この記事のポイント
 Microsoft製AIエージェント基盤の第一候補。Foundry全体のForrester TEI調査でROI 327%・3年で$49.5Mの効果
Microsoft製AIエージェント基盤の第一候補。Foundry全体のForrester TEI調査でROI 327%・3年で$49.5Mの効果- ローコードならCopilot Studio、プロコードで高度なカスタム制御が必要ならFoundry Agent Service
- 無料のPromptエージェント(GA)で社内FAQ自動化のPoCから始め、要件が固まってからWorkflow・Hostedへ段階拡大するのが最も失敗リスクが低い
- Hosted Agentsは4リージョン限定(Australia East/Canada/N. Central US/Sweden)、Japan East未対応
- 年間Foundry+Copilot Studio利用額$20,000超ならMS Agent Prepurchase Plan(ACU)で約5%のコスト削減が可能

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Microsoft Foundry Agent Serviceは、2025年5月にAzure AI Foundry Agent ServiceとしてGA、2026年3月16日にResponses APIベースの次世代ランタイムが正式GAされた、Microsoft製フルマネージドのAIエージェント構築プラットフォームです。
ノーコードのPromptエージェント(GA)、宣言型のWorkflowエージェント(プレビュー)、コンテナベースのHostedエージェント(プレビュー)の3種別を提供し、エンタープライズレベルのセキュリティ・観測・ガバナンスを標準で備えています。
Microsoft Foundry全体のForrester TEI調査ではROI 327%、開発者生産性35%向上が報告されており、Fujitsuは営業提案書作成で67%の生産性向上を達成しています。
本記事では、2026年4月時点の最新仕様で、3エージェント種別の使い分け、主要機能・先進ツール、モデル・リージョン、使い方、セキュリティ・MCP認証、料金体系(ACU事前購入プラン含む)、Copilot Studioとの比較まで体系的に解説します。
✅Microsoft 365 Copilot側の最新エージェント機能「Copilot Cowork」については以下の記事をご覧ください。
Copilot Coworkとは?機能や料金、Claude Coworkとの違いを解説
目次
Microsoft Foundry Agent Serviceとは
3つのエージェント種別(Prompt/Workflow/Hosted)
Microsoft Foundry Agent Serviceと他Microsoftサービスの使い分け
Azure OpenAI Assistants APIとの違い
Microsoft Foundry Agent Serviceの主要機能と先進ツール群
Microsoft Foundry Agent Serviceで利用可能なモデルとリージョン
Microsoft Foundry全体で利用できるパートナーモデル(参考)
Microsoft Foundry Agent Serviceの使い方
ステップ1:Microsoft Foundryプロジェクトのセットアップ
マルチエージェントシステム(Connected Agents)
Microsoft Foundry Agent Serviceの導入事例と段階的導入アプローチ
Microsoft Foundry Agent Serviceのセキュリティとプライバシー
Microsoft Foundry Agent Serviceの料金体系と事前購入プラン
Microsoft Agent Prepurchase Plan(ACU)による事前購入割引
Microsoft Foundry Agent Serviceとは
Microsoft Foundry Agent Service(旧Azure AI Foundry Agent Service/Azure AI Agent Service)は、AIエージェントの構築・デプロイ・スケーリングを一貫して支援するMicrosoft製のフルマネージドプラットフォームです。開発者は、Promptエージェント(ノーコード)/Workflowエージェント(宣言型)/Hostedエージェント(コンテナベース)の3種別を用途に応じて選び、Microsoft Foundryモデルカタログのモデルと、Web検索・ファイル検索・メモリ・コードインタプリタ・MCPサーバー・カスタム関数などの組み込みツールを組み合わせてエージェントを構築できます。
Bing、SharePoint、Azure AI Search、Microsoft Fabricなどの多様なデータソースや、Azure Logic Apps/Azure Functionsの1,400以上のコネクタとシームレスに統合し、業務ワークフロー全体を自動化できる点が特徴です。
プライベートネットワーキング、Microsoft Entra ID RBAC、エージェント専用Entra ID、コンテンツフィルターなどエンタープライズグレードのセキュリティ機能を標準搭載しており、金融・医療・公共など規制産業でも段階的な導入が進められています。Forrester TEI調査(2026年2月)では、Microsoft Foundry全体の導入企業で3年間ROI 327%、開発者生産性が最大35%向上したと報告されています。
なお、この327%はAgent Service単体ではなく、Foundryプラットフォーム全体(Models・Agent Service・Evaluations・Observability等を含む)の数値です。本記事では「Agent Service単体の効果」と「Foundry全体の効果」を混同しないよう、必要に応じて区別して記載します。


名称変更の歴史と2026年4月時点の位置づけ
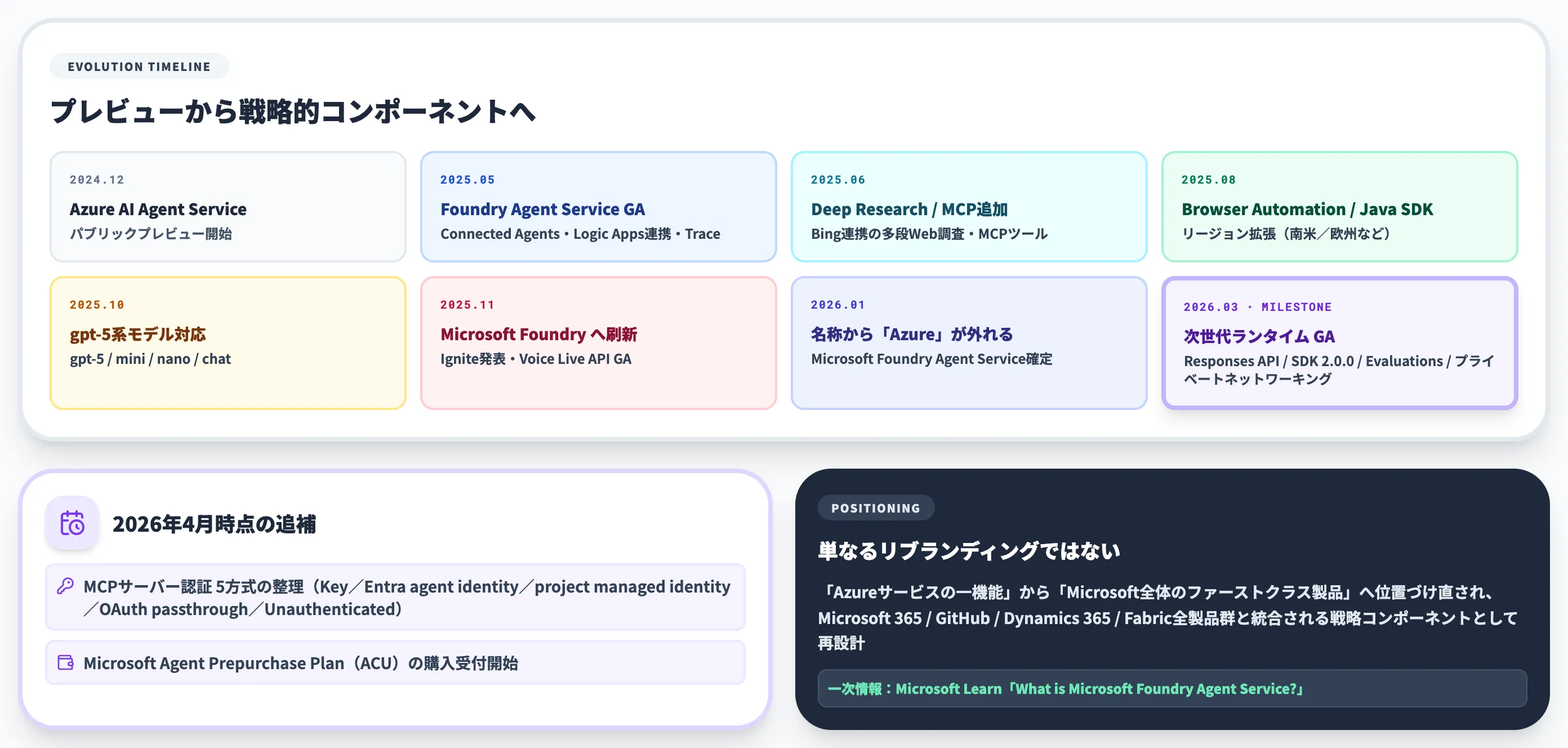
Microsoft Foundry Agent Serviceは、その進化とともに名称とアーキテクチャを更新してきました。以下のタイムラインで、主要なマイルストーンを整理しました。
-
2024年12月
Azure AI Agent Serviceとしてパブリックプレビュー開始
-
2025年5月
Azure AI Foundry Agent ServiceがGA(一般提供)。Connected Agents、Trace Agents、Logic Appsトリガー、Bing Custom Search、Morningstar、Foundry VS Code拡張などを同時リリース
-
2025年6月
Deep Researchツール(プレビュー)とMCPツールを追加
-
2025年8月
Browser Automationツール(プレビュー)、Java SDKプレビュー、Brazil South/Germany West Central/Italy North/South Central US等のリージョン拡張
-
2025年10月
gpt-5系モデル(gpt-5/gpt-5-mini/gpt-5-nano/gpt-5-chat)対応
-
2025年11月(Microsoft Ignite 2025)
Azure AI Foundry → Microsoft Foundry にブランド刷新。Voice Live APIが一般提供(GA)
-
2026年1月頃
サービス名が Microsoft Foundry Agent Service に。「Azure」を外し、Microsoftエコシステム全体への統合を強調
-
2026年3月16日:次世代ランタイムのGA
Responses APIベースの新ランタイムがGA。プライベートネットワーキング(パブリックエグレスなし)、Evaluations(GA)、SDK 2.0.0(azure-ai-projects)がGA。Hostedエージェント・Voice Live連携・Workflowエージェントはパブリックプレビュー
-
2026年4月時点の追補
MCPサーバー認証の整理(Key-based/Microsoft Entra agent identity(プレビュー)/project managed identity(プレビュー)/OAuth identity passthrough/Unauthenticated accessの実質5方式)、Microsoft Agent Prepurchase Plan(ACU)の購入受付開始
この一連の更新は単なるリブランディングではなく、AIエージェントが「Azureサービスの一機能」から「Microsoft全体のファーストクラス製品」へ位置づけ直されたことを意味します。エージェントはMicrosoft 365、GitHub、Dynamics 365、Fabricといった全製品群と深く統合される戦略的コンポーネントとして設計されており、Copilot StudioやMicrosoft Agent Framework、Entra Agent Registryとのエコシステム連携が前提になっています。
3つのエージェント種別(Prompt/Workflow/Hosted)
2026年4月時点のFoundry Agent Serviceでは、用途と開発スタイルに応じた3つのエージェント種別が利用できます。以下の表で、各種別の特性を整理しました。
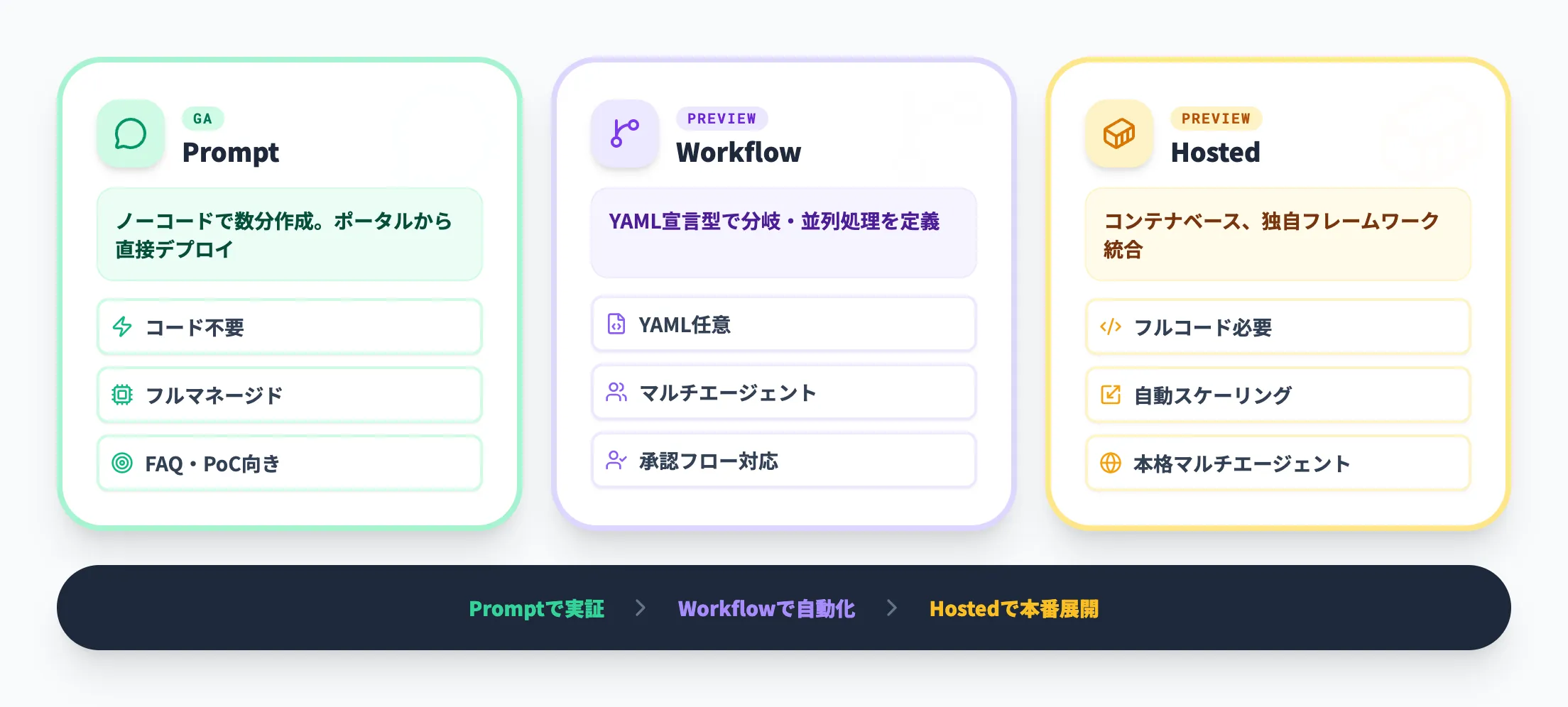
| 種別 | コード要否 | ホスティング | オーケストレーション | GA/プレビュー | 適したユースケース |
|---|---|---|---|---|---|
| Promptエージェント | 不要(ノーコード) | フルマネージド | 単一エージェント | GA | 社内FAQ、プロトタイピング、シンプルなツール連携 |
| Workflowエージェント | 不要(YAML任意) | フルマネージド | マルチエージェント、分岐ロジック | パブリックプレビュー | 承認ワークフロー、多段階処理、Human-in-the-Loop |
| Hostedエージェント | 必要 | コンテナベース、マネージド | カスタムロジック | パブリックプレビュー | 複雑なマルチエージェント、独自フレームワーク統合 |
この3種別で広い開発スタイルをカバーできる点が最大の利点です。ノーコードのPromptエージェントでPoC(概念実証)を数分で作成し、要件が複雑化すればWorkflowエージェントやHostedエージェントに段階的に移行できます。AI総研の導入支援でも、まずPromptエージェントで社内FAQ対応の成果を可視化し、経営層の承認を得てからHostedエージェントに拡張するパターンが最も成功率が高いことが分かっています。
PromptエージェントはMicrosoft Foundryポータルから直接作成でき、SDKやREST APIでもデプロイできます。HostedエージェントはMicrosoft Agent Framework、LangGraph、Semantic Kernel、独自コードなど任意のフレームワークで構築し、コンテナイメージとしてAgent Serviceにデプロイする設計です。
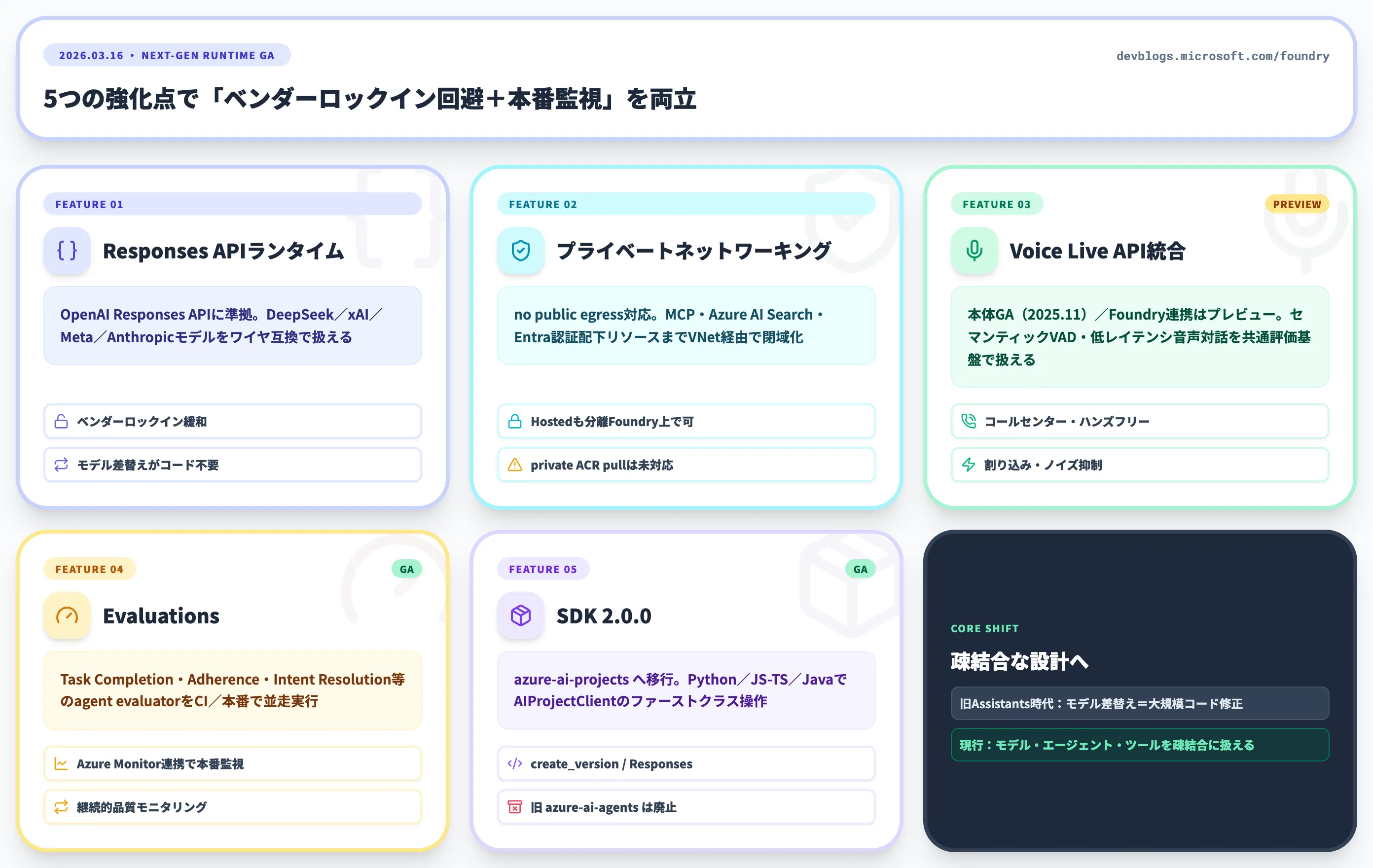
2026年3月GAで追加・強化された機能
次世代ランタイムのGAにあわせて、以下の機能が大幅に強化されました。
-
Responses APIを基盤とするランタイム
OpenAI Responses APIプロトコルに準拠しており、DeepSeek・xAI・Meta・Anthropicなど異なるプロバイダーのモデルをワイヤ互換で扱えるため、ベンダーロックインを緩和できます
-
プライベートネットワーキングの強化
「no public egress」構成でのデプロイに対応し、MCPサーバー/Azure AI Search/Entra認証配下リソースまでVNet経由で閉域化可能。Hostedエージェントもネットワーク分離されたFoundryリソース上でデプロイ可能だが、private-network-securedなACR(Azure Container Registry)からのコンテナイメージpullには未対応のため、コンテナ配信経路は別途設計する必要がある。Workflowエージェントについては送信側VNetインジェクションの対応範囲が一部限定される
-
Voice Live API(プレビュー)との統合
Azure AI Speech側のVoice Live APIは2025年11月にGA済み。Foundry Agent連携はプレビューで、セマンティックVAD・低レイテンシ音声対話・共通の評価基盤をエージェントから直接利用可能
-
Evaluations(GA)
Task Completion・Task Adherence・Intent Resolutionなどのagent evaluatorをCI/本番の両面で実行可能になり、Azure Monitor連携でプロダクション監視が可能
-
SDK 2.0.0(
azure-ai-projects)のGA
旧azure-ai-agentsからazure-ai-projectsへ移行。Python・JS/TS・JavaのSDKでエージェントがAIProjectClientのファーストクラス操作として扱える
ここでの注目点は、Responses APIへの切替により、モデルの差し替えがアプリケーションコードをほぼ変更せずに行える設計になった点です。旧Assistants API時代は「モデル差し替えにコード側の大規模修正が必要」でしたが、現行は「モデル・エージェント・ツールを疎結合に扱える」構成になっています。
Microsoft Foundry Agent Serviceと他Microsoftサービスの使い分け
Microsoft Foundry Agent Serviceは、Microsoftが提供する唯一のエージェント開発プラットフォームではありません。ローコード向けのCopilot Studio、従来のAzure OpenAI Assistants API、オープンソースのMicrosoft Agent Frameworkなど、用途・スキルセット・統合先に応じて選択肢が分かれます。
本章では、現場で混同されやすいCopilot StudioとAssistants APIとの違い、さらに「向いている場面/向かない場面」の導入判断ポイントを順に整理します。

Copilot Studioとの使い分け
もっとも相談が多いのが「Copilot Studioを使うべきか、Foundry Agent Serviceを使うべきか」という問いです。以下の表は、開発者像・統合エコシステム・カスタマイズ性・料金モデルの違いをまとめたものです。

| 項目 | Microsoft Foundry Agent Service | Copilot Studio |
|---|---|---|
| 主な開発者像 | プロコード開発者(Python/.NET/Java) | ローコード/市民開発者 |
| エコシステム | Azure全体(AI Search・Logic Apps・Functions等) | Microsoft 365ネイティブ(Teams・SharePoint等) |
| カスタマイズ性 | 高い(独自ツール・独自フレームワーク・コンテナデプロイ) | 中程度(ビジュアルビルダー・トピック設計) |
| マルチエージェント | Workflow/Hostedでネイティブ対応 | エージェント間のルーティングに対応 |
| CI/CD統合 | Azure DevOps/GitHub Actionsで完全対応 | 限定的 |
| 料金モデル | 従量課金(トークン+ツール使用量) | メッセージ単位課金(¥4,350/月/25Kメッセージ〜) |
実務で選ぶ際のポイントは、開発チームのスキルセットと統合先のエコシステムです。Microsoft 365中心の業務環境で市民開発者がエージェントを作るケースはCopilot Studioが適しています。一方、Azure上の独自アプリケーションに組み込む場合や、LangGraph・Semantic Kernelなどのフレームワークでカスタム制御が必要な場合はFoundry Agent Serviceが最適です。
両者は排他的ではなく、Copilot StudioのエージェントからFoundry Agent ServiceのエージェントをTool呼び出しで連携させるパターンも実装できます。AI総研の支援現場でも、社内問い合わせの一次対応をCopilot Studio、基幹データに触る処理をFoundry Agent Serviceに寄せる二段構成が標準パターンになりつつあります。
Azure OpenAI Assistants APIとの違い
現行のFoundry Agent ServiceはResponses APIに連なるアーキテクチャであり、従来のAssistants API(classic、2027年3月31日廃止予定)とは設計思想が異なります。以下の表で、両サービスの主な違いを整理しました。

| 機能 | Microsoft Foundry Agent Service | Azure OpenAI Assistants API |
|---|---|---|
| モデルの選択 | Azure OpenAIモデル+Foundryモデルカタログ(GPT-5系/o3/Llama/Grok/DeepSeek 等)。Anthropic ClaudeはAgent Service直接対応の一覧外で、Microsoft Foundry全体のパートナーモデル(プレビュー)として別枠で利用 | 主にAzure OpenAIモデル |
| データ統合 | Bing(Bing Custom Search含む)/SharePoint/Microsoft Fabric/Azure AI Searchなど広範 | 限定的 |
| セキュリティ | エンタープライズグレード(パブリックエグレスなし/Entra ID/Azure Monitor連携/SLAサポート) | 基本的なセキュリティ機能 |
| マルチエージェント | Connected Agents/Workflowでネイティブ対応、A2Aプロトコル対応(Foundry側のA2Aコネクションはプレビュー) | 限定的(ライブラリレベルでの個別実装が必要) |
| 開発者ツール | Foundry VS Code拡張、Trace Agents、SDK 2.0.0、Foundry Portal | Azure SDKが中心 |
| ストレージ | 独自Azure Blob/Cosmos DBを持ち込み可、またはプラットフォーム管理 | プラットフォーム管理のみ |
| 自動ツール呼び出し | サーバー側で自動処理 | クライアント側で処理が必要 |
| イベント駆動実行 | 対応(新着メール・顧客チケット受信時などに自動起動) | 非対応 |
| Hostedエージェント | 対応(サーバーレスコンテナ、自動スケーリング) | 非対応 |
| Anthropic Claudeモデルの利用 | Agent Serviceの直接対応モデル一覧には含まれないが、Microsoft Foundry全体ではClaude Opus 4.7/4.6/Sonnet 4.6/Haiku 4.5等をプレビューで利用可(Agent Serviceからは Hosted エージェント+Microsoft Agent Framework/Claude Agent SDK 経由で参照) | 非対応 |
この比較で注目すべきは、Foundry Agent Serviceは単なる「LLM対話ラッパー」ではなく、エンタープライズ全体のワークフローを統合するプラットフォームとして設計されている点です。Assistants APIがAIモデルとの対話に特化していたのに対し、Foundry Agent Serviceはマルチエージェント協調・外部システム連携・イベント駆動実行・エンタープライズセキュリティを一体でカバーしています。
そのため、プロトタイプや小規模な実験ではAssistants APIで十分ですが、本格的なエンタープライズ展開、複数部門をまたぐ業務自動化、コンプライアンス要件が厳しい環境ではFoundry Agent Serviceが最適な選択肢です。なお、Assistants APIは2027年3月31日に廃止予定のため、新規採用は避けるべきです。
【関連記事】
Azure AI services(旧Azure Cognitive Services)とは?その概要や料金を徹底解説
Microsoft Agent Frameworkとの関係
Microsoft Agent Frameworkは、Semantic KernelとAutoGenを統合した次世代のオープンソースエージェントフレームワークです。Foundry Agent Serviceと競合する製品ではなく、Foundry Agent Serviceのランタイム上でHostedエージェントを構築する際のフレームワーク選択肢の1つとして位置づけられます。
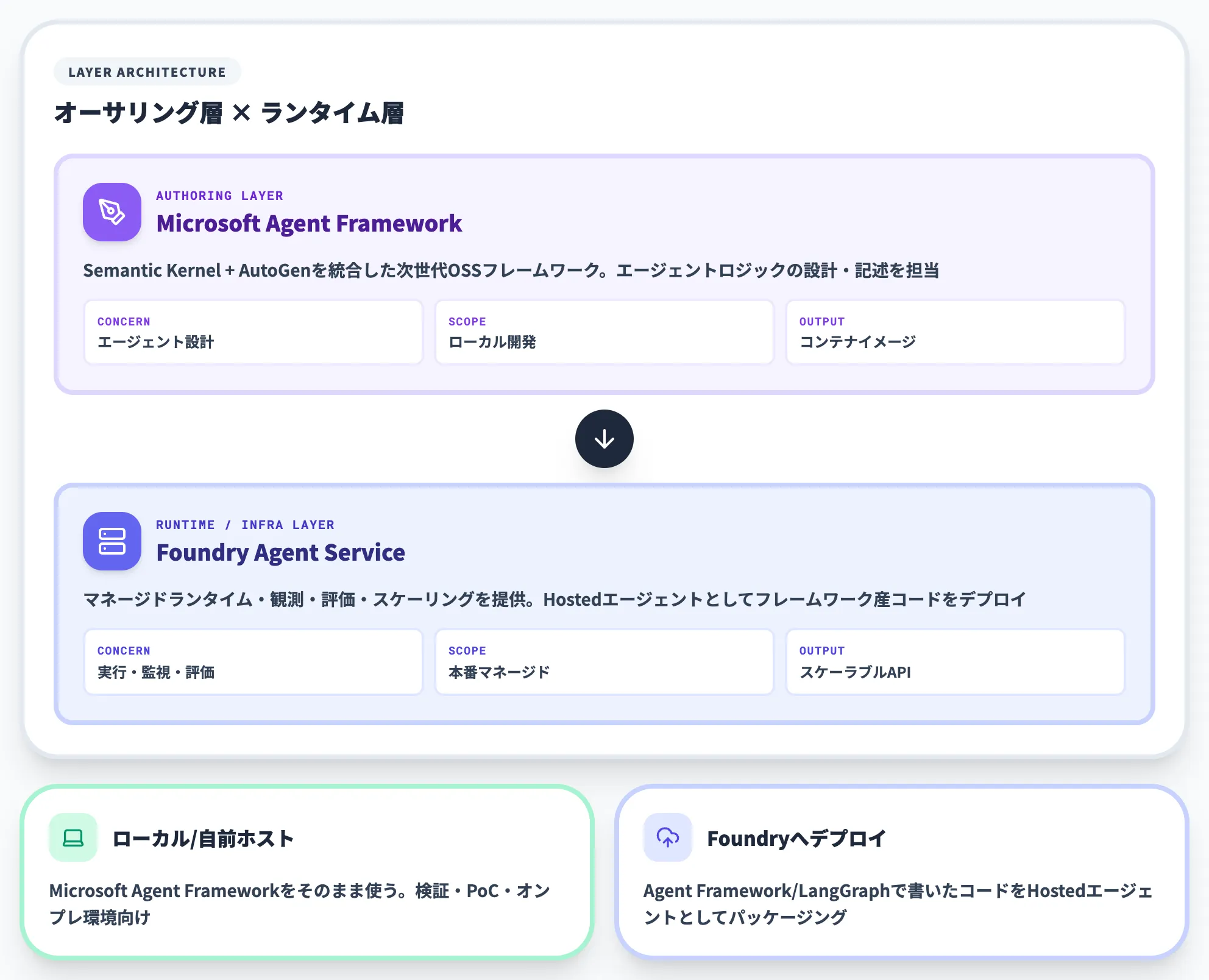
実務上は以下の分担になります。
- ローカル/自前ホスティング:Microsoft Agent Frameworkをそのまま使う
- Foundry Agent Serviceにデプロイ:Agent FrameworkまたはLangGraphで書いたコードをHostedエージェントとしてパッケージング
つまり、Agent Framework=オーサリングレイヤー、Foundry Agent Service=ランタイム/インフラレイヤー、という重なりのない関係です。両者を組み合わせれば、「ローカル開発→Foundryへのシームレスなデプロイ→観測・評価・スケーリングをマネージドに任せる」という流れが実現できます。
向いている場面 vs 向かない場面
Foundry Agent Serviceの導入を検討する際、すべてのユースケースに適しているわけではありません。以下の2つの表で、適用場面と非適用場面を整理しました。

向いている場面
| ユースケース | 理由 | 想定される効果 |
|---|---|---|
| カスタマーサポートの自動化 | FAQベースの問い合わせが多く、定型的な回答が可能 | 対応時間の大幅短縮、24時間対応 |
| 社内ヘルプデスクの構築 | IT・人事・総務の社内問い合わせが定型化しやすい | 問い合わせ処理コスト削減、従業員満足度向上 |
| ドキュメント分析・要約 | 大量の契約書・レポート・論文等の分析タスク | 分析時間の短縮、見落としリスク低減 |
| データ収集・市場調査 | 複数ソースからの情報収集と統合 | リサーチ工数削減、調査範囲拡大 |
| コード生成・レビュー | 定型的なコード生成、テストコード作成 | 開発速度向上、品質向上 |
| 業務プロセス自動化 | 承認ワークフロー、データ入力、レポート作成 | 事務作業時間の削減、ヒューマンエラー削減 |
| 多言語サポート | グローバル展開で多言語対応が必要 | 翻訳コスト削減、リアルタイム多言語対応 |
この表の共通点を抽出すると、向いているタスクは「定型性」「大量処理」「24時間稼働」「スケーラビリティ」を要件に持つ業務です。つまり、繰り返し発生する知識ベースのタスクが最も適しています。
向かない場面
| ユースケース | 理由 | 代替案 |
|---|---|---|
| 高度な創造的判断が必要 | AIは既存パターンの組み合わせで真の創造性には限界 | 人間の専門家による判断 |
| リアルタイムの物理的操作 | ロボット制御等の物理世界への直接介入 | ロボティクスプラットフォーム(ROS等) |
| 厳密な法的・医療的判断 | 誤判断のリスクが極めて高く法的責任が問われる | 人間専門家のサポートツールとしての活用 |
| 感情的サポートが主目的 | 深い共感や感情理解が必要なカウンセリング等 | 人間カウンセラー(AIは補助的に活用) |
| 完全にランダムなタスク | パターン化できない、毎回異なるアプローチが必要 | カスタム開発、人間による対応 |
| 極めて低コストが要件 | 大量の単純タスクでコスト制約が厳しい | RPA、スクリプト自動化 |
| 完全オフライン環境 | クラウド接続が不可の環境 | オンプレミスLLMソリューション |
向かない場面でも、人間の判断を補助するツールとしては有効な場合があります。医療診断ならAIは補助診断ツールとして医師をサポートし、最終判断は医師が行う。法的文書作成ならAIが下書きを作成し、弁護士がレビューする。こうしたHuman-in-the-Loop設計であれば、向かない領域でもAIの価値を引き出せます。
Microsoft Foundry Agent Serviceの主要機能と先進ツール群
Microsoft Foundry Agent Serviceは、迅速なエージェント開発、広範なデータ統合、柔軟なモデル選択、エンタープライズセキュリティの4本柱に加えて、2025〜2026年にかけてDeep Research・Voice Live・Hostedエージェントなど先進ツールを次々と追加してきました。本章では、主要機能の全体像とあわせて、先進ツールの特性・使い所を整理します。
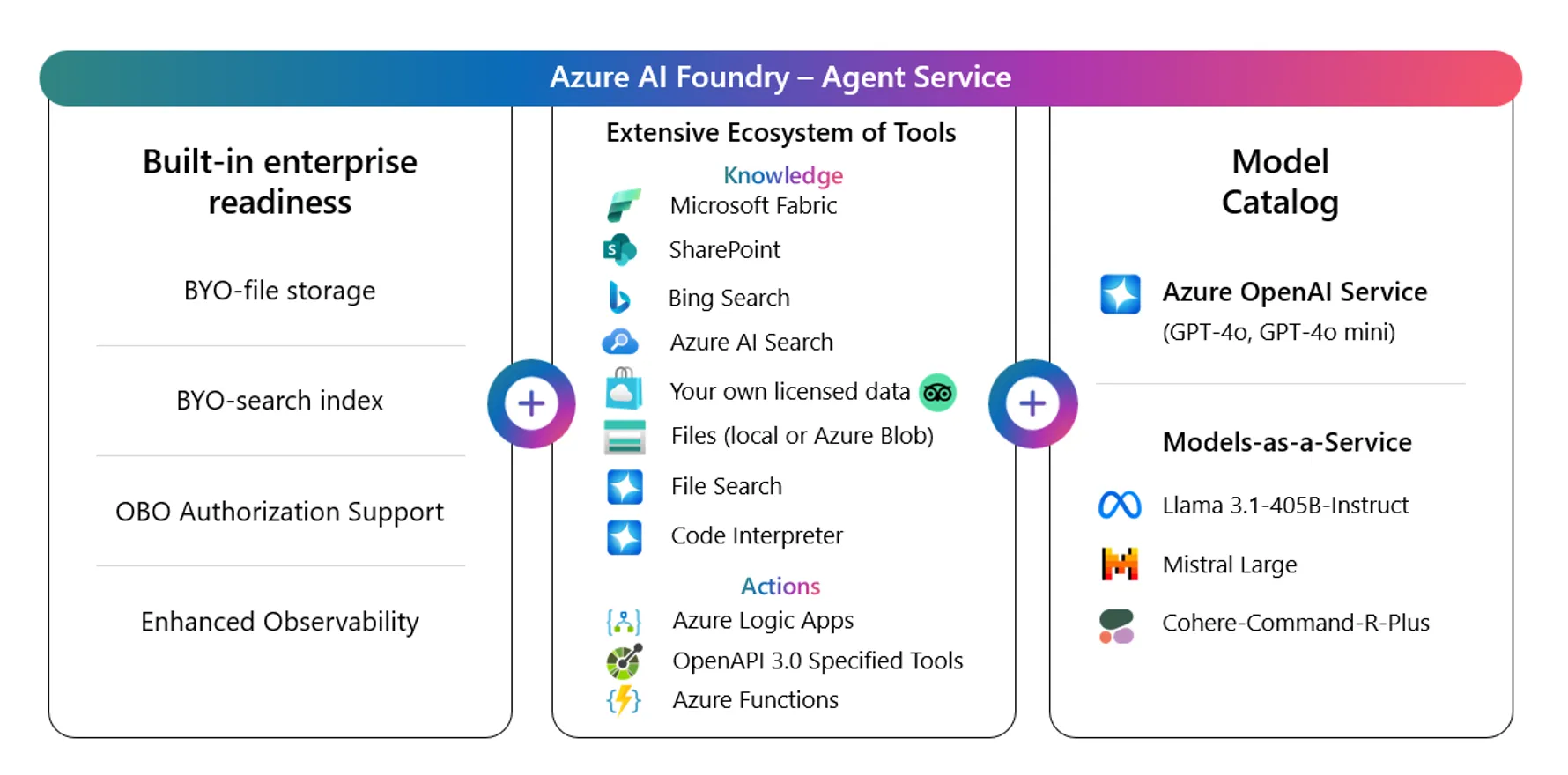
Microsoft Foundry Agent Serviceの構成要素 (参考:Microsoft)

迅速なエージェント開発と強力なAPI統合
Foundry Agent Serviceの現行ランタイムはAgents・conversations・responsesの3要素を中心とする設計で、旧Assistants APIとは別系統の新ランタイムとして整理されています。Microsoft Foundry SDK(azure-ai-projects 2.0.0)とVS Code拡張機能により、Python/.NET/Javaから同一のインターフェースでエージェントを操作できます。
統合機能として特に重要な4点を紹介します。
Logic Appsコネクタ
1,400以上のAzure Logic Appsコネクタを利用して、外部サービスと連携したタスクを自動化できます。Azure Logic Apps側からエージェントを直接トリガーすることも可能で、イベント駆動の業務自動化が組みやすい構成です。
連携可能サービスの例は以下のとおりです。
-
Microsoft製品
Azure App Service、Dynamics 365 Customer Voice、Microsoft Teams、M365 Excel など
-
主要なエンタープライズサービス
MongoDB、Dropbox、Jira、Gmail、Twilio、SAP、Stripe、ServiceNow など
これらを使うことで、顧客情報をデータベースから取得→メールを自動送信→承認ワークフローを開始、といった一連のフローをエージェントに任せられます。カスタマーサポート部門なら、定型問い合わせの自動応答とチケット起票までを1本のエージェントで閉じられる構成が典型です。
【関連記事】
Azure Logic Appsとは?主要機能や料金、設定手順をわかりやすく解説
Azure Functions
Azure FunctionsやAzure Durable Functionsと連携することで、外部システムとのやり取りを効率化できます。APIの呼び出しや非同期イベントの送受信を簡単に実装でき、請求書の自動承認処理、サプライチェーンのリアルタイム監視、顧客問い合わせに応じた動的な処理などを組み込めます。
Code Interpreter
安全な実行環境でPythonコードを記述・実行できるため、データ処理・分析・可視化をエージェントに任せられます。エージェントにデータ分析レポートを作らせる、機械学習モデルを使って予測する、結果をグラフ化する、といった使い方が可能です。
OpenAPIツール/カスタム関数
OpenAPI 3.0仕様に対応したツールで、外部APIとの連携を宣言的に定義できます。天気予報APIで気象情報を取得する、翻訳APIで多言語対応チャットボットを作る、地図APIで周辺店舗を検索するなど、外部サービスをエージェントの能力として組み込めます。
これらを組み合わせることで、エージェントを「単なる対話ボット」から「業務フロー全体を自動化する実行エンジン」へ引き上げられます。
ナレッジソースとの連携
Foundry Agent Serviceで構築されたエージェントは、以下の表にある様々なデータソースに安全にアクセスし、社内ナレッジを最大限に活用できます。
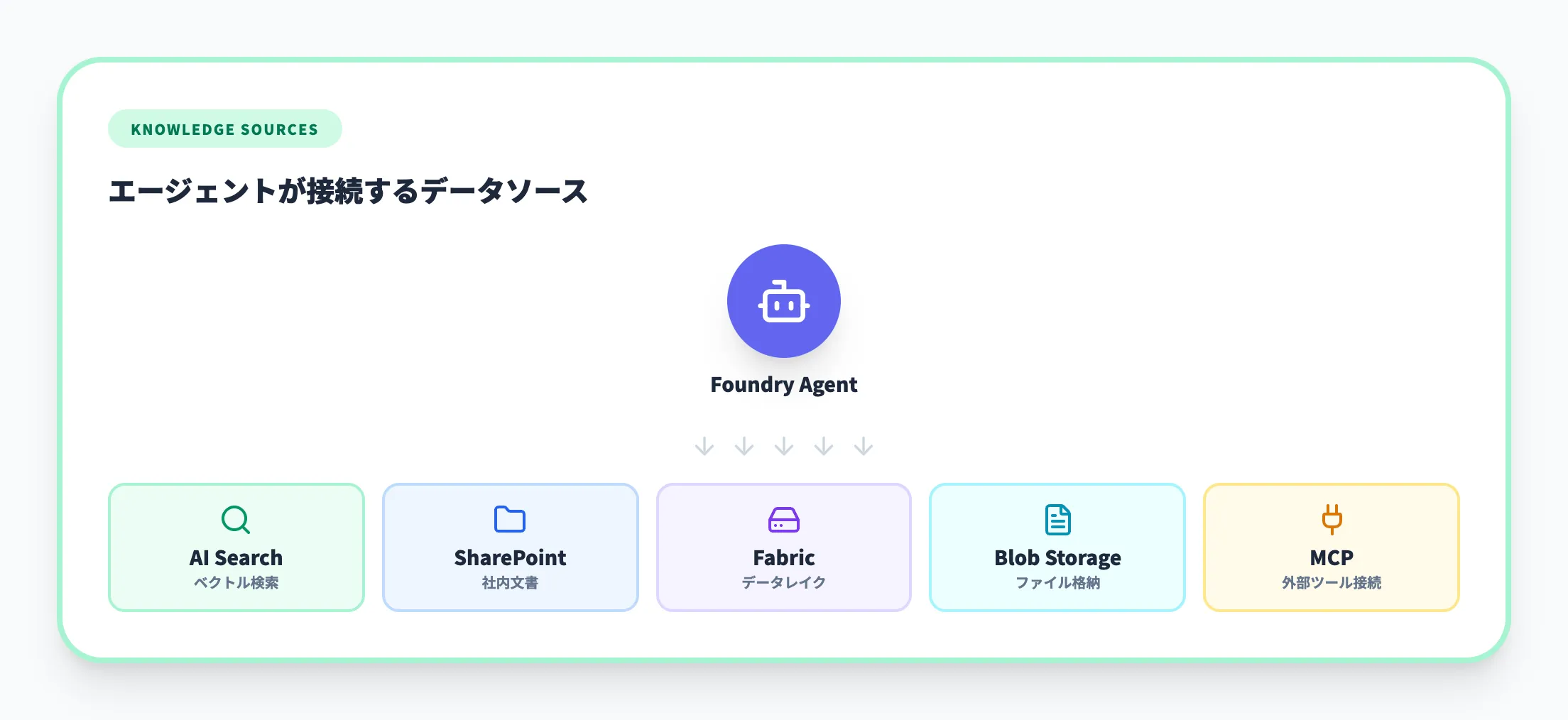

対応データソース (参考:Microsoft)
File Searchツールを有効化することで、エージェントがファイル内容を検索し、関連情報を取得できるようになります。
File Search有効化画面
以下のようにファイルをアップロードすることで、ナレッジを追加できます。
ファイルアップロード画面
Azure AI Search・Blob Storage・SharePointといった既存のナレッジソースと直接接続することも可能です。
ナレッジソース接続画面
代表的なデータソース連携を整理します。
-
リアルタイムWebデータ(Bing/Bing Custom Search)
Bing検索およびBing Custom Searchを利用して、インターネット上の最新情報やカスタマイズされた検索結果を取得できます
-
組織データ(SharePoint)
SharePointに保存されたドキュメントをエージェントが安全に参照し、社内限定情報に基づく専門的な応答が可能です
-
構造化データ(Microsoft Fabric)
Microsoft Fabricデータエージェントを通じてFabric内のテーブルにSQL不要で質問応答・分析ができます
-
その他のデータソース
Azure AI Search、Azure Blob Storage、ローカルファイル等と連携できます
-
ライセンスデータ
TripadvisorやMorningstarなどデータプロバイダーのライセンスデータで応答を高品質化できます
これらを組み合わせることで、顧客対応エージェントなら社内の製品DB・FAQ・過去対応履歴を参照した一貫した回答を返せますし、市場調査エージェントならBing検索で最新情報を収集しつつ社内レポートと突き合わせられます。社内ドキュメント検索の効率化は、多くの企業で最初に効果が出やすい領域です。
柔軟なモデル選択
Foundry Agent Serviceがエージェント定義で直接指定できる対応モデルは、公式のクォータ・モデル・リージョン対応表で示されている Azure OpenAIモデル と Foundryモデルカタログ(Azure直接販売)モデル の2系統です。
-
Azure OpenAIモデル
Azure OpenAI Service経由で、gpt-5シリーズ/gpt-4.1/gpt-4o/o3/o4-mini 等が利用可能
-
Foundryモデルカタログ(Azure直接販売)
MAI-DS-R1、grok-4/grok-4-fast-reasoning/grok-3/Llama-3.3-70B/Llama-4-Maverick、DeepSeek-V3.1/R1-0528、gpt-oss-120b 等
一方、Anthropic ClaudeなどのMarketplace経由パートナーモデルは、Microsoft Foundry全体ではプレビューで利用可能ですが、Foundry Agent Serviceの直接対応モデル一覧には含まれていません。Agent ServiceからClaudeを呼び出したい場合は、Hostedエージェントの実装フレームワーク(Microsoft Agent Framework/Claude Agent SDK等)の中で参照するか、Microsoft Foundry側のClaudeエンドポイントを直接叩く構成になります(詳細は本記事「Microsoft Foundry全体で利用できるパートナーモデル(参考)」節を参照)。
Microsoft Foundryポータルでは、以下のようにモデルの詳細を確認できます。
モデル詳細
「デプロイ」をクリックして名前や種類を設定すると、モデルのデプロイが可能です。
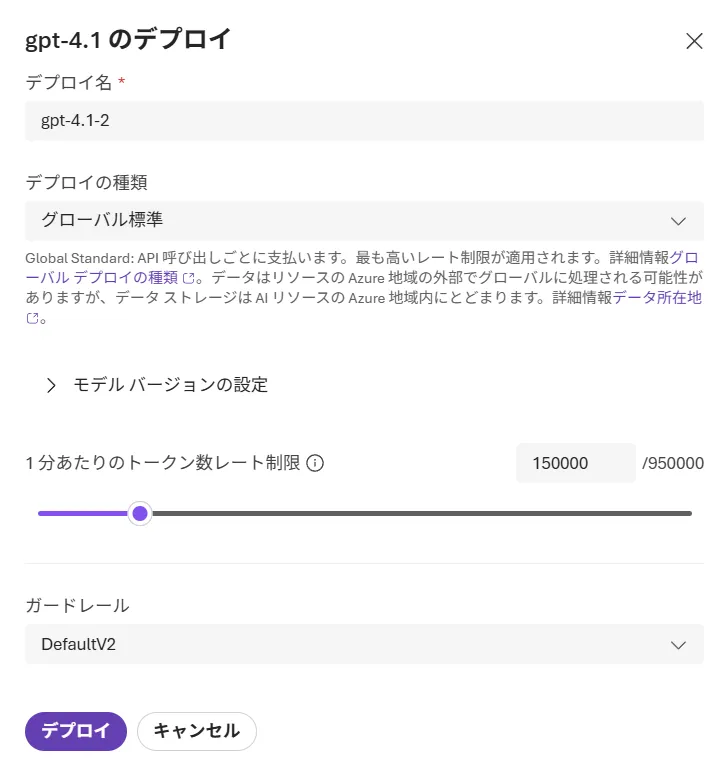
モデルデプロイ画面
この幅広い選択肢により、特定のタスクや業界に特化したモデル、コスト効率を重視したモデル、マルチモーダル対応モデルなど、要件に合わせた使い分けができます。テキストだけでなく画像や音声も扱えるマルチモーダルエージェントを構築したい場合はgpt-5やgpt-4o、長文・多段階推論を重視したい場合はo3/o4-miniやgrok-4-fast-reasoning(コンテキスト2M)が候補になります。Microsoft Foundry全体側のClaudeを使いたいケースでは、Hostedエージェント+Microsoft Agent Frameworkの構成で別建てに呼び出すのが整理しやすい構成です。
エンタープライズグレードのセキュリティ
Foundry Agent Serviceは、エンタープライズレベルのセキュリティ要件を満たすように設計されています。Azure Monitorとの連携による詳細な監査ログや監視機能も提供され、運用管理とセキュリティが強化されています。
Microsoft Foundryポータルでは、エージェントのRun ID、各ステップの入出力、トークン数をトレースできます。
エージェントのトレース画面
Application Insightsと接続することで、トークン消費・レスポンスタイムといったメトリクスを確認できます。
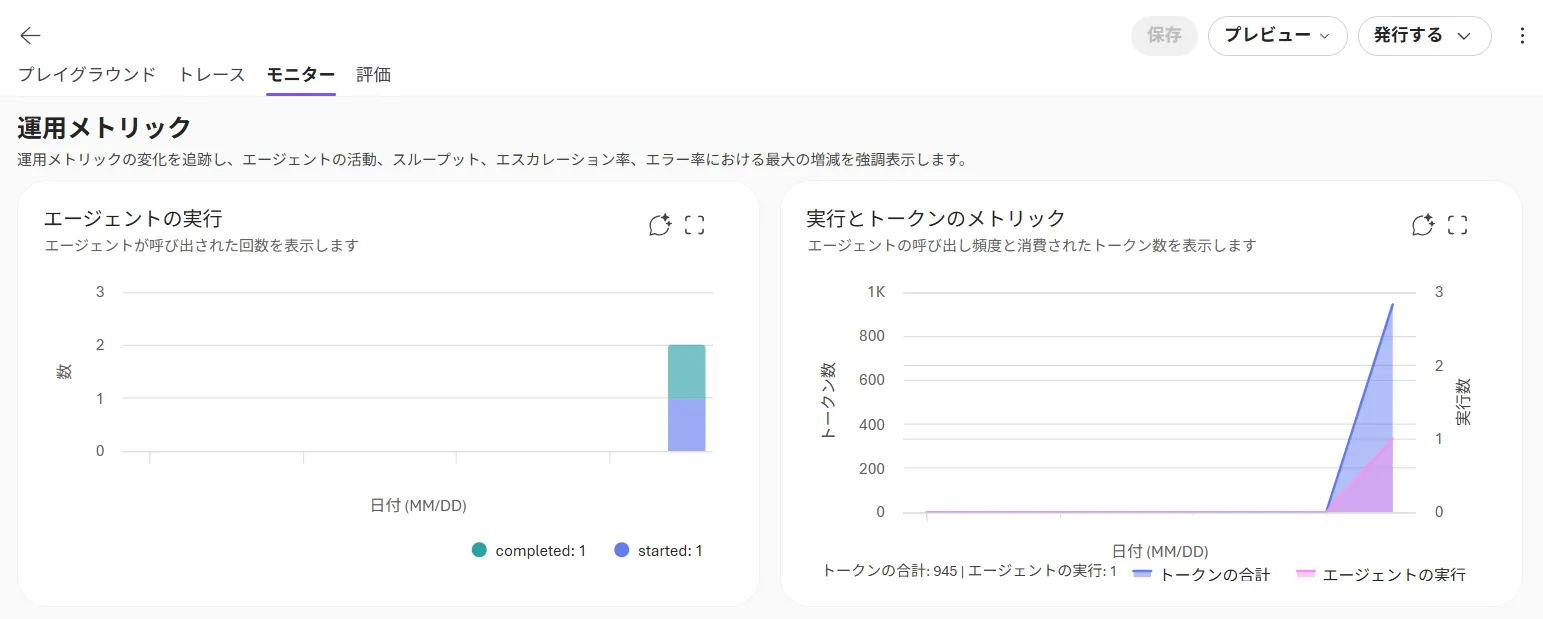
Application Insights連携画面
代表的なセキュリティ機能を整理します。
-
安全なデータ処理
エージェントとデータソース間の通信は暗号化され、機密性の高い情報も安心して扱えます
-
キーレスセットアップとOBO認証
キーレスセットアップやOn-Behalf-Of認証を活用することで、エージェントをセキュアに構成でき、リソース管理とデプロイの複雑さを軽減できます
-
ネットワークセキュリティ
BYO VNetによりデータトラフィックの公開を厳格に制御し、ネットワーク内の対話を閉域化できます
-
コンテンツフィルター
事前構築済み・カスタムのコンテンツフィルターで有害コンテンツを検出。プロンプトシールドでクロスプロンプトインジェクション攻撃から保護します
先進ツール群(2026年4月時点)
2025〜2026年にかけて、以下の先進ツールがFoundry Agent Serviceに追加されています。以下の表で、提供状況と用途を整理しました。
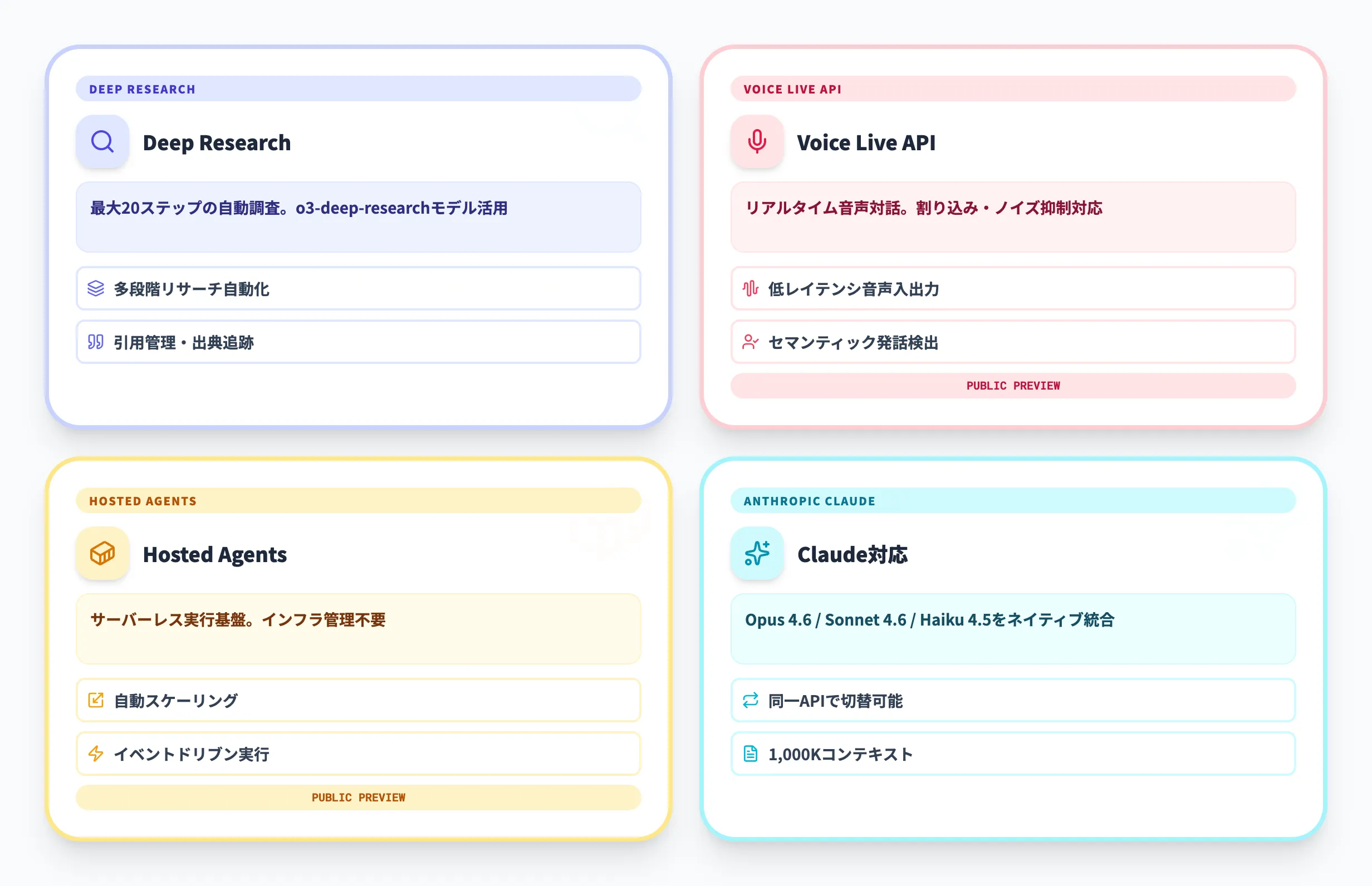
| ツール名 | 提供状況(2026年4月) | 主な機能 | ユースケース |
|---|---|---|---|
| Deep Research(classic) | deprecated(West US/Norway East) | Bing Search限定の多段階Web調査 | 後継へ移行推奨 |
| o3-deep-research + Web Search | 推奨構成(GA) | 自律的Web調査・出典付きレポート生成 | 市場調査、競合分析、学術調査 |
| Browser Automation | プレビュー | Webブラウザの自動操作 | データ収集、UI自動化、テスト |
| Voice Live API | GA(Foundry連携はプレビュー) | 低レイテンシ音声対話(speech-to-speech) | コールセンター、フィールドサポート、ハンズフリー |
| Hostedエージェント | パブリックプレビュー | サーバーレスコンテナベース実行 | 本番スケール、カスタムフレームワーク |
| Tracing(観測) | Promptエージェント:GA/Workflow・Hosted・custom:プレビュー | 実行の入出力・ツール呼び出しを可視化 | デバッグ、レイテンシ分析 |
| Agent Evaluators | GA(基本evaluator) | Task Completion・Adherence・Intent Resolutionなど | 継続的品質モニタリング |
なお、Anthropic ClaudeはFoundry Agent Service側の対応モデル一覧やツール群には含まれず、Microsoft Foundry全体のパートナーモデル(プレビュー)として別枠で提供される位置づけです。詳細は本記事の「Microsoft Foundry全体で利用できるパートナーモデル(参考)」節を参照してください。
これらのツールを連携させると、従来は複数サービスを組み合わせる必要があったワークフローを、単一プラットフォームで完結できます。たとえば「Web調査→Browser Automationで自動入力→Hostedエージェントで本番運用」といった一連のプロセスを、単一のFoundryプロジェクト内で設計・監視・スケールできる点が大きな実務的価値です。
Web調査の自動化:o3-deep-research + Web Search
旧Deep Researchツール(classic)はBing Search限定の多段階Web調査特化ツールでしたが、2026年4月時点ではdeprecated(非推奨)で、対応リージョンはWest USとNorway Eastに限定されています。公式はo3-deep-researchモデルを直接デプロイし、Web SearchツールまたはMCPツールと組み合わせる構成を推奨しています。
以下は、SDK 2.0.0でWeb調査エージェントを実装する例です。Web上の情報収集を自律的に行い、出典URLつきのレポートを返す設計です。
import os
from azure.ai.projects import AIProjectClient
from azure.ai.projects.models import PromptAgentDefinition
from azure.identity import DefaultAzureCredential
PROJECT_ENDPOINT = os.environ["PROJECT_ENDPOINT"]
AGENT_NAME = "MarketResearchAgent"
project = AIProjectClient(
endpoint=PROJECT_ENDPOINT,
credential=DefaultAzureCredential(),
)
agent = project.agents.create_version(
agent_name=AGENT_NAME,
definition=PromptAgentDefinition(
model="o3-deep-research",
instructions="""あなたは市場調査の専門家です。
Web上の最新情報をもとに、競合分析・市場規模・トレンド分析を含む
包括的なレポートを作成してください。出典URLを必ず付与してください。""",
tools=[{"type": "web_search"}],
),
)
openai = project.get_openai_client()
conversation = openai.conversations.create()
response = openai.responses.create(
conversation=conversation.id,
extra_body={
"agent_reference": {"name": AGENT_NAME, "type": "agent_reference"}
},
input="生成AIを活用したカスタマーサポート市場について、2026年の市場規模とトレンドを調査してください",
)
print(response.output_text)
このアプローチの利点は複数あります。
まず、人間のリサーチャーが数日かけて行うWeb横断調査を、数時間で自動化できる点です。通常の市場調査では複数のレポートサイト・業界誌・競合サイトを手動で巡回する必要がありますが、o3-deep-researchはこのプロセスを自動化します。
次に、調査の再現性と一貫性が担保される点です。同じパラメータで実行すれば常に同じ基準で情報を収集するため、調査バイアスを最小化できます。さらに、出典が応答に含まれるため、金融・医療・法律のようにコンプライアンス要件が厳しい業界でも引用根拠の追跡が容易です。
Voice Live API:リアルタイム音声対話
Voice Live APIは、Azure AI Speechが提供するリアルタイム音声対話APIで、2025年5月にパブリックプレビュー、2025年11月に一般提供(GA)となりました。従来のターンベース方式(ユーザーが話し終わるのを待ってから応答する)ではなく、低レイテンシのストリーミング音声入出力により、人間同士の会話に近い自然なやり取りが可能です。
Foundry Agent Service側では、このVoice Live APIをエージェントの音声インターフェースとして接続するVoice Agent Integrationが2026年に入ってプレビューとして提供されています。API本体(GA)とFoundry Agent Service連携部分(プレビュー)でステータスが異なる点に注意してください。
主な特徴は以下のとおりです。
-
セマンティック音声アクティビティ検出
ユーザーの発話意図を理解し、「えーと」などのフィラーワードと実際の質問を区別します
-
割り込み対応
ユーザーがエージェントの応答中に割り込んで話しかけた場合、エージェントは即座に応答を中断し、新しい入力に対応します
-
ノイズ抑制・エコーキャンセル
周囲の騒音やスピーカーからの音声フィードバックを自動除去し、クリアな音声認識を維持します
-
Foundryエージェントとの統合
テキストパイプラインと同じevaluator・tracingを共有するため、音声エージェントの品質監視もFoundryの統合ダッシュボードで一元管理できます
コールセンター、フィールドサポートでのハンズフリー操作、店舗接客など、音声インターフェースが求められるユースケースでは、Voice Live APIがエージェントの活用領域を大幅に広げます。
Hostedエージェント:サーバーレスなエージェント実行基盤
Hostedエージェントは、2026年4月時点でパブリックプレビューとして提供されているサーバーレスなエージェント実行環境です。開発者はインフラ管理を最小限に抑えつつ、カスタムコードで構築したエージェントをコンテナとしてデプロイできます。マネージドランタイムの課金は2026年4月1日以降に開始されており、デプロイ中はACR(Azure Container Registry)やApplication Insightsといった関連Azureリソースの料金も別途発生します。
対応リージョンは2026年4月時点でAustralia East/Canada Central/North Central US/Sweden Centralの4リージョンに限定されています(公式ドキュメント参照)。Japan Eastには未対応のため、日本国内にデータを完全に閉じ込めたい場合は、PromptエージェントまたはWorkflowエージェント(Japan East対応)側で設計する必要があります。
なお、Hostedエージェントはネットワーク分離されたFoundryリソース上で利用できますが、private-network-securedなACRからのコンテナイメージpullは公式に未対応とされています。閉域要件のある案件では、ACR側を公開エンドポイント経由とするか、ビルド済みイメージをサポート構成のレジストリ経由で配信する設計が必要です。
従来のセルフホストとの違いを整理します。
| 項目 | 従来のセルフホスト | Hostedエージェント(プレビュー) |
|---|---|---|
| インフラ管理 | Container Instances/App Service等を手動管理 | マネージド(管理負荷を大幅軽減) |
| スケーリング | 手動設定、オートスケールルール定義が必要 | リクエスト数に応じた自動スケール |
| プロトコル | 独自設計 | Responses/Invocations/Activity/A2Aの4プロトコル |
| 料金モデル | 常時稼働コスト発生 | セッション単位の従量課金(2026年4月〜) |
| 可用性 | SLA管理が必要 | プレビューのためSLA未提供 |
主な特徴として、同時アクティブセッションの上限はサブスクリプション+リージョン単位で50(クォータ申請により引き上げ可能)、アイドル15分で自動ディプロビジョニング、セッション保持は最大30日、という設計です。会話履歴とセッション状態($HOME//files)が自動で永続化されるため、バースト的な負荷にもサーバーレスに追従します。
実装イメージ(Hostedエージェントの基本フロー):
Hostedエージェントは、(1) 任意フレームワーク(Microsoft Agent Framework/LangGraph/Semantic Kernel等)でエージェントコードを実装し、(2) コンテナイメージとしてACRに格納、(3) Foundryプロジェクトのagents.create_version()にHostedエージェント定義を渡してデプロイ、という流れで構成します。以下は、コンテナ化したエージェントを参照してHostedエージェントとしてデプロイする骨格です。
# 1. コンテナイメージをビルドし ACR に push(Hosted エージェント本体)
az acr build \
--registry myregistry \
--image customer-support-agent:1.0 \
--file Dockerfile .
# 2. SDK 2.0.0 で Hosted エージェントを Foundry プロジェクトにデプロイ
import os
from azure.ai.projects import AIProjectClient
from azure.ai.projects.models import HostedAgentDefinition
from azure.identity import DefaultAzureCredential
PROJECT_ENDPOINT = os.environ["PROJECT_ENDPOINT"]
AGENT_NAME = "CustomerSupportAgent"
project = AIProjectClient(
endpoint=PROJECT_ENDPOINT,
credential=DefaultAzureCredential(),
)
agent = project.agents.create_version(
agent_name=AGENT_NAME,
definition=HostedAgentDefinition(
container_image="myregistry.azurecr.io/customer-support-agent:1.0",
# 必要に応じて環境変数・ポート・スケール設定を指定
),
)
print(f"Hosted エージェントデプロイ完了 (id: {agent.id}, version: {agent.version})")
# 3. Responses API 経由で Hosted エージェントと対話
openai = project.get_openai_client()
conversation = openai.conversations.create()
response = openai.responses.create(
conversation=conversation.id,
extra_body={
"agent_reference": {"name": AGENT_NAME, "type": "agent_reference"}
},
input="注文IDが見つからないという問い合わせを受けました。対応手順を提示してください",
)
print(response.output_text)
このアプローチの利点は3点あります。
1つ目はインフラ管理の大幅削減です。Container Instances/App Service等のセルフホストで必要だったオートスケール・パッチ・ヘルスチェック設定が不要になり、ビジネスロジックの開発に集中できます。2つ目はFoundry観測基盤との統合で、TracingとAgent EvaluatorsをHostedエージェントでもそのまま利用できるため、品質モニタリングが他種別と一貫します。3つ目はResponses/Invocations/Activity/A2Aの4プロトコルが標準化されている点で、フレームワークを跨いだ呼び出しが宣言的に記述できます。
Microsoft Foundry Agent Serviceで利用可能なモデルとリージョン
Foundry Agent Serviceがエージェント定義で直接指定できる対応モデルは、公式のクォータ・モデル・リージョン対応表で示されている通り、Azure OpenAIモデルとFoundryモデルカタログ(Azure直接販売)のモデルです。Anthropic ClaudeなどのMarketplace経由パートナーモデルは、Microsoft Foundry全体ではプレビューで利用できますが、Agent Serviceの対応モデル一覧には含まれていません。本章では、Agent Service直接対応のモデル群を整理し、続けて参考としてFoundry全体で利用できるClaudeをまとめます。
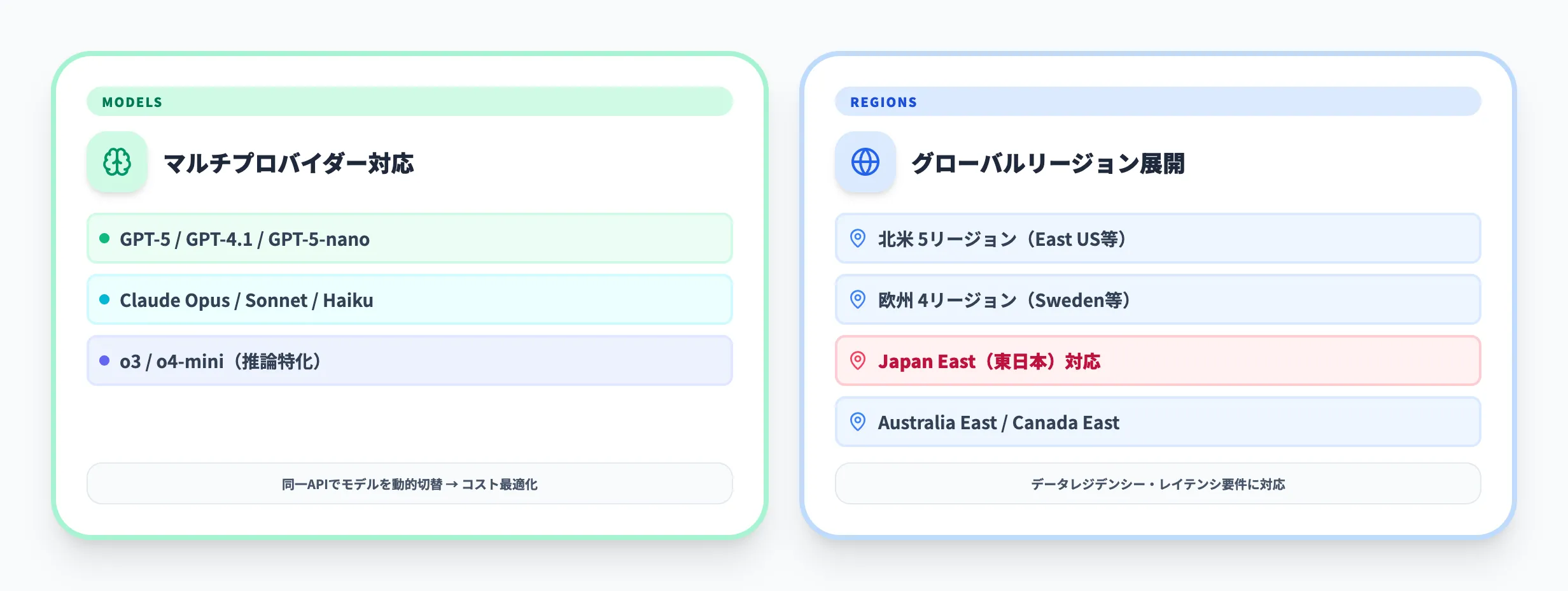
Foundry Agent Serviceの直接対応モデル

Model Catalog画面
| 提供元 | モデル名 | コンテキスト長 | 主な特徴 |
|---|---|---|---|
| Azure OpenAI | gpt-5 | 1M | マルチモーダル強化、最新フラッグシップ |
| gpt-5-mini | 1M | コスト効率の高い軽量版 | |
| gpt-5-nano | 1M | 超高速応答、エッジ向け | |
| gpt-4.1 | 1M | 安定した汎用モデル | |
| o3 | 200K | 推論特化 | |
| o4-mini | 200K | 軽量推論 | |
| Foundryモデルカタログ(直接販売) | grok-4 | 256K | xAIのフロンティア級推論 |
| grok-4-fast-reasoning | 2M | エージェント向け高速推論 | |
| grok-4-fast-non-reasoning | 2M | 高スループット・低レイテンシ | |
| grok-3/grok-3-mini | 128K | システムレベルワークフロー向け | |
| Llama-3.3-70B-Instruct | 128K | 企業Q&A・意思決定支援 | |
| Llama-4-Maverick-17B-128E-Instruct-FP8 | 1M | FP8最適化で高速・低コスト | |
| DeepSeek-V3.1 | 128K | マルチモーダル推論+グラウンデッドリトリーバル | |
| DeepSeek-R1-0528 | 128K | 長文・多段階推論 | |
| MAI-DS-R1 | 128K | Microsoft提供、決定論的推論 | |
| gpt-oss-120b | 128K | オープンエコシステムの再現性重視 |
モデル選択はビジネス成果に直結します。カスタマーサポートは応答速度が顧客満足度に影響するためgpt-5-nanoやgrok-4-fast-non-reasoningが適しており、契約書分析や市場調査のように精度が重視されるタスクではo3やgrok-4が有利です。コスト効率を優先する大量バッチ処理ならLlama-4-Maverick(FP8最適化)やDeepSeek-V3.1が選択肢になります。
Microsoft Foundry全体で利用できるパートナーモデル(参考)
Foundry Agent Service直接対応の枠とは別に、Microsoft Foundry全体ではAnthropic Claudeがパートナーモデルとしてプレビュー提供されています。Foundry Agent ServiceからClaudeを利用したい場合は、Hostedエージェント側の実装フレームワーク(Microsoft Agent Framework/Claude Agent SDK)からMicrosoft FoundryのClaudeエンドポイントを呼び出すか、Agent Service外で完結する別ワークロードとして構築するのが基本パターンです。
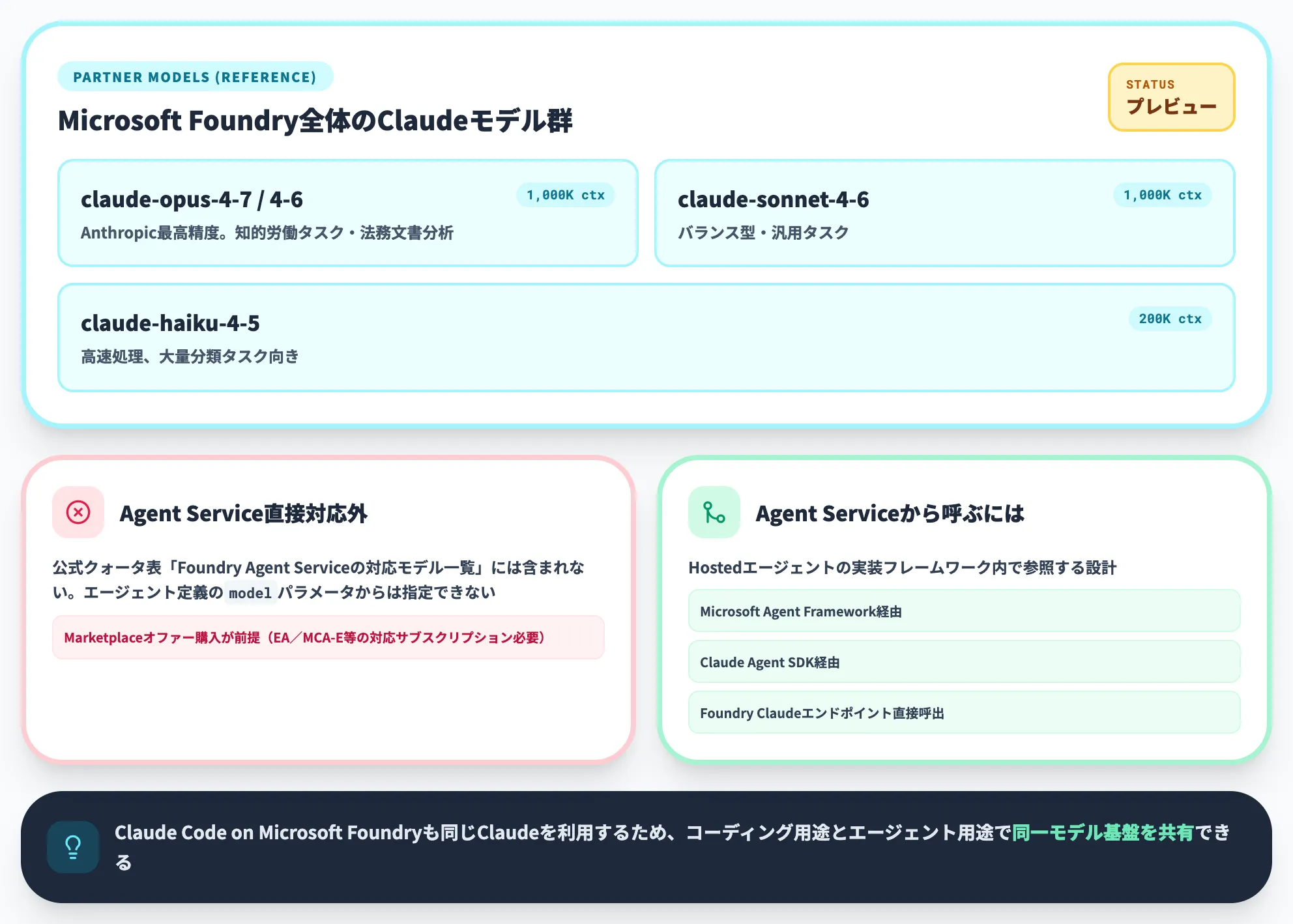
Microsoft Foundryポータル側のClaude設定画面は以下のように表示されます。
Anthropic Claude設定画面
| 提供元 | モデル名 | コンテキスト長 | 主な特徴 | 提供状況 |
|---|---|---|---|---|
| Anthropic(Marketplace) | claude-opus-4-7/claude-opus-4-6 | 1,000K | Anthropic最高精度、知的労働タスク | プレビュー |
| claude-sonnet-4-6 | 1,000K | バランス型、汎用タスク | プレビュー | |
| claude-haiku-4-5 | 200K | 高速処理、大量タスク | プレビュー |
Claudeモデルの実務的な特徴は、長文コンテキスト処理(Opus/Sonnet 4.6は最大1,000Kトークン)、指示追従性の高さ、XML形式サポート、Constitutional AIによる有害コンテンツ生成の抑制、の4点です。Azure側のClaude Code on Microsoft Foundryも同じMicrosoft FoundryのClaudeを利用するため、コーディング用途とエージェント用途で同一のモデル基盤を共有できます。利用にはEnterprise Agreement/MCA-Eなど対応サブスクリプションでのMarketplaceオファー購入が前提となります。詳細は公式のMicrosoft FoundryでClaudeモデルを利用するガイドを参照してください。
Foundry Agent Service内のモデル使い分けに関しては、Agent Service直接対応モデル一覧の範囲で、gpt-5/o3は複雑推論・法務文書分析・学術論文要約、gpt-5-mini/gpt-5-nanoは超高速応答が必要なチャットボット、Llama-4-Maverick/DeepSeek-V3.1はコスト効率を優先する大量バッチ処理、と特性に応じて切り替える設計が現実的です。Claudeを業務に取り込みたい場合は、Agent Service外のMicrosoft Foundry側で別建てし、Agent Serviceとは疎結合に呼び出す前提で設計するのが整理しやすい構成になります。
つまり、単一モデルで通すのではなく、同じエージェントアプリケーションでもタスクに応じてモデルを動的に切り替える設計が、品質とコストの両立には効きます。
利用可能なリージョンと選び方
Foundry Agent Serviceは、Azure OpenAI Responses APIが提供されるリージョンで利用可能です。Azure OpenAI対応リージョンとしては、East US/East US 2/West US/West US 3/North Central US/South Central US/Australia East/Canada East/France Central/Japan East/Sweden Central/Switzerland North/UK South などが主要候補になります。
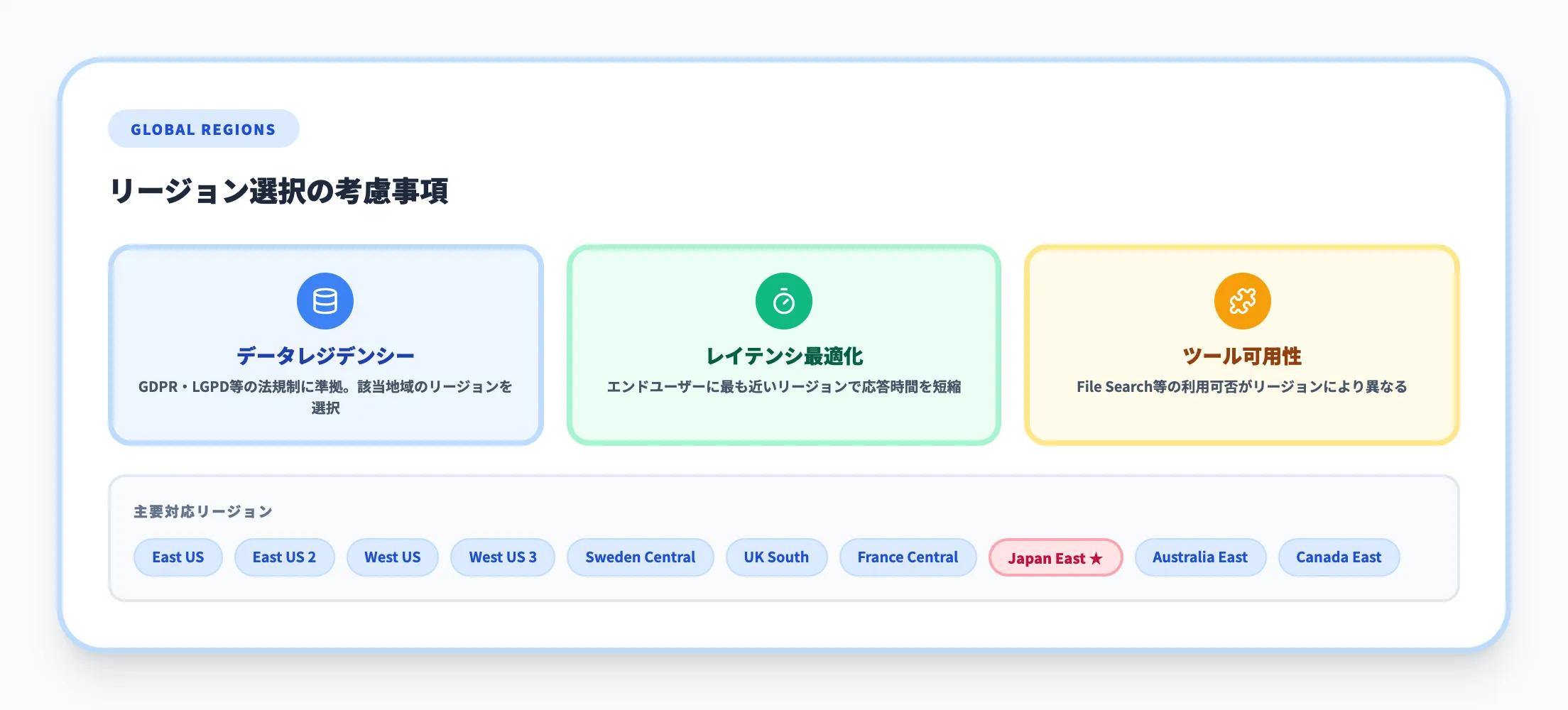
一方、Hostedエージェントのみ例外で、2026年4月時点で以下の4リージョン限定となっている点に注意が必要です。
- Australia East
- Canada Central
- North Central US
- Sweden Central
つまり、Japan EastでFoundry Agent Service自体は利用可能ですが、Hostedエージェントを動かすには上記4リージョンのいずれかにデプロイする必要があります。日本国内にデータを完全に閉じ込めたい場合、Hostedエージェントの利用は構造上制約があるため、PromptエージェントまたはWorkflowエージェントでの設計を基本線とし、Hostedエージェントは将来対応リージョンに入るのを待つ/海外リージョン利用を許容する、のいずれかを選ぶ形になります。
リージョン選択の実務的な考慮事項を整理します。
-
データレジデンシー要件
GDPRやブラジルLGPD等の法規制に準拠する必要がある場合、該当地域のリージョンを選択します
-
レイテンシ最適化
エンドユーザーに最も近いリージョンを選択することで応答時間を短縮できます
-
ツール可用性
一部リージョンではFile Searchが利用できないなど、ツールの可用性に差があります。事前に公式ドキュメントで確認してください
-
Hostedエージェントの制約
前述のとおり4リージョン限定のため、Hostedエージェントを使う予定がある場合は早期にリージョン方針を決めておきます
Microsoft Foundry Agent Serviceの使い方
本章では、Microsoft Foundry Agent Serviceを使った実践的な開発手順を、Portal操作とPython SDKの両面から段階的に説明します。基本的なエージェント構築から、Connected Agentsによるマルチエージェントシステムまでを一気通貫でカバーします。

ステップ1:Microsoft Foundryプロジェクトのセットアップ
前提条件は以下のとおりです。
- Azureサブスクリプション(無料試用版でも可)
- Azure CLI(バージョン2.50以上)
- Python 3.8以上(Python SDKを使う場合)
プロジェクト作成のコマンド例は以下のとおりです。
az login
az group create --name rg-ai-agents --location eastus
az ml workspace create \
--name ai-agent-project \
--resource-group rg-ai-agents \
--location eastus \
--kind project
Microsoft Foundryポータル側での操作手順は以下のとおりです。
- Microsoft Foundryにアクセスします
Microsoft Foundryポータルのトップ画面
- 作成したプロジェクトを選択、あるいはポータル上で直接プロジェクトを作成します
プロジェクト作成画面
プロジェクト作成後は、ポータル上でエージェントの作成やナレッジ追加といった操作を行えます。
プロジェクトのダッシュボード画面
- ポータルの「ホーム」を選択し、エンドポイントを確認します
プロジェクトのEndpoint確認画面
ステップ2:Python SDKのインストールと初期化
2026年3月のSDK 2.0.0 GAに伴い、旧azure-ai-agentsからazure-ai-projectsへ移行しています。新しいSDKではAIProjectClientがエージェント操作の中心になります。
pip install azure-ai-projects azure-identity
export PROJECT_ENDPOINT="https://your-project.services.ai.azure.com"
基本的なクライアント初期化は以下のようになります。AIProjectClientはエージェント操作の入口で、get_openai_client()で取得するOpenAI互換クライアントから会話・ファイル等のResponses API系操作を実行します。
import os
from azure.ai.projects import AIProjectClient
from azure.identity import DefaultAzureCredential
project = AIProjectClient(
endpoint=os.environ["PROJECT_ENDPOINT"],
credential=DefaultAzureCredential(),
)
print("プロジェクト接続成功")
Python SDKを使わずノーコードでエージェントを作る手順は、次のステップ3で説明します。
ステップ3:最初のエージェントを作成する
SDK 2.0.0ではエージェントはagents.create_version()でバージョン付きで作成し、PromptAgentDefinitionで振る舞いを定義します。シンプルな「製品推薦エージェント」を例に手順を示します。
import os
from azure.ai.projects import AIProjectClient
from azure.ai.projects.models import PromptAgentDefinition
from azure.identity import DefaultAzureCredential
PROJECT_ENDPOINT = os.environ["PROJECT_ENDPOINT"]
AGENT_NAME = "ProductRecommendationAgent"
project = AIProjectClient(
endpoint=PROJECT_ENDPOINT,
credential=DefaultAzureCredential(),
)
agent = project.agents.create_version(
agent_name=AGENT_NAME,
definition=PromptAgentDefinition(
model="gpt-5-mini",
instructions="""あなたは製品推薦の専門家です。
ユーザーの要望を聞き、製品カタログから最適な製品を推薦してください。
推薦時には、以下の情報を必ず含めてください:
1. 推薦理由
2. 製品の主な特徴
3. 価格帯
4. 類似製品との比較""",
),
)
print(f"エージェント作成完了 (id: {agent.id}, name: {agent.name}, version: {agent.version})")
ファイル検索やコードインタープリタなどのツールを利用する場合は、PromptAgentDefinitionのtools引数で構成を渡します。File Searchを利用するためのファイルアップロードはOpenAI互換クライアント経由で実行します。
openai = project.get_openai_client()
# 製品カタログをファイルとしてアップロード
with open("product_catalog.csv", "rb") as fp:
uploaded = openai.files.create(file=fp, purpose="assistants")
print(f"カタログファイルアップロード完了: {uploaded.id}")
ポータル側での操作も可能です。以下の画面で、ツールの追加やモデル設定をGUIから行えます。
- Microsoft Foundryポータルにアクセスし「ビルド」メニューの「エージェント」タブを開きます
エージェント一覧画面
- 「エージェントの作成」をクリックし、作成完了後に名前・モデル・手順を設定します
エージェント作成画面
- 設定ページで「ツールの追加」をクリックし、組み込むツールを選択します
ツール追加画面
ステップ4:エージェントとの会話を実行する
SDK 2.0.0ではOpenAI互換のResponses APIを通じてエージェントと対話します。会話状態はconversations.create()で生成し、responses.create()のextra_bodyで対象エージェントを参照します。
openai = project.get_openai_client()
conversation = openai.conversations.create()
response = openai.responses.create(
conversation=conversation.id,
extra_body={
"agent_reference": {"name": AGENT_NAME, "type": "agent_reference"}
},
input="リモートワークに最適な製品を推薦してください。予算は20万円です。",
)
print(response.output_text)
Microsoft Foundryポータルでは「プレイグラウンド」でエージェントとの対話を確認できます。
Agent Playgroundの対話画面
このアプローチの利点は3点あります。
1つ目は製品知識の自動更新で、カタログファイルを差し替えるだけでエージェントが最新情報を参照します。2つ目は一貫した推薦基準で、instructionsで定義した基準に基づき常に同じフォーマットで回答します。3つ目はスケーラブルな対応で、複数ユーザーからの同時リクエストにもスレッドで個別に対応できます。
マルチエージェントシステム(Connected Agents)
Foundry Agent ServiceのConnected Agents機能を使うと、複数の専門エージェントを連携させ、複雑なワークフローを自動化できます。

以下の表で、マルチエージェントのアーキテクチャパターンを整理しました。
| パターン | 構成 | 使用例 | メリット |
|---|---|---|---|
| Sequential(順次実行) | Agent A → Agent B → Agent C | データ収集→分析→レポート作成 | シンプル、デバッグ容易 |
| Parallel(並列実行) | Agent A, B, C(同時実行) | 複数ソースからの情報収集 | 高速処理 |
| Hierarchical(階層型) | Manager Agent → Worker Agents | タスク分解と並列処理 | 複雑なタスク管理 |
| Event-Driven(イベント駆動) | Trigger → Agent → Action | 異常検知→通知→対応 | リアルタイム対応 |
特に重要なのは、エージェント間通信プロトコルとしてAgent2Agent(A2A)が標準化されている点です。これにより、異なるチームが開発したエージェント同士でも相互運用性が保証され、エージェントのエコシステムを構築して部門横断の業務自動化を実現できます。なお、Foundry Agent Service側からA2A対応エンドポイントへ接続する機能は、2026年4月時点ではパブリックプレビューで提供されています。
以下は、「問い合わせ分類」→「FAQ検索」→「回答生成」→「エスカレーション」の4段階プロセスを自動化する簡易実装例です。
SDK 2.0.0では各エージェントをagents.create_version() + PromptAgentDefinitionで個別に定義し、Responses API側で連結します。
エージェント1:問い合わせ分類エージェント
classifier = project.agents.create_version(
agent_name="InquiryClassifierAgent",
definition=PromptAgentDefinition(
model="gpt-5-mini",
instructions="""顧客の問い合わせを以下のカテゴリに分類してください:
- technical_support(技術サポート)
- billing(請求関連)
- general_inquiry(一般問い合わせ)
- complaint(クレーム)
出力はJSON形式で、以下のフィールドを含めてください:
{
"category": "カテゴリ名",
"priority": "low/medium/high",
"keywords": ["キーワード1", "キーワード2"]
}""",
),
)
エージェント2:FAQ検索エージェント
faq = project.agents.create_version(
agent_name="FAQSearchAgent",
definition=PromptAgentDefinition(
model="gpt-5-mini",
instructions="""分類結果を受け取り、FAQデータベースから関連する情報を検索してください。
見つかった場合は、FAQ内容と信頼度スコアを返してください。
見つからない場合は、next_agentフィールドに"escalation"を設定してください。""",
tools=[
{"type": "azure_ai_search", "index_name": "customer-faq-index"}
],
),
)
エージェント3:回答生成エージェント
responder = project.agents.create_version(
agent_name="ResponseGenerationAgent",
definition=PromptAgentDefinition(
model="gpt-5",
instructions="""FAQ情報を基に、顧客向けの丁寧な回答を生成してください。
要件:
1. 敬語を使用
2. 解決手順を番号付きリストで提示
3. 追加のサポート連絡先を含める
4. 回答末尾に満足度確認の質問を追加""",
),
)
エージェント4:エスカレーション管理エージェント
escalation = project.agents.create_version(
agent_name="EscalationAgent",
definition=PromptAgentDefinition(
model="gpt-5-mini",
instructions="""FAQで解決できない問い合わせを処理してください。
1. 問い合わせ内容を要約
2. 適切な担当部門を特定
3. チケットシステムに登録(escalate_ticket関数を使用)
4. 顧客に「担当者から24時間以内に連絡する」旨を通知""",
tools=[
{
"type": "function",
"function": {
"name": "escalate_ticket",
"description": "チケットシステムに問い合わせを登録",
"parameters": {
"type": "object",
"properties": {
"department": {"type": "string", "enum": ["technical", "billing", "general"]},
"priority": {"type": "string", "enum": ["low", "medium", "high"]},
"summary": {"type": "string"},
},
"required": ["department", "priority", "summary"],
},
},
}
],
),
)
このマルチエージェントアプローチの利点は4点あります。
1つ目は専門性の分離で、各エージェントが特定の役割に特化するため、精度が向上します。2つ目は保守性の向上で、個別エージェントの改善が全体に影響を与えず、段階的な改良が可能です。3つ目は再利用性で、FAQエージェントは他のワークフロー(メール自動応答、チャットボット)でも流用できます。4つ目はスケーラビリティで、各エージェントを独立してスケールできるためボトルネックを解消しやすくなります。
詰まりポイント(実装でハマりやすい箇所):
- 会話メッセージ上限:長期運用するチャットでは途中で
message_limit_exceededが出るため、セッション単位でconversationsを切り替える設計が必須です(旧API時代のスレッドと同様、会話を「使い捨て」にする運用が安定) - ツール登録上限(128個/エージェント):MCP・関数ツールを増やしすぎると上限に達するので、Toolboxで共通化する設計に寄せます
- コンテキスト長のオーバーフロー:長文参照ではFile Searchに寄せ、メッセージ本文は1,500,000文字の上限に余裕を持たせます

Microsoft Foundry Agent Serviceの導入事例と段階的導入アプローチ
Microsoft Foundry Agent Service(および前身のAzure AI Agent Service)は、グローバル企業で実際に業務効率化の成果を上げています。本章では、一次ソースが公開されている代表的な導入事例と、AI総研の支援経験に基づく段階的な導入アプローチを紹介します。
公式事例に見る成果
現時点で公式プレスリリース・カスタマーストーリーが公開されており、定量効果が明示されている代表的な事例を紹介します。出典URLが確認できるものに絞っています。

-
Fujitsu:営業提案書自動作成で生産性67%向上
Fujitsuは、Fujitsu Kozuchi Composite AIをSemantic KernelとAzure AI Agent Service上でオーケストレーションし、複数の専門エージェントが顧客ニーズを解釈・社内ナレッジ横断検索・カスタマイズ提案書生成を担う構成を構築。提案書作成の生産性が67%向上し、約38,000人の従業員が活用しています
-
KPMG Clara:監査プラットフォームへのエージェント組み込み
KPMGは、監査プラットフォーム KPMG Clara にAzure AI Foundryのエージェント機能を組み込み、監査手続きの自動化・ドキュメント生成・リアルタイムインサイト提示を実現。規制産業向けの監査基盤でAIエージェントを活用するリファレンス事例となっています
-
KPMG:新人オンボーディング向けエージェントでフォローアップコール20%削減
KPMGは社内の新人オンボーディング向けに、テンプレート・ナレッジ検索を自動化する別のエージェントをAzure AI Foundry上で構築。新人からの問い合わせ対応にかかるフォローアップコールを20%削減しています
これらの事例に共通するのは、単体のLLM活用ではなく、専門エージェントを業務プロセスに組み込んで定型作業を継続的に自動化している点です。Fujitsuの営業提案書自動作成は「顧客要件抽出→社内事例検索→提案骨子生成→金額見積→レビュー」といった多段プロセス、KPMGも監査プラットフォーム本体(Clara)と新人オンボーディング向けの別エージェントを別ユースケースとして展開しており、社内・社外の業務それぞれにエージェントを切り分けて配置しています。
このパターンは、AI総研の支援現場でも再現性が高く、Promptエージェントで個々の専門処理を作り、Connected AgentsやWorkflowエージェントで結合する設計が定番になっています。社内のナレッジ検索に毎日30分以上かけているチームがあるなら、まずPromptエージェントでFAQ対応を自動化するPoCから始めるのが現実的な第一歩です。
【関連記事】
AIエージェントを企業に導入する全手順|事例・費用も解説
段階的導入の4フェーズ
Foundry Agent Serviceを本格的に導入する際、いきなり大規模展開するのではなく、段階的なアプローチが効果的です。Forrester TEI調査でも、段階的に導入した企業が6か月以内に投資回収を達成しています。以下のフェーズで、リスクを最小化しながら価値を実証できます。

フェーズ1:パイロットプロジェクト(1〜2ヶ月)
目的は技術検証と初期効果測定です。推奨アクションは以下のとおりです。
-
スコープの限定
単一部門・単一ユースケースに絞る(例:ITヘルプデスクの一般問い合わせ対応)。影響範囲が小さく、失敗してもリカバリ可能な領域を選ぶ
-
シンプルなエージェント構築
1〜2個のエージェントのみ使用。複雑なワークフローは避け、基本機能の検証に集中
-
並行運用
既存の人的プロセスを並行稼働させ、AIの回答を人間がレビュー。精度とユーザー満足度を測定
-
KPI設定
応答精度(正解率)、応答時間、ユーザー満足度(CSAT)、コスト削減額
成功基準の例は、正解率80%以上、平均応答時間5分以内、CSAT 4.0/5.0以上、コスト削減30%以上、といった具体値を置きます。パイロットで「理論上の効果」ではなく「実測された効果」を取ることで、次フェーズの予算承認が一気に通りやすくなります。
フェーズ2:部門展開(3〜6ヶ月)
目的はスケールアップとプロセス最適化です。推奨アクションは以下のとおりです。
-
対象範囲の拡大
パイロットで成功したユースケースを部門全体に展開。関連する他のユースケースも追加(例:ITヘルプデスク→人事・総務ヘルプデスク)
-
マルチエージェント化
Connected Agentsで複数エージェントを連携し、より複雑なワークフローの自動化に踏み込む
-
運用プロセスの確立
エージェントのモニタリング体制、エラー発生時のエスカレーションフロー、定期的な精度評価とチューニング
-
ユーザートレーニング
エンドユーザー向けの利用ガイド作成、効果的なプロンプト作成のトレーニング
このフェーズで得られる運用ノウハウが、次の全社展開でのトラブル予防にそのまま効きます。特にエスカレーションフローとモニタリング体制の設計は、本番運用の成否を左右します。
フェーズ3:全社展開(6〜12ヶ月)
目的は全社的な業務改革とROI最大化です。推奨アクションは以下のとおりです。
-
横展開
成功パターンを他部門に水平展開、部門横断のワークフロー自動化を設計
-
高度な機能の活用
o3-deep-research(市場調査・競合分析)、Browser Automation(データ収集・RPA代替)、Hostedエージェント(コスト最適化・グローバル展開)
-
データ統合
企業全体のナレッジベースを統合し、部門間でエージェントを共有
-
ガバナンス体制
AI利用ポリシーの策定、データプライバシー・セキュリティ監査、コンプライアンス確認
全社展開の成功要因は、経営層のコミットメントと、現場の声を反映した継続的改善サイクルです。トップダウンの方針だけでも、ボトムアップのフィードバックだけでも持続しません。両者を組み合わせる運用体制を最初から設計に織り込みます。
フェーズ4:継続的最適化(12ヶ月以降)
目的は長期的な価値創出と進化です。推奨アクションは以下のとおりです。
-
定期的なレビュー
四半期ごとのKPIレビュー、エージェントのパフォーマンス分析、新しいユースケースの発掘
-
モデルアップデート
新モデル(GPT-5/Claude/Grok 4等)へのマイグレーション、コスト最適化のためのモデル切り替え
-
エージェントの進化
ユーザーフィードバックを反映した指示文改善、新しいツール・機能の追加
-
ベストプラクティス共有
成功事例の社内共有、他部門への知見移転
このフェーズに入ると、AIエージェントが「導入して終わり」ではなく「継続的に進化する資産」として定着します。定期改善により、初期導入時の3〜5倍の効果を実現できるケースもあります。AI総研の支援現場でも、半年ごとにモデルを1段階上げつつ、フェーズ1〜3のKPIを定点観測するシンプルな運用が長期でもっとも安定します。
Microsoft Foundry Agent Serviceのセキュリティとプライバシー
Foundry Agent Serviceは、エンタープライズグレードのセキュリティ機能を標準で提供しています。プライベートネットワーキングはStandard Setupでサポートされ、対応ツール(MCPサーバー、Azure AI Search、Microsoft Entra認証配下のリソース等)に限ってエンドツーエンドのVNet経路を構成できます。一方、Bing検索やSharePointなど一部ツールは仕様上パブリックエンドポイントを経由するため、ツールごとに対応可否を確認する必要があります。Hostedエージェント自体はネットワーク分離されたFoundryリソース上で動作させられますが、private-network-securedなACRからのコンテナイメージpullには未対応のため、コンテナ配信経路は公開エンドポイント側で設計する必要があります。
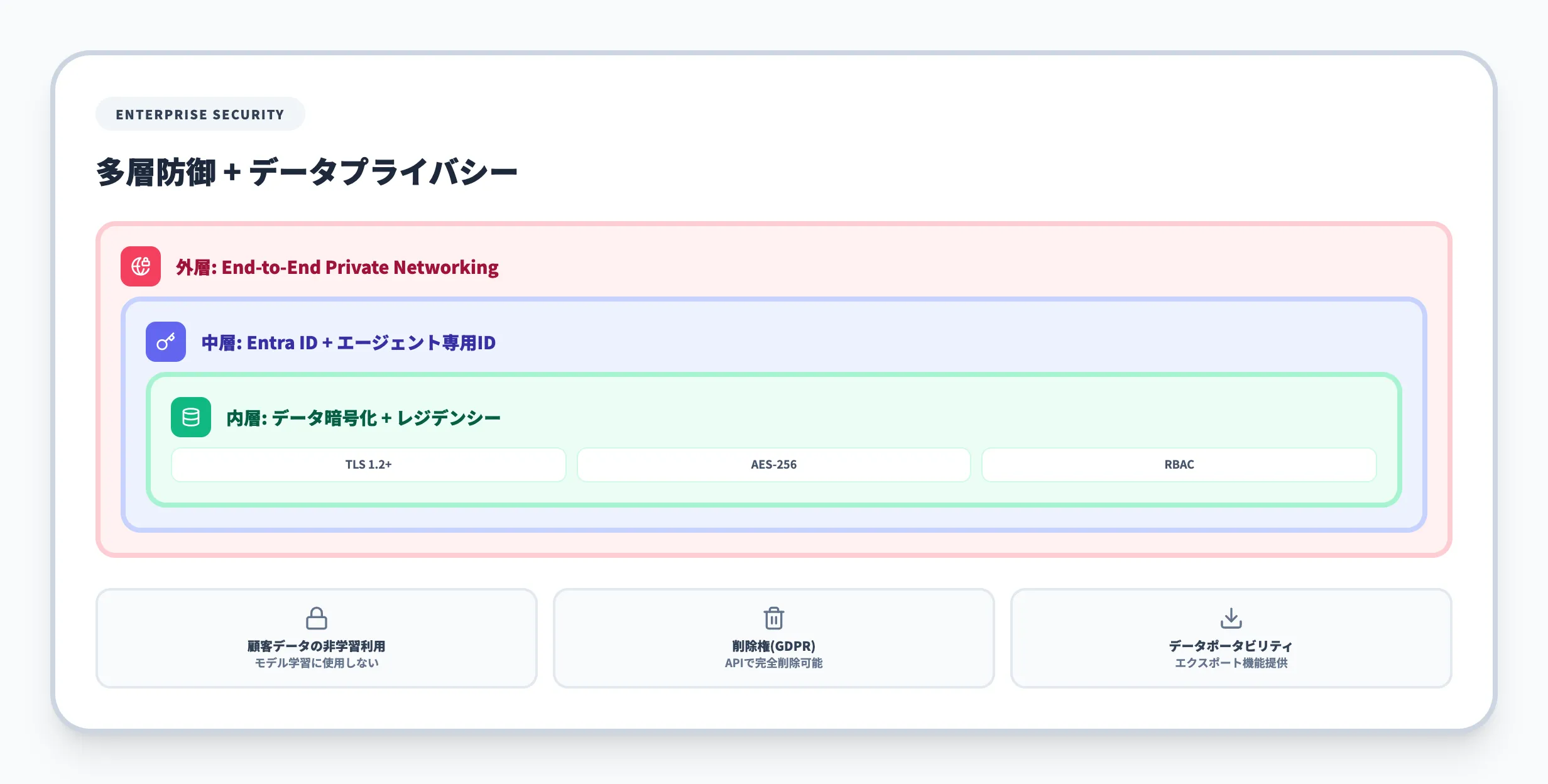
以下の表で、主要なセキュリティ機能を整理しました。
| セキュリティ機能 | 内容 | 対応する規制・標準 |
|---|---|---|
| データ暗号化 | 転送時(TLS 1.2+)、保存時(AES-256)の暗号化 | GDPR、HIPAA、PCI DSS |
| プライベートネットワーキング | BYO VNet対応(Standard Setup)。MCP・Azure AI Search等の対応ツールはVNet経路で接続可、Bing等は一部公開経路。Hostedエージェントはネットワーク分離されたFoundryリソース上で動作可だが、private-network-securedなACR pullは未対応 | 企業内ネットワークポリシー |
| エージェント専用ID | 各エージェントにMicrosoft Entra ID専用IDを付与、スコープされたアクセス制御 | ゼロトラスト、最小権限の原則 |
| Microsoft Entra ID統合 | SSO、多要素認証(MFA)、RBAC | ゼロトラストセキュリティ |
| RBAC(ロールベースアクセス制御) | 閲覧・編集・実行・管理をきめ細かく制御 | SOC 2、ISO 27001 |
| 監査ログ | すべてのAPI呼び出しをAzure Monitor/Application Insightsに記録 | コンプライアンス監査 |
| データレジデンシー | 選択したリージョン内でのみデータ処理・保存 | GDPR、各国データローカライゼーション法 |
| Abuse Monitoring | 不正利用・攻撃の自動検知とブロック | セキュリティベストプラクティス |
| OBO認証 | ユーザー権限の委譲、パスワード不要 | 最小権限の原則 |
この表で特筆すべきは、これらのセキュリティ機能が「オプション」ではなく「標準機能」として提供されている点です。追加コストなしで、エンタープライズレベルのセキュリティを確保できるため、スタートアップから大企業まで同じセキュリティレベルを享受できます。
MCPサーバー接続の認証方式
エージェントからMCPサーバー・外部SaaSへの接続には、公式ドキュメントで整理されている以下の認証方式が利用できます。用途に応じて使い分けることで、エージェントに最小権限を割り当てつつ、既存のIDパイプラインと統合できます。

| 認証方式 | 用途 | 特徴 |
|---|---|---|
| Key-based | 開発・検証環境やAPIキー必須のMCPサーバー | APIキー/PATを保管。鍵のローテーション管理が必須 |
| Microsoft Entra – agent identity | 本番のエージェント専用ID | エージェントごとに発行されるEntra IDでスコープ付き権限管理 |
| Microsoft Entra – project managed identity | プロジェクト共有の接続 | プロジェクト単位のマネージドIDで複数エージェントの共通アクセスを管理 |
| OAuth identity passthrough | ユーザー委譲アクセス | ユーザー本人としてOneDrive・Salesforce・Microsoft 365などOAuth準拠サービスへアクセス |
| Unauthenticated access | 公開MCPサーバー/網側で守るMCPサーバー | 認証不要のサーバー専用。利用前に規約とレート制限を要確認 |
この中で実務的価値が最も高いのはOAuth identity passthroughです。従来はユーザーのOneDrive・Salesforce・Jiraなどに対してサービスアカウントを用意する運用が一般的でしたが、OAuth identity passthroughを使えば、エージェントは「ユーザーが自分の権限で見られる範囲」にだけアクセスするため、情報漏洩リスクが構造的に下がります。金融・医療など情報アクセス監査が厳しい業界では、この方式を前提にした設計が標準になりつつあります。Entra系の2方式は2026年4月時点ではプレビュー扱いの機能があるため、本番採用時は最新ステータスを確認してください。
【関連記事】
Azure MCP Serverとは?使い方、料金、ツール一覧を徹底解説
データ処理とユーザーデータ削除
Foundry Agent Service FAQで公式に明示されているデータ処理方針は、以下の3点です。これ以上の「GDPR自動対応」「自動削除オプション」等の機能を断定する公式情報は2026年4月時点で確認できないため、要件があれば契約・設定レベルで対応する必要があります。
- モデル学習への非利用:顧客データはMicrosoftのモデル学習には使用されません
- 保持期間:データはAPI/SDKで明示的に削除するまで保持されます
- データレジデンシー:データはエンドポイントと同じリージョン内に保存されます(Standard SetupではAzure Storage/Cosmos DB/AI Searchを自分のサブスクリプション内に配置)
ユーザー単位でのデータ削除は、SDK 2.0.0のOpenAI互換クライアントから会話・ファイルを直接削除する実装で対応します。
Responses API系では会話状態をconversations、ファイルをfilesで扱うため、以下の流れになります。
openai = project.get_openai_client()
# 特定ユーザーの会話(metadataに user_id を埋めている前提)を削除
conversations = openai.conversations.list()
for conv in conversations.data:
if conv.metadata and conv.metadata.get("user_id") == "user_12345":
openai.conversations.delete(conversation_id=conv.id)
print(f"会話 {conv.id} を削除しました")
# アップロードファイルも削除
files = openai.files.list()
for f in files.data:
if f.filename.startswith("user_12345_"):
openai.files.delete(file_id=f.id)
print(f"ファイル {f.id} を削除しました")
セキュリティベストプラクティスとしては、以下の4点を運用開始時に組み込んでおくことをおすすめします。
-
最小権限の原則
エージェントには必要最小限のツールとデータアクセス権限のみ付与
-
定期的な監査
Azure Monitorのログを定期的にレビューし、異常なアクセスパターンを検知
-
プライベートエンドポイント使用
機密データを扱う場合は、パブリックインターネットを経由しない構成を選ぶ
-
バージョン管理
エージェントの指示文やツール設定を版管理し、変更履歴を追跡できるようにする
Microsoft Foundry Agent Serviceの料金体系と事前購入プラン
Foundry Agent Serviceの料金は、Promptエージェント・Workflowエージェントの作成・実行自体には追加課金がなく、使用したモデルのトークン消費量+ツール使用料+Azure基盤コストで構成されます。Hostedエージェントのマネージドランタイム課金は2026年4月1日から開始されており、関連Azureリソース(ACR・Application Insights等)の費用も別途発生します。

クォータと制限(2026年4月時点)
Agent Serviceにはリソース保護のためのサービス制限が設定されています。以下の表は公式ドキュメントに基づく主要な制限の一覧です。なお、Agent ServiceはAPIコール自体に独自のレート制限を設けていませんが、基盤となるモデルのTPM/RPM制限は適用されます。
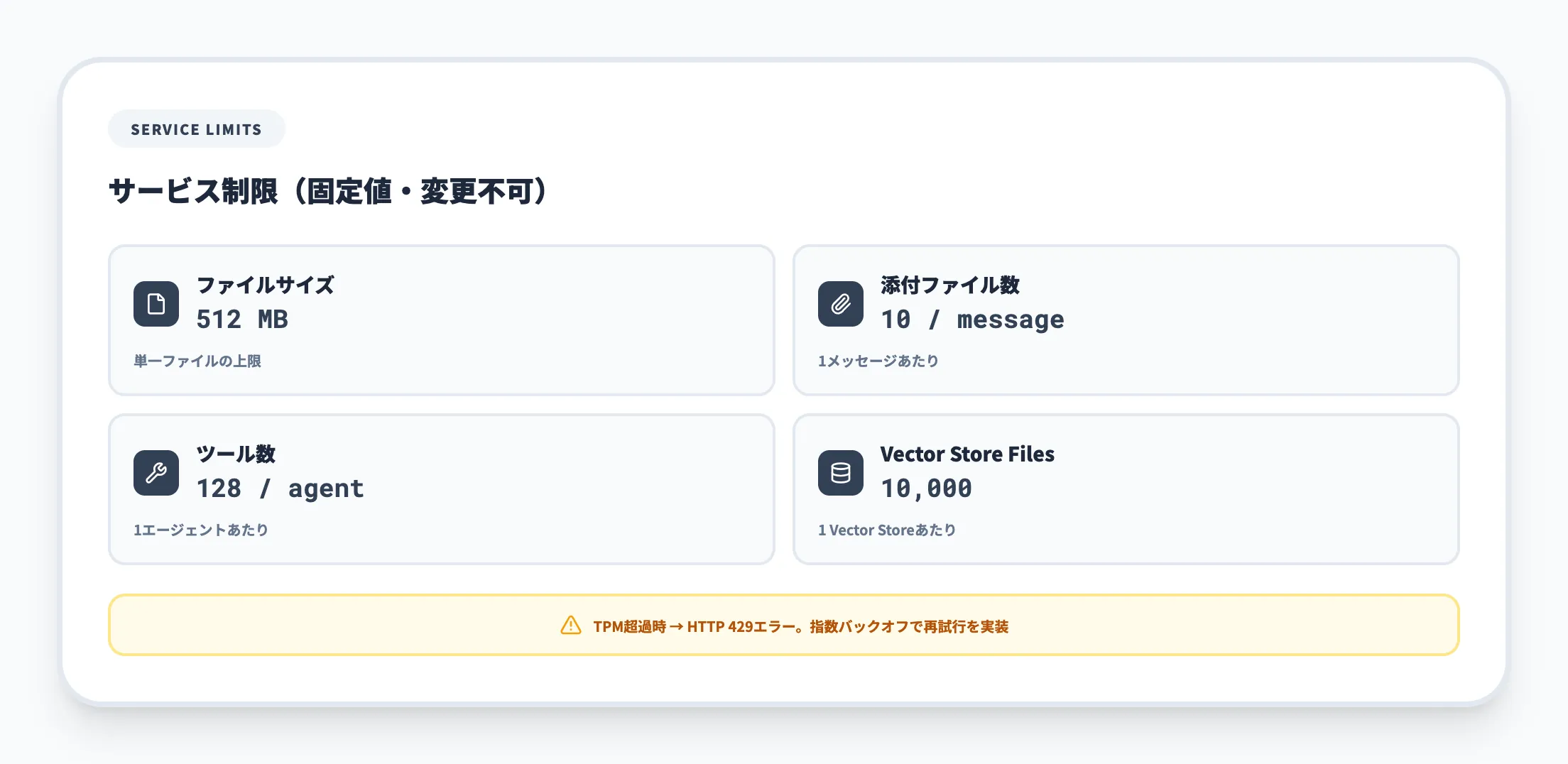
| 項目 | 制限値 | 変更可否 | 備考 |
|---|---|---|---|
| ファイルサイズ(1ファイル) | 512 MB | 固定 | アップロード可能な単一ファイルの上限 |
| エージェント/スレッドごとのファイル数 | 10,000 | 固定 | 1エージェントまたは1スレッドに紐付くファイル総数 |
| アップロードファイル合計(プロジェクト単位) | 300 GB | 固定 | Foundryプロジェクト全体でのファイル容量上限 |
| Vector Store添付ファイルのトークン数 | 2,000,000 トークン | 固定 | File Searchに使えるファイルあたりのトークン上限 |
| スレッドごとのメッセージ数 | 100,000 | 固定 | 1スレッドで保持できるメッセージの上限 |
| メッセージあたりのテキスト量 | 1,500,000 文字 | 固定 | 単一メッセージのテキストコンテンツ上限 |
| ツール数/エージェント | 128 | 固定 | 1エージェントに設定できるツールの上限 |
| Hostedエージェント同時アクティブセッション | 50/サブスクリプション/リージョン | 可(申請) | プレビュー時点のデフォルト |
これらのサービス制限は基本的に固定値で、サポートリクエストによる引き上げはHostedエージェントのセッション上限を除いてできません。モデル側のTPM(Tokens Per Minute)制限はAzure OpenAIのクォータ管理で調整可能です。
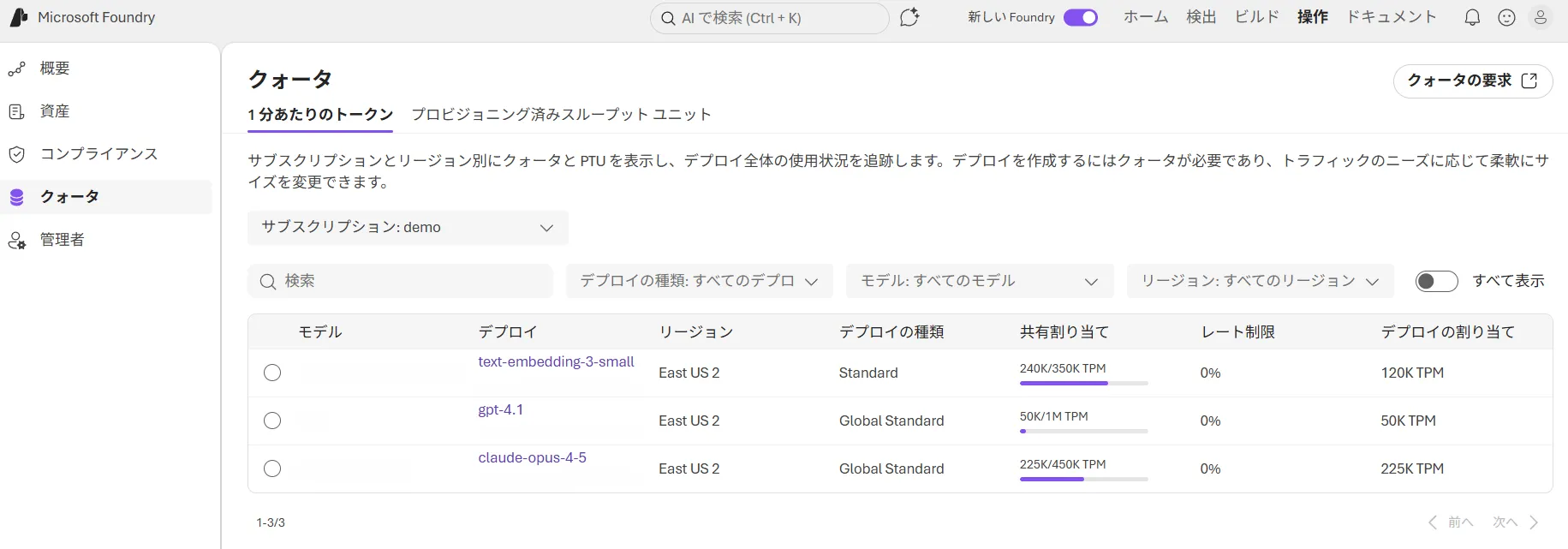
Quotas & Limits画面
本番運用で特に詰まりやすいのは、モデル側のTPM制限と、スレッドのメッセージ上限(100,000件)の2点です。長期間稼働するチャットセッションはスレッドローテーション設計(一定メッセージ数でアーカイブ→新スレッド発行)を必ず組み込みます。
代表的なエラーコードと推奨対応を以下にまとめます。
| エラーシナリオ | HTTPステータス | エラーコード | 推奨対応 |
|---|---|---|---|
| ファイルサイズ超過 | 400 | file_size_exceeded | ファイルを分割してアップロード |
| Vector Storeトークン上限 | 400 | token_limit_exceeded | ファイル内容を減らすか分割する |
| 会話メッセージ上限 | 400 | message_limit_exceeded | 新しい会話を発行する |
| メッセージ容量超過 | 400 | content_size_exceeded | 大容量はファイル化しFile Searchで参照 |
| ツール登録数超過 | 400 | tool_limit_exceeded | 未使用ツールを削除する |
| レート制限超過 | 429 | rate_limit_exceeded | ジッター付き指数バックオフで再試行 |
アプリケーション側で上記エラーコードを判定し、429はバックオフ再試行、400系は設計段階で構造を見直す、という切り分けが重要です。特にmessage_limit_exceededは長期運用ほど顕在化しやすく、会話状態を「セッション単位」とみなして使い捨てる設計にしておくと安定します。
以下は、Responses API呼び出しで429エラーを自動再試行する簡易な実装例です。
import time
import random
def respond_with_retry(openai, conversation_id, agent_name, user_input, max_retries=5):
"""クォータ超過時に自動再試行するResponses API呼び出し"""
for attempt in range(max_retries):
try:
return openai.responses.create(
conversation=conversation_id,
extra_body={
"agent_reference": {"name": agent_name, "type": "agent_reference"}
},
input=user_input,
)
except Exception as e:
status = getattr(e, "status_code", None)
if status == 429:
wait_time = (2 ** attempt) + (random.random() * 0.1)
print(f"クォータ超過。{wait_time}秒後に再試行します(試行 {attempt + 1}/{max_retries})")
time.sleep(wait_time)
else:
raise
raise Exception(f"{max_retries}回の再試行後もクォータ超過が解消されませんでした")
モデル別料金の考え方とAzure基盤コスト
コストの大部分はモデル実行コスト(トークン使用量)です。コスト最適化の鍵は「適切なモデル選択」と「トークン使用量の削減」です。Azure OpenAIモデル(直接販売)の料金は公式料金ページで確認できます。主な傾向として、gpt-5が最も高精度・高コスト、gpt-5-nanoが最も軽量・低コストです。
Azure Pricing Calculatorの見積もり画面
パートナー/コミュニティモデル(Claude、Llama等)はAzure Marketplaceのプロバイダー料金が適用されるため、上記とは別体系です。利用前にMarketplaceで最新料金を確認してください。
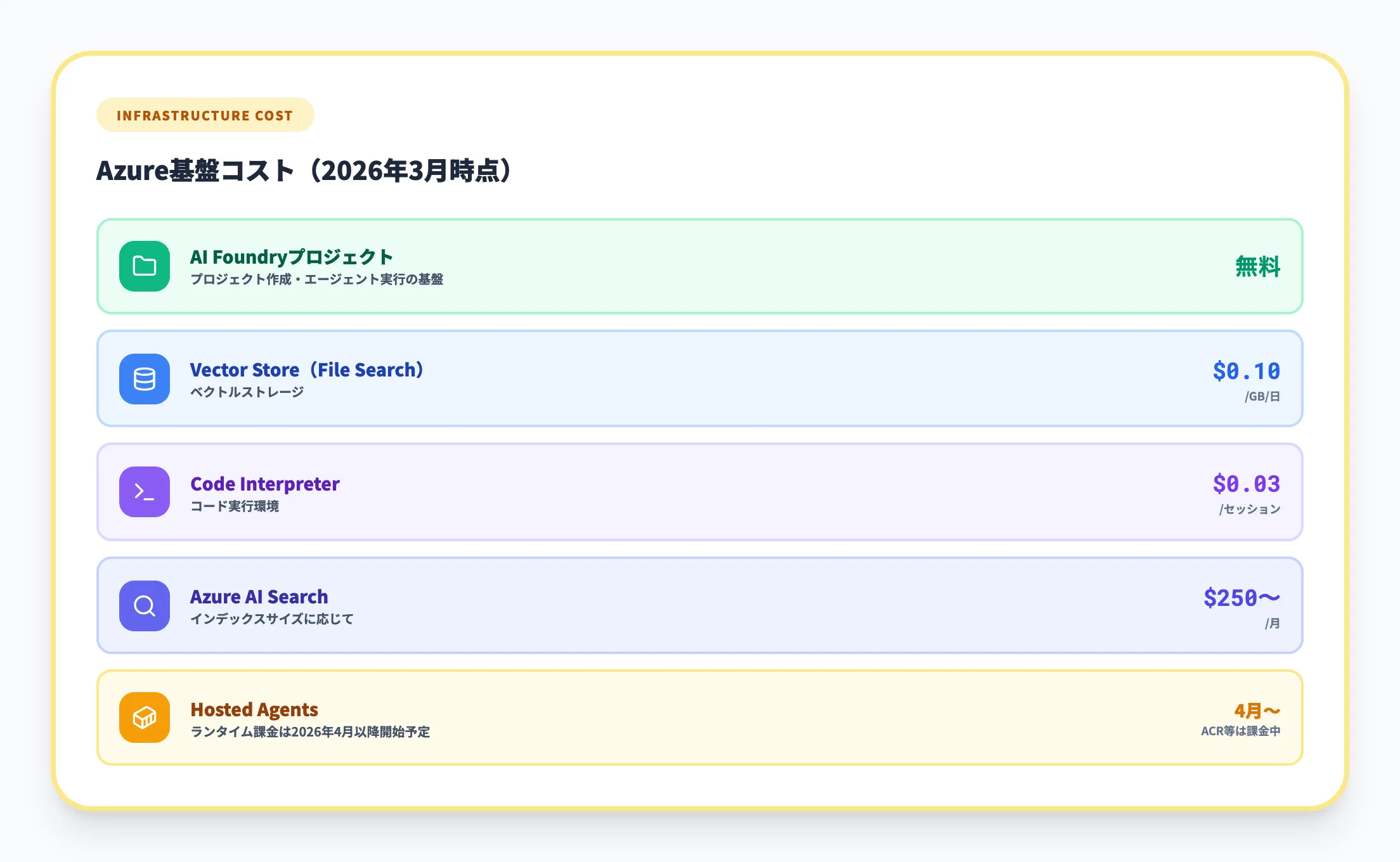
Azure基盤コストとしては、モデル以外に以下が発生します。
| リソース | 料金 | 備考 |
|---|---|---|
| Microsoft Foundryプロジェクト | 無料 | プロジェクト自体に課金なし |
| Vector Store(File Search) | $0.10/GB/日 | ベクトルストレージ |
| Code Interpreter実行 | $0.03/セッション | コード実行環境 |
| Azure AI Search | $250/月〜 | インデックスサイズに応じて |
| Hostedエージェント(ランタイム) | 2026年4月1日〜課金開始 | セッションのCPU/メモリ従量+関連Azureリソース(ACR・App Insights等) |
コスト最適化の基本は、問い合わせの複雑さに応じてモデルを振り分けることです。定型的な問い合わせには軽量モデル(gpt-5-nano/claude-haiku-4-5)、複雑な推論が必要な問い合わせにはフラッグシップ(claude-opus-4-6/o3)を使うと、品質を維持しながら全体コストを抑えられます。具体的な料金は公式料金ページで最新値を確認した上で、自社のトラフィックパターンに基づいて試算してください。
Microsoft Agent Prepurchase Plan(ACU)による事前購入割引
2026年3月、Microsoftは**AIエージェント向けの年間コミット型事前購入プラン「Microsoft Agent Prepurchase Plan」**の提供を開始しました。Agent Commit Units(ACU)を1年分まとめて購入することで、Microsoft Foundry・Copilot Studio・Fabric・GitHubの横断でAI利用料に充当できる仕組みです。
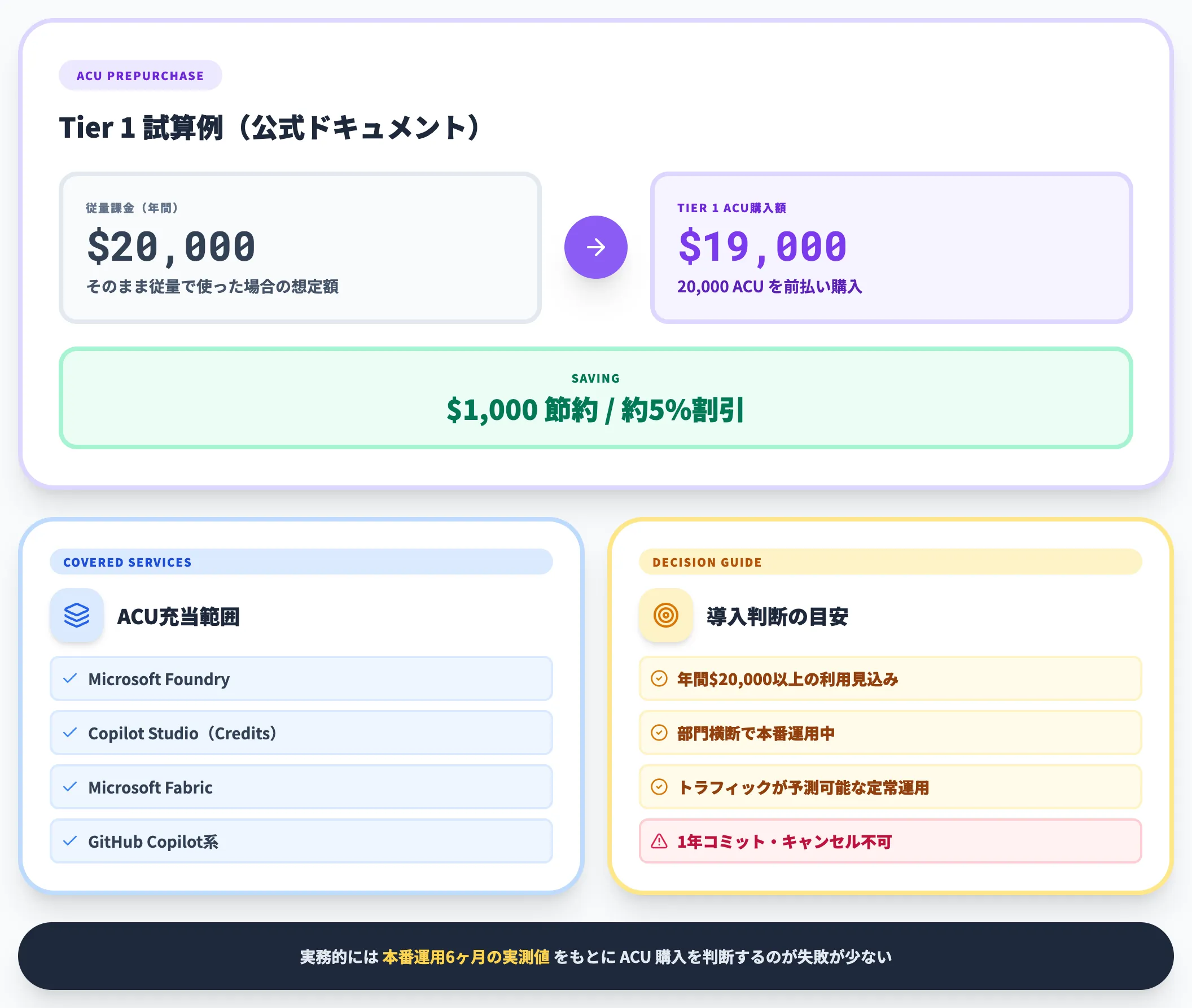
以下の表で、公式ドキュメントで公開されている試算例を整理しました。
| 購入ティア | 購入額 | 想定従量課金額 | 節約額 | 割引率 |
|---|---|---|---|---|
| Tier 1(20,000 ACUs) | $19,000 | $20,000 | $1,000 | 約5% |
ACUはFoundryトークン消費とCopilot Credit消費の両方に充当でき、余った分はFabricやGitHub Copilotの従量費用にも流用されます。適用順は (1) Foundry PTU予約、(2) Copilot Credit事前購入プラン、(3) ACU の順で、重複時は粒度の細かい割引が優先されます。
ACU導入を検討すべきケースは、以下の3つの条件が揃ったときです。
- 年間のFoundry + Copilot Studio利用額が$20,000(約300万円)以上の見込みがある
- 部門横断で複数のAIエージェントを本番運用している
- トラフィック量が予測できる定常運用フェーズに入っている
一方、PoCや月間コストが数万円レベルの段階では、キャンセル不可・1年コミットの制約がリスクになるため、従量課金のままのほうが無難です。AI総研の導入支援でも、本番運用開始から6ヶ月時点の実測値をもとにACU購入を判断する企業が多く、「まず半年回してから年間コミットを決める」運用が最も失敗が少ないパターンです。

Foundry Agent Serviceで構築したAgentを業務基盤として運用するなら
Agent Serviceのプロトタイプは動いた。ここから先は「1つのAgentの実験」ではなく「複数Agentが連携する業務基盤」としての設計が必要になります。
Promptで作ったFAQボット、Workflowで組んだ承認フロー、Hostedで書いたカスタムエージェントが増えていくほど、ガバナンス・観測・データ連携を横断的に見られる基盤が必要です。
AI Agent Hubは、Foundry Agent Serviceで構築したAgentを含め、全社のAIエージェントを1つのダッシュボードで一元管理できるエンタープライズAI基盤です。構築基盤を問わない統合管理で、PoCの先の本番運用を支援します。
-
Foundryで構築したAgentを含め全社管理を統合
Prompt・Workflow・HostedエージェントをFoundryで構築し、n8nやCopilot Studio製Agentも含めて1つの管理ダッシュボードに集約。構築基盤を問わない一元管理を実現します
-
AgentのデータアクセスにFabric OneLakeを活用
Foundryで構築したAgentが参照するデータをFabric OneLakeに仮想統合。基幹システムのデータをZero ETLで横断参照し、業務判断の精度を底上げします
-
使い慣れたMicrosoft環境をそのまま活用
Teams・Excel・Outlookなど既存ツールの延長でAIエージェントが動作。新しいツールの学習コストはゼロです
-
データは100%自社テナント内に保持
AIの学習対象から完全除外。Azure Managed Applicationsとして自社テナント内で動作が完了する設計です
AI総合研究所の専任チームが、設計から運用まで伴走支援します。まずは無料の資料で、自社の業務にどう活用できるかご確認ください。
Foundry AgentをAI業務基盤に拡張

構築した先の運用・管理・データ統合まで
Foundry Agent Serviceで構築したAIエージェントを、ガバナンスつきの業務基盤として全社展開。Fabric OneLakeのデータ統合と一元管理で、PoCの先の本番運用を支援します。
まとめ
Microsoft Foundry Agent Service(旧Azure AI Foundry Agent Service/Azure AI Agent Service)は、2025年5月にPromptエージェントがGAされ、2026年3月16日にResponses APIベースの次世代ランタイムが正式GAとなった、Microsoft製フルマネージドのAIエージェント開発プラットフォームです。Workflow/Hostedエージェントや音声エージェント連携は2026年4月時点でパブリックプレビュー、Evaluations・Tracing(Promptエージェント)・SDK 2.0.0などはGAという段階的な進化が続いており、Microsoft Agent Prepurchase Plan(ACU)で年間コミット予算のある企業には新たなコスト最適化手段も提供されています。
本記事で解説した価値は、以下の3点に集約されます。
-
ノーコードからフルコードまで対応する3エージェント種別
Promptエージェントで数分のPoC、Workflowエージェントで複数ステップの業務自動化、Hostedエージェントで独自フレームワークのコンテナデプロイと、開発チームのスキルと要件に応じた最適な選択が可能です。Fujitsuが営業提案書自動作成で67%の生産性向上を達成したように、適切なエージェント種別の選択が成果を左右します
-
Microsoft Foundry全体でForrester TEI調査ROI 327%の実績
これはAgent Service単体ではなくFoundryプラットフォーム全体の数値ですが、3年間で$49.5Mの定量的な効果が報告され、投資回収期間は6か月以内です。パイロットプロジェクトの成果を定量データとして経営層に示せることが、全社展開への予算承認を加速します
-
エンタープライズグレードのセキュリティとガバナンス
BYO VNetベースのプライベートネットワーキング、エージェント専用Entra ID、Tracing/EvaluationsによるObservability、MCPサーバー認証5方式により、金融・医療・法務などコンプライアンス要件が厳しい業界でも段階的な導入が進められます。KPMG Claraが規制産業の監査基盤として採用されている実績が、その信頼性を裏付けています
「AIエージェントに興味はあるが、どこから手をつければいいか分からない」という状況であれば、まずはAzure無料試用版(初月$200クレジット)でPromptエージェントを1つ作ることから始めてください。社内FAQの問い合わせ対応や、定型的なドキュメント検索の自動化が最もPoC効果を実感しやすいユースケースです。Promptエージェントの作成は無料で、課金はモデルのトークン消費量のみから発生します。
本記事の「使い方」セクションのコード例と公式クイックスタートを参考にすれば、最初のエージェントは30分以内に動作確認できます。成果が確認できたら、本記事の段階的導入アプローチに沿ってWorkflowエージェントやHostedエージェントに拡張していくのが、AI総研の導入支援でも最も成功率の高いパターンです。
参考リンク:










