この記事のポイント
 ストレージとコンピュートを分離した3層アーキテクチャで、データ量と処理能力を独立にスケールできるSQL分析特化のクラウド基盤
ストレージとコンピュートを分離した3層アーキテクチャで、データ量と処理能力を独立にスケールできるSQL分析特化のクラウド基盤- 2025年11月にCortex AISQL・Snowflake Intelligence・Cortex AgentsがGA化し、SQLからAI関数を直接呼び出してエージェントから自然言語でデータを叩ける基盤へ進化中
- Platform Credits(Standard $2/Enterprise $3/Business Critical $4)に加え、2026年4月からAI機能はEdition非依存のAI Credits(Global $2.00/Regional $2.20)で別建て課金
- Databricks(ML中心)・Microsoft Fabric(MS統合)・BigQuery(GCP統合)と比較し、マルチクラウドでSQL分析+AI連携を最重視するならSnowflakeが第一候補
- 日清食品でシミュレーション時間70%短縮、NTTドコモで社内ユーザー数10倍など、データ基盤刷新による定量効果が日本企業で実証されている

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Snowflakeは、ストレージとコンピュートを分離した3層アーキテクチャで、SQL分析からエージェント型AIまでを1つの基盤で支えるクラウドデータプラットフォームです。
2025〜2026年にかけてAI機能の一般提供化と専用課金体系の導入が進み、データ基盤を取り巻く環境は大きく変わりつつあります。
本記事では、仕組み・主要機能・料金体系・他データ基盤との比較・日本企業の導入事例・運用上の判断軸を、2026年6月時点の最新情報で体系的に解説します。
目次
Snowflakeとは——SQL分析からエージェントAIまでを1つの基盤で扱う
Snowflakeのアーキテクチャ——ストレージ・コンピュート・クラウドサービスの3層構造
Cortex AIとSnowflake Intelligence
Snowflakeとは——SQL分析からエージェントAIまでを1つの基盤で扱う
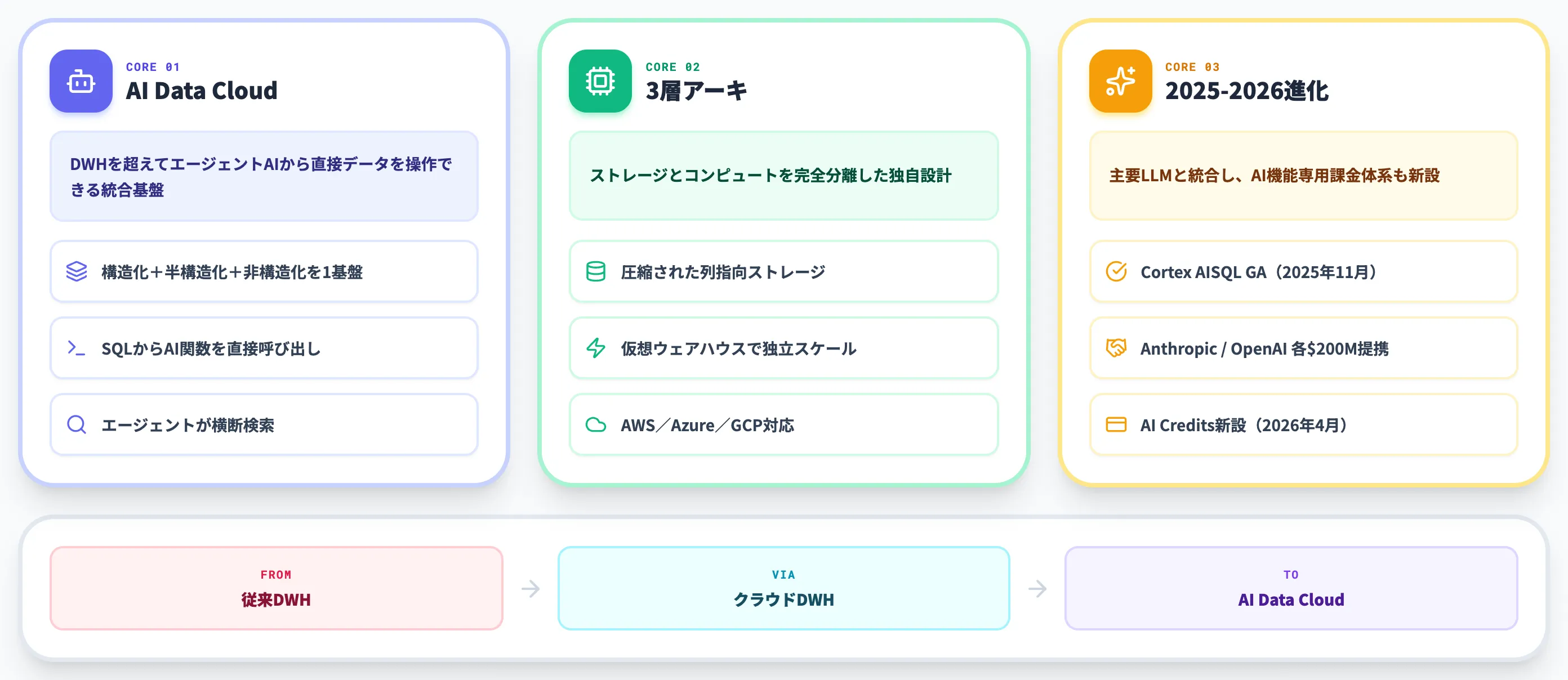
Snowflake(スノーフレーク)は、AWS・Microsoft Azure・Google Cloudの3大クラウド上で動くフルマネージド型のデータプラットフォームです。
2012年にカリフォルニアで創業され、2020年に米ソフトウェア企業として史上最大規模のIPOを果たした後、現在は「AI Data Cloud」を旗印に、SQL分析・データシェアリング・AIエージェント機能を1つの基盤で提供しています。
データの保存と処理を完全に切り離した独自アーキテクチャと、組織や企業をまたいでデータを共有できる仕組みが特徴で、データウェアハウス(DWH)の延長線上にありながら、その用途は分析・アプリケーション開発・エージェントAI構築まで広がっています。

Snowflakeの定義と位置づけ
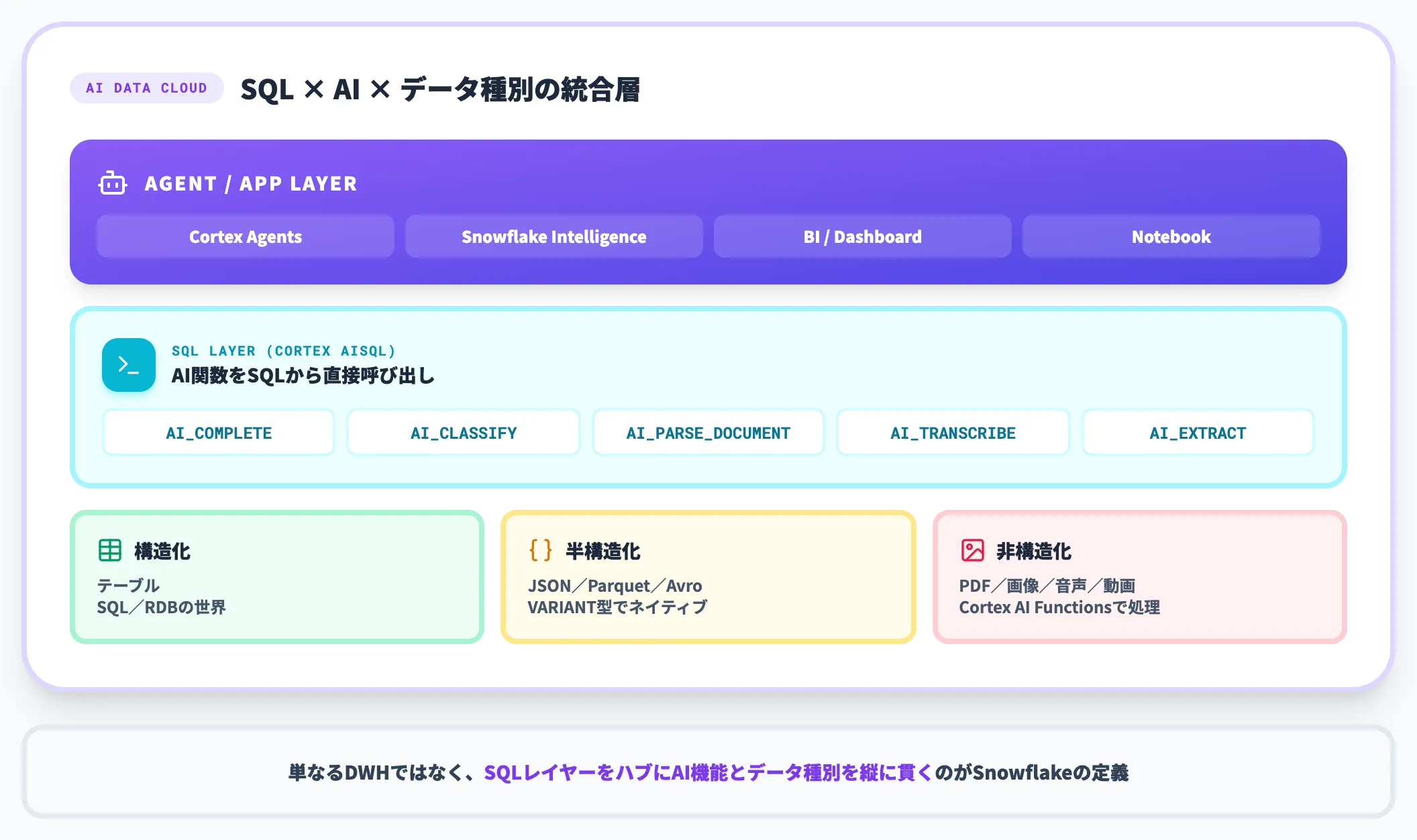
Snowflakeが自社プラットフォームを「AI Data Cloud」と呼んでいるのは、従来のDWHの守備範囲を超えて、エージェントAIから直接データを操作できる基盤に進化したことを示すためです。
具体的には、構造化データ(テーブル)・半構造化データ(JSON・Parquet・Avro)・非構造化データ(PDF・画像・音声・動画)を1つのSQLレイヤーで扱える設計になっています。
2025年11月にGA化されたCortex AISQLでは、AI_COMPLETE・AI_CLASSIFY・AI_PARSE_DOCUMENT・AI_TRANSCRIBEといったSQL関数の中からClaudeやGPTなどの大規模言語モデルを直接呼び出せるようになっており、データ分析者がPythonコードを書かずにAI処理を組み込めます。
つまり「AI Data Cloud」は単なるブランド標語ではなく、「SQLからAIを直接叩ける」「エージェントから構造化・非構造化データを統合的に扱える」という機能セットの呼び名です。
従来のDWH/データレイクとの違い

Snowflakeを「クラウド版のOracle」「クラウド版のTeradata」と捉えてしまうと、本質を見誤ります。従来のDWHとSnowflakeでは、設計思想が3つの観点で異なります。
-
コストモデル
従来DWHはハードウェア+ライセンスを先行投資する固定費型。Snowflakeは使用したクレジット数とストレージ容量に応じた従量課金型で、クエリを実行していない時間は仮想ウェアハウスを自動停止できる
-
スケーラビリティ
従来DWHはストレージとコンピュートが同じハードウェア上にあるため片方を増強すると他方も巻き込まれる。Snowflakeは3層を分離しているため、データ量はそのままで処理能力だけを倍にする、あるいはその逆も瞬時にできる
-
データ種別の扱い
従来DWHはリレーショナルなテーブルデータが主役で、JSON等の半構造化データやファイル類はデータレイクに逃がす設計が一般的。
Snowflakeは半構造化データをVARIANT型でネイティブに扱い、Apache Iceberg対応でデータレイク上のオブジェクトも同じSQLで参照できる
「DWH+データレイクを別々に持って、間をETLでつなぐ」という従来構成を、1つの基盤に統合したのがSnowflakeの基本的な立ち位置です。
Snowflakeが市場で選ばれている背景
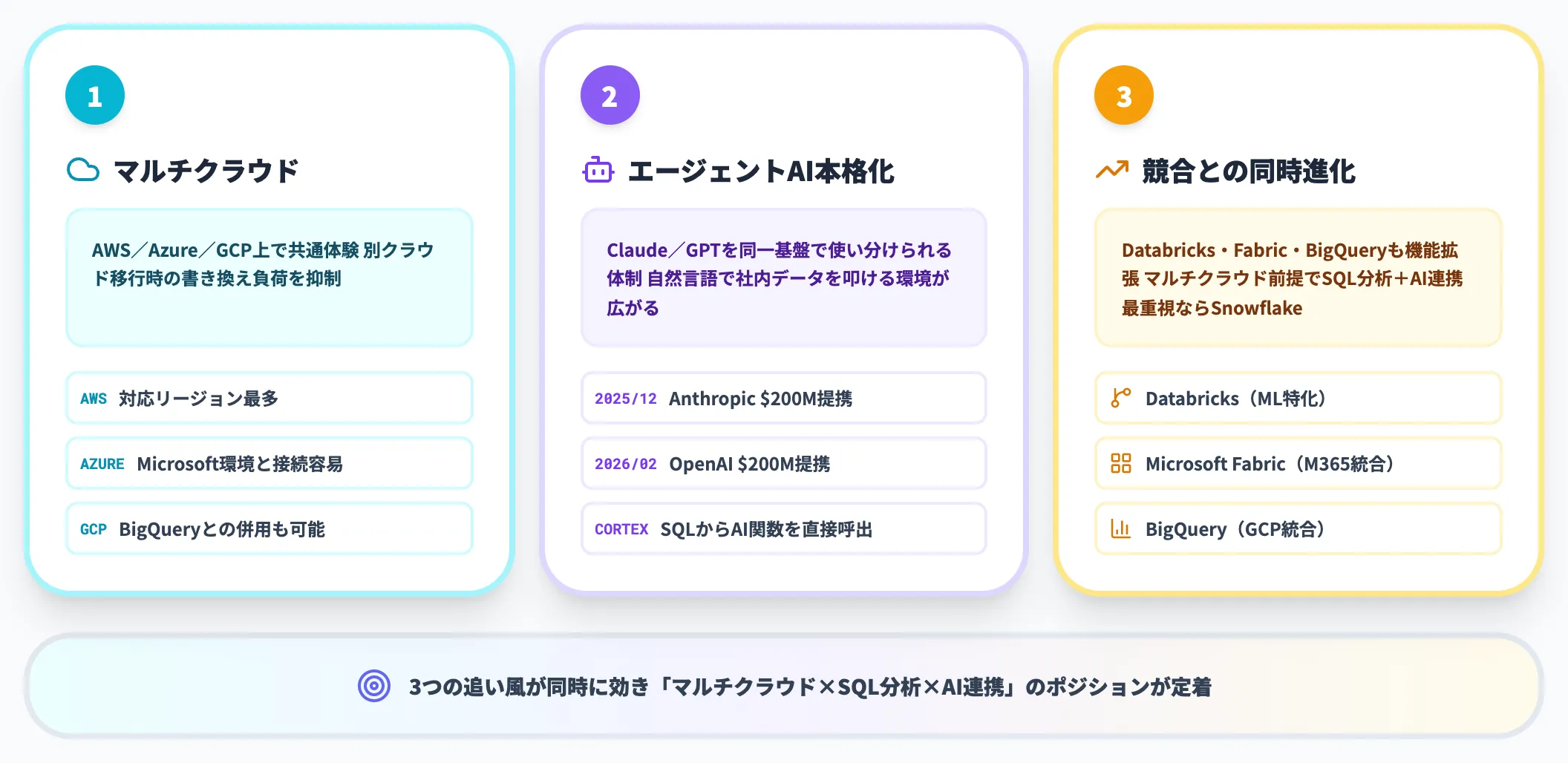
2026年時点でSnowflakeを採用する企業が増え続けているのは、以下の3つの追い風が同時に効いているからです。
- マルチクラウド対応
AWS・Azure・GCP上で共通した利用体験を提供しており、対応リージョン内では同じSQL資産を活かしやすい設計のため、後から別クラウドへ移行する場合の基盤書き換え負荷を抑えられる(ただし機能やリージョン提供範囲には差があり、特に新機能は公式リリースノートでの確認が前提)
- エージェント型AIの本格化
社内データに自然言語で問い合わせる用途が広がるなか、Snowflakeは2025年12月にAnthropicと$200Mのパートナーシップ、2026年2月にOpenAIとも$200Mのパートナーシップを締結し、Claude・GPTを同一基盤上で使い分けられる体制を整えた
- 競合の動き
Databricks・Microsoft Fabric・BigQueryも同領域で激しく機能拡張しており、「マルチクラウド前提でSQL分析+AI連携を最重視するなら、Snowflakeが妥当な選択肢」というポジションが市場で定着しつつある
3つの追い風が重なった結果、SnowflakeはAI時代のエンタープライズデータ基盤として、単なるDWHを超えた立ち位置を確立しつつあります。
Snowflakeのアーキテクチャ——ストレージ・コンピュート・クラウドサービスの3層構造
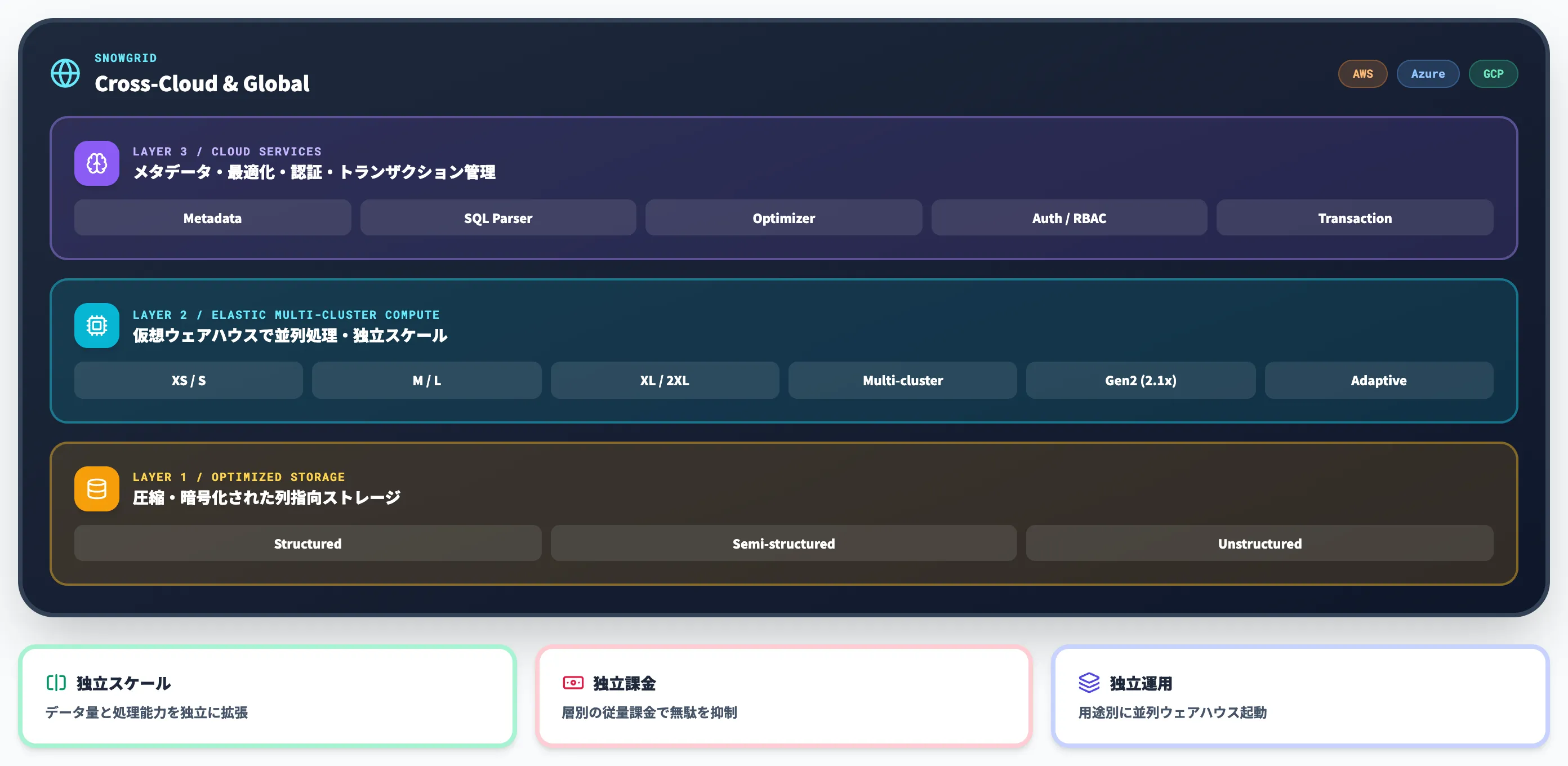
Snowflakeのアーキテクチャを理解する上で最も重要なのは、3層がそれぞれ独立にスケールし、独立に課金されるという設計です。
本セクションでは、各層がどんな役割を担い、なぜこの分離が運用上の優位性を生むのかを整理します。
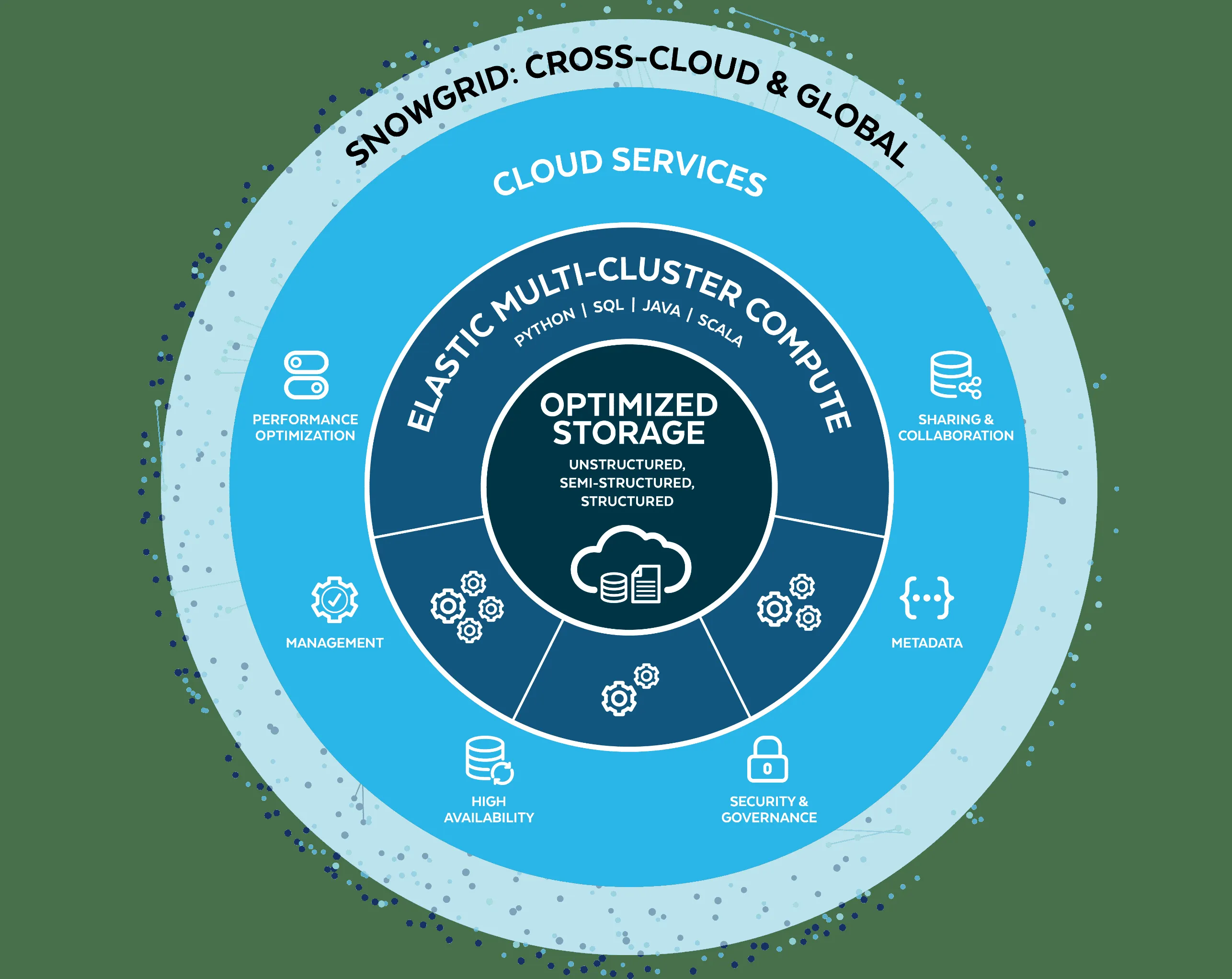
Snowflakeの3層アーキテクチャ全体像(出典:Snowflake公式 Data Cloud Architecture)
公式の図解では中心に「Optimized Storage」(Unstructured/Semi-structured/Structuredを統合)が置かれ、その外側に「Elastic Multi-Cluster Compute」、最も外側のリングに「Cloud Services」が並びます。
これら3層を取り囲む最外周の「Snowgrid: Cross-Cloud & Global」が、AWS/Azure/GCPをまたいだ一貫した利用体験の土台になっています。
ストレージ層——圧縮された列指向ストレージ
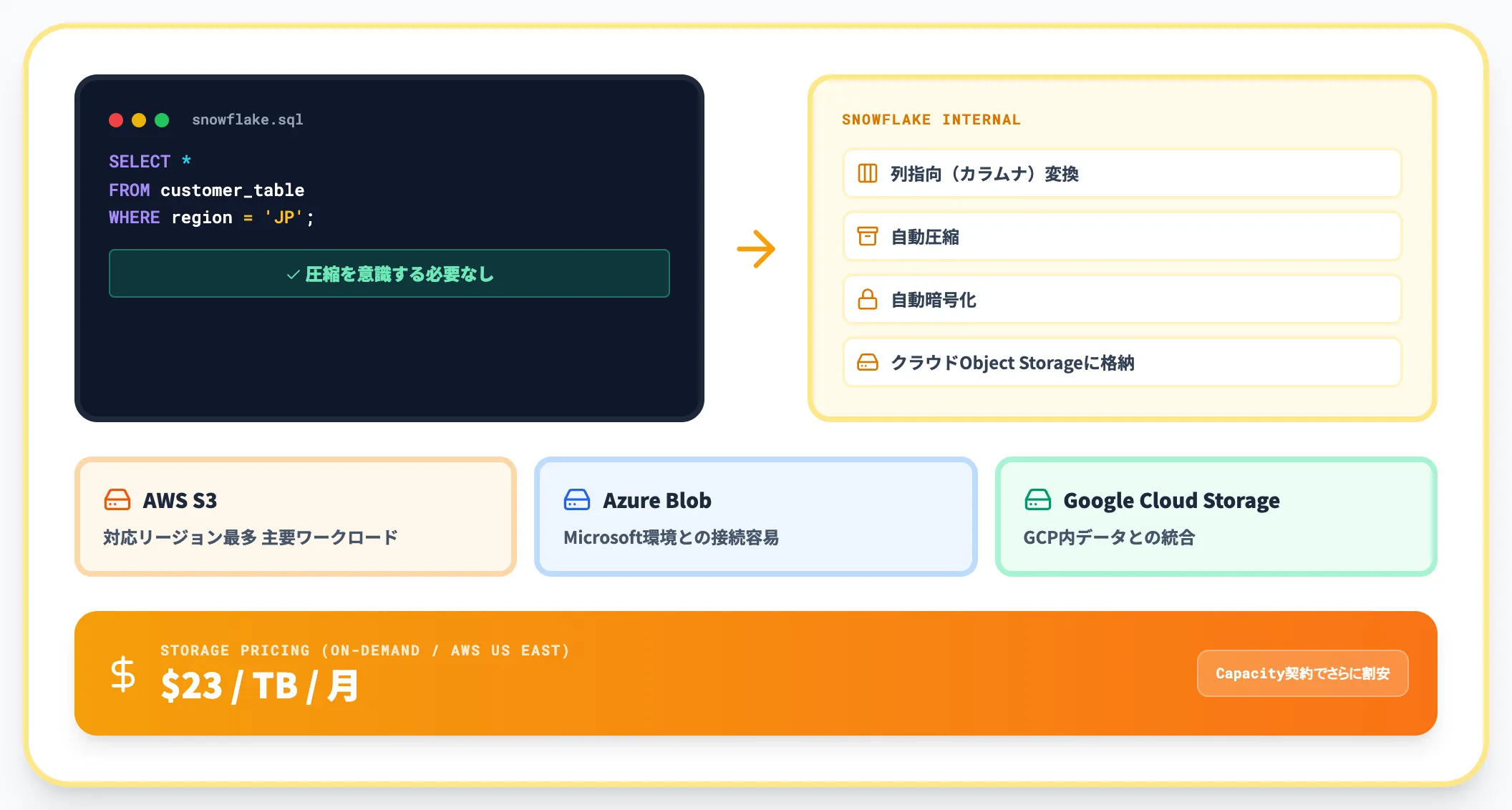
ストレージ層は、Snowflakeに投入されたすべてのデータを保管する基盤層です。データは内部で列指向(カラムナ)形式に変換され、自動的に圧縮・暗号化されて、AWS S3・Azure Blob Storage・Google Cloud Storageなどクラウドプロバイダーのオブジェクトストレージ上に保存されます。
ここで重要なのは、ユーザーはストレージのファイル形式や暗号化を意識しないという点です。SQLで「SELECT * FROM customer_table」と書けば、Snowflakeが裏側で圧縮データを解凍してクエリに応答します。
ストレージ料金は公式pricing上で**1TBあたり月額$23(On-Demand・AWS US East基準)**と明示されており、年間契約のCapacity Storageを選ぶとさらに割安になります。
コンピュート層と仮想ウェアハウス
コンピュート層は、クエリ・データロード・データ変換を実行する処理エンジン層です。ユーザーは「仮想ウェアハウス(Virtual Warehouse)」と呼ばれる計算リソースを必要に応じて起動し、用途別に複数のウェアハウスを並列で動かせます。

サイズはXS・S・M・L・XL・2XL・3XL・4XL・5XL・6XLの10段階で、1段階上げるごとにクレジット消費量が倍になります。たとえばService Consumption Table(2026年6月10日版)では、Standard WarehouseがXS=1/S=2/M=4/L=8/XL=16(クレジット/時)と定義されています。
2025年のSummitで発表されたStandard Warehouse Generation 2は、従来比で約2.1倍の分析高速化を実現したGA版の新世代ウェアハウスです。
AWSではXS=1.35/S=2.7/M=5.4とクレジット単価がやや上がる代わりに、同じワークロードを短時間で完了するためトータルコストが下がるケースが多くなります。
加えてSnowflake Adaptive Computeは、ユーザーが事前にサイズを指定しなくても、Snowflake側がクエリ特性を判定して最適な計算リソースを自動配分する仕組みです。
2026年6月16日にAWSの一部リージョンでGAとなっており、ウェアハウス管理の運用負荷を削るための機能として位置付けられています。
実務での使い方としては、「経営ダッシュボード用にM」「データサイエンス用にXL」「夜間バッチ用に3XL」のように用途別にウェアハウスを切り分け、それぞれを必要なときだけ起動するのが定石です。
クラウドサービス層——メタデータ管理・最適化・認証
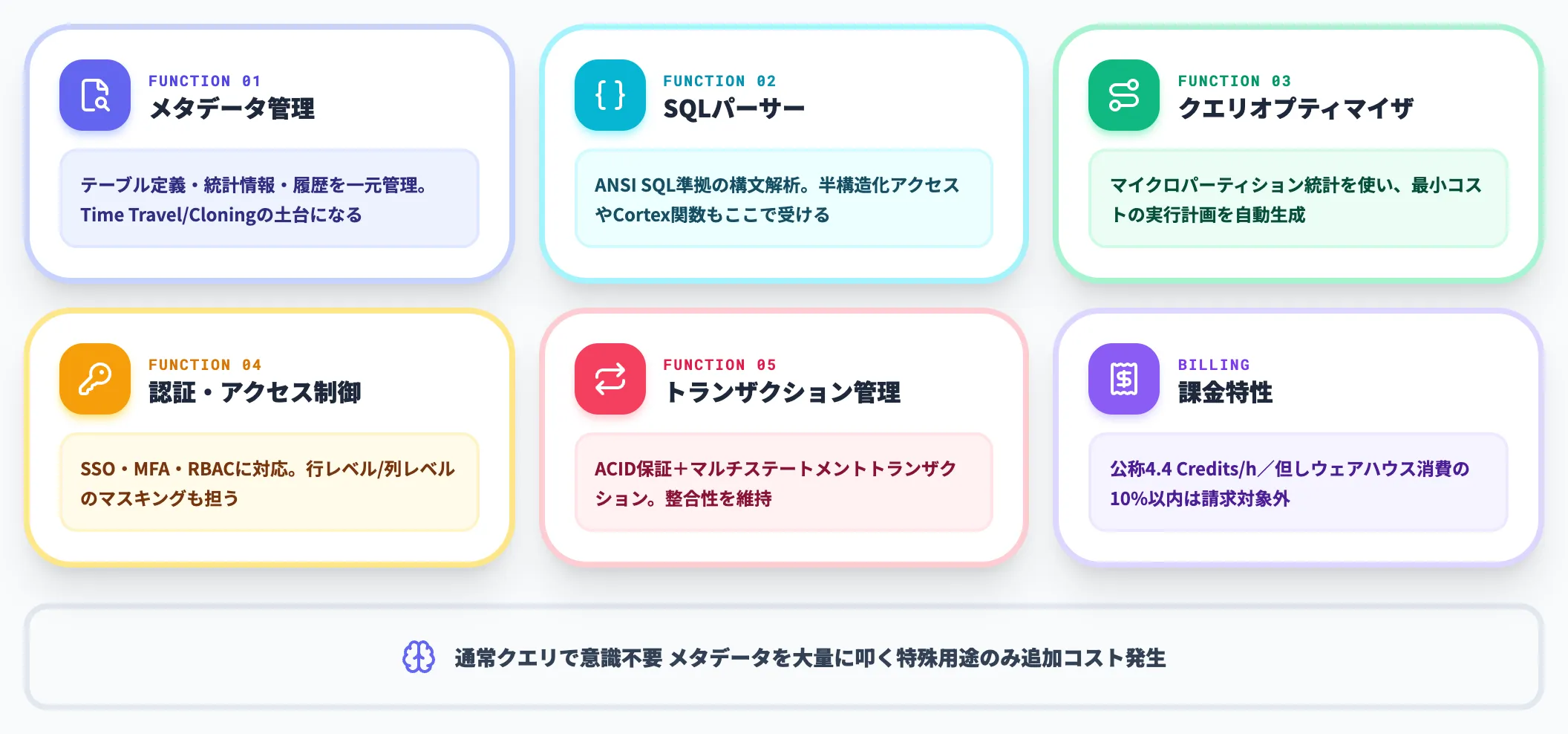
クラウドサービス層は、Snowflake全体を司る頭脳に相当する層です。ストレージ層・コンピュート層では実行されない、メタデータ管理・SQLパーサー・クエリオプティマイザ・認証・アクセス制御・トランザクション管理などを担います。
この層の動作は公式Service Consumption Tableに「4.4 Credits per hour of Cloud Services use」と定義されていますが、Virtual Warehouseのクレジット消費の10%以内であれば請求対象外になる「Cloud Services Adjustment」が設けられています。
つまり通常のクエリ実行ではクラウドサービス層の課金を意識する必要はなく、メタデータだけを大量に叩くような特殊な使い方をした場合のみ追加コストが発生する設計です。
マルチクラウド対応の構造

SnowflakeはAWS・Azure・GCPの3大クラウドに対応しており、契約時にどのクラウドのどのリージョンで動かすかを選びます。
ただしSnowflake PostgresやAdaptive Computeなど一部の新機能は提供クラウド・リージョンが限定されているため、本番採用前に対象クラウド/対象リージョンで該当機能が使えるかを公式リリースノートで確認しておく必要があります。
クロスリージョン・クロスクラウドのデータ複製機能(Replication)も用意されており、たとえば「東京リージョンのSnowflakeアカウントから、米国東部リージョンのSnowflakeアカウントへ夜間にデータを複製する」といった構成が可能です。これは災害復旧(DR)や、グローバルでデータ統合分析を行いたい多国籍企業のニーズを満たすために設計されています。
実務でマルチクラウド構成を組む際の判断軸は、「社内の既存クラウド契約・ネットワーク要件・コンプライアンス要件・利用したい機能の提供リージョン」の4つです。
データの所在地を決める基準は、Snowflake自体の対応範囲よりも、これら周辺要件側で決まります。
Snowflakeの主要機能
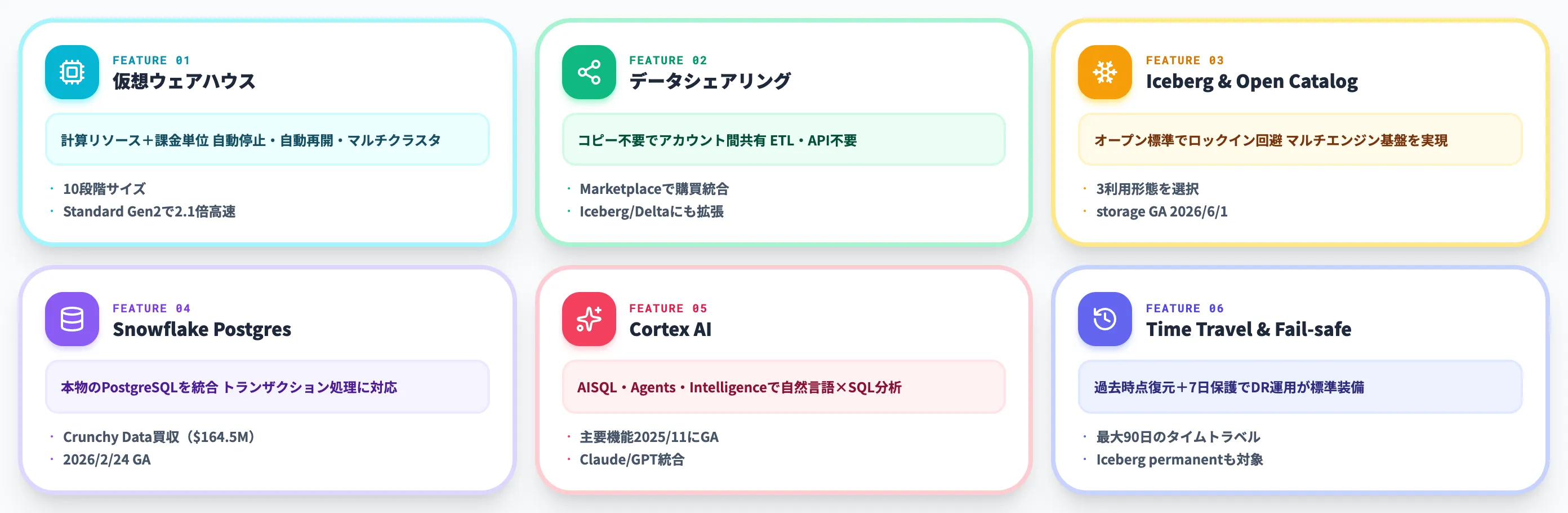
Snowflakeは2025年から2026年にかけて、AI Data Cloud戦略のもとで機能拡張を急加速しています。
本セクションでは、SQL分析の土台になる従来機能から、2026年6月時点で公式リリースされた最新機能までを6カテゴリで整理します。
仮想ウェアハウスと柔軟なスケーラビリティ
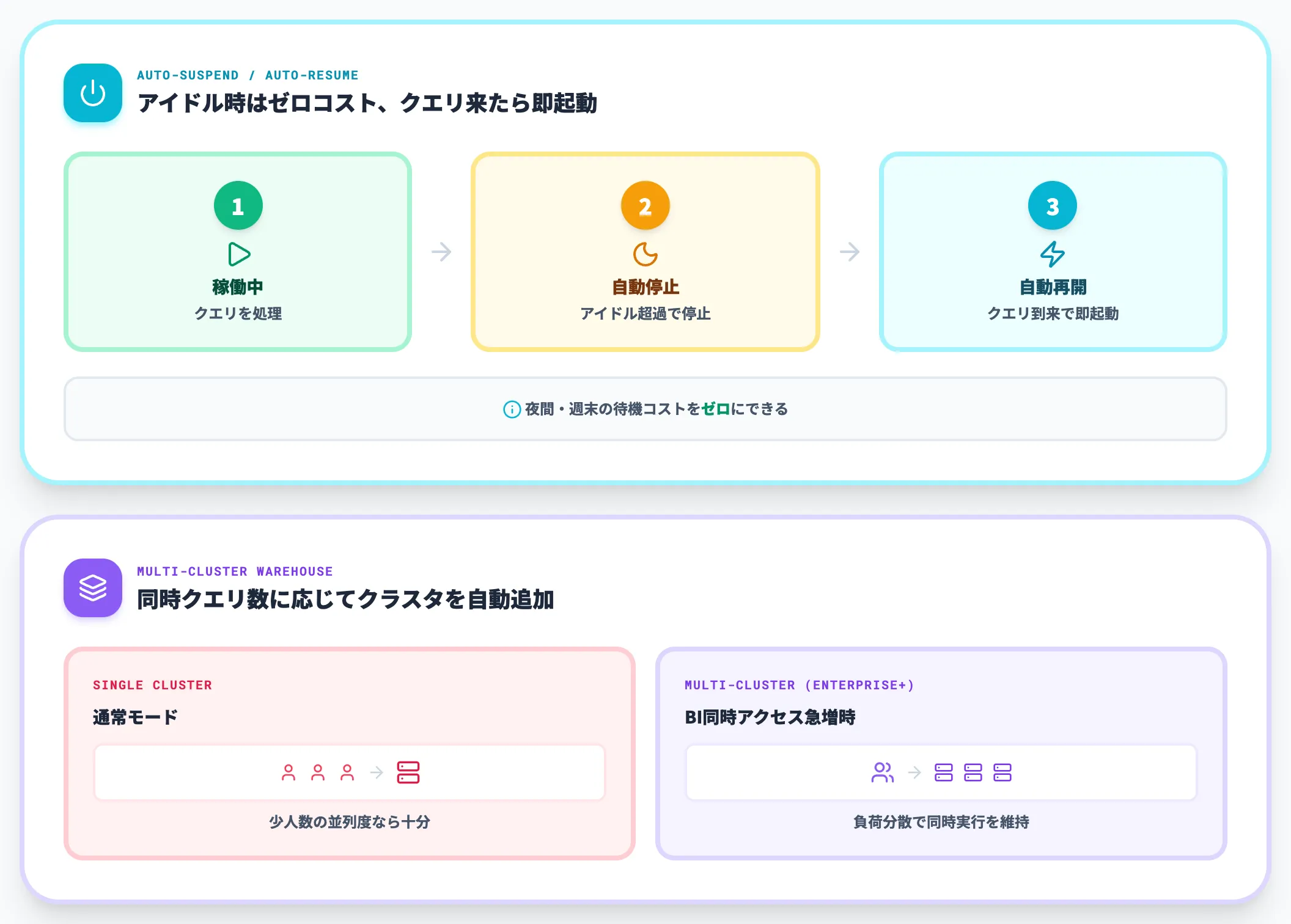
仮想ウェアハウスは、Snowflakeの計算リソースの単位であり、課金の単位でもあります。サイズ変更は数秒で完了し、起動・停止もユーザーがコマンド1つで実行できます。
実装面で便利なのは「自動停止」と「自動再開」の組み合わせです。アイドル時間が設定値を超えると自動的に停止し、次のクエリが来ると自動的に再起動する設定にしておけば、夜間や週末の待機コストをゼロにできます。
またマルチクラスタウェアハウス(Enterprise Edition以上)を使えば、同じウェアハウスに対する同時クエリ数が増えたときに、Snowflakeが自動的にクラスタを追加して負荷分散します。BIツールから多人数で同時アクセスする業務ダッシュボード基盤を作る場合に有効です。
データシェアリングとMarketplace
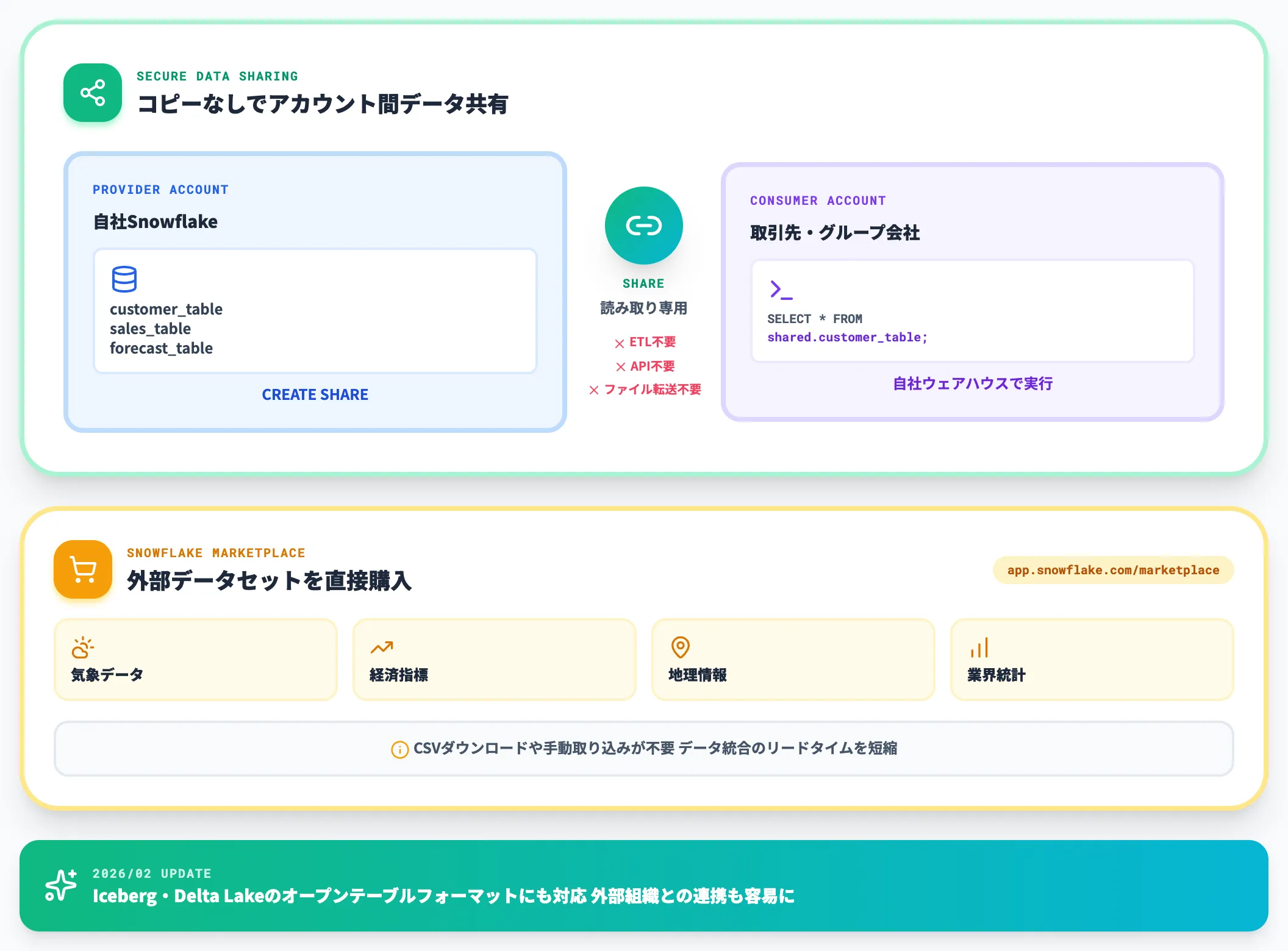
Snowflakeの設計上の差別化要素として最も大きいのが、データシェアリング機能です。
これは、自社のSnowflakeアカウントから別のSnowflakeアカウントに対して、データをコピーすることなくクエリ可能な形で共有する機能で、ETL・ファイル転送・APIアクセスのいずれも経由せずに済みます。共有された側は読み取り専用で対象テーブルにアクセスし、自社の仮想ウェアハウスで処理を実行する形になります。
Snowflake Marketplaceでは、世界各国の企業が公開しているデータセット(経済指標・気象データ・地理情報・業界統計など)を、自社アカウントから直接購入・利用できます。データ統合のために自社でCSVをダウンロードして取り込む手間が不要になるため、データ統合のリードタイムが短縮されます。
2025年10月に発表されその後2026年2月に詳細更新が入ったOpen Table Format対応のData Sharingでは、データシェアリングの対象がApache IcebergやDelta Lakeなどのオープンテーブルフォーマットにも拡張され、Snowflakeアカウントを持たない外部組織との連携もしやすくなっています。
Iceberg対応とOpen Catalog

2025年から2026年にかけて、Snowflakeが最も力を入れている領域の1つがオープン化です。データを特定ベンダーにロックインさせない設計をどこまで深められるかが、企業の長期投資判断を左右しています。
その中心になるのが、Apache Icebergテーブル対応とSnowflake Open Catalog(Apache Polarisのマネージドサービス)です。
Icebergテーブルには3つの利用形態があります。
-
Snowflake-managed
Snowflakeがカタログとライフサイクル管理(コンパクション等)を担う形態。
Snowflake storage for Iceberg(2026年6月1日にcommercial AWS/AzureでGA)を使うpermanent tableはFail-safeによる復旧にも対応し、運用負荷が最も低い(顧客管理の外部ボリューム型ではFail-safeは対象外)
-
External catalog managed
AWS Glue・Databricks Unity Catalogなど外部カタログを使う形態。
Snowflakeからは読み取り中心で、外部基盤側で管理を続けたい場合に選ぶ
-
Catalog-linked databases
リモートのIceberg RESTカタログに自動接続し、名前空間やテーブルの追加を自動同期する形態。
マルチエンジン基盤でリアルタイムに整合を取りたい場合に有効
2026年6月5日に追加されたDEFAULT_METADATA_WRITE_FORMATパラメータでは、CREATE TABLE文にICEBERGキーワードを書かなくてもIcebergテーブルとして作成できるようになっており、Iceberg化のハードルが大きく下がりました。
Snowflake Open Catalogは現時点(2026年6月)でGAかつ無料提供されており、課金開始は2026年上半期予定と公式ドキュメントに明記されています。Iceberg対応を本格的に進めるなら、課金が始まる前にPoC環境を整えておくのが定石です。
Snowflake Postgresの統合

2025年6月にSnowflakeは、エンタープライズ向けPostgreSQLサービスを提供するCrunchy Dataの買収を発表し、その技術を基盤に「Snowflake Postgres」を立ち上げました。
買収額は公式ブログでは非公表ですが、Snowflakeの10-Q(2025年7月期)では**$164.5 million in cash**と開示されています。
これは、Snowflakeの中で本物のPostgreSQLデータベースを動かせるようにする取り組みで、AIエージェントや業務アプリケーションがトランザクション処理を必要とする場面で、Snowflakeのストレージ・セキュリティ・ガバナンスの恩恵を受けながらPostgreSQLの互換性を活かせる構造になっています。
Snowflake Postgresは2026年2月24日にGAとなり、現時点では選択されたAWS/Azureリージョンで提供されています。
Databricks側も同じく2025年5月にNeonを買収してPostgres基盤を取り込んでおり、データクラウド × PostgreSQLというカテゴリ自体が業界の主戦場になっている状況です。
Cortex AIとSnowflake Intelligence

Snowflake上でAIを使うための機能群は、Cortex AIファミリーとして整理されています。2025年11月時点で、主要機能のほとんどがGA化されました。
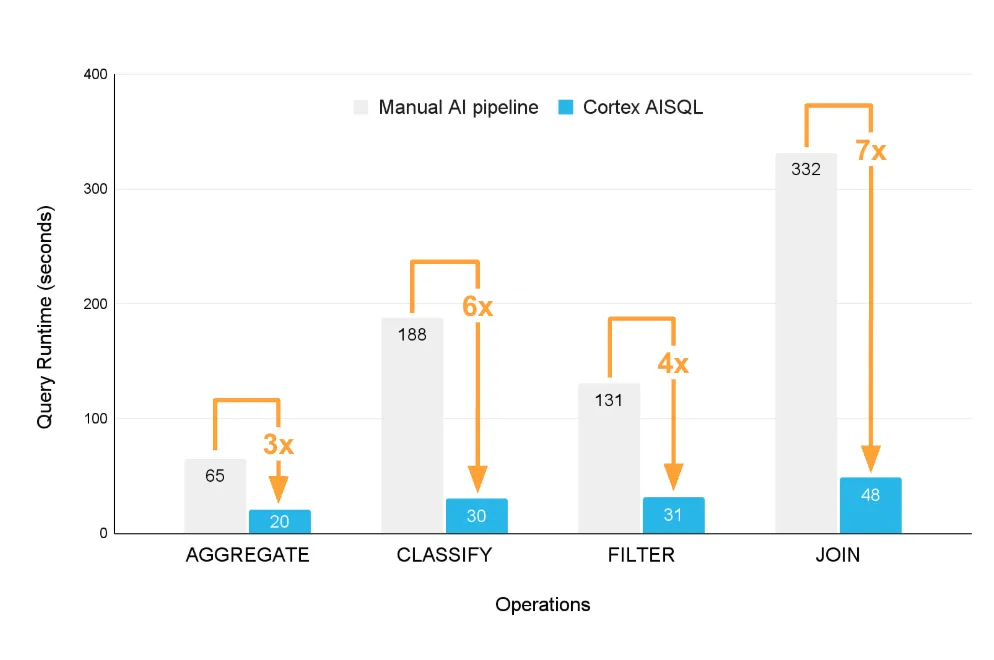
Cortex AISQLとManual AI pipelineの実行時間比較(出典:Snowflake Blog)
Snowflake自身のベンチマークでは、AGGREGATE処理で3倍、CLASSIFYで6倍、FILTERで4倍、JOINで7倍と、いずれの操作でも従来の手組みAIパイプラインに対して高速化が確認されています。SQL内からAI関数を直接呼び出せる利点は単に「コードがシンプルになる」だけでなく、実行効率にも直結します。
-
Cortex AISQL(GA)
SQL内からAI_COMPLETE・AI_CLASSIFY・AI_PARSE_DOCUMENT・AI_TRANSCRIBE・AI_EXTRACTなどのAI関数を直接呼び出せる。テキスト・ドキュメント・画像・音声・動画を1つのSQLで横断処理できる
-
Cortex Agents(GA)
構造化・非構造化データを1つのエージェントから横断検索する仕組み。Cortex Analyst(テーブル)・Cortex Search(ドキュメント)を組み合わせ、企業内の問い合わせを自然言語で処理する基盤になる
-
Snowflake Intelligence(GA)
Cortex Agentsを土台にしたユーザー向けインターフェース。業務担当者がSQLを書かずに自然言語でデータに質問し、その場でグラフ・テーブルの形で回答を得られる
-
Snowflake Semantic Views(public preview)
ビジネス用語と物理テーブルを紐づけるセマンティック層。「売上」「顧客」「リードタイム」などの組織共通の指標定義をSnowflake内で管理し、AIやBIツールが解釈ズレを起こさないようにする
これらが整ったことで、「SQL分析の延長線上でAIエージェントを社内展開する」という使い方が、PoCではなく本番運用の選択肢になりました。
Snowflakeが選ばれる軸が、SQL分析の使い勝手から、AI連携の深さへとシフトしつつあります。
AIエージェント時代のデータ基盤設計を考えるとき、Cortex Agents・Snowflake Intelligenceのような統合エージェント基盤を選択肢に入れるかどうかは、構成全体に大きく影響します。
タイムトラベル・Fail-safeによるデータ保護

実運用で重要な機能として、タイムトラベルとFail-safeがあります。
タイムトラベルは、過去の任意の時点のテーブル状態をクエリで取り出せる機能です。「30日前の状態でこのテーブルを見せて」「昨夜のバッチ実行前の状態に戻して」といった操作を、バックアップを別途取らずにSQL1つで実現できます。標準ではStandard Editionで1日、Enterprise Edition以上で最大90日まで保持期間を設定できます。
Fail-safeは、タイムトラベル期間を過ぎた後にSnowflakeがさらに7日間保持する非ユーザー操作領域です。万一の障害時にSnowflakeサポート経由でデータ復旧が可能になっています。
2026年6月1日にcommercial AWS/AzureでSnowflake storage for IcebergがGAとなり、これを使うIceberg permanent tableもFail-safeの保護対象になりました。一方、顧客管理の外部ボリュームを使うSnowflake-managed Iceberg(外部ストレージ型)はFail-safeの対象外なので、保護要件のある業務データを置くかどうかはストレージ方式の選択で決まります。
これらは「バックアップ/DR運用に専用の仕組みを別途構築しなくてよい」という意味で、運用工数を削減する要素になります。
Snowflakeの料金体系
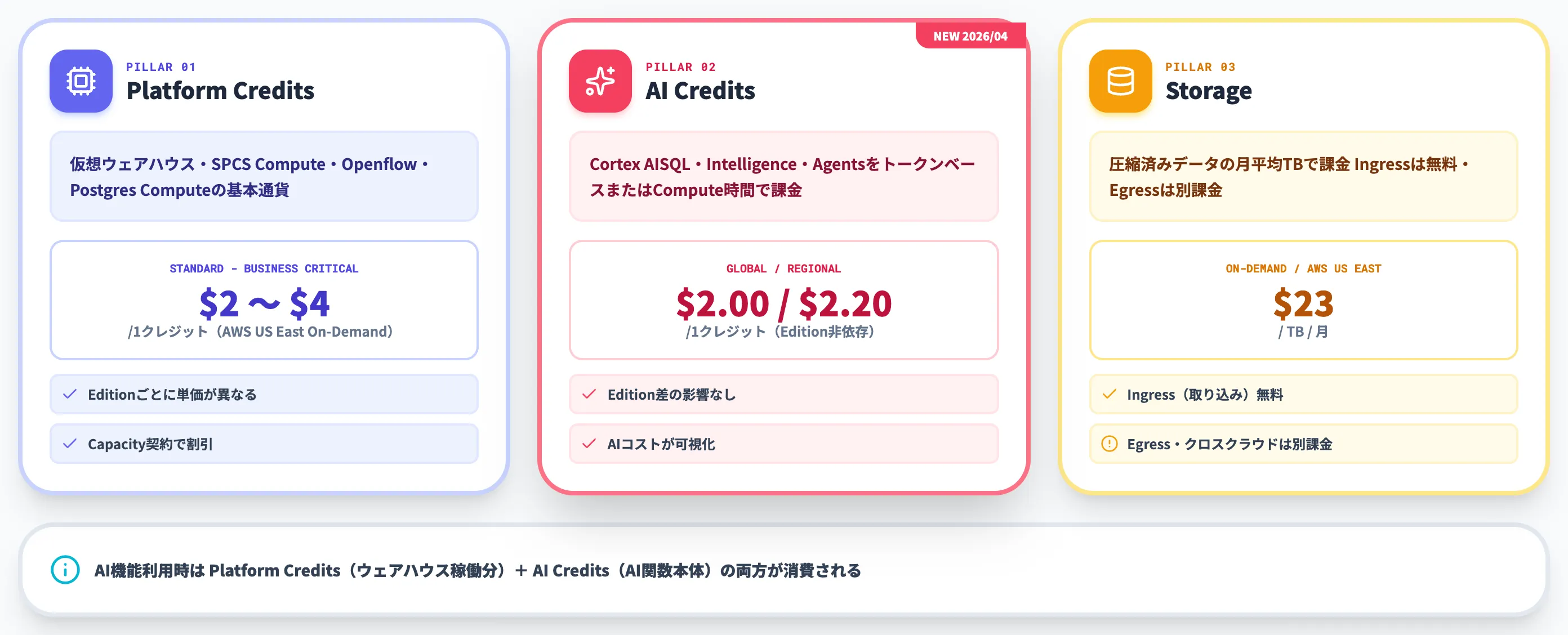
Snowflakeの料金で混乱しやすいのは、「クレジット」と一口に呼ばれているものが2種類あることです。
2026年4月1日以降、従来からの仮想ウェアハウス課金用「Platform Credits」に加え、AI機能専用の「AI Credits」が新設されました。本セクションでは、3本柱の構造と最新の単価を整理します。
Platform Creditsとエディション別単価

Platform Creditsは、仮想ウェアハウス・SPCS Compute・Openflow・Postgres Computeの利用に対して消費される基本通貨です。
公式pricingページに明示されている単価(AWS US East基準・On-Demand契約)は以下のとおりです。
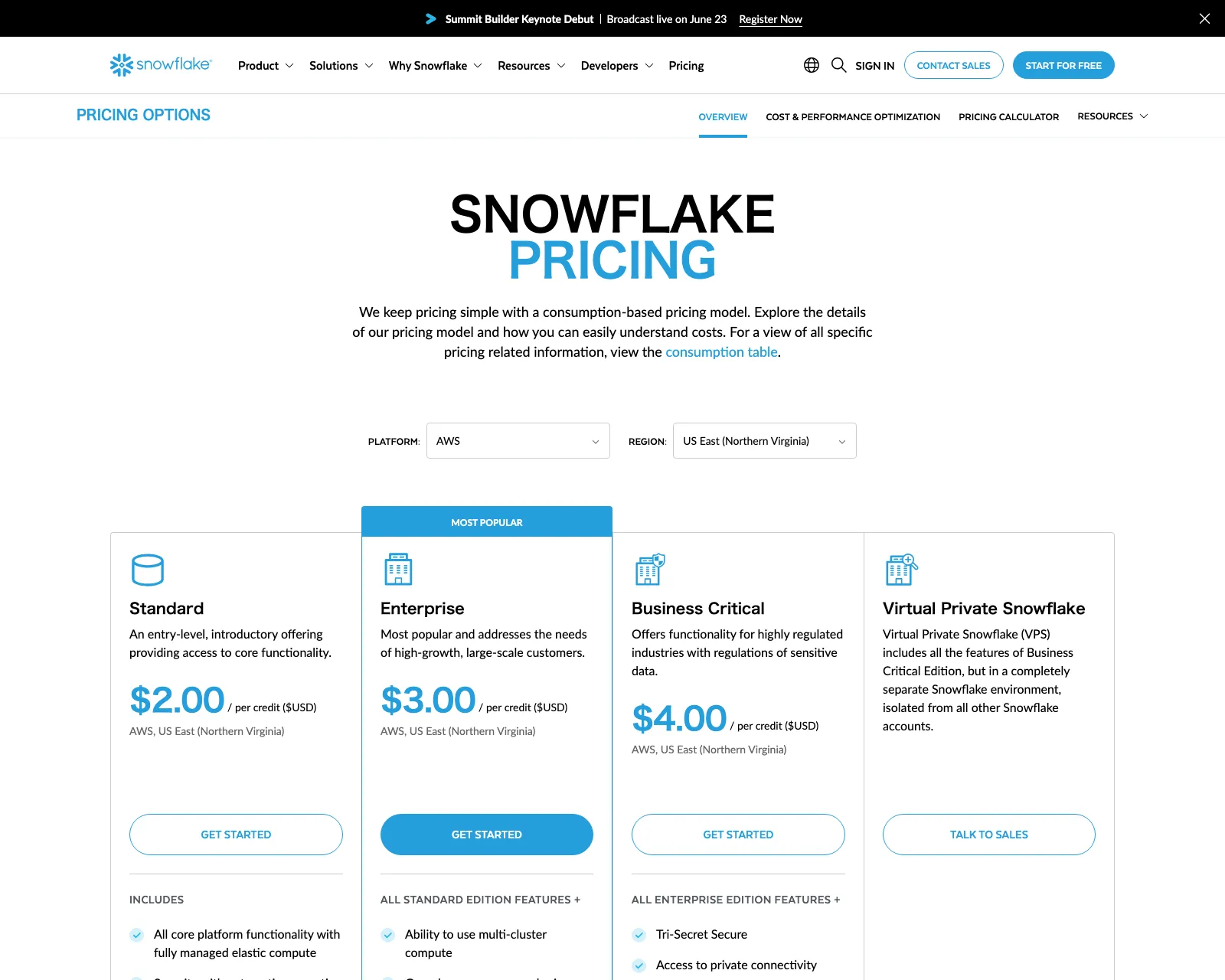
公式pricingページに掲載されている4エディションの単価カード(出典:Snowflake公式pricing)
| エディション | 1クレジット単価 | 主な対象 |
|---|---|---|
| Standard | $2.00 | 基本機能、暗号化、Snowpark、データシェアリング、タイムトラベル1日 |
| Enterprise | $3.00 | マルチクラスタウェアハウス、Materialized View、最長90日タイムトラベル |
| Business Critical | $4.00 | HIPAA/PCI対応、Tri-Secret Secure、PrivateLink、DR機能 |
| Virtual Private Snowflake(VPS) | 個別見積もり | 完全に隔離された専用環境 |
1クレジットの実態は「XSサイズの仮想ウェアハウスを1時間稼働させた量」と定義されており、Mサイズなら1時間で4クレジット、XLなら16クレジット、3XLなら64クレジットを消費します。
たとえばEnterprise Edition・MサイズでBI用ダッシュボードを1日8時間稼働させると、4クレジット × 8時間 × $3 = $96/日、月22営業日換算で月額約$2,100になります。
また契約形態でも単価が変わります。年間契約のCapacity Storage/Capacity Computeでは、Order Form上の割引条件やStorageのACVレンジに応じて単価が変わる仕組みで、長期利用と利用量が確定している組織ほど有利な単価を引き出しやすい設計です。具体的な割引率はSnowflakeとの個別契約交渉次第なので、PoC段階で年間利用量の試算とCapacity契約の見積もりを並行で進めるのがコスト最適化の定石になります。
AI Credits(2026年4月新設)
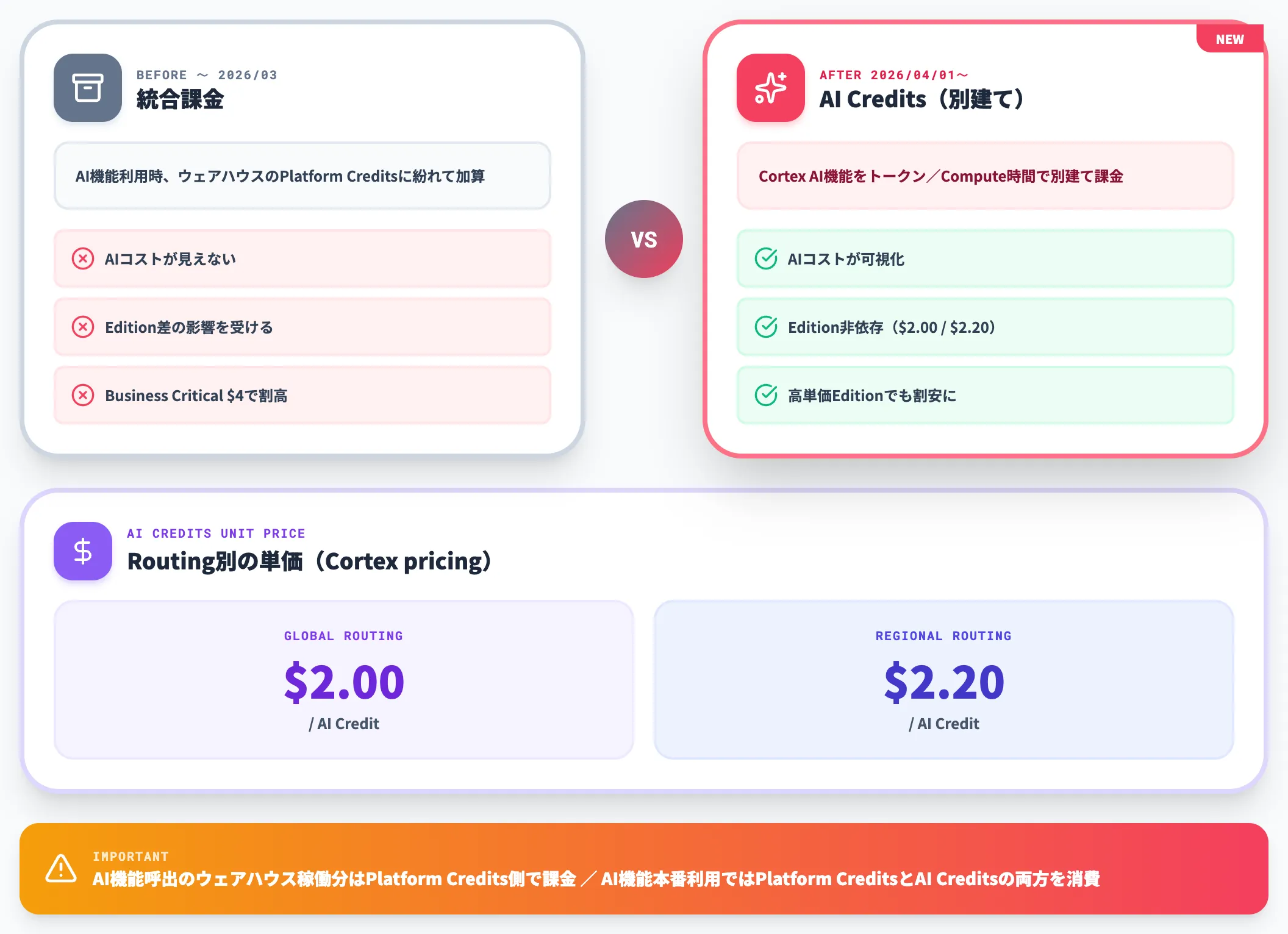
2026年4月1日施行のService Consumption Table改訂で、AI機能の課金はAI Creditsという別建ての通貨に切り出されました。
公式の文言は「AI Features bill at the rates set forth in Table 6」とされ、Cortex AISQL関数・Snowflake Intelligence・Cortex Agentsの利用はAI CreditsをトークンベースまたはCompute時間ベースで消費します。
この変更が実務に与える影響は、以下の2点に整理できます。
-
エディション差の影響を受けなくなった
公式のCortex pricingでは、AI Creditsの単価はGlobal routingが$2.00、Regional routingが$2.20と整理されており、Editionに依存しない。Business Critical・VPSのような高単価エディションを使っている組織でも、AI機能だけは割安に使える構造(routingの違いで$2.00/$2.20の差は残るため、リージョン差ゼロではない点には注意)
-
コスト管理の単位が分かりやすくなった
従来は「AI機能を呼んだ結果として仮想ウェアハウスのクレジットが膨らむ」構造だったため、AIコストが他の分析処理のコストに紛れて見えにくくなっていた。AI Creditsとして別建てになったことで、「今月のAI機能利用に対するコストはいくらか」が明確に把握できるようになっている
ただしAI Credits導入後も、Cortex AISQLを呼ぶ過程で仮想ウェアハウスが動く部分はPlatform Credits側で課金されるため、AI機能を本格利用するとPlatform CreditsとAI Creditsの両方が消費される点には注意が必要です。
また機能ごとに「AI Credits/100万トークン」「AI Credits/処理単位」のように消費単位が異なるため、想定ワークロードに合わせて公式pricingのTableで個別に試算するのが安全です。
ストレージとデータ転送(Egress)

ストレージは月平均TB数で課金されます。On-Demand契約のAWS US Eastで**$23.00/TB/月**、Capacity契約だとさらに割安になります。
データの圧縮率はテーブル内容に依存するため、社内見積もりを作るときは「データソース側の生サイズで仮見積もり→Snowflake側で再計測」の2段階で詰めるのが現実的です。
データ転送料金は、Snowflakeへの取り込み(Ingress)は無料ですが、Snowflakeから外部へ出す(Egress)場合と、リージョン間・クラウド間でデータを動かす場合に料金が発生します。
マルチクラウド構成を取る企業は、クロスクラウド転送のコストが想定よりも積み上がるケースが多いため、「どのリージョンにどのデータを置くか」をデータ設計時点で決めておくことが重要です。
コスト最適化の実務ポイント
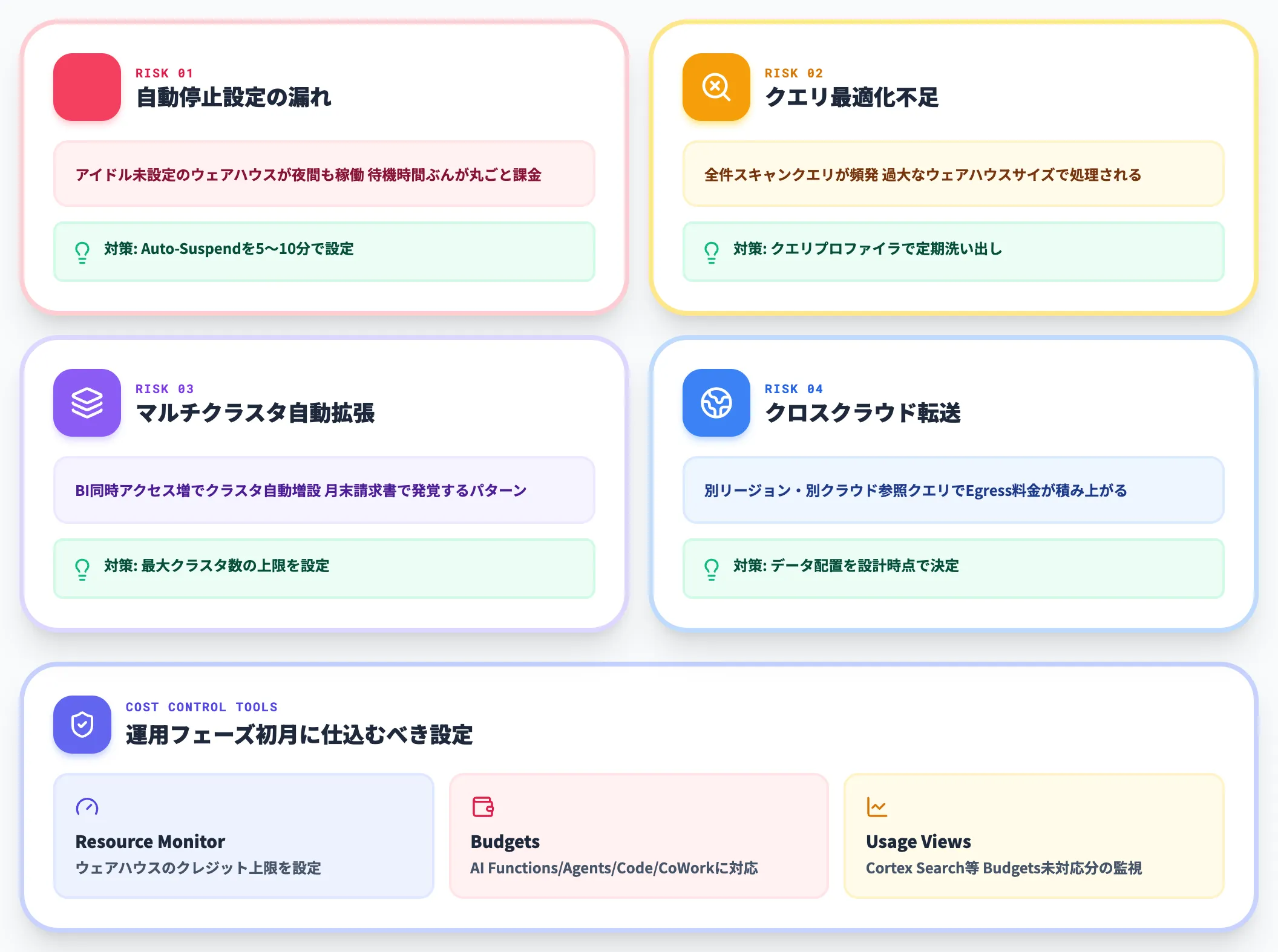
導入支援の現場で「想定の3倍コストが膨らんだ」と相談を受けるケースの大半は、以下の4要因に集約されます。
-
自動停止設定の漏れ
アイドル時間が設定されていない仮想ウェアハウスが夜間も稼働し続ける
-
クエリ最適化不足
テーブルスキャンが全件走るクエリが頻繁に流れ、不要に大きなサイズのウェアハウスで処理されている
-
マルチクラスタの自動拡張
BIツールの同時アクセス増加でクラスタが自動拡張し、月末に請求書を見て驚く
-
クロスクラウド転送
別リージョン・別クラウドにあるデータを参照するクエリでEgress料金が積み上がる
運用設計の初期で、「1日あたりのクレジット消費上限」「ウェアハウスごとのアイドル時間」「コストアラート閾値」をリソースモニターで明示的に設定しておくのが、コスト爆発を防ぐ最初の防波堤になります。
なおリソースモニターは仮想ウェアハウス向けの仕組みで、Cortex AI機能やServerless系の支出は対象外です。
AI Functions・Cortex Agents・Cortex Code・Snowflake CoWorkのAI Credits支出にはBudgetsを別立てで設定するのが正しい運用で、Cortex Searchは現時点ではusage viewsで監視(Budgets対応は今後予定)というのが公式の整理です。
Snowflakeと主要データ基盤の比較
Snowflakeを検討するときに最も多い問いは、「Databricks・Microsoft Fabric・BigQuery・Amazon Redshiftと、何が違うのか」です。
本セクションでは、各製品の設計思想と、AI総研の支援現場で見えてきたケース別の使い分けを整理します。
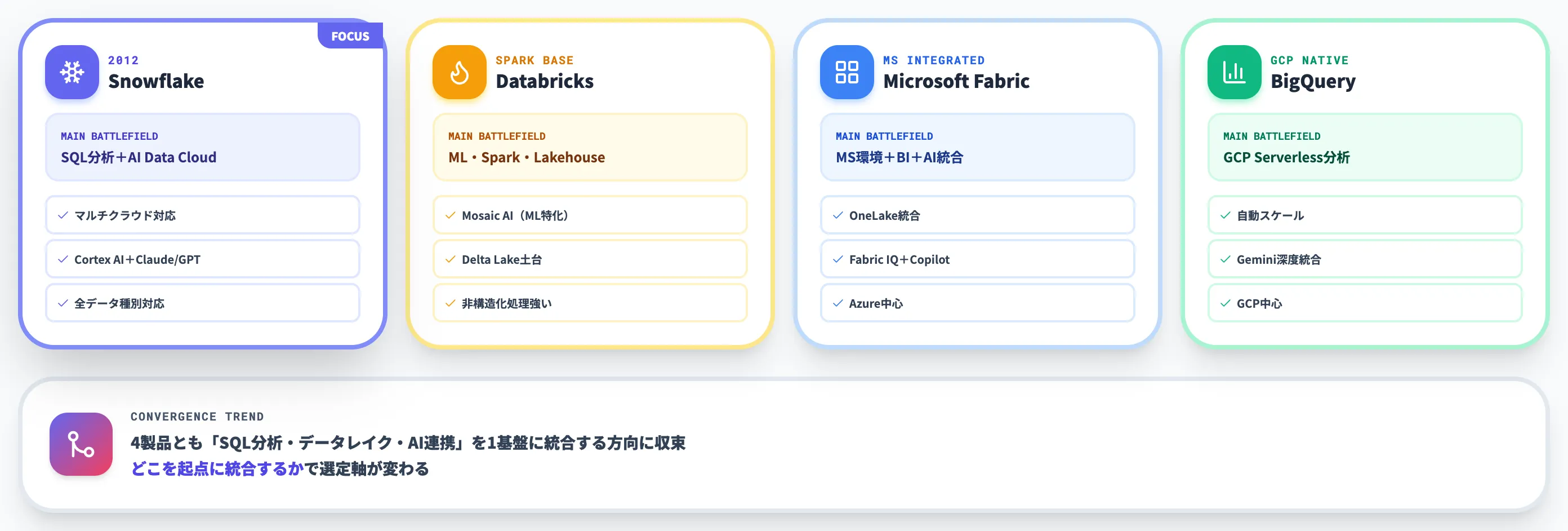
主要4プラットフォーム比較
以下の表で、Snowflake・Databricks・Microsoft Fabric・BigQueryの主要観点を比較しました。Amazon Redshiftは「AWSネイティブのSQL DWH」という独自ポジションで、3者と直接競合するわけではないため別枠で扱います。
| 観点 | Snowflake | Databricks | Microsoft Fabric | BigQuery |
|---|---|---|---|---|
| 出自 | クラウドDWH(2012) | Apache Spark/Lakehouse | OneLake+Synapse/Power BI統合 | GCP Serverless DWH |
| 主戦場 | SQL分析+AI Data Cloud | ML・Spark処理・Lakehouse | MS環境のデータ+BI+AI統合 | GCP上のServerless分析 |
| 強み | マルチクラウド対応、AI連携の汎用性 | Spark/ML/非構造化処理 | Microsoft 365との一気通貫 | 自動スケール、Gemini統合 |
| データ種別 | 構造化+半構造化+非構造化(Cortex) | 全種類(特に非構造化強い) | 全種類(OneLake統合) | 構造化+半構造化中心 |
| 課金 | Platform Credits+AI Credits+Storage | DBU+インフラ実費 | Capacity(F SKU)固定費型 | 従量(クエリTB単位) |
| AI連携 | Cortex AI+Claude/GPT統合 | Mosaic AI(ML特化) | Fabric IQ+Copilot | Gemini深度統合 |
| マルチクラウド | ◎(AWS/Azure/GCP) | ◎(AWS/Azure/GCP) | △(Azure中心) | △(GCP中心) |
この比較からわかるのは、Snowflake・Databricks・Microsoft Fabric・BigQueryのいずれも「SQL分析」「データレイク」「AI連携」を1つの基盤で提供する方向に収束しつつあり、どの機能が強いかではなく、どこを起点に統合するかで選定軸が変わってきている、という点です。
Databricksとの違い——SQL中心かML中心か
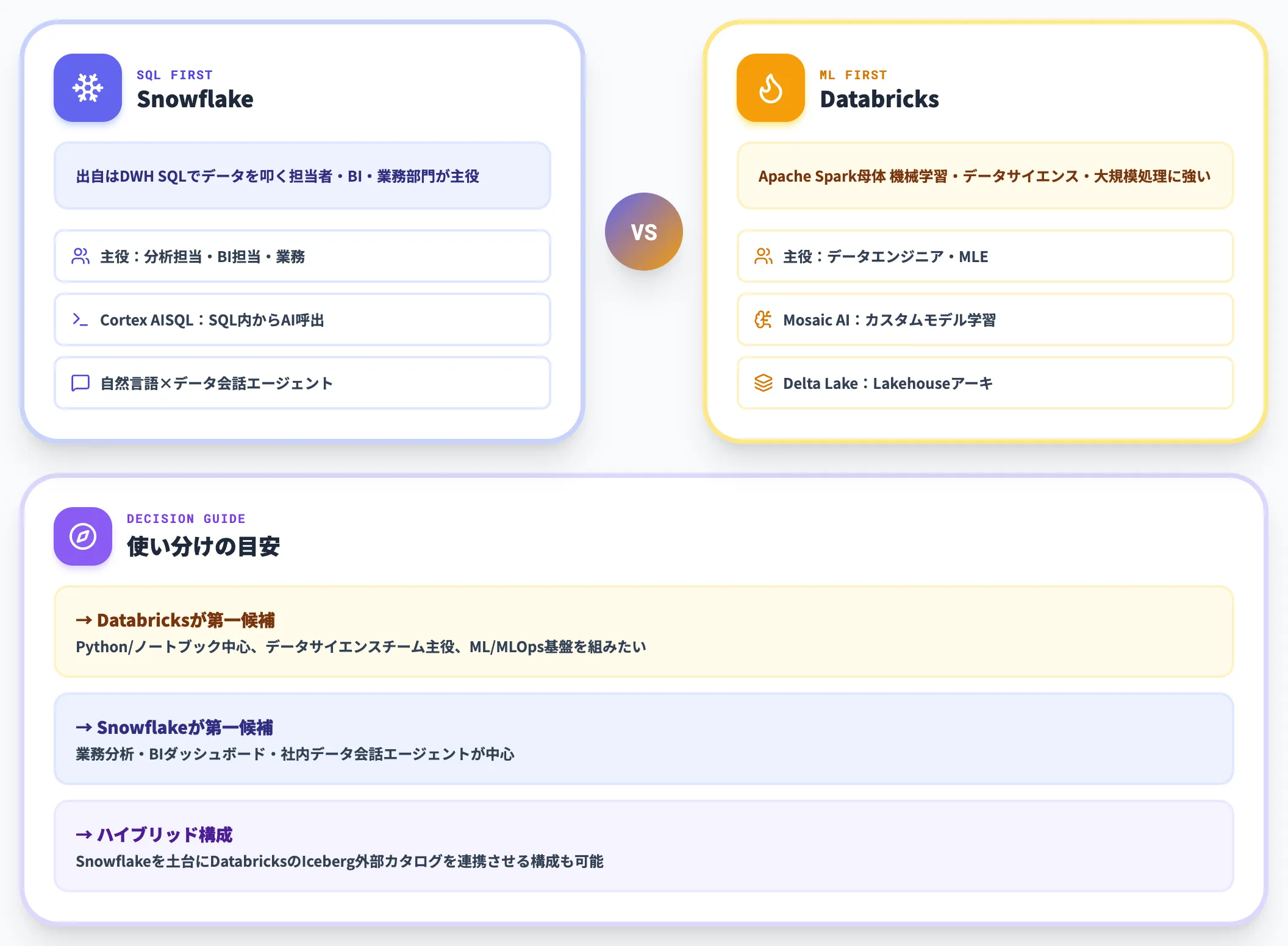
DatabricksはApache Sparkを母体とし、機械学習・データサイエンス・大規模データ処理に強い設計です。
Mosaic AIによるカスタムモデル学習基盤や、Delta Lakeを土台にしたLakehouseアーキテクチャが特徴で、データエンジニア・MLエンジニアが主役のチームで採用が進んでいます。
Snowflakeは出自がDWHであり、SQLでデータを叩く分析担当者・BI担当者・業務部門ユーザーが主役になる設計です。
直近はCortex AISQLでAI機能を「SQL内から呼び出す」アプローチを採っていることからも、SQL中心の世界観で進化しています。
実務での使い分けの目安は、「チームのスキルセット」と「処理する主データ」です。
- データサイエンスチームが主役で、Pythonコード・ノートブック中心の開発体制 → Databricks
- 業務分析・BIダッシュボード・社内データ会話エージェントが中心 → Snowflake
- 両方を同居させたい場合、Snowflakeの基盤に対してDatabricksのIceberg外部カタログを連携させるハイブリッド構成も実現可能
Microsoft Fabricとの違い
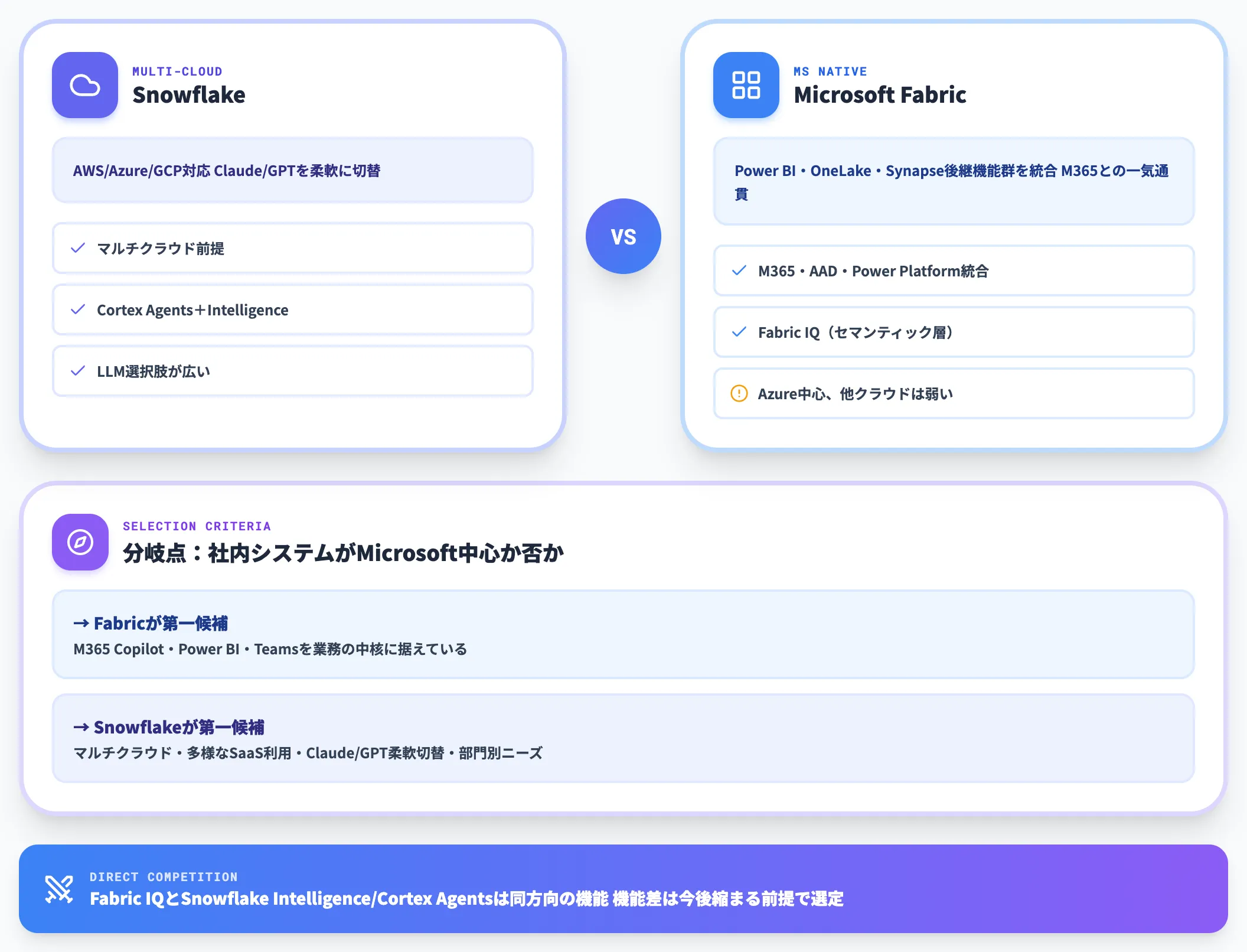
Microsoft Fabricは、Power BI・OneLake・Synapse Analyticsの後継機能群・Real-Time Intelligenceなどを1つのSaaSにまとめた製品です。
最大の特徴は、Microsoft 365・Azure AD・Power Platformとの深い統合です。
加えて2026年に入って、Fabric IQというセマンティック層が登場し、社内の業務語彙とFabric上のデータを結びつけてAIエージェントから自然言語で叩けるようにする方向で進化しています。
Snowflake Intelligence/Cortex Agentsと同じ方向の取り組みで、競合関係が直接的になりました。
選定基準としては、「社内システムがMicrosoft中心か否か」が最も大きな分岐点です。
- M365 Copilot・Power BI・Teamsを業務の中核に据えている → Fabric
- マルチクラウド・部門別に多様なSaaSを使う・Snowflake内でClaude/GPTを柔軟に切り替えたい → Snowflake
BigQueryとの違い

BigQueryは、Google Cloud Platform上で動くサーバーレスDWHです。クエリ単価がスキャンしたTB数で決まる従量課金モデルで、検索エンジン領域から派生したスケーラビリティとServerless体験が強みです。
Geminiモデルとの統合が深く、GCP上の他サービス(Cloud Run・Vertex AI・BigQuery ML)と一体運用しやすい設計になっています。
Snowflakeはマルチクラウド前提で、AWS/Azure/GCPに対応しています(ただしSnowflake PostgresやAdaptive Computeなど一部の新機能は提供クラウド・リージョンが限定)。
社内のクラウド戦略がGCP単独であればBigQueryの方が運用シンプルですが、AWS・Azureが混在する組織やマルチクラウドDR要件があるなら、Snowflakeの方が構成が組みやすくなります。
Agentic Data CloudというキーワードでGoogleが提示している「エージェント×データ基盤」の世界観は、Snowflakeのcortex Agents・Snowflake Intelligenceと正面から競合する領域で、各社の機能差が今後ますます縮まる前提で選定する必要があります。
Amazon Redshiftとの違い
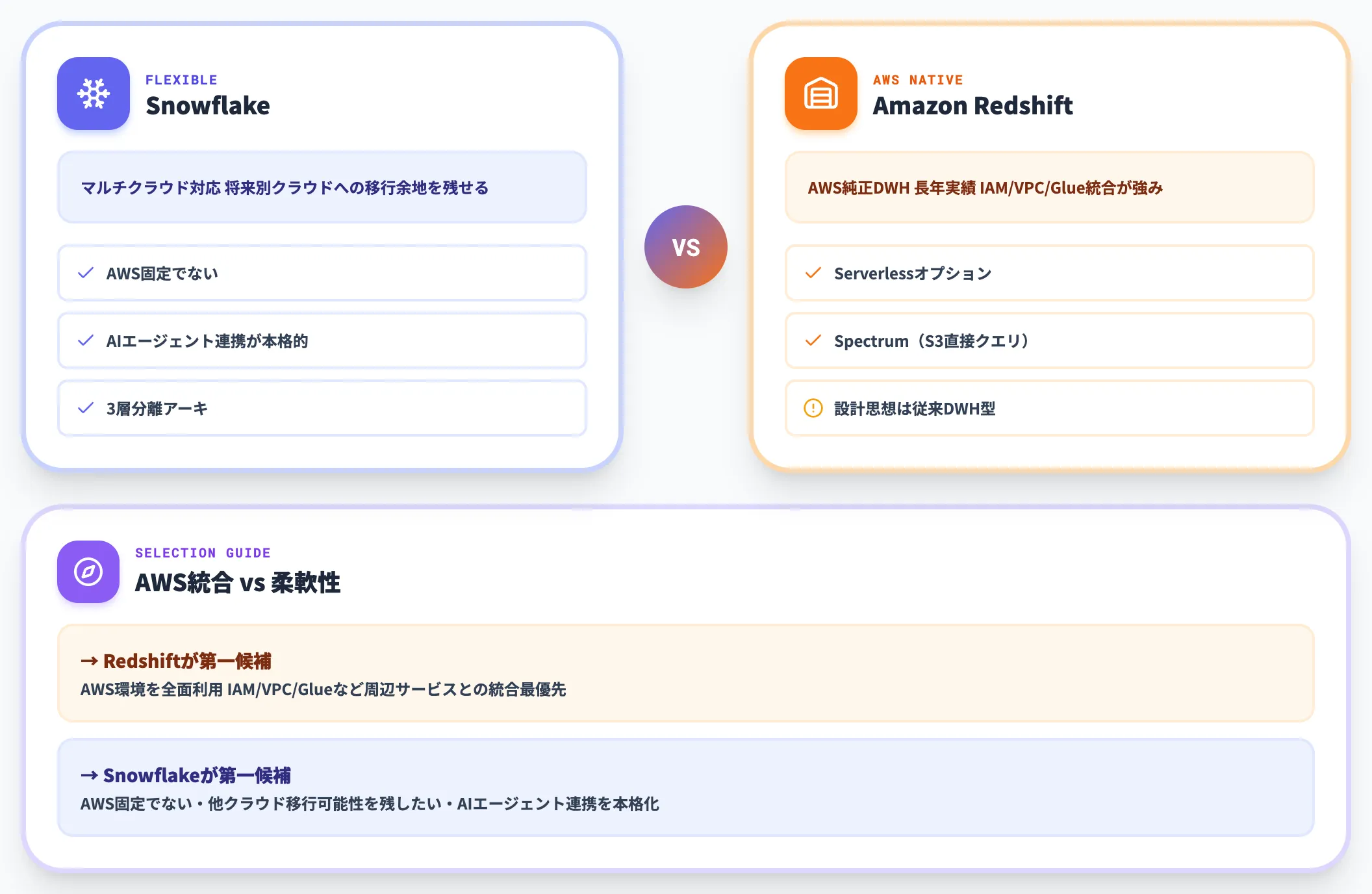
Amazon RedshiftはAWS純正のDWHで、長年DWH領域で使われてきた実績があります。
Serverlessオプションの追加やSpectrum機能(S3直接クエリ)など機能拡張が進んでいますが、設計思想の根幹は従来DWH型です。
AWS環境を全面利用していて、IAM/VPC/Glueなど周辺サービスとの統合を最優先するならRedshiftが自然な選択肢です。
一方、AWS固定ではなく将来的に他クラウドへの移行可能性を残したい、またはAIエージェント連携を本格的に進めたい場合は、Snowflakeの方が柔軟性が高くなります。
実務でのケース別使い分け

選定で迷う場面は、おおむね次の4パターンに集約されます。AI総研の支援現場で見えてきた整理を以下の表にまとめました。
| 状況 | 第一候補 | 補足 |
|---|---|---|
| マルチクラウド前提でSQL分析+AI Data Cloudを構築したい | Snowflake | Cortex AISQLでAI機能をSQLから直接利用 |
| M365・Power BI・Teamsに業務が集約済み | Microsoft Fabric | Fabric IQ+Copilotで一気通貫 |
| データサイエンス・大規模ML・Sparkベース処理が主軸 | Databricks | Mosaic AI・MLflowによるMLOps基盤 |
| GCP上でServerless分析を最低運用負荷で運用したい | BigQuery | Gemini統合とBigQuery ML |
| AWS純正で揃え、既存IAM/VPCに統合したい | Amazon Redshift | Spectrum+Serverlessで柔軟性確保 |
| 既存DBがOracle/Teradata/SQL Serverなど旧来DWH | Snowflake / Fabric | 移行支援ツール多く、コスト効果が出やすい |
選定の際にもう1段考えるべきは、「3年後に追加したい機能は何か」です。今のワークロードだけで決めると、エージェントAI・Iceberg・PostgreSQL統合といった将来の拡張で再選定が必要になりがちです。
Snowflakeを含む4製品とも開放路線(オープン標準・マルチクラウド・パートナー連携)を打ち出しているため、選定時点で「どの開放軸を最重視するか」を明確にしておくと、後悔の少ない選択になります。

Snowflakeの導入事例
Snowflakeの効果を理解する近道は、実際に導入した組織がどんな課題をどう解いたかを見ることです。
本セクションでは、日本国内の代表事例2件と業界別の活用パターンを整理します。
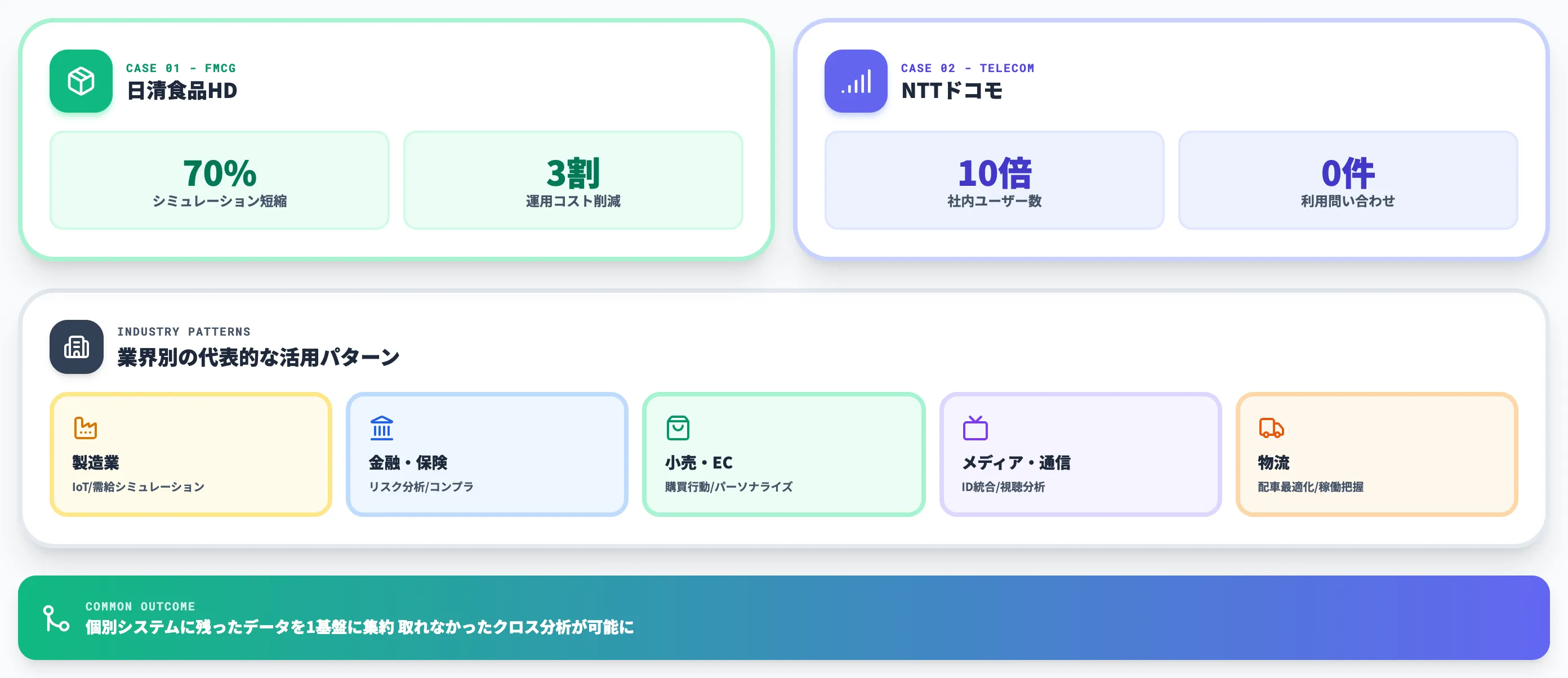
日清食品ホールディングスの導入効果
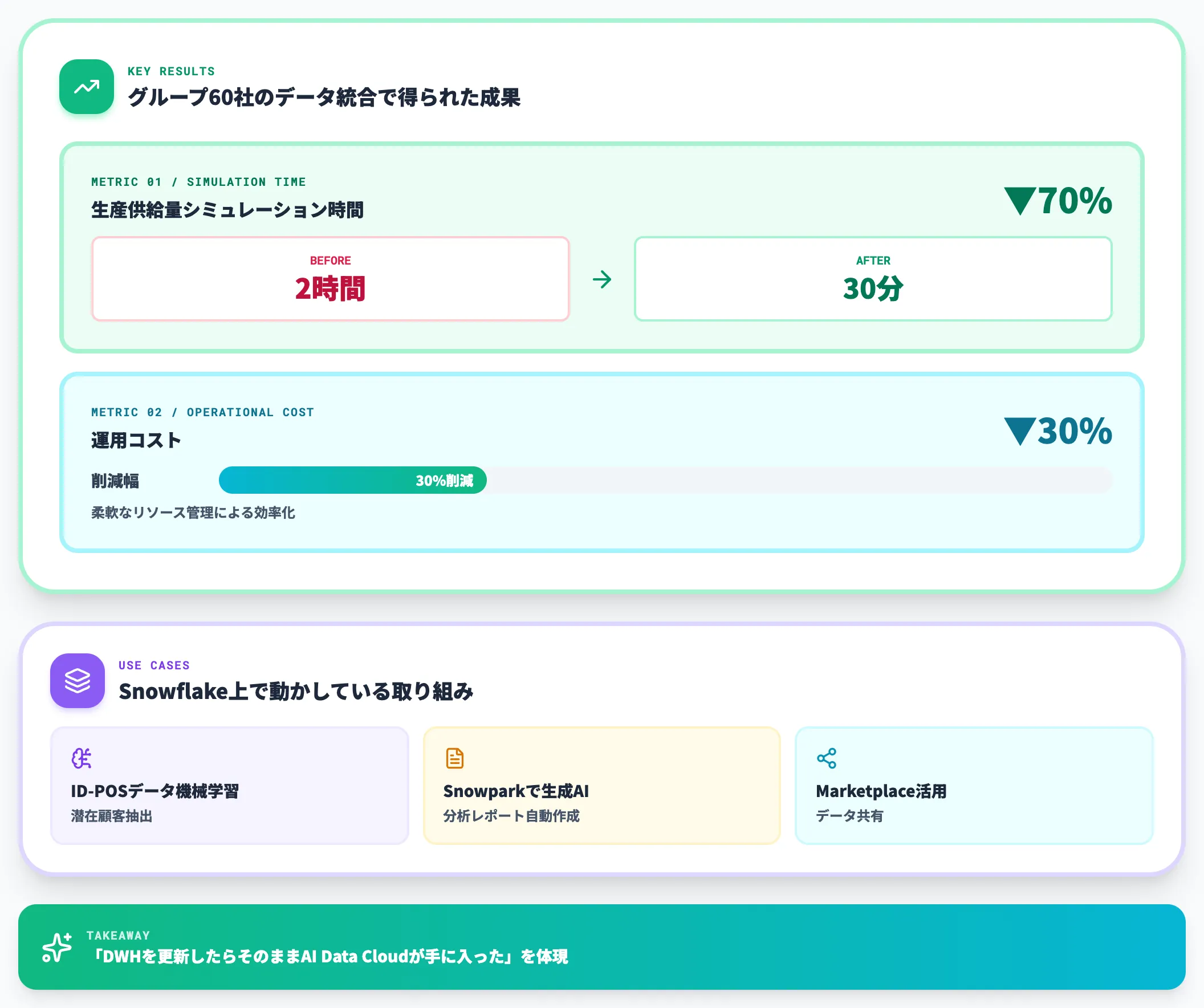
日清食品ホールディングスは、グループ60社のデータを統合する分析基盤としてSnowflakeを導入しました。背景には、基幹システム・業務システム・自社ECサイトなどに散在するデータを1か所に集約して、データドリブン経営を実現したいという目的があります。
日清食品ホールディングスの公式事例ページ(出典:Snowflake公式事例)
Snowflake公式事例ページではKEY RESULTSとしてシミュレーション時間「70%」短縮と運用コスト「3割」削減の2指標がトップに据えられており、テキスト本文より前に成果が読み取れる構成になっています。
導入効果として公表されているのは以下のとおりです。
- 生産供給量シミュレーションが2時間から30分に短縮(約70%削減)
- 運用コスト3割削減(柔軟なリソース管理による効率化)
同社はSnowflake上でID-POSデータを用いた潜在顧客抽出(機械学習)、Snowparkを使った生成AIによる分析レポート自動作成、Snowflake Marketplaceを活用したデータ共有といった用途を組み合わせています。
データ統合のスピードと、AI/ML活用までを1基盤で完結させた点が特徴的で、「DWHを更新したらそのままAI Data Cloudが手に入った」というSnowflake全体の方向性を体現しています。
NTTドコモの全社データ基盤刷新

NTTドコモは、dポイントクラブなど膨大な顧客データを管理する全社データ基盤として、オンプレミス中心の構成からSnowflakeへ全面移行しました。
背景には、上位システムのトラブル対応工数、ビジネスニーズに対応するリソース不足、事業部門ごとの複雑なルールがデータ利用の障壁になっていた、という3つの課題があります。
NTTドコモの公式事例ページ(出典:Snowflake公式事例)
公式事例ページの主見出しは「お客様にも社内ユーザーにも分かりやすく利用ルールを再整備」と「リソース利用状況に応じてコストを分担する仕組みを構築」の2本立てで、ガバナンスと自由なアクセスの両立がプロジェクト全体のテーマとして掲げられています。KEY RESULTSの「0件」はデータ利用に関する問い合わせがほぼなくなった状態を示します。
導入効果として公表されているのは以下のとおりです。
- 社内ユーザーアカウント数がオンプレ時代の約10倍に増加
- データ利用に関する問い合わせがほぼゼロに
- データ確認の手間がほぼ解消、ミスが減少
- リアルタイムロード処理が可能に(スケーリング柔軟性で即座のデータ連携を実現)
運用ルールを「プライバシーポリシー準拠」「法令準拠」「個別契約準拠」の3つに集約し、スキーマ再構成でシステムに実装した点が成功要因として挙げられています。今後はSnowflake Cortexによる生成AI機能をマーケティングのペルソナ作成等に活用する検討も進めています。
業界別の代表的な活用パターン

国内外の公開事例から、業界別に類型化すると以下のパターンが目立ちます。
-
製造業
IoTセンサーデータ・生産計画・需要予測の統合分析。日清食品のようなFMCG企業も含め、需給シミュレーションが代表的なユースケース
-
金融・保険業
リスク分析・コンプライアンスレポート・顧客行動分析。データガバナンス要件が厳しいためBusiness Critical Editionの採用が多い
-
小売・EC
購買行動分析・在庫最適化・パーソナライゼーション。Marketplace経由で気象・地理・経済データを取り込み、外部データとのジョインで意思決定の精度を上げる
-
メディア・通信
顧客ID統合・コンテンツ視聴分析・データシェアリングを起点としたパートナー連携
-
物流
配車最適化・在庫管理・トラック稼働状況把握。F-LINE株式会社のように、Tableauなどの可視化ツールとセットで導入するパターンが多い
業界に共通するのは、「個別システムに残ったままだったデータを1つの基盤に集約することで、これまで取れなかったクロス分析が可能になる」という効果です。Snowflakeの導入は単なるDWH更新ではなく、データ統合プロジェクトとして社内の合意形成を進める必要があります。
Snowflake導入で詰まる論点と判断軸

Snowflakeは万能ではありません。導入支援の現場で必ず議論になる4つの論点を、判断材料とあわせて整理します。
コスト爆発を防ぐための運用設計
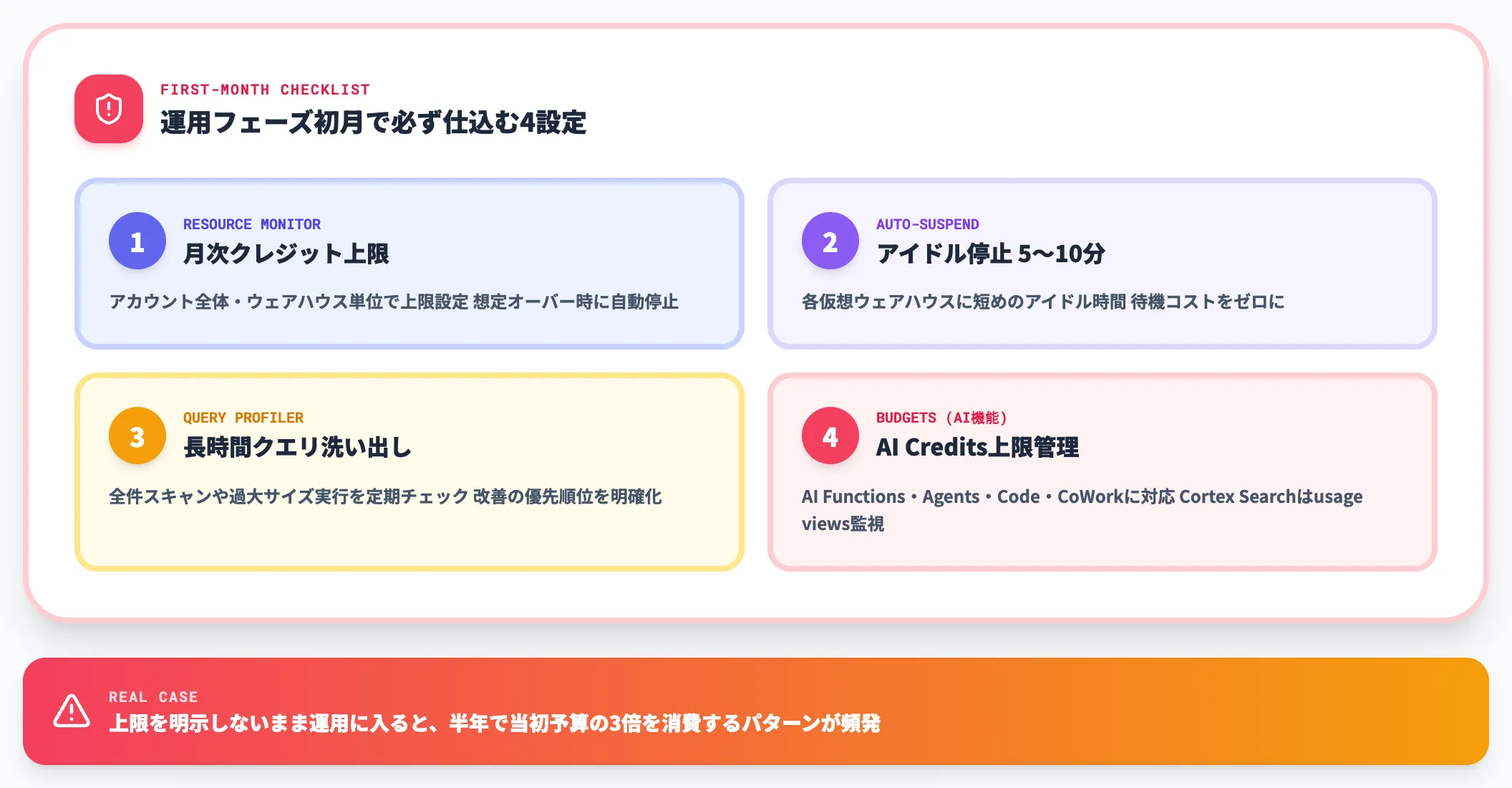
Snowflake導入後の最大の懸念は、月額コストが想定の数倍に膨らむケースです。従量課金モデルのため使った分だけ請求される構造は、油断するとそのまま下振れリスクに変わります。
実務で必ず初期に設定しておきたいのは以下の4点です。
- リソースモニターでアカウント全体・ウェアハウス単位の月次クレジット上限を設定する
- 各仮想ウェアハウスのAuto-Suspendを5〜10分など短めに設定する
- クエリプロファイラーで長時間クエリ・全件スキャンクエリを定期的に洗い出す
- AI機能・Serverless機能の利用が始まったらBudgetsを別立てで設定し、AI Functions・Cortex Agents・Cortex Code・Snowflake CoWorkのAI Credits支出を上限管理する(Cortex Searchは現時点ではusage views監視・Budgets対応は今後予定)
これらは「やった方がいい」レベルの話ではなく、運用フェーズに入った最初の1か月で必ず仕込んでおくべき設定です。
「組織として何クレジットまで使ってよいか」という上限を明示しないまま運用に入ると、半年で当初予算の3倍を消費するパターンが頻発します。
Iceberg移行戦略とデータ基盤の開放性

Apache Iceberg対応は、Snowflakeの将来戦略のなかでも最重要のテーマです。
「Snowflakeを起点にデータを集約する」のと「Snowflakeを1つのエンジンとしてIceberg上のデータを叩く」のは、設計思想として大きく異なります。前者は運用負荷が低く即効性がありますが、データのオーナーシップがSnowflake内部に閉じる構造になります。後者はマルチエンジン基盤を組めますが、カタログ管理・ライフサイクル管理の責任を社内側で持つ必要があります。
実務での判断軸は、「3年後の構成図を、Snowflake単体で完結させるか、複数エンジンを共存させるか」です。
- マルチエンジン構成を将来見据える → 最初からExternal CatalogまたはCatalog-linked Databasesで設計
- Snowflake単独で完結させる前提 → Snowflake storage for Icebergを使うpermanent tableでFail-safeまで活かす設計(外部ボリューム型はFail-safe対象外)
2026年6月からはDEFAULT_METADATA_WRITE_FORMATによってデフォルトでIcebergテーブルを作成できるようになっており、Iceberg化のハードルは確実に下がっています。
「とりあえずSnowflake-managedで始めて、後で外部カタログに移す」という段階的アプローチも取りやすい状況です。
リアルタイム処理の弱さと補完策

Snowflakeは、バッチ/準リアルタイム分析に最適化された設計です。Snowpipe Streamingでは秒単位のデータ取り込みが可能ですが、ミリ秒単位の超低遅延処理が必要な領域(広告配信のRTB・金融トレーディング・センサーのリアルタイム制御等)はSnowflakeの主戦場ではありません。
このようなケースでは以下の構成が現実的です。
-
超低遅延が必須
KafkaやKinesis、Apache FlinkなどのストリーミングエンジンとSnowflakeを併用し、リアルタイム処理は外部、集約後の分析はSnowflakeに寄せる
-
数秒〜数十秒の準リアルタイム
Snowpipe Streamingで対応可能
-
数分〜数時間のバッチ
標準のSnowpipe/COPY INTOで対応
「すべてをSnowflakeで完結させる」という発想ではなく、用途別に他のエンジンと組み合わせることを前提に設計するのが、現実解です。
Microsoft FabricのReal-Time Intelligence(KQLベース)のような専用エンジンと比較される場面では、Snowflakeの守備範囲を明示しておくとプロジェクトの期待値ズレが防げます。
既存DWH・DBからの移行判断
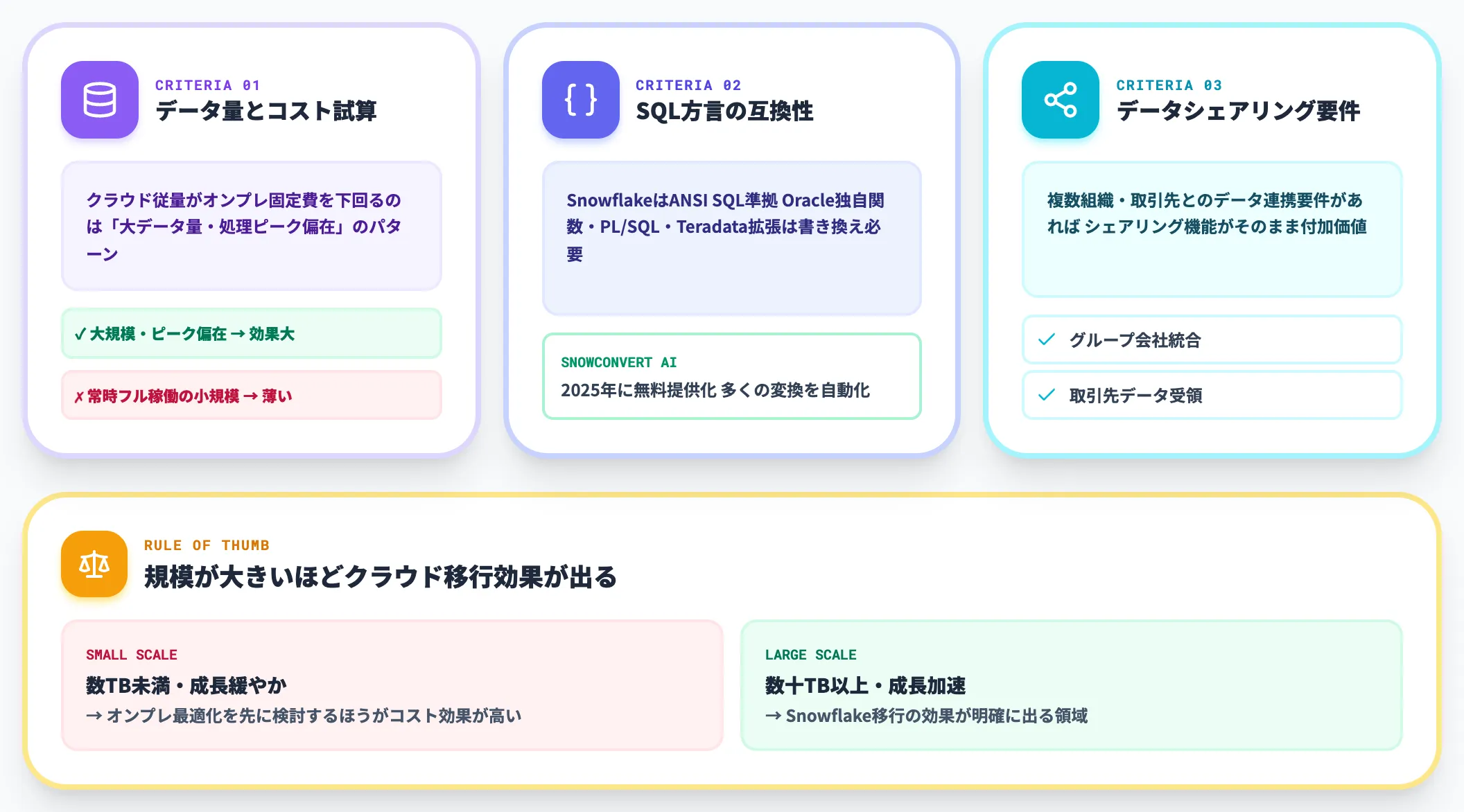
既存のOracle・Teradata・SQL Server・PostgreSQLからの移行プロジェクトでは、以下の3点が判断軸になります。
-
データ量とコスト試算
クラウド従量課金がオンプレ固定費を下回るのは、「データ量が大きい・処理ピークが偏在する」ユースケースが多い。常時フル稼働の小規模DBは移行効果が薄いケースも
-
SQL方言の互換性
SnowflakeはANSI SQL準拠だが、Oracle独自関数・PL/SQL・Teradata SQL拡張は書き換えが必要。SnowConvert AI(2025年に無料提供化)で多くの変換を自動化できる
-
データシェアリング要件
複数組織・取引先とデータ連携する要件があるなら、データシェアリング機能がそのまま付加価値になる
移行支援の現場感覚として、「規模が大きいほどクラウド移行効果が出る」という傾向が明確です。データ量が数TB未満で増加速度も緩やかなら、まずはオンプレ最適化を先に検討した方がコスト効果は高くなります。

Snowflakeを起点にデータ基盤×AI活用を業務に定着させる
Snowflakeの導入は、単なるDWH刷新ではなく、社内データをAIエージェントから使える状態に整えるプロジェクトとしての性格を強めています。
ただし、Snowflakeを契約してデータを投入しただけでは「PoCで止まる」ケースが多いのも事実です。
Cortex AISQL・Snowflake Intelligenceで業務担当者が自然言語で社内データに質問できるようにするには、データのセマンティック定義、業務プロセスとの統合、エージェントの権限設計、コスト管理の運用ルールまでをセットで設計する必要があります。
AI総合研究所では、PoCから全社展開までの設計、部門別ユースケース、AI運用における統制・セキュリティのチェックポイントを220ページにまとめた「AI業務自動化ガイド」を無料で公開しています。Snowflakeを起点にしたデータ基盤×AIの自社戦略を整理する手がかりとして活用ください。
Snowflakeを起点としたデータ基盤×AI活用を業務に定着させる

PoCから全社展開までの設計を1冊で
Snowflakeのような統合データクラウドを導入しても、社内の業務プロセスに組み込めなければPoC止まりで終わります。AI業務自動化ガイド(220ページ)では、部門別ユースケース、データ基盤を前提としたAIエージェントの実装パターン、運用における統制・セキュリティのチェックポイントを整理しています。
まとめ
本記事では、Snowflakeの基本概念から3層アーキテクチャ、主要機能、2026年4月新設のAI Credits、競合4製品との比較、導入事例、運用上の判断軸までを2026年6月時点の最新情報で整理しました。要点を再確認します。
-
Snowflakeはストレージとコンピュートを分離した3層アーキテクチャを持つクラウドデータプラットフォームで、SQL分析・データシェアリング・エージェントAIを1つの基盤で提供する。AWS/Azure/GCPの3大クラウドに対応するが、Snowflake PostgresやAdaptive Computeなど一部新機能は提供クラウド・リージョンが限定される
-
2025年11月にCortex AISQL・Snowflake Intelligence・Cortex AgentsがGA化し、SQLからAI関数を直接呼び出して非構造化データを処理できる「AI Data Cloud」としての性格が強まった。Anthropic・OpenAIとの$200Mパートナーシップで主要LLMが標準利用可能
-
料金は、Standard $2/Enterprise $3/Business Critical $4のPlatform Credits、2026年4月新設のAI Credits、$23/TB/月のStorageの3本柱で構成。年間Capacity契約ではOrder Form上の割引条件やStorageのACVレンジに応じて単価が変わる
-
競合との使い分けは、SQL分析+マルチクラウド+AI連携の柔軟性を重視するならSnowflake、ML中心ならDatabricks、MS環境ならFabric、GCP単独ならBigQueryが第一候補。3年後の拡張軸を見据えて選ぶことが重要
-
日清食品のシミュレーション70%短縮、NTTドコモの社内ユーザー10倍など、定量効果は日本企業で実証済み。導入で詰まる論点はコスト爆発・Iceberg移行・リアルタイム処理の弱さ・既存DWH移行の4つで、運用設計の初期に手を打つ必要がある
Snowflakeを選ぶか否かは、3年後にデータ基盤上でどんなAI活用を進めたいかという問いに帰着します。SQL分析の上にエージェントAIを乗せ、社内データを業務部門が自然言語で扱える状態にしたい組織にとって、Snowflakeは2026年時点の有力な選択肢です。まずは小規模なPoCでCortex AISQLの効果を体感し、コスト管理ルールとあわせて段階的に拡張していくのが、現実的な第一歩になります。










