この記事のポイント
 大規模データ分析・機械学習基盤にはAzure Databricksが第一候補。Spark分散処理とAutoScale対応で処理速度とコスト効率を両立できる
大規模データ分析・機械学習基盤にはAzure Databricksが第一候補。Spark分散処理とAutoScale対応で処理速度とコスト効率を両立できる- データレイクとDWHを一本化するならレイクハウス(Delta Lake)構成にすべき。メダリオン設計で品質と分析速度を両立できる
- データガバナンスはUnity Catalogで統一管理すべき。権限・監査ログの属人化を防ぎ、運用の安定性が格段に上がる
- Python・R・SQL・Scalaの混在チームでも同一ノートブックで協働できるため、分析チームの生産性向上に直結する
- コスト最適化にはDBUコミットメント割引の活用が有効。自動停止設定と組み合わせれば無駄な課金を大幅に抑えられる

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
大規模データの解析や機械学習をスピーディに回すには、処理性能だけでなく、データのガバナンスとチーム開発のしやすさが重要です。
本記事では、Azure上でApache Spark基盤をマネージドに使えるAzure Databricksについて、基本機能から使い方、活用例、料金の考え方まで整理します。レイクハウスやUnity Catalogといった2026年時点の運用観点も含め、導入判断に必要なポイントを押さえます。
✅Microsoft 365 Copilotの最新エージェント機能「Copilot Cowork」については、以下の記事をご覧ください。
Copilot Coworkとは?機能や料金、Claude Coworkとの違いを解説
目次
分析やAIのワークロードを1つのプラットフォームで完結できる
レイクハウス(Delta Lake)で分析基盤を一体化しやすい
データガバナンス(Unity Catalog)で権限と監査を揃えやすい
Azure Databricksの料金体系(2026年2月時点)
Azure Databricksとは
Azure Databricksは、Microsoft Azureのクラウド上で動くApache Sparkベースのデータ分析プラットフォームです。大きなデータを素早く処理したり、機械学習モデルを作成したり、リアルタイムでデータを分析することが得意です。
Apache Sparkという高速なデータ処理エンジンを使っており、大量のデータを分散して効率よく処理してくれます。
さらに、Azureのクラウドサービスと組み合わせることで、柔軟にリソースを使いながら、高いパフォーマンスを発揮します。

Azure Databricksイメージ図
クラウドの便利さとSparkの高速なデータ処理の両方を活用できるAzure Databricksについて、以下解説していきます。

Azure Databricksを使用するメリット
まずは、Azure Databricksを使用することで得られるメリットについてご紹介しましょう。
分析やAIのワークロードを1つのプラットフォームで完結できる
Azure Databricksは、データ処理、機械学習、ビジネスインテリジェンスなど、データに関する作業を一つのプラットフォームでまとめて行えるツールです。つまり、複数のツールを使い分ける必要がなく、一つの環境でプロジェクトをスムーズに進められるのです。
データサイエンスのワークフロー全体をカバーしているため、データの収集から分析、モデルの作成、結果の可視化までを一貫して行うことができます。
高速な分散処理が可能
Azure Databricksは、Apache Sparkの分散処理エンジンを使っているため、大量のデータを効率よく、高速に処理できます。
さらに、自動的にクラスターをスケーリングする機能を持っており、データの量や処理の負荷に応じて、必要な計算リソースを柔軟に増減させることができます。そのため、処理能力を無駄にすることなく、最適なパフォーマンスを維持することができるという訳です。
複数の言語に対応したノートブック環境
Azure Databricksでは、Python、R、SQL、Scalaといったデータサイエンスでよく使われる異なる言語を、同じノートブック内で扱うことができます。つまり、異なるプログラミング言語を使うメンバーがいても、同じ環境で作業ができ、チーム内での協力がスムーズに進められるのです。
各メンバーがチーム内でそれぞれの専門性を活かしつつ、スムーズに協働することが可能になります。
共同開発やバージョン管理機能
Azure Databricksは共同開発に適しています。
組み込みのバージョン管理システムを使うことで、コードの変更履歴を追跡できるので、誰がどの部分を変更したかを簡単に確認できます。
また、ノートブックの共有や同時編集機能を使って、複数のメンバーがリアルタイムで共同作業を行うことができるため、チーム全体でスムーズにプロジェクトを進めることが可能です。
レイクハウス(Delta Lake)で分析基盤を一体化しやすい
Azure Databricksは、データレイクとデータウェアハウスの良いところ取りをする「レイクハウス」アーキテクチャを取り入れやすい点も強みです。レイク上に蓄積したデータを、バッチ処理だけでなくSQLやBIのワークロードにもつなげやすくなります。
公式ドキュメントでも、レイクハウスの考え方や設計の要点が整理されています(Data Lakehouse とは - Azure Databricks)。例えば「メダリオン」などの段階設計を前提にすると、取り込みデータの品質と分析のスピードを両立しやすくなります。
データガバナンス(Unity Catalog)で権限と監査を揃えやすい
実運用では「誰が・どのデータに・どんな権限でアクセスできるか」を揃えないと、分析基盤はすぐに属人化します。Azure Databricksでは、Unity Catalogを軸に、データ資産(テーブル、ファイル、モデルなど)の権限管理や監査ログを整理しやすい構造になっています。
Unity Catalogの概要は公式ドキュメントにまとまっており(Unity Catalog とは - Azure Databricks)、ストレージへのアクセス方式(マネージドIDなど)と合わせて設計すると、セキュリティと運用性の両方が安定します。
Azure Databricksの基本的な使い方
では、さっそくAzure Databricksの基本的な使い方について解説していきます。
流れとしては、以下のようになります。
-
ワークスペースの準備
Databricksの操作やデータ処理を行うための作業環境を用意します。 -
クラスターの作成
データを処理するための計算リソース(仮想マシン)を用意します。 -
データのアップロード
処理や分析を行うデータを、クラウド上にアップロードして利用できるようにします。 -
ノートブックでのデータ処理
アップロードしたデータを使って、分析や集計、機械学習の処理を行います。 -
処理結果の可視化
処理したデータの結果を、視覚的に確認・分析します。
ワークスペースの準備
-
Azureポータルにサインイン
Azureポータルにアクセスして、アカウントにサインインします。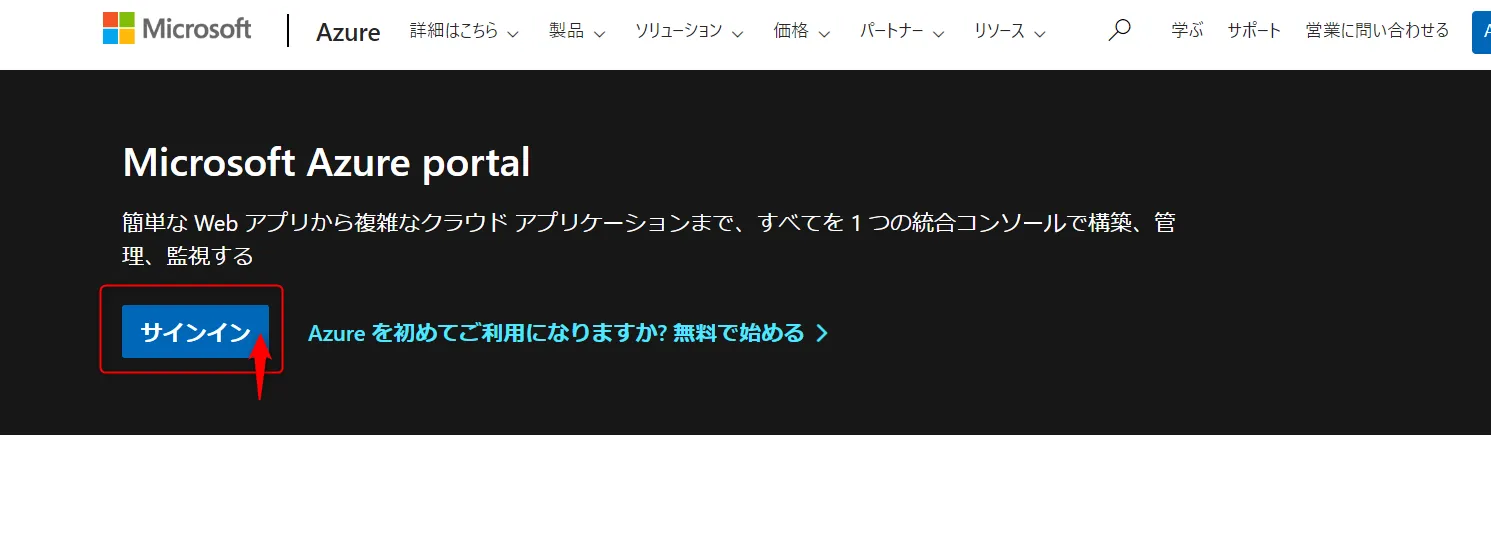
Azureポータル画面
-
リソースの作成
左側メニューから「リソースの作成」をクリックします。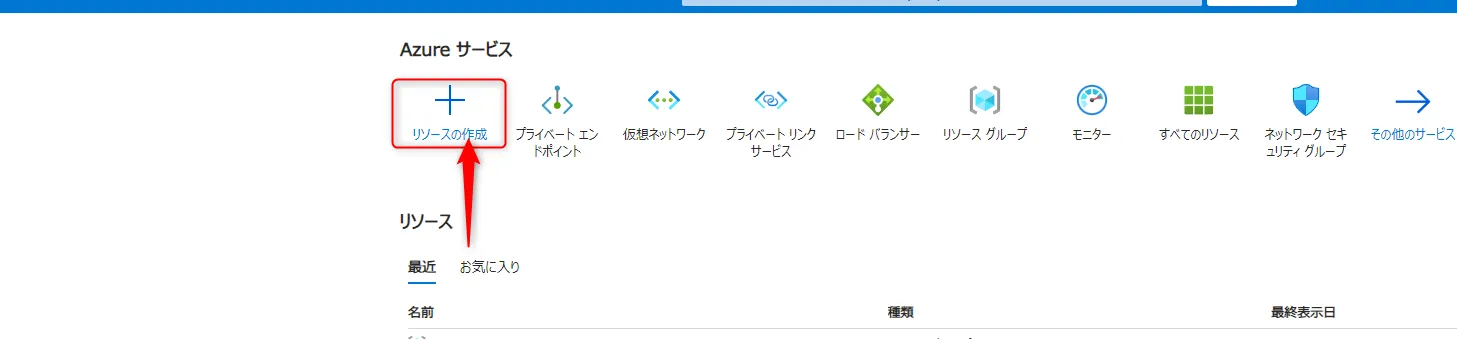
リソースの作成ボタン
-
Databricksを検索
①検索バーに「Databricks」と入力し、②表示された「Azure Databricks」を選択します。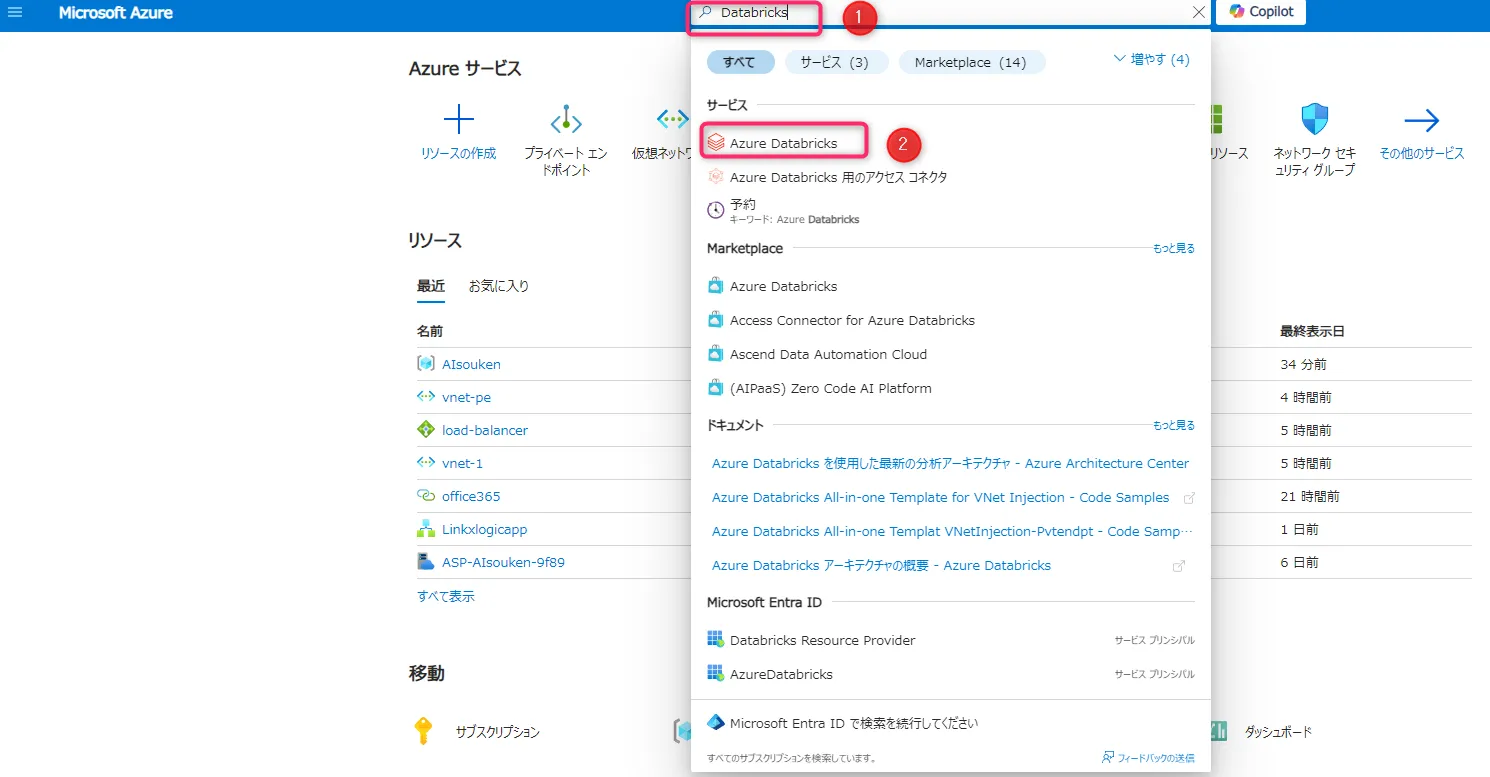
検索画面
-
Azure Databricksの作成
「+作成」をクリックします。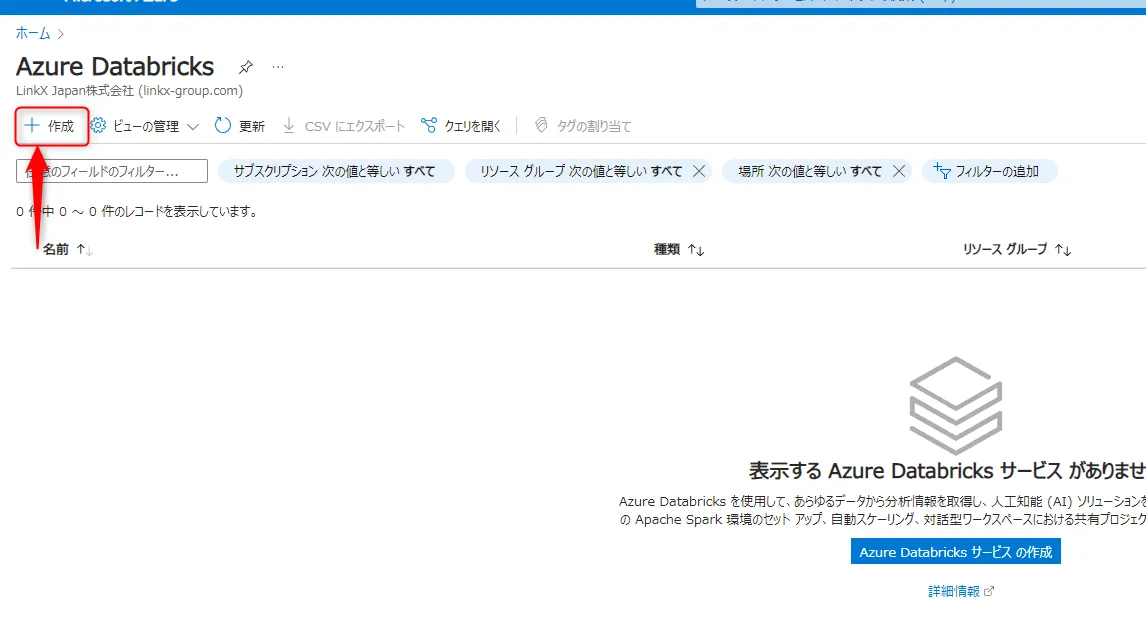
+作成ボタン
-
基本設定の入力
①「Azure Databricksの作成」ページで、以下の項目を入力し、②「次:ネットワーク」をクリックします。- サブスクリプション
- リソースグループ
- ワークスペース名
- リージョン
- 価格レベル
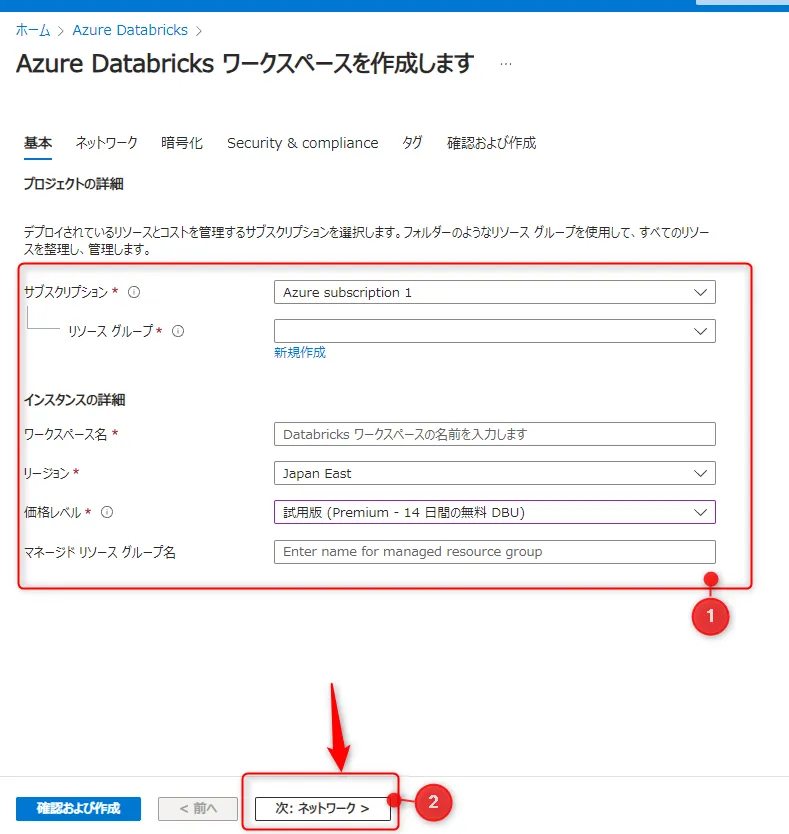
入力画面
-
ネットワークとタグの設定
必要に応じてネットワーク設定やタグを追加し、「確認および作成」をクリックします。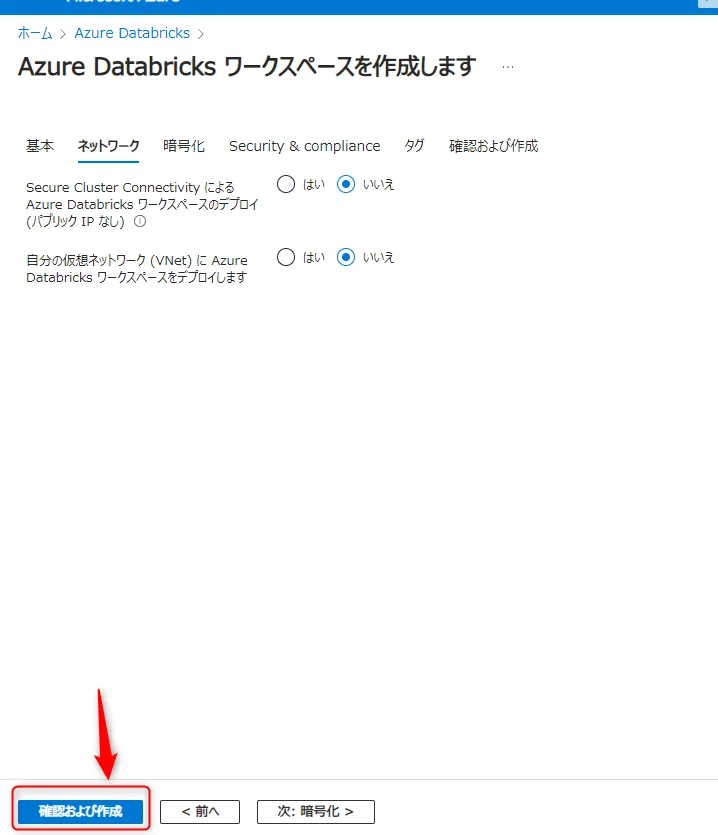
確認および作成ボタン
-
作成
設定内容を確認し、「作成」をクリックすると、Azure Databricksのワークスペースがデプロイされます。数分で作成が完了し、使用可能になります。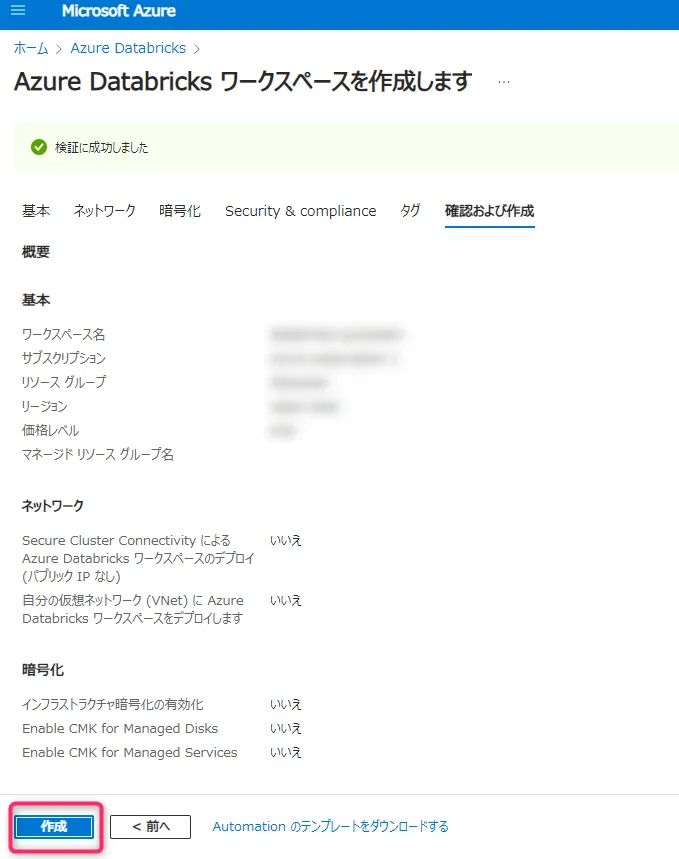
作成ボタン
-
Databricksポータルにアクセス
ワークスペースが作成されたらDatabricksポータルにアクセスします。ここからクラスターの作成やデータ処理が可能です。
これでAzure Databricksのワークスペースが準備でき、データ分析や処理を行う環境が整います。
クラスターの作成
クラスターを作成するPythonコードは、Databricksのノートブック内で実行します。
以下の手順でノートブックを作成し、コードを入力・実行しましょう。
- Azureポータルで作成したDatabricksのページから、「ワークスペースの起動」をクリックします。
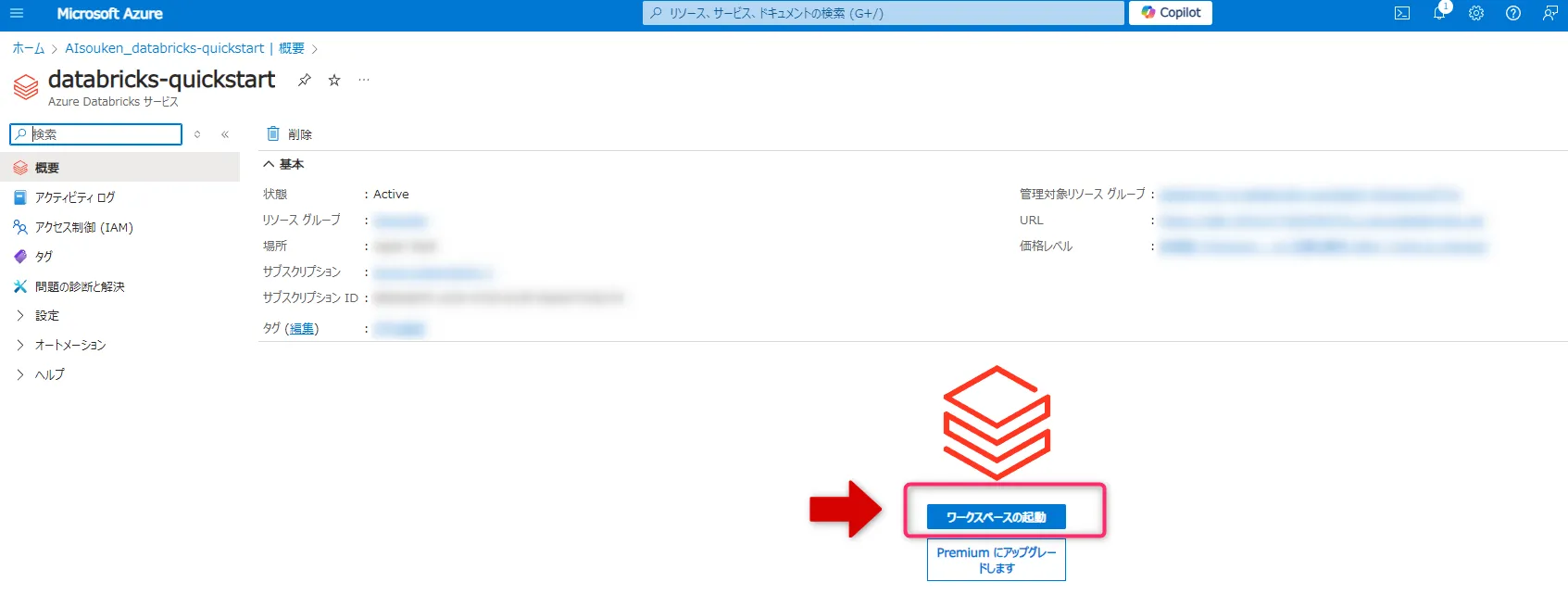
ワークスペースの起動ボタン
-
ワークスペース画面が表示されます。
この画面は、Azure Databricks のワークスペースにアクセスした際のホーム画面です。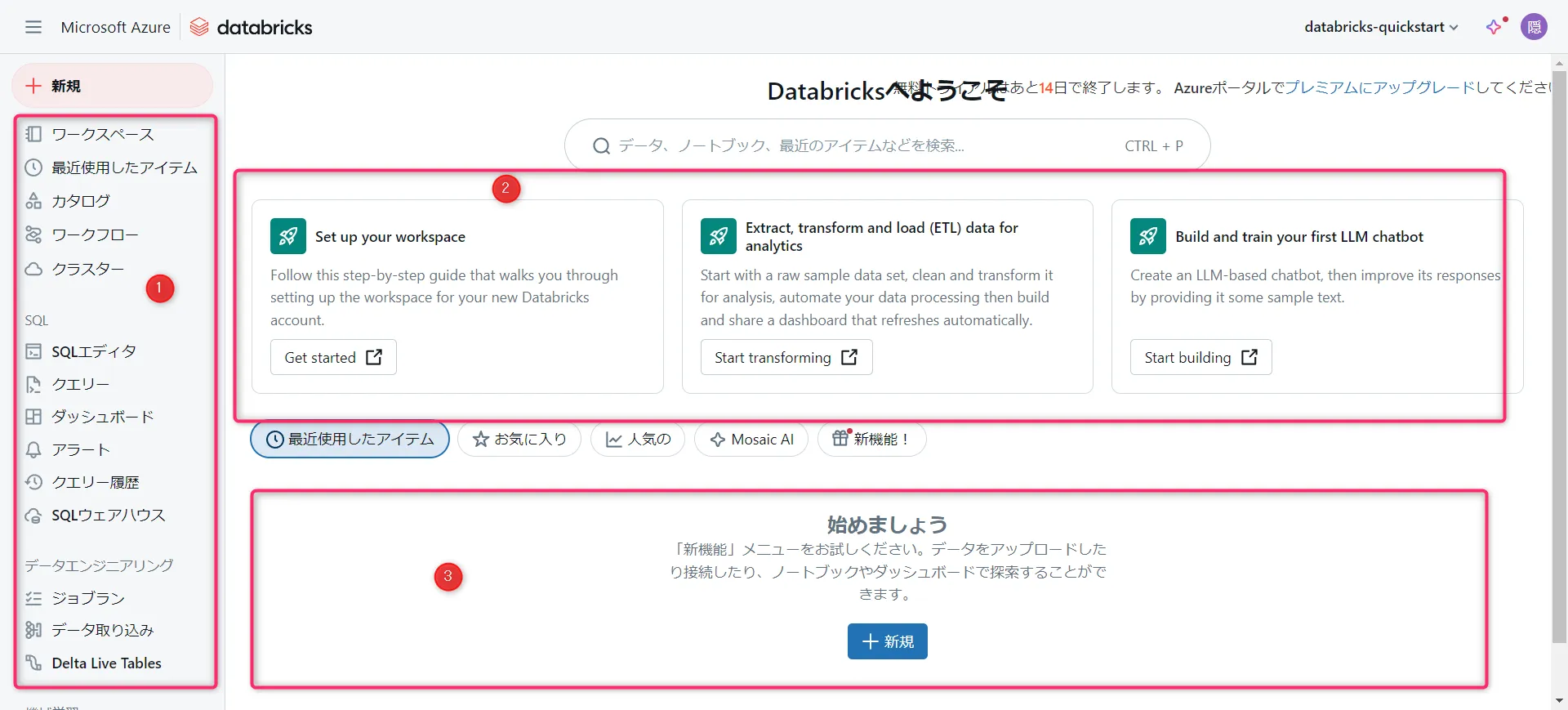
ワークスペース画面① 左側メニュー
ナビゲーションエリアです。ワークスペース全体で利用可能な機能やツールにアクセスするためのリンクが集まっています。クラスター管理、SQLエディタ、ワークフローなど、日常的に使う主要な機能に簡単にアクセスできる場所です。② メインコンテンツエリア
ここは実際の作業を行うスペースです。データの処理、クラスターの設定、ノートブックの作成、ETL作業、機械学習モデルの構築など、さまざまなアクションが実行されます。作業に関連する具体的な操作やガイドが表示されるスペースです。③ 下部メニュー
新規: 新しいリソースを作成するためのボタンです。データのアップロードやノートブックの作成が可能です。
-
クラスター作成
① ワークスペースのサイドバーで [クラスター] をクリックし、② [コンピューティングの作成] をクリック。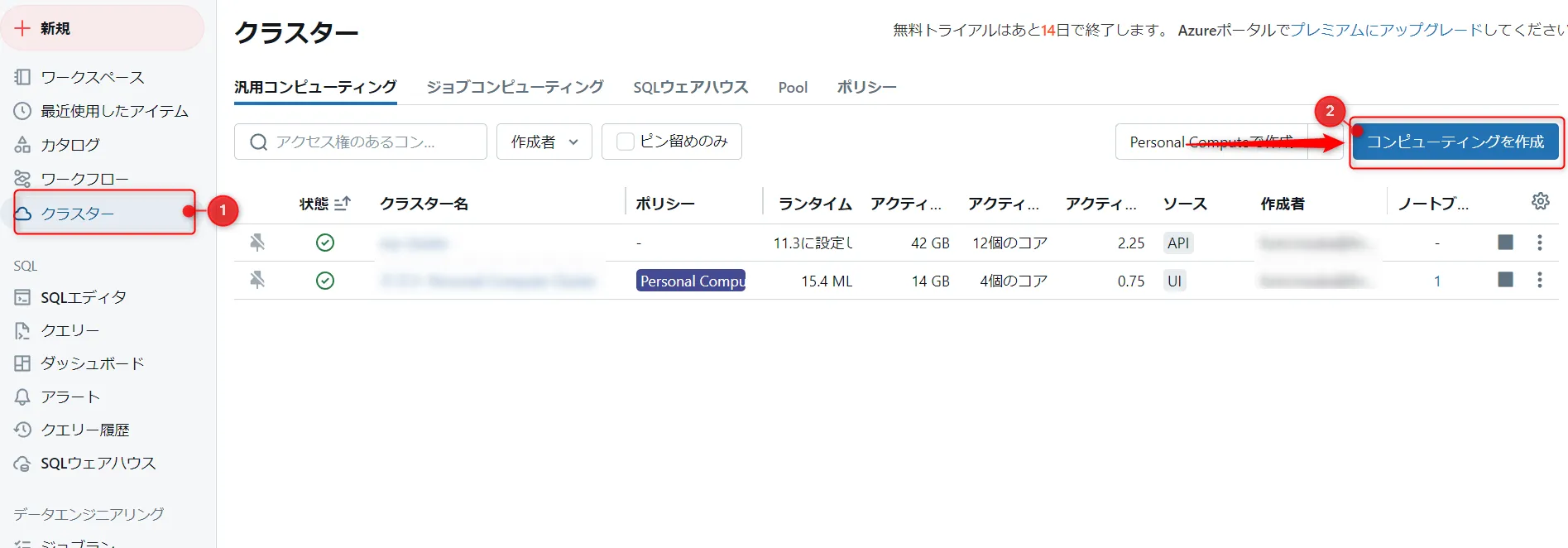
コンピューティングの作成ボタン
-
入力と作成
必要事項を入力し、[コンピューティングを作成] をクリックします。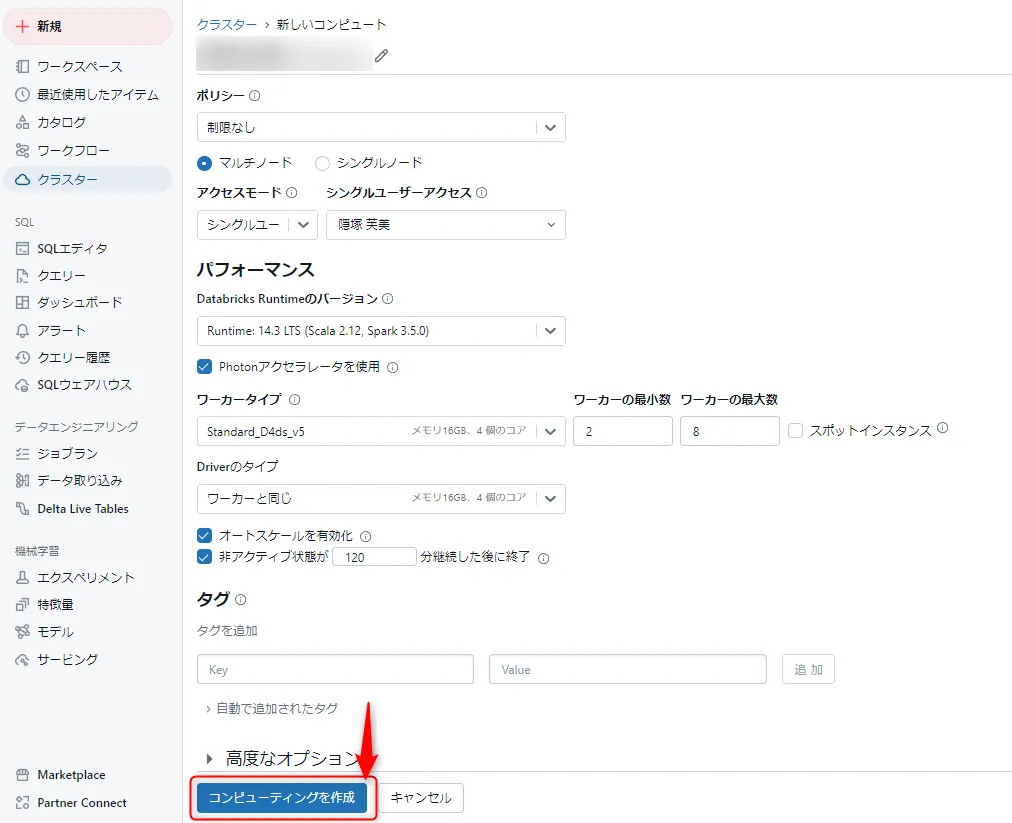
コンピューティングの作成入力画面
新しいコンピューティング リソースが自動で起動し、すぐに使用可能になります。
データのアップロード
-
ホーム画面左メニューから [新規] を選び、[データの追加またはアップロード] をクリックします。
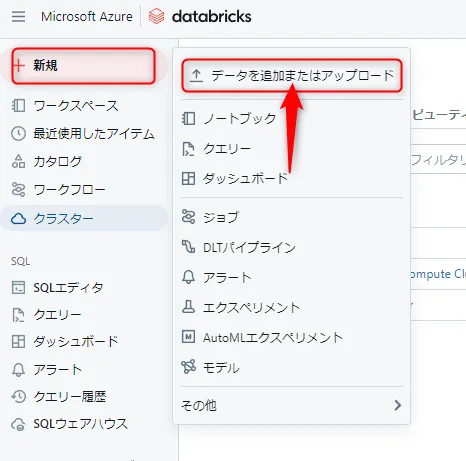
新規選択画面
-
[テーブルの作成または変更] をクリックします。
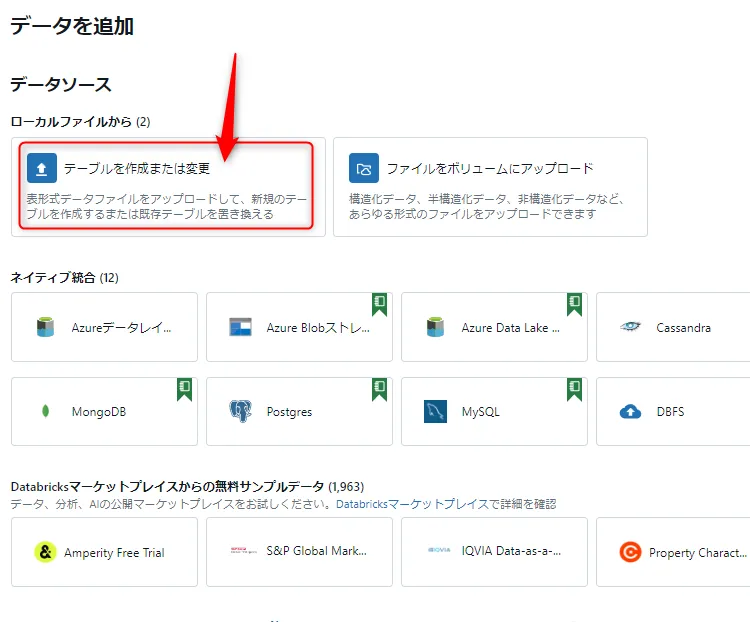
テーブルの作成または変更ボタン
-
ファイル ブラウザー ボタンをクリックするか、ドロップゾーンに直接ファイルをドラッグ&ドロップします。
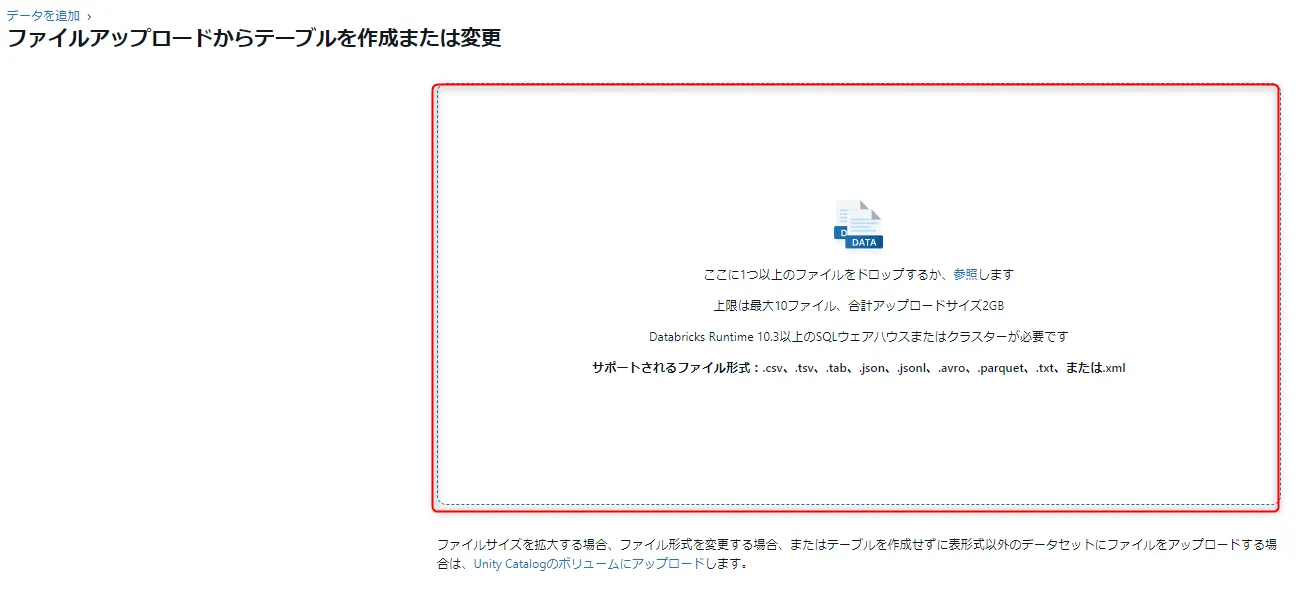
ドロップゾーンここでは、sample_data.csv というデータをアップロードしました。
sample_data.csv は、顧客や個人の基本的なプロフィール情報をまとめた架空のデータセットです。
ID、名前、年齢、性別、メールアドレス、電話番号、住所、職業、年収、登録日が載っています。 -
「テーブルを作成」をクリックします。
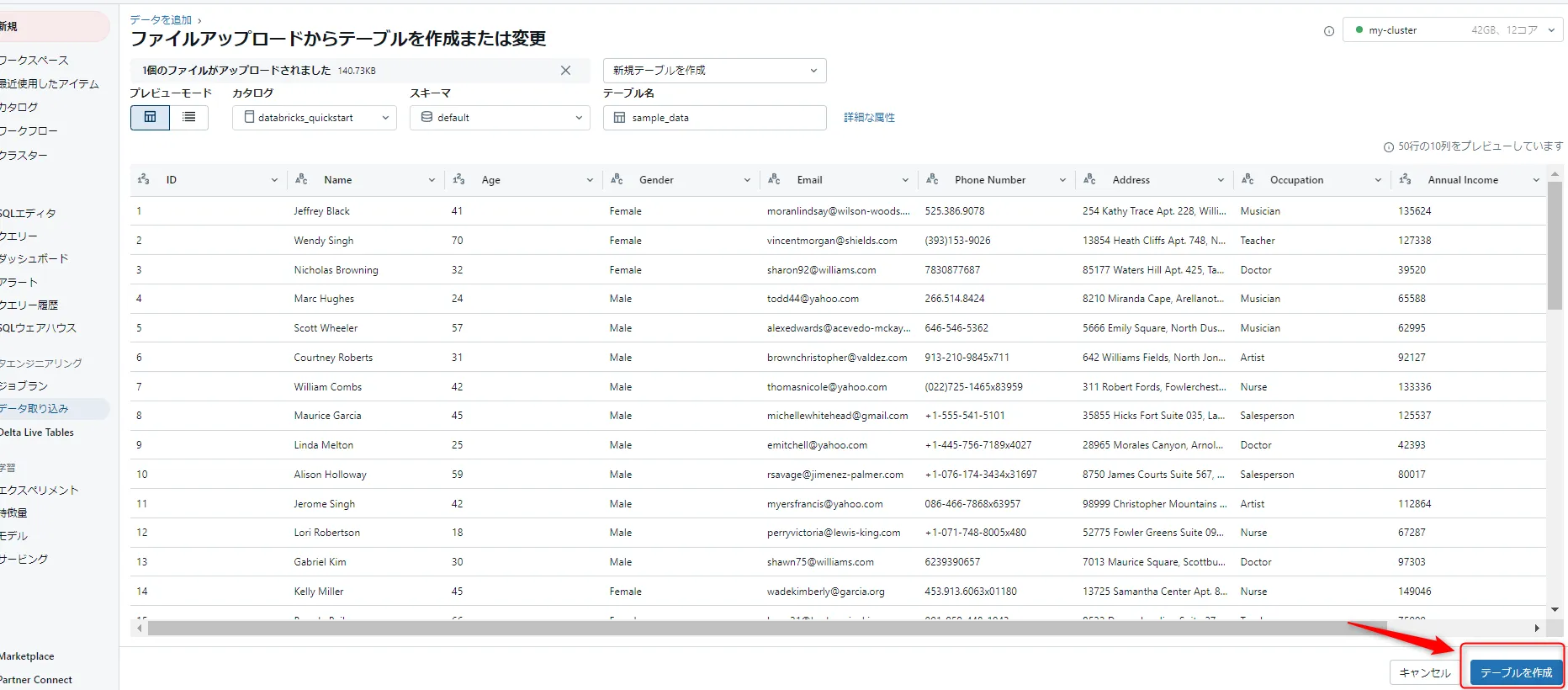
デーブルを作成ボタン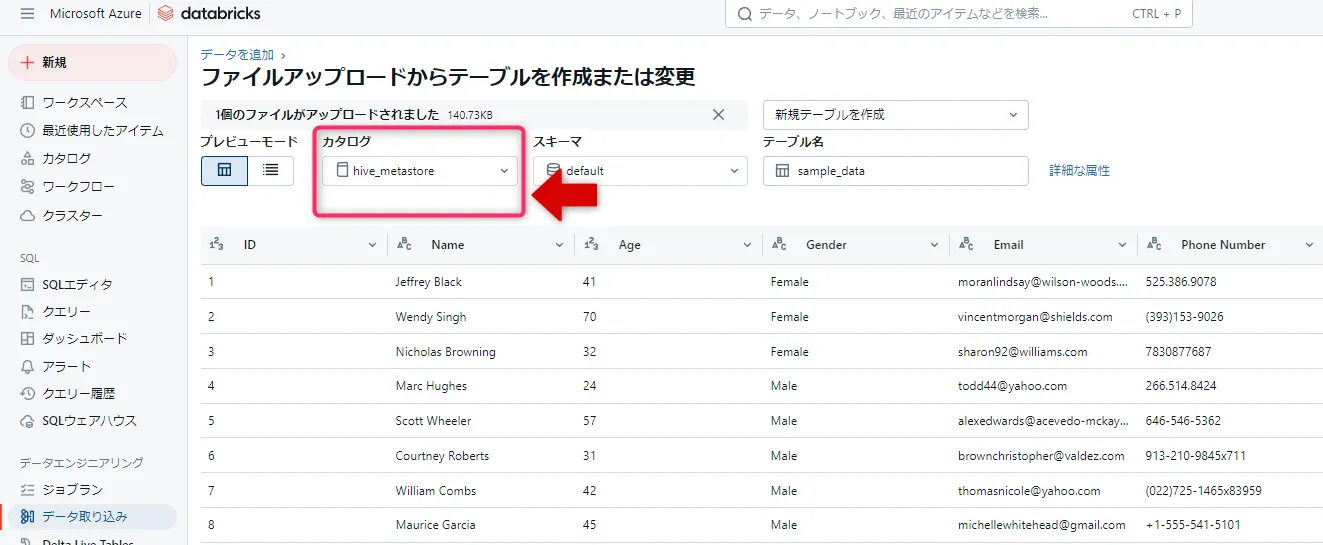
カタログ選択
-
sample_data のテーブルが作成されました。
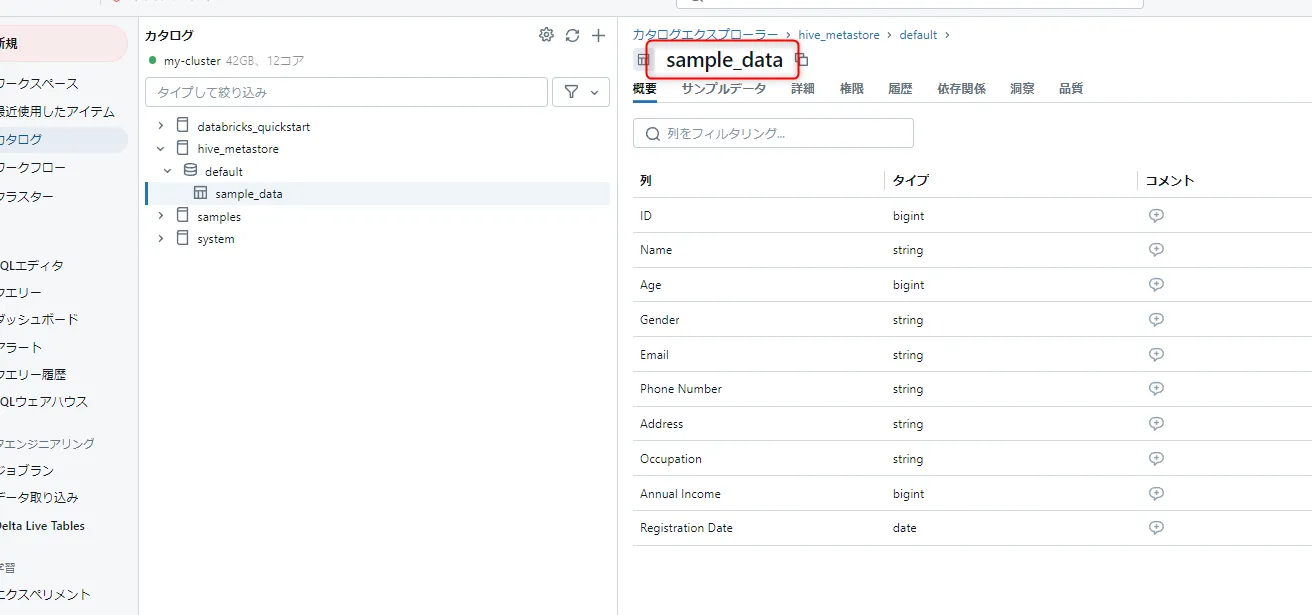
テーブル作成画面
ノートブックでのデータ処理
-
新規→ノートブックの作成
左メニューから [新規] をクリックし、[ノートブック] を選択します。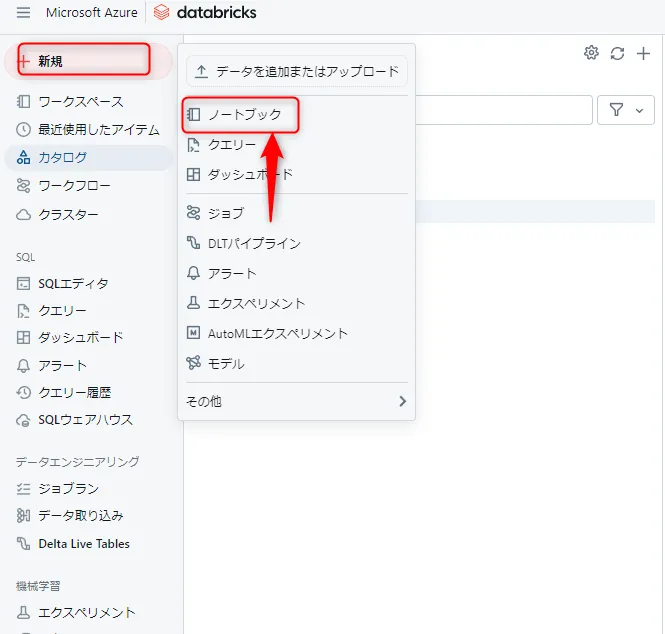
ノートブック選択画面
-
ノートブックの作成
ノートブックが作成されました。
ノートブック作成画面
-
テーブルの読み出し
上記で作成したテーブルを読み込むため、以下のコードをノートブックに記載します。その後、「▷」ボタンをクリックして実行します。# sample_data.csvを読み込むコード df = spark.sql("SELECT * FROM hive_metastore.default.sample_data") df.show() -
データの読み込み完了
データの読み込みが完了しました。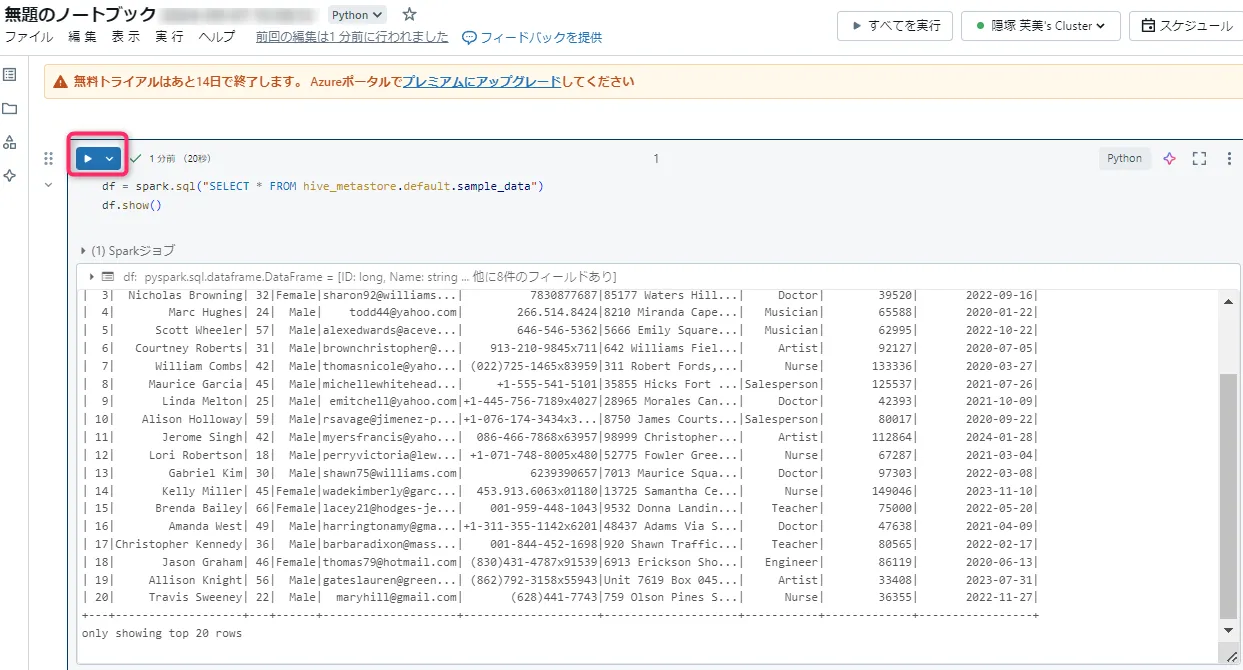
データの読み込み画面
-
簡単な集計
簡単な集計を行います。
例として、職業ごとの平均年収を計算するコードを作成しました。職業ごとの平均年収を計算するため、以下のコードをノートブックに記載し、実行します。# 職業ごとの平均年収を計算 df.groupBy("Occupation").avg("Annual Income").show()すると、このように集計されました。
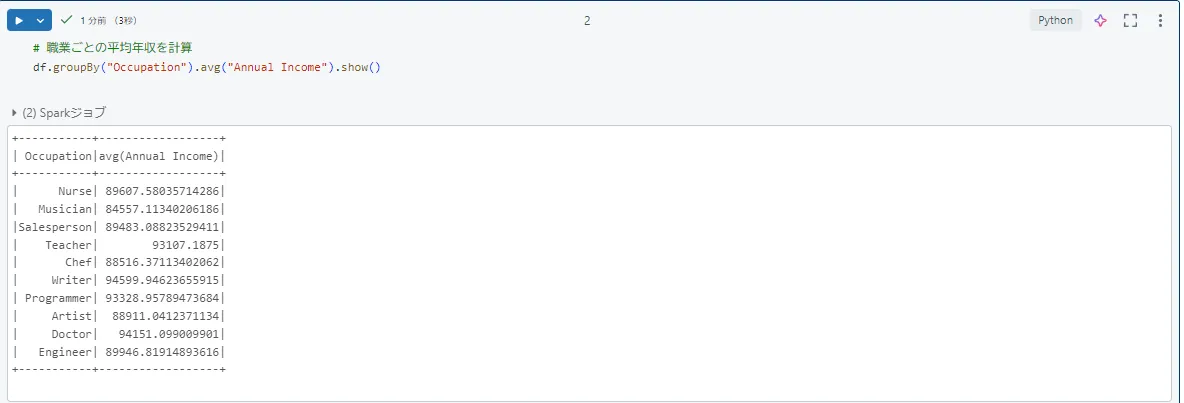
集計結果
処理結果の可視化
処理結果を可視化するために、以下のコードを使用してグラフを作成します。
import matplotlib.pyplot as plt
# Spark DataFrameをPandas DataFrameに変換
data = df.groupBy("Occupation").avg("Annual Income").toPandas()
# グラフの作成
plt.figure(figsize=(10, 6))
plt.bar(data['Occupation'], data['avg(Annual Income)'])
plt.title('Average Annual Income by Occupation')
plt.xlabel('Occupation')
plt.ylabel('Average Annual Income')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
すると、このようなグラフが作成されます。
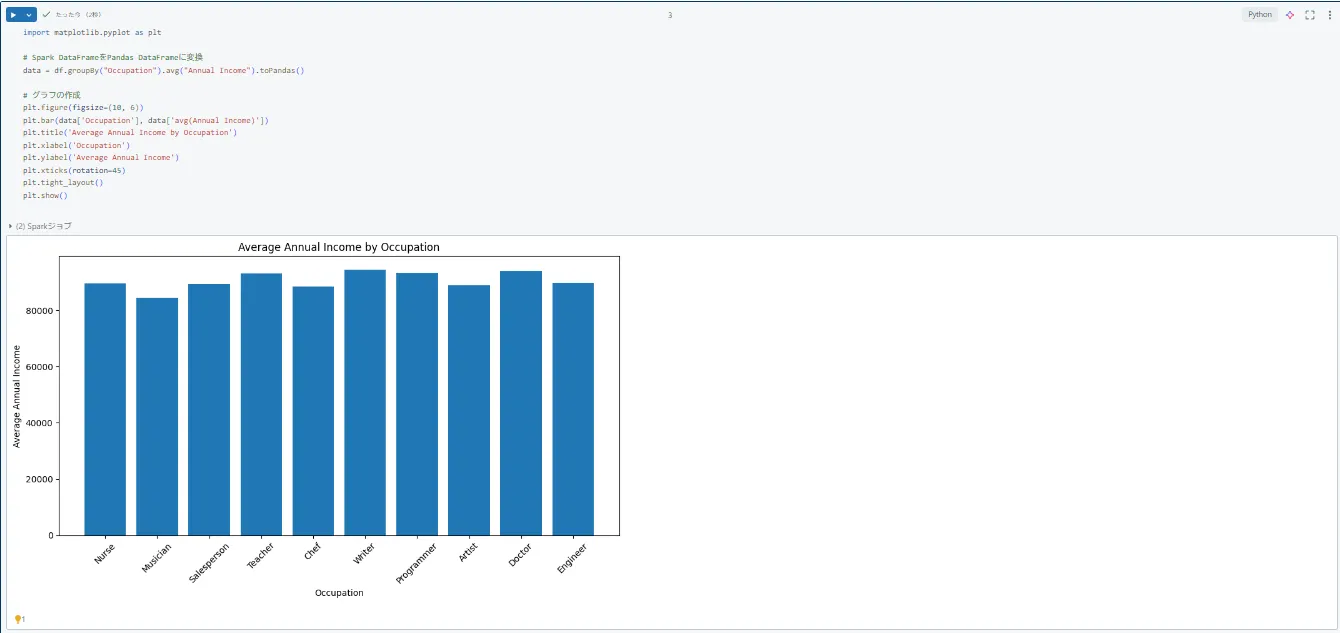
グラフ作成画面

Azure Databricksの活用事例
Azure Databricksは、データ処理や分析、機械学習のために多くの企業で活用されています。ここでは、Azure Databricksを使った具体的な活用事例をご紹介します。
顧客データ基盤の構築
多くの企業が顧客データを効率よく管理し、分析するために、Azure Databricksを使用して顧客データ基盤を構築しています。
例えば、
ある小売企業が全国の店舗から収集した膨大な顧客データをAzure Databricksに集約し、
そこから顧客の購入履歴や行動パターンを分析することができます。
Databricksの分散処理エンジンにより、大量のデータを迅速に処理でき、商品の売れ筋や在庫の最適化に役立てることができます。
また、Azure Blob Storageなどのストレージと連携することで、長期的なデータ保管もスムーズに行えます。
機械学習モデルの開発
Azure Databricksは、機械学習モデルの開発にも活用されています。PythonやMLlibなどのライブラリを活用して、大規模なデータを使ったモデルのトレーニングや評価を行うことができるのです。
例えば、
保険会社がAzure Databricksを使って、保険契約者のデータをもとにリスクスコアを予測する機械学習モデルを開発することができます。
このモデルは、契約者の年齢、過去の健康診断結果、生活習慣などのデータを分析し、リスクが高い契約者を特定します。こうすることで、より適切な保険料の提案やリスク管理が可能になります。
リアルタイム分析への応用
Azure Databricksは、リアルタイムデータの分析にも優れています。ストリーミングデータを処理して、リアルタイムでの意思決定やアクションをサポートすることが可能です。
例えば、
製造業で、工場の生産ラインで稼働している機械から収集されるセンサー情報をAzure Databricksでリアルタイムに分析することができます。
温度、振動、圧力などのデータをリアルタイムで監視し、異常値が発生した際には即座にアラートを出す仕組みを構築することで、機械の故障や生産の停止を未然に防ぎ、効率的な生産を実現することができます。
Azure Databricksの料金体系(2026年2月時点)
Azure Databricksの料金は、Databricksの利用料金(DBU)と、クラスターで使うAzure仮想マシンなどの基盤料金を組み合わせて決まります。DBUの単価やコミットメント割引は、公式の価格ページ(Azure Databricks の価格 | Microsoft Azure)に掲載されています。
料金体系の構成要素
料金は大きく分けて、Databricks側の課金とAzure側の課金に分かれます。
- DBU(Databricks Unit)
ノートブックの対話的実行、バッチ処理、SQL、サーバーレスなどのワークロードごとに、DBU単価が設定されています。
- クラスターの基盤料金(Azure VMなど)
DBUとは別に、クラスターを構成する仮想マシン、OSディスクなどのコストが発生します。
- ストレージ・ネットワーク
データをAzure Storageに置く場合の保存量、リージョン外へのデータ転送などが追加で課金されます。
- コミットメント(DBCU)
1年または3年で事前購入すると、従量課金のDBU料金と比べて最大37%の割引を受けられます。
価格例(2026年2月時点:Japan Eastリージョン想定)
以下は、Japan EastにおけるDBU単価の例です。実際の見積もりでは、DBUに加えてクラスターのAzure VM料金も加算されます。
| 項目 | 単位あたりの価格 | 補足 |
|---|---|---|
| Standard Jobs Compute(DBU) | 0.15 USD / 時間 | バッチ実行向けのDBU単価 |
| Standard All-Purpose Photon(DBU) | 0.40 USD / 時間 | 対話的実行向け。Photon有効時の例 |
| Premium All-Purpose Photon(DBU) | 0.55 USD / 時間 | Premiumの対話的実行向けの例 |
※価格は2026年2月時点、リージョン:Japan East、通貨:USDの参考値です。
運用では、常時起動の対話クラスターを最小限にし、ジョブ実行中心に寄せるだけでもコストが大きく変わります。加えてDBCUを組み合わせると、月次の利用量が読みやすいワークロードほど割引効果を出しやすくなります。

データ分析基盤の構築力をAI業務自動化にも活かすなら
Azure Databricksでデータ分析基盤を構築できる環境なら、AI業務自動化への展開もスムーズです。Microsoft環境でのAI業務自動化の段階設計を、220ページのガイドで解説しています。
データ分析基盤からAI業務自動化へ

Databricks活用からAI導入へ
Azure Databricksでデータ分析基盤を構築できる環境なら、AI業務自動化の導入もスムーズです。Microsoft環境でのAI業務自動化の段階設計を、220ページのガイドで解説しています。
まとめ
本記事では、Azure Databricksの概要、主要なメリット、基本的な使用方法、そして具体的な活用事例について解説しました。
Azure Databricksは、Apache Sparkをベースとした強力な分析プラットフォームであり、大規模データ処理から機械学習まで幅広いデータサイエンスのワークロードに対応できます。使いやすく処理能力も高性能であるため、多くの企業がデータ駆動型の意思決定や革新的なサービス開発に活用しています。
ぜひ、Azure Databricksを導入して、組織のデータ活用能力に役立ててください。
この記事が、皆様のお役に立てたなら幸いです。










