この記事のポイント
 コスト最優先の大量推論タスクではGemini 3 Flash($0.25/100万トークン)が第一候補
コスト最優先の大量推論タスクではGemini 3 Flash($0.25/100万トークン)が第一候補- 100万トークンコンテキストが必要な長文処理にはGemini Flashシリーズが最適。GPT系より費用対効果が高い
- 初期検証はGoogle AI Studioの無料枠で行い、本番環境ではVertex AIに移行すべき
- 大量データ処理・カスタマーサポート・ドキュメント分析の用途で導入効果が大きい
- 高精度な推論が必要な場面ではGemini ProやGPT-4oクラスとの使い分けが有効

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Googleが開発する軽量・高速AIモデル「Gemini Flash」は、2024年の1.5 Flashから2026年のGemini 3 Flashまで、わずか2年で4世代の進化を遂げました。
最新のGemini 3 Flashは、入力100万トークンあたり$0.25という低コストながら、複雑な推論やマルチモーダル処理にも対応するハイブリッド推論モデルです。
本記事では、Gemini Flashシリーズの全体像、各世代の特徴、最新モデルの機能と使い方、料金体系、企業導入事例まで徹底解説します。
✅Googleの最新動画生成AIモデル「Gemini Omni」については、以下の記事をご覧ください。
Gemini Omniとは?その性能や使い方、料金体系を徹底解説!
Gemini Flashとは

Gemini Flashは、Googleが開発したGeminiモデルファミリーの中で、速度と効率に重点を置いて設計された軽量・高速AIモデルシリーズです。GeminiファミリーにはGemini 3.1 ProやNanoなどの上位・軽量モデルも含まれますが、Flashはその中間に位置し、高い処理性能と低コストのバランスを追求したモデルとして設計されています。
2024年5月にGemini 1.5 Flashとして初めてリリースされて以降、2.0 Flash、2.5 Flash、3 Flashと急速に世代交代を重ねてきました。各世代で100万トークンの長大なコンテキストウィンドウ、マルチモーダル推論、ディスティレーション技術による軽量化を継承しつつ、推論能力やベンチマークスコアを大幅に向上させています。
Gemini Flashが注目される理由は、エンタープライズ向けの高頻度・大量処理タスクに最適化されている点にあります。要約、チャットアプリケーション、画像・動画キャプション、大量ドキュメントからのデータ抽出といった業務用途で、高い性能を低コストで実現できます。Google公式によれば、Gemini 3 Flashは入力100万トークンあたり$0.25、出力100万トークンあたり$1.50という価格設定で、大規模なAI活用を現実的なコストで展開できるモデルです。

Gemini Flashシリーズの進化
Gemini Flashは、わずか2年の間に4つの世代が登場し、各世代で大きな性能向上を実現してきました。ここでは、各世代の位置づけと進化のポイントを整理します。
以下の表で、Flashシリーズの進化を時系列で整理しました。世代を追うごとに推論能力とコスト効率が改善されていることがわかります。
| 世代 | リリース時期 | コンテキスト | 主な進化ポイント |
|---|---|---|---|
| Gemini 1.5 Flash | 2024年5月 | 100万トークン | ディスティレーション技術で軽量化、サブセカンドレイテンシー |
| Gemini 2.0 Flash | 2025年2月 | 100万トークン | ネイティブツール呼び出し、マルチモーダル出力、Thinking機能搭載 |
| Gemini 2.5 Flash | 2025年9月 | 100万トークン | ハイブリッド推論モデル、開発者が思考レベルを制御可能 |
| Gemini 3 Flash | 2026年3月 | 100万トークン | エンタープライズ向け高速推論、Agentic Vision対応 |
Gemini Flashシリーズの進化で最も注目すべきは、ベンチマークスコアの飛躍的な向上です。たとえば数学的問題解決能力を測るAIME 2025では、Gemini 1.5 Flash相当の27.5%からGemini 2.5 Flashで78.0%へと約3倍に向上しました。コーディング能力を測るLiveCodeBench v5でも、34.5%から63.5%へとほぼ倍増しています。
この急速な進化を支えているのが、Googleが開発したディスティレーション技術です。上位モデル(Pro)から重要な知識とスキルを抽出し、軽量なFlashモデルに転送するプロセスにより、コンパクトなモデルサイズを維持しながら高い性能を実現しています。2.5世代以降は「ハイブリッド推論」を導入し、開発者がモデルの思考プロセスの深さをタスクに応じて制御できるようになりました。
Gemini Flash最新モデルの主要機能
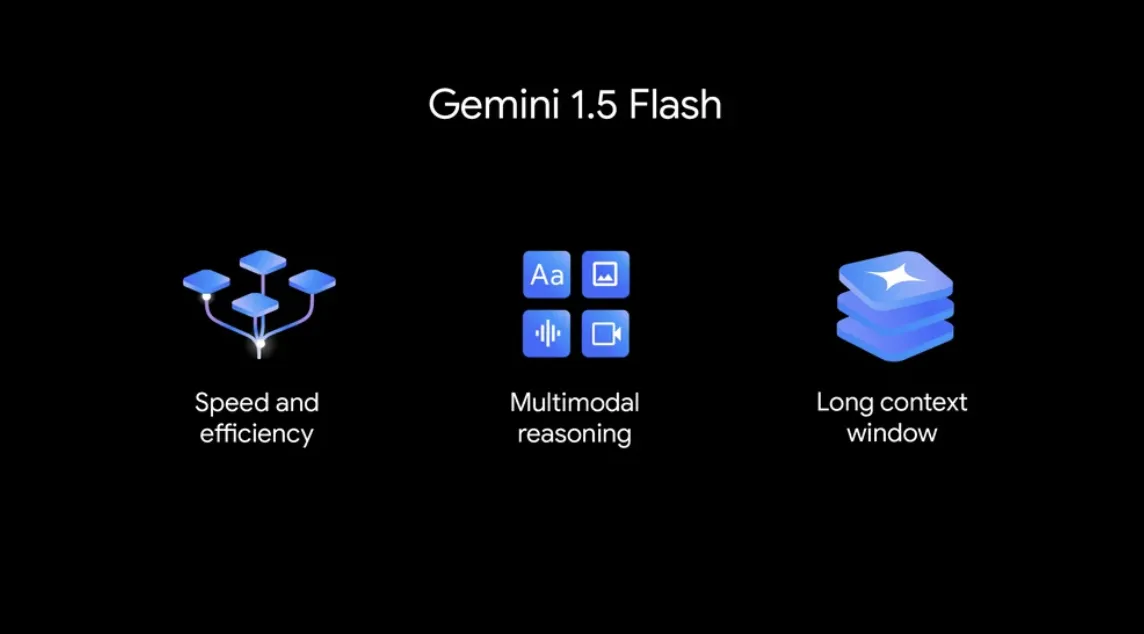
2026年3月時点の最新モデルであるGemini 3 Flashの主要機能を解説します。エンタープライズ向けの本格的な活用を支える機能が充実しています。
100万トークンのコンテキストウィンドウ
Gemini Flashの全世代に共通する強みが、最大100万トークンのコンテキストウィンドウです。これは1時間の動画、11時間の音声、3万行以上のコードベース、70万語以上の文章に相当するデータ量を一度に処理できることを意味します。
この長大なコンテキストにより、大量のドキュメントを横断した情報抽出や、長時間の会議録音の要約、大規模なコードベースの分析といったタスクを、分割処理なしで一括実行できます。従来のモデルでは複数回のAPI呼び出しが必要だったタスクを1回で完了できるため、開発工数と処理コストの両方を削減できます。
ハイブリッド推論
Gemini 2.5 Flash以降に導入されたGoogle独自の機能です。AIが応答を生成する際に、内部的にどれだけ「思考」プロセスを用いるかを開発者が制御できる仕組みで、タスクの難易度に応じてコストと精度のトレードオフを最適化できます。
単純な分類タスクでは思考を最小限に抑えて高速・低コストで処理し、複雑な推論が必要なタスクでは思考を深めて精度を高めるといった使い分けが可能です。これにより、同一モデルで幅広い難易度のタスクに対応でき、用途ごとにモデルを切り替える手間が不要になります。
マルチモーダル処理
テキスト、画像、音声、動画を統合的に処理する能力は、Gemini Flashシリーズの大きな特徴です。Gemini 3 Flashでは、複雑な動画分析やビジュアルQ&Aをニアリアルタイムで実行でき、数千件のドキュメントから構造化データを抽出してバックオフィス業務を効率化するといった用途にも対応しています。
Agentic Vision機能により、画像内の情報を能動的に調査し、コードを実行して分析結果を返すといった自律的な処理も可能になっています。
ベンチマーク性能
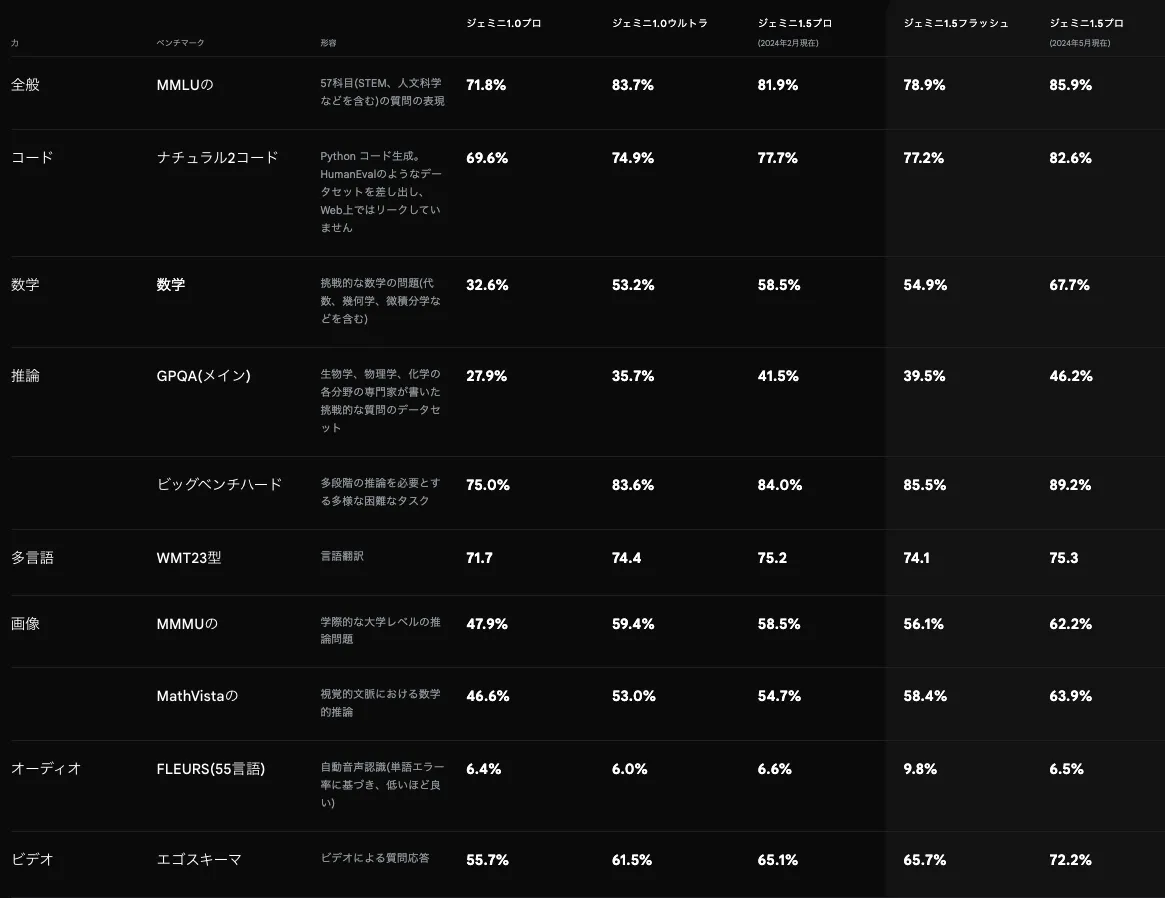
Geminiファミリーのパフォーマンス比較
Gemini 3 Flashは、軽量モデルでありながら、複数のベンチマークで上位モデルに匹敵するスコアを記録しています。以下の表で、Gemini 2.5 Flashからの主要ベンチマーク推移を示します。
| ベンチマーク | Gemini 2.5 Flash | Gemini 3 Flash | 評価内容 |
|---|---|---|---|
| AIME 2025 | 78.0% | さらに向上 | 数学的問題解決能力 |
| LiveCodeBench v5 | 63.5% | さらに向上 | コード生成能力 |
| GPQA diamond | 78.3% | さらに向上 | 科学的理解力 |
| Humanity's Last Exam | 12.1% | さらに向上 | 高難度複合タスク |
1.5 Flash世代ではPythonコード生成(HumanEval)で77.2%、GPQAで39.5%だったスコアが、2.5 Flash世代ではGPQA 78.3%と約2倍に向上しています。軽量モデルの性能が従来の上位モデルに追いつく速度は加速しており、コスト効率の面でFlashシリーズの優位性は広がり続けています。
Gemini Flashの使い方
Gemini FlashはGoogle AI Studio、またはVertex AIで利用できます。ここでは、それぞれの利用手順を解説します。
Google AI Studioの場合
Google AI Studioは、ブラウザ上でGeminiモデルを無料で試せる開発者向けの環境です。以下の手順で利用を開始できます。
-
Google AI Studioのページにアクセスします。
-
「利用規約の確認」にチェックを入れ、続行を選択します。
-
「モデルの選択」から、Gemini 3 Flash(または使用したいFlashモデル)を選択すれば準備完了です。
モデル選択画面
- 下のチャット欄にプロンプトを入力することで、Gemini Flashとの対話が可能です。
Google AI Studioでは無料プランでも1分あたり15リクエスト、1日あたり1,500リクエストまで利用できるため、個人開発やプロトタイプ検証に適しています。
Vertex AIの場合
エンタープライズ向けの本格運用では、Google CloudのVertex AIを利用します。SLAやデータガバナンスが保証された環境でGemini Flashを運用できます。
-
Google Cloudにアクセスし、アカウントを作成します。新規ユーザーには$300分の無料クレジットが90日間提供されます。
-
Vertex AIを有効にします。Google Cloud ConsoleからVertex AIのページにアクセスし、APIを有効化します。
-
Gemini Flash APIを有効にします。Vertex AIコンソールのモデルガーデンから、使用するFlashモデルを選択してエンドポイントを設定します。
-
APIリクエストを送信します。以下は、Gemini Flashを使用してテキストを要約するためのPythonサンプルコードです。
from google import genai
client = genai.Client()
response = client.models.generate_content(
model="gemini-3-flash",
contents="この長文テキストを要約してください。"
)
print(response.text)
このコードを実行すると、Gemini 3 Flashがテキストの要約を生成し、response.textに結果が格納されます。APIリクエストには処理したいデータや温度パラメータなどのオプションを指定でき、用途に応じたカスタマイズが可能です。
生成AIのAPIの選び方や活用方法については、関連記事で詳しく解説しています。

Gemini Flashの活用事例
Gemini Flashは、その高速処理と低コストにより、様々な業界で導入が進んでいます。ここでは、具体的な企業活用事例を紹介します。
第一興商 — Gemini Flashで多言語対応を実現
カラオケ大手の第一興商は、Gemini 2.0 Flashを活用した生成AIシステムを導入し、楽曲タイトルやアーティスト名のローカライズ処理を自動化しました。従来の機械翻訳では対応が困難だった固有名詞の翻訳精度において、ほぼ100%の正確性を達成しています。
音楽業界特有の「アーティスト名の表記揺れ」や「楽曲タイトルの意訳」といった課題に対して、Gemini Flashの長大なコンテキストウィンドウを活用し、大量の楽曲データベースを参照しながら適切な翻訳を生成する仕組みを構築しました。
グローバル企業でのGemini 3 Flash採用
Google Cloudの公式発表によると、Salesforce、Workday、Figmaといったグローバル企業がGemini 3 Flashを採用しています。これらの企業は、推論速度、効率性、大規模モデルに匹敵する推論能力を高く評価しています。
ある導入企業では、Gemini Flashの全社展開により社員1人あたり年間平均200時間の業務時間を削減し、その時間を顧客提案や新規プロジェクト企画などの付加価値の高い業務に充てることに成功しています。
開発者向けの活用
Gemini FlashはGemini Code Assistと連携したコード補完・レビューの基盤としても活用されています。100万トークンのコンテキストウィンドウにより、大規模なコードベース全体を把握した上での提案が可能です。
また、Gemini CanvasやGemini LiveといったGoogle製品群との統合により、ドキュメント作成からリアルタイム音声対話まで、幅広いインタラクション形式でFlashモデルを活用できます。
あー、もうこれ...
— Hiroya Iizuka (@0317_hiroya) May 18, 2024
音声文字起こしは全部Gemini Pro Flashにぶん投げ・一発OKな時代になったわけか...
ほぼ完璧な精度。
つまり...
Udemy/Youtube動画 => Gemini Pro による文字起こし => ブログ化、Kindle化 etc
などがもう、簡単にできてしまう時代になったってことか... pic.twitter.com/0exWQ2h3Za
Gemini Flashと競合モデルの比較
Gemini Flashと同等の価格帯に位置する競合モデルとの比較を通じて、Flashの強みと選定時の判断基準を整理します。
以下の表で、2026年3月時点の軽量モデル3種を比較しました。用途に応じた使い分けの参考にしてください。
| 項目 | Gemini 3 Flash | Claude Haiku 4.5 | GPT-4o mini |
|---|---|---|---|
| コンテキスト | 100万トークン | 200Kトークン | 128Kトークン |
| 入力料金(/100万トークン) | $0.25~$0.50 | $0.80 | $0.15 |
| 出力料金(/100万トークン) | $1.50~$3.00 | $4.00 | $0.60 |
| 推論速度 | 200トークン/秒以上 | 低レイテンシー重視 | 高速 |
| 強み | マルチモーダル、長文処理、コスト効率 | 精度、構造化出力、コードレビュー | 最低コスト、OpenAIエコシステム |
| ハイブリッド推論 | 対応 | 対応(Reasoning版) | 非対応 |
この比較から分かるのは、各モデルが異なるユースケースで最適化されているという点です。Gemini 3 Flashは100万トークンの圧倒的なコンテキスト長とマルチモーダル処理で差別化しており、長文ドキュメントの分析や動画処理といったタスクでは他モデルを大きくリードしています。
一方で、コード生成の精度においてはClaude Haiku 4.5が高い評価を得ており、最小コストを重視する場合はGPT-4o miniが有力な選択肢となります。
導入を検討する際には、以下の点に注意が必要です。
-
APIバージョン管理の複雑さ
Gemini Flashは1.5→2.0→2.5→3と急速にバージョンアップしており、旧バージョンのAPIが非推奨になるサイクルが短い傾向があります。移行計画を事前に策定し、バージョンアップに伴うAPI仕様変更に対応できる体制を整えておくことが重要です。
-
思考モードのコスト変動
ハイブリッド推論モデルでは、思考モードのON/OFFで料金が大きく変わります。思考モードONの場合、入力・出力ともに料金が2倍以上になるケースがあるため、タスクごとの思考レベル設定を適切に管理しないと想定外のコスト増につながります。
-
ハルシネーションのリスク
軽量モデルは上位モデルと比較してハルシネーション(事実と異なる情報の生成)が発生しやすい傾向があります。業務で利用する際は、生成結果の検証プロセスを組み込むことが不可欠です。
ChatGPTやClaudeとの詳細な比較については、各モデルの解説記事もあわせてご確認ください。

Gemini Flashの料金体系(2026年3月版)
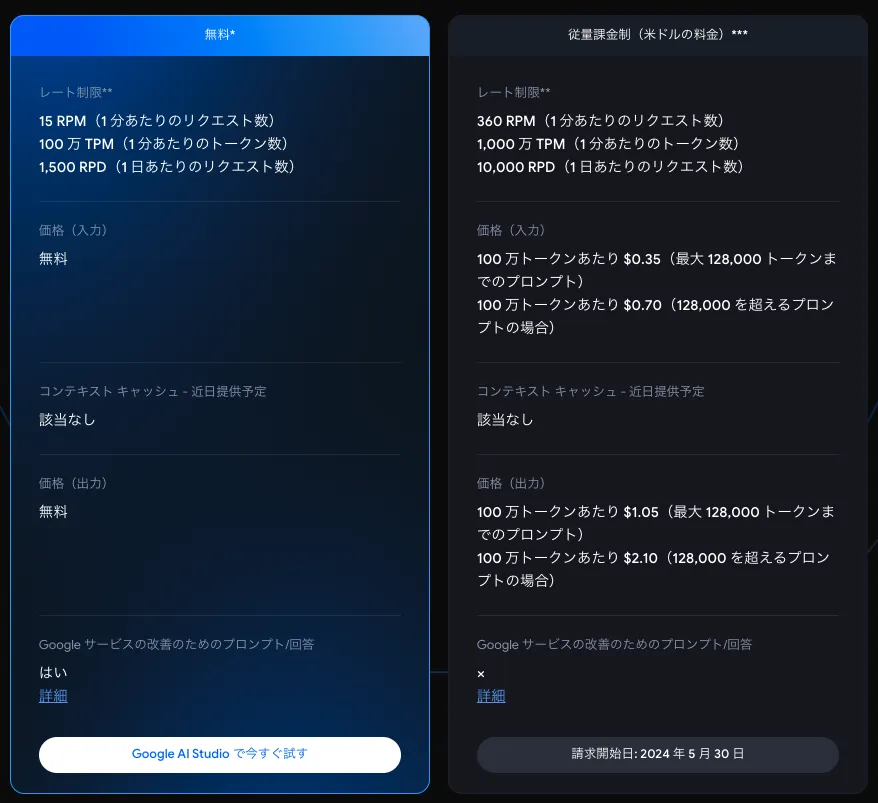
Gemini Flashの料金は、モデル世代とプラン(無料/従量課金)によって異なります。以下の表で、各世代のAPI料金を比較しました。
| モデル | 入力(/100万トークン) | 出力(/100万トークン) | 無料枠 |
|---|---|---|---|
| Gemini 1.5 Flash | $0.075 | $0.30 | 15 RPM / 1,500 RPD |
| Gemini 2.0 Flash | $0.10 | $0.40 | 15 RPM / 1,500 RPD |
| Gemini 2.5 Flash(思考OFF) | $0.15 | $0.60 | 15 RPM / 1,500 RPD |
| Gemini 2.5 Flash(思考ON) | $0.15 + 思考トークン課金 | $0.60 + 思考トークン課金 | 同上 |
| Gemini 3 Flash | $0.25 | $1.50 | 15 RPM / 1,500 RPD |
この料金表は2026年3月時点の概算であり、Googleの料金改定により変動する場合があります。最新の料金はGoogle AI for Developersの公式料金ページで確認してください。
従量課金プランのレート制限と無料プランの違いを以下にまとめます。
| 項目 | 無料プラン | 従量課金プラン |
|---|---|---|
| 1分あたりリクエスト数(RPM) | 15 | 360~2,000 |
| 1分あたりトークン数(TPM) | 100万 | 1,000万 |
| 1日あたりリクエスト数(RPD) | 1,500 | 10,000 |
| データのGoogle利用 | Googleサービス改善に利用 | 利用されない |
無料プランではユーザーデータがGoogleのサービス改善に利用される点に注意が必要です。企業利用では従量課金プランを選択し、データプライバシーを確保することを推奨します。
費用を抑えるためのポイントを以下に整理します。
-
思考モードの適切な制御
2.5 Flash以降のハイブリッド推論モデルでは、思考モードを必要なタスクにのみ有効化することでコストを大幅に削減できます。単純な分類や要約には思考OFFで対応し、複雑な推論が必要な場面でのみ思考ONに切り替えるのが効果的です。
-
コンテキストキャッシングの活用
繰り返し参照する長文データがある場合、コンテキストキャッシング機能を活用することで、同じ入力データに対する課金を削減できます。
-
軽量モデルの使い分け
タスクの複雑さに応じて、Gemini 3 FlashとFlash-Liteを使い分けることで、全体的なAPI利用コストを最適化できます。
Geminiの料金プラン全体の比較については、関連記事もあわせてご確認ください。
Gemini Flashの理解を業務へのAI導入計画に活かす

高速AIモデルの知識を業務設計へ
Gemini Flashの高速処理とコスト効率を理解した方なら、業務にAIを導入する際のモデル選定も的確に進められます。220ページの実践ガイドで、AIモデルを業務に組み込む段階的な手順を確認できます。
Gemini Flashの性能を理解した上で業務へのAI導入を始めるなら
Gemini Flashの高速処理能力と100万トークンのコンテキストウィンドウを理解した方は、大量データ処理を伴う業務でのAI活用イメージが具体的になっているはずです。ドキュメントの一括要約や多言語対応など、Flashの特性を活かせるユースケースは業務のあらゆる場面に存在します。
AI総合研究所では、最新AIモデルの特性を踏まえて業務プロセスにAIを導入するための実践ガイドを提供しています。220ページの資料で、モデル選定から段階的な導入までの手順を確認できます。
Gemini Flashの実力を把握した今、AI総合研究所のガイドで業務AI化の計画を具体化してみてください。
Gemini Flashの理解を業務へのAI導入計画に活かす
高速AIモデルの知識を業務設計へ
Gemini Flashの高速処理とコスト効率を理解した方なら、業務にAIを導入する際のモデル選定も的確に進められます。220ページの実践ガイドで、AIモデルを業務に組み込む段階的な手順を確認できます。
まとめ
本記事では、Gemini Flashシリーズの全体像から、最新モデルの機能、使い方、料金体系、企業活用事例まで解説しました。
Gemini Flashは、2024年の1.5 Flashから2026年のGemini 3 Flashまで急速に進化を遂げ、軽量モデルでありながら上位モデルに匹敵する性能を実現しています。100万トークンのコンテキストウィンドウ、ハイブリッド推論、マルチモーダル処理といった機能は、大量データの高速処理を求める企業ユースケースに適しています。
一方で、バージョンアップサイクルの速さやハルシネーションのリスクには注意が必要です。まずはGoogle AI Studioの無料プランでGemini 3 Flashを試し、自社の業務タスクとの相性を検証してみてください。
Nano Banana 2やGemini Diffusionなど、Geminiファミリーの他モデルについても関連記事で解説しています。










