この記事のポイント
 複雑なコードベースの長時間タスクを任せたいなら、Terminal-Bench 2.0で82.7%を記録したGPT-5.5が第一候補
複雑なコードベースの長時間タスクを任せたいなら、Terminal-Bench 2.0で82.7%を記録したGPT-5.5が第一候補- 日常タスクや高速応答が必要なワークフローでは、GPT-5.4から無理に切り替えずトークン効率の改善を見てから判断すべき
- 最高精度が求められる研究・法務・投資分析ならGPT-5.5 Pro、標準業務はGPT-5.5、コスト重視ならGPT-5.4 miniと明確に使い分ける
- OpenAI社内の85%がCodexを週次利用しており、数値もユースケースも公開されている点で、企業導入の参考値として引用しやすい
- サイバー能力の強化に伴いClassifierが厳格化されているため、セキュリティ用途はTrusted Access for Cyberの申請を前提に設計する

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
OpenAIは2026年4月23日に「GPT-5.5」を発表しました。
エージェント的コーディング・コンピュータ操作・ナレッジワーク・科学研究の各領域でGPT-5.4を明確に上回る性能を示しつつ、同じレイテンシで提供される効率重視の設計が特徴です。
2026年2月にパイロット提供が始まり同年4月に拡張された既存の「Trusted Access for Cyber」枠組みが、GPT-5.5の高まったサイバー能力に対応する安全運用の入口として重要性を増しています。
本記事では、GPT-5.5の主要な進化ポイント、GPT-5.4やClaude Opus 4.7との比較、モデルバリアントの使い分け、API・ChatGPT・Codexの利用方法、料金体系、企業での活用事例、運用上の注意点まで、2026年4月時点の公式情報をもとに整理します。
✅2026年6月9日、AnthropicがMythos-class初の一般公開モデル「Claude Fable 5」を発表しました。Opus 4.8の上位に位置する新最上位モデルの詳細はこちら。
▶︎Claude Fable 5とは?Mythos 5との違いや料金、使い方を解説
GPT-5.5とは?OpenAI最新フラグシップモデルの全体像

GPT-5.5(ChatGPT 5.5)は、OpenAIが発表した最新のフラグシップモデルです。
OpenAIは公式ブログで「最も賢く、直感的に使えるモデル」と位置づけ、エージェント的コーディング・コンピュータ操作・ナレッジワーク・初期段階の科学研究といった、コンテキストを横断した推論と行動を必要とする領域での飛躍を謳っています。
前モデルGPT-5.4の延長線上にありつつ、「より大きく、より高性能なモデルほど提供速度が遅くなる」というこれまでのトレードオフを崩し、GPT-5.4と同じ1トークンあたりのレイテンシで運用される点が大きな差別化要素です。
実運用での体感レスポンスを落とさず、知性だけを引き上げる設計になっています。

GPT-5.5のリリース概要
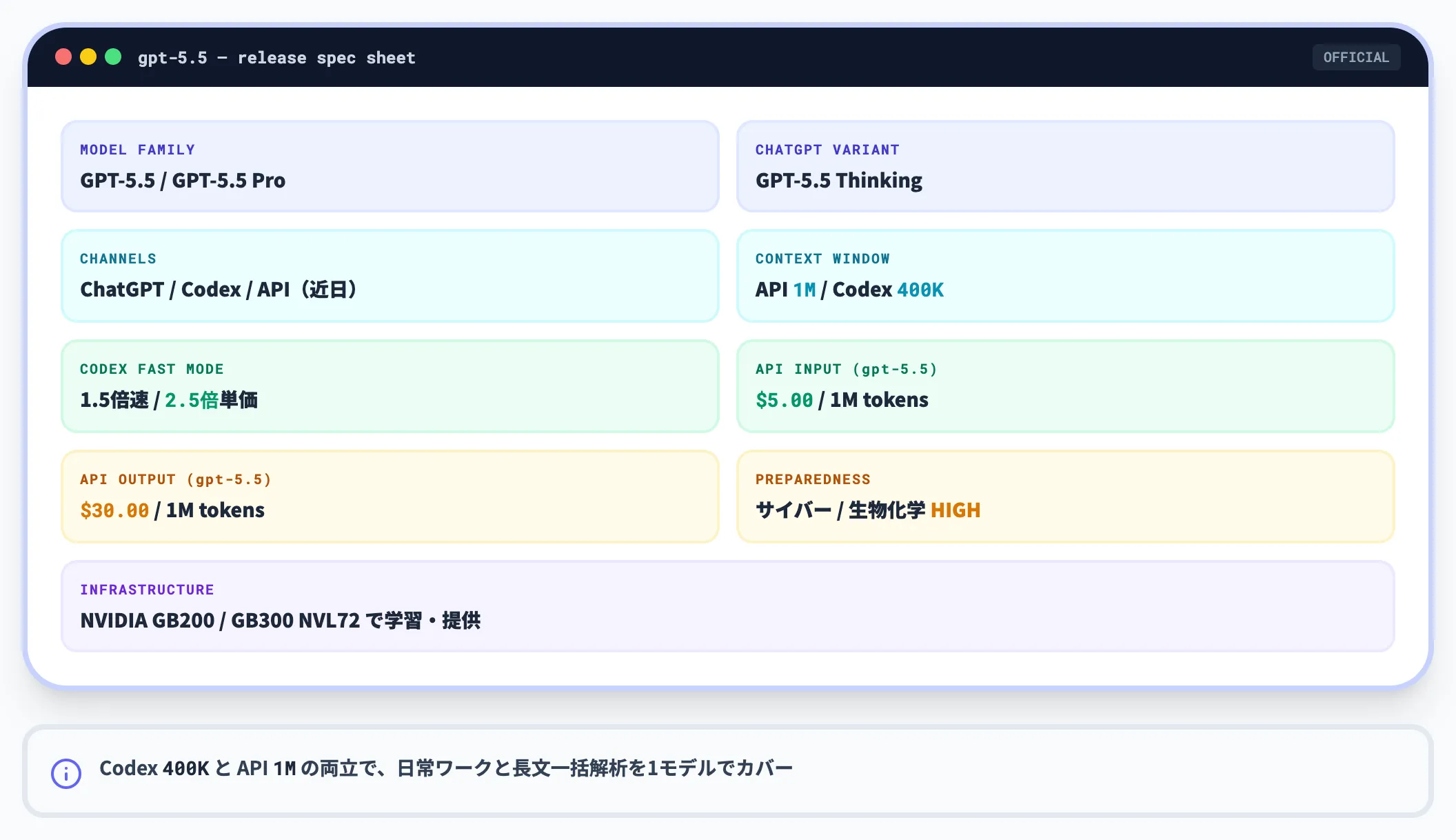
まずは基本情報を整理しておきます。
| 項目 | 内容 |
|---|---|
| モデルファミリー | GPT-5.5、GPT-5.5 Pro |
| ChatGPT提供形態 | GPT-5.5 Thinking |
| 主な利用チャネル | ChatGPT、Codex、API |
| コンテキストウィンドウ | API 約100万トークン(1,050,000)、Codex 40万トークン |
| Codex Fast mode | 1.5倍速、2.5倍のコスト |
| API入力料金 | $5 / 100万トークン(gpt-5.5) |
| API出力料金 | $30 / 100万トークン(gpt-5.5) |
| Preparedness Framework評価 | サイバーセキュリティ・生物/化学: High |
| 学習・提供基盤 | NVIDIA GB200 / GB300 NVL72 |
この表で特に実務に効く項目は、Codexの40万トークンコンテキストと、API約100万トークンコンテキストの両立です。
ChatGPT・Codex側で大規模コードベースを扱う日常ワークと、API経由の長文ドキュメント解析のどちらにも1モデルで対応できます。
GPT-5.5のモデル構成

GPT-5.5は、Proを含めた複数のバリアントで提供されています。呼び名が似ているため、先に整理しておきます。
-
GPT-5.5
標準のフラグシップ。ChatGPTではPlus/Pro/Business/Enterpriseに、CodexではPlus/Pro/Business/Enterprise/Edu/Goの各プランにロールアウトされています。
APIでも2026年4月24日からgpt-5.5として利用できます。
-
GPT-5.5 Pro
追加計算リソースを使ってより深い推論を行う高精度版です。ChatGPTではPro、Business、Enterpriseプランで利用可能で、APIでも同4月24日からgpt-5.5-proとして利用できます。
FrontierMath Tier 4やHumanity's Last Exam(with tools)など、最難ベンチマークで標準版を上回ります。
-
GPT-5.5 Thinking
ChatGPT上でGPT-5.5を推論強化モードで利用する形態です。Plus以上のプランでモデルピッカーから選択でき、コーディング・リサーチ・情報統合・文書中心のタスクで高い精度を発揮します。
APIモデルIDとしての独立リリースは「gpt-5.5」と「gpt-5.5-pro」の2系統で、GPT-5.5 ThinkingはChatGPT上での推論強化状態を指す呼称です。
この整理をしておくと、以降のベンチマーク比較や料金表が読みやすくなります。
GPT-5.5の主要な進化ポイント
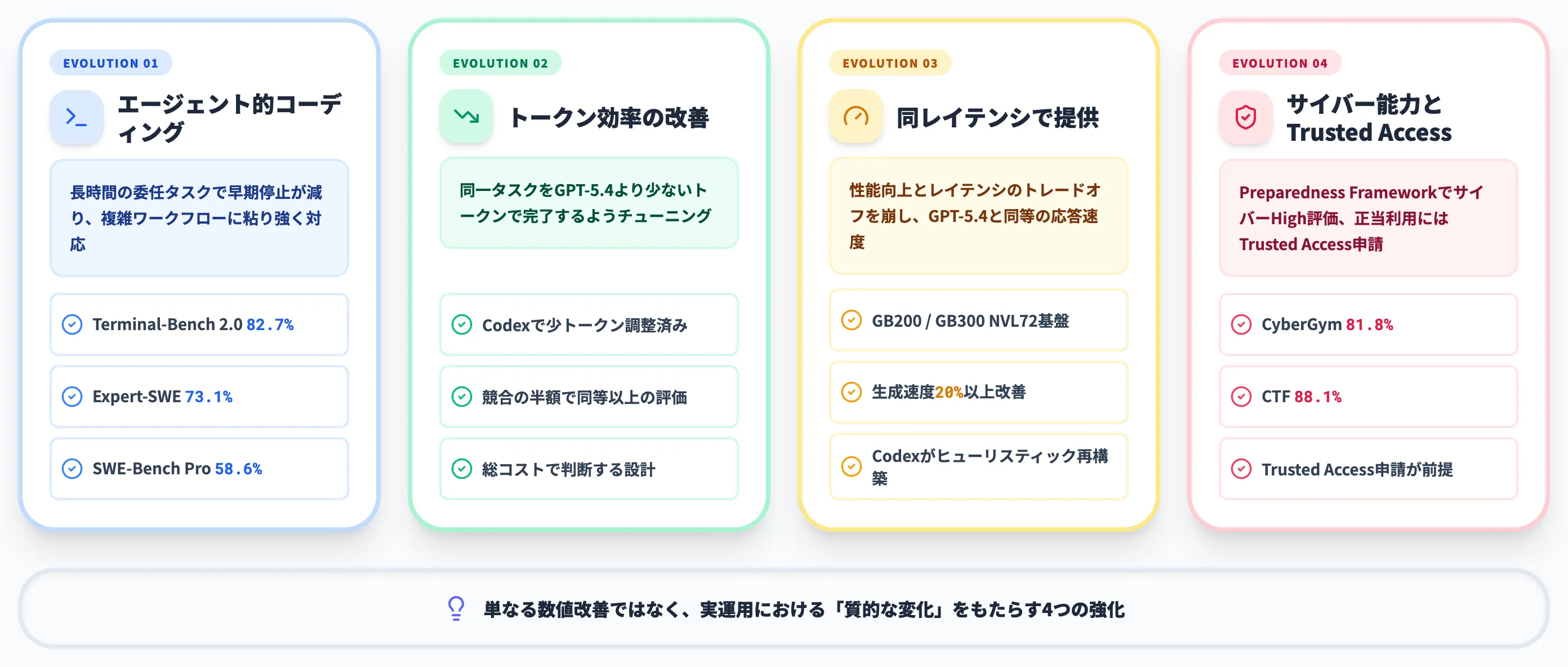
GPT-5.5は、GPT-5.4比で単なる数値改善にとどまらず、実運用における「質的な変化」をもたらす4つの強化が入っています。順に確認します。
エージェント的コーディングの強化
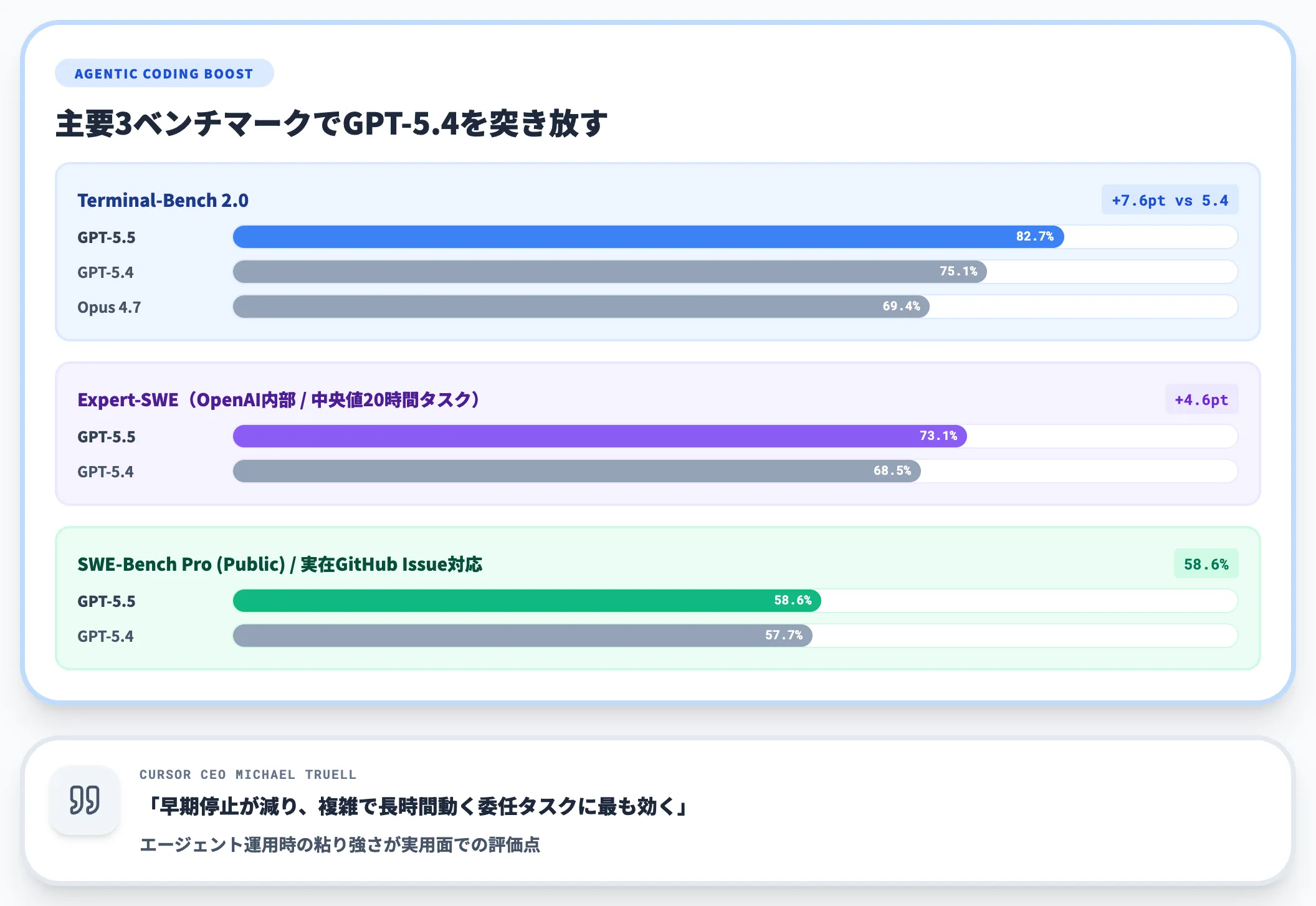
GPT-5.5でもっとも顕著に伸びているのが、エージェント的コーディングの領域です。
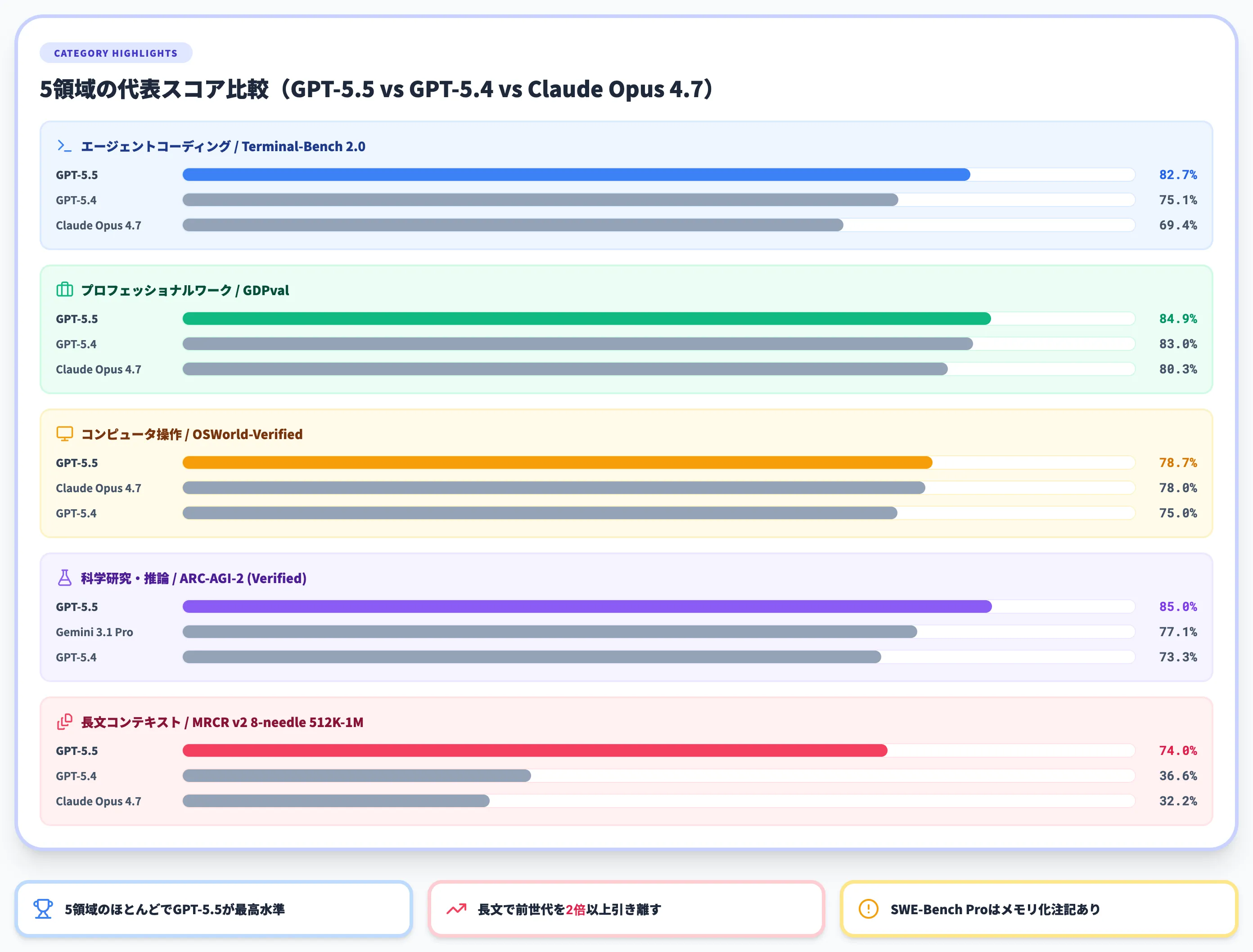
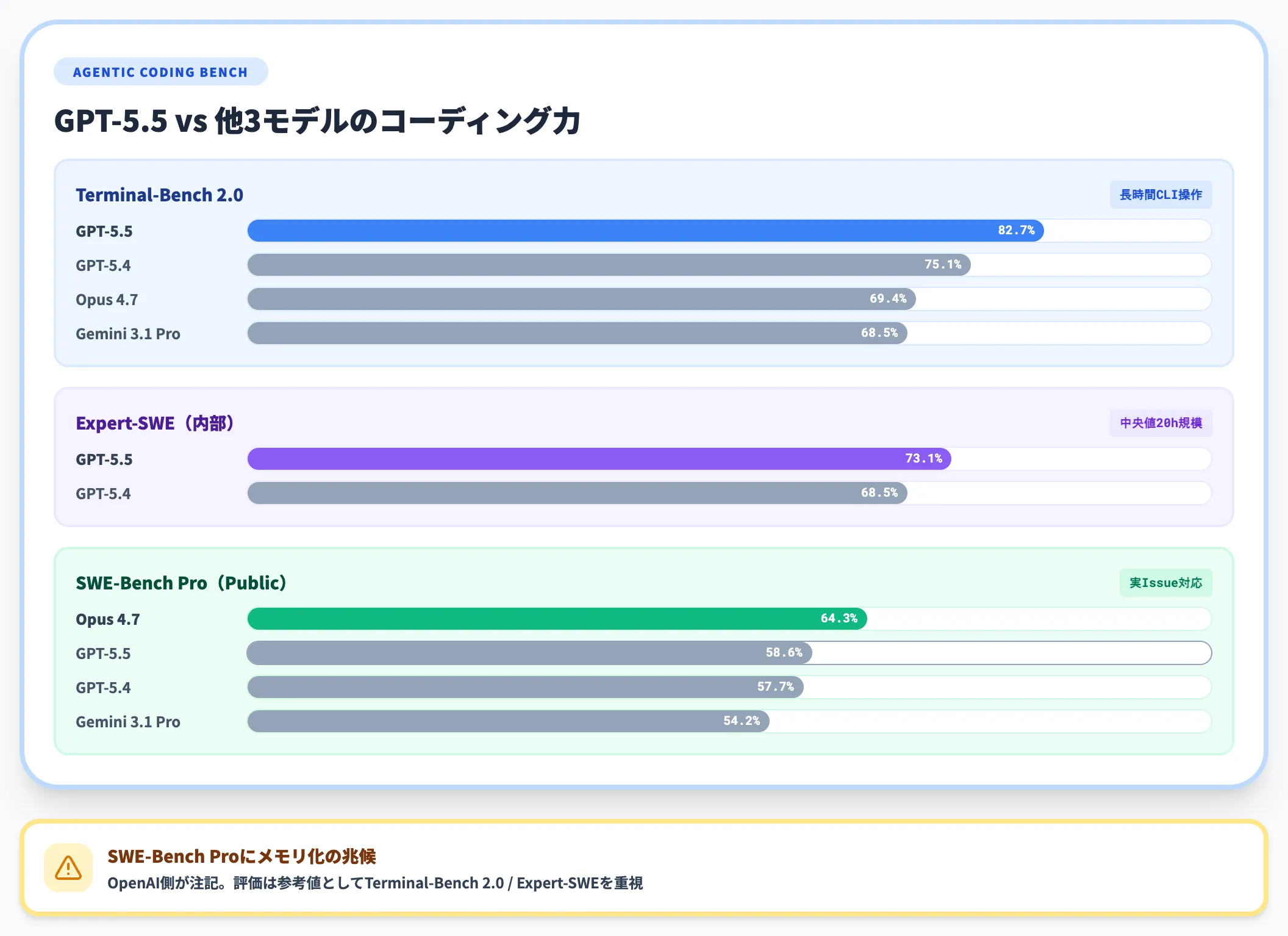
複雑なコマンドライン操作を要するTerminal-Bench 2.0で82.7%を記録し、GPT-5.4の75.1%を7.6ポイント、Claude Opus 4.7の69.4%を13ポイント以上引き離しました。
実在のGitHub Issue対応能力を評価するSWE-Bench Pro(Public)でも58.6%に到達し、OpenAI内部で実施された中央値20時間相当の長期コーディングタスクを扱うExpert-SWEでは73.1%(GPT-5.4は68.5%)です。いずれも「より少ないトークンで」スコアを伸ばしている点が共通しています。
Cursor CEOのMichael Truell氏は「GPT-5.5は早期停止が減り、複雑で長時間動く委任タスクに最も効く」とコメントしており、エージェント運用時の粘り強さが実用面での評価点です。
トークン効率の劇的な改善

GPT-5.5は、同じタスクをこなすのに必要なトークン数が大幅に減りました。
OpenAI公式によれば、Codex上での同一タスクをGPT-5.4より少ないトークンで完了できるようにチューニングされていると明記されています。
Artificial Analysis Coding Indexでは、競合フロンティアコーディングモデルの半分のコストで同等以上のインテリジェンスを提供するという評価も得ており、単価あたりのパフォーマンスが評価軸の中心になってきています。
GPT-5.4と同じレイテンシで提供
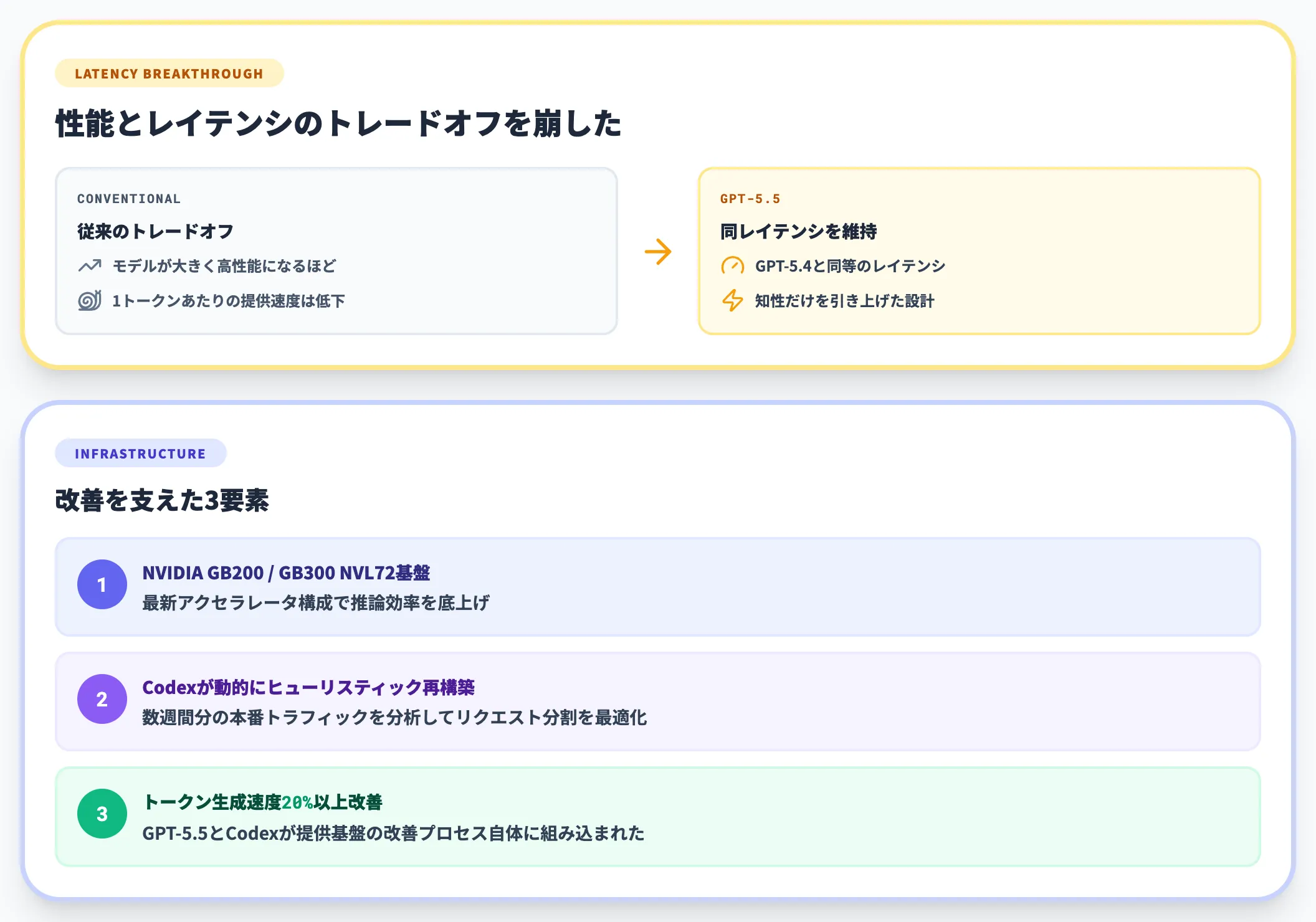
通常、モデルが大きく高性能になるほど1トークンあたりの提供速度が遅くなります。しかしGPT-5.5は、NVIDIA GB200 / GB300 NVL72ベースの提供環境改善にCodexとGPT-5.5が寄与した結果、GPT-5.4と同等のレイテンシを維持しています。
具体的には、Codexが数週間分の本番トラフィックを分析し、リクエスト分割のヒューリスティックを動的に再構築することで、トークン生成速度を20%以上引き上げた事例がOpenAI公式で公開されています。
GPT-5.5とCodexが提供基盤の改善プロセス自体に組み込まれている点が象徴的です。
サイバーセキュリティ能力の強化とTrusted Access

GPT-5.5は、Preparedness Frameworkにおいてサイバーセキュリティと生物/化学能力がいずれも「High」に分類されています。CyberGym 81.8%(GPT-5.4: 79.0%、Claude Opus 4.7: 73.1%)や、内部CTF(Capture-the-Flags)88.1%(GPT-5.4: 83.7%)といった能力向上に対応したものです。
これに伴い、不適切な利用を防ぐためのClassifierが厳格化され、サイバー系プロンプトの一部に対する拒否が強まっています。
正当な防御業務で制約を受けないよう、OpenAIはTrusted Access for Cyberという枠組みを用意しており、検証済みユーザーに対して制限を緩和した「サイバー寛容」バージョンを提供します。
Codexから順次展開中で、重要インフラ防御に従事する組織は別枠でGPT-5.4-Cyberにも申請可能です。
セキュリティ業務で活用する場合は、一般の ChatGPTユーザーとは別に、Trusted Accessの申請パスを前提に設計することが運用の出発点になります。
GPT-5.5のベンチマーク性能
GPT-5.5の性能を把握するうえで、領域別に主要ベンチマークを整理します。
エージェントコーディングベンチマーク
コーディングエージェントとしての能力を測る主要指標では、GPT-5.5が軒並み最高水準を記録しています。
ベンチマーク用語の解説
- SWE-Bench Pro(Public)
GitHubの実プロジェクトを題材にした1,865タスクで、複数ファイル・100行超に及ぶ大規模な修正をAIに行わせ、テストが通るパッチを出せた割合を測る指標。プロのエンジニアでも数時間〜数日かかる「長尺」のソフトウェアエンジニアリング能力を評価します。
- Terminal-Bench 2.0
ターミナル上での89タスク(モデル学習やシステム管理など)を多段階に実行できるかを測るベンチマーク。フロンティアモデルでも65%未満という難易度設計で、現場作業に近い粘り強さを評価します。
- Expert-SWE(Internal)
OpenAIが内部で構築したベンチマークで、人間の熟練エンジニアの所要時間中央値が20時間に及ぶ長期コーディングタスクを集めた評価セット。Codexユーザーが日常的に走らせている長尺ワークの実態を反映する設計。
| ベンチマーク | GPT-5.5 | GPT-5.4 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-Bench Pro(Public) | 58.6% | 57.7% | 64.3% | 54.2% |
| Terminal-Bench 2.0 | 82.7% | 75.1% | 69.4% | 68.5% |
| Expert-SWE(Internal) | 73.1% | 68.5% | – | – |
SWE-Bench Pro(Public)のみClaude Opus 4.7が上回っていますが、OpenAI側は同ベンチマークについてメモリ化の兆候があることを注記しており、評価の参考値としてのみ見るのが妥当です。
一方でTerminal-Bench 2.0とExpert-SWEは、長時間・複数ステップの現場運用に近いシナリオであり、GPT-5.5の優位性が明確に出ています。
プロフェッショナルワーク・知識労働
知識労働の実務品質を測るGDPvalやFinanceAgentでも、GPT-5.5はプロ向け業務での実用水準を引き上げています。
ベンチマーク用語の解説
- GDPval(wins or ties)
米国GDPに最も貢献する9産業から選ばれた44職種のリアルなホワイトカラー業務(提案書、財務分析、法務文書等)について、AI出力と業界エキスパート(平均14年超の実務経験)の成果物をブラインドで比較し、人間レビュアーが「同等以上」と判定した割合。
- FinanceAgent v1.1
Vals AIがStanfordや銀行・PEファンドの専門家と構築した、エントリーレベルの金融アナリスト業務を想定するベンチマーク。SEC提出書類などを使って、検索・分析・予測を多段階で解く537問構成。
- Investment Banking Modeling
投資銀行業務における財務モデリング(DCF、LBO、M&A評価など)の作成精度を評価するタスク群。OpenAI公式ブログに記載の指標。
- OfficeQA Pro
Databricksが構築した、米国財務省公報(約89,000ページ・2,600万超の数値を含む)を対象に、複数文書を横断した精緻な検索と数値計算・推論を要求する企業向けベンチマーク。フロンティアモデルでもコーパス提供下で平均34.1%と難度が高い設計です。
| ベンチマーク | GPT-5.5 | GPT-5.4 | GPT-5.5 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|---|
| GDPval(wins or ties) | 84.9% | 83.0% | 82.3% | 80.3% | 67.3% |
| FinanceAgent v1.1 | 60.0% | 56.0% | – | 64.4% | 59.7% |
| Investment Banking Modeling | 88.5% | 87.3% | 88.6% | – | – |
| OfficeQA Pro | 54.1% | 53.2% | – | 43.6% | 18.1% |
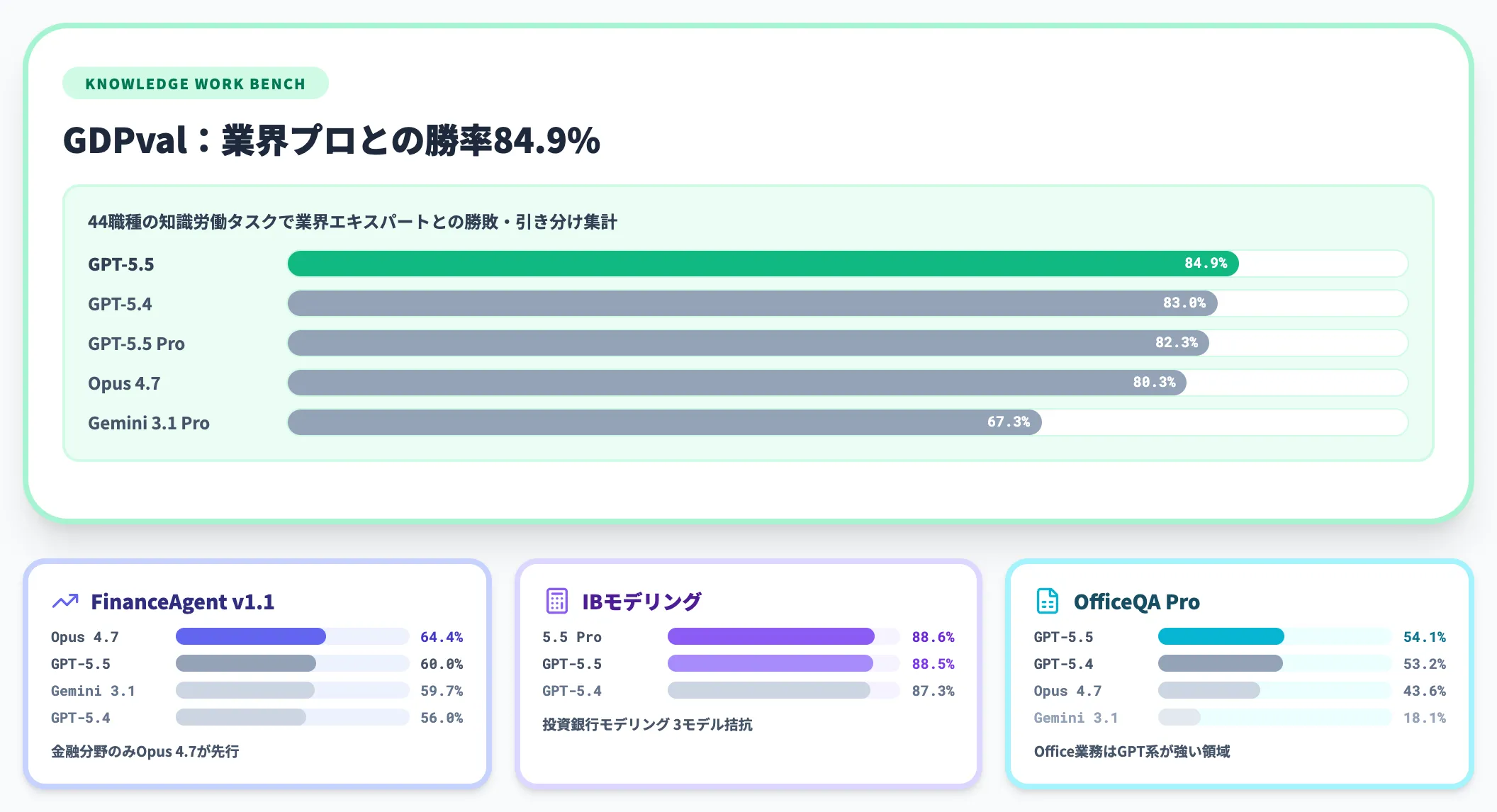
GDPvalは44の職種にわたる知識労働タスクで業界プロとの勝敗・引き分けを集計した指標です。GPT-5.5は84.9%で業界エキスパートのベースラインを超えており、オフィス業務の日常的なアウトプット品質で人間レビュアーと互角以上に判定される段階に入っています。
FinanceAgentのみClaude Opus 4.7が勝っており、金融分野の特定ドメインでは他モデルとの比較検討が残る点に留意しましょう。
コンピュータ操作・ツール活用
エージェントとしてブラウザやアプリを操作する能力もGPT-5.5の強みです。
ベンチマーク用語の解説
- OSWorld-Verified
実OS(Linux/Windows/macOS)上でブラウザやファイル操作などを多段階に行わせ、最終的に正しい結果に到達できるかを測る指標。コンピュータ・ユース能力の代表的ベンチマークで、実行ベースの自動評価を採用。
- Toolathlon
HKUST NLPらが構築したベンチマーク。32の実アプリケーション(Google Calendar、Notion、Kubernetes、BigQuery等)と604ツールを使い、平均約20ステップの操作で実環境に変更を加える長尺タスクを評価します。
- BrowseComp
OpenAIが公開した1,266問の難問集で、Web上に存在する「見つけにくく絡み合った情報」をブラウザを駆使して特定できるかを測る検索エージェント特化型ベンチマーク。GPT-4oでも素のままでは0.6%しか解けない難度。
- Tau2-bench Telecom(原文プロンプト)
Sierra Researchが開発したデュアルコントロール型ベンチマーク。AIエージェントとユーザーの双方がツールを使って共有環境を変更する通信業界のサポートシナリオを再現し、自律操作だけでなくユーザーへの指示・誘導能力も評価します。
- MCP Atlas
Scale AIが構築した、36の実MCPサーバーと220ツールを使う1,000タスクの大規模ベンチマーク。Model Context Protocolを介して3-6個のツールを自律的に選択・連結する能力を測ります。
| ベンチマーク | GPT-5.5 | GPT-5.4 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|
| OSWorld-Verified | 78.7% | 75.0% | 78.0% | – |
| Toolathlon | 55.6% | 54.6% | – | 48.8% |
| BrowseComp | 84.4% | 82.7% | 79.3% | 85.9% |
| Tau2-bench Telecom(原文プロンプト) | 98.0% | 92.8% | – | – |
| MCP Atlas | 75.3% | 70.6% | 79.1% | 78.2% |
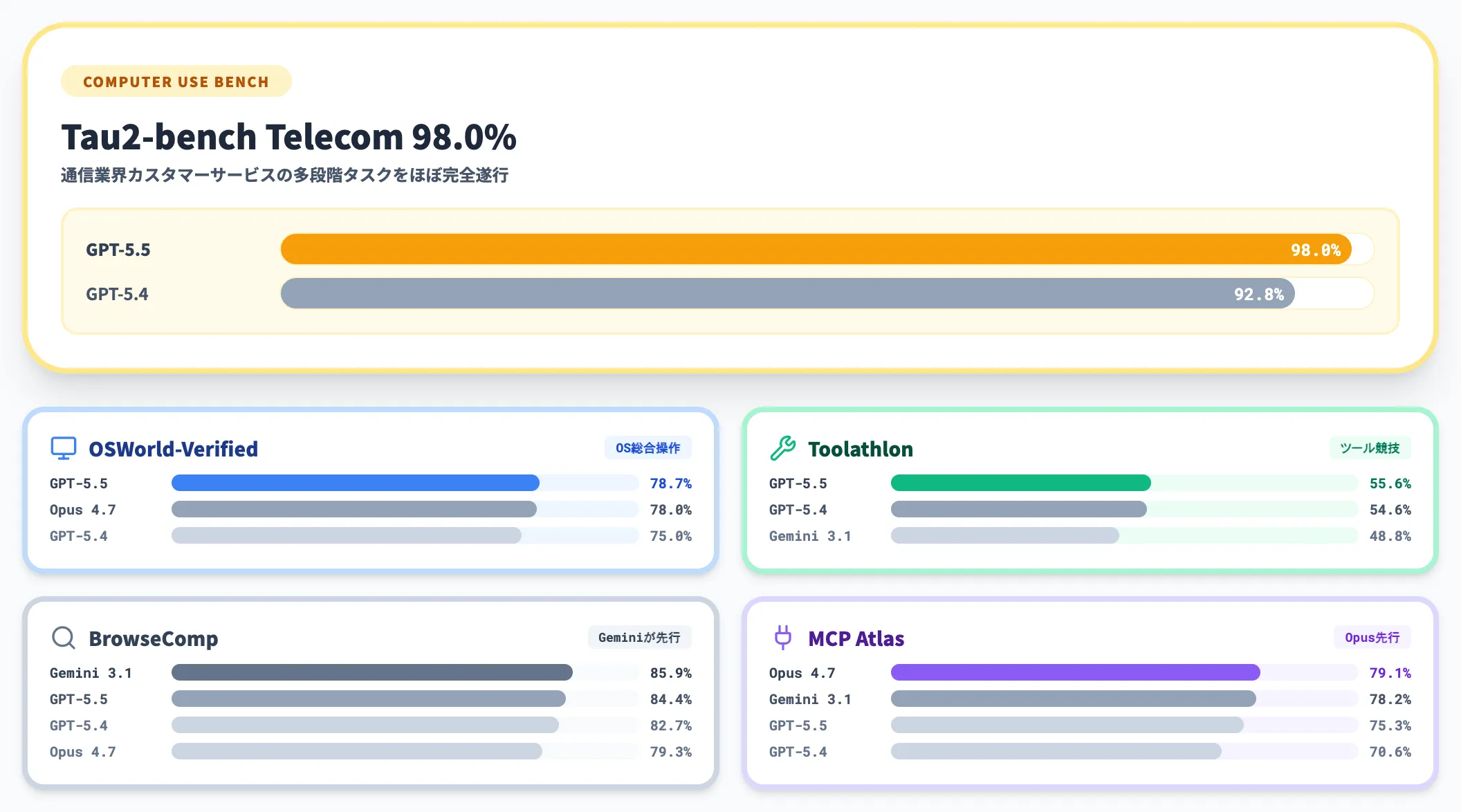
OSWorld-VerifiedはOSを実環境で操作する総合ベンチマークで、GPT-5.5は78.7%に到達しClaude Opus 4.7をわずかに上回っています。
Tau2-bench Telecomの98.0%は、通信業界のカスタマーサービスワークフローを想定した複雑な多段階タスクをほぼ完全にこなせる水準です。
BrowseCompはGemini 3.1 Proに及ばず、純粋な検索タスクでは競合の選択肢も現実的という読み解きになります。
科学研究・推論ベンチマーク
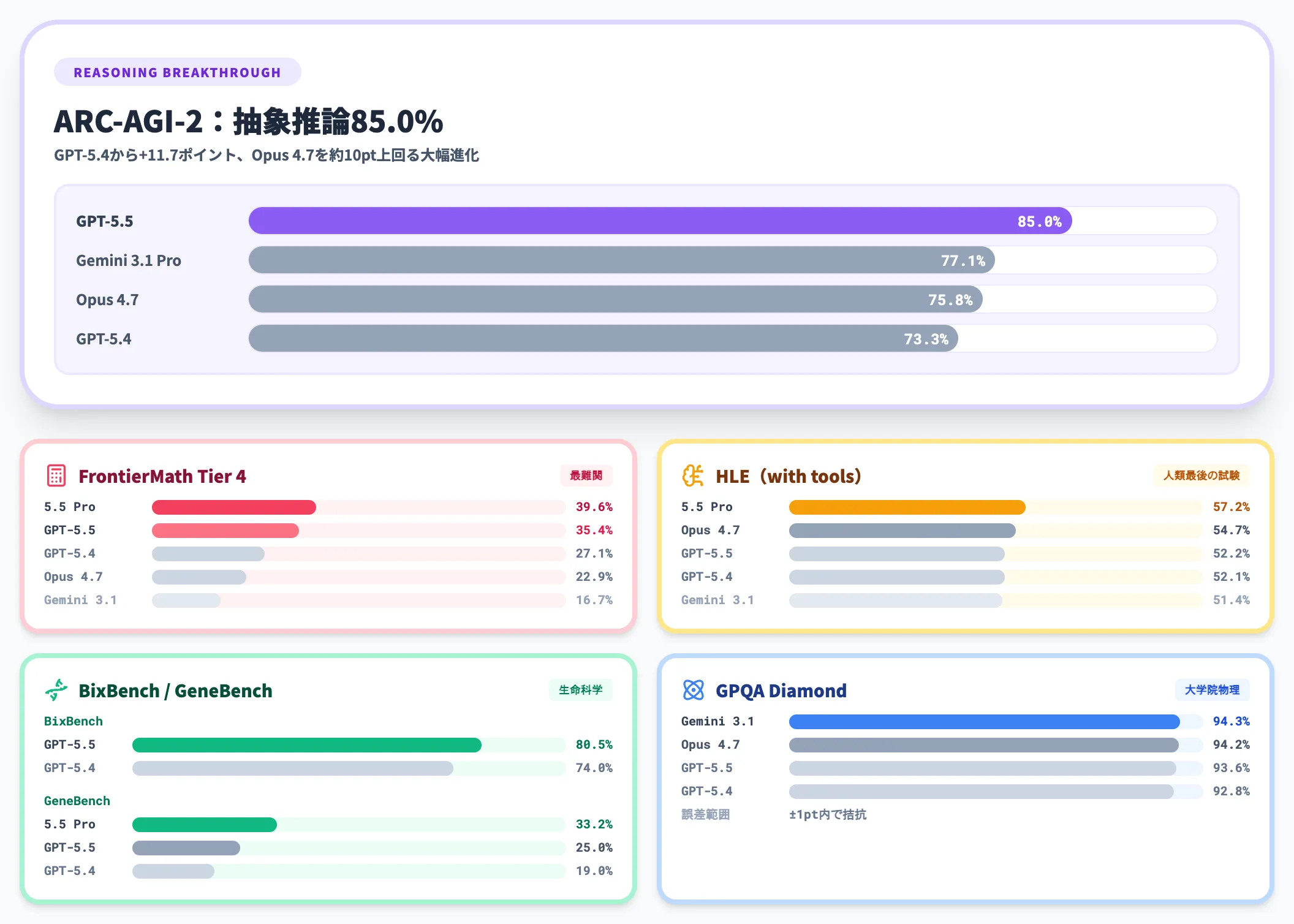
ドメイン固有の研究タスクや難関推論でも、GPT-5.5は世代更新のたびに伸びている領域です。
ベンチマーク用語の解説
- GeneBench
OpenAIが構築した、ゲノミクスや定量生物学の多段階データ分析タスク(103評価・10領域)。専門家が「データのクリーニング→統計モデル選択→結論の導出」までを一気通貫で行うワークフローを再現したベンチマーク。
- BixBench
FutureHouseが公開した計算生物学エージェント向けベンチマーク。53の解析シナリオに対して、AIエージェントがコード(Python/R/Bash)を実行しながら仮説検証や解析を行う前提で設計されています。
- FrontierMath Tier 1-3 / Tier 4
Epoch AIが数学者と構築した未公開の高度な数学問題集。Tier 1-3は大学院〜研究レベル、Tier 4は数学教授・ポスドクが数週間かけて1問を作成した50問構成で、解決に何十年もかかる可能性があるとされる最難関帯。
- GPQA Diamond
博士号取得者が作成した物理・化学・生物の多肢選択式問題198問からなる「Google-proof」ベンチマーク。30分以上のWeb検索を許しても非専門家は34%しか解けず、深い専門理解が問われます。
- Humanity's Last Exam(with tools)
世界500機関・約1,000人の専門家(教授・研究者・博士号保持者)が作成した2,500問のクローズドエンド学術ベンチマーク。数学・物理・生物・人文・工学などを横断し、検索では即答できない深い推論を求めます。「with tools」はツール利用を許可した条件下での評価。
- ARC-AGI-2(Verified)
François Chollet氏らによる抽象推論ベンチマーク。学習データに含まれない新規パターンに対する一般化能力を入出力ペアの形式で測り、AGIに近づいているかの代表的指標として広く参照されます。
| ベンチマーク | GPT-5.5 | GPT-5.4 | GPT-5.5 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|---|
| GeneBench | 25.0% | 19.0% | 33.2% | – | – |
| BixBench | 80.5% | 74.0% | – | – | – |
| FrontierMath Tier 1-3 | 51.7% | 47.6% | 52.4% | 43.8% | 36.9% |
| FrontierMath Tier 4 | 35.4% | 27.1% | 39.6% | 22.9% | 16.7% |
| GPQA Diamond | 93.6% | 92.8% | – | 94.2% | 94.3% |
| Humanity's Last Exam(with tools) | 52.2% | 52.1% | 57.2% | 54.7% | 51.4% |
| ARC-AGI-2(Verified) | 85.0% | 73.3% | – | 75.8% | 77.1% |
GeneBenchやBixBenchは多段階の生命科学データ分析を対象にしており、GPT-5.5は本来数日かかる専門家タスクを一定精度で遂行できる水準に近づいています。
ARC-AGI-2の85.0%は、抽象的推論能力の面でGPT-5.4(73.3%)から一段階踏み込んだ進歩です。
長文コンテキスト性能
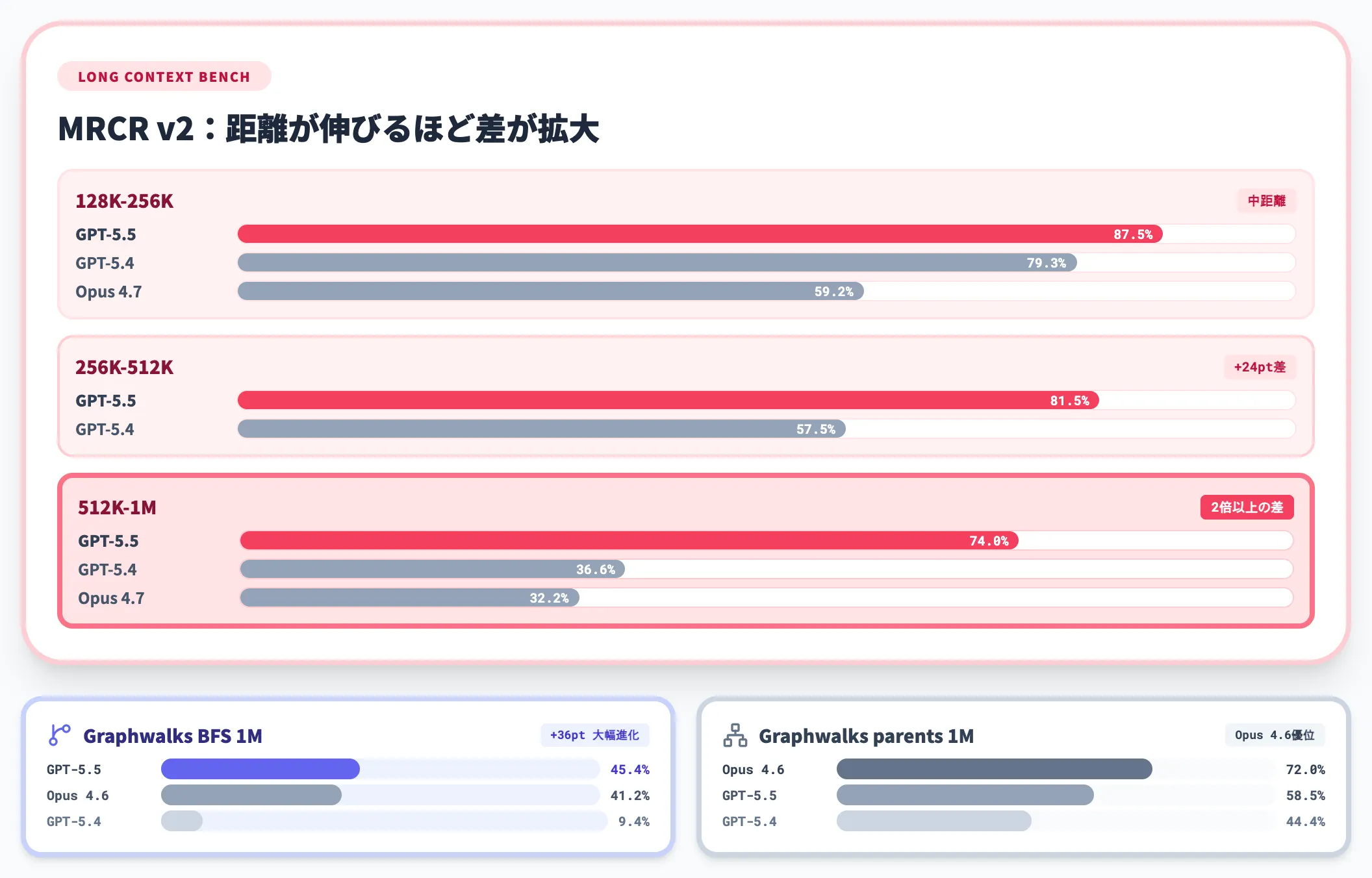
長文処理では、特に長距離になるほどGPT-5.5の優位性が拡大します。
ベンチマーク用語の解説
- OpenAI MRCR v2 8-needle(128K-256K / 256K-512K / 512K-1M)
Multi-Round Coreference Resolutionの略で、長い合成会話の中に同じ依頼(例「タピールの詩を書いて」)を8回紛れ込ませ、「i番目の出力を返して」と指示して正しく区別・参照できるかを測るテスト。コンテキスト長帯ごとの精度を評価します。
- Graphwalks BFS 1mil f1
100万トークン規模の有向グラフ(ハッシュ値のエッジリスト)を文脈に与え、指定ノードから幅優先探索(BFS)で到達可能なノード集合を返せるかをF1スコアで評価する長文推論ベンチマーク。
- Graphwalks parents 1mil f1
同じく100万トークン級のグラフから、特定ノードの親ノードを正確に列挙できるかを評価する指標。
| ベンチマーク | GPT-5.5 | GPT-5.4 | Claude Opus 4.7 |
|---|---|---|---|
| OpenAI MRCR v2 8-needle 128K-256K | 87.5% | 79.3% | 59.2% |
| OpenAI MRCR v2 8-needle 256K-512K | 81.5% | 57.5% | – |
| OpenAI MRCR v2 8-needle 512K-1M | 74.0% | 36.6% | 32.2% |
| Graphwalks BFS 1mil f1 | 45.4% | 9.4% | 41.2%(Opus 4.6) |
| Graphwalks parents 1mil f1 | 58.5% | 44.4% | 72.0%(Opus 4.6) |
512Kから1Mトークン帯の検索・参照で、GPT-5.4が36.6%だったMRCR v2をGPT-5.5は74.0%まで引き上げています。
超長文ドキュメントを丸ごと読み込んで分析する用途では、GPT-5.5がもっとも現実的な選択肢になります。
一方でGraphwalks parentsはClaude Opus 4.6(旧世代)が依然として上位にあり、グラフ構造を辿るタイプの推論では他モデル併用も視野に入ります。
GPT-5.5とGPT-5.4・競合モデルとの比較

ベンチマーク単体ではなく、「どのモデルをどう使い分けるか」の判断軸を整理します。ここが実務で一番詰まる論点です。
GPT-5.4からアップグレードすべきか

GPT-5.5は、GPT-5.4の後継として設計されています。以下の観点で使い分けを判断するのが現実的です。
-
即アップグレードすべきケース
長時間・複数ファイルにまたがるコーディング、大規模リファクタリング、超長文ドキュメント解析、サイバー防御業務、科学研究向けデータ分析。Terminal-Bench 2.0、Expert-SWE、MRCR v2の改善幅がそのまま効きます。
-
様子見でよいケース
短いQ&A、要約、翻訳、テンプレート生成。GPT-5.4で十分な精度が出ており、APIの単価差(入力$2.50→$5.00、出力$15.00→$30.00)を払ってまで切り替える実利が薄い領域です。
-
コスト最優先のケース
GPT-5.4 miniを据え置きで使い続け、一部の高難度タスクだけGPT-5.5にルーティングする二段構成が現実解になります。
Claude Opus 4.7 / Gemini 3.1 Proとの比較

競合フロンティアモデルとの比較では、それぞれ勝ち筋が異なります。
-
Claude Opus 4.7が優位な領域
SWE-Bench Pro(Public)、FinanceAgent、Graphwalks parents 1milなど。ただしメモリ化の注記があるベンチマークは割引が必要です。
-
Gemini 3.1 Proが優位な領域
BrowseCompの純粋検索能力、GPQA Diamondの一部(ただし誤差範囲)。
-
GPT-5.5がリードする領域
Terminal-Bench 2.0、OSWorld-Verified、GDPval、FrontierMath Tier 4、ARC-AGI-2、そして超長距離のMRCR v2。
実務的な使い分けとしては、長時間のエージェント型コーディングと知識労働統合が主戦場ならGPT-5.5、コード中心で安定性重視ならClaude Opus 4.7、検索主体のリサーチエージェントならGemini 3.1 Proという構成が当面のスタンダードになりそうです。
導入判断で詰まる論点
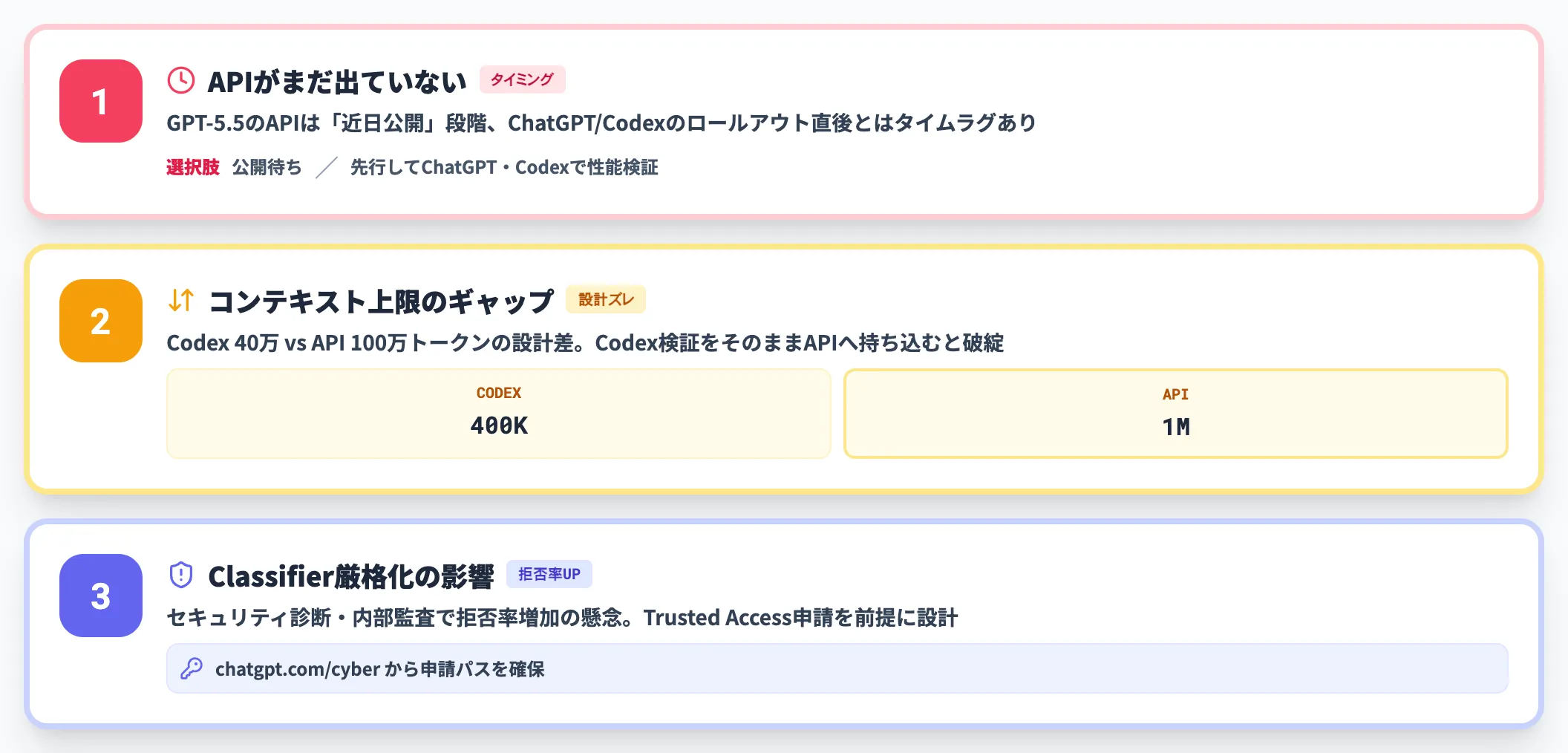
企業で複数モデルを併用する場合、選定の議論は以下3点で詰まりがちです。
-
API公開直後で運用知見が少ない
GPT-5.5のAPIは2026年4月24日に公開されたばかりで、本番運用での実トラフィック評価データはまだ揃っていません。API前提のシステム設計を進める場合は、ChatGPT/Codexで先行検証していたユースケースをそのままAPIに持ち込み、Batch・Flexで小規模に運用しながら他社事例の蓄積を待つのが安全です。
-
Codexでの400KコンテキストとAPI 1Mコンテキストのギャップ
Codexは40万トークン、APIは約105万トークン(1,050,000)で上限が異なります。Codexで動かす前提の検証をそのままAPI運用に持ち込む場合、後段のコンテキスト設計を切り替える必要があります。
-
Classifier厳格化の影響範囲
サイバー関連だけでなく、セキュリティ診断や内部監査用途でも拒否率が上がる可能性があります。Trusted Accessを取らずにいきなり本番運用に載せると、現場で詰まる確率が高くなります。
GPT-5.5の料金体系

GPT-5.5の料金は、API利用とChatGPT・Codexの各プランで体系が異なります。2026年4月時点の公式発表内容をもとに整理します。
ChatGPTプラン別のアクセス
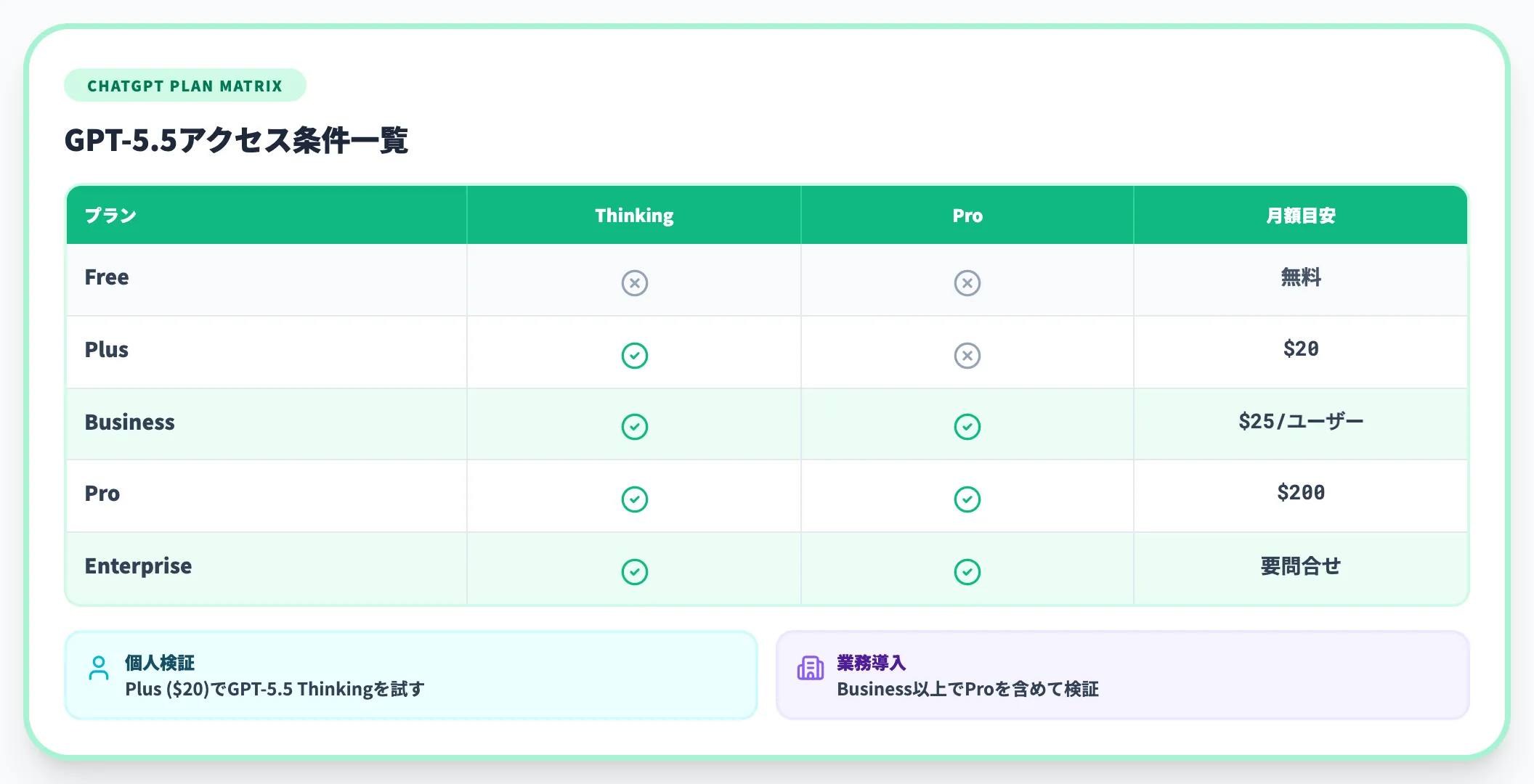
ChatGPTでGPT-5.5に触れるには、以下の条件に沿ってプランを選びます。
| プラン | GPT-5.5 Thinking | GPT-5.5 Pro | 月額料金(目安) |
|---|---|---|---|
| Free | 利用不可 | 非対応 | 無料 |
| Plus | モデルピッカーから手動選択可 | 非対応 | $20/月 |
| Business | モデルピッカーから手動選択可 | 対応 | $25/月/ユーザー |
| Pro | 対応 | 対応 | $200/月 |
| Enterprise | 対応 | 対応 | 要問い合わせ |
GPT-5.5 ProはPro、Business、Enterpriseの3プランに限定されている点が、GPT-5.4 Pro(Pro/Enterprise向け)と異なるポイントです。個人検証ではPlusで標準版を触り、業務導入ではBusiness以上でProを含めて触るのが合理的です。
Codexプランでの利用
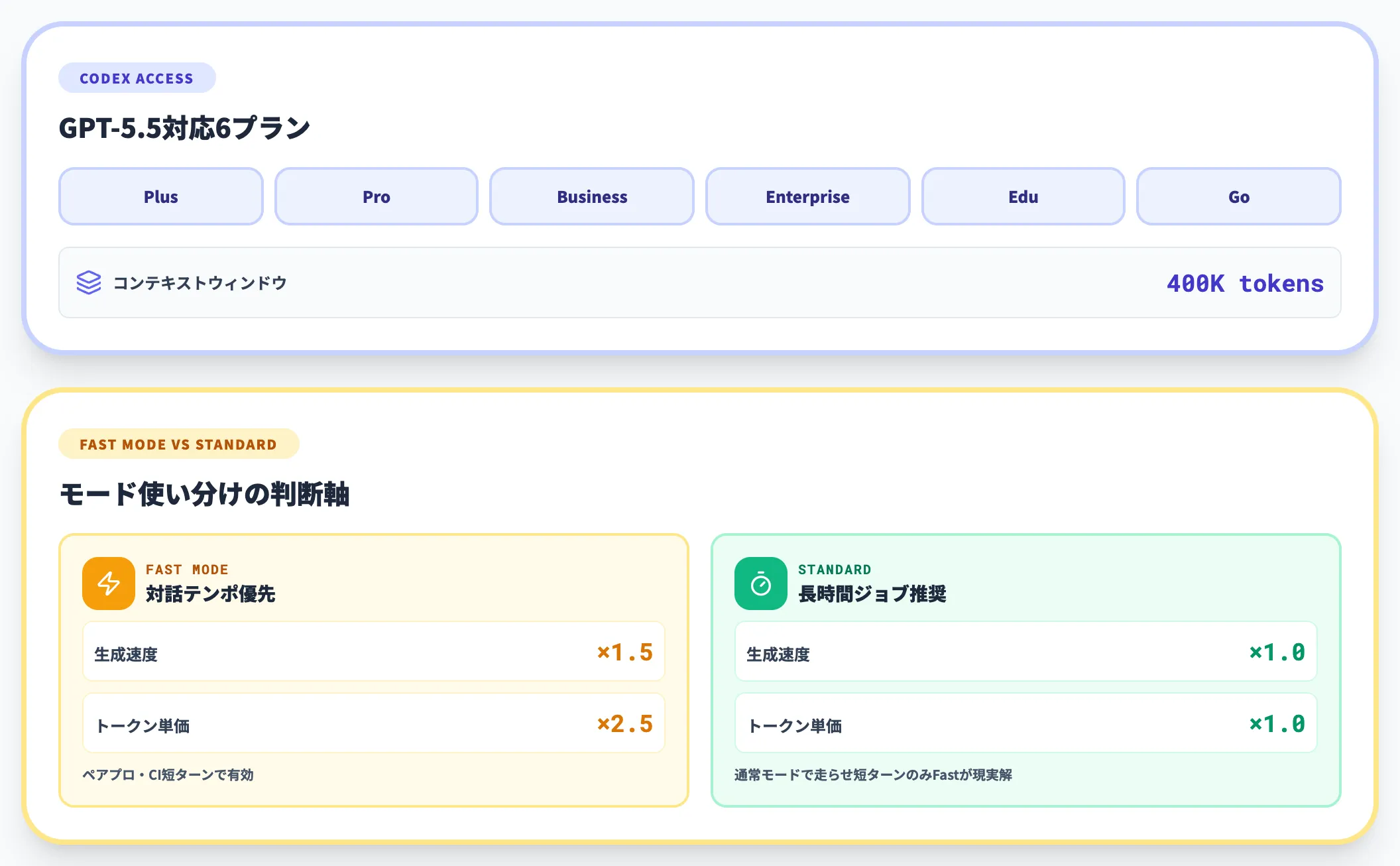
Codexでは以下のプラン群でGPT-5.5が利用可能です。
-
Codex対応プラン
Plus、Pro、Business、Enterprise、Edu、Goの各プランでGPT-5.5が使えます。Codex経由のコンテキストウィンドウは40万トークンです。
-
Codex Fast mode
1.5倍の生成速度と引き換えに、標準の2.5倍のトークン単価になります。インタラクティブなペアプログラミング用途やCIに組み込んだ短ターンのループで有効です。
-
長時間ジョブでの運用
Codexでの長時間タスクは、Fast modeを使わない通常モードのほうが費用対効果が高いケースが多い傾向です。開始時は通常モードで走らせ、ボトルネックになっている短ターンだけFast modeに切り替える二段運用が現実的です。
API料金
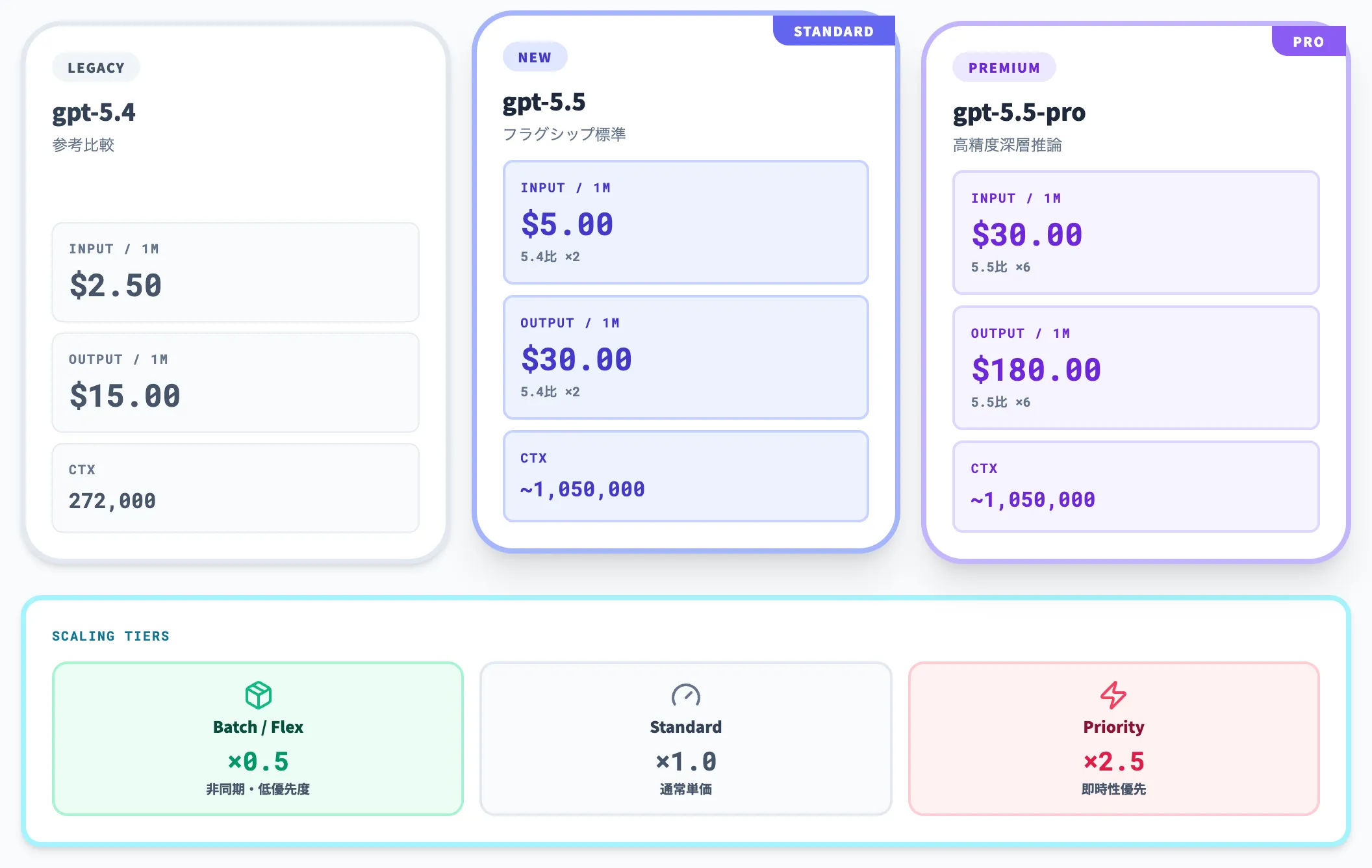
APIでも2026年4月24日に提供開始されました。標準単価は以下の通りで、長文入力時の追加条件やキャッシュ入力の扱いは後段の価格注記で補足します。
| モデル | 入力(100万トークン) | 出力(100万トークン) | コンテキストウィンドウ |
|---|---|---|---|
| gpt-5.5 | $5.00 | $30.00 | 約1,050,000 |
| gpt-5.5-pro | $30.00 | $180.00 | 約1,050,000 |
| gpt-5.4(参考) | $2.50 | $15.00 | 272,000(標準) |
標準のgpt-5.5はGPT-5.4の2倍の入力単価ですが、OpenAIは「GPT-5.5は高価だがトークン効率が高い」「CodexではGPT-5.4より少ないトークンで良い結果を出せるよう調整した」と説明しており、タスクの性質によっては総コストが逆転しうる設計です。Batch・Flex処理は標準の半額、Priority処理は2.5倍で提供されます。
価格注記
料金面で見落としがちなポイントを補足します。
-
272Kトークン超入力時の長文料金
gpt-5.5は272,000トークンを超える入力を含むセッションでは、そのセッション全体に対して入力単価が標準の2倍、出力単価が1.5倍に切り替わります。超過したぶんだけが高くなる従量制ではなく、当該リクエスト全体が長文料金条件で課金される設計のため、100万トークン近くまで投入する超長文ユースケースでは、表面の$5/$30だけで試算すると費用感を大きく過小評価する点に注意が必要です。
-
キャッシュ入力の差
gpt-5.5は同一プロンプトの再利用時にキャッシュ入力単価$0.50/100万トークンが適用され、繰り返し参照する大規模コンテキストの実効コストを大幅に下げられます。一方でgpt-5.5-proにはキャッシュ割引が用意されていないため、Proを長文・反復用途に使うと実コストが逆転しやすい点に注意してください。
-
リージョン処理と最新料金の確認
標準料金はグローバル処理を基準としており、Data residency / Regional processing endpointsを選択する場合は+10%が上乗せされます。APIは2026年4月24日に提供開始され、その後も値動きが発生する可能性があるため、本番導入直前に最新のpricing pageで差分を確認してください。
-
Batch / Flex / Priority
バッチ処理や非同期処理を組み合わせることで、コスト感を大きく変えられます。BatchとFlexは標準の半額、Priorityは2.5倍です。
-
既存GPT-5.4経由との比較設計
単価比較ではなく、「同じタスクを完走するまでの総トークン量×単価」で比較するのが実務的です。Codexの長時間タスクほどGPT-5.5のほうが有利になる傾向があります。
【関連記事】
ChatGPT APIとは?OpenAI APIの使い方や料金、活用事例を解説!
【関連記事】
ChatGPT APIの料金ガイド 2026年3月最新版 モデル別料金一覧とコスト削減のポイント

GPT-5.5の使い方

GPT-5.5はChatGPT、Codex、APIの3チャネルから利用できます(APIは2026年4月24日に提供開始)。ここでは主要な3チャネルの始め方を整理します。
ChatGPT
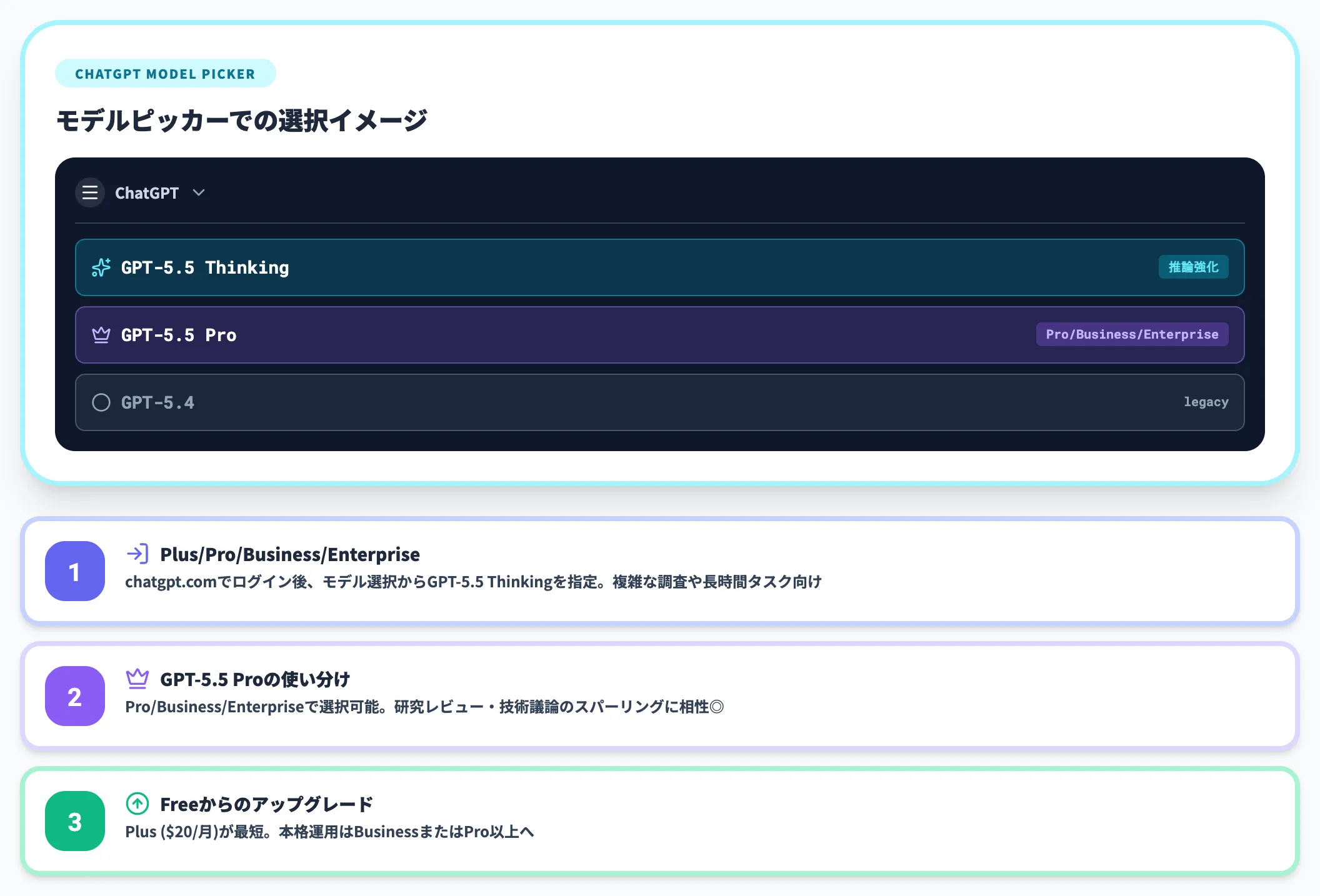
ChatGPTでGPT-5.5を使う場合は、以下の手順で進めます。
-
Plus/Pro/Business/Enterpriseでの使い方
ChatGPTにログインし、モデル選択からGPT-5.5 Thinkingを指定して利用します。
プラン別の提供範囲は前節の表の通りで、複雑な調査や長時間タスクで活用するのが前提です。
-
GPT-5.5 Proを使う場合
Pro、Business、Enterpriseプランで「GPT-5.5 Pro」を指定すれば、追加の計算リソースを使った高精度の回答が得られます。
研究レビューや技術議論のスパーリング相手として、マルチターンで活用するのが相性の良い使い方です。
-
Freeプランからのアップグレード判断
Freeプランではモデル選択ができないため、GPT-5.5を試したい場合はPlus($20/月)から始めるのが最短です。
業務で本格的にGPT-5.5 Proを使うならBusinessまたはPro以上へ切り替えます。
Codex
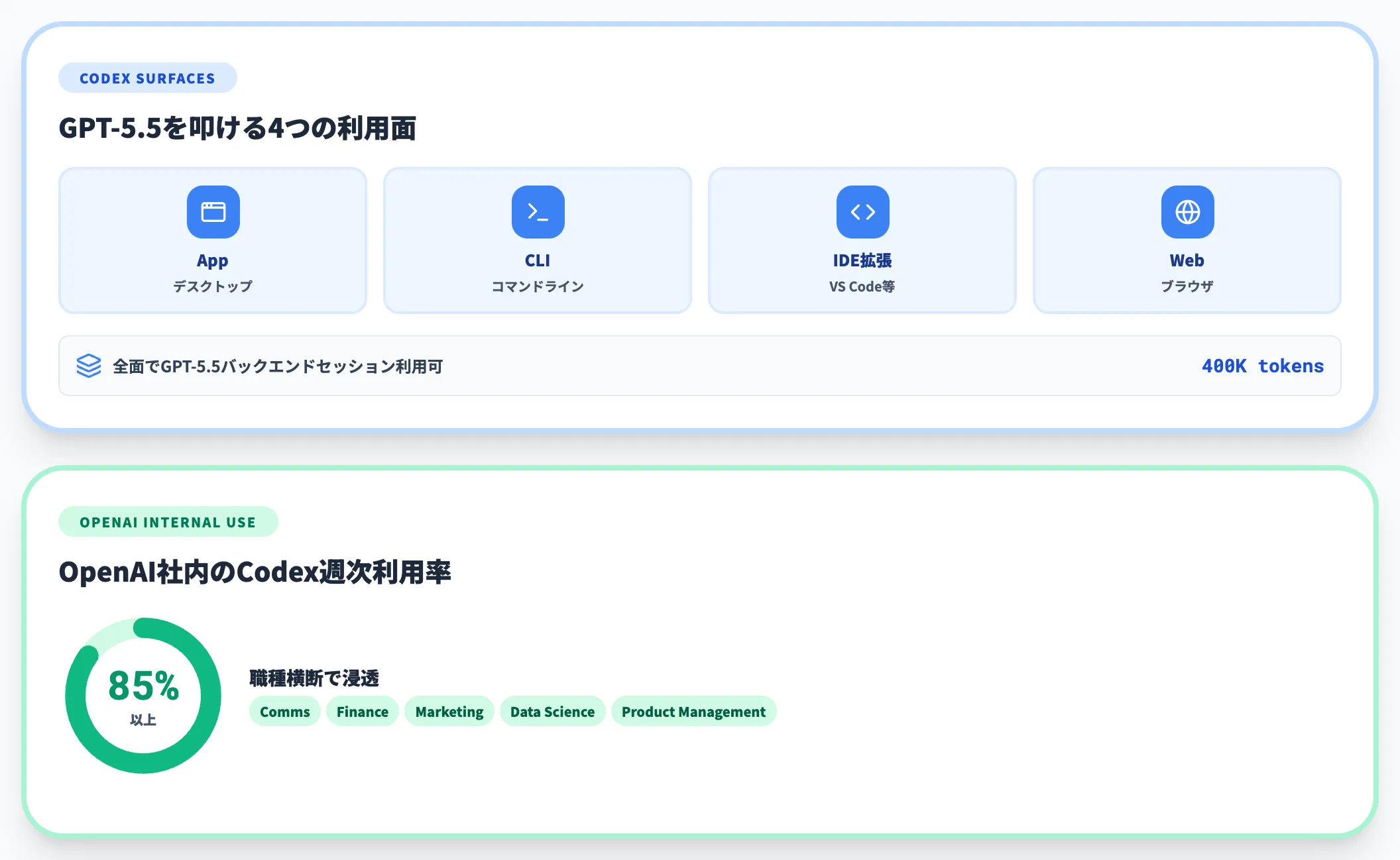
Codex経由では、以下のような使い方が中心になります。
-
利用面
Codexはapp/CLI/IDE extension/Webにまたがって利用できます。いずれの面からもGPT-5.5をバックエンドとしたセッションを開けます。コンテキストウィンドウは40万トークンまで使えます。
-
Fast mode
対話テンポを優先したい場合は、CodexのFast modeに切り替えます。トークン単価は2.5倍になるため、長時間実行ジョブでは通常モードが推奨です。
-
OpenAI社内の使われ方
OpenAI社内の85%以上がCodexを週次で使用しており、Comms・Finance・Marketing・Data Science・Product Managementまで職種横断で浸透しています。社外で参考事例を探すなら、まずOpenAI公式ブログで紹介されている自社事例が最新の基準値になります。
API
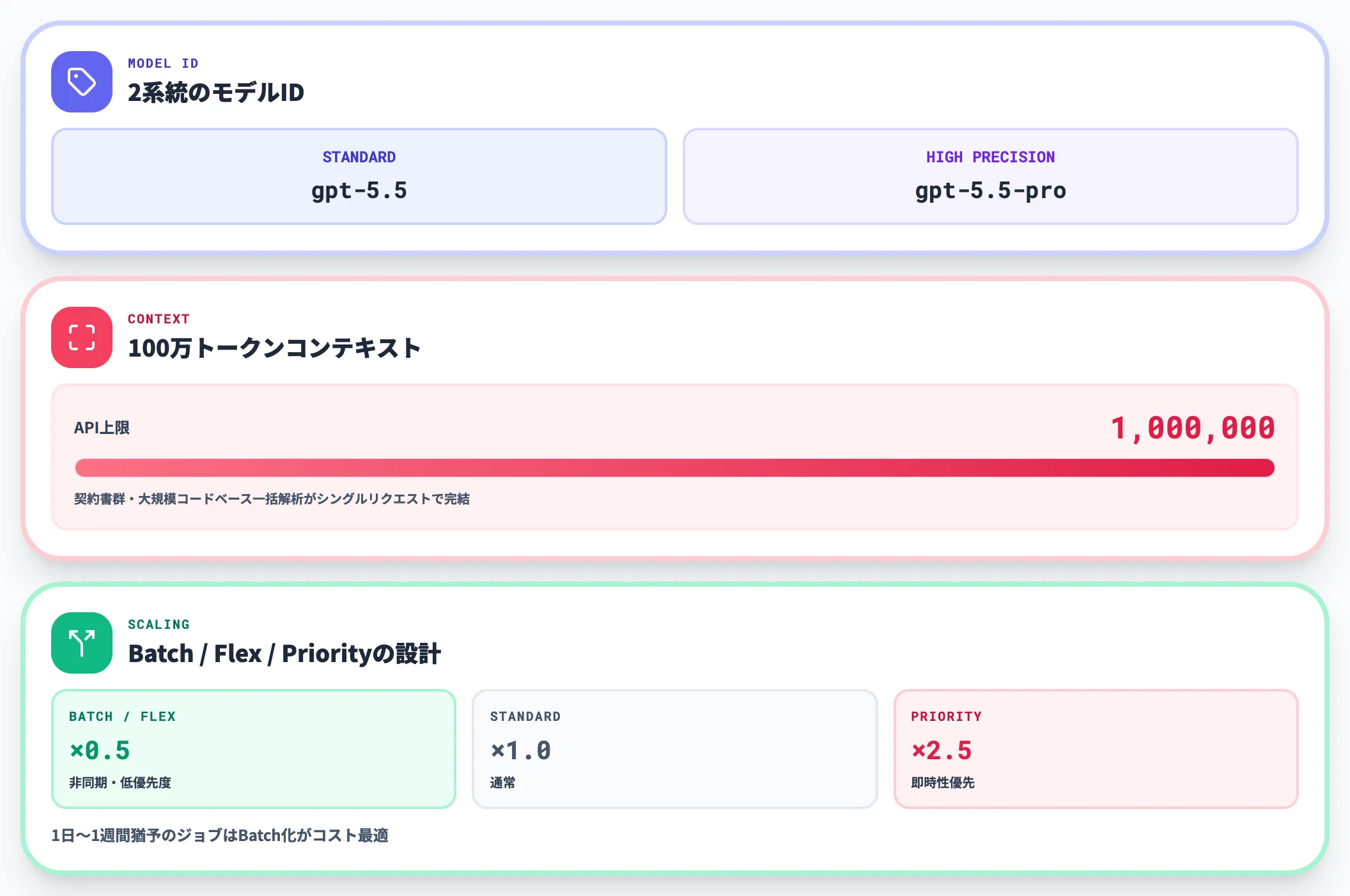
API経由でGPT-5.5を利用する場合、Responses APIおよびChat Completions APIから呼び出せます(2026年4月24日提供開始)。設計時には以下のポイントを押さえておきます。
-
モデルID
gpt-5.5(標準)とgpt-5.5-pro(高精度)の2系統です。用途に応じて明示的に使い分けます。
-
約100万トークンコンテキスト
API側は約105万トークン(1,050,000)まで扱えるため、長大な契約書群や大規模コードベースの一括解析がシングルリクエストで完結します。
-
Batch / Flex / Priorityの設計
非同期バッチ処理なら半額、低優先度のFlexも半額、即時性優先のPriorityは2.5倍です。1日〜1週間程度の猶予があるジョブは積極的にBatch化するのがコスト最適です。
GPT-5.5を実際に使ってみた(GPT-5.4との比較)
OpenAIはGPT-5.5について、コード作成、オンライン調査、情報分析、文書・スプレッドシート作成などの複雑な実務タスクに向けたモデルと説明しています。ChatGPTでは、PlusまたはBusinessユーザーがモデル選択画面からGPT-5.5 Thinkingを選択できます。
ここでは、ベンチマーク上の性能差を体感しやすくするため、GPT-5.4 ThinkingとGPT-5.5 Thinkingに同じプロンプトを入力し、コード生成、リサーチ要約、長文分析の3つのタスクで比較します。
ChatGPTで利用するモデルを選択する画面
デモ1: コード生成タスク
同じバグ入りFastAPIコードに対して、「バグ修正・セキュリティ指摘・テスト雛形作成」の3点を両モデルに依頼しました。
使用プロンプト
以下のPython FastAPIコードについて:
1. バグを特定して修正
2. セキュリティリスク(SQLインジェクション等)を指摘
3. テストコードのひな形を作成
修正後のコード全体と、変更箇所の説明を出力してください。
GPT-5.4 Thinkingがバグ修正とセキュリティ指摘を出力した画面
GPT-5.5 Thinkingが同じプロンプトに対してコード修正案を出力した画面
GPT-5.4とGPT-5.5の出力を比較すると、どちらもSQLインジェクション対策としてプレースホルダを適切に使用しており、基本的なセキュリティ対応は共通しています。一方で、GPT-5.4はget_db_connection関数内で接続エラーを明示的にハンドリングし、contextlib.closingを使ったリソース管理など、やや防御的で堅牢性を重視した実装になっています。
対してGPT-5.5は、with get_db_connection() as conn:によるコンテキストマネージャを前提としたシンプルな構成に加え、型ヒント(Optional[Tuple])の付与や「テスト時に差し替えやすい構造」といった設計意図のコメントが含まれており、可読性や保守性を意識したコードになっています。
実務では、単にコードが動くかどうかだけでなく、保守性やテスト容易性まで含めた品質が求められます。その点で、GPT-5.5は「修正するモデル」から一歩進み、「運用しやすいコードを設計するモデル」としての特徴が表れています。
デモ2: リサーチ要約タスク
エンタープライズ向けAIエージェント基盤について、複数サービスの比較を行い、情報統合力と構造化能力を検証しました。
使用プロンプト
「エンタープライズ向けAIエージェント基盤」の競合3社(Microsoft Copilot Studio、Anthropic Claude Agents、Google Gemini Enterprise Agent Platform)について:
- 各社の対応領域
- 料金モデル
- データガバナンス対応
- 導入企業事例
- 差別化ポイント
を比較表にまとめ、最後に「日本の大企業がどれを選ぶべきか」の推奨を1段落で書いてください。
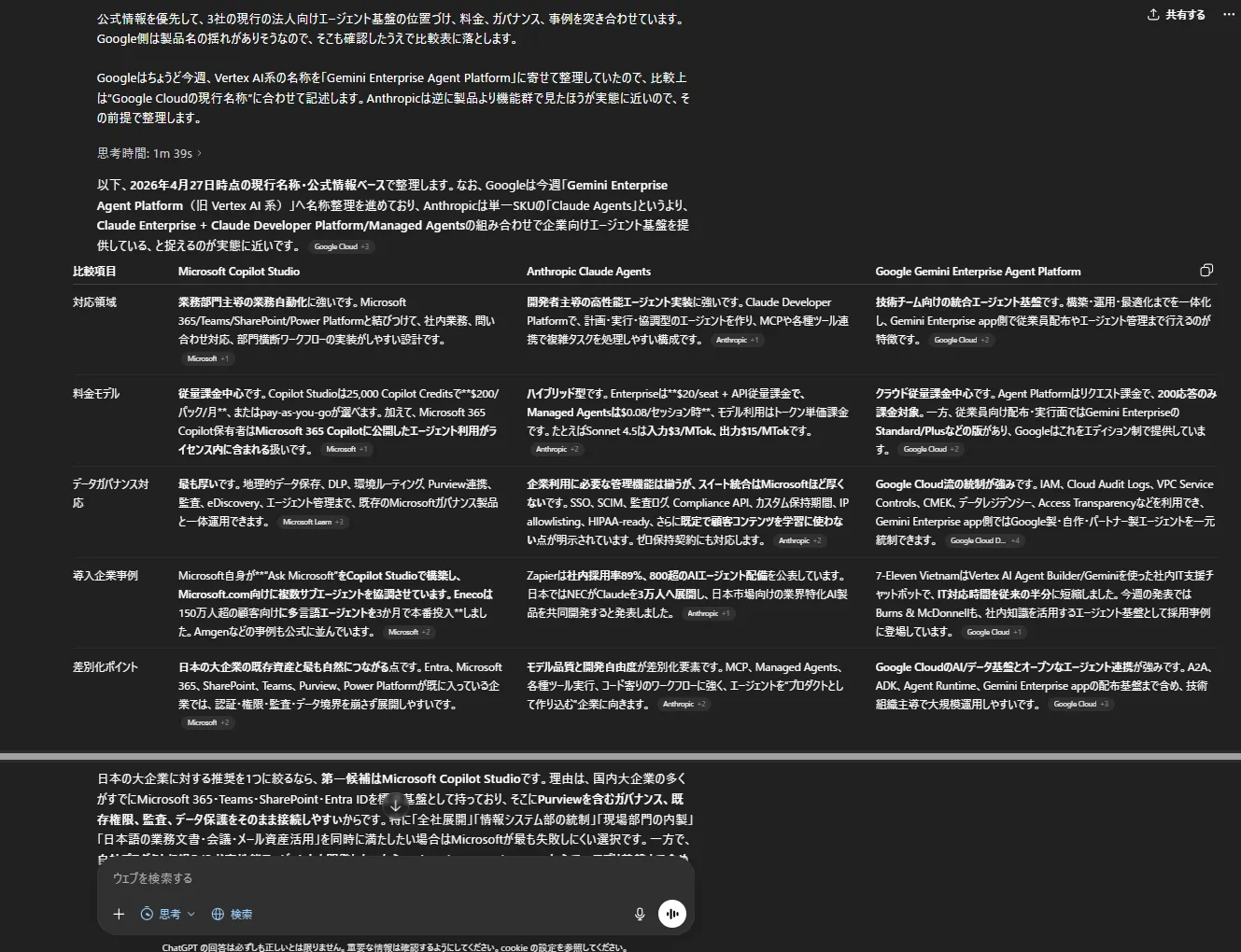
GPT-5.4 Thinkingが競合サービスの比較表を出力した画面
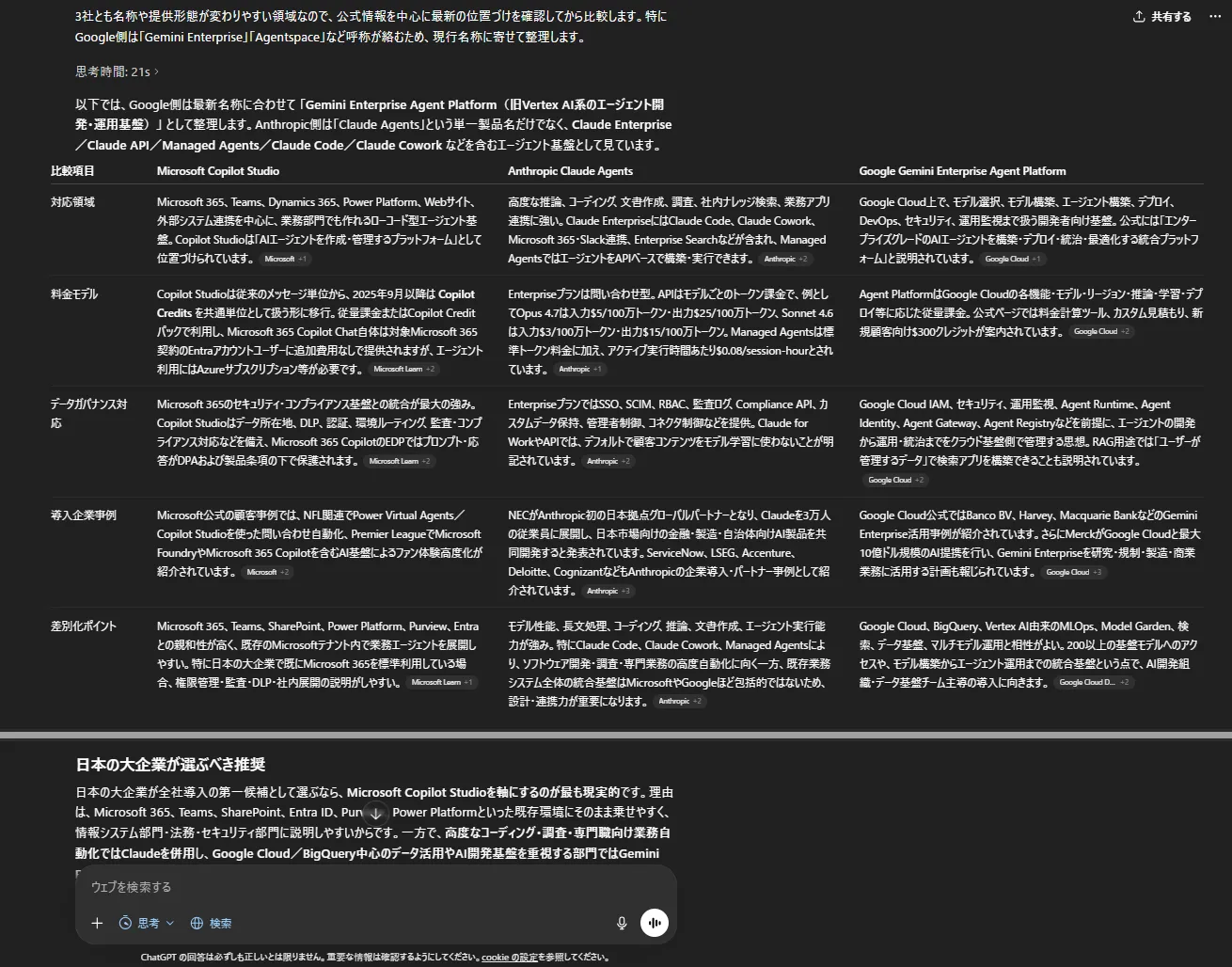
GPT-5.5 Thinkingが同じ条件で競合サービスを比較した画面
GPT-5.4とGPT-5.5の出力を比較すると、両者とも比較表の構造化や情報の網羅性は高く、主要な評価軸(対応領域・料金・ガバナンス・事例・差別化ポイント)を適切に整理できています。一方で、GPT-5.4は各項目の説明がややコンパクトで、読みやすさと整理のバランスを重視した「情報整理型」のアウトプットになっています。
対してGPT-5.5は、前提条件(名称変更・提供形態の違い)を明示したうえで比較を開始し、各社の位置づけや設計思想まで踏み込んで説明しています。また、最終的な推奨においても「Microsoftを全社基盤」「Anthropicを高付加価値業務」「Googleをデータ基盤」といった役割分担まで提示しており、単なる比較にとどまらず「実際の導入アーキテクチャ」を意識した意思決定支援型のアウトプットになっています。
このタスクでは、単なる情報整理ではなく、意思決定に直結する形で情報を再構成できるかが重要です。GPT-5.5は比較結果を踏まえて「どのように使い分けるか」まで提示しており、導入判断に使いやすい出力になっています。
デモ3: 長文分析タスク
30〜50ページ程度の技術レポートを入力し、長文理解と分析能力を検証しました。
使用プロンプト
添付したPDFについて:
1. この文書の主要な主張を3点に要約
2. 論拠の弱い or 検証が必要な箇所を指摘
3. 実務(エンタープライズAI導入)に適用する際の注意点を5つ挙げる

GPT-5.4 Thinkingが添付PDFの要点と注意点を整理した画面

GPT-5.5 Thinkingが同じPDFをもとに長文分析を行った画面
GPT-5.4とGPT-5.5の出力を比較すると、両者ともSystem Cardの主要論点(能力向上・安全性評価・限界)を正しく抽出できており、長文読解そのものの精度はどちらも高い水準にあります。一方で、GPT-5.4は文書内容を忠実に要約しつつ、論拠の弱さや評価の前提条件を丁寧に指摘する「分析寄り」のアウトプットになっており、特に評価のバイアスや代表性の限界など、注意深く読み解く姿勢が強く表れています。
対してGPT-5.5は、要約・リスク指摘に加えて、「なぜそれが実務上の問題になるのか」「企業導入ではどう設計すべきか」まで踏み込んでおり、アウトプット全体が実務適用を前提とした構造になっています。たとえば、権限分離、承認フロー、コネクタ防御、監査ログといった具体的な設計指針まで落とし込んでおり、単なる文書理解にとどまらない出力になっています。
長文コンテキスト性能の観点では、正確な要約だけでなく、文書内の前提やリスクを踏まえて具体的な注意点を導き出せるかが重要です。GPT-5.5は、読解結果を実務上の検討事項として整理できている点が特徴です。
3つのデモからわかったこと
3つのデモ(コード生成・リサーチ要約・長文分析)を通じて、GPT-5.4とGPT-5.5はいずれも高い基礎性能を持つことが確認できました。一方で、違いは「正しく答えられるか」ではなく「どこまで実務に踏み込めるか」にあります。
-
GPT-5.4
正確な分析・整理に強く、情報をわかりやすく構造化できます。
-
GPT-5.5
分析結果をもとに運用・導入方針まで踏み込み、導入判断や運用設計に使いやすい示唆を出せます。
企業利用では、単なる回答精度よりも、意思決定やシステム設計に活用できるかが重要です。その点で、GPT-5.5は「答えを出すモデル」から一歩進み、「業務に落とし込むための設計を提示するモデル」として位置づけられます。
GPT-5.5の活用事例とユースケース
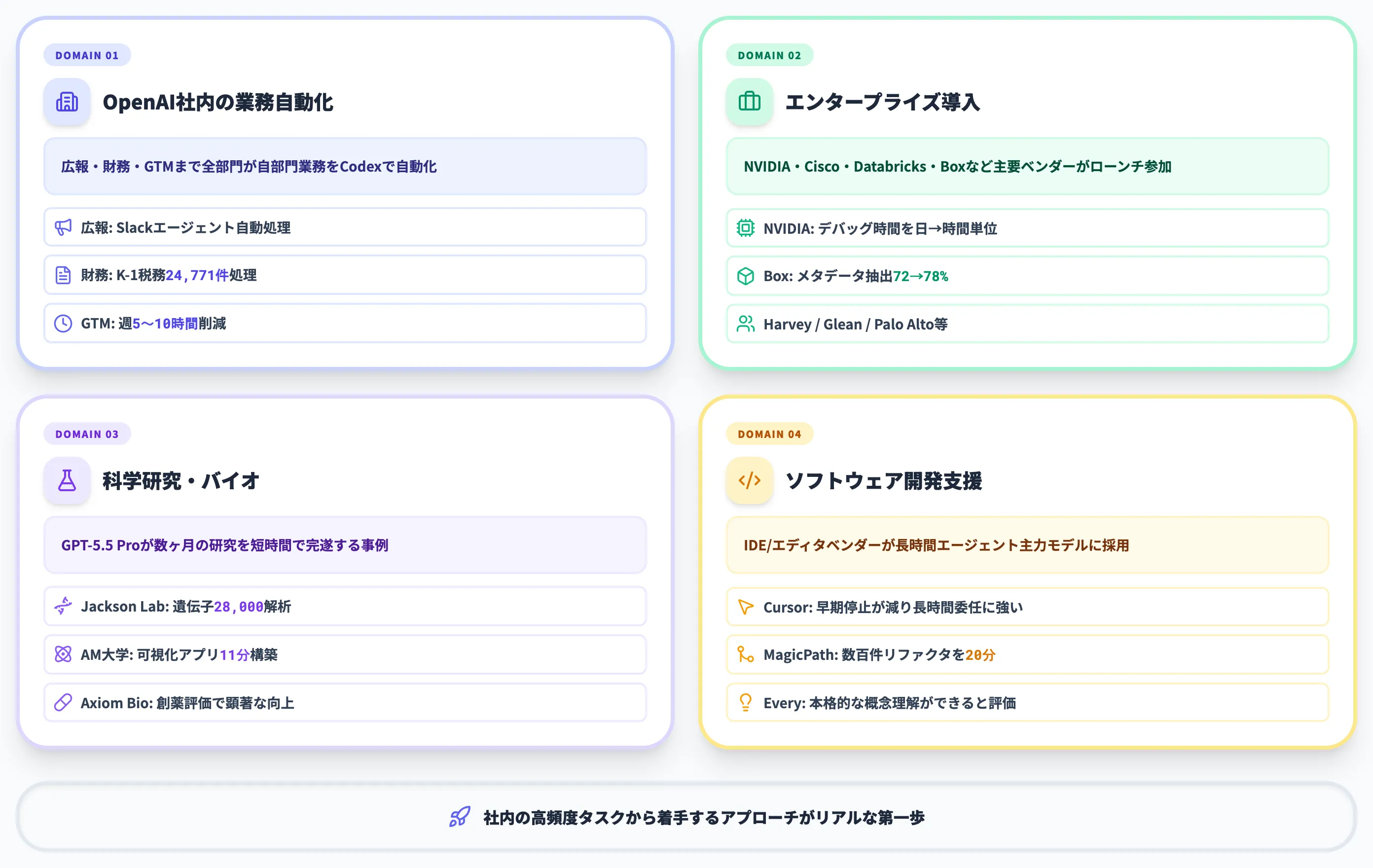
GPT-5.5は、リリース直後の時点で大企業・研究機関・SaaSベンダーの実運用事例が多数公開されています。ここでは領域別に代表的なユースケースを紹介します。
OpenAI社内の業務自動化

OpenAI自身が、社内ユースケースとして具体的な数字を公開しています。
-
広報(Comms)
半年分のスピーキングリクエストデータをGPT-5.5 in Codexで分析し、スコアリング・リスクフレームワークを自動構築。低リスク案件はSlackエージェントが自動処理し、高リスクのみ人間レビューに回す運用を実現しました。
-
財務(Finance)
24,771件のK-1税務フォーム(合計71,637ページ)をCodexで処理し、個人情報を除外しながらレビューを完了。前年より2週間早く処理を終えています。
-
Go-to-Market
週次ビジネスレポートの生成を自動化し、担当者1人あたり週5〜10時間の工数を削減しました。
これらの事例は「AIを使った全社展開」ではなく、各部門が自分たちの業務をCodexで自動化している点が特徴的です。自社で取り組む際も、特定の高頻度タスクから着手するアプローチが現実的な第一歩になります。
エンタープライズ・SaaSベンダーの導入
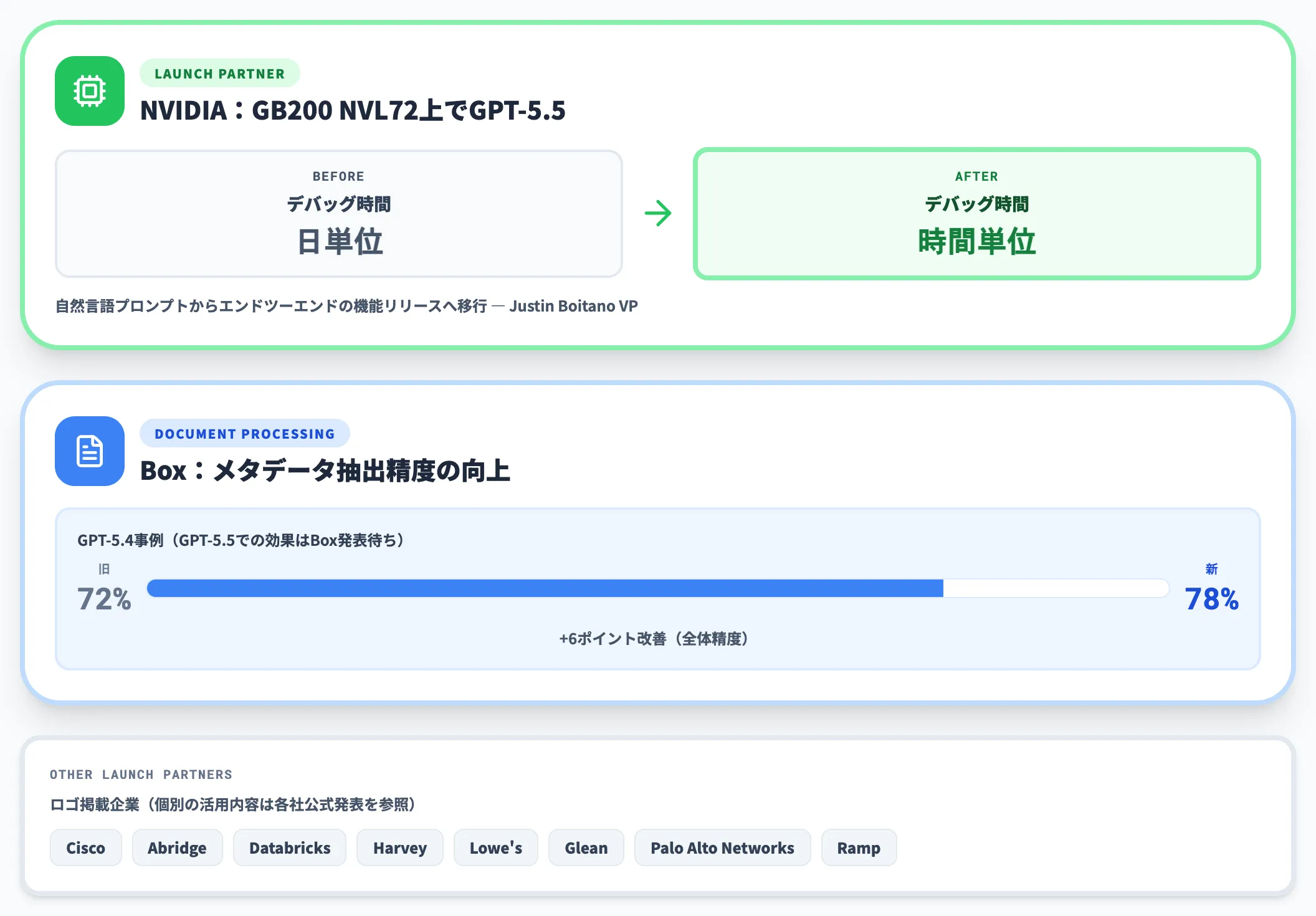
GPT-5.5のローンチパートナーとして、OpenAI公式発表のページ上には、NVIDIA、Cisco、Abridge、Databricks、Harvey、Box、Lowe's、Glean、Palo Alto Networks、Rampといった企業のロゴが掲載され、一部についてはコメントが公開されています。
-
NVIDIAの活用
GB200 NVL72上でGPT-5.5を動かし、自然言語プロンプトからエンドツーエンドの機能をリリースするスタイルに移行。デバッグ時間を「日単位から時間単位」へ短縮したとJustin Boitano VPがコメントしています。
-
Boxの文書処理(GPT-5.4事例)
Boxは前世代GPT-5.4時点で、メタデータ抽出の全体精度が72%から78%へ向上することを公式ブログで公開しています。GPT-5.5での効果は別途Box側の発表を待つ必要がありますが、文書抽出系タスクの改善方向性は参考になります。
-
その他のロゴ掲載企業
Cisco、Abridge、Databricks、Harvey、Lowe's、Glean、Palo Alto Networks、Rampなどは、現時点の公開一次ソースではロゴ掲載にとどまります。個別の活用内容は、各社の公式発表を追う必要があります。
科学研究とバイオ分野
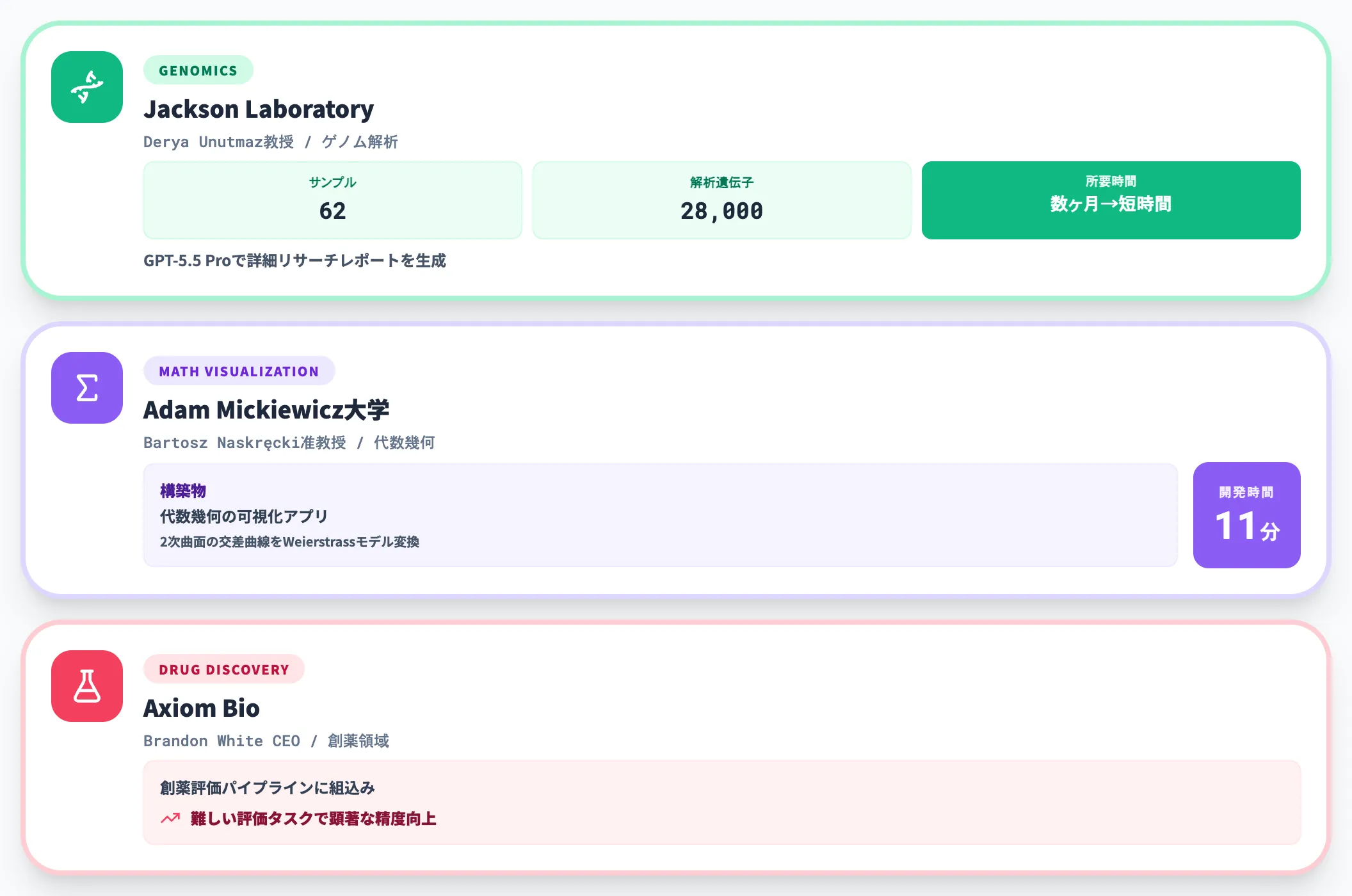
科学領域ではGPT-5.5 Proが研究パートナーとして機能する事例が公開されています。
-
Jackson Laboratoryのゲノム解析
Derya Unutmaz教授は、62サンプル・約28,000遺伝子の発現データをGPT-5.5 Proで分析し、通常チームで数ヶ月かかる詳細なリサーチレポートを短時間で生成したと公表しています。
-
Adam Mickiewicz大学の数学可視化
Bartosz Naskręcki准教授は、GPT-5.5 in Codexで代数幾何の可視化アプリを11分で構築。2次曲面の交差曲線をWeierstrassモデルに変換する研究用ツールを生成しています。
-
創薬領域
Axiom BioのBrandon White CEOは、GPT-5.5を創薬評価パイプラインに組み込み、難しい評価タスクで顕著な精度向上が確認できたとコメントしています。
ソフトウェア開発支援
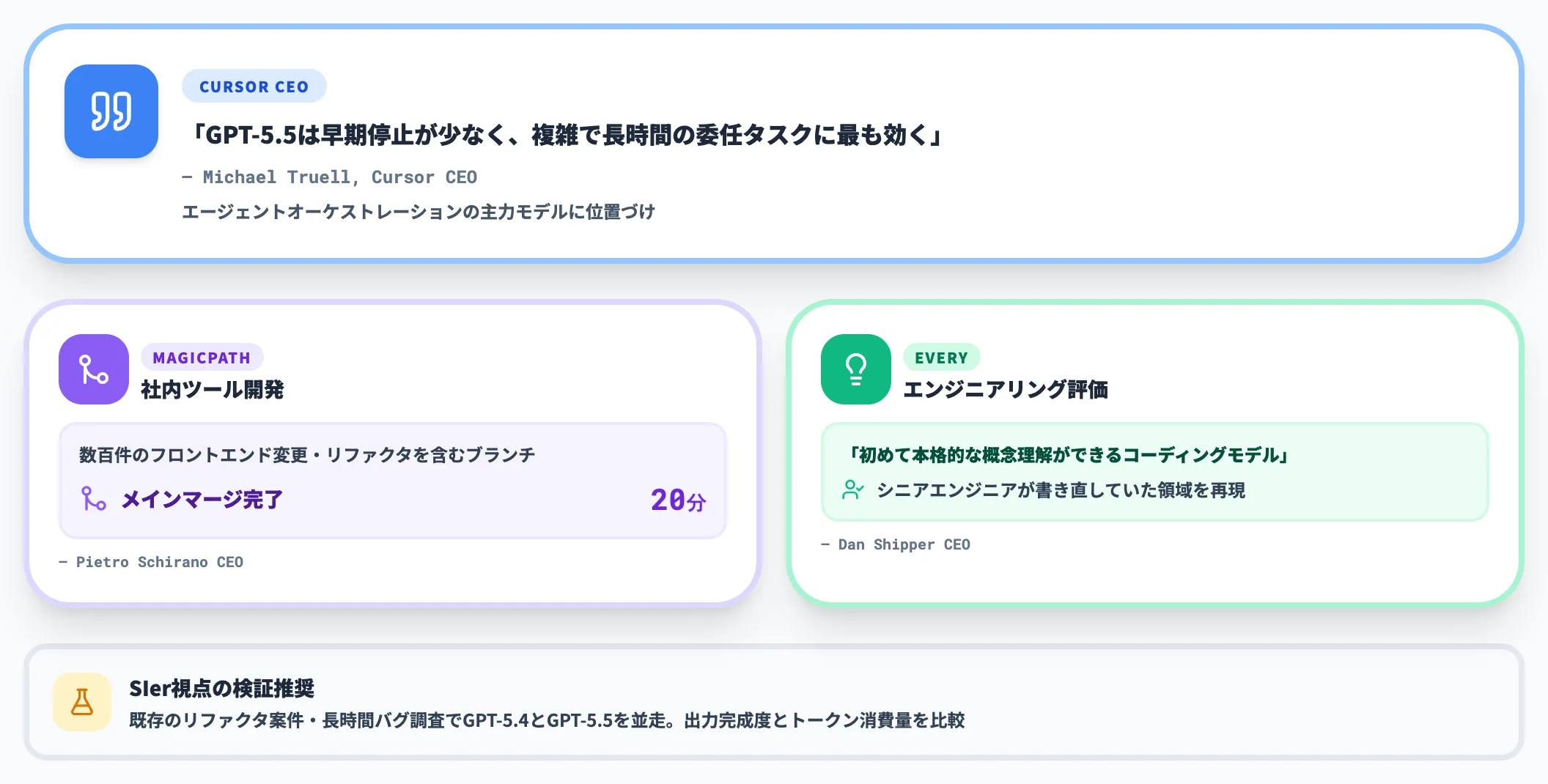
コーディング領域では、CursorのMichael Truell CEOをはじめとするIDE/エディタベンダーが早期評価を出しています。
-
Cursor
「GPT-5.5は早期停止が少なく、複雑で長時間の委任タスクに最も効く」(Michael Truell CEO)という評価で、エージェントオーケストレーションの主力モデルとして位置づけています。
-
社内ツール開発での効果
MagicPathのPietro Schirano CEOは、数百件のフロントエンド変更とリファクタを含むブランチを約20分でメインへマージできたと報告しています。
-
Everyのエンジニアリング
Dan Shipper CEOは「初めて本格的な概念理解ができるコーディングモデル」と評価し、既にシニアエンジニアが書き直していた領域をGPT-5.5が再現できたとしています。
特にコードベース全体の構造把握が求められるタスクで、GPT-5.4との差が明確に出ているのが印象的です。自社で試す際も、既存のリファクタ案件や長時間バグ調査を素材にしてGPT-5.4とGPT-5.5を並走させ、出力の完成度とトークン消費量を比較するのが実用的な検証方法になります。
GPT-5.5の注意点と安全性評価

GPT-5.5は高い能力を持つ一方で、運用時に把握すべき制約と手当てがあります。OpenAIが公開している安全性評価の要点と、現場運用で詰まりがちな論点を整理します。
Preparedness Frameworkでの位置づけ
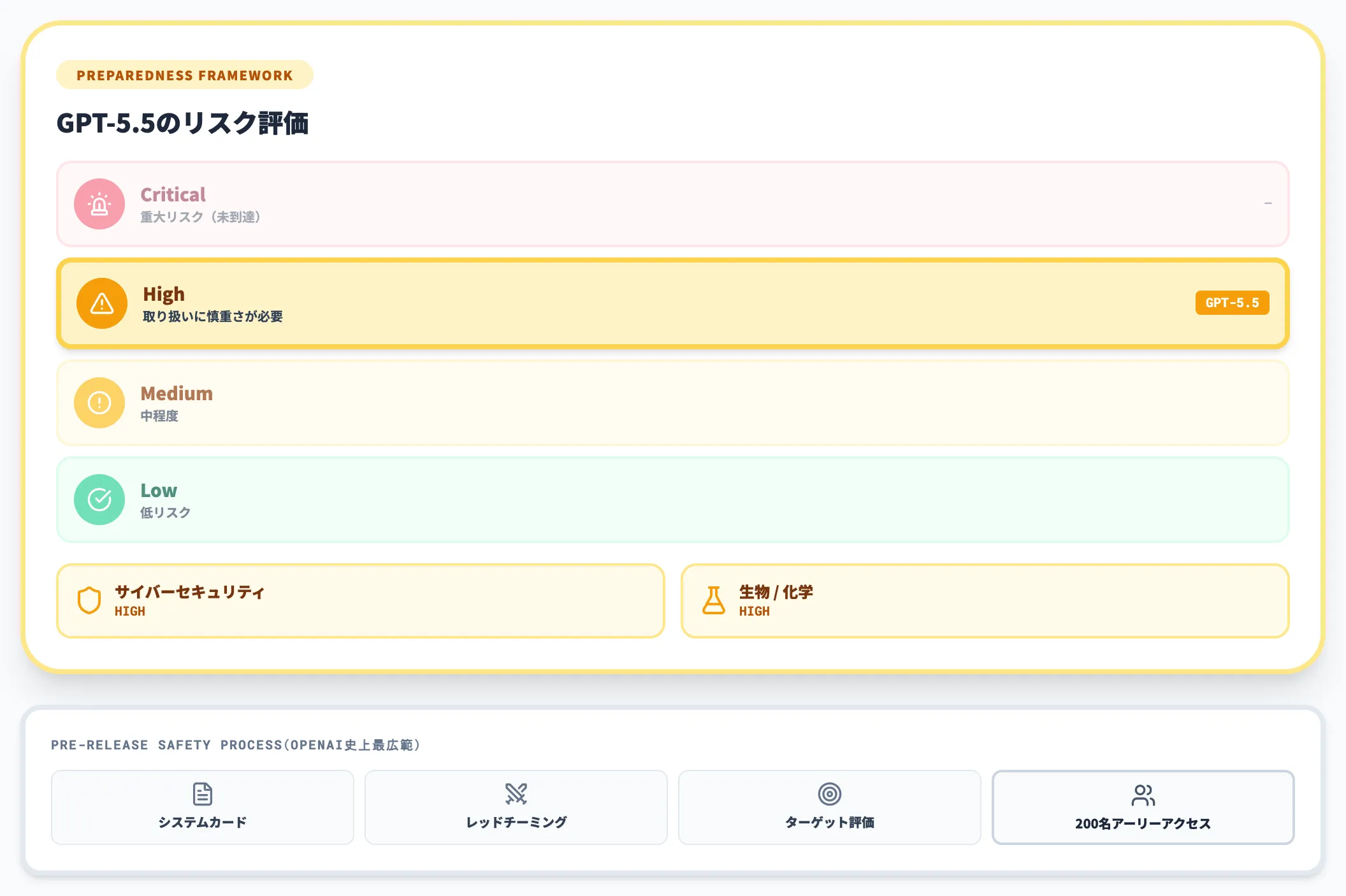
GPT-5.5は、OpenAIのPreparedness Frameworkにおいてサイバーセキュリティと生物/化学の両カテゴリでHigh評価を受けています。Critical(重大)までは至っていませんが、GPT-5.4からさらに一段階、能力の取り扱いに慎重さが求められる水準です。
これを受けて、システムカード・レッドチーミング・ターゲット評価・200名規模の信頼済みアーリーアクセスパートナーによる実ユースケース収集といった、OpenAI史上もっとも広範な安全性プロセスがリリース前に実施されたことが公表されています。
Trusted Access for Cyber
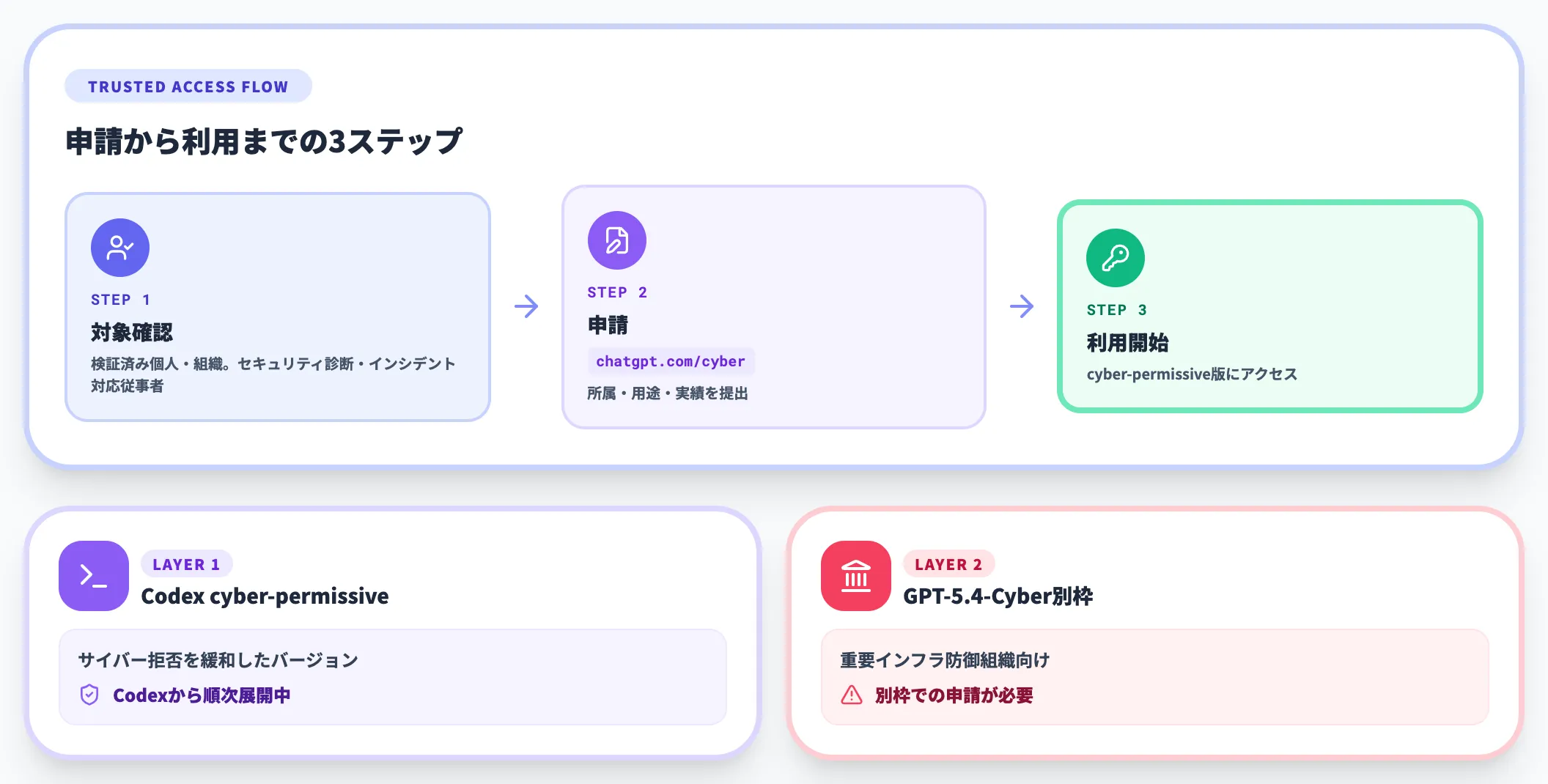
サイバー能力の強化に伴い、疑わしいリクエストを弾くClassifierが強化されています。正当な用途で拒否率が上がるケースを避けるため、OpenAIが2026年2月にパイロット提供を開始し同年4月に拡張した「Trusted Access for Cyber」の枠組みが、GPT-5.5の登場によって重要性を増しています。
-
対象
検証済みの個人・組織ユーザー。セキュリティ診断やインシデント対応の実務に従事しているユーザーが想定対象です。
-
提供範囲
まずCodex経由で、サイバー拒否を緩和した「cyber-permissive」バージョンが提供されます。重要インフラ防御に携わる組織は、別枠でGPT-5.4-Cyberにも申請できます。
-
申請フロー
chatgpt.com/cyberで申請を受け付けており、信頼シグナル(所属・用途・実績)を提出する形式です。防御業務の検証なしに一般ユーザーが高リスクタスクを回すと、Classifierに弾かれる頻度が上がります。
API公開後の移行計画

GPT-5.5のAPIは2026年4月24日に提供が始まりました。本番運用への移行は、いきなり切り替えず以下の順序で進めるのが安全です。
-
ChatGPT/Codexの検証結果をAPIへ持ち込む
発表前後でChatGPT・Codex上でユースケース別の精度検証を進めていた場合、その評価セットをそのままAPIに移して再現性を確認します。Codexで通った長時間タスクがAPIで挙動が変わっていないかをまず見るのが安全です。
-
既存GPT-5.4 APIとの並走期間
新APIが公開されても、GPT-5.4系は引き続き利用可能です。並走期間を設けて、実トラフィックでのコスト差と出力差を測ってから本番切り替えを判断します。
-
Azure経由の提供可否
Azure Codex・Microsoft Foundry経由でのGPT-5.5提供は、現時点のOpenAI公開一次ソースでは確認できません。エンタープライズ運用でAzure Codexを使う場合は、Microsoft側の公式発表を待って判断します。
実運用で詰まる論点
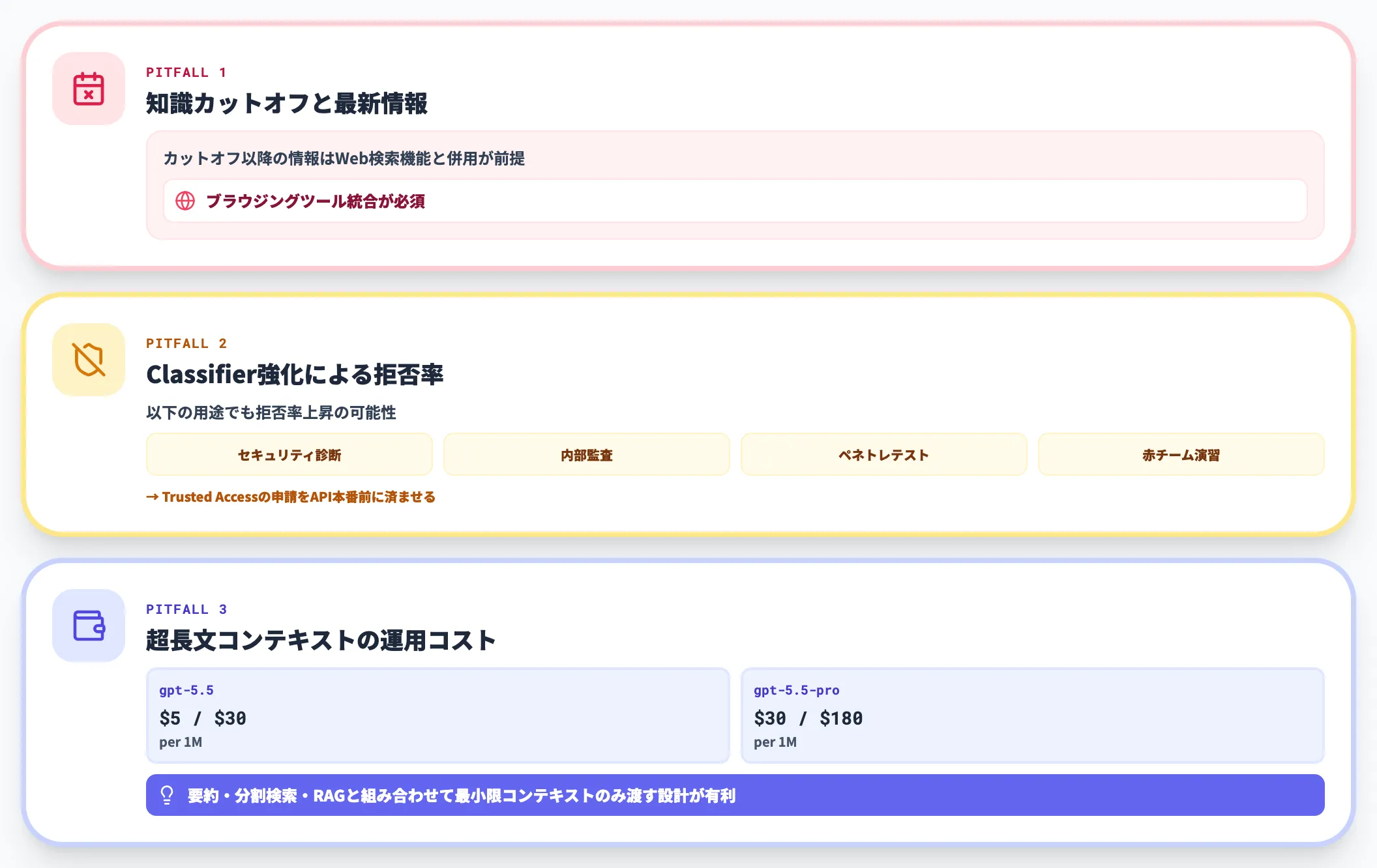
導入判断では、以下の3点が詰まりやすいポイントです。
-
知識カットオフと最新情報
モデルの知識カットオフ時点以降の情報は、Web検索機能と併用する設計が前提になります。ニュースやプレスリリースをリアルタイムに扱うエージェントは、ブラウジングツール統合が必須です。
-
Classifier強化による拒否率
サイバー系以外でも、セキュリティ診断・内部監査・ペネトレーションテスト・赤チーム演習の支援で拒否率が上がる可能性があります。Trusted Accessの申請をAPI本番前に済ませておくのが現実的です。
-
超長文コンテキストの運用コスト
標準のgpt-5.5でも入力$5/出力$30 per 1Mトークン、gpt-5.5-proは$30/$180 per 1Mトークンです。100万トークン近くまで使うケースや大量出力を伴うタスクでは総コストが大きくなりやすいため、要約・分割検索・RAGでの事前フィルタリングと組み合わせ、必要最小限のコンテキストのみGPT-5.5に渡す設計にしたほうが費用対効果が高くなります。

GPT-5.5の評価を自社業務への実装に進めるなら
GPT-5.5のエージェント能力は、ChatGPTやCodex上の並走評価で手応えを掴むところまでは各社が到達しつつあります。そこから先、実行ログや権限設計・基幹システム連携まで含めた業務フロー上にモデルを載せる層を誰が組むか、が本番運用への分水嶺になります。
ここで効いてくるのが、AI総合研究所の AI Agent Hub です。AI Agent Hubは、Azureテナント内で動くエンタープライズAIエージェント基盤として、GPT-5.5 APIやCodexで検証したエージェントをTeamsや既存業務システムと結び付け、実行と統制をまとめて担います。
- GPT-5.5で検証したAgentを業務フローに接続
Codexで動かした長時間タスクや文書処理を、AI-OCR Agent・請求書受領Agent・自動入力Agentなどの業務Agentと組み合わせ、Teamsから呼び出せる統合エージェントとして社内展開できます。
- GPT-5.5/Claude/Gemini併用時のガバナンスを一元化
複数モデルを使い分ける構成でも、Agent単位の実行ログ・アクセス権限・セキュリティスキャンを1つのダッシュボードで管理。Classifier厳格化時代の拒否率追跡やモデル切替時の影響分析も、個別ツールに分散させずに運用できます。
- 使い慣れたMicrosoft環境をそのまま活用
Teams・Excel・Outlookなど既存ツールの延長でAIエージェントが動作します。新しいツールの学習コストがかからず、現場がすぐに使い始められる設計です。
- データは100%自社テナント内に保持
AIの学習対象から完全除外。Azure Managed Applicationsとして自社テナント内で動作が完結するため、超長文コンテキストに社内情報を渡すユースケースでも外部流出リスクを抑えられます。
AI総合研究所の専任チームが、GPT-5.5のような最新モデルの評価設計から業務Agent実装・運用ガバナンスの整備まで伴走します。まずは無料の資料で、AI Agent Hubによるエージェント運用の全体像をご確認ください。
GPT-5.5で検証したAIを業務実装までつなぐ

Azureテナント内で完結するAIエージェント基盤
ChatGPTやCodexでGPT-5.5のエージェント能力を検証した先に、Teams・基幹システム連携・実行ログ・権限管理までを業務フローに組み込む設計が必要になります。AI総合研究所のAI Agent Hubは、Azureテナント内で動くエンタープライズAIエージェント基盤として、複数モデル併用時のガバナンスを1画面で運用できます。
まとめ
GPT-5.5は、OpenAIが発表した最新のフラグシップモデルで、エージェント的コーディングとナレッジワークの両領域で前モデルGPT-5.4を明確に上回る性能を示しつつ、同じレイテンシで提供される効率重視の設計が特徴です。
この記事のポイントを振り返ります。
-
エージェント的コーディングの飛躍
Terminal-Bench 2.0で82.7%を記録し、GPT-5.4(75.1%)やClaude Opus 4.7(69.4%)を引き離しました。長時間・複数ファイルの委任タスクで差が出ます。
-
トークン効率と同等レイテンシ
GPT-5.4と同じ1トークンあたりのレイテンシで、同一タスクに必要なトークン数を削減。実運用でのコスト試算を「単価」ではなく「総トークン量×単価」で行うのが合理的です。
-
モデルバリアント
標準のGPT-5.5、高精度のGPT-5.5 Pro、ChatGPT上での推論強化モードGPT-5.5 Thinkingの3系統に整理されています。
-
料金の目安
2026年4月24日に提供開始されたAPIは、gpt-5.5が入力$5.00/出力$30.00、gpt-5.5-proが入力$30.00/出力$180.00(100万トークンあたり)。Batch・Flexは半額、Priorityは2.5倍です。
-
サイバー能力強化とTrusted Access
Preparedness Frameworkでサイバー・生物/化学がHigh評価。セキュリティ業務で活用する場合はTrusted Access for Cyberの申請を前提に設計しましょう。
GPT-5.4を利用中の方は、まず長時間・大規模タスクや科学研究・サイバー業務のような差が出やすい領域で並走評価を行い、トークン効率と精度改善を確認したうえで段階的に切り替えるのが現実的なロードマップになります。短いQ&A中心の用途であれば、API公開直後のコスト推移を1〜2週間見てから本格切り替えを判断しても遅くありません。










