この記事のポイント
 Fabric上のデータを非エンジニアが直接分析したいなら、データエージェントが最適。SQLやDAXを書かずに自然言語でデータ取得できる
Fabric上のデータを非エンジニアが直接分析したいなら、データエージェントが最適。SQLやDAXを書かずに自然言語でデータ取得できる- Lakehouse・Warehouse・Power BIなど5種類のソースに対応しており、既存のFabric環境があるならすぐに導入すべき
- 組織固有の用語やビジネスロジックはサンプルクエリと指示で反映できるため、汎用AIチャットより業務精度が高い
- Copilot StudioやAzure AI Foundryとの連携でマルチエージェント構成にも発展でき、データ分析の自動化基盤として有効
- F2以上のFabric容量が必須のため、小規模チームにはコスト面で不向き。Power BI Premium P1以上を既に持つ組織から導入するのが現実的

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Microsoft Fabricデータエージェントは、Lakehouse・Warehouse・Power BIセマンティックモデルなどFabric上のデータに対して、自然言語で質問するだけで必要な情報を引き出せる会話型AIエージェント機能です。
SQLやDAXを書かなくても、データの専門家でないビジネスユーザーでもデータ分析が可能になります。
本記事では、データエージェントの基本的な仕組みから作成手順、Copilot StudioやAzure AI Foundryとの連携方法、Sky株式会社の導入事例、料金・ライセンス体系まで体系的に解説します。
✅Microsoft 365 Copilotの最新エージェント機能「Copilot Cowork」については、以下の記事をご覧ください。
Copilot Coworkとは?機能や料金、Claude Coworkとの違いを解説
目次
Microsoft Fabricデータエージェントの主な機能
Microsoft Fabric データエージェントとCopilotの違い
Azure AI Foundry Agent Serviceとの連携
Microsoft Fabricデータエージェントの活用事例
Microsoft Fabricデータエージェントの制限事項と注意点
Microsoft Fabricデータエージェントの料金・ライセンス
Microsoft Fabricデータエージェントとは?
Microsoft Fabricデータエージェントは、Microsoft Fabricが提供する会話型AIエージェント機能です。組織がFabric上に蓄積したデータに対して、自然言語(平易な英語)で質問を投げかけるだけで、AIが適切なクエリを自動生成・実行し、回答を返してくれます。

従来、企業のデータ分析にはSQLやDAXといったクエリ言語の知識が求められ、データの専門家でなければ必要な情報を引き出すことが困難でした。
データエージェントはこの障壁を取り除き、技術的な専門知識がなくても、チャットで質問するだけでデータに基づいた回答が得られる仕組みを実現しています。

Microsoft Fabricデータエージェントの仕組み
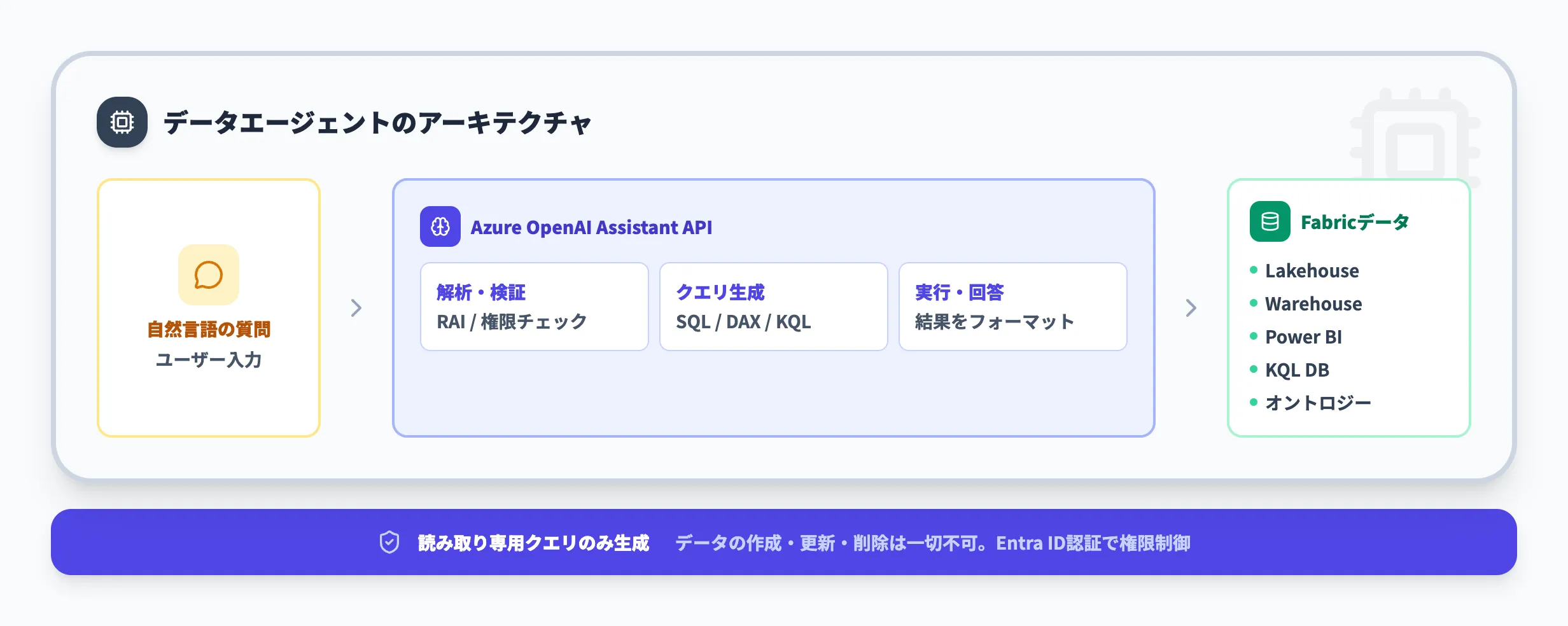
データエージェントはAzure OpenAI Assistant APIをベースにしたAIエージェントとして動作し、質問の解析からクエリの生成・実行までを自動で行います。
ここでは、データエージェントが質問を受け取ってから回答を返すまでの内部処理を解説します。
質問から回答までの処理フロー
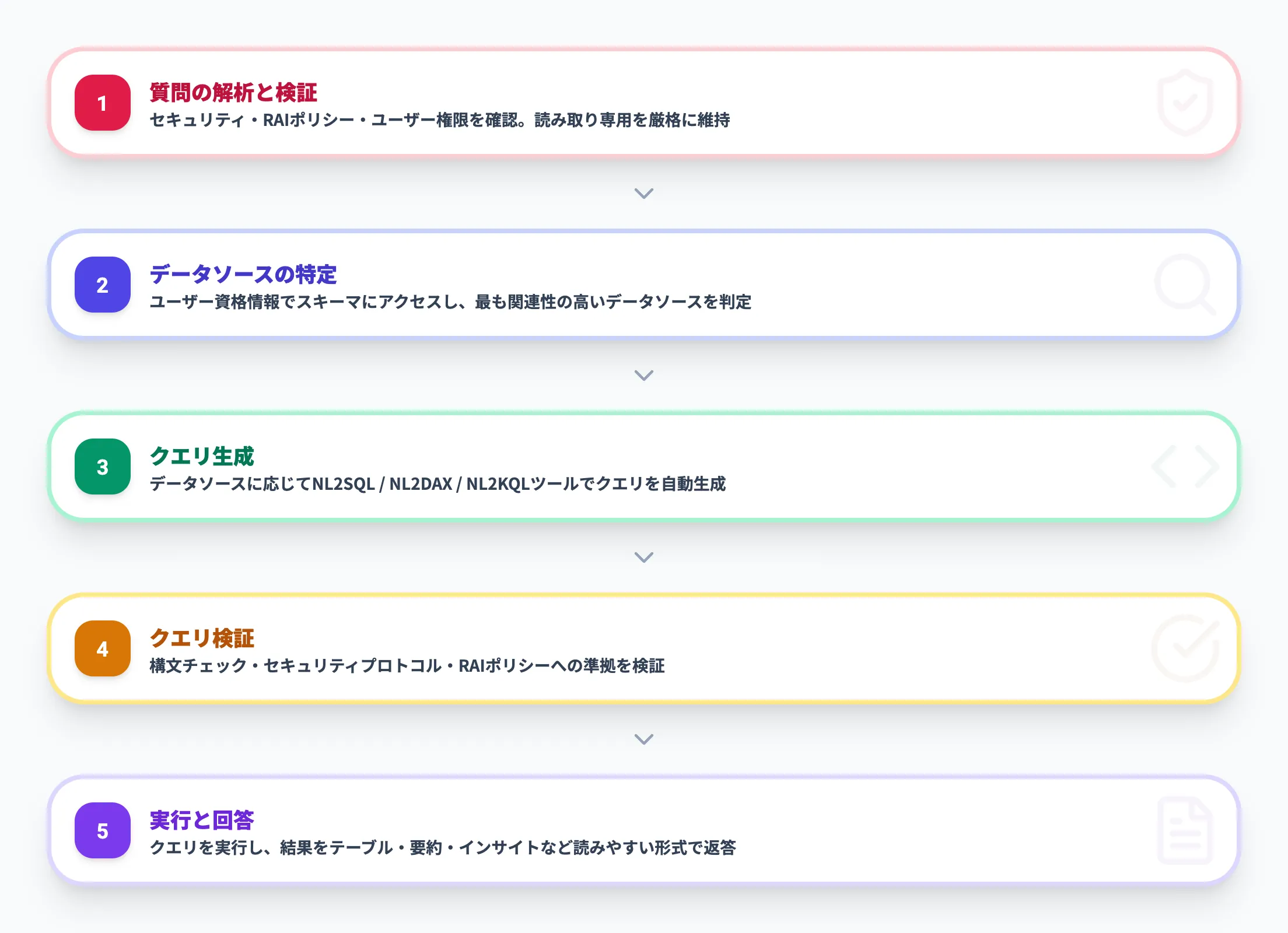
データエージェントは以下の5つのステップで質問を処理します。
-
質問の解析と検証
ユーザーの質問がセキュリティプロトコル、責任あるAI(RAI)ポリシー、ユーザー権限に準拠しているかを確認します。
データエージェントは読み取り専用のアクセスを厳格に維持しており、データの作成・更新・削除は一切行いません。
-
データソースの特定
ユーザーの資格情報を使ってデータソースのスキーマ(テーブル構造)にアクセスし、質問に最も関連性の高いデータソースを判定します。
Lakehouse、Warehouse、Power BIセマンティックモデル、KQLデータベース、オントロジーの中から適切なものが選ばれます。
-
クエリ生成
特定されたデータソースに応じて、適切なツールを呼び出してクエリを自動生成します。
-
クエリ検証
生成されたクエリが正しい構文になっているか、セキュリティプロトコルとRAIポリシーに準拠しているかを検証します。
-
実行と回答
検証を通過したクエリをデータソースに対して実行し、結果を人間が読みやすい形式(テーブル、要約、主要なインサイトなど)にフォーマットして返します。
このフローにより、ユーザーはSQL・DAX・KQLを自分で書くことなくデータにアクセスできます。
さらに、回答画面ではAIが踏んだ中間ステップや生成したクエリコードも確認できるため、結果の妥当性を検証することも可能です。
対応するクエリ言語
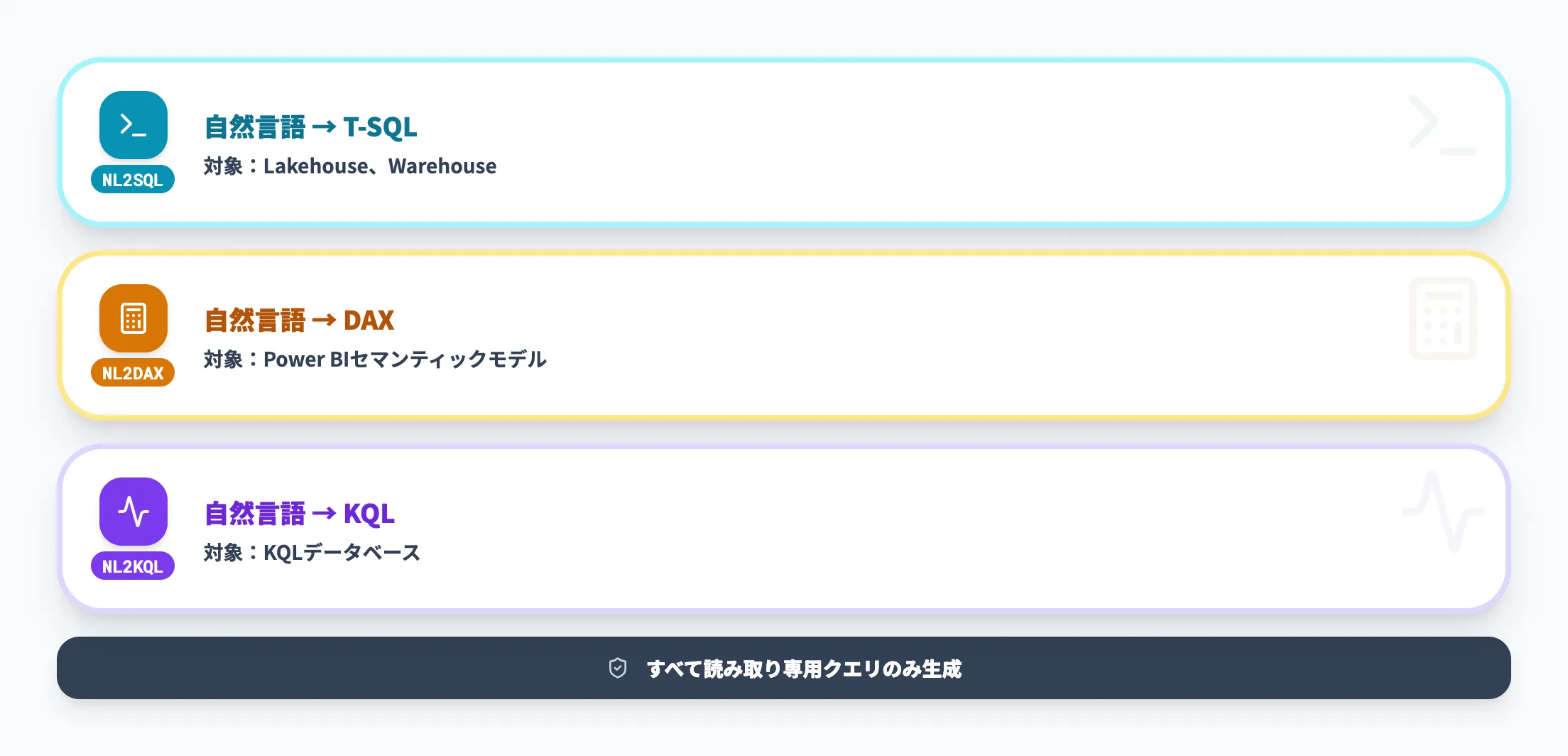
データエージェントは、データソースの種類に応じて以下の3種類のクエリ変換ツールを使い分けます。
| クエリ変換ツール | 対象データソース | 生成されるクエリ |
|---|---|---|
| NL2SQL(自然言語→SQL) | Lakehouse、Warehouse | T-SQLクエリ |
| NL2DAX(自然言語→DAX) | Power BIセマンティックモデル | DAXクエリ |
| NL2KQL(自然言語→KQL) | KQLデータベース | KQLクエリ |
いずれのツールも読み取り専用のクエリのみを生成します。データの作成・更新・削除を伴う操作は許可されておらず、データの整合性が保護されている点が特徴です。
なお、データエージェントはユーザー自身のMicrosoft Entra ID資格情報でデータにアクセスするため、ユーザーが権限を持たないデータには質問してもアクセスできません。
Azure OpenAI Serviceのキーやアクセストークンを別途用意する必要はなく、Fabric側で認証が自動処理されます。
Microsoft Fabricデータエージェントの主な機能
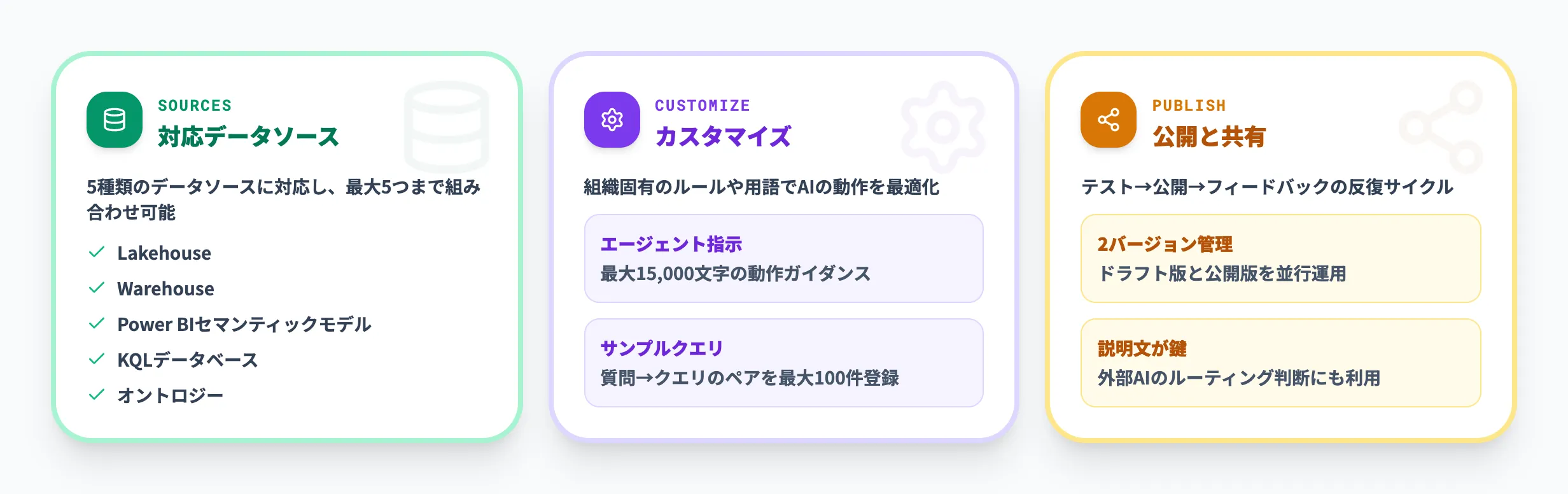
データエージェントが備える主要な機能について、以下の3つに分けて紹介します。
- 対応データソースの種類
- 組織に合わせたカスタマイズ方法
- そして作成したエージェントを同僚に共有する手順
対応データソース

データエージェントは以下の5種類のデータソースに対応しており、最大5つまで任意の組み合わせで接続できます。
| データソース | 概要 | 利用例 |
|---|---|---|
| Lakehouse | Fabricのデータレイクストレージ。テーブル形式で格納されたデータが対象 | 売上データ、顧客データなど大規模なトランザクションデータの分析 |
| Warehouse | Fabricのデータウェアハウス。構造化データの分析に最適 | 部門横断のKPIレポート、期間比較分析 |
| Power BIセマンティックモデル | Power BIのデータモデル。メジャーやリレーションシップが定義済み | 財務指標の問い合わせ、既存BI資産の活用 |
| KQLデータベース | リアルタイムデータの分析向け。Kusto Query Languageを使用 | ログ分析、IoTデータのモニタリング |
| オントロジー | ビジネスルール・セマンティクス・組織ナレッジを統合した知識ソース | 業務用語の解釈、ビジネスコンテキストの付与 |
たとえば「Power BIセマンティックモデルを3つ、Lakehouseを1つ、KQLデータベースを1つ」といった構成が可能です。データエージェントはユーザーの質問内容に応じて、最適なデータソースを自動で選択して問い合わせます。
また、Ignite 2025ではAzure AI Searchとの統合が発表され、PDFや技術ドキュメントなどの非構造化データにも対応できるようになりました。
カスタムインデックスをデータエージェントのソースとして追加することで、構造化データと非構造化データを横断した分析が可能になっています。
カスタマイズ機能
データエージェントの回答精度を高めるために、2種類のカスタマイズ手段が用意されています。
データエージェント指示
最大15,000文字の自然言語テキストで、AIの動作を細かくガイドできます。
たとえば「財務に関する質問はPower BIセマンティックモデルを使い、売上の生データ探索にはLakehouseを使え」といったルーティング指示や、社内固有の用語・略語の定義などを記述できます。
サンプルクエリ
「質問文 → 対応するSQL/KQLクエリ」のペアを最大100件(データソースごと)登録できます。
これは生成AIにおけるfew-shot learning(少数の例示による学習)にあたり、データエージェントはユーザーの新しい質問を処理する際に、登録されたサンプルの中から最も関連性の高い例を参照します。
サンプルクエリが多様であるほど、データエージェントはより正確なクエリを生成できるようになります。
ただし、2026年3月時点ではPower BIセマンティックモデルとオントロジーに対するサンプルクエリの登録は未対応です。
公開と共有
データエージェントの作成・テストが完了したら、公開ボタンを押して同僚に共有できます。公開時にはデータエージェントの説明文を入力します。
この説明文はユーザー向けのガイドとして機能するだけでなく、他のAIシステムやオーケストレーターがデータエージェントを適切に呼び出すための情報としても利用されます。
公開後はドラフト版と公開版の2バージョンが維持されます。ドラフト版で改善を続けながら、公開版を同僚に利用してもらうという運用が可能です。
同僚からのフィードバックをドラフト版に反映し、十分にテストしたうえで再公開するというサイクルで精度を高められます。
Microsoft Fabric データエージェントとCopilotの違い
FabricにはデータエージェントのほかにCopilot(コパイロット)も搭載されています。どちらも生成AIを使ってデータを処理・推論しますが、役割と用途が異なります。

以下の表で、両者の主な違いを整理しました。
| 比較項目 | データエージェント | Fabric Copilot |
|---|---|---|
| カスタマイズ性 | 高い。独自の指示やサンプルクエリで動作を細かく調整できる | 限定的。事前構成済みで、ユーザーによるカスタマイズは提供されていない |
| スコープ | スタンドアロン의 アーティファクト。外部システムとの連携を前提に設計されている | Fabric内のタスク支援に特化(ノートブックのコード生成、Warehouseクエリの支援など) |
| 連携先 | Copilot Studio、Azure AI Foundry、Microsoft 365 Copilot(Teamsなど)、Power BI Copilotなど外部ツールと統合可能 | Fabric内部の操作支援が中心 |
| 想定ユーザー | ビジネスユーザー、データアナリスト、アプリケーション開発者 | Fabricを直接操作するデータエンジニア、データサイエンティスト |
ここで注目すべきは、データエージェントがFabric外部のシステムとも連携できるスタンドアロン設計になっている点です。
Copilotが「Fabricの中で作業を助けるアシスタント」であるのに対し、データエージェントは「Fabricのデータを外部に公開するためのインターフェース」としての役割を持ちます。
つまり、Copilotは主にデータエンジニアやサイエンティストがFabric上で直接作業する際の補助として、データエージェントはビジネスユーザーや外部アプリケーションがFabricのデータにアクセスするための窓口として、それぞれ使い分けるのが適切です。
Microsoft Fabricデータエージェントの作り方
データエージェントの作成手順を、前提条件から公開までのステップで解説します。
前提条件
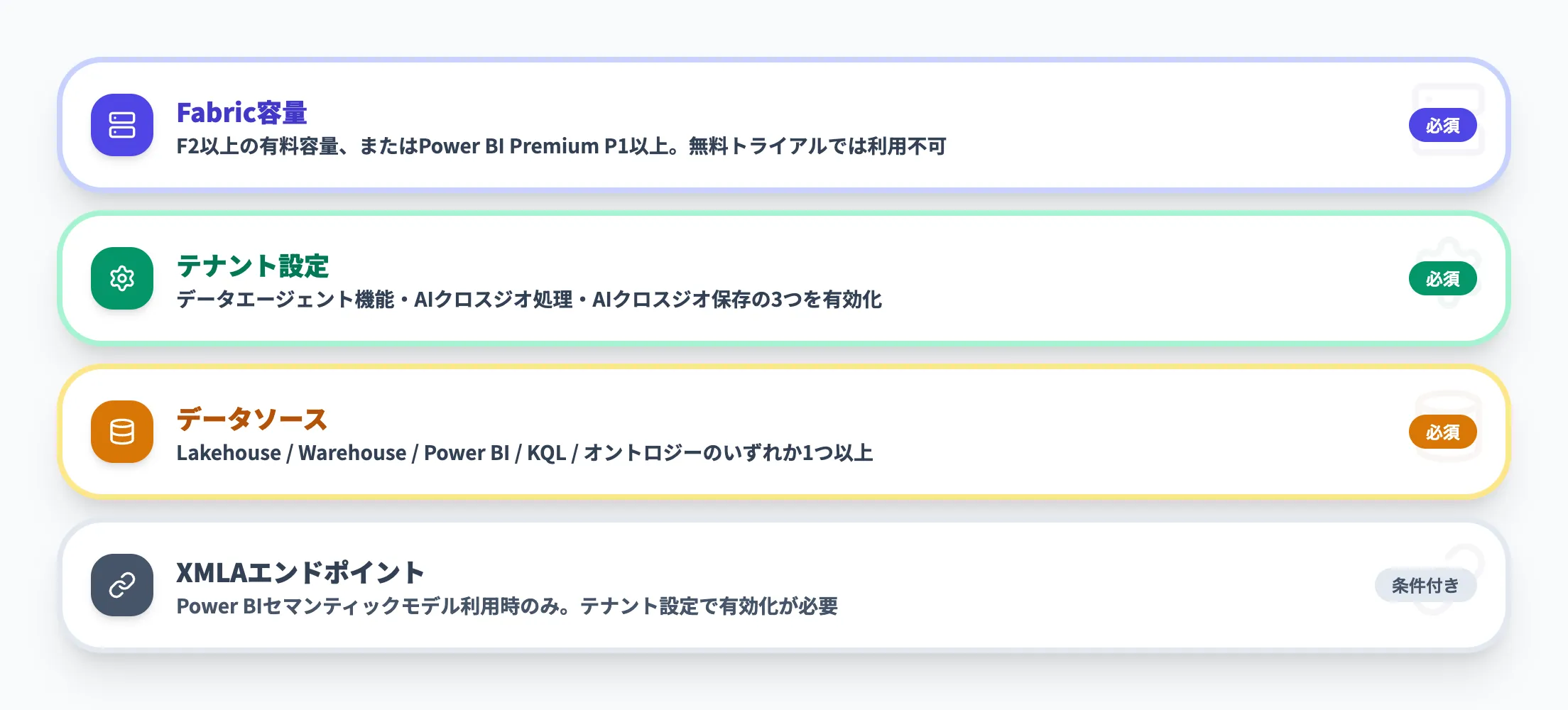
データエージェントを利用するには、以下の環境が整っている必要があります。
-
Fabric容量
F2以上の有料Fabric容量、またはMicrosoft Fabricが有効化されたPower BI Premium P1以上の容量が必要です。無料のFabric試用版容量では利用できません。
-
テナント設定
Fabric管理者がテナント設定でデータエージェント機能を有効化している必要があります。具体的には「Fabricデータエージェントのテナント設定」「AIのクロスジオ処理」「AIのクロスジオ保存」の3つを有効にします。
-
データソース
少なくとも1つのデータソース(Lakehouse、Warehouse、Power BIセマンティックモデル、KQLデータベース、オントロジーのいずれか)にデータが格納されている必要があります。
-
XMLA エンドポイント(Power BIの場合)
Power BIセマンティックモデルをデータソースとして使う場合は、「Power BIセマンティックモデルのXMLAエンドポイント」のテナント設定を有効にしておきます。
認証はMicrosoft Entra IDのユーザーIDで自動処理されるため、Azure OpenAI ServiceのAPIキーやアクセストークンを個別に取得する必要はありません。
作成から公開までのステップ
実際の作成手順は以下のとおりです。公式ドキュメントではAdventureWorksデータセットを使ったチュートリアルが提供されており、初めての場合はこちらに沿って試すのがおすすめです。
-
ステップ1 新規作成
ワークスペースで「+新しい項目」を選択し、「Fabric data agent」を検索して作成します。名前を入力すると初期設定画面に進みます。
-
ステップ2 データソースの追加
OneLakeカタログが自動表示されるので、データソースを選択して追加します。データソースは1つずつ追加し、最大5つまで組み合わせ可能です。
-
ステップ3 テーブルの選択
エクスプローラーにデータソース内のテーブル一覧が表示されます。チェックボックスでAIがアクセスできるテーブルを選択します。テーブル名やカラム名は、AIの精度向上のために分かりやすい命名にしておくことが推奨されます。
-
ステップ4 指示の追加
「Data agent instructions」から、AIへの動作指示を入力します。たとえば「顧客に関する質問はdimcustomerテーブルを使い、地理情報にはdimgeographyを参照せよ」といった具体的なガイダンスを記述します。
-
ステップ5 サンプルクエリの追加
「Example queries」から、質問文とそれに対応するSQLまたはKQLのペアを登録します。多様な例を登録するほど回答精度が向上します。
-
ステップ6 テストと改善
チャット画面で実際に質問を投げかけ、回答の精度を検証します。不正確な回答があれば、指示やサンプルクエリを追加・修正して精度を高めます。
-
ステップ7 公開
十分なテストが完了したら「Publish」を選択し、説明文を入力して公開します。公開後に生成されるURLをコピーすれば、ノートブック等からプログラムでアクセスすることも可能です。

公式のチュートリアルでは、数分でデータエージェントのリソースを作成してテストを開始できると案内されています。まずは小規模なデータセットで試し、指示やサンプルクエリを段階的に充実させていくアプローチが推奨されます。

Microsoft Fabricデータエージェントの連携先
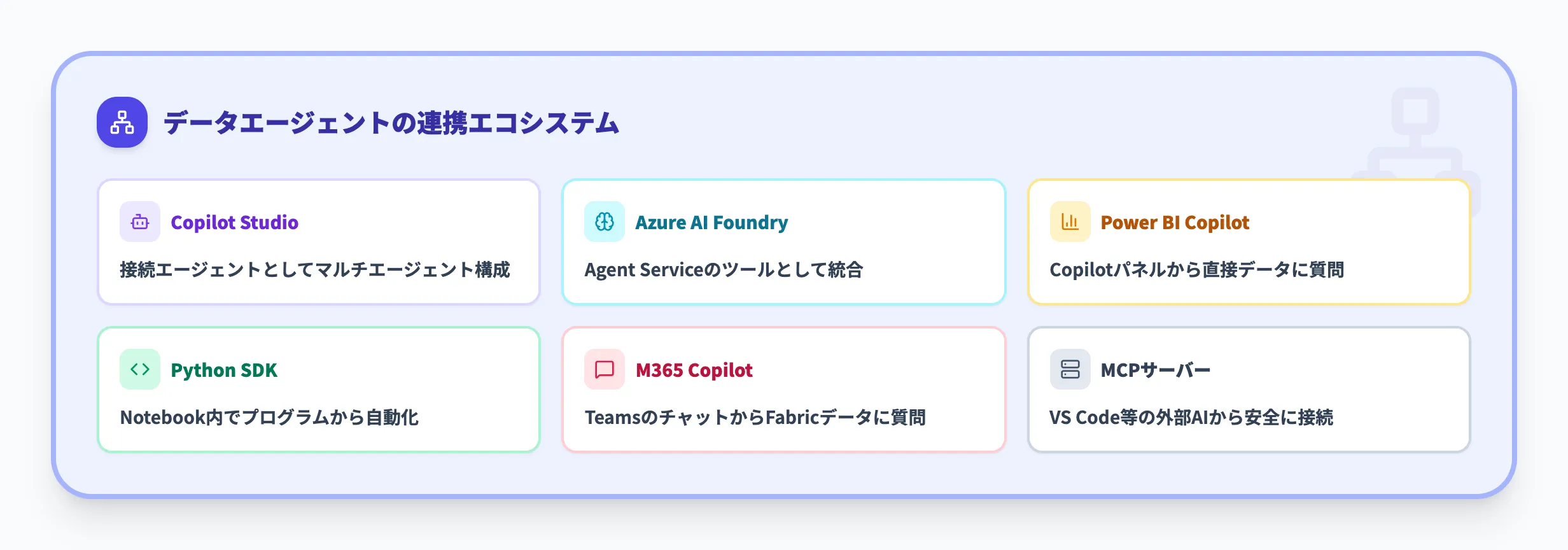
データエージェントの大きな強みは、Fabric内部にとどまらず外部のさまざまなサービスと連携できる点です。2026年3月時点で対応している主要な連携先を紹介します。
Microsoft Copilot Studioとの連携
Microsoft Copilot Studioで作成したカスタムAIエージェントに、Fabricデータエージェントを「接続エージェント(Connected Agent)」として追加できます。この構成により、マルチエージェント間のコラボレーションが実現します。
Copilot Studio側のエージェントがユーザーの質問を受け取り、データに関する質問をFabricデータエージェントに委譲するという流れです。
Fabricデータエージェントはエンタープライズデータに安全にアクセスし、組織のナレッジに基づいた回答を返します。
連携にあたっての主な要件は以下のとおりです。
- Fabricデータエージェントが公開済みであり、詳細な説明文が入力されていること
- FabricデータエージェントとCopilot Studioエージェントが同一テナント上にあること
- 両サービスに同一アカウントでサインインしていること
Azure AI Foundry Agent Serviceとの連携
Azure AI Foundryのコア機能であるAzure AI Foundry Agent Service(旧Azure AI Agent Service)を通じて、FabricデータエージェントをAzure AIエージェントのツールとして利用できます。
この統合により、Azure AIエージェントはFabricのOneLakeに蓄積された構造化データに直接アクセスし、より高度な推論や分析を実行できるようになります。たとえば、Azure AI Foundryで構築したカスタムエージェントが、CRMデータや売上データといったFabric上の業務データをリアルタイムに参照しながら回答するといったシナリオが実現します。
Power BI Copilotとの連携
Power BIのCopilotパネルからデータエージェントを直接利用することも可能です。Power BI左側のナビゲーションで「Copilot」を選択し、テキストボックスの「アイテムを追加」からデータエージェントを追加します。
この方法では、Power BIレポートやセマンティックモデルとデータエージェントを切り替えることなく、統一されたインターフェースでデータに質問できます。
Python SDKによるプログラム連携
Fabricノートブック内でPython SDKを使い、データエージェントをプログラムから操作することもできます。SDKはOpenAI Assistants APIをベースにしており、データエージェントの作成・更新・削除、データソースの接続、そしてクエリの実行と回答取得をコードで自動化できます。
さらに、SDKにはデータエージェントの回答品質を評価する機能もプレビューとして提供されています。構造化されたテストケースを用意し、回答の正確性をプログラムで検証できるため、本番運用前の品質管理に活用できます。
なお、Python SDKはFabricノートブック内での実行を前提としており、ローカル環境での実行はサポートされていません。
Microsoft 365 Copilotとの連携
2025年12月以降の公式ドキュメントでは、公開済みのFabricデータエージェントをMicrosoft 365 CopilotのAgent Storeに登録し、TeamsなどのM365アプリから直接利用する方法も案内されています。これにより、日常的に使っているTeamsのチャット画面からFabricのデータに質問できるようになります。
MCPサーバー対応
Ignite 2025で発表された新機能として、マネージドMCP(Model Context Protocol)サーバーエンドポイントが提供されています。これにより、VS Codeなどの外部AIシステムからFabricのエンタープライズデータに安全に接続できます。
MCPサーバーを介した接続では、行レベルセキュリティや列レベルセキュリティなどのFabric側のガバナンスポリシーが維持されるため、データの安全性を保ちながら外部システムとの連携が可能です。
Microsoft Fabricデータエージェントの活用事例
データエージェントが実際にどのように活用されているのか、公開されている導入事例と想定される活用シナリオを紹介します。
Sky株式会社の導入事例

国内でのデータエージェント活用事例として、Sky株式会社の導入事例が公開されています。
Sky株式会社は、2023年末からAzure上で社内チャットボット「SKYAI」を運用するなど生成AIの活用を積極的に推進していました。
しかし、RAG(検索拡張生成)機能付きの社内問い合わせボット開発時に、既存のデータ基盤が「人が活用すること」を前提に設計されていたため、AI利用に適さないという課題に直面しました。
具体的には、メタ情報の不足、RAG検索結果をAIに渡した際のトークン数の膨張、ベクトル検索時の関連性の低い結果の混入といった問題が生じていました。この課題を解決するために、Microsoft FabricとMicrosoft Foundry(Azure AI Foundry)を採用し、「AI-Readyなデータ基盤」を再構築しています。
以下の表に、導入スケジュールと主な成果をまとめました。
| 時期 | 内容 |
|---|---|
| 2025年1月 | マイクロソフトからFabric・Foundryの説明を受ける |
| 2025年6月 | AIエージェントのPoC着手 |
| 2025年7月 | PoC完了(着手から約1か月) |
| 2025年8月 | 本番運用を開始 |
注目すべきは、PoCから本番運用までわずか2か月という導入スピードです。最初のAIエージェントとして、週次の従業員アンケート結果を自動要約する機能をリリースしました。従来は半日程度かかっていたアンケート要約作業が自動化され、経営層だけでなく全社員がアンケート結果を活用できるようになっています。
開発面では、記述したコードはわずか数百行程度で済んでいます。Fabricデータエージェントは「対象スキーマをGUIで指定して自然言語で指示するだけで、複数テーブルを結合したSQLを簡単に作成できる」と評価されています。
提供開始から4か月で100件以上のAI活用アイデアが生まれ、2週間に1回のペースでリリースを実施中とのことです。
想定される活用シナリオ
公式ドキュメントや導入事例をもとに、データエージェントが効果を発揮する代表的なシナリオを整理しました。
-
経営ダッシュボードのセルフサービス化
経営層や部門マネージャーが、SQL知識なしに売上・コスト・KPIなどの経営指標を自然言語で問い合わせられるようになります。
「先月の東日本エリアの売上は?」「前年同期比で利益率はどう変化した?」といった質問にリアルタイムで回答できます。
-
カスタマーサポートのデータ分析
サポート担当者が問い合わせ履歴や顧客データに基づいた分析を、データ部門に依頼することなく自力で行えます。
「過去3か月で最も問い合わせが多い製品カテゴリは?」といった質問に即座に回答が得られます。
-
IoT・リアルタイムデータのモニタリング
KQLデータベースと連携し、IoTセンサーやアプリケーションログのリアルタイムデータを自然言語で分析できます。
「直近1時間でエラー率が高いサーバーは?」といった運用監視にも活用できます。
Microsoft Fabricデータエージェントの制限事項と注意点
データエージェントは2026年3月時点でパブリックプレビュー段階にあり、いくつかの制限事項があります。導入を検討する際には、機能面・データソース面・環境面の3つの観点で把握しておく必要があります。
機能面の制限
-
読み取り専用
データの作成・更新・削除を行うクエリは生成されません。あくまでデータの参照・分析に特化した機能です。
-
英語のみ対応
2026年3月時点では、質問・指示・サンプルクエリはすべて英語で入力する必要があります。日本語での質問には対応していないため、日本企業での活用では英語でのやり取りが前提となります。
-
LLMの変更不可
データエージェントが内部で使用するLLMはMicrosoft管理のAzure OpenAIモデルであり、ユーザーが別のモデルに変更することはできません。
データソース面の制限
-
Lakehouseのファイル直接参照は不可
Lakehouseのデータソースでは、テーブルとして登録されたデータのみが対象です。CSVやJSONファイルをそのまま読み取ることはできないため、事前にテーブルとして取り込んでおく必要があります。
-
サンプルクエリの上限
データソースごとに最大100件のサンプルクエリを登録できます。ただし、2026年3月時点ではPower BIセマンティックモデルとオントロジーに対するサンプルクエリ登録には対応していません。
なお、Ignite 2025で発表されたAzure AI Search統合により、PDFやドキュメントなどの非構造化データへの対応が可能になっています。ただし、データエージェント単体で直接非構造化ファイルを読み取るわけではなく、Azure AI Searchで構築したカスタムインデックスを経由する形式です。
環境・運用面の制限
-
リージョン制約
データソースのワークスペース容量と、データエージェントのワークスペース容量が異なるリージョンにある場合、クエリが実行できません。たとえば、LakehouseがNorth Europeにありデータエージェントの容量がFrance Centralにある構成ではエラーになります。
-
会話履歴の非永続性
バックエンドインフラの変更やモデルのアップグレード時に、過去の会話履歴がリセットされる場合があります。重要な分析結果は別途保存しておくことが推奨されます。
Microsoft Fabricデータエージェントの料金・ライセンス
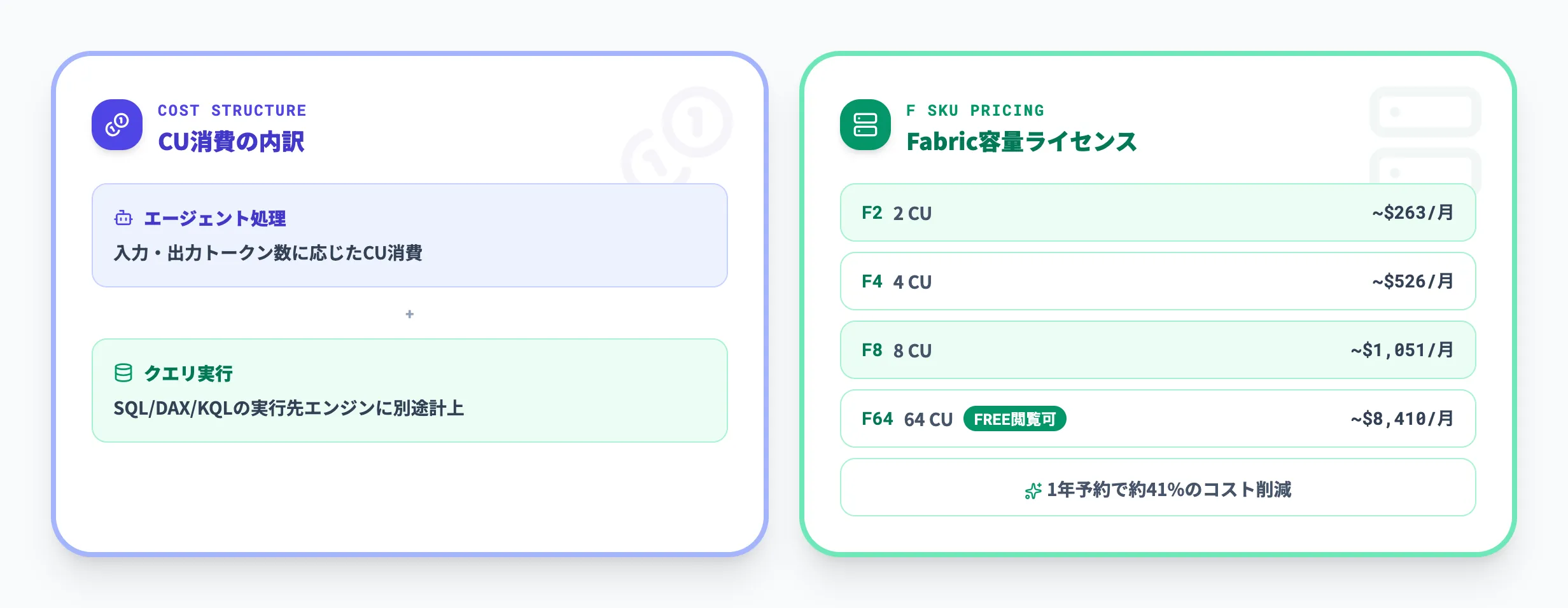
データエージェントを利用するにあたっての料金体系とライセンス要件を解説します。
Fabric Capacity Unitsの料金体系
Microsoft Fabricは容量単位(CU:Capacity Units)ベースの課金モデルを採用しています。
データエージェントの利用にはF2(2 CU)以上の容量が必要です。
データエージェントの利用コストは、大きく以下の2つで構成されます。
-
データエージェント自体のCU消費
データエージェントへのリクエストは、入力・出力トークン数に応じてCUを消費します。
質問の複雑さや回答の長さによって消費量が変動します。
-
クエリ実行先エンジンのCU消費
AIが生成して実行したSQL・DAX・KQLクエリの実行コストは、それぞれのクエリエンジン側(Lakehouse、Warehouse、Power BIセマンティックモデル、KQLデータベース)に別途計上されます。
つまり、Fabric容量の保有コスト(F SKUの月額料金)に加えて、データエージェントのリクエスト消費とクエリ実行消費が発生する点に注意が必要です。
以下の表は、主なSKUの参考月額料金です。実際の価格はリージョン、契約形態、為替などによって変動します。
| SKU | CU数 | 従量課金(月額) | 1年予約(月額) | 割引率 |
|---|---|---|---|---|
| F2 | 2 | 約263ドル | 約156ドル | 41% |
| F4 | 4 | 約526ドル | 約313ドル | 41% |
| F8 | 8 | 約1,051ドル | 約625ドル | 41% |
| F16 | 16 | 約2,102ドル | 約1,251ドル | 41% |
| F32 | 32 | 約4,205ドル | 約2,501ドル | 41% |
| F64 | 64 | 約8,410ドル | 約5,003ドル | 41% |
従量課金(Pay-as-you-go)はコミットメントなしで必要な期間だけ使えるため、検証フェーズでは従量課金から始めるのが一般的です。1年予約を選択すると約41%の割引が適用されます。
このほか、OneLakeストレージやF2〜F32の容量でPower BIコンテンツを共有する場合のPower BI Proライセンス(約14ドル/ユーザー/月)が別途必要になる場合があります。
データエージェントに必要なライセンス
データエージェントの利用に必要なライセンス要件を以下にまとめます。
-
Fabric容量ライセンス
F2以上の有料Fabric容量が必要です。代替として、Microsoft Fabricが有効化されたPower BI Premium P1以上の容量でも利用できます。
-
ユーザーライセンス
データソースへのRead権限を持つユーザーであれば、データエージェントに質問できます。
Power BIセマンティックモデルをデータソースとして追加する場合もRead権限のみで十分です。F64以上の容量を導入している場合は、無料ユーザーでもコンテンツの閲覧が可能です。
-
テナント管理者による設定
データエージェント機能、AIのクロスジオ処理・保存、Copilotのスタンドアロンエクスペリエンスなど、複数のテナント設定を管理者が有効化する必要があります。
データエージェントの試用にあたっては、まず最小のF2容量から開始し、利用状況に応じてスケールアップするアプローチが推奨されます。
【関連記事】
Microsoft Fabricとは?使い方や価格体系、できることを徹底解説!

データエージェントの先へ──業務プロセスまでAIで自動化するなら
データエージェントで「データに自然言語で質問する」環境が整ったら、次は「データに基づいて業務を自動実行する」段階です。
AI Agent Hubは、Fabricのデータ基盤をそのまま活かし、AIエージェントが業務プロセスを自律的に実行するソリューションです。データエージェントが担う「データ参照」の先にある「判断」と「アクション」までカバーします。
- Fabricのデータ基盤をAIエージェントのナレッジ基盤として活用
OneLakeに統合されたデータをAgentが直接参照し、業務判断の根拠にする
- Copilot Studioとの連携でマルチエージェント構成に発展
データエージェント+業務実行Agentを組み合わせ、分析→判断→処理を一連で自動化
- 構築基盤が違っても管理は1つ
Copilot Studio・n8n・Azure AI Foundryなどで構築したAgentを1つのダッシュボードで統合管理
AI総合研究所の専任チームが、設計から運用まで伴走支援します。まずは無料の資料で、自社の業務にどう活用できるかご確認ください。
データ問い合わせから業務自動化まで拡張

Fabricデータエージェントの先へ、業務プロセスをAI化
データエージェントによる自然言語分析の先に、AIエージェントが業務判断・処理まで自動実行。Fabricのデータ基盤をそのまま活かして業務全体をAI化します。
まとめ
本記事では、Microsoft Fabricデータエージェントの概要から仕組み、主な機能、作成手順、外部サービスとの連携、導入事例、制限事項、料金体系まで包括的に解説しました。
データエージェントの価値は、主に以下の3つに集約できます。
-
データ民主化の促進
SQLやDAXの知識がなくても、自然言語で質問するだけでFabric上のデータから回答を得られます。データ部門への分析依頼を待たず、ビジネスユーザー自身がデータドリブンな意思決定を行える環境が整います。
-
スタンドアロン設計による拡張性
Copilot Studio、Azure AI Foundry、Microsoft 365 Copilot(Teamsなど)、Power BI Copilot、Python SDK、MCPサーバーなど、多様なシステムと連携できます。マルチエージェント構成の一部として組み込むことで、組織全体のAI活用基盤に発展させることが可能です。
-
迅速な導入と反復改善
Sky株式会社の事例では、PoCから本番運用までわずか2か月で実現しています。指示とサンプルクエリの追加・修正で段階的に精度を高められるため、小さく始めて大きく育てる運用スタイルに適しています。
2026年3月時点ではプレビュー段階であり、日本語未対応やLLM変更不可などの制限がありますが、Ignite 2025で発表された非構造化データ対応やMCPサーバーサポートなど、機能拡張は急速に進んでいます。
まずはF2容量の従量課金で小規模な検証から始め、データエージェントの可能性を確認してみてください。










