この記事のポイント
 VLAは視覚・言語・行動を1つのネットワークで処理し、従来のルールベース制御と模倣学習を一段先へ進めるロボット基盤モデル
VLAは視覚・言語・行動を1つのネットワークで処理し、従来のルールベース制御と模倣学習を一段先へ進めるロボット基盤モデル- 主要モデルはHelix・π0.5・Gemini Robotics・GR00T N1.5・OpenVLA・RT-2の6系統。System1/System2構造とDiffusion Policyが2026年の主流
- 2026年はBoston Dynamics×DeepMind、Apptronik×DeepMindなど提携の表面化と、Figure 03の家庭投入準備、Tesla Optimus Gen 3の量産設計が同時並行で進む節目
- 導入判断は「オープン×自前運用(利用条件確認必須)」か「ロボット向けAPI×ベンダー統制」かの二択が中心。ヒューマノイドはまだ研究・パイロット段階で量産前提の選定は時期尚早
- Gemini Robotics-ERはAPIで触れるが「テキスト出力VLM」で制御コマンドは出さない点に注意。VLA本体はパートナー提携経由が中心

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
VLA(Vision-Language-Action)モデルは、ロボットのカメラ画像と自然言語の指示を入力に取り、関節やグリッパーを動かす行動コマンドを直接出力する、ロボット用の基盤モデルです。
2025年から2026年にかけてHelix(Figure AI)、π0.5(Physical Intelligence)、Gemini Robotics(Google DeepMind)、GR00T N1.5(NVIDIA)といったモデルが相次いで登場し、Boston Dynamics・Apptronik・Teslaなど実機ヒューマノイドとのパイロット統合や量産設計が同時に走り始めました。
本記事ではVLAの定義と仕組み、主要6系統の差、Tesla FSDやTuringの自動運転VLA、CES 2026で表面化した産業実装の最新動向、オープン/API利用やクラウド/エッジを含む導入判断軸、限界と注意点、そして料金・開発コストの桁感までを2026年6月時点の公式情報・公開情報を中心に体系的に整理します。
「自社のラインや業務にヒューマノイドを入れるべきか」を判断する材料として読み解いてください。
目次
VLAモデル(Vision-Language-Action)とは?ロボットを「言葉で動かす」基盤モデル
VLMとVLAの境界——「説明する」で止まるか「動かす」まで行くか
System 1 / System 2 デュアルアーキテクチャ
Diffusion Policy × Action Chunkingが標準パラダイムになった
主要VLAモデル6系統——ヒューマノイド・汎用ロボット系の比較とER補足
Helix(Figure AI)——フルボディ・フルハンド制御の家庭向けヒューマノイド
π0.5(Physical Intelligence)——新環境への汎化を初めて定量化したモデル
Gemini Robotics / Gemini Robotics-ER(Google DeepMind)——VLA本体と「身体推論VLM」の2階建て
GR00T N1 / N1.5(NVIDIA)——オープンなヒューマノイド基盤モデル
OpenVLA / OpenVLA-OFT——研究と自前PoCの第一候補
RT-2 / RT-2-X(Google DeepMind)——VLAのパラダイムを定めた先駆者
自動運転領域のVLA——Tesla FSD・Wayve・Turingが「車載基盤モデル」を作る
Tesla FSD v14——End-to-Endに振り切ったロボタクシー基盤
Wayve GAIA-3 と LINGO——世界モデル+VLAのハイブリッド
Turing——日本初のVLA公道走行を実現したスタートアップ
VLA × ヒューマノイドの2026年実装——CES 2026で見えた量産前線
Boston Dynamics × Google DeepMind——Atlasに統合される基盤モデル提携
Apptronik × Mercedes-Benz——Google DeepMind提携で進むApolloのAIモデル活用
Tesla Optimus Gen 3——FSD系基盤を流用するヒューマノイドの量産設計
Figure 03——家庭タスクを狙うHelixベースの量産機
ケース2:自動車・物流のライン投入——Google DeepMindとの提携軸でパイロット
ケース3:家庭・小売向け検証——FigureまたはGR00T参考設計の様子見
VLAの限界と注意点——「賢く動く」がまだ「安全に動く」ではない
行動の結果を予測できない——「掴んだら滑るかも」を見抜けない
標準化はまだこれから——重み・データ・評価の共通化が走り始めた段階
Gemini Robotics-ER API(身体推論VLM)
GR00T N1.5(オープンモデル自前運用・利用条件要確認)
VLAモデル(Vision-Language-Action)とは?ロボットを「言葉で動かす」基盤モデル
VLA(Vision-Language-Action)モデルは、ロボットのカメラ画像と自然言語の指示を入力に取り、関節角度やグリッパー開閉といった行動コマンドを直接出力する単一のニューラルネットワークです。
視覚(Vision)・言語(Language)・行動(Action)を1つのモデルで処理することから「VLA」と呼ばれ、2025年以降のロボット基盤モデルの標準的な設計パターンになりました。

「箱から赤いボトルを取って」と話しかけると、ロボットがカメラ越しに環境を解釈して、ボトルを掴むまでの一連の腕・指の動きを自分で組み立てて実行する——これがVLAの基本的な振る舞いです。
ルールや手続きを1つずつコードで書く従来のロボット制御や、決まったタスクだけを反復させる模倣学習と比べて、未知の指示や見たことのない物体にも一定の応答ができる点が決定的な違いになります。

VLMとVLAの境界——「説明する」で止まるか「動かす」まで行くか

VLA以前から、画像と言語を扱える基盤モデルは存在していました。GPT-4VやGemini、Claudeのように、画像を見て言語で説明・回答するモデルは**VLM(Vision-Language Model)**と呼ばれます。
VLMは「写っているものを言葉で表現する」までしかできません。一方VLAは、VLMの上に行動(Action)出力を追加し、物理世界の身体を持つロボットを直接動かすところまで踏み込みます。
以下の表で、VLM・VLA・従来のロボット制御の役割を整理しました。
| 区分 | 入力 | 出力 | 代表例 |
|---|---|---|---|
| 従来のロボット制御 | センサー値、固定の手順 | 事前定義された関節制御 | 産業用ロボットの軌道計画、ティーチングプレイバック |
| VLM | 画像・テキスト・動画 | 自然言語の説明・回答 | GPT-4V、Gemini 3、Claude |
| VLA | 画像・テキスト・ロボット状態 | 行動コマンド(関節角度・速度等) | Helix、π0.5、Gemini Robotics、GR00T N1.5 |
この表が示すように、VLAは「言葉が理解できる」VLMに、物理アクションを新たな出力モダリティとして足した構造になっています。
Google DeepMindはGemini Roboticsを「Gemini 2.0をベースに、物理アクションを新たな出力として加えたVLAモデル」と定義しており、この設計思想が業界共通の理解になっています(Google DeepMind公式ブログ)。
なぜ2026年に注目が一気に高まったのか

VLAという概念自体は2023年のGoogle RT-2にまで遡ります。それが2026年に急に注目を集めるようになった背景には、3つの転換があります。
モデル側の性能ジャンプ
2025年4月公開のπ0.5は、訓練データに含まれていない初見の家庭でも、食器の片付けやベッドメイキングで**OOD(分布外)成功率94%**を記録しました(Physical Intelligence公式ブログ)。
新環境への汎化は長くロボット研究の壁とされてきた課題で、ここを定量的に突破したインパクトは大きいです。
量産ヒューマノイドへの統合
2026年1月のCES 2026でBoston Dynamicsは、Atlas量産機の2026年出荷分をすべてHyundai RMACとGoogle DeepMindに割り当てると発表しました(Boston Dynamics公式ブログ)。これに合わせ、Google DeepMindの基盤モデルをAtlasに統合する提携も公表されています。
オープンソース化の進展
NVIDIAは2025年3月にGR00T N1を世界初のオープンヒューマノイド基盤モデルとして公開し(NVIDIA Newsroom)、Stanford主導のOpenVLAも7Bパラメータの重みを公開しました。
これにより研究者だけでなく、企業のR&D部門もVLAを自前で試せる環境が整いました。
VLAが「論文の中の話」から「ライン現場と家庭の話」に変わったのが、2025〜2026年にかけてのこの1年です。
VLAモデルの仕組みとアーキテクチャ

VLAの内部構造は、見かけ上は1つのニューラルネットワークですが、その中で何が起きているかを分解すると、複数の機能ブロックが連携しています。
ここでは、System 1 / System 2 アーキテクチャ・Diffusion PolicyとAction Chunking・Flow Matchingという、2026年時点のVLA設計を支配する3つの設計パターンを順に整理します。
Vision・Language・Actionの3層構造
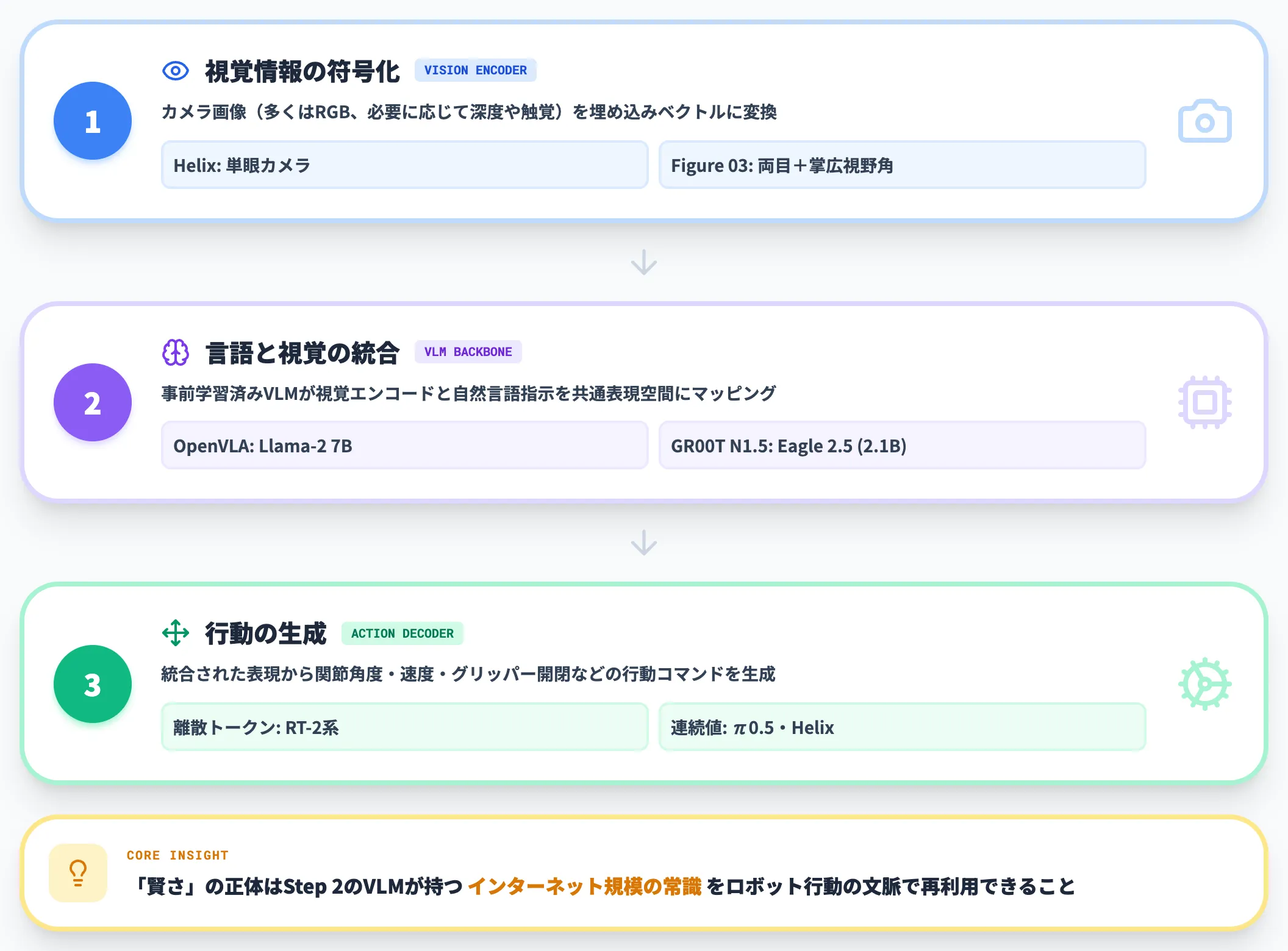
VLAの基本的な処理パイプラインは、3つのステップに分けて理解すると整理しやすいです。
-
視覚情報の符号化(Vision Encoder)**
カメラ画像(多くはRGB、必要に応じて深度や触覚)を埋め込みベクトルに変換します。
Helixは単眼カメラ、Figure 03は両目+掌の広視野角カメラを統合し、フレームレートは旧世代比2倍まで引き上げられています(Figure AI公式ブログ)。
-
言語と視覚の統合(VLM Backbone)**
事前学習済みのVLMが、視覚エンコードと自然言語指示を共通の表現空間にマッピングします。
OpenVLAはLlama-2 7B、GR00T N1.5はEagle 2.5 VLM(2.1Bパラメータ)をバックボーンに採用しています(NVIDIA Research)。
-
行動の生成(Action Decoder / Policy)**
統合された表現から、関節角度・速度・グリッパー開閉などの行動コマンドを生成します。
出力は離散トークンの場合(RT-2系)と連続値の場合(π0.5、Helix)があり、後者の方が高頻度・高精度制御に向きます。
VLAの「賢さ」の正体は、Step 2のVLMバックボーンが持つインターネット規模の常識知識を、ロボット行動の文脈で再利用できる点にあります。
「赤い物体は危険のサインのことがある」「ペンは尖っている方を相手に向けない」といった世界の常識を、ロボットがゼロから学ばずに済むようになりました。
System 1 / System 2 デュアルアーキテクチャ

2026年のVLA設計で主流になっているのが、人間の思考モデルになぞらえた「System 1 / System 2」のデュアル構造です。
Daniel Kahnemanの『ファスト&スロー』の枠組みを、ロボット制御に当てはめた設計思想と言えます。
以下の表で、Figure AIのHelixとNVIDIA GR00T N1.5のデュアル構造を整理しました。
| モデル | System 2(遅い思考) | System 1(速い反射) | 制御周波数 |
|---|---|---|---|
| Helix(Figure AI公式) | 7Bパラメータの汎用VLM。意図理解と長期計画 | 80Mパラメータのポリシー。連続制御 | System 2:7〜9Hz/System 1:200Hz |
| GR00T N1.5(NVIDIA Research) | Eagle 2.5 VLM(2.1B)。視覚言語推論 | Diffusion Transformer(DiT)ベース。ノイズ付き行動の精緻化 | アクションヘッドが高頻度動作 |
System 2は数Hz程度でゆっくり「次に何をすべきか」を考え、System 1はそれを受けて100〜200Hzで関節を動かす——この役割分担によって、長期的な意図理解と、リアルタイム制御の両立ができるようになりました。
Helixは35自由度のアクション空間を200Hzで制御し、手首姿勢・指の曲げ伸ばし・胴体・頭部向き・タスク完了率まで同時に出力します。指先センサーで3グラムの圧力を検知するレベルで、卵やフルーツのような繊細な物体も扱えるよう設計されています。
Diffusion Policy × Action Chunkingが標準パラダイムになった

もう1つの大きな技術潮流が、拡散モデル(Diffusion Policy)とアクションチャンク(Action Chunking)の組み合わせです。
-
Diffusion Policy
画像生成で使われる拡散モデルを行動生成に転用するアプローチです。ノイズだらけの行動列から徐々にノイズを除去し、滑らかで多様性のあるアクションを生成します。
単一の正解を当てに行く回帰モデルと違い、「同じ状況で複数の合理的な動き方がある」場合の表現力が高いのが特徴です。
-
Action Chunking
1ステップごとに次の動作を予測するのではなく、未来50ステップ分(約1秒)の動作系列をまとめて生成する設計です。π0.5は50ステップのアクションチャンクを採用し、推論回数を減らしつつ時間方向の整合性を確保しています。
この2つを組み合わせると、推論コストを抑えながら高頻度制御が可能になります。
OpenVLA-OFTでは、並列デコーディングとアクションチャンクの導入により推論速度が25〜50倍に高速化されたと報告されています(OpenVLA-OFT公式サイト)。
Flow Matchingという連続制御の精度を支える技術
Physical Intelligenceのπ0/π0.5は、Diffusion Policyの発展形であるFlow Matchingを採用しています。
Flow Matchingは「ノイズ分布から目標分布へ流れるベクトル場」を直接学習する手法で、拡散モデルの推論ステップを大幅に減らせる利点があります。
π0.5では離散自己回帰トークン復号と組み合わせ、高レベル行動は離散パスで「言語として」出力し、低レベルモーター制御は連続パスで生成する二段構成になっています。
「冷蔵庫を開けてジュースを取る」のような長期タスクと、「ボトルを掴むときの指先の力加減」のような高頻度制御を、1つのモデルで矛盾なく扱える設計です。
主要VLAモデル6系統——ヒューマノイド・汎用ロボット系の比較とER補足
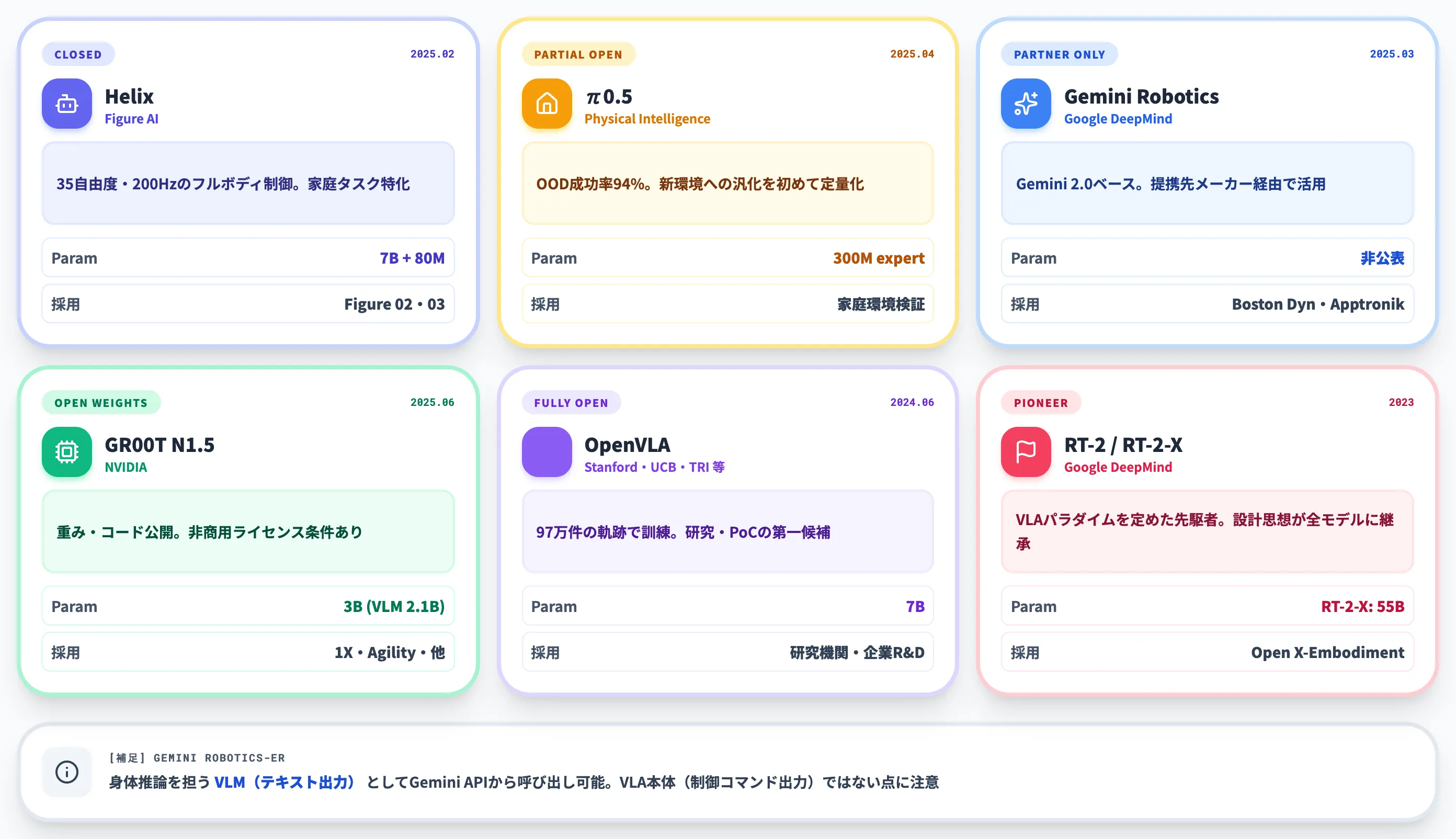
VLAは2024〜2026年に多数のモデルが公開され、それぞれ採用ロボット・パラメータ規模・公開方針が大きく異なります。
ここでは、ヒューマノイド・汎用ロボット系のVLA本体を6系統に整理し、合わせてAPI経由で触れる身体推論VLMであるGemini Robotics-ERの位置づけも補足します。
6系統のスペック比較とERの補足
以下の表で、主要VLAモデル6系統のパラメータ規模・公開状況・主な採用先と、補足としてGemini Robotics-ER(身体推論VLM)の位置づけをまとめました。
| モデル | 開発元 | 公開時期 | パラメータ規模 | 公開状況 | 主な採用先 |
|---|---|---|---|---|---|
| Helix | Figure AI | 2025年2月(Helix)/フルボディ自律のHelix 02も後続 | System 2:7B/System 1:80M | クローズド(Figureロボット専用) | Figure 02、Figure 03 |
| π0.5 | Physical Intelligence | 2025年4月 | Action expert 300M(総数非公表) | 一部研究向け公開 | 自社実験ロボット、家庭環境検証 |
| Gemini Robotics(VLA本体) | Google DeepMind | 2025年3月(初版) | 非公表(Gemini 2.0ベース) | パートナー提携経由(一般API公開なし) | Boston Dynamics・Apptronikなど提携先で活用方針を公表(具体的な統合範囲は非公表) |
| GR00T N1.5 | NVIDIA | 2025年6月 | 3B(うちVLM 2.1B) | 重み・コード・データセット公開(NVIDIAライセンス。モデルカードで非商用利用条件を規定) | 1X、Agility Robotics、Mentee Robotics、NEURA Robotics 等のアーリーアクセス組 |
| OpenVLA / OpenVLA-OFT | Stanford・UC Berkeley・TRI・Google DeepMind 等 | 2024年6月(本体)/2025年3月(OFT) | 7B | コードMIT・モデルはLlama-2ライセンス準拠 | 研究機関、企業R&D、ソフトロボット検証等 |
| RT-2 / RT-2-X | Google DeepMind | 2023年(RT-2)/2023年10月(RT-2-X) | RT-2-X:55B | 重み非公開、論文・データセット公開 | Google社内研究、Open X-Embodiment参加組 |
| [補足]Gemini Robotics-ER(身体推論VLM) | Google DeepMind | 2025年3月(初版)/2026年プレビュー時点でER 1.6 | 非公表 | Gemini APIプレビュー(テキスト出力VLM) | Geminiでロボット推論を組む開発者 |
表の最下行Gemini Robotics-ERは、本記事でVLA本体の「6系統」には数えていません。
制御コマンドを出すVLA本体ではなく、身体推論を担うVLMとしてAPIから呼べる補足扱いです。VLA本体側で見ると、Figure AIやPhysical Intelligenceのように完全自社統合型と、NVIDIA GR00T・OpenVLAのように外部開発者が触れる開放型で、企業側の打ち手はまったく違ってきます。
Helix(Figure AI)——フルボディ・フルハンド制御の家庭向けヒューマノイド
Helixは、Figure AIが2025年2月に発表したジェネラリストVLAです。
手首姿勢・指の曲げ・外転・胴体・頭部向き・タスク完了率を含む35自由度のアクション空間を200Hzで制御する設計で、上半身を細かく動かす家庭タスクに向きます。

HelixはFigure 02 / Figure 03のフルボディ制御を担うVLA。協調作業のデモが公開されている(出典:Figure AI)
System 2(7B VLM)が7〜9Hzでタスクを解釈し、System 1(80Mポリシー)が200Hzで連続制御するデュアル構成は、長期推論と高頻度制御の両立を体現する代表例です。
2025年10月発表のFigure 03はHelix前提に設計し直されたヒューマノイドで、カメラのフレームレートが2倍、レイテンシが1/4、視野角が60%拡大されました(Figure AI公式ブログ)。
手のひらにも広視野角・低遅延カメラが追加され、Helix側で「視覚と手のフィードバックが一致した状態」で行動生成できるようになっています。
後続のHelix 02ではフルボディ自律性が実証され、上半身だけでなく歩行や姿勢制御まで含めた連続行動生成が可能になりました。
π0.5(Physical Intelligence)——新環境への汎化を初めて定量化したモデル
π0.5は、スタートアップPhysical Intelligenceが2025年4月に公開したジェネラリストポリシーです。
最大の特徴は、訓練データに含まれていない初見の家庭でも、ロボットが家事タスクを実行できる点にあります。

π0.5はオープンワールド汎化を打ち出したPhysical Intelligenceのジェネラリストポリシー(出典:Physical Intelligence)
公式ブログによれば、Physical Intelligenceはサンフランシスコ市内のレンタル住宅3軒で、π0.5を搭載した移動マニピュレーターに「シンクに食器を入れる」「ベッドを整える」「衣類をランドリーバスケットに入れる」といった家事を依頼しました(Physical Intelligence公式ブログ)。
結果として、OOD(分布外=訓練に使っていない新環境)の評価で**言語追従率94%・タスク成功率94%**を達成しています。
π0からの主な改善は「異種ロボットのデータを混ぜたコトレーニング」で、約100の異なる訓練環境を組み合わせた時点で、テスト環境固有データを使ったベースラインに近い性能に到達することが示されました。
モバイルマニピュレーション用のデータも約400時間で効果が出ると報告されており、これは家庭環境でのVLA投入の現実味を大きく高めました。
Gemini Robotics / Gemini Robotics-ER(Google DeepMind)——VLA本体と「身体推論VLM」の2階建て
Gemini Roboticsは、Google DeepMindが2025年3月に発表したロボット向けモデル群です。
Gemini 2.0をベースに物理アクションを新たな出力モダリティとして追加した設計で、姉妹モデルとして以下の3系統が走っています。
-
Gemini Robotics
ロボットを直接制御するVLA本体。マルチ実体・汎化性能を重視。一般APIでの公開ではなく、Boston Dynamics・Apptronikなど提携パートナー経由の利用が中心。
-
Gemini Robotics-ER(Embodied Reasoning)
3D知覚・ポインティング・ロボット状態推定・アフォーダンス予測など、身体的推論を担うVLMです(公式ドキュメント上は出力がテキストのみのVision-Language Modelとして位置付けられています)。生成した推論結果は、別途用意したロボット制御APIや独自VLAに渡して動かす役割になります。2026年6月時点ではGemini Robotics-ER 1.6 PreviewがGemini APIから呼び出せます。
-
Gemini Robotics On-Device
ロボット本体側で動作する軽量版。クラウド往復なしでローカル推論できる。
Gemini Robotics-ER 1.6はGoogle AI Studio経由でAPIキーを取得すれば開発者が試せる状態にあり、
「ロボット向け身体推論VLMをAPIで呼ぶ」体験を最も気軽にできるモデルになっています。VLA本体(Gemini Robotics)の制御出力をAPIで叩けるわけではない点に注意してください。プレビュー段階のため本番利用は推奨されておらず、2026年6月19日以降は無制限APIキーは403エラーになるため、AI Studio側でセキュリティ制限の設定が必須です。
GR00T N1 / N1.5(NVIDIA)——オープンなヒューマノイド基盤モデル
NVIDIAは2025年3月のGTCで、世界初のオープンなヒューマノイドVLA「GR00T N1」を発表しました。続く2025年6月にGR00T N1.5がリリースされ、評価ベンチマーク「DreamGen」12タスクでの成功率は**N1の13.1%からN1.5では38.3%**まで引き上げられています(NVIDIA Research)。
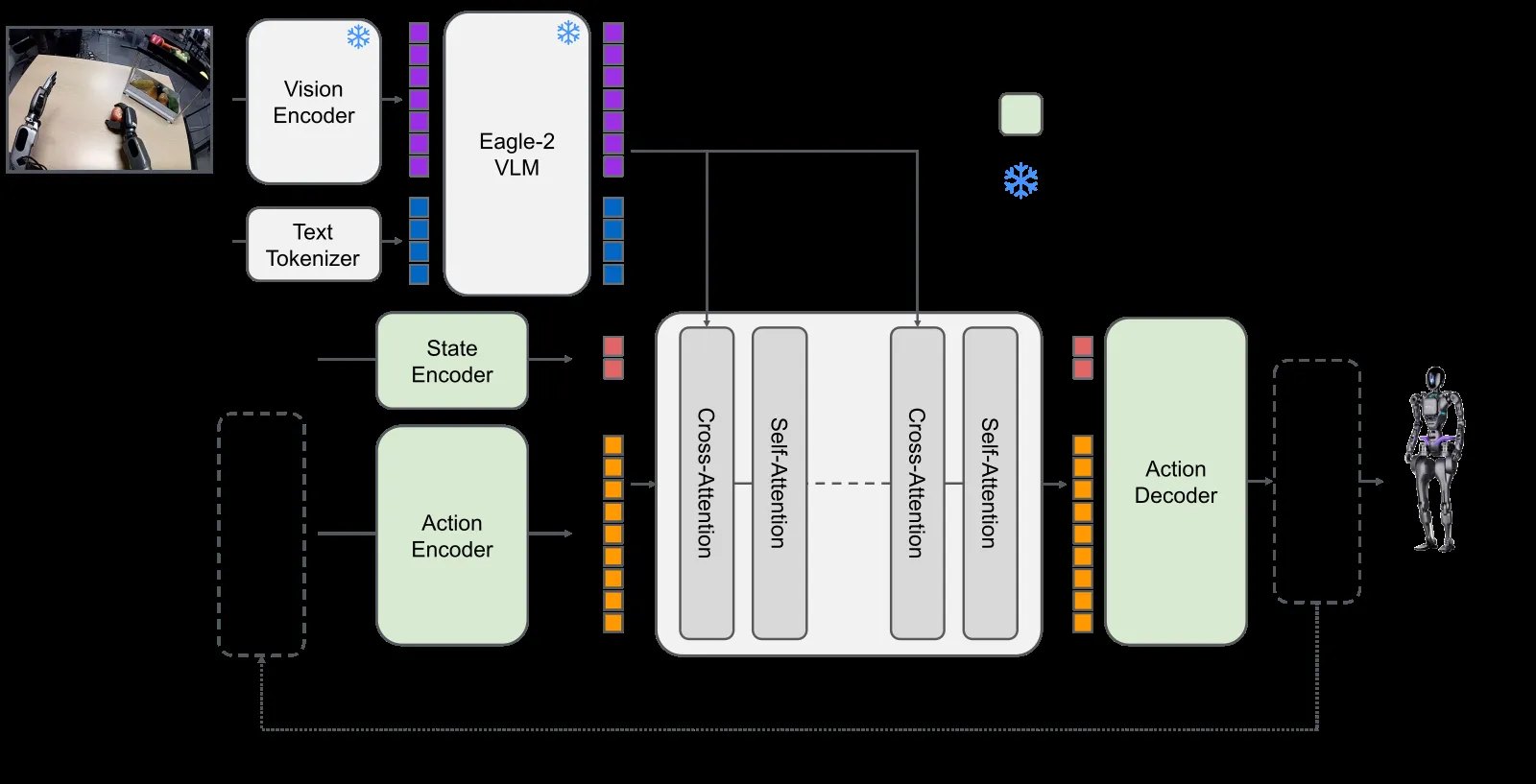
GR00T N1.5は凍結したEagle-2 VLMの上に、Action Encoder→DiT(Diffusion Transformer)ブロック→Action Decoderを重ねた構造(出典:NVIDIA Research)
アーキテクチャ図に示されているとおり、N1.5はVision Encoder+Text Tokenizerで視覚と指示文を共通空間に揃え、Eagle-2 VLMで身体的推論を行い、その出力をCross-Attention/Self-AttentionからなるDiT Blocksに流し込んで、ノイズ付きアクションを段階的に精緻化する設計です。
VLM(Eagle 2.5・2.1B)を凍結したまま、FLARE損失で将来潜在表現を整列させ、人間の動画データからも学習できる構造になりました。
GR00T-Dreamsを使った合成データ生成では、36時間でN1.5の訓練データを準備できたと報告されており、本来3か月かかる手動データ収集を圧縮しています(NVIDIA Technical Blog)。
GR00T N1.5の重みとデータセット・コードはHugging FaceとGitHubで公開され、1X Technologies・Agility Robotics・Boston Dynamics・Mentee Robotics・NEURA Roboticsが早期アクセスパートナーになっています。「自社で重みを触れる本格VLA」として最も近い距離感にあるのがGR00Tです。
ただし、Hugging Face上のNVIDIAモデルカードでは非商用利用を前提とした条件が示されており、商用展開を視野に入れる場合はNVIDIA側のライセンス条件と利用範囲を個別に確認する必要があります。「重み公開=商用ですぐ使える」とは読まないように注意してください。
OpenVLA / OpenVLA-OFT——研究と自前PoCの第一候補
OpenVLAは、Stanford・UC Berkeley・トヨタ自動車研究所(TRI)・Google DeepMindなどが共同開発した7BパラメータのオープンVLAです。
学習データはOpen X-Embodimentデータセットの970,000件のロボット軌跡で、22体の実機ロボットを含む33の学術研究室がデータを持ち寄った巨大セットになっています(GitHub openvla/openvla)。
性能面では、55BパラメータのRT-2-Xを29タスクで16.5ポイント上回る結果を示しました。7倍少ないパラメータで同等以上の汎用性を出している点が、オープンモデルとしての価値を高めています。
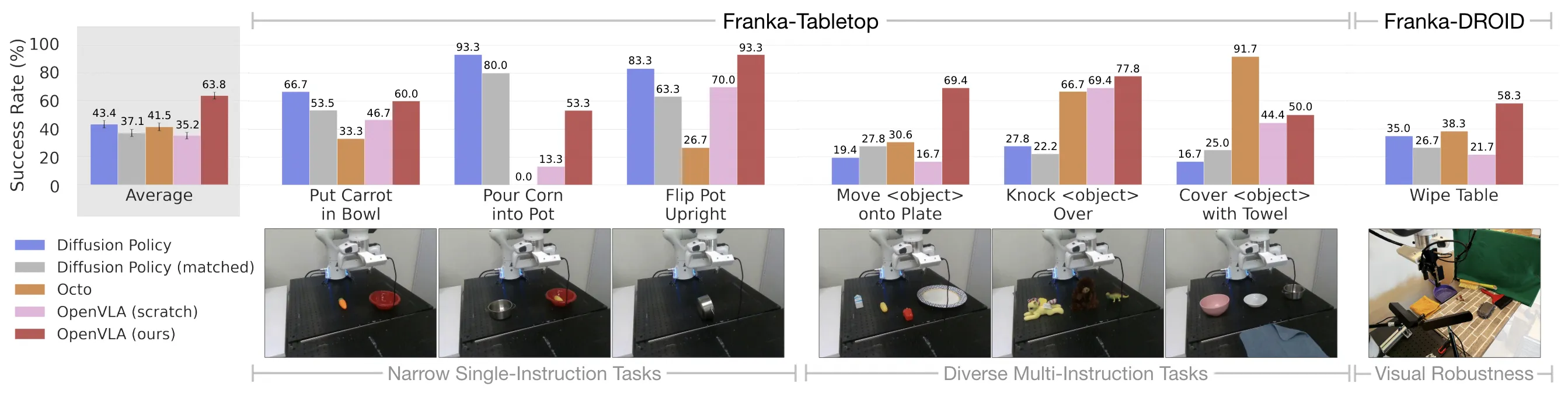
OpenVLAは「Cover object with Towel」「Wipe Table」など複数のタスクでDiffusion Policy・Octoを上回る成功率を示している(出典:OpenVLA)
公式の比較グラフでは、OpenVLAがNarrow Single-Instruction Tasks(カゴへの片付け・ポット注ぎ等)とDiverse Multi-Instruction Tasks(物体配置・カバー作業等)の両方で堅実なベースラインになっていることが確認できます。
2025年3月に公開された**OpenVLA-OFT(Optimized Fine-Tuning recipe)**は、L1回帰による連続行動空間・並列デコーディング・アクションチャンクを組み合わせて、推論を25〜50倍高速化しました。
OFT公式FAQでは、実験条件として8枚のA100/H100 80GBで1〜2日規模の学習が示されています。少数GPU構成でもタスク次第で動かせますが、その場合は所要時間が増える前提です。
素のOpenVLAをLoRAで小規模に試すなら単一A100で回せる例もあり、研究者から企業R&D部門まで距離感は近くなっています。
コードはMITライセンスですが、モデル本体はLlama-2ベースのためLlama Community Licenseの遵守が必要です。商用利用を視野に入れる場合はライセンス条件の確認が必須となります。
RT-2 / RT-2-X(Google DeepMind)——VLAのパラダイムを定めた先駆者
RT-2は2023年にGoogle DeepMindが発表したVLAの祖先にあたるモデルで、現代VLA研究の出発点です。Transformerベースの大規模VLMを共同微調整し、ロボットアクションを自然言語トークンとして出力する設計を初めて確立しました。
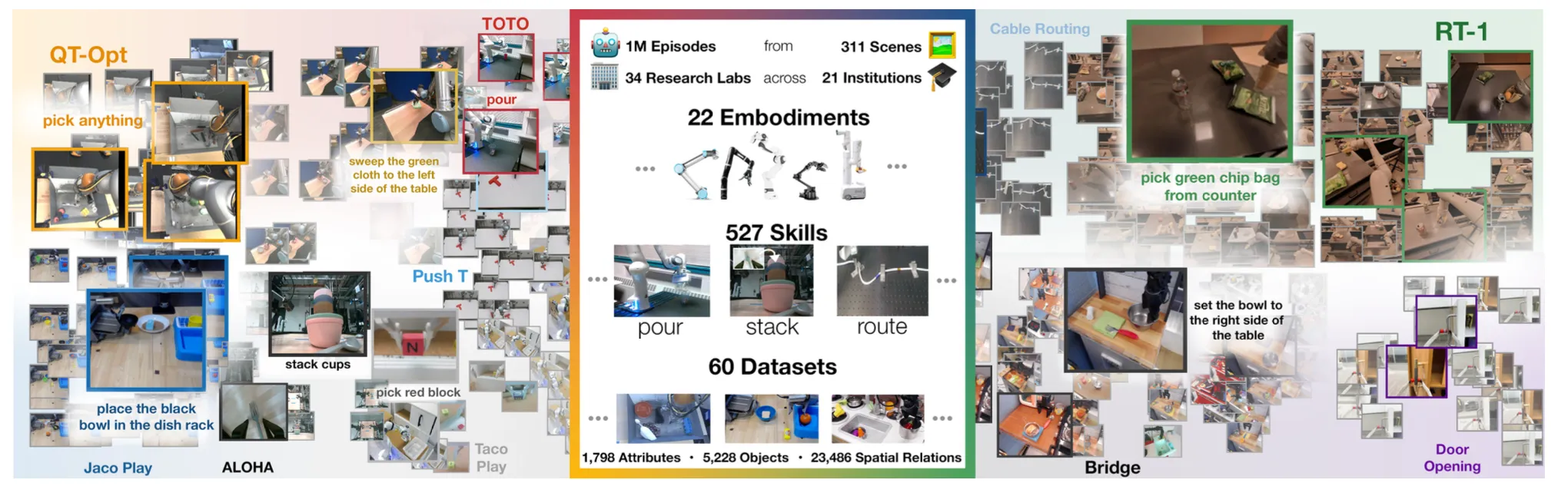
Open X-Embodimentは34研究機関が持ち寄った22体組・60データセット・527スキル・1M軌跡の統合データセット(出典:Open X-Embodiment)
続くRT-2-Xは、Open X-Embodimentデータセットで複数体組の軌跡を統合学習し、実世界スキルの性能が3倍に伸びたと報告されています(Open X-Embodiment公式)。図解で示されているとおり、Open X-Embodimentは22体組(QT-Opt・RT-1・Bridge・TOTO・ALOHA・Jaco Play等)×60データセット×527スキルの統合構成で、複数のロボット形態を横断する基盤データセットになっています。
重みは非公開ですが、「ロボットの行動をLLMの言語空間にマッピングする」という発想は、HelixからGR00T、OpenVLAに至る全モデルの設計に受け継がれています。VLAを語る上で外せない歴史的基盤と言えます。

自動運転領域のVLA——Tesla FSD・Wayve・Turingが「車載基盤モデル」を作る

ヒューマノイドと並ぶVLAのもう1つの主戦場が、自動運転です。車載カメラの映像を入力に、ハンドル・アクセル・ブレーキの操作コマンドを直接出力する点で、ロボット用VLAと構造はほぼ同じになります。
ここでは、米国・英国・日本の代表3社の取り組みを整理します。
Tesla FSD v14——End-to-Endに振り切ったロボタクシー基盤
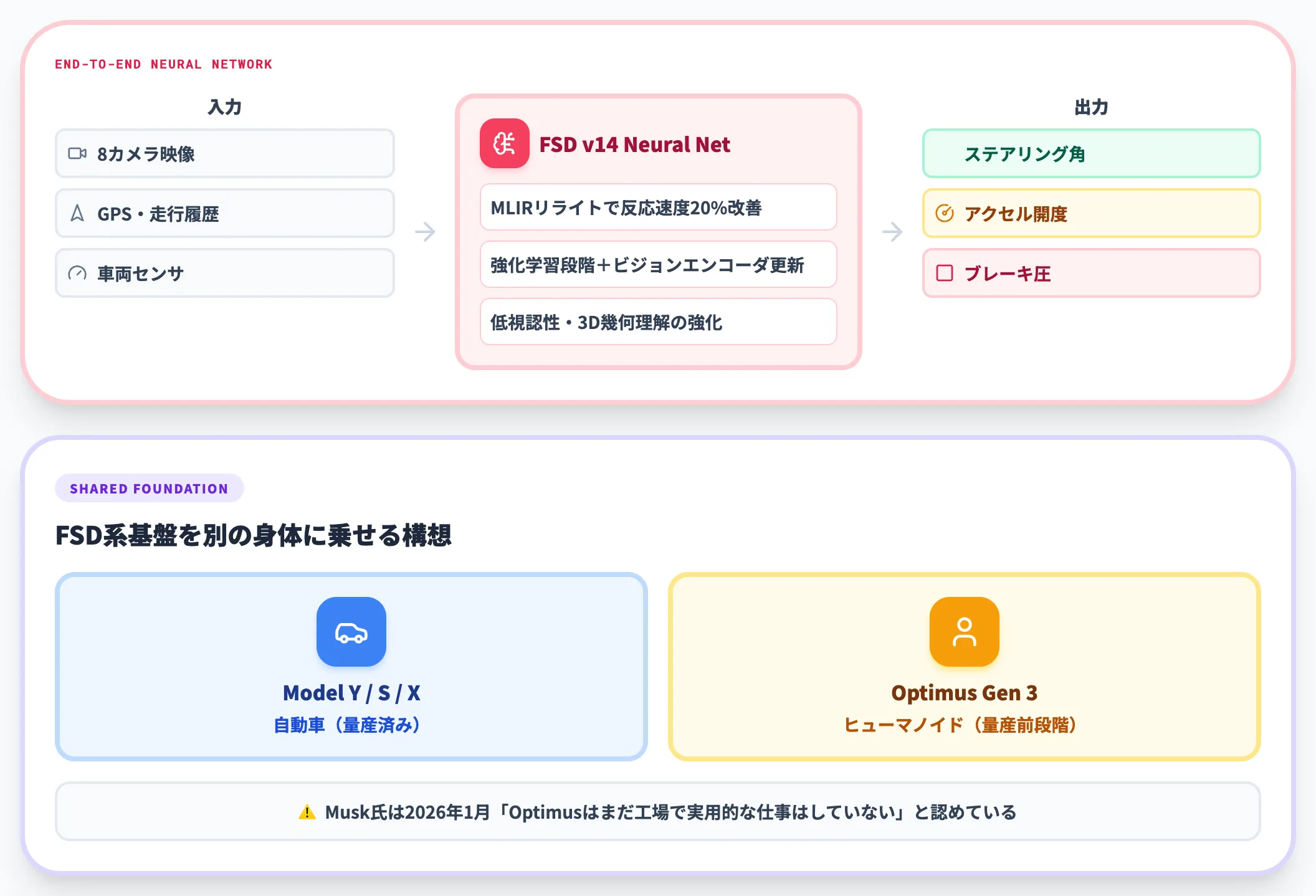
Teslaは、Full Self-Driving(FSD)の延長線上でEnd-to-Endニューラルネットワークに振り切ったアーキテクチャを採用しています。FSD v14系列はHardware 4(HW4)向けの量産対応版で、コンパイラとランタイムをMLIRで書き直して反応速度を20%改善しました(Electrek記事)。
v14.3では強化学習段階とビジョンエンコーダの両方が更新され、低視認性シーンや3D幾何理解が強化されています。
技術的にはVLA研究者の言う「VLA」と完全に同じ呼称ではないものの、**入力(映像)→ニューラルネットワーク内部での言語的推論→出力(操作コマンド)**という設計思想は共通です。Optimus(ヒューマノイド)と同じ系列のニューラルネット基盤を共有する構想が示されており、Teslaにとっては自動車もヒューマノイドも「同じ系統の基盤を別の身体に乗せる」前提で開発が走っています。
Optimus Gen 3はTesla社内の量産設計・生産準備段階にあると報じられていますが、Musk氏自身が2026年1月の決算説明で「Optimusはまだ工場で実用的な仕事をしていない」と認めており、ギガファクトリーへの大規模な実用配備までは公式に確認されていません。本記事では「量産実証フェーズの一例」として扱う前提で読んでください。
Wayve GAIA-3 と LINGO——世界モデル+VLAのハイブリッド
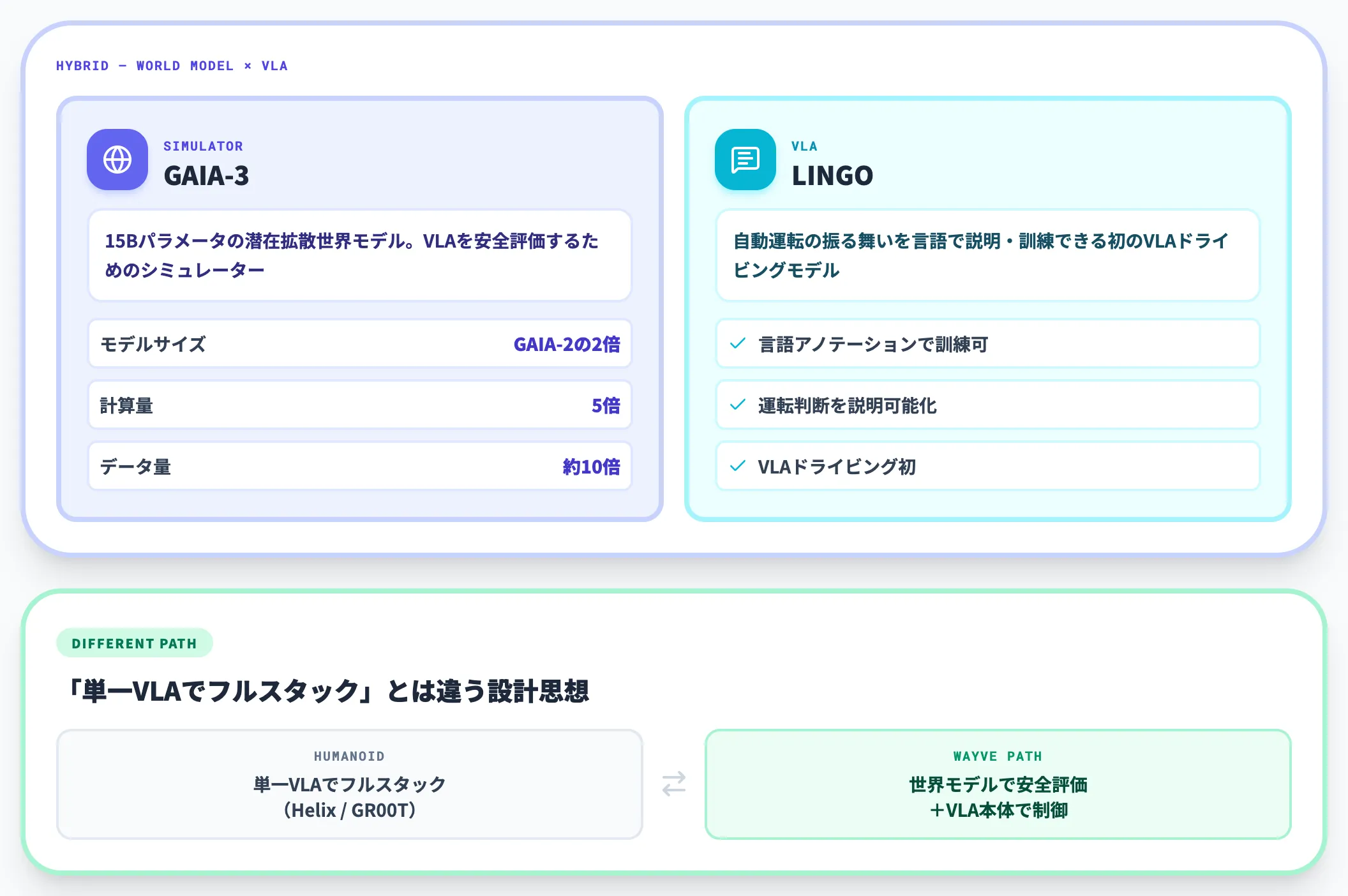
英Wayveは、自動運転の基盤モデルとして世界モデル(World Model)系のGAIAシリーズを開発しています。2025年12月公開のGAIA-3は15Bパラメータの潜在拡散世界モデルで、GAIA-2比でモデルサイズ2倍・計算量5倍・データ量約10倍に拡大されました(Wayve公式リリース)。
GAIA-3は車載VLA本体ではなく、「VLAを安全に評価するためのシミュレーター」として機能します。
実走行データを保ったまま、センサー構成や天候、想定外シナリオを変えて何度も走り直せるため、別系統で動かす自動運転AIの検証速度を一気に上げる役割です。
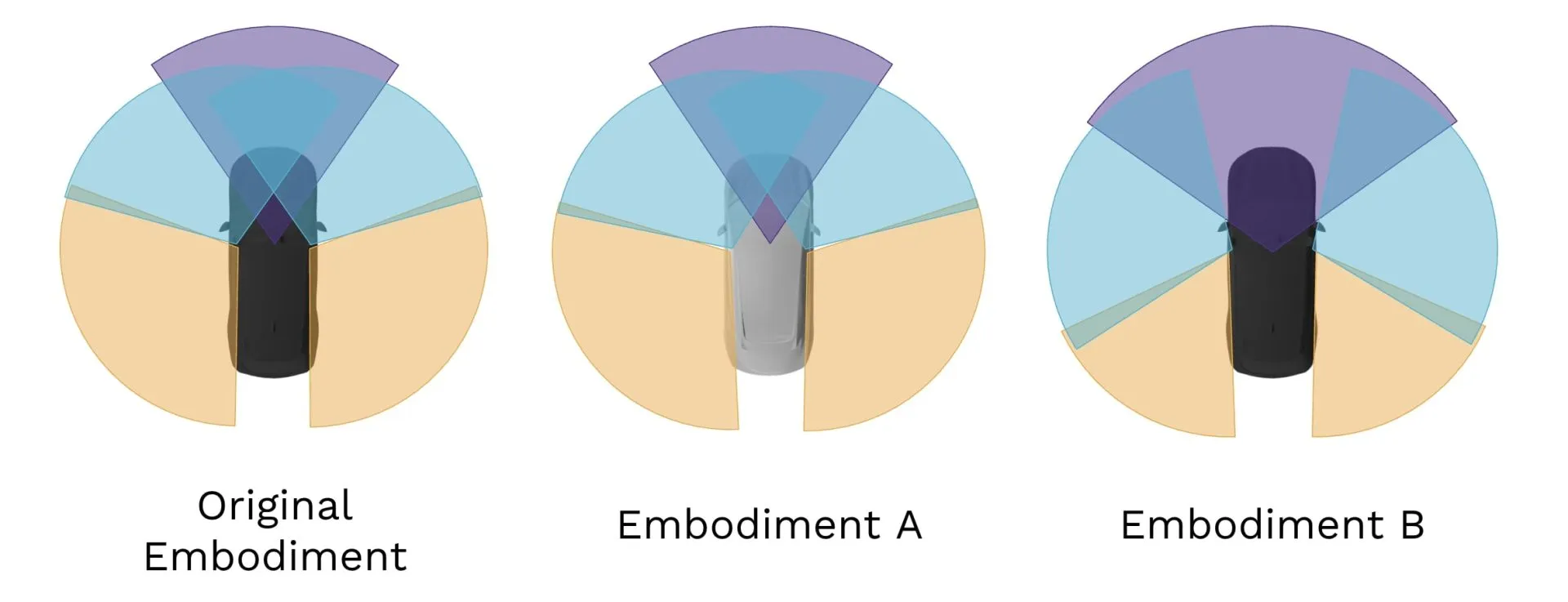
GAIA-3は同じ走行ログを車両構成(センサー配置)を変えて再生成できる。Original/A/Bでカメラ・LiDARの視野角が異なる(出典:Wayve)
VLA本体としてはWayveが「LINGO」を、自動運転の振る舞いを言語で説明・訓練できる初のVLAドライビングモデルとして開発しています。
世界モデル+VLAのハイブリッド構成は、ヒューマノイド系の「単一VLAでフルスタック」とは違った道筋として注目に値します。
Turing——日本初のVLA公道走行を実現したスタートアップ
日本では、自動運転スタートアップのTuring(チューリング)が2026年3月26日にVLAモデルによる公道でのリアルタイム自動運転制御を公開しました(公表事例としては国内初とされる、日本経済新聞報道)。

Turingは2026年3月、VLAモデルによる公道走行制御と、推論データセット「RACER」・画像トークナイザ「DriveTiToK」の公開を発表(出典:Turing株式会社 プレスリリース)
採用しているのは独自開発のCoVLA-Agentで、80時間超の走行動画に「自車両は低速で走行しており、右折します」といった言語記述を時刻同期で自動付与し、画像フレーム・将来軌跡・言語アノテーションを揃えて学習させています(Zenn Turing公式)。
学習可能クエリ方式で「将来t秒後の地点」をトークン化し、Vision-Language整合性と Language-Action 整合性の両方を成立させる設計です。
TuringはNEDOのGENIACプロジェクト第3期に採択されており、車載可能なフィジカル基盤モデルの開発を加速しています。2030年の完全自動運転実装を目標にしており、国内でVLAを軸にしたフルスタック自動運転を推進する数少ない企業として位置付けられます。
VLA × ヒューマノイドの2026年実装——CES 2026で見えた量産前線

VLAは2026年に「論文の世界」から「ライン・倉庫・家庭の世界」へ踏み出しました。CES 2026を起点に、誰がどのVLAを使ってどのロボットを量産するのかが具体名で表面化したのが今年の特徴です。
ここでは、押さえておくべき4つの実装パターンを整理します。
Boston Dynamics × Google DeepMind——Atlasに統合される基盤モデル提携
CES 2026でBoston Dynamicsは、新型の量産対応Atlas(電動ヒューマノイド)を披露し、2026年の出荷分はすべてHyundaiのRobotics Metaplant Application Center(RMAC)とGoogle DeepMindにコミット済みと発表しました(Boston Dynamics公式)。
これに合わせて、Google DeepMindの基盤モデルをAtlasに統合する提携も公表されています。
具体的にどのモデル系統(Gemini Robotics・Gemini Robotics-ER・他の研究モデル等)をどの役割で使うかまでは公式に明示されておらず、Atlasは身体を提供し、DeepMind側が認知のための基盤モデル群を提供する分業として進む構図です。

CES 2026で量産対応Atlasが披露された。2026年の出荷分はすべてHyundai RMACとGoogle DeepMindにコミット済み(出典:Boston Dynamics)
Hyundai Motor Groupは$26B規模の米国投資の一環として、年間30,000台のヒューマノイドを生産可能なロボット工場を建設する計画を発表しています(Hyundai Newsroom)。Atlasと自社プラント連携の両軸で、自動車業界初の本格的なヒューマノイド産業化を進めています。
Apptronik × Mercedes-Benz——Google DeepMind提携で進むApolloのAIモデル活用
米Apptronikのヒューマノイド「Apollo」は、Mercedes-Benzの実生産環境で物流・部材搬送・簡易検査タスクをパイロット運用しています。

Apptronik Apolloは産業向けヒューマノイドとしてMercedes-Benzと商業契約を結び、実証段階に入っている(出典:Apptronik「Mercedes-Benz commercial agreement」)
ApptronikはGoogle DeepMindと戦略提携し、Geminiを含むDeepMindのAIモデルをApolloのナビゲーション・物体認識・タスク実行に活用していく方針を打ち出しています。EMS大手のJabilとはApolloの製造・実証連携で協業を進めています。
製造業向けの大規模パイロットを軸に、車両メーカーや物流大手との実証を増やしている段階です。
Boston Dynamics×DeepMind、Apptronik×DeepMindの2件の提携が同時に走っていることで、Google DeepMindのGemini系モデルがヒューマノイド向け基盤モデルの主要候補の1つとして浮上しているのが、2026年6月時点の構図です。
Tesla Optimus Gen 3——FSD系基盤を流用するヒューマノイドの量産設計
Teslaは自社のFSDニューラルネットワーク基盤をOptimusに転用する設計で、Gen 3の量産準備を進めています。
Gen 3では手のDoF(自由度)が前世代の11から22に倍増し、AI5チップで前世代の約5倍のメモリ帯域を確保するなど、ハードウェア仕様は世代を大きく更新しました。
自動車のFSDで蓄積した実走データと推論基盤を人型に流用する設計思想は、車載VLA系の知見を最も大規模に転用しようとしているアプローチです。
ただし、Musk氏自身が2026年1月の決算説明で「Optimusはまだ工場で実用的な仕事をしていない」と認めており、ギガファクトリー内での大規模な実用配備までは公式に確認されていません。
「量産前提の設計が走っている」段階として読み、「すでに大規模実用化された」とは捉えないのが現時点の正しい距離感です。
Figure 03——家庭タスクを狙うHelixベースの量産機
Figure AIは2025年10月にFigure 03を発表し、Helixを脳として家庭・商用両方のタスクに対応する設計を打ち出しました。
BotQ製造施設で初期年間12,000台、4年間で計100,000台の生産目標を掲げています(Figure AI公式ブログ)。

Figure 03はHelix前提に設計し直され、頭部カメラのフレームレートが旧世代比2倍・視野角が60%拡大されている(出典:Figure AI)
価格は未公表ですが、Figureは2026年4月時点でBotQが生産フェーズに移行し、Figure 03が350台超、生産レートが1日1台から1時間1台に改善されたことを公式に公表しています(Figure AI公式「Ramping Figure 03 Production」)。
家庭タスク(食器洗い、洗濯、片付け)のデモも継続的に出ており、家庭向けヒューマノイドの最有力候補のひとつと見られています。ただし家庭向け一般販売や価格条件はまだ限定的です。
ヒューマノイド市場は**Boston Dynamics(産業)/Tesla(産業)/Figure(家庭)/Apptronik(産業)の4軸に分かれ、それぞれがGemini系(DeepMind提携)/FSD系(Tesla内製)/Helix(Figure内製)**の3系統の脳と組み合わさる構造が、2026年6月時点で見えてきました。

VLA導入の判断軸——オープンか商用か、クラウドかエッジか
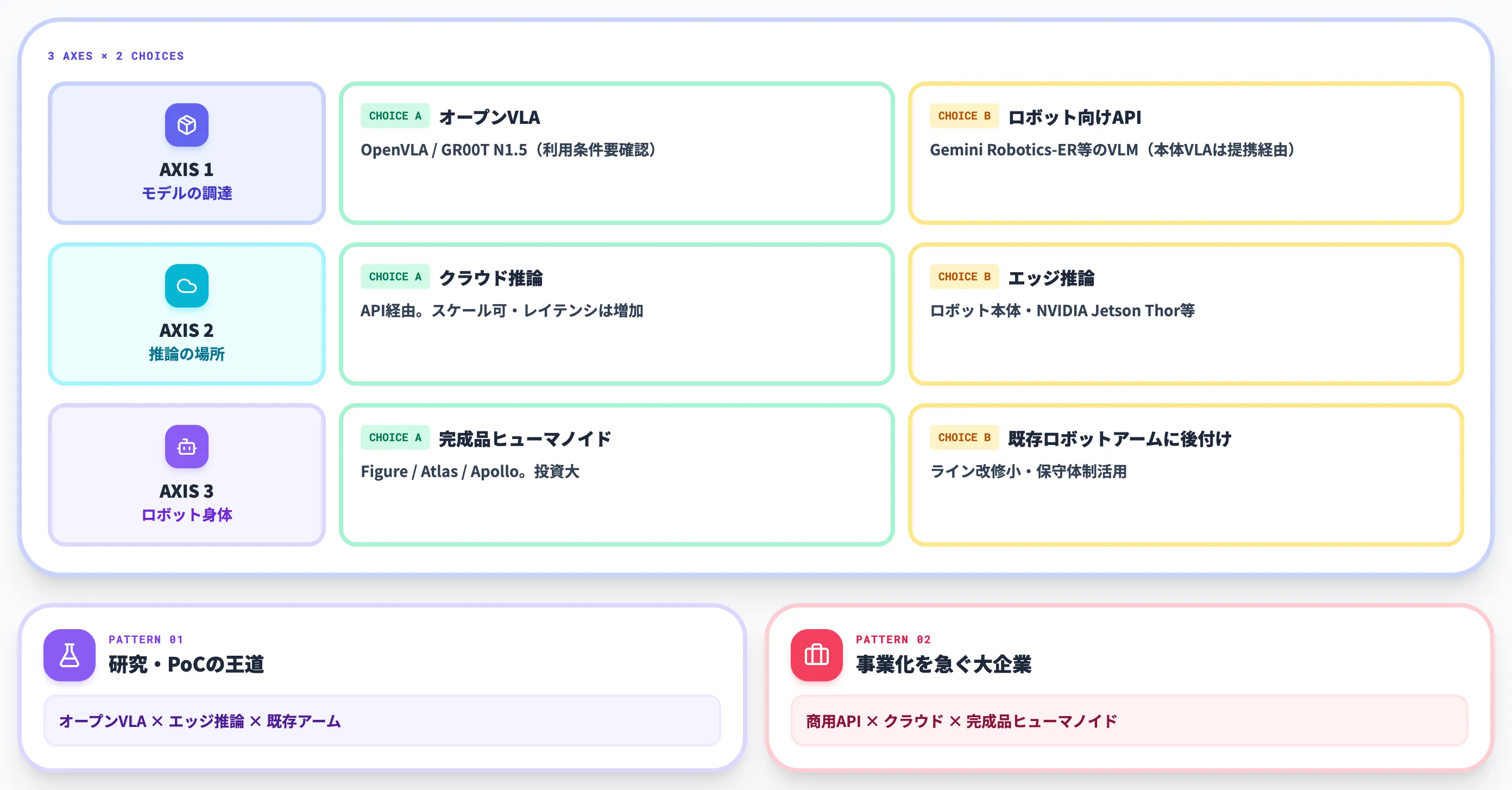
VLAを実際に企業で扱おうとすると、技術選定の軸は大きく3つに集約されます。
ここでは、実装方針を決めるための判断軸と、AI総研の支援現場で出てきた現実的な使い分けを整理します。
判断軸の整理
以下の表で、VLA導入時に押さえるべき3つの判断軸を整理しました。
| 判断軸 | 選択肢A | 選択肢B | 主な検討ポイント |
|---|---|---|---|
| モデルの調達 | オープンVLA(OpenVLA、GR00T N1.5・利用条件要確認) | ロボット向けAPI(Gemini Robotics-ER 等のVLM・本体VLAは提携経由) | 自社でファインチューニングする予算とエンジニア人員があるか、データ持ち出し制約があるか、API側の利用条件をどう吸収するか |
| 推論の場所 | クラウド推論(API経由) | エッジ推論(ロボット本体・NVIDIA Jetson) | レイテンシ要件、ネットワーク到達性、コスト構造 |
| ロボット身体 | 完成品ヒューマノイド(Figure、Atlas、Apollo) | 既存ロボットアームに後付け | 投資規模、ライン改修コスト、保守体制 |
これらの軸は独立ではなく、相互に影響します。「オープンVLA × エッジ推論 × 既存アーム」は研究・PoCの王道、「商用API × クラウド × 完成品ヒューマノイド」は事業化を急ぐ大企業のパターンになりがちです。
ケース1:研究・PoC段階——OpenVLA系で自前検証

自社で「VLAが本当に自分たちの業務に効くのか」を見極めたい段階では、OpenVLA系をLoRAファインチューニングするところから始めるのが現実的です。
970,000件の学習済みベースが提供されているため、自社の数百〜数千デモを足すだけで一定の性能が出ます。OFTで推論が25〜50倍高速化されているので、エッジで動かす道筋も見えやすくなりました。
学習リソースは目的によって幅があります。素のOpenVLAをLoRAで小規模ファインチューニングする例は単一A100で回せる構成が紹介されていますが、OpenVLA-OFT公式FAQでは実験条件として8枚のA100/H100 80GBで1〜2日規模が示されています。少数GPUでもタスク次第で動かせますが、所要時間は環境に応じて大きく増えます。
ライセンス面では、OpenVLAがLlama-2ベースのためLlama Community Licenseの遵守が必須、GR00T N1.5はNVIDIAモデルカードの利用条件確認が必要です。「研究段階はOpenVLAで進めて、商用化フェーズで利用条件を確認した上でGR00T等に乗り換える」という二段戦略を取る企業も増えています。
ケース2:自動車・物流のライン投入——Google DeepMindとの提携軸でパイロット
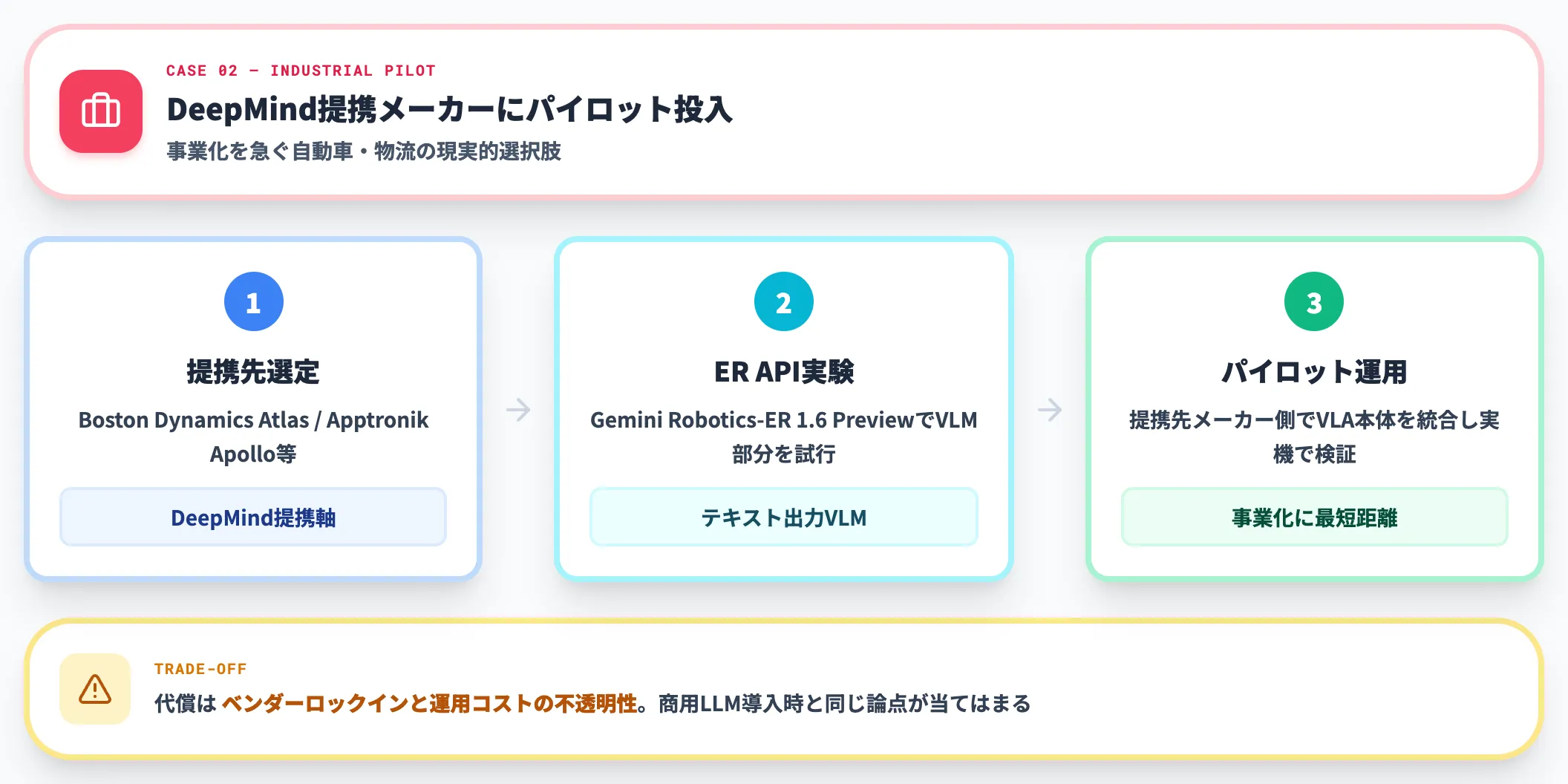
事業化を急ぐ自動車・物流の現場では、Google DeepMindと提携したロボットメーカー(Boston Dynamics Atlas、Apptronik Apollo)にパイロット投入するパスが、現実的な選択肢として浮上しています。
開発者が自社でロボット推論を試したい場合、Gemini Robotics-ER 1.6 PreviewはGemini APIで利用できます。
ただしERはテキスト出力のVLM(身体推論モデル)で、制御コマンドそのものをAPIから受け取れるVLAではない点に注意が必要です。実機の制御は別途用意したロボット制御層や、提携先メーカー側の統合に依存します。
代償はベンダーロックインと運用コストの不透明性で、AI研修やAI業務自動化ガイドで議論される「商用LLM導入時と同じ論点」がそのまま当てはまります。
ケース3:家庭・小売向け検証——FigureまたはGR00T参考設計の様子見
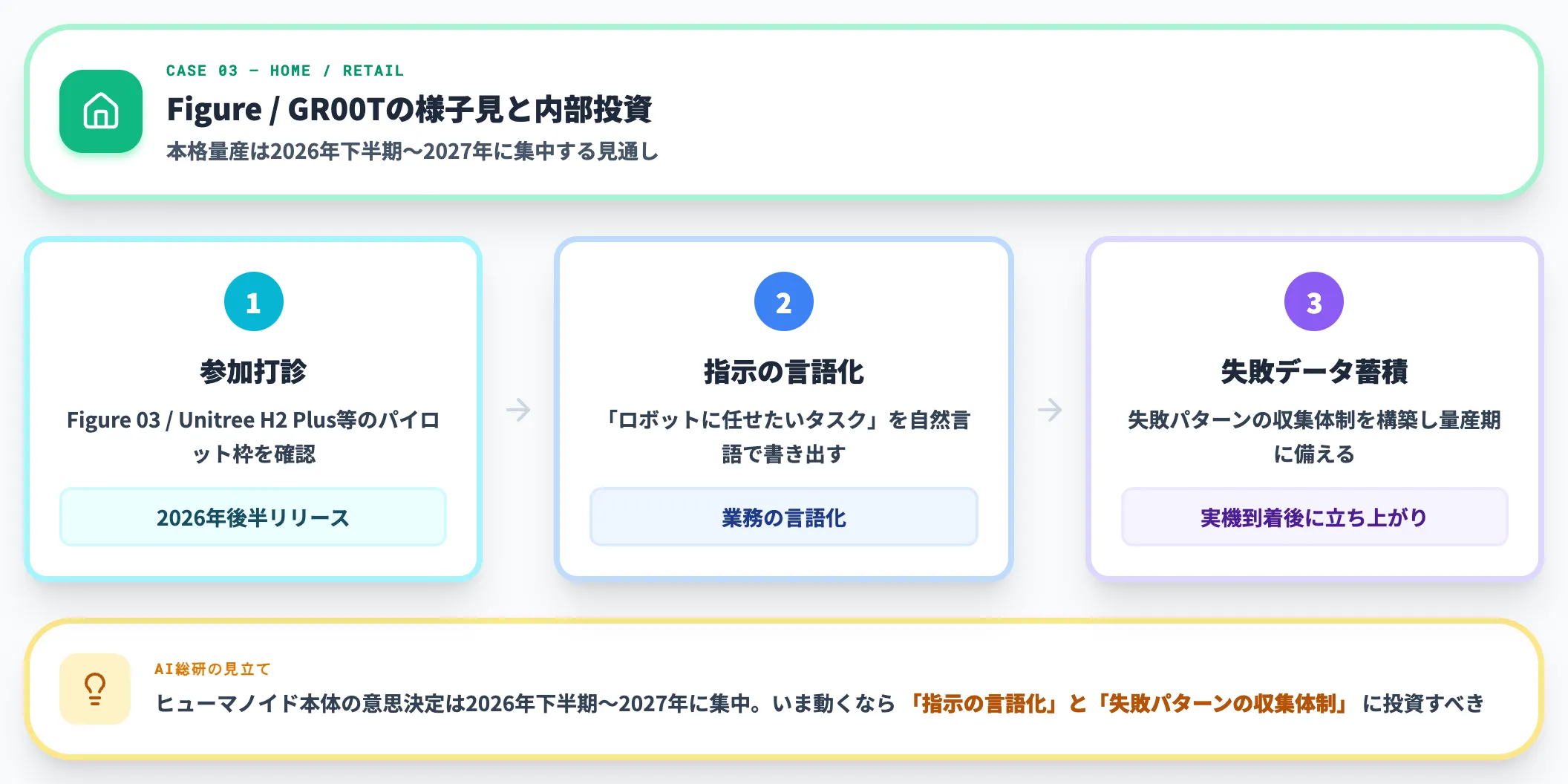
家庭タスクは2026年6月時点でまだ立ち上がり期です。
Figure 03は2026年4月時点でBotQが生産フェーズに入り350台超を製造、生産レートも1日1台→1時間1台まで改善された段階で(Figure AI公式「Ramping Figure 03 Production」)、家庭向け一般販売や価格条件はまだ限定的です。NVIDIA Isaac GR00T Reference Humanoid Robot(Unitree H2 Plus + Sharpa five-fingered hands + Jetson Thor)はUnitreeから2026年後半リリース予定です(NVIDIA Newsroom)。
家庭向け・小売向けの実装検討は、**まずパイロット参加可否の打診と、自社業務の言語化(「ロボットに任せたいタスクを、自然言語の指示として書き出せるか」)**から始めるのが順当な進め方です。本格量産を待つ間に「指示の設計と検証データの蓄積」を進めておけば、実機が来てから一気に立ち上がります。
AI総研の支援現場でも、ヒューマノイド本体の意思決定は2026年下半期〜2027年に集中する見方が強く、いま動き出すなら「指示の言語化」と「失敗パターンの収集体制」に投資することを推奨しています。
VLAの限界と注意点——「賢く動く」がまだ「安全に動く」ではない
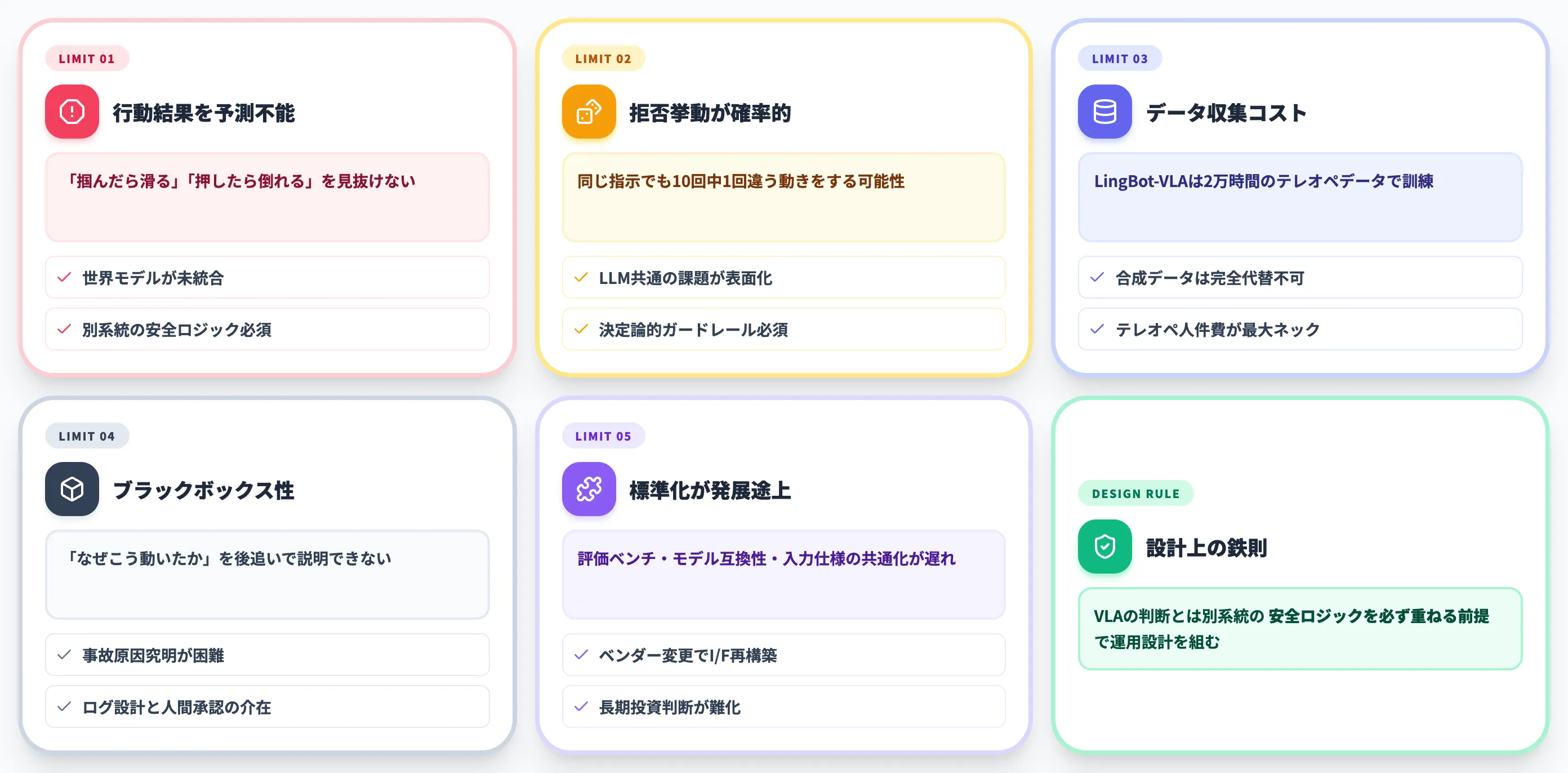
VLAは2026年に大きく前進しましたが、量産現場で完全自律的に走らせるには無視できない限界が残っています。SIerとしてVLA導入支援に入る際に、必ずチェックしている論点を整理します。
行動の結果を予測できない——「掴んだら滑るかも」を見抜けない
VLAの根本的な弱点として指摘されるのが、行動の結果を予測する能力の欠如です(ACCESS AI記事)。
「この角度で掴んだら滑って落ちる」「この力で押したら相手が転倒する」といった、自分のアクションが世界に与える影響をシミュレートする内部モデルは、現行VLAには明示的に組み込まれていません。Wayve GAIA-3のような世界モデルはまさにこのギャップを埋めようとする試みですが、Helixやπ0.5にはまだ統合されていません。
実運用では、**VLAの判断とは別系統の安全ロジック(衝突回避、力センサーによる滑り検知、緊急停止)**を必ず重ねる前提で設計する必要があります。
拒否挙動が確率的に揺らぐ——同じ指示で別の答えが返る
これはVLA固有ではなくLLM全体に通じる課題ですが、ロボット制御で表面化すると意味が違ってきます。
Cloudflare がClaude Mythos Previewの検証で報告したように、「同じプロジェクトに対しても、コード自体は変わっていないが環境変更後は同じ研究を実行することに同意した」「重大なメモリバグを特定した後、デモエクスプロイト作成を拒否。同じリクエストを異なる表現で提示すると異なる答えを得た」という確率的挙動が観察されています。
ロボット制御に置き換えると「同じシーン・同じ指示でも、ロボットが10回中1回違う動きをする可能性がある」ということです。
安全性が問われる現場では、ガードレール側の決定論的設計と、VLA行動の上限制約を明示的に組まないと事故になります。
データ収集コストが依然として高い
π0.5は400時間程度のモバイルマニピュレーションデータで効果的な汎化を達成しましたが、これは最先端の研究室がプロのテレオペレーターを動員した上での結果です。
LingBot-VLA(Ant Group)は20,000時間の両腕テレオペレーションデータを9体組のロボットから集めて訓練しました(MarkTechPost記事)。
桁が違うデータ規模が、汎化性能を支えている構図は変わっていません。
NVIDIAのGR00T-Dreamsのような合成データ生成パイプラインが進んでいますが、本物の物理世界のデータを完全代替するには至っていません。自社固有のタスクを学習させたい場合、テレオペレーションのコストが導入の最大ネックになることが多いです。
ブラックボックス性と説明可能性
VLAは一枚の大規模ニューラルネットワークで動くため、「なぜこの瞬間にロボットがこう動いたのか」を後追いで説明する手段が限定的です。
産業現場では、事故・ヒヤリハットの原因究明と再発防止が必須プロセスになります。VLA採用時に何をどこまでログに残すか、どのレイヤーで人間の承認を介入させるかは、運用設計の初期段階で必ず詰める必要があります。
標準化はまだこれから——重み・データ・評価の共通化が走り始めた段階
Open X-Embodimentが22体組・1M軌跡のデータセットを整備し、ICLR 2026ではVLA関連の投稿が164件規模に達したと報告されています(採録ベースの集計ではなくsubmissionベース)。VLA分野は「メインストリーム」に到達しつつあります。
ただし、評価ベンチマーク・モデル互換性・センサー入力仕様の標準化はまだ発展途上です。ベンダーが変わるとVLA側のインターフェースも変わる現状は、長期投資の意思決定を難しくしています。
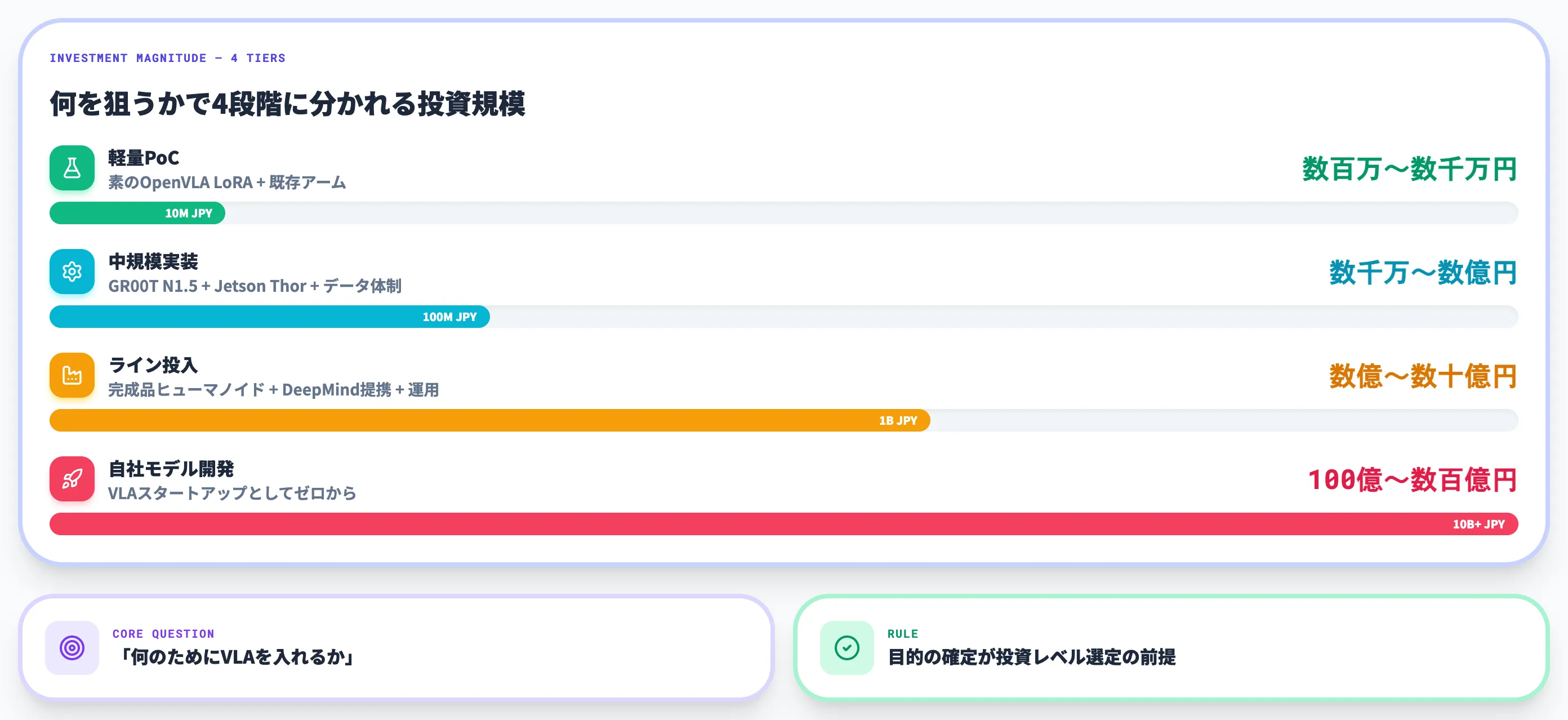
VLAの開発コスト——API・オープン運用・自社開発の桁感
VLAを業務に組み込む際のコスト構造は、選んだ調達方式によって桁が変わります。「API利用」「オープンモデル自前運用」「ゼロから自社開発」の3パターンで整理します。
Gemini Robotics-ER API(身体推論VLM)

Google DeepMindのGemini Robotics-ER 1.6 Previewは2026年6月時点でプレビュー段階で、Google AI Studio経由でAPIキーを取得して呼び出します。VLA本体ではなく身体推論VLM(テキスト出力)である点に注意してください。
-
入力
テキスト・画像・動画・音声(最大131,072トークン)
-
出力
テキスト(最大65,536トークン)
-
単価(プレビュー時点)
Google AI公式料金ページに掲載されている水準で、参考値として入力$1(テキスト/画像/動画)/音声$2/出力$5(いずれも100万トークンあたり)が公表されています。
※運用前に最新値を再確認してください。
-
注意点
2026年6月19日以降、無制限APIキーは403エラーになるため、AI Studio側でセキュリティ制限の設定が必須
商用ロボットメーカーがApollo・AtlasでGemini系モデルを統合する場合、Google Cloud経由の利用契約として別途料金が発生します。プレビュー段階ということもあり、価格交渉と契約条件が動きやすいタイミングでもあります。
GR00T N1.5(オープンモデル自前運用・利用条件要確認)

NVIDIA GR00T N1.5は重み・コード・データセットがオープン提供されていますが(NVIDIA Research)、Hugging Face上のNVIDIAモデルカードでは非商用利用を前提とした条件が示されています。商用化を視野に入れる場合は、利用範囲とNVIDIA側の条件を個別に確認する必要があります。
-
重み・コードの取得
研究・非商用利用の範囲ではダウンロード可能(商用利用はNVIDIAのライセンス条件確認が必要)
-
訓練コスト
GR00T-Dreams経由なら36時間規模、自社GPUクラスタ前提(NVIDIA Technical Blog)
-
推論ハードウェア
NVIDIA Jetson Thor(ロボット内蔵)または企業GPU
-
データ収集コスト
テレオペレーター人件費+ハードウェア。タスク数次第で数百万〜数億円規模
「重みは取得できるが、データと運用に金がかかり、商用利用は別途条件確認」というのがGR00Tのコスト構造です
。Isaac SimやCosmosとの統合を前提に、シミュレーションで合成データを生成しつつ実機データを最小化する設計が現実的です。
OpenVLA-OFT(オープンモデル小規模PoC)
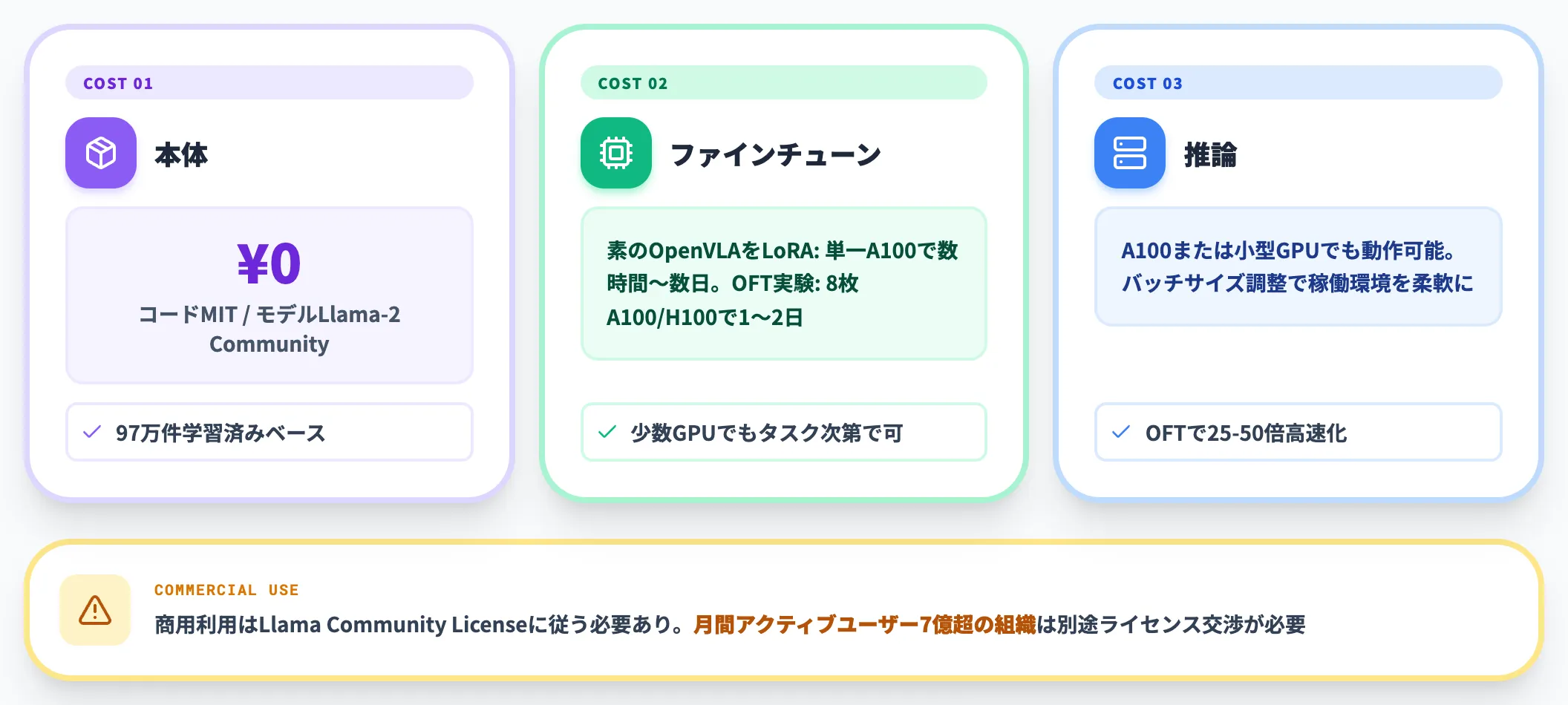
OpenVLA系は研究・PoC段階のコスト感が比較的軽く、自社の業務適合検証に使いやすい選択肢です。
- 本体 0円(コードMIT、モデルはLlama-2 Community License)
- ファインチューニング 素のOpenVLAをLoRAで回すなら単一A100で数時間〜数日の例あり。OpenVLA-OFT公式の実験条件は8枚A100/H100 80GBで1〜2日規模、少数GPUでも可能だが時間は増える
- 推論 A100または小型GPUでも動作可能(バッチサイズ調整)
商用利用の場合、Llama Community Licenseに従うため月間アクティブユーザー7億超の組織はライセンス交渉が必要です。多くの企業は対象外ですが、商用展開前に必ず確認しておきます。
ゼロからの自社VLA開発
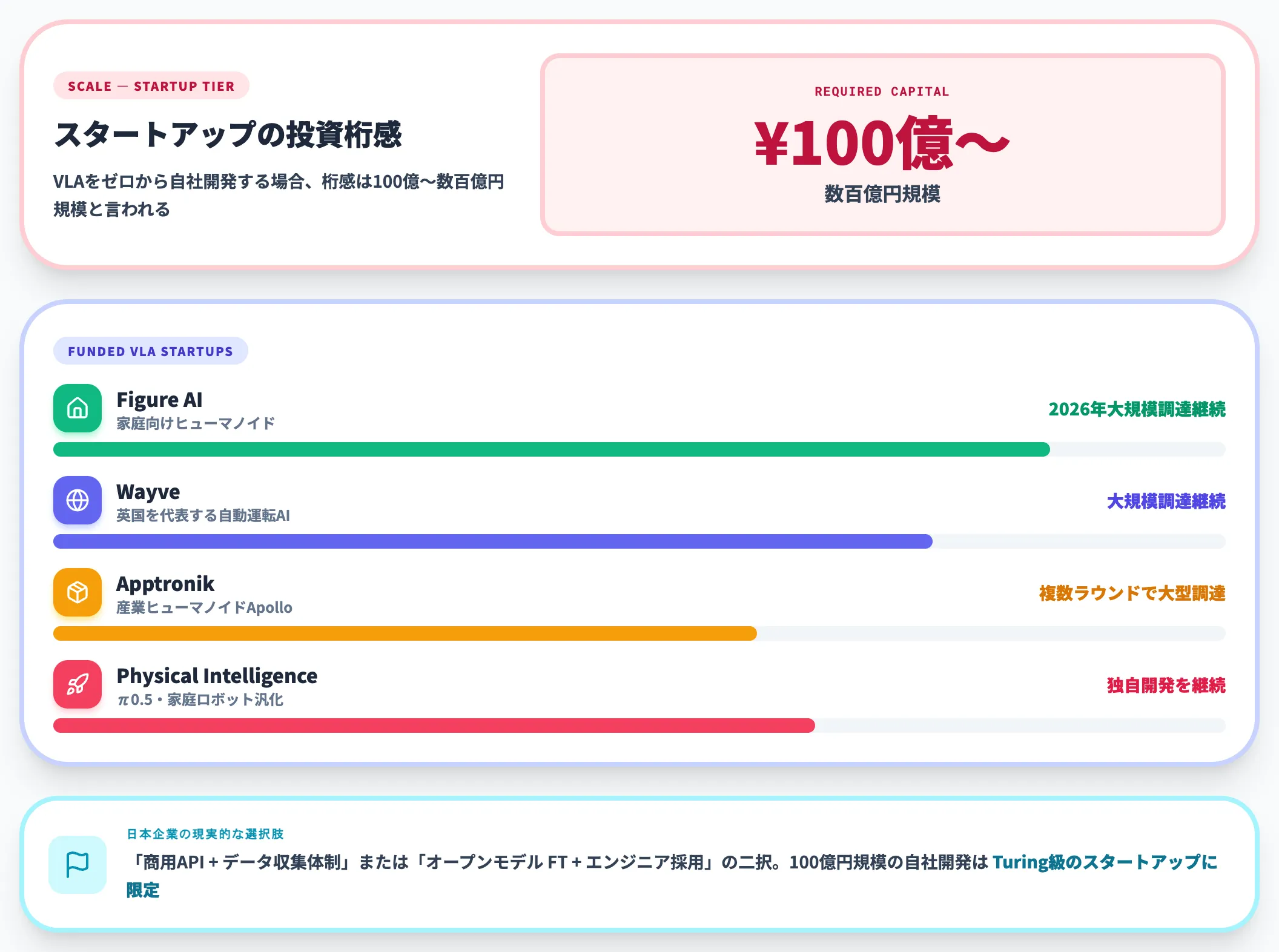
スタートアップが自社でVLAを開発するケース(Physical Intelligence、Figure AI、Wayve、Turingなど)の桁感は、開発に100億〜数百億円規模の投資が必要と言われています(ビジネス+IT記事)。
実際、Figure AIは2026年に巨額の資金調達を続けており、Wayveも英国を代表するAIスタートアップとして大規模調達を継続しています。
Apptronikも複数ラウンドでの大型調達が報じられていますが、具体的な調達額は出典ごとに差があるため、検討時には一次情報での最新確認を推奨します。
日本企業の現実的な選択肢としては、自社開発ではなく「商用API利用+データ収集体制構築」または「オープンモデルのファインチューニング+エンジニア採用」の二択になります。100億円規模の自社開発に踏み切るのは、Turing級のスタートアップに限られる前提で考えるのが妥当です。
投資全体の桁感
VLA導入の総投資額は、自社が選ぶ位置によって以下のように開きます。
| 投資レベル | 想定シナリオ | 総投資の桁感 |
|---|---|---|
| 軽量PoC | 素のOpenVLA LoRA(A100単体)/OpenVLA-OFTは8枚A100/H100想定/既存アーム | 数百万〜数千万円規模 |
| 中規模実装 | GR00T N1.5(利用条件確認の上で)+NVIDIA Jetson Thor+データ収集体制 | 数千万〜数億円規模 |
| ライン投入 | 完成品ヒューマノイド+DeepMind等との提携/Gemini Robotics-ER API活用+運用体制 | 数億〜数十億円規模 |
| 自社モデル開発 | VLAスタートアップとしてゼロから | 100億〜数百億円規模 |
桁が4段階あることが、VLA投資意思決定の難しさの本質です。「何のためにVLAを入れたいのか」を先に確定させなければ、適切な投資レベルは選べません。
VLAを待つ間に、社内のデジタル業務をAIエージェントで自動化するなら
VLA搭載ヒューマノイドが工場や家庭に並ぶのは、本記事で見たとおりまだ数年先の話です。ただし、経費精算・請求書処理・社内規定チェック・設計図面の検索といったデジタル業務領域のAIエージェント化は、今日から本格的に進められるフェーズに入っています。
ここで効いてくるのが、自社のAzureテナント内で完結するエンタープライズAI Agent内製化プラットフォーム AI Agent Hub です。
Microsoft Teamsから業務特化Agent群を呼び出し、SAP Concur・Dynamics 365等といった既存業務システムと接続して、申請・承認・データ入力をエージェントが代行します。
データは100%自社テナント内に閉じ、Agentがどこで動いてもダッシュボードで一元管理される設計です。
AI総合研究所の専任チームが、VLA時代を見据えた業務自動化の全体像づくりと、PoCから本番運用までの段階設計を伴走支援します。AI Agent Hubのサービスページで、自社のバックオフィス業務にどう適用できるかをご確認ください。
デジタル業務をAIエージェントで自動化

VLA時代を見据えた社内業務AIの内製化基盤
ヒューマノイドのVLA量産には数年単位の時間が必要ですが、経費精算・請求書処理・規定チェック・設計製図など社内のデジタル業務は今日からAIエージェントで自動化できます。AI Agent Hubのサービスページで、自社のAzureテナント内で動く業務AI内製化プラットフォームの全体像をご確認ください。
まとめ——VLAは「研究の話」から「自社の身体投資の話」へ
VLAは、視覚・言語・行動を1つのモデルで処理する設計を通じて、ロボット制御の前提を一段引き上げた基盤モデルです。
本記事の主要論点を、1行ずつ振り返ります。
- 定義 VLAはカメラ画像と自然言語の指示から行動コマンドを直接出力する基盤モデルで、VLMに「動かす」能力を加えた構造
- アーキテクチャ System 1 / System 2デュアル構造、Diffusion Policy + Action Chunking、Flow Matchingが2026年の標準パラダイム
- 主要モデル Helix・π0.5・Gemini Robotics・GR00T N1.5・OpenVLA-OFT・RT-2の6系統で、オープン度と汎用性のバランスが各社で異なる
- 自動運転VLA Tesla FSD・Wayve GAIA-3+LINGO・Turing CoVLA-Agentが車載基盤モデルとして並走中
- 2026年実装 Boston Dynamics×DeepMindのAtlas、Apptronik×Mercedes-BenzのApollo(DeepMind提携活用)、Tesla Optimus Gen 3の量産設計、Figure 03の家庭投入と、産業・家庭の双方で実機統合のパイロットが進行
- 導入判断軸 オープンVLA vs ロボット向けAPI、クラウド推論 vs エッジ推論、完成品ヒューマノイド vs 既存アームの組み合わせで、投資レベルが大きく変わる
- 限界 行動結果の予測不可能性、拒否挙動の確率性、データ収集コスト、ブラックボックス性、標準化の遅れが現時点の弱点
- コスト 軽量PoCの数百万円から自社開発の100億円規模まで、4段階の桁感が存在する
VLAは2026年現在「事業に効くか」を判断する局面に入っています。Gemini APIで身体推論VLMのGemini Robotics-ERを呼び、研究用途で公開されているGR00T N1.5やOpenVLA-OFTを使えば、自社のタスクに本当に効くかをPoCレベルで検証することは現実的です(GR00T等は利用条件の確認が前提)。
一方で、行動結果の予測不可能性や拒否挙動の確率性といった限界も明確に残っており、「VLA単体で完全自律」を前提にしない設計が現時点の正解になります。
自社のラインや業務にVLAを入れるなら、「指示の言語化」「失敗パターンの収集体制」「VLAとは別系統の安全ロジック」を先に整え、量産期に備えるのが現実的な打ち手です。










