この記事のポイント
 現行Fabricは6大ワークロード(Data Factory / Analytics / Databases / Real-Time Intelligence / Fabric IQ / Power BI)+OneLakeという構造で、Synapse・PBI・ADFの延長で捉えられる
現行Fabricは6大ワークロード(Data Factory / Analytics / Databases / Real-Time Intelligence / Fabric IQ / Power BI)+OneLakeという構造で、Synapse・PBI・ADFの延長で捉えられる- Mirroringが2025年内にAzure SQL DB・Cosmos DB・Snowflake・PostgreSQL含めてGAし、ETLパイプラインなしで近リアルタイムのデータレプリカが得られる
- Copilot利用要件は2025年4月以降F2以上に緩和され、初期検証コストが月$262前後まで下がった
- F64はPower BI Freeライセンス閲覧が可能になるPower BI Premium相当のライセンス閾値で、社内配信を想定した事業運用フェーズでは実質的な最小構成になる
- Ignite 2025で発表されたFabric IQは業務概念とデータをオントロジーで結ぶ意味レイヤーであり、Fabric Data AgentはMicrosoft 365 Copilotの宣言型エージェント公開(GA)・Copilot Studio連携(プレビュー)・MCP Server(プレビュー)の主に3経路で外部エージェントから呼び出せる

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Microsoft Fabricは、データ収集から可視化までを1つのSaaS環境で完結させる統合データ分析プラットフォームです。
Azure Synapse・Power BI・Azure Data Factoryといった既存製品を、OneLakeという共通ストレージの上で束ね直した「データ活用の新しい土台」として位置づけられています。
2025年11月のMicrosoft Ignite以降は、Fabric IQ・Fabric Data Agents・Mirroring対応ソースのGA拡大・dbt Job Integrationが揃い、分析基盤の役割に加えてAIエージェントに業務文脈を渡す土台としても使える設計に踏み込んでいます。
本記事では、6大ワークロードの中身、OneLakeとDirect Lakeの設計思想、Copilot・Data AgentのAI活用、F SKUの料金体系、初期構築の使い方、Databricks/Snowflakeとの使い分け、国内外の導入事例、セキュリティとガバナンス、そして導入判断で詰まる論点までを、2026年7月時点の最新情報で解説します。
目次
Microsoft Fabricとは?OneLakeで束ねた統合データ分析プラットフォーム
Azure Synapse/Power BI/Data Factoryとの位置づけ
Microsoft Fabricを構成する6つのワークロード
Data Factory:200+コネクタとdbt Job統合
Analytics:Data Engineering / Data Warehouse / Data Science
Databases:Fabric SQL DatabaseとMirroring GA
Real-Time Intelligence:イベントストリームのフル体験
Fabric IQ:オントロジーで意味レイヤーを整備する新ワークロード
Power BI:Fabricのフロントエンドとしての位置づけ
OneLakeとDirect Lake — Fabricの中心にある「One Copy」の設計
Shortcuts:Amazon S3・Google Cloud Storageへのゼロコピー参照
Direct LakeとMaterialized Lake Views:BIとレイクハウスの直結
課金の全体像:Capacity + OneLake Storage + ユーザーライセンス
Fabric Copilot・Data AgentのAI活用
Fabric IQ:オントロジーで業務概念をデータに接続する
FabricとDatabricks / Snowflakeの使い分け
併用パターン:Fabric(BI)+ Databricks(ML)+ Snowflake(データ共有)
ヤマシタ(介護福祉用具レンタル):全国70拠点でのDX人財配置を目指すデータ基盤
北國銀行/CCIグループ:リードタイムを大幅短縮、インフラ運用ほぼゼロ
グローバルエンジニアリング(電力小売):予測時間50%短縮・予測誤差40%削減
伊藤忠商事:FOODATAへの生成AI基盤導入とFabric検討
海外事例:Melbourne Airport / KPMG / One NZ
認証・認可:Entra ID × ロール × ワークスペース
Microsoft Purview統合:カタログ・ラベル・DLP・監査ログ
既存Azure Synapse Analyticsはどうするか
Microsoft Fabricとは?OneLakeで束ねた統合データ分析プラットフォーム

Microsoft Fabricとは、データ収集から可視化までを1つのSaaS環境で完結させる統合データ分析プラットフォームです。
Azure Synapse Analytics・Power BI・Azure Data Factoryといった既存製品を、OneLakeという共通ストレージの上で束ね直した「データ活用の新しい土台」として位置づけられています。
2025年11月のMicrosoft Igniteで発表されたFabric IQ(業務概念とデータをつなぐ意味レイヤー)とCopilotの組み合わせにより、Fabricは分析基盤の範囲を越え、AIエージェントに業務文脈を渡す土台の役割まで担う設計に踏み込んでいます。
Snowflake・Databricksと並ぶ「第三のプレイヤー」として、Microsoft 365やPower BIエコシステムを持つ組織の第一候補になっています。
Azure Synapse/Power BI/Data Factoryとの位置づけ
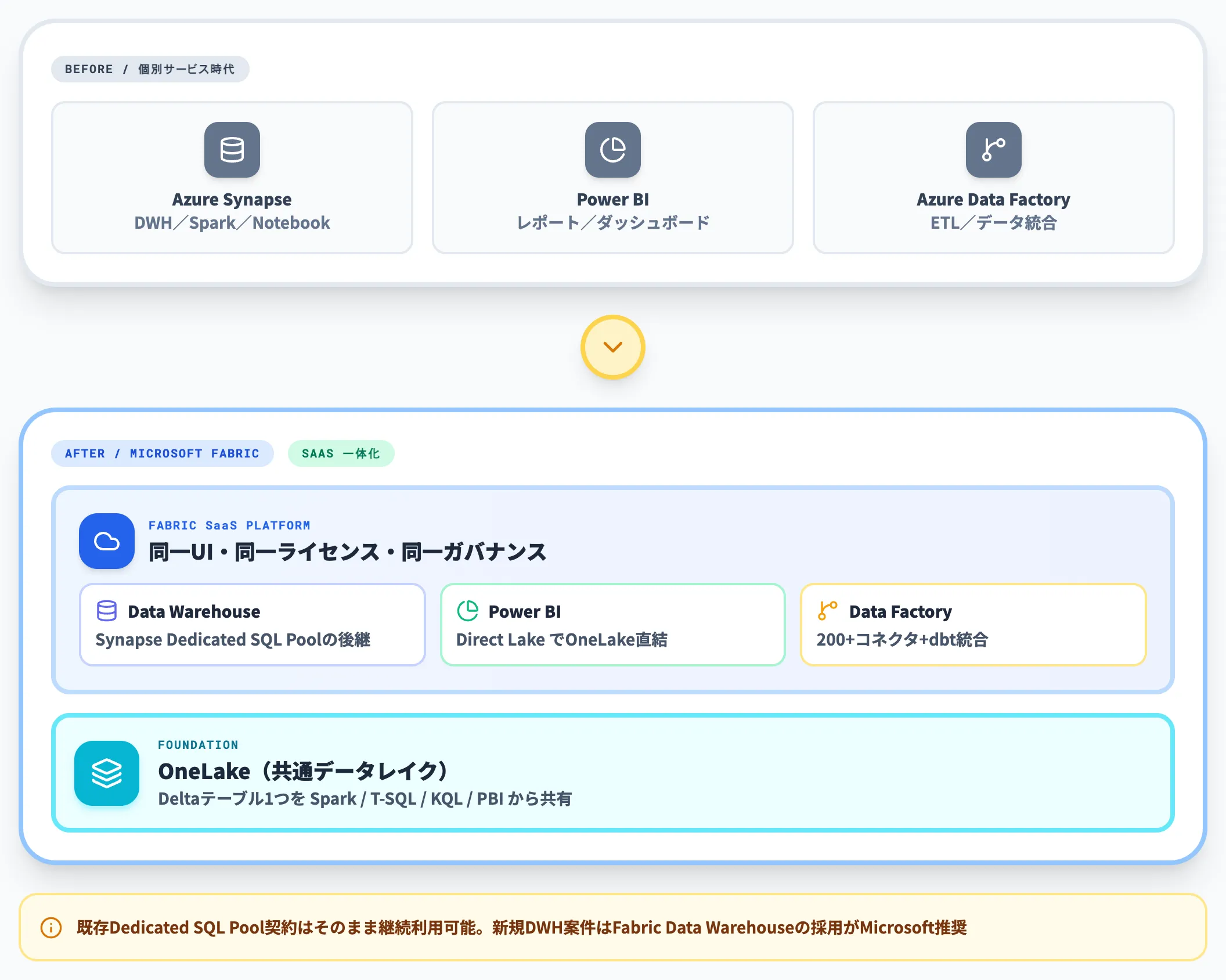
Fabricは、Azure Synapse Analyticsで扱っていたDWH・Sparkパイプライン・レイクハウス操作・Power BIの可視化・Azure Data Factoryのデータ統合を、SaaSの単一環境で束ね直したものです。
- Azure Data Factory/Synapse Analytics/Power BI:既存の運用ノウハウはそのまま活き、これら個別サービスからの移行を明確に想定した設計
- Fabric Data Warehouse
新規のDWH案件ではDedicated SQL PoolではなくFabric Data Warehouseの採用がMicrosoft推奨(既存契約は継続利用可)
ここでのポイントは、FabricはSynapse/Power BI/Data Factoryの後継ではなく、SaaSに束ね直した上位レイヤー、という点です。
既存の個別サービスは継続稼働しながら、新規案件はFabric側で立ち上げるハイブリッド構成が2026年時点の実運用パターンです。

Microsoft Fabricを構成する6つのワークロード
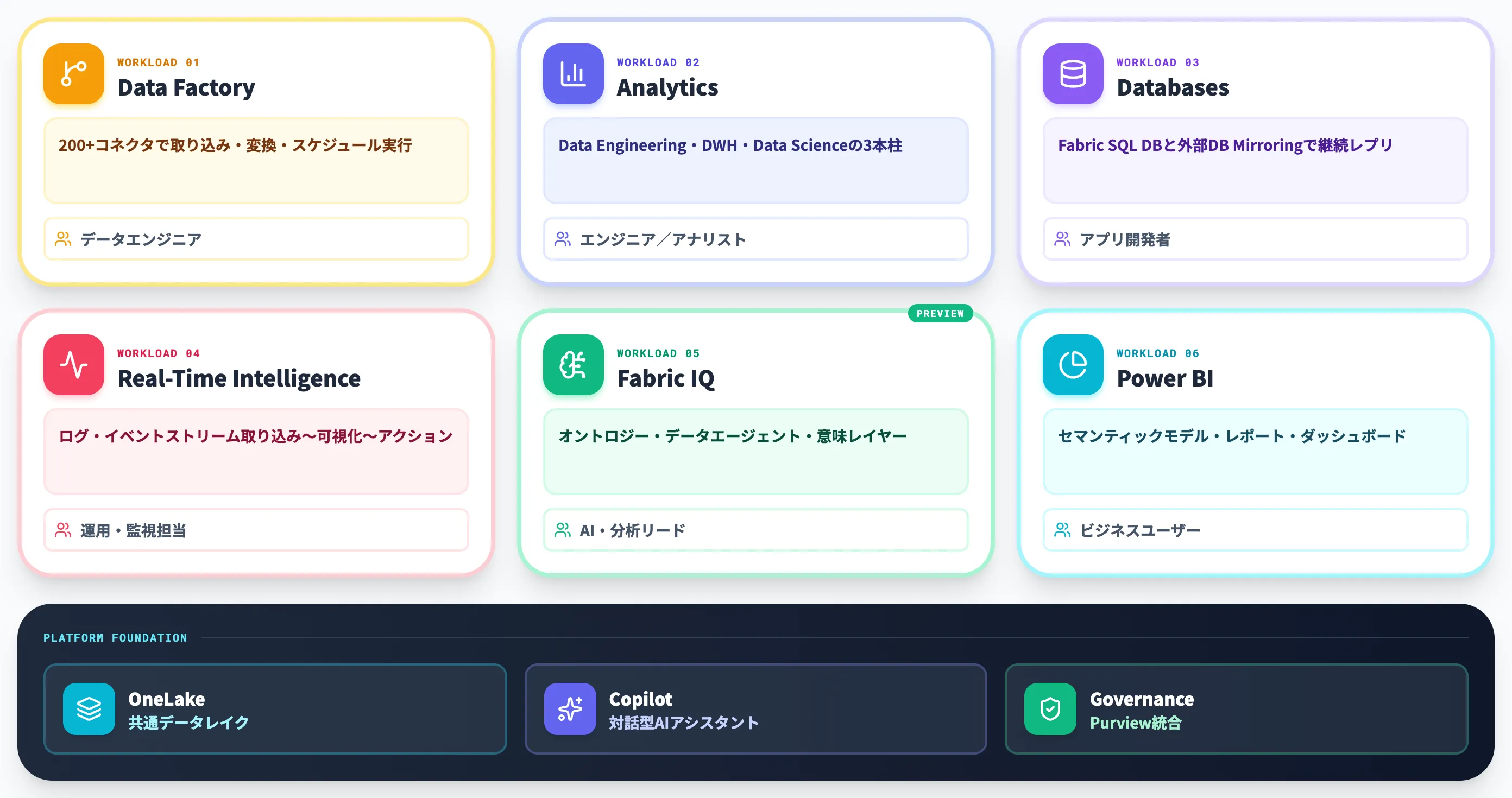
Fabricは、データ統合・分析・可視化・意味レイヤーといった役割ごとに分かれた「ワークロード」の集合として組み立てられています。現
行の公式ドキュメントでは、6大ワークロード(+Industry Solutions)が全てOneLakeの上で動く構造として提示されています。

Microsoft Fabricの6大ワークロード(Data Factory / Analytics / Databases / Real-Time Intelligence / IQ / Power BI)とFabric Platform層(Copilot・OneLake・Governance)の全体像(出典:Microsoft Learn)
以下の表で、6大ワークロードとその役割を整理しました。
| ワークロード | 役割 | 主な利用者 |
|---|---|---|
| Data Factory | データ統合・ETL/ELT。200+コネクタと自動化パイプライン | データエンジニア |
| Analytics(DE / DW / DS) | Data Engineering・Data Warehouse・Data Scienceの3本柱 | エンジニア/アナリスト/サイエンティスト |
| Databases | Fabric SQL Databaseと各種DBのMirroringによる継続レプリ | アプリ開発者・データエンジニア |
| Real-Time Intelligence | ログ・イベントストリームの取り込み〜可視化〜アクション | 運用・監視担当 |
| Fabric IQ(プレビュー) | オントロジー・データエージェント・意味レイヤー | AI・分析リード |
| Power BI | セマンティックモデル・レポート・ダッシュボード | ビジネスユーザー |
この表から分かるのは、Fabricは「役割別のワークロードを縦割りで並べている」のではなく、OneLakeという共通データ層の上に、業務役割ごとの入口を6つ設けている構造だという点です。
特に2025年11月のMicrosoft Igniteで加わった変化が2つあります。
ひとつはFabric IQという新しいワークロードが加わり、ビジネス概念とデータをつなぐ意味レイヤーがプラットフォームに標準装備されたこと。
もうひとつはMirroringの対応ソースがAzure SQL Database・Cosmos DB・Snowflake・PostgreSQL・SQL Serverまで含めてGAし、外部データの取り込み負荷が実務レベルで解消されたことです。
Data Factory:200+コネクタとdbt Job統合
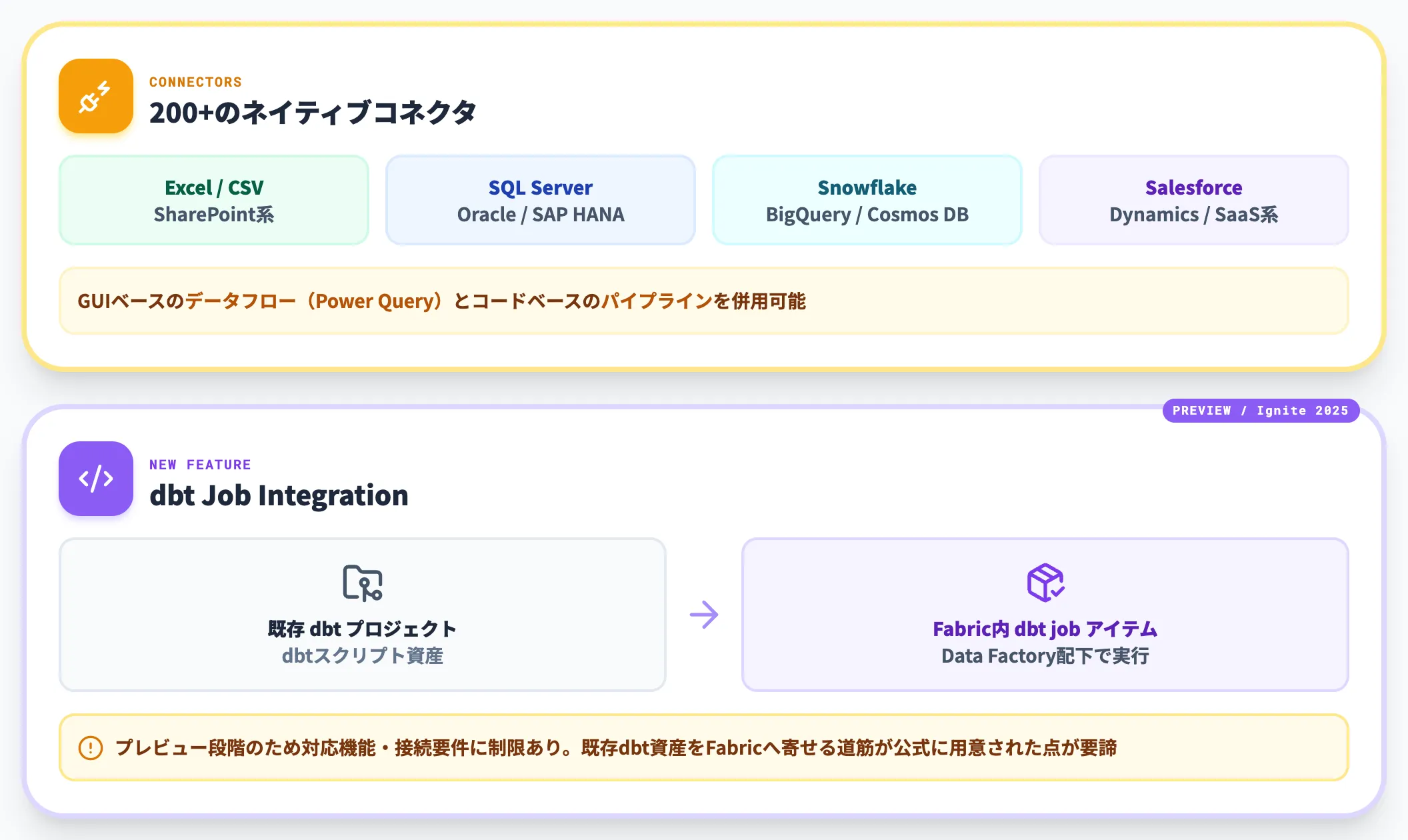
Data Factoryは、Fabric内でデータの取り込み・変換・スケジュール実行を担うワークロードです。
Excel・SQL Server・Oracle・SAP HANA・Snowflake・Salesforce・Google BigQuery・Cosmos DBなど200+のネイティブコネクタを持ち、GUIベースのデータフロー(Power Query)とコードベースのパイプラインを併用できます。
Ignite 2025ではdbt Job Integrationが発表され、既存のdbtプロジェクトをFabric内のdbt jobアイテムとして実行できるようになりました。
プレビュー段階のため対応機能・接続要件には制限がありますが、既存のdbtスクリプト資産を持つ組織がFabricへ寄せていく道筋が公式に用意されています。
【関連記事】
【Microsoft Fabric】Data Factoryとは?機能やADFとの違い、料金体系を徹底解説
Analytics:Data Engineering / Data Warehouse / Data Science
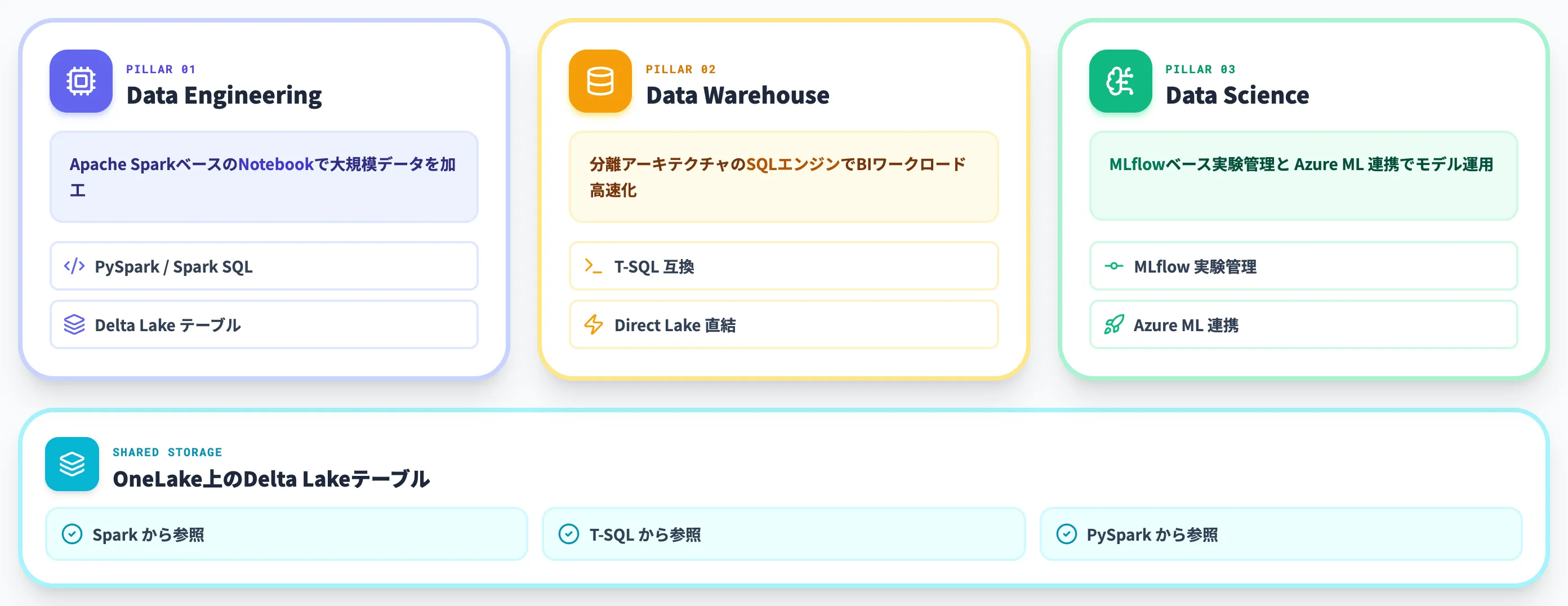
Analytics系は、レイクハウス操作(Data Engineering)・T-SQL型DWH(Data Warehouse)・機械学習(Data Science)を1つのUIから使い分ける構造です。
Data EngineeringではApache SparkベースのNotebookで大規模データを加工し、Data Warehouseでは分離アーキテクチャのSQLエンジンでBIワークロードを高速化、Data ScienceではMLflowベースの実験管理とAzure Machine Learning連携でモデル運用まで扱えます。
いずれもOneLake上のDelta Lakeテーブルを共有ストレージとして使うため、同じデータをSpark・T-SQL・PySparkのどれからも参照できます。
Databases:Fabric SQL DatabaseとMirroring GA
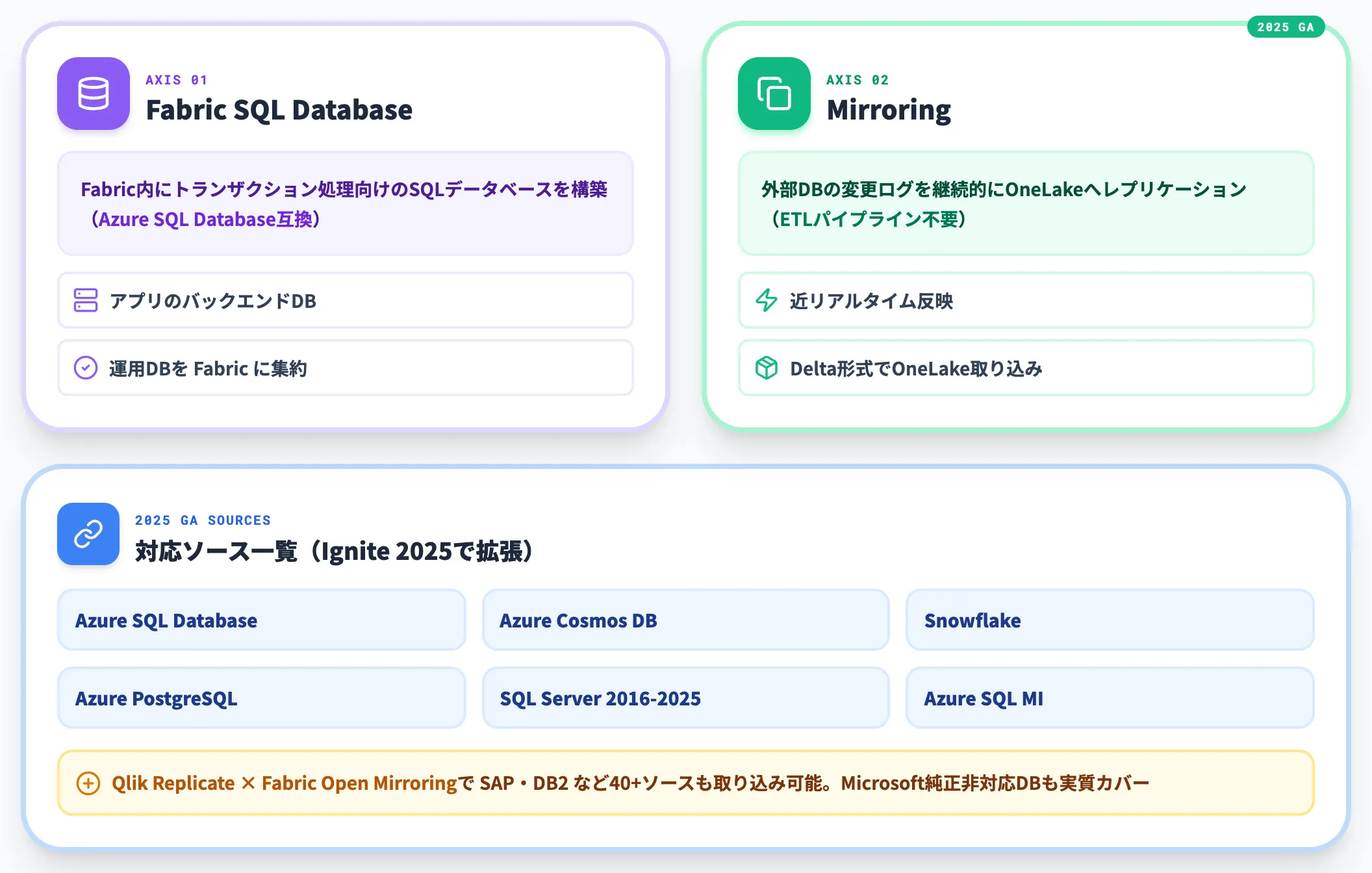
Databasesワークロードは、Fabric内にトランザクション処理向けのSQL Database(Azure SQL Database互換)を作れる機能と、外部データベースをFabric内に継続レプリケーションするMirroringの2軸で構成されています。
Mirroringは、Azure SQL Database・Azure Cosmos DB・Snowflake(管理テーブル/Apache Icebergテーブル)・Azure SQL Managed Instance・Azure Database for PostgreSQL・SQL Server 2016-2022/2025が2025年内にGAし、Mirroring対応ソース一覧に集約されています。
反映されたデータはDelta形式でOneLakeに取り込まれ、Spark・T-SQL・BIから即座に参照できます。
接続作成・権限・オンプレミス経由の場合のデータゲートウェイ・ソース側の設定などはMirroring接続ごとに必要ですが、ETLパイプラインを新規で組む必要がなくなる点が、既存のSynapseや個別ETL基盤で運用していた組織にとって最大の変化です。
Real-Time Intelligence:イベントストリームのフル体験
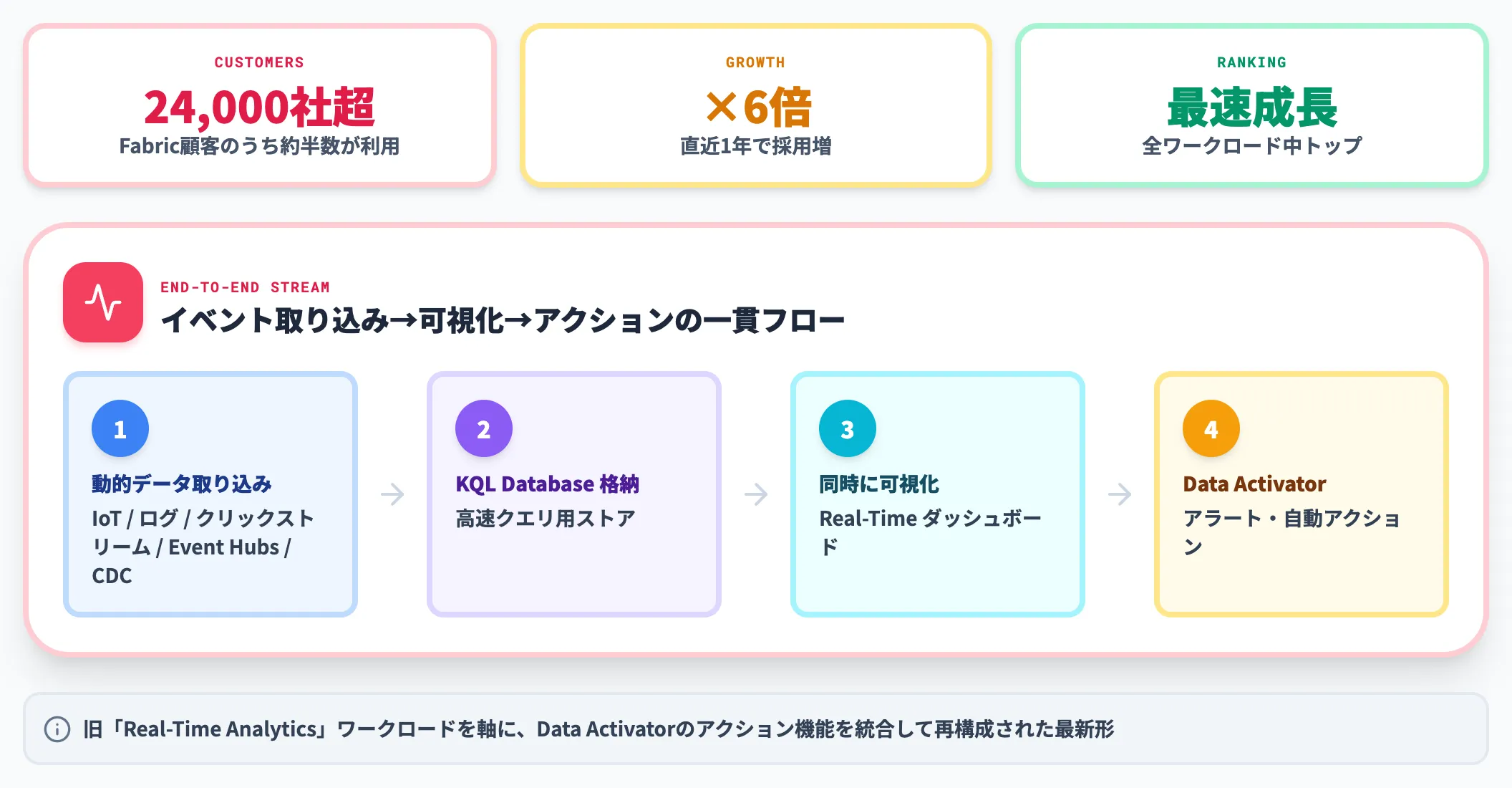
Real-Time Intelligenceは、旧「Real-Time Analytics」ワークロードを軸に、Data Activatorのアクション機能を統合して再構成されたワークロードです。
Microsoftの公式ブログによれば、Fabric顧客24,000社超のうち約半数が既に利用しており、直近1年で採用が6倍に伸びた最速成長ワークロードです。
IoTセンサー・アプリケーションログ・クリックストリーム・Azure Event Hubs・CDCなど動的データを、KQL Databaseに取り込みながら同時に可視化・アラート・自動アクションまで実行できます。
【関連記事】
【Microsoft Fabric】Real-Time Intelligenceとは?機能・料金を解説
Fabric IQ:オントロジーで意味レイヤーを整備する新ワークロード

Fabric IQは、Ignite 2025で発表された新しいワークロードで、業務概念とデータをつなぐ意味レイヤーを提供します。
構成アイテムは、オントロジー・Power BIセマンティックモデル・Plan・Graph・Data Agent・Operations Agentの6つで、既存のPower BIセマンティックモデルからオントロジーを自動生成できるようになっています。
Fabric IQは同時に、より広いMicrosoft IQ(Work IQ / Foundry IQ / Web IQ / Fabric IQの4層)の一部として位置づけられ、Microsoft 365 CopilotやMicrosoft Foundryのエージェントが業務データを正しく解釈するための土台として使われます。
Power BI:Fabricのフロントエンドとしての位置づけ

Power BIは、FabricにおけるBI・レポート・ダッシュボードの入口として位置づけられています。
Fabric登場以降のPower BIは「独立したBIツール」から「Fabricの一部として、OneLake上のデータへ即座にDirect Lakeで接続できるフロントエンド」に位置が変わりました。
既存のPower BIコンテンツはそのままFabric上に持ち込め、追加でCopilotによる自然言語レポート作成やFabric IQのオントロジー参照が使えるようになります。
【関連記事】
Microsoft FabricとPower BIの違い、連携手順をわかりやすく解説
OneLakeとDirect Lake — Fabricの中心にある「One Copy」の設計
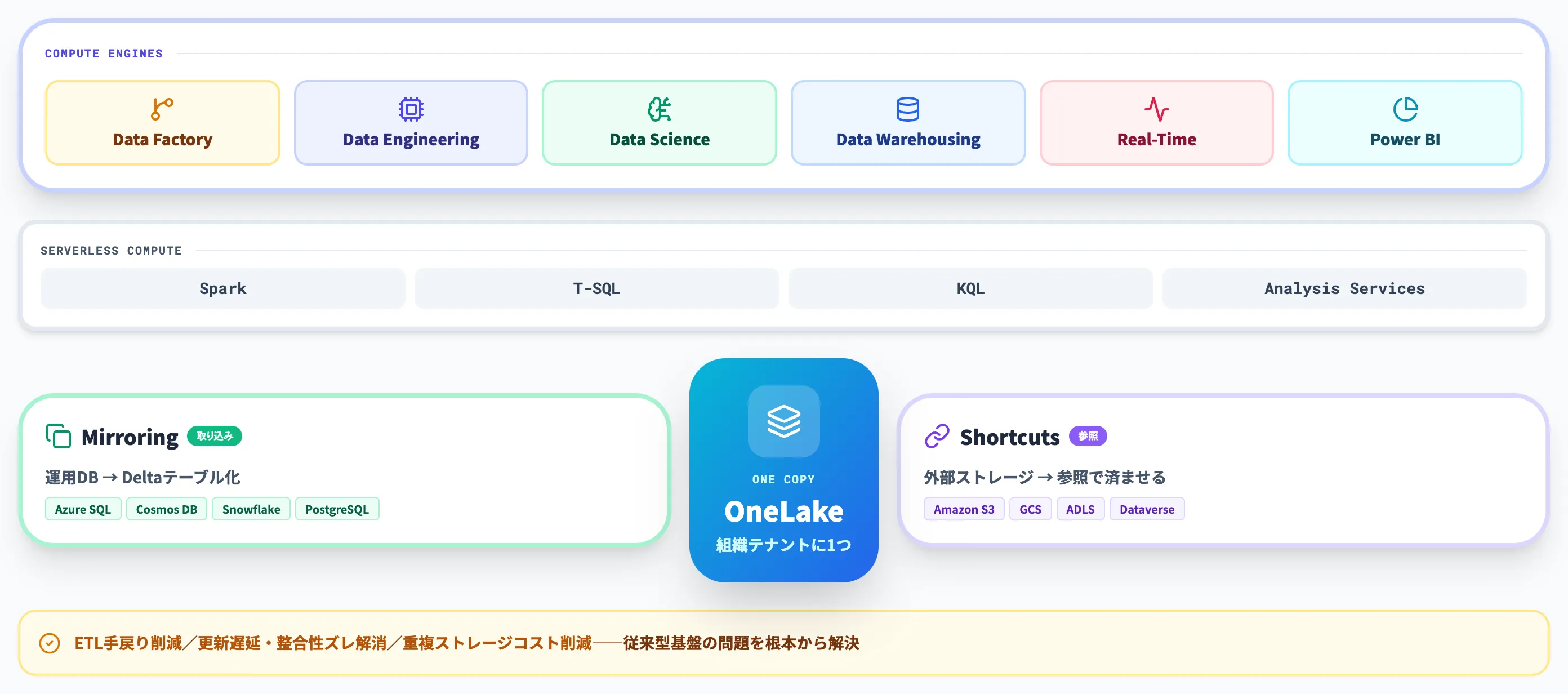
Fabricの技術的な中核は、全ワークロードが同じデータを参照する「One Copy」の設計思想にあります。
複数のシステムに同じデータをコピーして持たせる従来型のデータ基盤と異なり、OneLakeに集約したデータをSpark・T-SQL・KQL・Power BIから共通して参照・活用できる構造です。書き込み可否やデータコピーの有無は、ワークロードやMirroring・Shortcutsなどの接続方式によって異なり、Power BIやLakehouseのSQL分析エンドポイントなど基本的に読み取り側となる経路も含まれます。
この設計により、データ移動やETLの手戻りが減り、更新遅延・整合性ズレ・重複ストレージコストといった従来型基盤で常態化していた問題を根本から解決しやすくなっています。
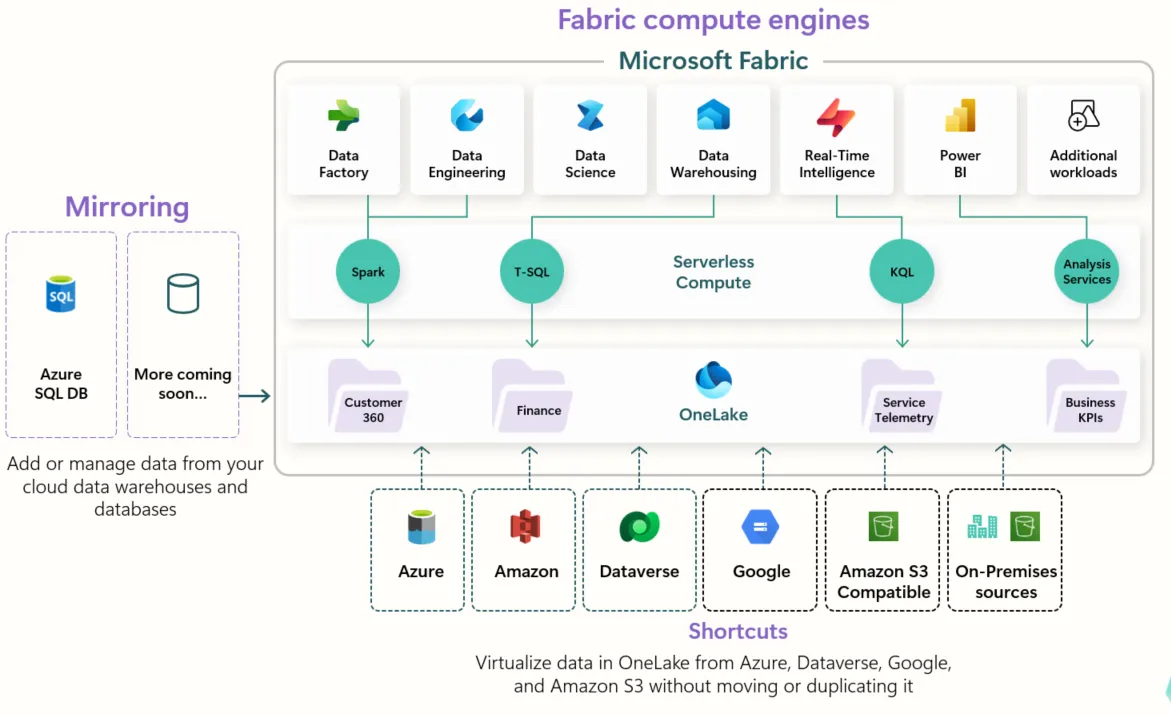
Fabric compute engines(Data Factory / Data Engineering / Data Science / Data Warehousing / Real-Time Intelligence / Power BI)がServerless Compute(Spark / T-SQL / KQL / Analysis Services)越しにOneLakeを共有し、Mirroringで運用DBを取り込み・Shortcutsで外部ストレージ(Azure / Amazon S3 / Google Cloud / Dataverse / オンプレ)を参照する俯瞰図(画像元:learn.microsoft.com/en-us/fabric/fundamentals/media/microsoft-fabric-overview/onelake-architecture.png。※図のMirroring欄は初期のAzure SQL DBのみが描かれた版で、2026年7月時点の対応ソース一覧は次段のMirroring節を参照)
この図でMirroring(左側)とShortcuts(下側)が対称的に配置されている点が着目点です。Mirroringは「取り込んでDeltaテーブル化」、Shortcutsは「取り込まず参照で済ませる」という別々の取り込み手段が、同じOneLakeに向かって共存する構造になっています。
OneLake:組織全体で1つのデータレイク
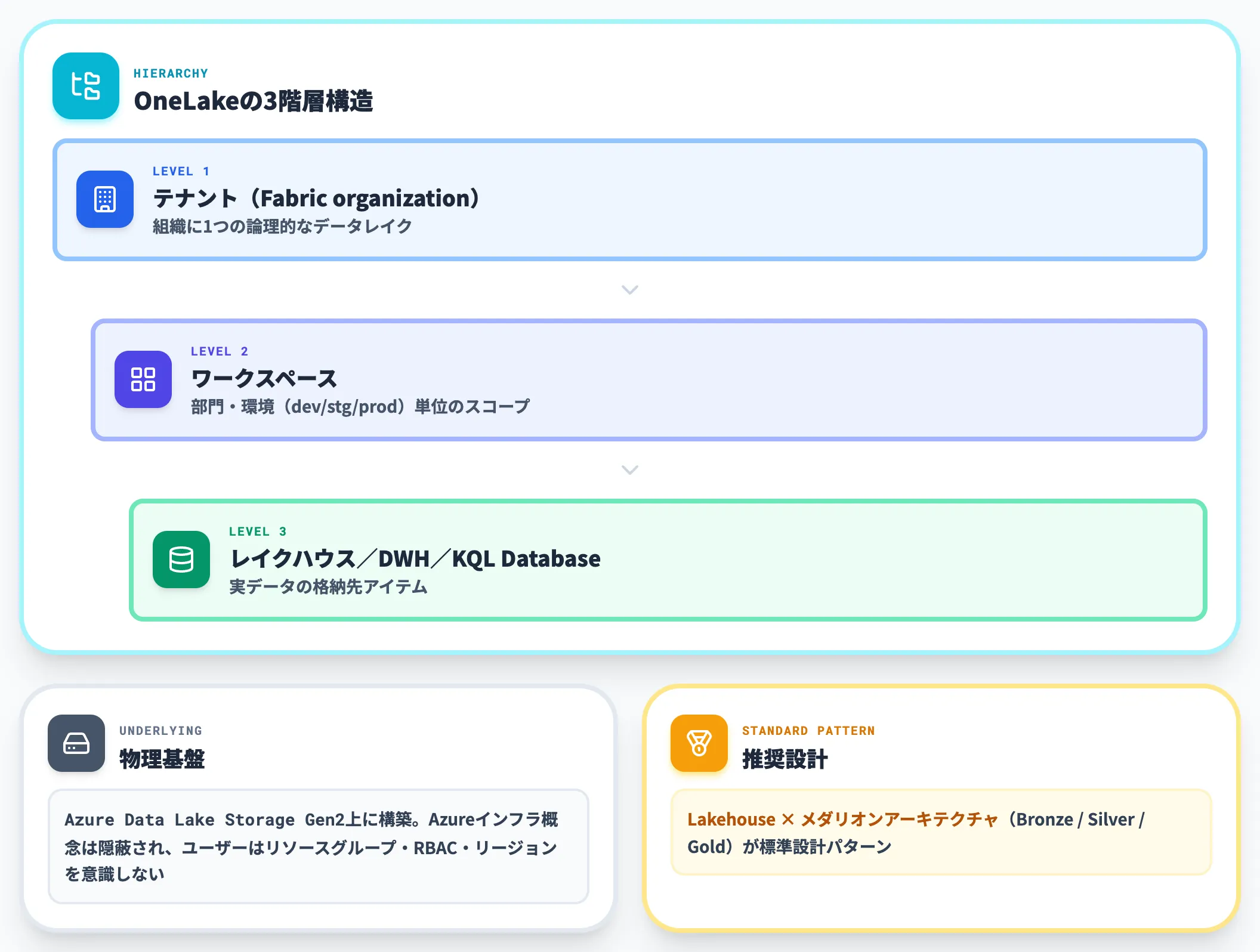
OneLakeは、Azure Data Lake Storage Gen2の上に構築された、Fabricテナントごとに1つだけ存在する論理的なデータレイクです。
ユーザーはリソースグループ・RBAC・リージョンといったAzureのインフラ概念を意識せず、テナント→ワークスペース→レイクハウスという階層でデータを管理できます。
データを整理する枠組みとしてのLakehouseとメダリオンアーキテクチャを組み合わせるのが標準的な設計パターンです。
【関連記事】
OneLakeとは?Fabricの統合データレイクを徹底解説
Shortcuts:Amazon S3・Google Cloud Storageへのゼロコピー参照

Shortcutsは、Fabric外にある既存ストレージのデータをコピーせずにOneLakeから参照する機能です。
Amazon S3・Google Cloud Storage・Azure Data Lake Storage・Dataverseなど主要な外部ストレージがサポートされており、既存のデータ基盤にある大量のデータを移動せずに、Fabric上のワークロードから即座に参照できる構造になっています。
書き込み可否はショートカットの種類と権限によって異なり、Amazon S3・Google Cloud Storage・Dataverseなどは読み取り専用です。マルチクラウド構成の組織や、既存のS3データレイクを持ち続けたい組織にとって、Fabricの導入ハードルを大きく下げる仕掛けになっています。
Mirroring:運用DB・外部DBからの継続レプリ
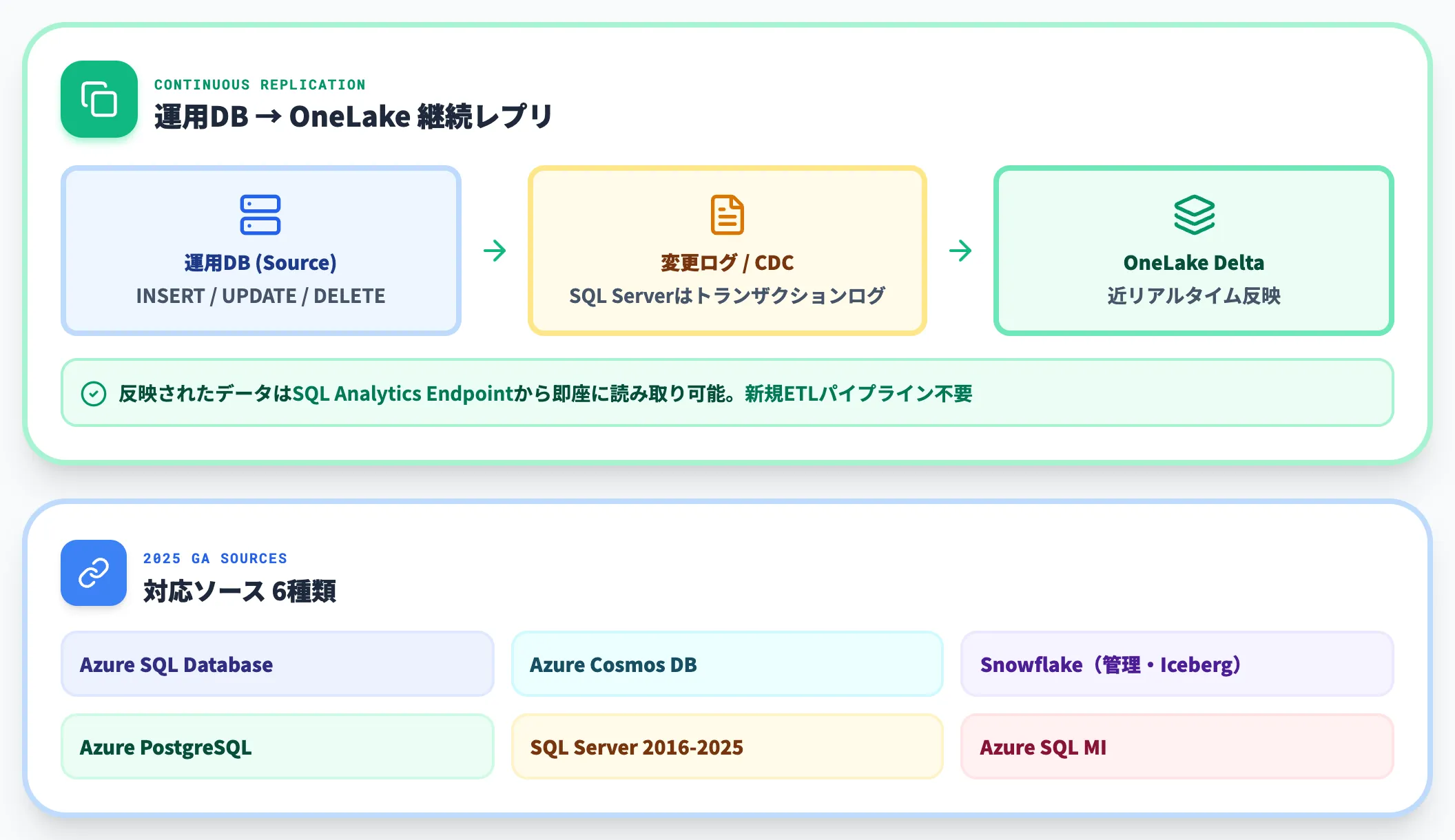
Mirroringは、外部の運用データベース(Azure SQL Database・Azure Cosmos DB・Snowflake・Azure Database for PostgreSQL・SQL Server 2016-2022/2025・Azure SQL Managed Instance)から、変更ログを継続的にOneLakeへレプリケーションする機能です。
ソースごとに異なる変更追跡機構を通じてDeltaテーブルへ反映されるため、新規のETLパイプラインを設計せずに済みます。
SQL Serverではトランザクションログが利用されるなどソース別に方式が変わりますが、いずれもソース側で発生したINSERT/UPDATE/DELETEが近リアルタイムでOneLakeに反映され、そのままSQL Analytics Endpointから読み取れます(Mirroring公式概要)。
加えてQlik ReplicateをFabric Open Mirroringと組み合わせることでSAPやDB2など40超のソースも取り込めるため、Microsoft純正で対応しないDBも実質的にカバーされています。
Direct LakeとMaterialized Lake Views:BIとレイクハウスの直結
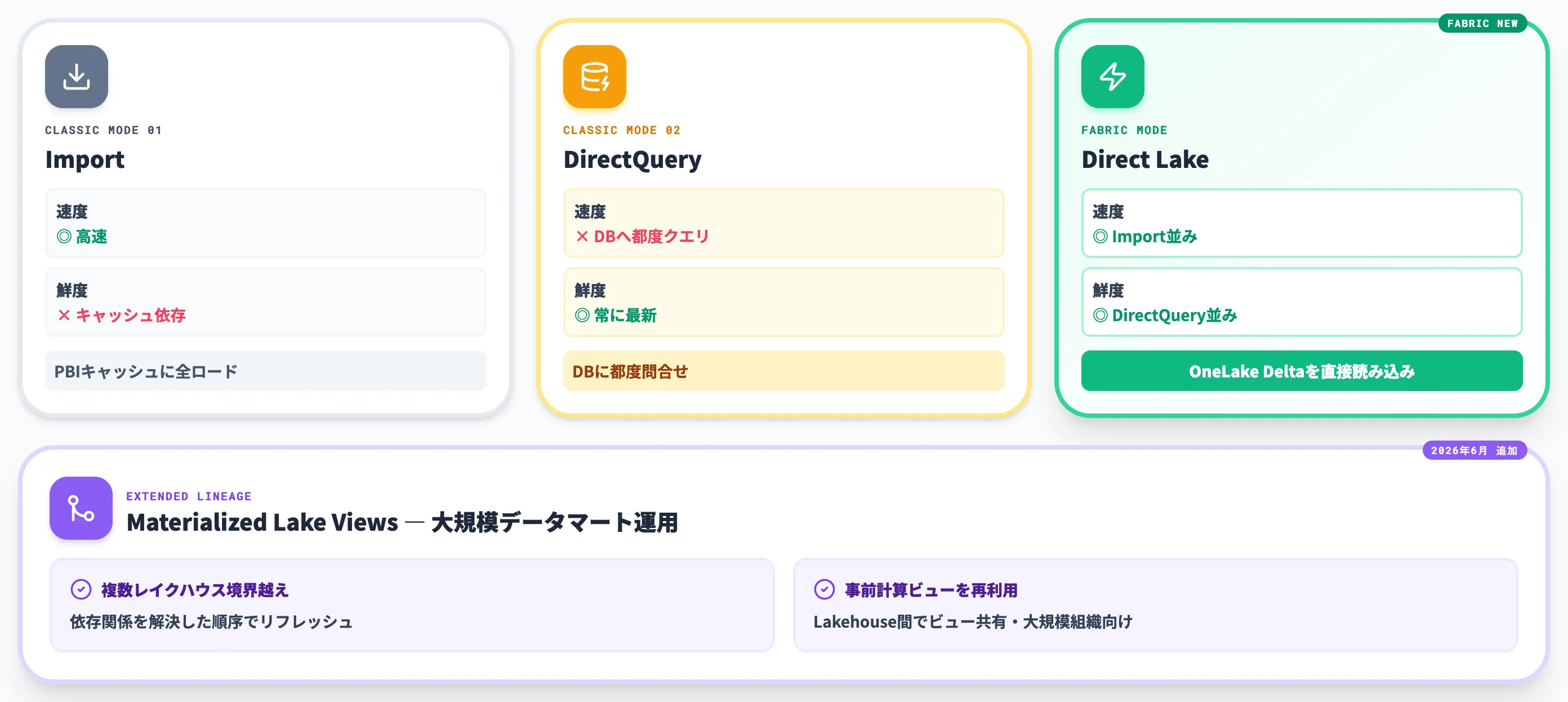
Direct Lakeは、Power BIがOneLake上のDeltaテーブルを直接読み込むモードです。
従来のImportモード(データをPower BIにキャッシュ)やDirectQueryモード(クエリを都度DBに投げる)と異なり、Import並みの高速性とDirectQuery並みの鮮度を両立します。
2026年6月にはMaterialized Lake ViewsのExtended lineageが追加され、複数のレイクハウス境界を越えて依存関係を解決した順序でリフレッシュされる構造になりました。
事前計算されたビューをLakehouse間で再利用できるため、大規模組織でのデータマート運用が現実的な選択肢に入ってきています。
Microsoft Fabricの料金体系

Fabricの料金は、コンピュート(Capacity)・ストレージ(OneLake Storage)・ユーザーライセンス(Power BI Pro / PPU / Free)の3層構造です。
Capacityは「F SKU」と呼ばれる13段階のティアから選び、CU(Capacity Unit)と呼ばれる単位でコンピュートを購入します。
Pay-as-you-goかReserved Instanceを選択でき、Reservedは概ね41%程度のディスカウントが利くのが基本パターンです(公式pricingページ)。
課金の全体像:Capacity + OneLake Storage + ユーザーライセンス

Fabricの支払いは、以下の3つの合算で構成されます。
-
Fabric Capacity(F SKU)
コンピュート消費の中心。全ワークロード(Data Factory・Spark・DWH・Power BI・Copilot)がここからCUを消費する
-
OneLake Storage
データ保存量に対する従量課金。US Eastでの目安はHot $0.026/GB/月・Cool $0.019/GB/月・Cold $0.004/GB/月 の3層で、アクセス頻度に応じてLifecycle Managementで階層を切り替えられる(Azure Retail Prices API・2026年7月時点/OneLake Storage Tiers・Lifecycle Managementは2026年7月22日にGA)
-
ユーザーライセンス
Power BI Pro($14/月/user)/PPU($24/月/user)/Free。F64以上のCapacityでは、FreeライセンスのViewerでもPower BIコンテンツを閲覧できる
Copilot・Data Agentも独立した月額料金ではなく、CU秒としてCapacityから消費される構造です。分単位でCapacityを停止(Pay-as-you-goの場合)することでコストを圧縮できます。
F SKUラインナップと価格の目安
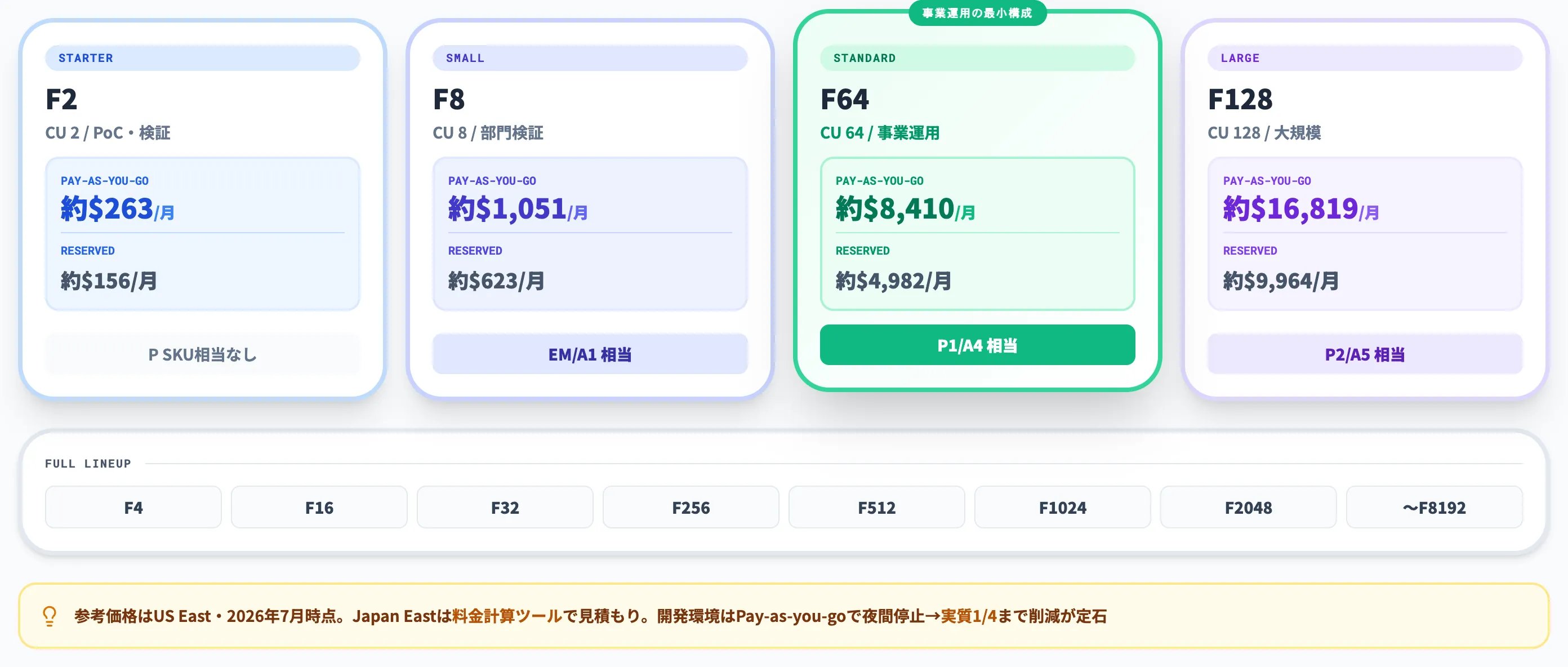
以下の表で、F SKUの主要ティアと月額目安(Pay-as-you-go / Reserved)を整理しました。
| SKU | CU | Pay-as-you-go月額 | Reserved月額 | Power BI Premium相当 |
|---|---|---|---|---|
| F2 | 2 | 約 $263 | 約 $156 | — |
| F4 | 4 | 約 $526 | 約 $311 | — |
| F8 | 8 | 約 $1,051 | 約 $623 | EM/A1相当 |
| F16 | 16 | 約 $2,102 | 約 $1,245 | EM2/A2相当 |
| F32 | 32 | 約 $4,205 | 約 $2,491 | EM3/A3相当 |
| F64 | 64 | 約 $8,410 | 約 $4,982 | P1/A4相当 |
| F128 | 128 | 約 $16,819 | 約 $9,964 | P2/A5相当 |
| F256 | 256 | SKUごとに倍増 | 同 | P3/A6相当 |
| F512 | 512 | SKUごとに倍増 | 同 | P4/A7相当 |
| F1024 | 1,024 | SKUごとに倍増 | 同 | P5/A8相当 |
| F2048〜F8192 | 2,048〜8,192 | SKUごとに倍増 | 同 | 対応するP SKUなし |
参考価格はUS Eastリージョン・2026年7月時点の目安で、実際の請求は契約リージョン・為替・キャンペーンにより変動します。Japan Eastを含む正式単価はAzureの料金計算ツールで見積もる必要があります。
Pay-as-you-goは分単位で停止・再開できるため、開発環境や検証環境では夜間・週末停止で実質コストを4分の1まで下げるのが定石です
。本番運用に近づくほどReservedが有利になります。
F64ラインで変わるもの
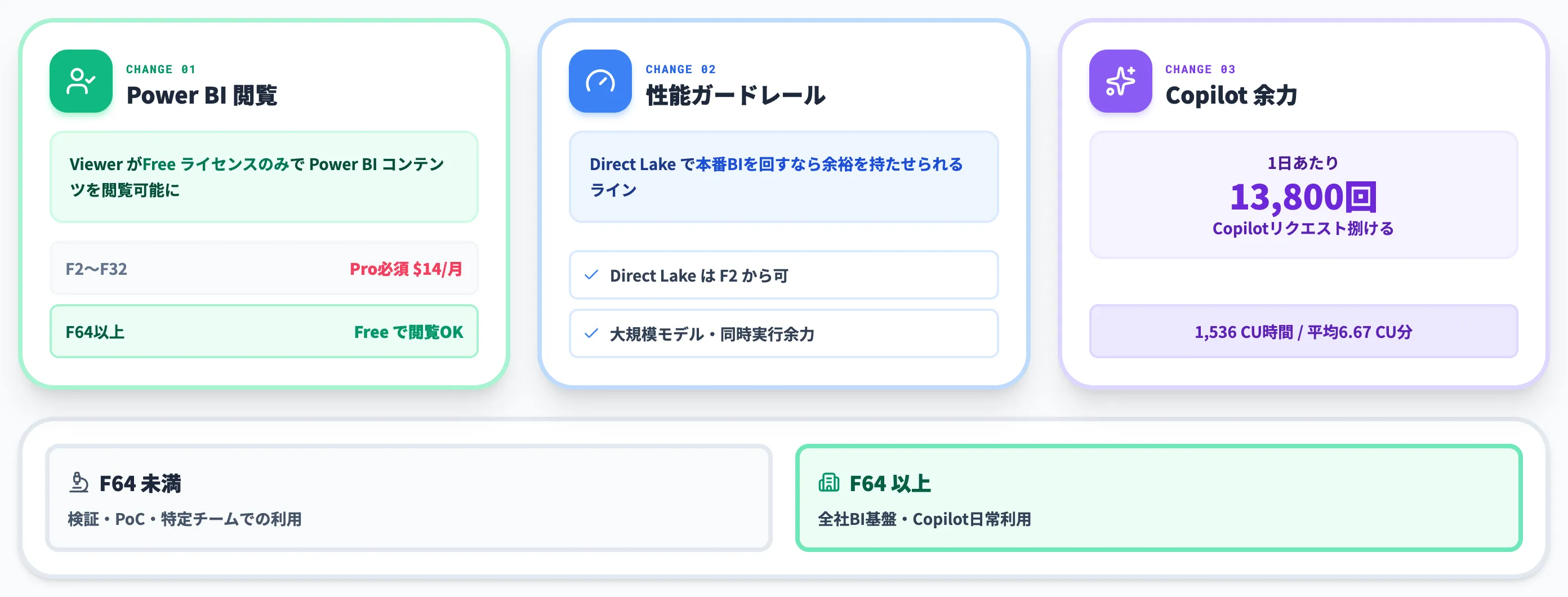
F64は「事業運用フェーズでの実質的な最小構成」として理解されています。
理由は3点です。
-
Power BI閲覧ライセンス
F64以上ではワークスペースのViewerがFreeライセンスのみでPower BIコンテンツを閲覧できる。F2〜F32ではViewerにもPro($14/月/user)が必要
-
性能ガードレール
Direct Lakeモード自体はF2から利用可能だが、SKUごとに大規模モデル・同時実行数などのガードレールがあり、Direct Lakeで本番BIを回すならF64以上で余裕を持たせるのが実務的
-
Copilotリクエスト量
F64は1日あたり1,536 CU時間の余力があり、約13,800回のCopilotリクエストを捌ける計算になる(1リクエスト平均6.67 CU分の場合)
F64未満は「検証・PoC・特定チームでの利用」、F64以上は「全社BI基盤・Copilot日常利用」というのが実務的な線引きです。
Copilot利用の要件はF2以上へ緩和

Copilot for Fabricの利用要件は2025年4月に大きく変わり、それまでF64以上必須だったのがF2以上の有償SKUなら利用可能になりました。CopilotリクエストはCU秒として消費され、入力プロンプト1,000トークンあたり 100 CU秒、出力1,000トークンあたり 400 CU秒、キャッシュ入力は 10 CU秒 です(公式Copilot消費ドキュメント)。
初期検証はF2(月額約 $263 Pay-as-you-go)から始めて、Copilot利用量とパフォーマンス要件を測定してからF64以上にスケールする段階的アプローチが現実的です。
無料トライアル(60日)の位置づけ

Microsoft Entra IDのテナントを持つユーザーは、Fabricの60日間の無料トライアルを利用できます。
付与されるTrial CapacityはF4またはF64相当で、割り当てられた容量はテナント環境によって異なります(Microsoft Fabric Trial)。
トライアル期間中はレイクハウス・DWH・ノートブック・Data Factory等の主要ワークロードで動作検証ができますが、Copilot・Fabric Data Agent・AI functions・AI services等のAI ExperiencesはTrial容量では利用できません。
AI系機能まで含めた検証を行うにはF2以上の有償Capacityを最低1つ用意する必要があり、割り当て容量と対象機能を事前に管理ポータルで確認したうえで、コンセプト検証に使うか有償SKU起点で始めるかを判断するのが実務的です。

Fabric Copilot・Data AgentのAI活用
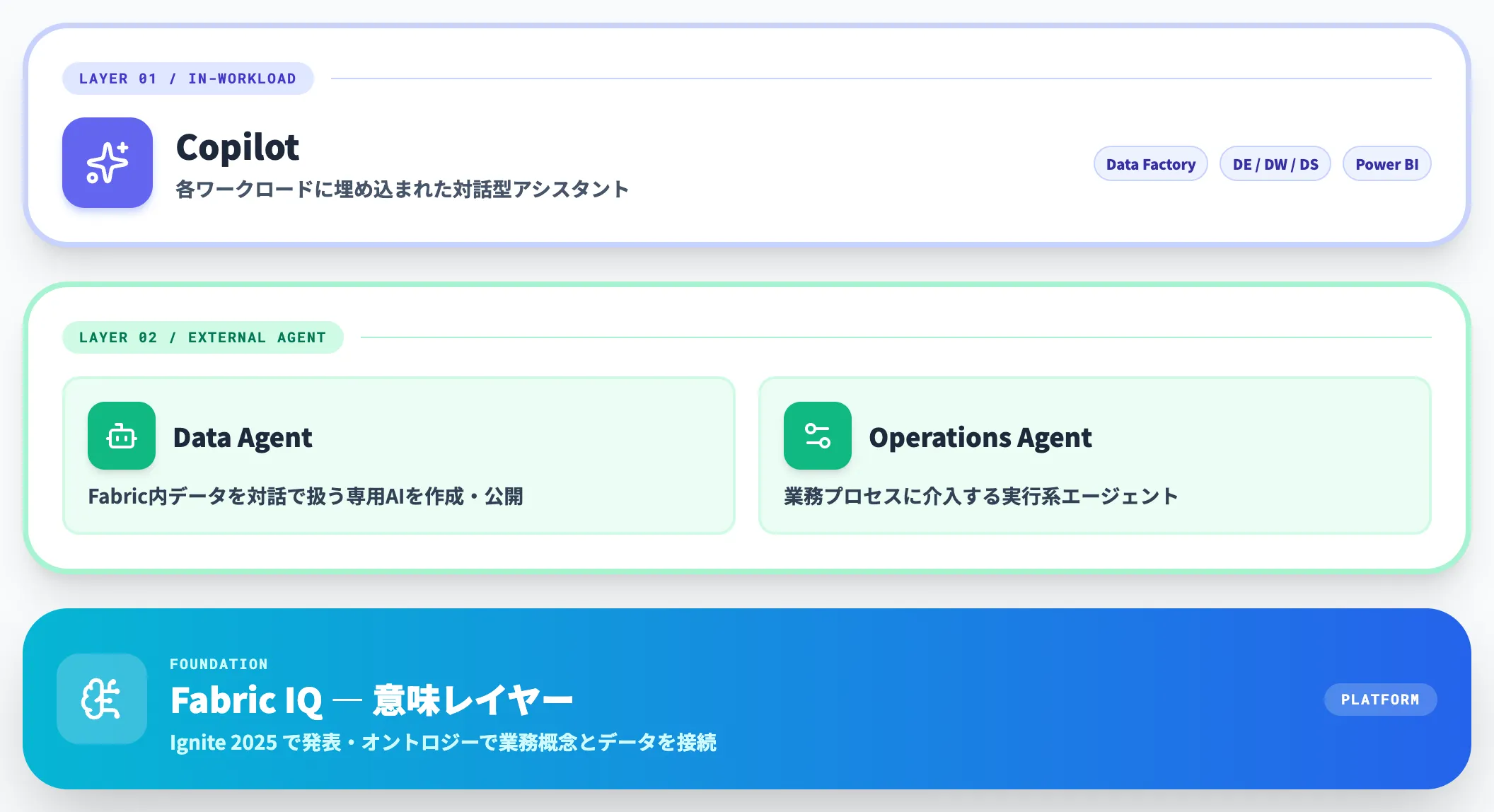
FabricのAI機能は2つのレイヤーに分かれています。Copilot(各ワークロード内で使う対話型アシスタント)と、Data Agent / Operations Agent(Fabric IQ経由で外部エージェントから呼び出せる意味レイヤー越しのAI)です。
Fabric IQが発表されたことで、この2レイヤー構成がプラットフォームとして明確化されました。
Copilot:各ワークロードの中で使う対話型アシスタント
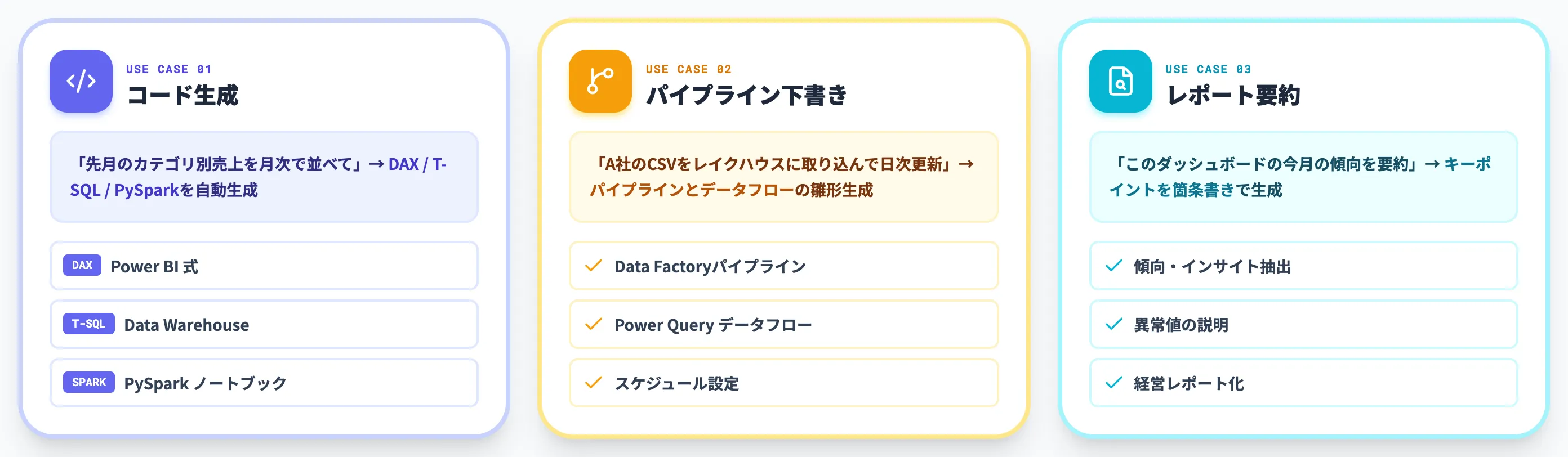
Fabric Copilotは、Data Factory・Data Engineering・Data Warehouse・Data Science・Power BIの各ワークロードに埋め込まれ、自然言語からSQL・DAX・PySpark・パイプライン定義を生成できます。
代表的なユースケースは以下の3つです。
-
DAX / SQL / PySpark生成
「先月のカテゴリ別売上を月次で並べて」といった自然言語から、Power BIのDAX式やData WarehouseのT-SQL 、SparkノートブックのPySparkコードを生成する
-
データフロー・パイプライン設計の下書き
「A社のCSVをレイクハウスに取り込んで日次で更新して」のような要件から、Data Factoryのパイプラインとデータフローの雛形を生成する
-
レポート要約とインサイト抽出
Power BIレポートの中で、「このダッシュボードの今月の傾向を要約して」と依頼するだけで、キーポイントの箇条書きが生成される
【関連記事】
【Microsoft Fabric】Copilotとは?AI機能や料金体系を徹底解説
Copilot for Power BIとは?AIデータ分析の活用法を解説
Fabric Data Agentsの主な外部連携経路
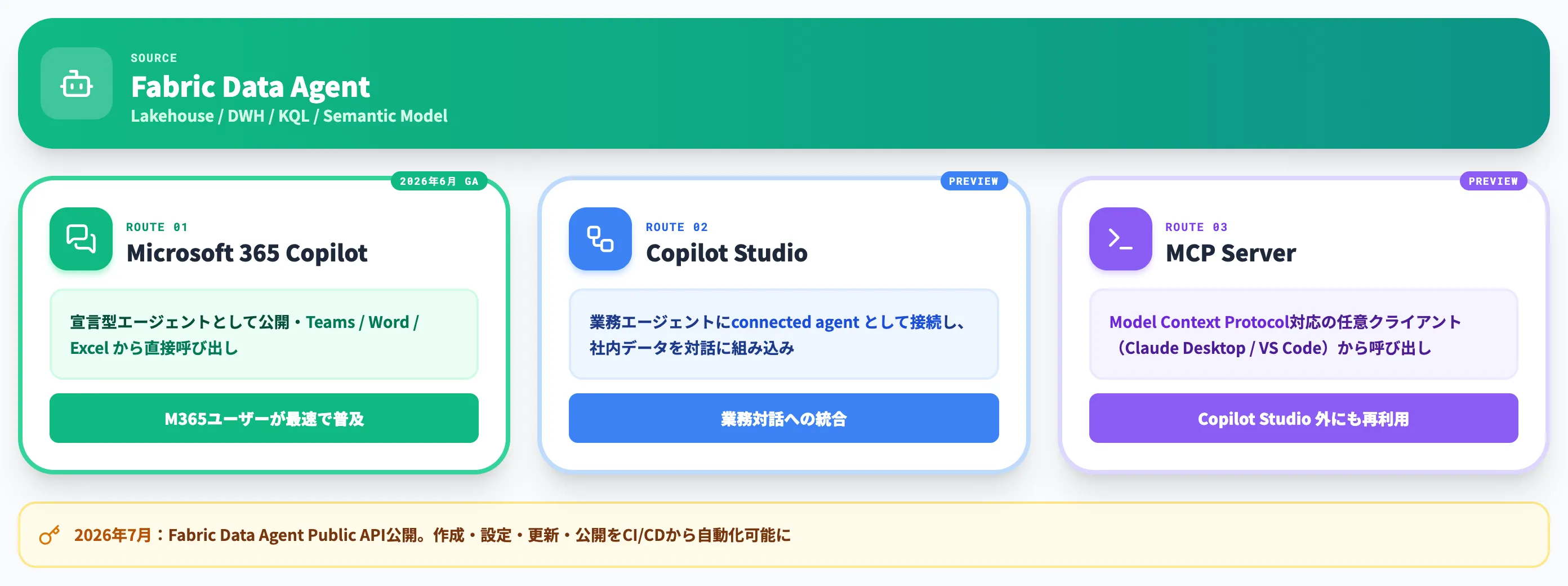
Fabric Data Agentsは、Fabric内のデータ(レイクハウス・DWH・KQL Database・Power BIセマンティックモデル)を対話で扱うための専用AIエージェントを、Fabric上で作成・公開できる機能です。
Fabric側で作ったData Agentを外部エージェントから呼び出す経路は、2026年7月時点で以下の3つが主要な選択肢です。
-
Microsoft 365 Copilotへの宣言型エージェント公開(GA)
Fabric Data AgentをMicrosoft 365 Copilot向けの宣言型エージェントとして公開する経路が2026年6月にGA。Teams・Word・ExcelなどMicrosoft 365上のCopilotから直接呼び出せる
-
Microsoft Copilot Studioのconnected agentとして利用(プレビュー)
Microsoft Copilot Studioで作成した業務エージェントにFabric Data Agentをconnected agentとして接続し、業務対話の中に社内データを組み込む
-
Data Agent MCP Serverとして利用(プレビュー)
Model Context Protocol(MCP)に対応した任意のクライアント(Claude Desktop / VS Code / 独自エージェント等)から、標準プロトコル越しにData Agentを呼び出す
Microsoft 365 Copilot経由は「M365ユーザーがそのまま業務チャットで社内データを聞く」ラインとして最速で普及しやすく、Copilot Studio連携は「業務エージェントの中にFabricデータを組み込みたい」ケース、MCP Serverは「Copilot Studio以外のエージェント・クライアントからも同じData Agentを再利用したい」ケースで使い分けます。
加えて2026年7月にはFabric Data Agent Public APIが公開され、データエージェントの作成・設定・更新・公開を独自ツールやCI/CDから自動化できるようになりました。
実行時の問い合わせ自体は、上記MCP Server等のランタイム経路を利用します。
【関連記事】
Microsoft Fabricデータエージェントとは?料金・使い方を解説
Fabric IQ:オントロジーで業務概念をデータに接続する
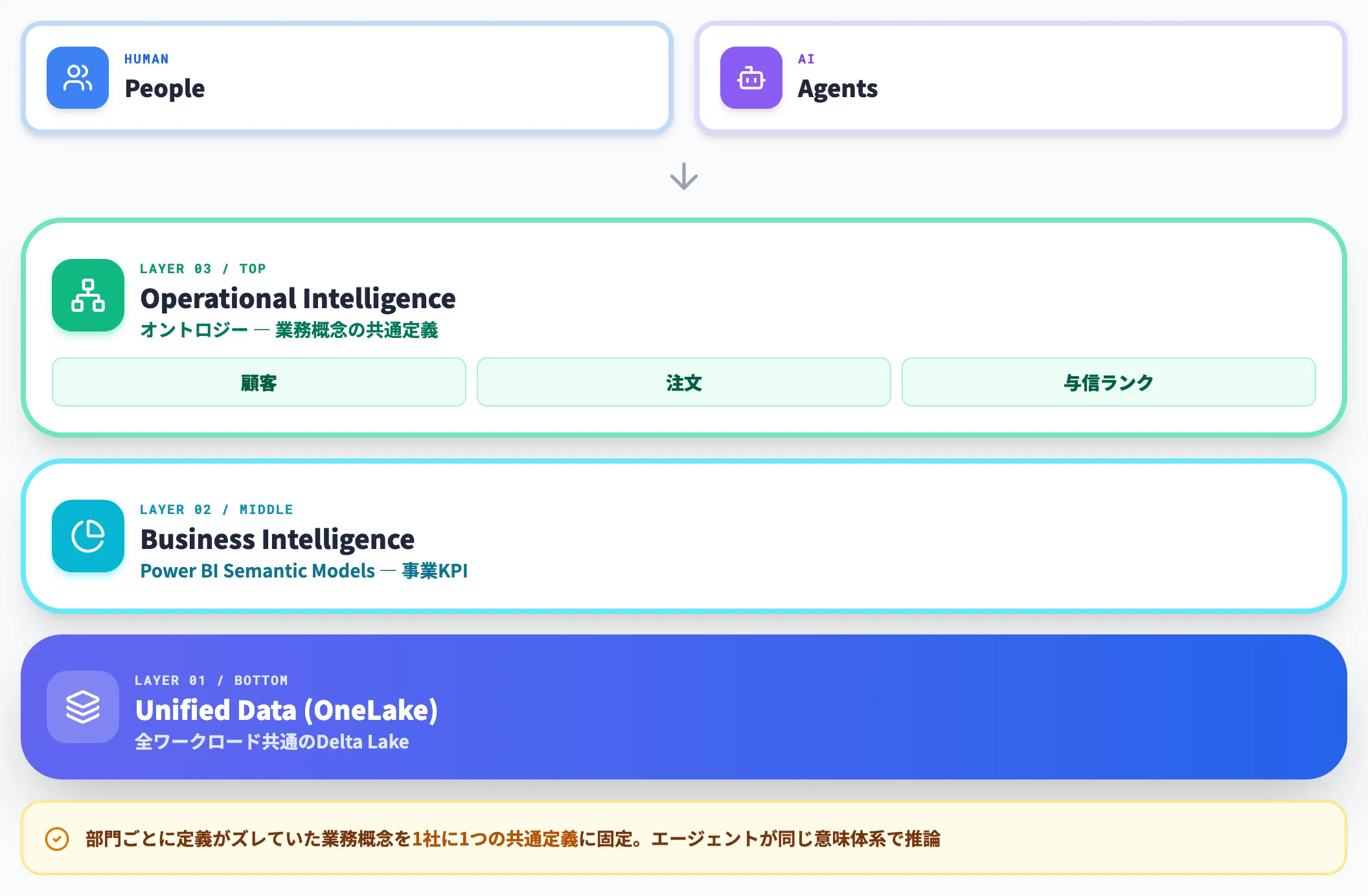
Fabric IQは、業務用語(顧客・製品・契約・機器など)と実データ(テーブル・カラム・値)を、オントロジーで明示的に結びつける意味レイヤーです。
OneLakeの生データがPower BIセマンティックモデルで「事業KPI」になり、その上にOntologyが「業務概念の共通語」を被せる、という3層の積み上げ構造です。
People(人)とAgents(AI)が同じレイヤーからアクセスする形になっており、AIエージェントも人と同じ意味体系でデータを解釈することを前提にしています。
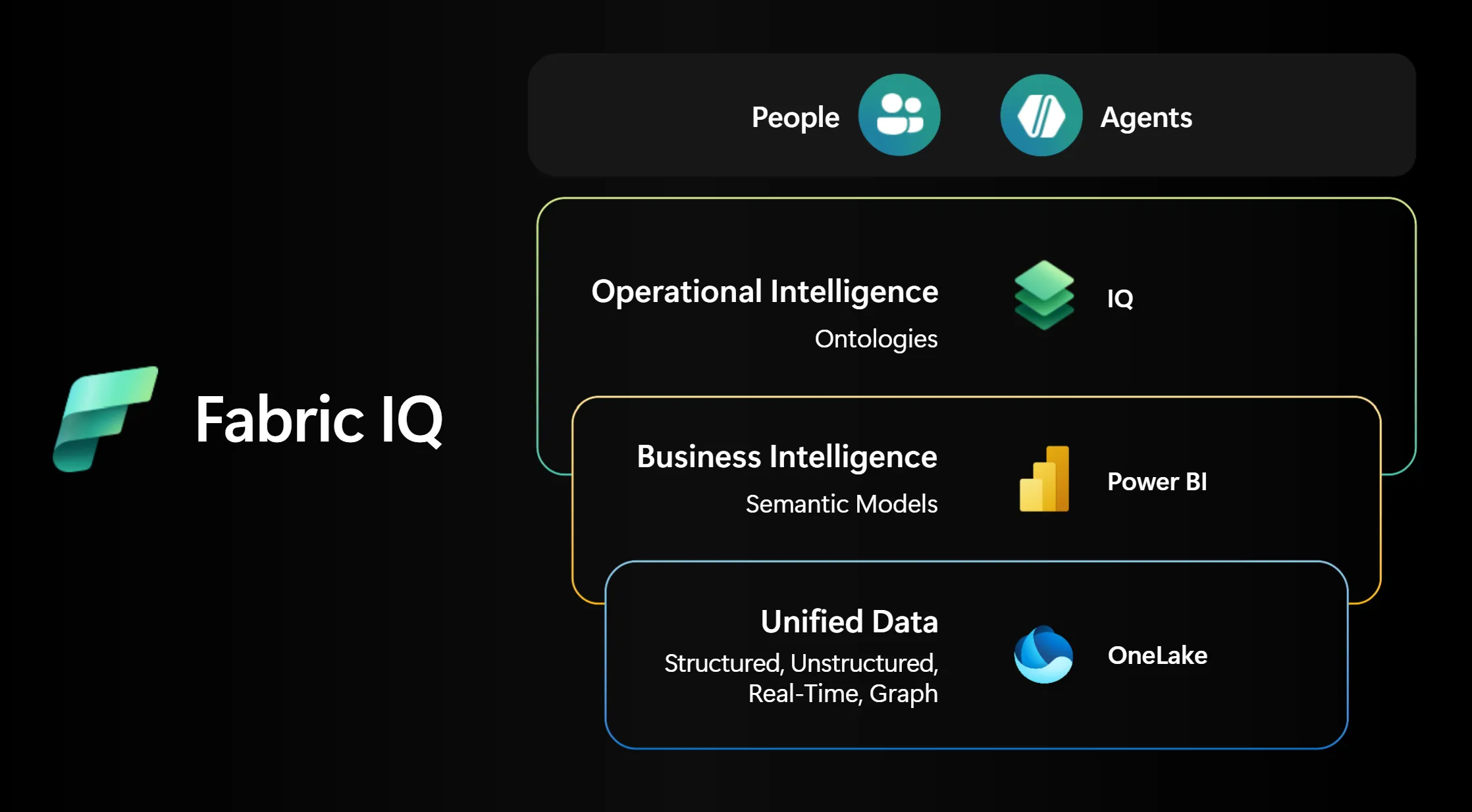
Fabric IQの3層構造。下からUnified Data(OneLake)/Business Intelligence(Power BI Semantic Models)/Operational Intelligence(Ontologies)と積み上がり、上部のPeopleとAgentsが同じ意味体系で業務データにアクセスする(出典:Microsoft Learn)
「顧客」「注文」「与信ランク」といった業務概念は部門ごとに定義が微妙にズレやすく、AIエージェントに単純な問いを投げるだけでは解釈が揺らぐという問題が長年続いていました。
オントロジーはこれを「1社に1つの共通定義」として固定し、エージェントが同じ意味体系で推論できるようにする仕組みです。
Fabric IQでは、このオントロジーをPower BIセマンティックモデルから自動生成でき、既存のBI資産を意味レイヤーに接続する橋渡し役として設計されています。
【関連記事】
オントロジーとは?基本要素やナレッジグラフとの違い、活用例をわかりやすく解説
Fabric IQのオントロジーとは?仕組みや使い方、構築料金を解説
Copilot利用時のCU消費と実務上の目安
CopilotリクエストはFabric CapacityのCUとして消費されます。
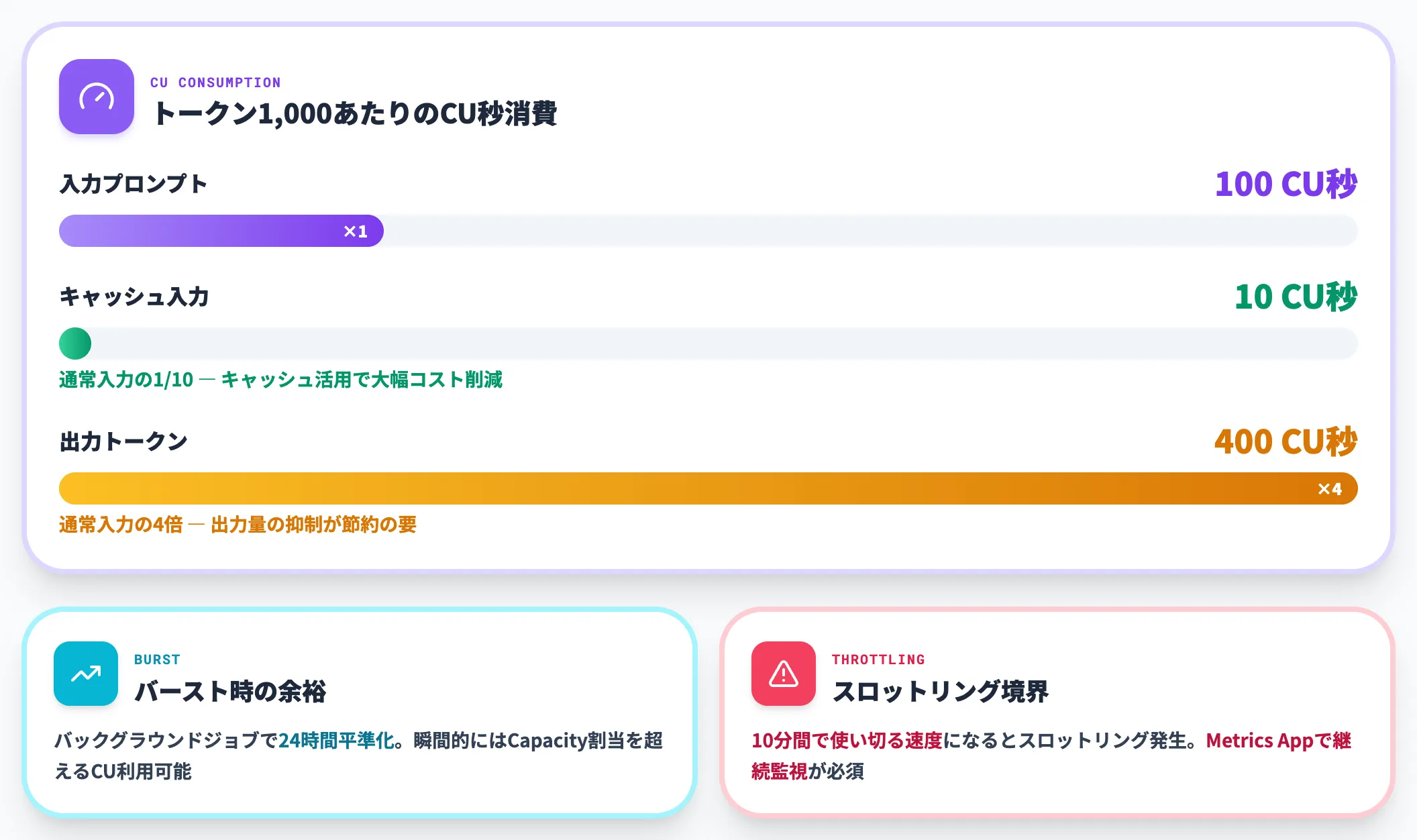
トークンあたりの消費レートは以下のとおりです(公式Copilot消費ドキュメント)。
| メトリック | 単位 | 消費率 |
|---|---|---|
| 入力プロンプト | 1,000トークン | 100 CU秒 |
| キャッシュされた入力プロンプト | 1,000トークン | 10 CU秒 |
| 出力 | 1,000トークン | 400 CU秒 |
Copilot操作はバックグラウンドジョブとして24時間で平準化されるため、瞬間的にはピーク時のCapacity割り当てを超えるCUも利用可能です。ただし、10分間で使い切る消費速度になるとスロットリングが発生するため、実務ではCapacityメトリックアプリで消費パターンを継続監視するのが必須です。
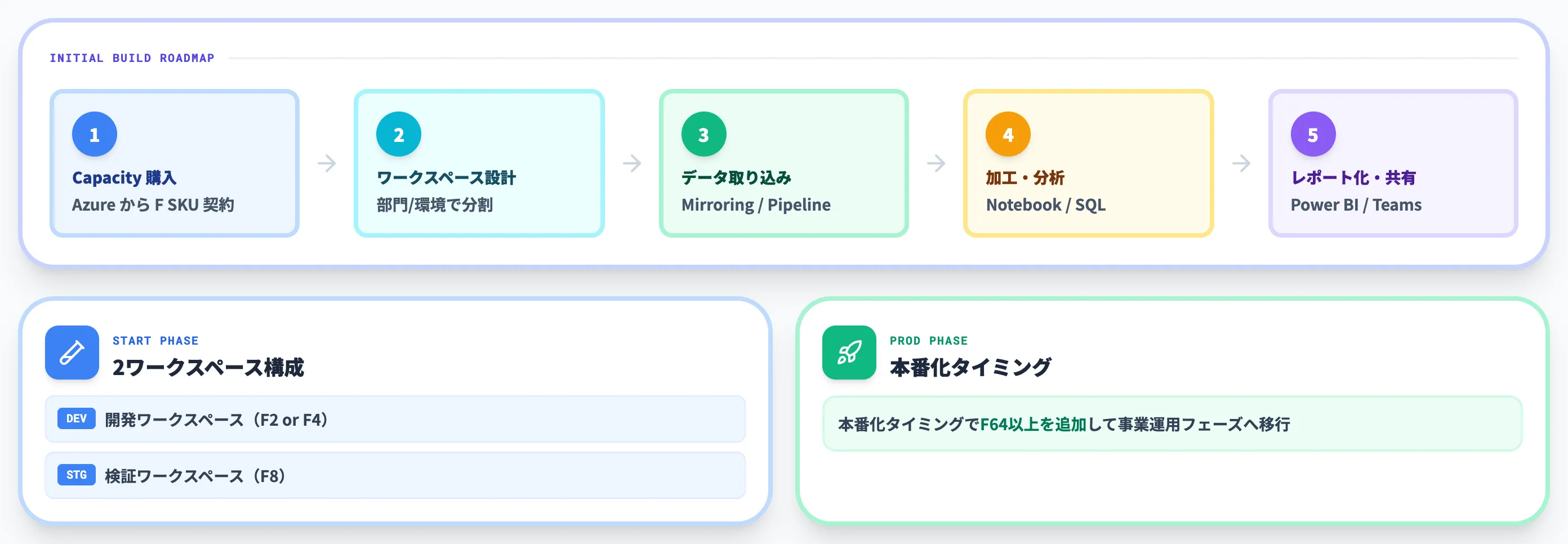
Microsoft Fabricの使い方(初期構築の流れ)
Fabricの初期構築は、Capacity購入 → ワークスペース設計 → データ取り込み → 加工・分析 → レポート化・共有 の順で進めます。
以下では、各工程で実際に触るUIと、初期設計で押さえるべきポイントを整理します。
Fabric Capacityの購入とワークスペース設計
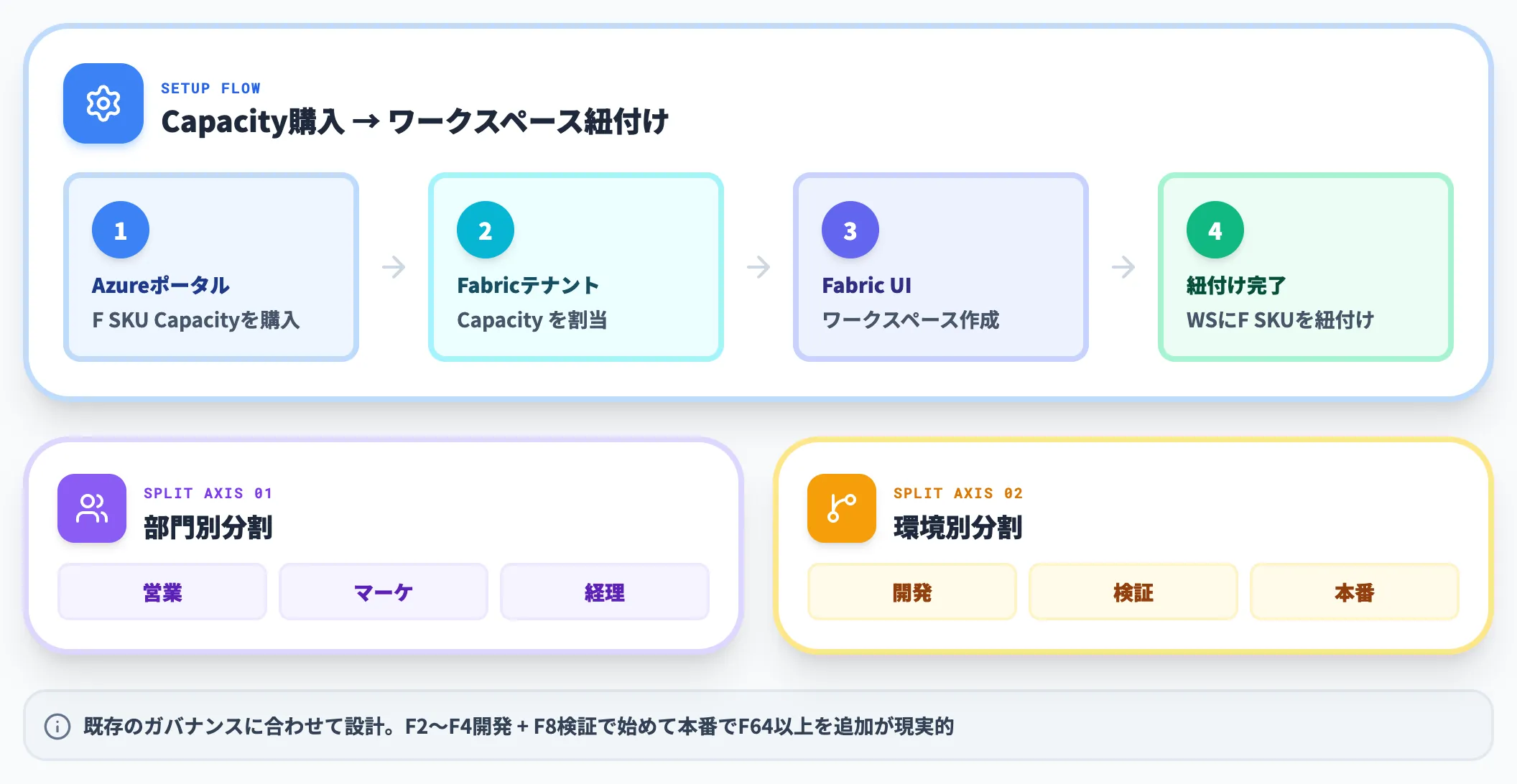
まずAzureポータルから Fabric Capacity(F SKU)を購入し、Fabricテナントに割り当てます。
Capacity購入後、Fabric UIからワークスペースを作成し、購入したF SKUに紐付けます。ワークスペースは組織の設計単位で、部門ごとに分けるか、開発/検証/本番で分けるかは、既存のガバナンスに合わせて設計します。
初期段階では「開発ワークスペース(F2またはF4)+ 検証ワークスペース(F8)」の2枚構成で始めて、本番化のタイミングでF64以上を追加する構成が現実的です。
OneLake / Lakehouseへのデータ取り込み

次にワークスペース内にLakehouse(レイクハウス)を作成し、データを取り込みます。
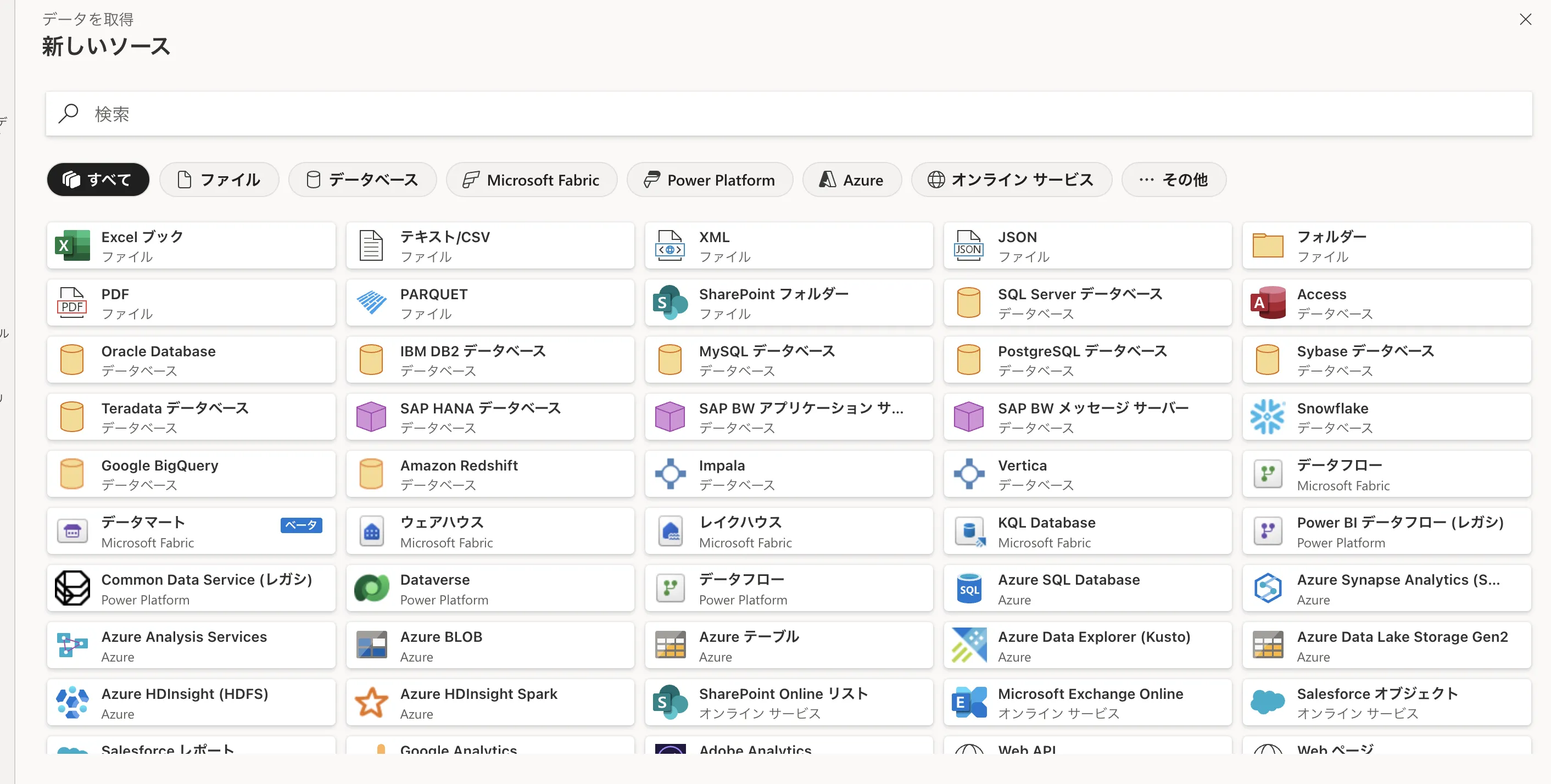
Fabric「データを取得」→「新しいソース」画面I。Excel・SharePoint・SAP HANA・Snowflake・Cosmos DB・Salesforce等の200+コネクタが並ぶ(撮影:AI総合研究所・Fabricテナントで取得)
取り込みには複数の選択肢があります。
少量のファイルなら「データを取得」からExcel / CSV / SharePoint / SQL Serverなどの200+コネクタを直接指定、大量データの継続取り込みならData Factoryのパイプラインや Mirroring を使います。
外部のAmazon S3やGoogle Cloud Storageにあるデータはコピーせず、OneLake Shortcuts で参照する構成も選べます。
MirroringとShortcutsをうまく組み合わせることで、既存の分析基盤から「一気に移行する」のではなく、「Fabricを参照レイヤーとして育てながら段階的に移す」進め方が可能になります。
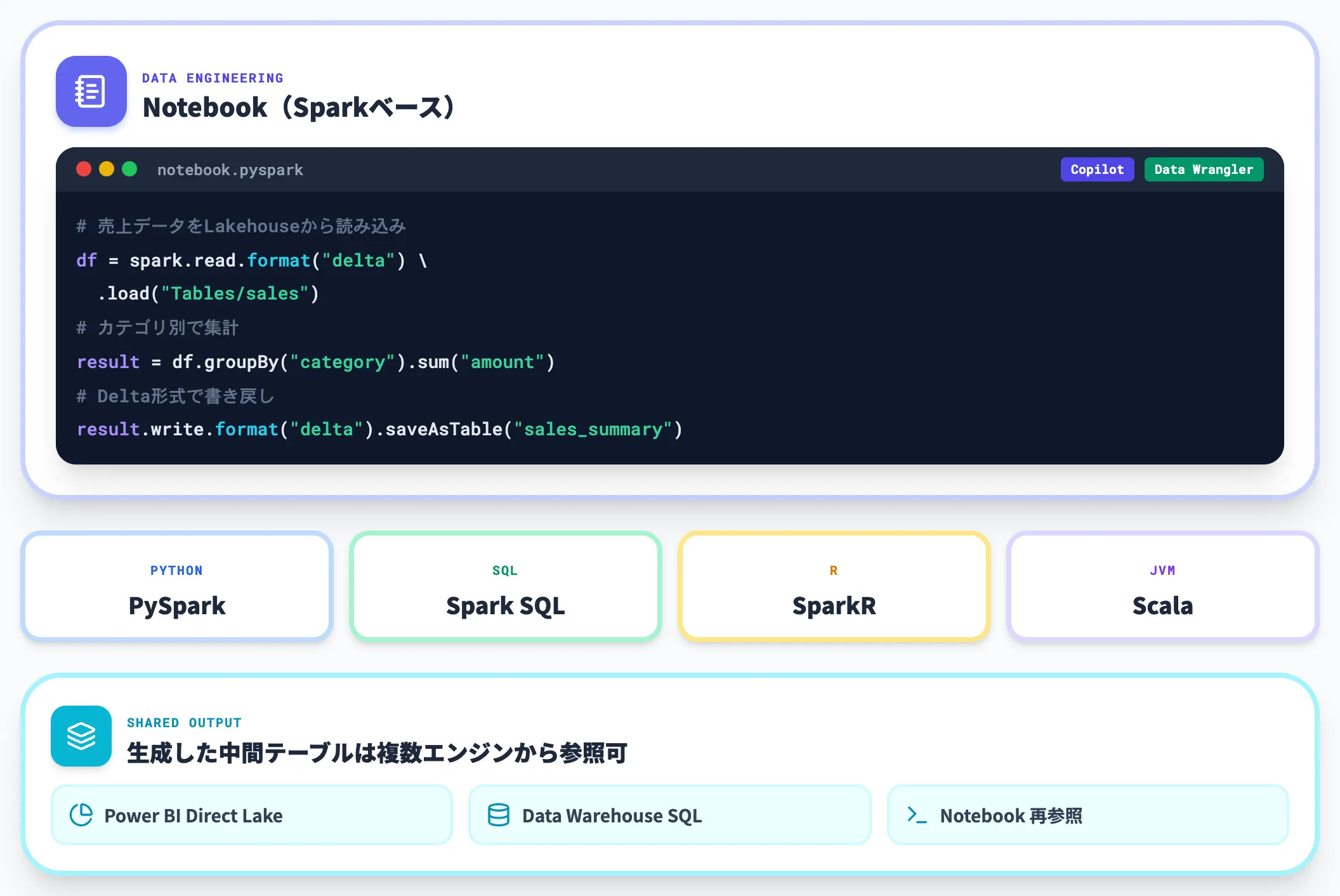
Notebook / SQLでの加工・分析
Lakehouseに取り込んだデータは、Notebook(Sparkベース)または SQLエディタ(T-SQL)で加工します。
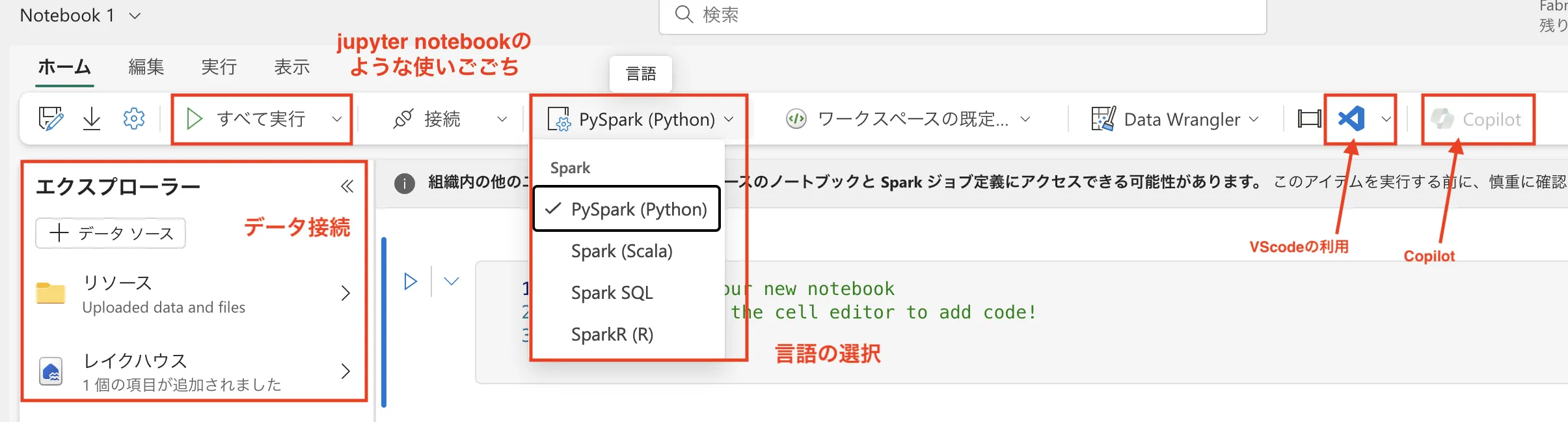
Fabric Data EngineeringのNotebook画面。PySpark(Python)・Spark SQL・Scala・SparkRに対応し、右上にData WranglerとCopilotボタンが常駐。エクスプローラーからLakehouse・リソースを参照する
NotebookはPySpark / Spark SQL / SparkR / Scalaに対応し、右上にCopilotボタンが常駐しています。自然言語でコード生成を依頼できるほか、Data WranglerでGUIベースのデータ整形も併用できます。
生成した中間テーブルはDelta形式でOneLakeに保存され、そのままPower BIのDirect LakeやData WarehouseのSQLクエリから参照できます。
同じデータをコピーせずに複数のエンジンから読める点が、従来の分析基盤との最大の違いです。
Power BIでのレポート化とTeams共有
加工が済んだデータは、そのまま Power BI でレポート・ダッシュボード化します。
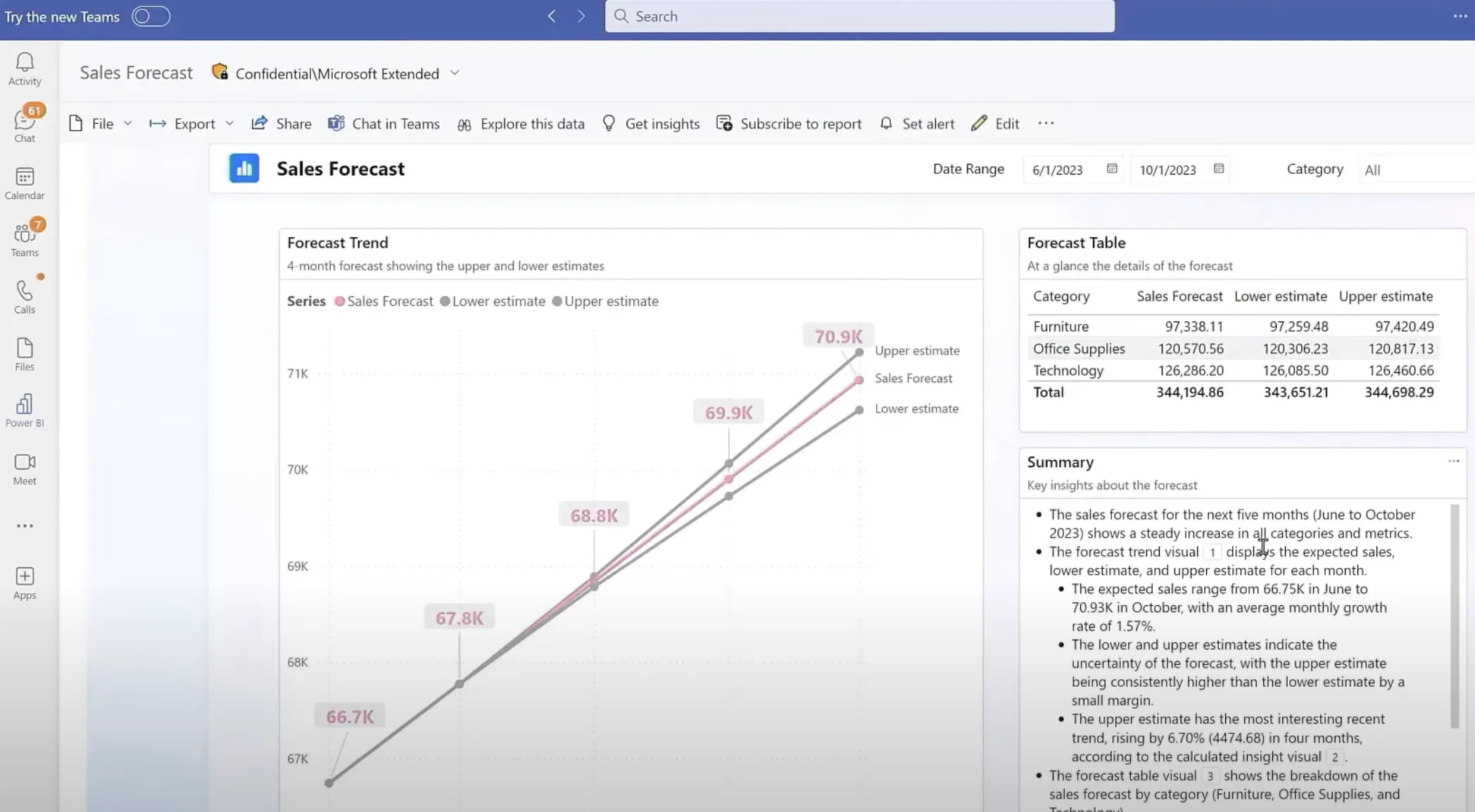
Teams上でPower BIレポート(Sales Forecast)を開いた画面。「Chat in Teams」「Explore this data」「Get insights」等でレポートを介した対話ができる
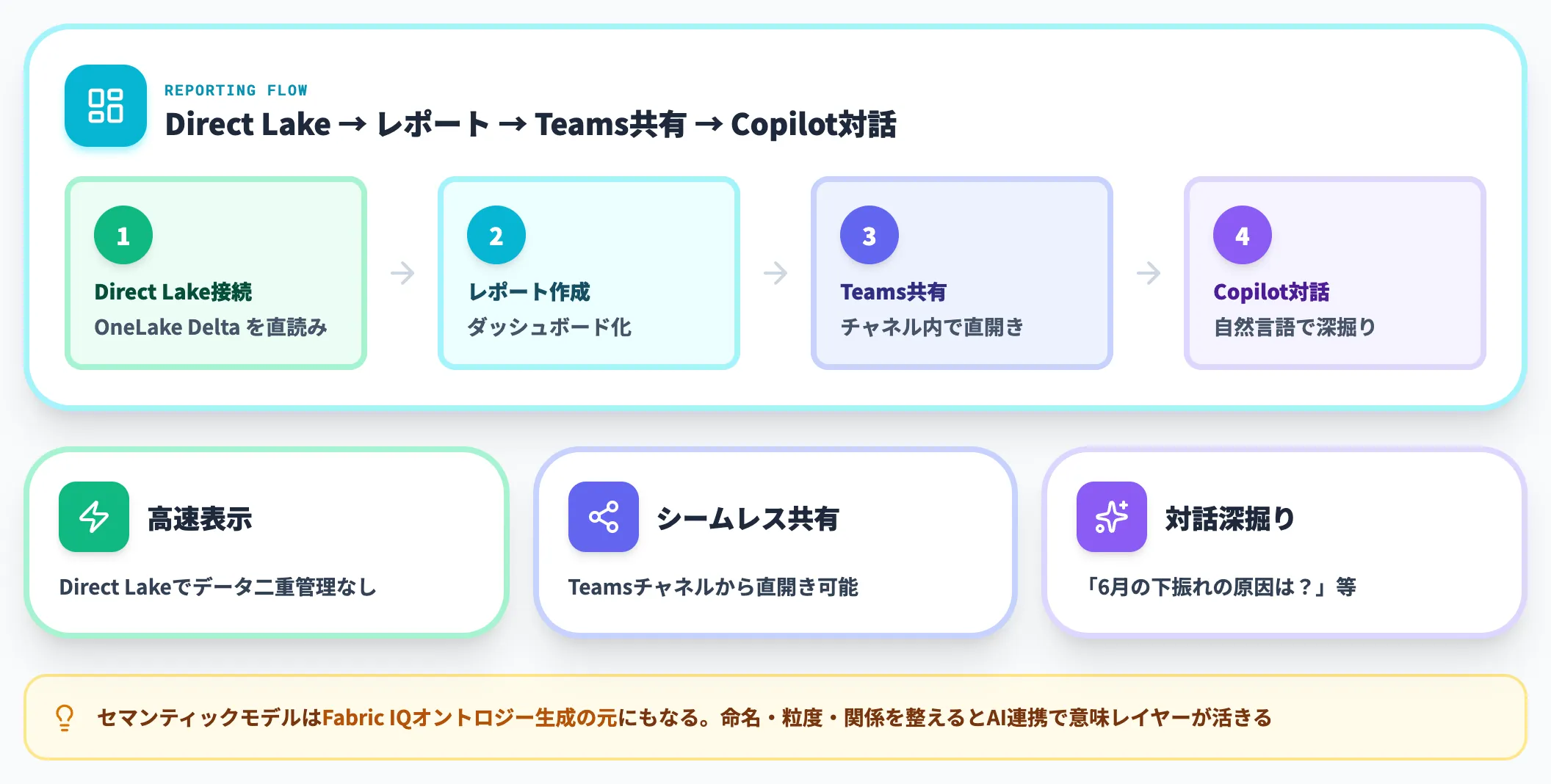
Direct Lakeモードを使えばデータの二重管理なしにレポートを高速表示でき、レポートはTeamsチャネル内から直接開ける形で共有できます。同じレポート上でCopilotによる自然言語質問(「6月の下振れの原因は?」など)も実行できます。セマンティックモデルはFabric IQのオントロジー生成の元にもなるため、レポート設計の段階で命名・粒度・関係を整えておくと、後続のAIエージェント連携で意味レイヤーがそのまま活きます。
運用ルール(コスト・ガバナンス・CI/CD)を決める
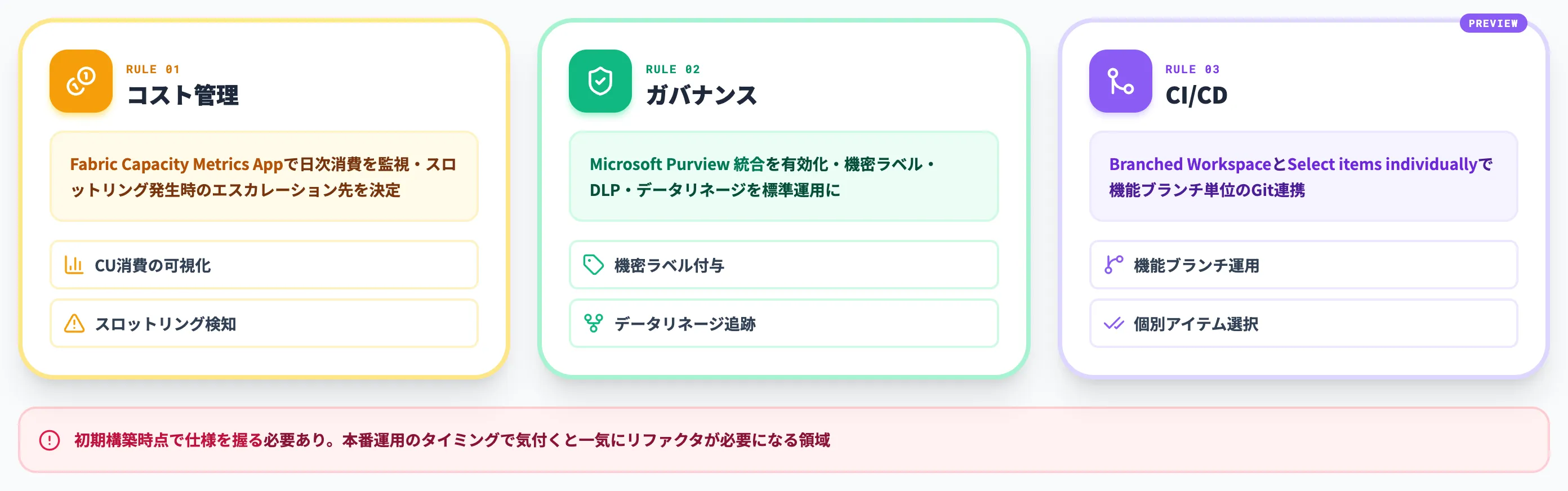
Capacityは選択したSKUの稼働時間に応じて課金され、CU消費量は性能やスロットリングに影響するため、ガバナンスと運用ルールを初期段階で決めておく必要があります。
- コスト
Fabric Capacity Metrics Appで日次消費を監視。スロットリング発生時のエスカレーション先を決める
- ガバナンス
Microsoft Purviewの統合を有効化し、機密ラベル・DLP・データリネージを標準運用に含める
- CI/CD
プレビュー提供中の Branched Workspace とSelect items individually(プレビュー)で、機能ブランチ単位のFabric開発をGit連携で回す
これらは初期構築の時点で仕様を固めておかないと、本番運用のタイミングで一気にリファクタが必要になる領域です。
FabricとDatabricks / Snowflakeの使い分け
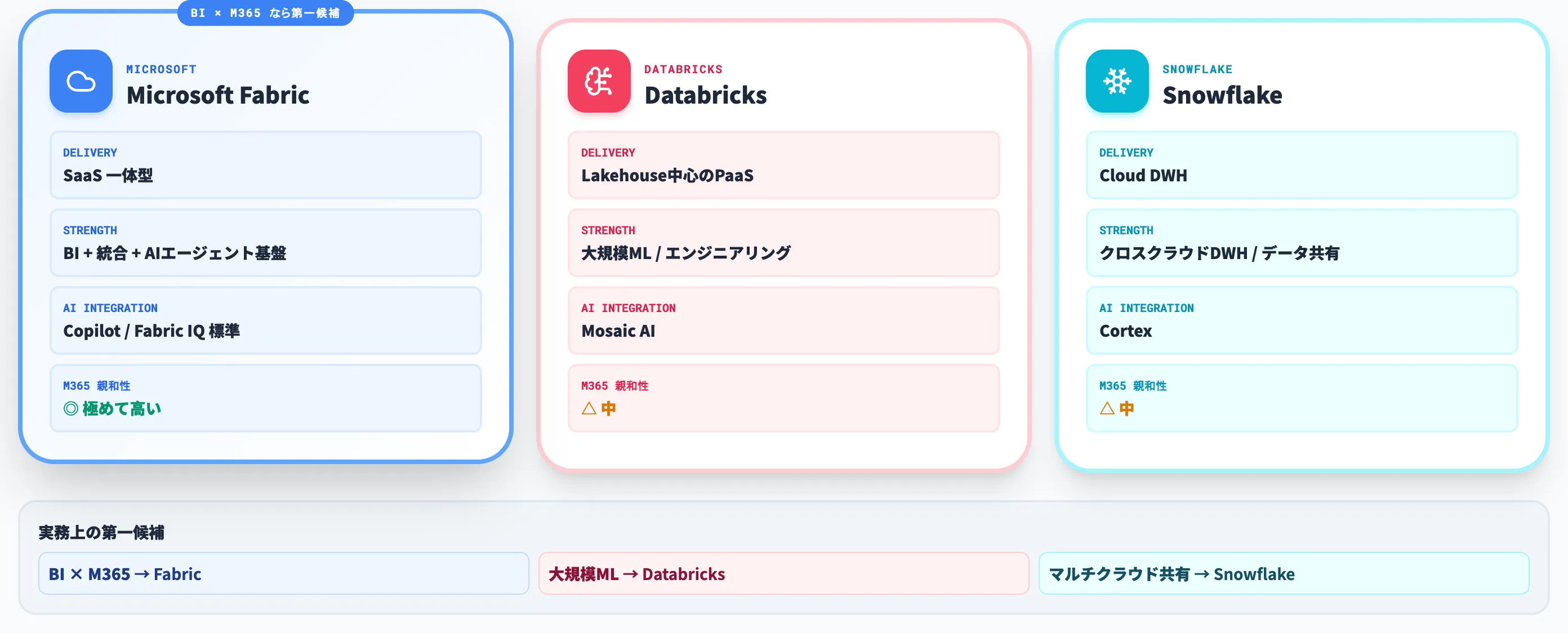
Fabric・Databricks・Snowflakeは、それぞれ設計思想が違います。中立比較ではなく、どのケースにどれを第一候補にするかをSIerの現場感でまとめます。
3プラットフォームの比較
以下の表で、3プラットフォームの主な設計軸を整理しました。
| 観点 | Microsoft Fabric | Databricks | Snowflake |
|---|---|---|---|
| デリバリー形態 | SaaS一体型 | Lakehouse中心のPaaS | Cloud DWH |
| 主軸ユースケース | BI + データ統合 + AIエージェント基盤 | 大規模ML / データエンジニアリング | クロスクラウドDWH / データ共有 |
| ストレージ形式 | Delta Lake(OneLake) | Delta Lake(Unity Catalog) | 独自 + Apache Iceberg |
| Power BI連携 | ネイティブ | コネクタ接続 | コネクタ接続 |
| AI統合 | Copilot / Fabric IQ標準 | Mosaic AI | Cortex |
| Microsoft 365との親和性 | 極めて高い | 中 | 中 |
この表から見えるのは、「BIとMicrosoft 365エコシステム」を持つ組織はFabric、「大規模MLとオープン性・柔軟性」を優先するならDatabricks、「マルチクラウドDWHとデータ共有」ならSnowflake、という選び分けが実務上の第一候補になるということです。
Fabricが第一候補になるケース

Fabricが第一候補になるのは、以下の条件が揃った組織です。
- Microsoft 365・Teams・Entra IDをすでに全社導入している
- Power BIでのBI資産が積み上がっている
- データ人材がData Engineer専任ではなく、アナリストもSQL / Notebookを触る
- Copilot / AIエージェント連携をBI領域から始めたい
BIとデータ活用を一体で運用したい組織にとって、FabricのSaaS一体型とCopilot標準装備の組み合わせは他プラットフォームでは代替しにくい強みです。
Databricksが第一候補になるケース
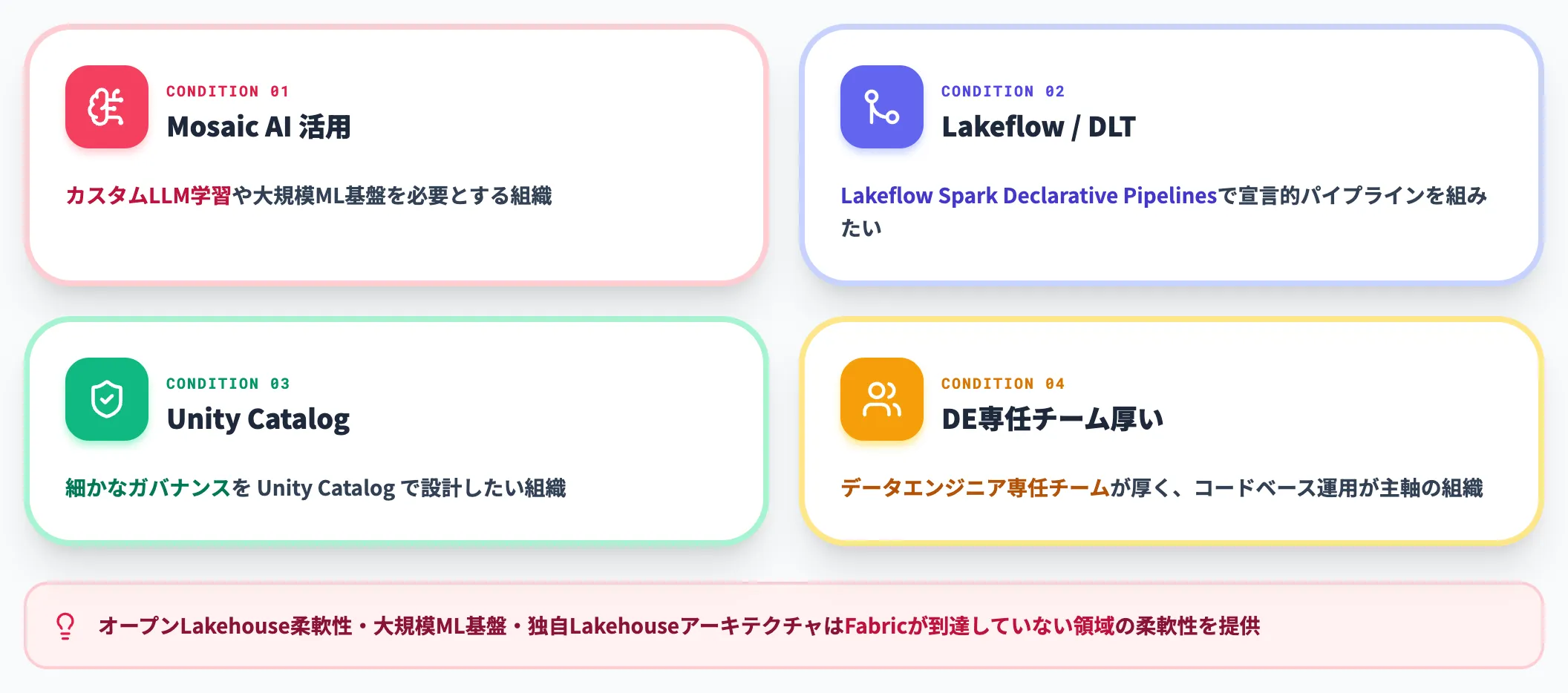
Databricks(Azure Databricks含む)が第一候補になるのは、大規模ML基盤・カスタムモデル学習・オープンLakehouseの柔軟性を優先するケースです。
Mosaic AI・Lakeflow Spark Declarative Pipelines(旧Delta Live Tables)・独自のLakehouseアーキテクチャは、Fabricが到達していない領域の柔軟性を提供します。
データエンジニア専任チームが厚い組織、カスタムLLMを学習させる需要がある組織、Unity Catalogでの細かなガバナンスを設計したい組織はDatabricks優位です。
Snowflakeが第一候補になるケース
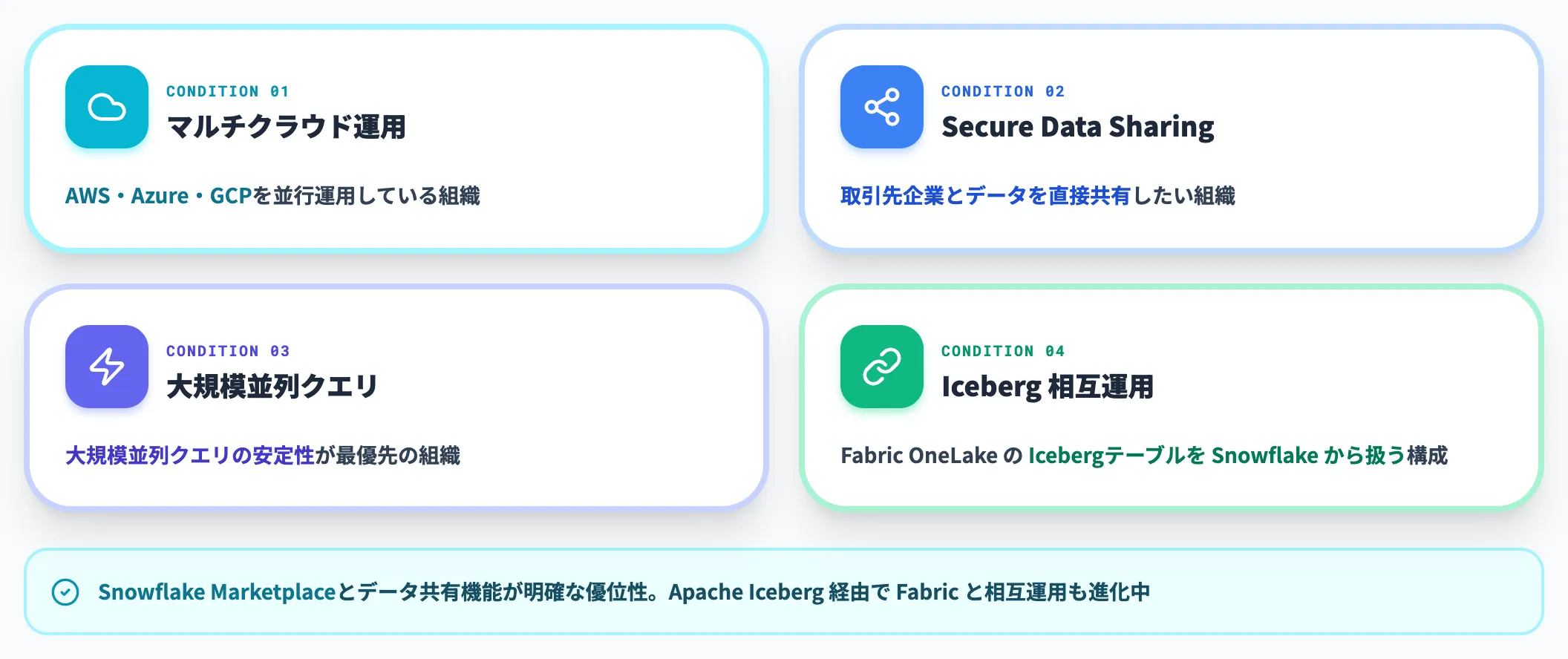
Snowflakeは、マルチクラウドDWH・組織外とのSecure Data Sharing・大規模並列クエリの安定性を必要とする組織で第一候補になります。
特に「AWS・Azure・GCPを並行運用している」「取引先企業とデータを直接共有したい」といった状況では、SnowflakeのMarketplaceとデータ共有機能が明確な優位性を持ちます。MicrosoftとSnowflakeはApache Iceberg経由での相互運用も進めており、OneLake上のIcebergテーブルをSnowflakeから扱う構成も可能になっています。
併用パターン:Fabric(BI)+ Databricks(ML)+ Snowflake(データ共有)
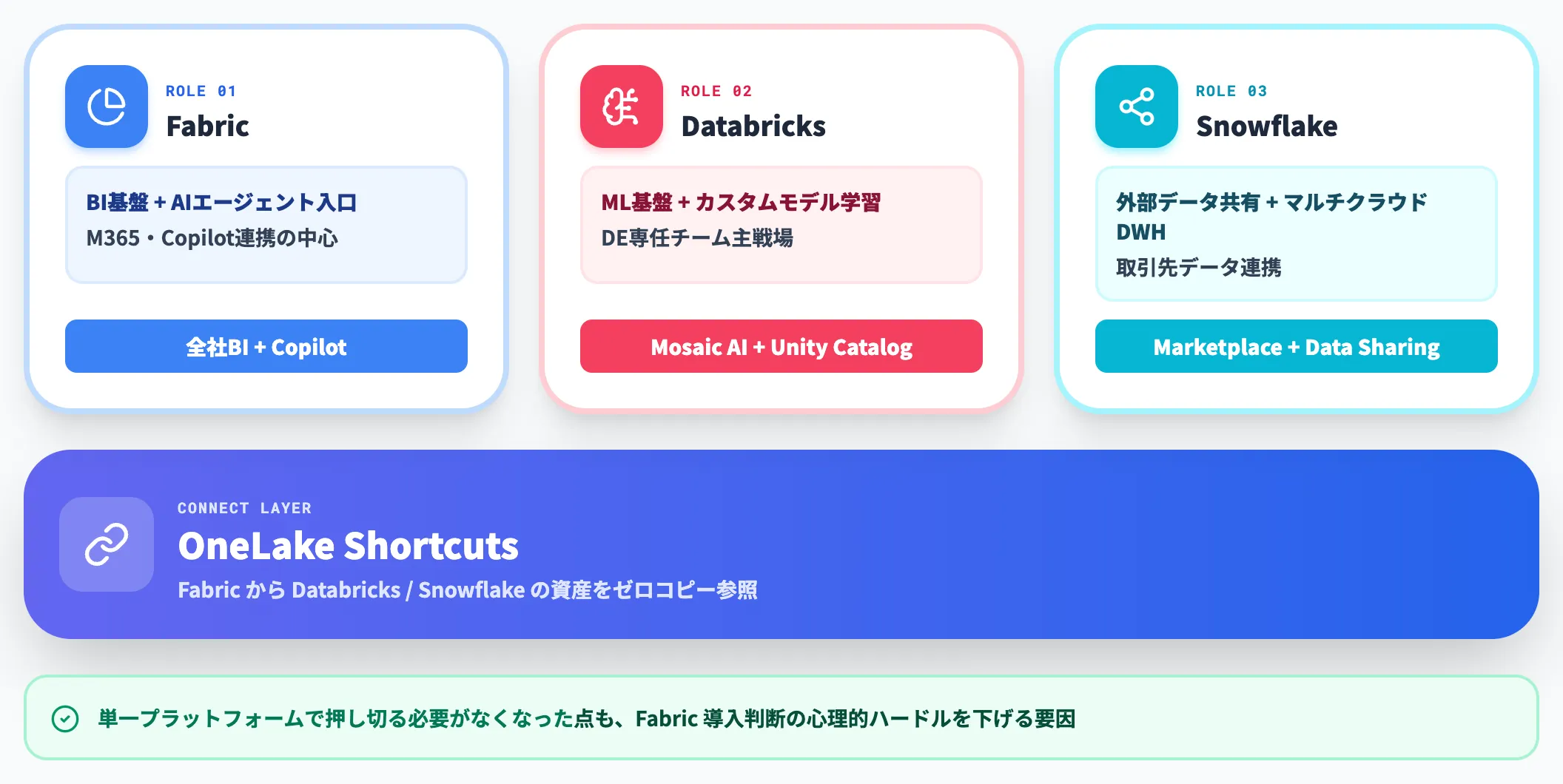
エンタープライズ領域では「FabricをBI基盤に、DatabricksをML基盤に、Snowflakeを外部データ共有に」という併用パターンも選択肢の一つになっています。
OneLakeのShortcutsで他プラットフォームのデータを参照できるため、Fabricを「BIとエージェントの入口」に据えつつ、既存のDatabricks / Snowflake資産をそのまま活かす構成が実現できます。
単一プラットフォームで完結させる必要がなくなった点も、Fabric導入判断の心理的ハードルを下げています。
【関連記事】
Azureのビッグデータ分析とは?Fabric・Databricks等の違いを徹底解説
AIエージェント時代のデータ基盤設計|主要プラットフォーム比較と構築を解説
Microsoft Fabricの導入事例と成果

Microsoft公式のCustomer Storiesページには、日本企業のFabric導入事例が2024年から継続して掲載されています。
ここでは、国内4社と海外3社を、業種・規模・成果の角度で整理します。
ヤマシタ(介護福祉用具レンタル):全国70拠点でのDX人財配置を目指すデータ基盤
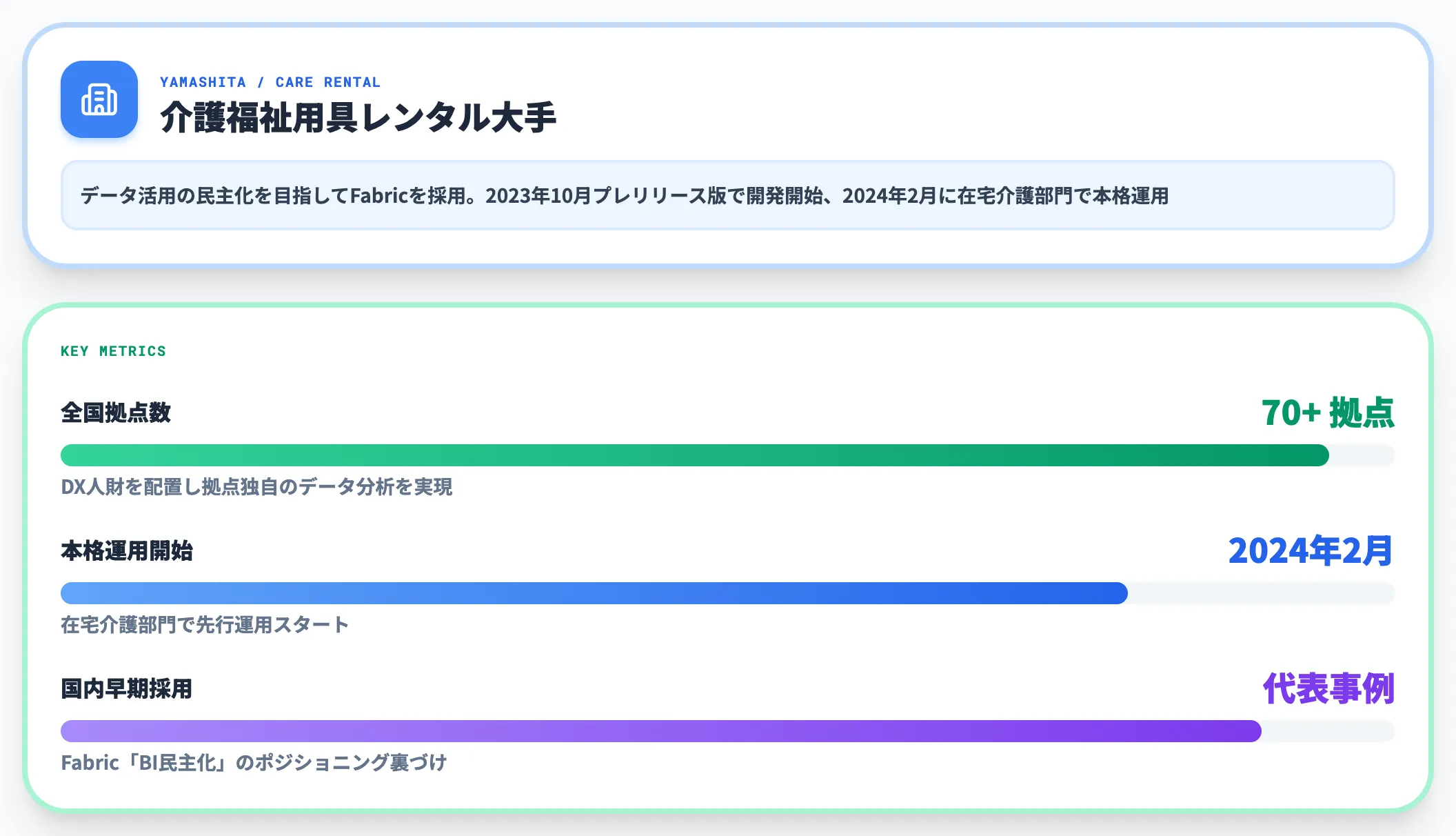
介護福祉用具レンタル大手のヤマシタは、データ活用の民主化を目指してFabricを採用しました。
2023年10月にプレリリース版で開発を開始し、2024年2月に在宅介護部門で本格運用を開始しました。全国70以上の拠点にDX人財を配置し、拠点ごとの独自データ分析を可能にすることを目標として掲げ、Fabricを土台にした業務改善が進んでいます。
国内でも早期の大規模採用事例で、Fabricの「BI活用の民主化」というポジショニングを裏づける代表例です。
北國銀行/CCIグループ:リードタイムを大幅短縮、インフラ運用ほぼゼロ

北國銀行と傘下のCCIグループは、次世代データ活用基盤としてFabricを採用しました。
導入前は、データ提供までの調整・準備・実装リードタイムが長く、必要な分析情報がタイムリーに届かない課題を抱えていました。Fabric導入後はデータ提供のリードタイムを大幅に短縮し、CapacityベースのSaaS運用によってインフラ運用負担がほぼゼロになったと公表されています。
地方銀行・金融業のように、コンプライアンスと運用効率の両立が必要な業界における参考事例です。
グローバルエンジニアリング(電力小売):予測時間50%短縮・予測誤差40%削減
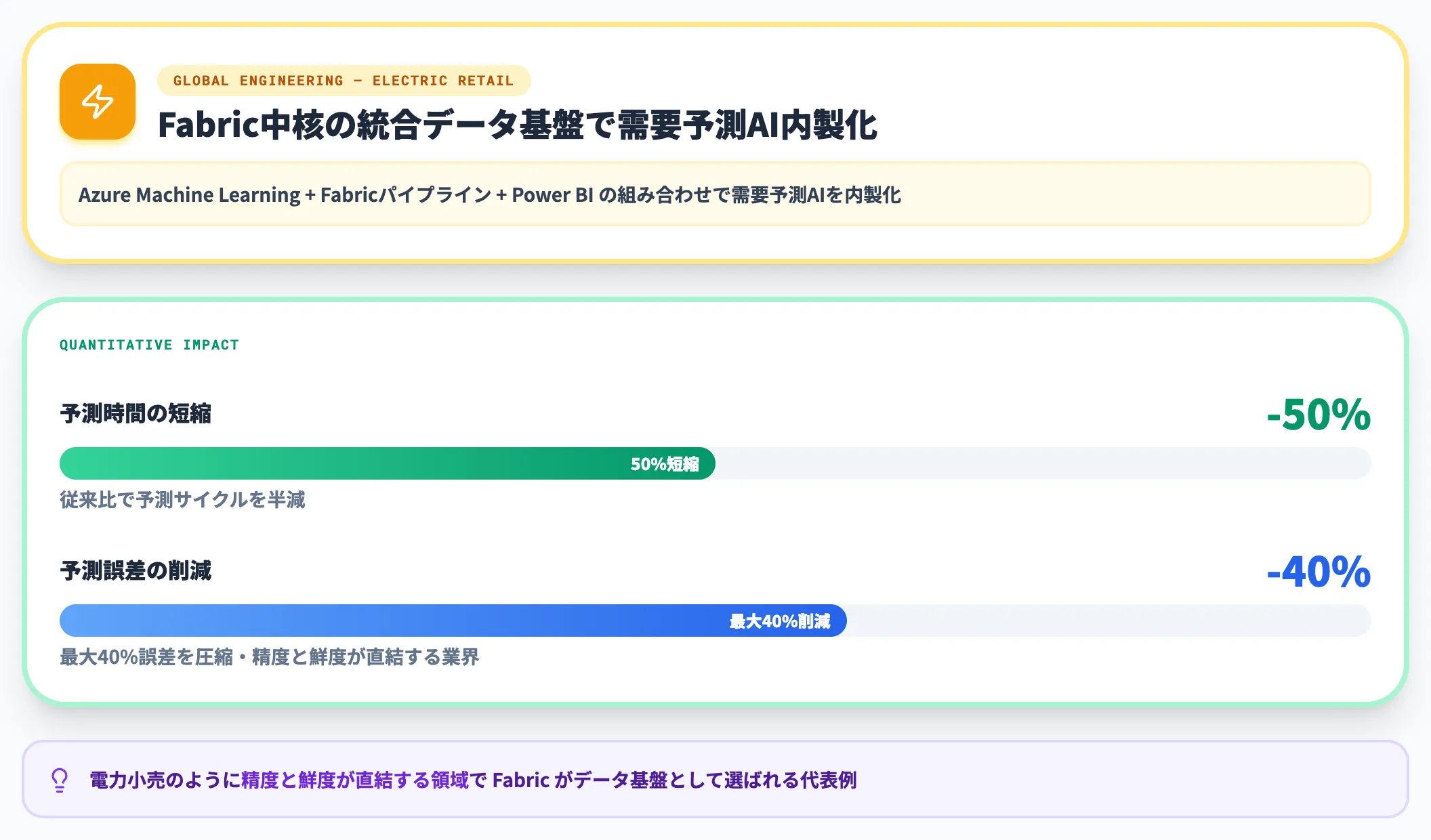
電力小売のグローバルエンジニアリングは、Fabricを中核にした統合データ基盤で需要予測AIを内製化しました。
結果として、予測時間を50%短縮し、予測誤差を最大40%削減しました。
公式事例ではAzure Machine Learning・Fabricパイプライン・Power BIの組み合わせで需要予測AIを内製化しており、電力小売のように精度と鮮度が直結する領域でFabricがデータ基盤として選ばれる代表例です。
伊藤忠商事:FOODATAへの生成AI基盤導入とFabric検討

食品業界データ分析サービス「FOODATA」を運営する伊藤忠商事は、FOODATAのPoCでAzure OpenAI ServiceとAzure AI Studioを用いた生成AI基盤を実装しました。
従来の「ダッシュボードで結論を得る」形から「対話ですぐに結論を得る」サービスへ進化させる取り組みで、Microsoft Fabricは全社共通のデータ前処理基盤として位置づけることを検討している段階と公表されています。
同社の事例は、AI層とデータ層を段階的に組み立てていく計画型アプローチの参考例です。
【関連記事】
Microsoft Fabric導入事例6選!国内企業の成果と導入パターンを解説
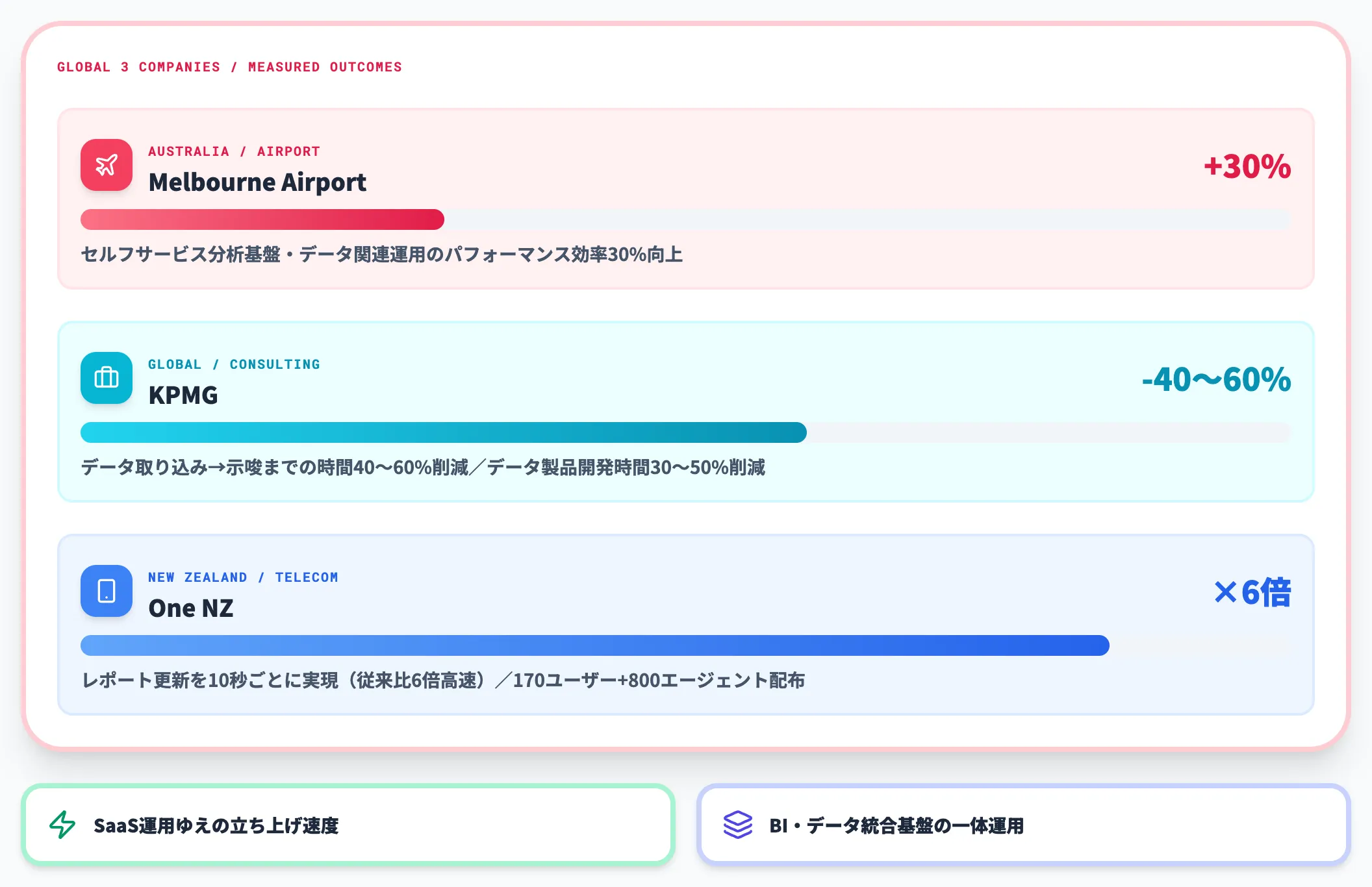
海外事例:Melbourne Airport / KPMG / One NZ
海外では、以下の事例が公表されています。
- Melbourne Airport
セルフサービス分析基盤としてFabricを導入し、データ関連運用のパフォーマンス効率が30%向上
- KPMG
データ取り込みから示唆までの時間を40〜60%削減、データ製品の開発時間を30〜50%削減
- One NZ(モバイルキャリア)
レポート更新を10秒ごとに実現(従来比6倍高速)、170のビジネスユーザーと800のエージェントに配布
3社に共通するのは、Fabricの「SaaS運用ゆえの立ち上げ速度」と「BI・データ統合基盤としての一体運用」で、既存の分析基盤より大きく業務時間を削減できたと公表している点です。

Microsoft Fabricのセキュリティとガバナンス
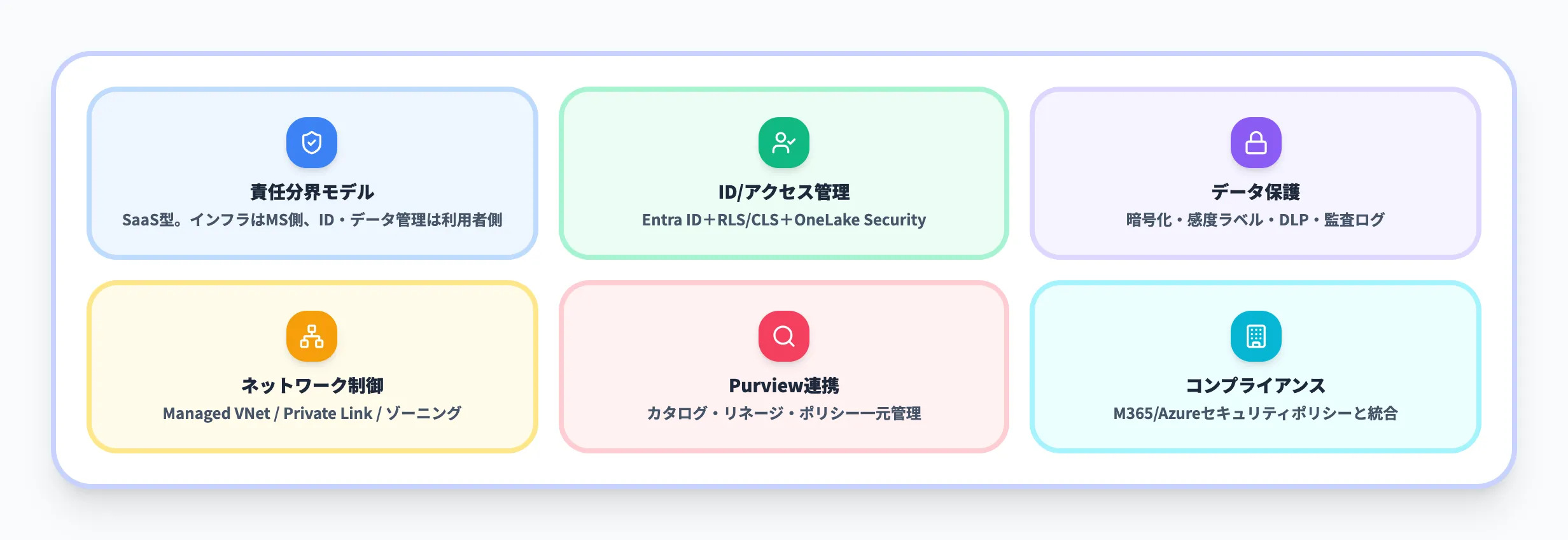
Fabricのセキュリティ・ガバナンスは、Microsoft Entra IDによる認証・認可、OneLake Securityによるデータ層のアクセス制御、Microsoft Purviewによるカタログ・ラベル・DLPの3つのレイヤーで構成されています。
Microsoft 365と共通のガバナンス基盤の上に乗るため、既存のセキュリティ設計を土台としてFabric側のテナント・ワークスペース・アイテム権限を再設計しやすい点が実務上の利点です。
認証・認可:Entra ID × ロール × ワークスペース
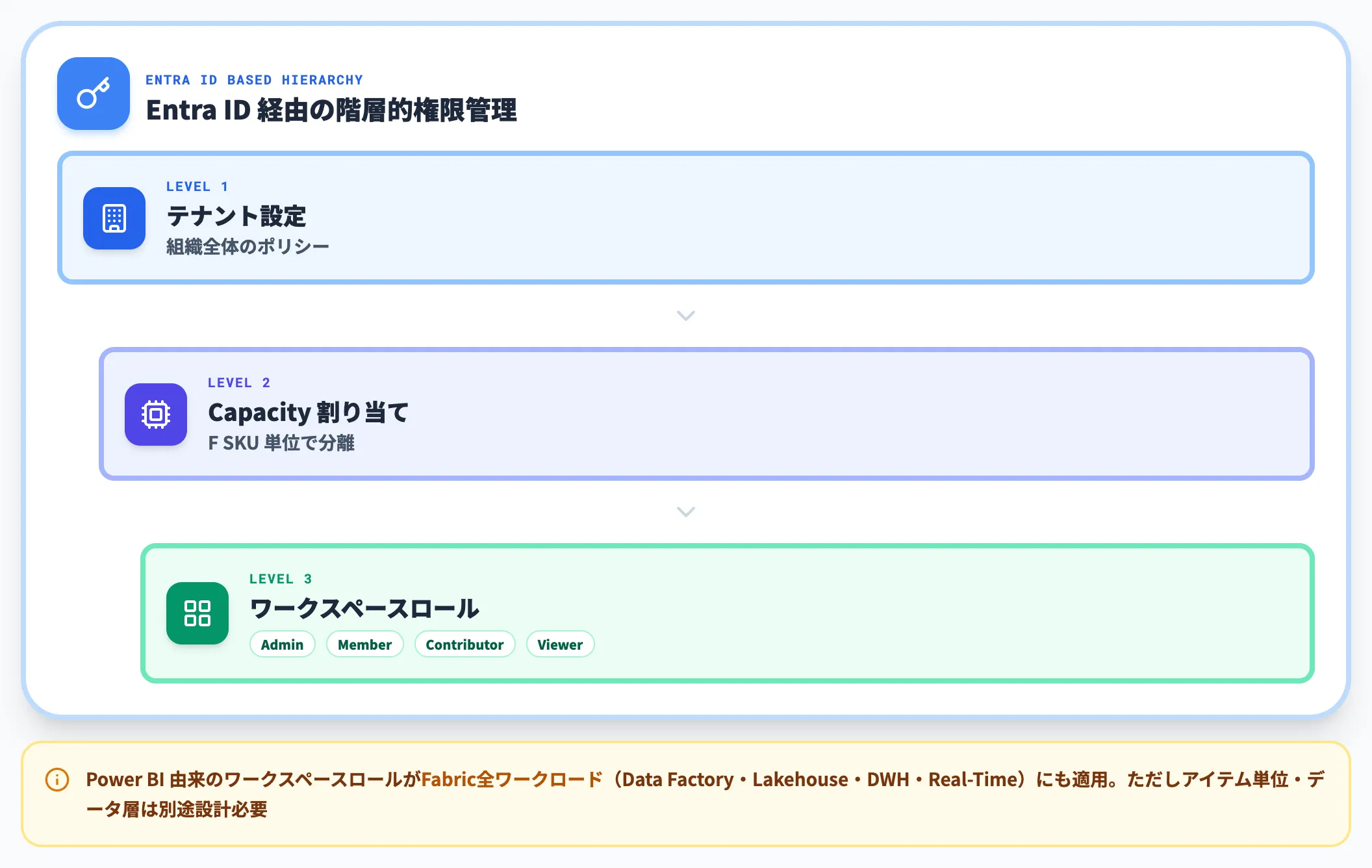
Fabricの認証はすべてMicrosoft Entra ID経由で行われ、テナント設定・Capacity割り当て・ワークスペースロール(Admin / Member / Contributor / Viewer)で権限が階層的に管理されます。
Power BI由来のワークスペースロール設計がFabric全ワークロード(Data Factory・Lakehouse・DWH・Real-Time Intelligence)にも適用されるため、既存のPower BI管理者権限を持つチームは同じロール設計を出発点として他ワークロードのガバナンスまで拡張しやすくなっています。
ただしアイテム単位の権限やデータ層のアクセス制御は別途設計が必要で、そのまま流用で済むわけではありません。
OneLake Security:データ層のアクセス制御

OneLake Securityは、OneLake上のテーブル・フォルダ・列単位でアクセス制御を設定する仕組みです。
Power BIで使われる RLS/CLS(行レベル/列レベル)の考え方がデータ層まで降りてきており、2026年7月時点ではLakehouse・Mirrored Database・Azure Databricks Mirrored Catalogを対象にサポートされています。
WarehouseやKQL Databaseは既存のアクセス制御機構で運用する構成が現時点の姿です。
Microsoft Purview統合:カタログ・ラベル・DLP・監査ログ
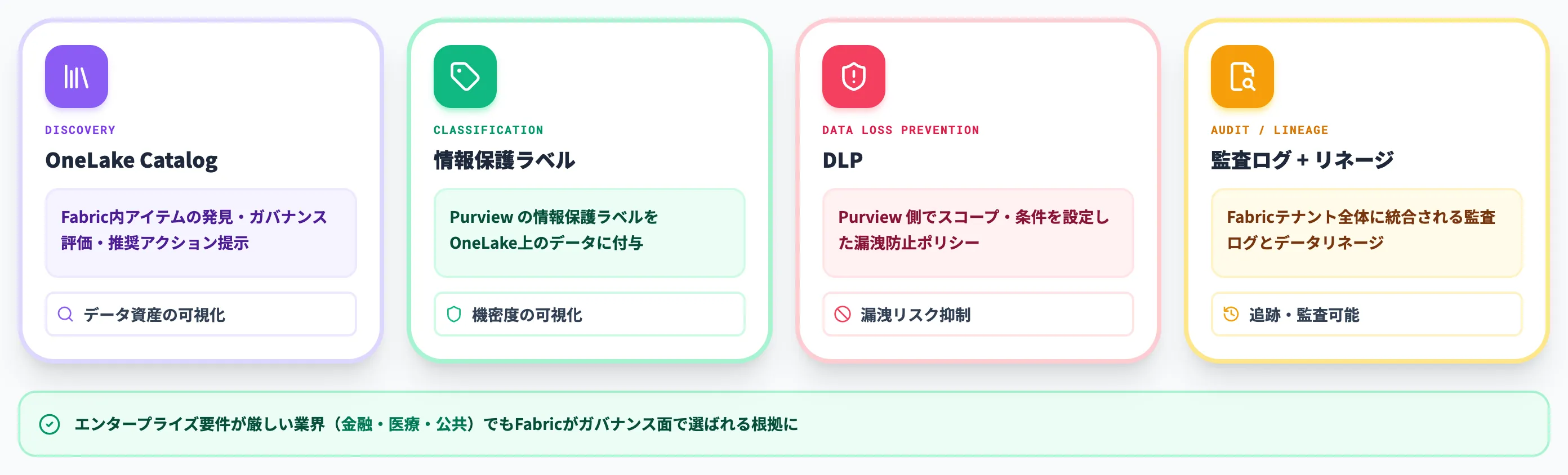
Microsoft PurviewはFabricに標準で組み込まれ、データカタログ・監査ログ・データリネージがFabricテナント全体に統合されます。
OneLake CatalogはFabric内のアイテム発見・ガバナンス評価・推奨アクション提示を担い、Purviewの情報保護ラベルはOneLake上のデータに付与できます。
ラベル・DLPポリシーはPurview側でスコープ・条件を設定する必要があり、Fabricテナント全体に一律で自動適用されるわけではないため、既存のMicrosoft 365ガバナンス設計と対応範囲を突き合わせた上でFabricへ拡張していく形になります。
エンタープライズ要件が厳しい業界(金融・医療・公共)でも、Fabricがガバナンス面で選ばれる根拠になっています。
Microsoft Fabricの導入判断で詰まる論点
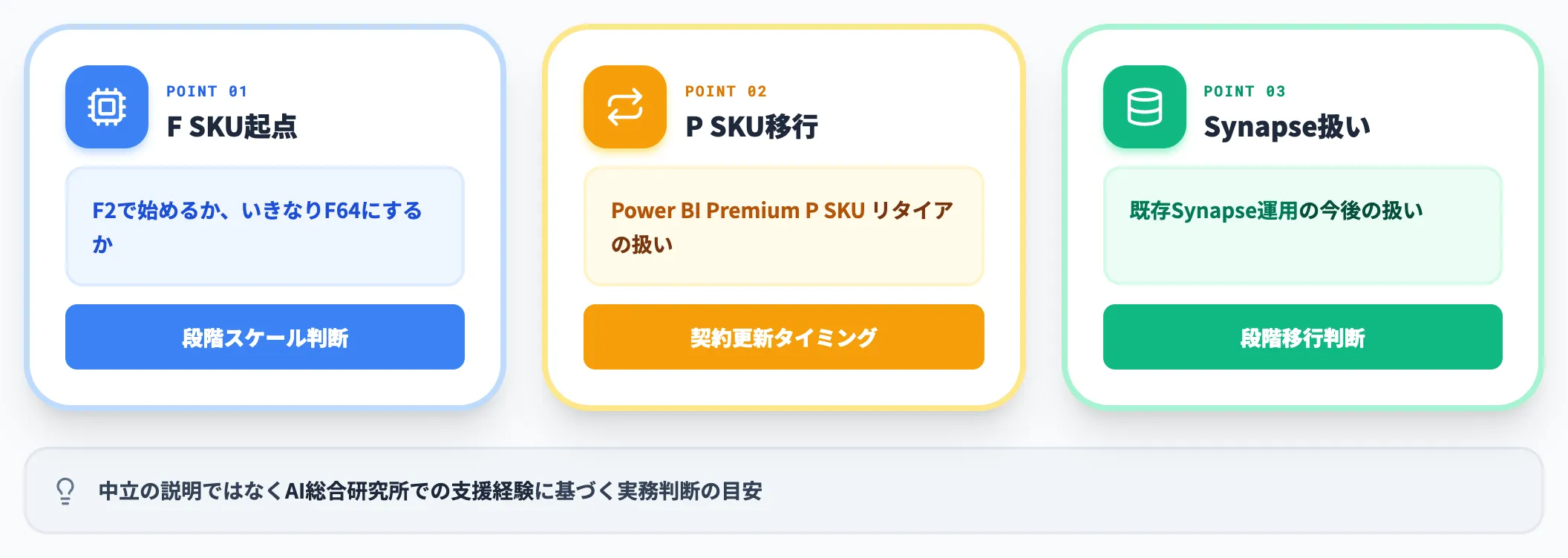
Fabricの導入検討で、「ここで手が止まりやすい」論点を3つ整理します。
AI総合研究所での支援経験に基づく実務判断の目安です。
どのF SKUから始めるか
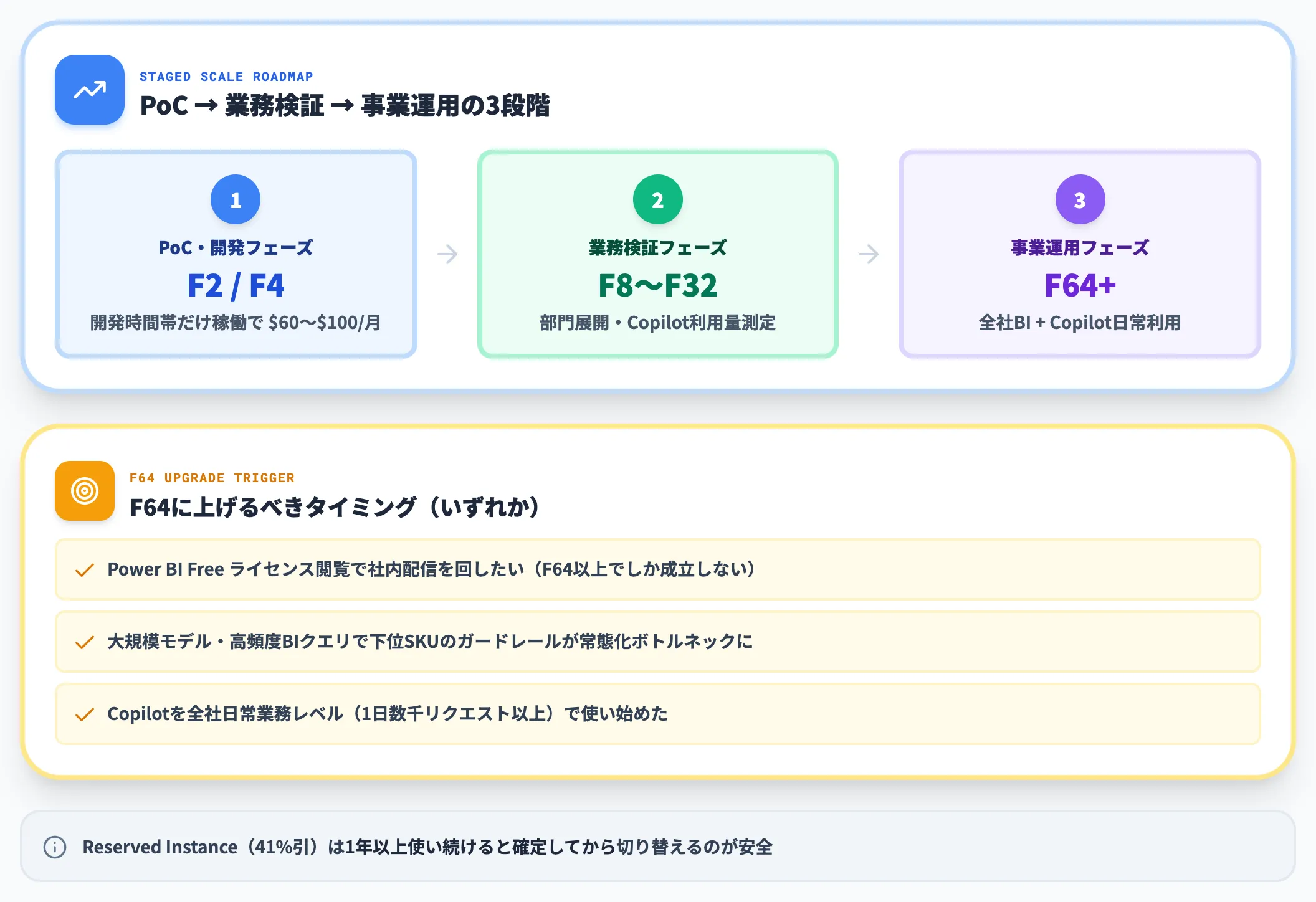
「F2で始めるか、いきなりF64にするか」は、Fabric導入で最初にぶつかる問いです。
実務的には、PoC・開発フェーズはF2またはF4(Pay-as-you-go)から始めて、業務検証でF8〜F32、事業運用でF64以上に段階的にスケールするのが定石です。
F2でもCopilotは動くため、初期の技術検証・データ取り込み検証・Copilot動作確認はF2のPay-as-you-go(開発時間帯だけ稼働で実質 $60〜$100/月)で十分カバーできます。
F64に上げるべきタイミングは、次のいずれかが揃った段階です。
- Power BI FreeライセンスのViewerだけで社内配信を回したい(F64以上でしか成立しない)
- 大規模モデルや高頻度BIクエリで、下位SKUの性能ガードレールが常態的なボトルネックになった
- Copilotを全社日常業務レベル(1日数千リクエスト以上)で使い始めた
Power BI Proライセンス($14/月/user)の削減額とF64との損益分岐は、現在のSKU料金+Fabricワークロードの処理負荷+想定ユーザー数から個別に見積もる必要があります。
Pro単純比較だけでもF64(月約 $8,410)と釣り合う人数は600名近くになるため、「30〜50名でF64に上げるべき」という単純ラインは成立しません。Reserved Instance(41%引き)は、Capacityが明確に「1年以上使い続ける」と確定してから切り替える形が安全です。
Power BI Premium P SKUからの移行判断
既存のPower BI Premium P SKU(P1〜P5)を持つ組織にとって、Fabric F SKUへの移行はMicrosoftのP SKUリタイア方針を受けて検討必須の論点になっています。
Microsoft Customer Agreement(MCA)等の通常契約では次回更新時にF SKUへの切り替えが必要ですが、有効なEnterprise Agreement(EA)を持つ顧客はEA終了まではP SKUを年次更新できる例外運用が用意されています。
契約種別ごとに移行タイミングが違うため、まず自社の契約形態を確認するのが最初のステップです。
機能面では、P1はF64、P2はF128、P3はF256と等価なティアが用意されており、Fabricワークロードを有効化することで従来のPower BI Premium機能に加えてFabric全ワークロードが使えるようになります。
移行の判断ポイントは、「Fabricワークロード(Data Factory / Data Engineering / DWH / Real-Time Intelligence)を今後3年で活用する見込みがあるか」の1点で、活用する見込みが立てばF SKU移行のタイミングでFabricを有効化するのが総合コスト面で有利です。

既存Azure Synapse Analyticsはどうするか
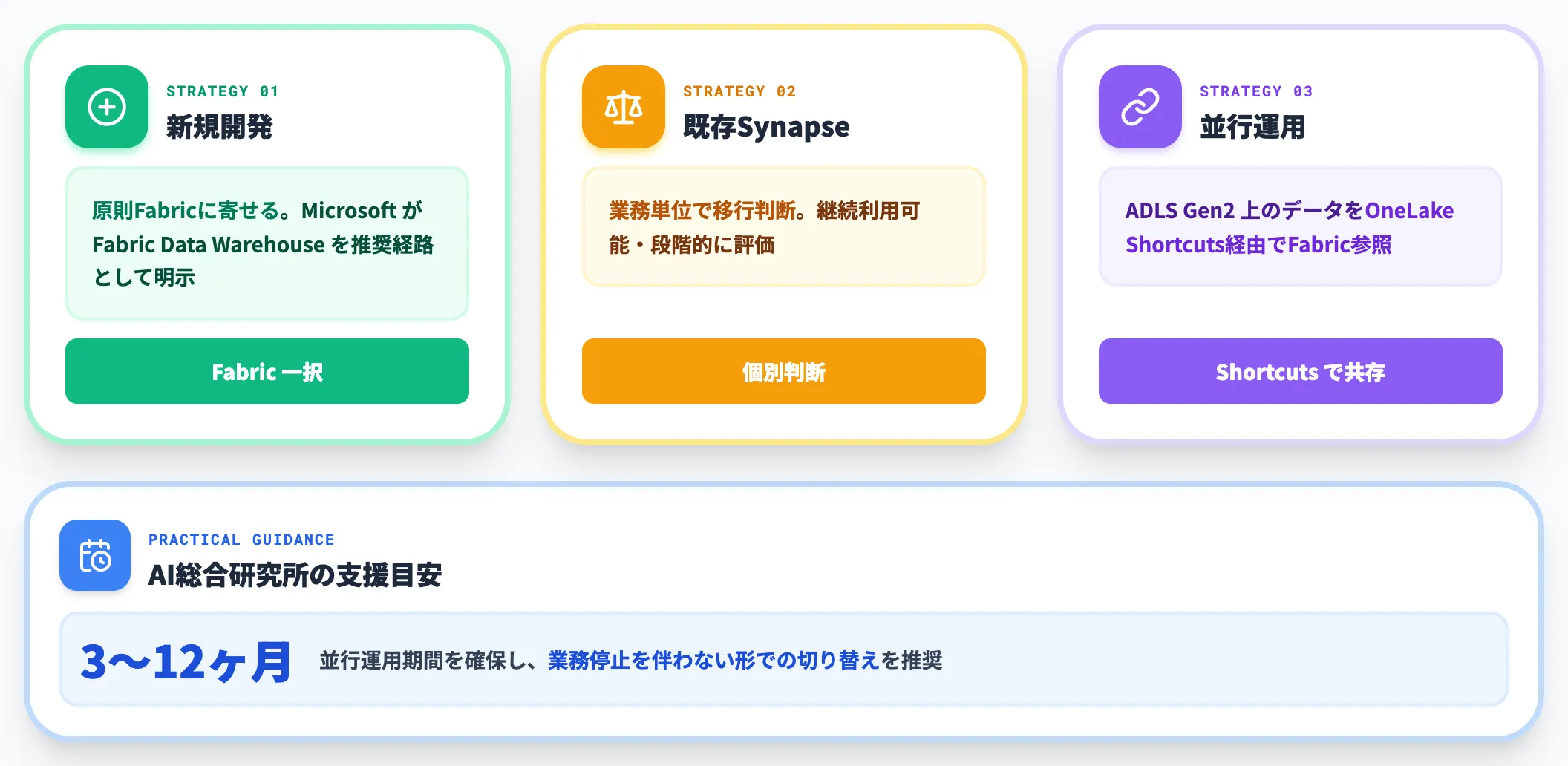
既存のAzure Synapse Analytics運用を持つ組織は、Synapseを今後どう扱うかの判断が必要です。
Azure Synapse AnalyticsのDedicated SQL Pool・Serverless SQL Pool・Spark Poolは継続提供されており、既存契約はそのまま利用できます。ただし新規のDWH案件についてはMicrosoftがFabric Data Warehouseを推奨経路として明示しており(公式ブログ)、既存のSynapse DWH資産をどう扱うかは段階的に判断していく形になります。
現実的な進め方としては、Synapseの新規開発は原則Fabricに寄せ、既存のSynapseワークロードは業務単位で移行を判断し、並行運用期間中はSynapseで利用しているADLS Gen2上のデータをOneLake Shortcuts経由でFabricから参照する構成が実務的です。
AI総合研究所の支援上の目安としては、並行運用期間を3〜12ヶ月確保し、業務停止を伴わない形での切り替えを推奨しています。
Fabric OneLakeで統合したデータを業務Agentのアクションにつなげるなら
FabricでOneLakeに統合したデータを「レポートで終わり」にせず、AIエージェントが業務を自走する土台として活用できるフェーズに入りました。
Microsoft 365 Copilot・Copilot Studio・Fabric IQで社内データを対話で扱える基本形は揃いましたが、業務単位でAgentを立ち上げて既存プロセスに組み込む実装工数はボトルネックとして残ります。
このレイヤーを担うのが、自社Azureテナント内で動くエンタープライズAIエージェント基盤です。
AI総合研究所のAI Agent Hubは、Teamsから呼び出せる業務特化Agent群を1つのダッシュボードで統合管理し、Fabric・Purview・Entra IDと連携して業務プロセスに載せる運用基盤として機能します。
- OneLakeのデータを業務Agentがアクションに変換
Fabric OneLakeに統合したデータを、Teams上のAgentが自然言語で照会→報告→申請までワンストップで実行。「分析して終わり」から「アクションまで完遂」への橋渡しができます。
- 業務単位で事前構築されたAgentを短期間で立ち上げ
経費精算・議事録・受発注・社内問い合わせなどの業務特化Agentを、Fabric OneLakeのデータをそのまま参照する形で運用開始。自社エンジニアリング工数を圧縮できます。
- Purview・Entra IDと連携したガバナンス統制
Agent単位のアクセス権限・実行ログ・セキュリティスキャンを1画面に集約。Fabricで整えたデータ主権をAgent実行層まで一貫して維持できます。
- データは100%自社Azureテナント内に保持
AIの学習対象から完全除外。Azure Managed Applicationsとして自社テナント内で動作が完了する設計です。
AI総合研究所の専任チームが、Fabricで統合したデータをAgentのアクションにつなげる設計まで一貫して支援します。AI Agent Hubのサービスページで、Fabric×Agentの実装例をご確認ください。
Fabricで統合したデータにAIエージェントを接続する

OneLakeの次はAIエージェントによる業務自動化
Fabric OneLakeで束ねたデータをAIエージェントから直接扱えるようにし、レポートで終わりだった分析を「アクションまで自走する業務プロセス」に変えます。AI Agent Hubは、Fabric・Purview・Entra IDと連携した業務エージェント基盤として、経費精算・議事録・受発注などの業務単位でエージェントを立ち上げます。
まとめ
本記事では、Microsoft Fabricについて、6大ワークロード+OneLakeの構造・料金・使い方・Databricks/Snowflakeとの使い分け・国内事例までを、2026年7月時点の最新情報で解説しました。
2026年時点で押さえておくべきポイントは次の3つです。
- FabricはAzure Synapse・Power BI・Data FactoryをSaaSで束ね直した統合データ基盤で、Ignite 2025で加わったFabric IQがAIエージェントを支える意味レイヤーとして6大ワークロード側に組み込まれた
- Mirroring/Shortcutsで既存データを移動せず統合でき、Copilot利用要件は2025年4月にF2以上へ緩和されて初期検証は月額$263前後から始められる
- Databricks/Snowflakeとの使い分けは「BI×Microsoft 365×AIエージェント」ならFabric、「大規模ML」ならDatabricks、「マルチクラウドDWH×データ共有」ならSnowflakeが第一候補
Fabricに統合したデータをレポートで終わらせず、AIエージェントが業務を自走する土台として使う設計が、これからの実務課題です。まずはF2ライセンスで初期検証を開始し、MirroringやShortcutsで既存データ資産を接続してからAI Agent Hub連携まで見通したロードマップを描くのが、最も現実的な第一歩になります。










