この記事のポイント
 Spark/Pythonでのデータ加工とBI分析を1つの環境で完結させたいチームはLakehouseが最適、Data Warehouseとの二重管理を回避
Spark/Pythonでのデータ加工とBI分析を1つの環境で完結させたいチームはLakehouseが最適、Data Warehouseとの二重管理を回避- SQL中心のBIチームにはData Warehouseが向いているが、非構造データやML連携が必要ならLakehouseを選ぶべき
- データ品質管理にはメダリオンアーキテクチャ(ブロンズ・シルバー・ゴールド)の採用が有効。段階的な品質向上でガバナンスとスピードを両立できる
- Power BIとの連携ではDirect Lakeモードを最優先で導入すべき。Importモードと比較してデータ鮮度とクエリ性能が大幅に改善する
- F2 SKUからスモールスタートが可能なため、PoCはLakehouse単体で始め、本番環境ではCU消費量を見極めてからSKUを拡張するのが安全

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Microsoft Fabric Lakehouseは、データレイクの柔軟性とデータウェアハウスの分析性能を1つの環境に統合したデータ基盤です。
Delta Lake形式によるACIDトランザクション対応と、Apache SparkおよびT-SQLによるデュアルエンジン分析を実現し、データのコピーや移動なしに多様な分析ワークロードへ対応します。
本記事では、Fabric Lakehouseの基本概念からData Warehouseとの使い分け、メダリオンアーキテクチャによるデータ設計、Direct Lakeモードを活用したPower BI連携、日本企業の導入事例、料金体系までを体系的に解説します。
✅Microsoft 365 Copilotの最新エージェント機能「Copilot Cowork」については、以下の記事をご覧ください。
Copilot Coworkとは?機能や料金、Claude Coworkとの違いを解説
目次
【詳細比較】Fabric Lakehouse vs Data Warehouse
Fabric LakehouseとDirect Lakeモード
Fabric Lakehouseとは?
Microsoft Fabric Lakehouse(レイクハウス)は、データレイクの柔軟性とデータウェアハウス(DWH)の分析性能を1つの環境に統合したデータストレージです。
構造化データ(売上テーブルなど)と非構造化データ(PDFやログファイルなど)をまとめて格納できます。分析にはApache Sparkで全データを処理できるほか、DeltaテーブルについてはT-SQLでもクエリが可能です。
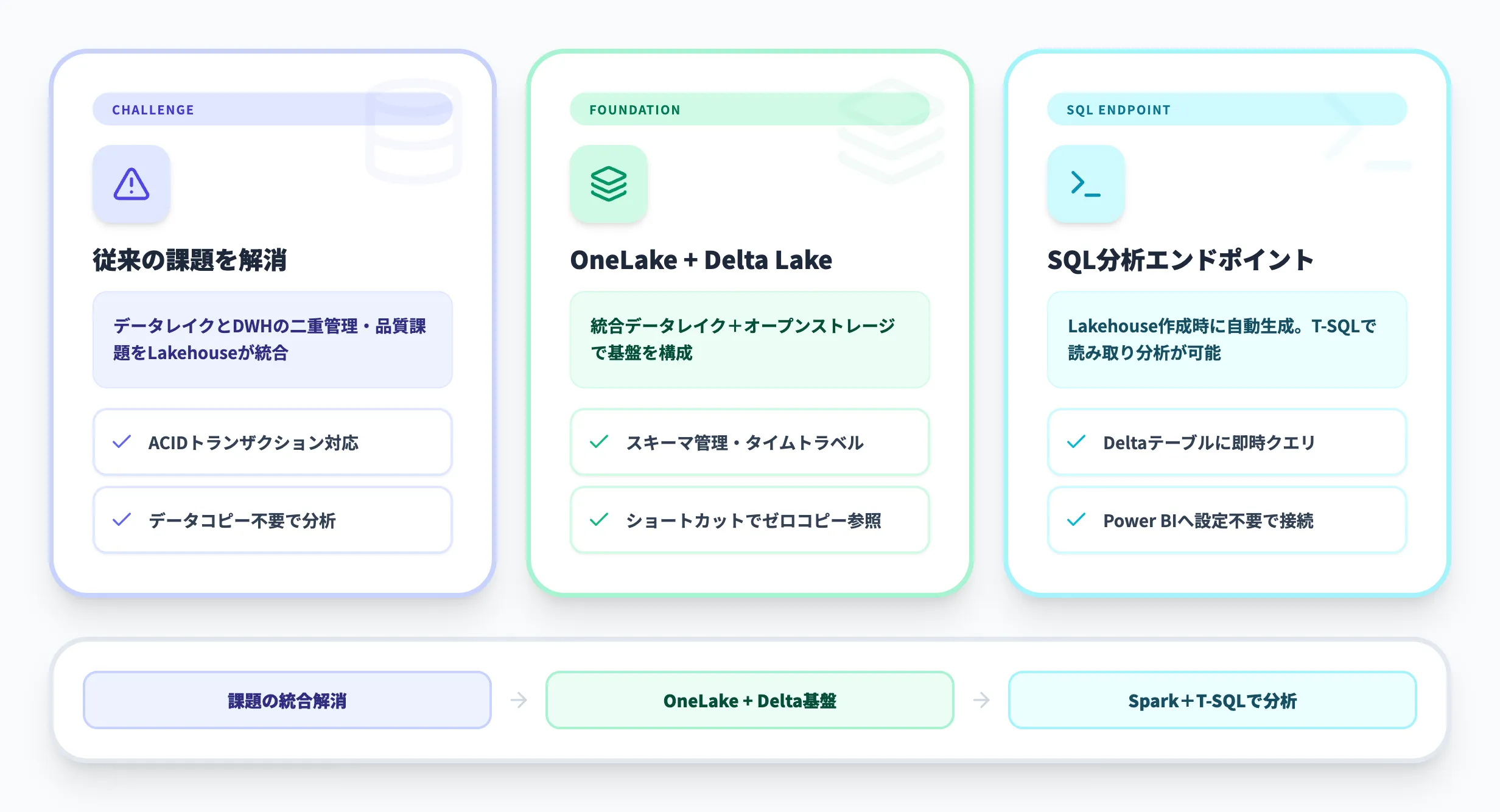
従来のデータ基盤では、生データを蓄積する「データレイク」と、分析用に整形した「データウェアハウス」を別々に構築し、その間でデータを移動させる必要がありました。
Lakehouseはこの2つの役割を1つの基盤に統合し、データのコピーや移動なしに分析できる環境を提供します。

データレイクとDWHの課題を解決する仕組み

従来型のデータ基盤では、次のような課題が長年の悩みとなっていました。
-
データレイクの課題
生データを大量に蓄積できるものの、トランザクション保証やスキーマ管理がなく、データ品質の担保が困難
-
データウェアハウスの課題
構造化データの高速分析には優れるが、非構造化データ(画像・PDF・ログ等)の格納に向かず、スキーマの変更にも手間がかかる
-
データの二重管理
レイクとDWHの間でETL(データの抽出・変換・格納)パイプラインを構築・維持するコストが発生し、データの鮮度や一貫性に差が出る
Fabric Lakehouseはこれらの課題を、後述するDelta Lake形式とOneLakeの組み合わせで解消しています。
OneLakeとDelta Lake形式
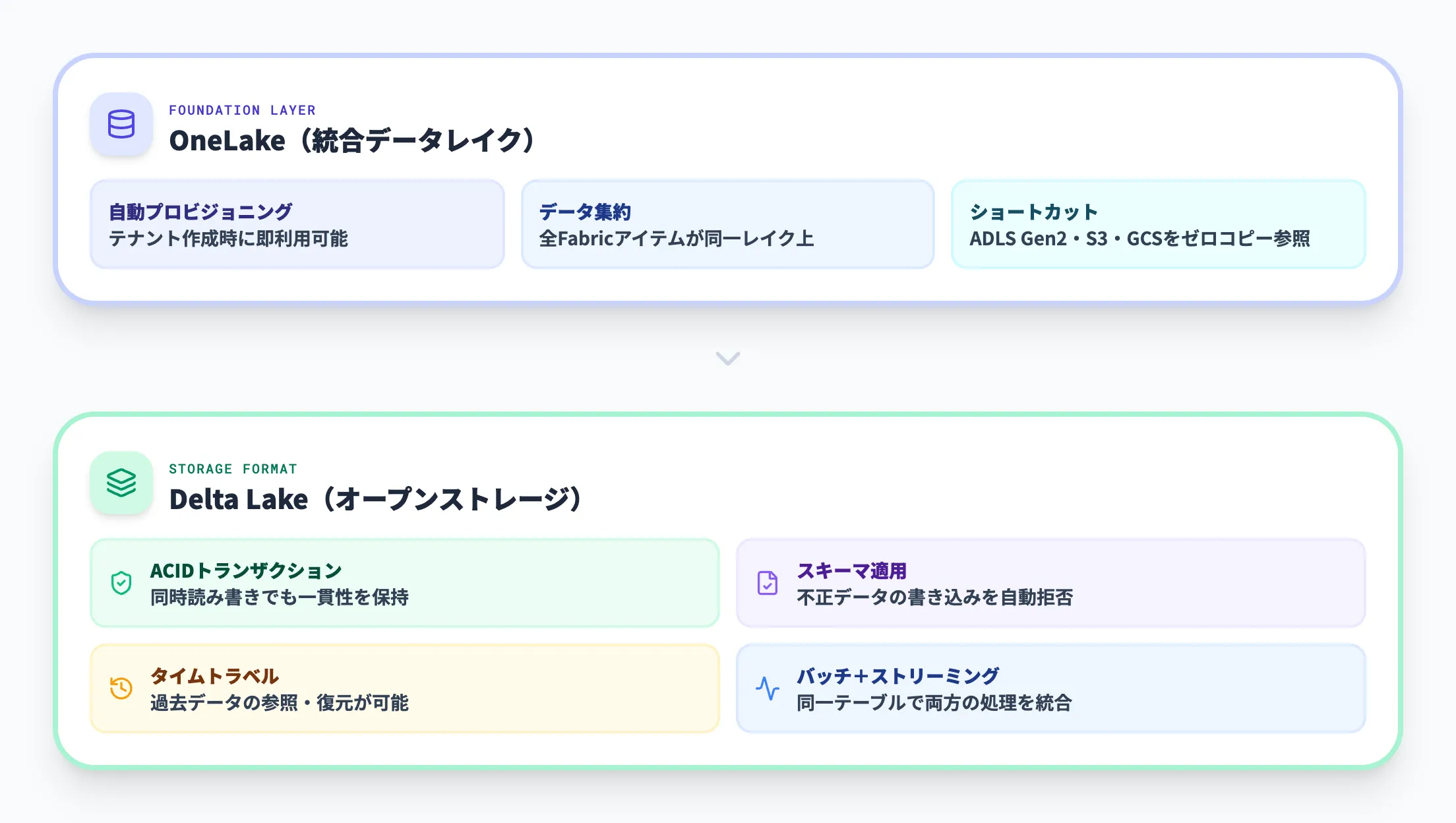
Fabric LakehouseがデータレイクとDWHの利点を両立できる理由は、2つの基盤技術にあります。
1.OneLake
OneLakeはFabricテナントに自動プロビジョニングされる統合データレイクで、組織のすべての分析データを1か所に集約します。
Lakehouse、Data Warehouse、その他のFabricアイテムはすべてOneLake上にデータを保存するため、データのサイロ化を防ぎ、ショートカット機能で物理コピーなしに外部データソース(Azure Data Lake Storage Gen2、Amazon S3、Google Cloud Storageなど)を参照できます。
2.Delta Lake形式
Delta Lakeは、Apache Parquetファイルの上にトランザクションログを追加したオープンソースのストレージレイヤーで、以下の機能を提供します。
-
ACIDトランザクション
複数のユーザーが同時にデータを読み書きしても、一貫性のある状態が保たれる
-
スキーマの適用
テーブルのカラム定義に合わないデータの書き込みを自動で拒否し、データ品質を保つ
-
タイムトラベル
過去の時点のデータを参照・復元できる。誤操作やデータ破損からの回復に有効
-
バッチとストリーミングの統合
バッチ処理とリアルタイムストリーミングの両方を同じテーブルで扱える
Fabricでは新規テーブルの書き込み時にDelta Lake形式が自動適用されるため、追加の設定なしにこれらの恩恵を受けられます。
SQL分析エンドポイントの自動生成

Lakehouseを作成すると、FabricがSQL分析エンドポイントを自動生成します。これは、Lakehouse内のDeltaテーブルに対してT-SQLでクエリを実行するための読み取り専用インターフェースです。
この仕組みにより、データエンジニアがSparkで加工・整理したテーブルを、SQLに慣れたビジネスアナリストがT-SQLで直接分析できます。さらに、既定のセマンティックモデル(旧称デフォルトデータセット)が同時に作成されるため、Power BIから追加設定なしでレポートを接続することも可能です。
Fabric Lakehouseの主要機能
Fabric Lakehouseの基本概念を理解したところで、ここからは実際のデータ操作に必要な主要機能を解説します。
データの取り込みからテーブル管理、分析エンジンの使い分けまで、Lakehouseを運用するうえで知っておくべき機能を整理します。

データ取り込みの6つの方法
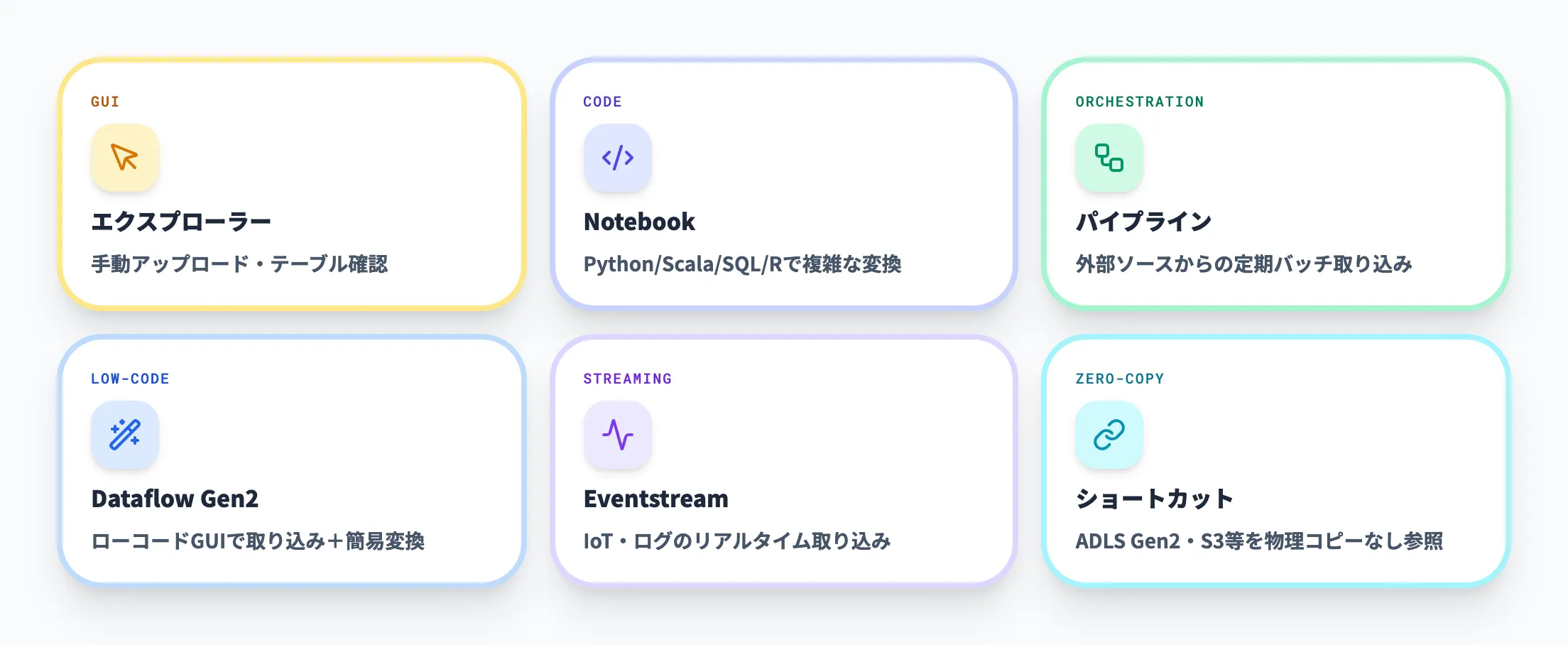
Fabric Lakehouseへのデータ取り込みには、用途に応じた6つの方法が用意されています。以下の表で、各方法の特性と向いているシナリオを整理しました。
| 方法 | 操作方式 | 向いているシナリオ |
|---|---|---|
| Lakehouseエクスプローラー | GUI | ファイルの手動アップロード、テーブルの確認・管理 |
| Notebook | コード(Python/Scala/SQL/R) | 複雑なデータ変換、データサイエンス、ML前処理 |
| パイプライン | GUI+コード | 外部ソースからの定期的なバッチ取り込み |
| Dataflow Gen2 | ローコード(GUI) | 非エンジニアによるデータ取り込みと簡易変換 |
| Eventstream | ストリーミング | IoTセンサーやアプリケーションログなどリアルタイムデータの継続的な取り込み |
| ショートカット | 設定のみ | 外部データ(ADLS Gen2、S3等)を物理コピーせず参照 |
ここで注目すべきは、ショートカットの存在です。ショートカットを使えばデータを物理的にコピーする必要がなく、OneLake外にあるデータソースをそのままLakehouse内のテーブルやファイルとして参照できます。
データの二重管理を防ぎ、ストレージコストも抑えられるため、既存のデータレイクからの移行時に特に有効です。
また、Azure Data Factoryを使い慣れたチームは、Fabric版Data Factoryのパイプラインで同様のETLワークフローを構築できます。
テーブルの自動検出と登録

Lakehouseはデータを2つのトップレベルフォルダーで管理します。
-
Tables
マネージドなDeltaテーブルを格納するフォルダー。ここに配置したデータは自動的にテーブルとして認識される
-
Files
非構造化データや非Delta形式のファイルを格納するフォルダー。CSV、Parquet、JSON、画像、PDFなど任意の形式に対応
Tablesフォルダーにファイルを配置すると、Fabricは自動でメタデータ(カラム名、データ型、パーティション構成など)を抽出し、メタストアにテーブルを登録します。手動でCREATE TABLE文を書く必要はありません。登録されたテーブルは、SparkからもSQL分析エンドポイントからもすぐにクエリ可能です。
SparkとT-SQLの使い分け

Fabric Lakehouseは、Apache SparkとT-SQLという2つの分析エンジンを同じデータに対して使い分けられます。
以下の表で、各エンジンの特性と適したユーザーを比較しました。
| 項目 | Apache Spark | T-SQL(SQL分析エンドポイント) |
|---|---|---|
| 対応言語 | Python、Scala、SQL、R | T-SQL |
| 操作方法 | Notebook、Sparkジョブ定義 | SQLエディター、外部ツール(SSMS等) |
| 書き込み | 可能(Delta形式で読み書き) | 読み取り専用 |
| 得意分野 | 大規模データ変換、ML、ストリーミング | アドホック分析、レポーティング、既存SQLスキルの活用 |
| 主なユーザー | データエンジニア、データサイエンティスト | ビジネスアナリスト、BIエンジニア |
つまり、データの加工・変換はSparkで行い、分析やレポーティングはT-SQLで行うという役割分担が基本的な使い方です。
1つのLakehouseに対して両方のエンジンからアクセスできるため、エンジニアとアナリストがそれぞれ得意なツールで同じデータを扱えます。
【詳細比較】Fabric Lakehouse vs Data Warehouse
Fabric Lakehouseの機能を把握したところで、最も多く寄せられる疑問に答えます。LakehouseとData Warehouse、どちらを使うべきかという問いです。
結論から言えば、どちらか一方だけを選ぶ必要はなく、用途に応じて使い分ける、あるいは併用するのが推奨されています。ここでは両者の違いを詳しく比較し、判断基準を示します。

機能比較表

以下の表で、LakehouseとData Warehouseの主要な違いを整理しました。
| 比較項目 | Lakehouse | Data Warehouse |
|---|---|---|
| 主な開発ツール | Apache Spark(Python、Scala、SQL、R) | T-SQL |
| 対応データ型 | 構造化・半構造化・非構造化 | 構造化データのみ |
| マルチテーブルトランザクション | 非対応 | 対応(ACID準拠) |
| データ書き込み | Spark経由(Notebook、ジョブ定義) | T-SQL(COPY INTO、INSERT、CTAS)、Spark、パイプライン、Dataflow Gen2 |
| SQL分析エンドポイント | 自動生成(読み取り専用) | 完全なDQL・DML・DDLに対応 |
| セキュリティ | テーブル・列・行レベル(SQL分析エンドポイント経由) | オブジェクトレベル、列レベル、行レベル、動的データマスキング |
| 得意なワークロード | データエンジニアリング、データサイエンス、ML、メダリオンアーキテクチャ | BIレポーティング、ディメンションモデリング、SQL中心のチーム |
| ストレージ形式 | Delta Lake(オープンフォーマット) | Delta Lake(オープンフォーマット) |
表から分かる通り、ストレージ形式は、同じDelta Lakeです。両者はOneLake上に同じオープンフォーマットでデータを保存するため、LakehouseのデータをData Warehouseから参照する(その逆も)ことが可能です。
つまり、どちらを選んでもデータがロックインされることはありません。
一方で、大きく異なるのは書き込みとトランザクションの扱いです。Data Warehouseは完全なACIDトランザクションとマルチテーブルトランザクションに対応しており、複数テーブルにまたがる更新を一括でコミットまたはロールバックできます。
Lakehouseはテーブル単位のACIDには対応していますが、マルチテーブルトランザクションには対応していません。
判断フロー
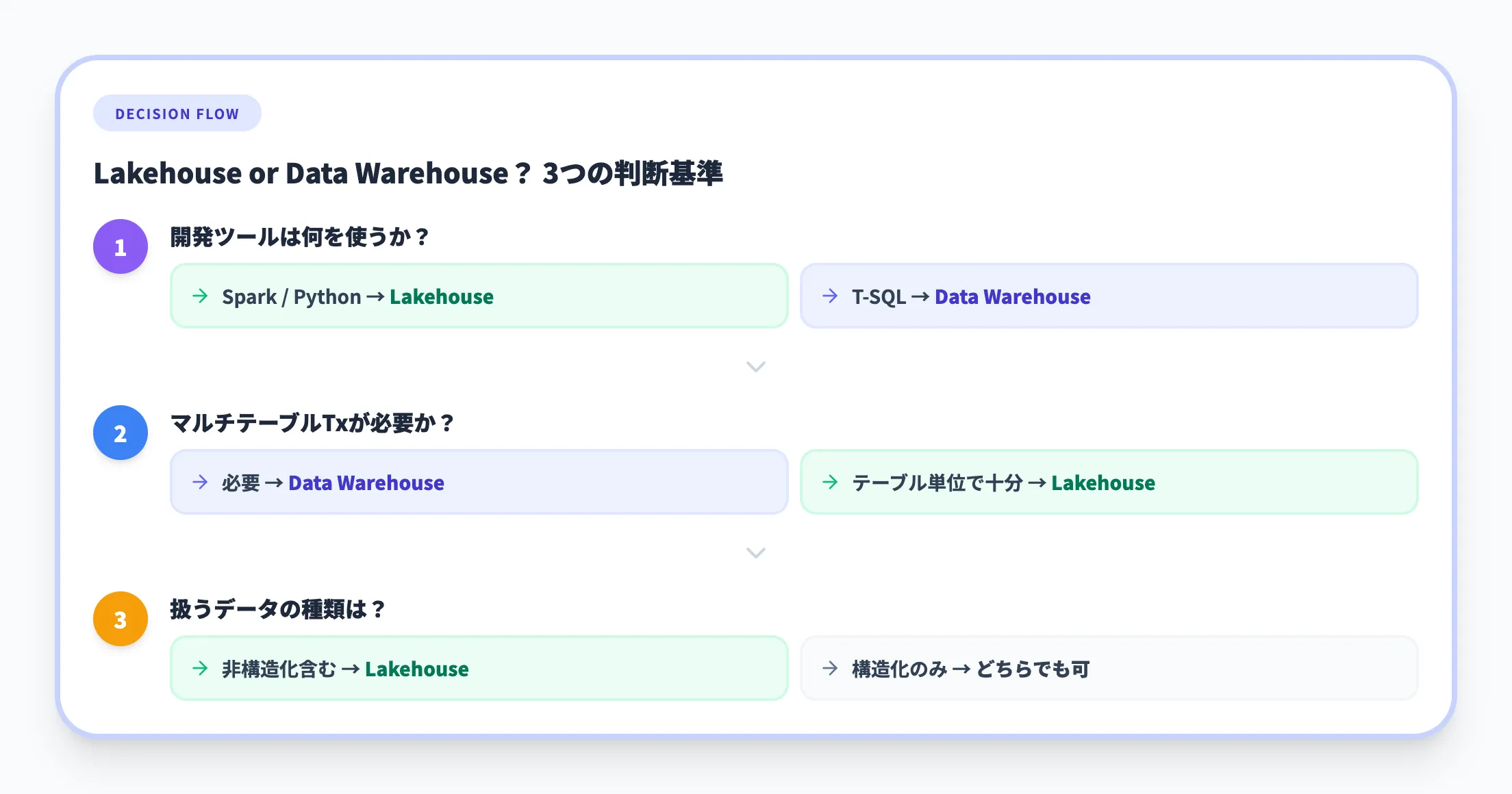
どちらを選ぶべきか迷う場合は、次の3つの質問で判断できます。
Microsoft公式のデシジョンガイドでも同様のフローが推奨されています。
-
開発ツールは何を使うか?
SparkやPythonで開発するチーム → Lakehouse。T-SQLで開発するチーム → Data Warehouse
-
マルチテーブルトランザクションが必要か?
複数テーブルへの一括更新・ロールバックが必要 → Data Warehouse。テーブル単位のトランザクションで十分 → Lakehouse
-
扱うデータの種類は?
非構造化データ(PDF、画像、ログ等)を含む → Lakehouse。構造化データのみ → どちらでも可
多くの場合、データエンジニアリングやデータサイエンスのワークロードにはLakehouseが適し、BIレポーティングやディメンションモデリングにはData Warehouseが適しています。
併用パターン
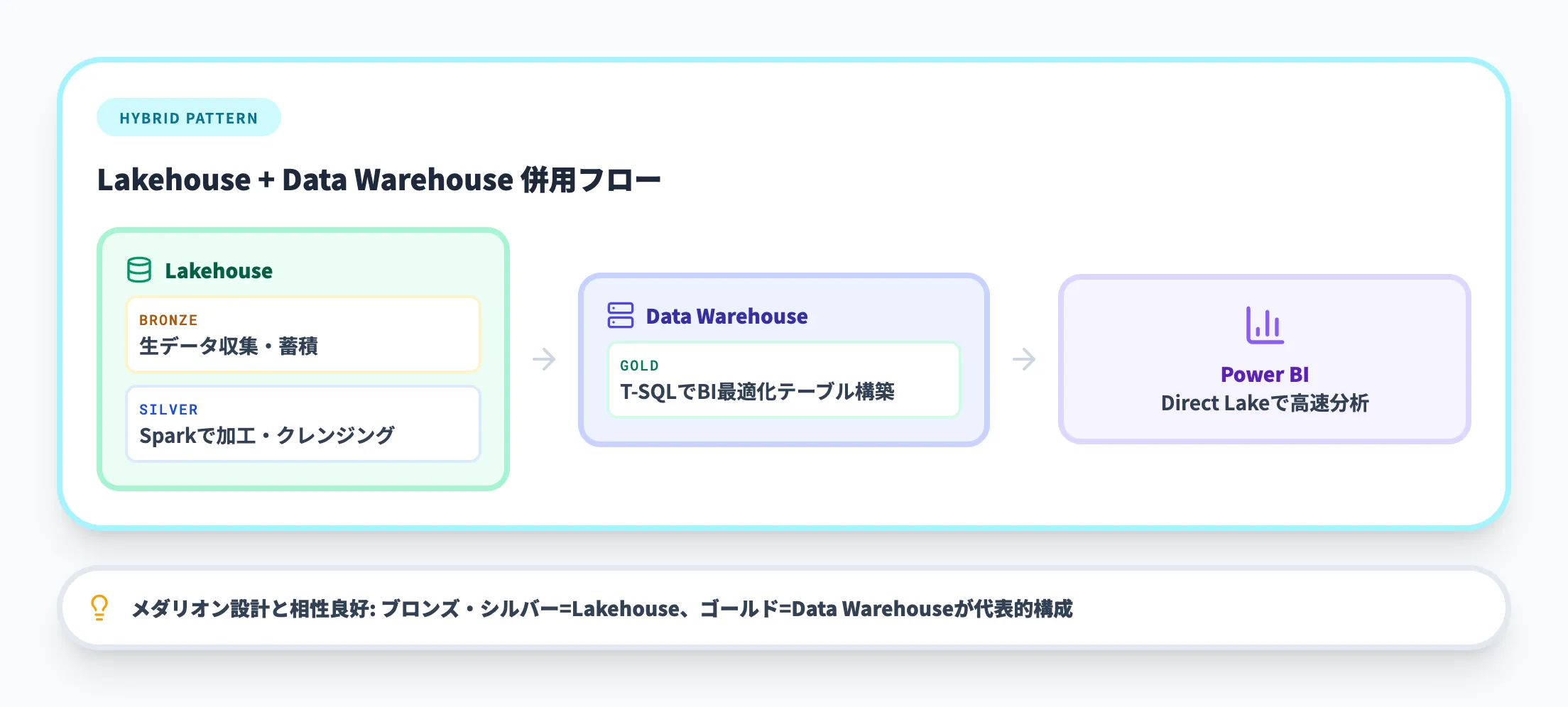
実運用では、LakehouseとData Warehouseを同じワークスペース内で併用するケースが多く見られます。
たとえば、Lakehouseでデータを収集・加工し、整理済みのデータをData Warehouseに投入してBI分析に使うという組み合わせです。
このパターンは次のセクションで解説するメダリオンアーキテクチャとも相性がよく、ブロンズ・シルバーレイヤーをLakehouse、ゴールドレイヤーをData Warehouseとして構成できます。
【関連記事】
Azure Data Factoryとは?Microsoft Fabricとの違いも解説
【Microsoft Fabric】Data Factoryとは?機能やADFとの違い、料金体系を徹底解説
【Microsoft Fabric】Data Warehouseとは?T-SQL機能や料金、移行方法を徹底解説
Lakehouseのデータ基盤をAI活用の土台に

メダリオンアーキテクチャで品質管理されたデータをAIが活用
Lakehouseに蓄積・品質管理されたデータを、AIエージェントが業務判断の根拠として直接参照。データ基盤構築からAI活用まで一気通貫で支援します。
Fabric Lakehouseのメダリオンアーキテクチャ
Fabric Lakehouseを本格的に運用するうえで押さえておきたいのが、メダリオンアーキテクチャです。
これはLakehouse内のデータを品質レベルごとに3つのレイヤーに分けて管理する設計パターンで、MicrosoftがFabricでの推奨設計アプローチとして公式に位置づけています。
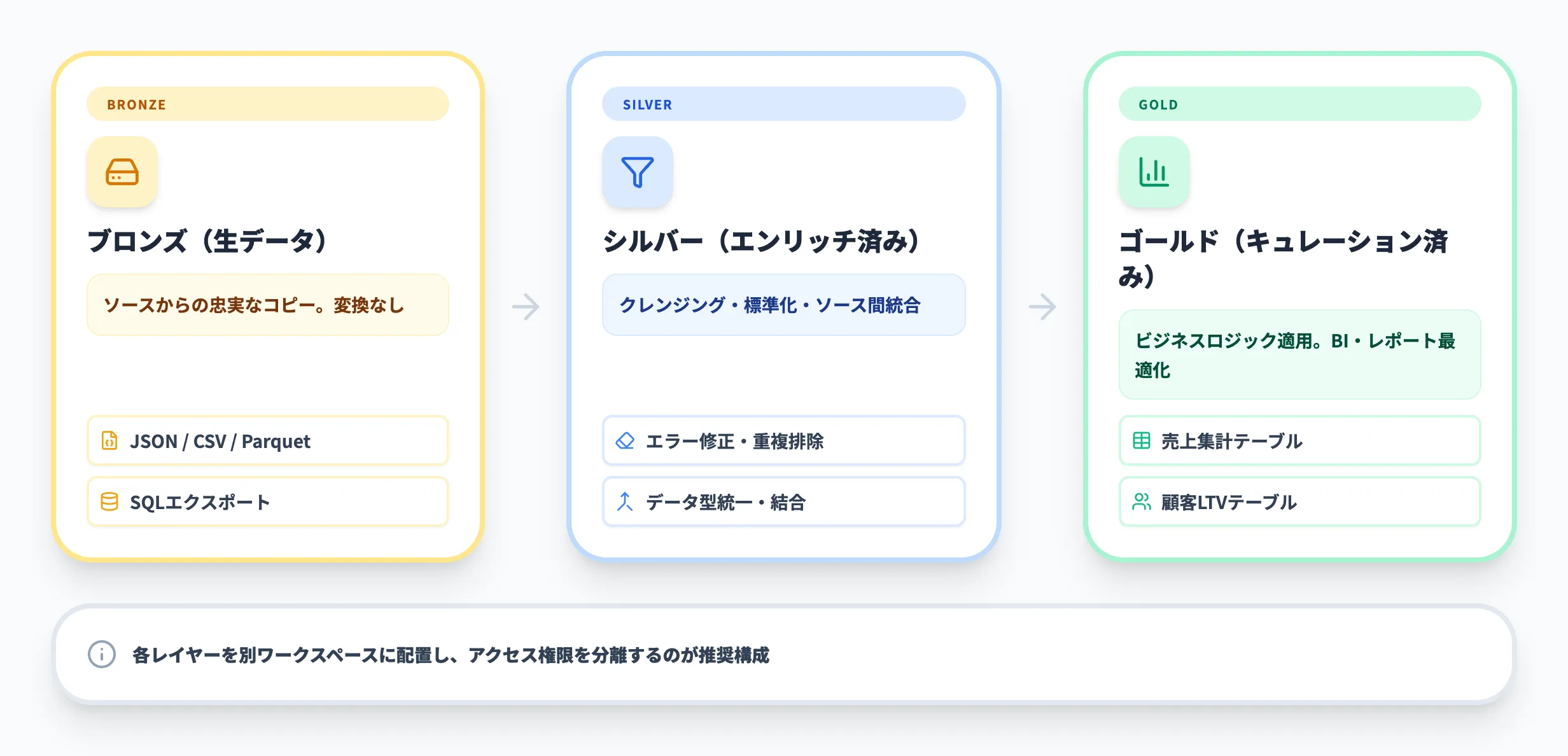
ブロンズ・シルバー・ゴールドの3層構造
メダリオンアーキテクチャは、データの品質を3段階で段階的に高めていく考え方です。
-
ブロンズレイヤー(生データ)
データソースから取り込んだ生データをそのまま保存する。変換や加工は行わず、元データの忠実なコピーとして保持する。JSON、CSV、Parquetなど元の形式をそのまま使うケースもある
-
シルバーレイヤー(エンリッチ済みデータ)
ブロンズのデータに対してクレンジング(エラー修正、重複排除)、フォーマット標準化、データ型の統一を施す。異なるソース間でのデータ統合もこの段階で行う
-
ゴールドレイヤー(キュレーション済みデータ)
ビジネスロジックを適用し、レポートやダッシュボード向けに最適化されたテーブルを構築する。売上集計テーブル、顧客分析ビューなど、消費者が直接参照する形に整形する
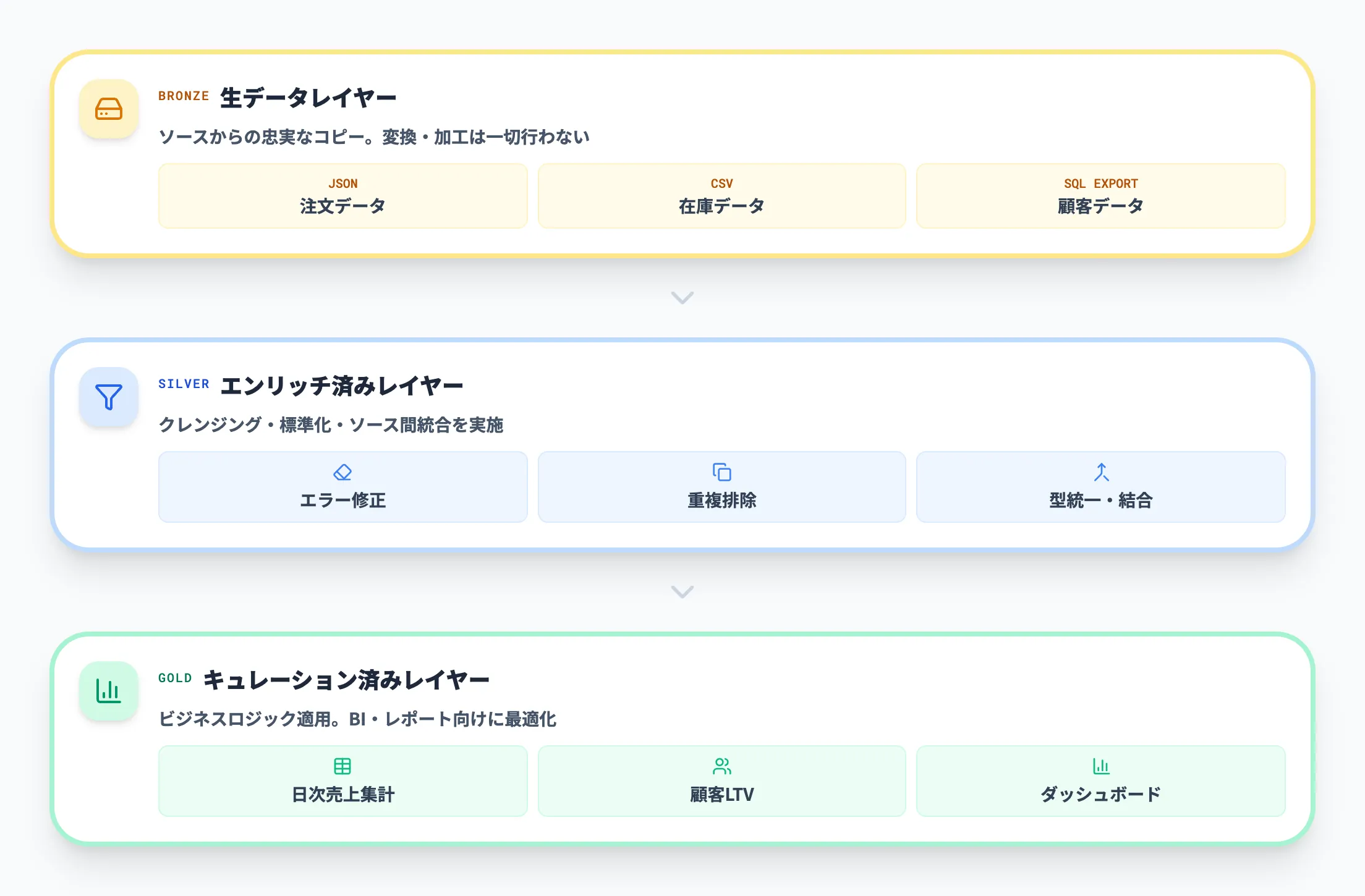
たとえばECサイトのデータ分析では、ブロンズに生の注文JSON・在庫CSV・顧客SQLエクスポートを格納し、シルバーで日付形式の統一や通貨変換・テストデータ除去を行い、ゴールドで日次売上ダッシュボードテーブルや顧客LTV(生涯価値)テーブルを構築するといった使い方になります。
2つの実装パターン

Fabricでメダリオンアーキテクチャを実装する方法には、大きく2つのパターンがあります。
以下の表で、各パターンの構成と特性を比較しました。
| パターン | ブロンズ | シルバー | ゴールド | 特徴 |
|---|---|---|---|---|
| パターン1 全Lakehouse | Lakehouse | Lakehouse | Lakehouse | Spark中心のチーム向け。SQL分析エンドポイントでBI接続 |
| パターン2 ハイブリッド | Lakehouse | Lakehouse | Data Warehouse | SQL中心のBIチームがゴールドを直接操作。完全なT-SQL対応 |
-
パターン1
Sparkを主力とするデータエンジニアリングチームに適しています。ゴールドレイヤーのLakehouseに生成されるSQL分析エンドポイントを通じて、Power BIからのレポーティングも可能です。 -
パターン2
データの加工まではSparkで行い、最終的な分析・レポーティング層でCREATE TABLE、ALTER TABLE、COPY INTO、マルチテーブルトランザクションなど完全なT-SQL DML・DDLを使いたいチームに向いています。
LakehouseのSQL分析エンドポイントでもビューやストアドプロシージャの作成は可能ですが、あくまで読み取り専用の範囲内であるため、テーブルの作成・変更や複数テーブルにまたがるトランザクションが必要な場合はData Warehouseが適しています。
いずれのパターンでも、各レイヤーを別々のワークスペースに作成することが推奨されています。レイヤーごとにアクセス権限を分離でき、ガバナンスが強化されるためです。
マテリアライズドレイクビューの活用
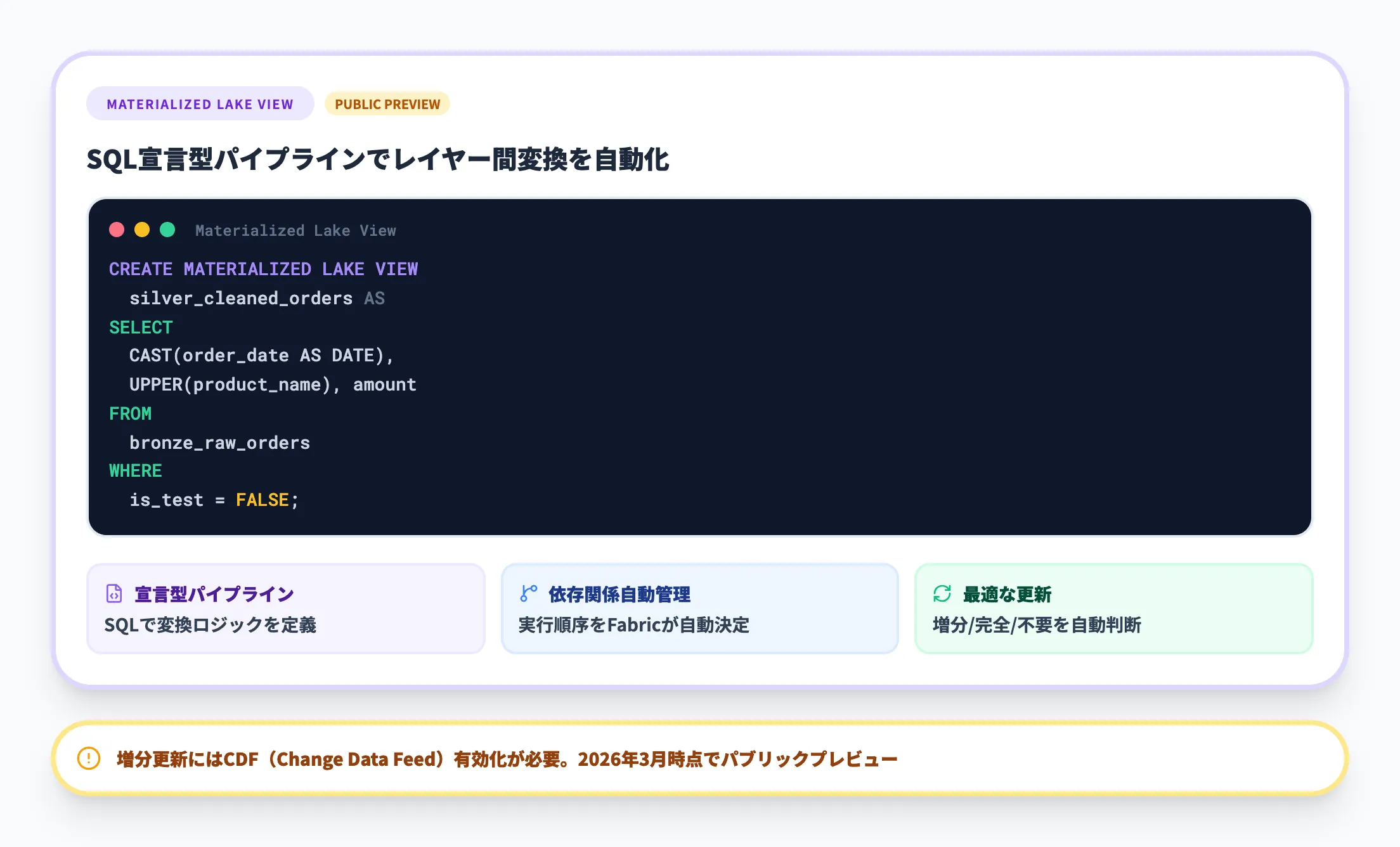
2026年のアップデートで注目すべき機能が、マテリアライズドレイクビュー(パブリックプレビュー)です。これは、メダリオンアーキテクチャの各レイヤー間でのデータ変換を、SQLステートメントで宣言的に定義できる機能です。
従来はレイヤー間のデータ移動にSparkパイプラインを手動で構築する必要がありましたが、マテリアライズドレイクビューでは以下のメリットがあります。
-
宣言型パイプライン
パイプラインを手動構築するのではなく、SQL文で変換ロジックを定義する
-
依存関係の自動管理
ビューの依存関係に基づいて、Fabricが実行順序を自動決定する
-
最適な更新
増分更新、完全更新、更新不要のいずれが適切かをシステムが自動判断する。なお、増分更新にはソーステーブルでChange Data Feed(CDF)が有効である必要がある
たとえば、ブロンズテーブルのデータをクレンジングして結合するシルバーレイヤービューを作成し、シルバーデータを集計するゴールドレイヤービューを定義すれば、更新のオーケストレーションはFabricが自動処理します。
パイプラインの保守コストを大幅に削減できる機能です。
Fabric LakehouseとDirect Lakeモード
Fabric Lakehouseに蓄積したデータをPower BIで分析する際に、パフォーマンスの鍵を握るのがDirect Lakeモードです。
ここでは、Power BIの3つのストレージモードを比較し、LakehouseとDirect Lakeを組み合わせる利点を解説します。

3つのストレージモードの違い
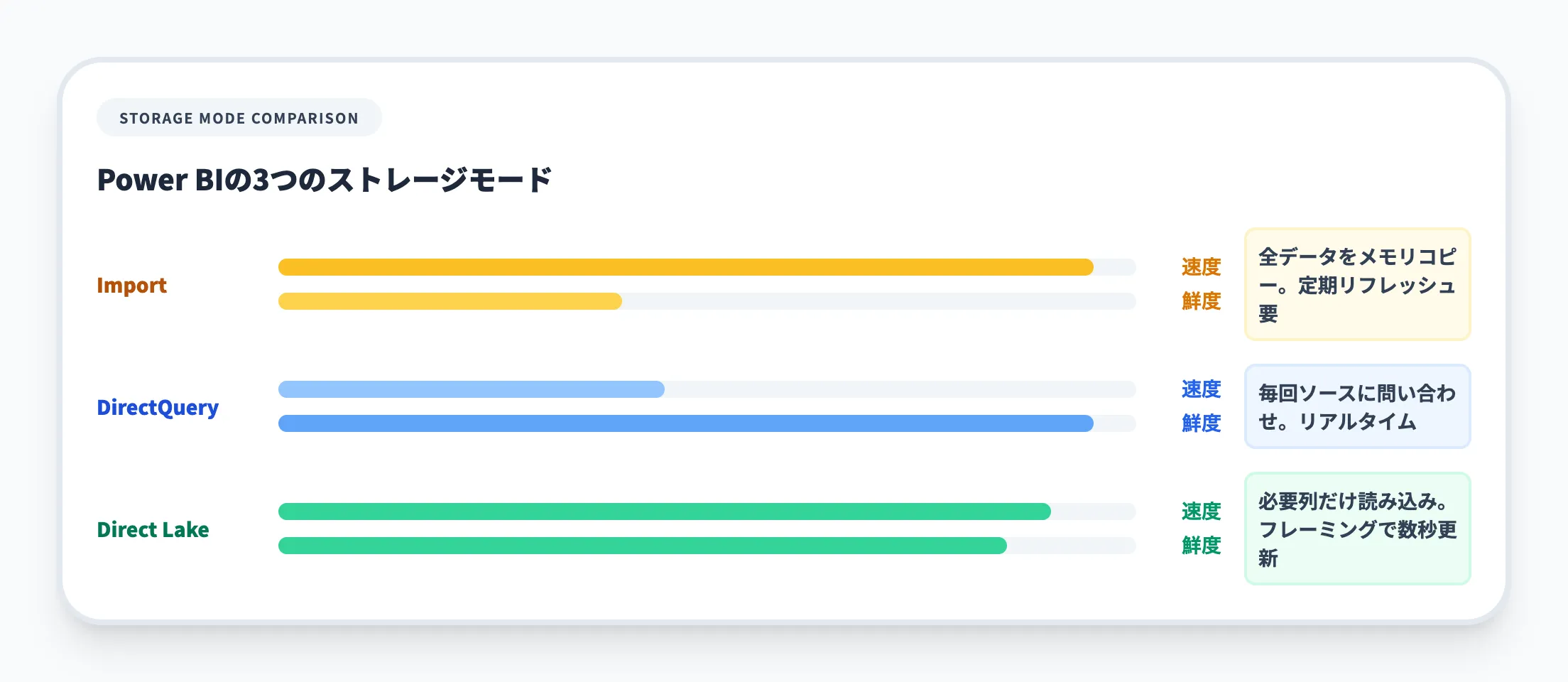
Power BIのセマンティックモデル(データモデル)には、テーブルごとにストレージモードを選択できます。以下の表で3つのモードの特性を比較しました。
| モード | データの取得方法 | 読み込み速度 | データ鮮度 | 向いている用途 |
|---|---|---|---|---|
| Import | データを丸ごとメモリにコピー | 高速 | 定期リフレッシュが必要(遅延あり) | 小〜中規模データ。セルフサービス分析 |
| DirectQuery | クエリのたびにデータソースに問い合わせ | ソース依存(遅い場合あり) | リアルタイム | ソース側でセキュリティ制御が必要な場合 |
| Direct Lake | OneLakeのDeltaテーブルから必要な列だけをメモリに読み込み | Importに匹敵 | 高いデータ鮮度(自動更新設定+フレーミング) | 大規模データ。Fabric Lakehouse / Warehouse |
ここで注目すべきは、Direct LakeモードがImportモードに匹敵するクエリ性能と、高いデータ鮮度を両立している点です。
Importモードではデータ全体をコピーする「リフレッシュ」に時間とリソースが必要ですが、Direct Lakeの「フレーミング」はDeltaテーブルのメタデータだけを解析するため、数秒で完了します。
ただし、フレーミング操作は自動リフレッシュ設定やセマンティックモデルの更新タイミングに依存するため、データソースの更新が即座にレポートへ反映されるとは限りません。
また、クエリがガードレール(後述)を超えた場合はDirectQueryモードへ自動フォールバックし、ソースに直接問い合わせるため、パフォーマンスが低下する可能性があります。
とはいえ、Importモードの長時間リフレッシュが不要になる点は大きなメリットです。
Lakehouseとの組み合わせで得られるメリット
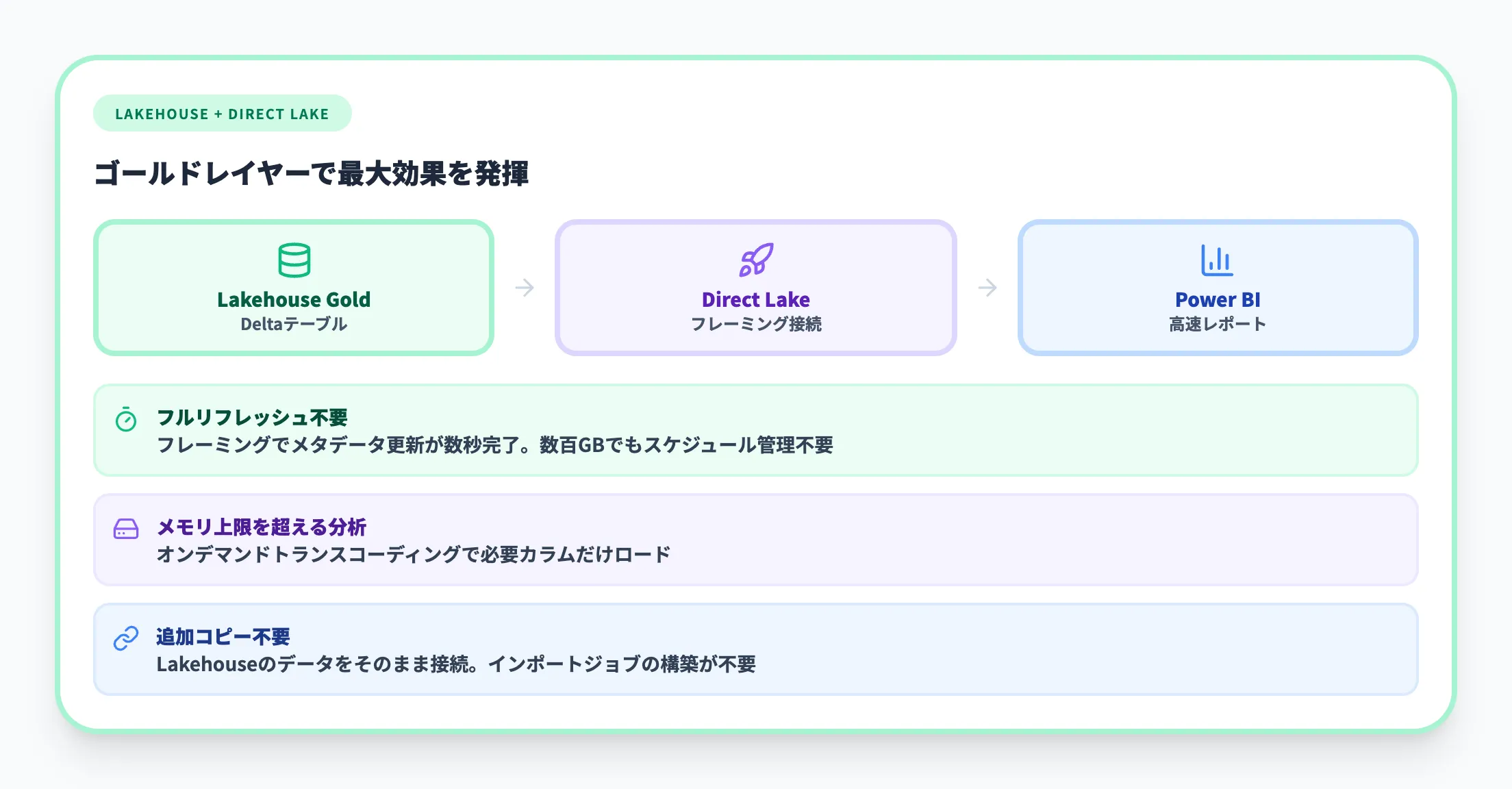
Fabric LakehouseとDirect Lakeモードの組み合わせは、メダリオンアーキテクチャのゴールドレイヤーで特に効果を発揮します。
-
フルリフレッシュ不要の高速分析
ゴールドレイヤーのDeltaテーブルをDirect Lakeモードで接続すれば、従来のImportモードのような長時間のフルリフレッシュが不要になる。
フレーミング操作によりメタデータの更新が数秒で完了するため、数百GBのデータセットでもリフレッシュスケジュールの管理負担を大幅に削減できる
-
容量を超えるデータの分析
Direct Lakeはクエリに必要なカラムだけをメモリにロードする「オンデマンドトランスコーディング」方式のため、セマンティックモデルのメモリ上限を超えるデータ量でも分析可能
-
既存のFabric投資を活用
Lakehouseで加工・蓄積したデータをそのままPower BIに接続でき、別途データのコピーやインポートジョブを作る必要がない
2026年時点では「Direct Lake on OneLake」も追加されており、複数のLakehouseやWarehouseのテーブルを1つのセマンティックモデルに混在させることが可能になっています(パブリックプレビュー中)。
【関連記事】
Microsoft FabricとPower BIの違い、連携手順をわかりやすく解説
【Microsoft Fabric】Data Engineeringとは?Sparkの機能や料金体系を徹底解説
【Microsoft Fabric】Data Scienceとは?MLflowやAutoML、料金体系を徹底解説
Microsoft Fabric導入事例6選!国内企業の成果と導入パターンを解説

Fabric Lakehouseの料金体系
Fabric Lakehouseの導入コストは、Microsoft Fabric全体のキャパシティ課金モデルに基づいています。
ここではCU課金の仕組みと、コスト最適化の考え方を解説します。

F SKUとCU課金の仕組み
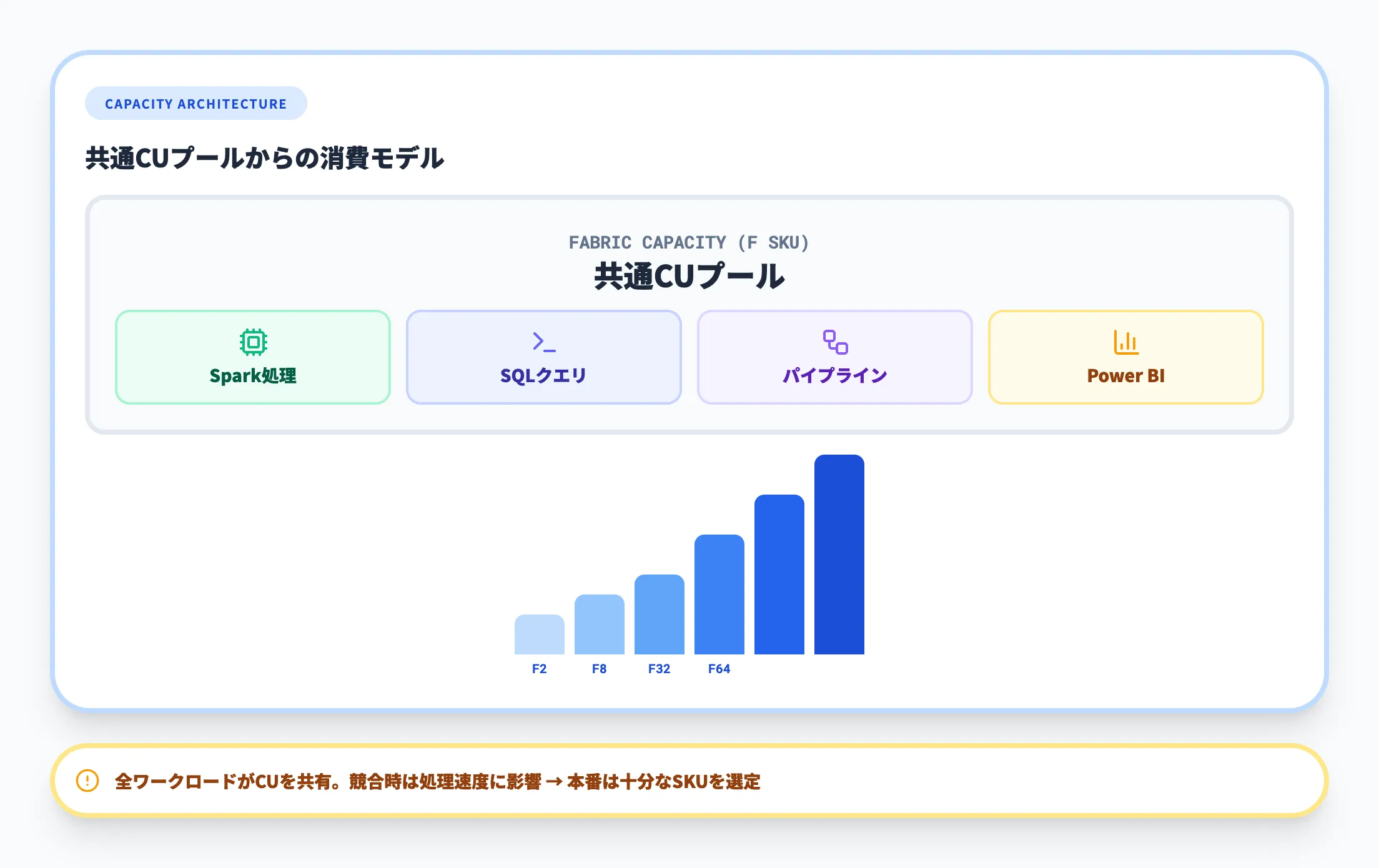
Fabric Lakehouseの利用料金は、Fabricキャパシティ(F SKU) 単位で課金されます。LakehouseやData Warehouse、Notebookなど、Fabric内の各ワークロードは共通のCU(Capacity Units)を消費する仕組みです。
Fabricの主なSKUとCU数は以下のとおりです。
| SKU | CU数 | 位置づけ |
|---|---|---|
| F2 | 2 | 個人検証・PoC向け |
| F4 | 4 | 小規模チーム |
| F8 | 8 | 小規模チーム |
| F16 | 16 | 中規模チーム |
| F32 | 32 | 中規模チーム |
| F64 | 64 | 部門・エンタープライズ |
| F128 | 128 | エンタープライズ |
| F256〜F2048 | 256〜2,048 | 大規模エンタープライズ |
ここで理解しておくべきは、CUはFabric内の全ワークロードで共有されるという点です。LakehouseのSpark処理、Data Warehouseのクエリ、パイプラインの実行、Power BIのDirect Lakeクエリなど、すべてが同じCUプールを消費します。ワークロードが競合すると処理速度に影響が出るため、本番環境では十分なCU数のSKUを選定することが重要です。
最新の価格情報はAzure公式の料金ページで確認できます。料金はリージョンによって異なります。
【関連記事】
Microsoft Fabricとは?使い方や価格体系、できることを徹底解説!
【Microsoft Fabric】Real-Time Intelligenceとは?機能や料金体系を徹底解説
従量課金と予約インスタンスの選択
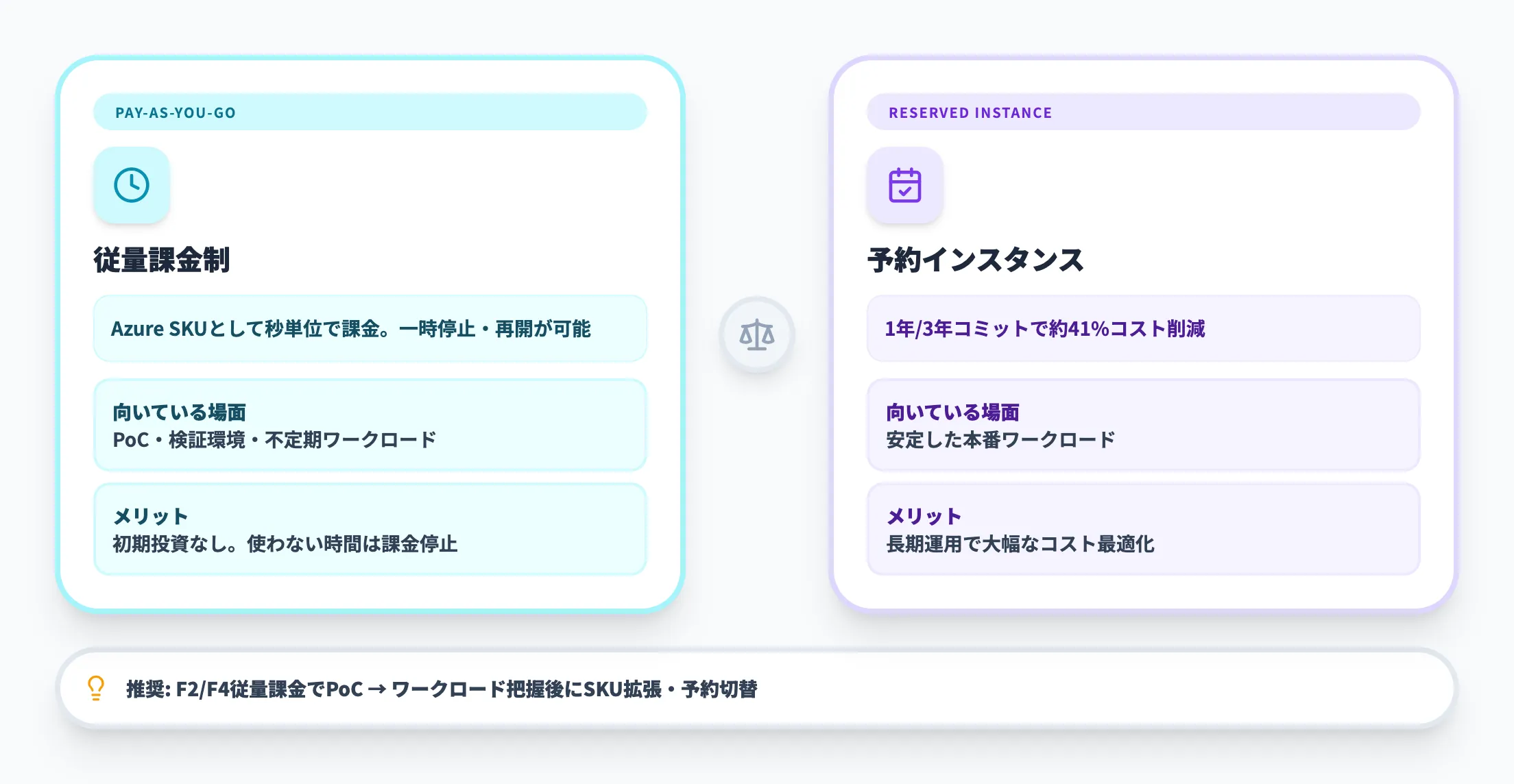
Fabricキャパシティの購入方法は2種類あります。
-
従量課金制(Pay-as-you-go)
Azure SKUとして秒単位で課金。ワークロードが不定期なPoC・検証環境向け。キャパシティの一時停止や再開も可能
-
予約インスタンス(1年 / 3年)
長期コミットにより、従量課金と比べて約41%のコスト削減が見込める。安定した本番ワークロード向け
スモールスタートする場合は、F2またはF4の従量課金で始め、ワークロードの実態を把握したうえでSKUのスケールアップや予約への切り替えを検討するのが現実的です。
ストレージ費用
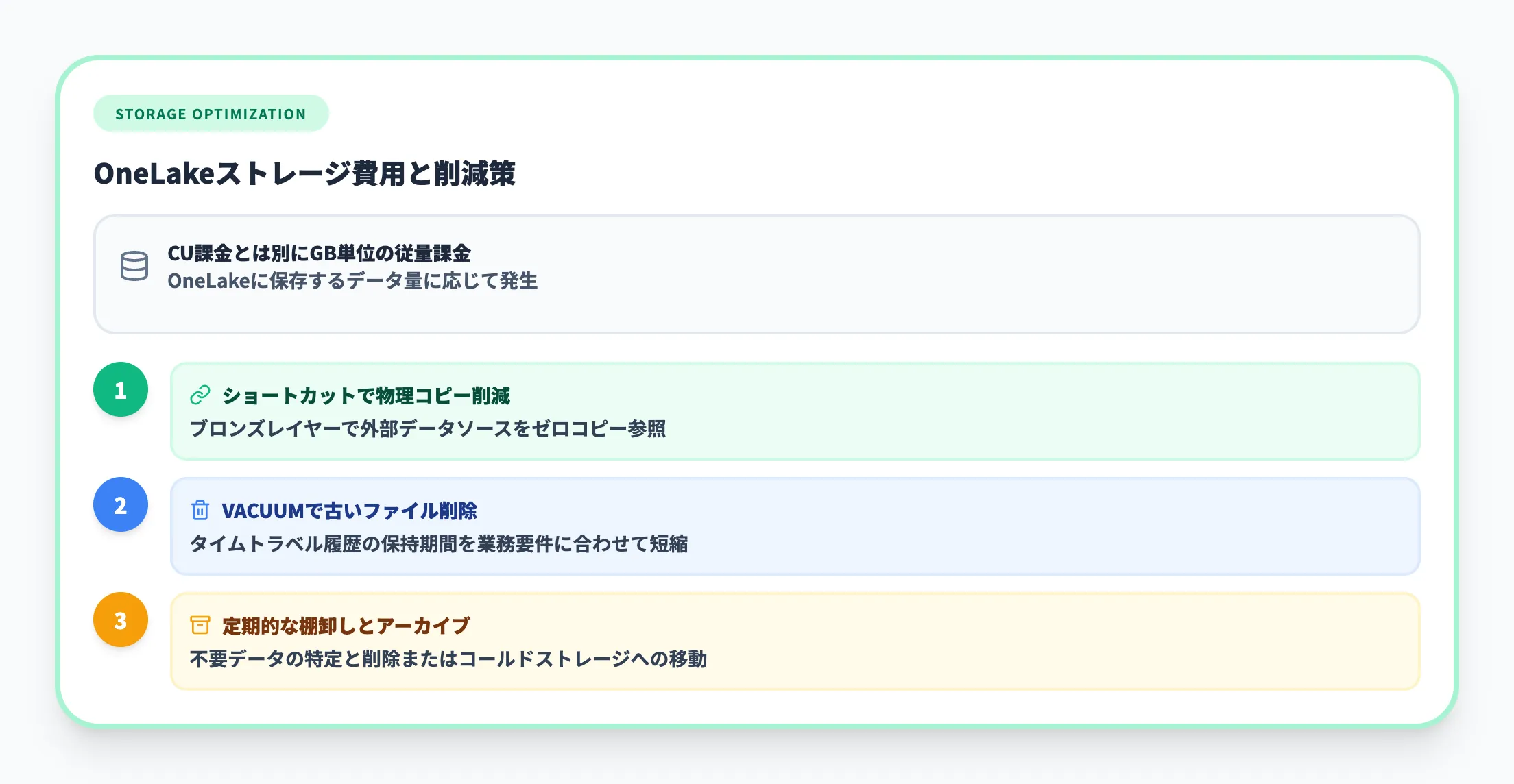
CU課金とは別に、OneLakeに保存するデータ量に対してストレージ費用が発生します。2026年3月時点で、OneLakeストレージはGB単位の従量課金です。
ストレージコストを抑えるには以下の対策が有効です。
- ブロンズレイヤーで外部データソースへのショートカットを使い、物理コピーを減らす
- Delta Lakeのタイムトラベル履歴の保持期間を業務要件に合わせて短縮する(VACUUMコマンドで古いファイルを削除)
- 不要なデータの定期的な棚卸しとアーカイブ
Microsoft Fabricの導入事例
Microsoft Fabricが実際の企業でどのように活用されているか、日本企業の導入事例を紹介します。

北國銀行 / CCIグループ(金融)
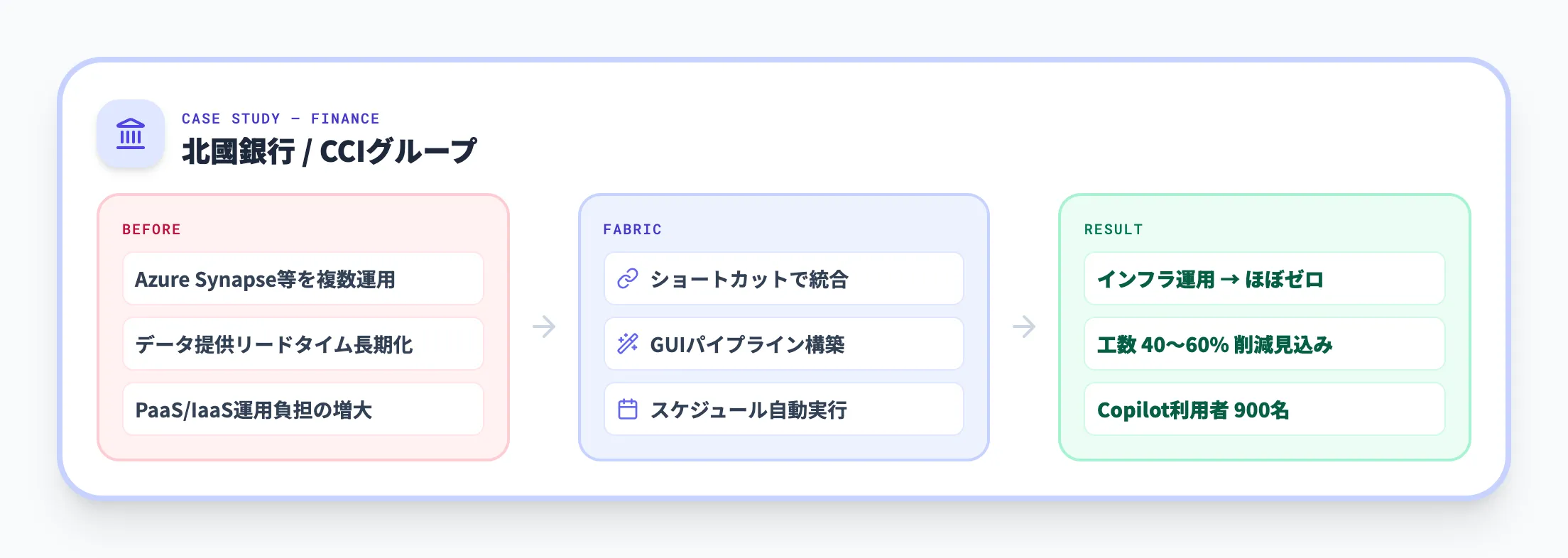
北國銀行は、Microsoft Fabricを採用して次世代データ活用基盤を構築しました。
-
導入前の課題
データの収集・整理・加工・分析に複数のツール(Azure Synapse Analytics等)を使用しており、データ提供までのリードタイムが長期化。PaaS/IaaSの組み合わせによるインフラ運用負担も増大していた
-
Fabricでの解決
ショートカット機能による物理コピーなしのデータ統合、GUIでのデータパイプライン構築、スケジュール自動実行を活用
-
導入効果
インフラ運用負担がほぼゼロに。データパイプライン構築に必要な工数を40〜60%削減できる見込み。Microsoft Copilotユーザーは900名に拡大
INPEX(エネルギー)
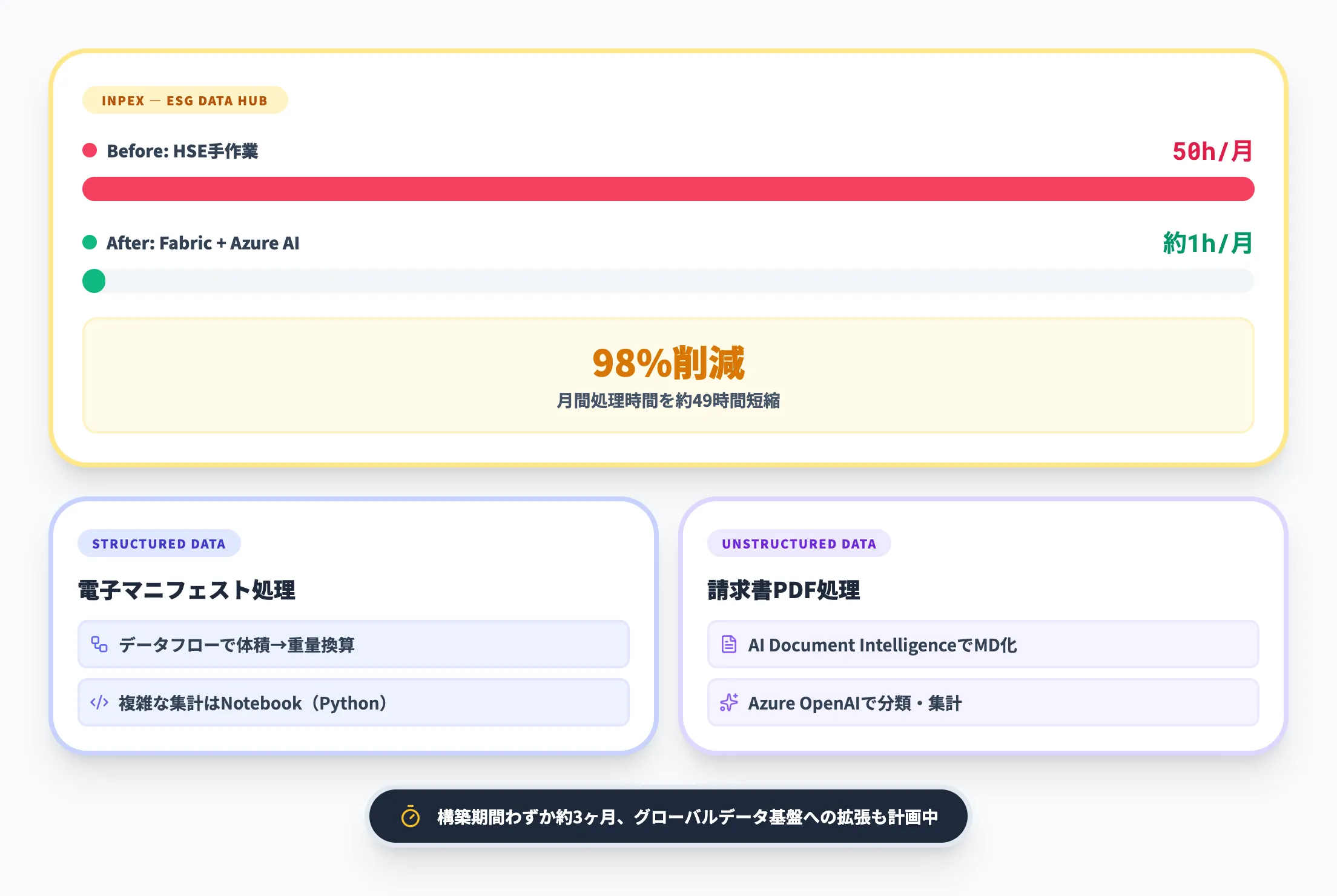
INPEXは、ESG報告業務の効率化を目的にMicrosoft Fabricを活用した「INPEX ESG Data Hub」を構築しました。
-
導入前の課題
GRI306(廃棄物の国際開示基準)対応で分類項目が増加し、HSE部門の分類・集計業務が月間15時間から50時間へ膨張
-
Fabricでの解決
構造化データ(電子マニフェスト)はDataflow+Notebook(Python)で処理、非構造化データ(PDF請求書)はAzure AI Document Intelligence+Azure OpenAIで分類・集計を自動化。複数の処理パターンをLakehouse上の1パイプラインに統合
-
導入効果
月間処理時間が50時間から約1時間へ短縮(約98%削減)。構築期間は約3か月。担当者は施策立案や改善提案に時間を使えるようになった
いずれの事例でも、Microsoft Fabricが構造化・非構造化データの統合管理と複数ツールを1つの基盤に集約するという2つの価値を提供していることが分かります。
Fabric Lakehouseの注意点と制限事項
Fabric Lakehouseは強力なデータ基盤ですが、導入・運用にあたって知っておくべき制限事項があります。
ここではメリットだけでなく、事前に把握しておくべきポイントを整理します。

SQL分析エンドポイントの制限

前述のとおり、LakehouseのSQL分析エンドポイントは読み取り専用です。以下の操作には対応していません。
- INSERT、UPDATE、DELETEなどのDML文
- CREATE TABLEなどのDDL文(ただしビューやテーブル値関数の作成は可能)
- マルチテーブルトランザクション
- 動的データマスキング
これらの操作が必要な場合は、Data Warehouseの利用を検討してください。
また、SQL分析エンドポイントにはDeltaテーブルのみが表示されます。Filesフォルダーに格納したCSVやParquetファイルは、Delta形式に変換しない限りSQL経由でクエリできません。
SKU別のガードレール

Direct Lakeモードでの利用を含め、LakehouseにはFabric SKUごとにリソース制限(ガードレール)が設けられています。以下の表は、主要なSKU別の制限値です。
| F SKU | テーブルあたりのParquetファイル数 | テーブルあたりの行数(百万行) | 最大モデルサイズ(GB) | 最大メモリ(GB) |
|---|---|---|---|---|
| F2 | 1,000 | 300 | 10 | 3 |
| F8 | 1,000 | 300 | 10 | 3 |
| F16 | 1,000 | 300 | 20 | 5 |
| F32 | 1,000 | 300 | 40 | 10 |
| F64 | 5,000 | 1,500 | 無制限 | 25 |
| F128 | 5,000 | 3,000 | 無制限 | 50 |
| F256 | 5,000 | 6,000 | 無制限 | 100 |
F64以上でモデルサイズが無制限になるため、大規模なデータセットをDirect Lakeモードで扱う場合は、F64以上のSKUが実質的な目安になります。
F2〜F32のSKUでも利用は可能ですが、テーブルあたり3億行・Parquetファイル1,000個という制限があるため、運用前にデータ量を見積もってSKUを選定することが重要です。
なお、これらのガードレールはクエリ単位で評価されるため、Deltaテーブルの最適化(V-Order、ファイルサイズの調整、パーティション設計)によって効率的にリソースを使うことが推奨されています。
Delta Lake形式への変換が必要なケース
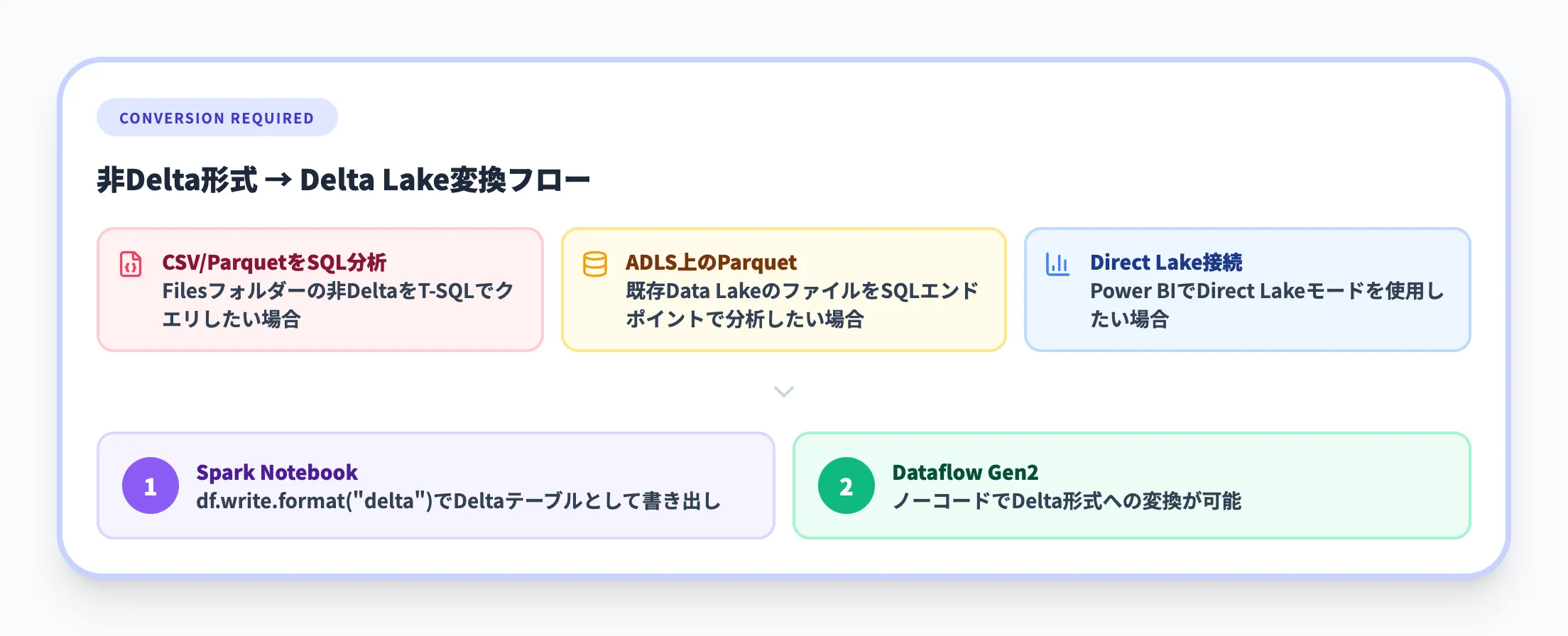
Lakehouseの分析機能をフルに活用するには、データをDelta Lake形式で管理することが基本です。以下のケースでは、明示的な形式変換が必要になります。
- CSVやParquetなどの非Delta形式でFilesフォルダーにアップロードしたデータをT-SQLでクエリしたい場合
- 既存のAzure Data Lake上のParquetファイルをSQL分析エンドポイントで分析したい場合
- Direct LakeモードでPower BIに接続したい場合
変換にはSparkのNotebookでDeltaテーブルとして書き出す方法が一般的です。Dataflow Gen2を使えば、ノーコードでDelta形式への変換も可能です。

Lakehouseに蓄積したデータを、AIエージェントの判断基盤にするなら
メダリオンアーキテクチャで段階的に品質管理されたデータは、AIエージェントが業務判断を行うための信頼性の高いナレッジ基盤になります。
AI Agent Hubは、Fabric Lakehouseのゴールドレイヤーに蓄積された高品質データを、AIエージェントが直接参照して業務を自動実行するソリューションです。データの蓄積と活用のサイクルをFabric上で完結させます。
- ゴールドレイヤーのデータをAgentが直接参照
メダリオンアーキテクチャで品質保証されたデータに基づき、AIエージェントが正確な業務判断を支援
- OneLakeのZero ETLでデータサイロを解消
物理コピーなしの仮想統合で、分散データをAIエージェントが横断的に活用
- データは原則として自社テナント内で処理・保持
AIの学習対象から完全除外。Azure Managed Applicationsとして自社テナント内で動作が完了する設計です
AI総合研究所の専任チームが、設計から運用まで伴走支援します。まずは無料の資料で、自社の業務にどう活用できるかご確認ください。
Lakehouseのデータ基盤をAI活用の土台に
メダリオンアーキテクチャで品質管理されたデータをAIが活用
Lakehouseに蓄積・品質管理されたデータを、AIエージェントが業務判断の根拠として直接参照。データ基盤構築からAI活用まで一気通貫で支援します。
まとめ
本記事では、Microsoft Fabric Lakehouseの基本概念からData Warehouseとの使い分け、メダリオンアーキテクチャ、Direct Lakeモード、導入事例、料金体系までを解説しました。
Fabric Lakehouseが提供する3つの価値は以下のとおりです。
-
データの統合管理
構造化・非構造化データを1つのLakehouseに集約し、Delta Lake形式でACIDトランザクション、スキーマ管理、タイムトラベルを実現。データレイクとDWHの二重管理を解消する
-
柔軟な分析基盤
Apache SparkとT-SQLの両方でデータにアクセスでき、データエンジニアからビジネスアナリストまで、それぞれの得意なツールで同じデータを扱える。Direct Lakeモードによる高速なPower BIレポーティングも可能
-
段階的な導入が可能
F2 SKUからスモールスタートし、メダリオンアーキテクチャで段階的にデータ品質を高めながら、Data Warehouseとの併用やDirect Lakeモードの導入へと拡張できる
導入を検討する場合は、まずF2またはF4の従量課金でPoCを実施し、チームのスキルセット(Spark中心かSQL中心か)と扱うデータの種類(非構造化データを含むか)を基にLakehouseとData Warehouseの使い分けを決定することをお勧めします。










