この記事のポイント
 SQLを書けるチームならApache Kafka自前運用に対する運用負荷を下げやすい有力候補。コスト優位はスループット・保持期間に依存するため個別比較は必要
SQLを書けるチームならApache Kafka自前運用に対する運用負荷を下げやすい有力候補。コスト優位はスループット・保持期間に依存するため個別比較は必要- V2料金モデルでV1比最大80%削減。1 SUジョブの月額は約$317で、大規模ほど単価が下がる段階割引設計
- 既存Azure PaaS構成はStream Analytics、Fabric環境はReal-Time Intelligenceが第一候補、併用可
- Power BI出力は2027年10月停止予定、新規構築はFabric連携前提に出力先を選定する
- 1/3 SU常時稼働で月額約$106、短時間PoCなら数ドルから。まずPortalでジョブ作成しEvent Hubsサンプルで動作確認が最速

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
「センサーデータは毎秒何千件も飛んでくるのに、分析結果は翌朝のバッチ処理待ち」——この"リアルタイム性のギャップ"を埋めるのが、Azure Stream Analyticsです。
本記事では、Azure Stream Analyticsの基本的な仕組みから主要機能(ウィンドウ関数、ノーコードエディター(プレビュー)、IoT Edge対応)、Azure Portalでのジョブ作成手順、V2料金モデルのJapan East実価格、Microsoft Fabric Real-Time Intelligenceとの使い分け、そして導入判断で詰まりやすい論点までを2026年3月時点の最新情報で解説します。
目次
Azure Stream Analyticsを導入するメリット
Azure Stream AnalyticsとFabric Real-Time Intelligenceの比較
Azure Stream Analyticsとは
Azure Stream Analyticsは、Microsoftが提供するフルマネージドのストリーム処理エンジンです。
アプリケーション、IoTデバイス、センサー、クリックストリームなどから絶え間なく流れてくるデータを、ミリ秒未満のレイテンシでリアルタイムに分析・変換できます。

従来、リアルタイムデータの分析基盤を構築するには、Apache KafkaやApache Flinkなどのオープンソース技術を組み合わせ、クラスターの構築・運用・スケーリングを自力で管理する必要がありました。
Azure Stream Analyticsはこうしたインフラ管理の負担を一切なくし、ビジネスロジックの記述に集中できるPaaS(Platform as a Service:インフラ管理をクラウド側に任せ、開発者はアプリケーションの構築に専念できる提供形態)型のサービスとして設計されています。
ジョブレベルで99.9%のSLA(サービスレベルアグリーメント)が保証されており、可用性ゾーン対応リージョンでは追加費用なしでリソースが複数ゾーンに自動分散されます。
SQLが書けるチームであれば、Kafka自前運用に対する運用負荷を下げやすい有力候補です。ただし、コスト優位性はスループット・データ保持期間・周辺構成に依存するため、個別の比較検討は必要です。

基本アーキテクチャ
Azure Stream Analyticsの処理は、**入力(Ingest)→ 処理(Analyze)→ 出力(Deliver)**の3ステップで構成されます。
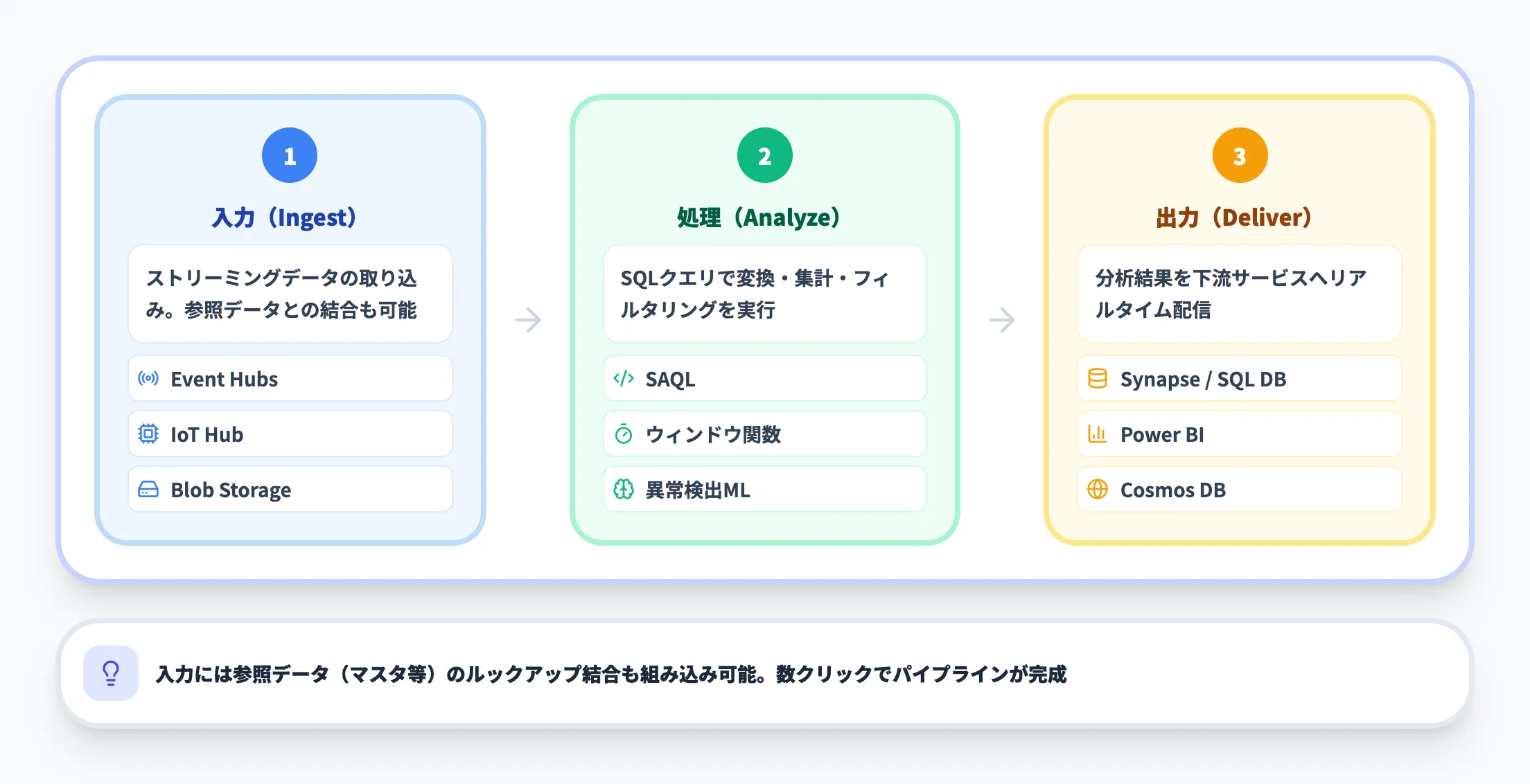
以下の表で、各ステップの役割と対応するAzureサービスを整理しました。
| ステップ | 役割 | 対応するサービス・データソース |
|---|---|---|
| 入力(Ingest) | ストリーミングデータの取り込み | Azure Event Hubs、Azure IoT Hub、Azure Blob Storage |
| 処理(Analyze) | SQLベースのクエリで変換・集計・フィルタリング | Azure Stream Analytics(クエリエンジン) |
| 出力(Deliver) | 分析結果を下流サービスに配信 | Azure Synapse Analytics、Power BI、Azure Cosmos DB、Azure SQL Database、Blob Storage |
この3ステップの設計により、データの取り込みから可視化・アクションまでを一気通貫で構築でき、Azure Portal上の数クリックでパイプラインを完成させることが可能です。
入力には、ストリーミングデータだけでなくBlob StorageやSQL Databaseに格納された参照データ(マスタデータなど)を結合するルックアップ処理も組み込めます。
データパイプラインにおける位置づけ
Azure Stream Analyticsは、Azureのデータ基盤エコシステムの中でリアルタイム処理の中核を担います。
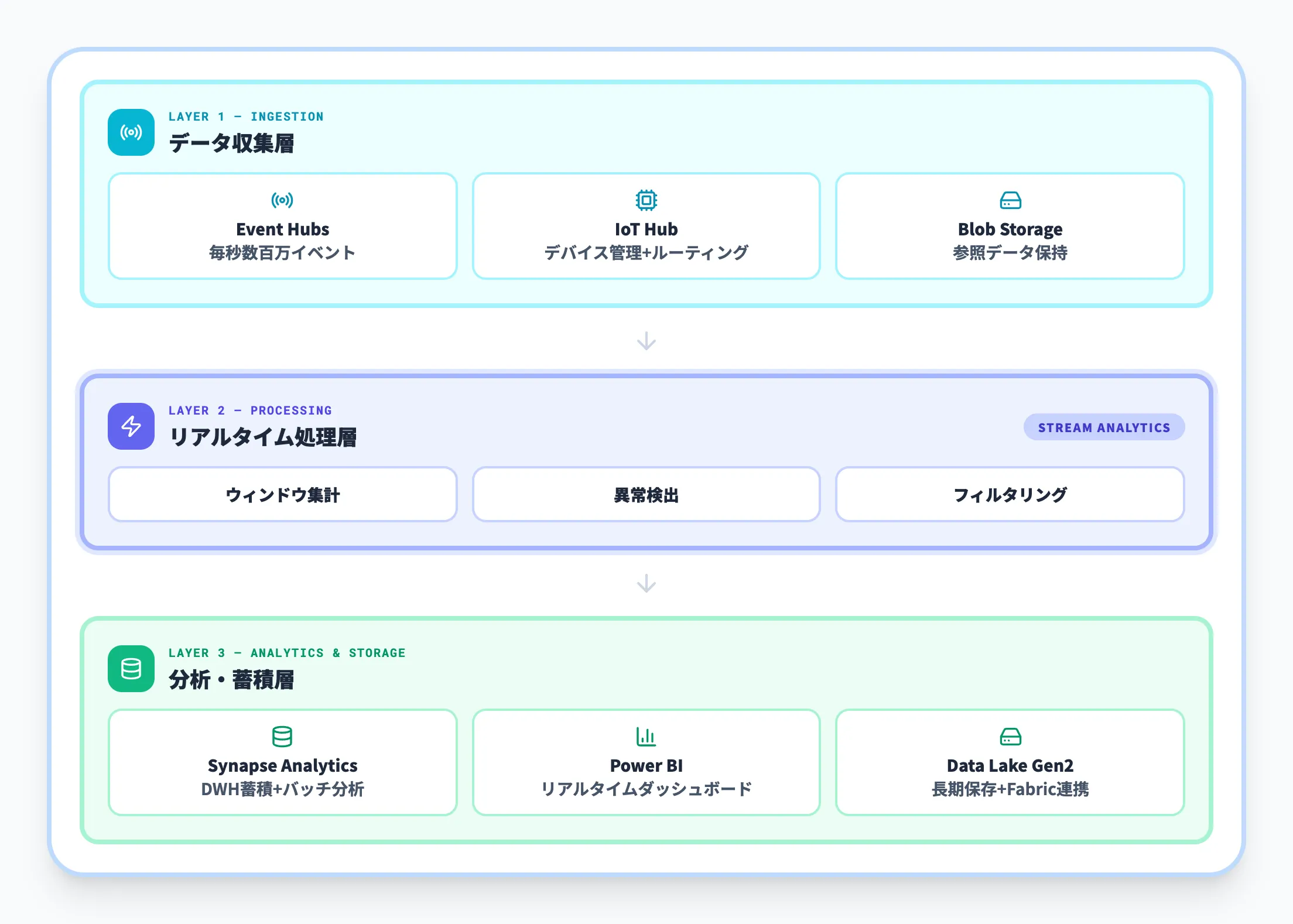
典型的な構成は以下のとおりです。
-
データ収集層
Azure Event Hubsが毎秒数百万イベントをキューイングし、Azure IoT Hubがデバイス管理とメッセージルーティングを担う
-
リアルタイム処理層
Azure Stream Analyticsがストリームデータを受け取り、ウィンドウ集計・異常検出・フィルタリングを実行する
-
分析・蓄積層
処理結果をAzure Synapse Analyticsのデータウェアハウスに蓄積してバッチ分析と組み合わせたり、Power BIにリアルタイム配信してダッシュボードを構築する
この構成により、「Event Hubs → Stream Analytics → Synapse / Power BI」という一貫したデータフローが実現します。既にEvent HubsやIoT Hubを導入済みの環境であれば、Stream Analyticsジョブを追加するだけでリアルタイム分析基盤を即座に立ち上げることが可能です。
Microsoft Fabric環境との併用も可能です。
Stream Analyticsの出力をAzure Data Lake Storage Gen2に書き込み、OneLakeのショートカット機能(ADLS Gen2互換API)を通じてFabric側から参照する構成が取れます。
Fabricとの使い分けについては後述の比較セクションで詳しく解説します。
Azure Stream Analyticsの主な機能
Azure Stream Analyticsは、SQLに慣れた開発者が短時間でストリーム処理ジョブを構築できる設計になっています。
ここでは、実務で特に重要な5つの機能を解説します。

SQLベースのストリームクエリ言語

Azure Stream Analyticsのクエリは、標準SQLを拡張した**Stream Analytics Query Language(SAQL)**で記述します。
SELECT、WHERE、GROUP BY、JOINといったおなじみの構文がそのまま使えるため、RDBMSの経験があればすぐに書き始められます。
通常のSQLとの大きな違いは、時間軸を扱うテンポラル演算子が組み込まれている点です。
例えば、「直近5分間のセンサー値の平均を計算する」「2つのストリームを時間差10秒以内で結合する」といった時系列特有の処理を、SQL文の中で自然に記述できます。
さらに、Azure Machine Learningとの連携によりクエリ内でML(機械学習)モデルを呼び出すことも可能です。
クラウドジョブではJavaScriptによるユーザー定義関数(UDF)とユーザー定義集計(UDA)に対応しており、SQLだけでは表現しきれない複雑なロジックを組み込めます。
ウィンドウ関数による時系列分析
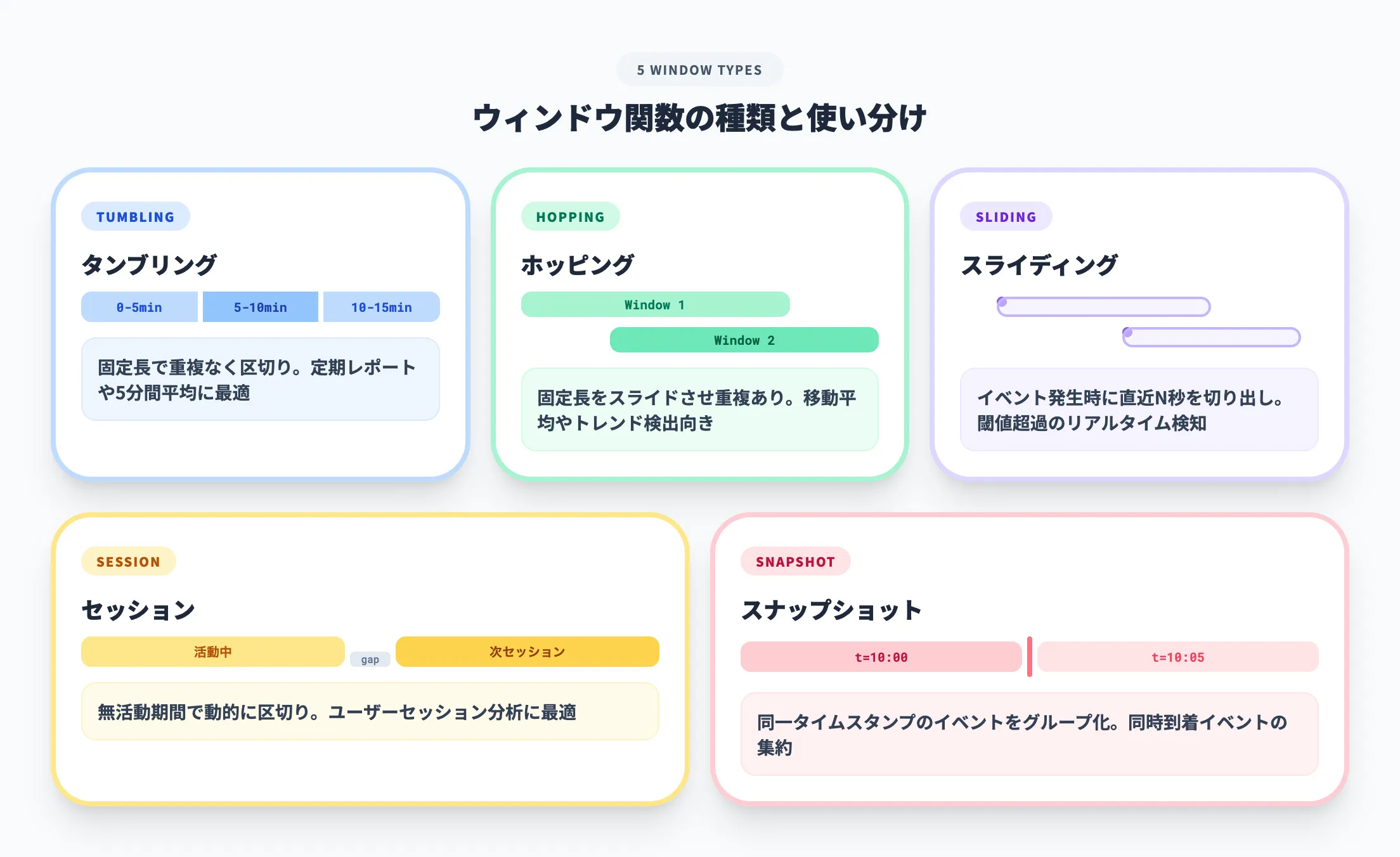
ストリームデータの分析で最も頻繁に使う機能がウィンドウ関数です。連続的に流れるデータを一定の区切りでまとめ、集計や比較を行います。
Azure Stream Analyticsが提供するウィンドウ関数は以下のとおりです。
| ウィンドウ種類 | 動作 | ユースケース |
|---|---|---|
| タンブリングウィンドウ | 固定長で重複なく区切る(例:5分ごと) | 定期レポート、5分間平均気温 |
| ホッピングウィンドウ | 固定長でスライドさせながら区切る | 移動平均、トレンド検出 |
| スライディングウィンドウ | イベント発生時に直近N秒を切り出す | 閾値超過のリアルタイム検知 |
| セッションウィンドウ | イベント間の無活動期間で区切る | ユーザーセッション分析 |
| スナップショットウィンドウ | 同一タイムスタンプのイベントをグループ化 | 同時到着イベントの集約 |
実務で最も使われるのはタンブリングウィンドウです。「5分ごとにセンサー値の平均を計算してアラートを判定する」といった定型的なリアルタイム集計に適しています。
一方、ユーザー行動分析のように「操作が途切れたらセッション終了」という動的な区切りが必要な場面ではセッションウィンドウが有効です。
ノーコードエディター(プレビュー)

Azure Stream Analyticsには、Azure Portal上で使える**ノーコードエディター(ドラッグ&ドロップ型のビジュアルエディター)**が用意されています。
SQLを書かなくても、入力ソースの選択 → 変換ロジックの設定 → 出力先の指定をGUI上で完結できます。フィルタリング、集計、結合といった基本操作はすべてノーコードで設定可能です。
この機能は、データエンジニアだけでなくビジネスアナリストやIT管理者がストリーム処理ジョブを構築する場面で特に有効です。
また、複雑なテンポラルジョインやカスタムUDFが必要な場合はSQLクエリエディターに切り替える必要があります。
ノーコードエディター画面
IoT Edgeへの展開
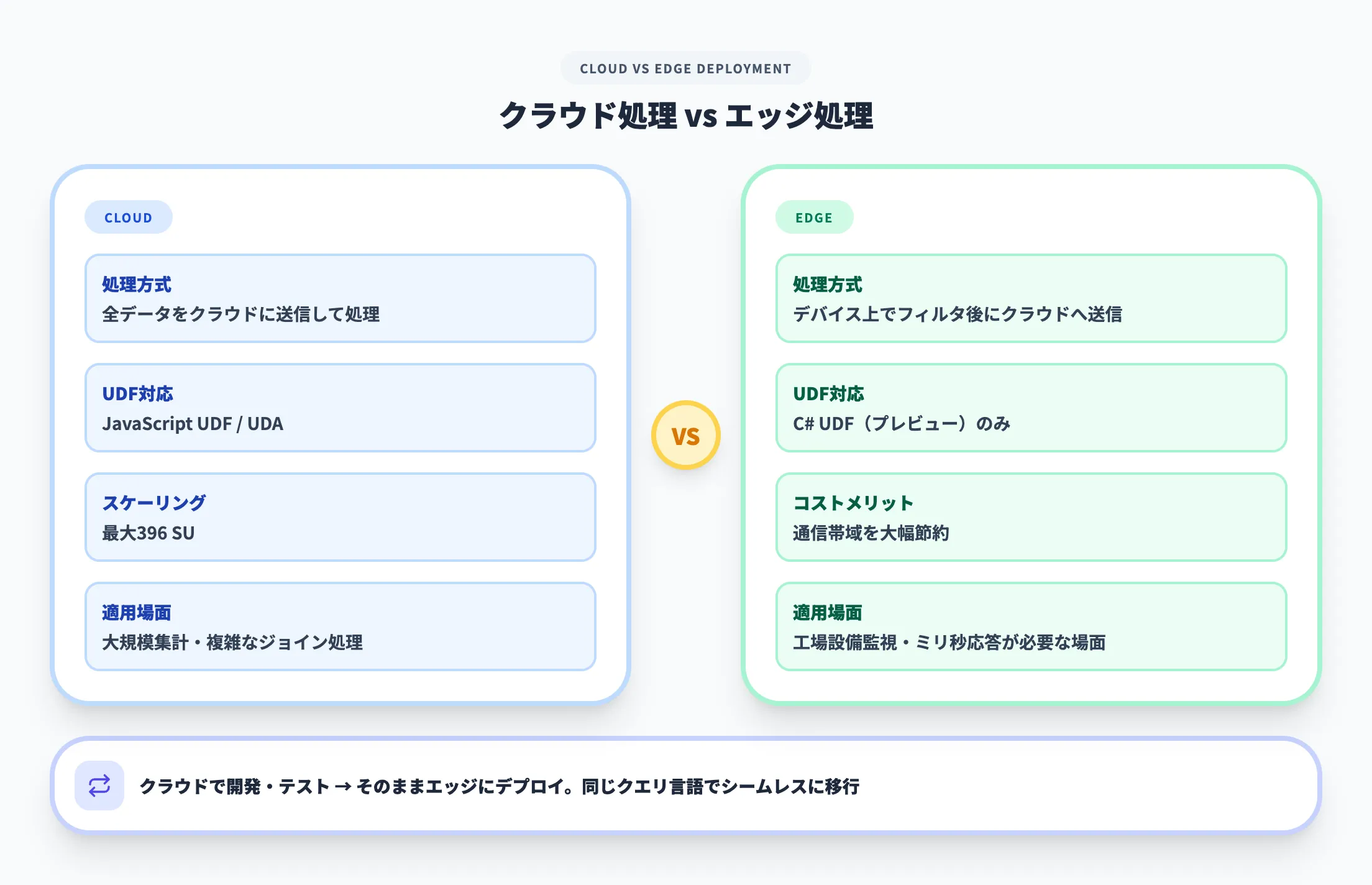
Azure Stream Analyticsは、クラウド上だけでなくIoT Edgeデバイス上でもクエリを実行できます。
Azure IoT Edge ランタイム上にStream Analyticsモジュールをデプロイすることで、データをクラウドに送信する前にエッジ側でフィルタリングや集計を行えます。
エッジ展開のメリットは2つあります。
-
ネットワーク帯域の節約
大量のセンサーデータをすべてクラウドに送るのではなく、異常値や集計結果だけを送信することで通信コストを大幅に削減できます。 -
レイテンシの短縮
工場の設備監視など、ミリ秒単位の応答が求められる場面では、クラウドへのラウンドトリップを省略できるエッジ処理が不可欠です。
クラウドとエッジで同じクエリ言語・開発ツールが使えるため、まずクラウドで開発・テストしたジョブをエッジにそのまま配布するワークフローが成立します。
入出力コネクタ

Azure Stream Analyticsは、Azureサービスとのネイティブ統合を中心に15種類以上の入出力コネクタを備えています。
主要な入力ソースと出力先を以下にまとめます。
| 区分 | サービス |
|---|---|
| ストリーム入力 | Azure Event Hubs、Azure IoT Hub、Azure Blob Storage、Apache Kafka(Confluent Cloud経由) |
| 参照入力 | Azure Blob Storage、Azure SQL Database |
| 出力先 | Azure SQL Database、Azure Synapse Analytics、Azure Cosmos DB、Azure Blob Storage / Data Lake Storage Gen2、Power BI(2027年10月停止予定)、Azure Event Hubs、Azure Functions、Azure Service Bus |
入力にはEvent HubsまたはIoT Hubを使うパターンが最も一般的です。
出力先はユースケースに応じて使い分け、リアルタイムダッシュボードならPower BI(ただし2027年10月停止予定のため新規ならFabric推奨)、長期蓄積ならAzure Data Lake StorageやSynapse、イベント駆動型のアクションならAzure FunctionsやEvent Hubsへの再配信が定番です。
2026年3月時点では、Delta Lake形式での出力にも対応しており、ADLS Gen2上にACIDトランザクション付きでストリームデータを書き込めるようになっています。
レイクハウスアーキテクチャを採用している環境では、バッチとストリームのデータを統一的に管理できる構成が取れます。
Azure Stream Analyticsを導入するメリット
「リアルタイム処理が必要なのは分かっているが、自前でインフラを構築・運用するリソースがない」——Stream Analyticsを検討するチームの多くが、この状態からスタートしています。
ここでは、どういう課題を抱えている組織にStream Analyticsが効くのかを整理します。
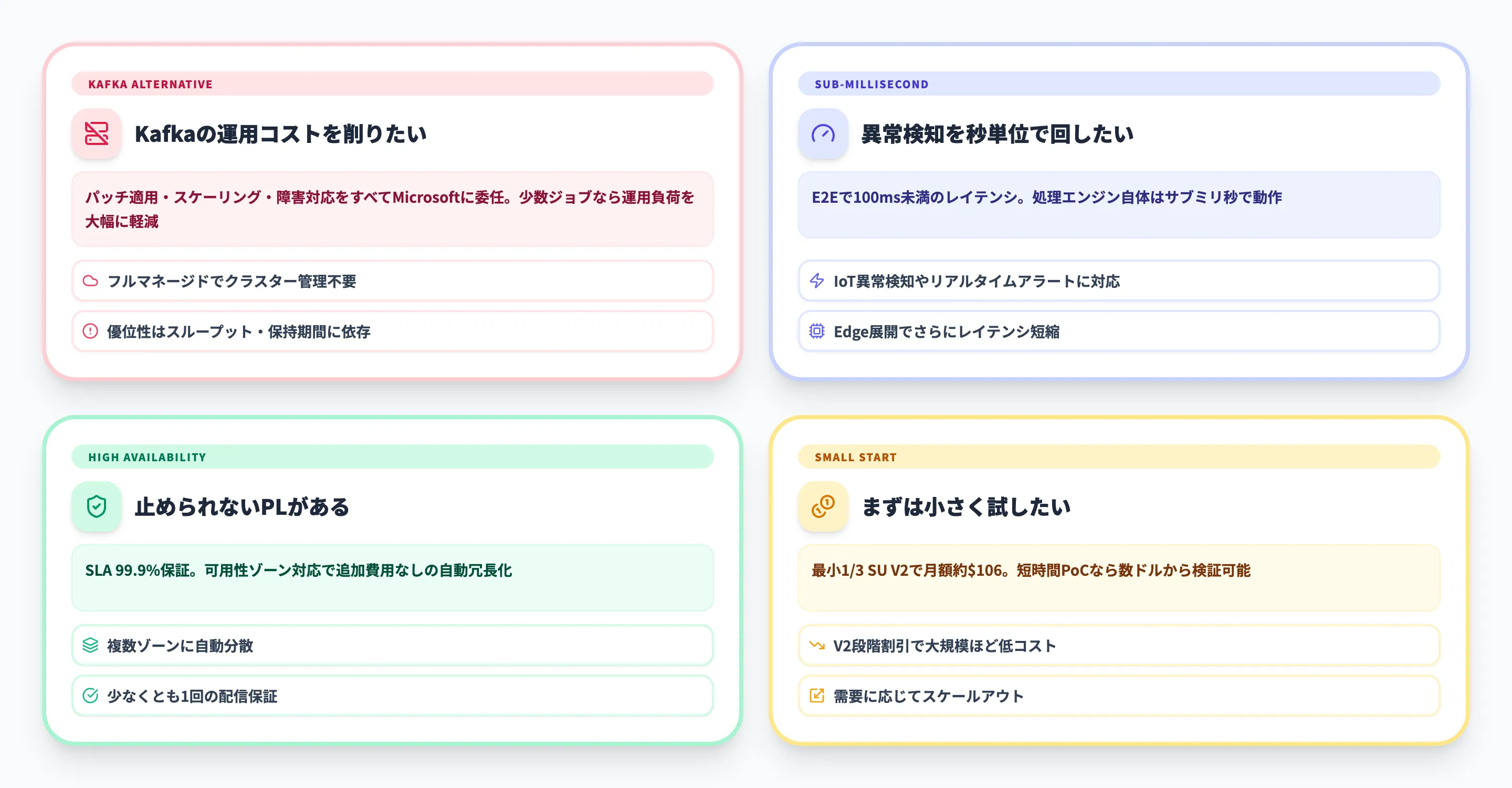
Apache Kafkaの運用コストを削りたい場合
Kafkaクラスターを自前運用するには、パッチ適用・スケーリング・障害対応をすべて自社で行う必要があります。
Stream Analyticsはこれらがすべてマネージドサービスとして提供されるため、ストリーム処理のジョブを数個動かす程度であれば、クラスター維持と比べて運用負荷とコストを下げやすいケースがあります。
ただし優位性はスループット・データ保持期間・運用体制に依存するため、個別の比較検討は必要です。数名のチームでリアルタイム分析を始めたい場合に特に有効です
-
異常検知を秒単位で回したい場合
Event Hubsへの入力からStream Analyticsの処理を経てEvent Hubsに出力するまで、ネットワーク遅延を含めて100ミリ秒未満のエンドツーエンドレイテンシを実現しています。処理エンジン自体はサブミリ秒で動作するため、IoTの異常検知やリアルタイムアラートなど、即座にアクションが必要な場面に対応できます
-
止められないパイプラインがある場合
ジョブレベルで99.9%のSLAが保証されています。可用性ゾーン対応リージョンでは追加費用なしで自動的にリソースが複数ゾーンに分散され、ゾーン障害時にも処理が継続します。
イベント処理の「少なくとも1回の配信」も保証されており、データの欠損リスクを最小化できます
-
まずは小さく試したい場合
課金はストリーミングユニット(SU)単位の時間課金です。V2モデルでは最小1/3 SUから開始でき、常時稼働でも月額約$106相当、短時間のPoCであれば数ドルから試せます。
負荷が増えたら段階的にスケールアウトでき、V2の段階的割引で利用量が増えるほど単価が下がる設計になっています
実際には「まず1つのStream Analyticsジョブで異常検知だけ動かし、効果を確認してから本格展開する」というステップを踏むケースが多くあります。
初期検証に必要なコストは1/3 SUで月額$100程度なので、PoCのハードルは低いと言えます。
Azure Stream Analyticsの利用手順
Azure Stream Analyticsは、Azure Portal上の操作だけでジョブを作成・実行できます。
ここでは、初めてStream Analyticsを触る方向けに、ジョブ作成から動作確認までの流れと、初期構築で詰まりやすいポイントを解説します。
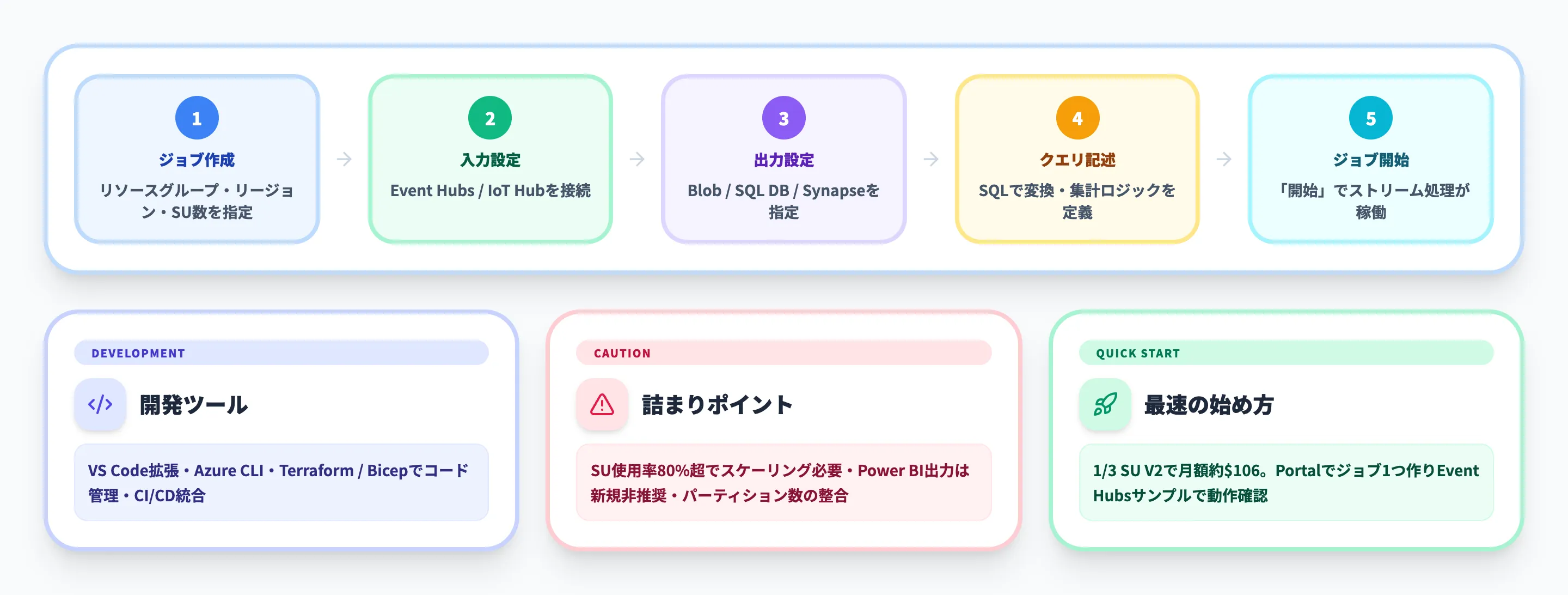
Azure Portalでのジョブ作成手順
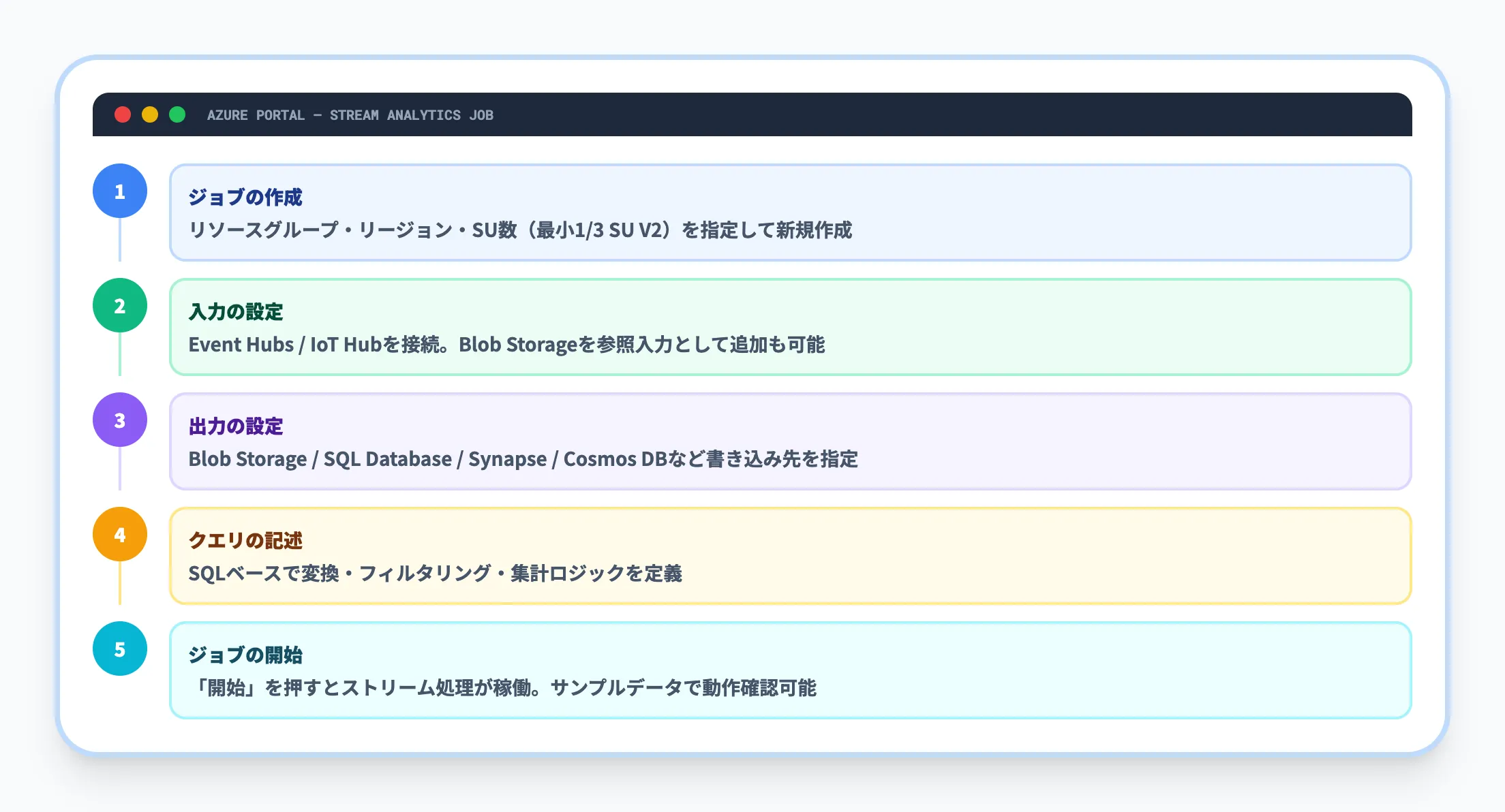
Stream Analyticsジョブの作成から動作確認までは、以下の5ステップで完了します。
| ステップ | 操作内容 |
|---|---|
| 1. ジョブの作成 | Azure Portalで「Stream Analyticsジョブ」を新規作成。リソースグループ、リージョン、SU数(最小1/3 SU V2)を指定する |
| 2. 入力の設定 | ジョブの「入力」からEvent HubsまたはIoT Hubを接続。Blob Storageを参照入力として追加することも可能 |
| 3. 出力の設定 | ジョブの「出力」から書き込み先(Blob Storage、SQL Database、Synapse、Cosmos DBなど)を指定する |
| 4. クエリの記述 | SQLベースのクエリで、入力データの変換・フィルタリング・集計ロジックを記述する |
| 5. ジョブの開始 | 「開始」を押すとジョブが起動し、ストリームデータの処理が始まる |
公式のクイックスタートガイドでは、IoT Hubからのセンサーデータを受け取り、温度が27度を超えるレコードだけをBlob Storageに書き出すサンプルジョブを数分で構築できます。
実際のAzure Portal画面で各ステップを見ていきます。以下はIoT Hubからのセンサーデータを受け取り、温度が27度を超えたレコードだけをBlob Storageへ書き出す最小構成のジョブです。
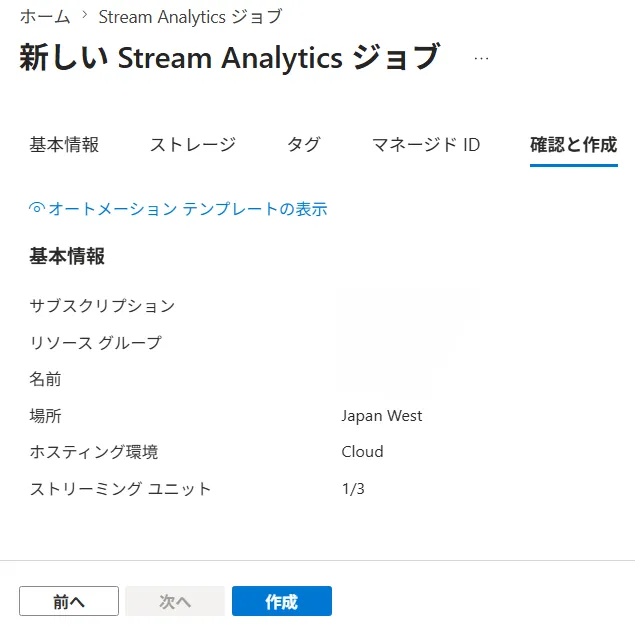
ジョブの新規作成画面
以下のように作成したジョブの概要を確認できます。
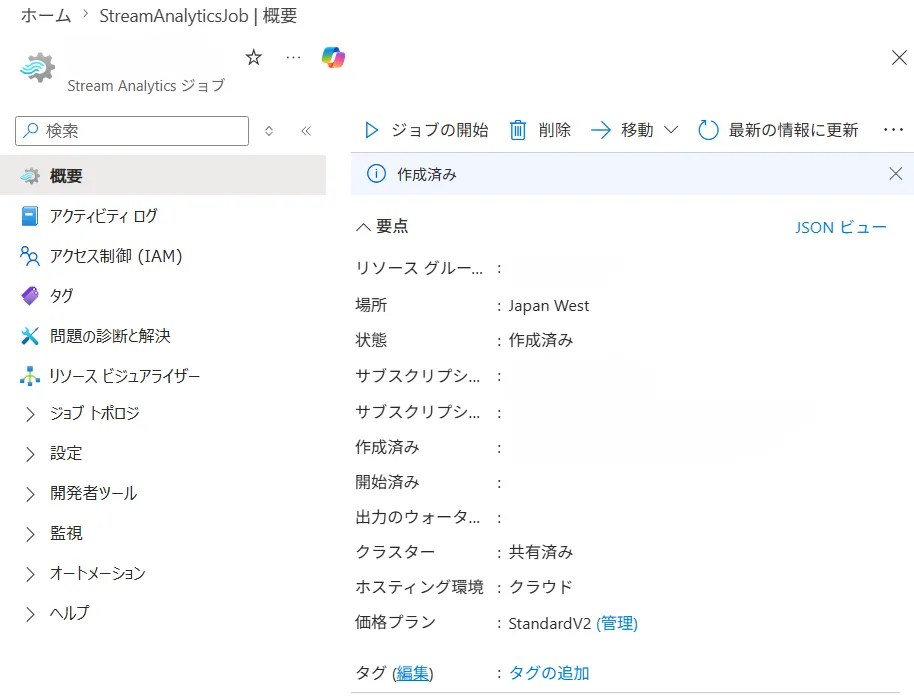
ジョブの概要確認画面
概要画面の左メニューから「入力」に「IoT Hub」を選択し、接続情報を入力します。
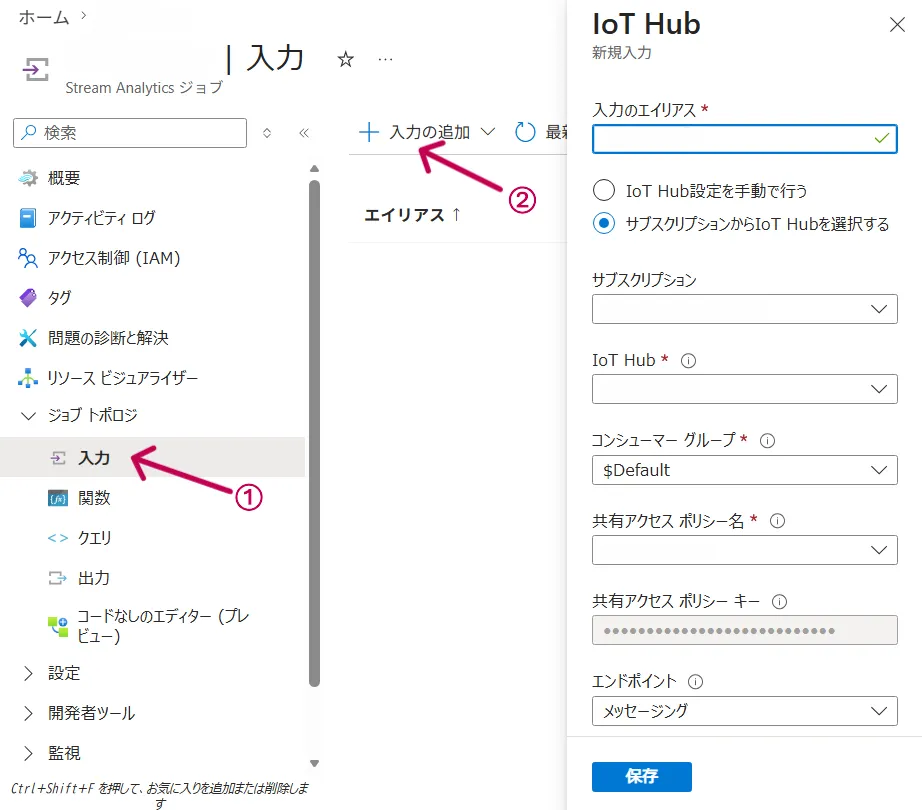
入力(Input)設定画面
概要画面の左メニューから「出力」に「Blob Storage または ADLS Gen2」を選択し、接続情報を入力します。
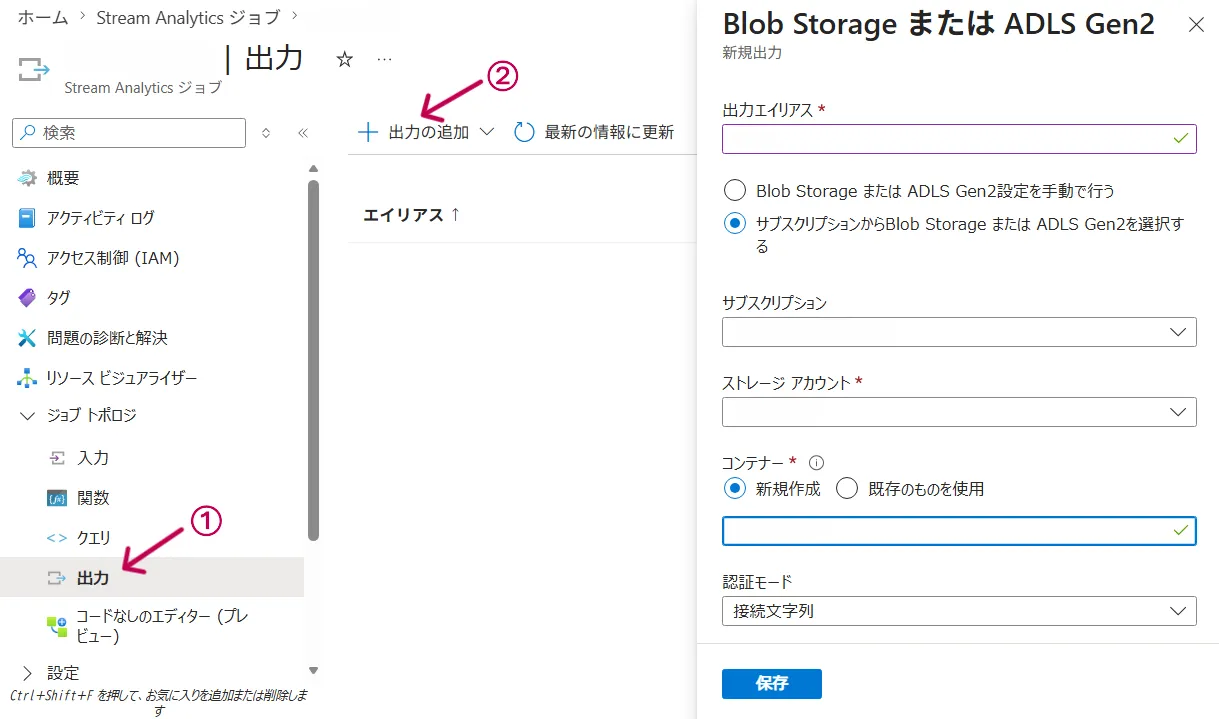
出力(Output)設定画面
概要画面の左メニューから「クエリ」を選択し、IoT Hubからのセンサーデータを受け取り、温度が27度を超えるレコードだけをBlob Storageに書き出すクエリを入力します。
実際に受け取ったセンサーデータを確認することも可能です。
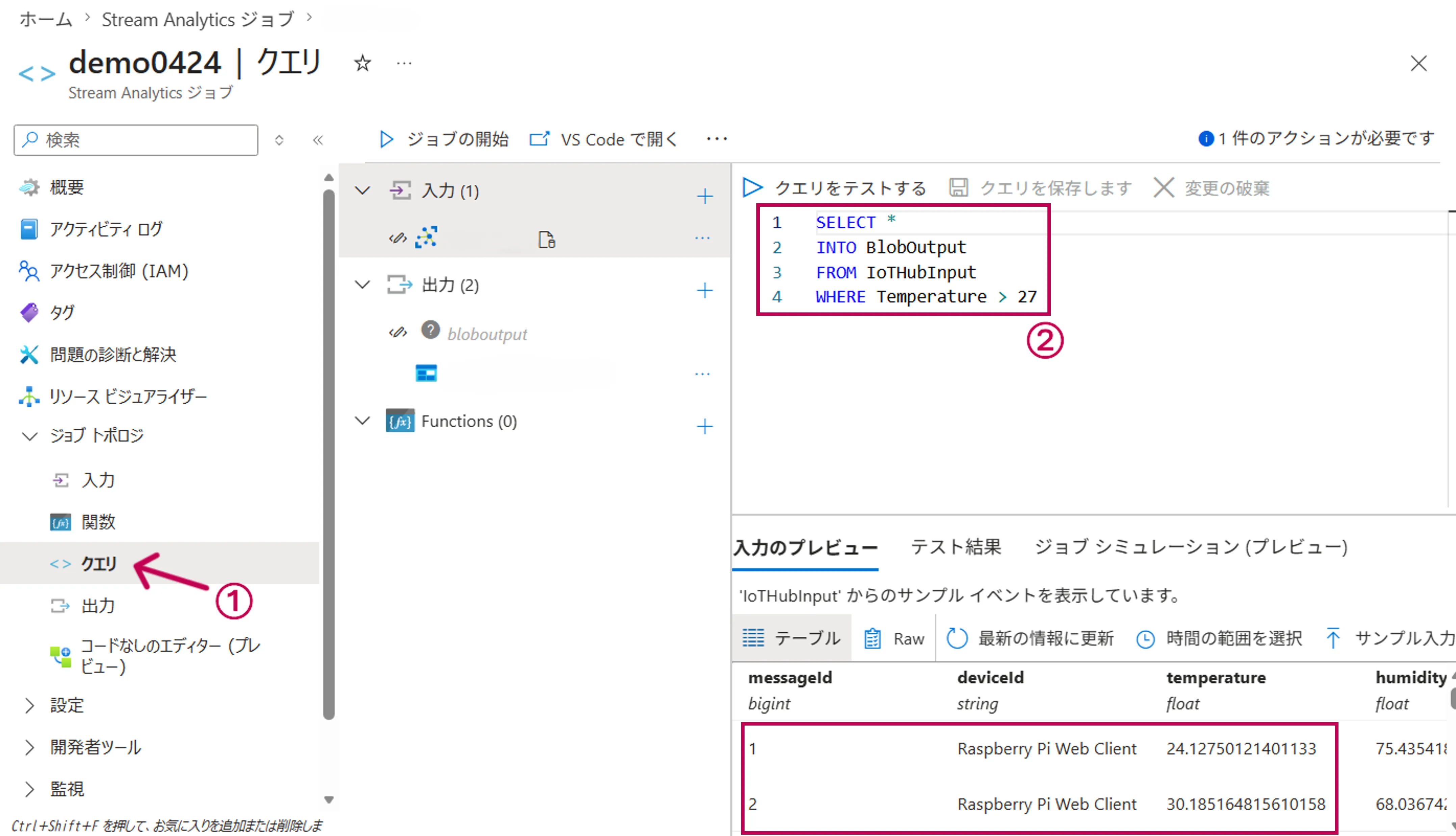
クエリエディター画面
概要画面で「開始」をクリックすると、実際にジョブが開始されます。
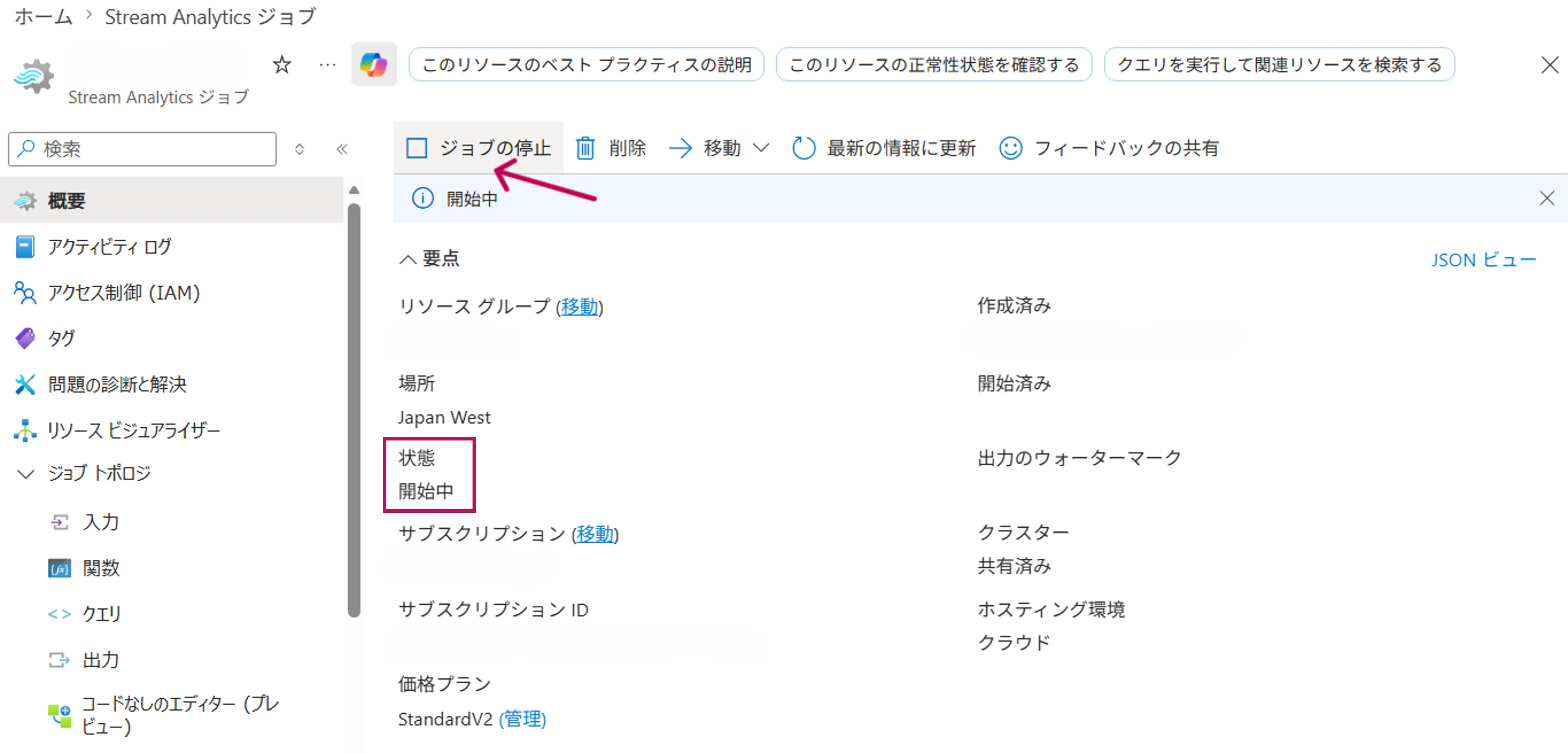
ジョブ開始画面
詳細な手順はAzure公式ドキュメントを参照してください。
クエリの基本構文
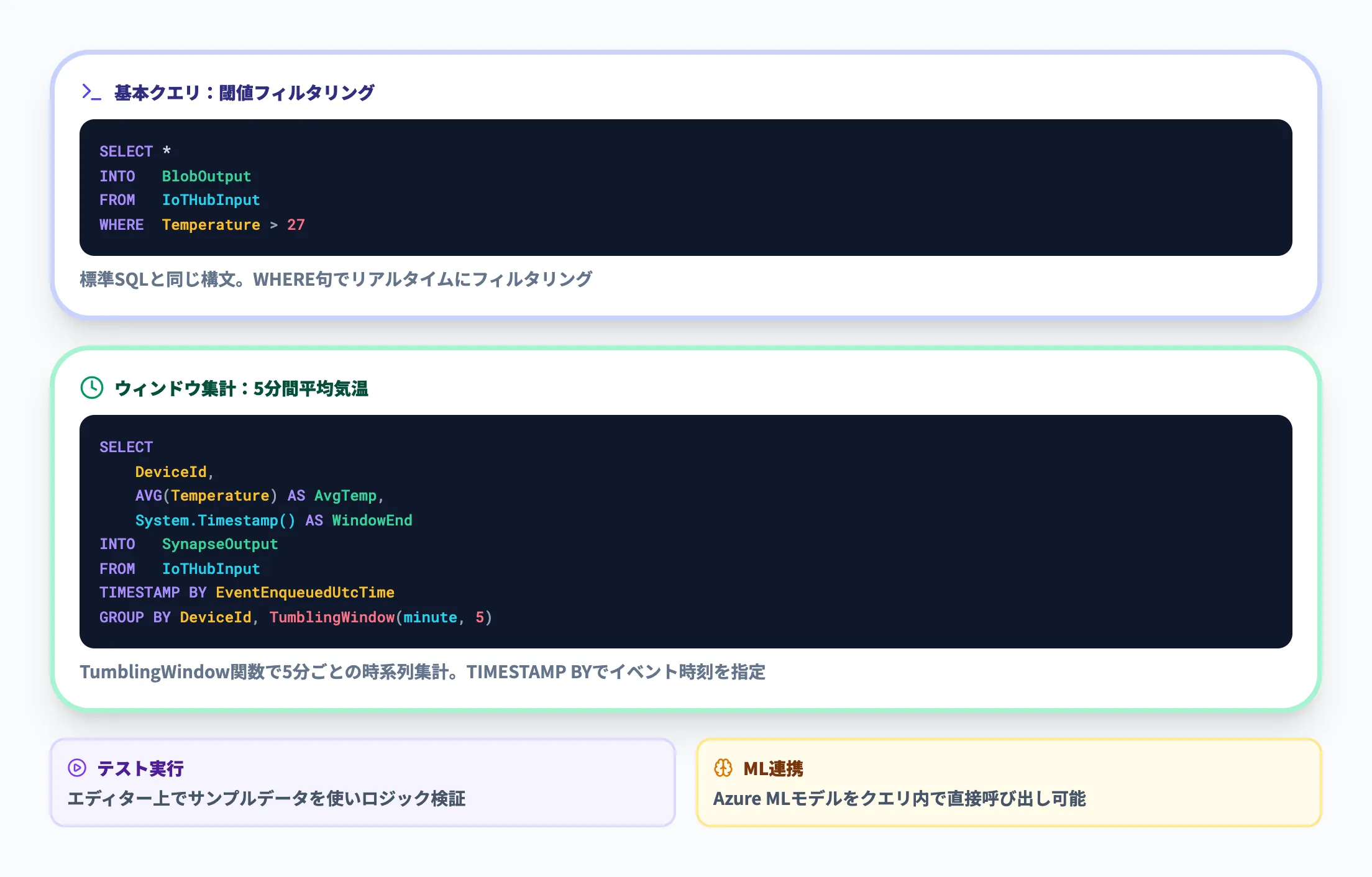
Stream Analyticsのクエリは、標準SQLに時間軸の概念を加えたものです。最もシンプルな例は以下のとおりです。
SELECT *
INTO BlobOutput
FROM IoTHubInput
WHERE Temperature > 27
ウィンドウ関数を使えば、「5分ごとの平均気温」のようなリアルタイム集計も1行で書けます。
SELECT
DeviceId,
AVG(Temperature) AS AvgTemp,
System.Timestamp() AS WindowEnd
INTO SynapseOutput
FROM IoTHubInput
TIMESTAMP BY EventEnqueuedUtcTime
GROUP BY DeviceId, TumblingWindow(minute, 5)
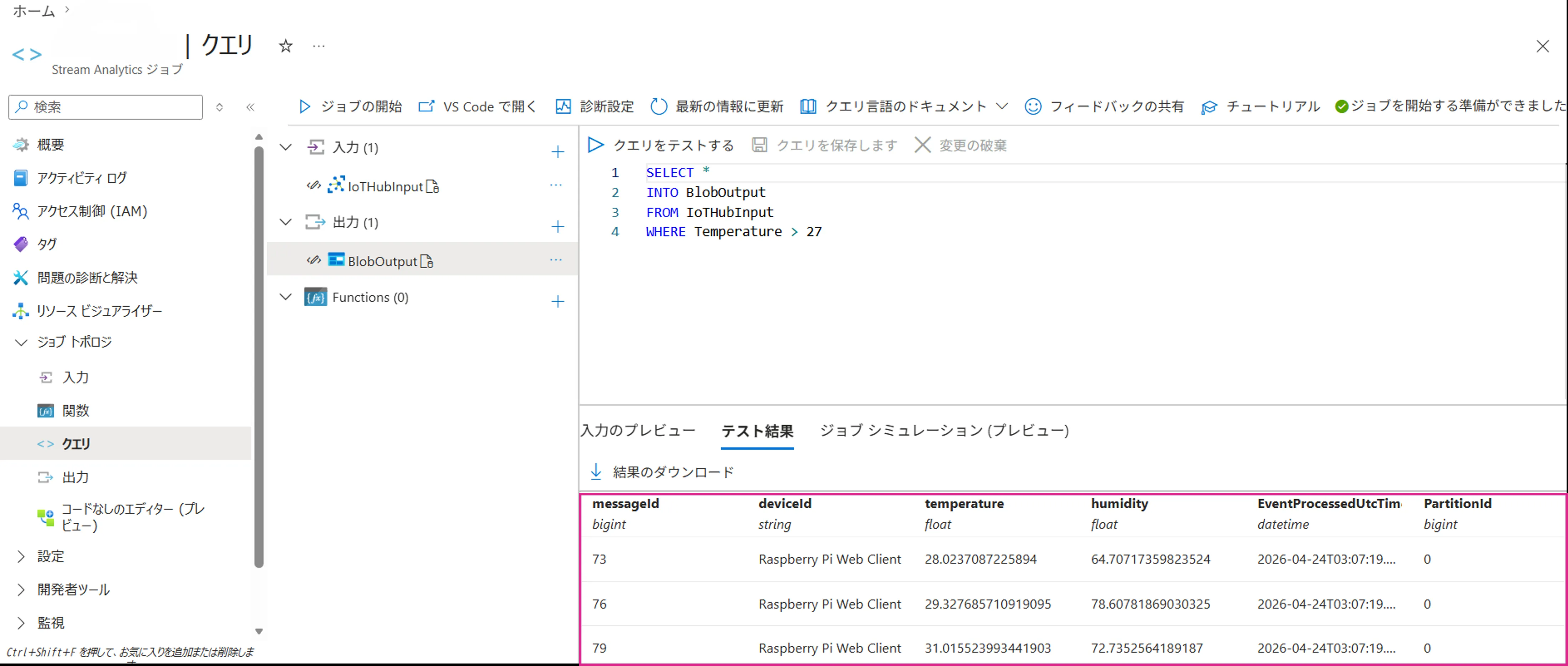
クエリエディターのテスト実行画面
クエリエディター上でサンプルデータを使ったテスト実行が可能なため、本番データを流す前にロジックを検証できます。
開発ツールとCI/CD

Azure Portal以外にも、以下の開発ツールからジョブを作成・管理できます。
-
Visual Studio Code
Stream Analytics拡張をインストールすることで、ローカルでのクエリ開発・テスト・デプロイが可能
-
Azure CLI / PowerShell
コマンドラインからのジョブ操作に対応。スクリプト化して定型作業を自動化できる
-
Terraform / Bicep / ARMテンプレート
Infrastructure as Codeとしてジョブ定義を管理し、CI/CDパイプラインに組み込める
チーム開発では、Visual Studio CodeでクエリをGit管理し、CI/CDパイプラインでAzureにデプロイする構成が推奨されています。ノーコードエディターで作ったジョブもSQLに変換できるため、まずノーコードでプロトタイプを作り、本番化の段階でコード管理に移行するアプローチも取れます。
初期構築で詰まりやすいポイント

Stream Analyticsのジョブ作成自体は簡単ですが、本番運用を見据えると以下のポイントでつまずくケースがあります。
- SU使用率が80%を超えたらスケーリングが必要
SU%利用率メトリクスを監視し、80%を超える状態が続く場合はSU数を増やす。突発的なスパイクに備え、常に余裕を持たせておくのが定石
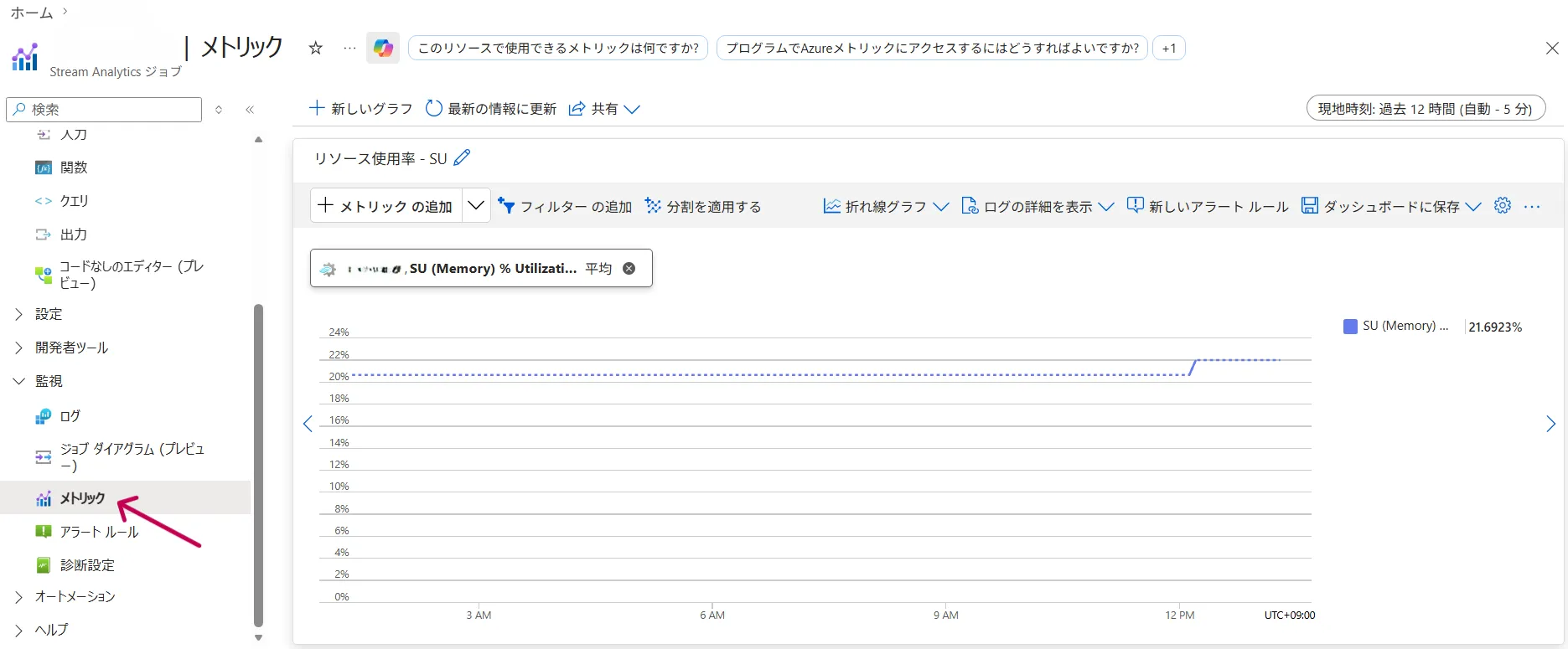
メトリクスグラフ画面
-
入力パーティション数とSU数のミスマッチ
Event Hubsのパーティション数とStream AnalyticsのSU数が合っていないと、並列処理が最適化されない。PARTITION BY句を活用し、各パーティションを独立して処理する構成にする
-
Power BI出力は新規で使わない
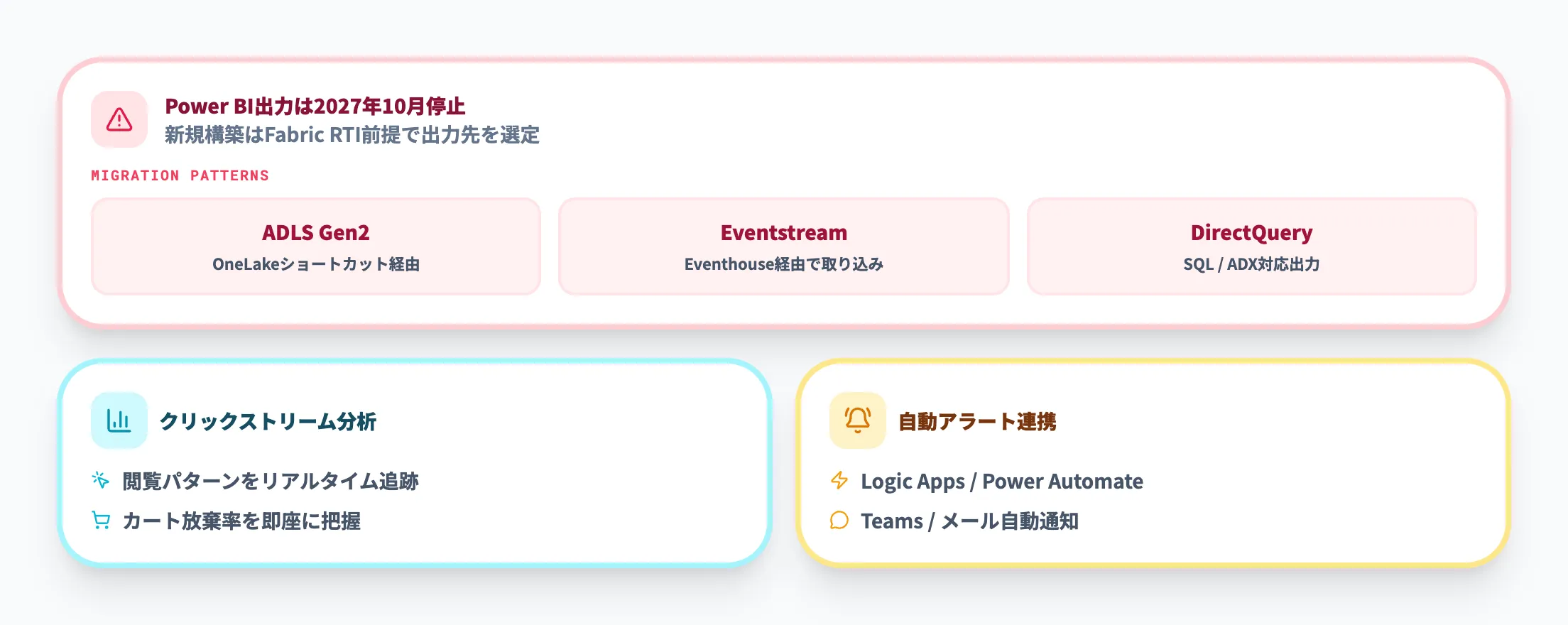
Power BI出力コネクタは2027年10月31日に停止が予定されています。
新規構築の場合は、Fabric Real-Time Intelligenceへの移行を前提に出力先を検討してください。
- 参照データの更新タイミング
Blob Storageの参照データは定期的にリロードされますが、更新間隔はBlobのタイムスタンプに依存します。マスタデータを頻繁に更新する場合は、SQL Databaseの参照入力の方が適しています

Azure Stream Analyticsの活用シーン
Azure Stream Analyticsは、「データは大量にあるのにリアルタイムで活用できていない」という課題を抱える組織で広く使われています。
ここでは代表的な4つのシーンを、解決すべき課題とセットで紹介します。

IoTセンサーデータの異常検出
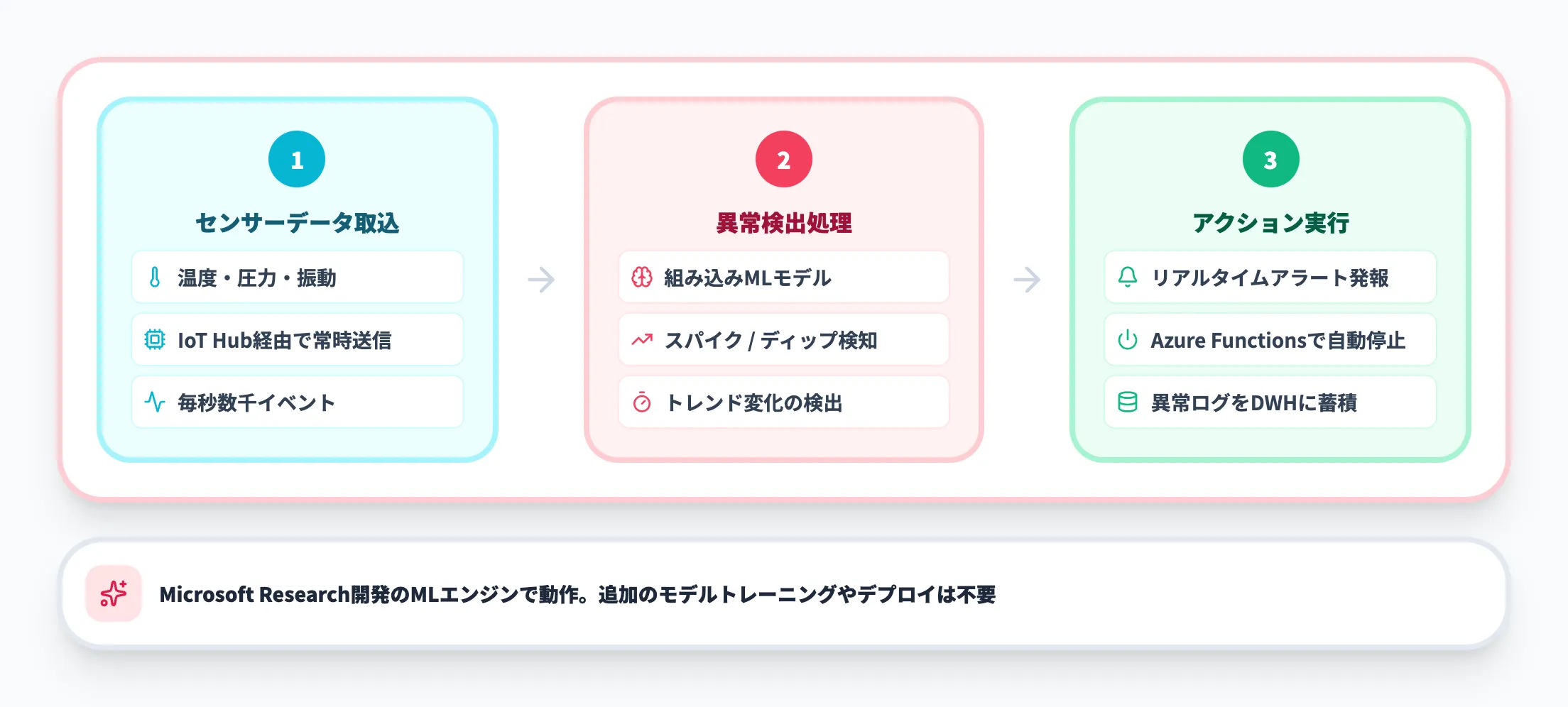
「設備の温度が閾値を超えてから、アラートが管理者に届くまでに数十分かかる」——この遅延が、設備の損傷拡大やラインの停止につながるケースは少なくありません。
Azure Stream Analyticsには組み込みの異常検出モデルが搭載されており、急上昇(スパイク)、急減(ディップ)、緩やかなトレンド変化を自動的に検出できます。
工場の温度センサーが通常範囲を逸脱した瞬間にアラートを発報し、Azure Functionsを通じて設備を自動停止させるといった構成が実現可能です。
組み込み異常検出関数の使用画面
この異常検出はMicrosoft Researchとの共同開発による機械学習エンジンで動作し、追加のMLモデルのトレーニングやデプロイは不要です。
数百台規模のセンサーを常時監視する場合でも、IoT Edgeとの併用でエッジ側の事前フィルタリングとクラウド側の異常検出を組み合わせることで、通信コストを抑えつつ検出精度を維持できます。
リアルタイムETL(ストリーミングETL)
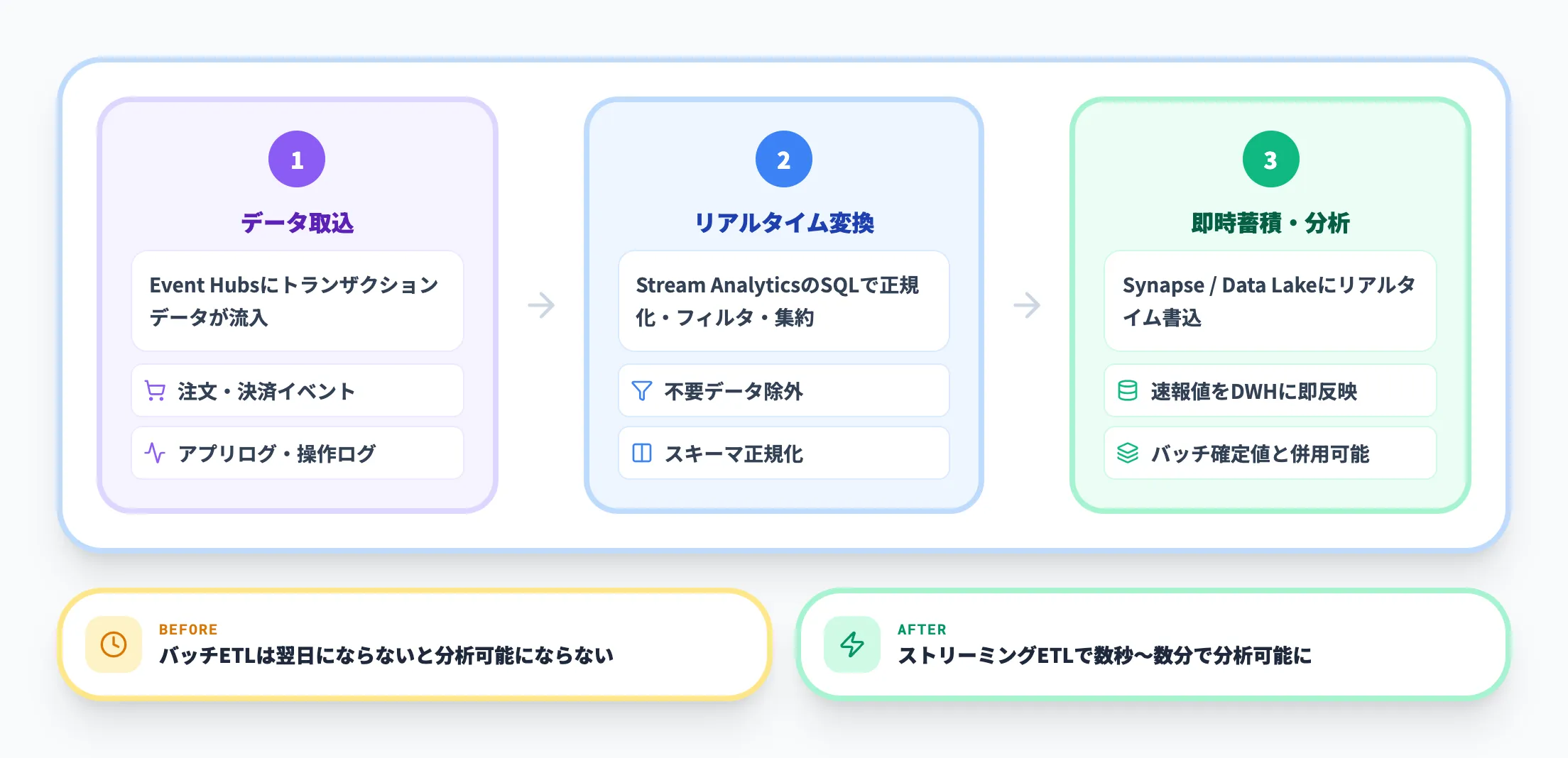
「日次のバッチETLでは、売上データや在庫データの分析結果が翌日にならないと出ない。経営判断のスピードが上がらない」——この課題に対する解がリアルタイムETLです。
Stream Analyticsを使えば、Event Hubsに流入するトランザクションデータを正規化・フィルタリング・集約し、Azure Synapse AnalyticsやData Lake Storageにリアルタイムで書き込めます。従来のバッチETLと併用することで、「速報値はリアルタイム、確定値はバッチ」というハイブリッドなデータパイプラインも構築できます。
Delta Lake形式での出力を使えば、ACIDトランザクション付きでストリームデータをレイクハウスに書き込めるため、Fabric環境との親和性も高い構成です。
ダッシュボードとリアルタイムアラート
Stream Analyticsの出力をPower BIのストリーミングデータセットに直接接続すると、数秒単位で更新されるリアルタイムダッシュボードを構築できます。
ADLS Gen2経由、Eventstream/Eventhouse経由、DirectQuery対応出力など複数の移行パターンがあり、要件に応じて選択します。
ECサイトのクリックストリーム分析では、ユーザーのページ閲覧パターンやカート放棄率をリアルタイムで追跡し、マーケティング施策の効果を即座に把握できます。異常値が検出された場合には、Azure Logic AppsやPower Automateと連携してTeamsチャンネルやメールに自動通知を送る構成も一般的です。
地理空間分析と予測メンテナンス

Stream Analyticsは地理空間関数をクエリ言語に組み込んでおり、緯度・経度のポイントデータに対するジオフェンシング(特定エリアへの出入り検知)処理をSQLだけで記述できます。
車両管理や配送トラッキングでは、車両がエリアに進入または離脱したタイミングでイベントを発火し、ドライバーへの通知や配車システムの更新を行うパターンが利用されています。
参照データ(地理空間ポリゴンデータ)をBlob Storageに配置し、ストリームデータとの結合で実現します。
「設備の状態監視データをクラウドに集約し、故障予兆を検出して保守チームに通知する」という予測メンテナンスのパターンでは、IoT Hub → Stream Analytics → Azure Machine Learningスコアリング → アラート発報という構成がよく採用されています。
Azure Stream AnalyticsとFabric Real-Time Intelligenceの比較
リアルタイムデータ分析のAzureサービスとして、Microsoft Fabric Real-Time Intelligenceも選択肢に挙がります。
「結局どっちを使えばいいのか」は、AI総研への相談でも最も多い論点です。両者は補完関係にありますが、設計思想とターゲットユーザーが明確に異なります。
設計思想の違い
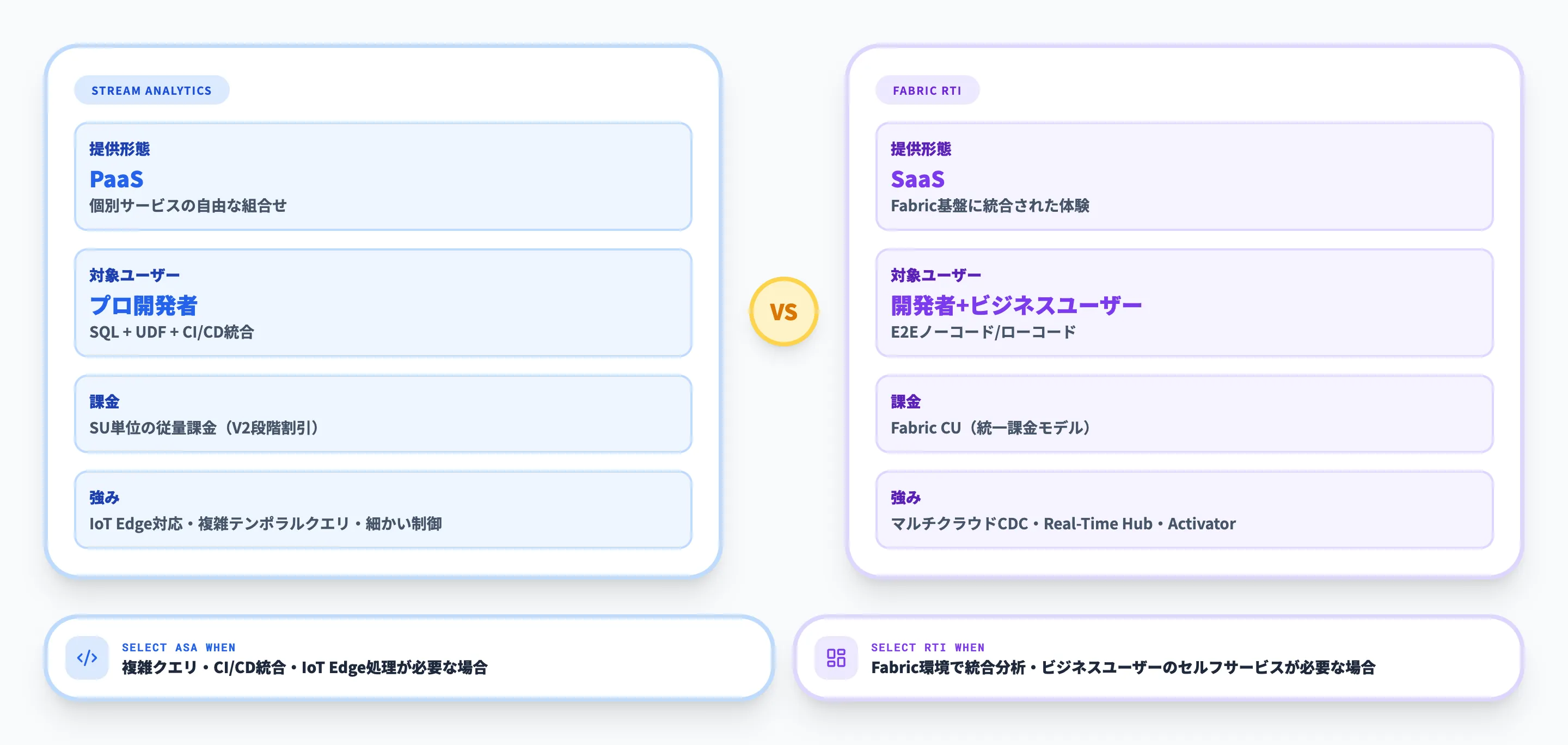
Azure Stream AnalyticsはPaaS型のサービスです。Azure上の各サービス(Event Hubs、IoT Hub、Synapse等)と個別に連携し、開発者がアーキテクチャを自由に設計できます。
複雑なイベント処理やカスタムUDFの組み込み、CI/CD(継続的インテグレーション/継続的デリバリー:コードの変更を自動でテスト・デプロイする仕組み)パイプラインとの統合など、プロの開発者が細かい制御を求める場面に適しています。
一方、Fabric Real-Time Intelligenceは**SaaS型(ソフトウェアをそのまま利用する形態)**です。
Microsoft Fabric基盤に統合された形で提供され、データの取り込みから分析・可視化・アクションまでをワンクリックで接続できます。
ローコード/ノーコードのエンドツーエンド体験を重視しており、ビジネスユーザーやシチズンデベロッパーがデータストリームを自ら発見して分析ソリューションを構築することを想定しています。
機能比較
Microsoft公式ドキュメントの情報をもとに、両サービスの主要な違いを比較します。
| 比較項目 | Azure Stream Analytics | Fabric Real-Time Intelligence |
|---|---|---|
| 提供形態 | PaaS(個別サービスの組み合わせ) | SaaS(Fabric基盤に統合) |
| 対象ユーザー | プロ開発者中心 | 開発者+ビジネスユーザー |
| 開発方式 | SQL + ノーコード(変換のみ) | エンドツーエンドのローコード/ノーコード |
| マルチクラウドコネクタ | Confluent Kafkaに対応 | Confluent Kafka、Amazon Kinesis、Google Pub/Sub対応 |
| CDC(変更データキャプチャ) | 別途Debezium等の導入が必要 | Cosmos DB、PostgreSQL、MySQL、Azure SQL対応 |
| 異常検出・予測 | 組み込みモデルあり(開発者向け) | 組み込みモデルあり(ビジネスユーザーも適用可) |
| 可視化 | Power BI連携(別途設定、2027年10月に停止予定) | Power BI + Real-Time Dashboardにワンクリック統合 |
| 課金モデル | SU単位の従量課金 | Fabric Capacity Unit(統一課金) |
| データカタログ | なし | Real-Time Hub(データストリームの統合カタログ) |
| アクション自動化 | Logic Apps / Azure Functionsと連携 | Fabric Activatorで組み込み連携 |
大きな違いはインテグレーションの深さです。Stream Analyticsは各Azureサービスを個別に組み合わせて自由度の高いアーキテクチャを構築できる一方、Fabric Real-Time Intelligenceはデータの取り込みからアクション発火までがFabric内で完結するため、導入スピードが速い設計になっています。
選び方の指針
どちらを選ぶべきかは、チームのスキルセットと既存環境で判断できます。AI総研の支援先での実績をもとに、判断基準を整理します。
-
Stream Analyticsを選ぶべきケース
既存のAzure PaaSアーキテクチャ(Event Hubs + Azure Functionsなど)にリアルタイム処理を追加する場合。
複雑なテンポラルクエリやカスタムUDFが必要な場合。CI/CDパイプラインとの統合が前提の場合。IoT Edgeでのエッジ処理が必要な場合
-
Fabric Real-Time Intelligenceを選ぶべきケース
Fabric環境を既に利用している、またはこれから導入する場合。ビジネスユーザーが自らダッシュボードやアラートを構築する要件がある場合。
マルチクラウドのデータストリーム(Kinesis、Google Pub/Sub等)を統合する場合。CDCでデータベースの変更を直接取り込む要件がある場合
実務では、既存のEvent Hubs + Stream Analytics構成を維持しつつ、新規のダッシュボード要件にはFabric Real-Time Intelligenceを採用するハイブリッド構成が増えています。
両者は排他的な選択ではなく、Stream Analyticsの出力をADLS Gen2に格納し、OneLakeのショートカット経由でFabric側から参照・分析する構成が実用的です。
特にPower BI出力コネクタの2027年10月停止を見据えると、可視化レイヤーの移行計画を早めに立てておくべきです。
移行パターンはADLS Gen2経由のOneLakeショートカット、Eventstream/Eventhouse経由、DirectQuery対応出力(SQL Server、Azure Data Explorerなど)と複数あり、既存ジョブの構成や可視化要件に応じて選択する形になります。
【関連記事】
Microsoft Fabric Real-Time Intelligenceとは?機能や料金体系を徹底解説
Azure Stream Analyticsの料金体系
Azure Stream Analyticsの料金は、ストリーミングユニット(SU)と呼ばれる計算リソースの使用量に基づく従量課金制です。
2023年7月に導入されたV2料金モデルへの移行が推奨されており、従来のV1モデルと比較して最大80%の値下げが実現されています。

V2料金モデル(推奨)
V2モデルでは、ストリーミングユニットの定義が見直されました。V1では6 SUが1つのストリーミングノードに対応していたのに対し、V2では1 SU = 1ストリーミングノードにシンプル化されています。
軽量なジョブ向けには1/3 SUや2/3 SUの分割容量も利用可能です。
以下は2026年3月時点のJapan East(東日本)リージョンにおけるV2 Standard料金です。
| 月間SU時間 | 1 SUあたりの単価(時間) |
|---|---|
| 0〜730 SU時間 | $0.4344 |
| 730〜5,840 SU時間 | $0.18588 |
| 5,840 SU時間超 | $0.15469 |
段階的割引が適用されるため、利用量が増えるほど1 SUあたりの単価が下がります。
たとえば1 SU V2のジョブを1か月(730時間)連続稼働させた場合の月額は約$317です。同じ計算量をV1で運用した場合(6 SU V1 × $0.138 = $0.828/時間 × 730時間 = 約$604)と比較すると、約47%のコスト削減になります。
さらに利用量が増える大規模環境では最大80%の削減に達します。
初期検証や軽量ジョブであれば1/3 SU V2(月額約$100)から始められるため、PoCのコストハードルは非常に低い設計です。
V1料金モデル
V1は固定単価のモデルで、Japan East(東日本)リージョンの料金は以下のとおりです。
| プラン | 1 SUあたりの単価(時間) |
|---|---|
| Standard | $0.138 |
| Dedicated | $0.138 |
V1では6 SU = 1ストリーミングノード(最大396 SU = 66ノード)という構成です。V1は引き続き利用可能ですが、非推奨(to be deprecated)のステータスであり、新規利用の場合はV2が推奨されています。
Azure Portal上のバナーからV2への切り替えが可能で、Visual Studio CodeではJobConfig.jsonの設定をStandard V2に変更することで移行できます。
IoT Edge料金
IoT Edge上で実行するStream Analyticsジョブの料金は別体系です。
| プラン | 料金 |
|---|---|
| S1(1デバイスあたり) | $1.00/月 |
| 5,000デバイス以上 | 個別見積もり |
エッジ側の処理で通信コストを削減できるため、デバイス数が多い場合でも全量をクラウドに送る構成よりトータルコストを抑えられるケースがあります。
コスト最適化のポイント
Stream Analyticsのコストを最適化するための主なアプローチは以下の3点です。
-
SU数の適正化
ジョブのSU使用率メトリクスを監視し、余剰があればSU数を削減する。最小1/3 SU V2からスケール可能なため、軽量ジョブは必要以上にリソースを割り当てない
-
クエリの効率化
パーティション分割を活用して並列処理を最適化し、1 SUあたりのスループットを最大化する。不要なカラムの除外やフィルタの早期適用も有効
-
V2モデルへの早期移行
V1で運用中のジョブがある場合、V2へ移行するだけで同じ計算量でのコストが大幅に下がる。
機能面の変更はないため、移行リスクは低い。V1は非推奨ステータスのため、早めの切り替えを推奨

Azure Stream Analyticsの注意点と制限事項
Azure Stream Analyticsは強力なサービスですが、導入前に把握しておくべき制限事項があります。
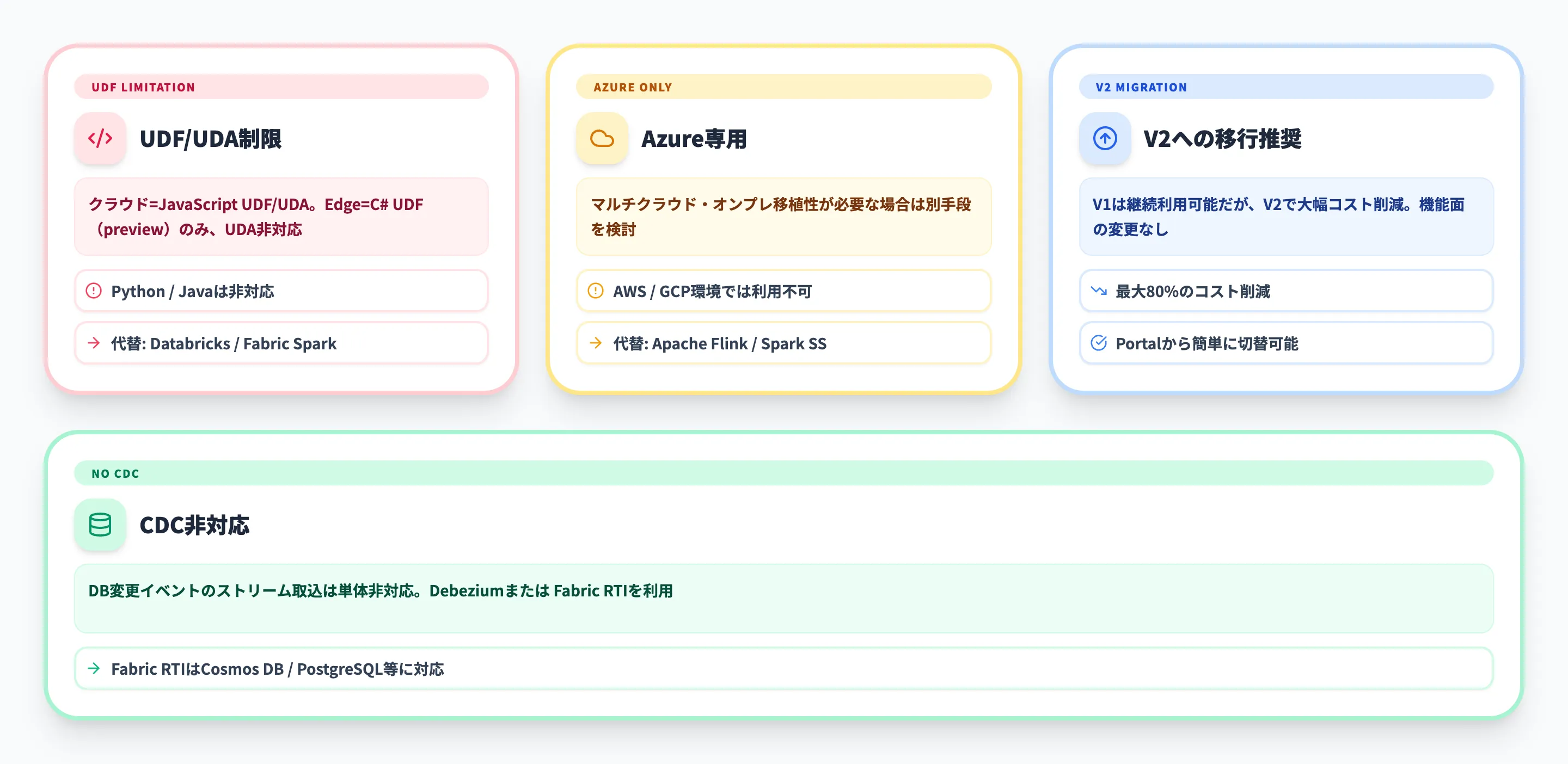
- UDF/UDAの対応言語が限定的
クラウドジョブではJavaScript UDF/UDAに対応していますが、IoT EdgeジョブではC# UDF(プレビュー)のみでUDA非対応です。
PythonやJavaで複雑な処理を実装したい場合は、Azure DatabricksのSpark Structured StreamingやFabric Data EngineeringのSparkジョブが代替候補になります
-
Azure専用のサービス
Stream AnalyticsはAzure上でのみ動作します。マルチクラウドやオンプレミス環境への移植性が求められる場合は、Apache FlinkやSpark Structured Streamingなどのオープンソース技術を検討してください。
ただし、IoT Edgeへのデプロイによりエッジ側での処理は可能です
-
V1モデルは非推奨
公式ドキュメントでSU V1は「to be deprecated」と明記されています。
V2への移行は機能面の変更を伴わないため、V1で運用中なら早期の切り替えを推奨します
-
CDC(変更データキャプチャ)は非対応
データベースの変更イベントをストリームとして取り込むCDCには、Stream Analytics単体では対応していません。
Debeziumなどの別サービスを組み合わせるか、Fabric Real-Time IntelligenceのネイティブCDC対応を利用する方法があります
これらの制限を踏まえたうえで、SQLベースのリアルタイム処理で要件が満たせるのであれば、Stream Analyticsはインフラ管理不要・低コスト・高信頼性の3点でバランスの取れた選択肢です。
導入判断で詰まる論点
Azure Stream Analyticsの導入を検討する際に、判断が分かれやすいポイントを整理します。
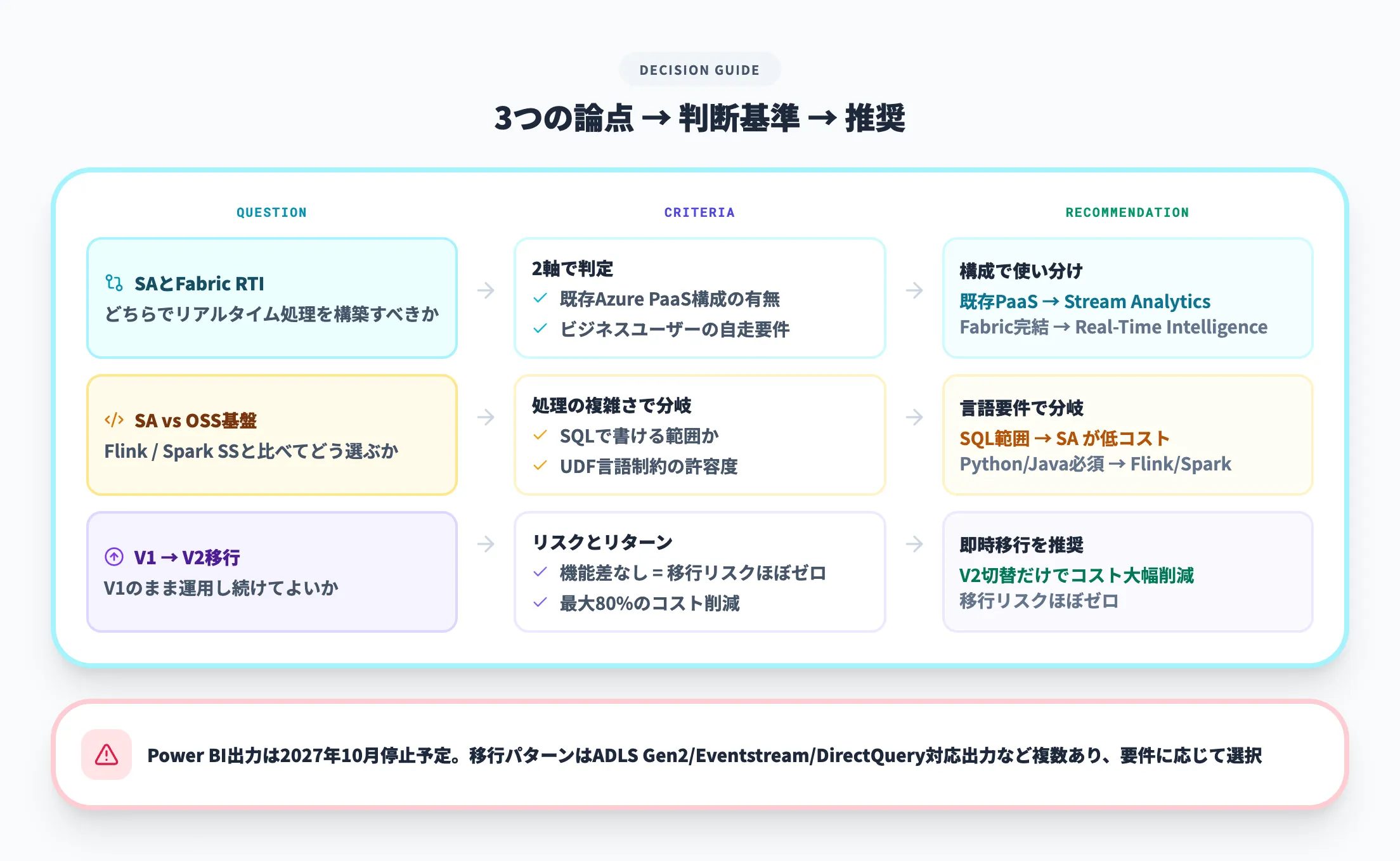
Stream Analytics vs Fabric Real-Time Intelligence
最も多い論点です。判断基準は明確で、「既存のAzure PaaS構成があるか」と「ビジネスユーザーが自分でダッシュボードを作る要件があるか」の2点で切り分けられます。
既存のEvent Hubs + Azure Functions構成に組み込むならStream Analytics、Fabric環境で完結させたいならReal-Time Intelligenceが素直な選択です。
迷った場合は、Stream Analyticsの出力をADLS Gen2に流しておけば、後からFabric側でも活用できるため、最初の選択を間違えてもリカバリしやすい構成になります
Stream Analytics vs Apache Flink / Spark Structured Streaming
SQLで書ける範囲の処理であれば、フルマネージドのStream Analyticsは運用負荷とコストを下げやすい選択肢です。
一方、PythonやJavaで複雑なステートフル処理を書く必要がある場合、UDF/UDAの言語制約がボトルネックになるため、FlinkやSpark Structured Streamingが適します。どちらが有利かはスループット・必要言語・運用体制に依存するため、要件ごとの比較が必要です
V1のまま運用し続けてよいか
機能面の変更はないため、V2への移行リスクはほぼゼロです。
V1は非推奨のステータスになっているため、コスト削減の観点だけでなく将来の廃止リスクも考慮して早期の切り替えを推奨します
リアルタイム分析からAI業務自動化へ

Microsoft環境でのAI活用を徹底解説
Stream Analyticsで培ったリアルタイムデータ処理の知見は、AI業務自動化のデータパイプライン設計にも活かせます。ストリーム処理からAI活用まで、220ページの実践ガイドで確認できます。
まとめ
Azure Stream Analyticsは、SQLベースのクエリ言語でストリーミングデータをリアルタイム処理するフルマネージドサービスです。
本記事で解説した内容をもとに、導入判断のポイントを整理します。
-
SQLが書けるチームなら、Kafkaクラスター自前運用の代替として有力
フルマネージドでインフラ管理が不要、SLA 99.9%、V2料金モデルで最大80%のコスト削減。コスト優位はスループットや保持期間に依存しますが、リアルタイム処理を「始める」ハードルが最も低い選択肢です
-
Fabricとの使い分けは「既存環境」で決まる
既存のAzure PaaS構成にはStream Analytics、Fabric環境ならReal-Time Intelligence。両者はADLS Gen2経由で併用できるため、排他的に選ぶ必要はありません
-
Power BI出力の2027年10月停止は、今すぐ設計に反映すべき
新規構築ではFabric連携を前提に出力先を選定してください。移行パターンはADLS Gen2経由、Eventstream/Eventhouse経由、DirectQuery対応出力など複数あり、要件に応じて選択します
まずはAzure Portal上でStream Analyticsジョブを1つ作成し、Event Hubsからのサンプルデータで動作を確認してみてください。1/3 SU V2であれば月額約$100で始められるため、チーム内で「リアルタイム処理でどこまでできるか」を検証するには十分です。既にFabric環境を利用している場合は、Fabric Real-Time Intelligenceとの比較検討も並行して進めることをお勧めします。










