この記事のポイント
 AI-ready dataは「品質5要件」だけでは足りず、2025年秋以降はオントロジー・意味レイヤーの重要度が急速に高まり、本記事では実務上の第6要件として整理する
AI-ready dataは「品質5要件」だけでは足りず、2025年秋以降はオントロジー・意味レイヤーの重要度が急速に高まり、本記事では実務上の第6要件として整理する- Gartnerは2026年までにAI-ready dataに支えられていないAIプロジェクトの60%が放棄されると予測している
- Fabric IQ・Databricks Genie Ontology・Snowflake Cortex Senseが2025年11月〜2026年6月にかけて相次いで発表され、代表3社が意味レイヤーを強化する流れが見えてきている
- INPEXは廃棄物データ処理50時間→1時間、ドコモはSnowflake Streamlitでコスト54%削減など、国内でも成果が明確
- 整備で詰まるのはオントロジー・リアルタイム・ガバナンスの3点。SIerとしてはケース別に着手順を分けるのが実務的

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
AI-ready data(AIレディデータ)は、AIモデルやAIエージェントが正確かつ安全に活用できる状態まで整備されたデータを指す概念です。単なる「データ品質」の話ではなく、意味レイヤーやガバナンスまでを含む、活用可能な状態そのものが問われます。
2025年11月のMicrosoft Ignite以降、Fabric IQ・Databricks Genie Ontology・Snowflake Cortex Senseなど、主要データ基盤ベンダーが相次いで「オントロジー・意味レイヤー」を打ち出しました。従来の品質5要件だけでは足りない時代に入っています。
本記事では、AI-ready dataの定義、Gartner予測「AIプロジェクトの60%放棄」の背景、ビッグデータやDWHとの違い、品質要件とオントロジー、主要3プラットフォーム、料金、導入ステップ、国内企業事例、そして整備で詰まる論点までを、2026年7月時点の最新情報で体系的に解説します。
目次
AI-ready dataとは?AIエージェント時代のデータ活用可能状態
Gartner予測「AIプロジェクトの60%放棄」の背景にあるデータ問題
AI-ready dataの品質要件とオントロジー・意味レイヤー
AI-ready data基盤を支える主要3プラットフォーム
AI-ready data基盤の料金体系とコスト見積もりの考え方
AI-ready dataとは?AIエージェント時代のデータ活用可能状態
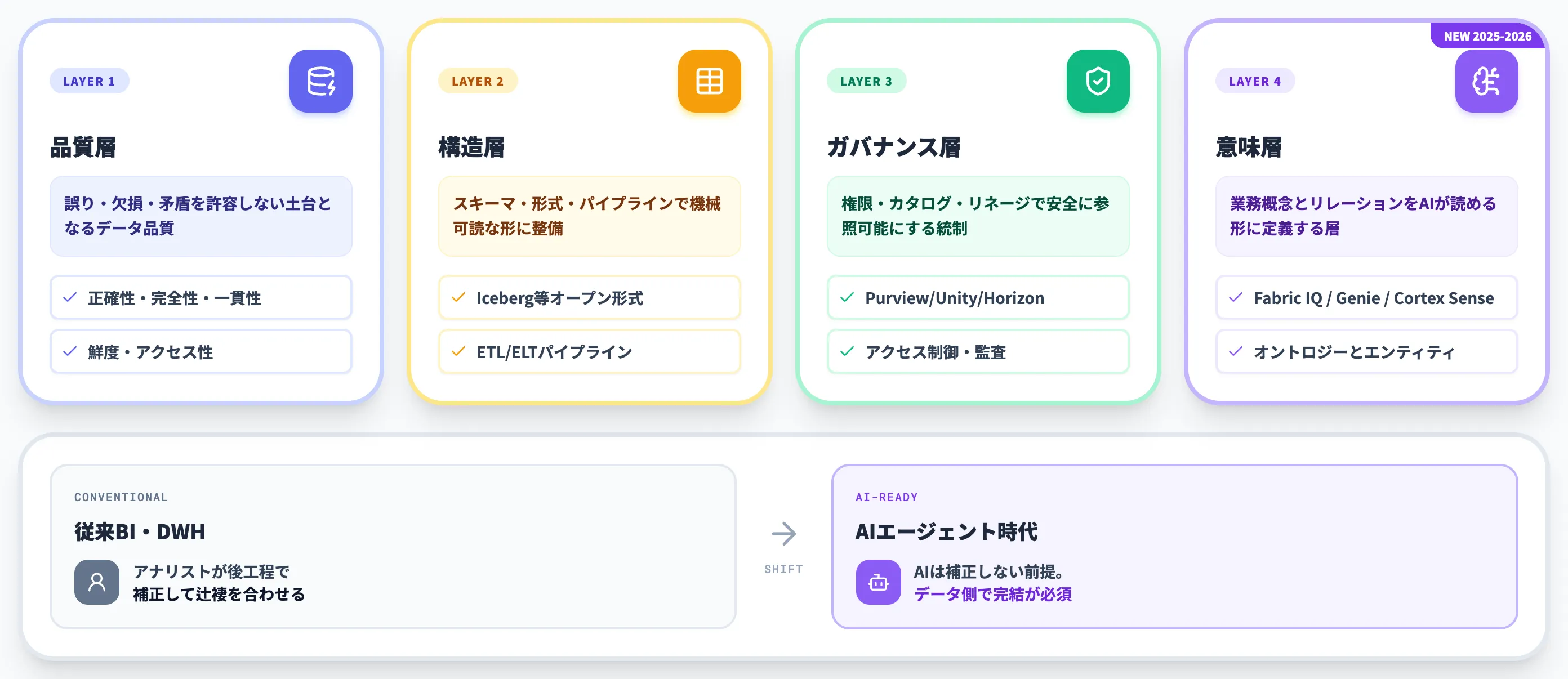
AI-ready data(AIレディデータ)とは、AIモデルやAIエージェントが正確かつ安全に活用できる状態まで整備されたデータを指す概念です。
単に大量のデータを保管しているだけでなく、品質・構造・ガバナンス・意味の4層が揃っている状態を指します。
2026年現在、AI-ready dataは従来の「データ品質」概念から、オントロジー・意味レイヤーまで含む総合概念へと拡張しつつあります。
2025年11月のFabric IQ発表、2026年6月のDatabricks Genie Ontology・Snowflake Cortex Sense発表と、代表的なデータ基盤ベンダーが相次いで意味レイヤーを打ち出したことで、実務の議論の中心に上がってきました。
AIエージェント時代のデータ層としての位置づけ
AI-ready dataがこれまでのデータ整備と一線を画すのは、AIが読み取り、判断し、行動する前提のデータ層として設計されている点です。
人間の分析者は多少のノイズを補正できましたが、AIエージェントは補正の余地なくデータをそのまま推論に使うため、データ層の整備水準が出力品質に直結します。
-
意味レイヤー(オントロジー)
「顧客とは何か」「注文と請求はどう繋がるか」を機械可読な形で持ち、AIが業務ドメインを理解できる基盤
-
データカタログと権限管理
どのデータがどの部門・役員限定かをメタデータで持ち、AIエージェントへの参照権限逸脱を防ぐ基盤
ここでのポイントは、AIエージェントに委ねる領域が広がるほど、データ層側で意味と権限を機械可読に持つ必要が増しているという点です。
品質要件・主要3プラットフォーム・料金は、後段のセクションで詳しく整理します。

Gartner予測「AIプロジェクトの60%放棄」の背景にあるデータ問題

Gartnerは2025年2月のリリースで、「2026年までに、AI-ready dataがサポートしないAIプロジェクトの60%が放棄される」と予測しています。
また、同じ調査で、63%の組織が「AIに適したデータ管理実践を持っていない、または持っているか不確か」と回答しました。
このセクションでは、なぜAI-ready dataの不備がAIプロジェクトの成否を分ける決定要因になっているのか、実務で起きる3つのリスクとして整理します。
ハルシネーションが構造的に増える

AIモデルは、参照データが不完全・矛盾・古い状態だと、その隙間を「もっともらしい創作」で埋めます。RAG(検索拡張生成)を組んでいても、参照する社内データ側の品質が低いと、回答の一部が実在しない条項や誤った数値になります。
これは「AIモデルの精度問題」ではなく、参照データ側の品質問題です。モデルをGPT-5.5やClaude Opus 4.7に切り替えても、根本原因が変わらない限りハルシネーションは減りません。
機密情報が意図せず出力される
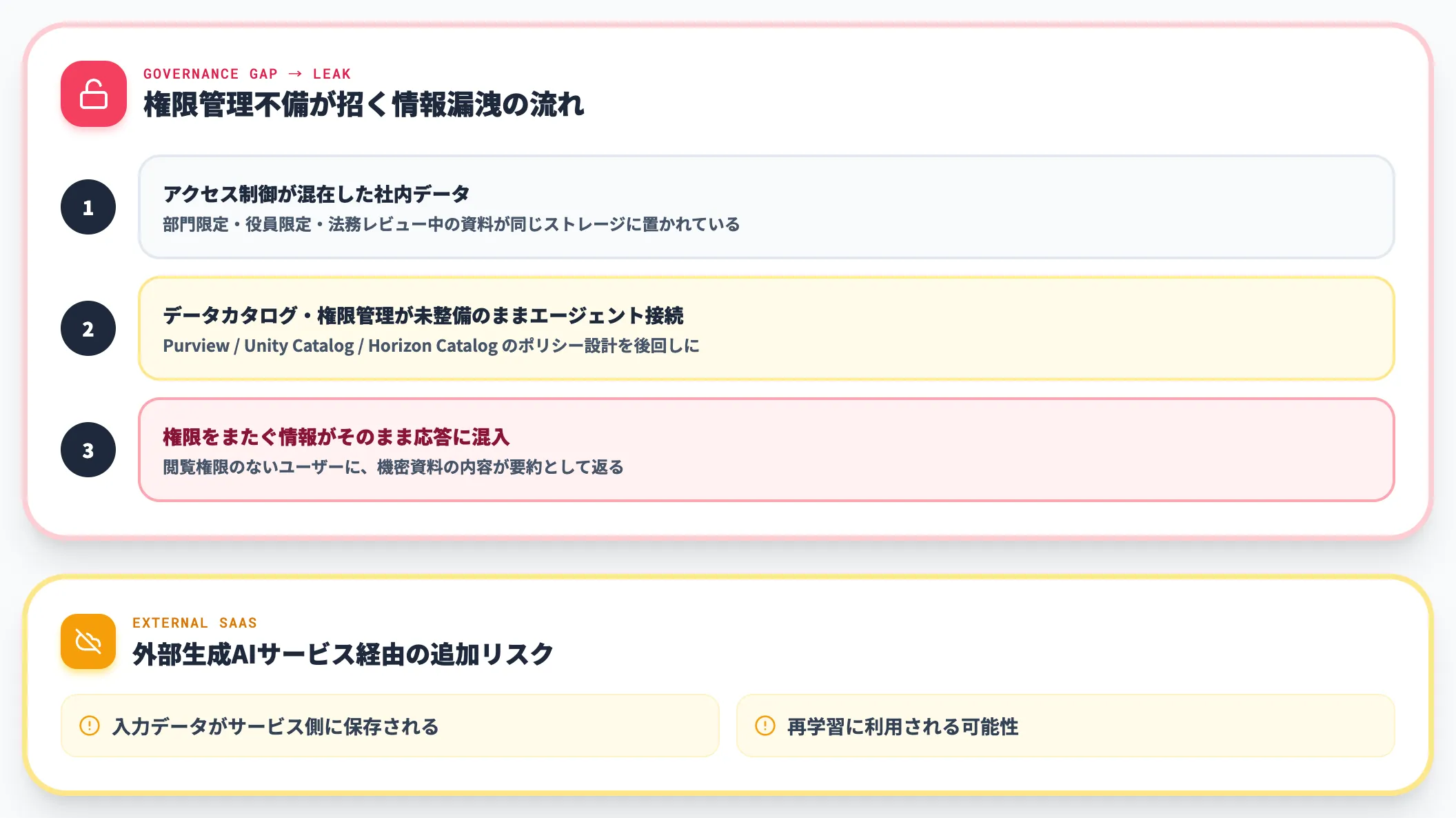
社内データの中には、部門限定・役員限定・法務レビュー中など、アクセス制御が本来かかるべき情報が混在しています。
データカタログと権限管理が整備されていない状態でAIエージェントに社内データを参照させると、権限をまたいだ情報がそのまま応答に出てくるインシデントが起きます。
外部の生成AIサービス経由でこれが起きると、入力データがサービス側に保存・再学習される可能性まで含めて事故になります。
競合とのAI活用速度差が業績差になる
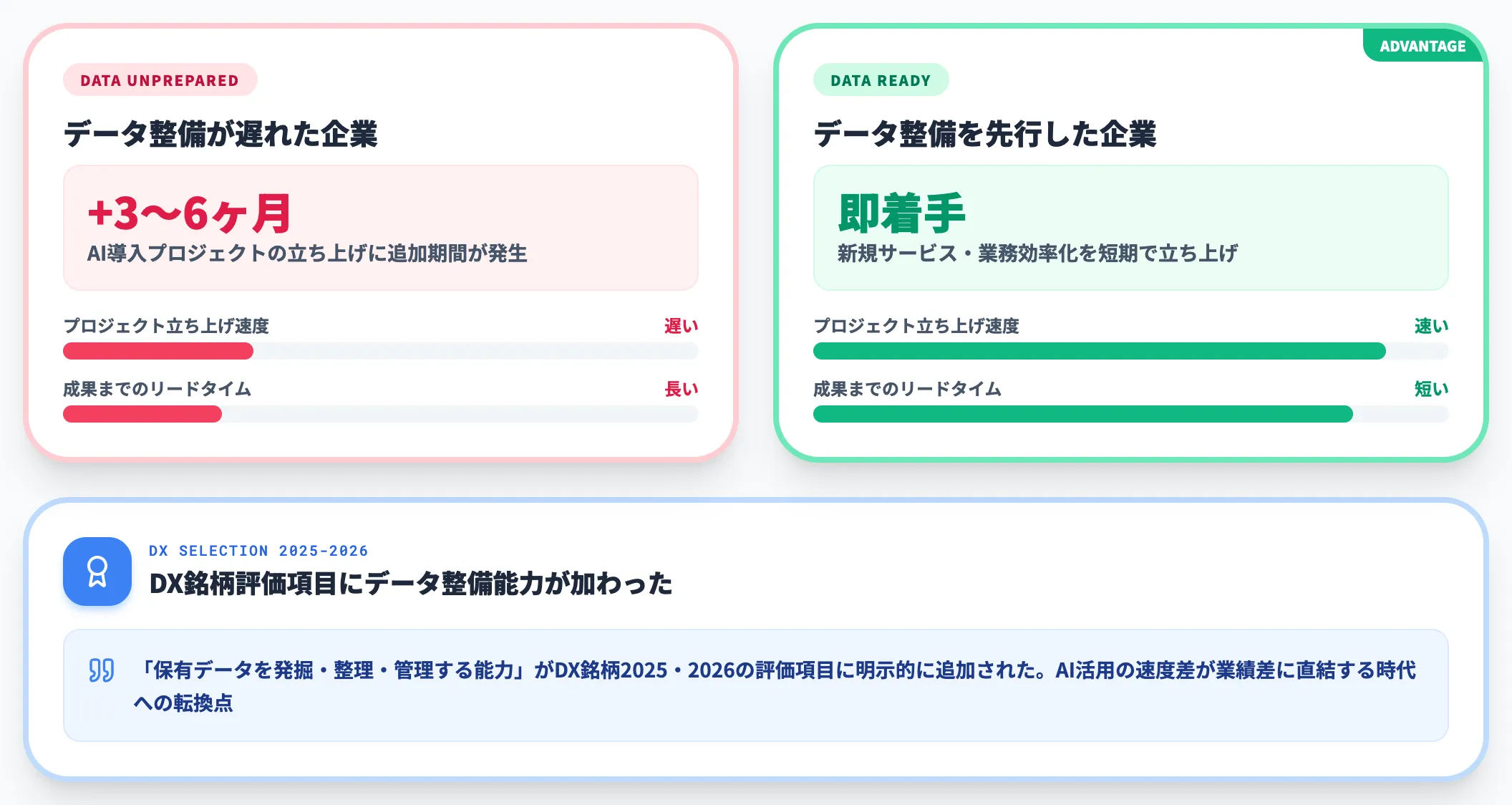
DX銘柄2025・2026の評価項目には「保有データを発掘・整理・管理する能力」が明示的に加わりました。データ整備が遅れた企業は、AI導入プロジェクトの立ち上げに毎回数か月から半年の追加期間が発生します。
AI活用の速度差が、そのまま新規サービス投入・業務効率化・顧客体験改善の速度差に変わる時期に入っています。「AIツールを導入したのに競合に追いつけない」の多くは、モデル選定ではなくデータ整備の遅れが原因です。
AI-ready dataとビッグデータ・DWHの違い
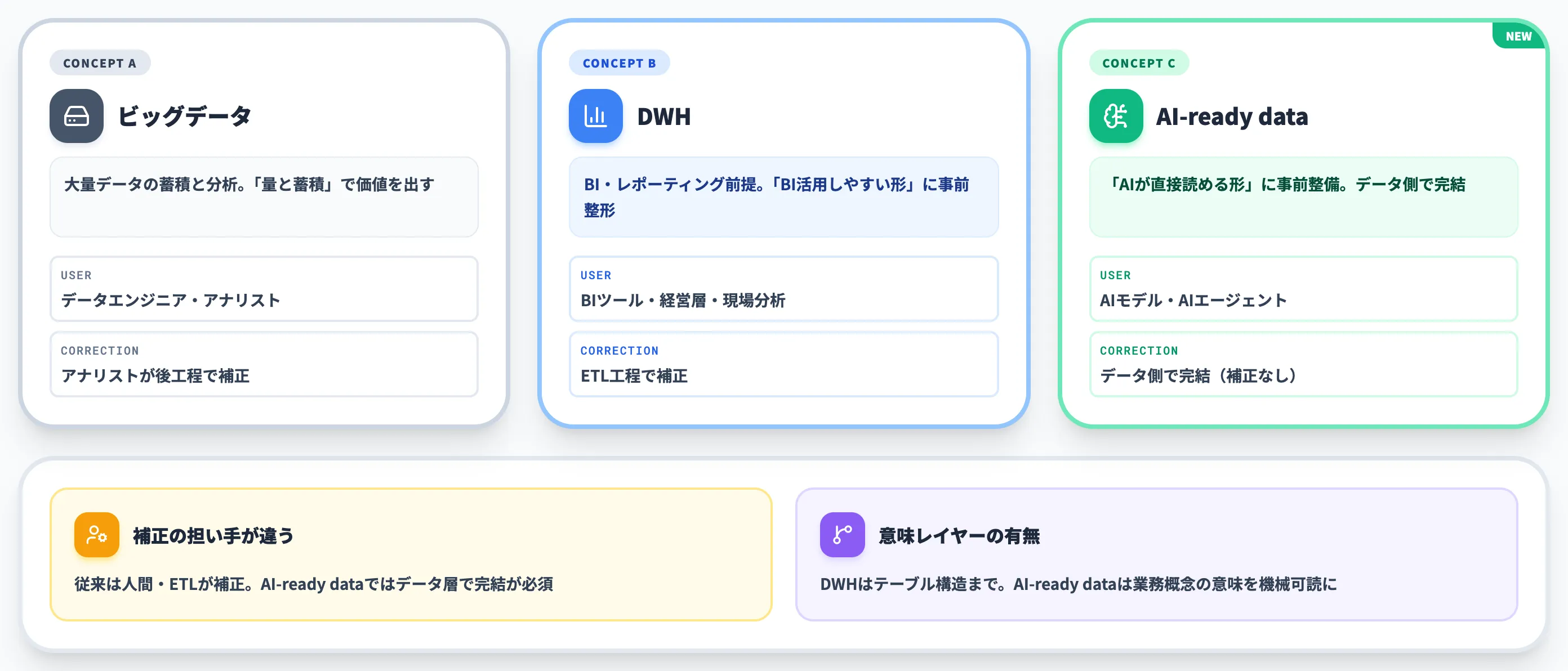
AI-ready dataは、既存のデータ管理概念であるビッグデータ・データウェアハウス(DWH)と混同されやすい概念です。ただし目的・重視ポイント・前提が根本的に違います。
以下の表で、3つの概念を整理しました。
| 項目 | ビッグデータ | DWH | AI-ready data |
|---|---|---|---|
| 主な目的 | 大量データの蓄積と分析 | BI・レポーティングのための構造化データ管理 | AIモデル・エージェントが活用できる状態への整備 |
| 重視ポイント | データ量・多様性・処理速度 | スキーマ設計・集計性能・履歴保持 | 品質・構造化・ガバナンス・意味レイヤー・リアルタイム性 |
| データ利用者 | データエンジニア・アナリスト | BIツール・経営層・現場分析担当 | AIモデル・AIエージェント・業務システム |
| 補正の担い手 | アナリストが補正 | ETL工程で補正 | データ側で完結(AIは補正しない前提) |
| 前提 | データの「量と蓄積」で価値を出す | 「BI活用しやすい形」に事前整形 | 「AIが直接読める形」に事前整備 |
この比較で決定的に違うのは「補正の担い手」です。ビッグデータやDWHでは、多少データが荒くても後工程の人間やETL処理で辻褄を合わせられました。AI-ready dataではAIが補正しないため、データ層で完結している必要があります。
もうひとつのポイントは「意味レイヤーの有無」です。DWHもスキーマ設計を持ちますが、それは「テーブル構造の設計」であって「業務概念の意味を機械が読める形」ではありません。
AI-ready dataでは、後述のオントロジーによって「顧客とは何か」「注文と請求はどう繋がるか」といった業務概念の意味を機械可読な形で持つ必要があります。
AI-ready dataの品質要件とオントロジー・意味レイヤー
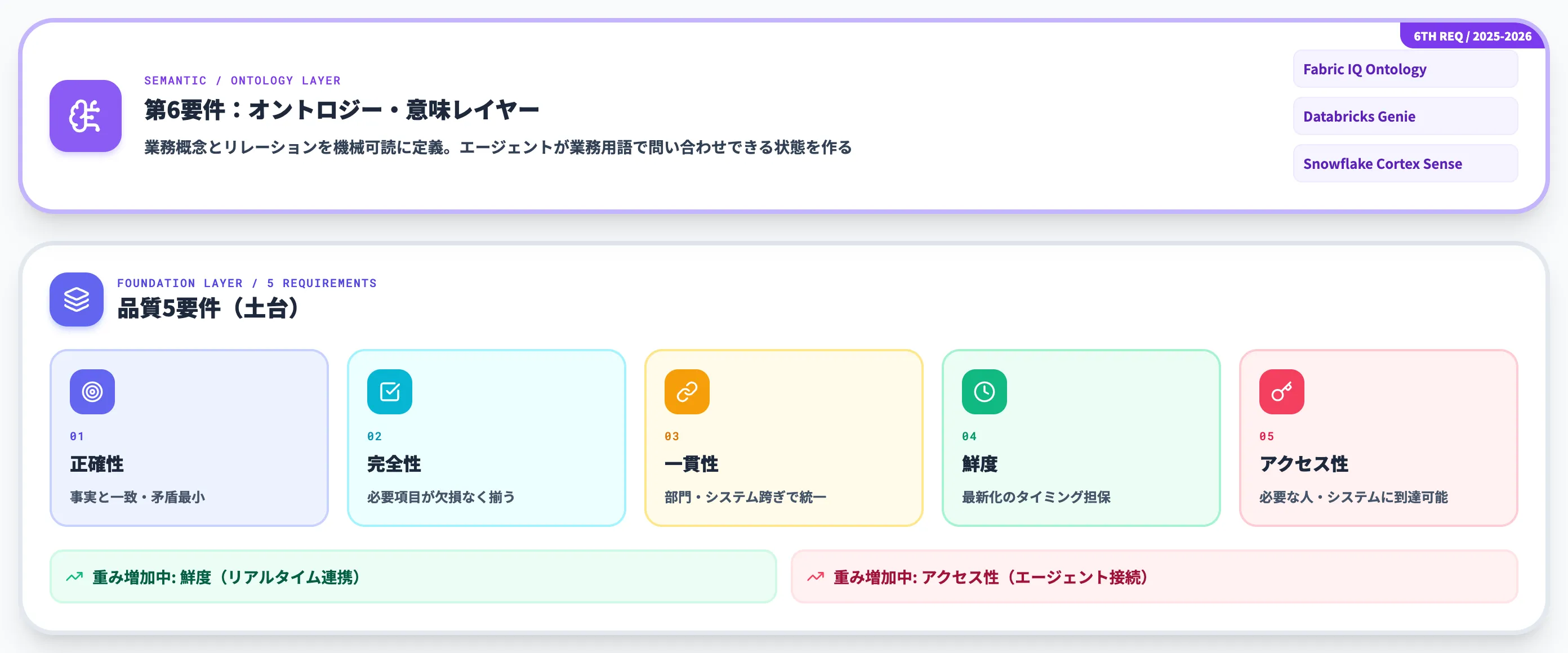
AI-ready dataの要件は、従来から言われてきた「品質5要件」に加えて、2025年秋以降は「オントロジー・意味レイヤー」の重要度が急速に高まっています。本記事ではこれを実務上の第6要件として整理します。
本セクションでは、まず基本の5要件を整理し、続けて意味レイヤーの位置づけを解説します。
AI-ready dataの品質5要件

以下の表で、AI-ready dataの品質5要件を整理しました。これらは業界で広く定着している一般的なデータ品質観点で、AI活用の前提として押さえておく必要があります。
なおGartner自身はAI-ready dataの整備手順として「AIユースケースへの整合/AI向けガバナンス/メタデータ高度化/パイプライン準備/データの保証・強化」の5ステップを示しており、品質観点はその土台になります。
| 要件 | 内容 | 満たされていないと起きること |
|---|---|---|
| 正確性(Accuracy) | データが事実と一致し、誤りや矛盾が最小限に管理されている | AI出力がハルシネーションを起こす |
| 完全性(Completeness) | 分析・推論に必要な項目が欠損なく揃っている | 判断根拠が抜けた回答が生成される |
| 一貫性(Consistency) | 部門・システム・時系列を跨いで表記や定義が揃っている | 同じ質問に対して異なる回答が出る |
| 鮮度(Timeliness) | 業務判断に間に合うタイミングで最新化されている | 古いデータに基づく誤った意思決定が発生する |
| アクセス性(Accessibility) | 必要な人・システムが必要な権限で取り出せる | AIエージェントがデータに到達できず不完全な回答になる |
この5要件の中で近年重みが増しているのが鮮度とアクセス性です。
AIエージェントは対話中にデータを参照するため、日次バッチ更新では追いつきません。ストリーミング取り込みやオープンテーブル形式(Apache Iceberg等)による準リアルタイム連携が実務要件になりつつあります。
第6要件:オントロジーと意味レイヤー
2025年11月のFabric IQ発表を皮切りに、Databricks Genie Ontology(2026年6月)、Snowflake Cortex Sense(2026年6月)と、代表的な3ベンダーが2025年11月〜2026年6月にかけて相次いで「意味レイヤー」を打ち出しました。
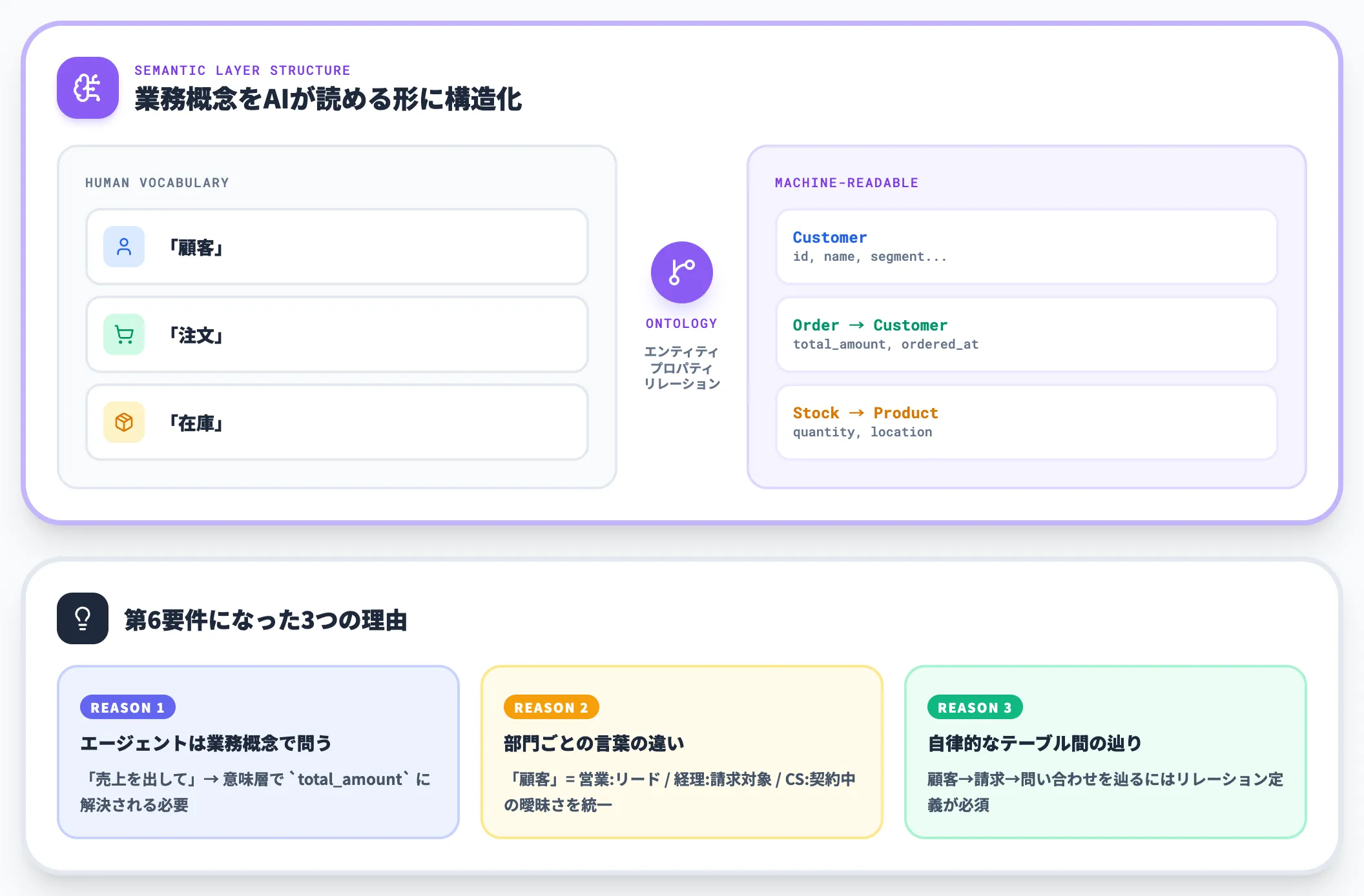
意味レイヤーとは、「顧客」「注文」「在庫」といった業務概念を、AIが理解できる形で構造化した層のことです。単なるテーブル定義ではなく、オントロジーという体系でエンティティ・プロパティ・リレーションを機械可読な形で表現します。
Fabric IQで統合されたセマンティックモデル画面(出典:Microsoft Fabric Blog)
なぜこの層が第6要件になったのか、理由は3つあります。
-
AIエージェントは「テーブル名」ではなく「業務概念」で問う
「注文の売上を出して」と言われたAIエージェントが 「orders.total_amount」 を正しく指すには、「注文=orders」「売上=total_amount」の対応が意味層で解決されている必要がある
-
同じ言葉が部門ごとに違う意味を持つ
「顧客」が営業部門ではリード、経理部門では請求対象、CSでは契約中のみを指す。この曖昧さを意味レイヤーで統一しないとエージェントは部門横断の質問に正しく答えられない
-
エージェントが自律的にデータ間を辿るとき、リレーション定義が必須
「顧客Aの請求書と直近の問い合わせを繋いで」と言われたエージェントが、顧客テーブル→請求テーブル→問い合わせテーブルを辿るには、テーブル間の意味的なリレーションが定義されている必要がある
従来はデータエンジニアがSQL・ETLで人力接続してきた領域を、AIエージェントが自律的に辿るには、意味層の整備が前提になります。
これが「AI-ready dataの5要件では足りない」と業界が判断した理由です。
【関連記事】
セマンティックレイヤーとは?意味層の仕組みとツール比較を解説
AI-ready data基盤を支える主要3プラットフォーム
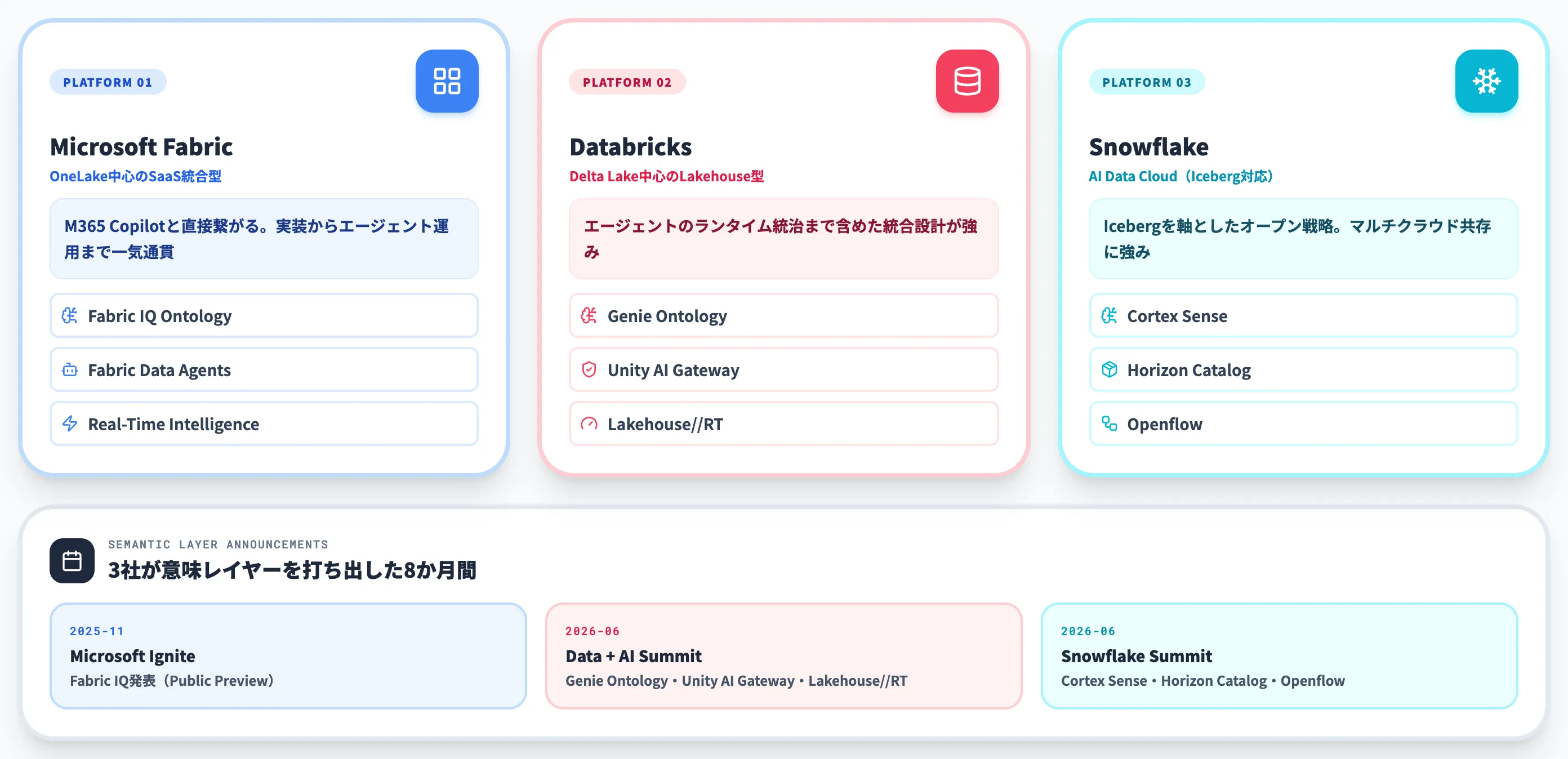
本記事ではAI-ready dataの実装プラットフォームとして、Microsoft Fabric・Databricks・Snowflakeの3社を代表例として扱います。
3社ともに2025年秋〜2026年6月にかけて「意味レイヤー・オントロジー・AIエージェント統治」を打ち出しており、選択の軸が「性能・料金」だけでなく「AI・エージェント対応の設計思想」も加わってきています。
本セクションでは、3社それぞれの2026年時点の位置づけと、選定の考え方を整理します。
Microsoft Fabric

Microsoft Fabricは、OneLakeを中心に、Data Factory・Lakehouse・Data Warehouse・Real-Time Intelligence・Data Science・Power BIを統合したSaaS型データ基盤です。
2025年11月のIgnite 2025で発表されたFabric IQにより、Fabricは「データプラットフォーム」から「インテリジェンスプラットフォーム」へと位置づけを変えました。
中核となるFabric IQ Ontology(Public Preview)は、顧客・注文・製品といった業務概念とその関係性を機械可読な形で管理し、AIエージェントの判断範囲を制御する意味層として機能します。
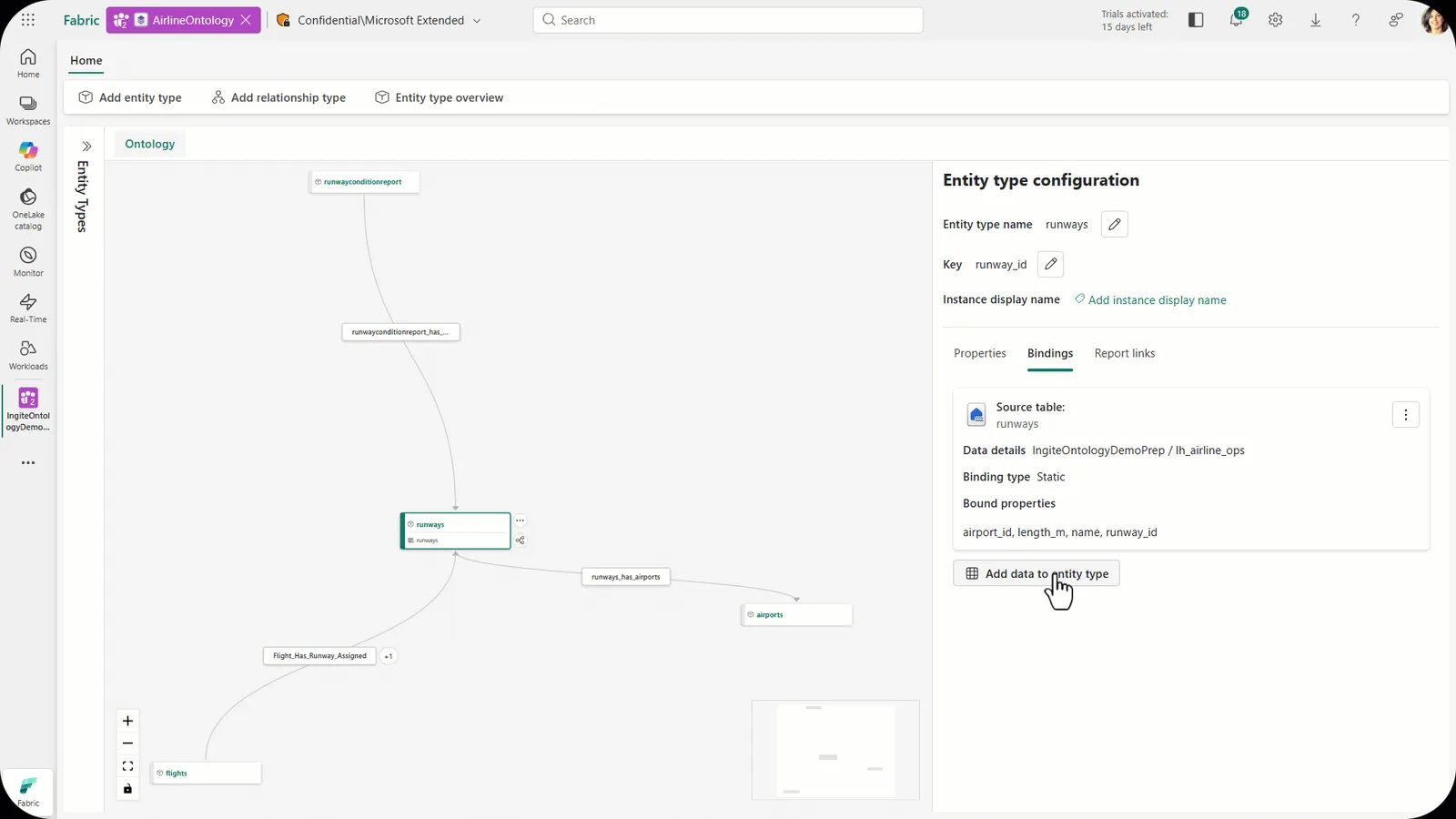
Fabric IQ Ontology の Entity type 編集画面(出典:Microsoft Fabric Blog)
Microsoft Fabricの強みは、M365 Copilotと直接繋がる点です。
Fabric Data AgentsをMicrosoft 365 CopilotのAgent Storeに公開すれば、Microsoft 365 CopilotやTeamsからOneLakeのデータに自然言語で問い合わせできます(同一テナント・ライセンス等の前提条件あり)。
既にMicrosoft 365環境を採用している企業にとっては、AI-ready dataの実装からエージェント運用までを一気通貫で組みやすい選択肢です。
Databricks

Databricksは、Delta Lake・Unity Catalogを核としたLakehouse型のデータ基盤で、Apache Sparkベースのデータエンジニアリングと機械学習に強みがあります。
2026年6月のData + AI Summit 2026で、Databricksは大きく3つを打ち出しました。
-
Genie Ontology(Public Preview)
ビジネスコンテキストを「living context layer」として自動抽出・グラフ化する意味層(Databricks公式docs)。Unity Catalog上に構築され、エージェントが業務用語で問い合わせできる状態を作る
-
Unity AI Gateway
モデル・MCPサービス・エージェント・スキル間のランタイム相互作用を統治するゲートウェイ。エージェントの権限・コスト・監査を一元管理する
-
Lakehouse//RT(Beta)
Delta LakeとApache Iceberg両対応のミリ秒級リアルタイム分析エンジン(Databricks公式press release)。AI-ready dataの「鮮度」要件に応える

Data + AI Summit 2026 で拡張された Unity Catalog(出典:Databricks Blog)
Databricksの強みは、エージェントのランタイム統治まで含めた統合設計です。
データ層だけでなく、AIエージェントが業務システムやツールにアクセスするときの権限・コスト・監査を、データガバナンスと同じUnity Catalog上で扱えます。エージェントを本格運用する段階で強く効いてきます。
Snowflake

Snowflakeは、クラウド型データウェアハウスから出発し、現在は「AI Data Cloud」として、データ共有・データアプリ・AI機能までを統合したプラットフォームに進化しています。
2026年6月のSummit 2026で発表された中核機能は次のとおりです。
Cortex Sense(Private Preview予定/2026年7月中旬予定)
静的なセマンティックレイヤーではなく、問い合わせ時にデータ・ビジネス定義・運用知識を動的に組み立てるコンテキスト層として、Snowflake公式ブログで発表。
現時点ではCoWork press releaseと併せて発表段階で、Private Previewの提供が予定されている。
Horizon Catalog(Apache Polaris基盤)
Apache Iceberg v3のGA対応と、外部エンジンからのIcebergデータへの双方向読み書きに対応(Snowflake公式press release)。
マルチプラットフォーム・マルチクラウド前提の統合カタログ。
Openflow
AWS・Azure・GCPで一般提供が始まったバッチ/インクリメンタルロードのデータ移動基盤(Snowflake公式blog)
Snowflakeの強みは、Icebergを軸としたオープン戦略です。データを1社ロックインせず、複数プラットフォームを跨いで扱いたい企業や、既存基盤との共存を重視する企業に向いています。
3プラットフォームの選び方
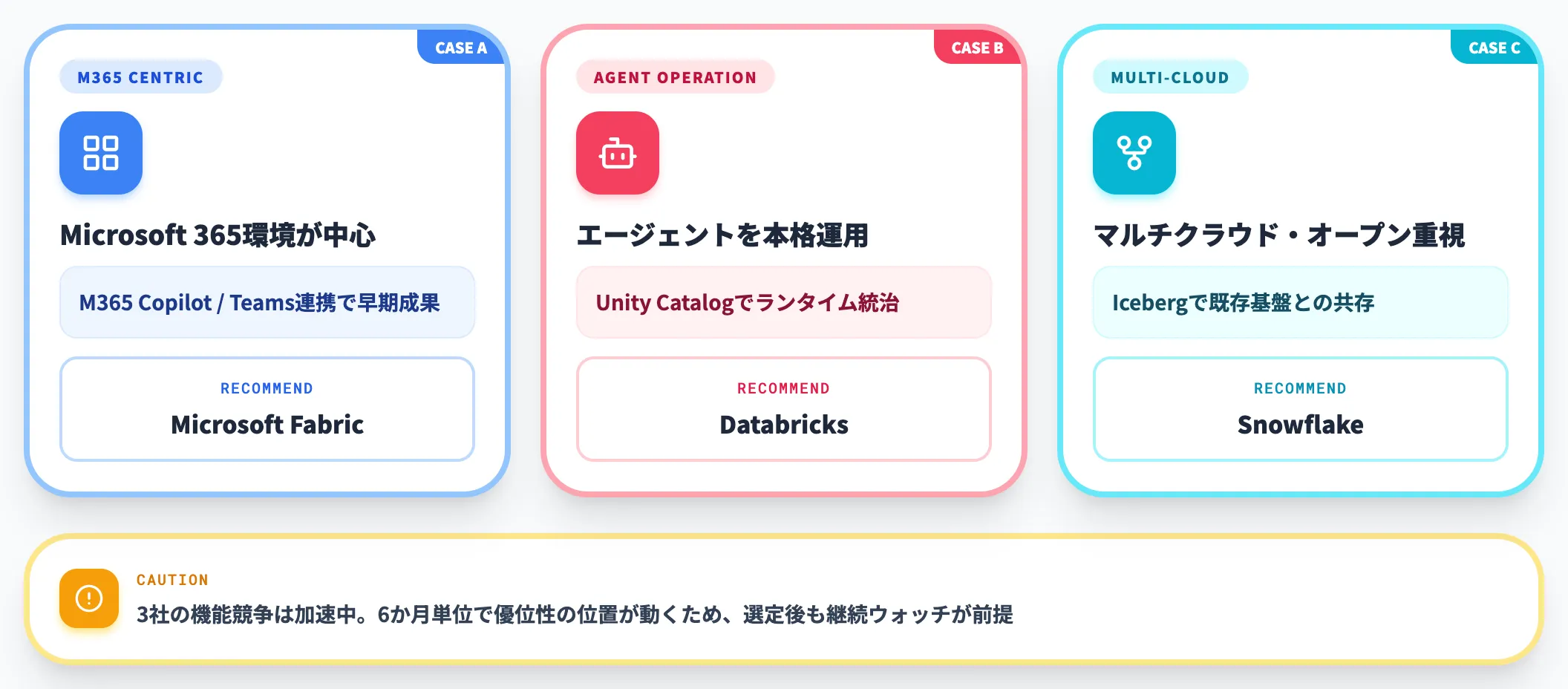
以下の表で、3プラットフォームの選定軸を整理しました。
| 選定軸 | Microsoft Fabric | Databricks | Snowflake |
|---|---|---|---|
| 主なアーキテクチャ | OneLake中心のSaaS統合型 | Delta Lake中心のLakehouse | クラウドDWH+Iceberg対応 |
| 意味レイヤー | Fabric IQ Ontology(Public Preview) | Genie Ontology(Public Preview) | Cortex Sense(発表済み・Private Preview予定) |
| エージェント統治 | Fabric Data Agents+M365 Copilot連携 | Unity AI Gateway | Cortex Agents |
| リアルタイム性 | Real-Time Intelligence | Lakehouse//RT(Beta) | Snowpipe Streaming+Dynamic Tables |
| 強み | M365環境との統合・BIとの一体化 | エージェント統治まで含めた統合 | Icebergオープン戦略・マルチクラウド |
| 相性の良い企業 | Microsoft 365採用済み・BI利用が広い | データエンジニアリング組織が強い・エージェント本格運用 | マルチクラウド・オープン戦略重視 |
実務での使い分けとしては、Microsoft 365環境が中心なら Fabric、エージェントを本格運用しUnity Catalogで統治したいなら Databricks、マルチクラウドで既存基盤との共存を重視するなら Snowflake という切り分けが現時点では自然です。
ただし3社の機能競争は加速しており、6か月単位で優位性の位置は動きます。

AI-ready data基盤の料金体系とコスト見積もりの考え方

AI-ready data基盤の料金は、3プラットフォームで課金モデル自体が大きく異なります。
「使った分だけ」で単純化できず、Fabricは容量ベース、DatabricksはDBU+クラウド基盤費、Snowflakeはクレジット消費と、単価計算のルールが全く違います。
本セクションでは、3社の課金構造と、コスト見積もりの考え方を整理します。単価は円安・為替・キャンペーンで頻繁に変動するため、実務では公式pricingページと個別見積もりで確認するのが標準です。
3社の課金モデル
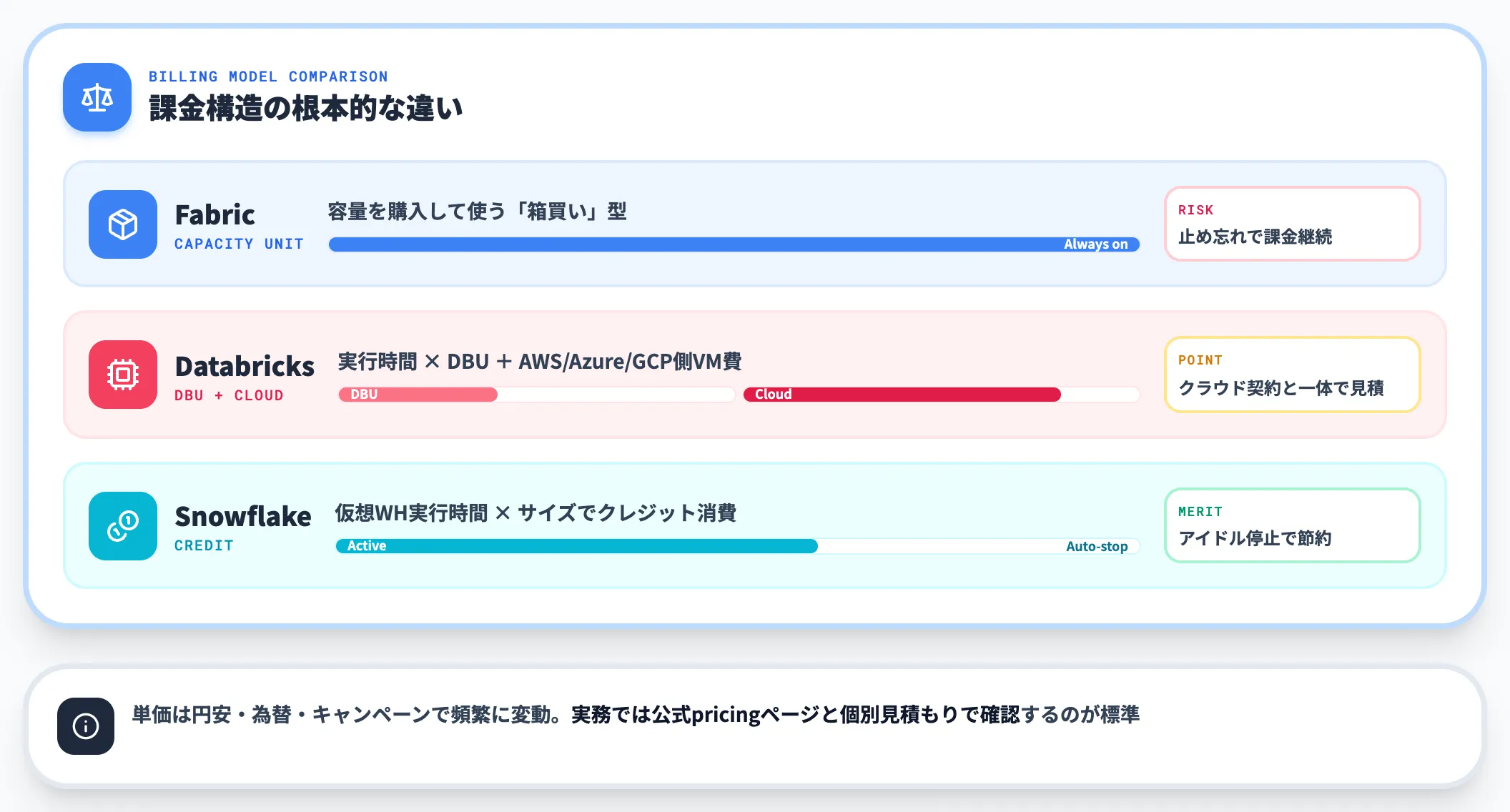
| プラットフォーム | 課金モデル | 意味 |
|---|---|---|
| Microsoft Fabric | CU(Capacity Unit)容量課金 | F2・F4・F64などのSKUで容量を購入。容量がアクティブな間は課金が続くため、停止するには手動でpause/resumeが必要。予約割引あり |
| Databricks | DBU(Databricks Unit)+クラウド基盤費 | クラスター実行時間あたりのDBU消費に加え、AWS/Azure/GCP側のVM・ストレージ・ネットワーク費が別途発生する |
| Snowflake | クレジット消費 | 仮想ウェアハウスの実行時間×ウェアハウスサイズでクレジットを消費。アイドル時は自動停止(設定次第)でクレジット消費が止まる |
この違いは実務のコスト構造に直結します。
Fabricは容量を止め忘れると使っていなくても課金が続くため運用管理が重要になり、Databricksはクラウド基盤費が支配的になるケースが多くAWS/Azure/GCPの契約と一体で見積もる必要があり、Snowflakeはウェアハウスサイズ設計とアイドル自動停止の設定が費用を左右します。
コスト見積もりの3つの観点

AI-ready data基盤のコスト見積もりでは、以下3点を分けて考えるのが実務的です。
-
保管コスト(ストレージ)
OneLake・Databricks側の外部ストレージ・Snowflake内部ストレージの月額単価。データ量に応じて課金され、外部Icebergで管理する場合はクラウド側のS3等の単価が支配的になる
-
計算コスト(コンピュート)
Fabricは容量課金、Databricks/Snowflakeは実行時間ベースの従量課金と、単価計算の枠組みが違う。Fabricの手動pause/resume、Databricksの自動終了設定、Snowflakeのアイドル自動停止など、無駄課金を防ぐ運用設計がそのままコストに反映される
-
AI/エージェントコスト(追加)
Fabric IQ・Copilot・Cortex AI・Mosaic AIなどのAI機能利用時に、追加のクレジット消費または別課金が発生する。ここは3社とも急速に単価が変動しているため、直近の公式pricingで確認が必須
実務での金額感は、扱うデータ量・ワークロード頻度・AI/エージェントの使用度で大きく振れるため、各社の個別見積もり(Microsoftアカウント担当者・Databricks/Snowflake営業)を取ってから検討するのが標準です。
初期のPoC段階では最小SKU(Fabric F2、Databricks Personal Compute、Snowflake X-Small)から検証を始め、実運用に耐えるスケールに段階的に上げていく流れが定石です。
AI-ready data整備の3フェーズ導入ステップ
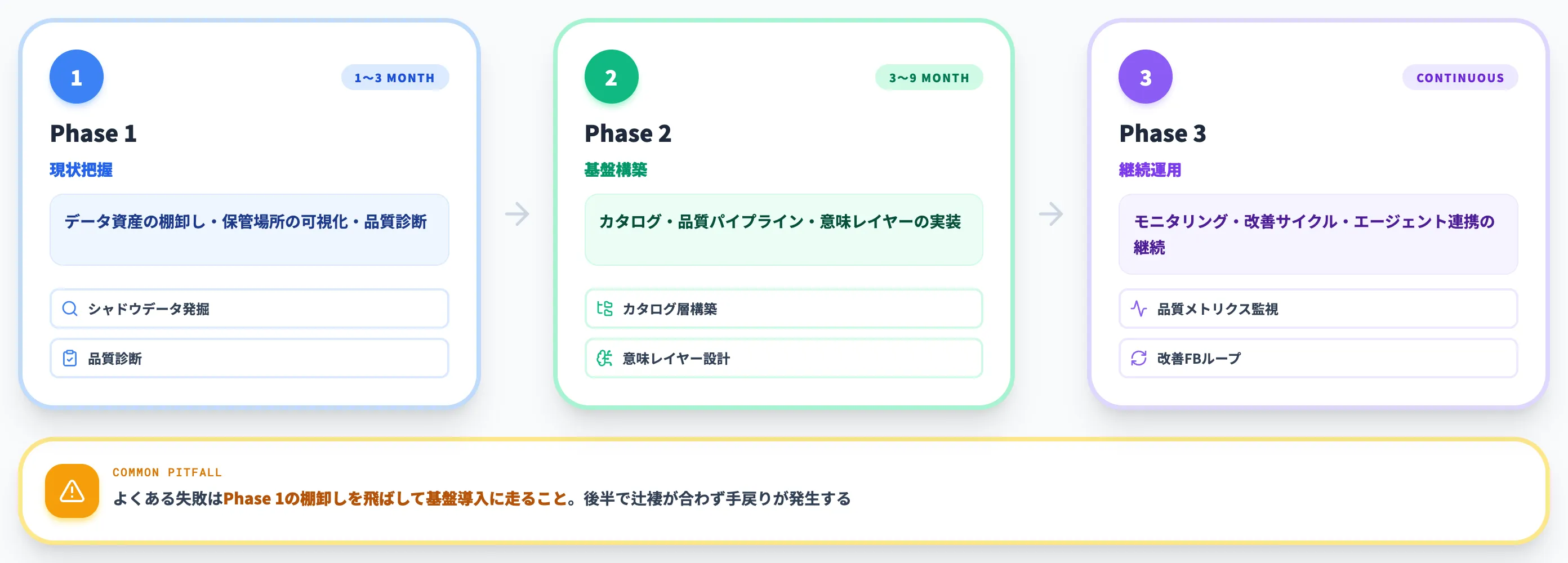
AI-ready dataの整備は、いきなり完成形を目指さず、3フェーズに分けて段階的に進めるのが実務的です。
多くの企業がPhase 1の棚卸しを飛ばしていきなり基盤導入に走り、後半で辻褄が合わずに手戻りが発生します。
以下の表で、3フェーズの構成を整理しました。
| フェーズ | 目的 | 主な作業 | 期間目安 |
|---|---|---|---|
| Phase 1 | 現状把握 | データ資産の棚卸し・保管場所の可視化・品質診断 | 1〜3か月 |
| Phase 2 | 基盤構築 | カタログ整備・品質パイプライン・意味レイヤー構築 | 3〜9か月 |
| Phase 3 | 継続運用 | モニタリング・改善サイクル・エージェント連携 | 継続 |
GartnerのAI-ready data roadmap(AIユースケース整合/AI向けガバナンス/メタデータ/パイプライン/保証・強化の5ステップ)とも方向性は近く、実務向けに3フェーズへ整理すると次のようになります。個別に見ていきます。
Phase 1:データ棚卸しと現状診断
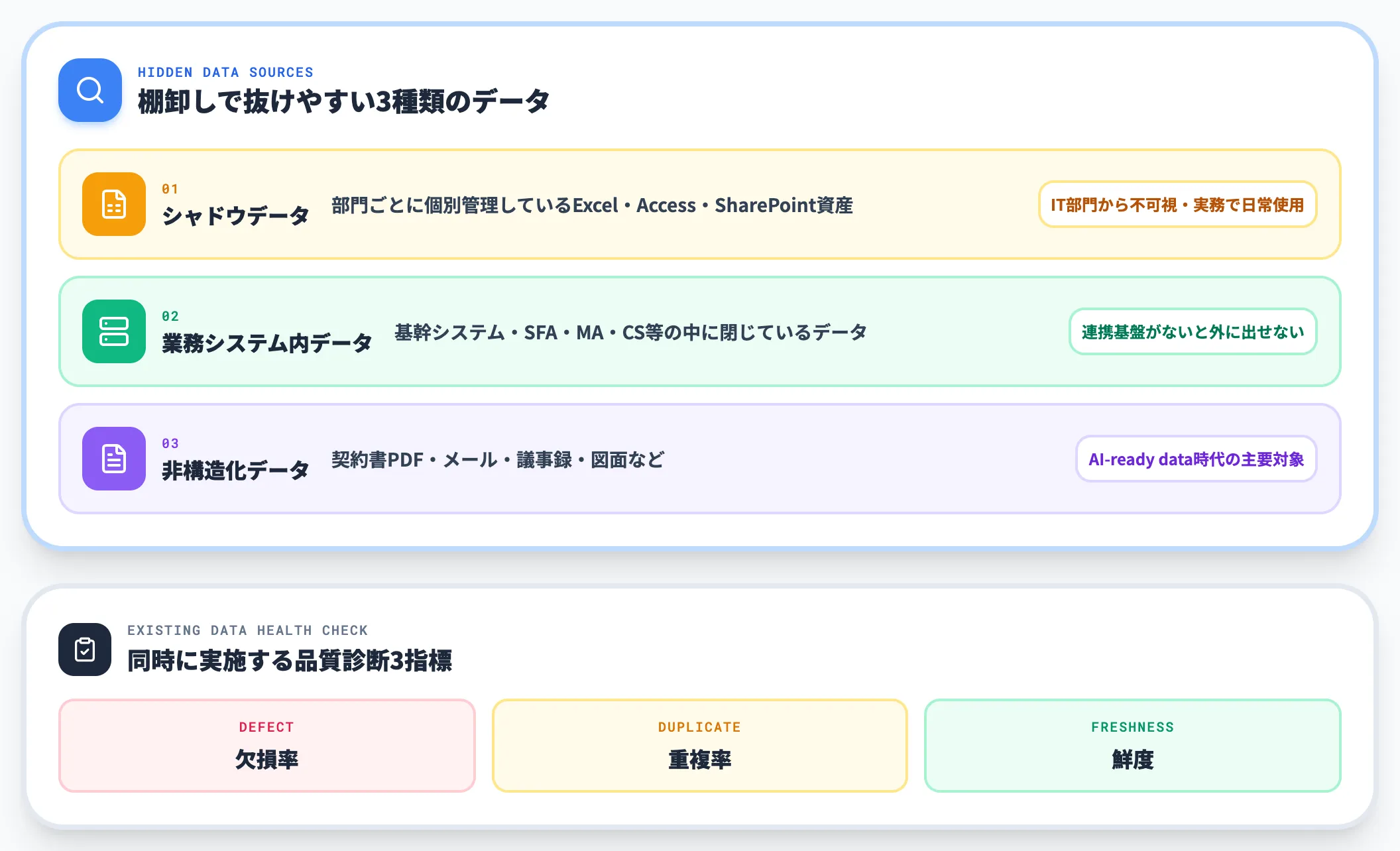
最初のフェーズは「自社のデータがどこに、どんな形で、どれくらいの量あるのか」の棚卸しです。抜けやすいのは以下の3種類です。
-
シャドウデータ
部門ごとに個別管理しているExcel・Access・SharePointの資産。IT部門から見えていないが、実務で日常的に使われている
-
業務システム内データ
基幹システム・SFA・MA・CS等の中に閉じているデータ。連携基盤がないと外に出せない
-
非構造化データ
契約書PDF・メール・議事録・図面など。従来のDWHでは扱えなかったが、AI-ready data時代には主要な対象
棚卸しと同時に、既存データの品質診断(欠損率・重複率・鮮度)も実施します。ここで「AIに使えるデータ」と「AI活用前に整備が必要なデータ」を切り分けます。
Phase 2:カタログ・品質・意味レイヤー
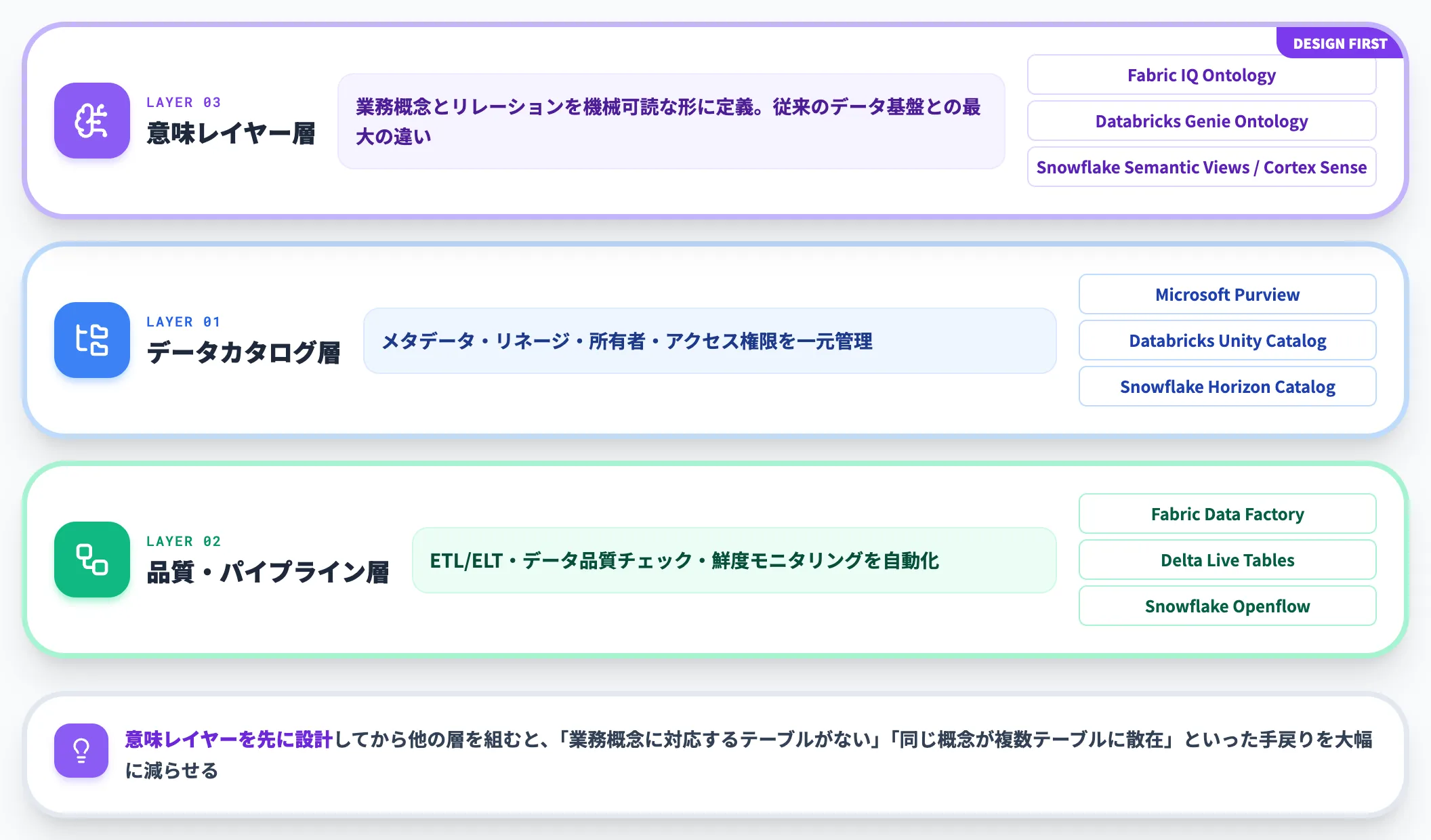
Phase 1の結果を踏まえ、AI-ready dataとして提供する層を実装します。実装対象は3層に分かれます。
-
データカタログ層
Microsoft Purview・Databricks Unity Catalog・Snowflake Horizon Catalogのいずれかを軸に、データ資産のメタデータ・リネージ・所有者・アクセス権限を一元管理する
-
品質・パイプライン層
ETL/ELT・データ品質チェック・鮮度モニタリングを自動化する。Fabric Data Factory・Databricks Delta Live Tables・Snowflake Openflowなど、基盤ネイティブのパイプライン機能が使える
-
意味レイヤー層
Fabric IQ Ontology・Databricks Genie Ontologyや、Snowflakeの現行機能(Semantic Views/Cortex Agents)などで、業務概念とリレーションを機械可読な形に定義する。Snowflake Cortex Senseは今後の意味レイヤー候補として選択肢に加わる。ここが従来のデータ基盤構築との最大の違い
意味レイヤー層を先に設計してから他の層を組むと、後工程で「業務概念に対応するテーブルがない」「同じ概念が複数テーブルに散在している」という手戻りを大幅に減らせます。
Phase 3:継続的モニタリングと改善サイクル

基盤構築が終わっても、AI-ready dataの整備は「継続的なメンテナンス」が本質です。以下3点をルーティン化する必要があります。
-
データ品質モニタリング
日次・週次で品質メトリクス(欠損率・重複率・鮮度)を可視化し、劣化を早期発見する
-
意味レイヤーの追随更新
新規テーブル追加や業務プロセス変更に合わせて、オントロジーを追随更新する。人手だけでは追いつかないため、Fabric IQやGenie Ontologyの自動抽出機能を組み合わせる
-
エージェント運用のフィードバック
AIエージェントの応答品質・利用ログを分析し、データ側の不備を特定して修正する。エージェント運用そのものがAI-ready dataの品質診断ツールになる
Phase 3はプロジェクトの終わりではなく、運用フェーズの始まりです。AI-ready dataの整備は「一度作って終わり」ではなく、ビジネス変化に合わせて継続進化する対象だと最初から捉えておくと、投資判断が正しく組み立てられます。
国内企業のAI-ready data整備事例
AI-ready data整備の効果は、国内企業の公表事例でも定量的に確認できます。
本セクションでは、Microsoft FabricとSnowflakeを使った3事例を、公式ソースの数値で整理します。
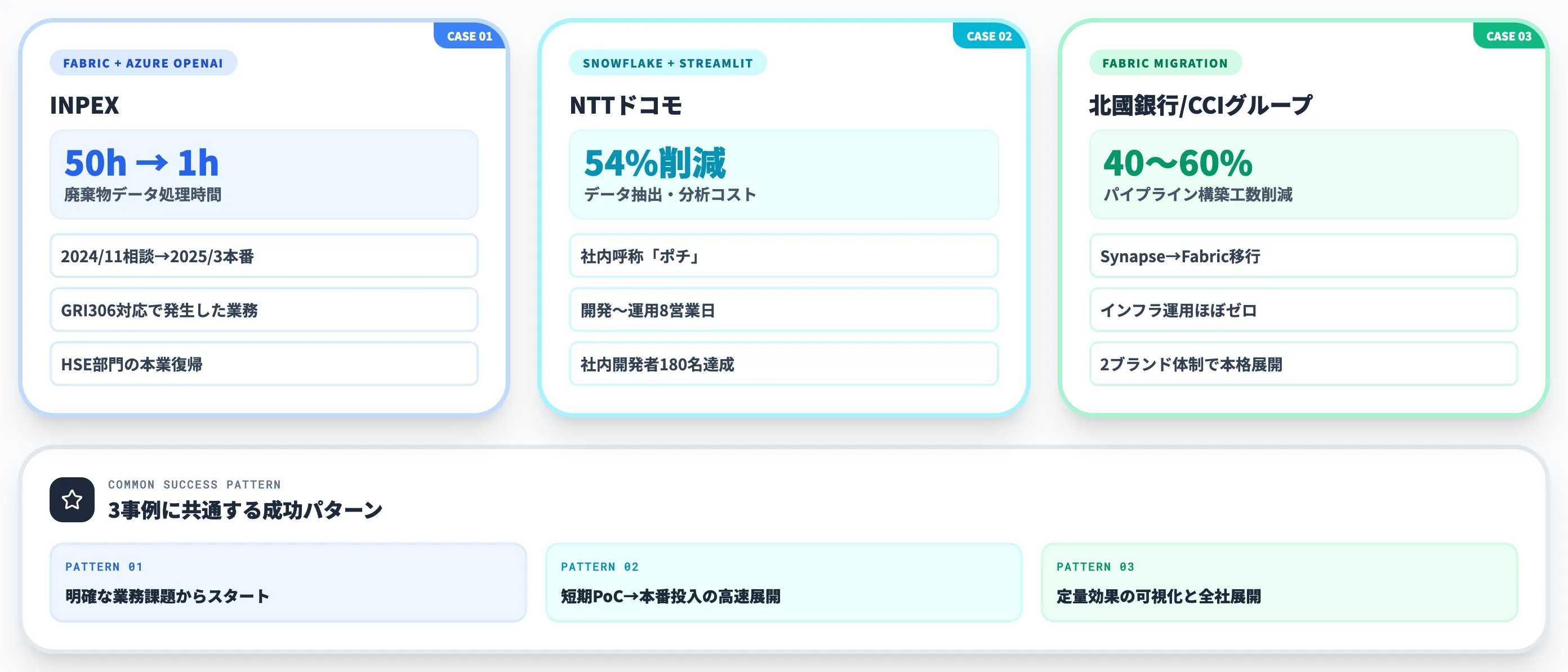
INPEX:廃棄物データ処理を50時間から1時間へ
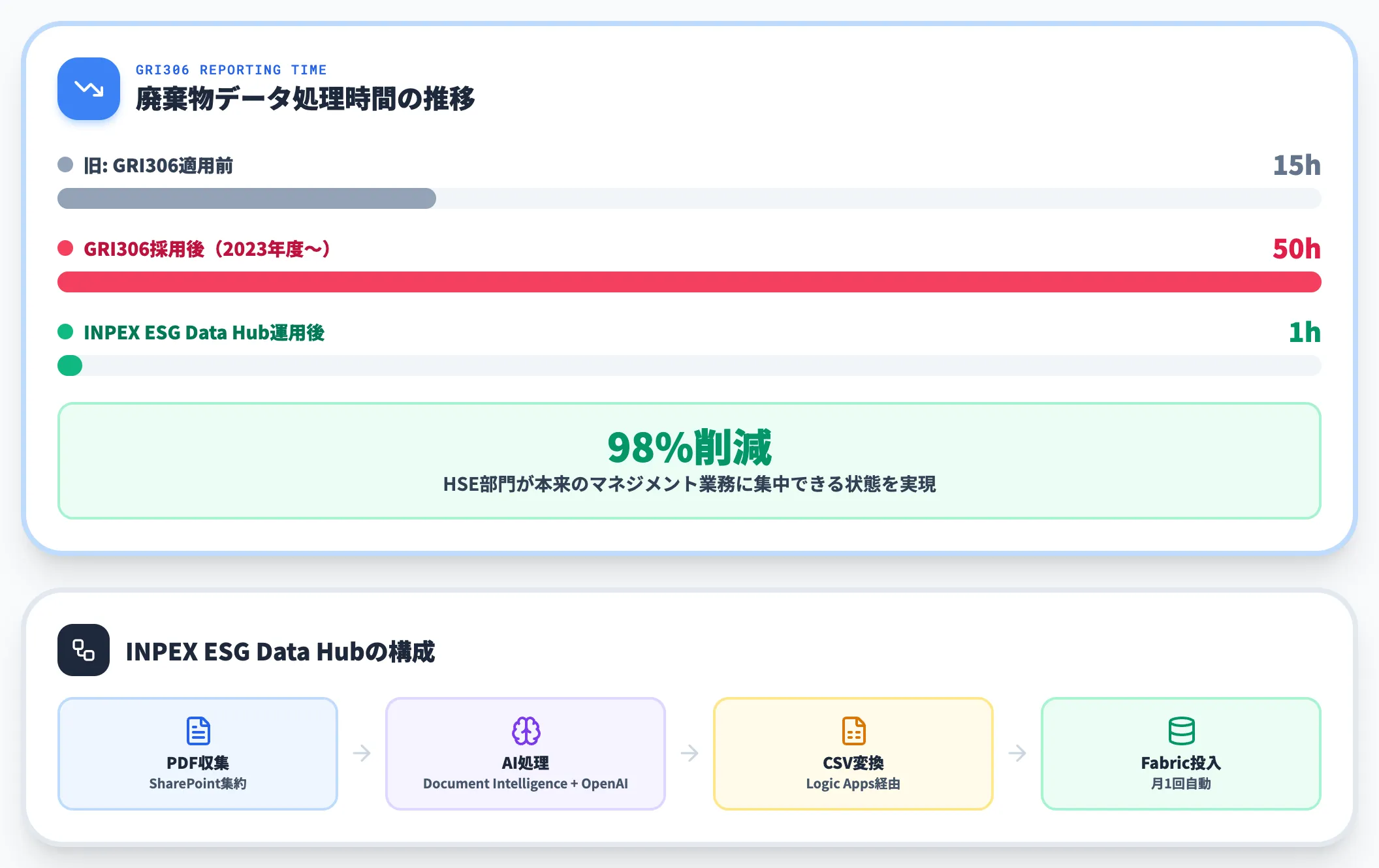
株式会社INPEX(旧・国際石油開発帝石)は、Microsoft FabricとAzure OpenAIを組み合わせた「INPEX ESG Data Hub」を、2024年11月の相談後、翌12月にテスト環境を構築してPoCに着手し、2025年3月に本番リリースしました。
背景は、2023年度からGRI306(国際的な廃棄物報告基準)を採用したことで、廃棄物分類・集計作業が月15時間から50時間に増えたことです。
構成は、各事業者から届く多様なPDFをSharePointに集約し、Azure AI Document IntelligenceとAzure OpenAIをAzure Functionsで組み合わせて処理、CSV化してAzure Logic Apps経由でFabricに月1回自動投入するというものです。
結果として、GRI306対応で50時間まで増えた分類・集計作業が約1時間に短縮され、HSE部門は本来のHSEマネジメント業務に集中できるようになりました。AI-ready dataとしてFabricに一元化したデータが、Azure OpenAIの意味理解と連動して初めて成立する構成です。

INPEXの事業拠点(出典:Microsoft Customer Stories)
NTTドコモ:分析コスト54%削減

NTTドコモは、Snowflake Streamlitを全社データ活用基盤に採用し、データ抽出・分析コストを54%削減したと2024年2月に発表しています。
社内で「ポチ」と呼ばれる簡易データ活用プラットフォームを構築し、頻出の分析パターンをメニュー化。目的に合ったアプリを選び、ターゲット条件を入力すれば分析結果が即座に返る設計です。アプリ開発から運用開始までわずか8営業日で実現しました。
2024年2月の発表時点で、社内の開発者は約180名に達しており、本社だけでなく全国の支店・支社でも開発できる体制が整っていました。
全社データ活用の高速化事例として、SnowflakeとStreamlitの組み合わせがAI-ready dataの分析活用フェーズをどれほど短縮できるかを示しています。
北國銀行:パイプライン工数40〜60%削減

北國銀行/CCIグループは、Microsoft Fabricを次世代データ活用基盤として採用し、データパイプライン構築工数を従来比40〜60%削減できる見込みと公表しています。
背景は、2022年秋に構築したAzure Synapse Analyticsベースの基盤が拡大に伴って複数ツール併用となり、データ提供までのリードタイムが長期化した点です。Fabricへの移行により、データの収集・加工・可視化を単一SaaS基盤で完結でき、インフラ運用の負担はほぼゼロに。
2025年10月には持株会社名を「CCIグループ」に変更し、2ブランド体制でデータドリブン経営を本格展開しています。地域金融機関の中で「AI-ready data基盤を導入したうえで、経営指標として活用する」段階に踏み込んだ先進事例です。
AI-ready data整備で詰まる3つの論点とケース別の始め方
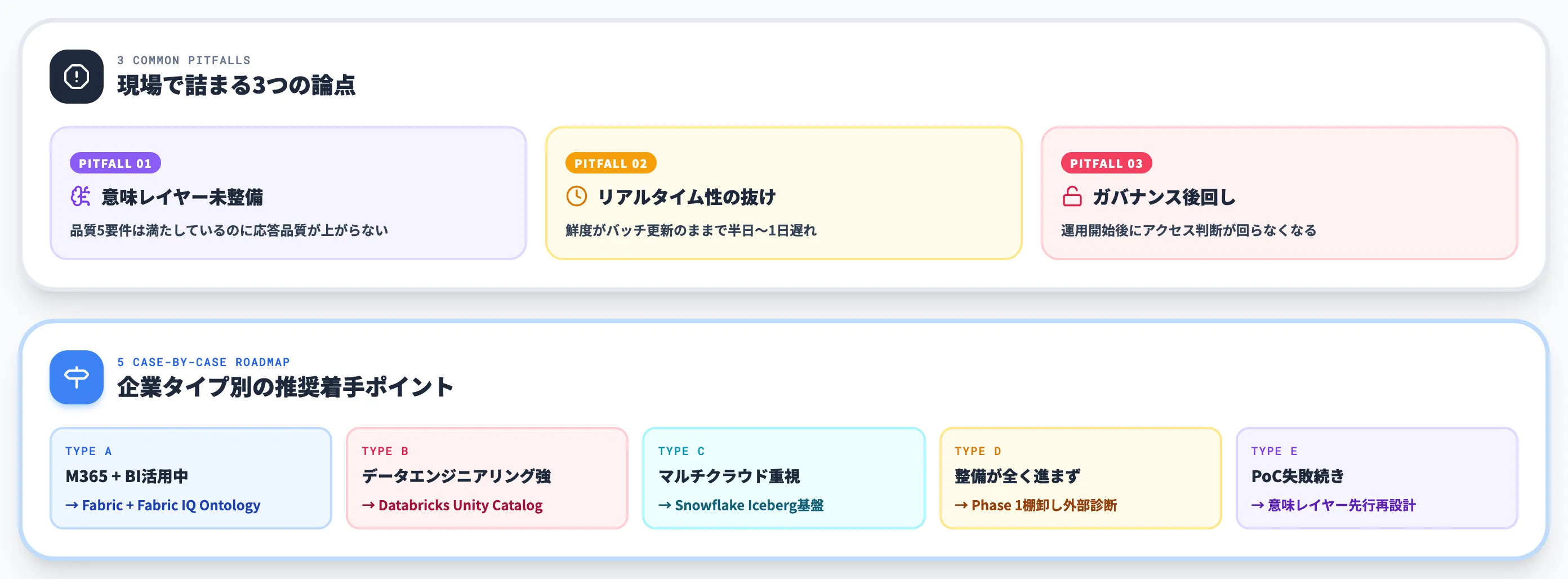
Phase 1〜3を機械的に進めれば必ず成功するわけではありません。実際の企業支援現場では、以下3つの論点で詰まるケースが繰り返し起きています。
本セクションでは3つの詰まりを整理したうえで、AI総合研究所として企業タイプ別に「どこから手を付けるべきか」の推奨を示します。
意味レイヤー未整備でエージェントが誤推論する
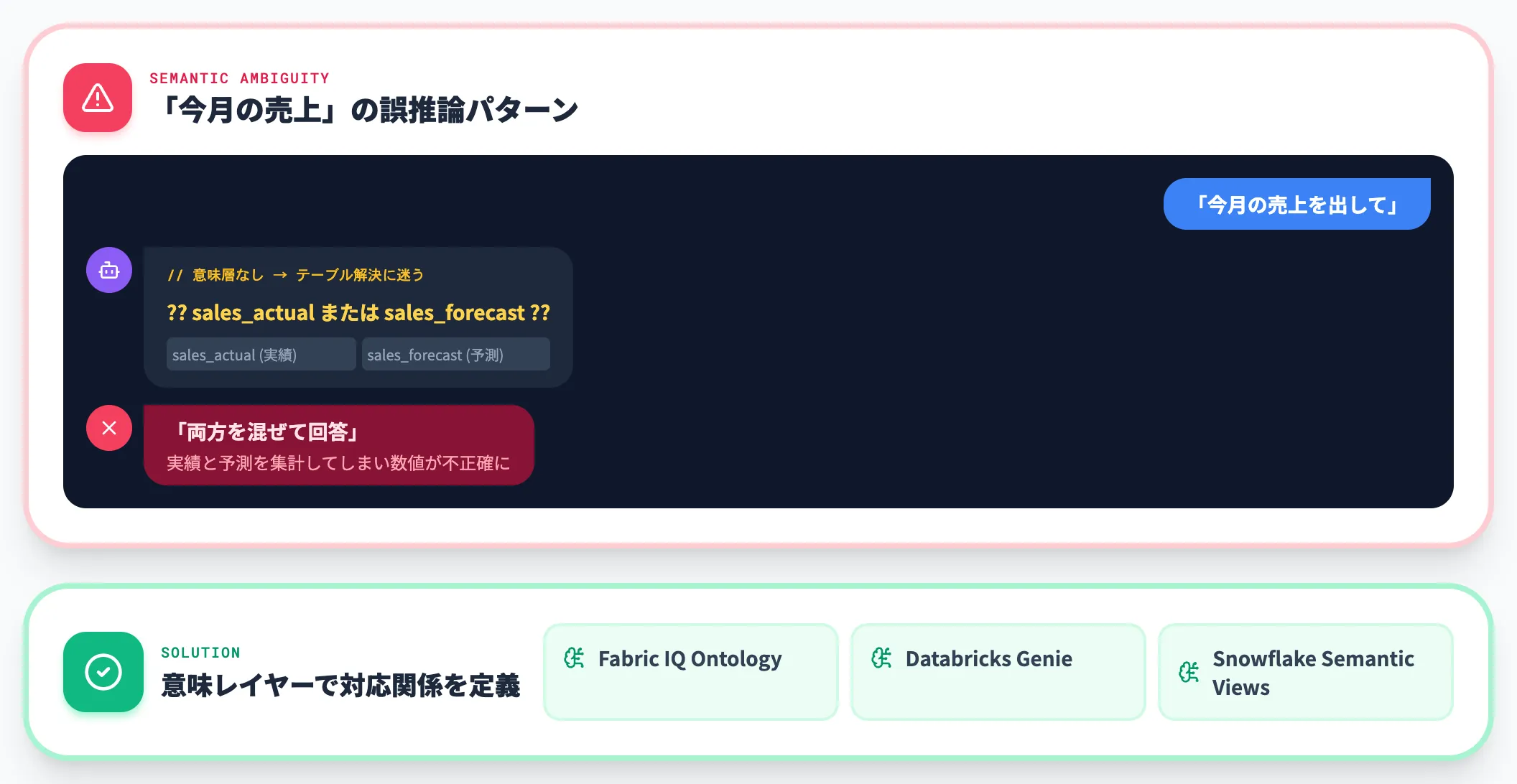
品質5要件は満たしているのに、AIエージェントの応答品質が上がらない——という相談が2026年に入ってから急増しています。原因の多くは、意味レイヤーが未整備で「業務概念とテーブルの対応」がAI側で解釈しきれていないことです。
具体的には、「今月の売上」と聞かれたエージェントが、「sales_actual」テーブルと「sales_forecast」テーブルのどちらを使うべきか判断できず、両方を混ぜて回答してしまうといった事象が起きます。
Fabric IQ Ontology・Databricks Genie Ontologyや、Snowflake側の現行意味定義機能を使って、業務概念の意味と対応関係を機械可読な形で定義する対策が必要です。
品質整備の陰で抜けやすいリアルタイム性
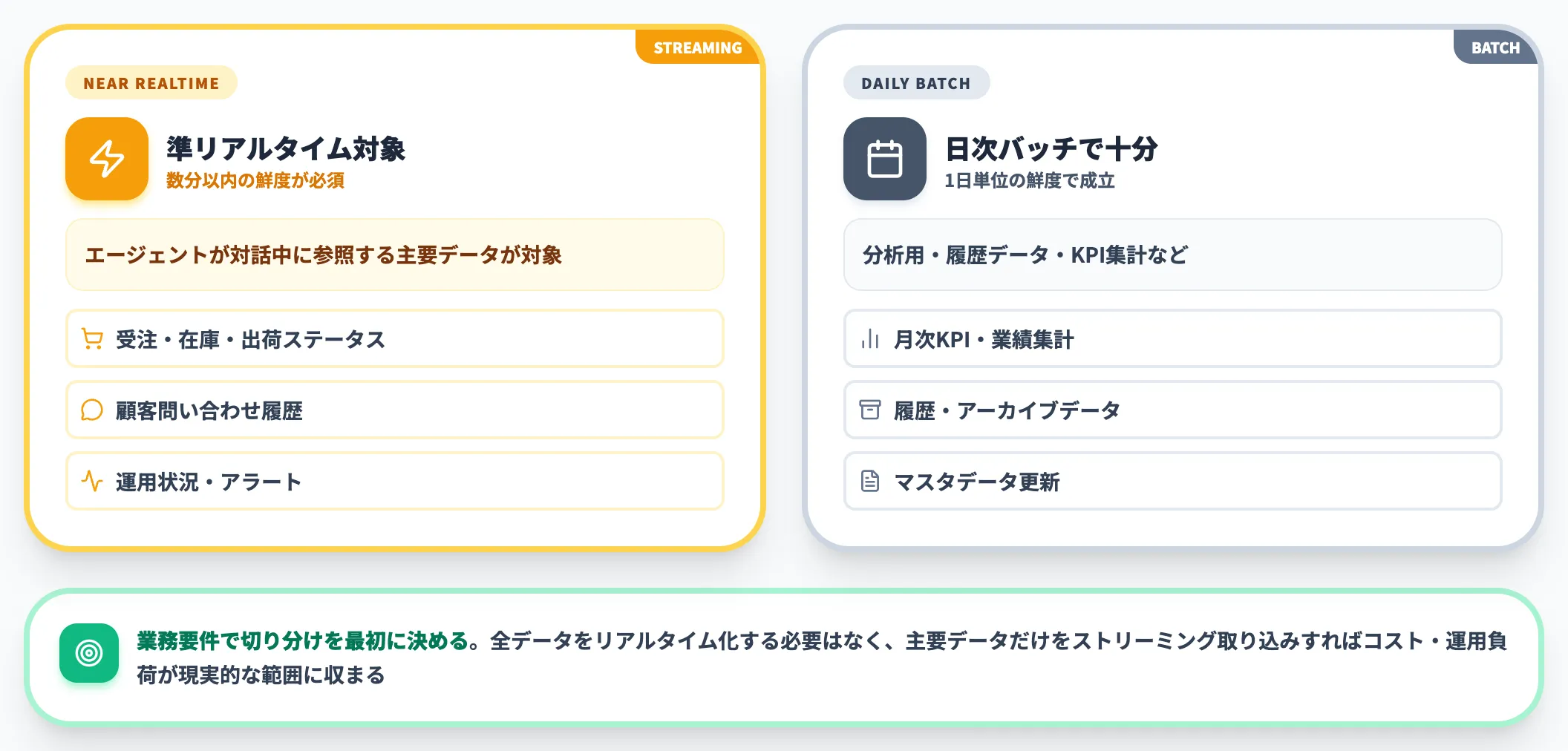
「データの正確性・完全性・一貫性は整えたが、鮮度がバッチ更新のままで、AIエージェントの回答が半日〜1日遅れている」というパターンです。
5要件のうち鮮度とアクセス性は後回しにされやすく、実運用に入ってから顕在化します。
対策は、業務要件ごとに「準リアルタイム(数分以内)」「日次バッチで十分」の切り分けを最初に決めることです。
全データをリアルタイム化する必要はなく、AIエージェントが対話中に参照する主要データだけをストリーミング取り込み対象にすれば、コストと運用負荷が現実的な範囲に収まります。
後回しにされたガバナンスが運用を止める
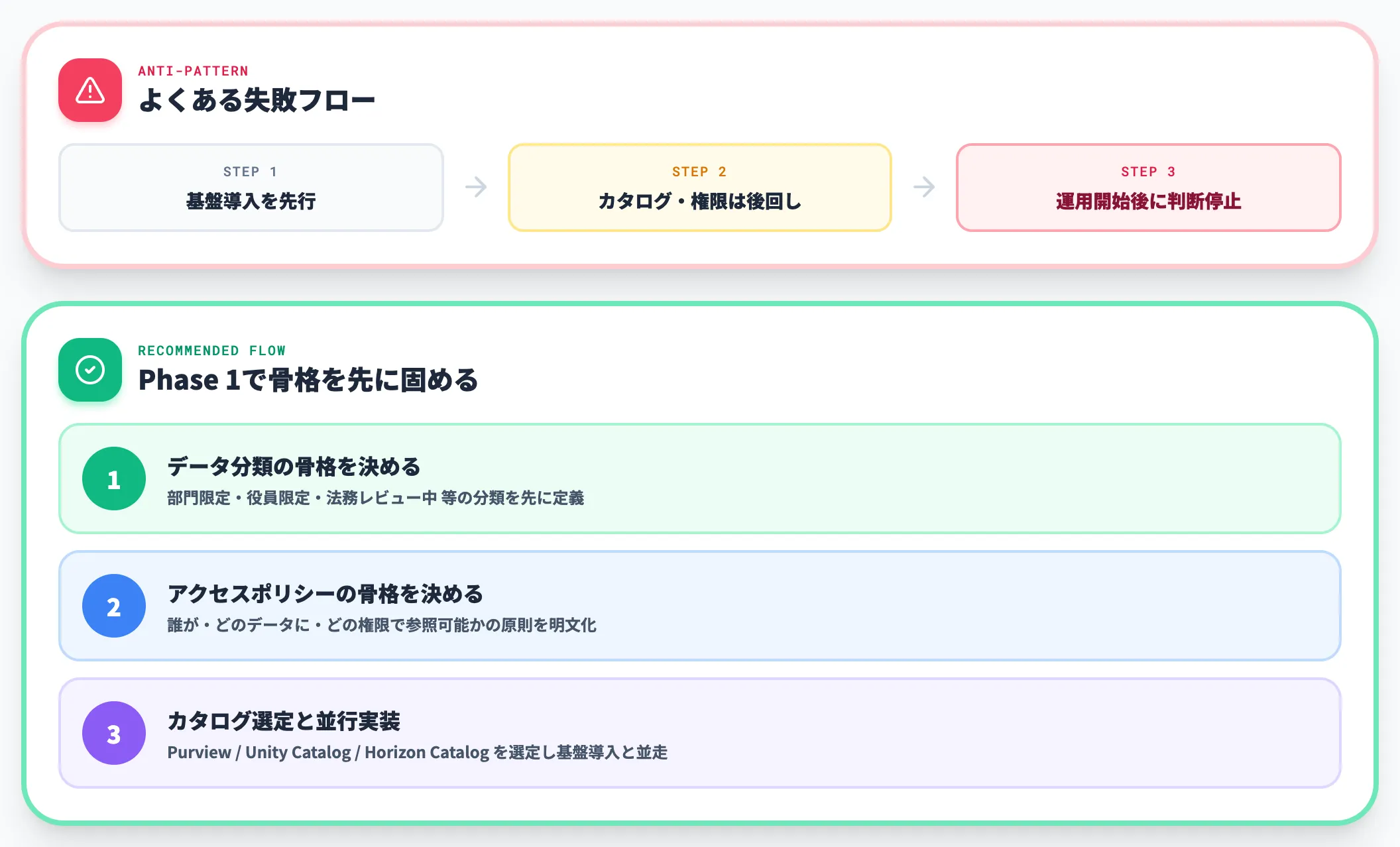
データカタログと権限管理の整備を後回しにして基盤導入を先に進め、運用開始後に「誰がどのデータにアクセスしてよいか」の判断が回らなくなるパターンです。運用開始後に判断が滞り、ガバナンス設計のやり直しが必要になるケースがあります。
対策は、Phase 1の棚卸し段階で「データ分類」と「アクセスポリシー」の骨格を先に決めることです。
基盤選定より前に、Microsoft Purview・Unity Catalog・Horizon Catalogのいずれで統治するかを決め、基盤導入と並行してポリシー実装を進めるのが実務的です。
ケース別:どこから手を付けるべきか

自社のAI-ready data整備をどこから始めるかは、企業タイプによって最適解が異なります。以下の表で、5タイプ別の推奨着手ポイントを整理しました。
| 企業タイプ | 推奨着手ポイント | 理由 |
|---|---|---|
| Microsoft 365採用済み・BI活用中 | Fabric+Fabric IQ Ontologyから着手 | 既存OneDrive/SharePoint/Teams資産をOneLakeに繋げやすく、意味層とM365 Copilot連携で早期成果が出る |
| データエンジニアリング組織が強い | DatabricksでUnity Catalog中心に整備 | Delta LakeベースでETLとMLOpsを両立でき、Unity AI Gatewayでエージェント統治まで先を見通せる |
| マルチクラウド・オープン戦略重視 | SnowflakeでIceberg基盤に集約 | Iceberg v3対応で他基盤との共存が容易、ベンダーロックインを避けたい大企業に適合 |
| データ整備が全く進んでいない | Phase 1棚卸しから外部診断で着手 | 基盤選定より前に、シャドウデータの可視化と品質診断で「整備対象の全体像」を掴む |
| AI活用のPoCが失敗続き | 意味レイヤー先行で再設計 | 品質整備だけでは解決しない場合、業務概念とテーブルの対応を整理し直すことで応答品質が改善する |
実務での支援経験から言えるのは、「基盤選定を急がず、Phase 1の棚卸しと意味レイヤーの設計を先に進める企業ほど、AI活用の立ち上がりが早い」というパターンです。
基盤は入れ替えられますが、意味レイヤーの設計思想はデータ運用文化そのものに影響するため、後から作り直すコストが桁違いに高くなります。

データ基盤構築のご相談はAI総合研究所へ
Microsoft Fabricをはじめとするデータ基盤の構築・移行を検討中の方に、AI総合研究所ではデータ収集から可視化・AI活用・運用まで一気通貫で支援しています。
- マルチプラットフォーム対応
Microsoft Fabric、Snowflake、Databricks、AWS、GCPなど、ビジネス要件に最適なデータプラットフォームを選定・構築
- データパイプライン・ETL構築
Azure Data Factory、dbt、Airflowを用いたETL/ELTパイプラインの設計・実装。データの収集・変換・統合を自動化
- AI-Ready Data構築
AIモデルの学習・推論に最適化されたデータ形式への変換、品質管理、特徴量エンジニアリングまで対応
- 運用・ガバナンス整備
Microsoft Purviewによるデータカタログ・系譜管理、監視体制の構築、継続的なパフォーマンス改善をサポート
まずは無料相談で、貴社のデータ基盤についてお気軽にご相談ください。
まとめ
本記事では、AI-ready dataについて、定義・Gartner予測「AIプロジェクトの60%放棄」・ビッグデータやDWHとの違い・品質5要件+オントロジー・主要3プラットフォーム・料金・3フェーズ導入ステップ・国内事例・詰まる論点までを、2026年7月時点の最新情報で解説しました。要点を改めて整理します。
-
AI-ready dataは「AIが直接読める状態」まで整備されたデータで、補正の担い手がデータ側に移った点でビッグデータ・DWHと根本的に異なる
-
GartnerはAI-ready dataに支えられていないAIプロジェクトの60%が2026年までに放棄されると予測。実務ではハルシネーション・情報漏洩・AI活用速度差の3リスクとして顕在化する
-
品質5要件(正確性・完全性・一貫性・鮮度・アクセス性)に加え、2025年秋以降はオントロジー・意味レイヤーの重要度が急速に高まっており、本記事では実務上の第6要件として整理した
-
本記事では代表例として Microsoft Fabric・Databricks・Snowflake を扱った。Fabric IQ Ontology/Databricks Genie Ontology/Snowflake Cortex Sense が2025年11月〜2026年6月にかけて相次いで発表され、意味レイヤー強化の流れが読み取れる
-
国内でもINPEX(50時間→1時間)、NTTドコモ(54%削減)、北國銀行/CCIグループ(パイプライン工数40〜60%削減)と、具体的な成果事例が公表されている
-
整備で詰まるのはオントロジー未整備・リアルタイム性の抜け・ガバナンス後回しの3点。企業タイプごとに着手順を分けるのが実務的
AI-ready dataの整備は、AI活用の成否を分ける最上流の投資です。まずは自社データの棚卸しと意味レイヤーの設計思想を固めることから着手し、そのうえで最適なプラットフォームを選定する順序を踏むと、AI活用の立ち上がりを大きく早められます。










