この記事のポイント
 社内ナレッジ検索をAIエージェントに統合するなら、Azure AI Search単体よりFoundry IQで権限制御付きの共通知識レイヤーを構築すべき
社内ナレッジ検索をAIエージェントに統合するなら、Azure AI Search単体よりFoundry IQで権限制御付きの共通知識レイヤーを構築すべき- Agentic Retrievalは従来RAG比36%の品質向上を実現しており、複雑な社内検索にはマルチクエリ検索が有効
- ナレッジベース構築はMicrosoft Foundryポータルから数ステップで完了でき、エージェント接続まで一気通貫で進めるのが最短ルート
- M365データ中心ならWork IQ、分析データならFabric IQ、外部データ込みの横断検索が必要ならFoundry IQが第一候補
- プレビュー段階のためティア別制限に注意が必要で、本番導入は料金体系のGA確定後に判断すべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Foundry IQは、Microsoft Foundryが提供するエンタープライズ向けのマネージド知識レイヤーです。
Azure AI Searchを基盤に、SharePoint、OneLake、Azure Blob Storage、Webなど複数のデータソースを横断して、AIエージェントに権限制御付きの回答を返すナレッジベースを構築できます。
本記事では、Foundry IQの概要からAgentic Retrievalの仕組み、Microsoft Foundryでの使い方、Work IQ・Fabric IQとの違い、料金体系、注意点までを2026年3月時点の公式情報に基づいて解説します。
目次
Foundry Agent Serviceや独自アプリへの接続
SharePoint・OneLake・Webを横断する業務アシスタント
Foundry IQとは
Foundry IQ(ファウンドリーIQ)は、Microsoft Foundry(旧Azure AI Foundry)が提供するAIエージェント向けのマネージド知識レイヤーです。
企業内に散在するデータを、権限制御付きのナレッジベースとしてまとめ、複数のAIエージェントから共通利用できるようにする仕組みです。
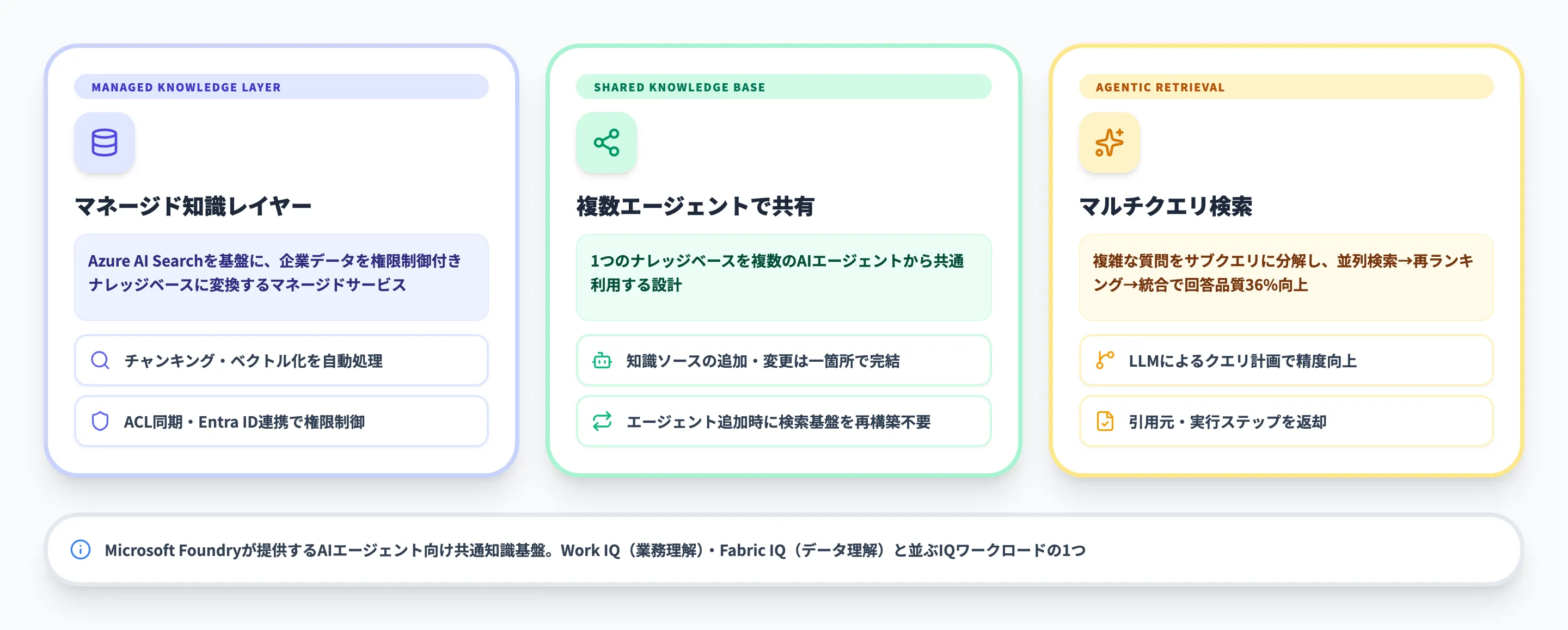
Microsoftによると、「企業データを再利用可能で権限制御付きのナレッジベースに変えるmanaged knowledge layer」と定義されています。2026年3月時点ではパブリックプレビューとして提供されており、Microsoft Foundryの新ポータルから設定できます。
ここで重要なのは、Foundry IQが単なる社内検索UIではなく、複数のAIエージェントから共通利用できる知識基盤として設計されている点です。
従来のRAGでは、エージェントごとにデータ接続・チャンキング・ベクトル化・検索ロジックを個別に構築する必要がありました。
Foundry IQは、この検索基盤をナレッジベース側に集約することで、知識の再利用性を高めています。

IQエコシステムでの位置づけ
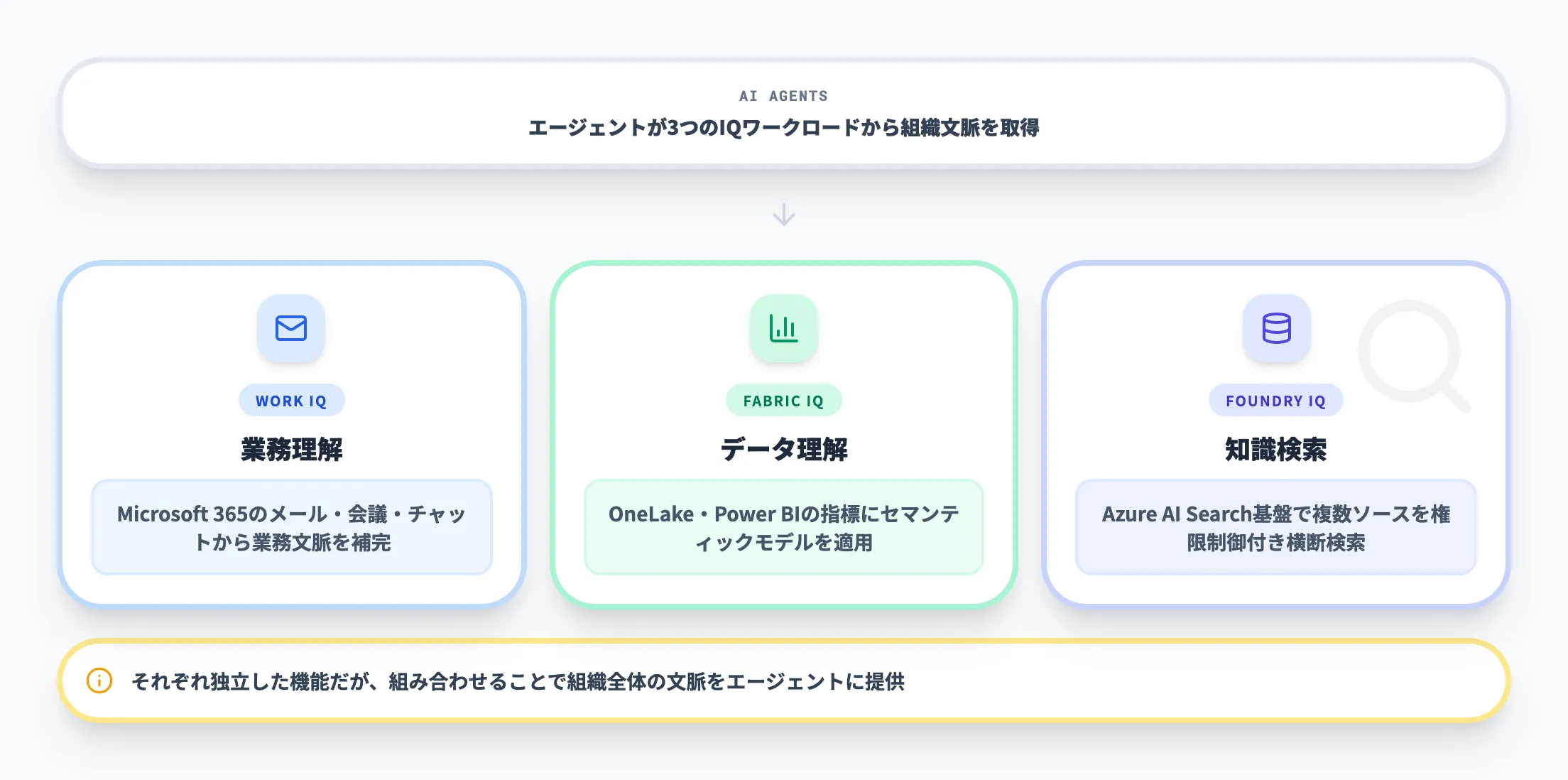
Foundry IQは単独の検索機能ではなく、Work IQやFabric IQと並ぶIQワークロードの1つです。
Microsoftはこの3つのIQワークロードを、エージェントに組織全体の文脈を提供するための仕組みとして位置づけています。
以下の表で、3つのIQワークロードの役割の違いを整理しました。
| レイヤー | 主な対象 | 役割 |
|---|---|---|
| Work IQ | Microsoft 365 | メール、会議、チャット、ファイルから業務文脈を補完する |
| Fabric IQ | Microsoft Fabric | データや指標の意味付けを行い、分析・推論を支援する |
| Foundry IQ | Microsoft Foundry | 複数ソースの知識を権限制御付きで検索し、エージェントに渡す |
つまり、Foundry IQが「知識検索」、Work IQが「業務理解」、Fabric IQが「データ理解」を担う構造です。
それぞれ独立した機能ですが、組み合わせることで組織全体の文脈をエージェントに渡せる設計になっています。
Azure AI Searchとの関係
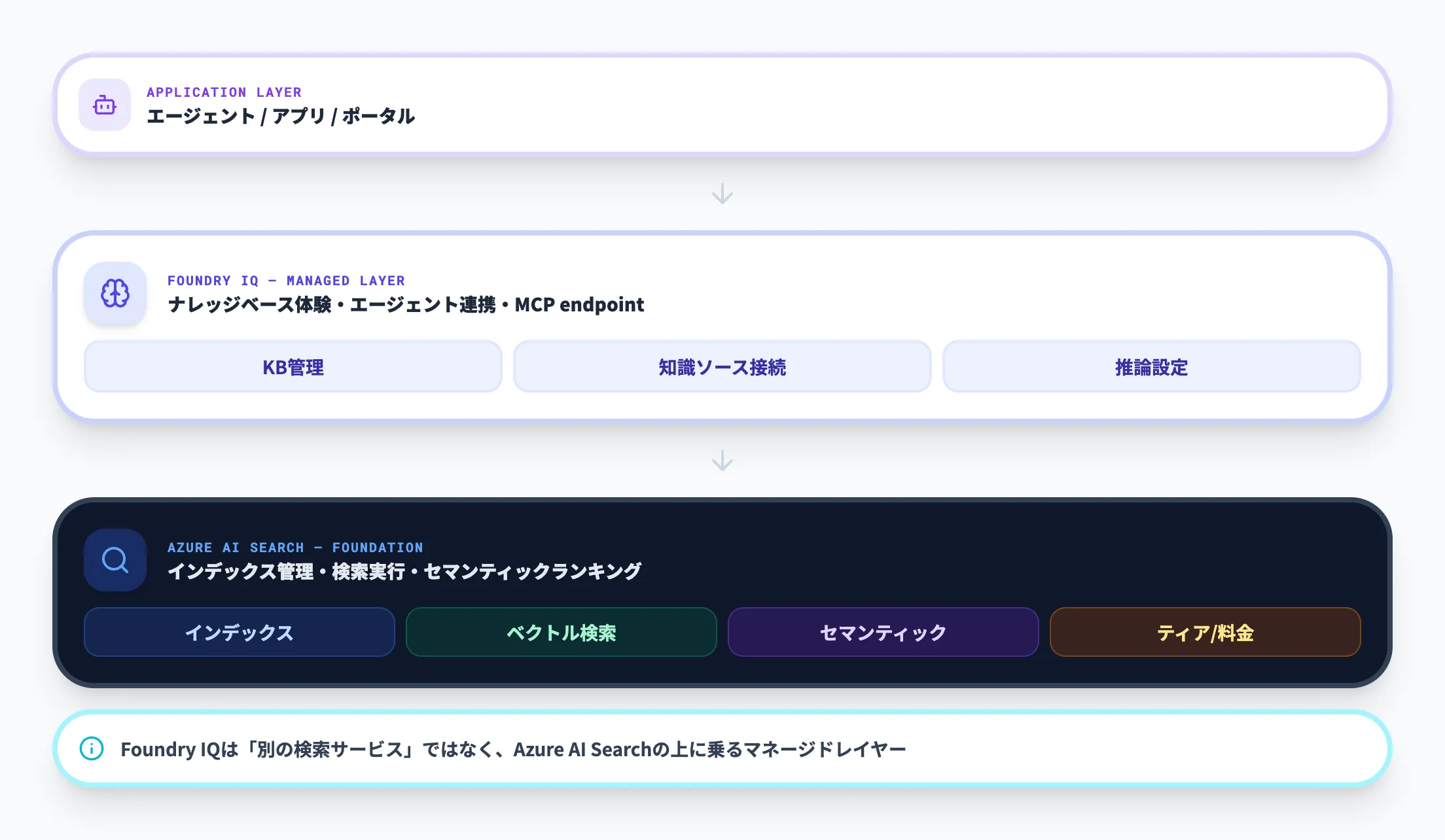
Foundry IQは、Azure AI Searchの上に構築されたレイヤーです。
Azure AI Searchがインデックス管理、検索実行、セマンティックランキングの基盤を担い、その上にFoundry IQのナレッジベース体験やエージェント連携が乗る構成になっています。
ここで理解しておきたいのは、Foundry IQが「別の検索サービス」ではないという点です。Azure AI Searchの検索基盤を、Microsoft Foundryのエージェント開発フローに組み込むためのマネージドレイヤーと捉えると分かりやすいです。
そのため、Foundry IQを使うにはAzure AI Searchのリソースが必須であり、ティアや料金もAzure AI Searchのプランに依存します。
AzureポータルのAI Searchリソース画面
Foundry IQが必要とされる背景

この節では、なぜFoundry IQのような共通ナレッジ基盤がエンタープライズのAIエージェント運用で求められているのかを整理します。
AIエージェントの導入が進むほど、「1つのアプリに1つの検索基盤」ではなく、複数のエージェントやアプリから共有できる知識層が必要になります。
この背景にあるのが、RAGを個別実装するたびに発生する重複と運用負荷の問題です。
従来のRAGが抱えやすい課題
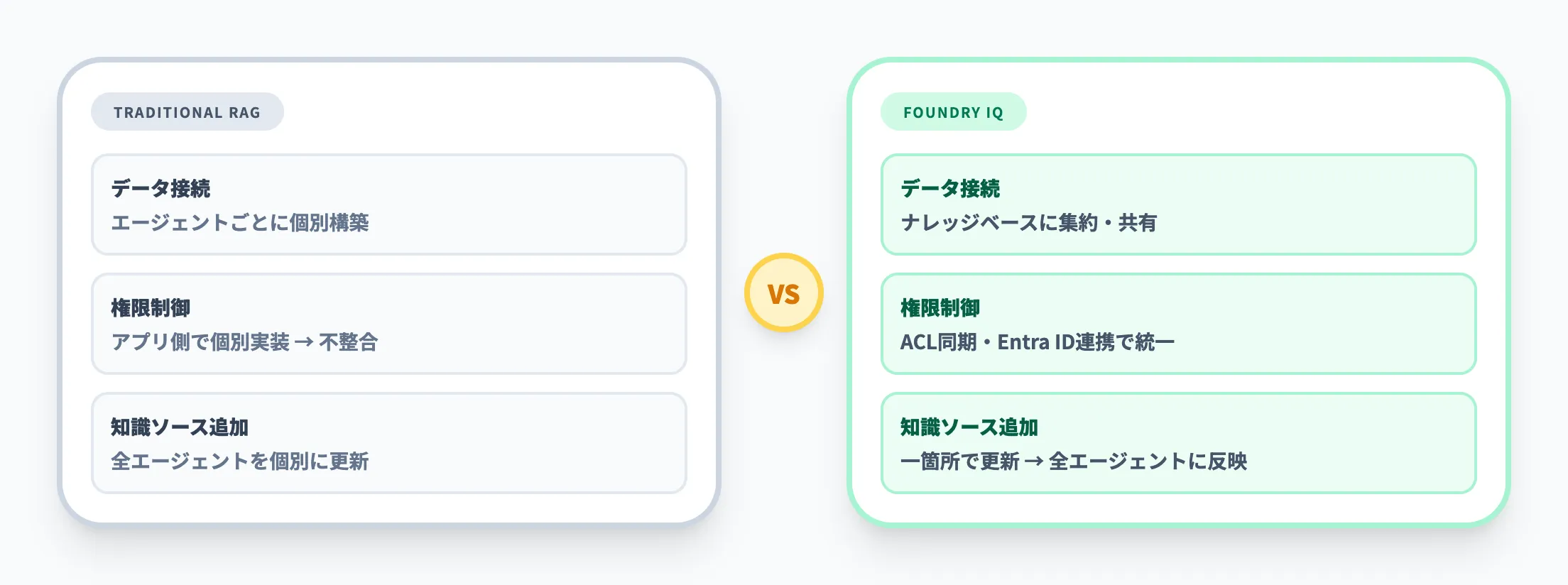
従来のRAG構成で起きやすい課題は、主に3つに分かれます。
- データ接続の重複
エージェントごとにSharePoint、Blob Storage、OneLake等への接続設定を個別に構築しがちです。
同じデータを参照しているのに、チャンキングやベクトル化のロジックがアプリごとに異なる状態が生まれやすくなります。
- 権限管理の不整合
閲覧権限の制御を各アプリ側で実装すると、エージェントAでは見える情報がエージェントBでは見えないといった不整合が起きやすくなります。
引用元の根拠表示も統一しにくくなります。
- 運用コストの増大
知識ソースを追加するたびに、全エージェントの検索設定を個別に更新する必要があります。
エージェントの数が増えるほど、この運用コストは比例して膨らみます。
Foundry IQは、こうした重複部分をナレッジベース側に集約する考え方です。複数のエージェントが同じナレッジベースを参照するため、知識ソースの追加や検索挙動の調整は一箇所で完結します。
権限制御付き知識基盤の必要性
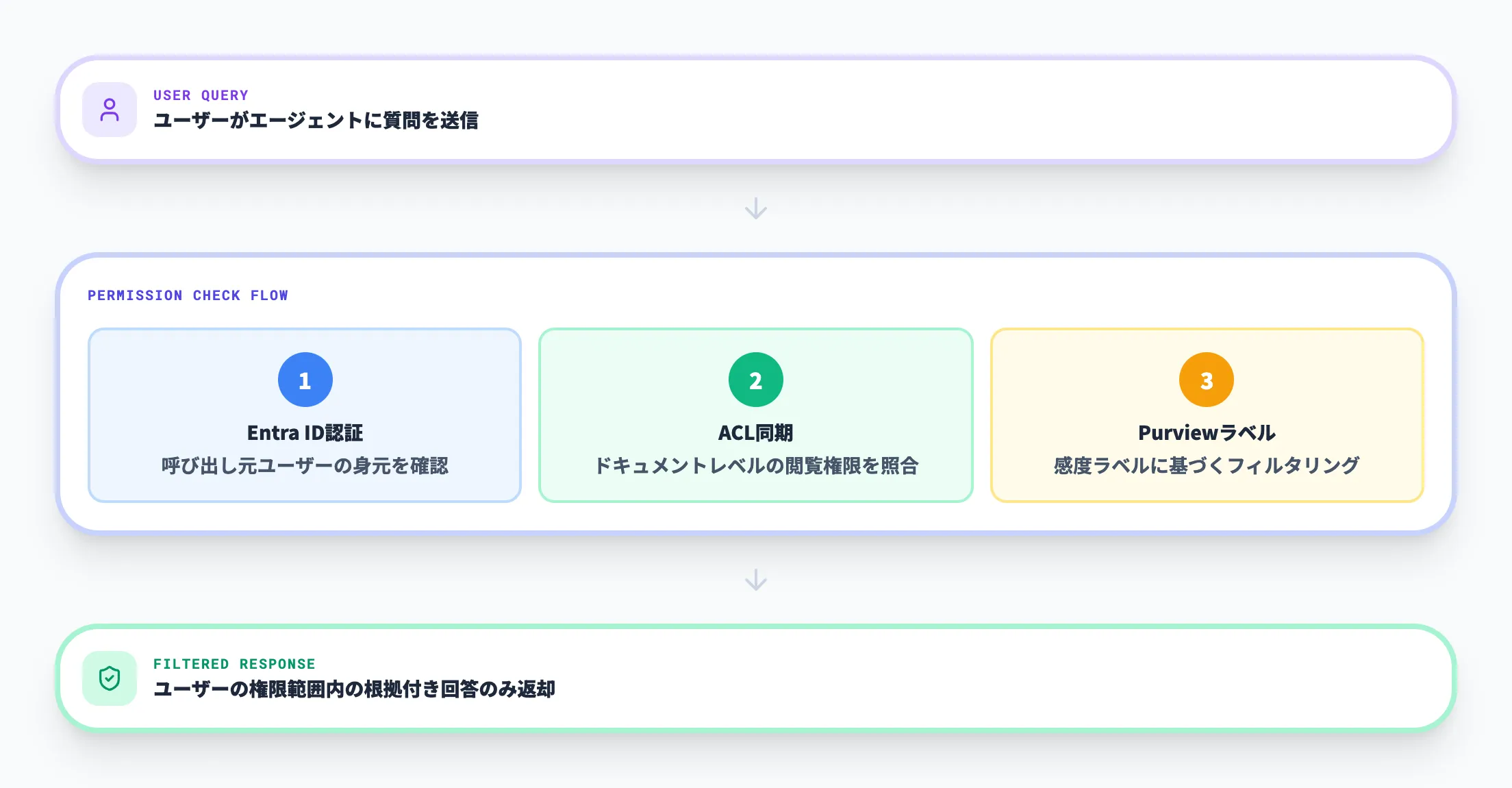
特にエンタープライズ用途では、「正しい情報を返すこと」だけでなく、「誰に見せてよいか」「どの資料が根拠か」を同時に管理する必要があります。
Foundry IQは、ACL(アクセス制御リスト)の同期、Microsoft Purviewの感度ラベルへの対応、呼び出し元のMicrosoft Entra IDでのクエリ実行に対応しています。
ただし、権限制御の対応度合いは知識ソースの種類によって異なります。特にRemote SharePointはACLとPurview sensitivity labelsへの対応が最も手厚く、他の知識ソースでは構成によって明示的な権限同期の設定が必要になる場合があります。
Foundry IQの仕組み
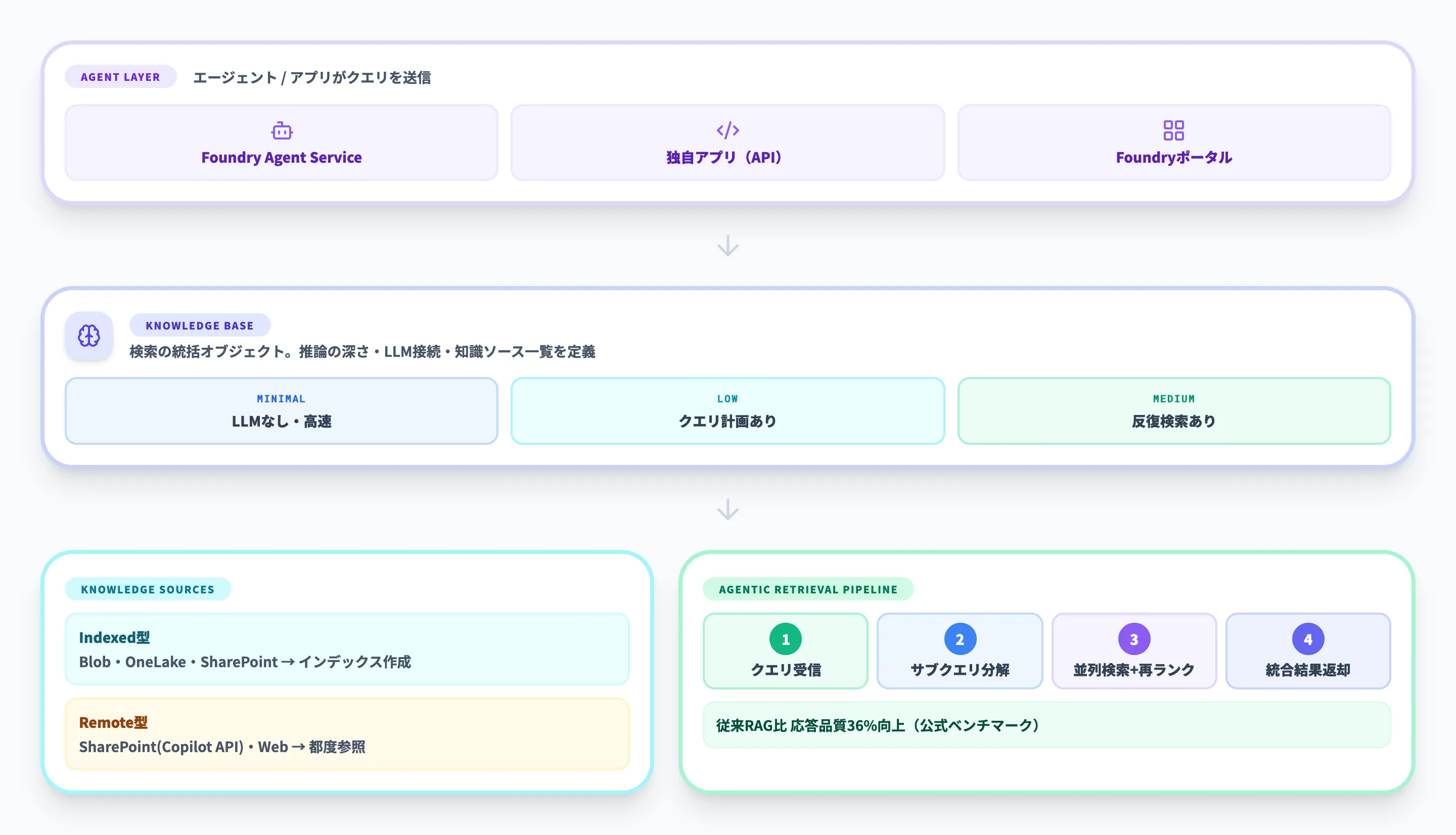
この節では、Foundry IQを構成するナレッジベース、知識ソース、Agentic Retrievalの3要素を解説します。それぞれの役割を分けて理解しておくと、構成設計や料金の見積もりがしやすくなります。
以下の表で、3つのコンポーネントの役割を整理しました。
| コンポーネント | 役割 |
|---|---|
| ナレッジベース | 検索全体を統括する最上位のオブジェクト。どの知識ソースを使うか、LLMで推論するか、推論の深さをどうするかを定義する |
| 知識ソース | データとの接続定義。Indexed型とRemote型の2系統がある |
| Agentic Retrieval | 複雑な質問をサブクエリに分解し、並列検索・再ランキング・統合を行うマルチクエリパイプライン |
Microsoft Learnでは、ナレッジベースがトップレベルのオーケストレーター、知識ソースがデータ接続、Agentic Retrievalが検索パイプラインとして説明されています。
ナレッジベースの役割
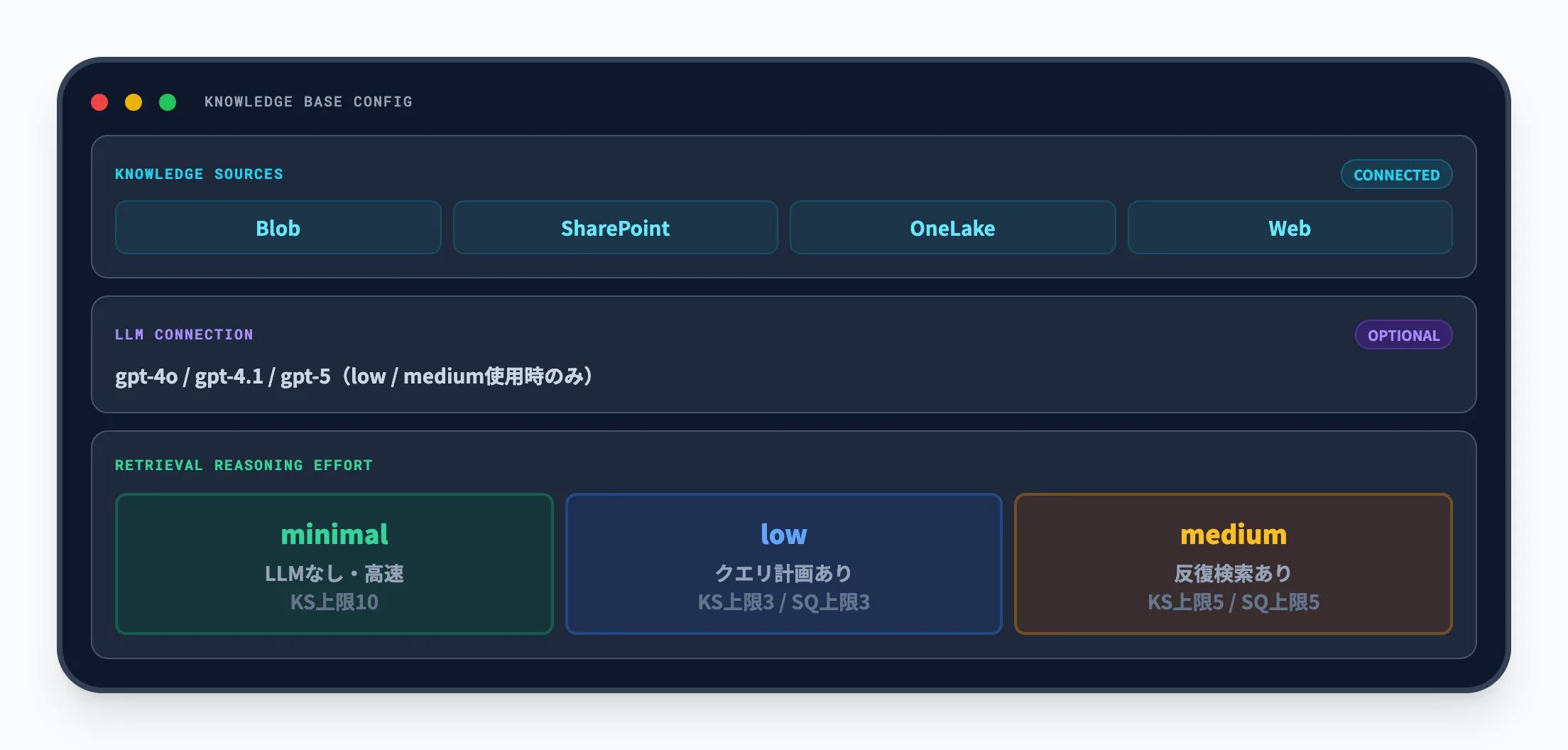
ナレッジベースは、Foundry IQの中心となるオブジェクトです。どの知識ソースを使うか、LLMを使った推論の深さをどうするかをここで設定します。
ここで重要なのは、ナレッジベースが「単なる検索対象の束」ではなく、検索のふるまいそのものを決める設定の中心だという点です。
ナレッジベースで制御できる主な設定は以下のとおりです。
- 参照する知識ソースの一覧
どのデータソースを検索対象にするかを指定します。
- クエリ計画に使うAzure OpenAIモデル(low / medium使用時)
lowまたはmediumの推論を使う場合に必要です。gpt-4o、gpt-4.1、gpt-5シリーズから選択します。minimalではLLMを使わないため、Azure OpenAIモデルの接続は不要です。
- 推論の深さ(Retrieval Reasoning Effort)
minimal、low、mediumの3段階から選択します。推論の深さによって、検索の精度、レイテンシ、コストのバランスが変わります。
推論の深さごとの動作の違いを以下の表にまとめました。
| 推論の深さ | LLM処理 | 知識ソース上限 | サブクエリ上限 | 回答合成 |
|---|---|---|---|---|
| minimal | なし | 10 | なし | 不可 |
| low | あり(クエリ計画) | 3 | 3 | 5,000トークン |
| medium | あり(クエリ計画+反復検索) | 5 | 5 | 10,000トークン |
minimalはLLMによるクエリ計画を行わず、速度とコストを優先する設定です。lowとmediumはLLMが質問を分析してサブクエリに分解するため、複雑な質問への対応力が高まりますが、レイテンシとコストは増えやすくなります。
mediumではさらに、初回の検索結果が不十分だった場合に反復検索を自動で実行します。
知識ソースの種類

知識ソースは、検索対象となるデータとの接続定義です。Microsoft Learnでは、Indexed型とRemote型の2系統に分けて説明されています。
以下の表で、両者の違いを整理しました。
| 種類 | 代表的なソース | 特徴 |
|---|---|---|
| Indexed | Azure Blob Storage、OneLake、SharePoint、既存検索インデックス | Azure AI Search側にインデックスを作成する。チャンキング・ベクトル化・メタデータ抽出・ACL同期を自動処理できる |
| Remote | SharePoint(Copilot Retrieval API経由)、Web(Bing Custom Searchベース。別途Grounding with Bing Searchの課金条件に注意) | データを取り込まず、クエリ時に元ソースへ直接アクセスする。リアルタイム性を重視する場合に向く |
Indexed型は、ドキュメントのチャンキング、埋め込み生成、メタデータ抽出、定期的なインデクサー実行まで自動化できるのが利点です。
更新頻度はインデクサーのスケジュール設定に依存します。
一方、Remote型はデータを取り込まずに権限付きで都度参照できます。ただし、Remote SharePointを利用するにはエンドユーザーにCopilotライセンスが必要です。
また、Web知識ソースを使う場合はAgentic Retrievalの回答合成機能が必須になる点にも注意が必要です。
Agentic Retrievalの仕組み
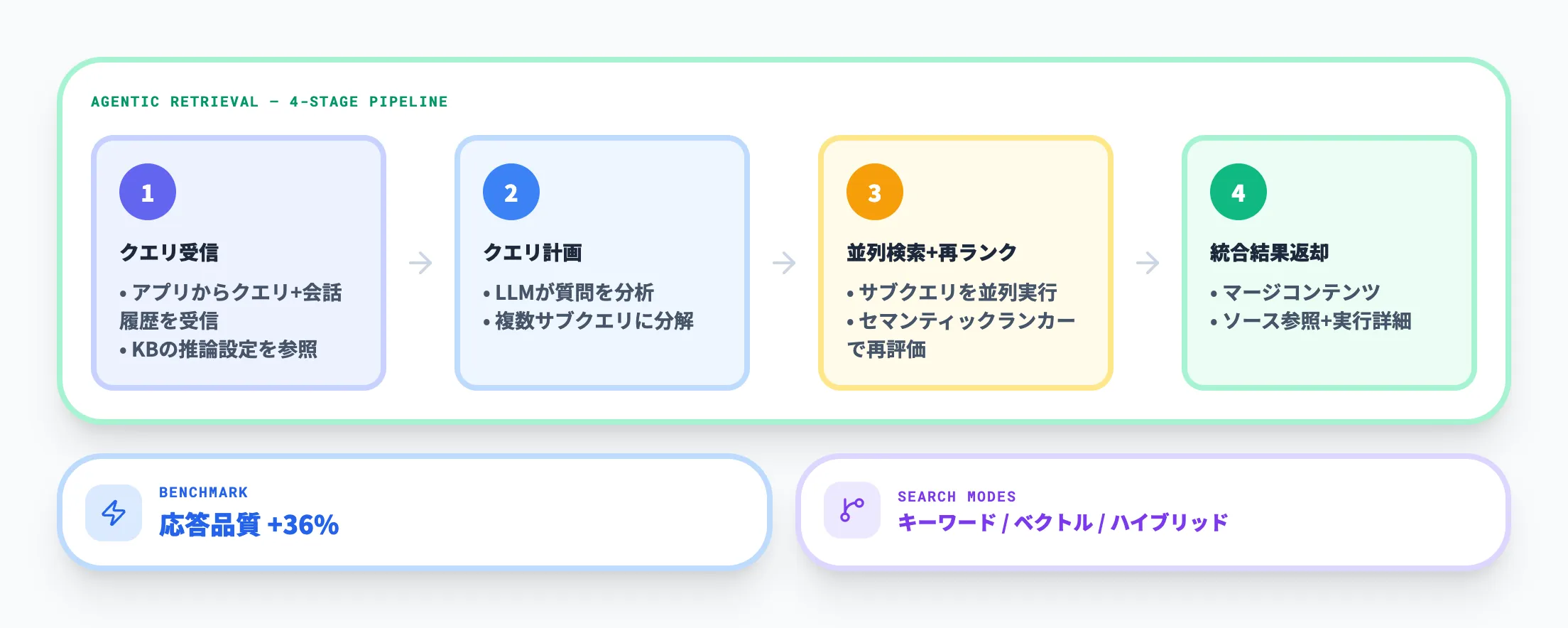
Agentic Retrievalは、Foundry IQの検索品質を左右する中核機能です。
公式概要では、「複雑な質問を複数のサブクエリに分解し、並列検索して、セマンティックランキングで再評価し、統合結果を返すマルチクエリパイプライン」と説明されています。
Microsoftの公式ベンチマークでは、Agentic Retrievalが従来の単発RAGと比べて応答品質を約36%向上させたと報告されています。
基本的な処理フローは次の4段階です。
- アプリケーションがナレッジベースにクエリと会話履歴を送信する
- Azure OpenAIのLLMがクエリを分析し、複数のサブクエリに分解するクエリ計画を作成する
- 生成されたサブクエリが知識ソースへ並列実行され、各結果がセマンティックランカーで再評価される
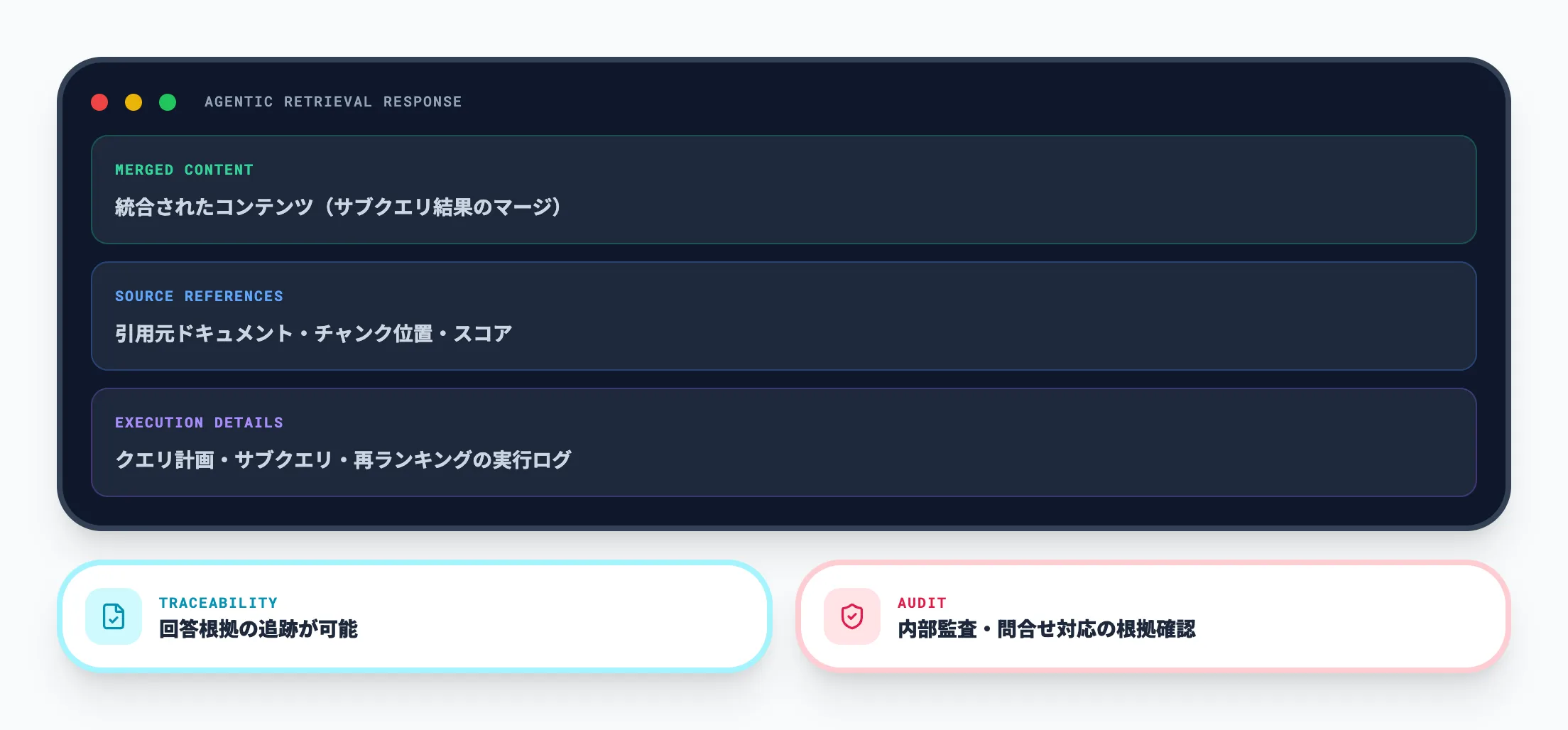
- 統合結果が、マージされたコンテンツ・ソース参照・実行詳細の3パートで返される
検索方式はキーワード検索、ベクトル検索、ハイブリッド検索を組み合わせられます。インデックスにテキストフィールドとベクトルフィールドの両方がある場合は自動でハイブリッド検索が実行されます。
結果には引用元や実行ステップの詳細が含まれるため、エージェント側で根拠付き回答を返しやすい構造になっています。
問い合わせ対応や社内ヘルプデスクのように、後から「なぜその回答になったか」を追跡したい用途に特に向いています。
AI検索基盤の次はAI業務自動化

Microsoft Teams上でAIエージェントが業務を代行
Foundry IQのAgentic Retrievalで高度なAI検索を実現したら、次は業務プロセスのAI自動化です。Teams上で動くAIエージェントが、日常業務を代行します。
Foundry IQの使い方

この節では、Foundry IQをMicrosoft Foundryで構築するときの前提条件と基本手順を解説します。
PoC段階ではポータルから始めるのが最も手軽で、実装段階でFoundry Agent ServiceやAzure AI Search APIに接続してコード化する流れが一般的です。
事前に必要なもの
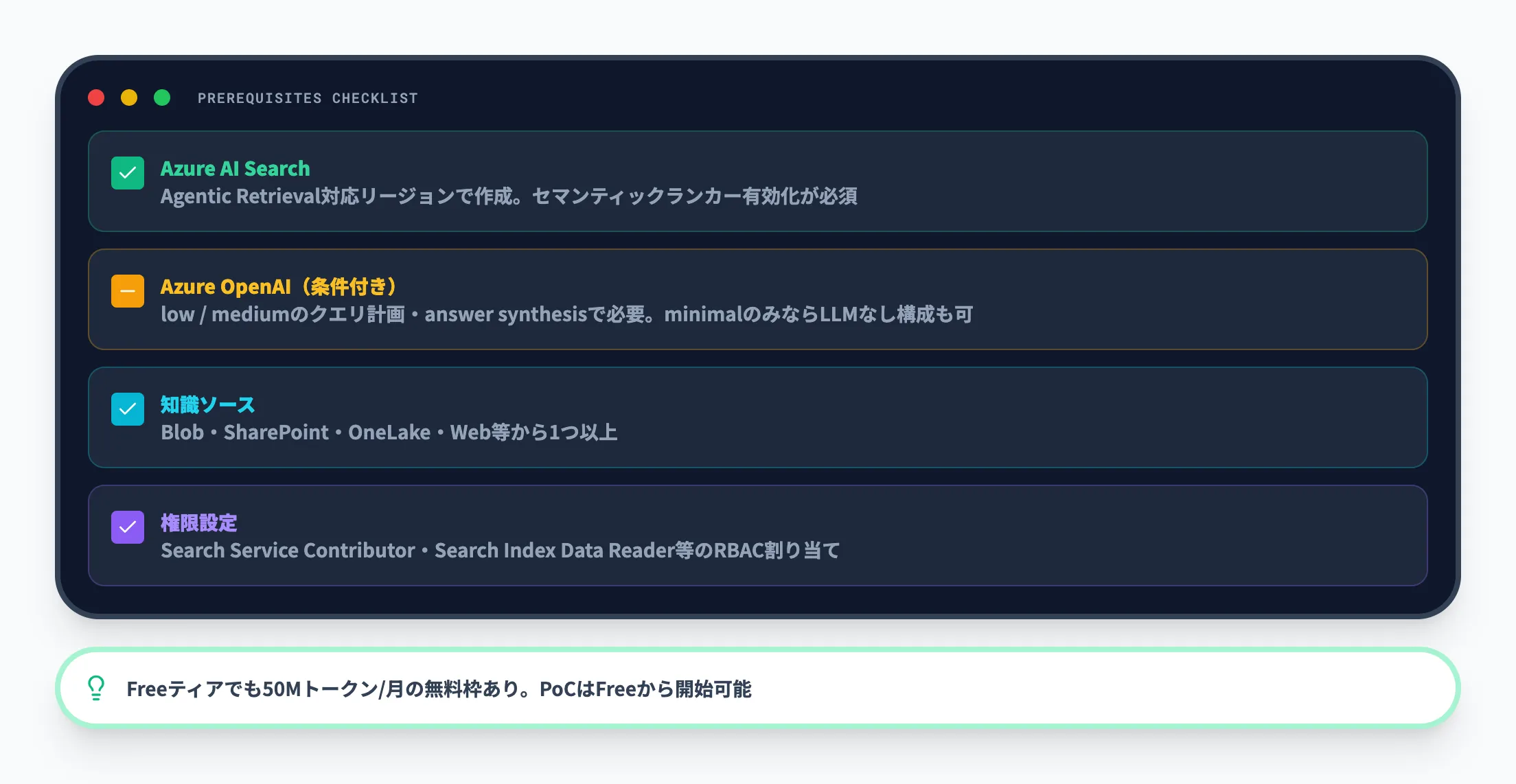
Foundry IQを使い始める前に、最低限押さえておくべき前提条件を整理しました。
| 項目 | 要点 |
|---|---|
| Azure AI Search | Agentic Retrieval対応リージョンで作成し、セマンティックランカーを有効化する。無効にするとAgentic Retrievalも使えなくなる |
| Azure OpenAI(low / medium使用時) | low / mediumのクエリ計画やanswer synthesisを使う場合に必要。minimalのみならLLMなし構成も可能。対応モデルはgpt-4o、gpt-4.1、gpt-5シリーズ |
| 知識ソース | 1つ以上の知識ソースを先に用意する(Blob、SharePoint、OneLake、Web等) |
| 権限設定 | Search Service Contributor、Search Index Data Readerなどのロールを割り当てる |
Azure AI SearchのFreeティアでも50Mトークン/月のAgentic Retrieval無料枠があるため、PoCはFreeティアから始めやすいです。ただし、managed identityやRBACを使う場合はBasic以上のティアが必要になります。
ポータルでの基本手順
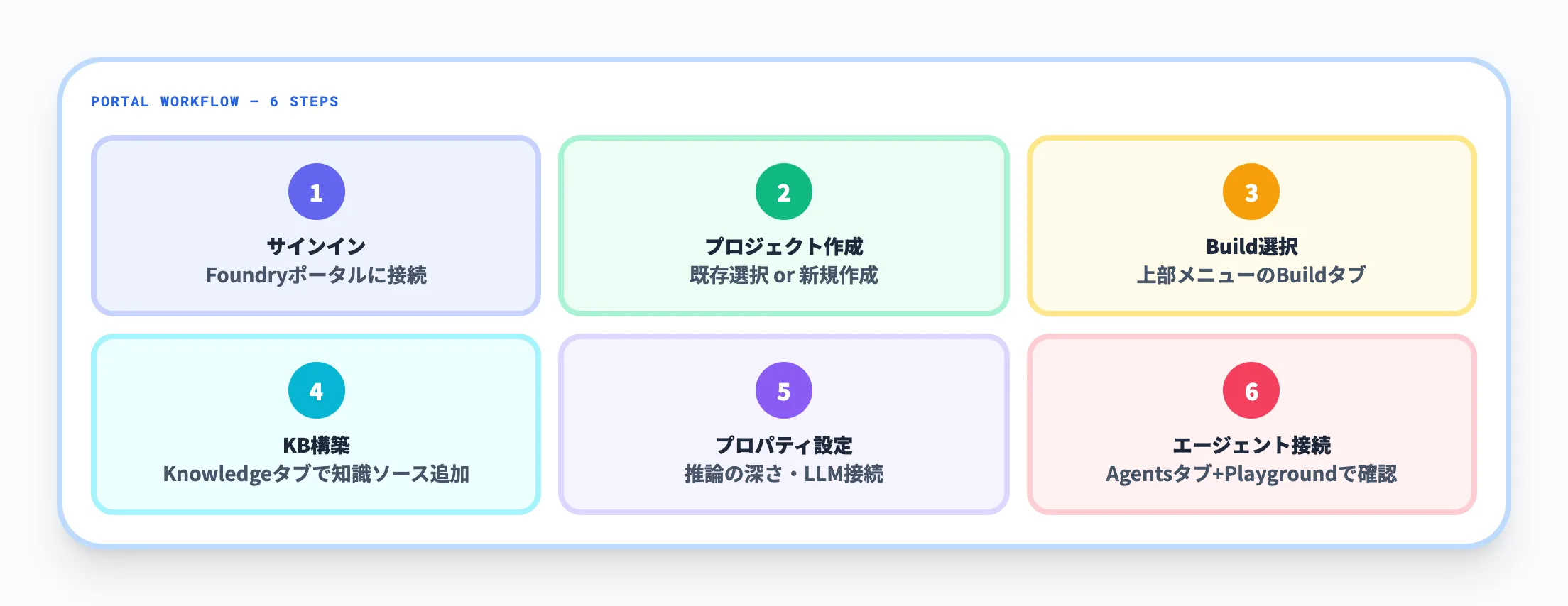
Microsoft Foundryの新ポータルからFoundry IQを設定する手順は、Microsoft Learnのワークフローに沿って以下のように進みます。
- Microsoft Foundryの新ポータルにサインインする
Foundryポータルサインイン画面
- 既存プロジェクトを選択するか、新規プロジェクトを作成する
プロジェクト選択作成画面
- 上部メニューのBuildを選択する
Buildメニュー画面
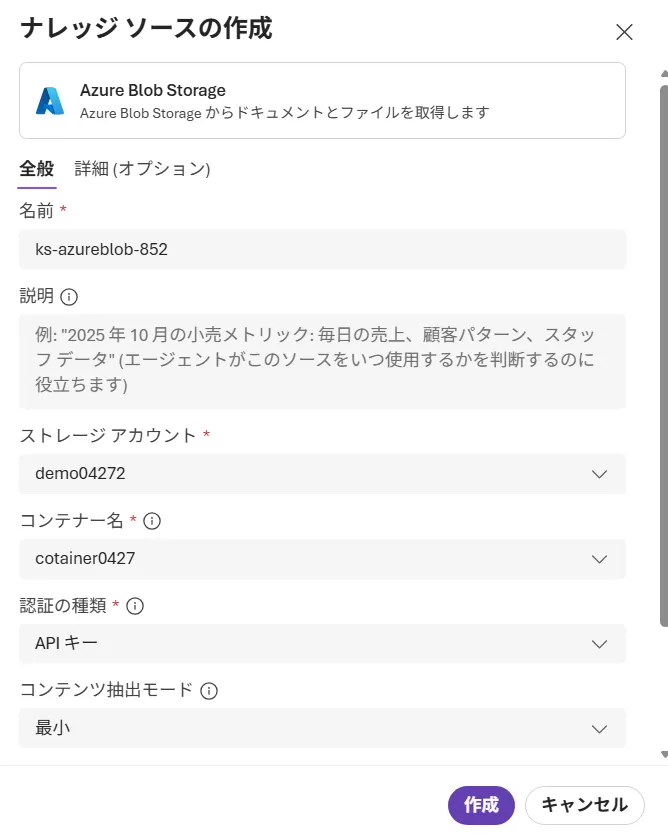
- Knowledgeタブで、Azure AI Searchサービスを接続し、知識ソースを1つずつ追加してナレッジベースを作成する
ナレッジソース作成画面
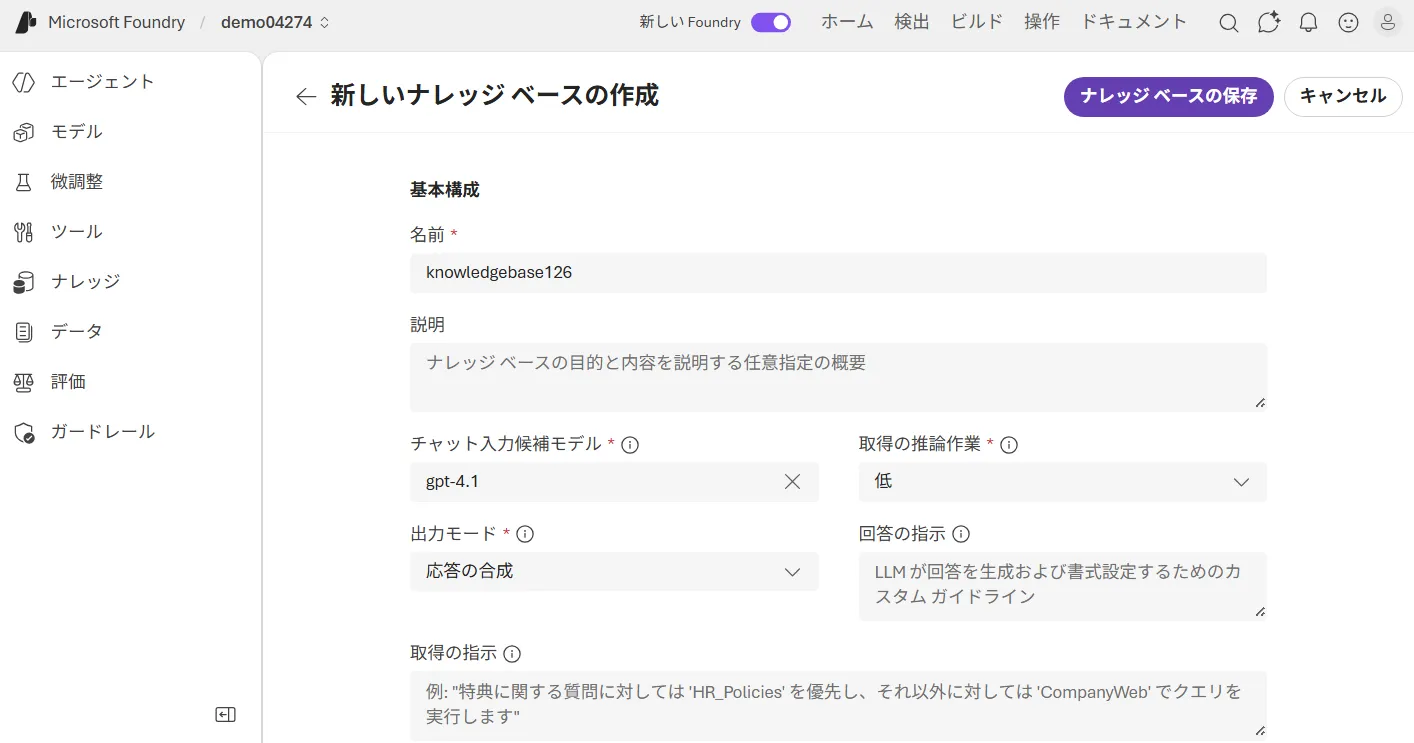
- ナレッジベースのプロパティ(推論の深さ、LLM接続など)を設定する
ナレッジベース設定画面
- Agentsタブでエージェントにナレッジベースを接続し、Playgroundで挙動を確認する
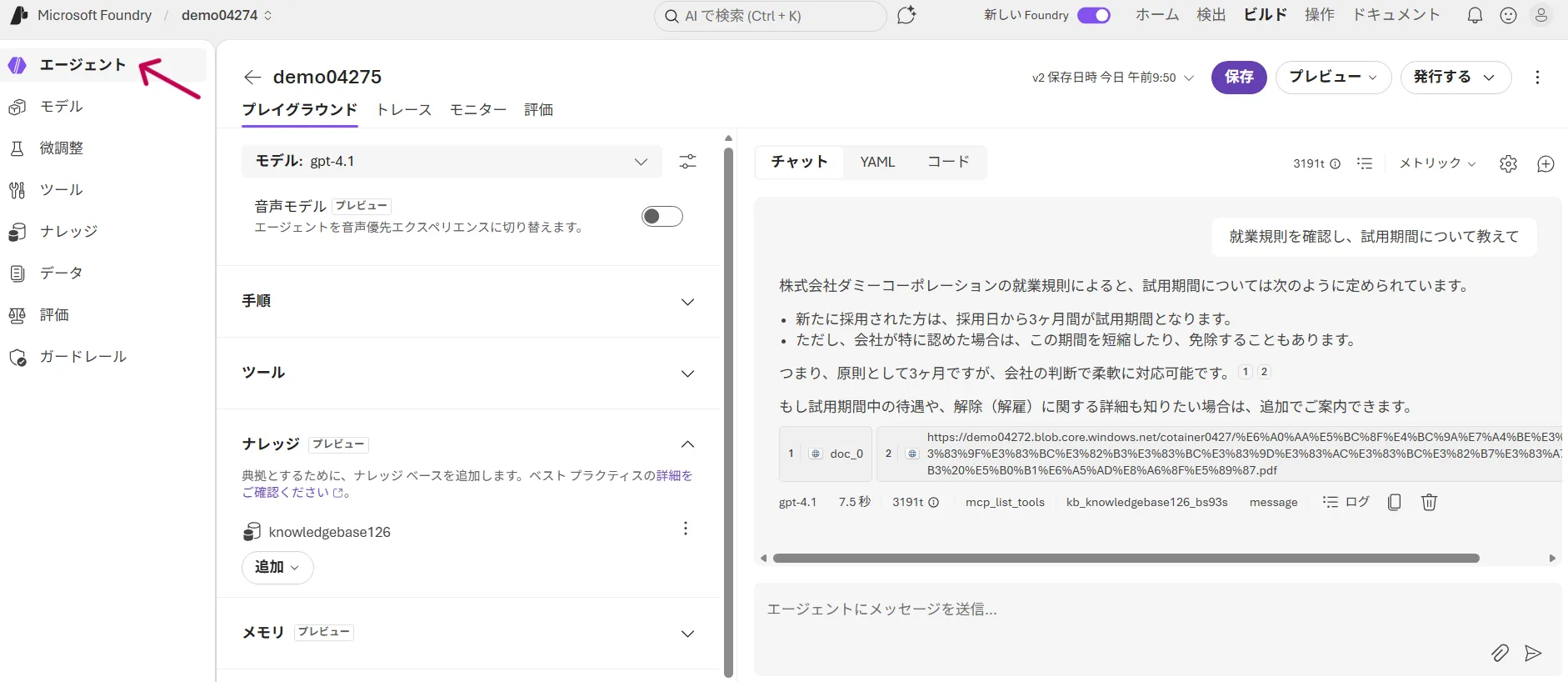
Playground動作確認画面
PoCではポータルの簡略化されたワークフローで十分ですが、本番に近づくほどmanaged identity、RBAC、ACL連携、インデクサーの更新スケジュールを明示的に設計する必要があります。
Foundry Agent Serviceや独自アプリへの接続

Foundry IQは、Foundry Agent Serviceと組み合わせると特に使いやすくなります。
公式ドキュメントでは、Foundry Agent Service側からナレッジベースのMCPエンドポイントをRemoteToolとして接続する方法が案内されています。
MCPエンドポイントの形式は以下のとおりです。
https://{search-service-endpoint}/knowledgebases/{knowledge-base-name}/mcp?api-version=2025-11-01-preview
Microsoft FoundryのAgents設定画面から「ツールの追加」を選択し、「モデルコンテキストプロトコル(MCP)」をクリックします。
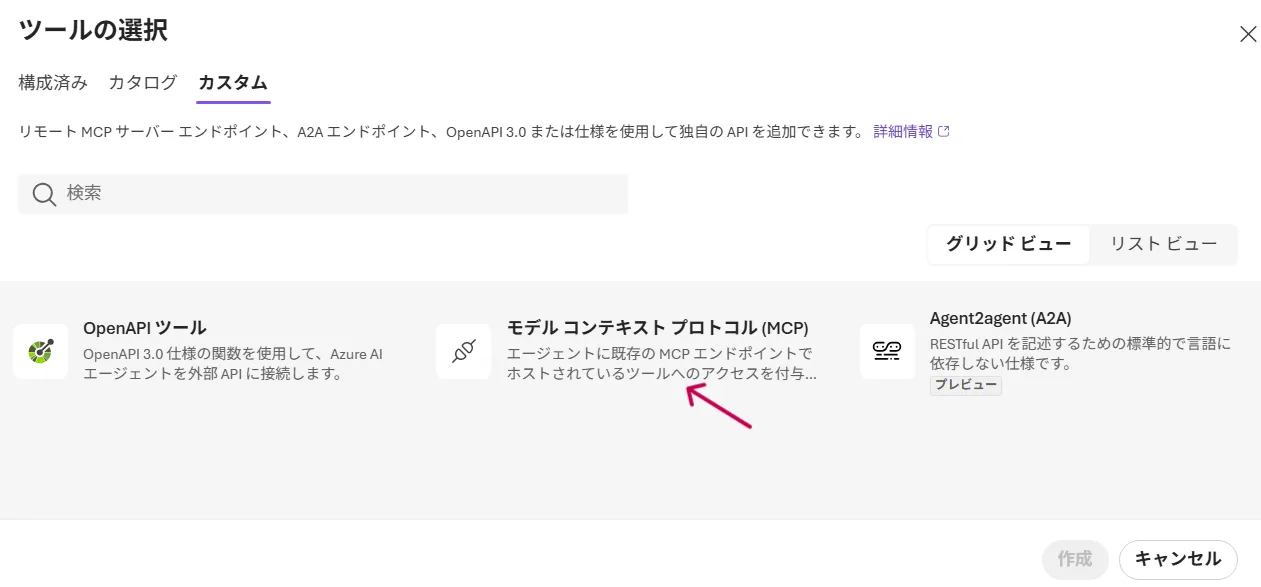
RemoteTool追加画面
エンドポイントと指定した形式のパラメータを設定することで、MCPをRemoteToolとして接続することができます。
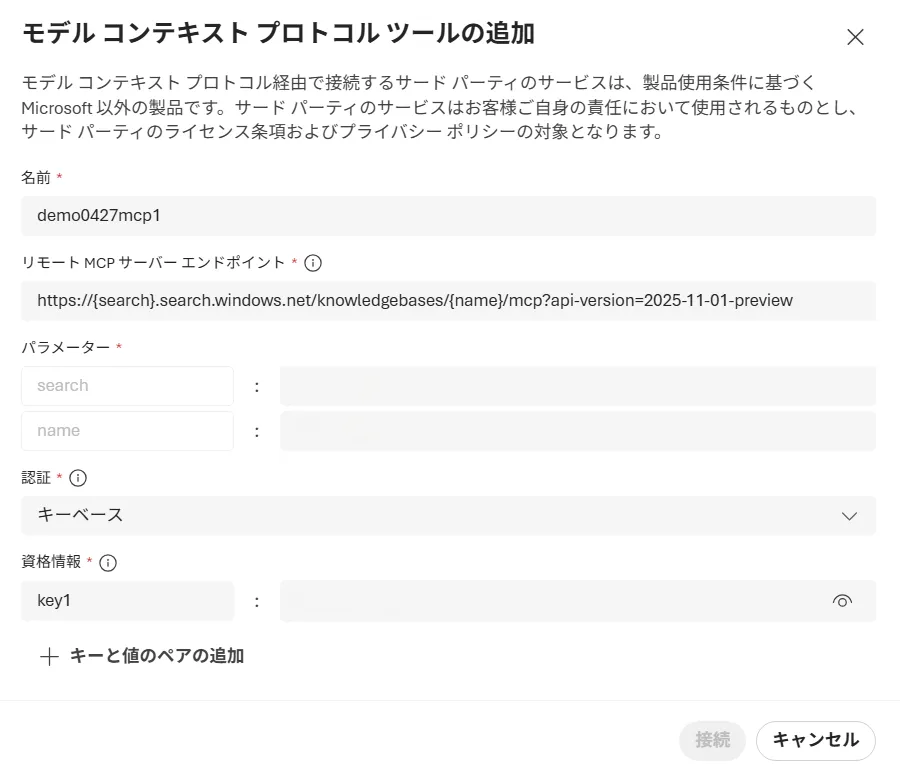
MCPエンドポイント設定画面
独自アプリから使う場合も、Azure AI SearchのナレッジベースAPIを直接呼び出すことで同じ検索パイプラインを利用できます。つまり、Foundry IQは「ポータル専用機能」ではなく、Foundry Agent Service、Microsoft Agent Framework、独自アプリケーションの共通知識層として機能する設計です。
Foundry IQの活用シーン

この節では、Foundry IQが特に力を発揮する代表的な活用シーンを紹介します。Foundry IQが向いているかどうかの判断基準は、「複数の知識ソースを横断したい」「権限制御を保ちたい」「同じナレッジを複数エージェントで再利用したい」の3条件がそろうかどうかです。
社内ナレッジ検索エージェント
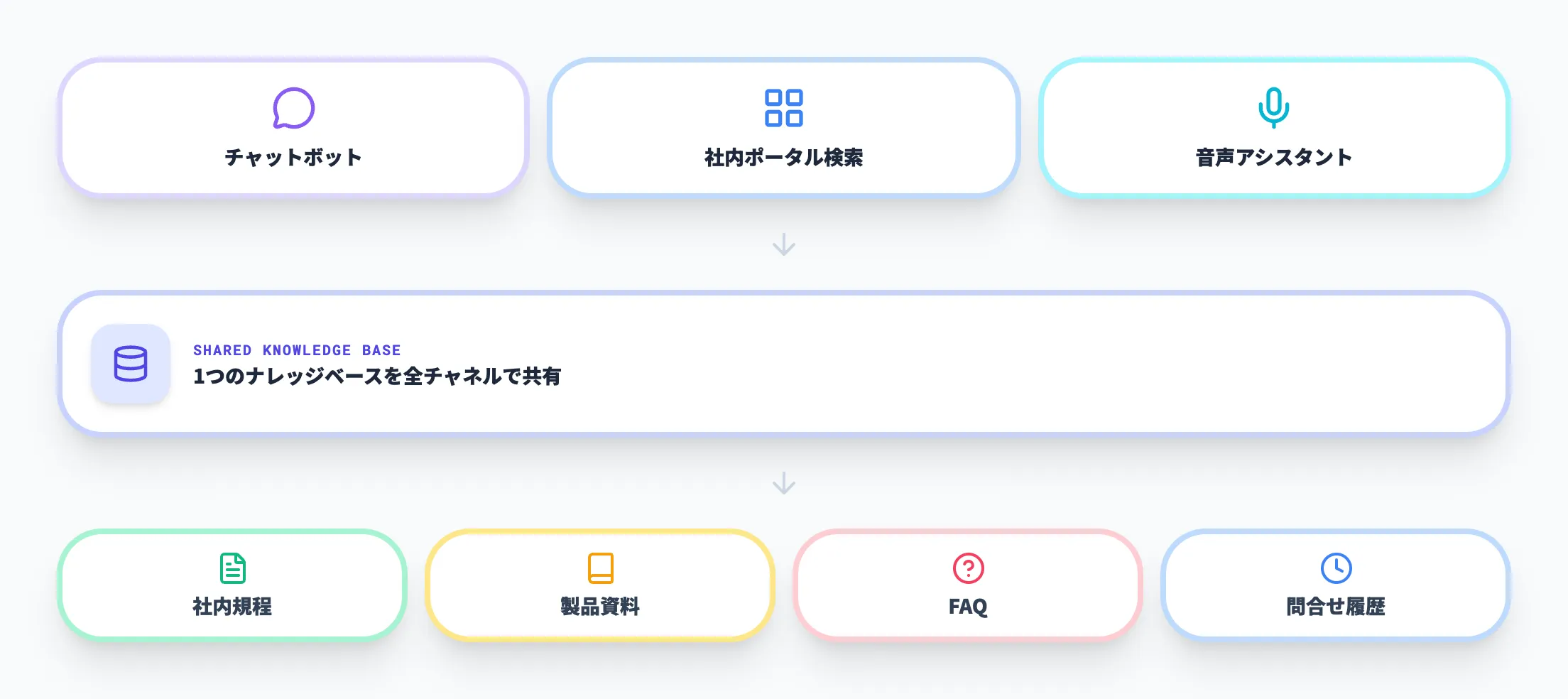
最も分かりやすい活用シーンは、社内規程、製品資料、FAQ、過去の問い合わせ履歴などを横断して回答する社内検索エージェントです。
特にサポート部門、法務部門、情報システム部門のように、参照すべき文書が多く、しかも閲覧権限に差がある領域で相性が良いです。
ナレッジベースを共通化しておけば、チャットボット、社内ポータル検索、音声アシスタントなど複数のチャネルから同じ知識層を使い回せます。
後からチャネルを増やしても、検索基盤を作り直す必要がありません。
SharePoint・OneLake・Webを横断する業務アシスタント
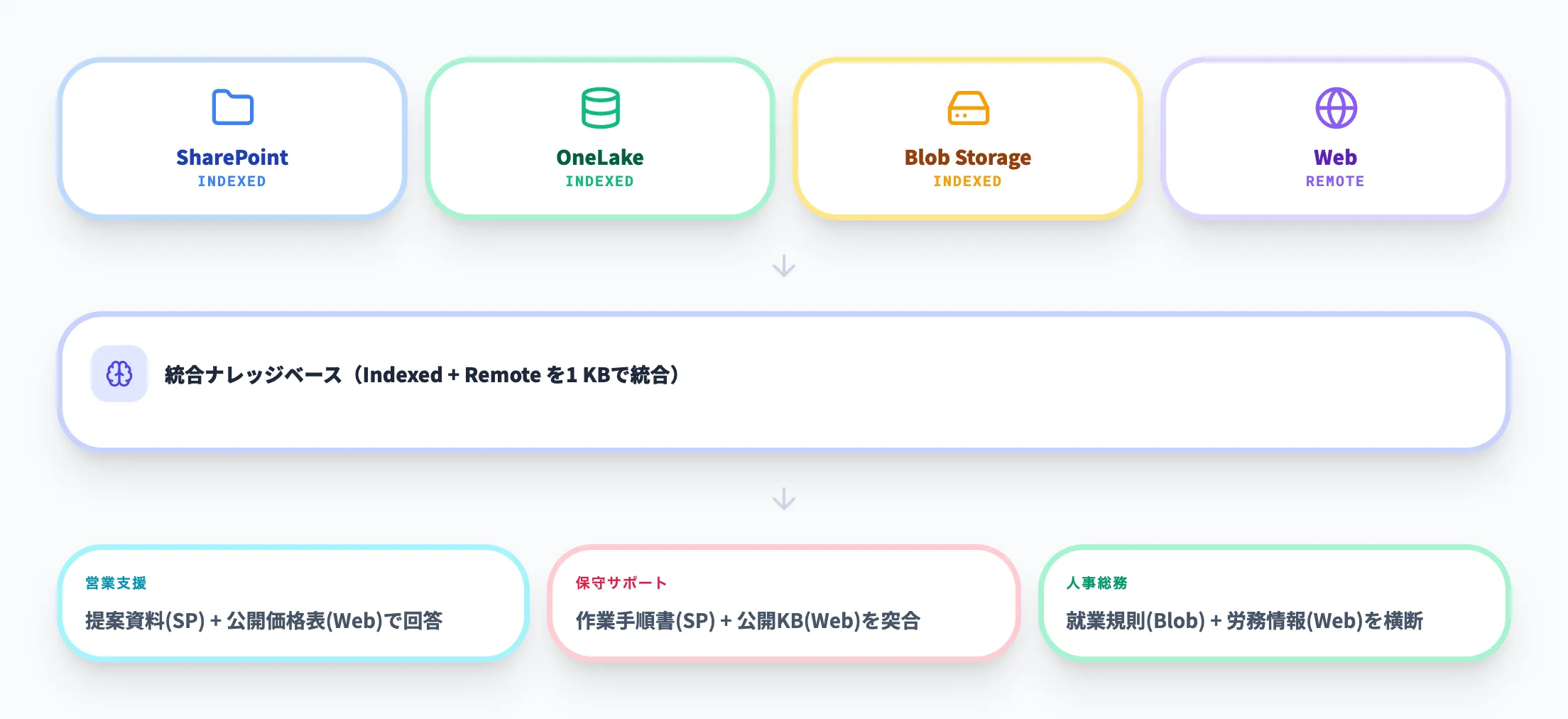
Foundry IQは、SharePoint、OneLake、Azure Blob Storage、Webをまたぐ知識ソースを1つのナレッジベースで組み合わせられます。社内資料と公開ドキュメントを同時に検索する「社内外ハイブリッド検索」に向いている構成です。
実務では以下のような構成が考えられます。
- 営業支援エージェント
社内の提案資料(SharePoint)と公開価格表(Web)を合わせて回答する
- 保守サポートエージェント
SharePointの作業手順書と製品の公開ナレッジベース(Web)を突き合わせて返答する
- 人事総務エージェント
就業規則(Blob Storage)と最新の労務関連情報(Web)を横断して回答する
知識ソースごとにIndexed型とRemote型を使い分けることで、更新頻度やセキュリティ要件に合わせた柔軟な構成を組めます。
複数ソース横断クエリ送信画面
長期蓄積データの横断検索(Ontario Power Generation)

Microsoft Tech Communityで紹介されている実例として、カナダの大手電力会社Ontario Power Generation(OPG)があります。
OPGは40年分の原子力発電所の運転データを保有していましたが、これらが静的なドキュメントに分散しており、新入社員が必要な知識にアクセスするのが困難な状況でした。
Agentic Retrievalを活用することで、数十年分の運転経験データを横断的に検索できる基盤を構築し、データ駆動の意思決定と新規スタッフの学習加速を実現しています。
長期間にわたって蓄積された文書が多いほど、単発検索では必要な情報にたどり着きにくくなるため、マルチクエリで網羅的に検索するAgentic Retrievalの特性が活きるケースです。
開発チーム向けのグラウンディング基盤
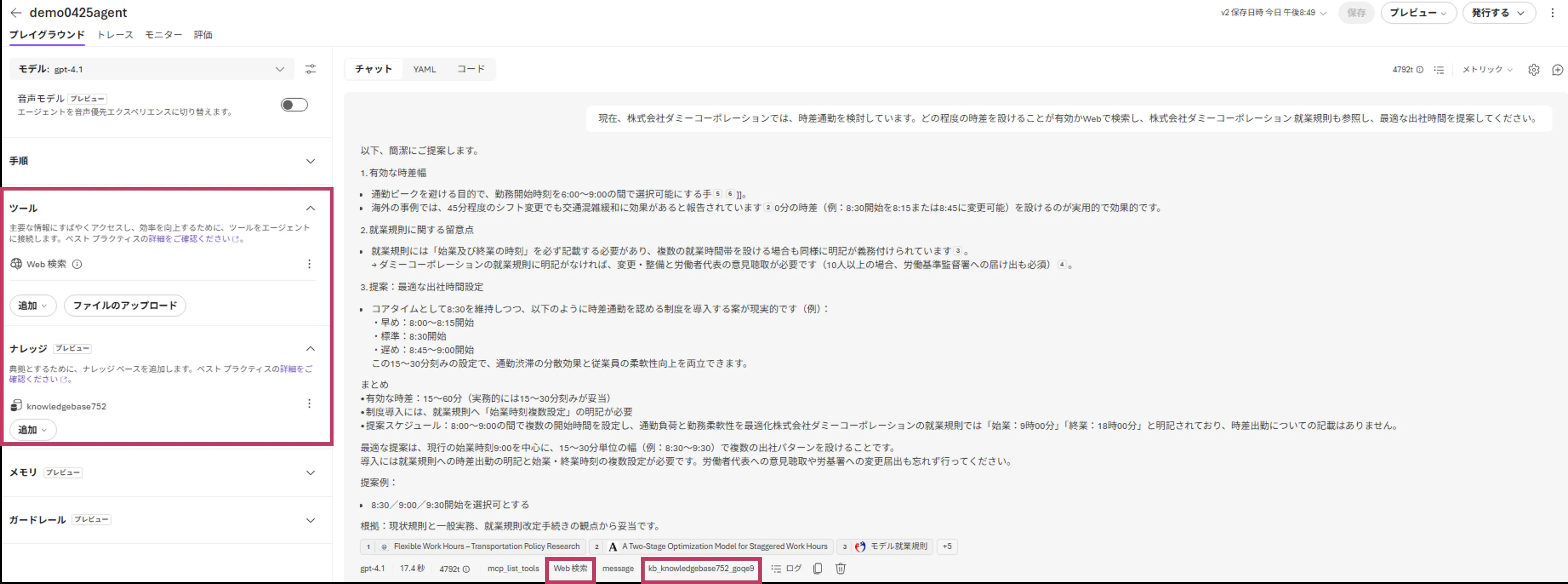
Microsoftは、Azure OpenAI demoとAgentic Retrieval pipeline exampleを公式サンプルとして公開しています。これは、Foundry IQの設計思想が社内検索UIに留まらず、エージェントやチャットアプリのグラウンディング基盤として使われることを示しています。
開発チーム視点では、回答品質の向上に加え、Agentic Retrievalのレスポンスにクエリ計画・実行ステップ・引用情報が含まれる点が実務上の利点です。回答の根拠を後から追跡できるため、問い合わせ対応や内部監査で「なぜその回答になったか」を確認しやすくなります。

Foundry IQと他の選択肢の違い

この節では、Foundry IQが既存のMicrosoftサービスやアプローチとどう違うのかを整理します。比較の軸は、「何を共通化したいか」と「どのレベルの検索が必要か」です。
Azure OpenAI On Your Dataとの違い
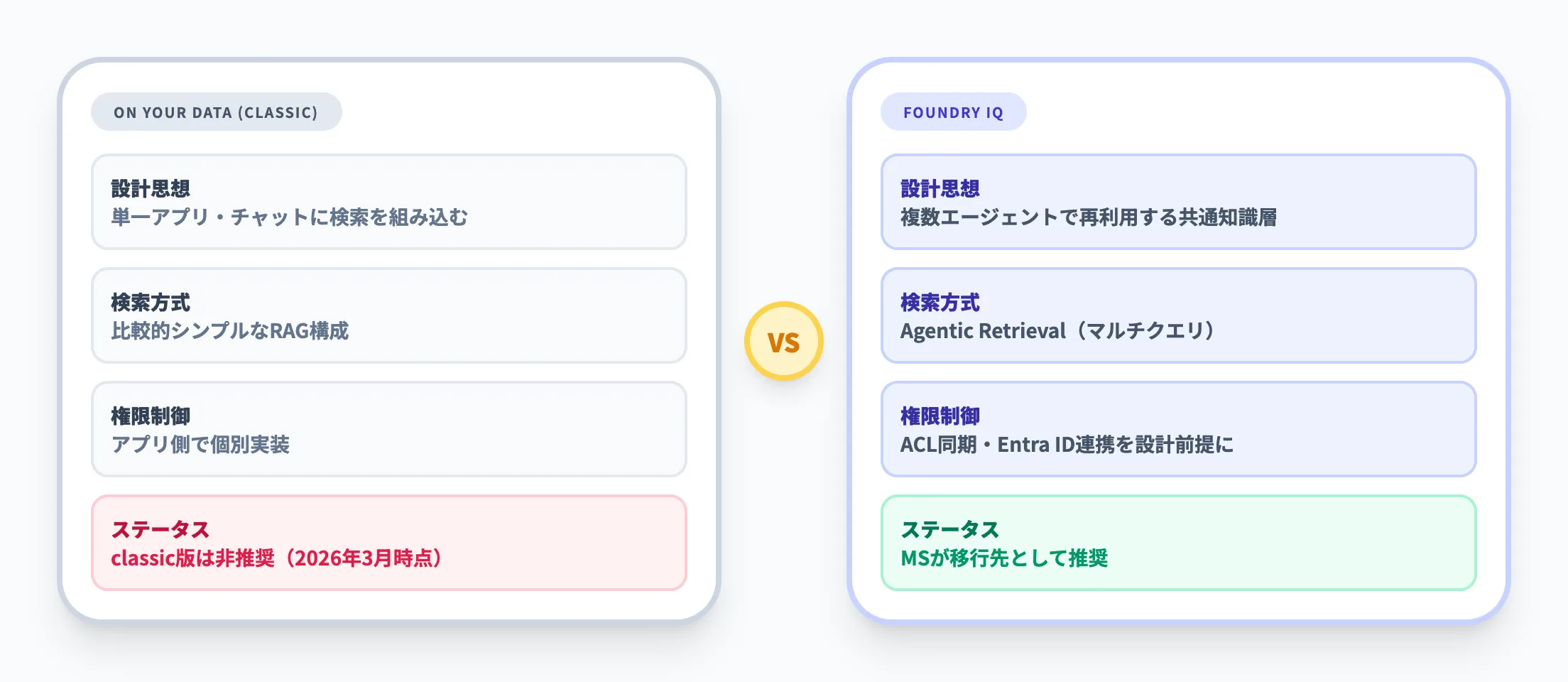
Foundry IQとOn Your Dataの違いを、主な観点で比較しました。
| 観点 | Azure OpenAI On Your Data | Foundry IQ |
|---|---|---|
| 設計思想 | 単一アプリやチャットに検索を組み込む | 複数エージェントで再利用できる共通知識層を構築する |
| 中心オブジェクト | チャット体験やアプリ構成 | ナレッジベースと知識ソース |
| 検索方式 | 比較的シンプルなRAG構成 | Agentic Retrievalによるマルチクエリ構成 |
| 権限制御 | アプリ側での実装に依存 | ACL同期やEntra ID連携を前提にした設計 |
| ナレッジ共有 | エージェント個別に接続 | 1つのナレッジベースを複数エージェントで共有 |
なお、Azure OpenAI On Your Data(classic)は2026年3月時点で非推奨となっており、Microsoftは後継としてFoundry Agent Service + Foundry IQへの移行を推奨しています。小規模なPoCや単一アプリだけなら従来のOn Your Data型でも動作しますが、新規構築であればFoundry IQで始める方が将来の移行リスクを避けられます。
Work IQ・Fabric IQとの違い
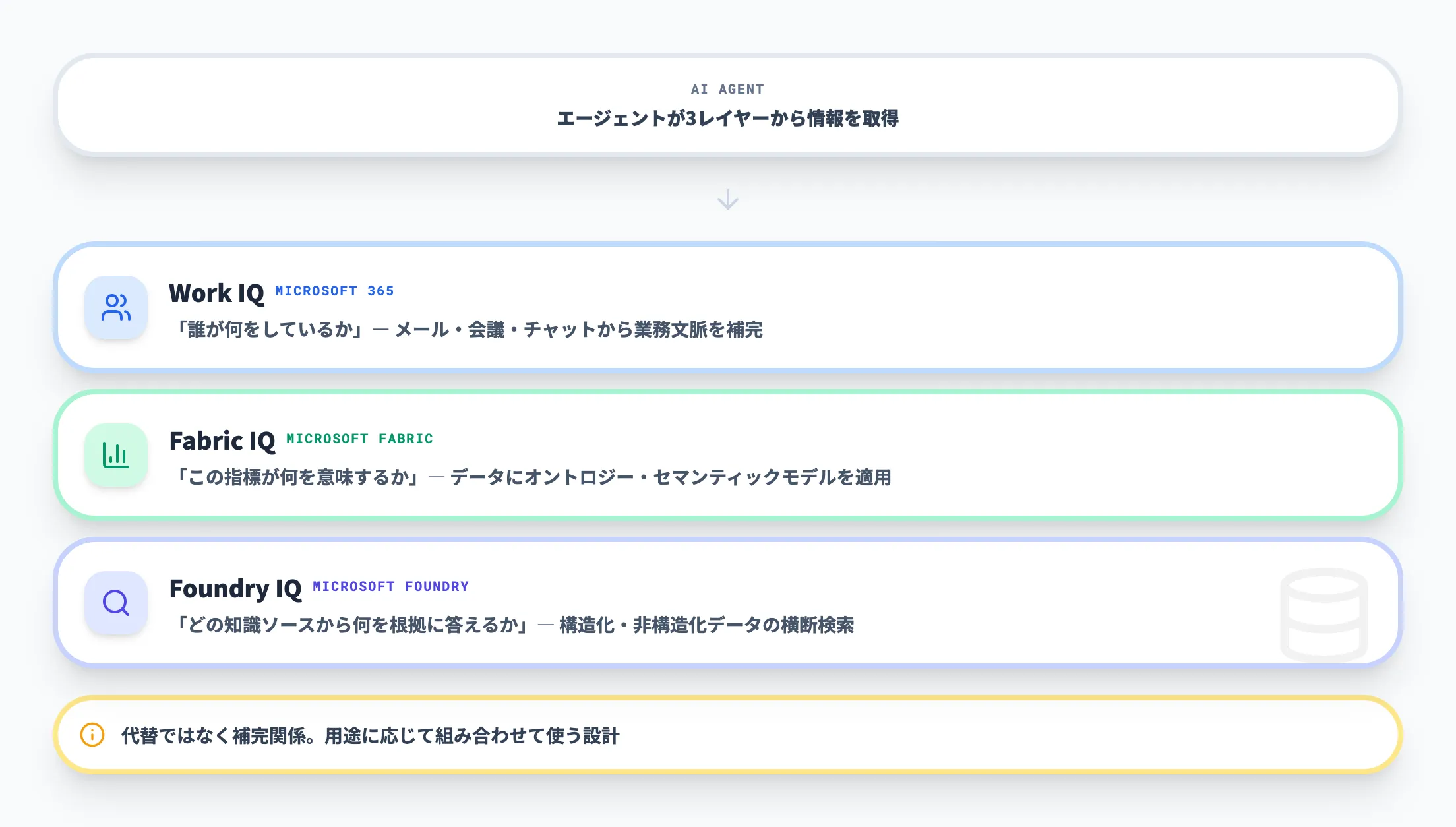
Work IQとFabric IQは、Foundry IQの代替ではなく補完関係にあります。以下のように役割が分かれています。
- Work IQ
「誰が何をしているか」という業務文脈を理解するためのレイヤー。Microsoft 365のメール、会議、チャット、ワークフローから協業シグナルを収集する。
- Fabric IQ
「この指標やデータが何を意味するか」という意味付けを行うレイヤー。OneLakeやPower BIのデータにオントロジーやセマンティックモデルを適用する。
- Foundry IQ
「どの知識ソースから何を根拠に答えるか」という知識検索を担うレイヤー。Azure、SharePoint、OneLake、Webの構造化・非構造化データを横断検索する。
Foundry IQだけで組織理解やデータの意味付けまで完全にカバーできるわけではありません。「知識検索が目的か」「業務文脈も含めるか」「分析の意味付けまで必要か」で、どのIQワークロードを組み合わせるかが変わります。
Copilot知識ソースとの違い
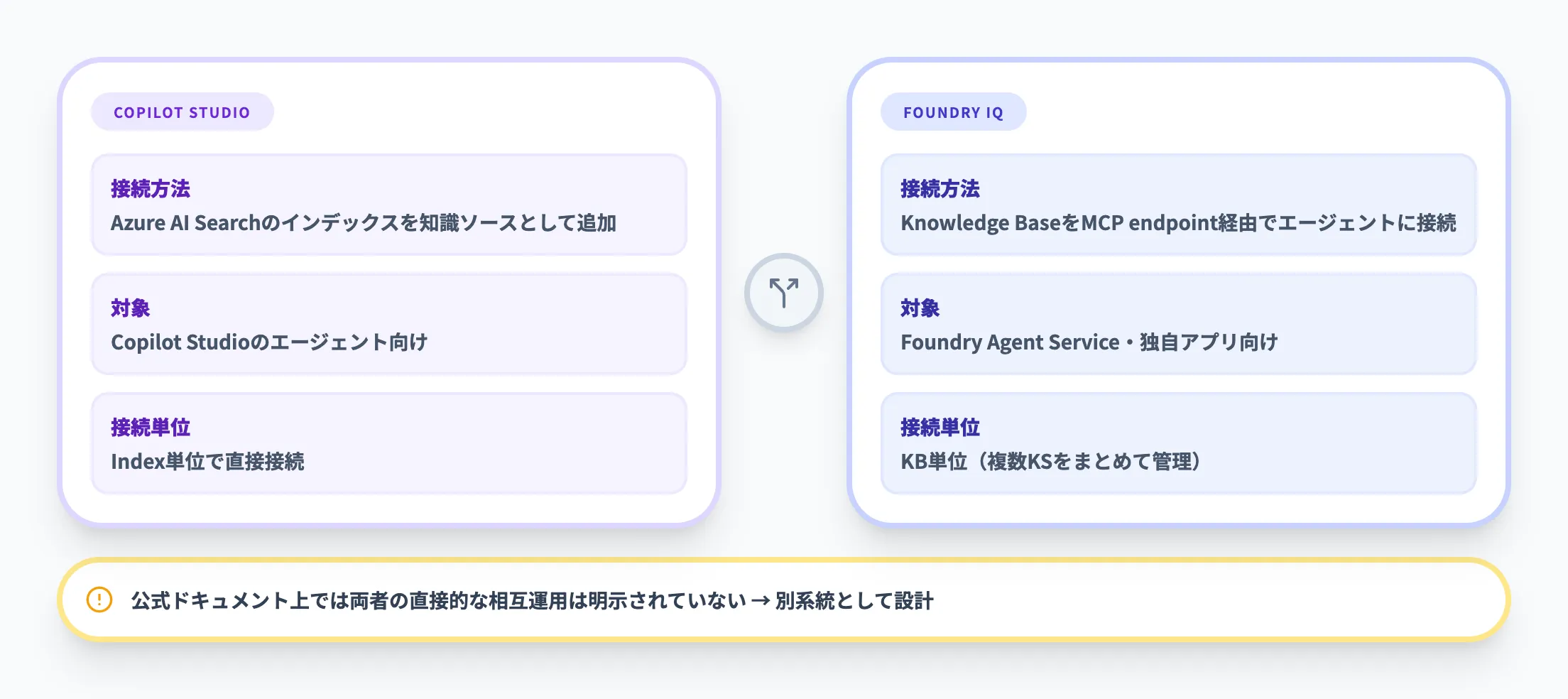
Foundry IQとCopilot Studioの知識接続は、現時点では別の接続モデルで提供されています。
Copilot StudioはAzure AI Searchのインデックスを知識ソースとして追加できる一方、Foundry IQはAzure AI Search上のknowledge baseをMCP経由でエージェントに接続する方式です。
Foundry IQの制約と導入時の注意点
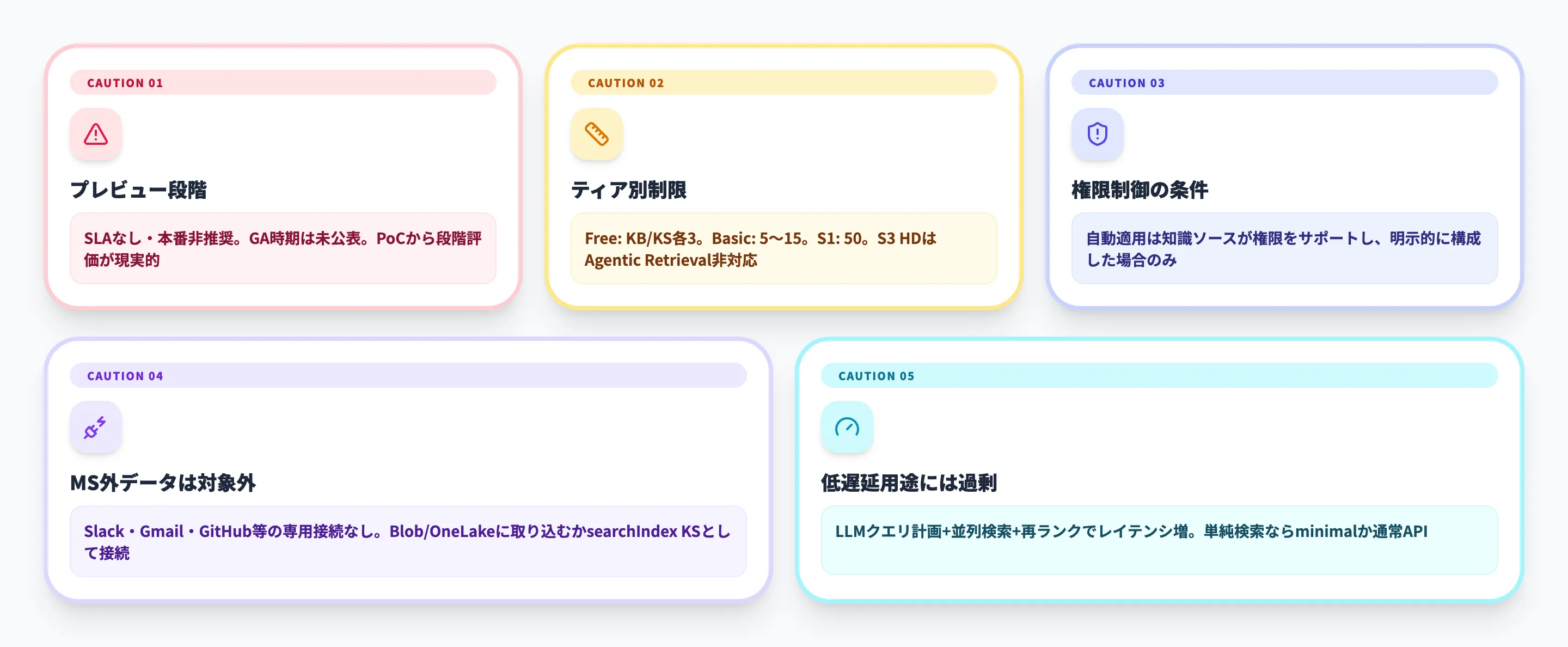
この節では、Foundry IQを導入する前に押さえておきたい制約と実務上の注意点をまとめます。Foundry IQは有力な選択肢ですが、2026年3月時点ではプレビュー段階のため、すべての本番要件にそのまま適用するのは早い段階です。
プレビュー段階でSLAがない
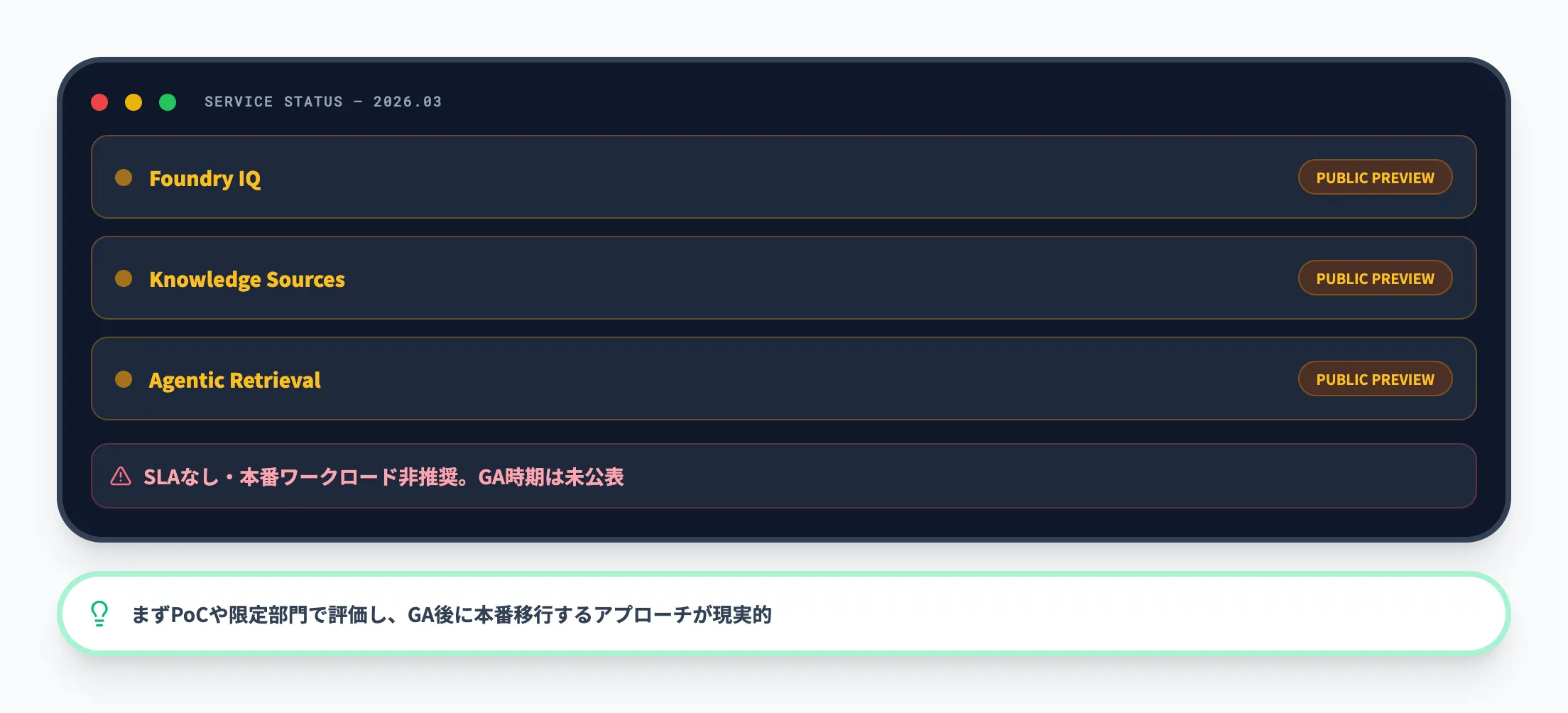
Foundry IQ、知識ソース、Agentic Retrieval関連のドキュメントはいずれも、パブリックプレビューでありSLAなし、本番ワークロード非推奨と明記されています。GA時期は2026年3月時点で未公表です。全社の基幹検索をいきなり載せ替えるのではなく、PoCや限定部門での評価から始めるのが現実的です。
ティア別の件数制限がある
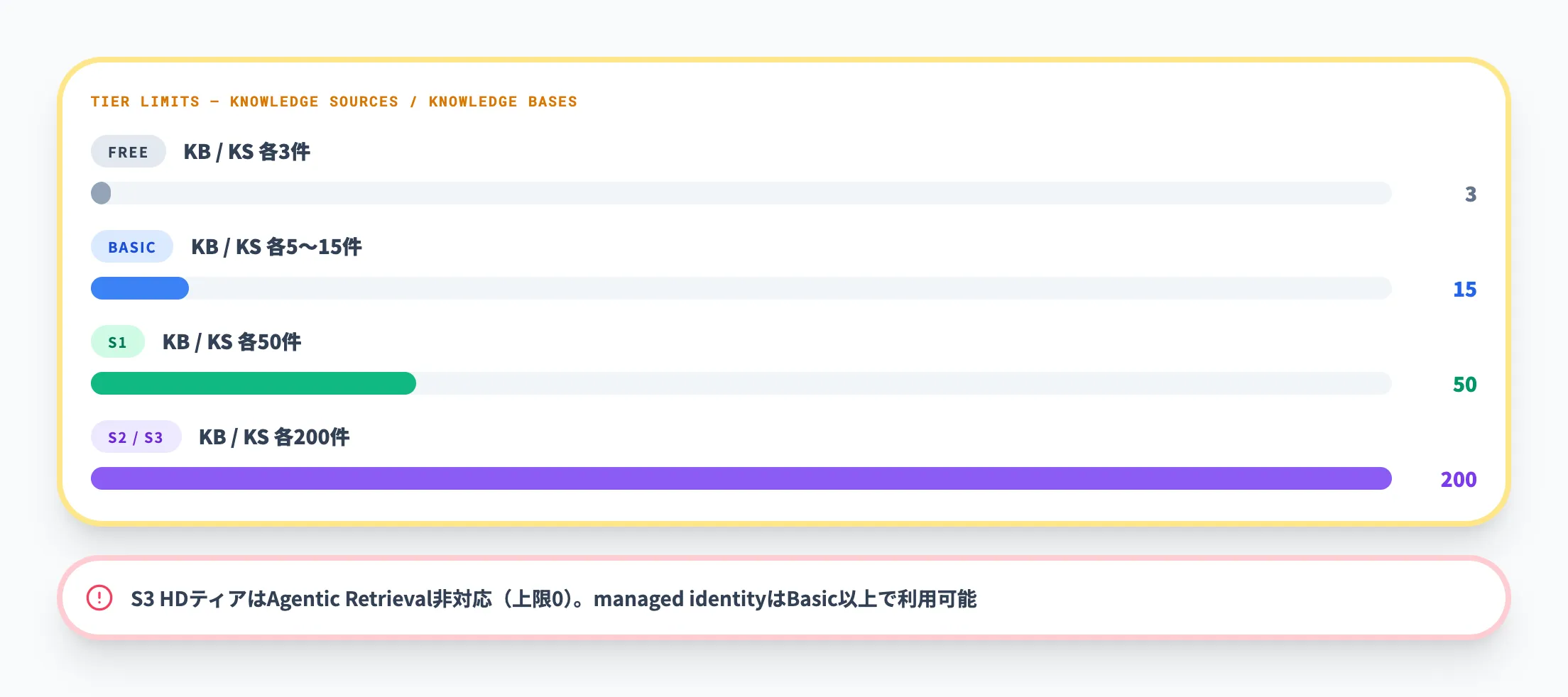
Azure AI Searchのティアごとに、ナレッジベースと知識ソースの上限が定められています。以下の表で主要なティアの制限を整理しました。
| リソース | Free | Basic | S1 | S2 / S3 |
|---|---|---|---|---|
| 知識ソース(サービス全体) | 3 | 5〜15 | 50 | 200 |
| ナレッジベース(サービス全体) | 3 | 5〜15 | 50 | 200 |
| 1ナレッジベースあたりの知識ソース(minimal) | 3 | 5〜10 | 10 | 10 |
| 1ナレッジベースあたりの知識ソース(low) | 3 | 3 | 3 | 3 |
| 1ナレッジベースあたりの知識ソース(medium) | 3 | 5 | 5 | 5 |
FreeティアではPoCに十分な範囲ですが、ナレッジベースや知識ソースが各3件までです。本番運用でmanaged identityを使う場合はBasic以上が必要になります。S3 HDティアはAgentic Retrieval非対応(上限0)である点にも注意してください。
用途ごとにナレッジベースを分ける設計の方が、1つのナレッジベースに全てを詰め込むよりも扱いやすくなります。
権限制御は自動適用されない場合がある
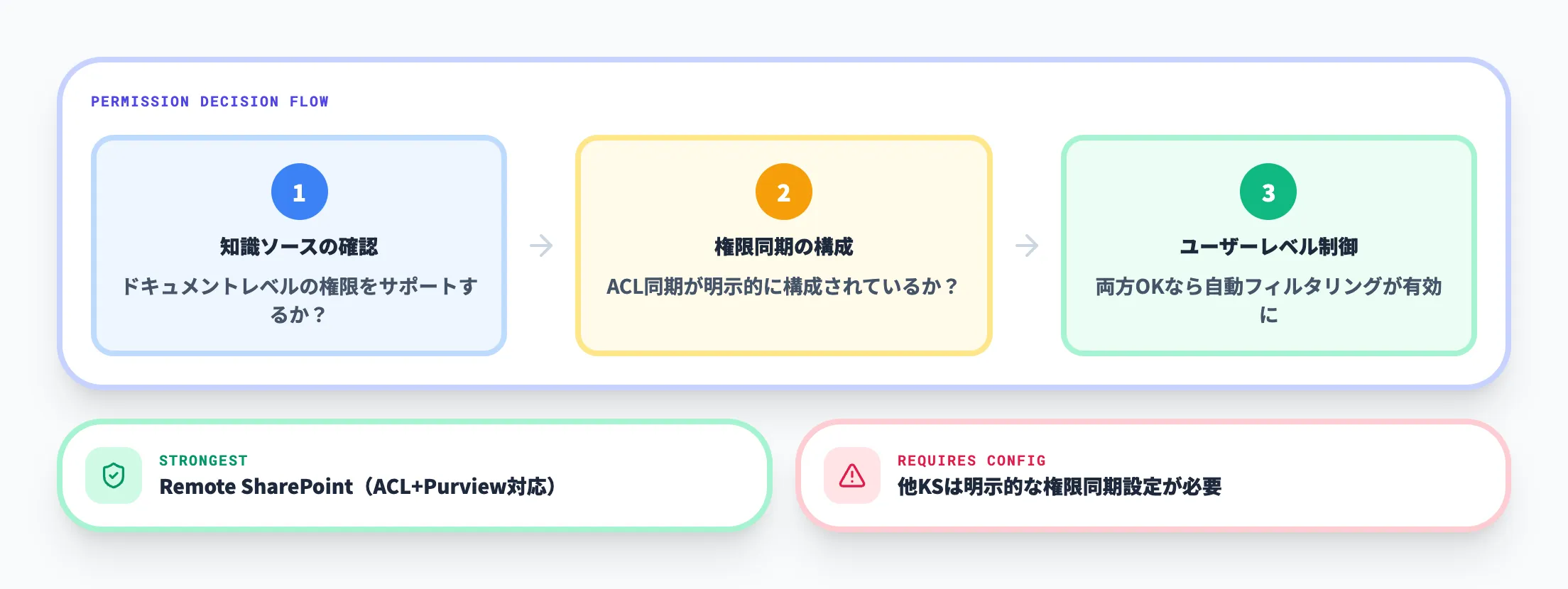
Foundry IQの権限制御は強力ですが、すべてのケースで自動的に効くわけではありません。公式FAQでは、「ユーザーレベルのアクセス制御は、知識ソースがドキュメントレベルの権限をサポートしており、かつその権限が同期用に明示的に構成されている場合にのみ適用される」と説明されています。
知識ソースのドキュメントに権限サポートが明示されていない場合、ドキュメントレベルのアクセス制御は自動では適用されません。権限制御を前提とする場合は、知識ソースごとの対応状況を事前に確認することが重要です。
Microsoftエコシステム外のデータは対象外

Foundry IQの専用knowledge sourceは、SharePoint、OneLake、Azure Blob Storage、既存検索インデックス、Webに限られます。SlackやGmail、GitHub Issuesなどを直接つなぐ専用knowledge sourceはありません。
これらを使いたい場合は、Azure Blob StorageやOneLakeに取り込むか、既存のAzure AI Search indexに投入してsearchIndex knowledge sourceとして利用する追加設計が必要です。
低遅延だけを求める用途には過剰になりうる
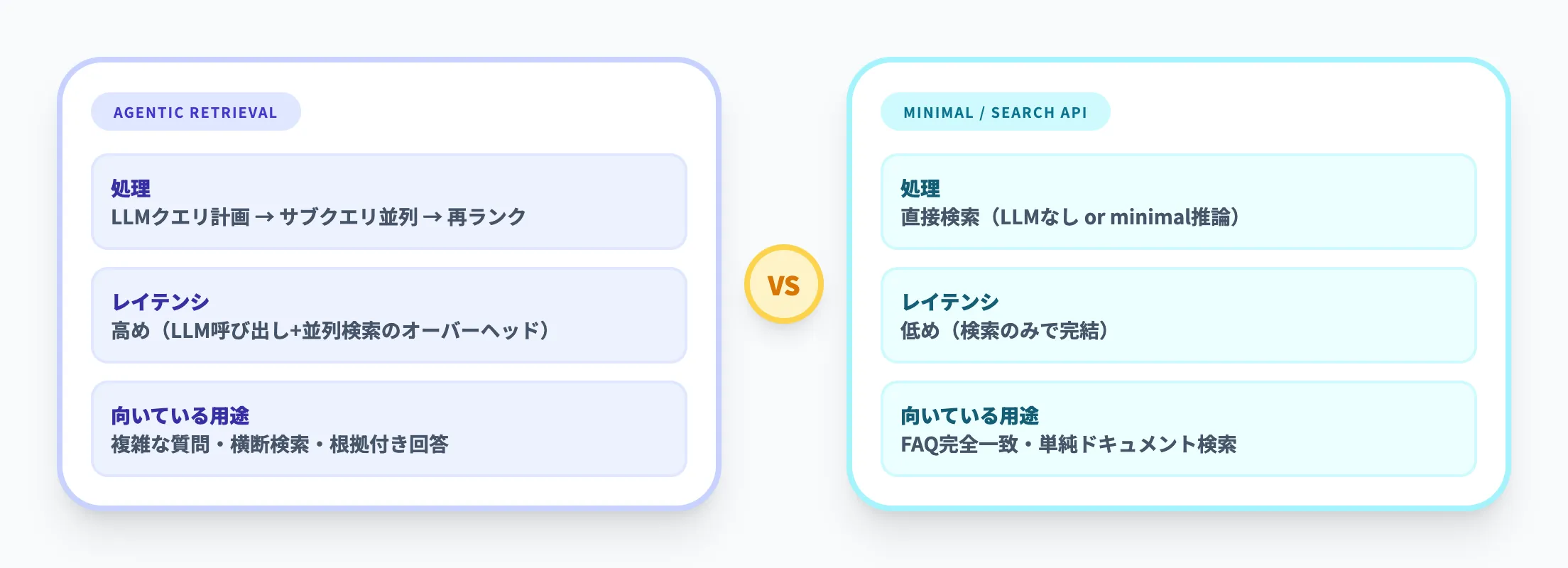
Agentic Retrievalは、LLMによるクエリ計画、サブクエリの並列実行、セマンティックランカーによる再評価を行うため、シンプルな単発検索よりもレイテンシが増えやすい設計です。Microsoft Learnでも、低遅延化のために高速モデルの採用、会話履歴の要約、知識ソースの絞り込み、推論設定の引き下げが推奨されています。
FAQの完全一致検索や、構造が単純なドキュメント検索だけが目的なら、minimal推論や通常のAzure AI Search APIの方が向く場合もあります。Foundry IQは「複雑な質問に正確に答えたい」場面でこそ価値を発揮する機能です。
AI Agent Hubのご案内
Foundry IQのAgentic Retrievalで高度なAI検索を実現したら、次は業務プロセスのAI自動化です。
- Agentic Retrievalで培ったRAG設計の知見を、業務自動化のAIエージェント設計にも活用
- ナレッジストアとセマンティック検索の経験を、社内文書の自動処理にも展開
- Teams上で完結するため、既存のMicrosoft環境にそのまま導入可能
- 自社テナント内で完結するセキュリティで、安心して業務データを扱える
AI検索基盤の次はAI業務自動化
Microsoft Teams上でAIエージェントが業務を代行
Foundry IQのAgentic Retrievalで高度なAI検索を実現したら、次は業務プロセスのAI自動化です。Teams上で動くAIエージェントが、日常業務を代行します。
Foundry IQの料金体系

この節では、Foundry IQの料金がどのような要素で構成されるかと、Japan Eastリージョン前提の目安を解説します。
Foundry IQ単体の固定ライセンスは存在しません。料金は、Azure AI Searchのサービス費用、Agentic Retrievalのトークン費用、Azure OpenAIのトークン費用の3つが組み合わさる構造です。「Foundry IQだけで月額いくら」とは言い切れないため、各構成要素を分けて理解する必要があります。
料金を構成する要素
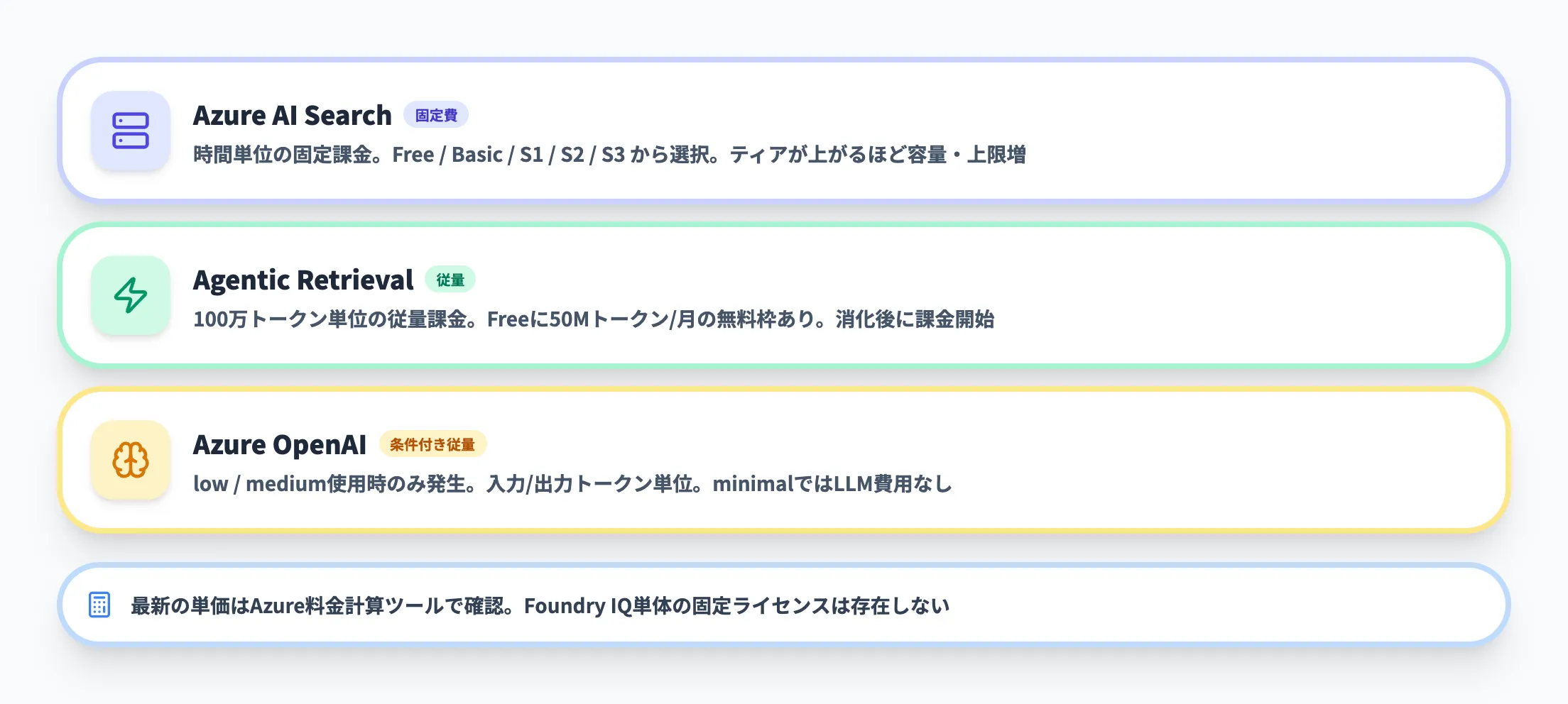
料金は主に3つの要素で構成されます。Japan Eastリージョンでの利用を前提にした構造を以下の表に示しますが、具体的な単価はリージョンや時期で変動するため、最新の正確な金額はAzure料金計算ツールで確認してください。
| 項目 | 課金の性質 | 補足 |
|---|---|---|
| Azure AI Search(ティア別固定費) | 時間単位の固定課金 | Free / Basic / S1 / S2 / S3から選択。ティアが上がるほどインデックス容量や知識ソース上限が増える |
| Agentic Retrieval トークン費用 | 従量課金(100万トークン単位) | Freeティアには50Mトークン/月の無料枠あり。無料枠消化後に課金開始 |
| Azure OpenAI モデル費用(low / medium使用時) | 従量課金(入力/出力トークン単位) | クエリ計画・回答合成に使用するモデルの料金。minimalでは発生しない |
FreeティアのAzure AI Searchでは50Mトークン/月のAgentic Retrieval無料枠が付属するため、小規模なPoCであれば実質的にAgentic Retrievalの追加費用なしで始められます。
コスト見積もりの具体例
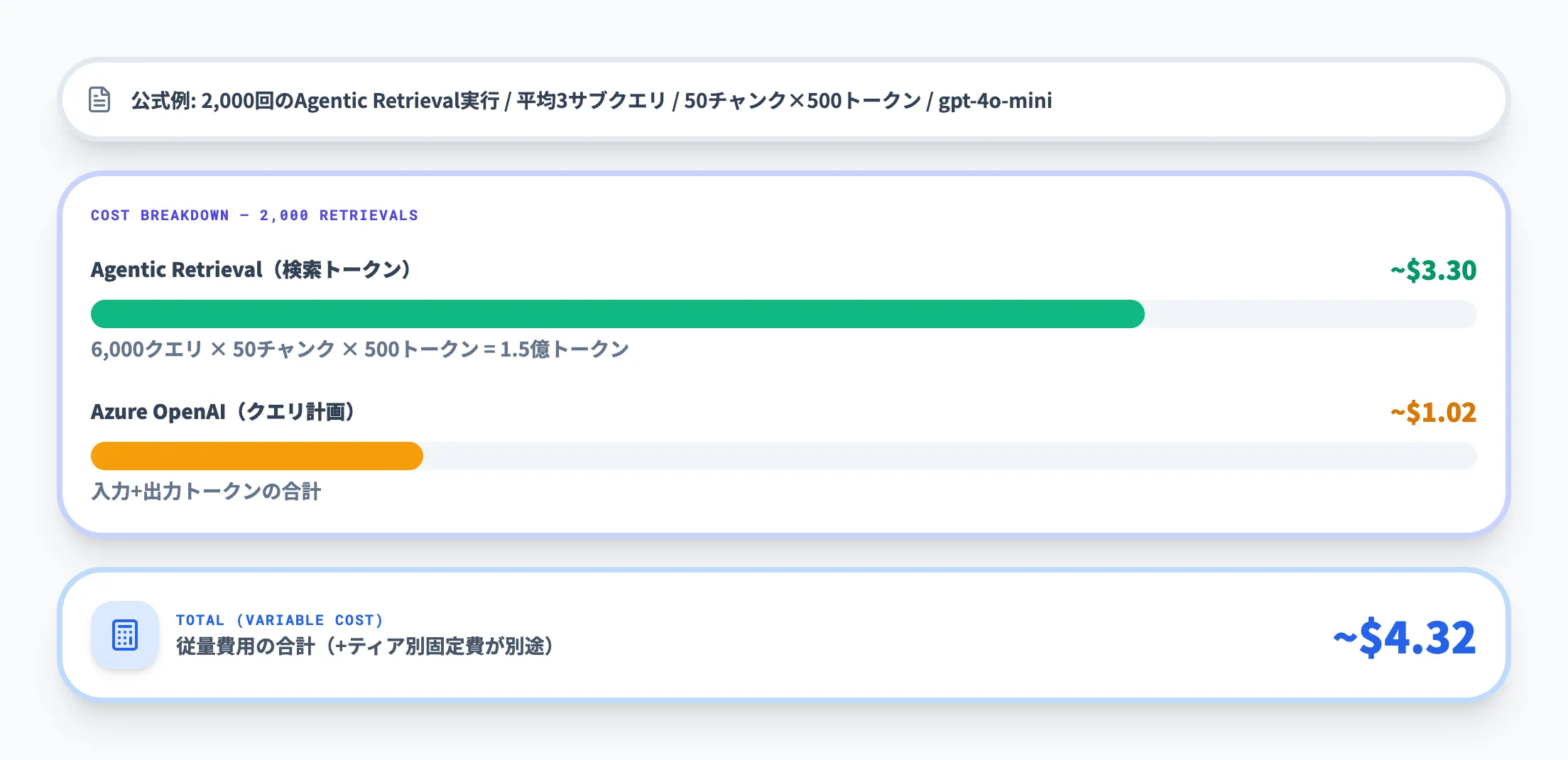
公式ドキュメントに記載された見積もり例を参考に、2,000回のAgentic Retrieval実行時のコスト構造を示します。
- 前提条件
平均3サブクエリ/回、1サブクエリあたり50チャンクを再ランキング、平均チャンクサイズ500トークン、gpt-4o-miniを使用
- Agentic Retrieval費用(Azure AI Search側)
2,000回 × 3サブクエリ = 6,000クエリ。50チャンク × 500トークン × 6,000 = 1億5,000万トークン。公式の見積もり例では約3.30ドル
- クエリ計画費用(Azure OpenAI側)
入力・出力トークンの合計で、公式の見積もり例では約1.02ドル
公式の見積もり例では、この前提条件での2,000回のAgentic Retrieval実行にかかる従量費用は合計で約4.32ドルとされています。これに加えて、Azure AI Search自体のサービス稼働費用(ティアに応じた時間単位の固定費)がかかります。具体的なティア別の月額はAzure料金計算ツールで確認してください。
コストを抑えるポイント
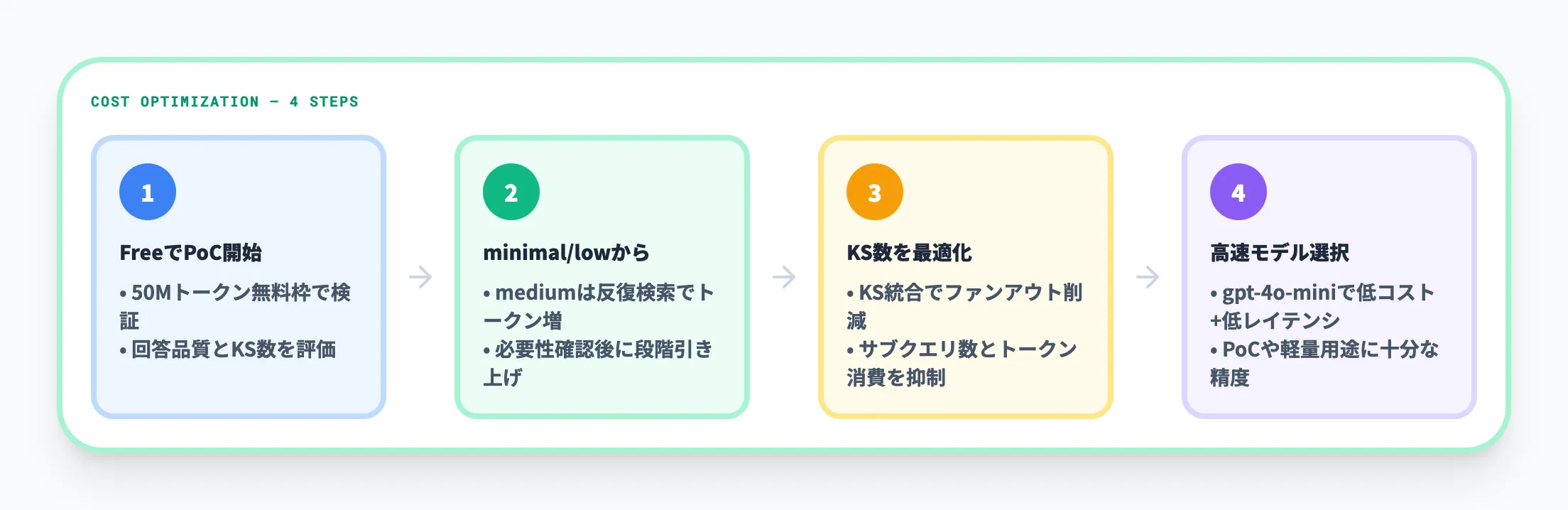
本番費用を左右しやすいのは「どのティアのAzure AI Searchを常時稼働するか」と「LLMにどこまで推論させるか」の2点です。コストを最適化するための考え方を以下にまとめました。
- FreeティアでPoCを開始する
50Mトークン/月の無料枠で回答品質と知識ソース数を検証できます。
- 推論の深さはminimalまたはlowから始める
mediumは反復検索でトークン消費が増えるため、必要性を確認してから段階的に上げるのが安全です。
- 知識ソースを統合してファンアウトを減らす
知識ソースの数を減らすと、サブクエリの並列数とトークン消費を抑えられます。
- 高速なモデルを選択する
gpt-4o-miniはgpt-4oより低コスト・低レイテンシで、PoCや軽量な用途には十分な精度を提供します。

まとめ
本記事では、Foundry IQの概要からAgentic Retrievalの仕組み、使い方、他サービスとの違い、料金体系、注意点までを解説しました。
- Foundry IQは、Azure AI Searchを基盤にした権限制御付きの共通知識レイヤーであり、1つのナレッジベースを複数エージェントで共有できる
- Agentic Retrievalのマルチクエリパイプラインにより、従来の単発RAGと比べて応答品質が約36%向上する
- ナレッジベース、知識ソース(Indexed / Remote)、推論の深さ(minimal / low / medium)の組み合わせで、精度とコストのバランスを制御できる
- Work IQやFabric IQとは補完関係であり、Foundry IQは知識検索を専門に担う位置づけ
- 2026年3月時点ではプレビューのため、FreeティアでのPoCから段階的に評価するのが現実的
複数のエージェントやアプリで同じ知識基盤を再利用したいなら、Foundry IQは有力な選択肢です。一方で、低遅延のみを重視する単純検索には過剰になる場合もあるため、まずは用途を絞ってPoCで検証することを推奨します。










