この記事のポイント
 新規ビッグデータ基盤はMicrosoft Fabricが第一候補、Synapse Analyticsはメンテナンスモード移行で新規採用は避ける
新規ビッグデータ基盤はMicrosoft Fabricが第一候補、Synapse Analyticsはメンテナンスモード移行で新規採用は避ける- MLOps・リアルタイムストリーミング処理が主要件はAzure Databricksが最適、FabricとDatabricksは相互補完で使い分け
- HDInsight 5.1以外は廃止進行中、既存Synapse/HDInsight環境は2026年中にFabric/Databricksへの移行計画を策定
- コスト面ではFabric CU課金とDatabricks DBU課金の単価差を検証し、月間処理量に応じた損益分岐点を把握した上で選定するのが有効
- 段階的導入ではFabric Trial容量でPoCを実施し、既存パイプラインの移行効果(40-60%削減の実績あり)を自社環境で検証すべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Microsoftのクラウドプラットフォーム「Azure」は、ビッグデータの管理と分析において包括的なサービス群を提供しています。2023年11月にGA(一般提供)されたMicrosoft Fabricの登場により、従来のAzure Synapse AnalyticsやData Factoryが統合され、データ分析基盤は大きな転換期を迎えています。
本記事では、2026年最新のAzureビッグデータ分析サービスの全体像を解説します。Microsoft FabricとAzure Databricksの2大プラットフォームを中心に、レガシーサービスの移行状況、AI・機械学習との統合、国内企業の導入事例、料金体系まで包括的にお伝えします。
Azureの基本情報については、以下の記事で詳しく解説しています。
Microsoft Azureとは?できることや各種サービスを徹底解説
目次
Microsoft Fabric(統合データ分析プラットフォーム)
Azure Databricks(高度な分析とMLOps基盤)
Azure Machine LearningとFabricの連携
ビッグデータ分析基盤を「分析」から「業務自動化」に拡張するなら
Azureのビッグデータ分析とは(2026年最新)
Azureのビッグデータ分析とは、Microsoft Azureクラウド上で提供される一連のサービスを活用し、大量のデータを収集・保存・処理・分析してビジネス上の意思決定に活かす取り組みを指します。Azureはストレージからデータ統合、分析、可視化に至るまでの全プロセスをカバーするサービスを提供しています。
2026年現在、Azureのビッグデータ分析基盤は大きな転換期にあります。2023年11月にGA(一般提供)されたMicrosoft Fabricが、従来のAzure Synapse Analytics・Azure Data Factory・Power BIを1つの統合プラットフォームに集約しました。2026年3月時点で28,000以上の組織がFabricを採用しており、Azureデータ分析の標準基盤として急速に普及しています。
一方で、従来のAzure Synapse Analyticsはメンテナンスモードに移行し、Azure HDInsightも大半のバージョンが廃止されるなど、既存サービスの統廃合が進んでいます。こうした変化を踏まえ、今後のビッグデータ分析基盤を検討する際には、Microsoft FabricとAzure Databricksの2大プラットフォームを軸に据えることが推奨されます。

ビッグデータの3V特性とAzureの対応
ビッグデータは、従来のデータベースやデータ管理ツールでは処理しきれない規模と複雑さを持つデータセットを指します。一般に「3V」と呼ばれる3つの特性で定義されており、Azureは各特性に対応する専用サービスを提供しています。以下の表でビッグデータの3V特性とAzureの対応サービスをまとめました。
| 特性 | 内容 | Azureの対応サービス |
|---|---|---|
| Volume(量) | テラバイトからペタバイト規模のデータ蓄積。IoTセンサー、業務トランザクション、ログデータなど | Azure Data Lake Storage Gen2、OneLake |
| Velocity(速度) | リアルタイムまたはニアリアルタイムでのデータ生成と処理。ストリーミングデータの即時分析 | Azure Event Hubs、Fabric Real-Time Intelligence |
| Variety(多様性) | 構造化データ(RDB、CSV)と非構造化データ(テキスト、画像、動画)の混在 | Microsoft Fabric、Azure Databricks |
この3V特性に加え、近年ではVeracity(正確性)とValue(価値)を加えた「5V」で議論されることも増えています。データの品質管理とビジネス価値への変換が重要視される中、Microsoft FabricのOneLakeやDatabricksのUnity Catalogといったデータガバナンス機能が注目されています。
Azureビッグデータ分析サービスの全体像
Azureのビッグデータ分析サービスは、Microsoft Fabricの登場により大きく再編されています。以下の表で、2026年3月時点の主要6サービスの位置づけと推奨用途を整理しました。
| サービス | 概要 | 2026年の状況 | 推奨用途 |
|---|---|---|---|
| Microsoft Fabric | Synapse・Data Factory・Power BIを統合した分析プラットフォーム | GA(推奨) | 新規プロジェクト全般 |
| Azure Databricks | Apache Sparkベースの高度な分析・ML基盤 | GA(推奨) | 大規模ML・リアルタイム処理 |
| Azure Data Factory | データ統合・ETL/ELTパイプライン | Fabric Data Factoryへ移行推奨 | 既存パイプラインの維持 |
| Azure Synapse Analytics | データウェアハウス・ビッグデータ分析 | メンテナンスモード | 既存環境の維持のみ |
| Azure HDInsight | Hadoop・Spark・Kafkaなどのオープンソース基盤 | 5.1以外は廃止進行 | 限定的(移行推奨) |
| Azure Data Lake Storage Gen2 | スケーラブルなデータレイクストレージ | GA(継続) | FabricのOneLake基盤として |
ポイントは、新規プロジェクトではMicrosoft FabricまたはAzure Databricksを選択することです。既存のSynapse AnalyticsやHDInsight環境を運用中の場合は、Fabricへの段階的な移行を計画する必要があります。

Azure Synapse Analyticsの初期画面
Microsoft Fabric(統合データ分析プラットフォーム)
Microsoft Fabricは、Microsoftが2023年11月にGAとしてリリースしたSaaS型の統合データ分析プラットフォームです。従来はAzure Data Factory(データ統合)、Azure Synapse Analytics(データウェアハウス)、Power BI(可視化)と個別に利用していたサービスが、Fabricでは1つのプラットフォームに統合されました。
Fabricの中核を担うのがOneLakeと呼ばれるデータレイクハウスです。OneLakeはAzure Data Lake Storage Gen2をベースに構築されており、組織内のすべてのデータを1つのレイクに集約できます。Fabric内の各サービス(Data Engineering、Data Science、Data Warehouse、Real-Time Intelligence、Power BI)がOneLakeを共有するため、データのコピーや移動なしに横断的な分析が可能です。
2026年3月時点で28,000以上の組織がFabricを採用しています。特に日本国内でも金融機関や製造業を中心に導入が進んでおり、既存のPower BIユーザーがFabricへ自然にアップグレードするケースが多く見られます。課金はCapacity Unit(CU)モデルを採用しており、F2(2 CU)からF2048(2,048 CU)まで柔軟にスケールできます。
Azure Databricks(高度な分析とMLOps基盤)
Azure Databricksは、DatabricksとMicrosoftが共同開発したApache Sparkベースの分析プラットフォームです。大規模なデータ処理、機械学習モデルの開発・運用(MLOps)、リアルタイムストリーミング処理に強みを持っています。
Databricksの特徴は、Delta Lakeを基盤としたレイクハウスアーキテクチャです。Delta LakeはACIDトランザクションをサポートするオープンソースのストレージレイヤーで、データレイクとデータウェアハウスの利点を兼ね備えています。Unity Catalogによるデータガバナンス機能も備えており、組織全体でのデータアクセス管理やリネージ追跡が可能です。
Microsoft FabricとAzure Databricksは競合ではなく相互補完の関係にあります。FabricはMicrosoftエコシステムとの統合やセルフサービスBI(Power BI)に強く、Databricksは大規模な機械学習パイプラインやマルチクラウド環境に強みがあります。実際に、Fabricのデータに対してDatabricksからアクセスするショートカット機能も提供されており、両者を併用する企業も少なくありません。
Azure Databricksの初期画像
2026年3月時点で注意が必要なのは、Databricks Standard Tierが2026年10月1日に廃止予定となっている点です。現在Standard Tierを利用中の場合は、Premium Tierへの移行を計画する必要があります。
レガシーサービスの現状と移行方針
Azureのビッグデータ分析サービスは統廃合が進んでおり、特にSynapse AnalyticsとHDInsightの2サービスは既存環境の移行計画が求められます。以下の表で各サービスの現状と推奨される移行先をまとめました。
| サービス | 現状 | 廃止・制限事項 | 推奨移行先 |
|---|---|---|---|
| Azure Synapse Analytics | メンテナンスモード | 新機能の開発停止。既存機能のバグ修正とセキュリティパッチのみ | Microsoft Fabric |
| Azure Synapse Analytics Runtime for Apache Spark | 廃止進行 | Spark 3.3以前は廃止済み。Spark 3.4は2025年11月廃止 | Fabric Spark / Databricks |
| Azure HDInsight 4.0/5.0 | 廃止済み | 2025年3月31日にリタイア | HDInsight 5.1またはFabric |
| Azure HDInsight on AKS | 廃止予定 | 2025年1月31日にリタイア | Fabric / Databricks |
| Azure HDInsight 5.1 | GA(限定継続) | ESP(Enterprise Security Package)は2026年7月31日にサポート終了 | Fabric / Databricks |
Synapse Analyticsからの移行では、Dedicated SQL PoolはFabric Data Warehouseへ、Synapse SparkはFabric SparkまたはDatabricksへの移行が推奨されています。Synapse Pipelineは、Fabric Data Factoryでほぼ同等の機能が提供されているため、パイプライン定義の移植が比較的容易です。
HDInsightについては、Hadoop・Spark・KafkaなどのOSS基盤をクラウドで利用していた環境を、FabricまたはDatabricksに移行する計画が必要です。特にESPを利用しているセキュリティ要件の高い環境では、2026年7月31日のサポート終了に先立った移行が急務です。
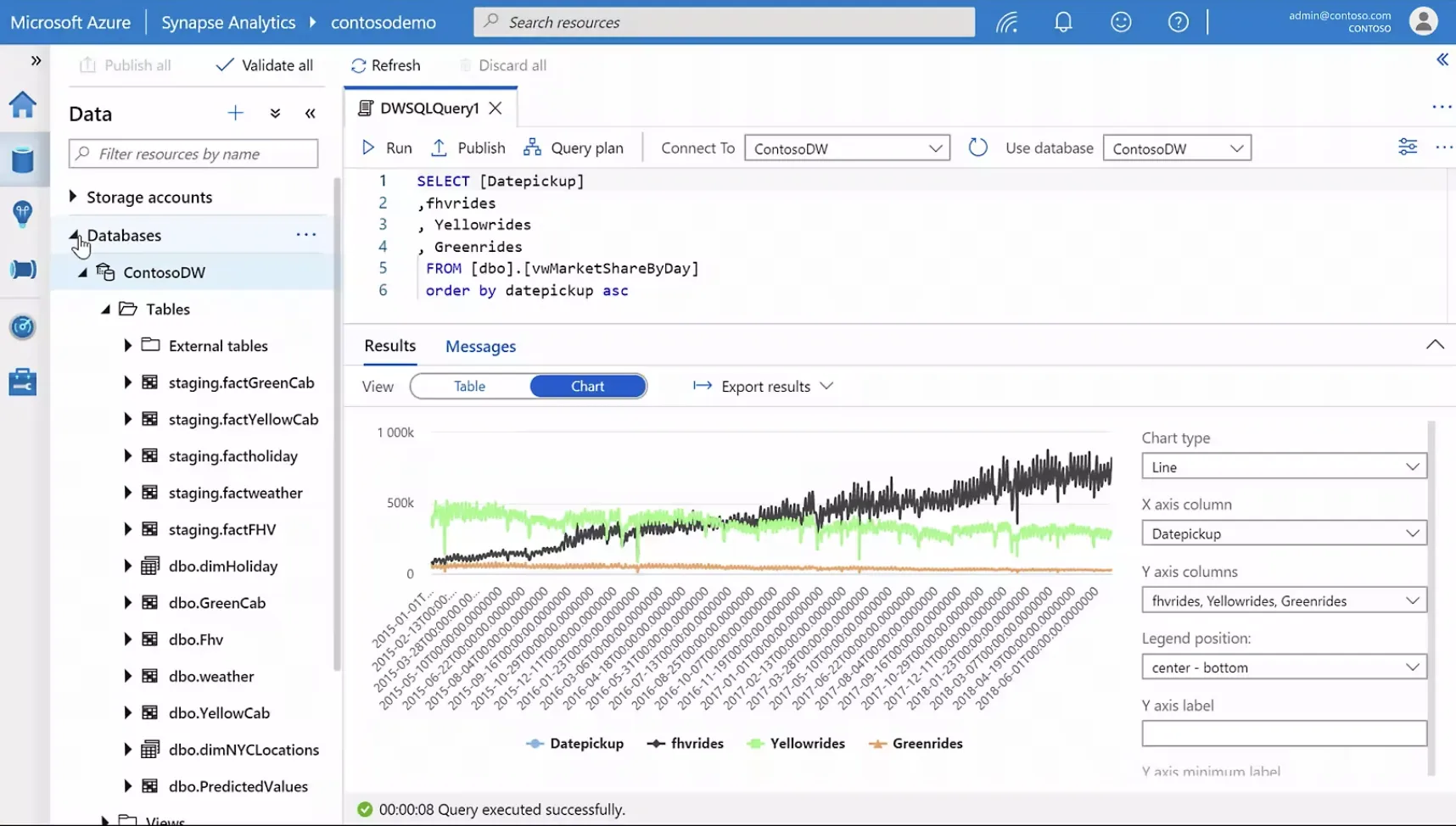
Azure Synapse Analyticsの分析画像

Azure HDInsightの初期画像
Microsoft Fabricの主要機能とOneLake
Microsoft Fabricは、データの取り込みから加工・分析・可視化・AI活用までを1つのプラットフォームで完結させる統合環境です。Fabricのアーキテクチャは、共通のデータ基盤であるOneLakeの上に複数のワークロードが乗る構造になっています。以下の表でFabricの主要コンポーネントを整理しました。
| コンポーネント | 機能 | 主な用途 |
|---|---|---|
| Data Factory | データ統合・ETL/ELTパイプライン | 外部データソースからの取り込み・変換 |
| Data Engineering | Sparkベースのデータ加工 | 大規模データの前処理・構造化 |
| Data Warehouse | T-SQLベースの分析用DWH | 構造化データの高速クエリ |
| Data Science | ノートブック・MLモデル開発 | 機械学習モデルの構築・デプロイ |
| Real-Time Intelligence | ストリーミングデータの処理・分析 | IoT・ログのリアルタイム監視 |
| Power BI | データ可視化・レポーティング | ダッシュボード・セルフサービスBI |
従来はこれらの機能を個別のAzureサービスとして契約・管理する必要がありましたが、Fabricでは1つのキャパシティ課金で全機能を利用できます。これにより、サービス間のデータ連携やアクセス権管理が大幅に簡素化されています。
Azure Blob Storageや外部のデータベースからFabricへデータを取り込む際にも、Data Factoryのコピーアクティビティやデータフローを利用してGUIベースでパイプラインを構築できます。既存のAzure Data Factoryのパイプラインをそのまま移行できるため、学習コストを抑えた移行が可能です。
OneLakeによるデータレイクハウスの統合
OneLakeは、Microsoft Fabricに組み込まれた組織全体で共有するデータレイクです。Azure Data Lake Storage Gen2のテクノロジーをベースに構築されており、Fabricのすべてのワークロードが同一のデータストアにアクセスします。従来のデータ分析では、Azure Cosmos DBやAzure SQL Databaseなど複数のデータソースからデータを抽出・コピーする必要がありましたが、OneLakeでは「ショートカット」機能を使って外部データをコピーなしで参照できます。
OneLakeの大きな利点は、Apache Parquet形式とDelta Lake形式をネイティブにサポートしている点です。データはオープンフォーマットで保存されるため、Fabric以外のツール(Azure Databricks、Power BIデスクトップなど)からも直接アクセスできます。ベンダーロックインのリスクを軽減しながら、統合的なデータ管理を実現する設計です。

Azure Data Lake Storageの初期画像
データガバナンスの面では、OneLake上のデータに対してMicrosoft Purview(旧Azure Purview)によるデータカタログ・リネージ追跡・機密ラベルの適用が可能です。これにより、誰がどのデータにアクセスしたか、データがどのように変換されたかを組織全体で可視化できます。
ビッグデータとAI・機械学習の統合
ビッグデータの真価は、AI・機械学習と組み合わせることで発揮されます。Azureでは、Azure OpenAI ServiceやAzure AI Servicesを活用して、蓄積したビッグデータにAIの力を加えた分析が可能です。以下の表でAzureのAI・機械学習関連サービスとビッグデータ分析での活用方法をまとめました。
| サービス | 概要 | ビッグデータとの統合ポイント |
|---|---|---|
| Azure Machine Learning | MLモデルの開発・トレーニング・デプロイ | Fabric/DatabricksのデータをMLパイプラインで処理 |
| Azure OpenAI Service | GPT-4o・o3などのLLM利用 | 大量テキストの要約・分類・構造化 |
| Azure AI Services | Vision・Speech・Languageなど事前構築AI | 画像・音声・テキストの分析・タグ付け |
| Fabric AI スキル | Fabric内でのノーコードAI機能 | OneLakeデータに対する自然言語クエリ |
特にMicrosoft Fabricでは、2024年以降にAIスキル機能が追加され、OneLake上のデータに対して自然言語で質問するだけで分析結果を取得できるようになりました。SQLやPythonの知識がなくても、ビジネスユーザーが直接データにアクセスして意思決定に活用できる環境が整いつつあります。
Azure Machine LearningとFabricの連携
Azure Machine LearningとMicrosoft Fabricは、相互に連携してMLOps(機械学習の運用管理)を効率化できます。FabricのData Science機能でノートブックを使ってモデルを開発し、Azure Machine Learningのマネージドエンドポイントにデプロイするワークフローが構築可能です。
具体的には、OneLakeに蓄積されたデータをFabric SparkまたはPandasで前処理し、MLflowでモデルの学習・評価を追跡した上で、Azure Machine Learningのレジストリにモデルを登録するという流れです。Azure Monitorと連携すれば、デプロイされたモデルの推論パフォーマンスやデータドリフトを継続的に監視することもできます。
Azure Databricksを利用する場合は、DatabricksのMLflowとUnity Catalogを活用したMLOps基盤が利用でき、モデルのバージョン管理・ステージング・本番デプロイまでを一貫して管理できます。大規模なモデル学習が必要な場合は、DatabricksのGPUクラスターを活用した分散学習が有効です。
ビッグデータ分析の導入事例
Azureのビッグデータ分析サービスは、国内企業でも様々な業種で導入が進んでいます。しかし実際には、Excelや個別ツールによる属人的なデータ管理から脱却できていない企業、オンプレミスのデータウェアハウスの老朽化に直面している企業、データが部門ごとにサイロ化して全社的な分析ができない企業が多く存在します。以下の表で、こうした課題を解決した国内企業の事例を紹介します。
| 企業 | 導入サービス | 課題 | 成果 |
|---|---|---|---|
| ヤマシタ | Microsoft Fabric | Excel中心の在庫管理で集計に数日かかっていた | Excel作業を撤廃しリアルタイム在庫管理を実現。経営判断の迅速化 |
| 北國銀行(CCI支援) | Microsoft Fabric | Synapse Analyticsからの移行。パイプラインの複雑化 | Fabric移行でパイプライン数を40-60%削減。運用コスト低減 |
| Sky | Azure Databricks + AI | AIエージェントの大規模展開 | 100件以上のAIエージェントを構築・運用。業務自動化を推進 |
| 日立ソリューションズ | Microsoft Fabric | 顧客向けデータ分析基盤の構築支援 | Fabric導入支援サービスとして体系化。複数業種での展開実績 |
北國銀行の事例は、Synapse AnalyticsからFabricへの移行における典型的な成功パターンです。従来は複雑に分岐していたETLパイプラインが、FabricのOneLakeとData Factoryの統合によって大幅に簡素化されました。パイプライン数が40-60%削減された結果、運用負荷とコストの両面で改善が実現しています。
Skyの事例では、Azure Databricksを基盤として100件以上のAIエージェントを構築しています。ビッグデータの蓄積・処理基盤としてDatabricksを活用しつつ、その上にAIエージェントを展開する構成は、データドリブンな業務自動化のモデルケースといえます。Azureの導入事例では、他にも様々な業種での活用が紹介されています。

ビッグデータ管理のベストプラクティス
Azureでビッグデータ分析基盤を構築・運用する際には、以下の4つの観点でのベストプラクティスを押さえることが重要です。
-
データガバナンスの確立
Microsoft PurviewやDatabricks Unity Catalogを活用し、データの分類・アクセス制御・リネージ追跡を組織全体で統一します。データの品質管理ルールを定め、入口となるデータ取り込み時にバリデーションを実施することで、下流の分析精度を維持できます。
-
コスト最適化の継続的な実施
FabricのCU消費量やDatabricksのDBU使用量を定期的にモニタリングし、過剰なリソース割り当てを見直します。Fabricでは自動スケーリングとスケジューリング機能を活用し、夜間・休日のキャパシティを削減することで大幅なコスト削減が可能です。Azure Cost Managementとの連携によるアラート設定も推奨されます。
-
セキュリティの多層防御
データの暗号化(保存時・転送時)、Microsoft Entra ID(旧Azure AD)によるアクセス管理、Private Endpointによるネットワーク分離を組み合わせた多層防御を構築します。特にFabricのワークスペースロールとOneLakeのアクセス許可を適切に設定し、最小権限の原則を徹底することが重要です。
-
段階的な移行と並行運用
Synapse AnalyticsやHDInsightからFabricへの移行は、一括ではなく段階的に進めます。まず影響の小さいレポーティング系ワークロードから移行し、ETLパイプラインやリアルタイム処理は動作検証を十分に行った上で切り替えます。移行期間中は新旧システムを並行運用し、データの整合性を検証しながら進めることが失敗リスクを最小化します。
Azureビッグデータ分析の料金(2026年3月版)
Azureのビッグデータ分析サービスは、利用するサービスと消費量に応じた従量課金が基本です。以下の表で主要サービスの料金体系を整理しました。なお、料金は2026年3月時点の情報であり、最新の正確な価格はAzure料金計算ツールで確認してください。
| サービス | 課金モデル | 参考料金(Japan East) | 備考 |
|---|---|---|---|
| Microsoft Fabric | Capacity Unit(CU)従量課金 | F2: 約$0.36/時間、F64: 約$9.22/時間 | CUの一時停止で課金停止可能 |
| Microsoft Fabric | CU予約インスタンス | 1年: 約25%割引、3年: 約50%割引 | 月額固定で安定したコスト管理 |
| Azure Databricks | DBU(Databricks Unit)従量課金 | Jobs Compute: $0.15-0.30/DBU(ティアによる) | VM料金が別途発生 |
| Azure Data Lake Storage Gen2 | ストレージ容量+トランザクション | Hot: 約$0.02/GB/月 | アクセス層(Hot/Cool/Archive)で単価変動 |
| Azure Synapse Analytics | DWU(既存環境) | DW100c: 約$1.51/時間 | 新規利用は非推奨 |
コスト最適化のポイントは、FabricのCU予約インスタンスの活用と、不要時のキャパシティ一時停止です。予約インスタンスを1年契約で購入すると約25%、3年契約で約50%の割引が適用されます。また、開発環境や非本番環境では夜間・休日にキャパシティを停止することで、コストを大幅に削減できます。
Azureのサポートプランの選択もコストに影響します。FabricやDatabricksの導入初期はProfessional Directプラン以上を利用し、技術的な問い合わせに対する迅速な対応を確保することを検討してください。

ビッグデータ分析基盤を「分析」から「業務自動化」に拡張するなら
ビッグデータのインサイトをAIエージェントが業務アクションにつなげる
Azure上のビッグデータ分析基盤で得られたインサイトを、レポートで眺めるだけでなく業務アクションに直結させる段階に来ています。
AI Agent Hubは、Microsoft FabricのOneLakeに集約したビッグデータ資産をAIエージェントの判断基盤として活用するエンタープライズAI基盤です。
- OneLakeのビッグデータをAgentナレッジとして直接参照
FabricやDatabricksで統合したデータにAIエージェントがアクセスし、自然言語での問い合わせから報告・申請まで自動実行します。
- 構築基盤が違っても管理は1つ
Fabric・Databricksどちらの環境で構築しても、1つの管理ダッシュボードでAgent活用状況を一元管理。シャドーAIの乱立を防ぎます。
- 使い慣れたMicrosoft環境をそのまま活用
Teamsなど既存のMicrosoftツールの延長でAIエージェントが動作。新しいツールの学習コストはゼロです。
- データは100%自社テナント内に保持
AIの学習対象から完全除外。Azure Managed Applicationsとして自社テナント内で動作が完了する設計です。
AI総合研究所の専任チームが、設計から運用まで伴走支援します。まずは無料の資料で、自社の業務にどう活用できるかご確認ください。
ビッグデータ基盤をAI業務自動化に拡張

データ分析からAgent実行まで一気通貫
Fabricに蓄積したビッグデータを、AIエージェントの業務判断基盤として活用。OneLakeのデータ仮想統合で、分析から業務アクションの自動実行まで一気通貫で構築できます。
まとめ
本記事では、Azureのビッグデータ分析サービスについて、2026年最新の全体像を解説しました。Microsoft Fabricの登場により、Azureのデータ分析基盤はSynapse Analytics・Data Factory・Power BIの個別サービスから、統合プラットフォームへと進化しています。Azure Databricksとの併用により、セルフサービスBIから大規模な機械学習パイプラインまで幅広いユースケースに対応できます。
Azureでビッグデータ分析基盤の構築・移行を進めるにあたり、以下の3ステップで検討を始めることを推奨します。
- 現状のデータ基盤を棚卸しする。利用中のSynapse Analytics・HDInsight・Data Factoryの環境と、データのボリューム・アクセスパターンを整理し、移行対象と優先順位を明確にします
- Microsoft FabricとAzure Databricksの評価環境を構築する。Fabricの試用版(無料トライアル)やDatabricksのCommunity Editionを活用し、実際のデータで処理性能とコストを検証します
- 段階的な移行計画を策定する。レポーティング系から着手し、ETLパイプライン、リアルタイム処理の順に移行を進めます。Microsoft LearnのFabric学習パスも活用しながら、チームのスキルアップを並行して進めることが成功の鍵です










