この記事のポイント
 建築図面・製造部品検査など画像内の微細要素を正確に読む業務にAgentic Visionが最適、従来の一発認識の見落としを段階検出
建築図面・製造部品検査など画像内の微細要素を正確に読む業務にAgentic Visionが最適、従来の一発認識の見落としを段階検出- Think-Act-Observeループによる自律的な画像調査は、人手による目視確認の工数削減に有効であり、品質管理プロセスの自動化を検討すべき第一候補となる
- 追加料金なしでGemini 3 Flashのトークン課金内に収まるため、コスト面でも導入障壁が低い。ただし中間トークンの消費量は事前に検証しておくべき
- まずはGoogle AI Studioでノーコード検証を行い、精度と費用対効果を確認したうえでPython SDKによる本番組み込みに進むアプローチが最適
- 単純な画像分類やOCR目的なら従来のVision APIで十分、Agentic Visionは段階調査と加工が要る複雑タスクに限定適用

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Googleは、Gemini 3 Flashに新機能「Agentic Vision」を導入し、画像認識のプロセスを根本から変革しようとしています。これは、AIがPythonコードを自律的に生成・実行し、画像をズームや加工しながら能動的に調査する仕組みで、従来の「一度見るだけ」の認識では困難だった微細な要素の特定や正確なカウントを可能にします。
本記事では、Think-Act-Observeループによる精度の向上メカニズムや、建築図面検査などの具体的なユースケース、さらに開発者向けのGoogle AI StudioやPython SDKを通じた実装手順について、2026年1月時点の情報を基に体系的に解説します。
✅Gemini 3.1 Proについては、以下の記事をご覧ください。
Gemini 3.1 Proとは?料金、使い方を徹底解説!
目次
Gemini 3 Flashの「Agentic Vision」とは?
Agentic Visionの仕組み(Think, Act, Observe)
画像認識における「Think, Act, Observe」ループ
Gemini 3 FlashのAPI利用料金(2026年1月時点)
Agentic Vision(Code Execution)利用時のコスト構造
Gemini 3 Flashの「Agentic Vision」とは?
Gemini 3 Flashの「Agentic Vision」は、簡単に言うと「Code Execution(Python実行)をツールとして有効化すると、AIが自分でPythonコードを書いて、画像を能動的に“調査”するような挙動を取れるようになる仕組み」です。
これまでの画像認識は、一度画像を見てそのまま答えを出す「一回きりの静的な認識」が基本でした。そのため、マイクロチップのシリアル番号や遠くの道路標識のような細かい要素は、うまく読めずに推測に頼ることがありました。
Agentic Visionでは、モデルが「ここは拡大して確認した方がよさそうだ」「境界線を引いて数えた方が安全だ」と判断し、内部でPythonコードを生成・実行して画像を加工しながら、段階的に答えを詰めていきます。
その結果、単に「見て当てる」のではなく、「必要に応じてズーム・注釈・再計算を行ったうえで判断する」という、より人間に近い検証プロセスを取れるようになっています。

Agentic Visionの仕組み(Think, Act, Observe)
Agentic Visionの中核にあるのが、「Think(考える)」「Act(実行する)」「Observe(観察する)」という3ステップのループです。
ここでは、このループがどのように画像理解を変えているのかを整理します。
全体像は、次の概念図で押さえるとイメージしやすいです。
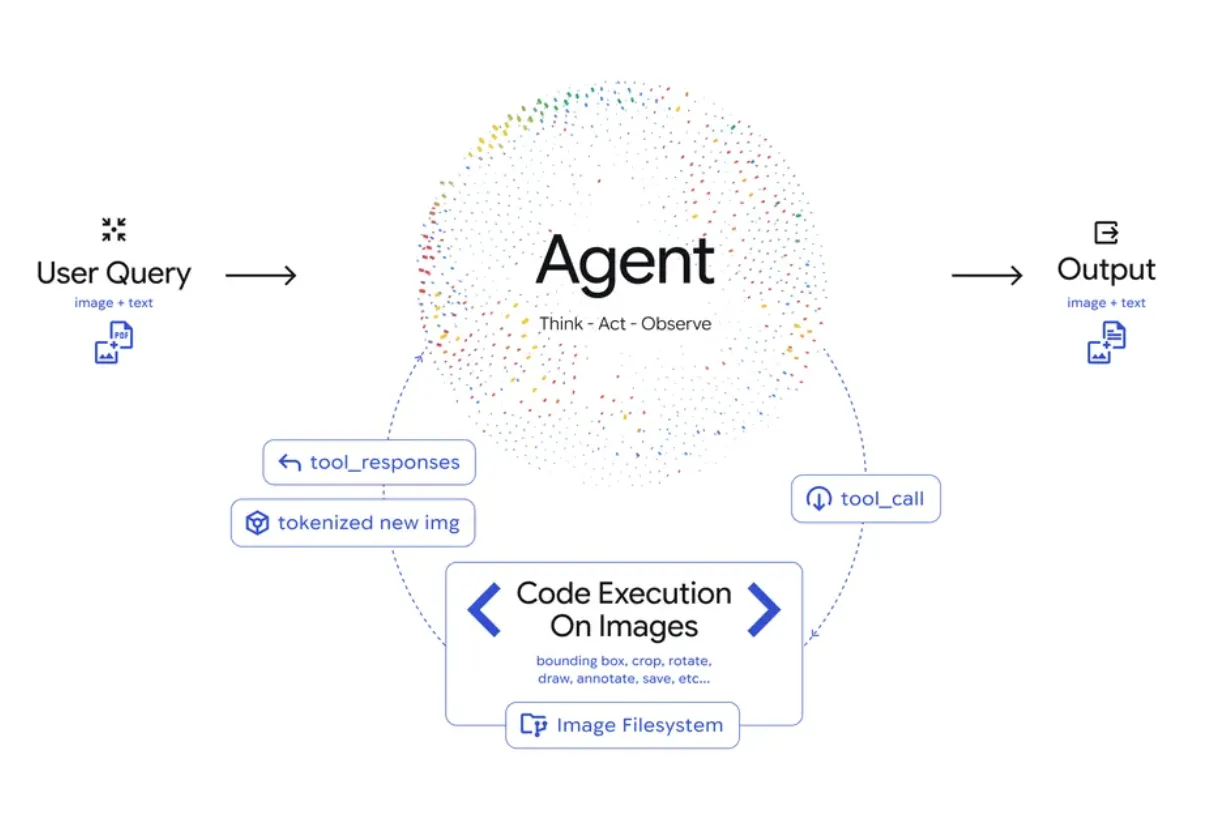
Think–Act–ObserveループとCode Executionによる反復処理の全体像(出典:Google公式ブログ)
このループを前提に、以下では各ステップで何が起きるかを順に見ていきます。
画像認識における「Think, Act, Observe」ループ
Agentic Visionは、次のような流れで画像を扱います。
-
Think(考える)
モデルは、ユーザーの指示と入力画像を見て、「どの部分をどう確認すべきか」を計画します。
たとえば「この図面の屋根の端を詳しく確認しよう」「この手の指を一本ずつ数えよう」といった形で、複数ステップのプランを立てます。
-
Act(実行する)
立てたプランに基づき、モデルがPythonコードを生成して実行します。
コードでできることの例は、次の通りです。- 画像の一部分だけを切り抜く(クロップ)
- 必要に応じて回転させる
- 指や物体の周りに枠線やラベルを描画する
- 表データを読み取って計算・集計する
-
Observe(観察する)
コードによって加工・生成された新たな画像(切り抜きや注釈付き画像)が、モデルのコンテキストに追加されます。
モデルは、元の画像と新しい画像をあらためて見比べながら、「より根拠のある最終回答」を生成します。
このように、Agentic Visionは「一度見て終わり」ではなく、必要に応じて画像を操作・再確認するループを回すことで、判断の精度と根拠を高めています。
コード実行による精度の向上
Googleは、Gemini 3 Flashでコード実行を有効にすると、多くのビジョン系ベンチマークで5〜10%の品質向上が得られると述べています。
公式ブログでは、Code Executionの有効/無効で主要なビジョン系ベンチマークのスコア差が示されています。
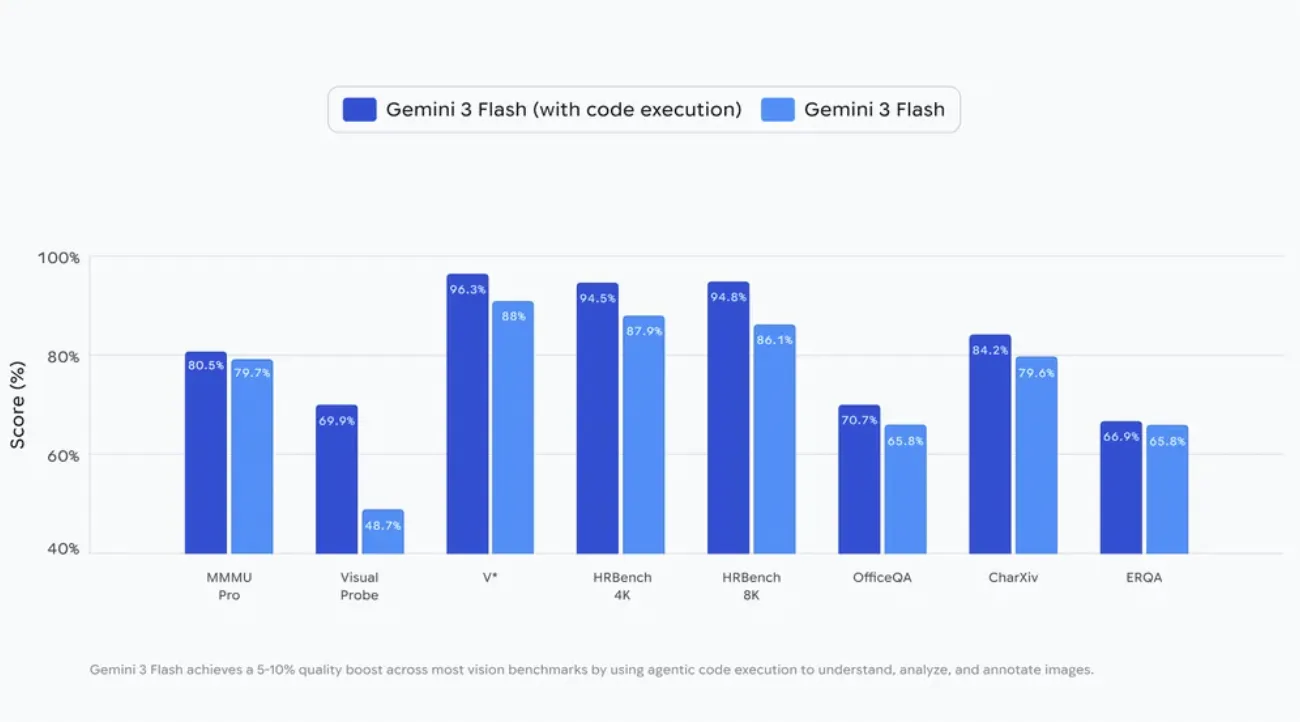
Code Execution有効化によるビジョン系ベンチマークのスコア差(出典:Google公式ブログ)
すべての指標で同じ幅ではないものの、多くのタスクで“数ポイント分”の押し上げが確認できます。
ここでいう「品質」は、細かいオブジェクトの認識や、表データを含む複雑な画像の読み取り精度などを指します。
ポイントは、次のように整理できます。
- 計算や集計は、Pythonによる決定論的な処理に任せることで、モデルの「感覚的な推測」に依存しにくくなる。
- 小さな文字や遠くの物体は、コードで切り抜いて拡大した上で再確認できるため、見落としが減る。
- 境界線やラベルを描画してから数えることで、カウント系のタスクでの勘違いを減らせる。
つまりAgentic Visionは、「モデルそのものを強化した」というより、「モデルに使える道具(コード実行)を渡して、確認プロセスを厚くした」と考えるとイメージしやすい仕組みです。
Agentic Visionのユースケース
Agentic Visionは、実際にどのような場面で役に立つのでしょうか。
ここでは、Google AI Studioのデモや公式ブログで紹介されている代表的な3つのユースケースを取り上げます。
細部のズームと検査(PlanCheckSolverの事例)
建築図面のように、細かい線や注記が大量に詰め込まれた画像では、「一度の視線」で全体を理解するのは困難です。
AIを使った建築図面検証プラットフォームPlanCheckSolver.comでは、Agentic Visionを活用することで、図面の検査精度を向上させています。
具体的には、次のような流れで利用されています。
- まず、図面全体を読み込んで、チェックが必要そうなエリア(屋根の端、特定の建物セクションなど)を特定する。
- Gemini 3 FlashがPythonコードを生成し、これらのエリアを個別の「パッチ画像」として切り抜く。
- 切り抜いた画像をコンテキストに追加し、建築基準への適合状況などを、細部まで確認しながら評価する。
デモでは、どの領域をクロップし、どんなPython処理を実行したかがログとコードとして可視化されています。
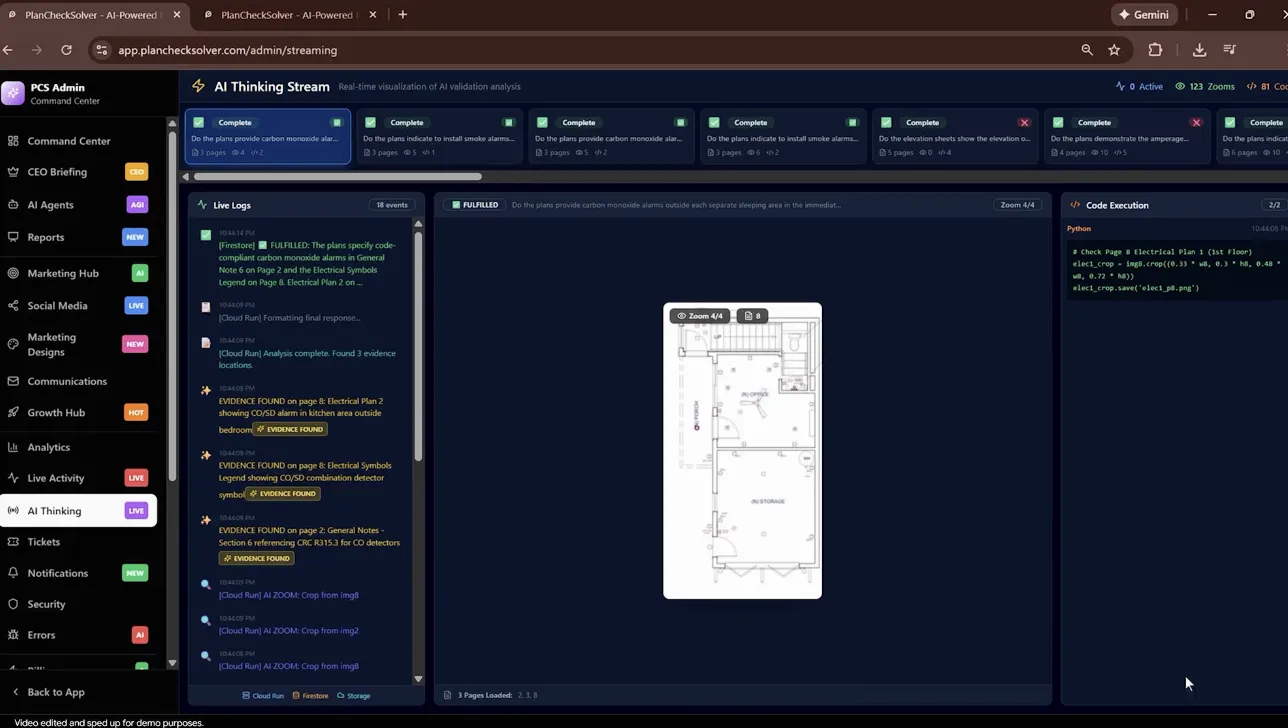
PlanCheckSolverのデモ画面(クロップ領域の生成とPython実行ログの例)
こうした“部分画像を作って追加し直す”反復により、高解像度入力でも根拠を積み上げやすくなります。
このように、図面を「部分ごとにズームしながら検査する」スタイルを自動化できるため、人間のレビューを補完する用途に適しています。
アノテーションによる正確なカウントと認識
「この写真に写っている指は何本か」といった、カウント系のタスクは、一見単純に見えて、LLMが誤答しやすい領域です。
Agentic Visionでは、単に「数える」のではなく、**数えるための視覚的なメモ(Visual Scratchpad)**を作りに行くのが特徴です。
たとえば、手の画像から指の本数を数える場合は、次のような手順になります。
- モデルが各指を検出し、Pythonコードでそれぞれの指にバウンディングボックスを描く。
- 各ボックスに「1」「2」「3」…と番号ラベルを書き込む。
- 最後に、描画した枠とラベルを見ながら、何本検出できているかを確認する。
以下の例のように、検出した対象に枠と番号を振ってから数えることで、カウントの根拠を画像上に残せます。
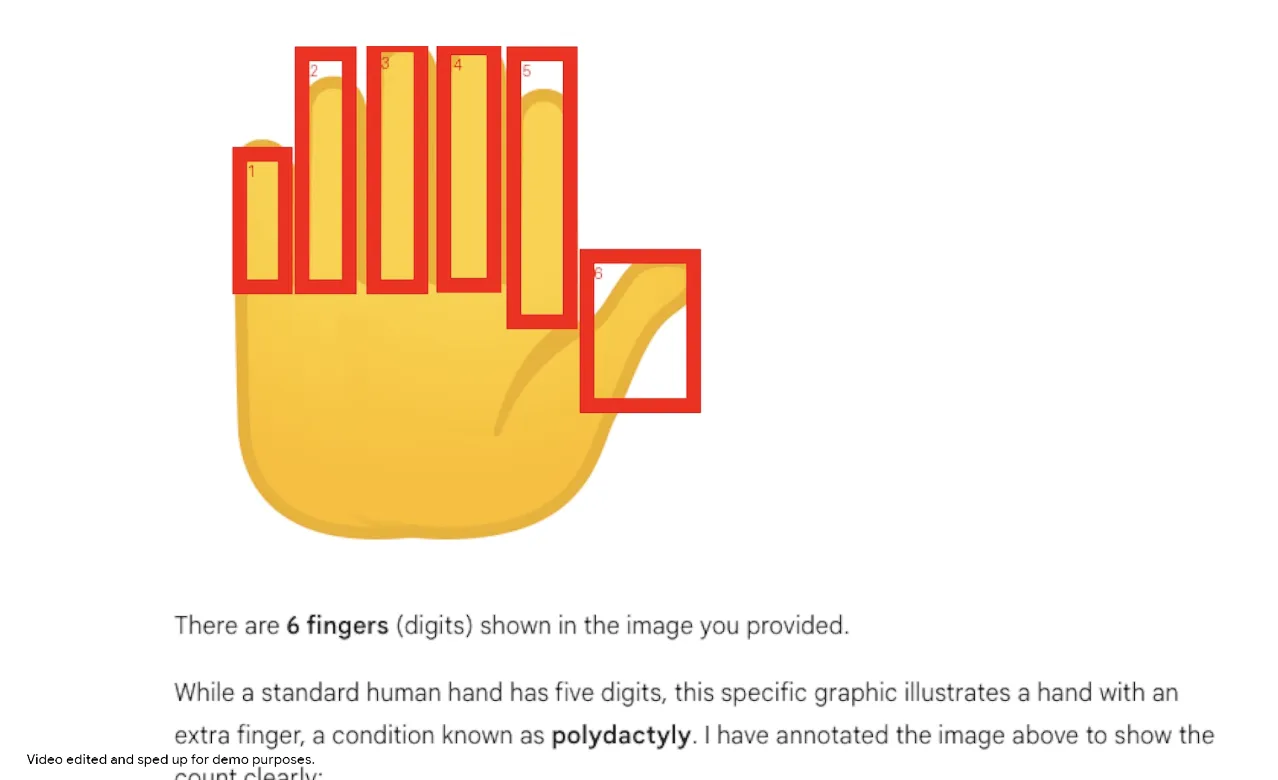
Visual Scratchpad(枠+番号ラベル)でカウントの根拠を可視化する例(出典:Google公式ブログ)
このように、「どこを数えたのか」が画像上で可視化されるため、モデルのカウント結果に対して人間がレビューしやすくなる点も利点です。
グラフ描画と視覚的な数値解析
表やグラフが含まれた画像を扱うとき、通常のLLMは「目で見て推測しながら計算する」形になり、複数ステップの計算や正規化が絡むと誤りが出やすくなります。
Agentic Visionでは、こうした処理を次のように進められます。
- 画像中の表やグラフから、生データの数字を読み取る。
- Pythonコードを生成して、必要な前処理(正規化、比率計算など)を実行する。
- Matplotlibなどを使って、新しい棒グラフなどを描画し直す。
具体例として、表データを正規化して棒グラフを描画し直すデモが示されています。

表データの抽出→正規化→Matplotlibでの再可視化(出典:Google公式ブログ)
これにより、「見た目で何となく判断する」のではなく、コードで再計算した結果をもとに、より一貫性のある説明や可視化を行えるようになります。
Agentic Visionの料金体系と提供形態
Agentic Visionは、2026年1月時点で次のような形で提供されています。
| 提供形態 | 主な用途 | 特徴 |
|---|---|---|
| Google AI Studio(Gemini API) | 開発者向けプロトタイピング | ブラウザで画像+プロンプトを投げ、ToolsでCode ExecutionをONにして挙動を確認できる |
| Gemini API(サーバーサイド) | 自社アプリ・サービスへの組み込み | REST/SDK経由でtoolsにCode Executionを指定し、Agentic Visionの挙動を呼び出せる |
| Vertex AI(Gemini on Vertex) | エンタープライズ向け運用 | GCPのプロジェクト管理・IAM・監査ログなどと統合した形で利用できる |
| Geminiアプリ(Thinkingモデル) | 一般ユーザー・ビジネスユーザー向け | モデル選択で「Thinking」を指定することで、Agentic Visionの動作が利用可能(2025年12月より順次ロールアウト) |
Gemini 3 FlashのAPI利用料金(2026年1月時点)
Gemini 3 Flashは、Gemini APIおよびVertex AIにおいて、次の料金体系で提供されています。
| 項目 | 料金 |
|---|---|
| 入力トークン | $0.50 / 100万トークン |
| 出力トークン | $3.00 / 100万トークン |
| オーディオ入力 | $1.00 / 100万トークン |
| コンテキストウィンドウ | 最大100万トークン |
| コスト削減オプション | 効果 |
|---|---|
| Context Caching | 大規模な繰り返しプロンプトで最大90%のコスト削減 |
| Batch API | 非同期処理で50%のコスト削減、高いレート制限 |
Agentic Vision(Code Execution)利用時のコスト構造
Code Executionを有効化しても、専用の追加料金は発生しません。コストはあくまで消費したトークン数に基づいて計算されます。
Agentic Visionでは、コード実行を行うことで次のような理由でトークン消費が増加します:
-
中間トークンの追加計上
- モデルが生成するPythonコード
- コード実行結果(ログ、集計値、処理データなど)
- これらは入力トークンとして追加計上される
-
画像データの増加
- 画像の切り抜き(crop)や注釈付き画像
- 追加の画像パーツをコンテキストに含めることで、全体のトークン消費量が増加
-
最終応答の出力
- モデルが返す最終応答(コードや実行結果の要約を含む)
- これは出力トークンとして計上される
コスト見積もりの考え方
Code Execution使用時のコスト = 基本料金 × (通常トークン + 中間トークン)
例えば、画像分析でコードを3回実行し、各実行で1,000トークンの中間結果が生成される場合、入力トークンとして約3,000トークンが追加計上されます。
Google AI Studioでの無料枠について
Google AI Studio経由でGemini APIを利用する場合、**Free tier(無料枠)**が設定されています。
Free tierの特徴
- トークン単価: Free of charge(無料)
- レート制限: モデルにより5〜15 RPM(requests per minute)
- 1日あたり: 最大1,000リクエスト(モデルにより異なる)
- データ利用: 「Used to improve our products: Yes」 - プロンプトと応答がGoogle製品の改善に利用される可能性がある
Paid tierの特徴
- トークン単価: 上記の従量課金料金が適用
- レート制限: 本番環境向けの高いレート制限
- データ利用: 「Used to improve our products: No」 - データは製品改善に利用されない

Agentic Visionの利用方法と実装ガイド
ここからは、実際にAgentic Visionを試すための導線を整理します。
一般ユーザー向けの「Geminiアプリ」、ノーコード寄りの開発環境である「Google AI Studio」、さらに本番環境に組み込みたいエンジニア向けの「Python SDK」という3つの入り口があります。
【一般・ビジネス向け】Geminiアプリでの利用手順
Geminiアプリでは、モデル選択で「Thinking」系のモデルを指定することで、Agentic Visionの挙動が順次ロールアウトされています。
利用の流れは、おおまかに次の通りです。
- Geminiアプリを開く(モバイルまたはWeb版)。
- モデル選択メニューから、Gemini 3 FlashのThinkingモードに対応したモデルを選ぶ。
- 画像をアップロードし、「細かい文字が読めるように拡大して確認して」など、コード実行が必要な指示を与える。
- 応答の中で、モデルがどのように画像をズーム・注釈しているかを確認する。
なお、すべての地域・アカウントで同じタイミングで利用できるわけではなく、順次展開されている点には注意が必要です。
【開発者向け】Google AI Studioでの設定(ノーコード)
Google AI Studioでは、ブラウザ上で簡単にAgentic Visionの挙動を試すことができます。
基本的な手順は次の通りです。
- Google AI Studioにアクセスし、Gemini 3 Flashのマルチモーダルモデルを選択する。
- 画像ファイルをアップロードし、テキストプロンプト(例:「この図面の屋根の端を詳しく検査して、問題がある箇所を教えてください」)を入力する。
- 右側または下部にある「Tools」設定パネルで、「Code Execution」をオンにする。
- 実行すると、モデルが必要に応じてPythonコードを生成・実行し、その結果を踏まえた回答を返す。
ノーコードで試せるため、「まず挙動を確認したい」「どこまでやってくれるのか感覚をつかみたい」といった用途に向いています。
【エンジニア向け】Python SDKによる実装コード
自社のシステムやアプリケーションに組み込みたい場合は、Googleの**Gen AI SDK(Python)**を使ってAgentic Visionを呼び出すのが手軽です。
以下は、公式ドキュメントのコード例をベースにしたイメージコードです。
from google import genai
from google.genai import types
client = genai.Client()
# 画像ファイルの準備(URI指定でもローカルアップロードでもOK)
image = types.Part.from_uri(
file_uri="https://goo.gle/instrument-img",
mime_type="image/jpeg",
)
# コンテンツ生成のリクエスト
response = client.models.generate_content(
model="gemini-3-flash-preview", # Agentic Vision対応のFlashモデル
contents=[
image,
"エクスプレッションペダル部分をズームして、ペダルがいくつあるか教えてください。"
],
# ここでコード実行ツールを有効化
config=types.GenerateContentConfig(
tools=[types.Tool(code_execution=types.ToolCodeExecution)]
),
)
print(response.text)
このように、「GenerateContentConfig」内の「tools」で「code_execution」を指定するだけで、モデル側が必要に応じてPythonコードを生成・実行してくれます。
アプリケーション側では、通常のGemini API呼び出しとほぼ同じインターフェースで扱えるため、既存ワークフローへの組み込みも比較的スムーズです。
Agentic Visionの今後の展望とロードマップ
Agentic Visionは、まだ登場したばかりの機能であり、今後も機能拡張が予定されています。
ここでは、公式発表で言及されている方向性を簡単に整理します。
暗黙的なコード実行動作の拡大
現時点では、Gemini 3 Flashは「細かい部分をズームして確認する」といった挙動については、比較的自律的に判断できるようになっています。
一方で、画像の回転や複雑な数値計算など、一部の挙動については、プロンプトで明示的に促した方が確実にコード実行が走る場面もあります。
今後は、こうした挙動についても、より多くをモデル側の暗黙的な判断に任せられるように改良していくとされています。
これが進むと、「ユーザーが細かく指示を出さなくても、モデルが自分で必要な操作を選び取る」場面が増えていくことが期待されます。
Web検索など外部ツール連携の強化
現状のAgentic Visionは、まず**Code Execution(Python)**を主要なツールとして示していますが、今後はWeb検索や逆画像検索など、より多くのツールを搭載し、世界理解をさらに深める方法も検討されています。
たとえば、次のような利用イメージが想定されています。
- 不明なロゴやランドマークが写っている画像を、Web検索を使って特定する。
- 画像中の商品について、カタログ情報やスペックページを検索して補足情報を取得する。
こうした外部情報との連携が進むと、「画像の中で見えているものが何か」をより広い文脈で理解しやすくなり、視覚的なグラウンディング(根拠付け)の幅が広がっていくと考えられます。

AIのビジョン技術進化を組織の業務自動化計画に組み込む
Agentic Visionのような視覚理解AIの進化は、将来の業務自動化の可能性を広げます。今のうちに組織としてAI導入の土台を整えておくことが重要です。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に進めるための実践ガイド(220ページ)を無料で提供しています。部門別のユースケースとBefore/After事例で、AI活用の具体的な進め方を示しています。
AI総合研究所が、最先端のAI技術動向を組織の業務改善につなげるための土台づくりを支援いたします。
AI画像認識の進化を業務設計に取り込む

Microsoft環境でのAI業務自動化ガイド
Agentic Visionのような最新AI機能を把握した次は、組織として画像認識を含むAI活用を業務に段階的に組み込む設計が重要です。220ページの実践ガイドを無料で提供しています。
まとめ
この記事では、Gemini 3 Flashに追加された新機能Agentic Visionについて、その概要からユースケース、料金の考え方、利用方法、今後の展望までを整理しました。
最後に、ポイントを簡単に振り返ります。
-
Agentic Visionとは何か
Code Execution(Python実行)を有効にすると、AIが自分でPythonコードを書き、画像をズーム・注釈・再計算しながら能動的に“調査”する仕組みで、従来の「一度見るだけ」の画像認識と異なるアプローチを取ります。
-
どこで威力を発揮するか
建築図面の検査、指や物体のカウント、表データの再計算・再描画など、細部の確認や数値処理が絡むタスクで精度向上が期待できます。
-
料金と提供形態のポイント
Agentic Vision専用の追加料金があるわけではなく、Gemini 3 Flashのトークン課金の中で、コード実行の中間トークンや最終出力分のトークンが積み上がる構造になっています。
AI Studio経由でFree tierが提供されることもありますが、最新の条件やデータ取り扱いは必ず公式情報で確認する必要があります。
-
どう始めるか
まずはGoogle AI StudioでCode Executionをオンにして、手元の画像を使って挙動を確認するのがおすすめです。そのうえで、必要に応じてGeminiアプリやPython SDKからワークフローに組み込んでいくとスムーズです。
Agentic Visionはまだ始まったばかりの機能ですが、「AIに画像を見せたときの“根拠”をどう担保するか」という課題に対して、一つの有力な選択肢になりつつあります。
建築、製造、検査、データ分析など、視覚的な根拠が重要な業務をお持ちであれば、早い段階でPoCレベルでも試しておく価値は十分にあるでしょう。







