この記事のポイント
 AI活用を前提としたデータ基盤構築なら、Sky社のようにFabric + Foundryで1ヶ月PoCから始めるのが最も効率的
AI活用を前提としたデータ基盤構築なら、Sky社のようにFabric + Foundryで1ヶ月PoCから始めるのが最も効率的- Synapse Analytics環境を運用中の企業は、北國銀行の事例のようにFabric移行でインフラ運用負担をほぼゼロにし工数40〜60%削減が見込める
- ESGデータの集計・分類のような定型業務は、INPEXのFabric + Azure AI構成で98%の工数削減が現実的な目標値
- 自社の課題が「BI高度化」「データサイロ解消」「AI/RAG連携」のいずれかで導入パターンが変わるため、目的の明確化が最優先
- コストを抑えるにはF2(月額約$292)で検証開始し、1年予約で約41%節約。F64以上ならPower BI閲覧者の無料化が効くため大規模展開に有利

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Microsoftの統合データ分析プラットフォーム「Microsoft Fabric」を、実際にどのような企業がどう活用しているのか。
2025年12月時点で28,000以上の組織が採用し、2025年3月のMicrosoft公式発表ではFortune 500の74%がFabricを活用しているとされています。国内でも金融・エネルギー・製造・商社・IT・介護など幅広い業界で導入が進んでいます。
本記事では、Microsoft公式のカスタマーストーリーとして公開されている国内6社の導入事例を中心に、各社が抱えていた課題と導入後の成果、Fabricの活用パターン、他データ基盤との比較、料金体系、導入のステップまでを体系的に解説します。
✅Microsoft 365 Copilotの最新エージェント機能「Copilot Cowork」については、以下の記事をご覧ください。
Copilot Coworkとは?機能や料金、Claude Coworkとの違いを解説
目次
【Sky株式会社】AI-Readyなデータ基盤を1ヶ月で構築
【北國銀行/CCIグループ】パイプライン構築工数を40〜60%削減
【ヤマシタ】データ活用民主化でシチズンデータサイエンティスト育成
【ロート製薬】グローバルERPのデータ連携基盤としてFabricを採用
【伊藤忠商事】FOODATAに生成AI基盤を実装、データ統合にFabricを検討
導入事例に見るMicrosoft Fabricの活用パターン
Microsoft Fabric導入のステップと成功のポイント
Microsoft Fabricの採用動向

Microsoft Fabricは、データの収集・蓄積・加工・分析・可視化までを一つのSaaS上で完結できる、Microsoftの統合データ分析プラットフォームです。
2023年11月のGA(一般提供開始)から約2年が経過した2025年12月時点で、Fabricを採用した組織は28,000以上に達しています。
また、2025年3月のFabCon 2025ではFortune 500企業の74%がFabricを活用していると発表されました。
Microsoft史上最も急速に成長するデータ分析プラットフォームとも評されており、日本国内でも金融・エネルギー・製造・商社・IT・介護など幅広い業界で導入事例が公開されています。

Microsoft Fabricの国内活用・導入事例6選

ここでは、Microsoft公式のカスタマーストーリーとして公開されている国内6社の導入事例を紹介します。
以下の表で、6社の業界・導入状況・主な成果を一覧で整理しました。
| 企業名 | 業界 | 導入状況 | 主な成果 |
|---|---|---|---|
| Sky株式会社 | ITサービス | 2025年8月 | PoC 1ヶ月完了、AI活用アイデア100件超 |
| 北國銀行/CCIグループ | 金融 | 2025年9月 | インフラ運用ほぼゼロ、パイプライン工数40〜60%削減 |
| INPEX | エネルギー | 2025年3月 | 月50時間→約1時間(98%削減) |
| ヤマシタ | 介護・福祉用具 | 2024年2月 | Excel作業廃止、リアルタイムBI化 |
| ロート製薬 | 製薬・日用品 | 2025年3月 | データ登録時間1/2、グローバルERP統合 |
| 伊藤忠商事 | 総合商社 | 検討・PoC段階 | 70件超の生成AI活用アイデア、RAG基盤として評価 |
6社に共通するのは、従来のデータ基盤の限界(ツールの分散、手作業の多さ、スケーラビリティの不足)を解決するために、Fabricを活用または有力候補として評価している点です。
それぞれの事例を詳しく見ていきます。
【Sky株式会社】AI-Readyなデータ基盤を1ヶ月で構築
企業概要
SKYSEA Client ViewやSKYPCEなどのソフトウェア製品を提供するSky株式会社(社員4,000名超、全国26拠点)は、2023年末から社内チャットボット「SKYAI」の開発に着手するなど、AI活用に積極的に取り組んでいます。
課題
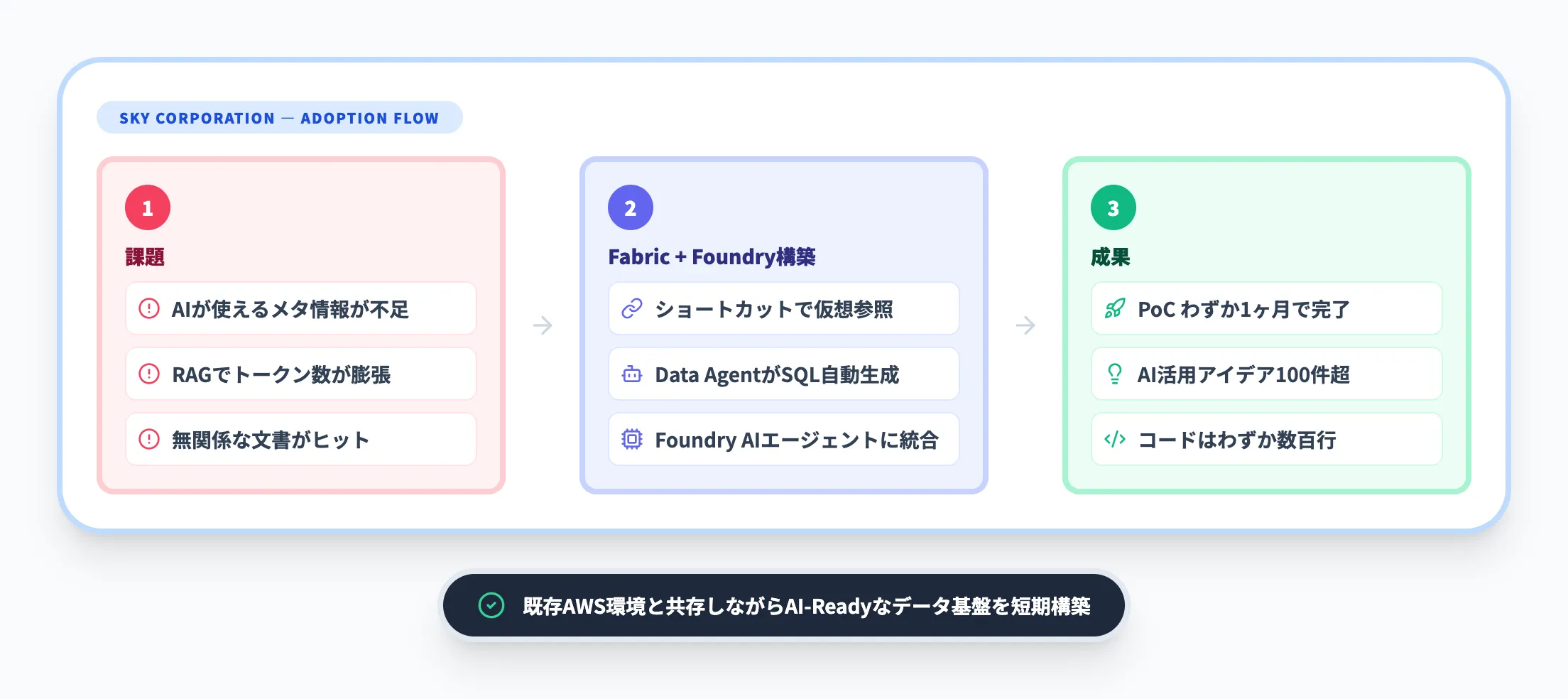
GPT 3.5ベースの社内チャットボットは約8割の社員に利用されるまでに浸透しましたが、RAG(検索拡張生成)でデータを活用しようとした際に大きな壁に直面しました。
- 既存のデータ基盤「Skyデータ ポータル」は「人が活用すること」を前提としており、AIが使うためのメタ情報が不足
- RAGの検索結果をそのままAIに渡すとコンテキストサイズが膨張し、トークン数が増大
- テキストをそのままベクトル化すると、関係のないドキュメントもヒットしてしまう
つまり、「AI-Ready」なデータ基盤を改めて構築する必要があったのです。
ソリューション
2025年1月にMicrosoftからFabricとMicrosoft Foundryの説明を受け、6月にPoCに着手。従業員向け週次アンケート調査の自動分析・要約をユースケースとして選定しました。
構成のポイントは以下のとおりです。
- On-Premises Data GatewayでAzureとAWS(既存クラウド)を接続
- Fabricのショートカット機能で実データをコピーせずに仮想参照
- Fabric Data Agentが自然言語からSQLを自動生成し、複数テーブルを結合
- Foundry上のAIエージェントにナレッジとして統合し、ユーザーに要約を回答
開発を担当した西村太陽氏は「記述したコードはわずか数百行程度。非常にいい開発体験でした」と述べています。
成果
- PoCは着手からわずか1ヶ月で完了、2025年8月に本番運用を開始
- アンケート集計の手作業(半日かかっていたデータ整理)が不要に
- 提供開始から4ヶ月で100件超のAI活用アイデアが社員から提案
- 2週に1本のペースでAIエージェントを新規リリース
Skyの事例が示すのは、Fabricが既存のAWS環境と共存しながら、AI活用のためのデータ基盤を短期間で構築できるという点です。
参考:Sky株式会社が Microsoft Fabric と Microsoft Foundry でデータ基盤を確立、AI エージェントによるデジタル ワーカー実現を目指す
【北國銀行/CCIグループ】パイプライン構築工数を40〜60%削減

企業概要
北陸地域を中心に金融サービスを提供する北國銀行(従業員1,000〜9,999名)は、2025年10月に持株会社名を「CCIグループ」へ変更し、金融と非金融の2ブランド体制で全国・海外展開を進めています。
課題
2022年秋にAzure Synapse Analyticsを中心としたデータ活用基盤を構築していましたが、利用が拡大するにつれ2つの課題が顕在化しました。
- データの収集・整理・加工・分析に複数のツールを使用しており、データ提供までのリードタイムが長期化
- 複数のPaaSとIaaSを組み合わせたシステム構成により、インフラ運用の負担が増大
データドリブン経営を推進するうえで、利用者が増えにくい状況は大きなボトルネックでした。
ソリューション
2024年1月にFabricのPoCを開始し、9月まで検証を実施。データ提供のリードタイム短縮、保守性向上、AutoML機能による利用者拡大の3点を検証しました。
FabricのシステムIT基盤グループ長を務める村松資大氏は選定理由について「データの収集・加工・可視化までを一貫して実現できることと、統合されたSaaSであること」と説明しています。
成果
- インフラ運用の負担がほぼゼロに削減(SaaSのため)
- データパイプライン構築工数を40〜60%削減できる見込み
- ショートカット機能で物理コピーなしにデータを統合
- GUIベースのパイプライン構築により、業務部門へのデータ提供作業を移管
- データの属人性が解消され、責任分界点が明確に
金融機関ならではのセキュリティ要件に対しては、Microsoft Sentinelを組み合わせることで、顧客の財務諸表や統合事業計画(IBP)を含むデータも制限なく扱えるようになりました。
今後はMicrosoft Purviewによるデータカタログ構築も検討されており、全社横断的なデータ基盤への進化が計画されています。
参考:北國銀行/CCIグループが次世代データ活用基盤を構築、Microsoft Fabric の採用でデータ提供のリード タイムを大幅に短縮、インフラ運用負担はほぼゼロに
【INPEX】ESGデータ処理を月50時間→約1時間に

企業概要
日本最大規模のエネルギー開発企業であるINPEX(国際石油開発帝石)は、石油・天然ガス・低炭素エネルギーの安定供給を事業の柱とし、HSE(健康・安全・環境)を最優先事項としています。
課題
2023年度報告からGRI306(国際的な廃棄物報告基準)に準拠した分類を導入したところ、廃棄物の分類項目が一気に増加。HSE部門での集計・取りまとめ業務が月間15時間から50時間に増大しました。
ソリューション
2024年11月にHSEユニットから社内デジタル部門に相談があり、翌月にはテスト環境を構築。Microsoft Fabricを中核に、Azure AI Document IntelligenceとAzure OpenAIを組み合わせた「INPEX ESG Data Hub」を構築しました。
データ処理の工夫は以下のとおりです。
-
電子マニフェスト(構造化データ)
Fabricのデータフローでシンプルな変換(体積→重量の換算など)を処理し、複雑な集計はノートブック(Python)で実行。
1つのパイプラインにデータフローとノートブックを混在できるFabricの特性を活用
-
請求書PDF(非構造化データ)
Azure AI Document IntelligenceでPDFをMarkdown化し、Azure OpenAIで分類・集計。
Azure FunctionsとLogic Appsで月次自動実行を実現
先進O&Mグループの廣田兼二郎氏は「2023年5月にパブリックプレビュー版が登場したころからFabricには注目していました。これならデータレイクハウスの考え方をクラウドに実装できると感じていた」と語っています。
成果
- HSE部門の処理時間を月50時間→約1時間に短縮(98%削減)
- 構築期間は約3ヶ月
- ルーティンワークから解放され、施策立案や改善提案に時間を充当
- オーストラリア拠点ではSAPデータ連携にもFabricを活用中。グローバルデータ基盤への拡張を計画
INPEXの事例は、Fabricが「データの集計・分析」だけでなく、AI(Document Intelligence + OpenAI)と組み合わせた業務自動化基盤としても機能することを示しています。
事例を参考にFabric×AI基盤を設計

データ統合からAI業務自動化まで一気通貫
国内導入企業のように、Fabricのデータ基盤にAIエージェント層を追加。パイロットから全社展開まで段階的に設計できます。
参考:Microsoft Fabric を活用した「INPEX ESG Data Hub」で ESG 報告業務を最適化、約 50 時間費やしていた廃棄物分類、集計の作業が不要に
【ヤマシタ】データ活用民主化でシチズンデータサイエンティスト育成

企業概要
介護用品レンタル・販売とリネンサプライ事業を展開する株式会社ヤマシタ(全国70拠点以上)は、「在宅介護のプラットフォーマー」を目指し、DX人財の育成とデータ活用の民主化を経営の柱としています。
課題
- 営業部門へのデータ提供を4名チームが毎朝Excelで手作業で行っていた
- データ作成工数の制限により、主要データ以外は週次/月次の提供にとどまっていた
- システム部では夜間1時間超の残業でデータ準備を実施、スポット依頼には1〜2日かかっていた
DX推進責任者の小川邦治氏は、Fabricの正式リリース(2023年11月)の前月に採用を決定。AI機能による自然言語でのデータ活用と、Microsoft Power Platformとの相性を評価したためです。
ソリューション
パートナーとしてMicrosoft製品に豊富な実績を持つ株式会社ジールを採用し、2023年10月にプレビュー版でデータ基盤構築に着手。
最も難易度が高い「介護用品レンタル・販売の新規/追加契約件数」の分析領域からスタートしました。
Microsoftの「Azure Innovate」プログラムによる資金面での支援も活用されており、先行事例がない段階でのROI算定リスクを軽減しています。
成果
- 毎朝のExcelデータ作成作業が完全に不要に
- 夜間1時間超のデータ準備作業もゼロに
- ダッシュボード作成は30分/件で可能(データマートが整備されていれば)
- 週次/月次→リアルタイムのデータアクセスに移行
- シチズンデータサイエンティストが十数名に増加、全拠点への配置を計画
ヤマシタの事例の最大のポイントは、「現場業務で必要なダッシュボードの開発を事業部門主体で進めている」という点です。
システム部はデータモデルの提供に専念し、可視化は現場が自ら行う体制を構築しています。
【関連記事】
Microsoft FabricとPower BIの違い、連携手順をわかりやすく解説
参考:データ活用民主化を推進するヤマシタ、そのためのデータ基盤として Microsoft Fabric を採用、全国 70 以上の拠点全てに DX 人財を配置することを目指す
【ロート製薬】グローバルERPのデータ連携基盤としてFabricを採用
企業概要
1899年創業のロート製薬(世界110か国以上に展開、グループ企業100社超)は、「ローカルビジネスの成長を尊重しつつ国際的な相乗効果を生み出す」という方針のもと、グローバルERP構築に取り組んでいます。
課題
- 各国に個別のERPが導入されており、業務や情報がサイロ化
- グループ間のSCM(サプライチェーンマネジメント)やファイナンスデータの連携に多くの手作業が発生
- 会計レポートのフォーマットが各国でバラバラ、手作業でのチェックと変換に工数がかかっていた
各国の文化や業務特性を尊重する企業文化のもと、一律統合ではなく2層型のERP構成が選択されました。
ソリューション
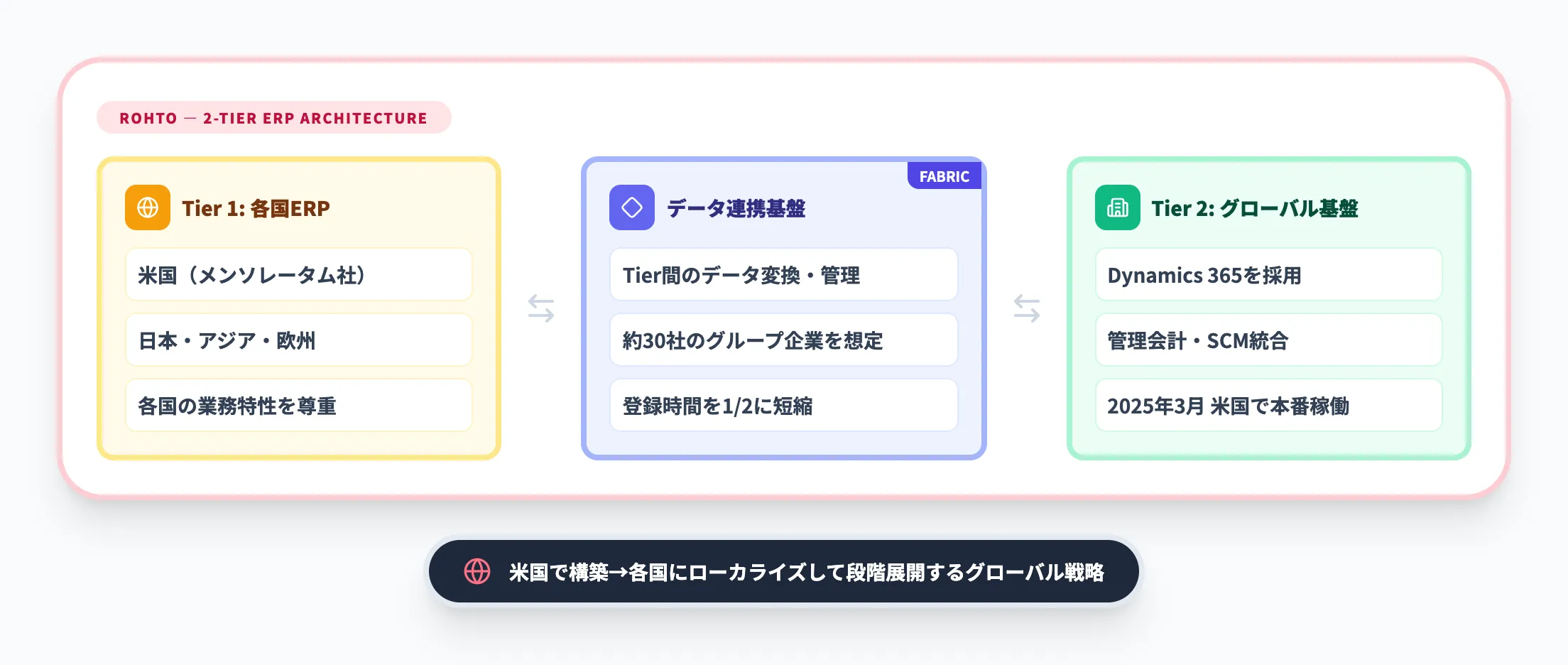
各国に導入するERPを「Tier 1」、グローバル共通基盤を「Tier 2」とし、Dynamics 365を採用。
Tier 1とTier 2の間のデータ連携基盤としてMicrosoft Fabricを配置するアーキテクチャが構築されました。
グローバルITセンターの前田達也氏は「各国でERPがバラバラの状態でも、Tier 2が各国の状況に合わせやすくするために、Microsoft Fabricを活用しています」と述べています。
成果
- 2025年3月に米国メンソレータム社でTier 1 + Tier 2 + Fabricが本番稼働
- 管理会計システムへのデータ登録時間が1/2に短縮
- 米国で構築した内容をコアテンプレートとし、各国にローカライズして段階展開する計画
- データ連携先は約30社のグループ企業を想定
ロート製薬の事例は、Fabricが「分析基盤」だけでなく、**グローバルERPのデータハブ(インターフェイス層)**としても機能することを示しています。
参考:ロート製薬が Dynamics 365 でグローバル ERP を構築、2 層型のシステム構成で各国の状況に柔軟に対応できる基盤を確立
【伊藤忠商事】FOODATAに生成AI基盤を実装、データ統合にFabricを検討

企業概要
総合商社の伊藤忠商事は、2023年5月にカンパニー横断型のタスクフォースを発足し、全社的な生成AI活用を推進しています。
食料カンパニーが取引先に提供するデータ分析ダッシュボード「FOODATA」への生成AI組み込みが、代表的なプロジェクトです。
課題
FOODATAは消費者の購買データ、消費者調査データ、SNS口コミ、味覚の定量データなどを集約した分析基盤ですが、2つの課題がありました。
- より高速なデータ処理と高い操作性への要求
- データ分析に加え、商品企画書の自動生成のようなアイデア出しまでカバーすることへの期待
食料カンパニーの塚田健人氏は「最終的に実現したいのは、FOODATAのダッシュボードをなくすこと。生成AIと対話することですぐに結論が得られるサービスにしたい」と述べています。
ソリューション
Azure OpenAI ServiceとAzure AI Studioを採用し、FOODATAに生成AI機能を実装。パートナーとして株式会社ヘッドウォータースが技術支援を担当しています。
全社の生成AI共通基盤として、以下の構想が進んでいます。
- Azure AI Studioを全社AI基盤として採用
- データの蓄積・クレンジング・前処理にMicrosoft Fabricを検討
- Fabricのノートブックでデータと生成AIの活用を一体化
ヘッドウォータースの西間木将矢氏は「Microsoft Fabricは、RAGを含むデータ基盤としてデファクトスタンダードになり得る」と評価しています。
現在の状況
2024年1月にPoCを開始し、商品企画書の自動生成に向けた検証が進行中。
全社では70件以上の生成AI活用アイデアが出ており、Fabricはこれらを支えるデータ統合基盤として検討されています。
参考:Microsoft Fabric と Azure AI Studio で「FOODATA」に生成 AI 基盤を実装、データ分析のダッシュボードから「すぐに結論が得られる」サービスへの進化を目指す
導入事例に見るMicrosoft Fabricの活用パターン

国内6社の導入事例を横断的に分析すると、Fabricの活用パターンは大きく3つに分類できます。
以下の表で、各パターンの特徴と該当する事例企業を整理しました。
| パターン | 主な用途 | Fabricの役割 | 該当事例 |
|---|---|---|---|
| BI基盤型 | データの可視化・ダッシュボード | データ統合 + Power BIで現場のセルフサービスBI | ヤマシタ、北國銀行 |
| データ統合ハブ型 | 複数システム間のデータ連携 | ERPや外部DBとの中間層としてデータ変換・管理 | ロート製薬、北國銀行 |
| AI/RAG連携型 | 生成AI・エージェントの業務自動化 | AI-Readyなデータを準備し、AIエージェントに供給 | Sky、INPEX、伊藤忠 |
それぞれのパターンについて、導入設計のポイントを解説します。
BI基盤型(ヤマシタ・北國銀行)

データの可視化とセルフサービス分析を主目的とするパターンです。ヤマシタではExcelベースの手動レポートをFabric + Power BIに置き換え、北國銀行では複数ツール間のデータ移動を統合しました。
このパターンの導入設計で重要な点は以下の3つです。
-
データモデルの整備を先行する
ヤマシタでは「システム部はデータモデルの提供まで、ダッシュボードは事業部門が作成」という役割分担を明確化。
データマートが整備されていれば、30分でダッシュボードを作成できる
-
最も難易度が高い領域から着手する
ヤマシタはあえて最も複雑なホームケア事業部から開始し、成功実績を示すことで全社展開の推進力にした
-
GUIベースの操作で利用者を拡大する
Fabricのデータフローやパイプライン構築はGUIで操作でき、プログラミング経験がなくても扱える。
北國銀行では業務部門へのデータ提供作業の移管が進んでいる
データ統合ハブ型(ロート製薬・北國銀行)

複数のデータソースを統合し、システム間のデータ連携を最適化するパターンです。
ロート製薬では各国ERPとグローバル基盤の間にFabricを配置し、北國銀行ではSynapse AnalyticsからFabricへの移行でシステム構成を簡素化しました。
このパターンのポイントは以下のとおりです。
- ショートカット機能でデータの物理コピーを最小化し、OneLake上で仮想的にアクセス
- SaaS型のためインフラ運用の負担がほぼゼロ(北國銀行の実績)
- 段階的な展開が可能。ロート製薬では米国から開始し、各国にローカライズして展開
AI/RAG連携型(Sky・INPEX・伊藤忠)
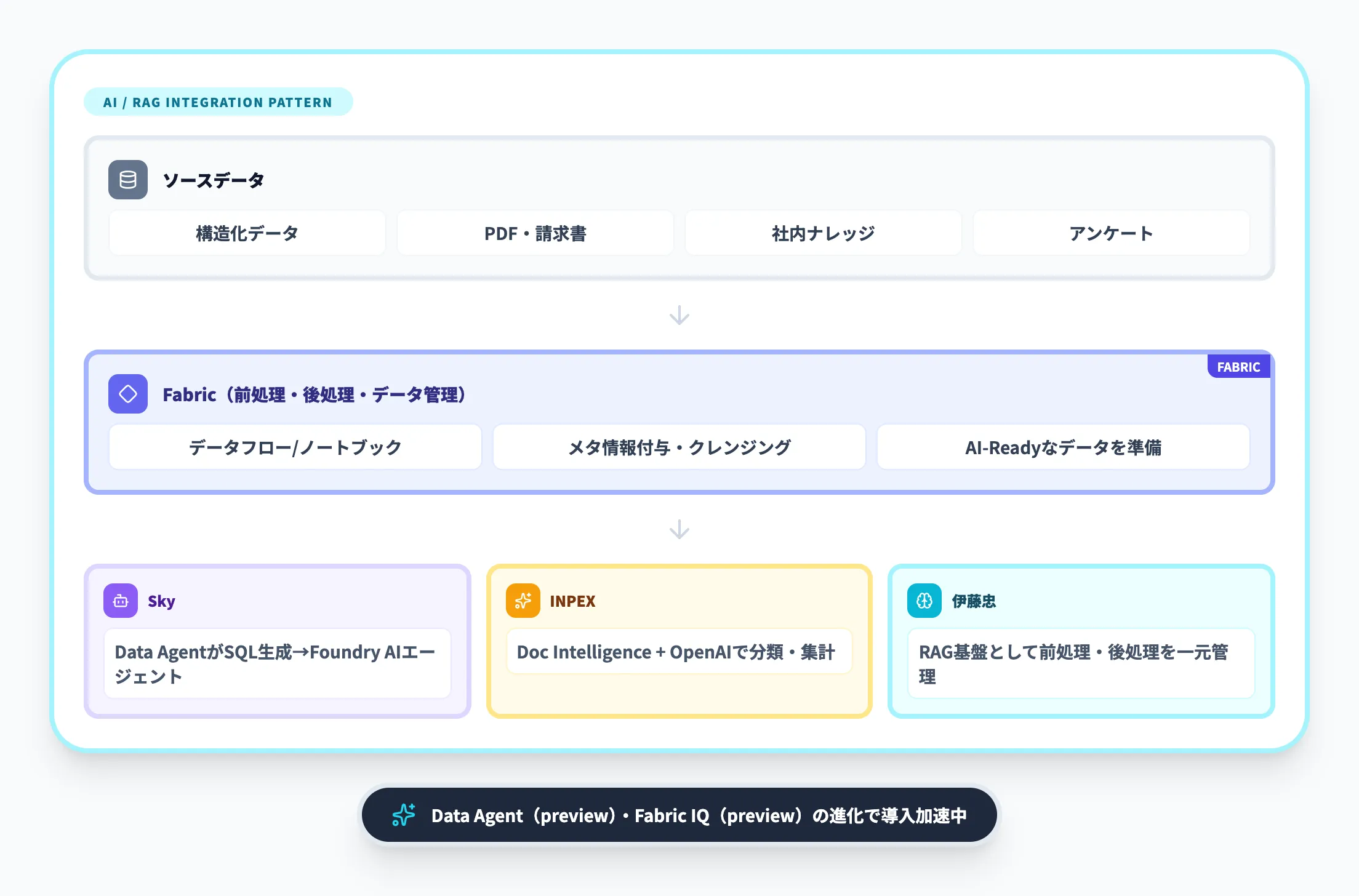
Fabricのデータ基盤をAIエージェントや生成AIのバックエンドとして活用するパターンです。
2025年以降のFabricの進化(Data Agent(preview)、Fabric IQ(preview)、Copilotの有償SKU(F2以上)への拡大)により、このパターンの導入が加速しています。
このパターンのポイントは以下のとおりです。
- Fabric Data Agentが自然言語からSQLを生成し、FoundryのAIエージェントと連携(Sky)
- 構造化データはデータフロー/ノートブック、非構造化データはAzure AI Document Intelligence + Azure OpenAIで処理(INPEX)
- RAGの回答品質を高めるために、ソースデータの前処理・後処理をFabricで一元管理(伊藤忠が検討中)
3つのパターンは排他的ではなく、北國銀行のように「BI基盤型で開始し、将来はAI活用基盤へ発展させる」という段階的な拡張が一般的です。
自社の現在の課題に合ったパターンから着手し、段階的に活用範囲を広げていく設計が推奨されます。
Microsoft Fabricの海外導入事例

日本国内だけでなく、海外でもFabricの導入事例が公開されています。以下の表で代表的な事例をまとめました。
| 企業名 | 業界・国 | Fabricの活用内容 | 主な成果 |
|---|---|---|---|
| One NZ | モバイル通信(ニュージーランド) | Real-Time Analytics導入 | レポート更新間隔が60秒→10秒(6倍高速化)、導入わずか2週間 |
| BDO Belgium | 会計・アドバイザリ(ベルギー) | M&A分析プラットフォーム構築 | Fabric + Power BIで遅延なしのデータアクセスを実現 |
| ZEISS | 光学技術(ドイツ) | エンタープライズ分析基盤「eVA」 | 構造化・非構造化データのサイロを解消 |
| Alltech | 持続可能な農業(米国) | 複数ERPの旅費データ統合 | セルフサービス分析を実現、データサイロ解消 |
| メルボルン空港 | 航空・空港(オーストラリア) | データ関連業務の効率化 | パフォーマンス効率30%向上 |
| Dener Motorsport | モータースポーツ(ブラジル) | 車両異常の分析 | 分析時間を約30分→数分に短縮 |
特に注目すべきは、One NZの事例です。Real-Time Analyticsの導入がわずか2週間で完了し、レポートの更新間隔を6倍に高速化しています。
Fabricの「Real-Time Intelligence」ワークロードは、IoTやログ分析のようなストリーミングデータのリアルタイム処理に強みを持っており、日本国内でも今後この領域の導入が増えると予想されます。
Microsoft Fabricと他データ基盤の比較

Fabricの導入を検討する際、Snowflake、Databricks、Google BigQueryとの比較は避けて通れません。
主要プラットフォームの機能比較
以下の表で主要な比較軸を整理しました。
| 比較項目 | Microsoft Fabric | Snowflake | Databricks | BigQuery |
|---|---|---|---|---|
| アーキテクチャ | 統合SaaS(OneLake中心) | マルチクラウドSaaS | マルチクラウドレイクハウス | GCPサーバーレス |
| 主要インターフェイス | ローコード / Power BI | SQL / Snowsight | Python / Sparkノートブック | SQL / コンソール |
| ストレージ形式 | Delta Parquet(OneLake) | プロプライエタリ(Iceberg対応) | Delta Lake(オープン標準) | カラムナー(独自) |
| AI統合 | Copilot / Data Agent(preview) / Fabric IQ(preview) | Cortex AI | Mosaic AI + MLflow | Vertex AI連携 |
| クラウド | Azure中心 | マルチクラウド | マルチクラウド | GCP中心 |
| 課金モデル | 主にCapacity(F SKU)中心 + ストレージ/オプション課金 | 消費ベース(クレジット制) | DBU + ストレージ二層 | 完全従量課金 |
| ガバナンス | Microsoft Purview | Horizon(内蔵) | Unity Catalog | Data Catalog |
組織タイプ別の選定ガイド
この比較表を読み解くうえで重要なのは、どのプラットフォームが「最良」かではなく、自社の環境と優先事項に合うかどうかです。以下に選定の目安を示します。
-
Microsoft 365 / Azureを既に利用している組織
Fabricが最も統合性が高い。Power BIとの連携、Entra IDによる認証統合、Purviewによるガバナンスが既存環境とシームレスにつながる。
前述のSky、北國銀行、INPEXはいずれもAzure利用企業。
-
マルチクラウド環境が必須の組織
SnowflakeまたはDatabricksが適する。Snowflakeは真のマルチクラウドSaaSとして、AWS・Azure・GCPで同一体験を提供
。Databricksはオープン標準(Delta Lake)でベンダーロックインを最小化。
-
AI/ML開発が事業の中核にある組織
Databricksが強い。非構造化データ(動画・音声・ログ)の処理やPython/Scalaでのモデル構築に最適化されている。
ただしスキル要件が高い(熟練データエンジニアが必要)。
-
GCPを中心に運用し、ゼロ管理を求める組織
BigQueryが適する。完全サーバーレスでPB級クエリをSQLで実行可能。インフラ管理は一切不要
なお、大企業ではハイブリッド戦略(Fabric + Databricksなど)も増えています。
DatabricksでAI/ML開発を行い、OneLakeのショートカットでPower BIユーザーにデータを提供するといった組み合わせが代表例です。
Microsoft Fabric導入のステップと成功のポイント

国内6社の導入事例から共通するパターンを抽出すると、Fabricの導入は以下の4ステップで進められています。
1. 課題の特定とFabricの適合性評価

導入の出発点は、現行のデータ基盤が抱える具体的な課題の特定です。6社の事例では以下のような課題がきっかけになっています。
- 複数ツールの乱立によるリードタイムの長期化(北國銀行)
- 手作業によるデータ整理の工数増大(INPEX、ヤマシタ)
- AIが活用できるデータ基盤の不在(Sky)
- グローバルなデータ連携の必要性(ロート製薬)
課題を明確にしたうえで、Fabricの「統合SaaS」「OneLakeによるデータ統合」「AI連携機能」が自社の課題解決に適しているかを評価します。
2. PoCの実施(1〜9ヶ月)

すべての事例でPoCが実施されており、その期間は**1ヶ月(Sky)から9ヶ月(北國銀行)**まで幅があります。
PoCを短期間で完了するためのポイントは以下のとおりです。
- 明確なユースケースを1つ選定する Skyは「週次アンケートの自動要約」、INPEXは「廃棄物データの自動分類」など、効果が測定しやすい業務を選んでいる
- GUIベースの開発を活用する Fabric Data AgentやデータフローはGUIで操作でき、コーディング量を最小化できる
- Microsoftの支援プログラムを活用する ヤマシタは「Azure Innovate」、北國銀行はMicrosoftとの毎週のディスカッションで技術課題を解決
3. 本番運用と組織体制の構築

PoCの成果が確認されたら、本番環境への移行と利用者拡大の体制を構築します。
- 役割分担の明確化 ヤマシタでは「システム部=データモデル提供、事業部門=ダッシュボード作成」と分離
- シチズンデータサイエンティストの育成 事業部門の担当者がFabricを直接操作できるスキルを身につけることで、データ活用の民主化が進む
- セキュリティの担保 北國銀行ではMicrosoft Sentinelとの組み合わせで金融機関レベルのセキュリティを実現
4. 段階的な拡張
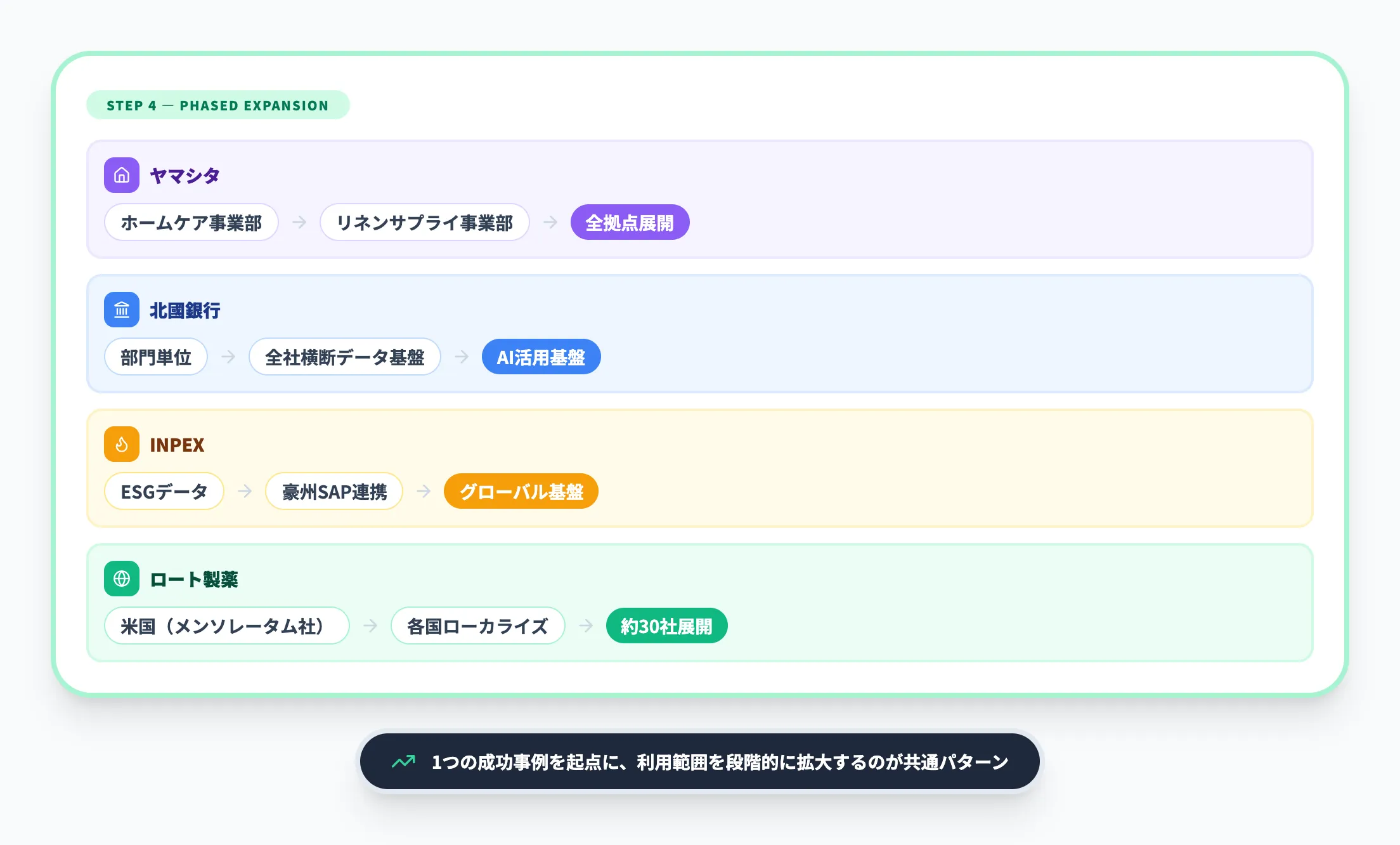
すべての事例に共通するのは、1つの成功事例を起点に利用範囲を段階的に拡大するというアプローチです。
- ヤマシタ:ホームケア事業部→リネンサプライ事業部→全拠点展開
- 北國銀行:部門単位→全社横断データ基盤→AI活用基盤
- INPEX:ESGデータ→オーストラリアのSAP連携→グローバルデータ基盤
- ロート製薬:米国(メンソレータム社)→各国にローカライズして展開
最初から全社導入を目指すのではなく、パイロットで効果を実証し、成功体験を積み重ねながら拡大することが、Fabric導入の成功パターンと言えます。

Microsoft Fabricの料金体系

Fabricの料金は、主にCapacity(F SKU)とOneLake Storageで構成されます。
加えて、SparkワークロードのAutoscale Billingやcapacity overageなどのオプションもあります。ここではFabricの導入コストを見積もるための主要な料金情報を整理します。
F SKU(Capacity Units)の料金
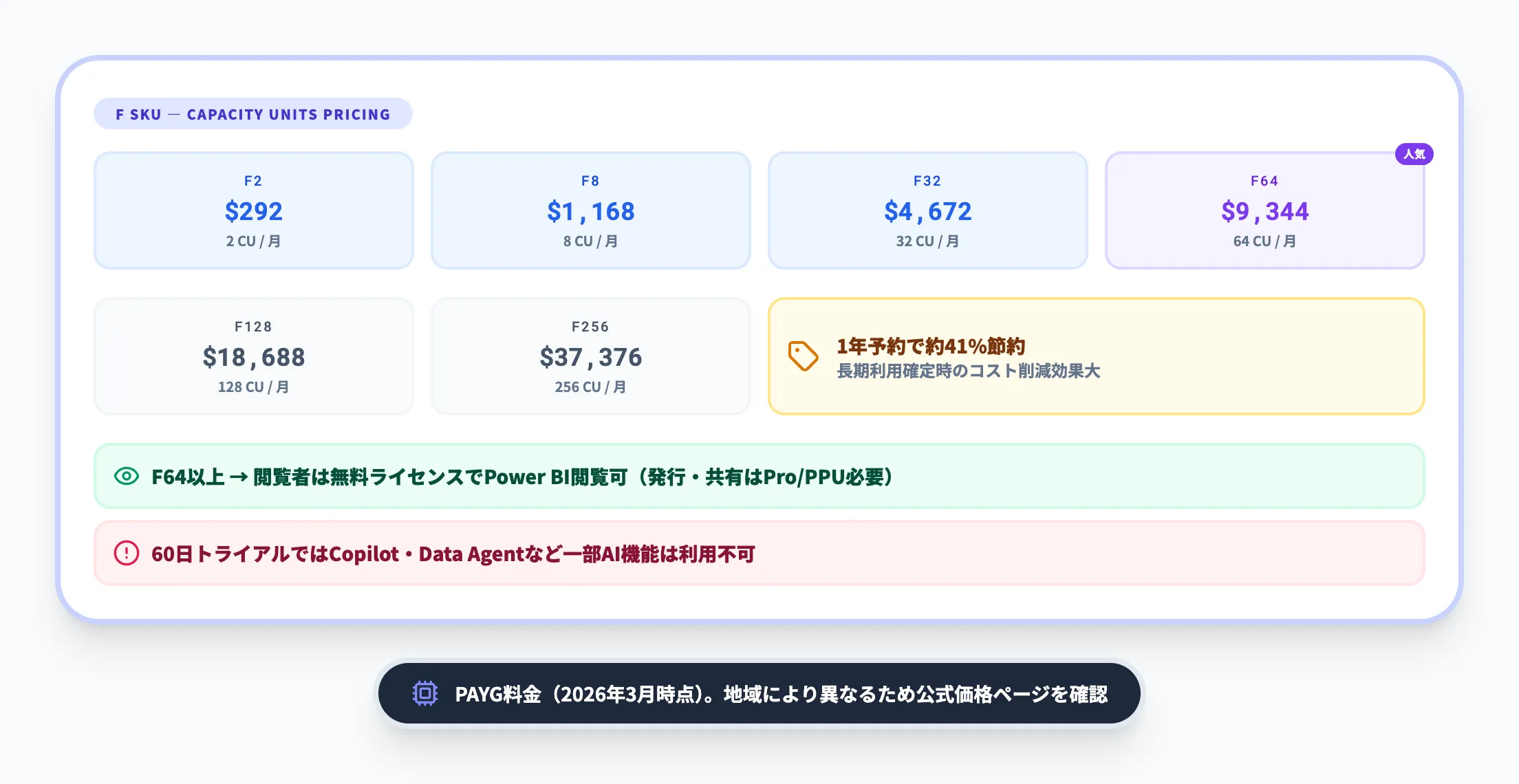
FabricのコンピューティングリソースはCapacity Units(CU)という単位で管理され、F SKUとしてサイズ別に提供されます。
以下の表で主要なSKUの月額目安を示します。
| SKU | CU数 | 月額目安(PAYG) | Power BI閲覧 |
|---|---|---|---|
| F2 | 2 | 約$292 | 別途Pro必要 |
| F4 | 4 | 約$584 | 別途Pro必要 |
| F8 | 8 | 約$1,168 | 別途Pro必要 |
| F16 | 16 | 約$2,336 | 別途Pro必要 |
| F32 | 32 | 約$4,672 | 別途Pro必要 |
| F64 | 64 | 約$9,344 | 無料ユーザーで閲覧可 |
| F128 | 128 | 約$18,688 | 無料ユーザーで閲覧可 |
| F256 | 256 | 約$37,376 | 無料ユーザーで閲覧可 |
料金を読み解くポイントは以下のとおりです。
- 1年予約で約41%の節約が可能。長期利用が確定している場合はコスト削減効果が大きい
- F64以上では、閲覧者(ビューアー)は無料ライセンスでPower BIコンテンツを閲覧できる。ただし、レポートの発行・共有・作成にはPro(¥1,499/ユーザー/月)またはPPUライセンスが引き続き必要
- 料金は地域によって異なる。上表は米国ドル建ての価格例であり、Japan East(東日本)リージョン等では異なる場合がある。最新の正確な価格は公式価格ページを確認すること
- 無料トライアル(60日間)が提供されており、PoCに活用可能。ただしトライアル容量ではCopilotやData Agentなど一部AI機能は利用できない点に注意。ヤマシタの事例ではMicrosoftの「Azure Innovate」による資金支援も活用されている
OneLake Storageの料金
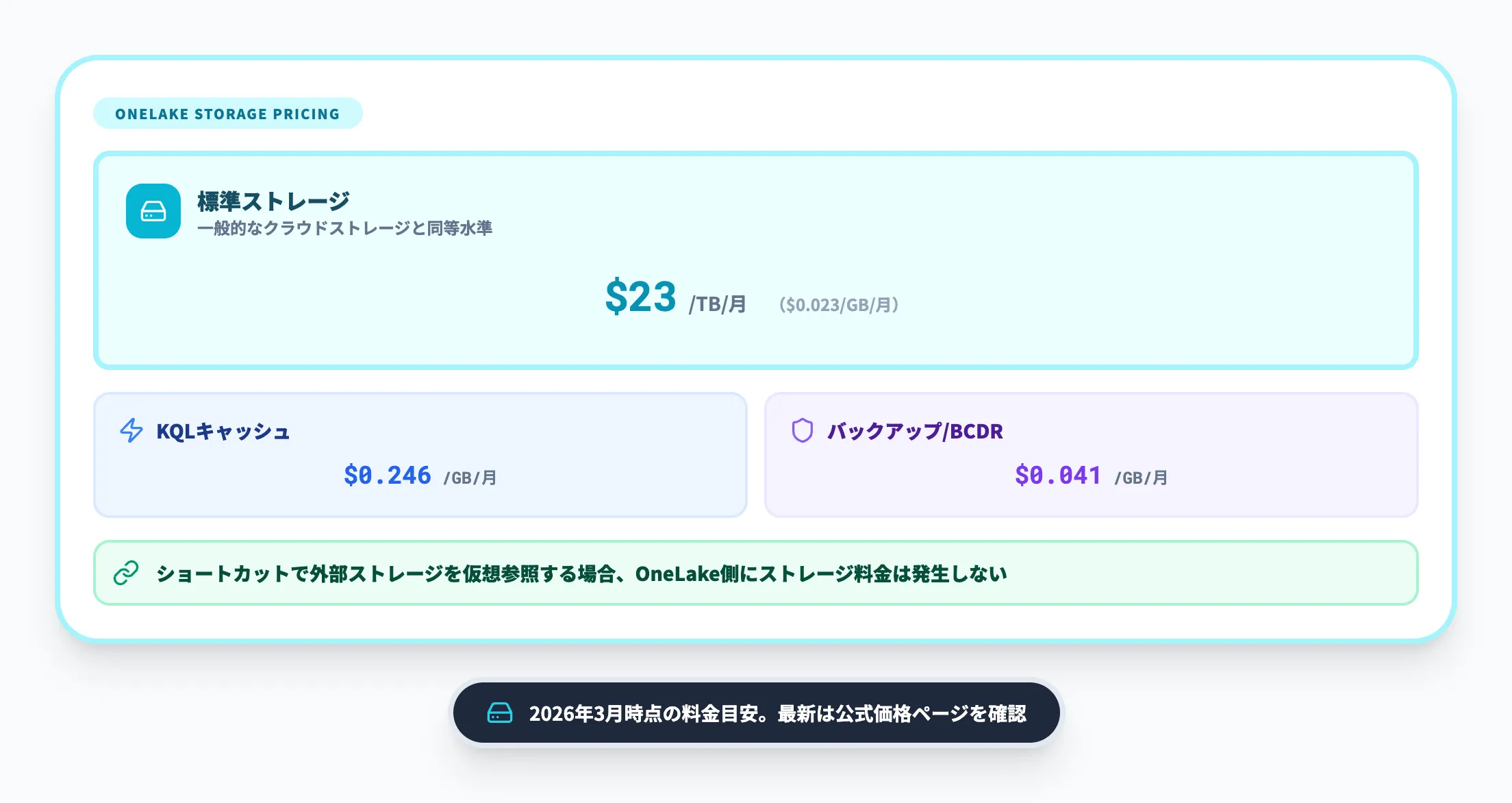
OneLakeのストレージ料金は以下のとおりです。
| ストレージ種別 | 料金目安 |
|---|---|
| 標準ストレージ | 約$0.023/GB/月(約$23/TB/月) |
| KQLキャッシュ | 約$0.246/GB/月 |
| バックアップ/BCDR | 約$0.0414/GB/月 |
標準ストレージの単価は1TBあたり約$23/月と、一般的なクラウドストレージと同等水準です。
ショートカット機能で外部ストレージのデータを仮想参照する場合、OneLake側にはストレージ料金が発生しない点も覚えておくとよいでしょう。
【関連記事】
OneLakeとは?Fabricの統合データレイクを徹底解説
【Microsoft Fabric】Lakehouseとは?機能や料金、Data Warehouseとの違いを徹底解説
【Microsoft Fabric】Data Warehouseとは?T-SQL機能や料金、移行方法を徹底解説
【Microsoft Fabric】Data Factoryとは?機能やADFとの違い、料金体系を徹底解説
【Microsoft Fabric】Data Engineeringとは?Sparkの機能や料金体系を徹底解説
【Microsoft Fabric】Real-Time Intelligenceとは?機能や料金体系を徹底解説
【Microsoft Fabric】Data Scienceとは?MLflowやAutoML、料金体系を徹底解説

導入事例を参考に、自社のFabric × AI活用を設計するなら
本記事で紹介した各社のように、Fabricでデータ基盤を統合した先にあるのは、そのデータをAIエージェントが業務に活かす仕組みの構築です。
AI Agent Hubは、Microsoft Fabricのデータ基盤をAIエージェントの業務実行基盤に拡張するエンタープライズAI基盤です。
- パイロット→全社展開の段階的な導入設計
Sky社のFabric + Foundry構成のように、小規模なPoCからスタートし、成果を確認しながら全社展開に進めます。組織規模や既存環境に合わせた導入ロードマップを提供します。
- Agent実行データがFabricに蓄積される好循環
AIエージェントの実行ログ・承認履歴・ROIデータがすべてFabricに集約。導入効果を定量的に把握し、次の展開判断に活用できます。
- 使い慣れたMicrosoft環境をそのまま活用
Teamsなど既存のMicrosoftツールの延長でAIエージェントが動作。新しいツールの学習コストはゼロです。
- データは100%自社テナント内に保持
AIの学習対象から完全除外。Azure Managed Applicationsとして自社テナント内で動作が完了する設計です。
AI総合研究所の専任チームが、設計から運用まで伴走支援します。まずは無料の資料で、自社の業務にどう活用できるかご確認ください。
事例を参考にFabric×AI基盤を設計
データ統合からAI業務自動化まで一気通貫
国内導入企業のように、Fabricのデータ基盤にAIエージェント層を追加。パイロットから全社展開まで段階的に設計できます。
まとめ
本記事では、Microsoft Fabricの国内導入事例6社を中心に、活用パターン、海外事例、他データ基盤との比較、料金体系、導入のステップまでを解説しました。
6社の事例から見えるFabricの価値は、大きく3つに集約できます。
-
1. 統合SaaSによるインフラ運用の簡素化
北國銀行がインフラ運用負担を「ほぼゼロ」にしたように、Fabricは個別のPaaS/IaaS管理から組織を解放します。
SaaSとして提供されるため、データエンジニアリングの専門チームがなくても運用を継続できる点が、特に人材リソースに制約のある組織にとって大きなメリットです。
-
2. AI時代のデータ基盤としての拡張性
SkyがFabric + Foundryで1ヶ月のPoCからAIエージェント基盤を構築し、INPEXがAzure AIとの組み合わせで業務自動化を実現したように、FabricはAI活用の「土台」として機能します。
2025年以降のCopilotの有償SKU(F2以上)への拡大、Data Agent(preview)、Fabric IQ(preview)の進化により、この傾向はさらに加速する見込みです。
-
3. 段階的な導入による投資リスクの最小化
全社の事例に共通するのは、「1つのユースケースからPoC→本番→段階的拡大」という導入パターンです。
60日間の無料トライアルやAzure Innovateなどの支援プログラムを活用すれば、初期投資を抑えながら効果を検証できます。
Fabricの採用組織が28,000を超え、日本国内でも金融・エネルギー・製造・商社・IT・介護と幅広い業界で導入が進む中、データ基盤の選定は「どのツールが最良か」ではなく「自社の課題と既存環境に何が最も適合するか」で判断することが重要です。
まずは自社のデータ活用における具体的な課題を特定し、Fabricの60日間無料トライアルやMicrosoft Fabricとは?使い方や価格体系、できることを徹底解説を参考に、小さなPoCから始めてみることをおすすめします。










