この記事のポイント
 Amazon Bedrock Agentsは、回答だけでなくAPI実行・状態保持まで含めた業務オーケストレーションをAWSマネージドで作りたい企業の第一候補
Amazon Bedrock Agentsは、回答だけでなくAPI実行・状態保持まで含めた業務オーケストレーションをAWSマネージドで作りたい企業の第一候補- マルチエージェント協調(2025年3月GA)でスーパーバイザー型の分業構成が可能。ただし最初はシングルエージェントで検証し段階的に拡張するのが安全
- 料金はモデル推論+周辺AWS合算方式。Nova Proなら月1,000クエリ約24ドル、Claude Sonnet 4.6なら約105ドルが目安
- Agents/AgentCore/Flowsは二者択一ではなく併用設計、マネージド完結はAgents、独自フレームワークや長時間実行はAgentCoreが本命
- 東京リージョンで基本機能は利用可能だが、コードインタープリテーション等の一部機能はリージョン制約あり。機能単位で対応を確認してから設計すべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Amazon Bedrock Agentsは、AWSの生成AI基盤であるAmazon Bedrock上で、推論・検索・API実行・会話継続をまとめて扱えるエージェント構築機能です。
2023年11月の一般提供以降、2025年3月にはマルチエージェント協調がGA、2025年10月にはAgentCoreが登場するなど、エージェント基盤としての成熟度が急速に上がっています。
本記事では、Amazon Bedrock Agentsの主要コンポーネント、マルチエージェント協調、Bedrockファミリー内での位置付け、使い方、導入事例、他クラウド基盤との比較、注意点、料金体系までを、2026年4月時点のAWS公式情報ベースで整理して解説します。
目次
Amazon Bedrock Agentsの主要コンポーネント
Amazon Bedrock Agentsのマルチエージェント協調
Bedrockファミリー内でのAmazon Bedrock Agentsの位置付け
Amazon Bedrock Agentsの活用例と導入事例
Amazon Bedrock Agentsと他エージェント基盤の比較
Amazon Bedrock Agentsの注意点と導入判断
Amazon Bedrock Agentsとは?
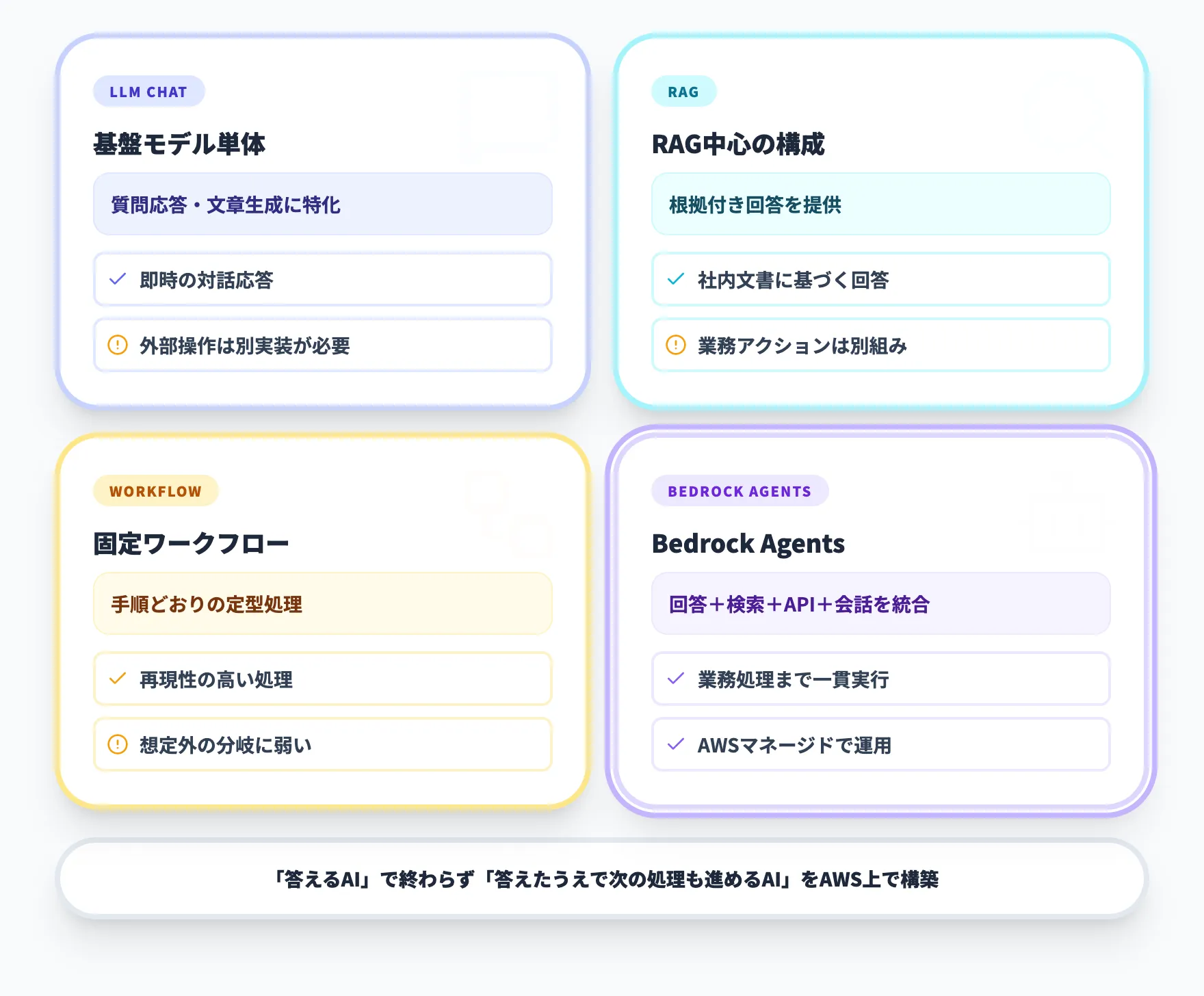
Amazon Bedrock Agentsは、Amazon Bedrockの上で動作するエージェント構築機能です。基盤モデルの推論だけでなく、社内データの参照、外部APIの実行、会話の継続、安全性制御までをまとめて扱えるため、「答えるAI」で終わらず「答えたうえで次の処理も進めるAI」をAWS上で作りたい企業に向いています。
Amazon Bedrock Agentsの公式ページでは、ユーザーの自然言語リクエストをモデルが複数ステップに分解し、必要なデータ取得やAPI呼び出しを組み合わせて最終応答まで導く仕組みとして紹介されています。AWSのドキュメントでは「Agents for Amazon Bedrock」と表記されることもありますが、製品ページでは「Amazon Bedrock Agents」と整理されています。
AWS News Blogによると、Agents for Amazon Bedrockは2023年7月にプレビュー、2023年11月28日に一般提供となりました。その後も機能拡張が続いており、2024年4月にReturn of Control、2024年11月にCustom Orchestration、2025年3月にマルチエージェント協調のGAと、継続的に大きなアップデートが入っています。
単純な生成AIチャットとの違いを整理すると、次のようになります。
| 方式 | 主な役割 | 物足りなくなりやすい点 |
|---|---|---|
| 基盤モデル単体のチャット | 質問応答や文章生成 | 外部システム操作や状態管理は別実装が必要 |
| RAG中心の構成 | 根拠付き回答 | 回答後の業務アクションは別に組む必要がある |
| 固定ワークフロー | 手順どおりの処理 | 想定外の質問や分岐への柔軟性が弱い |
| Amazon Bedrock Agents | 回答、検索、API実行、会話継続を統合 | 指示設計、権限設計、周辺AWS構成は自分で整理が必要 |
この表が示しているのは、RAGや固定ワークフローでは「回答」と「業務処理」が別々のシステムになりやすいのに対して、Amazon Bedrock Agentsはそこを1つの機能でつなげるという設計思想です。社内文書を読んで答えるだけでなく、答えたうえで申請処理や在庫更新まで進められるのが中核的な価値になります。

Amazon Bedrock Agentsの主要コンポーネント
Amazon Bedrock Agentsの価値は、モデルを呼び出せること自体ではなく、業務実装に必要な構成要素があらかじめ整理されている点にあります。ここでは、特に押さえるべきコンポーネントを機能別に見ていきます。
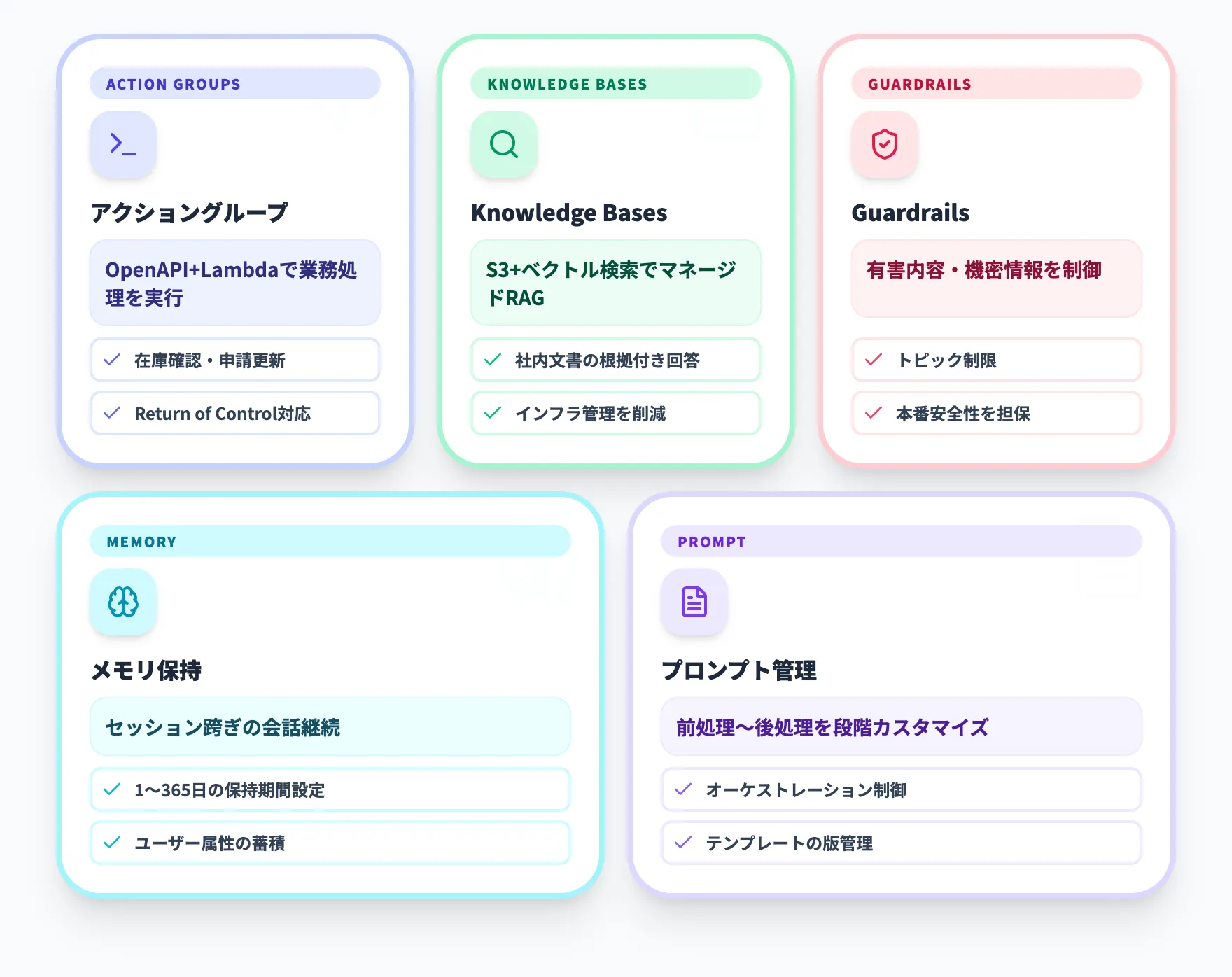
アクショングループとオーケストレーション
Create and configure agent manuallyでは、エージェントの実行先としてアクショングループとKnowledge Baseが中核要素とされています。アクショングループは、エージェントがどのAPIや業務処理を呼び出せるかを定義する仕組みです。

典型的には、OpenAPIスキーマとAWS Lambdaを組み合わせて、在庫確認、申請更新、注文登録、顧客情報取得のような処理を実行します。エージェントの仕組みに関するドキュメントでは、エージェントはユーザー入力をもとにタスクを分解し、必要なアクションを順に選んで実行すると説明されています。
オーケストレーションの柔軟性もこの2年で大きく広がりました。主な拡張を整理すると次のとおりです。
- 2024年4月 Return of Control
すべてをLambda任せにせず、エージェントからアプリケーション側へ処理制御を返す構成が取れるようになった。公式アナウンスで詳細が案内されている
- 2024年11月 Custom Orchestration
Lambdaで独自のオーケストレーション戦略を実装し、標準の推論ループを差し替えられるようになった。公式アナウンスを参照
- 2025年3月 Inline Agents
マルチエージェント協調のGA時に追加された機能で、実行時にエージェントの役割や動作を動的に調整できる
つまり、「標準の自動推論に乗る」だけでなく、「制御を返す」「計画ロジックを差し替える」「実行時に役割を変える」までできるのがAmazon Bedrock Agentsの強みです。段階的に制御の粒度を上げていけるため、最初はシンプルな自動推論で始めて、業務要件が見えてきてからCustom Orchestrationに進むアプローチが実務では有効です。
Knowledge BasesとGuardrails
Amazon Bedrock Agentsは、API実行だけでなく、回答精度と安全性を上げるための機能もまとめて扱えます。

それぞれの役割を整理すると、次の表になります。
| 機能 | 役割 | 実務上の意味 |
|---|---|---|
| Knowledge Bases | 社内文書やWeb、DB由来の情報を検索して回答へ反映 | RAG構成を別途組まずに済むため立ち上げが速い |
| Guardrails | 有害内容、機密情報、不要なトピックを制御 | 本番運用での安全性を担保しやすい |
Knowledge Basesは、Amazon S3に格納した社内文書をベクトル検索でき、エージェントの回答に根拠を付ける役割を果たします。社内ナレッジ検索にRAGを使いたいケースでは、別途LangChainやLlamaIndexを組むのではなく、Knowledge Basesに任せたほうがインフラ管理が減ります。
Guardrailsは、AIガバナンス設計と合わせて運用する機能です。業界の規制要件が厳しい金融・医療などでは、Guardrailsだけでなく、Lambda側の入力検証やIAMポリシーによる権限制御と組み合わせて多層防御を取ることが重要になります。
メモリ保持とプロンプト管理
Amazon Bedrock Agentsには、セッションをまたいだ会話情報を活用するメモリ機能が用意されています。メモリ機能のドキュメントでは、保持期間は1日から365日まで設定でき、セッションの会話要約やユーザー属性を蓄積できると案内されています。
また、作成手順のドキュメントでは、アイドル状態のセッションタイムアウトは既定で30分とされています。プロンプトテンプレートもエージェント側で管理でき、前処理・オーケストレーション・後処理の各段階でカスタマイズが可能です。
このため、FAQを返すだけのエージェントよりも、「前回の申請状況を踏まえて次の案内を出す」「継続的な問い合わせで必要情報を引き継ぐ」といった業務に向きます。メモリ機能がなければ、毎回最初から状況をヒアリングし直すことになるため、問い合わせ対応や社内ヘルプデスクのようなユースケースでは特に差が出ます。
Amazon Bedrock Agentsのマルチエージェント協調
2025年3月、Amazon Bedrock multi-agent collaborationがGAになりました。1つのスーパーバイザーエージェントが複数の専門エージェント(コラボレーター)を束ねる構成が一般提供されています。
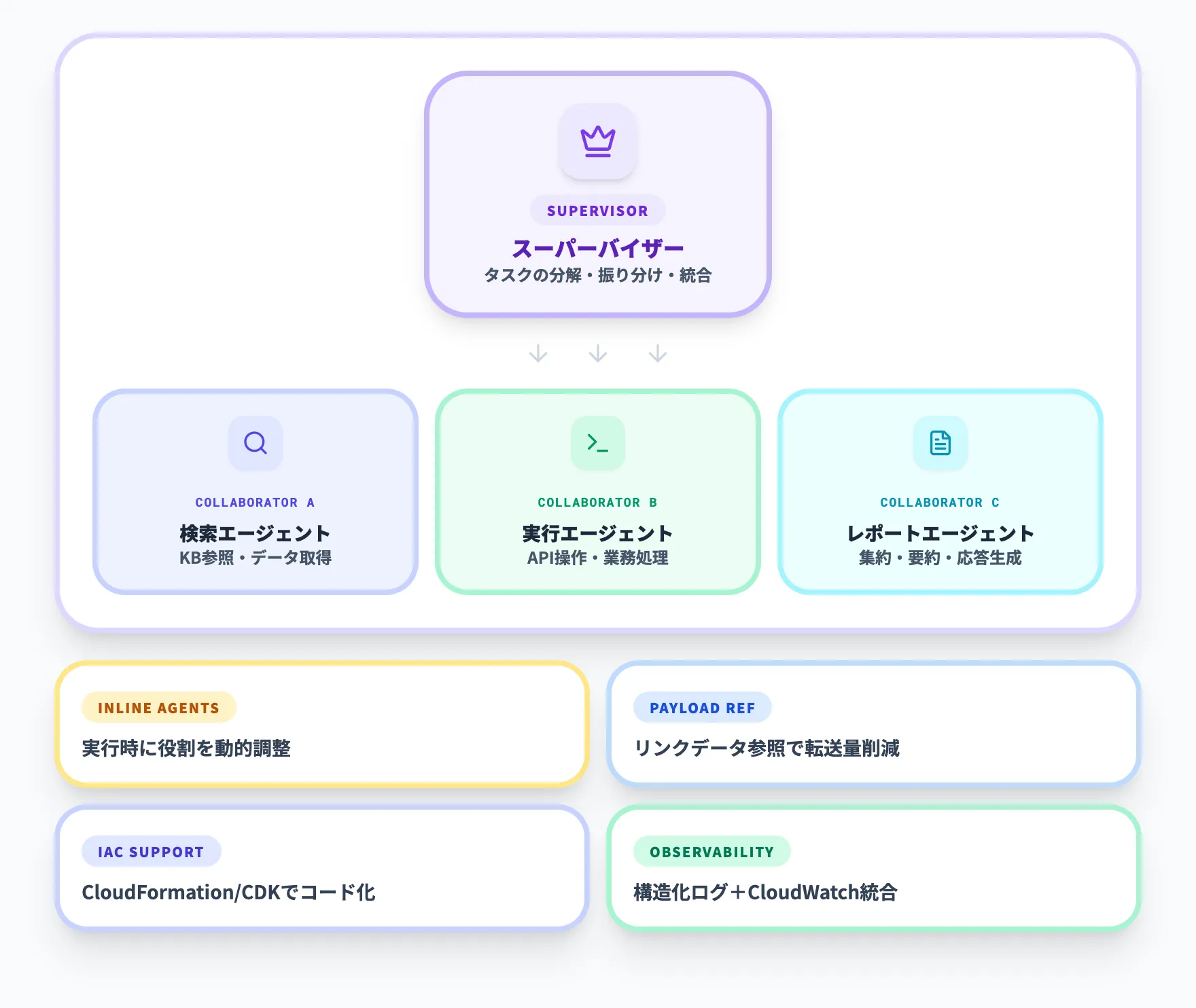
マルチエージェントGAのブログ記事では、金融・医療・サプライチェーン・製造・カスタマーサポートなど幅広い業種での活用事例が紹介されています。GA時に追加された主要機能は次のとおりです。
- Inline Agents
実行時にエージェントの役割や動作を動的に調整でき、ビジネス要件の変化に柔軟に対応可能
- Payload Referencing
スーパーバイザーがリンクデータを参照する方式を取ることで、データ転送量を削減しレスポンスを高速化
- Infrastructure as Code対応
AWS CloudFormationとCDKでエージェントネットワークをコード化し、複数アカウントへの展開を効率化
- Enhanced Observability
構造化されたログ、サブステップ追跡、CloudWatch統合で運用時の監視とデバッグが容易に
ただし、マルチエージェントの対応状況ドキュメントではいくつかの制約も案内されています。コラボレーターに使えるモデルはAnthropic Claude 3系、Claude 3.5系、Amazon Nova Pro/Lite/Microなどに限定されており、Custom Orchestrationを使うスーパーバイザーとコラボレーターはマルチエージェント協調の対象外です。
マルチAIエージェントの分業構成は魅力的ですが、何でも最初から分業化すれば良いわけではありません。AI総研の導入支援では、以下の判断基準を推奨しています。
- シングルエージェントで始めるべきケース
問い合わせ分類、在庫照会、申請状況確認のように対象領域が1つで、アクショングループが3つ程度に収まる業務
- マルチエージェントを検討すべきケース
専門領域が明確に分かれており(例:臨床データ × 規制情報 × データベース操作)、1つのエージェントに集約するとプロンプトの複雑化と精度低下が見込まれる業務
いきなり複雑化すると、プロンプト設計、権限設計、ログ設計、評価基準のすべてが膨らみます。PoCで1エージェントの精度とコストを確認してから、分業が必要な部分だけマルチ化するのが実務上は安全です。
Bedrockファミリー内でのAmazon Bedrock Agentsの位置付け
Amazon Bedrock Agentsは便利ですが、AWSには近い名前の周辺機能が多く、混同しやすい領域です。ここで切り分けておくと、設計判断を誤りにくくなります。

Bedrockファミリーは大きく3層に分けて捉えると整理しやすくなります。
| 層 | サービス | 役割 |
|---|---|---|
| 基盤層 | Amazon Bedrock本体 | 約100種の基盤モデルをAPIから呼ぶマネージド生成AI基盤 |
| エージェント層 | Bedrock Agents / AgentCore | Agents=推論・検索・API実行を統合するエージェント。AgentCore=任意FW・モデルで作ったエージェントの運用基盤 |
| 補助機能層 | Knowledge Bases / Guardrails / Flows | KB=マネージドRAG。Guardrails=安全性制御。Flows=視覚的ワークフロー構築 |
特に混同しやすいのが、Agents / AgentCore / Flowsの使い分けです。この3つは二者択一ではなく、用途に応じて組み合わせる前提で設計されています。
- Amazon Bedrock Agents
自然言語リクエストに基づいてモデルがタスクを分解・実行する構成。AWSマネージドで完結させたい場合の第一選択肢。本記事の主題
- Amazon Bedrock AgentCore
AgentCoreのGA告知では、任意のフレームワーク(LangGraph、CrewAIなど)、モデル、プロトコルで作ったエージェントを安全にデプロイ・運用する基盤と説明されている。Bedrock外のモデルや最大8時間の長時間実行が視野に入るなら、AgentsよりAgentCoreが本命になるケースがある
- Amazon Bedrock Flows
Flowsのドキュメントでは、プロンプト、基盤モデル、Knowledge Bases、Lambdaなどを視覚的につないで生成AIワークフローを組む機能と説明されている。対応ノード一覧ではAgent nodeも用意されており、Flowsの中にAgentsを組み込む構成も可能
AI総研の導入支援の経験では、この3つの選び方で判断が詰まるケースが多くあります。以下の条件分岐で考えると整理しやすくなります。
まずAWSマネージドで完結させたいかどうかを確認します。完結させたいなら、自然言語リクエストに応じた動的な計画実行が中心の場合はAgents、固定的な処理フローや条件分岐を見える形で設計したいならFlowsが合います。FlowsとAgentsを組み合わせて「Flowsの中からAgentsを呼ぶ」構成も実用的です。一方、LangGraphのような外部フレームワークを使いたい、Bedrock外のモデルも使いたい、長時間実行が必要、という条件が1つでもあるなら、AgentCoreを検討すべきです。
Amazon Bedrock本体の詳細(基盤モデル選定、料金体系全体など)については、別途「Amazon Bedrockとは」の記事で詳しく解説しています。
Amazon Bedrock Agentsの使い方
Amazon Bedrock Agentsは多機能ですが、最初のPoCは意外にシンプルです。チュートリアルでも、日時を返すLambda関数を呼び出す小さなエージェントから始めています。
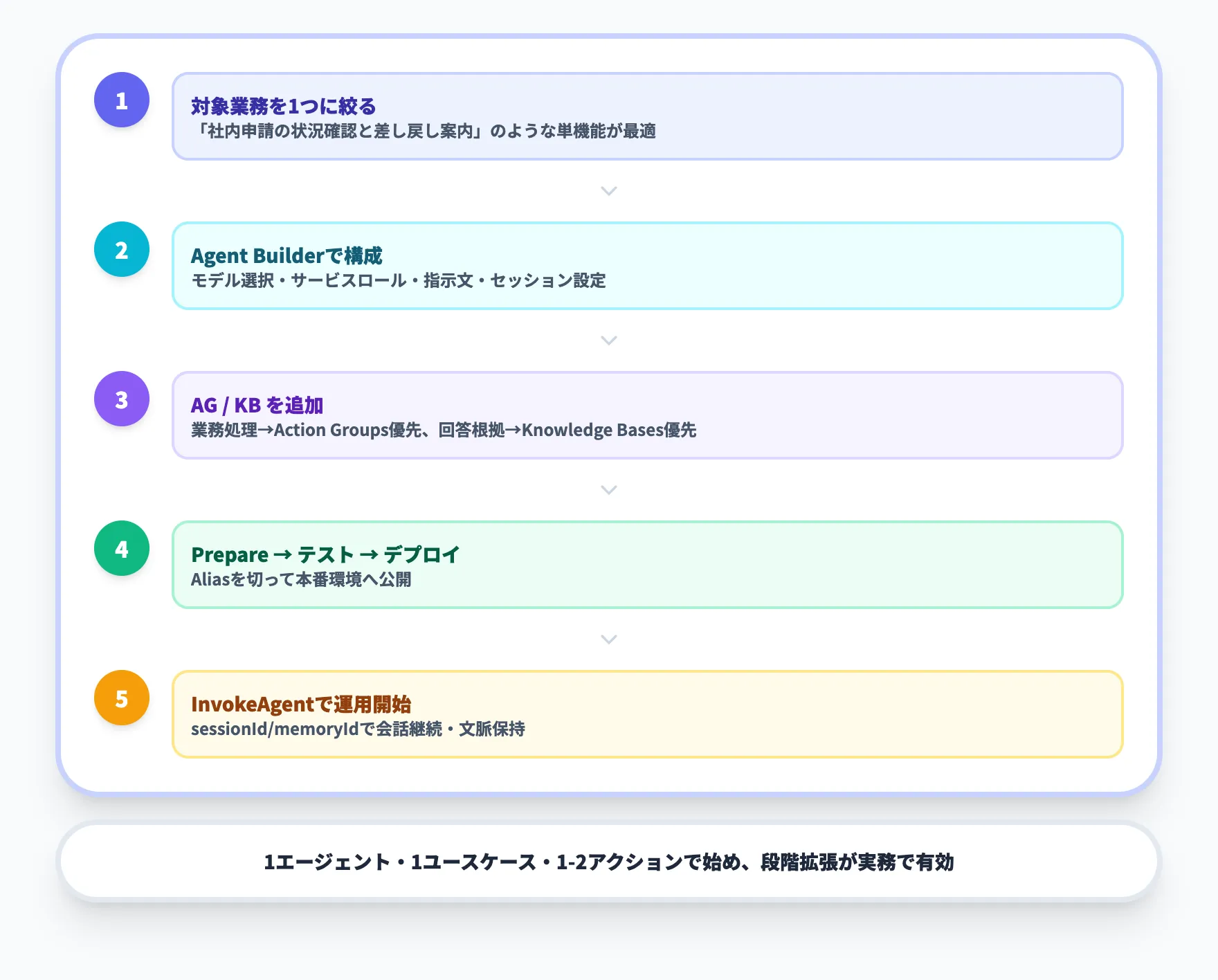
最小構成で始めるなら、流れは次の5段階です。
- まず、対象業務を1つに絞り、エージェントへの自然言語指示を決めます。例としては「社内申請の状況を確認し、必要なら差し戻し理由を返す」のような単機能が向いています。
- 次に、Agent builderでモデル、サービスロール、指示文、必要ならKMSやセッション設定を構成します。
- 続いて、アクショングループかKnowledge Baseを追加します。業務処理が主ならアクショングループ、回答根拠が主ならKnowledge Baseを先に作ると整理しやすくなります。
- その後、エージェントをPrepareしてテストし、問題がなければaliasを切ってデプロイします。
- 本番アプリからはInvokeAgentを呼び出し、必要に応じてsessionIdやmemoryIdを使って会話継続やユーザー別の文脈保持を行います。
PoC段階では、最初からマルチエージェントや複数ツールを盛り込みすぎないことが重要です。1エージェント、1ユースケース、1つか2つのアクションに絞ったほうが、失敗要因を切り分けやすくなります。本番化が見えてきたタイミングで、Knowledge Basesで回答精度を上げ、Guardrailsで安全性を担保し、必要ならマルチエージェントへ拡張するという段階設計が実務では有効です。
【関連記事】
AIエージェント(AI agent)とは?その仕組みや作り方、活用事例を解説

Amazon Bedrock Agentsの活用例と導入事例
Amazon Bedrock Agentsは、「問い合わせ対応から業務実行までをつなぐ」場面で価値が出やすい機能です。AWS公式の事例や技術ブログでも、その傾向がはっきり出ています。
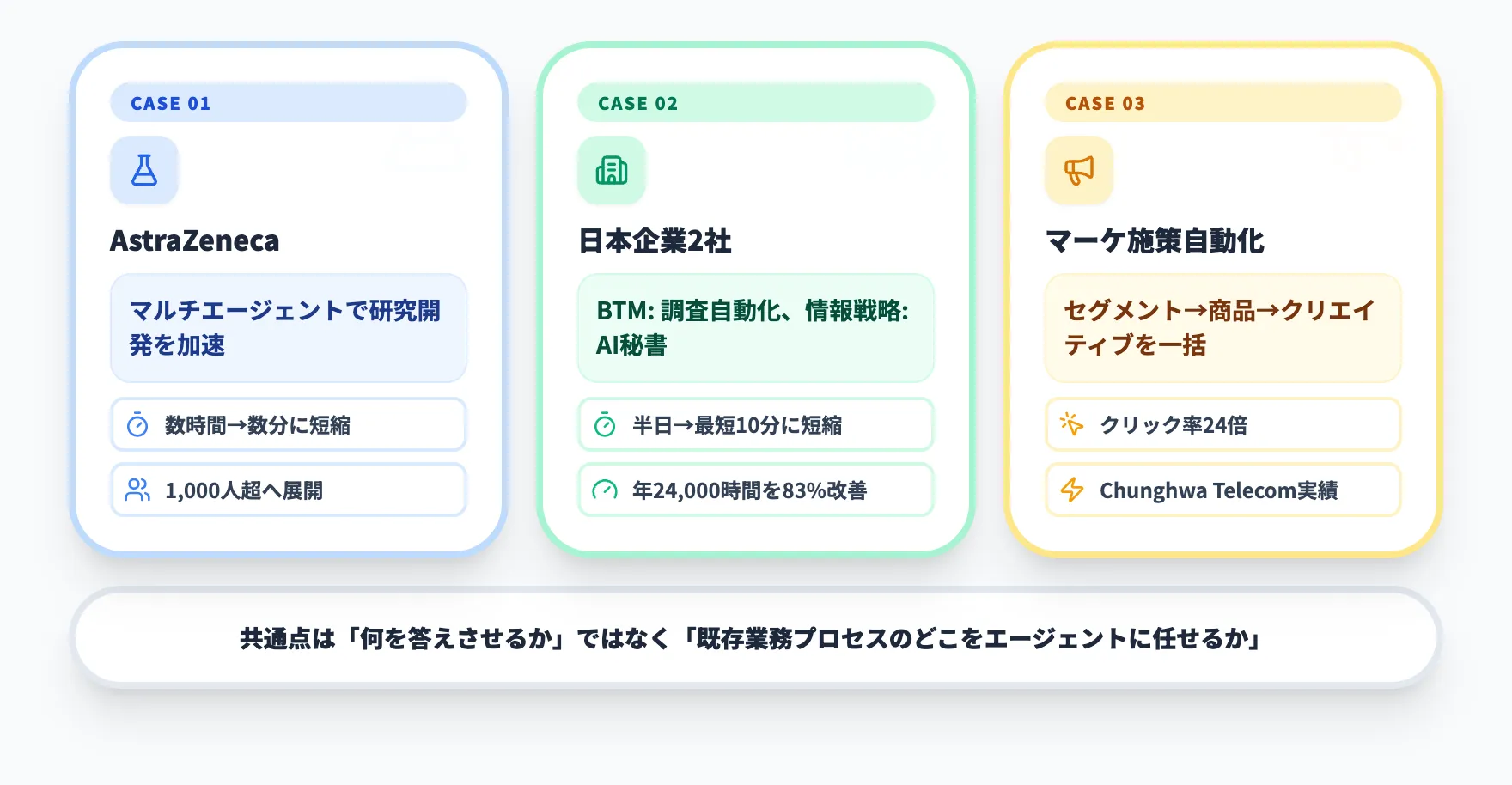
AstraZenecaのマルチエージェント活用
AstraZenecaのケーススタディでは、同社がAmazon Bedrock Agentsを使って研究開発向けのDevelopment Assistantを構築し、構造化データと非構造化データの両方を自然言語で引けるようにしています。
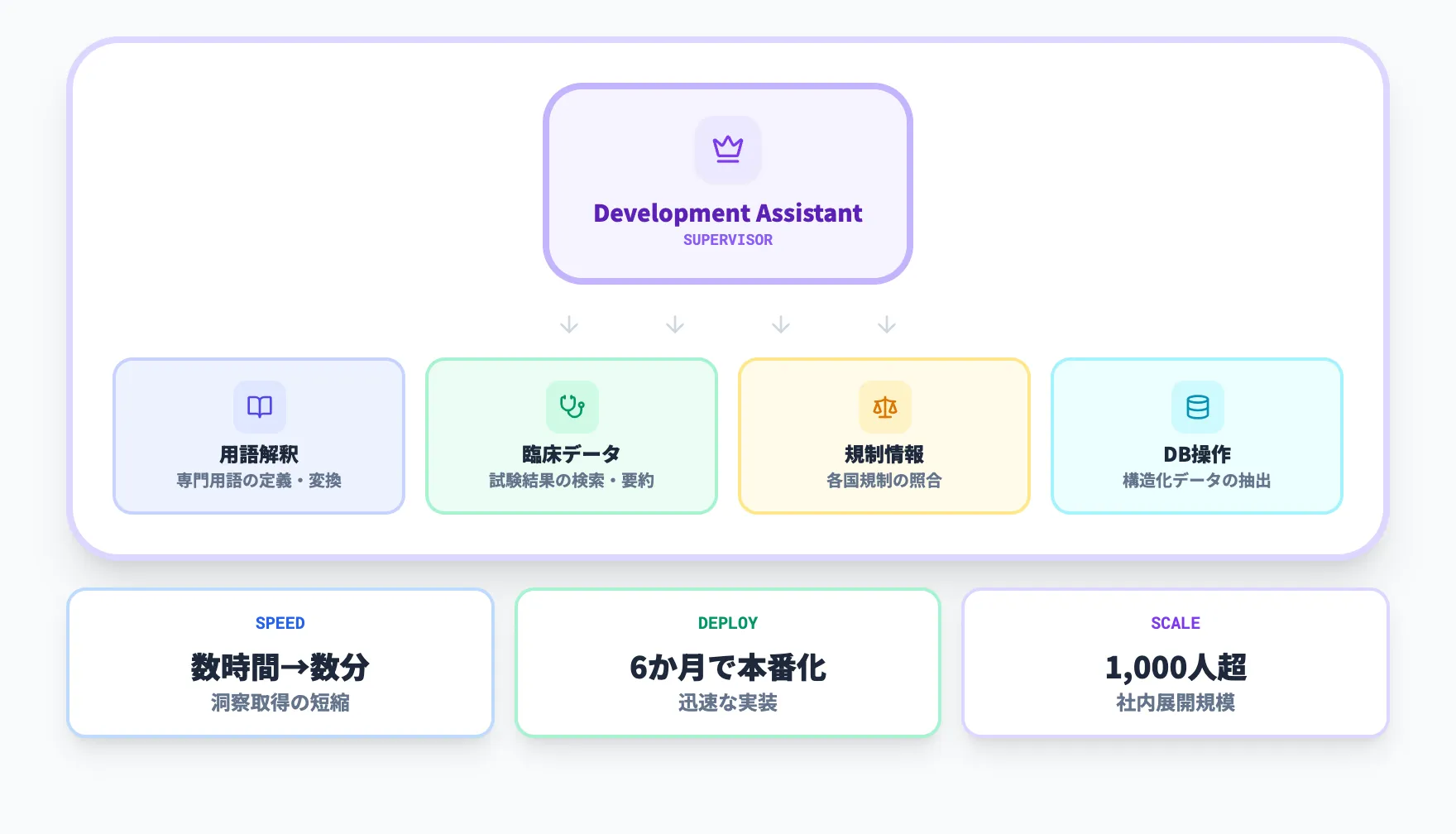
この事例のポイントは、1つの万能エージェントではなく、用語解釈、臨床、規制、データベース操作などの役割を分けたマルチエージェント構成を採ったことです。AWSの公開内容では、従来は数時間かかっていた洞察取得を数分単位に短縮し、6か月で本番化、1,000人超への展開を進めています。
医療業界の特殊事例に見えますが、「用語が難しい部門」「複数データソース」「専門エージェントへの振り分け」が必要な企業ならかなり再現性のあるパターンです。
日本企業のBedrock活用事例

日本国内でもAmazon BedrockとAgents周辺機能を活用した事例が出てきています。
株式会社BTMの事例では、Amazon Bedrock AgentCoreとStrands Agentsを使ってシステム調査を自動化し、従来は半日を要していた調査時間を最短10分ほどに短縮しています。エンジニアのトラブルシュート工数を大幅に削減した事例です。
また、株式会社情報戦略テクノロジーの事例では、Amazon BedrockとKnowledge Basesを活用して、社員一人ひとりに寄り添うAIエージェント秘書「パイオにゃん」を開発しています。年間24,000時間かかっていた情報探索業務を約83%改善できる見込みです。
これらの事例に共通するのは、「生成AIに何を答えさせるか」ではなく「既存の業務プロセスのどこをエージェントに任せるか」という業務起点のアプローチです。
マーケティング施策の自動化
AWS Machine Learning Blogのマーケティング事例では、Amazon Personalize、Knowledge Bases、Lambdaなどを組み合わせたマーケティングエージェントが紹介されています。

この構成では、エージェントが顧客セグメントの抽出、商品情報の取得、クリエイティブ生成を段階的に進めます。同記事では、Chunghwa Telecomが同種の構成を活用し、クリック率が24倍になったと紹介されています。
ここで重要なのは、生成AIが文章を書いただけではなく、顧客データ、商品データ、ブランド文脈をまたいで複数のツールを順番に使っている点です。Amazon Bedrock Agentsは、こうした「データ取得と生成を一体で回す」場面と相性が良いです。
Amazon Bedrock Agentsが向いている業務
ここまでの事例を踏まえると、Amazon Bedrock Agentsが特に向いているのは次のような業務です。
- 社内ナレッジ検索に加えて、申請更新や顧客照会などの実行系アクションまで返したい業務
- カスタマーサポートの自己解決導線で、FAQ回答だけでなく注文確認やステータス更新までつなげたい業務
- マーケティング、営業、運用のように、複数の社内システムやデータソースをまたいで自然言語で処理を進めたい業務
逆に、単純な検索画面や定型フローだけで足りる場合は、エージェントまで持ち込まずにKnowledge Bases単体やAIワークフローで済ませたほうが軽く仕上がります。「エージェントが必要なのか、ワークフローで十分なのか」を先に判断することが、設計のコスト感を左右します。
Amazon Bedrock AgentsはPoCを素早く始めやすい一方で、成果が出るかどうかは「どの業務に載せるか」「どこまで実行権限を持たせるか」で大きく変わります。技術検証だけで終わらせず、業務接続と運用設計まで含めて考えることが重要です。
Bedrock Agentsを業務実装につなぐ

エージェント検証の先にある接続設計と運用管理を整理
Amazon Bedrock AgentsでPoCを進めても、本番では業務システム連携、権限設計、実行ログ管理まで含めた設計が必要です。AI Agent HubのLPで、エージェントを業務に定着させる全体像をご確認ください。
Amazon Bedrock Agentsと他エージェント基盤の比較
AWS以外にも、GCPのVertex AI Agent BuilderやMicrosoftのFoundry Agent Serviceなど、クラウド各社がエージェント構築基盤を提供しています。既存のクラウド環境と目的に応じた選定が重要です。

2026年4月時点の主要な比較軸を整理すると、次の表になります。
| 比較軸 | AWS(Bedrock Agents + AgentCore) | GCP(Vertex AI Agent Builder) | Azure(AI Foundry Agent Service) |
|---|---|---|---|
| クラウド基盤 | AWS | Google Cloud | Microsoft Azure |
| 東京リージョン | 基本機能は対応 | 対応 | 対応 |
| マルチエージェント | Bedrock Agents: GA(2025年3月、スーパーバイザー型) | Agent Engine経由で可能 | Semantic Kernel経由で可能 |
| マネージドRAG | Knowledge Bases(S3 + ベクトルストア統合) | Vertex AI Search連携 | Azure AI Search連携 |
| ガードレール統合 | Guardrails(Bedrock機能として統合) | Vertex AIのコンテンツフィルタ | Azure AI Content Safety |
| 外部FW対応 | AgentCoreで任意FW対応(Agents本体はLambdaベース) | ADK(Agent Development Kit) | Semantic Kernel / AutoGen |
| オープンプロトコル | AgentCoreがA2A対応 | A2A発案元、ADK統合 | A2A対応(preview) |
| 強み | AWSサービスとのネイティブ連携、Agents→AgentCoreの段階拡張が可能 | BigQuery連携、ノーコードUI、A2A標準化推進 | Microsoft 365統合、Teams/Copilot連携 |
この比較から見えるのは、どの基盤も機能的には近づいてきているが、「既存のクラウド資産」「組織のツール環境」が選定の決め手になるという点です。
AWS中心のインフラでLambdaやS3を日常的に使っている企業なら、Amazon Bedrock Agentsはアクショングループ経由でシステム連携を最も手早く組めます。一方、Google Workspace中心ならVertex AI、Microsoft 365中心ならAzure AI Foundryのほうが業務導線への接続がスムーズです。
エージェント基盤の選定で本当に詰まるのは機能比較ではなく、「社内の既存システムとどうつなぐか」です。AzureとAWSの料金、サービス、性能を徹底比較も合わせて参考にしてください。
Amazon Bedrock Agentsの注意点と導入判断
Amazon Bedrock Agentsは「AWSがかなり面倒を見てくれる」サービスですが、それでも設計で詰まりやすい論点があります。PoCから本番へ進む前に、最低限ここは整理しておきたいポイントです。
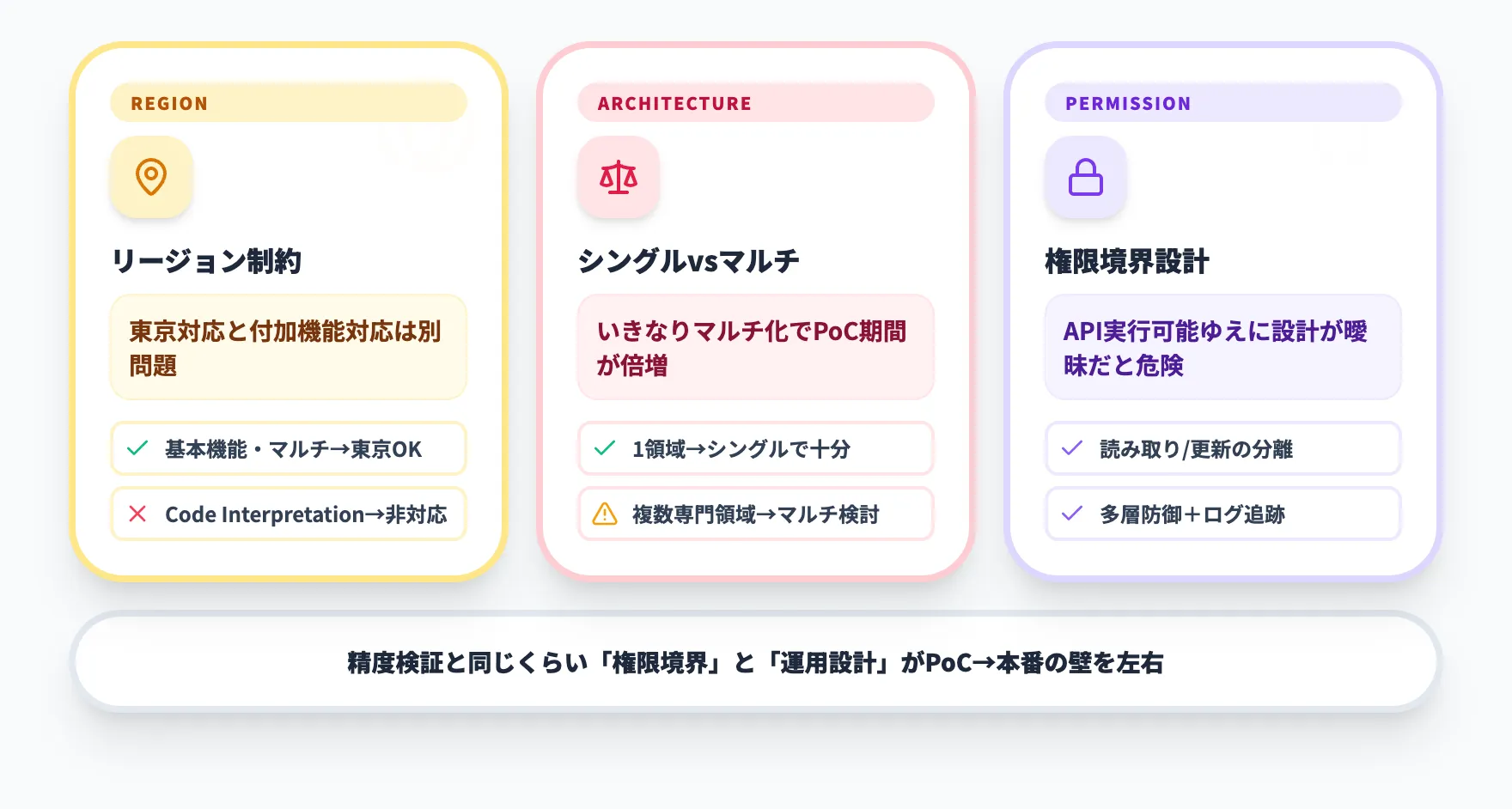
東京リージョンでの前提を分けて考える

対応Region一覧では、Amazon Bedrock Agentsは東京リージョンに対応しています。一方で、code interpretationは対応リージョンが米国東部、米国西部、欧州フランクフルトの3か所に限定されており、東京は含まれていません。
つまり「Amazon Bedrock Agentsが東京で使える」ことと、「使いたい付加機能まで東京で全部そろう」ことは別問題です。日本企業でデータ所在地やレイテンシの制約が重要なら、以下のように機能ごとに対応状況を確認するのが安全です。
| 機能 | 東京リージョン対応(2026年4月時点) |
|---|---|
| Bedrock Agents基本機能 | 対応 |
| マルチエージェント協調 | 対応 |
| Knowledge Bases | 対応 |
| Guardrails | 対応 |
| Code Interpretation | 非対応(米国東部・西部・フランクフルトのみ) |
この表の対応状況は変更される可能性があるため、設計着手時に公式の対応リージョンページで最新を確認してください。
シングルエージェントで足りるかを先に決める

マルチエージェント協調がGAになったことで「最初から分業化したい」という要望が出やすくなっていますが、AI総研の導入支援の経験では、いきなりマルチ構成にしてPoC期間が2倍以上に延びたケースが複数あります。
判断のポイントは単純で、対象業務の専門領域が1つか複数かです。問い合わせ分類、在庫照会、申請状況確認のような業務は、シングルエージェントにアクショングループを2〜3個つなげれば十分対応できます。AstraZenecaのように「用語解釈 × 臨床 × 規制」のように明確に異なる専門知識が要る場合に初めてマルチ化を検討してください。
業務実行権限の境界を曖昧にしない
Amazon Bedrock AgentsはAPIを実行できるからこそ、設計で曖昧にすると危険です。特に次の3点はPoC段階から切っておくべきです。
- 読み取り専用のアクションと更新系アクションを分ける
- Guardrailsだけに頼らず、API側でも入力検証と権限制御を行う
- 誰の代わりにどの処理を実行したのかを追えるログ設計にする
このあたりはモデル精度よりも先に詰まるポイントです。エージェント導入では、精度検証と同じくらい権限境界と運用設計が重要になります。AIエージェントを企業に導入する全手順でも、この「PoCから本番に移るときの壁」がボトルネックになりやすいと整理しています。
AIエージェント×データ基盤の設計論も合わせて確認すると、権限設計とデータ接続の全体像が見えやすくなります。
Amazon Bedrock Agentsの料金体系
Amazon Bedrock Agentsの料金を考えるときは、「エージェントに月額固定費がある」という理解ではなく、基盤モデル推論と周辺AWSサービスの組み合わせで見積もるのが基本です。

基本は基盤モデル推論課金
AWS News BlogのGA告知では、2023年11月28日の一般提供開始時点で、エージェントが行うモデル推論に対して課金され、InvokeAgent API自体には別料金がかからないと説明されています。2026年4月時点でも、AWS公式のAmazon Bedrock pricingではエージェント固有の追加課金ではなく、モデルや周辺機能の課金が中心に案内されています。
東京リージョンで利用できる主要モデルのオンデマンド料金を整理すると、次の表になります(2026年4月時点)。
| モデル | 入力(1Mトークンあたり) | 出力(1Mトークンあたり) |
|---|---|---|
| Claude Sonnet 4.6 | 3.00ドル | 15.00ドル |
| Claude Haiku 4.5 | 1.00ドル | 5.00ドル |
| Claude Opus 4.6 | 5.00ドル | 25.00ドル |
| Amazon Nova Pro | 0.80ドル | 3.20ドル |
| Amazon Nova Lite | 0.06ドル | 0.24ドル |
| Amazon Nova Micro | 0.035ドル | 0.14ドル |
出典:Amazon Bedrock pricingをもとに整理(2026年4月時点、東京リージョン)
エージェントは1回のユーザーリクエストに対して複数回のモデル推論を行います。エージェントの仕組みに関するドキュメントでは、前処理・オーケストレーション・Knowledge Base応答生成・後処理のステップごとにモデル呼び出しが発生すると説明されています。そのため、単純なチャット利用よりも実効トークン量は増える前提で見積もる必要があります。
見積もりでは周辺サービス費用も含める
Amazon Bedrock Agentsは単独で完結するより、Lambda、Knowledge Bases、S3、ベクトルストア、CloudWatchなどと組み合わせて使う構成が一般的です。実務上の見積もりは次のように分解して考えます。
| コスト項目 | どこで発生するか | 見積もりの勘所 |
|---|---|---|
| 基盤モデル推論 | エージェントの推論、回答生成、補助的なモデル呼び出し | モデル選択、応答長、会話ターン数 |
| Provisioned Throughput | 高トラフィック時の安定処理 | 常時負荷が高いかどうか |
| アクショングループ側処理 | Lambdaや接続先APIの実行 | 実行回数、処理時間、外部API料金 |
| ナレッジ連携 | Knowledge Basesやベクトル検索 | ドキュメント量、同期頻度、検索回数 |
| 監視とセキュリティ | ログ、暗号化、監査 | 本番運用で要求される監査レベル |
コスト最適化で最も効くのは、「一番安いモデルを選ぶ」ことではありません。無駄なツール呼び出し、長すぎる出力、過剰なRAG検索、不要なマルチエージェント化の方が、実務では影響が大きくなります。エージェントの指示文でアクショングループの呼び出し条件を明確にし、不要な推論ステップを減らすことが最も費用対効果の高い対策です。
PoCでは小さく始めるのが安全

PoC段階での目安として、シンプルなエージェント構成の月額イメージを試算すると次のようになります。
前提は、月1,000クエリ、1クエリあたり入力10,000トークン+出力5,000トークン(オーケストレーション含む)です。
- Amazon Nova Proの場合
入力:10,000 × 1,000 = 1,000万トークン × 0.80ドル/1M ≒ 8ドル。出力:500万トークン × 3.20ドル/1M ≒ 16ドル。合計で約24ドル/月。Lambda実行費やS3ストレージを加えても月30〜40ドル程度に収まる
- Claude Sonnet 4.6の場合
入力:1,000万トークン × 3.00ドル/1M ≒ 30ドル。出力:500万トークン × 15.00ドル/1M ≒ 75ドル。合計で約105ドル/月。周辺サービス込みで月120〜150ドル程度
この試算はPoC用の小規模構成です。本番化でクエリ量が10倍になれば比例して増えますが、その段階ではProvisioned Throughputやモデル選択の最適化で調整する余地があります。まず1エージェント、1モデルで始めてコスト感を掴み、本番化が見えてから拡張する段階設計が実務では安全です。
なお、AgentCoreを利用する場合は、AgentCore Pricingで案内されているとおり、vCPU 0.0895ドル/時間、メモリ 0.00945ドル/GB時間、ゲートウェイ呼び出し 0.005ドル/1,000回という別体系になります。従量課金で最低利用額はないため、AgentCoreの方が合う構成かどうかは用途次第です。

Amazon Bedrock AgentsをPoCで終わらせないなら
Amazon Bedrock Agentsは、エージェントの試作まではかなり速く進められます。ただし、本当に難しいのはその先です。どの業務システムに接続するのか、誰にどこまで実行権限を渡すのか、ログと監査をどう残すのかを決めないと、便利な検証で止まりやすくなります。
特に、社内アシスタントや問い合わせ対応のように業務フローへ直結するテーマでは、モデル精度だけでなく実行導線と運用設計が成果を左右します。AI Agent Hubは、こうした既存AI基盤の検証を、実際の業務接続や管理基盤の整備までどうつなげるかを整理するための資料です。
AI総合研究所の資料では、BedrockやSageMakerのような既存のAI基盤を前提に、業務システム接続、権限管理、実行ログの一元化をどう設計するかを整理しています。Amazon Bedrock Agentsの検証を本番活用につなげる判断材料としてご確認ください。
Bedrock Agentsを業務実装につなぐ
エージェント検証の先にある接続設計と運用管理を整理
Amazon Bedrock AgentsでPoCを進めても、本番では業務システム連携、権限設計、実行ログ管理まで含めた設計が必要です。AI Agent HubのLPで、エージェントを業務に定着させる全体像をご確認ください。
まとめ
Amazon Bedrock Agentsは、AWS上で「答えるAI」から「動くAI」へ進めるためのマネージド機能です。アクショングループで業務処理までつなげ、Knowledge BasesでRAGを組み、Guardrailsで安全性を確保し、マルチエージェント協調で分業構成まで取れる――これらの構成要素をAWSマネージドで一式そろえられるのが最大の強みです。
一方で、すべての機能が全リージョンで同じように使えるわけではなく、AgentCoreやFlowsとの使い分け、権限境界の設計、周辺AWSサービスを含めたコスト設計は自分で整理する必要があります。
AWS資産を活かしつつ、まずはマネージドにエージェントを作りたい企業にとって、Amazon Bedrock Agentsはかなり有力な選択肢です。まずは1つの業務で、シングルエージェントのPoCから始めてみてください。










