この記事のポイント
 Claude・Nova・Llamaなど100超のモデルを同一APIで切り替え可能。特定プロバイダーへのロックインを避けたい企業の第一候補
Claude・Nova・Llamaなど100超のモデルを同一APIで切り替え可能。特定プロバイダーへのロックインを避けたい企業の第一候補- AgentCore自体は2025年10月GA、2026年3月Policy Controls・EvaluationsがGA化で本番運用基盤として実用段階に到達
- Knowledge Bases+Guardrailsで社内RAGとガバナンス一体運用可、Agents/AgentCore/Flowsも同一プラットフォームで完結
- 初期費用ゼロのオンデマンド課金でPoCを即開始でき、効果を確認しながら段階的にスケール可能
- AWS資産を活用したい企業は既存のIAM・VPC・監査基盤をそのまま使えるため、ガバナンス面の追加負荷が小さい

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Amazon Bedrock(アマゾン ベッドロック)は、AWSが提供するフルマネージド型の生成AIプラットフォームです。AnthropicのClaude、AmazonのNova、MetaのLlamaをはじめ100超の基盤モデルを統一されたAPIから呼び出せるだけでなく、Bedrock Agents・Knowledge Bases・Guardrails・AgentCoreといった派生機能を含むファミリー全体の入口として位置づけられています。
本記事では、Amazon Bedrockの設計思想からファミリーの全体像、主要機能、利用できる基盤モデル、料金体系、国内企業の導入事例、Azure OpenAI・Vertex AIとの比較まで、2026年4月時点の最新情報をもとに整理しました。
目的別に読むべき記事の案内も用意していますので、「どこから手をつけるか」を整理したい方はぜひ参考にしてください。
Amazon Bedrockとは?
Amazon Bedrock(アマゾン ベッドロック)は、AWS(Amazon Web Services)が提供するフルマネージド型の生成AIプラットフォームです。
複数のAIプロバイダーが提供する基盤モデル(Foundation Model)を統一されたAPIから呼び出せる仕組みで、サーバーの構築・運用を意識せずに生成AIアプリケーションを開発できます。Bedrock Agents・Knowledge Bases・Guardrails・AgentCoreといった派生機能も含めたファミリー全体の入口として機能しているサービスです。
2023年9月に一般提供(GA)が開始され、同年10月に東京リージョンで利用可能となり、2025年2月に大阪リージョンにも拡大されました。2026年4月時点では、対応モデルが100種類を超えるまで広がり、エージェント運用基盤のAgentCoreや効率化機能(プロンプトキャッシュ・モデル蒸留など)が次々とGA化しており、AWSの生成AI戦略の中心に位置づけられているサービスです。
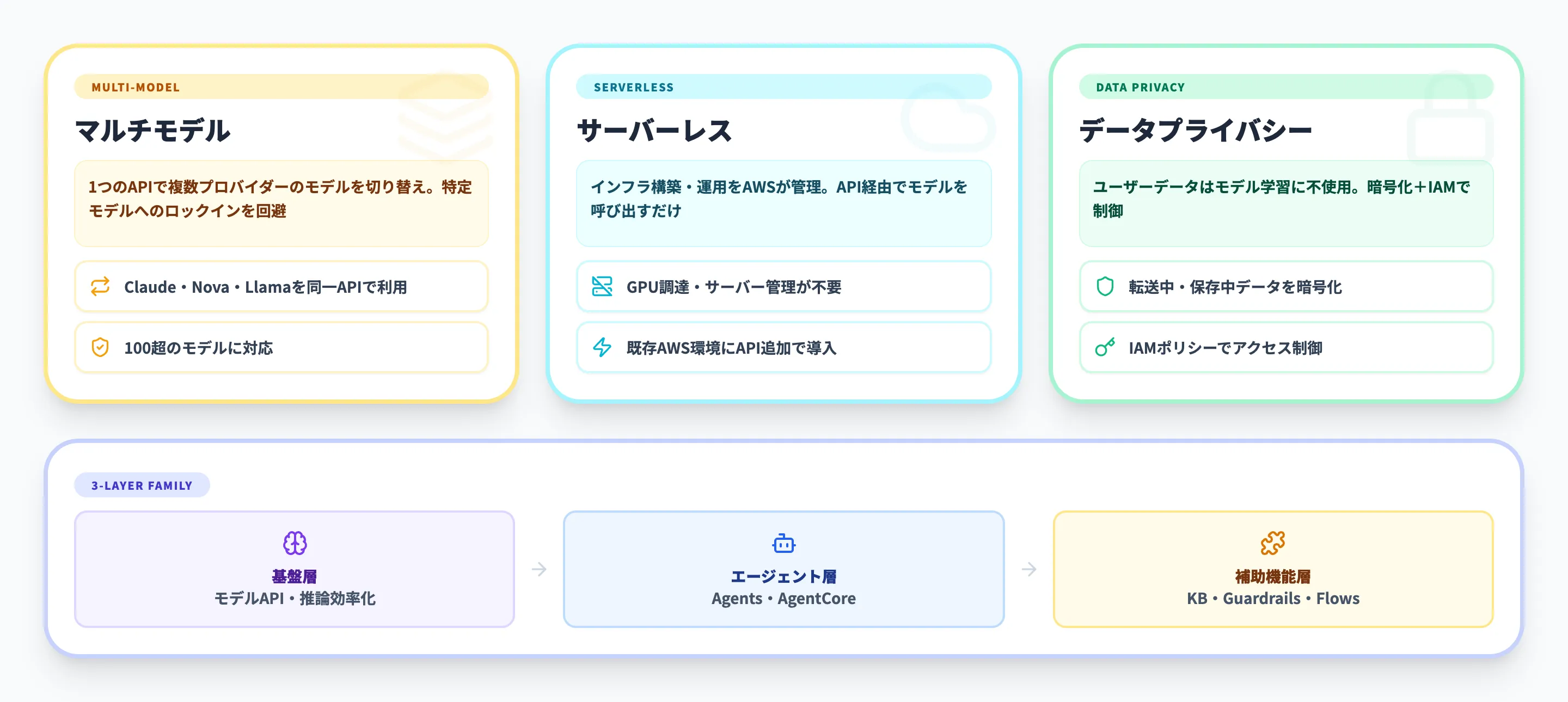
設計思想
Amazon Bedrockの設計は、次の3つの考え方で整理できます。
- マルチモデル
1つのAPIから複数プロバイダーのモデルを切り替えて利用できる。特定のモデルへのロックインを避けたい企業に向いた設計
- サーバーレス
インフラの構築・運用をAWSが担当する。利用者はAPI呼び出しだけに集中でき、GPUサーバーの調達は不要
- データプライバシー
入力データはモデルの再学習に使われない。転送中・保存時のデータは暗号化され、IAMポリシーで細かくアクセス制御できる
この3点が組み合わさることで、「生成AIを試したいが、GPUサーバーを自前で用意するのは難しい」という企業でも、既存のAWS環境にAPIを1つ追加する感覚で生成AIを導入しやすくなっています。
Bedrockが提供する機能は「モデルの呼び出し」だけにとどまりません。RAG・エージェント・安全性制御・運用基盤まで、生成AIアプリケーションに必要な機能群がファミリーとして同一プラットフォーム上に揃っています。次のセクションで、このファミリーの全体像を整理します。

Amazon Bedrockのファミリー全体像
Amazon Bedrockは単体のサービスではなく、複数の派生機能を含むファミリーとして理解するのが実態に近い捉え方です。ここでは、ファミリーを「基盤層」「エージェント層」「補助機能層」の3層で整理し、それぞれの役割と関連する記事の案内をまとめます。
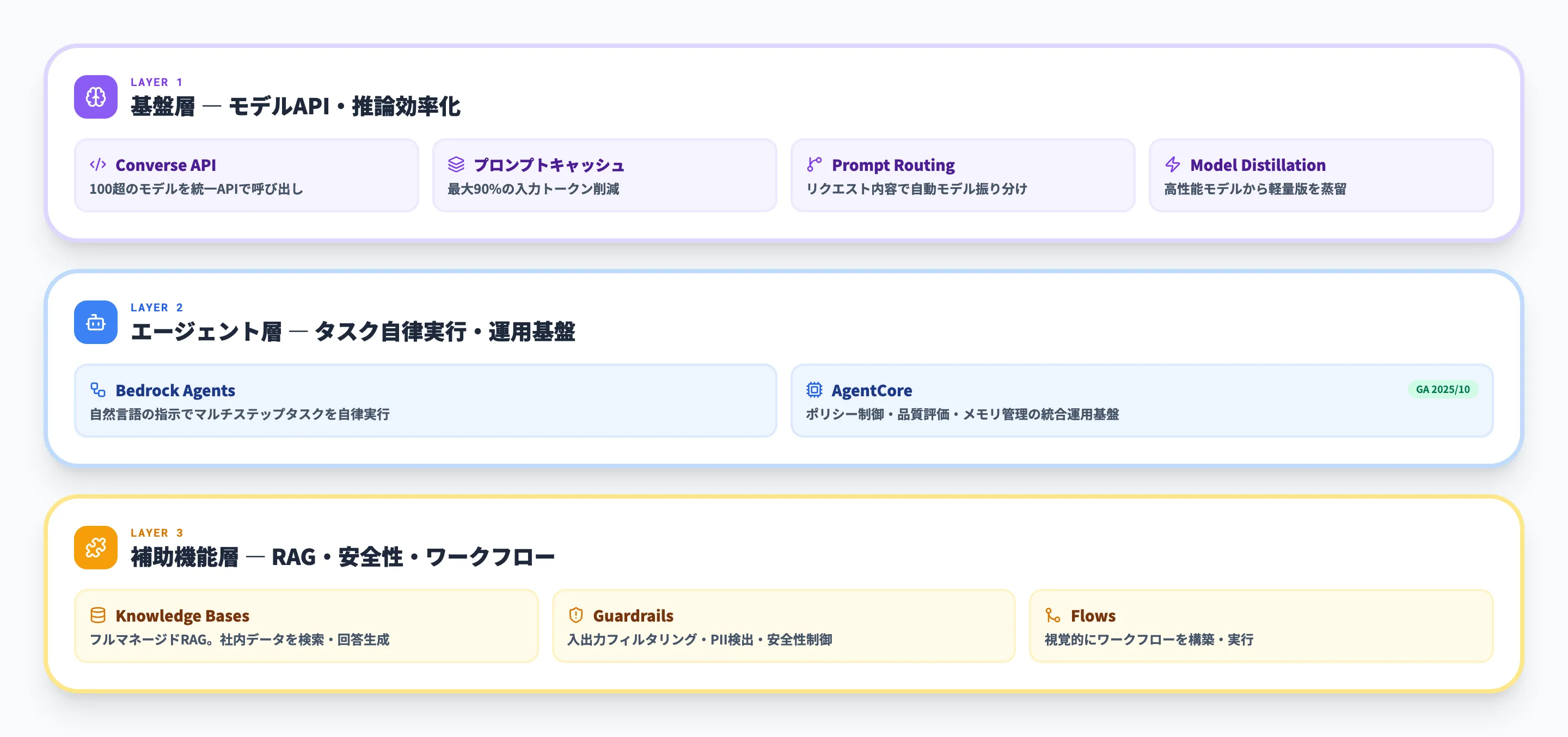
3層構造
Bedrockファミリーの構成を以下の表に整理しました。各層がどのような役割を持ち、どの機能が含まれるかを確認できます。
| 層 | 含まれる機能 | 役割 |
|---|---|---|
| 基盤層 | Amazon Bedrock本体(モデルAPI、Converse API、プロンプトキャッシング、Model Distillation) | 100超の基盤モデルへの統一アクセスと、推論の効率化を提供 |
| エージェント層 | Bedrock Agents、AgentCore | 自然言語による指示でタスクを自律実行するオーケストレーション基盤。AgentCore自体は2025年10月にGA、2026年3月にPolicy Controls・EvaluationsがGA化しポリシー制御・品質評価まで対応 |
| 補助機能層 | Knowledge Bases、Guardrails、Flows | RAG構築・安全性制御・ワークフロー設計。基盤層・エージェント層と組み合わせて使う |
この3層構造が意味するのは、「モデルを呼び出す」だけでなく、その上に社内データ連携・安全性制御・エージェント運用まで積み上げた生成AIアプリケーションを、AWSのマネージド環境で一貫して構築・運用できるという点です。外部ツールを複数組み合わせる構成と比較して、認証・ネットワーク・監査ログまわりの設計が簡略化されるメリットがあります。
どれから読むべきか
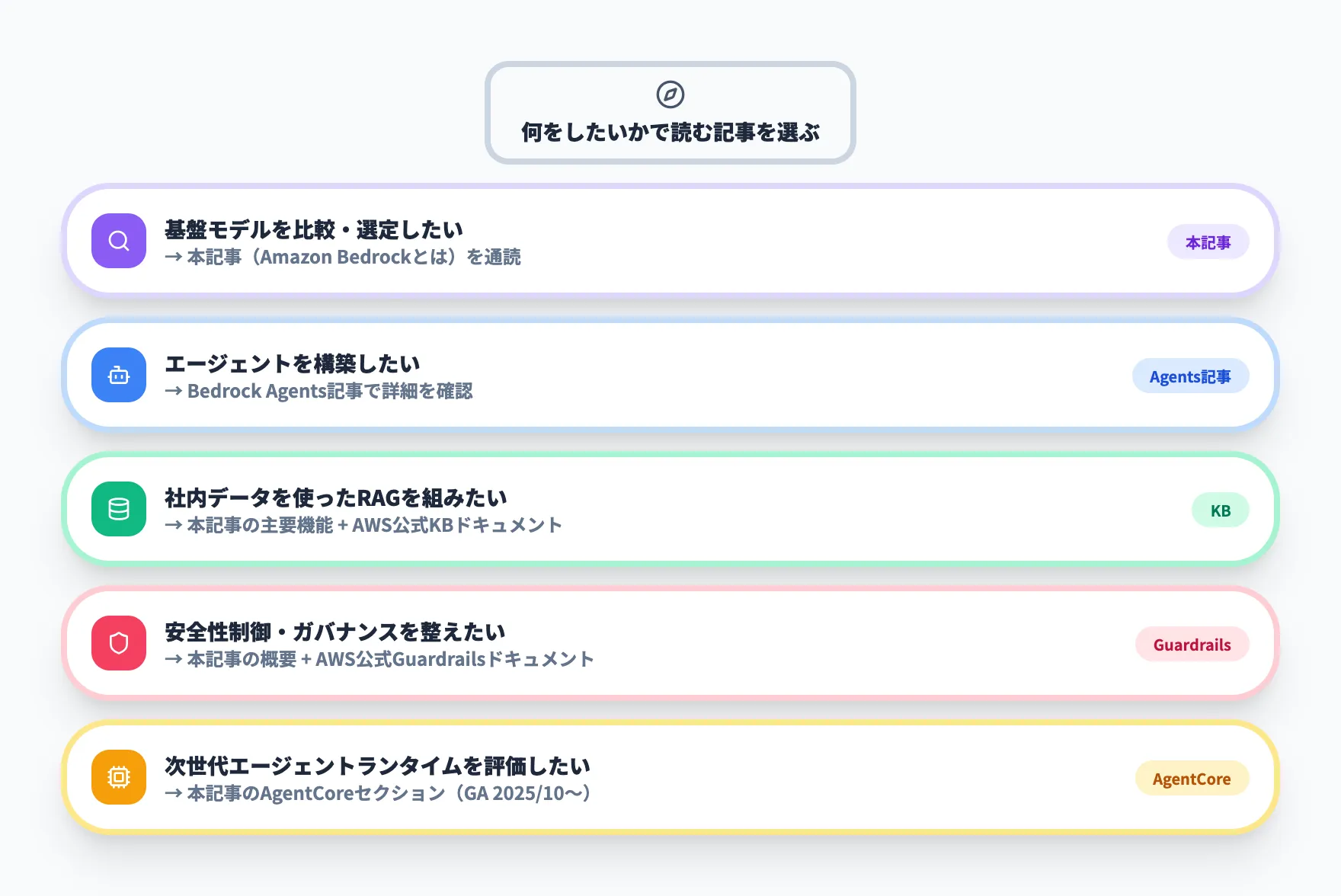
Bedrockファミリーは機能が多いため、「何をしたいか」で読む記事を分けるのが効率的です。以下に、目的別の案内を整理しました。
- 基盤モデルを比較・選定したい
本記事(Amazon Bedrockとは)を通読してください。モデル一覧・料金・クラウド比較までカバーしています
- エージェントを構築したい
Amazon Bedrock Agentsとは?機能や料金、使い方を解説で、アクショングループ・オーケストレーション・マルチエージェント協調の詳細を確認できます
- 社内データを使ったRAGを組みたい
Knowledge Basesの詳細は本記事の「主要機能」セクションで概要を押さえた上で、AWS公式のKnowledge Basesドキュメントを参照してください
- 安全性制御・ガバナンスを整えたい
Guardrailsの概要は本記事で、詳細設計はAWS公式のGuardrailsドキュメントが参考になります
- 次世代エージェントランタイムを評価したい
AgentCoreは2025年10月にGA化し、2026年3月にはPolicy Controls・Evaluationsも正式提供されています。本記事の「AgentCore」セクションで概要を確認できます
この案内を起点に、目的に合った記事に進んでもらえれば、必要な情報に最短でたどり着けるはずです。
Amazon Bedrockの主要機能
Amazon Bedrockは、基盤モデルへのアクセスだけでなく、生成AIアプリケーションの構築から本番運用までを支える機能群をまとめて提供しています。ここでは大きく、社内データ連携・安全性制御・タスク自動化・運用基盤・効率化の5つの観点で整理します。

Knowledge Bases(RAG構築)
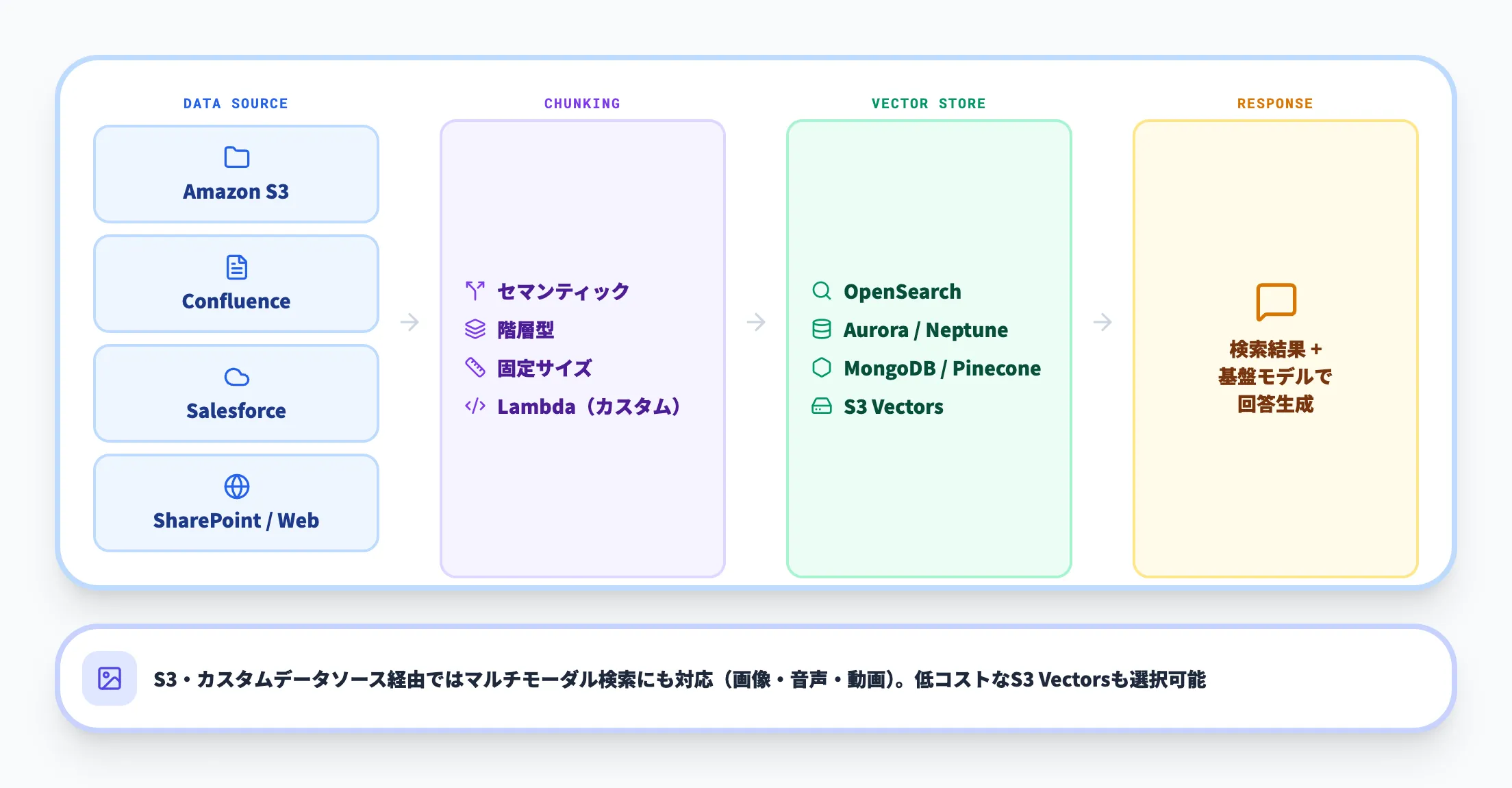
Knowledge Basesは、社内データを活用したRAG(検索拡張生成)をフルマネージドで構築できる機能です。
生成AIをそのまま使うと、モデルが学習していない社内情報については正確な回答が得にくいという課題があります。Knowledge Basesは、社内ドキュメントを検索して結果をモデルに渡すRAGパイプラインを、コードをほぼ書かずに構築できるよう設計されています。
対応するデータソースとベクトルストアを以下の表に整理しました。
| カテゴリ | 対応サービス |
|---|---|
| データソース | Amazon S3、Confluence、Salesforce、SharePoint、Webクローラー |
| ベクトルストア | Amazon OpenSearch Serverless、Aurora、Neptune Analytics、MongoDB、Pinecone、Redis Enterprise Cloud、Amazon S3 Vectors |
幅広いデータソースと複数のベクトルストアに対応しているため、すでにS3やSharePointに集約されている社内ドキュメントをそのまま検索対象にしやすい点が実務的なメリットです。チャンキング方式もセマンティック・階層型・固定サイズから選べ、Lambda関数を使った独自のチャンキングロジックも組み込めます。
2025年12月のAWS re:Invent以降は、Amazon S3またはカスタムデータソース経由のコンテンツについては、画像・音声・動画まで含めたマルチモーダル検索にも対応しています(Confluence・SharePoint等の他コネクタではマルチモーダルファイルはスキップされます)。低コストなベクトルストアであるAmazon S3 Vectorsへの対応も進み、対応データソースの範囲内で社内ナレッジを「文書だけ」に縛らずに横断検索できるようになってきました。
Guardrails(安全性・ガバナンス)
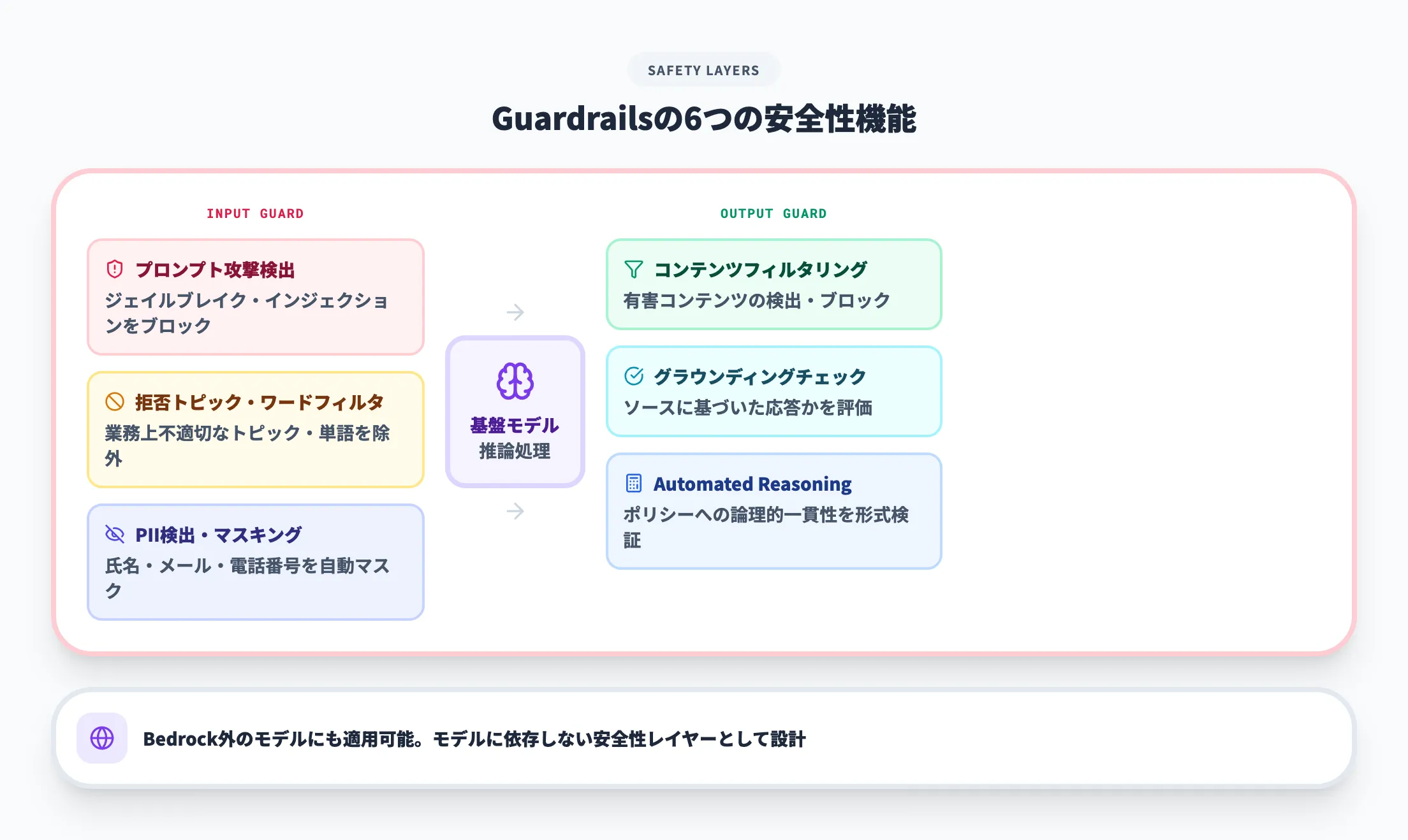
Guardrailsは、生成AIの入出力に対してフィルタリングや検証を自動で適用する安全性制御の機能です。
業務で生成AIを使う場合、不適切な回答や機密情報の漏洩をどう抑えるかは避けて通れません。Guardrailsでは、公式ドキュメントで案内されている以下の仕組みを使ってこの課題に対応できます。
- コンテンツフィルタリング
ヘイトスピーチ、暴力、不正行為などの有害コンテンツを検出・ブロックする
- 拒否トピック・ワードフィルター
業務上扱いたくないトピックや、社外秘の単語・フレーズを定義し、入出力から除外する
- PII検出・マスキング
個人識別情報(氏名・メールアドレス・電話番号など)をユーザー入力とモデル応答の両方で検出し、自動で削除やマスクを行う
- Automated Reasoning
ユーザーが定義したルール・ポリシーへの論理的な一貫性を、形式的ロジックを用いて検証する。現状は英語(US)のみ対応で、ポリシー範囲外の事実検証は対象外
- コンテキストグラウンディングチェック
モデルの応答が、提供されたソースコンテキストにきちんと基づいているかを評価する
- プロンプト攻撃検出
ジェイルブレイクやプロンプトインジェクションを検出して、ブロックする
Guardrailsで特徴的なのは、Amazon Bedrock上のモデルだけでなく、自社ホストや他社プロバイダーのモデルに対しても適用できる点です。
AIガバナンスの観点では、特定モデルに紐付かない「横断的な安全性レイヤー」として設計されているため、社内で複数のモデル・LLMを使い分けている場合でも統一的な制御を適用しやすくなります。
Agents(タスク自動化)
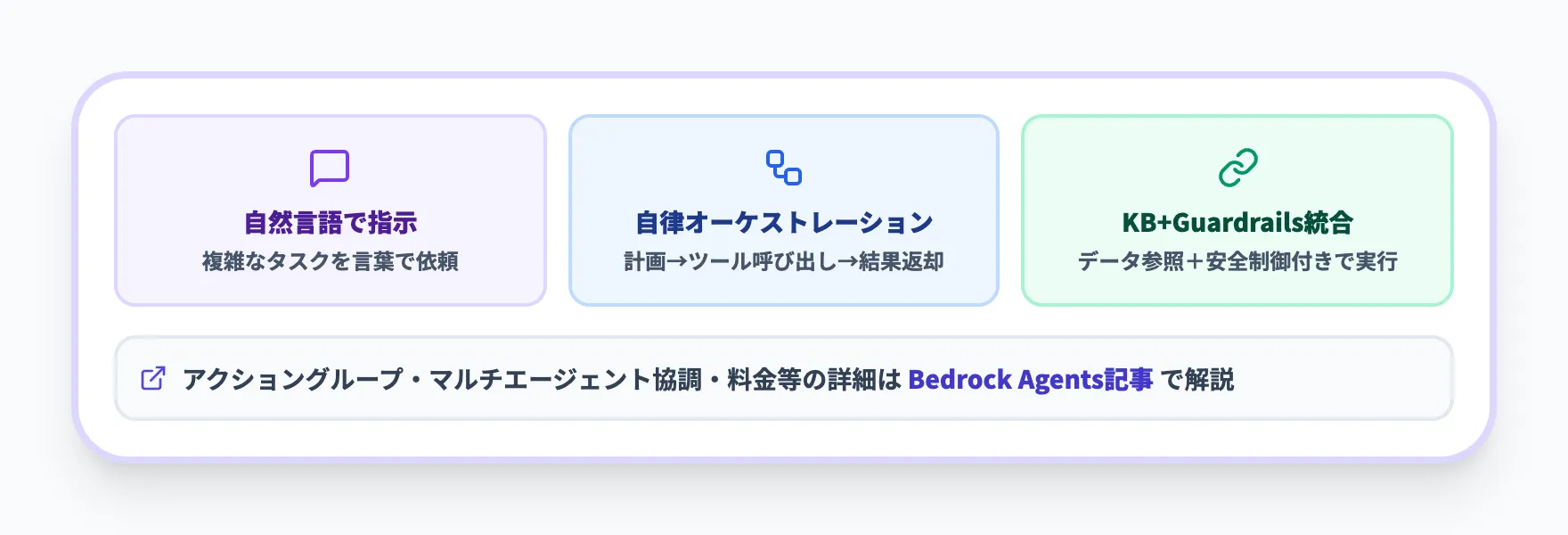
Agentsは、自然言語での指示をもとに、複数のステップやツール呼び出しを組み合わせてタスクを遂行するオーケストレーション機能です。Knowledge BasesやGuardrailsと組み合わせることで、社内データを参照しつつ安全制御を効かせた状態でタスクを遂行するエージェントを構築できます。
アクショングループの設計、オーケストレーションの仕組み、マルチエージェント協調、料金体系などの詳細はAmazon Bedrock Agentsとは?機能や料金、使い方を解説で網羅しています。本記事では概要にとどめ、詳細はそちらを参照してください。
AgentCore(エージェント運用基盤)
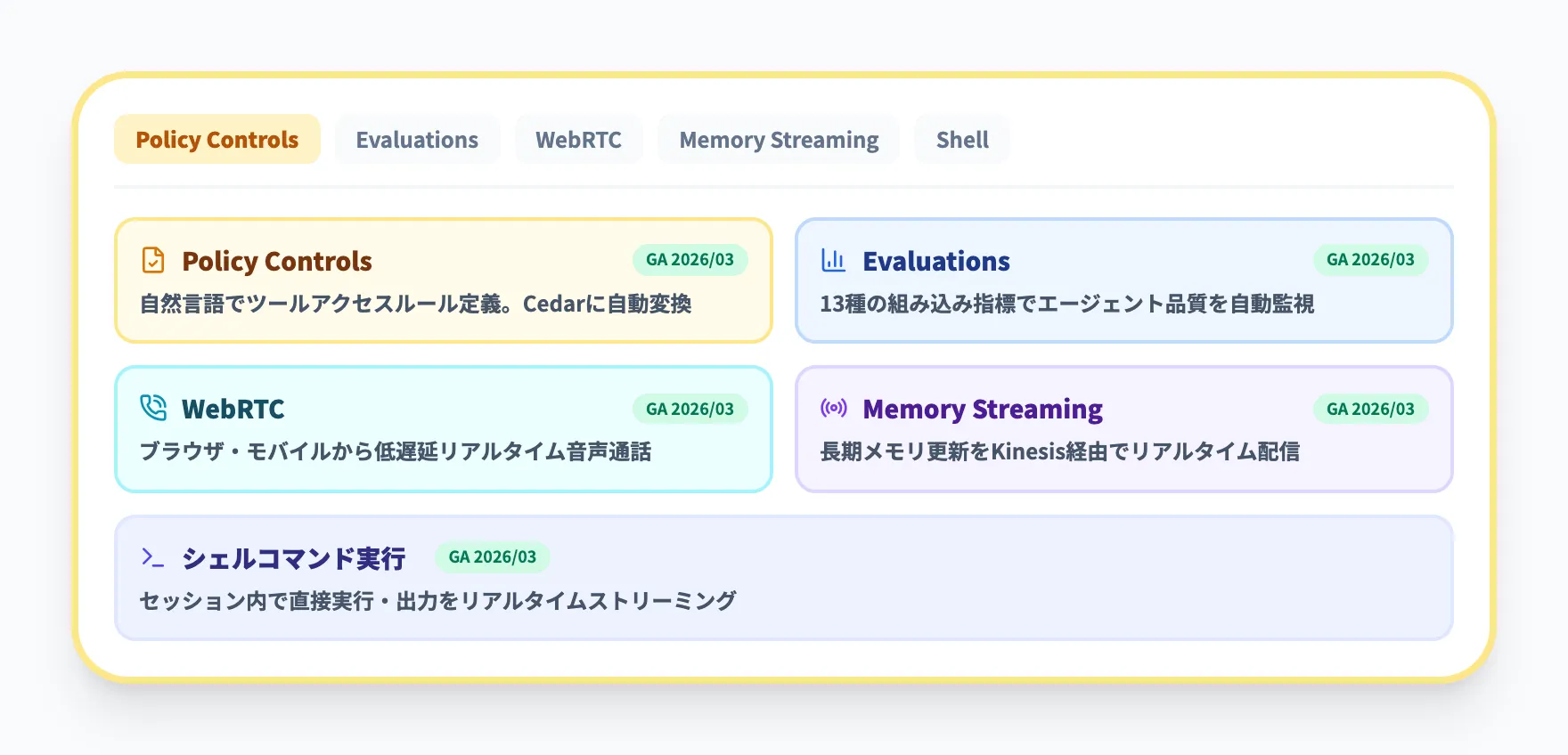
AgentCoreは、エージェントの開発から本番運用までを支える統合プラットフォームです。AgentCore自体は2025年10月にGAとなり、2026年に入ってからはPolicy ControlsやEvaluationsのGA化をはじめ、周辺機能の追加が続いています。
2026年3月時点で追加・GA化した主な機能を以下に整理しました。
| 機能 | 提供開始時期 | 区分 | 概要 |
|---|---|---|
| Policy Controls | 2026年3月 | GA | 自然言語でツールアクセスルールを定義し、AWSのオープンソースポリシー言語Cedarに自動変換 |
| Evaluations | 2026年3月 | GA | 13種の組み込み評価指標(正確性・有用性・ツール選択等)でエージェント品質を自動監視 |
| WebRTC | 2026年3月 | 機能追加 | ブラウザやモバイルから低遅延のリアルタイム音声通話を実現 |
| Memory Streaming | 2026年3月 | 機能追加 | エージェントの長期メモリ更新をAmazon Kinesis経由でリアルタイム配信 |
| シェルコマンド実行 | 2026年3月 | 機能追加 | 実行中セッション内でシェルコマンドを直接実行し、出力をリアルタイムでストリーミング |
この一覧から見えてくるのは、AgentCoreが「エージェントを動かす」だけでなく、ポリシー制御・品質評価・メモリ管理まで含めた運用面までカバーするようになった点です。Amazon Bedrockは従来の「モデルを呼び出すAPI」から、エージェントを設計・評価・制御まで一貫して扱えるプラットフォームへと役割を広げています。
特にPolicy ControlsとEvaluationsは、企業でエージェントを本番投入する際に問われやすい「実行範囲をどう制御するか」「品質をどう継続監視するか」という2点に、追加開発なしで対応できる点が実務的なメリットになります。
モデル運用を効率化する機能

主要機能に加えて、Amazon Bedrockには本番運用時のコストやレイテンシを抑えるための効率化機能も組み込まれています。代表的なものを以下にまとめました。
- プロンプトキャッシング
繰り返し利用する長いシステムプロンプトやドキュメントをキャッシュし、入力トークンの再課金を抑える機能。2026年1月にClaude Sonnet・Haiku・Opusの4.5系で1時間TTLオプションが追加され、長時間のセッションにも適用しやすくなった
- Intelligent Prompt Routing
対応するモデルファミリー内で、リクエストの内容に応じて軽量モデルと高性能モデルを自動で振り分ける機能。2026年4月時点ではClaude 3/3.5系やNova Lite/Nova Proなどが対応しており、すべてを高性能モデルに流す場合と比較して、品質を保ちながらコストを下げやすい
- Model Distillation
高性能モデルの出力をもとに、軽量モデルを蒸留(fine-tune)して特定タスク向けに高速化する機能。AWS公式によれば、最大で500%程度の高速化とおよそ75%のコスト削減を、最小限の精度低下で実現できるケースもあるとされている
- バッチ推論とFlex tier
リアルタイム性が不要な処理向けに、オンデマンド料金から最大50%割引されたバッチ推論と、優先度を下げる代わりに割引される推論枠(Flex)が提供されている
これらの機能をうまく組み合わせると、「品質とコストのバランス」をモデルだけで決めるのではなく、ルーティングやキャッシュ、蒸留といった運用レイヤーで調整できるようになります。本番運用に乗せるフェーズで効いてくる仕組みです。
Amazon Bedrockで利用できる基盤モデル

Amazon Bedrockの大きな特徴のひとつが、複数のAIプロバイダーが提供する基盤モデルを、同じAPIから選択・切り替えできる点です。2026年4月時点で100超のモデルが利用可能になっており、用途や要件に応じて最適なモデルを使い分けやすくなっています。
ここでは、主要なモデルプロバイダーごとに概要を見ていきます。
Anthropic Claude系
Anthropicが提供するClaudeシリーズは、Bedrock上で利用が広がっているモデルファミリーのひとつです。代表的なモデルを以下に整理しました。
| モデル | コンテキスト長 | 特徴 |
|---|---|---|
| Claude Opus 4.6 | 1Mトークン | 知的労働タスク・長文推論・コーディングで高い性能を発揮 |
| Claude Sonnet 4.6 | 1Mトークン | Opus 4.6に近い性能を比較的低コストで提供。エージェント用途と相性が良い |
| Claude Haiku 4.5 | 200Kトークン | 高速・低コスト。軽量なタスクやリアルタイム応答向け |
Claude Opus 4.6とSonnet 4.6は1Mトークン(およそ70万語相当)のコンテキストウィンドウに対応しているため、数百ファイル規模のコードベースや大量の社内ドキュメントを一度に読み込ませた上で推論する用途にも対応できます。大規模なRAGやコード解析を扱いたい場合の選択肢として有力です。
使い分けの目安としては、品質を最優先するならOpus 4.6、品質と単価のバランスを取るならSonnet 4.6、レイテンシとコストを重視するならHaiku 4.5、という整理が一般的です。詳しくはClaude Opus・Sonnet・Haikuの違いを比較した記事も合わせて参考にできます。
なお、東京リージョン(ap-northeast-1)では、Claude Sonnet 4.6 / Haiku 4.5ともにIn-Region提供はなく、クロスリージョン推論プロファイル経由での利用となります。グローバルプロファイル(global.anthropic.claude-sonnet-4-6 等)を指定して呼び出します。クロスリージョン推論でもリクエストはAWSリージョン間で処理されるため、東京からの呼び出しでも実用的なレイテンシで利用できます。
Amazon Nova系
Amazonが自社開発したNovaシリーズは、コストパフォーマンスを意識して設計されたモデルファミリーです。2025年12月のAWS re:InventではNova 2世代が発表され、第1世代からの性能向上も図られています。代表的なモデルを以下にまとめました。
| モデル | 特徴 | 想定用途 | 備考 |
|---|---|---|---|
| Nova Pro | テキスト・画像・動画を扱えるマルチモーダルモデル | 汎用的な業務アプリケーション | GA |
| Nova Lite | 高速・低コストの軽量モデル | チャットボット、リアルタイム応答 | GA |
| Nova 2 Lite | 第2世代。Nova 1比で性能向上 | コスト効率を重視した汎用タスク | GA |
| Nova 2 Pro | 第2世代のProモデル | 高品質な推論が必要な業務 | プレビュー |
NovaシリーズはAWSネイティブなモデルであるため、Bedrock上でのレイテンシや料金面で扱いやすい点が魅力です。ClaudeやLlamaと比較して単価が抑えられているため、大量リクエスト処理や軽量タスクのコスト最適化に向いています。Nova 2 Proはプレビュー段階のため、本番運用ではGA済みのNova ProやNova 2 Liteを軸に検討するのが安全です。
Meta Llama系
MetaがオープンソースとしてリリースしているLlamaシリーズも、Bedrock上でフルマネージドの形で利用できます。代表的なモデルは以下のとおりです。
| モデル | パラメータ数 | 特徴 |
|---|---|---|
| Llama 3.3 70B | 700億 | オープンソース系で品質が高く、Bedrock上ではレイテンシ面でも扱いやすい |
| Llama 3.1 405B | 4,050億 | 超大規模モデル。複雑な推論やコード生成に強い |
Llamaモデルは重みがオープンソースとして公開されているため、モデルの透明性やカスタマイズ性を重視したいユースケースで選ばれることが多いモデルです。クラウド上でフルマネージドに使えるBedrockと、自社環境への持ち込みやチューニングを選択肢として持てるのは、社内ガバナンスの観点でも柔軟性が高くなります。
その他のプロバイダー
上記に加え、以下のプロバイダーのモデルもBedrockから利用できます。
- Mistral AI
欧州発のオープンソースLLM。多言語対応とコスト効率に強みがある
- Cohere
検索・要約・分類に強いモデル。RAGのリランキングなどにも組み合わせやすい
- Stability AI
Stable Diffusion系の画像生成モデル。テキストからの画像生成ユースケース向け
- AI21 Labs
Jurassicシリーズ。テキスト生成・要約に対応
2025年12月のAWS re:Inventでは、18種類のオープンウェイトモデルが一度に追加され、Bedrockとしては過去最大規模のモデル拡充が行われました。Google、NVIDIA、MiniMax、Qwenなどのモデルもラインナップに加わり、ユースケースに合わせて選べるモデルの幅がさらに広がっています。
Amazon Bedrockの使い方
Amazon Bedrockを使い始めるまでの流れは、AWSの他のサービスと比べてもシンプルです。ここでは、AWSアカウントの準備からAPIの基本的な呼び出しまでを順番に整理します。
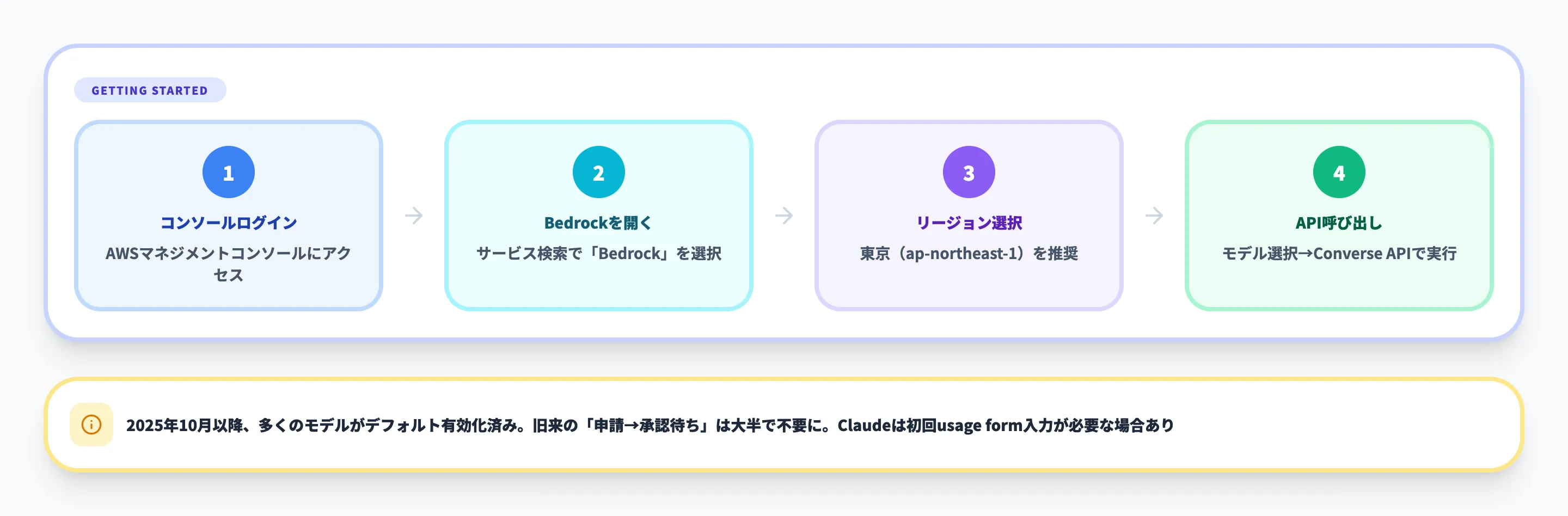
AWSアカウント準備とモデルアクセス申請

Amazon Bedrockを利用するには、まずAWSアカウントが必要です。すでにAWSを利用している企業であれば、既存のアカウントにそのまま機能を追加する形で始められます。
利用開始の基本的な流れは次のとおりです。
- AWSマネジメントコンソールにログインする
- 「Amazon Bedrock」を検索してサービスページを開く
- 利用するリージョン(東京 ap-northeast-1 など)を選択する
- モデルを選んでAPIから呼び出す
2025年10月のアップデート以降、多くのサーバーレス基盤モデルは商用リージョンでデフォルト有効化されました。以前のような「申請→承認待ち」のステップは大半のモデルで不要になっており、コンソールから数クリックで試せる状態になっています。なお、Anthropic Claudeは初回のみusage form(利用目的の入力)を求められる場合があります。
リージョンの選び方としては、東京・大阪リージョンを軸にしつつ、利用したい最新モデルがそのリージョンに直接来ていない場合は、クロスリージョン推論プロファイルでus-east-1などを経由する構成を検討するのが現実的です。
APIからの基本的な呼び出し
モデルアクセスが有効になったら、AWS SDK(Boto3など)からAPIを呼び出せます。
PythonでClaude Sonnet系を呼び出す基本的なコード例を示します。
import boto3
client = boto3.client("bedrock-runtime", region_name="us-east-1")
response = client.converse(
modelId="us.anthropic.claude-sonnet-4-6",
messages=[
{
"role": "user",
"content": [{"text": "Amazon Bedrockのメリットを3つ教えてください"}]
}
]
)
print(response["output"]["message"]["content"][0]["text"])
このコードで使っているのはConverse APIです。Converse APIはモデルに依存しない統一インターフェースになっており、modelIdを差し替えるだけでClaude・Nova・Llamaといった異なるモデルに同じコードで切り替えられます。上の例ではUS East (N. Virginia)リージョンにクロスリージョン推論プロファイル(us.anthropic.claude-sonnet-4-6)を指定していますが、東京リージョンから呼び出す場合はリージョンを ap-northeast-1、modelIdを global.anthropic.claude-sonnet-4-6 に変更してください。後からモデルを評価し直す際に、アプリケーション側のコードを大きくいじらずに済むのが利点です。
初めてBedrock APIを触る場合は、AWSマネジメントコンソールの「Playgrounds」からノーコードでモデルの応答を試す方法もあります。まずはPlaygroundで期待した出力が得られるかを確認してから、API化に進む流れが手戻りを減らしやすい進め方です。
AI Readyの観点では、PoC段階からIAMポリシーの設計やVPCエンドポイントの構成を意識しておくと、本番移行のときに権限・ネットワーク周りで手戻りを減らせます。

Amazon Bedrockの導入事例

Amazon Bedrockは、国内外の大手企業から中堅企業まで幅広く採用が進んでいるサービスです。ここでは、AWSの公式導入事例ページや各社の公開情報をもとに、国内企業の事例をいくつか紹介します。
竹中工務店:ベテランの知識継承を支援する「デジタル棟梁」
竹中工務店は、建設業界で課題となっているベテラン従業員の知識・経験の継承を目的に、AWSのAI・データ基盤を活用したナレッジ検索システム「デジタル棟梁」を構築しています。
AWS公式の導入事例によると、Amazon S3・RDS・Glue・SageMaker・Redshiftを組み合わせたデータ基盤の上に、施工ノウハウや設計判断の根拠を集約し、若手社員がアクセスしやすい仕組みを実現しています。AWS上でデータ基盤とAI基盤を一体的に整備した事例として、Bedrockを活用したRAG構成を検討する際の参考になります。
KDDI:議事録・提案書の作成時間を短縮
KDDIのアジャイル開発センターでは、Amazon Bedrockを活用して議事録と提案書の作成時間を最大1時間程度短縮した取り組みが公開されています。
会議のたびに発生する議事録作成や提案書のドラフト作業は、参加人数や会議体が増えるほど負荷が膨らみがちな業務です。「定型的だが時間がかかる」タイプの業務は、生成AIの効果が出やすい領域のひとつといえます。
エフピコ:若手4人が1カ月でAIアプリを開発
食品容器メーカーのエフピコでは、若手社員4名がAmazon Bedrockを活用し、日報作成補助・流行分析アプリケーションをおよそ1カ月で開発しました。営業日報の要約・分析にかかっていた時間を、月間700時間以上削減したと公表されています。
この事例から見えてくるのは、フルマネージドなBedrockであれば、ML専門チームを抱えていない企業でも業務アプリケーションレベルの生成AI活用に踏み出しやすい、という点です。1カ月という開発期間も、フルマネージドサービスならではのスピード感を示す指標として参考になります。
ソニーグループ:マルチモデルを前提とした生成AI基盤
ソニーグループの事例は、AWSの公式customer storiesページで取り上げられています。多様な事業ポートフォリオを持つグループ全体で生成AIを利用する場合、業務ごとに最適なモデルを選びたいというニーズが出てくる場面が多く、単一APIから複数モデルを切り替えられるBedrockの設計とかみ合いやすい構造です。
【関連記事】
AIエージェントで業務効率化|部門別Before/Afterと導入手順
Amazon Bedrock vs Azure OpenAI vs Vertex AI

「AWS、Azure、Google Cloudのどれで生成AI基盤を構築すべきか」は、多くの企業が一度は検討する論点です。ここでは、3大クラウドの生成AIプラットフォームを比較しながら、それぞれの位置づけを整理します。
まずは3サービスの主要な違いを以下の表にまとめました。
| 比較軸 | Amazon Bedrock | Azure OpenAI Service | Google Vertex AI |
|---|---|---|---|
| モデル戦略 | マルチプロバイダー(Claude、Nova、Llama、Mistral等) | OpenAI中心(GPT-5系、DALL-E等) | Google中心(Gemini) + 一部サードパーティ |
| エージェント基盤 | AgentCore(Policy/Evaluations GA) | Microsoft Foundry Agent Service | Vertex AI Agent Builder |
| RAG機能 | Knowledge Bases(フルマネージド) | Azure AI Search + Prompt Flow | Vertex AI Search |
| 安全性制御 | Guardrails(Automated Reasoning付き) | Azure AI Content Safety | Vertex AI Safety Filters |
| 自社モデル | Amazon Nova 2シリーズ | なし(OpenAI依存) | Geminiシリーズ |
| 強みのエコシステム | AWS全体(S3、Lambda、SageMaker等) | Microsoft 365、Dynamics、GitHub | Google Workspace、BigQuery |
表からも分かるように、3サービスはそれぞれ異なる強みを持っており、機能面だけで優劣をつけるよりも「どのクラウドエコシステムに乗っているか」「どのモデルプロバイダーを使いたいか」で選び分けるのが現実的です。
対応モデルの違い
3サービスを比較すると、最も差が出やすいのが利用できるモデルのラインナップです。
Bedrockはマルチプロバイダー戦略を採っており、ClaudeとLlamaとNovaを同じAPI体系で切り替えられます。Azure OpenAI Serviceは名前の通りOpenAIのモデル(GPT-5系)を中心に提供しており、Vertex AIはGoogleのGeminiが主力です。
特定モデルへの依存を避けたい場合や、用途ごとにモデルを使い分けたい場合には、マルチモデル設計のBedrockが扱いやすい構成になります。一方で、OpenAIのモデルだけで業務要件が満たせる場合は、Azure OpenAI Serviceに寄せたほうがシンプルな構成になるケースもあります。
エージェント基盤の比較

2026年時点で、3サービスともエージェント構築の機能を提供していますが、成熟度と設計思想に違いがあります。
BedrockはAgentsとAgentCoreを組み合わせ、エージェントの構築からポリシー制御・品質評価・メモリ管理まで一貫して扱える構成です。特にAgentCoreのPolicy Controls(自然言語→Cedar変換)とEvaluations(13種の品質指標)は、2026年3月にGA化したばかりの機能ですが、企業が本番運用で問われる「制御」と「品質監視」に追加開発なしで対応できる点で実務的な優位性があります。
Microsoft Foundry Agent Serviceは、Microsoft 365やDynamicsとの統合が強みで、業務アプリケーション内にエージェントを埋め込むシナリオに向いています。Vertex AI Agent Builderは、Geminiモデルとの密結合とBigQueryとの連携が特徴です。
エージェント基盤を重視する場合、「どのクラウドにデータがあるか」に加えて「ポリシー制御と品質評価の仕組みが組み込まれているか」も選定軸に入れると、本番運用フェーズでの手戻りを減らしやすくなります。
エコシステムの比較
モデルそのものの性能と並んで、選定の決め手になりやすいのが、既存のクラウド資産との相性です。
すでにAWS上でS3にデータを保存し、LambdaやSageMakerを活用している環境であれば、BedrockはIAM・VPC・CloudWatchなど既存のガバナンス体系にそのまま乗せられます。同じように、Microsoft 365やDynamicsを基盤にしている企業ではAzure OpenAIが、BigQueryやGoogle Workspaceを中心に使っている企業ではVertex AIがそれぞれ自然な選択肢になりやすい傾向があります。
AzureとAWSの料金、サービス、性能を徹底比較した記事も、クラウド全体の比較を確認したい場合の参考になります。
どう選ぶか
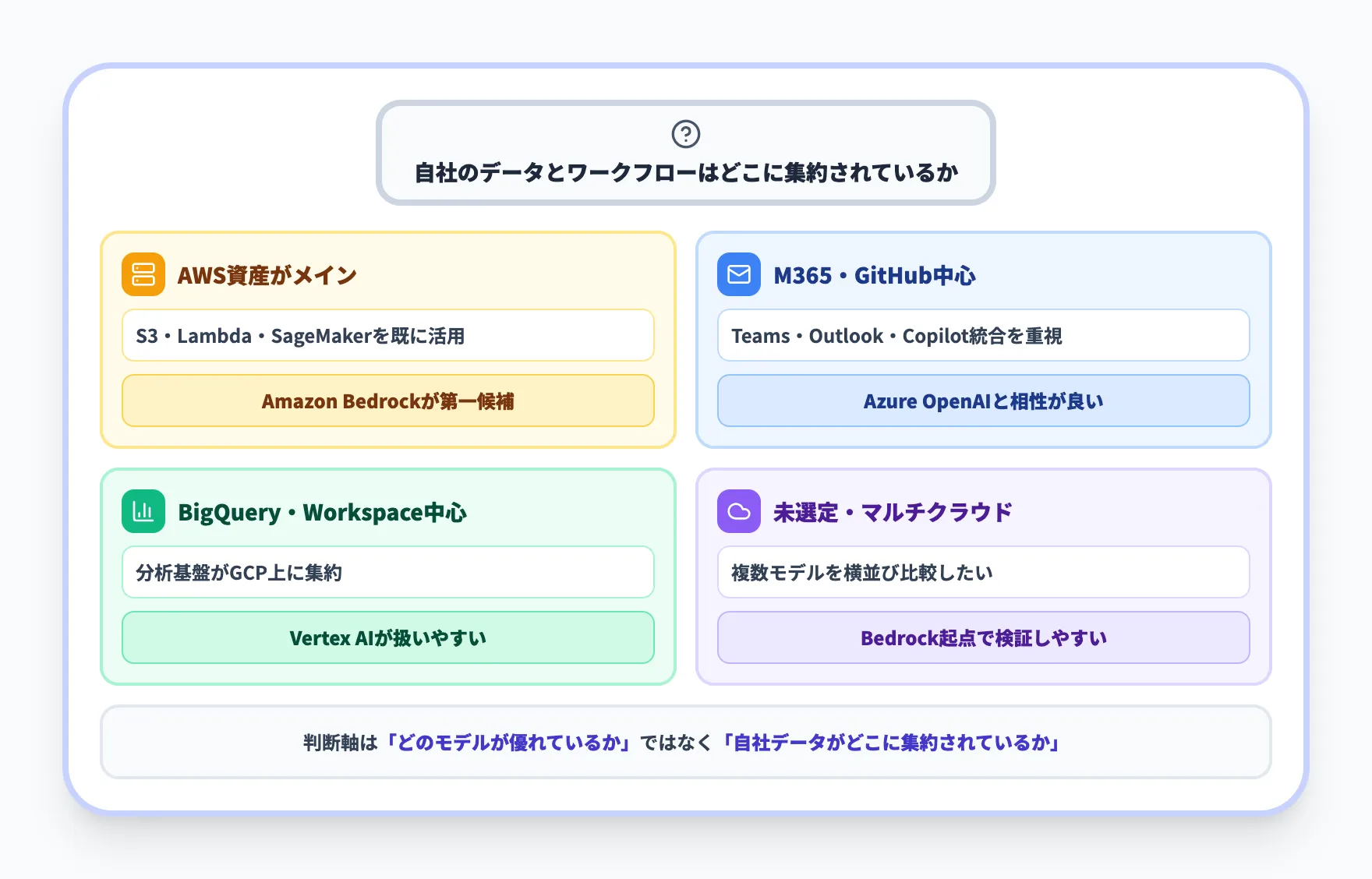
3サービスの位置づけを踏まえると、選定時の整理は次のように考えられます。
- AWS資産を中心に運用していて、マルチモデル戦略を取りたい場合
Amazon Bedrockが第一候補になりやすい。Claude・Nova・Llamaを同じAPIで使い分けられ、AWSの既存ガバナンスにそのまま組み込める
- Microsoft 365やGitHubを軸にしている場合
Azure OpenAI Serviceとの相性が良い。Microsoft 365 CopilotやGitHub Copilotとの統合面でメリットが出やすい
- データ分析基盤がBigQuery中心の場合
Vertex AIが扱いやすい。データパイプラインとの一体化や、Geminiモデルの最新機能を取り込みやすい
- クラウドが未選定、もしくはマルチクラウド構成を取る場合
モデルの選択肢が広いBedrockを起点に検証する流れが取りやすい。複数モデルを横並びで評価したい場合にも有効
こうして整理すると、判断軸は「どのモデルが優れているか」というよりも、「自社のデータとワークフローがどこに集約されているか」に近くなります。そこを起点に選ぶと、導入後の運用コストやスピード面でブレが少なくなります。
Amazon Bedrockの料金体系
Amazon Bedrockのコスト構造は完全従量課金が基本で、初期費用や最低利用料金はありません。2026年4月時点の料金体系を、課金モデル別に解説します。
最新の価格はAWS公式の料金ページで必ず確認してください。
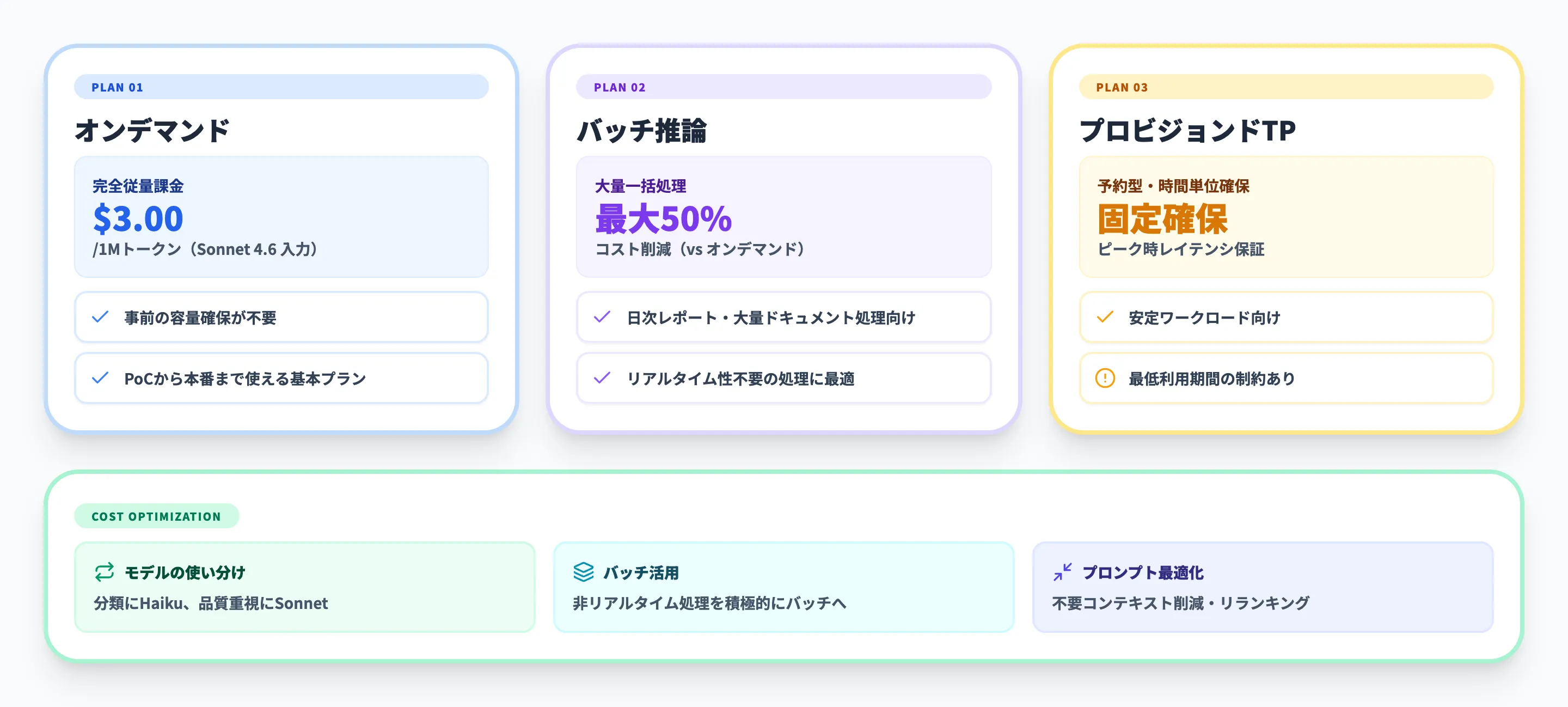
オンデマンド(従量課金)
最も基本的な課金モデルで、処理したトークン数に応じて課金されます。事前の容量確保が不要で、使った分だけ支払う仕組みです。
主要モデルのオンデマンド料金目安を以下に整理しました(2026年4月時点:US East (N. Virginia) リージョン)。
| モデル | 入力(/1Mトークン) | 出力(/1Mトークン) | 備考 |
|---|---|---|---|
| Claude Sonnet 4.6 | $3.00 | $15.00 | |
| Claude Haiku 4.5 | $0.80 | $4.00 | |
| Nova Pro(第1世代) | $0.80 | $3.20 | GA |
| Nova Lite(第1世代) | $0.06 | $0.24 | GA |
| Llama 3.3 70B | $0.72 | $0.72 |
Nova 2 Liteは第1世代と異なる料金体系(入力$0.30/1Mトークン、出力$2.50/1Mトークン)で提供されています。Nova 2 Proはプレビュー段階のため料金は変動する可能性があります。リージョンやモデルバージョンによる差異があるため、正確な価格はAWS公式の料金ページで確認してください。
たとえばClaude Sonnet 4.6で1日あたり10万トークン(入力7万+出力3万)を処理する場合、1日のコストは約$0.66(約100円)です。月間で約$20(約3,000円)となり、小規模なPoCであれば十分に検証可能な金額です。
バッチ推論
バッチ推論は、リアルタイム性が不要な大量のリクエストをまとめて処理する方式で、オンデマンドと比較して最大50%のコスト削減が可能です。
日次のレポート生成や大量ドキュメントの一括処理など、結果を翌日までに得られれば十分なユースケースに適しています。
プロビジョンドスループット
プロビジョンドスループットは、一定の処理能力を時間単位で確保する予約型のプランです。
リクエスト量が予測可能で安定しているワークロード向けで、ピーク時のレイテンシを保証できるメリットがあります。ただし最低利用期間の制約があるため、利用パターンが安定していない段階での採用はコスト面でリスクになります。
コスト最適化のポイント
Bedrockのコストを抑えるうえで意識しておきたい観点を3つ整理します。
- モデルの使い分け
すべてのリクエストにOpusやSonnetを使う必要はない。分類やルーティングのような軽い処理にはHaikuやNova Liteを、品質が求められるタスクにはSonnetやOpusを、と用途に応じて使い分けるだけでも単価差が大きく効いてくる
- バッチ推論とFlex tierの活用
リアルタイム性が不要な処理はバッチ推論やFlex tierに回す。オンデマンド比で最大50%程度の割引が効くため、レポート生成や夜間集計など定期処理のコスト圧縮に向く
- プロンプトの最適化とキャッシング
不要なコンテキストを削って入力トークン数を減らすだけでもコストは下がる。長いシステムプロンプトを繰り返し使う構成では、プロンプトキャッシングを併用すると入力側の課金を抑えやすい
コスト管理の観点では、AWS BudgetsやCost Explorerを使ってBedrock利用料にアラートを設定しておくと安心です。想定外の利用量を早めに検知できる基本的なガードレールになります。
Amazon Bedrock利用時の注意点と導入判断
Amazon Bedrockは強力なプラットフォームですが、導入前に把握しておくべき制約と判断ポイントがあります。ここでは、実際の導入検討で見落としやすい点を整理します。
リージョンとモデル提供範囲
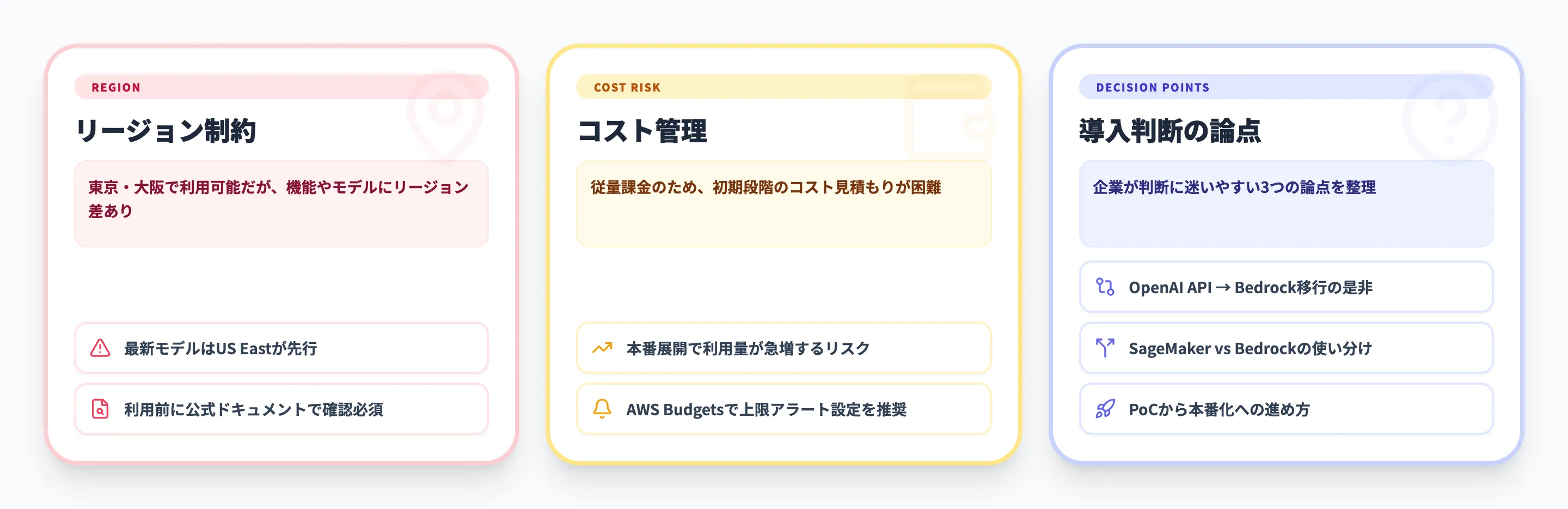
Amazon BedrockはすべてのAWSリージョンで利用できるわけではありません。
2026年4月時点で、Amazon Bedrock自体は東京リージョン(ap-northeast-1)と大阪リージョン(ap-northeast-3)の両方で利用可能です。ただし、利用できる機能やモデルにはリージョン差があります。
たとえば、最新のモデルはUS Eastでの提供が先行し、東京・大阪への展開が遅れるケースがあります。また、AgentCoreやKnowledge Basesなど一部の機能も、リージョンによって対応状況が異なります。利用したいモデルや機能がどのリージョンで使えるかは、AWSの公式ドキュメントで事前に確認してください。
コスト管理の課題
従量課金であるため、利用量が予測しにくい初期段階ではコストの見積もりが難しいという課題があります。
特に注意すべきは、PoCでは少量だった利用が本番展開後に急増するケースです。全社展開する前に、想定ユーザー数 × 1日あたりのリクエスト数 × 平均トークン数で月間コストをシミュレーションし、AWS Budgetsで上限アラートを設定しておくことが重要です。
導入判断で詰まる論点
企業がAmazon Bedrockの導入を検討する際に、判断が止まりやすいポイントは次の3つです。
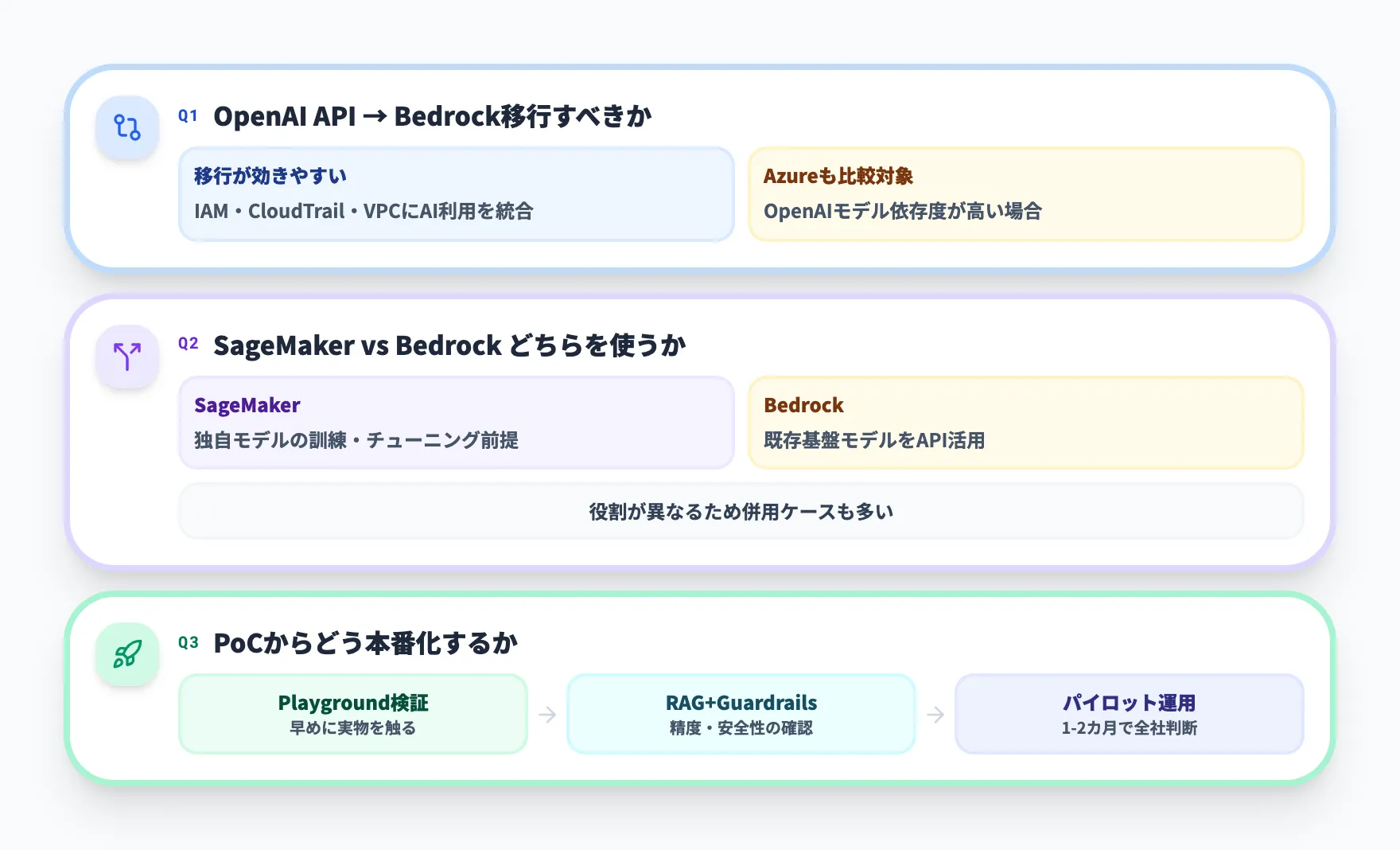
既存のOpenAI API契約があるが、Bedrockに移行すべきか
OpenAI APIを直接利用している場合、Bedrockへ寄せるメリットは「AWSの既存ガバナンス体系(IAM・CloudTrail・VPC)にAI利用を統合できる」点にあります。セキュリティやコンプライアンス要件が厳しい企業では、認証・監査・ネットワーク境界をAWS側に揃えられる効果が比較的大きく出やすい構成です。
一方、OpenAIモデルへの依存度が高い場合は、Azure OpenAI ServiceがOpenAI最新モデルへの追従面で扱いやすいケースもあります。提供リージョンやコンプライアンス認証の範囲はOpenAI直接契約とAzureで異なるため、要件と照らしながら比較するのが現実的です。
SageMakerとBedrockのどちらを使うべきか
Amazon SageMakerは自社でモデルをトレーニング・ファインチューニングすることを前提にした機械学習プラットフォームで、Bedrockは既存の基盤モデルをAPI経由で利用し、その上にアプリケーションを構築するためのサービスです。役割が異なるため、二者択一というよりは併用前提で位置づけたほうが実態に近いケースが多いです。
ざっくりした目安としては、自社データで独自モデルを訓練したいならSageMaker、既存モデルの活用で要件が満たせるならBedrockという整理が分かりやすく、両方を組み合わせている企業も少なくありません。
PoCからどう進めるべきか
まずはオンデマンド課金で小規模PoCを始め、効果を見ながら本番化を判断する流れが、リスクとコストのバランスを取りやすい進め方です。実務では以下のような段階で進めるケースが多いです。
- AWSコンソールのPlaygroundで、想定するプロンプトとモデルの応答を手動で検証する
- Knowledge Basesで社内データ(S3上のドキュメント等)をRAGに接続し、回答精度を評価する
- Guardrailsを設定して安全性要件を満たすことを確認する
- Converse APIで業務アプリケーションに統合し、限定ユーザーでパイロット運用を開始する
- コストと品質を1〜2カ月モニタリングし、全社展開の判断材料を揃える
長期間かけて要件定義を固めてから開発に入るよりも、Playgroundで早めに実物を触ってからPoCの是非を判断したほうが、要件と現実のギャップに気づきやすく、結果的に手戻りを減らしやすくなります。
AWSのKiro(仕様駆動のAI IDE)と組み合わせれば、アプリケーション開発自体もAIで加速できるため、PoC期間の短縮にもつなげやすい構成になります。

Amazon Bedrockの検証を業務実装まで進めるなら
Amazon Bedrockは、モデル選定やプロトタイピングを進めやすい一方で、実業務で成果を出すには、どの業務に組み込むか、どのシステムから呼び出すか、どこまで自動化を許可するかを別途設計する必要があります。
特に、社内データや既存SaaSと接続し、部門横断で使われる状態まで持っていくには、権限、実行ログ、例外時の人手介入まで整理しないと、PoCで止まりやすくなります。
AI総合研究所のAI Agent Hub資料では、Amazon Bedrockのような既存AI基盤を前提に、業務システム連携、管理ダッシュボード、実行導線の整備をどう進めるかを整理しています。Amazon Bedrockの検証を業務実装へつなぐ判断材料としてご確認ください。
Amazon Bedrockの検証を業務実装まで進める

モデル検証の先にある業務接続・運用設計を整理
Amazon Bedrockでモデル検証を進めても、実運用では業務システム連携、権限設計、実行ログの管理まで含めた設計が必要です。AI Agent HubのLPで、Amazon Bedrockの検証を業務実装につなぐ全体像をご確認ください。
Amazon Bedrockのまとめ
本記事では、Amazon Bedrockの設計思想からファミリー全体像、主要機能、利用できる基盤モデル、料金体系、導入事例、Azure OpenAI・Vertex AIとの比較までを、2026年4月時点の情報をもとに整理しました。
Amazon Bedrockがもたらす実務的な価値は、大きく次の3点に整理できます。
- マルチモデルの柔軟性
Claude、Nova、Llamaなど100超のモデルを同じAPIから切り替えて使えるため、特定プロバイダーへのロックインを避けつつ、用途ごとにモデルを選び直せる
- ファミリー全体での一貫運用
Knowledge Bases・Guardrails・Agents・AgentCore・Flowsが同一プラットフォーム上にあり、RAG・安全性制御・エージェント運用を一体的に扱える。AgentCore自体は2025年10月にGA、2026年3月にはPolicy Controls・EvaluationsもそれぞれGA化し、本番運用前提の構成として整ってきている
- 段階的な導入のしやすさ
オンデマンド課金で初期費用ゼロからPoCを始められ、効果を見ながらスケールを調整できる。すでにAWSを使っている環境であれば、IAM・VPC・監査ログ基盤をそのまま活かせるため、ガバナンス面の追加負荷も抑えやすい
最初の一歩としては、AWSコンソールのPlaygroundで自社業務に近いプロンプトを試し、Knowledge Basesに社内ドキュメントを接続してRAGの精度を確認するあたりから始めるのが取り組みやすい流れです。Bedrock自体には初期費用がかからないため、「まず触ってから判断する」ハードルが低い点が、検討初期に動きやすい大きな理由になります。
エージェントの構築を進めたい場合はAmazon Bedrock Agentsとは?機能や料金、使い方を解説を、AWSの他のAIサービスとの比較はAmazon Qとは?できることや料金、Bedrockとの違いを解説もあわせて参考にしてください。







