この記事のポイント
 Geminiの推論力と動画生成を統合した「Nano Bananaの動画版」
Geminiの推論力と動画生成を統合した「Nano Bananaの動画版」- Geminiアプリ・Google Flow・YouTube Shortsで提供開始
- 物理法則と世界知識の理解で、物語型・解説型の動画に強み
- 開発者・企業向けAPIは今後数週間で提供予定
- SynthID+C2PAで来歴管理、Avatarsは本人登録方式で悪用対策

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Gemini Omni(ジェミナイ オムニ)は、Google DeepMindが2026年5月19日のGoogle I/O 2026で発表した、any-to-anyマルチモーダル動画生成モデルです。
画像・テキスト・動画・音声の任意の組み合わせを入力にして、自然言語で会話するように動画を生成・編集できる点が特徴で、Geminiの推論能力と動画生成能力を1つのモデルに統合した次世代型の生成AIといえます。
本記事では、Gemini Omniの主要機能、Veo 3.1やRunway Gen-4など主要動画モデルとの違い、料金プラン、SynthIDなどの安全性、エンタープライズ視点での導入判断までを整理しました。
2026年5月時点の公式情報をベースに、AI動画生成の最新動向を理解しておきたい開発者・企画担当・経営層に向けた解説です。
目次
Genie・Veo・Nano Banana を束ねるワールドモデル
YouTube Shorts/YouTube Create App
SynthIDとC2PA Content Credentials
Gemini Omniのエンタープライズ活用シナリオと導入判断
Gemini Omniとは?

Gemini Omni(ジェミナイ オムニ)は、Google DeepMindが2026年5月19日のGoogle I/O 2026で発表した、any-to-anyマルチモーダル動画生成モデルです。
画像・テキスト・動画・音声を任意に組み合わせた入力から、自然言語で会話するように動画を生成・編集できる点が最大の特徴です。
公式ブログでは、Google DeepMindのCTO兼Chief AI ArchitectであるKoray Kavukcuoglu氏が「Gemini Omniは、Geminiの推論能力と創造能力が出会う場所」と説明しています。つまり、文章を理解する力と映像を作る力を1つのモデルに統合した、新世代の生成AIです。

Nano Bananaの「動画版」という位置づけ
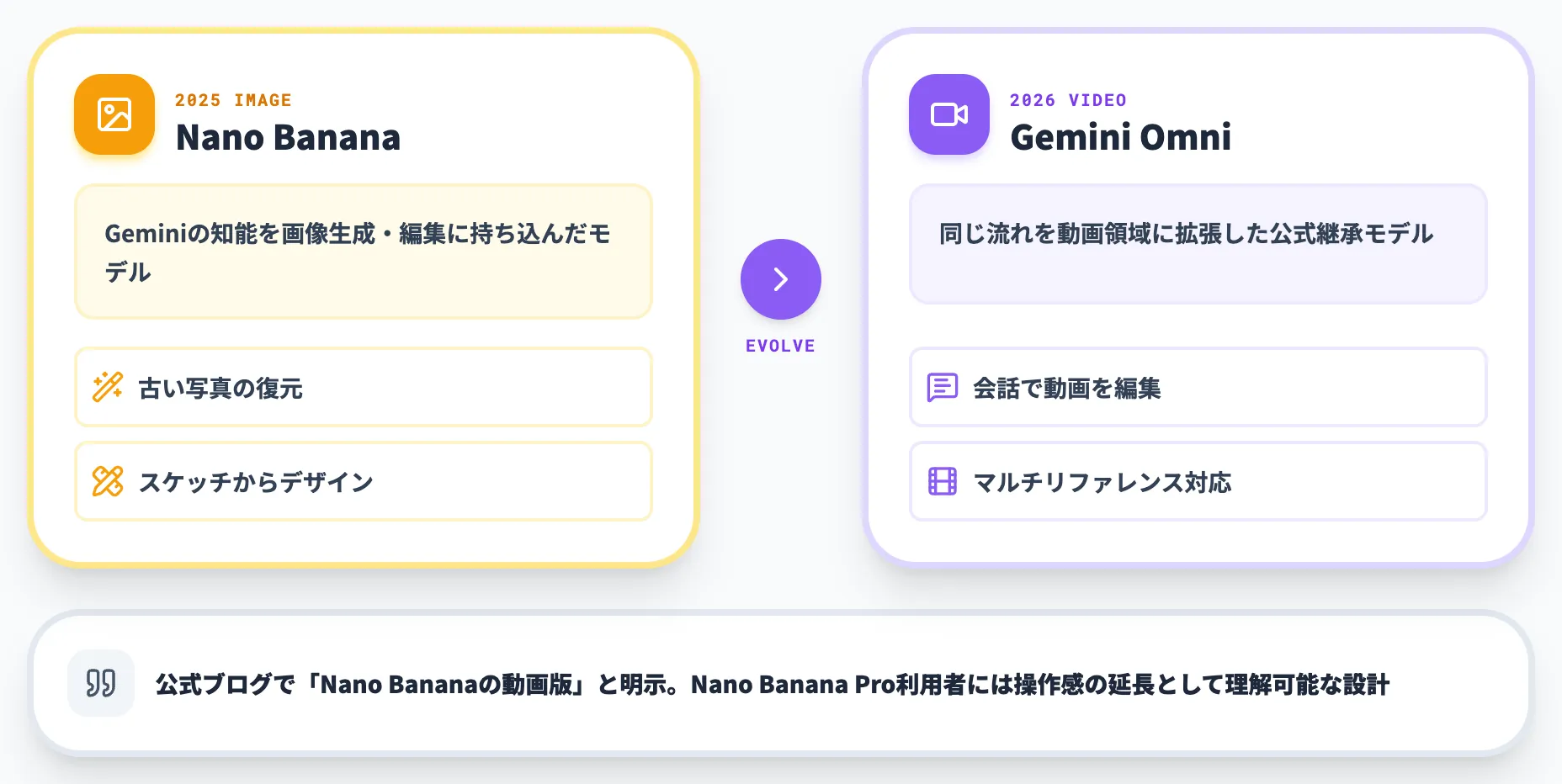
2025年に話題を集めたNano Bananaは、Geminiの知能を画像生成・編集に持ち込んだモデルでした。古い写真の復元、スケッチからのデザイン起こし、アイデアの視覚化など、画像領域での体験を一段引き上げた存在です。
Gemini Omniは、その流れを動画に拡張したモデルとして公式に位置づけられています。
実際、公式ブログでは「Nano Bananaの動画版」と明示されており、Nano Banana Proを試したユーザーであれば、その操作感の延長として理解しやすい設計です。
画像領域でNano Banana・Nano Banana 2が果たした役割を、動画領域でGemini Omniが担う構図といえます。
VeoとGemini Omniは別モデルとして併存
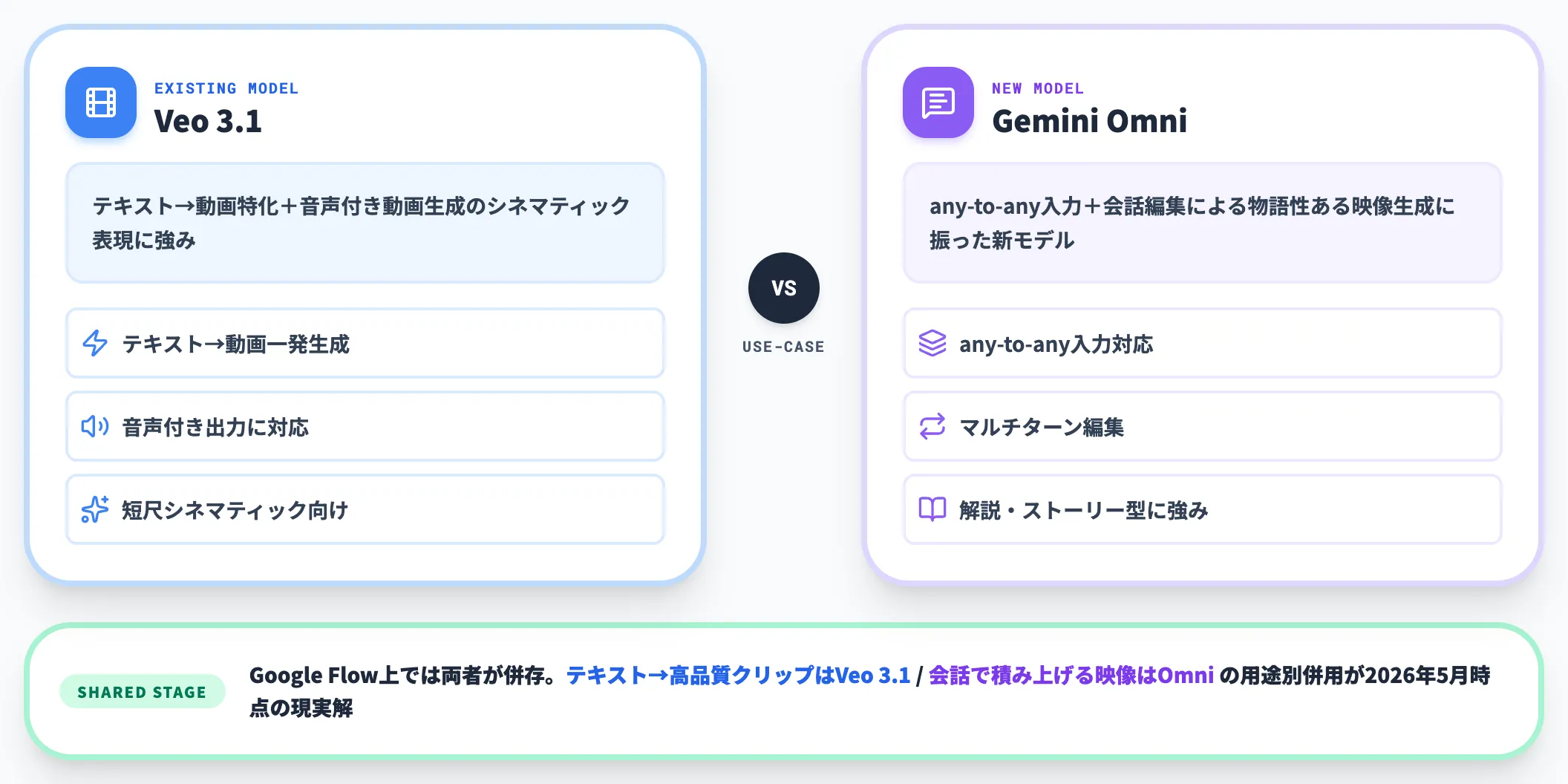
GoogleはこれまでVeo(およびVeo 3.1)を動画生成モデルとして提供してきましたが、Gemini Omniはその「後継」ではなく、会話編集とany-to-any入力を強みとする新モデルとして位置づけられています。
公式ブログでも、Gemini OmniのGeminiアプリ・Google Flow・YouTube Shortsへの展開は明示されているものの、Veoの終息や置き換えスケジュールは公表されていません。DeepMindのモデル一覧でもVeoは引き続き別モデルとして掲載されています。
そのため、Veoの「テキスト→動画特化+音声付き動画生成」とOmniの「会話編集+マルチリファレンス」を用途別に併用する運用が、2026年5月時点の現実解です。
Genie・Veo・Nano Banana を束ねるワールドモデル
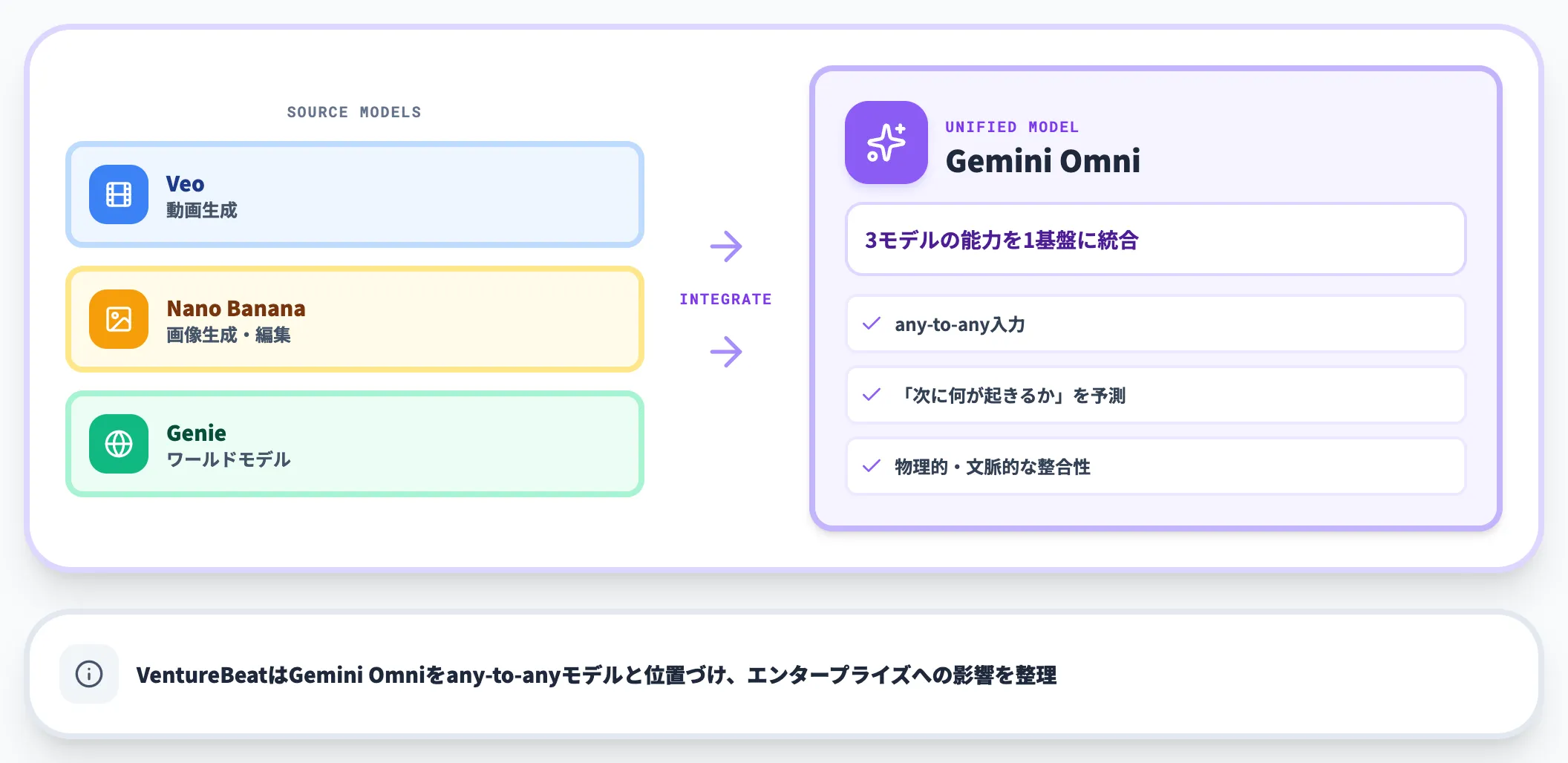
メディア報道では、Gemini Omniが既存の動画・画像・ワールドモデル各種の能力を1つの基盤に統合したものとされています。
具体的には、動画生成のVeo、画像生成・編集のNano Banana、インタラクティブなワールドモデルGenieの強みを束ね、「what happens next(次に何が起きるか)」を物理的・文脈的に予測するワールドモデルとしての側面を持たせている点が特徴です。
VentureBeatはGemini Omniをany-to-anyモデルと位置づけ、エンタープライズ視点での影響を整理しています。
Gemini Omniの主要機能
Gemini Omniは、単なる動画生成モデルではなく、会話で積み上げる動画制作プラットフォームとして設計されています。ここでは主要な機能を、用途別に整理します。
なお、実際の生成例はGemini Omniの使い方で解説しています。

会話による動画編集
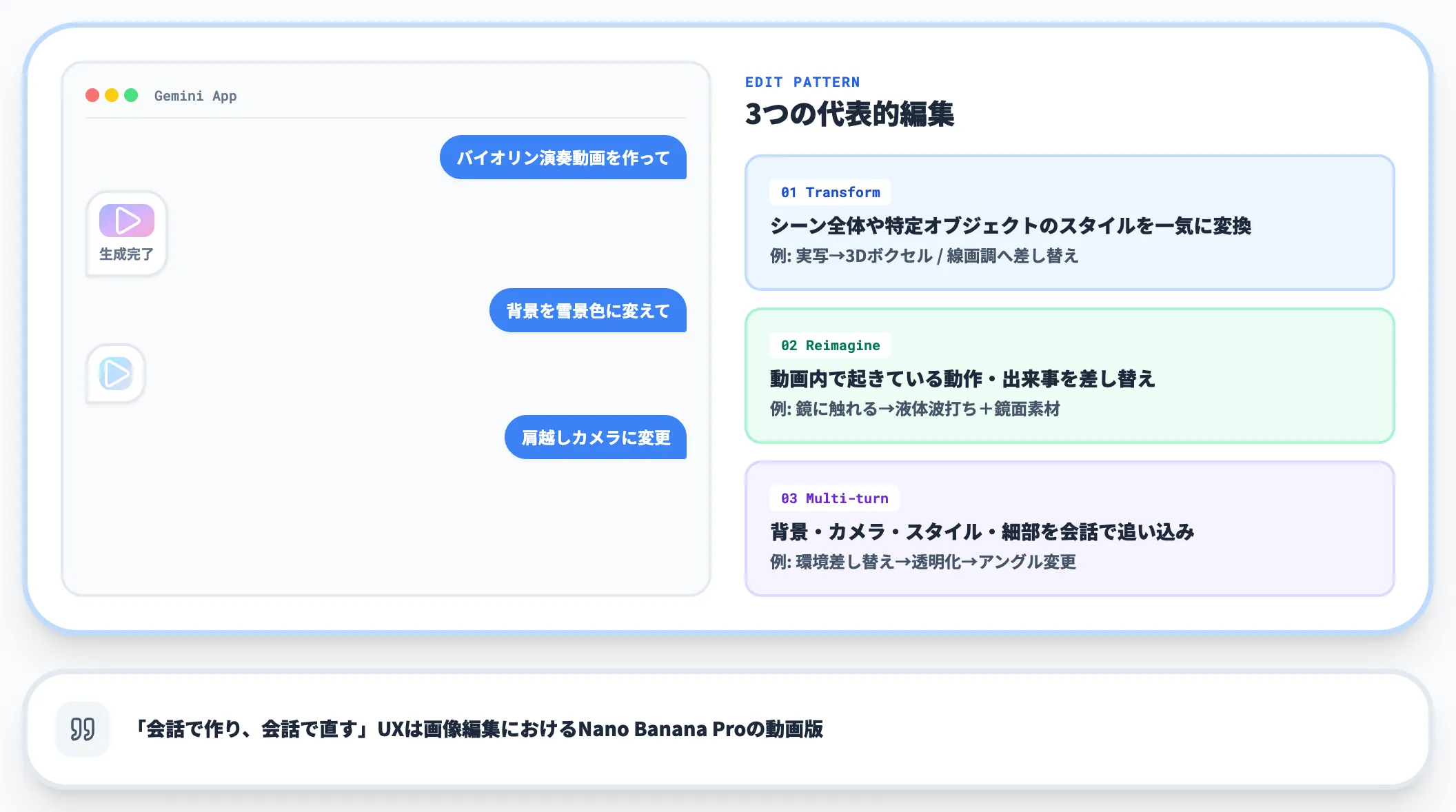
Gemini Omniの中核となるのが、自然言語によるマルチターン編集です。
各指示が前の文脈を引き継ぐため、登場キャラクターの見た目や物理法則、シーンの流れを保持しながら、繰り返し動画を変更できます。
公式が提示する代表的な編集パターンは次の3つです。
-
Transform the world
シーン全体や特定オブジェクトのスタイルを一気に変換する。撮影した実写動画を、3Dボクセルアートや線画調などに丸ごと差し替えられる
-
Reimagine the action
動画内で起きている「動作・出来事」を差し替える。「人が鏡に触れると、鏡が液体のように波打ち、腕が鏡面素材に変わる」のような書き換えも自然言語だけで指示できる
-
Multi-turn refinement
背景・カメラアングル・スタイル・細部を、会話を続ける形で段階的に追い込む。元のシーンの文脈を失わずに「バイオリン演奏動画 → 環境差し替え → バイオリンを透明化 → 肩越しカメラに変更」と積み上げられる
この「会話で動画を作り、会話で直す」というUXは、画像生成におけるNano Banana Proの動画版と捉えると理解しやすい設計です。
世界知識による生成

Gemini Omniは、シーンの見た目をそれらしくするだけでなく、「次に何が起きるか」を物理的・文脈的に推論します。
特徴的なのは以下の3点です。
-
物理法則への直感的な理解
重力・運動エネルギー・流体力学への理解が向上し、水や物体の動きが自然になる。連鎖反応コースを転がるビー玉のような映像でも、ワンカットの滑らかさが保たれる
-
歴史・科学・文化的背景の活用
Geminiが持つ世界知識を映像に接続する。タンパク質の折りたたみを粘土アニメで解説する、海馬の働きをスキューモーフィズム調で説明するなど、「意味のある映像」を構築できる
-
画面内テキストと動作のシンク
単にテキストをレンダリングするだけでなく、画面に表示する文字を動作・場面と論理的に同期させる。アルファベット26文字を珍しいアイテムと組み合わせて高速に切り替える、といった構成も自然言語だけで作れる
つまりGemini Omniは、写実性を超えた「ストーリー性のある映像生成」を主戦場に置いている、と公式は説明しています。
マルチリファレンス入力
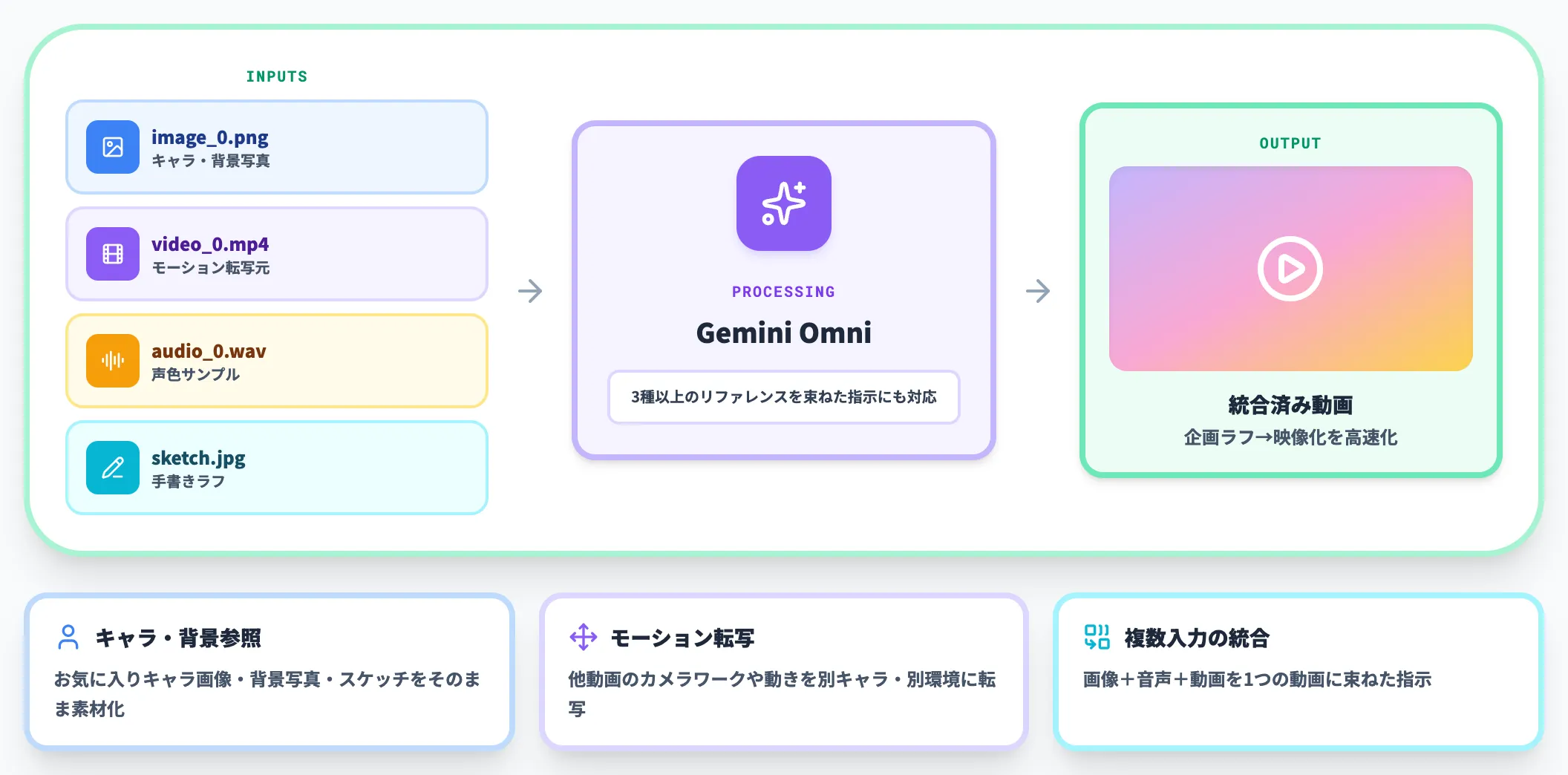
Gemini Omniは、画像・テキスト・動画・音声を組み合わせて1つの動画にまとめる「リファレンス機能」を備えています。
代表的な使い方は以下のとおりです。
-
キャラクター・背景の参照
お気に入りキャラクターの画像、背景シーンの写真、手書きスケッチなどを参照素材として渡し、それに沿った動画を生成する
-
モーション・スタイル転写
他動画のカメラワークや動きを参照し、別キャラクターや別環境に転写する。手書きスケッチを動きのガイドにして、実写風の映像を生成することも可能
-
複数入力の組み合わせ
「image_0.pngをベースにaudio_0.wavのリズムで、video_0.mp4と同じように要素が光る動画を作る」など、3種以上のリファレンスを束ねた指示にも対応する
スケッチや既存映像をそのまま「設計図」として使えるため、企画ラフから映像化までのリードタイムが大幅に短縮されます。
Avatars(デジタルアバター)
![]()
Gemini Omniには、自分の声と顔をベースにしたデジタルアバターを作る「Avatars」機能が搭載されています。
オンボーディングでは、ユーザー自身が一連の数字を読み上げる音声と映像を登録します。これにより、後から本人の見た目・声で動画を生成できる仕組みです。
OpenAIの旧Soraアプリで提供されていたCameos機能を参考にしつつ、ディープフェイク対策を意識した設計になっています。
ただし他人の動画に対して音声・発話を差し替える機能は、安全性検証が継続中のため今回のリリースでは見送られています。Gemini Omniが「変身しても声は本人のまま」というデモを示しつつ、その機能自体は提供しない、と明示している点は要注意です。
Gemini Omniの料金プラン
Gemini Omniの料金体系は、Geminiアプリのサブスクリプション内に組み込まれる方式が基本です。2026年5月時点では、個別の従量課金プランは未提供で、API料金も未発表となっています。

サブスクリプション別の利用可否
以下の表で、Gemini Omniの提供範囲をプラン別に整理しました。料金はGoogle公式発表に基づくI/O 2026時点の米国価格で、自分の利用頻度や検証規模に合わせて最初に試すプランを選ぶ判断材料として活用してください。
| プラン | Gemini Omni Flashの利用 | 主な特典 | 月額(2026年5月時点・米国) |
|---|---|---|---|
| 無料プラン | YouTube Shorts経由のみ | 基本機能のみ | 0円 |
| Google AI Plus | ○(Geminiアプリ・Flow) | Gemini Omni+3.5 Flashアクセス、Daily Brief(米国のみ)等 | $7.99 |
| Google AI Pro | ○(Geminiアプリ・Flow) | YouTube Premium Lite(一部地域)、より高い生成上限 | 料金維持(地域差あり) |
| Google AI Ultra(新ティア) | ○(Geminiアプリ・Flow) | Pro比5倍の利用上限、20TBストレージ、YouTube Premium、Gemini Spark(米国) | $100 |
| Google AI Ultra(上位) | ○(Geminiアプリ・Flow) | Pro比20倍の利用上限、Project Genieアクセス(18歳以上、グローバル) | $200(旧$250から値下げ) |
| 開発者・企業向けAPI | 今後数週間で提供予定 | 提供面・料金・SLA等の詳細は未発表 | 未発表 |
この表が示すとおり、無料体験はYouTube経由で可能ですが、本格的に会話編集を使い込むならAI Plus($7.99)以上のサブスクリプションが必要です。上記は2026年5月時点の米国基準価格であり、日本円での契約価格は地域・為替・税制により異なるため、Google One側の現地価格を必ず確認してください。Geminiの料金プランや利用上限の詳細は別記事で整理しています。
API提供のスケジュール感
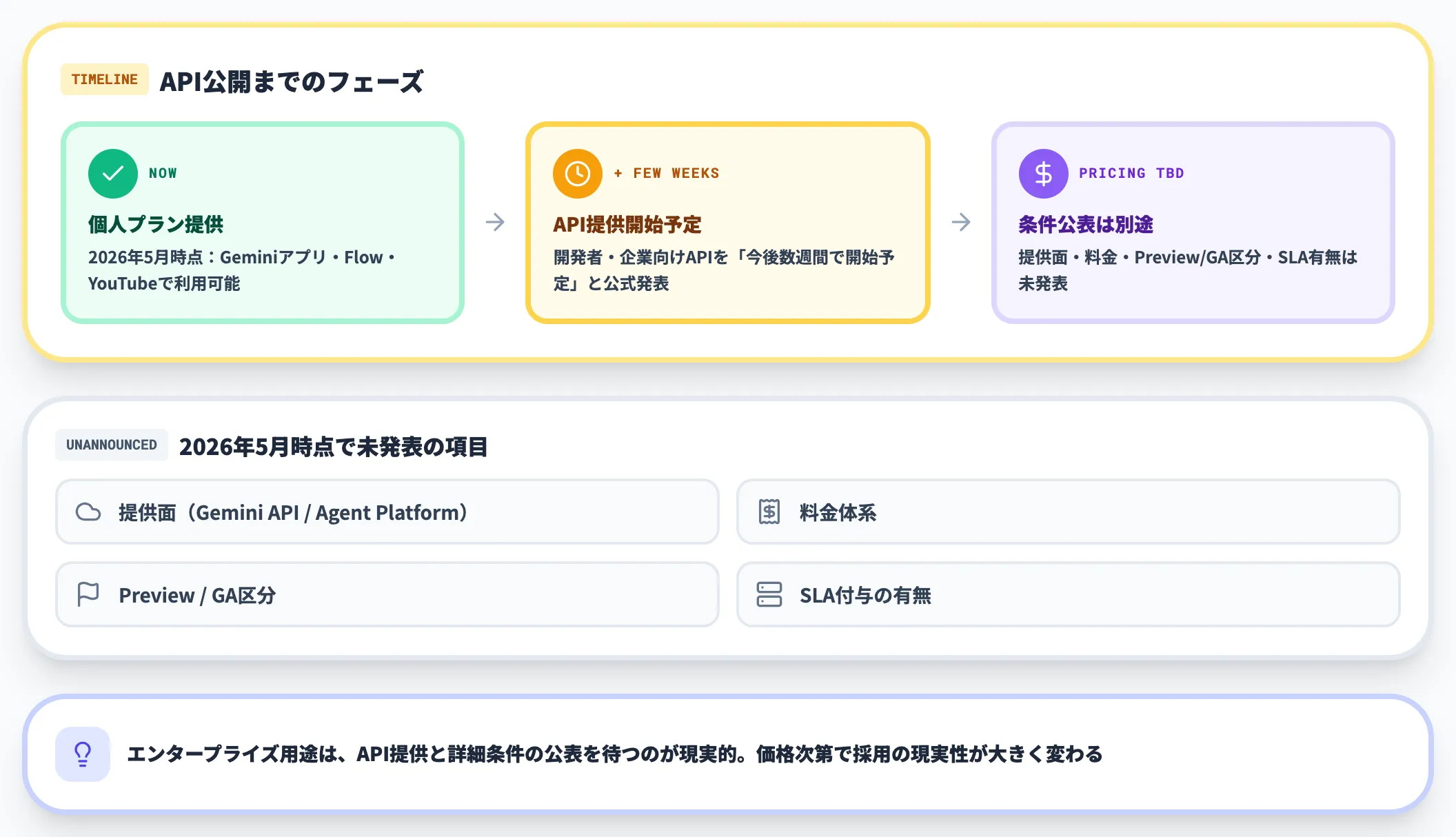
Google公式は、開発者・企業向けのAPI提供を「今後数週間で開始予定」としています。ただし、提供面(Gemini API経由か、Gemini Enterprise Agent Platform経由か)、料金体系、Preview/GA区分、SLA付与の有無については、2026年5月時点で公式の発表はありません。
エンタープライズ用途(自社サービスへの組み込み、社内ワークフローへの連携)を本格的に始めるには、このAPI提供と詳細条件の公表を待つのが現実的です。価格次第で、エンタープライズ採用の現実性が大きく変わるため、API公開時の料金発表は要注目です。
コスト比較の目安
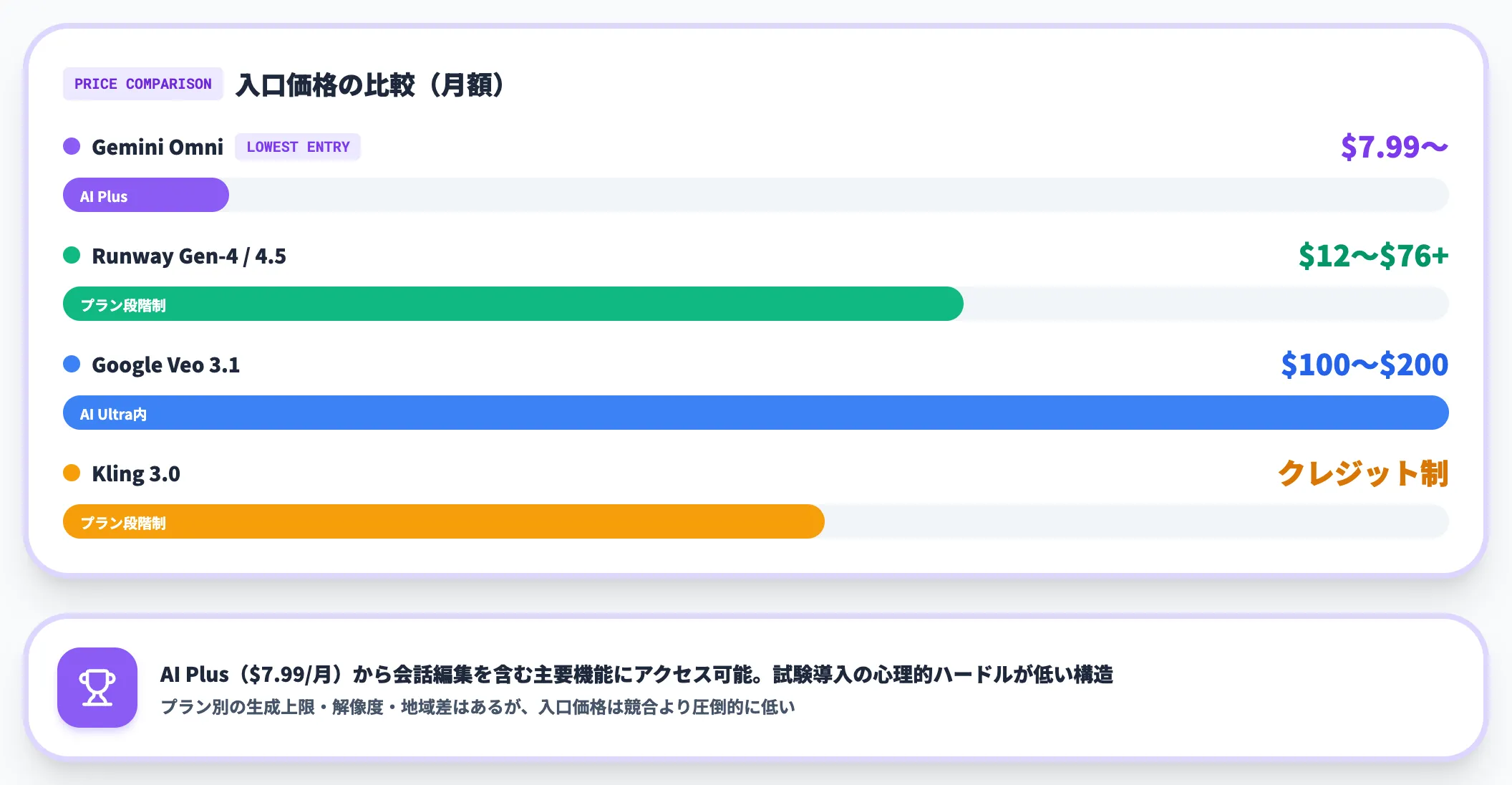
参考までに、競合モデルの料金水準は次のとおりです。
- Google Veo 3.1:Google AI Ultra($100または$200/月)内で利用
- Runway Gen-4 / Gen-4.5:$12〜$76+/月(プラン段階制)
- Kling 3.0:クレジット制(プラン段階制)
Gemini Omniは、AI Plus($7.99/月)から会話編集を含む主要機能にアクセスできる点で、競合より入口価格が低い構造になっています。プラン別の生成上限・解像度・地域差はあるものの、試験導入の心理的ハードルは低く設定されている、と整理できます。
Gemini Omniの使い方
Gemini Omniは複数のチャネルから利用できますが、現状は 個人向けのGeminiアプリ/Google Flowを軸に、YouTube連携で無料体験も可能、というのが基本構造です。API経由のエンタープライズ利用は数週間以内の提供開始が予告されています。
ここでは、利用チャネルごとの位置づけを整理します。

利用可能なチャネル一覧
以下の表で、Gemini Omniを利用できるチャネルを整理しました。それぞれ対象ユーザーと用途が異なるため、自分の使い方に合うチャネルを選ぶ際の判断材料として活用してください。
| チャネル | 対象ユーザー | 主な用途 |
|---|---|---|
| Geminiアプリ | Google AI Plus/Pro/Ultra加入者 | 会話型の動画生成・編集、Avatars作成 |
| Google Flow | Google AI Plus/Pro/Ultra加入者 | 映像制作向け統合環境、Veoとの併用 |
| YouTube Shorts | 一般ユーザー(無料) | 短尺動画への簡易適用 |
| YouTube Create App | 一般ユーザー(無料) | スマートフォン上でのShorts制作 |
| 開発者・企業向けAPI | 開発者・企業(今後数週間で提供予定) | アプリ組み込み・自社サービス連携 |
このうち、Geminiアプリ・Google Flowは会話編集をフルに使える本命チャネル、YouTube系は「まず触ってみる」段階で適した無料導入口、と整理できます。APIの提供開始後は、エンタープライズ向けの本格利用が可能になる見込みですが、提供面(Gemini API・Gemini Enterprise Agent Platform等)や料金条件は2026年5月時点で公式未発表です。
Geminiアプリ
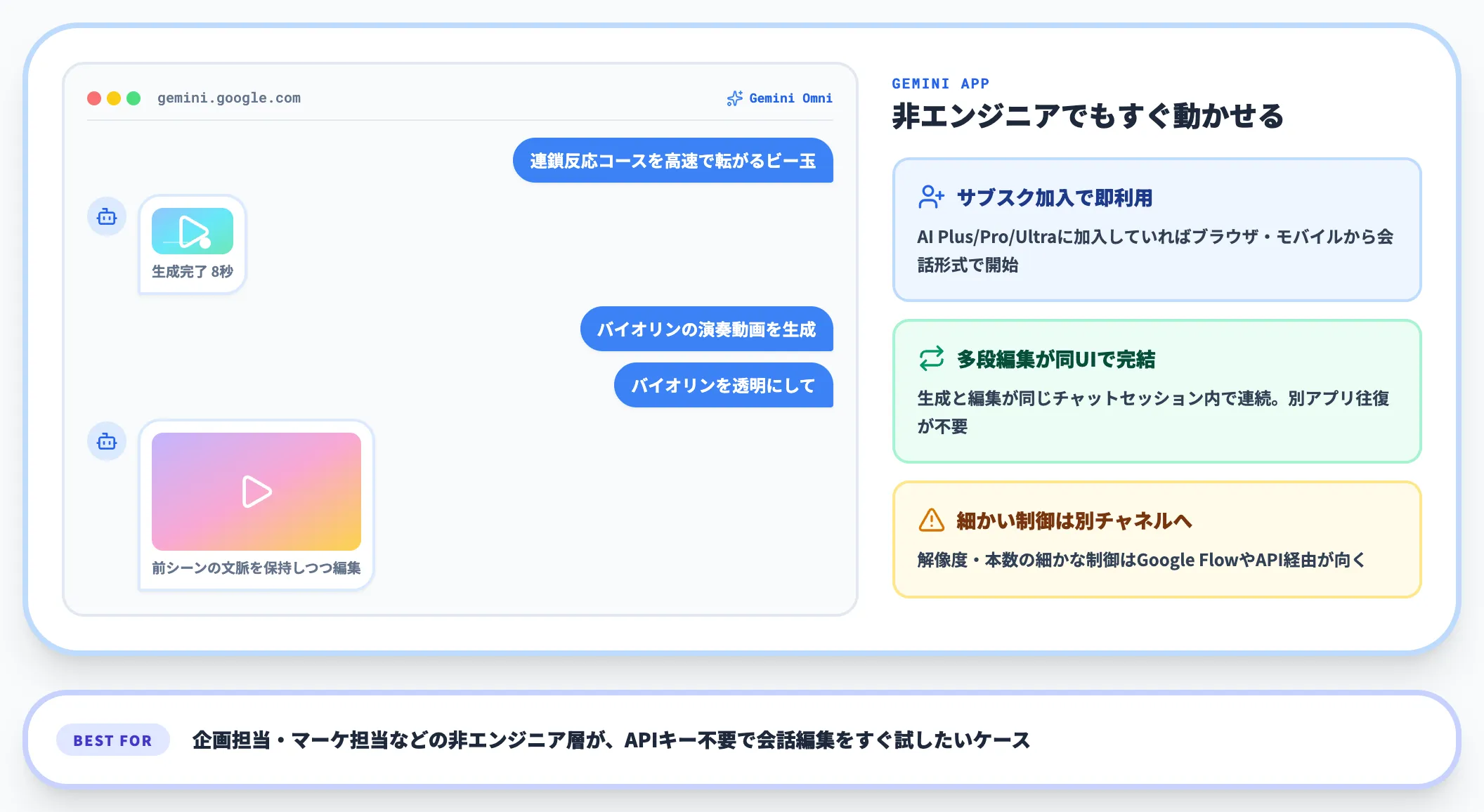
最も手軽にGemini Omniを試せるのが、Geminiアプリです。Google AI Plus/Pro/Ultraのいずれかのサブスクリプションに加入していれば、ブラウザ版・モバイル版から会話形式で動画生成・編集を開始できます。
実際の使用例(Geminiアプリ)
-
Geminiアプリ(ブラウザ版またはモバイルアプリ)にアクセスし、Googleアカウントでログインします。

-
ログイン後、ツールメニューから「動画を作成」を選択します。

-
プロンプト入力欄に生成したい動画の内容を自然言語で記述し、必要に応じて画像・動画・音声サンプルをリファレンスとして添付します。
【プロンプト例】
連鎖反応コースを高速で転がるビー玉。途切れのないスムーズなワンカット撮影。
- 生成ボタンを押すと、数秒〜十数秒で動画が生成されます。
実際に生成された動画は以下のとおりです。
まず驚かされるのが「物理法則の自然さ」です。ビー玉が斜面を転がる速度感、衝突したときの跳ね方、軌道の連続性が、従来の動画生成AIにありがちな「カクつき」や「不自然な加減速」なしに表現されています。
- 重力の表現:傾斜に応じた加速・減速が連続している
- 運動エネルギーの保存:衝突後の跳ね返りに違和感がない
- カメラワークの追従:ワンカット指定が崩れずに維持される
続けて、生成された動画に対して自然言語で編集を重ねていけます。
【多段編集の例】
- 1回目:「バイオリンの演奏動画を生成」と入力

- 2回目:「演奏者をある建物の中に移動させて」と追加指示

各ステップで、前のシーンの文脈(キャラクターの見た目・物理法則・空間構造)を保ったまま編集が積み重なります。「いったん別アプリで作成→別ツールで編集」というワークフローが、1つのチャットセッション内に統合されている点が大きな違いです。
Geminiアプリでの利用は、APIキー取得やコードの記述が不要なため、企画担当・マーケ担当などの非エンジニア層でもすぐに動画生成を始められる点が大きなメリットです。一方で、生成解像度や本数の細かな制御が必要な場合は、後述のGoogle FlowやAPI経由のほうが向きます。
Google Flow
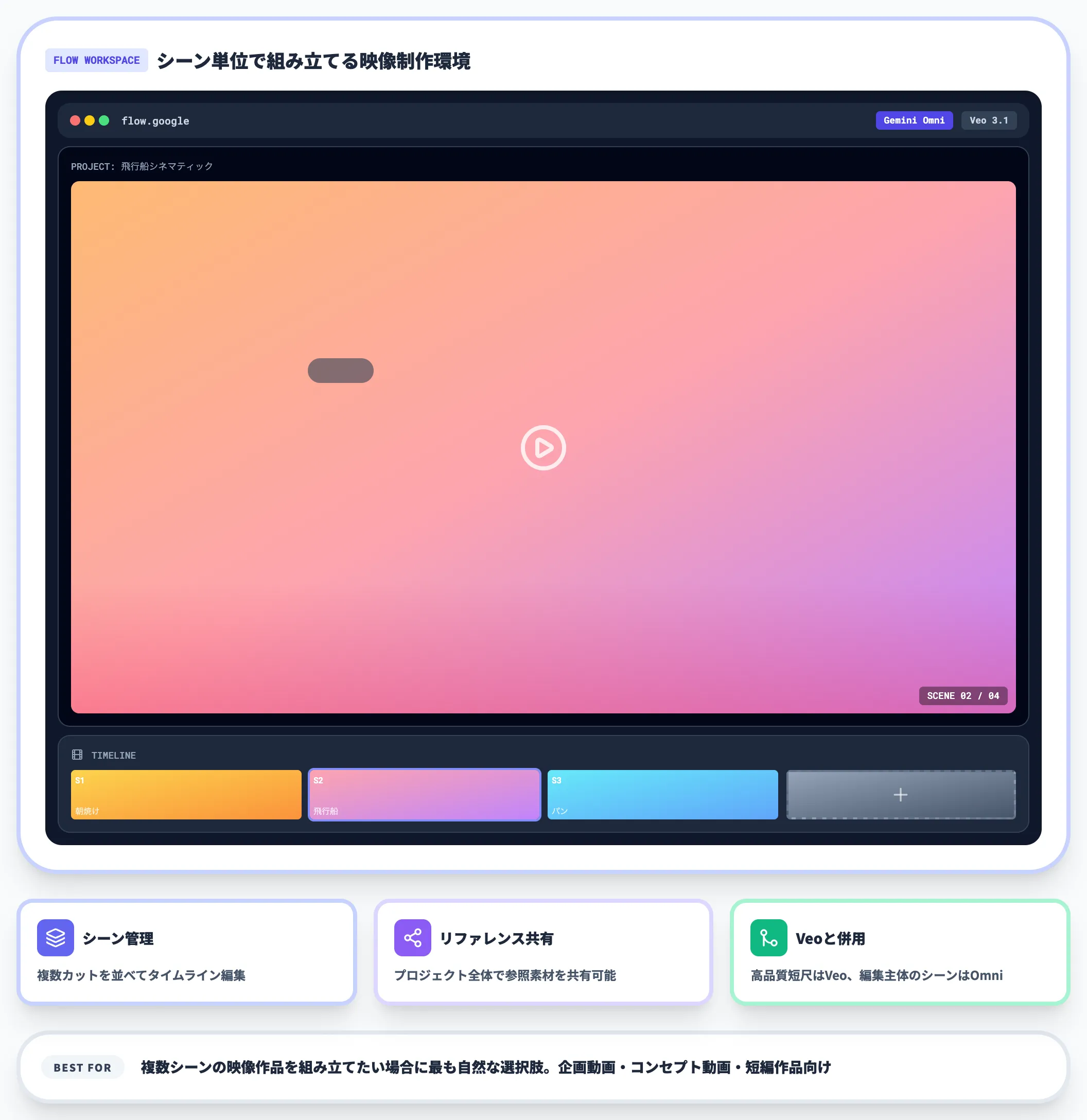
映像制作向けの統合環境として、Google FlowからもGemini Omniを利用できます。FlowはGoogleのAI動画制作ツールで、Veoとの併存運用や絵コンテ作成、シーン管理など、より制作ワークフロー寄りのUIが提供されます。
Flow経由でGemini Omniを使う流れは次のとおりです。
Google Flowは、複数シーンの映像作品を組み立てるための統合環境です。
実際の使用例(Google Flow)
-
Google Flowにアクセスし、新規プロジェクトを作成します。
-
プロジェクト画面で、生成モデルとしてGemini Omniを選択します。
-
プロンプトを入力し、必要に応じてリファレンス素材(画像・動画・音声)をアップロードします。
【プロンプト例】
朝焼けの東京湾に浮かぶレトロフューチャー風の飛行船。カメラはゆっくりと右にパンしながら、レインボーブリッジを背景に映し出す。シネマティック、16:9。
生成された動画はタイムライン上に配置され、続けて別のシーンを生成・追加していくことで複数シーンの映像作品を組み立てられます。
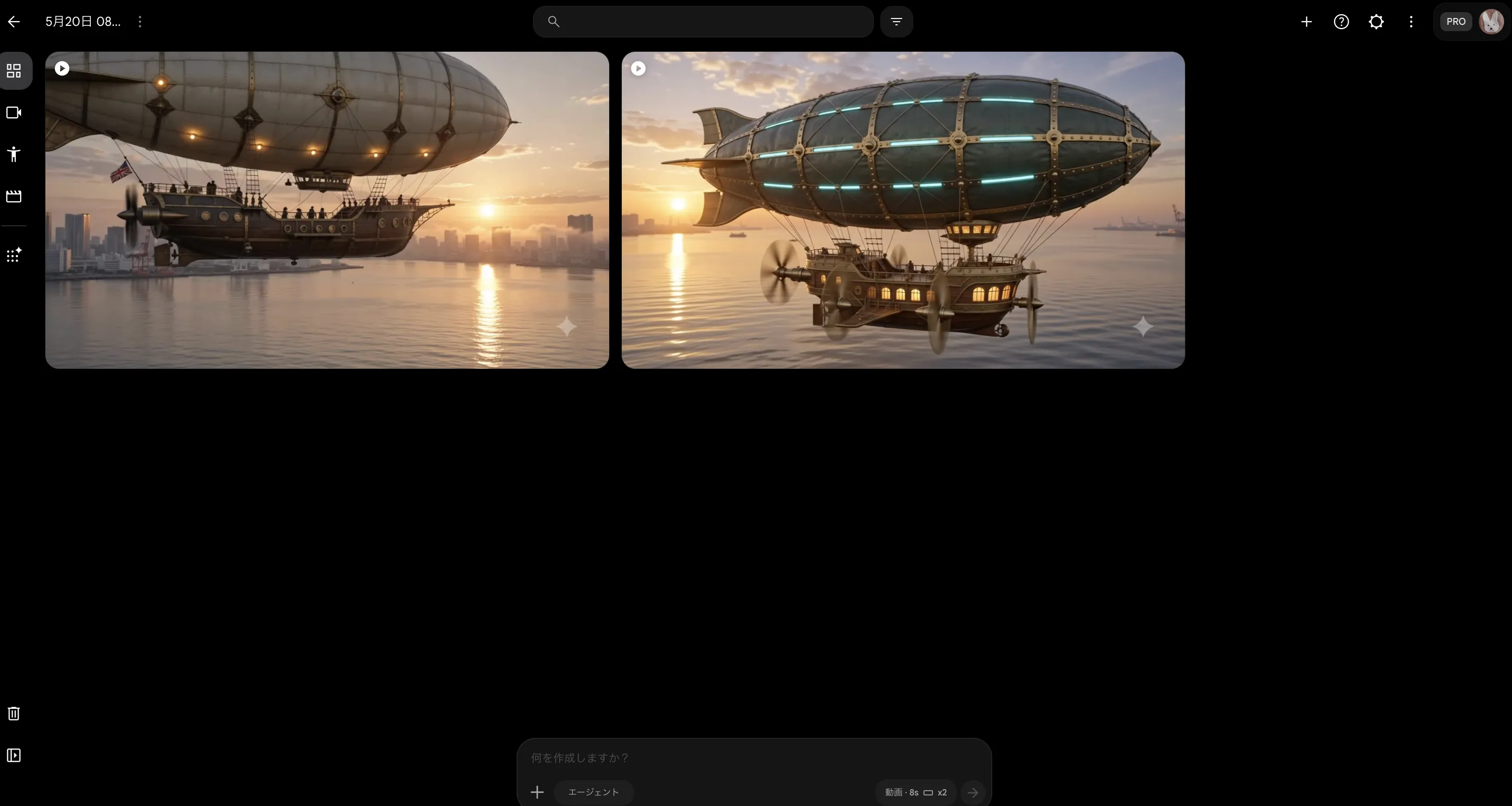
実際にされた結果は以下のとおりです。
Flowが優れているのは、「シーン間のキャラクター・スタイル一貫性をAI側が維持してくれる」点です。
例えばシーン1で生成した飛行船のデザインを、シーン2・3でも崩れずに登場し、ライティングや空気感もプロジェクト全体で揃えることも可能です。
- シーン管理:複数カットを並べてタイムライン編集
- リファレンス共有:プロジェクト全体で参照素材を共有可能
- Veoとの併用:高品質短尺はVeo、編集主体のシーンはOmni
Flowは「単発の動画生成」よりも「複数シーンの映像作品を組み立てる」用途に向くため、企画動画・コンセプト動画・短編作品を作りたい場合に最も自然な選択肢になります。
YouTube Shorts/YouTube Create App
YouTube ShortsとYouTube Create Appでは、Gemini Omniの一部機能が無料で利用可能です。発表週から順次ロールアウトされており、課金プランへの加入なしで生成AIによる動画制作を試せます。
利用フローは次のとおりです。
YouTube Shorts/Create Appでは、Geminiアプリ・Flowで提供される機能のうち一部が無料で利用可能です。
Avatars(デジタルアバター)の登録と利用
![]()
Gemini Omniの目玉機能のひとつ「Avatars」を使う場合、本人のデジタルアバターを事前に登録する必要があります。
本人のアバター登録には、本人による能動的な記録(数字読み上げ)が必要です。
開発者・企業向けAPI(今後数週間で提供予定)
Google公式は、Gemini Omniを開発者・企業向けに今後数週間でAPI経由で提供開始予定としています。
アプリ組み込み・自社サービス連携・カスタマイズされた業務動画生成パイプラインなど、エンタープライズ用途を本格化するチャネルがここです。
ただし、2026年5月時点では以下の情報は公式未発表となっています。
| 項目 | 公開済み情報(2026年5月時点) |
|---|---|
| 提供面 | Gemini API経由か、Gemini Enterprise Agent Platform経由かは未発表 |
| モデルID | 未公開 |
| 対応解像度・動画長 | 未公開 |
| 料金体系 | 未公開(トークン課金/秒単位課金等の形式も未確定) |
| Preview/GA区分 | 未発表 |
| SLA・データ保持・地域選択 | 未発表 |
| AI Content Detection API連携 | 信頼パートナー向け先行提供で、一般提供時期は未確認 |
そのため、API公開時の発表内容を待った上で、PoCを設計するのが現実的です。
先行する個人プランでの検証は今すぐ進められるため、API公開前のリードタイムを使ってユースケースを絞り込んでおくのが推奨アプローチです。
【関連記事】
Gemini APIとは?Vertex AI活用と料金を解説
Gemini Omniと主要動画生成モデルの比較

AI動画生成市場は、Google系のVeo 3.1、Runway Gen-4・Runway Gen-4.5、中国系のKling AI(Kling 3.0)、Seedance 2.0など、複数の現役モデルが競い合う構造です。
本記事では現役モデルとの比較を軸に、Gemini Omniの差別化を整理します。
主要モデルの比較表
以下の表で、Gemini Omniと現役の主要動画生成モデルを並べて整理しました。
各モデルの強みと位置づけを把握したうえで、自社の用途に合うモデル選びの起点として活用してください。
| 項目 | Gemini Omni Flash | Google Veo 3.1 | Runway Gen-4.5 | Kling 3.0 |
|---|---|---|---|---|
| 提供元 | Google DeepMind | Google DeepMind | Runway | Kuaishou |
| 入力モダリティ | テキスト・画像・動画・音声 | テキスト・画像 | テキスト・画像 | テキスト・画像 |
| 強み | 物理+世界知識+会話編集 | 音声付き動画生成 | キャラクター一貫性・速度 | モーション品質・多言語リップシンク |
| 代表的な料金 | AI Plus/Pro/Ultra内(YouTube無料) | AI Ultraサブスク内 | $12〜$76+/月 | クレジット制(プラン制) |
| 主要チャネル | Geminiアプリ・Flow・YouTube | Geminiアプリ・Flow | Runwayアプリ | Kling AIアプリ |
この比較から見えてくるのは、Gemini Omniの差別化軸が「any-to-any入力」「世界知識を活かしたストーリー性」「マルチターン編集」の3点に集約されている、という点です。
Veo 3.1との比較
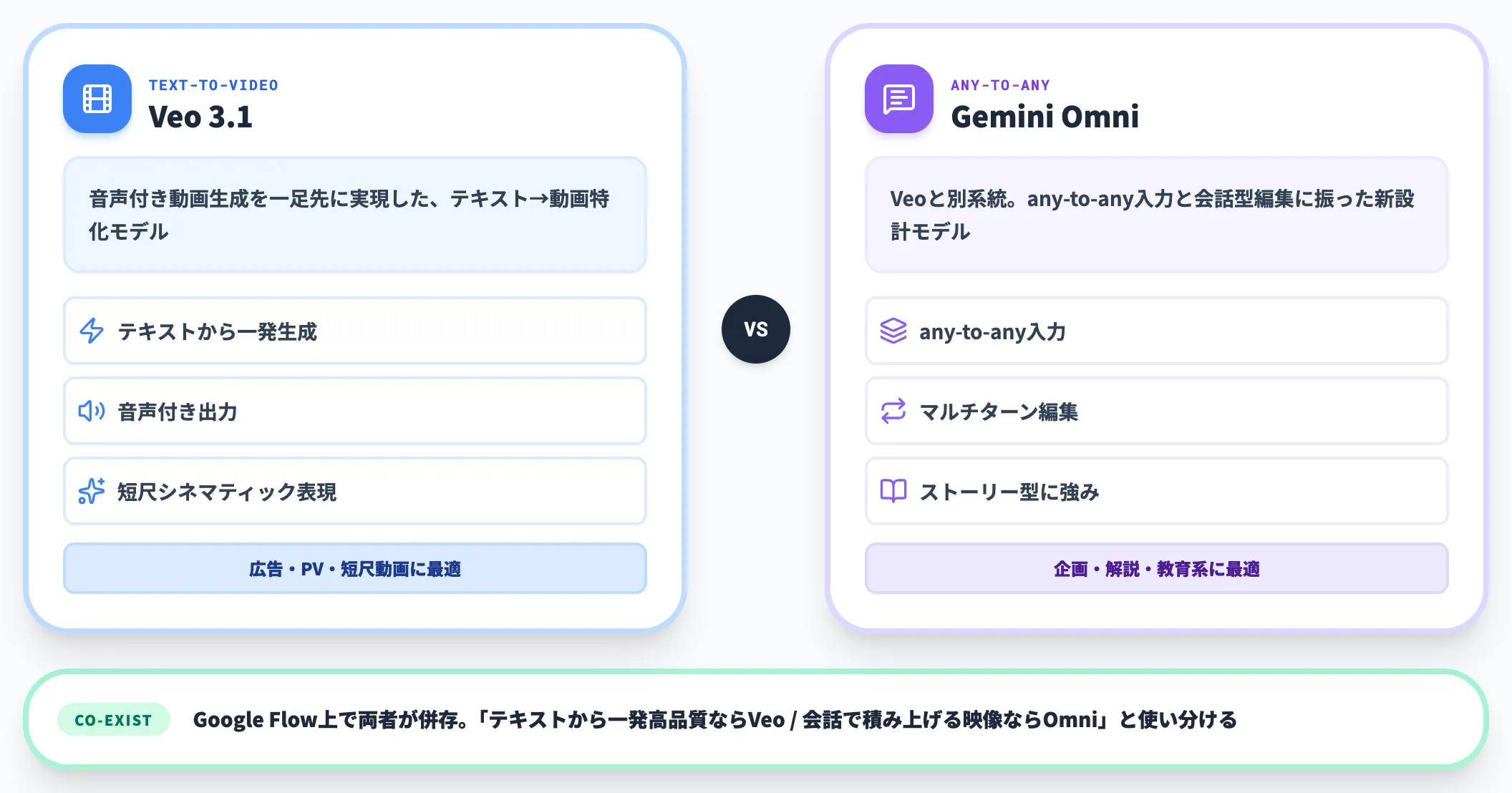
Veo 3.1は、Google AI Ultraサブスクリプションで提供されてきた動画生成モデルで、音声付き動画生成を一足先に実現していました。
テキスト→動画生成に特化し、ハイクオリティな短尺シネマティック表現に強みを持ちます。
Gemini Omniは、Veoと別系統の新モデルとして、any-to-any入力と会話型編集に振った設計です。「テキストから一発で高品質な動画」ならVeo 3.1、「会話で積み上げるストーリー性ある映像」ならOmni、という棲み分けが現状の構図です。Google Flow上では両者が併存しており、用途別に使い分けられます。
Runway Gen-4 / Gen-4.5との比較
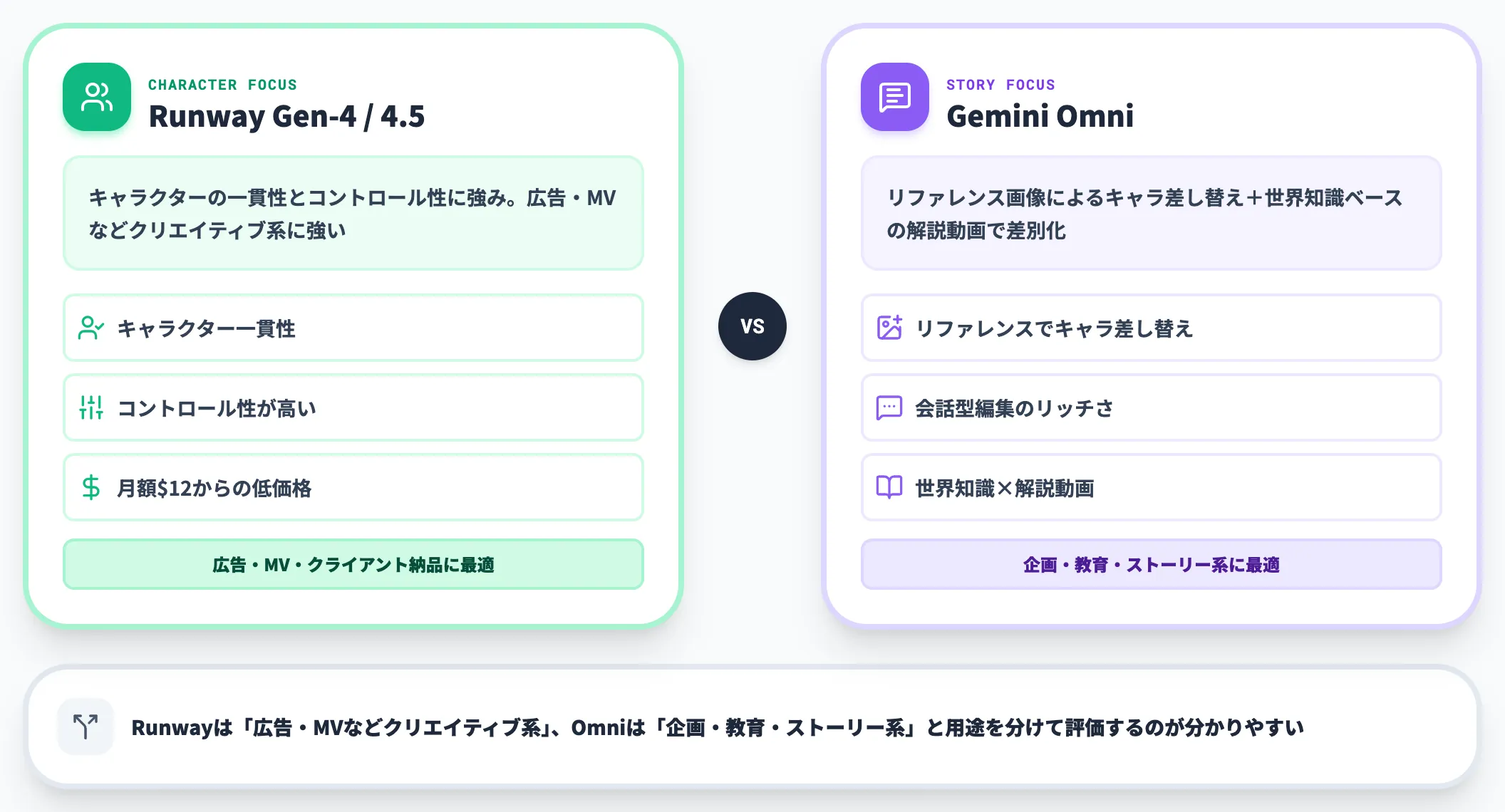
Runway Gen-4・Runway Gen-4.5は、キャラクターの一貫性とコントロール性に強みを持つモデルで、広告制作やクライアント納品など「何度も同じキャラを使う」用途で支持を集めています。月額$12からの低価格帯で始められる点も魅力です。
Gemini Omniは、リファレンス画像によるキャラクター差し替えに加え、会話型編集のリッチさと世界知識ベースの解説動画生成で差別化を図ります。Runway Gen-4系が「広告・MVなどクリエイティブ系」、Omniが「企画・教育・ストーリー系」と整理すると分かりやすい構図です。
Kling 3.0との比較
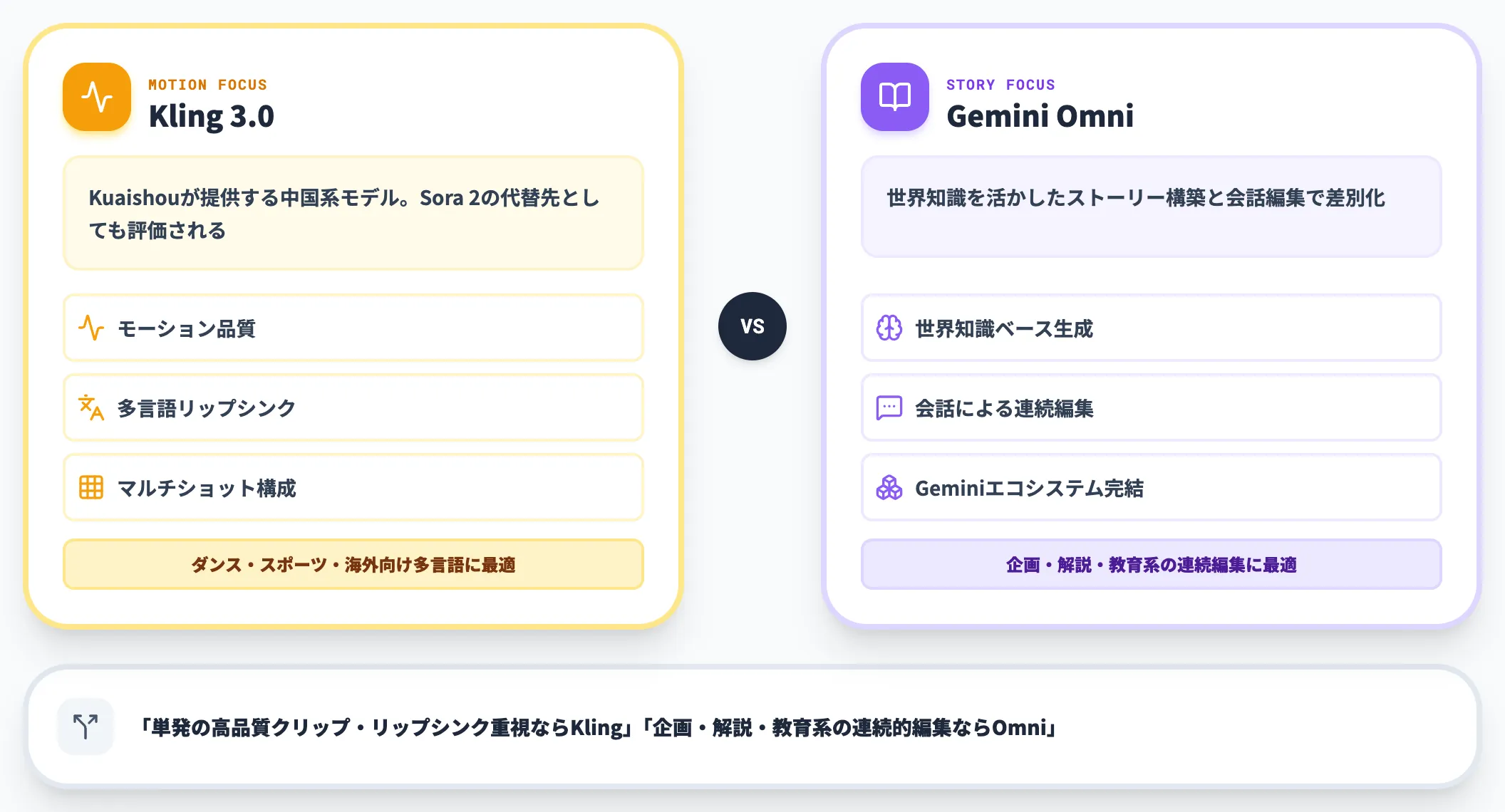
Kling AI(Kling 3.0)は、Kuaishouが提供する中国系の動画生成モデルで、モーション品質や多言語のリップシンク、マルチショット構成に強みを持ちます。Sora 2の代替先としても評価されています。
Gemini Omniは、世界知識を活かしたストーリー構築と会話編集で差別化し、Geminiエコシステム内で完結したい組織に向きます。Kling 3.0と用途を分けて評価するなら、「単発の高品質クリップ・リップシンク重視ならKling」「企画・解説・教育系の連続的な編集ならOmni」と整理できます。

モデル選定の判断軸
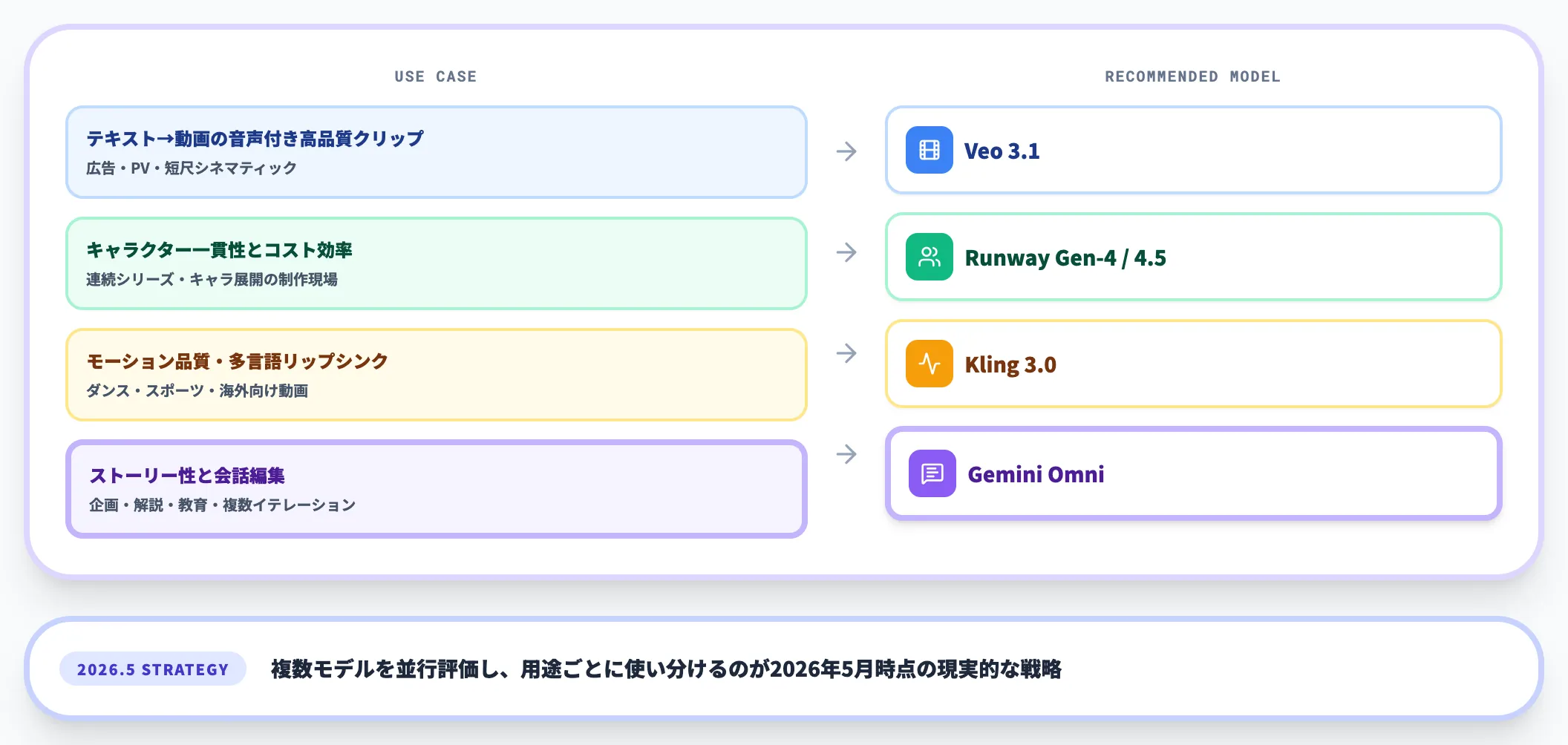
ここまでの比較を踏まえると、現時点でのモデル選定はおおむね次のように整理できます。
-
テキスト→動画の音声付き高品質クリップ → Veo 3.1
広告・PV・短尺シネマティック表現で、Geminiエコシステム内で完結したい組織。AI Ultra契約をすでに持つ企業
-
キャラクター一貫性とコスト効率 → Runway Gen-4 / Gen-4.5
連続シリーズ・キャラクター展開を継続する制作現場、月額$12からの導入ハードルの低さ
-
モーション品質・多言語リップシンク → Kling 3.0
ダンス・スポーツなど動きの多い映像、海外向け多言語動画でSora 2の代替を探していたユーザー
-
ストーリー性と会話編集 → Gemini Omni
企画・解説・教育コンテンツ、複数イテレーションを前提とする企画フェーズ、any-to-any入力を活かしたい用途
複数モデルを並行して評価し、用途ごとに使い分けるのが2026年5月時点の現実的な戦略です。
Gemini Omniの安全性と透明性
生成AI動画の悪用懸念に対し、Gemini Omniは複数の安全機構を組み込んでいます。エンタープライズ導入時の説明責任を果たすうえで、ここは押さえておきたいポイントです。
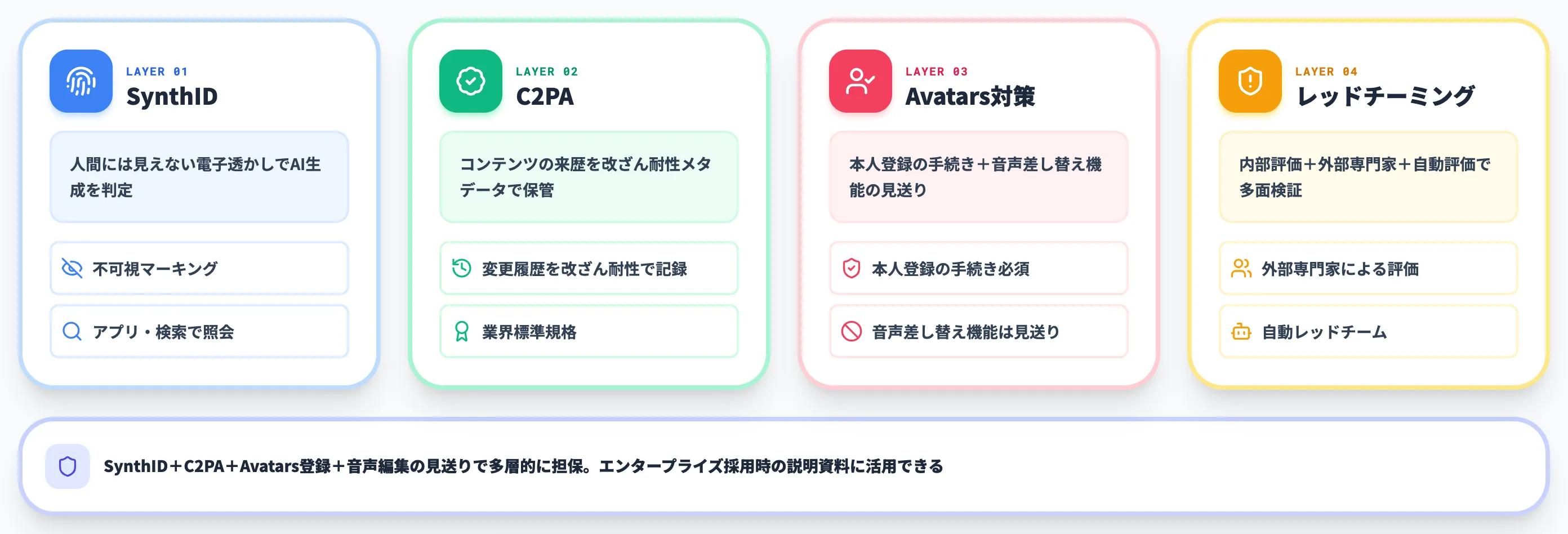
SynthIDとC2PA Content Credentials
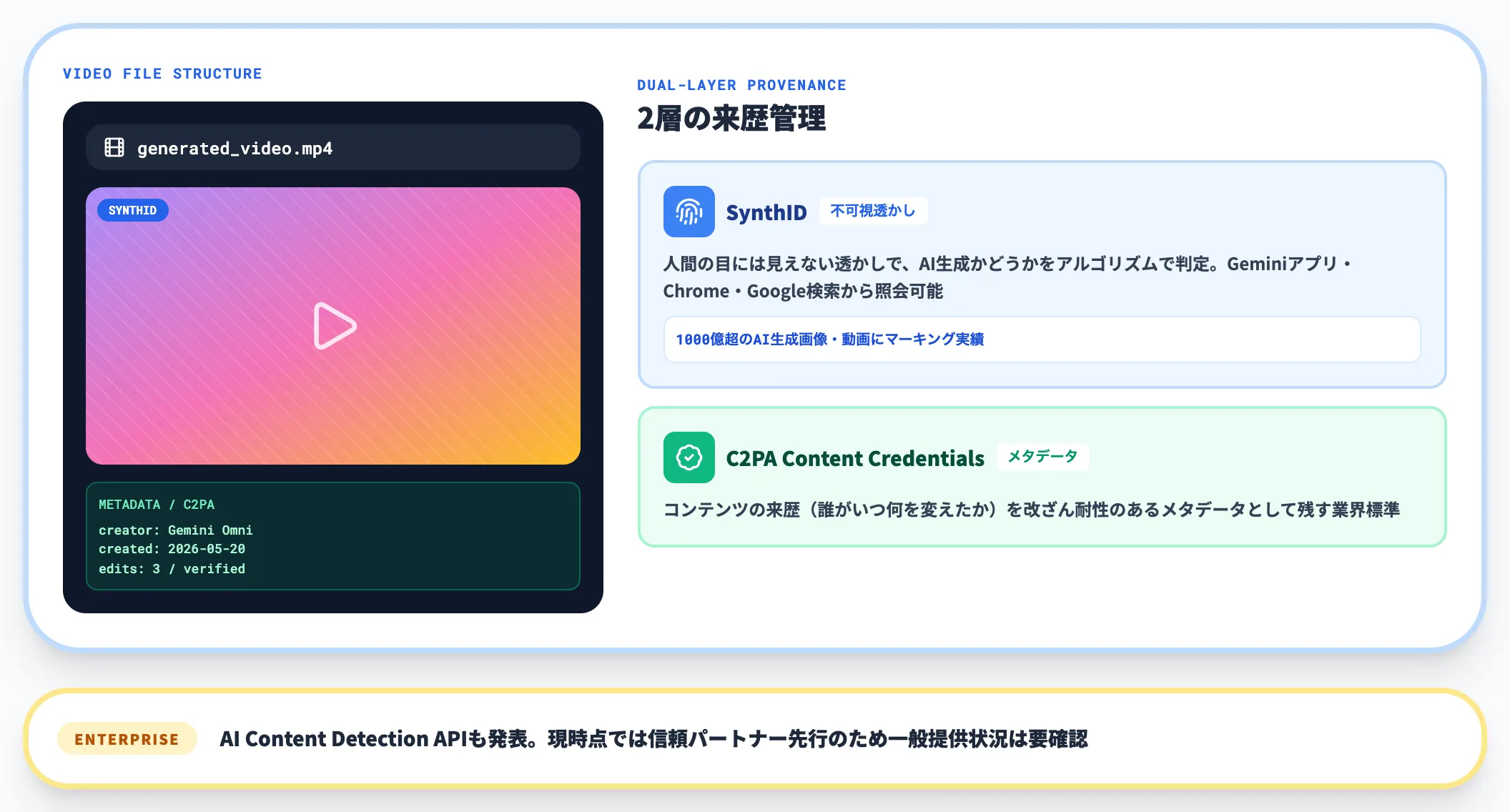
Gemini Omniで生成・編集されたすべての動画には、SynthIDによる電子透かしとC2PA Content Credentialsが自動で埋め込まれます。
-
SynthID
人間の目には見えない透かしで、AI生成かどうかをアルゴリズムで判定できる。Geminiアプリ・Gemini in Chrome・Google検索から照会可能。GoogleはSynthIDで1000億超のAI生成画像・動画にマーキングを行っており、OpenAI・ElevenLabs・Kakaoが標準採用に動いている
-
C2PA Content Credentials
コンテンツの来歴(誰がいつ何を変えたか)を改ざん耐性のあるメタデータとして残す業界標準。コンテンツの出所追跡に役立つ
エンタープライズ向けには、Gemini Enterprise Agent Platform(旧Vertex AI)上でAI Content Detection APIも新たに発表されました。ただし、現時点では信頼されたパートナー(trusted partners)向けに提供を開始した段階であり、一般企業がすぐに評価・利用できるとは限りません。一般提供の状況は要確認です。Google製と他社モデルの両方のAI生成コンテンツを検出できる仕組みが整いつつあります。
Avatarsのディープフェイク対策
![]()
前述のとおり、AvatarsのオンボーディングではユーザーがGoogleが指定した数字を読み上げる手順が用意されています。これは「本人による登録」という形で、なりすまし利用を抑制する設計です。
加えて、他人の動画の音声を差し替える編集機能は意図的にリリース見送りになっています。技術的には可能であっても、ディープフェイク悪用リスクが高い機能は段階的に公開する、という慎重なポリシーが取られています。
内部・外部のレッドチーミング

公式の安全性ページでは、Gemini Omni Flashの開発過程で実施された評価活動が紹介されています。具体的には次のとおりです。
- 学習・開発中の自動評価および人手評価
- 開発チーム外の専門家による人間レッドチーミング
- スケールに対応する自動レッドチーミング
- リリース前の倫理・安全レビュー
これらはGoogleのAI原則とGen AI Prohibited Use Policy、Gemini APIの追加利用規約に沿って行われています。エンタープライズで採用する際の説明資料として、この設計プロセスは押さえておきたい情報です。
Gemini Omniのエンタープライズ活用シナリオと導入判断
API提供前の現時点では、Gemini Omniは個人向けプロダクトとしての色合いが強いものの、業務利用のユースケース仮説は既に複数描けます。ここでは活用シナリオを整理した上で、エンタープライズ導入における判断軸を整理します。

想定される活用シナリオ
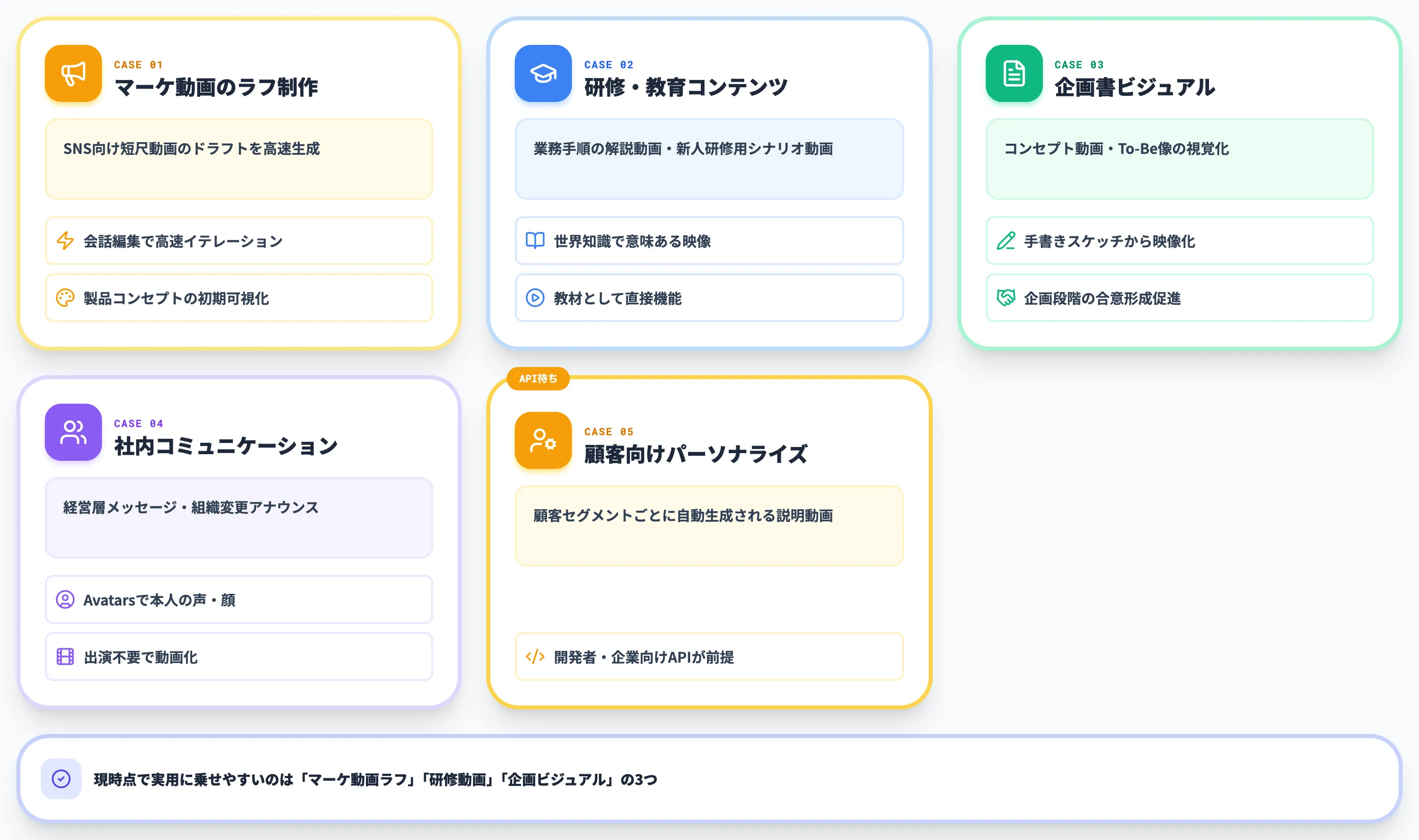
以下に、現時点で実現性の見えやすい業務ユースケースを整理しました。各シナリオで「どの機能が効くか」も併記しています。
-
マーケティング動画のラフ制作
製品コンセプトの初期ビジュアル化、SNS向け短尺動画のドラフト作成。会話編集による高速イテレーションが効く
-
研修・教育コンテンツの制作
業務手順の解説動画、新人研修用のシナリオ動画。世界知識を活かした「意味のある映像」がそのまま教材として機能する
-
企画書・提案書の補助ビジュアル
コンセプト動画、To-Be像の視覚化。手書きスケッチを元にした映像化で、企画段階の合意形成が早まる
-
社内コミュニケーション動画
経営層からのメッセージ動画、組織変更のアナウンス。Avatarsを使えば、本人が出演しなくても本人の声と顔で動画化できる
-
顧客向けのパーソナライズ動画
(API提供後)顧客セグメントごとに自動生成される説明動画。開発者・企業向けAPIによる組み込みが前提
このうち、現時点で実用に乗せやすいのは「マーケ動画ラフ」「研修動画」「企画ビジュアル」の3つです。Avatarsを業務利用するには社内ポリシー整備が必要で、API待ちのものは数週間〜数ヶ月のリードタイムが見込まれます。
導入判断で詰まる論点

ここまでの整理を踏まえると、Gemini Omniのエンタープライズ導入で詰まりやすい論点は次の5つです。
-
「いつ動くべきか」の判断
個人プランでの先行検証ならすぐに開始できるが、業務組み込みはAPI提供開始後が現実的。先行検証だけ進めて本格導入はAPI公開と詳細条件の発表を待つのが、2026年5月時点の合理的な選択
-
「個人プランでの検証範囲」の線引き
業務動画の素材・スクリプトを個人プランに投入してよいか、データ取り扱いの観点で社内ルールを定める必要がある。機密情報や顧客個人情報を含まない範囲での検証に限定するのが安全
-
「Avatarsの社内利用ルール」
本人同意・撮影記録の保管・本人退職後の取り扱いなど、ガバナンス整備が必要。安易に導入せず、人事・法務との事前すり合わせが推奨される
-
「商用利用と権利処理」
生成動画の商用利用可否、参照に使う画像・人物・音声・ブランド素材の権利処理が実務上の論点になる。第三者の肖像・著作物・商標を含む素材をリファレンスに使う場合、許諾や利用条件の確認が必要になる場合がある。商用利用の可否や出力物の扱いは、**利用チャネルごとの規約(Geminiアプリ/Google Flow/開発者・企業向けAPI)**でそれぞれ確認し、禁止用途はGen AI Prohibited Use Policyで確認するのが安全
-
「Veo・Runway・Klingとの使い分け」
既にVeo・Runway Gen-4・Kling 3.0などを契約している組織は、用途別の使い分けを設計する必要がある。ストーリー性ある企画動画はOmni、テキスト→動画の音声付き高品質クリップはVeo 3.1、キャラ展開の継続制作はRunway、モーション・多言語リップシンクはKling、と用途を分けて評価するのが現実的
これらの論点は、API提供を待つ間に社内ポリシー設計とPoC企画を進めておくことで、API公開直後にスムーズな本格導入につなげられます。
導入を3段階で進める実務シナリオ
複数のAI動画モデルを並行検証してきた支援現場の観点では、Gemini Omniの導入は次の3段階で進めるのが現実的です。
- 個人検証フェーズ(2026年5〜6月)
企画担当者がAI Plus個人プランに加入し、機密情報を含まない素材でユースケースを試す。Veo 3.1・Runway Gen-4・Kling 3.0と並行比較する - API評価フェーズ(API提供開始直後)
開発者・企業向けAPI(提供面・料金は今後発表)の条件を確認し、自社ワークフロー組み込みのPoCを計画する。AI Content Detection APIの提供状況(信頼パートナー先行)も合わせて確認 - 本番導入フェーズ(PoC後)
社内ガバナンス整備、Avatars利用ルール策定、教育動画・マーケ動画など特定用途での本番運用
特に「先行する個人検証で価値を見極め、API提供前にPoC企画を仕込んでおく」動き方が、API公開直後の競争で先行するために重要です。

Gemini Omniの体験を組織のAI業務設計に広げるなら
Gemini Omniを試して動画制作の生産性向上を実感したなら、次に問われるのは「組織としてAIをどう業務に組み込むか」という段階設計です。動画生成だけでなく、経理・人事・営業など部門ごとにAIを定着させていくフェーズで、多くの企業が「PoCで止まる」「現場が使わない」「ROIが見えない」という壁にぶつかります。
AI総合研究所が公開している220ページのAI業務自動化ガイドは、Copilot Chat → M365 Copilot → Copilot Studio → Microsoft Foundry/AI Agent Hubの順で、Microsoft環境でのAI業務自動化を段階的に進める実践手順をまとめています。経費精算・申請承認・請求書受領・人事・総務・情シス・経営企画など部門別ユースケースをBefore/After/KPI付きで整理しており、AI導入の「次の一歩」を設計するための材料として活用いただけます。
AI総合研究所では、生成AIの最新動向を追いかける段階から、業務への定着・全社展開までを一気通貫で支援しています。まずは無料の資料で、自社のAI業務自動化の進め方をご確認ください。
AI活用の視野を組織の業務設計に広げる

220ページの実践ガイドで段階的なAI業務自動化を設計
Gemini Omniのようなマルチモーダル動画AIを試した後、次に問われるのは組織としてAIを業務に組み込む段階設計です。AI総合研究所が公開した220ページの実践ガイドが、Microsoft環境でAI業務自動化を段階的に進める手順を整理しています。
まとめ
本記事では、Google I/O 2026で発表された動画生成モデル「Gemini Omni」について、機能・使い方・競合比較・料金・安全性・エンタープライズ導入の判断軸を解説しました。
- Gemini Omniは、Geminiの推論能力と動画生成を統合したany-to-anyマルチモーダルモデル。Nano Bananaの動画版として位置づけられ、Veoとは別系統の新モデルとして併存する
- 主要機能は会話編集/世界知識ベースの生成/マルチリファレンス入力/Avatarsの4つ。物理法則と歴史・科学・文化的背景の理解が組み合わさり、意味のある映像生成を実現する
- 競合比較では、Veo 3.1の音声付き高品質クリップ、Runway Gen-4のキャラクター一貫性、Kling 3.0のモーション品質に対し、Omniは会話編集とストーリー性で差別化
- 提供はGeminiアプリ・Google Flow・YouTube連携から開始。開発者・企業向けAPIは今後数週間で提供予定(提供面・料金・SLA等の詳細は未発表)
- 安全性はSynthID+C2PA Content Credentials+Avatars登録手順+音声編集機能の見送りで多層的に担保
- エンタープライズ導入は、個人検証→API評価→本番導入の3段階で進めるのが現実的。API公開前にPoC企画を仕込んでおくことが先行のカギ
Gemini Omniは、AI動画生成の主戦場を「短尺の高品質クリップ」から「会話で積み上げる物語性ある映像」に押し広げる存在です。API提供開始と詳細条件の発表を待ちつつ、まずは個人プランでの先行検証から始めるのが、2026年5月時点で最も合理的なアプローチといえます。










