この記事のポイント
 社内に散らばるデータをAIエージェントに任せるなら、オントロジーでビジネスの「意味」を先に定義してからLLMを乗せるのが本命ルート
社内に散らばるデータをAIエージェントに任せるなら、オントロジーでビジネスの「意味」を先に定義してからLLMを乗せるのが本命ルート- 単発のRAG PoCで終わらせたい案件はオントロジー不要。複数業務を跨いで長期運用するAI基盤を作るなら第一候補
- Palantir AIPは先行ノウハウ、Fabric Ontologyは既存基盤の親和性、NTTデータLITRONは国内ガバナンス対応が強み
- いきなりヘビーウェイトを狙わず、ライトウェイトなコアエンティティ定義から始めて段階的に拡張するのが現実的
- 導入コストは「モデル設計費+プラットフォーム利用料+継続運用」の3層で見積もり、ROIは業務価値換算で押さえるべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
オントロジーとは、ある領域に存在する概念とその関係を機械が理解できる形で体系化した「意味の地図」を指します。
従来はセマンティックウェブや医療・学術領域の専門用語として扱われてきましたが、2026年現在、PalantirやMicrosoft Fabric、NTTデータが相次いで「企業のオントロジー」を AIエージェントの基盤として位置づけ、再評価が進んでいます。
本記事では、情報科学としての基本定義からAIエージェント時代に再注目される背景、クラス・プロパティ・関係といった構成要素、ナレッジグラフやRDF/OWLとの違い、RAG強化・自然言語クエリといった活用パターン、主要プラットフォーム比較、導入判断と段階的な構築ステップ、コストの考え方までを体系的に解説します。
目次
なぜ今、オントロジーがAIエージェント基盤として再評価されるのか
Palantir・NTTデータ・Microsoftが動き出した背景
2.自然言語でビジネス質問に答える(NL2Ontology)
オントロジーとは?企業データに「意味」を与える仕組み

オントロジー(ontology)とは、ある領域に存在する概念とその関係を、機械が解釈できる形で体系化した「意味の地図」です。
情報科学では「共有された概念化の形式的で明示的な仕様」と定義され、人間にとって自然な世界の捉え方を、計算機が推論・再利用できる構造へと変換する役割を担います。
2026年現在、オントロジーはセマンティックウェブや医療知識ベースといった伝統的な領域にとどまらず、企業のデータ基盤とAIエージェントをつなぐ共通言語として再定義されつつあります。
Palantir・Microsoft・NTTデータが相次いで「企業のオントロジー」を前面に出してきたことが、この潮流を象徴しています。
「企業の世界モデル」としての現代的な役割
2020年代後半に入り、オントロジーは企業にとっての「世界モデル」という性格を帯びてきました。
売上・在庫・顧客・契約・機器・サプライヤーといった要素が、どんな属性を持ち、どう関係し、どんな制約の下で動くのかを明示するモデルです。
-
Palantir
自社のOntologyを「組織のデジタルツイン」と呼び、生データを「実世界のビジネスオブジェクト」として扱う層と説明しています(Palantir Foundry Ontology Overview)。
-
Microsoft
同様に、Fabric IQのオントロジーを「ドメインとOneLakeソース間で意味を統一するエンタープライズボキャブラリ」と定義しています(Microsoft Learn)。
ここでのポイントは、AIエージェントや人間が同じ言語で会話できる共有レイヤーが必要になってきた、という点です。
LLMの性能が上がっても、企業固有の商流・組織・業務ルールを知らなければ、現場で使える判断はできません。オントロジーは、この「業務の意味」をAIに渡すための土台として機能します。

なぜ今、オントロジーがAIエージェント基盤として再評価されるのか
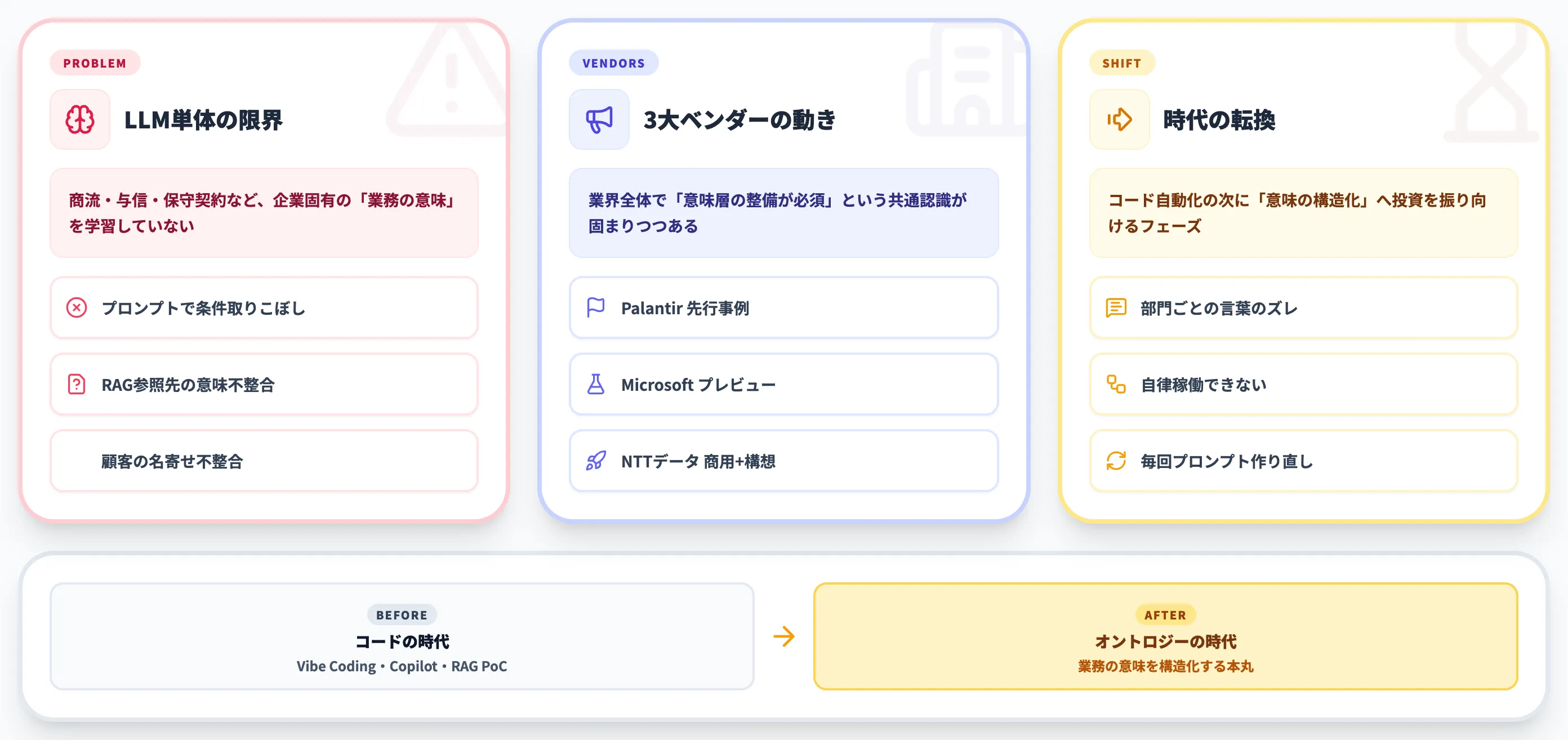
オントロジー自体は1990年代から研究されてきた枯れた概念です。にもかかわらず2026年になって再評価されているのは、AIエージェントをエンタープライズで本格運用しようとした企業が、ほぼ例外なく同じ壁にぶつかっているからです。
LLM単体の限界:ビジネスドメインを理解しない
大規模言語モデル(LLM)は、一般的な言語知識や常識的な推論では高いパフォーマンスを発揮します。
しかし、自社の商流・顧客セグメント・与信ポリシー・保守契約の体系といった個別企業の「業務の意味」は学習していません。

この結果、よくある失敗は次のような形で現れます。
- プロンプトに大量の業務ルールを書き込んでもAIが条件を取りこぼす
- RAGで社内ドキュメントを引かせても、参照先の「意味」がつながらず曖昧な回答になる
- 複数システムを横断した問い合わせで、同じ「顧客」が別物として扱われる
これらは個別のプロンプト改善では根本解決しません。「社内にどんな概念が存在し、どう関係しているか」という構造化された共通言語がない限り、AIはアドホックな連想しかできないからです。
Palantir・NTTデータ・Microsoftが動き出した背景
2026年に入り、大手ベンダーが相次いで「オントロジー」を前面に出し始めています。
各社の動きを整理すると、時期の近さが目を引きます。
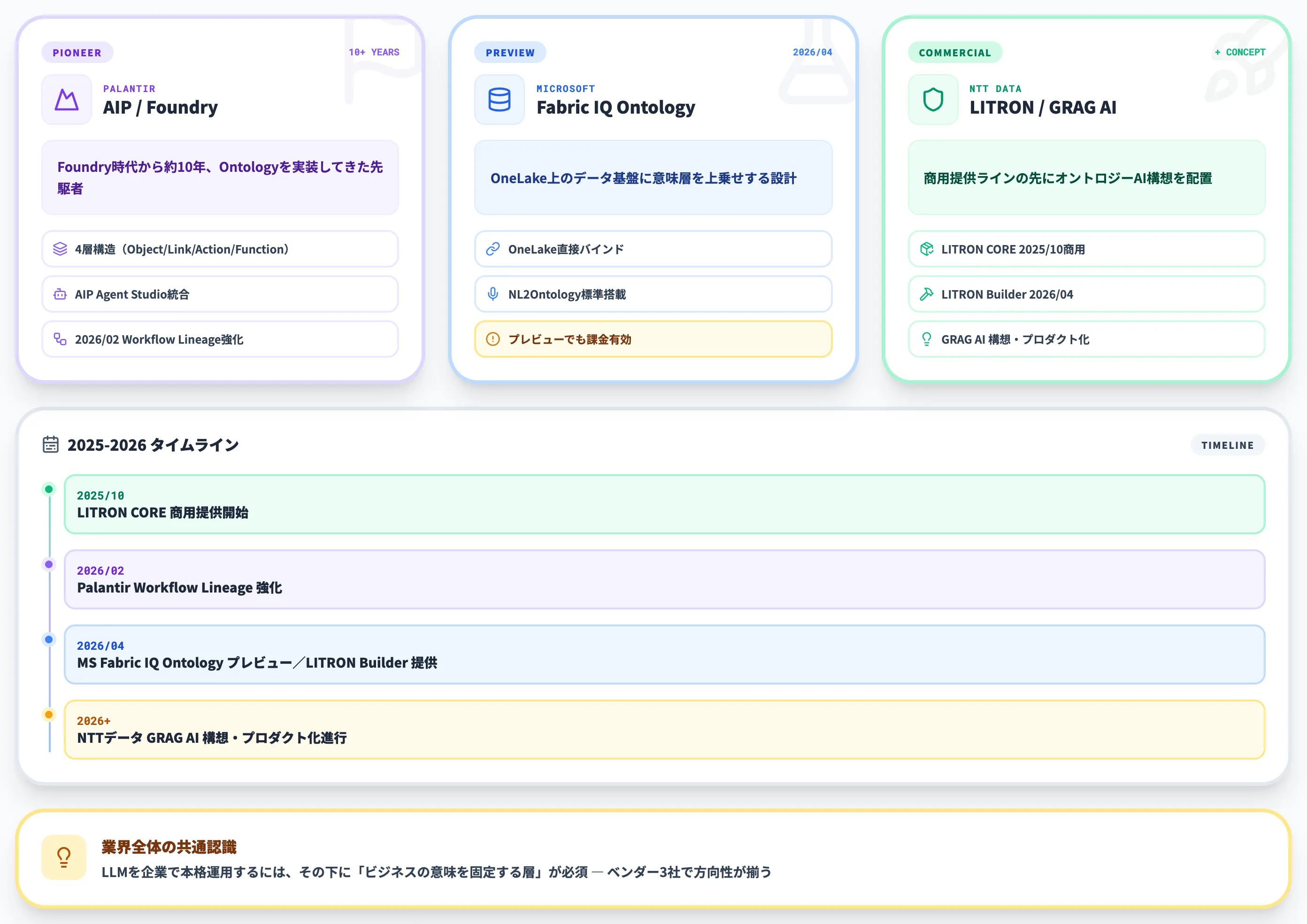
以下の表は、主要ベンダーが発表したオントロジー関連プロダクトと位置づけを整理したものです。
Palantirは長年の先行事例、MicrosoftとNTTデータは直近で一般提供や新プロダクト発表が続くフェーズにあり、成熟度はそれぞれ異なります。
| ベンダー | プロダクト/概念 | 動き | 出典 |
|---|---|---|---|
| Palantir | AIP / Foundry Ontology | Foundry時代から約10年以上にわたりOntologyを実装してきた先行事例。AIP Agent Studioでエージェント基盤と一体化 | Palantir公式 |
| Microsoft | Fabric IQ Ontology | 2026年4月時点でプレビュー提供、NL2Ontology搭載 | Microsoft Learn |
| NTTデータ | LITRON CORE / Builder(商用提供)/GRAG AI(構想・プロダクト化段階) | LITRON COREは2025年10月、LITRON Builderは2026年4月から提供(初期はパブリッククラウド提供、オンプレは今後対応予定)。GRAG AIはオントロジーAIとして構想・プロダクト化段階 | NTTデータプレス |
この表が示すのは、各社が個別にマーケティングしているというより、「LLMを企業で本格運用するには、その下にビジネスの意味を固定する層が要る」という共通認識が業界全体で固まりつつある、ということです。
Palantirは先行事例、Microsoftはプレビュー展開、NTTデータは商用提供開始と構想段階の併走、とフェーズは異なりますが、方向性は同じ意味層の整備に向いています。
NTTデータはForesight Day 2026で、2030年までに従来型の情報システムが役割を終え、AIが業務遂行の主体となる未来像を提示し、その中核として「オントロジーAI(GRAG AI)」を位置づけています(GRAG AIは企画・プロダクト化段階との公式説明)。
また、arpableの分析記事は「コードの時代からオントロジーの時代へ」という言葉で、Vibe CodingやCopilot型開発の先にオントロジー整備が本丸として控える、と指摘しています。
「コードの時代」から「オントロジーの時代」へ
ここ数年、企業のAI活用は「Vibe Coding」「Copilot導入」「RAG構築」など、コードやプロンプトの自動生成を中心に進んできました。
ただ、現場で運用を回し始めるほど、同じ悩みが顕在化しています。
- 部門ごとに言葉の定義が違い、AIの回答がズレる
- データ基盤を拡張しても、エージェントが自律的に動けない
- 新しい業務にAIを展開するたびに、プロンプトを一から作り直している
自社で10名規模以上のAIエージェント活用チームを抱え、複数業務にAIを展開し始めているなら、それは「コード自動化」だけでなく「意味の構造化」=オントロジーに投資を振り向けるフェーズに入っているサインです。
AI総合研究所が支援先で観察してきた共通パターンとしても、このタイミングでオントロジー整備に舵を切った企業は、その後のAIエージェント横展開が圧倒的に速くなります。
オントロジーの基本要素
オントロジーを設計するときに押さえるべき基本要素は、エンティティ・プロパティ・リレーション・公理の4つです。
さらに、構築スタイルとしてヘビーウェイトとライトウェイトの2種類があります。

エンティティ(クラス/型)
エンティティは、ドメインに存在する「もの」や「概念」のカテゴリを表します。
具体的には、顧客・製品・契約・設備・注文・センサー・シフトなど、業務で登場する名詞がほぼそのままエンティティ候補になります。
Palantirのドキュメントでは「Object Type」、Microsoft Fabricでは「エンティティ型」と呼ばれますが、指しているものはほぼ同じです。
再利用可能な論理モデルとして、名前・説明・識別子・属性・制約を1カ所に標準化します。
プロパティ(属性)
プロパティは、エンティティが持つ個別の性質や事実を表現します。「顧客」なら氏名・メールアドレス・法人番号・与信ランク、「設備」なら型番・設置場所・稼働時間、といった具合です。
プロパティを設計する際は、以下の観点で整理すると筋がよくなります。
- データ型
文字列・数値・日時・列挙型など。単位(ミリ秒・円・kW等)まで合わせておくとダウンストリームで事故が減る
- 識別子か否か
顧客コード・契約番号のように、エンティティインスタンスを一意に特定するためのキー
- 制約
必須/任意、値の範囲、有効期間など、業務ルールとして守られるべき条件
これらを明示しておくと、オントロジー全体の品質チェックが自動化でき、生データとのバインディングも精度が上がります。
リレーション(関係)
リレーションは、エンティティ同士のつながり方を定義します。
「顧客は注文を発行する」「注文は製品を含む」「エンジニアは設備を保守する」といった関係を、方向・多重度・意味付きで書き下したものです。
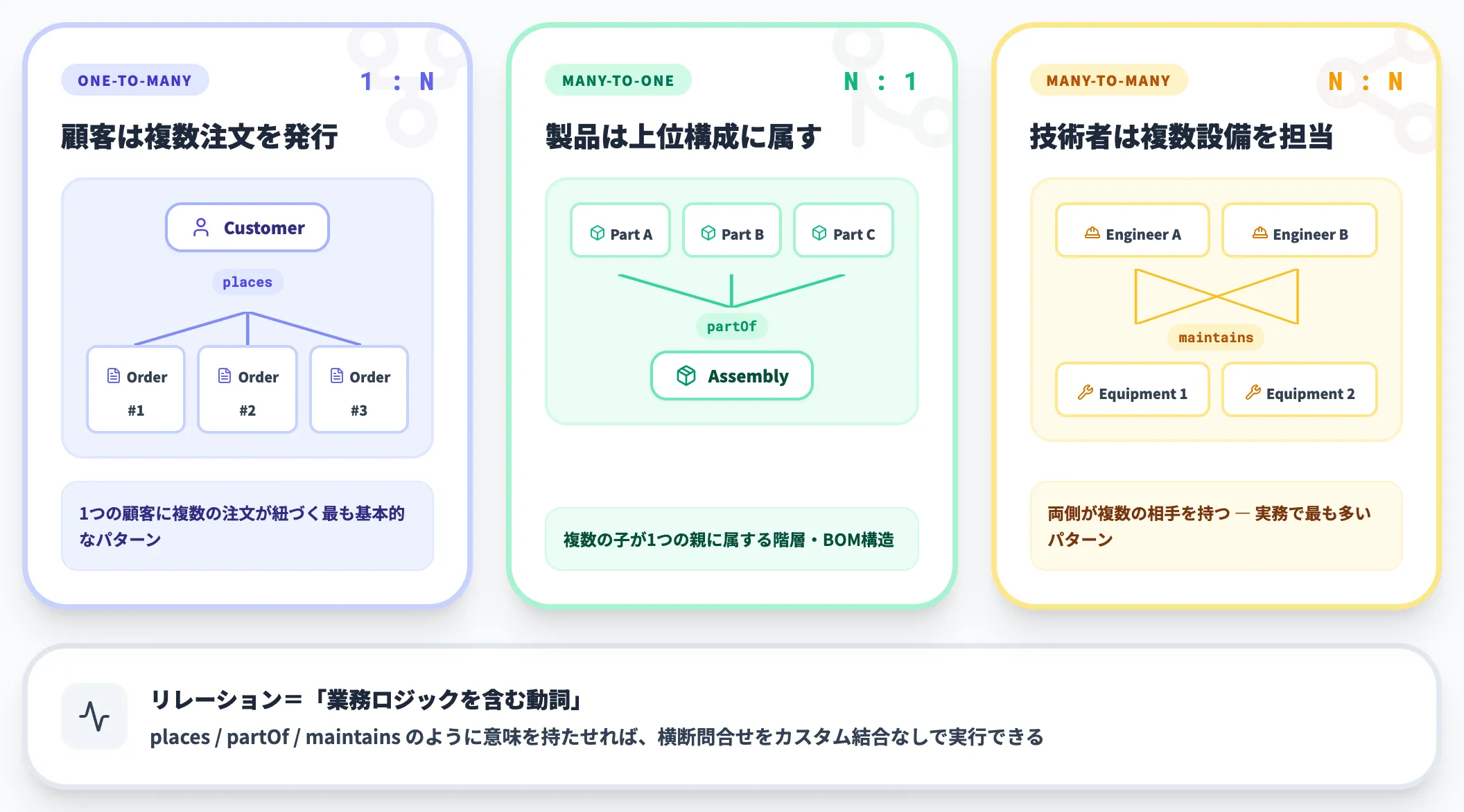
以下の表は、代表的なリレーションパターンを整理したものです。リレーションは単なる外部キーではなく、業務ロジックを含んだ「動詞」として設計される点がポイントです。
| リレーション例 | 多重度 | 意味 |
|---|---|---|
| Customer places Order | 1:N | 顧客は複数の注文を発行する |
| Product partOf Assembly | N:1 | 製品は上位アセンブリに属する |
| Engineer maintains Equipment | N:N | エンジニアは複数の設備を担当する |
こうしたリレーションを明示的に持つことで、「ある顧客の注文に紐づく製品のサプライヤーまで一気に辿る」といった横断的な問い合わせが、カスタム結合ロジックなしで実行できるようになります。
公理・制約・ルール
公理は、ドメイン全体で成り立つべき論理的な決まりごとを指します。
「契約は必ず1人以上の担当者を持つ」「注文金額は0以上である」「同じ顧客に重複する与信枠を発行しない」など、業務上必ず守られるべき条件です。

Microsoft Fabric Ontologyでは、これらを「Condition–Action Rules」として扱い、オントロジーのUIからルールを作成しつつ、実体は Fabric Activator item として保存・実行される設計になっています。
オントロジー自体はエージェントやワークフローが参照する共有コンテキスト層として位置づけられており、AIエージェントやワークフローはこの文脈を利用して業務判断の前提をそろえることができます。
ヘビーウェイト vs ライトウェイト
オントロジーには、記述の厳密さに応じて大きく2つのスタイルがあります。
-
ヘビーウェイト
OWLなどを用いて公理・制約を厳密に書き下す。
論理推論で明示されていない事実まで導き出せる反面、設計・運用コストが大きい
-
ライトウェイト
主要なエンティティ・プロパティ・関係だけを実務レベルで定義する。大手プラットフォーム(Palantir・Microsoft Fabric等)のデフォルトはこちらに近い
どちらが正解かは一概には言えませんが、企業導入の最初の一歩としてはライトウェイトで始めるのが現実解です。
医療や製薬のように記号推論の厳密さが求められる領域以外では、ヘビーウェイトから入るとPoCが立ち上がらないまま設計に半年以上を費やすリスクがあります。
オントロジーと関連概念の違い
オントロジーは、知識表現・ナレッジグラフ・RDF/OWL・従来のデータベース設計といった周辺概念と混同されがちです。
ここでは「抽象度」「役割」「実装手段」の3軸で切り分けていきます。
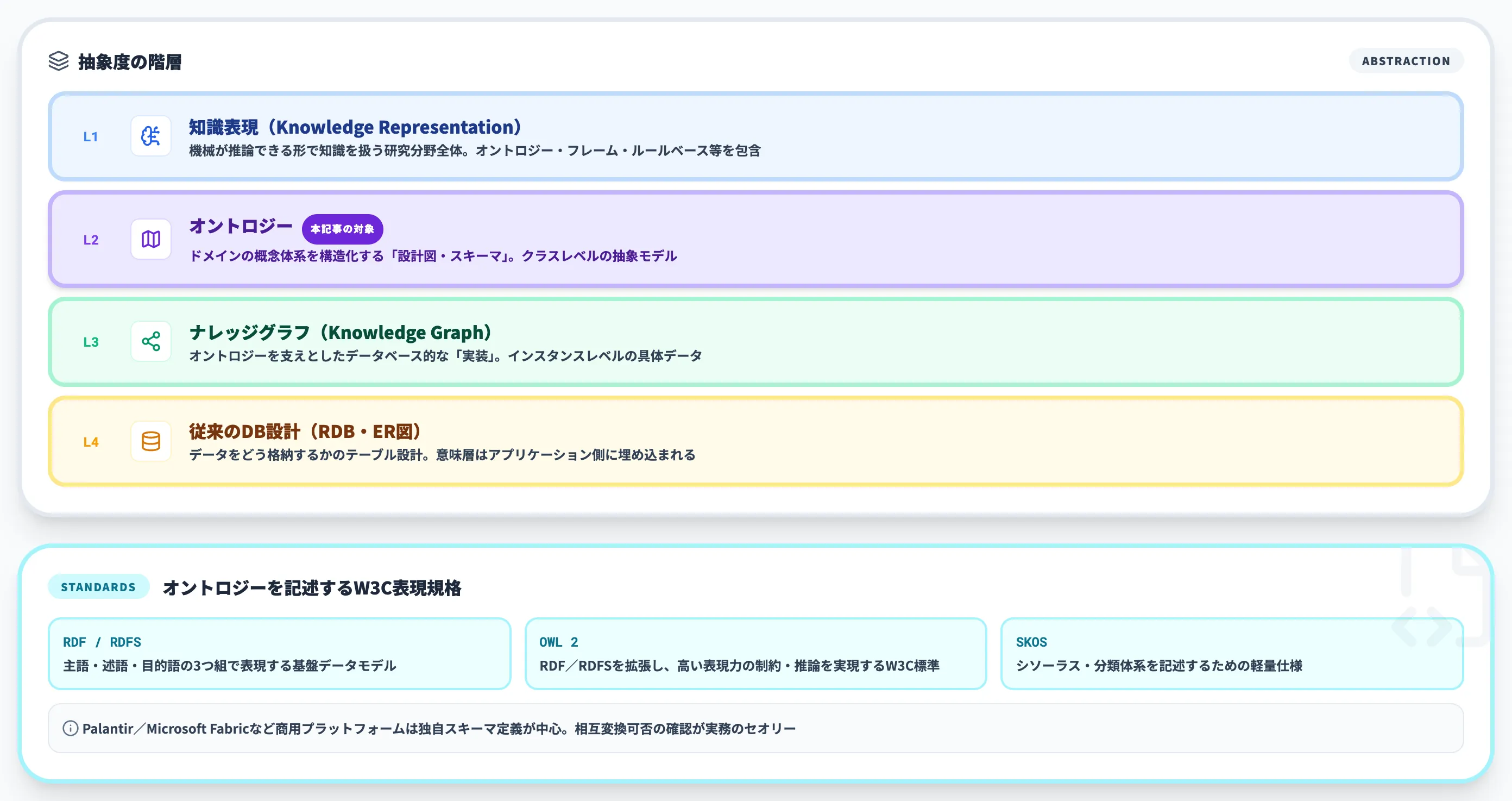
vs 知識表現(上位概念と手法)
知識表現(Knowledge Representation, KR)は、機械が推論できる形で知識を扱うための研究分野全体を指します。
オントロジーは、その知識表現の中でも「ドメインの概念体系を構造化する」ための代表的な手法のひとつです。
関係を単純化すると、「知識表現という広い枠のなかに、オントロジー・フレーム・セマンティックネット・ルールベース等が並ぶ」という構図になります。
ビジネス文脈でオントロジーを語るときは、「知識表現のうち、企業データに意味を与えるために使う方法」と理解すれば十分です。
vs ナレッジグラフ(設計図 vs 実装)
ナレッジグラフとオントロジーは、しばしば混同されますが、役割が異なります。
ナレッジグラフはエンティティ同士の関係をノードとエッジで表現したデータベース的な実装で、オントロジーはそのグラフを支えるスキーマ・設計図にあたります。
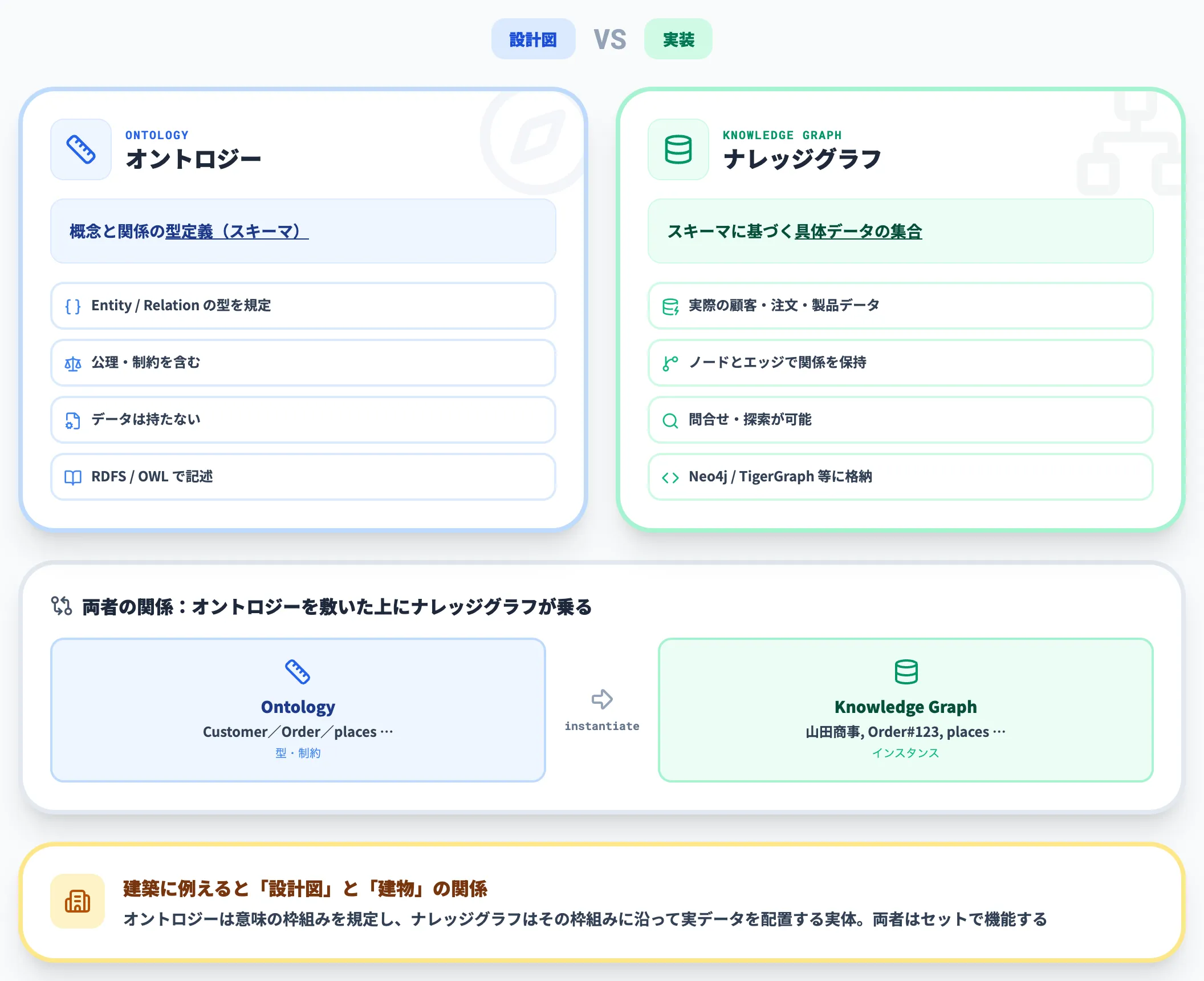
以下の表で、両者の違いを整理します。
| 項目 | オントロジー | ナレッジグラフ |
|---|---|---|
| 役割 | 概念体系の設計図(スキーマ) | エンティティ・関係の実データ |
| 粒度 | クラスレベル(抽象) | インスタンスレベル(具体) |
| 変更頻度 | ドメイン変更時のみ更新 | データ更新に応じて常時更新 |
| 代表技術 | OWL、RDFS | Neo4j、GraphDB、各種グラフDB |
この表からも見えるように、オントロジー(設計)とナレッジグラフ(実装)は、建築で言えば設計図と建物の関係に近いものです。片方だけあっても十分な価値は出ません。
RDF/OWL/SKOSの位置づけ
RDF・OWL・SKOSは、オントロジーを記述するための表現規格です。オントロジーそのものではなく、「どう書き下すか」を定めた言語・仕様という位置づけになります。
それぞれの役割は次のとおりです。
-
RDF(Resource Description Framework)
「主語・述語・目的語」の3つ組でデータを表現するW3C標準。オントロジーやナレッジグラフの基盤データモデル
-
RDFS(RDF Schema)
RDFに型・クラス・サブクラス関係を与える軽量な語彙
-
OWL(Web Ontology Language)
RDF/RDFSを拡張し、より表現力の高い制約・推論を可能にするW3C標準。現在はOWL 2 Second Editionが維持されている
-
SKOS(Simple Knowledge Organization System)
シソーラスや分類体系を記述するための軽量仕様
企業導入の文脈では、PalantirやMicrosoft Fabricのようなエンタープライズ向けプラットフォームは、OWLなどの標準規格を直接は使わず、独自のスキーマ定義で実装していることが多い点に注意が必要です。
研究・公共データ・医療の知識ベースではOWLが主流ですが、商用SaaSでオントロジーを運用する場合は、ベンダー独自の記法とOWL/RDFの相互変換可否を確認するのが実務のセオリーです。
vs 従来のDB設計
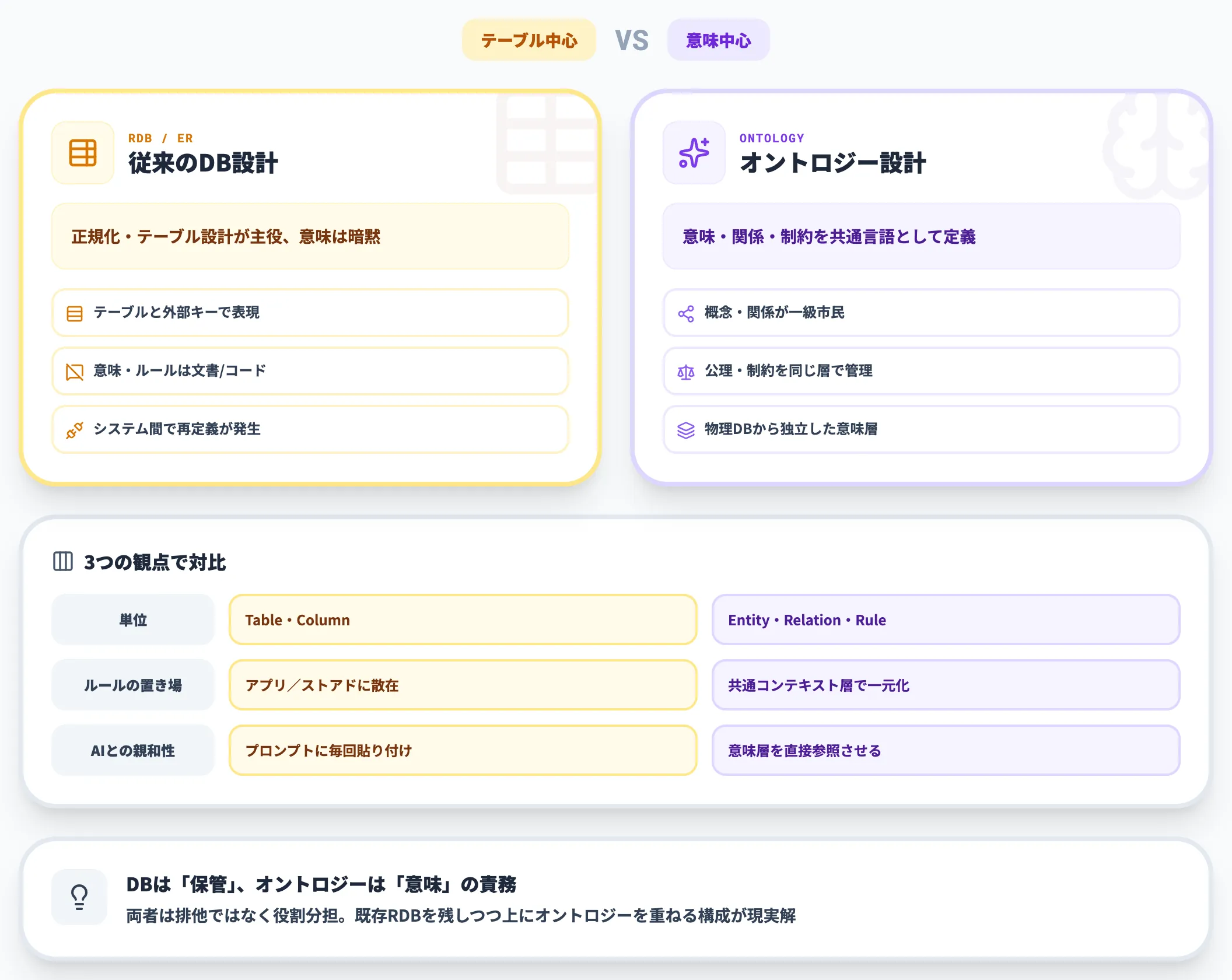
従来のリレーショナルDB設計(ER図・正規化)と比べると、オントロジーは次の点が異なります。
- 意味(概念)をアプリケーションから切り離し、データ層と独立に管理する
- 階層関係や推論ルールをスキーマ自体に埋め込める
- 複数データソースをまたいだ共通ボキャブラリとして機能する
「RDBでも同じことができるのでは」と感じる読者も多いはずです。実際、ライトウェイトなオントロジーはER図と重なる部分も少なくありません。
ただし、AIエージェントが自然言語で問い合わせる相手として機能するには、RDBのテーブル定義よりも一段抽象的な概念モデルが必要になります。
オントロジーは、そのために最適化されたレイヤーと考えるのが分かりやすい整理です。
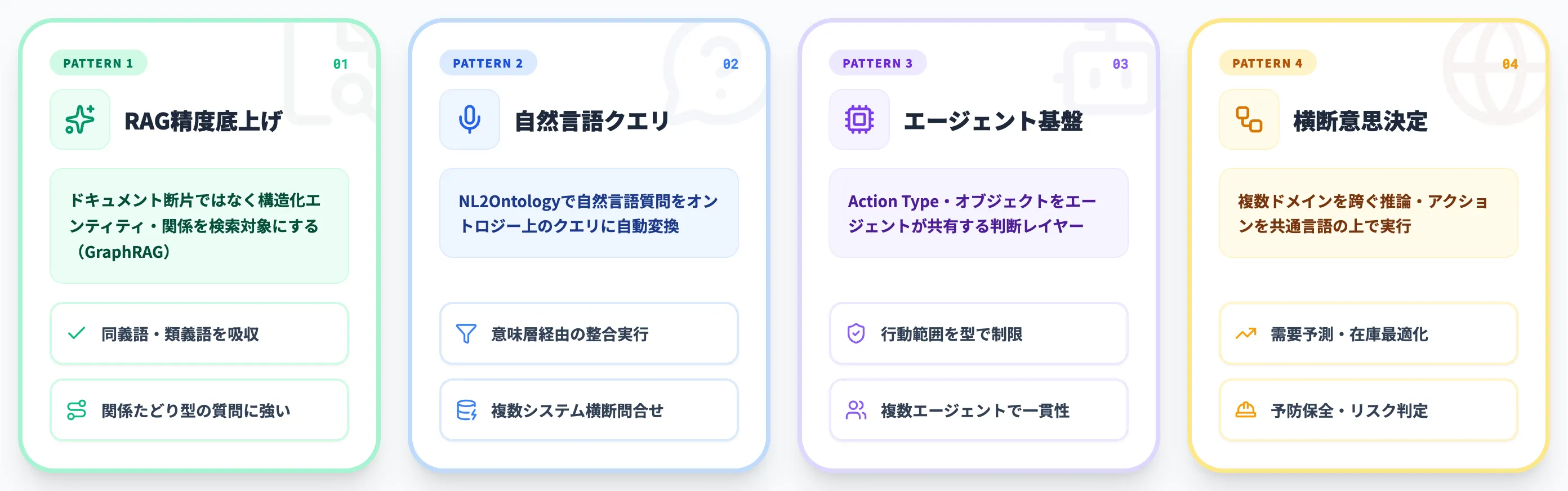
AIエージェント時代のオントロジー活用パターン
オントロジーは、単体で価値を生むよりも、LLMやAIエージェントと組み合わせることで本領を発揮します。
ここでは実務で頻出する4つの活用パターンを取り上げます。
1.RAGの精度を構造化で底上げする
一般的なRAGは、ドキュメントをチャンクに分割し、ベクトル検索で類似度の高い断片を取ってきてLLMに渡す方式です。
シンプルで立ち上がりが早い反面、文脈の深さや関係性の理解が弱いという弱点があります。
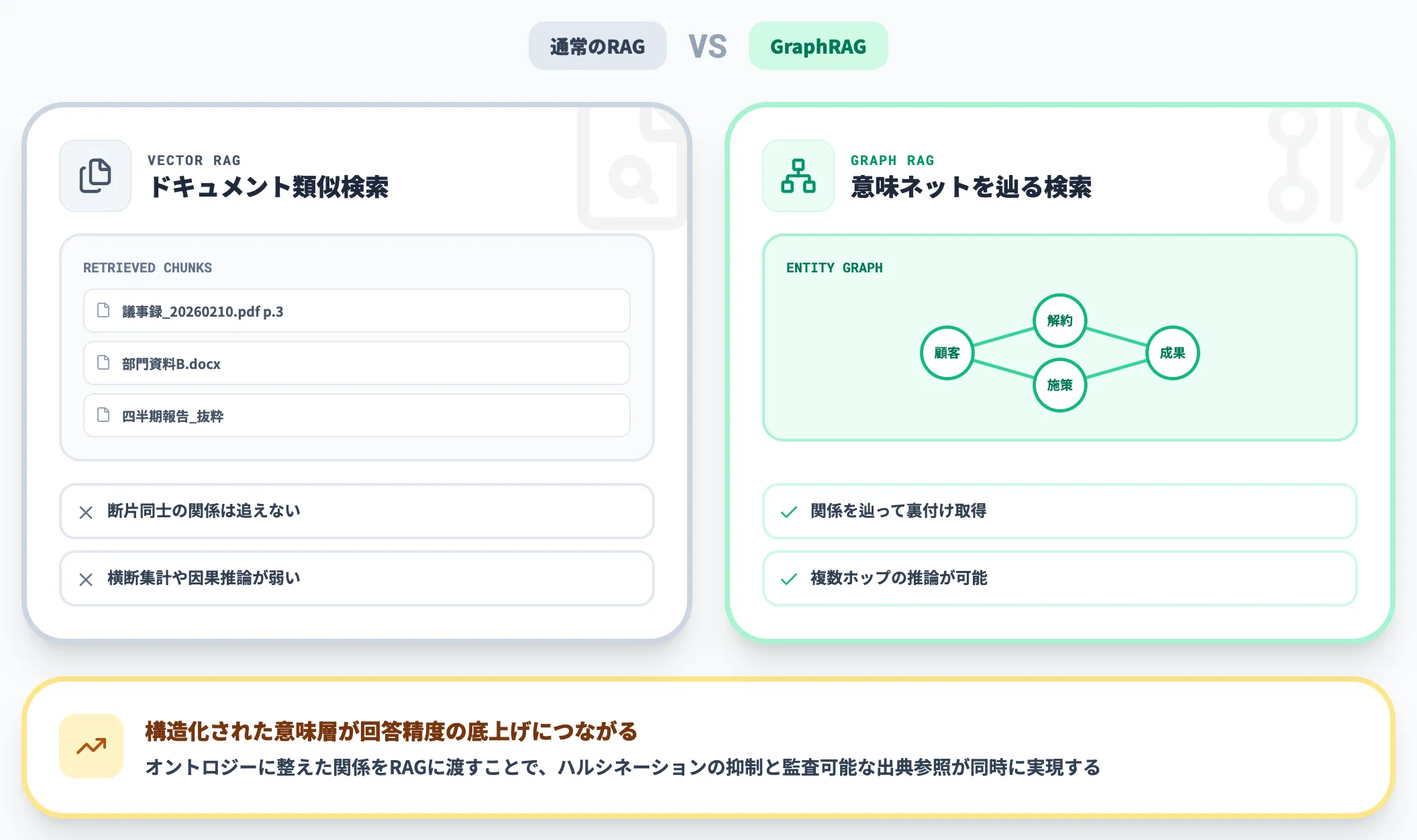
オントロジーを組み合わせると、検索対象がドキュメントの断片ではなく「構造化されたエンティティと関係」になるため、次のような改善が見込めます。
- 同義語・類義語・上位下位概念の揺れを吸収できる
- 「この顧客に紐づく未完了の案件」といった関係たどり型の問い合わせに強くなる
- 回答根拠としてエンティティのメタデータを引ける
これはGraphRAGと呼ばれる実装パターンとして知られています。
MicrosoftはMicrosoft Research Project GraphRAGとして別系統でGraphRAG技術を展開しており、Fabric Ontology側では自然言語クエリ(NL2Ontology)やグラフ表現といった親和性の高い機能を提供しています。
Palantir AIP側も、Agent StudioのツールとしてOntologyのオブジェクトクエリやセマンティック検索をエージェントから呼び出せる設計で、GraphRAG的な実装と組み合わせやすい位置づけです。
2.自然言語でビジネス質問に答える(NL2Ontology)
Microsoft Fabricのオントロジーには、NL2Ontologyと呼ばれる自然言語クエリ機能が組み込まれています(Microsoft Learn)。
ユーザーが「今月、北日本エリアで遅延している注文を教えて」と聞くと、LLMがその質問をオントロジー上のクエリに変換し、関連データを横断的に取得して答える仕組みです。
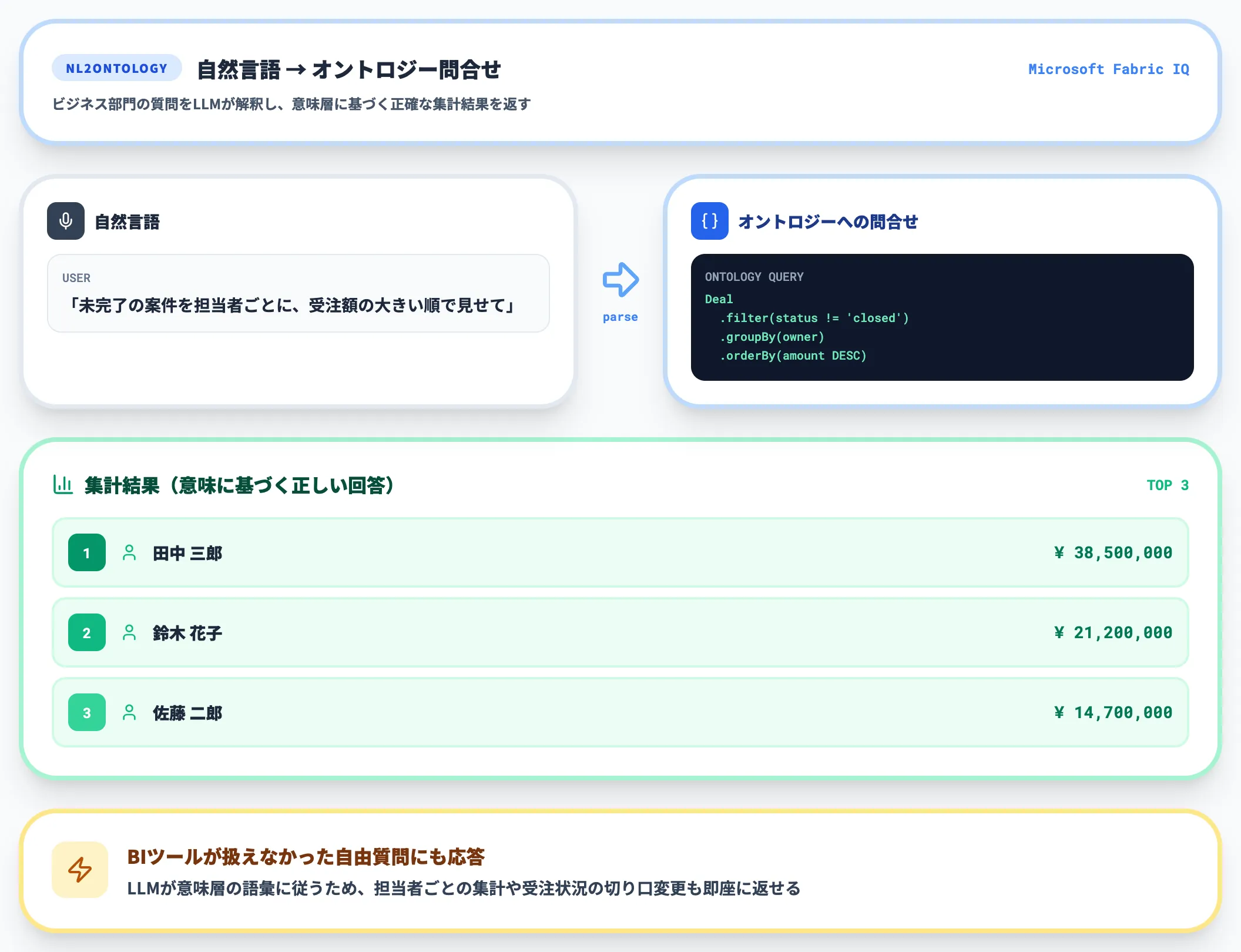
ここでの決定的な違いは、LLMが直接テーブルを読んでいるのではなく、オントロジーという中間層を経由している点にあります。
これにより、複数システムにまたがった問い合わせでも、フィルター条件・結合ロジック・単位換算がオントロジー側の定義と整合した形で実行されます。
3.AIエージェントの判断基盤として使う
PalantirのAIP Agent Studioは、AIエージェントの上でOntologyを前提に設計されています。
エージェントは、Ontologyに定義されたオブジェクト(顧客・設備・注文等)と、そのオブジェクトに紐づくAction Type(更新・承認・発注など)を組み合わせて動作します。
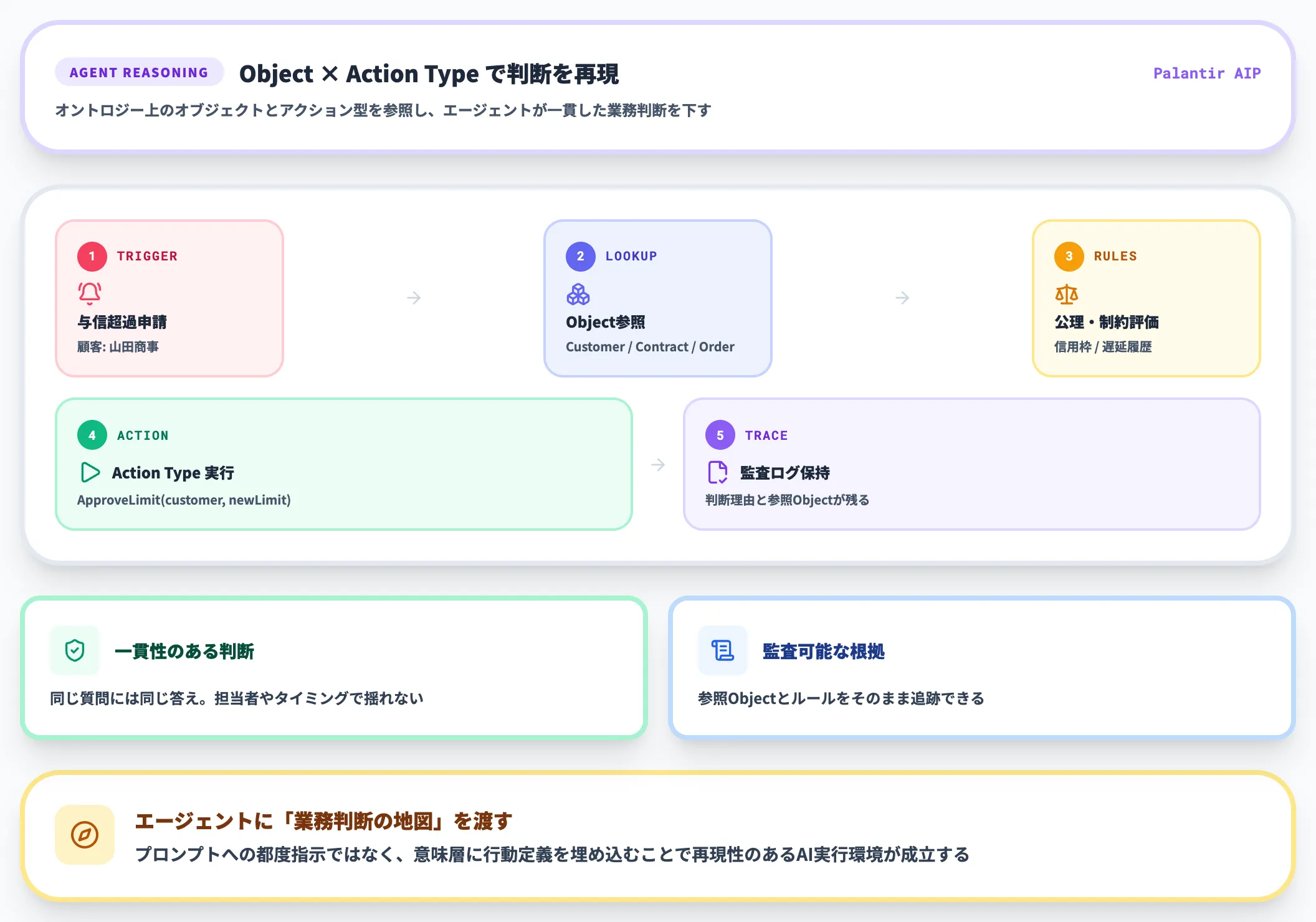
この構造の利点は3つあります。
- エージェントが取りうる行動がAction Typeの範囲に限定されるため、意図しない操作が起きにくい
- 同じOntologyを複数のエージェントが共有するため、業務間で判断の一貫性が保たれる
- Ontologyに埋め込まれた制約・権限が**ガバナンスとしてそのまま効く
NTTデータのLITRON COREも同じ方向性で、統括エージェント・特化エージェント・自動生成エージェントが共通の業務基盤上で動く構造を取っています。
4.クロスドメインの意思決定自動化
オントロジーの真価は、複数ドメインを横断した判断が必要になったときに最も表れます。
たとえば需要予測では、販売実績・在庫・サプライヤー納期・生産能力・天候・物流コストといった、本来別システムに散らばる情報を組み合わせる必要があります。
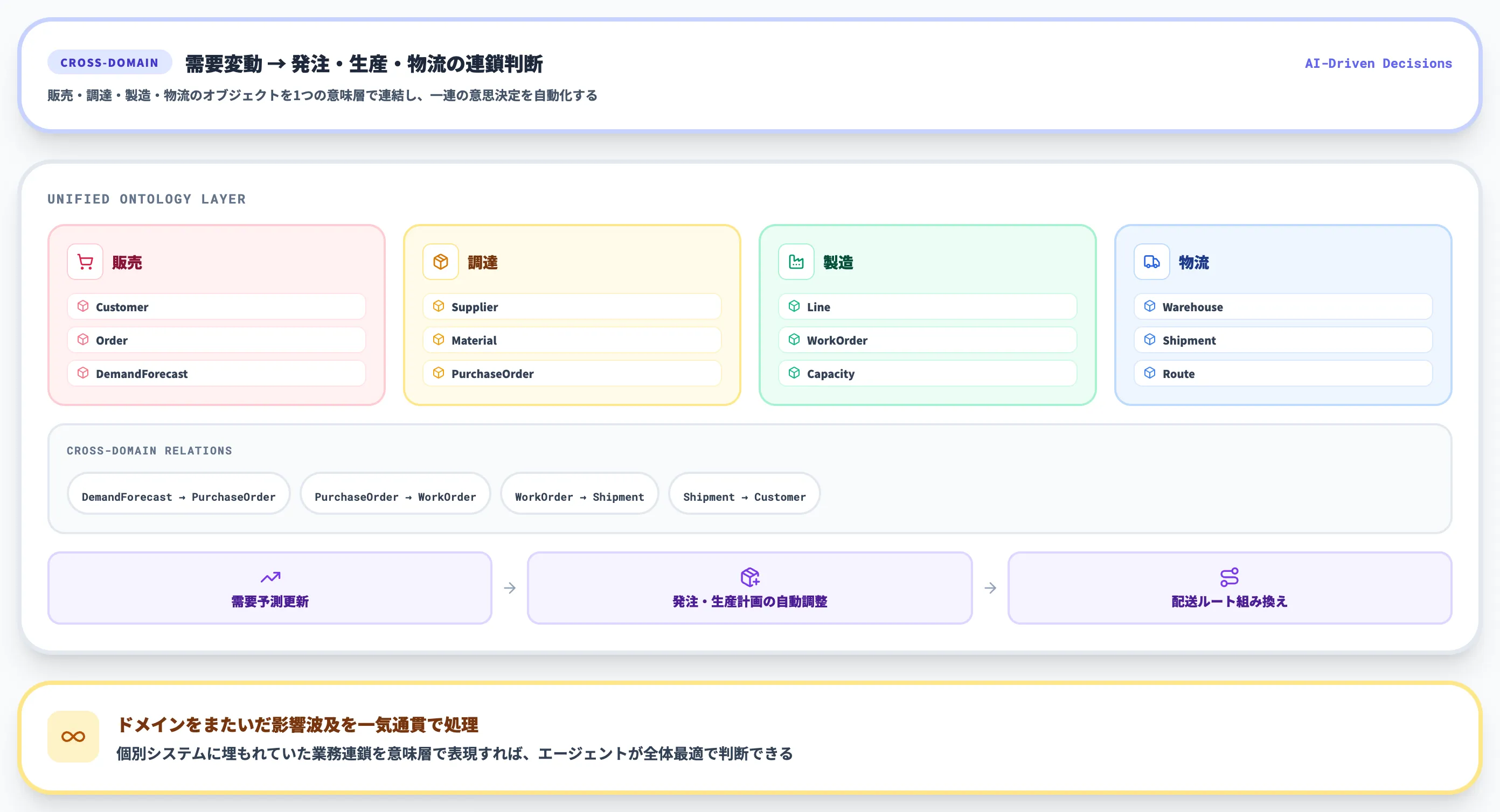
オントロジーで各ドメインの概念と関係を統一しておくと、AIエージェントは「在庫不足が予測される場合、代替サプライヤーの発注リードタイムを確認し、必要なら生産計画を調整する」といった業務を跨ぐ推論・アクションを、共通言語の上で実行できます。
これはNTTデータが「GRAG AI(オントロジーAI)」の代表的な適用領域として挙げている需要予測・予防保全にも重なります。

オントロジーが向いている場面・向かない場面
オントロジーは強力な概念ですが、すべての企業・プロジェクトに必要なものではありません。
投資対効果の観点から、向いている場面と向かない場面を明確に分けて考えることが重要です。
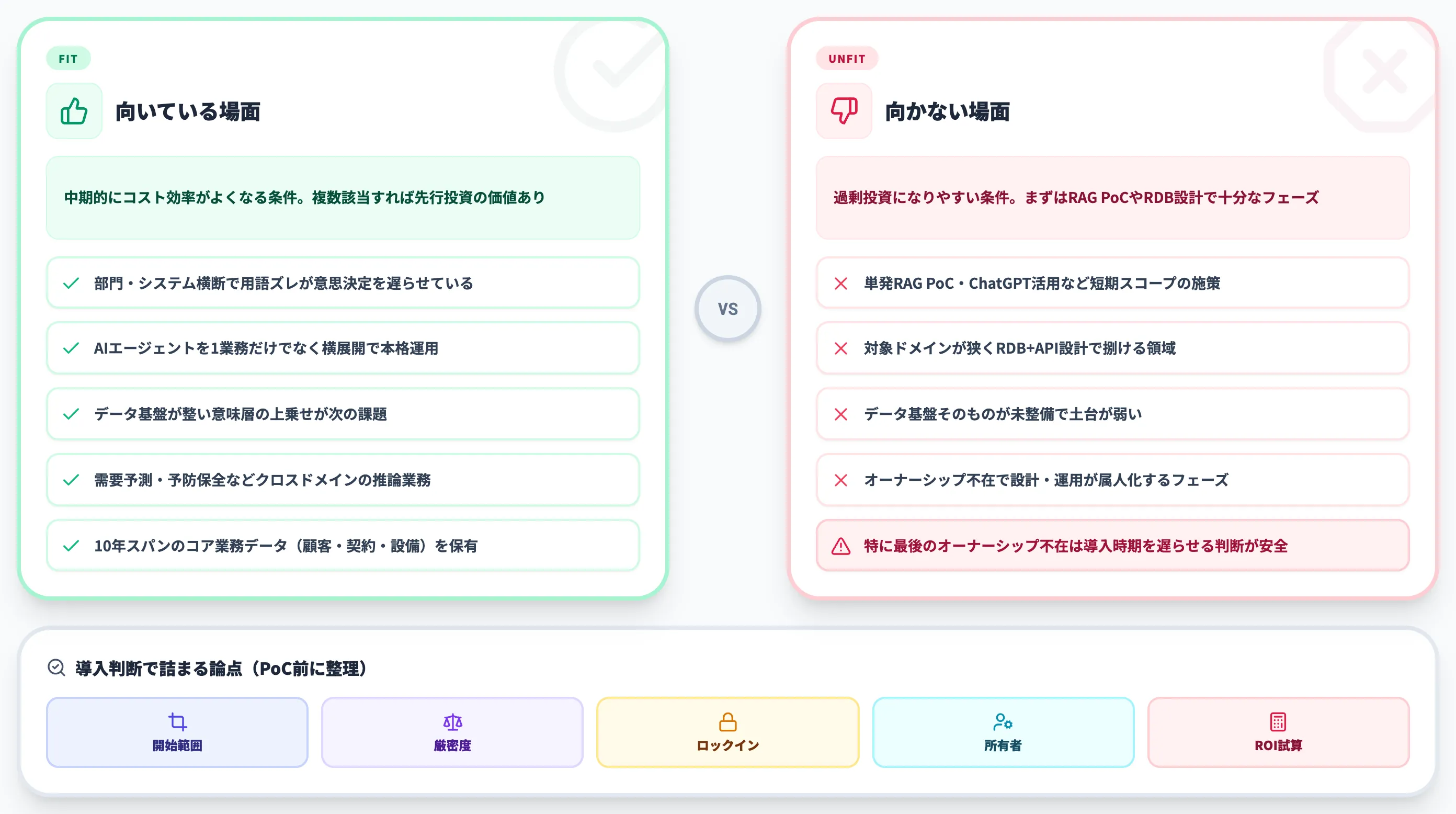
向いている場面
オントロジー導入が効いてくるのは、次のような条件が揃った企業です。
- 業務が複数部門・複数システムにまたがり、用語のズレが意思決定の遅延を生んでいる
- AIエージェントを1業務だけでなく横展開で本格運用する予定がある
- データ基盤(レイクハウス・DWH)が既に整備されており、意味層の上乗せが次の課題になっている
- 需要予測・予防保全・リスク判定のように、クロスドメインの推論が価値を生む業務がある
- 10年スパンで使うコア業務データ(顧客・契約・製品・設備)を持っている
これらに複数該当するなら、AI総合研究所の支援経験からも、オントロジー整備に先行投資する方が中期的にコスト効率がよくなる傾向が強く見られます。
向かない場面
一方、次のようなケースではオントロジー導入は過剰投資になりやすいので注意が必要です。
- 単発のRAG PoC・ChatGPT活用など、スコープが狭く短期的な施策
- 対象ドメインが狭く、RDB+API設計で十分にさばける領域
- データ基盤そのものが未整備で、オントロジーを乗せる土台が弱い
- 社内にオーナーシップを持つチーム・人材がおらず、設計と運用が属人化しそうなフェーズ
特に最後の「オーナーシップ不在」は深刻で、オントロジーは定義した瞬間から継続メンテナンスが必要な資産です。
組織として所有者を決められないなら、導入時期を遅らせる判断のほうが安全です。
導入判断で詰まる論点

実務で判断に迷うポイントを、AI総合研究所の支援現場でよく挙がる順に整理しておきます。
- どの範囲から始めるか
全社一括は現実的でなく、1〜2ドメイン(例:顧客と注文、設備と保守)に絞るのが定石
- ヘビーウェイト vs ライトウェイト
厳密推論が業務要件でない限り、ライトウェイト+段階拡張が安全
- ベンダーロックイン
PalantirやFabricの独自記法に寄せると可搬性が下がる。OWL/RDF互換の有無を必ず確認する
- オーナーシップ
情シス主導か、業務部門主導か、ハイブリッドか。どれも可能だが、意思決定者を1人に明確化しないと定義が揺れる
- AIエージェントのコスト転嫁
オントロジー整備がAIエージェントの運用費削減にどう効くかを、事前に試算しておくとROI説明がしやすい
これらの論点は、PoCに入る前に社内で一度議論しておくと、プロジェクト後半での手戻りが減ります。
オントロジー構築の段階的ステップとベストプラクティス
オントロジー構築は、一気に完成させる性質のプロジェクトではありません。
段階的にスコープを広げ、AIとの連携を深めていくのが現実解です。ここでは5ステップのモデルで整理します。

1.対象ドメインを絞ってパイロット
最初のステップは、オントロジーを適用するドメインを絞ることです。
顧客管理・受発注・設備保全といった1〜2ドメインに限定し、3〜6カ月で小さな成果を出すことを目指します。

パイロットの選定基準は次のとおりです。
- 現場が困っている具体的な業務課題があること
- データソースが複数あり、意味のすり合わせが必要な領域であること
- 成果を測る定量指標(工数削減・回答精度・リードタイム等)が設定できること
この段階で「全社オントロジー」を狙うと、抽象的なクラス設計に時間を取られ、価値が見えないまま予算が切れるリスクが高くなります。
2.コアエンティティ・リレーションの定義
対象ドメインが決まったら、エンティティ(顧客・製品・設備等)を10〜30個ほど洗い出し、その間のリレーションを業務の動詞として書き下します。

この工程では、以下を心がけるとモデルが筋よくなります。
- 業務担当者とホワイトボードで実際の業務フローを描きながら定義する
- プロパティは最小限から始め、必要に応じて追加する
- 多重度(1対多・多対多)と双方向性を必ず明記する
PalantirはOntologyのドキュメントでObject Type・Link Type・Action Type・Functionの4層を定義しており、このモデルは他プラットフォームを使う場合でも設計の参考になります。
3.データバインディングと品質検証
次に、定義したエンティティ・プロパティを実データソースにバインドします。レイクハウスのテーブル、イベントストリーム、BIセマンティックモデルなどが主なバインド対象です。
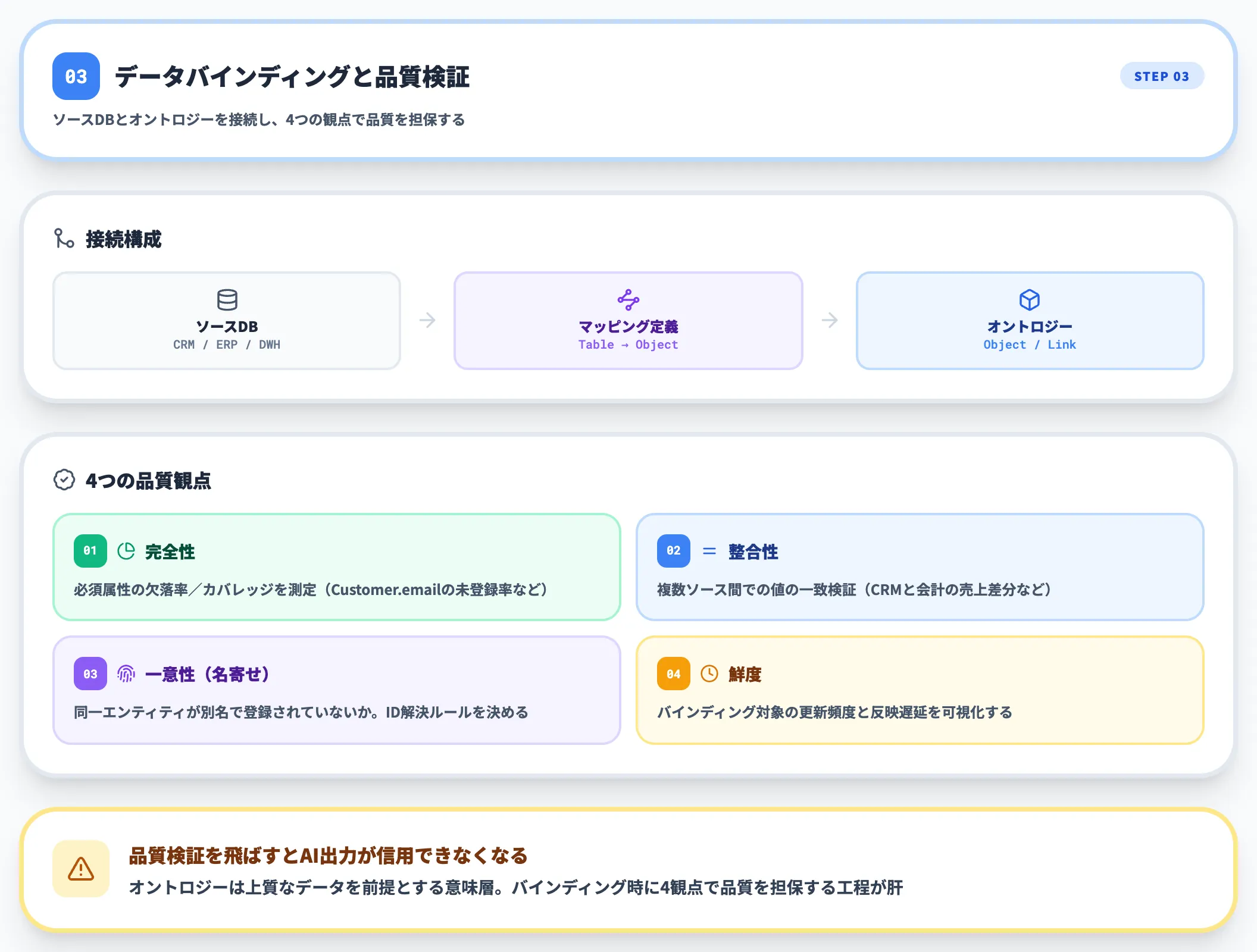
この段階で必ず行うべき作業は次のとおりです。
- 識別子(ID)の重複・欠損チェック
- データ型・単位の整合確認
- スキーマ進化ルール(カラム追加・削除)への対応設計
- **データ系列(リネージ)**の可視化
Microsoft Fabric Ontologyの場合、データバインディングは専用UIから行い、オントロジーグラフとして可視化できます。
バインド直後は想定外のデータ品質問題が必ず出てくるので、ここを軽視しないのが鉄則です。
4.AIエージェント・LLMとの連携
オントロジーが実データと接続されたら、いよいよAIエージェントを乗せていきます。典型的なパターンは2つです。
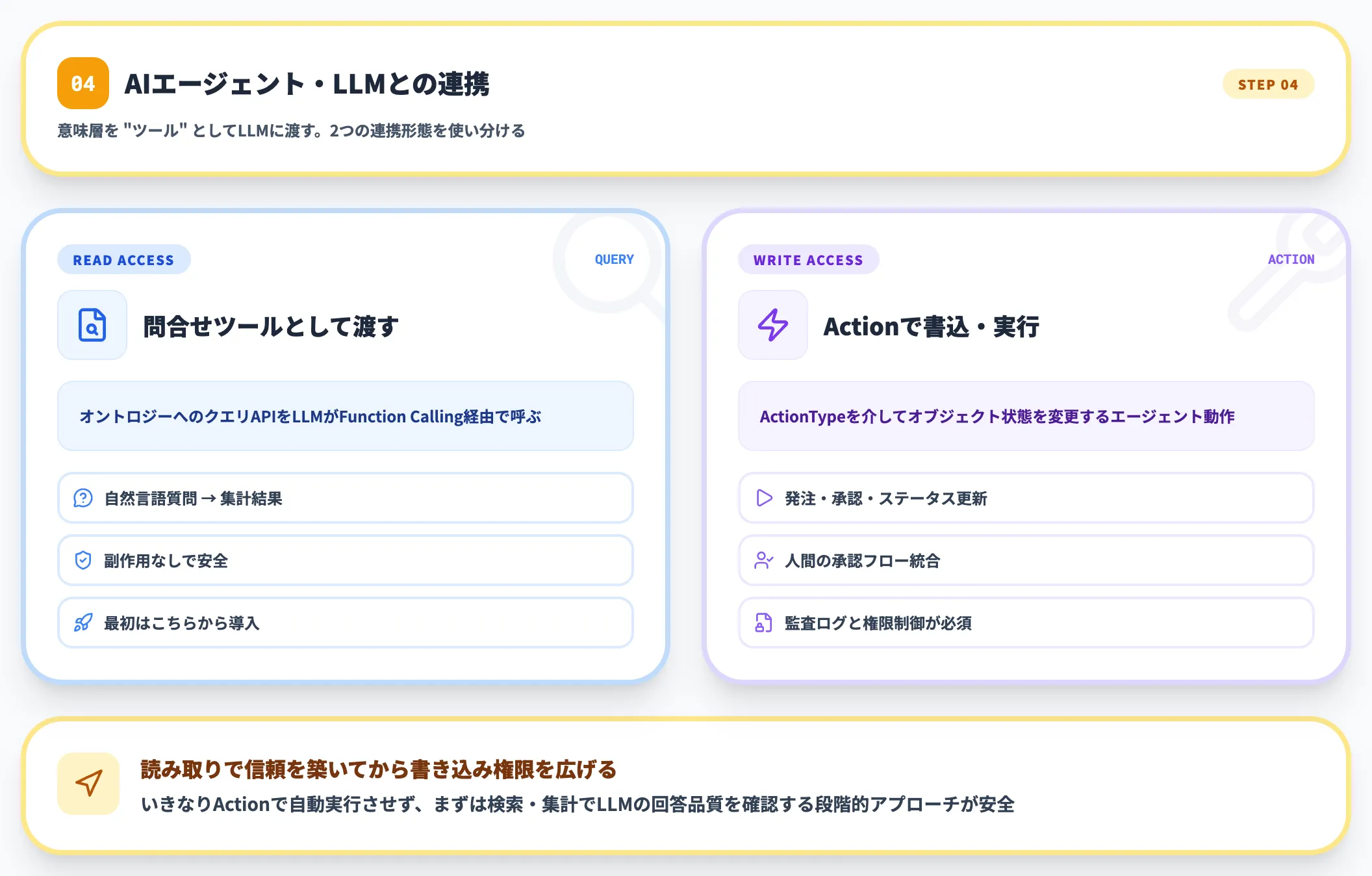
- 読み取り側
自然言語クエリ(NL2Ontology)で業務質問に答えるエージェント
- 書き込み側
オントロジー上のAction Typeを通じて、承認・更新・発注といった操作を行うエージェント
読み取り側から先に展開するのが定石で、書き込み権限を持たせるのは、オントロジーの制約・ルールと権限設計が十分に検証できた後にするのが安全です。
自律型AIエージェントやマルチAIエージェントの構成と組み合わせる場合、各エージェントの権限境界をオントロジー側で明示するのがガバナンス面で有効です。
5.運用・拡張・ガバナンス
パイロットで成果が出たら、対象ドメインを拡張していきます。このフェーズで重要なのは、次の3点です。
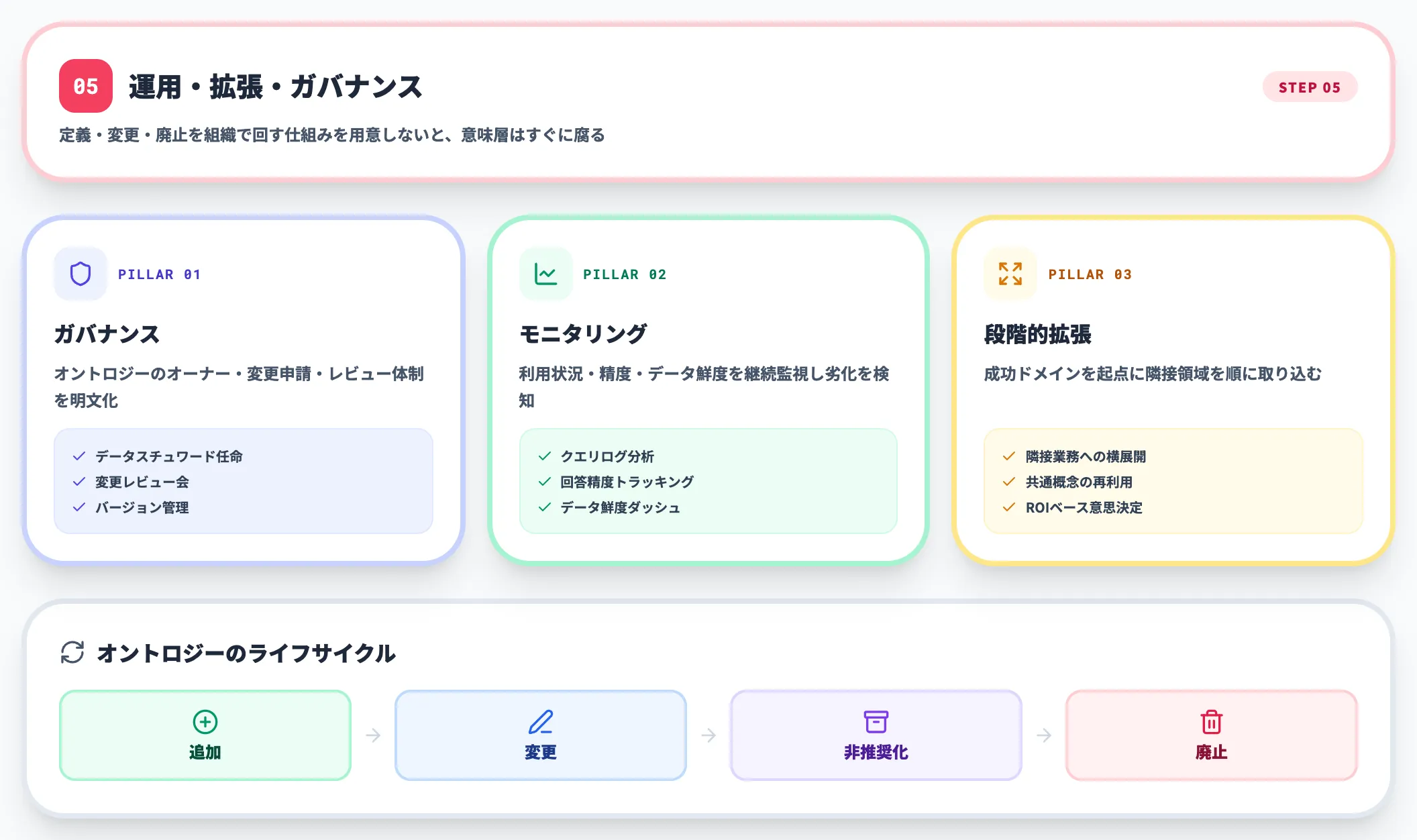
- オントロジーのバージョン管理(変更履歴・後方互換性)
- 定義変更時の影響分析(どのエージェント・ダッシュボードが影響を受けるか)
- 業務部門と情シスの役割分担(意味定義は業務側、実装は情シス側が基本)
AI総合研究所の支援現場では、このガバナンス設計が不十分なままドメインを広げたプロジェクトが、半年後に「誰もオントロジーの正本を知らない」状態に陥るのをよく見ます。
最初のStep1と同じ熱量で、運用ルールにも投資してください。
詰まりポイント
実装で現場がハマりやすい箇所を、事前に押さえておきます。
- 概念と実装を同時に設計してしまう
まずは意味(概念モデル)だけを固めてからバインドするのが鉄則
- 全員一致を狙いすぎる
部門間で用語が完全に一致することは稀。「差分を明示する」運用で回す
- 推論ルールを書きすぎる
ライトウェイトで始める意味を忘れると、更新のたびに整合チェックが破綻する
- ドキュメントだけ残して本体が更新されない
正本はツール内に置き、ドキュメントは自動生成する設計にする
これらは経験者なら頷く「よくある失敗」ですが、初めて導入する企業はほぼ全部踏みます。
先回りで回避フローを組み込んでおくのが最も費用対効果の高い投資です。
オントロジー基盤の主要プラットフォーム
オントロジーをスクラッチで構築する企業もありますが、2026年時点では主要ベンダーのプラットフォームを使う選択肢が現実的です。ここでは代表的な3つを比較します。
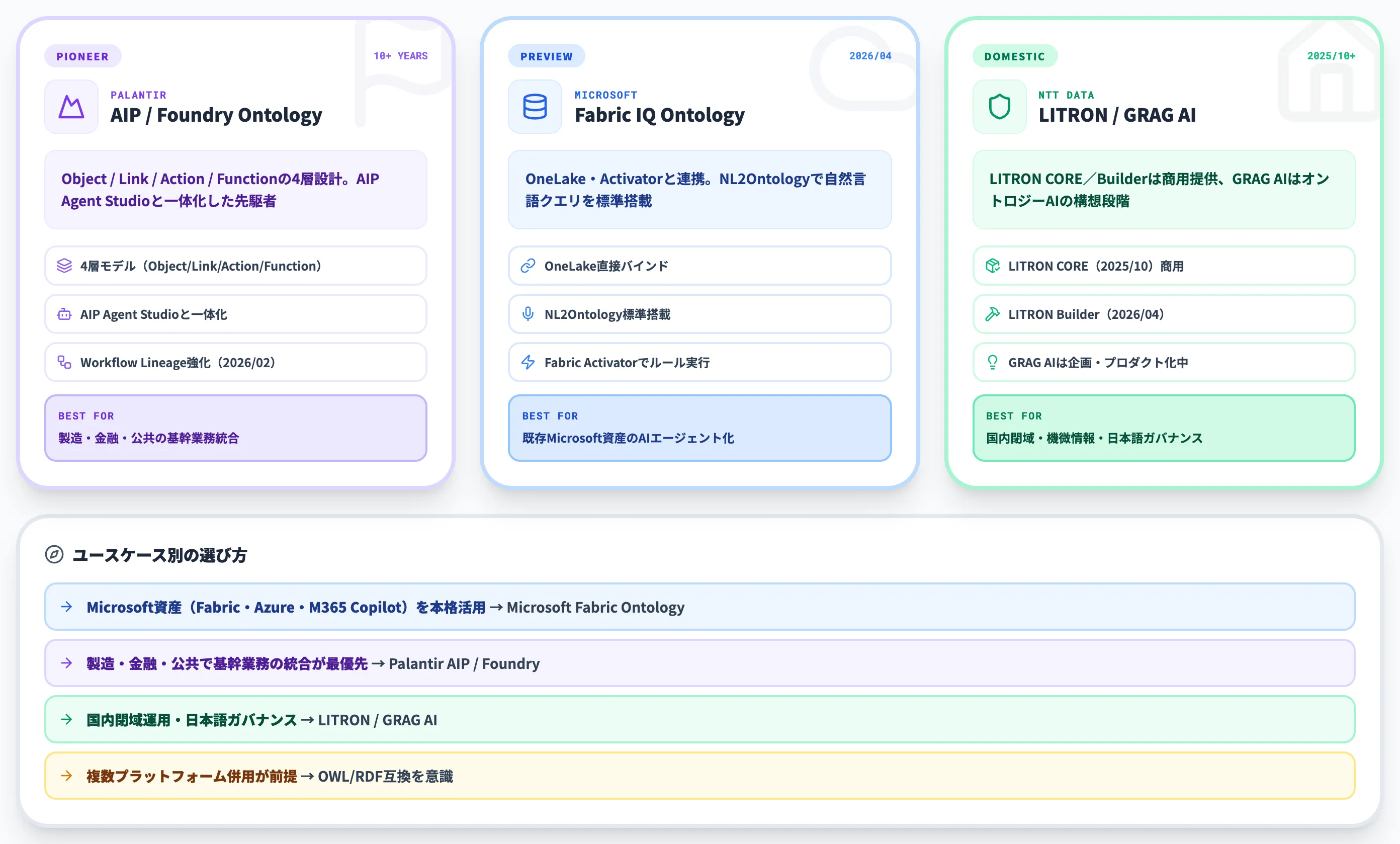
以下の表は、Palantir・Microsoft Fabric・NTTデータの3プラットフォームを、特徴・強み・想定ユースケースで整理したものです。
| プラットフォーム | 位置づけ | 特徴 | 想定ユースケース |
|---|---|---|---|
| Palantir AIP / Foundry Ontology | 先駆者 | Object / Link / Action / Functionの4層設計、AIP Agent Studioと一体化 | 製造・金融・公共の基幹業務統合 |
| Microsoft Fabric Ontology | プレビュー/データ基盤統合 | OneLake・Activatorと連携、NL2Ontology搭載 | 既存Microsoft資産を持つ企業のAIエージェント化 |
| NTTデータ LITRON / GRAG AI | 国内ガバナンス対応 | LITRON CORE/Builderは商用提供中(Builderは初期パブリッククラウド、オンプレは今後対応予定)。GRAG AIは構想・プロダクト化段階 | 国内大手の業務特化AI、機微情報を扱う業界 |
この表から分かるように、各プラットフォームは「どこに強いか」がはっきり分かれています。
以下で個別に掘り下げます。
Palantir AIP
Palantirは、Foundry時代から約10年以上オントロジーを実装してきた先駆者です。
2026年時点ではAIP(AI Platform)と一体化し、AIエージェント開発基盤の中心にOntologyを据えています。
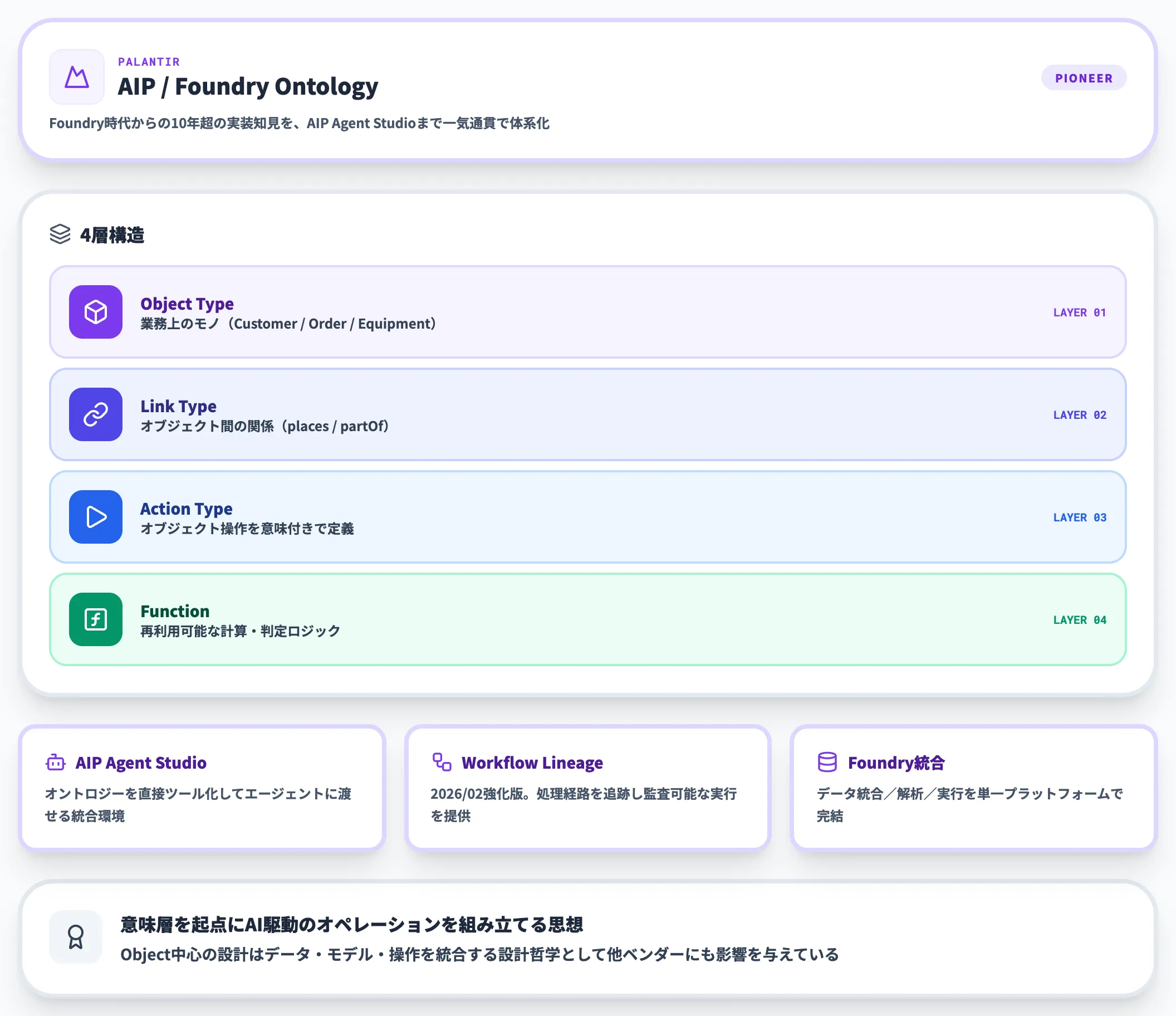
Palantir Ontologyの特徴は、Object・Link・Action・Functionの4層で構成される点にあります。
Object TypeとLink Typeでビジネスの「意味」を表現し、Action TypeとFunctionで「どう動くか」を定義する設計です。
2026年2月のアップデートでは、複数Ontologyを横断するWorkflow Lineageも強化されています(Palantir公式)。
大規模な基幹業務を一つの意味モデルに統合したい企業には最有力候補ですが、コスト・導入工数は大きく、全社規模のコミットメントがある組織向けという性格です。
Microsoft Fabric
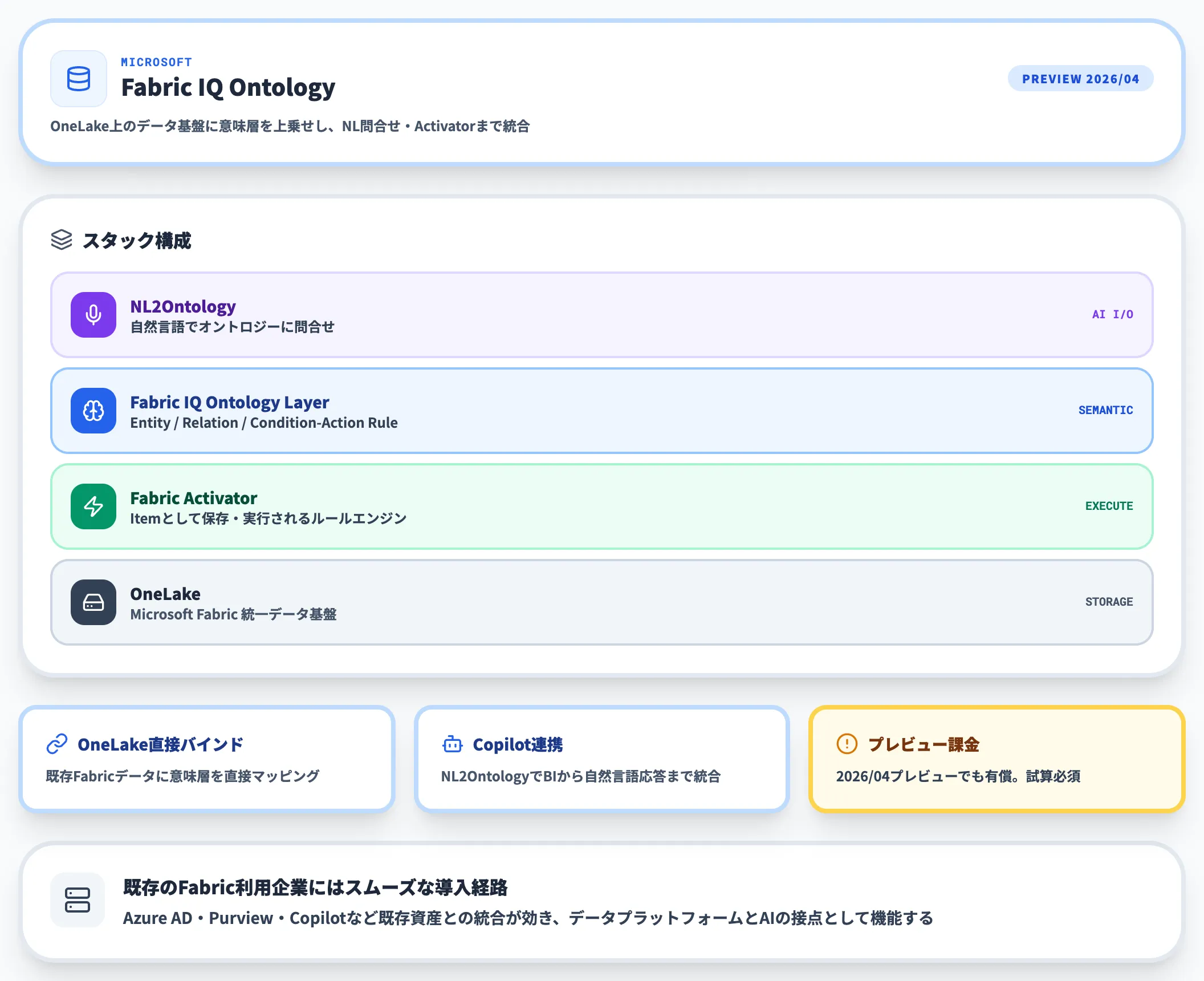
Microsoft Fabric Ontologyは、Fabric IQワークロードの一部として提供されているプレビュー機能です。
2026年4月18日時点ではプレビュー段階ながら、課金自体は既に有効で、CU(Capacity Unit)消費の内訳も公開されています(キャパシティ消費の公式ドキュメント)。
ただし一部のメーターは未適用で、今後の更新が予告されています。
主な特徴は次のとおりです。
- OneLake上のデータを直接バインドできるため、既存Fabric資産をそのまま活用できる
- NL2Ontologyによる自然言語クエリが標準搭載
- Fabric Activatorと連携してCondition-Action Rulesを実装できる
- グラフ表現でエンティティ関係を視覚的に探索できる
既にMicrosoft FabricやOneLakeを導入している企業にとっては、意味層の上乗せとして非常に自然な選択肢です。
Fabric IQ全体のセマンティック・インテリジェンス機能と併用すると、AIエージェント連携の構成が揃います。
NTTデータ LITRON / GRAG AI(国内)

NTTデータのLITRONシリーズは、エージェント型AI基盤として以下の構成で商用提供されています。
- LITRON CORE
2025年10月提供開始のエージェント基盤。統括エージェント・特化エージェント群・エージェント自動生成を備える(公式)
- LITRON Builder
2026年4月提供開始。自然言語ノーコード・ローコード・コーディングで業務特化エージェントを構築可能。初期はパブリッククラウド提供で、オンプレミス対応は今後予定とされている(公式)
- LITRON Multi Agent Simulation
複数ペルソナによるシミュレーション
この商用提供ラインの先に位置づけられ
ているのが、因果推論能力を持つ「GRAG AI(オントロジーAI)」です。
NTTデータはForesight Day 2026でGRAG AIをオントロジー起点のAI基盤として掲げていますが、公式の社員記事では「企画・プロダクト化段階」と説明されており(NTTデータ社員インタビュー)、LITRON CORE/Builderのような一般提供プロダクトとしては整理されていません。
需要予測・予防保全・個別最適化といったクロスドメインの判断業務を対象領域として掲げていますが、選定時はLITRON CORE/Builderの提供範囲とGRAG AIの構想段階を切り分けて見るのが実務上の安全策です。
国内拠点・閉域運用・日本語ガバナンス対応が強みで、機微情報を扱う業界や全社的な基幹システム再編で選択肢に入ります。
ユースケース別の使い分け
3プラットフォームをどう選ぶかは、既存のデータ基盤とガバナンス要件で決まります。AI総合研究所の選定支援における目安は次のとおりです。
- 既にMicrosoft資産(Fabric・Azure・M365 Copilot)を本格活用 → Microsoft Fabric Ontologyが第一候補
- 製造・金融・公共で基幹業務の統合が最優先 → Palantir AIP / Foundry Ontology
- 国内閉域運用・日本語ガバナンス・NTTデータ既存取引あり → LITRON / GRAG AI
- 複数プラットフォーム併用が前提 → OWL/RDF互換のある設計を意識し、ベンダーロックインを最小化
どの選択肢も、2026年時点では「早期導入企業が運用知見を蓄えているフェーズ」です。
プロダクション本番適用を急ぐより、PoCから始めて自社に合うパターンを見つけるほうが失敗しづらい段階と言えます。
導入コストの考え方
オントロジーはエンタープライズ製品のため、公開価格での直接比較が難しい領域です。
ここでは金額そのものよりも、「どこにコストが発生するか」という構造をおさえ、見積もりとROI評価の考え方を整理します。

初期コスト:モデル設計と外部支援の相場観
オントロジー導入の初期コストは、大きく以下の3要素に分かれます。
-
モデル設計費用
エンティティ・リレーション・制約の整理に要する工数 -
データバインディング費用
実データソースとの接続・品質検証 -
外部支援費用
ベンダー/SIerのコンサルティング・実装支援
このうちモデル設計は、1ドメインのパイロットで3〜6カ月・専任人員2〜4名規模が目安となるケースが多くみられます。
外部支援を活用する場合、業界・要件・対象範囲によってコスト幅は大きく変動するため、一律の相場を出しにくい点に注意が必要です。
運用コスト:プラットフォーム利用と内製化
運用フェーズでは、次の2種類のコストが継続的に発生します。
- プラットフォーム利用料
Palantir・Microsoft Fabric・LITRON等のサブスクリプション費用
- 内製化・メンテナンス人件費
オントロジーのメンテナンス、新規ドメイン追加、ガバナンス運用
プラットフォーム利用料は公開価格が出ていない製品が多いため、自社の利用規模・リージョン・契約形態に応じた個別見積もりが必須です。
2026年時点では、Microsoft Fabric Ontologyはプレビューながら課金自体は有効で、一部メーターが未適用の状態(キャパシティ消費の公式ドキュメント)です。
Palantir/NTTデータはいずれも個別商談ベースで、LITRON Builderは初期がパブリッククラウド中心(オンプレは今後対応予定)である点も、見積もり時に確認しておくべき前提となります。
ROI設計の軸:業務価値換算の考え方
オントロジー導入のROIは、プラットフォーム費用だけで判断しようとすると評価しづらくなります。AI総合研究所が支援先で使っている評価軸を紹介します。
- AIエージェント横展開の速度
2つ目・3つ目の業務にAIエージェントを展開する際の短縮日数
- 横断問い合わせの工数削減
複数システムをまたぐデータ集約・突合作業の自動化率
- 判断リードタイム
需要予測・与信判定・保全判断など業務決定のサイクル短縮
- データ品質の向上
定義揺れによる手戻り件数・手作業修正の削減
これらを1〜2年の範囲で試算し、プラットフォーム費用+内製工数を上回るかどうかで判断するのが筋のよい進め方です。
初年度だけで回収を狙うと、多くのケースで無理が出るため、2〜3年スパンのROI設計を前提に経営層と合意しておくと、プロジェクトが安定します。

オントロジーで整えた意味を、AIエージェントの業務実行までつなぐなら
オントロジーで整えた「意味の地図」は、それ自体が成果物ではなく、AIエージェントが業務を実行するための共通基盤です。意味層を構造化できても、そこから先の「実際にTeamsから呼び出され、基幹システムを更新し、承認フローを回す」部分で設計が止まると、現場に届くROIは生まれません。
AI総合研究所が提供するAI Agent Hubは、オントロジーで意味を整えたデータ基盤の上で、AIエージェントが業務を実際に動かすためのエンタープライズ向け実行基盤です。M
icrosoft Fabric OneLakeと接続し、Teamsからのチャット起点で承認フロー・基幹システム更新・実行ログ記録までを一気通貫で回す設計になっており、Azure Managed Applicationsとして自社テナント内に閉じて構築されるため、オントロジーに蓄えた機微な業務データを外部に出さずに運用できます。
AI総合研究所の専任チームが、オントロジー整備の次にくるAIエージェント業務実行設計を、データ基盤・権限設計・運用ガバナンスの観点から伴走支援します。
AI Agent Hubの全体像と導入プロセスは、無料の資料で体系的にご確認いただけます。
意味層の整備をAIエージェント運用までつなぐ

オントロジー整備の次の一手を設計する
オントロジーでビジネスの意味を固めたあと、それをTeams上の業務アクションに変換し、実行ログ・権限・セキュリティを一元管理するAIエージェント基盤の設計を、AI Agent HubのLPで体系的に確認できます。
まとめ|オントロジー導入をどう判断するか
本記事では、オントロジーを「企業データに意味を与える仕組み」として整理し、AIエージェント時代に再注目される理由・基本要素・関連概念との違い・活用パターン・主要プラットフォーム・導入ステップ・コストの考え方を解説しました。
2026年の潮流として押さえておくべきポイントは次の3つです。
- LLM単体では企業の「意味」を扱いきれないため、オントロジーという構造化レイヤーの必要性が高まっている
- Palantir・Microsoftが企業向けオントロジー基盤を展開し、NTTデータもLITRON/GRAG AIで意味層志向を強めており、選択肢と検討材料が広がっている
- いきなり全社ヘビーウェイトではなく、1ドメインのライトウェイト導入から段階拡張するのが現実解
導入判断で迷う読者の次の一歩として、AI総合研究所が現場で推奨しているのは以下の順序です。
まずは自社のどの業務を「複数システム横断・複数エージェント展開」の対象にしたいかを棚卸しし、そのうえでPoC対象ドメインを1〜2つ選定します。
続いて、既存データ基盤(Fabric・Snowflake・その他)に近いプラットフォームでライトウェイト構築を試し、3〜6カ月で成果指標を確認してから横展開の判断に進むのが、手堅いルートです。
コードやプロンプトの自動化に続くAI活用の本丸は、企業が自社の「世界モデル」を自前で整えることにあります。
オントロジーはそのための共通言語として、2026年以降のエンタープライズAI戦略の中心に据える価値が十分にある技術だと言えます。










