この記事のポイント
 SNSバナーやプレゼン資料など「テキスト入り画像」を頻繁に作成する業務はGPT Image 1.5が第一候補、テキストレンダリング精度が競合超え
SNSバナーやプレゼン資料など「テキスト入り画像」を頻繁に作成する業務はGPT Image 1.5が第一候補、テキストレンダリング精度が競合超え- 既存画像の部分修正やスタイル変更が必要なケースではこのモデルが最適で、顔立ちや構図を維持したまま編集できるため差し戻しが減る
- ChatGPTアプリのImages専用ワークスペースを使えば、プロンプト調整から出力確認まで一画面で完結でき、制作フローの効率化に有効
- API経由での大量生成やシステム組み込みにはgpt-image-1.5エンドポイントを選ぶべきで、従量課金のため使った分だけのコスト管理が可能
- 写真レベルのリアリズムやブランド厳密準拠が求められる用途ではAI生成だけに頼るのは避けるべきであり、デザイナーによる最終調整との併用が現実的

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
2025年12月、OpenAIは新しい画像生成体験「ChatGPT Images」と、その中核となる最新モデル「GPT Image 1.5」を公開しました。従来のモデルに比べ、顔立ちやロゴを維持したままの編集精度、複雑なレイアウトの指示追従性、そしてテキストレンダリングの品質が飛躍的に向上しています。
本記事では、このGPT Image 1.5について、ChatGPTアプリでの新しい使い方から、API経由での実装方法、料金体系、そしてNano Banana Proなど競合モデルとの使い分けまでを体系的に解説します。
目次
GPT Image 1.5 / ChatGPT Imagesとは
2. 指示の分解と関係性の維持(Instruction following)
GPT Image 1.5の料金体系(ChatGPT / API)
Image Generation API(gpt-image-1.5)の料金
Nano Banana Proとの比較:どちらをどう使い分けるべきか
5. デザイン・開発ワークフローのブレスト&プロトタイピング
GPT Image 1.5 / ChatGPT Imagesとは

GPT Image 1.5は、OpenAIが提供する最新の画像生成・編集モデルです。2025年12月に公開され、新しいChatGPT Images体験を支えるフラグシップ画像モデルとして位置づけられています。
GPT Image 1.5の主な進化ポイントは、ざっくり次のように整理できます。
- 画像編集の精度が向上し、顔立ちやロゴ、ライティングを保ったまま細部を修正できる
- コンセプトを保ちつつ、広告風・雑誌風・ポスター風など、スタイルごとに大胆に作り変えられる
- 長い指示文の中に含まれる複数要素の関係性(グリッド、位置関係など)をより正確に再現できる
- テキストレンダリングが改善され、インフォグラフィックや新聞風レイアウトなど「文字が主役」の画像でも崩れにくい
- ChatGPTアプリには、画像に特化した新しい「Images」スペースが追加されている
従来の「画像だけを作るAI」というよりも、テキストモデルと一体化した「ビジュアル・アシスタント」というイメージで捉えると分かりやすいモデルです。

GPT Image 1.5の主な機能と特徴
GPT Image 1.5を実務で使い倒すうえで重要なのは、「どんな編集が得意か」「どのレベルまでレイアウトを任せられるか」を押さえておくことです。
ここでは、とくにビジネス利用で効いてくる4つの特徴に絞って整理します。

1. 細部を保つ高精度な編集
まずは、元画像に対してどこまで自然に手を入れられるか、というポイントです。
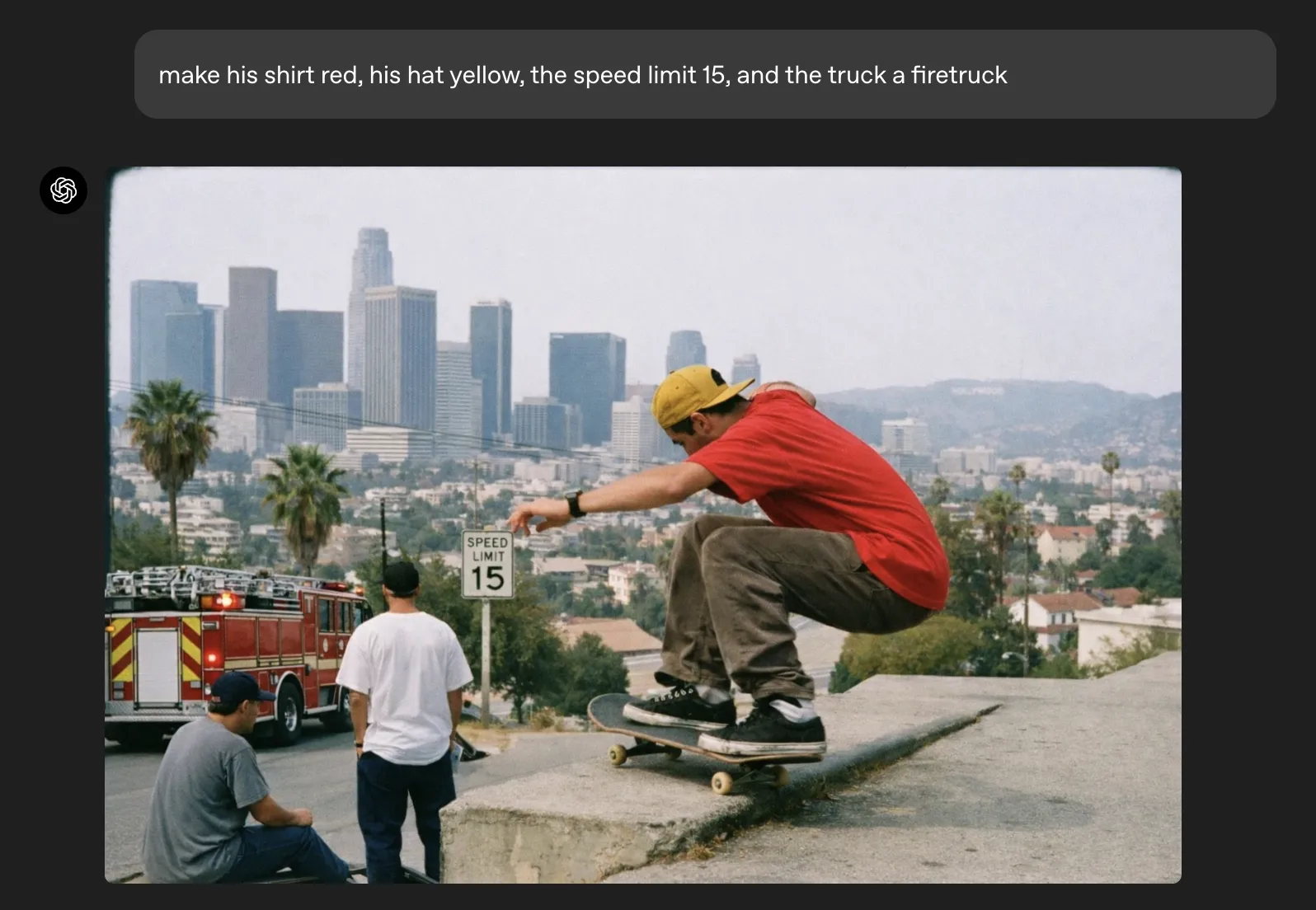
下の例では、ロサンゼルスの丘の上でスケートボードをしている写真をベースにしています。

(参考:OpenAI)
この元画像に対して、
- シャツの色を赤に、帽子を黄色に変える
- トラックを消防車に差し替える
- スピードリミットの標識を「15」に変更する
といった指示をまとめて与えると、背景の空気感やフィルムの質感は保ったまま違和感の少ない編集結果が得られます。
(参考:OpenAI)
さらに、同じ写真に対して
- 左側に観客の群衆を追加
- 手前にワシを追加
- 奥の空に飛行船を追加
といった形でオブジェクトを増やしても、ライティングや奥行きの整合性が大きく崩れないのが特徴です。

(参考:OpenAI)
このように、「元のテイストは残しつつ、必要な要素だけを足したり入れ替えたりする」タイプの編集がかなり実用的なレベルになっています。
2. 指示の分解と関係性の維持(Instruction following)
長いプロンプトに含まれる「位置関係」や「グリッド構造」を、以前よりかなり忠実に再現できるようになっているのもポイントです。
6×6グリッドの比較(左:GPT Image 1.5、右:旧モデル) (参考:OpenAI)
上のスクリーンショットは、同じ6×6グリッドの指示を旧モデル(右)とGPT Image 1.5(左)に投げた比較です。
- 各マスのサイズやマージン
- 行・列の順序
- 「どのマスにどのアイコンを置くか」という対応関係
といった要素が、左側のGPT Image 1.5のほうが指示どおりにきれいにそろっているのが分かります。
この性質のおかげで、
- インフォグラフィックのベースレイアウト
- UIモックアップのラフ
- 表形式の図解(行・列・ヘッダー・凡例つき)
のような「構造込みで指示したい」タスクに使いやすくなっています。
3. 実用レベルになったテキストレンダリング
テキストレンダリングも、旧モデルと比べるとかなり実用寄りになっています。

(参考:OpenAI)
上の例では、「Markdownで書かれた記事を、新聞の紙面としてレイアウトしてほしい」という指示を与えています。
- 見出し・小見出し・本文
- 表に含まれる数値やパーセンテージ
- 段組みや余白の取り方
といった要素を、内容を書き換えずにかなり自然な紙面として描画できているのが分かります。
極端に小さな文字や崩れやすいフォントではまだ破綻もありますが、
- 新聞風レイアウト
- スライド1枚目風のタイトル+サマリ
- コードスニペットや数式を含む技術記事風レイアウト
といった「文字量の多い画面」を、アイデア出し〜たたき台作りのレベルではそのまま使える精度まで引き上げてきているのがGPT Image 1.5の特徴です。
4. コンセプトを保ったクリエイティブ変換
いわゆるスタイル変換に近い使い方ですが、GPT Image 1.5は「コンセプトは固定、周辺のデザインだけ大きく変える」用途に向いています。
- 同じ人物写真から、広告バナー風・雑誌の表紙風・ポスター風など複数のクリエイティブを展開する
- SaaSプロダクトのスクリーンショットを起点に、LP用ヒーロー画像やSNS用サムネイルをまとめて生成する
といったケースで、顔つき・ロゴ・全体の構図はなるべく維持しつつ、色味やタイポグラフィだけ大胆に変えるといったコントロールがしやすくなっています。
GPT Image 1.5の使い方
ここでは、まずChatGPTアプリに追加された画像専用の「Images」画面から使い始める想定で説明します。
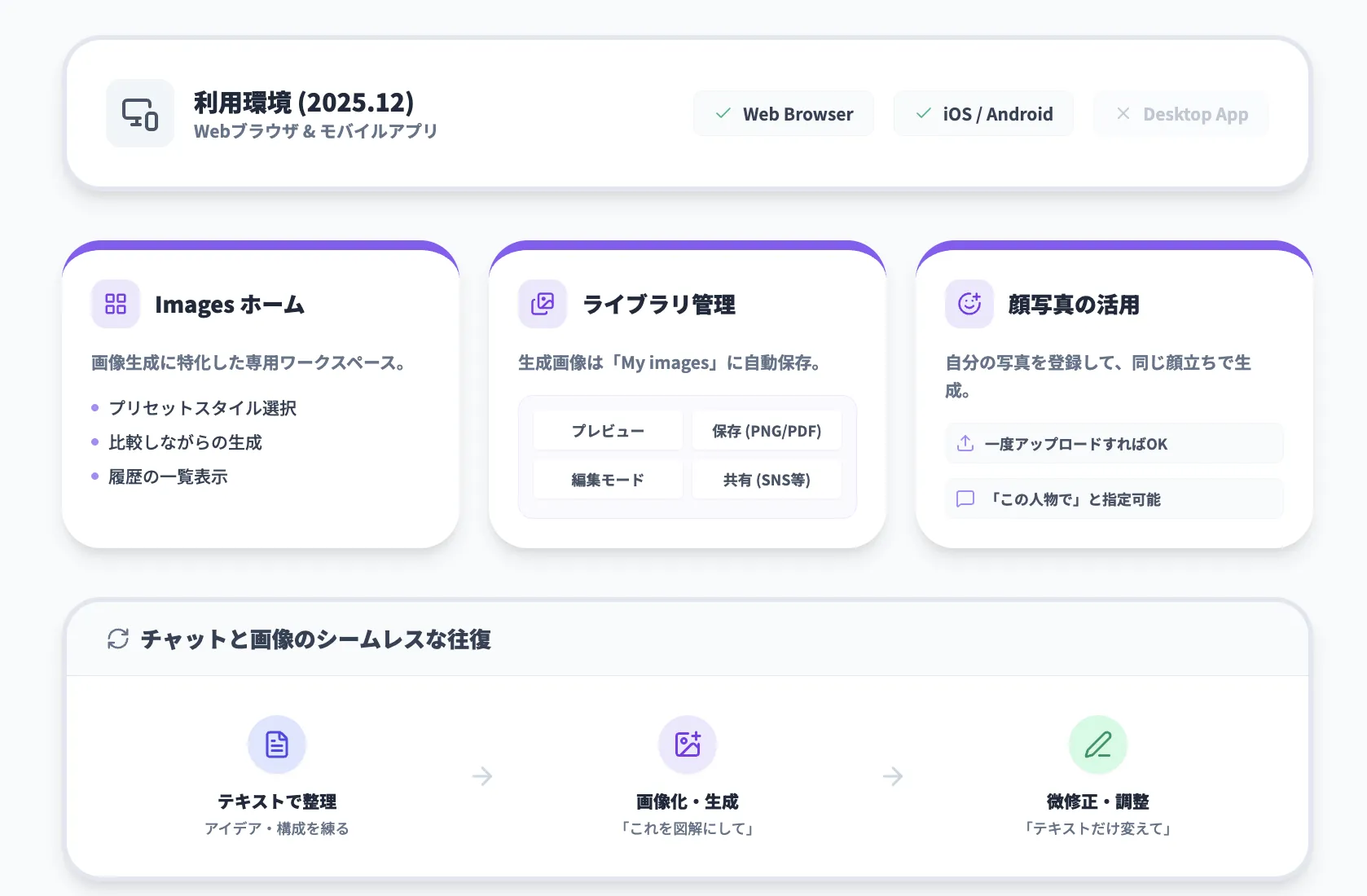
利用環境(2025年12月時点)
ChatGPT Imagesは、2025年12月時点では**Webブラウザとモバイルアプリ(iOS / Android)**で利用できます。デスクトップアプリ単体からは利用できないため、PCで使う場合もブラウザ版ChatGPTにアクセスする前提です。
モバイルで利用する場合は、ChatGPTモバイルアプリを最新バージョンにアップデートしておく必要があります。
Images専用ホーム
ChatGPTのサイドバーやメニューから、画像専用のホームビューにアクセスできます。ここでは次のようなことができます。
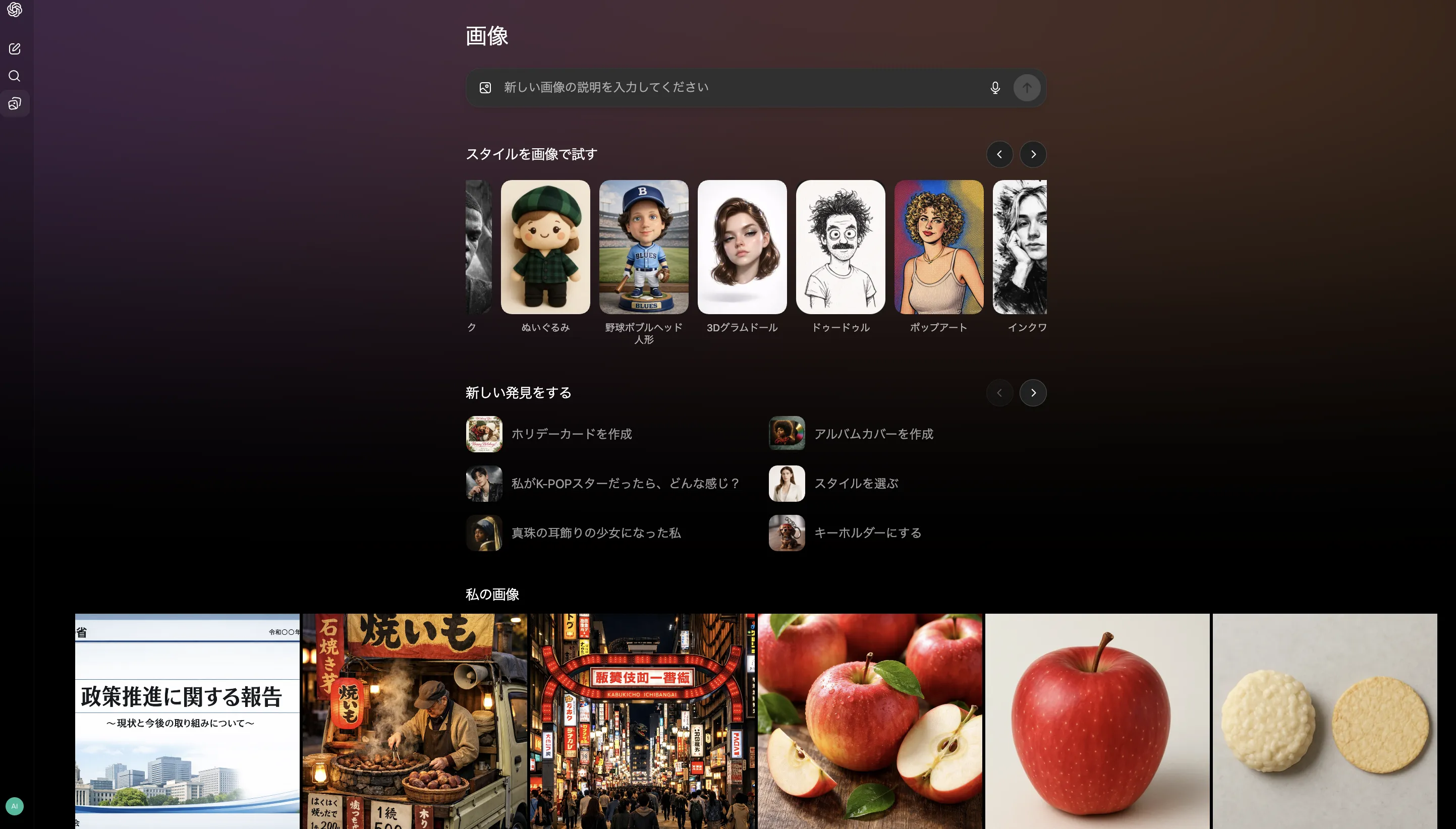
- プロンプトを書かずに使えるプリセットスタイルの選択
- 最近生成した画像の一覧表示
- 複数パターンを並べて比較しながらの生成
テキスト用のチャットとは分離された、「画像作業に特化したワークスペース」というイメージです。
Imagesライブラリと画像管理
ChatGPTで生成した画像は、自動的に「My images(日本語UI = 私の画像)」に保存されます。
Webブラウザでは左側ナビゲーションの「画像タブ」から、モバイルアプリではメニューからアクセスできます。
ここから次の操作が可能です。
- 画像のプレビュー表示
- 画像のコピー(他アプリへの貼り付け用)
- 編集モードへの遷移
- 端末への保存(pngまたはPDF形式)
- 他アプリへの共有(X・Linkedin Redditなど)
画像を削除したい場合は、その画像を生成したチャットスレッドごと削除する形になります(会話一覧から該当スレッドを削除)。
顔写真の活用イメージ
ChatGPT Imagesでは、自分や同じ人物の写真をアップロードしておくと、その人物の顔立ちをある程度保ったままスタイルやシーンを変えた画像を生成できます。
- 最初にセルフィーやポートレートをアップロード
- 以降、「この人物を元に」「前にアップした自分の写真を使って」などの指示で同じ人物を登場させる
- 何度もカメラロールから探してアップロードし直す手間を減らせる
プロフィール画像のバリエーションや、社内向けコンテンツに同じキャラクターを何度も登場させるケースで便利です。
チャットと画像の往復
テキストモデルと同じスレッド上で動作するため、
- まず文章でアイデア・構成・メッセージを整理
- 「この内容を1枚の図解にして」「LP用のヒーロー画像にして」と依頼
- 生成結果を見ながら、「テキストだけ変えて」「配色をもっと落ち着かせて」と微修正
というループを、チャットから離れずに回せるのがChatGPT Imagesの強みです。
APIでの使い方:gpt-image-1.5モデル
開発者向けには、GPT Image 1.5は「gpt-image-1.5-2025-12-16」というモデル名で提供されています。
基本的な利用イメージは従来のImages APIと同じです。
*参考:OpenAI
対応する入力パターン
gpt-image-1.5は、次のような入力パターンをサポートします。
- テキストのみ(Text → Image)
- 画像+テキスト(Image → Image)
- 複数画像の参照(スタイル・構図の継承)
- マスクを使った部分編集
商品カタログのバリエーション、UIモックアップの量産、ブランドガイドラインを守ったクリエイティブ生成など、「ベース画像を起点にした大量生成」に向いています。
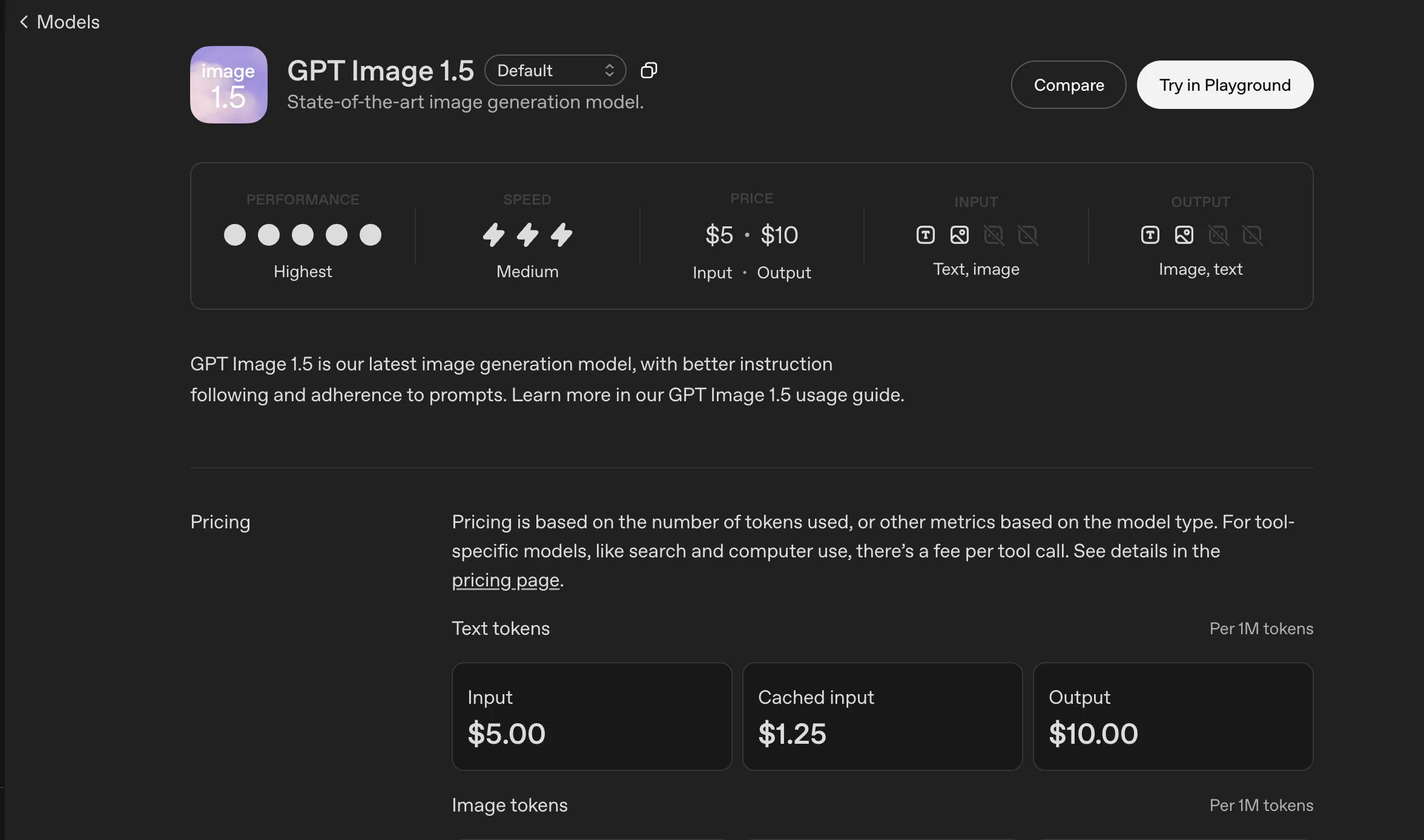
GPT Image 1.5の料金体系(ChatGPT / API)

GPT Image 1.5(ChatGPT Images)自体には追加の月額料金はなく、各プラン(Free / Go / Plus / Edu / Pro)の利用枠の中で画像生成・編集が利用できます。
一方で、ChatGPT上で「1日◯枚まで」「1ヶ月◯枚まで」といった具体的な生成枚数の上限値は公開されていません。
GPT Image 1 / DALL·E 3のときと同様に、実際の上限はメッセージ上限やサーバー負荷に応じたフェアユース制御で調整される、と考えておくのが現実的です。
【関連記事】
ChatGPTの料金プラン一覧を比較!無料・有料版の違い・支払い方法を解説
Image Generation API(gpt-image-1.5)の料金
APIでgpt-image-1.5を使う場合は、トークン単位の従量課金になります。
料金は「テキストとして扱うトークン」と「画像として扱うトークン」で分かれています。
テキストトークン(Text)の料金イメージ
| モデル | 入力(1M tokens) | キャッシュ入力(1M tokens) | 出力(1M tokens) |
|---|---|---|---|
| GPT-image-1.5 | 約5ドル | 約1.25ドル | 約10ドル |
| GPT-image-1 | 約5ドル | 約1.25ドル | (出力課金なし) |
| GPT-image-1-mini | 約2ドル | 約0.20ドル | (出力課金なし) |
画像トークン(Image)の料金イメージ
| モデル | 入力(1M tokens) | キャッシュ入力(1M tokens) | 出力(1M tokens) |
|---|---|---|---|
| GPT-image-1.5 | 約8ドル | 約2ドル | 約32ドル |
| GPT-image-1 | 約10ドル | 約2.5ドル | 約40ドル |
| GPT-image-1-mini | 約2.5ドル | 約0.25ドル | 約8ドル |
解像度・品質・プロンプト内容によって実際に消費されるトークン数は変わるため、「1枚あたりいくらか」を正確に見積もるには、上記のトークン単価と実際のトークン使用量を掛け合わせて計算する必要があります。
大まかなコスト感をつかみたい場合も、OpenAIのPricingページに掲載されている最新の単価表を前提に、自前でシミュレーションする前提にしておくのが安全です。
Nano Banana Proとの比較:どちらをどう使い分けるべきか

GPT Image 1.5(ChatGPT Images)とNano Banana Pro(Gemini 3 Pro Image)は、どちらも「高精度なテキストレンダリング」と「高度な編集機能」を持つフラッグシップ級の画像生成モデルです。
GPT Image 1.5 は、旧モデルの「GPT Image 1」と比べると編集精度やレイアウトの素直さがかなり改善しています。
しかし、日本語テキストの描写や、1枚の完成度という意味での“画の強さ”は、依然として Nano Banana Pro 側が一枚上手という印象です。
| 観点 | GPT Image 1.5(ChatGPT Images) | Nano Banana Pro(Gemini 3 Pro Image) |
|---|---|---|
| 提供元 | OpenAI | Google DeepMind |
| 主な入り口 | ChatGPT(Web / モバイルのImagesホーム) | Geminiアプリ、Gemini API、Vertex AI など |
| テキストレンダリングの傾向 | 英語中心に安定。日本語は小さな文字や文字量が多いと崩れやすい | 日本語・多言語テキストの可読性重視。看板やインフォグラフィックで文字が読みやすい |
| 編集・出力の傾向 | 既存画像の局所編集や「1枚ものの図解」のベース作成に向く | 高解像度出力や複数画像統合などスタジオ寄りの画づくりに向く |
| 料金イメージ | ChatGPTプラン内で利用+APIはトークン課金(gpt-image-1.5) | Geminiプラン+Gemini API / Vertex AIのトークン課金 |
ざっくり言えば、
- 文字量が少ないビジュアル(写真風・広告風・図解のベース)や既存画像の編集が主目的なら GPT Image 1.5
- 日本語テキストをきちんと読ませたい看板・パッケージ・インフォグラフィックなど「文字が主役」の画像を作るなら Nano Banana Pro 一択に近い
という整理になります。

GPT Image 1.5ならではのプロンプトテクニック
同じモデルでも、プロンプトの書き方次第で出力品質は大きく変わります。GPT Image 1.5は「差分編集」「レイアウト指定」「テキスト保持」に強みがあるため、ここではその特性を踏まえた“書き方のコツ”を3つに絞って紹介します。
細かいテクニックよりも、「どういう発想で指示を書くと安定するか」を押さえるイメージです。

テクニック1:差分編集を前提に「ステップ」で考える
一発で完成形を狙うよりも、以下の2ステップで考えた方が安定します。
- ベース画像を作る
- ベース画像に対して差分だけ指示する
【プロンプト例】
この画像をベースにして、右側の看板のテキストだけ「AI総合研究所」に変更してください。
フォントは和風の筆文字で、既存のネオンの色味と調和するように。その他の部分(人物・雨・反射)は一切変更しないでください。
「変える場所」と「変えない場所」をセットで指定するのがコツです。
テクニック2:レイアウトを箇条書きで宣言する
プロンプトへの追従が強いため、レイアウトを箇条書きで宣言 → 図解化してもらうパターンが有効です。
【プロンプト例】
6×6のグリッドで構成されたインフォグラフィックを作成します。
次の条件をすべて守ってください。
- 各マスは同じ大きさ
- 行番号・列番号は左端と上端に小さく表示
- 1行目のマスには、左から順に「βの記号」「ビーチボール」「レモン」「ロボット」「水槽」「カエル」を配置
- 2行目は…
指示が長くなってもよいので、「どのマスに何を置くか」を明文化すると崩れにくくなります。
テクニック3:テキスト部分は「書き換え禁止」を明示する
テキストをそのまま残したい場合には、「一文字も変えない」ことをはっきり書きます。
【プロンプト例】
以下のMarkdownを、新聞記事風の紙面としてレイアウトしてください。
- 見出し・小見出し・本文・表の内容は一文字も変えないこと
- 数字・記号もすべてそのままにすること
- レイアウトだけ変更し、内容は絶対に書き換えないこと
GPT Image 1.5の活用シナリオ
GPT Image 1.5(ChatGPT Images)は、「おしゃれな画像が作れるツール」というだけでなく、日常業務のかなり広い範囲を置き換えられる実務ツールです。
ここでは、ビジネスとクリエイティブの両面で代表的な活用シナリオを整理します。

1. SNSバナー・サムネイル制作
XやYouTube、Instagramなどのクリエイティブは、テキストの読みやすさと一瞬で目を引くデザインが命です。
GPT Image 1.5はテキストレンダリングが強化されているため、タイトルやCTAを直接画像に埋め込んだ「そのまま使えるバナー」を量産できます。
こんなときに便利
- ブログ記事やYouTube動画のサムネイルを素早く量産したい
- 週次キャンペーンのSNSバナーを毎回ゼロから作るのがしんどい
- デザイナー不在でも、最低限見栄えする告知画像を用意したい
新規生成向け
ブログ記事のアイキャッチ画像を作成してください。
テーマ:
「GPT Image 1.5とは?精度と使い方をわかりやすく解説」
条件:
- 16:9 横長
- 左側にシンプルなイラスト(PC画面とカメラアイコン)
- 右側に大きな日本語タイトル
「GPT Image 1.5とは?」
サブタイトルに小さめの文字で
「ChatGPTの新・画像生成の特徴と使い方を解説」
- 見出しは太めのサンセリフ体で、スマホでも読める大きさ
- 背景は薄いブルー系のグラデーションで、情報量はシンプルに
既存サムネのリライト
このサムネイル画像をベースに、タイトルだけ差し替えてください。
変更点:
- 日本語のタイトルを
「GPT Image 1.5の料金とAPIの使い方」
に変える
- レイアウトと色、イラストはそのまま維持
- 文字の可読性を優先して、やや太めのゴシック体に調整
2. 業務資料・レポートの図解化
レポートやプレゼン資料では、表や文字だけでは伝わりにくい構造や関係性を、1枚の図に落とし込む場面が多くあります。
GPT Image 1.5は、Markdownや箇条書きから「ちゃんと読めるレイアウトつき図解」を起こすのが得意です。
こんなときに便利
- ホワイトペーパーや営業資料の概念図・アーキテクチャ図を作りたい
- レポート内のベンチマーク表を“新聞風レイアウト”で見せたい
- 研修資料のフローチャートやプロセス図を一気に用意したい
プロンプト例(Markdown → 新聞風レイアウト)
以下のMarkdownを、縦長1枚の「新聞風レイアウト」の画像にしてください。
条件:
- 見出し、本文、表をそのまま使用
- 文字はすべて可読な大きさで、日本語が潰れないように
- 左上に大きな見出し、その下にリード、中央に表、右下に補足コラム風の囲み
Markdown:
(ここにGPT-5.2やGPT Image 1.5の説明Markdownを貼る)
プロンプト例(フローチャート)
次のステップを説明するフローチャート図を作成してください。
- Step1: ユーザーがテキストで指示を入力
- Step2: ChatGPTが画像プロンプトを整理
- Step3: GPT Image 1.5が画像を生成
- Step4: ユーザーが修正点を指示
- Step5: 画像を再生成して完成
条件:
- A4縦を想定した縦長キャンバス
- それぞれのステップを長方形のボックスで表示
- 矢印で流れをつなぐ
- ボックス内の日本語は読みやすい太さ・サイズで
3. EC・カタログ向けの商品画像バリエーション
GPT Image 1.5は、「元画像の雰囲気は崩さずに一部だけ変える」編集が得意です。これにより、ECサイトやカタログ制作でよくある次のようなタスクを置き換えられます。
典型的な使い方
- 1枚のマスタ画像から、色違い・背景違いのバリエーションを量産
- 静的な商品写真を、ライフスタイルシーンに合成して広告用画像に
- モデルの顔や体型を維持したまま、服や小物だけ差し替え
プロンプト例(色違い・背景違い)
この商品写真をベースに、色違いと背景違いの画像を6枚作成してください。
条件:
- 商品の形状・ロゴ・質感はそのまま維持
- 色のバリエーション:
1. ホワイト
2. ブラック
3. ネイビー
- 背景のバリエーション:
- 無地の白背景(EC商品ページ用)
- 木のテーブルの上(ライフスタイル写真)
- すべて正面からの角度で、影の向きは元画像と揃える
プロンプト例(ライフスタイル化)
この商品の画像を、ライフスタイル写真風に編集してください。
条件:
- 商品は手前に大きく、そのままの比率で配置
- 背景を、自然光が差し込む木製デスクの上に変更
- ぼかした観葉植物とノートPCを背景に入れる
- 商品の色味とロゴは変えない
4. 自分の「顔」やブランドキャラを使ったコンテンツ制作
ChatGPT Imagesの新機能として、一度アップロードした顔写真をもとに「自分の顔のライクネスを再利用」する仕組みが用意されています(ユーザーが許可した場合)。GPT Image 1.5は、このライクネスを保ったままスタイルやシーンを変えるのが得意です。
こんなときに便利
- ブログやSNS用のアイコン・アバターのバリエーションを作りたい
- 研修資料や社内通達に、同じ人物が登場するイラストを使いたい
- 「顔出しはしたくないが、自分ベースのキャラ」は欲しい
プロンプト例(アイコン展開)
先ほど登録した私の顔のライクネスを使って、SNSアイコン用の画像を4パターン作成してください。
条件:
- 顔の特徴はそのまま維持
- スタイル:
1. フラットイラスト
2. 手描き風のラフスケッチ
3. ビジネス向けのシンプルなポートレート
4. ポップな漫画風アイコン
- すべて正方形(1:1)、背景はシンプルでアイコンとして使いやすいデザイン
プロンプト例(登場キャラつき解説資料)
この顔写真をもとにしたキャラクターを主人公として、
「GPT Image 1.5の使い方」を解説する4コマ漫画風の画像を作成してください。
条件:
- 各コマに簡単な日本語の吹き出しテキストを入れる
- 顔の特徴と髪型は全コマで一貫させる
- 背景はシンプルなオフィス風
5. デザイン・開発ワークフローのブレスト&プロトタイピング
GPT Image 1.5は、「作り込む前のたたき台」を高速で出す用途にも相性が良いです。テキスト説明だけ渡して、UIモックや構図案、配色案を一気に生成し、そこからFigmaやデザインツールで仕上げていくフローが組めます。
こんなときに便利
- 新LPのヒーローセクション案をいくつか見比べたい
- WebアプリのダッシュボードUIの方向性だけ先に固めたい
- ロゴやキービジュアルの「イメージボード」をまず共有したい
プロンプト例(LPヒーローセクション案)
新しいSaaSプロダクトのLP用ヒーローセクションのデザイン案を3パターン作成してください。
プロダクト:
- 「PromptFlow」:LLMプロンプトを管理・評価するBtoB向けSaaS
条件:
- 16:9 横長
- 左側にコピーとCTAボタンのスペース
- 右側に「ダッシュボードUI」のイメージ
- それぞれ配色と雰囲気を変える
1. クリーンでミニマルな白ベース
2. ダークモードベースのテック感強め
3. ポップなアクセントカラーを使ったスタートアップ向け
- テキストはダミーでも良いが、英語・日本語が崩れないように
6. 「テキスト+コード+画像」を一気通貫で回す
ChatGPT内でGPT-5.2シリーズとGPT Image 1.5を組み合わせると、説明文・コード・画像をまとめて生成/修正するフローを簡単に組めます。
代表的なパターン
- ChatGPTに仕様を投げて
→ API仕様書やチュートリアルMarkdownを生成 - そのMarkdownをGPT Image 1.5に渡し
→ 新聞風レイアウト or チートシート画像を作る - 必要に応じてCodex(コーディングエージェント)に渡し
→ LPやドキュメントサイトのHTML/CSSを構築
ざっくりプロンプト例
さきほどあなたが作ってくれた「GPT Image 1.5の解説記事」のMarkdownを使って、
A4縦1枚のチートシート風ポスター画像を作成してください。
条件:
- 見出しと重要な箇条書きを中心に要約
- 小さな文字でも読めるレイアウト
- 日本語を含むテキストが崩れないように
- 右下に「作成:ChatGPT Images / GPT Image 1.5」と小さく表記
このあたりをベースに、自社のワークフローに合わせて「どこをGPT Image 1.5に任せるとインパクトが大きいか」を逆算していくと、導入メリットと必要なプラン/APIの条件が見えやすくなります。
GPT Image 1.5の商用利用について
画像生成まわりの商用利用は、「OpenAI側の公式ルール」と「自社側のポリシー」を切り分けて考えると整理しやすくなります。

OpenAI公式の前提:出力の権利と禁止用途
現行のOpenAI Services Agreementや各種ポリシーでは、ざっくり次のような立て付けになっています。
- ChatGPTやAPIに入力したテキスト・画像などは「Input」、モデルから返ってくる出力は「Output」と定義される
- 企業向けサービス(ChatGPT Team / Business / Enterprise / APIなど)では、Inputの権利はユーザー(顧客)に残り、Outputの権利もユーザーが持つと明記されている
- OpenAIは、サービスを提供するために必要な範囲でのみCustomer Content(Input+Output)を利用できる(不正利用の検知や法令遵守などを目的とする限定的な利用に限られる)
- 一方で、違法行為や差別・ヘイト、著作権・商標の侵害など、利用規約に反する用途は禁止されている
ユーザーデータの学習
また、学習データとしての利用に関しては、サービス種別によって扱いが分かれています。
- ChatGPT Team / Business / Enterprise / APIなどのビジネス向けサービス
→ デフォルトではCustomer Contentはモデル学習に利用されない(別途、契約ベースで合意する場合を除く)
- ChatGPT Free / Go / Plus / Proなどの個人向けサービス
→ デフォルトではコンテンツがモデル改善に利用されるが、設定画面からオプトアウトが可能
つまり「生成した画像そのものをビジネスで使うこと」は原則可能ですが、使い方が法律やOpenAIの利用規約に反していないかを別途チェックする必要があります。
現場で押さえておきたい権利まわりのポイント
実務でリスクになりやすいのは、AI側というより「こちらが入力する素材」のほうです。
特に注意したいポイントは次の通りです。
- 他サービスから取得した画像・写真を、そのサービスの規約に反する形で二次利用していないか
- 有名キャラクター、ブランドロゴ、実在の建築物など、第三者の知財に強く依存したテーマになっていないか
- 顔写真や名札・ナンバープレートなど、個人が特定され得る情報が写り込んでいないか
- 社外秘の図面・UIデザイン・企画書など、機密情報をそのまま入力していないか
OpenAI側の契約ではCustomer Contentの権利がユーザー側にある前提ですが、そもそもユーザー側がその素材を自由に扱う権利を持っているかは別問題です。
ここは法務・知財担当と一度すり合わせておくと安全です。
チームとして決めておきたい運用ルール
最後に、社内ルールとしてあらかじめ線引きをしておくと、現場の判断がかなり楽になります。例えば、次のような決め方が考えられます。
利用レベルの区分
- 社内資料・プロトタイプ向け(リスク低):AI画像をそのまま使ってよい
- 公式ブログ・ホワイトペーパー向け(中):AI画像+人手での軽いレタッチを必須にする
- 広告バナー・LPのキービジュアルなどブランド中核(高):必ずデザイナーと法務の確認を経る
入力側のルール
- 他社サービスから取得した画像やストックフォトは、「プロンプトに添付してよいもの」と「NGなもの」を明文化する
- 顧客情報・機密情報・生のログなどは、原則プロンプトに入れない
表示・説明まわり
- 対外向けクリエイティブでAI生成物を使う場合、「AIを利用して作成した」旨をどこまで明示するか
- 生成画像をそのまま納品物に含めるとき、契約書や発注書にどう表記するか(例:第三者AIサービス利用の有無)
こうしたルールを「OpenAIの利用規約に準拠しつつ、自社としてどこまで許容するか」という観点で決めておくと、
個々の案件ごとに毎回ゼロから議論しなくてよくなります。

AI画像生成の実務活用を業務プロセス全体のAI化に広げるなら
GPT Image 1.5のテキストレンダリング精度や編集の一貫性を体験したことで、AIが「指示どおりの成果物を出力できる」段階に到達していることが実感できたはずです。画像生成はあくまで業務AI活用の一領域であり、資料作成・データ分析・ワークフロー自動化まで範囲を広げれば、効率化の効果は数倍に膨らみます。
AI総合研究所では、画像生成を含むAIツールの業務展開を体系的に進めるためのガイド資料を提供しています。どの業務領域から着手し、どう段階的に拡大するかの判断材料が揃っており、クリエイティブ業務以外へのAI導入も具体的にイメージできます。
AI画像生成の業務活用をプロセス全体のAI化に広げる

テキストからビジュアルを生む体験を業務自動化の入口に
GPT Image 1.5の高精度な画像生成でAIの実力を実感したなら、次は業務プロセス全体へのAI展開を検討するステップです。資料作成やデータ分析の自動化まで視野に入れた実践ガイドをご活用ください。
まとめ:GPT Image 1.5で「文章から実務レベルのビジュアル」へ
GPT Image 1.5 / ChatGPT Imagesの登場により、画像生成AIは完全に「実験」から「実務」フェーズ**に入りつつあります。
- 編集の一貫性
- テキストレンダリング
- 指示の追従性
- 生成速度とコスト
といった、現場で効くポイントが着実に改善されており、マーケティング・EC・教育・社内資料など、既存のワークフローの中にそのまま組み込めるレベルになりました。
開発者にとっては、gpt-image-1.5 をAPIから呼び出すことで、
- 既存プロダクトに「画像生成・編集」機能を追加
- 社内専用の「バナー自動生成ツール」「プロトタイプスタジオ」を構築
といった形で、既存のビジネスの手前に「AIレイヤー」を一枚挟むことが現実的な選択肢になります。
まずはChatGPTアプリのImagesから、「このレベルの画がどのくらいの手間で出るのか」を体感してみてください。
そのうえで、自社のどの業務なら置き換えやすいか、どこはまだ人間のほうが良いかを切り分けていくのが、2026年に向けた現実的な一歩になります。










