この記事のポイント
 新規構築ならFabric、既存Synapse環境は計画的移行が2026年時点の推奨方針
新規構築ならFabric、既存Synapse環境は計画的移行が2026年時点の推奨方針- SQLベースのBI分析ならSynapse、Sparkベースの機械学習ならDatabricksが適任
- 専用SQLプールの一時停止と予約購入の併用で最大65%のコスト削減が可能
- 2026年8月のPrivate Link必須化は既存ユーザーが最優先で対応すべき変更
- 集英社・リコー・プロテリアルの事例が示す、データサイロ解消と全社横断分析の実現

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Azure Synapse Analyticsは、Microsoftが提供するエンタープライズ向けの統合データ分析サービスです。SQLベースのデータウェアハウス、Apache Sparkによるビッグデータ処理、データ統合パイプラインを1つのワークスペースに集約し、大規模なデータ分析基盤を効率的に構築できます。
本記事では、Azure Synapse Analyticsの基本機能から使い方、料金体系、導入事例、Microsoft FabricやAzure Databricksとの違い、そして2026年時点の最新動向までを体系的に解説します。
目次
Azure Synapse Analyticsを構成するコンポーネント
Azure Synapse Analyticsの主な機能と使い方
Azure Synapse Analyticsを導入するメリット
Azure Synapse AnalyticsとMicrosoft Fabricの違い
Fabric Migration Assistantによる移行
Azure Synapse Analyticsとは
Azure Synapse Analytics(アジュール シナプス アナリティクス)は、Microsoft Azureが提供するエンタープライズ向けの統合データ分析サービスです。
データウェアハウス(DWH)とビッグデータ分析を1つのプラットフォームに統合し、データの取り込みから加工・分析・可視化までを一貫して行える点が最大の特徴です。

もともとはAzure SQL Data Warehouseという名称でDWH機能のみを提供していましたが、2019年のリブランドでApache SparkやPipelines(データ統合)、Synapse Studioなどの機能が統合され、現在のAzure Synapse Analyticsへと進化しました。
データ分析基盤の構築を検討する企業にとって、Azure Synapse Analyticsは「データの収集から分析・意思決定支援まで」をカバーする選択肢のひとつです。
ただし、2024年以降はMicrosoftが次世代分析基盤として位置づけるMicrosoft Fabricの台頭もあり、2026年現在は既存Synapseユーザーの運用継続と、Fabricへの段階的移行の両面で注目されています。

SQL Data Warehouseからの進化
Azure Synapse Analyticsの前身であるAzure SQL Data Warehouseは、大量の構造化データをSQLで集計・分析するためのクラウドDWHサービスでした。
2019年11月のIgniteカンファレンスで、MicrosoftはこのサービスをAzure Synapse Analyticsへと大幅に拡張しています。従来のSQL DWH機能に加えて、以下の要素が統合されました。

- Apache Spark
ビッグデータ処理と機械学習向けのオープンソースエンジン
- Synapse Pipelines
Azure Data Factoryと同等のETL/ELT(データの抽出・変換・読み込みを自動化する仕組み)パイプライン機能
- Data Explorer(2025年10月廃止済み)
ログやIoTデータ向けのリアルタイム分析エンジンとして提供されていたが、2025年10月7日にリタイアし、後継のFabric Real-Time Intelligence / Eventhouseへ移行された
- Synapse Studio
すべての機能を統合管理するWebベースのUI
つまり、SQLでの定型集計からビッグデータの探索分析、データの取り込み・変換までを1つのワークスペース内で完結させる統合分析基盤へと進化したのがAzure Synapse Analyticsです。
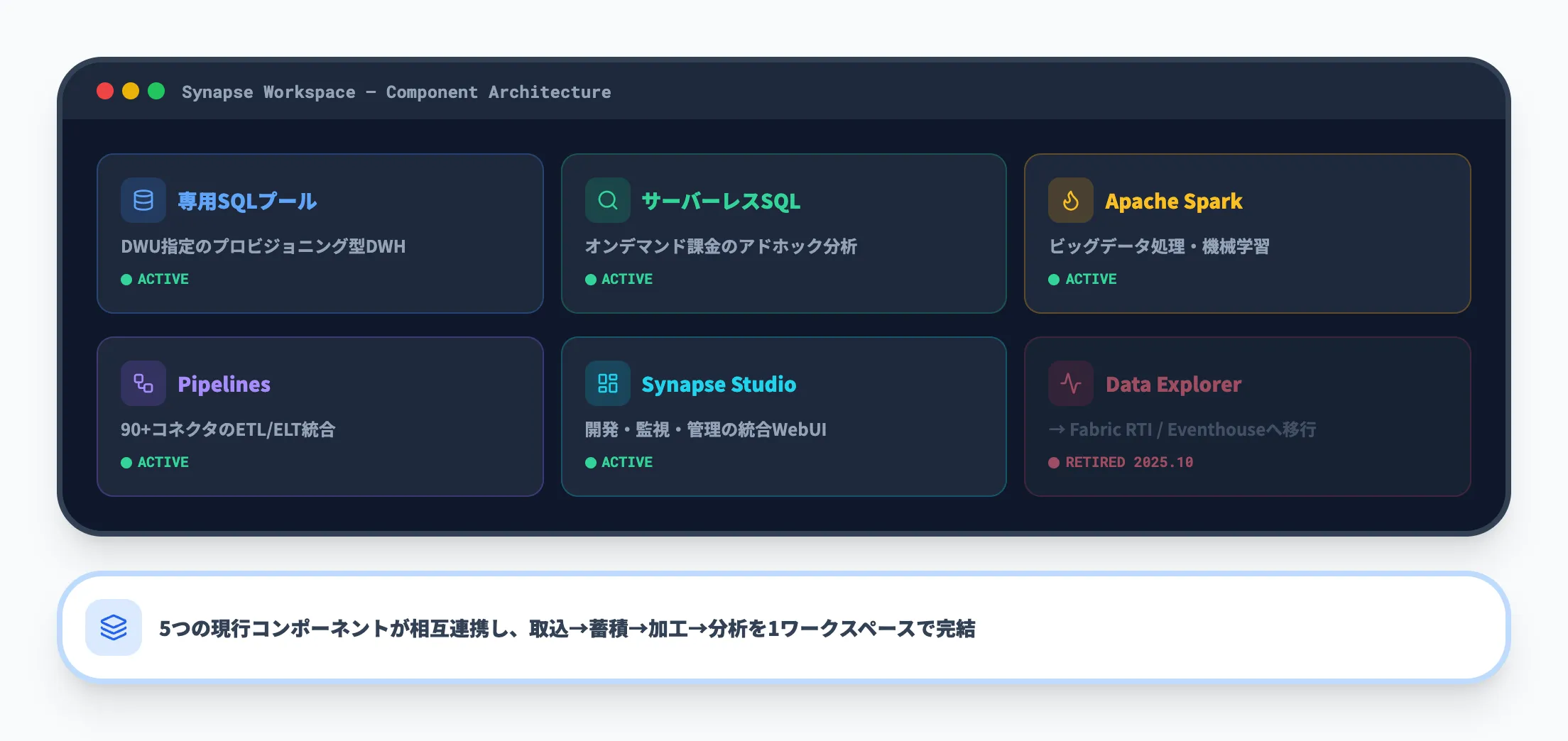
Azure Synapse Analyticsを構成するコンポーネント
Azure Synapse Analyticsは、以下のコンポーネントで構成されています。それぞれが異なる分析ニーズに対応しており、用途に応じて組み合わせて使用します。
| コンポーネント | 役割 | 主な用途 | 状態 |
|---|---|---|---|
| 専用SQLプール | 事前にリソースを確保するDWH | 大量データの定型レポート・BIダッシュボード | 提供中 |
| サーバーレスSQLプール | オンデマンドでクエリ実行 | データレイク上のアドホック分析・探索 | 提供中 |
| Apache Sparkプール | ビッグデータ処理・ML | ETL、機械学習モデルの学習・推論 | 提供中 |
| Synapse Pipelines | データ統合・ETL/ELT | 90以上のデータソースからの取り込み・変換 | 提供中 |
| Synapse Studio | 統合管理UI | 開発・監視・セキュリティ管理を一元化 | 提供中 |
| Data Explorer | ログ・IoTのリアルタイム分析 | 時系列データの探索・ストリーミング分析 | 2025年10月廃止 |
Data Explorerは2025年10月7日にリタイアし、同等の機能はMicrosoft FabricのReal-Time Intelligence / Eventhouseに引き継がれています。
現在利用可能な5つのコンポーネントが相互に連携し、データの取り込み・蓄積・加工・分析を1つのワークスペースで完結できる点がAzure Synapse Analyticsの設計思想です。次のセクションでは、各コンポーネントの機能を詳しく解説します。
Azure Synapse Analyticsの主な機能と使い方
Azure Synapse Analyticsの主要コンポーネントについて、それぞれの機能と使いどころを詳しく見ていきます。また、ワークスペースの作成から分析開始までの基本的な流れも紹介します。

専用SQLプールとサーバーレスSQLプール
Azure Synapse AnalyticsのSQL機能は、2つの異なるリソースモデルで提供されています。用途やコスト要件に応じて使い分けることが重要です。

専用SQLプール
あらかじめコンピューティングリソースを確保(プロビジョニング)して使う方式です。DWU(Data Warehouse Unit)という単位でリソース量を指定し、予測可能なパフォーマンスを確保できます。
定期レポートやBIダッシュボードなど、安定した処理能力が必要なワークロードに向いています。
スケールは100DWU(DW100c)から30000DWU(DW30000c)まで段階的に設定でき、一時停止機能を使えば利用していない時間帯のコストを抑えることも可能です。
サーバーレスSQLプール
リソースの事前確保が不要で、クエリを実行した分だけ課金される方式です。Azure Data Lake Storage上のParquet、CSV、JSONファイルに対して直接T-SQLでクエリを実行でき、データレイクの中身を手軽に探索したいときに便利です。
ワークスペースを作成した時点で自動的に利用可能になるため、追加のセットアップは不要です。
一般的な使い分けとしては、日常的なBI用途には専用SQLプール、アドホックなデータ探索や検証にはサーバーレスSQLプールという組み合わせが多く見られます。
Apache Sparkプール
Azure Synapse AnalyticsにはApache Sparkが統合されており、ノートブック上でPython、Scala、SQL、Rを使ったビッグデータ処理を実行できます。

主な活用場面は以下のとおりです。
- 大量データのETL処理(抽出・変換・読み込み)
- Azure Machine Learningと連携した機械学習モデルの学習・推論
- データレイク上のファイルに対する探索的データ分析
- Delta Lake形式でのデータ管理(ACID準拠:データの整合性と一貫性を保証するトランザクション処理)
クラスターの起動が迅速で、ノード数の自動スケーリングにも対応しているため、処理量に応じた柔軟なリソース管理が可能です。
Apache Sparkノートブックでは、Pythonなどを使ってデータレイク上のデータを柔軟に分析できます。
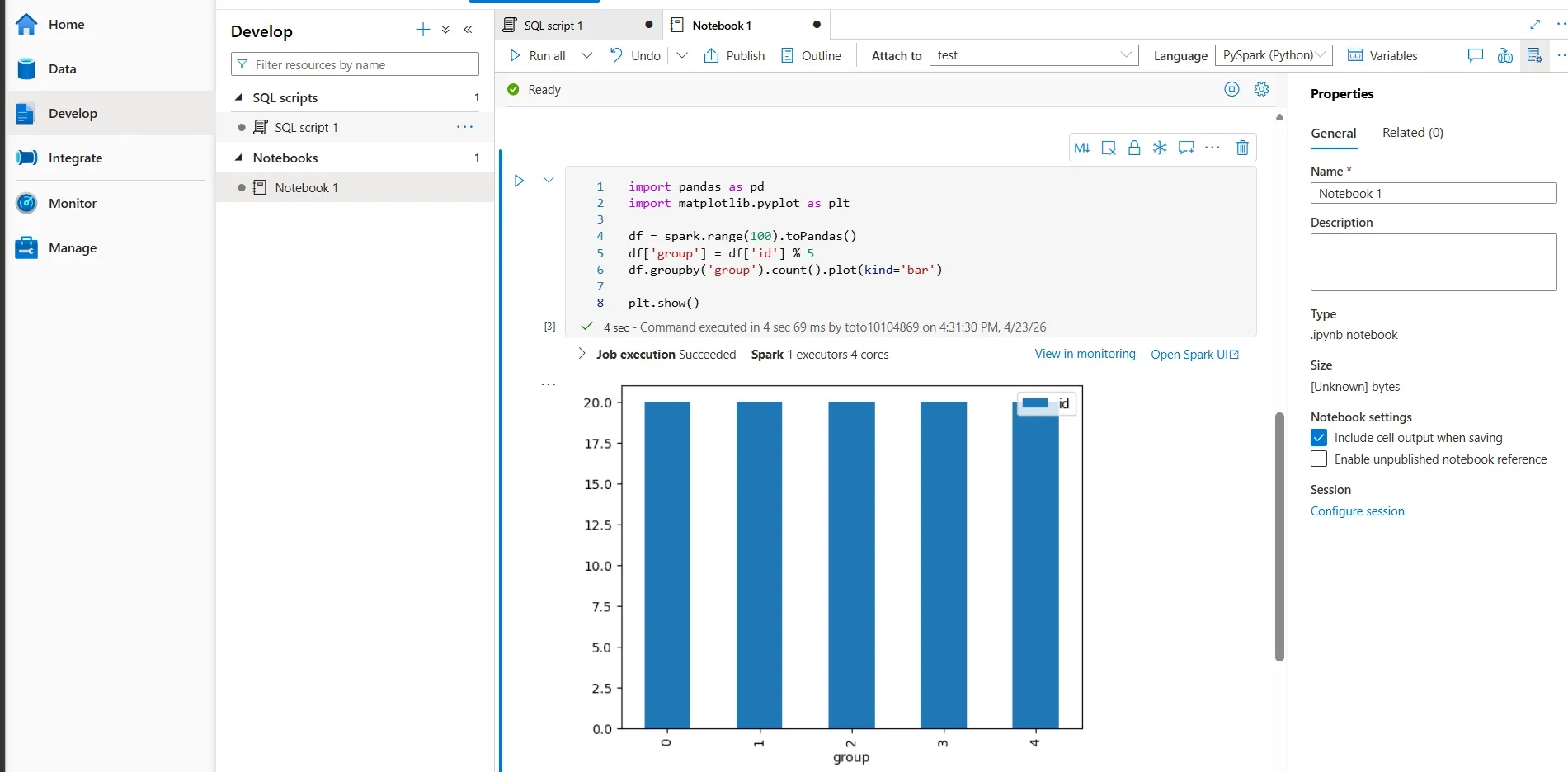
PySparkでデータを読み込み、集計結果をノートブック上で確認している画面
Synapse Pipelines(データ統合)
Synapse Pipelinesは、Azure Data Factoryと同じデータ統合エンジンをベースにした機能です。
90以上のデータソースに対応するコネクタを備え、コードを書かずにGUIベースでETL/ELTパイプラインを構築できます。
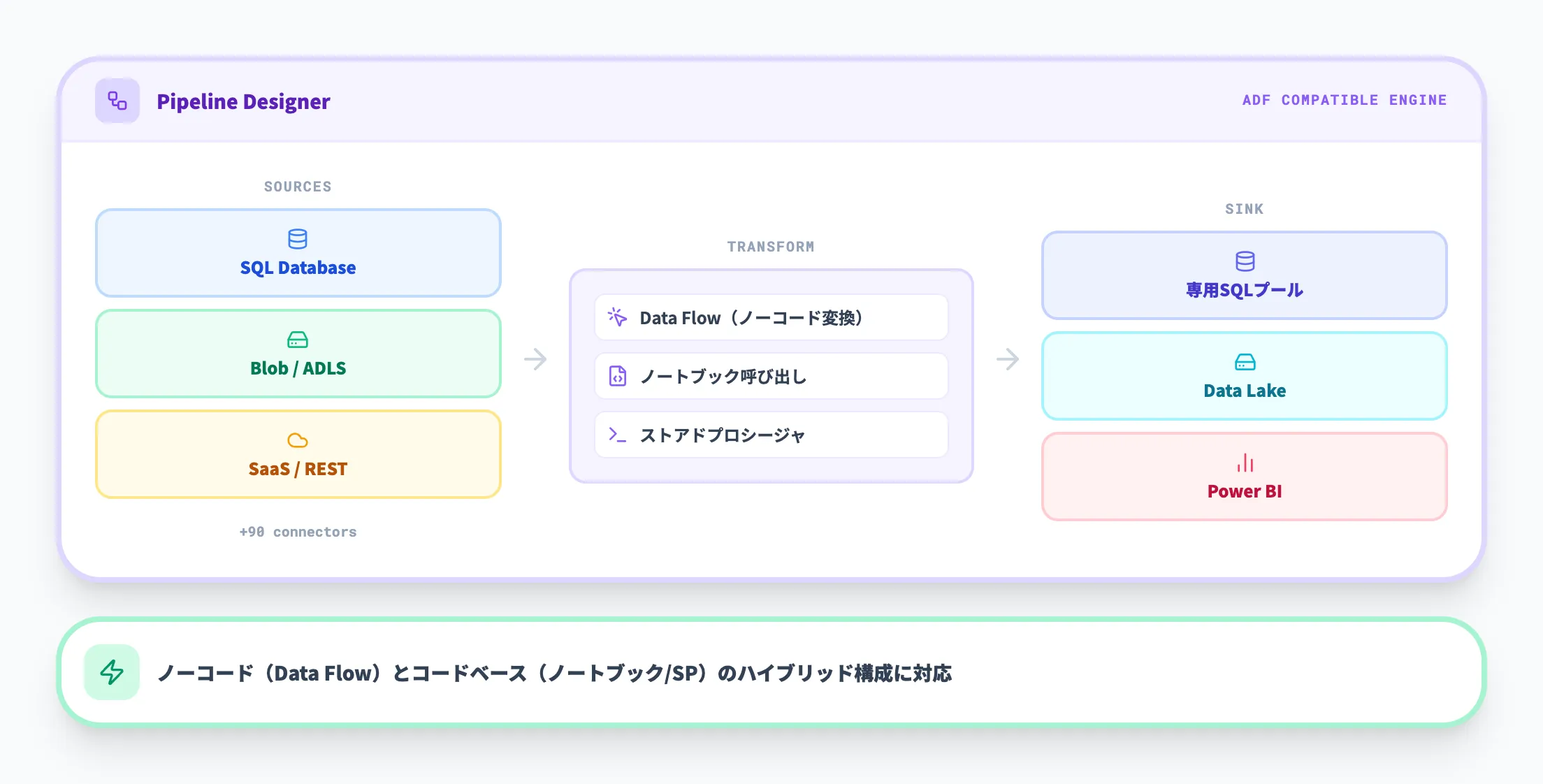
データフローアクティビティを使えば、SQLやSparkの知識がなくてもデータの変換・クレンジング処理を視覚的に設計できます。
もちろん、ノートブックやストアドプロシージャをパイプライン内で呼び出すことも可能で、ノーコードとコードベースの処理を組み合わせた柔軟なパイプライン構成に対応しています。
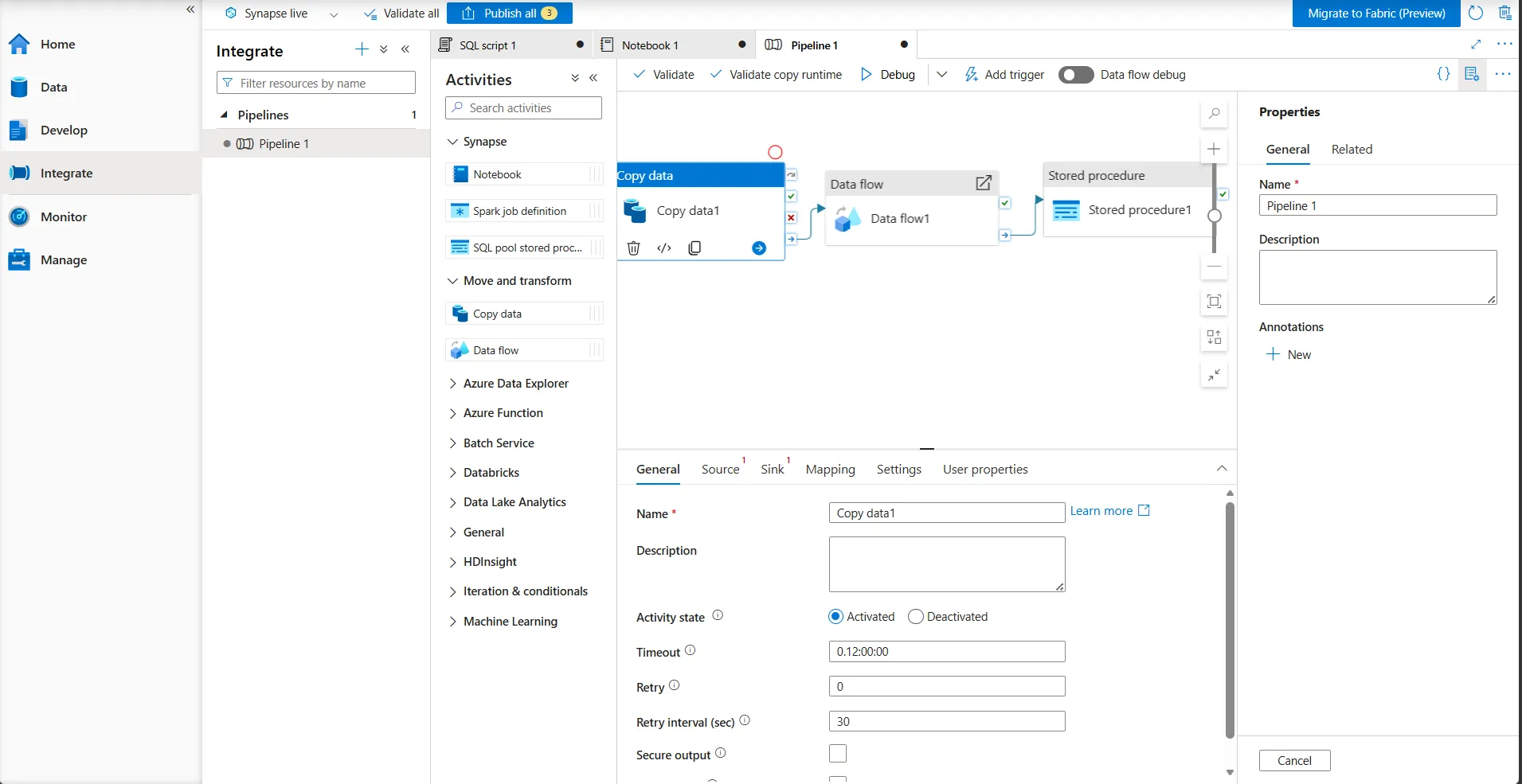
Copy・Data Flow・Stored Procedureを接続したパイプライン設計画面
Synapse Studio
Synapse Studioは、上記すべてのコンポーネントをブラウザから統合管理するためのWebベースのUIです。
- SQLスクリプトやSparkノートブックの開発・実行
- パイプラインの設計・スケジュール管理
- リソースの使用状況やクエリパフォーマンスの監視
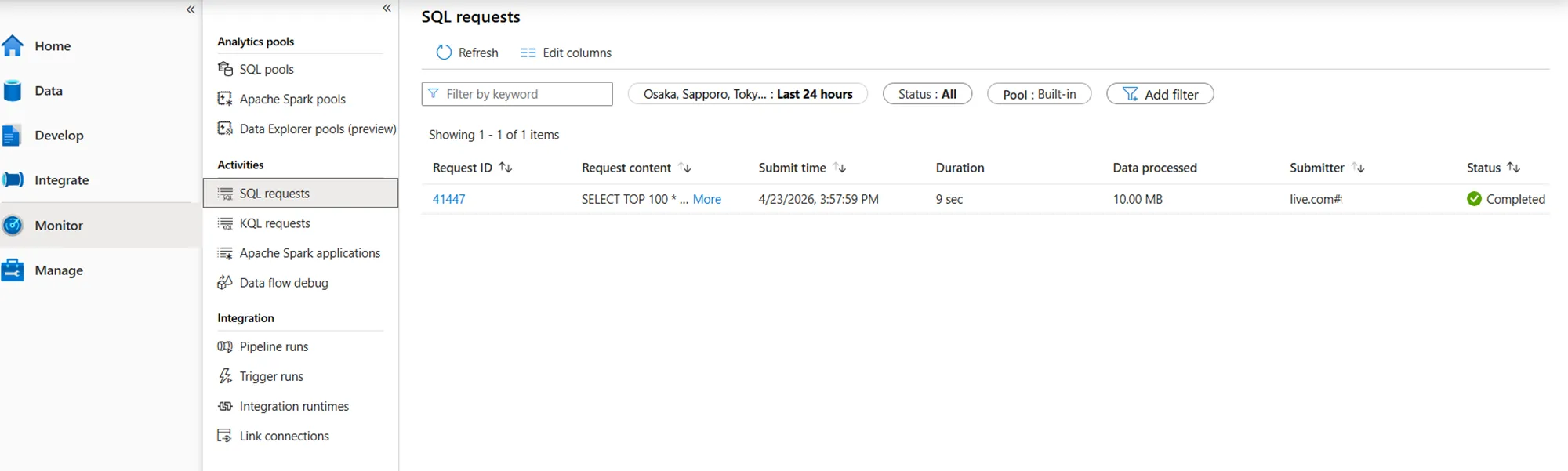
SQLリクエストやパイプライン実行のステータスと所要時間を確認している画面
- ロールベースアクセス制御(RBAC:役割に応じてアクセス権限を管理する仕組み)によるセキュリティ管理
- Power BIとの統合によるデータ可視化
Synapse Studioはすべてのワークロードを一画面で扱えるWeb UIです。まずホーム画面から全体像を確認します。
Synapse Studioのホーム画面
「データ」ハブでは、接続されているデータソースやデータベースを一覧で管理できます。
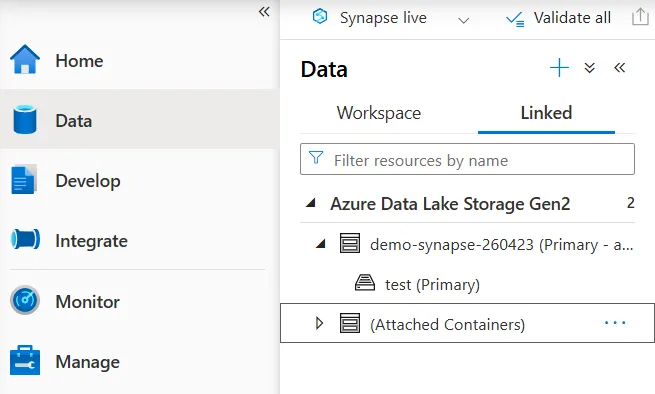
Synapse Studioのデータハブでデータソースを表示している画面
開発・運用・監視をひとつの画面で完結できるため、複数のツールを行き来する手間が減り、チーム全体の生産性を向上させやすい設計になっています。
Azure Synapse Analyticsの始め方
Azure Synapse Analyticsを使い始めるには、Azure Portalからワークスペースを作成するのが最初のステップです。
Microsoft Learnの公式チュートリアルでは、以下の手順でコア機能を順に体験できます。
- Synapseワークスペースを作成する
- サーバーレスSQLプールでデータを分析する
- Apache Sparkで分析する
- 専用SQLプールでデータを分析する
- ストレージアカウント内のデータを分析する
- パイプラインでデータ統合を自動化する
- Power BIでデータを可視化する
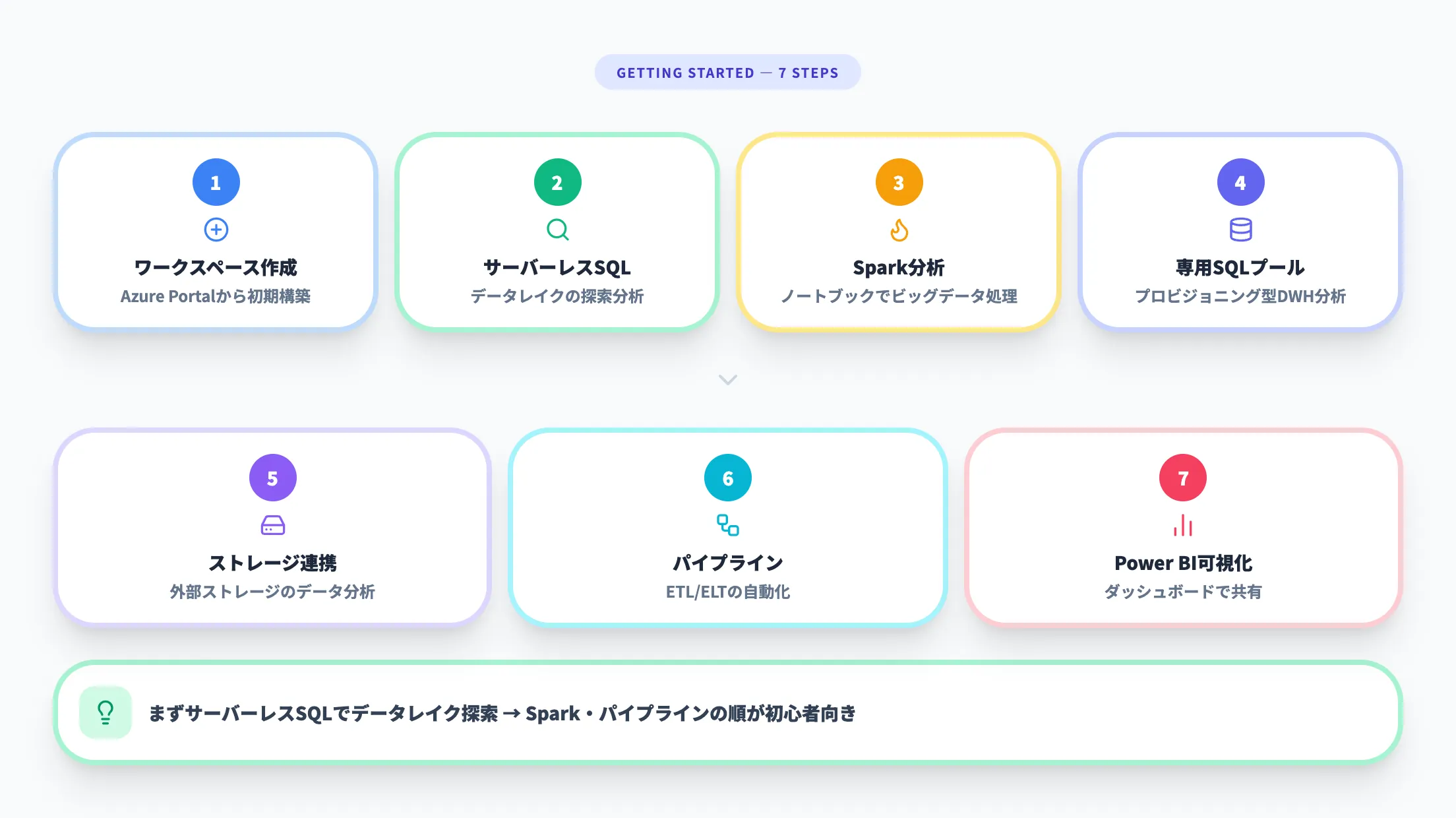
Azure Synapse Analyticsは、Azure Portalからワークスペースを作成することで利用を開始できます。
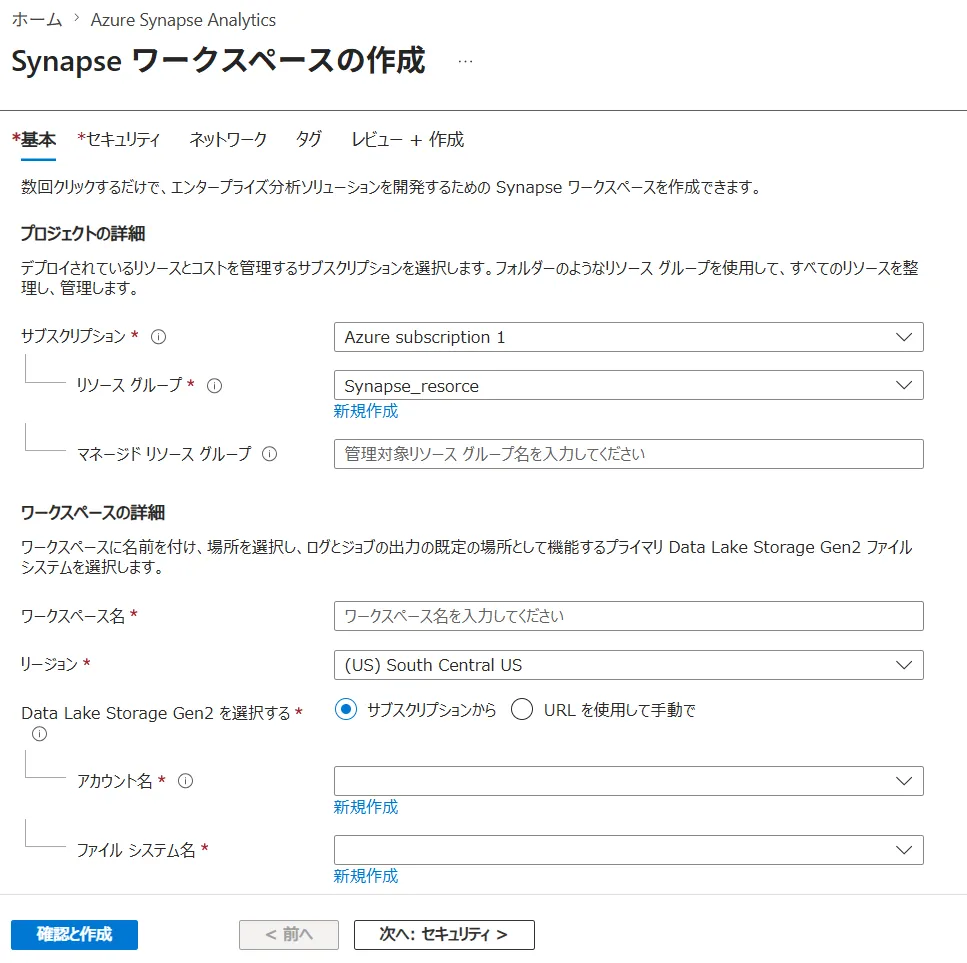
Azure PortalでSynapseワークスペースの基本設定を行っている画面
サーバーレスSQLプールを利用することで、データレイク上のファイルをそのままSQLで分析できます。
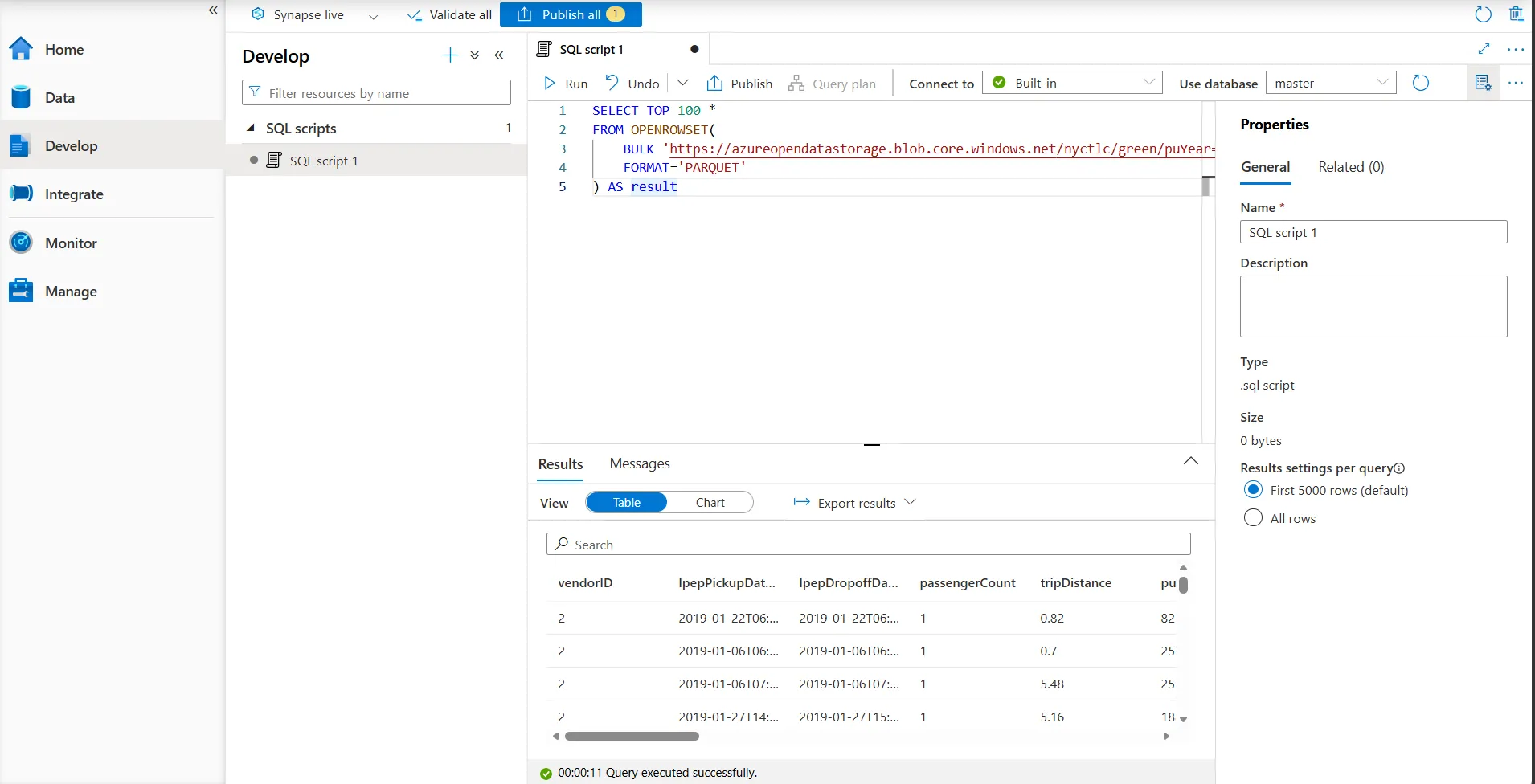
OPENROWSETを使ってデータレイク上のファイルを直接クエリしている画面
クエリ実行後は、処理データ量や実行時間などの詳細も確認できます。
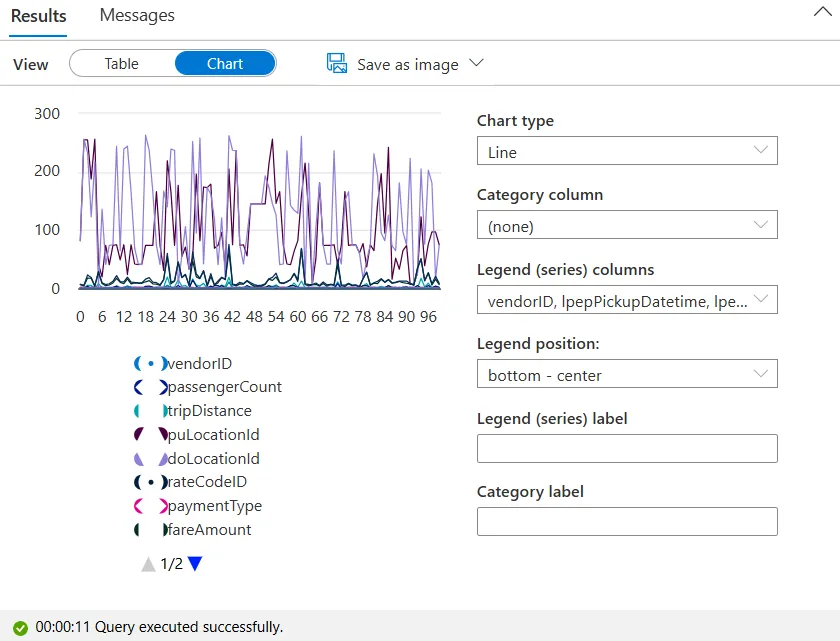
クエリ結果と処理時間・データ量が表示されている画面
まずはサーバーレスSQLプールでデータレイク上のファイルを探索し、次にSparkやパイプラインを試すという流れが、初めてのユーザーにとって取り組みやすい順序です。
Azure Synapse Analyticsを導入するメリット
Azure Synapse Analyticsを導入することで、企業のデータ分析基盤にどのような効果が期待できるのか。主なメリットを3つの観点から整理します。

データ分析基盤の一元化
「部署ごとにデータの集計方法が違い、同じ売上データなのに会議で数字が合わない」——この状況に覚えがあるなら、それはデータサイロ化が進んでいるサインです。
多くの企業では、DWH・データレイク・ETLツール・BIツールが別々のサービスとして分かれており、データの分断と管理コストの増加が課題になっています。
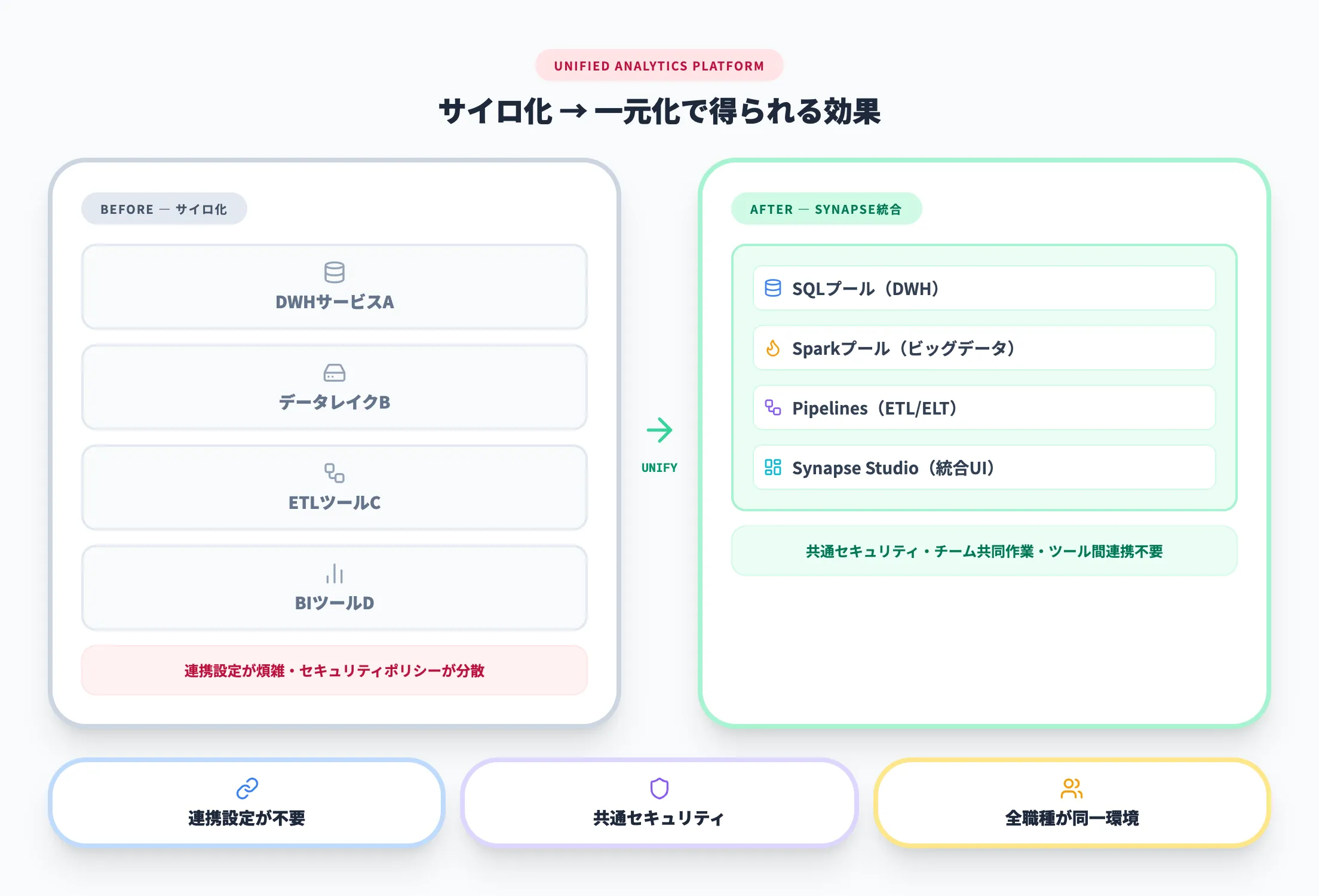
Azure Synapse Analyticsは、これらの機能を1つのワークスペースに統合することで、以下の効果をもたらします。
- データの取り込みから可視化まで、ツール間の連携設定が不要
- 共通のセキュリティポリシーとアクセス管理を適用可能
- 開発者・データエンジニア・アナリストが同じ環境で共同作業できる
特に、既にAzureの他サービス(Azure Storage、Azure SQL Database、Power BIなど)を利用している企業にとっては、既存資産との統合がスムーズに進む点が実務上の大きな利点です。
マルチ言語対応と柔軟なクエリ方式
Azure Synapse Analyticsでは、T-SQL、Python、Scala、Rなど、複数のプログラミング言語を使い分けることができます。
SQLに慣れたデータアナリストは専用SQLプールやサーバーレスSQLプールで分析でき、Pythonを使うデータサイエンティストはSparkノートブックで機械学習モデルを構築できます。
つまり、チーム内の異なるスキルセットを持つメンバーが、それぞれ得意な言語で同じデータにアクセスし分析を進められるわけです。
加えて、サーバーレスSQLプールを使えば、Parquet形式やCSV形式のファイルに対してデータを移動させることなく直接クエリを実行できるため、「まず中身を見たい」という探索的な分析にも即座に対応できます。
セキュリティとガバナンス
エンタープライズ向けのデータ分析基盤として、Azure Synapse Analyticsは多層的なセキュリティ機能を備えています。

- ネットワークセキュリティ
マネージド仮想ネットワーク、Private Link、ファイアウォールルールによるネットワーク分離
- 認証とアクセス制御
Microsoft Entra ID(旧Azure AD)との統合、列レベル・行レベルのデータアクセス制御、動的データマスキング
- データ保護
保存時・転送時の暗号化、Azure Key Vaultとの統合による鍵管理
- 監査と脅威検出
SQL監査ログ、Advanced Threat Protection、Microsoft Purviewとの統合によるデータカタログ・分類
金融・医療・製造など、データの取り扱いに厳格な規制がある業界でも採用しやすい設計になっています。
ただし、2026年8月以降はTrusted Services方式のストレージ接続が廃止されPrivate Linkへの移行が必要となるため、この点は後述の「注意点」セクションで詳しく解説します。
Azure Synapse Analyticsの導入事例
Azure Synapse Analyticsは、国内の大手企業を中心にデータ分析基盤として採用されています。ここでは、業界の異なる3社の導入事例を紹介します。

集英社(出版業)
2026年に創業100周年を迎える集英社は、紙媒体の出版に加え、デジタルコンテンツや海外市場の売上データが分散するサイロ化の課題を抱えていました。
Azure Synapse AnalyticsとPower BIを組み合わせたデータ分析基盤を構築し、多岐にわたる販売データを横断的に分析できる環境を整備しています。この基盤により、必要なときに必要な形で販売情報を分析できるようになり、DXに向けた土台づくりが実現しました。
リコー(製造業→デジタルサービス)
OAメーカーからデジタルサービス企業への変革を進めるリコーは、データ分析を推進するプラットフォームとしてAzure Synapse Analyticsを採用しました。
従来は事業部門ごとにデータ分析環境が分かれていましたが、Synapseによる統合分析基盤を構築することで、全社横断でのデータ活用を推進しています。
出典:マイナビTECH+ 事例で学ぶMicrosoft Azure活用術
プロテリアル(製造業)
日立金属から独立したプロテリアルは、データガバナンスの確立を目指してAzure Synapse AnalyticsとPower BIでデータ分析基盤を構築しました。
製造業特有の品質管理データや生産データの可視化・分析を通じて、データに基づく意思決定を組織全体で推進する取り組みを進めています。
出典:マイナビTECH+ 事例で学ぶMicrosoft Azure活用術
Azure Synapse AnalyticsとMicrosoft Fabricの違い
データ分析基盤の選定において、Azure Synapse AnalyticsとMicrosoft Fabricの関係は最も頻繁に問われるテーマです。MicrosoftはFabricを次世代の統合分析基盤として位置づけており、Synapseの各機能に対応するワークロードをFabric上で提供しています。ただし、FabricがSynapseの全機能を完全に包含しているわけではなく、ネットワーク制御などSynapse固有の優位性が残る領域もあります。

ここでは両者のアーキテクチャの違いと、新規導入時の判断基準、既存環境からの移行方法を整理します。
アーキテクチャと設計思想の違い
Azure Synapse AnalyticsとMicrosoft Fabricの設計思想には、根本的な違いがあります。
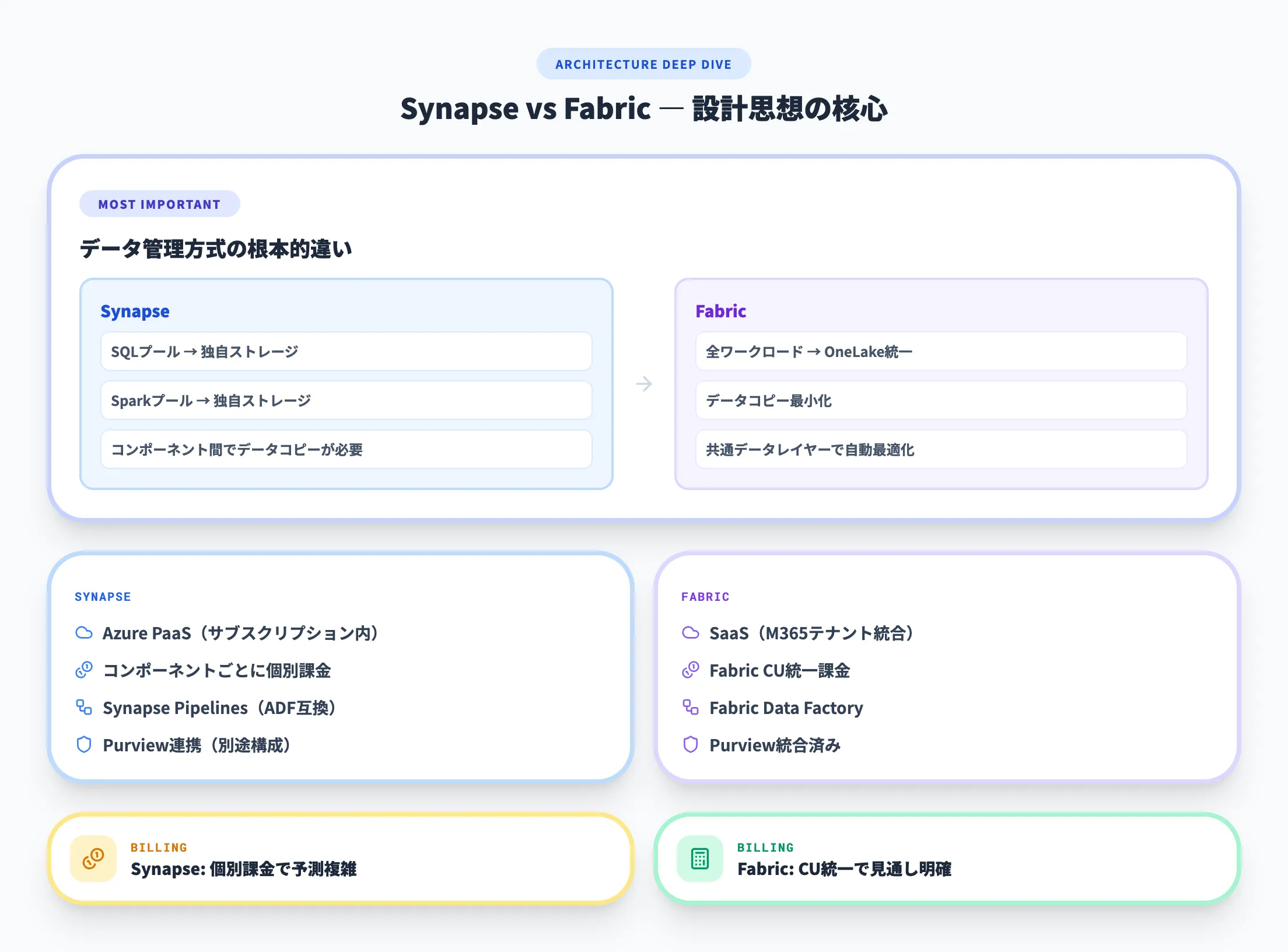
| 観点 | Azure Synapse Analytics | Microsoft Fabric |
|---|---|---|
| 提供形態 | Azure PaaS(インフラはクラウド側が管理し、ユーザーはアプリケーション部分を構築) | SaaS(ソフトウェアをそのまま利用する形態。Microsoft 365テナントと統合) |
| データストレージ | 各コンポーネントが個別にストレージを管理 | OneLakeで全ワークロードが統一 |
| 課金方式 | コンポーネントごとに個別課金 | Fabric容量ユニット(CU)で統一課金 |
| データ統合 | Synapse Pipelines(ADF互換) | Fabric Data Factory |
| DWH | 専用SQLプール(T-SQL) | Fabric Data Warehouse(T-SQL互換) |
| データレイク | Azure Data Lake Storage Gen2 | OneLake(自動最適化) |
| ビッグデータ処理 | Spark プール | Fabric Data Engineering(Sparkベース) |
| リアルタイム分析 | Data Explorer(2025年10月廃止) | Fabric Real-Time Intelligence |
| ガバナンス | Purview連携(別途構成) | Purview統合済み |
最も大きな違いはデータの管理方式です。Synapseでは、SQLプール・Sparkプールなど各コンポーネントがそれぞれ独自のストレージを持つため、コンポーネント間でデータをコピー・移動する必要がありました。一方、FabricではOneLakeがすべてのワークロードの共通データレイヤーとなり、データのコピーを最小限に抑えた設計になっています。
もうひとつの実務的な違いは課金方式です。Synapseはコンポーネントごとに個別の課金(DWU、vCore時間、データ処理量など)が発生するため、コスト予測がやや複雑です。Fabricは容量ユニット(CU)で統一されており、コストの見通しが立てやすい構造です。
新規導入時の選び方
2026年3月時点では、Microsoftは新規のデータ分析基盤構築にはMicrosoft Fabricを推奨しています。公式ブログにおいても、FabricをSynapseおよびAzure Data Factoryからの「次世代の飛躍(next-gen leap)」と表現しています。
ただし、Azure Synapse AnalyticsはModern Lifecycle Policyに基づいて引き続きサポートされており、廃止の予定は発表されていません。以下の判断基準が参考になります。
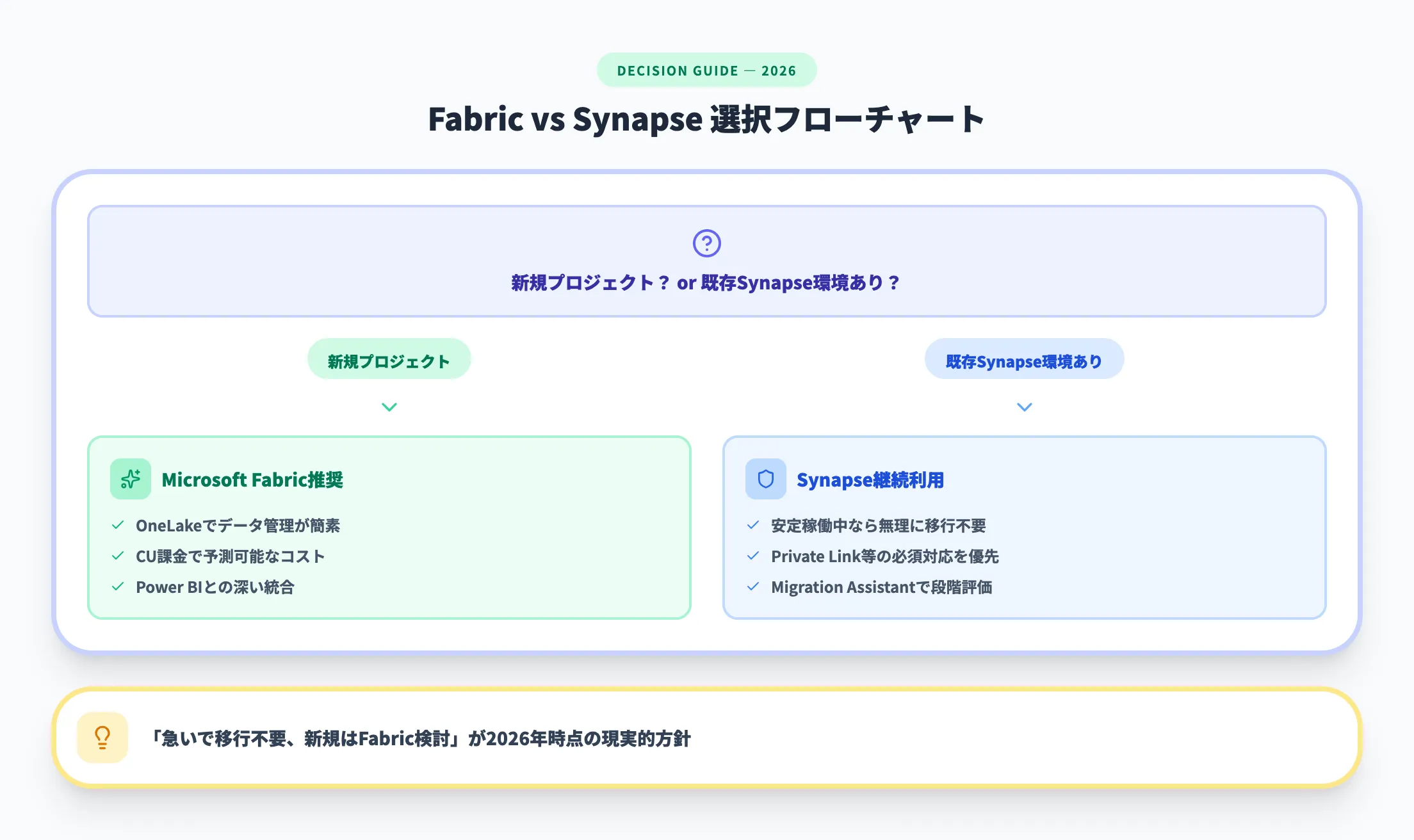
- Fabricを選ぶべきケース
新規でデータ分析基盤をゼロから構築する場合。OneLakeによるデータ管理の簡素化、CU課金による予測可能なコスト構造、Power BIとの深い統合を活かしたい場合
- Synapseを継続利用するケース
既存のSynapse環境が安定稼働しており、Fabricへの移行リソースがすぐに確保できない場合。また、マネージド仮想ネットワークやPrivate Linkの詳細なネットワーク制御が必要な場合
「急いで移行する必要はないが、新規プロジェクトにはFabricを検討する」が2026年時点の推奨方針です。
ただし、Fabricのネットワーク制御はSynapseほど成熟していないため、金融機関や医療機関など厳格なネットワーク要件がある場合は、Synapseの継続利用が現実的な選択になります。
【関連記事】
Microsoft Fabric導入事例6選!国内企業の成果と導入パターンを解説
Fabric Migration Assistantによる移行
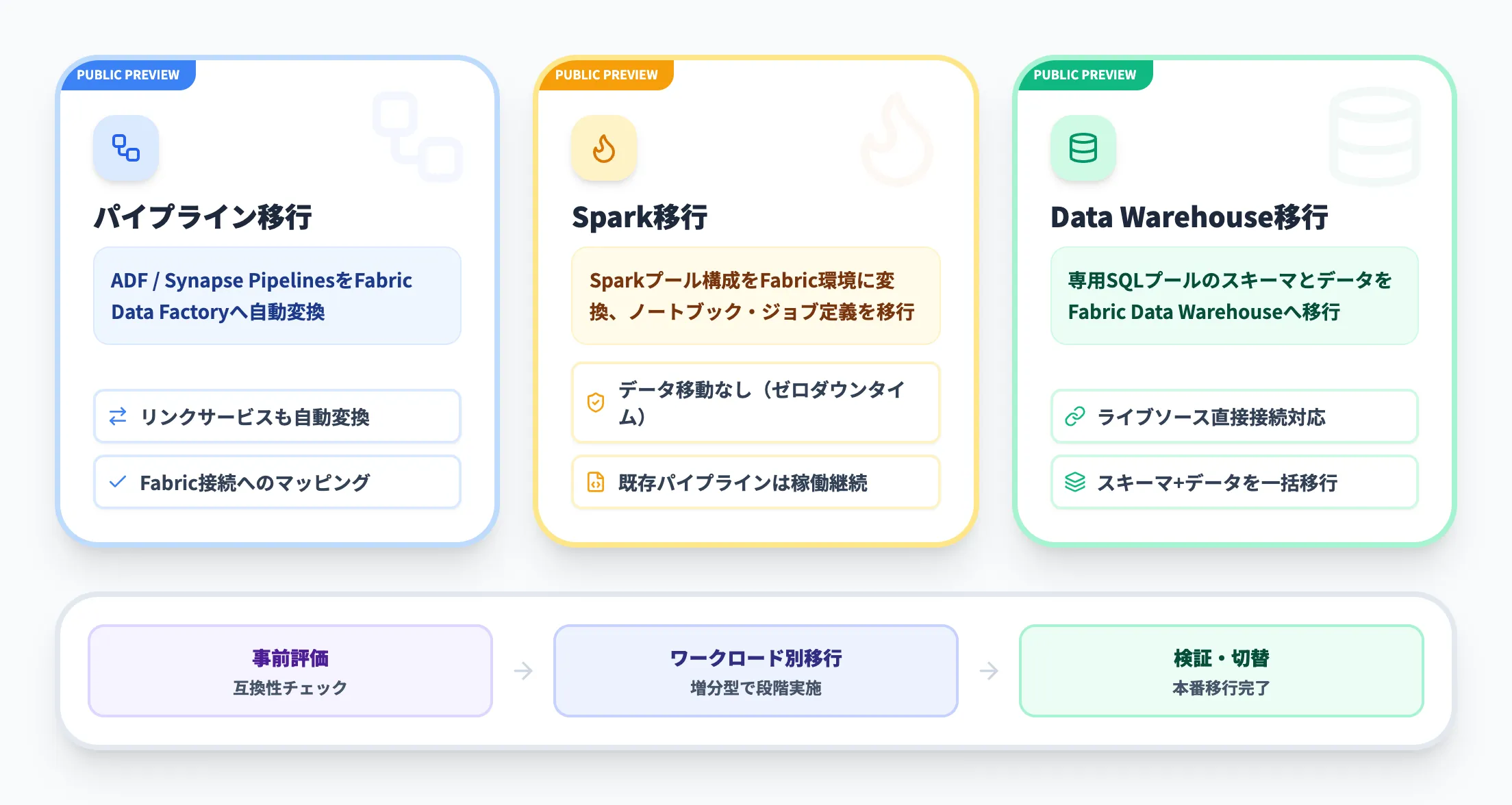
既存のSynapse環境からFabricへ移行する場合、Microsoftは3種類のMigration Assistantを提供しています。
2026年3月時点ではいずれもパブリックプレビューの段階であり、本番環境への適用は検証を十分に行ったうえで判断する必要があります。
- パイプライン移行アシスタント(パブリックプレビュー)
Azure Data FactoryおよびSynapse Pipelinesのパイプラインを自動でFabric Data Factoryに変換する。リンクサービスのFabric接続への変換も含む
- Spark移行アシスタント(パブリックプレビュー)
Synapse Sparkプールの構成をFabric環境に変換し、ノートブックとSparkジョブ定義を移行する。移行プロセス中にデータは移動しないため、既存パイプラインはダウンタイムなしで稼働を続けられる
- Data Warehouse移行アシスタント(パブリックプレビュー)
専用SQLプールのスキーマとデータをFabric Data Warehouseに移行する。ライブソースインスタンスへの直接接続機能(パブリックプレビュー)にも対応
Microsoftは「assessment-first approach」(事前評価から始めるアプローチ)を推奨しており、まず現環境の互換性を評価したうえで、段階的に移行を進めることを勧めています。
一括移行ではなく、ワークロードごとに検証しながら進める増分型の移行が現実的です。

Azure Synapse AnalyticsとAzure Databricksの違い
Azure上のデータ分析基盤として、Azure Synapse AnalyticsとAzure Databricksはよく比較されます。両者はいずれもビッグデータ処理とデータ分析を扱いますが、設計思想と得意領域が異なります。
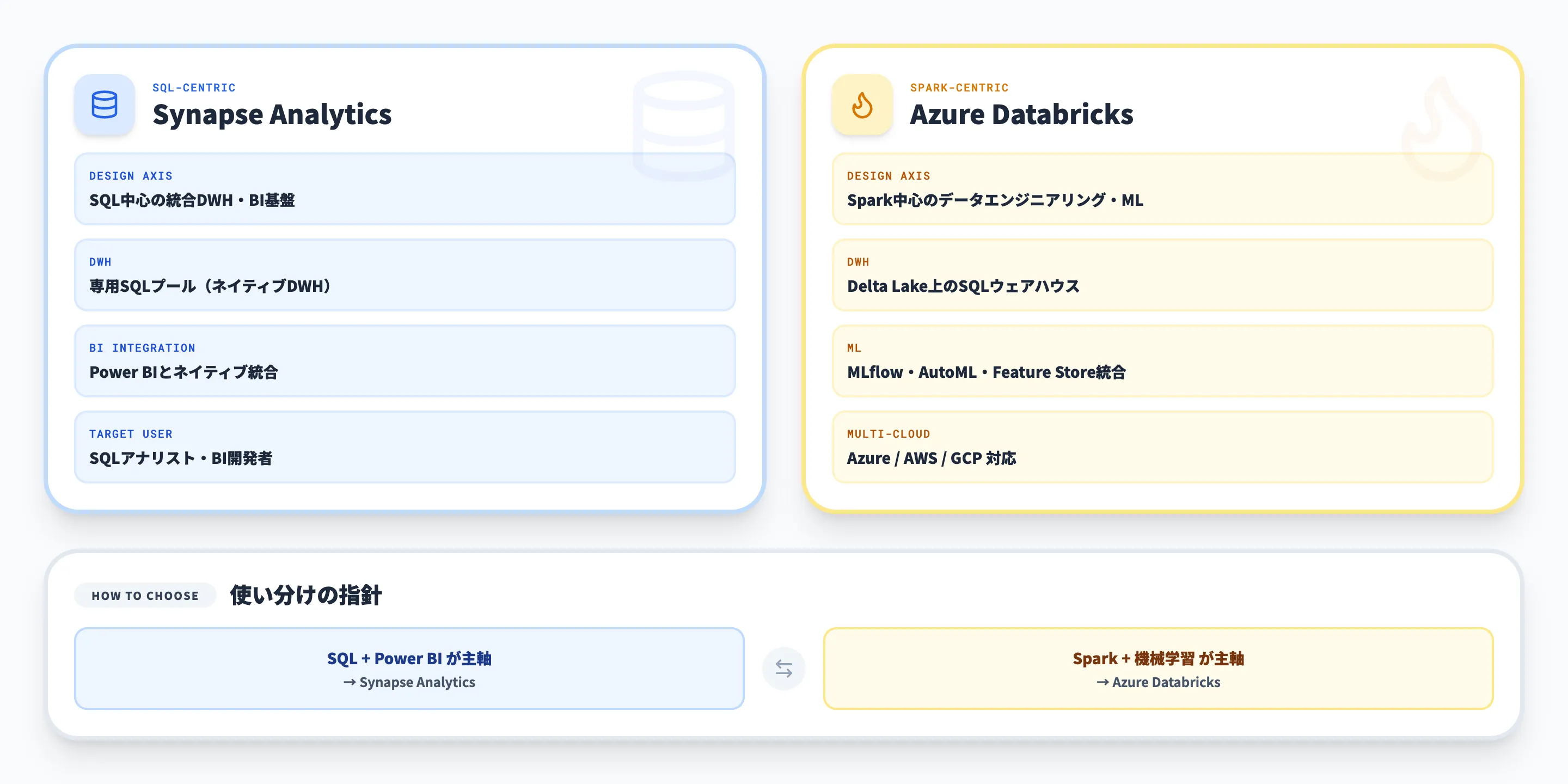
| 観点 | Azure Synapse Analytics | Azure Databricks |
|---|---|---|
| 設計の軸 | SQL中心の統合DWH・BI基盤 | Spark中心のデータエンジニアリング・ML基盤 |
| DWH機能 | 専用SQLプール(ネイティブDWH) | Delta Lake上のSQLウェアハウス |
| 機械学習 | Azure ML連携(T-SQL PREDICT関数) | MLflow統合、AutoML、Feature Store |
| 対応クラウド | Azureのみ | Azure、AWS、GCP(マルチクラウド) |
| BI統合 | Power BIとネイティブ統合 | Power BI、Tableau、Lookerなど複数対応 |
| ガバナンス | Purview連携 | Unity Catalog |
| 主なユーザー | SQLに慣れたデータアナリスト・BI開発者 | データエンジニア・データサイエンティスト |
選択の指針としては、SQLベースのDWHとBI(Power BI)が主軸ならAzure Synapse Analytics、Sparkベースのデータ処理と機械学習が主軸ならAzure Databricksという切り分けが基本です。
実際には両者を組み合わせて使うケースも珍しくありません。たとえば、DatabricksでETL処理と特徴量エンジニアリングを行い、加工済みデータをSynapseの専用SQLプールに投入してBI分析するといった構成です。
「BIダッシュボードの裏側はSynapse、データパイプラインと機械学習はDatabricks」という併用構成が複数の企業で採用されています。
どちらか一方に絞ろうとして要件に合わない選択をするよりも、得意領域で使い分ける方が結果的にコストも運用負荷も下がるケースが多いです。







