この記事のポイント
 Fabric上のSpark処理はLakehouse・Notebook・Sparkジョブ定義の3アイテムを軸にしたData Engineeringが最適解
Fabric上のSpark処理はLakehouse・Notebook・Sparkジョブ定義の3アイテムを軸にしたData Engineeringが最適解- Runtime 1.2は2026年3月末でサポート終了、新規はRuntime 1.3(Spark 3.5 GA)を選びRuntime 2.0は本番回避
- Native Execution Engine(Velox+Apache Gluten)は最大4倍の高速化が見込めるため、大規模バッチ処理では必ず有効化すべき
- コスト最適化にはStarterプール(5〜10秒起動)を開発・検証に、Autoscale Billingを本番ワークロードに使い分けるのが有効
- Synapse Spark既存環境は公式移行パスで段階的にFabricへ移行すべき。マルチクラウド要件がある場合のみDatabricksが候補になる

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Microsoft FabricのData Engineeringは、Apache Sparkを基盤としたデータ加工・変換のためのワークロードです。Lakehouse・Notebook・Sparkジョブ定義を中心に、必要に応じて環境(Environment)やパイプラインと組み合わせながら、OneLake上のデータをPySpark・SQL・Scala・Rの4言語で処理できます。
本記事では、Data Engineeringの基本概念から主要コンポーネント、2026年3月時点の最新ランタイム情報(Runtime 1.3 GA・2.0 Preview)、Native Execution Engineによる最大4倍の高速化、環境設定・ライブラリ管理の実務的な使い方、DatabricksやAzure Synapse Sparkとの違い、そして料金体系までを体系的に解説します。
✅Microsoft 365 Copilotの最新エージェント機能「Copilot Cowork」については、以下の記事をご覧ください。
Copilot Coworkとは?機能や料金、Claude Coworkとの違いを解説
目次
Fabric Data Engineeringの主要コンポーネント
Runtime 2.0(Experimental Public Preview)
Fabric Data Engineeringの環境設定とライブラリ管理
Azure Synapse SparkやDatabricksとの違い
Fabric Data Engineeringの活用シーンと注意点
Fabric Data Engineeringとは?
Fabric Data Engineeringは、Microsoft Fabricが提供するデータ加工・変換に特化したワークロードです。
企業が大量のデータを収集・保存・処理・分析するためのインフラストラクチャとシステムを、フルマネージドなApache Spark環境上で設計・構築・管理できます。
従来、データエンジニアリング基盤を構築するにはSparkクラスタの構築・VNet設定・ランタイム管理など多くの準備が必要でした。Fabric Data Engineeringでは、こうしたインフラ層をMicrosoftが管理するため、エンジニアはデータの加工と活用に集中できます。

Data Engineeringワークロードの主要アイテムは、Lakehouse・Notebook・Sparkジョブ定義の3つです。
- Lakehouseを使ったデータの作成・管理
構造化データと非構造化データを一元管理するストレージ基盤を構築できます。Delta Lake形式で保存されるため、SQLとSparkの両方からアクセスできます。
- Notebookを使ったデータ加工・分析コードの記述
対話型のWeb開発環境で、データの取り込みから前処理・変換・可視化までをコードで実行します。PySpark・Spark SQL・Scala・Rの4言語に対応しています。
- Sparkジョブ定義を使ったバッチ・ストリーミング処理
PythonやScalaで記述したSparkアプリケーションをバッチジョブとして実行できます。スケジュール実行やパイプラインからのトリガー実行にも対応します。
また、Data Factoryのパイプラインと連携することで、外部データソースからLakehouseへのデータ取り込みやオーケストレーションを構築できます。パイプライン自体はData Factory側のアイテムですが、Data Engineeringと組み合わせて使うのが一般的です。
これらのアイテムはすべてOneLake(Fabric統合データレイク)上のデータを共通して参照・操作できるため、データの移動やコピーを最小限に抑えた効率的なパイプライン構築が可能です。

Fabric Data Engineeringの主要コンポーネント
このセクションでは、Data Engineeringワークロードを構成する主要コンポーネントの役割と特徴を解説します。
各コンポーネントがどのように連携してデータパイプラインを形成するかを理解することで、実務での設計に役立てられます。

Notebook
Notebookは、Data Engineeringワークロードの中心的な開発ツールです。
Webブラウザ上で動作する対話型の開発環境であり、コードの実行・可視化・ドキュメント化をひとつのインターフェースで完結できます。
Notebookの主な特徴を以下の表にまとめます。
| 機能 | 内容 |
|---|---|
| 対応言語 | PySpark、Spark SQL、Scala、R |
| 開発支援 | IntelliSense(コード補完)、変数エクスプローラー |
| データ視覚化 | コードなしで表形式データをグラフに変換 |
| ユーティリティ | NotebookUtils(ファイル操作・シークレット取得・ノートブック連鎖) |
| 実行方式 | 対話型、スケジュール実行、パイプラインからのトリガー実行 |
注目すべきは、1つのNotebook内でセルごとに言語を切り替えられる点です。たとえばデータ読み込みはPySparkで、集計クエリはSpark SQLで、結果の可視化はRで、といった使い分けがひとつのNotebook上で完結します。
Sparkジョブ定義
Sparkジョブ定義(Spark Job Definition)は、Sparkクラスタ上でバッチ処理を実行するための設定セットです。入力/出力のデータソース、変換ロジック、Sparkアプリケーションの構成設定をひとまとめに定義します。
Notebookが対話型の開発・探索に適しているのに対し、Sparkジョブ定義は本番運用でのスケジュール実行や定型処理に向いています。
Python(.py)、Scala(.jar)、R(.R)のファイルを指定でき、リトライポリシーの設定やSpark Structured Streamingによる無期限実行にも対応します。
環境(Environment)
環境(Environment)は、Sparkセッションの構成を一元管理するアイテムです。ランタイムバージョン、ライブラリ依存関係、Sparkコンピュートのプロパティをまとめて定義し、NotebookやSparkジョブ定義にアタッチして利用します。
Azure Synapse Sparkではプールレベルで設定していた構成が、Fabricでは環境という独立したアイテムとして管理される点が大きな違いです。
これにより、同じワークスペース内で用途別に複数の環境を作成し、NotebookごとにSpark構成を切り替えるといった柔軟な運用が可能になります。
Lakehouseとの連携
Data Engineeringの処理対象となるデータは、Lakehouseに格納されます。Lakehouseは構造化データ(テーブル)と非構造化データ(ファイル)を一元的に保存できるストレージ基盤で、Delta Lake形式がデフォルトです。
NotebookからLakehouseのデータを読み込む場合、デフォルトLakehouseからは相対パスで、別のLakehouseからはABFS(Azure Blob File System)パスで指定します。2026年時点では、Notebookの「Get Data」機能によりAzure Blob Storage、PostgreSQL、Amazon S3などの外部ソースからも直接データを取得できるようになっています。
【関連記事】
【Microsoft Fabric】Lakehouseとは?機能や料金、Data Warehouseとの違いを徹底解説
【Microsoft Fabric】Data Warehouseとは?T-SQL機能や料金、移行方法を徹底解説
Fabric Sparkランタイムの仕組み
Fabric Data Engineeringの実行基盤となるのがApache Sparkランタイムです。
このセクションでは、2026年3月時点で利用できるランタイムバージョンと、パフォーマンスを大幅に向上させるNative Execution Engineについて解説します。
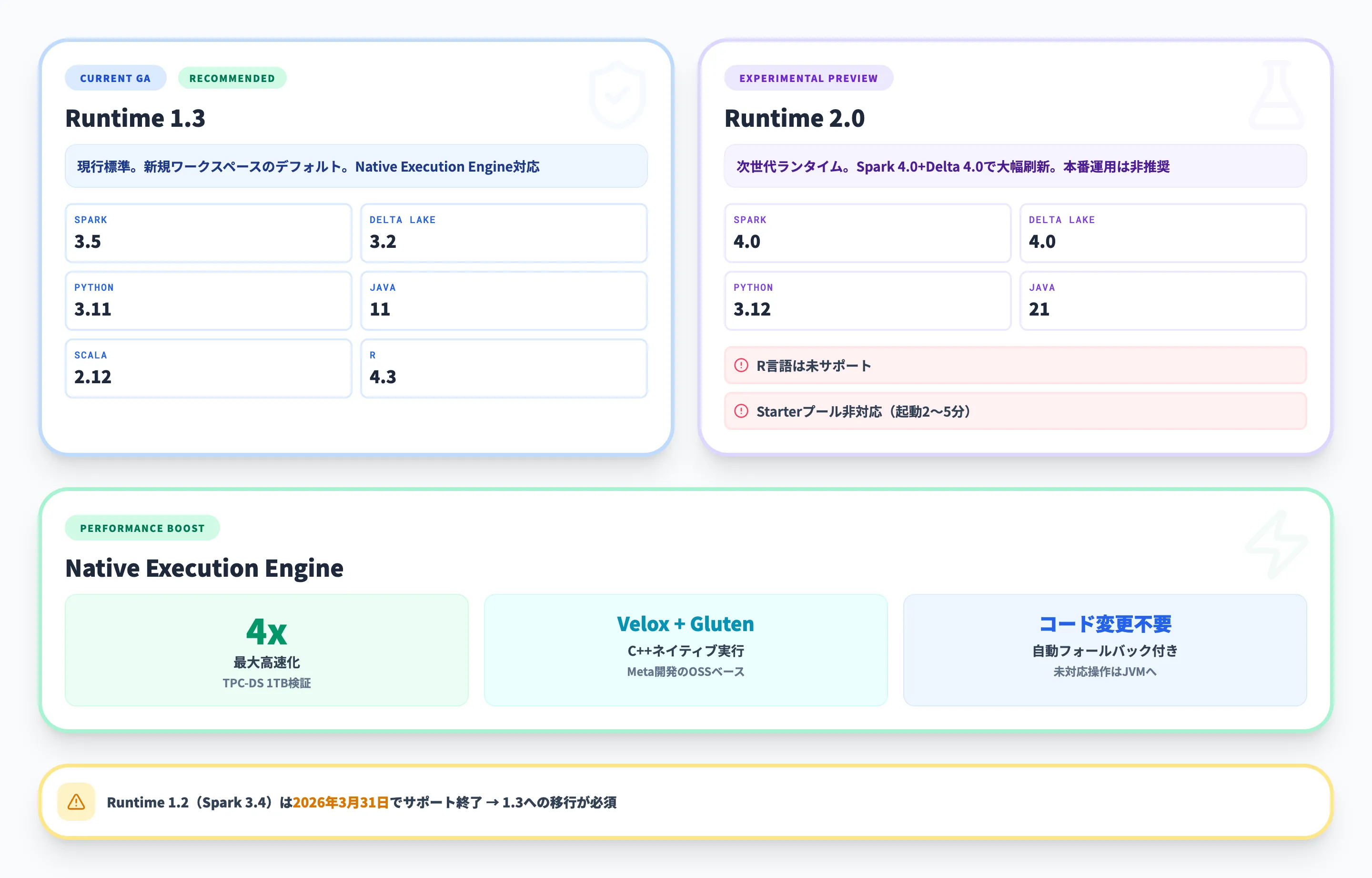
Runtime 1.3(現行GA)
Runtime 1.3はFabricの現行標準ランタイムで、新規作成されるワークスペースではデフォルトでこのバージョンが適用されます。
以下の表に、Runtime 1.3の主要コンポーネントをまとめます。
| コンポーネント | バージョン |
|---|---|
| Apache Spark | 3.5 |
| Delta Lake | 3.2 |
| Python | 3.11 |
| Java | 11 |
| Scala | 2.12 |
| R | 4.3 |
Runtime 1.3の最大の特徴は、後述するNative Execution Engineに対応している点です。これにより従来のOSS Sparkと比較して最大4倍のクエリ高速化が実現されます。
Runtime 2.0(Experimental Public Preview)
Runtime 2.0は次世代ランタイムで、大規模データ処理に向けた大幅な刷新が行われています。
2026年3月時点ではExperimental Public Previewとして提供されています。
| コンポーネント | バージョン |
|---|---|
| Apache Spark | 4.0 |
| Delta Lake | 4.0 |
| Python | 3.12 |
| Java | 21 |
Spark 4.0への対応はFabricが業界に先駆けて提供しているもので、新しいSpark Connect API、改善されたANSIモード、強化された構造化ストリーミングなどが含まれます。
ただし、Experimental Public Previewには以下の制約があるため、本番運用には推奨されていません。
- R言語は未サポート(PySpark・Spark SQL・Scalaの3言語のみ対応)
- Starterプールは対象外で、セッション起動に2〜5分程度かかる
- 一部のライブラリやコネクタが未対応の可能性がある
評価・検証目的で使用し、GAリリースを待って移行するのが現時点でのベストプラクティスです。詳細はRuntime 2.0の公式ドキュメントを参照してください。
Native Execution Engine
Native Execution Engineは、Spark Data Engineeringの処理パフォーマンスを飛躍的に向上させる高速化機構です。
Metaが開発したVelox(C++データベース加速ライブラリ)とApache Gluten(JVMベースのSQLエンジンをネイティブ実行に置き換える中間レイヤー)を組み合わせて実現されています。

主な特徴は以下のとおりです。
- 最大4倍の高速化
TPC-DS 1TBベンチマークで検証された性能向上です。データの取り込み、バッチジョブ、ETL処理、インタラクティブクエリの幅広いシナリオで効果を発揮します。
- コード変更不要
既存のSparkコードをそのまま高速化でき、ベンダーロックインのリスクがありません。Apache Spark APIとの互換性を維持しています。
- 自動フォールバック
未対応の操作やデータ型が含まれるクエリは、自動的に従来のSpark JVMエンジンにフォールバックします。処理の中断は発生しません。
有効化は環境(Environment)設定の「Acceleration」タブからトグルで切り替える方法が最も簡単です。
Notebook単位で有効にしたい場合は、先頭セルに以下を記述します。
%%configure
{
"conf": {
"spark.native.enabled": "true"
}
}
ただし、Native Execution Engineには制限事項もあります。
ユーザー定義関数(UDF)、array_contains関数、Structured Streaming、JSON/XML/CSV形式のクエリ、ANSIモード有効時はネイティブ実行されず従来のJVMエンジンにフォールバックします。
ParquetとDelta形式のデータで最も効果を発揮するため、OneLake上のDelta Lakeデータに対する処理が主な適用対象です。
Fabric Notebookの主要機能
Fabric Notebookは、Data Engineeringの日常的な開発作業を支える中心的なツールです。このセクションでは、Notebookの実践的な機能と使い方を解説します。

マルチ言語サポート
Fabric Notebookは、PySpark(Python)、Spark SQL、Scala、Rの4言語をサポートしています。
Notebook全体のデフォルト言語を設定したうえで、各セルの先頭にマジックコマンドを記述することでセルごとに言語を切り替えられます。
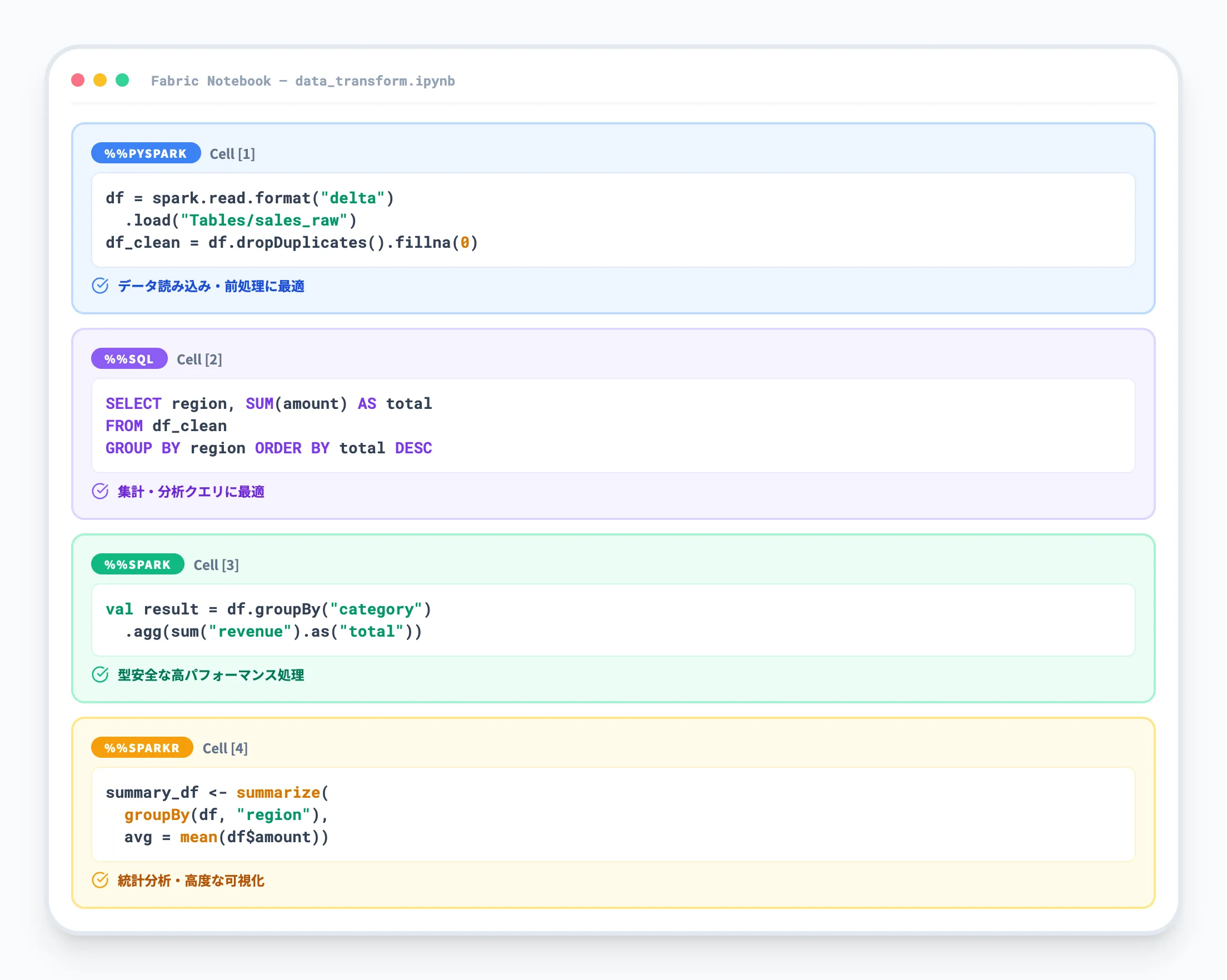
マジックコマンドの一覧を以下の表に示します。
| マジックコマンド | 言語 | 用途 |
|---|---|---|
| %%pyspark | Python | データ加工・ML・汎用処理 |
| %%sql | Spark SQL | 集計・分析クエリ |
| %%spark | Scala | 型安全な高パフォーマンス処理 |
| %%sparkr | R | 統計分析・可視化 |
実務では、PySpark(データの読み込み・変換)とSpark SQL(集計・分析クエリ)を組み合わせる使い方が最も一般的です。
Scalaはパフォーマンスを重視するバッチ処理に、Rは統計分析や高度な可視化に向いています。
IntelliSenseと変数エクスプローラー
NotebookのセルエディタはMonacoエディター(VS Codeの基盤技術)をベースにしており、コード補完、パラメータヒント、構文ハイライトなどのIDEライクな開発支援機能が利用できます。
変数エクスプローラーは、現在のSparkセッションで定義されたPySpark変数の名前・型・長さ・値をリスト表示する機能です。大量のデータフレームを扱うワークフローでは、中間結果の確認やデバッグを効率化できます。
データの視覚化
Notebookの実行結果は、テーブル表示に加えてコードを書かずに折れ線グラフ・棒グラフ・円グラフなどに変換できます。
Apache Spark DataFrameやPandas DataFrameの結果に対して、列の選択やグルーピングを指定するだけでインタラクティブなグラフを生成できるため、探索的データ分析(EDA)のスピードが向上します。
NotebookUtils
NotebookUtils(旧称MSSparkUtils)は、Fabricノートブック内で利用できる組み込みユーティリティパッケージです。
データエンジニアリングの日常業務で頻繁に必要となる操作をコード数行で実現できます。
主な機能カテゴリは以下のとおりです。
- ファイルシステム操作
OneLake上のファイルやフォルダの作成・コピー・移動・削除、一覧取得を行えます。
- シークレット取得
Azure Key Vaultに格納されたAPIキーやパスワードなどのシークレットをNotebookから安全に取得できます。
- ノートブックの連鎖実行
別のNotebookを子プロセスとして呼び出し、値の受け渡しやパイプライン的な処理フローを構築できます。
- 環境変数の取得
Sparkセッションの構成情報やワークスペース情報を取得できます。
High Concurrencyモード
High Concurrencyモードは、複数の互換NotebookでSparkセッションを共有できる仕組みです。
通常はNotebookごとに個別のセッションが起動しますが、このモードを有効にすると1つのセッション上で最大5つのNotebookを同時実行でき、セッション起動のオーバーヘッドとリソース消費を削減できます。
共有にはいくつかの条件があり、同じワークスペース、同じ既定Lakehouse、同じSpark計算設定・ライブラリ構成のNotebookである必要があります。
小規模なクエリを頻繁に実行する場合や、関連する複数のNotebookを順に実行する開発作業に特に効果的です。異なるライブラリ要件や異なるLakehouseを参照するNotebookは別セッションで実行する必要があります。
Fabric Data Engineeringの環境設定とライブラリ管理
Sparkジョブの実行環境を適切に構成することは、パフォーマンスとコスト効率に直結します。このセクションでは、Sparkプールの種類と選択基準、ライブラリの管理方法を解説します。

Starterプールの特徴
Starterプールは、Fabricがあらかじめ準備している即時利用型のSparkプールです。手動設定は不要で、Notebook起動時に5〜10秒でSparkセッションが開始されます。
Fabricはユーザーのワークロードパターンを学習し、需要を予測してプールを事前準備(proactive provisioning)することで、起動の高速化とアイドル時間の最小化を両立しています。
探索的な分析やNotebookでの対話型開発では、設定不要で高速に起動するStarterプールが最適です。
Customプールの設定
Customプールは、ノードサイズやスケーリング設定を細かく調整できるSparkプールです。本番運用の大規模バッチ処理や、特定のメモリ要件があるワークロードに適しています。

以下の表に、Fabricで選択可能なノードサイズをまとめます。
| ノードサイズ | vCore数 | メモリ |
|---|---|---|
| Small | 4 | 32 GB |
| Medium | 8 | 64 GB |
| Large | 16 | 128 GB |
| X-Large | 32 | 256 GB |
| XX-Large | 64 | 512 GB |
利用できるノード数は、契約しているFabric容量(SKU)と1 CU = 2 Spark vCoreの換算比率に加え、**burst factor(3倍)**の影響を受けます。
たとえば公式ドキュメントの例ではF64(64 CU)で最大384 Spark vCoreが利用可能とされ、Smallノード(4 vCore)なら最大96ノード、Mediumなら48ノード、Largeなら24ノードまで構成できます。
Customプールの作成自体は無料で、課金はSparkセッションがアクティブな間のみ発生します。アイドル状態のプールには課金されません。
ライブラリのインストールと管理
Fabricの各ランタイムにはPySpark・Delta Lake・MLflowなどの標準ライブラリが組み込まれていますが、業務要件に応じて追加のライブラリをインストールできます。
ライブラリの管理は主に2つのレベルで行います。
- 環境レベル
環境に追加したライブラリは、その環境をアタッチしたすべてのNotebookとSparkジョブで利用可能になります。
%pipや%condaによるインストールに加え、カスタムの.whlファイルやJARファイルのアップロードにも対応します。環境へのライブラリ追加は「Publish」操作後5〜15分で反映されます。
- インラインレベル
Notebookのセッション内でのみ有効な一時的なインストールです。%pipや%condaコマンドをセル内で実行することで、セッション終了時に自動で消えるライブラリを追加できます。
試験的なパッケージの検証や、特定のNotebookだけで必要なライブラリに適しています。
なお、Azure Synapse Sparkで利用可能だったワークスペースレベルのライブラリ管理はFabricでは提供されていません。すべてのライブラリ管理は環境またはインラインレベルで行います。

Azure Synapse SparkやDatabricksとの違い
Fabric Data Engineeringの導入を検討する際に必ず比較対象となるのが、Azure Synapse SparkとDatabricksです。このセクションでは、両プラットフォームとの主要な違いと使い分けの基準を解説します。

Azure Synapse Sparkとの比較
Azure Synapse Sparkは、Fabricの前身にあたるSparkサービスです。
MicrosoftはSynapse SparkからFabricへの移行パスを公式に整備しており、ノートブック・Sparkジョブ定義・ライブラリ・構成設定のそれぞれについて移行ガイドが提供されています。
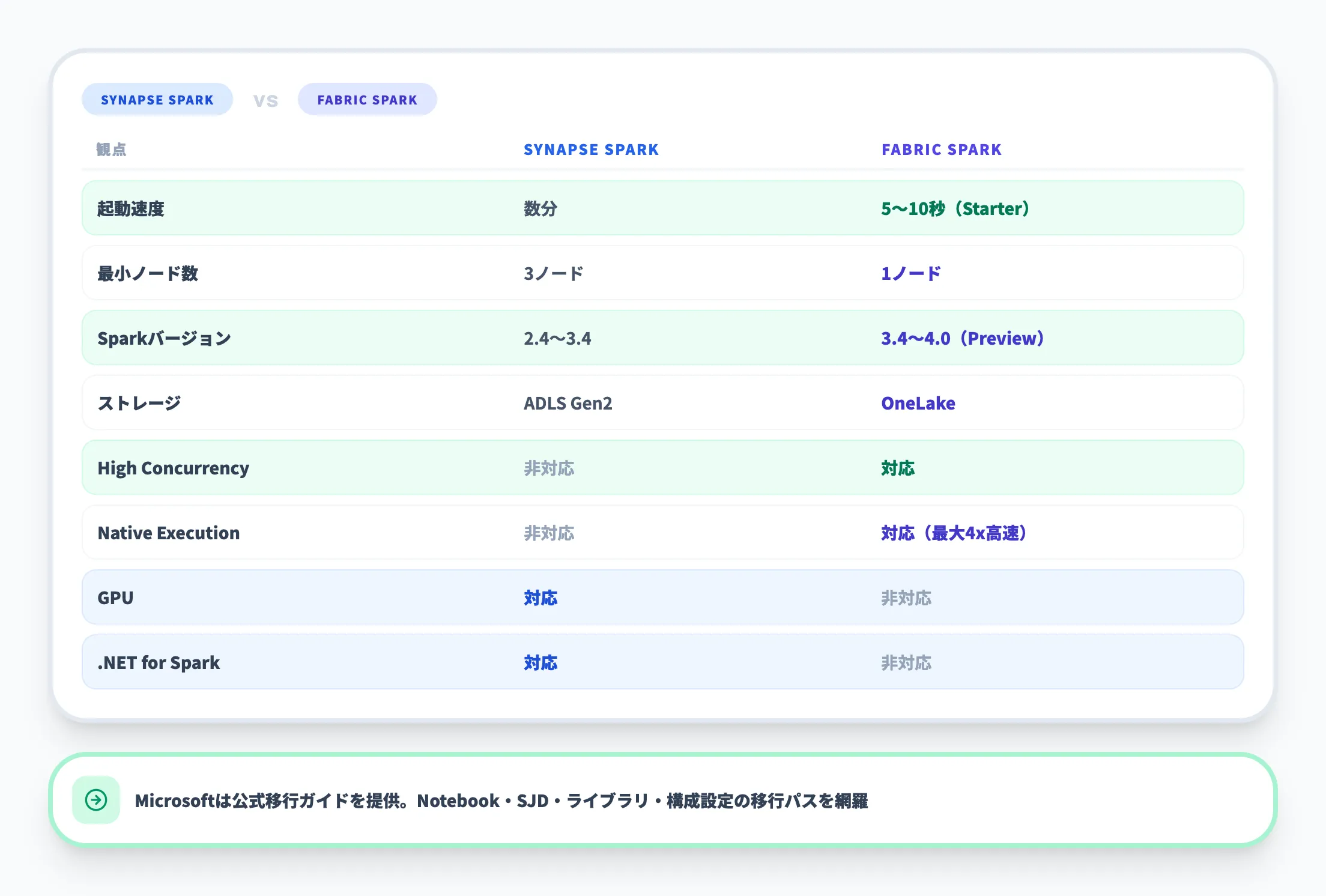
以下の表に主要な違いをまとめます。
| 観点 | Azure Synapse Spark | Fabric Spark |
|---|---|---|
| プールモデル | 固定コンピュートリソース(最大200ノード) | 構成テンプレート(容量vCoreで制約) |
| 起動速度 | プール起動に数分 | Starterプールで5〜10秒 |
| 最小ノード数 | 3ノード | 1ノード |
| Sparkバージョン | 2.4〜3.4 | 3.4〜4.0(Runtime 2.0 Preview) |
| ストレージ | ADLS Gen2 | OneLake |
| メタストア | 内部HMS + 外部HMS対応 | 内部HMS(Lakehouseベース)のみ |
| High Concurrency | 非対応 | 対応 |
| Native Execution Engine | 非対応 | 対応(最大4倍高速) |
| V-Order最適化 | 非対応 | デフォルト有効 |
| GPUプール | 対応 | 非対応 |
| .NET for Spark(C#) | 対応 | 非対応 |
| CI/CD | 自前構築 | Deployment Pipelines組み込み |
Fabricを選ぶべき場面は、OneLake統合・高速起動・High Concurrency・Native Execution Engineを活用したい場合です。
一方、GPUアクセラレーションが必要な機械学習ワークロードや、外部Hive Metastoreとの連携が必要な既存環境では、Synapse Sparkに優位性があります。
Databricksとの使い分け
DatabricksはApache Sparkの開発元が設立した企業のプラットフォームであり、特にデータエンジニアリングと機械学習の分野で実績があります。
Fabricとは設計思想が異なるため、組織の状況に応じた使い分けが推奨されます。

| 観点 | Fabric Data Engineering | Databricks |
|---|---|---|
| 設計思想 | SaaS型(クラスタレス、自動管理) | 計算リソースの選択肢が広く、クラスタ/サーバーレスを含めて細かく制御可能 |
| インフラ管理 | 完全マネージド | サーバーレスからカスタムクラスタまで選択可能 |
| BI連携 | Power BIとDirect Lake統合 | SQL Warehouse + BI Connector |
| ML/AI | Data Scienceワークロード + Fabric IQ | MLflow(開発元)+ MosaicAI |
| マルチクラウド | Azure専用 | Azure / AWS / GCP対応 |
| パイプライン | Data Factory統合 | Delta Live Tables |
| ガバナンス | Microsoft Purview統合 | Unity Catalog |
| 対象ユーザー | ビジネスアナリストから開発者まで | データエンジニア・MLエンジニア中心 |
以下の基準で選択するのが実務的です。
- Fabricが適している組織
Microsoft 365・Azure・Power BIなどMicrosoft製品への既存投資がある組織。
非エンジニアも含むセルフサービス分析を重視する場合。インフラ管理を最小化して迅速にデータ基盤を構築したい場合。
- Databricksが適している組織
データエンジニアリングチームが社内に確立されている組織。Python・Spark・Scalaのスキルがあり、クラスタ構成を細かく制御したい場合。
マルチクラウド戦略を推進している場合。本番レベルのMLモデルデプロイが主要な要件の場合。
- ハイブリッドアプローチ
データエンジニアリングとMLにはDatabricks、ガバナンスとBIにはFabricという組み合わせも実務では多く見られます。
OneLakeのショートカット機能を使えば、Databricksで処理したデータをFabricからシームレスに参照できます。
Fabric Data Engineeringの活用シーンと注意点
Fabric Data Engineeringは万能ではありません。
このセクションでは、どのような場面で最も効果を発揮し、どのような場面では他の選択肢が適しているかを整理します。

向いているケース
以下のユースケースでは、Fabric Data Engineeringが特に強みを発揮します。
- メダリオンアーキテクチャの実装
Bronze(生データ)→ Silver(クレンジング済み)→ Gold(分析用)の3層構造を、Lakehouse + Notebookで構築するパターンです。
ワークスペースを層ごとに分離し、パイプラインでデータフローを制御することで、データ品質と処理の追跡性を確保できます。
- ETL/ELTパイプラインの構築
外部ソースからOneLakeへのデータ取り込みと、NotebookやSparkジョブ定義での変換処理を組み合わせたパイプラインです。
Shortcut機能によるデータの仮想参照と、Spark Notebookによるクレンジング・変換、Data Factoryによるオーケストレーションの3段構成が推奨パターンです。
- 探索的データ分析(EDA)
Starterプールの高速起動(5〜10秒)とNotebookの対話型UIにより、データの探索と仮説検証を効率的に進められます。
- Power BIとの統合分析
LakehouseのDeltaテーブルにDirect Lakeモードでアクセスすることで、データのインポートやリフレッシュなしにリアルタイムに近いBI分析が可能です。
【関連記事】
Microsoft Fabric導入事例6選!国内企業の成果と導入パターンを解説
向かないケース
一方、以下のようなケースではFabric Data Engineeringが最適とは限りません。
- GPUが必要な深層学習ワークロード
Fabric SparkプールはMemory Optimizedノードファミリーのみで、GPUアクセラレーションには対応していません。
大規模言語モデルのファインチューニングやディープラーニングの学習にはAzure Machine LearningやDatabricksが適しています。
- 超大規模クラスタ(200ノード超)
Fabricのノード数は容量SKUに依存します。数百ノード規模のクラスタが必要な場合はDatabricksが選択肢となります。
- マルチクラウドのデータ処理基盤
FabricはAzure専用プラットフォームです。AWS・GCPにもまたがるマルチクラウド戦略が必要な場合はDatabricksが適しています。
- 外部Hive Metastoreとの連携
既存のデータカタログを外部Hive Metastore(Azure SQL DB等)で管理しており、そのまま利用したい場合はFabricでは対応できません。
V-Order最適化の活用
V-OrderはFabric Data Engineeringでデフォルト有効のDelta Lake書き込み最適化です。ParquetファイルのデータをV-Order形式で並べ替えることで、読み取り時のI/Oを削減し、クエリパフォーマンスを向上させます。
V-Orderの適用は書き込み時にCPUコストが発生しますが、その後のクエリ性能が向上するため、「書き込みは少なく読み取りは多い」分析ワークロードに特に効果的です。
書き込み頻度が非常に高いストリーミング処理では、必要に応じて無効化を検討してください。
Fabric Data Engineeringの料金体系
Fabric Data Engineeringの料金は、Fabric全体のCapacity Unit(CU)ベースの課金モデルに基づいています。このセクションでは、Spark固有の課金の仕組みと、3つの課金オプションを解説します。

CUからSpark vCoreへの換算
Fabricでは、1 CU(Capacity Unit) = 2 Spark vCoreの比率でリソースが割り当てられます。
以下の表に、代表的なF SKUとSpark vCoreの関係をまとめます。
| F SKU | CU数 | Spark vCore数 |
|---|---|---|
| F2 | 2 | 4 |
| F4 | 4 | 8 |
| F8 | 8 | 16 |
| F16 | 16 | 32 |
| F32 | 32 | 64 |
| F64 | 64 | 128 |
| F128 | 128 | 256 |
| F256 | 256 | 512 |
Fabricの料金はリージョン・契約形態(EA / CSP / Pay-as-you-go)・通貨によって変動するため、正確な金額はAzure Pricing CalculatorまたはFabric価格ページで確認してください。
1年または3年の予約購入を利用すると、Pay-as-you-goと比較して**最大約41%**のコスト削減が見込めます。長期運用が確定している場合は予約購入を検討してください。
課金モデルの選択肢
Fabric Data Engineeringの課金は、3つのモデルから選択できます。
| 課金モデル | 特徴 | 適用場面 |
|---|---|---|
| Starterプール | Fabricキャパシティから消費。アイドル時間は非課金 | 探索的分析、対話型開発 |
| Customプール | Fabricキャパシティから消費。ノード構成をカスタマイズ可能 | 本番バッチ処理、大規模ETL |
| Autoscale Billing | Spark実行コストをキャパシティ外に分離できる従量課金 | バースト的・不定期なSparkジョブ |
いずれのモデルでも、Sparkセッションがアクティブな間のみ課金が発生し、セッション未使用時の課金はありません。
デフォルトのセッション有効期限は20分で、2分間操作がない場合にプールが自動解放されます。
Autoscale Billing(従量課金)の仕組み

Autoscale Billingは、SparkジョブをFabricキャパシティ外にオフロードし、専用のサーバーレスリソースで実行する従量課金モデルです。
課金は**Spark usage rate(0.5 CU hour)**に基づき、アクティブなジョブの計算時間に対してのみ発生します。アイドル時間やジョブ待機時間は課金されません。
なお、Autoscale Billingを有効にしても、OneLakeストレージや非Sparkワークロード(Data Warehouse、Power BIなど)のためのベースFabric capacityは別途必要です。
Autoscale BillingはあくまでSparkジョブの実行コストのみをキャパシティ外に分離する仕組みです。
Autoscale Billingが特に有効なのは、以下のようなケースです。
- Sparkの使用量が日によって大きく変動するワークロード
- 他のFabricワークロードとリソースの競合を避けたい場合
- Sparkの課金を独立してモニタリング・管理したい場合
Autoscale Billingはキャパシティ単位でオプトインする仕組みで、管理者がCU上限を設定してコストの上限管理を行えます。上限に達すると、バッチジョブはキューに入り、インタラクティブジョブはスロットリングされます。
安定して予測可能なSparkワークロードは通常のキャパシティモデルで、バースト的なジョブはAutoscale Billingで運用するというハイブリッド構成も可能です。
【関連記事】
Microsoft Fabricとは?使い方や価格体系、できることを徹底解説!
【Microsoft Fabric】Real-Time Intelligenceとは?機能や料金体系を徹底解説
【Microsoft Fabric】Data Scienceとは?MLflowやAutoML、料金体系を徹底解説

Data Engineeringで整備したデータをAIエージェントの判断基盤にするなら
Spark NotebookやLakehouseで加工・整備したデータは、レポートの入力で終わりではなく、AIエージェントが業務判断を下すための基礎データとして直接活用できます。
AI Agent Hubは、Data Engineeringのパイプライン出力をAIエージェントのナレッジとして直結させるエンタープライズAI基盤です。
- Spark加工データをAgentがナレッジとして直接参照
NotebookやLakehouseで整備したデータを、AIエージェントがTeamsから自然言語で問い合わせ。ETLパイプラインの出力がそのまま業務判断の入力になります。
- Native Execution Engineの高速化でデータ鮮度を維持
4倍の高速処理でデータ準備時間を短縮。AIエージェントが参照するデータの鮮度を維持し、タイムリーな業務判断を支えます。
- 使い慣れたMicrosoft環境をそのまま活用
Teamsなど既存のMicrosoftツールの延長でAIエージェントが動作。新しいツールの学習コストはゼロです。
- データは100%自社テナント内に保持
AIの学習対象から完全除外。Azure Managed Applicationsとして自社テナント内で動作が完了する設計です。
AI総合研究所の専任チームが、設計から運用まで伴走支援します。まずは無料の資料で、自社の業務にどう活用できるかご確認ください。
Spark加工データをAgent業務判断に直結

データ加工からAI業務自動化へ
Data EngineeringのSpark NotebookやLakehouseで加工・整備したデータを、AIエージェントの業務判断基盤として直接活用。データ加工からAI活用までをFabric内で完結させます。
まとめ
本記事では、Microsoft FabricのData Engineeringワークロードについて、基本概念から主要コンポーネント、Sparkランタイム、Notebookの使い方、環境設定、他プラットフォームとの比較、料金体系までを解説しました。
Fabric Data Engineeringの価値は、大きく3点に集約されます。
1つ目はインフラ管理の大幅な簡素化です。Starterプールの5〜10秒起動、環境による構成一元管理、V-Orderの自動最適化により、データエンジニアはSparkクラスタの管理ではなく、データの加工と活用に集中できます。
2つ目はNative Execution Engineによるパフォーマンスの飛躍です。コード変更なしで最大4倍の高速化が得られ、処理時間の短縮はそのままCU消費量の削減とコスト削減につながります。
3つ目はFabricエコシステム内のシームレスな統合です。NotebookからLakehouseのデータを直接処理し、結果をPower BIでDirect Lakeモードにより即座に可視化する。この一連のフローがOneLakeを基盤としてデータ移動なしに実現できる点が、他のSparkプラットフォームにはない固有の強みです。
Data Engineeringの導入を検討している場合は、まずFabricの60日間無料トライアルでStarterプール上のNotebookを試し、既存のSparkワークロードとの互換性を確認するのが最もリスクの低い第一歩です。







