この記事のポイント
 PC操作の自動化が必要なエージェント構築には、ネイティブ・コンピュータ操作を搭載したGPT-5.4が第一候補
PC操作の自動化が必要なエージェント構築には、ネイティブ・コンピュータ操作を搭載したGPT-5.4が第一候補- 日常的な質問応答には標準版、複雑な推論タスクにはThinking、最高精度が求められる場面にはProと明確に使い分けるべき
- GPT-5.2比で誤り率33%減・エラー率18%低下を達成しており、精度面でGPT-5.2に留まる理由はない
- 100万トークンのコンテキストウィンドウは長文ドキュメント分析に有効。Tool Search機能と組み合わせたエージェント構成が最適
- API料金は入力$2.50/出力$15.00(100万トークン単位)で、272K超過時は割増。大量処理にはバッチAPIの活用でコストを抑えるべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
2026年3月5日、OpenAIは最新フラグシップモデル「GPT-5.4」をリリースしました。
推論・コーディング・エージェント機能の成果を1つのフロンティアモデルに集約し、AIが画面を見てマウスやキーボードを操作する「ネイティブ・コンピュータ操作」を搭載した点が最大の特徴です。
本記事では、GPT-5.4の主要な新機能、GPT-5.2との違い、ベンチマーク性能、3つのモデルバリアント(標準・Thinking・Pro)の使い分け、API料金、ChatGPTプラン別のアクセス方法まで徹底解説します。
GPT-5.4とは?OpenAI最新フラグシップモデルの全貌

GPT-5.4は、OpenAIが2026年3月5日にリリースした最新のフラグシップAIモデルです。
推論・コーディング・エージェントワークフローの成果を1つのモデルにまとめた、いわば「何でも任せられるAIの司令塔」のような存在です。
OpenAIはGPT-5.4を「プロフェッショナルワークのための最も高性能かつ効率的なフロンティアモデル」と表現しています。
GPT-5.3-Codexのコーディング能力を取り込み、文書理解・ツール操作・長時間タスクの実行まで、1つのモデルで完結できるようになりました。

GPT-5.4のリリース概要
まずは基本仕様を押さえておきましょう。
| 項目 | 内容 |
|---|---|
| リリース日 | 2026年3月5日 |
| モデルID | gpt-5.4(スナップショット: gpt-5.4-2026-03-05) |
| コンテキストウィンドウ | 最大105万トークン(入力)、12.8万トークン(出力) |
| 知識カットオフ | 2025年8月31日 |
| APIモデル | gpt-5.4(標準)、gpt-5.4-pro(高性能) |
| ChatGPT提供形態 | GPT-5.4 Thinking(推論強化モード) |
| 主な新機能 | ネイティブ・コンピュータ操作、Tool Search、Mid-Response Steering |
コンテキストウィンドウが105万トークンに拡大されている点が目を引きます。
OpenAI史上最大のサイズであり、大規模なコードベースや文書群を丸ごと読み込んで処理できるようになりました。
GPT-5.4のモデル構成
GPT-5.4はAPIモデルとChatGPT上の提供形態に分かれています。名前が似ているため混乱しやすいポイントなので、先に整理しておきます(詳細は後述。
-
gpt-5.4
推論・コーディング・ツール操作を統合した汎用モデルです。
APIでは推論レベルを5段階で設定でき、日常的なプロフェッショナルワークの大半をカバーします。
-
gpt-5.4-pro
追加の計算リソースを投入し、より深い推論を行う高性能モデルです。
ARC-AGI-2で83.3%、BrowseCompで89.3%と、標準版を上回るベンチマークスコアを記録しています。
-
GPT-5.4 Thinking)
ChatGPT上でgpt-5.4を推論強化モードで利用する形態です。
事前に短い作業計画(プリアンブル)を提示し、ユーザーが途中で方向修正できるMid-Response Steering機能を備えています。
なお、APIで利用する場合の独立モデルIDはgpt-5.4とgpt-5.4-proの2種類です。「GPT-5.4 Thinking」はAPIの別モデルではなく、ChatGPTでの利用時に推論機能が有効化された状態を指します。
GPT-5.4の主要な新機能

GPT-5.4では、これまでのモデルにはなかった4つの主要な新機能が追加されています。順番に見ていきましょう。
ネイティブ・コンピュータ操作
GPT-5.4の最大の特徴は、AIが直接PCを操作できるネイティブ・コンピュータ操作機能を搭載した点です。
具体的には、モデルがスクリーンショットを解釈し、マウスクリックやキーボード入力といったアクションを自律的に実行します。Webブラウザの操作、ソフトウェア間のデータ転送、フォーム入力など、これまで人間が手作業で行っていたPC操作をAIに委任できるようになりました。
OpenAIはこの機能について、公式ブログで「汎用モデルとしては初めてネイティブ・コンピュータ操作機能を搭載した」と説明しています。
従来はClaudeのComputer Use機能など、特定モデルの専用機能として提供されていた領域に、GPTシリーズが本格参入した形です。
コンピュータ操作の性能を測定するOSWorld-Verifiedベンチマークでは、GPT-5.4が**75.0%**を記録し、人間のパフォーマンス(72.4%)を上回りました。
【関連記事】
AIエージェント(AI agent)とは?その仕組みや作り方、活用事例を解説
Tool Search機能
Tool Search機能は、大量のツール定義を効率的に管理するための仕組みです。
従来のAPIコールでは、利用可能なすべてのツール定義をプロンプトに含める必要がありました。しかしツール数が増えるほど入力トークンが膨れ上がり、コストと応答時間の両面で課題がありました。
Tool Search機能では、モデルが実行時に必要なツールだけを動的に読み込みます。OpenAI開発者ドキュメントによると、この仕組みによりトークン使用量を最大47%削減できるとされています。
エージェントワークフローで多数のツールを組み合わせる場合、Tool Searchは運用コストを大幅に抑える鍵となります。
実際の削減効果を示したのが以下のグラフです。
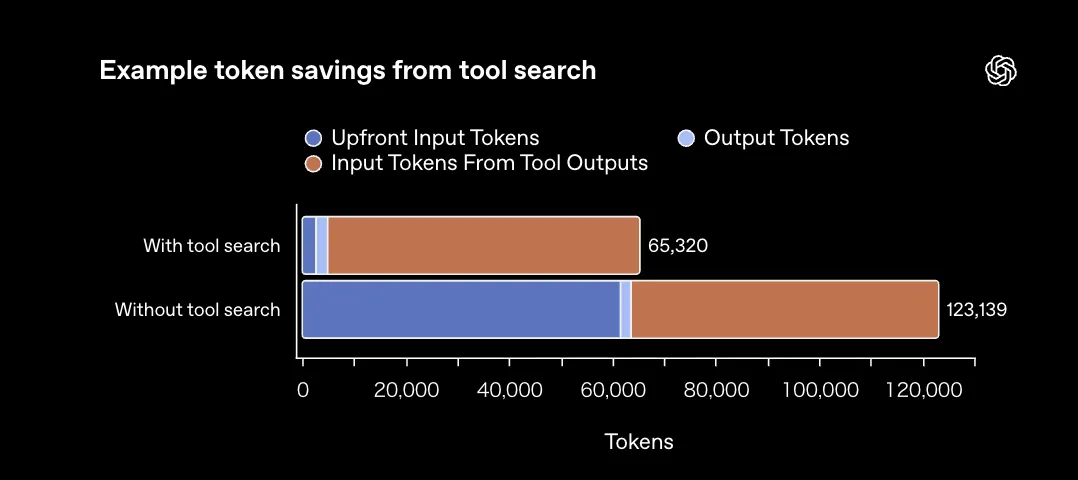
Tool Search使用時のトークン消費量比較(参照:OpenAI)
Tool Searchなしでは123,139トークンを消費するところ、Tool Searchを有効にすると65,320トークンまで圧縮されています。入力トークン(Upfront Input Tokens)の大幅な削減が、コスト減の主な要因です。
100万トークンのコンテキストウィンドウ
GPT-5.4は最大105万トークンのコンテキストウィンドウをサポートしています。これはOpenAI史上最大であり、大規模なコードリポジトリや長大な法務文書を丸ごと読み込んだうえで分析・回答できるようになります。
ただし、標準的なリクエスト(27.2万トークン以下)と長文リクエスト(27.2万トークン超)では料金体系が異なる点に注意が必要です。27.2万トークンを超える場合、入力料金が2倍、出力料金が1.5倍に設定されています。料金の詳細はこの記事の料金セクションで解説します。
Mid-Response Steering(思考途中の介入)
GPT-5.4 Thinkingでは、AIの思考プロセスが進行中でもユーザーが介入して方向修正できるMid-Response Steering機能が追加されました。
従来の推論モデルでは、出力が完了するまで待ってから修正指示を出す必要がありました。
GPT-5.4 Thinkingでは、モデルが複雑なクエリに対して事前に作業計画(プリアンブル)を提示し、ユーザーはその計画を確認しながらリアルタイムで指示を追加・変更できます。
この機能により、意図しない方向に進んだ出力を最初からやり直す必要がなくなり、処理時間とトークン消費の無駄を削減できます。
GPT-5.4とGPT-5.3・GPT-5.2との比較

GPT-5.4は、ChatGPTのデフォルトモデルだったGPT-5.3 InstantおよびGPT-5.2から大幅な進化を遂げています。「アップグレードする価値があるのか?」を判断するために、3モデルの性能面と機能面の違いを整理します。
性能面の進化

主要な性能指標を並べると、改善幅がよくわかります。
| 指標 | GPT-5.2 | GPT-5.3 Instant | GPT-5.4 |
|---|---|---|---|
| GDPval(知識労働) | 70.9% | - | 83.0% |
| OSWorld-Verified(PC操作) | 47.3% | - | 75.0% |
| BrowseComp(Web検索) | 65.8% | - | 82.7% |
| ハルシネーション率(Web利用時) | 基準 | 26.8%低減 | さらに改善 |
| ハルシネーション率(内部知識のみ) | 基準 | 19.7%低減 | さらに改善 |
| クレーム単位の誤り率 | 基準 | - | 33%減少 |
| レスポンス全体のエラー率 | 基準 | - | 18%低下 |
注目すべきポイントは2つあります。まずGDPvalが70.9%→83.0%と12ポイント以上向上した点です。
GDPvalは44の専門職にわたる知識労働の能力を測定するベンチマークで、スプレッドシート作成やプレゼン資料生成など日常的なオフィスワークの品質が大きく上がったことを示しています。
もう1つは事実精度の段階的な改善です。
GPT-5.3 Instantの時点でハルシネーション率がWeb利用時に26.8%低減されていましたが、GPT-5.4ではさらにクレーム単位の誤り率33%減少を達成しています。
GPT-5.2→5.3→5.4と世代を追うごとに、回答の信頼性が着実に向上していることがわかります。
機能面の違い
性能の向上に加え、使える機能そのものも大きく変わっています。
| 機能 | GPT-5.2 | GPT-5.3 Instant | GPT-5.4 |
|---|---|---|---|
| コンピュータ操作 | 非対応 | 非対応 | ネイティブ対応 |
| Tool Search | 非対応 | 非対応 | 対応(トークン47%削減) |
| コンテキストウィンドウ | 20万トークン | 12.8万トークン | 105万トークン |
| Mid-Response Steering | 非対応 | 非対応 | 対応(Thinking版) |
| Web検索連携 | 基本対応 | 文脈統合型に改善 | さらに強化 |
| 不要な拒否・説教調 | あり | 大幅に削減 | さらに改善 |
| 推論レベル設定 | high/low | - | none/low/medium/high/xhigh |
| 主な用途 | 汎用 | ChatGPTデフォルト(高速・日常会話) | 全領域統合 |
ざっくりまとめると、GPT-5.3 Instantが「日常会話の自然さと事実精度」を改善したのに対し、GPT-5.4は「それらを引き継ぎつつ、PC操作やエージェント機能まで1つのモデルに統合した」のが最大の違いです。
従来はコーディングにGPT-5.3-Codex、推論にGPT-5.2 Thinkingと使い分ける必要がありましたが、GPT-5.4なら1つのモデルですべてをカバーできます。
ベンチマーク性能比較
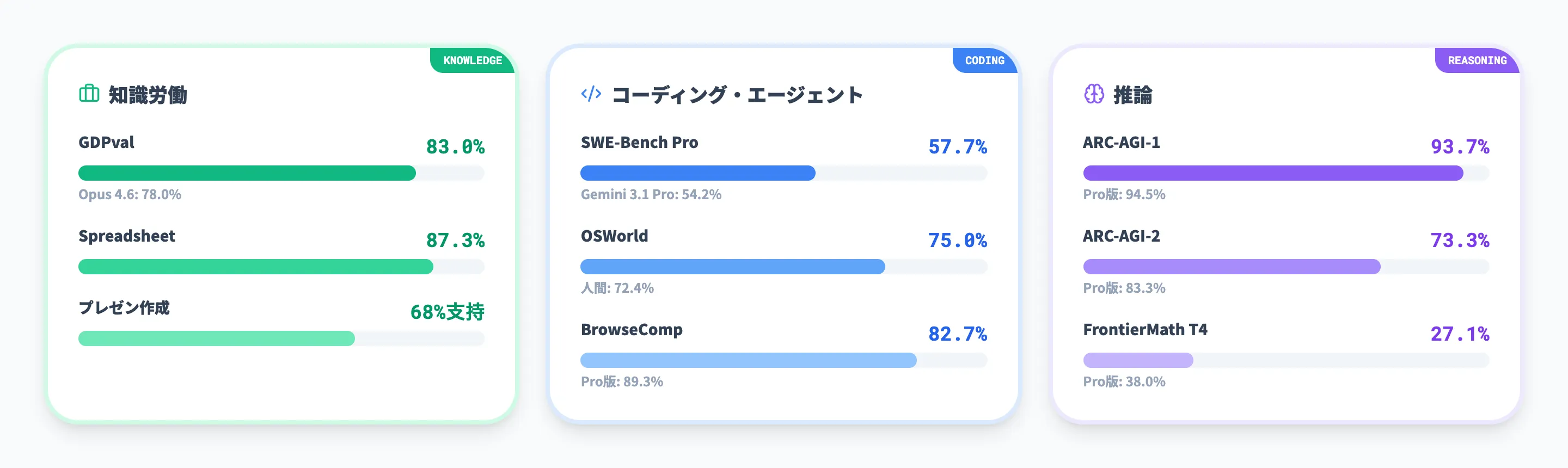
GPT-5.4は複数のベンチマークで競合モデルを上回る成績を記録しています。分野別に詳しく見ていきましょう。
知識労働ベンチマーク
GDPvalは44の専門職にわたる実務能力を測るベンチマークで、スプレッドシート作成やプレゼン資料生成なども評価対象です。
| ベンチマーク | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1 Pro |
|---|---|---|---|
| GDPval(知識労働全体) | 83.0% | 78.0% | 非公開 |
| GDPval-Spreadsheet(表計算) | 87.3% | - | - |
| プレゼン作成の人間評価 | 68%が支持 | - | - |
GDPvalにおいて、GPT-5.4はClaude Opus 4.6の78.0%を5ポイント上回る83.0%を達成しました。以下のグラフは、各モデルの業界専門家に対する勝率を示したものです。
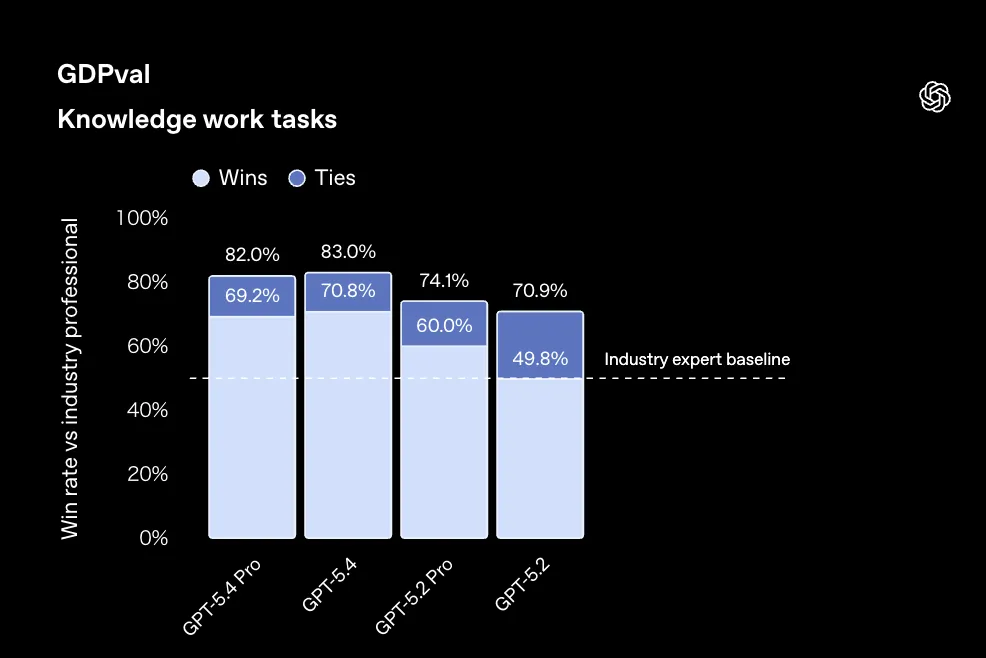
GDPvalにおけるモデル別勝率(参照:OpenAI)
特にスプレッドシート作成では87.3%と高いスコアを記録しており、GPT-5.2時代の68.4%から約19ポイントの改善です。
以下は同一条件でスプレッドシートを生成した結果の比較です。
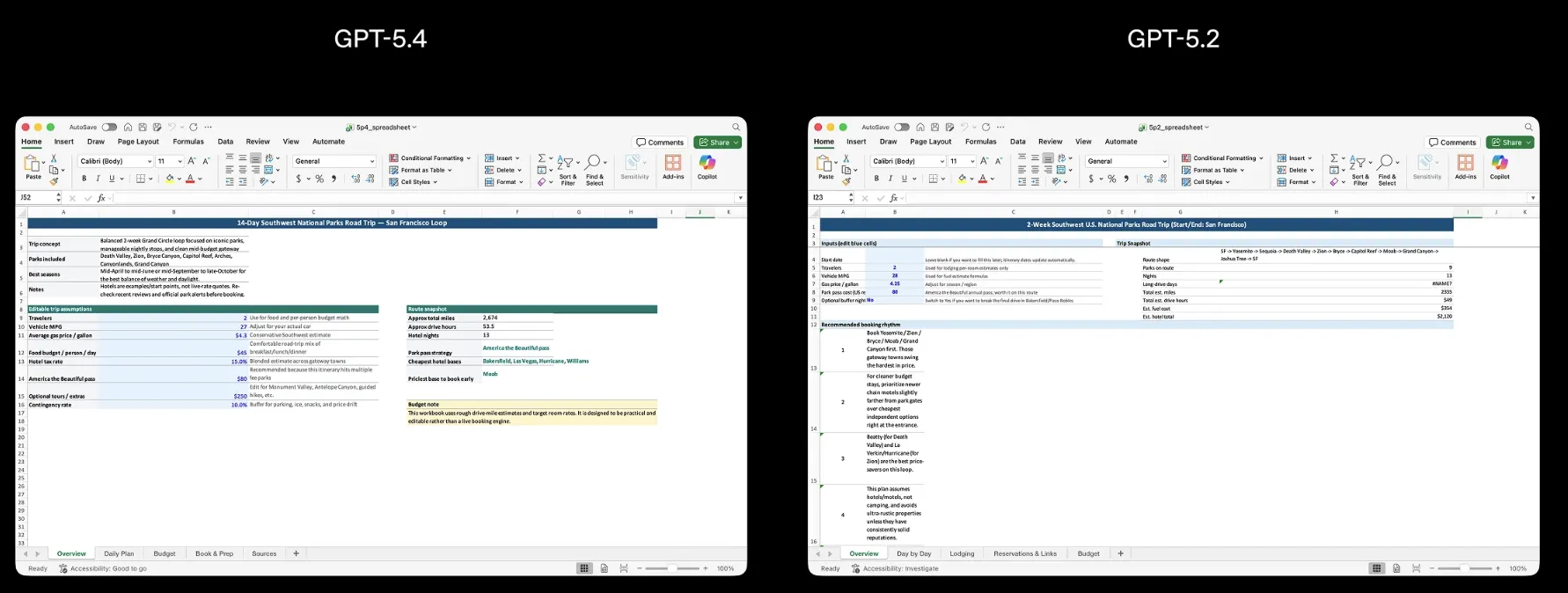
GPT-5.4(左)とGPT-5.2(右)によるスプレッドシート出力の比較
GPT-5.4は表の構造やフォーマットの整合性が大きく向上しており、数値の改善が実際の出力品質に直結していることが確認できます。
また、プレゼン資料の作成でも、品質差が視覚的に表れています。
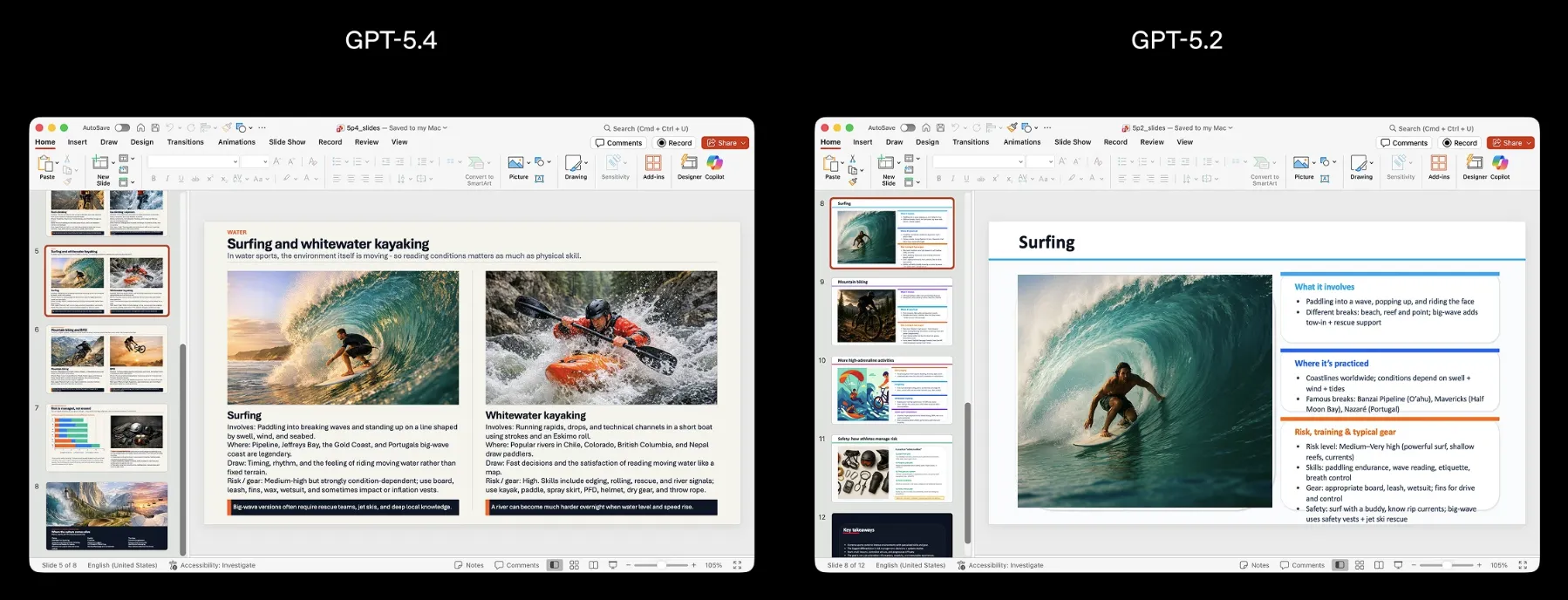
GPT-5.4(左)とGPT-5.2(右)によるプレゼン資料出力の比較
GPT-5.4はレイアウト構成や画像配置が洗練されており、人間評価で68%がGPT-5.4を支持した結果と整合しています。
コーディング・エージェントベンチマーク
コーディングとエージェント能力に関する主な結果は次のとおりです。
| ベンチマーク | GPT-5.4 | GPT-5.4 Pro | 競合最高値 |
|---|---|---|---|
| SWE-Bench Pro(ソフトウェア工学) | 57.7% | - | Gemini 3.1 Pro: 54.2% |
| Terminal-Bench 2.0(ターミナル操作) | 75.1% | - | - |
| OSWorld-Verified(PC操作) | 75.0% | - | 人間: 72.4% |
| WebArena-Verified(ブラウザ操作) | 67.3% | - | - |
| BrowseComp(Web検索) | 82.7% | 89.3% | Gemini 3.1 Pro: 85.9% |
| Toolathlon(ツール活用) | 54.6% | - | - |
| MCP Atlas(MCP連携) | 67.2% | - | - |
**OSWorld-Verifiedで人間のパフォーマンス(72.4%)を超える75.0%**という結果が象徴的です。
以下のグラフで、GPT-5.4とGPT-5.2のパフォーマンス推移を確認できます。
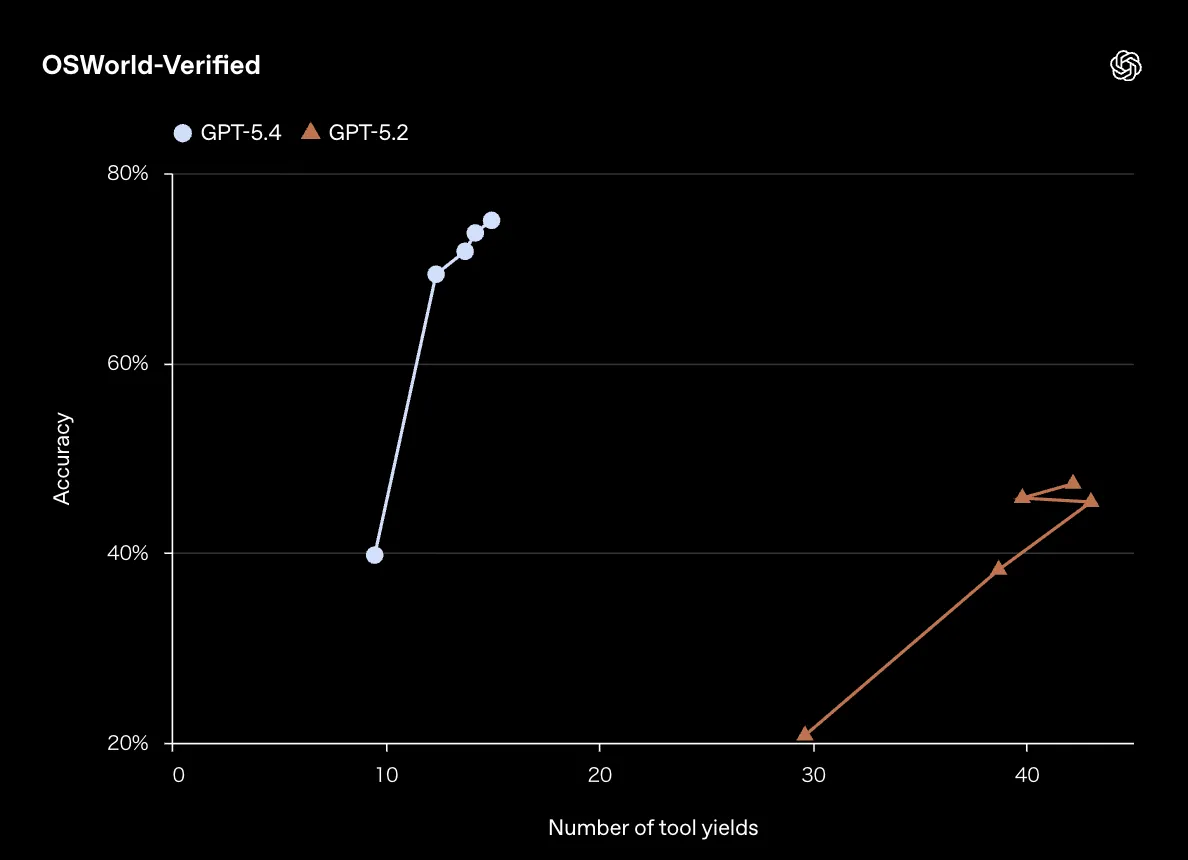
OSWorld-Verifiedの精度とツール実行回数の比較(参照:OpenAI)
つまりGPT-5.4は少ない操作ステップでより正確にタスクを完了できるようになりました。操作効率の改善は、実運用でのレスポンス時間やAPIコストの削減に直結します。
そしてSWE-Bench Proでは、精度とレイテンシのバランスでも進化が見られます。
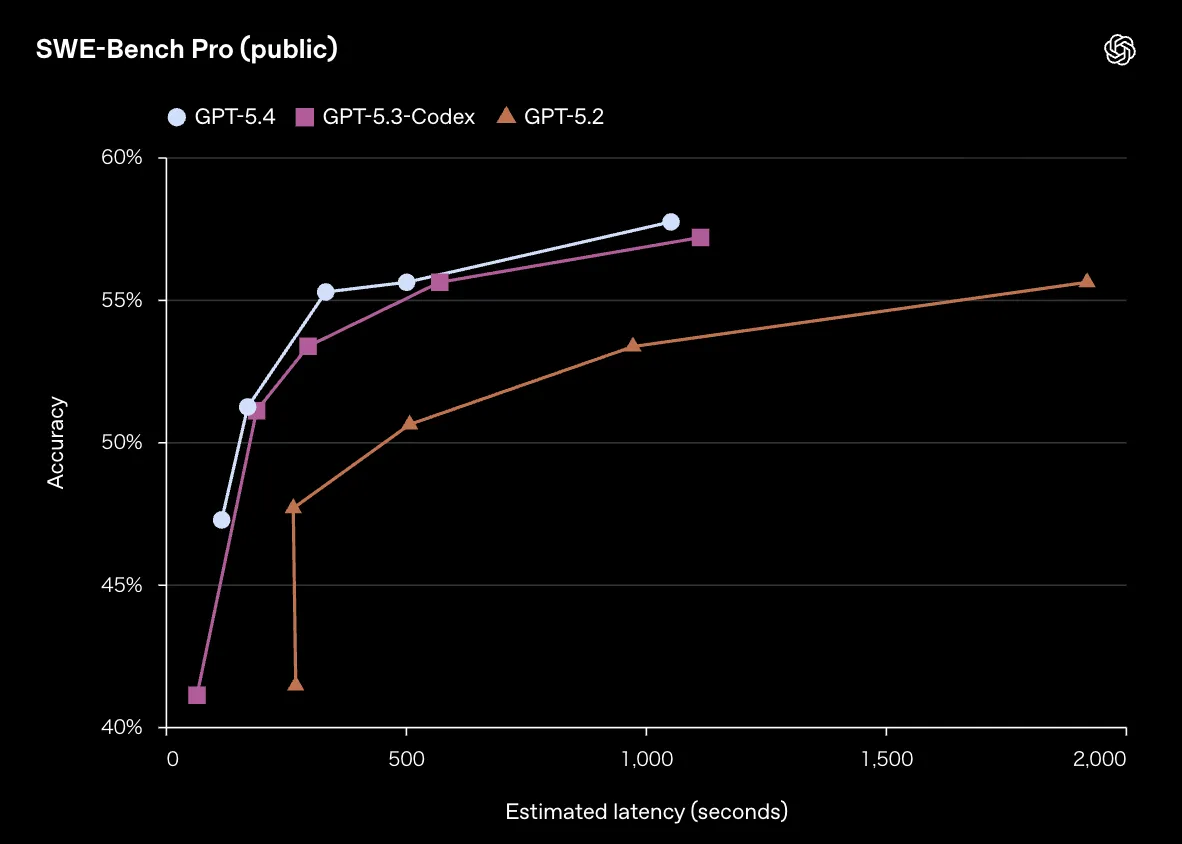
SWE-Bench Proにおける精度とレイテンシの推移(参照:OpenAI)
GPT-5.2は2,000秒(約33分)かけても56%程度にとどまる一方、GPT-5.4は1,000秒(約17分)で58%に到達しています。開発タスクの実行速度と精度の両面で改善が進んでいます。
BrowseCompでも、GPT-5.4の進化幅が確認できます。
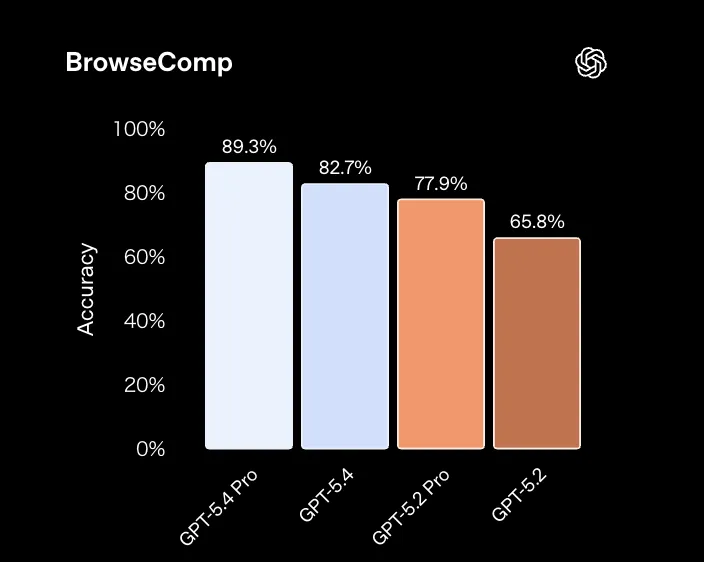
BrowseCompにおけるモデル別精度(参照:OpenAI)
GPT-5.4 Proが89.3%で最高スコアを記録し、標準版も82.7%とGPT-5.2の65.8%から約17ポイント改善しています。
そして、ツール活用能力を測るToolathlonでも、GPT-5.4は明確な優位性を示しています。
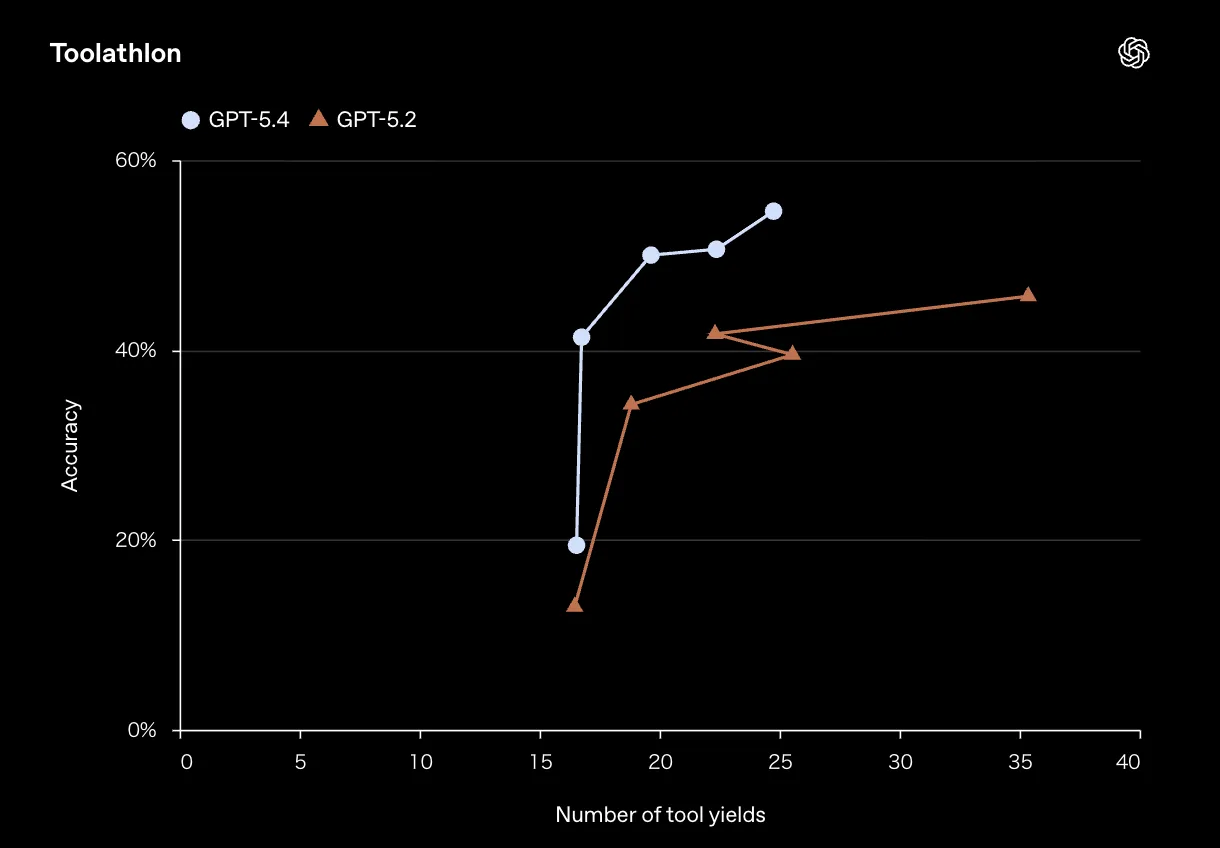
Toolathlonにおける精度とツール実行回数の比較(参照:OpenAI)
OSWorldと同様に、GPT-5.4はGPT-5.2より少ないツール実行回数で高い精度を達成しています。
推論ベンチマーク
高度な推論能力を測定するベンチマークも見ておきましょう。
| ベンチマーク | GPT-5.4 | GPT-5.4 Pro |
|---|---|---|
| ARC-AGI-1 | 93.7% | 94.5% |
| ARC-AGI-2 | 73.3% | 83.3% |
| FrontierMath Tier 4 | 27.1% | 38.0% |
ARC-AGI-2では、GPT-5.4 Proが83.3%を達成しています。
FrontierMath Tier 4は数学の最先端問題を扱う難関ベンチマークであり、Pro版の38.0%は現時点で最高水準のスコアです。
エージェント的な推論能力を測るτ²-bench Telecomでも、世代間の着実な進化が確認できます。
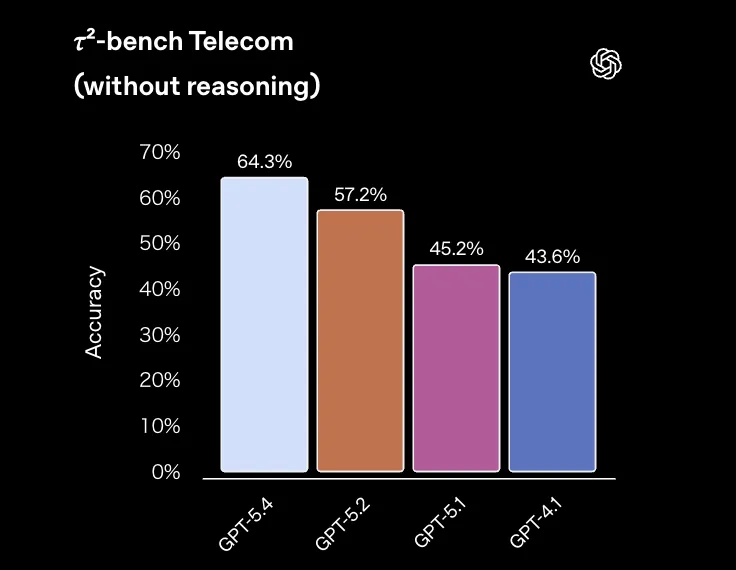
τ²-bench Telecom(推論なし設定)のモデル別精度(参照:OpenAI)
推論なし設定でもGPT-5.4は64.3%を記録し、GPT-5.2(57.2%)、GPT-5.1(45.2%)、GPT-4.1(43.6%)を大きく上回っています。
世代を追うごとにベースラインの能力自体が底上げされていることがわかります。
事実精度の向上
ベンチマークの数値改善に加え、回答の事実精度も大幅に向上しています。
OpenAIの評価によると、GPT-5.4はGPT-5.2と比較して個別クレーム(主張)の誤り率が33%減少し、レスポンス全体でエラーが含まれる確率も18%低下しました。
ハルシネーション(AIが事実と異なる情報を生成する現象)の抑制は、企業でのAI活用における最大の課題の1つです。
この改善により、ビジネス文書の作成やデータ分析など、正確性が求められるタスクでの信頼性が向上しています。
事実精度に関連する他の評価指標でも、GPT-5.4はGPT-5.2を上回っています。
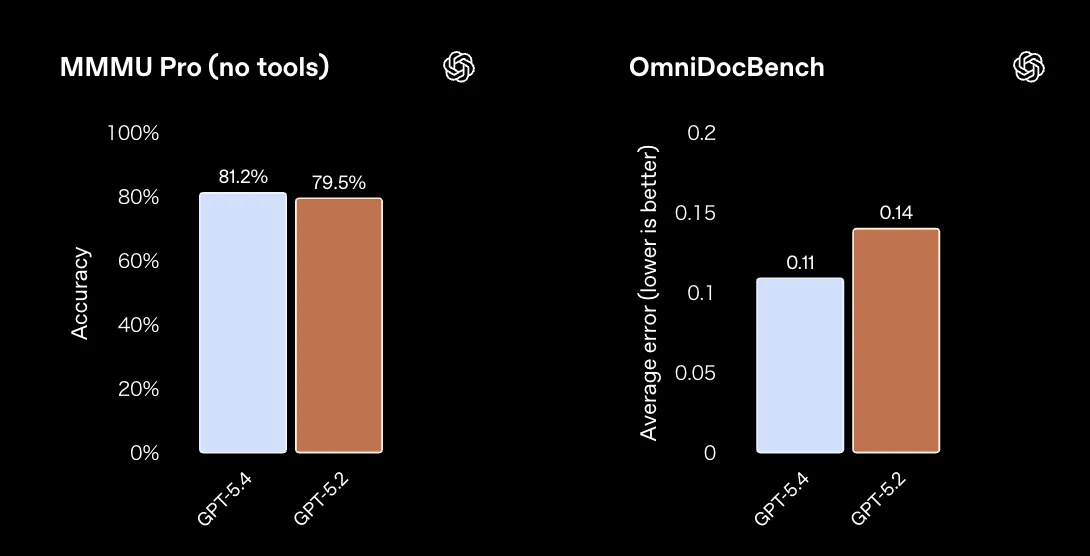
MMMU Pro(マルチモーダル理解)とOmniDocBench(文書理解エラー率)(参照:OpenAI)
MMMU Proでは81.2%(GPT-5.2: 79.5%)、OmniDocBenchでは平均エラー率0.11(GPT-5.2: 0.14)と、いずれも改善が確認されています。
特にOmniDocBenchのエラー率低下は、後述するエンタープライズ文書処理での精度向上を裏づけるものです。
GPT-5.4の料金体系

GPT-5.4の料金は、API利用とChatGPTプランで体系が異なります。
2026年3月時点の最新情報を整理します。
ChatGPTプラン別のアクセス
ChatGPTのプランによって使えるバリアントが異なります。
| プラン | GPT-5.4 Thinking | GPT-5.4 Pro | 月額料金(目安) |
|---|---|---|---|
| Free | 自動切替で一部利用あり(手動選択不可) | 非対応 | 無料 |
| Plus | モデルピッカーから手動選択可能 | 非対応 | $20/月 |
| Business | モデルピッカーから手動選択可能 | 対応 | $25/月/ユーザー |
| Pro | 対応 | 対応 | $200/月 |
| Enterprise | 対応 | 対応 | 要問い合わせ |
| Edu | 対応 | 対応 | 要問い合わせ |
GPT-5.4 ThinkingはPlus以上のプランでモデルピッカーから手動選択が可能です。
Freeプランでも会話内容に応じて自動的にGPT-5.4 Thinkingに切り替わる場合があります。GPT-5.4 ProはPro、Business、Enterprise、Eduプランで利用できます。
GPT-5.4のAPI料金
GPT-5.4の標準版はGPT-5.2と比較して、入力料金が$1.75→$2.50(約43%増)、出力料金が$14.00→$15.00(約7%増)となっています。
入力料金の上昇幅が大きい点に注意が必要ですが、同等タスクを少ないトークンで処理できる効率化を考慮すると、実質コストはモデルの性能向上に見合ったものといえます。
| モデル | 入力(100万トークンあたり) | キャッシュ入力 | 出力(100万トークンあたり) |
|---|---|---|---|
| gpt-5.4 | $2.50 | $0.25 | $15.00 |
| gpt-5.4-pro | $30.00 | - | $180.00 |
| gpt-5.2(レガシー) | $1.75 | $0.175 | $14.00 |
| gpt-5.2-pro(レガシー) | $21.00 | - | $168.00 |
あわせて把握しておきたい追加料金体系もあります。
-
27.2万トークン超過時の割増料金
入力が27.2万トークンを超えるリクエストでは、セッション全体の入力料金が2倍、出力料金が1.5倍に設定されます。
つまりgpt-5.4の場合、入力$5.00/100万トークン、出力$22.50/100万トークンとなります。
-
バッチ・フレックス処理
非リアルタイムのバッチ処理では、標準料金の50%で利用可能です。一方、優先処理(Priority)は標準料金の2倍です。
-
リージョン処理
リージョン処理エンドポイントを利用する場合、10%の追加料金が発生します。
APIの料金や利用方法について詳しくは、ChatGPT APIの料金解説をご覧ください。
GPT-5.4の使い方

GPT-5.4はChatGPT、API、GitHub Copilot、Microsoft Foundryの4つのチャネルで利用できます。それぞれの始め方を解説します。
ChatGPTアプリ
ChatGPTでGPT-5.4を利用する手順は次のとおりです。
Plus/Pro/Businessプランの場合
ChatGPTにログインし、チャット画面上部のモデルピッカーからGPT-5.4 Thinkingを選択します。
会話を開始すると、モデルがまず短い作業計画(プリアンブル)を提示するので、内容を確認してからやり取りを進めましょう。
Freeプランの場合
モデルピッカーからの手動選択はできませんが、会話の内容に応じてGPT-5.4 Thinkingに自動的に切り替わる場合があります。
確実にGPT-5.4を利用したい場合はPlusプラン($20/月)へのアップグレードを検討してください。
GPT-5.4 Proを使う場合
Pro($200/月)、Business、Enterprise、Eduプランで利用可能です。
モデルピッカーに表示されるGPT-5.4 Proを選択するだけで、追加の計算リソースを使った最高精度の回答が得られます。
ChatGPTのアカウント登録やプラン変更について詳しくは、ChatGPT(チャットGPT)とは?日本語での始め方や料金、使い方を徹底解説!をご覧ください。
API
APIでGPT-5.4を利用するには、OpenAI Platformでアカウントを作成し、APIキーを取得したうえで以下の手順で呼び出します。
基本的なリクエストの構成は次のとおりです。
-
モデルIDの指定
標準版はgpt-5.4、高精度版はgpt-5.4-proをモデルIDに指定します。
-
推論レベルの設定
reasoning_effortパラメータでnone、low、medium、high、xhighの5段階から選択できます。
日常的なタスクにはlowやmedium、複雑な分析にはhighやxhighが適しています。noneに設定すると推論機能がオフになり、temperatureやtop_pの従来型パラメータが利用可能です。
-
コンピュータ操作の有効化
ネイティブ・コンピュータ操作を利用する場合は、Computer Use APIを有効にしたうえでリクエストを送信します。
スクリーンショットの送信とアクション指示のループで動作します。
-
Tool Searchの設定
大量のツール定義を利用する場合、Tool Searchを有効にすることでトークン消費を最大47%削減できます。
ツール定義をOpenAIのサーバーに事前登録し、モデルが必要に応じて動的に読み込む仕組みです。
APIキーの取得方法や詳しい使い方は、ChatGPT APIとは?OpenAI APIの使い方や料金、活用事例を解説!をご参照ください。
GitHub Copilot
GPT-5.4はリリース当日の2026年3月5日からGitHub Copilotでも一般提供(GA)されています。
対応プランは次のとおりです。
-
Copilot Pro / Pro+
個人開発者向けプラン。Copilot Chatのモデル選択でGPT-5.4を指定できます。
-
Copilot Business / Enterprise
組織向けプラン。管理者がCopilot設定でGPT-5.4ポリシーを有効にすると、メンバーが利用可能になります。
GPT-5.4のエージェント的なコーディング能力(SWE-Bench Pro: 57.7%)がCopilot上でも活用でき、コード補完だけでなく複数ファイルにまたがるリファクタリングやバグ修正にも対応します。
【関連記事】
GitHub Copilotの料金プラン一覧!個人・法人プランの違いと選び方を解説
Microsoft Foundry(Azure OpenAI)
GPT-5.4はMicrosoft Foundry(旧Azure AI Foundry)でも近日中に一般提供が予定されています。
Microsoft Foundry経由で利用する場合のポイントは次のとおりです。
-
エンタープライズ向けのセキュリティとガバナンス
Azureのネットワーク・ID管理・コンプライアンス機能と統合して利用できます。
データがOpenAIのサーバーに送信されないプライベートエンドポイント構成も可能です。
-
エージェントワークフローの本番運用
GPT-5.4のネイティブ・コンピュータ操作やTool Search機能を、Foundry Agent Service上でスケーラブルに実行できます。
-
既存のAzure OpenAI Serviceからの移行
Azure OpenAI Serviceを利用中の場合、モデルデプロイメントでgpt-5.4を選択するだけで切り替えが可能です。

GPT-5.4の3つのモデルバリアントと使い分け

GPT-5.4には3つのバリアントがあり、利用シーンに応じた使い分けが重要です。それぞれの特徴と向いている用途を見ていきます。
GPT-5.4(標準)
GPT-5.4の標準バリアントは、推論・コーディング・ツール操作を統合した汎用モデルです。
APIでは推論レベルをnone、low、medium、high、xhighの5段階で設定できます。推論レベルをnoneに設定した場合、temperatureやtop_pなどの従来型パラメータも利用可能です。
向いている用途は次のとおりです。
-
日常的な文書作成・要約
メールの下書き、レポートの要約、議事録の整理など、高度な推論を必要としないタスクに最適です。推論レベルをnoneまたはlowに設定することで、応答速度とコストを最適化できます。
-
コーディング支援
GPT-5.3-Codexの能力が統合されているため、コード生成・レビュー・デバッグに別モデルを呼び出す必要がありません。
-
エージェントワークフロー
Tool SearchやコンピュータAPI操作を活用した自動化タスクに利用できます。
5.4 Thinking
GPT-5.4 ThinkingはChatGPT上でgpt-5.4を推論強化モードで利用する形態です。
Plus、Business、Proプランではモデルピッカーから手動選択が可能であり、Freeプランでも会話の内容によって自動的にGPT-5.4 Thinkingに切り替わる場合があります。
特徴的なのは次の2点です。
-
作業計画の事前提示
複雑なクエリに対して、モデルが短い作業計画(プリアンブル)を冒頭に提示します。ユーザーはモデルの作業方針を事前に確認できます。
-
Mid-Response Steering
思考の途中でユーザーが介入し、方向修正の指示を追加できます。出力が完了するまで待つ必要がなくなるため、特に長い回答を生成するタスクで効率的です。
GPT-5.4 Thinkingは、戦略立案、複雑な分析、多段階の問題解決など、深い思考が求められるタスクに向いています。
GPT-5.4 Pro
GPT-5.4 Proは追加の計算リソースを投入し、より深い推論を行う最高性能モデルです。
APIに加え、ChatGPTではPro、Business、Enterprise、Eduプランで利用可能です。
APIモデルとChatGPT提供形態の違いを整理すると次のようになります。
| 項目 | gpt-5.4(API) | GPT-5.4 Thinking(ChatGPT) | gpt-5.4-pro(API) |
|---|---|---|---|
| 利用チャネル | API | ChatGPT(Plus以上で手動選択可、Freeは自動切替) | API、ChatGPT(Pro/Business/Enterprise/Edu) |
| 推論レベル | 5段階で設定可能 | 自動 | 最大性能で固定 |
| コンピュータ操作 | 対応 | 対応 | 対応 |
| API入力料金 | $2.50/100万トークン | - | $30.00/100万トークン |
| API出力料金 | $15.00/100万トークン | - | $180.00/100万トークン |
| 適した用途 | 汎用タスク | 複雑な分析・戦略立案 | 高精度が必要な研究・専門業務 |
Pro版は標準版の12倍の料金ですが、ARC-AGI-2のスコアが73.3%→83.3%と10ポイント向上するなど、最高精度が求められる場面で真価を発揮します。
一般的なビジネスユースなら標準版で十分な性能が得られるので、まずは標準版から試すのが現実的です。
GPT-5.4のユースケース

ここまで機能やベンチマークを見てきましたが、実務ではどう使えるのでしょうか。リリース直後に報告されている活用事例と想定ユースケースを紹介します。
エンタープライズ文書処理
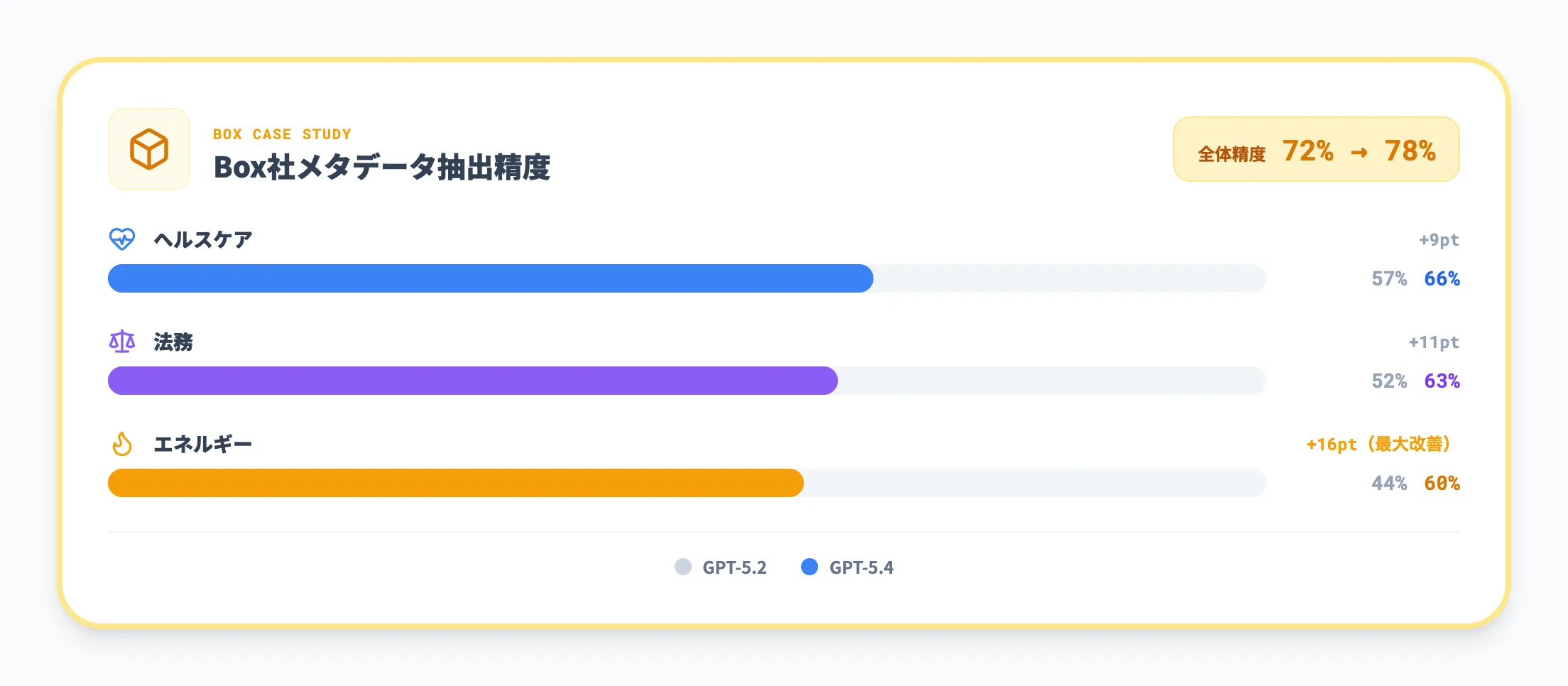
クラウドコンテンツ管理のBoxは、GPT-5.4を活用したメタデータ抽出の評価結果を公式ブログで公開しています。
Boxの評価では、GPT-5.4によるメタデータ抽出の全体精度が72%から78%へ向上しました。業種別のQ&A(質問応答)パフォーマンスは以下のとおりです。
| 業種 | GPT-5.2 | GPT-5.4 | 改善幅 |
|---|---|---|---|
| ヘルスケア | 57% | 66% | +9pt |
| 法務 | 52% | 63% | +11pt |
| エネルギー | 44% | 60% | +16pt |
特にエネルギー業界で16ポイントの改善が目立ちます。規制文書や技術レポートなど、専門性が高く構造が複雑な文書ほどGPT-5.4の精度向上が顕著に表れている形です。
また、文書タイプ別では臨床データ(81%→86%)、法的契約書(82%→85%)、政府統計出版物(60%→70%)でも精度が向上しています。
以下は、GPT-5.4とGPT-5.2がそれぞれ生成したWord文書の比較です。
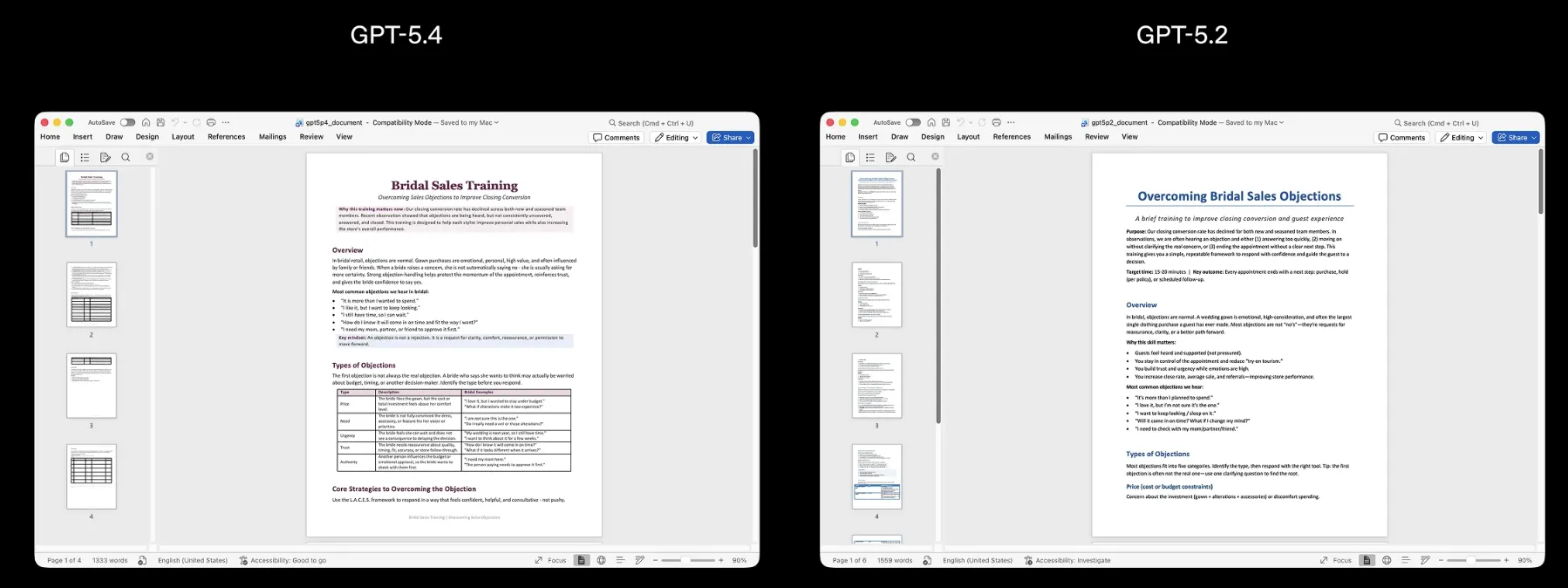
GPT-5.4(左)とGPT-5.2(右)による同一テーマのWord文書出力比較
GPT-5.4はセクション構造の整理、表の適切な配置、読みやすいフォーマットの維持など、文書としての完成度が大きく向上しています。メタデータ抽出精度の数値改善が、実際の出力品質に反映されていることを確認できる事例です。
コーディング・開発支援
GPT-5.4はGPT-5.3-Codexのコーディング能力を統合しており、SWE-Bench Proで57.7%(Gemini 3.1 Proの54.2%を上回る)を記録しています。
開発支援では、たとえば次のようなユースケースが考えられます。
-
コードベース全体の分析
100万トークンのコンテキストウィンドウにより、大規模なリポジトリ全体を読み込んだうえでバグの特定や設計レビューが可能になります。
-
ビルド・実行・検証・修正ループ
GPT-5.4はコードを書く→実行する→結果を検証する→問題があれば修正する、というエージェント的なループを自律的に回せます。
-
ターミナル操作の自動化
Terminal-Bench 2.0で75.1%を記録しており、CLIベースの開発タスクも効率的に支援します。
OpenAI Codexとは?主な特徴や使い方、料金体系を徹底解説!もご参照ください。
エージェントワークフロー
GPT-5.4のネイティブ・コンピュータ操作とTool Search機能を組み合わせることで、従来は複数のツールや手作業が必要だったワークフローを自動化できます。
具体的には、次のようなシナリオが想定されます。
-
データ収集と入力の自動化
Webサイトからデータを収集し、社内システムのフォームに入力する作業を、AIがスクリーンショットを見ながら自律的に実行します。
-
レポート作成の自動化
複数のソースからデータを取得し、スプレッドシートにまとめ、プレゼン資料として整形する一連の作業を、1つのプロンプトで指示できます。GDPvalのスプレッドシートスコア87.3%がこの実力を裏づけています。
-
ソフトウェアテストの自動化
OSWorld-Verifiedで人間を超えるスコアを記録しているため、ブラウザやアプリケーションの操作テストをAIに委任できる可能性があります。
AIエージェントとは──日本・世界の事例を徹底紹介では、AIエージェントの活用事例をさらに詳しく解説しています。
GPT-5.4の注意点と安全性評価
GPT-5.4は高い性能を持つ一方で、利用にあたって把握すべきリスクと制限もあります。OpenAIが公開した安全性評価の結果と、実運用で気をつけたいポイントを整理します。
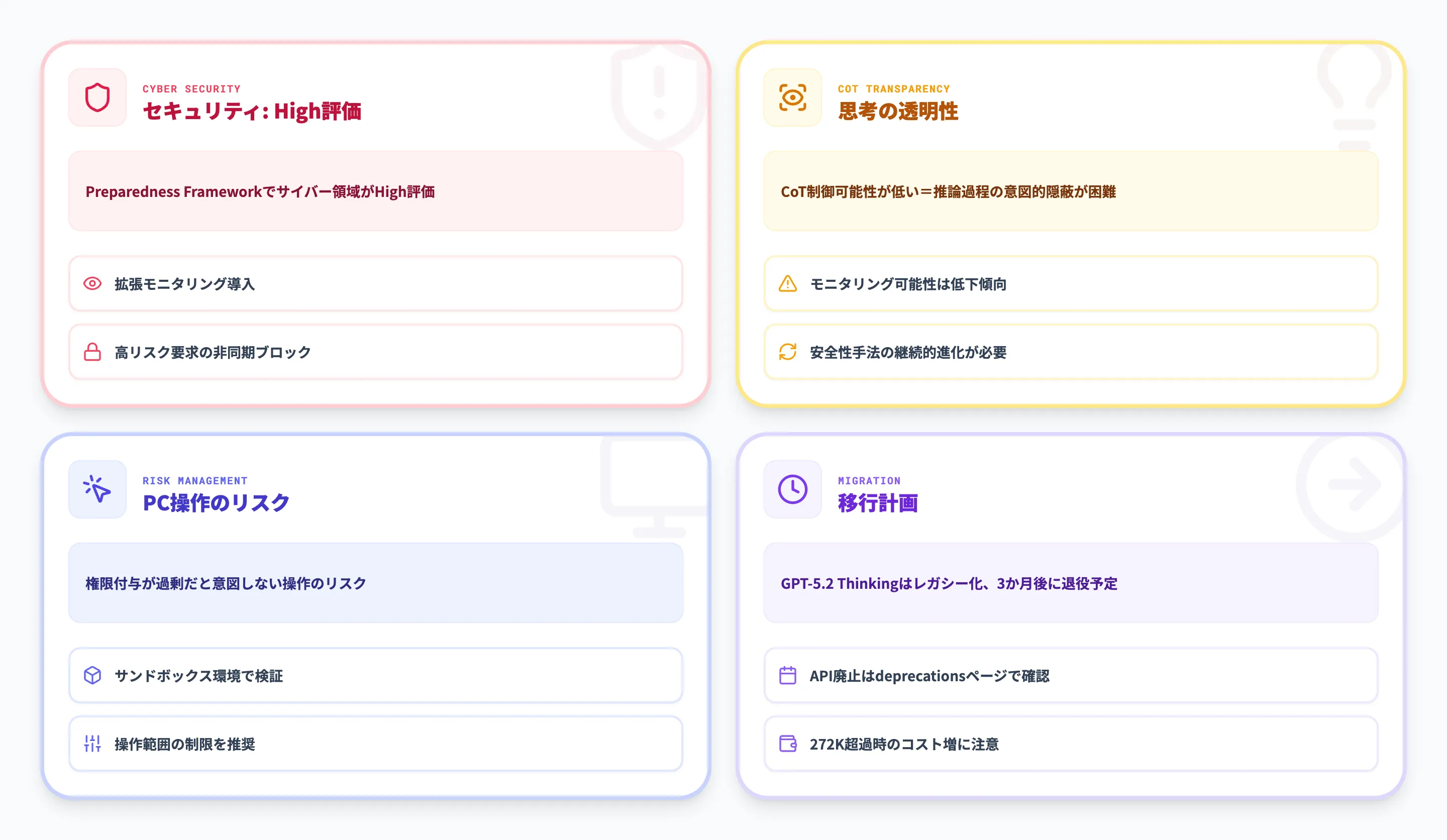
Preparedness Framework評価
OpenAIはGPT-5.4 Thinking System Cardを公開し、安全性評価の詳細を報告しています。
GPT-5.4は、OpenAIの安全性フレームワーク(Preparedness Framework)においてサイバーセキュリティ領域でHigh(高)評価を受けています。
これにより、以下のような追加の安全対策が講じられています。
-
拡張サイバーセーフティスタック
モニタリングシステム、信頼済みアクセス制御、高リスクリクエストに対する非同期ブロッキングが導入されています。
-
生物・化学・核領域のリスク評価
専門的な知識を悪用されるリスクが評価されており、該当するクエリには制限が設けられています。
思考の透明性とモニタリング
GPT-5.4 Thinkingの思考過程(Chain-of-Thought)に関して、重要な特性が確認されています。
OpenAIはGPT-5.4 Thinking System Cardにおいて、CoT制御可能性(Chain-of-Thought Controllability)という評価指標を導入しています。
GPT-5.4 ThinkingのCoT制御可能性は低い水準と報告されており、OpenAIはこの結果を「モデルが推論過程を意図的に隠蔽しにくいことを示唆する」と位置づけています。
一方で、13の評価環境にわたる集計では、GPT-5.4 ThinkingのCoTモニタリング可能性がGPT-5 Thinkingよりも低下しているという結果も報告されています。
モデルの能力向上に伴い、安全性の監視手法も継続的に進化させる必要があります。
利用時の注意点
実際に使ううえで留意しておきたい点をまとめます。
-
コンピュータ操作のリスク管理
ネイティブ・コンピュータ操作は強力な機能ですが、AIに実行権限を与えすぎると意図しない操作が行われるリスクがあります。
本番環境での利用にあたっては、操作範囲の制限やサンドボックス環境での検証を推奨します。
-
272Kトークン超過時のコスト増
100万トークンのコンテキストウィンドウは便利ですが、27.2万トークンを超えるリクエストでは入力料金が2倍、出力料金が1.5倍になります。大量の文書を処理する際はコスト試算が重要です。
-
知識カットオフ
GPT-5.4の知識カットオフは2025年8月31日です。それ以降の情報については、Web検索機能との併用が必要です。
-
GPT-5.2からの移行計画
ChatGPT上のGPT-5.2 Thinkingはレガシーモデルに移行されており、3か月後に退役予定です。APIの廃止スケジュールはdeprecationsページで確認してください。

最新AIモデルの進化を見据えて組織のAI業務設計を固める
GPT-5.4の性能と料金体系を理解した上で、自社の業務にAIをどう活かすかの全体像を描く準備が整いました。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に進めるための実践ガイド(220ページ)を無料で提供しています。部門別のBefore/After付きユースケースと、PoC設計から全社展開までのロードマップを掲載しています。
AI総合研究所が、最新のAIモデル動向を踏まえた業務自動化の計画策定をお手伝いいたします。
最新モデルの理解を組織のAI活用に接続

Microsoft環境でのAI業務自動化ガイド
GPT-5.4のエージェント機能を把握したら、次は組織としてAIを段階的に業務に組み込む設計が重要です。Copilot Chatからの段階的導入方法を220ページで解説します。
まとめ
GPT-5.4は、OpenAIが2026年3月5日にリリースした最新フラグシップモデルです。推論・コーディング・エージェント機能を1つのモデルに集約し、AIの実務活用における新たな段階を切り開いています。
この記事のポイントを振り返りましょう。
-
ネイティブ・コンピュータ操作
OSWorld-Verifiedで75.0%と人間の72.4%を超え、AIによるPC操作が実用レベルに到達しました。
-
大幅な性能向上
GDPvalで83.0%(GPT-5.2の70.9%から+12.1pt)、事実精度はクレーム単位の誤り率33%減少を達成しています。
-
APIモデルとChatGPT提供形態
gpt-5.4(標準)、gpt-5.4-pro(高精度)のAPIモデルに加え、ChatGPTではGPT-5.4 Thinking(途中介入対応)として利用できます。
-
新機能
Tool Searchによるトークン47%削減、100万トークンコンテキスト、Mid-Response Steeringが追加されました。
-
API料金
入力$2.50/100万トークン、出力$15.00/100万トークン。27.2万トークン超過時は割増料金が適用されます。
ChatGPT上のGPT-5.2 Thinkingはレガシーモデルに移行されており、順次退役が予定されています。GPT-5.2を利用中の方は、早めに移行計画を立てつつ、GPT-5.4の新機能を活かした業務効率化を検討してみてください。
OpenAIのモデル全体について詳しくは、ChatGPTのモデルとは?OpenAIの最新モデル一覧と特徴を解説をご覧ください。










