この記事のポイント
 T-SQLスキルを持つBIチームにはFabric Data Warehouseが第一候補。手動チューニング不要で高速クエリが実現し、学習コストを最小化できる
T-SQLスキルを持つBIチームにはFabric Data Warehouseが第一候補。手動チューニング不要で高速クエリが実現し、学習コストを最小化できる- マルチテーブルACIDトランザクションが必要な業務(財務・在庫管理等)ではLakehouseよりData Warehouseを選ぶべき
- 行レベル・列レベルセキュリティと動的データマスキングが標準搭載されており、個人情報を扱う環境に最適。追加ツールなしできめ細かなアクセス制御が可能
- Synapse専用SQLプール運用中の組織はFabric Migration Assistantで段階移行、CU課金モデルへの移行でコスト最適化も見込める
- Spark/Pythonでのデータ加工中心ならLakehouseが適する、T-SQL vs Sparkのチームスキルとトランザクション要件の2軸で判断

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Microsoft Fabric Data Warehouseは、OneLake上にDelta Lake形式で構築されたエンタープライズ規模のリレーショナルデータウェアハウスです。
T-SQLベースで主要なDML・DDLに対応し、マルチテーブルACIDトランザクションを備え、SQLに慣れたチームがすぐに使い始められます。
本記事では、Fabric Data Warehouseの基本概念からアーキテクチャ、T-SQL機能、Lakehouseとの使い分け、セキュリティ、Synapse専用SQLプールからの移行方法、料金体系までを体系的に解説します。
✅Microsoft 365 Copilotの最新エージェント機能「Copilot Cowork」については、以下の記事をご覧ください。
Copilot Coworkとは?機能や料金、Claude Coworkとの違いを解説
目次
【詳細比較】Fabric Data Warehouse vs Lakehouse
Synapse専用SQLプールからFabric Data Warehouseへの移行
Fabric Data Warehouseの注意点と制限事項
Fabric Data Warehouseとは?
Microsoft Fabric Data Warehouseは、OneLake上にDelta Lake形式で構築されたエンタープライズ規模のリレーショナルデータウェアハウスです。
従来のデータウェアハウスと同じようにT-SQLでテーブルの作成・データの読み書き・変換・分析ができるうえ、SaaS型のフルマネージドサービスとして提供されるため、インフラの構築・運用が不要です。

Fabric Data Warehouseの主な特徴は次のとおりです。
-
広いT-SQL対応
テーブルの作成(DDL)、データの挿入・更新・削除(DML)、ビュー、ストアドプロシージャ、関数など主要なT-SQL操作に対応する(一部非対応の構文あり。詳細は後述)
-
マルチテーブルACIDトランザクション
複数テーブルにまたがる更新を一括でコミットまたはロールバックでき、データの一貫性が保証される
-
Delta Lake形式のオープンストレージ
データはOneLake上にオープンなDelta Lake形式で保存されるため、他のFabricワークロード(Lakehouse、Spark、Power BI等)から同じデータに直接アクセスできる
-
コンピューティングとストレージの分離
処理能力(コンピューティング)とデータ保存領域(ストレージ)が独立しており、ワークロードに応じて柔軟にスケーリングできる
-
自律的なワークロード管理
パフォーマンスチューニングのためにインデックスの作成やノブの調整が不要。
統合クエリオプティマイザーが自動で最適な実行プランを選択する
つまり、Fabric Data WarehouseはSQLに慣れたチームが、インフラ管理の負担なく、エンタープライズ品質のDWHをすぐに使い始められる環境として設計されています。

従来のDWHとの違い

Fabric Data Warehouseと、Azure Synapse Analytics専用SQLプールや従来のSQL ServerベースのDWHとの最大の違いは、ストレージの基盤がDelta Lake(Parquetファイル+トランザクションログ)であることです。
Synapse専用SQLプールは専用のコンピューティングとカラムナーストレージを組み合わせた分散DWH基盤ですが、Fabric Data WarehouseはOneLake上のDelta Lake形式を基盤としています。
これにより、同じデータに対してSparkやPower BIからも直接アクセスでき、データのサイロ化を防げます。
また、Synapse専用SQLプールでは容量(DWU)を手動で管理する必要がありましたが、Fabric Data WarehouseではDWUのような個別チューニングが不要で、コンピューティングの自動スケーリングが組み込まれています。
ただし、Fabric全体としてはF SKU / CUのキャパシティ設計やスケールアップ・スケールダウンの検討は必要です。
Fabric Data Warehouseのアーキテクチャ
Fabric Data Warehouseが手動チューニングなしで高いパフォーマンスを実現できる理由は、4つのアーキテクチャ要素にあります。
ここでは、その中核となる設計を解説します。

統合クエリオプティマイザー

Fabric Data Warehouseの統合クエリオプティマイザーは、送信されたSQLクエリに対して分散クラウド環境で最適な実行プランを自動生成するエンジンです。
テーブルの結合方法、データの移動先、CPU・メモリ・ネットワークの使い方など、複数の実行方法のコストを評価し、最適なプランを選択します。
たとえば、小さなテーブルをブロードキャストする方が大きなテーブルをシャッフルするよりも効率的な場合、オプティマイザーが自動で判断します。
開発者がJOINの順序を手動で最適化したり、クエリヒントを付けたりする必要はありません。複雑なT-SQLクエリや不適切に書かれたクエリでも、自動で最適化されます。
さらに、オプティマイザーは過去のクエリ実行から継続的に学習し、最適化アルゴリズムを改良していきます。
分散クエリ処理

Fabric Data Warehouseの分散クエリ処理エンジンは、クエリの実行に必要なコンピューティングリソースを複数のノードに自動分散します。
ここで重要なのは、SELECT(読み取り)とDML(書き込み)が別々のリソースプールで実行されるという設計です。
夜間のETLジョブが翌朝のダッシュボードレポートの速度に影響を与えない仕組みになっています。
クラウドインフラの迅速なプロビジョニングにより、クエリ量やデータ量の変動に応じてコンピューティングリソースが自動でスケールアップ・スケールダウンします。
小規模なデータセットからマルチペタバイト規模まで対応可能です。
バッチモード実行とキャッシュ
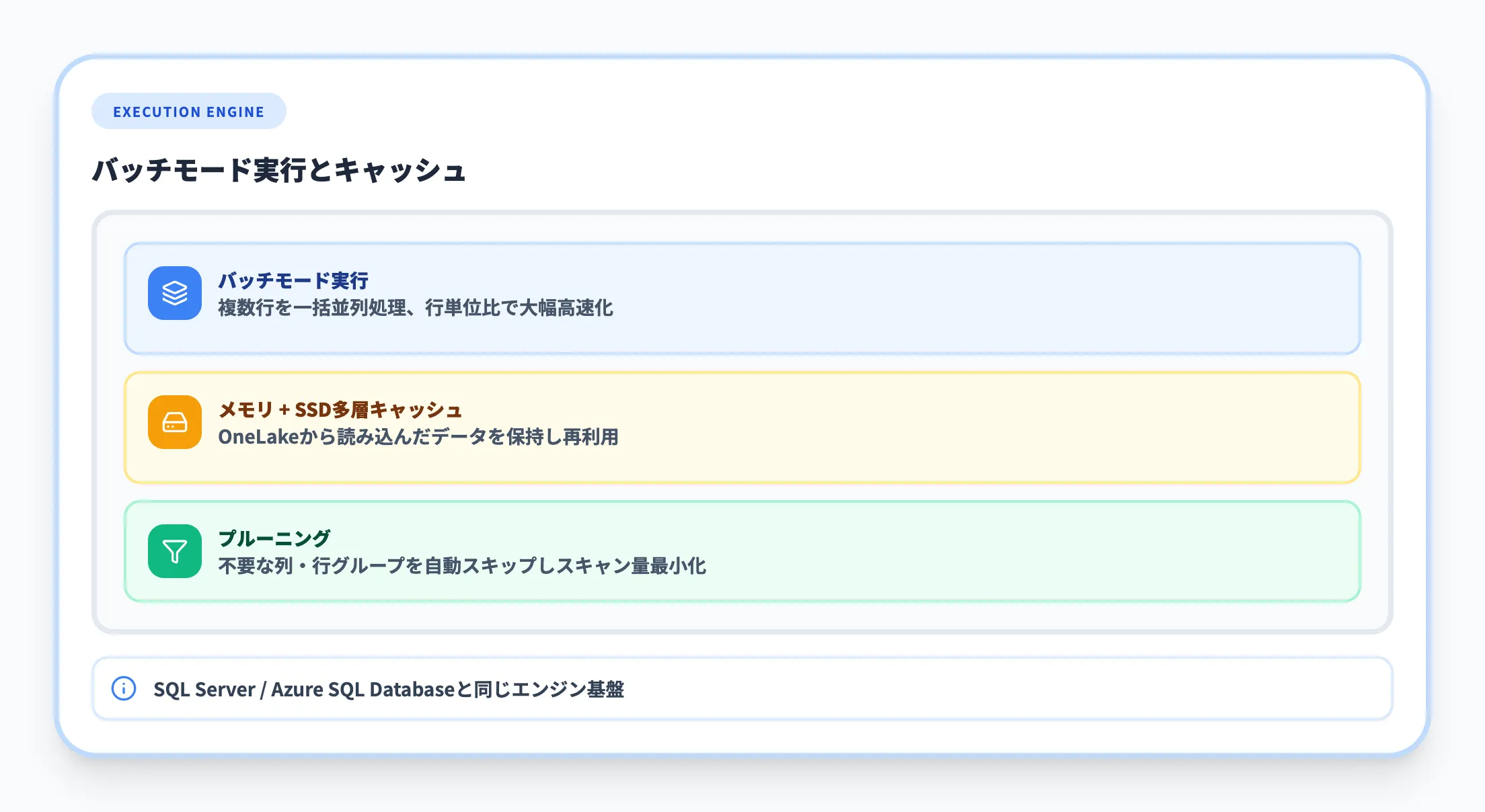
クエリ実行エンジンは、SQL ServerやAzure SQL Databaseと同じエンジンをベースとしています。バッチモード実行により複数の行を一括で並列処理し、従来の行ごとの処理と比較してクエリ速度が大幅に向上します。
データアクセスにはメモリとSSDの多層キャッシュを活用し、OneLakeから読み込んだデータをキャッシュに保持することで、繰り返しアクセスされるデータのクエリ速度を高めています。
また、列と行グループの削除(プルーニング)によって、クエリに関係ないデータセグメントを自動でスキップし、スキャン量を最小化します。
Fabric Data WarehouseのT-SQL機能

Fabric Data Warehouseは、SQLに慣れたチームがすぐに活用できることを目指して設計されています。
ここでは、対応するT-SQL機能と、現時点での制限事項を整理します。
対応するT-SQL操作

以下の表で、Fabric Data Warehouseが対応する主要なT-SQL操作を整理しました。
| カテゴリ | 対応する操作 |
|---|---|
| データ定義(DDL) | CREATE / ALTER / DROP TABLE、CREATE VIEW、CREATE FUNCTION、CREATE PROCEDURE |
| データ操作(DML) | INSERT、UPDATE、DELETE、MERGE、SELECT INTO、COPY INTO、CTAS |
| クエリ(DQL) | SELECT、JOIN、サブクエリ、CTE(標準・順次・ネスト)、ウィンドウ関数 |
| トランザクション | マルチテーブルACIDトランザクション(BEGIN / COMMIT / ROLLBACK) |
| セキュリティ | GRANT / DENY / REVOKE、行レベルセキュリティ、列レベルセキュリティ、動的データマスキング |
| その他 | 一時テーブル(#temp)、TRUNCATE TABLE、sp_rename、クエリヒント(一部) |
ここで注目すべきは、MERGE構文がGA(一般提供)として提供されている点です。
MERGE文は「存在すればUPDATE、なければINSERT」というUpsert処理をSQLで簡潔に記述でき、ETLパイプラインのデータ同期に頻繁に使用されます。
また、COPY INTOコマンドによる一括データ読み込みにも対応しており、Azure Data Lake Storage Gen2やAzure Blob Storageからの大量データ投入を高速に実行できます。
データ取り込みの方法

Fabric Data Warehouseへのデータ取り込みには、用途に応じた複数の方法が用意されています。
-
COPY INTO
外部ストレージ(ADLS Gen2、Blob Storage等)からの大量データ一括読み込み。パフォーマンスが最も高い
-
INSERT...SELECT / CTAS / SELECT INTO
他のテーブルやクロスデータベースクエリからのデータ取り込み。変換しながら新しいテーブルを作成する場合に有効
-
パイプライン(Data Factory)
Azure Data Factoryと同様のGUIベースのパイプラインで、外部ソースからの定期的なバッチ取り込みを自動化
-
Dataflow Gen2
ノーコード・ローコードのビジュアルインターフェースでデータ変換と取り込みを実行
【関連記事】
【Microsoft Fabric】Data Factoryとは?機能やADFとの違い、料金体系を徹底解説
DWHの高品質データをAgent回答基盤に

SQLデータをAI業務自動化に直結
Data WarehouseにT-SQLで整備した業務データを、AIエージェントのナレッジソースとして活用。SQLスキルを活かしたAI業務自動化を実現します。
【詳細比較】Fabric Data Warehouse vs Lakehouse

Fabric Data Warehouseの機能を理解したところで、Fabric Lakehouseとの違いをDWHの視点から詳しく比較します。
機能比較表

以下の表で、Data WarehouseとLakehouseの主要な違いを整理しました。
| 比較項目 | Data Warehouse | Lakehouse |
|---|---|---|
| 主な開発ツール | T-SQL | Apache Spark(Python、Scala、SQL、R) |
| 対応データ型 | 構造化データのみ | 構造化・半構造化・非構造化 |
| データ書き込み | T-SQL(COPY INTO、INSERT、CTAS等)、Spark、パイプライン、Dataflow Gen2 | Spark中心(Notebook、ジョブ定義)に加え、パイプライン・Dataflow Gen2でも取り込み可能 |
| マルチテーブルトランザクション | 対応(ACID準拠) | 非対応(Delta LakeのテーブルレベルACIDはあり) |
| SQL分析エンドポイント | 主要なDQL・DML・DDLに対応 | 自動生成(読み取り専用) |
| セキュリティ | オブジェクトレベル、列レベル、行レベル、動的データマスキング(読み書き両方で適用) | テーブル・列・行レベル(SQL分析エンドポイント経由、アクセスモードに依存) |
| 得意なワークロード | BIレポーティング、ディメンションモデリング、SQL中心のチーム | データエンジニアリング、データサイエンス、ML |
| ストレージ形式 | Delta Lake(オープンフォーマット) | Delta Lake(オープンフォーマット) |
注目すべきは、セキュリティの運用モデルの違いです。
Data Warehouseは読み書き両方の操作に対してRLS・CLS・DDMをSQL中心で一元管理できます。
Lakehouseでもアクセスモードによってはこれらのセキュリティ機能を利用できますが、SQL分析エンドポイントが読み取り専用のため、書き込みを含むワークロード全体でのSQL中心のセキュリティ運用が必要な場合はData Warehouseが適しています。
また、両者は同じOneLake上にDelta Lake形式でデータを保存するため、併用が可能です。
たとえば、メダリオンアーキテクチャのブロンズ・シルバーレイヤーをLakehouseで構成し、ゴールドレイヤーをData Warehouseにする構成が多く採用されています。
DWHを選ぶべきケース

次のような要件がある場合は、Data Warehouseが適しています。
- T-SQLで開発・運用する既存のスキルセットを活かしたい
- マルチテーブルトランザクション(複数テーブルへの一括更新・ロールバック)が必要
- 行レベル・列レベルのセキュリティや動的データマスキングが求められる
- スタースキーマやスノーフレークスキーマのディメンションモデリングを行う
- BIレポーティング用のキュレーションされたデータマートを構築する
【関連記事】
Microsoft FabricとPower BIの違い、連携手順をわかりやすく解説
【Microsoft Fabric】Data Engineeringとは?Sparkの機能や料金体系を徹底解説
【Microsoft Fabric】Data Scienceとは?MLflowやAutoML、料金体系を徹底解説
Fabric Data Warehouseのセキュリティ

Fabric Data Warehouseは、エンタープライズレベルのきめ細かなデータ保護機能を提供しています。ここでは、Data Warehouseのセキュリティ機能を解説します。
3つのデータ保護テクノロジー

Fabric Data Warehouseが提供する主要なデータ保護機能は以下の3つです。これらを組み合わせて使うことが推奨されています。
-
行レベルセキュリティ(RLS)
WHERE句のフィルター述語を使い、ユーザーの属性(部門、地域など)に応じて閲覧可能な行を制限する。
例:「営業部門のユーザーは自部門の売上データのみ閲覧可能」といった制御が可能。
-
列レベルセキュリティ(CLS)
GRANT / DENY文でテーブル内の特定の列へのアクセスをユーザーやロールごとに制御する。
例:たとえば「給与カラムは人事部門のみ閲覧可能」といった制御が可能・
-
動的データマスキング(DDM)
マスク関数を使って、権限のないユーザーにはメールアドレスや電話番号などの機密データをマスクして表示する。
元のデータは変更せず、表示時のみマスキングされる。
これらのセキュリティ機能はLakehouseのSQL分析エンドポイントでもアクセスモードに応じて利用可能です。
しかし、書き込みを含むSQL中心の運用ではData Warehouseのほうがセキュリティ設計を一元管理しやすく、機密データを扱うBIワークロードではData Warehouseが整理しやすいです。
Fabricプラットフォームとの統合
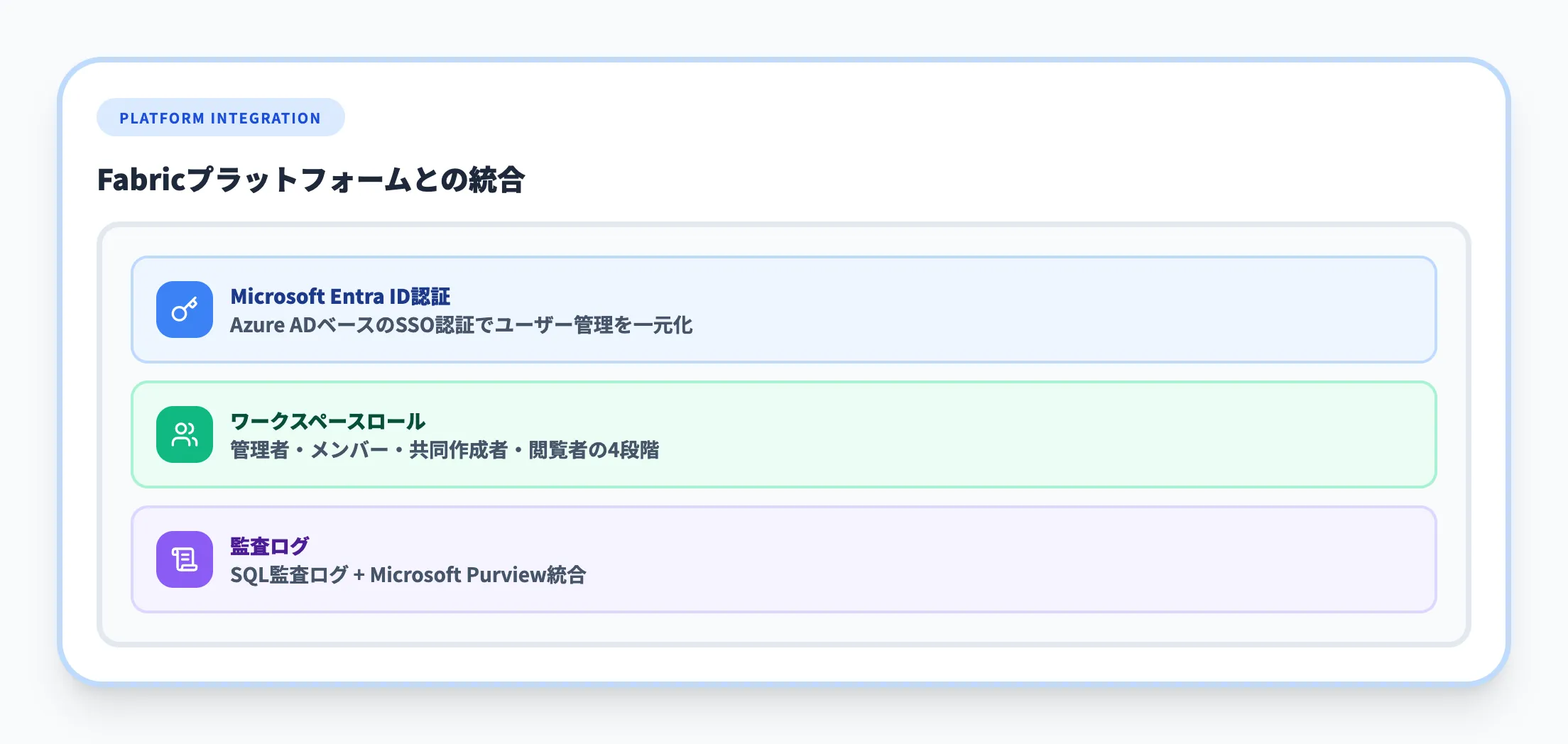
データ保護機能に加え、Fabric Data Warehouseは以下のプラットフォームレベルのセキュリティとも統合されています。
-
Microsoft Entra ID認証
Azure Active DirectoryベースのSSO認証でユーザー管理を一元化
-
ワークスペースロール
管理者・メンバー・共同作成者・閲覧者の4つのロールでアクセスレベルを制御
-
監査ログ
SQL監査ログの記録と、Microsoft Purviewとの統合によるコンプライアンス対応
個人情報保護法やGDPR対応が求められる企業では、これらのセキュリティ機能をレイヤーとして組み合わせることで、包括的なデータガバナンスを構築できます。

Synapse専用SQLプールからFabric Data Warehouseへの移行

Azure Synapse Analytics専用SQLプールを利用している企業にとって、Fabric Data Warehouseへの移行は重要な検討事項です。
Microsoftは公式に移行パスを提供しており、ここではその要点を解説します。
Fabric Migration Assistantの活用

Microsoftは、Synapse専用SQLプールからFabric Warehouseへの移行を自動化するFabric Migration Assistantを提供しています。
スキーマ(DDL)の変換、データの移行、コード(DML)の書き換え支援を含む自動化エクスペリエンスにより、移行作業を効率化できます。
移行時に注意すべきデータ型の違い
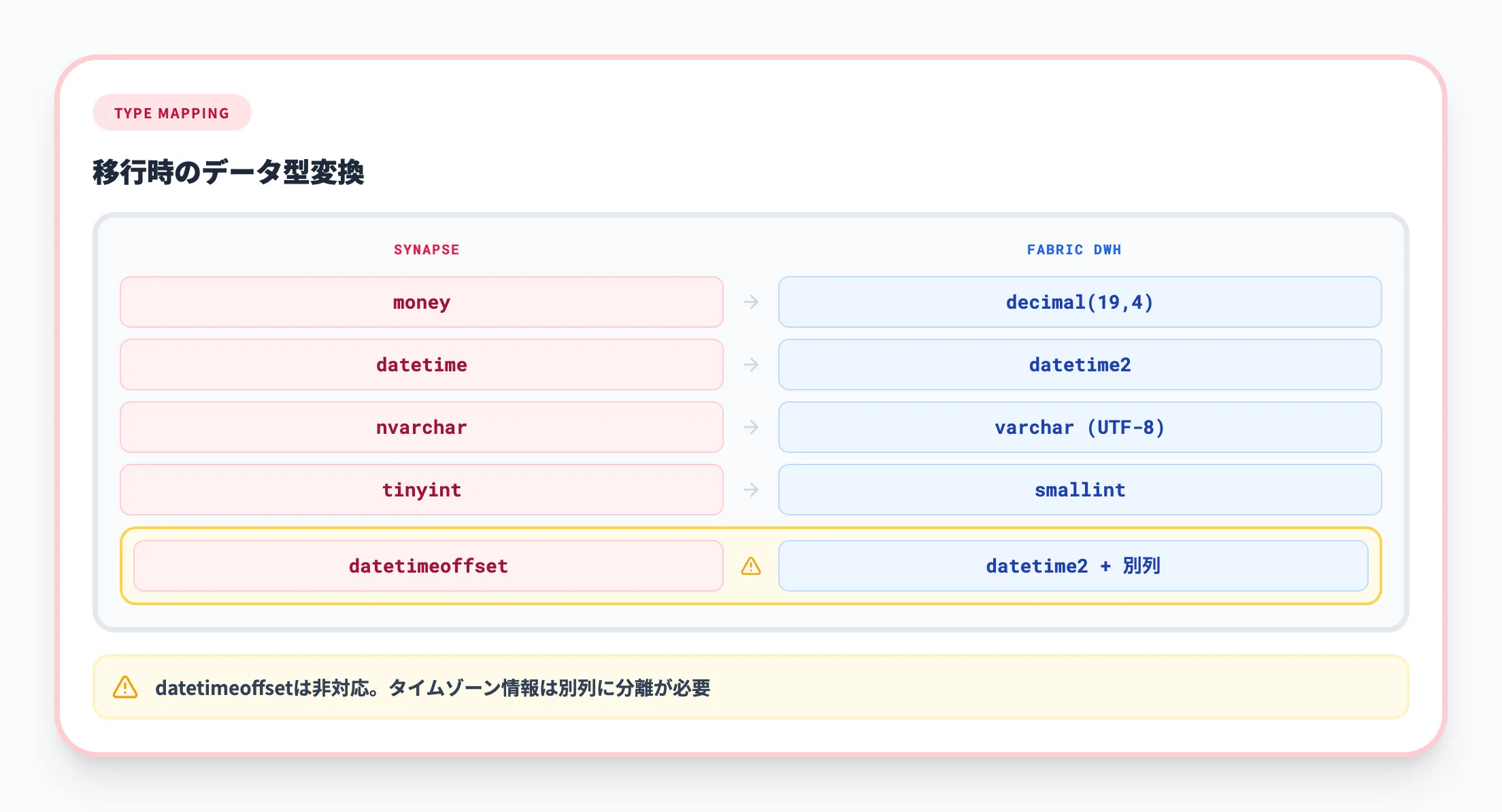
Synapse専用SQLプールとFabric Data Warehouseでは、一部のデータ型に違いがあります。以下の表は、移行時に変換が必要なデータ型の対応関係です。
| Synapse専用SQLプール | Fabric Data Warehouse |
|---|---|
| money | decimal(19,4) |
| smallmoney | decimal(10,4) |
| smalldatetime | datetime2 |
| datetime | datetime2 |
| nchar | char |
| nvarchar | varchar |
| tinyint | smallint |
| binary | varbinary |
| datetimeoffset | datetime2(タイムゾーンオフセット情報は別列に分離が必要) |
特に注意が必要なのは、datetimeoffset型がFabricでは非対応であるという点です。
タイムゾーン情報を保持する必要がある場合は、オフセットを別の列に分離する設計変更が必要になります。
また、nchar / nvarcharはchar / varcharに変換されます。Unicodeデータの扱いについては、FabricのvarcharがデフォルトでUTF-8をサポートしているため、多くの場合は問題なく移行できます。
移行のアプローチ

移行方法は大きく2つに分かれます。
-
リフトアンドシフト
既存のデータモデルを最小限の変更でFabric Warehouseに移行する方法。スタースキーマやスノーフレークスキーマが整っている環境、移行の時間・コストに制約がある場合に適している
-
段階的最新化
移行を機にアーキテクチャを見直し、Fabricの新機能(メダリオンアーキテクチャ、Lakehouseとの併用、Direct Lakeモード等)を取り込みながら段階的に移行する方法。レガシDWHが長期間運用されている場合に推奨
いずれの場合も、まずPoCで小規模なデータマートを移行し、パフォーマンスとT-SQL互換性を検証してから本格移行に進むのが推奨されています。
Fabric Data Warehouseの料金体系

Fabric Data Warehouseの料金は、Microsoft Fabric全体のキャパシティ課金モデルに基づいています。
F SKUとCU課金の仕組み

Fabric Data WarehouseはFabricキャパシティ(F SKU)のCU(Capacity Units)を消費して動作します。
LakehouseやNotebook、Power BIなどの他のFabricワークロードと同じCUプールを共有する仕組みです。
以下の表は、主要なF SKUの一覧です。
| SKU | CU数 | 位置づけ |
|---|---|---|
| F2 | 2 | 個人検証・PoC向け |
| F4〜F8 | 4〜8 | 小規模チーム |
| F16〜F32 | 16〜32 | 中規模チーム |
| F64〜F128 | 64〜128 | 部門・エンタープライズ |
| F256〜F2048 | 256〜2,048 | 大規模エンタープライズ |
Data Warehouseの処理では、内部的にSELECT(読み取り)とDML(書き込み)の実行リソースが分離されている設計のため、読み取りクエリと書き込み処理が互いのパフォーマンスに干渉しにくいという特徴があります。
課金上はFabric共通のCUプールで消費されます。
最新の料金はAzure公式の料金ページで確認できます。
従量課金と予約の選択
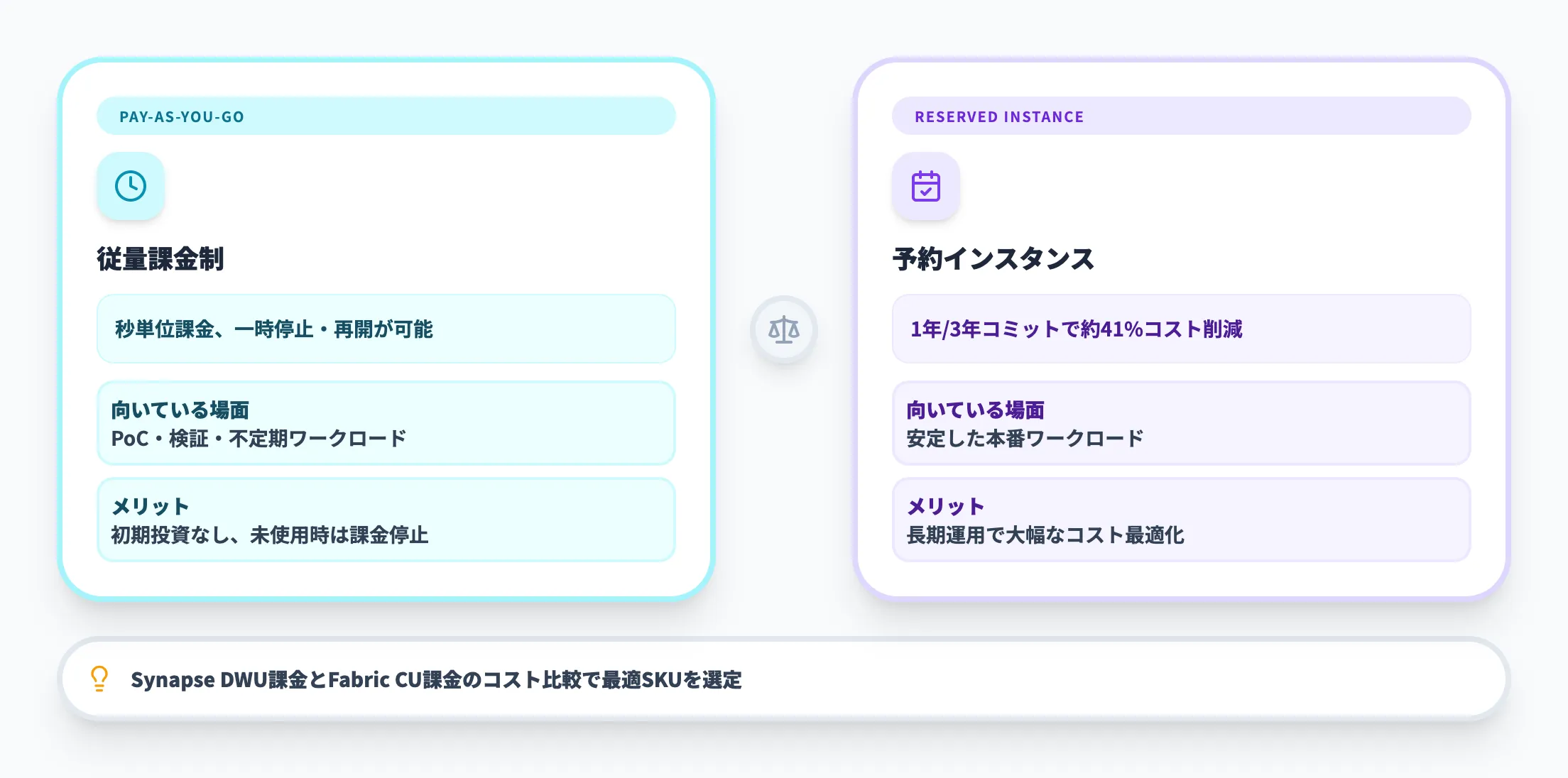
購入方法はLakehouseと同様に2種類あります。
-
従量課金制(Pay-as-you-go)
秒単位で課金。一時停止も可能なため、PoC・検証環境に適している
-
予約インスタンス(1年 / 3年)
長期コミットにより約41%のコスト削減。安定した本番ワークロード向け
Synapse専用SQLプールからの移行では、現行のDWU課金とFabricのCU課金でコスト比較を行ったうえで、最適なSKUを選定することが重要です。
Fabricは秒課金・予約・Fabricキャパシティのpause/resumeで柔軟なコスト制御が可能ですが、Synapse専用SQLプールもコンピュート停止中はストレージ課金のみになるため、実コストは既存の運用パターンと容量設計に基づいた比較が必要です。
【関連記事】
Microsoft Fabricとは?使い方や価格体系、できることを徹底解説!
【Microsoft Fabric】Real-Time Intelligenceとは?機能や料金体系を徹底解説
Microsoft Fabric導入事例6選!国内企業の成果と導入パターンを解説
Fabric Data Warehouseの注意点と制限事項

Fabric Data Warehouseは強力なDWHですが、2026年3月時点で一部の制限事項があります。導入前に把握しておくべきポイントを整理します。
T-SQLの非対応コマンド

2026年2月時点のT-SQL surface areaドキュメントに基づくと、以下のT-SQL機能は非対応です。
- マテリアライズドビュー(CREATE MATERIALIZED VIEW)
- トリガー
- シノニム
- 再帰クエリ
- BULK LOAD
- FOR XML
- SET ROWCOUNT
- SET TRANSACTION ISOLATION LEVEL
- 手動作成のマルチカラム統計
また、ALTER TABLE操作は一部のみ対応しています。
NULLを許可するカラムの追加、カラムの削除、NOT ENFORCED制約付きのPRIMARY KEY / UNIQUE / FOREIGN KEY制約の追加・削除が可能ですが、その他のALTER TABLE操作はブロックされます。
リージョン制限
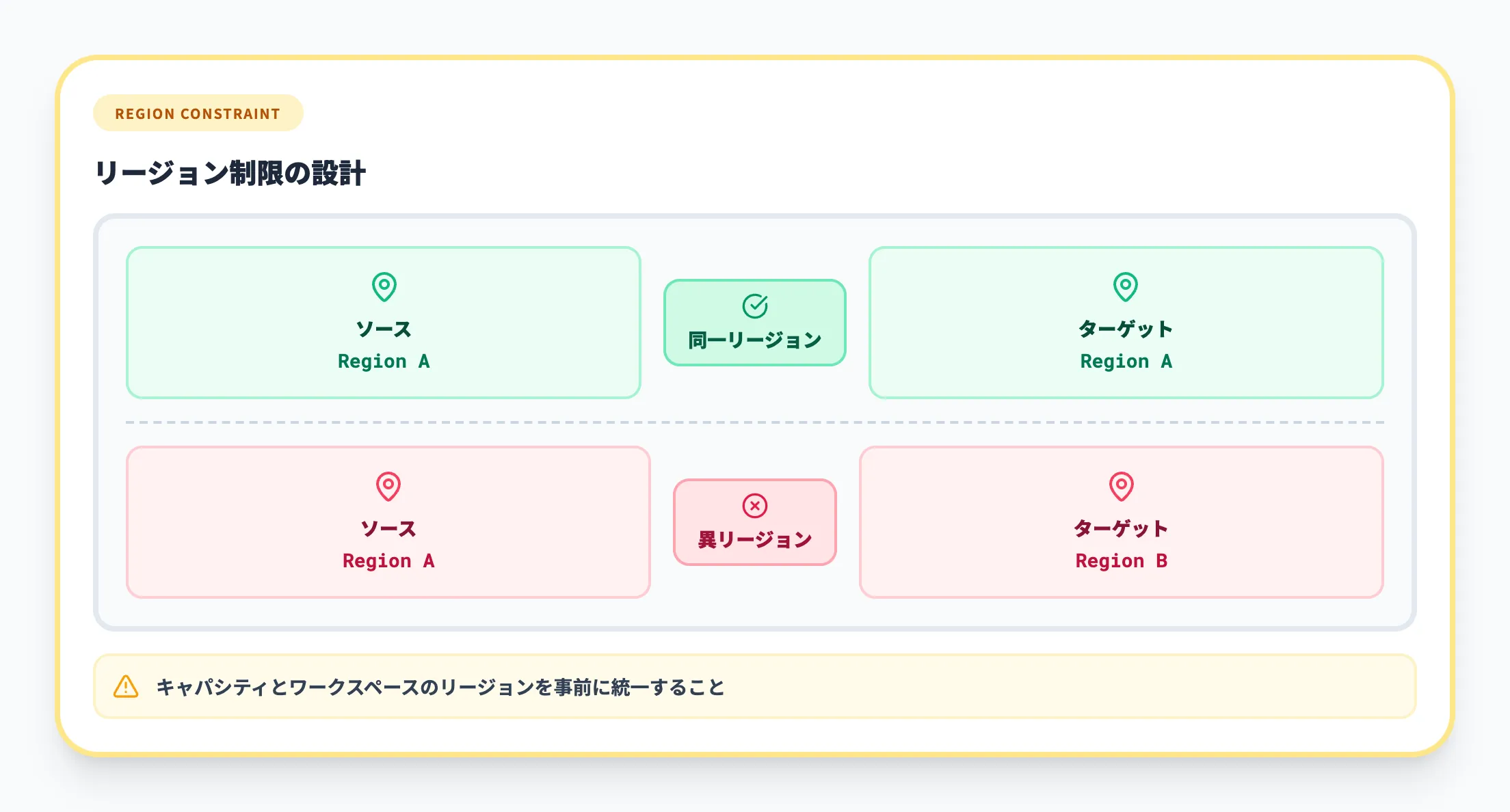
Fabric Data WarehouseとSQL分析エンドポイントの接続は、ソースとターゲットが同一リージョンに存在する必要があります。
異なるリージョン間の接続(ワークスペースやキャパシティが異なるリージョンにある場合を含む)はサポートされず、認証やクエリが失敗する可能性があります。
パフォーマンスのベストプラクティス

Fabric Data Warehouseでは手動チューニングは基本的に不要ですが、以下の点を意識するとパフォーマンスが向上します。
- 自動データ圧縮を活用する。バックグラウンドで断片化されたファイルを自動統合する機能が組み込まれている
- COPY INTOによる一括読み込みでは、小さいファイルを避け100MB以上のまとまったファイルで取り込むとインジェスト速度が向上する
- タイムトラベルとゼロコピー複製(クローンテーブル)を活用し、テスト環境を本番データから安全に分離する

Data Warehouseの高品質データをAIエージェントの判断基盤にするなら
T-SQLで整備した正規化済みの業務データは、AIエージェントが正確な回答を返すための最も信頼性の高い土台です。
AI Agent Hubは、Data Warehouseの業務データをAIエージェントのナレッジソースとして直結させるエンタープライズAI基盤です。
- SQLで整備した業務データをAgentが直接参照
Data Warehouseに蓄積した業務データを、AIエージェントがナレッジソースとしてリアルタイムに参照。SQLスキルを持つチームがデータ整備からAI活用まで一貫して推進できます。
- 行レベル・列レベルセキュリティがAgent制御にも継承
Data Warehouseに設定したきめ細かなアクセス制御が、AIエージェントのデータ参照にもそのまま適用。データガバナンスを維持したままAI活用を拡大できます。
- 使い慣れたMicrosoft環境をそのまま活用
Teamsなど既存のMicrosoftツールの延長でAIエージェントが動作。新しいツールの学習コストはゼロです。
- データは100%自社テナント内に保持
AIの学習対象から完全除外。Azure Managed Applicationsとして自社テナント内で動作が完了する設計です。
AI総合研究所の専任チームが、設計から運用まで伴走支援します。まずは無料の資料で、自社の業務にどう活用できるかご確認ください。
DWHの高品質データをAgent回答基盤に
SQLデータをAI業務自動化に直結
Data WarehouseにT-SQLで整備した業務データを、AIエージェントのナレッジソースとして活用。SQLスキルを活かしたAI業務自動化を実現します。
まとめ
本記事では、Microsoft Fabric Data Warehouseの基本概念からアーキテクチャ、T-SQL機能、Lakehouseとの使い分け、セキュリティ、Synapseからの移行、料金体系までを解説しました。
Fabric Data Warehouseが提供する3つの価値は以下のとおりです。
-
SQL中心のエンタープライズDWH
T-SQLベースで主要なDML・DDLに対応し、マルチテーブルACIDトランザクションを備え、既存のSQLスキルをそのまま活かせる。統合クエリオプティマイザーにより手動チューニングも不要
-
きめ細かなセキュリティ
行レベル・列レベルセキュリティと動的データマスキングに対応し、個人情報やセンシティブデータを扱うBI分析にも安心して利用できる
-
柔軟な移行と拡張
Fabric Migration Assistantを活用したSynapseからの移行パスが用意されており、Lakehouseとの併用やDirect LakeモードによるPower BI連携にも対応。段階的な導入と拡張が可能
導入を検討する場合は、まずPoCとして既存のデータマートを1つFabric Data Warehouseに移行し、T-SQL互換性とクエリパフォーマンスを検証することをお勧めします。Lakehouseとの使い分けは、チームのスキルセット(T-SQL中心かSpark中心か)と、マルチテーブルトランザクションやセキュリティ要件の有無で判断するのが現実的です。










