この記事のポイント
 新規データレイク構築ではMicrosoft Fabric+OneLakeを第一候補とすべき。ADLS Gen2単体設計は将来の移行コストが増大する
新規データレイク構築ではMicrosoft Fabric+OneLakeを第一候補とすべき。ADLS Gen2単体設計は将来の移行コストが増大する- ストレージ階層はSmart Tierの自動階層化に任せるのが最適。手動のHot/Cool切り替え運用は管理負荷に見合わない
- 段階的導入ではPoC環境をFabric Trial容量で構築し、本番移行前にOneLakeショートカットで既存ADLS Gen2と共存させる設計が有効

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Azure Data Lakeは、Microsoft Azureが提供するクラウドベースのビッグデータプラットフォームです。2026年にはMicrosoft FabricのOneLakeとの連携が本格化し、Smart Tierによる自動階層化やSynapse Data Explorerの廃止に伴うアーキテクチャ移行など、データレイク戦略は大きな転換期を迎えています。本記事では、ADLS Gen2の構成サービスから料金体系、IoT・医療・マーケティング分野の導入事例、2026年最新の移行ガイドまでを網羅的に解説します。
Azureとは?入門者向けにできること、使い方を徹底解説
Azure Data Lakeとは(2026年最新ガイド)
Azure Data Lakeは、Microsoft Azureが提供する大規模データを効率的に保存・管理・処理するためのクラウドベースのビッグデータプラットフォームです。構造化データ、半構造化データ、非構造化データを元の形式のまま保存し、必要なタイミングで分析やAI・機械学習に活用できる仕組みを提供しています。
以下の表で、Azure Data Lakeの基本情報を整理しました。データレイクの概念から構成サービス、2026年の注目動向まで、このサービスの全体像を把握するための7項目です。
| 項目 | 内容 |
|---|---|
| サービス名 | Azure Data Lake(Azure Data Lake Storage Gen2を中核とする統合プラットフォーム) |
| 提供元 | Microsoft Azure |
| 核心原理 | Schema-on-Read方式。データを元の形式で保存し、分析時にスキーマを適用する |
| 対比手法 | データウェアハウス(Schema-on-Write方式。保存前にスキーマ定義・加工が必要) |
| 主な構成サービス | Azure Data Lake Storage Gen2(保存)、Azure Synapse Analytics(分析)、Azure HDInsight(処理) |
| 2026年注目動向 | Smart Tier自動階層化のパブリックプレビュー、Microsoft Fabric OneLakeとの統合、Synapse Data Explorer廃止に伴うFabric Eventhouse移行 |
| 代表的ツール | Azure Databricks、Power BI、Apache Spark、Azure Data Factory |
Azure Data Lakeが採用しているデータレイクとは、データをそのままの形式で保存し、必要になったときに分析・加工を行う仕組みです。これに対してデータウェアハウス(DWH)は、保存前にデータを整理・加工してから格納する方式を採ります。データレイクは画像・動画・センサーデータなどの非構造化データも一緒に保存でき、将来の活用方法が決まっていない段階でもデータを無駄なく蓄積できるという強みがあります。
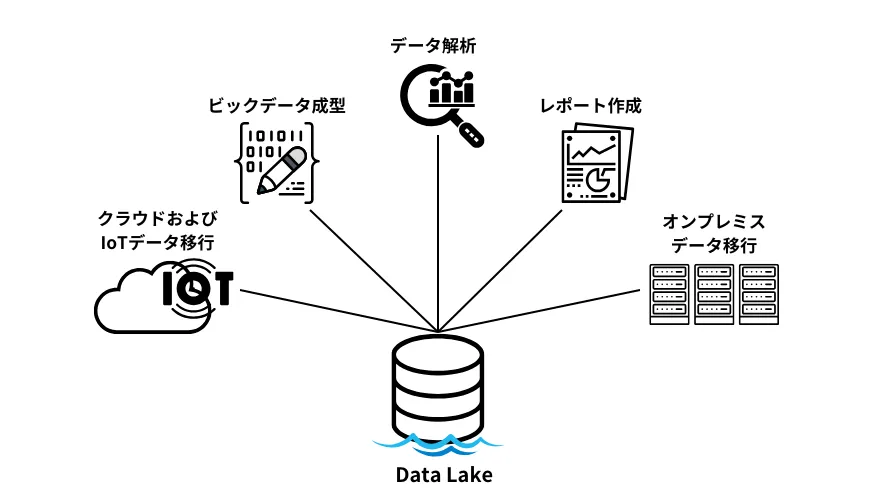
DataLakeイメージ(参考:公式ホームページ)
以下の比較表は、データレイクとデータウェアハウスの違いを6つの観点から整理したものです。企業がどちらのアプローチを採用すべきかを判断する際の参考になります。
| 比較項目 | データレイク | データウェアハウス(DWH) |
|---|---|---|
| 対象データ形式 | 構造化・半構造化・非構造化すべて | 主に構造化データ |
| スキーマ適用 | Schema-on-Read(読み取り時に定義) | Schema-on-Write(書き込み前に定義) |
| 分析用途 | 探索的分析・機械学習・リアルタイム処理 | 定型レポート・高速クエリ |
| ストレージコスト | 低い(階層化ストレージで最適化可能) | 高い(計算リソースと一体の課金が多い) |
| 柔軟性 | 高い(事前のデータ加工が不要) | 限定的(スキーマ変更にコストがかかる) |
| 2026年の位置づけ | Lakehouse統合(Fabric OneLake)が主流に | Fabric Data Warehouseとして進化 |
実務で選ぶ際のポイントは、既存データの形式と将来の活用方針です。非構造化データが多い場合やAI・機械学習への展開を見据える場合はデータレイクが有利です。一方、定型的なBI(ビジネスインテリジェンス)レポートが中心であればデータウェアハウスが適しています。2026年現在では、両者の長所を統合したレイクハウスアーキテクチャが主流になりつつあり、Microsoft FabricのOneLakeがその代表格です。
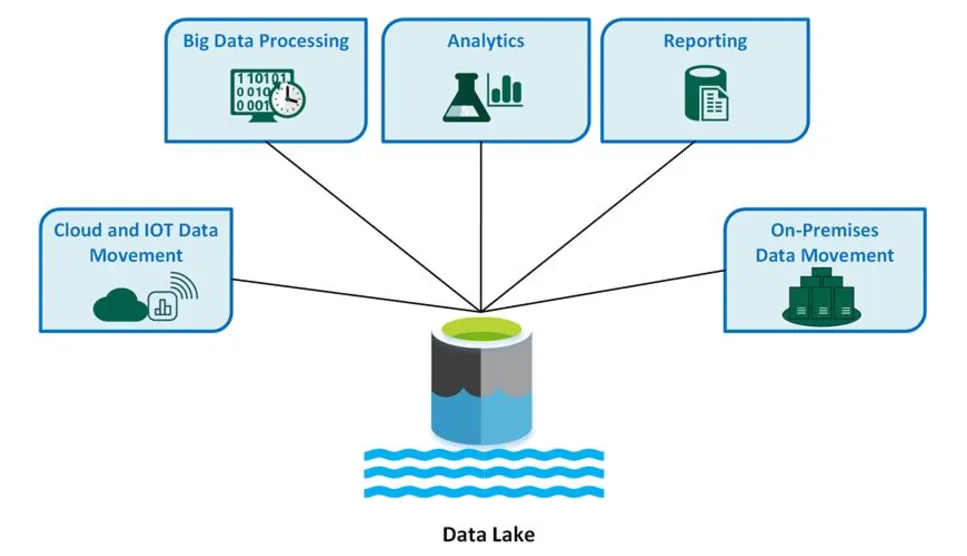 データレイクイメージ図(参考:マイクロソフト)
データレイクイメージ図(参考:マイクロソフト)

Microsoft FabricとOneLakeが変えるデータレイク戦略の2026年動向
2026年のAzureデータレイク戦略を語るうえで、Microsoft Fabricの存在は避けて通れません。FabricはADLS Gen2をSaaS化したOneLakeを中核に据え、データの保存・分析・可視化・AI活用をひとつのプラットフォームに統合するサービスです。2026年3月時点で世界28,000以上の組織がFabricを採用しており、データレイクの在り方そのものが大きく変わりつつあります。
この変化を加速させているのが、以下の3つの動きです。
第一に、Azure Synapse Data Explorerの廃止です。2025年10月7日にリタイアが完了し、リアルタイムデータ分析はFabricのEventhouse(KQLデータベース)への移行が推奨されています。既存のSynapseパイプラインもFabric Data Factoryに移行するための自動化ツールが提供されており、専用SQLプールについてはAI支援のMigration Assistantが利用可能です。
第二に、Azure HDInsightのバージョン整理です。HDInsight 4.0と5.0は2025年3月31日に廃止され、現在はHDInsight 5.1(Spark 3.3.0、Hadoop 3.3.4)のみが稼働しています。さらに、Enterprise Security Package(ESP)も2026年7月31日にサポート終了が予定されており、ESPを利用している組織は早急な移行計画が必要です。
第三に、Smart Tier(自動階層化)のパブリックプレビューです。2025年11月に発表されたこの機能は、ADLS Gen2のデータアクセスパターンを自動分析し、ホット・クール・コールド・アーカイブの各層に最適配置する仕組みです。監視操作料金は10,000操作あたり$0.04で、手動での階層管理が不要になることから、ストレージコストの大幅な削減が期待されています。
データレイク市場そのものも急成長を続けており、2025年の$186.8億から2030年には$517.8億に達する見込みです(CAGR 22.62%、Mordor Intelligence調べ)。さらに、データレイクとデータウェアハウスを統合したレイクハウス管理市場も2025年の$56.1億から2035年には$403.1億まで拡大すると予測されています(CAGR 21.8%、Market.us調べ)。こうした市場の急拡大が、Microsoftのデータプラットフォーム戦略の積極的な再編を後押ししているといえます。
構成サービスとデータレイク設計の実践
Azure Data Lakeは、主に3つのサービスによって構成されています。データの保存を担うAzure Data Lake Storage Gen2、分析を担う**Azure Synapse Analytics、処理を担うAzure HDInsight**です。なお、以前はデータ分析サービスとしてAzure Data Lake Analyticsも存在しましたが、2024年2月29日をもって廃止され、Azure Synapse Analyticsへの移行が完了しています。
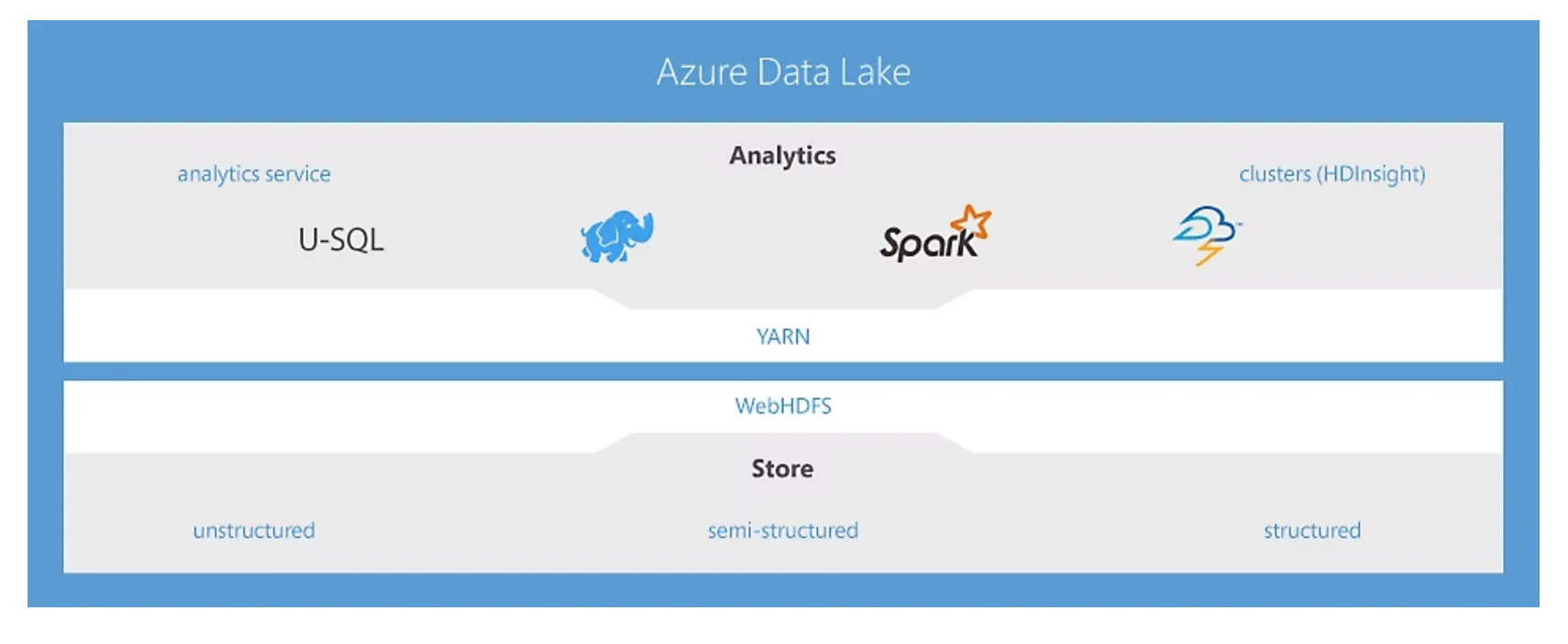 Azure Data Lakeイメージ(参考:マイクロソフト)
Azure Data Lakeイメージ(参考:マイクロソフト)
以下の表で、各構成サービスの役割と主要機能、2026年3月時点のJapan East参考料金を整理しました。実際の料金は利用量や契約形態によって変動するため、導入検討時にはAzure料金計算ツールでの試算を推奨します。
| サービス | 役割 | 主要機能 | Japan East参考料金(2026年3月時点) |
|---|---|---|---|
| ADLS Gen2(ホット層) | データ保存 | HDFS互換・階層型名前空間・Smart Tier対応 | 約$0.02/GB/月(LRS) |
| ADLS Gen2(クール層) | 低頻度データ保存 | 30日最低保持・読取コスト増 | 約$0.01/GB/月(LRS) |
| ADLS Gen2(コールド層) | 極低頻度データ保存 | 90日最低保持・読取コスト増 | 約$0.0045/GB/月(LRS) |
| ADLS Gen2(アーカイブ層) | 長期保存 | 180日最低保持・リハイドレーション必要 | 約$0.001/GB/月(LRS) |
| Synapse Analytics(サーバーレス) | データ分析 | T-SQL対応・オンデマンド課金 | $5/TB(処理データ量) |
| Synapse Analytics(専用プール) | 大規模分析 | DWU単位のプロビジョニング・最大65%予約割引 | DW100cで約$1.51/時 |
| HDInsight 5.1 | データ処理 | Spark 3.3.0・Hadoop 3.3.4・Kafka・HBase | ノード構成による従量課金 |
この料金体系から分かるのは、ADLS Gen2のアクセス層を適切に使い分けることで、ストレージコストを最大95%削減できるという点です。たとえば、10TBのデータのうち頻繁にアクセスするのが1TB、残り9TBが年に数回しかアクセスしないのであれば、1TBをホット層(月額約$20)、9TBをアーカイブ層(月額約$9)に配置するだけで、全量ホット保存の場合(月額約$200)と比較して約85%のコスト削減になります。
ADLS Gen2・Synapse Analytics・HDInsightの機能と料金
Azure Data Lake Storage Gen2は、Azure Data Lake全体の中心となるサービスです。Azure Blob Storageの高いスケーラビリティとコスト効率に、Hadoop Distributed File System(HDFS)互換の階層型名前空間を組み合わせた設計になっています。
 (出典元:公式ホームページ)
(出典元:公式ホームページ)
ADLS Gen2の主な特徴を以下に整理します。
-
ペタバイト級スケーラビリティ
データ量の増加に応じて自動的に拡張可能で、容量不足の心配がありません。IoTデバイスからリアルタイムで送られるセンサーデータや、大量の画像ファイルをそのまま保存できます。
-
HDFS互換の階層型名前空間
ディレクトリやファイルの操作がアトミックに実行されるため、大規模データのリネームや移動が高速です。Apache Hadoop、Apache Spark、Azure Databricksなどのビッグデータツールとシームレスに連携できます。
-
Smart Tier自動階層化(2025年11月プレビュー)
データのアクセスパターンを自動分析し、ホット・クール・コールド・アーカイブの4層に最適配置する新機能です。手動での階層管理が不要になり、ストレージコストの最適化を自動で実現します。
-
Microsoft Entra IDとACLによるセキュリティ
Microsoft Entra IDとの統合により、POSIX準拠のアクセス制御リスト(ACL)を使った細かなアクセス管理が可能です。GDPR・HIPAAなどの業界標準にも対応しています。
Azure Synapse Analyticsは、データの取り込みから保存・変換・分析・可視化までを一つの環境で管理できる統合分析プラットフォームです。サーバーレスSQLプールを使えば、使用したデータ量($5/TB)のみの課金で済むため、定常的なリソース維持コストが発生しません。Power BIやAzure Machine Learningとの連携も容易で、分析結果の可視化やAIモデル構築までスムーズに進められます。
 Azure Synapse Analyticsイメージ
Azure Synapse Analyticsイメージ
ただし、Synapse Analyticsについては2026年現在、Microsoft Fabricへの移行が推奨されています。Synapseの専用SQLプールについてはFabric Data Warehouseへ、パイプラインについてはFabric Data Factoryへの移行ツールが用意されているため、新規導入の場合はMicrosoft FabricのLakehouseを検討するのが合理的です。
Azure HDInsightは、Apache Hadoop、Spark、Kafka、HBaseなどのオープンソーステクノロジーをAzure環境で活用できるマネージドビッグデータ処理サービスです。2026年3月時点で稼働しているのはHDInsight 5.1のみで、Spark 3.3.0とHadoop 3.3.4をサポートしています。
 Azure HDInsightイメージ
Azure HDInsightイメージ
HDInsightを利用する際の注意点として、Enterprise Security Package(ESP)が2026年7月31日にサポート終了を迎えます。ESP利用中のクラスターは期限後に削除される可能性があるため、Microsoft FabricのReal-Time IntelligenceやData Engineeringへの移行を計画的に進める必要があります。
ユースケースとコスト比較
Azure Data Lakeは、IoTデータのリアルタイム分析から医療画像のAI解析、マーケティングデータの統合まで、幅広いユースケースに対応します。ここでは、実際の導入事例と、競合サービスとのコスト比較を紹介します。
IoT・医療・マーケティングの活用事例と導入成果
以下の表で、Azure Data Lakeの代表的な活用分野と、2026年時点の注目動向を整理しました。
| 活用分野 | 主なユースケース | 導入効果の目安 | 2026年注目動向 |
|---|---|---|---|
| IoT・製造 | センサーデータの蓄積・異常検知・予知保全 | ダウンタイム40%削減・保全コスト25%削減 | Azure IoT Hubとの直接統合、エッジコンピューティング連携 |
| 医療 | 医療画像(X線・MRI)の保存・AI診断支援 | 画像分析精度の向上・診断時間短縮 | HIPAA準拠のコールド層活用、AI画像解析パイプライン |
| マーケティング | 顧客行動データの統合・感情分析・パーソナライゼーション | 売上3%向上・1,500人の営業担当が活用 | Fabric OneLakeとPower BIのリアルタイムダッシュボード |
| 金融 | トランザクション分析・不正検知・リスクモデリング | 分析速度10倍以上・コンプライアンス対応自動化 | Synapse→Fabric移行によるリアルタイム不正検知 |
| 小売 | 在庫最適化・需要予測・サプライチェーン分析 | レガシーシステム17件廃止・$2億以上のビジネス価値 | Fabric Data Agentによる自然言語でのデータ問い合わせ |
Nestle USAの導入事例は、Azure Data Lakeの企業活用を象徴する代表的な成功例です。Deloitteとの協業により、社内に分散していた15以上のデータソースをAzure Data Lakeに統合し、17件のレガシーシステムを廃止しました。統合されたデータ基盤上に構築されたSales Recommendation Engineは、毎週1,500人以上の営業担当者に活用され、売上を3%向上させています。プロジェクト全体で$2億以上のビジネス価値を創出したとされており、段階的なデータ移行アプローチの有効性を示しています。
製造業のIoT活用では、工場設備から送られるセンサーデータ(温度・圧力・振動など)をADLS Gen2にリアルタイムで蓄積し、Apache Sparkで異常パターンを検知する手法が広く採用されています。ある製造企業では、予知保全モデルの導入により計画外ダウンタイムを40%削減、保全コストを25%削減し、設備寿命を15%延長する成果を上げています。Azure IoT HubとADLS Gen2を直接接続することで、データの取り込みから分析までのレイテンシを最小化できる点も、製造現場での採用を後押ししています。
医療画像の保存とAI解析では、X線やMRIなどの大容量画像データをADLS Gen2のコールド層に保存し、分析が必要なタイミングでホット層に移動させるアプローチが一般的です。ADLS Gen2はHIPAA準拠の暗号化を標準で備えており、患者データの安全な管理が可能です。Azure Machine Learningと連携した画像分類モデルにより、疾患の早期発見や診断支援の精度向上が実現しています。
Azure Data Lakeと競合サービスの料金を比較する際に重要なのは、ストレージ単価だけでなく、分析ツールとの統合コストを含めた総所有コスト(TCO)です。ADLS Gen2のホット層は約$0.02/GB/月で、AWS S3 Standard(約$0.025/GB/月、東京リージョン)やGoogle Cloud Storage Standard(約$0.023/GB/月、東京リージョン)と同水準ですが、Synapse AnalyticsやPower BIとのネイティブ統合を考慮すると、Microsoft環境を中心に構築している企業にとってはTCO面で優位性があります。

導入時の注意点と活用ガイド
Azure Data Lakeの導入には、ストレージ設計やセキュリティ構成、コスト管理など複数の注意点があります。以下の表で、よくある課題とその対策を整理しました。
| 注意点 | リスク | 対策 |
|---|---|---|
| データスワンプ化 | ガバナンスなしにデータを蓄積すると、利用不能な「データの沼」になる | カタログ(Microsoft Purview)によるメタデータ管理、命名規則・フォルダ構造の事前設計 |
| アクセス層の選定ミス | ホット層に全データを保存するとコストが過大になる | Smart Tierの活用、アクセスパターン分析に基づく層配置、ライフサイクル管理ポリシーの設定 |
| Fabric移行の計画不足 | Synapse Data Explorer廃止やHDInsight ESP終了への対応が遅れる | 移行タイムライン策定、Fabric Migration Assistantの活用、並行運用期間の確保 |
| セキュリティ設計の不備 | データ暗号化やアクセス制御の設定漏れ | Microsoft Entra IDとPOSIX ACLの併用、ネットワーク分離(Private Endpoint)、Azure Monitorによる監査ログ |
| コスト見積もりの誤り | トランザクション料金やデータ転送料金を見落とす | Azure料金計算ツールでの事前試算、Azure Blob Storageの料金体系の理解、予約容量の検討 |
特にデータスワンプ化は、データレイク導入で最も多い失敗パターンです。データを無制限に蓄積できるメリットが裏目に出て、誰がどのデータをどの目的で保存したのか分からなくなるケースが多発しています。Microsoft Purviewを使ったデータカタログの構築、フォルダ構造と命名規則の事前設計、データ所有者の明確化の3点を導入初期から徹底することが、データスワンプ化を防ぐ鍵になります。
段階的導入ステップとよくある質問
Azure Data Lakeの導入は、以下の3ステップで進めることを推奨します。
-
ステップ1 要件定義とストレージアカウント作成(1〜2週間)
まずAzureポータルでストレージアカウントを作成し、プライマリサービスとしてAzure Data Lake Storage Gen2を選択します。階層型名前空間を有効化し、LRS(ローカル冗長ストレージ)またはZRS(ゾーン冗長ストレージ)の冗長性を選定します。同時に、データの分類・命名規則・フォルダ構造を設計し、ガバナンス方針を策定します。
-
ステップ2 データ取り込みとPoC(2〜4週間)
Azure Data FactoryまたはAzCopyを使って、既存データソースからADLS Gen2へのデータ取り込みパイプラインを構築します。小規模なデータセットでPoC(概念実証)を実施し、Synapse AnalyticsのサーバーレスプールまたはFabric Lakehouseで分析クエリの動作確認を行います。
-
ステップ3 本番運用とスケールアップ(1〜2か月)
PoCの結果を踏まえて本番環境を構築し、アクセス層のライフサイクル管理ポリシーやSmart Tierを設定します。Azure Monitorによるコスト監視、Microsoft Purviewによるデータガバナンスを有効化し、段階的にデータソースを追加していきます。
以下は、Azureポータルを使ったストレージアカウント作成からコンテナー作成までの具体的な手順です。
1.Azureポータル(portal.azure.com)にアクセスし、Azureアカウントでサインインします。
Azureポータル画面
2.「リソースの作成」で「storage account」を検索し、「ストレージ アカウント」をクリックします。
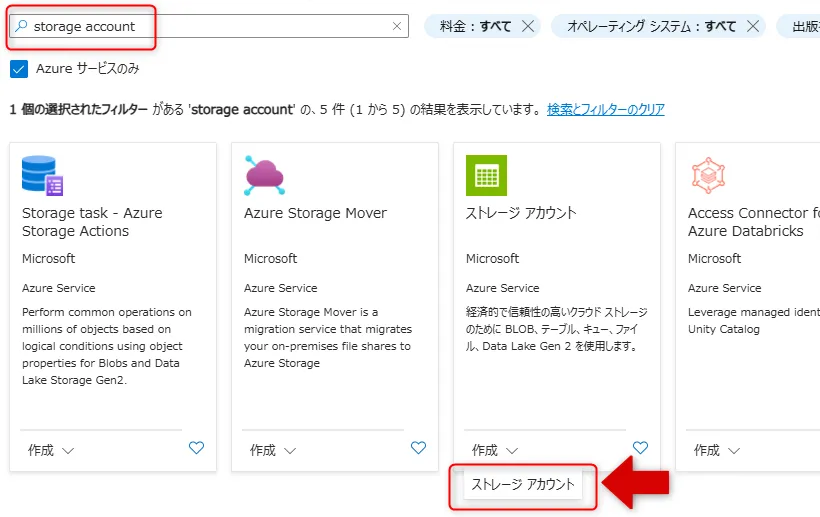
ストレージアカウント選択画面
3.「基本」タブでプライマリサービスとして「Azure Blob Storage または Azure Data Lake Storage Gen 2」を設定し、リージョンにJapan Eastを選択します。
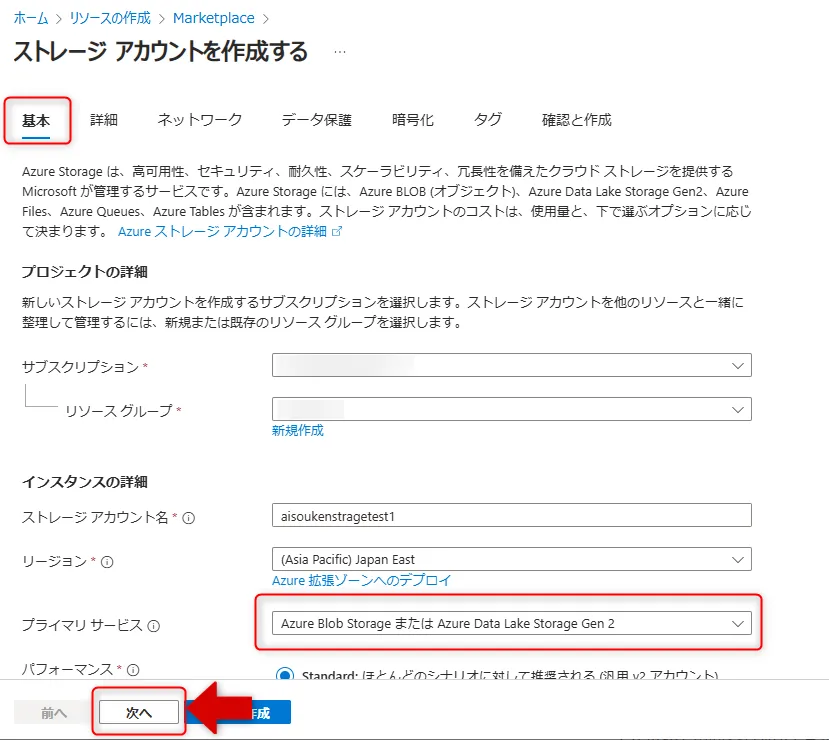
基本タブ画面
4.「詳細」タブで階層型名前空間を有効にし、必要に応じてSFTPやNFSv3を構成します。
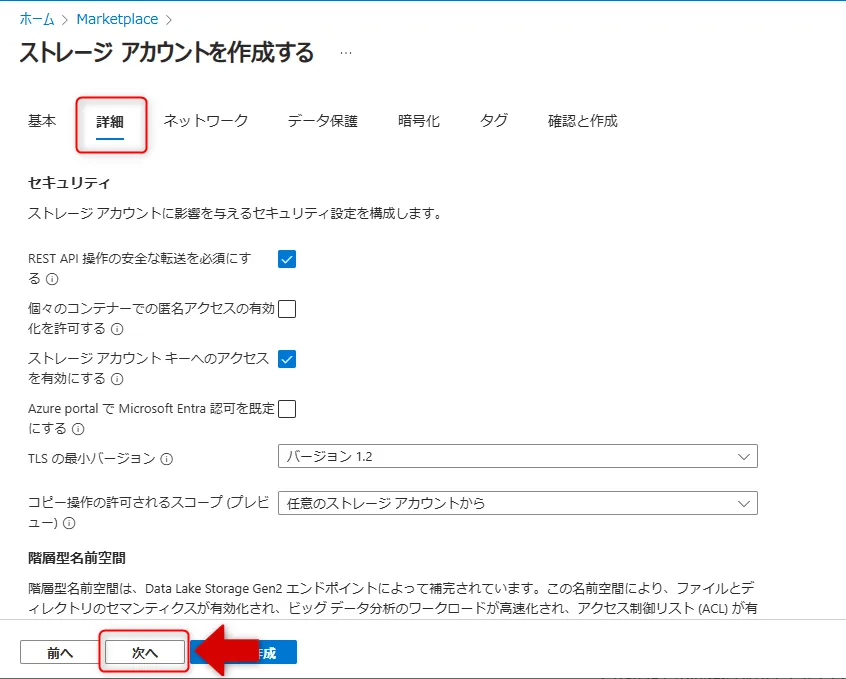
詳細タブ画面
5.「ネットワーク」タブでパブリックアクセスまたはPrivate Endpointを選択します。
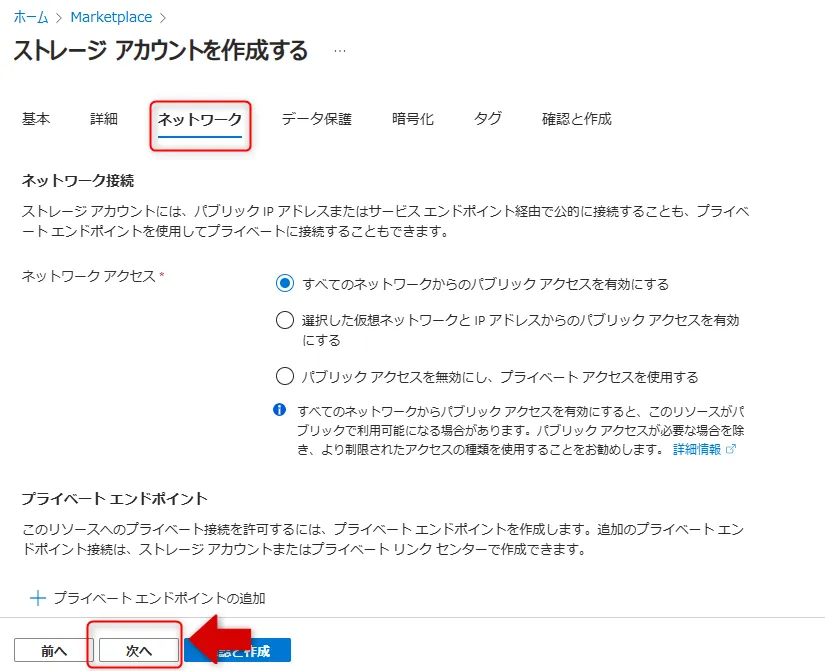
ネットワークタブ画面
6.「データ保護」タブで論理削除やバージョン管理を構成します。
データ保護タブ画面
7.「暗号化」タブで暗号化方式(Microsoftマネージドキーまたはカスタマーマネージドキー)を選択し、「確認と作成」をクリックします。
暗号化画面
8.設定内容を確認し、「作成」をクリックします。
確認と作成画面
9.デプロイ完了後「リソースに移動」をクリックします。
デプロイ完了画面
10.ストレージアカウントの「データストレージ」から「コンテナー」を選択し、「+ コンテナー」をクリックしてデータコンテナーを作成します。
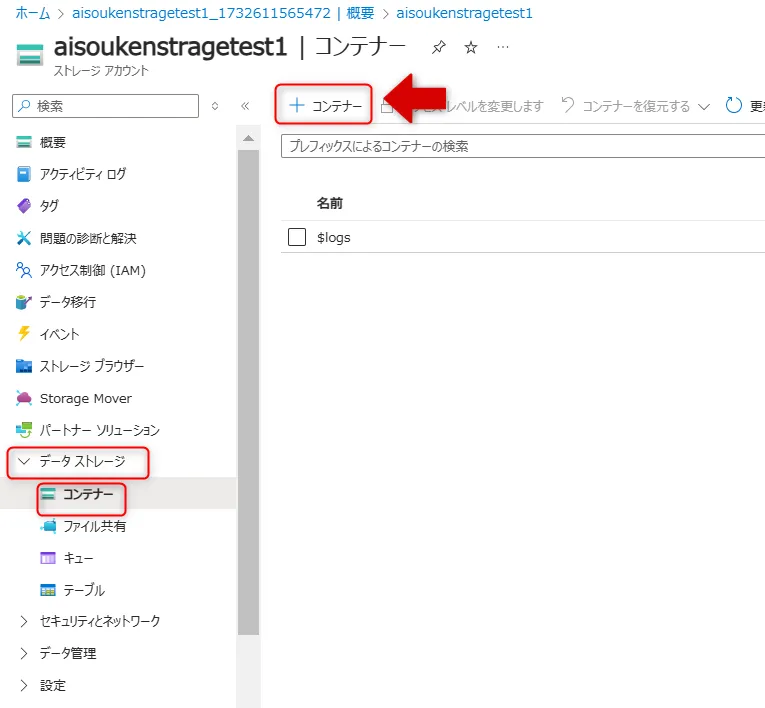
コンテナー選択画面
11.コンテナー名を入力し、適切なアクセスレベルを設定して「作成」をクリックします。
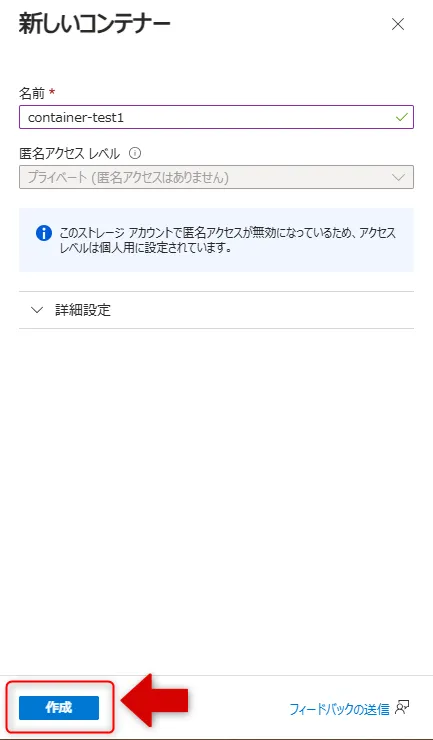
コンテナー作成画面
12.コンテナーが正常に作成されたことを確認します。この後、Azure Synapse AnalyticsやDatabricks、Fabric Lakehouseと連携して分析・処理を開始できます。

コンテナー作成確認画面
よくある質問
-
Azure Data LakeとMicrosoft Fabric OneLakeはどう使い分けるのか
ADLS Gen2は汎用的なデータレイクストレージで、Hadoop・Spark・Databricksなど多様なツールとの統合に適しています。OneLakeはFabricネイティブなSaaS型データレイクで、Power BIやFabric Lakehouseとの統合に最適化されています。新規導入でMicrosoft環境中心の場合はOneLakeを、マルチクラウドや既存Hadoopワークロードがある場合はADLS Gen2を選択するのが基本方針です。
-
ADLS Gen2の無料枠はあるのか
Azure無料アカウントでは、Azure Storageとして12か月間5GBのLRSホット層Blob Storageが無料で利用できます。ADLS Gen2として大規模に利用する場合は従量課金となりますが、Smart Tierを活用することでコストを自動最適化できます。
-
ビッグデータ管理の第一歩として何から始めるべきか
まずは小規模なPoCとして、1つのデータソース(たとえばCSVファイルや業務データベースのエクスポート)をADLS Gen2に取り込み、Synapse Analyticsのサーバーレスプールでクエリを実行してみることを推奨します。この段階ではストレージ料金(数十円〜数百円/月)とクエリ料金($5/TB)のみで、初期投資なしにデータレイクの価値を検証できます。

データレイク基盤の知見をAI業務自動化にも活かすなら
Azure Data Lakeでデータ基盤を構築してきた経験は、AI業務自動化のデータソース設計に直結します。AI業務自動化ガイドでは、データレイクの構築力を活かしたAI導入の進め方を220ページにわたって解説しています。
データレイク基盤からAI業務自動化へ

Data Lakeの構築力をAI活用に展開
Azure Data Lakeでデータ基盤を構築してきた経験は、AI業務自動化のデータソース設計にも直結します。220ページの実践ガイドで、Microsoft環境でのAI導入を計画してみませんか。
まとめ
本記事では、Azure Data Lakeの基本概念から構成サービス、2026年最新のSmart Tier機能やMicrosoft Fabric連携、IoT・医療・マーケティング分野の導入事例、料金体系、段階的な導入手順までを解説しました。
Azure Data Lakeが企業にもたらす価値は、大きく3つに集約されます。第一に、Schema-on-Read方式により非構造化データを含むあらゆるデータを元の形式で保存し、将来の分析やAI活用に備えられること。第二に、ADLS Gen2の4層ストレージとSmart Tierにより、ペタバイト級のデータを低コストで管理できること。第三に、Synapse Analytics・Databricks・Microsoft Fabricとのネイティブ統合により、保存から分析・可視化・AI活用までのパイプラインをAzure環境内で完結できることです。
2026年はMicrosoft FabricのOneLakeが急速に普及し、従来のSynapse Analytics中心のアーキテクチャからFabricベースのレイクハウスアーキテクチャへの移行が加速しています。新規導入の場合はFabric OneLakeの採用を検討し、既存ADLS Gen2環境がある場合は段階的なFabric統合を進めることで、データレイクの価値を最大化できるでしょう。まずはAzureポータルでストレージアカウントを作成し、小規模なPoCからデータレイクの導入効果を実感してみてください。










