この記事のポイント
 「新たなデータを生成しつつ潜在表現も獲得したい」場面では、確率分布ベースのVAEがオートエンコーダより有効な選択肢
「新たなデータを生成しつつ潜在表現も獲得したい」場面では、確率分布ベースのVAEがオートエンコーダより有効な選択肢- 潜在空間の連続性と再パラメータ化トリックにより、通常のオートエンコーダでは不可能な滑らかなデータ補間が実現でき、生成タスクではVAEを選ぶべき
- 損失関数は再構成誤差とKLダイバージェンスの2項構成が基本で、KL項の重み調整が生成品質を左右する最重要パラメータ
- 初学者がVAEを体験するならGoogle ColabでのMNIST実装が最適で、GPU環境なしでも画像生成の全工程を試せる
- Stable Diffusionの基盤技術として画像生成に強いほか、異常検知・ノイズ除去にも有効だが、高解像度画像の直接生成にはGAN併用が必要

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
VAE(変分オートエンコーダ)は、入力データの潜在的な確率分布を学習し、新たなデータを生成できるディープラーニングの生成モデルです。画像生成・異常検知・ノイズ除去など幅広い分野で活用されています。
本記事では、オートエンコーダとの違い、エンコーダ・デコーダの構造、学習プロセス、Google Colabでの実装手順、CVAE・β-VAE・VQ-VAEなどの派生手法を解説します。
目次
VAEとは
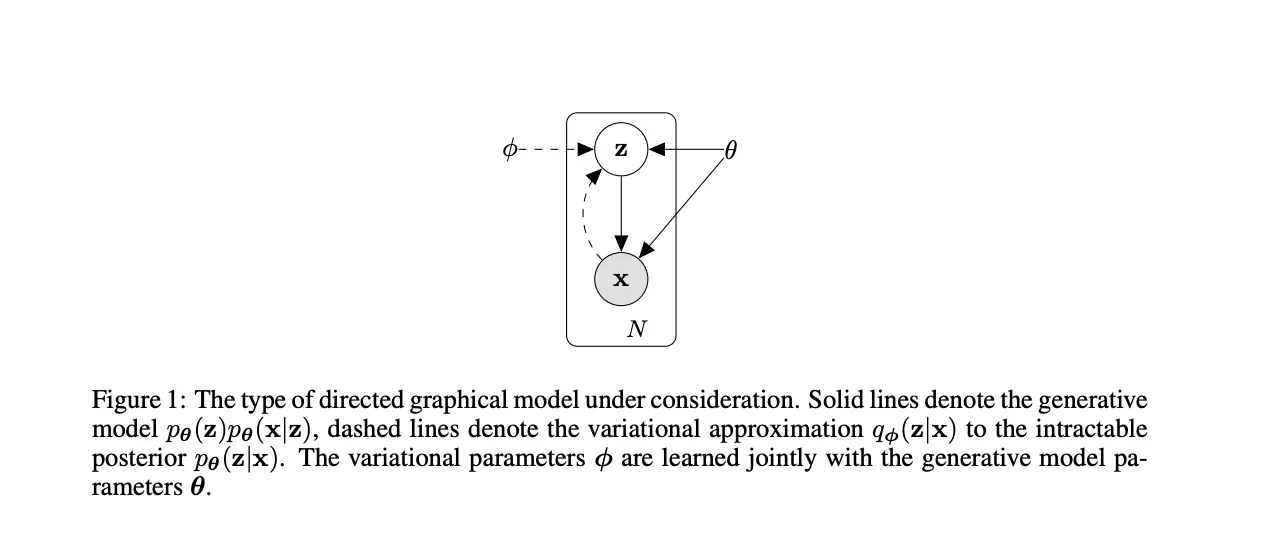
VAEのモデルの内部 参照:論文
変分オートエンコーダ(Variational Autoencoder:VAE)は、データから潜在的な確率分布を学習し、新たなデータを生成できるモデルです。
従来のオートエンコーダは入力データを圧縮・復元する過程で特徴表現を獲得しますが、VAEはそこに確率分布という概念を導入することで、入力データに対する潜在空間の分布を学習します。
これにより、学習済みモデルからランダムサンプルを生成すると、多様な新しいデータを生み出せる点が大きな特徴です。

オートエンコーダとの違い
オートエンコーダは入力データをエンコード・デコードし、入力と類似した出力を再現します。
一方、VAEはデータを潜在空間で確率分布として扱い、その分布からサンプリングして出力を生成します。
これにより、VAEは新たなデータ生成が可能になり、オートエンコーダよりも表現力と柔軟性が高まります。
確率分布と潜在空間
VAEの中核は、入力データを潜在空間と呼ばれる低次元表現にマッピングし、その潜在空間上で確率分布を仮定する点です。
たとえば、潜在空間内でガウス分布を想定し、そこからサンプルを引くことで新しいデータ表現を得ます。
結果として、潜在変数をランダムに生成してからモデルを通すと、様々なバリエーションの出力が得られます。
VAEの目的
VAEは、単なるデータ復元にとどまらず、データ生成、特徴表現獲得、ノイズ除去など幅広い目的で利用されます。
特に「潜在変数」という明示的な確率モデルを持つため、生成モデル分野での基盤的存在となっており、画像、音声、テキストといった多様な領域に応用可能です。
VAEの構造
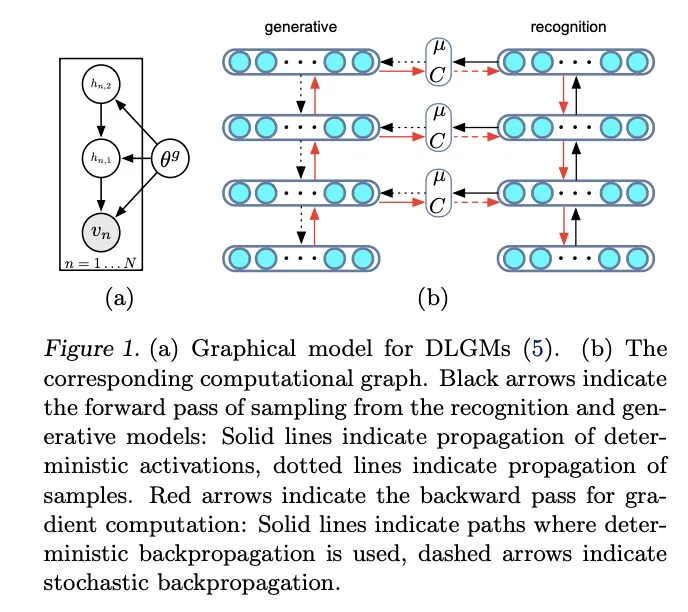
VAEの構造 参照:論文
エンコーダ
VAEのエンコーダは、入力データを潜在空間にマッピングする役割を持ちます。
通常のオートエンコーダと異なり、エンコーダは特定の潜在変数(平均と分散など)を出力し、それらをもとに確率分布が定義されます。
こうして得られた分布パラメータは、潜在変数をサンプリングするために用いられます。
デコーダ
デコーダは、潜在変数から元のデータ空間へ戻すプロセスを担います。
ランダムにサンプリングされた潜在変数を入力することで、オリジナルのデータに近いサンプルを生成できます。
これにより、VAEは単純な再構成だけでなく、新規なデータ生成能力を獲得します。
潜在変数
潜在変数は、元のデータを圧縮した表現であり、VAEの中核的存在です。
これらは確率分布に従いサンプリングされ、デコーダを通して多種多様なデータを生み出せます。
潜在空間が上手く学習されれば、類似した潜在変数からは似た特徴のデータが再構成され、データ間の連続性や関係性を直観的に捉えられます。
損失関数
VAEの学習では、単純な再構成誤差(入力と出力の違い)だけでなく、潜在空間の分布が標準正規分布などの事前分布に近づくよう、KLダイバージェンスという項が加えられます。
- 再構成誤差:入力データと再構成データの差
- KLダイバージェンス:潜在分布と事前分布のずれを測る指標
これらを合わせた損失関数を最小化することで、VAEは潜在空間を整え、汎用的なデータ生成性能を獲得します。
VAEの学習プロセス
VAEの学習プロセスは4つの手順に沿って進みます。
- エンコーダでデータを潜在空間に変換
入力データを潜在空間上の確率分布にマッピングします。この分布は、データの特徴を圧縮して表現します。
- 潜在空間からサンプリング
潜在変数は再パラメータ化トリックを用いてサンプリングされます。これにより、微分可能性を確保しつつ、生成過程を学習可能にします。
- デコーダでデータを再構成
サンプリングされた潜在変数をもとに、元のデータを再構成するようにデコーダを訓練します。
- 損失関数の最適化
損失関数には再構成誤差とKLダイバージェンスが含まれます。この2つの要素のバランスを取りながらモデルを最適化します。
以下では、各技術的要素について詳しく説明します。
変分推論
VAEは、潜在変数の分布パラメータを推定するために、変分推論と呼ばれる手法を用います。
変分推論により、複雑な確率分布を近似的に扱い、計算可能な形で潜在空間を学習可能にします。この近似により、VAEは大規模データでも効率的に学習できます。
再パラメータ化トリック
再パラメータ化トリックとは、確率的サンプリングを微分可能な操作に変換する工夫です。
平均と分散から得た標準正規分布のサンプルにスケール・シフトを施すことで、バックプロパゲーションが可能になります。これにより、勾配ベースの最適化アルゴリズムで学習を進められます。
学習の難易度調整
VAEの学習は、損失関数内に確率分布が絡むため、調整が難しい場合があります。
特に、VAEの学習は以下の2つの損失項の調整が難点です。
- KLダイバージェンス
潜在空間の分布が事前分布(通常は標準正規分布)に近づくように調整されます。ただし、これが大きくなりすぎると潜在空間が単純化しすぎてしまい、意味のある表現が得られなくなる可能性があります。
- 再構成誤差
元データと復元データの類似性を高めるための項です。これを優先しすぎると、潜在空間がデータに過度にフィットし、汎化性能が低下するリスクがあります。
これら2つのバランスを適切に取ることが、VAE学習成功の鍵です。
VAEの実装手順(Google Colab)
それでは、実際にVAEを手元で構築し、理解を深めます。
シンプルなVAE(Variational Autoencoder)を構築し、Google Colab上で動作させる手順を解説します。
手書き文字画像(MNIST)を使って、VAEの基本的なトレーニングと画像生成を実装します。
最終的に出来上がったコードは以下に示しています。ここからはステップバイステップでどのように実装したのか、その出力結果も合わせて解説します。
**最終的なコード例**
import torch
from torch import nn, optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
transform = transforms.Compose([
transforms.ToTensor(), # データを0~1の範囲にスケーリング
])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
class VAE(nn.Module):
def __init__(self, latent_dim=20):
super(VAE, self).__init__()
# エンコーダ
self.encoder = nn.Sequential(
nn.Linear(28 * 28, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU()
)
self.fc_mu = nn.Linear(64, latent_dim) # 平均
self.fc_logvar = nn.Linear(64, latent_dim) # 分散
# デコーダ
self.decoder = nn.Sequential(
nn.Linear(latent_dim, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 28 * 28),
nn.Sigmoid()
)
def encode(self, x):
h = self.encoder(x)
return self.fc_mu(h), self.fc_logvar(h)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
return self.decoder(z)
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
def loss_function(recon_x, x, mu, logvar):
BCE = nn.functional.binary_cross_entropy(recon_x, x, reduction='sum') # 再構成誤差
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp()) # KLダイバージェンス
return BCE + KLD
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = VAE().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
epochs = 5 # 短めのエポック数
for epoch in range(epochs):
model.train()
train_loss = 0
for data, _ in train_loader:
data = data.view(-1, 28 * 28).to(device) # 画像をフラット化
optimizer.zero_grad()
recon_batch, mu, logvar = model(data)
loss = loss_function(recon_batch, data, mu, logvar)
loss.backward()
train_loss += loss.item()
optimizer.step()
print(f'Epoch {epoch + 1}, Loss: {train_loss / len(train_loader.dataset):.4f}')
model.eval()
with torch.no_grad():
z = torch.randn(16, 20).to(device) # ランダムな潜在変数
sample = model.decode(z).cpu()
sample = sample.view(16, 1, 28, 28)
fig, axes = plt.subplots(1, 16, figsize=(16, 2))
for i, ax in enumerate(axes):
ax.imshow(sample[i].squeeze(), cmap='gray')
ax.axis('off')
plt.show()
- ライブラリのインポート
まず、VAEを実装するために必要なライブラリをインポートします。
import torch
from torch import nn, optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
- データセットの準備
MNISTデータセットをダウンロードしてデータローダを作成します。transforms.ToTensor()を使い、データを0~1の範囲にスケーリングします。
# データセットの準備
transform = transforms.Compose([
transforms.ToTensor(), # データを0~1の範囲にスケーリング
])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
- VAEモデルの定義
次に、VAEモデルを定義します。ここでは、エンコーダ、デコーダ、再パラメータ化の基本的な構造を含むシンプルなVAEを実装します。
class VAE(nn.Module):
def __init__(self, latent_dim=20):
super(VAE, self).__init__()
# エンコーダ
self.encoder = nn.Sequential(
nn.Linear(28 * 28, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU()
)
self.fc_mu = nn.Linear(64, latent_dim) # 平均
self.fc_logvar = nn.Linear(64, latent_dim) # 分散
# デコーダ
self.decoder = nn.Sequential(
nn.Linear(latent_dim, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 28 * 28),
nn.Sigmoid()
)
def encode(self, x):
h = self.encoder(x)
return self.fc_mu(h), self.fc_logvar(h)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
return self.decoder(z)
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
- 損失関数の定義
損失関数は再構成誤差(Binary Cross Entropy)とKLダイバージェンスを組み合わせたものです。
def loss_function(recon_x, x, mu, logvar):
BCE = nn.functional.binary_cross_entropy(recon_x, x, reduction='sum') # 再構成誤差
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp()) # KLダイバージェンス
return BCE + KLD
- モデルのトレーニング
モデルをトレーニングします。データを28×28ピクセルから1次元に変換してエンコーダに入力します。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = VAE().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
epochs = 5 # 短めのエポック数
for epoch in range(epochs):
model.train()
train_loss = 0
for data, _ in train_loader:
data = data.view(-1, 28 * 28).to(device) # 画像をフラット化
optimizer.zero_grad()
recon_batch, mu, logvar = model(data)
loss = loss_function(recon_batch, data, mu, logvar)
loss.backward()
train_loss += loss.item()
optimizer.step()
print(f'Epoch {epoch + 1}, Loss: {train_loss / len(train_loader.dataset):.4f}')
出力例:
Epoch 1, Loss: 188.3710
Epoch 2, Loss: 140.2615
Epoch 3, Loss: 128.2777
Epoch 4, Loss: 123.0578
Epoch 5, Loss: 119.7851
- 生成画像の表示
トレーニング済みモデルを使って潜在空間から新しい画像を生成し、表示します。
model.eval()
with torch.no_grad():
z = torch.randn(16, 20).to(device) # ランダムな潜在変数
sample = model.decode(z).cpu()
sample = sample.view(16, 1, 28, 28)
fig, axes = plt.subplots(1, 16, figsize=(16, 2))
for i, ax in enumerate(axes):
ax.imshow(sample[i].squeeze(), cmap='gray')
ax.axis('off')
plt.show()
最終的に実行すると以下のような結果が出るはずです。
出力例:
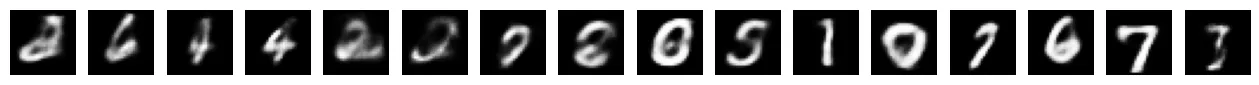
これは、VAE(Variational Autoencoder)によって生成された手書き数字のサンプル画像です。
各数字は、MNISTデータセットの分布を基に、ランダムな潜在変数から生成された数字です。
潜在空間(低次元空間)から値をサンプリングし、その値を使ってVAEのデコーダが生成したものです。
数字の形状がMNISTデータに似ていれば、VAEがトレーニングデータの分布を正しく学習できていることを意味します。
VAEの出力結果に対する評価ポイント
-
数字が視覚的に認識可能か
- 8、6、4 など、数字の形状が明確に区別できる。
- モデルがトレーニングデータから学習した分布をうまく再現していることが分かります。
-
ノイズやぼやけ具合
- 多少ぼやけた数字(例: 2、7 など)が含まれるのは、モデルが完璧ではないことを示しています。
- エポック数を増やしたり、ネットワーク構造を調整することで改善する可能性があります。
結果からわかること
-
成功している点:
VAEは、ランダムな潜在変数からMNISTに似た数字を生成する能力を学習しました。これは、VAEがトレーニングデータの分布を潜在空間にうまく圧縮し、その空間から新しいデータを生成できることを示しています。 -
改善の余地:
ぼやけている部分があるため、さらなるトレーニングやネットワーク構造の改良によって、よりシャープな画像を生成できる可能性があります。
考えられる次のステップ
本結果を踏まえ、以下のようなステップでさらに理解を深められるでしょう。
-
潜在空間の操作
- 潜在変数を少しずつ変化させることで、数字がどのように変わるかを観察します。
-
ハイパーパラメータ調整
- 潜在次元数やエンコーダ/デコーダの層数を変更して結果を比較してみてください。
-
別のデータセットで試す
- 他のデータセット(例: CIFAR-10など)を使ってVAEを試してみてください。
実際にデータセットを使ってVAEに触れてみてください。
VAEの応用
VAEは、私たちの生活にも使われている技術です。以下ではどのように応用されているかを簡単に解説します。
画像生成
VAEは、学習済みの潜在空間から新しい画像を生成できます。
絵画や顔写真、デザインパターンなど、多様な画像をランダムに生成したり、潜在空間上で数値を操作して画像を連続的に変化させるなど、創造的な応用が可能です。
特に、Stable Diffusionのような画像生成AIでは、VAEが重要な役割を果たします。
Stable Diffusionは、潜在空間での画像生成を効率化するためにVAEを使用し、より滑らかで高品質な画像生成を実現しています。
VAEは512×512ピクセルの画像を低次元の潜在表現(例:8×8)に圧縮し、計算負荷を減らしながら高精度な画像を再構築するのに役立ちます。
また、Stable Diffusionでは、異なるVAEを適用することで、画像の色味やシャープネスを調整することが可能です。
例えば、実写系の画像に適した「vae-ft-mse-840000-ema-pruned」や、アニメ調の画像に適した「kl-f8-anime2」など、用途に応じてVAEを使い分けられます。
関連記事:Stable Diffusionとは?利用方法の一覧や使い方、料金体系を徹底解説!
異常検知
データを再構成するVAEの特性を利用すれば、異常データの検出ができます。正常なデータから学習したVAEは、類似パターンをうまく復元しますが、異常なデータは再構成誤差が大きくなる傾向があります。この性質を利用することで、産業や医療での異常検知に活用可能です。
データの表現学習
VAEが学んだ潜在空間は、高次元データを低次元で表現する良質な特徴表現になり得ます。これらの潜在表現を下流タスク(分類、回帰など)に利用することで、データ理解や解析が容易になります。
ノイズ除去
VAEは入力データの重要特徴を抽出し、再構成するため、ノイズを含むデータからノイズ成分を取り除く手法としても使えます。たとえば、ノイズ混じりの画像を入力してクリーンな画像を出力することで、画質改善に貢献します。
以下の記事からもVAEの応用例について学べます。
関連記事:画像生成AIとは?その仕組みや無料で使えるおすすめサービスを紹介!

VAEの種類
Conditional VAE (CVAE)
CVAEは、特定のラベル情報や条件付きでデータ生成を行うVAEの拡張版です。
例えば、数字画像生成の場合、「数字の7を生成する」といった条件を付けることで、条件に合致したデータを生成できます。
β-VAE
β-VAEは、KLダイバージェンス項に重み付け(β)を行い、潜在空間の圧縮と再構成精度のバランスを制御します。
これにより、潜在表現の解釈性が向上したり、潜在次元間の独立性を強めることが可能です。
Vector Quantized VAE (VQ-VAE)
VQ-VAEは潜在空間を連続値ではなく離散的なコードブックで表現します。
これにより、潜在表現が離散的シンボル列となり、テキスト処理のような離散的データ表現に適した手法として注目されています。
Disentangled VAE
潜在空間を独立した要因に分解し、解釈性を向上させる手法です。
Hierarchical VAE
階層的な潜在空間を持つことで、複雑なデータ構造のモデル化を可能にします。
VAEのメリット・デメリット
メリット(データの生成、表現学習など)
VAEはデータ生成能力を備え、表現学習にも優れています。
潜在空間を持つことで、データ間の関係性を明示的にモデル化でき、既存データから多彩なバリエーションを生み出せる点は強力な長所です。
デメリット(画像のぼやけなど)
一方で、VAEが生成する画像は、しばしばぼやけたり曖昧になったりすることがあります。
GAN(敵対的生成ネットワーク)のようにシャープな画像を得るのはやや困難です。
また、適切なハイパーパラメータ調整が難しく、KLダイバージェンスと再構成誤差のバランスが悪いと潜在空間が有効に活用されない場合もあります。
| メリット | デメリット |
|---|---|
| 潜在空間に確率分布を持たせることで、データ生成が滑らかになる。 | 損失関数のバランス調整(特にKL項)が難しい。 |
| 潜在変数の操作が容易で、生成モデルとしての柔軟性が高い。 | GANと比較すると生成品質が劣る場合がある。 |
| 再構成誤差だけでなく、分布の制約も考慮して学習するため安定。 | モデルが複雑で、トレーニングに時間がかかる場合がある。 |
| 応用範囲が広く、画像生成、異常検知、データ補完に適している。 | 高次元データでは性能が低下することがある。 |
VAEの将来展望
VAEは研究が続き、さまざまな改良版が提案されています。より表現力の高い潜在空間や、安定的な学習手法が開発され、VAEは今後さらに性能向上が期待されます。
画像生成AIにおけるVAEの役割
近年の画像生成技術や生成モデル分野では、VAEは基礎的手法として位置づけられ、他の生成モデル(GAN、拡散モデルなど)との組み合わせも検討されています。
VAEを活用することで、より解釈可能な潜在表現や、安定したデータ生成が可能になり、クリエイティブツールやコンテンツ生成などの応用が広がっています。
新しい応用分野
VAEは画像やテキストにとどまらず、音声合成、医療データ解析、分子設計など幅広い分野での拡張が見込まれます。
潜在空間を活用して未知のパターンを発見し、新たな価値を創出する研究が続々と進行中です。
生成モデルの知見を組織のAI導入に活かす
VAEの仕組みを理解した方は、AIが「何をどこまでできるか」を技術的に判断できる力を持っています。その知見は、組織としてAIを業務プロセスに実装する段階で大きなアドバンテージになります。次のステップは、個別の技術検証から組織全体のAI導入ロードマップへの展開です。
AI総合研究所では、Microsoft環境での段階的なAI業務自動化を220ページの実践ガイドにまとめています。AI総合研究所の専任チームが、技術評価から導入計画の策定まで一貫して支援します。まずはガイドで、自社に合った導入ステップをご確認ください。
生成モデルの知見を組織のAI導入に活かす

技術理解から業務プロセス設計へ
VAEの仕組みを理解した方は、AIの可能性と限界を技術的に判断できます。その知見を組織のAI業務自動化に活かすための段階設計を220ページの実践ガイドで解説しています。
まとめ
VAE(変分オートエンコーダ)には、大きく3つの価値があります。
1つ目は、確率分布の導入により、単なるデータ復元を超えた多様なデータ生成が可能な点です。潜在空間からのサンプリングで、学習データにない新しいバリエーションを生み出せます。
2つ目は、潜在空間を明示的にモデル化することで、画像生成・異常検知・ノイズ除去・表現学習など幅広い分野に応用できる点です。Stable Diffusionの基盤技術としても重要な役割を果たしています。
3つ目は、CVAE・β-VAE・VQ-VAEなど目的に応じた派生手法への拡張性がある点です。条件付き生成、解釈性向上、離散表現など、用途に合わせたモデル選択が可能です。
まずはGoogle Colabで本記事のMNIST実装コードを実行し、生成画像の品質を確認してください。次にエポック数やネットワーク構造を変更して改善効果を検証し、自社データの異常検知や特徴抽出への適用を検討するステップへ進むアプローチが有効です。
参考文献
-
Kingma, D. P., & Welling, M. (2013): Auto-Encoding Variational Bayes (https://arxiv.org/pdf/1312.6114)
変分オートエンコーダ(VAE)の基本理論を提案。変分推論と再パラメータ化トリックを用いることで、潜在変数を通じた効率的な生成モデル学習を可能にした。生成モデルの分野で革新的な技術基盤を築いた論文。 -
Rezende, D. J., Mohamed, S., & Wierstra, D. (2014): Stochastic Backpropagation and Approximate Inference in Deep Generative Models (https://arxiv.org/pdf/1401.4082)
再パラメータ化トリックと確率的バックプロパゲーションを活用して、深層生成モデルにおける近似推論を効率化。VAEのフレームワークをさらに広げ、複雑なデータ分布を扱う能力を示した。











