この記事のポイント
 Power BIとの連携を重視したML活用なら、OneLake統合でデータ移動なしに実験からスコアリングまで完結するFabric Data Scienceが最適
Power BIとの連携を重視したML活用なら、OneLake統合でデータ移動なしに実験からスコアリングまで完結するFabric Data Scienceが最適- MLflowが標準組み込みのため、実験管理・モデルバージョニングを追加構築なしで始められる点がAzure ML単体より導入ハードルが低い
- データ前処理はData Wrangler(ノーコード)、大規模パイプラインはSynapseML、BIへの予測埋め込みはSemantic Linkが有効
- 本番適用はバッチスコアリング(PREDICT関数)を基本とすべき。リアルタイムエンドポイントはPreview段階のためミッションクリティカル用途は避けるべき
- エンタープライズMLOpsや厳格なモデルガバナンスが必要ならAzure ML、マルチクラウド要件があるならDatabricksを選ぶべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
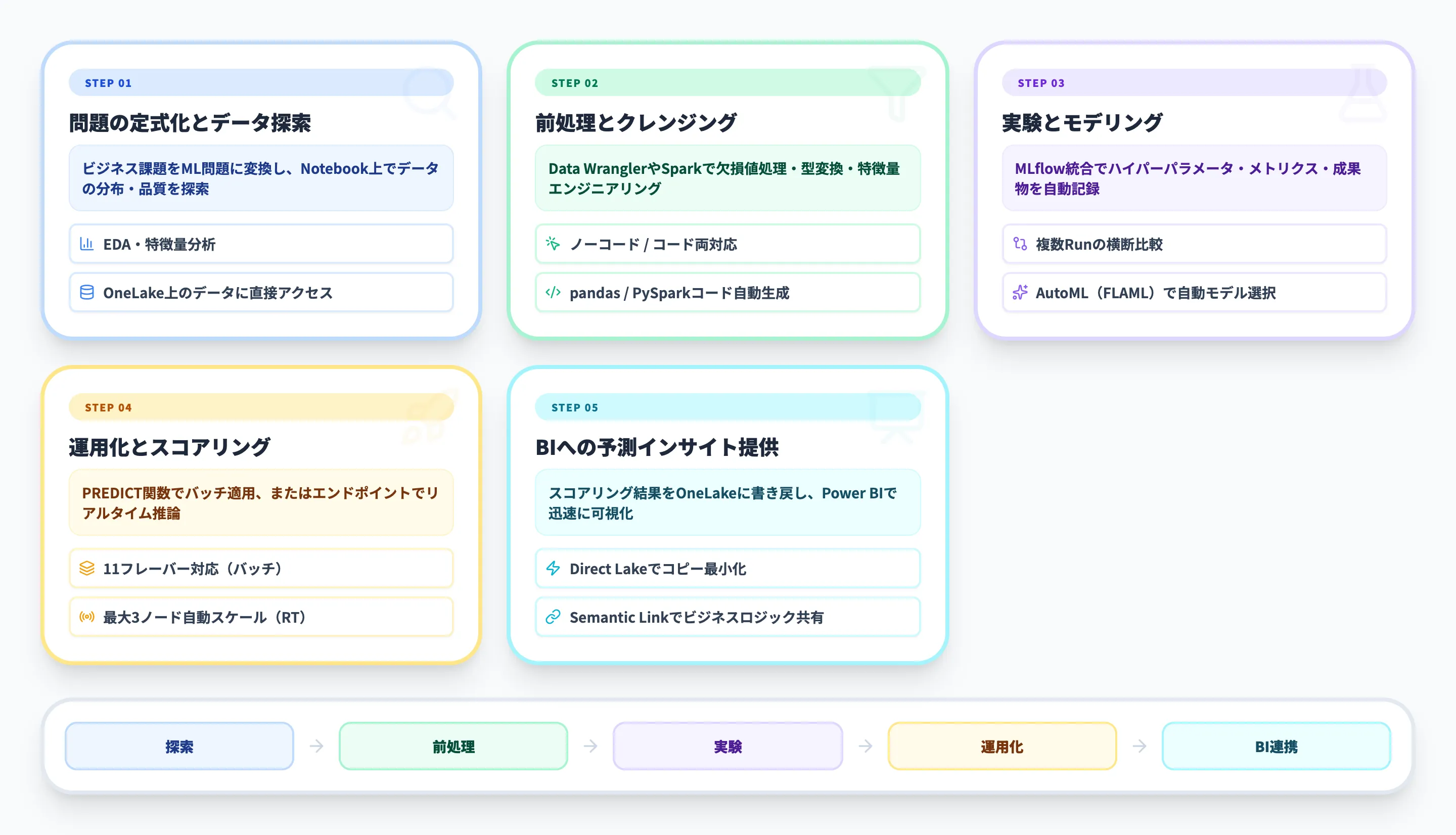
Microsoft FabricのData Scienceは、データの探索からML実験・モデル管理・スコアリング・BIへの予測インサイト提供までをひとつのプラットフォームで完結させるワークロードです。
MLflowが標準で組み込まれており、実験のトラッキングやモデルのバージョン管理をコード数行で実現できます。
本記事では、Data Scienceワークロードの基本概念から主要ツール(Data Wrangler・SynapseML・Semantic Link)、ML実験とMLflow統合の使い方、モデルのスコアリング(バッチ+リアルタイム)、AutoML機能、Azure Machine LearningやDatabricksとの違い、そして料金体系までを体系的に解説します。
✅Microsoft 365 Copilotの最新エージェント機能「Copilot Cowork」については、以下の記事をご覧ください。
Copilot Coworkとは?機能や料金、Claude Coworkとの違いを解説
目次
Fabric Data ScienceのML実験とMLflow統合
Fabric Data Scienceのモデル管理とバージョニング
Azure Machine LearningやDatabricksとの違い
Fabric Data Scienceとは?
Fabric Data Scienceは、Microsoft Fabricが提供する機械学習と高度な分析に特化したワークロードです。
データの探索・前処理からモデルの学習・評価・バージョン管理・本番スコアリング、さらにはPower BIレポートへの予測インサイト提供まで、データサイエンスのエンドツーエンドのプロセスをひとつのプラットフォーム内で完結できます。
従来、データサイエンティストがMLプロジェクトを進めるには、データの取得(データレイク)、前処理(Python環境)、実験管理(MLflow/Weights & Biases等)、モデルデプロイ(Kubernetes/クラウドサービス)、可視化(BIツール)をそれぞれ個別に構築・連携する必要がありました。
Fabric Data Scienceでは、これらがOneLakeとLakehouseを基盤としてネイティブに統合されているため、データの移動やツール間の接続設定を最小限に抑えてMLワークフローを構築できます。

Fabric Data Scienceの主要ツール
このセクションでは、Data Scienceワークロードを構成する4つの主要ツールの役割と特徴を解説します。
各ツールがMLワークフローのどのフェーズをカバーするかを把握することで、効率的なプロジェクト設計が可能になります。

Notebook
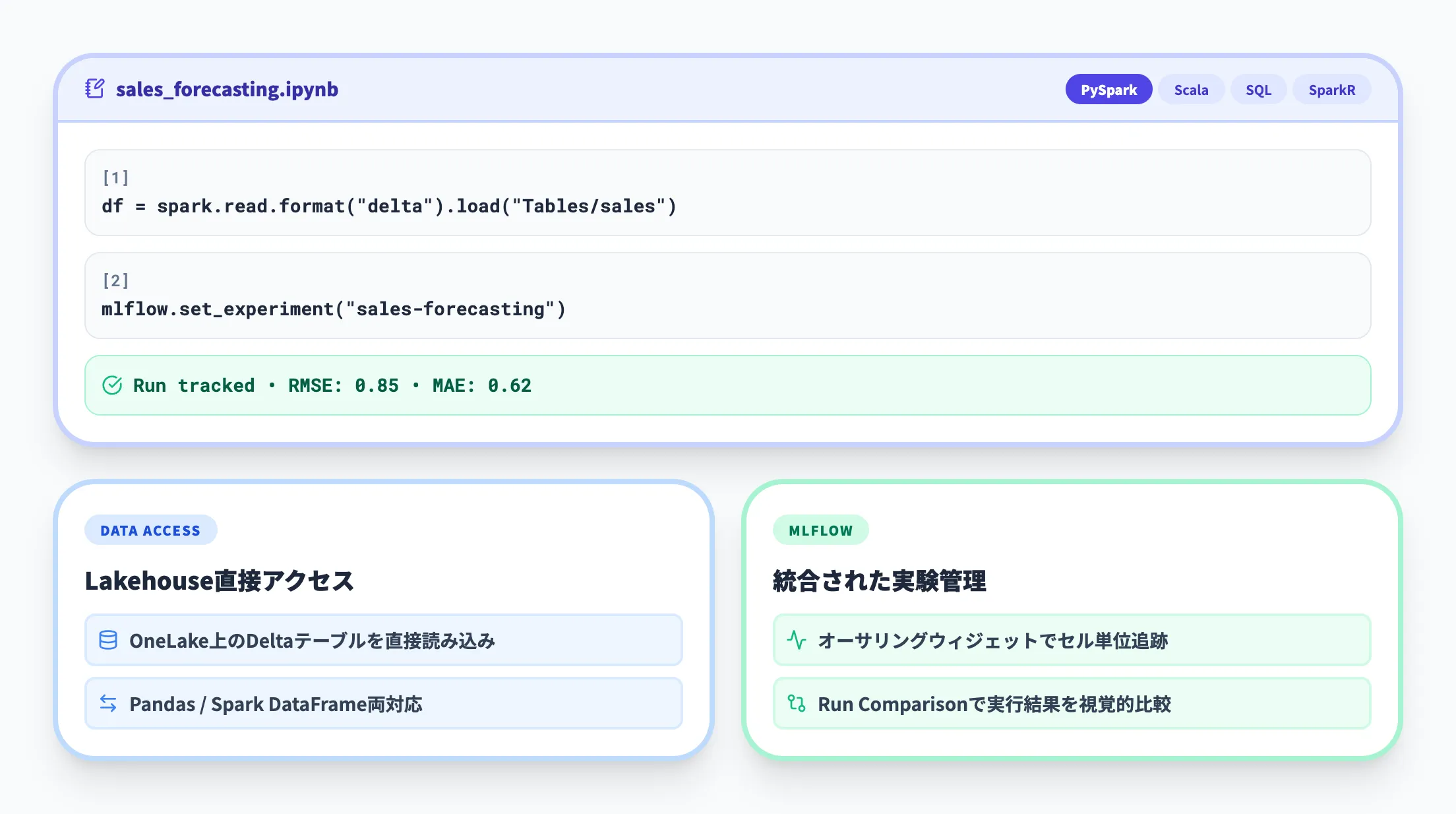
NotebookはData Scienceワークロードの中心的な開発環境です。主にPySpark・Spark(Scala)・Spark SQL・SparkRをサポートしており、用途に応じてPython notebookも利用できます。
データの読み込みからモデルの学習・評価・スコアリングまでをひとつのインターフェースで実行できます。
LakehouseにアタッチしたNotebookからは、OneLake上のDeltaテーブルを直接Pandas DataFrameやSpark DataFrameに読み込めるため、データの移動やコピーが不要です。
FabricのNotebookにはMLflow統合とオーサリングウィジェットが備わっており、セル単位でRunを追跡しながら実験管理を進められます。
Data Wrangler

Data Wranglerは、Notebook内から起動できるノーコードのデータ前処理ツールです。
ソート・フィルタ・型変換・欠損値処理・ワンホットエンコーディング・Flash Fill(例示ベースの自動列生成)など19種類の操作をGUI上で実行でき、各操作はPython(pandas)またはPySparkのコードとして自動生成されます。
操作結果はリアルタイムでプレビューされ、確定するとNotebookに関数としてエクスポートされます。
コードが自動生成されるため、ノーコードで前処理を設計しつつ、生成されたコードをNotebookのパイプラインに組み込むという使い方が可能です。
SynapseML

SynapseML(旧MMLSpark)は、Apache Spark上で大規模なMLパイプラインを構築するためのオープンソースライブラリです。
Fabric PySparkランタイムにプリインストールされており、追加設定なしで利用できます。
SynapseMLの主な特徴を以下の表にまとめます。
| 機能 | 内容 |
|---|---|
| 統一API | Python・R・Scala・Java・.NETで同一のAPI |
| プリビルトAI | テキスト分析・画像認識・異常検知など50以上のモデルを内蔵 |
| ONNXエコシステム | TensorFlow・scikit-learn・LightGBM・XGBoost・PyTorchのモデルをSpark上で分散実行 |
| Azure OpenAI統合 | AI Functionsでpandas/PySpark DataFrameを直接LLMに接続 |
| 責任あるAI | 分散SHAP・LIME・ICE等のモデル解釈ツール |
SynapseMLは、数百万行規模のデータに対して前処理からモデル学習・推論までのパイプラインを1つのSparkジョブで実行できる点が強みです。
特にAzure OpenAI統合では、非同期並列処理とエクスポネンシャルバックオフにより、単一スレッド処理と比較して最大10倍のスループット向上が見込めます。
Semantic Link

Semantic Linkは、Power BIのセマンティックモデルとData Scienceノートブックを橋渡しする機能です。
SemPy Pythonライブラリを通じて、Power BIで定義されたメジャー(計算式)・テーブル関係・データカテゴリなどのビジネスロジックをNotebook側から直接利用できます。
FabricDataFrame(Pandas DataFrameのサブクラス)がセマンティック情報を保持し、Power BIメジャーの評価やデータ品質の検証を行えます。これにより、BIチームが定義したビジネスロジックをデータサイエンスチームが再実装する必要がなくなります。
2025年12月公開のv0.13.0では、Fabricアセットを扱う機能が拡充され、Notebook上からのプログラム的な管理がさらに強化されています。
【関連記事】
Microsoft FabricとPower BIの違い、連携手順をわかりやすく解説
【Microsoft Fabric】Data Warehouseとは?T-SQL機能や料金、移行方法を徹底解説
【Microsoft Fabric】Data Factoryとは?機能やADFとの違い、料金体系を徹底解説
Fabric Data ScienceのML実験とMLflow統合
Fabric Data Scienceの実験管理は、MLflowが標準で組み込まれているのが最大の特徴です。
このセクションでは、ML実験の作成から、Runのトラッキング・比較・モデルへの保存までの一連のワークフローを解説します。
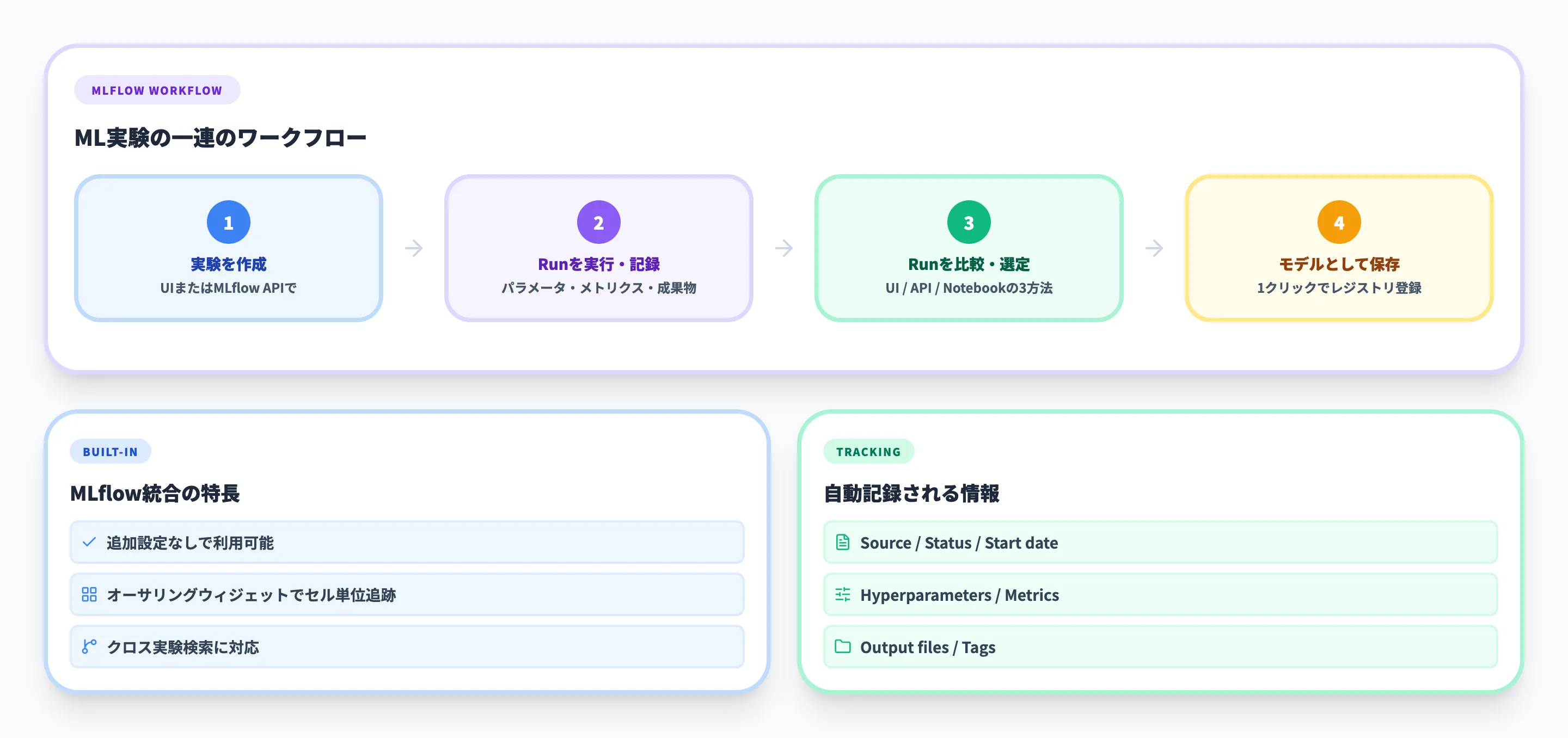
ML実験とは

ML実験(Experiment)は、関連するML実行(Run)を整理・管理するための単位です。
たとえば「売上予測モデル」という実験の中に、異なるアルゴリズムやハイパーパラメータで実行した複数のRunを格納し、メトリクスを横断的に比較できます。
実験の作成は、FabricのUIから「新しいアイテム」→「実験」を選択する方法と、Notebook内でMLflow APIを使う方法の2通りがあります。
import mlflow
# 実験を作成(または既存の実験を選択)
mlflow.set_experiment("sales-forecasting")
with mlflow.start_run():
# ハイパーパラメータを記録
mlflow.log_param("n_estimators", 100)
mlflow.log_param("max_depth", 5)
# モデルを学習
model = train_model(params)
# メトリクスを記録
mlflow.log_metric("rmse", 0.85)
mlflow.log_metric("mae", 0.62)
# モデルを保存
mlflow.sklearn.log_model(model, "model")
Runのトラッキングと記録内容

各Runには以下の情報が自動的に記録されます。
| 記録項目 | 内容 |
|---|---|
| Source | 実行元のNotebook名 |
| Status | 完了・失敗・実行中などのステータス |
| Start date | 実行開始日時 |
| Hyperparameters | キー・バリュー形式のパラメータ(文字列) |
| Metrics | キー・バリュー形式の評価指標(数値) |
| Output files | モデルファイル・データファイル等の成果物 |
| Tags | 任意のメタデータ(チーム名・プロジェクト名等) |
Notebook内ではMLflowオーサリングウィジェットが利用でき、セル単位でRunの開始・終了・メトリクス記録を追跡できます。
また、「Run comparison」ビューでセル実行ごとの結果を視覚的に比較することも可能です。
Runの比較とフィルタリング
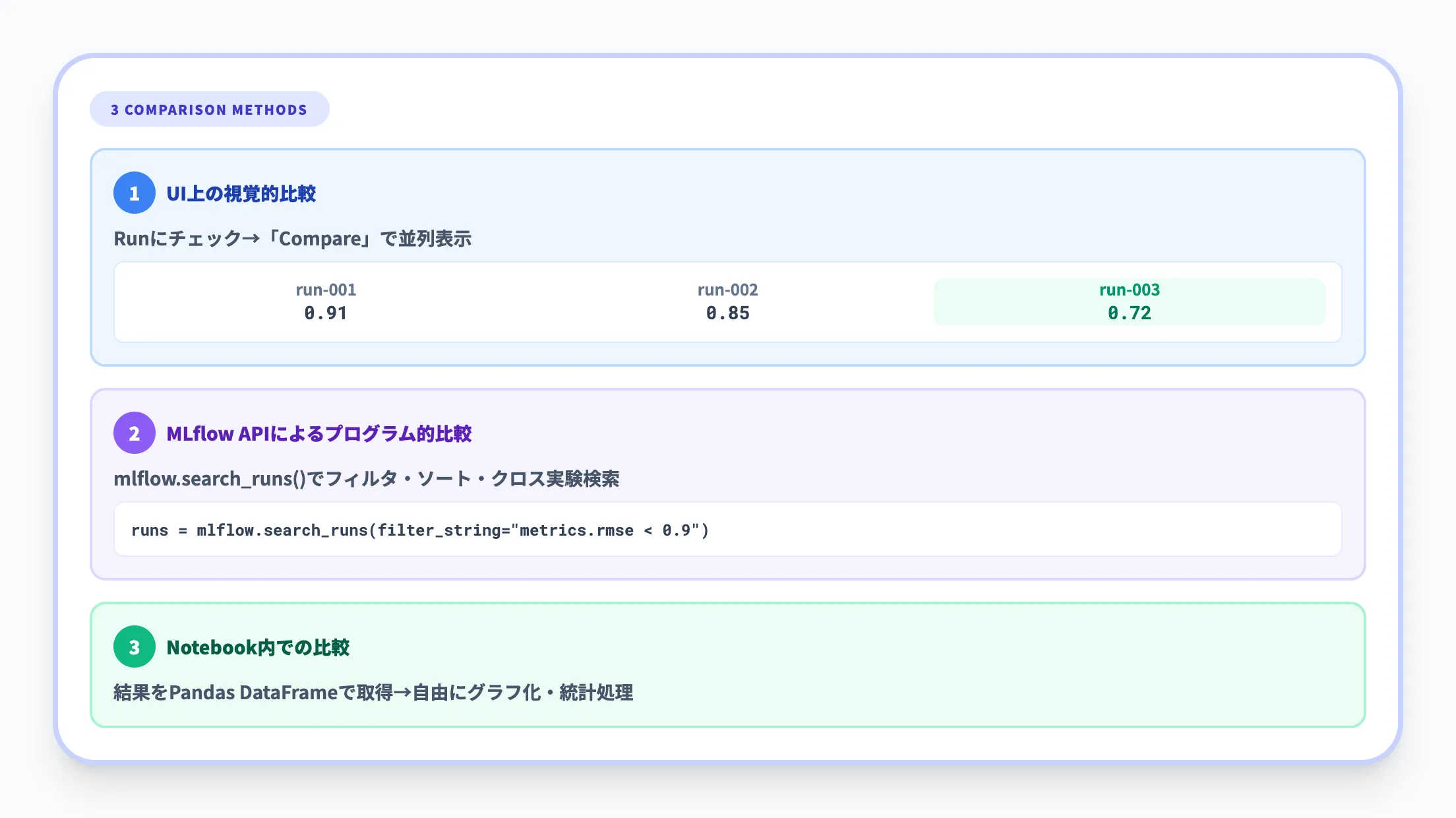
複数のRunを比較する方法は3つあります。
- UI上の視覚的比較
実験ビューで比較したいRunにチェックを入れ、「Compare」を選択します。
プロパティ・メトリクス・ハイパーパラメータを並べて表示でき、グラフの種類(散布図・棒グラフ等)もカスタマイズできます。
- MLflow APIによるプログラム的比較
mlflow.search_runs()を使い、フィルタ条件・ソート順・取得件数を指定してRunを検索できます。
クロス実験検索にも対応しており、異なる実験間でのRun比較も可能です。
- Notebook内での比較
Notebook上でRunの結果をPandas DataFrameとして取得し、自由にグラフ化・統計処理できます。
Runからモデルへの保存
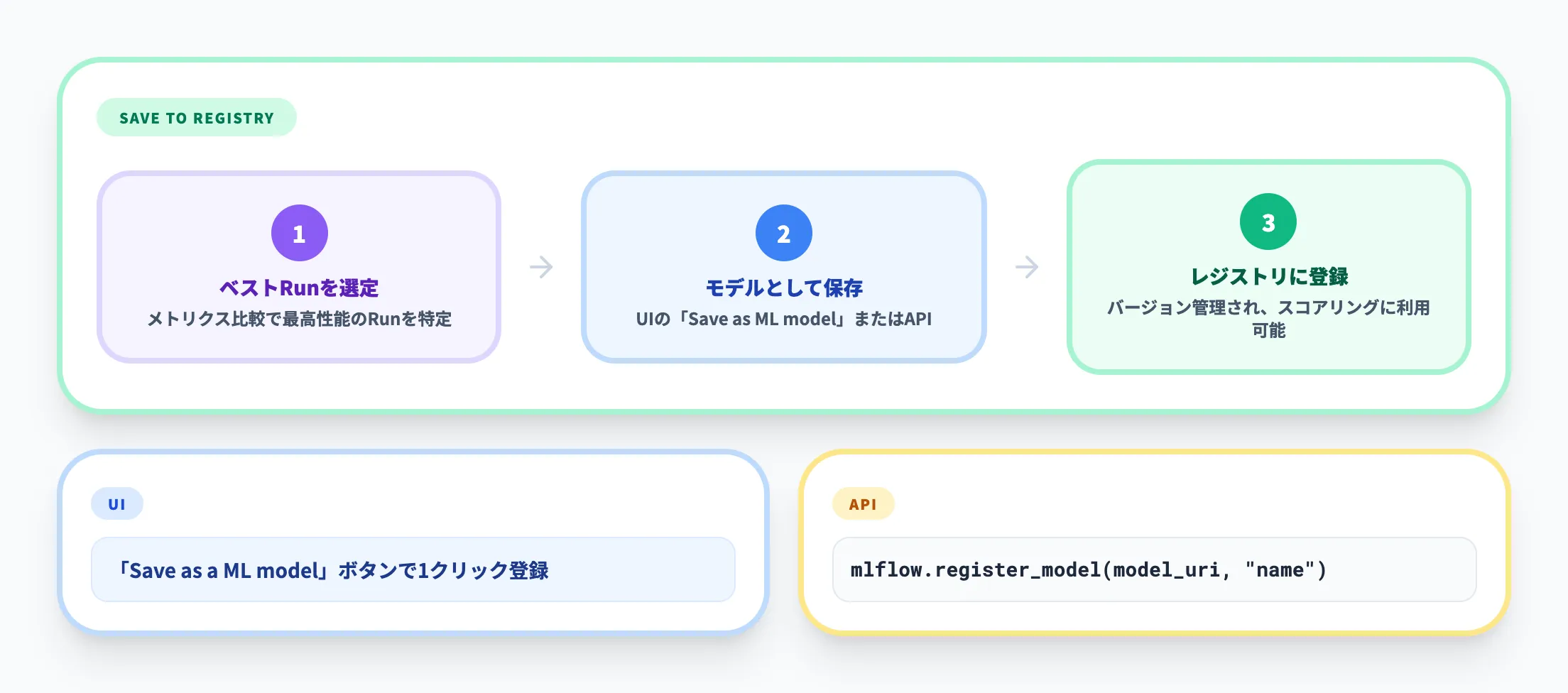
ベストパフォーマンスのRunが見つかったら、UIの「Save as a ML model」ボタンで1クリックでモデルレジストリに登録できます。
MLflow APIからの登録(mlflow.register_model())にも対応しています。保存されたモデルはバージョン管理され、次のセクションで解説するスコアリングや比較に利用できます。
Fabric Data Scienceのモデル管理とバージョニング
MLflowのモデルレジストリをベースとしたFabricのモデル管理機能は、学習済みモデルのバージョン管理・比較・本番適用をワンストップで行えます。
このセクションでは、モデルの作成からバージョン管理、タグ付け、比較までを解説します。

モデルの作成とバージョニング

Fabricでは、MLflowの標準パッケージ形式でモデルを管理します。1つのモデルに対して複数のバージョン(イテレーション)を持たせることができ、各バージョンには以下の情報が紐づきます。
| 情報 | 内容 |
|---|---|
| Time Created | バージョン作成日時 |
| Run Name | 生成元のRun名 |
| Hyperparameters | 学習時のパラメータ |
| Metrics | 評価指標 |
| Model Schema / Signature | 入出力のスキーマ定義 |
| Logged files | モデルファイルと関連成果物 |
| Tags | 任意のメタデータ |
モデルの作成はUIから「新しいアイテム」→「MLモデル」を選択するか、MLflow APIのmlflow.register_model()を使います。
既存のモデル名を指定した場合は自動的に新バージョンとして追加されます。
モデルの比較とタグ管理
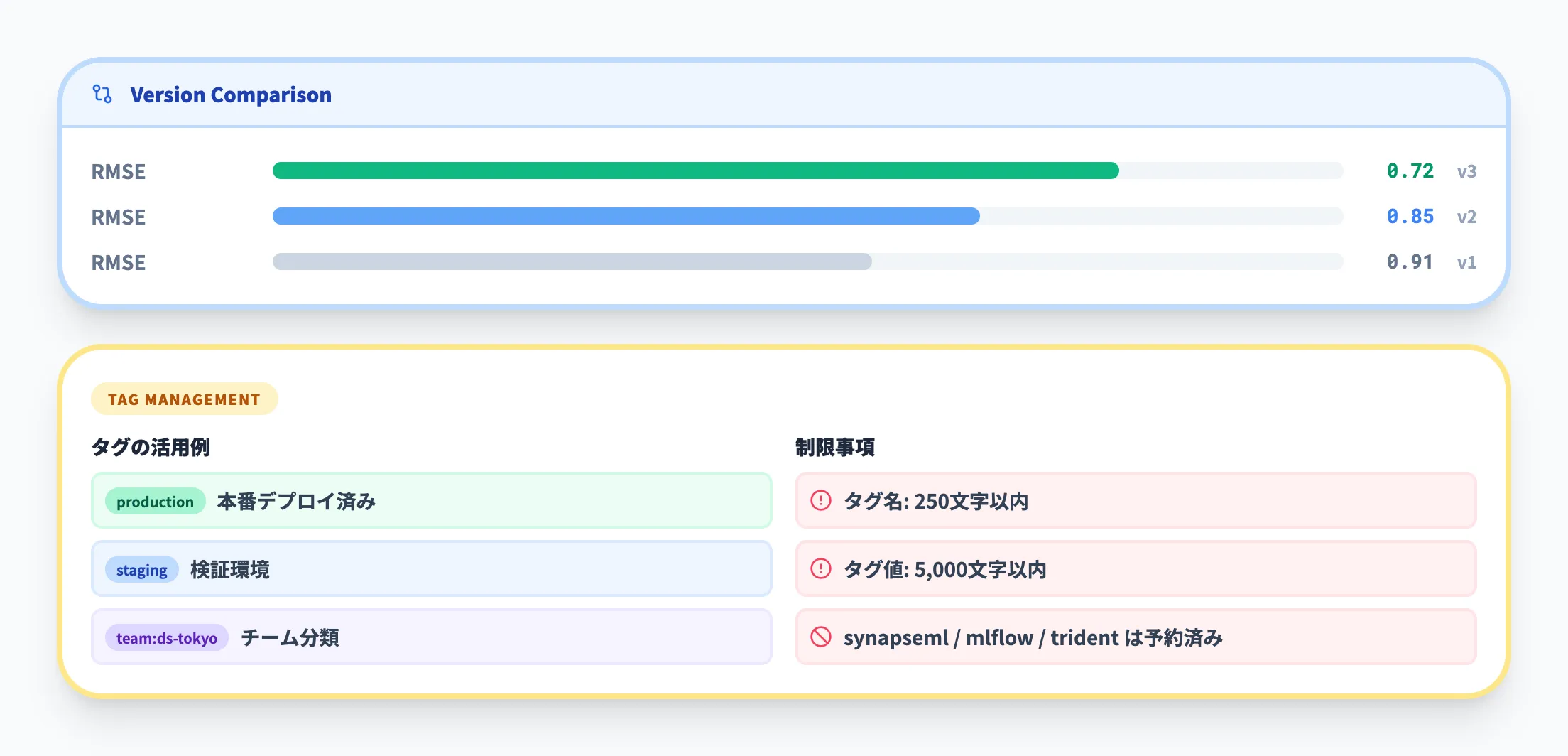
バージョン間の比較は、実験のRun比較と同様にUIとAPIの両方で行えます。メトリクス・パラメータを並べたテーブル表示と、グラフによる視覚的な傾向分析が可能です。
タグはモデルバージョンに対して任意のキー・バリューペアを設定でき、プロジェクト名・チーム名・デプロイ環境(staging / production)などの分類に活用できます。
ただし、タグ名は250文字以内・値は5,000文字以内で、synapseml・mlflow・tridentで始まるプレフィックスはシステム予約のため使用できません。
モデルの適用(スコアリング)

登録されたモデルは、次の2つの方法で本番データに適用できます。
- バッチスコアリング
PREDICT関数を使い、Apache Spark上で大規模データに対してモデルを一括適用します。詳細は次のセクションで解説します。
- リアルタイムスコアリング
モデルをエンドポイントにデプロイし、REST APIで個別の推論リクエストに応答します。こちらも次のセクションで詳しく解説します。
Fabric Data Scienceのモデルスコアリング
学習済みモデルを本番データに適用する方法は、バッチスコアリングとリアルタイムスコアリングの2つです。
このセクションでは、それぞれの仕組み・対応モデル・使い分けを解説します。
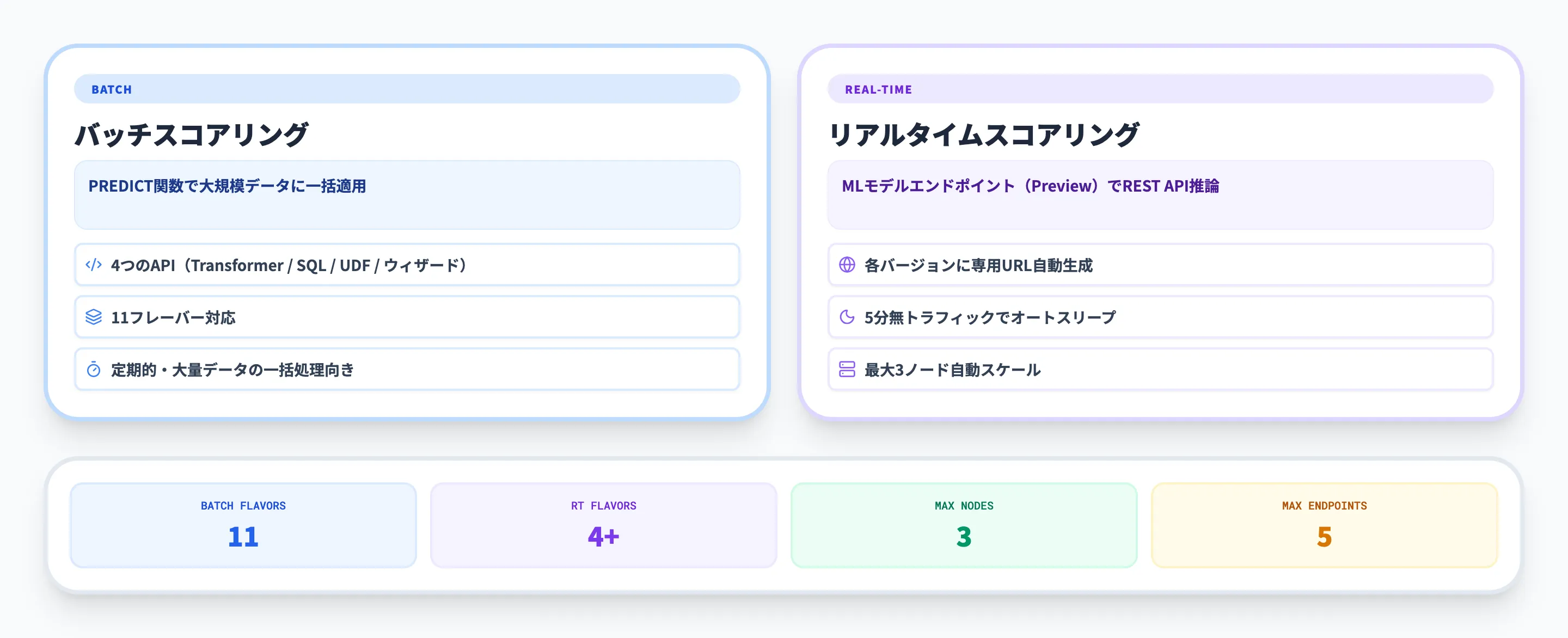
バッチスコアリング(PREDICT関数)

PREDICT関数は、FabricのあらゆるコンピュートエンジンでMLflowモデルをバッチ適用できるスケーラブルな関数です。
以下の4つの呼び出し方法があります。
- Transformer API
model.transform(test_data)でSpark DataFrameに対して直接スコアリングを実行します。
- Spark SQL API
SQLTransformerを使い、PREDICT文でSQLクエリ内からモデルを呼び出します。
- PySpark UDF
model.to_udf()でモデルをUDF化し、Spark DataFrameの列操作として適用します。
- ガイド付きUIウィザード
入力テーブルの選択→列マッピング→出力テーブル指定をGUIで行い、スコアリングNotebookを自動生成します。
PREDICT関数が対応するモデルフレーバーは以下のとおりです。
| 対応フレーバー |
|---|
| CatBoost, Keras, LightGBM, ONNX, Prophet, PyTorch, Sklearn, Spark, Statsmodels, TensorFlow, XGBoost |
モデルはMLflow形式で保存され、シグネチャ(入出力スキーマ)が定義されている必要があります。マルチテンソルの入出力はサポートされていません。
リアルタイムスコアリング(MLモデルエンドポイント)
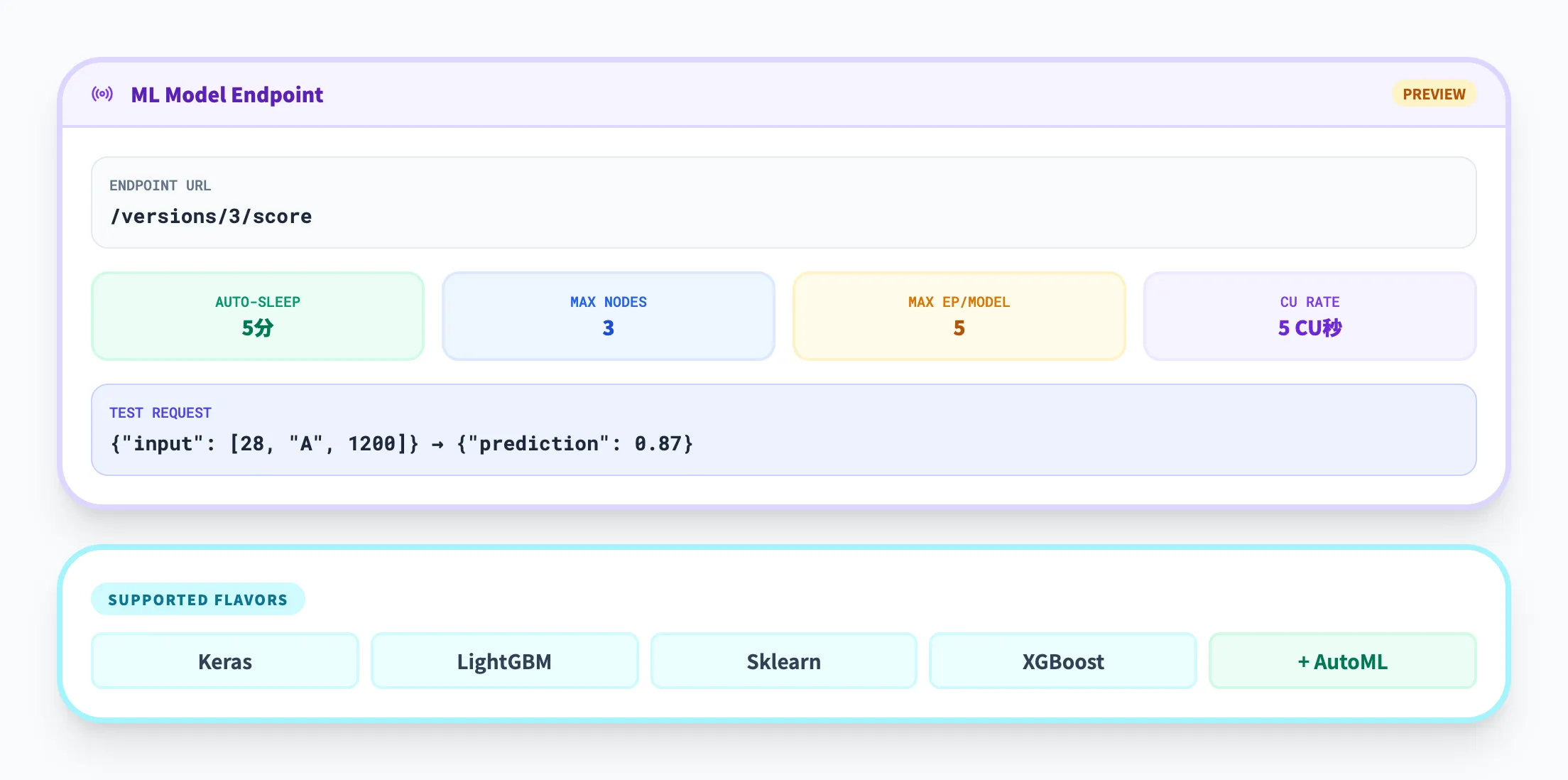
MLモデルエンドポイントは、2026年3月時点でPreviewとして提供されているリアルタイム推論機能です。
登録したモデルの各バージョンに対して、REST APIでアクセス可能なエンドポイントが自動的に生成されます。
主な特徴を以下の表にまとめます。
| 項目 | 内容 |
|---|---|
| デプロイ方式 | フルマネージド(インフラ設定不要) |
| APIアクセス | 各バージョンに専用URL(/versions/{n}/score) |
| オートスリープ | トラフィックなし5分でスケールゼロ(設定でオン/オフ可) |
| スケーリング | 最大3ノードまで自動スケール |
| 同時エンドポイント数 | 1モデルにつき最大5バージョン |
| テスト | UI上からサンプルリクエストを直接送信可能 |
対応するモデルフレーバーはKeras・LightGBM・Sklearn・XGBoostで、2026年1月からはAutoMLで学習したモデルにも対応しています。
テンソルベースのスキーマやスキーマ未定義のモデルには対応していません。
2026年2月のアップデートでは、エンドポイントのモニタリング機能が追加され、リクエスト数・エラー率・レイテンシの可視化やバージョン間のメトリクス比較が可能になっています。
バッチとリアルタイムの使い分け

以下の基準で選択するのが実務的です。
| 観点 | バッチスコアリング | リアルタイムスコアリング |
|---|---|---|
| 適用タイミング | 定期的・大量データの一括処理 | 個別リクエストへの即時応答 |
| ユースケース | 日次の売上予測、週次のリスク評価 | Webアプリからの推論API、チャットボット |
| 対応モデル | 11フレーバー(幅広い) | 4フレーバー+AutoML(限定的) |
| スケーリング | Spark容量に依存 | 最大3ノード自動スケール |
| 課金 | Spark CU消費 | エンドポイント専用CU(後述) |
大量のデータに対して定期的にスコアリングを実行する場合はバッチ、アプリケーションやAPIから個別の推論リクエストに応答する場合はリアルタイムを選択します。

Fabric Data ScienceのAutoML機能
AutoML(自動機械学習)は、モデルの選択・ハイパーパラメータチューニング・特徴量エンジニアリングを自動化する機能です。
2026年3月時点ではPreviewとして提供されています。Fabric Data Scienceでは、コードファーストとローコードの2つのアプローチが用意されています。

コードファーストAutoML(FLAML)
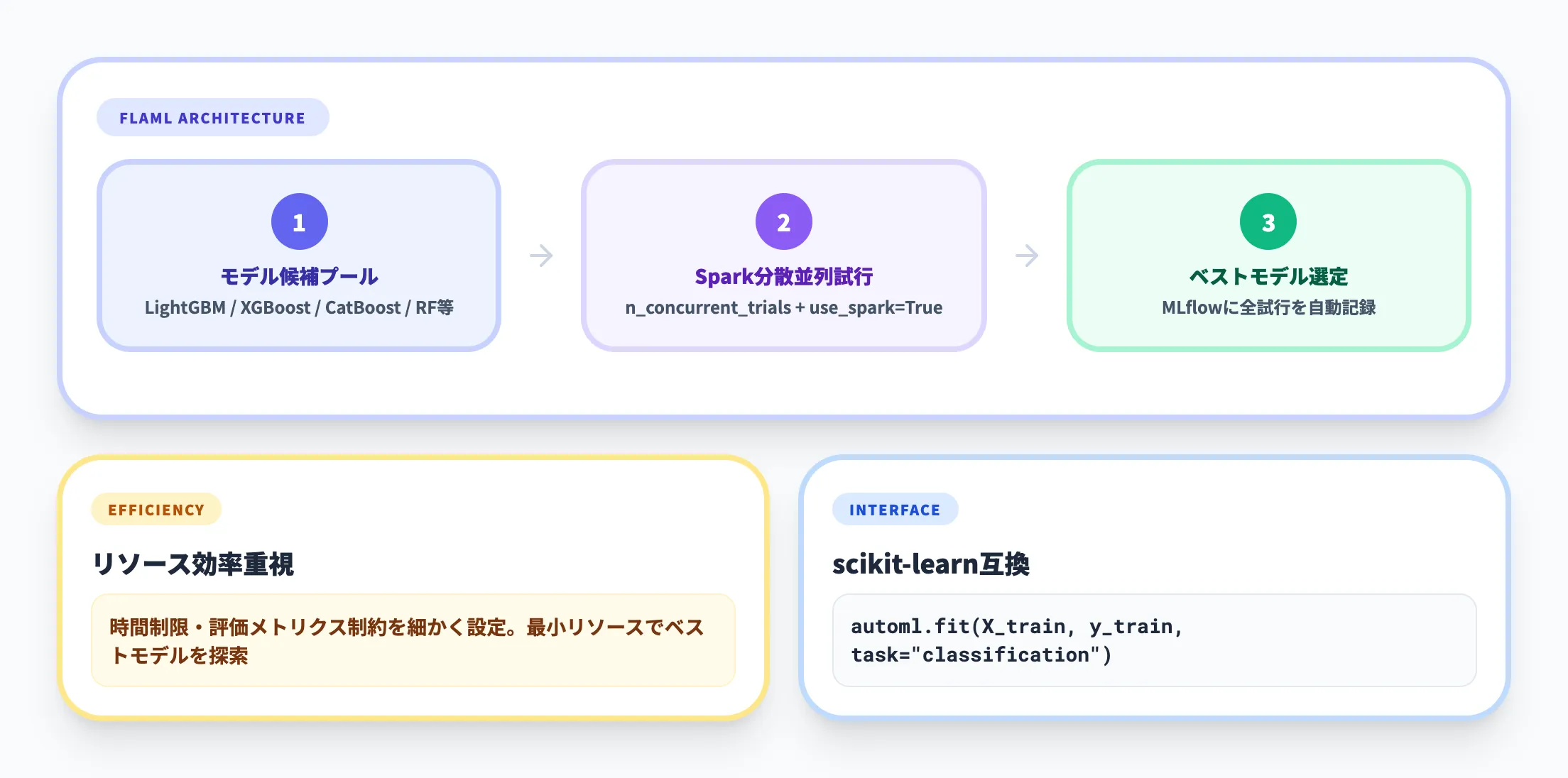
FLAML(Fast and Lightweight AutoML)は、リソース効率を重視した自動モデル選択ライブラリです。
scikit-learn互換のfit/predictインターフェースを持ち、Notebook上でPythonコードから呼び出します。
対応するタスクと主要なモデルを以下の表にまとめます。
| タスク | 主要モデル |
|---|---|
| 分類 | LightGBM, XGBoost, CatBoost, Random Forest, Logistic Regression, SVC, Extra Trees, PySpark GBT等 |
| 回帰 | LightGBM, XGBoost, CatBoost, Random Forest, Elastic Net, SGD, PySpark GLR等 |
| 時系列予測 | ARIMA, SARIMAX, Prophet, LightGBM, Temporal Fusion Transformer, Holt-Winters等 |
FLAMLの特筆すべき点は、Apache Sparkとの分散統合です。n_concurrent_trialsとuse_spark=Trueを指定することで、複数のハイパーパラメータ試行をSparkクラスタ上で並列実行できます。
また、MLflow統合により、すべての試行結果が自動的に実験として記録されます。
時間制限や評価メトリクスの制約を細かく設定できるため、「計算リソースを最小限に使いながら、指定時間内でベストなモデルを見つける」という実務的な運用に適しています。
ローコードAutoML(ウィザード)

ローコードAutoMLは、GUIウィザード形式で最小限のコードでモデルを構築する方式です。回帰・二値分類・多クラス分類・時系列予測の4タスクに対応しており、学習データの選択→タスクの指定→実行の3ステップで自動的にモデルの選択と学習が完了します。
auto_featurize機能により、データ型の推定・欠損値の補完・カテゴリ変数のエンコーディングなどの特徴量エンジニアリングも自動で実行されます。
データサイエンスの専門知識がないビジネスアナリストでも、基本的なML予測モデルを構築できるように設計されています。
AutoMLの注意点

AutoMLはモデル構築を自動化しますが、以下の点に注意が必要です。
- Preview機能であり、本番環境での利用は慎重に検討する
- 深層学習モデル(大規模なニューラルネットワーク)のチューニングには対応していない
- 自動選択されたモデルの解釈性と性能のトレードオフは、ドメイン知識に基づいて判断する必要がある
Azure Machine LearningやDatabricksとの違い
Fabric Data Scienceの導入を検討する際に比較対象となるのが、Azure Machine LearningとDatabricksです。このセクションでは、3つのプラットフォームの設計思想の違いと使い分けの基準を解説します。

Azure Machine Learningとの比較

Azure Machine Learning(Azure ML)は、MicrosoftのエンタープライズMLプラットフォームです。
Fabric Data Scienceとは位置づけが異なり、本格的なMLOps(モデルの本番運用と継続的な改善サイクル)に特化しています。
以下の表に主要な違いをまとめます。
| 観点 | Fabric Data Science | Azure Machine Learning |
|---|---|---|
| 設計思想 | OneLake統合型・BI密結合 | エンタープライズMLOps特化 |
| コンピュート | Fabricキャパシティ(共有CU) | 専用コンピュートインスタンス/クラスタ |
| 実験管理 | MLflow(組み込み) | MLflow + Azure ML独自機能 |
| モデルデプロイ | バッチ(PREDICT)+ エンドポイント(Preview) | マネージドエンドポイント(GA)+ Kubernetes |
| パイプライン | Data Factoryパイプライン | Azure ML Pipelines(Designer / SDK v2) |
| 責任あるAI | SynapseML(SHAP/LIME) | 責任あるAIダッシュボード(包括的) |
| BI連携 | Power BI Direct Lake(ネイティブ) | Power BI(接続設定が必要) |
| GPU | 非対応 | GPU対応(NC/ND/NVシリーズ) |
| 課金 | Fabric CU(他ワークロードと共有) | コンピュート単位の従量課金 |
Fabric Data Scienceが適しているのは、OneLake上のデータに対してML分析を行い、結果をPower BIで可視化するパターンです。
データの前処理から可視化までがFabric内で完結するため、基盤の構築コストが低く済みます。
一方、Azure MLが適しているのは、本番環境でのモデル管理と継続的デプロイ(CI/CD for ML)が必要な場合や、GPUを使った深層学習、厳格な監査・ガバナンス要件がある場合です。
Databricksとの比較

DatabricksはApache Sparkの開発元が設立した企業のプラットフォームで、MLflowの開発元でもあります。機械学習においてはFeature Store・Model Servingなど成熟した機能を持ちます。
| 観点 | Fabric Data Science | Databricks |
|---|---|---|
| 設計思想 | SaaS型・OneLake統合 | クラスタ/サーバーレスの柔軟な選択 |
| MLflow | 組み込み(Fabric版) | 開発元(最新機能が先行) |
| Feature Store | なし(手動管理) | Unity Catalog Feature Store |
| Model Serving | エンドポイント(Preview) | Model Serving(GA、GPU対応) |
| マルチクラウド | Azure専用 | Azure / AWS / GCP |
| AutoML | FLAML + ローコード(Preview) | AutoML(GA、Feature Store連携) |
| LLM/GenAI | SynapseML + Azure OpenAI | MosaicAI + Foundation Model APIs |
| BI連携 | Power BI Direct Lake | SQL Warehouse + BI Connector |
以下の基準で選択するのが実務的です。
- Fabric Data Scienceが適している場合
Microsoft 365・Azure・Power BIへの既存投資がある。OneLake上のデータに対するML分析が主要ユースケース。MLの本番運用よりも分析・可視化の速度を重視する。
- Databricksが適している場合
データサイエンスチームが社内に確立されている。Feature Store・Model Servingの成熟した機能が必要。マルチクラウド対応やGPUベースの大規模モデル学習が要件。
- 使い分けの視点
カスタムモデルの本番運用要件が明確でない段階であれば、まずFabricで始め、MLOpsの要件が具体化した段階でAzure MLやDatabricksへのスケールアウトを検討するのが現実的です。
【関連記事】
Microsoft Fabric導入事例6選!国内企業の成果と導入パターンを解説
【Microsoft Fabric】Real-Time Intelligenceとは?機能や料金体系を徹底解説
Fabric Data Scienceの料金体系
Fabric Data Scienceの料金は、Fabric全体のCapacity Unit(CU)ベースの課金モデルに基づいています。
このセクションでは、Notebook実行時のSpark課金とリアルタイムエンドポイントの課金を解説します。

Notebook/Spark実行の課金

Data ScienceのNotebook実行やLakehouse操作は、Data Engineeringワークロードと同じSparkベースの課金モデルに従います。
1 CU = 2 Spark vCoreの換算で、Fabricキャパシティからリソースが割り当てられます。
課金モデルは3つから選択できます。
| 課金モデル | 特徴 | 適用場面 |
|---|---|---|
| Starterプール | キャパシティから消費、5〜10秒で起動 | 探索的分析、EDA、モデルのプロトタイピング |
| Customプール | キャパシティから消費、ノード構成カスタマイズ | 大規模な学習ジョブ、SynapseMLパイプライン |
| Autoscale Billing | Spark実行コストをキャパシティ外に分離できる従量課金 | バースト的な学習ジョブ |
いずれのモデルでもSparkセッションがアクティブな間のみ課金が発生します。デフォルトのセッション有効期限は20分で、2分間操作がない場合にプールが自動解放されます。
リアルタイムエンドポイントの課金

MLモデルエンドポイント(Preview)は、Spark課金とは別にエンドポイント専用のCU消費が発生します。
以下の表に、シナリオ別のCUレートをまとめます。
| シナリオ | CUレート | 1時間あたりCU消費 |
|---|---|---|
| 非アクティブ(デプロイなし) | 0 | 0 CU Hour |
| アクティブだがアイドル(オートスリープ) | 5 CU秒 | 0.42 CU Hours |
| 1エンドポイント・低トラフィック(1ノード) | 5 CU秒 | 5 CU Hours |
| 1エンドポイント・高トラフィック(最大3ノード) | 15 CU秒 | 15 CU Hours |
| 5エンドポイント・全て高トラフィック | 75 CU秒 | 75 CU Hours |
基本レートは1モデルエンドポイント(バージョン)あたり1秒1ノードにつき5 CU秒です。
トラフィックに応じて最大3ノードまで自動スケールし、トラフィックがない場合はオートスリープ(デフォルトで5分)でスケールゼロに縮退します。
エンドポイントの課金はFabric Capacity Metricsアプリでは「バックグラウンド操作」として分類され、請求項目名は「ML Model Endpoint Capacity Usage CU」です。
コスト最適化のポイント

Fabric Data Scienceのコストを最適化するには、以下のアプローチが有効です。
- 探索フェーズはStarterプールで高速に回し、本格的な学習ジョブのみCustomプールに切り替える
- リアルタイムエンドポイントはオートスリープを有効にし、不要なバージョンのエンドポイントは無効化する
- 安定したワークロードにはFabricキャパシティの1年/3年予約(最大約41%割引)を活用する
- Spark課金の詳細はAzure Pricing CalculatorまたはFabric価格ページで確認する

Data Scienceの予測モデルをAIエージェントの業務判断に組み込むなら
MLflowで管理するモデルの予測結果をレポートで確認するだけでなく、その結果に基づいてAIエージェントが業務アクションを自動実行する仕組みが求められています。
AI Agent Hubは、Fabric Data Scienceの予測出力をAIエージェントの業務判断に直結させるエンタープライズAI基盤です。
- MLモデルの予測→Agentの業務アクションを自動連鎖
在庫予測→発注提案、需要予測→価格調整のように、モデルの出力をAIエージェントが受け取り、Teamsでの承認リクエストや基幹システムへの反映まで自動実行します。
- Agent実行ログでモデルのビジネスインパクトを定量評価
AIエージェントの実行履歴がFabricに蓄積され、予測精度と業務成果の相関を可視化。モデル改善の優先順位を投資対効果で判断できます。
- 使い慣れたMicrosoft環境をそのまま活用
Teamsなど既存のMicrosoftツールの延長でAIエージェントが動作。新しいツールの学習コストはゼロです。
- データは100%自社テナント内に保持
AIの学習対象から完全除外。Azure Managed Applicationsとして自社テナント内で動作が完了する設計です。
AI総合研究所の専任チームが、設計から運用まで伴走支援します。まずは無料の資料で、自社の業務にどう活用できるかご確認ください。
データサイエンスの知見をAI業務自動化に活かす

分析基盤の延長線上にAgent基盤を構築
Fabric Data Scienceで得た分析知見を業務に活かすには、AIエージェントが判断から実行まで担う仕組みが必要です。AI Agent Hubは自社Azureテナント内で、Fabricの分析基盤と連動したAI業務自動化を構築できます。
まとめ
本記事では、Microsoft FabricのData Scienceワークロードについて、基本概念から主要ツール、ML実験とMLflow統合、モデル管理、スコアリング、AutoML、他プラットフォームとの比較、料金体系までを解説しました。
Fabric Data Scienceの価値は、大きく3点に集約されます。
-
OneLake基盤でのMLワークフロー統合
データの探索から前処理・学習・スコアリング・Power BIでの可視化まで、データを移動させることなくひとつのプラットフォーム内で完結できます。ツール間の接続設定やデータパイプラインの構築コストが大幅に削減されます。
-
MLflowの標準組み込みによる実験管理の簡素化
追加のインフラ構築や設定なしで、実験のトラッキング・Runの比較・モデルのバージョン管理が利用可能です。セル単位のRunトラッキングや1クリックでのモデル登録など、データサイエンティストの日常業務を効率化する機能が充実しています。
-
Power BIとの密結合によるインサイトの迅速な提供
Semantic LinkとDirect Lakeモードにより、学習済みモデルの予測結果をデータコピーを最小限に抑えつつBIレポートに反映できます。データサイエンスの成果をビジネス意思決定に直結させるスピードが、他のMLプラットフォームにはない固有の強みです。
Data Scienceワークロードの利用を検討している場合は、まずFabricの60日間無料トライアルでStarterプール上のNotebookを試し、OneLake上のデータに対するML実験のワークフローを体験するのがリスクの低い第一歩です。







