この記事のポイント
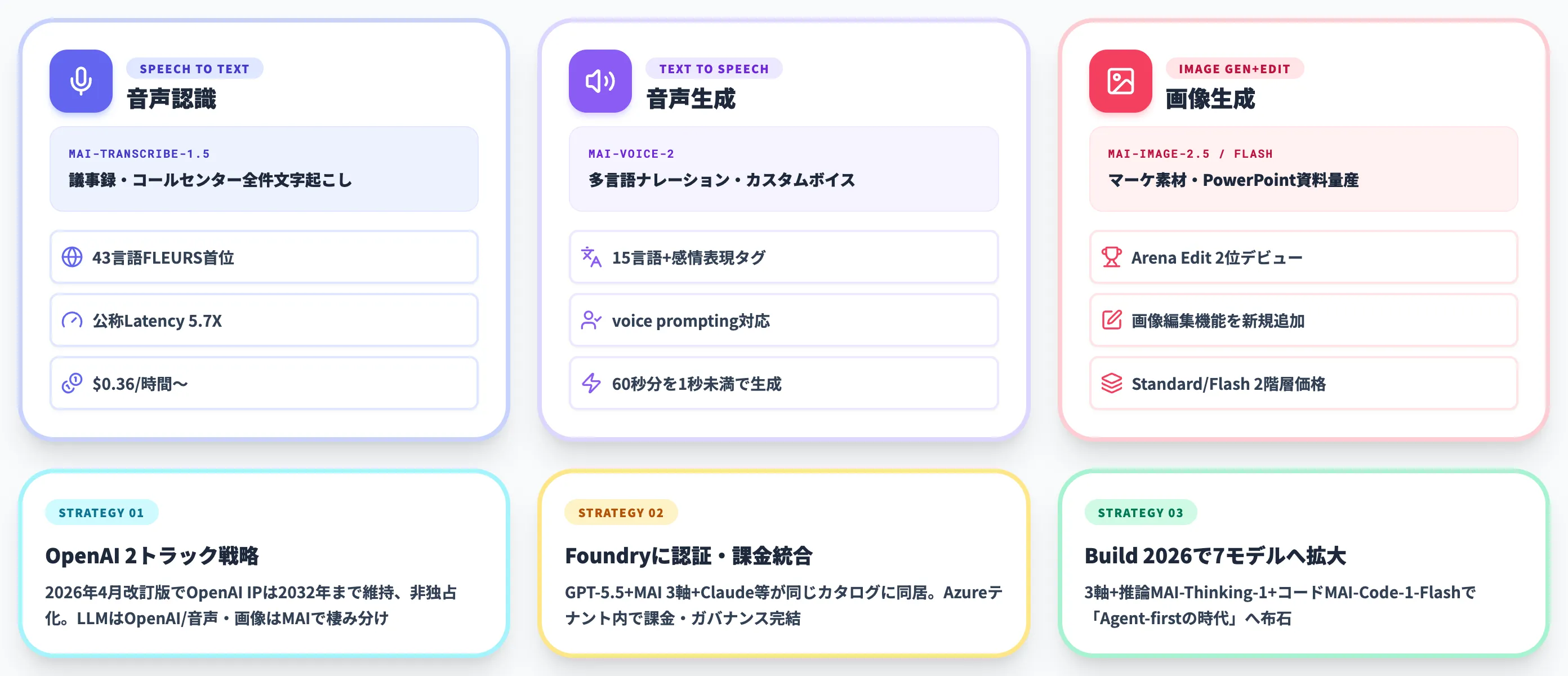
 議事録・字幕・コールセンターを全件文字起こししたいなら、43言語対応・$0.36/時間のMAI-Transcribe-1.5が第一候補
議事録・字幕・コールセンターを全件文字起こししたいなら、43言語対応・$0.36/時間のMAI-Transcribe-1.5が第一候補- 多言語ナレーションを内製したい場合は15言語対応のMAI-Voice-2、ただし公式言語リストに日本語が含まれないため日本語用途はAzure Neural TTS等との併用前提
- マーケ素材・PowerPoint資料の量産は、Arena Image Edit 2位のMAI-Image-2.5(Standard)とコスト最適化用のFlash版を試行錯誤量で使い分けるのが現実解
- Microsoft FoundryのモデルカタログにMAI 3軸+GPT-5.5+Claude等が同居し、用途別に最適モデルを使い分ける「2トラック戦略」が標準的な構成になった
- Build 2026では7モデル拡張に加え、MAI-Thinking-1(AIME 25で97%・SWE-Bench Pro 53%)とMaia 200チップ共設計(GB200比性能30%向上)で自社モデル路線が本格化

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Microsoft MAIは、Mustafa Suleyman氏率いるMicrosoft AI(MAI)部門が自社で訓練・運用している基盤AIモデル群の総称です。2026年4月2日に音声認識・音声生成・画像生成の3モデルがMicrosoft Foundryに登場し、6月2日のBuild 2026では7モデルへ一気に拡張されました。
本記事は「3軸(音声認識・音声生成・画像生成)の最新世代をどの業務に使えばいいのか」という読者の目線に揃え、議事録/多言語ナレーション/マーケ素材という業務目的別に各モデルの仕様・料金・競合との位置をワンセットで整理します。
後半ではMAIモデル群全体の戦略、SIer視点での採用判断、主要3軸モデル横断の料金体系、そしてFoundryのモデルを業務エージェントとして業務に定着させる進め方までを2026年6月時点の公式情報で解説します。
目次
Microsoft MAIモデルとは?2027年フロンティアを目指すMicrosoft AIの3軸基盤
Microsoft Foundry / Azure Speech / MAI Playgroundの3つの提供窓口
議事録・コールセンター分析を任せるなら——MAI-Transcribe-1.5
競合モデル比で公称Latency 5.7Xのバッチ処理速度と$0.36/時間
競合との位置——vs Whisper / GPT-Transcribe / Gemini
多言語ナレーション・カスタムボイスを内製するなら——MAI-Voice-2
voice promptingとidentity preservation
競合との位置——vs ElevenLabs / OpenAI TTS
適用パターン——「英語起点・多言語拡張・カスタムボイス」の3段で設計する
マーケ素材・PowerPoint資料を量産するなら——MAI-Image-2.5
競合との位置——vs DALL-E / Imagen / Nano Banana
MAIモデル群の全体戦略——Build 2026の7モデルと拡張カテゴリ
MAI-Thinking-1——Microsoft初の本格的な推論モデル
MAI-Code-1-Flash——GitHub Copilotネイティブのコーディングモデル
Frontier Tuning・Mayo Clinic共同開発・配布パートナーの拡張
3軸+推論+コード——「Agent-firstの時代」への布石
Microsoft MAIモデルとは?2027年フロンティアを目指すMicrosoft AIの3軸基盤
Microsoft MAIは、Microsoft AI(MAI)部門が他社モデルからの蒸留に頼らず自前で訓練している基盤AIモデル群を指すブランドです。同部門を率いるMustafa Suleyman氏(DeepMind共同創業者・Inflection AI創業者)は、2027年までにテキスト・画像・音声の生成と応答すべてで最先端水準に到達するというロードマップを公言しています。
本記事のタイトルにある「3つのAIモデル」は、その入口となる音声認識・音声生成・画像生成の3軸を指します。2026年4月2日に初代3モデルがMicrosoft Foundryでパブリックプレビュー提供され、続く6月2日のBuild 2026で各系列が最新世代に更新されると同時に、推論・コードを含む7モデル体制へ拡大しました。

Build 2026の基調講演で発表された7つのMAIモデル(出典:Microsoft AI)
画像で示されているとおり、7モデルは音声・画像・推論・コードの4カテゴリにまたがり、Voice・Imageには本体モデルとFlash版が同時に発表された設計になっています(Image-2.5-Flashは提供開始済み、Voice-2-Flashは coming soon)。業務目的別の解説に入る前に、3軸の最新世代マップと、Microsoftが自社モデル路線を本格化した戦略的背景、そして提供窓口を押さえておきます。
3軸(音声認識・音声生成・画像生成)の最新世代マップ
最初に、本記事の主役である3軸の系列を、初代と最新世代の対応で整理します。
以下の表で、4月初代→6月最新世代の進化点を一覧化しました。表のあとに、各業務目的でなぜこの3軸が起点になるのかを補足します。

| 系列 | 初代(2026年4月) | 最新世代(2026年6月Build) | 主な進化点 |
|---|---|---|---|
| 音声認識 | MAI-Transcribe-1(25言語) | MAI-Transcribe-1.5 | 43言語に拡張、entity biasing追加、初代Azure Fast比2.5倍→1.5は競合モデル比最大5倍(公称Latency 5.7X) |
| 音声生成 | MAI-Voice-1(英語のみ) | MAI-Voice-2 / Voice-2-Flash(coming soon) | 15言語に拡張、感情表現タグ、voice prompting追加 |
| 画像生成 | MAI-Image-2 | MAI-Image-2.5 / 2.5-Flash | 画像編集機能追加、Arena Edit 2位、Standard/Flash 2階層価格 |
各系列で「対応言語の拡張・新機能の追加」が一斉に進み、Voice / Imageには軽量Flash版(Voice-2-Flashは coming soon、Image-2.5-Flashは提供開始)も加わったのが特徴です。Transcribe系列にFlash版はまだなく、本体1.5世代で速度と精度を両立させる方向で更新されています。
LLM(テキスト生成)はOpenAIに任せ、その周辺の音声・画像生成をMAIで自社化するという棲み分けの輪郭が、最新世代でより明確になっています。
なぜMicrosoftは自社モデル路線を本格化したのか
注意したいのは、自社モデルの拡充がOpenAIとの決別を意味するわけではないという点です。
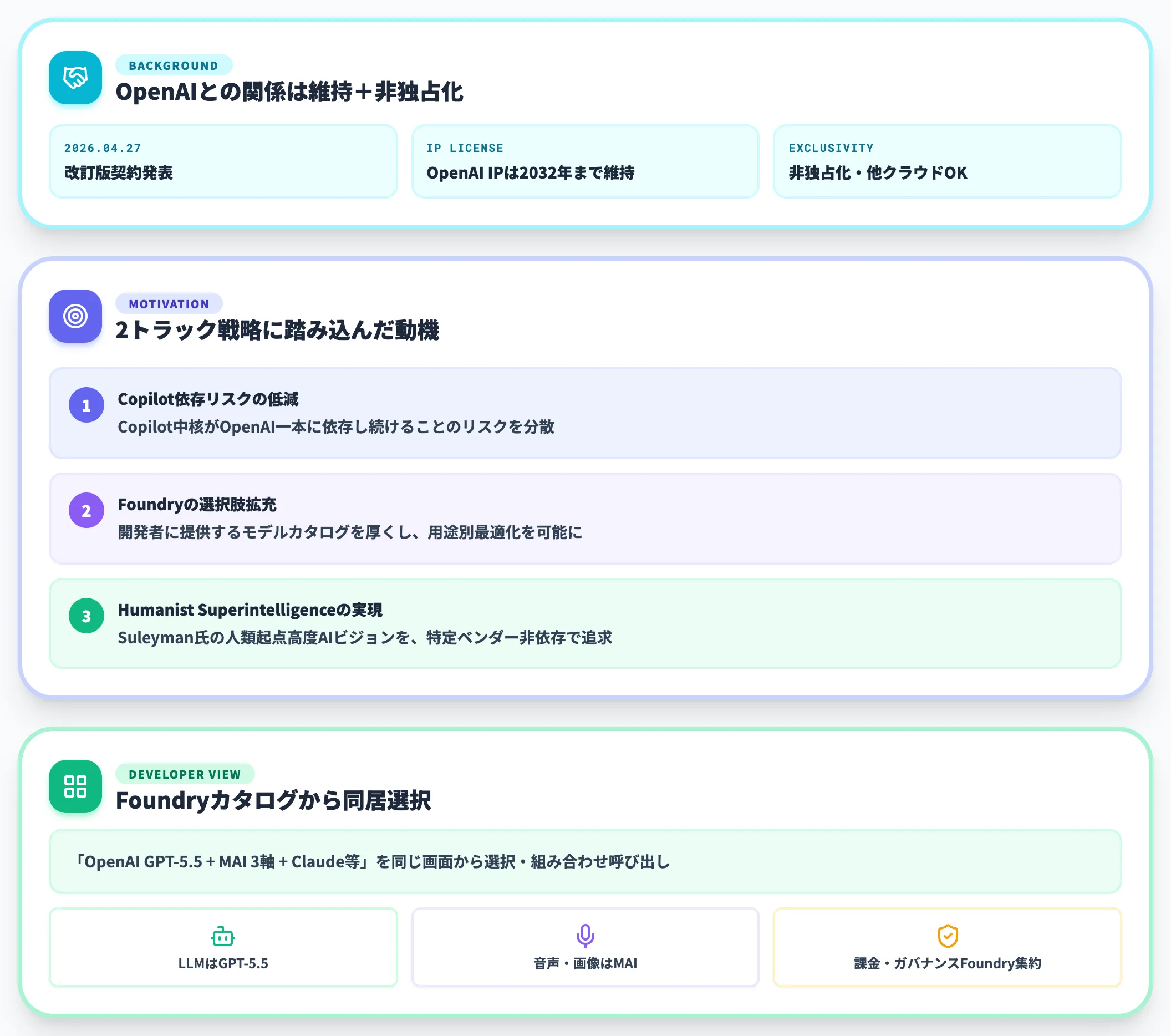
2025年10月に再構築された後、2026年4月27日には改訂版(amended agreement)が発表されました。MicrosoftのOpenAI IPライセンスは引き続き2032年まで維持される一方、非独占化され、OpenAIは他クラウドでも提供可能になっています。OpenAI側もAzureに対して総額約2,500億ドル規模のクラウド利用枠を契約しており、商業的・技術的に依存関係は維持されつつも、両社の関係は「単一クラウド独占」から「複数クラウド同居」のフェーズに移ったというのが2026年6月時点の整理です。
そのうえでMicrosoftが2トラック戦略に踏み込んだ動機は、Copilotの中核がOpenAIモデル一本に依存し続けることのリスク低減と、Foundry上で開発者に提供する選択肢を厚くすることにあります。Suleyman氏が打ち出した「Humanist Superintelligence」というビジョンも、特定ベンダーに依存しない人類起点の高度AIシステムを志向する考え方として、この自社モデル路線と連動します。
開発者から見える具体的な変化は、Microsoft Foundryのモデルカタログで**「OpenAI GPT-5.5 + MAI 3軸 + Claude等」**を同じ画面から選択・組み合わせて呼び出せるようになったことです。LLM・音声・画像という用途別に最適なモデルを使い分け、課金・認証・ガバナンスをFoundryに一本化する設計が現実解になりつつあります。
Microsoft Foundry / Azure Speech / MAI Playgroundの3つの提供窓口
3軸のモデルは、目的に応じて3つのチャネルから利用できます。以下のリストで、各窓口の役割を整理します。

-
Microsoft Foundry
開発者がAPI経由でMAIモデルを呼び出すためのメインの提供窓口。Azure OpenAI Service・Anthropic Claudeなど他社モデルと同じFoundryカタログに並ぶ。
-
Azure Speech
MAI-Transcribe / MAI-Voice系列はAzure Speechリソース経由でデプロイ可能。Personal Voice機能との統合や、Azure Speech既存ユーザーの延長として呼び出せる。
-
MAI Playground
ノーコードで試せる試用環境。公式では米国を含む一部市場のみで提供されており、EUは近日対応。日本拠点ではPlaygroundに依存せず、Foundry経由を基本路線にして試用するのが安全です。

議事録・コールセンター分析を任せるなら——MAI-Transcribe-1.5
ここからは業務目的ごとに、対応するMAIモデルの仕様・料金・競合との位置・適用パターンをワンセットで整理します。
まずは「音声→テキスト」を業務で動かしたいケース。会議録の自動文字起こし、コールセンターログの一括分析、字幕生成といった用途であれば、MAI-Transcribe-1.5が第一候補になります。

MAI-Transcribe-1.5(出典:Microsoft AI)

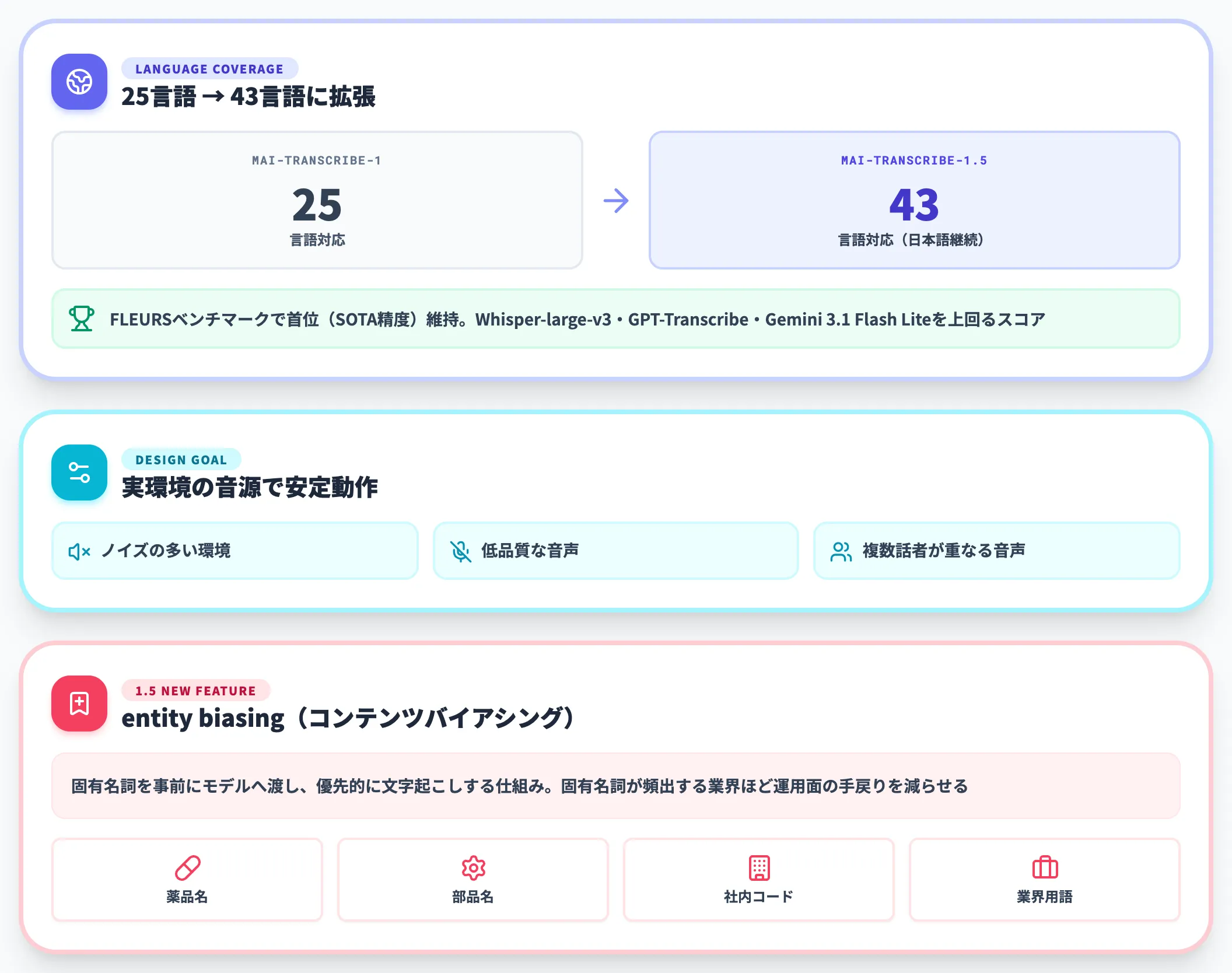
43言語FLEURS首位とentity biasing
MAI-Transcribe-1.5は、初代1(25言語)から対応言語が43言語に拡大しました。日本語も継続して対応言語に含まれます。
MicrosoftのFoundry公式ブログによると、MAI-Transcribe-1.5は業界標準の音声認識ベンチマーク「FLEURS」において首位(SOTA精度)を維持しており、Whisper-large-v3やGPT-Transcribe、Gemini 3.1 Flash Liteなどの主要競合を上回るスコアを出し続けています。
設計上は、ノイズの多い環境・低品質な音声・複数話者が重なる音声でも安定して文字起こしできることを重視しており、研究室のクリーン音声だけでなく実環境の音源を意識して訓練されています。
1.5世代で追加された「entity biasing(コンテンツバイアシング)」は実務インパクトが大きい機能です。社名・商品名・業界用語・社内コードといった固有名詞をあらかじめモデルに渡しておくと、それらを優先的に文字起こしする仕組みで、薬品名・部品名・社内用語が頻出する業界ほど運用面の手戻りを減らせます。
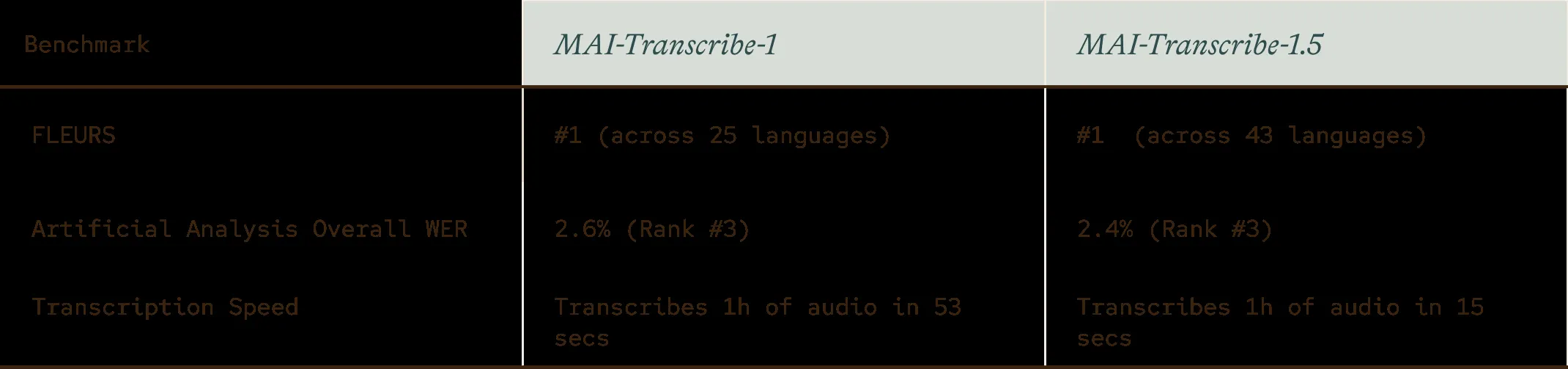
初代MAI-Transcribe-1と1.5の主要ベンチマーク比較(出典:Microsoft AI)
表で示されているとおり、1.5世代は対応言語をほぼ倍増(25→43言語)させながらFLEURS首位を保ち、転写速度は約3.5倍(53秒→15秒)まで加速しています。
競合モデル比で公称Latency 5.7Xのバッチ処理速度と$0.36/時間
MAI-Transcribe-1.5のもう一つの軸は、バッチ処理のスループットと単価のバランスです。
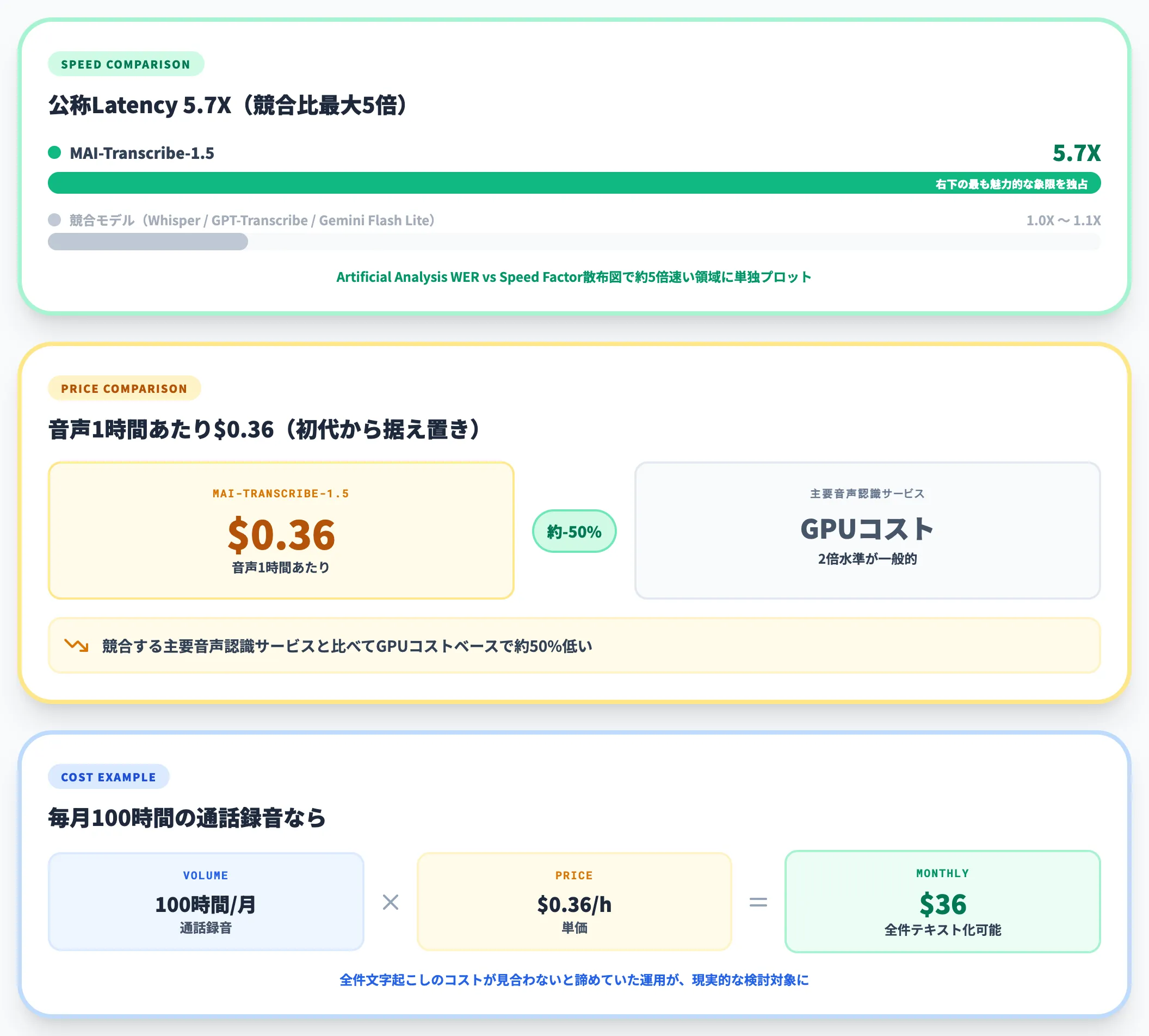
公式モデルページのスペック表では、公称Latency 5.7X(競合する主要モデルとの比較で最大約5倍) の速度でバッチ文字起こしを処理できると示されています。長尺音声(会議録音やコールセンターログのまとめ処理)を扱う現場にとっては直接コストに効きます。
料金は初代1から据え置きで音声1時間あたり$0.36からです。競合する主要音声認識サービスと比べてGPUコストベースでおよそ50%低いとされており、長時間音源を扱う業務では効果が大きい価格帯です。
社内に毎月100時間の通話録音があるなら、月額わずか$36でテキスト化できる計算になります。これまでは「全件文字起こしのコストが見合わない」という理由で諦めていた運用が、現実的な検討対象に入ってきます。
ただし、リアルタイム文字起こし(streaming)・話者分離(ダイアライゼーション)といった機能は段階的な追加扱いです。公式はstreaming対応を「coming soon(近日提供)」と明記しており、現時点ではバッチ前提のユースケースから入り、リアルタイム要件は後続アップデートで補完するのが現実的です。話者分離も同様に未対応・将来対応予定の扱いです。
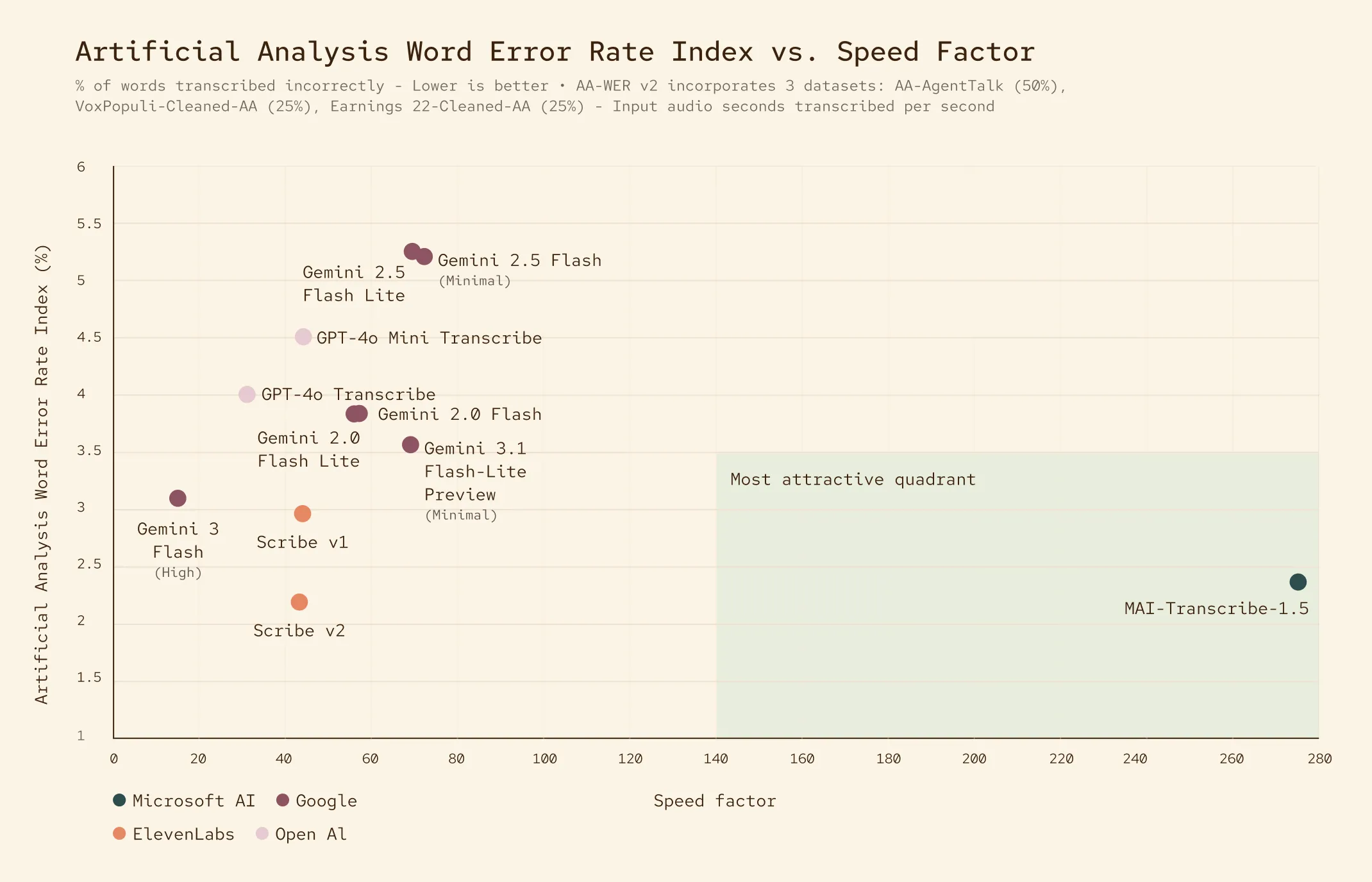
Artificial AnalysisのWER対Speed Factor散布図。MAI-Transcribe-1.5が右下の「最も魅力的な象限」を独占(出典:Microsoft AI)
散布図で示されているとおり、MAI-Transcribe-1.5は他社が並ぶ「Speed factor 50付近」のクラスタから大きく離れ、約5倍速い領域に単独でプロットされています。これが公称「Latency 5.7X」の根拠となる位置取りです。
競合との位置——vs Whisper / GPT-Transcribe / Gemini
音声認識の主要選択肢との位置関係を整理します。以下の表は、現時点で代表的に検討されるモデルを「対応言語数」「速度」「料金水準」「特徴」の観点で並べたものです。価格はベンダーごとに課金単位が異なるため目安として参照してください。

| モデル | 対応言語 | 速度の特徴 | 料金水準(目安) | 強み |
|---|---|---|---|---|
| MAI-Transcribe-1.5 | 43言語 | 公称Latency 5.7X(競合比最大5倍) | $0.36/時間〜 | 43言語のFLEURS首位精度、entity biasing |
| Whisper-large-v3 | 約100言語 | バッチ前提 | OSSなら無料、API課金 | 言語数の多さ、OSS版あり |
| OpenAI GPT-Transcribe | 多言語 | APIベース | API課金 | LLMとの統合性 |
| Gemini 3.1 Flash Lite | 多言語 | APIベース | API課金 | マルチモーダル統合 |
表から読み取れるのは、MAI-Transcribe-1.5が「対応言語の数で勝負するのではなく、よく使われる43言語に絞ってFLEURS精度・価格・速度・固有名詞対応で勝ちにきている」という方針です。
100言語をフラットにカバーする必要があるならWhisper、Microsoft Foundryでの統合性とコストパフォーマンスを取るならMAI-Transcribe-1.5、という棲み分けになります。
適用パターン——「全件文字起こし」を起点に二次活用を組む
MAI-Transcribe-1.5の単価が変えるのは「文字起こしできる範囲」です。次のような順序で業務に組み込むと、現場で効果が出やすくなります。

-
会議録・商談録音の全件テキスト化と検索可能化
-
コールセンター通話の感情分析・クレーム検出・スクリプト遵守監査
-
動画コンテンツの字幕生成・アクセシビリティ対応
-
ポッドキャスト・インタビュー音源のSEO転用
-
音声エージェント・口述入力アプリの裏側エンジン
「文字化したテキストをどの二次活用に流すか」を最初に決めておかないと、テキストが溜まるだけで意思決定に効きません。entity biasingで固有名詞を整えたうえで、感情分析やキーワード抽出などのLLM処理に渡す設計をセットで描くのがコツです。
多言語ナレーション・カスタムボイスを内製するなら——MAI-Voice-2
「テキスト→音声」を業務に組み込みたいケースでは、MAI-Voice-2が選択肢になります。最大の特徴は、15言語対応・感情表現タグ・voice promptingという3点を同時に成立させている点です。

15言語対応と感情表現タグ
MAI-Voice-2は、初代1(英語のみ)から大幅に拡張され、公式モデルページでは15言語対応と明記されています。
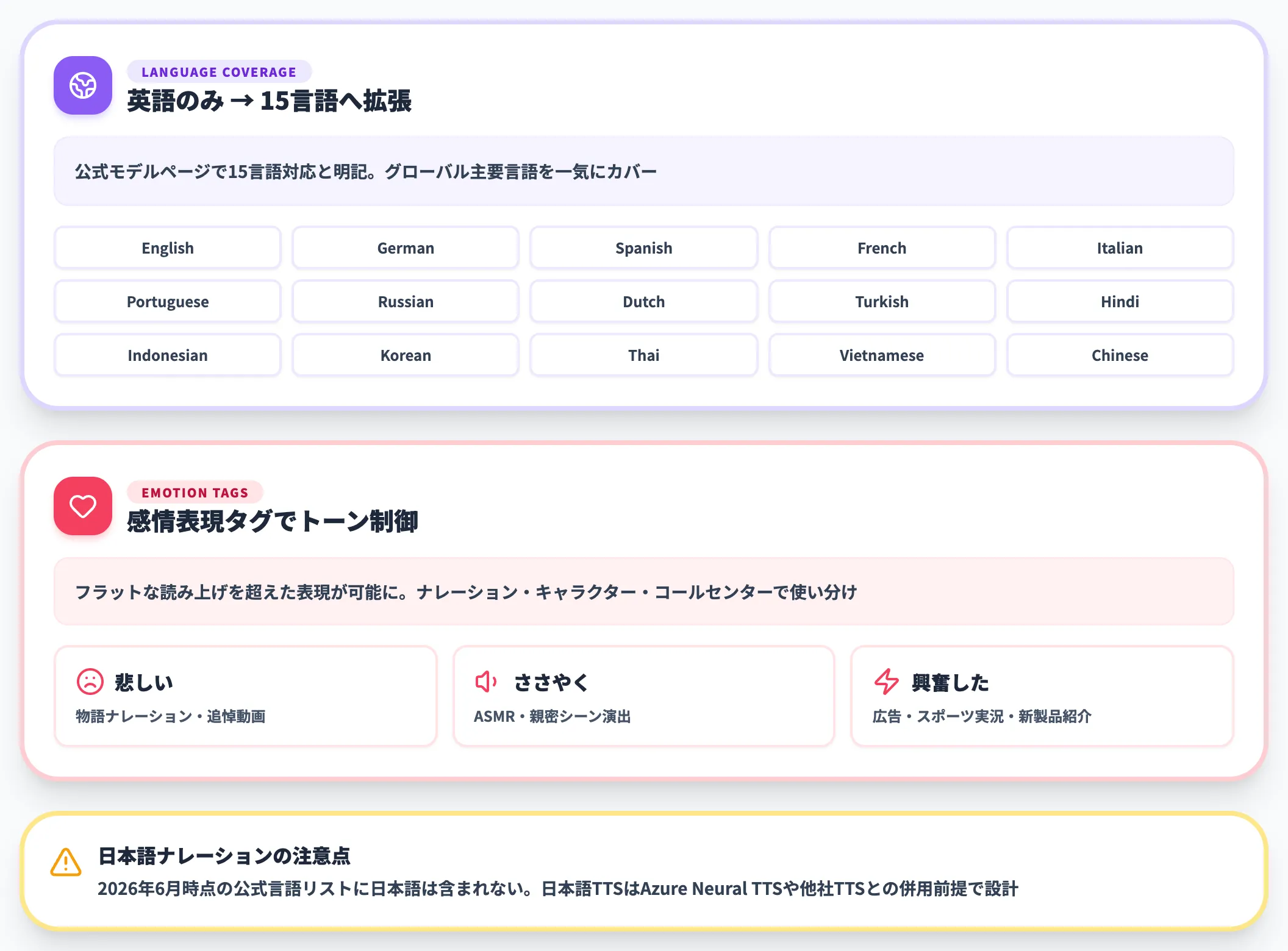 具体的には、ドイツ語、スペイン語、フランス語、ヒンディー語、インドネシア語、イタリア語、韓国語、オランダ語、ポルトガル語、ロシア語、タイ語、トルコ語、ベトナム語、中国語、英語といったグローバル主要言語をカバーします。
具体的には、ドイツ語、スペイン語、フランス語、ヒンディー語、インドネシア語、イタリア語、韓国語、オランダ語、ポルトガル語、ロシア語、タイ語、トルコ語、ベトナム語、中国語、英語といったグローバル主要言語をカバーします。
加えて、感情表現の制御がより細かく指定できるようになりました。「悲しい」「ささやく」「興奮した」といった粒度のタグでトーンをコントロールできるため、ナレーション・キャラクターボイス・コールセンター応答といった用途で、フラットな読み上げを超えた表現が可能になります。
voice promptingとidentity preservation
Voice-2で追加された機能の中で実務インパクトが大きいのが、**voice prompting(音声プロンプト)とidentity preservation(話者一貫性)**です。
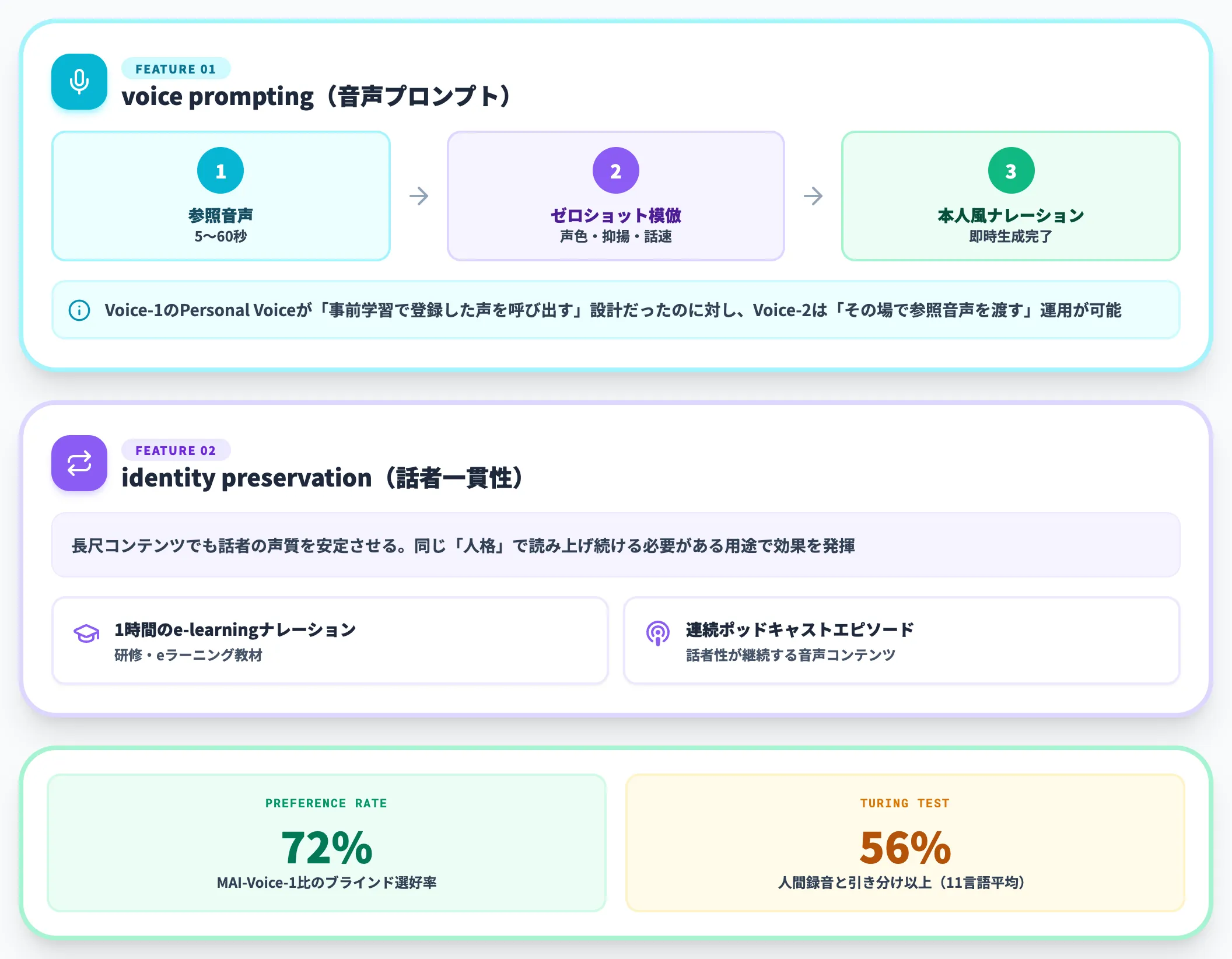
voice promptingは、5〜60秒の参照音声を渡すだけで、声色・抑揚・話速・アクセント・話し方のスタイルをゼロショットで模倣できる機能です。Voice-1のPersonal Voice(10秒サンプルからのカスタムボイス)が「事前学習で登録した声を呼び出す」設計だったのに対し、Voice-2は「その場で参照音声を渡す」運用ができる点が違います。
identity preservationは、長尺コンテンツでも話者の声質を安定させる仕組みです。1時間のe-learningナレーションや連続するポッドキャストエピソードなど、長時間にわたって同じ「人格」で読み上げ続ける必要がある用途で効果を発揮します。
公式発表によると、MAI-Voice-2はMAI-Voice-1に対して72%のブラインド比較で選好されたと報告されており、品質改善は数値裏付けがある状態です。
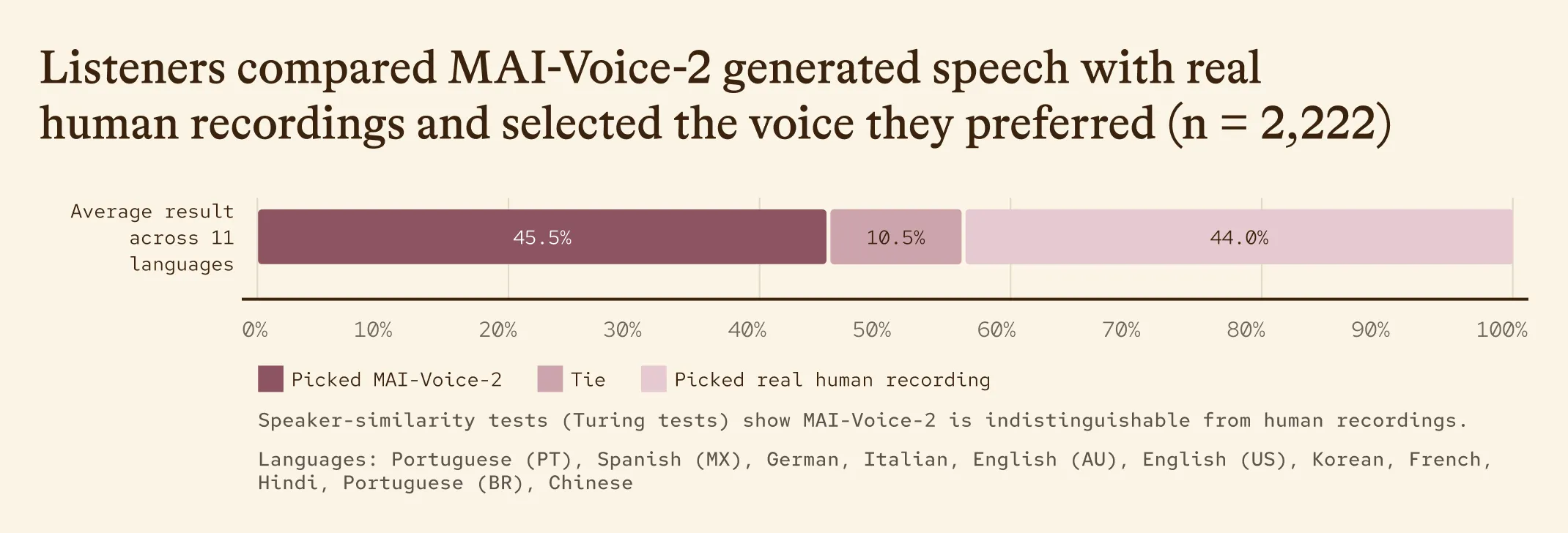
MAI-Voice-2と実際の人間録音を比較したTuringテスト結果(11言語平均・n=2,222)(出典:Microsoft AI)
チャートが示すとおり、Voice-2は11言語の平均で「人間の録音と引き分け以上」が約56%(MAI 45.5% + Tie 10.5%)と、ブラインドリスナーが本物と判別できないレベルまで品質を高めています。
悪用防止のため、公式は「承認・ライセンスされた音声のみが本番環境で合成可能。承認のないvoice cloningは構造的に不可能」と明記しています。社内ナレーター・経営者の声などを使う場合も、同意取得と本人確認のフローを併設して運用設計するのが前提になります。
60秒/1秒の高速生成と料金の確認ポイント
生成速度の高速性は、初代Voice-1から継承された強みです。単一GPU上で60秒分の音声を1秒未満で生成できる設計で、リアルタイム読み上げや音声エージェントとの組み合わせを想定すると、このレイテンシはそのままユーザー体験に効きます。
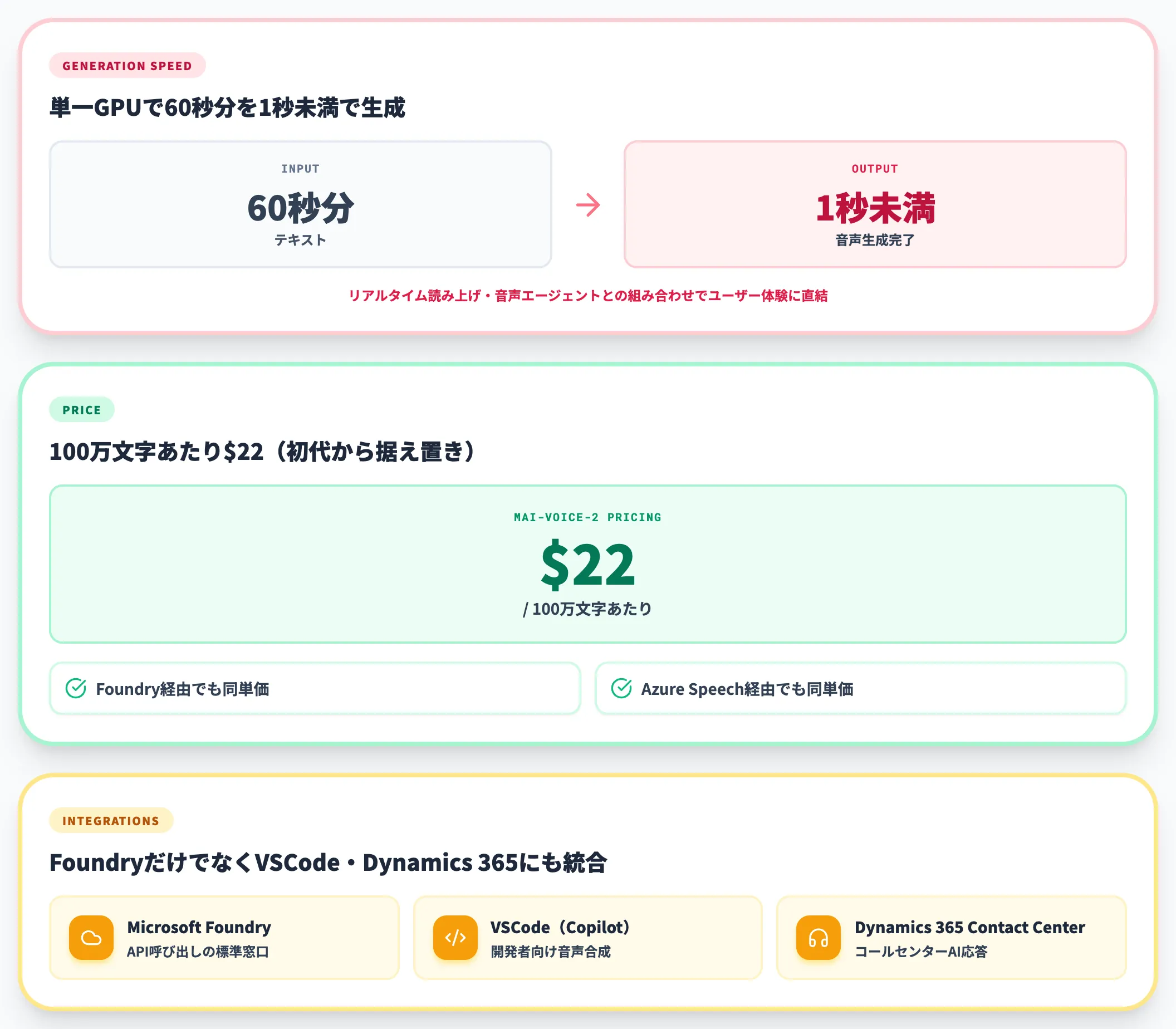
価格は、公式モデルページで100万文字あたり$22と明示されています。初代Voice-1からの据え置きで、Foundry経由・Azure Speech経由いずれの提供窓口でも同じ単価が適用されます。
MAI-Voice-2はFoundryに加えて、GitHub Copilotが動くVSCodeおよびDynamics 365 Contact Centerに統合されることが公式に発表されています。とくにDynamics 365 Contact Centerでの統合は、コールセンター業務でのAI応答ボイスを自社環境に持ち込みたい組織にとって新しい選択肢を提供する動きです。
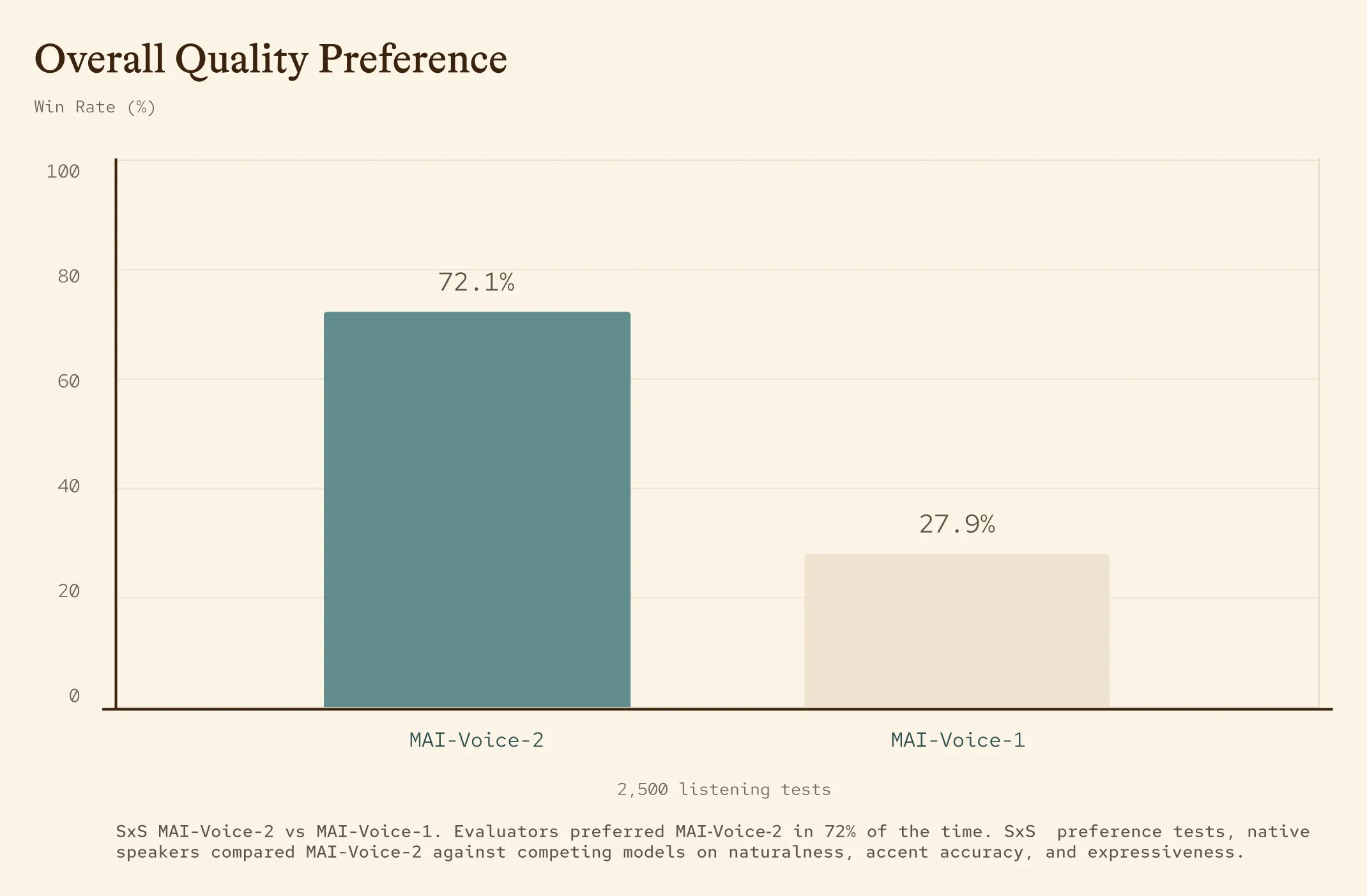
MAI-Voice-2 vs MAI-Voice-1のSxSブラインド比較(2,500件のリスニングテスト)(出典:Microsoft AI)
競合との位置——vs ElevenLabs / OpenAI TTS
音声生成カテゴリの主要競合は、ElevenLabsとOpenAI TTSです。
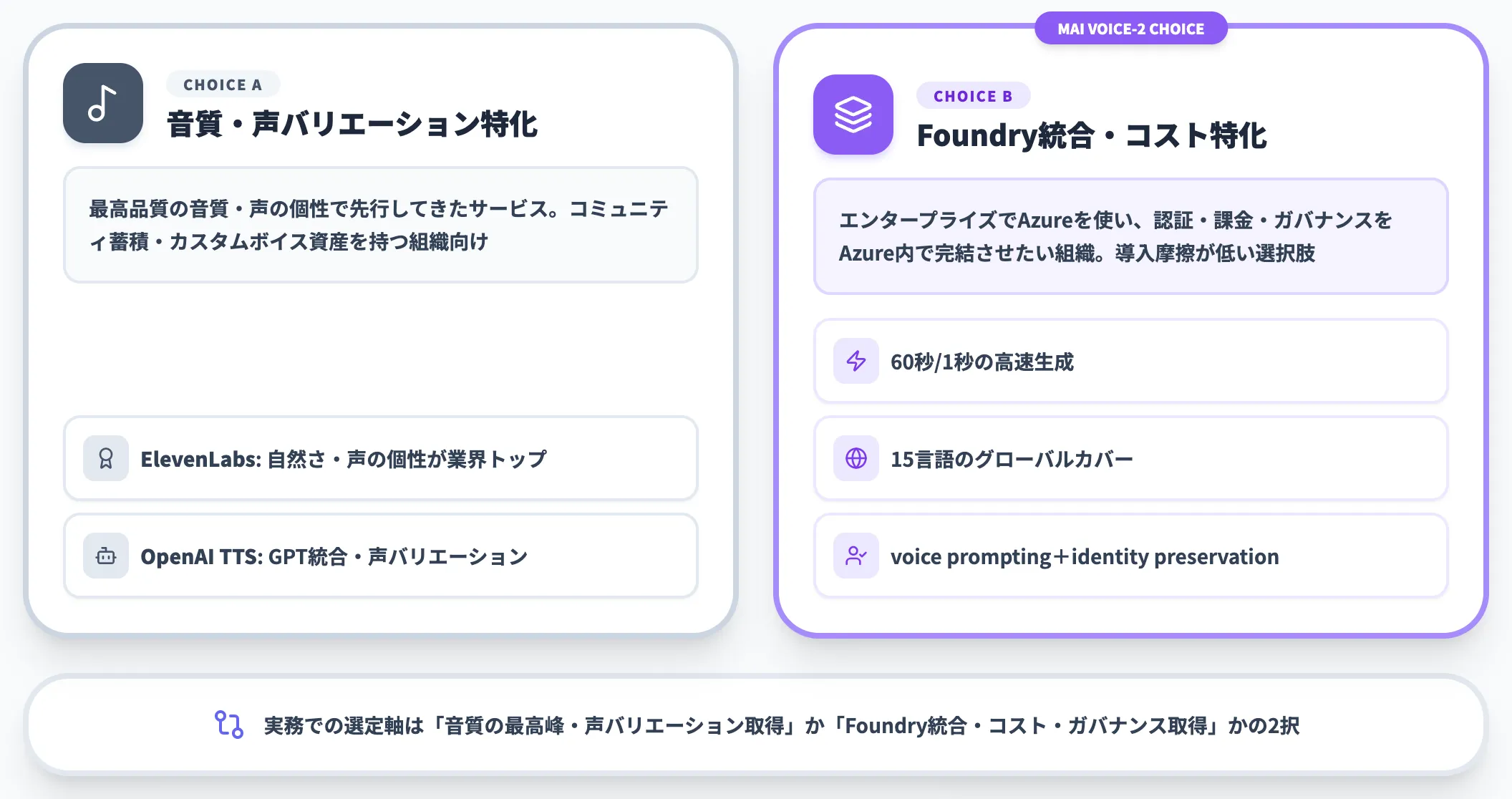
ElevenLabsは自然さと声バリエーション、コミュニティ蓄積で先行してきたサービスで、純粋な音質や声の個性、すでに学習させたカスタムボイス資産を持つ組織には依然として強い選択肢です。
MAI-Voice-2は、60秒/1秒の生成速度・15言語のグローバルカバレッジ・voice prompting・identity preservationの組み合わせで差別化を狙っており、エンタープライズ環境ですでにAzureを使っていて認証・課金・ガバナンスをAzure内で完結させたい組織にとっては導入摩擦が低い選択肢になります。
実務での選定軸は「音質の最高峰・声バリエーションを取りに行くか、Foundry統合・コスト・ガバナンスを取りに行くか」の2択として整理するのが現実的です。
【関連記事】
ElevenLabs(イレブンラボ)とは?使い方や料金、商用利用について解説
適用パターン——「英語起点・多言語拡張・カスタムボイス」の3段で設計する
MAI-Voice-2を業務に組み込む際は、対応言語と感情表現の組み合わせを意識して、以下のような段階で適用範囲を広げると失敗が少なくなります。
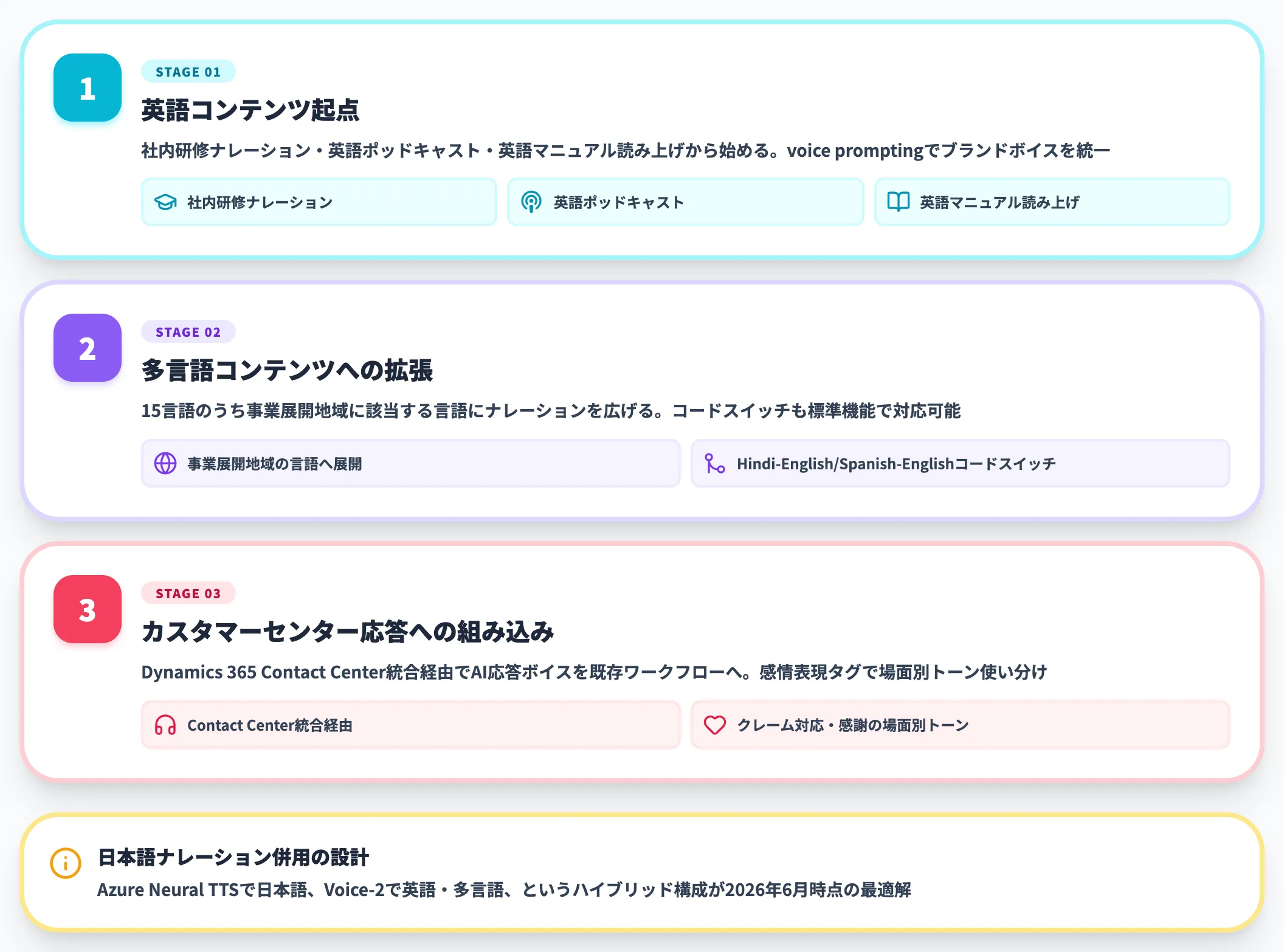
-
英語コンテンツ起点
社内研修ナレーション、英語ポッドキャスト、英語マニュアル読み上げから始める。voice promptingで社内ナレーター・経営者の声を参照音声として渡し、ブランドボイスを統一する
-
多言語コンテンツへの拡張
15言語のうち事業展開地域に該当する言語にナレーションを広げる。Hindi-English/Spanish-Englishのコードスイッチが必要な現場では、Voice-2の標準機能で対応可能
-
カスタマーセンター応答への組み込み
Dynamics 365 Contact Center統合経由で、AI応答ボイスを既存コールセンターワークフローに接続する。感情表現タグでクレーム対応・感謝表現などの場面別トーンを使い分ける
日本語ナレーションが必要な場合は、Azure Neural TTSで日本語、Voice-2で英語・多言語、というハイブリッド構成を組むのが2026年6月時点の最適解です。
マーケ素材・PowerPoint資料を量産するなら——MAI-Image-2.5
画像生成・編集を業務に組み込みたいケースでは、MAI-Image-2.5が選択肢になります。初代Image-2(生成のみ)からは画像編集機能の追加・Arena Image Edit 2位デビュー・標準/Flashの2階層価格という3点で進化しています。

MAI-Image-2.5(出典:Microsoft AI)

Arena Image Edit 2位と画像編集機能
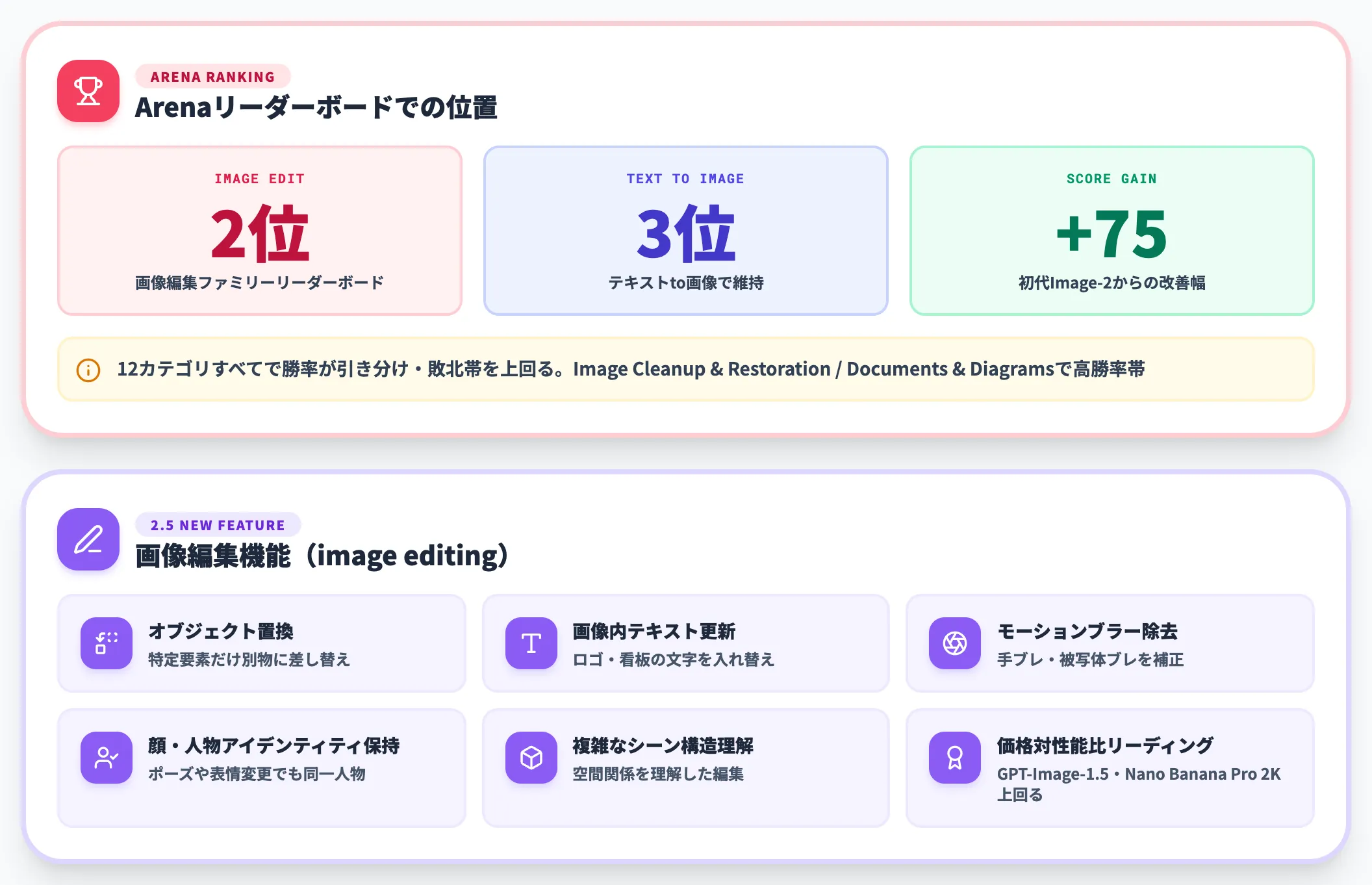
Image-2.5の客観的な性能指標として最も注目されているのが、Arena.aiでの画像モデルファミリーリーダーボードでの順位です。
公式リリースによると、MAI-Image-2.5はArena Image Editリーダーボードで第2位デビューを果たし、テキストto画像でも第3位を維持。初代Image-2からArenaスコアで**+75ポイントの改善**を達成しています。とくにテキスト描写と様式化された画像で大きく伸びており、ロゴや看板テキストを画像内に焼き込むケースで実務的に効きます。
画像編集機能(image editing)は2.5世代で新規追加された目玉機能で、以下のような操作が可能になりました。
-
画像内オブジェクトの置換(特定要素だけ別物に差し替え)
-
画像内テキストの更新
-
モーションブラーの除去
-
顔・人物のアイデンティティ保持(ポーズや表情を変えても同一人物として認識される)
-
複雑なシーン構造・空間関係の理解
公式リリースでは、競合のGPT-Image-1.5やNano Banana Pro 2KをArena評価で上回り、価格対性能比でリーディングと自己評価しています。
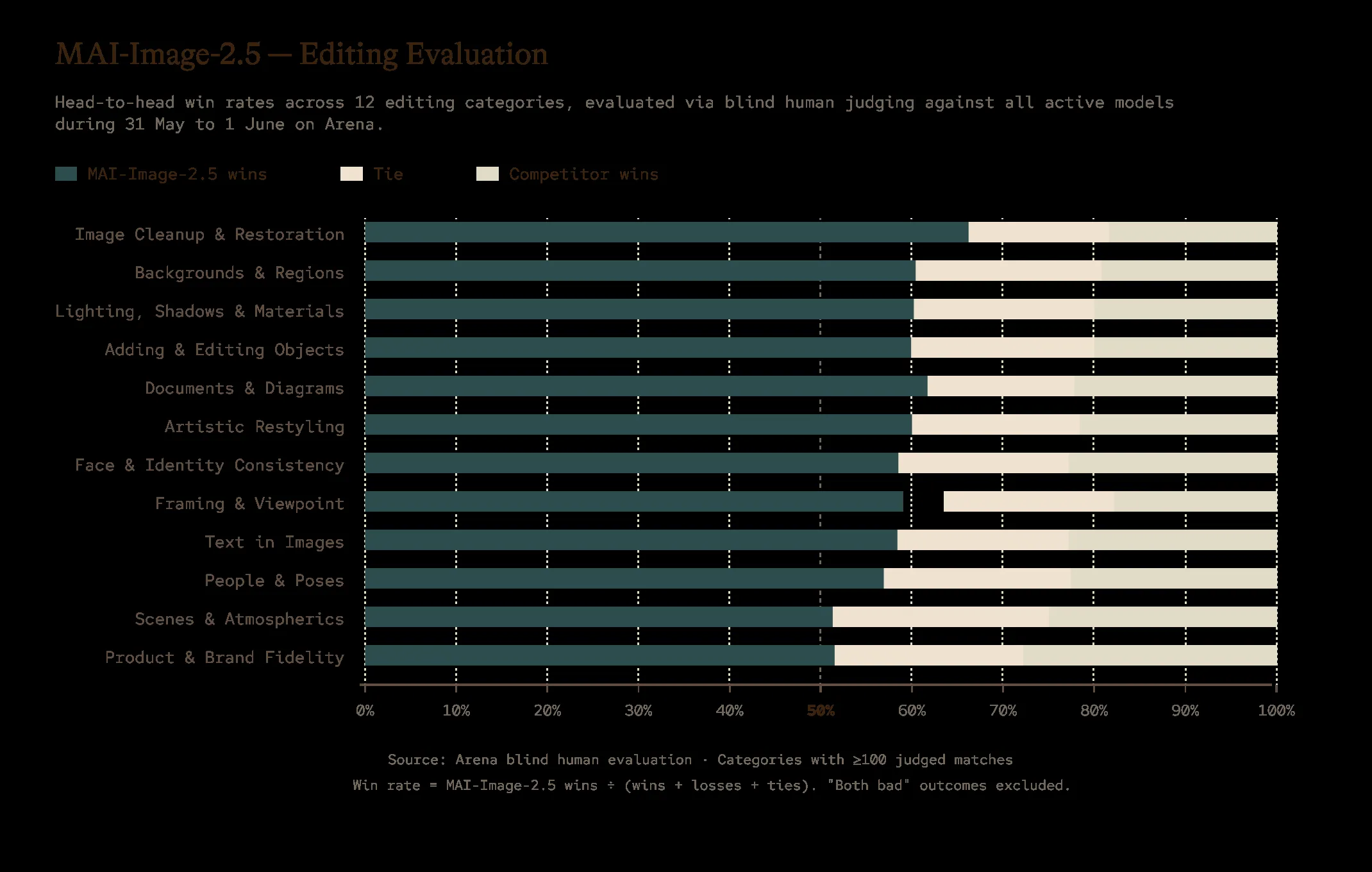
Arena Image Edit 12カテゴリでのMAI-Image-2.5勝率(2026年5月31日〜6月1日のブラインド評価)(出典:Microsoft AI)
チャートで示されているとおり、12カテゴリすべてで勝率(紺色帯)が引き分け・敗北帯を上回っています。とくにImage Cleanup & RestorationとDocuments & Diagramsが高勝率帯にあり、業務系画像生成で重視される「ロゴ・看板テキスト・図表内の文字描写」での強さがArenaの12カテゴリ評価でも裏付けられた形です。
Standard / Flash 2階層の価格戦略
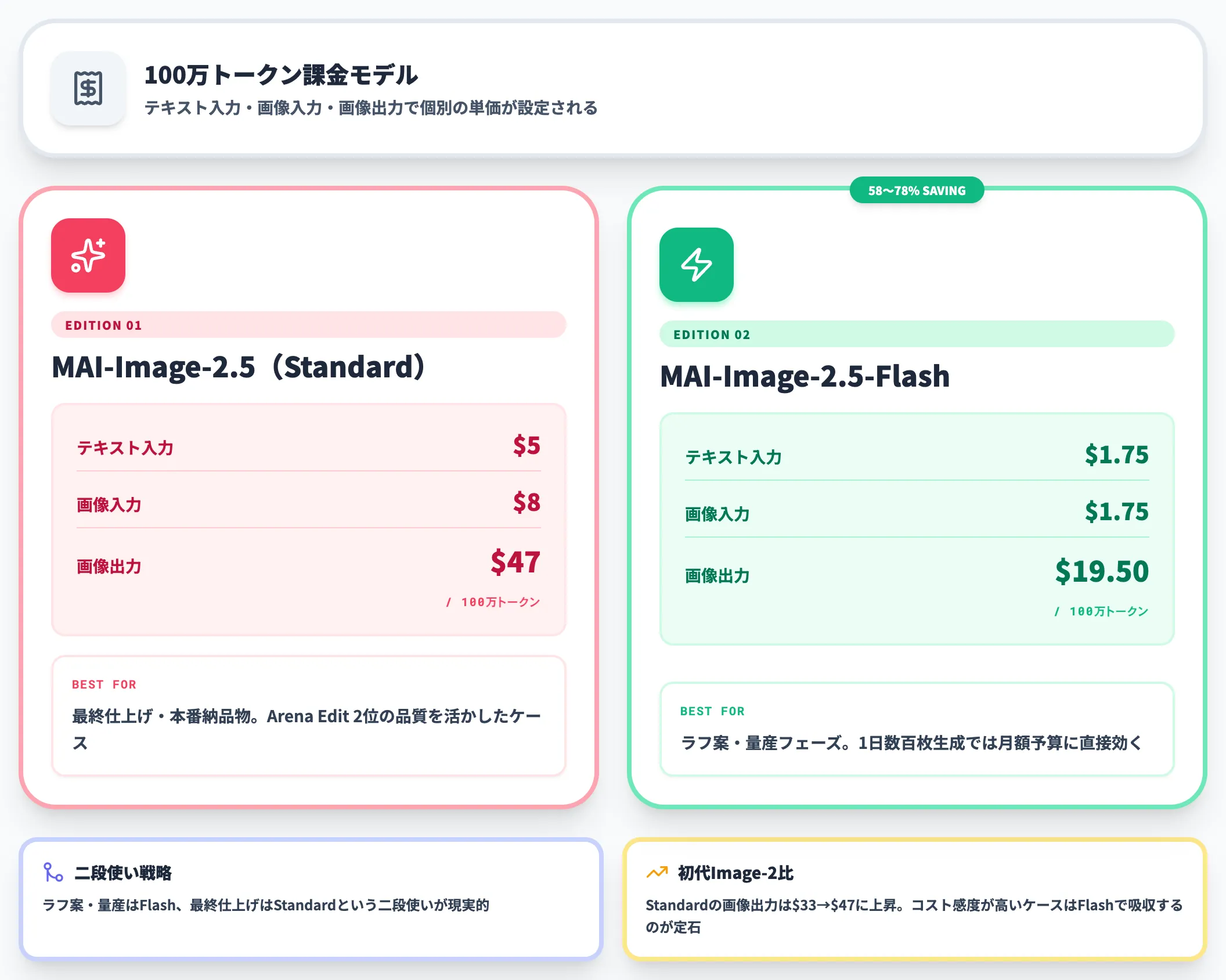
MAI-Image-2.5は、用途に応じて選べる2階層の価格体系を持ちます。以下の表で4つの単価を整理しました。
| エディション | テキスト入力 | 画像入力 | 画像出力 |
|---|---|---|---|
| MAI-Image-2.5(Standard) | $5/100万トークン | $8/100万トークン | $47/100万トークン |
| MAI-Image-2.5-Flash | $1.75/100万トークン | $1.75/100万トークン | $19.50/100万トークン |
Flash版はStandard版に対して各単価で約58〜78%安く設定されています。
画像生成はインタラクティブな試行錯誤が前提のワークフローなので、ラフ案・量産フェーズはFlash、最終仕上げはStandardという二段使いが現実的です。1日に数百枚を生成する用途では、Flash版の単価差がそのまま月額予算に効きます。
なお、初代Image-2の画像出力単価は$33/100万トークンと公表されていたため、Standard 2.5は$33→$47と上昇しています。これは編集機能・Arena Editでの上位ランクなど品質向上の対価と位置づけられる更新で、コスト感度が高い用途ではFlashへの切り替えで吸収するのが定石です。
PowerPoint / OneDrive統合と業務適用
MAI-Image-2.5は、Foundry経由の開発者向け提供と並行して、Microsoftの主要プロダクトへの統合が進んでいます。
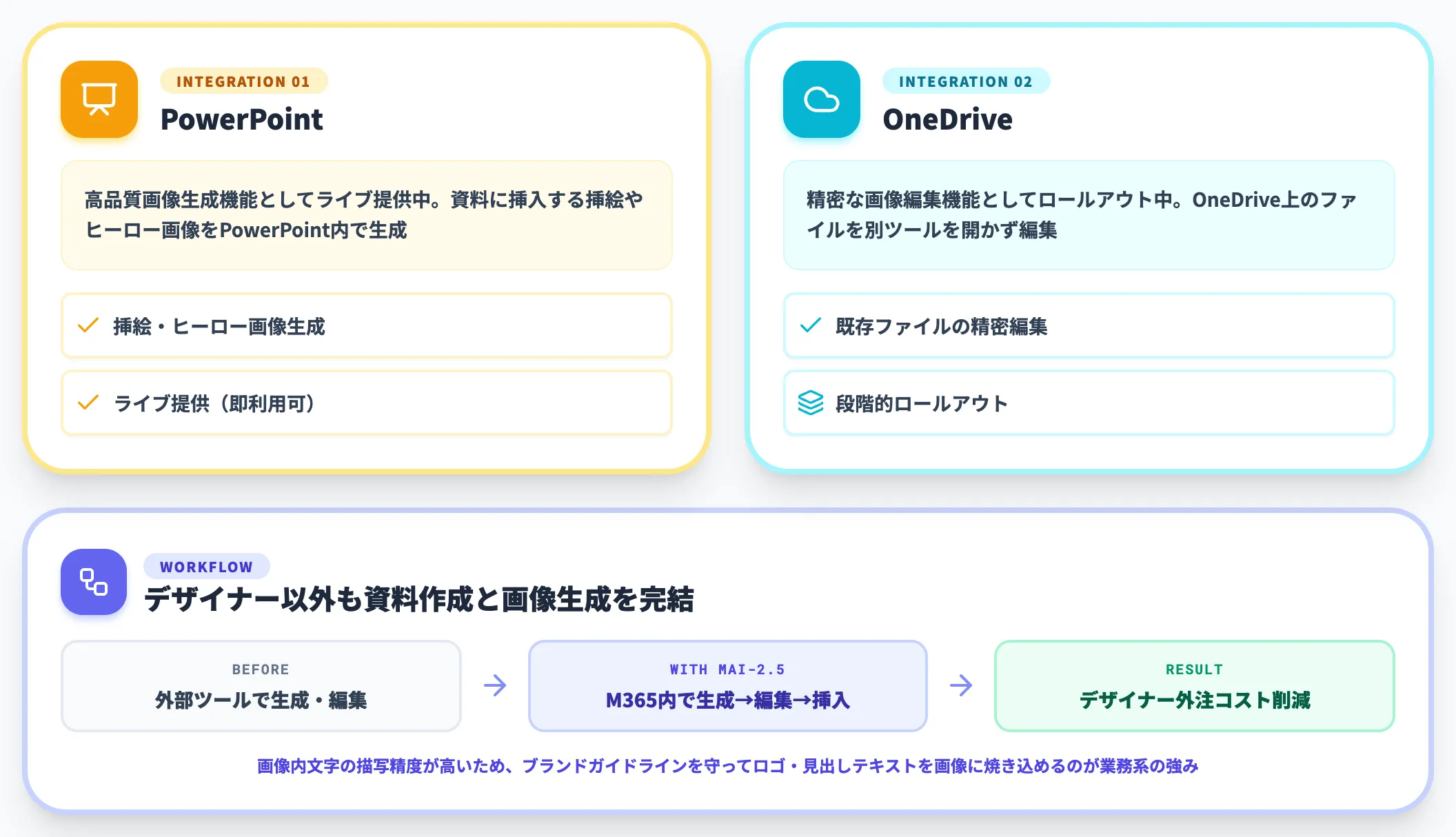
公式リリースで明示されている統合先は以下の2つです。
-
PowerPoint
高品質画像生成機能としてライブ提供中。資料に挿入する挿絵やヒーロー画像をPowerPoint内で生成できる。
-
OneDrive
精密な画像編集機能としてロールアウト中。OneDrive上のファイルに対して、別ツールを開かずに編集が可能。
Microsoft 365 Copilotユーザーが「資料に合わせた挿絵を生成したい」と思った時に、別ツールを開かずにそのままMAI-Image-2.5を呼び出せる体験は、デザイナー以外のスタッフが資料作成と画像生成を同じツール上で完結できる動線です。画像内文字の描写精度が高い点も、ブランドガイドラインを明示的に守りたい企業ではロゴ・見出しテキストを画像に焼き込むケースで実務的に効きます。
競合との位置——vs DALL-E / Imagen / Nano Banana
画像生成カテゴリでは、OpenAIのGPT-Image系列、GoogleのImagenシリーズ、Geminiベースの「Nano Banana」系がMAI-Image-2.5の主な競合です。
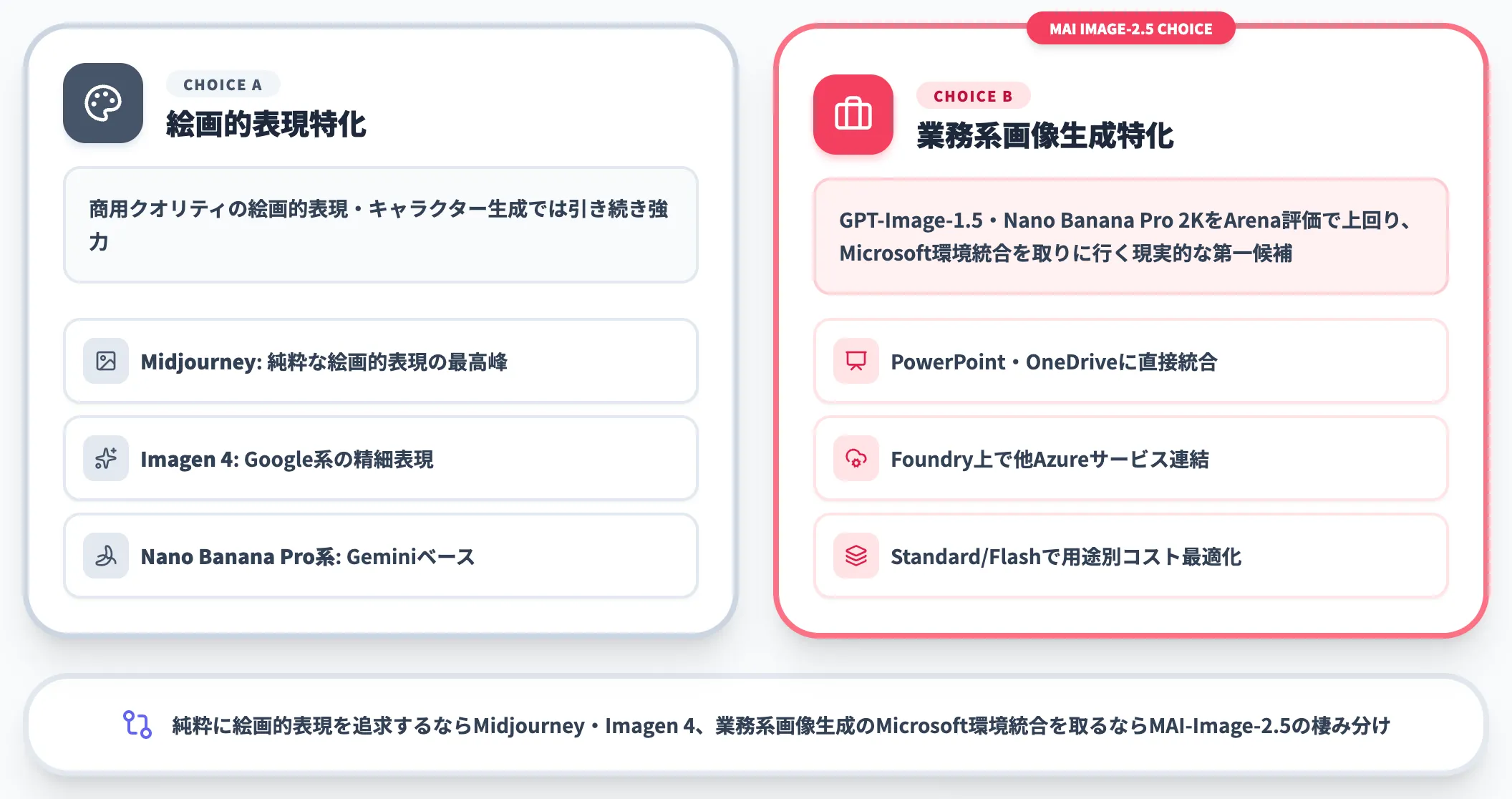
公式リリースでは、MAI-Image-2.5はGPT-Image-1.5とNano Banana Pro 2KをArena評価で上回ったと明示されています。商用クオリティの絵画的表現やキャラクター生成という意味では、Midjourney・Imagen 4・Nano Banana Pro系が引き続き強力な選択肢ですが、MAI-Image-2.5は次の3点で業務系画像生成の現実的な第一候補に位置づけられます。
-
PowerPoint・OneDriveなどMicrosoft Copilot系のMicrosoft 365アプリに直接統合されている
-
Foundry上で他のAzureサービスと連結できる
-
Standard / Flashの2階層で用途別にコスト最適化できる
純粋に絵画的表現を追求するならMidjourney・Imagen 4、業務系画像生成のMicrosoft環境統合を取るならMAI-Image-2.5、という棲み分けになります。
【関連記事】
Imagen4とは?使い方や料金・商用利用、プロンプトのコツを解説!
適用パターン——マーケ・営業・社内資料の3レイヤー
MAI-Image-2.5は、用途に応じて以下の3レイヤーで段階導入すると効果を出しやすくなります。
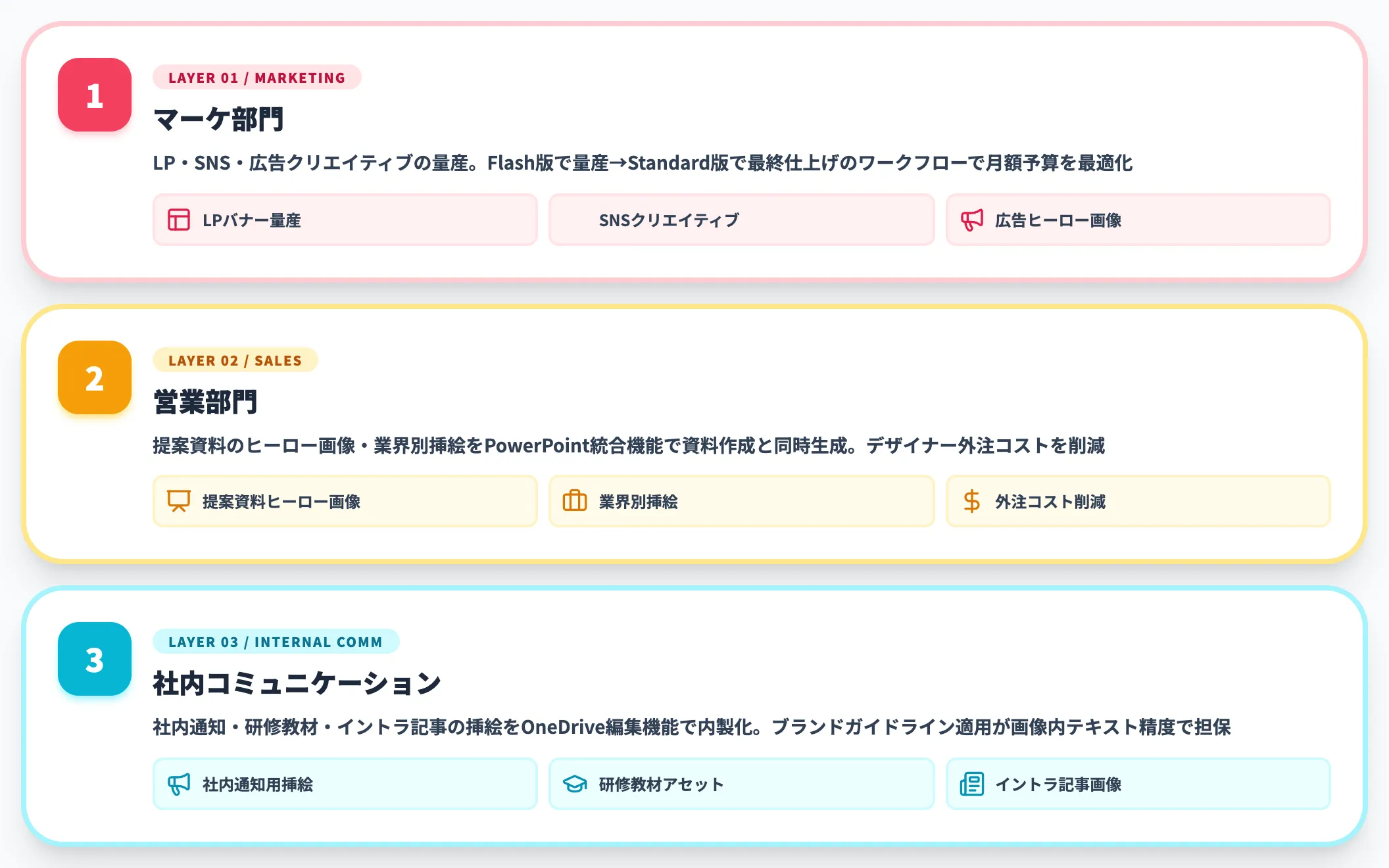
-
マーケ部門
LP・SNS・広告クリエイティブの量産。Flash版で量産→Standard版で最終仕上げ、というワークフローで月額予算を最適化
-
営業部門
提案資料のヒーロー画像・業界別挿絵をPowerPoint統合機能で資料作成と同時生成。デザイナー外注コストを削減
-
社内コミュニケーション
社内通知・研修教材・イントラ記事の挿絵をOneDrive編集機能で内製化。ブランドガイドライン適用が画像内テキスト精度で担保しやすい

MAIモデル群の全体戦略——Build 2026の7モデルと拡張カテゴリ
3軸の業務目的別整理を押さえたところで、ここからは「3軸の外側で何が起きているのか」「MAIモデル群全体の戦略はどう描かれているのか」という全体像を整理します。
3モデルの直接の選定判断には効きませんが、今後のロードマップを読み解くうえで踏まえておきたい背景です。
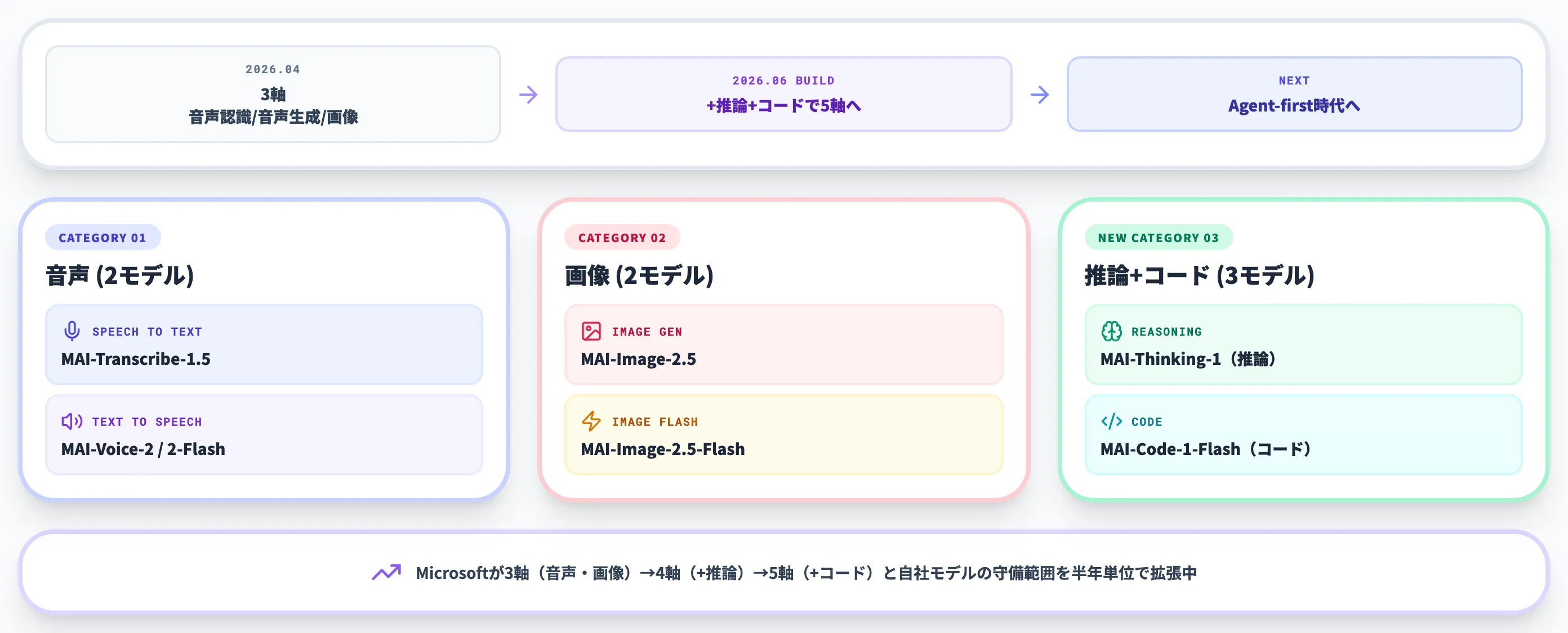
Build 2026で発表された7モデルの全体像
2026年6月2日のBuild 2026で、Microsoftは7つのMAIモデルを一気に発表しました。本記事で扱った3軸(Transcribe / Voice / Image)の最新世代に加え、推論モデル「MAI-Thinking-1」とコード生成モデル「MAI-Code-1-Flash」が新カテゴリとして加わっています。
以下の表で、7モデル全体のカテゴリ分けを整理しました。本記事の主役である3軸(音声認識・音声生成・画像生成)はこれまでのセクションで詳述したため、ここでは新カテゴリの2モデルにフォーカスします。
| カテゴリ | モデル名 | 概要 |
|---|---|---|
| 推論(新カテゴリ) | MAI-Thinking-1 | 中規模の推論モデル。Claude Sonnet 4.6に並ぶ性能と公式自己評価 |
| コード(新カテゴリ) | MAI-Code-1-Flash | 5Bパラメータの軽量コードモデル。GitHub Copilot・VSCode統合 |
| 画像 | MAI-Image-2.5 / 2.5-Flash | (本記事の主要解説対象) |
| 音声認識 | MAI-Transcribe-1.5 | (本記事の主要解説対象) |
| 音声生成 | MAI-Voice-2 / 2-Flash(coming soon) | (本記事の主要解説対象) |
7モデル展開の意味は、Microsoftが3軸(音声・画像)→4軸(+推論)→5軸(+コード)へと自社モデルの守備範囲を半年単位で広げているという事実です。
MAI-Thinking-1——Microsoft初の本格的な推論モデル

MAI-Thinking-1(出典:Microsoft AI)
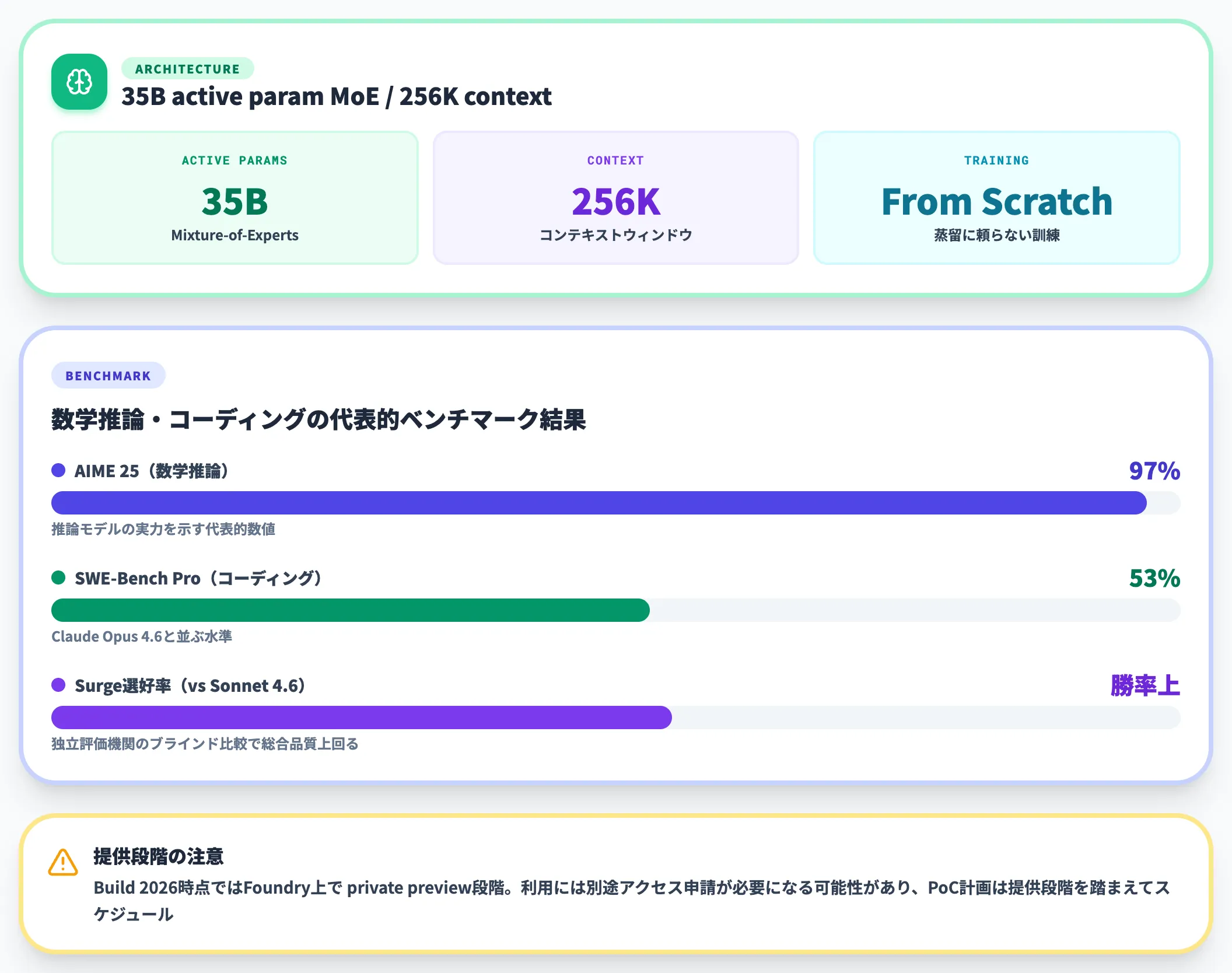
MAI-Thinking-1は、Microsoftにとって初めての本格的な推論モデルです。これまでOpenAIに依存してきたLLM領域へのMicrosoft自身の参入を意味する重要なリリースです。
Microsoft AI公式が公表している主要スペックとベンチマーク数値は以下のとおりです。
-
アーキテクチャ: 35B active parameter MoE(Mixture-of-Experts)、256Kコンテキストウィンドウ
-
AIME 25で97%: 数学・推論能力の代表的ベンチマークで、推論モデルの実力を端的に示す数値
-
SWE-Bench Proで53%: 最難関クラスのコーディングベンチマークで、AnthropicのClaude Opus 4.6と並ぶ水準
-
Sonnet 4.6に対する選好率: 独立評価機関Surgeのブラインド比較で、品質の総合評価でSonnet 4.6を上回ったとMicrosoftが公表
蒸留に頼らない「from scratch」訓練を明言している点もポイントで、独立した学習データ・学習プロセスでこの水準に到達したことが、Microsoftの自社モデル路線の真剣度を示します(McKinseyベンチでGPT-5.5に対しコスト効率10倍という公式コメントは、後述の「Frontier Tuning」でチューニングしたカスタムMAIモデル=Excel特化版や企業向け版についての話で、MAI-Thinking-1本体単体のベンチではない点に注意)。
MAI-Code-1-Flash——GitHub Copilotネイティブのコーディングモデル

MAI-Code-1-Flash(出典:Microsoft AI)
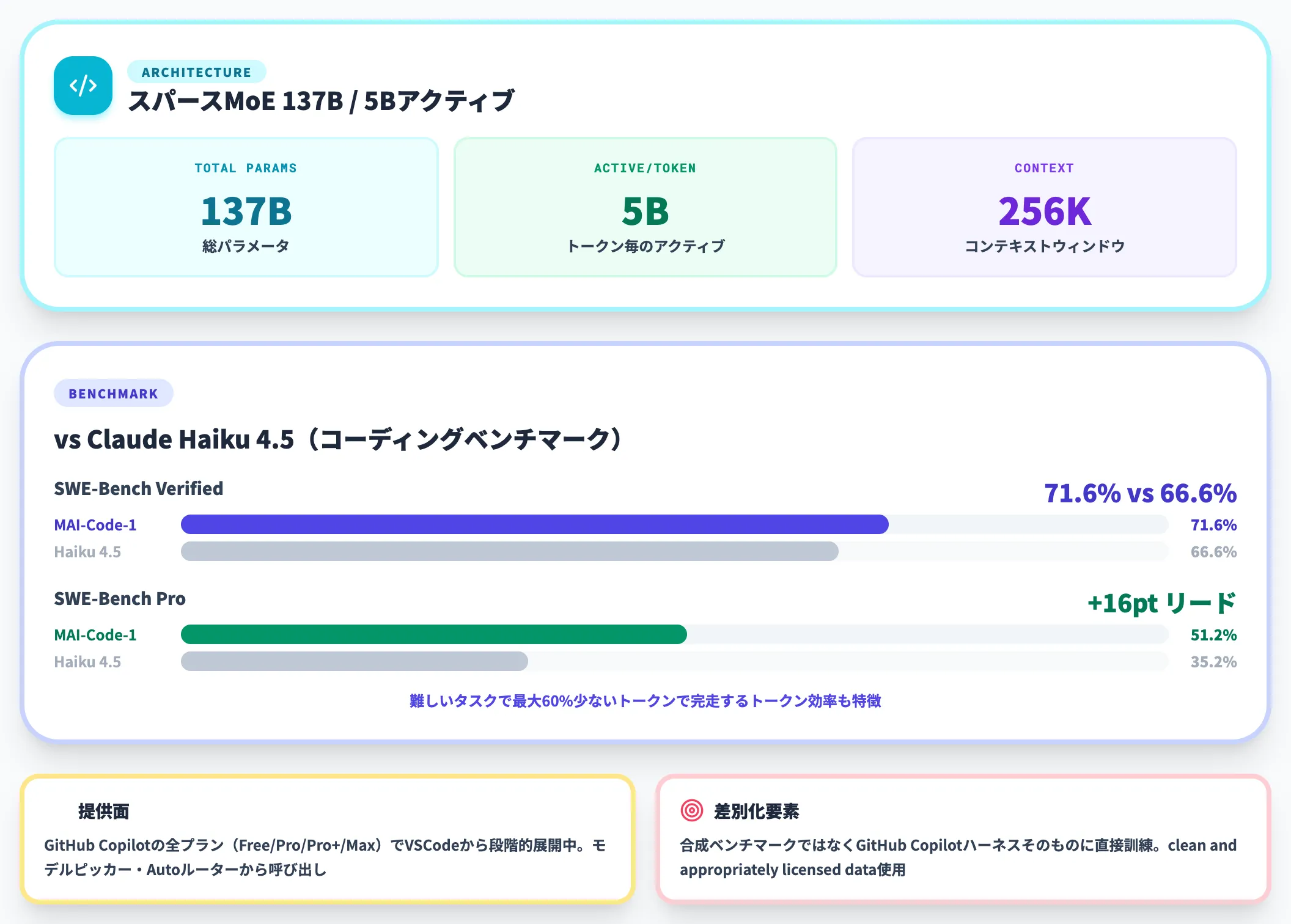
MAI-Code-1-Flashは、GitHub Copilotのために設計された推論効率重視のエージェント型コーディングモデルです。
Microsoft AI公式リリースとGitHub Changelogで示されている主要スペックは以下のとおりです。
-
アーキテクチャ: スパースMoE構成で総パラメータ137B/トークン毎のアクティブ5B、256Kコンテキストウィンドウ
-
SWE-Bench Verified 71.6%: Claude Haiku 4.5(66.6%)を上回る
-
SWE-Bench Pro 51.2%: Haiku 4.5の35.2%に対して**+16ポイントのリード**
-
トークン効率: 難しいタスクで最大60%少ないトークンで完走
-
訓練データ: 2026年3〜5月に「clean and appropriately licensed data」で訓練。合成ベンチマークではなくGitHub Copilotハーネスそのものに直接訓練されている点が他のコードモデルとの差別化要素
提供面では、GitHub Copilotの全プラン(Free / Pro / Pro+ / Max)でVS Codeから段階的に展開中で、対象ユーザーから順次ロールアウトされます。GitHub Copilotのモデルピッカーと新しいAutoルーターから呼び出せる前提で、自社ユーザーへの提供開始タイミングは契約プランと公式アナウンスを併せて確認してください。Microsoftにとっては、Haiku 4.5並みかつより安価という価格対性能比で、GitHub Copilotの裏側エンジンを自社製に置き換える動きとして位置づけられます。
MAIモデルとMaia 200チップの共設計
Build 2026のもう一つの注目ポイントは、Microsoftが自社モデルを自社シリコン(Maia 200チップ)と共設計していることを公式に明示した点です。
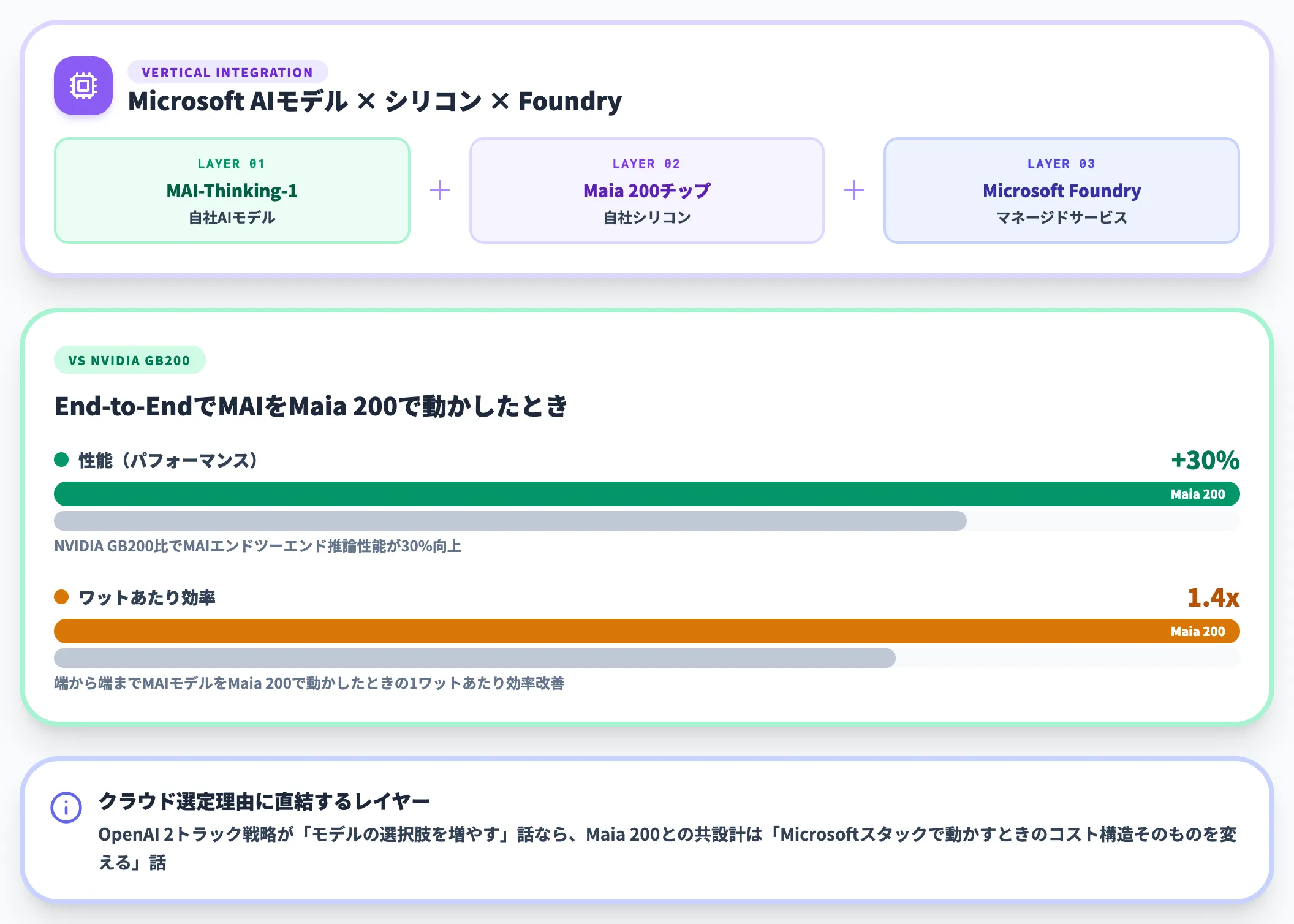
Build 2026 MAIキーノートトランスクリプトによると、MAI-Thinking-1はMaia 200チップ向けに最適化されており、NVIDIA GB200との比較で以下の効率向上が公表されています。
- 性能で30%向上
- ワットあたり1.4倍の効率改善(端から端まで(end-to-end)MAIモデルをMaia 200で動かした場合)
これは「Microsoft AIモデル × Microsoftシリコン × Microsoft Foundry」という垂直統合のシナジーが、ベンチマーク数値として可視化された最初の事例です。OpenAI 2トラック戦略が「モデルの選択肢を増やす」話だとすれば、Maia 200との共設計は「Microsoftスタックで動かすときのコスト構造そのものを変える」話で、エンタープライズユーザーがクラウド契約を選ぶ理由のレイヤーに直結します。
Frontier Tuning・Mayo Clinic共同開発・配布パートナーの拡張
Build 2026のMAI関連発表は、ベースモデル7種のリリースだけでは語り尽くせません。以下の3つは、3軸記事のテーマからはやや外れますが、MAI全体戦略を読み解くうえで踏まえておきたい動きです。

-
Frontier Tuning
強化学習を現実の業務環境に適用し、AIが特定ワークフローに完全適応するチューニング技法。公式リリースで挙げられているExcel向けカスタムMAIモデルは「GPT-5.4に並ぶ性能を10倍効率で達成」、企業向けカスタムMAIも「テスト対象モデル中で最高勝率を約10倍低コストで実現」と公表されており、ベースMAIモデルを企業ワークフローに合わせて再学習する経路が確立しつつある
-
Mayo Clinicとの医療向けフロンティアモデル共同開発
Mayo Clinicの臨床知識・de-identifiedな臨床データ・縦断的インサイトと、MicrosoftのAI基盤を組み合わせた医療フロンティアモデル。最初はMayo Clinic自身の環境で展開し、その後Microsoft Foundryを通じて広く提供される計画
-
配布パートナーの拡張
MAIモデルはMicrosoft Foundryに加えて、OpenRouter / Fireworks / Basetenなどの第三者プラットフォームでも開発者向けに広く提供される予定。Foundry単独ではなく、マルチプラットフォーム配信でMAIモデルの利用接点を増やす方針
医療領域へのフロンティアモデル投入と、汎用ベースモデル→業務特化チューニング(Frontier Tuning)→マルチプラットフォーム配布、という展開で、Microsoftは自社モデルの裾野を急速に広げています。
3軸+推論+コード——「Agent-firstの時代」への布石
3軸(音声・画像)に推論・コードを加えることで、Foundryユーザーが業務エージェントを組み立てるときに「LLM・推論・コード生成・音声・画像」のすべてをMAIブランドで揃えられる体制が見え始めています。

Suleyman氏はBuild 2026のキーノートでこの方針を「Agent-firstの時代」というキーワードで整理しており、3軸モデル単体ではなくエージェント実行基盤(Microsoft Foundry)+実行ランタイム(Windows / Microsoft Execution Containers等)+ハードウェア(Maia 200) を含めた一体設計として今後拡張されていく見通しです。
Build 2026では、MAIモデル本体と並行してMicrosoft Foundry側の業務エージェント機能も大幅強化されました。MAIモデルを業務に組み込むうえで併せて押さえておきたい主な発表は以下のとおりです。
-
Toolboxes in Foundry
エージェントが接続できるツール群をパッケージ化する機能。public preview段階で、MAIモデルを起点にしたエージェントが社内ツールへ繋ぎ込みやすくなる
-
Voice Live
リアルタイム音声パスをFoundryに追加。MAI-Voice-2 / MAI-Transcribe-1.5を双方向のリアルタイム音声エージェントとして組み合わせる土台
-
Foundry agents → Teams / Microsoft 365 Copilot publish
Foundryで作ったエージェントをTeams・Microsoft 365 Copilotに直接公開する機能。2026年6月にGA予定と公表
-
Memory in Foundry Agent Service
procedural / user / sessionの3層メモリをエージェントに付与(public preview)。MAIモデルを使うエージェントで対話文脈・ユーザー設定を継承できる
-
Hosted agents in Foundry Agent Service
本番運用向けのマネージドランタイム。2026年7月初頭にGA予定で、自前でランタイムを組まずにMAIモデル駆動エージェントを本番投入できる
つまり、MAI 3軸+推論+コードという「モデル側の拡充」と、Foundryのコントロールプレーン強化という「実行基盤側の拡充」が同じBuildで同時に進んだ、というのが2026年6月時点のMicrosoft AIスタックの現在地です。
OpenAIとの2トラック戦略を踏まえた使い分け
冒頭でも触れたとおり、Microsoftが自社モデルを拡充してもOpenAIとの関係が解消されるわけではありません。
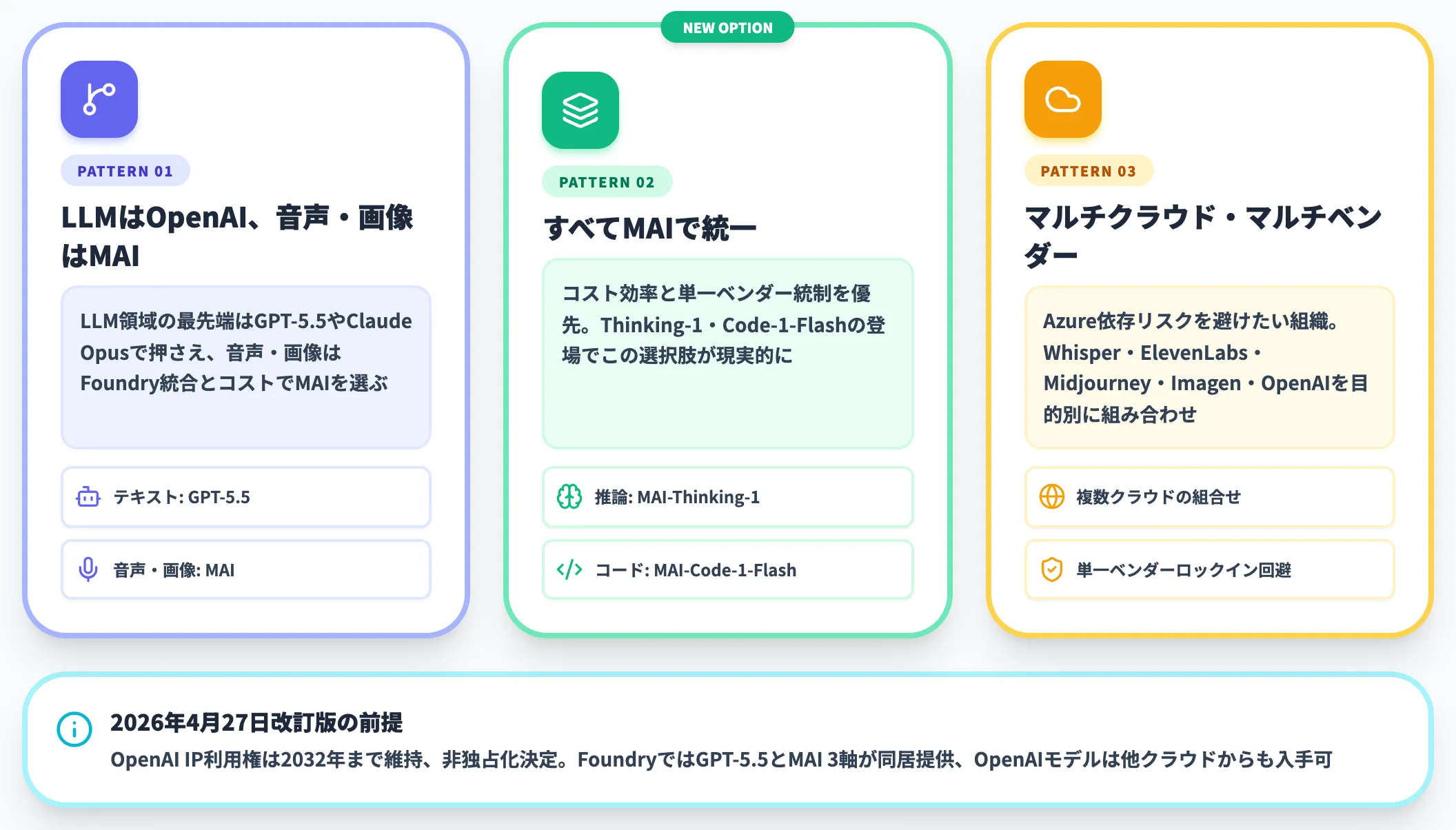 2026年4月27日の改訂版契約でも2032年までのOpenAI IP利用権は維持されており、FoundryではOpenAI GPT-5.5とMAI 3軸が同居して提供されます。一方で同改訂版で非独占化が決まったため、OpenAIモデルは他クラウドからも入手可能になっており、ベンダー選択の自由度は両社にとって増しています。
2026年4月27日の改訂版契約でも2032年までのOpenAI IP利用権は維持されており、FoundryではOpenAI GPT-5.5とMAI 3軸が同居して提供されます。一方で同改訂版で非独占化が決まったため、OpenAIモデルは他クラウドからも入手可能になっており、ベンダー選択の自由度は両社にとって増しています。
開発者・SIerから見た現実的な使い分け方は、次の3パターンに集約されます。
-
LLMはOpenAI、音声・画像はMAI
LLM領域の最先端はGPT-5.5やClaude Opusで押さえ、音声・画像はFoundry統合とコストでMAIを選ぶ
-
すべてMAIで統一
コスト効率と単一ベンダー統制を優先する組織。MAI-Thinking-1・MAI-Code-1-Flashの登場で、この選択肢が現実的になってきた
-
マルチクラウド・マルチベンダー
Azure依存リスクを避けたい組織。Whisper・ElevenLabs・Midjourney・Imagen・OpenAIなどを目的別に組み合わせる
どのパターンを選ぶかは、既存のクラウド契約状況・データガバナンス要件・コスト最適化の優先度で決まります。
SIer視点で見るMAI採用判断
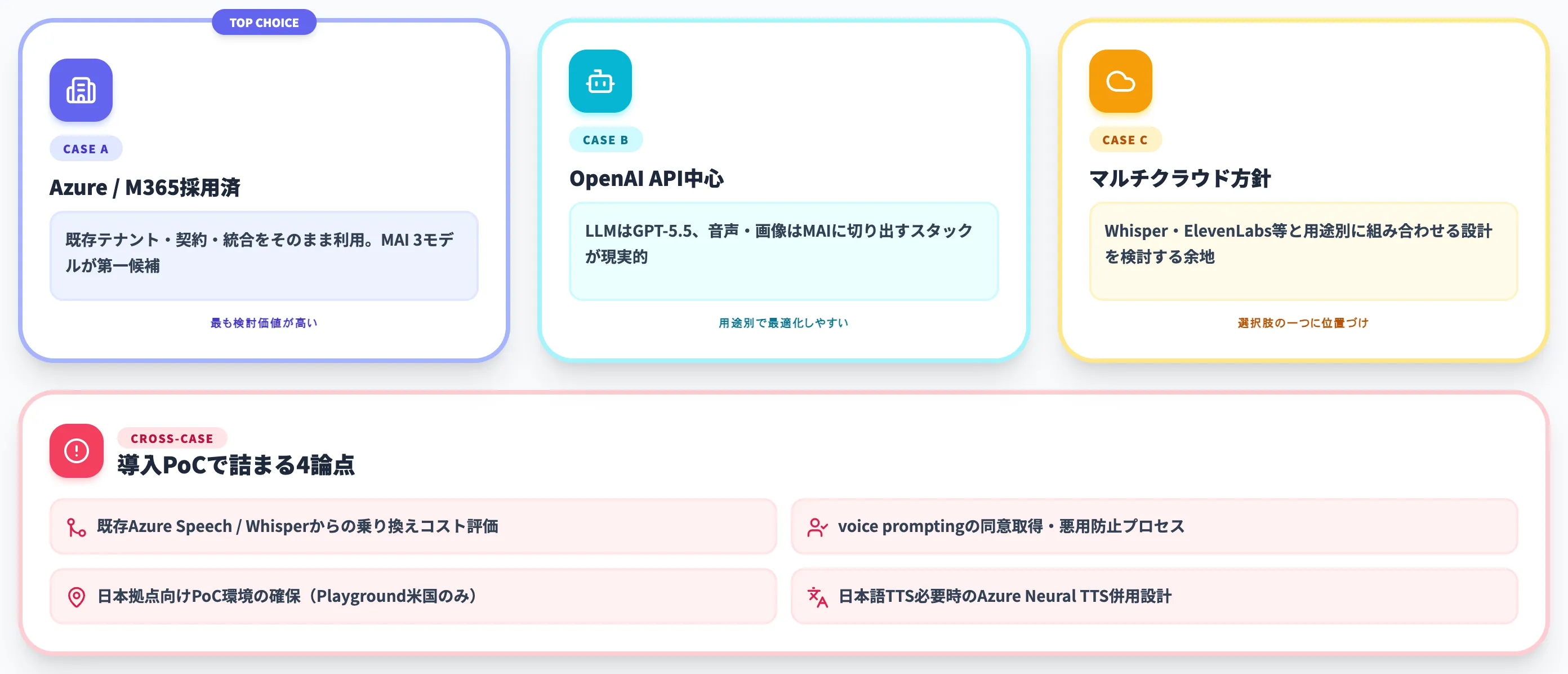
ここでは、AI総合研究所が支援する企業のケースを踏まえ、MAI 3モデルの採用判断をケース別に整理します。
「3モデルそれぞれを業務でどう使うか」は前半の業務目的別H2で扱ったので、ここでは企業の既存スタック・調達方針・データガバナンスといった組織側の条件に焦点を当てます。
Azure / Microsoft 365を採用済みの企業のケース
すでにAzureテナントを運用し、Microsoft 365 Copilotを部門展開している企業にとって、MAI 3モデルは第一候補に置く価値があります。理由は以下の3点です。

-
Foundry経由のため認証・課金・ガバナンスを既存のAzureテナントで完結できる
-
新規ベンダー追加にともなう調達・契約・セキュリティ評価のコストがほぼかからない
-
PowerPoint・OneDrive・Dynamics 365 Contact Centerなど既存業務ツールへの統合が同時進行で進んでいる
「結論先行で言えば、Azure系を採用済みかつ音声・画像のSaaS料金を最適化したい組織であれば、MAI 3モデルは現時点で最も検討価値が高い」というのがSIer視点の評価です。
OpenAI API中心で動いている開発チームのケース
LLM部分はOpenAI API中心で開発しているチームでも、音声・画像系の周辺機能はMAIに切り出す価値があります。
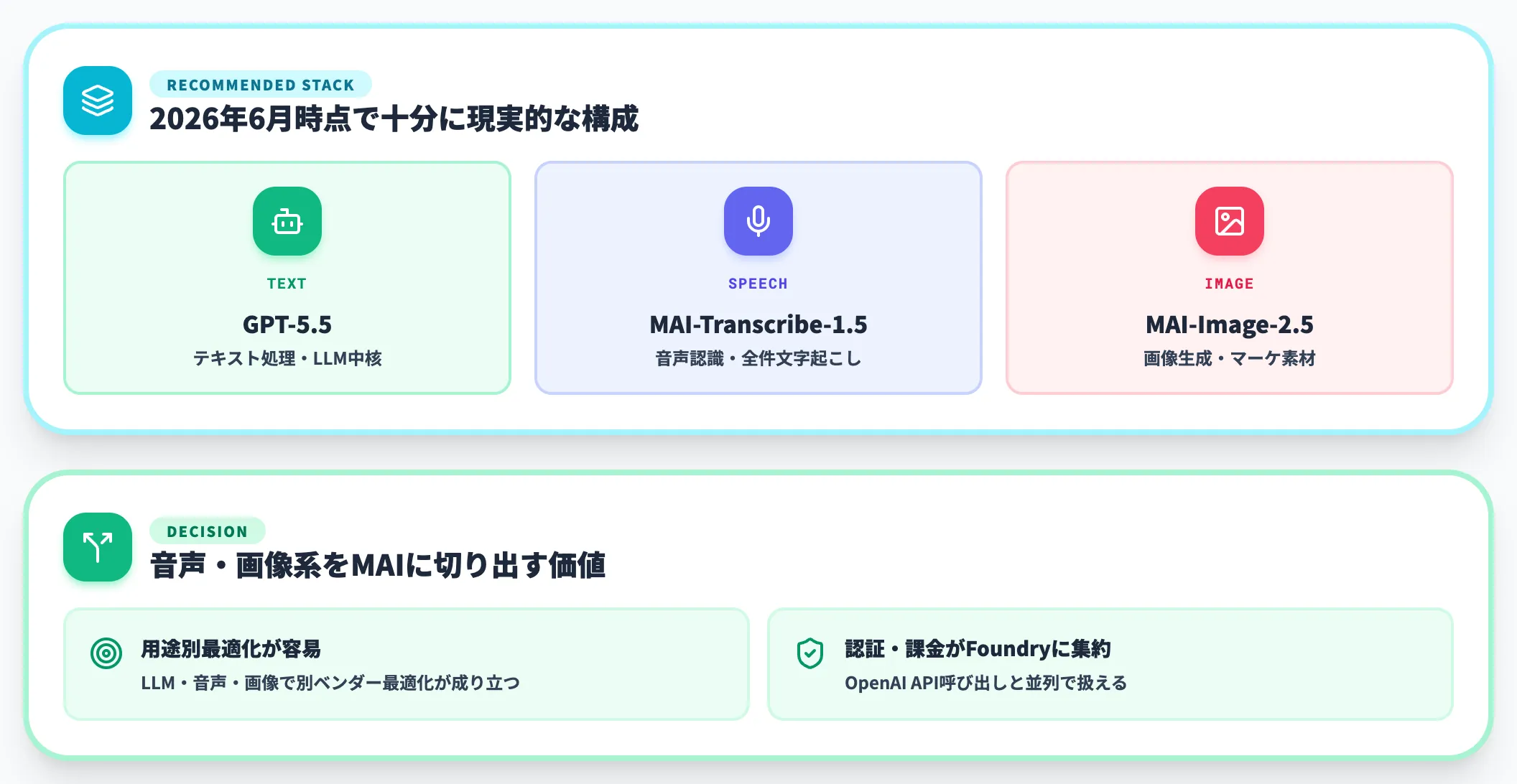
理由は、LLMと音声・画像が別ベンダーで最適化されている方が、用途ごとに最適なモデルを選択しやすいためです。Foundry経由でMAIを呼び出せばOpenAI API呼び出しと並列で扱え、認証・課金もFoundryに集約できます。GPT-5.5でテキスト処理、MAI-Transcribe-1.5で音声認識、MAI-Image-2.5で画像生成、というスタックは2026年6月時点で十分に現実的な構成です。
マルチクラウドで音声・画像を統一したい企業のケース
Microsoft依存を避けたい意思決定がある場合、Whisper(OSS)や独立系SaaS(ElevenLabs等)も依然として有力です。MAIは選択肢の一つとして比較表に並べる程度の位置づけになります。
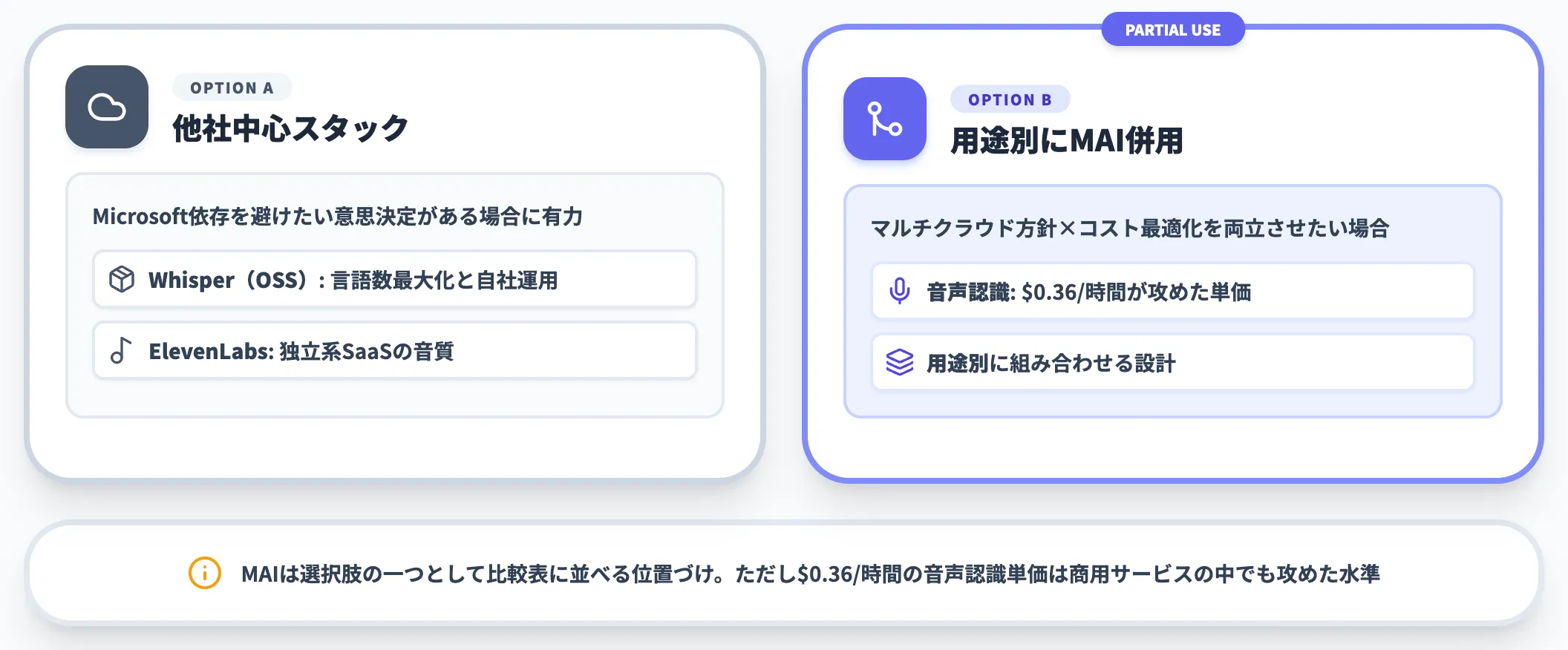
ただし、コスト面でMAI-Transcribe-1.5の$0.36/時間は商用音声認識のなかでも攻めた単価のため、「マルチクラウド方針 × コスト最適化」を両立させる場合は、用途別にMAIと他社を組み合わせる設計を検討する余地があります。
導入PoCで詰まる論点——ケース横断の4点
MAI 3モデルの導入を検討するときに、実際に判断が分かれる論点を4つ挙げておきます。先回りで整理しておくと、社内の合意形成がスムーズになります。
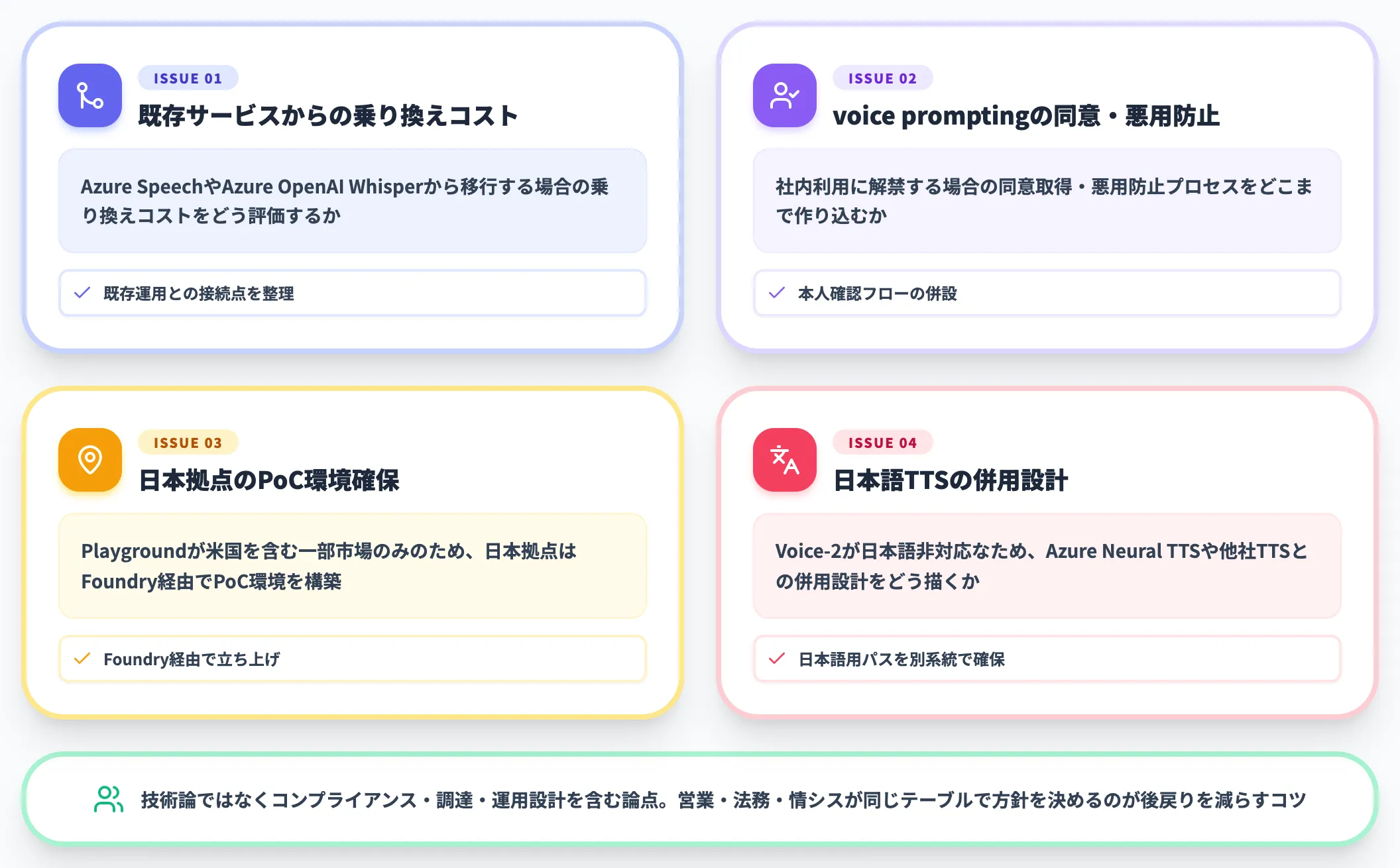
-
既存のAzure SpeechやAzure OpenAI Whisperからの乗り換えコストをどう評価するか
-
voice promptingを社内利用に解禁する場合の同意取得・悪用防止プロセスをどこまで作り込むか
-
MAI Playgroundが米国を含む一部市場のみの提供(EUは近日対応)のため、日本拠点はPlayground依存せずFoundry経由でのPoC環境をどう確保するか
-
日本語TTSが必要な場合、Voice-2単体ではなくAzure Neural TTSや他社TTSと併用する設計をどう描くか
これらは単なる技術論ではなく、コンプライアンス・調達・運用設計を含む論点です。導入PoCの段階で営業・法務・情シスが同じテーブルに着いて方針を決めておくのが、後戻りを減らすコツになります。
MAI主要3軸モデルの料金体系まとめ
最後に、3軸の最新世代+Image-2.5 Flash版の料金を横断比較できる形でまとめます(MAI-Thinking-1・MAI-Code-1-Flash・MAI-Voice-2-Flashなど新カテゴリ・Flash派生の単価は別途公式モデルページで確認してください)。

すべてSaaS型のAPI課金で、Microsoft Foundry経由での提供となるため、Azureインフラのようなリージョン別SKU価格ではなく、利用量ベースの単価で公表されています。価格はいずれも2026年6月時点の公式情報に基づきます。
主要3軸+Image Flash版の価格一覧
以下の表で、各モデルの課金単位と価格を整理しました。表のあとに、実際にコスト試算する際のポイントを補足します。
| モデル | 課金単位 | 価格(2026年6月時点) |
|---|---|---|
| MAI-Transcribe-1.5 | 音声1時間あたり | $0.36〜 |
| MAI-Voice-2 | 100万文字あたり | $22(公式モデルページ) |
| MAI-Image-2.5(Standard) | 100万トークンあたり | テキスト入力$5 / 画像入力$8 / 画像出力$47 |
| MAI-Image-2.5-Flash | 100万トークンあたり | テキスト入力$1.75 / 画像入力$1.75 / 画像出力$19.50 |
表から見えるのは、Microsoftが3軸とも「主要競合より安価」を明確に打ち出しているという点です。
とくに音声認識の$0.36/時間は、商用音声認識の中でもかなり攻めた価格設定で、長尺音声を扱う業務にとっては従来の見積りを書き換えるレベルの単価です。画像生成のFlash版も、Standardに対して各単価で約58〜78%安く設定されており、ラフ案量産フェーズのコストを大幅に圧縮できます。
なお、MAI-Voice-2-Flash・MAI-Thinking-1・MAI-Code-1-Flashの正式単価については、2026年6月時点で公式モデルページ・Foundryプライシング画面で個別に確認するのが安全です(本表は3軸の主要モデル+Image Flashに絞った早見として扱い、新カテゴリの単価が確定次第アップデートしてください)。
コスト試算の考え方
実務での見積りでは、単価よりも「処理ボリューム」を先に固定するのがポイントです。次の順序で試算すると、過剰見積りや見積り不足を防げます。

-
月間の音声時間(議事録・通話・動画素材の総時間)を棚卸しする
-
月間のナレーション需要(合計文字数)を棚卸しする
-
月間の画像生成需要(リクエスト数×平均トークン量・Standard/Flashの比率)を見積もる
-
上記を各モデルの単価に掛け合わせて月額コストを試算する
この順序で進めれば、「とりあえず入れたが想定外に高くなった」「逆にPoCで止まって本格利用に進まない」という両極端の失敗を避けられます。価格表の数字を眺めるよりも、自社の運用ボリュームを棚卸しする方が判断は早いです。
MAIモデルのMicrosoft Foundry経由での課金は、既存のAzureサブスクリプションに集約できるため、調達側のオペレーション負荷は低く抑えられます。複数のAIサービスをそれぞれ別契約・別請求で管理する場合と比べて、IT部門・経理部門の運用工数が下がる点も実務上のメリットです。

MAIモデルをエージェントとして業務に定着させるなら
MAI 3モデルの料金と特徴を押さえても、それだけで業務プロセスが回り始めるわけではありません。FoundryでAPIを叩くフェーズの先には、「議事録自動化」「コールセンター応答」「マーケ素材生成」といった業務フローにモデルを埋め込み、誰がいつ呼び出し、結果をどこに格納し、誰が承認するかという設計が必ず必要になります。
AI Agent Hubは、Microsoft FoundryのMAIモデルを呼び出すAIエージェントを、自社のAzureテナント内で構築・管理・運用するエンタープライズAI基盤です。Foundry上でモデルを試した後の「業務実装」段階を、設計から運用まで支えます。
-
MAIモデルを呼び出すエージェントをTeamsから実行
社員がTeamsチャットからAgentを呼び出し、議事録テキスト化・画像生成・ナレーション作成といったMAIモデル活用タスクを実行。学習コストはゼロで、既存のMicrosoft 365環境にそのまま乗ります。
-
AI-OCR Agent・自動入力Agentなど9種類のAgentと組み合わせ可能
MAI-Transcribe-1.5で生成したテキストを、AI-OCR Agentと組み合わせて社内システムに自動入力するワークフローを構築できます。MAI単体では完結しない業務プロセスを、Agentの組み合わせで一気通貫化します。
-
使い慣れたMicrosoft環境をそのまま活用
Teams・Excel・Outlookなど既存ツールの延長でAIエージェントが動作。新しいツールの学習コストはゼロです。
-
データは100%自社テナント内に保持
AIの学習対象から完全除外。Azure Managed Applicationsとして自社テナント内で動作が完了する設計です。
AI総合研究所の専任チームが、Microsoft Foundryのモデル選定から業務エージェント設計、本番運用まで一貫してサポートします。AI Agent HubのLPで、MAIモデルを業務に乗せる全体像をご確認ください。
MAIモデルをエージェントとして業務に定着させる

Foundryのモデル群を実装基盤までつなぐ
Microsoft FoundryのMAIモデル群を試すだけで終わらせず、議事録自動化・コールセンター分析・マーケ素材生成といった業務プロセスに組み込むには、自社Azureテナント内でMAIを呼び出すエージェント基盤の設計が必要です。AI Agent HubのLPで、Foundryモデルを業務に乗せる全体像をご確認ください。
まとめ
本記事では、Microsoft MAIの3軸(音声認識・音声生成・画像生成)の最新世代を、業務目的別に2026年6月時点の公式情報で解説しました。要点を改めて整理します。
-
議事録・コールセンター分析 → MAI-Transcribe-1.5
43言語対応・FLEURS首位(avg WER 4.9%)・公称Latency 5.7X(競合比最大5倍)・$0.36/時間。entity biasingで固有名詞認識を底上げし、長尺音声の全件文字起こしを現実的な単価帯に引き下げる。
-
多言語ナレーション・カスタムボイス → MAI-Voice-2
15言語対応・感情表現タグ・voice prompting・identity preservationでVoice-1から72%選好率向上。Foundry・VSCode・Dynamics 365 Contact Centerに統合される。日本語TTSはAzure Neural TTS等との併用前提。
-
マーケ素材・PowerPoint資料 → MAI-Image-2.5
Arena Image Edit 2位デビュー・画像編集機能追加・Standard/Flashの2階層価格。PowerPoint・OneDriveに直接統合され、業務系画像生成の現実解になる。
-
MAIモデル群の全体戦略
2026年4月の初代3モデルから6月Build 2026でMAI-Thinking-1・MAI-Code-1-Flashを含む7モデルへ拡大。Suleyman氏のHumanist SuperintelligenceビジョンとOpenAIとの2トラック戦略が背景。
-
SIer視点での採用判断
Azure / Microsoft 365を採用済みかつ音声・画像のSaaS料金を最適化したい組織であれば、MAI 3モデルは現時点で最も検討価値が高い。マルチクラウド方針の組織は用途別にMAIと他社を組み合わせる設計を検討する余地がある。
Microsoft FoundryのモデルカタログにMAI 3軸・GPT-5.5・Claude等が同居する状態は、開発者にとって「LLM・音声・画像を用途別に最適なモデルで組み立てる」運用が現実解になったことを意味します。次の一歩として現実的なのは、自社の音声・画像系ワークフローを棚卸しして「どこにMAIを差し込めるか」を1つだけ決め、Foundry上で小さなPoCを始めることです。価格・速度・精度のいずれも公式公称値が出ているので、自社データでの検証は週単位で進められます。










