この記事のポイント
 データレイクとデータウェアハウスを使い分けてETLが二重化しているなら、Lakehouse構成のDatabricksに統合するのが第一候補
データレイクとデータウェアハウスを使い分けてETLが二重化しているなら、Lakehouse構成のDatabricksに統合するのが第一候補- 大規模ETL・ストリーミング・AI/MLが主役の組織にはDatabricks、SQL分析・BI主体ならSnowflakeのほうが立ち上がりが速い
- Mosaic AIならRAGエージェント構築から評価・本番運用まで単一プラットフォームで完結、ベクトル検索もUnity Catalogでガバナンス可
- 料金はDBU従量課金、Jobs ComputeはAll-Purpose Computeより安く設定、定常パイプラインはJobsクラスターに寄せるのが鉄則
- Databricks上で構築したAIを業務に乗せるフェーズでは、Microsoft Teams等の実行UIと業務ガバナンスを別レイヤーで設計する必要がある

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Databricks(データブリックス)は、データレイク・データウェアハウス・AI/MLを一つの基盤にまとめた「Lakehouse Platform」を提供するデータインテリジェンス企業です。Delta Lakeによるストレージ統合、Unity Catalogによるデータガバナンス、Mosaic AIによるAIエージェント基盤までを単一プラットフォームで提供しています。
本記事では、Databricksの基本概念と「Lakehouse」とは何かから始め、Delta Lake・Unity Catalog・Mosaic AIといった構成要素、SnowflakeやMicrosoft Fabricとの違い、DBU課金の仕組み、田辺三菱製薬・リクルートなどの導入事例までを2026年4月時点の最新情報で体系的に解説します。
目次
なぜDatabricksが必要なのか?データレイク/ウェアハウスの限界
Databricks AI/BI Genie(自然言語BI)
Genie Code(旧Databricks Assistant)
Databricks vs Snowflake / Microsoft Fabric
Databricksとは?
Databricks(データブリックス)は、データ・分析・AIを一つのプラットフォームに統合した「データインテリジェンス基盤」を提供する企業およびその製品名です。
2013年にApache Sparkの開発者が創業し、現在はLakehouse Platformとしてグローバル1万社以上に導入されています。AWS・Azure・Google Cloudのいずれの上でも動作し、オブジェクトストレージ上に直接データを置きながら、データウェアハウスのような信頼性とBI性能を提供することが最大の特徴です。

これまでデータ活用の現場では、大量のログや非構造化データは「データレイク(安価で柔軟)」に、BIや経営レポート用のクリーンなデータは「データウェアハウス(高速で整形済み)」に、と用途に応じて2つのストレージを使い分けることが一般的でした。しかしこの構成では、ETL(データ変換)が二重化したり、データの鮮度が層によってずれたり、AI/ML用と分析用でデータコピーが増えたりといった運用負荷が生じます。
Databricksはこの課題に対し、「データレイクの上に直接、データウェアハウス級の機能を載せる」というアプローチで答えを出しました。これがLakehouseという考え方です。
Databricksの位置づけ
Databricksは単一のサービスというより、データ基盤・分析基盤・AI/ML基盤・ガバナンスを束ねたプラットフォーム製品です。エンジニア・データサイエンティスト・アナリスト・BIユーザーが同じデータ・同じ権限管理のもとで作業できる「単一の作業場」を提供することを目的に設計されています。
公式ドキュメントでは「統一されたオープンな分析プラットフォーム」と定義されており、構成要素はオープンソースを軸にしています。Delta Lake(ストレージ)、Unity Catalog(ガバナンス)、MLflow(実験管理)、Apache Spark(分散処理)はすべてオープンソースで公開されており、特定クラウド・特定フォーマットへのロックインを避けやすい構造です。
Databricksが提供する4つのレイヤー
Databricksをひとことで説明すると複雑になりがちですが、提供する機能を4つのレイヤーに分けると整理しやすくなります。
- データレイヤー
Delta Lake / Unity Catalog / Lakehouse Federation など、データの保管と統合を担う部分
- 処理レイヤー
Apache Spark / Photon / Lakeflow / Databricks SQL など、ETLや分析クエリを担う部分
- AI/MLレイヤー
Mosaic AI / MLflow / Databricks AI/BI Genie など、生成AIエージェントや機械学習モデルを担う部分
- アプリ・共有レイヤー
Databricks Apps / Delta Sharing / Marketplace / Lakebase など、アプリ実装とデータ流通を担う部分
この4層が同じUnity Catalog配下で権限管理されるため、「データを動かさずに、SQL・Python・MLモデル・LLMエージェントすべてを同じ場所で実行できる」点がDatabricksの最大の強みです。
各クラウドベンダーとの関係
Databricks自体はクラウド非依存の製品で、AWS・Azure・Google Cloudのいずれかの上にDatabricksワークスペースを構築します。
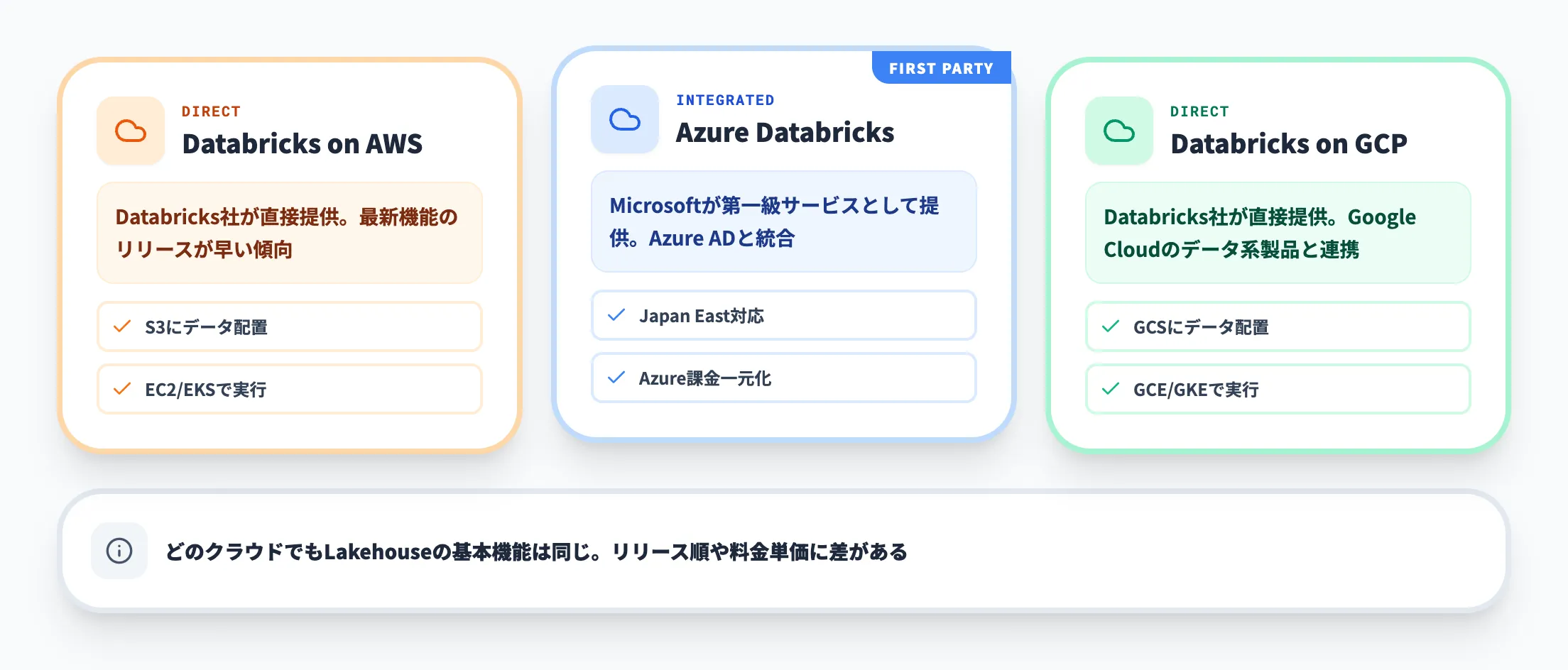
このうちAzure環境では、Microsoftが第一級サービスとして提供する「Azure Databricks」という形になっており、Azure ADと統合されたID管理やJapan Eastリージョンでの提供などが実現されています。AWS・GCPでは「Databricks on AWS」「Databricks on Google Cloud」という形で同社が直接提供します。どのクラウドを選んでもLakehouseの基本機能は同じですが、利用可能な最新機能のリリース順や料金単価には差があります。

なぜDatabricksが必要なのか?データレイク/ウェアハウスの限界
ここではDatabricksが解決しようとしている根本的な課題を整理します。Lakehouseが登場した背景を理解すれば、「自社にDatabricksが必要かどうか」を判断しやすくなります。
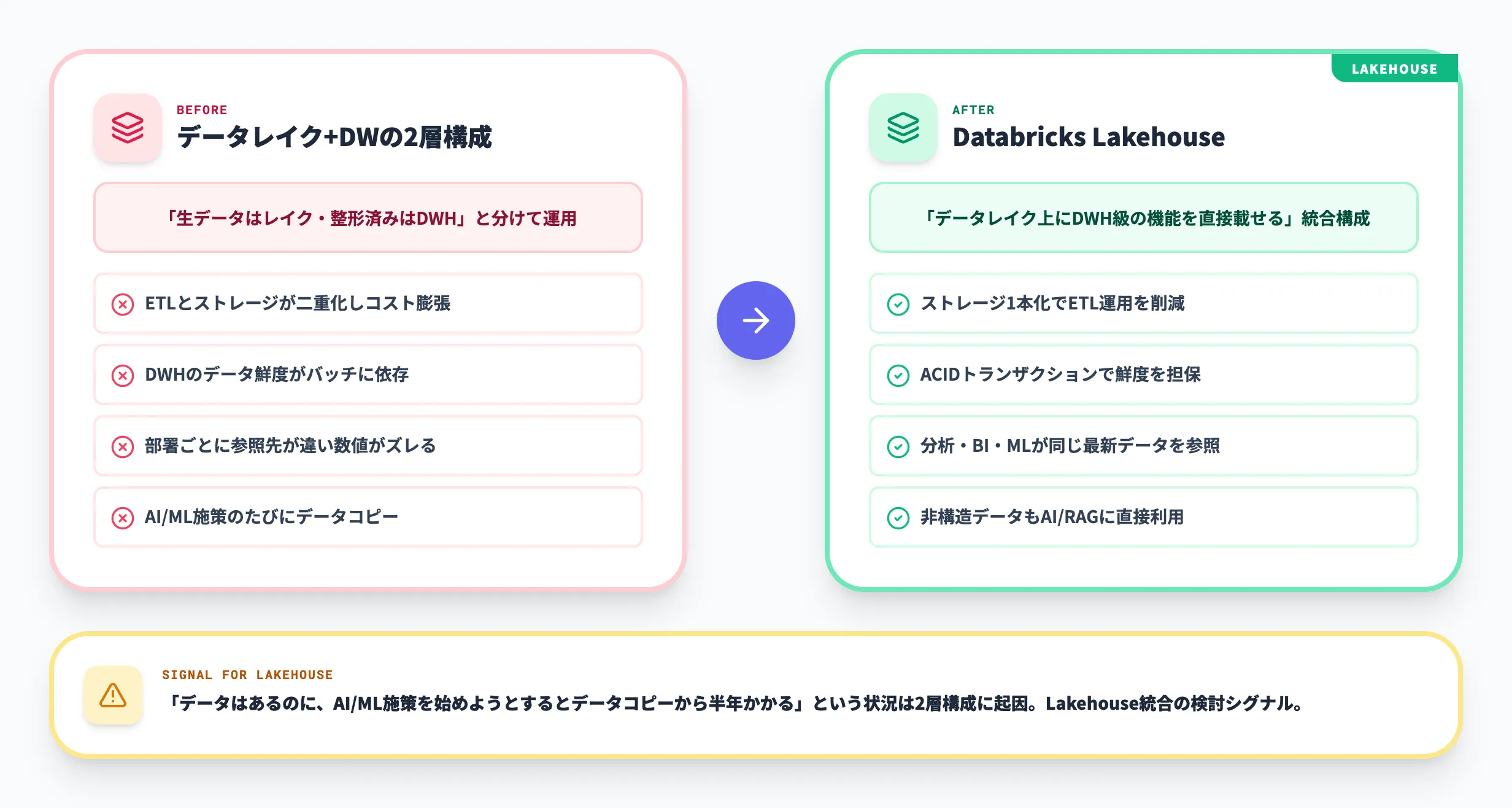
従来のデータレイク+データウェアハウス2層構成の課題
2010年代以降、多くの企業はAmazon S3やAzure Blobなどのデータレイクに生データを溜め、必要なデータだけを定期バッチでデータウェアハウス(Snowflake / Redshift / BigQuery等)に流す2層構成を取ってきました。この構成は安価かつ柔軟ですが、規模が大きくなると複数の課題が顕在化します。
具体的には、データレイクとウェアハウスの両方にデータを持つことでストレージコストとETL運用が二重化し、ウェアハウス側のデータ鮮度はETLの実行頻度に依存するため最新ではありません。また、データサイエンティストは生データへのアクセスを求めてレイク側を使い、アナリストはBIのためにウェアハウス側を使うため、同じ事象に対する数値が部署ごとに異なるといった「数値のズレ」も発生します。
Lakehouseが解決するもの
Lakehouseは「データレイクの上に、データウェアハウスの信頼性と性能を直接載せる」というアーキテクチャです。Databricksはこのコンセプトを最初に提唱した企業で、Microsoft Learnの公式定義でも「データレイクとデータウェアハウスの利点を組み合わせたデータ管理システム」と説明されています。

Lakehouseが解決するのは主に次の3点です。1つ目は、ストレージを1つに集約することでデータの重複を減らし、ETL運用とコストを削減できる可能性が高まる点。2つ目は、ACIDトランザクションをデータレイク上で実現することで、分析・BI・MLが同じ最新データを参照できる点。3つ目は、構造化データだけでなく画像・PDF・ログ・音声といった非構造化データもAIワークロードに直接使えるため、生成AI時代のRAG構築や非構造データ分析にそのまま利用できる点です。
DXを推進する組織で「データはあるのに、AI/ML施策を始めようとするとデータコピーから半年かかる」という状況がある場合、それは2層構成に起因していることが多く、Lakehouseへの統合を検討する具体的なシグナルです。
Databricks Lakehouseの基本構成
Databricks Lakehouseは複数のオープンソース技術を組み合わせて成り立っています。ここでは代表的な4つの構成要素を見ていきます。

Delta Lake(ストレージレイヤー)
Delta Lakeは、データレイク上のParquetファイルにACIDトランザクション・スキーマ強制・タイムトラベル(バージョン履歴)を追加するオープンソースのストレージ層です。Databricks社が開発し、現在はLinux Foundation配下のOSSとして公開されています。
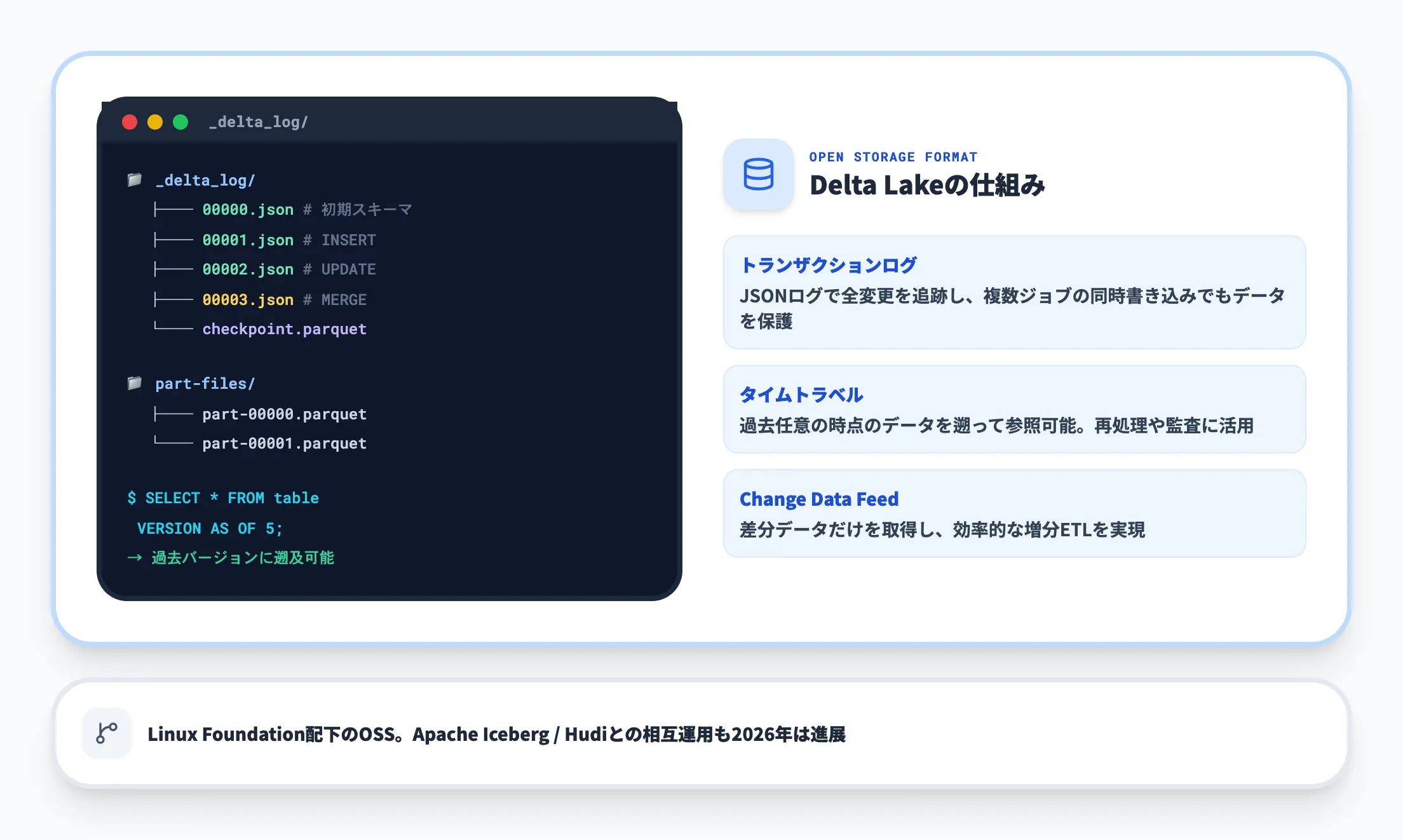
通常のデータレイクではファイルを上書きするとデータの整合性が壊れる危険がありますが、Delta Lakeはトランザクションログで全変更を追跡し、複数ジョブが同時に書き込んでもデータが破壊されないことを保証します。さらに、過去任意の時点のデータを「時間を遡って」参照できるタイムトラベル機能や、変更データだけを差分取得するChange Data Feedを備えており、ETLパイプラインの再実行や監査要件にも応えられます。
:::
なお、競合フォーマットとしてApache Iceberg・Apache Hudiがあり、近年はDatabricks自身もIcebergの読み書きをサポートする方向に動いています。
フォーマット選定は「Delta Lakeを選ぶ=Databricksにロックインされる」という単純な構図ではありません。
Unity Catalog(ガバナンスレイヤー)
Unity CatalogはDatabricksが提供する統一データ・AIガバナンスソリューションです。公式ドキュメントでは、tables / views / volumes / functions / models などをsecurable objectとして階層的に管理する仕組みと定義されています。ファイルはvolumesやexternal locationsを経由して統治され、行/列レベルのアクセス制御、データリネージ追跡、監査ログ、データ検索機能を一元的に提供します。
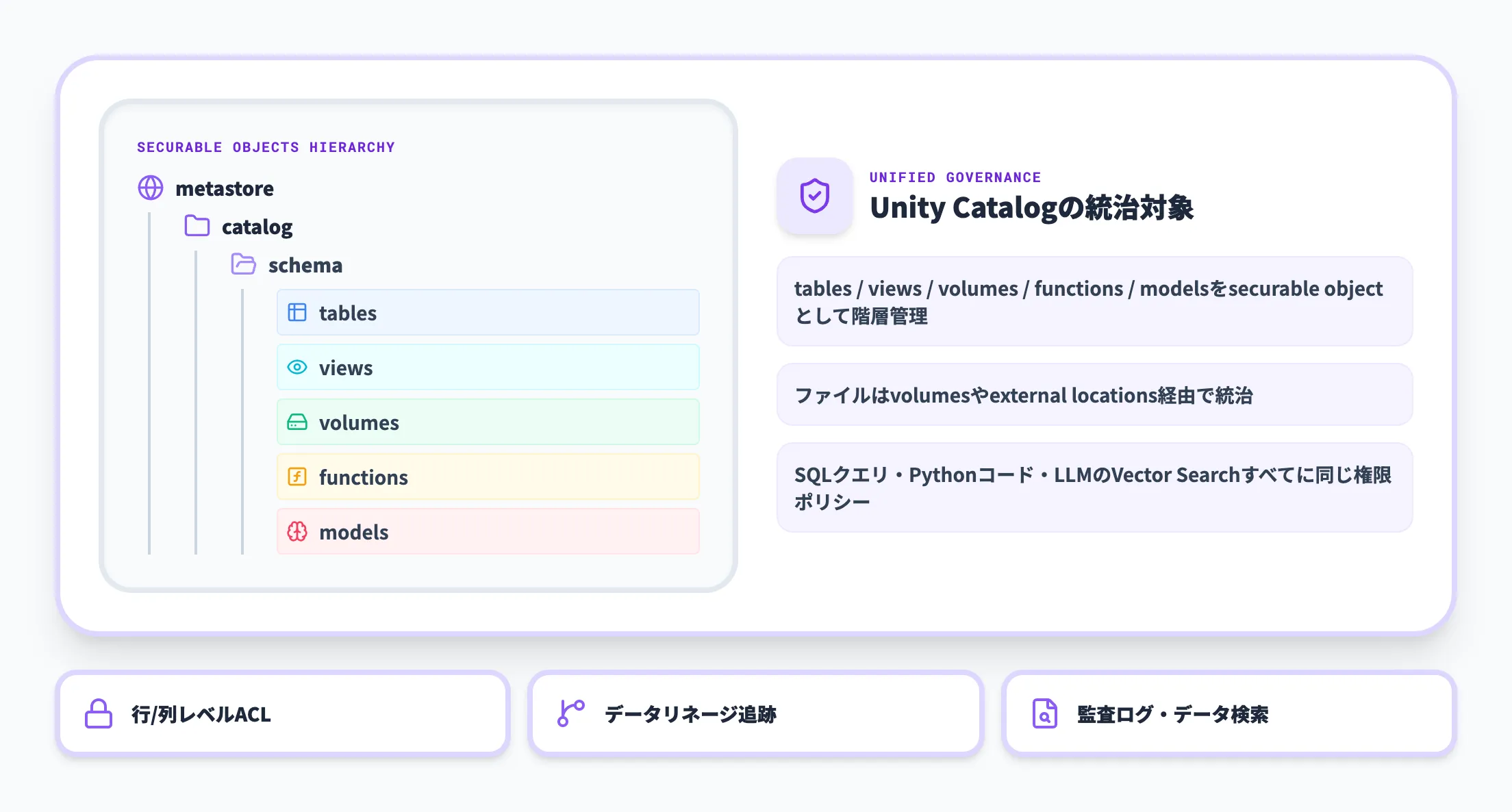
Lakehouseで最も難しいのは「同じデータをBIユーザーとデータサイエンティストとAIエンジニアの全員に開きながら、機密項目だけは隠す」というガバナンスです。Unity Catalogはこの問題に対し、SQLクエリ・Pythonコード・REST API・LLMのVector Searchすべてに同じ権限ポリシーを適用できる仕組みを提供します。Snowflake Horizonと並ぶ、Lakehouse時代の標準的なガバナンスレイヤーです。
Apache Spark / Photonエンジン
Databricksの分散処理エンジンは、創業者たちが開発したApache Sparkがベースです。Sparkは大規模データに対する分散変換・分散学習のデファクトスタンダードで、Pythonでpandas風に書きながら数十TBのETLを並列実行できます。
そのSparkに加えて、Databricksは独自開発の「Photon」というネイティブ実行エンジンを提供しています。PhotonはC++で実装されたSQL実行エンジンで、Sparkクエリを内部的に書き換えて最大数倍の高速化を実現します。BIダッシュボードから叩かれるDatabricks SQLでは、このPhotonが標準で使われます。
メダリオンアーキテクチャ
Databricksでは「メダリオンアーキテクチャ」と呼ばれるデータ整流パターンが推奨されています。これはBronze(生データ)→ Silver(クレンジング済み)→ Gold(業務指標化)の3層に段階的にデータを精製していく考え方です。
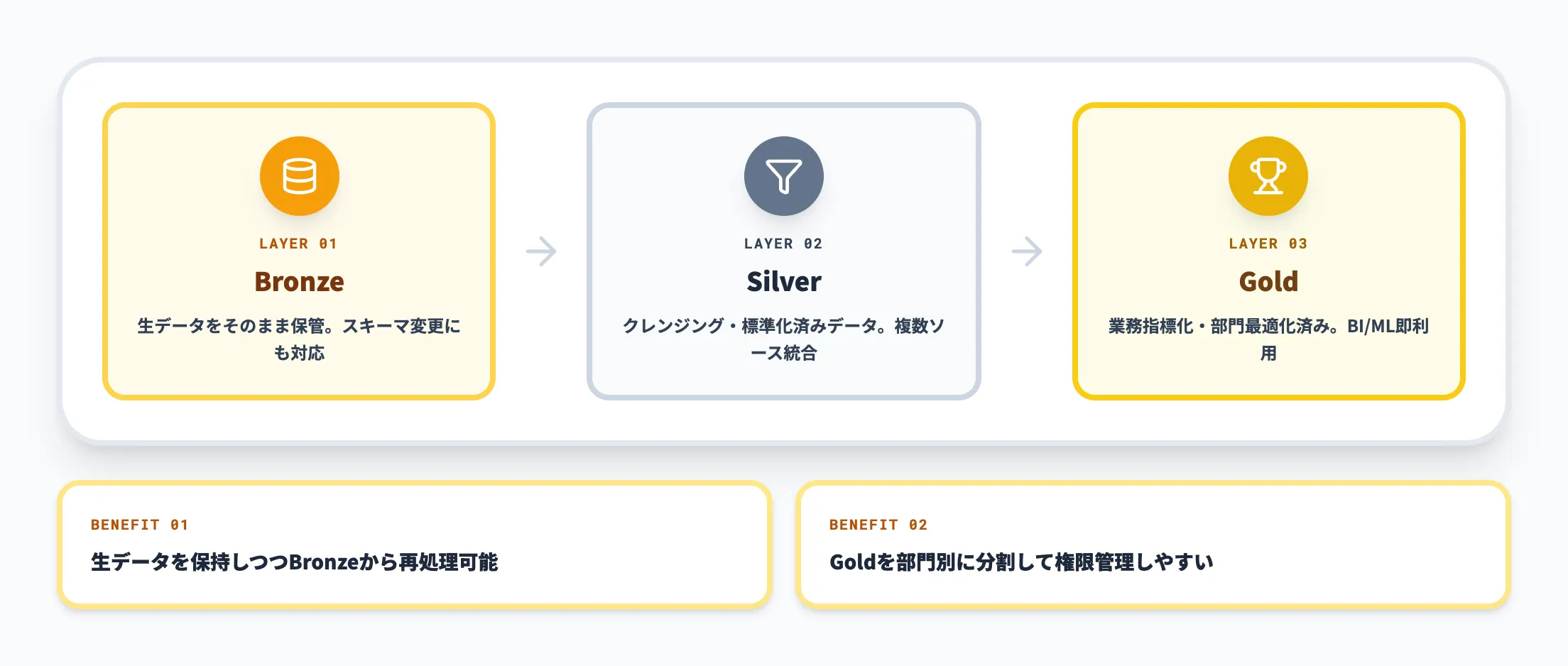
メダリオンの利点は、生データを常に保持しつつ、上位レイヤーは特定の用途に最適化できる点にあります。たとえばBronzeを再処理することで過去データを遡って指標を作り直す、Goldだけを部門別に分割して権限管理する、といった運用が可能になります。Databricksが推奨する「データの設計パターン」として、新規構築時は基本的にこの考え方をベースにする組織が多くなっています。
Databricksの主要機能(2026年版)
2026年現在、Databricksは「データインテリジェンスプラットフォーム」へと進化し、AI関連の機能群が大きく拡充されています。代表的な機能を紹介します。

Mosaic AI(生成AI・エージェント基盤)
Mosaic AIは、Databricks上で生成AIアプリケーションやエージェントを構築・運用するための統合ブランドです。2023年のMosaicML買収を契機に整備され、現在は次の構成要素を含みます。

- Mosaic AI Vector Search
Lakehouseのテーブルから直接インデックスを作成できるベクトル検索基盤。Unity Catalogでガバナンスされる
- Mosaic AI Model Serving
基盤モデル(Llama・Claude・GPT-OSS等)を従量課金 or プロビジョンドスループットでホストするモデル推論基盤
- Mosaic AI Agent Framework
RAGエージェントやマルチステップエージェントを構築するためのSDK
- Mosaic AI Gateway
モデル呼び出しを一元プロキシし、利用ログ・コスト・PIIマスキングを管理するLLMゲートウェイ。2025年6月時点でGA済み。なお、刷新版の「new AI Gateway endpoint experience」はGCP等でBeta提供となっており、エンドポイント管理UIの新体験のみBeta段階です
- MLflow 3 GenAI評価(旧Mosaic AI Agent Evaluation)
LLMジャッジを使ってエージェント応答を自動評価する機能。従来のAgent EvaluationはMLflow 2系のlegacy扱いとなり、現行はMLflow 3のGenAI評価への移行が公式に推奨されています
通常のRAG構築では「ベクトルDB」「モデルAPI」「評価基盤」を別々のサービスでつなぐ必要がありますが、Mosaic AIはそのすべてをLakehouse上で完結できる点が最大の差別化要素です。社内データの権限管理(Unity Catalog)と、エージェントが参照する権限管理を1セットで設計できるため、PoCで終わらせず本番運用まで持っていきやすくなります。
Databricks SQL
Databricks SQLは、Lakehouse上のデータに対してBIツール(Tableau / Power BI / Looker等)やSQLクライアントから直接クエリを発行できるSQLウェアハウス機能です。Photon実行エンジンと専用クラスター(SQL Warehouse)の組み合わせで、データウェアハウス専用製品に匹敵するBI性能を実現しています。
これにより、データウェアハウスを別途用意せずともDatabricksだけで「ETL→Lakehouse→BI」までを完結でき、Snowflakeなど他のDWH製品とDatabricksを併用していた組織が、SQL分析もDatabricksに寄せる動きが加速しています。
Databricks AI/BI Genie(自然言語BI)
AI/BI Genieは、Databricks上のテーブルに対して自然言語で質問するとSQLが生成され、結果が返ってくるという自然言語BI機能です。BIダッシュボードを作るほどでもないが「先月の関東エリアの売上は?」のような問い合わせに即答したい、というユースケースに向いています。
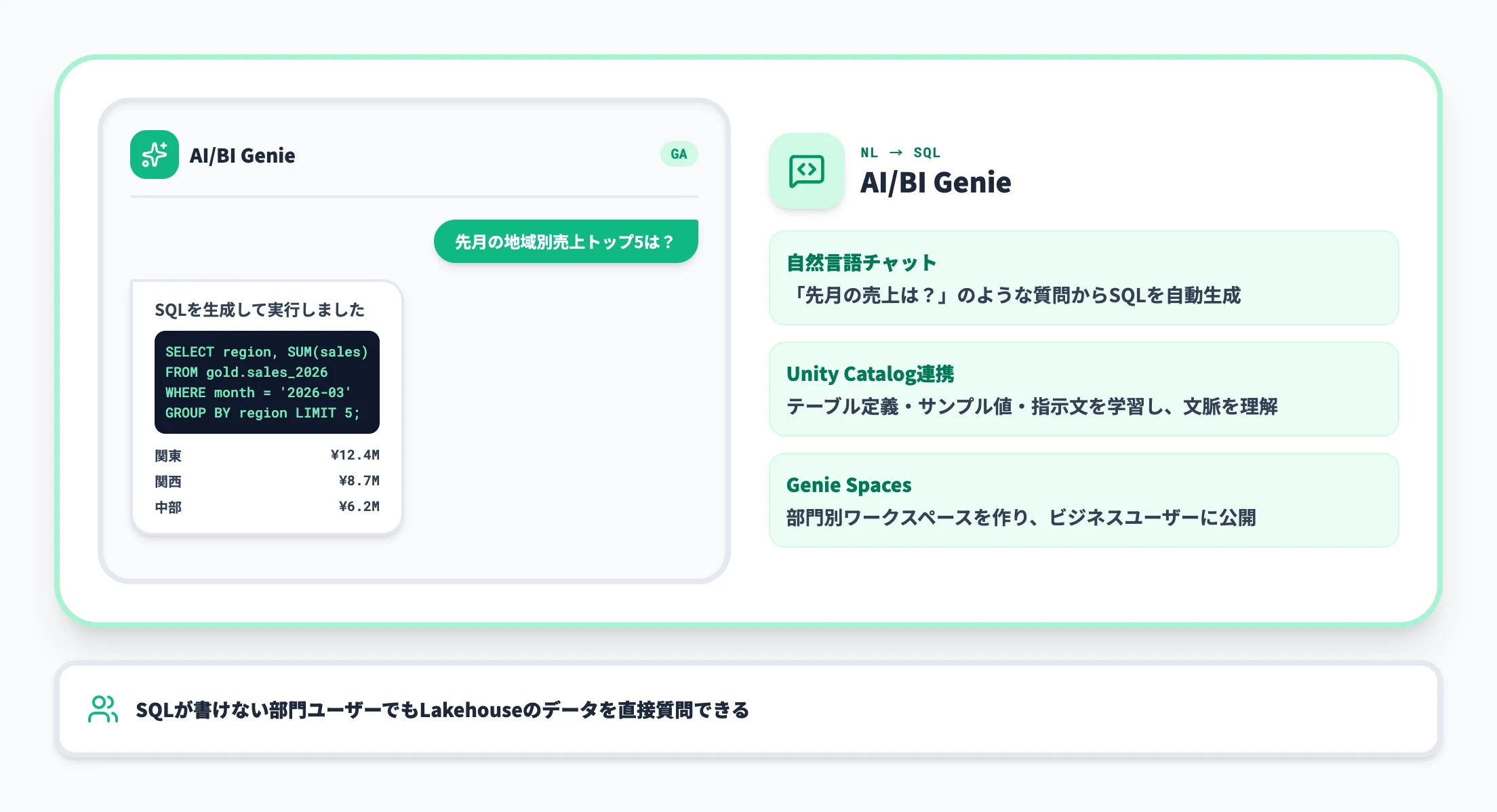
ポイントは、Genieが生成したSQLとその実行権限がUnity Catalog配下で管理されるため、「LLMが社内データを勝手に開示してしまう」事故を防ぎやすい点です。Snowflake Cortex AnalystやMicrosoft Fabricのデータエージェントと比較される機能領域です。
Lakeflow(統合データパイプライン)
Lakeflowは2024年に発表された、Delta Live Tables・Auto Loader・Workflowsを統合した新しいデータパイプライン製品です。SaaSコネクタ・ストリーミング・宣言型ETL・スケジュール実行までを一つの製品で提供します。

これまでDelta Live Tables(DLT)だけでは扱いづらかった「外部SaaSからの取込」をLakeflow Connectが担うようになりました。ただしSaaSコネクタはGAのものとPublic Preview / Beta段階のものが混在しているため、対象SaaSがすでにGAで提供されているケースに限ってはFivetranやAirbyteを別途使わずDatabricksだけで完結する構成が現実的になりつつある、という温度感です。
Lakebase(運用DB統合)
Lakebaseは、Databricksが提供するサーバーレスPostgres機能で、2026年に一般提供(GA)されました。これにより、これまで別系統で運用していたOLTP(業務系DB)とOLAP(分析系DB)を、同じLakehouse基盤の上に置けるようになります。
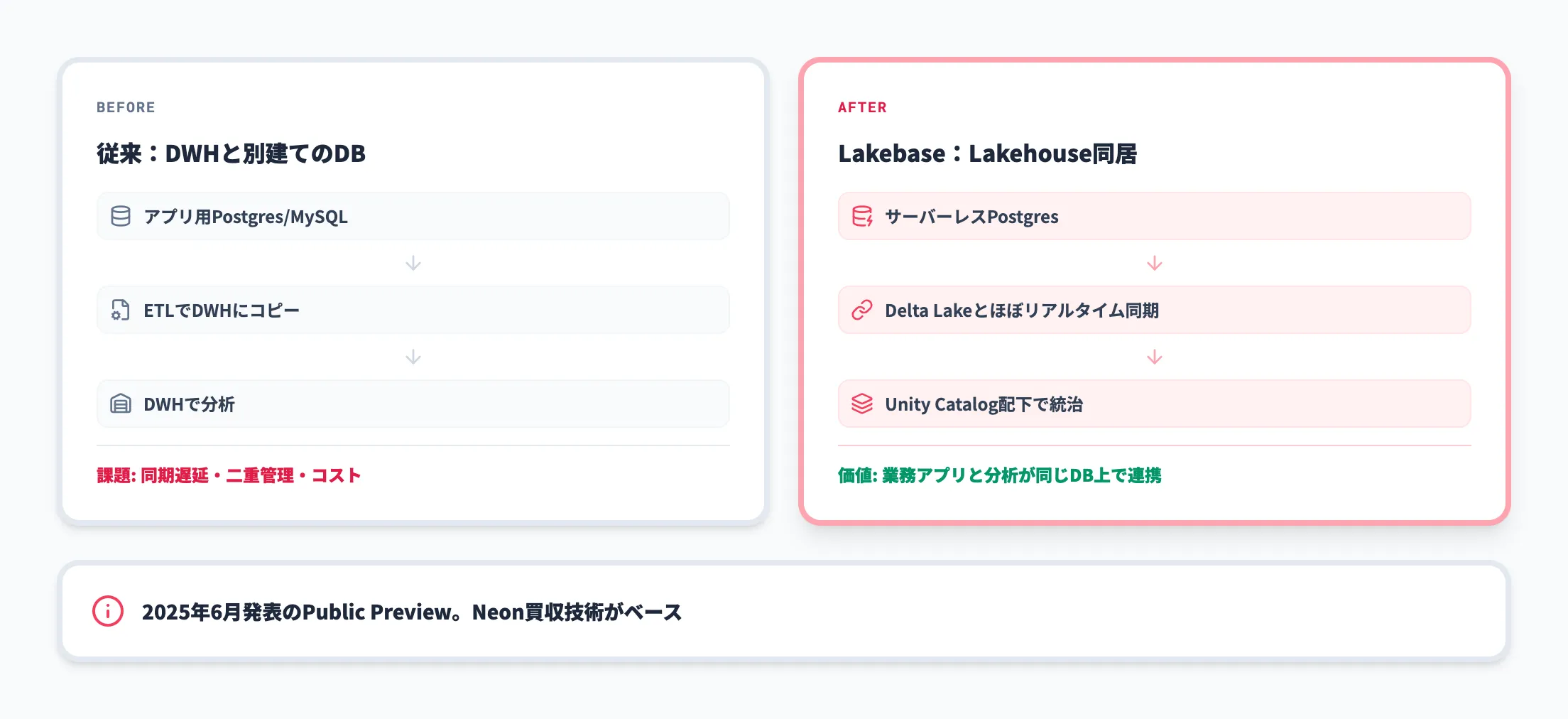
2026年3月のAzure Databricks リリースノートでは、Lakebaseインスタンスがオートスケーリング対応版として既定で作成されるようになったことが告知されています。アプリケーションの運用DBとデータ分析基盤を分けずに済むため、リアルタイムレコメンドやエージェントの状態管理など、低レイテンシ要件のあるユースケースに有効です。
Genie Code(旧Databricks Assistant)
Databricks Assistantは2026年のGenie Codeへのリブランドを経て、エージェント型のコード支援機能へと進化しています。データパイプラインの構築・デバッグ・ダッシュボード作成・本番運用までを自律的に進められるようになり、エージェントモードがGAになりました。
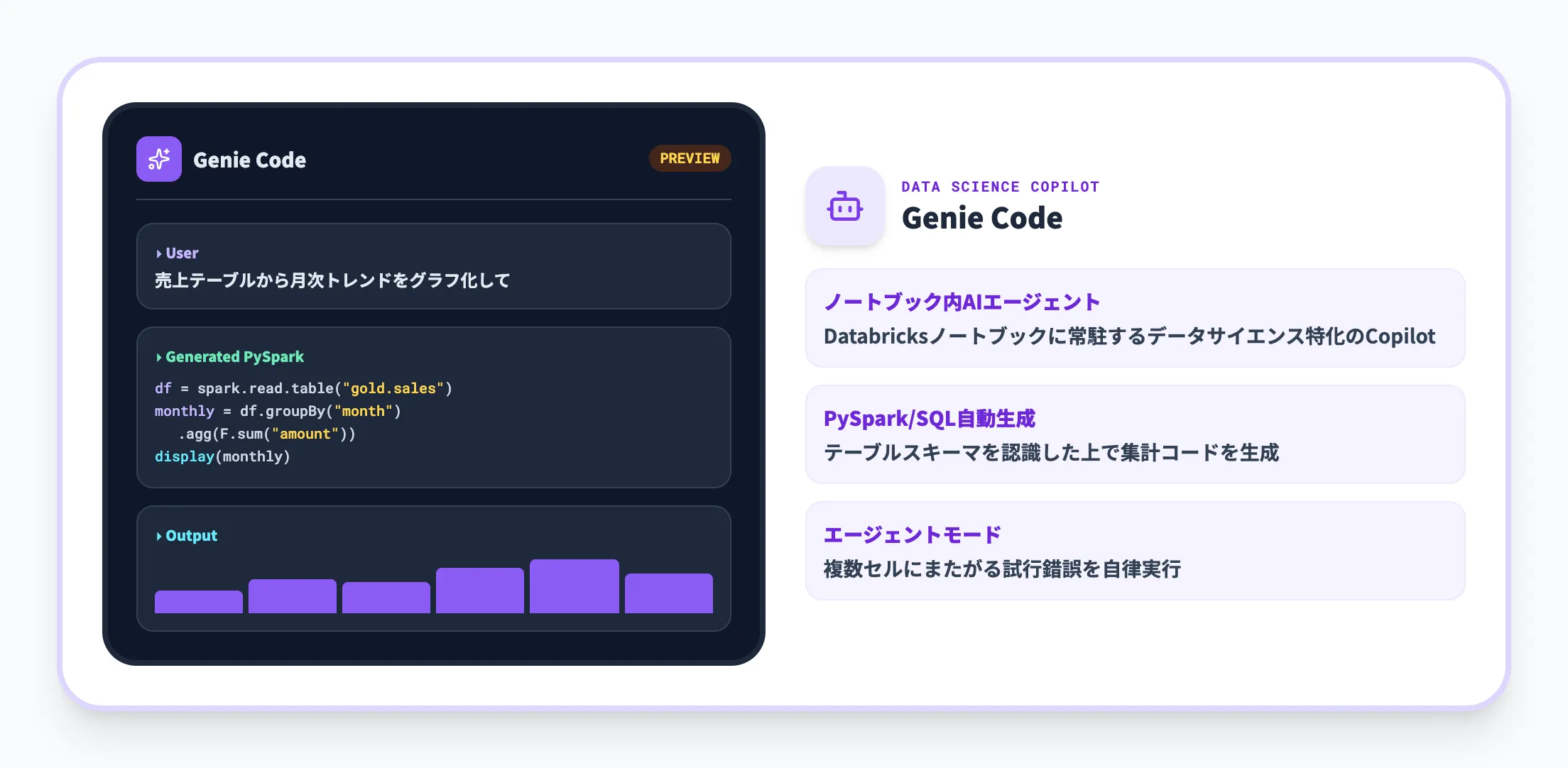
Notebook内で「このパイプラインが失敗している原因を調べて修正して」と指示すれば、Genie Codeがエラーログを読み取り、修正コードを提示してテスト実行までを自動で進めるイメージです。

Databricks vs Snowflake / Microsoft Fabric
Databricksの選定で必ず比較対象となるのがSnowflakeとMicrosoft Fabricです。それぞれの違いを整理しておきます。

Databricks vs Snowflake
両社とも「データ+AI」の統合プラットフォームを掲げていますが、出自と得意領域が異なります。

| 観点 | Databricks | Snowflake |
|---|---|---|
| 出自 | Apache Spark / Lakehouse | クラウドネイティブDWH |
| 得意領域 | ETL・ストリーミング・AI/ML・非構造化データ | SQL分析・BI・高同時実行 |
| データ形式 | 構造化+非構造化(画像・PDF・ログ等) | 構造化+半構造化中心 |
| インターフェース | Python / SQL / Scala(コード中心) | SQL中心(学習コスト低) |
| AI機能 | Mosaic AI(エージェント・評価まで統合) | Cortex AI(モデル呼び出し中心) |
| ガバナンス | Unity Catalog | Snowflake Horizon |
| 料金モデル | DBU(処理量+クラウドVM) | クレジット(仮想ウェアハウス) |
この比較から分かるのは、両者は「同じ製品の競合」というより、得意領域がずれた製品だという点です。実際、2026年の比較記事では、両者を併用する企業が「Databricksでデータ整流とML、Snowflakeで分析・BI配信」と役割分担している例が紹介されています。
選び方の目安として、組織の中心人員がデータエンジニア/データサイエンティストでありPython・Sparkを書く人が多い場合はDatabricksが立ち上がりやすく、SQLアナリストとBI担当者が中心で「SQLだけで完結させたい」組織はSnowflakeが立ち上がりやすい傾向があります。
Databricks vs Microsoft Fabric
Microsoft Fabricは2023年に登場したMicrosoftの統合データ・分析プラットフォームで、Power BI・Synapse・Data Factory・Real-Time Analyticsを束ねています。Databricksとは特に「Microsoft環境で使うLakehouse製品」という文脈で比較されます。

| 観点 | Databricks | Microsoft Fabric |
|---|---|---|
| ストレージ | Delta Lake(オープン) | OneLake(Delta互換) |
| 提供形態 | クラウド非依存(AWS/Azure/GCP) | Azure統合(Microsoft 365連携) |
| BI統合 | 外部BIツール接続 | Power BIネイティブ統合 |
| AI機能 | Mosaic AI(成熟) | Fabric Copilot / Data Agent |
| 価格モデル | 従量課金(DBU) | 容量予約(CU) |
| ガバナンス | Unity Catalog | OneLake + Purview |
| 強み | AI/ML・大規模ETL | Microsoft環境統合・BI |
選択の目安は、Microsoft 365とPower BIが業務の中核にある組織はFabricのほうが既存資産を活かしやすく、逆に大規模なAI/ML開発・マルチクラウド要件・高度なETLが中心ならDatabricksが優位です。両者とも内部はDelta Lakeベースで相互運用も可能なため、段階的に併用する選択肢もあります。DatabricksについてはMicrosoft Fabric Lakehouseの解説記事と読み比べると差分が掴みやすいです。
Databricksの導入事例
Databricksは国内外で大規模な導入実績があります。代表例を紹介します。
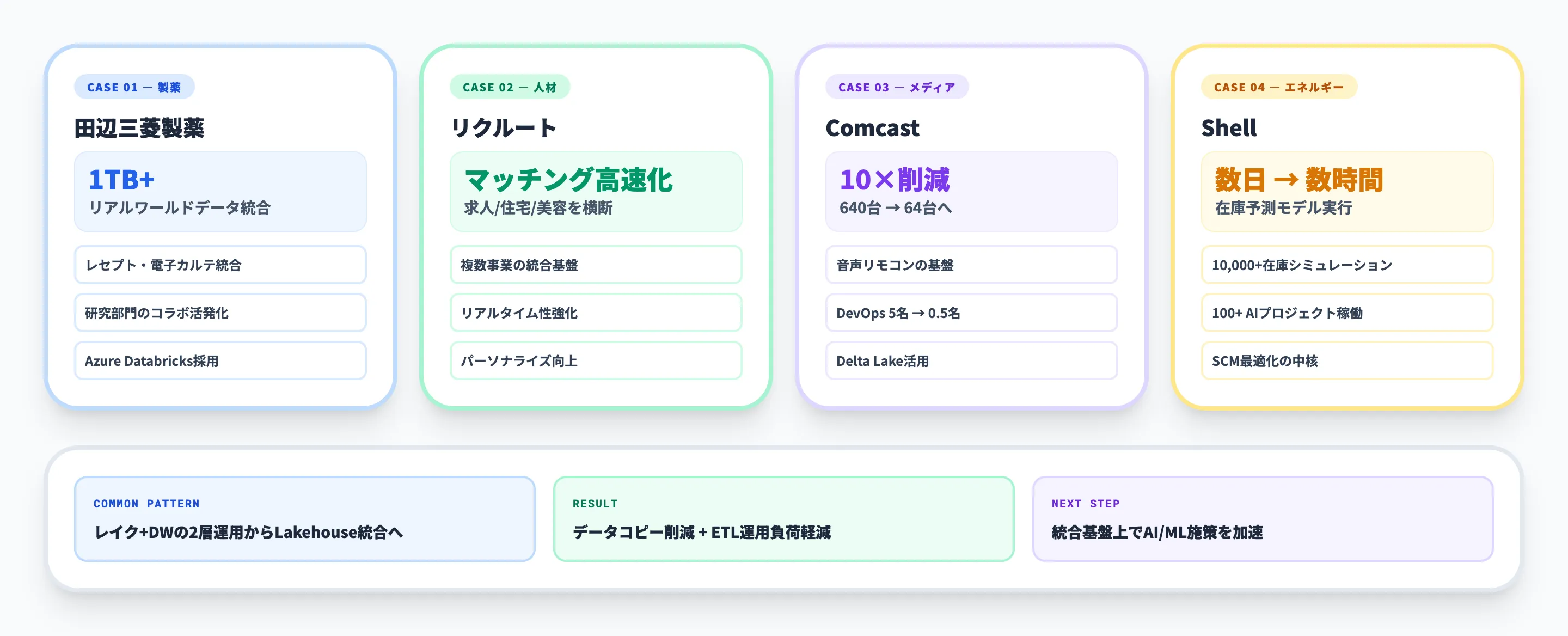
田辺三菱製薬(製薬・日本)
田辺三菱製薬のAzure Databricks事例では、レセプト・特定検診・介護データ・電子カルテ・臨床画像といったリアルワールドデータの分析基盤としてAzure Databricksが採用されました。従来のオンプレ環境では扱いが難しかった1テラバイトを超えるビッグデータを処理できるようになり、研究開発部門のメンバー間のコラボレーションも活発化したと報告されています。

リクルート(人材・日本)
リクルートのDatabricks事例では、求人・住宅・美容など複数の事業領域にまたがるマッチングロジックの基盤としてDatabricksが活用されています。リアルタイム性とパーソナライズ機能を強化することで、より効果の高いレコメンドを提供できるようになりました。

Comcast(メディア・米国)
米Comcastは音声認識ベースのテレビリモコン基盤にDatabricks Delta Lakeを採用し、公式事例では「Delta Lake導入により計算リソースを640台から64台へ10分の1に削減」「200名のオンボーディングに必要なDevOpsエンジニアを5名から0.5名まで削減」といった具体的な定量効果が報告されています。
Shell(エネルギー・グローバル)
Shellの事例では、全部品・全施設にわたる1万以上の在庫シミュレーションをDatabricks上で実行し、在庫予測モデルの実行時間を「数日」から「数時間」へ短縮しています。同社は現在100以上のAIプロジェクトをDatabricks上で運用しており、サプライチェーン最適化の中核基盤となっています。
これらの事例に共通するのは、「データレイクとデータウェアハウスを別々に運用していた組織が、Lakehouse統合によってデータコピーとETLを削減し、その上でAI/ML施策を加速させた」というパターンです。すでに大量のデータがS3やAzure Blobに蓄積されているが活用が進まない、というフェーズの組織には参考になります。
Databricksの料金体系
Databricksの料金は**DBU(Databricks Unit)**という単位で従量課金されます。ここではDBUの仕組みと、ワークロード別の単価感を整理します。

DBU課金の仕組み
DBUは「1時間あたりに使える処理能力」を表す単位で、利用したワークロードの種類とクラスタータイプによってDBU/時の値が変わります。請求額は以下の式で計算されます。

請求額 = DBU単価 × DBU/時 × 利用時間 + クラウドVM料金
つまり、Databricksに支払う料金(DBU課金分)と、その下で動くクラウドVM(EC2 / Azure VM / GCE)への料金の両方が発生します。Azure Databricksの場合はVM料金もAzure側に統合されて請求される一方、AWS上のDatabricksではDatabricksとAWSへ別々に請求が来る点に注意が必要です。
ワークロード別の単価感
Databricksではワークロードの種類に応じてDBU単価が異なります。同じコードでもどのクラスター上で動かすかで請求額が大きく変わるため、ワークロード設計が重要です。

| ワークロード | 用途 | DBU単価の傾向 |
|---|---|---|
| Jobs Compute | スケジュールジョブ・本番ETL | 定常処理向けで最も安価 |
| All-Purpose Compute | ノートブック対話・探索分析 | Jobsより高単価。インタラクティブ向け |
| SQL Compute(Serverless) | BIクエリ・SQLウェアハウス | 中間。Photon前提で高速 |
| Model Serving | 推論API・基盤モデル提供 | リクエスト規模で大きく変動 |
| Mosaic AI Model Serving | LLM呼び出し(Llama・Claude等) | トークン課金 |
具体的な倍率はクラウド・プラン・リージョンで異なります。たとえばAzure DatabricksのPremium tier公式価格例ではAll-PurposeとJobsの差は約1.8倍程度ですが、AWS / GCP では別の比率になります。実務でコストが膨らみやすいのは、本来Jobs Computeで動かすべき定常パイプラインを開発時のままAll-Purpose Computeで動かし続けてしまうケースです。Jobs Computeへの切り替えだけで請求額を大きく削減できることもあるため、コスト最適化の最初の一歩として検討する価値があります。
また、Mosaic AI Model Serving経由でLLMを呼ぶ場合、Azure DatabricksのSKU別DBU表(2026年3月時点)によると、Claude Sonnet 4.5の入力1Mトークンあたり42.857DBU、出力1Mトークンあたり214.286DBUなどモデルごとに細かく定義されています。LLMコストはこのDBU換算でまとめて請求される形になります。
料金プラン
プラン体系はクラウドベンダーごとに異なります。

- Databricks on AWS
2025年10月1日以降、現行プランはPremium / Enterprise の2層
- Databricks on Google Cloud
Standard tier workspaceは2025年10月1日でEOL。現行はPremium / Enterprise pricing tierの2層
- Azure Databricks
Standard / Premium の2層。Standardは2026年10月1日に廃止予定で、以後はPremiumに集約される
行/列レベルのアクセス制御やUnity Catalogのフル機能、コンプライアンス機能はPremium以上で利用できるため、エンタープライズ用途では実質Premium以上が必須となります。
2026年4月時点:Japan East(東日本)リージョンでもAzure DatabricksのStandard・Premiumプランが提供されています。最新の単価はAzure Databricksの価格ページで確認してください。

Databricks導入で詰まる論点
Databricksは強力なプラットフォームですが、導入を進めると必ずいくつかの論点で立ち止まることになります。ここでは、AI総合研究所が支援する中で繰り返し議論になるポイントを整理します。

「Databricksだけで完結するのか」問題
Databricksは「データ・分析・AI/MLを単一基盤で完結させる」という思想ですが、実際の組織では既存のSnowflake・BigQuery・Power BI・Tableauなどがすでに動いています。これら全てをDatabricksに置き換えるべきかは、現場で必ず議論される論点です。

AI総合研究所のスタンスとしては、「データレイヤーとETLはDatabricksに寄せる、BI配信は既存ツールを継続利用する」というハイブリッド構成が現実的なケースが多いと考えています。Lakehouseの強みである「データを動かさずに済む」点を活かしつつ、ユーザー側のBI体験を変えずに移行できるためです。逆にBIまで含めて全社的にDatabricks SQL/Genieへ集約するのは、組織のアナリスト人員がSQLに習熟していないとハードルが高くなります。
既存DWHからの移行か、共存か
すでにSnowflake / Redshift / BigQueryが動いている組織では、「乗り換えるか共存するか」が大きな判断ポイントです。

- 乗り換え推奨: ETL負荷が大きい、AI/ML施策を加速したい、データコピーが社内に乱立している
- 共存推奨: BI主体・SQLアナリスト中心、移行投資より新規施策への投資を優先したい
判断に迷う場合は、まず「データレイク層をDelta Lakeに統一し、Databricksでの新規施策(RAG・予測モデル)から始める」という小さな統合パイロットが有効です。既存DWHを残したままDelta Lake層からデータを供給する構成にすることで、リスクを抑えながらDatabricksの効果を検証できます。
業務システムへの接続フェーズ
Databricks上でMosaic AIを使ってRAGエージェントを構築できても、それを「現場の業務フロー」に乗せる工程は別の設計が必要です。AIエージェントを毎日触るのは現場社員であり、彼らが普段使うのはMicrosoft TeamsやSlack、業務システムであって、Databricksワークスペースではありません。
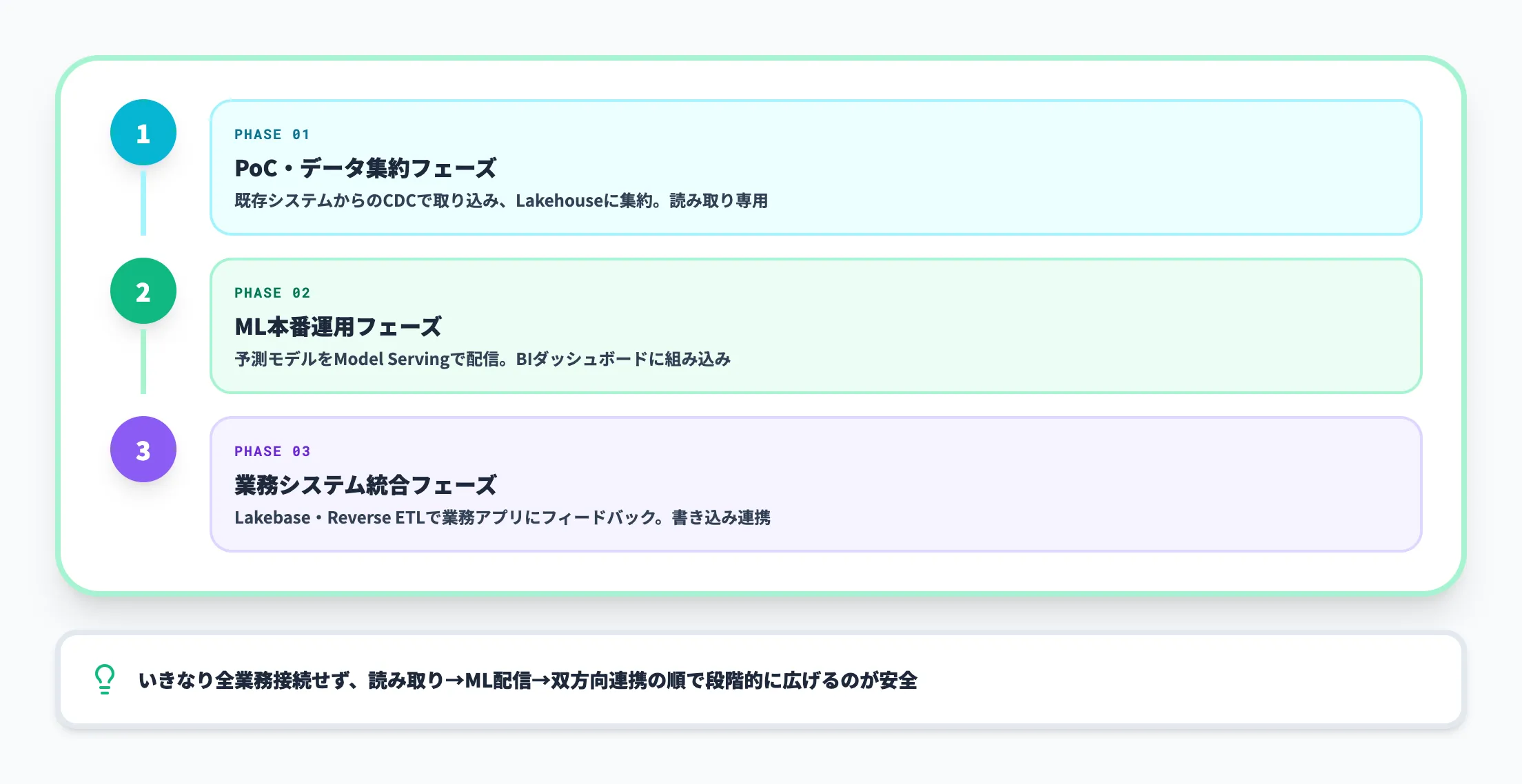
このフェーズで詰まるのは、「Databricks Unity Catalogによるデータガバナンス」と「業務側のエージェント実行ガバナンス(誰がいつ何を呼んだか)」を、誰がどう設計するかという論点です。AI総合研究所が提供するAI Agent Hubでは、Databricks上で構築したAI/エージェントをTeamsから呼び出せるようにし、実行ログ・権限管理・コスト管理を業務側で一元化する設計を支援しています。Databricks上の検証で終わらせず、業務に乗せるところまで含めて設計することが、PoC死を回避する最短ルートです。
Lakehouseの先にある業務定着を設計する

Mosaic AIを成果に変える進め方
Databricksでデータと基盤モデルを統合しても、現場業務との接続設計がなければAI投資は可視化できません。PoCから全社展開までの段階設計、部門別ユースケース、データガバナンスと業務活用を両立させる進め方を整理したAI業務自動化ガイド(220ページ)を無料で公開中です。
まとめ
本記事では、Databricksの基本概念から構成要素、SnowflakeやMicrosoft Fabricとの違い、料金体系、導入で詰まる論点までを2026年4月時点の情報で解説しました。
Databricksは単なるデータウェアハウスでもデータレイクでもなく、「Lakehouse」というアーキテクチャを軸に、Delta Lake・Unity Catalog・Mosaic AIといった構成要素を組み合わせて、データ・分析・AIを単一基盤で扱えるようにする統合プラットフォームです。特に2026年現在は、Mosaic AI Vector SearchやAgent Frameworkを使ったエージェント構築、Lakeflowによるデータ統合、Lakebaseによる運用DB統合など、AIアプリの本番運用までをカバーする方向で機能拡張が続いています。
Databricks導入を検討する際の次のステップは、(1)既存のデータレイク・データウェアハウス構成を棚卸しして「2層化による無駄」を可視化する、(2)Lakehouse化しやすいユースケース(AI/ML施策・非構造化データ分析)を1つ選んでパイロットを走らせる、(3)パイロットで構築したAIをどう業務UIに乗せるかを並行設計する、という順で進めるのが現実的です。データ基盤側のDatabricksと、業務実装側のAI Agent Hubのように、レイヤーを分けて設計するとPoCで止まりにくくなります。







