この記事のポイント
 Azure上でRAGを構築するなら、Azure AI Searchを検索基盤の第一候補にすべき
Azure上でRAGを構築するなら、Azure AI Searchを検索基盤の第一候補にすべき- ベクトル検索単体よりハイブリッド検索+セマンティックランカーの併用で検索精度を最大化すべき
- Agentic Retrievalは複雑な質問の回答精度を高めるが、プレビュー段階のため本番導入は慎重に判断すべき
- ElasticsearchからAzure AI Searchへの移行は、Azureネイティブ統合とマネージド運用の観点で合理的
- SKUはFreeで検証し、本番ではBasic以上を選ぶべき。セマンティックランカーはStandard以上が必須

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
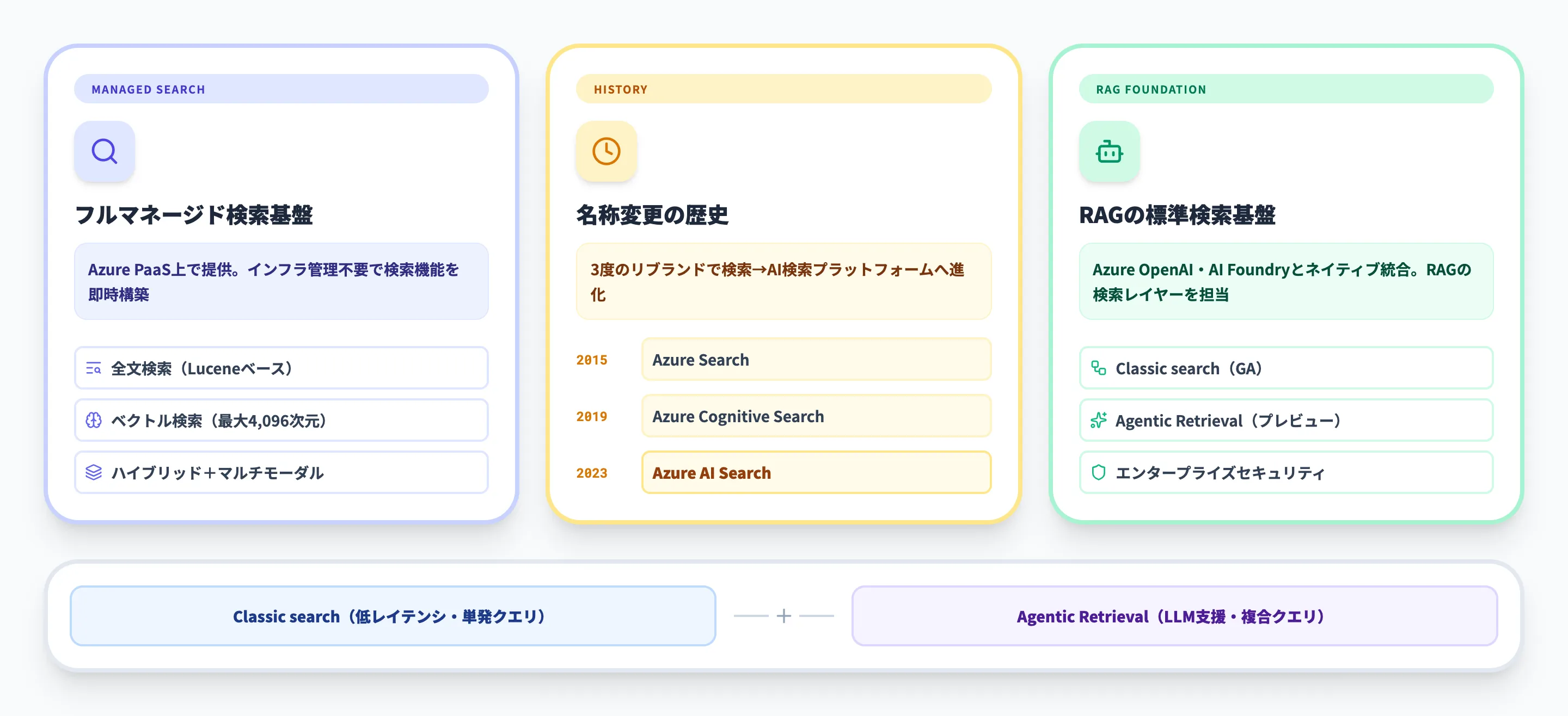
Azure AI Search(旧Azure Cognitive Search)は、Microsoft Azureが提供するフルマネージドの検索プラットフォームです。全文検索・ベクトル検索・ハイブリッド検索に加え、LLMと連携するAgentic Retrieval(パブリックプレビュー)を備え、RAG構成やAIエージェントの知識基盤として活用が広がっています。
本記事では、Azure AI Searchの主要機能からRAG構築の仕組み、Elasticsearch等との比較、SKU別料金体系、導入手順、セキュリティまでを2026年3月時点の公式情報にもとづいて整理します。
Azure上で検索基盤やRAGを検討している方はぜひ参考にしてください。
目次
Classic searchとAgentic Retrievalの違い
Azure AI SearchとMicrosoftエコシステムの連携
Azure OpenAI ServiceとAI Foundry
Microsoft 365・SharePoint・OneDrive
Azure AI Searchとは
Azure AI Searchは、Microsoft Azureが提供するフルマネージドの検索プラットフォームです。企業が保有するドキュメントやデータに対して、全文検索・ベクトル検索・ハイブリッド検索・マルチモーダル検索を統合的に実行でき、生成AIアプリケーションにおけるRAG(Retrieval-Augmented Generation)の検索基盤としても広く利用されています。
このサービスはもともと「Azure Search」(2015年)として登場し、「Azure Cognitive Search」(2019年)を経て、2023年11月に現在の名称「Azure AI Search」に改名されました。名称変更にあわせてベクトル検索やセマンティックランキングがGA(一般提供)となり、検索エンジンとしての機能が大きく進化しています。

Azure AI Searchが注目される背景
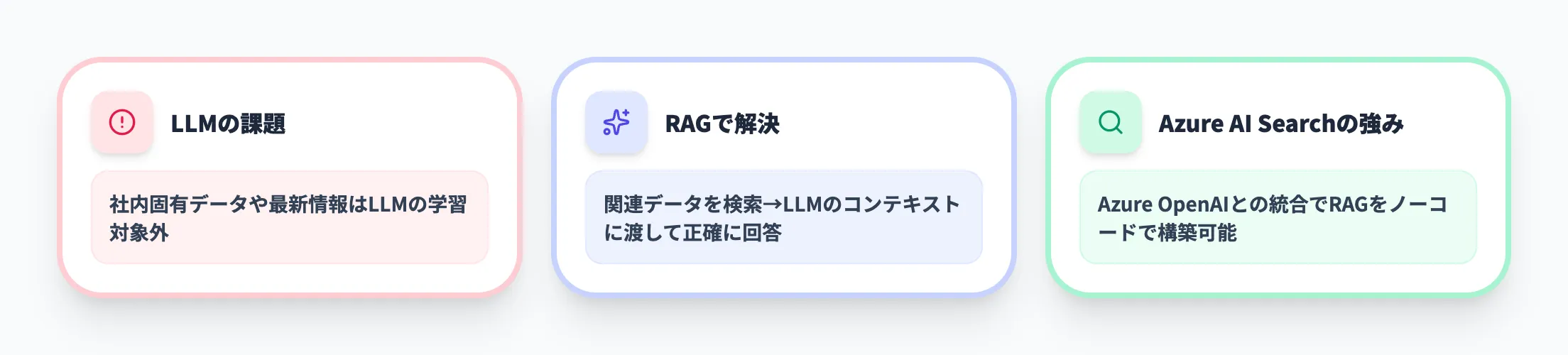
Azure AI Searchへの関心が高まっている最大の理由は、RAGアーキテクチャの普及です。ChatGPTをはじめとする大規模言語モデル(LLM)は幅広い知識を持つ一方、社内固有のドキュメントや最新のデータについては学習していません。この課題を解決するのがRAGパターンで、LLMが回答を生成する前に関連データを検索・取得してコンテキストとして渡す仕組みです。
Azure AI SearchはAzure OpenAI Serviceと組み合わせることで、このRAGパターンを標準的に構築できます。Azureポータルからノーコードでインデックスを作成し、LLMとの接続まで一気通貫で設定できる点が、他の検索エンジンにはない強みです。
Classic searchとAgentic Retrievalの違い
2026年3月時点で、Azure AI Searchには2つの検索エンジンが搭載されています。
以下の表で、両者の設計思想と使い分けを整理しました。
| 観点 | Classic search | Agentic Retrieval(パブリックプレビュー) |
|---|---|---|
| 検索対象 | 1つの検索インデックス | Knowledge Base(複数のKnowledge Source) |
| クエリ処理 | 単一リクエスト→単一レスポンス | LLMがクエリを分解→サブクエリを並列実行 |
| チャット履歴の考慮 | なし | あり(会話コンテキストを入力に使用) |
| レスポンス形式 | スキーマに基づくフラットな検索結果 | LLM生成の回答+ソース参照+実行ログ |
| 想定ユースケース | Webサイト検索、アプリ内検索 | RAGチャットボット、エージェント連携 |
| ステータス | GA(一般提供) | パブリックプレビュー |

Classic searchは低レイテンシで予測しやすい挙動が特長で、EC検索やサイト内検索など単発クエリに適しています。一方、Agentic Retrievalは「昨年度の売上データをまとめて、前年比の分析もしてほしい」のような複合的な質問をLLMがサブクエリに分解し、並列で検索・統合してくれるため、対話型AIアプリケーションやエージェントワークフローに向いています。

Azure AI Searchの主要機能
Azure AI Searchは単なるキーワード検索にとどまらず、AIを組み合わせた複数の検索手法とクエリ体験を1つのサービスで提供しています。ここでは、検索タイプからインデックス処理まで主要機能を網羅的に解説します。
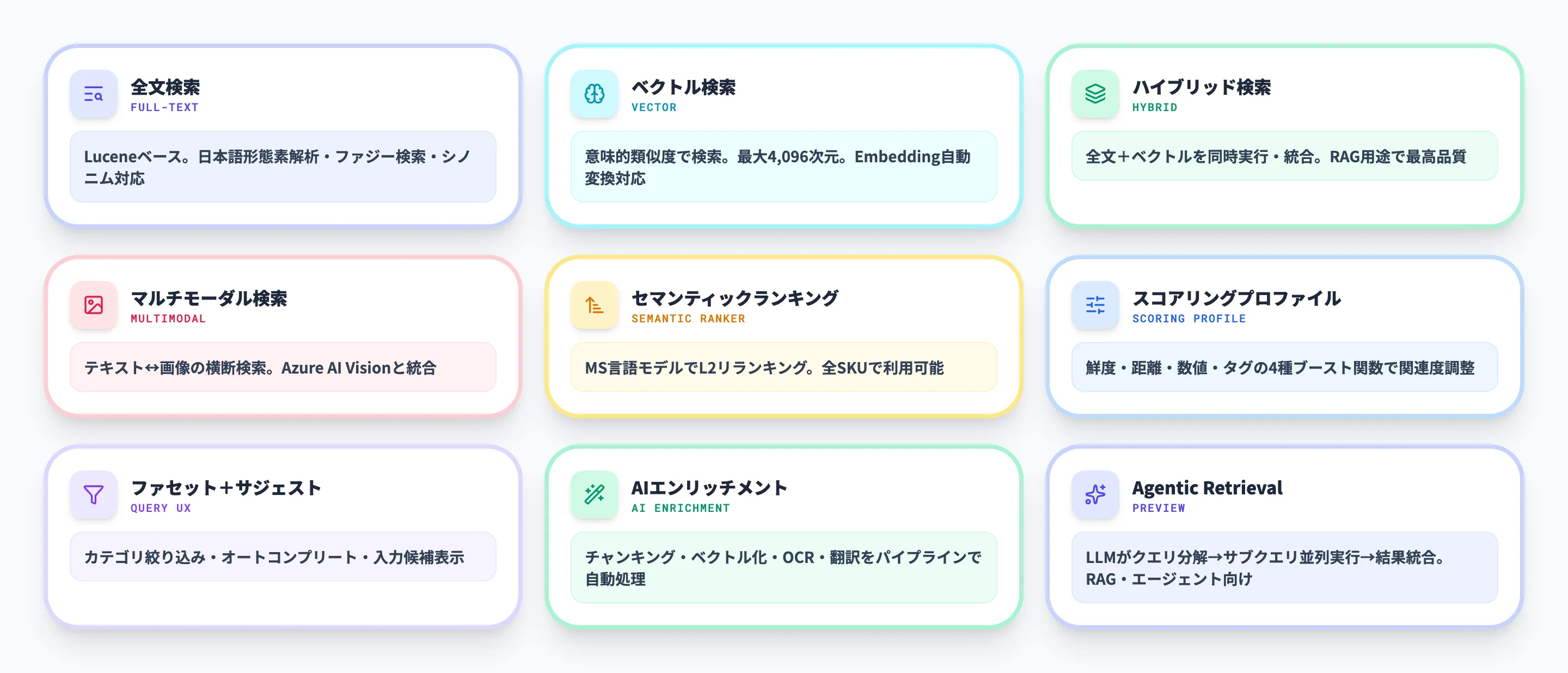
全文検索・ベクトル検索・ハイブリッド検索

Azure AI Searchが提供する検索手法は、大きく3種類に分類できます。
- 全文検索(Full-text search)
Apache Luceneベースのテキスト検索エンジンです。トークナイズ、ファジー検索、オートコンプリート、シノニムマッチング、ジオ検索などをサポートします。日本語のアナライザーも利用可能で、形態素解析による精度の高い検索結果を得られます。
- ベクトル検索(Vector search)
テキストや画像をベクトル(数値配列)に変換し、意味的な類似度で検索する手法です。「節約方法」と「コスト削減」のように表現は異なるが意味が近い検索意図に対応できます。最大4,096次元のベクトルフィールドをサポートしています。
- ハイブリッド検索(Hybrid search)
全文検索とベクトル検索を同時に実行し、結果を統合する方式です。キーワード一致の精度とセマンティックな再現率を両立でき、RAG用途では最も高い検索品質が得られるとされています。
実務でRAGアプリケーションを構築する場合、まずハイブリッド検索から始めるのが定石です。キーワードの厳密一致が必要な場面では全文検索を、製品画像のような非テキストデータを扱う場面ではベクトル検索やマルチモーダル検索を組み合わせるのが効果的です。
マルチモーダル検索
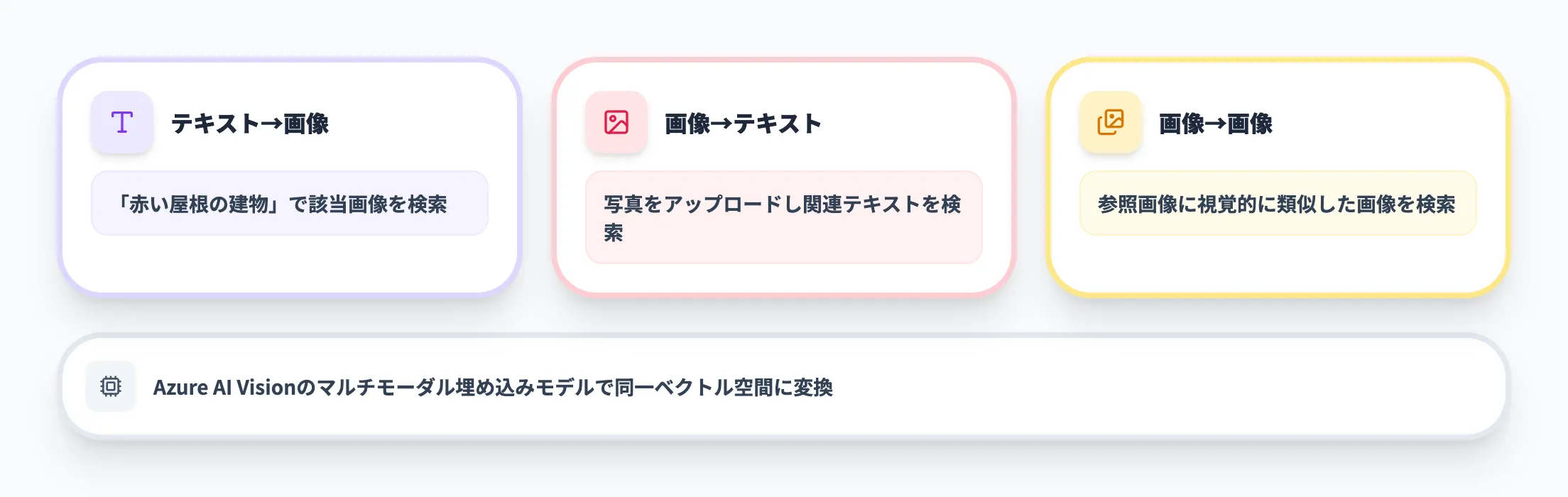
マルチモーダル検索は、テキストと画像を同一のベクトル空間に埋め込み、モダリティをまたいだ検索を可能にする機能です。Azure AI Visionのマルチモーダル埋め込みモデルを使い、以下のような検索パターンに対応します。
- テキスト→画像検索
「赤い屋根の建物」というテキストクエリで、該当する画像を含むドキュメントを検索
- 画像→テキスト検索
写真をアップロードし、その画像に関連するテキストコンテンツを検索
- 画像→画像検索
参照画像に視覚的に類似した画像を検索
マルチモーダル検索を使うには、統合ベクトル化のパイプラインでPDFやOffice文書からインライン画像を自動抽出し、画像の説明文生成とベクトル変換を行います。製品カタログ、設計図面、医療画像など、テキストだけでは検索しきれないドキュメントを扱う業務で特に有効です。
セマンティックランキング
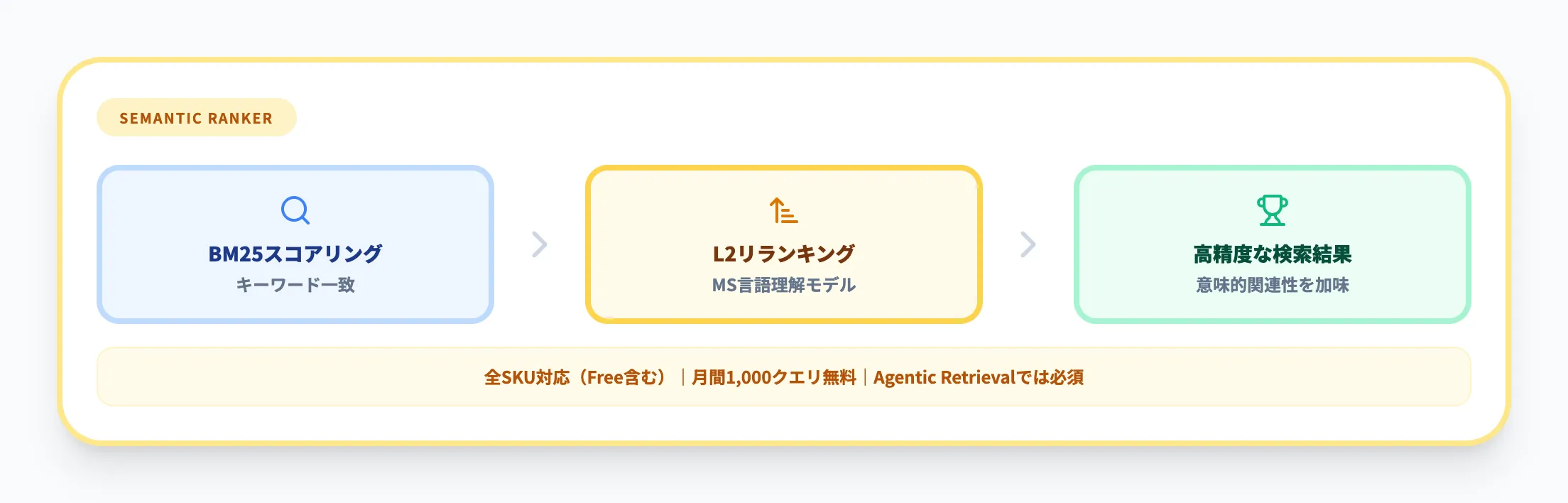
セマンティックランキングは、検索結果をMicrosoftの言語理解モデルで再ランク付け(L2リランキング)する機能です。従来のBM25スコアリングでは拾いきれない意味的な関連性を加味し、検索精度を引き上げます。
Free SKUを含む全SKUで利用可能で、月間1,000件のクエリまでは無料です(以降は1,000クエリあたりの従量課金)。Agentic Retrievalでは必須コンポーネントとして組み込まれており、サブクエリごとに自動でセマンティックランキングが適用されます。
ファセットナビゲーション
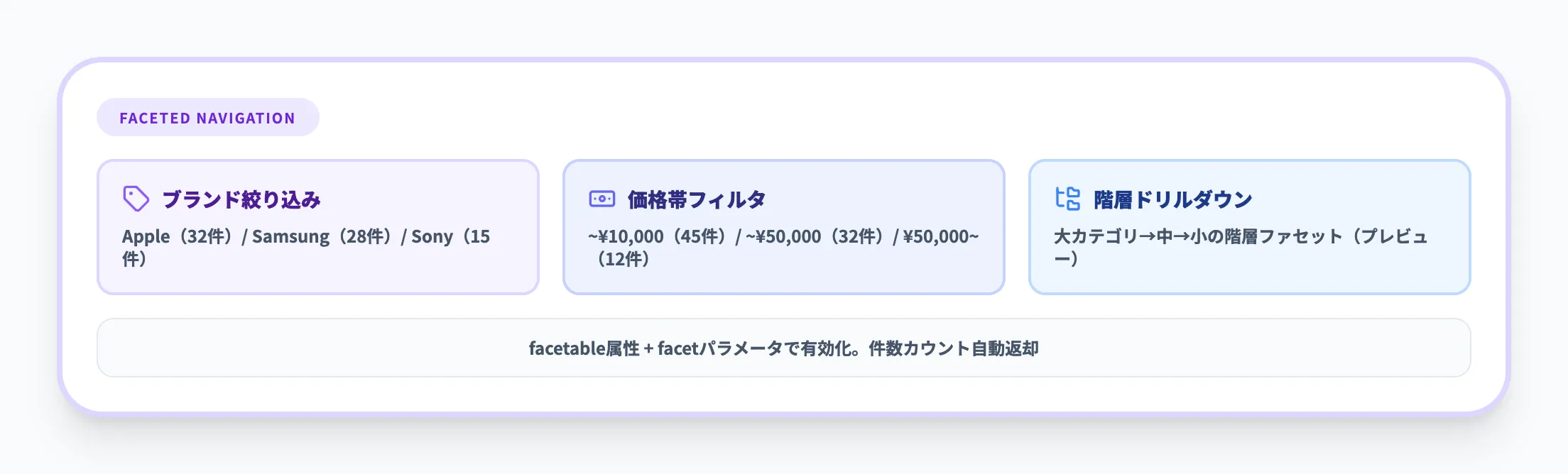
ファセットナビゲーションは、検索結果に対してカテゴリ別の絞り込みUIを提供する機能です。ECサイトの「ブランド」「価格帯」「カラー」による絞り込みや、ドキュメント検索の「部署」「文書種別」「作成年」によるフィルタリングなど、ユーザーが自分で検索結果を絞り込む操作を実現します。
インデックス定義でフィールドにfacetable属性を設定し、クエリリクエストにfacetパラメータを指定するだけで利用できます。Azure AI Searchはファセットごとの件数カウントを自動で返すため、UIに「カテゴリA(32件)」のような集計付きフィルタを表示可能です。階層ファセット(プレビュー)を使えば、大カテゴリ→中カテゴリ→小カテゴリのようなドリルダウンも構築できます。
オートコンプリートとサジェスト

オートコンプリートとサジェストは、ユーザーの入力途中に候補を表示する検索補助機能です。
- オートコンプリート
入力中の部分文字列からクエリ語句を補完する。たとえば「az」と入力すると「azure」「azure ai」などの候補を表示
- サジェスト
部分文字列に一致するドキュメントを候補として返す。ユーザーがクリックすると該当ドキュメントに直接遷移できる
どちらもインデックスにサジェスターを定義することで有効になります。サジェスター対象のフィールドはプレフィックス一致用の追加トークナイズが行われるため、インデックスサイズがやや増加する点に留意してください。検索ボックスの入力体験を大幅に向上できる機能で、ECサイトやポータルサイトでは標準的に実装されています。
スコアリングプロファイル

スコアリングプロファイルは、検索結果の関連度スコアをビジネスロジックに基づいてカスタマイズする機能です。デフォルトのBM25スコアリングに対して、特定フィールドの重み付けや、鮮度・距離・数値範囲に応じたブースト関数を追加できます。
利用可能なブースト関数は以下の4種類です。
- freshness
日付フィールドの値が新しいほどスコアを引き上げる(新着コンテンツの優先表示に有効)
- magnitude
数値フィールドの大小に応じてスコアを調整する(売上数やレビュー評価による並べ替えに有効)
- distance
地理座標フィールドの距離に応じてスコアを変動させる(近い店舗を上位表示するケースに有効)
- tag
タグフィールドとクエリパラメータのマッチングでスコアを上げる(ユーザーの関心カテゴリに基づくパーソナライズに有効)
スコアリングプロファイルはセマンティックランキングとも併用でき、BM25スコア→スコアリングプロファイル→セマンティックリランキングの順に適用されます。「検索品質は悪くないが、ビジネス的に見せたい順序が違う」という場合に効果を発揮します。
AIエンリッチメント
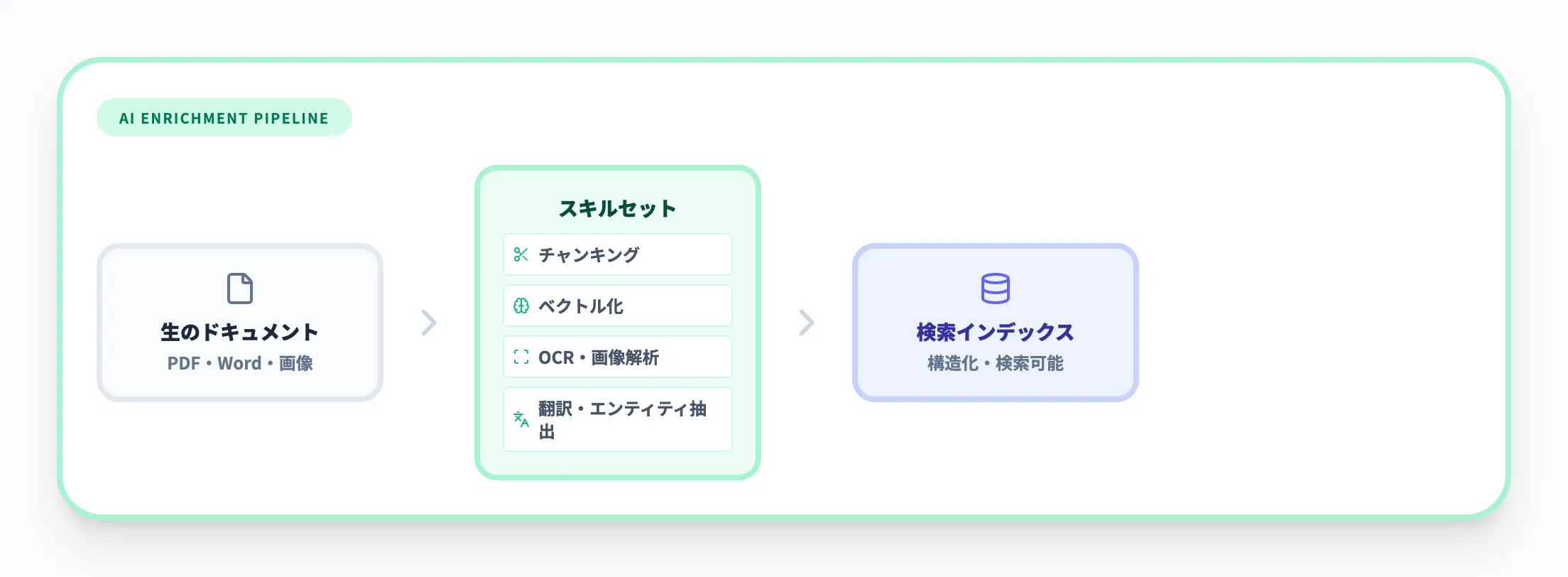
AIエンリッチメントは、インデックス作成時にデータを自動加工する仕組みです。具体的には以下のような処理をパイプラインとして組み込めます。
- チャンキング
長文ドキュメントをRAGに適したサイズに自動分割
- ベクトル化(統合ベクトル化)
テキストをEmbeddingモデルで自動的にベクトルに変換
- OCR・画像解析
PDFや画像からテキストを抽出
- 翻訳・エンティティ抽出
Azure AI servicesのスキルを呼び出し、コンテンツを構造化
これらの処理はスキルセットとして定義し、インデクサーの実行時に自動適用されます。生のPDFやWord文書を投入するだけで、検索可能なインデックスが構築される点が、Azure AI Searchの大きな強みです。
ナレッジストア
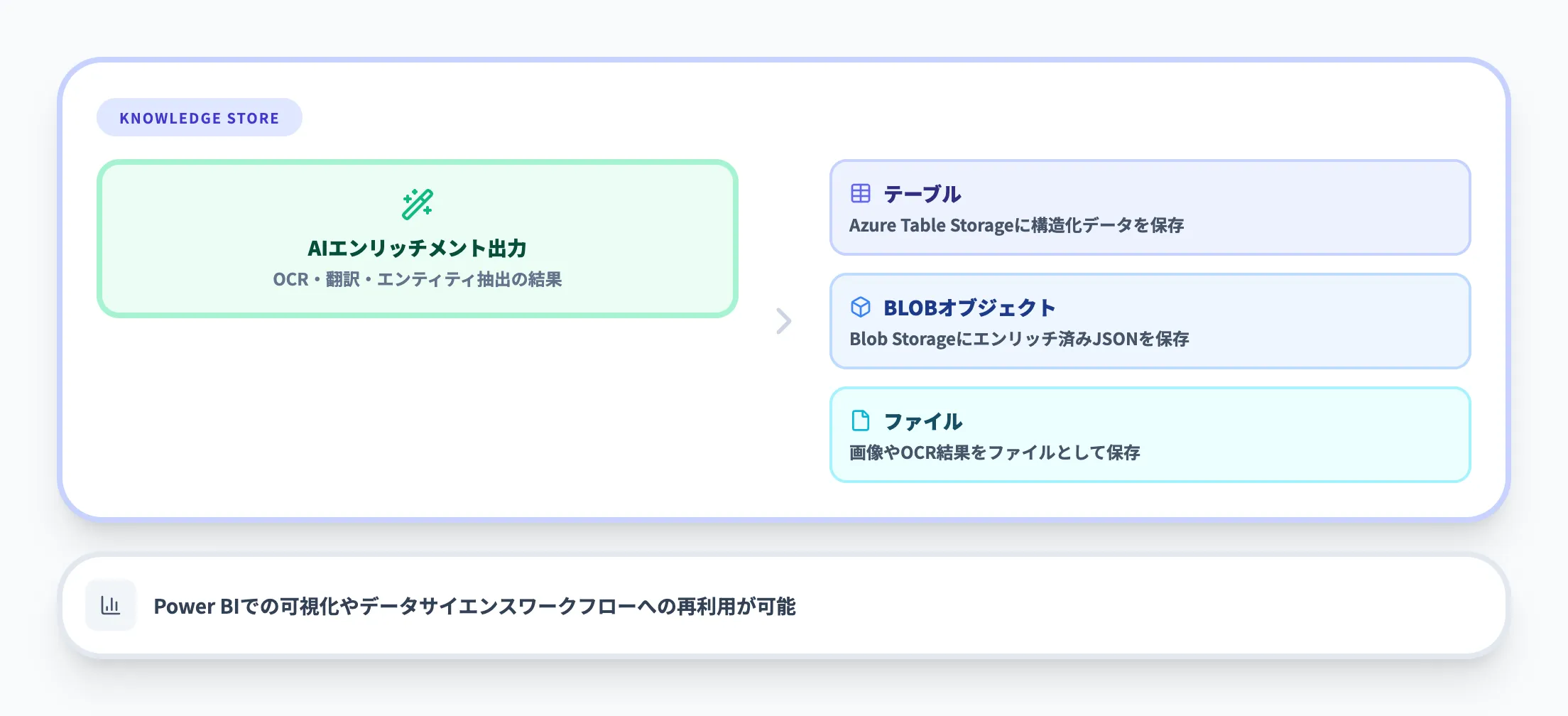
ナレッジストアは、AIエンリッチメントで加工されたデータを検索インデックスとは別にAzure Storageに永続化する機能です。エンリッチメントの出力をテーブル、BLOBオブジェクト、ファイルの3種類のプロジェクションとして保存できます。
検索インデックスはクエリ応答に最適化されたデータ構造のため、分析や二次加工には向いていません。ナレッジストアを使えば、OCRで抽出したテキストやエンティティ抽出の結果をAzure Table StorageやBlob Storageに保存し、Power BIでの可視化やデータサイエンスワークフローへの入力として再利用できます。
たとえば、大量の契約書PDFをエンリッチメントで処理し、抽出した当事者名・契約金額・有効期限をテーブルプロジェクションに保存すれば、検索とは別にBIダッシュボードで契約状況を一覧化できます。検索インデックスとナレッジストアを同時に出力するよう設定できるため、追加のETL処理は不要です。
Agentic Retrieval(パブリックプレビュー)
Agentic Retrievalは、2025年11月のプレビューAPIで導入された新しい検索パイプラインです。ユーザーやAIエージェントからの複雑な質問に対して、LLMがクエリプランを自動生成し、複数のサブクエリを並列実行して結果を統合します。
主な特徴は以下のとおりです。
- Knowledge Base
検索対象となるKnowledge Source(インデックスやBlob、SharePoint、OneLake、Webなど)を束ねるオーケストレーションオブジェクト
- LLM支援のクエリ分解
gpt-4o、gpt-4.1、gpt-5シリーズのモデルがクエリプランニングを担当。チャット履歴もコンテキストとして利用可能
- 3部構成のレスポンス
グラウンディングデータ(回答の根拠)、ソース参照(引用元)、アクティビティログ(実行計画)の3つをまとめて返す

Agentic RetrievalはAzure AI FoundryのFoundry IQ機能の基盤としても採用されており、AIエージェントソリューションのナレッジレイヤーとして位置づけられています。なお、2026年3月時点ではパブリックプレビューであり、利用可能なリージョンに制限があります。
Azure AI SearchでRAGを構築する仕組み
生成AIアプリケーションにおいて、Azure AI Searchが最も注目されているのはRAG(検索拡張生成)の検索基盤としての役割です。ここでは、RAGの基本的な仕組みと、Azure AI Searchが提供する2つの構築パターンを解説します。
RAGにおけるAzure AI Searchの役割
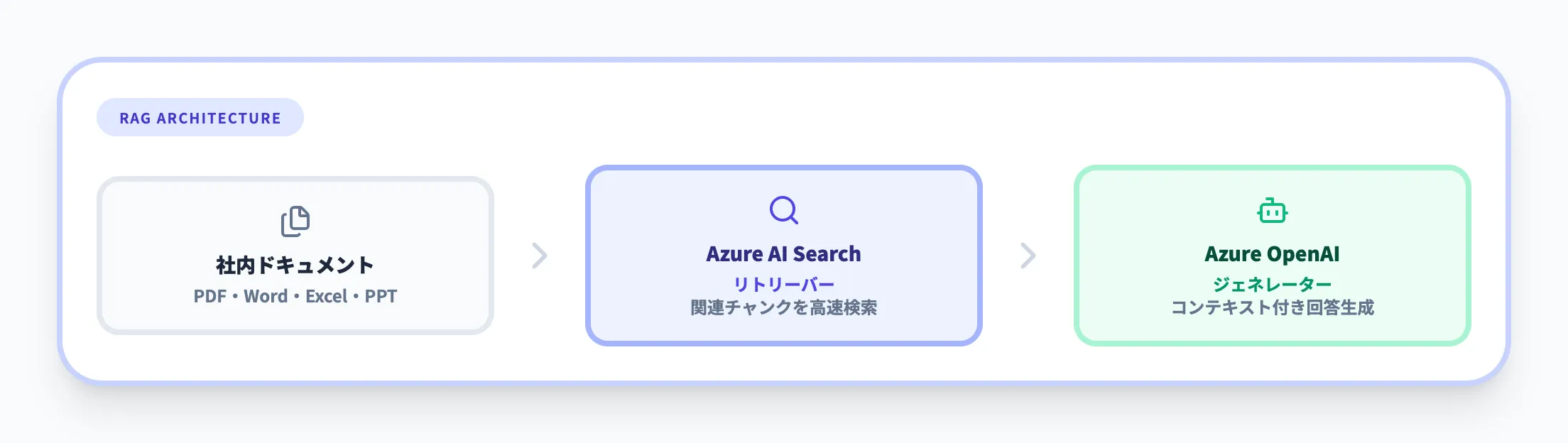
RAGは、LLMが回答を生成する前に外部データソースから関連情報を取得し、その情報をコンテキストとしてプロンプトに含める手法です。これにより、LLMが学習していない社内文書や最新データに基づいた正確な回答が可能になります。
Azure AI Searchは、このRAGパターンにおける**リトリーバー(情報検索エンジン)**を担います。社内のPDF、Word、PowerPoint、Excelなどのドキュメントをインデックスに取り込み、ユーザーの質問に関連するチャンクを高速に返す——この検索品質がRAGの回答精度を左右します。
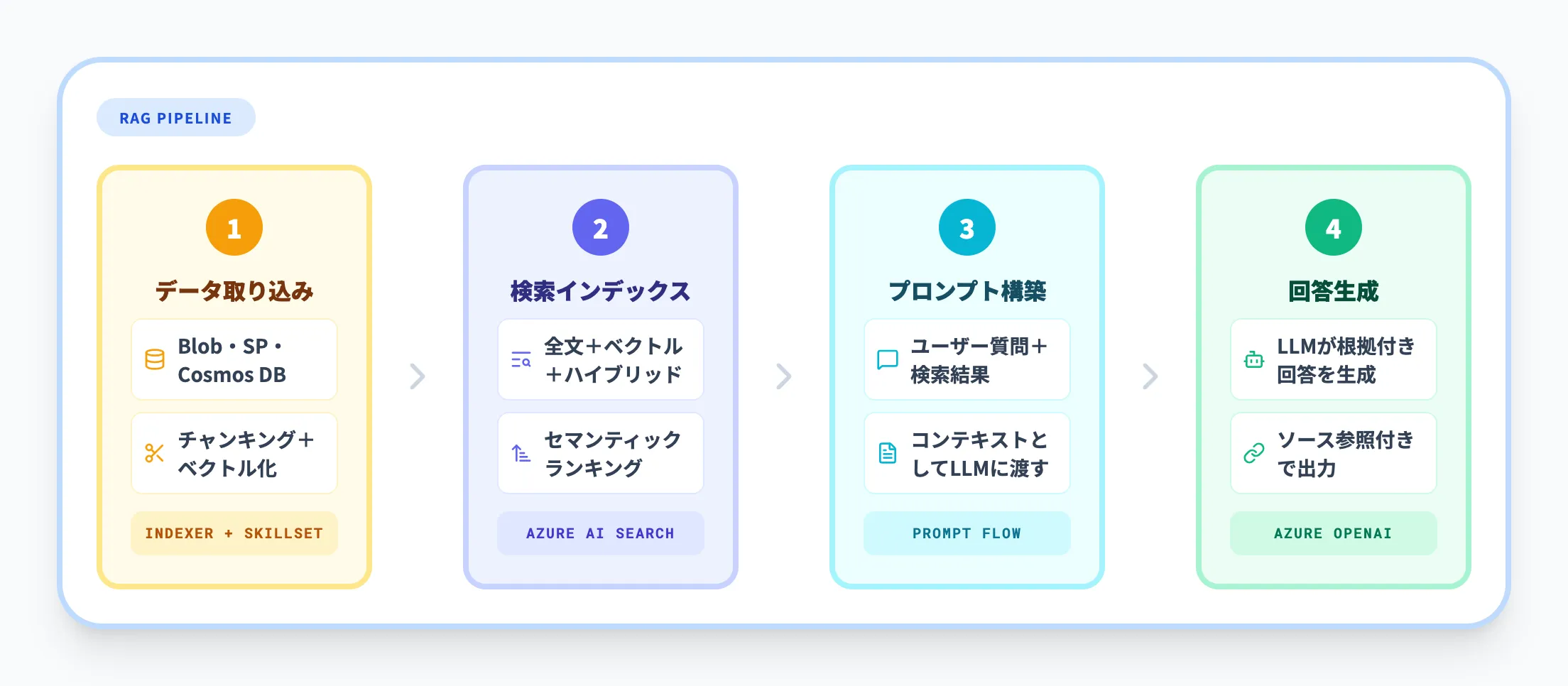
Classic RAGパターン
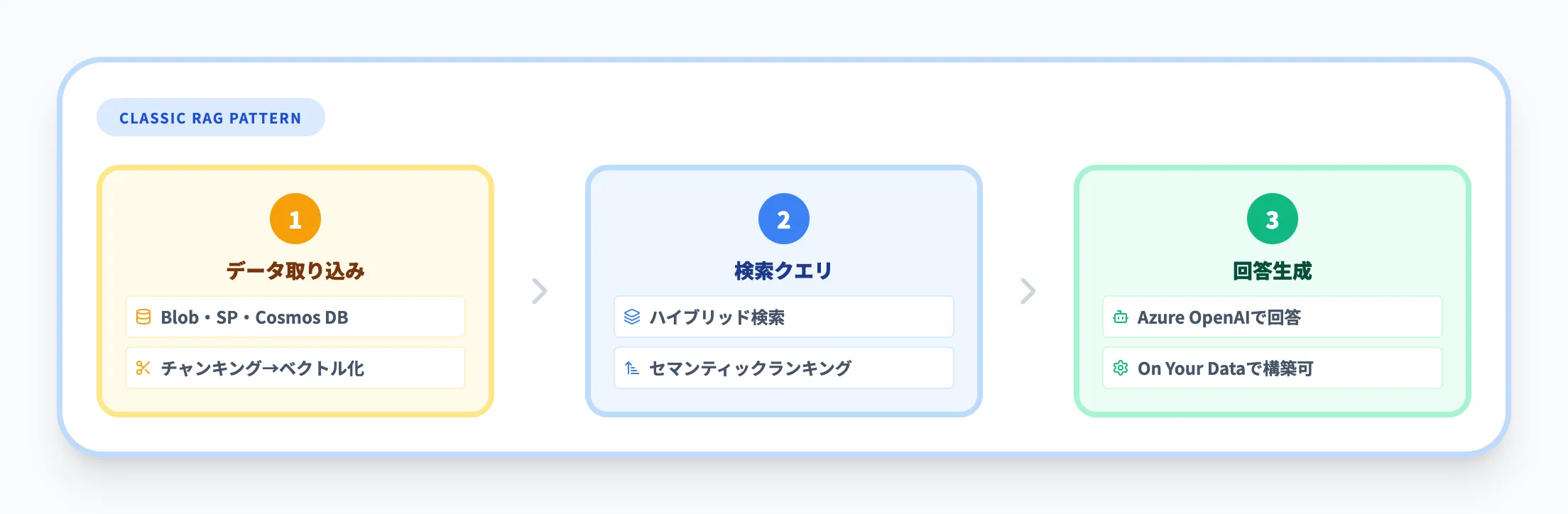
Classic RAGは、Azure AI Searchの従来型検索エンジン(Classic search)を使ったRAG構成です。以下の流れで動作します。
- データ取り込み
Blob StorageやCosmos DB、SharePointなどのデータソースからインデクサーがドキュメントを取得し、チャンキング→ベクトル化→インデックス登録を自動実行
- 検索クエリ
ユーザーの質問をハイブリッド検索(全文検索+ベクトル検索)で実行し、セマンティックランキングで上位結果を絞り込む
- 回答生成
検索結果をAzure OpenAI Serviceに渡し、LLMがコンテキストに基づいて回答を生成
Classic RAGパターンは実績が豊富で、レイテンシが低く、コストも予測しやすい点がメリットです。Azure OpenAIのOn Your Data機能を使えば、Azureポータル上の設定だけでこの構成を構築することもできます。
Agentic Retrievalパターン
Agentic Retrievalパターンは、より複雑な質問や対話型シナリオに対応するための新しいRAG構成です。
Classic RAGとの最大の違いは、LLMがクエリプランニングに参加する点です。ユーザーが「昨年の製品不良レポートと改善策を比較してまとめてほしい」と質問した場合、LLMがこの複合的な要求を「製品不良レポートの検索」「改善策の検索」「時期の絞り込み」といった複数のサブクエリに分解し、それぞれを並列に実行します。
各サブクエリの結果はセマンティックランキングで再ランク付けされたあと、統合されて3部構成のレスポンス(グラウンディングデータ、ソース参照、実行ログ)として返されます。

対話的なAIアシスタントや、複数の知識ソースをまたいで情報を引き出す必要があるエージェントワークフローには、Agentic Retrievalパターンが適しています。ただし、LLMによるクエリプランニングの分だけレイテンシが増すため、単純な検索にはClassic RAGの方が効率的です。
Azure AI Searchの活用事例
Azure AI Searchは検索基盤として多様な業務シナリオに適用できます。ここでは代表的な活用パターンと企業の導入実績を紹介します。
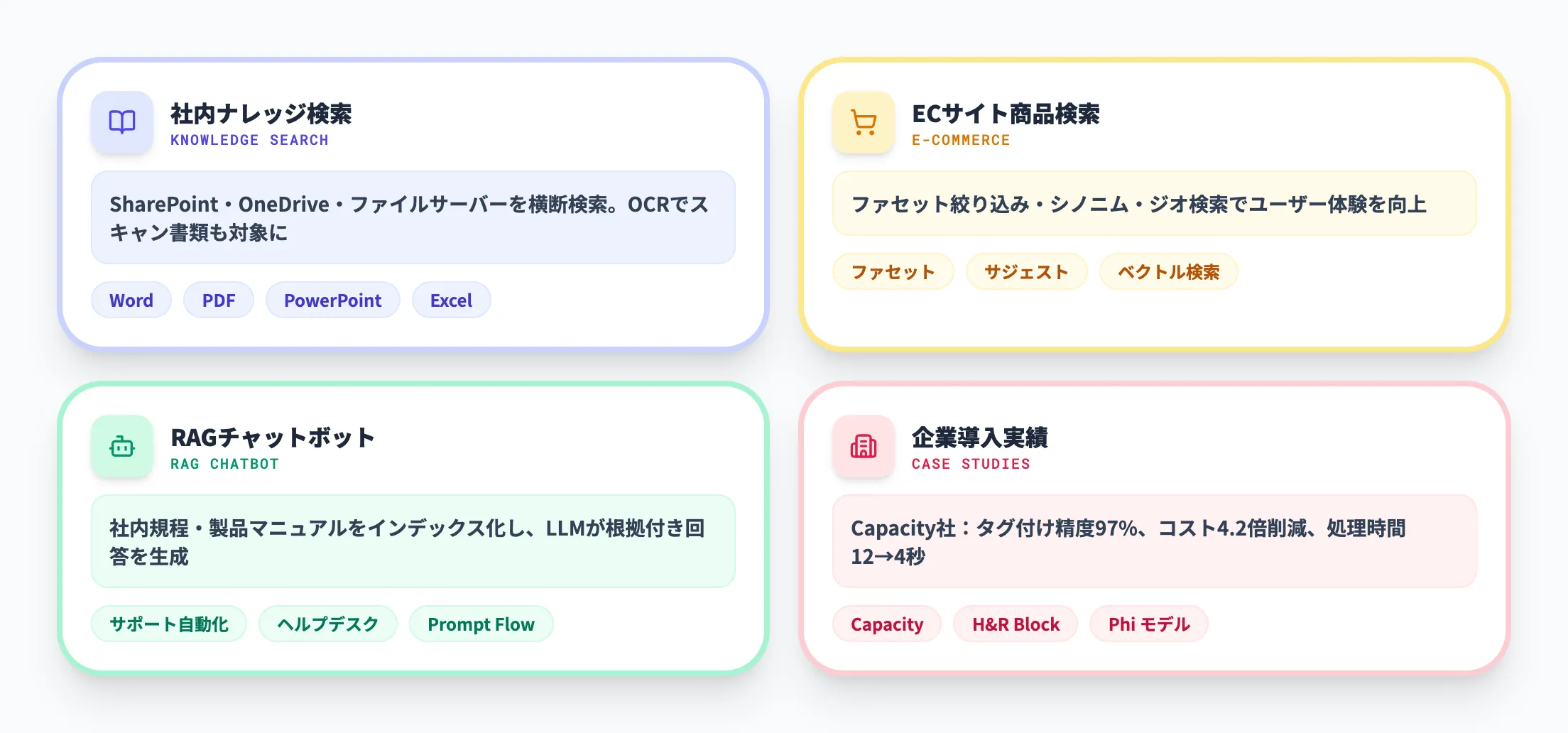
社内ナレッジ検索
最も一般的な活用パターンが、社内ドキュメントの横断検索です。SharePointやOneDrive、ファイルサーバーに散在するWord、PDF、PowerPointなどをAzure AI Searchのインデックスに取り込むことで、メタデータとコンテンツの両方を対象とした高度な検索が実現します。
AIエンリッチメントでOCRを適用すれば、スキャンされた書類や画像内のテキストも検索対象に含められます。社内のナレッジ検索に毎日30分以上かけているチームがあれば、Azure AI Searchで検索基盤を構築するだけで業務時間の大幅な削減が期待できます。
ECサイトの商品検索

ファセットナビゲーション(絞り込み)、オートコンプリート、シノニムマッチング、ジオ検索といった機能を組み合わせることで、ECサイトの商品検索を高度化できます。たとえば「赤いワンピース」というあいまいなキーワードに対しても、ベクトル検索で意味的に近い商品をヒットさせ、セマンティックランキングで関連度順に並べ替えることが可能です。
RAGチャットボット

Azure AI SearchとAzure OpenAI Serviceを組み合わせたRAGチャットボットは、カスタマーサポートや社内ヘルプデスクの自動化に活用されています。社内規程や製品マニュアルをインデックスに登録し、ユーザーの質問に対してLLMがドキュメントの内容を踏まえた回答を生成する構成です。
Azure AI FoundryのPrompt Flowを使えば、検索→プロンプト構築→LLM呼び出し→回答生成の一連のフローをノーコードで設計できます。
企業の導入実績

Azure AI Searchの導入事例として、サポート自動化プラットフォームを提供するCapacity社の事例が参考になります。同社はAzure AI SearchとMicrosoftのPhiモデルを組み合わせ、ドキュメントのタグ付け精度97%、従来パイプライン比4.2倍のコスト削減を達成しました。要約処理の所要時間も12〜14秒から4〜5秒に短縮されています。
また、H&R Block社は、Azure AI Searchを基盤としたRAGアプリケーションで確定申告の質問応答を自動化しています。

Azure AI SearchとMicrosoftエコシステムの連携
Azure AI Searchの大きな強みの1つが、Microsoftのクラウドサービス群とのネイティブな統合です。

検索基盤を単体で使うだけでなく、データソース・AI・分析・運用監視まで一貫してAzureの管理下で完結できる点が、他の検索エンジンとの決定的な違いです。
Azure OpenAI ServiceとAI Foundry

Azure AI Searchの最も重要な連携先がAzure OpenAI Serviceです。RAG構成ではAzure AI Searchがリトリーバー、Azure OpenAI Serviceがジェネレーターを担い、検索結果をLLMのコンテキストとして渡すことで社内データに基づいた回答を生成します。
Azure AI Foundryを使えば、この検索→プロンプト構築→LLM呼び出しの一連のフローをPrompt Flowで視覚的に設計できます。さらに、Foundry IQはAgentic Retrievalを基盤としており、AIエージェントのナレッジレイヤーとしてAzure AI Searchが組み込まれています。
Microsoft 365・SharePoint・OneDrive

企業の社内データの多くはMicrosoft 365環境に存在します。Azure AI SearchはSharePoint OnlineやOneDriveをデータソースとして直接接続できるインデクサーを提供しており、Word・Excel・PowerPoint・PDFなどのドキュメントを自動的にクロールしてインデックスに取り込みます。
SharePointのサイト構造やメタデータ(作成者、更新日、コンテンツタイプ)もインデックスに含められるため、「営業部が作成した提案書」「2025年以降に更新された規程」のような業務に即した絞り込み検索が可能です。
Microsoft FabricとOneLake
Microsoft Fabricのデータレイク基盤であるOneLakeは、Azure AI Searchのデータソースとして接続できます。Fabricに集約されたデータをAzure AI Searchでインデックス化し、検索可能にすることで、データレイクの資産をRAGやエージェントワークフローに活用する構成が実現します。
特にFabricのSilverレイヤー(クレンジング済みデータ)をAzure AI Searchのインデクサーで取り込む構成は、エージェントグラウンディングの推奨パターンとして公式のデータアーキテクチャガイドに記載されています。
Copilot Studio
Microsoft Copilot Studioでカスタムエージェントを構築する際、Azure AI Searchを検索グラウンディングのソースとして接続できます。Copilot Studioのエージェントがユーザーの質問を受け取ると、Azure AI Searchで社内データを検索し、その結果をもとにLLMが回答を生成する構成です。
FabricデータエージェントをCopilot Studioに接続すれば、Azure AI Searchのインデックスを含む複数のデータソースをまたいだエージェント間連携も可能です。ノーコードでRAGチャットボットを構築したい場合に有力な選択肢になります。
Azure Functions(カスタムスキル)

Azure Functionsは、AIエンリッチメントのパイプラインに独自の処理を組み込むための実行基盤です。Azure AI Searchのカスタムスキルとして、Azure Functionsでホストした任意のコードをスキルセットに追加できます。
たとえば、社内独自の分類ロジックや、外部APIを呼び出してメタデータを付与する処理、業界固有の用語を正規化する変換などを、標準スキルでは対応できないケースで実装します。カスタムスキルはREST APIインターフェースに準拠していれば言語を問わないため、Python・C#・Node.jsなど開発チームの得意な言語で実装可能です。
Azure MonitorとLog Analytics
Azure Monitorの診断ログを有効にすると、Azure AI Searchの検索クエリログ、インデクサー実行ログ、スロットル発生状況などを収集・分析できます。Log Analyticsワークスペースに送信すれば、KQLクエリでクエリのレイテンシ分布やエラー率の推移を可視化でき、検索品質の継続的な改善に活用できます。
運用面では「どのクエリが遅いか」「どのインデクサーが失敗しているか」「スロットリングが発生していないか」を把握することが、検索基盤の安定運用に不可欠です。Azure Monitorのアラートルールを設定しておけば、異常発生時に即座に通知を受けられます。
Azure AI Searchと他の検索サービスの比較
Azure AI Searchはフルマネージドの検索サービスですが、選択肢は他にもあります。ここではElasticsearchとAmazon OpenSearch Serviceとの違いを整理します。

以下の表で、3サービスの主要な特性を比較しました。
| 観点 | Azure AI Search | Elasticsearch | Amazon OpenSearch Service |
|---|---|---|---|
| 提供形態 | フルマネージド(PaaS) | セルフホスト or Elastic Cloud | マネージド(AWS) |
| ベクトル検索 | ネイティブ対応(GA) | 8.0以降で対応 | k-NNプラグインで対応 |
| RAG統合 | Azure OpenAI / Foundryと統合 | 自前で構築 | Amazon Bedrockと連携 |
| Agentic Retrieval | あり(プレビュー) | なし | なし |
| AIエンリッチメント | 組み込み(スキルセット) | Ingestパイプラインで別途構築 | Ingestパイプラインで別途構築 |
| 運用負荷 | 低(インフラ管理不要) | 高(クラスタ管理が必要) | 中(AWS管理だがチューニング必要) |
| エコシステム | Azure / Microsoft 365 / Fabric | 幅広いOSS連携 | AWS中心 |
| 料金モデル | SU単位の時間課金 | ノード単位 or 利用量課金 | インスタンス単位の時間課金 |
すでにAzure環境を利用している企業にとって、Azure AI Searchは初期構築の手軽さとRAG統合の深さが最大のメリットです。Blob StorageやSharePointからのデータ取り込み、Azure OpenAI Serviceとの接続、Entra IDによる認証が、すべてAzureの統合管理のもとで完結します。
一方、マルチクラウド環境やオンプレミスでの運用を重視する場合はElasticsearchの柔軟性が有利です。AWS中心のインフラであればAmazon OpenSearch Serviceが自然な選択肢になります。
選定の判断ポイントは、既存のクラウド基盤との親和性とRAG構築の優先度の2軸で考えるとシンプルです。RAGを最短で立ち上げたいAzureユーザーにはAzure AI Search、カスタマイズ性と柔軟な構成を優先するならElasticsearch、という棲み分けが実態に近い選択になります。
Azure AI Searchの始め方
Azure AI Searchの導入は、Azureポータルからの操作で完結します。ここではリソース作成からインデックス構築までの流れを解説します。
Azureポータルでのリソース作成
まずAzureの無料アカウントを作成し、Azureポータルにログインします。「リソースの作成」から「Azure AI Search」を選択し、リソースグループ、サービス名、リージョン、SKU(料金レベル)を指定します。
Free SKUであれば課金なしで3つまでのインデックスを作成でき、チュートリアルや検証用途に十分です。本番環境ではBasic以上を選択してください。
インデックスの設計と作成

検索インデックスは、検索対象となるデータの構造を定義するスキーマです。フィールドごとに「検索可能(searchable)」「フィルタ可能(filterable)」「ソート可能(sortable)」などの属性を設定します。
ベクトル検索を使う場合は、Collection(Edm.Single)型のベクトルフィールドを追加し、次元数(最大4,096)とベクトル検索プロファイルを指定します。統合ベクトル化を有効にすれば、テキストデータのベクトル変換をインデックス作成時に自動で行えます。
データソースの接続
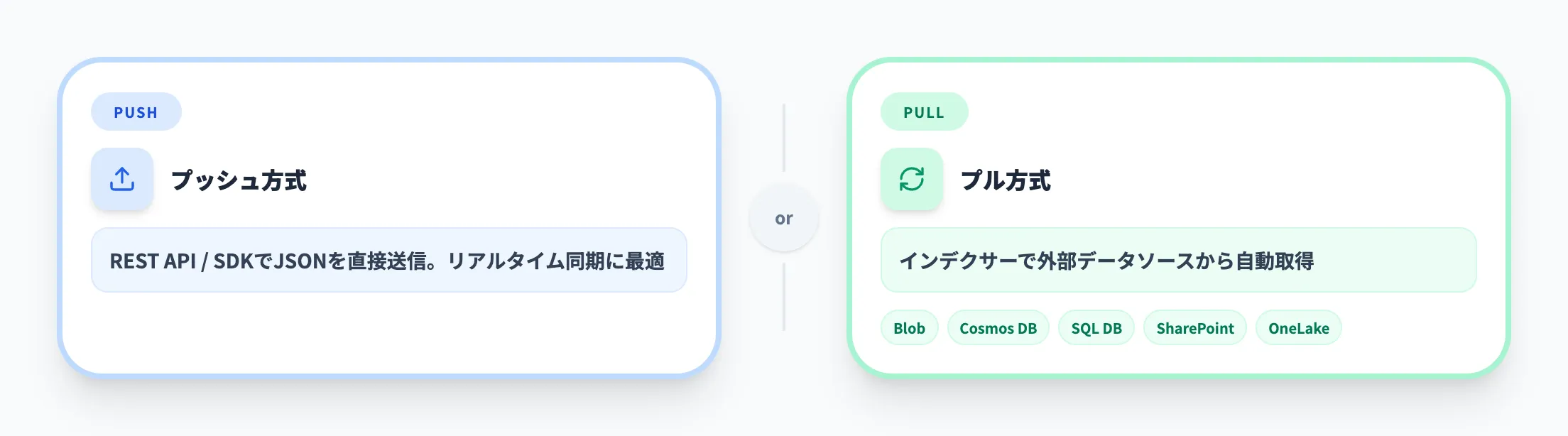
Azure AI Searchはプッシュ方式(REST API / SDKでJSONを直接送信)とプル方式(インデクサーで外部データソースから自動取得)の2つのデータ取り込み方法を提供しています。
プル方式で対応しているデータソースには、以下のようなものがあります。
- Azure Blob Storage
- Azure Cosmos DB
- Azure SQL Database
- SharePoint Online
- Microsoft OneLake
インデクサーにスケジュールを設定すれば、データソースの更新を自動的に検出してインデックスに反映されます。プル方式が対応していないデータソースや、リアルタイム同期が必要な場合はプッシュ方式を選択してください。
Azure AI SearchのREST APIは.NET、Java、JavaScript、Pythonの各SDKでも利用可能です。開発環境に合わせてSDKを選べるため、既存のアプリケーションへの検索機能の組み込みも比較的スムーズに進められます。
Azure AI Searchの料金体系

Azure AI Searchの料金は、SKU(価格レベル)ごとの検索ユニット(SU)単位の時間課金が基本です。検索ユニットは「パーティション(ストレージ/スループット)× レプリカ(クエリの並列処理/可用性)」で構成され、増やすほど課金が直線的に増加します。
SKU別の料金一覧

以下の表は、2026年3月時点のJapan Eastリージョンにおける検索ユニット1個あたりの料金です。
| SKU | 時間単価 | 月額目安(730時間) | パーティションあたりストレージ | 最大SU |
|---|---|---|---|---|
| Free | $0 | $0 | 50 MB | — |
| Basic | $0.133 | 約$97 | 15 GB(最大45 GB) | 9 |
| Standard S1 | $0.444 | 約$324 | 160 GB(最大1.9 TB) | 36 |
| Standard S2 | $1.774 | 約$1,295 | 512 GB(最大6 TB) | 36 |
| Standard S3 | $3.552 | 約$2,593 | 1 TB(最大12 TB) | 36 |
| Standard S3 HD | $3.552 | 約$2,593 | 1 TB(最大3 TB) | 36 |
| Storage Optimized L1 | $3.839 | 約$2,802 | 2 TB(最大24 TB) | 36 |
| Storage Optimized L2 | $7.677 | 約$5,604 | 4 TB(最大48 TB) | 36 |
月額目安は検索ユニット1個(パーティション1 × レプリカ1)の場合の概算です。たとえばStandard S1でレプリカを3に増やして高可用性を確保すると、月額は約$324 × 3 = 約$972になります。
S3 HDはマルチテナント向けの高密度ホスティングモードで、1サービスあたり最大3,000インデックスを作成できる代わりに、インデクサーが使えずAPIによるプッシュ型のデータ取り込みのみに対応しています。
Free SKUは評価・学習用で、インデックス数やドキュメント数に厳しい制限があります。本番環境の最小構成はBasicで、SLA(サービスレベル契約)の対象はレプリカ3以上の構成です。
セマンティックランカーとAgentic Retrievalの追加課金

SKUの基本料金に加え、以下のプレミアム機能には従量課金が発生します。
- セマンティックランカー
Free SKUを含む全SKUで利用可能。月間1,000クエリまで無料で、以降は1,000クエリ単位の従量課金
- Agentic Retrieval
月間5,000万トークンまで無料(Freeプラン)。上位SKUではFreeプラン(デフォルト)とStandardプラン(従量課金)を選択可能。Standardプランでは無料枠の消費後、100万トークン単位で課金される。詳細な単価はAzure AI Searchの料金ページで確認できる
加えて、Agentic RetrievalのLLMクエリプランニングに使用するAzure OpenAIのトークン料金も別途発生します。クエリプランニングにはgpt-4o、gpt-4.1、gpt-5シリーズのモデルが必要で、入出力トークンの従量課金はAzure OpenAI側の請求に計上されます。
コスト最適化のポイント

Azure AI Searchのコストを抑えるための実務的なポイントは以下のとおりです。
- SKUの見極め
まずFreeで検証し、インデックスサイズと想定クエリ量が見えてからBasicまたはS1に移行する
- レプリカの最適化
開発環境ではレプリカ1で運用し、本番環境でのみ可用性要件に応じてレプリカを増やす
- パーティションの計画
インデックスサイズがSKUのパーティション上限を超えない範囲でSKUを選ぶ。S1の160 GBで足りるならS2に上げる必要はない
- Agentic RetrievalのReasoning Effort調整
LLM処理を最小限に抑えるLow設定を使えば、レイテンシとコストの両方を削減できる
Azureの料金計算ツールを使えば、SKU・パーティション数・レプリカ数を指定して月額の見積もりが可能です。
Azure AI Searchの注意点とセキュリティ

Azure AI Searchは強力な検索基盤ですが、導入前に把握しておくべき制限事項やセキュリティの仕組みがあります。
SKU選択時の注意点

Azure AI SearchのSKUは、作成後に一部を除いて変更が制限されています。2026年3月時点では、Basic ↔ Standard(S1/S2/S3)間のSKU変更はサポートされていますが、Free→BasicやStandard→Storage Optimizedへの変更はできません。後者の場合は新しいサービスを作成してインデックスを移行する必要があります。
また、2024年4月以降に作成されたサービスはパーティション容量とベクトルクォータが拡大されています。それ以前に作成された古いサービスを使っている場合は、サービスのアップグレードを検討してください。
ネットワークセキュリティと認証
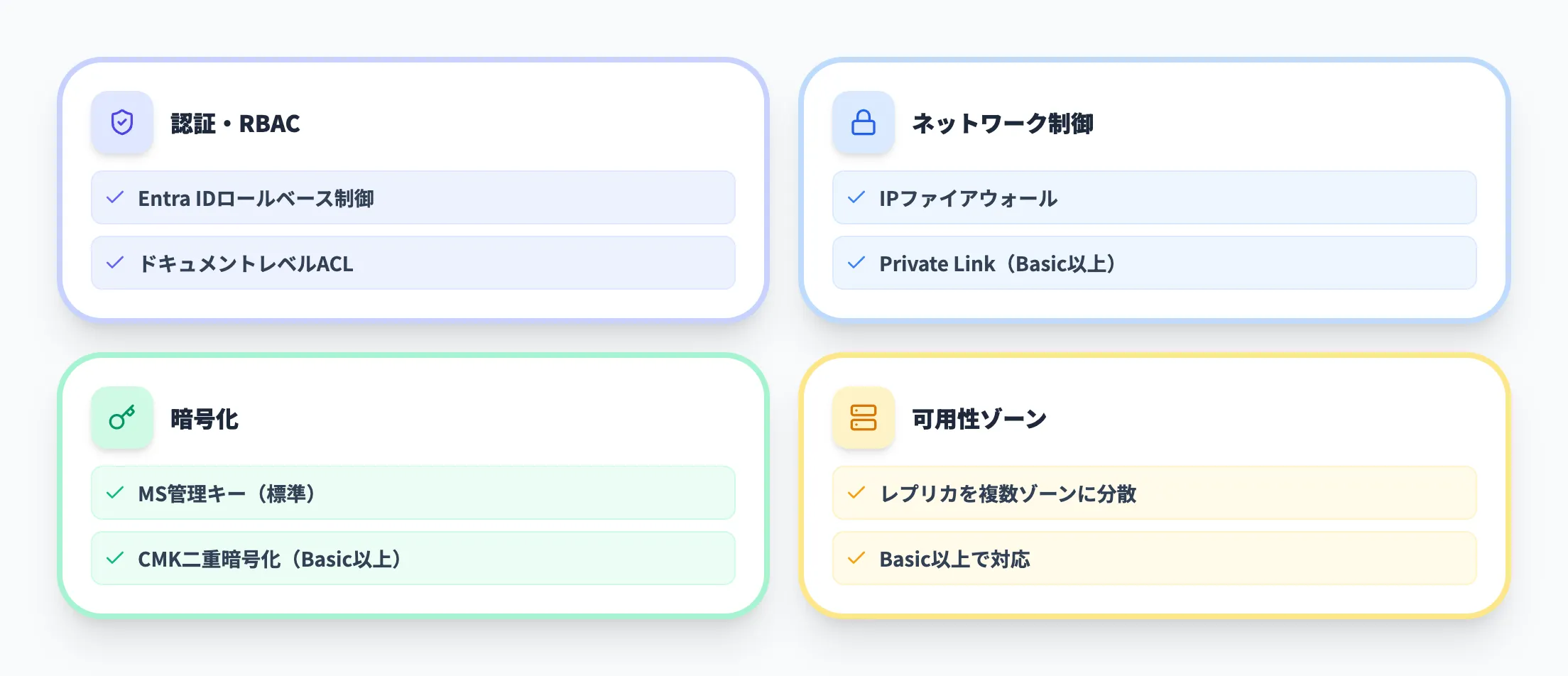
Azure AI Searchは、エンタープライズ環境に必要なセキュリティ機能を多層で備えています。
- 認証・アクセス制御
Microsoft Entra IDによるロールベースアクセス制御(RBAC)と、ドキュメントレベルのアクセス制御(セキュリティトリミング)を組み合わせて、ユーザーごとに閲覧可能なドキュメントを制限可能
- ネットワーク制御
IPファイアウォールとAzure Private Linkによるプライベートエンドポイント接続に対応。インバウンド通信をVNet内に閉じた構成が可能(Basic以上)
- 暗号化
保存データのMicrosoft管理キーによる暗号化に加え、カスタマーマネージドキー(CMK)による二重暗号化をサポート(Basic以上)
- 可用性ゾーン
Basic以上のSKUでAzureの可用性ゾーンに対応。レプリカを複数のゾーンに分散配置することで、データセンター障害時の可用性を確保
なお、Free SKUではIPファイアウォール、Private Link、CMK、マネージドID、可用性ゾーンが利用できません。セキュリティ要件のある本番環境では、必ずBasic以上のSKUを選択してください。
制限事項

Azure AI Searchには、SKUごとに異なる上限が設定されています。実務で特に影響しやすい制限をまとめます。
| 制限項目 | Free | Basic | S1 | S2 | S3 | S3 HD |
|---|---|---|---|---|---|---|
| インデックス数 | 3 | 5 or 15 | 50 | 200 | 200 | 1,000/パーティション |
| インデクサー数 | 3 | 5 or 15 | 50 | 200 | 200 | 非対応 |
| スキルセット数 | 3 | 5 or 15 | 50 | 200 | 200 | 非対応 |
| パーティション上限 | — | 3 | 12 | 12 | 12 | 3 |
| レプリカ上限 | — | 3 | 12 | 12 | 12 | 12 |
Basicの「5 or 15」は、2017年12月以前に作成されたサービスが5、それ以降は15です。2024年4月以降に作成されたサービスではパーティション容量とベクトルクォータが拡大されているため、古いサービスを使っている場合はアップグレードを検討してください。
Freeはインデックス3つまでという厳しい制限があり、複数環境やプロジェクトを並行して扱うことが難しい点に注意が必要です。詳細な制限値は公式のサービス制限ページで確認できます。
AI検索基盤をAIエージェントの業務自動化に統合するなら
AI Searchのベクトル検索・セマンティック検索・Agentic Retrievalは、AIエージェントが社内ナレッジを自動検索して回答・対応するための中核技術になります。
-
AI Searchのベクトル検索を、AIエージェントが社内ナレッジの自動検索に活用できる
セマンティック検索で関連文書を高精度に取得し、AIエージェントが正確な回答を自動生成します。 -
Teams上で完結するため、既存のMicrosoft環境にそのまま導入可能
社内で利用しているMicrosoft 365環境を変更することなく、AIエージェントを追加できます。 -
自社テナント内で完結するセキュリティで、安心して業務データを扱える
業務データが外部サービスに送信されることなく、自社のセキュリティポリシーの範囲内で運用できます。
AI検索基盤をAIエージェントの業務自動化に統合

Microsoft Teams上でAIエージェントが業務を代行
AI Searchのベクトル検索・セマンティック検索を、AIエージェントが社内ナレッジ検索や問い合わせ対応の自動化に活用できます。Teams上で完結するため、既存のMicrosoft環境にそのまま導入可能。自社テナント内で完結するセキュリティで、安心して業務データを扱えます。
まとめ
Azure AI Searchは、従来のキーワード検索からベクトル検索、そしてLLMと連携するAgentic Retrievalまでを1つのマネージドサービスで提供する検索プラットフォームです。
本記事の要点を整理すると、以下の3点に集約されます。
- RAG構築の標準基盤
Azure OpenAI ServiceやMicrosoft Foundryとの統合により、RAGアーキテクチャの検索レイヤーを最短で構築可能
- 段階的なスケーリング
FreeからStorage Optimized L2まで7段階のSKUがあり、検証から大規模本番運用まで同一サービスで対応
- エンタープライズセキュリティ
Entra ID、Private Link、ドキュメントレベルACL、可用性ゾーンにより、法人環境のコンプライアンス要件に対応
まずはFree SKUでインデックスを作成し、ハイブリッド検索の精度を確認するところから始めてみてください。Azure環境で検索基盤やRAGの導入を検討しているなら、Azure AI Searchは最初に評価すべきサービスです。










