この記事のポイント
 研究・プロトタイピング用途では動的計算グラフとPythonic記法のPyTorchが第一候補で、Second Talentの2026年分析ではNLP・ビジョンなど深層学習領域の実装の約85%が採用と推計される事実上の標準
研究・プロトタイピング用途では動的計算グラフとPythonic記法のPyTorchが第一候補で、Second Talentの2026年分析ではNLP・ビジョンなど深層学習領域の実装の約85%が採用と推計される事実上の標準- 学習を始めるならAnaconda仮想環境でCUDA対応版をインストールし、数十行のMNIST画像分類から着手するのが最短ルート
- 本番運用前にtorch.compileを適用し、大規模学習はFSDP2+TorchTitan、エッジ展開はExecuTorch(2025年10月に1.0/2026年4月にPyTorch Core統合)という2026年版のスタックを押さえる
- プロダクションのモバイル・組み込みはExecuTorch、Google TPU上の大規模学習はJAX、既存TFXパイプライン保守はTensorFlowと、用途に応じて使い分けるのが現実解
- H100の1 GPU-hour換算で代表例約2〜4倍(AWS p5でRunPod比約2〜2.4倍、GCP a3-highgpu-8gで約3〜4倍)の価格差があり、スポットインスタンス+混合精度学習の組み合わせがコスト最適化の鍵

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
PyTorchは、Metaが主導するオープンソースのディープラーニングフレームワークで、2022年からはLinux Foundation配下のPyTorch Foundationが運営しています。
2026年6月時点の最新版は5月13日リリースのバージョン2.12で、リリース頻度は四半期から2か月ごとに加速し、torch.compile・FSDP2・ExecuTorchなど研究から本番運用までを一貫してカバーする基盤として進化を続けています。
本記事では、PyTorchの定義と最新動向、Anacondaでの環境構築からMNIST画像分類の実装、torch.compile・FSDP2・ExecuTorchなど高度な機能、TensorFlow・JAXとの違い、GPUクラウド学習コストの相場までを2026年6月時点の最新情報で体系的に解説します。
目次
PyTorchとは——Metaが主導するディープラーニングフレームワーク
押さえておくべき非推奨化——TorchScriptは2.10で deprecated
形状変換(reshape / view / permute)
本番運用に向けた高度な機能——torch.compile・FSDP2・ExecuTorch
ExecuTorch——スマホ・組み込みへのオンデバイス展開
TorchScript→torch.exportへの移行を計画する
PyTorchとは——Metaが主導するディープラーニングフレームワーク
PyTorch(パイトーチ)は、Metaが主導して開発するオープンソースのディープラーニングフレームワークです。Pythonベースの直感的なAPIと、NumPy互換のテンソル演算をGPUで高速実行できる仕組みを組み合わせ、研究から実装までを1つのコードベースで完結させられる点が大きな特徴です。


運営体制は2022年に転換しており、MetaからLinux Foundation配下のPyTorch Foundationへ移管されました。理事会にはAMD・AWS・Google Cloud・Meta・Microsoft・NVIDIAなど主要ベンダーが名を連ね、特定企業に依存しない中立基盤として運営されています。
このセクションでは、PyTorchの基本的な位置づけと、なぜ研究分野で「事実上の標準」と呼ばれるのかを整理します。

動的計算グラフとPythonicな設計

PyTorch最大の技術的特徴は、**動的計算グラフ(Define-by-Run)**を採用している点です。コードを実行しながら計算グラフを構築していく方式のため、通常のPythonコードと同じように print や pdb でモデル内部を確認できます。
これは深層学習フレームワークとしては当たり前に見えますが、初期のTensorFlowが採用していた静的計算グラフ(実行前にグラフ全体を定義する方式)と比べると、デバッグ・実験のしやすさが桁違いです。
研究者がモデルの一部を頻繁に書き換えながら実験するワークフローでは、この「Pythonicに書ける」性質が大きな生産性差を生みます。
主要な研究分野で事実上の標準
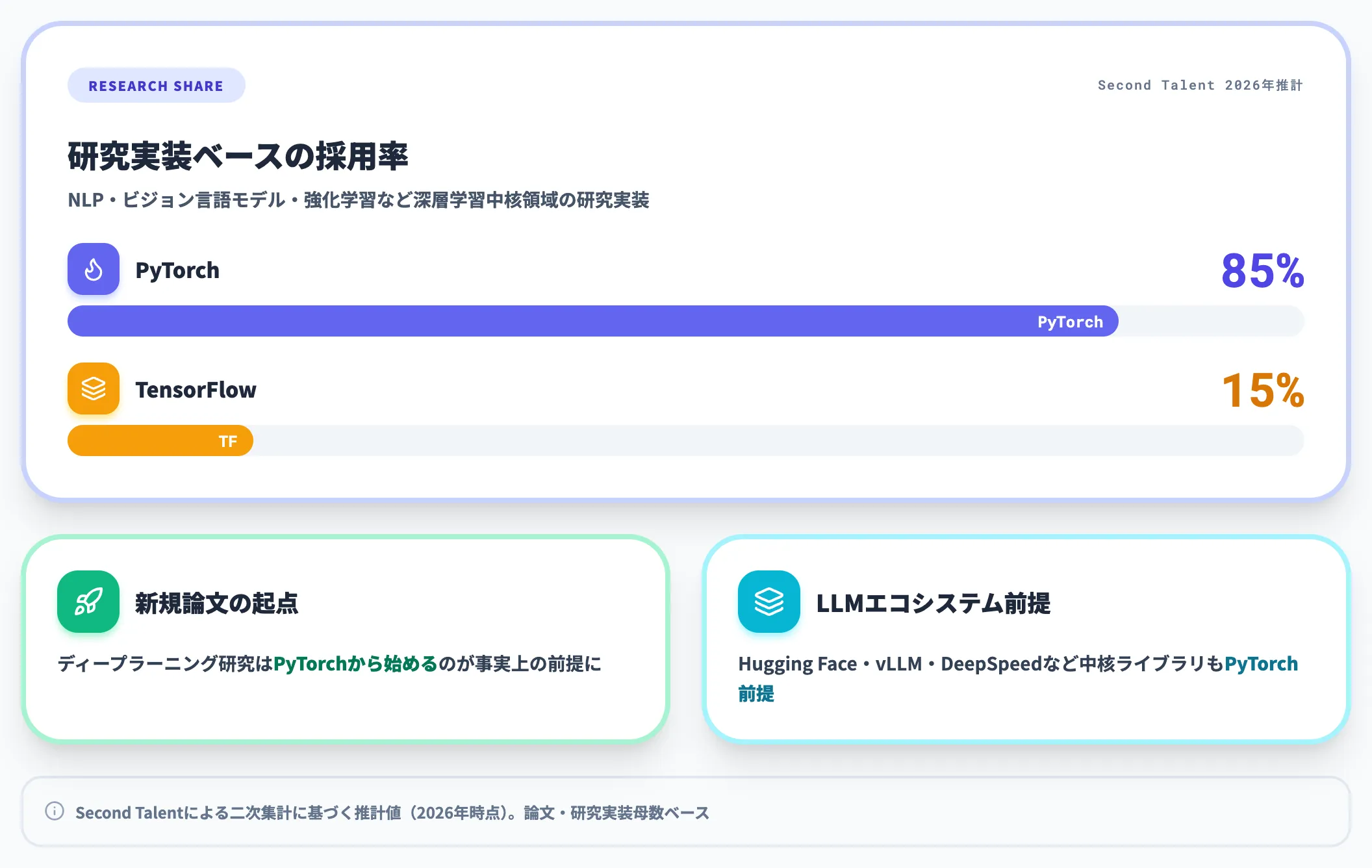
PyTorchが研究分野でどれほど浸透しているかは、論文採用率の数字に表れています。2026年時点のSecond Talentの分析では、NLP・ビジョン言語モデル・強化学習など深層学習中核領域の研究実装ベースで、PyTorchが約85%・TensorFlowが約15%という構成と推計されています(あくまで二次集計に基づく推計値)。
新規のディープラーニング研究はPyTorchから始めるのが事実上の前提になっています。
Hugging Face・vLLM・DeepSpeedなど現代のLLMスタックの中核ライブラリもPyTorch前提で設計されており、最新研究を試したいならHugging Face上のモデルをPyTorchで動かす形が標準ルートです。機械学習・深層学習領域で論文を追いかける読者にとって、PyTorchのスキルはほぼ必須スキルセットになっています。
LLM・オープンウェイトモデルの基盤としてのPyTorch

PyTorchは研究ツールにとどまらず、フロンティアLLMや公開モデルの基盤としても広く使われています。OpenAIは2020年に研究プラットフォームをPyTorchへ標準化したことを公式に発表しており、研究側のスタックの大部分はPyTorch前提です。
公開モデル側では、MetaのLlamaシリーズの公式実装がPyTorch前提で公開され、重みも state_dict 形式(あるいはsafetensors)で配布されています。Hugging Faceに並ぶオープンウェイトLLMの多くがPyTorchで読み書きできる形式のため、社内ファインチューニングや推論最適化を進める実務でもPyTorchを触る場面が増えています。
ここでは位置づけのみを整理し、具体的なバージョン進化と新機能は次のセクションで扱います。
PyTorch 2.12と直近のアップデート動向
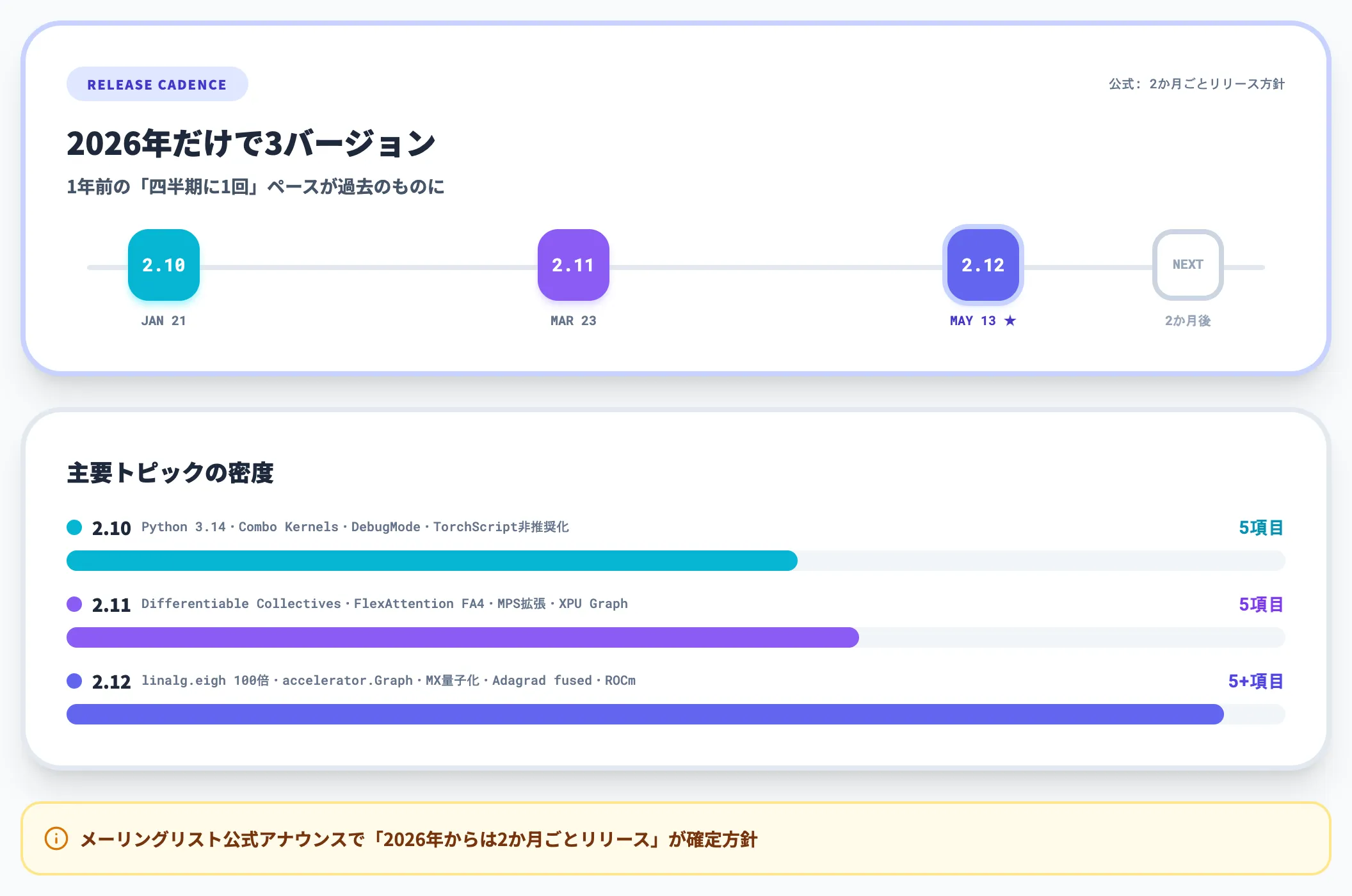
PyTorchは2026年に入ってからリリースペースが明確に加速し、6月時点ですでに2.10・2.11・2.12と3バージョンが世に出ています。最新版は2026年5月13日リリースのバージョン2.12で、開発者向けメーリングリストでは「2026年からは2か月ごとリリース」が公式方針としてアナウンスされました。
本セクションでは、直近3バージョンの主要な変化と、業務上注意すべき非推奨化を整理します。

2026年の3バージョンを並べた進化マップ
以下の表で、PyTorch 2.10〜2.12の主要トピックを比較しました。1年前の「四半期に1回」ペースが過去のものになっていることが分かります。
| バージョン | リリース日 | 主要トピック |
|---|---|---|
| 2.10 | 2026年1月21日 | Python 3.14 / 3.14t(freethreaded)対応、Combo Kernels、varlen_attn()、DebugMode、TorchScript非推奨化 |
| 2.11 | 2026年3月23日 | Differentiable Collectives、FlexAttention FA4バックエンド、MPS拡張、RNN/LSTMのGPU Export対応、XPU Graph |
| 2.12 | 2026年5月13日 | linalg.eigh 最大100倍高速化、torch.accelerator.Graph、MX量子化対応、Adagrad fused、ROCm強化 |
2.12は2,926コミット・457コントリビューターを束ねた大規模リリースで、ハードウェア横断のAPI整備と量子化対応が一気に進みました。
PyTorch 2.12の注目アップデート
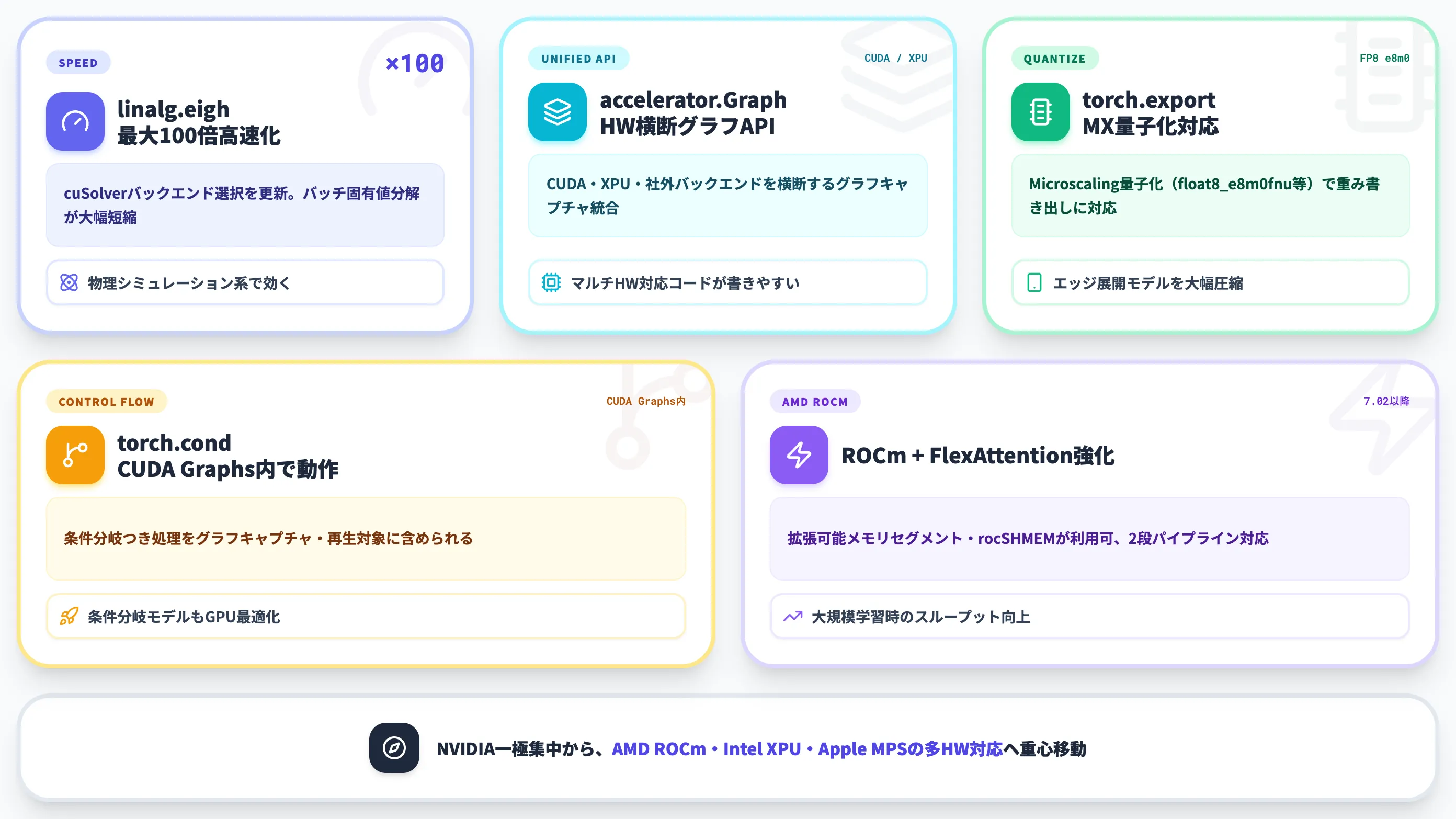
公式リリースブログを読み解くと、2.12は「ハードウェアに依存しないAPIを増やす」方向に振れています。代表的な改善は以下のとおりです。
-
linalg.eighがCUDA上で最大100倍高速化
cuSolverバックエンドの選択を更新したことで、バッチ固有値分解の処理時間が大幅に短縮された。物理シミュレーションや行列分解を多用する科学計算系のモデルで効く。
-
torch.accelerator.Graphの導入
CUDA・XPU(Intel GPU)・社外バックエンドを横断する形で、グラフキャプチャと再生を1つのAPIにまとめた。マルチハードウェア対応のコードを書きやすくする狙い。
-
torch.exportがMicroscaling(MX)量子化に対応
float8_e8m0fnu等の新しい量子化フォーマットで重みを書き出せるようになり、エッジ展開時のモデルサイズと推論コストを大幅に圧縮できる。
-
torch.condがCUDA Graphs内で動作
これまでGPUグラフ化が難しかった「条件分岐つきの処理」を、グラフのキャプチャ・再生対象に含められるようになった。
-
ROCmとFlexAttentionの強化
AMD ROCm(ROCm 7.02以降)で拡張可能メモリセグメントとrocSHMEMが利用可能になり、FlexAttentionは2段パイプライン対応で大規模学習時のスループットが上がる。
このリリースが示しているのは、PyTorchがNVIDIA一極集中から多ハードウェア対応へ重心を移しているという方向性です。AMD ROCm・Intel XPU・Apple MPSの各バックエンドが同じAPIで扱えるようになることで、企業のGPU調達戦略にも幅が出ます。
押さえておくべき非推奨化——TorchScriptは2.10で deprecated

新機能と同じくらい重要なのが、廃止・非推奨化の動向です。
特に押さえておくべきは、TorchScriptが2.10で正式に非推奨になったことです。これまでモデルのシリアライズや本番デプロイで広く使われてきた torch.jit.script / torch.jit.trace は、今後 torch.export(モデルエクスポート)とExecuTorch(エッジ/組み込み向けランタイム)に役割が引き継がれます。
TorchScript前提で構築されている既存パイプラインがある組織は、2026年中に移行計画を立てておくのが安全圏です。
加えて、2.12からCUDA 12.8のホイール提供は終了し、デフォルトはCUDA 13.0に切り替わりました。古い世代のGPU(Pascal・Voltaなど)はCUDA 12.6のホイールに退避する運用になります。社内のドライバ更新計画と合わせて見直すべきタイミングです。
PyTorchの主要機能・できること
PyTorchは「テンソル演算」「自動微分」「ニューラルネットワーク構築」の3つを核とし、その周囲を画像・音声・テキスト用の公式ライブラリと、Hugging Face等のサードパーティが取り囲む構造になっています。
本セクションでは、初学者が「何を学べば全体像をつかめるか」を整理します。
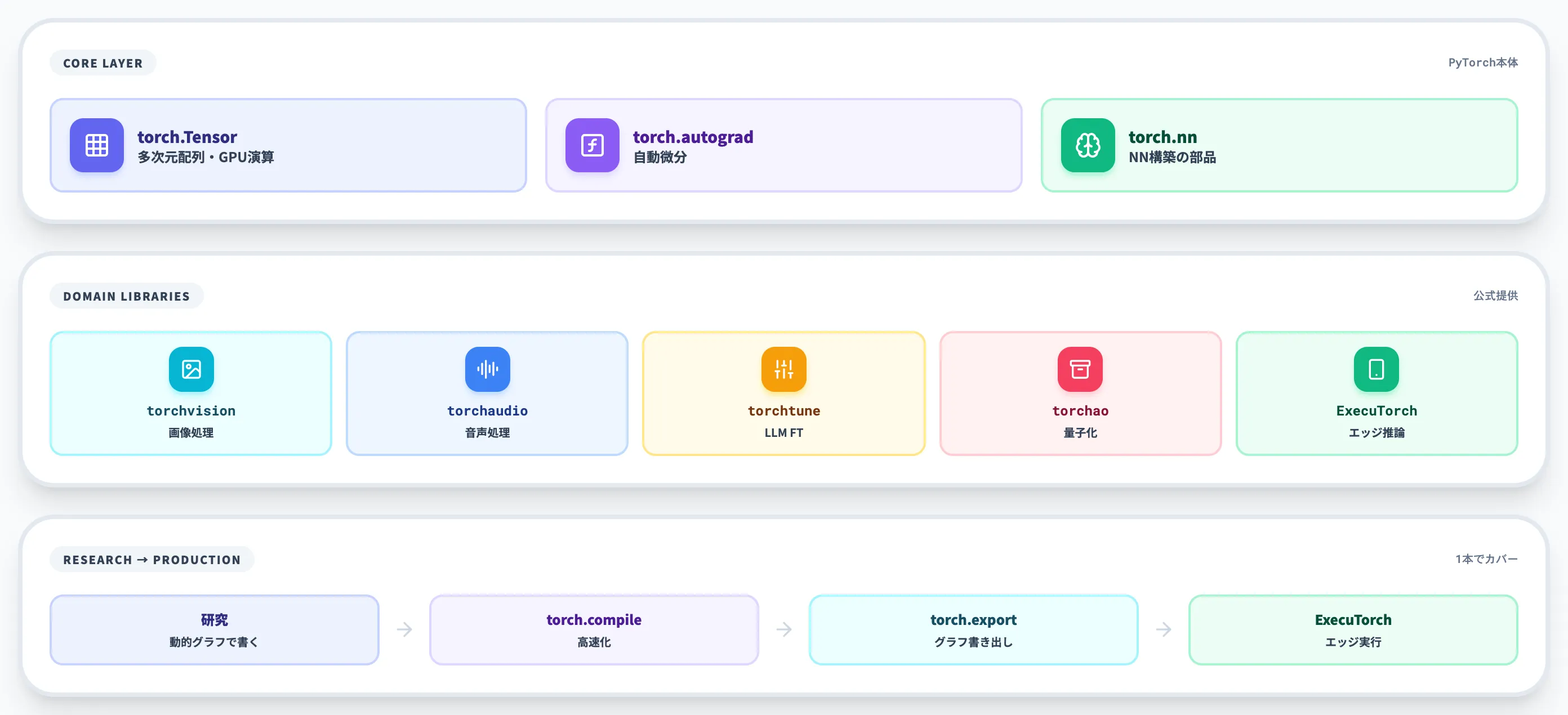
コア機能の3点セット
PyTorchで最初に押さえるべき機能は、以下の3点に集約されます。
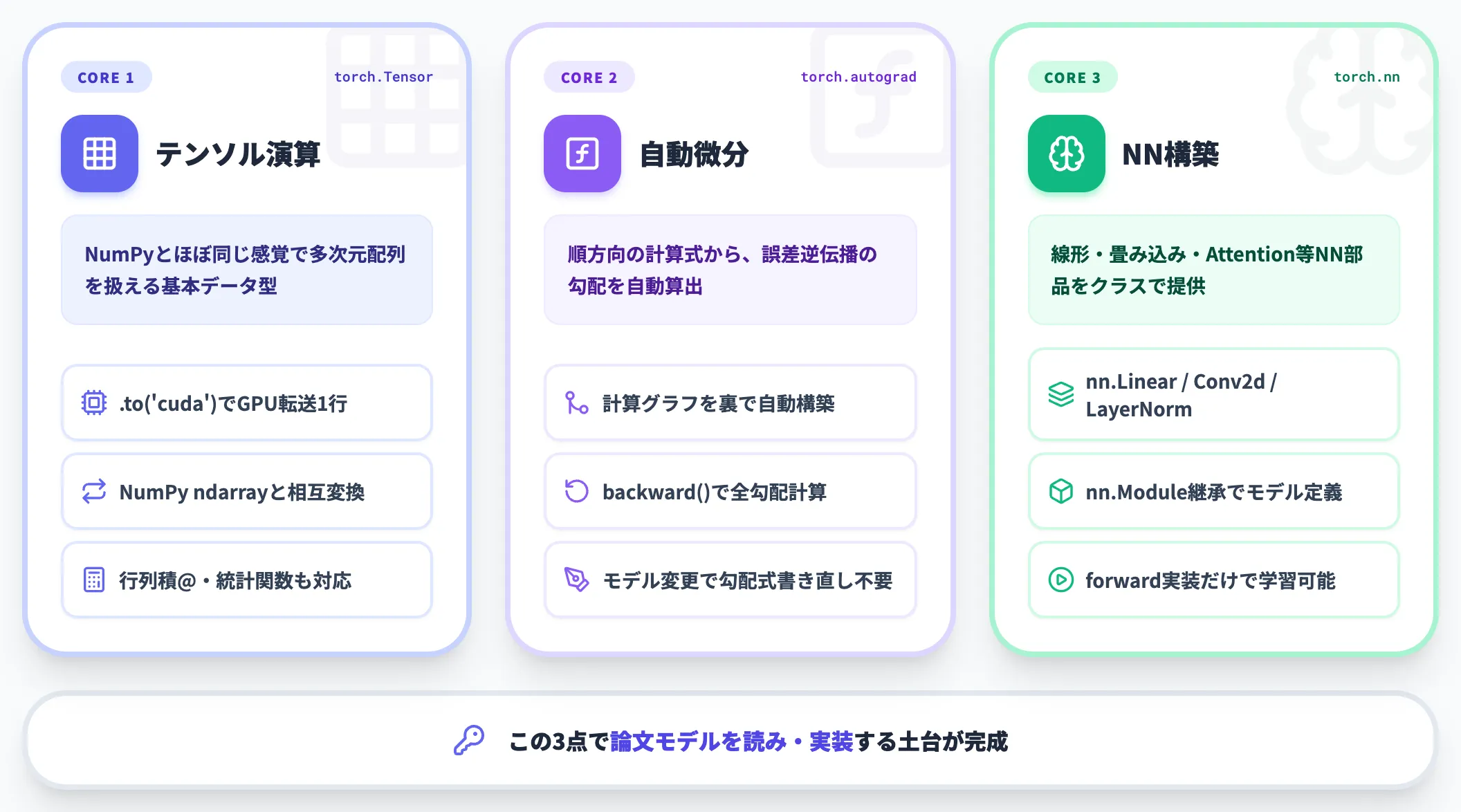
-
テンソル演算(torch.Tensor)
NumPyとほぼ同じ感覚で多次元配列を扱える。GPU上に置けば自動的に高速演算され、.to('cuda')の1行で切り替わる。
-
自動微分(torch.autograd)
順方向の計算をPythonで書くと、誤差逆伝播に必要な勾配を自動で計算してくれる仕組み。研究者がモデルを変えるたびに勾配計算式を書き直す手間がなくなる。
-
ニューラルネットワーク構築(torch.nn)
線形層・畳み込み・Attention・LayerNormなど、深層学習で使う基本部品をクラスとして提供する。nn.Moduleを継承してforward処理を書くだけで、学習可能なモデルが完成する。
この3点が理解できれば、論文に出てくる新しいモデルアーキテクチャを読み解き、自分で実装するための土台ができます。
主要ドメイン別の公式ライブラリ
PyTorchはコア機能の上に、ドメイン別の補助ライブラリを公式に提供しています。以下の表で、用途と主な機能をまとめました。
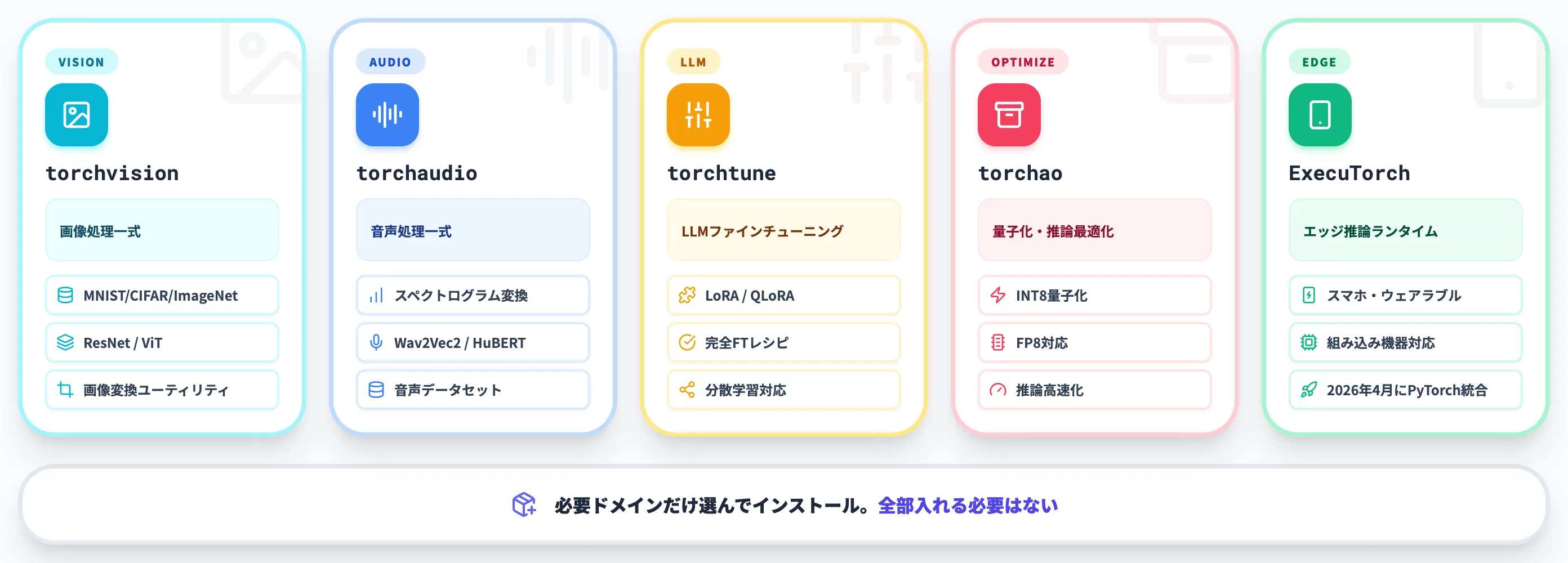
| ライブラリ | 主な用途 | 代表的な機能 |
|---|---|---|
| torchvision | 画像処理 | データセット(MNIST/CIFAR/ImageNet)、定番モデル(ResNet/ViT)、画像変換ユーティリティ |
| torchaudio | 音声処理 | スペクトログラム変換、定番モデル(Wav2Vec2/HuBERT)、音声データセット |
| torchtune | LLMファインチューニング | LoRA / QLoRA / 完全ファインチューニングのレシピ、分散学習対応 |
| torchao | 量子化・最適化 | INT8 / FP8等の量子化、推論高速化 |
| ExecuTorch | エッジ推論 | スマホ・組み込み向けのオンデバイス実行ランタイム |
必要なドメインの公式ライブラリだけインストールして使う形が標準で、すべて入れる必要はありません。
研究から本番運用までを1本でカバーする
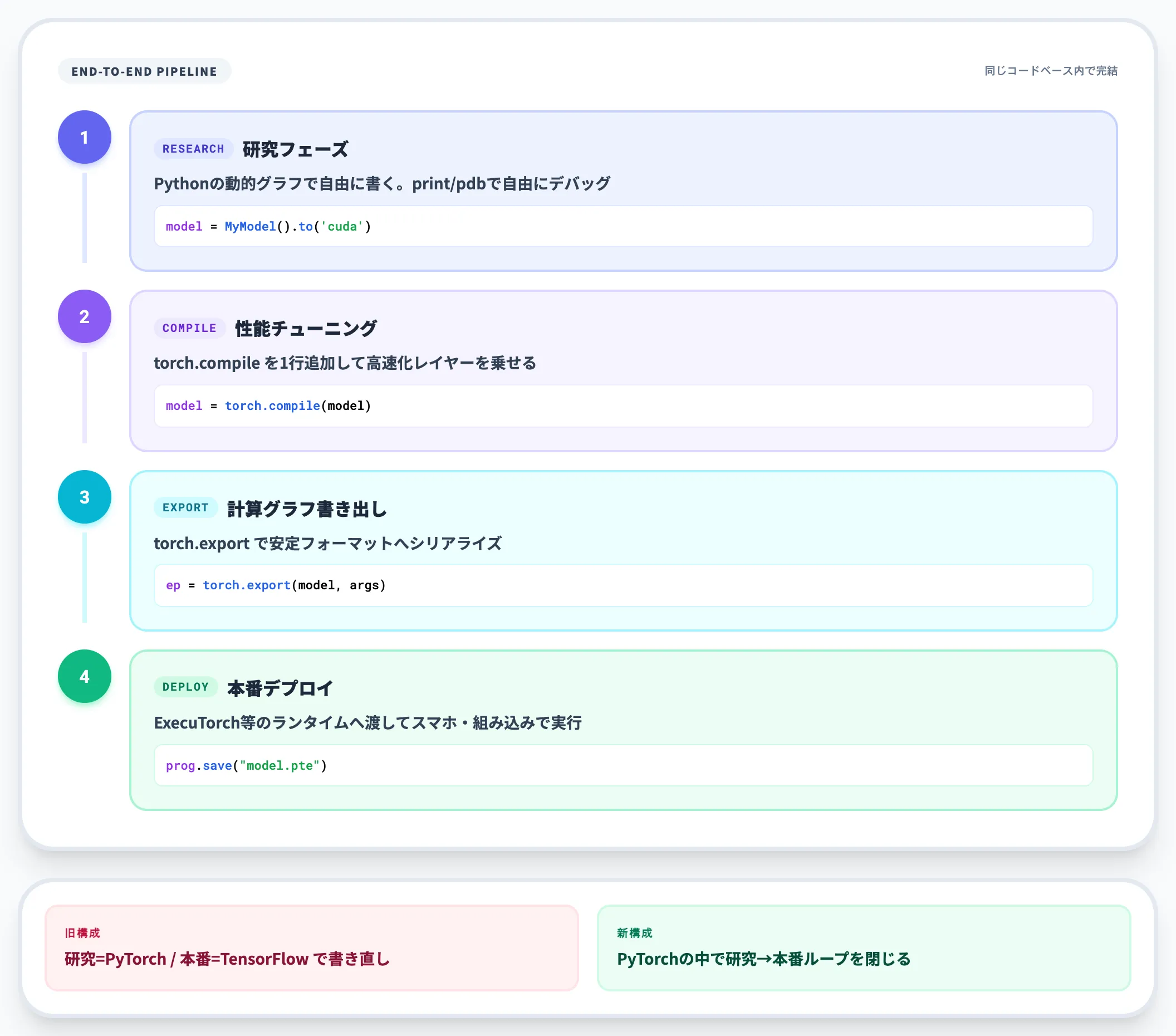
PyTorchが他の選択肢と差別化されているのは、研究用途で書いたコードをほぼそのまま本番運用に持っていけることです。
研究フェーズではPythonの動的グラフで書き、性能チューニング段階で torch.compile をかけて高速化し、デプロイ時には torch.export で計算グラフを書き出してExecuTorch等のランタイムに渡せます。
「研究はPyTorch、本番はTensorFlow」と書き直す時代は終わりつつあり、PyTorchの中だけで研究→本番のループを閉じられる点が、近年の研究・スタートアップ・大手AI企業の採用拡大を支える背景になっています。
PyTorchのインストールと環境構築
本セクションでは、PyTorchを動かすまでの環境構築手順を、ローカルマシン(Windows・macOS・Linux)にAnacondaで仮想環境を作る前提で解説します。
公式インストーラーセレクタで自分の環境を選んで生成されたコマンドを使うのが最短ですが、ここではAnaconda+pipの標準パターンを順を追って示します。

前提環境とPython・CUDAバージョン
PyTorch 2.12時点の対応環境は次のとおりです。
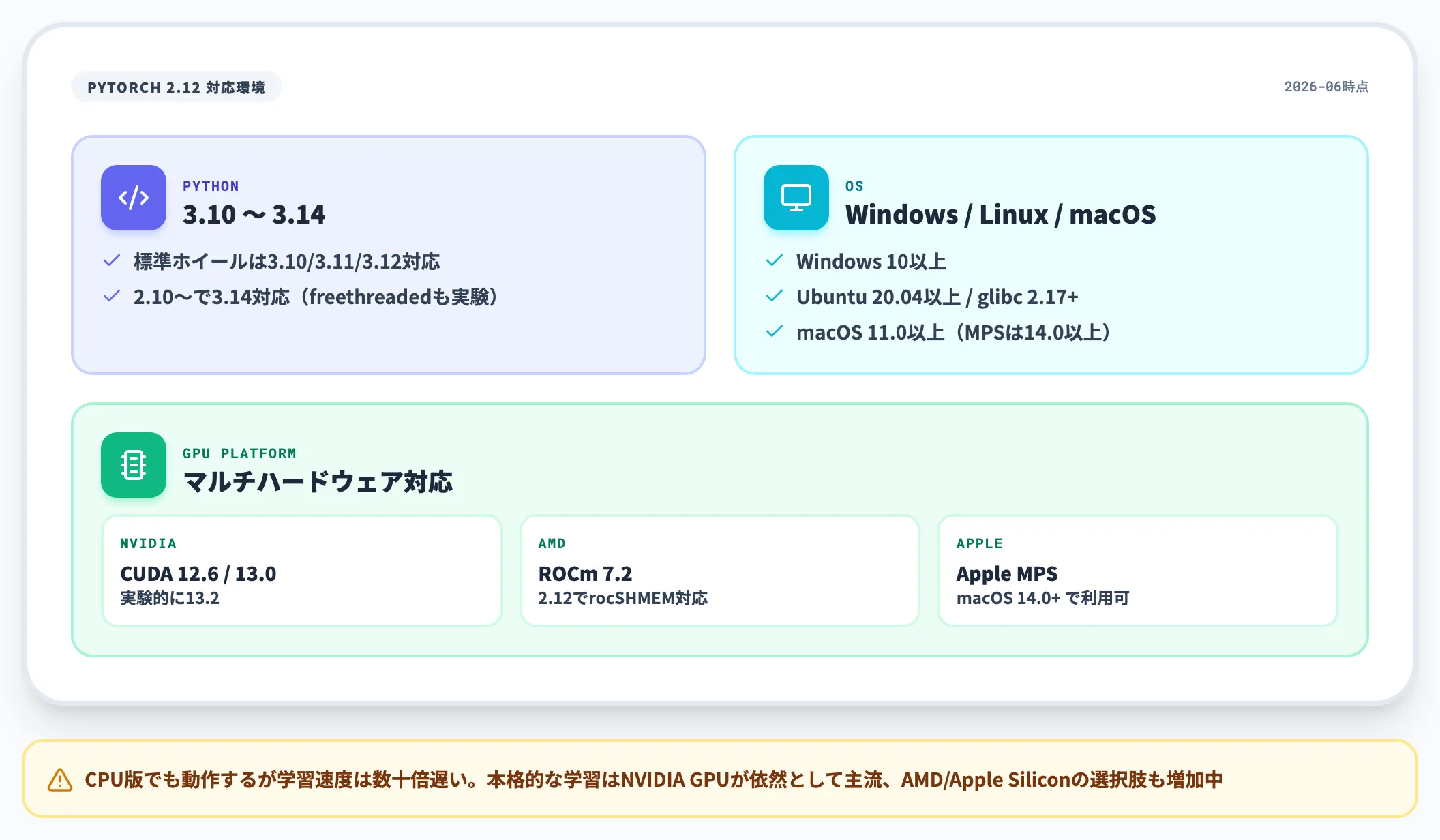
- Python: 3.10〜3.14(2.10以降はPython 3.14の自由スレッドビルドも実験的に対応)
- OS: Windows 10以上 / Linux(glibc 2.17以上、Ubuntu 20.04以上推奨)/ macOS(x86_64は10.15以上、Apple Silicon arm64は11.0以上。MPSバックエンド利用時はmacOS 14.0以上)
- GPU計算プラットフォーム: NVIDIA CUDA 12.6 / 13.0(実験的に13.2)、AMD ROCm 7.2、Apple MPS(Metal)
- CPU版: GPUなし環境でも動作するが学習速度は数十倍遅くなる
本格的に学習を回すならNVIDIA GPU+CUDAが依然として主流ですが、AMD GPUやApple Siliconでも動かせる選択肢が増えています。GPUハードウェア側のTensorコアを活用することで、ディープラーニング特有の行列演算が大幅に高速化される点も押さえておくと、後段の混合精度学習の理解が早くなります。
Anaconda仮想環境の作成
複数プロジェクトでPythonライブラリのバージョンが衝突するのを避けるため、まずは仮想環境を切るところから始めます。Anacondaを使う場合、次のコマンドで「pytorch_env」という名前の環境を作成します。
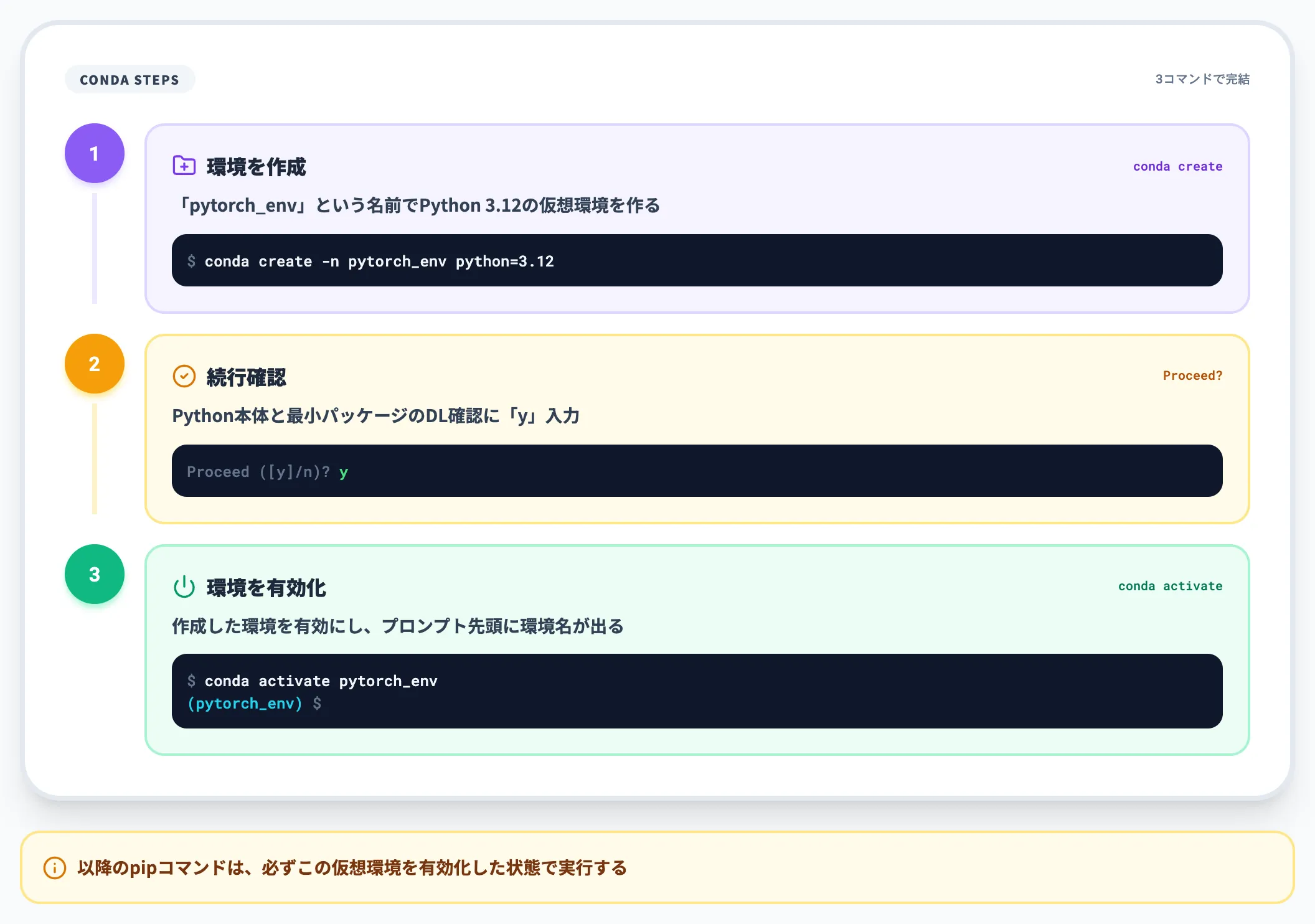

conda create -n pytorch_env python=3.12 のように実行すると、必要なパッケージの取得が始まります。
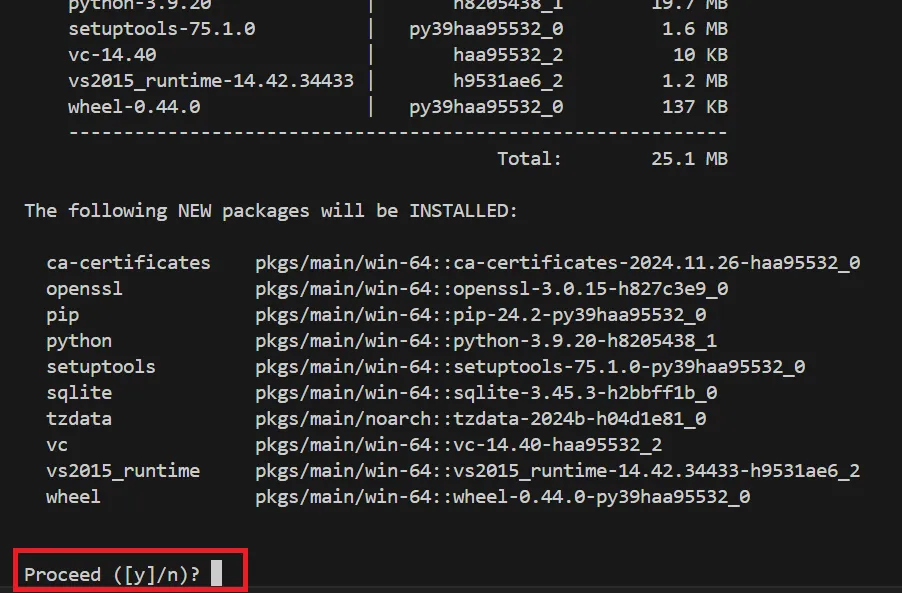
途中で続行確認が出るので「y」を入力すると、Python本体と最小限のパッケージがダウンロード・インストールされます。
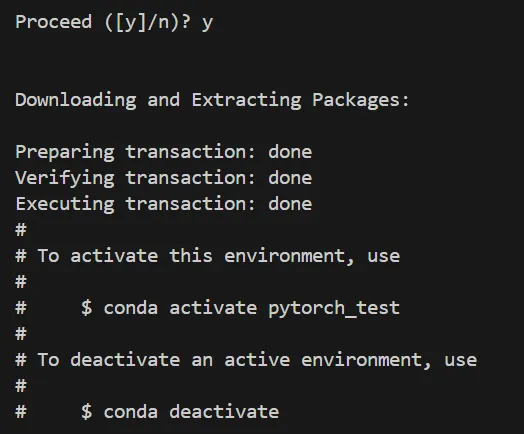
完了後は conda activate pytorch_env で作成した環境を有効化し、プロンプトの先頭に環境名が表示される状態にしておきます。

以降のpipコマンドは、必ずこの仮想環境を有効化した状態で実行してください。
PyTorch本体と関連パッケージのインストール
仮想環境を有効化したら、PyTorch本体と画像処理用のtorchvision、音声処理用のtorchaudioをpipで導入します。
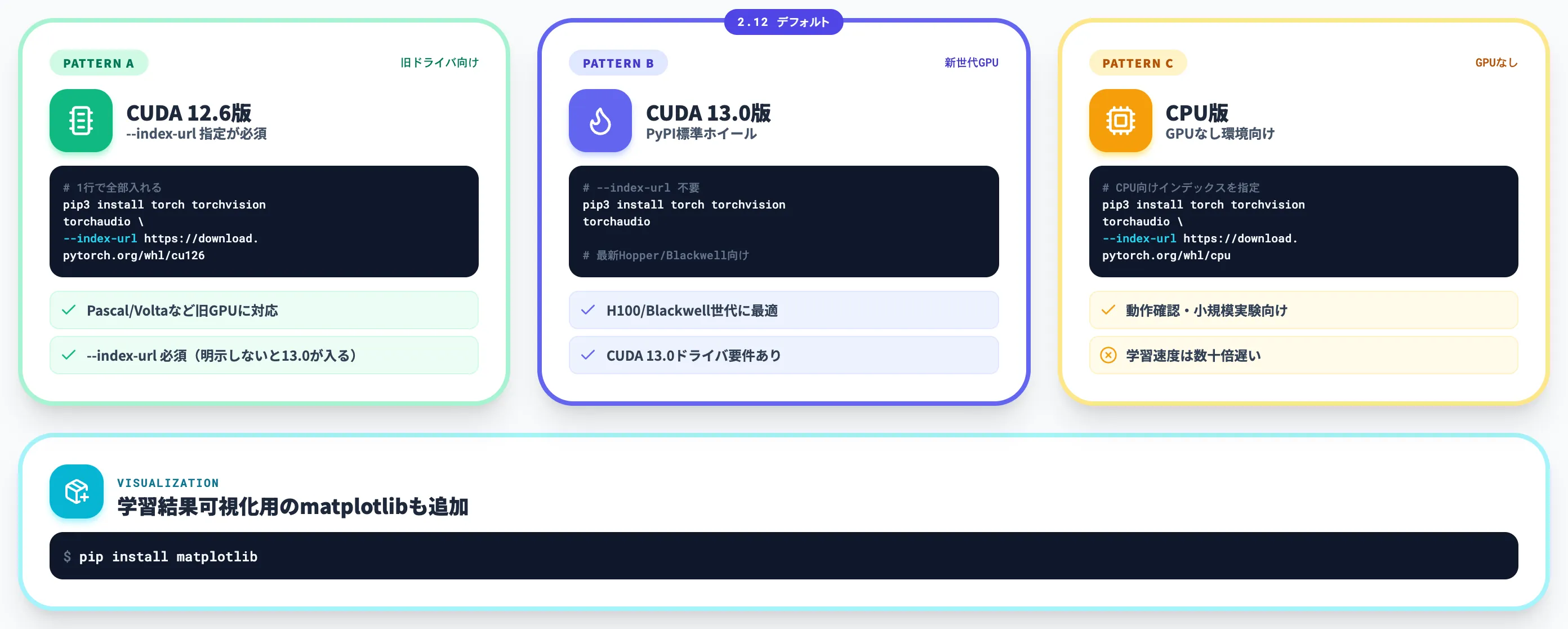
CUDA対応GPU環境であれば、CUDA 12.6向けの例として pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126 を実行します。PyTorch 2.12のPyPIデフォルトホイールはCUDA 13.0版になるため、CUDA 12.6を使いたい場合は必ず --index-url 指定が必要です。CPU版は pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu のようにCPU向けインデックスを明示します。

GPU版はホイールファイルが大きいため、回線環境によっては数分〜十数分かかります。
「done」または「Successfully installed」の表示で、PyTorch・torchvision・torchaudioの導入は完了です。
後続のMNIST実装で結果を可視化するため、グラフ描画用のmatplotlibも pip install matplotlib で追加しておきます。
インストール確認とGPU認識のチェック
Pythonインタプリタを起動し、次の2行でインストール状態を確認します。
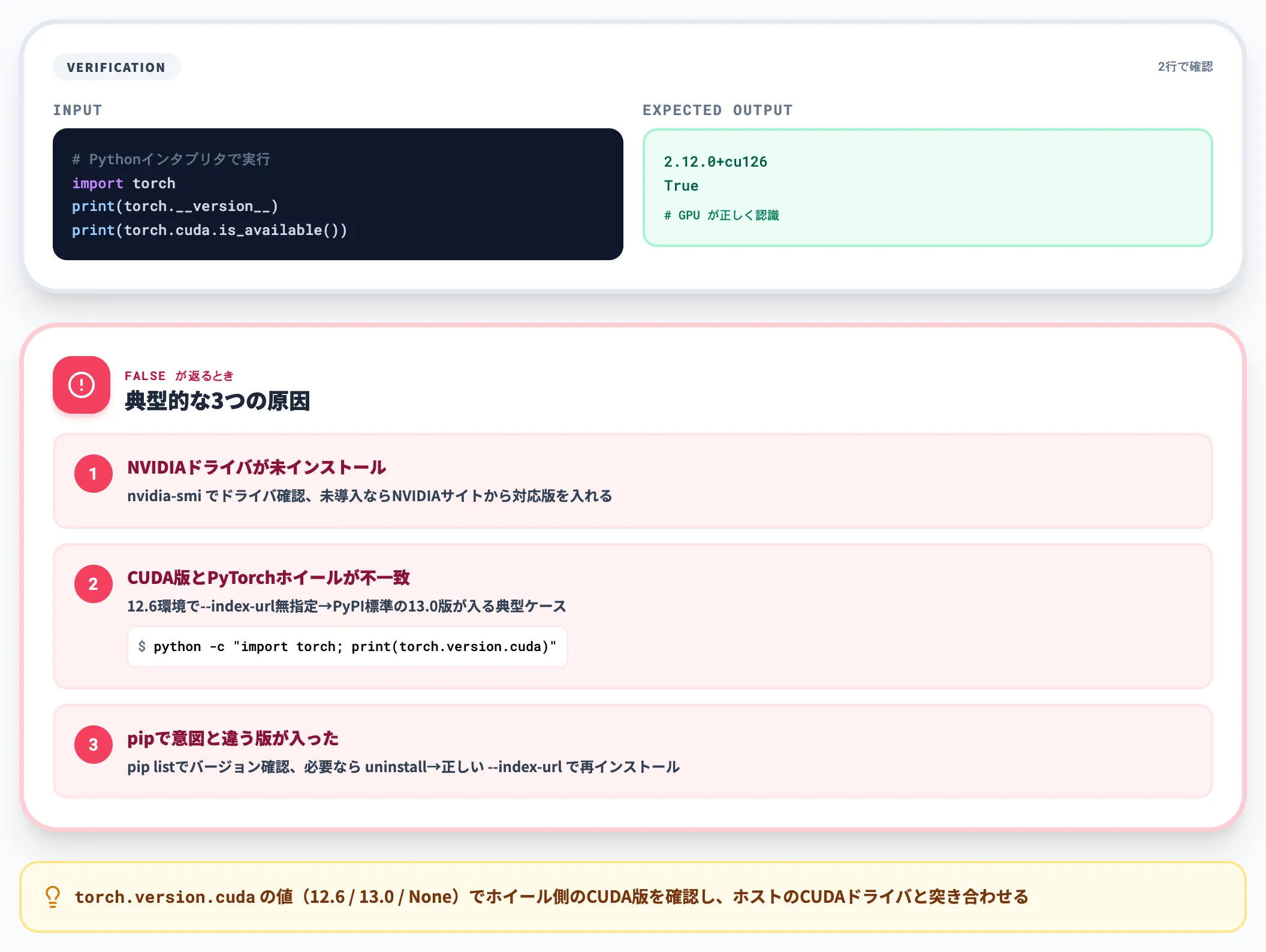
import torch
print(torch.__version__)
print(torch.cuda.is_available())
torch.__version__ で導入バージョン(例: 2.12.0+cu126)が表示され、torch.cuda.is_available() が True を返せば、GPUが正しく認識されている状態です。
False が返るときは、NVIDIAドライバが未インストール/CUDAバージョンとPyTorch側のホイールが不一致/pipで意図と違う版が入っている、のいずれかが典型的な原因です。
詰まりポイントは「CUDA 12.6環境なのに --index-url を付けずにインストールした結果、PyPIデフォルトのCUDA 13.0版が入ってしまいドライバと不一致」というケースです。torch.version.cuda の値(例: 12.6 / 13.0 / None)でホイール側のCUDAバージョンを確認し、ホストのCUDAドライバとずれていないかを必ず突き合わせてください。
PyTorchの基本操作——テンソルと自動微分
本セクションでは、ディープラーニングのモデル実装に進む前に必ず押さえておくべき2つの基本操作を、最小限のコードで確認します。
公式チュートリアルの「60 Minute Blitz」と同じ流れで進めるので、手元のpython環境で同時に動かしながら読むと理解が早まります。


テンソル(torch.Tensor)の作成と基本演算
PyTorchで扱うデータはすべて torch.Tensor クラスで表現されます。テンソルは多次元配列の総称で、スカラー・ベクトル・行列・3次元以上の配列を統一的に扱う型です。
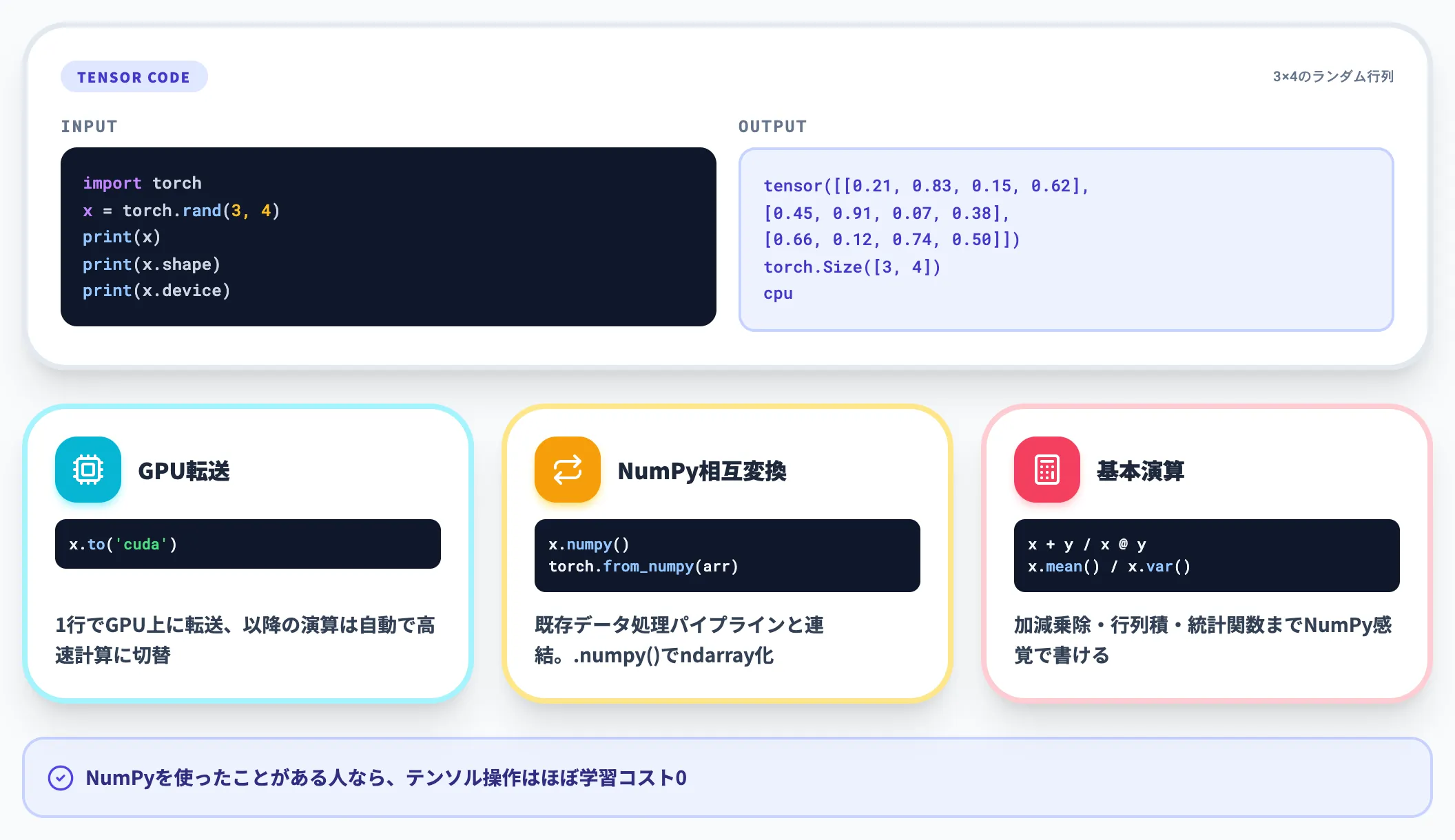

たとえば3×4のランダム行列を作るなら、次のように書きます。
import torch
x = torch.rand(3, 4)
print(x)
print(x.shape) # torch.Size([3, 4])
print(x.device) # cpu または cuda:0
x.to('cuda') でGPUに転送でき、以降の演算は自動でGPU上の高速計算に切り替わります。NumPyの ndarray と相互変換できるため、既存のデータ処理パイプラインからの移行もスムーズです。
加減乗除や行列積(@ 演算子)、平均・分散などの統計関数も、NumPyとほぼ同じ書き方で動きます。
形状変換(reshape / view / permute)
ニューラルネットワークの実装では、テンソルの形状を頻繁に変える操作が必要になります。代表的な変換は view / reshape / permute の3つです。


x = torch.arange(12)
print(x.shape) # torch.Size([12])
y = x.view(3, 4) # 形状を3×4に変える
print(y.shape) # torch.Size([3, 4])
z = y.permute(1, 0) # 軸の順序を入れ替える
print(z.shape) # torch.Size([4, 3])
view はメモリレイアウト維持を前提とした高速な形状変更、reshape は必要ならメモリコピーを行う汎用版です。permute は軸の入れ替えで、画像データを「バッチ×チャンネル×縦×横」と「バッチ×縦×横×チャンネル」の間で並べ替える際などに使います。
自動微分(autograd)
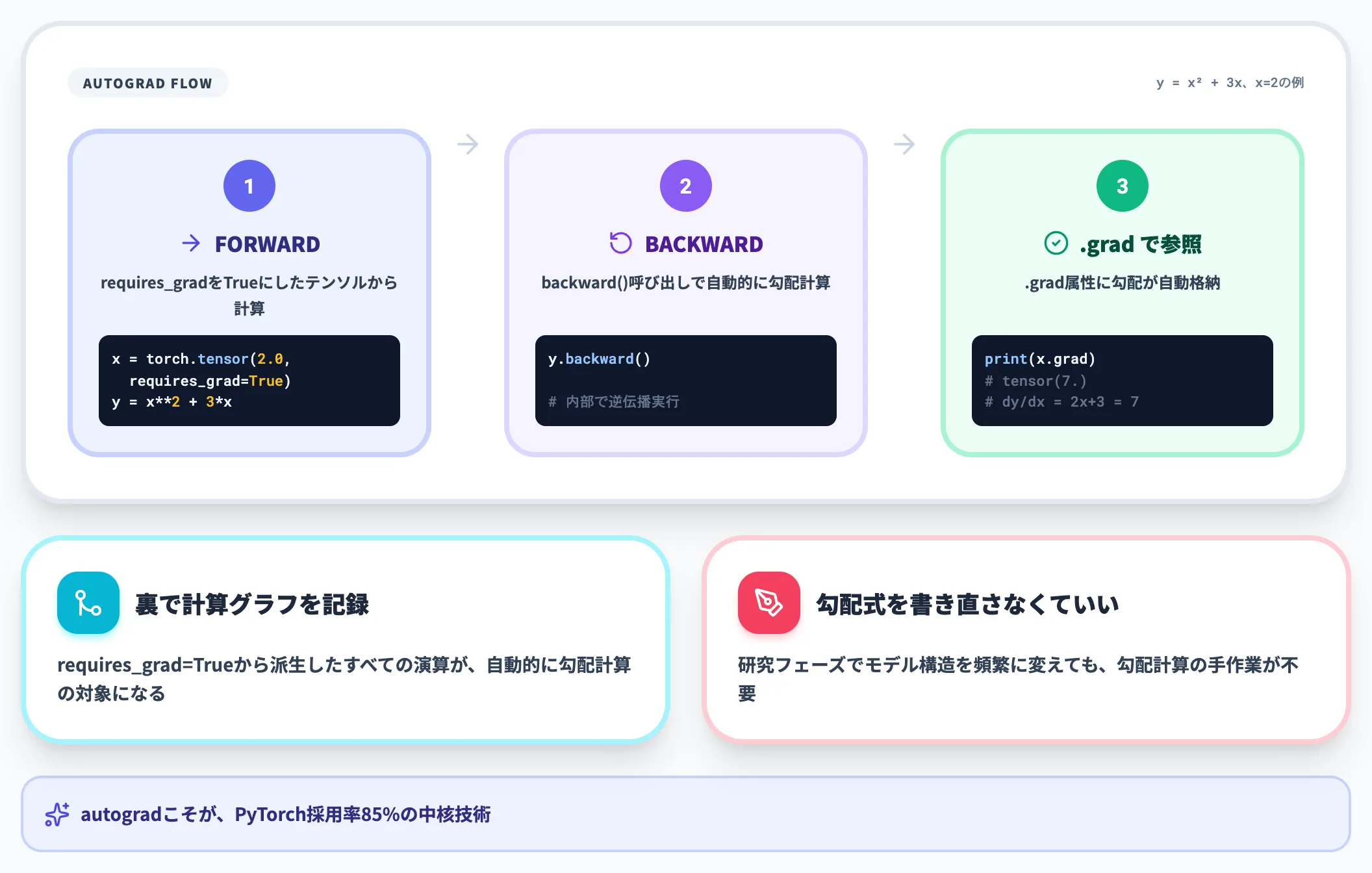
自動微分は、ニューラルネットワークを「学習」させるための心臓部です。順方向の計算を書くと、PyTorchが裏で計算グラフを記録し、逆伝播時に勾配を自動計算してくれます。
簡単な例として、y = x^2 + 3x を x = 2 の点で微分してみます。
x = torch.tensor(2.0, requires_grad=True)
y = x**2 + 3*x
y.backward()
print(x.grad) # tensor(7.)(dy/dx = 2x + 3 = 7)
requires_grad=True を指定したテンソルから派生した計算は、すべて勾配計算の対象になります。backward() を呼ぶだけで、ニューラルネットワーク全体の勾配が .grad 属性に格納される仕組みです。
このautogradの仕組みを内部に持っているため、PyTorchではモデルを書き換えても勾配計算式を手で書き直す必要がありません。研究フェーズで構造を頻繁に変える際の生産性差が、ここから生まれます。
PyTorchでMNIST画像分類モデルを実装する
ここまでの基本操作を踏まえ、PyTorch学習の定番であるMNIST手書き数字データセットを使った画像分類モデルを実装します。
数字0〜9の手書き画像(28×28ピクセル)を10クラスに分類するシンプルな問題で、簡単なCNN(畳み込みニューラルネットワーク)でも精度98%超に到達するため、ディープラーニング入門の事実上の標準題材です。MNISTは画像認識タスクの「Hello, World」と呼ばれる位置づけで、ここで作る分類器の構造を理解すれば、CIFAR-10やImageNetといった本格的なデータセットに進む土台ができます。
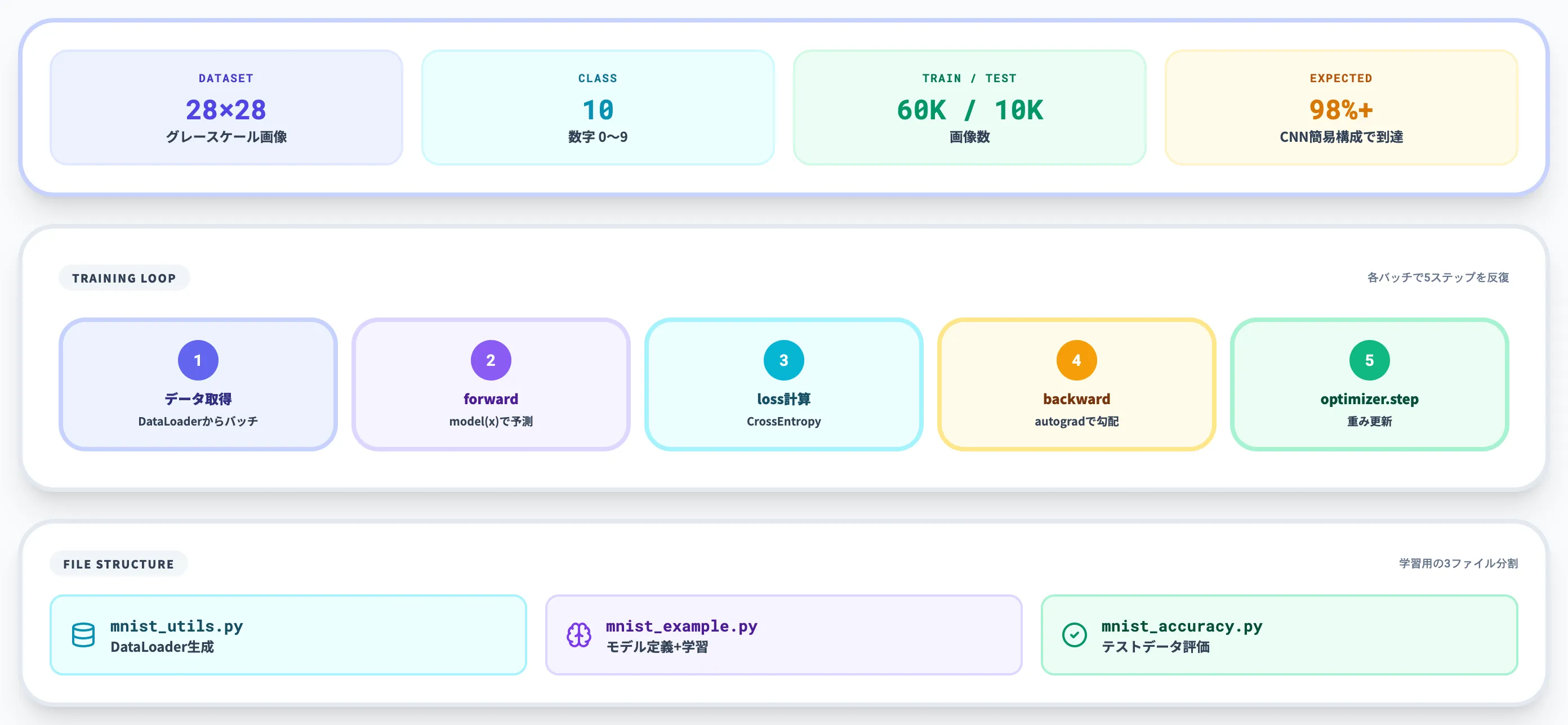
全体構成と作成するファイル
以下の表で、本セクションで作成する3ファイルの役割を整理しました。
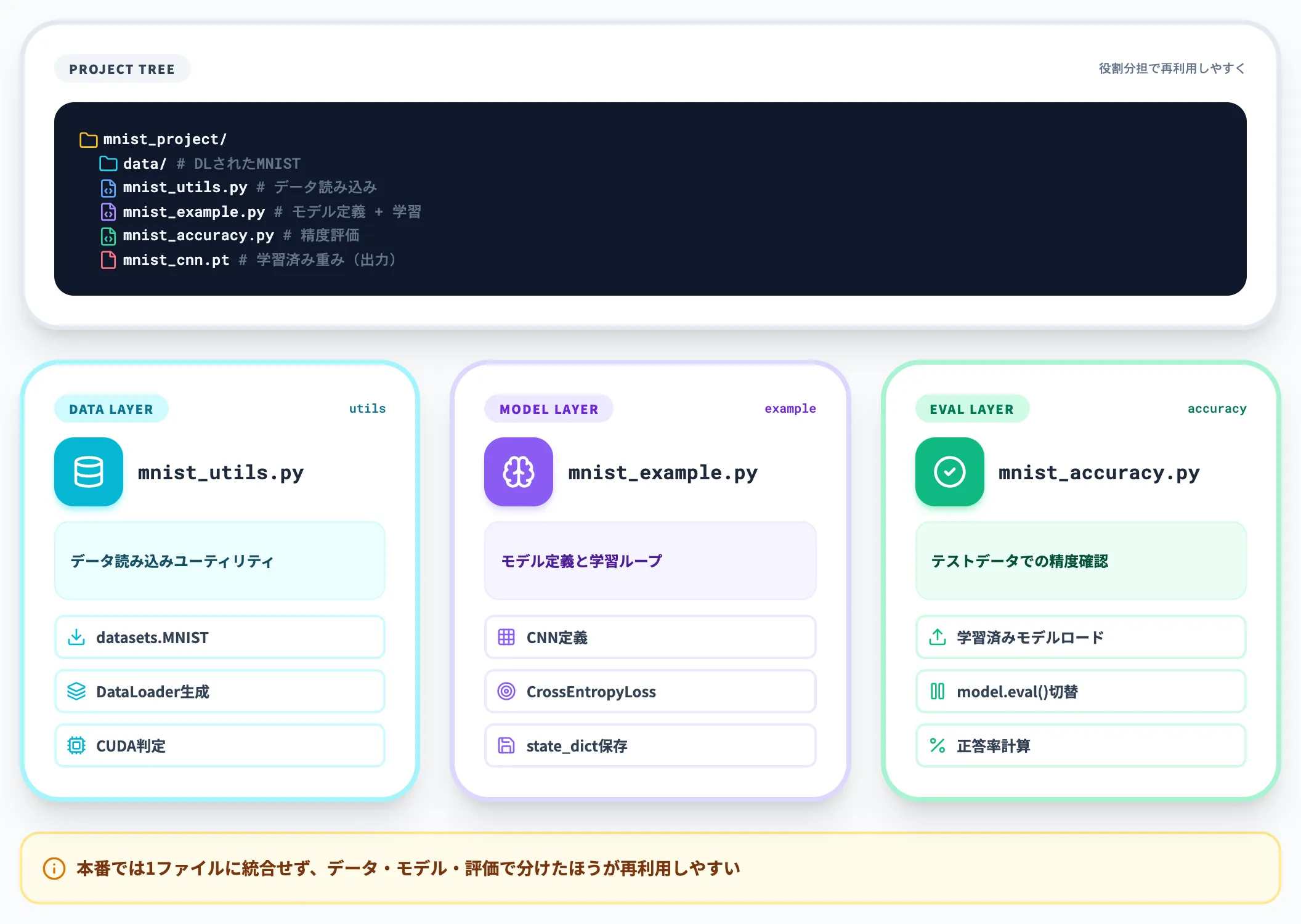
| ファイル | 役割 | 主な内容 |
|---|---|---|
| mnist_utils.py | データ読み込みとユーティリティ | DataLoader生成、画像変換、CUDA判定 |
| mnist_example.py | モデル定義と学習ループ | CNN定義、損失関数、最適化、学習・保存 |
| mnist_accuracy.py | 評価(テストデータでの精度確認) | 学習済みモデルのロード、精度計算 |
この3ファイル分割は学習用の構成で、本番では1ファイルにまとめるより、データ・モデル・評価を分けたほうが再利用しやすい配置です。
データ読み込みとユーティリティ
最初に、データセットの読み込みとDataLoaderの作成を担当する mnist_utils.py を作ります。
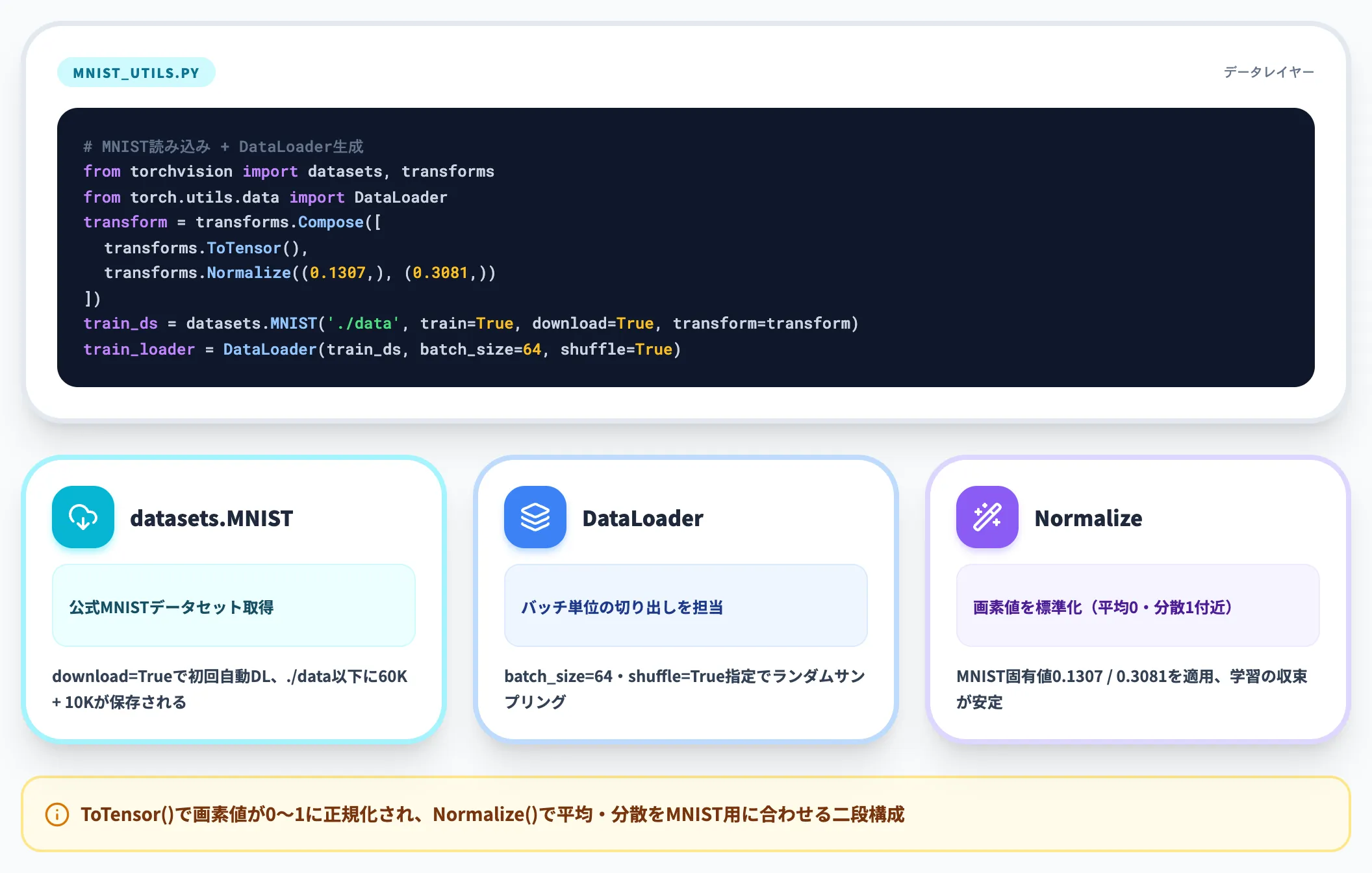
torchvision.datasets.MNIST で公式データセットを取得し、DataLoader でバッチ単位に切り出す形が標準です。transforms.ToTensor() で画素値を0〜1に正規化したテンソルに変換し、transforms.Normalize((0.1307,), (0.3081,)) でMNIST固有の平均・標準偏差を当てます。
モデル定義と学習スクリプト
次に、CNNのモデル定義と学習ループを書いた mnist_example.py を作成します。
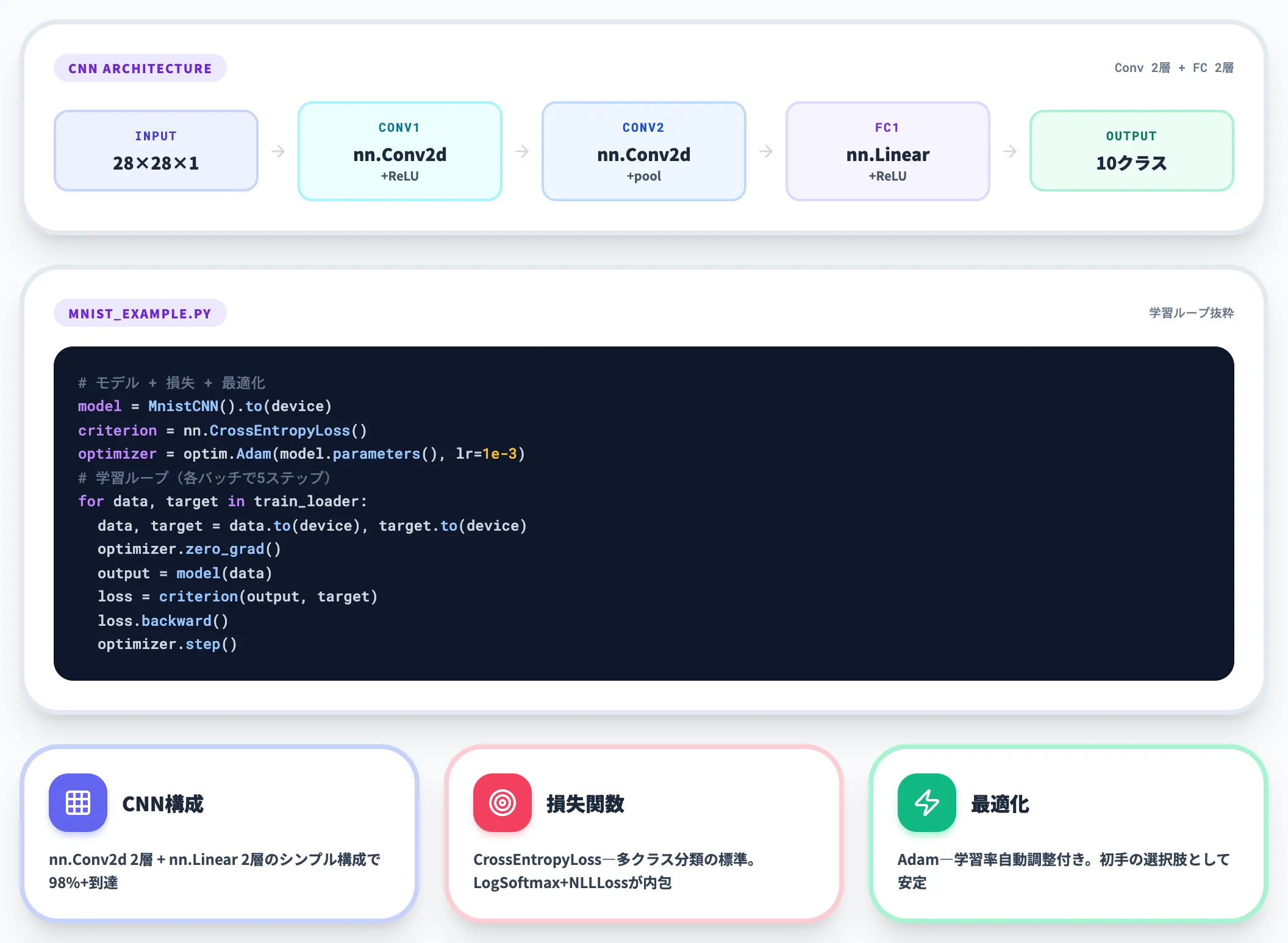
モデルは nn.Conv2d 2層+全結合2層のシンプルな構成で、損失関数に nn.CrossEntropyLoss、最適化に optim.Adam を使います。学習ループは「データ取得 → forward → loss計算 → backward → optimizer.step」の5ステップを各バッチで繰り返す典型形です。
MNISTデータセットのダウンロードと学習実行
スクリプトを実行すると、初回はMNISTデータセットを自動でダウンロードします。

ダウンロードはバックグラウンドで進み、トレーニング画像60,000枚とテスト画像10,000枚が取得されます。

スクリプト実行ディレクトリ直下に data/ フォルダが自動生成され、ここにバイナリ形式のデータセットが格納されます。
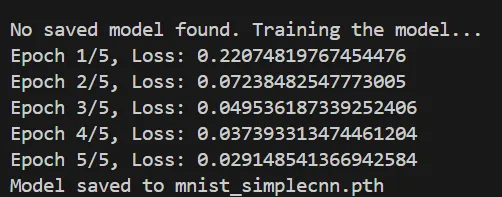
学習が始まると、エポックごとに損失(loss)と進捗が表示されます。CPU実行だと1エポックあたり数分かかりますが、GPU環境なら数十秒で完了します。

学習が終わると、torch.save(model.state_dict(), 'mnist_cnn.pt') の出力で重みファイルが保存されたことを確認できます。
精度評価(mnist_accuracy.py)
学習済みモデルをロードし、テストデータでの正答率を計算するスクリプトが mnist_accuracy.py です。
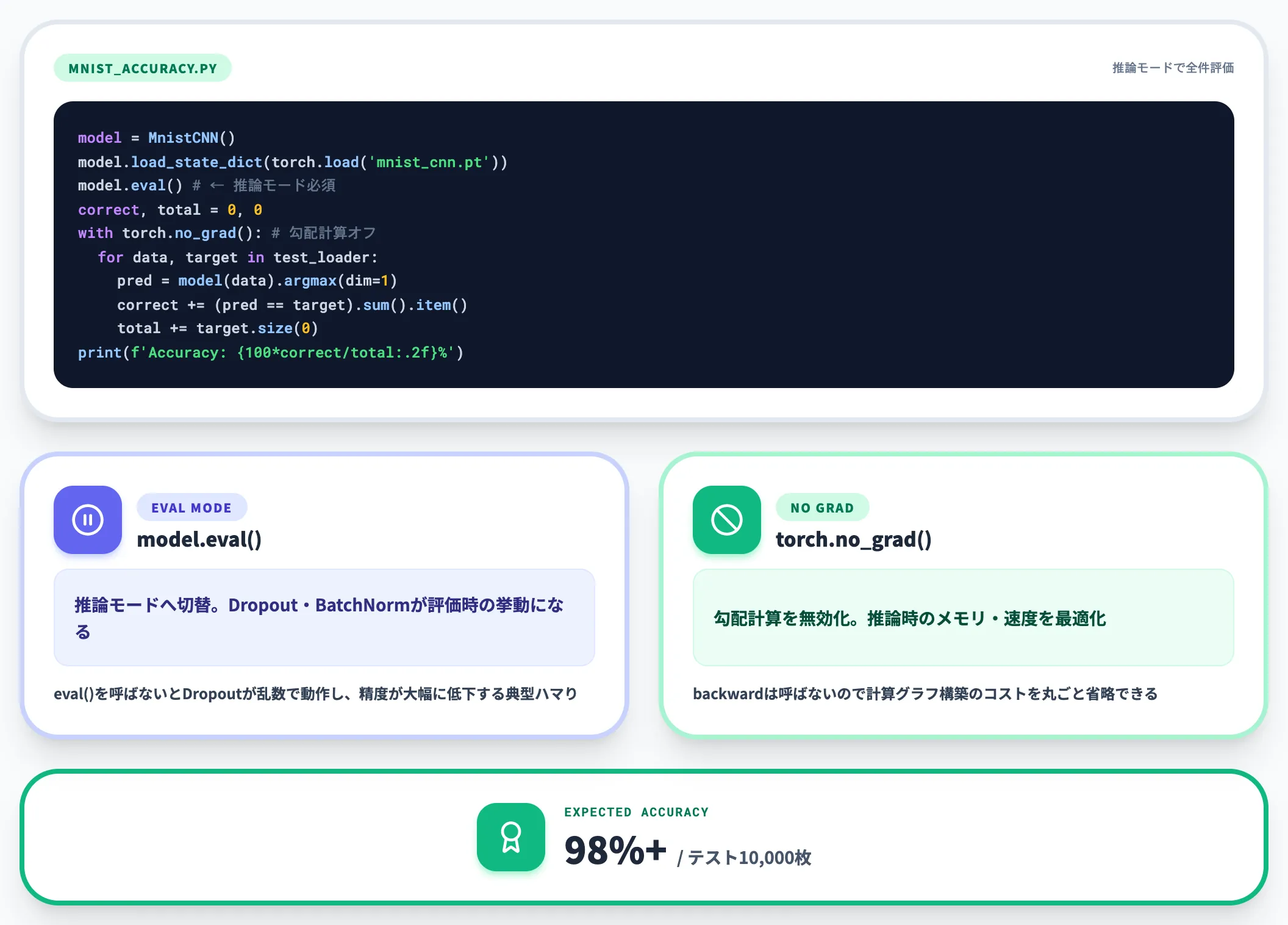
model.eval() で推論モードに切り替え、torch.no_grad() ブロック内で勾配計算を無効化することで、メモリ消費と推論速度を最適化できます。
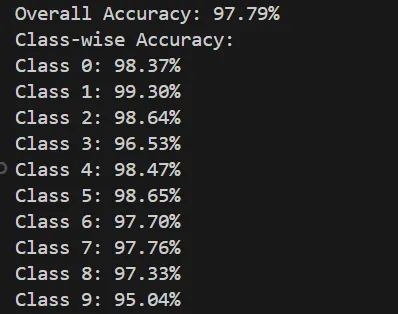
実行すると、テスト10,000枚に対する正答率が出力されます。本構成でも98%超に到達し、PyTorchで数十行のコードでも実用レベルの画像分類器が作れることが体感できます。
詰まりポイント——実装時に多いハマり方
実装で頻発するハマり方を3点だけ先回りで挙げておきます。

-
CUDAテンソルとCPUテンソルが混ざる
モデルとデータの一方だけ.to('cuda')を忘れると、RuntimeError: Expected all tensors to be on the same deviceが出る。データ転送は学習ループの先頭でdata, target = data.to(device), target.to(device)の1行を必ず置く。
-
勾配がリセットされず累積する
optimizer.zero_grad()を学習ループの先頭で呼び忘れると、前バッチの勾配が累積して学習が崩れる。loss.backward()の前に必ず置く。
-
評価モードへの切り替え忘れ
model.eval()を呼ばずに評価を実行すると、Dropout・BatchNormが学習時の挙動のままになり、精度が大きく下がる。逆に評価後に学習へ戻すならmodel.train()を忘れずに。
これらは初学者の3大ハマりポイントで、エラーメッセージから直接の原因が見えにくいだけに、最初から意識しておくと挫折を避けられます。
本番運用に向けた高度な機能——torch.compile・FSDP2・ExecuTorch
研究やプロトタイピングを一通り回せるようになった次の論点は、本番運用です。学習速度、大規模分散学習、エッジ展開の3つは、それぞれ別々のPyTorch機能でカバーされています。
本セクションでは、本番運用前に必ず把握しておくべき高度な機能を整理します。

torch.compile——学習・推論の高速化レイヤー

torch.compile は、PyTorch 2.0で導入されたコード変換ベースの高速化機能です。Pythonのモデル定義をTorchDynamo経由でグラフ化し、TorchInductorバックエンドで最適化されたCUDA/CPUコードを生成します。
使い方は1行追加するだけです。
model = MyModel().to('cuda')
model = torch.compile(model) # ここだけ追加
mode='max-autotune' を指定すると、より積極的に最適化を試みて高速化効果を引き出せます。
実際の高速化率はモデル構造と入力サイズに依存しますが、公式の解説では多くのモデルで学習スループットが大きく改善する事例が報告されています。速度向上は環境依存のため、本番投入前に自社モデルでベンチマークを取って判断するのが正解です。
FSDP2——100B+モデルにも届く分散学習
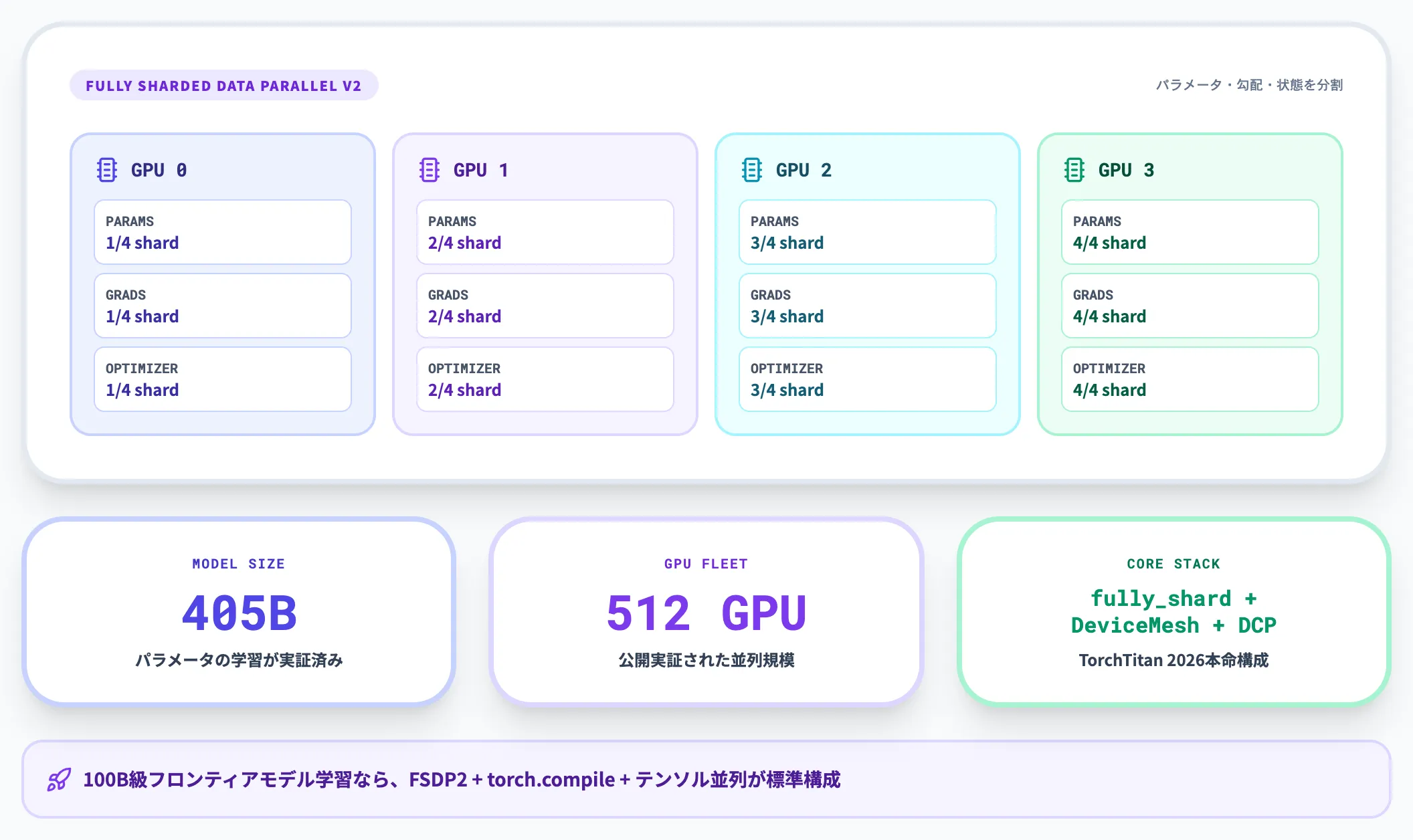
大規模言語モデル(LLM)など、単一GPUに乗り切らないモデルを扱う場合は、**FSDP2(Fully Sharded Data Parallel v2)**が標準的な選択肢になります。
FSDP2はモデルのパラメータ・勾配・オプティマイザ状態をGPU間で分割保持する分散学習方式で、メモリ使用量を大幅に削減できます。TorchTitan公式リポジトリとtechbytesの2026年5月の解説記事では、FSDP2が「PyTorchネイティブな大規模学習の中心」に位置づけられ、fully_shard、DeviceMesh、DCP(分散チェックポイント)、TorchTitan の組み合わせで405Bパラメータ・512GPU規模の学習が公開実証されています。
100B級のフロンティアモデル学習を視野に入れている組織なら、FSDP2+torch.compile+テンソル並列の組み合わせが2026年版の本命構成です。
ExecuTorch——スマホ・組み込みへのオンデバイス展開

学習はサーバ・クラウドで回しても、推論はユーザー端末で動かしたいケースが増えています。ExecuTorchはPyTorchで学習したモデルをスマホ・ウェアラブル・組み込み機器で動かすための公式ランタイムで、2025年10月22日に1.0が正式リリースされ、2026年4月にはPyTorch Coreプロジェクトに統合されました。
特徴は次の3点です。
- 50KBのベースフットプリント: マイコン搭載機器までカバー
- 12以上のハードウェアバックエンド対応: Apple・Qualcomm・ARM・MediaTek・Vulkan・x86 CPU等
- PyTorch標準のexportフローで配備: 学習コードを書き直さず、
torch.exportで計算グラフを書き出してExecuTorchランタイムへ載せる構成
Metaの自社製品(Instagram・WhatsApp・Messenger・FacebookアプリやReality Labsのウェアラブル機器)でオンデバイスAIを支える基盤として実運用されており、エンタープライズでもエッジAI戦略の柱として採用が進んでいます。
TorchScript→torch.exportへの移行を計画する

前のセクションでも触れたとおり、TorchScriptは2.10で非推奨化されました。後継となるのは torch.export で、計算グラフを安定したフォーマットに書き出し、ExecuTorch等のランタイムで動かす構成が標準になります。
既存パイプラインがTorchScript依存になっている組織は、2026年中に torch.export への置き換え調査を始めるのが、痛みを最小化するルートです。
PyTorch vs TensorFlow vs JAX——フレームワーク選定の軸
ディープラーニングフレームワークを選ぶときに必ず比較対象になるのが、TensorFlowとJAXです。3者は同じ問題を解くツールでありながら、得意領域がはっきり分かれます。
本セクションでは、2026年時点での選定軸を整理します。
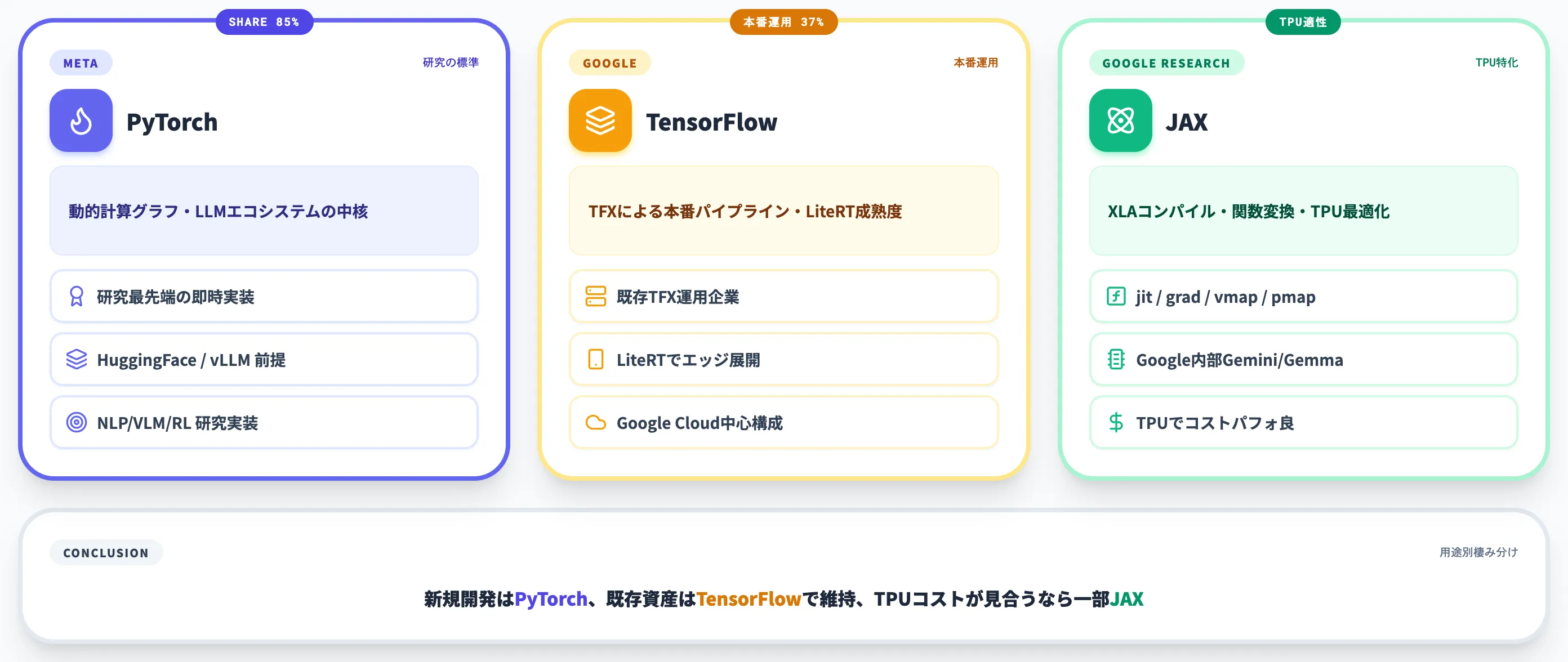
3フレームワークの位置づけ比較
以下の表で、PyTorch・TensorFlow・JAXの強みと向き不向きを整理しました。
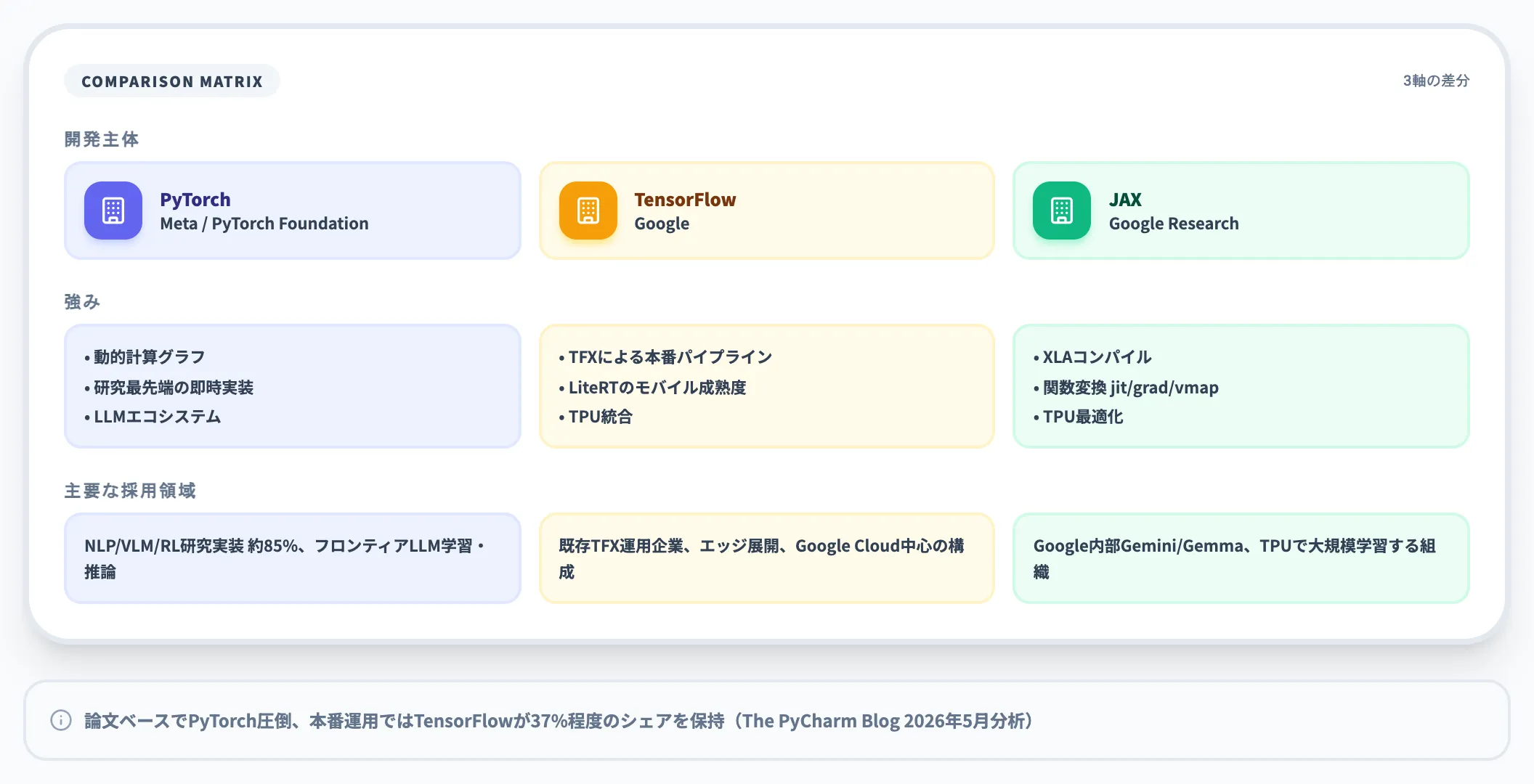
| フレームワーク | 開発主体 | 強み | 主要な採用領域 |
|---|---|---|---|
| PyTorch | Meta / PyTorch Foundation | 動的計算グラフ・研究最先端の即時実装・LLMエコシステム | Second Talent推計でNLP/VLM/RL等の研究実装の約85%、フロンティアLLM学習・推論 |
| TensorFlow | TFXによる本番パイプライン・LiteRTのモバイル成熟度・TPU統合 | 既存TFX運用企業、エッジ展開(LiteRT)、Google Cloud中心の構成 | |
| JAX | Google Research | XLAコンパイル・関数変換(jit/grad/vmap/pmap)・TPU最適化 | Google内部(Gemini/Gemma学習)、TPUで大規模学習する組織 |
研究論文ベースでPyTorchが圧倒している一方、企業の本番運用ではTensorFlowも依然として37%程度の市場シェアを保つとThe PyCharm Blogの分析で報告されています。
ケース別の選び方
実務的には、次のような分かれ方になります。
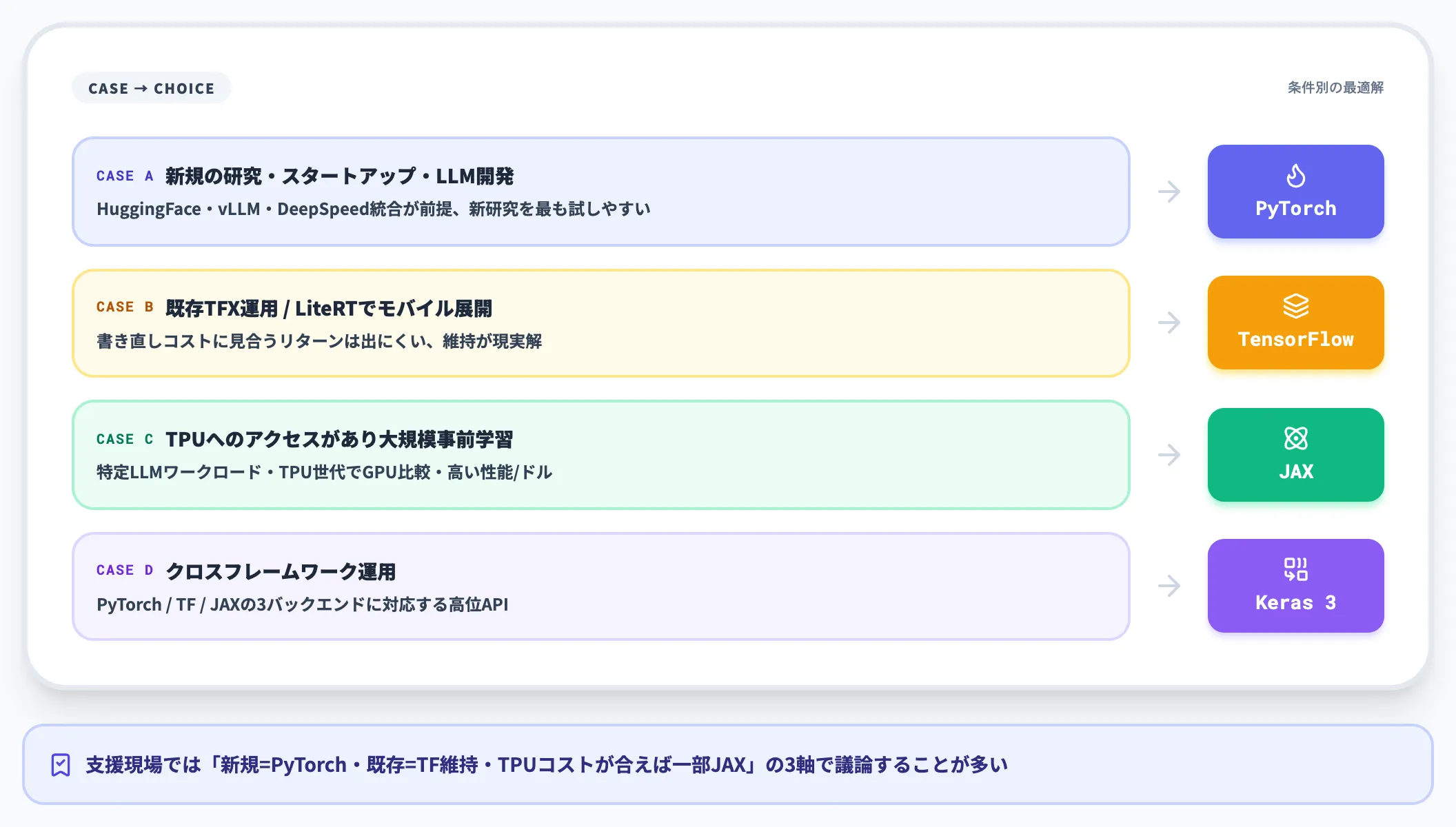
- 新規の研究・スタートアップ・LLM開発: 第一候補はPyTorch。Hugging Face・vLLM・DeepSpeedとの統合が前提で、新しい研究を最も試しやすい環境が揃う
- 既存TFX運用がある、もしくはLiteRTでモバイル展開する: TensorFlowを維持。書き直しコストに見合うリターンは出にくい
- TPUへのアクセスがあり、大規模事前学習を回す: JAX。Google Cloudの分析では、特定のLLM推論・学習ワークロード・特定TPU世代において、GPU比較で高い性能/ドルを示す例が報告されている
- クロスフレームワークで運用したい: Keras 3(PyTorch / TensorFlow / JAXバックエンド対応)を検討する
AI総研の支援現場でも、新規開発はPyTorch、既存資産はTensorFlowで維持、TPUコストが見合うなら一部JAX、という棲み分けで議論を整理することが多くなっています。
「全部PyTorchで統一」は本当に正解か

研究分野でPyTorchが事実上の標準になったとはいえ、「すべての社内資産をPyTorchに統一すべきか」は別の論点です。
すでにTFXで本番運用が安定している組織なら、PyTorchに書き直すコストは膨大で、得られる便益は限定的です。一方、新規プロジェクトで研究最先端の手法を取り込みたい場面では、PyTorch以外を選ぶと主要な論文実装を素早く試すコストが上がります。
「既存資産は維持しつつ、新規はPyTorch」という二系統運用が、実務上は最もコスト効率の良い落とし所になるケースが多いです。
PyTorch学習・推論のGPUコスト相場
本セクションでは、PyTorchで学習・推論を回すうえで避けて通れない、GPUクラウドのコスト相場を整理します。2026年6月時点の代表的な価格帯と、コスト最適化の打ち手を提示します。
主要クラウドのGPU料金比較
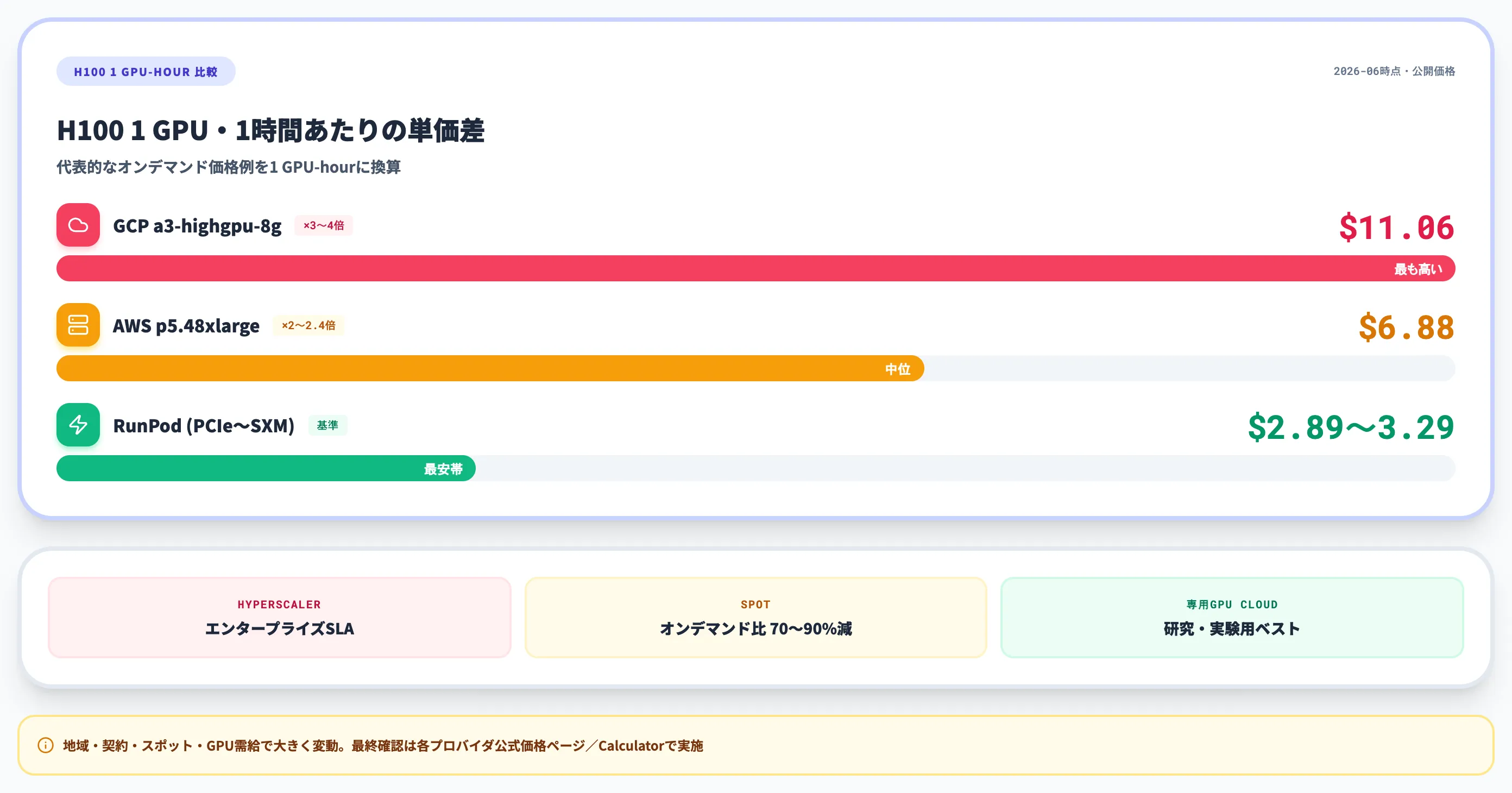
主要なGPUオプションの代表的なオンデマンド価格例を以下の表にまとめました。出典はAWS Price List API(us-east-1 Linux オンデマンド)・Google Cloud GPU料金・Google Cloud Accelerator-optimized VM料金・RunPod価格・Lambda Labs GPU料金で、2026年6月時点の公開価格を参照しています。地域・契約・スポット価格・GPU需給で大きく変動するため、最終確認は各プロバイダの公式価格ページ/Calculatorで行ってください。
価格はすべて1 GPU・1時間あたりに換算しています(複数GPUインスタンスは記載GPU数で除算)。
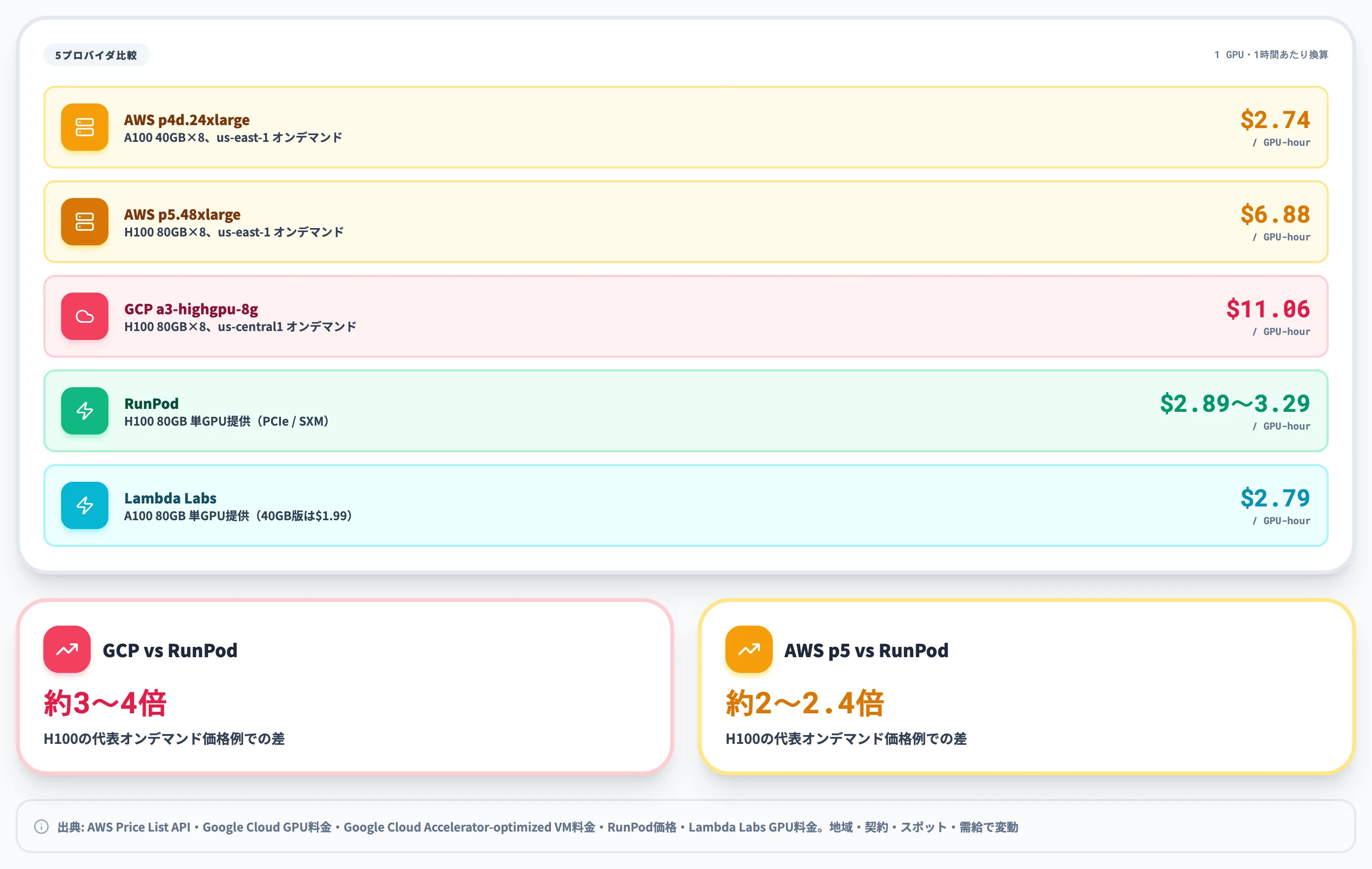
| 区分 | プロバイダ/インスタンス | GPU | 1 GPU-hour(目安) | 備考 |
|---|---|---|---|---|
| ハイパースケーラー(AWS) | p4d.24xlarge(A100 40GB×8) | A100 40GB | 約$2.74/hr | $21.96/hr ÷ 8、us-east-1 Linuxオンデマンド(2026年6月時点)、Amazon SageMaker経由でも提供。A100 80GBが必要ならp4de.24xlarge側 |
| ハイパースケーラー(AWS) | p5.48xlarge(H100 80GB×8) | H100 80GB | 約$6.88/hr | $55.04/hr ÷ 8、us-east-1 Linuxオンデマンド(2026年6月時点) |
| ハイパースケーラー(Google Cloud) | a3-highgpu-8g(H100 80GB×8) | H100 80GB | 約$11.06/hr | $88.49/hr ÷ 8、us-central1オンデマンド(2026年6月時点)、Accelerator-optimized VM料金 / Cloud Calculatorで確認 |
| 専用GPUクラウド | RunPod | H100 80GB | 約$2.89〜$3.29/hr | PCIe $2.89 / SXM $3.29、単GPU提供、米国基準 |
| 専用GPUクラウド | Lambda Labs | A100 80GB | 約$2.79/hr | 単GPU提供(A100 40GBは約$1.99/hr) |
1 GPU-hourに揃えると、H100の代表的なオンデマンド価格例ではAWS p5(約$6.88/hr)はRunPod(約$2.89〜$3.29/hr)の約2〜2.4倍、GCP a3-highgpu-8g(約$11.06/hr)はRunPod比で約3〜4倍になります。地域・契約形態・スポット価格・GPU需給で実際の単価は上下するため、調達計画は時期・対象リージョンでの再確認が前提です。
コスト最適化の3つの打ち手
PyTorch学習コストを下げるための代表的な打ち手は次の3つです。

-
スポットインスタンスの活用
ハイパースケーラー側のスポットインスタンスを使うと、オンデマンド比で70〜90%のコスト削減が可能。チェックポイント保存とリスタート処理を実装することで、インスタンスの中断リスクを吸収できる。
-
混合精度学習(mixed precision training)
torch.ampを使ってFP16/BF16を混在させると、学習速度が1.5〜2倍程度速くなり、メモリ使用量も削減できる。
-
専用GPUクラウドへの移行
本番運用を伴うとは限らない研究・実験フェーズなら、RunPodやLambda Labsなど専用GPUクラウドの利用でハイパースケーラーよりトータルコストが下がるケースが多い。エンタープライズSLA要件がない検証用途では特に有効。
「AWS/GCP一択でないと安心できない」というポリシーが社内にあるかどうかが、最初の論点になります。スタートアップ・研究部門なら専用GPUクラウドを活用し、本番推論だけハイパースケーラーで稼働する組み合わせが、実務的な落とし所として現実的です。
自社運用 vs クラウド利用の判断軸
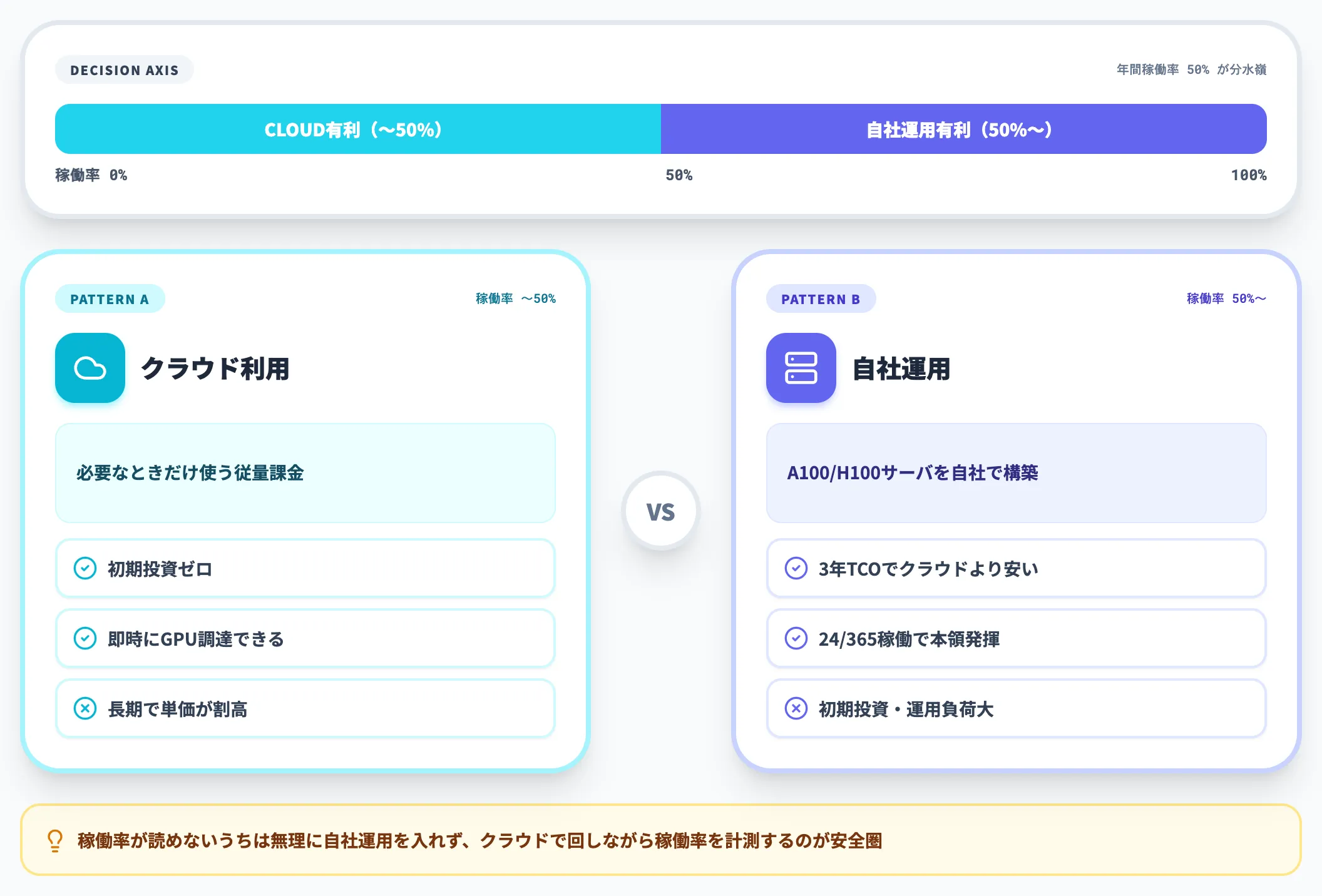
長期で大量に学習を回す組織なら、自社でA100/H100サーバを構築する選択肢も検討対象になります。
VRLA Techの試算では、GPUを24時間365日稼働させる前提だと、3年TCOで自社運用のほうがクラウドより安くなるケースが多いと指摘されています。一方、稼働率が50%を切る場合はクラウドのほうが経済的になります。
判断基準は「年間でGPUをどれだけ稼働させるか」が最も大きな軸で、稼働率が読めないうちは無理に自社運用を入れずクラウドで回す、というスタンスが安全圏です。

PyTorch活用を業務に定着させる
PyTorchで自社モデルの開発・運用ループが回り始めたら、次に来るのは「業務側のどこにこのAIを組み込むか」という問いです。
技術スタックとしてPyTorchを使いこなせるようになっても、業務プロセスへの組み込みパターン・PoCから全社展開までの設計・運用統制の設計を別軸で整理しないと、社内のAI活用は研究室の中で止まってしまいます。
AI総合研究所では、PoCから全社展開までの進め方、部門別ユースケース、AI運用における統制・セキュリティのチェックポイントを220ページにまとめた「AI業務自動化ガイド」を無料で公開しています。PyTorchで作ったモデルを業務に定着させる次の一手を整理する出発点として活用ください。
ディープラーニング基盤の知見を組織のAI活用に広げる

PoCから全社展開までを1冊で整理
PyTorchで自社モデルの開発・運用が回り始めたら、次の論点は「業務側のどこにAIを組み込むか」です。AI業務自動化ガイド(220ページ)では、PoC段階から全社展開までの進め方、部門別ユースケース、AI運用における統制・セキュリティのチェックポイントを整理しています。
まとめ
本記事では、PyTorchについて、定義・最新バージョン2.12の動向・主要機能・環境構築・MNIST実装・本番運用機能・他フレームワークとの比較・GPUコスト相場までを、2026年6月時点の最新情報で整理しました。要点を改めてまとめます。
-
PyTorchはMetaが主導するオープンソース深層学習フレームワークで、2022年からはLinux Foundation配下のPyTorch Foundationが運営。動的計算グラフとPythonic設計により、Second Talentの2026年分析ではNLP・ビジョンなど深層学習中核領域の実装の約85%がPyTorchと推計される事実上の標準
-
最新版は2026年5月13日リリースの2.12で、linalg.eigh最大100倍高速化・torch.accelerator.Graph統合API・MX量子化対応・ROCm/FlexAttention強化など、ハードウェア横断のAPI整備と量子化対応が前進。TorchScriptは2.10で非推奨化済み
-
始め方の最短ルートはAnaconda仮想環境+GPU対応版pipインストール+MNIST画像分類実装。テンソル・自動微分・nn.Module の3点を押さえれば、論文モデルの実装読解と再現に進める
-
**本番運用のスタックは torch.compile(高速化)+FSDP2+TorchTitan(100B+規模学習)+ExecuTorch(2025年10月に1.0、2026年4月にPyTorch Core統合)**の組み合わせが2026年版の本命。TorchScript依存パイプラインがあるなら
torch.exportへの移行計画を立てる時期
-
H100の1 GPU-hour比較ではAWS p5がRunPod比で約2〜2.4倍、GCP a3-highgpu-8gで約3〜4倍の差があり、スポットインスタンス+混合精度学習の組み合わせがコスト最適化の鍵。年間稼働率が高い場合は自社運用、低い場合はクラウドという稼働率主導の判断軸が現実的
PyTorchは「研究の最先端を最短ルートで触る」「学習からエッジ推論まで1つの基盤で完結させる」という2026年のディープラーニング基盤の中核です。まずはAnaconda+MNIST実装の数十行から手を動かし、自社で扱う問題に置き換えながら、本番運用機能とコスト構造を順番に押さえていくのが、最も挫折の少ない学習ルートになります。










