この記事のポイント
 リアルタイム音声エージェントの「不自然な間」に困るならVAD+barge-in型ではなくモデルネイティブ全二重対話前提でUX要件から再設計
リアルタイム音声エージェントの「不自然な間」に困るならVAD+barge-in型ではなくモデルネイティブ全二重対話前提でUX要件から再設計- 同時通訳・コーチング・コンタクトセンター等、応答遅延が品質を左右する領域はInteraction Modelsの広範リリースを待つ価値が高い
- 既存gpt-realtimeやGemini Liveとは入力モダリティ・「ターン検出依存 vs 全二重」・「単一モデル vs 二重モデル分業」の設計次元で別物
- 広範リリースは年内予定、今後数か月で限定研究プレビュー開始。GA時期・料金・提供形態は未公表のため、本番投入計画は2026年内に確定できない前提で検討する
- 音声・対話AIを業務に組み込むなら、モデル選定の前に「どの業務プロセスのどこを音声にするか」の段階的設計から始めるのが現実的

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Interaction Modelsは、Thinking Machines Lab(Mira Murati氏が創業した新興AI企業)が2026年5月に発表した、音声・動画・テキストを200ms単位のマイクロターンで同時並行処理する新しい対話AIモデル群です。
VADやbarge-inを組み合わせて応答を返す既存の商用realtime APIに対し、Thinking Machinesはターン検出ハーネスでインタラクティブ性を作り込む構成を超える設計として、話しながら聞く・見ながら反応する全二重対話をモデル本体のレベルで実装したと説明しています。
本記事では、Interaction Modelsの仕組み、代表モデルTML-Interaction-Smallの構成、FD-benchベンチマーク数値、gpt-realtime / Gemini Liveとの比較、想定ユースケース、公開状況までを、2026年5月時点の公式一次情報をもとに整理します。
目次
Interaction Model + Background Modelの二重構成
Interaction Modelsの性能と他社realtime APIとの比較
Interaction Modelsとは?
Interaction Models(インタラクションモデル)は、Thinking Machines Labが2026年5月11日に公開した研究プレビューで発表した、音声・動画・テキストをリアルタイムに同時並行で扱う新しい対話AIモデル群です。
ひと言で言うと、「AIが話している最中でもユーザーの声を聞き、カメラ映像を見ながら反応できる」設計の対話AIです
これまで音声AIアシスタントが「話し終わるのを待つ→返事を返す」という会話のやりとりだったところを、人間同士の自然な会話のように「同時に話す・聞く・見る」を成立させる、というのが目玉です。
既存の商用汎用realtime APIの多くは、上記のVADやbarge-inを含むターン検出ハーネスでインタラクティブ性を作り込んできました(Moshiなど小規模・専門型のfull-duplex研究は別系統として進んでいます)。
Interaction Modelsはこの前提を取り払い、話している最中に聞き、見ながら反応することをモデル本体のレベルで実現した点が新規性です。
このモデル群は、OpenAIで元CTOを務めていたMira Murati氏が2025年2月に創業した同社の最初のフロンティアモデル公開で、調達済みのシード資金は20億ドル(評価額120億ドル)規模です。
Interaction Modelsが向き合う課題

gpt-realtimeやGemini Liveなどの商用realtime APIでも、VAD(音声区切り検出)やbarge-in機能を組み合わせて応答遅延を数百ミリ秒〜1秒台まで縮められます。
Thinking Machinesは、こうした構成をターン検出ハーネスでインタラクティブ性を作り込んでいると整理し、以下の場面で不自然さが残ると説明しています。
- 相槌や同意の挿入が遅れて会話のテンポが崩れる
- ユーザーが話している途中で割り込めず、長い独白を最後まで聞いてから返す
- 画面共有・カメラ映像の変化を契機に、AI側から自発的に発話する挙動(speech-out visual proactivity)が限定的
Thinking Machinesはこれらの限界を「ターン検出ハーネス依存という設計の限界」と整理し、入力と出力を時間軸上で同時に進めるアーキテクチャに置き換えました。
代表モデル「TML-Interaction-Small」
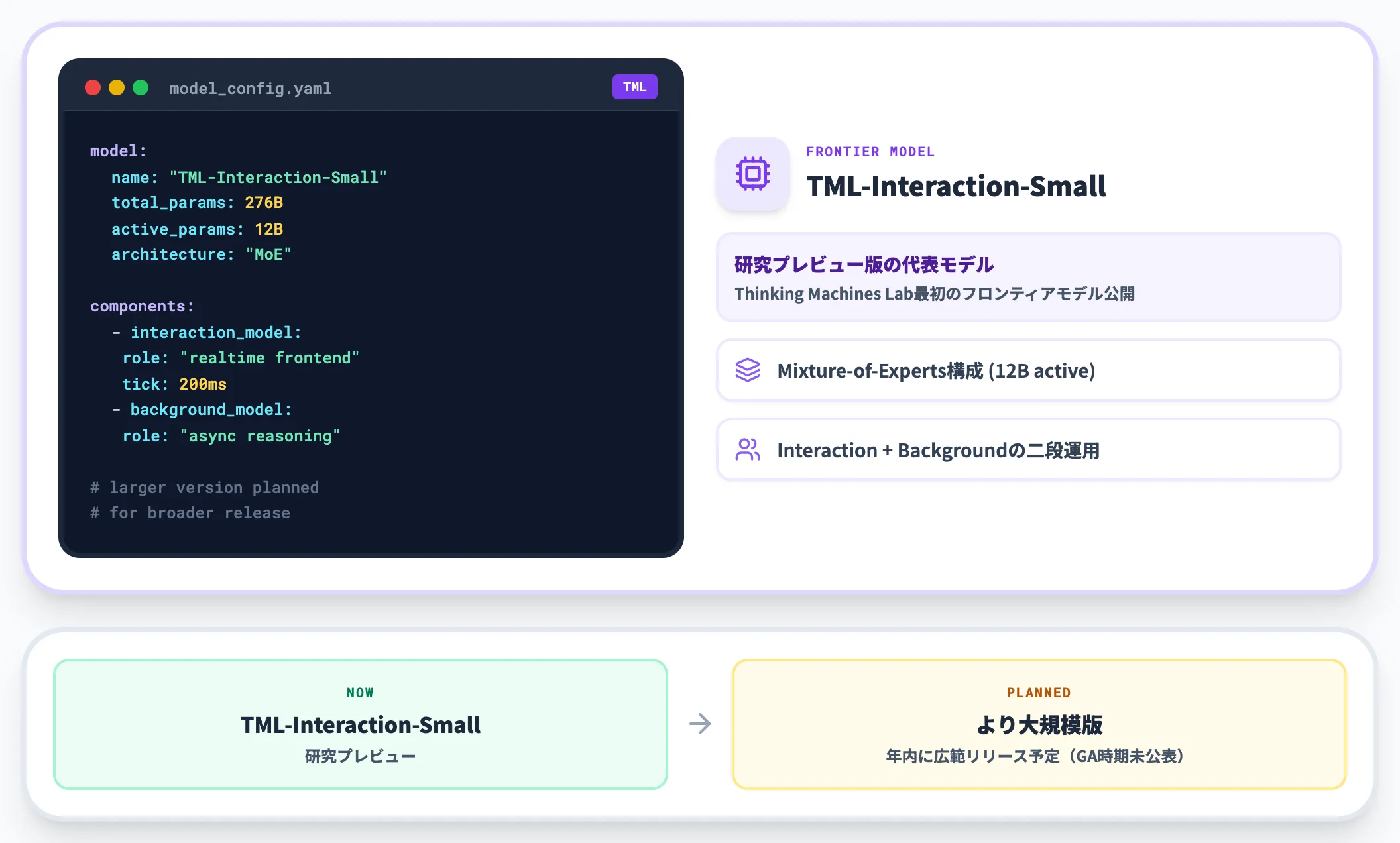
今回の研究プレビューで公開された代表モデルがTML-Interaction-Smallです。総パラメータ276B(うちアクティブ12B)のMixture-of-Experts(MoE:必要なパラメータだけを呼び出す混合専門家構成)構成で、リアルタイム応答を担う「Interaction Model」と、複雑な推論を非同期で行う「Background Model」の二段構成で運用されます。
「Small」と付くのは、より大規模なバージョンを年内により広いリリース予定とアナウンスされているためです。
GA時期や提供形態(API・マネージドサービス等)は2026年5月時点で未公表です。

Interaction Modelsの仕組み

Interaction Modelsの設計上の中心は、「200msのマイクロターン」で入出力を継続的にやりとりする時間認識アーキテクチャです。ターン制との根本的な違いを順に整理します。
200msマイクロターンによる連続処理

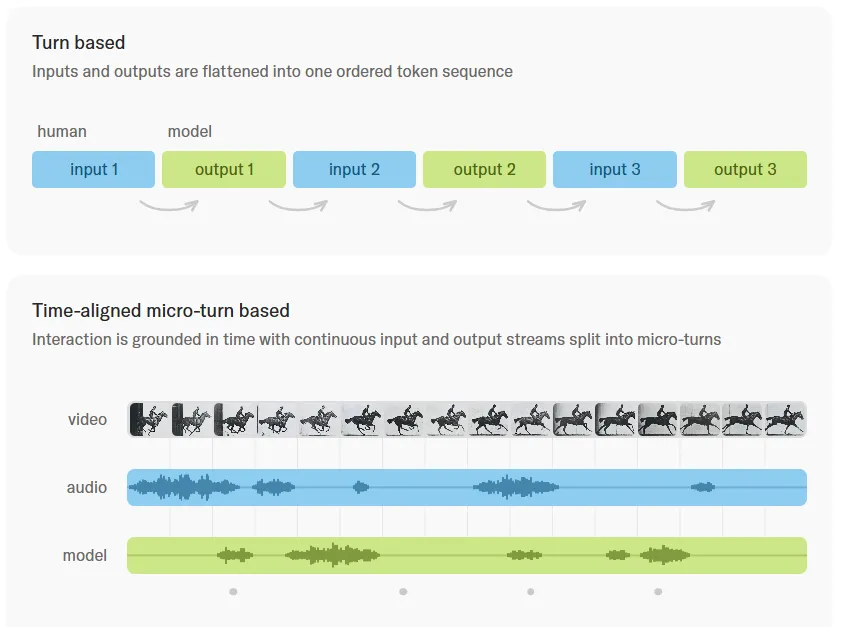
Turn basedとTime-aligned micro-turn basedの処理時系列比較(出典:Thinking Machines Lab)
商用の汎用realtime APIの多くは、VADでユーザーの発話を1つのトークン列として確定させてから処理を始めます。Interaction Modelsは音声・動画ストリームを200ms単位の細かいチャンクに区切り、各チャンクごとに入力受信と出力生成を交互に進めます。
これによって以下の挙動が成立します。
-
割り込み対応
ユーザーが話している途中でも、モデル側が「Yes」「なるほど」といった短い相槌や、割り込み発話を生成できる
-
視覚連動
カメラ映像の変化(手の動き・画面のスクロール・物の出現)に対して、発話を止めて反応するなど、視覚イベントを発話の中に織り込める
-
時間認識
「3秒数えて」「次の信号で進んで」のような時間に依存した指示を、内部時計と同期して処理する
このマイクロターンの仕組みは、論文系の先行研究であるSynchronous LLMs as Full-Duplex Dialogue Agentsの流れにある全二重(full-duplex)アプローチを、フロンティア級のスケールに引き上げた実装と整理できます。
Encoder-free early fusion
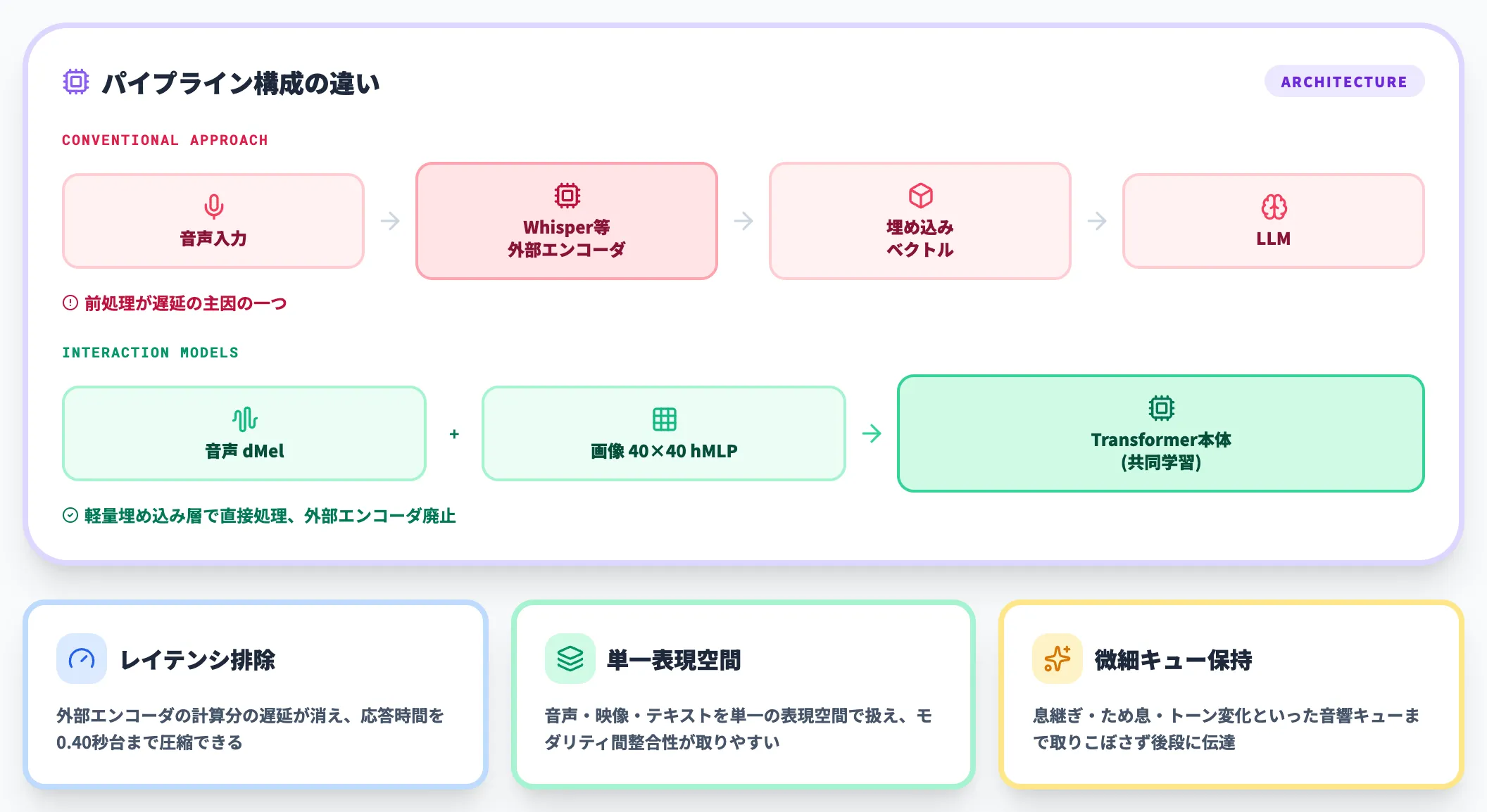
もう一つの設計要点が、音声・映像の事前エンコーダを廃したencoder-free early fusionです。
通常、音声や動画をLLMに渡す際は、専用エンコーダ(Whisper系の音声エンコーダ、CLIP系の画像エンコーダなど)でいったん埋め込みベクトルに変換します。この前処理が遅延の主因の一つでした。
TML-Interaction-Smallは、大規模な外部エンコーダを使わず、音声はdMelとして軽量埋め込み層に渡し、画像は40×40パッチに分割してhMLPで符号化する設計に切り替えています。
これらのコンポーネントはTransformer本体と一緒にゼロから共同学習されています。
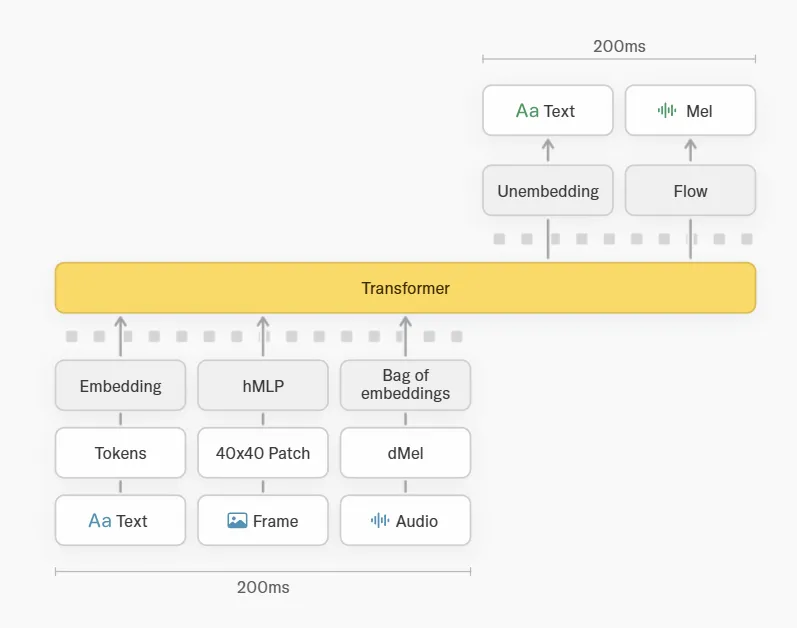
Encoder-free early fusionによるInteraction Modelsの処理構造(出典:Thinking Machines Lab)
これにより以下の効果が出ます。
- 外部エンコーダの計算分のレイテンシが消える
- 音声・映像・テキストを単一の表現空間で扱えるため、モダリティ間の整合性が取りやすい
- 微細な音響キューまで取りこぼさずに後段に伝わる
結果として、応答遅延を0.40秒台まで圧縮しつつ、音声キューへの反応性(後述のCueSpeak指標)を従来比で大きく引き上げています。
Interaction Model + Background Modelの二重構成

リアルタイム性と推論深度を両立させるため、Thinking Machinesは役割の異なる2つのモデルを併走させる構成を採用しています。
役割分担を以下の表に整理しました。
| モデル | 役割 | 動作モード |
|---|---|---|
| Interaction Model(TML-Interaction-Small) | ユーザーと常時やりとりするフロント。相槌・即応・視覚反応を担当 | 200msマイクロターンで連続稼働 |
| Background Model | ツール利用・ウェブ検索・複雑推論を担当 | Interaction Modelからの依頼を受けて非同期で実行 |
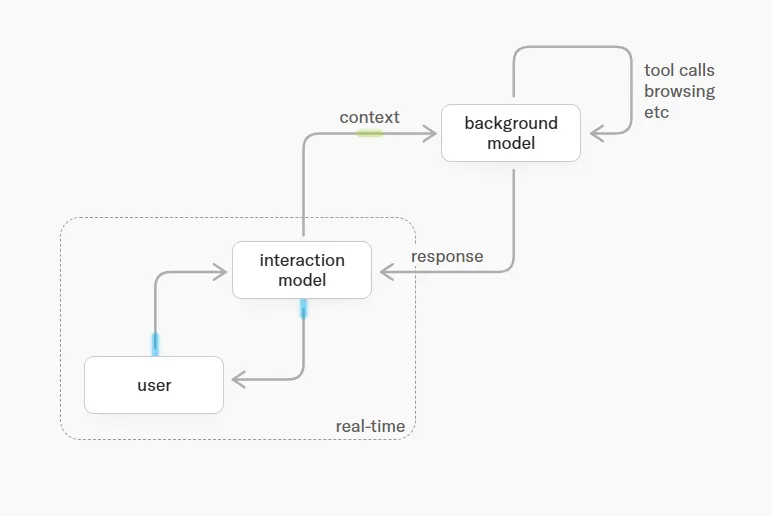
Interaction ModelとBackground Modelの役割分担(出典:Thinking Machines Lab)
この表のポイントは、「速い応答」と「深い推論」を1つのモデルで兼ねさせていないことです。
ユーザー体験のテンポはInteraction Modelが担保し、答えに長考が必要な場面だけBackground Modelに投げるため、平均応答が遅くなりません。
これはアシスタント設計でいう「フロント受付」と「奥のオペレーター」の分業に近い構成で、人間のコンタクトセンターの運用イメージに近いと言えるでしょう。
Interaction Modelsの性能と他社realtime APIとの比較
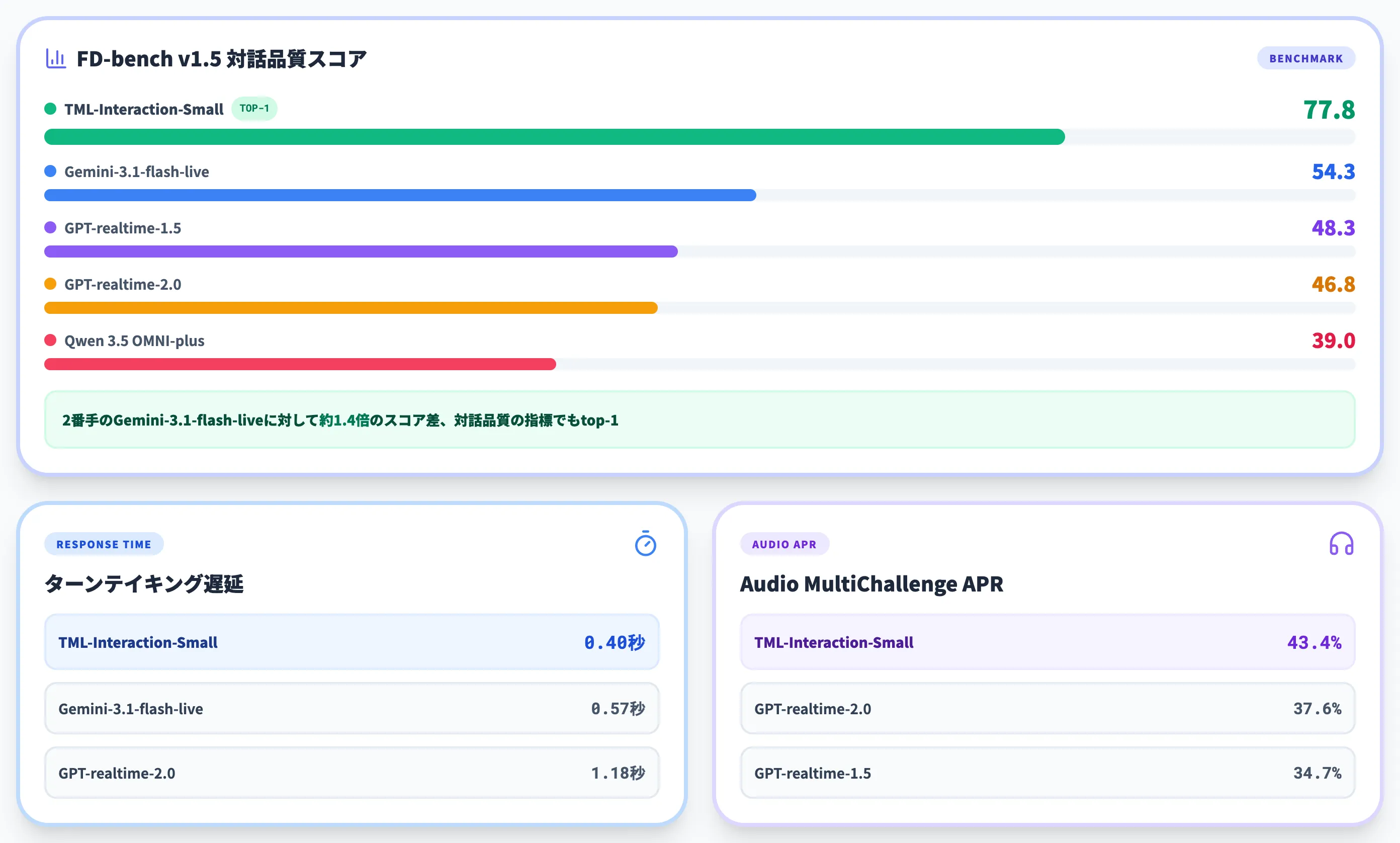
公式が公開している主要ベンチマーク値を、競合realtime APIと並べて整理します。
応答遅延・対話品質の数値
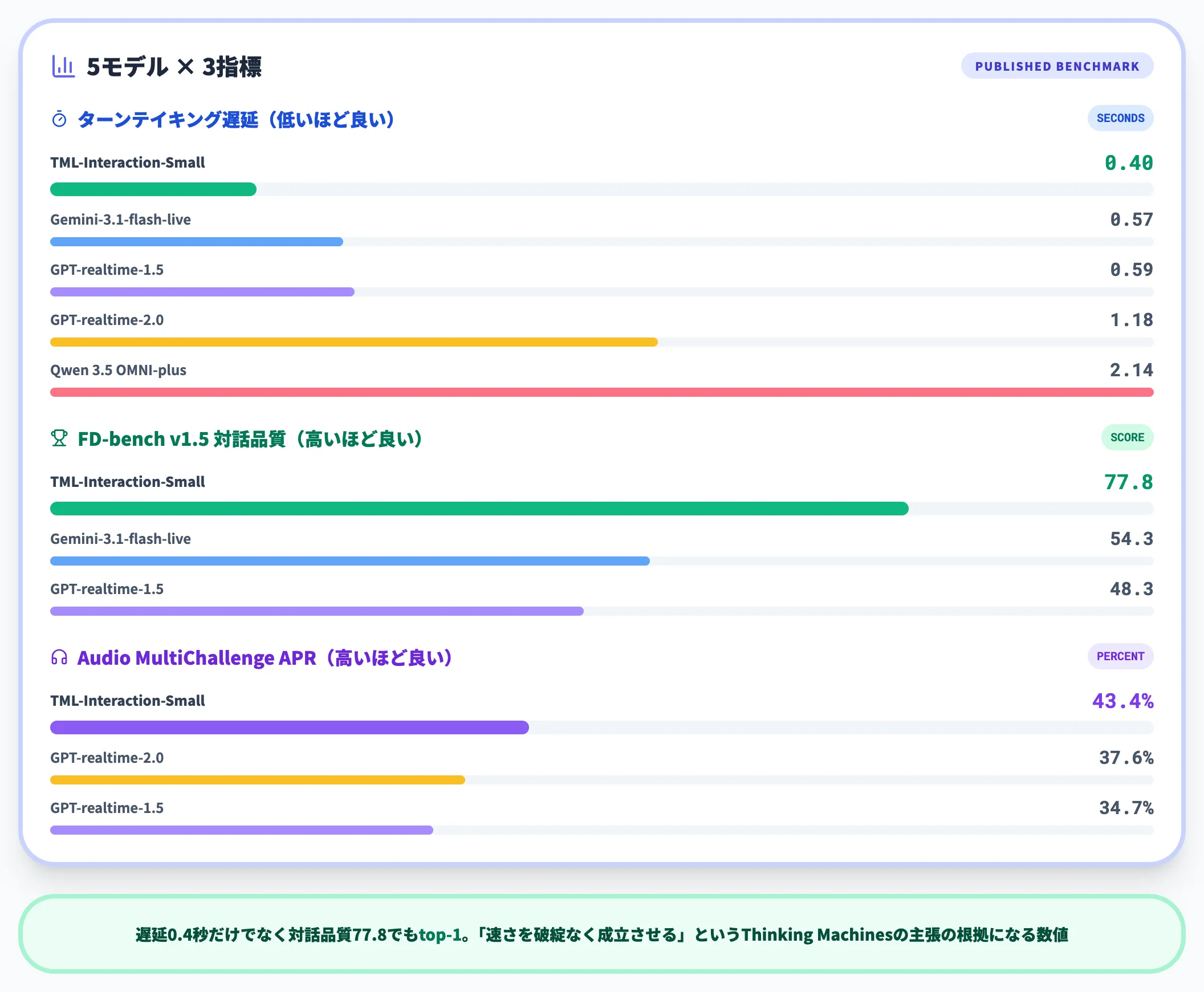
以下の表は、Thinking Machinesが公表したベンチマーク結果のうち主要指標を抜粋したものです。指標名の意味を先に整理しておきます。
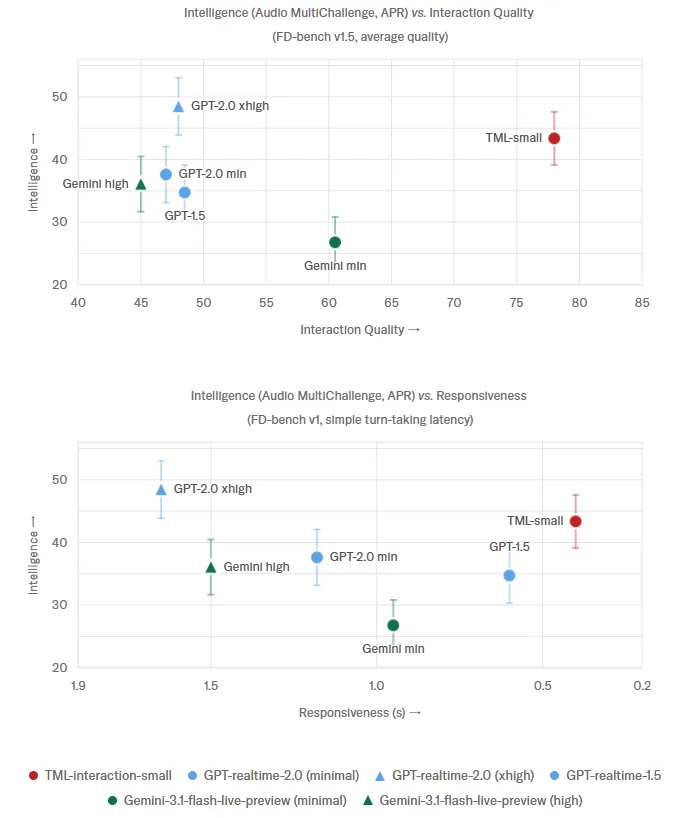
FD-bench v1.5 × Audio MultiChallenge APRにおけるTML-Interaction-Smallと他社realtime APIの位置付け(出典:Thinking Machines Lab)
| モデル | ターンテイキング遅延 | FD-bench v1.5(対話品質) | Audio MultiChallenge APR |
|---|---|---|---|
| TML-Interaction-Small | 0.40秒 | 77.8 | 43.4% |
| Gemini-3.1-flash-live(minimal) | 0.57秒 | 54.3 | 26.8% |
| GPT-realtime-1.5 | 0.59秒 | 48.3 | 34.7% |
| GPT-realtime-2.0(minimal) | 1.18秒 | 46.8 | 37.6% |
| Qwen 3.5 OMNI-plus-realtime | 2.14秒 | 39.0 | (非公表) |
FD-benchでは2番目に高いGemini-3.1-flash-live(minimal)の54.3に対してTMLは77.8と、約1.4倍のスコア差があります。
遅延0.4秒という速さだけでなく、対話品質の指標でもtop-1である点が、「速さを破綻なく成立させる」というThinking Machinesの主張の根拠になっています。
時間認識・視覚反応の独自ベンチマーク
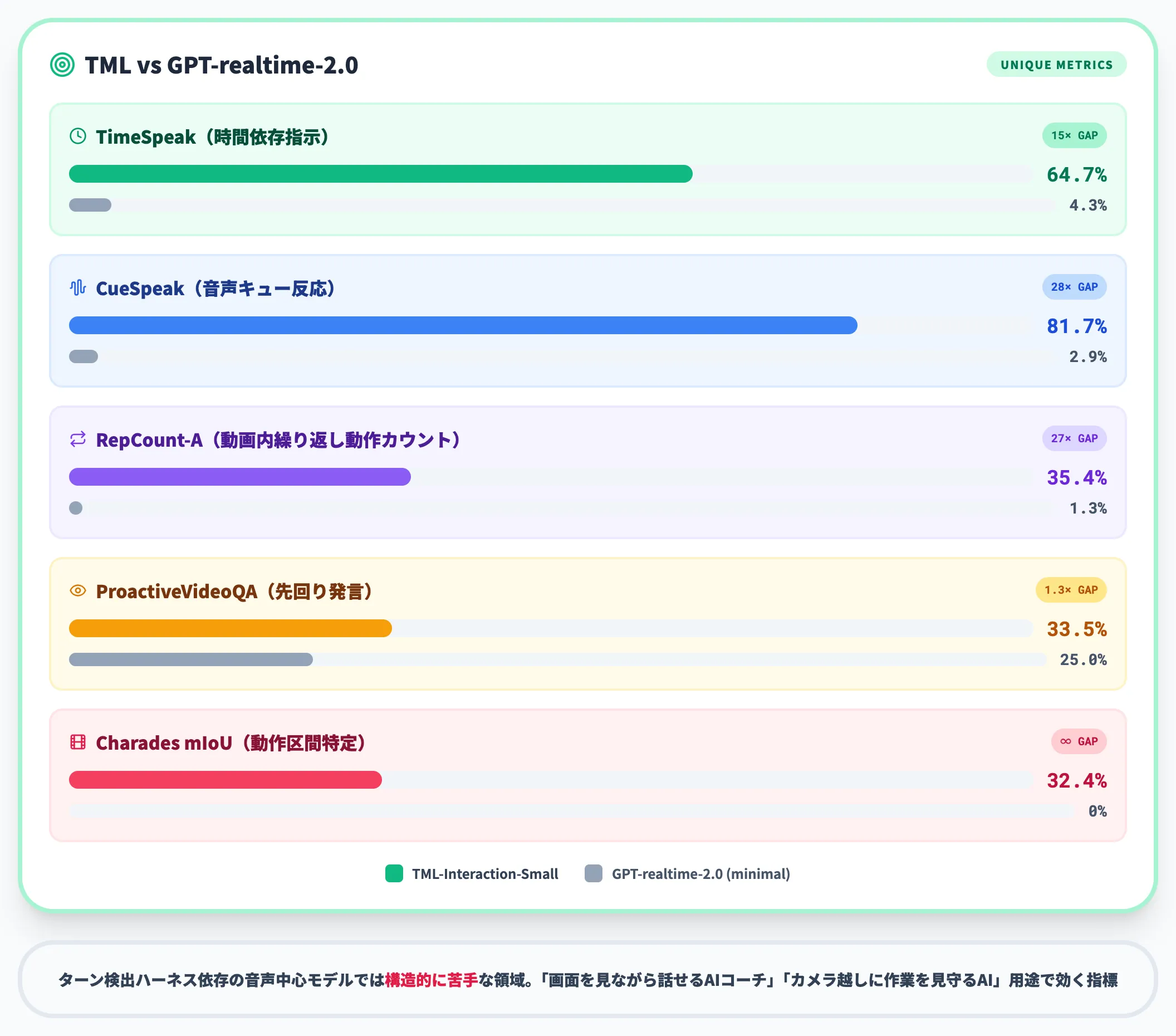
公式は既存の音声LLMベンチマークで差が見えにくい領域として、独自指標を提示しています。
以下の数値はいずれもGPT-realtime-2.0(minimal)との比較で公表されたものです。
-
TimeSpeak
時間に依存した指示(「5秒数えて」等)への正確な対応。TML-Interaction-Smallは64.7%、GPT-realtime-2.0(minimal)は4.3%
-
CueSpeak
言語的な音声キュー(コードスイッチ等)への反応。同81.7% vs 2.9%
-
RepCount-A
動画内の繰り返し動作の正確なカウント。同35.4% vs 1.3%
-
ProactiveVideoQA
動画の変化を先回りで質問・発言する能力。同33.5% vs 25.0%
-
Charades mIoU
動画内の動作区間の特定。同32.4% vs 0%
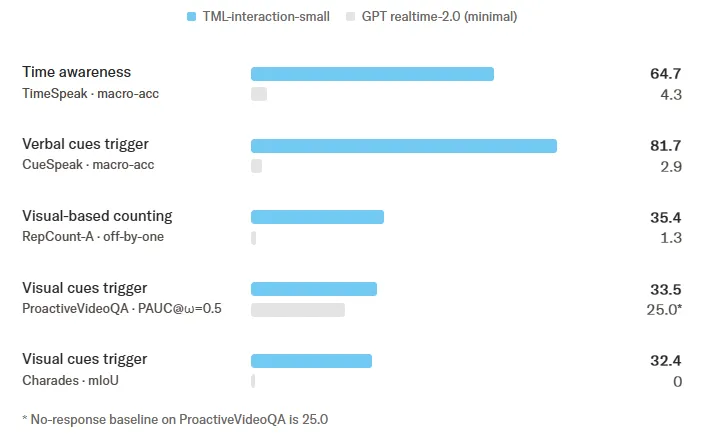
時間認識・音声キュー・視覚反応に関するインタラクティビティ評価(出典:Thinking Machines Lab)
これらは「画面を見ながら話せるAIコーチ」「カメラ越しに作業を見守るAI」のような用途で効いてくる指標で、Thinking Machinesはターン検出ハーネス依存の音声中心モデルでは構造的に苦手な領域だと整理しています。
Gemini Liveなど他社モデルの値が一律に公表されているわけではないため、表の数値はあくまで「GPT-realtime-2.0(minimal)との対比」として読むべきです。それでも差の桁が大きく、設計次元の違いがUXに直結する領域だと示唆されます。
既存realtime APIとの設計次元の違い

数値の優劣に加えて、設計思想のレイヤーで見たほうが本質をつかみやすい比較ポイントを以下に整理しました。
なお比較対象API側の仕様はOpenAI Realtime ConversationsとVertex AI Gemini Live APIの公式情報に基づきます。
| 観点 | gpt-realtime(OpenAI) | Gemini Live(Google) | Interaction Models |
|---|---|---|---|
| 対話制御 | VAD+barge-inでターン検出 | VAD+barge-in/proactive audio | 200msマイクロターンの全二重 |
| 入力モダリティ | 音声・テキスト・画像(動画非対応) | 音声・テキスト・画像/動画 | 音声・動画・テキスト |
| 推論統合 | 単一モデルが応答と推論を兼任 | 単一モデルが応答と推論を兼任 | Interaction+Backgroundの分業 |
| 視覚連動の発話 | 画像入力に応じた応答は可だが、映像変化を契機に自発発話する挙動は限定的 | 動画入力に対応するが、映像変化を契機に自発発話する挙動は限定的 | 映像変化を契機に自発的に発話する(speech-out visual proactivity) |
| 時間認識 | 明示的な内部時計を持たない | 明示的な内部時計を持たない | 時間軸を一級市民として扱う |
| 想定UX | 「Push-to-Talk」「Wake-word」寄り | 「Push-to-Talk」「Wake-word」寄り+常時音声入力 | 「常時オン」型 |
同じ「リアルタイム音声AI」というラベルに見えても、入力モダリティと視覚連動の挙動に差があります。gpt-realtimeは動画入力に対応しておらず、Gemini Liveは動画入力に対応するものの、両者とも視覚変化を契機にAI側から能動的に話し始める挙動は標準機能としては提供されていません。
realtime APIで実装したプロダクトをInteraction Modelsに置き換えるとき、API差し替えだけでなくUX設計そのものの見直しが必要になるという点は押さえておくべきです。
Interaction Modelsの想定ユースケース

公式ブログとデモ動画から推測される、Interaction Modelsが効く領域を業務ドメインごとに整理します。

コンタクトセンター・カスタマーサポート
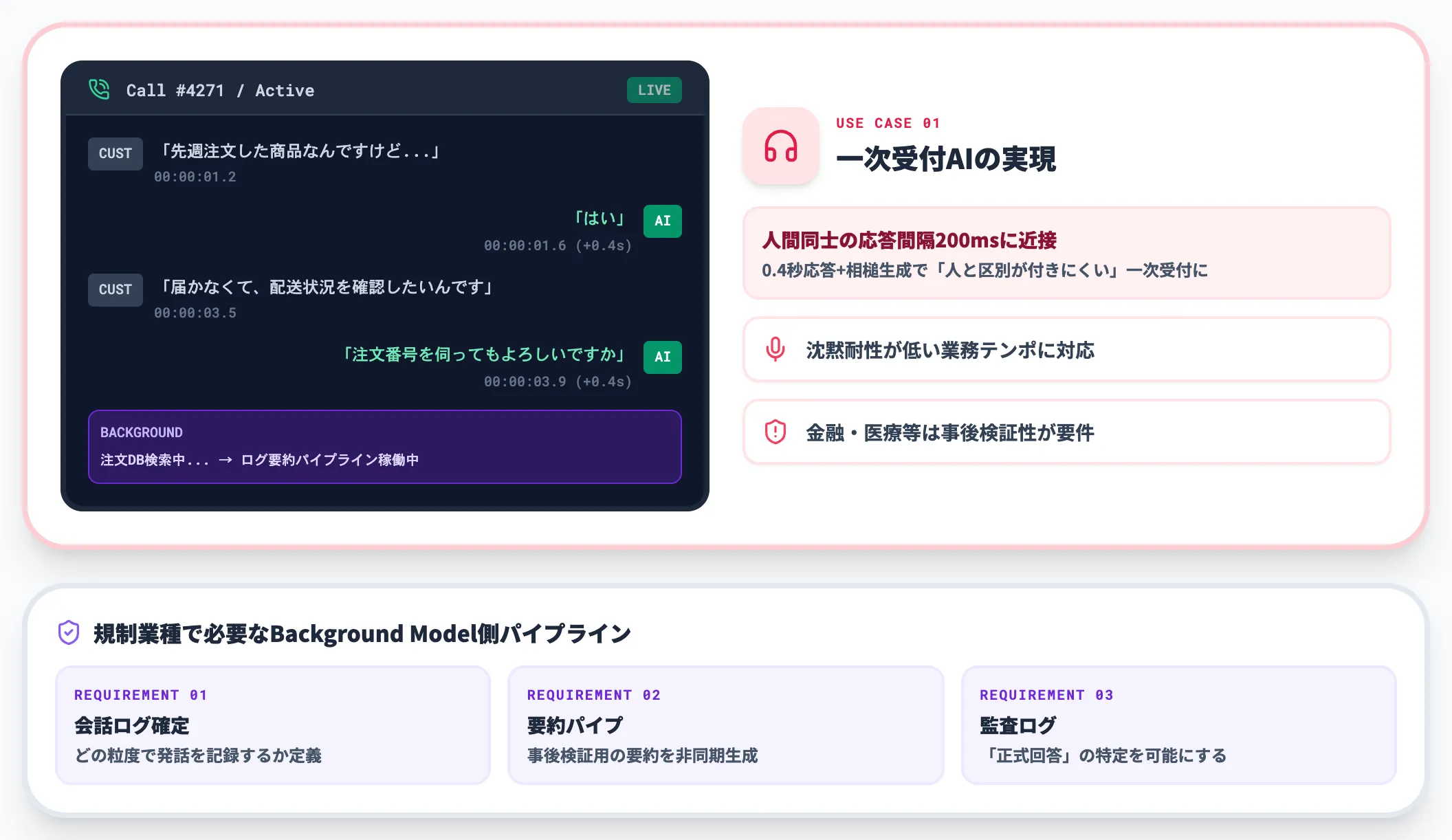
オペレーターと顧客の会話は沈黙への耐性が低い場面が多く、会話研究では人間同士の応答間隔は約200ms程度に収まると報告されています。
長めの無音は違和感や聞き返しにつながりやすく、コンタクトセンターのオペレーター業務はこのテンポを前提に設計されています。
Interaction Modelsの0.4秒応答と相槌生成は、この領域で「人と区別が付きにくい」一次受付AIに一歩近づく可能性があります。
同時通訳・多言語コミュニケーション
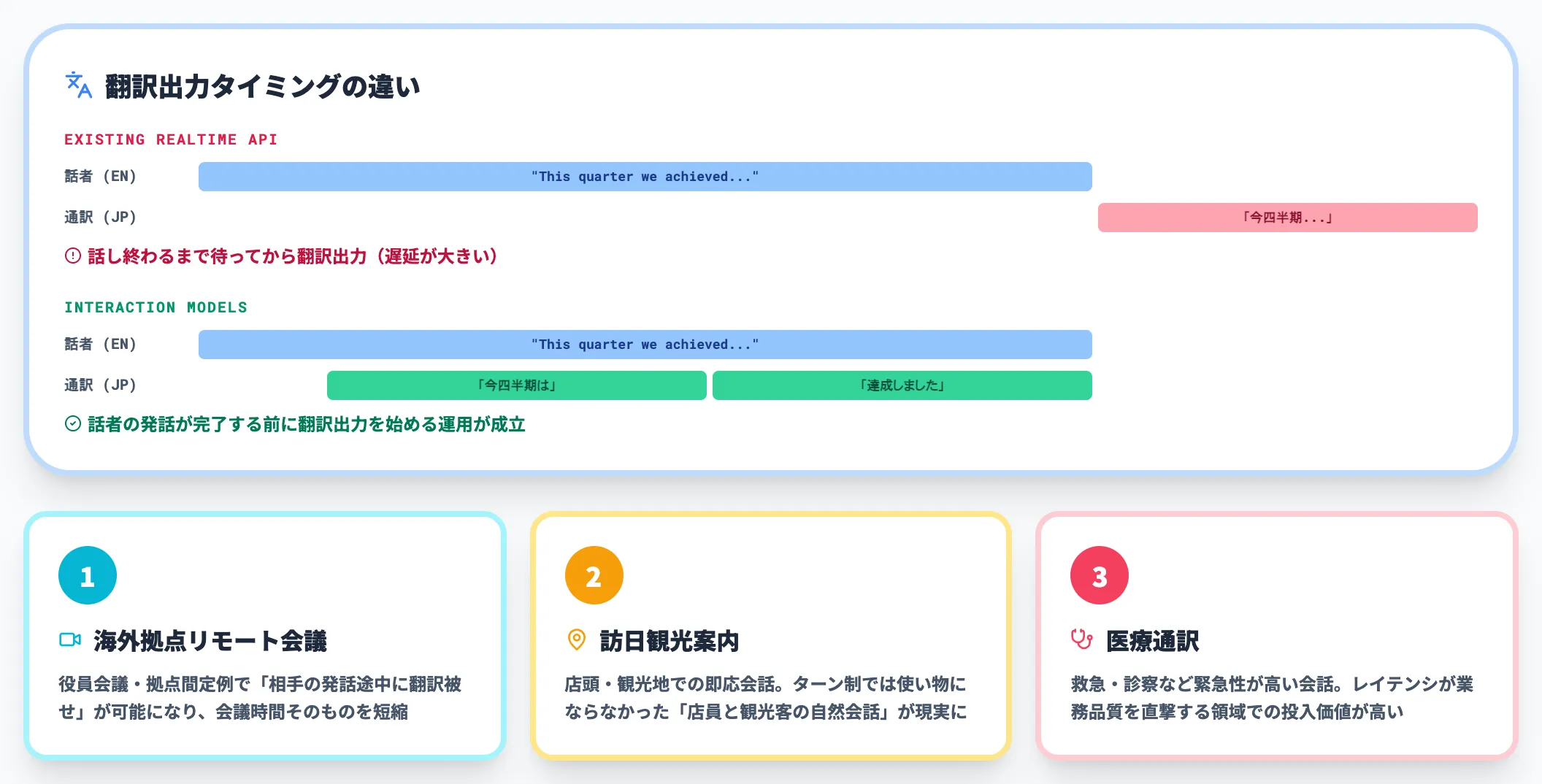
「相手が話している最中に翻訳音声を被せる」という同時通訳の挙動は、ターン検出ハーネスに依存する既存realtime APIでは安定して再現しにくい領域です。
Interaction Modelsの全二重設計は、話者の発話が完了する前に翻訳出力を始める運用に直接対応します。
海外拠点とのリモート会議、訪日観光案内、医療通訳のようにレイテンシが業務品質を直撃する領域では、一般提供のタイミングで投入価値が高い候補になります。
Audio interjectionのデモ(出典:Thinking Machines Lab)
スキルコーチング・接客トレーニング
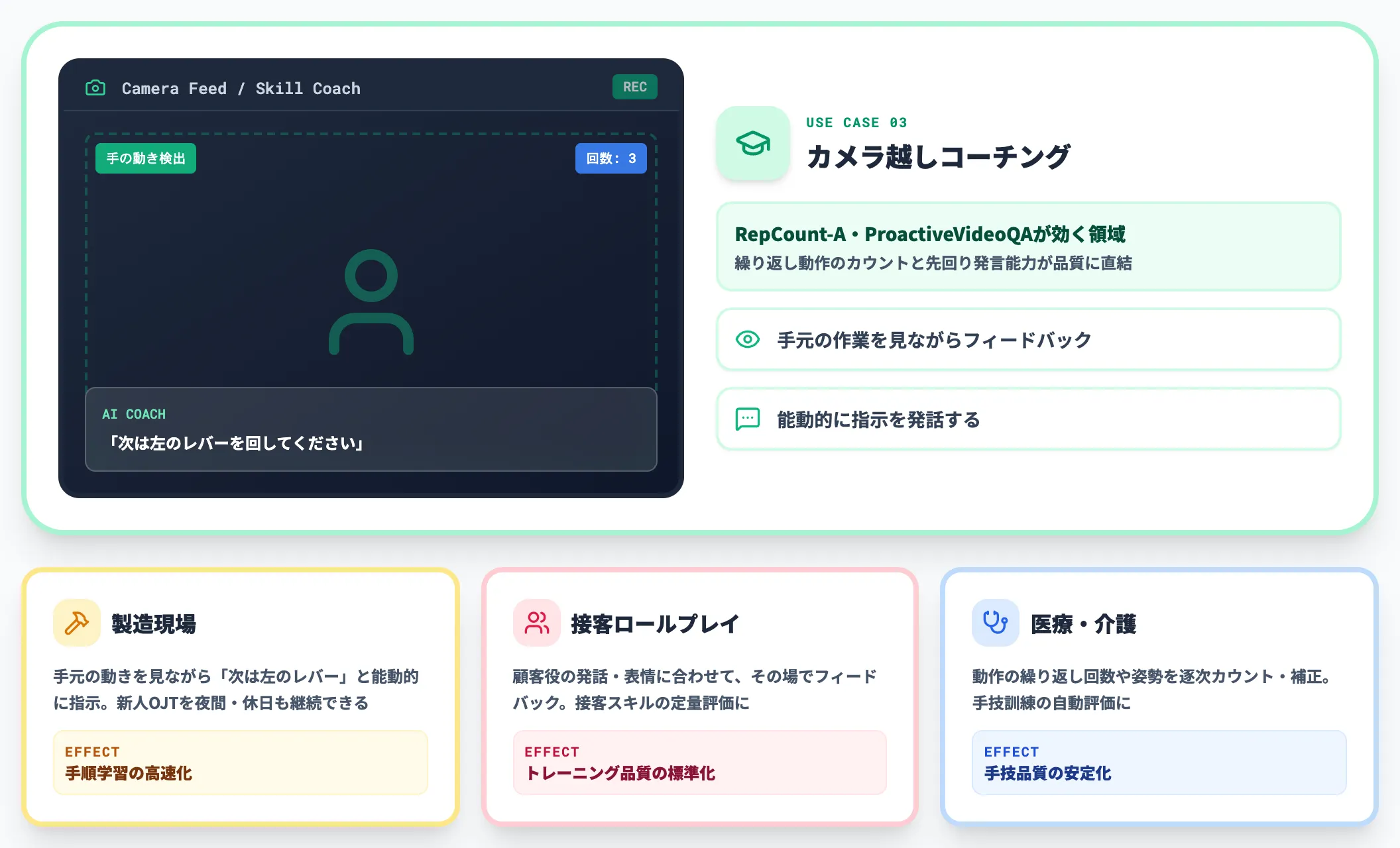
カメラ越しに手元の作業や接客の様子を見ながら、リアルタイムでフィードバックを返す用途は、独自指標のRepCount-A・ProactiveVideoQAが効く典型です。
- 製造現場の手順学習:手元の動きを見ながら「次は左のレバー」と能動的に指示
- 接客ロールプレイ:顧客役の発話・表情に合わせてその場でフィードバック
- 医療・介護の手技訓練:動作の繰り返し回数や姿勢を逐次カウント・補正
generative UIのツール実行とUI生成デモ(出典:Thinking Machines Lab)
これらはAIが会話する仕組みや生成AIと対話型AIの違いで扱ってきた対話AIの延長線にありつつ、ターン制では取り切れなかった「常時オン・視覚連動」の領域に踏み込みます。
既存音声基盤との関係
「ではAzure AI Speechのような既存の音声基盤は置き換わるのか?」という問いが当然出てきます。
現実的には、マイク入力・話者分離・音声合成・電話線統合といった周辺アセットは既存基盤が担い、対話エンジン部分だけがInteraction Modelsに置き換わる形が当面の標準になると見ています。アプリケーションレベルで一気に乗り換える話ではありません。
Interaction Modelsを導入判断するときに詰まる論点
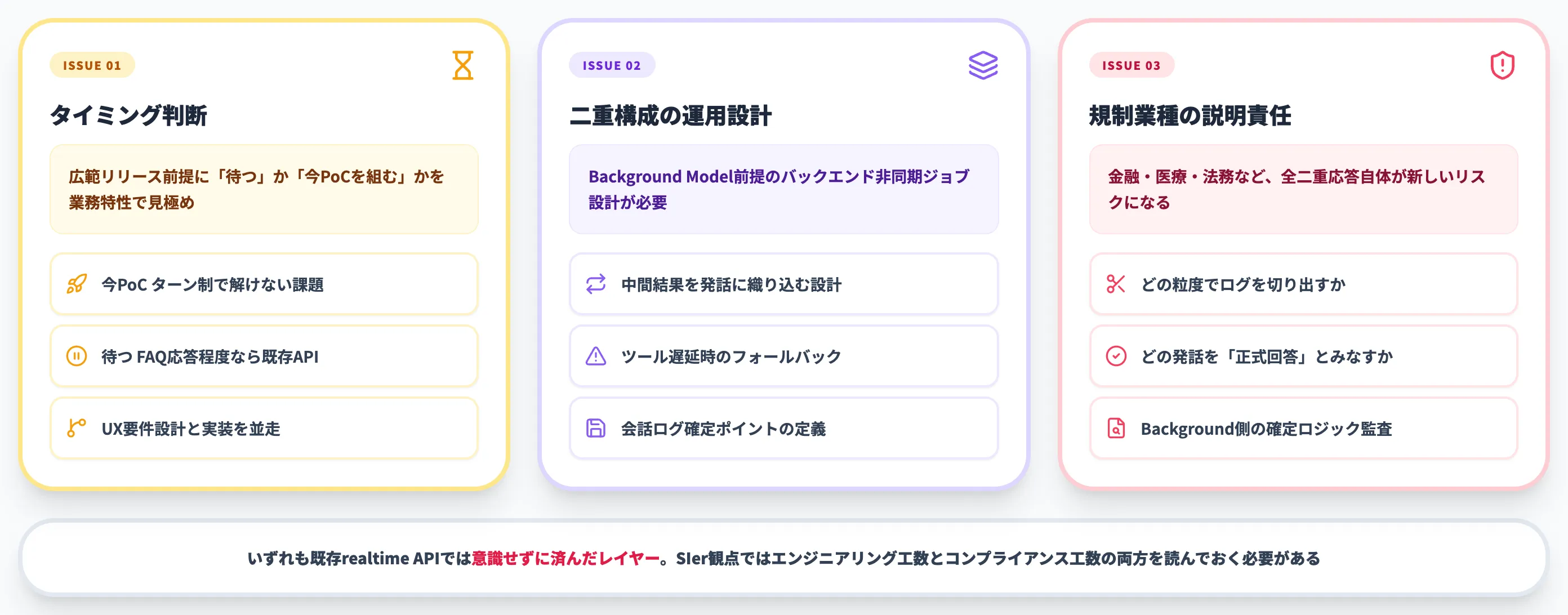
新しい設計次元のモデルを採用するかどうかは、機能比較表だけでは判断できません。
実案件で詰まりやすい論点を3つ挙げます。
「待つ」か「今PoC(試作検証)を組む」かの判断軸
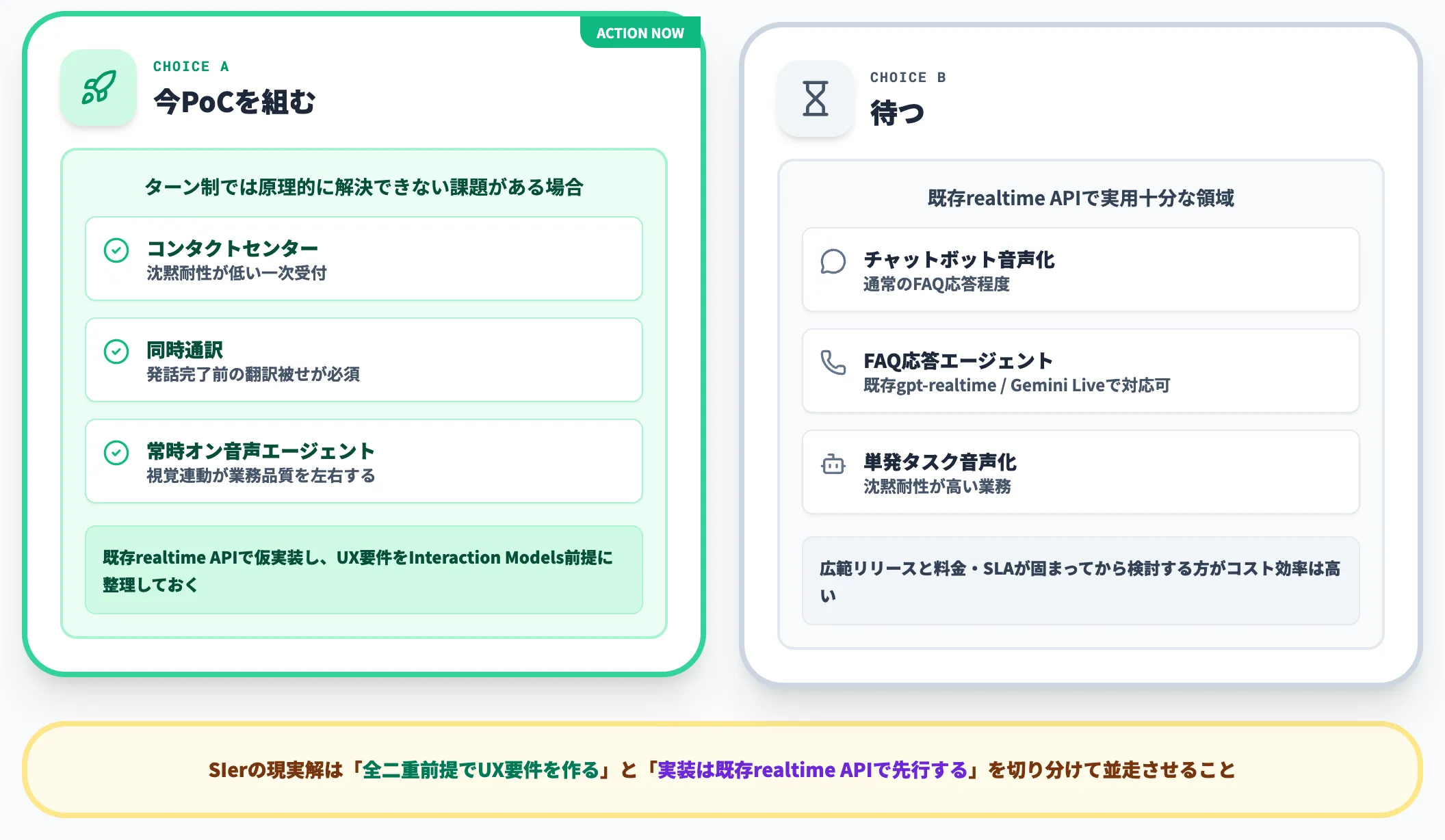
公式の説明では、今後数か月以内に限定研究プレビューを開始し、より広いリリースは年内を目指すとされています。
具体的なGA時期・提供形態は未公表のため、今すぐ本番投入できる選択肢ではありません。一方、リリースを待ってから着手するとUX設計の手戻りが大きくなる領域もあります。
-
今PoCを組むべきケース
コンタクトセンター・同時通訳・常時オンの音声エージェントなど、ターン検出ハーネス依存の構成では原理的に解決しにくい課題を抱えている。
既存realtime APIで仮実装して、UX要件をInteraction Models前提に整理しておくのが有効
-
待つべきケース
チャットボットの音声化・FAQ応答程度であれば、既存のgpt-realtimeやGemini Liveでも実用十分。
Interaction Modelsの広範リリースと料金・SLA(Service Level Agreement:稼働率や応答速度などの品質保証契約)が固まってから検討する方がコスト効率は高い
支援経験から見ても、「全二重前提でUX要件を作っておく」と「実装は既存realtime APIで先行する」を切り分けて並走させるのが現実解です。
Background Model前提の運用設計
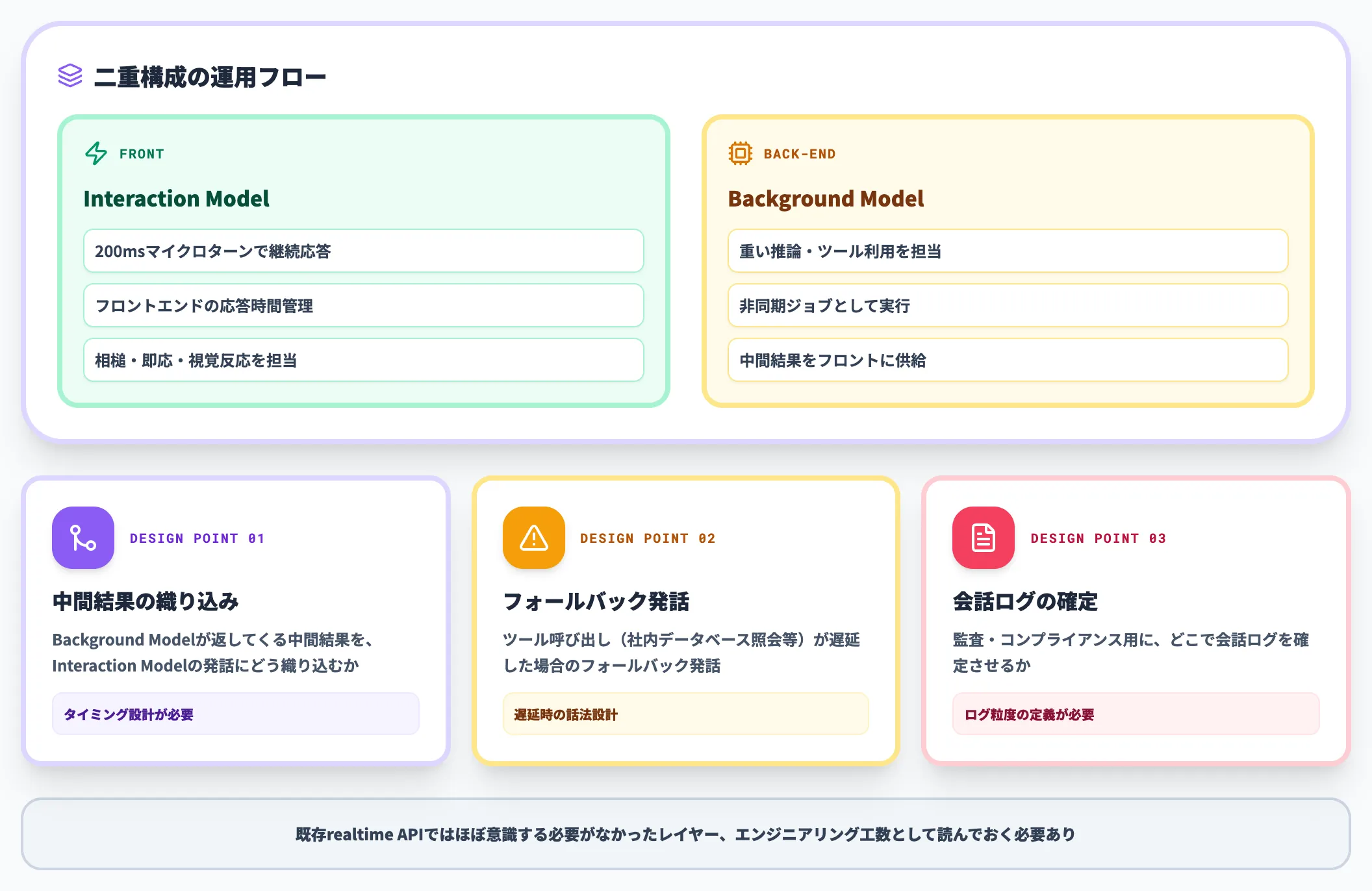
Interaction Modelsは単独のAPIエンドポイントではなく、Interaction+Backgroundの二重構成で初めて成立します。Background Model側は重い推論やツール利用を担うため、フロントエンドの応答時間管理だけでなく、バックエンド側の非同期ジョブ設計が必要になります。
具体的には以下のような論点が出ます。
- Background Modelが返してくる中間結果を、Interaction Modelの発話にどう織り込むか
- ツール呼び出し(社内データベース照会等)が遅延した場合のフォールバック発話
- 監査・コンプライアンス用に、どこで会話ログを確定させるか
これらは既存realtime APIではほぼ意識する必要がなかったレイヤーで、エンジニアリング工数として読んでおく必要があります。
規制業種での発話の説明責任
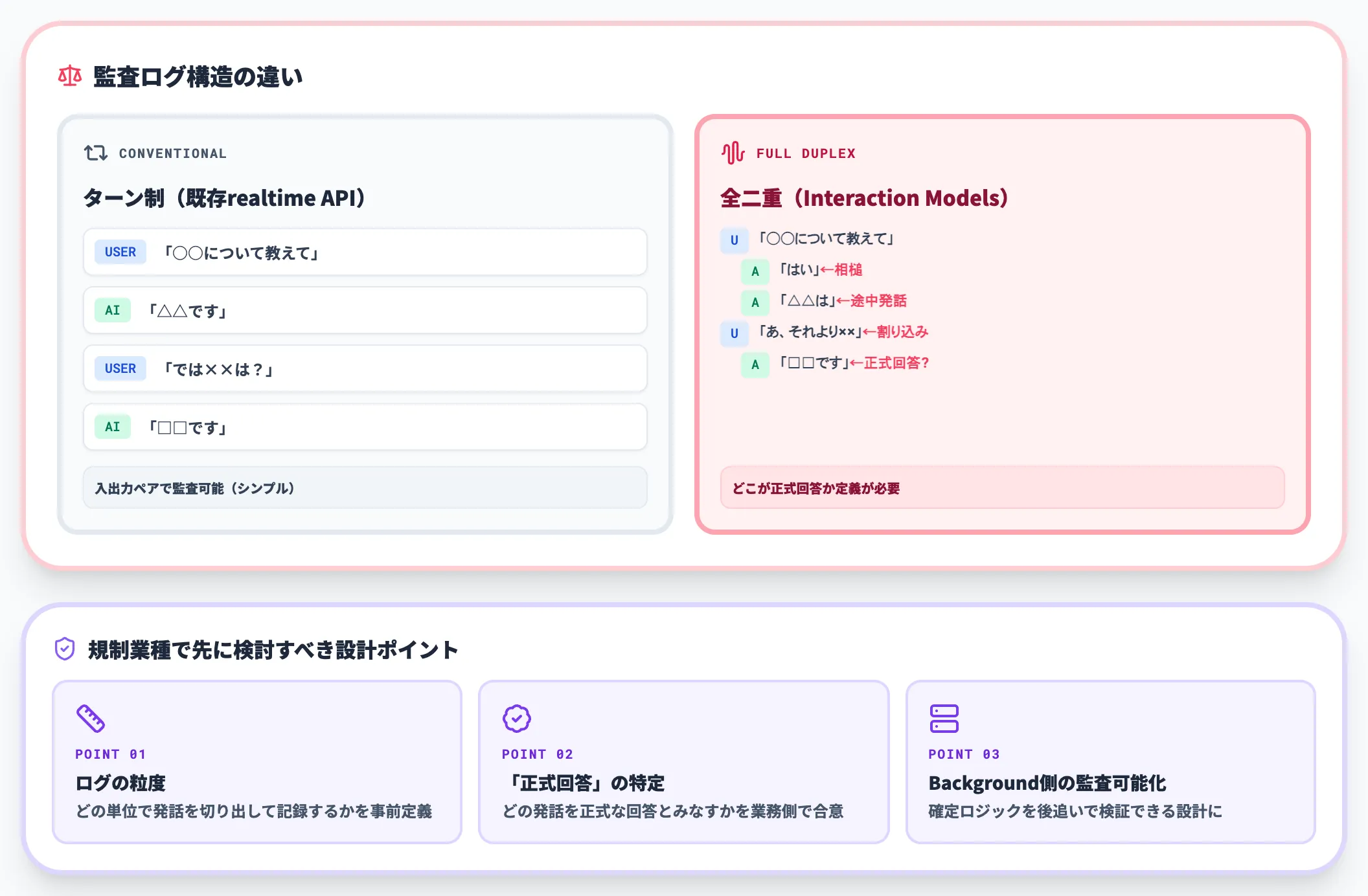
金融・医療・法務など、AI発話に説明責任が伴う業種では、「相槌や割り込み発話を含む全二重応答」自体が新しいリスクになります。
ターン制であれば「ユーザー入力 → AI応答」のペアでログを取れば監査になりますが、全二重では発話が連続するため、どの粒度でログを切り出すか、どの発話を「正式回答」とみなすかの定義が必要です。
Background Model側の確定ロジックを監査可能にしておく設計が、規制業種では先に検討すべきポイントになります。
Interaction Modelsの公開状況と料金
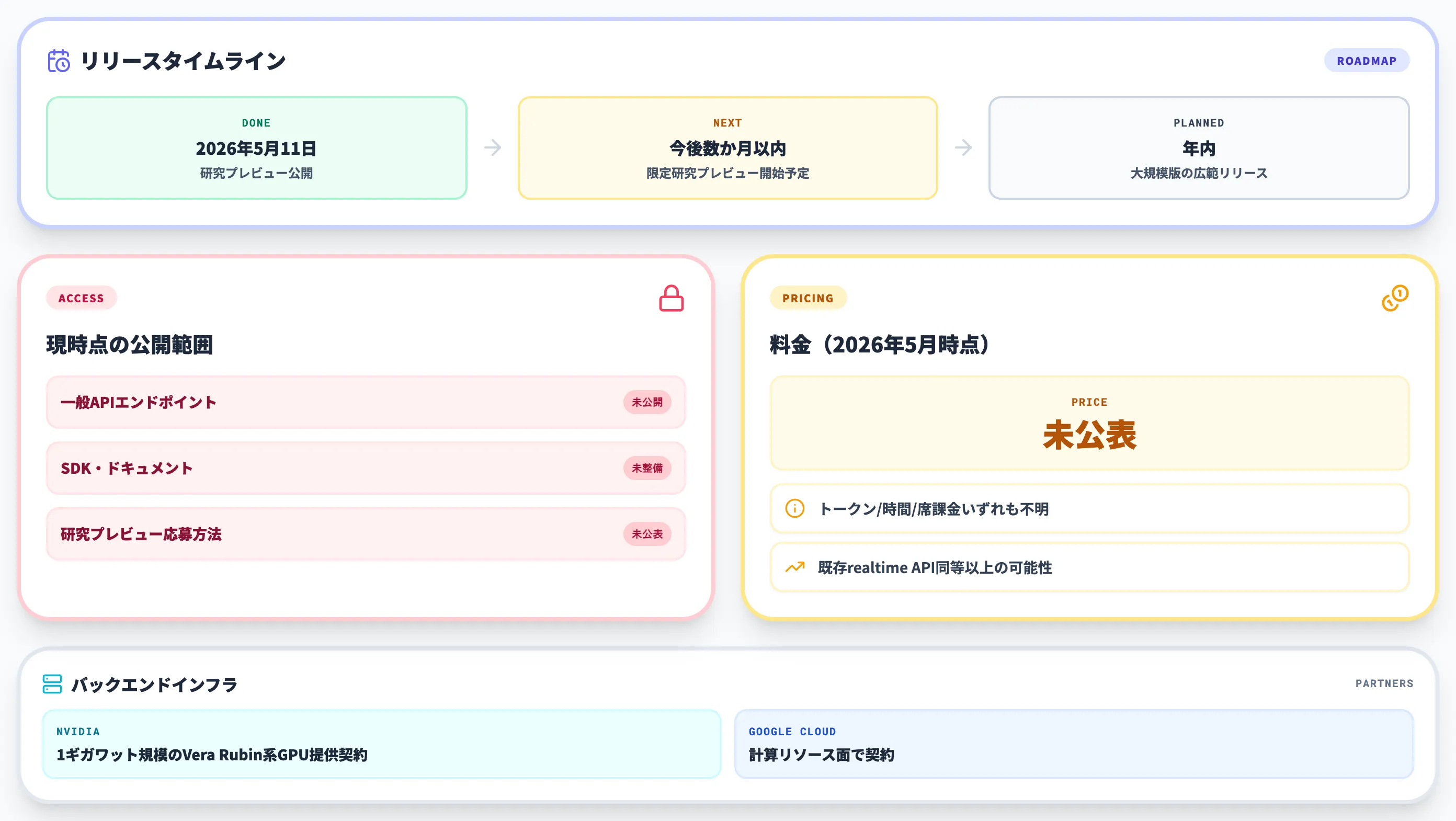
2026年5月時点の利用可能性と料金は以下のとおりです。
現在の公開範囲
公式ブログでは、TML-Interaction-Smallと付随するBackground Modelについて「今後数か月以内に限定研究プレビューを開始しフィードバックを集める」と説明されています。
2026年5月12日時点で限定研究プレビュー自体が稼働中かどうか、パートナーの選定状況、応募窓口は公表されていません。
- 一般のAPIエンドポイントは未公開
- パブリックなSDKやドキュメントは未整備
- 限定研究プレビューの応募方法やパートナーリストも未公表
Thinking Machines Lab自体はインフラ面でNVIDIAと1ギガワット規模のVera Rubin系GPU提供契約を、計算リソース面でGoogle Cloudと契約を結んでおり、本格展開に向けたバックエンドは整いつつあります。

Thinking Machines LabとNVIDIAの1ギガワット規模GPU提供契約(出典:NVIDIA Blog)
より広いリリースのロードマップ
公式は「より大規模なInteraction Modelを年内により広くリリース予定」と説明しています。
具体的なGA時期や提供形態(API・マネージドサービス・パートナーOEM等)は2026年5月時点で未公表です。

料金(2026年5月時点)
料金は未公表です。研究プレビュー段階で価格情報は提示されておらず、一般提供時にトークン課金・時間課金・席課金のどの体系が採用されるかも明らかになっていません。
参考として既存のrealtime API系の料金構造を見ておくと、入力音声・出力音声トークンの単価がテキストモデルの数倍に設定されており、Interaction Modelsも同等以上の単価になる可能性があります。
本格採用を検討する場合、ピーク同時接続セッション数を試算しておき、リリース時に即座にコスト評価できる準備をしておくのが現実的な動き方です。
音声・対話AIを業務に組み込む段階的アプローチ
Interaction Modelsのような全二重対話モデルが普及すると、音声インターフェースは「限定的な実験」から「業務プロセスの一部」へと役割が変わります。
ただし、モデルだけ用意すれば業務が変わるわけではありません。
業務側の整理として、まず以下のような問いを順に詰めるのが現実的です。
- どの業務プロセスのどの会話を、まず音声AI化するか(候補は1〜2業務に絞る)
- 既存のチャネル(電話・チャット・対面)と音声AIをどう切り替えるか
- AIが担う範囲と人が担う範囲をどの粒度で線引きするか
- ログ・監査・例外処理の設計をどこに置くか
AI総合研究所では、Microsoft環境を中心としたAI業務自動化の段階的設計を220ページのガイドにまとめています。「音声AIをいきなり入れる」のではなく、業務プロセス全体のAI化の中で音声をどこに配置するかを設計したい場合に役立つ内容です。
音声・対話AIを業務全体のAI化につなげる

AI業務自動化ガイドで段階的な導入を設計
Interaction Modelsのような全二重対話モデルが普及すると、音声インターフェースは限定的な実験から業務プロセスの一部に変わります。AI総合研究所のガイドでは、Microsoft環境を中心に業務プロセス全体のAI化を段階的に進めるための手順を220ページで紹介しています。
まとめ
Interaction Modelsは、Thinking Machines Lab(Mira Murati氏創業)が2026年5月に公開した、音声・動画・テキストを200msマイクロターンで同時並行処理する全二重対話AIです。代表モデルTML-Interaction-Smallは276B MoE構成で、応答遅延0.4秒・FD-bench 77.8という数値を公表しています。
既存のgpt-realtimeやGemini Liveとの違いは性能差そのものより、ターン検出ハーネス依存の音声中心構成 vs モデルネイティブな全二重・単一モデル vs 二重モデル分業という設計次元の違いにあります。入力モダリティでもgpt-realtimeは動画非対応、Gemini Liveは動画対応と差があり、Interaction Modelsは両者と並べて評価する位置にあります。コンタクトセンター・同時通訳・視覚連動コーチングなど、応答テンポと視覚反応が品質を左右する領域で投入価値が高い候補です。
広範リリースは年内予定、今後数か月以内に限定研究プレビューを開始する段階で、料金・GA時期・提供形態はいずれも未公表です。本番採用を待つ間にやれることは、全二重前提でUX要件を整理し、既存realtime APIで先行PoCを組んでおくこと。リリース時に手戻りなく載せ替えられる準備が、いま手元でできる現実的な一手になります。










