この記事のポイント
 動画を含む全モダリティ対応ならGemini 3.1 ProかGPT-5.2を選ぶべき。テキスト・画像特化の高精度用途ならClaude Opus 4.6が有力
動画を含む全モダリティ対応ならGemini 3.1 ProかGPT-5.2を選ぶべき。テキスト・画像特化の高精度用途ならClaude Opus 4.6が有力- 企業導入はAzure OpenAI Serviceを基盤にし、セキュリティとファインチューニングの両立を狙うのが現実解
- 市場規模は2030年に108億ドル到達見込みで、今から導入を始めなければ競合に遅れる
- まずは文書理解や画像分析など単一ユースケースでPoCを実施し、効果を実証してから全社展開すべき
- 計算コストとハルシネーションが最大の課題。RAGとの併用でハルシネーションを抑制し、軽量モデル(Gemini Flash等)でコストを制御すべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
マルチモーダルAIは、テキスト・画像・音声・動画など異なる種類のデータを統合して処理できるAI技術です。
2025年の市場規模は29.9億ドルに達し、2030年には108億ドル(CAGR 29.29%)へと急成長が見込まれています。
本記事では、GPT-5.2、Gemini 3.1 Pro、Claude Opus 4.6など主要マルチモーダルAIモデルの比較から、教育・医療・企業での導入事例、導入メリット・課題・料金体系まで網羅的に解説します。
マルチモーダルAIとは
マルチモーダルAI(multimodal AI)は、テキスト・画像・音声・動画・センサーデータなど、複数の異なるモダリティ(情報の種類)を統合して処理する人工知能技術です。従来のAIがテキストのみ、画像のみといった単一のデータタイプに特化していたのに対し、マルチモーダルAIは人間のように複数の感覚情報を組み合わせて理解・判断できる点が大きな特徴です。
たとえば、会話の中で言葉だけでなく相手の表情や声のトーンを考慮して意味を理解するように、マルチモーダルAIも自然言語処理と画像認識を組み合わせてより深い理解を実現します。AIとDXの融合が進む中、マルチモーダルAIは企業のデジタル変革を加速させる中核技術として注目を集めています。
《遂にChatGPT Plusユーザーに解放された”DALL-E3”が区分されるマルチモーダルAIとは?》数値/音声/テキスト/画像など複数種類のデータを組み合わせて、処理する AIモデル。人間のようなインプット情報の多様性がシングルモーダルAIとの大きな違いです。では、マルチモーダルAIの代表例は?↓ pic.twitter.com/n5edYs70PD
— 坂本将磨@AI総合研究所 (@LinkX_group) October 20, 2023
市場調査によると、マルチモーダルAI市場は2025年の29.9億ドルからCAGR(年平均成長率)29.29%で急成長し、2030年には108.1億ドルに達すると予測されています。特にアジア太平洋地域はCAGR 42.67%と最も速い成長が見込まれており、日本企業にとっても重要な技術領域です。
以下の表で、マルチモーダルAIとシングルモーダルAI(単一のデータタイプに特化したAI)の違いを整理しました。
| 比較項目 | マルチモーダルAI | シングルモーダルAI |
|---|---|---|
| データの扱い | テキスト・画像・音声・動画などを統合処理 | テキストのみ、画像のみなど一種類に特化 |
| 処理方法 | 複数モダリティの情報を相互参照しながら統合分析 | 単一モダリティを対象として処理 |
| 応用分野 | 医療診断、自動運転、マルチメディア検索、ロボティクスなど | 音声認識単体、画像分類単体、テキスト生成単体など |
| 精度の特性 | 複数情報の組み合わせにより文脈理解が向上 | 特化分野での精度は高いが文脈把握に限界あり |
| 代表モデル | GPT-5.2、Gemini 3.1 Pro、Claude Opus 4.6 | BERT(テキスト)、ResNet(画像)、Whisper(音声) |
この表から分かるように、マルチモーダルAIの強みは「複数の情報を統合的に処理できる」点にあります。実務では、テキストで書かれた報告書の内容と添付された画像・グラフを同時に理解したり、動画の映像と音声を組み合わせて状況を分析したりする場面で威力を発揮します。

マルチモーダルAIの仕組みと技術基盤
マルチモーダルAIが複数の情報を統合処理するためには、モダリティごとに異なるデータを共通の表現空間に変換する仕組みが必要です。その中核を担うのが「エンコーダー」と「アテンション機構」です。
マルチモーダルAIは一般的に3つの層で構成されています。まず、各モダリティのデータを取り込む入力層があります。画像認識にはビジョンエンコーダー(ViTなど)、音声認識には音声エンコーダー(Whisperなど)、テキストにはトークナイザーが使われます。次に、これらの異なるモダリティの情報を共通のベクトル空間にマッピングするアダプター層があります。最後に、統合されたマルチモーダル表現をもとに推論・生成を行う大規模言語モデル(LLM)が出力を生成します。
この3層構造によって、たとえば「この画像に写っているものは何ですか?」というテキストの質問と画像データを同時に処理し、画像の内容を言語で説明することが可能になります。AIとIoTの融合により、センサーデータや環境情報まで統合する応用も広がっています。
近年ではリコーがGENIACプロジェクトにおいて、600万枚以上の学習用データを人工生成し、独自のアダプターを開発することでオープンソースのビジョンエンコーダーとLLMを効率的に接続する手法を確立しました。このように、マルチモーダルAIの技術基盤は日本企業においても着実に進化しています。
主要マルチモーダルAIモデル比較(2026年版)
2026年現在、マルチモーダルAIの主要プレイヤーはOpenAI、Google、Anthropicの3社です。各社のモデルはそれぞれ異なる強みを持っており、用途に応じた使い分けが重要です。ここでは代表的なモデルとプラットフォームを紹介します。
GPT-5シリーズとAzure OpenAI Service
OpenAIのGPT-5シリーズは、テキスト・画像・音声・動画を統合処理できるマルチモーダルAIの代表格です。2025年12月にリリースされたGPT-5.2は、ビジネス現場での標準モデルとして定着しています。
最近 周りで「AOAI」(エーオーエーアイ) ってよく聞く👂
— ちょまど🦕ITエンジニア (@chomado) September 13, 2023
「Azure OpenAI」の略なんだね💡
(OpenAI の ChatGPTやGPT-4をはじめとする多様な生成AIモデルを、
Microsoft Azure のクラウドプラットフォーム上で利用できるサービス。
Azure のセキュリティの機能が使えたりなどとても便利)
企業での利用にはAzure OpenAI Serviceが広く活用されています。Microsoftのクラウド基盤上でOpenAIモデルを利用でき、高度なセキュリティとプライバシー保護が提供されます。ユーザーのデータはそのユーザーのモデルのファインチューニングにのみ使用され、他の目的には利用されません。

カスタマイズすることで得られる機能 (参考:Microsoft)
Azure OpenAI Serviceではファインチューニングにより個社のデータに合わせたモデル調整が可能です。また、GPT-5.2ではネイティブな画像生成機能も搭載され、チャット内で直接画像の生成・編集ができるようになりました。ChatGPTの無料プランでも画像・音声の処理が利用可能で、マルチモーダルAIの活用ハードルは大きく下がっています。
Gemini 3シリーズ(Google)
GoogleのGeminiは、テキスト・画像・音声・動画・コードを同一APIで処理できる点で最も包括的なマルチモーダル対応を実現しています。Google検索、Googleマップ、YouTubeなどGoogleのエコシステムとの統合が強みです。
マルチモーダルのGemini 1.5は英語の動画をあげ、日本語でざっと説明してもらう時も大変便利✨。マルチモーダルなので、動画にあるソースコードまで引っ張ってきて解説をしてくれる😮。Python講義動画の日本語ガイドを書いてもらった時の様子↓。Gemini 1.5はこれからの学びの形を大きく変えます🚀。 https://t.co/hTpjSRJjjA pic.twitter.com/VVvRDqVhg7
— sangmin.eth | 安全なう (@gijigae) February 29, 2024
Gemini 3.1 Proは最大200万トークンのコンテキストウィンドウを持ち、長時間の動画分析や大量の文書処理に対応できます。Gemini 3 Flashは軽量・高速モデルとして、リアルタイム処理が求められる場面で威力を発揮します。
従来のマルチモーダルが複数モデルを組み合わせて作られたのに対し、Geminiは最初からマルチモーダルの生成AIとして設計+学習されてる📺↓。ゆえに、上述したPythonの講義動画も音声に加え、画像まで完璧に処理できる。2024年、多くの人の働き方や生活の仕方が本格的に変わります。 pic.twitter.com/BlJhJjCNvO
— sangmin.eth | 安全なう (@gijigae) February 29, 2024
Claude Opus 4.6(Anthropic)
AnthropicのClaudeは、テキストと画像の入力に対応するマルチモーダルAIです。Claude Opus 4.6は知的労働タスクやコーディングにおいて最高水準の性能を誇り、SWE-Bench Verifiedで80.8%を達成しています。200Kトークンのコンテキストウィンドウと長文理解能力が特徴で、複雑な文書分析や専門領域の推論に強みを持っています。
以下の表で、2026年3月時点の主要マルチモーダルAIモデルを比較しました。
| モデル | 開発元 | 対応モダリティ | コンテキスト | 主な強み |
|---|---|---|---|---|
| GPT-5.2 | OpenAI | テキスト/画像/音声/動画 | 200K | 総合的な推論力、画像生成、Azure統合 |
| GPT-4.1 | OpenAI | テキスト/画像 | 1M | コスト効率、大量文書処理 |
| Gemini 3.1 Pro | テキスト/画像/音声/動画/コード | 2M | 最大コンテキスト、Googleエコシステム統合 | |
| Gemini 3 Flash | テキスト/画像/音声/動画/コード | 1M | 軽量・高速・低コスト | |
| Claude Opus 4.6 | Anthropic | テキスト/画像 | 200K | コーディング、長文理解、安全性 |
| Claude Sonnet 4.6 | Anthropic | テキスト/画像 | 200K | バランス型、日常利用向け |
この比較表から見えてくるポイントは、動画を含む全モダリティ対応ではGeminiとGPT-5が先行している一方、テキスト・画像特化でもClaude Opus 4.6のような高精度モデルがビジネス用途で高い評価を得ているということです。2026年のAIモデル選定では、自社の業務で扱うデータの種類に応じて最適なモデルを選ぶことが重要になっています。
マルチモーダルAIの活用事例
マルチモーダルAIは、教育・医療・企業の業務効率化・顧客サービスなど、幅広い分野で実用化が進んでいます。ここでは具体的な導入事例を業界別に紹介します。
教育分野
世界的に人気の高い語学学習アプリDuolingoは、GPT-4を活用した「Duolingo Max」を提供しています。テキスト・音声・画像を組み合わせたマルチモーダルな学習体験を実現し、ユーザーの進捗に応じてカスタマイズされた学習プランを提供しています。
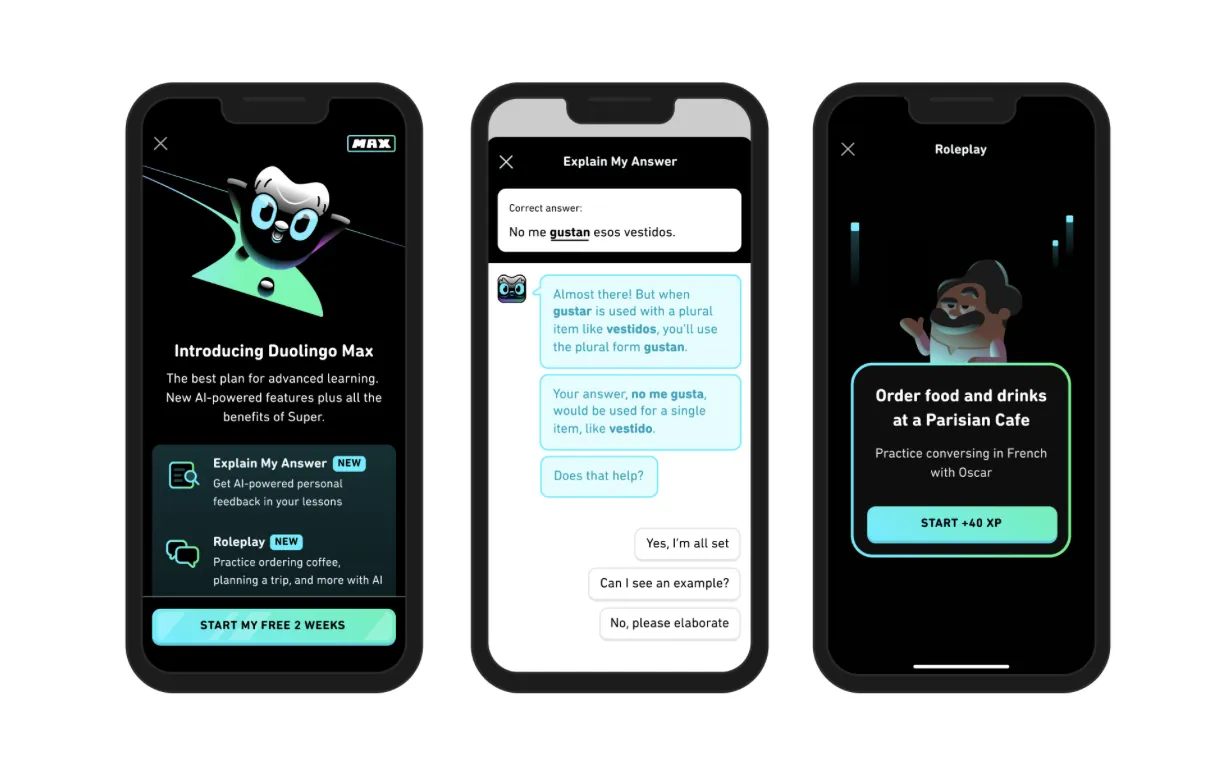
Duolingo Max (参考:Duolingo)
Duolingo Maxでは、AIが学習者の会話内容を理解し、文法の誤りを指摘するだけでなく、なぜその回答が間違っていたのかを文脈に沿って説明する機能を備えています。テキストと音声の双方を活用した言語学習は、マルチモーダルAIならではの効果的な学習手法です。
医療・ヘルスケア分野
医療領域での生成AI活用は急速に進展しており、マルチモーダルAIによる診断精度の向上が注目されています。
2023年6月、日本医科大学はマルチモーダルAIを前立腺がん検査に導入する画期的な取り組みを発表しました。従来の検査ではMRI画像、血液検査結果、臨床データがそれぞれ個別に分析され統合されていませんでしたが、マルチモーダルAIはこれらのデータを同時に統合解析することで、前立腺がんの診断精度を大幅に向上させることが期待されています。
医療ビッグデータを多角的に解析 (引用:日本医科大学)
このようなAIの統合解析は、最適な治療法の選択や病気の進行予測にも応用可能です。複数の医療データを横断的に分析できるマルチモーダルAIは、今後の精密医療において不可欠な技術基盤となるでしょう。
NEC、理化学研究所、日本医科大学が、前立腺がんの医療ビッグデータを多角的に構築するマルチモーダルAIを構築!
— ヒロシズ💊製薬で新規事業 (@Hiro_health_biz) June 20, 2023
✓複数のデータ形式を統合して高度な認識や理解を実現するAI
✓既存手法よりも再発予測精度を10%向上
こんな解析手法があるのか…勉強になります🤔https://t.co/XZNtVIuf2F pic.twitter.com/r5znXtv7am
企業の業務効率化
日本企業でもマルチモーダルAIの実務適用が加速しています。リコーは経済産業省・NEDOのGENIACプロジェクトにおいて、図表を含む日本語文書を高精度に読解するマルチモーダルLLMの基本モデルを2025年6月に開発完了しました。600万枚以上の学習データを人工生成し、日本語の文書理解に特化したモデルを構築しています。
さらにリコーは損保ジャパンとの共創事例として、保険マニュアルの読解にマルチモーダルLLMを適用し、ファインチューニングにより基本モデルを大幅に上回る精度を達成しています。保険契約業務の効率化につながる実用的な成果として注目されています。
そのほかにも、日立製作所は品質保証業務にAIエージェントを適用して作業時間を8割以上短縮し、ソフトバンクは「交通理解マルチモーダルAI」で低遅延のエッジAI技術による遠隔サポートシステムを開発するなど、生成AIによる業務自動化の流れが産業界全体に広がっています。
顧客サービス・接客分野
音声認識と自然言語理解を組み合わせたAIチャットボットや仮想アシスタントにより、顧客との対話がより自然で効果的になっています。
AimeHotelは、ホテルのチェックイン・チェックアウト・部屋の予約・レストランの予約などを自動化できるバーチャルAI受付ソフトウェアを開発し、マルチモーダルAIによる接客業務の革新を示しています。
テキスト・音声・画像を統合処理することで、顧客のスクリーンショットや音声メッセージを同時に理解し、文脈に沿ったきめ細かい対応が可能になります。通信業界では、モデムのLEDランプの写真とテキストメッセージを組み合わせた問い合わせ対応など、マルチモーダルならではのカスタマーサポートも実用化されています。
先端デバイスとの融合
マルチモーダルAIは、ウェアラブルデバイスとの融合によってさらなる進化を遂げています。AIデバイス企業Brilliant Labsは、世界初のマルチモーダルAI搭載グラス「Frame」を発表しました。
このメガネをかけると、目の前のものをリアルタイムで解析し、ウェブ検索・文字翻訳・画像生成が可能です。AIロボットやウェアラブルデバイスとの統合により、マルチモーダルAIは私たちの生活に直接溶け込む技術へと進化しています。
Just tried on a prototype pair of Frame glasses from Brilliant Labs, an upcoming pair of smart glasses that can do image recognition, translation, text overlay, but in a very, very light and thin frame. pic.twitter.com/cRIo8xO59w
— ben sin (@bencsin) February 27, 2024

マルチモーダルAI導入のメリット
マルチモーダルAIを導入することで、企業は単一モダリティのAIでは実現できなかった多角的な業務改善が可能になります。ここではAI導入がもたらす仕事の変化を踏まえ、5つの主なメリットを解説します。
-
文脈理解の飛躍的な向上
テキストだけでは把握しきれない情報を、画像・音声・動画から補完的に取得することで、AIの文脈理解力が大幅に向上します。医療診断では、画像とテキストの統合分析により単一モダリティでは見落とされがちな微細な異常も検出可能になります。
-
業務効率化と生産性向上
複数のデータソースを一括処理できるため、従来は人手で行っていた情報の統合・照合作業を自動化できます。日立製作所の品質保証業務では作業時間8割削減を実現しており、日本のAI導入の最前線を示す成果です。
-
ユーザー体験の高度化
テキスト・音声・画像を組み合わせた自然な対話が可能になることで、顧客サービスや教育アプリのユーザー体験が大きく向上します。Duolingo Maxのようにマルチモーダルな学習体験を提供することで、学習効果と継続率の向上が期待できます。
-
意思決定の精度向上
複数の情報源からのデータを統合分析することで、より多角的で精度の高い意思決定支援が可能になります。損保ジャパンとリコーの事例のように、図表を含む複雑な文書の自動読解は保険業務の効率化と判断精度の向上に直結しています。
-
新たなビジネス機会の創出
マルチモーダルAIにより、従来は技術的に困難だった領域でのAI活用が可能になります。Brilliant Labs「Frame」のようなウェアラブルデバイスの登場は、マルチモーダルAIが新たな製品カテゴリを生み出す可能性を示しています。
これらのメリットは相互に関連しており、文脈理解の向上が業務効率化を促し、業務効率化がさらなる導入領域の拡大につながるという好循環を生み出します。
マルチモーダルAI導入の課題と注意点
マルチモーダルAIには大きな可能性がある一方で、導入にあたっては慎重に対処すべき課題も存在します。AI導入時の課題を事前に把握し、適切な対策を講じることが成功の鍵です。
-
計算コストとインフラ要件
複数モダリティのデータを同時処理するマルチモーダルAIは、シングルモーダルAIと比較して大幅に高い計算リソースを必要とします。特に動画処理を含む場合、GPU/TPUのコストが急増するため、PoC段階でコスト試算を十分に行うことが重要です。
-
ハルシネーションと精度のばらつき
マルチモーダルAIは複数の入力を統合する際に、モダリティ間の情報が矛盾する場合にハルシネーション(事実でない内容の生成)が発生するリスクがあります。医療や金融など精度が求められる分野では、AIの出力を人間が検証するワークフローの設計が不可欠です。
-
プライバシーとデータセキュリティ
画像・音声・動画など、個人を特定可能な情報を大量に処理するため、データの収集・保管・利用におけるプライバシー保護が最優先事項となります。特に顔認識や音声認識を含む処理では、AI倫理のガイドラインに従った厳格なデータ管理が求められます。
-
データバイアスと公平性
学習データに含まれるバイアスが、複数のモダリティを通じて増幅される可能性があります。特定の言語・文化・地域のデータに偏った学習を行うと、出力結果にも偏りが生じるため、学習データの多様性確保と継続的なバイアス監視が必要です。
-
モデル選定と技術的な依存リスク
2026年現在、OpenAI・Google・Anthropicの3社が主要プレイヤーですが、各社のモデルは対応モダリティや性能特性が異なります。特定のプラットフォームに過度に依存すると、API仕様の変更や料金改定の影響を受けやすくなるため、マルチベンダー戦略の検討が推奨されます。
これらの課題は技術の急速な進化とともに改善が進んでいますが、現時点では人間の判断とAIの自動処理を適切に組み合わせる「Human-in-the-Loop」のアプローチが最も実践的です。
マルチモーダルAIの料金比較(2026年3月版)
マルチモーダルAIを業務に導入する際、コストは重要な検討要素です。以下の表で、2026年3月時点の主要モデルのAPI料金を比較しました。
| モデル | 入力(per 1Mトークン) | 出力(per 1Mトークン) | 対応モダリティ | コンテキスト |
|---|---|---|---|---|
| GPT-5.2 | $1.75 | $14.00 | テキスト/画像/音声/動画 | 200K |
| GPT-4.1 | $2.00 | $8.00 | テキスト/画像 | 1M |
| Gemini 3.1 Pro | $2.00 | $12.00 | テキスト/画像/音声/動画 | 2M |
| Gemini 3 Flash | $0.25 | $1.50 | テキスト/画像/音声/動画 | 1M |
| Claude Opus 4.6 | $5.00 | $25.00 | テキスト/画像 | 200K |
| Claude Sonnet 4.6 | $3.00 | $15.00 | テキスト/画像 | 200K |
コスト効率を重視する場合はGemini 3 Flash(入力$0.25/出力$1.50)が圧倒的に有利です。一方、最高精度が求められるタスクではClaude Opus 4.6やGPT-5.2が選択肢となりますが、出力トークンあたりのコストは10倍以上の差があります。用途と予算に応じた適切なモデル選定が重要です。
個人やチームでの利用には、各社のサブスクリプションプランも利用可能です。以下の表にまとめました。
| プラン | 月額料金 | 利用可能モデル | マルチモーダル対応 |
|---|---|---|---|
| ChatGPT Plus | $20 | GPT-4o、GPT-5.2(制限あり) | 画像生成・音声入出力 |
| ChatGPT Pro | $200 | 全モデル無制限 | 全モダリティ対応 |
| Gemini Advanced | $19.99 | Gemini 3.1 Pro、3 Flash | 画像・音声・動画対応 |
| Claude Pro | $20 | Claude Sonnet 4.6、Haiku | 画像入力対応 |
| Claude Max | $100/$200 | Claude Opus 4.6含む全モデル | 画像入力対応 |
月額$20前後のプランでもマルチモーダル機能を利用できるため、まずはChatGPT PlusやGemini Advancedなどの個人プランで機能を試し、効果を確認した上でAPI連携による本格導入を検討する段階的なアプローチがおすすめです。

マルチモーダルAIの知見から組織のAI導入計画を立てる
テキスト・画像・音声を横断的に処理するマルチモーダルAIの可能性を理解したことで、組織の業務にAIを導入する具体的なイメージが浮かんできたのではないでしょうか。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に設計する実践ガイド(220ページ)を無料で提供しています。マルチモーダル機能を含むAI技術を業務に組み込む際のPoC→全社展開の流れを、部門別のBefore/After付きで整理しています。
AI総合研究所が、マルチモーダルAIの知見を組織の業務改善計画として形にするお手伝いをします。
【無料DL】AI業務自動化ガイド(220P)

Microsoft環境でのAI活用を徹底解説
Microsoft環境でのAI業務自動化・AIエージェント活用の完全ガイドです。Microsoft環境でのAI業務自動化の段階設計を詳しく解説します。
まとめ
本記事では、マルチモーダルAIの基礎概念から最新モデル比較、業界別活用事例、導入メリット・課題・料金体系まで網羅的に解説しました。
マルチモーダルAI市場は2025年の29.9億ドルからCAGR 29.29%で急成長しており、GPT-5.2、Gemini 3.1 Pro、Claude Opus 4.6といった最新モデルは、テキスト・画像・音声・動画を統合処理する能力を急速に高めています。日本企業においても、リコーのGENIACプロジェクトや日立の品質保証AI、日本医科大学の診断AIなど、実用レベルでの導入事例が着実に増えています。
まずはChatGPT PlusやGemini Advancedなど月額$20前後のプランでマルチモーダル機能を試し、自社の業務データでの効果を検証してみてください。AGIへの道筋の中で、マルチモーダルAIは「AIが人間のように複数の感覚を統合して世界を理解する」ための重要な一歩であり、自律型AIエージェントの発展とともに、その活用範囲はさらに広がっていくでしょう。








