この記事のポイント
 AI導入を「PoC止まり」にしないにはPeople・Process・Technology・Dataの4軸を並行整備、1軸だけの先行投資は効果が限定的
AI導入を「PoC止まり」にしないにはPeople・Process・Technology・Dataの4軸を並行整備、1軸だけの先行投資は効果が限定的- インフラはGPUクラスタ・クラウド・エッジのハイブリッド構成が最適解。オンプレミス単独やクラウド単独では将来のスケーラビリティに限界があるため避けるべき
- データ整備はAI Readyの最重要ボトルネック。メタデータ・カタログ・リネージの整備とRAGを見据えたアクセス制御を、AI導入より先に着手すべき
- 人材ギャップと経営層の理解不足が最大の阻害要因であり、技術投資の前にリテラシー研修と経営層向けROI可視化を優先すべき
- まずは5領域の自己評価チェックリストでギャップを特定し、改善ロードマップを策定してから段階的にAI導入を進めるのが最適な順序

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
「AI Ready」とは、AIツールを導入するだけでなく、組織全体が継続的かつ安全にAIを活用できる土台が整った状態を指します。
インフラ・データ・業務プロセス・人材の4つの軸がバランスよく整備されていることが条件であり、どれか1つだけ優れていても不十分です。
本記事では、AI Readyを構成する4つの要素を体系的に整理し、自社の現状を評価するチェックリストや、導入を阻む課題への対策までを2026年3月時点の情報を交えて解説します。
AI Readyとは?定義と4つの構成要素

AI Ready(AIレディ)とは、組織がAIを「安全に」「継続的に」活用できる準備が整った状態を指す概念です。ここでは、AI Readyの定義と、評価の軸となる4つの構成要素を整理します。

AI Readyの捉え方
「AI Ready」という言葉は、使う主体によって意味合いが異なります。
以下に代表的な定義を整理しました。
| 主体 | AI Readyの定義 |
|---|---|
| 内閣府(統合イノベーション戦略推進会議) | AI戦略2019において、「人間中心のAI社会原則」を"AI-Readyな社会"における社会的枠組みとして位置づけ |
| インフラベンダー | GPU・ネットワーク・ストレージなど、AIワークロードに対応したインフラが整った状態 |
| データ基盤ベンダー | 品質・ガバナンスを備えた「AI-ready data」が利用可能な状態 |
| コンサルティング/SI | 組織文化・プロセス・人材を含む包括的なトランスフォーメーションが進んだ状態 |
本記事では特定の製品に依存せず、企業が実務的にAIを継続活用できる状態を「AI Ready」と定義します。
そのうえで、Google CloudのAI Adoption Frameworkをはじめ複数のベンダー資料でも採用されているPeople・Process・Technology・Dataの4軸で整理します。
People・Process・Technology・Dataの4つの軸

AI Readyの達成度は、以下の4つの観点から評価します。
-
People(人材・スキル)
経営層から現場まで、AIの活用方法だけでなく限界やリスクも含めた基本理解が共有されている状態。
データリテラシーやAIリテラシーを持つ人材が組織内に一定数いることが前提となる
-
Process(プロセス・ガバナンス)
AI案件の企画・検証・本番化のプロセスが定義されている状態。
モデルの評価・モニタリング・改善・廃止といったライフサイクル管理のルールが整備されていることが条件となる
-
Technology(インフラ・ツール)
AIワークロードを支えるインフラ(GPUクラスタ、クラウド基盤、AI PCなど)と、運用を支える技術的な仕組み(MLOps基盤、ログ・監査、API連携など)が整っている状態
-
Data(データ)
AIが利用できるレベルに整備された「AI-ready data」が存在する状態。
データ品質・ガバナンス・カタログ・系譜(リネージ)が一定水準を満たしていることが条件となる
4つのどれか1つが優れていても「AI Ready」とは言いづらく、バランスが重要です。
まずは自社のボトルネックがどの軸にあるかを見極めることが、最初の一歩になります。
なぜ今AI Readyが企業に求められるのか

AI Readyは、もはや一部の先進企業だけの課題ではありません。ここでは、AI Readyが今なぜ重要なのか、その背景を整理します。
生成AI時代の競争環境の変化

2024年以降、生成AIの業務活用が急速に広がり、AIを使えるかどうかが企業の競争力を左右する状況になっています。
企業への生成AI導入はすでに多くの業種で進んでおり、その範囲は日々拡大しています。
特にMicrosoft 365 CopilotやGoogle Workspaceのように、日常業務のSaaSにAI機能が標準搭載されるようになったことで、「AIを使うかどうか」ではなく「AIを組織として使いこなせるかどうか」が問われる時代に入りました。
この変化により、IT部門だけでなく経営企画・人事・法務を含めた全社的な準備、すなわちAI Readyが必要になっています。DXリテラシーの底上げが、その前提条件にもなります。
「データ不足」で頓挫するAIプロジェクト

AI活用の失敗原因として頻繁に挙がるのが、データ品質の低さや、AIで使える形にデータが整備されていないことです。
ガートナー社は、2025年末までに生成AIプロジェクトの少なくとも30%がPoC後に放棄されると予測しており、その要因としてデータ品質の低さ、リスク管理の不備、コスト増大、事業価値の不明確さの4点を挙げています。
AIツール自体は高性能でも、学習・推論に使えるデータが整備されていなければ成果は出ません。
また、PoCの段階では少量のサンプルデータで検証したものの、本番展開時に実データとの乖離が大きく性能が出ないというパターンも繰り返されています。
こうした背景から、AIを導入する前に「組織としてAIを受け入れる準備ができているか」を点検するAI Readyの考え方が、DX推進の前提条件として注目されています。
AI Readyのインフラ要件

AI Readyを構成する4つの軸のうち、最もイメージしやすいのがTechnology(インフラ)です。
ここでは、AIワークロードを支えるコンピューティング基盤、ストレージ・ネットワーク、セキュリティの3つの観点から要件を整理します。
GPUクラスタ・クラウド・エッジの使い分け
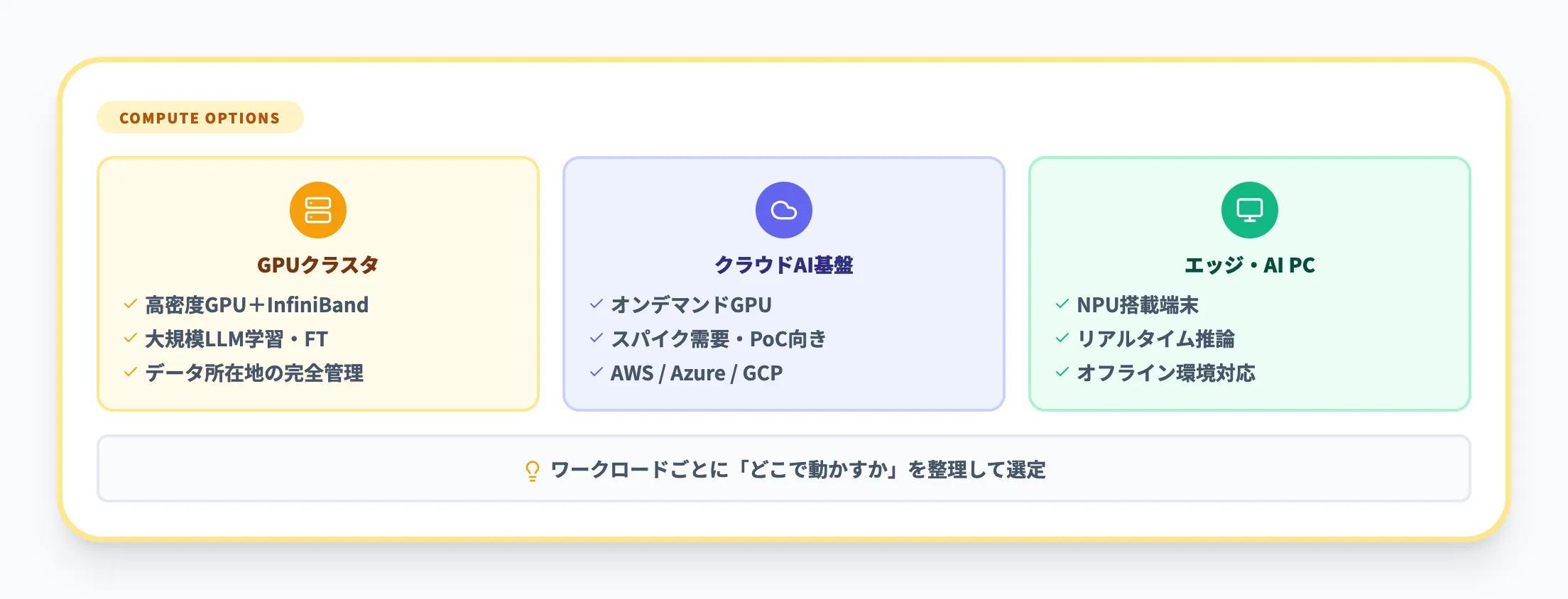
AI向けインフラでは、従来のCPU中心のサーバーだけでなく、複数のコンピューティング形態を組み合わせて設計します。以下に代表的な選択肢を整理しました。
| 形態 | 特徴 | 主な用途 |
|---|---|---|
| GPUクラスタ(オンプレミス) | 高密度GPU、NVMeストレージ、InfiniBand等の高速ネットワークで構成 | 大規模LLMの学習・ファインチューニング |
| クラウドAI基盤(AWS / Azure / GCP等) | GPUインスタンスや専用AIクラスタをオンデマンドで利用 | スパイク的な需要、PoC、ハイブリッド構成 |
| エッジ・AI PC(NPU搭載等) | ローカルでの推論能力を備えたクライアント端末 | リアルタイム推論、オフライン環境でのAI活用 |
どこまでをオンプレミスで持ち、どこからをクラウドに任せるかは、セキュリティ・コスト・レイテンシ要件によって変わります。
AI Readyを目指す際は、どのワークロードをどこで動かすかを整理したうえで、必要なコンピューティングを選定することが重要です。
ストレージとネットワークの設計ポイント

AIワークロードは、計算だけでなくデータの出入りにも大きな負荷をかけます。特に大規模モデルやRAG基盤では、ストレージとネットワークの設計がボトルネックになりやすくなります。
設計上の主な観点は次の3つです。
-
スループット
学習データや特徴量を高速に読み書きするために、NVMeストレージや分散ストレージの帯域を確保する。
バックアップやレプリケーションも含めた全体スループットを見る必要がある
-
レイテンシ
対話型AIやリアルタイム推論では、ネットワーク遅延がユーザー体験に直結する。
データセンター内だけでなく、エッジやWAN経由のアクセスも考慮が必要
-
拡張性
モデル・データ量の増加にあわせて段階的にGPU・ストレージ・ネットワークを増設できる構成かどうか。
ラックあたりの電力・冷却・スペース制約を含めたキャパシティプランニングが求められる
AI Readyなインフラとは、単にGPUがあるだけではなく、ストレージ・ネットワーク・電源・冷却まで含めて、AI向けの高密度・高負荷を長期的に支えられる設計になっている状態です。
セキュリティとゼロトラスト設計

AIインフラは、長期的には基幹インフラに近い位置づけになります。
そのため、セキュリティ・ゼロトラスト・監視の観点からもAI Readyかどうかを確認する必要があります。
主な設計ポイントは以下のとおりです。
ゼロトラスト前提のアクセス制御
ネットワーク境界ではなくIDベースでアクセス範囲を制御し、ユーザー・サービス・エージェントごとに認証・認可を都度評価する。NISTのZero Trust Architecture(NIST SP 800-207)では、ZTAへの移行に向けた考え方が整理されている
-
監視とログの一元化
インフラのメトリクス(GPU利用率、温度、電力)とアプリケーションログ(APIコール、エラー)を一元収集し、AIワークロードごとのコスト・性能・エラー傾向を定期レビューする
-
可観測性と運用証跡
推論APIの呼び出し状況やエラー、遅延といった運用ログを適切に保管し、トラブルシュートや監査に対応できる体制を整える
近年は「主権AI(Sovereign AI)」や「AI-readyな主権環境」といったキーワードも登場しており、データ所在地や暗号鍵管理を管轄内に置くことを重視する動きもあります。
生成AIのセキュリティリスクへの理解を前提としたうえで、自社のセキュリティ要件に応じたAIインフラ設計が求められています。
AI Readyのデータ基盤(AI-ready data)

多くのAI導入の失敗事例で共通するのは、「インフラは整ったが、データがAI向けに整備されていなかった」というパターンです。ここでは、AI-ready dataの要件と、それを支えるデータ基盤のアーキテクチャを整理します。
AI-ready dataの品質条件
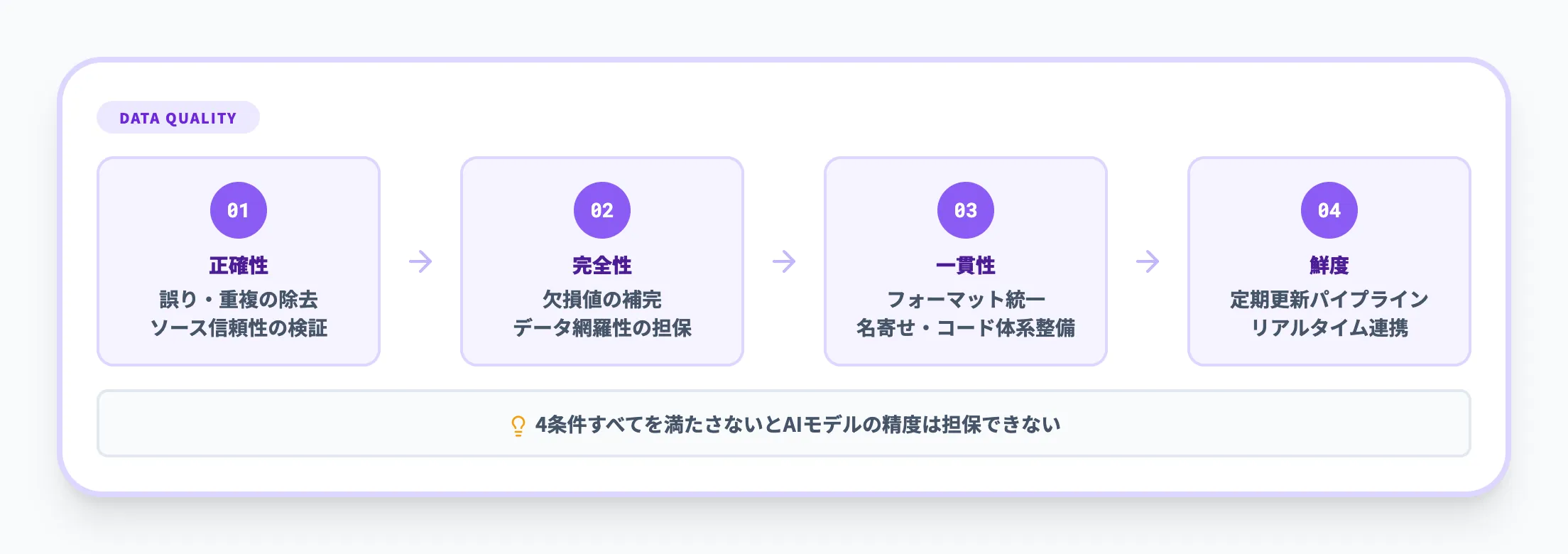
「AI-ready data」とは、単にデータが大量にある状態ではなく、AIから安心して使えるように整えられたデータを指します。
統一された標準定義があるわけではありませんが、実務上は以下のような要件が共通して求められるケースが多くなっています。
- 高品質で、欠損・重複・矛盾が許容範囲に抑えられている
- 利用目的に合った粒度で整形されている
- メタデータ(意味情報)やデータカタログで、誰が見ても理解できる状態になっている
- データの系譜(リネージ)が追跡可能で、どこから来てどの処理を経ているかが分かる
- アクセス権限やマスキングポリシーなどのガバナンスルールが適用されている
この前提が満たされていないと、生成AIや機械学習の精度だけでなく、説明責任やコンプライアンスの面でもリスクが高くなります。
データサイロの解消と統合アーキテクチャ
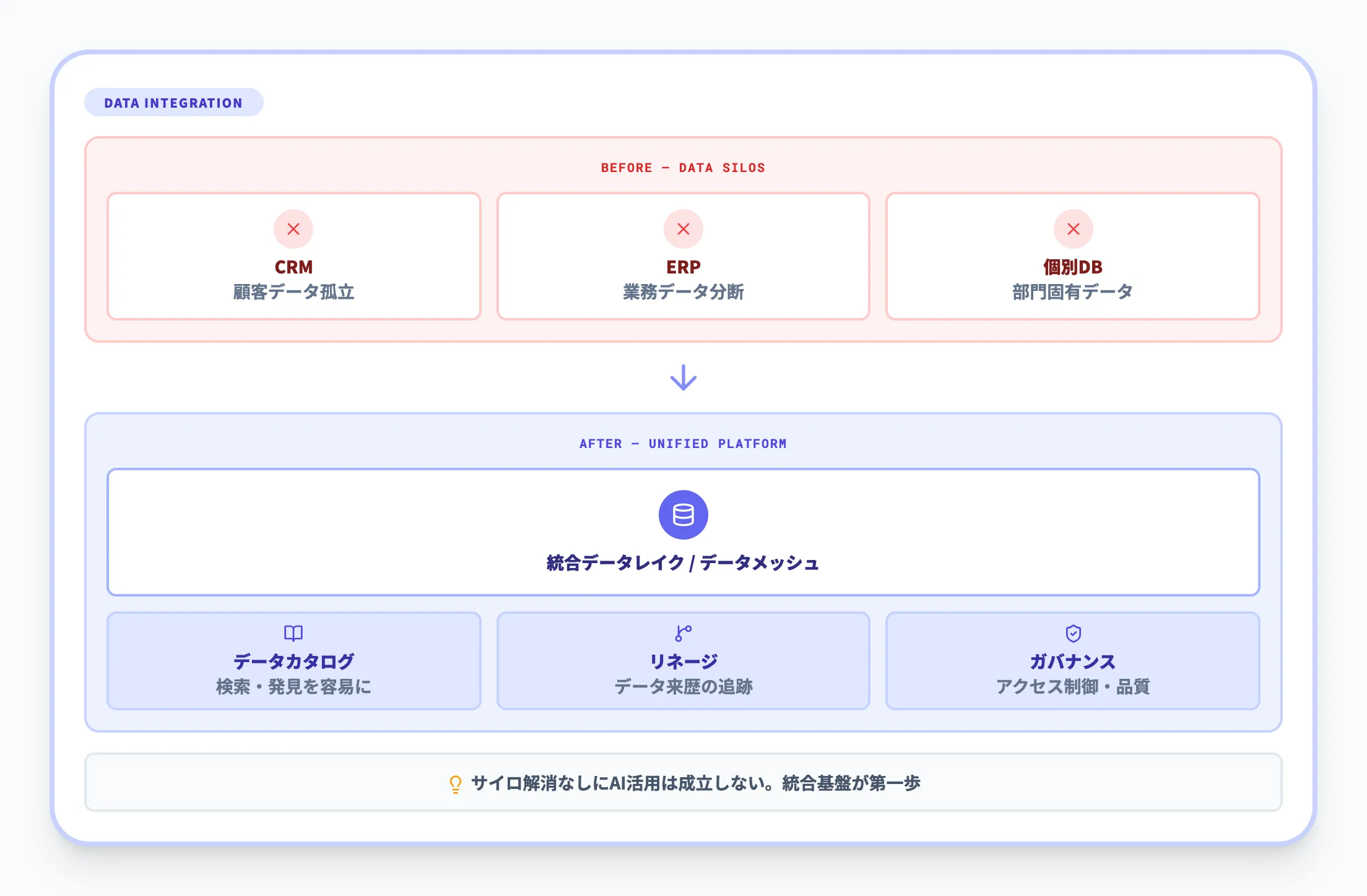
AI Readyなデータ基盤では、部門ごとのデータサイロを越えて全社的にデータを統合するアーキテクチャが求められます。代表的なパターンを以下に整理しました。
| パターン | 特徴 | AI活用との相性 |
|---|---|---|
| DWH(データウェアハウス)中心 | スキーマ設計済みのDWHに業務データを集約。BIやレポーティングに強い | 構造化データ中心。非構造データとの連携は追加設計が必要 |
| データレイク+DWH | 生データをデータレイクに集約し、分析用途に応じてDWHにマートを展開 | ETL/ELTパイプラインの設計と運用が鍵 |
| データレイクハウス | データレイクとDWHの特性を組み合わせ、構造・半構造・非構造データを一元管理 | RAGやベクトル検索、特徴量ストアなどAIワークロードとの相性が良い |
いずれの構成でも、AIで使える形にする変換処理(パイプライン)と、ガバナンス・カタログをどのレイヤーで実現するかが重要になります。AI Readyを目指す前に、現状のデータ基盤がどの段階まで進んでいるかを棚卸しすることが有効です。
生成AI・RAGを見据えたデータ設計

生成AIやRAG(Retrieval-Augmented Generation)を前提とすると、従来のBIと比べてデータ設計のポイントが変わります。特に重要な3点を整理します。
非構造データの扱い
PDF・Office文書・メール・ナレッジ記事など、非構造データがAI活用の中心になりやすい。
テキスト抽出・セクション分割・要約・ベクトル化といった前処理パイプラインが必須となる
-
アクセス制御とフィルタリング
RAG検索では「ユーザーが閲覧可能な情報だけを候補にする」仕組みが求められる。権限情報の同期遅延や共有リンクの扱いを誤ると、検索結果に見えるべきでない文書が混ざる原因になる。Azure AI Searchでは、document-level access controlやsecurity filterの考え方が整理されている
-
データ更新と再インデックス
ナレッジやマニュアルは頻繁に更新されるため、インデックス更新の仕組みを設計段階から組み込む必要がある。更新頻度・インデックスのラグ・再構築コストのバランスがポイントとなる
AI Readyなデータ基盤とは、構造化データ・非構造データ・権限情報を一体で扱い、AIにとって利用しやすい形で提供できる状態だと言えます。
【関連記事】
AI-ready dataとは?要件・ツール・導入ステップを解説
AI Readyの業務適用とユースケース

AI Readyは、インフラやデータ基盤だけでは完結しません。
実際にエンドユーザーが使う業務環境まで視野に入れ、どの業務にどの形でAIを届けるかを設計する必要があります。
エンドユーザーAIの位置づけ
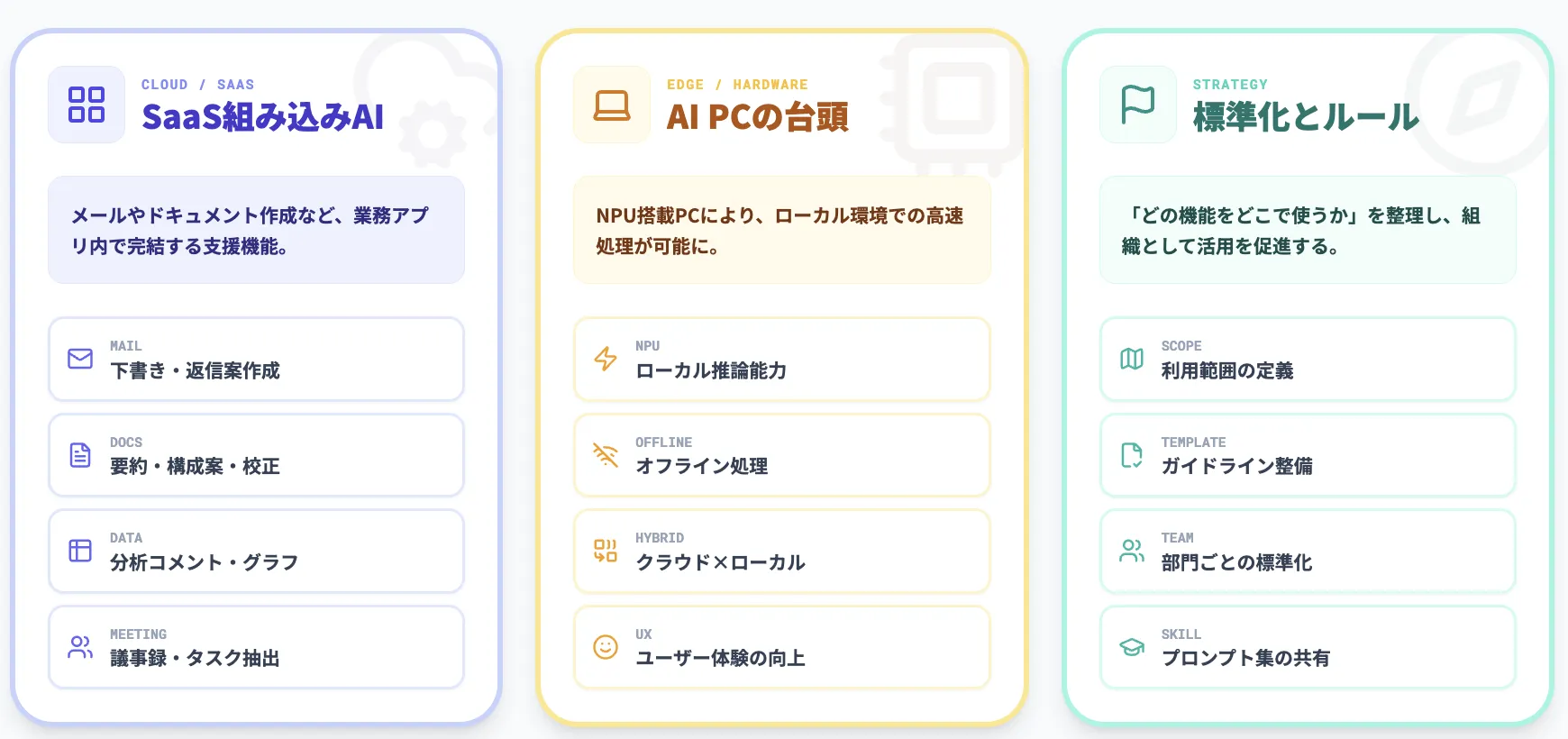
Microsoft 365やGoogle WorkspaceなどのSaaSに生成AI機能が標準搭載されるようになり、「エンドユーザーAI」の役割が拡大しています。主な活用例を以下に整理しました。
- メールの下書き作成や返信案の提案
- ドキュメントの要約や構成案の生成
- スプレッドシートの分析コメントやグラフ提案
- 会議の要約やアクションアイテム抽出
これに加えて、NPU搭載のAI PCではローカルで音声認識・要約・翻訳を行う機能も登場しており、クラウド側のAIと組み合わせることでユーザー体験を高める構成も増えています。
AI Readyな企業では、どのAI機能を、どの部門で標準的に使うかを整理し、ガイドラインやテンプレートを整備することが重要になります。
SaaS AI機能の活用と統制

SaaS製品に組み込まれたAI機能は手軽に使える一方で、統制設計なしに展開するとリスクが生じます。主な統制ポイントは以下の3点です。
-
権限とデータ境界
どのユーザー・グループが、どのデータに対してAI機能を使えるのか。
外部共有ファイルや機密情報がAIの学習・ログにどこまで利用されるのかを明確にする
-
監査・ログ
どのユーザーが、どのコンテンツをAIに投げ、どんな出力を得たかの記録範囲を定める。
誤用や情報漏えいが疑われるケースを検知・レビューできる体制を整える
-
設定とポリシー管理
テナント設定やDLP(Data Loss Prevention)ルールをAI機能にも適用する。
部門ごとに利用可否を切り分ける場合は、そのルールと例外処理を明文化しておく
AI ReadyなSaaS活用とは、ユーザーが自然にAIを使える状態と組織として制御と説明責任を果たせる状態の両方が成立していることを意味します。
現場でのユースケース
業務への適用例は業種によって多様ですが、部門横断で共通しやすいパターンがあります。以下に代表的な3パターンを整理しました。
-
営業
商談メモやメール履歴から提案書の叩き台を生成する。CRMデータと会話ログを組み合わせ、クロスセルやアップセルの候補を提案する
-
コールセンター
音声通話の文字起こしと要約、FAQとの突き合わせによるオペレーター支援。
応対履歴からクレームの兆候を検知し、エスカレーション判断を支援する
-
バックオフィス
規程・マニュアル・過去の申請書をもとに文書テンプレートや回答案を生成する。契約書・請求書・稟議書から主要項目を抽出し、システムへの入力を半自動化する
AI Readyを議論する際は、こうした具体的なユースケースと「それを支えるインフラ・データ・組織」のつながりをセットで整理しておくと、投資の優先順位が決めやすくなります。
【関連記事】
生成AIによる業務自動化とは?メリット・実例・導入ステップを解説

AI Readyな組織と運用プロセス

AI Readyを「技術的に可能な状態」とだけ捉えると、PoCが乱立して終わるケースが多くなります。
ここでは、People(人材・組織)とProcess(運用プロセス)の観点から、AI Readyな状態に必要な体制を整理します。
AI CoEとプロダクトチーム体制
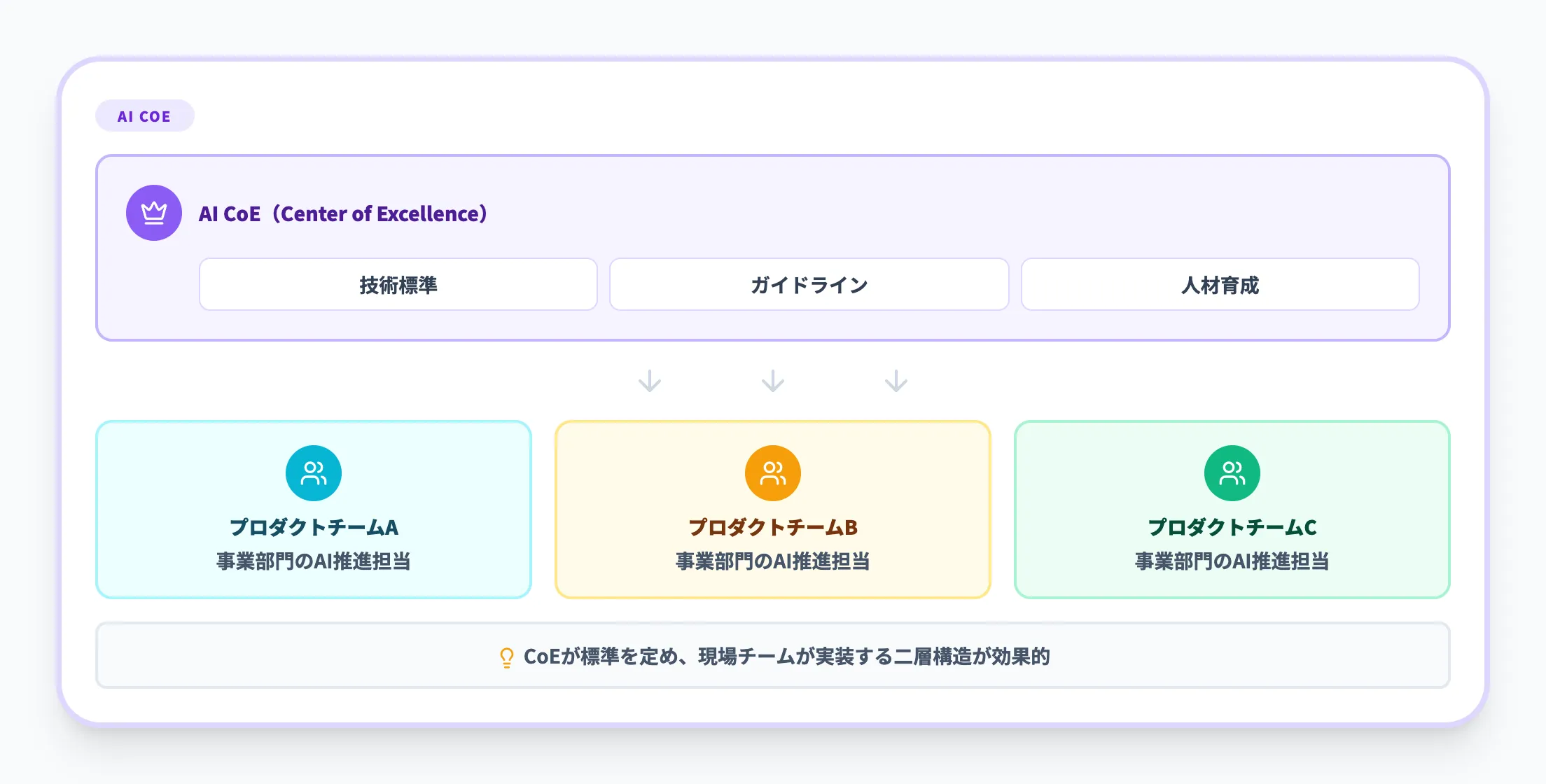
AI Readyな組織では、以下のような体制が整備されていることが求められます。
-
AI CoE(Center of Excellence)の設置
全社横断のAI戦略・標準・ベストプラクティスを策定する組織。インフラ・データ・セキュリティ・人事など関係部門を巻き込んだ調整窓口の役割を担う
-
プロダクトチーム型の推進
部門別のユースケースを「プロダクト」として扱い、PO(プロダクトオーナー)・エンジニア・データ人材でチームを構成する。
一度作って終わりではなく、使われ方の観測から改善のサイクルを回す
-
AIリテラシーとガイドライン
一般社員向けのAIリテラシー研修と、プロンプトの書き方やデータの扱い方のガイドラインを整備する。
組織として「やってはいけないこと」「グレーゾーンの扱い」を明文化する
-
AIガバナンスの設計
モデルやプロンプトの振る舞いを点検・説明できるよう、入出力のログ方針と保管ルールを定める。
利用審査、例外対応、インシデント対応、ベンダーリスクの扱いを明文化する
PeopleとProcessの土台がなければ、いくらインフラとデータ基盤を整備しても、AIの業務浸透は限定的になります。
PoCから本番展開までの標準プロセス
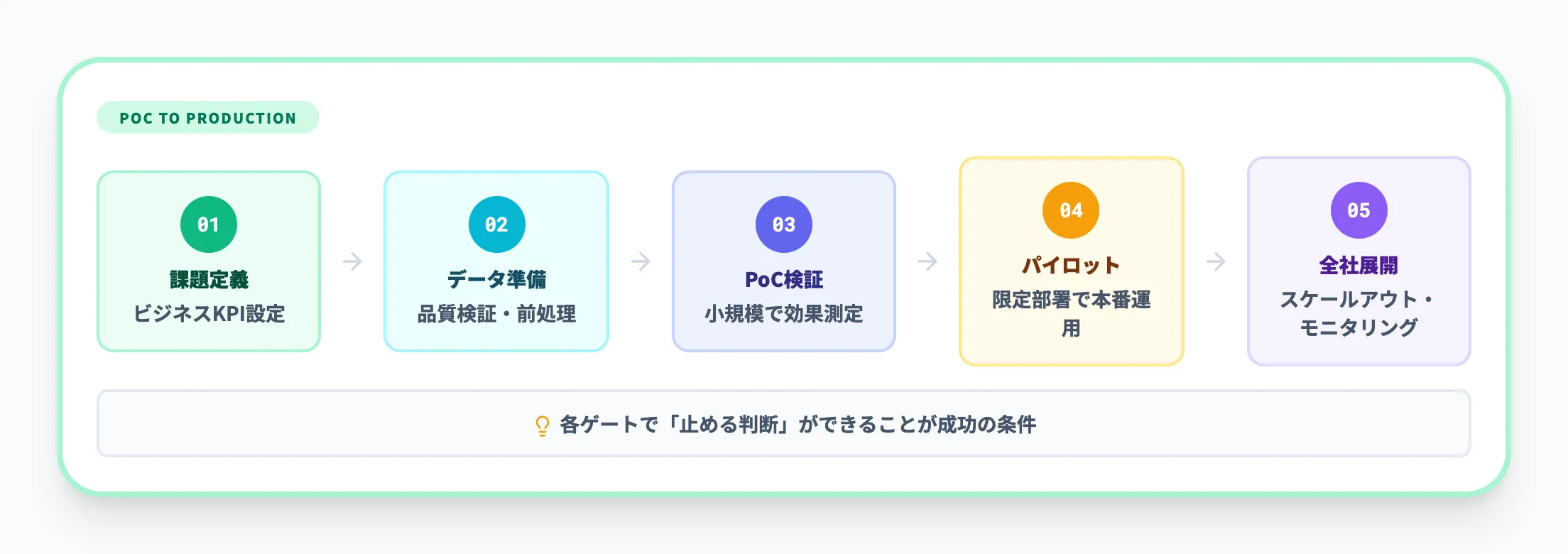
AI案件が「PoC止まり」になりがちな背景には、プロセス設計の不足があります。AI Readyな運用プロセスでは、以下のステップが標準化されています。
- 課題の定義と優先度付け ビジネスKPIと結びついた課題を定義し、AIが有効かどうかを評価する
- PoC・パイロット 限られたデータ・ユーザーで検証し、効果とリスクを確認する
- 本番化とスケール セキュリティ・運用・サポート体制を整え、対象部門やユーザーを広げる
- モニタリングと継続的改善 モデル性能、業務指標、ユーザー満足度をモニタリングし、定期的に改善する
着手前に「目的KPI・利用データ区分・期待コスト・運用責任者」を最低限そろえる入口ゲートを設けると、PoC止まりの発生を抑えやすくなります。
一方で、よくあるアンチパターンも押さえておく必要があります。
- 技術検証だけで終わり、業務プロセスや担当者の変化を設計していない
- PoCで使ったデータと実データが大きく異なり、本番で性能が出ない
- 担当者の異動やベンダー任せで責任の所在が曖昧になる
AI Readyとは、PoCから本番までの道筋が「例外的なプロジェクト」ではなく「標準プロセス」として組織に組み込まれている状態です。
AI Ready化を阻む課題と対策

AI Readyの重要性を理解していても、実現までの道のりには共通する障壁が存在します。
ここでは、多くの企業で共通して見られる代表的な課題と、それぞれの対策を整理します。
データ品質と基盤構築の壁

最も根本的な課題が、AIに使えるデータの品質と量の不足です。多くの企業では、データが部門ごとにサイロ化しており、フォーマットの統一や名寄せが進んでいません。
対策としては、全社的なデータカタログの整備から始め、優先度の高い業務領域から段階的にAI-ready dataの定義と品質基準を適用していくアプローチが有効です。
最初から完璧を目指すのではなく、1つのユースケースで成功体験を作ることを優先します。
人材・組織文化のギャップ
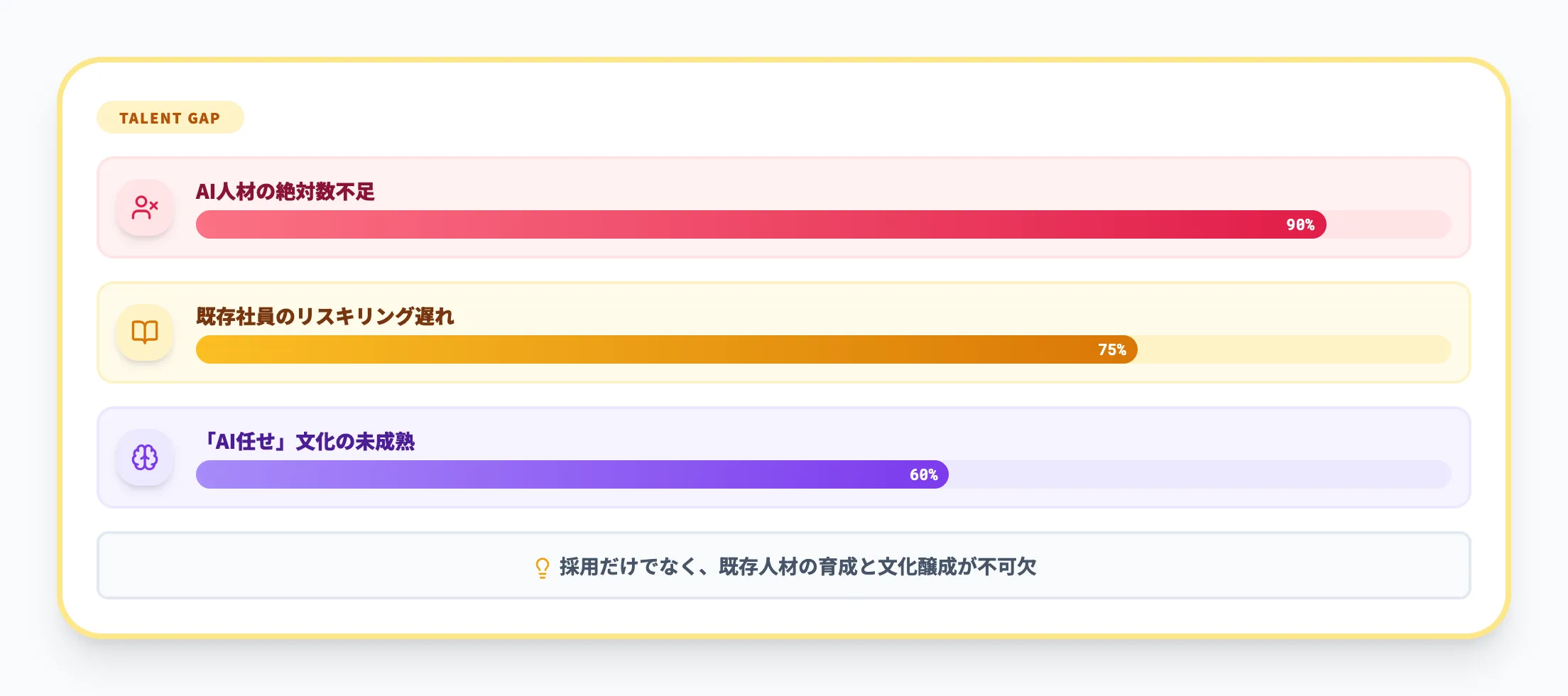
AI人材の採用・育成が追いつかないことに加え、現場の「AIに仕事を奪われるのではないか」という心理的抵抗がAI Ready化を遅らせるケースがあります。
対策としては、まず一般社員向けのAIリテラシー研修を実施し、AIは業務を代替するものではなく支援するツールであるという共通認識を作ることが重要です。
AI人材の育成を計画的に進めることも欠かせません。
あわせて、経営層がAI活用のビジョンを具体的に示し、推進体制(CoEやプロダクトチーム)に明確な権限と予算を付与します。
経営層の理解不足とPoC疲れ

経営層がAIの可能性を過大評価、または過小評価することで、投資判断が歪むケースがあります。「とりあえずPoCをやってみよう」という意思決定が繰り返された結果、成果が見えないままPoCが乱立する「PoC疲れ」に陥る企業も少なくありません。
対策としては、AI投資をポートフォリオとして管理し、各案件に「入口ゲート」(目的KPI、データ区分、運用責任者)を設けることで、投資対効果の見える化と案件の絞り込みを同時に進めます。
経営層が定期的にAI案件のレビューに参加する仕組みも有効です。
【関連記事】
AI導入で企業が抱える課題・問題点とは?具体例と解決方法を解説
AI Ready化の投資判断とコスト
AI Readyは概念であり特定の製品ではありませんが、実現には相応の投資が必要です。ここでは、AI投資を評価する際の考え方を整理します。

AI投資の評価では、「目に見える削減効果」だけに注目すると中長期的に歪みが生じます。以下の4つの軸で投資効果を捉えることが重要です。
| 評価軸 | 内容 |
|---|---|
| TCO(総保有コスト) | インフラ費用(クラウド/オンプレ)、ライセンス、運用要員、教育コストを一体で評価 |
| 業務効率化・売上貢献 | 工数削減だけでなく、案件獲得率・顧客満足度・解約率などのビジネス指標への寄与も見る |
| リスク低減・コンプライアンス | 手作業ミスの削減、記録の標準化、説明責任の確保など、リスク面の改善効果を定量・定性の両方で評価 |
| 定着度(アダプション) | 何割のユーザーがどの頻度でAIを使っているか。「AIを使わないと不便」と感じる状態が目標 |
AI導入のコスト規模は、SaaS中心か内製か、GPU投資の有無、既存基盤の状況などによって大きく異なります。
SaaS組み込み型のAI機能(Microsoft 365 CopilotやGoogle Workspace with Gemini等)を活用すれば、既存のライセンス費用にアドオンする形で比較的小さな追加投資から始めることも可能です。
AI Readyを目指す企業では、これらの観点を組み合わせた「ポートフォリオマネジメント」により、どのユースケースにどの程度投資するかを決めていくアプローチが増えています。
AI Ready度を評価するチェックリスト

ここまでの内容を踏まえ、自社のAI Ready度を簡易的に評価するための観点を整理します。
ここでは、前半で整理した4軸(People・Process・Technology・Data)を実務の評価単位に分解し、インフラ・データ・業務プロセス・人材/組織・ガバナンスの5領域でチェックします。
ガバナンスをProcessから独立させたのは、担当部門(法務・情報セキュリティ)が異なり、評価の粒度を分けた方が実務上使いやすいためです。
領域別チェック項目
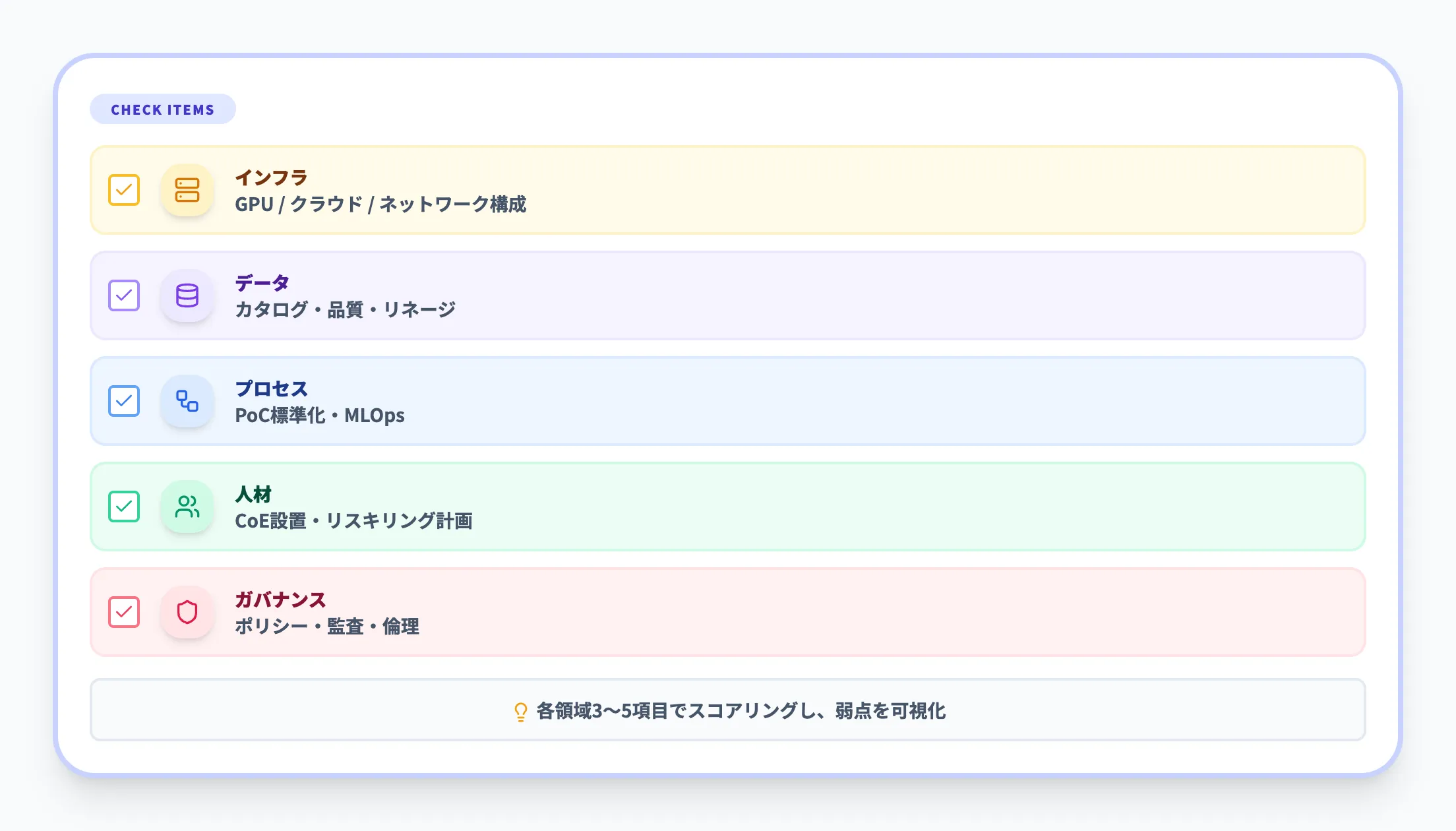
自社ワークショップなどでは、以下の表を使って1〜5点で採点し、証跡(具体例)と責任者を書き込むと議論がしやすくなります。
| 領域 | 代表的なチェック項目 | 自己評価(1〜5) | 証跡・具体例 | 主担当 |
|---|---|---|---|---|
| インフラ | 主要ワークロードを支える基盤の選択方針が定まっているか | 方針資料、アーキテクチャ図 | 情シス/インフラ | |
| データ | AI-ready dataの定義と、品質・メタデータ・カタログ・リネージの整備状況はどうか | データ辞書、カタログ画面 | データ担当/IT | |
| 業務プロセス | AIを組み込んだ業務プロセス設計や、PoC→本番展開の標準フローがあるか | 標準フロー、テンプレート | 各業務部門/DX推進 | |
| 人材・組織 | AI CoEやプロダクトチームなど、継続的にAIを運用・改善する体制があるか | 組織図、ロール定義 | 経営企画/人事 | |
| ガバナンス | AI利用ガイドライン、データ利用規程、監査・ログの仕組みが整備されているか | 規程類、監査ログ | 情報セキュリティ/法務 |
低スコア領域が見えたら、次の一手をあらかじめ用意しておくと評価が行動に直結しやすくなります。
たとえば、インフラならワークロード分類と配置方針の策定、データなら優先ドメインからのカタログ整備開始、人材・組織ならCoEの役割定義が最初の一歩になります。
短期・中期の改善ステップ
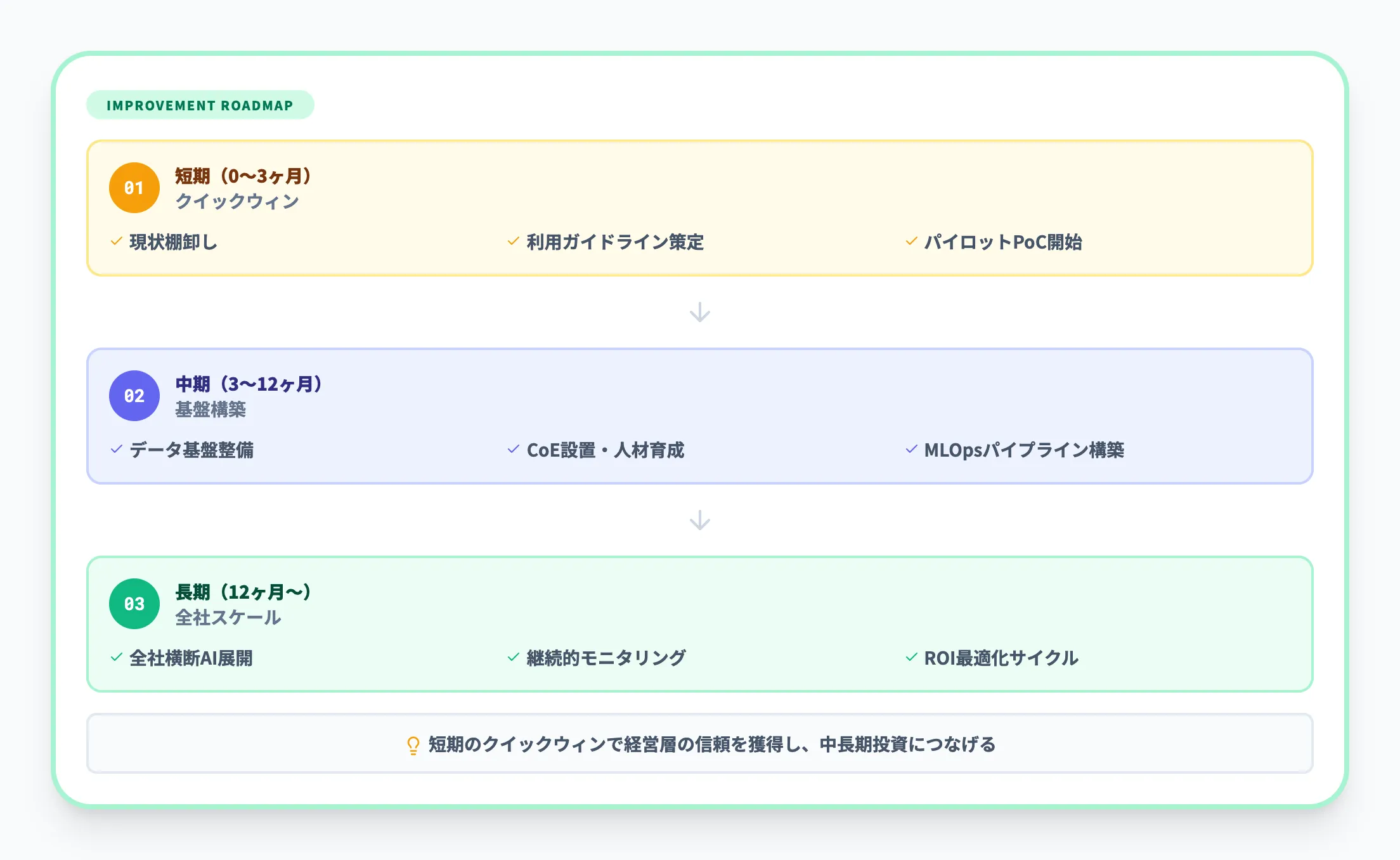
チェックの結果「すべてが低い」ように見えても、一度に全部を解決する必要はありません。現実的には次のようなステップで進めるケースが多くなっています。
-
短期(〜6か月程度)
既存のAI活用・PoC案件を棚卸しし、重複やPoC止まりの案件を整理する。
AI利用ガイドラインのドラフトを作成し、基本ルールを社内に提示する。代表的なユースケースを選び、SaaS AI機能での活用方法を標準化する
-
中期(〜2年程度)
データカタログ・メタデータ管理・リネージ管理の仕組みを導入し、AI-ready dataを増やしていく。
RAGやナレッジ検索など、コアとなるAIプラットフォーム基盤を段階的に整備する。AI CoEやプロダクトチームを正式な組織として位置づけ、予算と権限を付与する
こうしたステップを踏むことで、「AIを使ってみる段階」から「AIを前提に業務を設計する段階」へと移行しやすくなります。

AI Readyの要件整理を具体的な導入計画に進めるなら
インフラ・データ・プロセス・人材の4要件を把握した後に必要なのは、「どの業務からAIを適用するか」を具体的に決めるフェーズです。全社一斉導入ではなく、効果が見えやすい業務領域でPoCを回し、成功パターンを横展開する段階的アプローチが現実的です。
AI総合研究所のAI業務自動化ガイドでは、AI Readyの状態から具体的な業務自動化に進むためのステップと、領域ごとの優先度判断の考え方を整理しています。自社のAI Ready度を把握した次の一手として、ご活用ください。
AI Readyの要件整理を具体的な導入計画に落とす

戦略から実行への橋渡し
インフラ・データ・プロセス・人材の4要件を把握した次のステップは、業務単位でAI適用を進める具体的なアクションです。業務自動化の導入ステップを整理したガイドです。
まとめ
本記事では、AI Ready(AIレディ)というキーワードを、People・Process・Technology・Dataの4つの視点から体系的に整理しました。
AI Readyのポイントをあらためてまとめると、次のようになります。
- AI Readyとは、単にAIを導入している状態ではなく、組織が継続的かつ安全にAIを運用できる土台が整っている状態を指す
- インフラ面では、GPUクラスタ・クラウド・エッジのハイブリッド構成と、ゼロトラスト前提のセキュリティ設計が重要になる
- データ面では、AI-ready dataの定義に沿って品質・メタデータ・リネージ・アクセス制御を整え、構造化・非構造データを一体で扱えるデータ基盤が必要となる
- 組織面では、AI CoE・プロダクトチーム・PoC→本番展開の標準プロセスが、長期的なAI活用の鍵となる
- AI Ready化を阻む代表的な課題(データ品質不足・人材ギャップ・経営層の理解不足)を認識し、自社に合った対策を講じることが実現への近道となる
AI Readyかどうかは、単一のプロジェクトや製品で決まるものではなく、インフラ・データ・業務・組織が時間をかけて整っていくプロセスそのものです。自社の現状を冷静に棚卸しし、「まずどの領域から現実的に改善できるか」という視点でロードマップを描くことが、AIの価値を最大化する近道になります。










