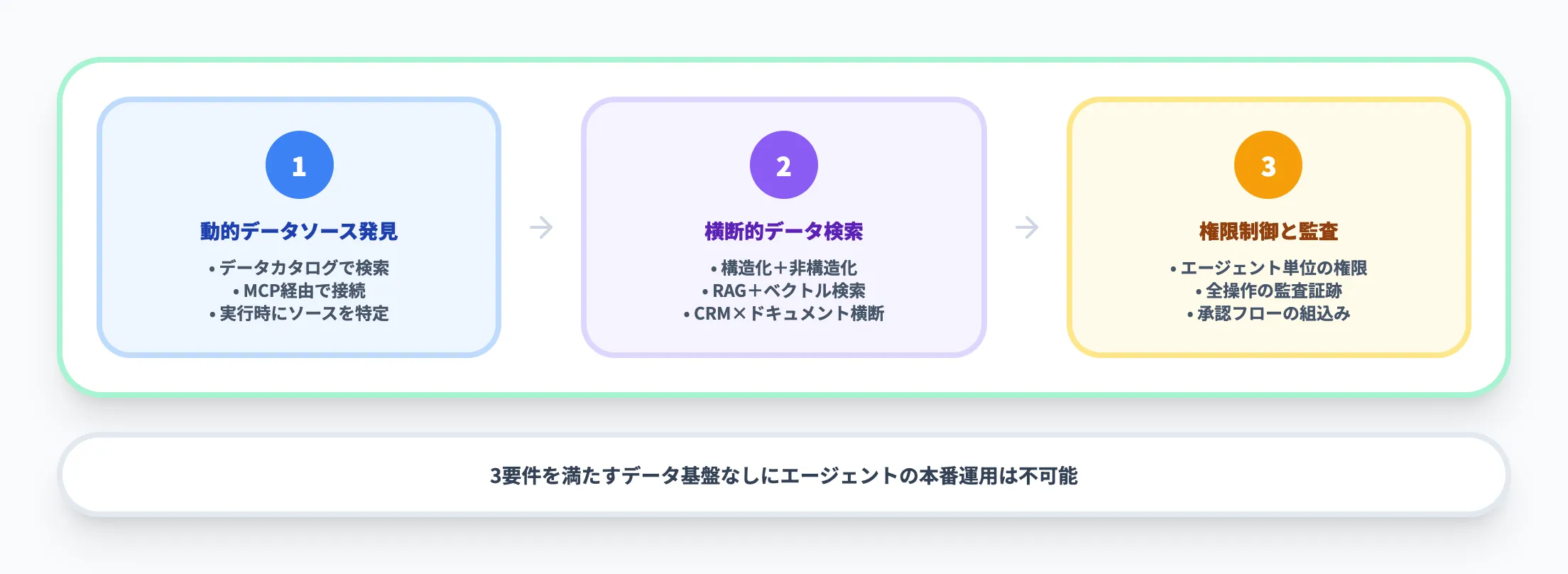
動的なデータソース発見
エージェントは実行時にタスクに必要なデータソースを特定する必要があります。
「どこにどんなデータがあるか」を検索可能なデータカタログと、エージェントがプログラマティックに接続できるインターフェース(MCP等)が不可欠です。
構造化・非構造化データの横断検索
営業エージェントが顧客への提案を作成する場合、CRMの構造化データ(売上実績)と、SharePoint上の非構造化データ(過去の提案書PDF)の両方にアクセスする必要があります。
RAGやベクトル検索を組み合わせた横断的なデータアクセス層が求められます。
実行時の権限制御と監査
自律型AIエージェントは人間の介入なしにデータを読み書きするため、「どのエージェントが、どのデータに、どのような操作を行ったか」の監査証跡が必須です。従来のユーザーベースの権限管理に加え、エージェント単位のアクセス制御が必要になります。
データ品質がエージェントの判断に与える影響
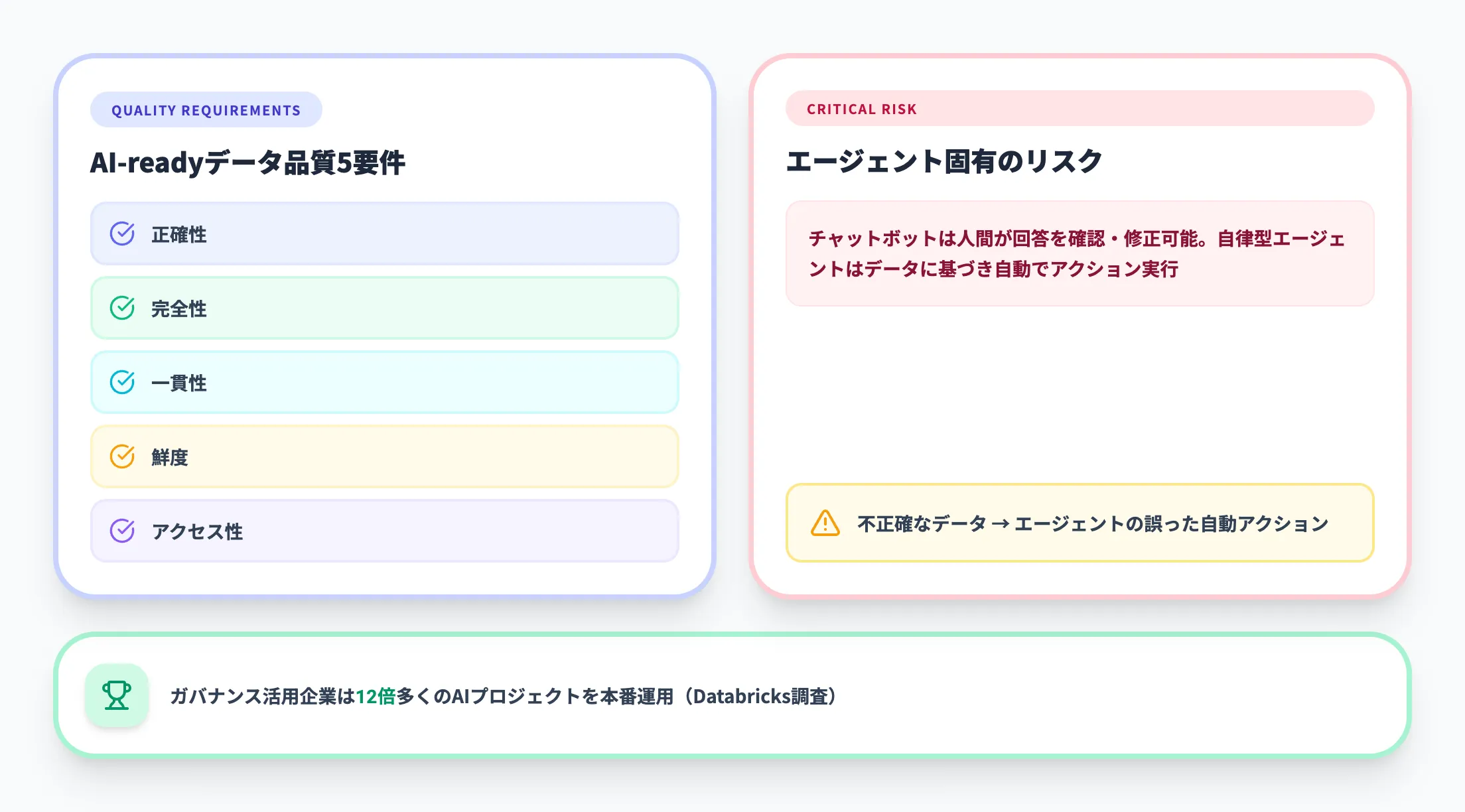
エージェントの判断精度は、アクセスするデータの品質に直接依存します。
AI-readyなデータ整備で解説している5つの品質要件(正確性・完全性・一貫性・鮮度・アクセス性)は、エージェントAIにおいてはさらに重要度が増します。
チャットボットの場合は人間が回答を確認して判断を修正できますが、自律型エージェントはデータに基づいて自動的にアクションを実行するためです。
データが古い・不正確であれば、エージェントの行動もそのまま誤りを含むことになります。
実際に、Databricksの「2026 State of AI Agents」レポートによると、ガバナンスを積極的に活用する企業は12倍多くのAIプロジェクトを本番運用できているとされています。
エージェント時代のデータ基盤は、品質管理とガバナンスが成功の前提条件です。モデルを変える前に、まずデータの品質を疑うべきです。
AIエージェントのデータ接続を支えるプロトコル

AIエージェントが企業データに安全にアクセスするための技術基盤として、2026年時点で2つの重要なプロトコルが標準化されつつあります。ここでは、それぞれの役割と補完関係を解説します。
MCP(Model Context Protocol)

MCP(Model Context Protocol)は、Anthropicが2024年に公開したオープンプロトコルで、AIモデル(エージェント)とデータソースやツールを接続する標準規格です。
2026年時点でMCPサーバーのエコシステムは急速に拡大しており、データベース(PostgreSQL、MySQL、MongoDB等)からSaaS API、ファイルシステムまで幅広いデータソースへのアクセスを提供しています。
主な特徴は以下のとおりです。
-
標準化されたデータアクセス
MCPサーバーを通じて、エージェントはデータベースのクエリ実行、ファイルの読み書き、外部APIの呼び出しを統一的なインターフェースで行えます。
-
Streamable HTTP Transport
2025年の仕様更新で、従来のHTTP+SSEに代わる方式として整理が進んだ通信方式です。単一エンドポイントでリクエストとストリーミングレスポンスを扱えるため、リモート環境への展開やロードバランサー、認証ミドルウェアとの統合がしやすくなりました。
-
Enterprise Readiness
2026年のロードマップでは、監査証跡、SSO統合認証、ゲートウェイ動作、構成ポータビリティが優先領域として掲げられています。
MCPは主要なIDEやエージェント開発基盤で対応が広がっており、ローカル開発からリモート接続まで活用範囲が拡大しています。
A2A(Agent-to-Agent Protocol)

A2A(Agent-to-Agent Protocol)は、Googleが2025年4月に発表し、2025年6月にLinux Foundation傘下のプロジェクトとして発足した、エージェント同士が相互に通信するためのオープンプロトコルです。AWS、Cisco、Microsoft、Salesforce、SAPなど100以上の組織が支持しています。
MCPが「エージェントとツール/データソース間」の接続を担うのに対し、A2Aは「エージェントとエージェント間」の通信を担います。
主な特徴は以下のとおりです。
-
Agent Card
各エージェントが自身の能力をJSON形式で公開し、他のエージェントが動的に発見・タスク委任できる仕組みです。
-
長時間タスク対応
ストリーミングと非同期オペレーションにより、分散環境での長期実行ワークフローをサポートします。
-
セキュリティ
JWT / OIDC認証、暗号化、きめ細かい認可をビルトインでサポートしています。
MCPとA2Aの補完関係

以下の表で、2つのプロトコルの役割の違いを整理しました。
| 観点 | MCP | A2A |
|---|---|---|
| 接続対象 | エージェント ↔ ツール/データソース | エージェント ↔ エージェント |
| 主な用途 | データベースクエリ、API呼び出し、ファイル操作 | タスク委任、結果共有、協調作業 |
| 標準化団体 | Anthropic主導(オープン仕様) | Linux Foundation(Google寄贈) |
| 通信方式 | HTTP + SSE / Streamable HTTP | HTTP + JSON-RPC + SSE(gRPCオプション) |
| 対応SDK | Python, TypeScript等 | Python, JavaScript, Java, C#, Go |
実務で押さえるべきポイントは、MCPとA2Aは競合ではなく補完関係にある点です。たとえば、営業エージェントがA2Aを使って在庫管理エージェントにタスクを委任し、在庫管理エージェントがMCPサーバー経由でデータベースに問い合わせる、という多層的な連携が可能になります。つまり、MCPは「データとの接点」、A2Aは「エージェント同士の協調」を担う二層構造です。
【比較】主要プラットフォームのAIエージェント×データ機能
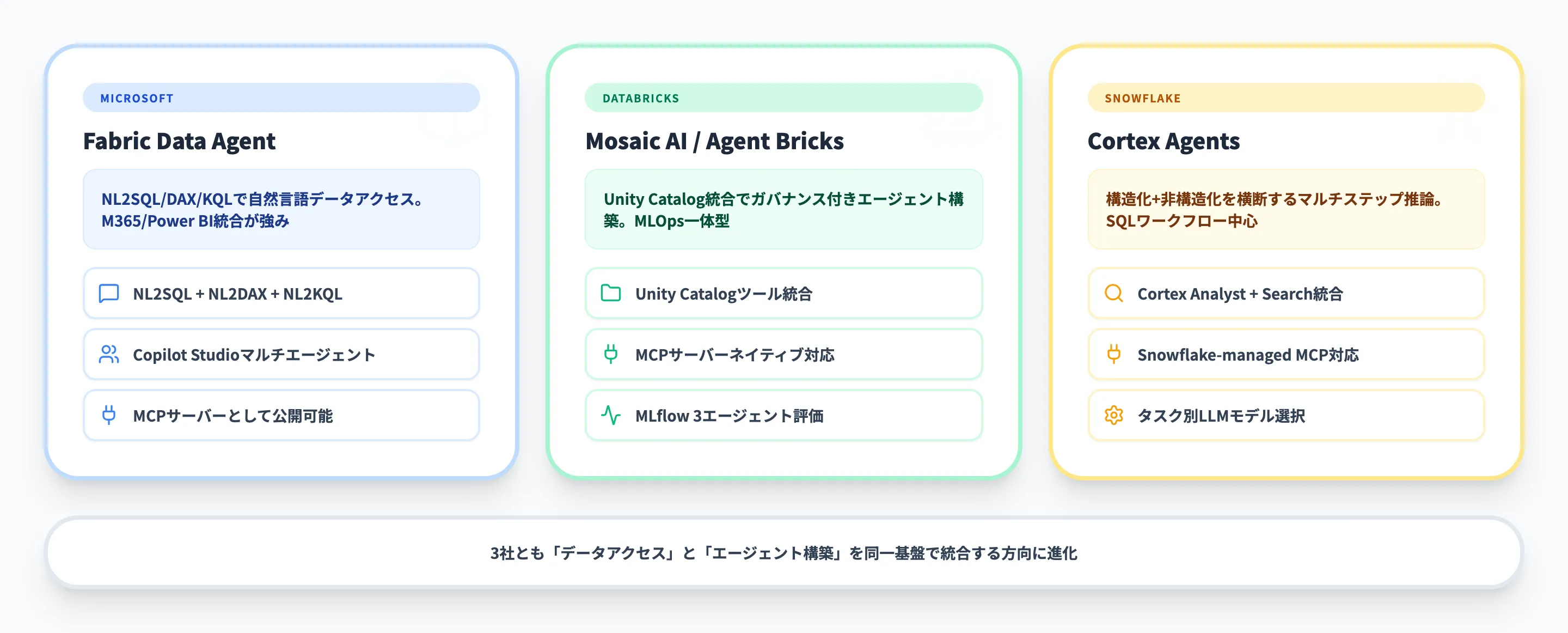
AIエージェントとデータ基盤を統合する機能は、主要プラットフォームで急速に進化しています。
ここでは、2026年時点での3社の最新機能を比較します。
Microsoft Fabric Data Agent

Microsoft Fabric Data Agentは、Fabricに内蔵されたAIエージェント機能です(2026年3月時点でプレビュー)。
自然言語でデータに問い合わせ、レイクハウス・ウェアハウス・Power BIセマンティックモデルから回答を取得できます。
標準機能ではSQL・DAX・KQLによる読み取りクエリが中心ですが、Azure AI Search index連携(プレビュー)を組み合わせることで、PDFやテキストファイルなどの非構造化データを扱う構成も可能です。
2026年時点の主な機能は以下のとおりです。
-
NL2SQL / NL2DAX / NL2KQL
自然言語をSQL(レイクハウス/ウェアハウス向け)、DAX(Power BIセマンティックモデル向け)、またはKQL(Real-Time Intelligence向け)に自動変換して読み取りクエリを実行します。
-
Copilot Studio統合
Fabric Data AgentをCopilot Studioに公開し、マルチエージェントオーケストレーションとして他のエージェントと連携できます。
Teams内から直接データドリブンな質問応答が可能です。
-
MCPサーバーとして利用可能(プレビュー)
Data AgentをMCPサーバーとして公開でき、現時点ではVS Code経由で利用できます。
Fabric上のデータ資産をMCP経由で外部エージェントに接続したい場合に有効です。
-
Microsoft Foundry統合
Microsoft Foundry(旧Azure AI Foundry)のAgent ServiceからFabric Data Agentを呼び出し、エンタープライズガバナンスポリシーを自動適用できます。
Databricks Mosaic AI / Agent Bricks

Databricksでは、Mosaic AI Agent FrameworkやAgent Bricksを通じて、Unity Catalog・MLflow・LLMガードレールを統合したエンドツーエンドのエージェント構築基盤を提供しています。
主な特徴は以下のとおりです。
-
Unity Catalogツール統合
Unity Catalogに登録された関数(テーブル検索、パラメータベースのクエリ等)をエージェントのツールとして直接利用できます。
構造化データへの安全なアクセスがガバナンス付きで実現します。
-
MCPサーバー接続
外部APIやサードパーティツールへのアクセスをMCPサーバー経由でネイティブにサポートしています。
Databricksは、クエリが事前にわかる場合はUnity Catalog関数、それ以外はMCPサーバーの使い分けを推奨しています。
-
MLflow 3によるエージェント評価
エージェントの各ステップの入出力をMLflow Tracingで記録し、ボトルネックの特定や品質モニタリングを行えます。エージェント間の比較評価も可能です。
Snowflake Cortex Agents

SnowflakeのCortex Agentsは、構造化・非構造化データを横断してマルチステップ推論を行うエージェント機能です。
主な特徴は以下のとおりです。
-
Cortex Analyst + Cortex Search統合
構造化データにはCortex Analyst(NL2SQL)、非構造化データにはCortex Search(ハイブリッド検索)を使い分け、エージェントが自動的に適切なツールを選択します。
-
カスタムツールとMCP対応
Stored ProceduresやUDFで独自ツールを実装できるほか、Snowflake-managed MCP serverを通じてCortex Analyst、Cortex Search、SQL実行などをMCP経由で外部に公開できます。
-
LLM選択の柔軟性
タスクごとにGPTまたはClaudeを選択でき、コストと精度のバランスを調整できます。
以下の表で、3プラットフォームのエージェント×データ機能を比較しました。
| 観点 | Fabric Data Agent | Databricks Mosaic AI / Agent Bricks | Snowflake Cortex Agents |
|---|---|---|---|
| NL2SQL | NL2SQL + NL2DAX + NL2KQL | Genie spaces / UC functions / MCP | Cortex Analyst |
| 非構造化データ | 直接接続は構造化中心、Azure AI Search index連携でPDFやテキストファイルに対応(プレビュー) | ベクトル検索インデックス | Cortex Search |
| MCP対応 | Data AgentをMCPサーバーとして利用可能(プレビュー、VS Code対応) | あり(managed MCP servers、Public Preview) | あり(Snowflake-managed MCP server) |
| マルチエージェント | Copilot Studio連携 | Agent Framework | カスタムツール拡張 |
| モデル評価 | Responsible AIチェック | MLflow Tracing / Agent Eval | ビルトイン品質監視 |
| 強み | Microsoft 365 / Power BI統合 | オープンソースとMLOps | SQL中心のワークフロー |
3社の方向性は共通しており、「データアクセス」と「エージェント構築」を同一基盤で統合する方向に進化しています。
では、どう選ぶべきか。M365/Power BIが既に社内基盤として定着している企業はFabric Data Agentが最も導入コストが低いです。既存のPower BIレポートやSharePointのデータをそのままエージェントに接続できるため、新たなデータ移行が不要です。
マルチクラウド環境でMLOpsも含めて管理したい場合はDatabricksが適しています。Unity CatalogによるクロスプラットフォームのガバナンスとMLflow Tracingによるエージェント評価が一体化している点が強みです。
SQL中心の分析ワークフローをエージェント化したい場合はSnowflake Cortex Agentsが有力です。Cortex AnalystとCortex Searchの自動使い分けにより、構造化・非構造化データの横断検索を最もシンプルに実現できます。
AIエージェント向けデータ基盤の設計パターン

AIエージェントがデータにアクセスする方式は、ユースケースに応じて大きく3つのパターンに分類できます。ここでは各パターンの仕組み、適した場面、設計上の注意点を解説します。
RAG型(検索拡張生成)
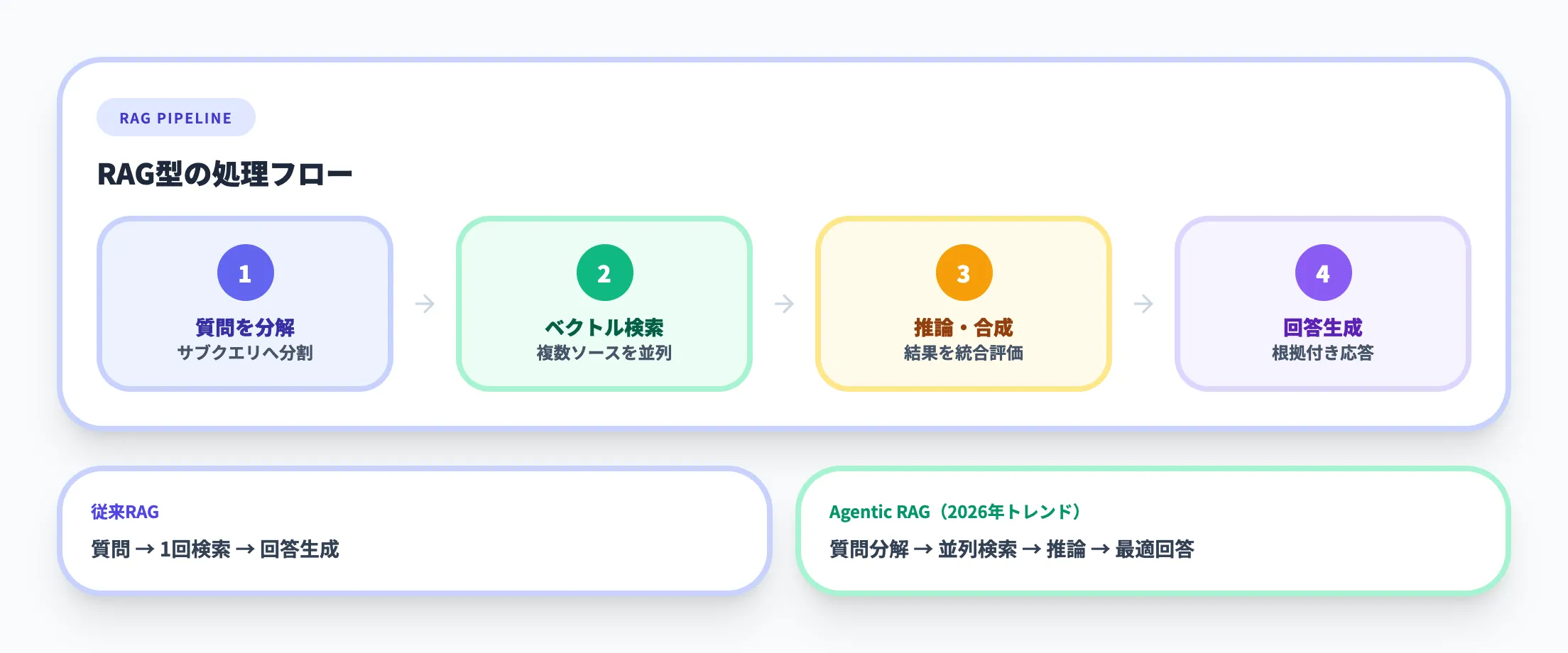
RAG(Retrieval-Augmented Generation)型は、エージェントが質問に回答する前に関連するドキュメントやデータを検索し、その情報をもとに回答を生成するパターンです。
社内ナレッジベース、マニュアル、過去の提案書といった非構造化データの活用に適しておりGraphRAGのようにグラフ構造を活用して関連性を強化する手法も登場しています。
2026年のトレンドとしては、従来のRAGをさらに進化させたAgentic RAG(エージェント型RAG) が注目されています。
従来のRAGでは「ユーザーの質問→1回の検索→回答生成」という単純なフローでしたが、Agentic RAGではエージェントが質問を自律的にサブクエリへ分解し、複数のデータソースに並列で検索を実行し、結果を推論しながら最適な回答を組み立てます。
Microsoftのクラウド導入フレームワークでは、このAgentic RAGをMCPと並ぶエージェントのデータ取得戦略として位置づけ、非構造化データの検索・引用・合成にはAgentic RAG、リアルタイムデータへのアクセスやアクション実行にはMCPという使い分けを推奨しています。
NL2SQL型(自然言語→クエリ)
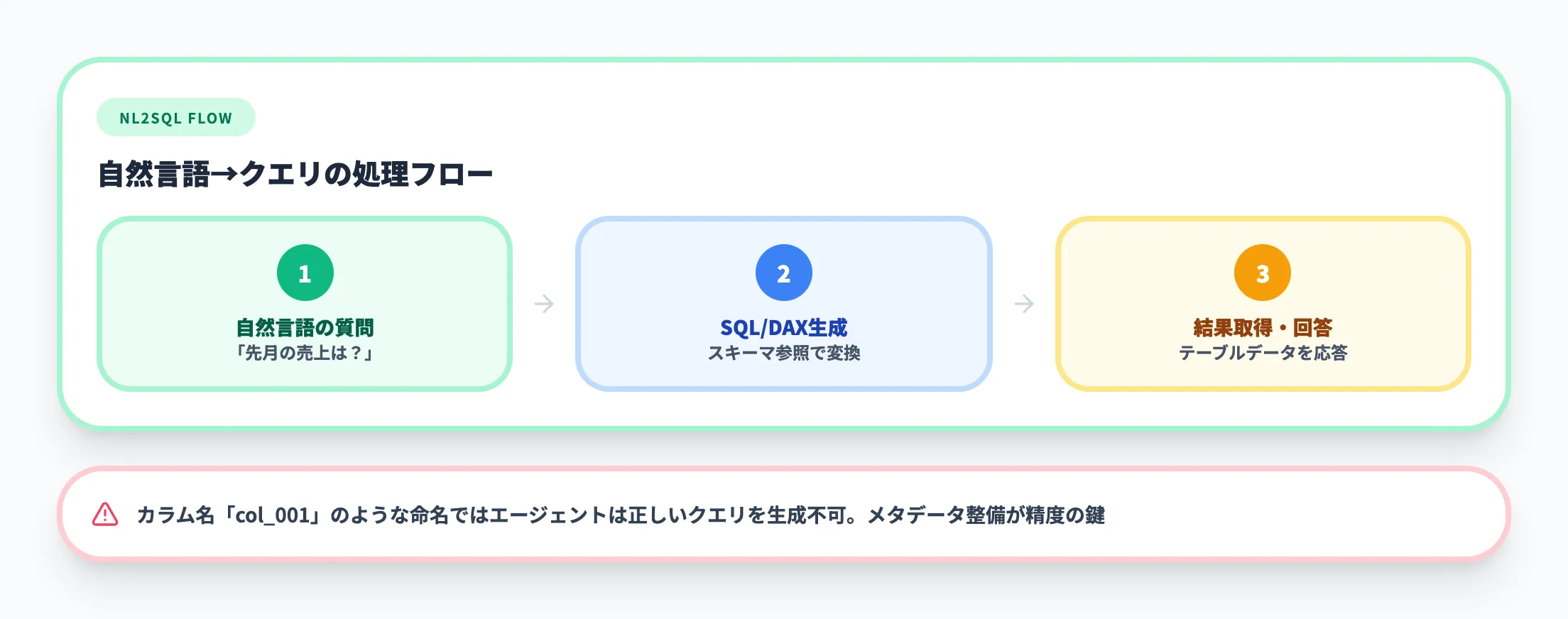
NL2SQL型は、エージェントがユーザーの自然言語の質問をSQLやDAXに変換してデータベースに直接問い合わせるパターンです。
売上実績、在庫数、KPIダッシュボードなど構造化データの分析に適しています。Fabric Data AgentのNL2SQL/NL2DAX、Snowflake Cortex Analyst、DatabricksのGenie spaces(自然言語によるテーブルアクセス)やUnity Catalog関数がこのパターンを支えます。
パイプライン型(ETL自動化)
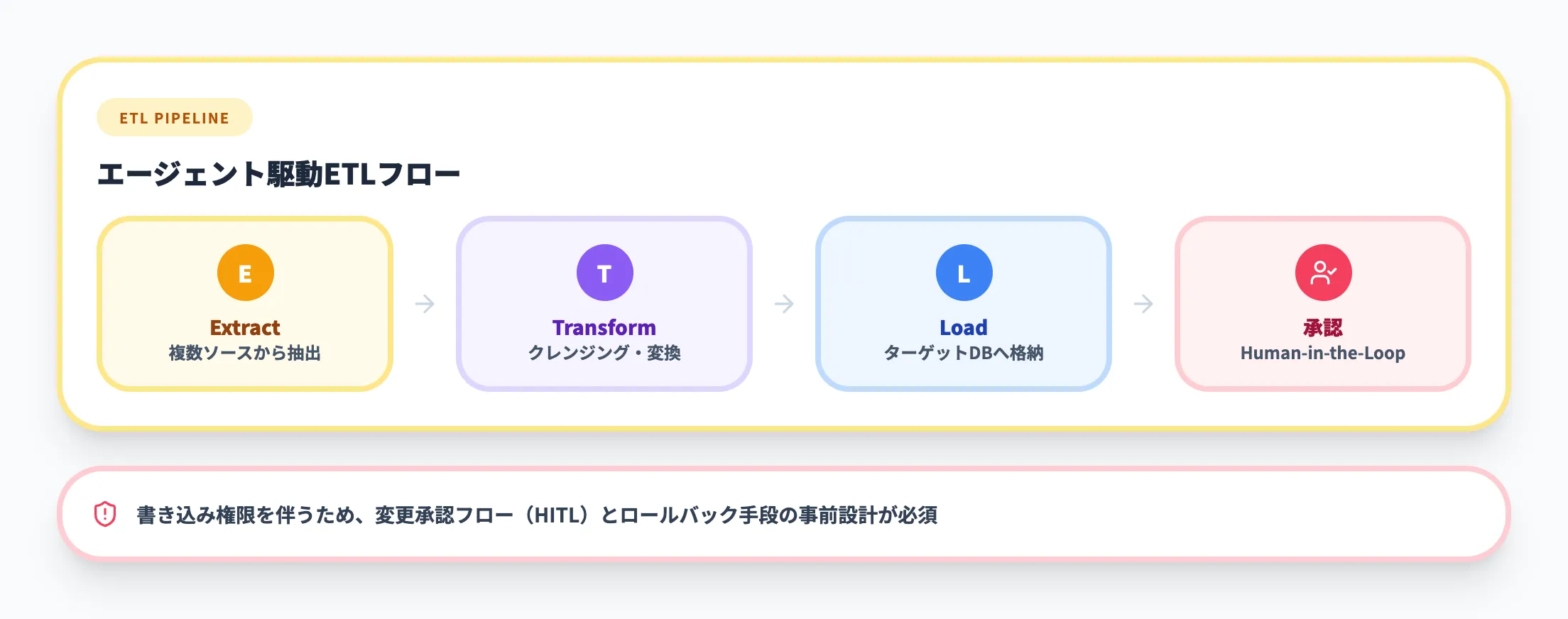
パイプライン型は、エージェントがデータの抽出・変換・ロード(ETL)を自律的に計画・実行するパターンです。
定期的なデータ統合、レポート生成の自動化、異種データソースの結合といった反復的なデータ処理に適しています。Snowflake Cortex Codeのようなコーディングエージェントや、Fabric Data Factoryとの連携がこのパターンを支えます。
以下の表で、ここまで紹介した3パターンの使い分けを整理しました。
| パターン | 適した場面 | 主なデータ種類 | 対応プラットフォーム |
|---|---|---|---|
| RAG型 | ナレッジ検索、FAQ、提案書作成 | 非構造化(文書、PDF) | Cortex Search / ベクトル検索 |
| NL2SQL型 | KPI分析、売上レポート、在庫照会 | 構造化(テーブル) | Fabric NL2SQL / Cortex Analyst |
| パイプライン型 | ETL自動化、レポート生成、データ統合 | 構造化+非構造化 | Cortex Code / Data Factory |
実際のエージェントは複数のパターンを組み合わせて使うケースが大半です。たとえば営業支援エージェントなら、CRMの売上データにはNL2SQL、過去の提案書にはRAGでアクセスし、両方の結果を統合して提案を作成します。
パターン選定で迷ったら、まず「エージェントがアクセスするデータの種類」で判断してください。構造化データ中心ならNL2SQL型から、非構造化データ中心ならRAG型から始めるのが最もリスクが低い入り方です。
【データレイヤー設計】メダリオンアーキテクチャ 2.0
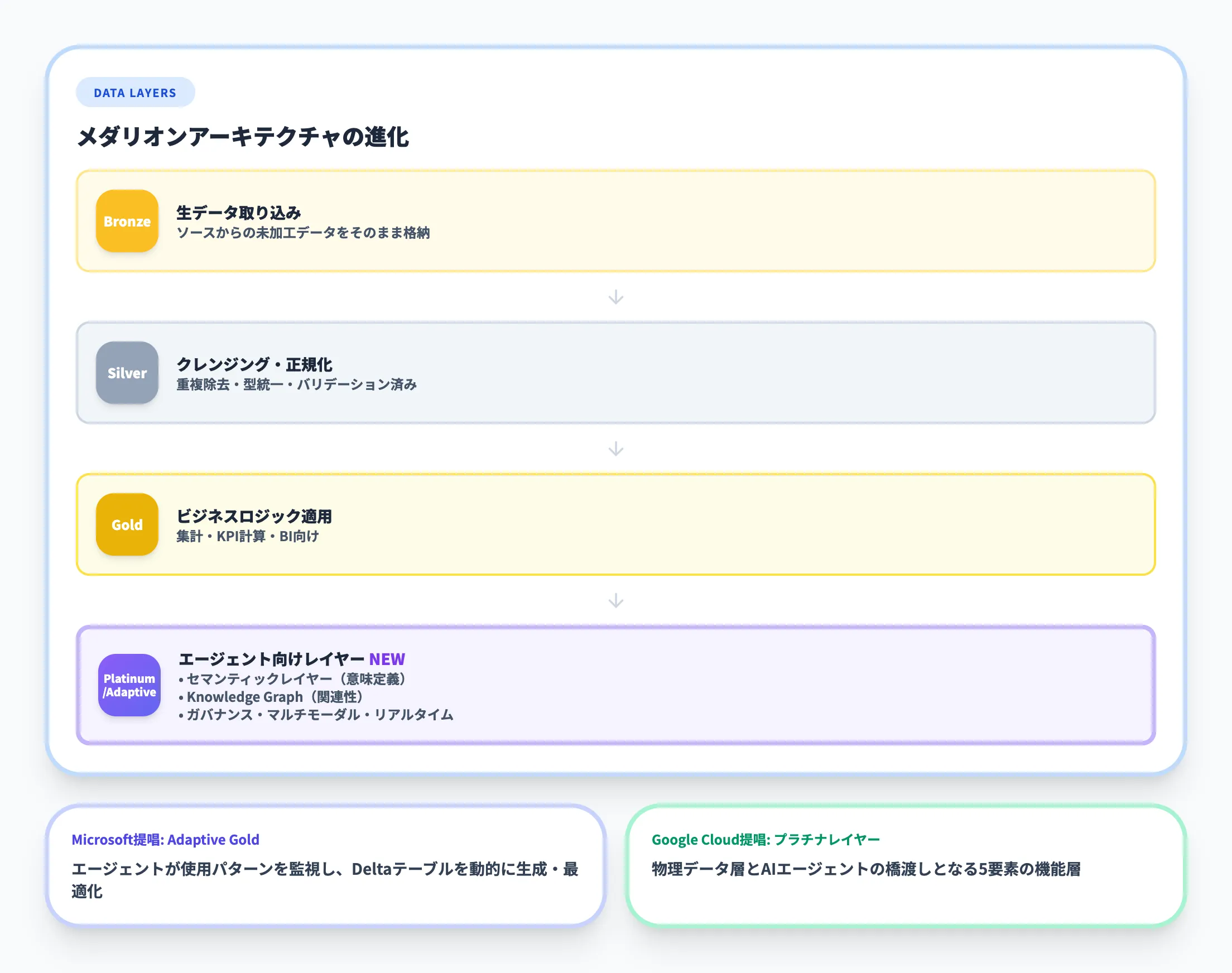
上記の3パターンがデータへの「アクセス方式」を定義するのに対し、エージェントがアクセスするデータそのものの整理方法として注目されているのがメダリオンアーキテクチャ 2.0です。
従来のメダリオンアーキテクチャでは、Bronze(生データ取り込み)→ Silver(クレンジング・正規化済み)→ Gold(ビジネスロジック適用済み)の3層でデータを段階的に品質向上させます。
エージェントAI時代には、この上にエージェント向けのレイヤーが求められるようになりました。
Adaptive Gold(Microsoft)
Microsoftのクラウド導入フレームワークでは、Adaptive Gold(アダプティブ ゴールド) を提唱しています。Adaptive Goldは、エージェント駆動型プロセスでビジネスニーズに合わせて進化する精選データセットを動的に作成するアプローチです。
エージェントが頻繁なクエリと集計パターンを監視し、価値の高いデータの組み合わせをDeltaテーブルとして自動的に具体化します。従来の静的なGold層と異なり、使用パターンに応じてデータのキュレーションが継続的に最適化される点が特徴です。
プラチナレイヤー(Google Cloud Japan)
一方、Google Cloud Japanの技術記事では、Gold層の上にプラチナレイヤーを設ける「メダリオンアーキテクチャ 2.0」を提案しています。
プラチナレイヤーは、物理的なデータ層とAIエージェントの間の橋渡しとなる機能層で、セマンティックレイヤー(データの意味定義)、Knowledge Graph(データ間の関連性)、ガバナンス(アクセス制御・監査)、マルチモーダル対応、リアルタイム対応の5要素で構成されます。
いずれのアプローチも、従来の「人間のBI分析向け」のGold層だけではエージェントの動的なデータアクセスに対応しきれないという課題に対する回答です。
データ基盤の設計時には、アクセスパターン(RAG / NL2SQL / パイプライン)とデータレイヤー(メダリオン構成)の両方を組み合わせて検討する必要があります。

マルチエージェントオーケストレーション・データ連携
1つのエージェントで完結しないタスクでは、複数のエージェントが役割分担して協調する「マルチエージェント」アーキテクチャが有効です。
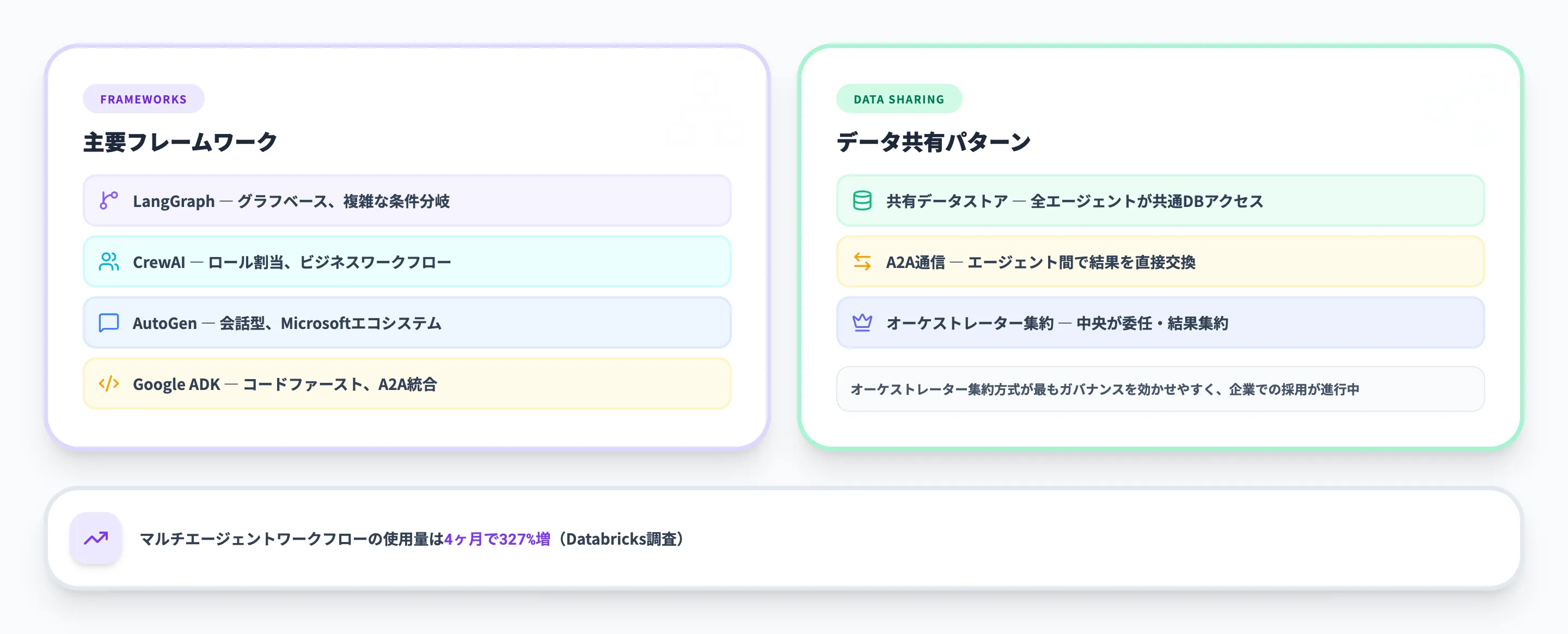
Databricksの調査では、マルチエージェントワークフローの使用量が4ヶ月で327%増加したと報告されています。
ここでは、主要なオーケストレーションフレームワークと、マルチエージェント環境でのデータ共有パターンを解説します。
主要フレームワーク比較
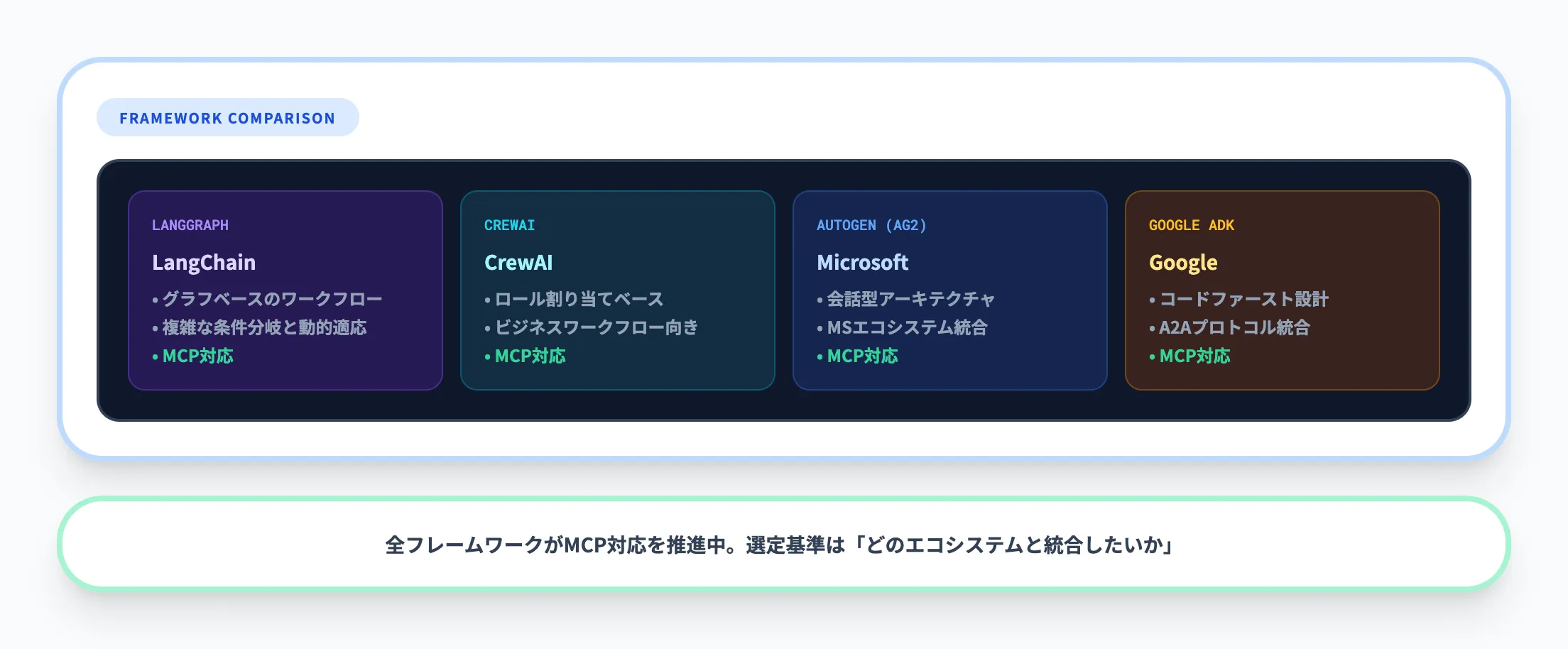
以下の表で、2026年時点の主要フレームワークの特徴を整理しました。
| フレームワーク | 開発元 | 設計思想 | 強み |
|---|---|---|---|
| LangGraph | LangChain | グラフベースのワークフロー | 複雑な条件分岐と動的適応に強い |
| CrewAI | CrewAI | ロール割り当てベースの協調 | 直感的なエージェント定義、ビジネスワークフロー向き |
| AutoGen(AG2) | Microsoft | 会話型エージェントアーキテクチャ | Microsoftエコシステムとの統合、ラピッドプロトタイピング |
| Google ADK | コードファーストの包括的フレームワーク | A2Aプロトコル統合、Vertex AI連携、マルチモーダル対応 |
すべてのフレームワークがMCPへの対応を進めているため、データアクセスの観点ではどれを選んでも大差ありません。
選定基準は「どのエコシステムと統合したいか」で決めるのが現実的です。Microsoft環境ならAutoGen、Google Cloud中心ならADK、既にLangChainを使っているならLangGraph、ビジネスワークフローの自動化が目的ならCrewAIが最短経路です。
マルチエージェントでのデータ共有パターン

マルチエージェント環境でデータを共有するには、主に以下の3つのアプローチがあります。
-
共有データストア方式
すべてのエージェントが共通のデータレイク(OneLakeやDelta Lake等)にアクセスする方式です。
データの一貫性が保たれやすい反面、アクセス制御の設計が複雑になります。
-
A2A通信方式
エージェント間でA2Aプロトコルを使い、タスクの結果を直接やり取りする方式です。
各エージェントが自身のデータソースを持ち、必要な情報だけを他のエージェントに共有します。
-
オーケストレーター集約方式
中央のオーケストレーターエージェントが各専門エージェントにタスクを委任し、結果を集約する方式です。Copilot StudioやLangGraphのスーパーバイザーパターンがこれに該当します。
実務では、オーケストレーター集約方式が最もガバナンスを効かせやすく、企業での採用が進んでいます。
中央のオーケストレーターが全体のフローを管理するため、監査証跡の取得や権限管理が一元化できるためです。
AIエージェント×データ基盤の企業事例

AIエージェントとデータ基盤を組み合わせた実際の導入事例を紹介します。
Walmart:AIエージェントによるサプライチェーン最適化

Walmartは、AIエージェントをサプライチェーン領域で積極的に活用しています。
同社が導入している自己修復型の在庫管理エージェントは、販売データ・在庫データ・需要予測データを横断的に分析し、自律的に在庫補充や異常検知を実行します。
生鮮食品のロス削減、在庫切れ率の低減、設備メンテナンスの効率化といった領域で成果を上げているほか、サプライヤーとの価格交渉をエージェントが自動化する取り組みも進んでいます。
この事例のポイントは、エージェントが単一のデータソースではなく複数の業務システムを横断してデータにアクセスするアーキテクチャを採用している点です。
サプライチェーン全体のデータを統合し、エージェントが動的にアクセスできる基盤を構築したことが、これらの成果につながっています。
参考:Walmart's U.S. Supply Chain Playbook Goes Global
メルカリ:データ分析エージェント「Socrates」
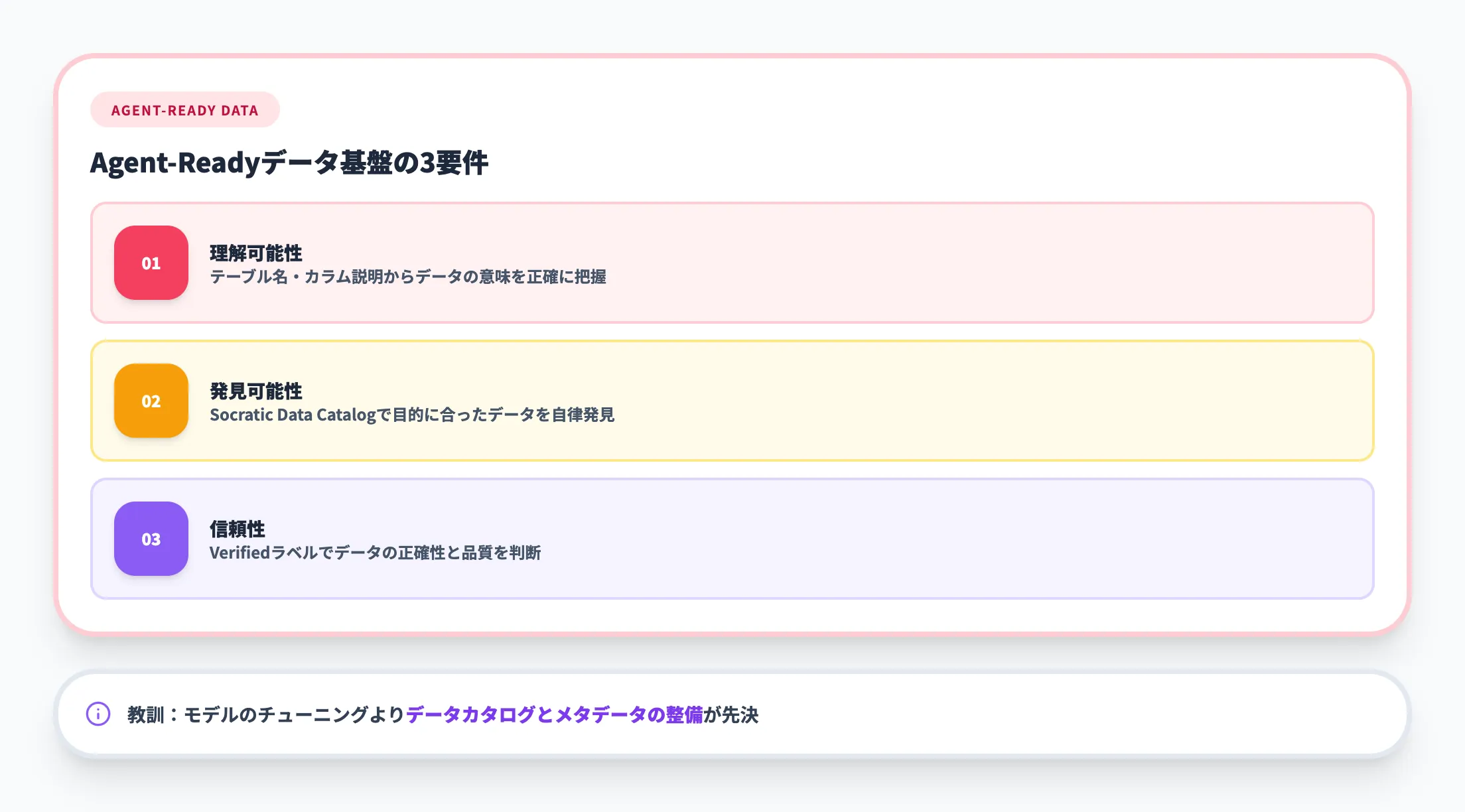
メルカリのエンジニアが公開した発表資料では、データ分析AIエージェント「Socrates」の構築と、そこから得られたAgent-Readyなデータ基盤の設計指針が共有されています。
Socratesは、会話を通じて利用者のデータ分析を支援するエージェントで、分析要求の理解と具体化、関連データの探索、BigQueryクエリの生成・実行、Pythonによる高度な分析・可視化、結果の解釈と洞察提示までを自律的に行います。
この取り組みから導き出されたAgent-Readyデータ基盤の要件は3つです。
- 理解可能性
エージェントがテーブル名やカラムの説明からデータの意味を正確に把握できること
- 発見可能性
Socratic Data Catalogによりエージェントが目的に合ったデータソースを自律的に発見できること
- 信頼性
Verifiedラベルによりデータの正確性と品質をエージェントが判断できること
この事例が示す重要な教訓は、エージェントの精度向上はモデルのチューニングよりもデータカタログとメタデータの整備が先決という点です。
カラム名の命名規則やテーブルの説明文など、人間にとっては自明な情報も、エージェントには明示的に提供する必要があります。
主要なデータ基盤プラットフォームの料金体系

AIエージェントを動かすデータ基盤のコストは、エージェントの実行頻度やアクセスするデータ量に大きく依存します。ここでは、主要3プラットフォームのエージェント関連コストを整理します。
Microsoft Fabric(Data Agent)
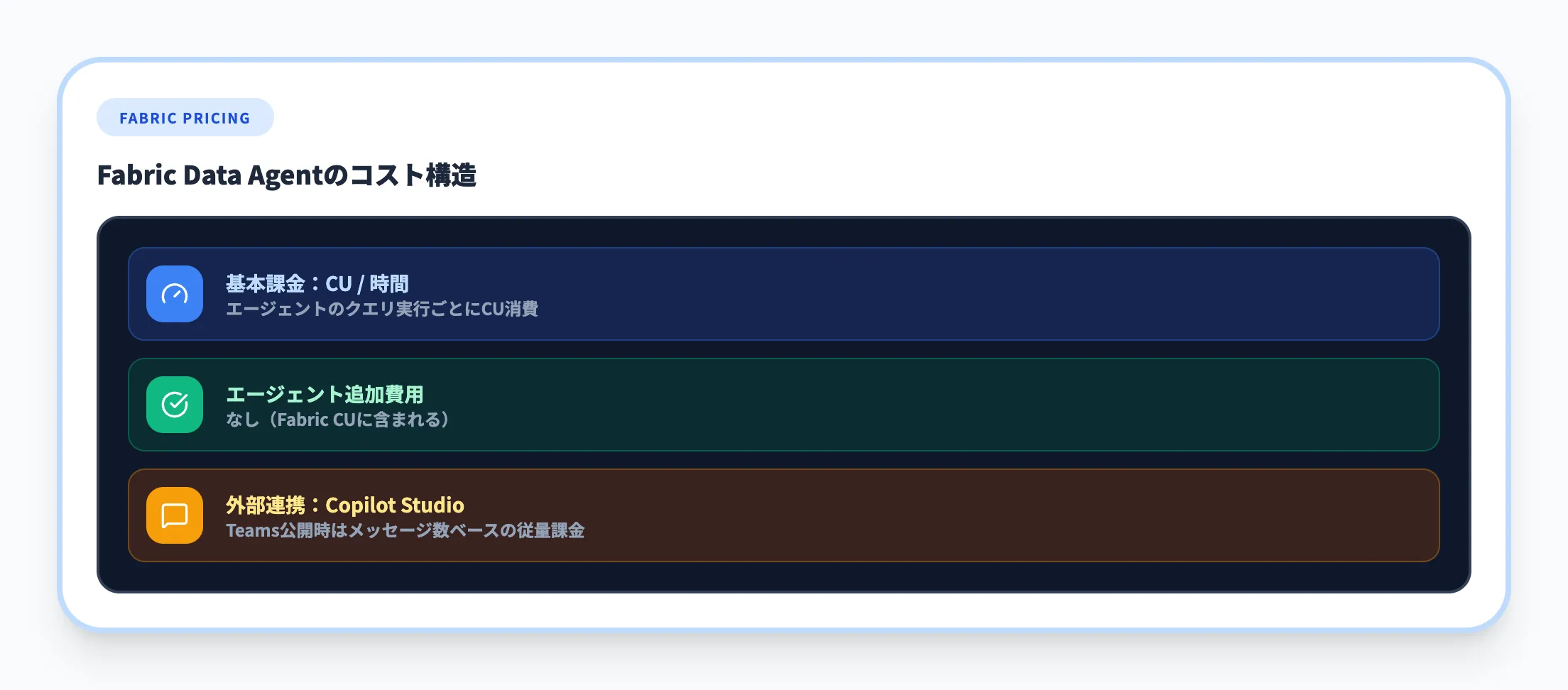
Fabric Data Agentの利用はFabricのCU(Capacity Unit)課金に含まれます。エージェントがクエリを実行するたびにCUが消費される仕組みです。
エージェント関連の追加コストとして、Copilot Studio経由でTeamsに公開する場合はCopilot Studioの従量課金(メッセージ数ベース)が別途発生します。Fabricの基本料金については、AI-readyデータ基盤の料金体系で解説しています。
Databricks(Mosaic AI Agent Framework)
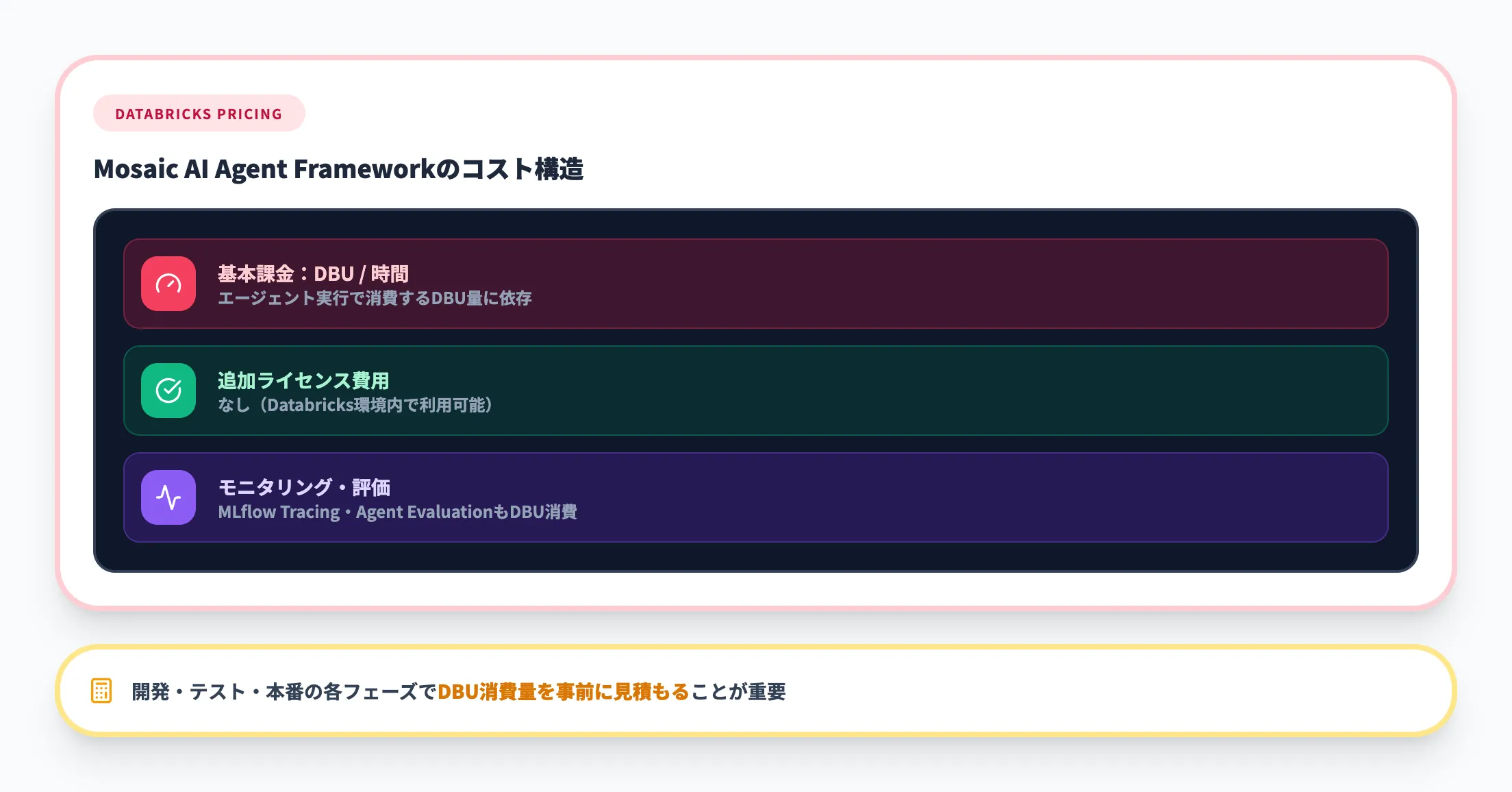
DatabricksのAgent Frameworkは追加ライセンス費用なしでDatabricks環境内で利用できます。コストはエージェントの実行に使用するDBU(Databricks Unit)の消費量に依存します。
MLflow TracingによるモニタリングやAgent Evaluationの実行にもDBUが消費されるため、開発・テスト・本番の各フェーズでのDBU消費量を見積もる必要があります。
Snowflake(Cortex Agents)
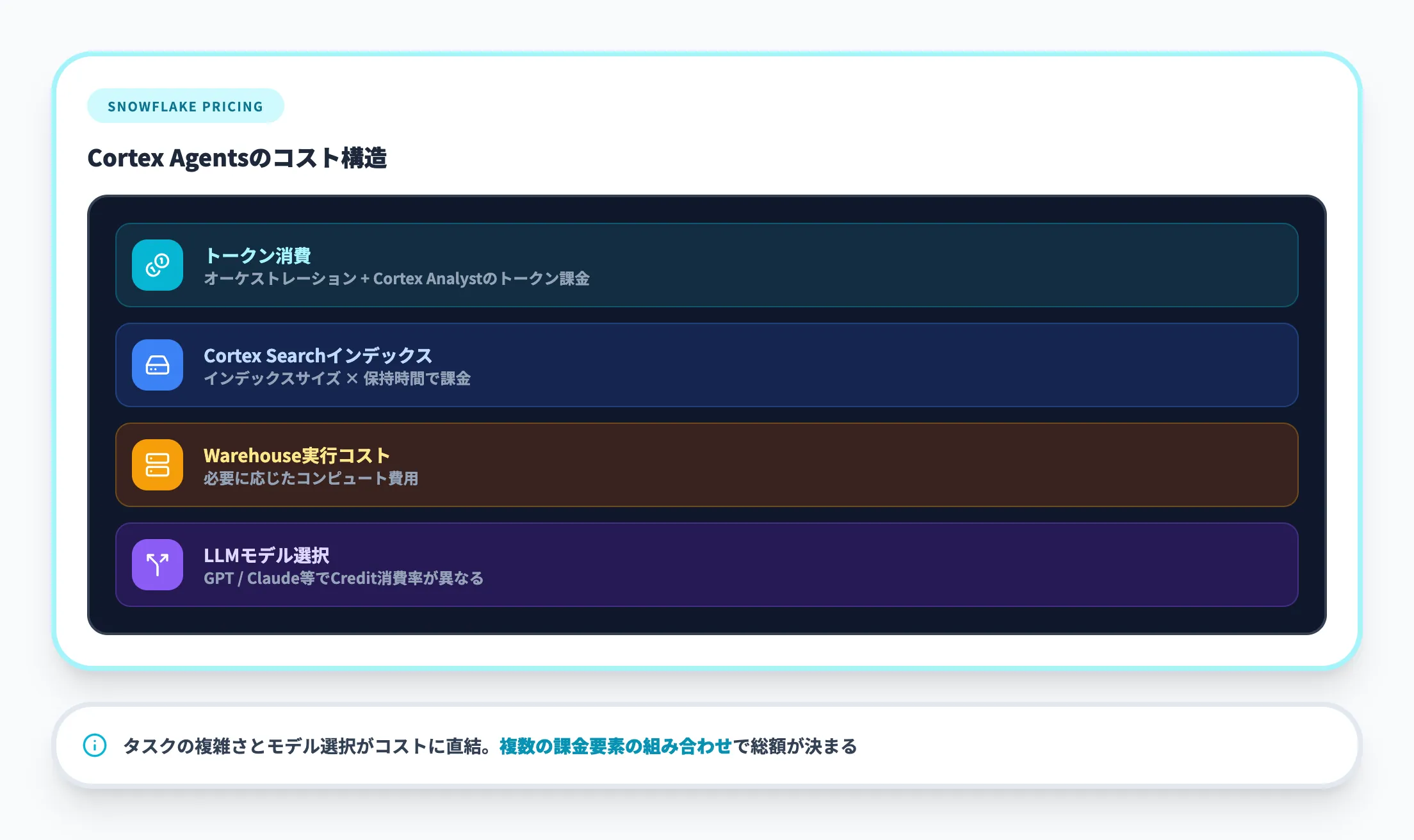
Snowflake Cortex Agentsのコストは、単純な「時間課金」ではなく複数の要素で構成されます。エージェントのオーケストレーションに使うトークン消費、Cortex Analystのトークン課金、Cortex Searchのインデックスサイズと保持時間、必要に応じたWarehouse実行コストなどの組み合わせで決まります。
使用するLLMモデル(GPT / Claude等)によってCredit消費率が異なるため、タスクの複雑さとモデル選択がコストに直結します。
3プラットフォームのコスト構造比較
以下の表で、エージェント関連コストの構造を比較しました。
| 観点 | Fabric Data Agent | Databricks Mosaic AI | Snowflake Cortex Agents |
|---|---|---|---|
| 基本課金 | CU / 時間 | DBU / 時間 | トークン + インデックス保持 + Warehouse |
| エージェント追加費用 | なし(CUに含む) | なし(DBUに含む) | なし(各サービスの課金に含む) |
| LLMコスト | Fabric容量のCU消費に含まれる | 選択モデルに依存 | モデルごとのトークン課金 |
| 外部連携コスト | Copilot Studio従量課金 | クラウドインフラ費用 | Snowpark Container Services |
3社とも専用の固定ライセンスではなく、利用量ベースの課金が中心です。つまり、エージェントの実行頻度とクエリの複雑さがコストを直接決定します。
PoCの段階から利用量の計測とアラート設定を必ず組み込んでください。 エージェントは自律的にクエリを繰り返すため、人間が手動で分析するよりも実行回数が桁違いに多くなり、想定外のコストが発生するリスクがあります。
AIエージェント向けのデータ基盤構築における注意点

AIエージェントとデータ基盤の統合を進めるうえで、よく見られる落とし穴と対策を解説します。
ガバナンス不在のままエージェントを展開する

エージェントがどのデータにアクセスし、どのようなアクションを実行したかの監査証跡なしに本番運用を始めると、コンプライアンス上のリスクが急増します。
しかし実態として、自律エージェント向けの成熟したガバナンスを持つ企業はわずか**21%**にとどまっています(Deloitte, 2026)。
一方で、ガバナンスを整備した企業ほど成果は大きく、Databricksの調査ではガバナンスを積極活用する企業は12倍、評価ツールを導入した企業は6倍多くのAIプロジェクトを本番運用しているという統計が報告されています(Databricks, 2026)。
まずデータカタログとアクセス制御を整備してからエージェントを展開する、という順序が重要です。
Human-in-the-Loopの設計を省略する
エージェントの自律性が高いほど、誤った判断がビジネスに与える影響も大きくなります。重要な意思決定(発注、顧客対応、データ変更等)にはエージェントの提案を人間が承認するチェックポイントを設計してください。
MCPのTool Confirmation機能やGoogle ADKのHITL機能が活用できます。
データ品質の問題をエージェント側で解決しようとする
エージェントの回答精度が低い原因を「プロンプトの改善」や「モデルの変更」で解決しようとするケースがありますが、多くの場合は入力データの品質が根本原因です。
エージェントのチューニングの前に、データの正確性・完全性・鮮度を確認するフローを組み込むことが先決です。
コスト管理を後回しにする
エージェントは自律的にクエリを繰り返すため、人間の手動分析とは実行回数が桁違いです。たとえば、1つの質問に対してエージェントが内部で5〜10回のサブクエリを実行するケースは珍しくありません。
対策として、CU / DBU / Creditの上限アラートをPoCの初日から設定してください。「本番前に整備する」では遅く、PoCの時点で想定外のコストが発生するリスクがあります。
単一ベンダーに全面依存する
エージェントのエコシステムは急速に進化しているため、特定のベンダーやフレームワークに過度に依存すると、技術の陳腐化リスクが高まります。
MCPやA2Aといったオープンプロトコルを活用し、データアクセス層とエージェントロジックを疎結合に設計することで、将来の柔軟性を確保できます。

データ基盤からAIエージェント運用まで一気通貫

Fabricのデータ資産をAIアクションに直結
Fabricで整備したデータ基盤の次のステップは、そのデータをAIエージェントが業務に活かす仕組みです。Zero ETLによるデータ仮想統合からTeams上でのAgent実行まで、エンタープライズ対応のAI基盤をご確認ください。
まとめ
AIエージェント向けデータ基盤の選定は、自社の環境と目的で決まります。
- M365/Power BIが社内基盤の企業 → Fabric Data Agent一択。データ移行なしでエージェント化できるため、導入コストが最も低い
- マルチクラウドでMLOpsも統合管理したい → Databricks。Unity CatalogとMLflow Tracingによるクロスプラットフォームのガバナンスが強み
- SQL中心の分析をエージェント化したい → Snowflake Cortex Agents。構造化・非構造化の横断検索が最もシンプル
設計パターンの選択も明確です。非構造化データ(社内文書・PDF)が中心ならRAG型から、構造化データ(売上・KPI)が中心ならNL2SQL型から始めてください。迷ったら「エージェントがアクセスするデータの種類」で判断するのが最もリスクが低い入り方です。
ただし、どのプラットフォーム・パターンを選んでも、ガバナンスの整備が先決です。ガバナンスを積極活用する企業は本番運用数が12倍という調査結果(Databricks, 2026)が示すとおり、データカタログ・アクセス制御・監査証跡の3点セットなしにエージェントを展開すべきではありません。
次のステップとしては、まず自社のエージェント活用候補を1〜2件に絞り、そのユースケースに必要なデータソースとアクセスパターンを明確にしてください。1業務で2ヶ月のPoCを回し、利用量ベースのコスト計測を組み込んだうえで横展開するのが、2026年時点で最も確実な戦略です。










