この記事のポイント
 Microsoft環境ではFoundry「Web Search」(Bing基盤・GA)から実装し、Web IQ本体はLimited Access申請の2段構え
Microsoft環境ではFoundry「Web Search」(Bing基盤・GA)から実装し、Web IQ本体はLimited Access申請の2段構え- 性能はp95 165ms未満・競合比2.5倍速、passage-level evidenceでトークン効率も既存検索APIを上回る
- Microsoft IQの4メンバー(Foundry IQ・Fabric IQ・Work IQ・Web IQ)のうちWeb IQは外部ライブWeb文脈補完を専任
- Web IQ本体はAzure顧客向けLimited Access(REST/MCP/SDK・申請必須)でFoundry Web SearchとはAPI別系統
- Tavily・Perplexity Sonar・Exaからの乗り換え判断軸は「Microsoftスタック統合」「passage証拠」「Bingインデックス継承」

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Microsoft Web IQは、Microsoftが2026年6月2日のBuild 2026 Day1で発表したAIエージェント向けの次世代Webグラウンディング APIスイートです。
20年蓄積したBingのWebインデックスを基盤に、人間のブラウジング用ではなく機械推論用にゼロから組み直した「AI向け検索エンジン」として設計され、p95 165ミリ秒未満・競合比2.5倍速・低トークン消費を同時に実現します。
本記事では、Web IQの公式定義から、解こうとした課題、主な機能と性能、Microsoft IQ全体での位置づけ、Foundry「Web Search」(GA)とWeb IQ専用API(Limited Access)の使い分け、料金と提供状況、Tavily・Perplexity Sonar・Exa・Braveなど競合APIからの乗り換え判断軸までを2026年6月時点の公式情報で体系的に整理します。
目次
Web IQの公式定義「a search engine for AI systems」
Microsoft IQプラットフォーム第4のメンバーとしての位置づけ
Web IQが解こうとした課題——「人間向けBing検索」から「エージェント向けWeb検索」への再設計
旧Bing Search APIの廃止とGrounding with Bing Searchへの一本化
Bingインデックスを継承しつつ「ゼロから組み直した」設計思想
Web IQの主な機能と性能——GDSAT・レイテンシ・トークン効率の3軸で既存を上回る
Web IQのカバレッジ(web/news/images/video等のsix+ verticals)
GDSAT(Grounding Satisfaction)の評価軸
Microsoft IQ全体での位置づけ——Work IQ・Foundry IQ・Fabric IQとの役割分担
Foundry IQとの連携:Web IQをknowledge sourceとして束ねる構造
Microsoft Copilot・ChatGPTでのgrounding既採用実績
Foundryでの3つのWebグラウンディングツール比較(GA・Bing基盤)
Web IQ本体のLimited Access申請ルート(REST/MCP/SDK)
詰まりやすいポイント(VPN・Private Endpoint非対応)
zero data retention・publisher preferencesの扱い
Web IQとは

Microsoft Web IQ(ウェブ・アイキュー)は、Microsoftが2026年6月2日のBuild 2026 Day1で発表した、AIエージェント向けに設計された次世代のWebグラウンディング APIスイートです。
「a search engine for AI systems(AIシステム向けの検索エンジン)」と定義されており、Bingの20年分のWebインデックスを継承しつつ、人間がブラウザで閲覧する検索ではなく、LLMやエージェントが推論で使う検索として組み直されています。
本セクションでは、Web IQの公式定義、Build 2026での発表概要、Microsoft IQプラットフォーム第4のメンバーとしての位置づけを順に整理します。性能・使い方・料金については後段のセクションで扱います。
Web IQの公式定義「a search engine for AI systems」
Web IQの設計思想は、「Bingが人々にWeb検索をさせるために作られたのに対し、Web IQはAIエージェントが正しい情報を見つけるために作られている」と説明されています。
つまりWeb IQは「BingをAIのために置き換える」のではなく、「Bingを人間向け検索のまま残し、AIエージェント向けには別の入口(Web IQ)を開く」という設計です。
この設計判断が、後述する性能と価格構造の前提になります。検索結果ページをHTMLでレンダリングする必要がなく、人間にとっての「読みやすさ」を担保する必要もないため、その分エージェントに必要な「証拠の粒度」と「呼び出しコスト」に最適化できる、という考え方です。
公式サイトのヒーローでも、「AI applications are only as good as the information they reason from(AIアプリケーションは参照する情報の質を超えられない)」というメッセージで、grounding品質の重要性が前面に打ち出されています。
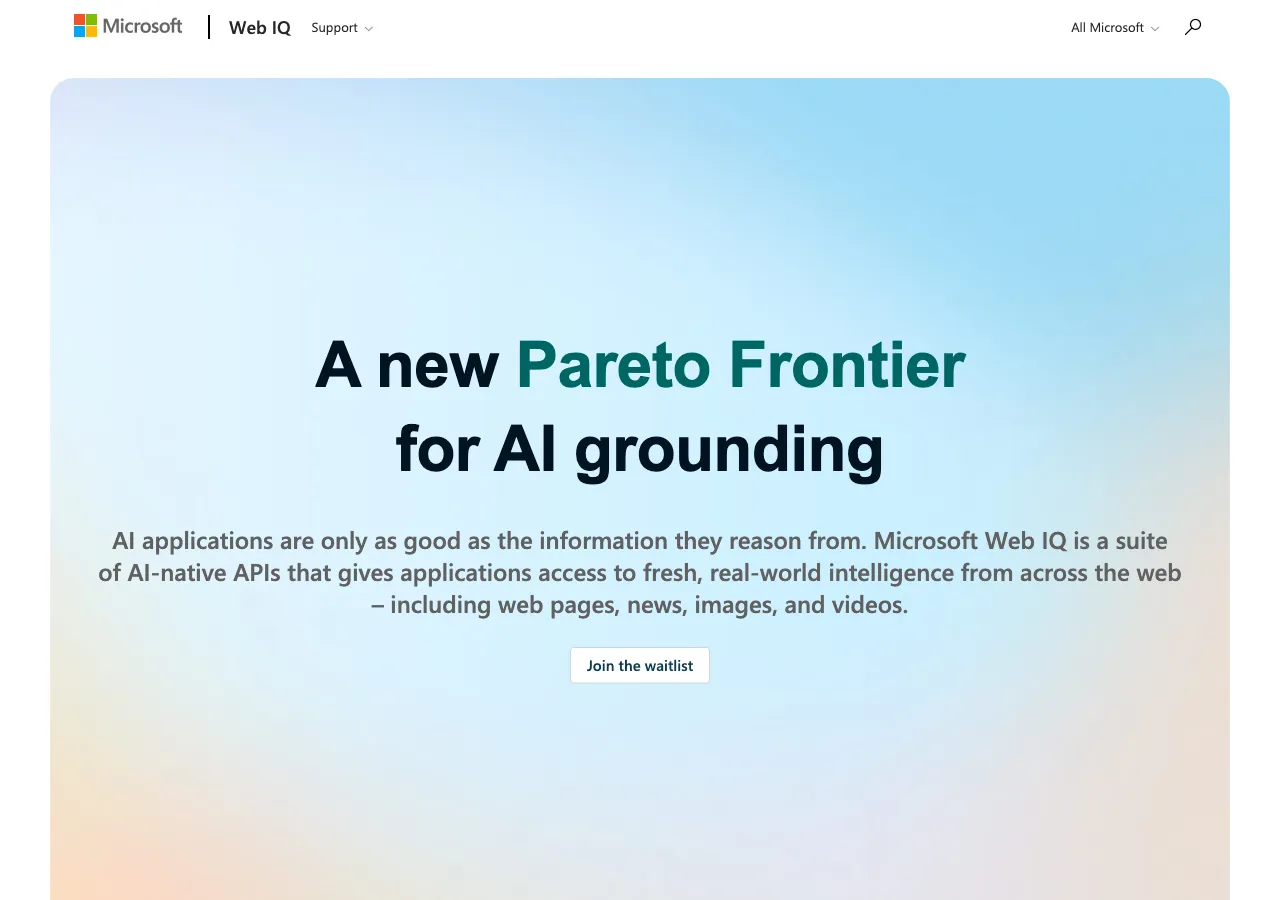
Microsoft Web IQ 公式サイト「A new Pareto Frontier for AI grounding」(出典:Microsoft)
「a new Pareto Frontier」という打ち出しから、Web IQ単体の機能訴求というより、「grounding品質とコストのトレードオフ自体を動かす」という位置づけを狙っているのが読み取れます。
Microsoft IQプラットフォーム第4のメンバーとしての位置づけ
Microsoft IQは、エージェントに「世界知識」と「企業知識」をまとめて与えるためのコンテキストレイヤーです。Build 2026時点で4つのメンバーが揃いました。
以下の表で、Microsoft IQ 4メンバーの役割分担を整理しました。Web IQが担う領域がどこかを最初に押さえると、後段のFoundry IQ統合の話が頭に入りやすくなります。
| メンバー | 担当領域 | 主なデータソース |
|---|---|---|
| Foundry IQ | 統合知識レイヤー | SharePoint・OneLake・Azure Blob・MCP・Web IQ等を束ねる |
| Fabric IQ | ビジネスセマンティクス | Microsoft Fabric・オントロジー |
| Work IQ | ワーク文脈 | Microsoft 365(メール・会議・ドキュメント) |
| Web IQ | ライブWeb情報 | web/news/images/video等のsix+ verticals(公式FAQ:commerce含む) |
4メンバーの分担を一言で表すと、Foundry IQ=「束ねる」、Fabric IQ=「意味づける」、Work IQ=「働き方を理解する」、Web IQ=「Webから補う」、という構造です。
これまでMicrosoft IQには「企業の内側」を扱うメンバー(Work・Fabric・Foundry)しかなく、Webからの最新情報補完は旧来のGrounding with Bing Searchのようなレイヤーに頼っていました。Web IQの登場で、4方向の文脈補完が同じプラットフォーム上で揃ったことになります。

Web IQが解こうとした課題——「人間向けBing検索」から「エージェント向けWeb検索」への再設計

Web IQが新設された背景には、エージェントが必要とするWeb検索と、人間が必要とするWeb検索が、根本的に異なる仕様であるという認識があります。
公式ブログはWeb IQを「Bingを基盤にしつつ、エージェント時代に向けてゼロからアーキテクチャを組み直した」と説明しています。なぜそれだけの再設計が必要だったのか、Bing Search APIの系譜と合わせて整理します。
旧Bing Search APIの廃止とGrounding with Bing Searchへの一本化
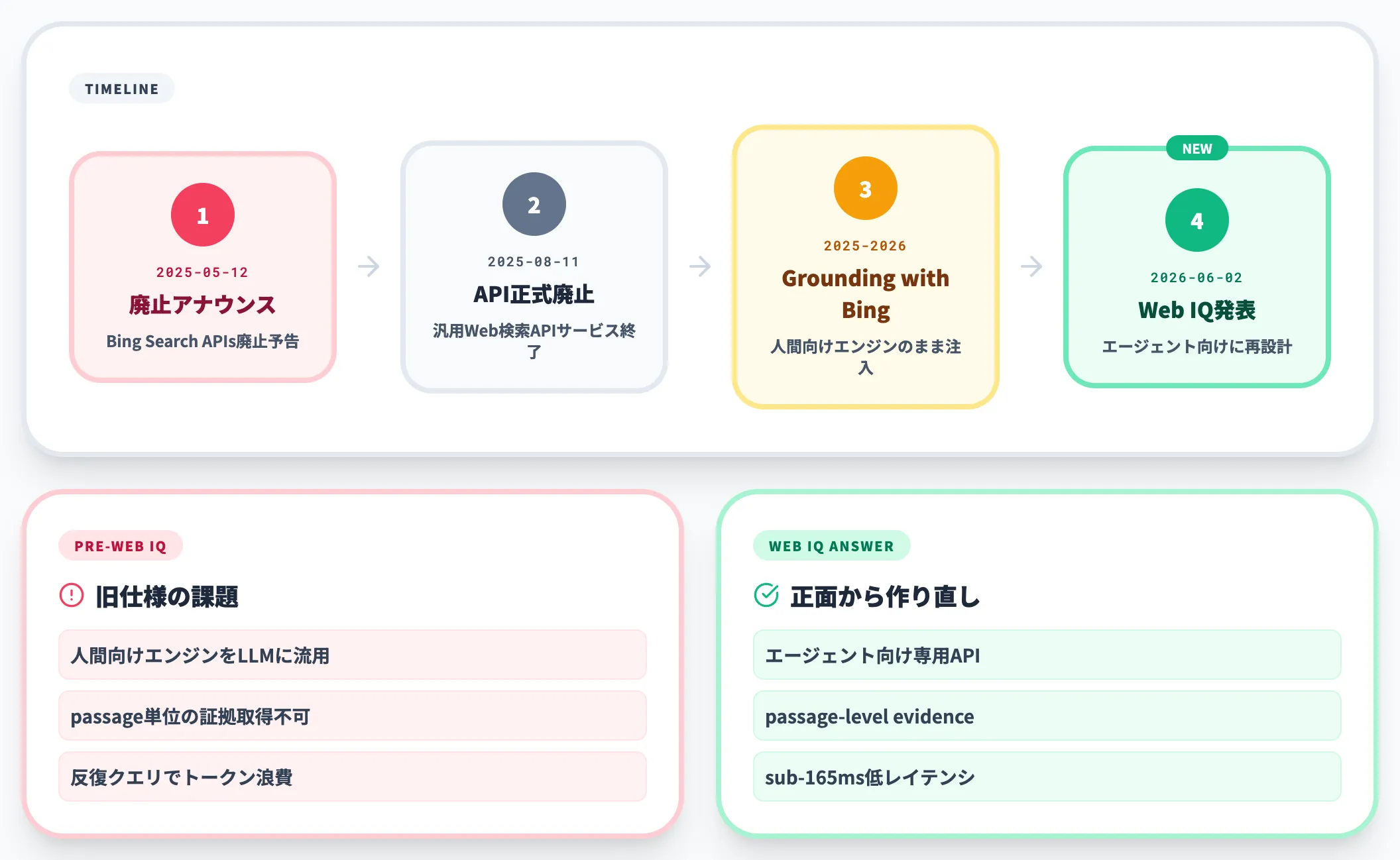
Microsoftは長年提供してきた汎用Web検索API「Bing Search APIs」を、2025年8月11日に廃止しました(廃止アナウンス自体は2025年5月12日)。
これは検索結果ページのデータをそのままアプリに渡す形式で、AI用途を主眼に置いていませんでした。廃止後の代替として、Microsoftは「Grounding with Bing Search」を打ち出し、Azureエージェントから利用する想定でBing検索結果をLLMのコンテキストに注入する仕組みを用意しました。
ただしGrounding with Bing Searchは、APIの裏側で動くBing検索エンジン自体は人間向けのままで、AIエージェントが必要とする「passage単位の証拠」「低レイテンシ反復クエリ」「トークン効率」を最適化したものではありませんでした。
ここを正面から作り直したのがWeb IQ、という流れです。
人間UI向け検索とエージェント検索の構造的な違い
PPC LandのWeb IQ詳細記事は、人間向け検索とエージェント検索の違いを次のように整理しています。
以下のリストで、両者の構造的な違いを整理しました。Web IQがどこを最適化したのかを理解する前提になります。
-
人間向け検索の前提
クエリは1ターンで、結果は10件程度のリンクリスト、ユーザーがリンクを開いて本文を読む
-
エージェント検索の前提
クエリは推論サイクルの中で繰り返し発行され、結果は本文そのもの(passage)が即座に必要で、レイテンシが推論速度に直結する
-
コスト構造の違い
人間向けは1検索1セッション。エージェント向けは1タスクで数十回〜数百回呼ばれるため、1呼び出しあたりのトークンコストが全体のROIを左右する
つまりエージェントは「URL一覧」ではなく「本文の必要箇所だけ」を、しかも「短時間で何度でも」必要としています。
Web IQはこの前提に合わせて、結果をドキュメント単位ではなくpassage(本文の抜粋)と構造化されたevidence objectで返す設計に切り替えました。エージェントはそのまま推論コンテキストに流し込めるため、HTMLパーサや要約処理を挟む必要がなくなります。
Bingインデックスを継承しつつ「ゼロから組み直した」設計思想
公式ブログはWeb IQのアーキテクチャを「Built on Bing, Re-Architected for the Agentic Era」と表現しています。
Bingの強みであるグローバルなWebインデックス・更新頻度・出版社ポリシー対応はそのまま継承する一方で、APIレイヤー、ランキングモデル、レスポンスフォーマットはエージェント向けに作り直されました。
具体的には次の3点が新設計の核です。
-
passage-level evidence object
ドキュメント単位ではなく、本文の関連箇所(passage)を構造化オブジェクトとして返す
-
sub-165msの専用レイテンシインフラ
5データセンターに分散配置された専用エンドポイントから低レイテンシで応答
-
publisher preferencesとライセンシング
20年分のBingとの関係を活かし、AI学習・grounding用途について出版社の優先設定を尊重する設計
「Bingを丸ごとAIに最適化した」のではなく、「Bingの土台の上にAI向けの新しい検索層を載せた」と理解するのが正確です。
公式のアーキテクチャ図では、最下層に「Bing index ecosystem(マッシブなグローバルインデックス・継続的な鮮度・出版社エコシステム・品質シグナル)」を置き、その上に「Leading edge systems(分散検索・グローバルルーティング・パッセージ抽出・鮮度安全性)」、最上層に「Engine of SOTA models(埋め込み検索・セマンティックランキング・パッセージ+証拠抽出)」を重ねる3層構造が示されています。
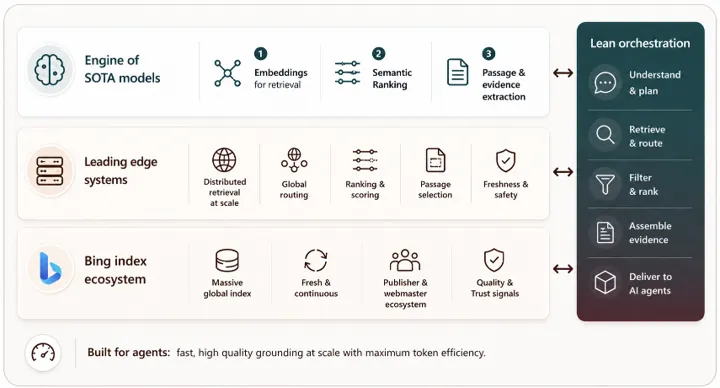
Web IQの3層構成:Bingインデックスエコシステム+Leading edge systems+SOTAモデルエンジン(出典:Bing Search Blog)
下から順に「土台のBingをそのまま流用」「中間でエージェント向けの検索ロジックを再実装」「上段で最新モデルによる意味理解と証拠抽出」というレイヤー構造で、どこまでが既存資産でどこから新規実装かが視覚的に整理されています。
Web IQの主な機能と性能——GDSAT・レイテンシ・トークン効率の3軸で既存を上回る

Web IQは、GDSAT(Grounding Satisfaction)・レイテンシ・トークン効率の3軸で、既存のグラウンディングAPIを上回ることを主張しています。
p95で165ミリ秒を切り、競合比2.5倍速、3,000クエリの実運用テストで品質・トークン効率のフロンティアに位置すると公表されています。
本セクションでは、APIのカバレッジ、性能数値の元データ、評価軸を順に整理します。
Web IQのカバレッジ(web/news/images/video等のsix+ verticals)
Web IQは単一のAPIではなく、扱う情報種別ごとに分かれたAPI群として提供されます。
公式FAQは「full-spectrum coverage across six+ verticals including commerce, not just web and news(webとnewsだけでなく、commerceを含む6つ以上の垂直領域を網羅)」と説明しており、Bingで扱える領域を順次エージェント向けに開放する設計です。
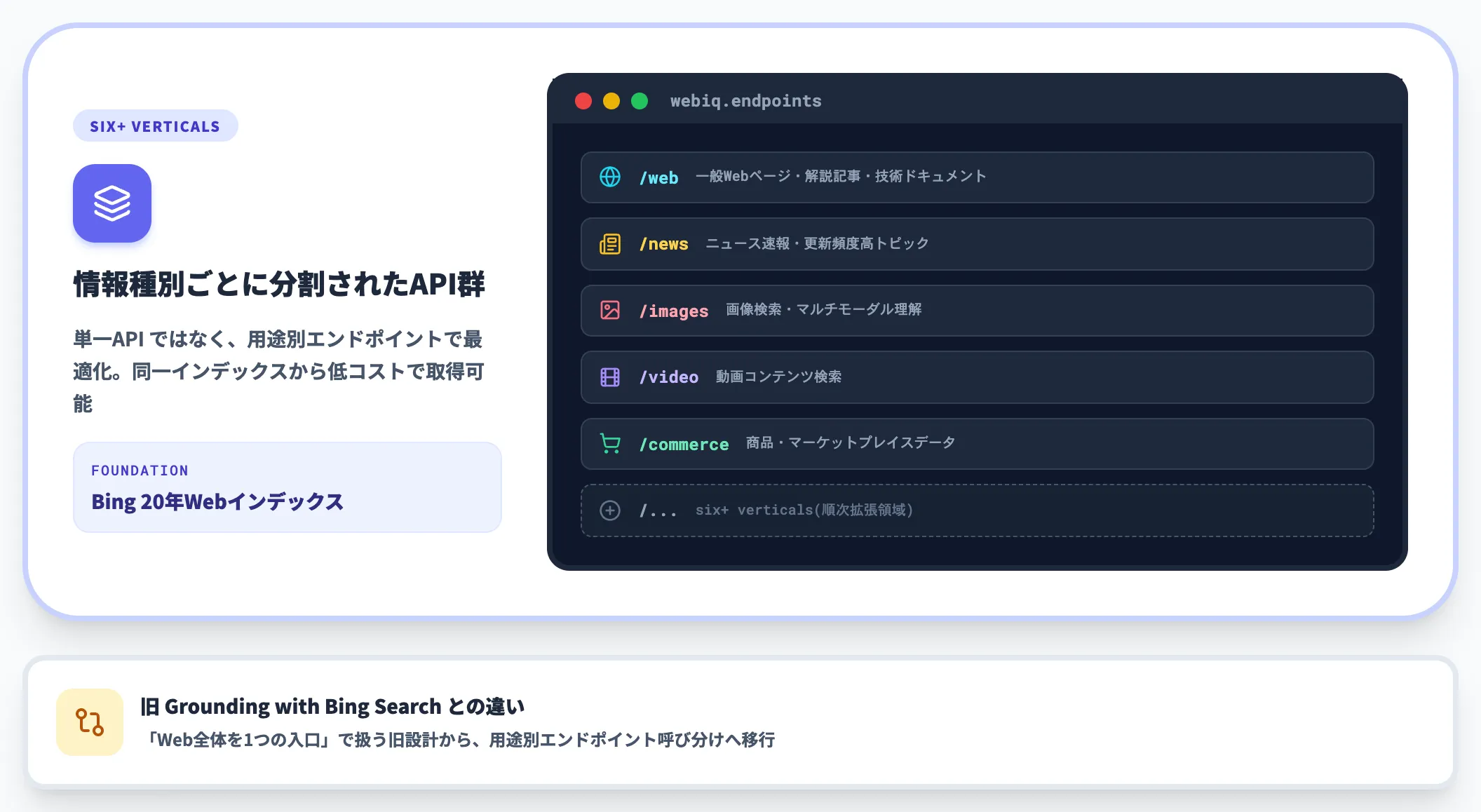
以下の表で、現時点で確認できる主要な情報種別を整理しました。エージェントの用途に応じて必要なエンドポイントを呼び分ける構成です。
| 情報種別 | 主な用途 |
|---|---|
| Web pages | 一般的なWebページ検索。解説記事・技術ドキュメント・公開資料 |
| News | ニュース速報・更新頻度の高いトピック |
| Images | 画像検索。マルチモーダルエージェントのビジュアル理解 |
| Video | 動画コンテンツの検索 |
| Commerce | 商品・マーケットプレイスデータ(公式FAQ明記) |
| その他 | 公式は「six+ verticals」と表現しており、今後拡張される領域あり |
従来のGrounding with Bing Searchは「Web全体を1つの入口」で扱う設計でしたが、Web IQは情報種別ごとに最適化されています。
たとえばニュース速報はインデックスの更新頻度が重要なのでNewsエンドポイント、商品比較はCommerceエンドポイント、というように呼び分けると、同じグローバルインデックスの中から用途に最適な結果を低コストで取れます。
レイテンシ:p95 165ms未満・競合比2.5倍速
性能面でWeb IQが最も強くアピールしているのが、レイテンシです。公式ブログでは「p95で165ミリ秒未満」「次点の代替品と比較してほぼ2.5倍速い」と明示されています。
測定条件も公開されており、以下の5つのAzureデータセンターから、3,000クエリで構成されたグローバルクエリセットを実行した結果です。
- West US2
- North Central US
- East US2
- North Europe
- South Korea
北米・欧州・アジアの3地域・5データセンターで均等に評価しており、地域差を均した上での「2.5倍速」という主張です。日本国内の利用ではSouth Korea DCが最も地理的に近いため、レイテンシの実感に近い基準として読めます。
レイテンシがエージェント運用に効く理由は、「同じタスクの中で何度もクエリを発行する」性質にあります。1回のクエリで200ミリ秒短縮されても、10〜50回繰り返せばタスク全体で数秒〜十数秒の差になります。これがエージェントのスループットとUXに直結します。
公式ブログに掲載された6社の競合との比較グラフでは、Web IQの164.4msに対して、競合は最速のC社で406.2ms、最遅のG社で2090.2msと、3〜13倍の差が示されています。
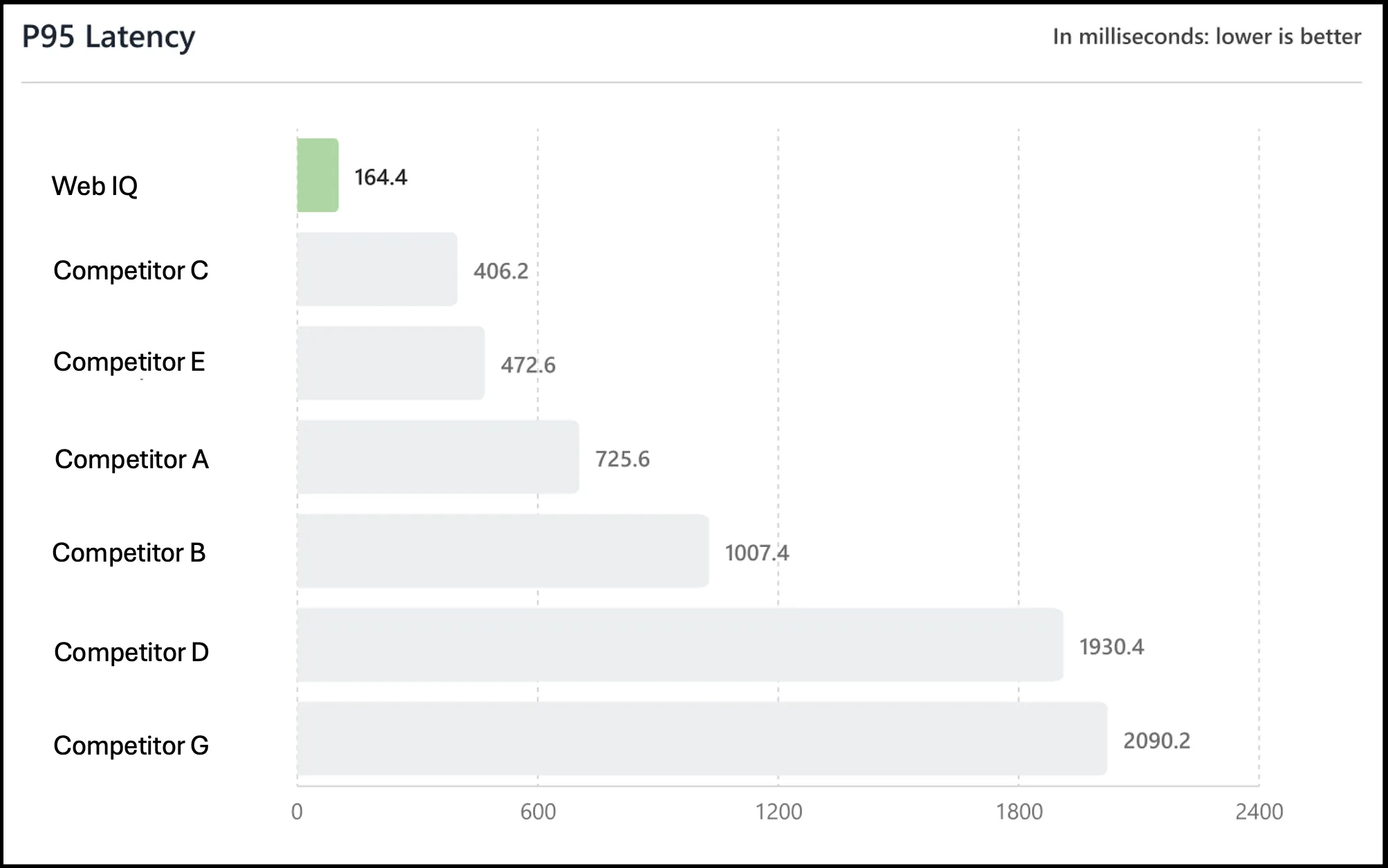
Web IQ 164.4msと匿名化された競合6社のP95レイテンシ比較(出典:Bing Search Blog)
競合名は「Competitor A〜G」と匿名化されていますが、レンジを見るとWeb IQ単独で「一桁早い帯」に飛び出していることが分かります。エージェントの反復クエリ運用では、この差がそのままタスク完了時間と単位コストに乗ってきます。
トークン効率とpassage-level evidence
レイテンシと並んで強調されているのが、トークン効率です。公式は「fewer tokens in, better answers out, lower cost per call(少ない入力トークンで、より良い回答を、1呼び出しあたり低コストで)」というスローガンで表現しています。
ドキュメント単位ではなくpassage単位で結果を返すため、エージェントが受け取るトークン数が削減され、結果として1呼び出しあたりのコストも下がる構造です。
3,000クエリの実運用テストでは、Web IQが「品質対トークン数のフロンティアで有利な位置を占めている」と公式ブログで報告されています。具体的なトークン削減率の数値は公表されていませんが、入力トークン側を構造的に圧縮する打ち手として位置づけられています。
エージェントの実務的なコスト試算では、「LLMの呼び出しコスト+grounding APIコスト」が支配的になりやすく、grounding結果がそのまま入力トークンに乗ります。Web IQのpassage設計は、この入力トークン側を構造的に減らす設計です。
公式ブログの散布図では、X軸に平均トークン数、Y軸にGrounding Satisfactionを置いて、Web IQと競合5社のトレードオフを可視化しています。
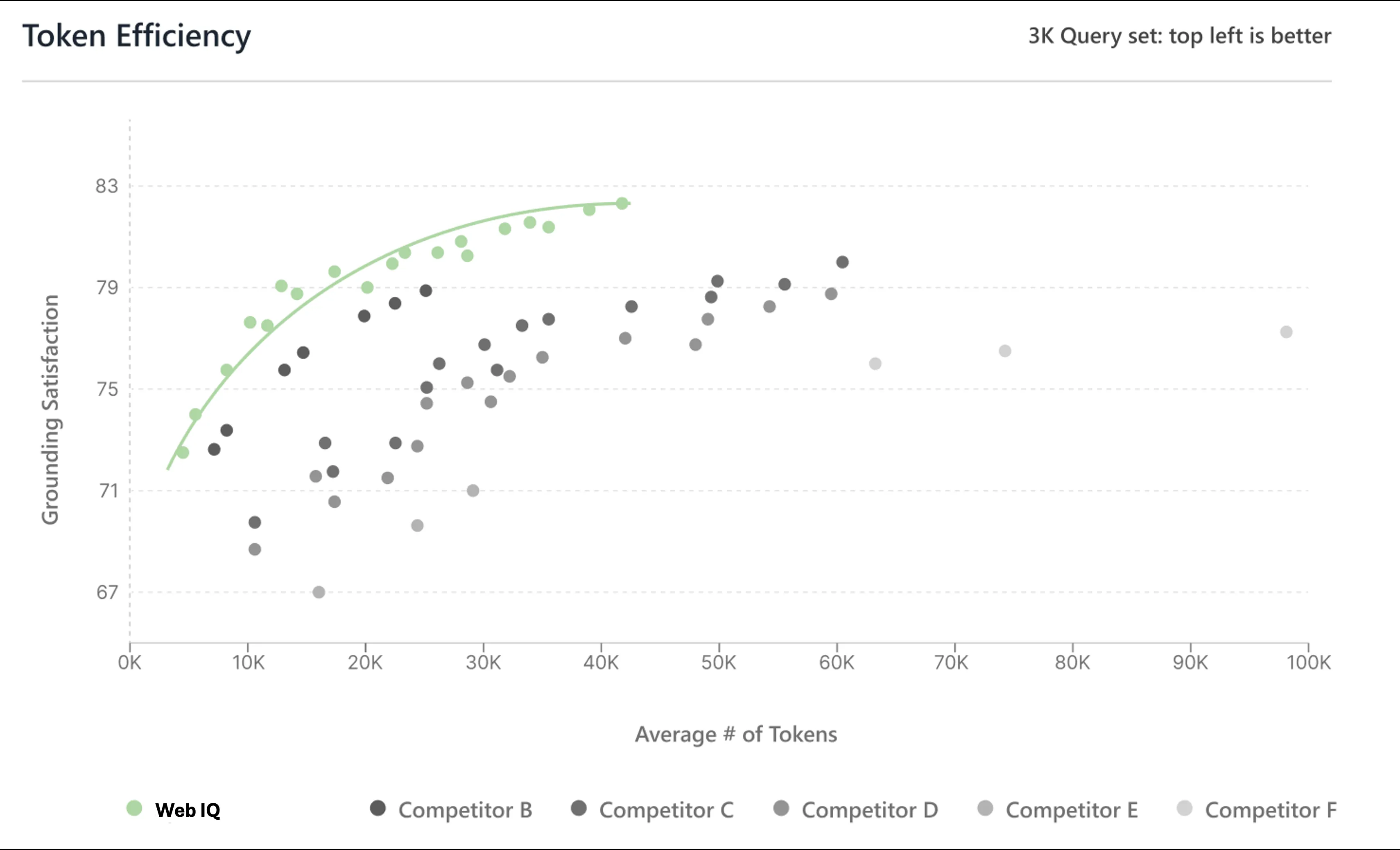
3,000クエリにおけるトークン消費量とGrounding Satisfactionの散布図。左上ほど効率が良い(出典:Bing Search Blog)
Web IQ(緑)の点群は左上のフロンティアに集中しており、競合より少ないトークンで同等以上のgrounding品質に到達していることが分かります。同じ品質を得るのに必要なトークン量が少なくなれば、その分だけLLM側の入力料金も縮小します。
GDSAT(Grounding Satisfaction)の評価軸
Web IQは性能を測る独自指標としてGDSAT(Grounding Satisfaction)を打ち出しています。これはエージェント側から見たgroundingの満足度を、完全性・新鮮性・権威性の3要素で評価する仕組みです。
以下のリストで、GDSATの構成要素を整理しました。レイテンシだけでは測れない「結果の質」を構造化する評価軸です。
-
Completeness(完全性)
クエリに対して必要な情報が網羅されているか
-
Freshness(新鮮性)
情報が現在の時点で最新か、更新サイクルがクエリ性質に合っているか
-
Authority(権威性)
出典が信頼できる情報源か、SEOで上位に来るだけの低品質コンテンツでないか
従来のWeb検索APIは「関連度スコア」で結果をランク付けしますが、エージェント用途では「最新性」と「権威性」を重視する場面が多くなります。GDSATはこの違いを明示的に評価する仕組みとして設計されました。
公式ブログでは、Web IQと競合6社のGDSATスコアも比較公開されています。
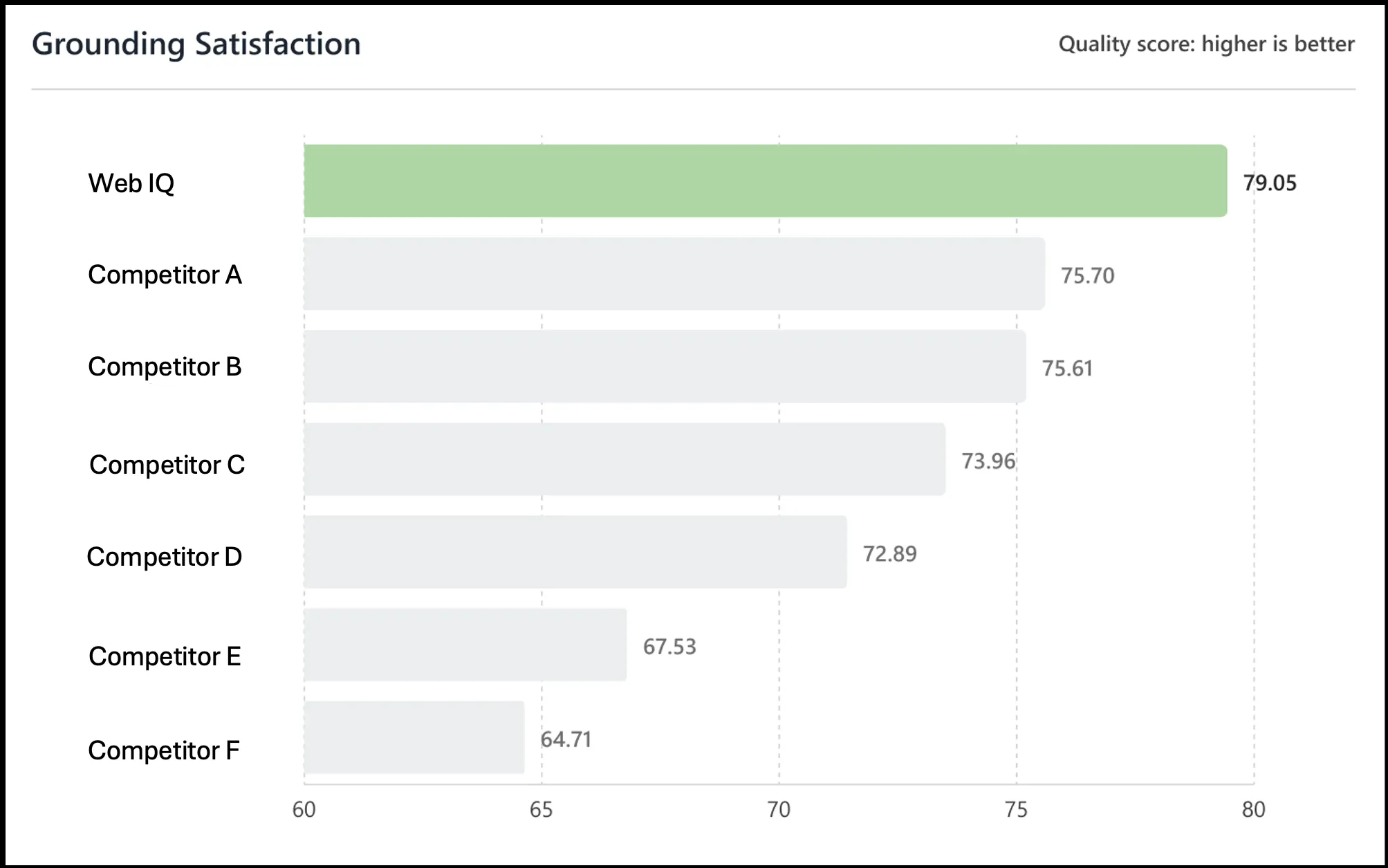
Web IQ 79.05と匿名化された競合6社のGrounding Satisfactionスコア比較(出典:Bing Search Blog)
Web IQの79.05に対して、競合最良のA社が75.70、最低のF社が64.71と、レイテンシほど大差ではないものの、上位帯でも3〜4ポイントの優位を保っています。
grounding品質は数値の絶対差より「上位帯での差」が実運用の信頼性に効くため、この水準で先行している意義は大きいと言えます。
Microsoft IQ全体での位置づけ——Work IQ・Foundry IQ・Fabric IQとの役割分担
Web IQは単独で使うものではなく、Foundry IQに束ねられて、Work IQ・Fabric IQと並ぶナレッジソースとして動くのが標準的な構成です。
Microsoft IQプラットフォーム全体としては「企業の中身(Work・Fabric・Foundry)」と「外側(Web)」を1つの基盤で統合し、エージェントが境界を意識せずに参照できる状態を作るのが狙いです。本セクションでは、4 IQsの相互関係と、Web IQがすでに使われている実例を整理します。
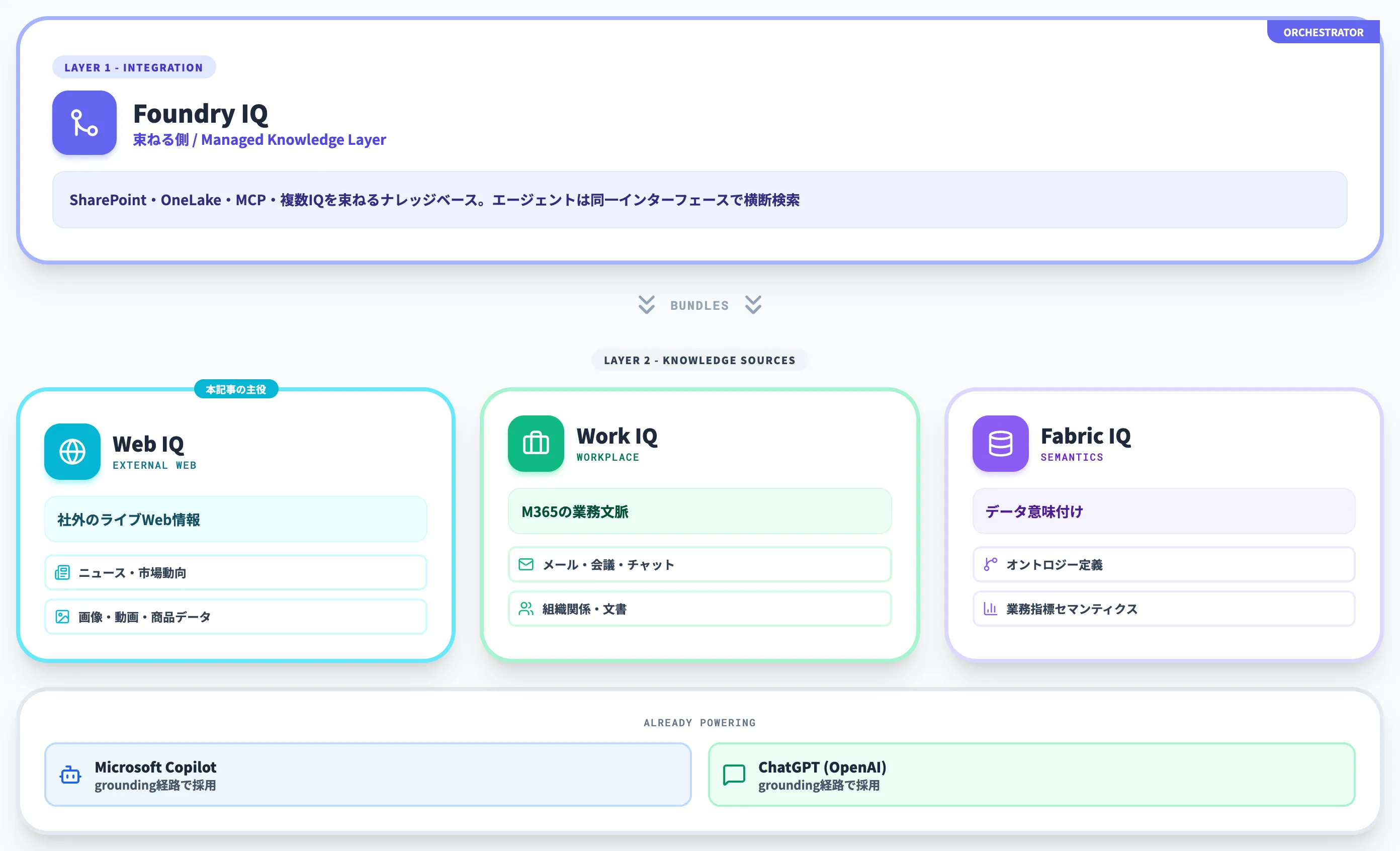
Microsoft IQ全体像と4 IQsの相互関係
Microsoft IQは「コンテキスト・レイヤー」と位置づけられています。エージェントが回答や行動に必要な文脈を、どのソースから、どの権限制御で、どの構造で取るかを統一的に扱うための仕組みです。
以下の表で、4 IQsを「束ねる側」と「束ねられる側」で整理しました。Web IQは束ねられる側です。
| レイヤー | メンバー | 役割 |
|---|---|---|
| 統合レイヤー(束ねる側) | Foundry IQ | 複数ソースを束ねたナレッジベースとしてエージェントに提供 |
| ナレッジソース(束ねられる側) | Web IQ | ライブWeb・ニュース・画像・動画・閲覧 |
| ナレッジソース | Work IQ | M365のメール・会議・ドキュメント・組織関係 |
| ナレッジソース | Fabric IQ | Microsoft Fabricのオントロジー・データセマンティクス |
つまり、Foundry IQが「束ねる側」、Web IQ・Work IQ・Fabric IQが「束ねられる側」という階層構造です。
開発者から見ると、Foundry IQのナレッジベースを1つ作って、その中でWeb IQ・Work IQ・Fabric IQをソースとして登録する流れになります。エージェントから見ると、ソースの違いは隠蔽され、同じインターフェースで横断検索できます。
Foundry IQとの連携:Web IQをknowledge sourceとして束ねる構造
Foundry IQ公式FAQによれば、Foundry IQはSharePoint・OneLake・Azure AI Search・File Search・MCPなど複数のソースを束ねるmanaged knowledge layerとして設計されています。
Build 2026のFoundry IQ強化発表では、ここにWeb IQが新しいナレッジソースとして追加されました。
Foundry開発ブログは「sub-165msレイテンシとzero data retentionで、ライブWeb・licensed publisher・marketplaceデータをエージェントに与える」と説明しています。
Foundry IQのナレッジソース選択画面でも、Web IQ(Web:Ground with real-time web content via Bing)が、Work IQ・Fabric IQ(OneLake Catalog)・MCP Server・Azure AI Search Indexなどと同じ層に並ぶカードとして提供されています。
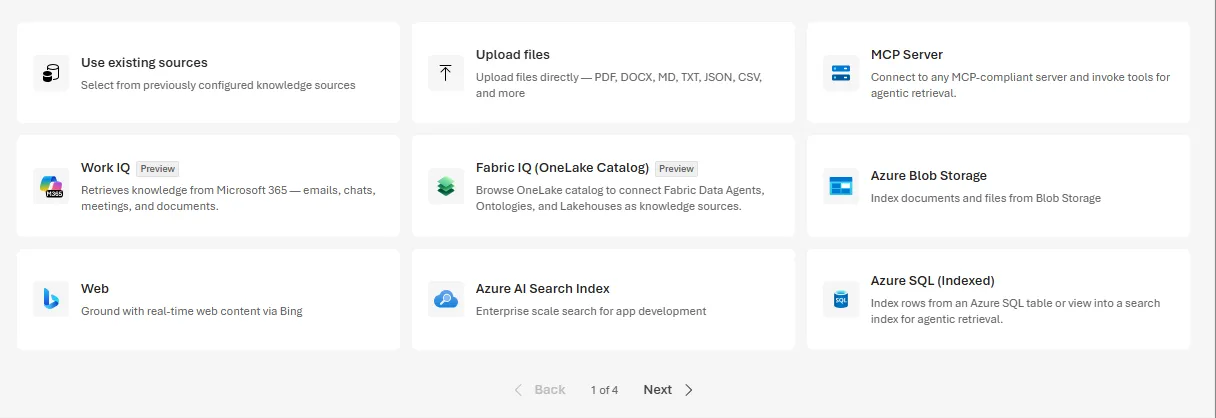
Foundry IQのナレッジソース選択画面。Web・Work IQ・Fabric IQが同じ層に並ぶ(出典:Microsoft Foundry開発ブログ)
開発者はFoundryポータル上で複数ソースをポチポチ選んでナレッジベースを組み立てる感覚で、Web IQも他のソースと同じ操作感で組み込めるようになっています。ただしFoundry IQ公式ブログは「Microsoft Web IQ is available in limited access through the Foundry IQ MCP knowledge source」と明示しており、Foundry IQ経由であってもWeb IQ自体はLimited Access扱いです。GAで先に触れるのは、別系統のFoundry Web Search/Grounding with Bing系になります。
Work IQ・Fabric IQとの分担
Web IQと並ぶ「束ねられる側」のナレッジソースとして、Work IQとFabric IQが位置づけられています。
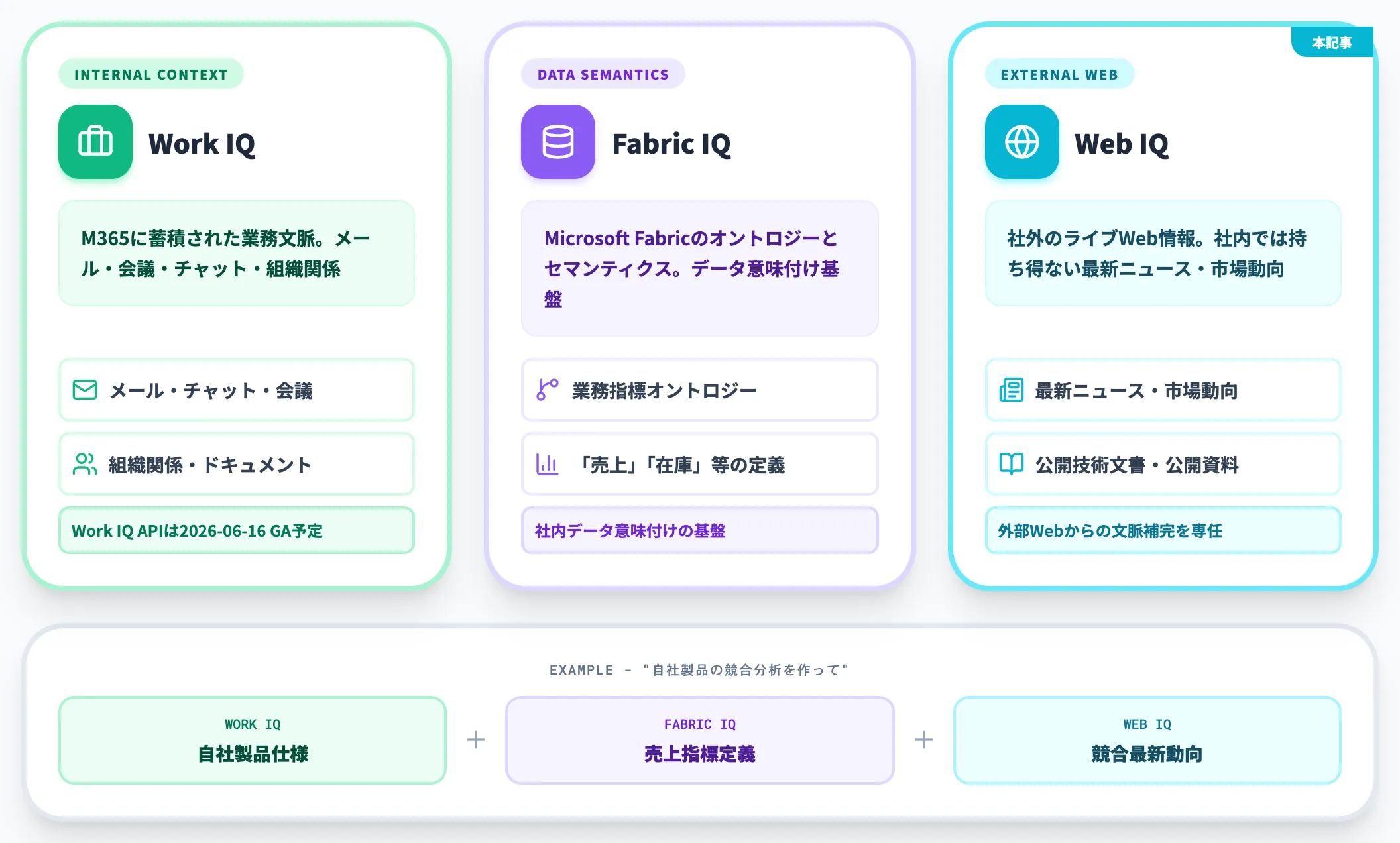
以下のリストで、3つのナレッジソースのカバー範囲を整理しました。重複しない設計になっており、エージェントは必要な範囲のソースだけを呼び出します。
-
Work IQ
Microsoft 365に蓄積された業務文脈。メール・会議・ドキュメント・チャット・組織関係。Work IQ APIは2026年6月16日にGA予定
-
Fabric IQ
Microsoft Fabricのオントロジーとセマンティクス。「売上」「在庫」のような業務指標の意味を共有する基盤
-
Web IQ
社外のライブWeb情報。社内では持ち得ない最新ニュース・市場動向・公開技術文書
「社内の業務文脈はWork IQ、社内のデータ意味付けはFabric IQ、社外の最新情報はWeb IQ」という分担が成立しています。
実務では、たとえば「自社製品の競合分析を作って」というエージェント指示に対して、自社製品の仕様や売上はWork IQ・Fabric IQから、競合の最新動向はWeb IQから取ってきて、Foundry IQが束ねる、という分担が自然に組めるようになります。
Microsoft Copilot・ChatGPTでのgrounding既採用実績
Web IQは新発表のプロダクトですが、実は内部的にはすでに2つの主要サービスで使われていることが公表されています。
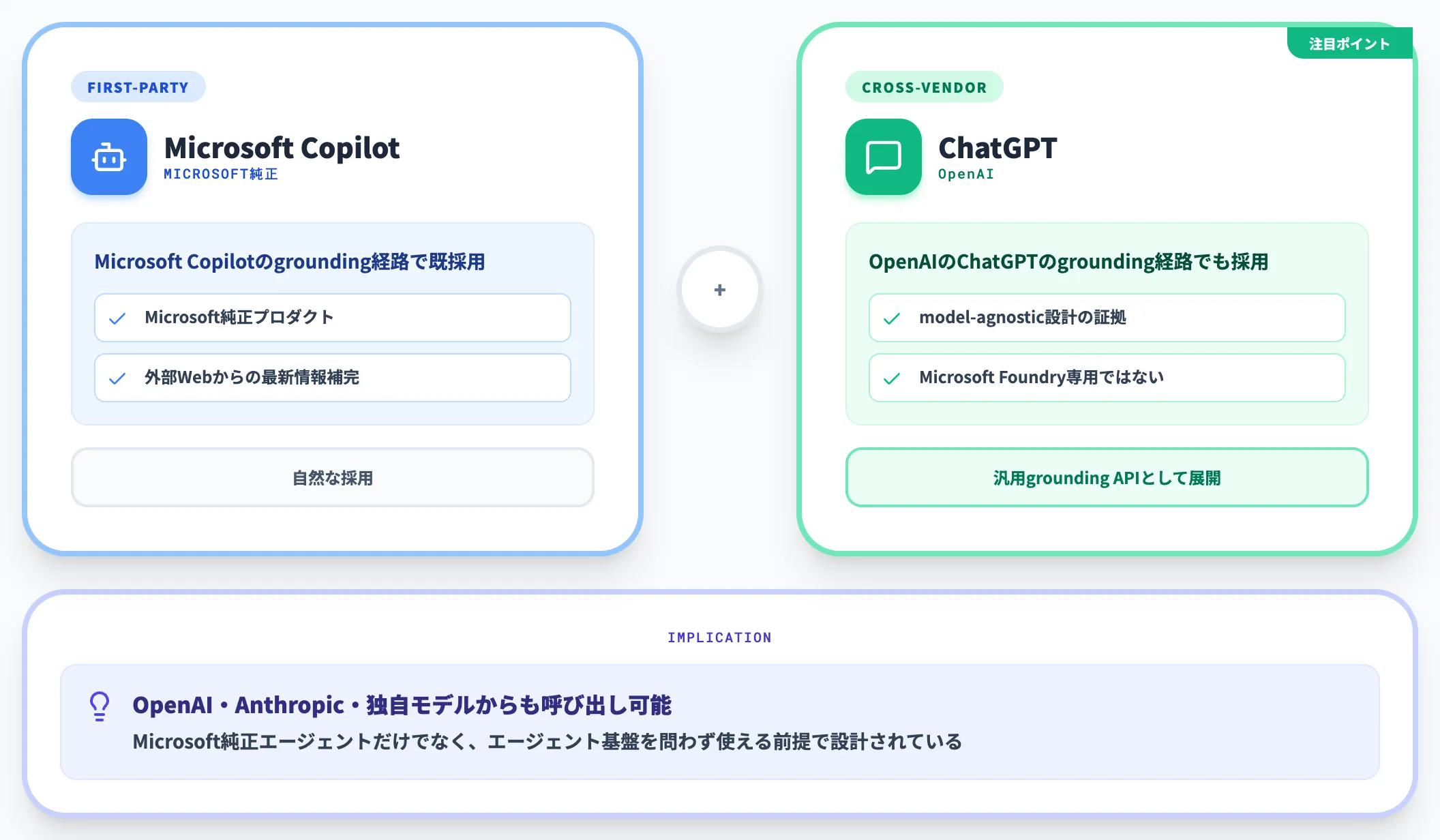
- Microsoft Copilot: Microsoft Copilotのgrounding経路で既採用
- ChatGPT: OpenAIのChatGPTのgrounding経路でも採用
Microsoft Copilotは自社プロダクトなので自然な採用ですが、ChatGPTでの採用は、Web IQが「Microsoft Foundry専用」ではなく「model-agnosticな汎用grounding API」として設計されていることを示しています。
つまりWeb IQは、Microsoft純正のエージェントだけでなく、OpenAI・Anthropic・独自モデルのいずれを使うエージェントからも呼び出せる前提で作られています。これは後段の競合比較で重要なポイントになります。

Web IQの使い方
2026年6月時点でWeb IQ関連の機能を実装する経路は、大きく2系統に分かれます。
公式FAQは「Web IQ is purpose-built for AI agents and multi-step workflows, while Grounding with Bing is designed for traditional search」と、Web IQと従来のGrounding with Bing系を別物として位置づけています。
Foundry Agent Serviceの「Web Search」ツールはGrounding with Bing系のGA一般ツールであり、これを使ってもWeb IQ本体(passage-level evidence・sub-165msレイテンシ・GDSAT 79.05)の性能がそのまま得られるわけではない、という前提を最初に押さえてください。
本セクションでは、(A) GA一般利用のFoundry「Web Search」ツール、(B) Web IQ本体のLimited Access申請ルート、(C) MCP連携、(D) 実装で詰まりやすい論点、の順で整理します。

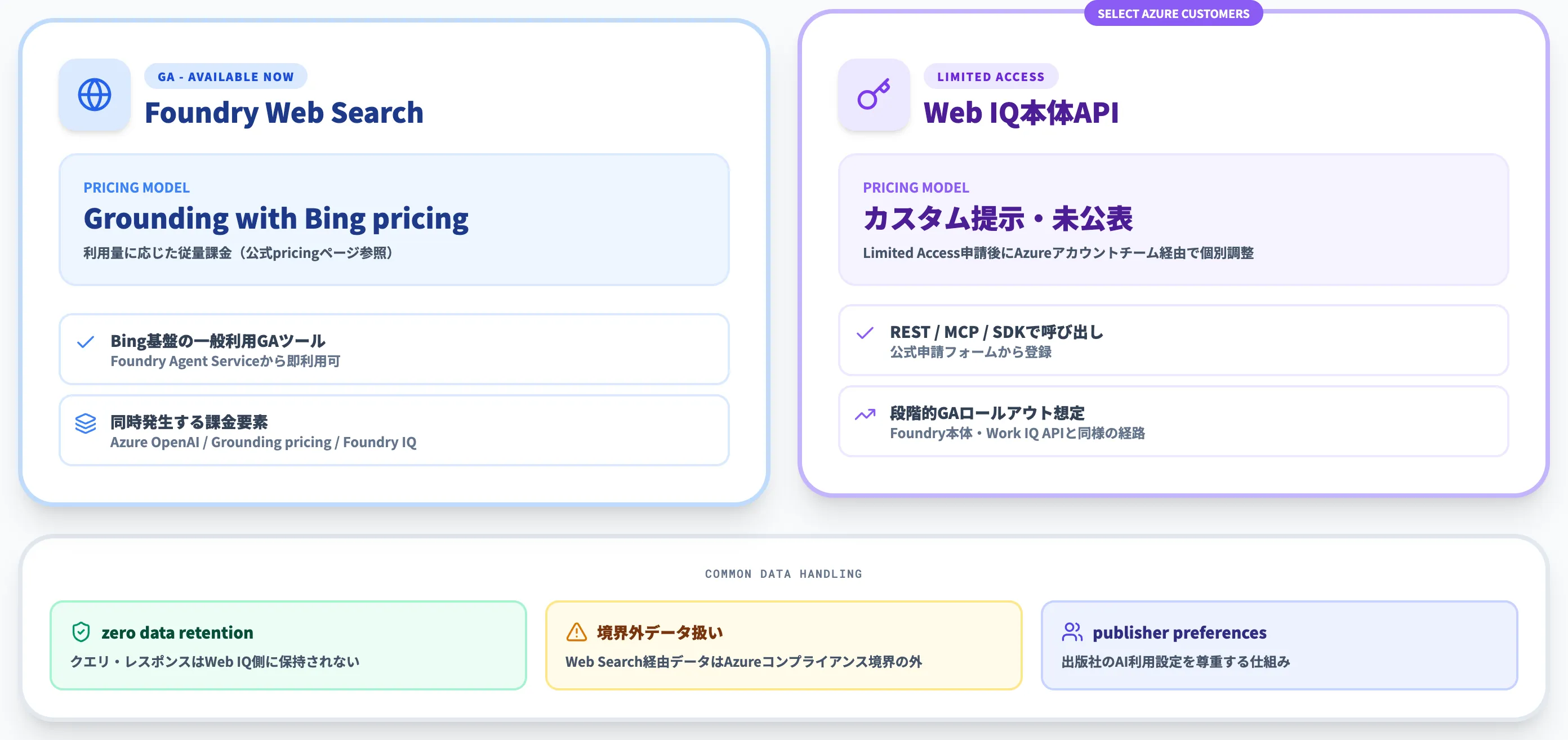
Foundryでの3つのWebグラウンディングツール比較(GA・Bing基盤)
Microsoft Learnのweb grounding overviewによれば、Foundry Agent ServiceにはWebグラウンディング用のツールが3つあります。いずれもBing基盤・Grounding with Bing系で、Web IQ本体とは別系統です。
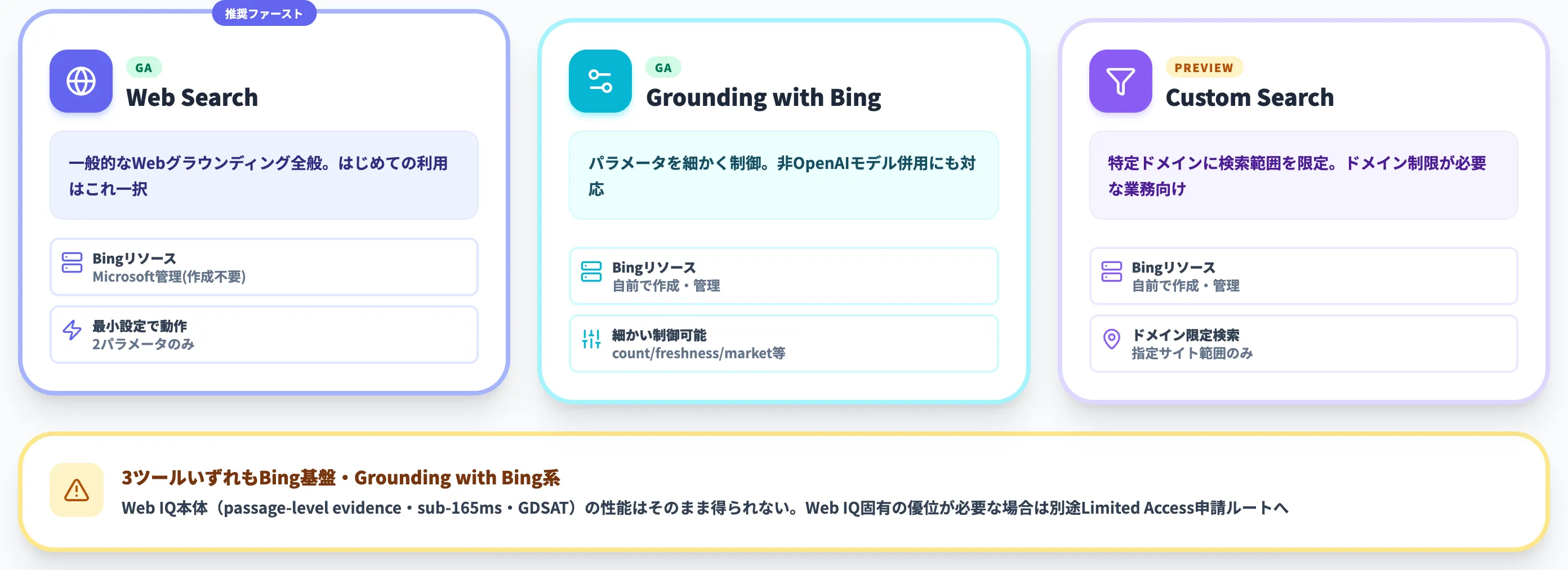
以下の表で、3ツールの違いを整理しました。「とりあえずWebからの最新情報をエージェントに渡したい」用途であれば、まずこの3つの中から選びます。
| ツール | 状態 | Bingリソース | 主な用途 |
|---|---|---|---|
| Web Search(推奨) | GA | Microsoft管理 | 一般的なWebグラウンディング全般 |
| Grounding with Bing Search | GA | 自前で作成・管理 | パラメータを細かく制御したい場合・非OpenAIモデル併用 |
| Grounding with Bing Custom Search | Preview | 自前で作成・管理 | 特定ドメインに検索範囲を限定したい場合 |
はじめて触る場合は「Web Search」ツール一択です。MicrosoftがBingリソースを内部で管理するため、開発者側でリソースを作る必要がありません。
ただし繰り返しになりますが、これらはBing検索結果をエージェントに渡す従来型グラウンディング系のツールで、Web IQ本体ではありません。
passage-level evidenceや低レイテンシ・トークン効率といったWeb IQ固有の優位を業務要件として必要とする場合は、次節のWeb IQ専用API経路を検討します。
Web IQ本体のLimited Access申請ルート(REST/MCP/SDK)
Web IQ本体の利用は、2026年6月時点でselect Azure customers向けのLimited Accessです。公式FAQは「Web IQ is currently available in limited access to select enterprise customers building AI agents and applications at scale」と明示しています。
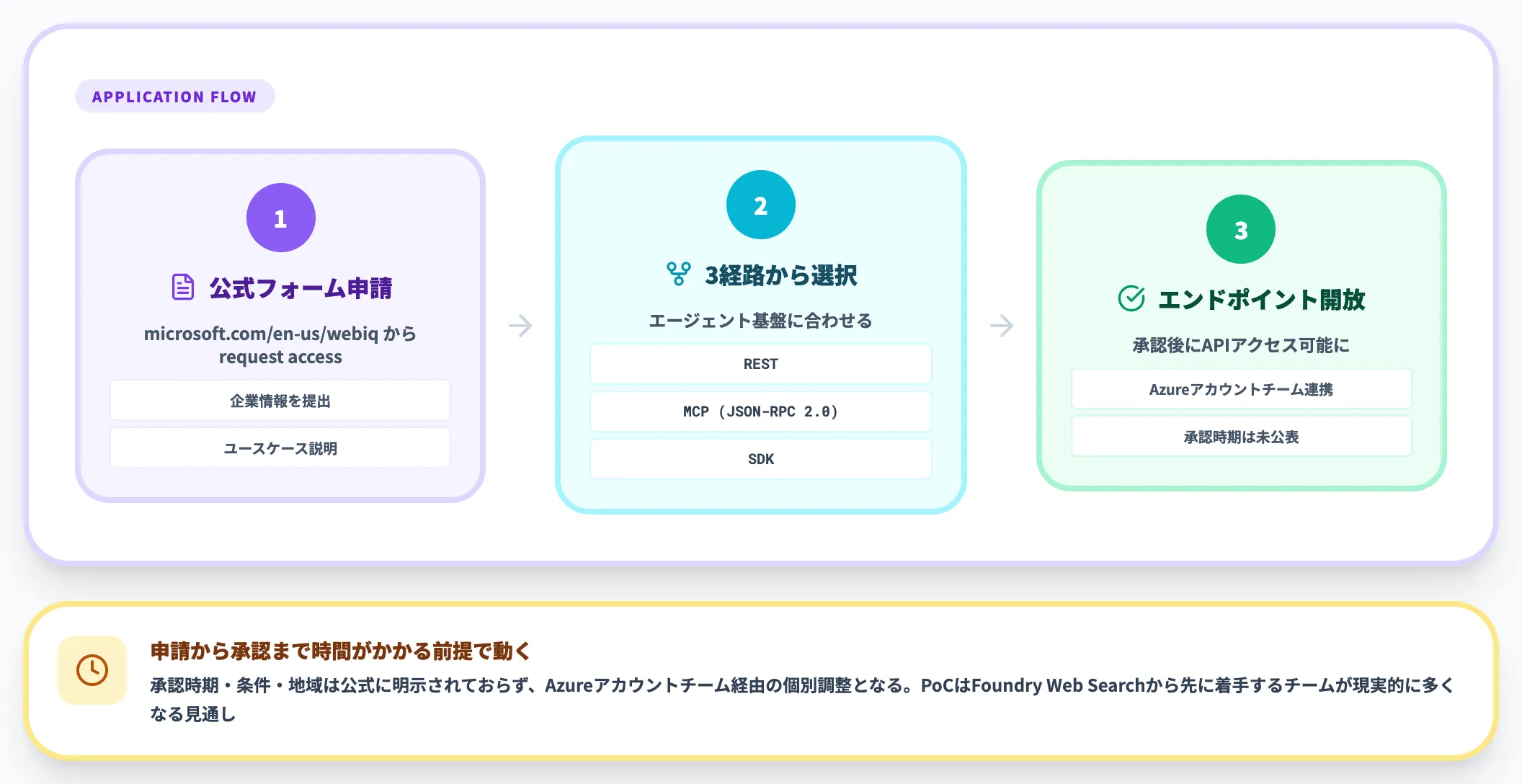
アクセス申請の流れは次のとおりです。
-
Web IQ公式サイトの申請フォームから「request access」
公式ページのフォームで企業情報・ユースケースを提出する
-
REST/MCP(JSON-RPC 2.0)/SDKの3経路から選択
公式FAQは「Send a query via REST, MCP (JSON-RPC 2.0), or SDK」と説明。エージェント基盤に合わせて選ぶ
-
承認後、Web IQ本体エンドポイントが開放
承認時期・条件・地域は公式に明示されておらず、Azureアカウントチーム経由の個別調整となる
申請してから承認まで時間がかかる前提で、PoCはFoundry Web Searchから先に着手するチームが現実的に多くなる見通しです。
Foundry Web Searchツールの設定パラメータ
Web Searchツールは、最小限の設定で動かせるのが特徴です。主要なオプションパラメータは2つだけです。
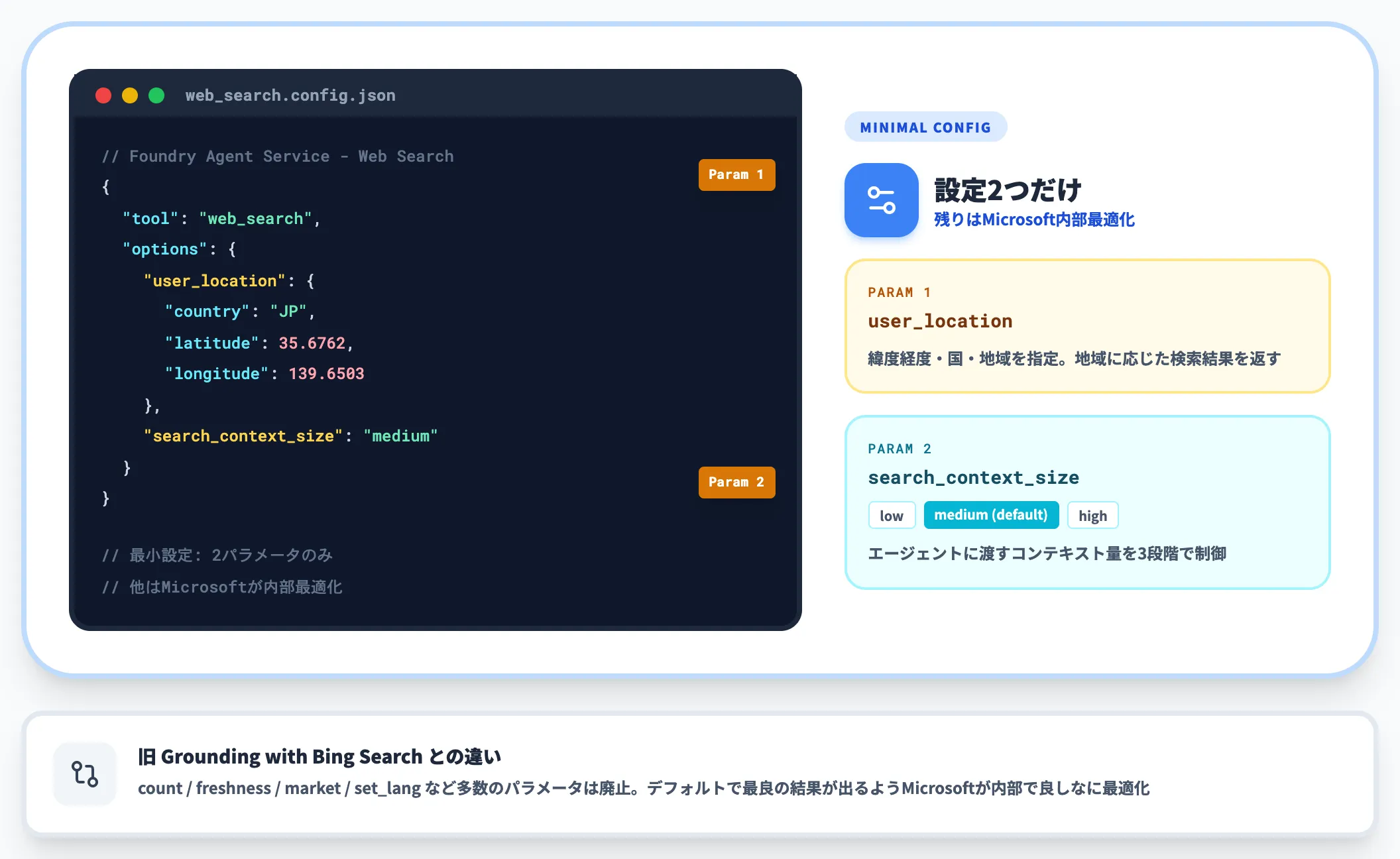
-
user_location
緯度経度・国・地域などのユーザーロケーション情報。「地域に応じた検索結果」を返す
-
search_context_size
low(少なめ)・medium(標準・デフォルト)・high(多め)の3段階。エージェントに渡すコンテキストの量を制御
従来のGrounding with Bing Searchではcount・freshness・market・set_langなど細かいパラメータが用意されていましたが、Web SearchはそれらをMicrosoftが内部で良しなに最適化する方針です。開発者が設定する項目を減らし、デフォルトで最良の結果が出るように作られています。
MCP連携と外部エージェントからの呼び出し
Web IQはMCP(Model Context Protocol)ネイティブで設計されています。これは、Foundry外のエージェント(Claude Code・Cursor・独自開発エージェント等)からも、MCPサーバ経由で呼び出せることを意味します。
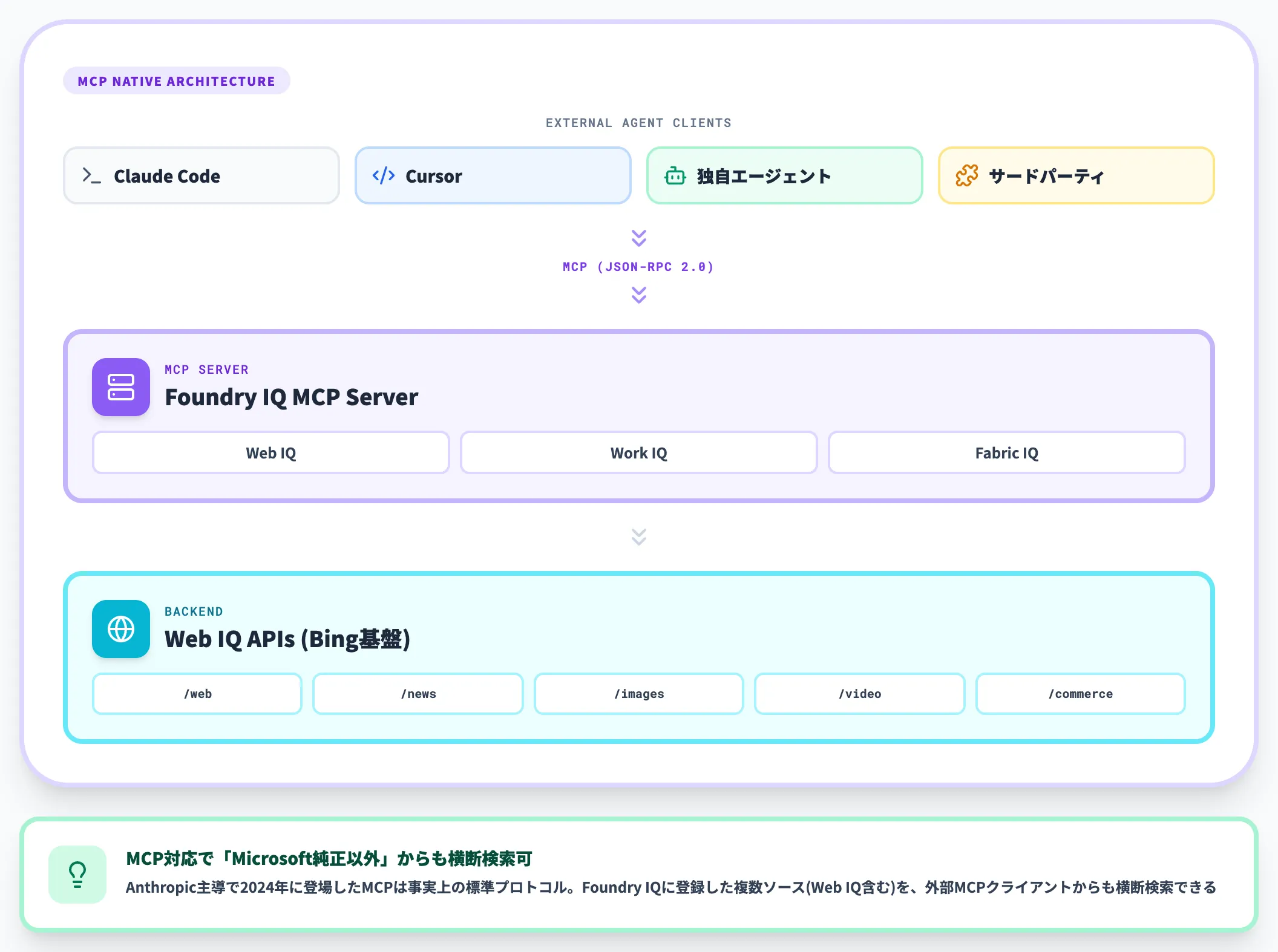
MCP(Model Context Protocol)は、Anthropic主導で2024年に登場し、いまやAIエージェント業界の事実上の標準になりつつあるプロトコルです。Web IQがMCP対応している意味は、「Microsoft純正エージェント以外からも、同じプロトコルで呼び出せる」という点にあります。
FoundryのナレッジベースはFoundry IQ MCP serverとして外部公開できる設計で、Foundry IQに登録した複数ソース(Web IQを含む)を、外部MCPクライアントからも横断検索できます。
詰まりやすいポイント(VPN・Private Endpoint非対応)
実装段階で詰まりやすい論点もMicrosoft Learnに明記されています。事前に把握しておくと、PoC段階での手戻りを防げます。
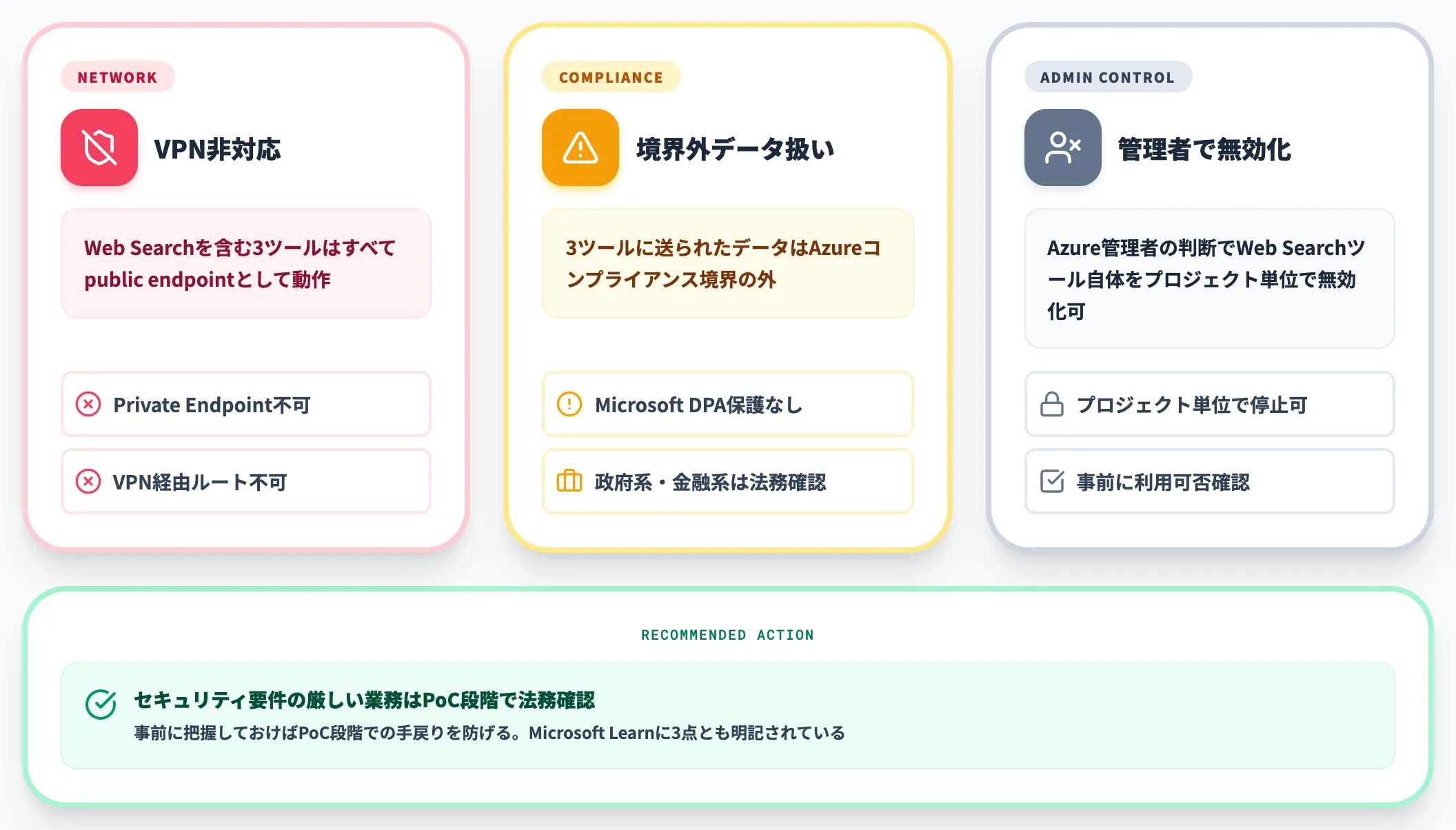
-
VPN・Private Endpoint非対応
Web Searchを含む3ツールはすべてpublic endpointとして動作。ネットワーク制限されたFoundryプロジェクトでも、これらツールはVPNやprivate endpointを経由しない
-
Azureコンプライアンス境界の外
Web Search・Grounding with Bing Search・Bing Custom Searchの3ツールに送られるデータは、Azureのコンプライアンス境界の外に出る扱い
-
管理者による無効化
Azure管理者の判断で、Web Searchツール自体をプロジェクト単位で無効化できる
セキュリティ要件の厳しい業務で使う場合は、特に「Azureコンプライアンス境界の外」の扱いに注意が必要です。
Microsoft Data Protection Addendum(DPA)の保護がWeb Searchから送ったデータには適用されないと明記されており、政府系・金融系の案件では事前に法務確認が必要になります。
Web IQの提供状況と料金
Web IQ本体(passage-level evidenceや低レイテンシを直接得るREST/MCP/SDK経路)と、Foundry「Web Search」ツール(Bing基盤のGA一般グラウンディング)は、提供形態も課金も別系統です。
本セクションでは、Web IQ本体のLimited Accessの位置づけ、Foundry Web Search経由の課金経路、データ取り扱いを分けて整理します。
現在は限定アクセス
Foundry IQ公式ブログは、Web IQ本体の提供形態を「Available today for select Azure customers」と説明しています。
公式FAQも「Web IQ is currently available in limited access to select enterprise customers building AI agents and applications at scale」と明示しています。
専用のWeb IQ APIエンドポイントとして直接エージェントから呼び出す経路は、現時点でフォーム申請ベースの限定アクセスです。具体的なアクセス条件・申請手順はWeb IQ公式サイトのフォーム経由となっており、申請から承認までの目安期間は公式には公表されていません。
「将来Web IQが選定企業を絞り続ける」のではなく、「ロールアウト初期段階では絞り、順次拡大していく」というMicrosoftの慣例的なリリースパターンです。Microsoft Foundry本体や直近のWork IQ APIも同様の段階的GA経路をたどっています。
Foundry Web Searchの現行課金
Web IQ本体のLimited Accessとは別に、Foundry Agent Serviceの「Web Search」ツールはGAで一般プロジェクトから利用可能です。ただしこれはGrounding with Bingベースで動くツールであり、Web IQ本体(passage-level evidence・低レイテンシ・GDSAT)とは別系統である点には注意が必要です。
Web Searchツールの課金は、公式によれば現行のGrounding with Bing pricingが適用されます。具体的な単価表は公式pricingページで定義されており、2026年6月時点の最新値は同ページで確認してください。
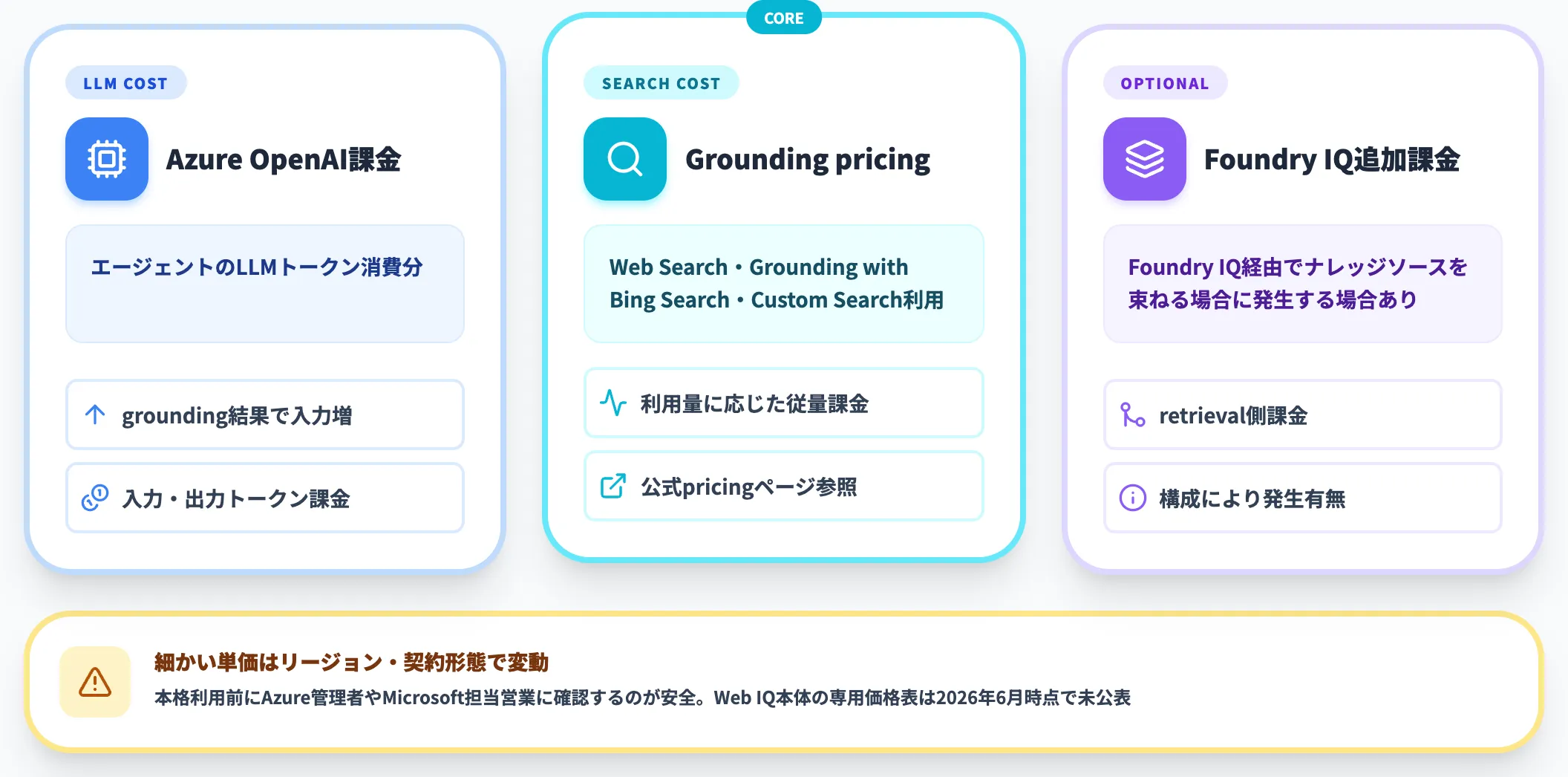
以下のリストで、Foundry経由でWeb Searchを使うときに発生する課金要素を整理しました。
-
Azure OpenAIモデル課金
エージェントのLLMトークン消費分。Web Searchツール経由でgrounding結果を受け取ると入力トークンが増える
-
Grounding with Bing pricing
Web Search・Grounding with Bing Search・Bing Custom Searchの利用に対して発生する従量課金(公式pricingページ参照)
-
Foundry IQ Agentic Retrieval(オプション)
Foundry IQ経由でナレッジソースを束ねる場合、Foundry IQ側のretrieval課金が別途発生する場合がある
細かい単価はリージョンや契約形態で変わるため、本格利用前にAzure管理者やMicrosoft担当営業に確認するのが安全です。2026年6月時点ではSaaS型サブスクリプションではなく、利用量に応じた従量課金体系が中心です。
Web IQ本体の専用価格表は2026年6月時点で公表されておらず、Limited Access申請後にカスタム提示される運用と見られます。
zero data retention・publisher preferencesの扱い
データ取り扱いの点では、Web IQは公式に「zero data retention」と明示されています。エージェントが投げたクエリやレスポンスはWeb IQ側のサーバには保持されない設計です。

ただし注意点として、前述のとおりFoundryのWeb Searchツール経由で送ったデータは、Azureコンプライアンス境界の外(Bing側)に出る扱いになります。Microsoft Data Protection Addendumや政府系の高セキュリティ要件は適用されません。
publisher preferencesについては、Web IQが20年分のBingとの関係を引き継いでおり、Webサイト運営者が「AI用途への利用可否」を設定できる仕組みになっています。出版社・著作権者側の意向を尊重する設計が、Web IQの差別化要素の一つです。
申請・問い合わせルート
select Azure customersとしてWeb IQ単体APIへのアクセスを希望する場合、現時点で公開されている申請窓口は限定的です。

実務的には次の3経路が有力です。
-
Azureアカウントチーム経由
Enterprise契約を持つ組織は、担当アカウントエグゼクティブ経由で要件を伝える
-
Microsoft FastTrack
Foundry関連の早期導入支援プログラムを使う
-
公式問い合わせフォーム
Web IQ公式ページから関心表明を送る(具体的な申請プロセスは順次案内)
当面はFoundry経由のWeb Searchで実装を進め、Limited Accessが必要になった段階で個別申請する流れが現実的です。
Web IQと競合・既存ツールの選び方
Web IQの登場でAIエージェント向けgrounding API市場は大きく動きますが、既存のTavily・Perplexity Sonar・Exa・Braveがすぐ消えるわけではありません。
選定はクラウドスタック・課金モデル・grounding方式・統合先で決まります。本セクションでは、主要grounding APIの比較表とケース別推奨、導入判断で詰まる論点を整理します。
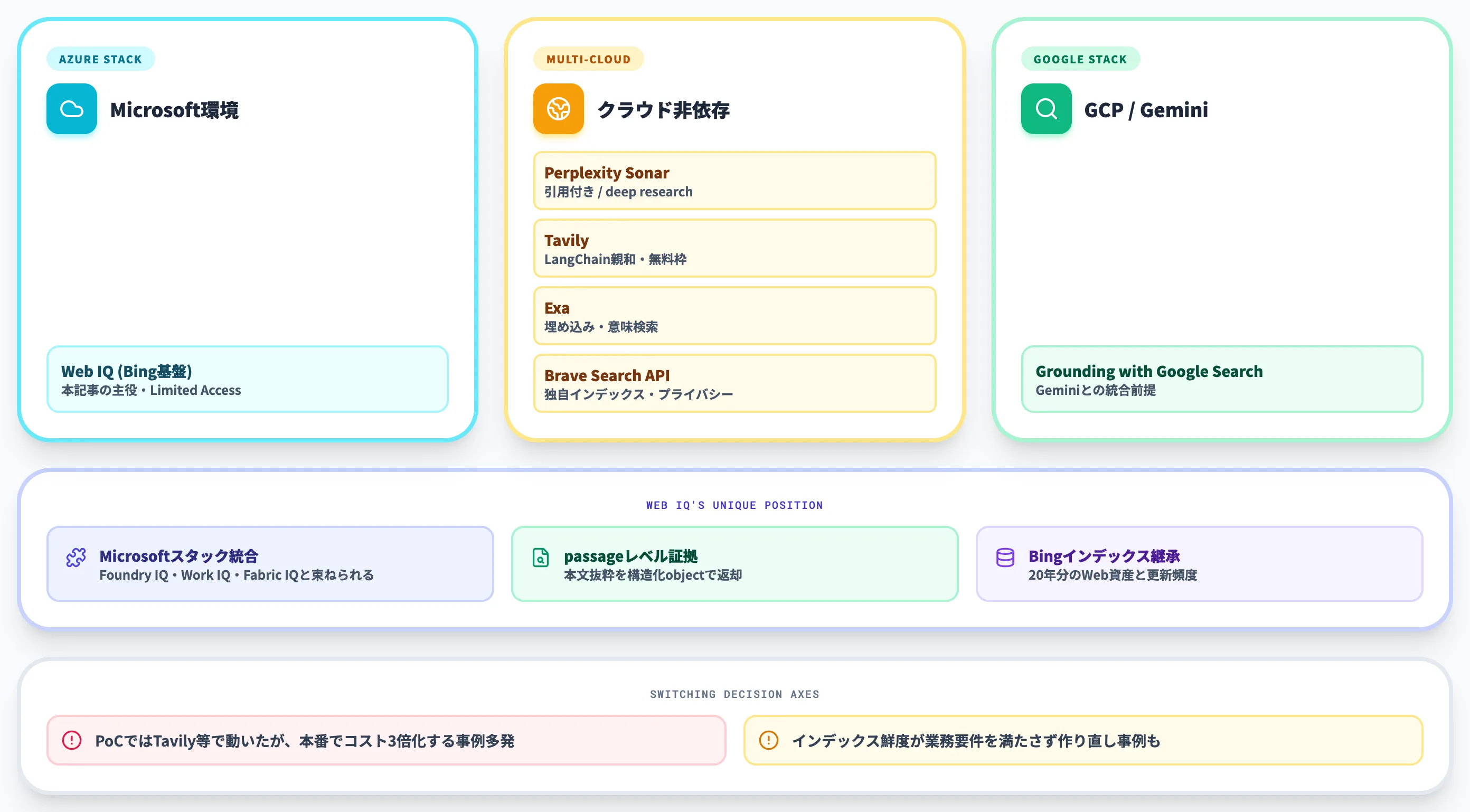
主要grounding APIの比較表
以下の表で、エージェント向け主要grounding APIの位置づけを整理しました。Web IQが置かれる競合状況の地図として参照してください。
| API | 提供元 | 主な強み | 主なクラウドスタック |
|---|---|---|---|
| Web IQ | Microsoft(Bing基盤) | passage-level evidence・p95 165ms・Microsoft IQ統合 | Azure/Microsoft Foundry |
| Perplexity Sonar | Perplexity | 会話的レスポンス・引用付き・deep research経路 | クラウド非依存 |
| Tavily | Tavily | 開発者向け敷居が低い・無料枠あり・LangChain親和性 | クラウド非依存 |
| Exa | Exa | 埋め込み・意味理解ベースの検索・deep research向け | クラウド非依存 |
| Brave Search API | Brave | 独自インデックス(公式:30 billion pages超)・プライバシー重視・MCP対応 | クラウド非依存 |
| Grounding with Google Search | GoogleインデックスとGemini統合 | Google Cloud/Gemini |
各サービスは設計思想が異なるため、「どれが速い」「どれが安い」だけで選ぶと判断を誤ります。
独立ベンチマークによれば、Brave・Firecrawl・Exa・Parallel Search Proが品質面でほぼ同等という結果が出ています。Web IQは今回新参入のため、まだ独立ベンチマークでの順位は確立されていません。
ケース別推奨(Microsoft環境/マルチクラウド/深掘り研究)
AI総合研究所の支援現場で観察している傾向と、各サービスの設計思想を踏まえると、以下のケース別推奨が現実的です。

実務的な使い分けとしては、まずクラウドスタックで一次選別し、次に用途で二次選別するのが効率的です。
-
Microsoft環境でエージェントを構築するチーム → Foundry Web Search → 必要に応じてWeb IQ本体のLimited Access
まずGAのFoundry「Web Search」(Bing基盤・Copilot Studio・GitHub Copilotとも統合容易)でWebグラウンディングを実装し、passage-level evidence・低レイテンシ・GDSATといったWeb IQ本体固有の優位が業務要件として必要になった段階でLimited Access申請に進む2段階。Foundry IQでWork IQ・Fabric IQと束ねる構成もそのまま組める
-
マルチクラウド・無料起点で素早く検証するチーム → Tavily
LangChain連携と無料枠で「とりあえずRAGエージェントを動かしたい」最初の選択肢。クラウド非依存
-
長文の深掘り研究・引用重視のエージェント → Perplexity Sonar/Exa
「deep research」モードや埋め込みベースの意味検索が必要なケース。学術リサーチ・市場調査エージェント向け
-
独自インデックスと低コストが必要 → Brave Search API
GoogleにもBingにも依存したくない、独自インデックスを使いたいプライバシー重視チーム
-
Google Cloud+Gemini構成 → Grounding with Google Search
Geminiとの統合が前提のチームは、Google Cloud内で完結する経路が自然
Microsoft環境のチームから見ると、Web IQが「Microsoftスタックの中で純正に動くagent-nativeなgrounding API」として加わった点は大きな選択肢の整理になります。Microsoft純正のWeb grounding導線はFoundry Web Search/Grounding with Bing Search/Bing Custom Searchもあるため複数経路から選べる構造で、ユースケース次第で使い分けます。
これまでTavily等の外部APIをAzureから呼んでいたチームが、Microsoft IQの統合性・コンプライアンス・課金一元化を理由に乗り換えを検討するケースが増えてくる見通しです。
導入判断で詰まる論点(速度・鮮度・著作権・コスト)
Web IQと競合の選定で詰まりやすい論点は、AI総合研究所の支援現場では次の4つに集約されます。

-
速度:エージェントの推論サイクル中の体感差
1リクエスト200ms差は単発では小さいが、エージェントが10〜50回呼ぶタスクでは数秒〜十数秒の差。p95値での比較が重要
-
鮮度:インデックス更新頻度とニュース対応
ニュース速報や時事系トピックを扱うなら、Bing・Google系の更新頻度が優位。Braveは公式で「日次1億件超のページ更新」を公表(Brave Search API)しているため独立系の中では強い。Exaは用途別に要確認
-
著作権・出版社対応:grounding結果の利用可否
publisher preferencesに対応しているか、AI用途のライセンス契約が成立しているか。法務観点のリスク管理に直結
-
コスト構造:従量課金とエージェントROI
1リクエスト単価ではなく、「タスク1件あたりの平均呼び出し回数 × 単価 × LLMトークン消費」で総コスト試算が必要。Web IQはトークン効率での優位を主張
これらの論点は、PoC段階でほとんど顕在化せず、本番運用に移してから初めて気づくケースが多いものです。
実際の現場でも、「PoCではTavilyで動いたが、本番のスループットでコストが想定の3倍になった」「インデックス鮮度が業務要件を満たさず作り直し」といった事例が出ています。
選定段階で「自社のエージェントが1タスクあたり何回groundingを呼ぶか」「どの程度の鮮度が業務要件か」を見積もっておくことが、最終的なROIに最も効きます。

Web知識をエージェントの業務実行までつなぐなら
Web IQで外部知識のグラウンディングを整えると、エージェントが「最新情報を踏まえた回答」を返すまでは到達します。一方で業務での本番運用には、社内データ連携・ガバナンス・実行統制・Teams等の社内UIまでをつないだ運用基盤が別途必要になります。Web IQはエージェントの入力側を強化するレイヤーであり、業務適用までを支える層ではないからです。
ここで効いてくるのが、Microsoft Teamsから呼び出せるエンタープライズAIエージェント内製化プラットフォーム AI Agent Hub です。Foundry・Copilot Studioで構築したエージェントをMicrosoft環境のまま運用する基盤として、Web IQで整えたgrounding経路をそのまま業務実行までつなぎます。
-
Foundry・Copilot Studioのエージェントを1画面で統合管理
Web IQをグラウンディング源にして構築したエージェントも、他のCopilot Studio製エージェントも、AI Agent Hubのダッシュボードで実行ログ・アクセス権限・セキュリティスキャンを一元管理できます
-
Web経由の最新情報を社内データと組み合わせて業務実行に変換
Web IQで取得した外部情報を、Microsoft Fabric OneLakeに仮想統合された社内データと組み合わせ、TeamsチャットからAgentが報告・申請・承認まで実行します
-
社内データ・業務ログは自社テナント内で管理
Azure Managed Applicationsとして自社テナント内で動作し、社内データ・実行ログ・承認履歴はAIの学習対象から除外。Web IQ等の外部Webグラウンディング経由で取得したクエリ・公開Web情報については、各Microsoftサービス(Foundry Web Search/Grounding with Bing/Web IQ)の利用条件に従う扱いになります
AI総合研究所の専任チームが、Web IQを含むMicrosoft IQ構成でのgrounding設計から、エージェントの業務適用・運用統制までを伴走支援します。Web IQの先に必要となるエージェント運用基盤の全体像を、まず無料の資料でご確認ください。
Web知識を活かすAIエージェント運用基盤

PoCから本番運用まで段階設計
Web IQで外部知識のグラウンディングを整えても、社内データ連携・実行統制・運用管理を含めた業務基盤の設計が別途必要になります。AI Agent HubはMicrosoft Foundry・Copilot Studioで構築したエージェントをTeamsから呼び出し、実行ログと権限管理を1画面で統合する企業向けAIエージェント内製化プラットフォームです。
まとめ
本記事では、Build 2026 Day1で発表されたMicrosoft Web IQについて、製品定義・解こうとした課題・性能・Microsoft IQ全体での位置づけ・使い方・料金と提供状況・競合との選び方を2026年6月時点の公式情報で整理しました。要点を改めて整理します。
-
Web IQはBingの20年インデックスを継承しつつエージェント時代向けにゼロから組み直したWebグラウンディングAPIスイートで、2026年6月2日のBuild 2026 Day1に発表され、Microsoft IQ第4のメンバーとして登場した
-
「人間向けBing検索」とは設計思想が異なり、passage-level evidenceとMCPネイティブで、エージェントが反復呼び出ししても効率が落ちない構造になっている
-
p95 165ミリ秒未満・競合比2.5倍速・3,000クエリ・5DC測定で実証済み。GDSAT・レイテンシ・トークン効率の3軸で既存のグラウンディングAPIを上回ると主張している
-
Foundry IQに束ねられて、Work IQ・Fabric IQと並ぶナレッジソースとして動く。Microsoft Copilot・ChatGPTのgrounding経路ですでに採用されている
-
2026年6月時点の利用ルートは2系統:(A) GAのFoundry「Web Search」ツール(Bing基盤・Grounding with Bing pricing)と、(B) Web IQ本体(REST/MCP/SDK経由・select Azure customers向けLimited Access・申請フォーム)。両者は別系統で、Foundry Web SearchがWeb IQ本体の性能をそのまま提供するわけではない
-
競合選定はクラウドスタックと用途で決まる:Microsoft環境ならまずFoundry Web Search、本格的なWeb IQ機能が必要ならLimited Access申請。マルチクラウド・無料起点ならTavily、深掘り研究ならPerplexity Sonar・Exa、独自インデックスならBrave、Google Cloud構成ならGrounding with Google Search
Web IQは新発表からまだ1日のプロダクトで、Limited Accessの対象拡大・専用価格表・サードパーティ独立ベンチマークなど、続報が随時出てくる見通しです。MicrosoftスタックでAIエージェントを構築するチームは、まずGAのFoundry Web SearchでBing基盤の一般的なグラウンディングを実装し、passage-level evidenceや低レイテンシの実需が顕在化した段階でWeb IQ本体のLimited Access申請を検討する流れが現実的です。










