この記事のポイント
 社内ナレッジ検索の精度に不満があるなら、RAGが第一の解決策。ハルシネーション抑制と最新情報の反映を両立できる唯一の手法
社内ナレッジ検索の精度に不満があるなら、RAGが第一の解決策。ハルシネーション抑制と最新情報の反映を両立できる唯一の手法- 小規模ならChatGPTのCustom GPTs、本格構築はAzure AI Search+Azure OpenAI Serviceの組合せが最適
- ファインチューニングとの使い分けは明確で、最新情報や社内データの活用はRAG、応答スタイルの最適化はファインチューニングが有利
- Azure AI Searchの料金はBasicプランで月額約$75から。SaaS型RAGなら月額3万円前後で導入可能
- 2026年はAgentic RAGが主流に。AIエージェントが検索→判断→再検索を自律的に繰り返し、従来のRAGより高精度な回答を生成

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
RAG(Retrieval-Augmented Generation)は、LLMが回答を生成する際に外部の知識データベースから関連情報を検索し、その情報を基に回答を生成する技術です。社内文書や最新の業界情報など、LLM単体では持ち得ないデータを活用でき、ハルシネーションの抑制と回答精度の向上を実現します。
2026年現在、RAGはAgentic RAGやGraphRAGへと進化し、AIエージェントと組み合わせた自律的な情報検索が主流になりつつあります。Azure AI SearchやLangChainなど、構築を支えるツール群も急速に成熟しています。
本記事では、RAGの基本的な仕組みから実装方法、料金・コスト、活用事例、導入時の注意点までを体系的に解説します。
RAGの最新動向に関する論文も参照しながら、実務に役立つ情報を網羅しています。
目次
RAG(検索拡張生成)とは
RAG(Retrieval-Augmented Generation)は、大規模言語モデル(LLM)が回答を生成する際に、外部の知識データベースから関連情報を検索し、その情報を基に回答を生成する技術です。
LLM単体ではインターネット上の公開情報しか学習していないため、自社の社内規程やマニュアル、最新の業界動向といった非公開情報については正確に回答できません。RAGは、この「LLMの知識の限界」を検索技術で補完する仕組みです。
検索によって取得した関連情報をプロンプトに追加することで、ハルシネーション(もっともらしい嘘)を抑制し、回答の正確性と信頼性を大幅に向上させることができます。

RAGの仕組み
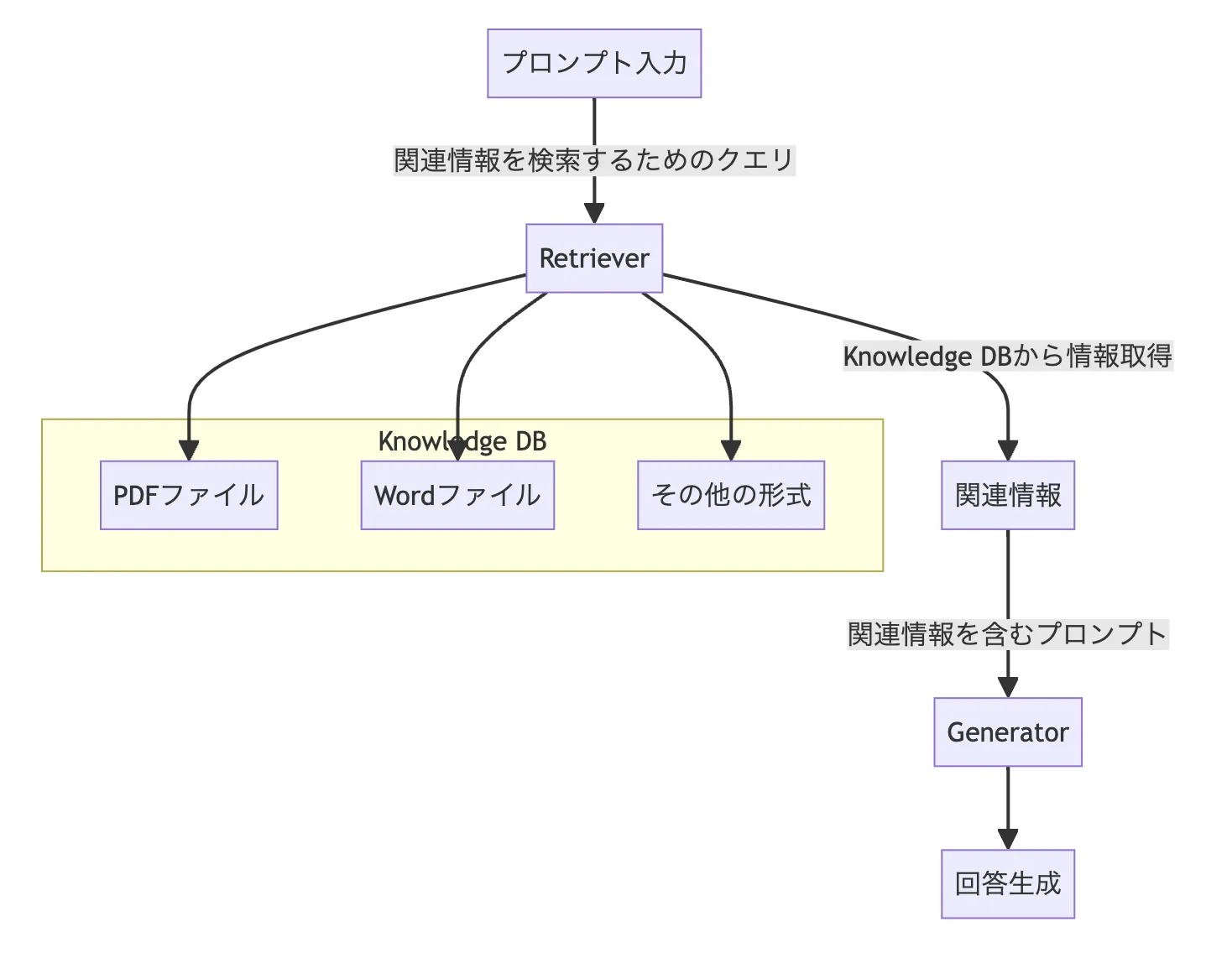
RAGの仕組み
RAGは「検索」「拡張」「生成」の3つのフェーズで動作します。以下のステップに沿って、順を追って解説します。
-
プロンプト入力
ユーザーからの質問やコマンドが入力されます。たとえば「AI総合研究所の運営会社はどこですか?」のような質問です。
-
検索(Retriever)
入力されたプロンプトを解析し、あらかじめ構築しておいた知識データベース(Knowledge DB)から関連情報を検索します。この段階では、ベクトル検索やキーワード検索、あるいはその両方を組み合わせたハイブリッド検索が使われます。
-
拡張(Augmentation)
検索で取得された関連情報を、元のプロンプトに追記する形でLLMに渡します。LLMにとっては「追加のヒント」が与えられた状態になります。
-
生成(Generator)
拡張されたプロンプトを受け取ったLLMが、検索結果を根拠として回答を生成します。「AI総合研究所の運営会社はLinkX Japan株式会社です」のように、外部データに基づいた正確な回答が得られます。
この仕組みにより、LLMが学習していない情報であっても、検索で補完することで正確な回答が可能になります。
RAGの進化
RAG研究のタイムライン
RAGは2023年以降に急速に発展し、複数のアプローチが生まれています。以下の表で、RAGの進化段階を整理します。
| 世代 | 特徴 | 向いているケース |
|---|---|---|
| Naive RAG | 基本的な検索→生成のパイプライン。シンプルだが精度に限界がある | PoCや小規模な社内FAQ |
| Advanced RAG | 検索前後で最適化を行う。Re-ranking(再順位付け)やクエリ変換で精度向上 | 本番運用の社内検索システム |
| Modular RAG | 複数のモジュールを組み合わせ、データソースや検索手法を柔軟に切り替える | 複数の部門・データソースをまたぐ検索 |
| Agentic RAG | AIエージェントが「追加検索が必要か」「どのデータソースを使うか」を自律的に判断し、繰り返し検索する | 複雑な質問への高精度回答、エンタープライズ用途 |
2026年時点で特に注目すべきはAgentic RAGです。従来のRAGが「1回検索して1回生成する」のに対し、Agentic RAGはAIエージェントが検索結果を評価し、不十分であれば別のクエリやデータソースで再検索を繰り返します。MicrosoftのAzure AI Searchも2026年にエージェント検索(Agentic Retrieval)をプレビュー提供しており、この流れが業界標準になりつつあります。
また、GraphRAGは知識をエンティティ(人名・組織名・概念など)の関係グラフとして構造化し、単純なベクトル検索では見落とす「間接的な関連性」を捉えることができます。ドキュメントが追加されるたびにグラフが成長し、回答の質が向上していく点が特徴です。
RAGが注目される理由とメリット・デメリット
RAGは2026年現在、企業のAI活用において最も導入が進んでいる技術の一つです。ここでは、RAGのメリットとデメリット、そして類似技術との使い分けを整理します。
RAGのメリット
RAGを導入する最大のメリットは、LLMが学習していないデータを活用できることです。
-
最新情報・社内データの反映
LLMの学習データには含まれない社内マニュアルや最新の製品情報を、検索を通じてリアルタイムに回答へ反映できます。
-
ハルシネーションの抑制
検索結果を根拠として回答を生成するため、LLMが事実と異なる情報を生成するリスクを大幅に低減できます。
-
モデルの再学習が不要
ファインチューニングのようにモデル自体を再学習させる必要がなく、データベースを更新するだけで知識を最新に保てます。
RAGのデメリット
一方で、RAGには以下の課題があります。
-
検索基盤の構築・運用コスト
知識データベースの構築、インデックス化、定期的なデータ更新など、検索基盤の構築と維持に費用と工数がかかります。
-
検索精度が回答品質を左右する
検索結果が的外れであれば、生成される回答も的外れになります。チャンキング(文書の分割)やベクトル化の設計が回答品質に直結します。
-
レイテンシの増加
検索フェーズが追加されるため、LLM単体での回答よりも応答時間が長くなる傾向があります。
これらのデメリットは、適切な設計と運用で軽減できます。特にチャンキング戦略と検索手法の選定は、RAGの精度を左右する最も重要なポイントです。
RAGとファインチューニングの違い
LLMをカスタマイズする手法として、RAGとファインチューニングはよく比較されます。
| 比較項目 | RAG | ファインチューニング |
|---|---|---|
| 手法 | 外部データベースから検索して回答に反映 | 学習データでモデルのパラメータを再調整 |
| 得意なこと | 最新情報・社内データの反映、事実確認 | 応答スタイルの最適化、ドメイン特化 |
| データ更新 | データベース更新のみで即反映 | 再学習が必要(コストと時間がかかる) |
| コスト | 検索基盤の構築・運用費 | 学習用GPU費用、データ整備費 |
| 組み合わせ | 可能(RAG + ファインチューニングで最高精度) | 可能 |
実務での選び方は明確です。社内ナレッジの検索やFAQ対応など「正確な情報を引き出す」用途にはRAGが向いています。一方、特定の業界用語や応答トーンをモデルに覚えさせたい場合はファインチューニングが有効です。多くの企業では、RAGで情報の正確性を担保しつつ、ファインチューニングで応答品質を調整するハイブリッドアプローチを採用しています。
RAGとロングコンテキストLLMの使い分け
2026年現在、Claude Opus 4.6やGemini 3 Proなど100万トークン以上のコンテキストウィンドウを持つLLMが登場しています。「大量のドキュメントをそのままLLMに渡せるなら、RAGは不要では?」という疑問が生まれるのは自然なことです。
結論から言えば、ロングコンテキストLLMとRAGは代替関係ではなく補完関係にあります。
-
ロングコンテキストLLMだけで対応できるケース
対象ドキュメントが数十ページ程度で、全文を読み込んでも問題ない場合。コスト感度が低く、応答速度への要求が緩い場合
-
RAGが必要なケース
対象データが数千〜数万ページ規模で、全文をLLMに渡すとトークンコストが膨大になる場合。データの更新頻度が高く、常に最新情報を反映する必要がある場合。セキュリティ上、全データをLLMに送信できない場合
2026年のベストプラクティスは「Long Context RAG」と呼ばれるハイブリッドアプローチです。RAGで関連情報を粗く絞り込み、その結果をロングコンテキストLLMに読み込ませることで、コストと精度の両立を実現します。
RAGの主要な検索・生成手法
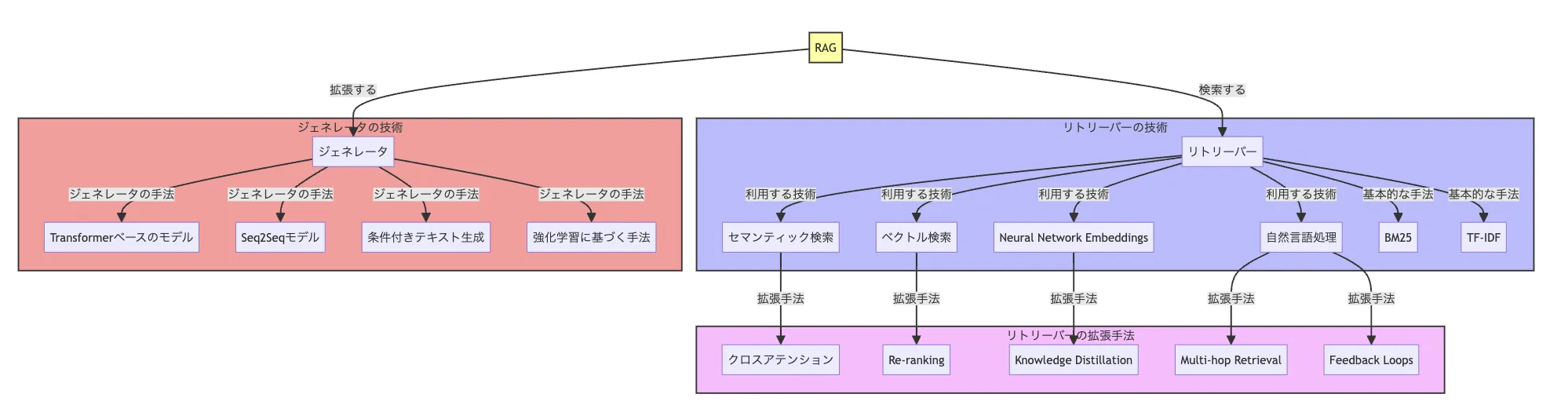
RAGの検索手法と拡張性の手法の概要図
RAGシステムは「リトリーバー(検索)」と「ジェネレーター(生成)」の2つの部分で構成されています。それぞれの代表的な手法を解説します。
リトリーバー(検索)の手法
リトリーバーは、ユーザーのクエリに関連するデータを大規模なコーパスから見つけ出す役割を担います。
| 手法 | 説明 | 適した場面 |
|---|---|---|
| キーワード検索(BM25) | 単語の出現頻度と文書の長さを考慮したランキング。完全一致に強い | 型番・法令番号など正確なキーワードが明確な場合 |
| ベクトル検索 | テキストを数値ベクトルに変換し、意味的な類似性で検索する | 「似た概念」を探したい場合。表現揺れに強い |
| ハイブリッド検索 | キーワード検索とベクトル検索を組み合わせた手法 | 多くのRAGシステムで推奨される標準的なアプローチ |
| セマンティック検索 | クエリの意味を深層的に理解して関連性の高い情報を検索する | 自然言語の質問に対する高精度な検索 |
多くの場合、ハイブリッド検索を採用することで、キーワード検索の正確性とベクトル検索の柔軟性を両立できます。Azure AI Searchではハイブリッド検索に加えてセマンティックランキングも提供しており、検索精度をさらに高めることが可能です。
ジェネレーター(生成)の手法
ジェネレーターは検索された情報をもとに、自然言語で回答を生成します。
| 手法 | 説明 |
|---|---|
| Transformerベースのモデル | GPT-5、Claude Opus 4.6、Gemini 3 Proなど。複雑な言語パターンを理解し高品質なテキストを生成する |
| Seq2Seqモデル | 入力テキストから新しいテキストを生成する。RAGでは主にTransformerモデルが使われる |
| 条件付きテキスト生成 | 特定の条件やスタイルに基づいてテキストを生成する。トーンや長さの制御に使われる |
RAGの精度を高めるテクニック
RAGの回答品質を向上させるために、以下のテクニックが実務で広く使われています。
-
チャンキング戦略の最適化
ドキュメントをどのサイズで分割するかは精度に直結します。チャンクが大きすぎると検索のノイズが増え、小さすぎると文脈が失われます。一般的には200〜500トークン程度が推奨されますが、ドキュメントの性質に応じた調整が必要です。
-
Re-ranking(再順位付け)
検索結果をLLMやクロスエンコーダモデルで再評価し、より関連性の高い情報を上位に表示します。Azure AI Searchのセマンティックランキングがこれに相当します。
-
クエリ変換
ユーザーの質問をそのまま検索に使うのではなく、LLMで検索に適した形に変換する手法です。曖昧な質問を具体的なサブクエリに分解するAgentic RAGの基盤技術でもあります。
-
メタデータフィルタリング
文書のタイトル、作者、更新日などのメタデータを検索条件に加えることで、検索結果の関連性を高めます。
これらのテクニックは単独で使うよりも、組み合わせて適用することで効果を発揮します。特に「ハイブリッド検索 + セマンティックランキング + 適切なチャンキング」の3点セットは、多くの本番システムで採用されている定番の構成です。
RAGの実装方法
ここでは、RAGを実際に構築するための代表的な方法を3つ紹介します。
Azure AI Foundryで構築する場合
MicrosoftのAzure AI Foundry(旧Azure AI Studio)を使えば、エンタープライズ向けのRAGシステムをGUIベースで構築できます。
構築の3ステップ:
- Azure OpenAI Serviceでモデルをデプロイする
Azure OpenAI Studioのチャットボット画像
Azure OpenAI Serviceのチャットプレイグラウンドで、GPT-4oやGPT-5 miniなどのモデルをデプロイします。コードを書かなくてもGUI上でモデルの動作を確認できます。
- On Your Dataで自社データを追加する
Azure AI Foundryでデータを追加(On Your Data)
On Your Data機能を使うと、Azure Blob Storage上のPDFやWord、CSVファイルをアップロードするだけで、自動的にチャンキングとインデックス化が行われます。
- Azure AI Searchで検索手法を選択する
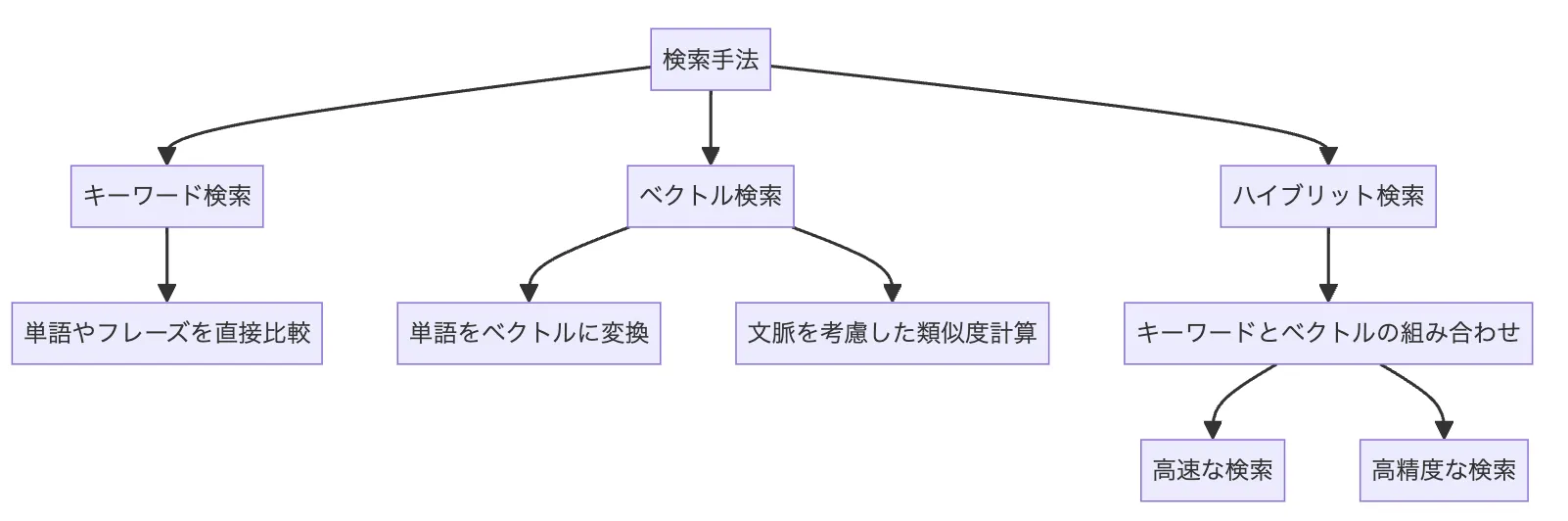
Azure AI Search検索機能
Azure AI Searchでは、以下の3つの検索手法が用意されています。
-
キーワード検索
従来型のテキストマッチング
-
ベクトル検索
テキストを数値に変換し、意味的な類似度で検索する手法。Azure AI Searchのベクトル検索で詳しく解説しています
-
ハイブリッド検索
キーワード検索とベクトル検索を組み合わせた手法。精度と再現率のバランスが取れるため、多くのケースで推奨されます
2026年にはさらに**エージェント検索(Agentic Retrieval)**がプレビューとして追加されました。LLMがクエリを分析してサブクエリに分解し、並列で実行する仕組みで、複雑な質問への回答精度が大幅に向上します。新規構築の場合は、Microsoftもエージェント検索からの開始を公式ドキュメントで推奨しています。
詰まりポイント:チャンクサイズの設定
RAG構築で最も「想定より精度が出ない」と悩むポイントがチャンクサイズです。デフォルト設定のまま進めると、検索結果にノイズが多すぎたり、逆に必要な文脈が切れたりします。まずは300〜500トークンで試し、検索結果を確認しながら調整するのが実践的なアプローチです。
ChatGPTで行う場合

知識の補填方法
小規模なRAGであれば、ChatGPTの機能で手軽に始めることができます。
-
Custom GPTsを使う方法
ChatGPT Plusユーザーであれば、GPTsにPDFやCSVファイルをアップロードして知識を追加できます。社内のFAQや製品マニュアルを読み込ませれば、そのデータに基づいた回答が得られます。ノーコードで構築できるため、PoCとして最適です
-
プロンプトに情報を直接入力する方法
プロンプトに参照情報を貼り付けて回答を生成させる方法です。厳密にはRAGではありませんが、小規模な知識補完として有効です
ChatGPTでの構築は手軽な反面、大量のドキュメントには対応しづらく、検索精度の細かい制御もできません。本格的なRAGシステムを構築する場合は、Azure AI SearchやLangChainの利用を検討してください。
主要フレームワーク
RAGシステムの構築を支援するフレームワークが複数存在します。プロジェクトの要件に応じて選択してください。
| フレームワーク | 特徴 | 向いているケース |
|---|---|---|
| LangChain | RAG構築の最も広く使われるフレームワーク。LLMとデータソースの接続を容易にする | 柔軟なカスタマイズが必要なプロジェクト |
| LlamaIndex | データの読み込み・インデックス化に特化。ドキュメント量が多いケースに強い | 大量の社内ドキュメントを扱う場合 |
| Semantic Kernel | Microsoftが開発。Azure OpenAI Serviceとの統合がシームレス | Microsoft環境での開発 |
| Dify | ノーコード/ローコードでRAGアプリを構築可能。GUI操作で完結する | エンジニアリソースが限られるチーム |
エンジニアリソースが潤沢であればLangChainやLlamaIndexが自由度の高い選択肢です。一方、非エンジニアのチームでRAGを導入したい場合は、DifyやCopilot Studioのようなノーコードツールから始めるのが現実的です。
【関連記事】
Microsoft Copilot Studioとは?できることや使い方、料金体系を解説!

RAGの活用事例
RAGは様々な業界・用途で導入が進んでいます。ここでは、公開されている導入事例を4件紹介します。
アサヒビール:社内情報検索システム
アサヒビールは、Azure OpenAI Serviceの生成AIを活用した社内情報検索システムを導入しています。Azure AI SearchとCosmos DBを組み合わせ、社内の多様な形式のデータをRAGで検索可能にしました。
検索結果には100文字程度の要約が表示されるなど、ユーザビリティにも工夫がなされています。
社内検索システムのデモ画面(参考:アサヒビール)
LINEヤフー:全社員向け業務効率化ツール「SeekAI」
LINEヤフーは、全社員を対象とした生成AI業務支援ツール「SeekAI」を本格導入しています。RAG技術を活用し、社内データとLLMを連携させたチャット型の業務支援システムで、社員が社内の情報に自然言語で質問できる環境を実現しました。
AGC:社内向け生成AI環境「ChatAGC」
ガラス・化学大手のAGCは、2023年から社内向け生成AI環境「ChatAGC」を運用し、RAGを組み込むことで社内データを活用した応答を実現しています。研究開発や製造現場での技術文書検索など、専門性の高い情報へのアクセスを効率化しています。
Beiersdorf社:科学者向けデータベース
スキンケア大手のBeiersdorfは、Azure AI Search(旧Azure Cognitive Search)を導入し、900人以上の科学者が膨大な研究データに一元的にアクセスできる環境を構築しました。文書要約やセマンティック検索の機能により、情報探索の効率が大幅に向上しています。
参考:Microsoft導入事例

BeiersdorfのAzure AI Search
これらの事例に共通するのは、RAGを「社内ナレッジ検索の高度化」に使っている点です。社内に蓄積されたドキュメントの量が多いほど、RAGの導入効果は大きくなります。社内のナレッジ検索に毎日30分以上かけているなら、RAGによる検索効率化で月間10時間以上の工数削減が見込める状態です。

RAGの料金・コスト
RAGシステムの構築には、主に「検索基盤」と「LLM API」の2つのコストが発生します。以下の表で、代表的な構成パターンごとの料金目安を整理します。
| 構成パターン | 主なコスト項目 | 月額目安(2026年3月時点) |
|---|---|---|
| Azure AI Search + Azure OpenAI Service | AI Search Basic: 約$75/月、OpenAI API: 従量課金 | 月額$100〜$500程度(利用量による) |
| ChatGPT Custom GPTs | ChatGPT Plus: $20/月 | $20/月(小規模用途) |
| SaaS型RAGサービス | サービス利用料 | 月額3万円〜10万円程度 |
| LangChain + OpenAI API(セルフホスト) | OpenAI API: 従量課金、インフラ費 | 月額数千円〜(利用量による) |
Azure AI Searchの料金は、プランとレプリカ数・パーティション数によって決まります。Basicプランは検索ユニット(SU)あたり$0.101/時間(Japan Eastリージョン)で、月額約$75です。Standard S1プランは$0.344/時間/SUで月額約$250となり、ベクトル検索やセマンティックランキングを本格的に利用する場合はS1以上が推奨されます。
参考:Azure AI Search料金
LLM APIのコストは利用量に依存します。たとえばGPT-4o miniの入力トークン単価は$0.15/100万トークン、GPT-4oは$2.50/100万トークンです。RAGでは検索結果をプロンプトに追加するため、通常の対話よりもトークン消費が多くなる点に注意してください。
参考:ChatGPT API料金ガイド
コストを抑えるには、まずChatGPT Custom GPTsやDifyで小さく始め、効果を確認してからAzure AI Searchへの移行を検討する段階的なアプローチが有効です。
RAG導入時の注意点
RAGを導入する際に、事前に把握しておくべきポイントを整理します。
検索データの品質が回答品質を決める
RAGは「検索結果が正しければ回答も正しい」が成り立つ一方、「検索結果が不適切であれば回答も不適切になる」という構造です。データベースに古い情報や誤った情報が含まれていると、RAGはそれを根拠として回答を生成してしまいます。定期的なデータ更新とメンテナンスの体制を構築してください。
情報漏えいのリスク
社内の機密情報をRAGのデータベースに格納する場合、アクセス制御が不十分だとLLMを通じて情報が漏えいする可能性があります。Azure AI Searchでは、Microsoft Entra IDベースのアクセス制御やドキュメントレベルのセキュリティトリミングが可能です。プライベートエンドポイントによるネットワーク分離も併用してください。
チャンキングとインデックス設計は試行錯誤が前提
チャンクサイズ、オーバーラップ(チャンク間の重複)、メタデータの設計は、ドキュメントの性質やユースケースによって最適解が異なります。最初から完璧な設計を目指すのではなく、PoCで検索精度を計測しながら反復的に改善するアプローチが現実的です。
導入判断で詰まる論点
RAGの導入を検討する際に、多くの企業が以下の2つの論点で判断に迷います。
-
RAGで十分か、ファインチューニングも必要か
社内データの検索精度を高めたいだけならRAGで十分です。ただし「自社独自の専門用語をLLMに理解させたい」「応答のトーンを企業ブランドに合わせたい」といった要件がある場合は、RAGとファインチューニングの組み合わせを検討してください
-
SaaS型RAGか、自社構築か
月額3万円前後のSaaS型RAGは導入が容易ですが、検索ロジックのカスタマイズやデータのオンプレミス管理ができない場合があります。機密性の高い情報を扱う場合や、検索精度を細かく制御したい場合は、Azure AI SearchやLangChainでの自社構築が適しています
RAGの知見をAI業務自動化の第一歩に
RAGは生成AIの性能を大幅に高める技術ですが、個別技術の導入だけでは組織全体の業務変革にはつながりません。AI活用を点から面に広げるには、どの業務にどの順番でAIを導入するかという全体設計が欠かせません。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に進めるための実践ガイド(220ページ)を無料で提供しています。Copilot Chatから始めてCopilot Studio、Microsoft Foundryへと段階を踏む導入設計と、部門別のBefore/After付きユースケースを収録しています。
AI総合研究所の実践ガイドで、RAGの理解を組織のAI導入設計に活かす次のステップをご確認ください。
AI技術の理解を組織の業務改革に活かす

RAGの知見から全社AI導入設計へ
RAGのような先端技術を理解した次のステップは、組織としてAIを業務プロセスに組み込む設計です。Microsoft環境での段階的なAI導入を設計する実践ガイド(220ページ)を無料で提供しています。
まとめ
RAGは、LLMの知識の限界を検索技術で補完する、企業のAI活用における最も実用的な技術です。
本記事のポイントを3つに整理します。
-
小さく始めて段階的に拡大する
ChatGPTのCustom GPTsやDifyで効果を検証し、成果が確認できたらAzure AI Searchでの本格構築に移行するのが堅実な進め方です。最初から大規模なシステムを構築する必要はありません
-
検索精度の改善は継続的な取り組み
チャンキング戦略、検索手法の選定、データの品質管理はRAGの精度を左右する重要な要素です。PoCでベースラインを確立し、ユーザーフィードバックをもとに反復的に改善していくアプローチが効果的です
-
2026年はAgentic RAGの実用化が進む年
AIエージェントが検索・判断・再検索を自律的に繰り返すAgentic RAGは、従来のRAGの精度限界を突破する技術として急速に普及しています。新規構築であればAgentic RAGを前提とした設計を検討してください










