この記事のポイント
 金融・法務など知識労働タスクの自動化にはClaude Opus 4.6が第一候補、GDPval-AAでGPT-5.2を上回り専門領域の信頼性が高い
金融・法務など知識労働タスクの自動化にはClaude Opus 4.6が第一候補、GDPval-AAでGPT-5.2を上回り専門領域の信頼性が高い- 大規模コードベースの保守・リファクタには1Mトークンコンテキスト+エージェント的コーディング機能の組合せが最適
- API料金は入力$5/出力$25(100万トークン)で据え置き、200K超はプレミアム料金のためcontext compactionでコスト抑制
- effortコントロールでタスクの複雑さに応じ推論コストを調整可能、定型はlow・高精度分析はmaxの運用が合理的
- Excel/PowerPoint連携やAgent Teamsで開発者以外のビジネスユーザーへAI活用を拡張、全社AI導入の起点に適する

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Anthropicは2026年2月、フラグシップモデルの最新版となる「Claude Opus 4.6」を発表しました。エージェント的なコーディング、長文コンテキスト処理、ツール連携を大きく強化したモデルで、知識労働やソフトウェア開発を対象にした“実務寄り”のアップデートが特徴です。
Opus 4.6は、Terminal-Bench 2.0やGDPval-AA、BrowseCompなど複数のベンチマークで業界トップ水準のスコアを記録し、特に金融・法務などの知識労働タスクではOpenAI GPT-5.2を大きく上回る結果が報告されています。
本記事では、Claude Opus 4.6の位置づけ・機能・料金・評価ベンチマーク・安全性・他モデルとの比較を、2026年2月時点の公式情報をもとに整理し、どのようなユースケースで採用を検討すべきかを解説します。
✅2026年6月9日、AnthropicがMythos-class初の一般公開モデル「Claude Fable 5」を発表しました。Opus 4.8の上位に位置する新最上位モデルの詳細はこちら。
▶︎Claude Fable 5とは?Mythos 5との違いや料金、使い方を解説
目次
Claude Opus 4.6とは?フロンティアモデルとしての概要
Claude Opus 4.6の特徴:対応領域・性能ベンチマーク・安全性
知的労働タスク(Knowledge work / GDPval-AA)
マルチドメイン推論(Multidisciplinary reasoning / Humanity’s Last Exam)
エージェント検索(Agentic search / BrowseComp)
長文コンテキスト:検索精度(Long-context retrieval)
長文コンテキスト:推論の一貫性(Long-context reasoning)
長期タスクの一貫性(Long-term coherence)
出力トークン上限と「US限定推論(US-only inference)」
Claude APIとClaude Developer Platformでの利用パターン
Sonnet・HaikuなどClaude内モデルとの住み分け
セキュリティやコンプライアンス面で気をつけることはありますか?
Claude Opus 4.6とは?フロンティアモデルとしての概要
Claude Opus 4.6は、Anthropicが提供するClaudeシリーズの最上位モデル(Opusクラス)の最新版です。2026年2月5日に発表され、前世代のOpus 4.5をベースに、長時間タスク・エージェント的なコーディング・長文コンテキスト処理・検索能力を重点的に強化しています。
コードベースの解析や財務・法務・リサーチなどの知識労働、ブラウザ操作を含むエージェントタスクまでをカバーする"仕事用フロンティアモデル"として位置づけられている点が特徴です。

Claude Opus 4.6の特徴:対応領域・性能ベンチマーク・安全性
Claude Opus 4.6は、「難度の高い知的労働」と「長時間走り続けるエージェントタスク」に強みを持つ最上位モデルです。
ここでは、どのような領域をターゲットにしているのか、他社モデルと比べてどの程度の性能なのか、そして安全性のプロファイルはどうなっているのかを、ベンチマークと公式情報をもとに整理します。
対応領域と主な強み
Anthropicのベンチマーク一覧を見ると、Opus 4.6は「エージェント型コーディング」「ツール利用」「検索」「オフィスタスク」「高度な推論」など、幅広いカテゴリで4.5世代や他社モデルを上回っています。
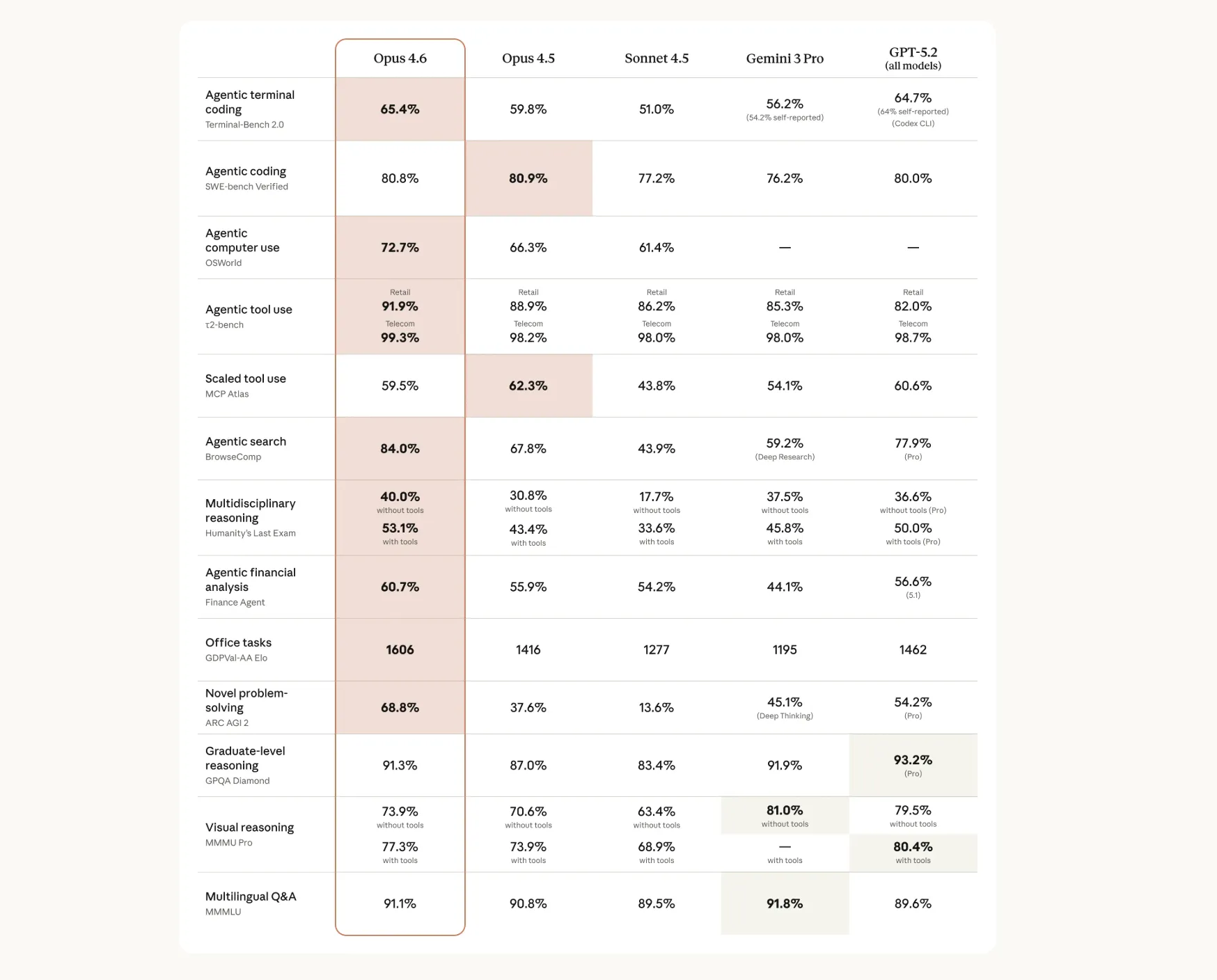
Claude Opus 4.6の能力マップ(各種ベンチマーク一覧)*
想定されているコアユースケースは、次のような領域です。
- 財務・法務・リサーチなどの知的労働タスク(レポート作成・分析・要約・ドラフト作成など)。
- 大規模コードベースを相手にしたエージェント型コーディング/デバッグ/コードレビュー。
- 数十万〜100万トークン級のログ・議事録・技術文書を扱う長文コンテキストタスク。
- サイバーセキュリティやライフサイエンスなど、専門性の高いドメインでの調査・分析タスク。
これらを支えるために、Opus 4.6では 1Mトークンのコンテキストウィンドウ(β)と最大128kトークンの出力、長時間エージェント向けのコンテキストコンパクション(自分で要約しながら走り続ける仕組み)などが用意されています。
知的労働タスク(Knowledge work / GDPval-AA)
知的労働の実タスクを集めたGDPval-AAでは、Opus 4.6はEloスコア1606でトップに立っています。
同じ評価でGPT-5.2は1462、Opus 4.5は1416、Sonnet 4.5は1277、Gemini 3 Proは1195という位置づけで、Opus 4.6はGPT-5.2より約+144ポイント、Opus 4.5より約+190ポイント上という差になっています。
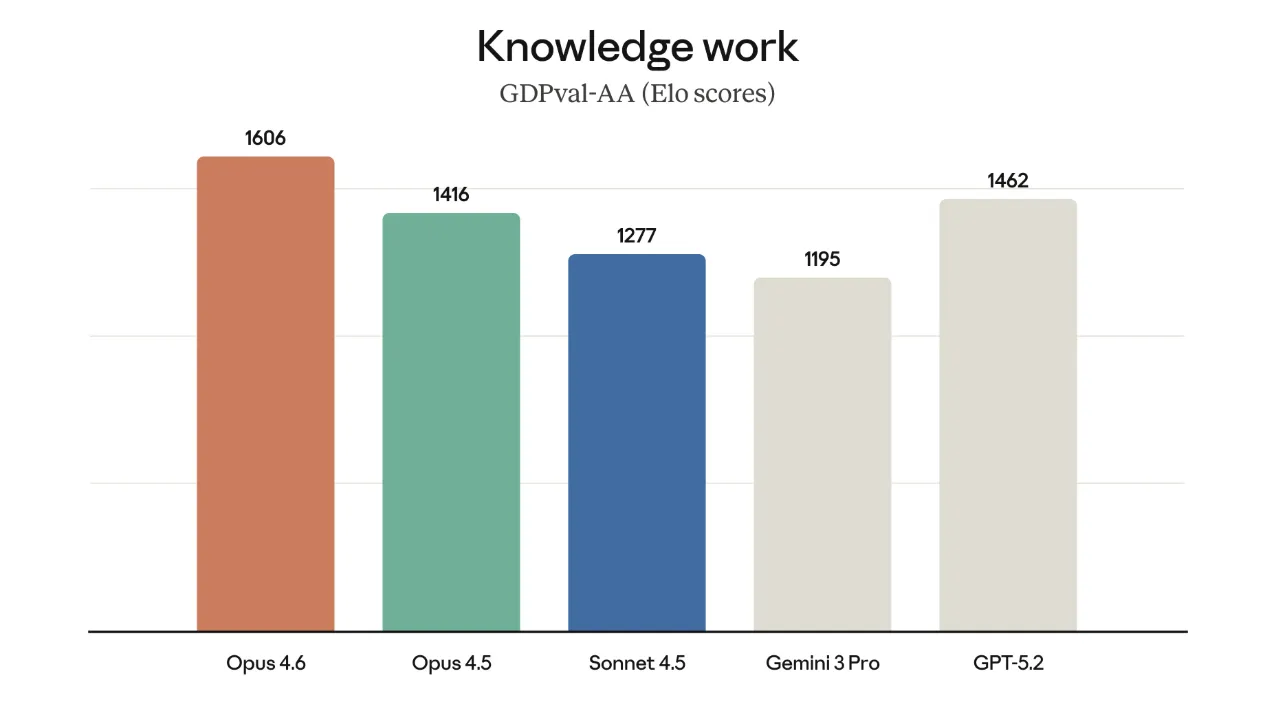
Knowledge work(GDPval-AAのEloスコア)
このスコアは、財務モデルのレビューや契約レビュー、調査レポート作成といった「現場の仕事そのもの」に近いタスクで、どれだけ安定して高品質なアウトプットを出せるかを示す指標です。
問題集ベースのベンチマークに強いだけでなく、「人間のナレッジワーク」をどの程度代替・補完できるかという観点で、一段上の水準にあると評価できます。
マルチドメイン推論(Multidisciplinary reasoning / Humanity’s Last Exam)

Multidisciplinary reasoning(Humanity’s Last Exam)
Humanity’s Last Examは、複数分野にまたがる高度な推論力を測る評価です。
Opus 4.6はツールなし・ツールありの両方で、Opus 4.5やSonnet 4.5、Gemini 3 Pro、GPT-5.2系より高い精度を記録しており、「検索・コード実行・外部ツールを組み合わせた複雑なタスク」を任せたときの安定感につながります。
難しいリサーチ案件や、複数の前提条件を踏まえて意思決定案を出させるようなケースで、前世代よりも破綻しにくくなっています。
エージェント検索(Agentic search / BrowseComp)
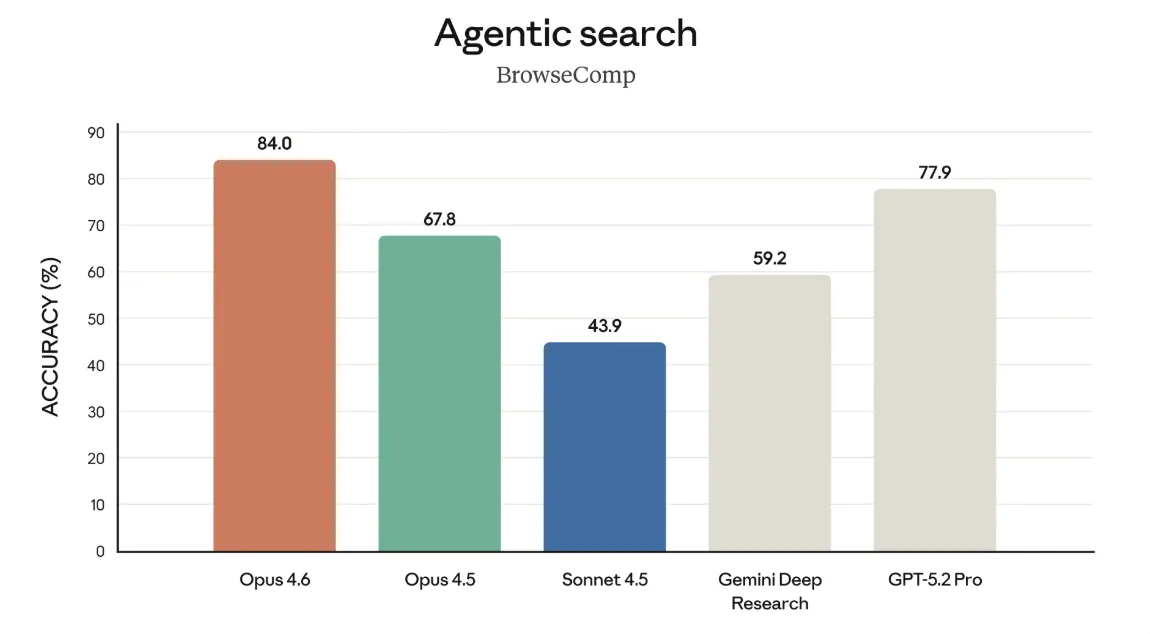
Agentic search(BrowseComp)
BrowseCompは、「難しい情報をウェブから自律的に探し出せるか」を測る評価です。
Opus 4.6は正答率84.0%で、Opus 4.5(67.8%)やSonnet 4.5(43.9%)、Gemini Deep Research(59.2%)、GPT-5.2 Pro(77.9%)を大幅に上回っています。
単純な検索クエリの生成だけでなく、複数回の検索・ページ遷移を通じて目的の情報にたどり着く「エージェント検索」の精度が上がっている点がポイントです。
長文コンテキスト:検索精度(Long-context retrieval)
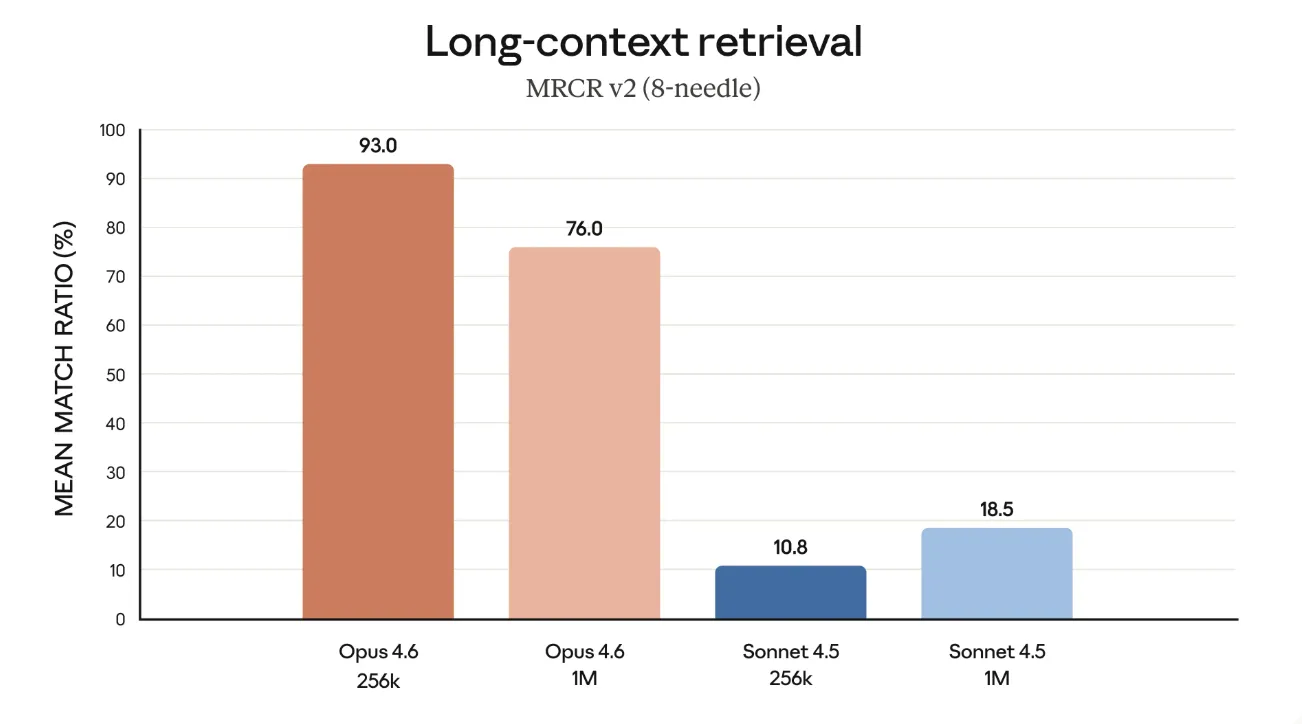
Long-context retrieval(MRCR v2・8-needle)
MRCR v2(8-needle)は、膨大なテキストの中に埋め込まれた複数の"針"となる情報を探し出す、いわゆる「needle-in-a-haystack」系のベンチマークです。
Opus 4.6は、256kトークンの設定で93.0%、1Mトークンでも76.0%のマッチ率を記録しており、同条件のSonnet 4.5(256kで10.8%、1Mで18.5%)と比べて桁違いのリトリーバル精度を示しています。
議事録やログ、長期のプロジェクトメモなどを1回のプロンプトにまとめて流し込み、「特定の論点だけ抜き出してほしい」といった使い方をしたときに、投入したコンテキストをきちんと活かせるモデルになっていると言えます。
長文コンテキスト:推論の一貫性(Long-context reasoning)
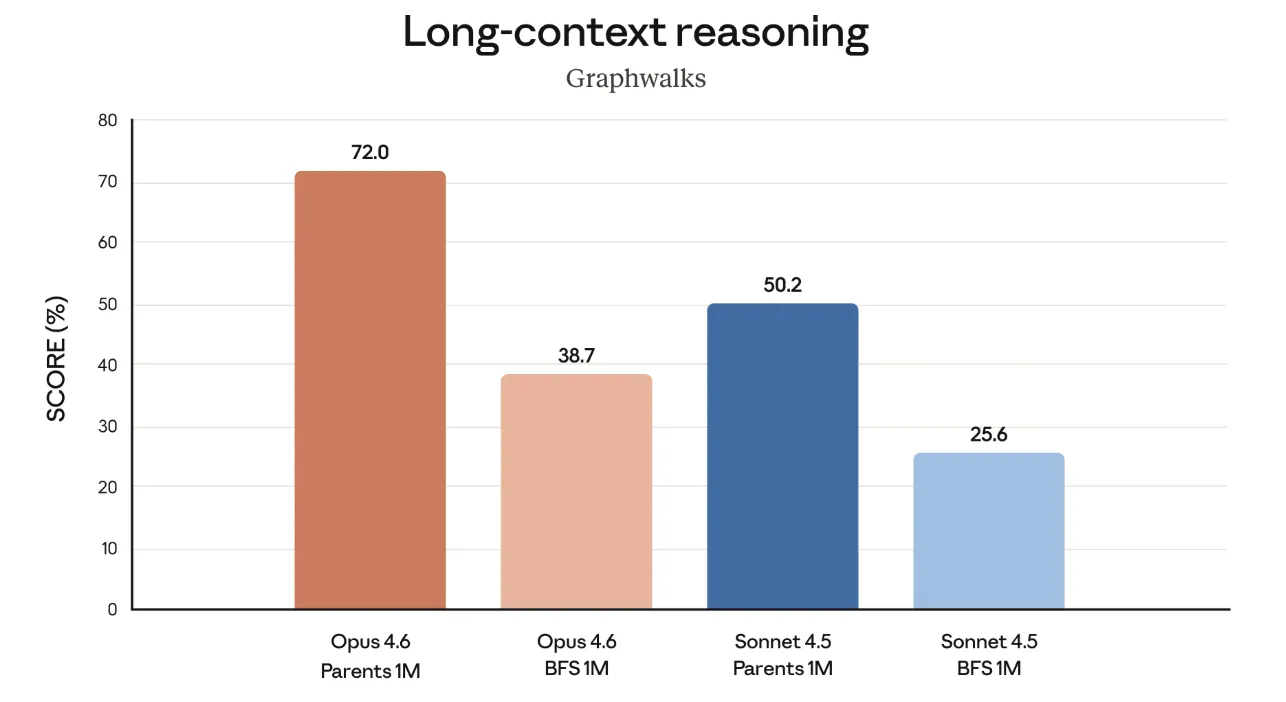
Graphwalksは、長いコンテキストを辿りながら推論を行う能力を評価するベンチマークです。
1Mトークン設定で、Opus 4.6はParents探索で72.0%、BFS探索で38.7%というスコアを出しており、Sonnet 4.5(Parents 1Mで50.2%、BFS 1Mで25.6%)を大きく上回っています。
単に「情報を見つける」だけでなく、「見つけた情報同士の関係性を保ったまま考え続ける」場面で、4.5世代から質的な改善が入っていることが分かります。
要件定義書・設計書・仕様変更履歴など、相互に関連した長い文書をまとめて渡して議論させるケースで、Opus 4.6の強みが出やすい部分です。
長期タスクの一貫性(Long-term coherence)
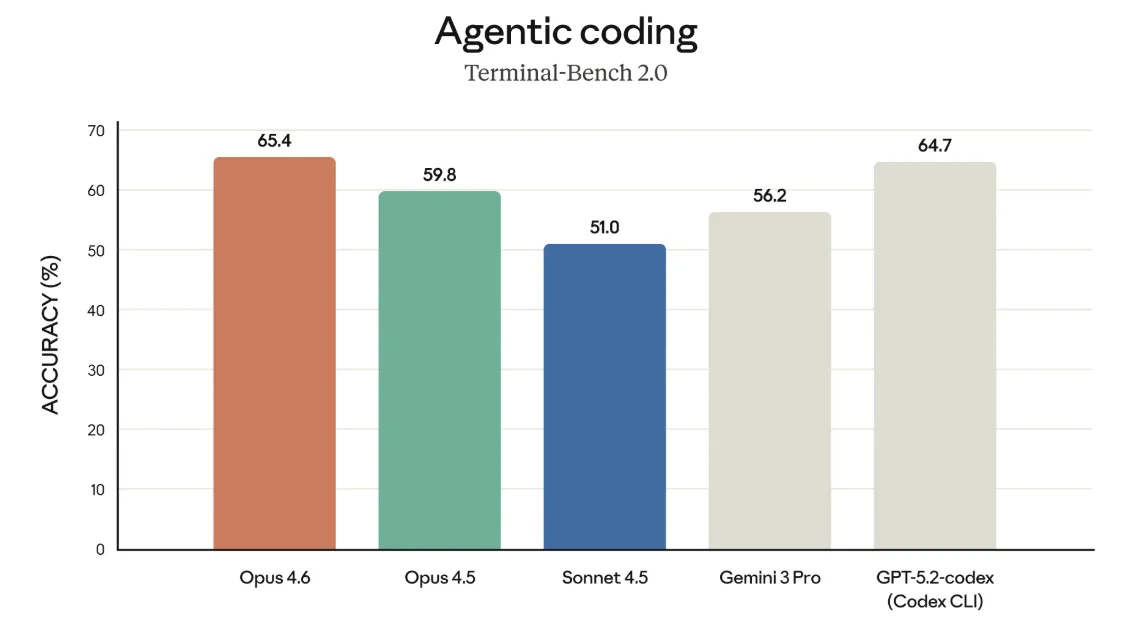
Agentic coding(Terminal-Bench 2.0)
Terminal-Bench 2.0は、ターミナル経由で自律的に開発タスクをこなす「エージェントコーディング」の能力を測る評価です。
Opus 4.6は正答率65.4%で、Opus 4.5(59.8%)やSonnet 4.5(51.0%)、Gemini 3 Pro(56.2%)を上回り、GPT-5.2 Codex CLI(64.7%)とほぼ同等の水準に位置しています。
コードベースの理解からコマンド実行、結果の解釈までを含めた一連の開発フローを任せたときに、4.5世代よりも失敗が少なくなることが期待できます。
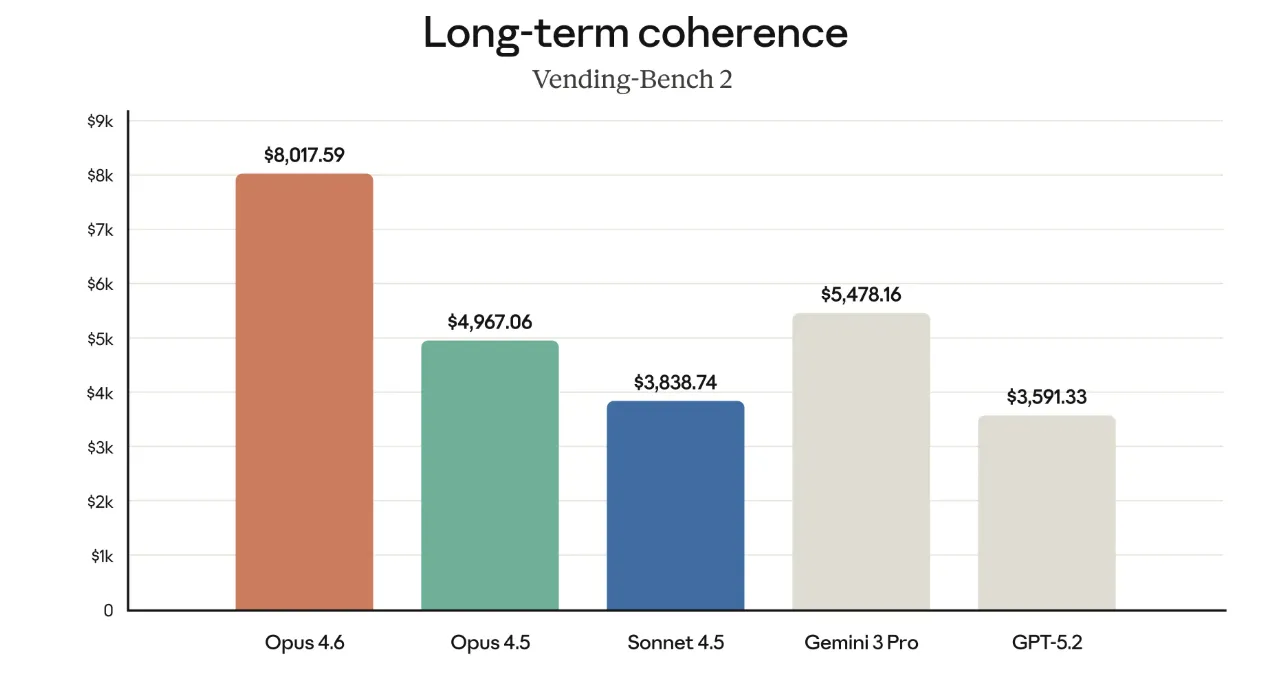
Vending-Bench 2は、長期にわたるシミュレーション的なタスクを通じて「一貫性を保った意思決定ができるか」を見る評価です。
ここでもOpus 4.6は、金額換算で約8,000ドル相当のスコアとなっており、Opus 4.5(約5,000ドル)、Sonnet 4.5(約3,800ドル)、Gemini 3 Pro(約5,400ドル)、GPT-5.2(約3,600ドル前後)を上回っています。
長時間のセッションで段階的に仕様を詰めていく場合や、複数回に分けて行われるプロジェクトを通しで任せるようなケースでも、途中で文脈が崩れにくいモデルだと考えられます。
コーディング・デバッグと多言語開発
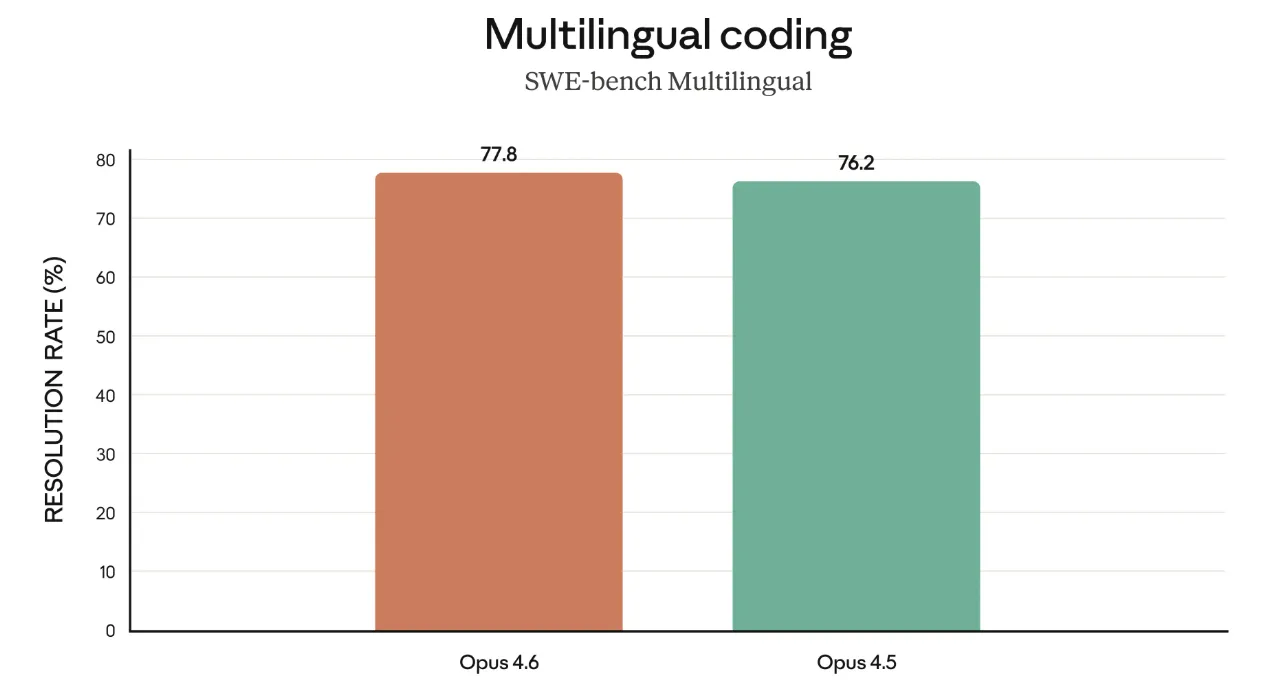
SWE-bench Multilingualでは、Opus 4.6は77.8%、Opus 4.5は76.2%というスコアで、多言語のIssueやコードベースを扱うタスクでも、4.5世代から堅実に底上げされています。
日本語を含む多言語のコメント・ドキュメントを前提とした開発チームでも、前世代以上に安定した振る舞いが期待できます。
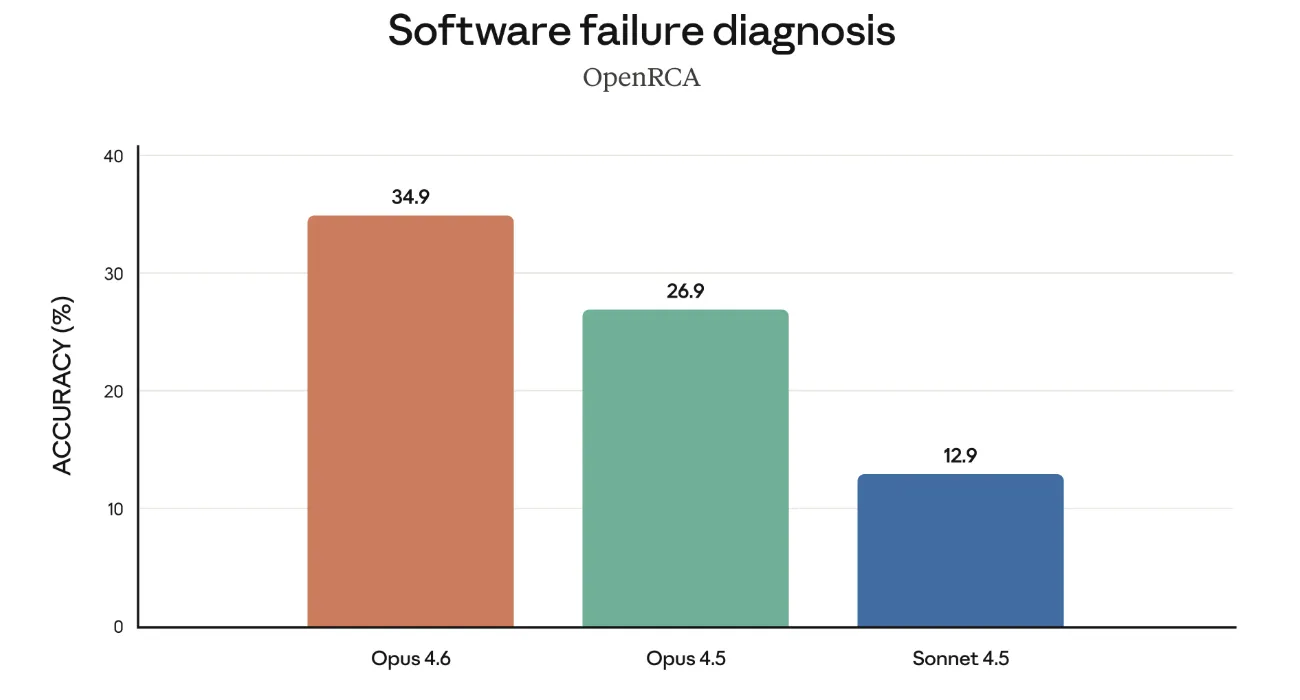
ソフトウェア障害の根本原因を当てるOpenRCAでは、Opus 4.6が34.9%、Opus 4.5が26.9%、Sonnet 4.5が12.9%という結果です。
ログやスタックトレース、設定ファイルなどをまとめて読み込み、「何が壊れているのか」「どこから調べるべきか」を整理させる用途で、Opus 4.6を使う意義が大きくなっています。
専門ドメイン:ライフサイエンスとサイバーセキュリティ
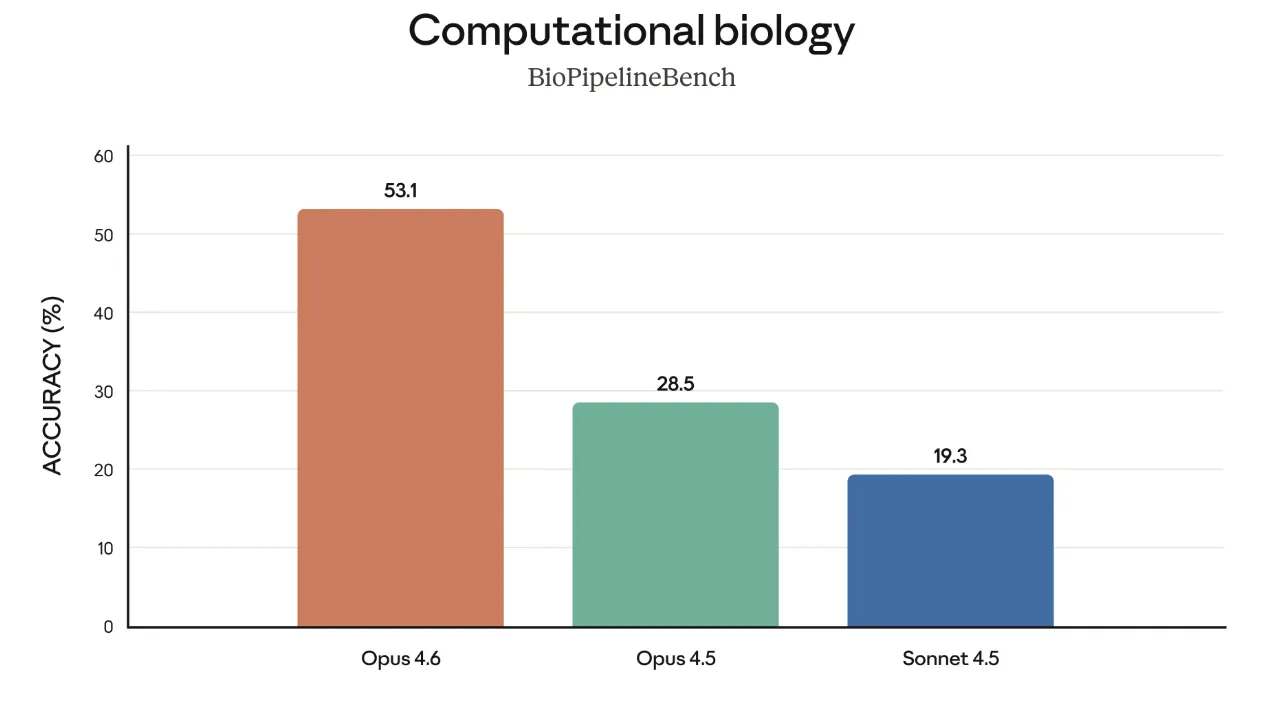
BioPipelineBench(計算生物学のタスク群)では、Opus 4.6が53.1%、Opus 4.5が28.5%、Sonnet 4.5が19.3%と、ライフサイエンス領域でのパイプライン設計や解析タスクに対する理解力がほぼ倍増しています。
専門用語や複雑な前提知識が多い分野でも、4.5世代からジャンプアップしていることが見て取れます。
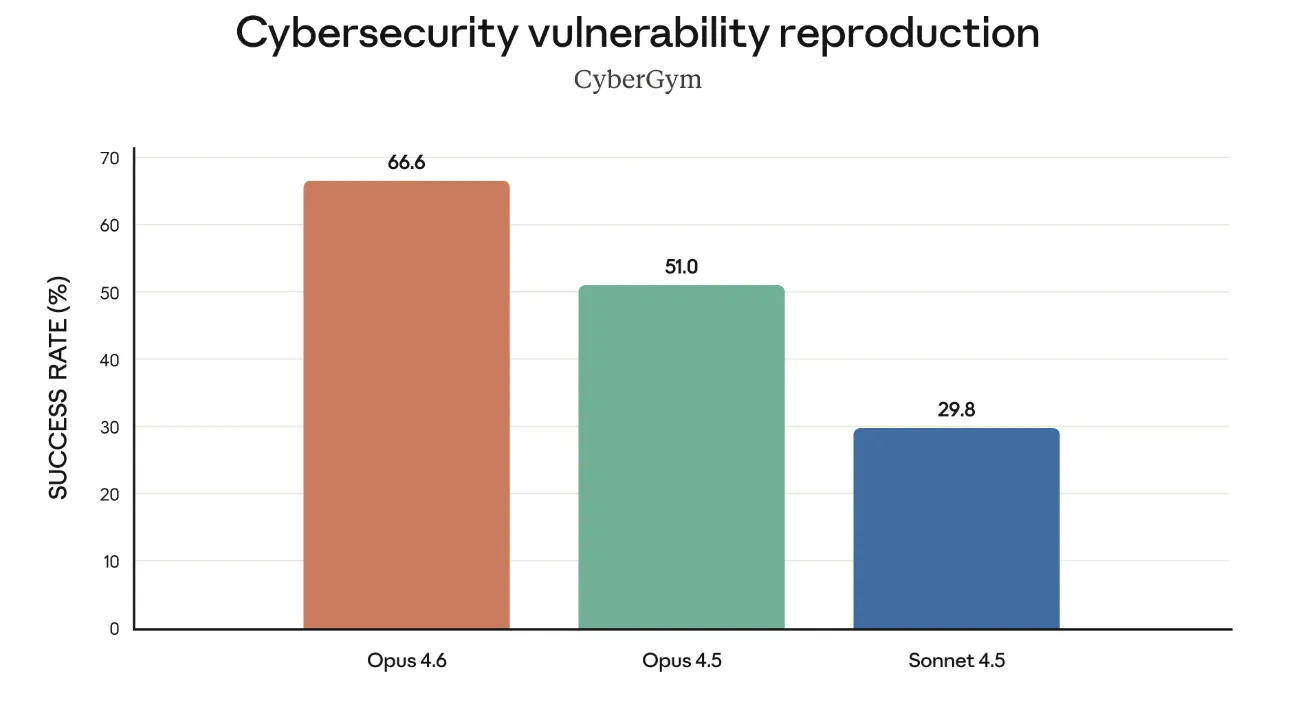
サイバーセキュリティのCyberGymでは、Opus 4.6が66.6%、Opus 4.5が51.0%、Sonnet 4.5が29.8%と、既存モデルを大きく上回る「脆弱性の再現・理解能力」を示しています。
これを防御側のタスク(脆弱性診断レポートの下書き、パッチ案の検討など)に活用することで、セキュリティチームの生産性を高める、というのがAnthropic側の想定です。
安全性とミスアラインメント
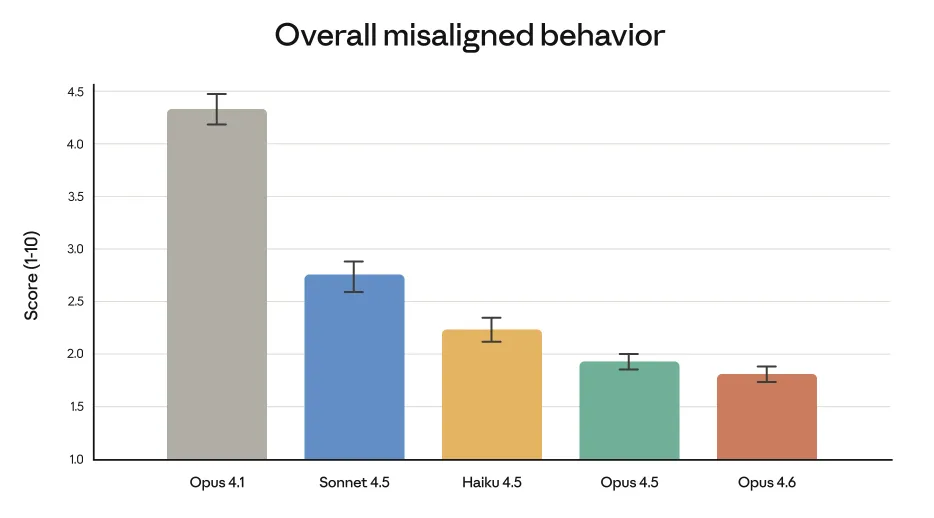
性能が上がるほど、安全性とのトレードオフが気になるところですが、Opus 4.6はここでもバランスを崩していません。
Anthropicの自動化された行動監査では、「欺瞞」「迎合」「危険な行為への協力」といったミスアラインド行動の総合スコアが、4.x世代の中で最も低い水準まで下がっています。
グラフを見ると、Opus 4.1 → Sonnet 4.5 → Haiku 4.5 → Opus 4.5 → Opus 4.6の順にスコアがなだらかに改善しており、Opus 4.6はOpus 4.5をさらに一歩下回る位置にあります。

また、正当な質問に対して過剰に拒否してしまう「オーバーリフューザル」の率も、Opus 4.6では低減されています。
ユーザーの意図を読み取りつつ、本当に危険な依頼だけをきちんと断る方向に調整されているため、「せっかくの高性能モデルなのに答えてくれない」という場面は減りやすくなります。
Opus 4.6に対しては、既存モデル以上に広範な安全性評価が行われており、ユーザーのメンタルヘルスへの影響評価や、高度な規制領域での利用に関するテスト、新しい解釈可能性の手法を使った検査などが追加されています。
特にサイバーセキュリティ領域では、攻撃側と防御側の両方のユースケースを想定した安全策が導入されており、今後も脅威の状況に応じて保護メカニズムを更新していく方針が示されています。
Claude Opus 4.6の料金と利用制限
Claude Opus 4.6は次のような経路から利用できます。
- claude.aiの有料プラン(Pro/Max/Team/Enterprise)
- Claude API
- Amazon BedrockやGoogle Cloudなど、主要クラウドからの提供
以下では、Claude Opus 4.6のAPI料金や、長文コンテキストに関するプレミアム料金、出力トークン上限や実行場所の制約など、コストと制限に関わるポイントを整理します。
Claude APIの料金体系
Opus 4.6のAPI料金は、前世代モデルと同水準に据え置かれています。
- 入力トークン:100万トークンあたり 5ドル
- 出力トークン:100万トークンあたり 25ドル
この料金は、標準コンテキスト(おおむね200Kトークンまで)の利用を前提とした水準です。トークン単価だけを見ると、同じクラスのフロンティアモデルと同程度か、やや高めのレンジに位置付けられます。
1Mトークンコンテキストとプレミアム料金
1Mトークンコンテキスト(ベータ)を利用する場合、200Kトークンを超える部分にはプレミアム料金が適用されます。
- 200Kトークンを超える入力部分:100万トークンあたり 10ドル
- 200Kトークンを超える出力部分:100万トークンあたり 37.5ドル
大量のドキュメントやコードベースを一度に読み込ませると、このプレミアムゾーンに入りやすくなります。
実運用では、「どこまでを1回のプロンプトに載せるか」「どこからを分割・要約するか」といった設計でコストをコントロールすることが重要です。
出力トークン上限と「US限定推論(US-only inference)」
Opus 4.6の出力トークン上限は最大128Kトークンに設定されています。これにより、長大なレポートやコード、マニュアルなどを1回の出力でまとめて生成しやすくなっています。
また、規制要件やデータ所在地要件に対応するためのオプションとして、US限定推論(US-only inference)も提供されています。US内での実行を指定した場合、トークン単価は通常の約1.1倍となり、コストとコンプライアンスのトレードオフを取る形になります。
Claude Opus 4.6の使い方
ここでは、具体的な操作手順ではなく、「どこで」「どのような形で」Claude Opus 4.6を利用できるのかを整理します。個人で試すだけなのか、APIやクラウド経由で本格運用するのかによって、選ぶ窓口が変わります。
claude.aiでの利用パターンと個人利用
個人ユーザーが最初にOpus 4.6を試す場合は、ブラウザ経由でアクセスできるclaude.aiがもっとも手軽です。
- ProやMaxなどの有料プランで、チャット画面からモデルとして「Claude Opus 4.6」を選択する。
- テキスト入力やファイルアップロード、ツール呼び出しなどを組み合わせて利用する。
- 調査メモや企画書のドラフト、コードのレビュー依頼などを日常的なチャットの延長で試す。
まずはここで「どの業務に効きそうか」を見極め、そのうえでAPIやクラウド経由の導入を検討する流れが現実的です。
Claude APIとClaude Developer Platformでの利用パターン
開発者向けには、Claude APIとClaude Developer PlatformからOpus 4.6を利用できます。
- モデル名
claude-opus-4-6を指定して呼び出す。 - effortパラメータで、
low/medium/high/maxの4段階から推論の“深さ”を制御する。 - Adaptive thinkingを有効にすると、モデル側が自動的に「ここは深く考えた方がよい」と判断した場面でextended thinkingを使う。
- context compactionを使うと、長い対話やタスクの途中で古いコンテキストを要約に置き換え、コンテキスト上限にぶつかりにくくできる。
エージェントの実装や長時間タスクの設計では、このあたりのパラメータ設計が性能とコストのバランスを左右します。
主要クラウド経由での利用パターン
Opus 4.6は、Amazon BedrockやGoogle Cloudなど主要クラウドからも順次提供されています。
- 既にこれらのクラウドを使っている企業であれば、IAMやネットワーク制御、監査ログなど既存の枠組みの中でOpus 4.6を呼び出せる。
- 他社モデルと並べてABテストを行ったり、用途ごとにモデルを使い分けたりしやすい。
すでにクラウド標準が決まっている組織では、「まずは自社クラウド上でOpus 4.6をPoCに組み込む」という進め方が現実的です。
Claude Code・Coworkでの利用パターン
ソフトウェア開発や業務フローの自動化に踏み込む場合は、Claude CodeやCoworkとの組み合わせが重要になります。
- Claude Code
- IDEやターミナルと連携し、Opus 4.6にコードレビューやバグ修正、テスト生成を任せる。
- エージェントチーム機能で、複数エージェントが大規模リポジトリを分割して読み、改善案を出す。
- Cowork
- 調査・レポート作成・資料ドラフト作成など、複数のタスクを同時並行で走らせる。
- 社内ツールやSaaSと連携したワークフロー単位の自動化を構成する。
まずはブラウザで試し、次にCode/Coworkへ」「PoCがうまくいったらAPIやクラウドに落とし込む」といった段階的な導入が想定されています。

Claude Opus 4.6のユースケース
ここでは、Claude Opus 4.6を実際の業務に当てはめたときのイメージをつかみやすくするために、代表的なユースケースをいくつか取り上げます。ベンチマークのスコアを、そのまま業務シーンに翻訳したイメージで捉えると分かりやすくなります。
ソフトウェア開発・コードレビューでの活用
ソフトウェア開発の文脈では、Opus 4.6は次のような場面で活用が期待されています。
- 既存リポジトリを読み込み、アーキテクチャや依存関係を俯瞰した技術メモを生成する。
- バグレポートやエラーログを入力し、原因候補の洗い出しと修正パッチ案を提示してもらう。
- 技術的負債が溜まっている箇所を特定し、段階的なリファクタリング計画を一緒に考えてもらう。
エンジニアが最後の判断を行う前段階として、「候補の洗い出し」と「修正のたたき台作成」をOpus 4.6に任せるイメージです。
調査レポート・ホワイトペーパー作成での活用
長文コンテキストと検索能力を活かせば、調査レポートやホワイトペーパー作成のワークフローをまとめて支援できます。
- テーマや対象読者、前提条件を入力し、レポート構成案と必要なインプットの一覧を出してもらう。
- 公開資料や社内ドキュメントを並行で読み込ませ、矛盾や抜け漏れの少ないサマリを作る。
- 途中で方向性を変えつつも、1Mコンテキストやコンパクションによって議論の流れを保ちながら書き直していく。
特に「複数の長文資料をまとめて扱う調査プロジェクト」において、Opus 4.6の強みが出やすい領域です。
財務分析・事業シミュレーションでの活用
GDPval-AAでのスコアからも分かるように、Opus 4.6は財務・法務・経営企画といった知識労働領域も強く意識して設計されています。
- 複数年度の財務諸表や管理会計データを読み込ませ、シナリオ別の収益・コスト構造の変化を整理してもらう。
- 投資案件やM&A候補に関する情報をまとめ、想定シナリオとリスク要因のリストを作成させる。
- 関連する規制や契約条件を参照しながら、留意すべきポイントを抜き出してもらう。
もちろん最終判断は人間側の責任になりますが、「どんな論点があり得るか」「どこを検証すべきか」の候補出しに使うと相性が良い領域です。
社内ナレッジ・ドキュメント整理での活用
社内の議事録や設計書、手順書が増えてくると、「どこに何が書いてあるか」が分からなくなりがちです。Opus 4.6は長文コンテキストと検索能力を活かして、こうしたナレッジ整理にも使えます。
- 過去の議事録や仕様書をまとめて読み込ませ、共通の論点や決定事項を一覧にする。
- 新しく作成する資料について、「既存のどの文書と関連があるか」「どの前提条件を引き継ぐべきか」を提示してもらう。
- Coworkやプラグイン経由で、既存のナレッジベースやチケット管理ツールと連携する。
ナレッジがサイロ化しがちな組織ほど、Opus 4.6をエントリーポイントとして“横断検索+要約”を整備する価値があります。
Claude Opus 4.6と他モデルの比較
このセクションでは、Claudeシリーズ内での位置づけと、他社フロンティアモデルとの比較の観点を整理します。細かいスコアの優劣というより、「どんな用途でどのモデルを選ぶか」という判断軸に落とし込むことが目的です。
Claude Opus 4.5との違い
Opus 4.5から4.6への主な進化ポイントをまとめると、次のようになります。
- コンテキスト:200Kに加えて1Mトークンコンテキスト(ベータ)に対応。
- ベンチマーク:Terminal-Bench 2.0やOSWorld、BrowseCompなどのエージェント系評価で大きくスコアを伸ばした。
- 知識労働:GDPval-AAでEloスコアが大きく上昇し、金融・法務・ビジネス領域での性能が向上。
- API機能:Adaptive thinkingやeffort、context compactionなど、長時間タスク向けの制御機能が追加。
- 製品連携:Claude CodeのAgent Teams、Claude in Excel/PowerPointなどが強化。
単なる「精度アップ」ではなく、エージェント的な使い方と長文タスクに合わせて周辺機能が整備された世代と捉えると分かりやすいです。
Sonnet・HaikuなどClaude内モデルとの住み分け
同じClaudeファミリーの中で、Opus 4.6は次のように位置付けられます。
- Opus:最高性能・最高コスト帯。長文タスクやエージェント、重要な意思決定が絡む業務向け。
- Sonnet:性能とコストのバランスが良い中核モデル。日常的なチャットや軽量ワークフローの中心。
- Haiku:高速・低コスト。リアルタイム性や大量リクエストに向いた用途。
実運用では、HaikuやSonnetで受付・前処理を行い、難しい部分や長文処理だけをOpus 4.6にエスカレーションする構成が現実的です。
他社フロンティアモデルとの比較ポイント
GPT-5シリーズやGemini 3シリーズなど、他社のフロンティアモデルと比較する際には、次のような観点で整理すると判断しやすくなります。
- 知識労働タスク
- GDPval-AAなどの評価で、金融・法務・リサーチ系タスクにどこまで強いか。
- コーディング・エージェント
- Terminal-BenchやOSWorldなど、エージェント型コーディング/PC操作タスクの性能。
- 長文コンテキスト
- 1Mトークン級のコンテキストを「どこまで実用的に」使えるか。
- 料金・運用
- トークン単価だけでなく、extended thinkingや1Mコンテキストを多用したときの実コスト。
最終的には、自社のコードベース・ドキュメント・業務フローに対してPoCを行い、「どのモデルが一番“人の時間を浮かせてくれるか”」という観点で比較する必要があります。
Claude Opus 4.6のFAQ
最後に、Claude Opus 4.6を検討する際によく出てくる疑問を簡単に整理します。詳細な仕様は公式ドキュメントに委ねつつ、判断に影響しやすいポイントだけを押さえます。
Claude Opus 4.6は無料で使えますか?
現時点では、Opus 4.6はclaude.aiの有料プランやAPI、クラウド経由での提供が中心で、完全無料での利用は想定されていません。ライトに試したい場合は、まずclaude.aiの有料プランから検討する形になります。
1Mトークンコンテキストは本番運用でも使えますか?
1Mトークンコンテキストはベータ扱いで、200Kトークンを超える部分にはプレミアム料金がかかります。安定性とコストを踏まえると、本番運用ではまず200Kコンテキスト+context compactionの組み合わせを基本とし、1Mコンテキストは限定的な場面(大規模コードベースの解析など)に絞る設計が現実的です。
日本語タスクでも性能は期待できますか?
公開ベンチマークの多くは英語中心ですが、前世代モデル時点で多言語タスクの性能が高かったこともあり、Opus 4.6でも日本語の業務文書やコード解説で十分な性能を発揮することが期待されています。ただし、日本固有の制度や商習慣が絡むタスクについては、プロンプト設計と結果のレビューが欠かせません。
セキュリティやコンプライアンス面で気をつけることはありますか?
Anthropic側で安全性評価や防御策が用意されているとはいえ、モデルがそのまま自社のセキュリティポリシーや法令遵守を保証してくれるわけではありません。
- どのデータを外部モデルに送信してよいか。
- ログの保存・アクセス権限・マスキングの方針。
- モデル出力に対する二次チェック体制。
こうした点は、Opus 4.6を含むどのモデルを採用する場合でも、別途自社側で設計する必要があります。
既に他社モデルを使っていますが、Opus 4.6を追加する価値はありますか?
既にGPTシリーズやGeminiシリーズなどを導入している場合でも、次のような条件に当てはまるならOpus 4.6を追加検討する余地があります。
- コーディングタスクで、長時間のエージェント作業や複雑な根本原因解析が多い。
- 財務・法務・リサーチなど、知識労働タスクの比重が高い。
- 長文コンテキストでの情報保持や検索精度に課題を感じている。
このような場合は、特定領域の“専門モデル”としてOpus 4.6を併用する構成が有力な選択肢になります。

モデル性能の理解を組織のAI業務自動化設計に活かすなら
Claude Opus 4.6のような最新モデルの性能や料金特性を把握することは、AI導入の第一歩にすぎません。実際に成果を出す企業は、モデル選びと同じ重さで「どの業務にAIを任せるか」「どの部門からどの順番で入れるか」「ROIをどう説明するか」を設計し切っています。個別モデルの比較に留まらず、組織全体のAI業務自動化ロードマップに接続できるかどうかで、投資対効果が大きく変わります。
AI総合研究所では、Copilot Chat → M365 Copilot → Copilot Studio → Microsoft Foundry/AI Agent Hub の順にAI業務自動化を段階的に進めるための220ページの実践ガイドを無料で提供しています。経費精算・請求書処理・申請承認・人事・総務・情シス・経営企画といった部門別ユースケースをBefore/After・KPI付きで収録しており、モデル選定で得た知見を業務設計に展開する際の土台として活用いただけます。
AI総合研究所の専任チームが、Microsoft MVP/Solution Partner認定の実績をもとに、モデル選定から業務プロセスへの組み込みまで伴走支援します。まずは無料ガイドで、自社に合った段階設計の全体像をご確認ください。
AI技術の理解を組織の業務設計に活かす

Microsoft環境でのAI業務自動化ガイド
Claude Opus 4.6のような最新AIの進化を踏まえ、組織としてAI業務自動化を段階的に進めるための220ページの実践ガイドです。部門別ユースケースとROI設計を収録しています。
Claude Opus 4.6のまとめ
最後に、Claude Opus 4.6のポイントを簡単に振り返ります。
Opus 4.6は、Anthropicの最上位モデルとして、コーディング・長文コンテキスト・検索・知識労働といった複数の領域を同時に強化したフロンティアモデルです。Terminal-Bench 2.0やGDPval-AA、BrowseComp、各種ドメインベンチマークで高いスコアを記録しており、「開発と知識労働の両方を支えるAIチームメイト」として設計されています。
料金面では、標準コンテキストであれば前世代と同水準のトークン単価が維持されている一方、1Mコンテキストや高いeffort設定を多用するとコストが増えやすくなります。そのため、どのタスクをOpus 4.6に任せるか、どの範囲を他モデルでカバーするかといった設計が重要です。
また、Claude CodeのAgent TeamsやCowork、Claude in Excel/PowerPointなど周辺製品との連携が強化されたことで、単なるチャットボットではなく、「既存の開発フローやOfficeワークに入り込むAI」として位置づけられるようになりました。
今後は、単一モデルの性能だけを見るのではなく、複数モデルやエージェント基盤を組み合わせた全体設計の中で、「Opus 4.6にどの役割を担わせるか」を考えることが重要になります。自社の業務フローやデータの性質を踏まえつつ、まずは限定的なユースケースからPoCを行い、相性を確かめていくのが現実的なアプローチです。










