この記事のポイント
 コストを抑えつつ高精度な推論が必要な業務には、Gemini 2.5 Flashを第一候補にすべき
コストを抑えつつ高精度な推論が必要な業務には、Gemini 2.5 Flashを第一候補にすべき- Thinking Budgetの調整により、単純タスクは思考オフで高速処理し、複雑な分析は思考オンで精度を確保する使い分けが有効
- 100万トークンのコンテキスト長を活かせば、長文ドキュメントの一括解析や大規模データのバッチ処理に最適
- すべてのタスクにProモデルを使うのはコスト過剰であり、Flashで十分な精度が出るケースでは避けるべき
- まずは無料枠のGeminiアプリで検証し、効果が確認できたらAPI経由で本番ワークフローに組み込む段階的導入が最適

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
2025年5月、Google DeepMindは高速処理と高度な推論能力を両立させた次世代AIモデル「Gemini 2.5 Flash」を発表しました。従来のモデルが抱えていた速度と精度のトレードオフを解消するため、思考機能(thinking)のオン/オフをタスクに応じて切り替える「ハイブリッド推論」という新たなアプローチを採用しています。
本記事では、このGemini 2.5 Flashについて、仕組み、料金体系、具体的な使い方、そしてビジネスでの活用事例までを、2025年12月時点の最新情報に基づいて徹底解説します。
ChatGPTの新料金プラン「ChatGPT Go」については、以下の記事をご覧ください。
ChatGPT Goとは?料金や機能、広告の仕様、Plus版との違いを解説
✅Googleの最新動画生成AIモデル「Gemini Omni」については、以下の記事をご覧ください。
Gemini Omniとは?その性能や使い方、料金体系を徹底解説!
✅2026年6月9日、AnthropicがMythos-class初の一般公開モデル「Claude Fable 5」を発表しました。Opus 4.8の上位に位置する新最上位モデルの詳細はこちら。
▶︎Claude Fable 5とは?Mythos 5との違いや料金、使い方を解説
目次
Gemini 2.5 ファミリーにおけるFlash/Pro/Flash-Liteの位置づけ
Gemini 2.5 Flashの思考機能とハイブリッド推論【thinking budgetの仕組み】
thinking budgetの範囲と目安(0〜24,576トークン)
個人〜小規模チーム向け:Google AI Pro/Ultraの料金と特徴
開発者・企業向け:Gemini Developer APIの料金(Standard/Batch)
Gemini 2.5 Flashの使い方【Geminiアプリ/Canvas/Deep Research/API】
GeminiアプリでGemini 2.5 Flashを試す手順
APIからGemini 2.5 Flashを呼び出す基本コード例
Gemini 2.5 Flashの主要機能【マルチモーダル・長文理解・コーディング】
マルチモーダル対応:テキスト・画像・動画・音声・ドキュメント
Gemini 2.5 Flashと他モデルの比較【Gemini 2.5 Pro/Flash-Lite/他社モデル】
Gemini 2.5 Flash vs Gemini 2.5 Pro:性能・コスト・用途の違い
Gemini 2.5 Flash vs Gemini 2.5 Flash-Lite:コスト効率とユースケース
Gemini 2.5 Flash vs 他社モデルの位置づけ
Gemini 2.5 Flash利用時の注意点とベストプラクティス【セキュリティ・運用・ガバナンス】
Gemini 2.5 Flashとは?
Gemini 2.5 Flashは、Google DeepMindが提供するGemini 2.5ファミリーの中核モデルであり、「低レイテンシ×高い推論性能×マルチモーダル対応」を両立したワークホースモデルとして位置づけられています。
2025年4月の発表以降、1Mトークンの長大なコンテキストとthinking機能を活かし、チャットボットから業務自動化、エージェント型アプリケーションまで幅広い用途で採用が進んでいます。

Gemini 2.0 Flash系から引き継いだ高速性を維持しつつ、数学・科学・コード・長文化ベンチマークで大きく性能を伸ばしている点も特徴です。

Gemini 2.5 ファミリーにおけるFlash/Pro/Flash-Liteの位置づけ

Gemini 2.5ファミリーには、主に次の3系統があります。
- Gemini 2.5 Pro
高性能・高コスト帯のフラッグシップ。thinkingは必ず有効で、最大32,768トークンまで深く推論します。
- Gemini 2.5 Flash
性能とコストのバランスが良い「主力モデル」。thinkingを0〜24,576トークンの範囲で制御可能です。
- Gemini 2.5 Flash-Lite
さらに軽量・低コスト・高速なモデル。thinking機能はサポート対象外で、より小さなモデルサイズとレイテンシを重視しています。
モデル選定のイメージは次の通りです。
- まず検討するのがFlash(多くの業務にちょうど良い)
- より高精度な推論・長い推論ステップが必要ならPro
- リアルタイム性や極端な低コストを重視する場合はFlash-Lite
この棲み分けを理解しておくと、後述する料金や活用事例を読んだ際に、自社の用途に合うモデルを選びやすくなります。
Gemini 2.5 Flashの思考機能とハイブリッド推論【thinking budgetの仕組み】
Gemini 2.5 Flash固有の特徴である「thinking」と「思考バジェット」の仕組みを整理します。
thinking機能は、モデルが最終回答を出す前に内部で行う「思考プロセス」を明示的に扱う仕組みです。
Gemini 2.5 Flashは、この思考プロセスにどれだけトークンを割り当てるかを「thinking budget」として指定できます。
thinkingのオン/オフで何が変わるのか

まず、thinkingをオン/オフした場合に、どのような違いが出るかを整理します。
- thinking オフ(budget = 0)
- 事実の検索や簡単な変換など、推論の浅いタスクに適しています。
- レイテンシとコストを最小限に抑えたい場合に有効です。
- thinking オン(budget > 0)
- 数学問題、複雑な指示、長い文章の再構成など、複数ステップの推論が必要なタスクで精度が向上します。
- 代わりにトークン消費量とレスポンス時間は増えます。
具体例として、以下のように使い分けられます。
- 「東京の今日の天気は?」
→ thinkingオフで十分(外部ツールとの連携や検索グラウンディングを使うケース) - 「機械学習モデルの過学習を防ぐ方法を、数学的な根拠とともに整理して」
→ thinkingオンで、関連概念を整理しつつ段階的に説明する方が安定した回答を期待できます。
thinking budgetの範囲と目安(0〜24,576トークン)
Gemini 2.5 Flashのthinking budgetは、0〜24,576トークンの範囲で指定できます。
0に設定した場合はthinkingが完全に無効化され、それ以上の値ではモデル側が必要な範囲で思考トークンを使います。
開発者が目安として使いやすいよう、以下のような表で整理できます。

運用上は、まず「0もしくは小さな値」で試し、品質が足りない場合のみ段階的に上げていくと、コストと精度のバランスを取りやすくなります。
thinkingを使ったコスト最適化の考え方
thinking budgetは「上げれば上げるほど良い」というものではありません。
重要なのは、ユースケースごとに必要最低限の思考量を見極めることです。
- レスポンスが主に定型・FAQ寄りであれば、ほぼ常に0で十分です。
- コード生成や設計レビューなど、構造を持ったアウトプットが必要な場合は、4,096〜8,192程度を上限とするケースが多くなります。
- 研究開発や高度な分析レポートなど、一問一答の価値が高いタスクでは、24,576まで上げることも検討できます。
運用初期は、「thinking budgetとトークン使用量・レイテンシ・ユーザー満足度」をログからモニタリングし、徐々に最適値を探るのが現実的です。
Gemini 2.5 Flashの料金体系
ここでは、個人利用・開発者・企業利用それぞれの観点から、Gemini 2.5 Flashの料金体系と選び方を整理します。
Gemini 2.5 Flashは、「アプリとして使う場合」と「API/Vertex AIとして使う場合」で料金の考え方が異なります。
個人利用であればサブスクリプション中心、開発者・企業利用であればトークン従量課金が基本です。

無料で使う場合:Geminiアプリの無料枠と制限
まず、もっとも入りやすいのがGeminiアプリ(ブラウザ/モバイルアプリ)の無料利用です。
Geminiアプリの無料版でも、Gemini 2.5 Flashにアクセスできます。
- 無料で使える範囲の例
- 日常的なチャット・翻訳・文章作成
- 画像の要約や簡単な指示
- 軽めのコード補助
一方で、以下のような制限があります。
- thinkingを多用した重いタスクでは、回数や利用頻度に制約がかかる場合があります。
- Deep ResearchやGemini Live、Canvasなどの一部機能は、無料版では回数制限や制約があります。
日常的な調べ物や小規模な仕事であれば、まず無料版を試し、物足りなくなった段階で有料プランを検討する流れが自然です。
個人〜小規模チーム向け:Google AI Pro/Ultraの料金と特徴
本格的に使いたい個人や小規模チームは、「Google AI Pro」や「Google AI Ultra」といったサブスクリプションが候補になります。
日本向けの案内(2025年12月時点)では、Google AI Proは月額2,900円(税込)前後で提供されています。
| プラン | 月額料金(日本向けの目安) | 含まれる主な内容 |
|---|---|---|
| 無料版 | 0円 | Gemini 2.5 Flash、制限付きでPro、Deep Researchの一部機能など |
| [Google AI Pro](Google AI Proとは?できることや料金、制限について解説!【2025年最新】) | 2,900円前後 | Gemini 2.5 Flash / 2.5 Pro、Deep Researchの拡張、Gemini Live、Canvas、Gemini in Gmail / Docs 等 |
| Google AI Ultra | 高額(米ドル圏で約$250 / 月程度) | 上位モデルへの優先アクセス、大容量クラウドストレージ、追加のAI機能など |
個人利用やスモールビジネスでは、AI Proで十分なケースが多いと考えられます。
Ultraは、ヘビーユースや高度な動画生成などを含むケースで検討するプランです。
【関連記事】
▶︎Geminiの料金プランを比較!無料・有料版の違いと選び方【2025年最新】
開発者・企業向け:Gemini Developer APIの料金(Standard/Batch)
アプリケーションやバックエンドでGemini 2.5 Flashを利用する場合は、Gemini Developer APIの従量課金モデルを使います。
2025年12月時点の公式料金(Standard tier)は以下の通りです(単位は米ドル/100万トークン)。
| 項目 | 料金(Standard / 100万トークンあたり) |
|---|---|
| 入力(テキスト・画像・動画) | $0.30 |
| 入力(音声) | $1.00 |
| 出力(thinkingトークンを含む) | $2.50 |
| コンテキストキャッシュ(テキスト・画像・動画) | $0.03 |
| コンテキストキャッシュ(音声) | $0.10 |
| ストレージ料金 | $1.00 / 1時間あたり100万トークン |
バッチAPIを利用すると、標準料金の約半額で利用できます。
| 項目 | 料金(Batch / 100万トークンあたり) |
|---|---|
| 入力(テキスト・画像・動画) | $0.15 |
| 入力(音声) | $0.50 |
| 出力(thinkingトークンを含む) | $1.25 |
- リアルタイム応答が必要なチャットボットやインタラクティブなアプリケーション
→ Standard API - 夜間バッチ処理やログ解析など、即時性が不要な処理
→ Batch API
という使い分けが一般的です。
Vertex AIでの料金とエンタープライズ利用
GCP環境ですでにシステムを構築している企業であれば、Vertex AI経由でGemini 2.5 Flashを利用する選択肢も有力です。
料金体系はGemini APIと近い水準ですが、以下のようなメリットがあります。
- プロジェクト単位での権限管理・監査ログ
- Private Service Connect 等を用いたネットワーク分離
- プロビジョンドスループットやSLA
- 既存のGCPリソースとの親和性(Cloud Storage・BigQueryなど)
具体的な単価や割引体系は利用規模や契約内容に応じて変わるため、企業利用ではGCP営業担当やパートナー経由で見積もりを取るのが一般的です。
Gemini 2.5 Flashの使い方【Geminiアプリ/Canvas/Deep Research/API】
ここでは、コードを書かない個人利用から、本番システムへの組み込みまで、代表的な使い方をステップ形式で整理します。
Gemini 2.5 Flashは、「アプリで使う」「プロトタイプで試す」「APIで組み込む」という3つの階層で触れられます。
本記事で引用しているスクリーンショットは、既存の記事と同じ画像パスをそのまま利用しています。
GeminiアプリでGemini 2.5 Flashを試す手順
まずは、ブラウザ上のGeminiアプリから試す方法です。
サインインさえ済んでいれば、追加の準備なく利用できます。
-
Geminiアプリにアクセスする
ブラウザでGemini公式サイト にアクセスし、Googleアカウントでログインします。 -
モデルを選択する
画面右上(もしくは入力欄付近)のモデル選択ドロップダウンから、「Fast」を選びます。
-
プロンプトを入力する
チャット欄に質問や指示文を入力して送信します。

-
回答を確認し、必要に応じて追い質問する
Gemini 2.5 Flashは、構造化されたテキストや箇条書き、表などを用いて回答します。
「もう少し詳しく」「表でまとめて」「日本語で簡単に説明して」などと追い質問すると、同じコンテキストを保ったまま深掘りができます。
この流れで「文章作成」「要約」「簡単な調査」「コード補助」などを一通り試すことができます。
Canvas機能でコード・デザイン・ドキュメントを編集する
Canvasは、Geminiアプリ内のインタラクティブな編集スペースです。
テキストやコード、画像を並べて編集しながら、Geminiに変更提案や追記を依頼できます。
まず、Canvasボタンから新しいキャンバスを開きます。
キャンバス上では、例えば次のような使い方ができます。
- スライド案やLP構成案を書き並べて、Geminiに改善案を出してもらう
- HTMLやCSSコードを貼り付け、デザイン案を修正してもらう
- 図解のラフスケッチと説明文を並べ、文章のブラッシュアップを依頼する
画像や補助説明を渡す場合は、以下のようにプロンプトと素材を組み合わせます。
コードを扱う場合、Geminiが自動生成・修正したコードがその場でプレビューされます。
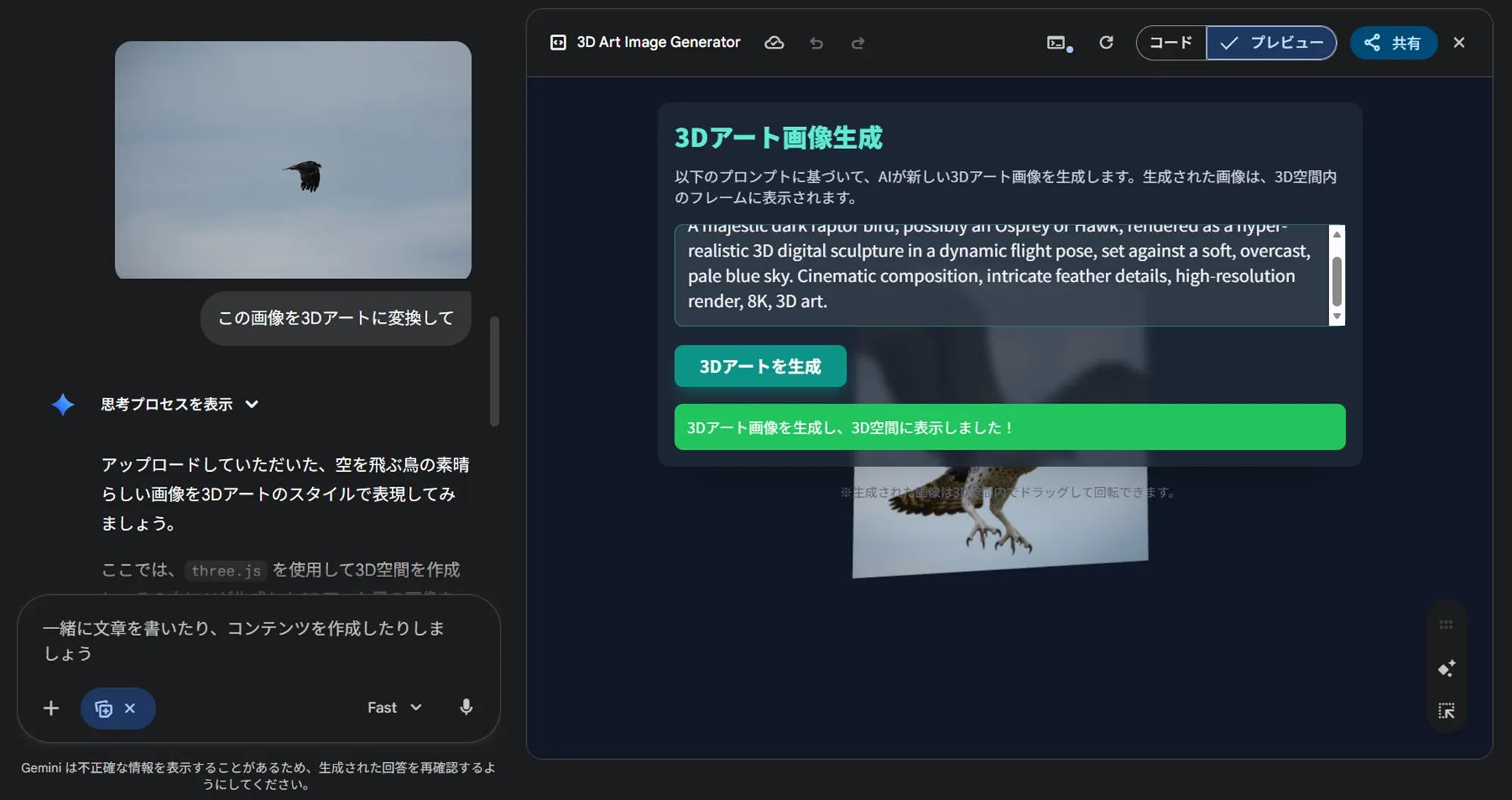
デザイナーやエンジニアだけでなく、マーケ担当者が資料・バナー案を作る際にも有効です。
【関連記事】
▶︎【Google】Gemini Canvasとは?使い方や料金、できることを徹底解説
Deep Researchでリサーチタスクを自動化する
Deep Researchは、複数のWebサイトを横断的に調査し、レポートとしてまとめる機能です。
Gemini 2.5 Flashそのものは推論モデルですが、Deep Researchと組み合わせることで、調査タスク全体を効率化できます。
-
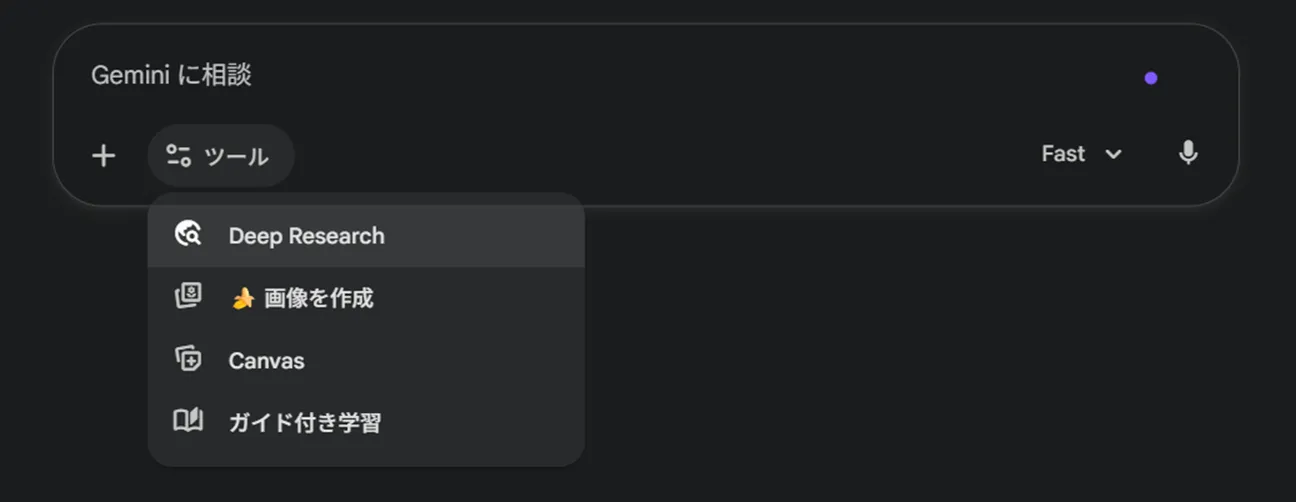
入力欄の左下にある「Deep Research」ボタンをクリックします。
-
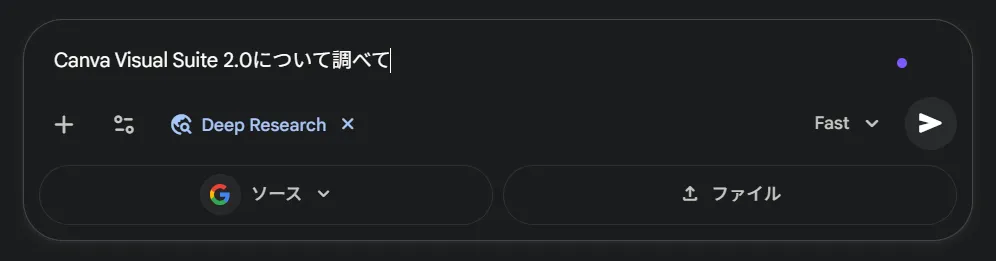
調べたいテーマを入力します。
-
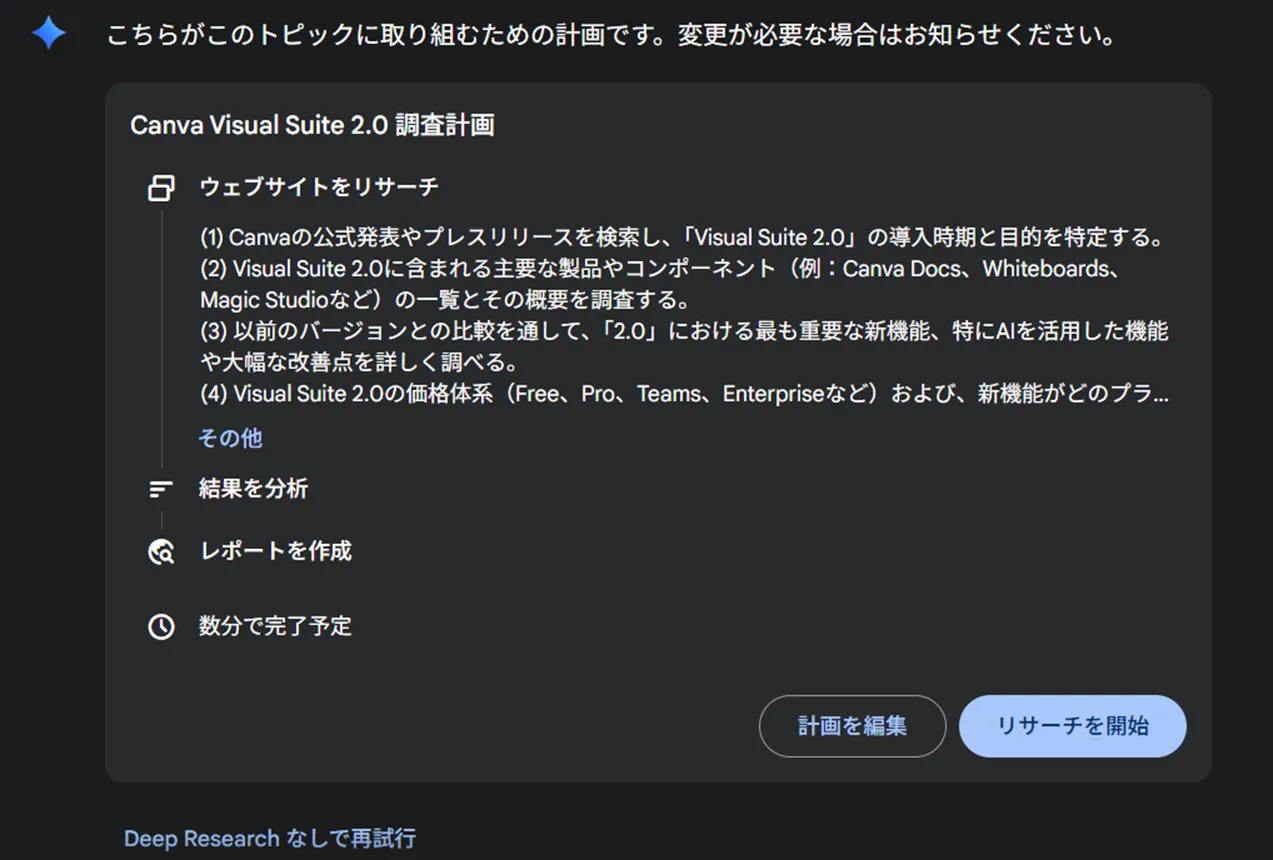
Geminiが提示する調査方針を確認し、「開始」を選びます。
-
複数サイトの情報を統合したレポートが生成されます。
生成されたレポートはGoogleドキュメント形式で保存・共有できるため、社内レビューや追記もスムーズです。
【関連記事】
▶︎Gemini Deep Researchとは?使い方や料金、活用事例を徹底解説!
APIからGemini 2.5 Flashを呼び出す基本コード例
開発者向けには、Gemini APIを使ってGemini 2.5 Flashを呼び出す方法が用意されています。
ここではPythonでのシンプルな例を示します(擬似コード)。
from google import genai
client = genai.Client(api_key="YOUR_API_KEY")
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="過学習を防ぐ方法を、数学的な根拠とともに整理してください。",
config={
"thinking": {
"thinking_budget": 4096 # thinking上限トークン数
}
}
)
print(response.output_text)
実際のパラメーター名やエンドポイントは、公式ドキュメントの最新版に従ってください。
Gemini 2.5 Flashの主要機能【マルチモーダル・長文理解・コーディング】
ここでは、Gemini 2.5 Flashが特に得意とする3つの側面を整理します。
Gemini 2.5 Flashは、単なるチャットボット用モデルではなく、マルチモーダル・長文理解・コーディングの3領域でバランス良く性能を発揮します。
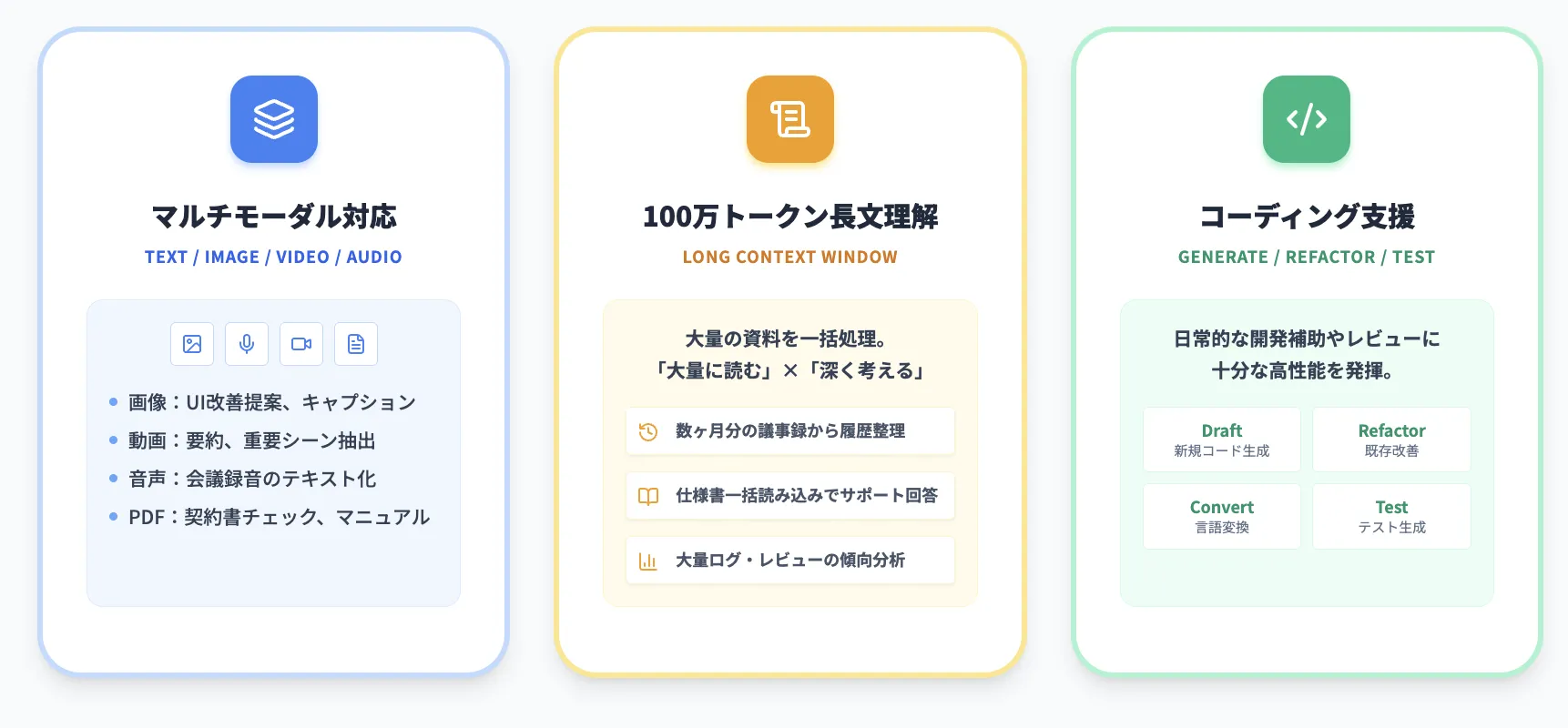
マルチモーダル対応:テキスト・画像・動画・音声・ドキュメント
Gemini 2.5 Flashは、ネイティブにマルチモーダル対応しており、テキストだけでなく画像・音声・動画・PDFといった複数の形式をまとめて扱うことができます。
代表的な入力と出力の組み合わせは次の通りです。
| 入力モダリティ | 代表的な入力例 | 出力例 | 利用シーン |
|---|---|---|---|
| テキスト | 説明文・仕様書・ログ | 要約・翻訳・構造化 | ナレッジ整理、社内FAQ |
| 画像 | 製品写真・UIスクリーンショット | キャプション生成・UI改善提案 | EC商品登録、UXレビュー |
| 動画 | プレゼン動画・操作説明動画 | 要約・重要シーン抽出 | 社内研修、カスタマーサクセス |
| 音声 | 会議録音・講演 | テキスト化・要約 | 会議メモ自動作成 |
| PDF/ドキュメント | マニュアル・契約書 | 条項比較・要点抽出 | 法務チェック、営業支援 |
マルチモーダル処理を組み合わせることで、従来は人手で分解・整理していた資料群を、1つのプロンプトでまとめて扱いやすくなります。
100万トークンコンテキストを活かした長文理解
最大約100万トークンのコンテキストウィンドウを持つGemini 2.5 Flashでは、大量のテキストや複数のドキュメントを1回のリクエストで処理できる点が大きな強みです。
例えば、次のようなユースケースが考えられます。
- 過去数か月分の議事録をまとめて読み込ませ、意思決定の履歴を整理する
- 製品仕様書・設計ドキュメント・サポートFAQを一括で読み込み、技術サポート用の回答案を生成する
- ログやレビュー、アンケート自由回答をまとめて解析し、主要な論点や改善点を抽出する
このような長文タスクでは、thinking budgetと組み合わせることで、「大量に読み込む」×「深く考える」という両方の要件を1モデルで満たせます。
コーディング支援・コード変換・バグ修正の強み
Gemini 2.5 Flashは、コード生成系ベンチマークや数学系ベンチマークで、前世代のFlashモデルを大きく上回るスコアを記録しています。
そのため、以下のようなコーディングタスクにも有力な選択肢になります。
- 新規コードのドラフト生成(APIクライアント、Webアプリの骨組みなど)
- 既存コードのリファクタリングやコメント生成
- 異なる言語間でのコード変換(例:Python → TypeScript)
- テストコード生成やバグの候補箇所の指摘
理念としては「Proほど重いタスクには使わないが、日常的な開発補助やレビューには十分な性能」という位置づけです。

Gemini 2.5 Flashの活用シーン
ここでは、Gemini 2.5 Flashをどのような業務に組み込めるかを、ユースケース別に整理します。
Gemini 2.5 Flashの特徴は、「万能選手だがコスト効率が良い」点です。
ここでは、代表的な活用シーンを具体的な業務イメージとともに紹介します。

チャットボット・カスタマーサポートへの適用
チャットボットでは、応答遅延とコストがユーザー体験に直結します。
Gemini 2.5 Flashは、thinkingをオフにした高速応答と、複雑な問い合わせ時だけthinkingをオンにする設計に向いています。
| シナリオ | thinking推奨設定 | 期待される効果 |
|---|---|---|
| FAQ・営業時間・料金の案内 | 0 | レイテンシ・コスト最小化 |
| 契約プランの提案・比較 | 1,024〜4,096 | 条件を踏まえた柔軟な提案 |
| トラブルシューティング | 4,096〜8,192 | 症状から原因を推論しやすくなる |
問い合わせ内容が複雑な場合は、人間オペレーターへのエスカレーションと組み合わせることで、一次対応の自動化率を高めつつ、顧客体験を損なわない構成にできます。
日常業務の自動化・効率化(文書作成・要約・メール・会議録)
日々のホワイトカラー業務では、文章ベースのタスクが多くの時間を占めます。
Gemini 2.5 Flashは、これらのタスクをドラフト作成・要約・翻訳などで支援できます。
具体例としては次のようなものがあります。
- 会議録の自動要約とTODOリスト生成
- 報告書のたたき台作成(見出し構成+本文ドラフト)
- メール返信案や定型文の生成
- 社内ドキュメントの整理とFAQ化
いずれも、「最終確認は人間が行う」前提であれば、品質と効率のバランスが取りやすい領域です。
大規模テキスト・ログ・ナレッジのバッチ処理
バッチAPIと長いコンテキストを組み合わせることで、夜間バッチや定期レポート生成にも適用できます。
- 数十万件規模のカスタマーレビューから、トレンドや不満点を抽出する
- アプリケーションログをまとめて解析し、異常パターンや改善候補を整理する
- 週次・月次レポートのテンプレートを用意し、Gemini 2.5 Flashに埋めてもらう
こうした処理はリアルタイム性が低い一方で、トークン量が大きくなります。
そのため、Batch APIで単価を半額に抑えつつ処理する構成が現実的です。
マルチモーダル解析(画像・PDF・動画をまとめて処理)
業務によっては、画像・PDF・スライド・動画など、さまざまな形式の資料が混在します。
Gemini 2.5 Flashのマルチモーダル対応を活かせば、これらを1つのワークフローに統合できます。
- 製品写真+スペック表PDFから、ECサイト用の商品説明文を生成
- UIスクリーンショット+ログから、改善すべき導線を指摘
- セミナー動画+配布資料から、要約と主要なスライド説明を生成
これにより、従来は担当者が各資料を見比べながら手作業で行っていた仕事を、大幅に短縮できます。
エージェント型アプリケーションの基盤として使う
Gemini 2.5 Flashは、「情報収集→計画→実行→振り返り」といった一連のタスクを任せるエージェント型アプリケーションの基盤としても有力です。
代表的なエージェント例は以下の通りです。
- 特定テーマのニュースや技術情報を継続的に収集・要約する調査エージェント
- タスク管理ツールと連携し、優先順位付けや日次計画を提案するパーソナルアシスタント
- コード生成・テスト・デプロイまでの一連の流れを補助する開発エージェント
- 社内ナレッジと外部Web情報を組み合わせて分析するデータ分析エージェント
thinking budget・長大コンテキスト・ツール呼び出しを組み合わせることで、**単発のチャットを超えた「継続的なタスク実行」が視野に入ります。
Gemini 2.5 Flashと他モデルの比較【Gemini 2.5 Pro/Flash-Lite/他社モデル】
ここでは、Geminiシリーズ内および他社モデルとの比較視点を整理し、「結局どれを選ぶべきか」を明確にします。
Gemini 2.5 Flashを検討する際、多くの企業・個人が気にするのは 「ProやFlash-Lite、ClaudeやGPTと比べてどうなのか」 という点です。
Gemini 2.5 Flash vs Gemini 2.5 Pro:性能・コスト・用途の違い
大まかな違いは次の通りです。
| 観点 | Gemini 2.5 Flash | Gemini 2.5 Pro |
|---|---|---|
| thinking | オン/オフ切替可能(0〜24,576) | 常にオン(128〜32,768) |
| コスト | Flashの方が安価 | Proの方が高価 |
| 推論性能 | 多くのベンチマークで高スコアだが、Proには一歩譲る領域もある | 数学・コード・長文推論で全体的に高い性能 |
| 用途 | 実務寄りのアプリケーション、チャットボット、業務自動化 | 高難度の推論タスク、研究開発、複雑なエージェント |
日常業務や顧客向けアプリケーションでは、まずFlashで検証し、どうしても精度が不足する領域のみProに切り替える、という使い方がコスト面でも現実的です。
Gemini 2.5 Flash vs Gemini 2.5 Flash-Lite:コスト効率とユースケース
Flash-Liteは、「とにかく速く・安く」を重視する開発者向けモデルです。
| 観点 | Gemini 2.5 Flash | Gemini 2.5 Flash-Lite |
|---|---|---|
| 主眼 | バランス型(性能×コスト) | 低コスト・低レイテンシ特化 |
| 料金(API) | 入力$0.30/出力$2.50(標準) | 入力$0.10/出力$0.40程度(参考値) |
| 推論性能 | HLE・AIMEなどで高スコア | Flashよりやや低めだが十分実用 |
| 適した用途 | ある程度の推論・精度が必要な業務アプリ | 大量トラフィックを捌くチャット、軽量なバックエンド処理 |
トラフィック量が非常に多いサービスでは、Flash-Liteを優先的に検討し、一部の高難度タスクだけFlashにルーティングする構成も考えられます。
Gemini 2.5 Flash vs 他社モデルの位置づけ
他社モデル(例:OpenAIのo4-mini、o3、Anthropic Claude 3.7 Sonnetなど)と比較すると、Gemini 2.5 Flashは次のようなポジションと捉えられます。
- コスパ重視の中〜上位モデル層
- 数学・科学・コード・長文ベンチマークで、軽量モデルとしては高水準
- 「最強性能」よりも、「広範な用途で安定して使えること」を重視
実務では、既存のインフラや利用中のクラウドサービスとの相性が重要です。
すでにGoogle WorkspaceやGCPを導入済みであれば、Gemini 2.5 Flashを採用することで、認証・ログ・請求管理などの運用負荷を抑えやすくなります。
Gemini 2.5 Flash利用時の注意点とベストプラクティス【セキュリティ・運用・ガバナンス】
ここでは、実際にGemini 2.5 Flashを業務へ組み込む際の注意点と運用上の工夫を整理します。
モデル単体の性能が高くても、運用やガバナンスが整っていないと、セキュリティリスクやコスト超過につながります。
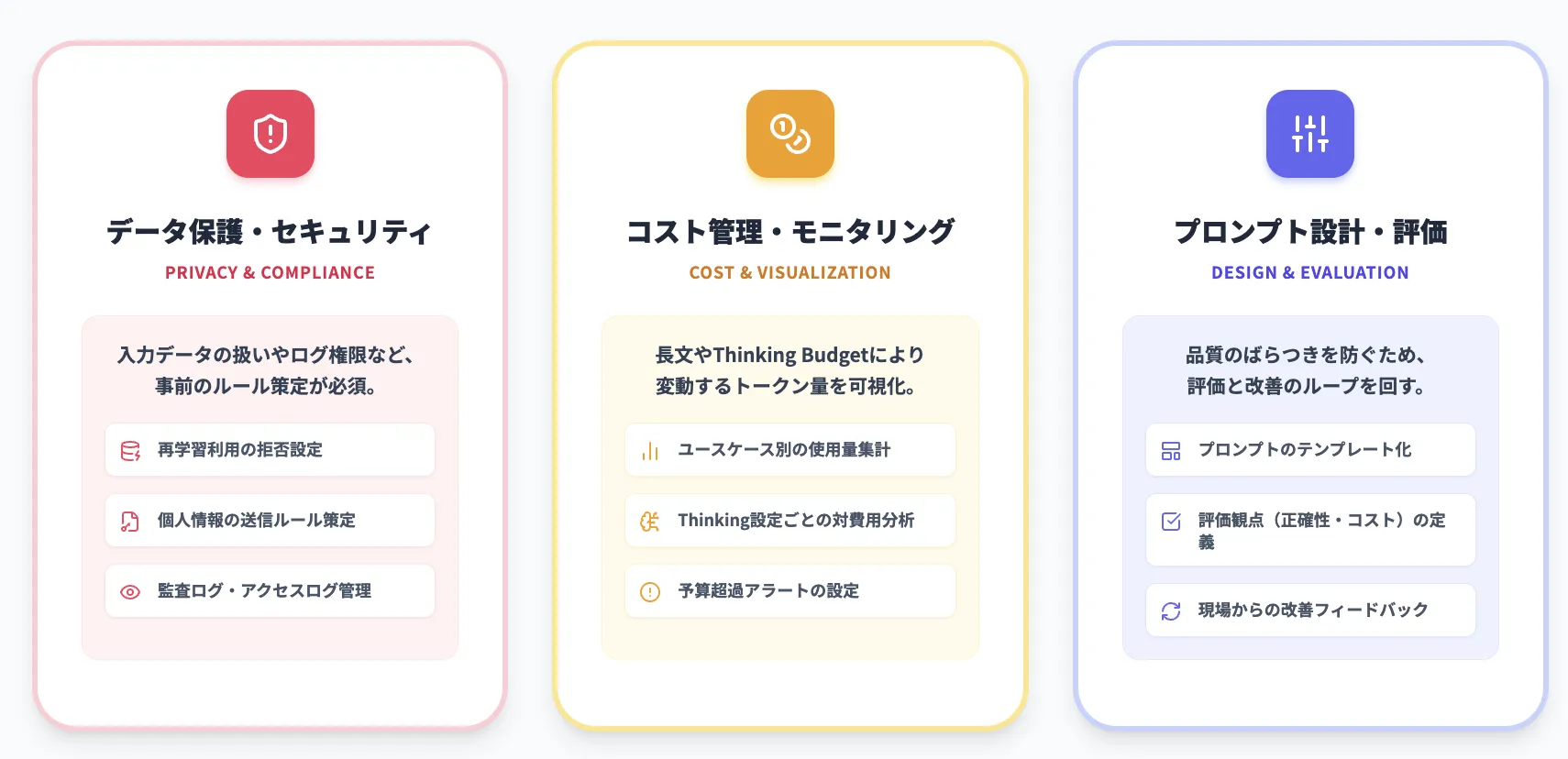
データ保護・プライバシー・ログ設定のポイント
企業利用では、少なくとも次の点を事前に確認しておくことをおすすめします。
- 入力データがモデルの再学習に使われるかどうかの設定
- ログ保存期間とアクセス権限
- 個人情報や機密情報を含むデータをどこまで送信してよいかの社内ルール
- 監査ログ・アクセスログの取得方法
Vertex AIや一部のエンタープライズ向けプランでは、「顧客データをモデル再学習に利用しない」設定がデフォルトまたは選択可能なため、利用プランに応じたデータ保護方針を確認しておくことが重要です。
コスト管理とモニタリング(トークン使用量の可視化)
Gemini 2.5 Flashは、thinking budgetと長大コンテキストにより、使い方次第でトークン使用量が大きく変動します。
そのため、以下のようなモニタリング体制が有効です。
- プロジェクト・ユーザー・ユースケース別のトークン使用量の集計
- thinking budgetごとの平均レスポンスタイムとコストの可視化
- 月次・週次での予算と実績の比較
API利用であれば、リクエストごとにthinking budgetやコンテキスト長をログに残し、「どのパターンが最も費用対効果が高いか」を後から分析**できるようにしておくと改善が進めやすくなります。
プロンプト設計・評価プロセスの整え方
最後に、プロンプト設計と評価の体制についてです。
Gemini 2.5 Flashは柔軟なモデルですが、プロンプト次第で品質が大きく変わる点は他モデルと同様です。
- 代表的なユースケースごとに、ベースとなるプロンプトテンプレートを用意する
- 出力品質を評価する観点(正確性・一貫性・安全性・コスト等)を決める
- 社内でのフィードバックループ(現場からの改善提案)を仕組み化する
Google AI StudioやVertex AIの評価機能を併用すると、プロンプトや設定変更が品質に与える影響を定量的に比較しやすくなります。

よくある質問(FAQ)
Gemini 2.5 Flashに関してよく寄せられる疑問を、簡潔なQ&A形式でまとめます。
Q1. Gemini 2.5 Flashは完全に無料で使えますか?
基本的な利用であれば、Geminiアプリの無料版からGemini 2.5 Flashにアクセスできます。
ただし、利用回数・機能・thinkingの使い方などに制限があるため、業務で継続的に使う場合は有料プラン(Google AI Proなど)やAPI利用を検討した方が現実的です。
Q2. thinkingをオンにするとどれくらい遅くなりますか?
タスク内容やネットワーク環境によって異なりますが、thinking budgetを増やすほどレスポンス時間は長くなります。
FAQレベルでは0、分析・設計タスクでは4,096〜8,192程度から試し、小さい値から調整するのが推奨です。
Q3. ChatGPTやClaudeをすでに使っていますが、Gemini 2.5 Flashも導入する意味はありますか?
あります。特に以下のようなケースでは導入メリットが出やすくなります。
- Google WorkspaceやGCPをすでに利用しており、認証・運用を統合したい場合
- 1Mトークンコンテキストを活かした長文処理を行いたい場合
- 価格と性能のバランスが良いモデルを追加で選択肢に入れたい場合
Q4. 企業で導入する場合、最初に何から始めるべきですか?
多くの企業では、次のようなステップで進めています。
- 無料版やProプランで、少人数のチームがPoCを実施
- 代表的なユースケース(チャットボット/要約/レポート生成など)を絞り込む
- APIやVertex AIで小さな本番導入を行い、コストと品質をモニタリング
- うまくいったユースケースを横展開し、社内教育を進める
Gemini 2.5 Flashの理解を業務でのAI活用に結びつける

AI業務自動化ガイド
Gemini 2.5 Flashのハイブリッド推論やコスト効率を理解したなら、次は自社業務へのAI導入を具体的に進めてみませんか。AI総合研究所のAI業務自動化ガイドでは、AIモデルの選定から業務フローへの組み込みまで、220ページで実践手法をまとめています。
Gemini 2.5 Flashの理解を業務でのAI活用に結びつける
Gemini 2.5 Flashのハイブリッド推論やコスト効率を理解したことで、AIモデルを業務に組み込む際の判断基準が明確になったのではないでしょうか。タスクに応じた思考量の調整という考え方は、社内のAI活用設計においても重要な指針になります。
AI総合研究所では、AIモデルの選定基準から業務フローへの実装、運用時のコスト最適化まで体系的にまとめた「AI業務自動化ガイド」を無料で提供しています。Gemini 2.5 Flashで得た知見を、組織全体のAI戦略に発展させるための実践資料です。
Gemini 2.5 Flashの理解を業務でのAI活用に結びつける
AI業務自動化ガイド
Gemini 2.5 Flashのハイブリッド推論やコスト効率を理解したなら、次は自社業務へのAI導入を具体的に進めてみませんか。AI総合研究所のAI業務自動化ガイドでは、AIモデルの選定から業務フローへの組み込みまで、220ページで実践手法をまとめています。
まとめ:Gemini 2.5 Flashは「実務寄りのハイブリッド推論モデル」
本記事では、Gemini 2.5 Flashの仕組み・料金・使い方・活用事例・他モデルとの比較を、2025年12月時点の情報に基づいて解説しました。
ポイントを整理すると、次のようになります。
- ハイブリッド推論モデルとしての位置づけ
thinkingのオン/オフとthinking budgetにより、タスクごとにコストと精度のバランスを調整できます。 - 1Mトークンコンテキストとマルチモーダル対応
長文・複数ドキュメント・画像・動画・音声をまとめて扱えるため、ナレッジ系業務との相性が良いモデルです。 - コストパフォーマンスの良さ
API料金は100万トークンあたり入力$0.30/出力$2.50と、thinking機能を備えたモデルとしてはバランスの取れた価格帯です。 - 用途の広さ
チャットボット・業務自動化・大規模バッチ処理・エージェント型アプリケーションまで、幅広いユースケースに対応できます。
AI総合研究所では、Gemini 2.5 Flashを含む各種生成AIモデルの導入・活用支援を行っています。
- どのモデルを選べばよいか分からない
- 社内業務のどこからAI化すべきか整理したい
- PoCから本番運用までを一気通貫で進めたい
といった課題があれば、お気軽にご相談ください。
実際のユースケース設計やコスト試算、プロンプト設計の標準化など、現場目線での伴走支援が可能です。










