この記事のポイント
 最も長期・自律的なエージェント業務にはClaude Fable 5、複雑な推論と日常コーディングにはOpus 4.8、コスト効率重視の本番デフォルトはSonnet 4.6が第一候補
最も長期・自律的なエージェント業務にはClaude Fable 5、複雑な推論と日常コーディングにはOpus 4.8、コスト効率重視の本番デフォルトはSonnet 4.6が第一候補- API料金はFable 5(入力$10/出力$50)がOpus 4.8($5/$25)の2倍。Opus 4.8には2.5x速度のFast mode($10/$50)も追加された
- Sonnet 4.6はOpus級コーディング性能を6割の単価で実現。1Mコンテキストも標準料金で利用可能で、実務上の本番デフォルト候補
- Haiku 4.5は最速・最安。リアルタイム応答・大量分類・要約は単価が1/10になるためHaikuで十分なケースが大半
- 4階層時代の運用は「Haikuで一次仕分け→Sonnet本処理→Opus深掘り→Fableで長期自律業務」のスイッチング設計が費用対効果で最も優れる

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Anthropicが提供するClaude(クロード)は、2026年6月のClaude Fable 5登場で「Fable / Opus / Sonnet / Haiku」の4階層構造に再編されました。
従来の3階層フラグシップだったOpusの上に新最上位モデルClaude Fable 5が乗り、Opus自身も2026年5月のOpus 4.8リリースで世代更新が進んでいます。
本記事では、Fable 5・Opus 4.8・Sonnet 4.6・Haiku 4.5の4モデルについて、性能・料金体系・使い分けを2026年6月時点の最新情報で体系的に解説します。
目次
Claudeの4モデル構成——Fable 5が上位層に加わった4階層
Claude Fable 5・Opus 4.8・Sonnet 4.6・Haiku 4.5それぞれの強み
Claude Fable 5の強み——長期自律エージェントの新標準
Claude Opus 4.8の強み——effort制御とDynamic Workflows
Claude Sonnet 4.6の強み——実務上の本番デフォルト候補
Claude Haiku 4.5の強み——最速レスポンスと最安単価
Batch APIとプロンプトキャッシングによるコスト最適化
Claudeの4モデル構成——Fable 5が上位層に加わった4階層
Anthropic社が開発するClaude(クロード)は、2026年6月のClaude Fable 5発表により、これまでの「Opus・Sonnet・Haiku」3階層から、Fable 5を最上位に置く4階層構造へ再編されました。
本セクションでは、まず2026年6月時点のClaudeモデルラインナップ全体と、4モデルの命名・位置づけを整理します。

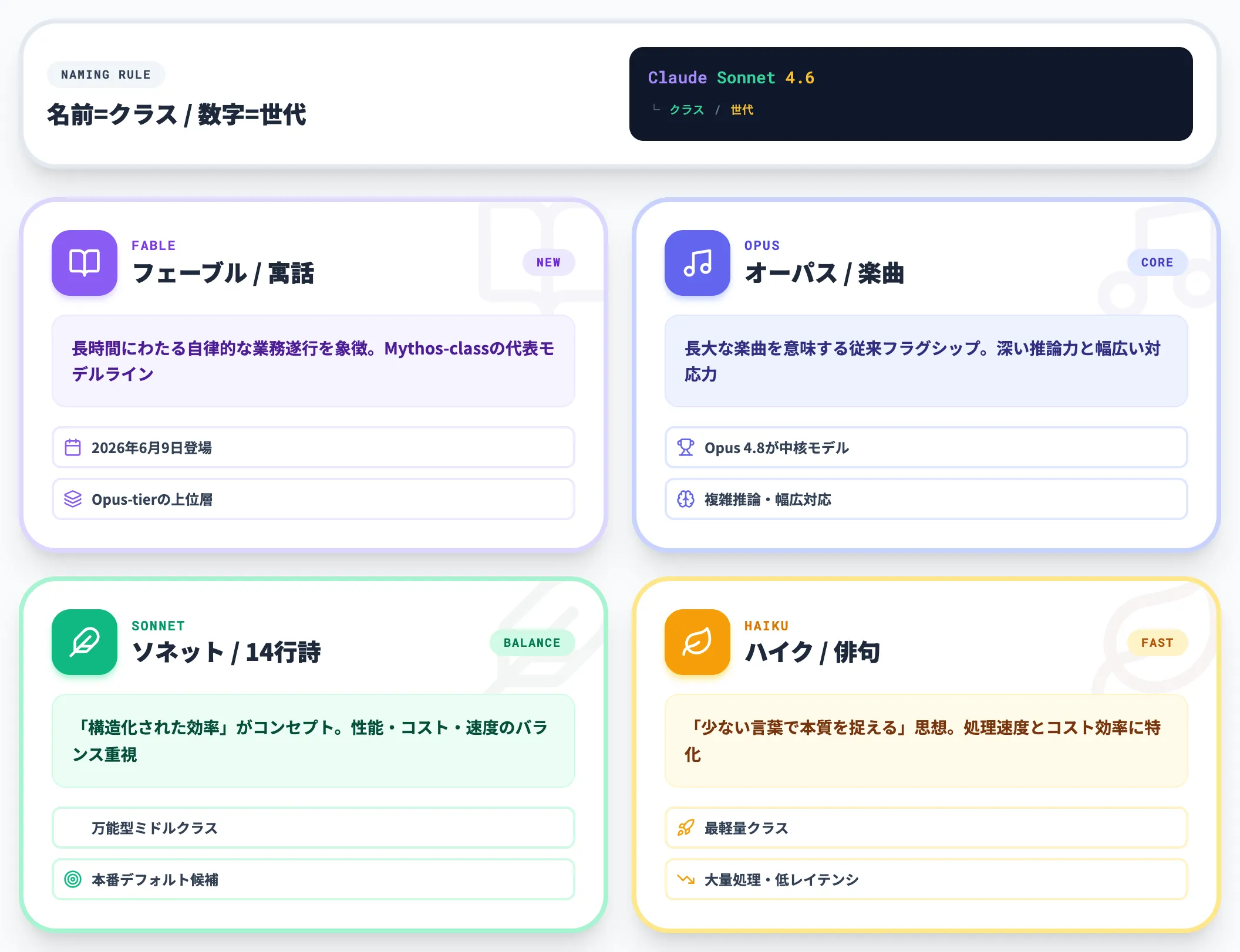
Claudeモデルの階層と命名ルール
Claudeのモデルは、名前がモデルの「クラス」を、数字がモデルの「世代」を表す二層構造になっています。以下で4つのクラスの特徴を整理します。
-
Fable(フェーブル)
2026年6月9日に登場した新最上位クラスです。「寓話」を意味する名前のとおり、長時間にわたる自律的な業務遂行を象徴するモデルラインで、Mythos-classと呼ばれる「Opus-tierの上に位置する新階層」として設計されています。
-
Opus(オーパス)
従来のフラグシップクラスです。長大な楽曲を意味する名前のとおり、深い推論力と幅広い対応力を持ち、現行版のOpus 4.8(2026年5月28日リリース)が中核モデルとして位置づけられています。
-
Sonnet(ソネット)
中位クラスです。14行定型詩のように「構造化された効率」がコンセプトで、性能とコスト・速度のバランスに優れた万能モデルとして設計されています。
-
Haiku(ハイク)
最軽量クラスです。俳句のように「少ない言葉で本質を捉える」思想で、処理速度とコスト効率に特化したモデルです。
なお、Mythos-class内部にはFable 5と並んで「Claude Mythos 5」も存在しますが、Mythos 5はProject Glasswing経由の招待制限定提供であり、一般のClaude API契約者は呼び出せません。Fable 5とMythos 5は同じ基盤モデルを共有し、セーフガードの強度と提供範囲だけが異なる構成です。本記事ではAPI契約者が実利用できるFable 5を「Mythos-class代表」として扱います。
2026年6月時点の4モデル一覧
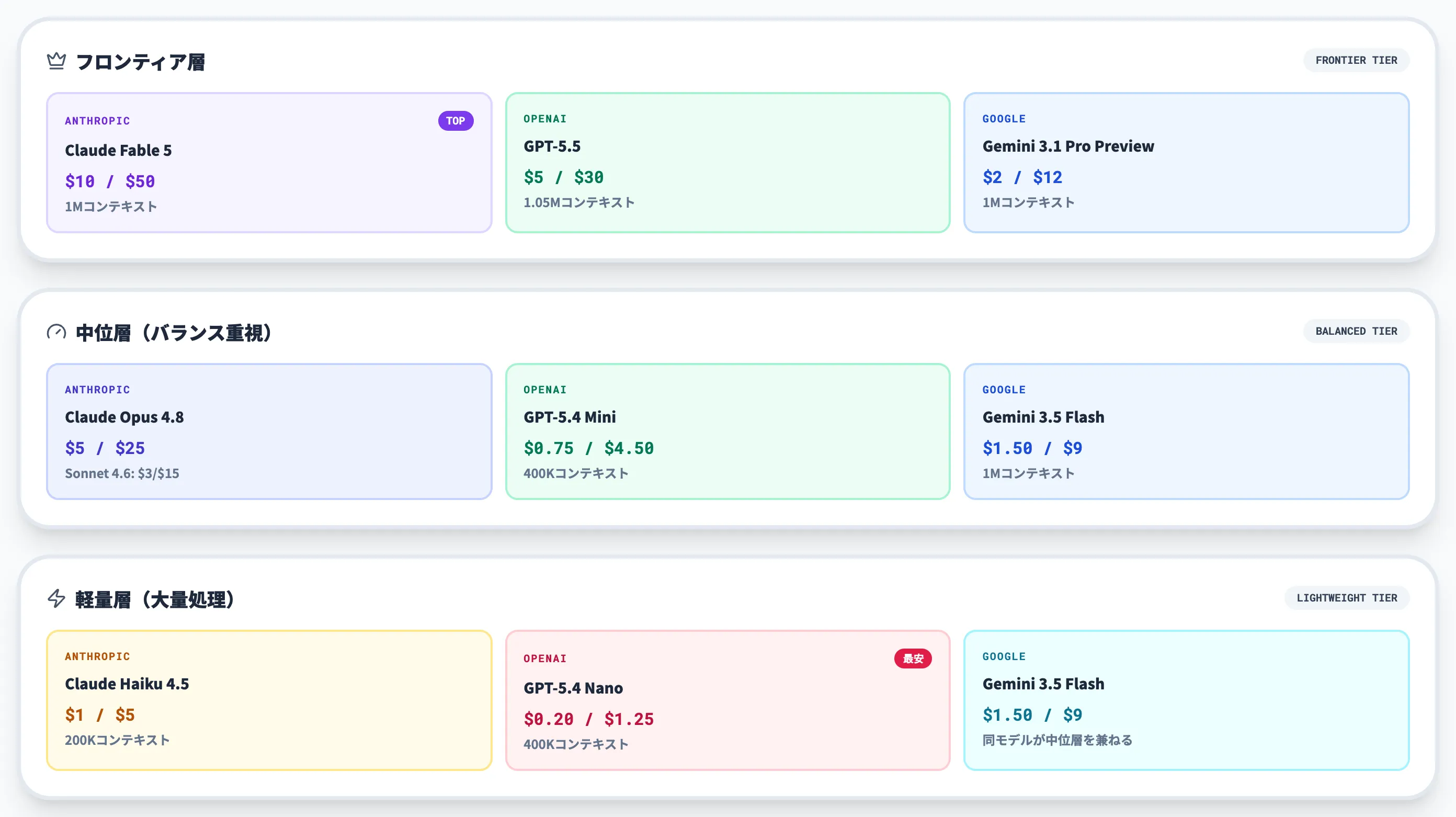
以下の表は、2026年6月時点で一般提供されているClaudeの主要4モデルの基本スペックをまとめたものです。

| 項目 | Claude Fable 5 | Claude Opus 4.8 | Claude Sonnet 4.6 | Claude Haiku 4.5 |
|---|---|---|---|---|
| リリース日 | 2026年6月9日 | 2026年5月28日 | 2026年2月17日 | 2025年10月15日 |
| Claude API ID | claude-fable-5 | claude-opus-4-8 | claude-sonnet-4-6 | claude-haiku-4-5-20251001 |
| API alias | claude-fable-5 | claude-opus-4-8 | claude-sonnet-4-6 | claude-haiku-4-5 |
| 階層 | Mythos-class | Opus-tier | Sonnet-tier | Haiku-tier |
| 公式の位置づけ | 最も能力の高い一般公開モデル | 最もインテリジェントなOpus-tierモデル | 速度と知性の最適バランス | フロンティアに近い最速モデル |
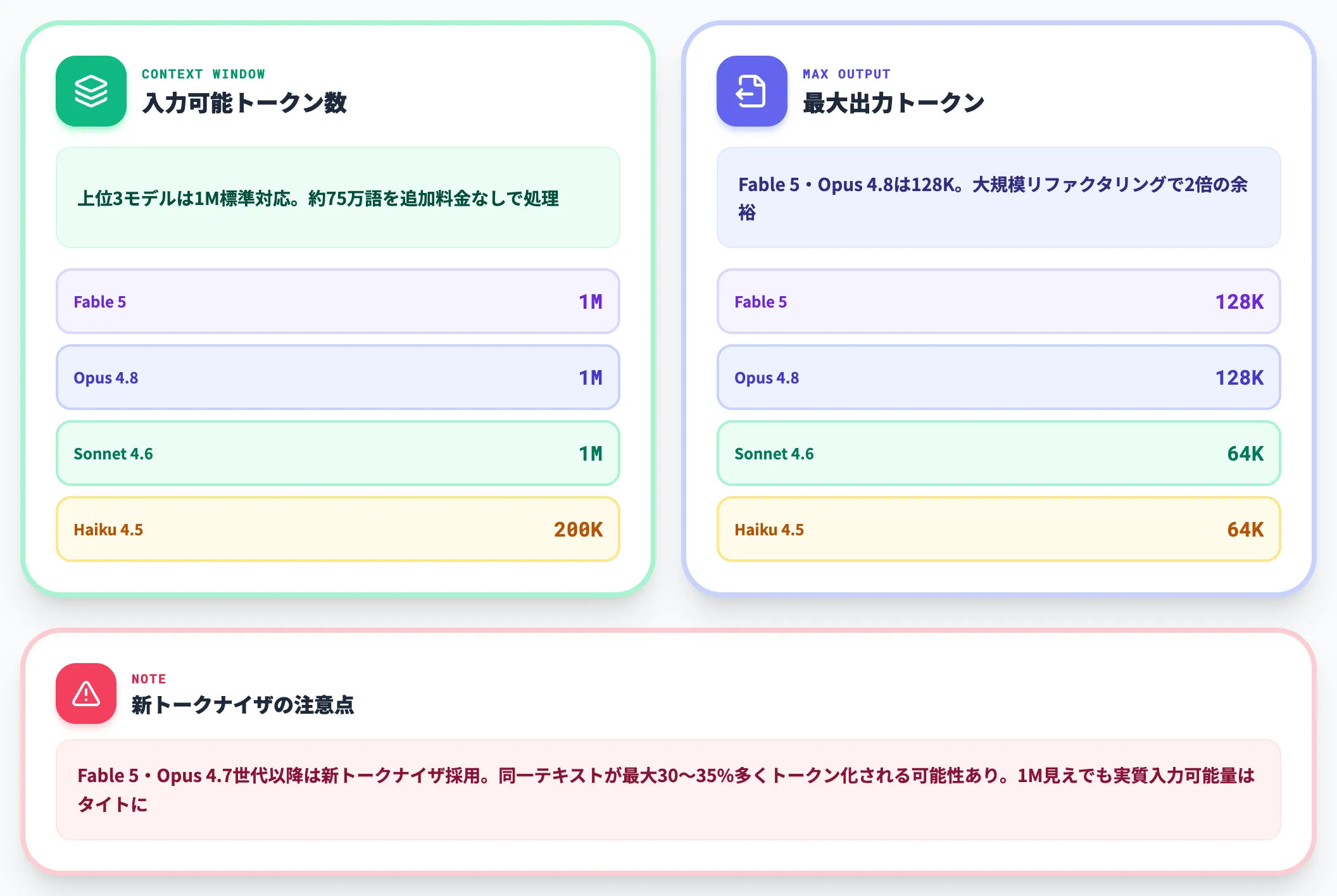
| コンテキストウィンドウ | 1Mトークン | 1Mトークン | 1Mトークン | 200Kトークン |
| 最大出力 | 128Kトークン | 128Kトークン | 64Kトークン | 64Kトークン |
| Adaptive Thinking | 対応(常時ON) | 対応 | 対応 | 非対応 |
| Extended Thinking | 非対応 | 非対応 | 対応 | 対応 |
| レイテンシ | 中程度 | 中程度 | 高速 | 最速 |
| Reliable knowledge cutoff | Jan 2026 | Jan 2026 | Aug 2025 | Feb 2025 |
この比較から見えるのは、Fable 5・Opus 4.8・Sonnet 4.6の3モデルが揃って1Mトークン・標準料金で利用可能になり、長文処理がフラグシップ層の標準機能になった点です。
400ページ超の書籍に相当するテキストを追加料金なしで一度に処理できる規模で、法務文書のレビュー・大規模コードベースの解析・複数報告書の横断分析などが3モデル共通の土台になっています。
加えてAdaptive Thinking(タスクの複雑さに応じてAIが思考の深さを自動調整する機能)に対応するのはFable 5・Opus 4.8・Sonnet 4.6の上位3モデル、Extended Thinking(手動でトークン予算を設定する旧方式の拡張思考)に対応するのはSonnet 4.6・Haiku 4.5の2モデルです。
Fable 5・Opus 4.8はExtended Thinking非対応、Haiku 4.5はAdaptive Thinking非対応という形で、4モデルの思考制御は対応状況が分かれています。
Haikuは200Kコンテキストとレイテンシ「最速」を特性として残しており、大量リクエストをさばくリアルタイム処理ではこの構成が運用コストに直結します。

Claude Fable 5・Opus 4.8・Sonnet 4.6・Haiku 4.5それぞれの強み
4モデルの全体像を把握したところで、ここからはそれぞれの強みと得意領域を個別に見ていきます。
Claude Fable 5の強み——長期自律エージェントの新標準
Claude Fable 5は、Anthropicが「最も能力の高い一般公開モデル」と位置づける新最上位モデルです。
Mythos-class初の一般提供版として、Opus 4.8の上位に独立した階層が用意されました。

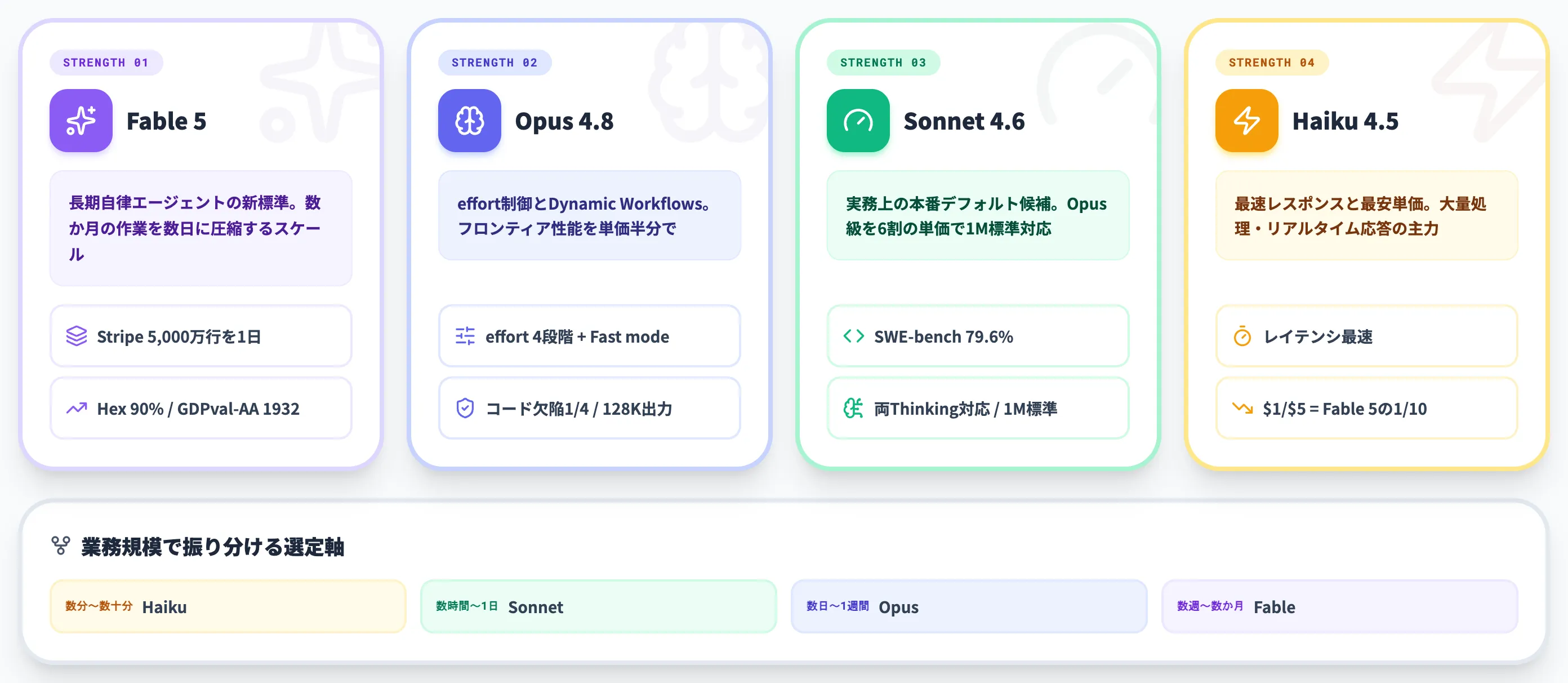
Fable 5の強みは、大きく3つに集約されます。
-
数か月の作業を数日に圧縮するスケール
決済プラットフォームのStripeは、「Fable 5を用いて、本来2か月かかる見積もりだった5,000万行規模のRubyコードベースのマイグレーションを1日で完了した」とAnthropic公式ブログでコメントしています。
短期タスクではなく、人手で数週間〜数か月かかる大規模業務において優位が表れるモデルです。
-
長時間分析タスクでの集中力維持
分析プラットフォームのHexは、「自社のコア分析ベンチマーク(複雑かつ長時間の分析タスクを評価)で、Fable 5が初めて90%を達成した」と報告しています。
金融特化型のリサーチプラットフォームHebbiaもHebbia Finance Benchmarkで最高スコアを記録したと公表しており、長文書解釈・財務分析・複雑チャート読解の領域で差が顕著です。
-
Adaptive Thinking常時ONとフォールバック設計
Fable 5はAdaptive Thinkingが常時ONで、開発者がトークン予算を手動設定する必要がありません。
さらに、サイバー・生物化学・モデル蒸留の3領域は3層分類器で検出され、検出時には自動でOpus 4.8にフォールバックされる仕組みになっています。
つまりFable 5は、「人手で数日〜数か月かかる規模の業務」に投入するためのモデルです。短〜中規模のコーディング・通常の業務文書解釈であれば、料金が半分のOpus 4.8で十分なケースが多くなります。
Claude Opus 4.8の強み——effort制御とDynamic Workflows
Claude Opus 4.8は、2026年5月28日にリリースされたOpus-tier最新世代です。前世代のOpus 4.7から、推論力・コーディング・エージェント操作のすべてで性能が前進しています。
Opus 4.8の強みは以下の3点です。
-
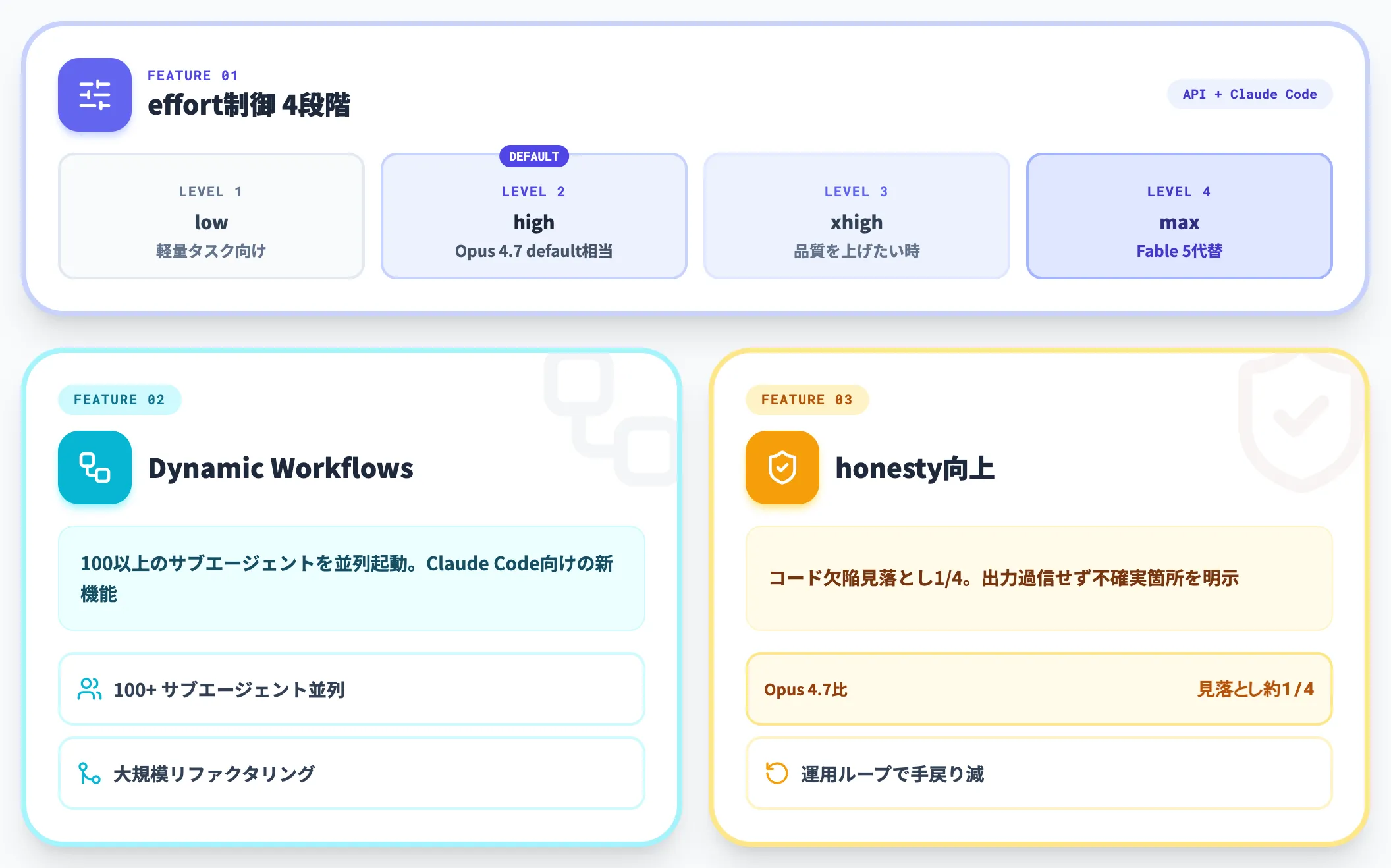
ユーザーレベルのeffort制御
タスクの難易度に応じて推論の深さを「low / high / xhigh / max」の4段階で指定できるeffortパラメータが、APIとClaude Codeの両方で正式提供されました。
デフォルトは「high」で、Opus 4.7の「default」と同じトークン量で性能が向上しています。Fable 5を使うほどではないが品質を上げたいケースでは、effort=「xhigh」または「max」の設定が現実的な選択肢になります。
-
Dynamic Workflows(Claude Code向け)
Claude Codeに追加された新機能で、100以上のサブエージェントを並列起動し、大規模なコードベース移行・横断リファクタリングを一気に進められます。
Stripe事例のような大規模業務をFable 5に投げる前に、まずOpus 4.8 + Dynamic Workflowsで成果が出るかを試す運用が合理的です。
-
honesty(誠実性)の大幅向上
Anthropicは「Opus 4.8はコード欠陥を見落とす確率がOpus 4.7の約1/4になった」と公表しています。
エージェントが自分の出力を過信せず、不確実な箇所を明示する挙動が強化された結果、運用ループでの手戻りが減ります。
Opus 4.8の出力上限は128Kトークンで、Sonnet・Haikuの64Kに対して2倍の余裕があります。長大なコード生成や複数ファイルにまたがる大規模リファクタリングなど、出力量の多いタスクではこの差が効きます。
Claude Sonnet 4.6の強み——実務上の本番デフォルト候補
Claude Sonnet 4.6は、2026年2月17日にリリースされた中位モデルです。A
nthropic公式は「速度と知性の最適バランス」と位置づけており、コスト・性能・運用しやすさの3点を踏まえると、多くの企業にとって本番ワークロードのデフォルト候補になりやすいモデルです。
Sonnet 4.6の強みは以下の3点です。
-
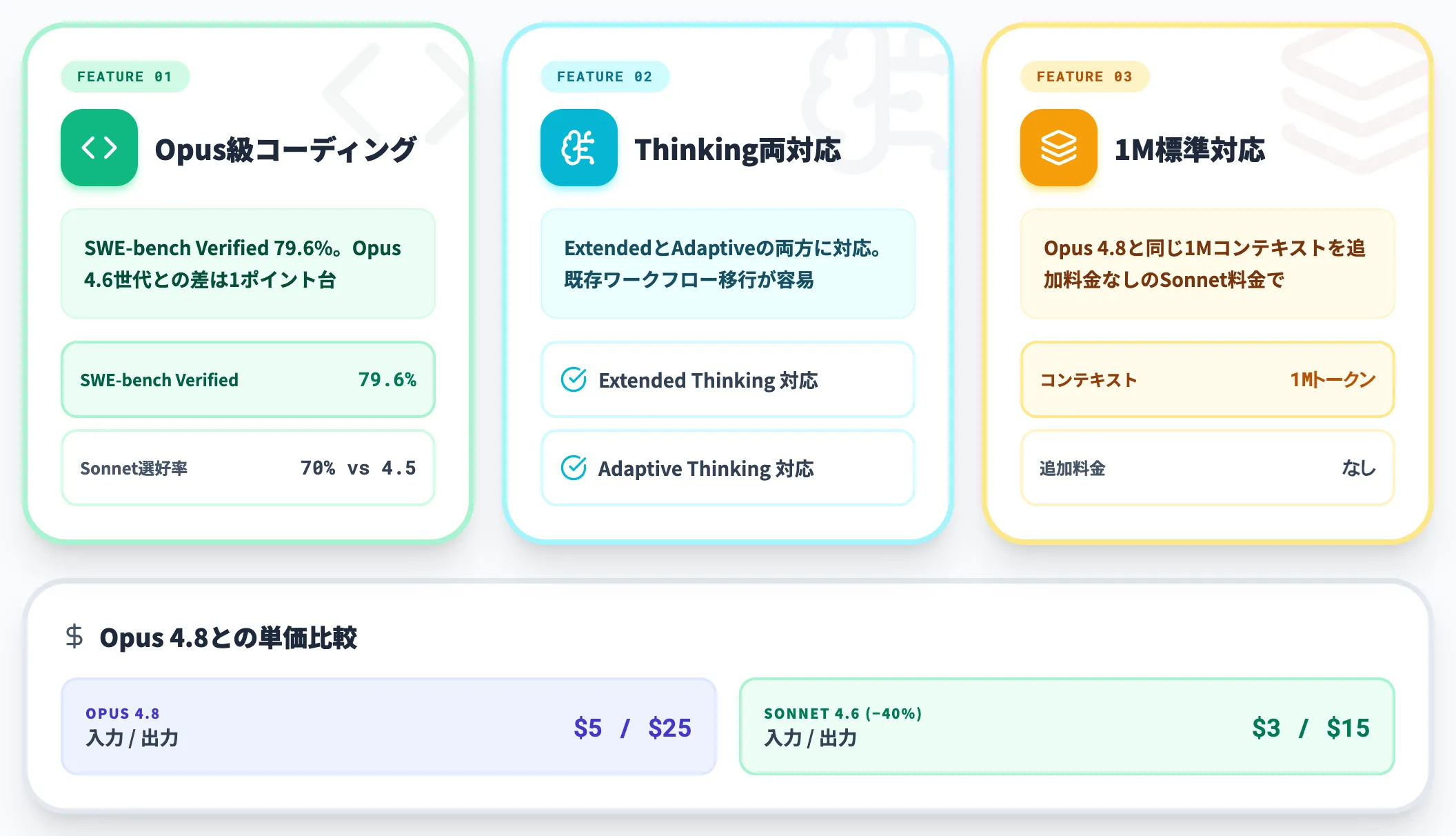
Opus級コーディング性能を約60%の単価で
SWE-bench Verifiedで約79.6%を記録し、Opus 4.6世代との差はわずか1ポイント台にまで縮まっていました。
Claude Code上のユーザーテストでは、70%のユーザーが前世代のSonnet 4.5よりSonnet 4.6を、59%がOpus 4.5よりSonnet 4.6を選好したとAnthropicが報告しています。
-
Extended Thinking・Adaptive Thinking両対応
ThinkingモデルがOpus 4.8(Adaptive Thinkingのみ)と異なり、Sonnet 4.6は両方に対応します。
Extended Thinkingで手動の予算管理を残しつつ、Adaptive Thinkingで自動調整も使えるため、既存ワークフローからの移行が容易です。
-
1Mコンテキスト標準対応
Opus 4.8と同じ1Mトークンのコンテキストウィンドウを標準料金で利用できます。
法務文書レビュー・長文要約・大規模コード解析がSonnet料金で実行可能になり、コストパフォーマンスが大きく改善しました。
入力$3 / 出力$15という料金水準は、Opus 4.8の$5 / $25と比べて入力で40%、出力で40%安価です。性能差が限定的であることを踏まえると、日常的なコード作成・ドキュメント生成・分析レポート・チャットボットのバックエンドなど、幅広い業務でSonnet 4.6が最もコスト効率の良い選択肢になります。
Claude Haiku 4.5の強み——最速レスポンスと最安単価
Claude Haiku 4.5は、2025年10月15日にリリースされた最軽量モデルです。
Anthropicは公式に「フロンティアに近いインテリジェンスを持つ最速モデル」と位置づけています。
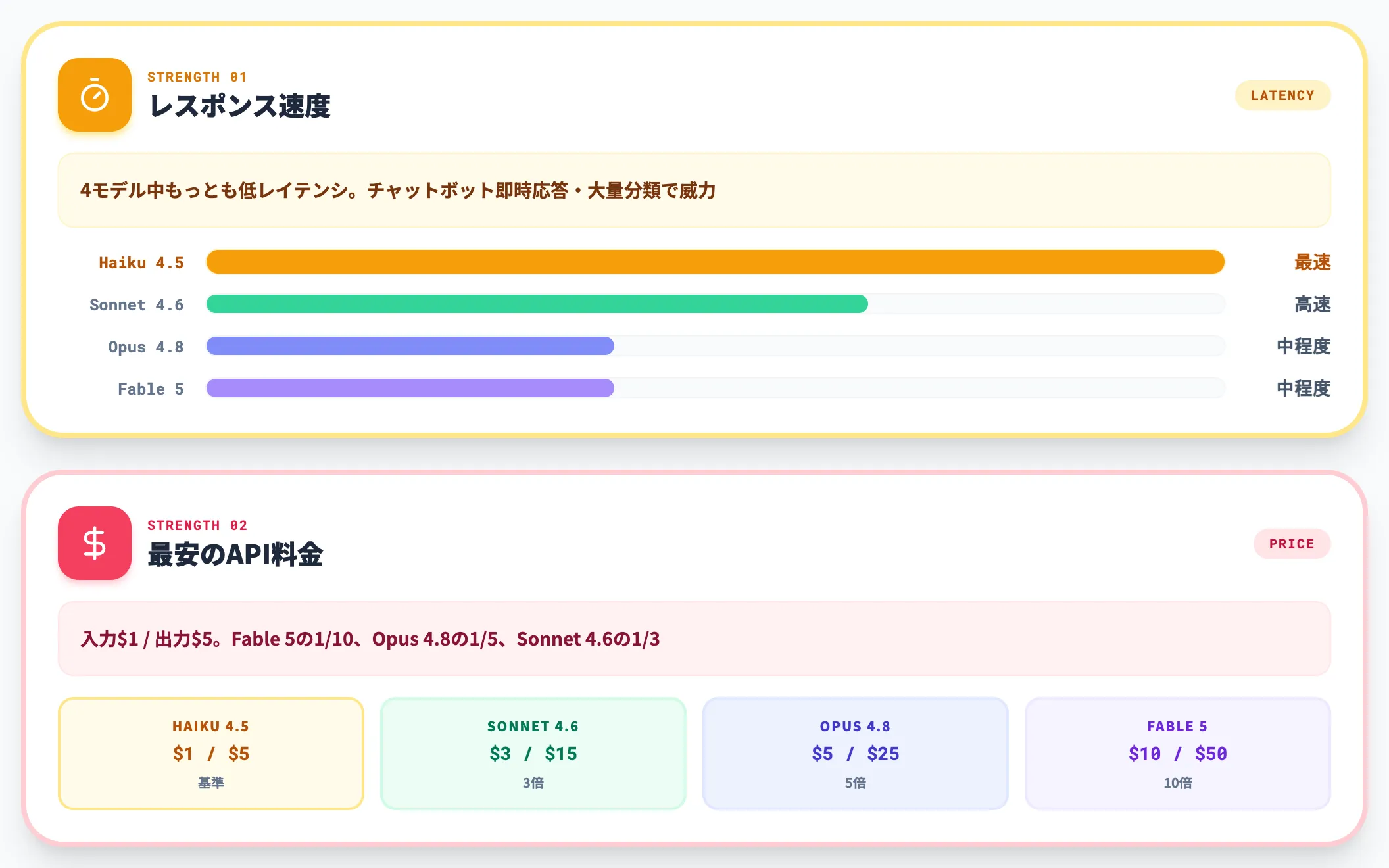
Haiku 4.5の強みは以下の2点です。
-
圧倒的なレスポンス速度
4モデル中もっともレイテンシが低く、即時応答が求められるシーンに最適です。チャットボットのリアルタイム応答・大量データの分類と抽出・カスタマーサポートの自動化など、ユーザーを待たせたくない場面で威力を発揮します。
-
最安のAPI料金
入力$1 / 出力$5(1Mトークンあたり)は、Sonnet 4.6の3分の1、Opus 4.8の5分の1、Fable 5の10分の1です。大量処理が前提のバッチワークロードでは、この価格差が月間のAPI費用に大きく影響します。
Haiku 4.5の注意点は、Adaptive Thinkingに非対応である点と、コンテキストウィンドウが200Kに留まる点です。Extended Thinkingは対応しているため、手動でトークン予算を設定すれば拡張思考自体は利用できます。
すべてのタスクに深い推論が必要なわけではありません。「要約して」「分類して」「定型フォーマットに変換して」といったシンプルなタスクであれば、Haikuで十分な品質が単価1/10で得られます。
4モデルの性能を公式ベンチマークで比較
各モデルの定性的な強みを把握したところで、本セクションでは公式ベンチマークの数値で具体的な性能差を整理します。ここで紹介するデータは、いずれもAnthropicが公式ブログ・システムカード・モデル発表ページで公開したものです。

コーディング性能
ソフトウェア開発における実践的な問題解決力を測る代表的ベンチマークは、SWE-bench VerifiedとSWE-bench Pro、そして高難度版のFrontierCodeです。
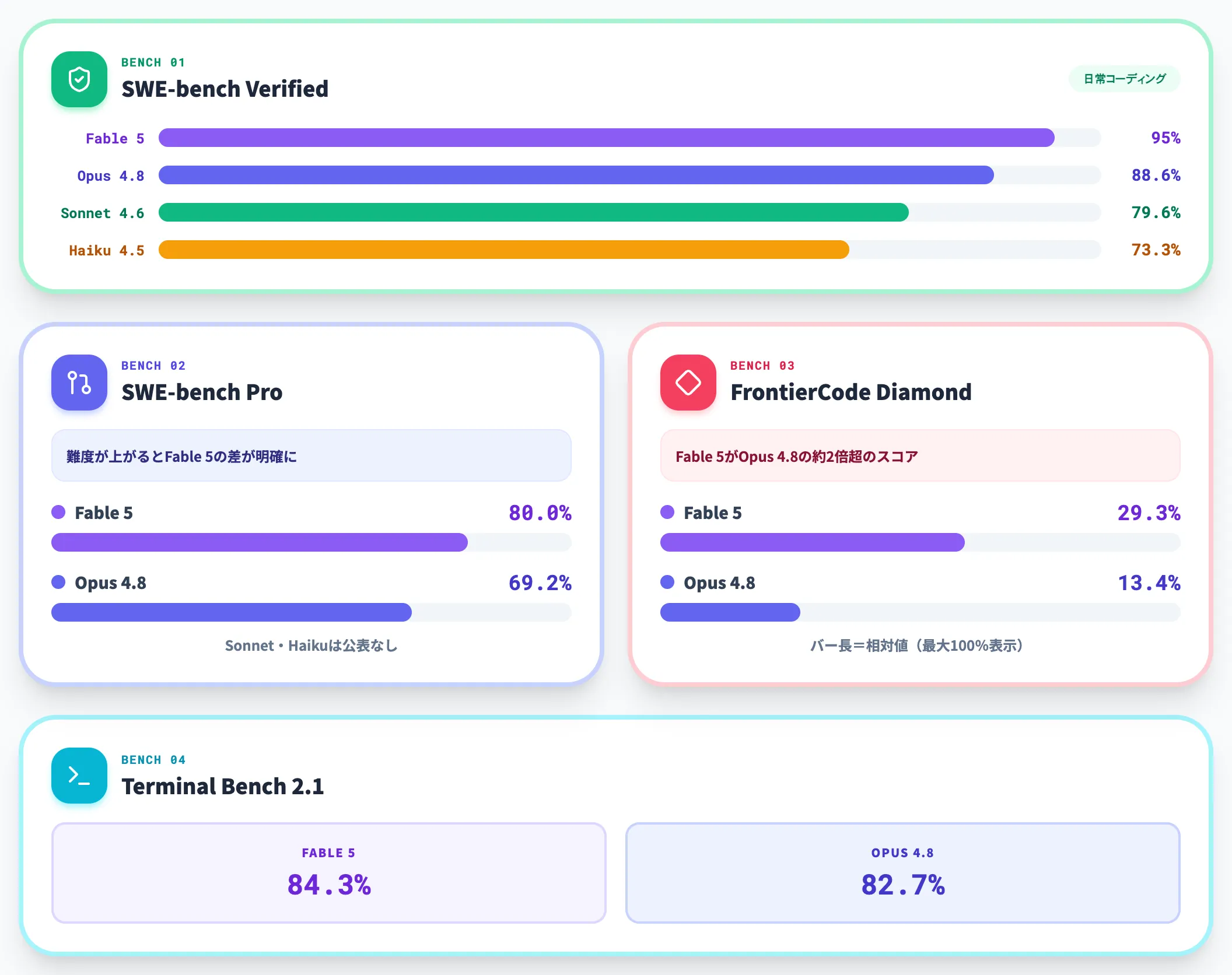
| ベンチマーク | Fable 5 | Opus 4.8 | Sonnet 4.6 | Haiku 4.5 |
|---|---|---|---|---|
| SWE-bench Verified | 95% | 88.6% | 79.6% | 73.3% |
| SWE-bench Pro | 80.0% | 69.2% | 公表なし | 公表なし |
| FrontierCode Diamond | 29.3% | 13.4% | 公表なし | 公表なし |
| Terminal Bench 2.1 | 84.3% | 82.7% | 公表なし | 公表なし |
この比較から見えるのは、SWE-bench Verifiedは4モデルすべてが70%超を達成しており、日常的なコーディングタスクではHaiku 4.5でも実用的な水準だという点です。
一方で、難度が上がるSWE-bench ProとFrontierCode Diamondでは、Fable 5とOpus 4.8の差が明確に開きます。とくにFrontierCode Diamondでは、Fable 5がOpus 4.8の約2倍超のスコアを記録しており、「数か月の作業を数日に圧縮する」スケールのタスクでFable 5を選ぶ根拠が数値に表れています。
Sonnet 4.6・Haiku 4.5はSWE-bench Pro・FrontierCode Diamond・Terminal Benchの公式数値が公表されていませんが、SWE-bench VerifiedではSonnet 4.6が79.6%を記録しています。Fable 5の約3割・Opus 4.8の約6割の料金で実用的なコーディング性能を提供している点が実務上の選定理由になります。
推論・知識
学術レベルの難問や専門知識を問うベンチマークでは、モデル間の差がより顕著に表れます。
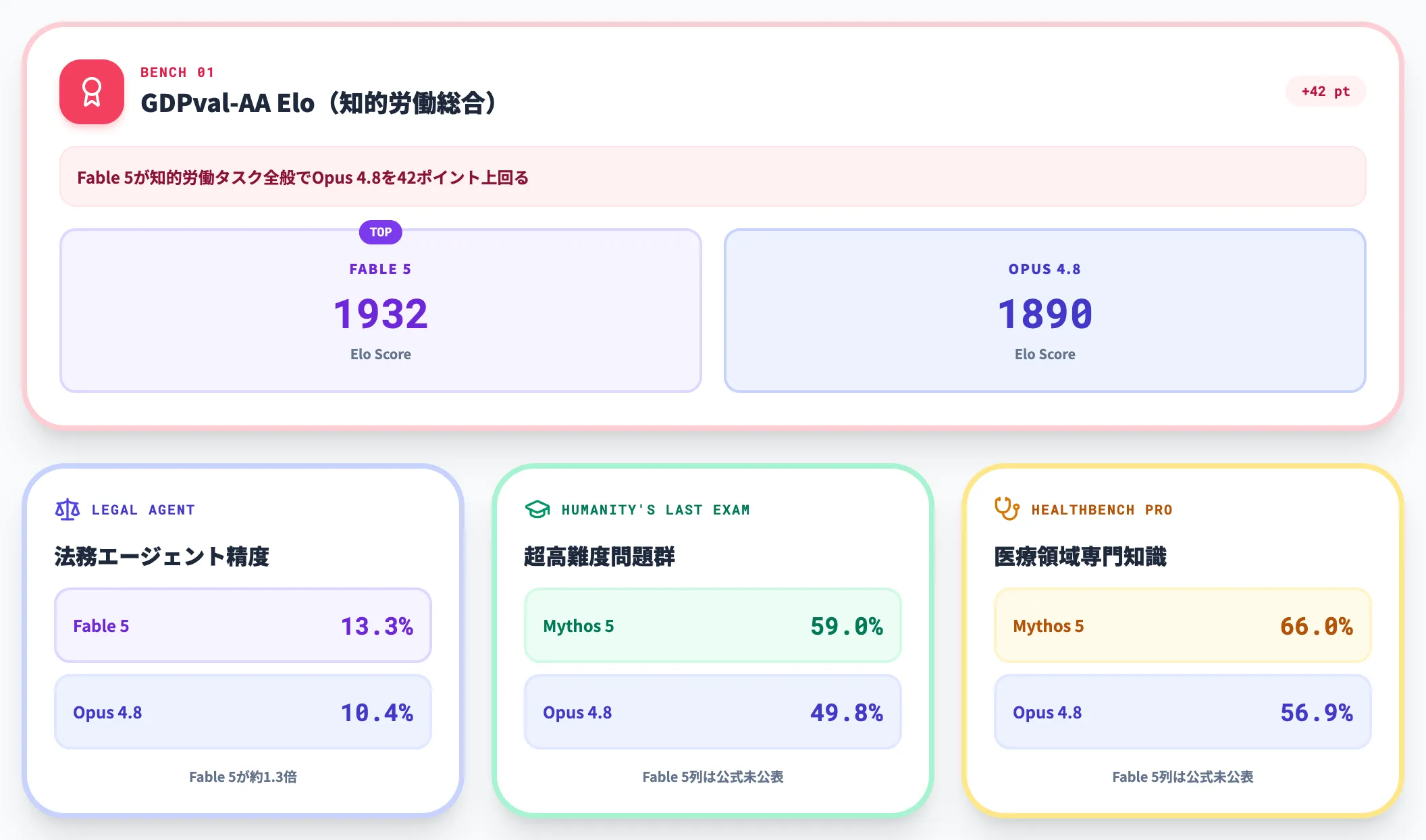
| ベンチマーク | Fable 5 | Opus 4.8 | 補足 |
|---|---|---|---|
| GDPval-AA(Elo) | 1932 | 1890 | 知的労働タスクの総合評価 |
| Humanity's Last Exam(tools無) | 公表なし(Mythos 5は59.0%) | 49.8% | 専門家が設計した超高難度問題群 |
| Legal Agent Benchmark | 13.3% | 10.4% | 法務エージェントの精度評価 |
| HealthBench Professional | 公表なし(Mythos 5は66.0%) | 56.9% | 医療領域の専門知識評価 |
GDPval-AAでは、Fable 5のElo 1932がOpus 4.8の1890を42ポイント上回っており、知的労働タスク全般でFable 5が一段上のレンジに入っていることが読み取れます。
特にLegal Agent BenchmarkではFable 5がOpus 4.8の約1.3倍のスコアを出しており、コーディング以外の長期エージェント業務でもFable 5のリードが明確に表れる傾向があります。
なお、Humanity's Last ExamやHealthBench Professionalは、Anthropic公式ベンチマーク表ではMythos 5側の数値のみが公表されており、一般提供版のFable 5列は未公表です。Fable 5の実利用上の数値はMythos 5と完全一致するわけではないため、これらの領域での性能評価は今後の公式更新と独立評価を待つ必要があります。
Sonnet 4.6・Haiku 4.5は同ベンチマーク表での横並び公表が限定的ですが、汎用業務の品質ベースラインとしてはSonnet 4.6が「Opus 4.5世代と同等以上」とAnthropicが説明しており、専門知識タスクでもまず試すべき選択肢になります。
エージェント操作・コンピュータ利用
AIがコンピュータを直接操作して作業を遂行する能力を測るOSWorld-Verifiedでは、Fable 5・Opus 4.8の双方が高い数値を記録しています。
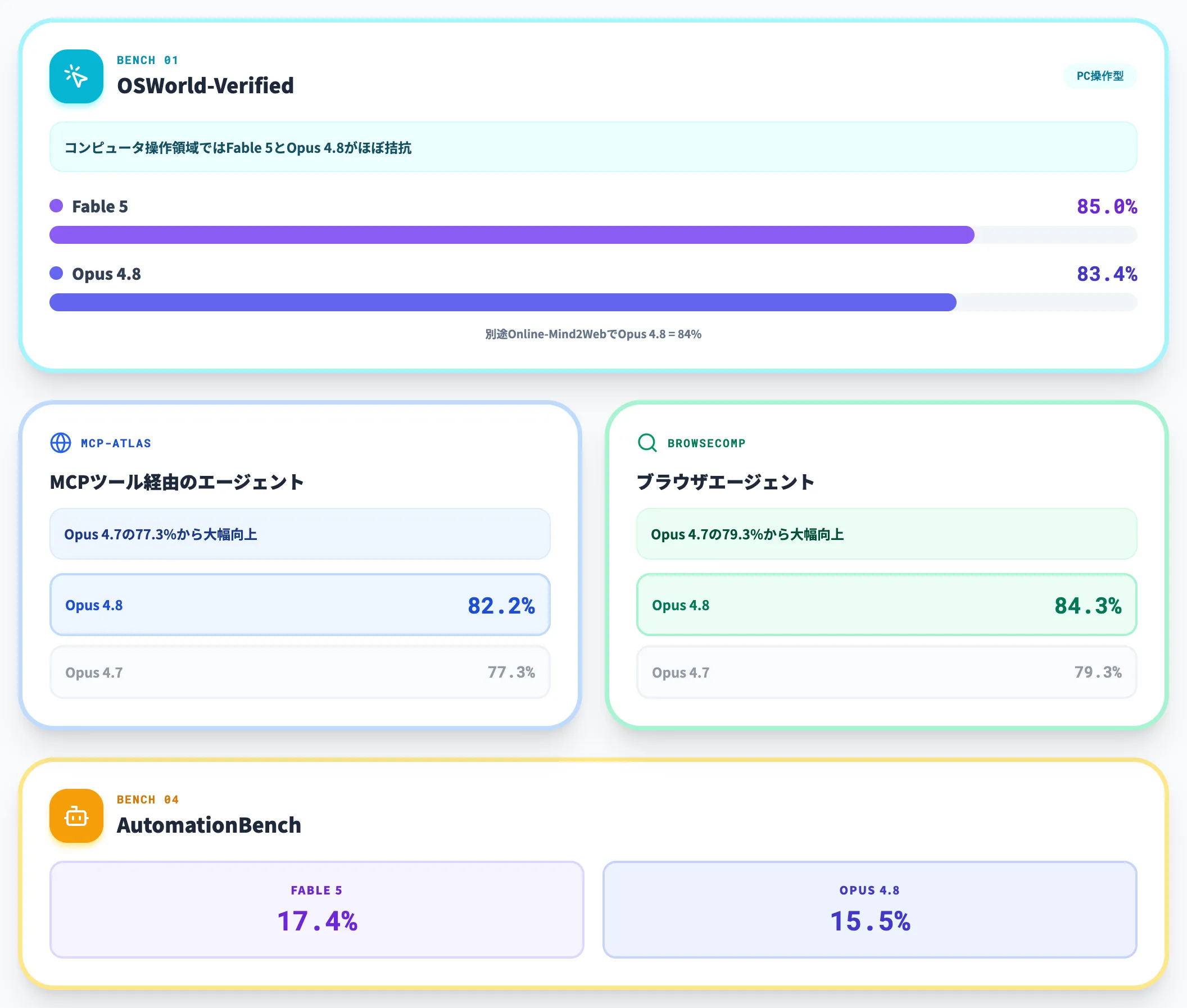
| ベンチマーク | Fable 5 | Opus 4.8 | 補足 |
|---|---|---|---|
| OSWorld-Verified | 85.0% | 83.4% | システムカードベース。別途Online-Mind2Webで84% |
| MCP-Atlas | 公表なし | 82.2% | Opus 4.7の77.3%から大幅向上 |
| BrowseComp | 公表なし | 84.3% | Opus 4.7の79.3%から大幅向上 |
| AutomationBench | 17.4% | 15.5% | 自動化タスク全般 |
この比較から分かるのは、コンピュータ操作・ブラウザエージェントの領域では、Opus 4.8がFable 5と数値上ほぼ拮抗しているという点です。
Anthropic公式によれば、Opus 4.8はコンピュータ利用とブラウザエージェントの両方で「これまでテストされた中で最も強力なモデル」とされており、Online-Mind2Webでも84%を記録しています。
Webフォームの入力・スプレッドシート操作・複数タブの横断作業といったPC操作型エージェントを構築するなら、料金半分のOpus 4.8で十分なケースが多くなります。「2倍の単価を払う必然性」が出てくるのは、Fable 5の優位が際立つ長期自律業務領域に絞られます。
コンテキスト長と出力上限
長文処理能力は、業務で扱う文書の規模によってモデル選択を左右する重要な要素です。
| 項目 | Fable 5 | Opus 4.8 | Sonnet 4.6 | Haiku 4.5 |
|---|---|---|---|---|
| コンテキストウィンドウ | 1Mトークン | 1Mトークン | 1Mトークン | 200Kトークン |
| 最大出力 | 128Kトークン | 128Kトークン | 64Kトークン | 64Kトークン |
| 1M対応の追加料金 | なし | なし | なし | 1M非対応 |
1Mトークンのコンテキストウィンドウは、約75万語の英語テキストを一度に処理できる規模で、上位3モデルすべてが追加料金なしで利用できます。
法務文書のレビュー・大規模なコードベースの解析・数百ページに及ぶ技術仕様書の横断検索など、大量のテキストを一括で処理したいユースケースでは、Sonnet 4.6を起点に試すのが最もコスト効率の良い選択になります。
ただし、Fable 5・Opus 4.7世代以降は新トークナイザを採用しており、Anthropic公式の注記によれば、旧モデル世代と比べて同一テキストが最大30〜35%程度多くトークン化される可能性がある点には注意が必要です。1Mコンテキスト見えでも、実質の入力可能量は少しタイトになります。
4モデルの料金体系とサブスクプラン
本セクションでは、4モデルの料金体系を「API利用」と「サブスクリプション(claude.ai)」の両面から整理します。

API料金(1Mトークンあたり)
以下の表は、2026年6月時点の公式API料金をモデル別にまとめたものです(すべてAnthropic公式料金ページに基づきます)。
| 項目 | Fable 5 | Opus 4.8 | Sonnet 4.6 | Haiku 4.5 |
|---|---|---|---|---|
| 入力トークン | $10 | $5 | $3 | $1 |
| 出力トークン | $50 | $25 | $15 | $5 |
| Fast mode(入力) | ― | $10 | ― | ― |
| Fast mode(出力) | ― | $50 | ― | ― |
| キャッシュ書き込み(5分) | $12.50 | $6.25 | $3.75 | $1.25 |
| キャッシュ読み取り | $1 | $0.50 | $0.30 | $0.10 |
| Batch API(入力) | $5 | $2.50 | $1.50 | $0.50 |
| Batch API(出力) | $25 | $12.50 | $7.50 | $2.50 |
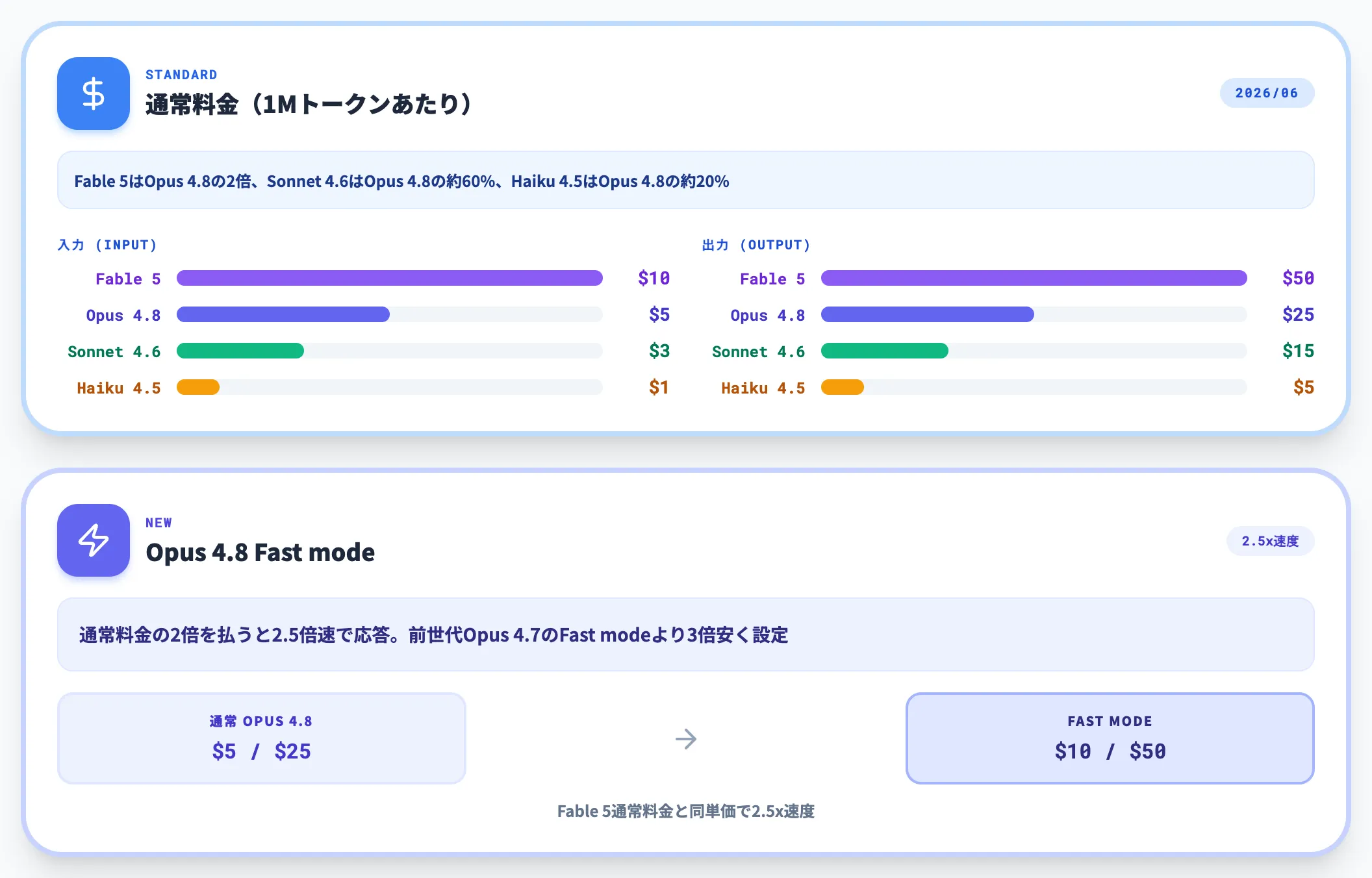
料金比率を整理すると、**Fable 5はOpus 4.8の2倍、Sonnet 4.6はOpus 4.8の約60%、Haiku 4.5はOpus 4.8の約20%**の単価水準です。
Fable 5の入力$10・出力$50という設定は、一般提供されるClaudeモデルの中で最も高い単価で、Fable 5を全タスクで常時走らせる運用は単価面で現実的ではありません。
注目すべきは、**Opus 4.8で新設されたFast mode(入力$10/出力$50)**です。通常料金の2倍を払うことで2.5倍速で応答が返ってくる設計で、前世代Opus 4.7のFast mode(入力$30/出力$150)と比べて3倍安く設定されています。低レイテンシが必要なエージェントワークフローでは、Opus 4.8のFast modeがFable 5通常料金と同単価で利用できるため、用途次第で有力な選択肢になります。
たとえば月間1,000万トークンの出力を処理する場合、Fable 5では$500、Opus 4.8(通常)では$250、Sonnet 4.6では$150、Haiku 4.5では$50となり、Fable 5とHaiku 4.5では月額$450の差が生じます。
Batch APIとプロンプトキャッシングによるコスト最適化
API利用のコストをさらに削減するテクニックとして、Batch APIとプロンプトキャッシングがあります。
-
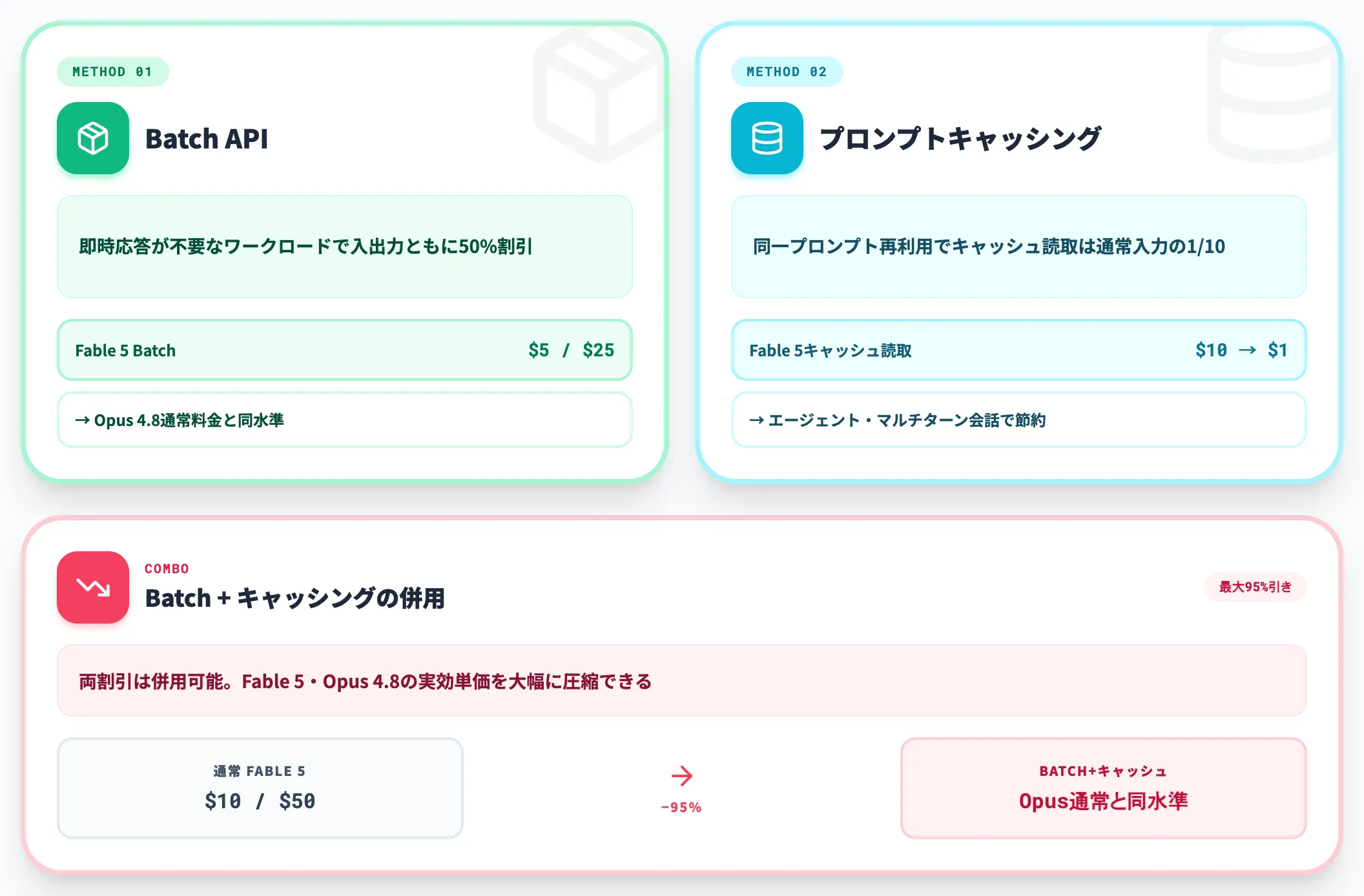
Batch API
即時応答が不要なワークロード(レポートの一括生成、大量データの分析など)では、Batch APIを利用すると入力・出力ともに50%割引が適用されます。Fable 5のBatch料金は入力$5 / 出力$25で、通常のOpus 4.8料金と同水準まで下がります。
-
プロンプトキャッシング
同じシステムプロンプトやコンテキストを繰り返し使う場合、キャッシュ読み取り料金は通常入力の10分の1です。Fable 5では$10 → $1、Opus 4.8では$5 → $0.50になるため、エージェント型ワークフローやマルチターン会話では大幅な節約につながります。
-
Batch + キャッシングの組み合わせ
両方の割引は併用可能です。Batch APIでキャッシュ対応のプロンプトを使えば、通常料金の最大95%引きに近い水準でFable 5・Opus 4.8を利用できるケースもあります。
Fable 5を本番ワークロードに組み込む際は、まずBatch + キャッシングで「実効単価をOpus 4.8通常料金と同等水準まで圧縮できるか」を試算し、それでもコストが見合わないタスクはOpus 4.8・Sonnet 4.6に振り分ける運用が現実的です。
サブスクリプションプラン(Free / Pro / Max / Team / Enterprise)
APIではなくclaude.ai(チャット版)で利用する場合は、以下のサブスクリプションプランから選択します。

| プラン | 月額料金 | 利用可能モデル | 特徴 |
|---|---|---|---|
| Free | $0 | Sonnet・Haiku | 5時間ごとにリセットされるセッション制 |
| Pro | $20 | 全モデル(Fable 5含む) | Freeの約5倍のメッセージ量 |
| Max 5x | $100 | 全モデル | Proの5倍のメッセージ量 |
| Max 20x | $200 | 全モデル | Proの20倍のメッセージ量 |
| Team Standard | $25 / ユーザー | 全モデル | SSO・管理者ダッシュボード・Slack連携・Claude Code CLI |
| Team Premium | $125 / ユーザー(年払い$100) | 全モデル | 高度なツール利用・優先アクセス |
| Enterprise | カスタム | 全モデル | カスタムレート制限・監査ログ・専用サポート |
Freeプランでも Sonnet 4.6 とHaiku 4.5は利用可能です。Opus 4.8とFable 5を使いたい場合はProプラン以上が必要になります。「まずSonnet 4.6で試して、Fable 5やOpus 4.8が必要と感じたらProに移行する」という段階的アプローチが合理的です。
Fable 5の利用枠は2026年6月22日まで追加料金なし
サブスクリプション枠でのFable 5利用には、Anthropic公式の段階的ロールアウトが適用されます。
| 時期 | サブスクリプションでの扱い | 補足 |
|---|---|---|
| 2026年6月9日〜6月22日 | Pro / Max / Team / seat-based Enterpriseで追加料金なしで利用可 | 段階的にロールアウト・API利用とusage-based Enterpriseは対象外 |
| 2026年6月23日以降 | Usage Credits(従量課金)を消費して利用 | サブスク本体の追加料金は変更なし |
| 容量確保後(時期未公表) | サブスクリプションの標準機能として再統合予定 | Anthropic公式が明示 |
つまり現時点では、Pro・Max・Team・seat-based Enterpriseの契約者は2026年6月22日までFable 5を追加料金なしで検証できる期間になっており、6月23日以降は使った分だけクレジットを消費する形になります(API利用とusage-based Enterpriseは対象外)。
Pro契約・Max契約の枠でFable 5を業務利用する想定であれば、まずは6月22日までに自社ワークロードでの実効コストを計測し、6月23日以降のUsage Credits消費見込みを試算しておくのが現実的な進め方です。さらに大量に使う場合はMaxプラン(月額$100〜$200)が選択肢に入ります。
【関連記事】
Claudeの料金プラン徹底比較!無料・有料版の違いと選び方を解説

ユースケース別の使い分けとモデルスイッチング戦略
ベンチマークと料金を把握できたら、次は「自分の業務にはどのモデルを使えばいいのか」という実践的な判断基準に落とし込みます。
本セクションでは、AI総研の支援現場で実際に使っているケース別の使い分け軸を整理します。
ユースケース別おすすめモデル
以下の表は、代表的なユースケースごとに最適なモデルを整理したものです。

| ユースケース | 推奨モデル | 選定理由 |
|---|---|---|
| 数か月規模の大規模リファクタリング・マイグレーション | Fable 5 | Stripe事例(2か月→1日)が示す長期自律業務での優位 |
| 通常のコーディング業務(数百〜数千行規模) | Opus 4.8 | 料金1/2でフロンティア性能。Fable 5の優位が出にくい規模 |
| 数時間規模の複雑文書解釈・財務分析 | Fable 5 | Hex 90%・Hebbia最高スコア事例で実証 |
| 日常的なコード作成・レビュー | Sonnet 4.6 | SWE-bench Verified 79.6%・1Mコンテキストでコスト効率が最大 |
| 大規模リファクタリング・複雑バグ修正(中規模) | Opus 4.8 | 128K出力・effort=xhigh/maxで長期整合性を維持 |
| 法務・金融文書の精密分析 | Fable 5 or Opus 4.8 | Legal Agent BenchmarkでFable優位。中規模ならOpus 4.8 |
| 技術文書・レポート作成 | Sonnet 4.6 | 構造化された長文出力と適度な推論力 |
| 大量データの分類・タグ付け | Haiku 4.5 | 最安のAPI料金で大量処理のコストを抑制 |
| チャットボットのリアルタイム応答 | Haiku 4.5 | 最速のレイテンシで待ち時間を最小化 |
| 要約・翻訳・フォーマット変換 | Haiku 4.5 | 定型処理で十分な品質、速度重視 |
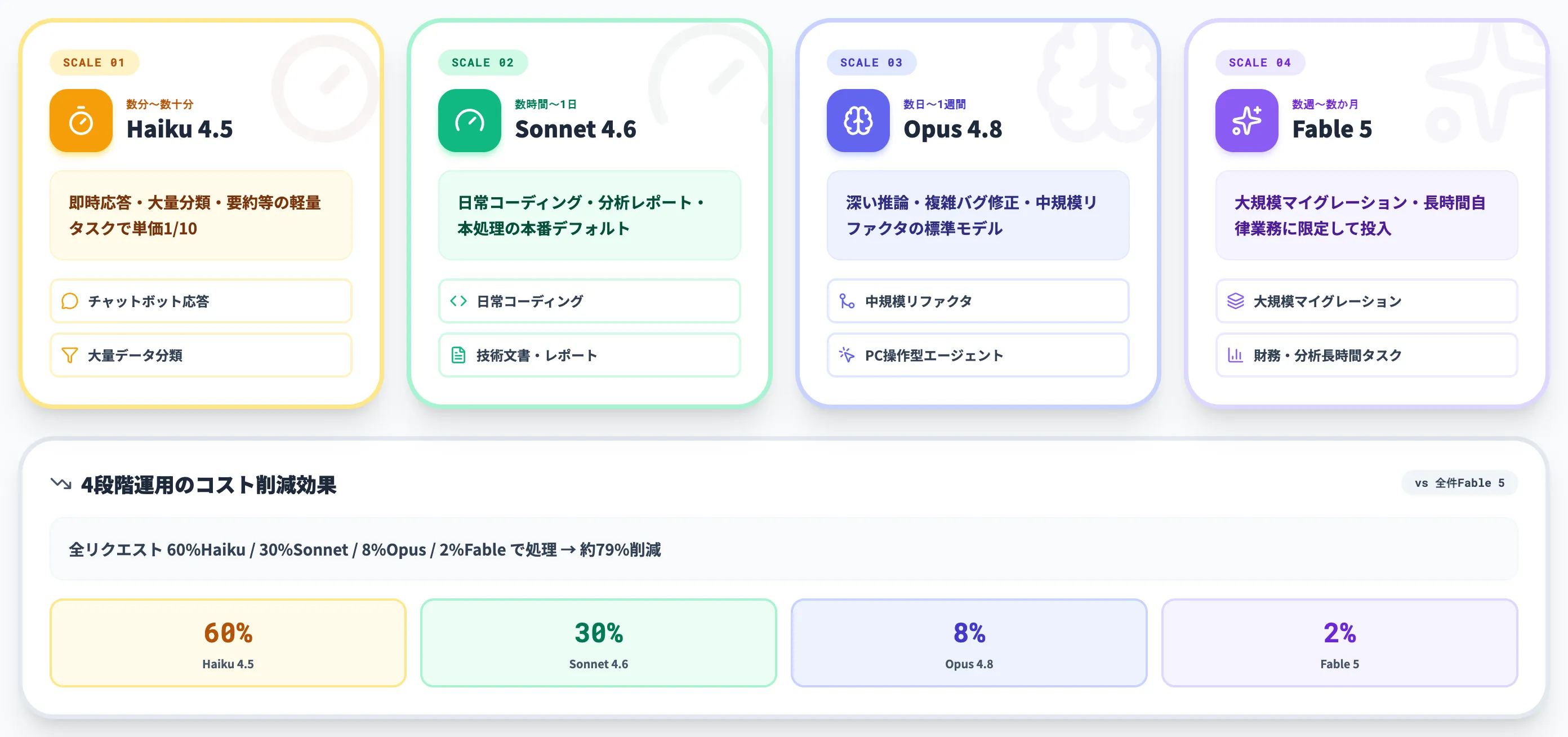
実務で選ぶ際のポイントは、**「人手で何時間〜何日かかる業務か」**という軸です。
人手で数か月かかる規模の業務であればFable 5、数日〜1週間規模ならOpus 4.8、数時間〜1日規模ならSonnet 4.6、数分〜数十分規模はHaiku 4.5、という所要時間の階段で考えると判断がぶれません。Fable 5を全業務に投入するのではなく、「Fable 5が単価2倍を回収できる業務規模か」を毎回問うのが、4階層時代の運用設計の基本です。
4段階モデルスイッチングの実践
企業のAI活用では、単一モデルですべてをまかなうのではなく、タスクの性質に応じてモデルを切り替える「モデルスイッチング」が効果的です。Fable 5登場後は、これまでの3段階構成に「長期自律業務専用のFable 5枠」が加わった4段階運用が現実的になります。

たとえば以下のようなワークフローが考えられます。
-
初期スクリーニングはHaiku 4.5
大量のサポートチケットや問い合わせを高速に分類し、優先度や担当を振り分けます。レイテンシが最小・単価が最安なので、ボリュームをさばく一次仕分けに最適です。
-
主要な分析・生成はSonnet 4.6
分類後の本格的な対応(回答生成、レポート作成、コード修正など)はSonnet 4.6で処理します。1Mコンテキストが標準料金で使えるため、長文書を投げ込んでも追加コストがかかりません。
-
難しいケースはOpus 4.8
Sonnetの精度が不十分だったケースや、深い推論・複雑なエージェント操作が必要な案件はOpus 4.8にエスカレーションします。effort=xhighやmaxで思考の深さを上げる運用も組み込めます。
-
長期自律業務だけFable 5
人手で数か月かかる規模のマイグレーション・複雑文書の長時間分析など、限定したユースケースだけFable 5で処理します。Batch + キャッシングを併用して実効単価を圧縮するのが前提です。
この4段階運用により、品質を維持しながらAPI費用を大幅に削減できます。
仮に全リクエストの60%をHaiku、30%をSonnet、8%をOpus 4.8、2%をFable 5で処理する場合、全件Fable 5で処理する場合と比べてAPI費用を約79%削減できる試算です(入出力1:1比率・各モデルの公式単価で簡易計算)。
GPTシリーズ・Geminiシリーズとの位置づけ比較
Claudeの4モデルを選ぶ前に、「そもそもClaudeでいいのか」という比較検討をしたい方もいるでしょう。
本セクションでは、OpenAIのGPTシリーズとGoogle DeepMindのGeminiシリーズとの位置づけを、フラグシップから軽量モデルまでまとめて整理します。
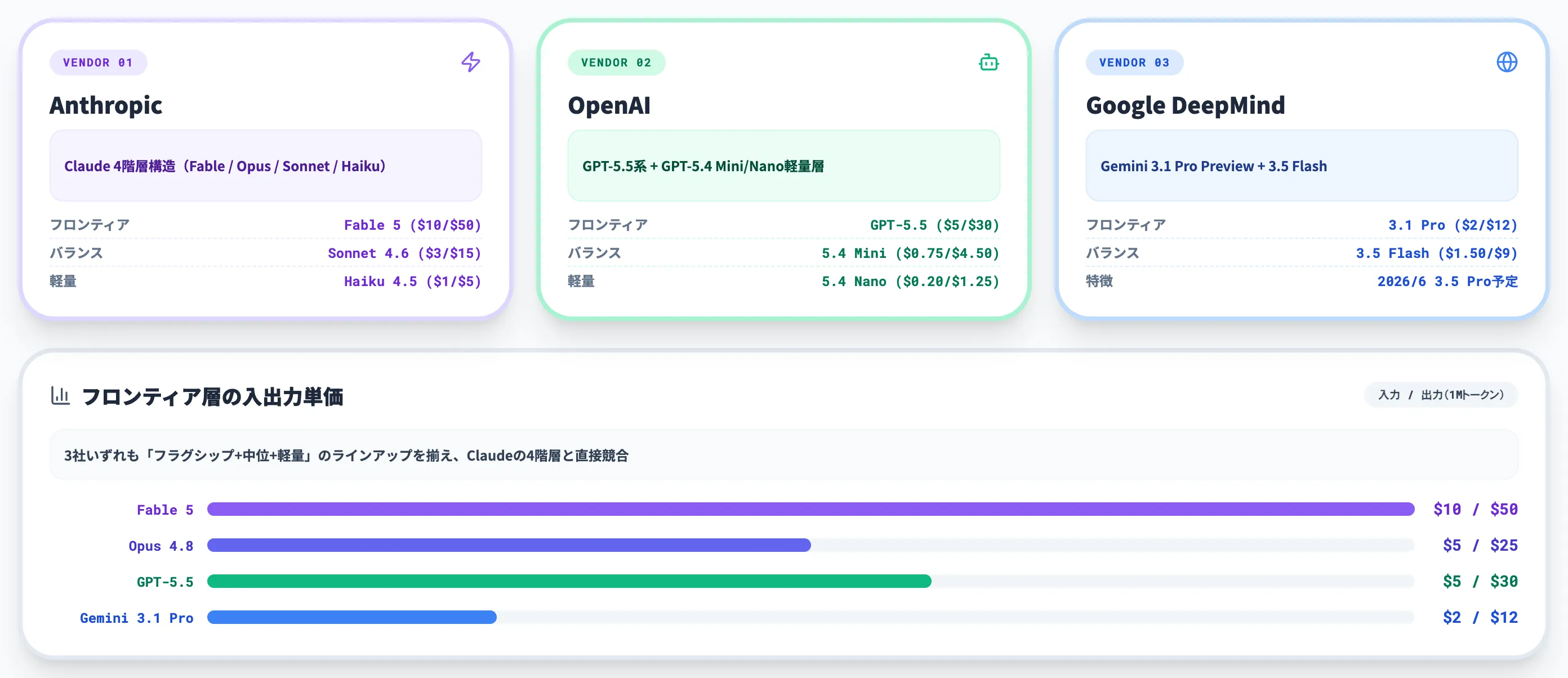
主要競合モデルとの料金・性能比較
GPTシリーズもGeminiシリーズも、Claudeと同様に「フロンティア・中位・軽量」の階層構成を取っています。以下の表で、Claude 4モデルと両シリーズの主要モデルを横並びで整理しました。
| モデル | 提供元 | 入力料金 | 出力料金 | コンテキスト | 強み |
|---|---|---|---|---|---|
| Claude Fable 5 | Anthropic | $10 | $50 | 1M | 長期自律業務・複雑文書解釈で全モデル中トップ級 |
| Claude Opus 4.8 | Anthropic | $5 | $25 | 1M | コンピュータ操作・ブラウザエージェントで業界最高水準 |
| Claude Sonnet 4.6 | Anthropic | $3 | $15 | 1M | コスト効率と汎用性のバランスでフロンティア級コーディング |
| Claude Haiku 4.5 | Anthropic | $1 | $5 | 200K | 高速・低単価の大量処理 |
| GPT-5.5 | OpenAI | $5 / $10(>272K) | $30 / $45(>272K) | 1.05M | ChatGPTエコシステム・Codex/Responses API連携 |
| GPT-5.4 Mini | OpenAI | $0.75 | $4.50 | 400K | OpenAI軽量層・Sonnet帯より低単価 |
| GPT-5.4 Nano | OpenAI | $0.20 | $1.25 | 400K | 大量処理向け最安級 |
| Gemini 3.5 Flash | Google DeepMind | $1.50 | $9.00 | 1M | 2026年5月リリース・コーディング・エージェント系で旧Proを上回る |
| Gemini 3.1 Pro Preview | Google DeepMind | $2(≤200k)/$4 | $12(≤200k)/$18 | 1M | Pro系最新Preview・Google Workspace統合 |
この比較から見えるのは、3社いずれも「フラグシップ+中位+軽量」のラインアップを揃え、Claudeの4階層と直接競合している点です。
GPTシリーズはGPT-5.5系(標準版GPT-5.5に加えgpt-5.5-proも提供)を最上位帯に、GPT-5.4 Mini($0.75/$4.50)・GPT-5.4 Nano($0.20/$1.25)を軽量帯として揃えており、低単価帯の選択肢はSonnet 4.6・Haiku 4.5と直接競合します。
なお、GPT-5.5のStandard課金は272Kトークン以下の入力で入力$5/出力$30、272K超では入力2倍・出力1.5倍の入力$10/出力$45に切り替わります。Batch APIやFlex tierを使うとさらに割引が効き、長文側でも入力$5/出力$22.50、短文側で入力$2.50/出力$15程度まで下がります。
Geminiシリーズは動きが激しく、2026年5月19日にGemini 3.5 Flashがリリースされ、Google公式は同モデルがコーディング・エージェント系の主要ベンチマークでGemini 3.1 Pro Previewを上回ると説明しています。
Gemini 3.5 Proは2026年6月内のリリース予定で、Pro系の現行Previewは引き続き3.1です。コスト感度が高いバッチ処理ではGemini軽量系がClaude 4モデルより選ばれやすい構図になります。
GPT-5.5などの主要推論モデル単体ではテキスト・画像入力が中心ですが、OpenAI API全体では gpt-audio-1.5 や gpt-realtime-2 など音声入出力対応モデルも提供されており、ChatGPT・Codex・Responses API周辺機能と組み合わせれば音声・動画を含むマルチモーダルワークフローを構成できます。
Claudeが特に差別化されているポイント
Claudeが他社モデルに対して優位を出しやすい領域は、以下の3つです。

-
コーディング・長期エージェント業務
Fable 5はSWE-bench Pro 80.0%、Opus 4.8は88.6%(SWE-bench Verified)と、コーディング系ベンチマークでGPTシリーズ・Geminiシリーズの現行モデルを上回るスコアを記録しています。テキスト中心のエージェント業務であればClaudeが第一候補です。
-
コンピュータ操作型エージェント
Opus 4.8がOSWorld-Verified 83.4%・Online-Mind2Web 84%と、ブラウザ・PC操作で業界最高水準を記録しています。
Web操作を伴う業務エージェントを構築するなら、料金半分のOpus 4.8でフロンティア性能が取れる構図です。
-
Sonnet 4.6のコストパフォーマンス
Sonnet 4.6は、フロンティア級の推論・コーディング性能をSonnet価格帯($3/$15)で狙えるため、API費用を重視する企業には大きなメリットがあります。本番デフォルトをSonnet 4.6に据え、必要に応じてOpus 4.8・Fable 5にエスカレーションする運用が、コスト管理の観点でも合理的です。
一方、既存のGPT-4系やGemini系との連携が業務に深く組み込まれている場合、移行コストも含めた総合判断が必要になります。Microsoft Foundry経由でClaude Opus 4.8を利用すれば、既存のAzure基盤を残したままClaudeを組み込む構成も可能です。
Claudeモデル選びの注意点と乗り換え判断
性能・料金・使い分けの軸を把握したうえで、実際に運用を始める前に押さえておきたい注意点があります。本セクションでは、レート制限・データ保持ポリシー・モデル更新ルールの3点を整理します。

レート制限とプランの関係
Claude APIにはレート制限(1分間あたりのリクエスト数やトークン数の上限)が設けられています。この制限は利用ティア(Tier 1〜4)によって異なり、より上位のティアでは高い制限が適用されます。
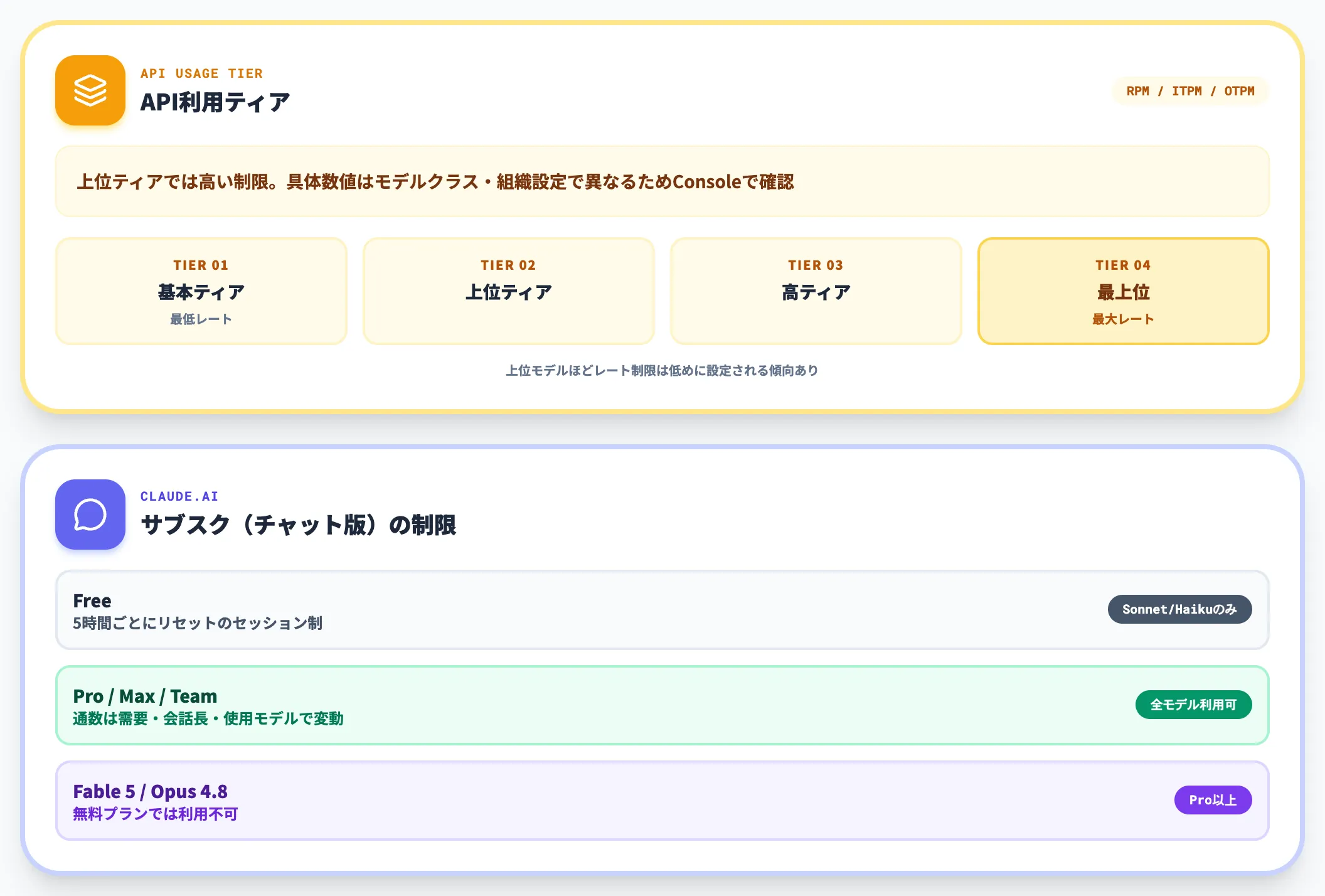
注意すべきは、上位モデルほどレート制限が低く設定される傾向がある点です。具体的なRPM・ITPM・OTPMの値はモデルクラス・利用ティア・組織設定ごとに異なり、Anthropicは「ConsoleまたはRate Limits APIで自社設定を確認する」よう案内しています。大量のFable 5リクエストを短時間で処理したい場合は、本番接続前に自社のティアで取得できる上限を確認してください。
claude.ai(チャット版)を利用する場合も、プランごとに利用量の上限があります。現在のClaude無料プランでは5時間ごとにリセットされるセッション制が採用されており、利用可能な通数は需要状況・会話の長さ・使用モデルによって変動します。Opus 4.8とFable 5は無料プランでは利用できません。
Claude Codeの利用制限と対処法で、モデル別の制限と運用ノウハウを整理しているので、エンジニアリング用途の方は併せて参照してください。
Fable 5の30日データ保持ポリシーとZDR対象外
Fable 5・Claude Mythos 5には、これまでのClaudeモデルにはなかった30日間のデータ保持ポリシーが新たに適用されています。
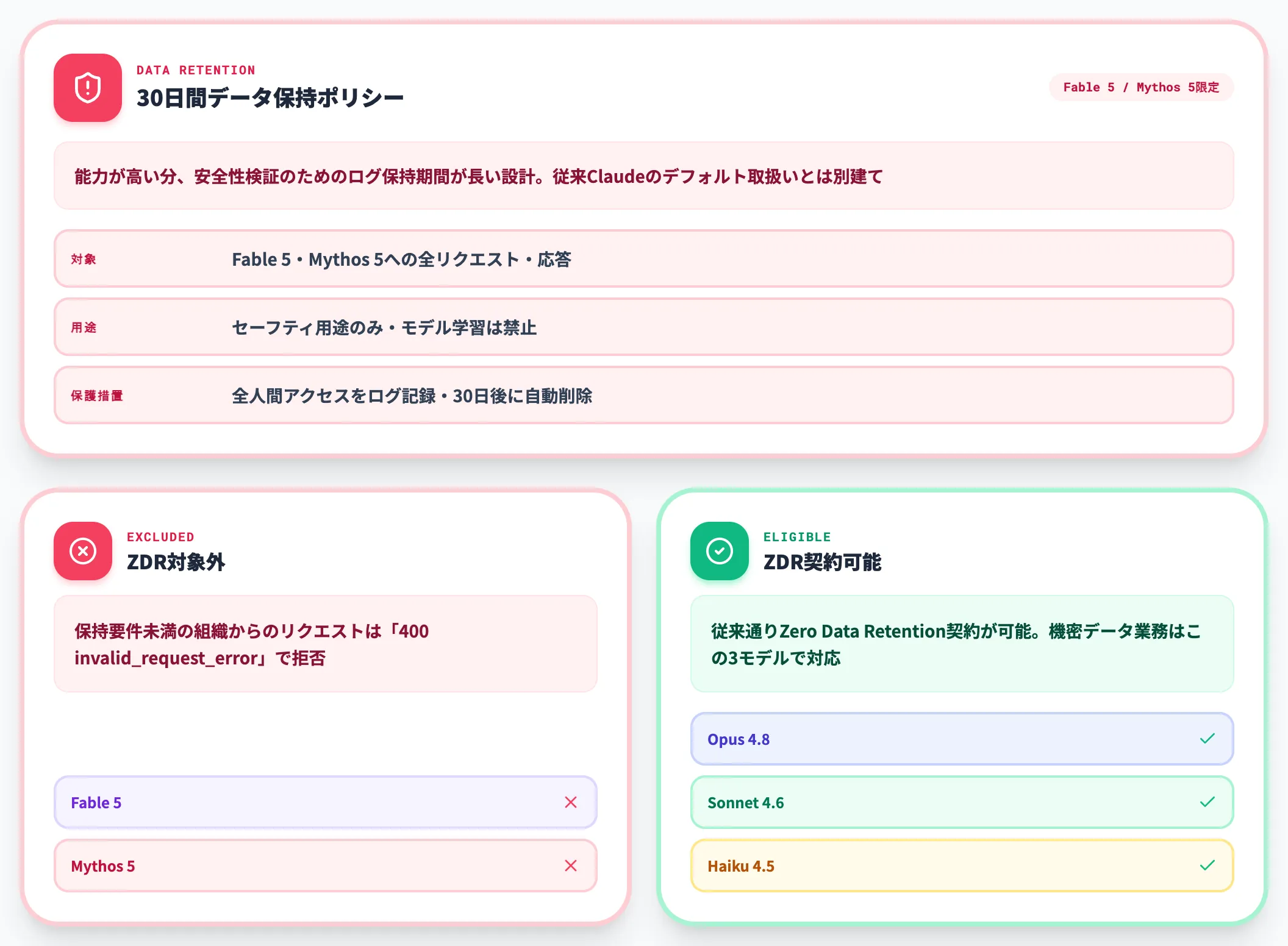
- 対象: Fable 5・Mythos 5および将来の同等以上モデルへの全リクエスト・応答
- 用途: セーフティ用途のみ。モデル学習やそれ以外の目的での利用は禁止
- 保護措置: 全人間アクセスをログ記録。ほぼ全ケースで30日後に自動削除
- 公式ドキュメント: Anthropic公式サポート記事
従来のClaude APIのデフォルトデータ取扱いとは別建てのポリシーで、Fable 5・Mythos 5は「能力が高い分、安全性検証のためのログ保持期間が長くなる」設計です。
機密データを扱う業務でFable 5を使う場合、この30日保持ポリシーが自社のデータ取り扱い規程・契約上の要件と整合するかを、法務・情報セキュリティ担当者と事前確認しておくのが安全です。
特に、Claude API上のFable 5・Mythos 5にはZero Data Retention(ZDR)契約が適用されません。Anthropic公式ドキュメントによれば、保持要件を満たさない組織からのリクエストは「400 invalid_request_error」で拒否されます。Opus 4.8・Sonnet 4.6・Haiku 4.5はこの制約の対象外で、従来通りZDR契約が可能です。
モデル更新・バージョン管理の考え方
Claudeのモデルは定期的に更新されます。APIで利用する際は、モデルIDの指定方法に注意が必要です。
-
エイリアス指定
「claude-opus-4-8」のような日付なしのIDです。Claude 4.6世代以降は、エイリアスもスナップショットと同様に特定リリースを指すピン留め扱いに変更されており、新世代がリリースされても自動で乗り換わるエバーグリーン参照ではありません。新世代に切り替えたい場合は、明示的に新しいエイリアスやスナップショットIDへ更新する必要があります。
-
スナップショット指定
「claude-haiku-4-5-20251001」のように日付付きのIDを指定する方式です。Claude 4.5世代以前のスナップショットは旧来の挙動どおりで、出力の再現性が重要なプロダクション環境では引き続き安定した選択肢になります。
また、旧世代モデルは順次非推奨(deprecated)になります。たとえばClaude Opus 4.1(「claude-opus-4-1-20250805」)は2026年8月5日に廃止予定で、Claude Sonnet 4・Opus 4は2026年6月15日に廃止予定です。長期運用を前提とする場合は、最新世代への移行計画を立てておくことを推奨します。
4モデル時代の乗り換え判断
旧世代Claude(Opus 4.6・Sonnet 4.5など)を業務で使っている場合、Opus 4.8・Sonnet 4.6への移行は単価据え置きで性能向上が見込めるため、原則として移行が合理的です。

一方、Fable 5への乗り換えは、以下の3軸で判断するのが現実的です。
- 業務が「数時間以上の自律実行」を要求するか
- Pro/Max契約者なら2026年6月22日までの無料利用期間に利用量・月間上限を測定したか
- API利用者なら30日データ保持ポリシーが業務要件と整合するか
3軸のいずれもクリアできるなら、Fable 5の能力を業務に組み込む価値が出てきます。逆に1つでも引っかかるなら、Opus 4.8で十分なケースが大半です。

Claudeモデルを業務エージェント基盤として組み込むなら
Claude Fable 5の登場で、AIエージェントが扱えるタスクの長さと複雑さが一段広がりました。ただし、4モデルそれぞれの強みを業務でフル活用するには、モデル選定だけでなく社内システム連携・権限管理・実行ログ・データ保持条件まで含めた運用基盤の設計が必要になります。
たとえば、Fable 5を「大規模マイグレーション」「四半期コード監査」のような重い業務に予算化し、Opus 4.8を日常標準モデルに据え、Sonnet 4.6で軽作業、Haiku 4.5で一次仕分け——という4段階運用を社内で回すには、モデルごとの実行ログをまとめて管理できる仕組みが要ります。さらにFable 5の30日データ保持・ZDR対象外という制約は、機密データを扱う部門ほど事前のポリシー整合が欠かせません。
ここで効いてくるのが、Microsoft Teamsから呼び出せる自社Azureテナント内のAIエージェント運用基盤、AI総合研究所のAI Agent Hubです。
-
モデル選定の自由度を保ったまま統一管理
Fable 5・Opus 4.8・Sonnet 4.6・Haiku 4.5・他社モデルを業務ごとに使い分けつつ、実行ログ・権限・セキュリティスキャンを1つのダッシュボードで管理できます。
-
Teamsから呼び出せる9種類の業務特化Agent
経費申請・請求書受領・設計製図・規程チェックなど業務特化Agentが既に用意されており、Claude各モデルを呼び出して業務を完結させます。
-
使い慣れたMicrosoft環境をそのまま活用
Teams・Excel・Outlookなど既存ツールの延長でAIエージェントが動作。新しいツールの学習コストはゼロです。
-
実行統制を自社Azureテナント内で完結
業務システムへのアクセス・実行ログ・権限はAzure Managed Applicationsとして自社テナント内で動作します。外部モデルAPI(Fable 5・Opus 4.8等)を呼び出す部分は、各提供元のデータ保持条件を踏まえてモデル選定とデータ取扱いを整合させる設計が可能です。
AI総合研究所の専任チームが、フロンティアモデル選定から業務システム連携、運用設計まで一貫してサポートします。AI Agent HubのLPで、自社の業務にどう活用できるか具体例とあわせてご確認ください。
モデル選定の次は業務エージェント基盤への組み込み設計

Claude活用を成果につなげる段階設計
Fable 5・Opus 4.8・Sonnet 4.6・Haiku 4.5を業務に組み込むなら、モデル選定だけでなく社内システム連携・権限管理・実行ログ・外部モデル利用時のデータ保持条件まで含めた運用基盤の設計が必要です。Microsoft Teamsから呼び出せる自社Azureテナント内のAIエージェント運用基盤、AI Agent HubでClaude各モデルを業務エージェントとして組み込む構成をご覧ください。
まとめ
本記事では、2026年6月時点のClaude 4モデル——Fable 5・Opus 4.8・Sonnet 4.6・Haiku 4.5の違いを、階層構造・ベンチマーク・料金・使い分け・競合比較・乗り換え判断の6つの軸で比較しました。要点を改めて整理します。
-
Fable 5の登場でClaudeは4階層構造に再編された。Mythos-classと呼ばれる新最上位層に位置する一般公開モデルで、Opus-tierの上に独立して配置
-
コーディング・推論・長期エージェントの全領域でFable 5が前世代を更新。Stripe事例(2か月→1日)・Hex 90%・GDPval-AA Elo 1932など、長時間自律業務での優位が明確
-
Opus 4.8は単価据え置きでフロンティア性能を維持。effort制御(low/high/xhigh/max)・Dynamic Workflows・Fast mode($10/$50で2.5x速度)・コード欠陥見落とし1/4など、運用面での進化も大きい
-
Sonnet 4.6が実務上の本番デフォルト候補。Opus 4.5世代相当の性能を約60%の単価で、1Mコンテキスト標準料金、両Thinking対応というバランスが他に並ぶものがない
-
Haiku 4.5は最速・最安で大量処理の主力。チャットボット・分類・要約は単価1/10で十分な品質
-
4階層時代の運用は「Haiku→Sonnet→Opus→Fable」の4段階ルーティングが費用対効果で最も優れる。Fable 5は「全業務に開放」ではなく「重い業務に予算化」する設計が現実的
2026年6月のFable 5登場により、「全件Opusで安心」「Sonnetで十分」のどちらでもない、タスクの所要時間と複雑さに応じた4段階の使い分けが標準的な運用パターンになりました。
まずはClaude(Proプラン以上)でFable 5を6月22日までに試し、自社業務での品質改善幅と月間利用量を測ったうえで、6月23日以降の本格運用設計に進むのが、Fable 5世代のAI活用を業務に定着させる最初の一手になります。










