この記事のポイント
 AIエージェントを社内データで動かす前提があるなら、個別Agentを育てる前にオントロジーで共通言語を先に設計するのが最短ルート
AIエージェントを社内データで動かす前提があるなら、個別Agentを育てる前にオントロジーで共通言語を先に設計するのが最短ルート- Power BIセマンティックモデル整備済み+Direct Lake中心なら自動生成が第一候補、Import/DirectQueryは手動構築も
- プレビュー段階だが課金開始、Modeling・AI Operations+Fabric Graph再構築・Activatorも見積もり対象に
- グラフ機能は上流データの反映が手動リフレッシュ前提。運用設計で更新スケジュールを先に決めるのが安全
- オントロジーをpreview段階のMCPサーバー経由でAIエージェントから参照させる方針が公式ブログで案内済み。共有権限設計は早期に詰めておくのが安全

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Fabric IQのオントロジーとは、Microsoft Fabric上でビジネス用語・エンティティ・関係性を一元定義し、OneLake上のデータにバインドするセマンティックレイヤーの新アイテムです。
従来のPower BIセマンティックモデルより広く、ドメイン横断の推論、AIエージェントのグラウンディング、条件–アクションルールまでを1つのモデルで扱える点が特徴です。
本記事では2026年4月時点のパブリックプレビューを前提に、オントロジーの構造、データバインディング、NL2Ontologyクエリ、作成手順、FabCon Atlantaで発表された最新機能、CU消費モデル、導入判断で詰まりやすい論点までを体系的に解説します。
目次
Fabric IQ ワークロードにおけるオントロジーの位置づけ
条件–アクションルール(Fabric Activator連携)
Data Agent / Operations Agent への接続
併用パターン:既存セマンティックモデルからのオントロジー生成
2026年のアップデート(FabCon Atlanta発表)
Azure Private Linkによるワークスペース単位のネットワーク分離
Fabric IQ オントロジーとは?
Fabric IQのオントロジーとは、Microsoft Fabric上でビジネス用語・エンティティ・関係性・ルールを一元定義し、OneLake上の実データにバインドする「セマンティックレイヤー」のアイテムです。
2025年11月のMicrosoft Ignite 2025で発表されたFabric IQワークロードの中核アイテムで、2026年4月時点ではパブリックプレビューとして提供されています。
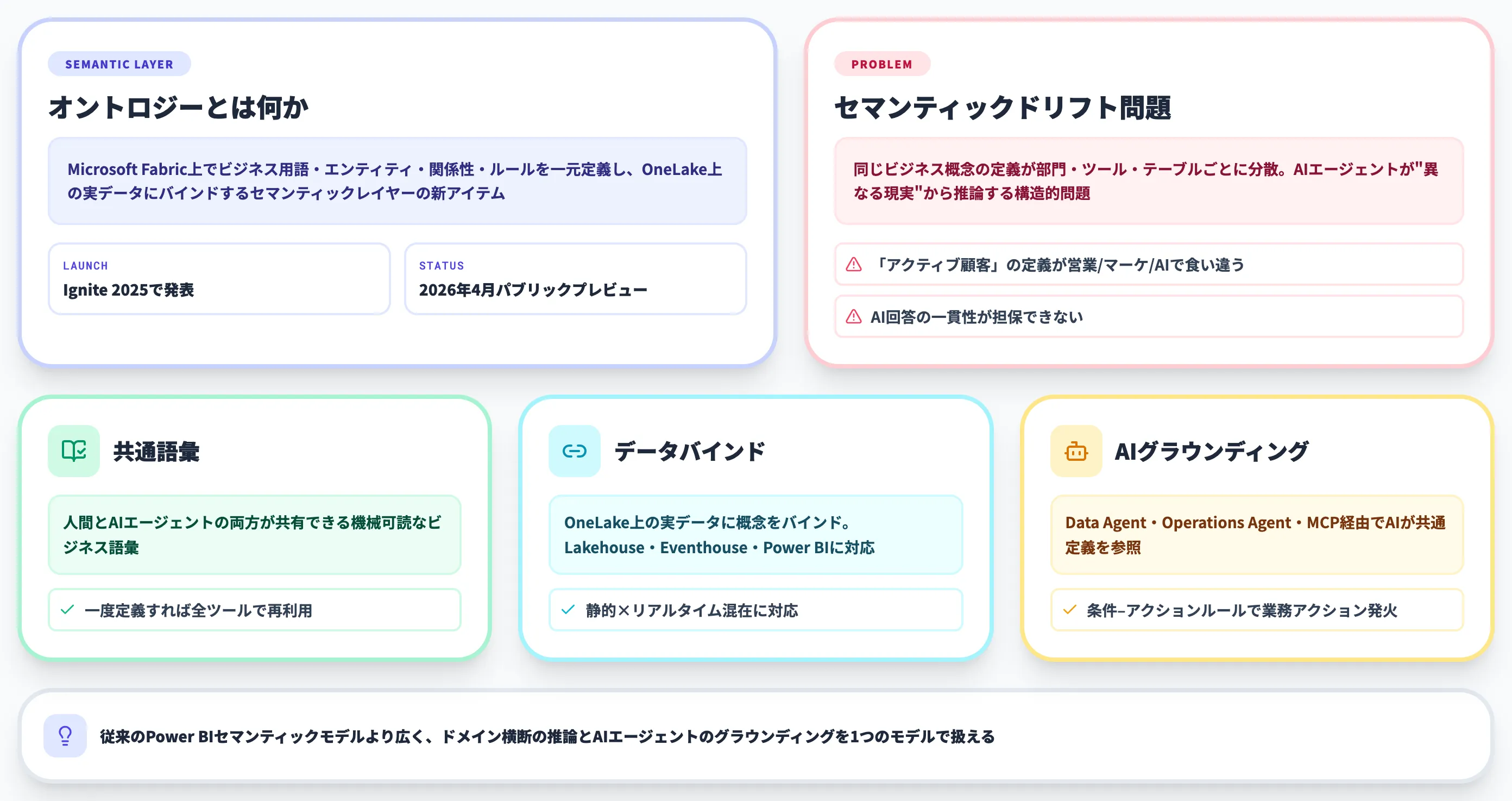
従来のデータ基盤では「顧客」「製品」「注文」といったビジネス用語の定義が部門・ツール・テーブルごとに分散し、同じ単語でも意味が微妙にずれるという問題がありました。
VentureBeatの分析では、この「セマンティックドリフト」によりエンタープライズのAIエージェントが"異なる現実"から推論してしまう構造的問題が指摘されています。
Fabric IQのオントロジーはこれに対して、人間とAIエージェントの両方が共有できる機械可読なビジネス語彙として設計されており、一度定義した概念をダウンストリームツール(Data Agent・Operations Agent・Power BIなど)から同じ言語で参照できるようにします。

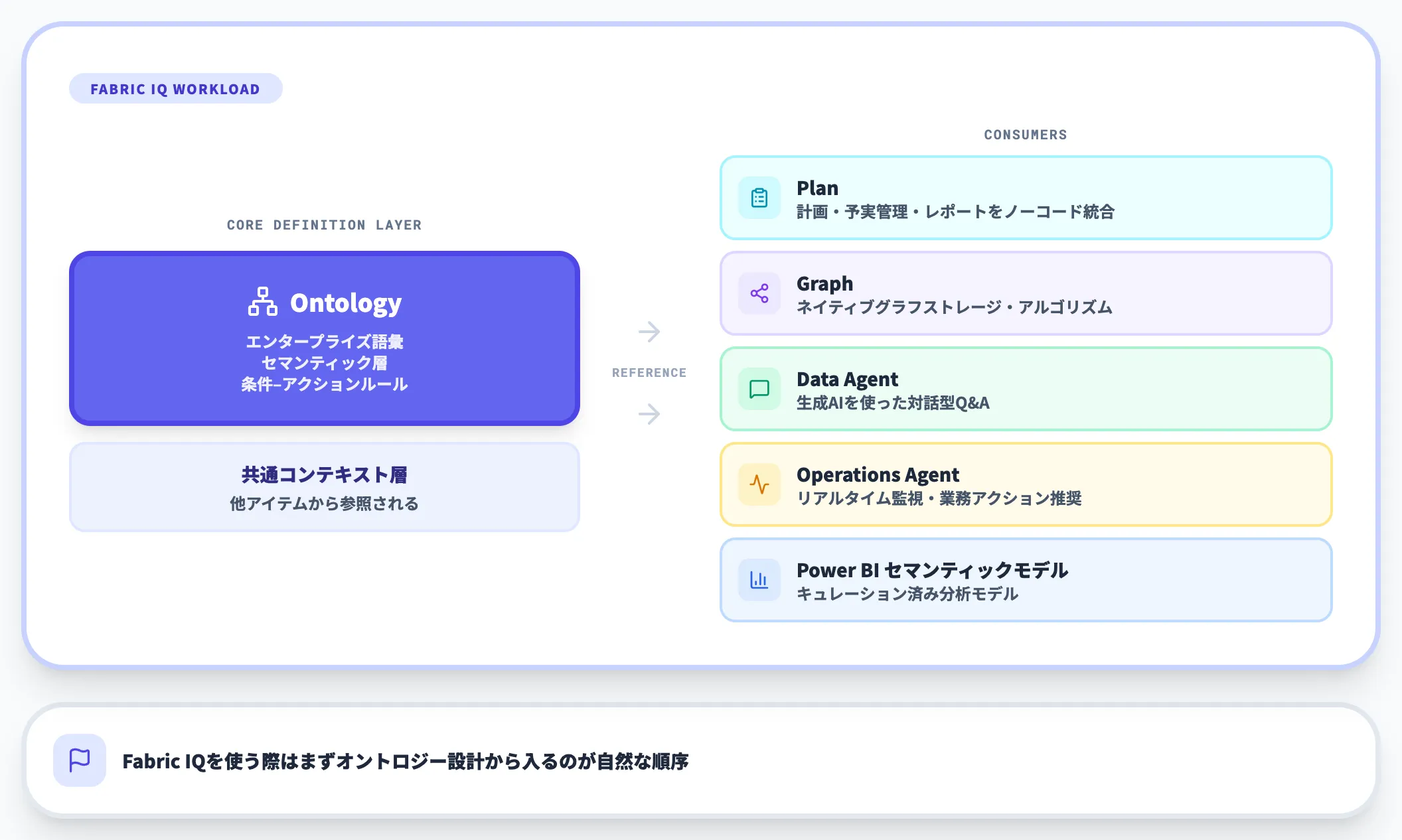
Fabric IQ ワークロードにおけるオントロジーの位置づけ
Fabric IQは、Microsoft公式ドキュメントによれば次の6つのアイテムで構成されるワークロードです。オントロジーはその中で「共通言語を定義するコアアイテム」という役割を担います。
| アイテム | 役割 |
|---|---|
| Ontology(プレビュー) | エンタープライズ語彙・セマンティック層・条件–アクションルールを定義 |
| Plan(プレビュー) | 計画・予実管理・レポートをノーコードで統合 |
| Graph(プレビュー) | ネイティブグラフストレージ・グラフアルゴリズムを提供 |
| Data Agent(プレビュー) | 生成AIを使った対話型Q&Aシステム |
| Operations Agent(プレビュー) | リアルタイムデータを監視し業務アクションを推奨するエージェント |
| Power BI セマンティックモデル | レポート向けのキュレーション済み分析モデル |
この表の中でPlan/Graph/Data Agent/Operations Agentはオントロジーが定義した語彙を利用する側のアイテムであり、オントロジーは「他アイテムから参照される共有コンテキスト層」として中心に置かれます。
つまり、Fabric IQを使う際はまずオントロジー設計から入るのが自然な順序です。
セマンティックドリフト問題への解
Fabric IQのローンチ記事では、従来型データ基盤が抱える「同じビジネス概念に対して定義が分散している状態」を明確な課題として挙げています。
例えば同じ「アクティブ顧客」でも、営業ダッシュボード・マーケティングレポート・AIエージェントの回答でそれぞれ計算式が違う、といった状況です。

オントロジーはこれを、ビジネス概念を一度だけ定義し、OneLake上の実データにバインドすることで解消します。
Power BI、ノートブック、Copilot、Data Agentのいずれから見ても同じ定義が使われるため、ダウンストリームで定義が増殖・分岐することを防げます。
従来のセマンティックモデルとの違い(概要)
同じ「セマンティック」という語を使いますが、Power BIのセマンティックモデルと役割は異なります。
Power BIセマンティックモデルが「レポート・ダッシュボードのためのディメンショナルモデル」であるのに対し、オントロジーは「クロスドメインの推論とAIエージェントのグラウンディングのためのビジネスモデル」です。両者は排他ではなく併用することができ、詳しくは後述のセクションで比較します。
SIerとして現場を見る立場からは、既にPower BIセマンティックモデルを整備している企業はオントロジーを「その拡張」として導入するのが移行コストが最小です。
ゼロからオントロジーを書き起こす前に、既存モデルからの自動生成を検討してください。
Fabric IQ オントロジーのコア概念
Fabric IQ オントロジーを理解するには、公式ドキュメントが定義する4つの構成要素に加え、Fabric Activatorと連動する条件–アクションルールを押さえる必要があります。

以下の表で、オントロジーを構成する要素とその役割を整理しました。
| 要素 | 役割 | 具体例 |
|---|---|---|
| エンティティ型(Entity Type) | 実世界の概念の再利用可能な論理モデル | Customer, Product, Shipment, Sensor |
| エンティティインスタンス | データバインディングから生成される具体的な出現 | 顧客ID=12345のCustomer |
| プロパティ | エンティティに紐づく名前付きファクト(データ型宣言) | Customerのname, email, status |
| リレーションシップ | エンティティ型/インスタンス間の方向性リンク | Customer places Order(1対多) |
| 条件–アクションルール | Fabric Activator連携で発火する業務ルール | 冷蔵庫温度が基準超過時にアラート送信 |
この表が示すのは、オントロジーが単なる「用語集」ではなく、制約・カーディナリティ・ルールまで含む実行可能なモデルであるという点です。
テーブルのスキーマ定義よりも、UMLのクラス図に近い発想と考えると理解しやすいでしょう。
エンティティ型
エンティティ型は、名前・説明・識別子・プロパティ・制約を標準化した「概念のマスタ定義」です。1つのテーブルの上位に概念を昇格することで、ソース間で競合する列レベル定義を排除する設計思想が取られています。
例えば「Shipment」というエンティティ型を一度定義すれば、物流部門のテーブルと在庫管理部門のテーブルでそれぞれ「shipment_id」「ship_no」と別名で管理されていても、オントロジー上では同じ「Shipment」として扱えるようになります。
エンティティインスタンス
エンティティインスタンスは、データバインディング経由で生成される個々の具体的な出現です。公式では「セマンティック行(semantic row)」と表現されており、どのソースから、いつ有効な値として取得されたかを追跡します。
インスタンスは生データそのものではなく、標準化されたビジネスオブジェクトとして扱われる点がポイントです。
AIエージェントからは「CustomerインスタンスのリストをOrderとのリレーションシップ付きで取得」という形でアクセスできます。
プロパティ
プロパティは、エンティティに対するデータ型宣言付きの名前付きファクトです。ソースデータへのバインドとセマンティック注釈(識別子・メタデータ属性)を含めることができ、概念レベルでの型・単位・命名の一貫性と、ルール・品質チェックを付与できます。
例えばCustomerエンティティに「email(string, 一意, null不可)」というプロパティを定義しておけば、ソーステーブルが複数あってもプロパティレベルで整合性チェックが働きます。
リレーションシップ
リレーションシップは、エンティティ型またはインスタンス間の型付き・方向付きリンクです。属性(distance、confidence、effectiveAtなど)とカーディナリティルール(1対多・多対多など)を持たせられます。
リレーションシップを明示的にモデル化することで、カスタムJOINロジックなしに「あるOrderに紐づくShipmentの温度センサーの異常履歴」といった複数ホップをまたぐビジネス質問に答えられるようになります。
条件–アクションルール(Fabric Activator連携)
オントロジーのルール定義はFabric Activatorと統合されており、「条件が満たされたときに通知・アラート・業務アクションを発火する」というガバナンス付きのリアルタイムアクションを、ビジネスルールとしてオントロジーに記述できます。
これにより、エージェントが「答えを返す」だけでなく「監査可能なアクションを取る」ところまで踏み込めるのがFabric IQの設計思想です。
データバインディングとオントロジーグラフ
オントロジーの概念定義が終わったら、次はデータバインディングでOneLake上の実データと紐づけます。
バインディングによって、生データ行がガバナンス付きのビジネスオブジェクトに変換されます。
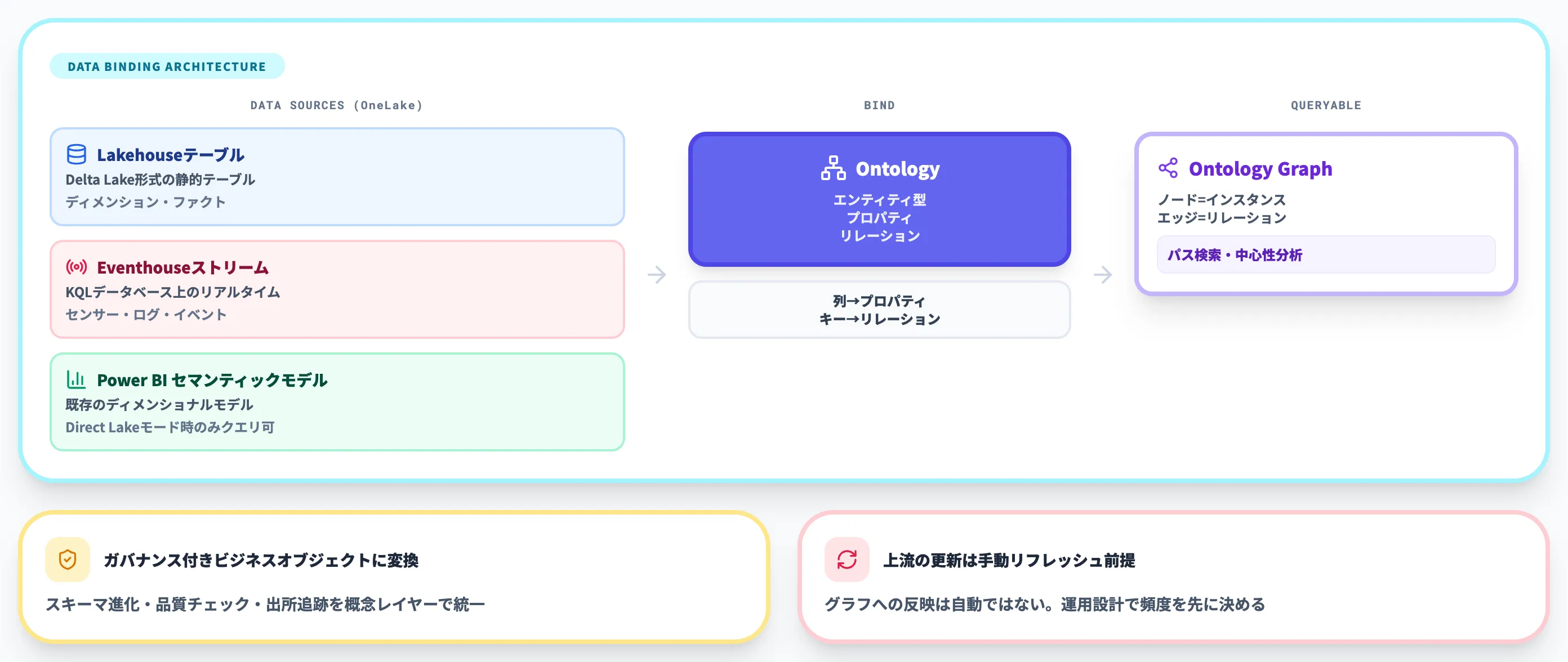
データバインディングの仕組み
データバインディングは、オントロジー定義(エンティティ型・プロパティ・リレーションシップ)を、OneLake上の具体データソースに接続します。対応ソースは以下の3つです。

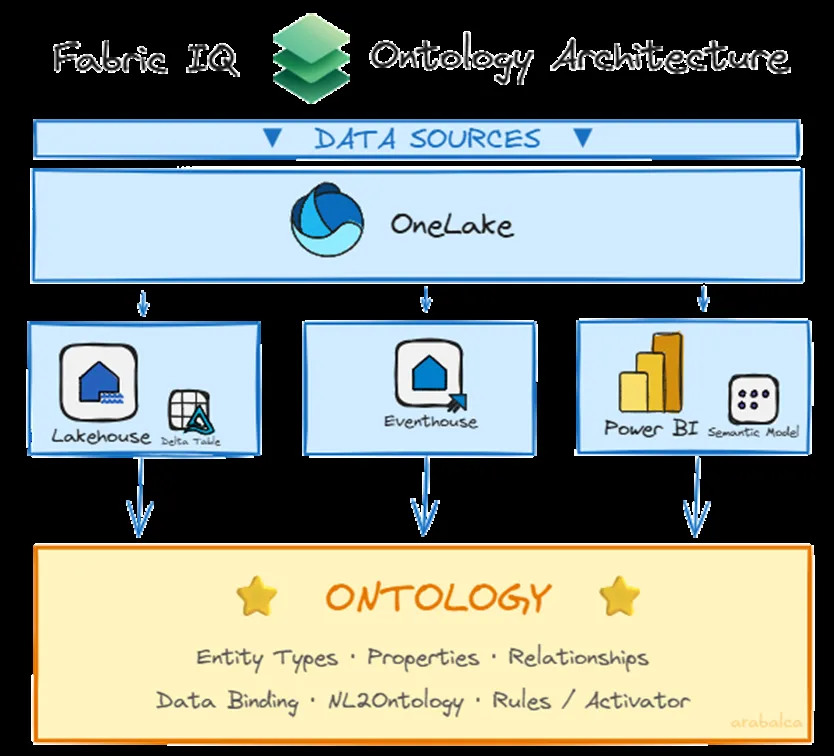
オントロジーをLakehouse・Eventhouse・Power BIセマンティックモデルにバインドする構成(出典:Microsoft Fabric Community)
- Lakehouseテーブル
Delta Lake形式の静的テーブル。ディメンション・ファクトデータが主な対象
- Eventhouseストリーム
KQLデータベース上のリアルタイムストリーム。センサーデータ・ログ・イベントが対象
- Power BIセマンティックモデル
既存のディメンショナルモデルからオントロジーの定義(エンティティ型・リレーションシップ)を生成できる。
ただし、データバインディングとクエリは公式ドキュメントによりDirect Lake モードかつ背後のLakehouseがinbound public access enabledの場合に限ってサポートされ、Import / DirectQuery モードはサポート対象外である点に注意
バインディング定義には、データ型、識別子キー、列→プロパティのマッピング、キー→リレーションシップのマッピングが含まれます。
スキーマ進化ルール、データ品質チェック(null許容・範囲・一意性)、出所追跡(provenance)も概念レイヤーで統一されます。
オントロジーグラフ
オントロジーグラフは、データバインディングとリレーションシップ定義から構築されるクエリ可能なインスタンスグラフです。
Microsoft Fabric Graphに依存する機能で、テナント側でGraph機能を有効化しておく必要があります。
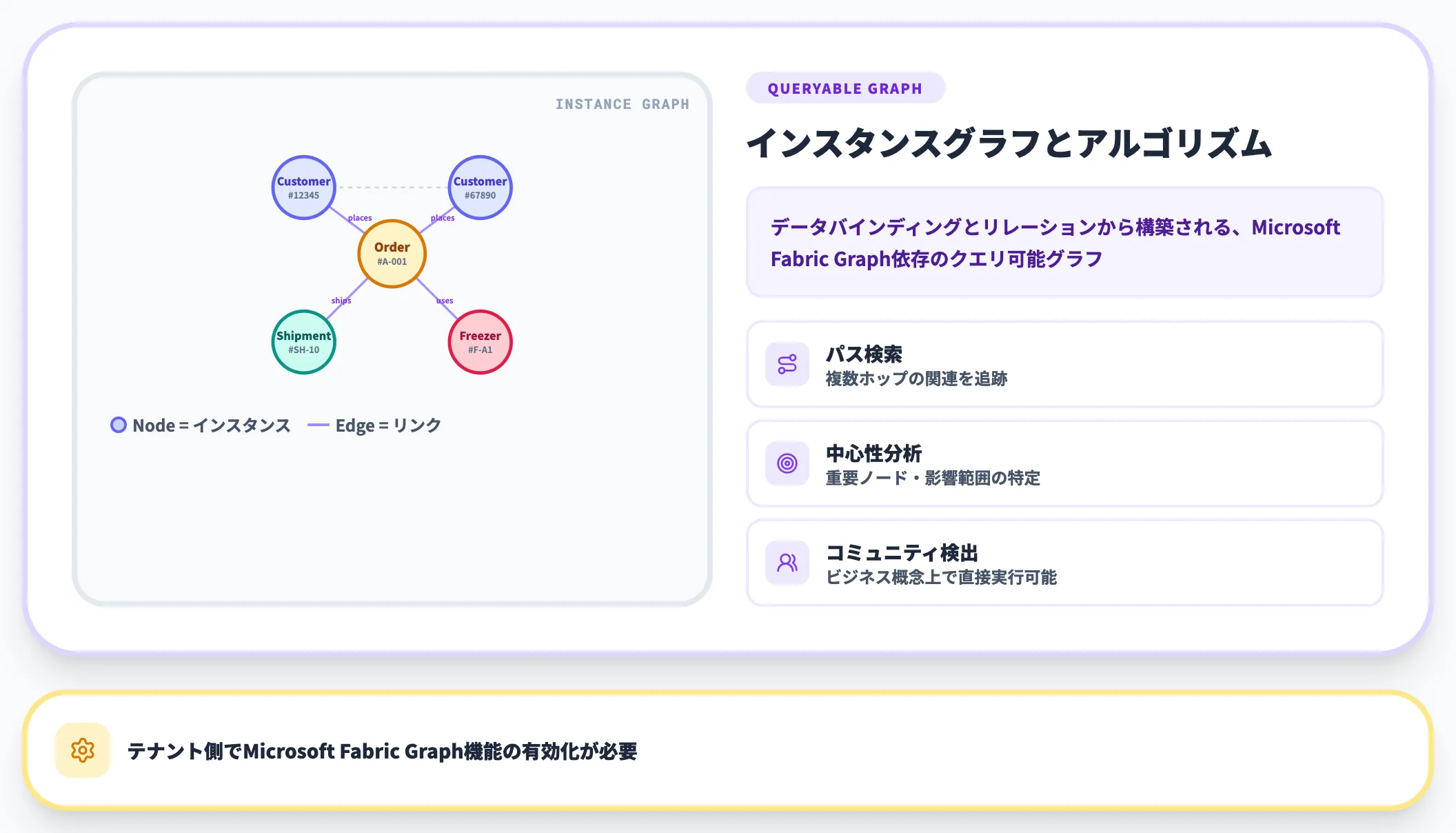
グラフ上では、ノードがエンティティインスタンス、エッジが(アサートまたは派生した)リンクで、メタデータ属性とソース系列を保持します。
パス検索、中心性分析、コミュニティ検出といったグラフアルゴリズムをビジネス概念上で直接実行できる点が強みです。
手動リフレッシュの注意点(詰まりポイント)
バインディング設計で最も見落とされやすいのが上流データの更新反映です。公式ドキュメントは明確に「上流データソースの新しい行などの更新は、オントロジー項目に表示される前に手動でリフレッシュする必要がある」と記載しています。

つまり、Eventhouseストリームからリアルタイムで流れてきた値が、自動ではオントロジーグラフには反映されません。運用設計段階で以下を決めておく必要があります。
- リフレッシュ頻度: ワークスペースのスケジューラで何時間おきに更新するか
- 更新対象の粒度: 全エンティティ型か、特定のホットなエンティティだけか
- コスト影響: グラフリフレッシュはCU消費に直結するため、頻度とコストのトレードオフを事前検討
支援経験からは、最初はリアルタイム性を求めず1時間〜6時間おきのバッチリフレッシュで運用を始め、ユースケースに応じて短縮していくのが安全です。
オントロジークエリとNL2Ontology
オントロジーを構築したら、ビジネス用語でクエリを投げることができるようになります。
Fabric IQの特徴は、同じ質問をGQLのような構造化クエリでも自然言語でも投げられ、バックエンドの実行エンジンが自動で選ばれる点にあります。
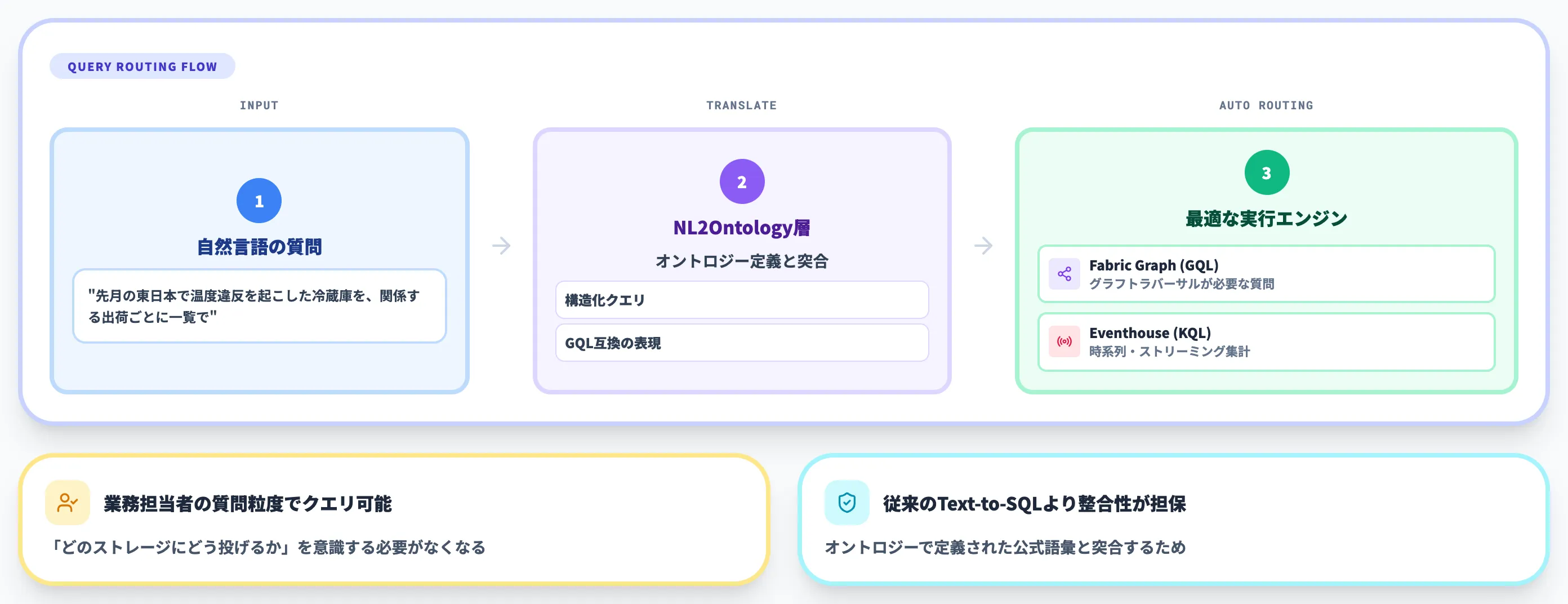
構造化クエリとバックエンドの自動ルーティング
オントロジークエリは、エンティティ型を起点に、プロパティフィルタ・リレーションシップ走査・時間軸集計を記述します。
公式ドキュメントによれば、オントロジー層はクエリを最も効率的なシステムに自動送信する仕組みを持ちます。

- グラフトラバーサルが必要な質問 → Fabric Graph上でGQLとして実行
- 時系列・ストリーミング集計 → Eventhouse上でKQLとして実行
この自動ルーティングにより、エンジニアが「この質問はどのストレージにどう投げるべきか」を意識する必要がなくなり、業務担当者の質問粒度でクエリを書けるのが実務的な価値です。
NL2Ontology(自然言語→構造化クエリ)
NL2Ontologyは、自然言語の質問を構造化クエリに変換する層です。
ユーザーが「先月の東日本リージョンで温度違反を起こした冷蔵庫を、関係する出荷ごとに一覧で」と質問すれば、オントロジー上で定義されたフィルタ・結合・単位・有効性ウィンドウに沿って構造化クエリに変換・実行されます。
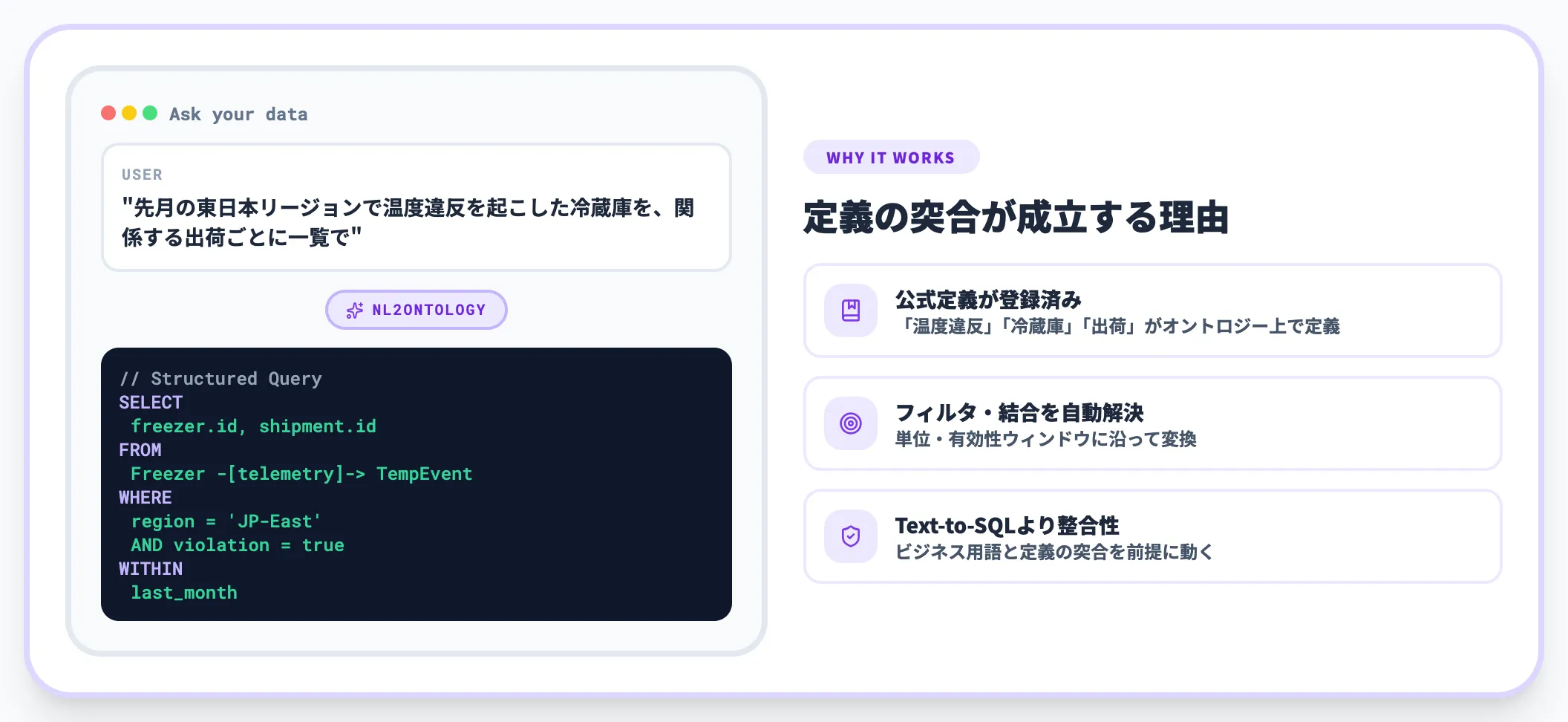
これが成立するのは、オントロジーで「温度違反」「冷蔵庫」「出荷」が公式定義として登録されており、NL2Ontology層がその定義と突合できるからです。単に「LLMに自然言語で聞ける」というのと本質的に違う点で、従来のText-to-SQLよりもビジネス用語の整合性が担保されやすい設計です。
Data Agent / Operations Agent への接続
Fabric Data Agentはオントロジーをソースとして接続できます。
これによりData Agentがビジネス概念を理解した回答を返せるようになり、単なる「社内検索ボット」から「社内の共通言語で会話できる分析エージェント」へと性質が変わります。

一方、Operations Agentについては、2026年3月31日時点の公式ドキュメントではEventhouse / KQLデータベースをコンテキストソースとする構成が前提として説明されています。
オントロジーをコンテキストソースとして接続する機能は、2026年3月のAzure公式ブログで「ontologies can also serve as context sources for maps and soon in operations agents」として近日提供予定と案内されている段階です。
現時点でOperations Agentから直接オントロジーを参照する設計を組むのは時期尚早で、まずはData Agent側で接続パターンを検証するのが安全です。
Power BI セマンティックモデルとの違い・併用

オントロジーとPower BIセマンティックモデルは同じ「セマンティック層」の系譜にありますが、目的とスコープが異なります。
両者の使い分けと併用パターンを整理します。

比較表:目的・スコープの違い
以下の表で、オントロジーとPower BIセマンティックモデルの違いを整理しました。
| 観点 | オントロジー | Power BI セマンティックモデル |
|---|---|---|
| 主目的 | クロスドメイン推論・AIエージェントのグラウンディング | レポート・ダッシュボードの分析基盤 |
| スコープ | ドメイン横断のビジネス語彙全体 | 分析対象テーブル群のディメンショナルモデル |
| モデル形式 | エンティティ型+プロパティ+リレーションシップ+ルール | ファクト表+ディメンション表+メジャー |
| クエリ言語 | オントロジークエリ、GQL、KQL、NL2Ontology | DAX、MDX |
| ルール・アクション | 条件–アクションルール(Activator連携) | 計算列・メジャーによる集計が中心 |
| AIエージェント接続 | Data Agent・Operations Agent・MCP(予定) | Copilot for Power BI中心 |
| 主な消費者 | エージェント・アプリケーション・BI | レポート閲覧者・BIユーザー |
つまりオントロジーは「AIと業務システムのための共通言語」、セマンティックモデルは「人が見るためのKPIモデル」という棲み分けです。両者は排他ではなく、同じFabric環境の中で同時に運用できます。
併用パターン:既存セマンティックモデルからのオントロジー生成
公式チュートリアルは、オントロジー作成方法として「Power BIセマンティックモデルから生成」と「OneLakeから手動構築」の2通りを提示しています。既にセマンティックモデルが整備済みなら、そのディメンションとリレーションシップをブートストラップとしてオントロジー定義を生成できます。
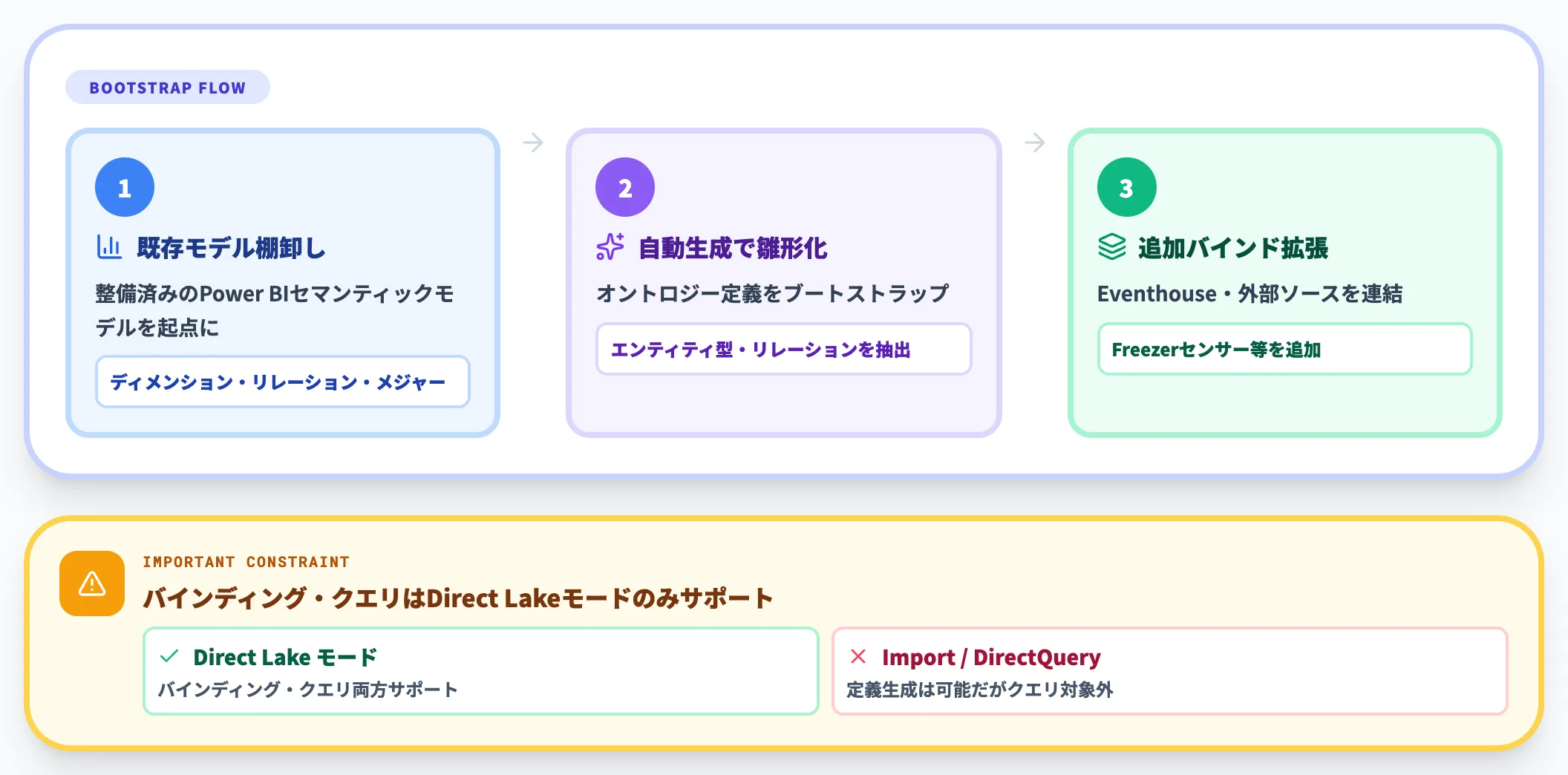
ただし、セマンティックモデルからの生成に関する公式ドキュメントによれば、生成されたオントロジーのデータバインディングとクエリはDirect Lake モードのセマンティックモデルかつ背後のLakehouseがpublic accessを許容している場合に限ってサポートされます。Import / DirectQuery モードのモデルは定義生成のソースにはできますが、そのままではバインディング・クエリの対象外です。既存モデルがImport中心の組織では、別途Direct Lakeへの移行か、OneLakeから手動でバインディングを設定する判断が必要になります。
この前提を踏まえてEventhouseのストリーミングデータや外部ソースからのエンティティ(Freezerセンサーなど)を追加でバインドすれば、分析向けモデルをベースに「AIエージェントが使える推論モデル」へと拡張できます。
実務上の使い分け
現場で導入支援を行う立場からは、セマンティックモデルとオントロジーは役割を分離し、以下のように設計するケースが多いです。
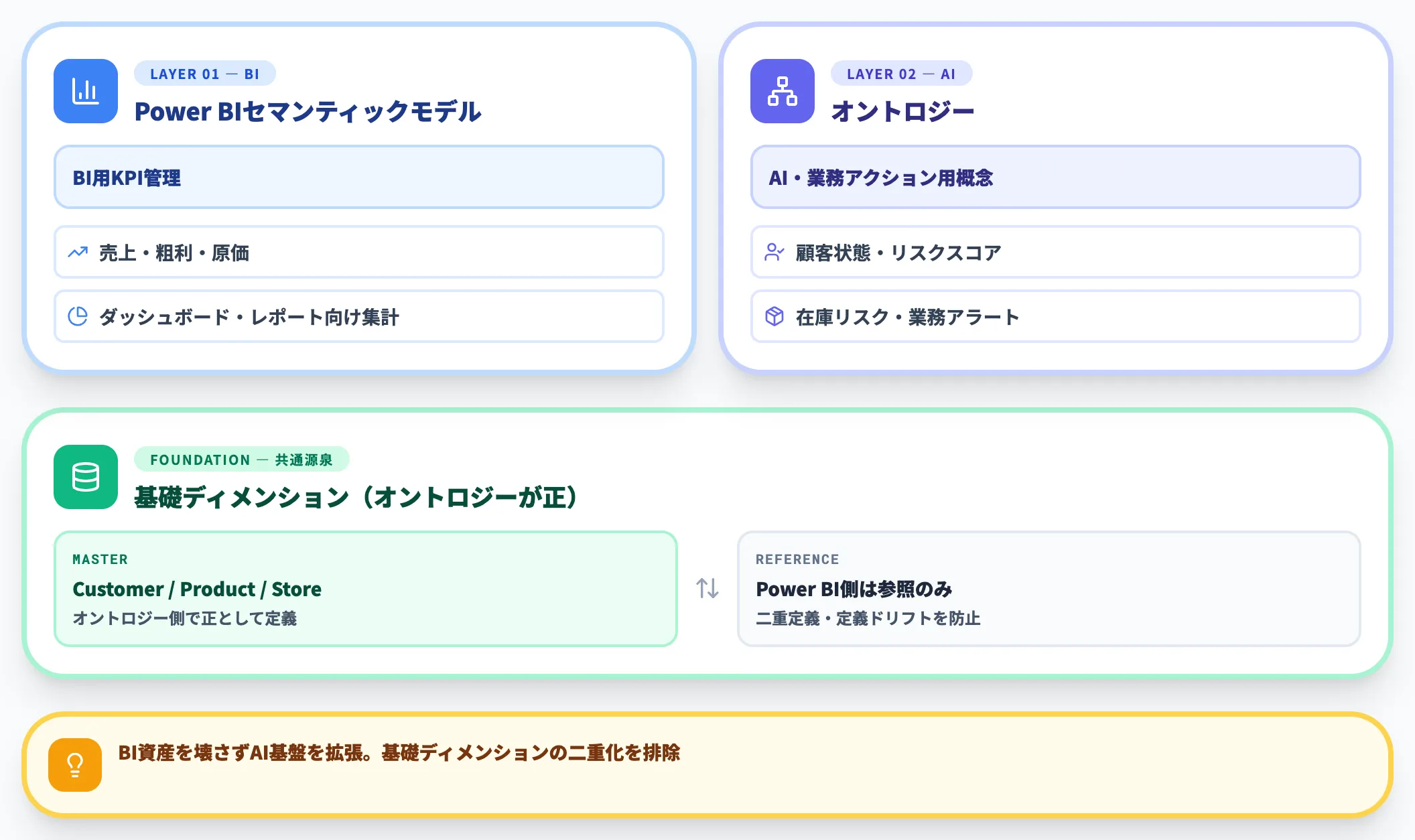
- BI用KPI(売上・粗利・原価など)→ Power BIセマンティックモデルで管理
- AIエージェント・業務アクション用の概念(顧客状態・リスクスコア・在庫リスクなど)→ オントロジーで管理
- 両方の源泉となる基礎ディメンション(Customer・Productなど)→ オントロジー側で正として定義し、セマンティックモデルはそれを参照
このパターンを取ると、BIの既存資産を壊さずにAIエージェント基盤を拡張でき、かつ基礎ディメンション定義が二重化するのを防げます。
Fabric IQ オントロジーの作成手順
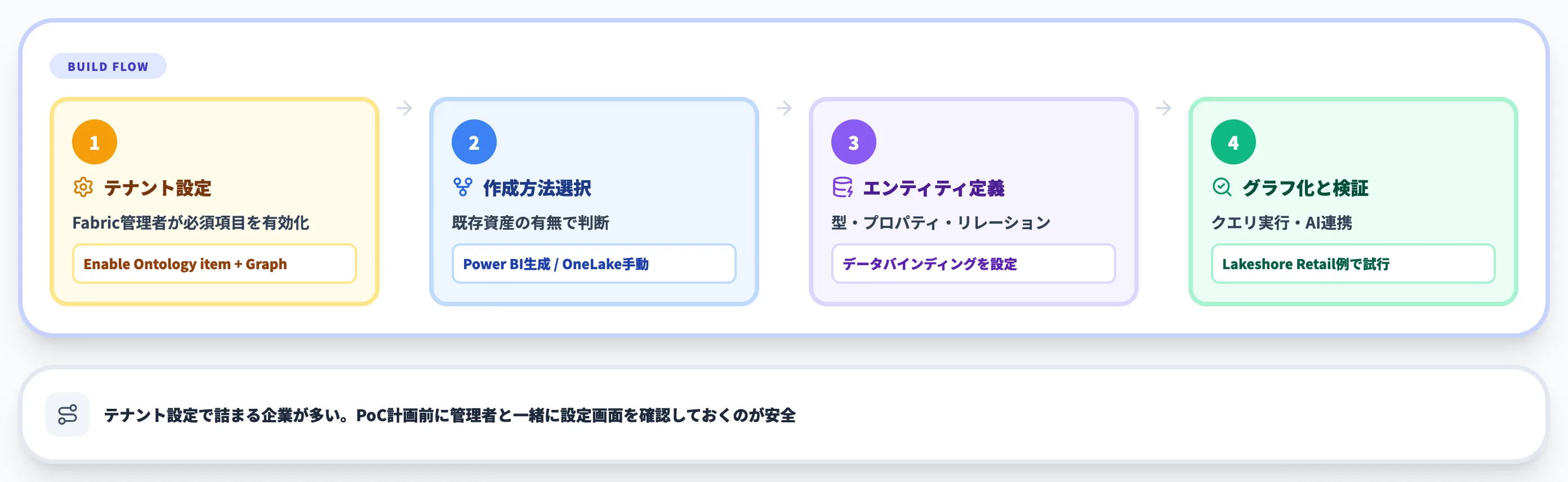
オントロジーを実際に作成する手順を、公式チュートリアル(Lakeshore Retailシナリオ)をベースに整理します。
Fabricポータルでオントロジーを作成しエンティティ型を定義している画面(出典:Microsoft Learn)
前提:テナント設定の有効化
オントロジーを使うには、Fabric管理者があらかじめテナント設定でいくつかの項目を有効化する必要があります。
必須と任意(Data Agent連携時のみ)に分けて整理すると以下の通りです。
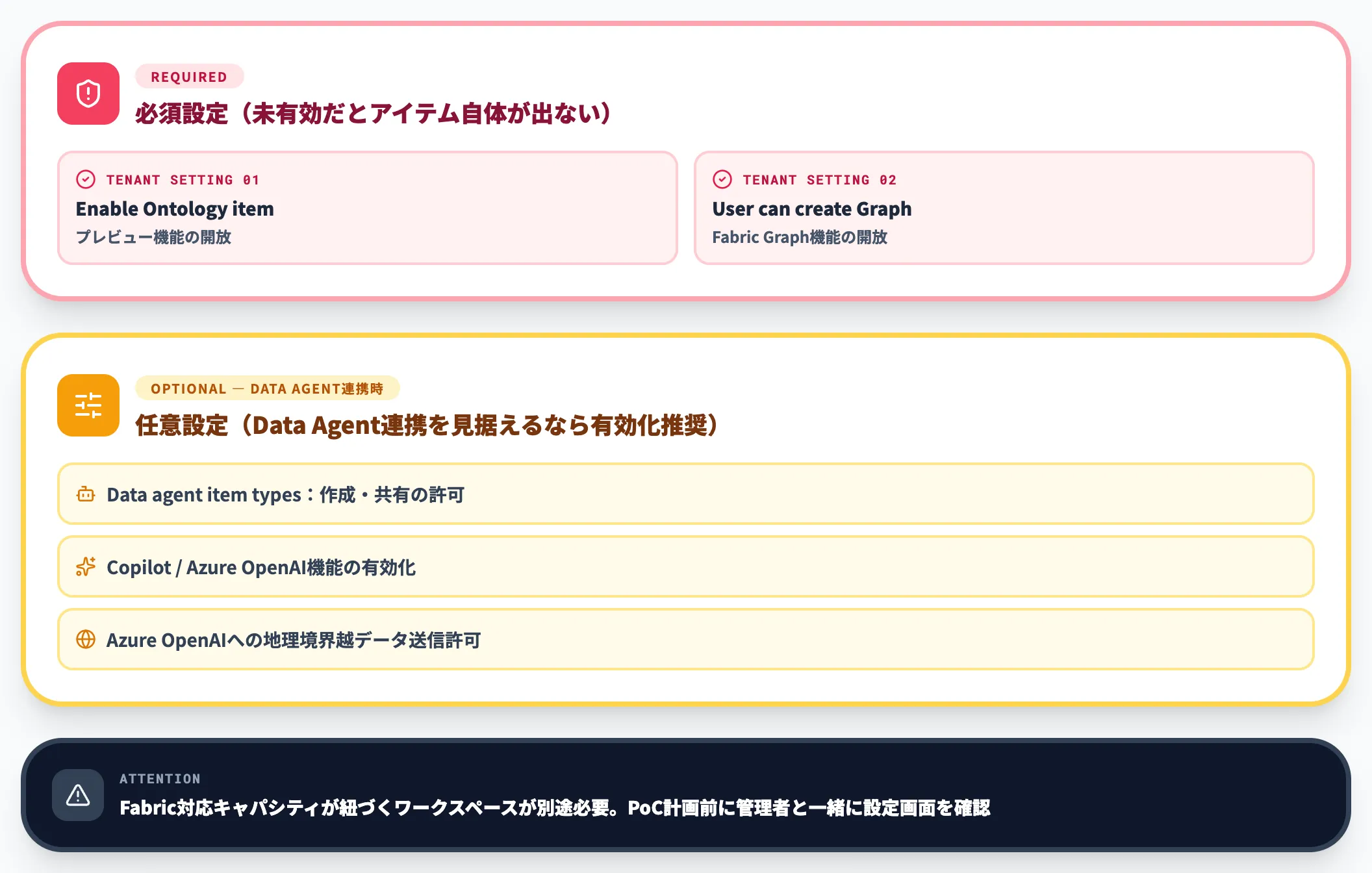
必須設定(これを忘れると「オントロジー」アイテム自体が新規作成メニューに出てこない)
- Enable Ontology item(プレビュー)
- User can create Graph(プレビュー)
任意設定(オントロジーをFabric Data Agentと組み合わせる場合に必要)
- Users can create and share Data agent item types(プレビュー)
- Users can use Copilot and other features powered by Azure OpenAI
- Azure OpenAI へのデータ送信に関する2つの設定(地理的境界を越えた処理・保存の許可)
加えて、Fabric対応キャパシティが紐づくワークスペースが必要です。ここで詰まる企業が多いため、PoC計画前に管理者と一緒にテナント設定画面を確認しておくことをおすすめします。
Data Agentとの連携を最初から見据えるなら任意設定もまとめて有効化しておくと、後工程の手戻りが減ります。
2つの作成方法の使い分け
公式チュートリアルは2つの作成方法を提示しています。選択軸は以下の通りです。
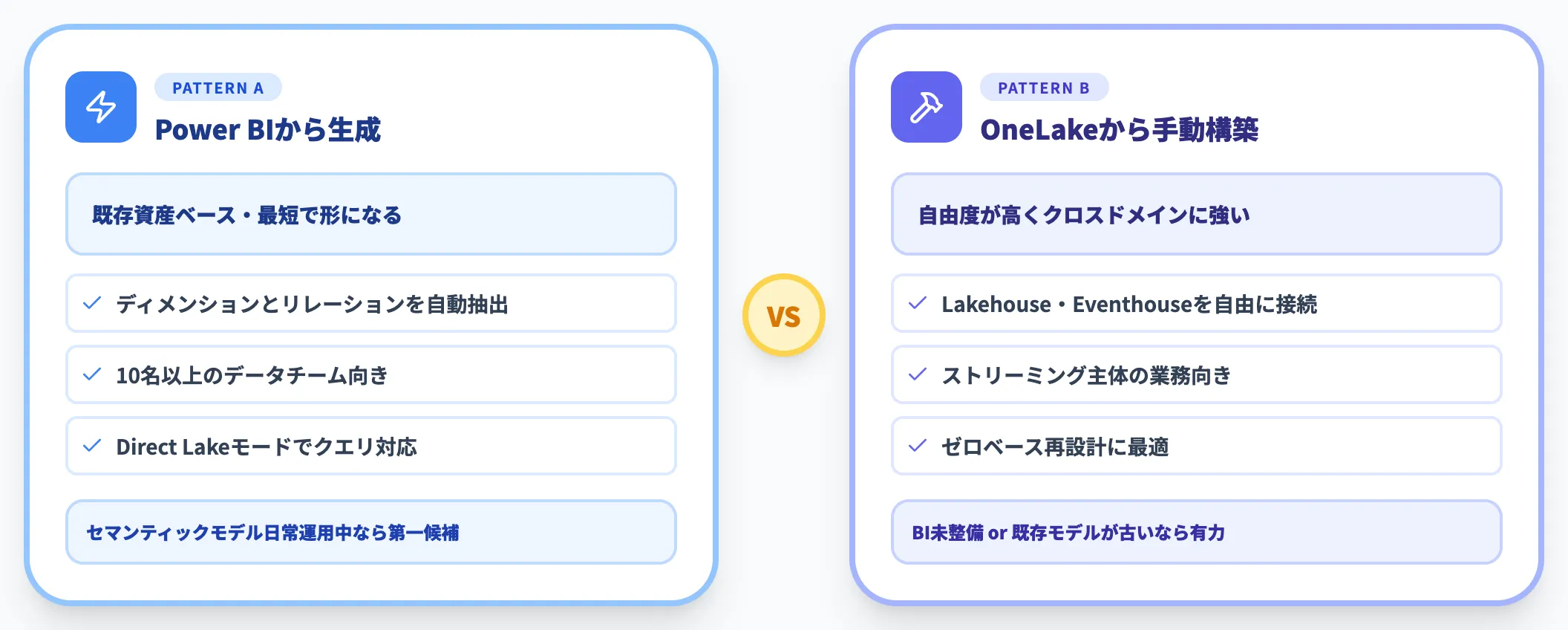
- Power BI セマンティックモデルから生成
既存のセマンティックモデルがあるケース。ディメンション・リレーションシップをブートストラップでき、最短で形になる
- OneLake から手動構築
セマンティックモデルがない、あるいは最初からオントロジー主体で設計したいケース。自由度が高く、ストリーミングやクロスドメインの複雑なモデルに向く
10名以上のデータチームで既にPower BIが日常運用されているなら前者、これからデータ基盤を作る・既存モデルが古く再設計したいなら後者、という判断軸で選んでください。
Lakeshore Retailサンプルで学ぶ実装イメージ
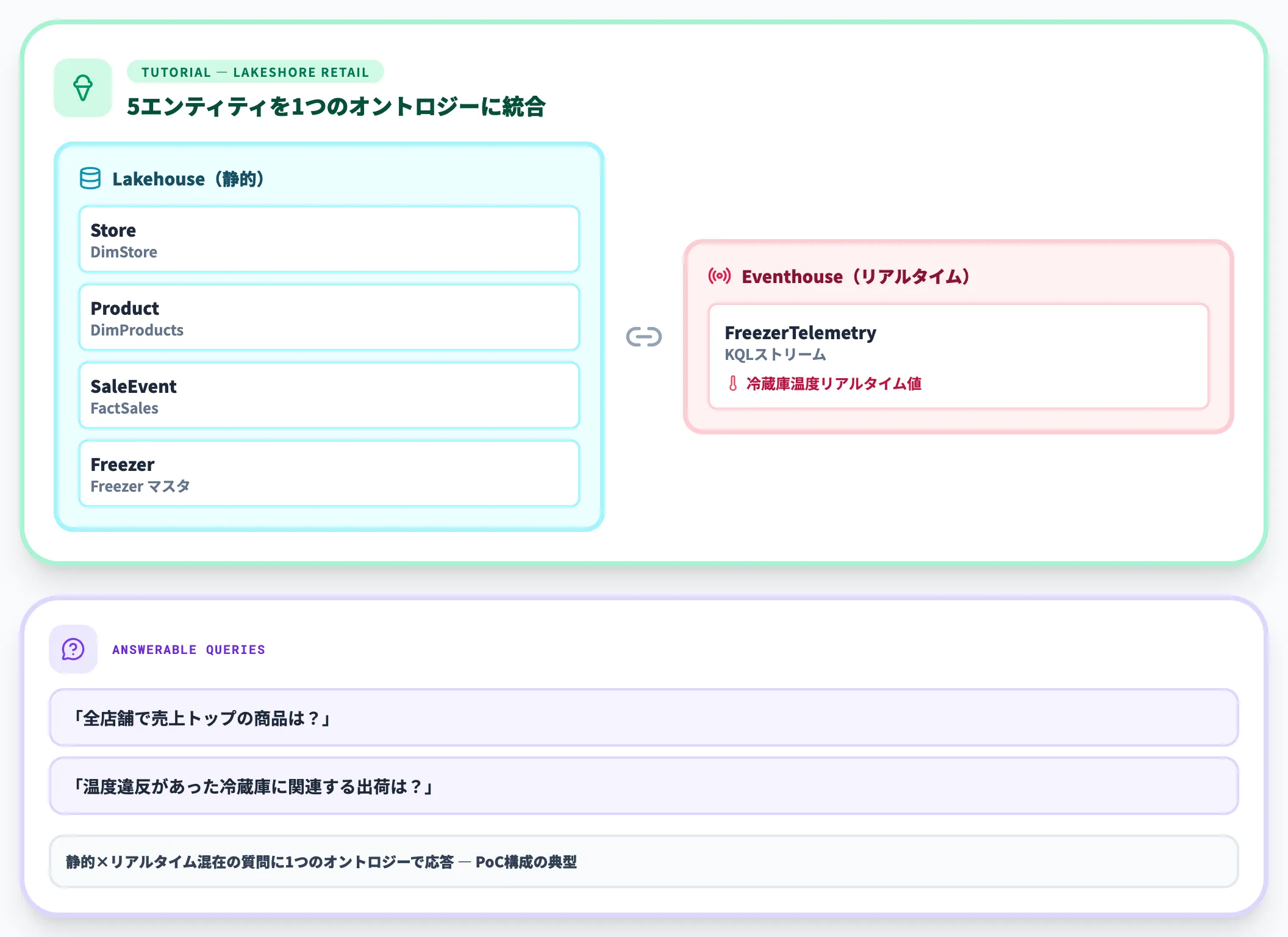
チュートリアルのサンプルシナリオは、架空のアイスクリーム小売業「Lakeshore Retail」を題材に以下のエンティティを扱います。
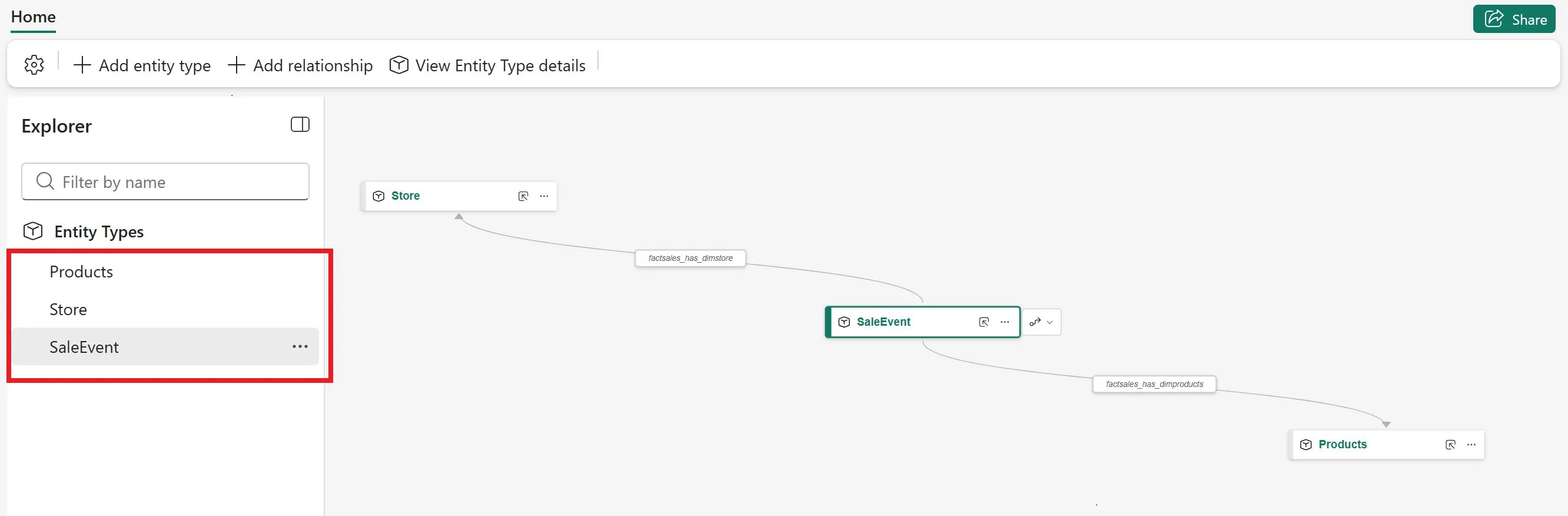
Lakeshore Retailサンプルのエンティティ型を追加している画面(出典:Microsoft Learn)
| エンティティ型 | データソース | 用途 |
|---|---|---|
| Store | Lakehouse(DimStore) | 店舗マスタ |
| Product | Lakehouse(DimProducts) | 商品マスタ |
| SaleEvent | Lakehouse(FactSales) | 販売ファクト |
| Freezer | Lakehouse(Freezer) | 冷蔵庫マスタ |
| FreezerTelemetry | Eventhouse(KQLストリーム) | 冷蔵庫温度のリアルタイム値 |
この構成で、静的な販売データとリアルタイムの温度ストリームを1つのオントロジーに統合し、「全店舗で売上トップの商品は?」「温度違反があった冷蔵庫に関連する出荷は?」といった静的×リアルタイム混在の質問に答えられる状態を作ります。
これがFabric IQオントロジーの典型的なPoC構成です。
2026年のアップデート(FabCon Atlanta発表)
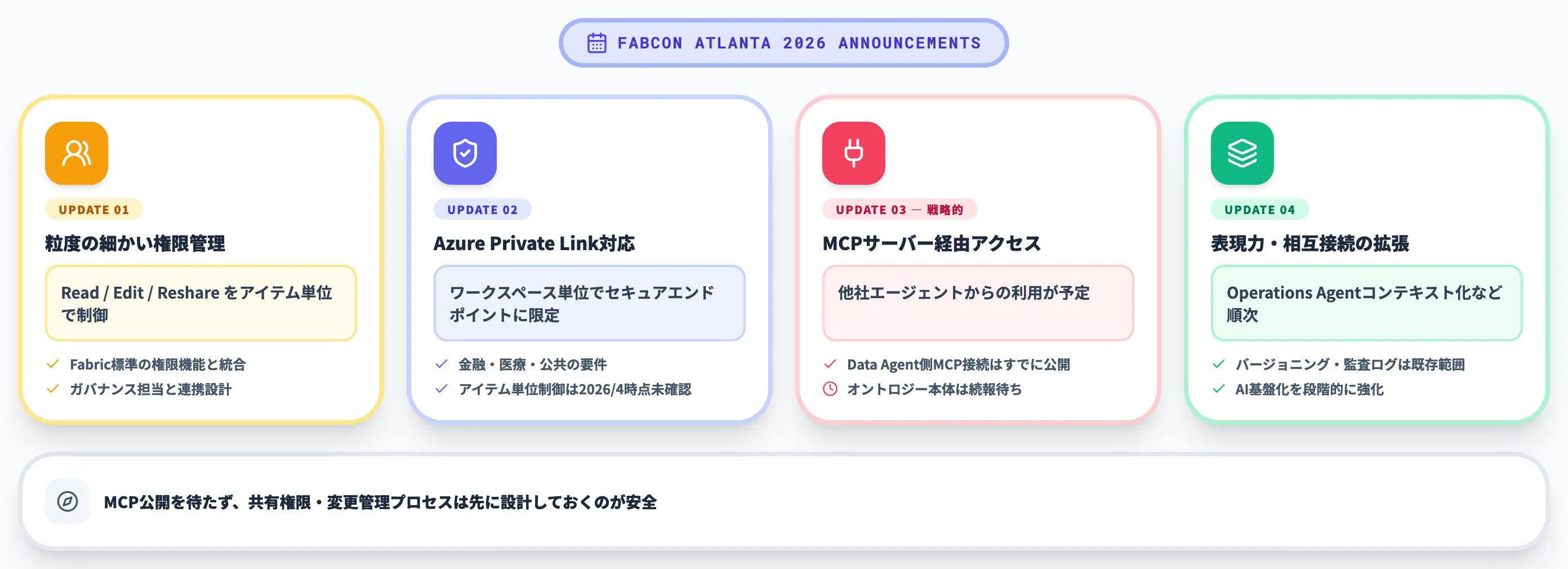
Fabric公式ブログによれば、FabCon Atlanta 2026でオントロジーに対する重要な機能拡張がプレビュー発表されました。2026年4月時点では一部が順次展開中です。
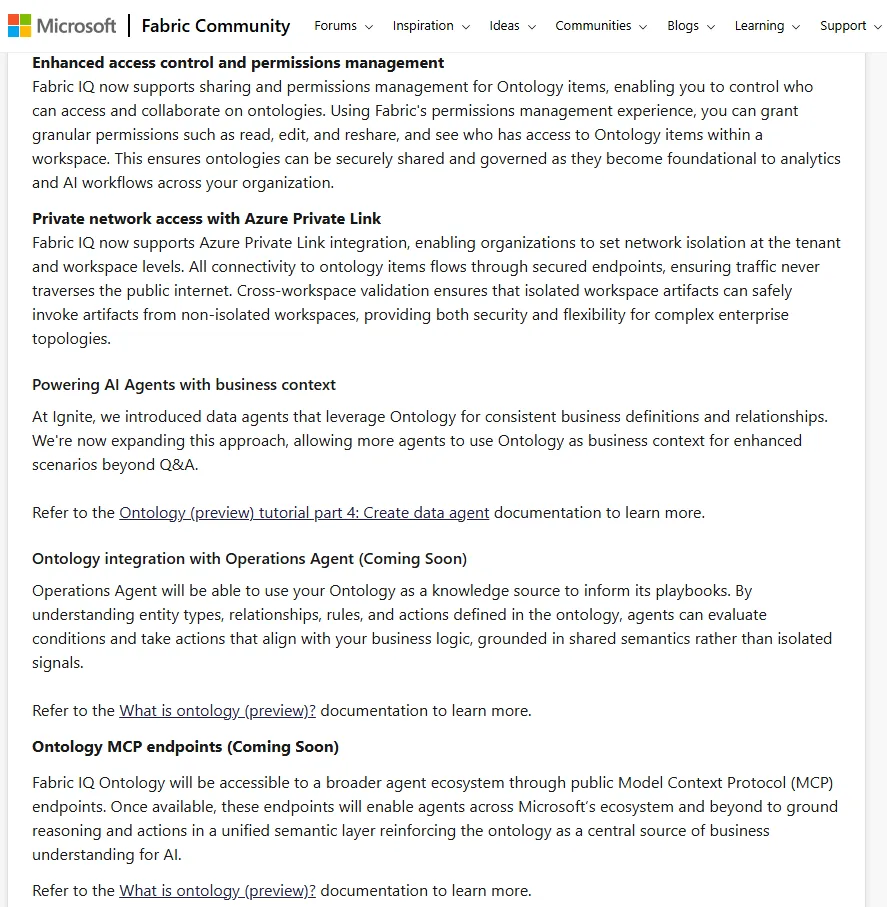
FabCon Atlanta 2026で発表されたオントロジーの権限管理・Private Link・MCP拡張(出典:Microsoft Fabric Blog)
共有と権限管理
オントロジーアイテムに対して、Read・Edit・Reshareといった粒度の細かい権限を付与できるようになりました。
Fabric標準の権限管理エクスペリエンスと統合されており、ワークスペース内で誰がどのオントロジーアイテムにアクセスできるかを可視化できます。
オントロジーが組織のAIワークフロー・分析の基盤になるほど、誰がエンティティ型を変更できるかのガバナンスが重要になります。
変更は下流の全ツールに影響するため、データガバナンス担当と連携して「Editは専任チームのみ」「ReadはAI利用部門に広く開放」といった権限設計を早めに固めておくのが実務的です。
Azure Private Linkによるワークスペース単位のネットワーク分離
オントロジーアイテム単体に対する接続制御機能ではありませんが、Fabricのテナント/ワークスペース単位のPrivate Linkにより、オントロジーを配置したワークスペースへのパブリックアクセスを制限できます。
サポート対象シナリオに従って構成することで、ワークスペースへの接続トラフィックをセキュアエンドポイント経由に絞り込めるため、規制業界(金融・医療・公共)でのセキュリティ要件を満たしやすくなります。
MCP(Model Context Protocol)サーバー経由でのアクセス予定
戦略的に重要なのが、MCP経由でのオントロジー参照です。
2026年3月のAzure公式ブログでは、オントロジーがpreview段階のMCPサーバーから利用可能になる予定と案内されています。
いずれにせよ、AIエージェント基盤化に向けてはオントロジーをデータパイプラインと同じ規律でバージョン管理・ガバナンスする体制を早期に整えることが重要です。
MCP公開のタイミングを待たず、共有権限・変更管理プロセスは先に設計しておくのが安全です。
表現力の強化
その他、Operations Agentのコンテキストソース化など、オントロジーをより表現力豊かに・より相互接続的に・より信頼性の高いAI基盤として機能させるための拡張が順次予定されています。
なお、バージョニング・監査ログといったガバナンス機能については、現行のFabric IQ概要ドキュメント時点ですでに説明範囲に含まれている領域です。
Fabric IQ オントロジーの料金体系
オントロジーはプレビュー段階ながら既に課金が有効(一部メーターを除く)で、Microsoft Fabricのキャパシティユニット(CU)ベースで消費されます。
別途シート単位ライセンスを購入する必要はありません。

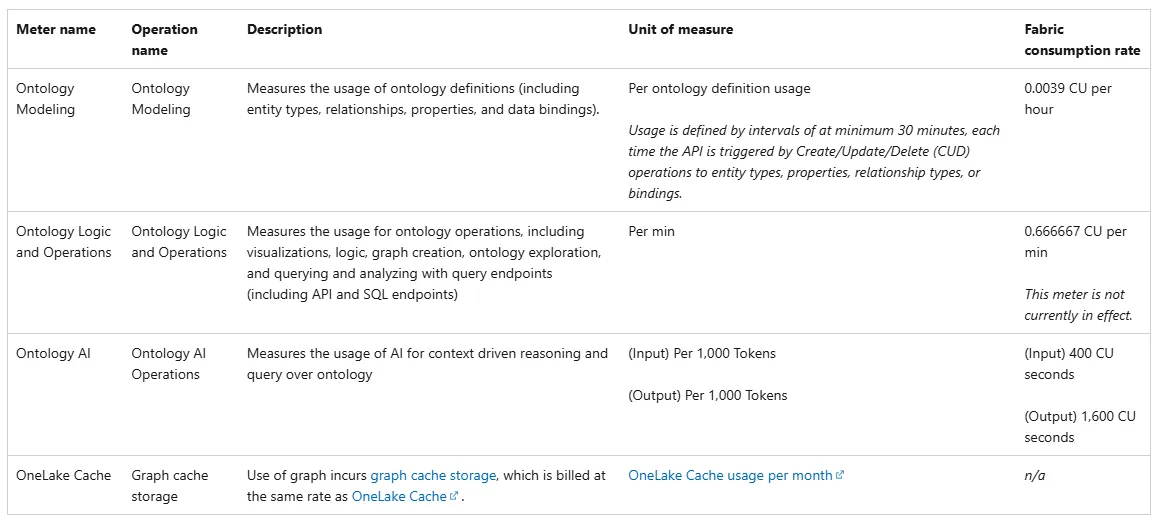
Fabric IQ オントロジーの課金メーター一覧(出典:Microsoft Learn)
消費メーターの構成要素
オントロジーの料金は主に以下3つのメーターで計測されます。
| メーター | 計測対象 | 消費レート |
|---|---|---|
| Ontology Modeling | エンティティ型・プロパティ・リレーションシップ・データバインディングの定義使用量(CUD操作) | 0.0039 CU/時間 × 定義数 |
| Ontology Logic and Operations | 可視化・ロジック・グラフ作成・クエリ・エクスプロレーション | 0.666667 CU/分 (現時点ではメーター自体は未課金。ただし利用者は基盤となるFabric Graph使用量で課金される) |
| Ontology AI Operations | AIによるコンテキスト推論・自然言語クエリ | 入力 400 CU秒/1,000トークン、出力 1,600 CU秒/1,000トークン |
加えて、グラフキャッシュストレージがOneLake Cacheと同レートで別途課金されます。
さらに、オントロジーのルール機能はFabric Activatorと連動するため、ルールの実行に対してはActivator側のキャパシティ消費も別途発生します。
つまりオントロジー1アイテムを本番運用する場合、Modeling・AI Operations・Fabric Graph(再構築・コンピュート)・Activator(ルール実行)の最低4系統を見積もり対象に入れる必要があります。
料金例(2026年4月時点)
公式ドキュメントの計算例を、実務で想定するケースに当てはめると以下のようになります。
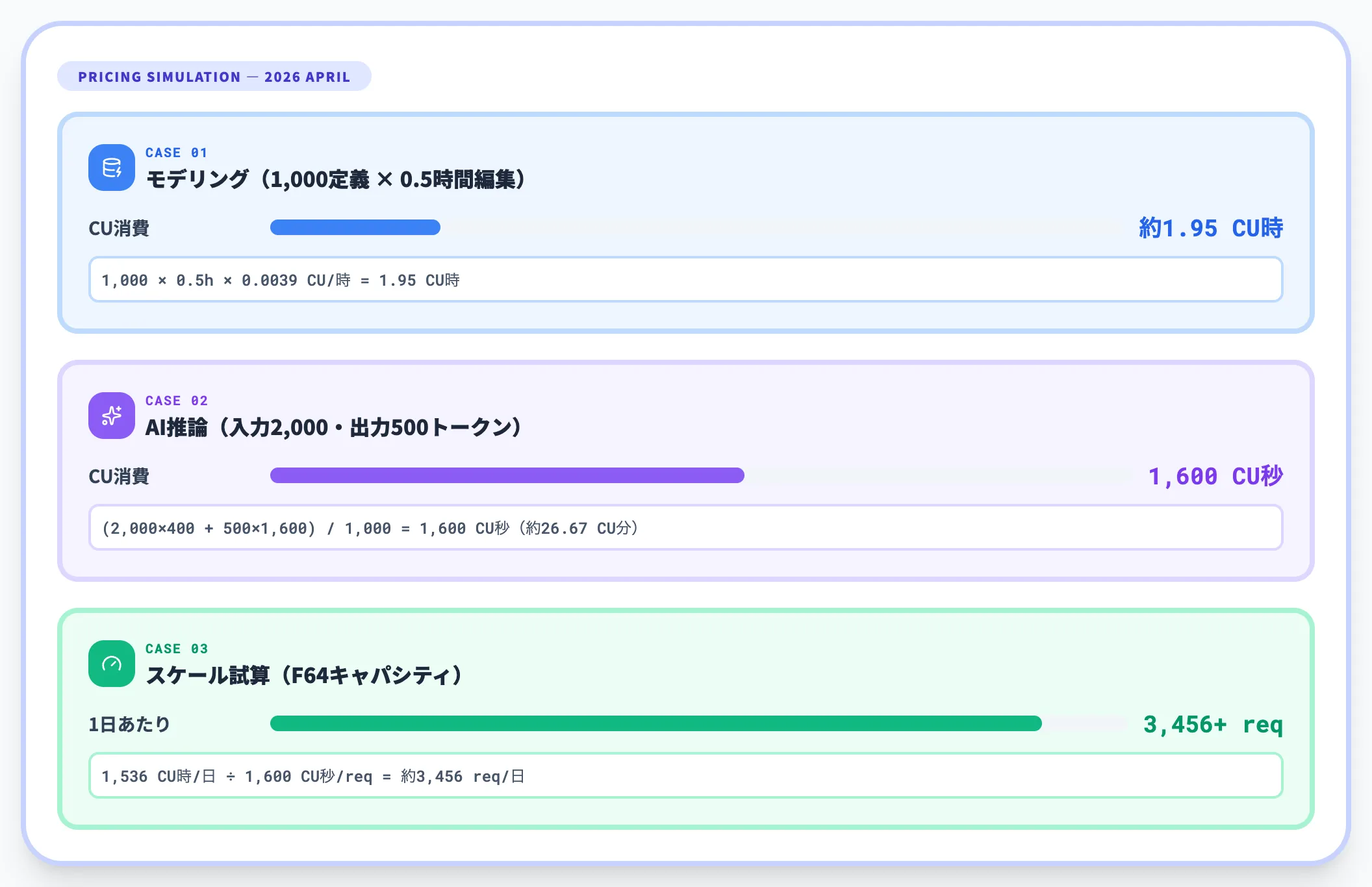
- モデリング:1,000定義に対してプロパティを1回編集 → 1,000 × 0.5時間 × 0.0039 CU/時 = 約1.95 CU時
- AI推論:入力2,000トークン・出力500トークンの自然言語クエリ1回 → (2,000×400 + 500×1,600)/1,000 = 1,600 CU秒(約26.67 CU分)
- スケール試算:F64キャパシティ(1日1,536 CU時)で、同程度のAIクエリを1日3,456リクエスト以上実行可能
運用上の注意
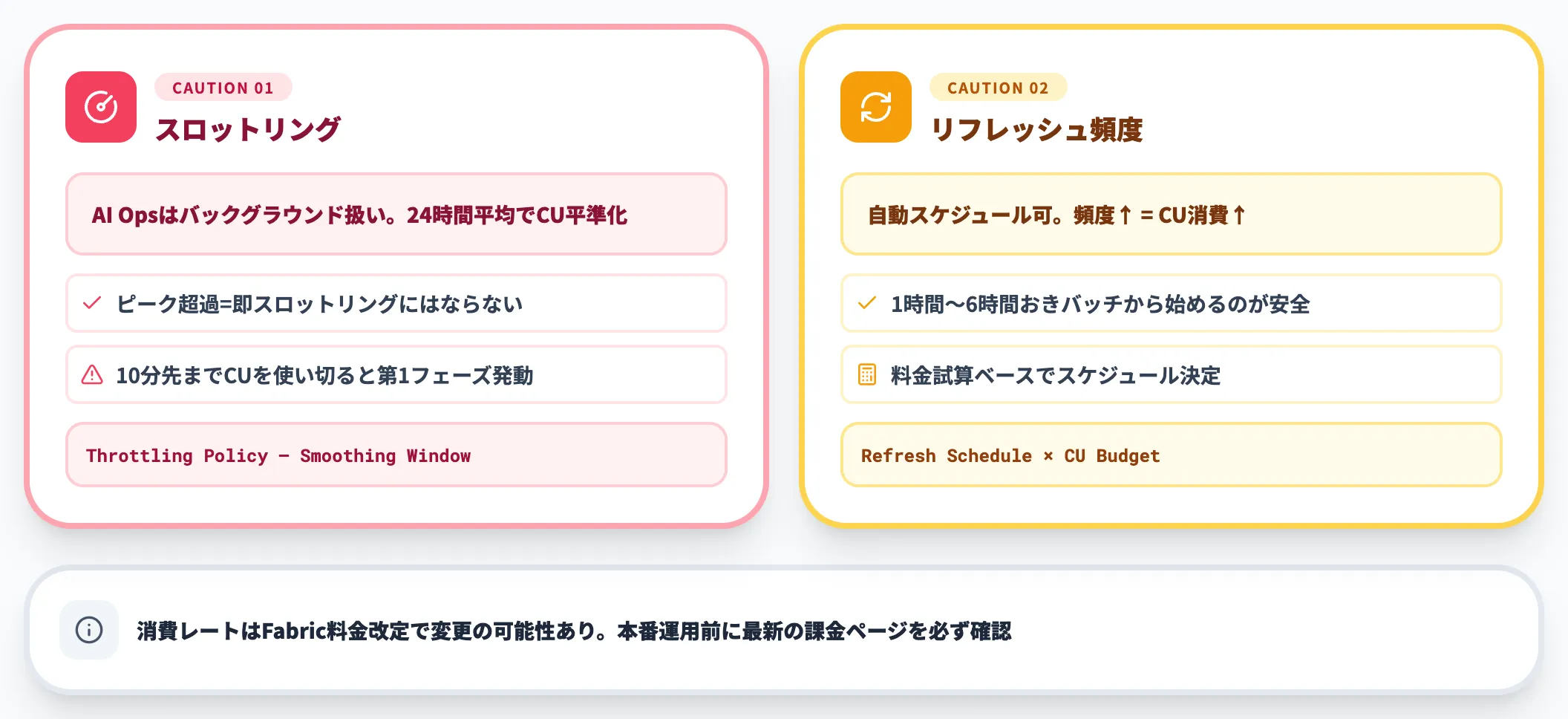
AI Operationsはバックグラウンドジョブとして扱われ、24時間平均でCU消費が平準化されます。
つまりピーク時に一時的にCUを超過しても即スロットリングにはならない設計ですが、スロットリングポリシーにより10分先までのCUを使い切るとThrottling第1フェーズが発動します。
また、グラフリフレッシュは自動スケジュールにもできますが、頻度を上げればCU消費も比例して増えます。リフレッシュスケジュールは料金試算のうえで決定するのが鉄則です。
導入判断で詰まる論点と向き不向き

Fabric IQオントロジーは強力な設計思想を持つ一方、全ての企業にいま導入すべき機能というわけではありません。実装前に判断すべき論点と、向き不向きを整理します。
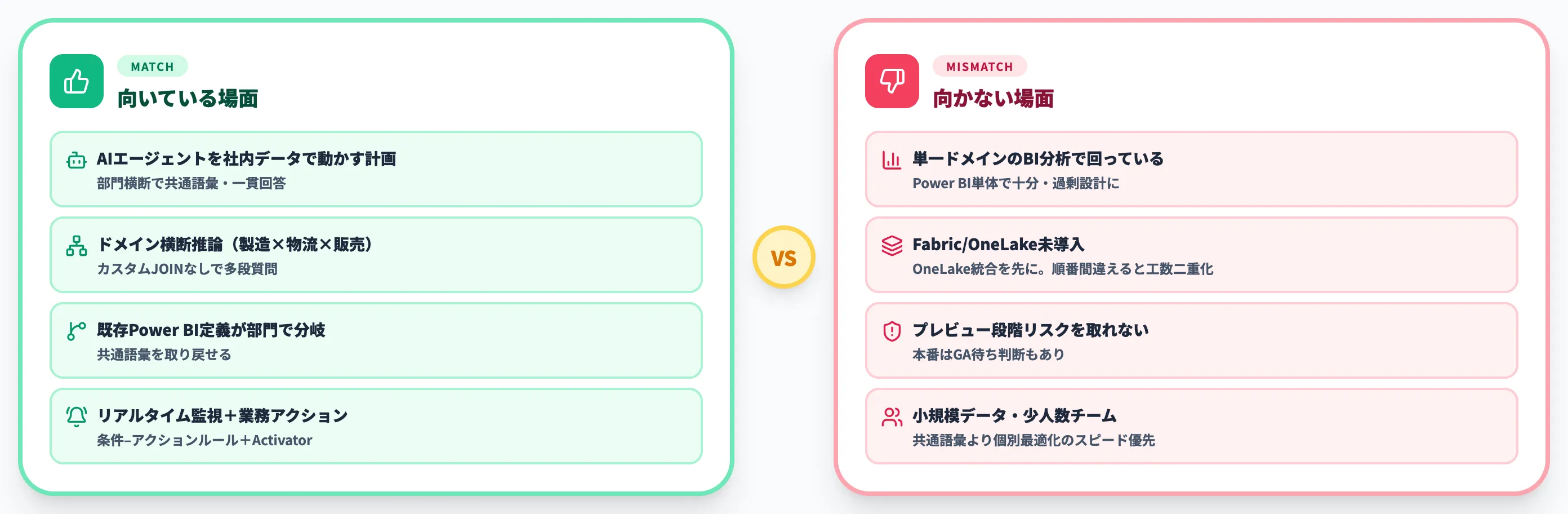
Fabric IQ オントロジーが向いている場面
以下の表で、オントロジーが効果を発揮しやすいケースを整理しました。
| 状況 | オントロジーが効く理由 |
|---|---|
| AIエージェントを社内データで動かす計画がある | エージェントが共通の語彙でデータを解釈でき、部門横断で一貫した回答ができる |
| ドメインをまたいだ推論が必要(製造×物流×販売など) | リレーションシップを事前定義でき、カスタムJOINなしで多段質問に答えられる |
| 既存Power BIセマンティックモデルがあるが定義が部門で分岐 | 既存モデルをベースにオントロジー化し、共通語彙を取り戻せる |
| リアルタイム監視+業務アクション(アラート・通知)が必要 | 条件–アクションルール+Fabric Activator連携で統一的に実装できる |
特に「AIエージェントを複数部門で使う」企業にとっては、エージェント個別に独自のコンテキストを作るより、オントロジーで共通言語を先に定義する方が長期保守コストが下がるという点が最大の価値です。
Fabric IQ オントロジーが向かない場面
一方で、以下のケースでは現時点での導入を急ぐ必要はありません。
| 状況 | 導入を急がない理由 |
|---|---|
| 単一ドメインのBI分析だけで業務が回っている | Power BIセマンティックモデルで十分。オントロジーは過剰設計になる |
| データ基盤がFabric/OneLakeにまだ乗っていない | 前提となるOneLake統合が先。順番を間違えると工数が二重化 |
| プレビュー段階の機能を本番運用するリスクを取れない | 2026年4月時点でGAではない。本番運用ならGAを待つ判断もあり得る |
| 小規模なデータ・少人数のチーム | 共通語彙の分散コストより、個別最適化のスピードが重要なフェーズ |
導入判断で詰まる論点
実装支援の現場で繰り返し議論になる論点を3つ挙げます。
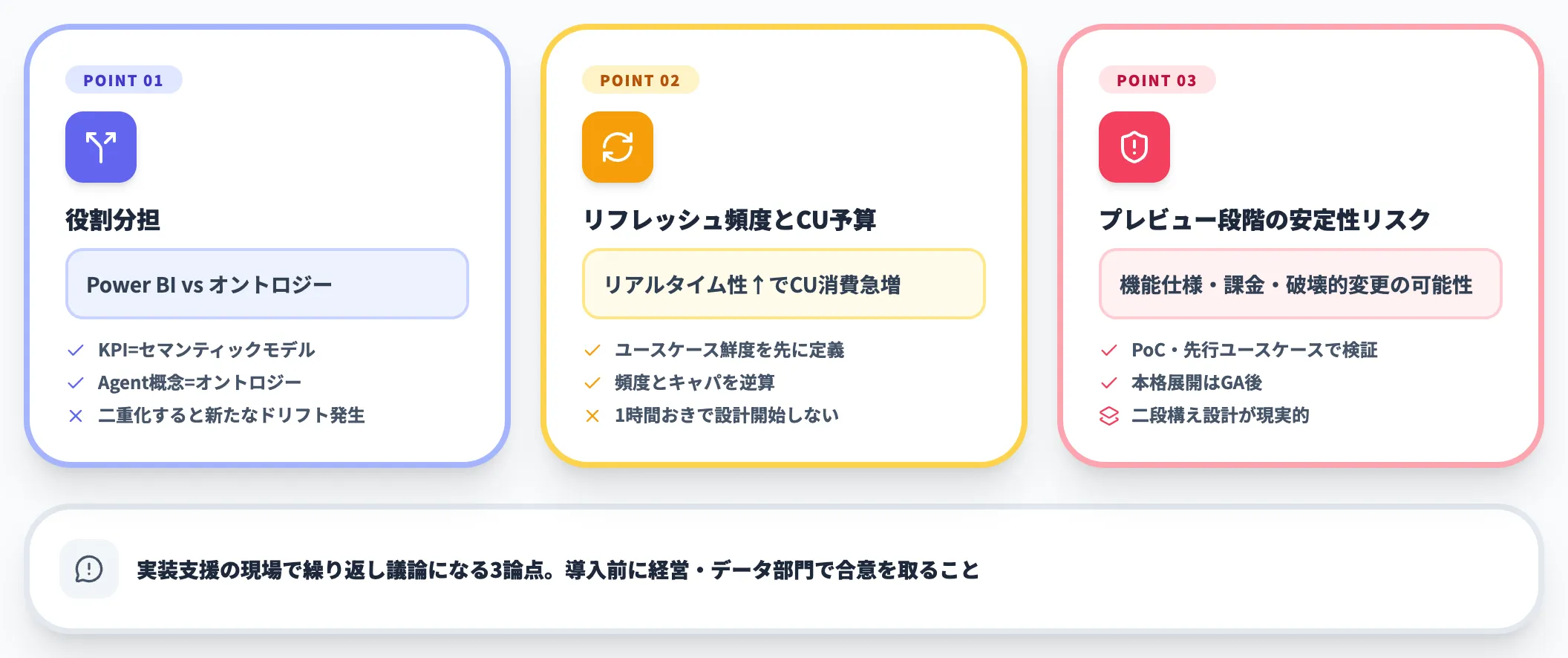
① Power BI セマンティックモデルとの役割分担
「レポート用KPIはセマンティックモデル、エージェント用の概念はオントロジー」と役割分離できれば運用がシンプルになります。両方で同じ概念を定義すると二重化が発生し、定義ドリフトを新たに生むため、基礎ディメンションは片方に一本化する設計が重要です。
② グラフリフレッシュ頻度とCU予算
リアルタイム性を求めてリフレッシュ頻度を上げると、CU消費が急増します。最初から1時間おきリフレッシュで設計するのではなく、ユースケースで必要な鮮度を先に定義し、それに合わせた頻度とキャパシティを決めるのが安全です。
③ プレビュー段階の安定性リスク
GA前の機能を本番利用に持ち込むリスクは、機能仕様の変更・課金モデルの変更・互換性のない破壊的変更の可能性を受容できるかで決まります。PoC・先行ユースケースで検証しつつ、本格展開はGA後に計画する二段構えが現実的です。
【ケース別】推奨ルート
ケース別の推奨ルートは以下のようになります。

- 既にPower BIセマンティックモデルあり(Direct Lake中心) + AIエージェント展開計画あり
→ セマンティックモデルからのオントロジー自動生成が第一候補。1つの部門で小さく検証
- 既にPower BIセマンティックモデルあり(Import / DirectQuery中心)
→ 定義生成は流用できるが、データバインディング・クエリはサポート対象外。Direct Lakeへの移行計画とセットで検討するか、OneLakeから手動構築するルートも比較する
- OneLake導入済み + BI整備はこれから
→ OneLakeから直接オントロジー構築。BIとエージェント基盤を同時に設計
- Fabric未導入
→ まずFabric/OneLakeの導入を優先。オントロジーはフェーズ2で検討
いずれのルートでも、MCPエンドポイント公開を見越してオントロジーの変更管理プロセス(Edit権限・バージョニング・レビュー体制)を初期から整えるのが、後々の運用コストを抑えるポイントです。
まとめ
Fabric IQ オントロジーは、ビジネス語彙・エンティティ・関係性・条件–アクションルールを1箇所に集約し、OneLake上の実データにバインドするセマンティックレイヤーの中核アイテムです。
本記事の要点を3つに整理します。
- セマンティックドリフト問題の構造的解:部門・ツールごとに散らばる定義を一元化し、人間とAIエージェントが同じ言語でデータを解釈できるようにする基盤
- Power BIセマンティックモデルとの併用設計が鍵:BI用KPIはセマンティックモデル、エージェント・業務アクション用の概念はオントロジー、という役割分離が実務の定石
- MCPサーバー経由でのエコシステム基盤化が予定:オントロジーがpreview MCPサーバーから利用可能になる方針が公式ブログで案内済み。提供時期や接続形態は続報待ちだが、共有権限・バージョニング・リフレッシュスケジュールは先回りで設計する価値がある
次のステップとしては、まず自社のPower BIセマンティックモデル資産を棚卸しし、オントロジー化できるドメインから1つ選んでPoCを始めるのが現実的です。Lakeshore Retailチュートリアルを1周すれば、所要1〜2日で実装イメージを掴めます。
Fabric IQ上のエージェント活用を自社テナント内で完結させる

AI Agent Hubでオントロジー × AIエージェントの内製化基盤を設計
Fabric IQのオントロジーはAIエージェントの共通言語になりますが、Agentそのものの実行・管理・権限分離は別の設計が必要です。AI Agent HubならAzure Managed Applicationsとして自社テナント内にAgent基盤を構築でき、OneLakeのデータをZero ETLで活用しながら、TeamsからAgentを呼び出せます。Fabric IQと組み合わせた内製化パターンをサービスページで紹介しています。










