この記事のポイント
 難易度の高いコーディングや長時間エージェント運用を任せたいなら、SWE-bench Pro 64.3%の実力を持つOpus 4.7が現状の第一候補
難易度の高いコーディングや長時間エージェント運用を任せたいなら、SWE-bench Pro 64.3%の実力を持つOpus 4.7が現状の第一候補- 4.6を本番運用中で「短時間タスクが中心」のチームなら、新トークナイザーの実効コスト増を加味して継続も合理的
- xhigh強度とTask Budgets(public beta)を組合せれば、難問精度とエージェントループのコスト見通しを両立
- 設計図・スクリーンショット解析が業務の中心なら、3.75MPビジョン対応は4.6からの乗り換え理由になる
- 価格は$5/$25で据え置きだが、新トークナイザーで同じテキストの消費トークン量が最大35%増える点を見積もりに織り込むこと

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Claude Opus 4.7は、2026年4月16日にAnthropicが公開した新世代の最上位モデルで、SWE-bench Pro 64.3%・SWE-bench Verified 87.6%という前世代Opus 4.6を大幅に上回るコーディング性能を備えています。
4.6時点ですでに採用されていたadaptive thinkingとeffortパラメータに加え、4.7では「xhigh」レベルが追加。さらにClaude Platform API側ではマルチターン全体にトークン予算を割り当てるTask Budgets(public beta)が登場し、長時間のエージェント運用を細かく制御できるようになりました。
本記事では、4.6からの差分・3.75MP高解像度ビジョン・新トークナイザーによる実効コスト影響・Cyber Verification Program等の安全側の変更を、公式情報と主要ベンチマークをもとに整理します。
あわせて、API・Claude Pro/Max/Team・Bedrock・Vertex AI・Microsoft Foundry・GitHub Copilotという入手経路ごとの使い方と、4.6からの乗り換え判断軸・想定ユースケース・料金・導入で詰まる論点まで一気通貫で解説します。
✅2026年6月9日、AnthropicがMythos-class初の一般公開モデル「Claude Fable 5」を発表しました。Opus 4.8の上位に位置する新最上位モデルの詳細はこちら。
▶︎Claude Fable 5とは?Mythos 5との違いや料金、使い方を解説
目次
Claude Pro / Max / Team / Enterprise(claude.ai)
Amazon Bedrock / Google Vertex AI / Microsoft Foundry
Cyber Verification Programとセキュリティ機能
Claude Opus 4.7とは?
Claude Opus 4.7は、Anthropicが2026年4月16日に一般提供を開始したフラグシップモデルで、Claude Opus 4.6の後継として「高度なソフトウェア開発・長時間のエージェント運用・高解像度ビジュアル理解」の3軸で前世代を更新しました。
Anthropic公式ページでは「Opus 4.6に比べて高度なソフトウェアエンジニアリングで顕著に改善し、特に最も難易度の高いタスクで大きな伸びがある」と説明されています。
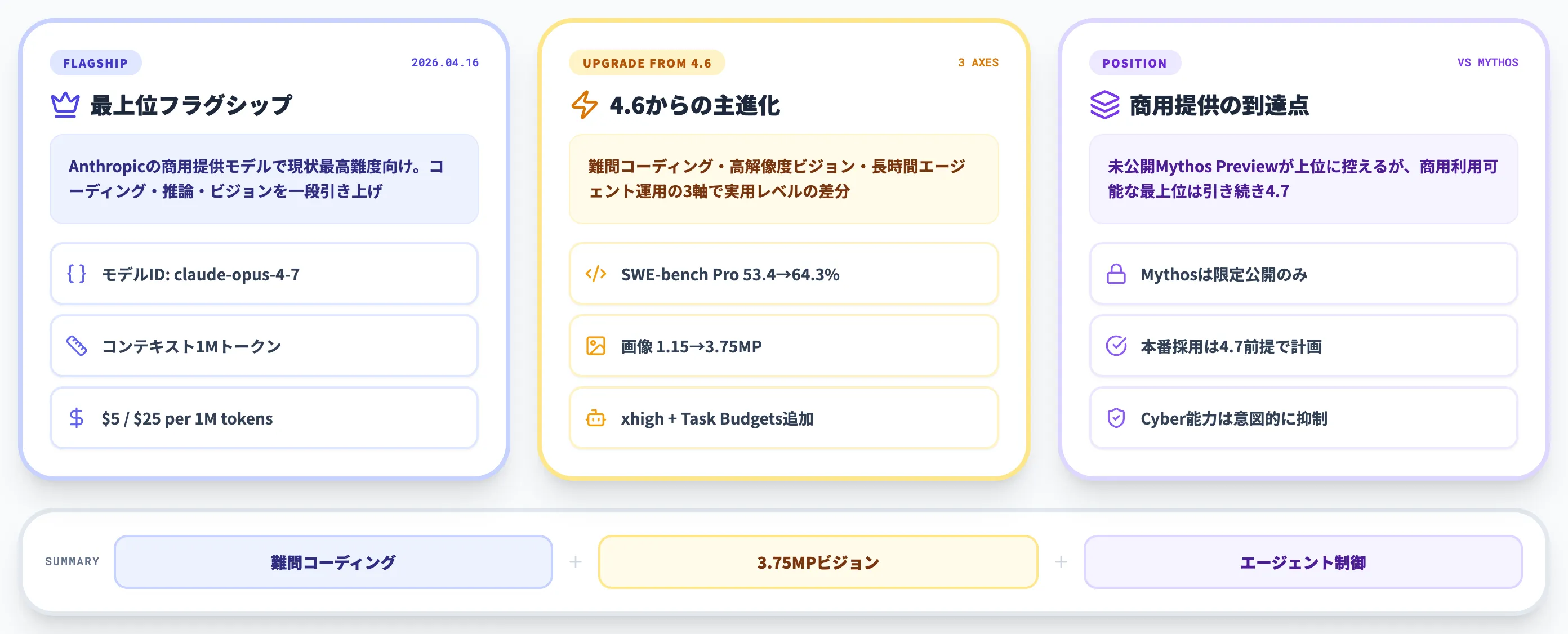
主要な変化は次の5点に集約できます。
- 難問コーディングで4.6を大幅更新(SWE-bench Proで53.4%→64.3%)
- 推論強度に「xhigh」レベルが追加(high と max の中間)
- 「Task Budgets」でエージェントループ全体にトークン予算を割り当て可能
- ビジョン解像度が1.15MPから3.75MPに拡大(長辺2,576pxまで)
- 新トークナイザー導入で同じテキストでも最大35%多くトークンを消費
冒頭で押さえておきたいのは、Opus 4.7が「Mythos Preview」と呼ばれる未公開上位モデルには及ばないとAnthropic自身が認めている点です。
これはセーフティ評価のため一般公開を見送っている社内モデルで、Opus 4.7は「公開可能な範囲での最良モデル」として位置づけられています(Axios報道)。
「最上位=Mythos」ではなく「商用提供されている最強=Opus 4.7」という整理で読み進めると、後述のベンチマーク比較の意味が掴みやすくなります。

Claudeシリーズにおける位置づけ
Claudeのモデル系統は「Opus(最上位)/Sonnet(バランス)/Haiku(高速)」の3系統が並走しており、Opus 4.7はこのうちOpus系列の2026年4月時点における最新版です。
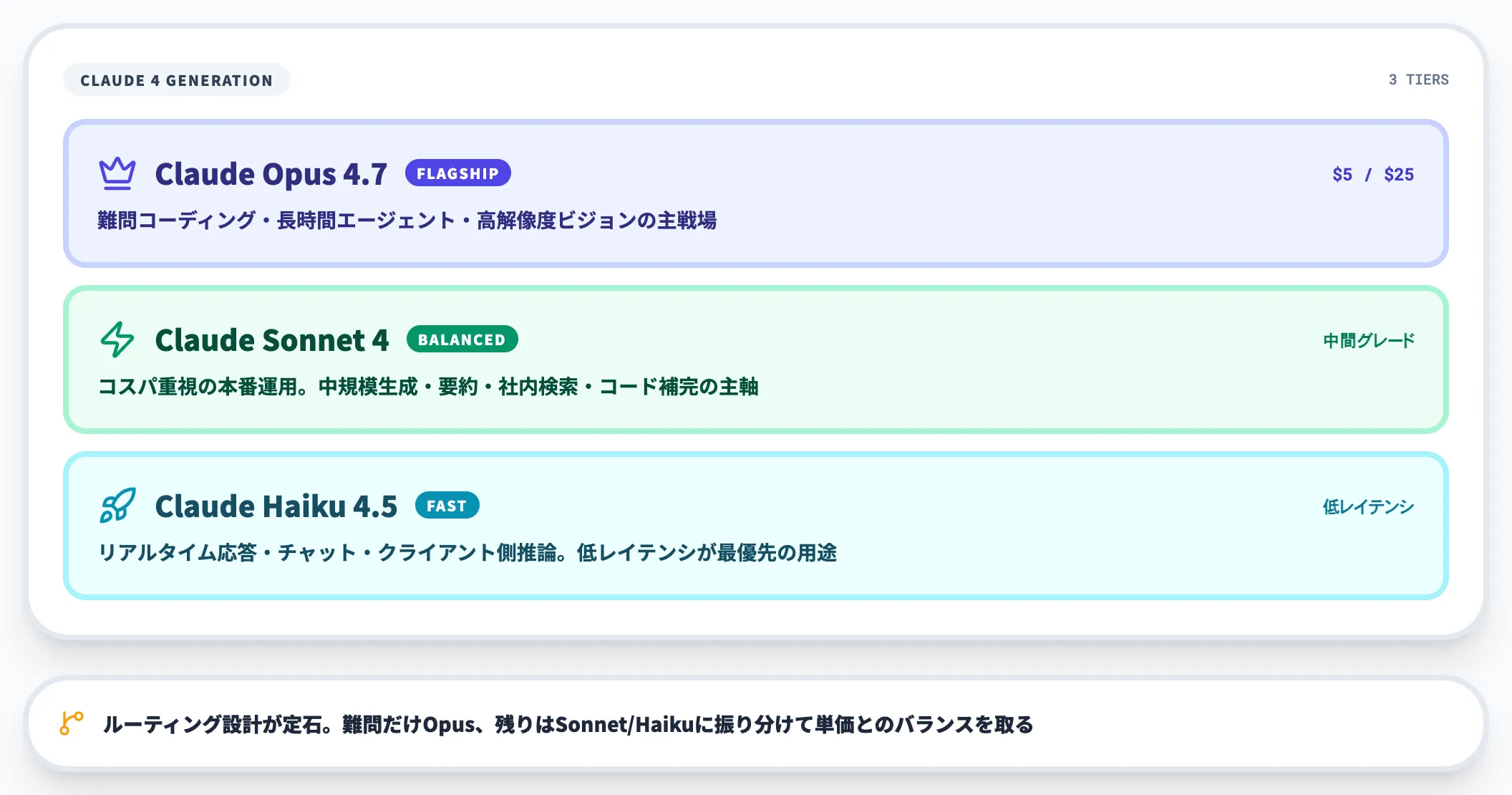
- Opus 4.7
最高難度の推論・コーディング・エージェント運用向け。本記事の主題。
- Claude Sonnet 4.6(後継Sonnetが控える可能性あり)
日常開発・社内ツール・大量バッチ処理など費用対効果優先の用途向け。
- Claude Haiku 4.5
リアルタイム応答・低レイテンシのチャット用途・クライアント側推論向け。
3系統の使い分けの基本方針はClaude Opus・Sonnet・Haikuの違いを参照してください。
Opus 4.7は単価が高いため「全タスクをOpus 4.7に寄せる」のではなく、「難しい一部だけをOpus 4.7、残りをSonnet/Haiku」とルーティング設計するのが実務では一般的です。
4.6世代との関係
Claude Opus 4.7は4.6から短期で投入された差分リリースで、コンテキスト長や基本単価は据え置いたまま、推論制御・ビジョン・コーディング精度を中心に磨き込まれた構成です。
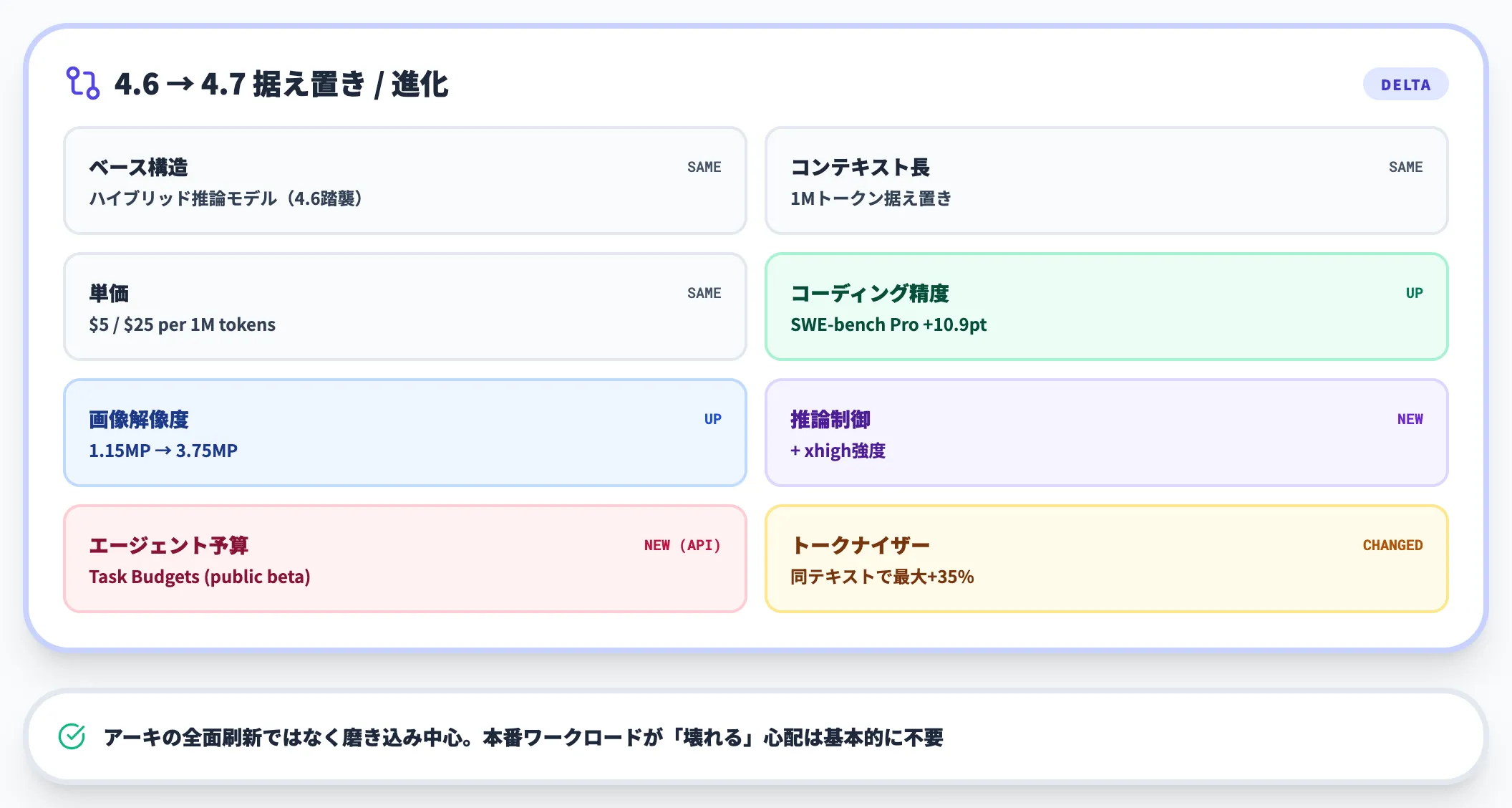
- ベース構造:Opus 4.6を踏襲した「ハイブリッド推論モデル」(即応モードと拡張思考の使い分け)
- コンテキスト長:1Mトークン(4.6から据え置き)
- 単価:入力 $5 / 出力 $25 per 1M tokens(4.6から据え置き)
- 主な進化:コーディング性能・ビジョン解像度・推論制御の粒度・長期メモリ
そのため「4.6で十分動いている本番ワークロードを4.7に置き換えると壊れるか?」という心配は基本的に不要です。
一方で、Claude Platform API側でマルチターンのトークン消費を目安予算で自己調整させたいチームや、APIやClaude Codeでxhigh強度の推論を業務に組み込みたいチームにとっては、乗り換える価値が高いリリースになっています。
;;;message
なお、Task Budgetsは2026年4月時点でClaude Platform APIのpublic beta提供で、claude.ai・Claude Code・Cowork(旧Claude for Work)のUIには未提供です。
これらの環境ではExtended thinkingトグルやxhigh強度(Claude Code側)など別のレバーを使う形になります。
:::
Claude Opus 4.7の主な強化ポイント
ここではOpus 4.7が「実務上、どう改善されているか」を、ベンチマーク数値と業務インパクトの両面から整理します。
先に示したとおり、改善は均等ではなく「難問コーディング」「ビジョン」「長時間エージェント運用」に偏っています。

コーディング性能の伸び
Opus 4.7のコーディング性能は、Anthropicが社内・外部の複数ベンチマークで4.6を上回ったと公表しています。代表的な数値を整理します。

| ベンチマーク | Opus 4.6 | Opus 4.7 | 主な競合(参考) |
|---|---|---|---|
| SWE-bench Pro | 53.4% | 64.3% | GPT-5.4: 57.7% / Gemini 3.1 Pro: 54.2% |
| SWE-bench Verified | 80.8% | 87.6% | Gemini 3.1 Pro: 80.6% |
| 93タスク社内コーディングベンチ | — | +13%(4.6比) | — |
| Rakuten-SWE-Bench(実バグ解決数) | — | 約3倍(4.6比) | — |
この表で押さえたいのは、Opus 4.7の伸びが「平均的な改善」ではなく「難問領域で顕著」という点です。
SWE-bench Proのように現実のリポジトリでテストされる難易度の高いタスクほどスコア差が大きく、簡単なタスクでは差が出にくい傾向があります(Officechai報道)。
実務に置き換えると、「日常的なコード補完や軽いリファクタは4.6・Sonnetで十分、レガシーコードの調査やマルチファイル横断のバグ修正にOpus 4.7」という棲み分けが現実的です。
高解像度ビジョン対応
Opus 4.7は、Claudeシリーズで初めて高解像度画像入力に対応したモデルです。
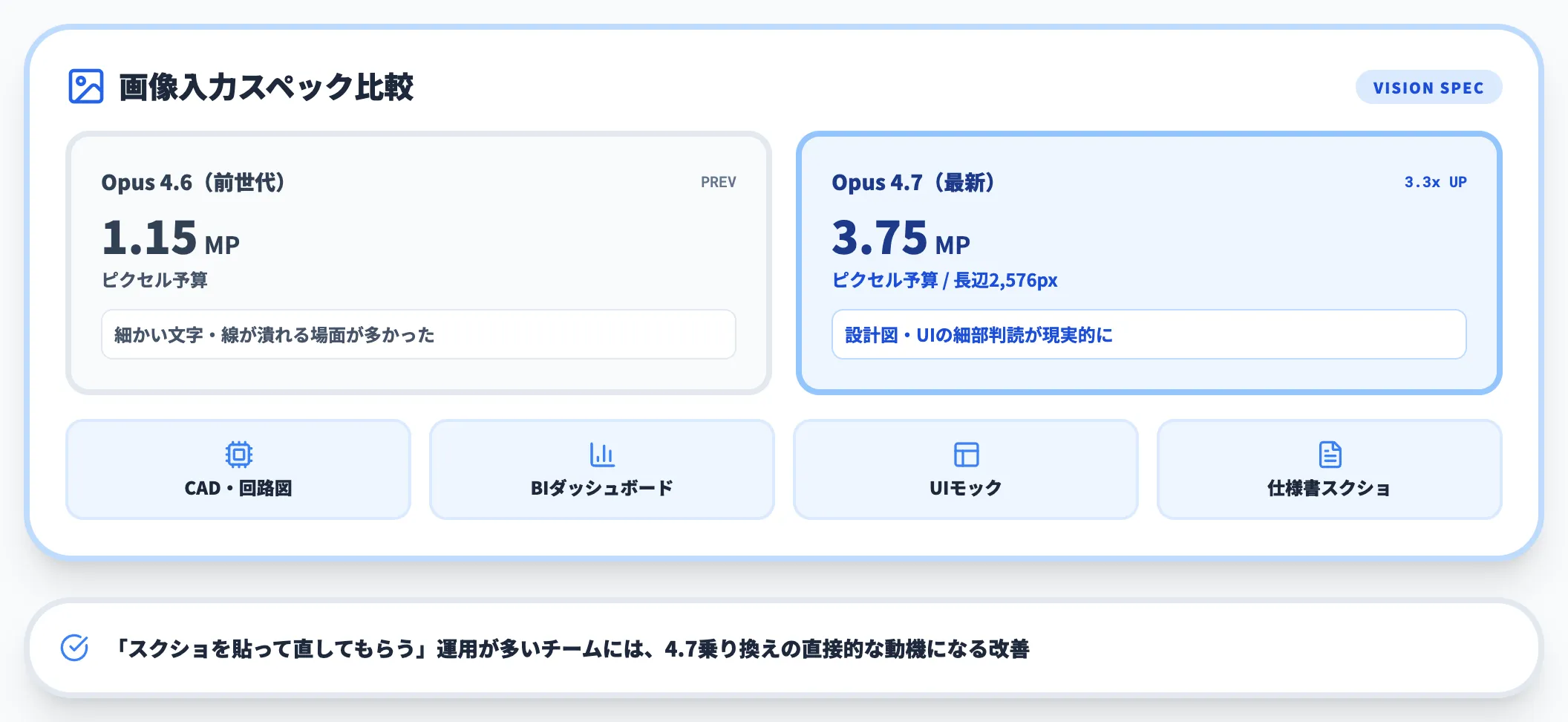
- ピクセル予算:1.15MP → 3.75MP(約3.3倍)
- 長辺サイズ:従来比3倍超の最大2,576px
- 主な恩恵:CADや回路図、UIスクリーンショット、データ可視化グラフの細部判読
Anthropicの公式モデルページでは、設計図やダッシュボード解析、UIモックレビューといった「画像の中の細かい文字や線」を読む用途を主たる用途として挙げています。
実装段階で「スクショを貼ってAIに直してもらう」運用を多用するチームでは、4.6時代に画像が縮小されて文字が潰れる問題が顕著だったため、3.75MP対応は乗り換え理由になりやすい改善点です。
長時間エージェント運用の安定性
Opus 4.7は、複数ステップにまたがる「エージェントループ」での挙動制御を強化しています。代表的な改善は以下の3つです。
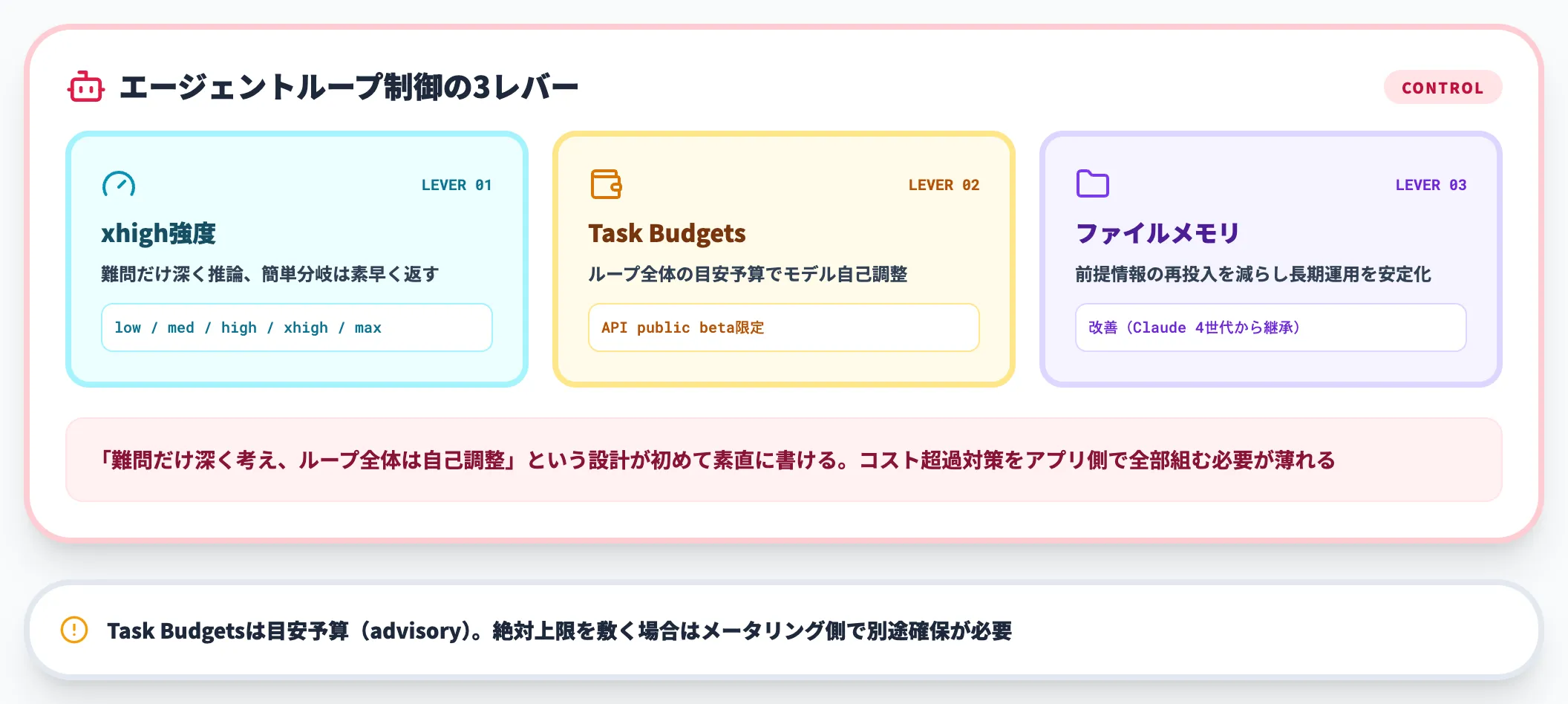
- xhigh推論レベル
従来の「high」と「max」の中間に位置する強度。難問だけ推論を深め、簡単な分岐は素早く返す制御が可能。
- Task Budgets(ベータ)
1ターン単位ではなく、エージェントループ全体にトークン予算を割り当てる仕組み(最小20,000トークン)。
- ファイルシステムベースのメモリ
長期マルチセッション作業のメモを保持し、新しいタスクで前提情報の再投入を減らす。
xhighとTask Budgetsの組み合わせで「難問だけ深く考えつつ、ループ全体ではモデルに残予算を自己調整させてコストを見通しやすくする」という設計が素直に書けるようになりました。
4.6まではlow / medium / high / max の4段階effortと1ターン単位のmax_tokensしかなく、難問に合わせてmaxに寄せると簡単な分岐まで深く推論してコストが跳ねる、highに落とすと一部の難問で精度が落ちる、という二択になりがちで、ループ全体のコスト見通しはアプリ側で別に組む必要がありました(Task Budgetsはあくまで目安予算で、絶対上限を敷く役割はメータリング側に残ります)。
導入を検討する場合、まず長時間ジョブ(コードベース全体のリファクタや、ドキュメント生成パイプラインなど)でxhigh強度の効果を計測し、Claude Platform APIで自前のエージェントループを組んでいるチームはあわせてTask Budgets(public beta)の挙動も並行検証して、4.6運用と並走しながら段階的に置き換えるのが安全な進め方です。
Claude Opus 4.7の新機能
ここでは強化点のうち、API利用者・エージェント運用者の実装に直接影響する3つの新機能を、仕様レベルで整理します。

xhigh推論レベル
xhighは、Anthropicが従来提供していた「low / medium / high / max」の各effortレベルに追加された5段階目の強度です。

- 位置づけ:high と max の中間(「extra high」の略)
- ねらい:難問で精度を確保しつつ、maxまで使うほどのコストはかけたくない場合の中継点
- 適用例:コードレビュー、設計レビュー、複数ファイルの依存関係解析
これまで「highでは推論不足、maxでは過剰」という間の領域が表現できず、結果的にmaxで回してコストが膨らむケースが多くありました。xhighの追加により、難易度に応じた段階的な推論強度設計が可能になります。
Task Budgets
Task Budgetsは、複数ターンにまたがる「エージェント実行全体」に1つの目安予算(advisory token budget)を渡し、Claudeが残予算を見ながら自律的に深さや探索量を調整する新しいパラメータです。
厳密に処理を遮断するハード上限ではなく、モデル側のself-regulationを誘導する仕組みである点が要注意です。
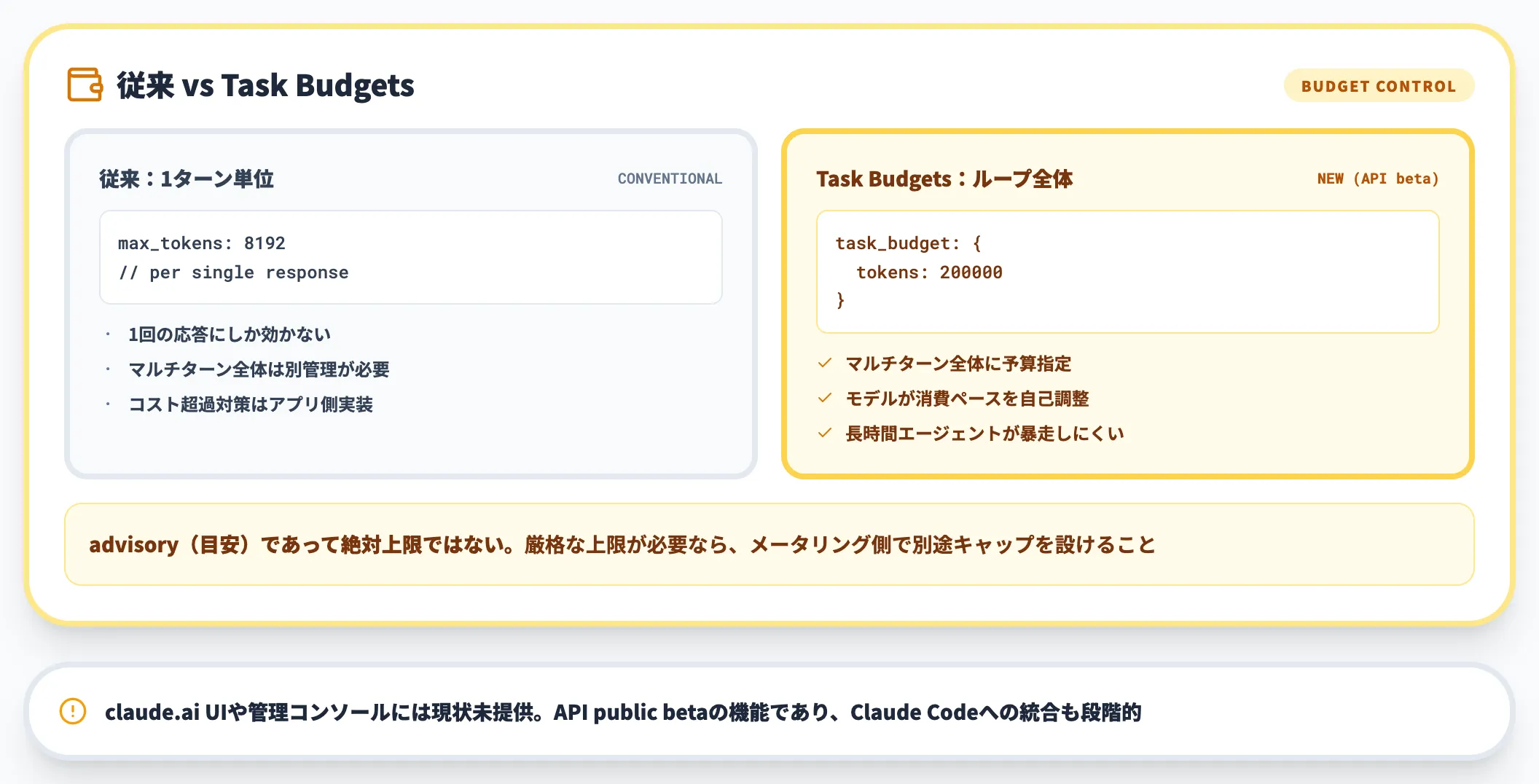
- 単位:1ターンではなくタスク全体(マルチターンの集合)
- 最小値:20,000トークン
- 提供範囲:2026年4月時点でClaude Platform APIのpublic beta(claude.ai・Claude Code・Cowork のUIには未提供)
エージェントが想定外のループでトークンを過剰消費する傾向をモデル自身が自己調整しやすくなるため、Claude Platform APIで自前のエージェントループを組むCIジョブ・夜間バッチ・社内ツールと相性が良い機能です。あくまでモデルへの「目安」であり、強制的なハード遮断ではないため、絶対上限を敷きたい場合は呼び出し側でトークンメータリングや打ち切りロジックを別に持っておく必要があります。
2026年4月時点ではclaude.ai・Claude Code・Cowork(旧Claude for Work)にはTask Budgets UIが提供されていないため、これらの環境で同等の挙動を再現する場合もラッパー側で実装する形になります。
ファイルシステムベースのメモリ
Opus 4.7は、エージェントが「自分用のメモを書き出して、後のセッションで読み返す」ためのファイルシステムベースのメモリ運用が改善されました(Claude 4世代から導入されている枠組みの強化です)。
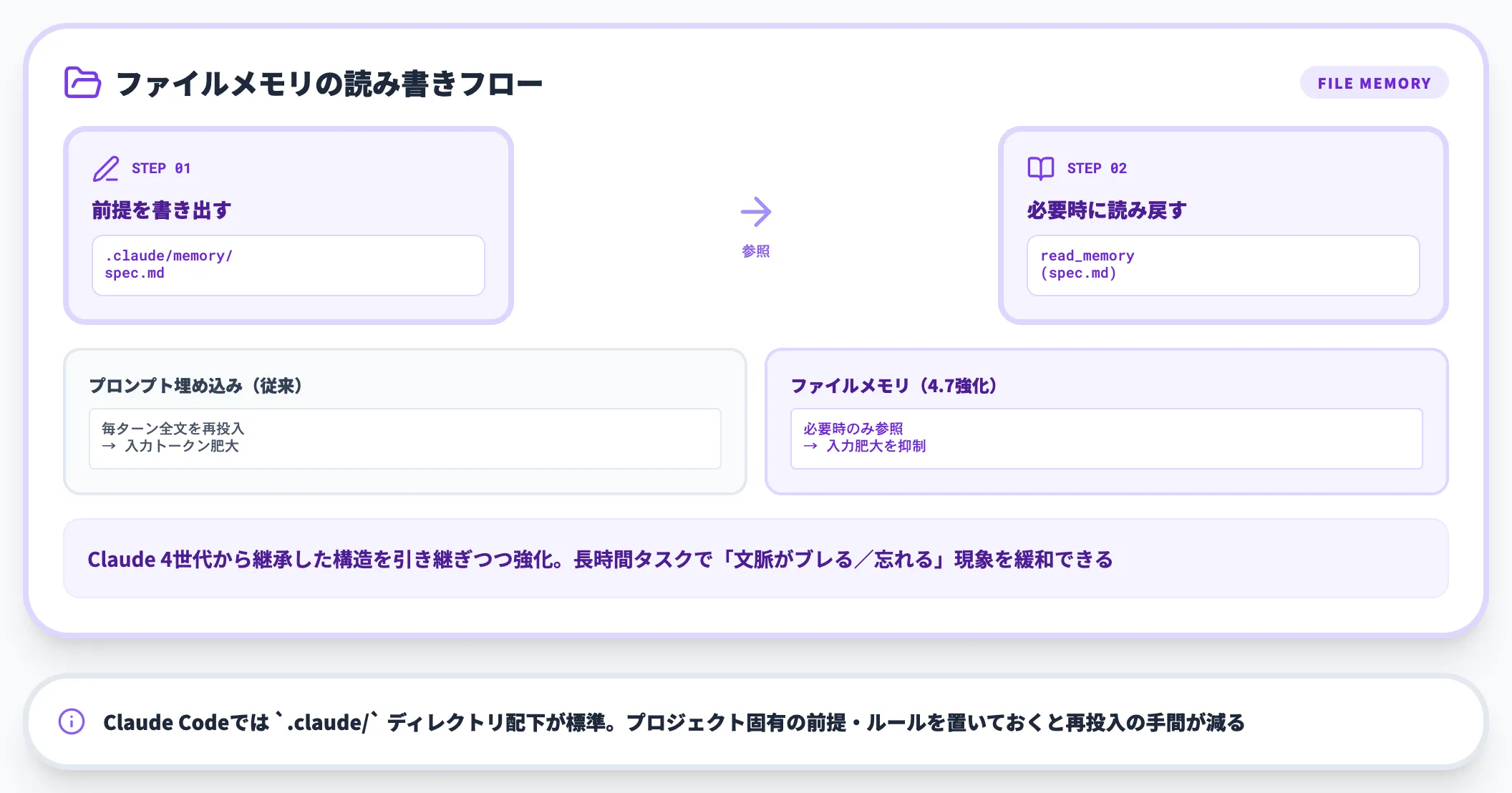
- 用途:長期プロジェクトでの作業ログ、設計判断のメモ、調査結果のキャッシュ
- 効果:マルチセッション作業で前提情報の再投入を減らし、文脈保持コストを下げる
- 補足:CLAUDE.mdのような明示的メモリ運用と併用可能
これは、Claude Codeなどの開発エージェントを「数日〜数週間にまたがる長期タスク」で運用するときに効きます。
短時間チャットだけで使うユーザーには直接の恩恵は少ないものの、本番運用での運用コストとレスポンス品質に影響する重要な変化です。
Claude Opus 4.6・他社モデルとの比較
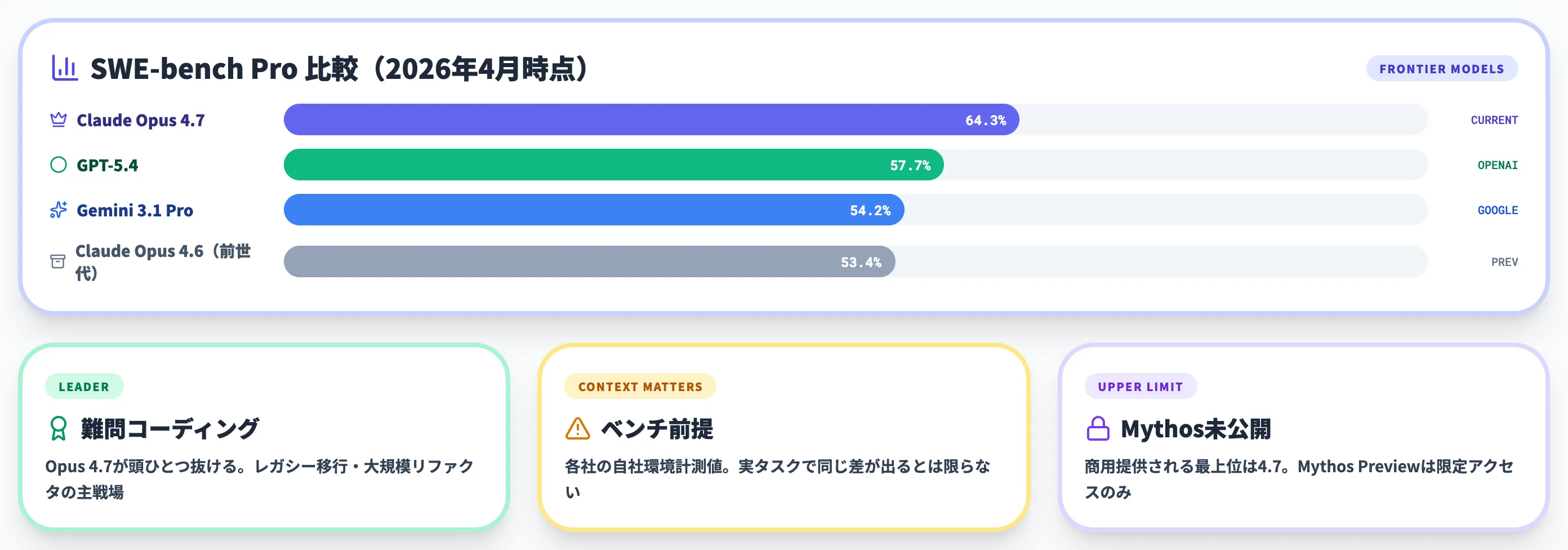
ここではOpus 4.7を「直前世代の4.6」「同時期の他社フロンティアモデル(GPT-5.4 / Gemini 3.1 Pro)」「Anthropic未公開のMythos Preview」と並べて比較します。
先に結論を出しておくと、難問コーディングと長時間エージェント運用の組み合わせでは現状Opus 4.7が抜けており、その上にMythos Previewがいる構図です。
Opus 4.6 → 4.7 の差分
| 項目 | Opus 4.6 | Opus 4.7 |
|---|---|---|
| SWE-bench Pro | 53.4% | 64.3% |
| SWE-bench Verified | 80.8% | 87.6% |
| 画像解像度(最大) | 1.15MP | 3.75MP(長辺2,576px) |
| 推論強度 | low / medium / high / max | + xhigh(中間段) |
| エージェント予算制御 | 1ターン単位 | + Task Budgets(ループ全体) |
| メモリ | ファイルシステムメモリ(Claude 4世代から) | ファイルシステムメモリの安定性・容量制御を改善 |
| トークナイザー | 旧版 | 新版(同テキストで最大35%増) |
| 入力 / 出力単価 | $5 / $25 | $5 / $25(据え置き) |
表を読み解くポイントは「単価は据え置きでも、新トークナイザーの影響で実効コストは上振れる」点です。同じ社内ベンチを回しても、4.7のほうが請求トークンが増えるケースがあるため、コスト見積もりは「単価×推定トークン×1.0〜1.35」のレンジで持つ必要があります。
GPT-5.4 / Gemini 3.1 Pro との比較
代表的な公開ベンチマークを並べると、難問コーディング領域でOpus 4.7が一歩抜けています。

| モデル | SWE-bench Pro | SWE-bench Verified |
|---|---|---|
| Claude Opus 4.7 | 64.3% | 87.6% |
| GPT-5.4 | 57.7% | — |
| Gemini 3.1 Pro | 54.2% | 80.6% |
| Claude Opus 4.6(参考) | 53.4% | 80.8% |
注意したいのは、ベンチマーク種別と評価環境を揃えなければ直接比較が成立しないという点です。
今回はOfficechaiが掲載しているAnthropic公表値を参照していますが、各社ベンダーが自社環境で計測した値であり、ユーザー側の実タスクで同じ差が出るとは限りません。
実務的な使い分けとしては、コーディング・エージェント運用が主軸ならOpus 4.7、汎用的なRAGや日本語業務ライティング中心ならGPT-5.4・Gemini 3.1 Proも候補に残す、という整理が現実的です。
「全部Opus 4.7に寄せる」「全部GPT系に寄せる」のどちらでもなく、ワークロード単位で適材適所を組むほうが費用対効果は高くなります。
Mythos Previewとの関係
Anthropicは、Opus 4.7のリリース発表の中で「未公開のMythos Previewには及ばない」と明言しました。Mythos Previewは安全性評価のため一般公開されておらず、選定されたテック・サイバーセキュリティ企業のみがアクセスできるとされています(Axios)。
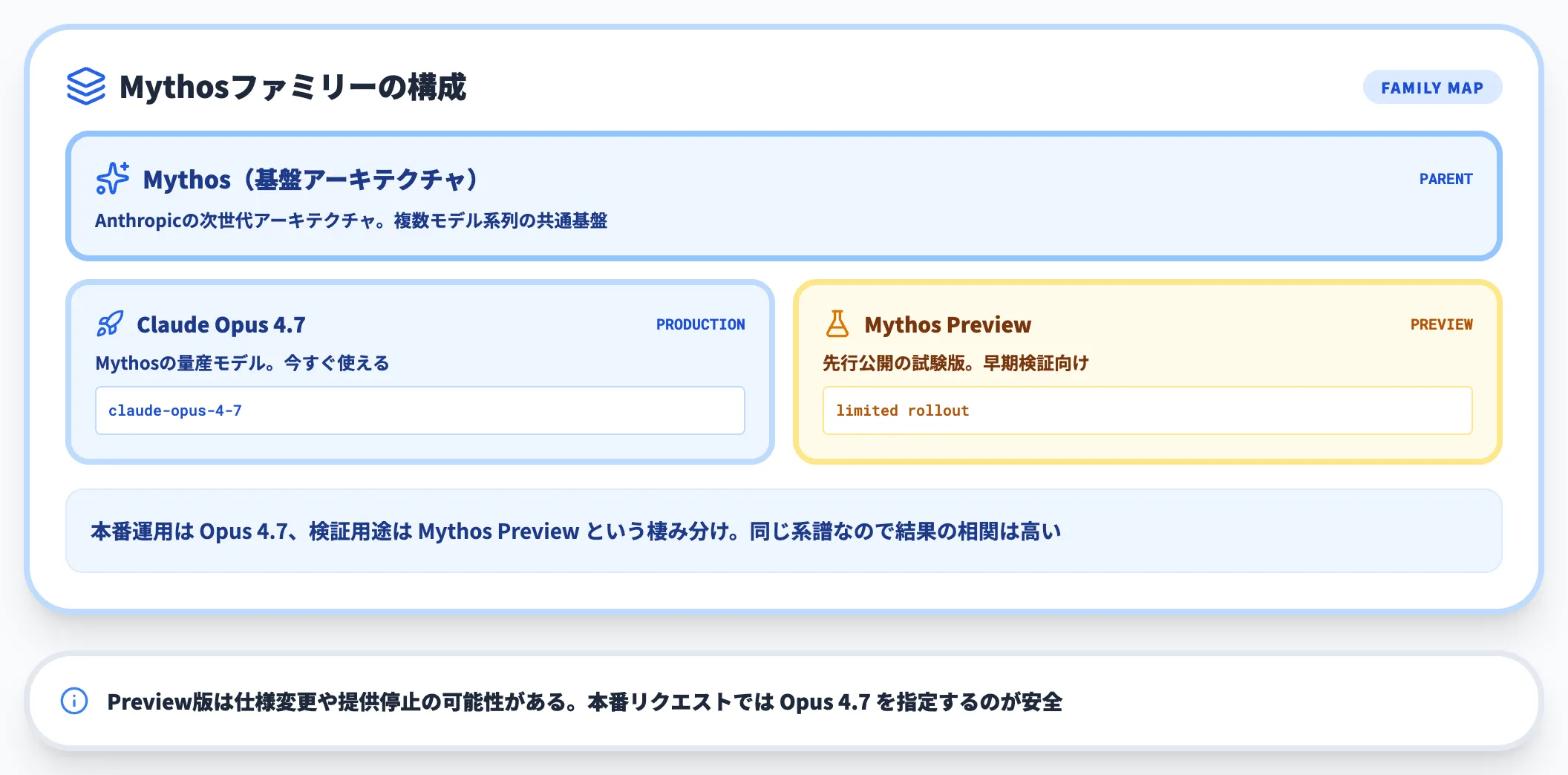
ここから読み取れるのは、「Anthropicは性能上限を意図的に絞って商用提供している」という現状です。
本番システムでMythos Previewを期待するのは現実的ではなく、商用利用可能な最上位は引き続きOpus 4.7という前提で導入計画を組む必要があります。

Claude Opus 4.7の使い方
Opus 4.7は単一の入手経路ではなく、用途に応じて複数のチャネルから利用できます。ここでは「個人で試したい」「企業向けにAPIで組み込みたい」「クラウドベンダー側の管理下で動かしたい」「エディタに組み込みたい」の4観点で整理します。
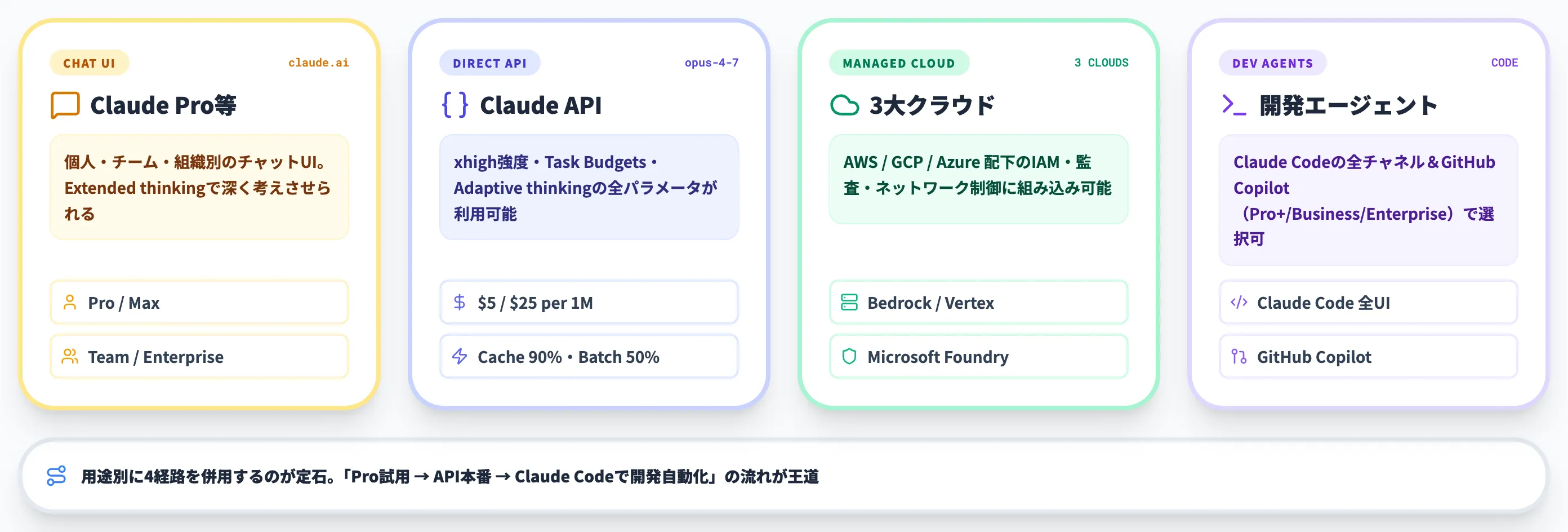
Claude Pro / Max / Team / Enterprise(claude.ai)
claude.aiのチャットUIから「Opus 4.7」をモデル選択メニューから指定して利用できます。

- Claude Pro / Max
個人〜小規模チーム向け。4.6・Sonnet・Haikuと同じ画面でモデルを切り替えながら使える。
- Claude Team / Enterprise
組織向け。管理者がモデル利用ポリシーを設定でき、Opus 4.7の利用範囲やExtended thinkingの使い分けに関するガバナンスを敷きやすい(xhigh強度の指定はClaude CodeとClaude Platform APIで利用可能、Task BudgetsはAPI側のpublic beta機能で、claude.ai上のTeam / Enterprise UIには2026年4月時点で未提供)。
「まず触って判断したい」段階では、Claude ProでOpus 4.7とExtended thinkingの組み合わせを試すのが最短ルートです(claude.ai上のUIではExtended thinkingのトグル切り替えが基本で、xhighを含む細かいeffort強度の指定はClaude CodeやAPI側で行います)。
プロンプトエンジニアリングやClaude Proの機能制限の範囲は4.6時点と大きく変わりません。
Claude API(Anthropic直接)
API経由では、モデルIDに claude-opus-4-7 系を指定して呼び出します。リクエスト時に推論強度(xhigh含む)と、ベータ機能のTask Budgetsを指定する設計です。
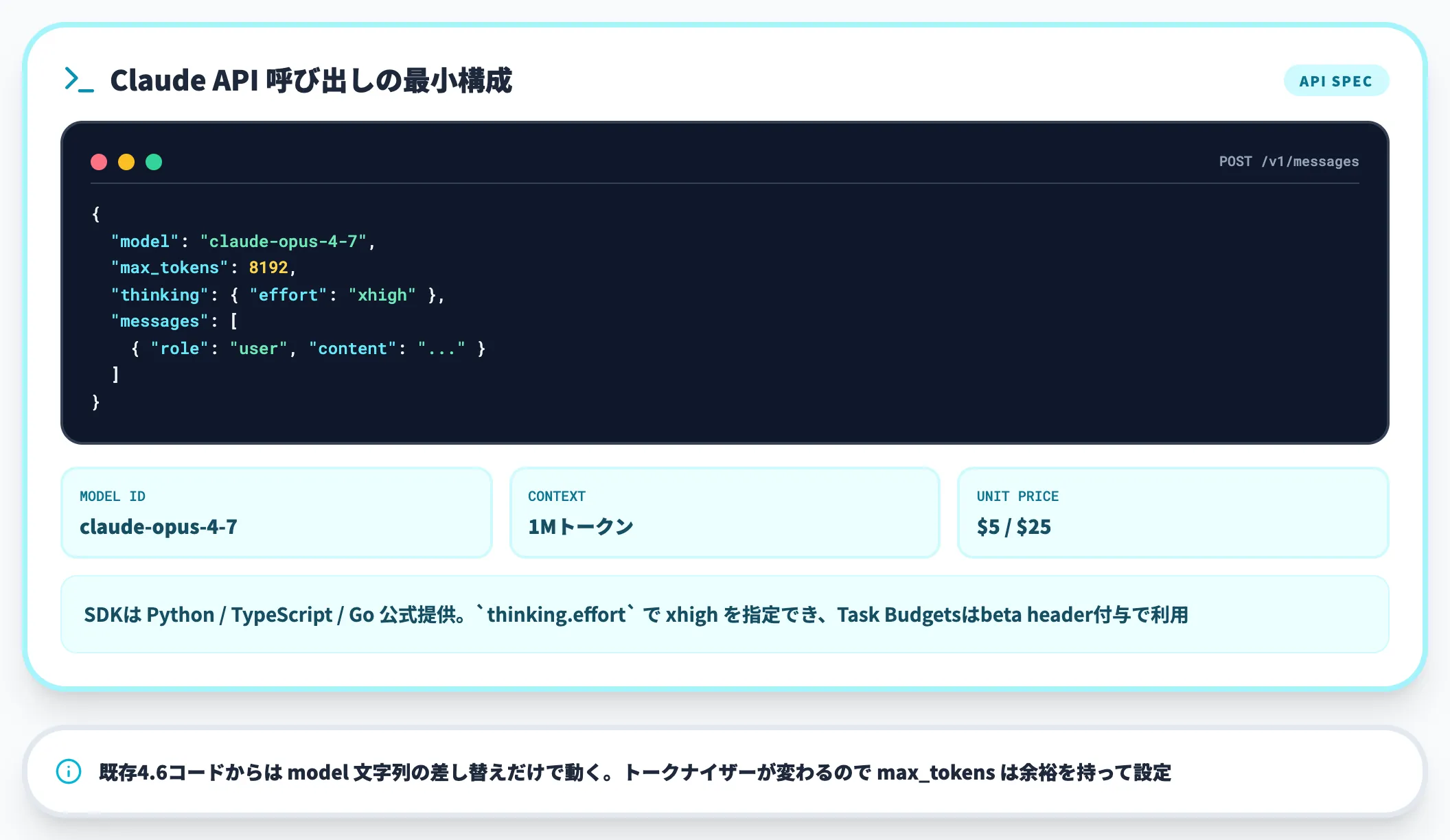
- 入力単価:$5 / 1M tokens(プロンプトキャッシングで最大90%削減、バッチ50%削減)
- 出力単価:$25 / 1M tokens
- コンテキスト:1Mトークン
- 最大出力:128,000トークン
API利用時は、新トークナイザーでトークン消費が上振れる点を必ず初期検証で計測してください。本番に投入する前に、自社の代表的なプロンプト・出力パターンで4.6と4.7のトークン消費量を比較しておくと、予算超過事故を避けられます。
Amazon Bedrock / Google Vertex AI / Microsoft Foundry
エンタープライズ向けには、3大クラウドのマネージド経路でも提供されています。
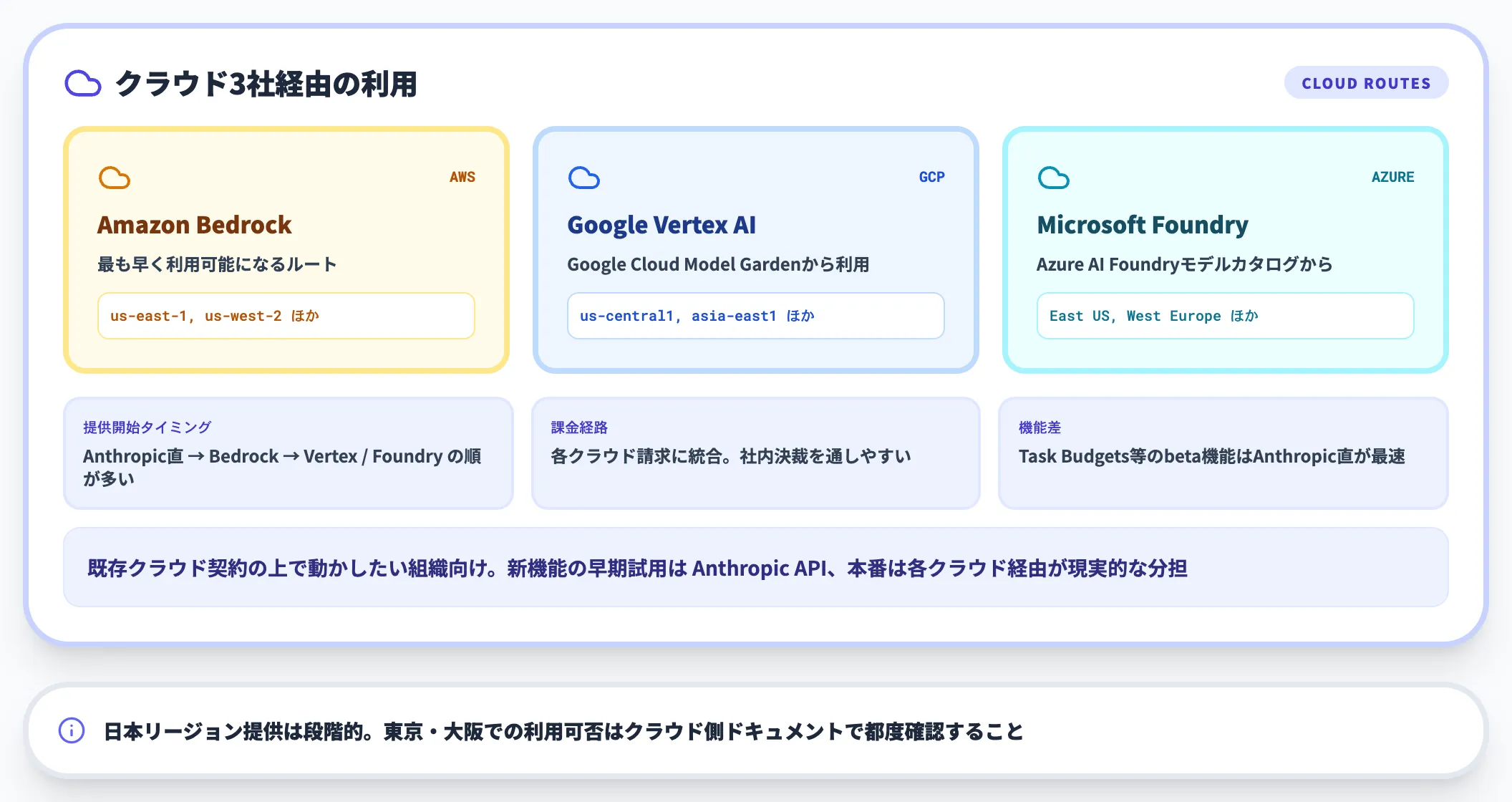
- Amazon Bedrock:AWSアカウント内でモデル呼び出し・権限管理・監査ログを一括運用
- Google Vertex AI:GCPプロジェクト配下でClaude APIを利用
- Microsoft Foundry:Azure環境でClaude Code含むAnthropic製品を利用
クラウド側のIAMやネットワーク制御に組み込みたい大企業ユースでは、Anthropic直接APIではなくこれらのマネージド経路を選ぶケースが多くなります。
Claude Code / GitHub Copilot
開発エージェント用途では、Opus 4.7はClaude Codeのモデルとして選択でき、GitHub Copilotでも利用可能になっています。

- Claude Code:CLI / Web / Desktop / IDE拡張・Claude Code Channelsなど全チャネルでモデル選択可
- GitHub Copilot:Copilot Pro+ / Copilot Business / Copilot Enterprise の各プランで提供(無料・Proプランは対象外)。Visual Studio・VS Code・JetBrains・GitHub.comの統合環境からOpus 4.7を選択可能
「コーディング中心で4.7の恩恵を受けたい」場合は、すでに4.6でClaude Codeを運用しているなら設定を1か所変えるだけで切り替えられます。
GitHub Copilotで使う場合は、Copilot Pro+ / Business / Enterpriseのいずれかのプランが必要で、加えて組織管理者のモデルポリシー設定でOpus 4.7を許可しないと開発者個人で選べない点に注意してください。
Claude Opus 4.7の活用シナリオ
Opus 4.7の改善点を踏まえると、効果が出やすい用途・出にくい用途がはっきり分かれます。「全タスクをOpus 4.7に寄せる」のは費用対効果が悪く、ケースを絞って投入するのが定石です。
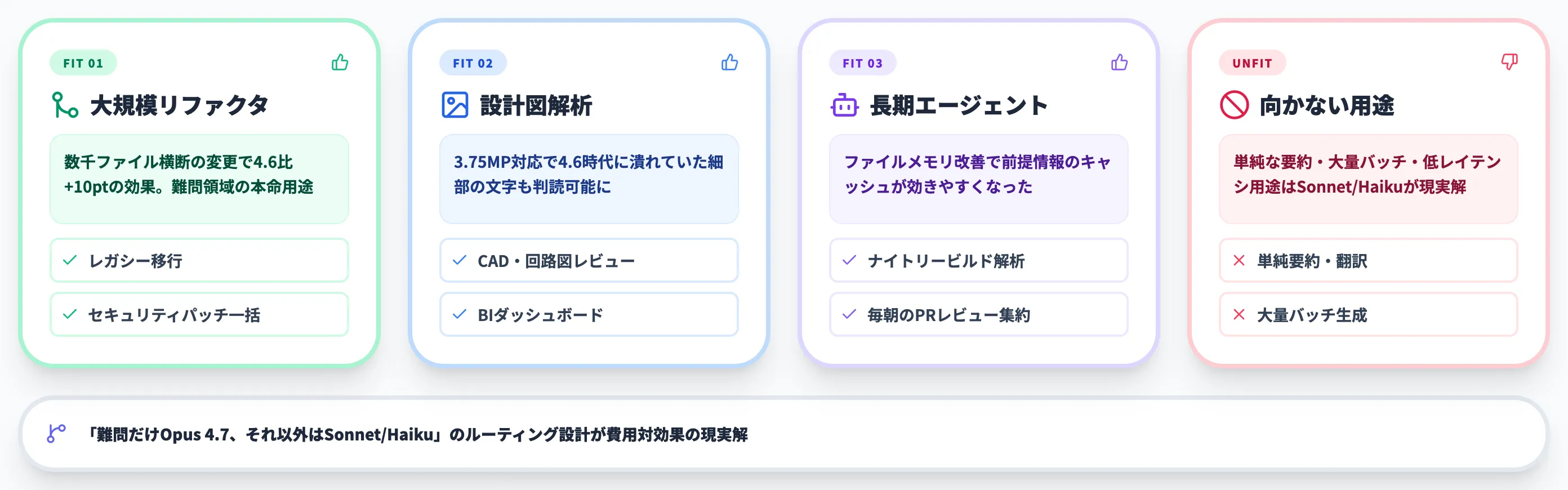
コードベース全体のリファクタ・大規模バグ修正
数百〜数千ファイル規模のリポジトリで、依存関係を横断する変更を行う用途はOpus 4.7の主戦場です。SWE-bench Proで4.6比10ポイント以上の改善があるとおり、難問領域での精度上昇が直接効きます。

- 想定タスク:レガシーコードのフレームワーク移行、テストカバレッジ拡張、セキュリティパッチの一括適用
- 推奨設定:xhigh強度を中心に、自前のエージェントループを組むAPIワークロードではTask Budgets(Claude Platform API public beta)をループ全体の目安予算として併用し、絶対上限はメータリング側で確保
- 併用:Claude Code Hooksでテスト・Lintの自動実行を組み合わせる
10名以上の開発チームで「リファクタを誰も着手しないまま負債が増えている」状態なら、Opus 4.7にxhighモードで作業を任せて、人がレビューする運用が現実的です。
「人がレビューに専念し、書き換えはAIに任せる」という分業が成立する水準まで来ています。
設計図・ダッシュボード解析
3.75MP対応により、4.6時代に画像が縮小されて細部が読めなかった用途で大きな改善が得られます。
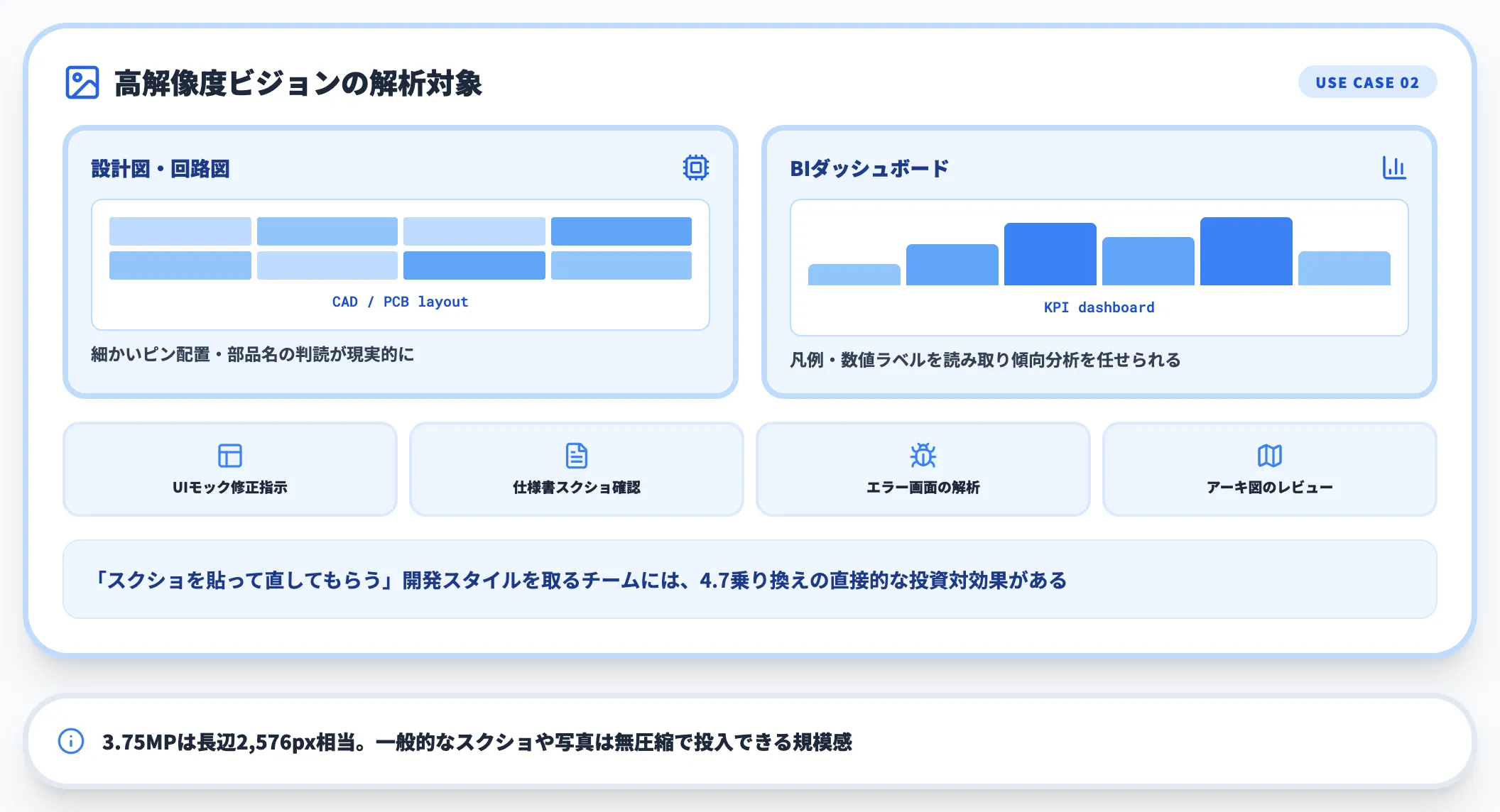
- CADや回路図のレビュー
- BIダッシュボードのスクリーンショット解析
- UI/UXモックの整合性チェック
製造業や金融業で「設計図を貼ってAIにレビューしてもらう」運用を検討していたが、文字が潰れて使えなかったチームは、4.7で再評価する価値があります。
長期エージェントの常駐運用
Claude Code Routinesのような「定期的にエージェントが働く」運用では、ファイルシステムメモリの安定性向上が効きます。
Claude Platform APIで自前のループを実装している場合は、Task Budgets(public beta)をループ全体の目安予算として併用し、モデル側に消費を自己調整させる設計も組み合わせられます(厳密な打ち切りはメータリング側で別途確保が必要。2026年4月時点でClaude Code・Cowork・Routines側のUIではTask Budgetsは未提供)。
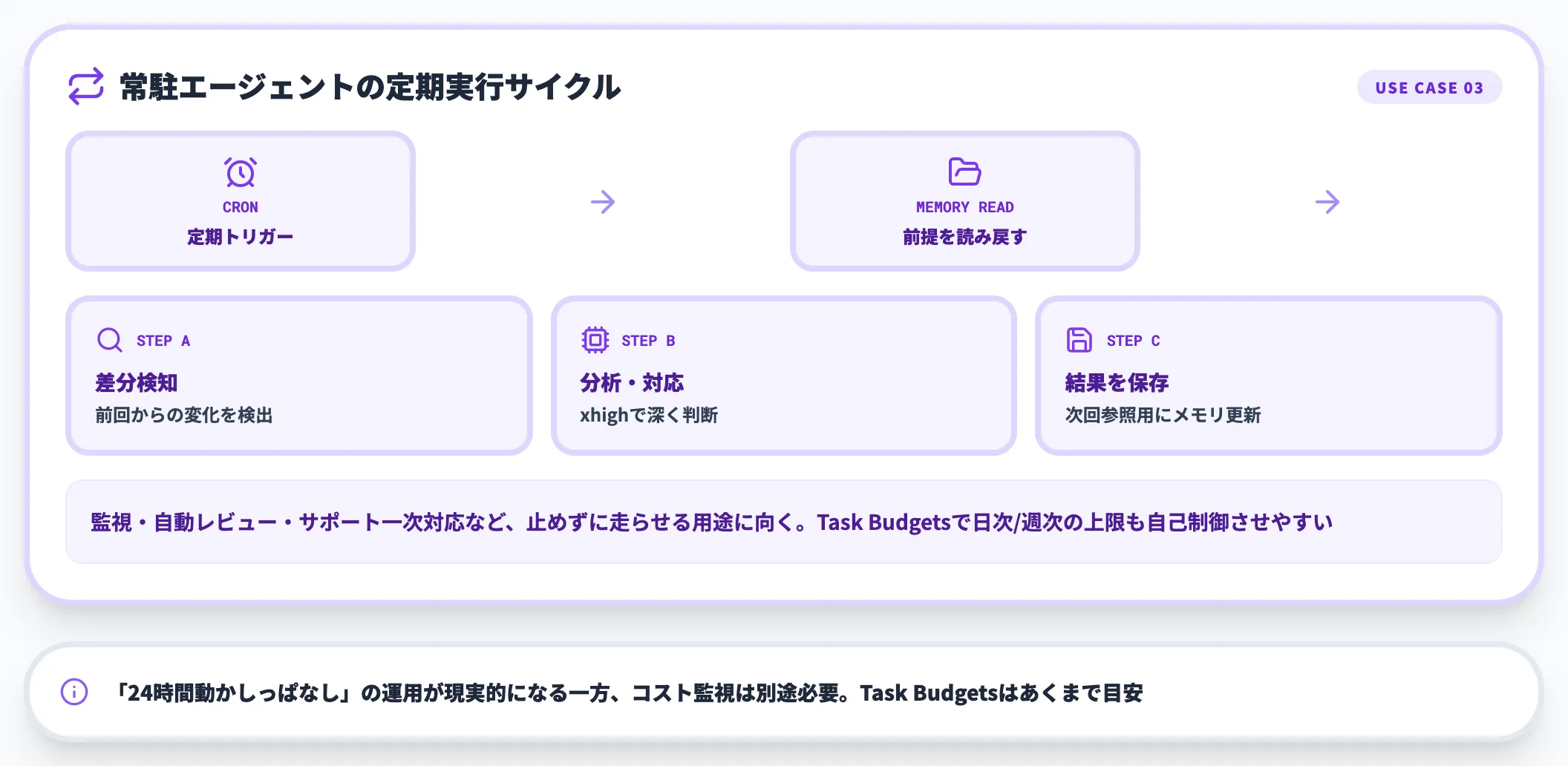
- ナイトリービルドの失敗解析と一次対応
- 毎朝のPRレビュー集約
- 週次の依存パッケージ更新提案
4.6世代でもファイルシステムメモリ自体は提供されていましたが、長期運用では容量管理や読み戻しの安定性に課題が残るケースがありました。
4.7ではこの領域が改善されており、前提情報のキャッシュをより素直に効かせやすくなった結果、長期運用のコスト効率が伸びやすくなっています。
向かない用途
逆に、以下の用途ではOpus 4.7のオーバースペックが目立ちます。
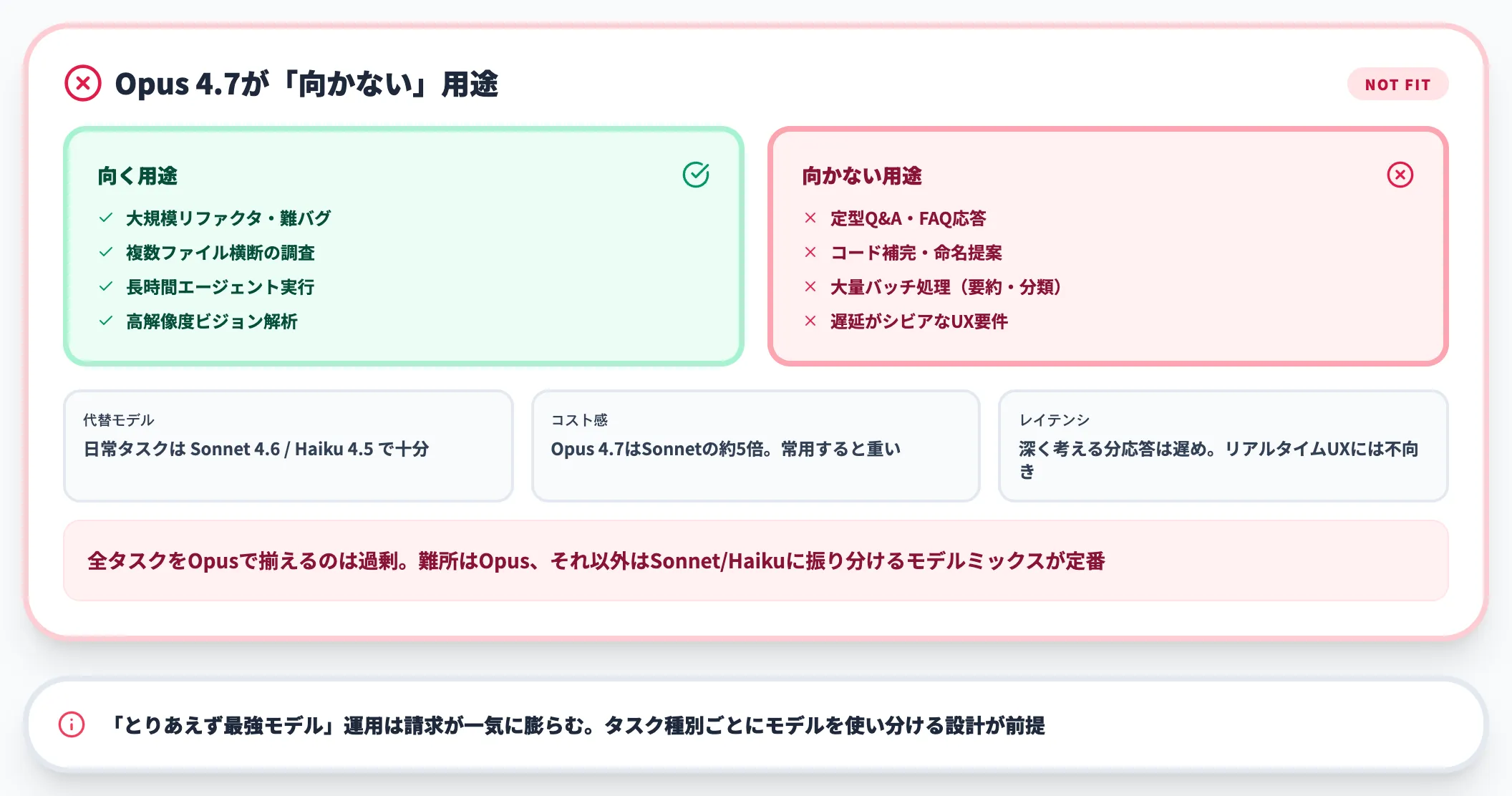
- 単純な要約・翻訳(Sonnet/Haikuで十分)
- 大量バッチでのテキスト生成(コスト効率が悪い)
- レイテンシが最重要のリアルタイム応答(応答時間が伸びる)
費用対効果を考えると、「Opus 4.7 + Sonnet/Haikuのルーティング」という構成が現実解です。難問だけOpus 4.7、それ以外はSonnet/Haikuに振り分けることで、品質と単価の両方を最適化できます。

Claude Opus 4.7の料金体系
Opus 4.7の料金は、4.6から名目上据え置きですが、新トークナイザーの影響で実効コストは上振れる可能性があります。
ここでは「単価」「割引手段」「実効コストの考え方」の3層で整理します。
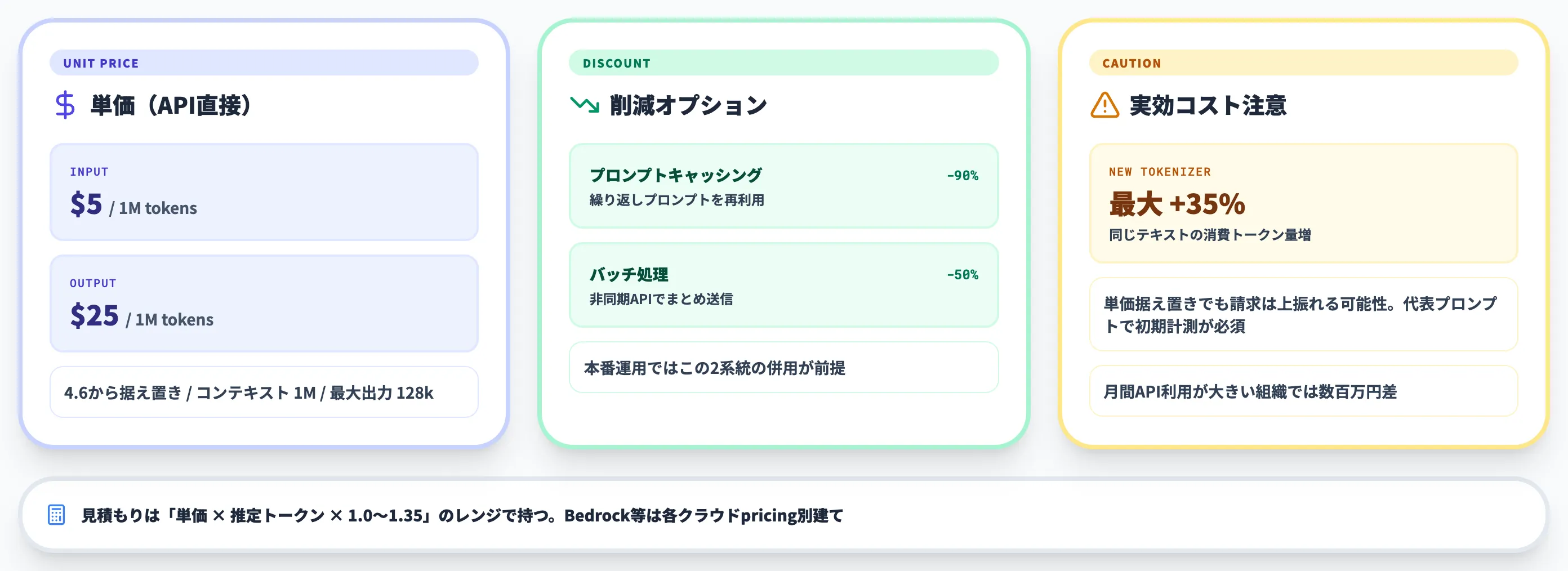
単価表(API直接利用、2026年4月時点)
API直接利用時のトークン単価は次のとおりです。
| 項目 | 単価 |
|---|---|
| 入力 | $5 / 1M tokens |
| 出力 | $25 / 1M tokens |
| コンテキスト長 | 1M tokens |
| 最大出力 | 128,000 tokens |
4.6からの改定はありません。Bedrock・Vertex AI・Foundry経由の単価は各クラウドのpricingページに別建てで掲載されており、リージョナル/マルチリージョン推論を選んだ場合に約10%のプレミアムが上乗せされる構造もあるため、Anthropic直接APIと同額とは限りません。
最終的な見積もりは各クラウドのコスト計算機での試算と、コミットメント割引・為替レートの確認をセットで行うことを推奨します。
コスト削減オプション
Anthropicは公式に2系統の削減手段を提供しています。
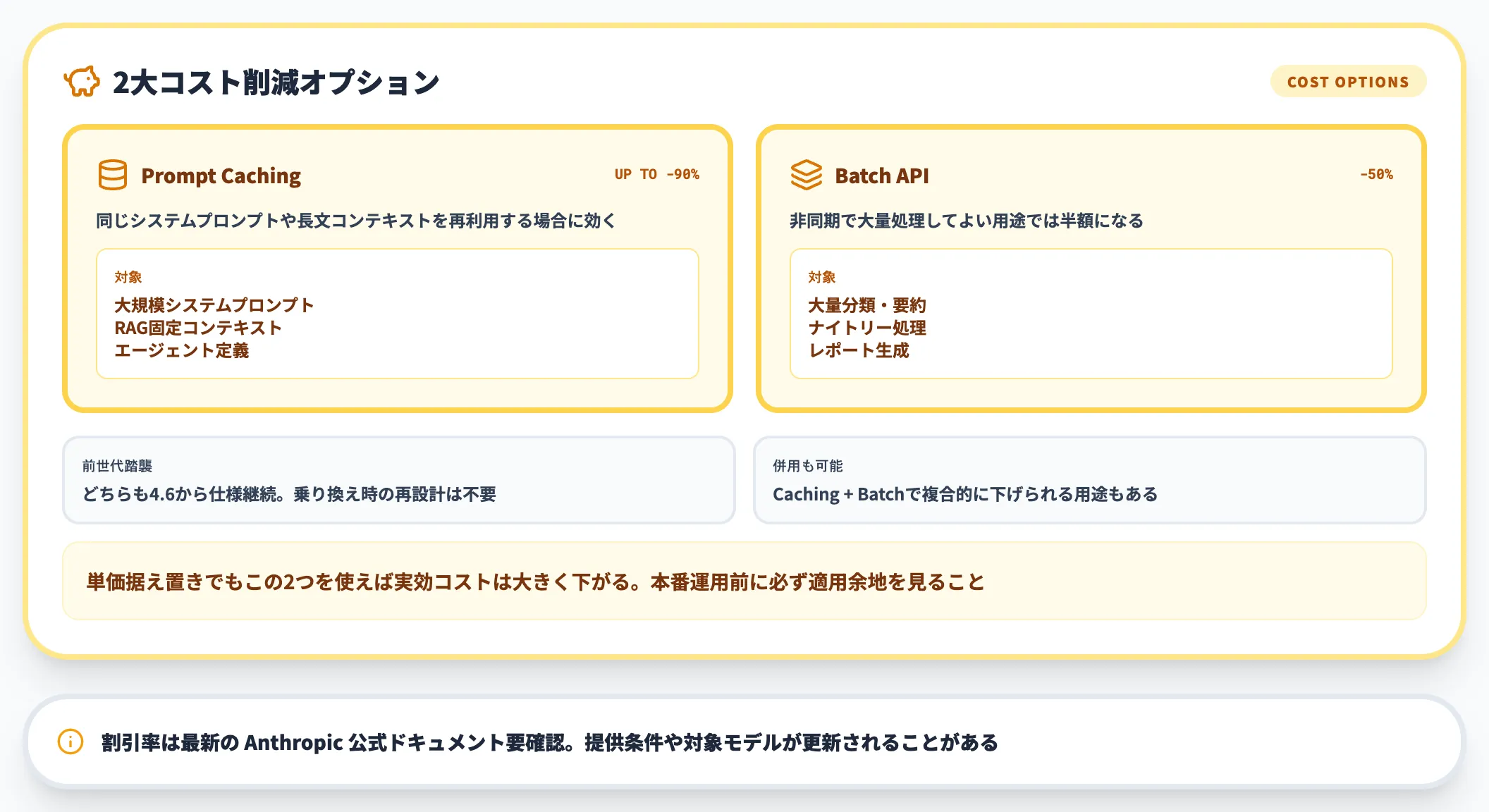
- プロンプトキャッシング
繰り返し使うプロンプトをキャッシュし、最大90%の入力コスト削減。長いシステムプロンプトを使う運用で効果大。
- バッチ処理
非同期APIでまとめて投げる方式。50%のコスト削減。リアルタイム応答が不要なバッチ用途向け。
xhighやTask Budgetsを使う本番運用では、これらの削減手段を併用することが前提になります。例えば、毎晩のリポジトリ全体スキャンをバッチ処理+プロンプトキャッシングで回せば、同じ作業を同期APIで回す場合の数分の1のコストに抑えられます。
新トークナイザーによる実効コストへの影響
4.7では新トークナイザーが導入されており、同じテキストでも最大35%多くのトークンを消費する可能性があります。

- 単価は据え置きだが、消費トークンが増えれば請求額は増える
- 影響度はテキストの種類による(日本語・コード・特殊記号で挙動が異なる)
- 既存ワークロードの初期計測が必須
「単価が同じだから移行コストはゼロ」という想定は危険です。本番投入前に、自社の代表的なプロンプト・出力パターンで4.6 vs 4.7のトークン消費量を計測し、月間請求額のシミュレーションを更新する必要があります。
月間API利用が大きい組織では、35%増の見積もり差が数百万円単位で響くケースもあります。
Claude Opus 4.7導入で詰まる論点
ここではOpus 4.7導入を検討する際に、判断や設定で迷いやすい論点を「乗り換え判断」「セキュリティ」「実装互換性」の3軸で整理します。
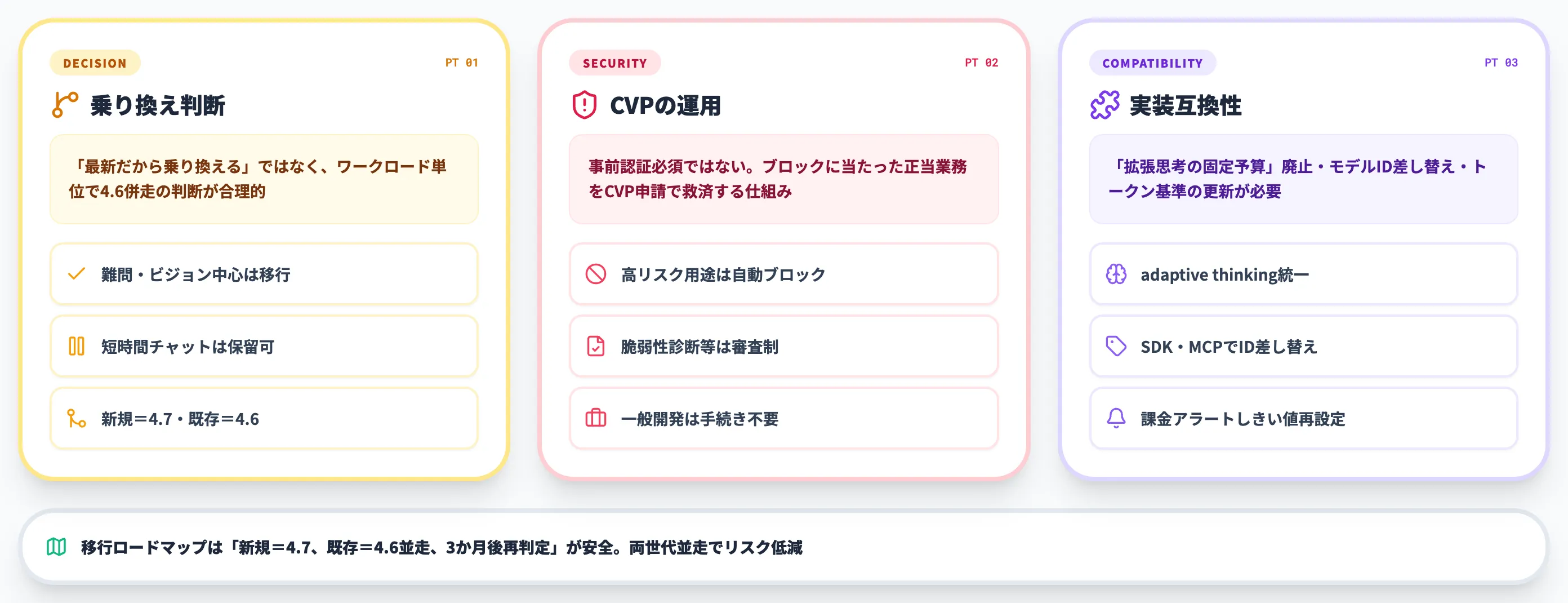
4.6から乗り換えるべきか
「とにかく最新モデルに乗せ替えるべき」という単純な判断は推奨しません。Anthropicは4.6を引き続き提供しており、ワークロードごとに切り替え判断するのが合理的です。
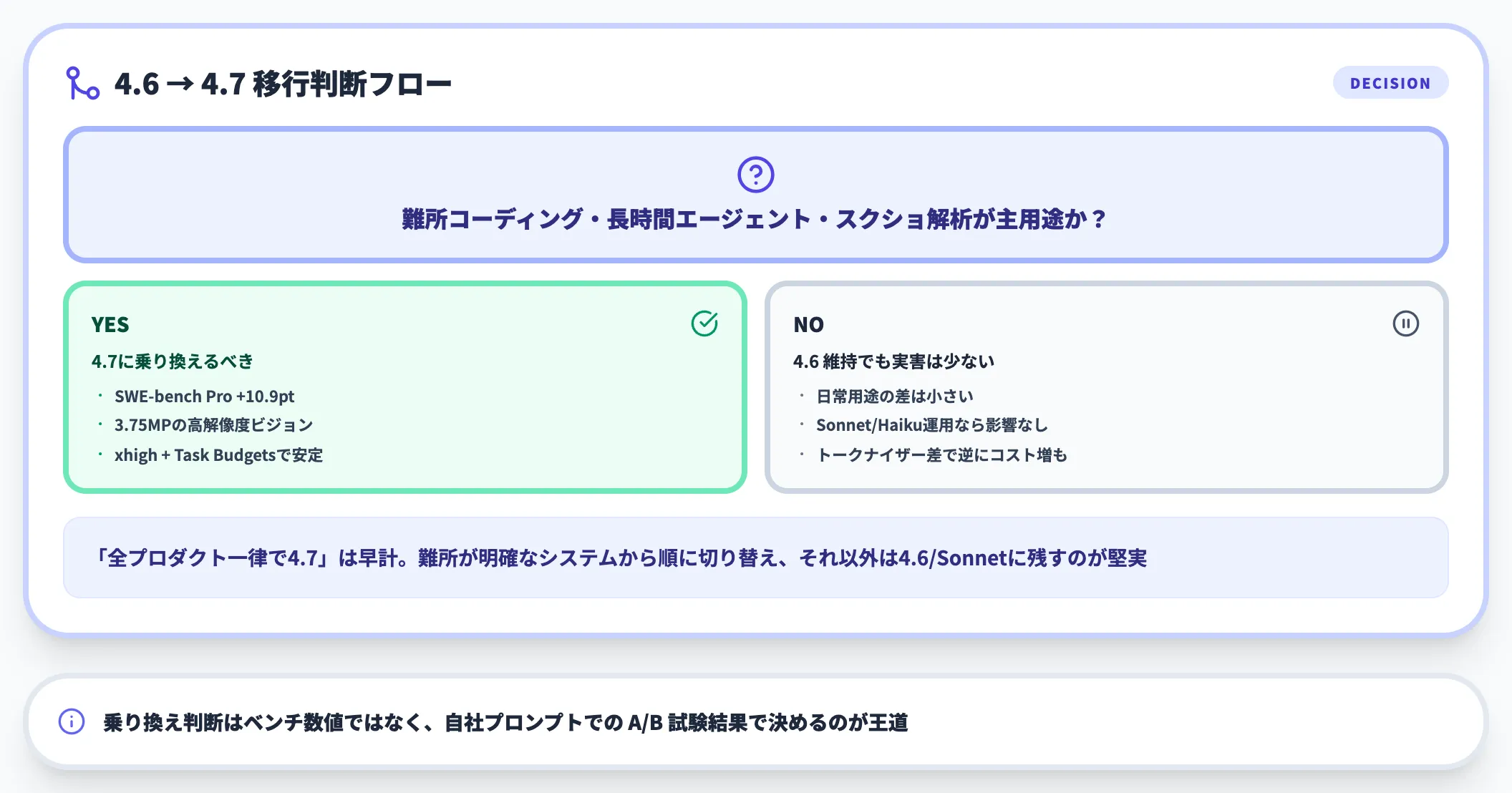
- 乗り換えるべきケース
難問コーディング・長時間エージェント運用・3.75MPビジョンが業務の中心
- 乗り換えを保留してよいケース
短時間チャット・要約・翻訳が中心で、4.6で品質に不満がない
- 段階移行が合うケース
Opus 4.6で運用中の本番ジョブを残しつつ、新規プロジェクトから4.7に切り替える
実務的な進め方は「新規プロジェクト=4.7、既存本番=4.6で並走、3か月後に再判定」というステップで、いきなり全置換しないことです。
新トークナイザーのコスト影響と、ライブラリ・ツール側のモデルID対応状況を見極める時間が必要になります。
Cyber Verification Programとセキュリティ機能
Anthropicは4.7に合わせてCyber Verification Program(CVP)を整備しました。これは「すべてのサイバーセキュリティ用途で事前認証を必須にする」運用ではなく、ポリシー上ブロックがかかった正当な業務利用を救済するための申請枠です。

- 攻撃的・防御的サイバー能力を要求するプロンプトのうちポリシー違反と判定されたものは自動でブロック
- 正当なセキュリティ業務(脆弱性診断・レッドチーム・脅威ハンティング等)でブロックに当たった場合、CVP経由で審査・利用継続を申請できる
- 学習段階で「Mythos Preview比でサイバー能力を意図的に下げた」と説明
一般的なソフトウェア開発・データ分析用途では追加の手続きは不要です。
ペネトレーションテスト・脆弱性スキャン・レッドチーミング自動化など、ポリシー判定に引っかかりやすい用途を本番運用したい組織では、運用設計の段階でCVPの申請プロセスと連絡窓口を確認しておくと、ブロック発生時に止まらずに済みます。
実装互換性で詰まる箇所
4.6から4.7に移行する際、実装側で書き換えが必要になりやすい箇所が3点あります。
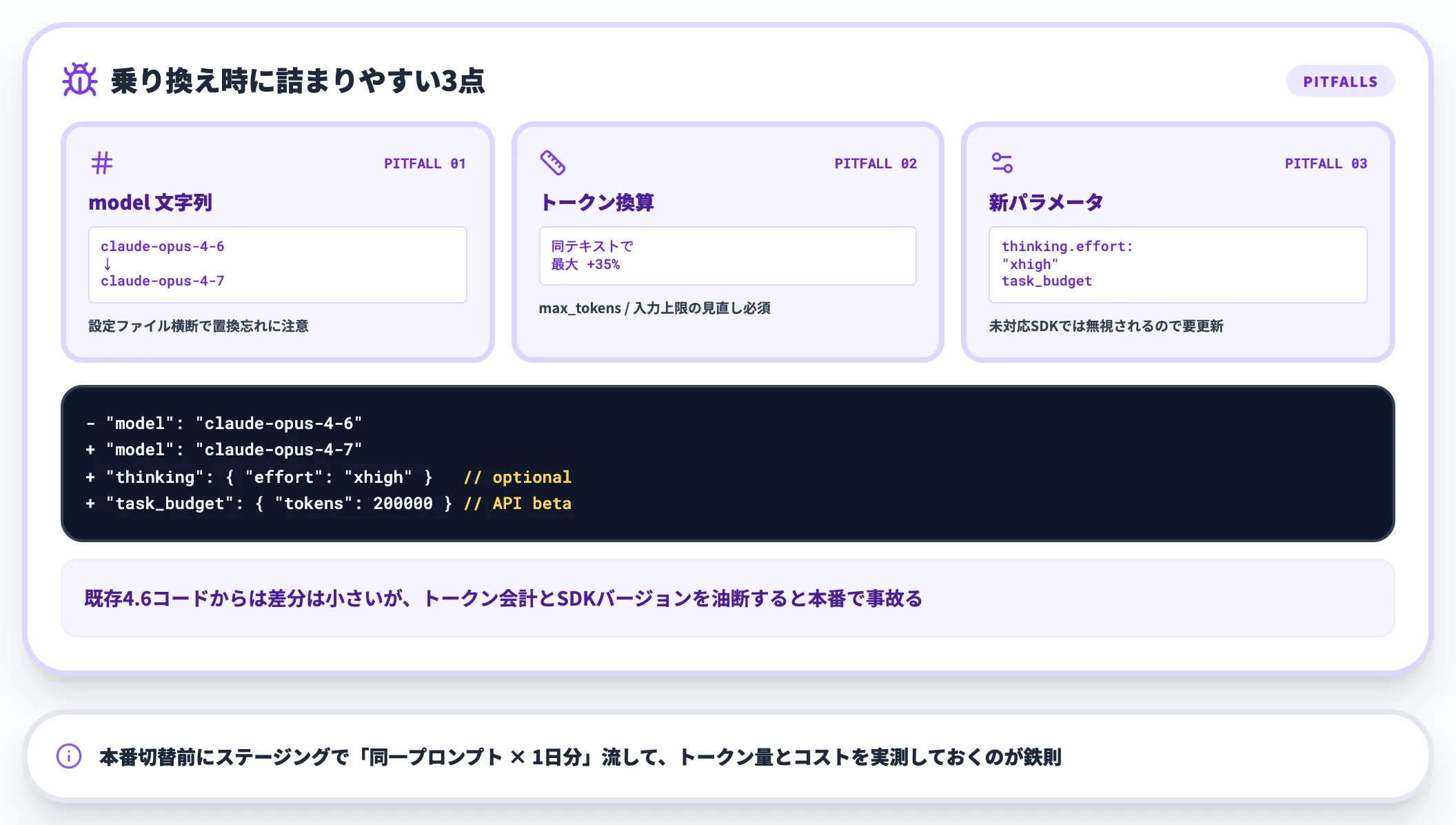
- 拡張思考の固定予算指定
廃止され、thinking: {"type": "adaptive"}に統一。固定予算で組まれたコードは要修正。
- モデルID
クライアントSDK・MCPサーバ・ツール統合先で、新IDへの差し替えが必要。
- トークン消費量の見積もり
ログ・課金アラートのしきい値を新トークナイザー基準で再設定。
特に「拡張思考の固定予算」を使った社内ツールは、4.7で動かなくなる可能性があるため、移行前のコードレビューが必須です。
Opus 4.6を残しておけば旧コードはそのまま動くため、すぐに切り替えず両世代並走で移行リスクを下げる運用を推奨します。
Claude Opus 4.7の検証から業務全体のAI化に広げるなら
Opus 4.7のコーディング精度や長時間エージェント運用の手応えを社内で確認すると、「同じ発想を開発以外の業務にも適用できないか」という議論が必ず出てきます。
経費精算、契約書レビュー、稟議の一次承認、社内ヘルプデスクといった「型のあるオペレーション」は、AIエージェントを設計しやすい領域です。
AI総合研究所が提供する「AI業務自動化ガイド」は、Microsoft環境でのAI業務自動化を、Copilot Chat → M365 Copilot → Copilot Studio → Microsoft Foundry/AI Agent Hubの順に段階設計する220ページの実践資料です。
経費・申請・請求書・人事・総務・情シス・経営企画といった部門別に、Before/After/KPIつきのユースケースを掲載しているため、Claude Opus 4.7のような最上位モデルを「開発以外の業務」へどう接続するかの全体像を掴めます。
Opus 4.7で開発業務の生産性が一段上がるタイミングは、業務側のAI化ロードマップを更新する好機です。
まずは無料の資料で、自社の業務プロセスのどこから着手するのが現実的かをご確認ください。
Claude Opus 4.7の業務適用を全社AI化につなげる

AI業務自動化ガイドで段階的な導入を設計
Claude Opus 4.7のような最上位モデルで開発・分析業務の精度が上がる一方、AIの活用範囲はコーディングだけではありません。AI総合研究所のガイドでは、Microsoft環境で業務プロセス全体のAI化を段階的に進めるための手順を220ページで紹介しています。
まとめ
Claude Opus 4.7は、コーディング・ビジョン・長時間エージェント運用の3軸で4.6を実用的なレベルで更新したフラグシップモデルです。SWE-bench Pro 64.3%・SWE-bench Verified 87.6%という難問領域での伸び、xhigh強度の追加とClaude Platform APIにおけるTask Budgets(public beta)による細やかな推論制御、3.75MPの高解像度ビジョン対応は、開発チームのワークフロー設計を更新する十分な理由になります。
一方で「単価は据え置きだが新トークナイザーで実効コストが最大35%上振れる」「Mythos Previewが上にいる」「ポリシーブロックに当たる正当なセキュリティ業務はCVP申請の運用設計が必要」「Task Budgetsはまだclaude.ai・Claude Code・Cowork側のUIに来ていない」といった制約は、導入計画段階で必ず織り込む必要があります。乗り換えを検討する場合は、まず新規プロジェクトで4.7、既存本番は4.6を並走させ、3か月程度のコスト・品質計測を経て段階移行するのが安全です。
最初の一歩としては、Claude ProでOpus 4.7を選択し、自社の代表的な難問タスクをExtended thinkingオンで試すこと。そこで効果が見えれば、Claude CodeやAPI上でxhigh強度を試し、GitHub Copilot(Pro+ / Business / Enterprise)のモデル設定も切り替え、Claude Platform APIで自前のエージェントループを組む場合はTask Budgetsを目安予算として併用しつつ、絶対上限はメータリング側で確保する設計に進むと無理がありません。










