この記事のポイント
 AWSでML基盤を統合したいならSageMaker、基盤モデルをAPI利用するだけならBedrockが選びやすい
AWSでML基盤を統合したいならSageMaker、基盤モデルをAPI利用するだけならBedrockが選びやすい- ノーコード(Canvas)からフルカスタム(HyperPod)まで、チーム構成に合わせた段階導入が可能
- HyperPod Checkpointless Trainingで障害復旧2分以内・95% goodput、Cursor/Kiro IDEからの直接接続にも対応
- 無料枠(初回2ヶ月)でノートブック250時間・トレーニング50時間を使えるため、PoCコストを抑えて検証可能
- Savings Plansで最大64%のコスト削減。JFEスチールやPerplexityの学習40%高速化など実績が導入判断の参考になる

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Amazon SageMakerは、AWSが提供するデータ・分析・機械学習・生成AI開発を統合した次世代マネージドプラットフォームです。2024年12月のリブランドにより、従来のML特化サービスはAmazon SageMaker AIに改称され、Unified StudioやLakehouseを含む「データ・分析・AIの中心」として再定義されました。
本記事では、SageMaker AI・Unified Studio・Lakehouse・Canvas・HyperPodの5大コンポーネントから、3大クラウドML基盤との比較、料金体系、国内外の導入事例までを体系的に解説します。
目次
SageMaker Unified Studio(統合開発環境)
SageMaker Lakehouse(データレイクハウス)
Forethought Technologies(MLコストの最適化)
Amazon SageMaker vs Azure Machine Learning vs Vertex AI
Amazon SageMakerとは?
Amazon SageMakerは、AWSが提供するデータ・分析・機械学習・生成AI開発を統合した次世代マネージドプラットフォームです。データ準備からモデル学習、デプロイ、BI分析、生成AI構築までを一つの環境でカバーし、企業のデータ活用を一気通貫で支えます。

2017年のサービス開始以来、AWSのML基盤として広く使われてきましたが、2024年12月のre:Invent 2024で次世代プラットフォームとして大幅にリブランドされました。現在のSageMakerは「データ・分析・AIの中心」として、ML開発だけでなくデータレイクハウスやBIツールとの統合まで含む包括的なプラットフォームに進化しています。
従来のML環境とSageMaker AIの違い
機械学習プロジェクトを自社で進める場合、GPUインスタンスの調達、学習環境の構築、モデルのバージョン管理、推論エンドポイントのスケーリングなど、コードを書く以外の作業が膨大に発生します。SageMaker AI(次世代Amazon SageMakerにおけるML開発コンポーネント)は、これらのインフラ管理をAWSに任せ、データサイエンティストがモデル開発に集中できる環境を提供します。
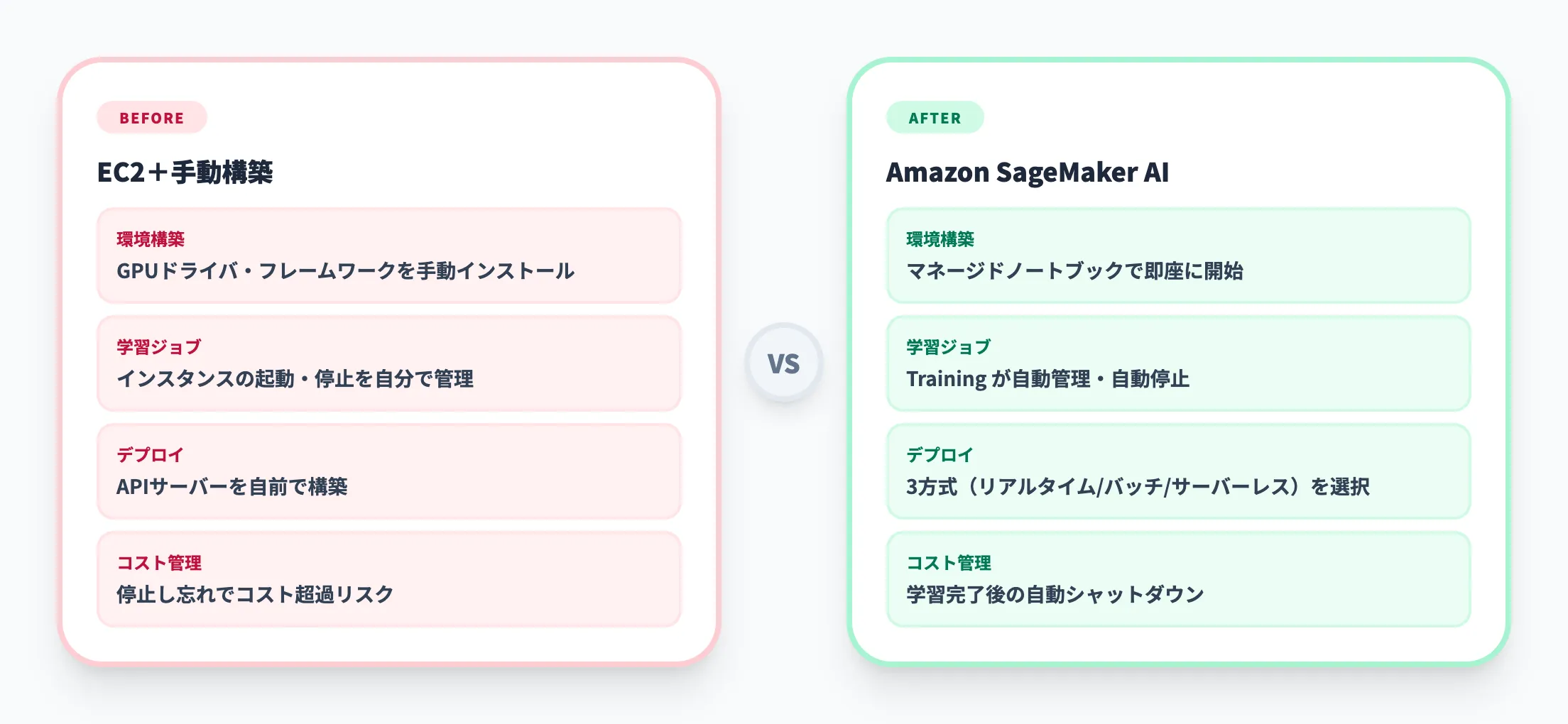
以下の表で、従来のML環境とSageMaker AIの違いを整理しました。
| 項目 | 従来のML環境(EC2+手動構築) | Amazon SageMaker AI |
|---|---|---|
| 環境構築 | GPUドライバ・フレームワークを手動インストール | マネージドノートブックで即座に開始 |
| 学習ジョブ | インスタンスの起動・停止を自分で管理 | SageMaker Trainingが自動管理・自動停止 |
| モデルデプロイ | APIサーバーを自前で構築 | リアルタイム・バッチ・サーバーレス推論を選択するだけ |
| スケーリング | Auto Scalingの設定を自前で実装 | 自動スケーリング組み込み |
| 実験管理 | MLflowなどを別途導入 | SageMaker Experimentsで標準対応 |
| コスト管理 | インスタンスの停止し忘れでコスト超過リスク | 学習完了後の自動シャットダウンで無駄を削減 |
この表が示すように、SageMaker AIを使うことでMLプロジェクトのインフラ運用コストが大幅に下がります。特に「GPUインスタンスの停止し忘れ」による想定外のコスト発生は、ML初期導入で頻繁に起きる問題ですが、SageMaker AIのTrainingジョブは学習完了後に自動でリソースを解放するため、この問題が構造的に解消されます。
SageMaker AIへの進化(2024年12月〜)
2024年12月、AWSは次世代のAmazon SageMakerを発表しました。この刷新で、従来のML開発機能はSageMaker AIとして再定義され、新たにデータレイクハウスや統合開発環境が加わっています。
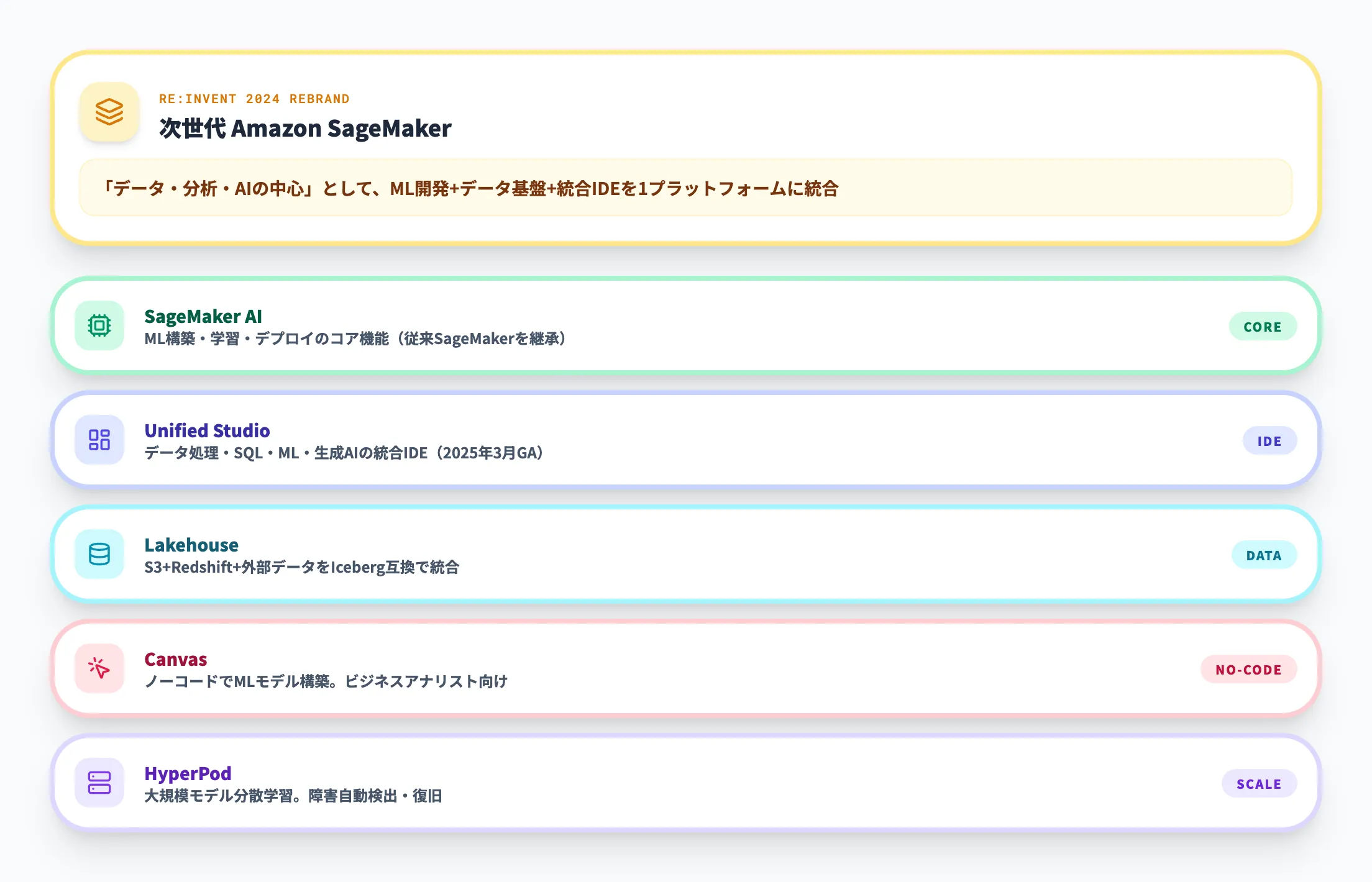
刷新後のSageMakerは、以下の5つのコンポーネントで構成されています。
- SageMaker AI
ML モデルの構築・学習・デプロイを担うコア機能。従来のSageMakerの主要機能を継承
- SageMaker Unified Studio
データ処理・SQL分析・ML開発・生成AI構築を一つの画面で行える統合開発環境。2025年3月にGA(一般提供)
- SageMaker Lakehouse
S3データレイク、Redshiftデータウェアハウス、サードパーティデータをApache Iceberg互換で統合するデータレイクハウス
- SageMaker Canvas
ノーコードでMLモデルを構築できるビジュアルツール。ビジネスアナリスト向け
- SageMaker HyperPod
大規模モデルの分散学習に特化したマネージドクラスター基盤。詳細はSageMaker HyperPodとはで解説
つまり、現在のSageMakerは「MLツール」の枠を超えて、企業のデータ基盤とAI開発を一つのプラットフォームに統合する役割を担っています。Amazon Bedrockが「既存の基盤モデルをAPIで手軽に使う」サービスなのに対し、SageMakerは「自社データでモデルを育てる・データ基盤ごと統合する」サービスという位置付けです。

Amazon SageMakerの主要機能
SageMakerは、MLの初心者からデータサイエンティスト、インフラエンジニアまで、それぞれの役割に応じた機能を提供しています。ここでは5つの主要コンポーネントを、実務での使いどころとともに解説します。
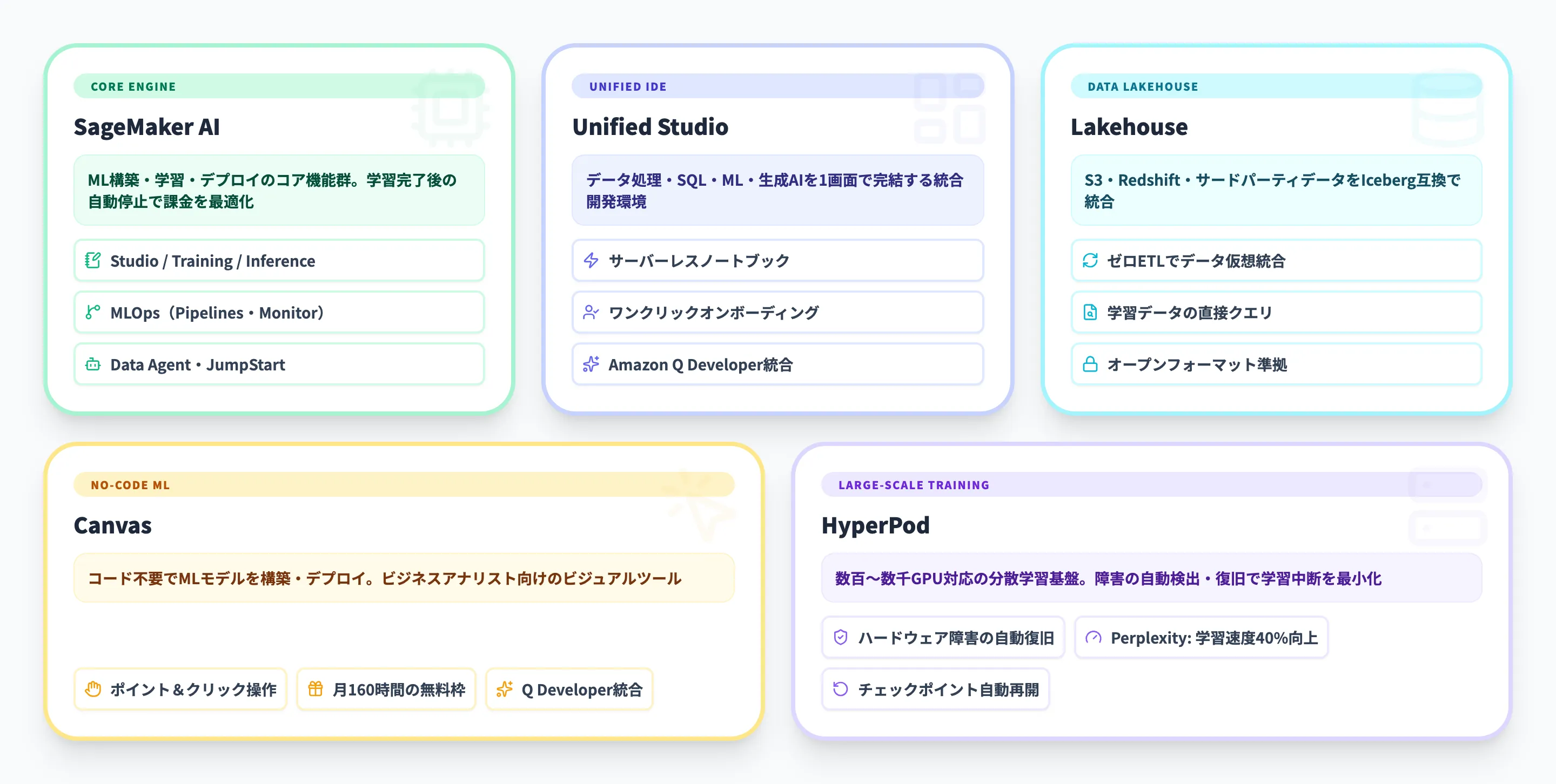
SageMaker AI(ML構築・学習・デプロイ)
SageMaker AIは、MLモデルのライフサイクル全体をカバーするSageMakerのコア機能群です。「データの前処理→モデルの学習→デプロイ→モニタリング」という一連の流れを、すべてマネージド環境で実行できます。学習フレームワークはTensorFlow・PyTorch・XGBoost・Scikit-learnなど主要なものに対応しているため、既存のコード資産をそのまま持ち込めます。
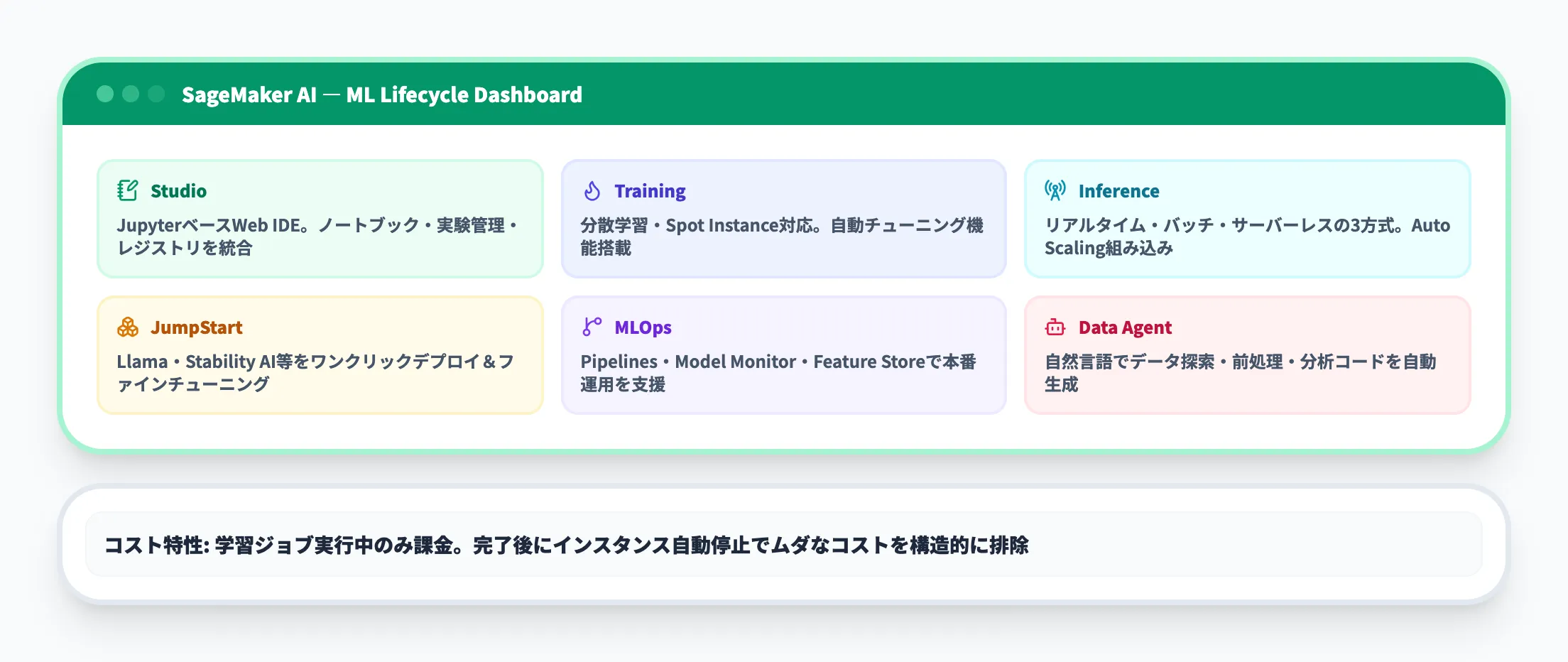
以下がSageMaker AIの主要機能です。
- Studio
JupyterベースのWeb IDEで、ノートブック編集・実験管理・モデルレジストリ・デバッグまでを一画面で操作できる統合環境
- Training
分散学習やSpot Instanceの活用に対応したマネージド学習基盤。ハイパーパラメータの自動チューニング機能も搭載
- Inference
リアルタイム推論、バッチ推論、サーバーレス推論の3種類から用途に応じて選択可能。Auto Scalingが組み込まれている
- JumpStart
事前学習済みモデル(Hugging Face、Meta Llama、Stability AI等)をワンクリックでデプロイし、ファインチューニングもできるモデルハブ
- MLOps(Pipelines・Model Monitor・Feature Store)
CI/CDパイプラインの構築、本番モデルの品質監視、特徴量の一元管理など、本番運用に必要な機能群
- Data Agent
自然言語で指示するだけで、データの探索・前処理・分析コードの生成を自動化するAIアシスタント。2026年4月に日本・豪州向け geo-specific inference 対応
SageMaker AIの強みは、学習ジョブの実行中だけ課金される従量課金制と、学習完了後にインスタンスが自動停止される仕組みにあります。EC2でGPUインスタンスを常時起動する構成と比べて、コストの予測と管理がしやすい設計です。
SageMaker Unified Studio(統合開発環境)
SageMaker Unified Studioは、データエンジニアリング・SQL分析・ML開発・生成AIアプリ構築を一つのWeb画面で完結させる統合開発環境です。2025年3月にGA(一般提供)となりました。
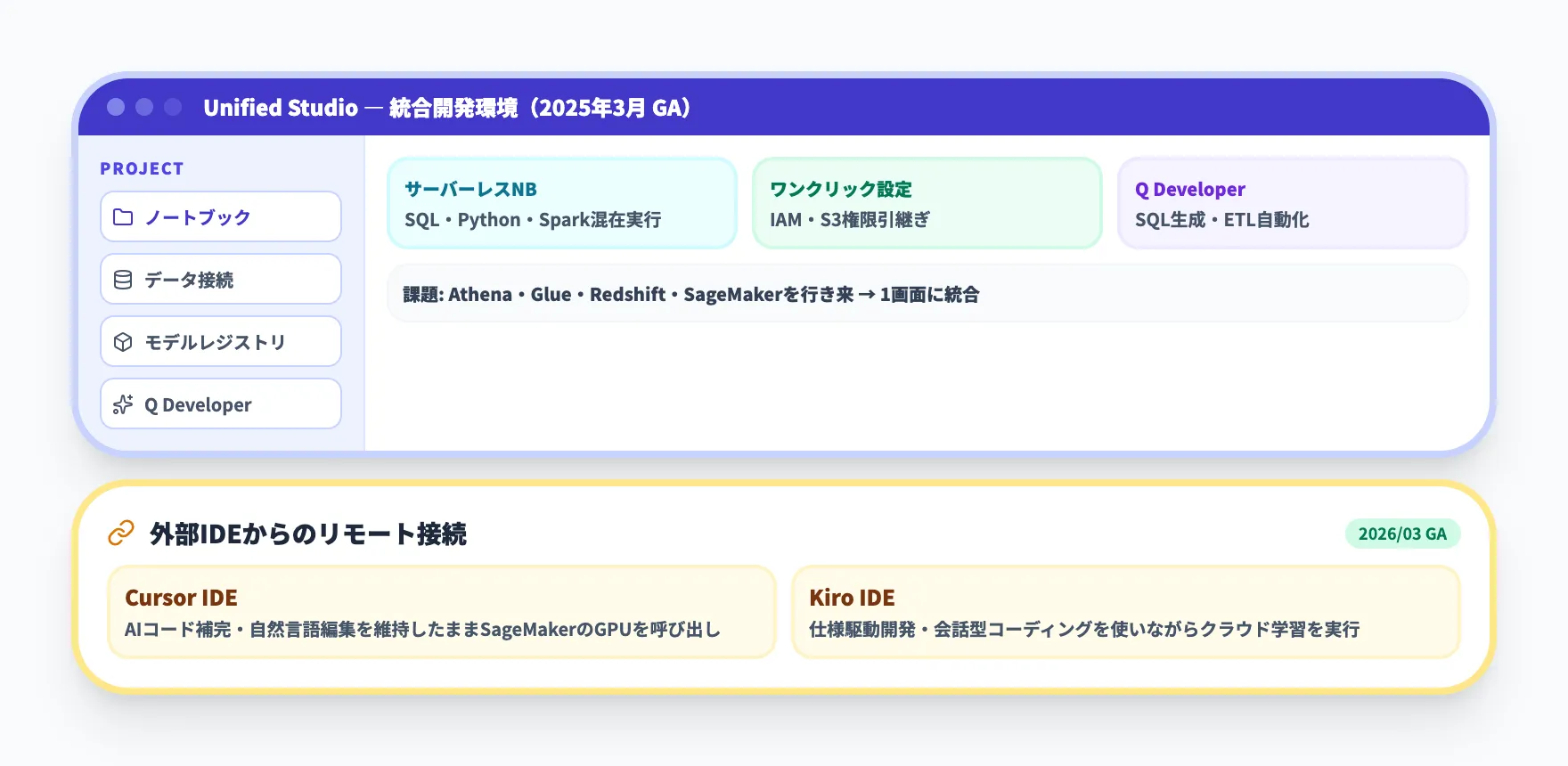
従来、AWS上でデータ分析とML開発を行うには、Amazon Athena、AWS Glue、Amazon Redshift、SageMaker Studioといった複数のコンソールを行き来する必要がありました。Unified Studioはこれらを1つのプロジェクト画面に統合し、チーム内の異なる役割(データエンジニア・アナリスト・データサイエンティスト)が同じ環境で作業できるようにしています。
主な特徴を以下にまとめます。
- サーバーレスノートブック
SQL・Python・Apache Sparkを1つのノートブックで混在実行できる。バックエンドにAmazon Athena for Apache Sparkを使い、ペタバイト規模のデータ処理にもスケール
- ワンクリックオンボーディング
既存のIAMロールとS3バケットの権限をそのまま引き継げるため、数週間かかっていた初期設定が数分で完了
- Amazon Q Developer統合
自然言語でSQLクエリの生成、ETLジョブの作成、トラブルシューティングを支援するAIアシスタントが組み込まれている
- Cursor / Kiro IDE リモート接続
2026年3月、ローカルのCursor IDEとKiro IDEからSageMaker Unified Studioへリモート接続できるようになり、各IDEのAI支援機能(コード補完・自然言語編集・仕様駆動開発)を維持したままSageMakerのスケーラブルなコンピュートにアクセス可能
データとMLツールが分離していると「データの準備に全工数の7割を取られる」というのはML現場の定番の課題です。Unified Studioはこの問題に対するAWSの回答であり、データの発見からモデルのデプロイまでをシームレスにつなぐことを目指しています。Cursor・Kiro対応によって、開発者は使い慣れたエディタ環境のままクラウドのGPUリソースを呼び出せるため、ローカル開発とクラウド学習の境界がさらに薄くなりました。
SageMaker Lakehouse(データレイクハウス)
SageMaker Lakehouseは、Amazon S3上のデータレイク、Amazon Redshiftのデータウェアハウス、サードパーティのデータソースをApache Iceberg互換のオープンフォーマットで統合するデータレイクハウス基盤です。
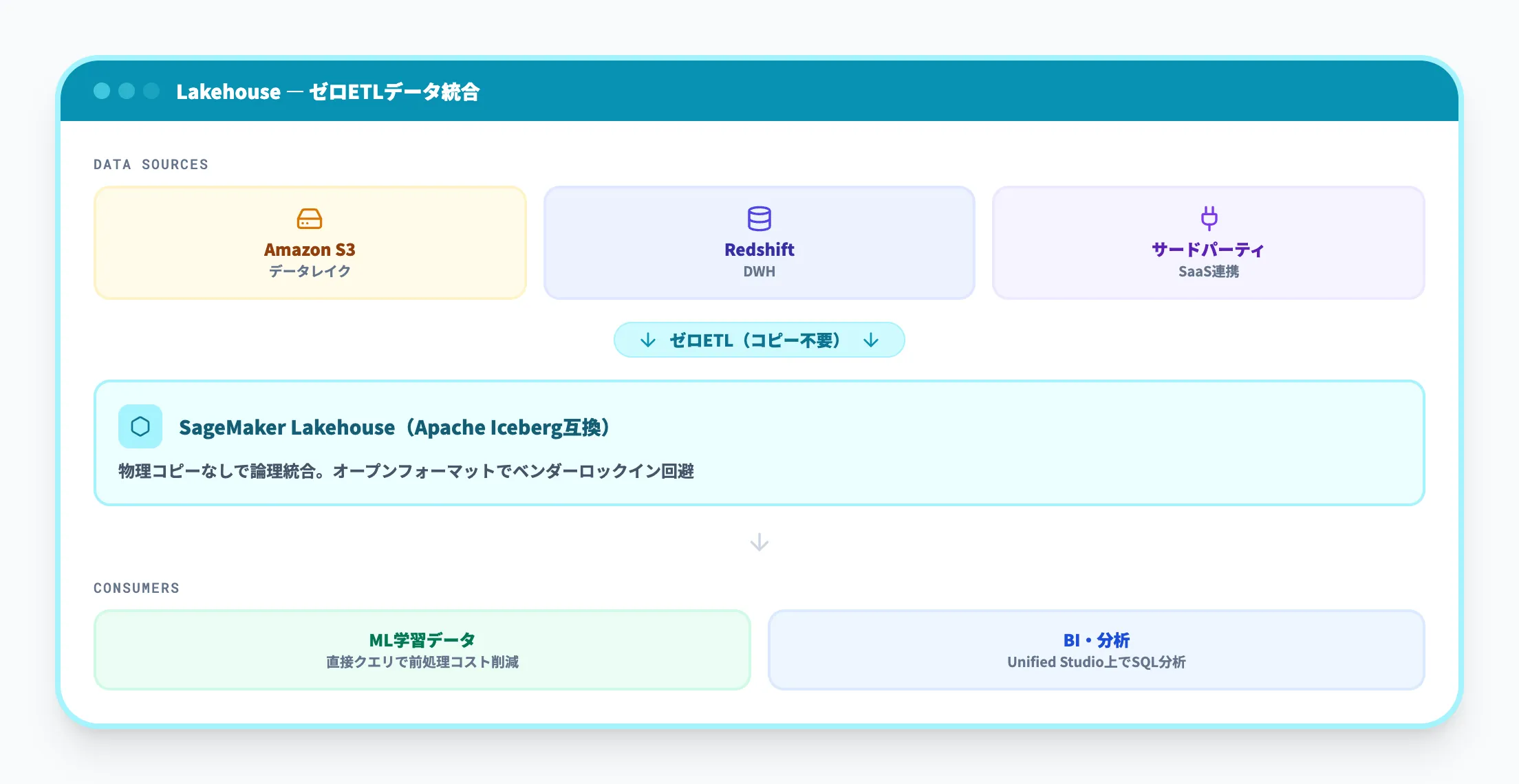
企業のデータは通常、S3のログデータ、Redshiftの業務データ、SaaSからの連携データなど、複数の場所に散在しています。Lakehouseは「ゼロETL統合」によって、これらのデータをコピーせずに一つの論理的なデータストアとして扱えるようにします。Aurora MySQL/PostgreSQL、RDS for MySQLに加え、Salesforce・ServiceNow・Zendeskといった主要SaaSがゼロETL対応に含まれており、運用系のデータを分析基盤に取り込む手間が大幅に下がっています。
re:Invent 2025ではAmazon DynamoDB との zero-ETL 統合も追加され、NoSQLで保持しているトランザクションデータをコピーや変換なしでLakehouse側からクエリできるようになりました。Apache Iceberg互換フォーマットで保存されるため、ACID準拠の高速SQL分析やタイムトラベルクエリ(過去スナップショットの参照)といった機能もそのまま使えます。
ML開発の観点で重要なのは、学習データの準備コストが下がる点です。従来は「S3のログを前処理してRedshiftに入れ、そこからSageMakerに渡す」といった多段階のETL(データ加工・変換)パイプラインが必要でしたが、Lakehouseではデータがある場所にそのままクエリを発行し、学習データとして直接利用できます。
SageMaker Canvas(ノーコードML)
SageMaker Canvasは、コードを書かずにMLモデルを構築・デプロイできるビジュアルポイント&クリック型のMLツールです。主にビジネスアナリストや、ML経験のない業務担当者をターゲットにしています。
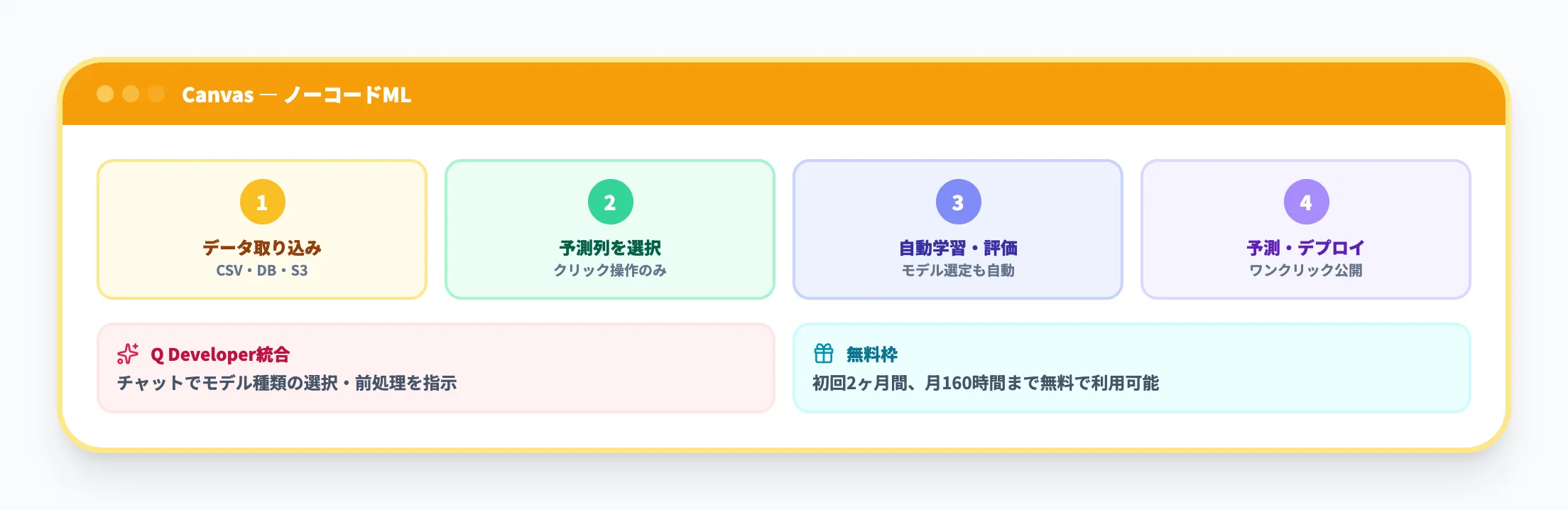
CSVファイルやデータベースからデータを取り込み、予測したい列を選ぶだけで、Canvasが自動的にデータのクレンジング・モデルの選定・学習・評価を行います。需要予測AI、顧客離反予測、不正検知といった典型的なMLユースケースに対応しています。
2026年時点では、Amazon Q DeveloperがCanvasにも統合されており、チャットベースの自然言語インターフェースでモデルの種類を選んだり、データの前処理を指示したりすることが可能です。
Canvasは初回2ヶ月間、月160時間まで無料で利用できるため、MLの導入検証をコードなしで始めたい場合の入口として適しています。
SageMaker HyperPod(大規模学習基盤)
SageMaker HyperPodは、大規模言語モデル(LLM)や基盤モデルの分散学習に特化したマネージドクラスター基盤です。数百〜数千のGPUを使った学習ジョブで発生するハードウェア障害の検出と自動復旧を行い、学習の中断を最小限に抑えます。
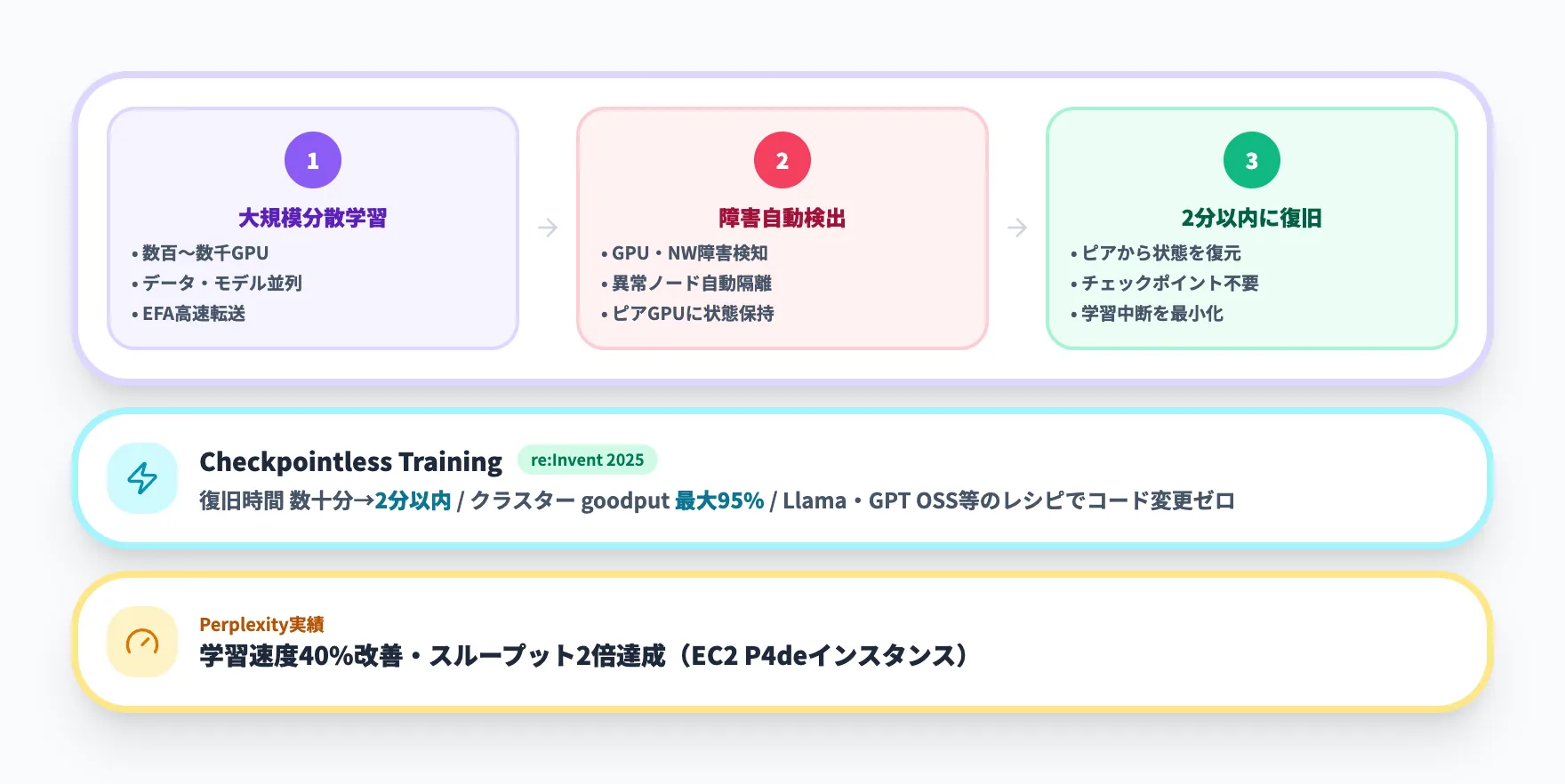
HyperPodの最大の価値は、大規模学習で避けられないハードウェア障害への自動対応です。数週間〜数ヶ月にわたる学習ジョブでは、GPUやネットワークの故障が統計的に避けられません。HyperPodは障害を検出すると自動的にノードを修復・交換し、最後のチェックポイントから学習を再開する仕組みを備えています。
re:Invent 2025ではCheckpointless Trainingが発表され、障害復旧の仕組みがさらに強化されました。従来は数十分〜数時間かかっていた復旧時間が2分以内に短縮され、数千GPU規模のクラスターでも最大95%のトレーニングgoodputを達成できます。チェックポイント保存の代わりに、各GPUがピアGPU上にモデルシャードのコピーを保持する仕組みになっており、Llama・GPT OSS等のレシピを使えばコード変更なしで有効化できる点も実務上の負担を抑えています。
Perplexityの事例では、HyperPodの分散学習ライブラリを活用することで基盤モデルの学習速度を40%改善し、学習スループットを2倍に引き上げています。
2026年1月にはライフサイクルスクリプトのデバッグ機能が強化され、クラスターノードの起動時に発生する問題の特定と解決が容易になりました。
Amazon SageMakerの使い方
SageMakerを使い始めるまでの手順は、2025年3月のUnified Studio GAによって大幅に簡素化されています。ここでは、AWSアカウントを持っている前提で、ML開発を始めるまでの流れを解説します。

Unified Studioのセットアップ
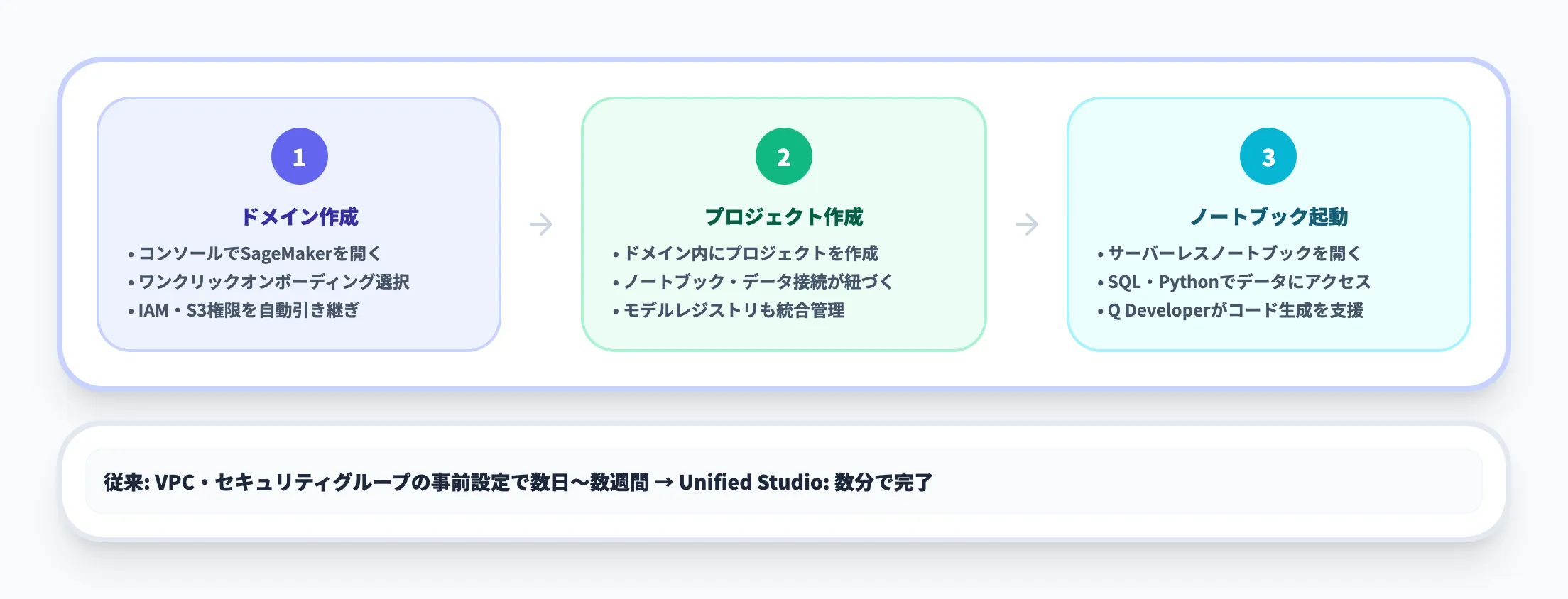
SageMaker Unified Studioの初期設定は、以下の3ステップで完了します。
- ステップ1 ドメインの作成
AWSマネジメントコンソールでSageMakerを開き、Unified Studioのドメインを作成する。ワンクリックオンボーディングを選択すると、既存のIAMロールとS3権限がそのまま引き継がれる
- ステップ2 プロジェクトの作成
ドメイン内にプロジェクトを作成する。プロジェクトにはノートブック・データ接続・モデルレジストリがまとめて紐づく
- ステップ3 ノートブックの起動
サーバーレスノートブックを開き、SQLまたはPythonでデータにアクセスする。Amazon Q Developerが画面右側に常駐しており、自然言語でコード生成を依頼できる
従来のSageMaker Studioでは、VPCやセキュリティグループの事前設定が必要で、初期設定に数日〜数週間かかるケースも珍しくありませんでした。Unified Studioのワンクリックオンボーディングにより、この手間が数分に短縮されています。
ノートブックでのモデル開発
Unified Studioのサーバーレスノートブックは、SQL・Python・Apache Sparkを1つのノートブック内で切り替えて使用できます。

典型的なMLモデルの開発フローは以下のとおりです。
- データの探索 SQLセルでLakehouse上のデータに直接クエリを発行し、学習対象のデータセットを確認
- データの前処理 Pythonセル(またはSageMaker Data Wrangler)でクレンジング・特徴量エンジニアリングを実施
- モデルの学習 SageMaker Trainingジョブを起動。学習用インスタンスが自動で起動し、完了後に自動停止する
- 実験の記録 SageMaker Experimentsにハイパーパラメータ・メトリクス・モデルアーティファクトが自動保存される
コードを書かずに進めたい場合は、SageMaker Canvasに切り替えることで、同じデータに対してビジュアルUIでモデル構築を行うこともできます。
モデルのデプロイと推論
学習したモデルを本番環境にデプロイする方法は、用途に応じて3種類から選択できます。
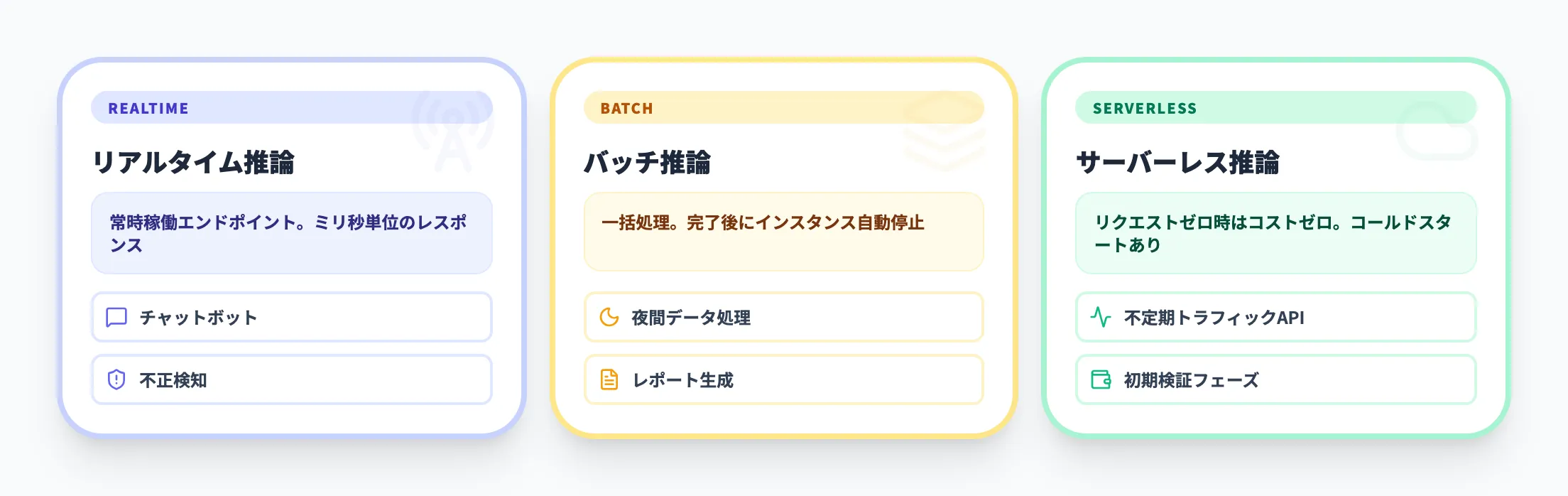
以下の表で、推論方式の使い分けを整理しました。
| 推論方式 | ユースケース | 特徴 |
|---|---|---|
| リアルタイム推論 | チャットボット、レコメンド、不正検知 | 常時稼働のエンドポイント。ミリ秒単位のレスポンス |
| バッチ推論 | 夜間の大量データ処理、レポート生成 | 一括処理。処理完了後にインスタンス自動停止 |
| サーバーレス推論 | トラフィックが不定期なAPI | リクエストがない間はコストゼロ。コールドスタートあり |
リアルタイム推論は応答速度が最も重要なシナリオ(顧客対応チャットや決済時の不正検知)に向きます。一方、夜間バッチで翌朝のレコメンドリストを生成するような用途なら、バッチ推論でコストを大幅に抑えられます。
トラフィックが読めない段階であれば、まずサーバーレス推論で始めてコストを最小化し、リクエスト数が安定してきたらリアルタイム推論に切り替えるのが実務的なアプローチです。

Amazon SageMakerの導入事例
SageMakerは、製造業からテクノロジー企業まで、幅広い業界で採用されています。ここでは、定量的な成果が公開されている4つの事例を紹介します。
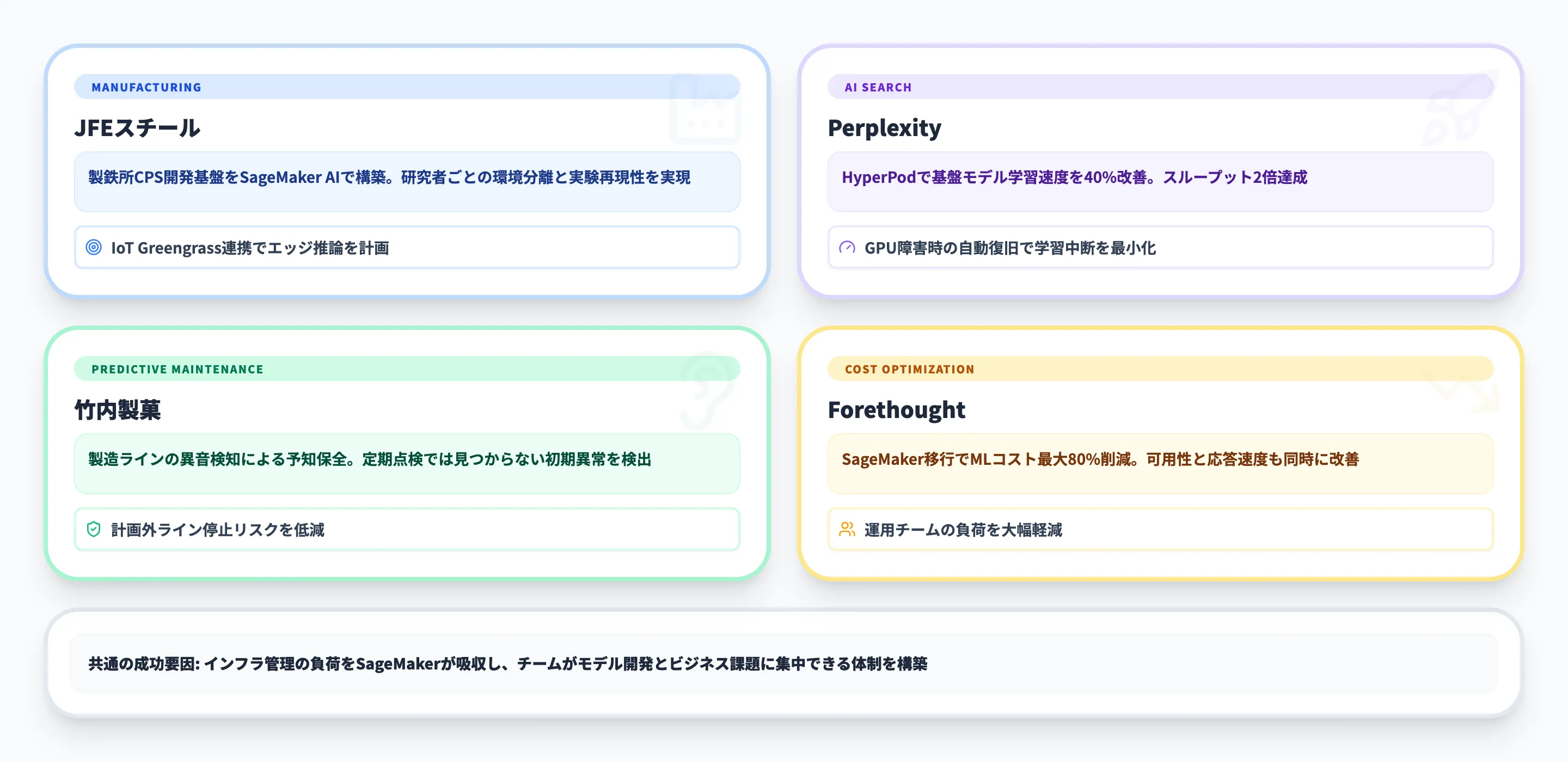
JFEスチール(製鉄所CPS開発基盤)
JFEスチールは、製鉄所のプロセス全体をデジタル空間に再現する「インテリジェント製鉄所」構想のもと、SageMaker AIを中核としたCPS(サイバーフィジカルシステム)開発実行基盤を構築しました。

JFEシステムズとAWSの3社協業で進められたこのプロジェクトでは、以下の課題を解決しています。
- 研究者ごとの環境分離 従来は開発環境を共有しており、ライブラリの競合が頻発。SageMaker AIの個別インスタンスで解消
- 環境構築の簡素化 GPUドライバやフレームワークの手動セットアップが不要に
- 実験の再現性向上 SageMaker Trainingがハイパーパラメータやモデルの格納場所を自動記録。過去の実験をいつでも再現可能
今後はAWS IoT Greengrassとの統合により、SageMaker AIで開発したモデルを製鉄所のエッジサーバーに配信し、リアルタイム推論を行う計画です。
Perplexity(基盤モデル学習の高速化)
AI検索サービスを提供するPerplexityは、SageMaker HyperPodを活用して基盤モデルの学習速度を40%改善しました。
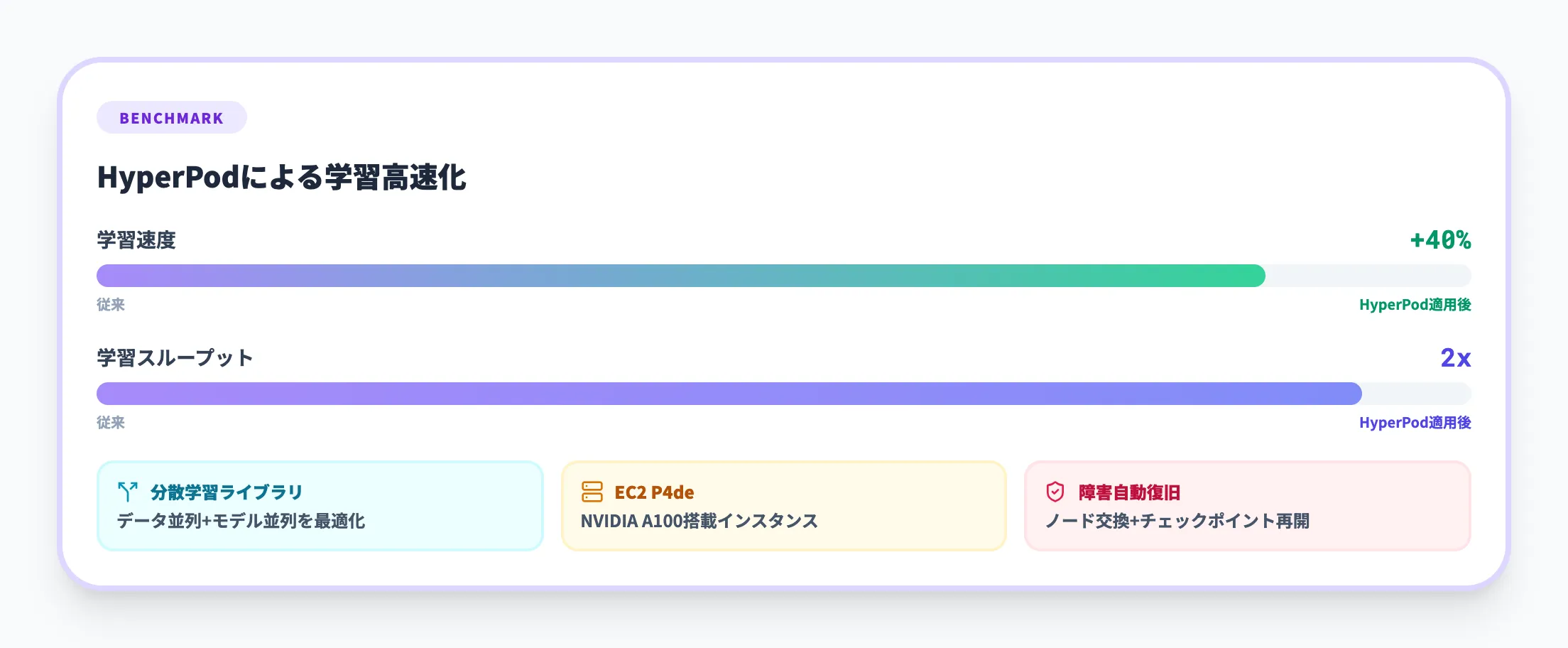
HyperPodに内蔵された分散学習ライブラリ(データ並列・モデル並列)を使うことで、GPU間のデータ転送を最適化し、学習スループットを2倍に引き上げています。EC2 P4deインスタンス(NVIDIA A100搭載)上で実行され、ハードウェア障害時は自動的にノードを交換して最後のチェックポイントから学習を再開します。
基盤モデルの学習ジョブは数週間〜数ヶ月に及ぶため、40%の短縮はGPU利用料の直接的な削減にもつながります。
竹内製菓(異音検知による予知保全)
竹内製菓は、製菓製造ラインのチェーンコンベアに発生する異音を検知するために、SageMaker AIを使った予知保全システムを導入しました。
コンベア設備で録音した音声データをAmazon S3に保存し、SageMaker AIでMLモデルを学習させることで、設備故障の予兆を検出できるようになっています。従来の定期点検では見つけられなかった初期段階の異常を機械学習で検知し、計画外のライン停止リスクを低減しています。
Forethought Technologies(MLコストの最適化)
カスタマーサポートAIを提供するForethought Technologiesは、SageMaker AIへの移行によってMLコストを最大80%削減しました。
SageMaker AIのマネージドインフラによってインスタンスの最適化が自動化され、可用性と応答速度の改善も同時に達成しています。自社でGPUクラスターを管理していた時代と比べて、運用チームの負荷も大幅に軽減されました。
これらの事例に共通するのは、SageMakerがインフラ管理の負荷を吸収することで、チームがモデル開発やビジネス課題の解決に集中できるようになった点です。特にML基盤の運用を自社で抱えている企業にとっては、SageMakerへの移行が運用コストと人的リソースの両面で効果を発揮しています。
【関連記事】
AIエージェントを企業に導入する全手順|事例・費用も解説
Amazon SageMakerの検証を業務実装まで進める

モデル開発の先にある業務接続・運用設計を整理
Amazon SageMakerでモデル開発を進めても、実運用では業務フローへの接続、権限管理、運用監視まで含めた設計が必要です。AI Agent HubのLPで、Amazon SageMakerの検証を業務実装につなぐ全体像をご確認ください。
Amazon SageMaker vs Azure Machine Learning vs Vertex AI
MLプラットフォームの選定では、AWS・Azure・Google Cloudそれぞれが提供するML基盤を比較するケースが多くなります。ここでは3サービスの特徴と選定基準を整理します。
なお本セクションのAmazon SageMakerは、2024年12月にリブランドされた次世代統合プラットフォーム(SageMaker AI / Unified Studio / Lakehouse / Canvas / HyperPodを含む)として比較しています。Azure Machine Learning・Vertex AIはML開発に焦点を当てた構成のため、SageMaker側のほうがカバー範囲は広い点を踏まえてご覧ください。

3大ML基盤の比較表
以下の表で、3サービスの主要な違いをまとめました。
| 比較項目 | Amazon SageMaker | Azure Machine Learning | Google Vertex AI |
|---|---|---|---|
| 提供開始 | 2017年 | 2018年(現行版) | 2021年 |
| 統合IDE | Unified Studio(GA) | Azure ML Studio | Vertex AI Workbench |
| ノーコードML | Canvas | AutoML + Designer | AutoML |
| 大規模学習 | HyperPod | AML Compute Cluster | Vertex AI Training |
| モデルハブ | JumpStart | Azure AI Model Catalog | Model Garden |
| データレイクハウス | Lakehouse(Iceberg) | Microsoft Fabric Lakehouse | BigLake |
| MLOps | Pipelines + Model Monitor | AML Pipelines + Endpoints | Vertex AI Pipelines |
| 生成AI統合 | Bedrock連携 | Azure OpenAI連携 | Gemini連携 |
| 無料枠 | 初回2ヶ月 | 無料アカウント枠 | 初回利用クレジット |
| 東京リージョン | 対応 | 対応(Japan East) | 対応 |
機能面ではどのサービスも「データ準備→学習→デプロイ→モニタリング」のML全工程をカバーしており、大きな差は出にくくなっています。実務上の選定ポイントは機能比較よりも、自社の既存環境との統合コストです。
どう選ぶか
ML基盤の選定は、自社のデータとワークロードがどのクラウドに集中しているかで決まるケースがほとんどです。
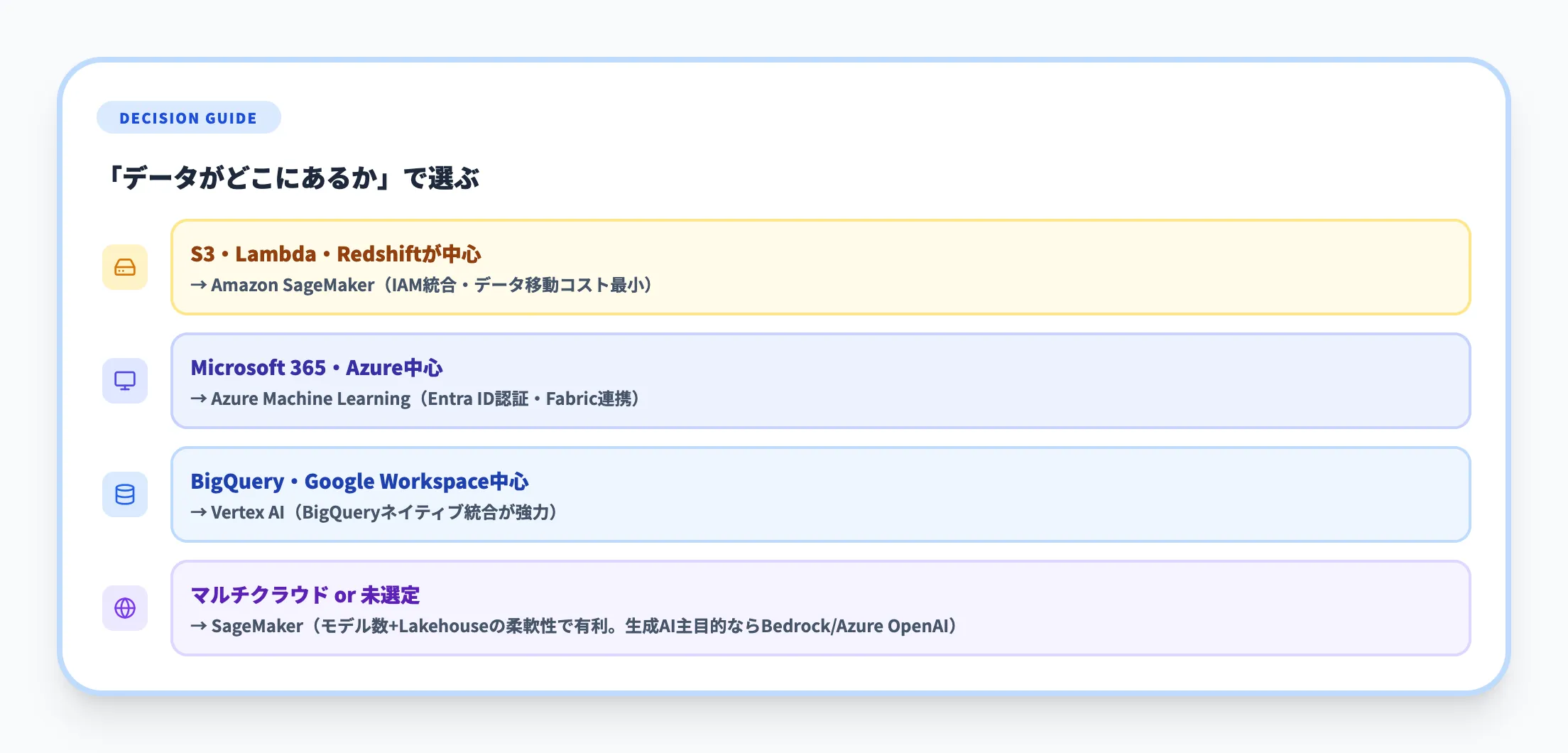
- AWS資産がメインの場合
S3・Lambda・Redshiftなど既存のAWS資産との連携コストが小さく、IAMによるアクセス管理も統一できる。SageMakerが最初の検討候補になりやすい
- Microsoft 365 / Azure中心の場合
Azure Machine Learningを選べば、Microsoft Entra ID(旧Azure AD)による認証統合やMicrosoft Fabricとのデータ連携が自然につながる
- BigQuery / Google Workspace中心の場合
Vertex AIはBigQueryとのネイティブ統合が強力。データ分析基盤がGCP上にまとまっているなら移動コストを抑えやすい
- マルチクラウドまたは未選定の場合
対応モデル数の多さとデータレイクハウスの柔軟性からSageMakerで検証を始めやすい。ただし生成AIのAPI利用が主目的なら、Amazon BedrockやAzure OpenAIで先にPoCを回すほうが早い場合もある
「どのサービスが優れているか」よりも「自社のデータがどこに集約されているか」を起点に選ぶほうが、結果的にコストと時間の浪費を抑えやすくなります。
【関連記事】
AzureとAWSの料金、サービス、性能を徹底比較
Kiroとは?AWSが開発した"仕様駆動"の次世代AI IDEの概要・料金・使い方を解説
Amazon SageMakerの料金体系
SageMakerの料金は従量課金制で、使用した機能・インスタンスタイプ・稼働時間に応じて課金されます。「基本料金ゼロ、使った分だけ支払う」という構造のため、小規模な検証から大規模な本番運用まで柔軟にスケールできます。

無料利用枠(初回2ヶ月)
SageMakerには初回2ヶ月間の無料枠が用意されており、PoCや学習目的で主要機能を試すことができます。
| 対象機能 | 無料枠の内容 |
|---|---|
| Studioノートブック | ml.t3.mediumインスタンス250時間 |
| トレーニング | m4.xlarge / m5.xlargeインスタンス50時間 |
| リアルタイム推論 | m4.xlarge / m5.xlargeインスタンス125時間 |
| サーバーレス推論 | オンデマンド推論15万秒 |
| Canvas | セッション時間 月160時間 |
| HyperPod | m5.xlargeインスタンス50時間 |
この無料枠で、モデルの学習から推論エンドポイントの構築まで一通り検証できます。特にCanvasの月160時間はノーコードML検証に十分な量であり、ビジネスチームがコードなしでMLの価値を体感するのに適しています。
オンデマンド料金
無料枠を超えた後は、使用したインスタンスタイプと稼働時間に基づく従量課金になります。以下は代表的なインスタンスの参考価格です。
| インスタンスタイプ | 用途 | 東京リージョン参考価格 |
|---|---|---|
| ml.t3.medium | ノートブック・軽量処理 | 約$0.065/時間 |
| ml.m5.xlarge | トレーニング・推論(汎用) | 約$0.298/時間 |
| ml.g5.xlarge | GPU学習・推論(NVIDIA A10G) | 約$1.69/時間 |
| ml.p4d.24xlarge | 大規模学習(NVIDIA A100×8) | 約$45.22/時間 |
2026年4月時点の参考価格です。最新の正確な料金はAWS公式の料金ページで確認してください。東京リージョンはUS Eastと比べて10〜30%程度の上乗せがある場合があります。
料金を抑えるポイントは、学習ジョブにSpot Instanceを活用することです。SageMaker TrainingはManaged Spotトレーニングに対応しており、オンデマンド価格から最大90%の割引で学習ジョブを実行できます。中断のリスクはありますが、チェックポイント機能と組み合わせることで、コストを大幅に削減できます。
Savings Plans(最大64%割引)
長期的にSageMakerを使うことが確定している場合、SageMaker Savings Plansで最大64%のコスト削減が可能です。
| 項目 | 内容 |
|---|---|
| コミット期間 | 1年または3年 |
| 最大割引率 | 64%(3年・全額前払い) |
| 対象 | ノートブック・トレーニング・推論・Data Wrangler・バッチ変換 |
| 支払い方法 | 全額前払い / 一部前払い / 前払いなし |
Savings Plansは「1時間あたり○ドル」という使用量コミットメントに対して割引が適用される仕組みです。インスタンスファミリーやリージョンを問わず柔軟に適用されるため、利用パターンが変わっても無駄になりにくい設計になっています。
まずはオンデマンドで利用パターンを把握し、3〜6ヶ月の実績データをもとにSavings Plansの適用を検討するのが実務的な進め方です。
Amazon SageMaker利用時の注意点と導入判断
SageMakerは機能が豊富な反面、導入時に判断を迷いやすいポイントがあります。ここでは、実務で特に問われる論点を整理します。
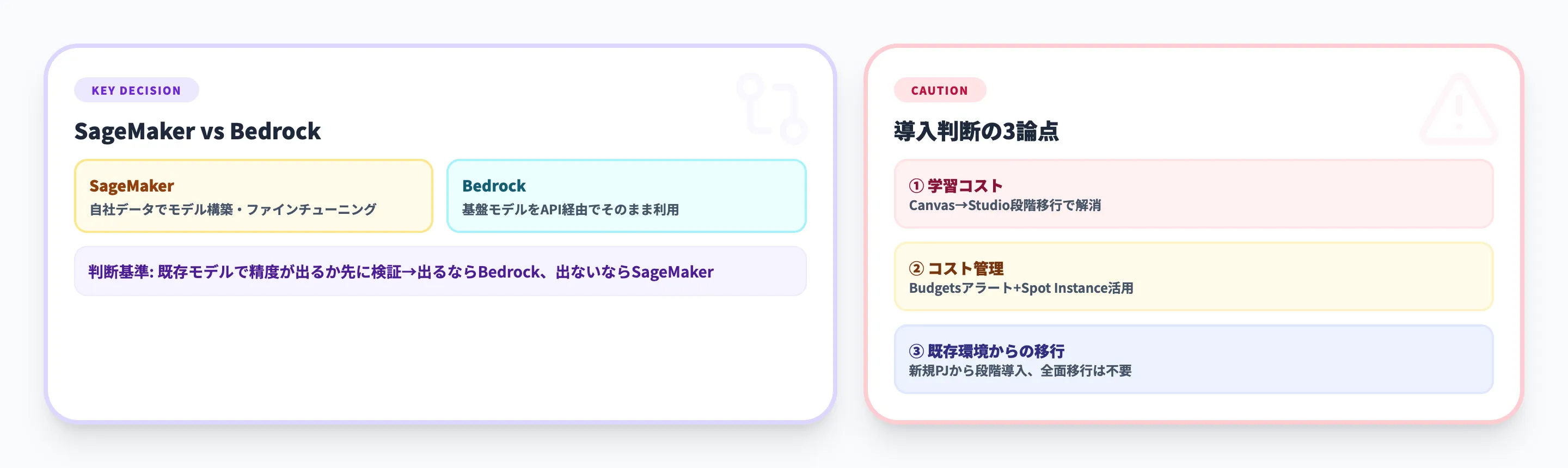
SageMakerとBedrockの使い分け
AWS上でAIを活用する際、最も多い質問が「SageMakerとBedrockのどちらを使うべきか」です。結論としては、モデルを自社で育てるか、既存モデルをAPIで使うかで分かれます。

| 判断基準 | SageMaker | Bedrock |
|---|---|---|
| 主な目的 | 自社データでモデルを構築・ファインチューニング | 基盤モデルをAPI経由でそのまま利用 |
| 想定ユーザー | データサイエンティスト・MLエンジニア | アプリ開発者・業務チーム |
| データ活用 | 学習データとして直接使用 | RAG(検索拡張生成)やプロンプトで間接利用 |
| 運用負荷 | 中〜高(モデル管理・MLOpsが必要) | 低(APIコールのみ) |
| 代表的なユースケース | 需要予測、異常検知、独自モデル開発 | チャットボット、文書要約、コード生成 |
実務では両者を排他的に選ぶ必要はありません。たとえば、「社内文書の検索・要約はBedrockのRAGで構築し、製造ラインの品質予測はSageMakerで独自モデルを開発する」という併用パターンは多くの企業で見られます。
迷った場合の判断手順としては、まず「既存の基盤モデル(Claude、Llama等)で十分な精度が出るか」をBedrockで検証し、要件を満たすならそのままBedrock、満たせない場合のみSageMakerでのファインチューニングやカスタムモデル構築に進む順序が、初期投資とリスクのバランスを取りやすくなります。基盤モデルで完結する用途なら、Amazon Bedrock Agentsを使ってツール連携まで含めたワークフローを組むという選択肢もあります。
導入判断で詰まる論点
SageMakerの導入を検討する際に、よく挙がる3つの論点を整理します。

学習コストと必要なスキルセット
SageMakerは機能が豊富な分、チーム内に一定のスキルが求められます。Canvasであればノーコードで使えますが、本格的なモデル開発にはPythonとMLの基礎知識が必要です。
段階的なアプローチとしては、まずCanvasでMLの価値を体感し、その後SageMaker Studioでの本格開発に移行する、という2段構えが効果的です。AWS公式のセットアップガイドと無料枠を活用すれば、初期投資ゼロで学習を始められます。AI PoCの進め方で解説しているように、小さく始めて成果を確認してからスケールするのが導入成功のカギです。
コスト管理の難しさ
SageMakerの従量課金は柔軟な反面、利用量の予測が難しいという声は多く聞かれます。特に学習ジョブの試行錯誤フェーズでは、想定以上のGPU利用時間が発生しがちです。
対策としては、AWS Budgetsでコストアラートを設定する、SageMaker TrainingのManaged Spot Instanceを活用する(最大90%割引)、学習ジョブの最大実行時間をパラメータで制限する、の3点が有効です。
既存のML環境からの移行判断
すでにEC2上でJupyterHub+自前のMLパイプラインを構築している場合、SageMakerへの移行コストが論点になります。移行のメリットはインフラ管理からの解放ですが、既存のパイプラインのリファクタリングが必要になるケースもあります。
全面移行ではなく、新規プロジェクトからSageMakerを使い始め、既存環境との共存期間を設けるのが現実的です。SageMaker Python SDKは既存のPythonコードとの親和性が高いため、学習ジョブの部分だけ先にSageMakerに移すといった段階的な移行が可能です。

Amazon SageMakerの検証を業務実装まで進めるなら
Amazon SageMakerでモデル開発や評価を進められても、実業務で使われる状態にするには、どの業務フローへ組み込むか、誰がどのモデルを使えるか、出力結果をどう管理するかまで設計する必要があります。
特に、推論APIと既存システムを接続し、部門運用へ広げる段階では、精度検証だけでなく権限、監査ログ、運用体制の整理が欠かせません。ここが曖昧だと、PoC後に止まりやすくなります。AIエージェントとしてフルスタックで業務に組み込むには、モデル開発の先にあるツール連携や承認フローの設計まで含めた検討が必要です。
AI総合研究所のAI Agent Hub資料では、Amazon SageMakerやBedrockのような既存AI基盤を前提に、業務システム連携、管理ダッシュボード、実行導線の整備をどう進めるかを整理しています。Amazon SageMakerの検証を業務実装へつなぐ判断材料としてご確認ください。
Amazon SageMakerの検証を業務実装まで進める
モデル開発の先にある業務接続・運用設計を整理
Amazon SageMakerでモデル開発を進めても、実運用では業務フローへの接続、権限管理、運用監視まで含めた設計が必要です。AI Agent HubのLPで、Amazon SageMakerの検証を業務実装につなぐ全体像をご確認ください。
まとめ
Amazon SageMakerは、データ・分析・機械学習・生成AI開発を統合した次世代マネージドプラットフォームです。2024年12月のリブランドで、従来の機械学習サービスはAmazon SageMaker AIに改称され、それを中心にUnified Studio・Lakehouse・Canvas・HyperPodを束ねる包括的なプラットフォームへ進化しました。
本記事の要点を3つにまとめます。
- 段階的に始められる
Canvasのノーコードから、SageMaker AIのフルカスタム開発、HyperPodの大規模学習まで、チームの成熟度に合わせてスケールアップできる。無料枠(初回2ヶ月)で主要機能を一通り検証可能
- データ基盤とMLを統合できる
SageMaker LakehouseとUnified Studio、2026年追加のCursor/Kiro IDE連携により、データの分散管理という構造的な課題を解消。データの準備に費やしていた時間をモデル開発に振り向けやすくなる
- Bedrockとの使い分けが鍵
基盤モデルのAPI利用ならBedrock、自社データでのモデル構築ならSageMaker。両者は排他的ではなく、用途に応じた併用が実務上の現実解
最初の一歩としては、SageMaker Canvasの無料枠で自社データを使ったML予測を試し、価値が確認できた段階でSageMaker AIでの本格開発に進む2段階のアプローチが取り組みやすい進め方です。MLが業務にどう効くかを小さく検証してから投資判断するほうが、PoC止まりのリスクを抑えやすくなります。










